Kubernetesドキュメントのこのセクションには、個々のタスクの実行方法を示すページが含まれています。タスクページは、通常、短い手順を実行することにより、1つのことを行う方法を示します。
タスクページを作成したい場合は、ドキュメントのPull Requestの作成を参照してください。
これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
Kubernetesドキュメントのこのセクションには、個々のタスクの実行方法を示すページが含まれています。タスクページは、通常、短い手順を実行することにより、1つのことを行う方法を示します。
タスクページを作成したい場合は、ドキュメントのPull Requestの作成を参照してください。
Kubernetesのコマンドラインツールkubectlを使用すると、Kubernetesクラスターに対してコマンドを実行できるようになります。
kubectlは、アプリケーションのデプロイ、クラスターリソースの調査と管理、ログの表示などに使用できます。
kubectlの操作の完全なリストを含む詳細については、kubectlのリファレンスドキュメントを参照してください。
kubectlはさまざまなLinuxプラットフォーム、macOS、Windows上にインストールできます。 下記の中から好きなオペレーティングシステムを選んでください。
kindを使うと、ローカルのコンピューター上でKubernetesを実行することができます。
このツールはDockerとPodmanのどちらかのインストールが必要です。
Quick Startに、kindの起動と実行に必要なことが書かれています。
kindと同じように、minikubeは、Kubernetesをローカルで実行するツールです。
minikubeはオールインワンまたはマルチノードのローカルKubernetesクラスターをパーソナルコンピューター上(Windows、macOS、Linux PCを含む)で実行することで、Kubernetesを試したり、日常的な開発作業のために利用できます。
ツールのインストールについて知りたい場合は、公式のGet Started!のガイドに従ってください。
minikubeが起動したら、サンプルアプリケーションの実行を試すことができます。
Kubernetesクラスターの作成、管理をするためにkubeadmツールを使用することができます。
最低限実行可能でセキュアなクラスタを、ユーザーフレンドリーな方法で稼働させるために必要なアクションを実行します。
kubeadmのインストールでは、kubeadmをインストールする方法を示しています。 一度インストールすれば、クラスターを作成するために使用できます。
kubectlのバージョンは、クラスターのマイナーバージョンとの差分が1つ以内でなければなりません。 たとえば、クライアントがv1.32であれば、v1.31、v1.32、v1.33のコントロールプレーンと通信できます。 最新の互換性のあるバージョンのkubectlを使うことで、不測の事態を避けることができるでしょう。
Linuxへkubectlをインストールするには、次の方法があります:
次のコマンドにより、最新リリースをダウンロードしてください:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/arm64/kubectl"
特定のバージョンをダウンロードする場合、コマンドの$(curl -L -s https://dl.k8s.io/release/stable.txt)の部分を特定のバージョンに書き換えてください。
たとえば、Linux x86-64へ1.32.0のバージョンをダウンロードするには、次のコマンドを入力します:
curl -LO https://dl.k8s.io/release/v1.32.0/bin/linux/amd64/kubectl
そして、Linux ARM64に対しては、次のコマンドを入力します:
curl -LO https://dl.k8s.io/release/v1.32.0/bin/linux/arm64/kubectl
バイナリを検証してください(オプション)
kubectlのチェックサムファイルをダウンロードします:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl.sha256"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/arm64/kubectl.sha256"
チェックサムファイルに対してkubectlバイナリを検証します:
echo "$(cat kubectl.sha256) kubectl" | sha256sum --check
正しければ、出力は次のようになります:
kubectl: OK
チェックに失敗すると、sha256は0以外のステータスで終了し、次のような出力を表示します:
kubectl: FAILED
sha256sum: WARNING: 1 computed checksum did NOT match
kubectlをインストールしてください
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
ターゲットシステムにルートアクセスを持っていない場合でも、~/.local/binディレクトリにkubectlをインストールできます:
chmod +x kubectl
mkdir -p ~/.local/bin
mv ./kubectl ~/.local/bin/kubectl
# そして ~/.local/bin を $PATH の末尾 (または先頭) に追加します
インストールしたバージョンが最新であることを確認してください:
kubectl version --client
または、バージョンの詳細を表示するために次を使用します:
kubectl version --client --output=yaml
aptのパッケージ一覧を更新し、Kubernetesのaptリポジトリを利用するのに必要なパッケージをインストールしてください:
sudo apt-get update
# apt-transport-httpsはダミーパッケージの可能性があります。その場合、そのパッケージはスキップできます
sudo apt-get install -y apt-transport-https ca-certificates curl gnupg
Kubernetesパッケージリポジトリの公開署名キーをダウンロードしてください。 すべてのリポジトリに同じ署名キーが使用されるため、URL内のバージョンは無視できます:
# `/etc/apt/keyrings`フォルダーが存在しない場合は、curlコマンドの前に作成する必要があります。下記の備考を参照してください。
# sudo mkdir -p -m 755 /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.32/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
sudo chmod 644 /etc/apt/keyrings/kubernetes-apt-keyring.gpg # 特権のないAPTプログラムがこのkeyringを読めるようにします
/etc/apt/keyringsフォルダーは既定では存在しないため、curlコマンドの前に作成する必要があります。適切なKubernetesのaptリポジトリを追加してください。
v1.32とは異なるKubernetesバージョンを利用したい場合は、以下のコマンドのv1.32を目的のマイナーバージョンに置き換えてください:
# これにより、/etc/apt/sources.list.d/kubernetes.listにある既存の設定が上書きされます
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.32/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo chmod 644 /etc/apt/sources.list.d/kubernetes.list # command-not-foundのようなツールが正しく動作するようにします
apt-get updateとapt-get upgradeを実行する前に、/etc/apt/sources.list.d/kubernetes.listの中のバージョンを上げる必要があります。
この手順についてはChanging The Kubernetes Package Repositoryに詳細が記載されています。aptのパッケージインデックスを更新し、kubectlをインストールしてください:
sudo apt-get update
sudo apt-get install -y kubectl
Kubernetesのyumリポジトリを追加してください。
v1.32とは異なるKubernetesバージョンを利用したい場合は、以下のコマンドのv1.32を目的のマイナーバージョンに置き換えてください:
# これにより、/etc/yum.repos.d/kubernetes.repoにある既存の設定が上書きされます
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/repodata/repomd.xml.key
EOF
yum updateを実行する前に、/etc/yum.repos.d/kubernetes.repoの中のバージョンを上げる必要があります。
この手順についてはChanging The Kubernetes Package Repositoryに詳細が記載されています。yumを使用してkubectlをインストールしてください:
sudo yum install -y kubectl
Kubernetesのzypperリポジトリを追加してください。
v1.32とは異なるKubernetesバージョンを利用したい場合は、以下のコマンドのv1.32を目的のマイナーバージョンに置き換えてください。
# これにより、/etc/zypp/repos.d/kubernetes.repoにある既存の設定が上書きされます
cat <<EOF | sudo tee /etc/zypp/repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/repodata/repomd.xml.key
EOF
zypper updateを実行する前に、/etc/zypp/repos.d/kubernetes.repoの中のバージョンを上げる必要があります。
この手順についてはChanging The Kubernetes Package Repositoryに詳細が記載されています。zypperを使用してkubectlをインストールしてください:
sudo zypper install -y kubectl
kubectlがKubernetesクラスターを探索し接続するために、kubeconfigファイルが必要です。
これは、kube-up.shによりクラスターを作成した際や、Minikubeクラスターを正常にデプロイした際に自動生成されます。
デフォルトでは、kubectlの設定は~/.kube/configに格納されています。
クラスターの状態を取得し、kubectlが適切に設定されていることを確認してください:
kubectl cluster-info
URLのレスポンスが表示されている場合は、kubectlはクラスターに接続するよう正しく設定されています。
以下のようなメッセージが表示されている場合は、kubectlは正しく設定されていないか、Kubernetesクラスターに接続できていません。
The connection to the server <server-name:port> was refused - did you specify the right host or port?
