This article is more than one year old. Older articles may contain outdated content. Check that the information in the page has not become incorrect since its publication.
Enhancing Kubernetes API Server Efficiency with API Streaming
Managing Kubernetes clusters efficiently is critical, especially as their size is growing. A significant challenge with large clusters is the memory overhead caused by list requests.
In the existing implementation, the kube-apiserver processes list requests by assembling the entire response in-memory before transmitting any data to the client. But what if the response body is substantial, say hundreds of megabytes? Additionally, imagine a scenario where multiple list requests flood in simultaneously, perhaps after a brief network outage. While API Priority and Fairness has proven to reasonably protect kube-apiserver from CPU overload, its impact is visibly smaller for memory protection. This can be explained by the differing nature of resource consumption by a single API request - the CPU usage at any given time is capped by a constant, whereas memory, being uncompressible, can grow proportionally with the number of processed objects and is unbounded. This situation poses a genuine risk, potentially overwhelming and crashing any kube-apiserver within seconds due to out-of-memory (OOM) conditions. To better visualize the issue, let's consider the below graph.
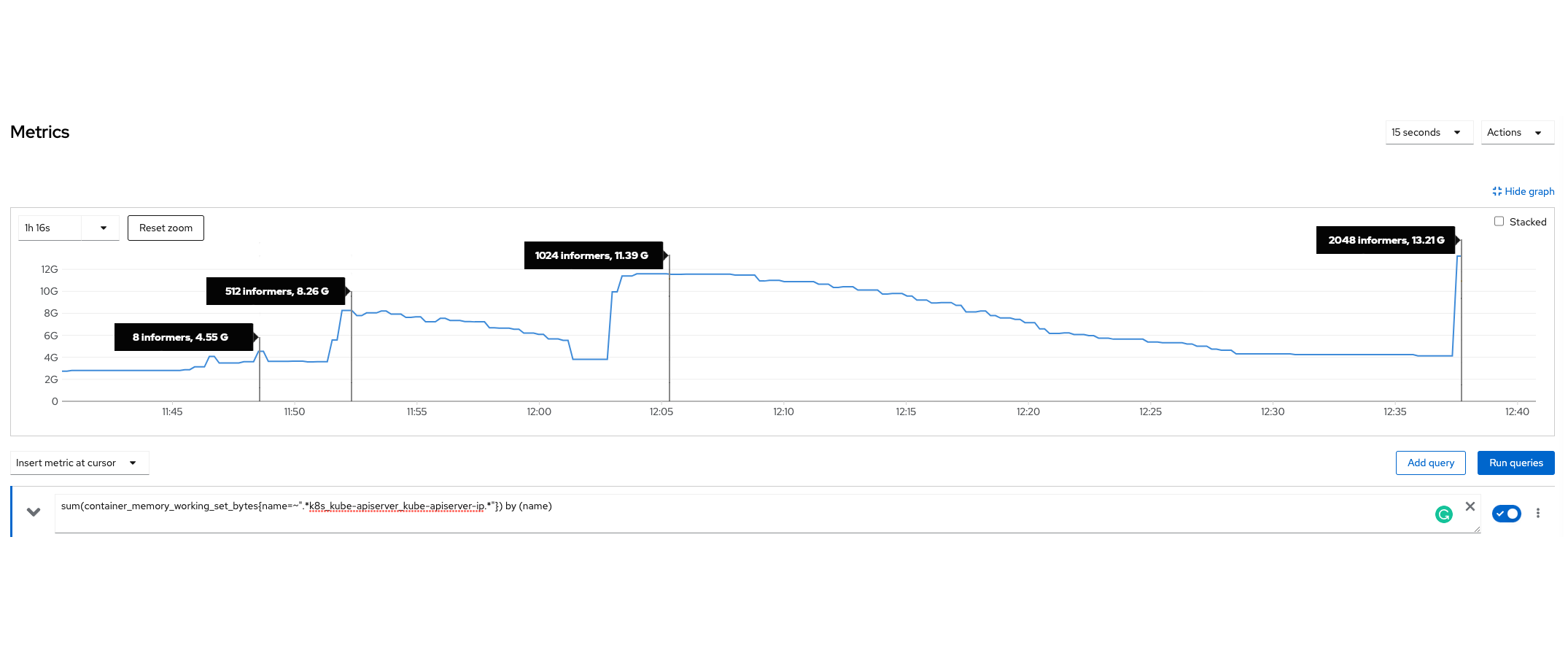
The graph shows the memory usage of a kube-apiserver during a synthetic test. (see the synthetic test section for more details). The results clearly show that increasing the number of informers significantly boosts the server's memory consumption. Notably, at approximately 16:40, the server crashed when serving only 16 informers.