たとえば、ラップトップ上(ローカル環境)でKubernetesクラスターを起動するような場合、Minikubeなどのツールを最初にインストールしてから、上記のコマンドを再実行する必要があります。
kubectl cluster-infoがURLレスポンスを返したにもかかわらずクラスターにアクセスできない場合は、次のコマンドで設定が正しいことを確認してください:
kubectl cluster-info dump
Kubernetes 1.26にて、kubectlは以下のクラウドプロバイダーが提供するマネージドKubernetesのビルトイン認証を削除しました。 これらのプロバイダーは、クラウド固有の認証を提供するkubectlプラグインをリリースしています。 手順については以下のプロバイダーのドキュメントを参照してください:
(この変更とは関係なく、他の理由で同じエラーメッセージが表示される可能性もあります。)
kubectlはBash、Zsh、Fish、PowerShellの自動補完を提供しています。 これにより、入力を大幅に削減することができます。
以下にBash、Fish、Zshの自動補完の設定手順を示します。
Bashにおけるkubectlの補完スクリプトはkubectl completion bashコマンドで生成できます。
補完スクリプトをシェル内に読み込ませることでkubectlの自動補完が有効になります。
ただし、補完スクリプトはbash-completionに依存しているため、事前にインストールしておく必要があります(type _init_completionを実行することで、bash-completionがすでにインストールされていることを確認できます)。
bash-completionは多くのパッケージマネージャーから提供されています(こちらを参照してください)。
apt-get install bash-completionまたはyum install bash-completionなどでインストールできます。
上記のコマンドでbash-completionの主要スクリプトである/usr/share/bash-completion/bash_completionが作成されます。
パッケージマネージャーによっては、このファイルを~/.bashrcにて手動で読み込ませる必要があります。
これを調べるには、シェルをリロードしてからtype _init_completionを実行してください。
コマンドが成功していればすでに設定済みです。そうでなければ、~/.bashrcファイルに以下を追記してください:
source /usr/share/bash-completion/bash_completion
シェルをリロードし、type _init_completionを実行してbash-completionが正しくインストールされていることを検証してください。
次に、kubectl補完スクリプトがすべてのシェルセッションで読み込まれるように設定する必要があります。 これを行うには2つの方法があります:
echo 'source <(kubectl completion bash)' >>~/.bashrc
kubectl completion bash | sudo tee /etc/bash_completion.d/kubectl > /dev/null
sudo chmod a+r /etc/bash_completion.d/kubectl
kubectlにエイリアスを張っている場合は、エイリアスでも動作するようにシェルの補完を拡張することができます:
echo 'alias k=kubectl' >>~/.bashrc
echo 'complete -o default -F __start_kubectl k' >>~/.bashrc
/etc/bash_completion.d内のすべての補完スクリプトを読み込みます。どちらも同様の手法です。 シェルをリロードしたあとに、kubectlの自動補完が機能するはずです。 シェルの現在のセッションでbashの自動補完を有効にするには、~/.bashrcを読み込みます:
source ~/.bashrc
Fishにおけるkubectlの補完スクリプトはkubectl completion fishコマンドで生成できます。
補完スクリプトをシェル内に読み込ませることでkubectlの自動補完が有効になります。
すべてのシェルセッションで使用するには、~/.config/fish/config.fishに以下を追記してください:
kubectl completion fish | source
シェルをリロードしたあとに、kubectlの自動補完が機能するはずです。
Zshにおけるkubectlの補完スクリプトはkubectl completion zshコマンドで生成できます。
補完スクリプトをシェル内に読み込ませることでkubectlの自動補完が有効になります。
すべてのシェルセッションで使用するには、~/.zshrcに以下を追記してください:
source <(kubectl completion zsh)
kubectlにエイリアスを張っている場合でも、kubectlの自動補完は自動的に機能します。
シェルをリロードしたあとに、kubectlの自動補完が機能するはずです。
2: command not found: compdefのようなエラーが出力された場合は、以下を~/.zshrcの先頭に追記してください:
autoload -Uz compinit
compinit
kubectl convertプラグインをインストールする異なるAPIバージョン間でマニフェストを変換できる、Kubernetesコマンドラインツールkubectlのプラグインです。
これは特に、新しいKubernetesのリリースで、非推奨ではないAPIバージョンにマニフェストを移行する場合に役に立ちます。
詳細については非推奨ではないAPIへの移行を参照してください。
次のコマンドを使用して最新リリースをダウンロードしてください:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl-convert"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/arm64/kubectl-convert"
バイナリを検証してください(オプション)
kubectl-convertのチェックサムファイルをダウンロードします:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl-convert.sha256"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/arm64/kubectl-convert.sha256"
チェックサムファイルに対してkubectl-convertバイナリを検証します:
echo "$(cat kubectl-convert.sha256) kubectl-convert" | sha256sum --check
正しければ、出力は次のようになります:
kubectl-convert: OK
チェックに失敗すると、sha256は0以外のステータスで終了し、次のような出力を表示します:
kubectl-convert: FAILED
sha256sum: WARNING: 1 computed checksum did NOT match
kubectl-convertをインストールしてください
sudo install -o root -g root -m 0755 kubectl-convert /usr/local/bin/kubectl-convert
プラグインが正常にインストールできたことを確認してください
kubectl convert --help
何もエラーが表示されない場合は、プラグインが正常にインストールされたことを示しています。
プラグインのインストール後、インストールファイルを削除してください:
rm kubectl-convert kubectl-convert.sha256
kubectlのバージョンは、クラスターのマイナーバージョンとの差分が1つ以内でなければなりません。 たとえば、クライアントがv1.32であれば、v1.31、v1.32、v1.33のコントロールプレーンと通信できます。 最新の互換性のあるバージョンのkubectlを使うことで、不測の事態を避けることができるでしょう。
macOSへkubectlをインストールするには、次の方法があります:
最新リリースをダウンロードしてください:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/amd64/kubectl"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/arm64/kubectl"
特定のバージョンをダウンロードする場合、コマンドの$(curl -L -s https://dl.k8s.io/release/stable.txt)の部分を特定のバージョンに置き換えてください。
例えば、Intel macOSへ1.32.0のバージョンをダウンロードするには、次のコマンドを入力します:
curl -LO "https://dl.k8s.io/release/v1.32.0/bin/darwin/amd64/kubectl"
Appleシリコン上のmacOSに対しては、次を入力します:
curl -LO "https://dl.k8s.io/release/v1.32.0/bin/darwin/arm64/kubectl"
バイナリを検証してください(オプション)
kubectlのチェックサムファイルをダウンロードします:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/amd64/kubectl.sha256"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/arm64/kubectl.sha256"
チェックサムファイルに対してkubectlバイナリを検証します:
echo "$(cat kubectl.sha256) kubectl" | shasum -a 256 --check
正しければ、出力は次のようになります:
kubectl: OK
チェックに失敗すると、shasumは0以外のステータスで終了し、次のような出力を表示します:
kubectl: FAILED
shasum: WARNING: 1 computed checksum did NOT match
kubectlバイナリを実行可能にしてください。
chmod +x ./kubectl
kubectlバイナリをPATHの中に移動させてください。
sudo mv ./kubectl /usr/local/bin/kubectl
sudo chown root: /usr/local/bin/kubectl
/usr/local/binがPATH環境変数の中に含まれるようにしてください。インストールしたバージョンが最新であることを確認してください:
kubectl version --client
または、バージョンの詳細を表示するために次を使用します:
kubectl version --client --output=yaml
kubectlをインストールし、検証した後は、チェックサムファイルを削除してください:
rm kubectl.sha256
macOSでHomebrewパッケージマネージャーを使用していれば、Homebrewでkubectlをインストールできます。
インストールコマンドを実行してください:
brew install kubectl
または
brew install kubernetes-cli
インストールしたバージョンが最新であることを確認してください:
kubectl version --client
macOSでMacPortsパッケージマネージャーを使用していれば、MacPortsでkubectlをインストールできます。
インストールコマンドを実行してください:
sudo port selfupdate
sudo port install kubectl
インストールしたバージョンが最新であることを確認してください:
kubectl version --client
kubectlがKubernetesクラスターを探索し接続するために、kubeconfigファイルが必要です。
これは、kube-up.shによりクラスターを作成した際や、Minikubeクラスターを正常にデプロイした際に自動生成されます。
デフォルトでは、kubectlの設定は~/.kube/configに格納されています。
クラスターの状態を取得し、kubectlが適切に設定されていることを確認してください:
kubectl cluster-info
URLのレスポンスが表示されている場合は、kubectlはクラスターに接続するよう正しく設定されています。
以下のようなメッセージが表示されている場合は、kubectlは正しく設定されていないか、Kubernetesクラスターに接続できていません。
The connection to the server <server-name:port> was refused - did you specify the right host or port?
たとえば、ラップトップ上(ローカル環境)でKubernetesクラスターを起動するような場合、Minikubeなどのツールを最初にインストールしてから、上記のコマンドを再実行する必要があります。
kubectl cluster-infoがURLレスポンスを返したにもかかわらずクラスターにアクセスできない場合は、次のコマンドで設定が正しいことを確認してください:
kubectl cluster-info dump
Kubernetes 1.26にて、kubectlは以下のクラウドプロバイダーが提供するマネージドKubernetesのビルトイン認証を削除しました。 これらのプロバイダーは、クラウド固有の認証を提供するkubectlプラグインをリリースしています。 手順については以下のプロバイダーのドキュメントを参照してください:
(この変更とは関係なく、他の理由で同じエラーメッセージが表示される可能性もあります。)
kubectlはBash、Zsh、Fish、PowerShellの自動補完を提供しています。 これにより、入力を大幅に削減することができます。
以下にBash、Fish、Zshの自動補完の設定手順を示します。
Bashにおけるkubectlの補完スクリプトはkubectl completion bashコマンドで生成できます。
補完スクリプトをシェル内に読み込ませることでkubectlの自動補完が有効になります。
ただし、補完スクリプトはbash-completionに依存しているため、事前にインストールしておく必要があります。
ここではBash 4.1以降の使用を前提としています。 Bashのバージョンは下記のコマンドで調べることができます:
echo $BASH_VERSION
バージョンが古い場合、Homebrewを使用してインストールもしくはアップグレードできます:
brew install bash
シェルをリロードし、希望するバージョンを使用していることを確認してください:
echo $BASH_VERSION $SHELL
Homebrewは通常、/usr/local/bin/bashにインストールします。
type _init_completionを実行することで、bash-completionがすでにインストールされていることを確認できます。
ない場合は、Homebrewを使用してインストールすることができます:
brew install bash-completion@2
このコマンドの出力で示されたように、~/.bash_profileに以下を追記してください:
brew_etc="$(brew --prefix)/etc" && [[ -r "${brew_etc}/profile.d/bash_completion.sh" ]] && . "${brew_etc}/profile.d/bash_completion.sh"
シェルをリロードし、type _init_completionを実行してbash-completion v2が正しくインストールされていることを検証してください。
次に、kubectl補完スクリプトがすべてのシェルセッションで読み込まれるように設定する必要があります。 これを行うには複数の方法があります:
補完スクリプトを~/.bash_profile内で読み込ませる:
echo 'source <(kubectl completion bash)' >>~/.bash_profile
補完スクリプトを/usr/local/etc/bash_completion.dディレクトリに追加する:
kubectl completion bash >/usr/local/etc/bash_completion.d/kubectl
kubectlにエイリアスを張っている場合は、エイリアスでも動作するようにシェルの補完を拡張することができます:
echo 'alias k=kubectl' >>~/.bash_profile
echo 'complete -o default -F __start_kubectl k' >>~/.bash_profile
kubectlをHomebrewでインストールした場合(前述の通り)、kubectlの補完スクリプトはすでに/usr/local/etc/bash_completion.d/kubectlに格納されているでしょうか。
この場合、なにも操作する必要はありません。
BASH_COMPLETION_COMPAT_DIRディレクトリ内のすべてのファイルを読み込むため、後者の2つの方法が機能します。どの場合でも、シェルをリロードしたあとに、kubectlの自動補完が機能するはずです。
Fishにおけるkubectlの補完スクリプトはkubectl completion fishコマンドで生成できます。
補完スクリプトをシェル内に読み込ませることでkubectlの自動補完が有効になります。
すべてのシェルセッションで使用するには、~/.config/fish/config.fishに以下を追記してください:
kubectl completion fish | source
シェルをリロードしたあとに、kubectlの自動補完が機能するはずです。
Zshにおけるkubectlの補完スクリプトはkubectl completion zshコマンドで生成できます。
補完スクリプトをシェル内に読み込ませることでkubectlの自動補完が有効になります。
すべてのシェルセッションで使用するには、~/.zshrcに以下を追記してください:
source <(kubectl completion zsh)
kubectlにエイリアスを張っている場合でも、kubectlの自動補完は自動的に機能します。
シェルをリロードしたあとに、kubectlの自動補完が機能するはずです。
2: command not found: compdefのようなエラーが出力された場合は、以下を~/.zshrcの先頭に追記してください:
autoload -Uz compinit
compinit
kubectl convertプラグインをインストールする異なるAPIバージョン間でマニフェストを変換できる、Kubernetesコマンドラインツールkubectlのプラグインです。
これは特に、新しいKubernetesのリリースで、非推奨ではないAPIバージョンにマニフェストを移行する場合に役に立ちます。
詳細については非推奨ではないAPIへの移行を参照してください。
次のコマンドを使用して最新リリースをダウンロードしてください:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/amd64/kubectl-convert"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/arm64/kubectl-convert"
バイナリを検証してください(オプション)
kubectl-convertのチェックサムファイルをダウンロードします:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/amd64/kubectl-convert.sha256"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/arm64/kubectl-convert.sha256"
チェックサムファイルに対してkubectl-convertバイナリを検証します:
echo "$(cat kubectl-convert.sha256) kubectl-convert" | shasum -a 256 --check
正しければ、出力は次のようになります:
kubectl-convert: OK
チェックに失敗すると、shasumは0以外のステータスで終了し、次のような出力を表示します:
kubectl-convert: FAILED
shasum: WARNING: 1 computed checksum did NOT match
kubectl-convertバイナリを実行可能にしてください。
chmod +x ./kubectl-convert
kubectl-convertバイナリをPATHの中に移動してください。
sudo mv ./kubectl-convert /usr/local/bin/kubectl-convert
sudo chown root: /usr/local/bin/kubectl-convert
/usr/local/binがPATH環境変数の中に含まれるようにしてください。インストールしたバージョンが最新であることを確認してください
kubectl convert --help
何もエラーが表示されない場合は、プラグインが正常にインストールされたことを示しています。
プラグインのインストール後、インストールファイルを削除してください:
rm kubectl-convert kubectl-convert.sha256
kubectlのインストール方法に応じて、次の方法を使用してください。
システム上のkubectlバイナリの場所を特定してください:
which kubectl
kubectlバイナリを削除してください:
sudo rm <path>
<path>を前のステップのkubectlバイナリのパスに置き換えてください。
例えばsudo rm /usr/local/bin/kubectl。
Homebrewを使用してkubectlをインストールした場合は、次のコマンドを実行してください:
brew remove kubectl
kubectlのバージョンは、クラスターのマイナーバージョンとの差分が1つ以内でなければなりません。 たとえば、クライアントがv1.32であれば、v1.31、v1.32、v1.33のコントロールプレーンと通信できます。 最新の互換性のあるバージョンのkubectlを使うことで、不測の事態を避けることができるでしょう。
Windowsへkubectlをインストールするには、次の方法があります:
最新の1.32のパッチリリースをダウンロードしてください: kubectl 1.32.0。
または、curlがインストールされていれば、次のコマンドも使用できます:
curl.exe -LO "https://dl.k8s.io/release/v1.32.0/bin/windows/amd64/kubectl.exe"
バイナリを検証してください(オプション)
kubectlのチェックサムファイルをダウンロードします:
curl.exe -LO "https://dl.k8s.io/v1.32.0/bin/windows/amd64/kubectl.exe.sha256"
チェックサムファイルに対してkubectlバイナリを検証します:
コマンドプロンプトを使用して、CertUtilの出力とダウンロードしたチェックサムファイルを手動で比較します:
CertUtil -hashfile kubectl.exe SHA256
type kubectl.exe.sha256
PowerShellにて-eqオペレーターを使用して自動で検証を行い、TrueまたはFalseで結果を取得します:
$(Get-FileHash -Algorithm SHA256 .\kubectl.exe).Hash -eq $(Get-Content .\kubectl.exe.sha256)
kubectlバイナリのフォルダーをPATH環境変数に追加します。
kubectlのバージョンがダウンロードしたものと同じであることを確認してください:
kubectl version --client
または、バージョンの詳細を表示するために次を使用します:
kubectl version --client --output=yaml
kubectlをPATHに追加します。
Docker Desktopをすでにインストールしている場合、Docker Desktopインストーラーによって追加されたPATHの前に追加するか、Docker Desktopのkubectlを削除してください。Windowsへkubectlをインストールするために、ChocolateyパッケージマネージャーやScoopコマンドラインインストーラー、wingetパッケージマネージャーを使用することもできます。
choco install kubernetes-cli
scoop install kubectl
winget install -e --id Kubernetes.kubectl
インストールしたバージョンが最新であることを確認してください:
kubectl version --client
ホームディレクトリへ移動してください:
# cmd.exeを使用している場合はcd %USERPROFILE%を実行してください。
cd ~
.kubeディレクトリを作成してください:
mkdir .kube
作成した.kubeディレクトリへ移動してください:
cd .kube
リモートのKubernetesクラスターを使うために、kubectlを設定してください:
New-Item config -type file
kubectlがKubernetesクラスターを探索し接続するために、kubeconfigファイルが必要です。
これは、kube-up.shによりクラスターを作成した際や、Minikubeクラスターを正常にデプロイした際に自動生成されます。
デフォルトでは、kubectlの設定は~/.kube/configに格納されています。
クラスターの状態を取得し、kubectlが適切に設定されていることを確認してください:
kubectl cluster-info
URLのレスポンスが表示されている場合は、kubectlはクラスターに接続するよう正しく設定されています。
以下のようなメッセージが表示されている場合は、kubectlは正しく設定されていないか、Kubernetesクラスターに接続できていません。
The connection to the server <server-name:port> was refused - did you specify the right host or port?
たとえば、ラップトップ上(ローカル環境)でKubernetesクラスターを起動するような場合、Minikubeなどのツールを最初にインストールしてから、上記のコマンドを再実行する必要があります。
kubectl cluster-infoがURLレスポンスを返したにもかかわらずクラスターにアクセスできない場合は、次のコマンドで設定が正しいことを確認してください:
kubectl cluster-info dump
Kubernetes 1.26にて、kubectlは以下のクラウドプロバイダーが提供するマネージドKubernetesのビルトイン認証を削除しました。 これらのプロバイダーは、クラウド固有の認証を提供するkubectlプラグインをリリースしています。 手順については以下のプロバイダーのドキュメントを参照してください:
(この変更とは関係なく、他の理由で同じエラーメッセージが表示される可能性もあります。)
kubectlはBash、Zsh、Fish、PowerShellの自動補完を提供しています。 これにより、入力を大幅に削減することができます。
以下にPowerShellの自動補完の設定手順を示します。
PowerShellにおけるkubectlの補完スクリプトはkubectl completion powershellコマンドで生成できます。
すべてのシェルセッションでこれを行うには、次の行を$PROFILEファイルに追加します。
kubectl completion powershell | Out-String | Invoke-Expression
このコマンドは、PowerShellを起動する度に自動補完のスクリプトを再生成します。
生成されたスクリプトを直接$PROFILEファイルに追加することもできます。
生成されたスクリプトを$PROFILEファイルに追加するためには、PowerShellのプロンプトで次の行を実行します:
kubectl completion powershell >> $PROFILE
シェルをリロードした後、kubectlの自動補完が機能します。
kubectl convertプラグインをインストールする異なるAPIバージョン間でマニフェストを変換できる、Kubernetesコマンドラインツールkubectlのプラグインです。
これは特に、新しいKubernetesのリリースで、非推奨ではないAPIバージョンにマニフェストを移行する場合に役に立ちます。
詳細については非推奨ではないAPIへの移行を参照してください。
次のコマンドを使用して最新リリースをダウンロードしてください:
curl.exe -LO "https://dl.k8s.io/release/v1.32.0/bin/windows/amd64/kubectl-convert.exe"
バイナリを検証してください(オプション)。
kubectl-convertのチェックサムファイルをダウンロードします:
curl.exe -LO "https://dl.k8s.io/v1.32.0/bin/windows/amd64/kubectl-convert.exe.sha256"
チェックサムファイルに対してkubectl-convertバイナリを検証します:
コマンドプロンプトを使用して、CertUtilの出力とダウンロードしたチェックサムファイルを手動で比較します:
CertUtil -hashfile kubectl-convert.exe SHA256
type kubectl-convert.exe.sha256
PowerShellにて-eqオペレーターを使用して自動で検証を行い、TrueまたはFalseで結果を取得します:
$($(CertUtil -hashfile .\kubectl-convert.exe SHA256)[1] -replace " ", "") -eq $(type .\kubectl-convert.exe.sha256)
kubectl-convertバイナリのフォルダーをPATH環境変数に追加します。
プラグインが正常にインストールされたことを確認してください。
kubectl convert --help
何もエラーが表示されない場合は、プラグインが正常にインストールされたことを示しています。
プラグインのインストール後、インストールファイルを削除してください:
del kubectl-convert.exe
del kubectl-convert.exe.sha256
Kubernetes v1.15 [stable]kubeadmで生成されたクライアント証明書は1年で失効します。 このページでは、kubeadmで証明書の更新を管理する方法について説明します。
KubernetesにおけるPKI証明書と要件を熟知している必要があります。