Why does kube-apiserver allocate so much memory for list requests?
Our investigation revealed that this substantial memory allocation occurs because the server before sending the first byte to the client must:
- fetch data from the database,
- deserialize the data from its stored format,
- and finally construct the final response by converting and serializing the data into a client requested format
This sequence results in significant temporary memory consumption. The actual usage depends on many factors like the page size, applied filters (e.g. label selectors), query parameters, and sizes of individual objects.
Unfortunately, neither API Priority and Fairness nor Golang's garbage collection or Golang memory limits can prevent the system from exhausting memory under these conditions. The memory is allocated suddenly and rapidly, and just a few requests can quickly deplete the available memory, leading to resource exhaustion.
Depending on how the API server is run on the node, it might either be killed through OOM by the kernel when exceeding the configured memory limits during these uncontrolled spikes, or if limits are not configured it might have even worse impact on the control plane node. And worst, after the first API server failure, the same requests will likely hit another control plane node in an HA setup with probably the same impact. Potentially a situation that is hard to diagnose and hard to recover from.
Streaming list requests
Today, we're excited to announce a major improvement.
With the graduation of the watch list feature to beta in Kubernetes 1.32, client-go users can opt-in (after explicitly enabling WatchListClient feature gate)
to streaming lists by switching from list to (a special kind of) watch requests.
Watch requests are served from the watch cache, an in-memory cache designed to improve scalability of read operations. By streaming each item individually instead of returning the entire collection, the new method maintains constant memory overhead. The API server is bound by the maximum allowed size of an object in etcd plus a few additional allocations. This approach drastically reduces the temporary memory usage compared to traditional list requests, ensuring a more efficient and stable system, especially in clusters with a large number of objects of a given type or large average object sizes where despite paging memory consumption used to be high.
Building on the insight gained from the synthetic test (see the synthetic test, we developed an automated performance test to systematically evaluate the impact of the watch list feature. This test replicates the same scenario, generating a large number of Secrets with a large payload, and scaling the number of informers to simulate heavy list request patterns. The automated test is executed periodically to monitor memory usage of the server with the feature enabled and disabled.
The results showed significant improvements with the watch list feature enabled. With the feature turned on, the kube-apiserver’s memory consumption stabilized at approximately 2 GB. By contrast, with the feature disabled, memory usage increased to approximately 20GB, a 10x increase! These results confirm the effectiveness of the new streaming API, which reduces the temporary memory footprint.
Enabling API Streaming for your component
Upgrade to Kubernetes 1.32. Make sure your cluster uses etcd in version 3.4.31+ or 3.5.13+.
Change your client software to use watch lists. If your client code is written in Golang, you'll want to enable WatchListClient for client-go.
For details on enabling that feature, read Introducing Feature Gates to Client-Go: Enhancing Flexibility and Control.
What's next?
In Kubernetes 1.32, the feature is enabled in kube-controller-manager by default despite its beta state. This will eventually be expanded to other core components like kube-scheduler or kubelet; once the feature becomes generally available, if not earlier. Other 3rd-party components are encouraged to opt-in to the feature during the beta phase, especially when they are at risk of accessing a large number of resources or kinds with potentially large object sizes.
For the time being, API Priority and Fairness assigns a reasonable small cost to list requests. This is necessary to allow enough parallelism for the average case where list requests are cheap enough. But it does not match the spiky exceptional situation of many and large objects. Once the majority of the Kubernetes ecosystem has switched to watch list, the list cost estimation can be changed to larger values without risking degraded performance in the average case, and with that increasing the protection against this kind of requests that can still hit the API server in the future.
The synthetic test
In order to reproduce the issue, we conducted a manual test to understand the impact of list requests on kube-apiserver memory usage. In the test, we created 400 Secrets, each containing 1 MB of data, and used informers to retrieve all Secrets.
The results were alarming, only 16 informers were needed to cause the test server to run out of memory and crash, demonstrating how quickly memory consumption can grow under such conditions.
Special shout out to @deads2k for his help in shaping this feature.
Kubernetes 1.33 update
Since this feature was started, Marek Siarkowicz integrated a new technology into the
Kubernetes API server: streaming collection encoding.
Kubernetes v1.33 introduced two related feature gates, StreamingCollectionEncodingToJSON and StreamingCollectionEncodingToProtobuf.
These features encode via a stream and avoid allocating all the memory at once.
This functionality is bit-for-bit compatible with existing list encodings, produces even greater server-side memory savings, and doesn't require any changes to client code.
In 1.33, the WatchList feature gate is disabled by default.