デフォルトでは、kubeadmはクラスターの実行に必要なすべての証明書を生成します。 独自の証明書を提供することで、この動作をオーバーライドできます。
そのためには、--cert-dirフラグまたはkubeadmのClusterConfigurationのcertificatesDirフィールドで指定された任意のディレクトリに配置する必要があります。
デフォルトは/etc/kubernetes/pkiです。
kubeadm init を実行する前に与えられた証明書と秘密鍵のペアが存在する場合、kubeadmはそれらを上書きしません。
つまり、例えば既存のCAを/etc/kubernetes/pki/ca.crtと/etc/kubernetes/pki/ca.keyにコピーすれば、kubeadmは残りの証明書に署名する際、このCAを使用できます。
また、ca.crtファイルのみを提供し、ca.keyファイルを提供しないことも可能です(これはルートCAファイルのみに有効で、他の証明書ペアには有効ではありません)。
他の証明書とkubeconfigファイルがすべて揃っている場合、kubeadmはこの状態を認識し、外部CAモードを有効にします。
kubeadmはディスク上のCAキーがなくても処理を進めます。
代わりに、Controller-managerをスタンドアロンで、--controllers=csrsignerと実行し、CA証明書と鍵を指し示します。
PKI certificates and requirementsには、外部CAを使用するためのクラスターのセットアップに関するガイダンスが含まれています。
check-expirationサブコマンドを使うと、証明書の有効期限を確認することができます。
kubeadm certs check-expiration
このような出力になります:
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Dec 30, 2020 23:36 UTC 364d no
apiserver Dec 30, 2020 23:36 UTC 364d ca no
apiserver-etcd-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
apiserver-kubelet-client Dec 30, 2020 23:36 UTC 364d ca no
controller-manager.conf Dec 30, 2020 23:36 UTC 364d no
etcd-healthcheck-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-peer Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-server Dec 30, 2020 23:36 UTC 364d etcd-ca no
front-proxy-client Dec 30, 2020 23:36 UTC 364d front-proxy-ca no
scheduler.conf Dec 30, 2020 23:36 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Dec 28, 2029 23:36 UTC 9y no
etcd-ca Dec 28, 2029 23:36 UTC 9y no
front-proxy-ca Dec 28, 2029 23:36 UTC 9y no
このコマンドは、/etc/kubernetes/pkiフォルダ内のクライアント証明書と、kubeadmが使用するKUBECONFIGファイル(admin.conf,controller-manager.conf,scheduler.conf)に埋め込まれたクライアント証明書の有効期限/残余時間を表示します。
また、証明書が外部管理されている場合、kubeadmはユーザーに通知します。この場合、ユーザーは証明書の更新を手動または他のツールを使用して管理する必要があります。
kubeadmは外部CAによって署名された証明書を管理することができません。kubeadmは/var/lib/kubelet/pki以下にあるローテート可能な証明書でkubeletの証明書の自動更新を構成するのでkubelet.confは上記のリストに含まれません。
期限切れのkubeletクライアント証明書を修復するには、Kubelet クライアント証明書のローテーションに失敗しましたを参照ください。
kubeadm version 1.17より前のkubeadm initで作成したノードでは、kubelet.confの内容を手動で変更しなければならないというbugが存在します。
kubeadm initが終了したら、client-certificate-dataとclient-key-dataを置き換えて、ローテーションされたkubeletクライアント証明書を指すようにkubelet.confを更新してください。
client-certificate: /var/lib/kubelet/pki/kubelet-client-current.pem
client-key: /var/lib/kubelet/pki/kubelet-client-current.pem
kubeadmはコントロールプレーンのアップグレード時にすべての証明書を更新します。
この機能は、最もシンプルなユースケースに対応するために設計されています。 証明書の更新に特別な要件がなく、Kubernetesのバージョンアップを定期的に行う場合(各アップグレードの間隔が1年未満)、kubeadmがクラスターを最新かつ適度に安全に保つための処理を行います。
証明書の更新に関してより複雑な要求がある場合は、--certificate-renewal=falseをkubeadm upgrade applyやkubeadm upgrade nodeに渡して、デフォルトの動作から外れるようにすることができます。
kubeadm upgrade nodeコマンドの--certificate-renewalのデフォルト値がfalseになっているという[bug(https://github.com/kubernetes/kubeadm/issues/1818)]問題があります。
この場合、明示的に--certificate-renewal=trueを設定する必要があります。kubeadm certs renew コマンドを使えば、いつでも証明書を手動で更新することができます。
このコマンドは/etc/kubernetes/pkiに格納されているCA(またはfront-proxy-CA)の証明書と鍵を使って更新を行います。
コマンド実行後、コントロールプレーンのPodを再起動する必要があります。 これは、現在すべてのコンポーネントと証明書について動的な証明書のリロードがサポートされていないため、必要な作業です。 スタティックPodはローカルkubeletによって管理され、API Serverによって管理されないため、kubectlで削除および再起動することはできません。
スタティックPodを再起動するには、一時的に/etc/kubernetes/manifests/からマニフェストファイルを削除して20秒間待ちます(KubeletConfiguration structのfileCheckFrequency値を参照してください)。
マニフェストディレクトリにPodが無くなると、kubeletはPodを終了します。
その後ファイルを戻して、さらにfileCheckFrequency期間後に、kubeletはPodを再作成し、コンポーネントの証明書更新を完了することができます。
certs renewは、属性(Common Name、Organization、SANなど)の信頼できるソースとして、kubeadm-config ConfigMapではなく、既存の証明書を使用します。両者を同期させておくことが強く推奨されます。kubeadm certs renew は以下のオプションを提供します:
Kubernetesの証明書は通常1年後に有効期限を迎えます。
--csr-onlyを使用すると、証明書署名要求を生成して外部CAとの証明書を更新することができます(実際にはその場で証明書を更新しません)。詳しくは次の段落を参照してください。
また、すべての証明書を更新するのではなく、1つの証明書を更新することも可能です。
ここでは、Kubernetes certificates APIを使用して手動で証明書更新を実行する方法について詳しく説明します。
Kubernetesの認証局は、そのままでは機能しません。 cert-managerなどの外部署名者を設定するか、組み込みの署名者を使用することができます。
ビルトインサイナーはkube-controller-managerに含まれるものです。
ビルトインサイナーを有効にするには、--cluster-signing-cert-fileと--cluster-signing-key-fileフラグを渡す必要があります。
新しいクラスターを作成する場合は、kubeadm設定ファイルを使用します。
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
controllerManager:
extraArgs:
cluster-signing-cert-file: /etc/kubernetes/pki/ca.crt
cluster-signing-key-file: /etc/kubernetes/pki/ca.key
Kubernetes APIでのCSR作成については、Create CertificateSigningRequestを参照ください。
ここでは、外部認証局を利用して手動で証明書更新を行う方法について詳しく説明します。
外部CAとの連携を強化するために、kubeadmは証明書署名要求(CSR)を生成することもできます。 CSRとは、クライアント用の署名付き証明書をCAに要求することを表します。 kubeadmの用語では、通常ディスク上のCAによって署名される証明書をCSRとして生成することができます。しかし、CAはCSRとして生成することはできません。
kubeadm certs renew --csr-onlyで証明書署名要求を作成することができます。
CSRとそれに付随する秘密鍵の両方が出力されます。
ディレクトリを--csr-dirで渡すと、指定した場所にCSRを出力することができます。
csr-dirを指定しない場合は、デフォルトの証明書ディレクトリ(/etc/kubernetes/pki)が使用されます。
証明書はkubeadm certs renew --csr-onlyで更新することができます。
kubeadm initと同様に、--csr-dirフラグで出力先ディレクトリを指定することができます。
CSRには、証明書の名前、ドメイン、IPが含まれますが、用途は指定されません。 証明書を発行する際に、正しい証明書の使用法を指定するのはCAの責任です。
opensslでは、openssl caコマンドを使って行います。
cfsslでは、configファイルのusagesで指定します。
お好みの方法で証明書に署名した後、証明書と秘密鍵をPKIディレクトリ(デフォルトでは/etc/kubernetes/pki)にコピーする必要があります。
Kubeadmは、CA証明書のローテーションや交換を最初からサポートしているわけではありません。
CAの手動ローテーションや交換についての詳細は、manual rotation of CA certificatesを参照してください。
デフォルトでは、kubeadmによって展開されるkubeletサービング証明書は自己署名されています。
これは、metrics-serverのような外部サービスからキューブレットへの接続がTLSで保護されないことを意味します。
新しいkubeadmクラスター内のkubeletが適切に署名されたサービング証明書を取得するように設定するには、kubeadm initに以下の最小限の設定を渡す必要があります。
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
serverTLSBootstrap: true
すでにクラスターを作成している場合は、以下の手順で適応させる必要があります。
kube-systemネームスペースにあるkubelet-config-1.32 ConfigMapを見つけて編集します。そのConfigMapのkubeletキーの値としてKubeletConfigurationドキュメントを指定します。KubeletConfigurationドキュメントを編集し、serverTLSBootstrap: trueを設定します。
/var/lib/kubelet/config.yamlにserverTLSBootstrap: trueフィールドを追加し、systemctl restart kubeletでkubeletを再起動します。serverTLSBootstrap: trueフィールドは、kubeletサービングのブートストラップを有効にします。
証明書をcertificates.k8s.ioAPIにリクエストすることで、証明書を発行することができます。
既知の制限事項として、これらの証明書のCSR(Certificate Signing Requests)はkube-controller-managerのデフォルトサイナーによって自動的に承認されないことがあります。
kubernetes.io/kubelet-serving を参照してください。
これには、ユーザーまたはサードパーティーのコントローラーからのアクションが必要です。
これらのCSRは、以下を使用して表示できます:
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-9wvgt 112s kubernetes.io/kubelet-serving system:node:worker-1 Pending
csr-lz97v 1m58s kubernetes.io/kubelet-serving system:node:control-plane-1 Pending
承認するためには、次のようにします:
kubectl certificate approve <CSR-name>
デフォルトでは、これらのサービング証明書は1年後に失効します。
KubeadmはKubeletConfigurationフィールドrotateCertificatesをtrueに設定します。これは有効期限が切れる間際に、サービング証明書のための新しいCSRセットを作成し、ローテーションを完了するために承認する必要があることを意味します。
詳しくはCertificate Rotationをご覧ください。
これらのCSRを自動的に承認するためのソリューションをお探しの場合は、以下をお勧めします。 クラウドプロバイダーに連絡し、ノードの識別をアウトオブバンドのメカニズムで行うCSRの署名者がいるかどうか尋ねてください。
サードパーティーのカスタムコントローラーを使用することができます。
このようなコントローラーは、CSRのCommonNameを検証するだけでなく、要求されたIPやドメイン名も検証しなければ、安全なメカニズムとは言えません。これにより、kubeletクライアント証明書にアクセスできる悪意のあるアクターが、任意のIPやドメイン名に対してサービング証明書を要求するCSRを作成することを防ぐことができます。
このページでは、kubeadmクラスターのコンテナランタイムcgroupドライバーに合わせて、kubelet cgroupドライバーを設定する方法について説明します。
Kubernetesのコンテナランタイムの要件を熟知している必要があります。
コンテナランタイムページでは、kubeadmベースのセットアップではcgroupfsドライバーではなく、systemdドライバーが推奨されると説明されています。
このページでは、デフォルトのsystemdドライバーを使用して多くの異なるコンテナランタイムをセットアップする方法についての詳細も説明されています。
kubeadmでは、kubeadm initの際にKubeletConfiguration構造体を渡すことができます。
このKubeletConfigurationには、kubeletのcgroupドライバーを制御するcgroupDriverフィールドを含めることができます。
KubeletConfigurationのcgroupDriverフィールドを設定していない場合、kubeadmはデフォルトでsystemdを設定するようになりました。フィールドを明示的に設定する最小限の例です:
# kubeadm-config.yaml
kind: ClusterConfiguration
apiVersion: kubeadm.k8s.io/v1beta3
kubernetesVersion: v1.21.0
---
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
cgroupDriver: systemd
このような設定ファイルは、kubeadmコマンドに渡すことができます:
kubeadm init --config kubeadm-config.yaml
Kubeadmはクラスター内の全ノードで同じKubeletConfigurationを使用します。
KubeletConfigurationはkube-system名前空間下のConfigMapオブジェクトに格納されます。
サブコマンドinit、join、upgradeを実行すると、kubeadmがKubeletConfigurationを/var/lib/kubelet/config.yaml以下にファイルとして書き込み、ローカルノードのkubeletに渡します。
このガイドで説明するように、cgroupfsドライバーをkubeadmと一緒に使用することは推奨されません。
cgroupfsを使い続け、kubeadm upgradeが既存のセットアップでKubeletConfiguration cgroupドライバーを変更しないようにするには、その値を明示的に指定する必要があります。
これは、将来のバージョンのkubeadmにsystemdドライバーをデフォルトで適用させたくない場合に適用されます。
値を明示する方法については、後述の「kubelet ConfigMapの修正」の項を参照してください。
cgroupfsドライバーを使用するようにコンテナランタイムを設定したい場合は、選択したコンテナランタイムのドキュメントを参照する必要があります。
systemdドライバーへの移行既存のkubeadmクラスターのcgroupドライバーをsystemdにインプレースで変更する場合は、kubeletのアップグレードと同様の手順が必要です。
これには、以下に示す両方の手順を含める必要があります。
systemdドライバーを使用する新しいノードに置き換えることも可能です。
この場合、新しいノードに参加する前に以下の最初のステップのみを実行し、古いノードを削除する前にワークロードが新しいノードに安全に移動できることを確認する必要があります。kubectl get cm -n kube-system | grep kubelet-configで、kubelet ConfigMapの名前を探します。kubectl edit cm kubelet-config-x.yy -n kube-systemを呼び出します(x.yyはKubernetesのバージョンに置き換えてください)。cgroupDriverの値を修正するか、以下のような新しいフィールドを追加します。 cgroupDriver: systemd
このフィールドは、ConfigMapのkubelet:セクションの下に存在する必要があります。
クラスター内の各ノードについて:
kubectl drain <node-name> --ignore-daemonsetsを使ってドレーンします。systemctl stop kubeletを使用して、kubeletを停止します。systemdに変更します。var/lib/kubelet/config.yamlにcgroupDriver: systemdを設定します。systemctl start kubeletでkubeletを起動します。kubectl uncordon <node-name>を使って行います。ワークロードが異なるノードでスケジュールするための十分な時間を確保するために、これらのステップを1つずつノード上で実行します。 プロセスが完了したら、すべてのノードとワークロードが健全であることを確認します。
Kubernetes v1.18 [beta]Kubernetesを使用してLinuxノードとWindowsノードを混在させて実行できるため、Linuxで実行するPodとWindowsで実行するPodを混在させることができます。このページでは、Windowsノードをクラスターに登録する方法を示します。
kubectl version.WindowsコンテナをホストするWindowsノードを構成するには、Windows Server 2019ライセンス(またはそれ以上)を取得します。 VXLAN/オーバーレイネットワークを使用している場合は、KB4489899もインストールされている必要があります。
コントロールプレーンにアクセスできるLinuxベースのKubernetes kubeadmクラスター(kubeadmを使用したシングルコントロールプレーンクラスターの作成を参照)
LinuxベースのKubernetesコントロールプレーンノードを取得したら、ネットワーキングソリューションを選択できます。このガイドでは、簡単にするためにVXLANモードでのFlannelの使用について説明します。
FlannelのためにKubernetesコントロールプレーンを準備する
クラスター内のKubernetesコントロールプレーンでは、多少の準備が推奨されます。Flannelを使用する場合は、iptablesチェーンへのブリッジIPv4トラフィックを有効にすることをお勧めします。すべてのLinuxノードで次のコマンドを実行する必要があります:
sudo sysctl net.bridge.bridge-nf-call-iptables=1
Linux用のFlannelをダウンロードして構成する
最新のFlannelマニフェストをダウンロード:
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
VNIを4096、ポートを4789に設定するために、flannelマニフェストのnet-conf.jsonセクションを変更します。次のようになります:
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan",
"VNI" : 4096,
"Port": 4789
}
}
Typeの値を"host-gw"に変更し、VNIとPortを省略します。Flannelマニフェストを適用して検証する
Flannelの構成を適用しましょう:
kubectl apply -f kube-flannel.yml
数分後、Flannel Podネットワークがデプロイされていれば、すべてのPodが実行されていることがわかります。
kubectl get pods -n kube-system
出力結果には、実行中のLinux flannel DaemonSetが含まれているはずです:
NAMESPACE NAME READY STATUS RESTARTS AGE
...
kube-system kube-flannel-ds-54954 1/1 Running 0 1m
Windows Flannelとkube-proxy DaemonSetを追加する
これで、Windows互換バージョンのFlannelおよびkube-proxyを追加できます。 互換性のあるバージョンのkube-proxyを確実に入手するには、イメージのタグを置換する必要があります。 次の例は、Kubernetes 1.32.0の使用方法を示していますが、 独自のデプロイに合わせてバージョンを調整する必要があります。
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/kube-proxy.yml | sed 's/VERSION/v1.32.0/g' | kubectl apply -f -
kubectl apply -f https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-overlay.yml
ホストゲートウェイを使用している場合は、代わりに https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-host-gw.yml を使用してください。
Windowsノードでイーサネット(「Ethernet0 2」など)ではなく別のインターフェースを使用している場合は、次の行を変更する必要があります:
wins cli process run --path /k/flannel/setup.exe --args "--mode=overlay --interface=Ethernet"
flannel-host-gw.ymlまたはflannel-overlay.ymlファイルで、それに応じてインターフェースを指定します。
# 例
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-overlay.yml | sed 's/Ethernet/Ethernet0 2/g' | kubectl apply -f -
Containers機能をインストールし、Dockerをインストールする必要があります。
行うための指示としては、Dockerエンジンのインストール - Windowsサーバー上のエンタープライズを利用できます。wins、kubelet、kubeadmをインストールします。
curl.exe -LO https://raw.githubusercontent.com/kubernetes-sigs/sig-windows-tools/master/kubeadm/scripts/PrepareNode.ps1
.\PrepareNode.ps1 -KubernetesVersion v1.32.0
kubeadmを実行してノードに参加します
コントロールプレーンホストでkubeadm initを実行したときに提供されたコマンドを使用します。
このコマンドがなくなった場合、またはトークンの有効期限が切れている場合は、kubeadm token create --print-join-command
(コントロールプレーンホスト上で)を実行して新しいトークンを生成します。
次のコマンドを実行して、クラスター内のWindowsノードを表示できるようになります:
kubectl get nodes -o wide
新しいノードがNotReady状態の場合は、flannelイメージがまだダウンロード中の可能性があります。
kube-system名前空間のflannel Podを確認することで、以前と同様に進行状況を確認できます:
kubectl -n kube-system get pods -l app=flannel
flannel Podが実行されると、ノードはReady状態になり、ワークロードを処理できるようになります。
Kubernetes v1.18 [beta]このページでは、kubeadmで作られたWindowsノードをアップグレードする方法について説明します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: 1.17. バージョンを確認するには次のコマンドを実行してください:kubectl version.Windowsノードから、kubeadmをアップグレードします。:
# 1.32.0を目的のバージョンに置き換えます
curl.exe -Lo C:\k\kubeadm.exe https://dl.k8s.io/v1.32.0/bin/windows/amd64/kubeadm.exe
Kubernetes APIにアクセスできるマシンから、 ノードをスケジュール不可としてマークして、ワークロードを削除することでノードのメンテナンスを準備します:
# <node-to-drain>をドレインするノードの名前に置き換えます
kubectl drain <node-to-drain> --ignore-daemonsets
このような出力結果が表示されるはずです:
node/ip-172-31-85-18 cordoned
node/ip-172-31-85-18 drained
Windowsノードから、次のコマンドを呼び出して新しいkubelet構成を同期します:
kubeadm upgrade node
Windowsノードから、kubeletをアップグレードして再起動します:
stop-service kubelet
curl.exe -Lo C:\k\kubelet.exe https://dl.k8s.io/v1.32.0/bin/windows/amd64/kubelet.exe
restart-service kubelet
Kubernetes APIにアクセスできるマシンから、 スケジュール可能としてマークして、ノードをオンラインに戻します:
# <node-to-drain>をノードの名前に置き換えます
kubectl uncordon <node-to-drain>
Kubernetes APIにアクセスできるマシンから、次を実行します、 もう一度1.32.0を目的のバージョンに置き換えます:
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/kube-proxy.yml | sed 's/VERSION/v1.32.0/g' | kubectl apply -f -
dockershimから他のコンテナランタイムに移行する際に知っておくべき情報を紹介します。
Kubernetes 1.20でdockershim deprecationが発表されてから、様々なワークロードやKubernetesインストールにどう影響するのかという質問が寄せられています。
この問題をよりよく理解するために、dockershimの削除に関するFAQブログが役に立つでしょう。
dockershimから代替のコンテナランタイムに移行することが推奨されます。 コンテナランタイムのセクションをチェックして、どのような選択肢があるかを確認してください。 問題が発生した場合は、必ず問題の報告をしてください。 そうすれば、問題が適時に修正され、クラスターがdockershimの削除に対応できるようになります。
このページでは、クラスター内のノードが使用しているコンテナランタイムを確認する手順を概説しています。
クラスターの実行方法によっては、ノード用のコンテナランタイムが事前に設定されている場合と、設定する必要がある場合があります。
マネージドKubernetesサービスを使用している場合、ノードに設定されているコンテナランタイムを確認するためのベンダー固有の方法があるかもしれません。
このページで説明する方法は、kubectlの実行が許可されていればいつでも動作するはずです。
kubectlをインストールし、設定します。詳細はツールのインストールの項を参照してください。
ノードの情報を取得して表示するにはkubectlを使用します:
kubectl get nodes -o wide
出力は以下のようなものです。列CONTAINER-RUNTIMEには、ランタイムとそのバージョンが出力されます。
# For dockershim
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.16.15 docker://19.3.1
node-2 Ready v1.16.15 docker://19.3.1
node-3 Ready v1.16.15 docker://19.3.1
# For containerd
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.19.6 containerd://1.4.1
node-2 Ready v1.19.6 containerd://1.4.1
node-3 Ready v1.19.6 containerd://1.4.1
コンテナランタイムについては、コンテナランタイムのページで詳細を確認することができます。
Kubernetesのdockershimコンポーネントは、DockerをKubernetesのコンテナランタイムとして使用することを可能にします。
Kubernetesの組み込みコンポーネントであるdockershimはリリースv1.24で削除されました。
このページでは、あなたのクラスターがどのようにDockerをコンテナランタイムとして使用しているか、使用中のdockershimが果たす役割について詳しく説明し、dockershimの削除によって影響を受けるワークロードがあるかどうかをチェックするためのステップを示します。
アプリケーションコンテナの構築にDockerを使用している場合でも、これらのコンテナを任意のコンテナランタイム上で実行することができます。このようなDockerの使用は、コンテナランタイムとしてのDockerへの依存とはみなされません。
代替のコンテナランタイムが使用されている場合、Dockerコマンドを実行しても動作しないか、予期せぬ出力が得られる可能性があります。
このように、Dockerへの依存があるかどうかを調べることができます:
docker psなど)を実行したり、Dockerサービスを再起動したり(systemctl restart docker.serviceなどのコマンド)、Docker固有のファイル(/etc/docker/daemon.jsonなど)を変更しないことを確認すること。/etc/docker/daemon.json など)にプライベートレジストリやイメージミラーの設定がないか確認します。これらは通常、別のコンテナランタイムのために再設定する必要があります。コンテナランタイムとは、Kubernetes Podを構成するコンテナを実行できるソフトウェアです。
KubernetesはPodのオーケストレーションとスケジューリングを担当し、各ノードではkubeletがコンテナランタイムインターフェースを抽象化して使用するので、互換性があればどのコンテナランタイムでも使用することができます。 初期のリリースでは、Kubernetesは1つのコンテナランタイムと互換性を提供していました: Dockerです。 その後、Kubernetesプロジェクトの歴史の中で、クラスター運用者は追加のコンテナランタイムを採用することを希望しました。 CRIはこのような柔軟性を可能にするために設計され、kubeletはCRIのサポートを開始しました。 しかし、DockerはCRI仕様が考案される前から存在していたため、Kubernetesプロジェクトはアダプタコンポーネント「dockershim」を作成しました。
dockershimアダプターは、DockerがCRI互換ランタイムであるかのように、kubeletがDockerと対話することを可能にします。 Kubernetes Containerd integration goes GAブログ記事で紹介されています。
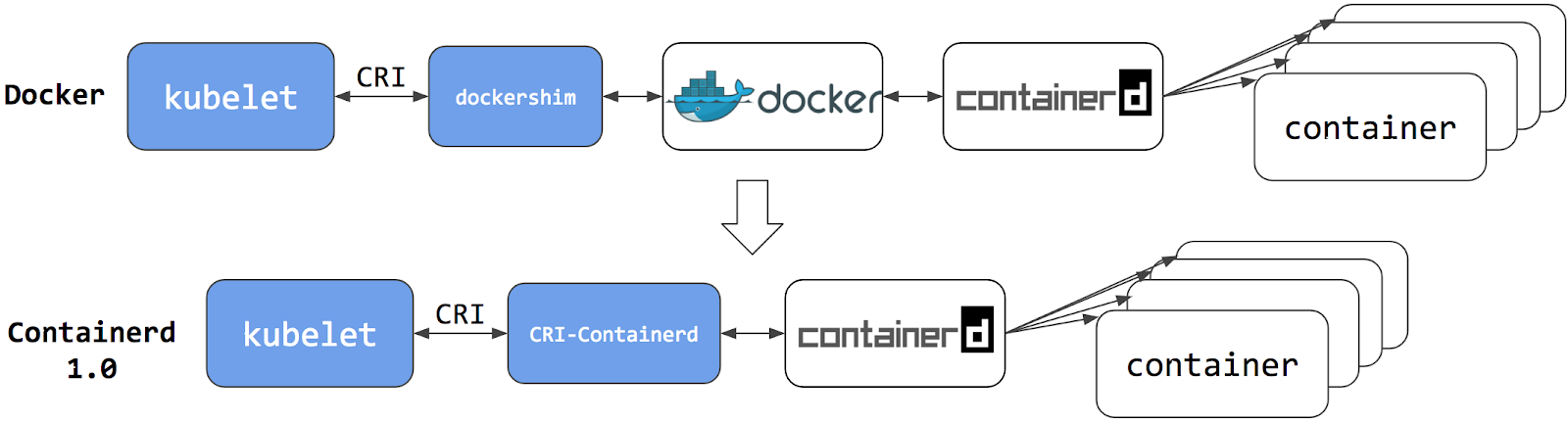
コンテナランタイムとしてContainerdに切り替えることで、中間マージンを排除することができます。
これまでと同じように、Containerdのようなコンテナランタイムですべてのコンテナを実行できます。
しかし今は、コンテナはコンテナランタイムで直接スケジュールするので、Dockerからは見えません。
そのため、これらのコンテナをチェックするために以前使っていたかもしれないDockerツールや派手なUIは、もはや利用できません。
docker psやdocker inspectを使用してコンテナ情報を取得することはできません。
コンテナを一覧表示できないので、ログを取得したり、コンテナを停止したり、docker execを使用してコンテナ内で何かを実行したりすることもできません。
この場合でも、イメージを取得したり、docker buildコマンドを使用してビルドすることは可能です。
しかし、Dockerによってビルドまたはプルされたイメージは、コンテナランタイムとKubernetesからは見えません。
Kubernetesで使用できるようにするには、何らかのレジストリにプッシュする必要がありました。
Kubernetes 1.20でdockershimは非推奨になりました。
dockershimの削除に関するFAQから、ほとんどのアプリがコンテナをホストするランタイムに直接依存しないことは既にご存知かもしれません。 しかし、コンテナのメタデータやログ、メトリクスを収集するためにDockerに依存しているテレメトリーやセキュリティエージェントはまだ多く存在します。 この文書では、これらの依存関係を検出する方法と、これらのエージェントを汎用ツールまたは代替ランタイムに移行する方法に関するリンクを集約しています。
Kubernetesクラスター上でエージェントを実行するには、いくつかの方法があります。エージェントはノード上で直接、またはDaemonSetとして実行することができます。
歴史的には、KubernetesはDockerの上に構築されていました。 Kubernetesはネットワークとスケジューリングを管理し、Dockerはコンテナをノードに配置して操作していました。 そのため、KubernetesからはPod名などのスケジューリング関連のメタデータを、Dockerからはコンテナの状態情報を取得することができます。 時が経つにつれ、コンテナを管理するためのランタイムも増えてきました。 また、多くのランタイムにまたがるコンテナ状態情報の抽出を一般化するプロジェクトやKubernetesの機能もあります。
いくつかのエージェントはDockerツールに関連しています。
エージェントはdocker psやdocker topといったコマンドを実行し、コンテナやプロセスの一覧を表示します。
またはdocker logsを使えば、dockerログを購読することができます。
Dockerがコンテナランタイムとして非推奨になったため、これらのコマンドはもう使えません。
Podがノード上で動作しているdockerdを呼び出したい場合、Podは以下のいずれかを行う必要があります。
Dockerデーモンの特権ソケットがあるファイルシステムをvolumeのようにマウントする。
Dockerデーモンの特権ソケットの特定のパスを直接ボリュームとしてマウントします。
例: COSイメージでは、DockerはそのUnixドメインソケットを/var/run/docker.sockに公開します。
つまり、Pod仕様には/var/run/docker.sockのhostPathボリュームマウントが含まれることになります。
以下は、Dockerソケットを直接マッピングしたマウントを持つPodを探すためのシェルスクリプトのサンプルです。
このスクリプトは、Podの名前空間と名前を出力します。
grep '/var/run/docker.sock'を削除して、他のマウントを確認することもできます。
kubectl get pods --all-namespaces \
-o=jsonpath='{range .items[*]}{"\n"}{.metadata.namespace}{":\t"}{.metadata.name}{":\t"}{range .spec.volumes[*]}{.hostPath.path}{", "}{end}{end}' \
| sort \
| grep '/var/run/docker.sock'
/var/runをマウントすることができます(この例 のように)。
上記のスクリプトは、最も一般的な使用方法のみを検出します。クラスターノードをカスタマイズし、セキュリティやテレメトリーのエージェントをノードに追加インストールする場合、エージェントのベンダーにDockerへの依存性があるかどうかを必ず確認してください。
様々なテレメトリーおよびセキュリティエージェントベンダーのための移行指示の作業中バージョンをGoogle docに保管しています。 dockershimからの移行に関する最新の手順については、各ベンダーにお問い合わせください。
クライアント証明書認証を使用する場合、easyrsa、opensslまたはcfsslを使って手動で証明書を生成することができます。
easyrsaはクラスターの証明書を手動で生成することができます。
パッチが適用されたバージョンのeasyrsa3をダウンロードして解凍し、初期化します。
curl -LO https://dl.k8s.io/easy-rsa/easy-rsa.tar.gz
tar xzf easy-rsa.tar.gz
cd easy-rsa-master/easyrsa3
./easyrsa init-pki
新しい認証局(CA)を生成します。
--batchで自動モードに設定します。--req-cnはCAの新しいルート証明書のコモンネーム(CN)を指定します。
./easyrsa --batch "--req-cn=${MASTER_IP}@`date +%s`" build-ca nopass
サーバー証明書と鍵を生成します。
引数--subject-alt-nameは、APIサーバーがアクセス可能なIPとDNS名を設定します。
MASTER_CLUSTER_IPは通常、APIサーバーとコントローラーマネージャーコンポーネントの両方で--service-cluster-ip-range引数に指定したサービスCIDRの最初のIPとなります。
引数--daysは、証明書の有効期限が切れるまでの日数を設定するために使用します。
また、以下のサンプルでは、デフォルトのDNSドメイン名としてcluster.localを使用することを想定しています。
./easyrsa --subject-alt-name="IP:${MASTER_IP},"\
"IP:${MASTER_CLUSTER_IP},"\
"DNS:kubernetes,"\
"DNS:kubernetes.default,"\
"DNS:kubernetes.default.svc,"\
"DNS:kubernetes.default.svc.cluster,"\
"DNS:kubernetes.default.svc.cluster.local" \
--days=10000 \
build-server-full server nopass
pki/ca.crt、pki/issued/server.crt、pki/private/server.keyを自分のディレクトリにコピーします。
APIサーバーのスタートパラメーターに以下のパラメーターを記入し、追加します。
--client-ca-file=/yourdirectory/ca.crt
--tls-cert-file=/yourdirectory/server.crt
--tls-private-key-file=/yourdirectory/server.key
opensslは、クラスター用の証明書を手動で生成することができます。
2048bitのca.keyを生成します:
openssl genrsa -out ca.key 2048
ca.keyに従ってca.crtを生成します(-daysで証明書の有効期限を設定します):
openssl req -x509 -new -nodes -key ca.key -subj "/CN=${MASTER_IP}" -days 10000 -out ca.crt
2048bitでserver.keyを生成します:
openssl genrsa -out server.key 2048
証明書署名要求(CSR)を生成するための設定ファイルを作成します。
山括弧で囲まれた値(例:<MASTER_IP>)は必ず実際の値に置き換えてから、ファイル(例:csr.conf)に保存してください。MASTER_CLUSTER_IPの値は、前のサブセクションで説明したように、APIサーバーのサービスクラスターのIPであることに注意してください。また、以下のサンプルでは、デフォルトのDNSドメイン名としてcluster.localを使用することを想定しています。
[ req ]
default_bits = 2048
prompt = no
default_md = sha256
req_extensions = req_ext
distinguished_name = dn
[ dn ]
C = <country>
ST = <state>
L = <city>
O = <organization>
OU = <organization unit>
CN = <MASTER_IP>
[ req_ext ]
subjectAltName = @alt_names
[ alt_names ]
DNS.1 = kubernetes
DNS.2 = kubernetes.default
DNS.3 = kubernetes.default.svc
DNS.4 = kubernetes.default.svc.cluster
DNS.5 = kubernetes.default.svc.cluster.local
IP.1 = <MASTER_IP>
IP.2 = <MASTER_CLUSTER_IP>
[ v3_ext ]
authorityKeyIdentifier=keyid,issuer:always
basicConstraints=CA:FALSE
keyUsage=keyEncipherment,dataEncipherment
extendedKeyUsage=serverAuth,clientAuth
subjectAltName=@alt_names
設定ファイルに基づき、証明書署名要求を生成します:
openssl req -new -key server.key -out server.csr -config csr.conf
ca.key、ca.crt、server.csrを使用して、サーバー証明書を生成します:
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \
-CAcreateserial -out server.crt -days 10000 \
-extensions v3_ext -extfile csr.conf -sha256
証明書署名要求を表示します:
openssl req -noout -text -in ./server.csr
証明書を表示します:
openssl x509 -noout -text -in ./server.crt
最後に、同じパラメーターをAPIサーバーのスタートパラメーターに追加します。
cfsslも証明書を生成するためのツールです。
以下のように、コマンドラインツールをダウンロードし、解凍して準備してください。
なお、サンプルのコマンドは、お使いのハードウェア・アーキテクチャやCFSSLのバージョンに合わせる必要があるかもしれません。
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl_1.5.0_linux_amd64 -o cfssl
chmod +x cfssl
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssljson_1.5.0_linux_amd64 -o cfssljson
chmod +x cfssljson
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl-certinfo_1.5.0_linux_amd64 -o cfssl-certinfo
chmod +x cfssl-certinfo
成果物を格納するディレクトリを作成し、cfsslを初期化します:
mkdir cert
cd cert
../cfssl print-defaults config > config.json
../cfssl print-defaults csr > csr.json
CAファイルを生成するためのJSON設定ファイル、例えばca-config.jsonを作成します:
{
"signing": {
"default": {
"expiry": "8760h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "8760h"
}
}
}
}
CA証明書署名要求(CSR)用のJSON設定ファイル(例:ca-csr.json)を作成します。
山括弧で囲まれた値は、必ず使用したい実際の値に置き換えてください。
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names":[{
"C": "<country>",
"ST": "<state>",
"L": "<city>",
"O": "<organization>",
"OU": "<organization unit>"
}]
}
CAキー(ca-key.pem)と証明書(ca.pem)を生成します:
../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca
APIサーバーの鍵と証明書を生成するためのJSON設定ファイル、例えばserver-csr.jsonを作成します。
山括弧内の値は、必ず使用したい実際の値に置き換えてください。
MASTER_CLUSTER_IPは、前のサブセクションで説明したように、APIサーバーのサービスクラスターのIPです。
また、以下のサンプルでは、デフォルトのDNSドメイン名としてcluster.localを使用することを想定しています。
{
"CN": "kubernetes",
"hosts": [
"127.0.0.1",
"<MASTER_IP>",
"<MASTER_CLUSTER_IP>",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [{
"C": "<country>",
"ST": "<state>",
"L": "<city>",
"O": "<organization>",
"OU": "<organization unit>"
}]
}
APIサーバーの鍵と証明書を生成します。
デフォルトでは、それぞれserver-key.pemとserver.pemというファイルに保存されます:
../cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \
--config=ca-config.json -profile=kubernetes \
server-csr.json | ../cfssljson -bare server
クライアントノードが自己署名入りCA証明書を有効なものとして認識できない場合があります。
非プロダクション環境、または会社のファイアウォールの内側での開発環境であれば、自己署名入りCA証明書をすべてのクライアントに配布し、有効な証明書のローカルリストを更新することができます。
各クライアントで、次の操作を実行します:
sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
認証に使用するx509証明書のプロビジョニングにはcertificates.k8s.ioAPIを使用することができます。クラスターでのTLSの管理に記述されています。
このページでは、ネームスペースのデフォルトのメモリー要求と制限を設定する方法を説明します。
Kubernetesクラスターはネームスペースに分割することができます。デフォルトのメモリー制限を持つネームスペースがあり、独自のメモリー制限を指定しないコンテナでPodを作成しようとすると、コントロールプレーンはそのコンテナにデフォルトのメモリー制限を割り当てます。
Kubernetesは、このトピックで後ほど説明する特定の条件下で、デフォルトのメモリー要求を割り当てます。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
クラスターにネームスペースを作成するには、アクセス権が必要です。
クラスターの各ノードには、最低でも2GiBのメモリーが必要です。
この演習で作成したリソースがクラスターの他の部分から分離されるように、ネームスペースを作成します。
kubectl create namespace default-mem-example
以下は、LimitRangeのマニフェストの例です。このマニフェストでは、デフォルトのメモリー要求とデフォルトのメモリー制限を指定しています。
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: Container
default-mem-exampleネームスペースにLimitRangeを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults.yaml --namespace=default-mem-example
default-mem-exampleネームスペースでPodを作成し、そのPod内のコンテナがメモリー要求とメモリー制限の値を独自に指定しない場合、コントロールプレーンはデフォルト値のメモリー要求256MiBとメモリー制限512MiBを適用します。
以下は、コンテナを1つ持つPodのマニフェストの例です。コンテナは、メモリー要求とメモリー制限を指定していません。
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo
spec:
containers:
- name: default-mem-demo-ctr
image: nginx
Podを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod.yaml --namespace=default-mem-example
Podの詳細情報を表示します:
kubectl get pod default-mem-demo --output=yaml --namespace=default-mem-example
この出力は、Podのコンテナのメモリー要求が256MiBで、メモリー制限が512MiBであることを示しています。 これらはLimitRangeで指定されたデフォルト値です。
containers:
- image: nginx
imagePullPolicy: Always
name: default-mem-demo-ctr
resources:
limits:
memory: 512Mi
requests:
memory: 256Mi
Podを削除します:
kubectl delete pod default-mem-demo --namespace=default-mem-example
以下は1つのコンテナを持つPodのマニフェストです。コンテナはメモリー制限を指定しますが、メモリー要求は指定しません。
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-2
spec:
containers:
- name: default-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1Gi"
Podを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-2.yaml --namespace=default-mem-example
Podの詳細情報を表示します:
kubectl get pod default-mem-demo-2 --output=yaml --namespace=default-mem-example
この出力は、コンテナのメモリー要求がそのメモリー制限に一致するように設定されていることを示しています。 コンテナにはデフォルトのメモリー要求値である256Miが割り当てられていないことに注意してください。
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
1つのコンテナを持つPodのマニフェストです。コンテナはメモリー要求を指定しますが、メモリー制限は指定しません。
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-3
spec:
containers:
- name: default-mem-demo-3-ctr
image: nginx
resources:
requests:
memory: "128Mi"
Podを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-3.yaml --namespace=default-mem-example
Podの詳細情報を表示します:
kubectl get pod default-mem-demo-3 --output=yaml --namespace=default-mem-example
この出力は、コンテナのメモリー要求が、コンテナのマニフェストで指定された値に設定されていることを示しています。 コンテナは512MiB以下のメモリーを使用するように制限されていて、これはネームスペースのデフォルトのメモリー制限と一致します。
resources:
limits:
memory: 512Mi
requests:
memory: 128Mi
ネームスペースにメモリーリソースクォータが設定されている場合、メモリー制限のデフォルト値を設定しておくと便利です。
以下はリソースクォータがネームスペースに課す制限のうちの2つです。
LimitRangeの追加時:
コンテナを含む、そのネームスペース内のいずれかのPodが独自のメモリー制限を指定していない場合、コントロールプレーンはそのコンテナにデフォルトのメモリー制限を適用し、メモリーのResourceQuotaによって制限されているネームスペース内でPodを実行できるようにします。
ネームスペースを削除します:
kubectl delete namespace default-mem-example
このページでは、Namespaceで実行されるコンテナが使用するメモリーの最小値と最大値を設定する方法を説明します。 LimitRange で最小値と最大値のメモリー値を指定します。 PodがLimitRangeによって課される制約を満たさない場合、そのNamespaceではPodを作成できません。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.クラスター内の各ノードには、少なくとも1GiBのメモリーが必要です。
この演習で作成したリソースがクラスターの他の部分から分離されるように、Namespaceを作成します。
kubectl create namespace constraints-mem-example
LimitRangeの設定ファイルです。
apiVersion: v1
kind: LimitRange
metadata:
name: mem-min-max-demo-lr
spec:
limits:
- max:
memory: 1Gi
min:
memory: 500Mi
type: Container
LimitRangeを作成します。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints.yaml --namespace=constraints-mem-example
LimitRangeの詳細情報を表示します。
kubectl get limitrange mem-min-max-demo-lr --namespace=constraints-mem-example --output=yaml
出力されるのは、予想通りメモリー制約の最小値と最大値を示しています。 しかし、LimitRangeの設定ファイルでデフォルト値を指定していないにもかかわらず、 自動的に作成されていることに気づきます。
limits:
- default:
memory: 1Gi
defaultRequest:
memory: 1Gi
max:
memory: 1Gi
min:
memory: 500Mi
type: Container
constraints-mem-exampleNamespaceにコンテナが作成されるたびに、 Kubernetesは以下の手順を実行するようになっています。
コンテナが独自のメモリー要求と制限を指定しない場合は、デフォルトのメモリー要求と制限をコンテナに割り当てます。
コンテナに500MiB以上のメモリー要求があることを確認します。
コンテナのメモリー制限が1GiB以下であることを確認します。
以下は、1つのコンテナを持つPodの設定ファイルです。設定ファイルのコンテナ(containers)では、600MiBのメモリー要求と800MiBのメモリー制限が指定されています。これらはLimitRangeによって課される最小と最大のメモリー制約を満たしています。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo
spec:
containers:
- name: constraints-mem-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "600Mi"
Podの作成
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod.yaml --namespace=constraints-mem-example
Podのコンテナが実行されていることを確認します。
kubectl get pod constraints-mem-demo --namespace=constraints-mem-example
Podの詳細情報を見ます
kubectl get pod constraints-mem-demo --output=yaml --namespace=constraints-mem-example
出力は、コンテナが600MiBのメモリ要求と800MiBのメモリー制限になっていることを示しています。これらはLimitRangeによって課される制約を満たしています。
resources:
limits:
memory: 800Mi
requests:
memory: 600Mi
Podを消します。
kubectl delete pod constraints-mem-demo --namespace=constraints-mem-example
これは、1つのコンテナを持つPodの設定ファイルです。コンテナは800MiBのメモリー要求と1.5GiBのメモリー制限を指定しています。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-2
spec:
containers:
- name: constraints-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1.5Gi"
requests:
memory: "800Mi"
Podを作成してみます。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-2.yaml --namespace=constraints-mem-example
出力は、コンテナが大きすぎるメモリー制限を指定しているため、Podが作成されないことを示しています。
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-2.yaml":
pods "constraints-mem-demo-2" is forbidden: maximum memory usage per Container is 1Gi, but limit is 1536Mi.
これは、1つのコンテナを持つPodの設定ファイルです。コンテナは100MiBのメモリー要求と800MiBのメモリー制限を指定しています。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-3
spec:
containers:
- name: constraints-mem-demo-3-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "100Mi"
Podを作成してみます。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-3.yaml --namespace=constraints-mem-example
出力は、コンテナが小さすぎるメモリー要求を指定しているため、Podが作成されないことを示しています。
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-3.yaml":
pods "constraints-mem-demo-3" is forbidden: minimum memory usage per Container is 500Mi, but request is 100Mi.
これは、1つのコンテナを持つPodの設定ファイルです。コンテナはメモリー要求を指定しておらず、メモリー制限も指定していません。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-4
spec:
containers:
- name: constraints-mem-demo-4-ctr
image: nginx
Podを作成します。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-4.yaml --namespace=constraints-mem-example
Podの詳細情報を見ます
kubectl get pod constraints-mem-demo-4 --namespace=constraints-mem-example --output=yaml
出力を見ると、Podのコンテナのメモリ要求は1GiB、メモリー制限は1GiBであることがわかります。 コンテナはどのようにしてこれらの値を取得したのでしょうか?
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
コンテナが独自のメモリー要求と制限を指定していなかったため、LimitRangeから与えられのです。 コンテナが独自のメモリー要求と制限を指定していなかったため、LimitRangeからデフォルトのメモリー要求と制限が与えられたのです。
この時点で、コンテナは起動しているかもしれませんし、起動していないかもしれません。このタスクの前提条件は、ノードが少なくとも1GiBのメモリーを持っていることであることを思い出してください。それぞれのノードが1GiBのメモリーしか持っていない場合、どのノードにも1GiBのメモリー要求に対応するのに十分な割り当て可能なメモリーがありません。たまたま2GiBのメモリーを持つノードを使用しているのであれば、おそらく1GiBのメモリーリクエストに対応するのに十分なスペースを持っていることになります。
Podを削除します。
kubectl delete pod constraints-mem-demo-4 --namespace=constraints-mem-example
LimitRangeによってNamespaceに課される最大および最小のメモリー制約は、Podが作成または更新されたときにのみ適用されます。LimitRangeを変更しても、以前に作成されたPodには影響しません。
クラスター管理者としては、Podが使用できるメモリー量に制限を課したいと思うかもしれません。
例:
クラスター内の各ノードは2GBのメモリーを持っています。クラスター内のどのノードもその要求をサポートできないため、2GB以上のメモリーを要求するPodは受け入れたくありません。
クラスターは運用部門と開発部門で共有されています。 本番用のワークロードでは最大8GBのメモリーを消費しますが、開発用のワークロードでは512MBに制限したいとします。本番用と開発用に別々のNamespaceを作成し、それぞれのNamespaceにメモリー制限を適用します。
Namespaceを削除します。
kubectl delete namespace constraints-mem-example
このページでは、Nodeに対して拡張リソースを指定する方法を説明します。拡張リソースを利用すると、Kubernetesにとって未知のノードレベルのリソースをクラスター管理者がアドバタイズできるようになります。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.kubectl get nodes
この練習で使いたいNodeを1つ選んでください。
Node上の新しい拡張リソースをアドバタイズするには、HTTPのPATCHリクエストをKubernetes APIサーバーに送ります。たとえば、Nodeの1つに4つのドングルが接続されているとします。以下に、4つのドングルリソースをNodeにアドバタイズするPATCHリクエストの例を示します。
PATCH /api/v1/nodes/<選択したNodeの名前>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "add",
"path": "/status/capacity/example.com~1dongle",
"value": "4"
}
]
Kubernetesは、ドングルとは何かも、ドングルが何に利用できるのかを知る必要もないことに注意してください。上のPATCHリクエストは、ただNodeが4つのドングルと呼ばれるものを持っているとKubernetesに教えているだけです。
Kubernetes APIサーバーに簡単にリクエストを送れるように、プロキシを実行します。
kubectl proxy
もう1つのコマンドウィンドウを開き、HTTPのPATCHリクエストを送ります。<選択したNodeの名前>の部分は、選択したNodeの名前に置き換えてください。
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1dongle", "value": "4"}]' \
http://localhost:8001/api/v1/nodes/<選択したNodeの名前>/status
~1は、PATCHのパスにおける/という文字をエンコーディングしたものです。JSON-Patch内のoperationのpathはJSON-Pointerとして解釈されます。詳細については、IETF RFC 6901のsection 3を読んでください。出力には、Nodeがキャパシティー4のdongleを持っていることが示されます。
"capacity": {
"cpu": "2",
"memory": "2049008Ki",
"example.com/dongle": "4",
Nodeの説明を確認します。
kubectl describe node <選択したNodeの名前>
出力には、再びdongleリソースが表示されます。
Capacity:
cpu: 2
memory: 2049008Ki
example.com/dongle: 4
これで、アプリケーション開発者は特定の数のdongleをリクエストするPodを作成できるようになりました。詳しくは、拡張リソースをコンテナに割り当てるを読んでください。
拡張リソースは、メモリやCPUリソースと同様のものです。たとえば、Nodeが持っている特定の量のメモリやCPUがNode上で動作している他のすべてのコンポーネントと共有されるのと同様に、Nodeが搭載している特定の数のdongleが他のすべてのコンポーネントと共有されます。そして、アプリケーション開発者が特定の量のメモリとCPUをリクエストするPodを作成できるのと同様に、Nodeが搭載している特定の数のdongleをリクエストするPodが作成できます。
拡張リソースはKubernetesには詳細を意図的に公開しないため、Kubernetesは拡張リソースの実体をまったく知りません。Kubernetesが知っているのは、Nodeが特定の数の拡張リソースを持っているということだけです。拡張リソースは整数値でアドバタイズしなければなりません。たとえば、Nodeは4つのdongleをアドバタイズできますが、4.5のdongleというのはアドバタイズできません。
Nodeに800GiBの特殊なディスクストレージがあるとします。この特殊なストレージの名前、たとえばexample.com/special-storageという名前の拡張リソースが作れます。そして、そのなかの一定のサイズ、たとえば100GiBのチャンクをアドバタイズできます。この場合、Nodeはexample.com/special-storageという種類のキャパシティ8のリソースを持っているとアドバタイズします。
Capacity:
...
example.com/special-storage: 8
特殊なストレージに任意のサイズのリクエストを許可したい場合、特殊なストレージを1バイトのサイズのチャンクでアドバタイズできます。その場合、example.com/special-storageという種類の800Giのリソースとしてアドバタイズします。
Capacity:
...
example.com/special-storage: 800Gi
すると、コンテナは好きなバイト数の特殊なストレージを最大800Giまでリクエストできるようになります。
以下に、dongleのアドバタイズをNodeから削除するPATCHリクエストを示します。
PATCH /api/v1/nodes/<選択したNodeの名前>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "remove",
"path": "/status/capacity/example.com~1dongle",
}
]
Kubernetes APIサーバーに簡単にリクエストを送れるように、プロキシを実行します。
kubectl proxy
もう1つのコマンドウィンドウで、HTTPのPATCHリクエストを送ります。<選択したNodeの名前>の部分は、選択したNodeの名前に置き換えてください。
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "remove", "path": "/status/capacity/example.com~1dongle"}]' \
http://localhost:8001/api/v1/nodes/<選択したNodeの名前>/status
dongleのアドバタイズが削除されたことを検証します。
kubectl describe node <選択したNodeの名前> | grep dongle
(出力には何も表示されないはずです)
Kubernetes v1.11 [beta]クラウドプロバイダーはKubernetesプロジェクトとは異なるペースで開発およびリリースされるため、プロバイダー固有のコードを`cloud-controller-manager`バイナリに抽象化することでクラウドベンダーはKubernetesのコアのコードとは独立して開発が可能となりました。
cloud-controller-managerは、cloudprovider.Interfaceを満たす任意のクラウドプロバイダーと接続できます。下位互換性のためにKubernetesのコアプロジェクトで提供されるcloud-controller-managerはkube-controller-managerと同じクラウドライブラリを使用します。Kubernetesのコアリポジトリですでにサポートされているクラウドプロバイダーは、Kubernetesリポジトリにあるcloud-controller-managerを使用してKubernetesのコアから移行することが期待されています。
すべてのクラウドには動作させるためにそれぞれのクラウドプロバイダーの統合を行う独自の要件があり、kube-controller-managerを実行する場合の要件とそれほど違わないようにする必要があります。一般的な経験則として、以下のものが必要です。
cloud-controller-managerを正常に実行するにはクラスター構成にいくつかの変更が必要です。
kube-apiserverとkube-controller-managerは**--cloud-providerフラグを指定してはいけません**。これによりクラウドコントローラーマネージャーによって実行されるクラウド固有のループが実行されなくなります。将来このフラグは非推奨になり削除される予定です。kubeletは--cloud-provider=externalで実行する必要があります。これは作業をスケジュールする前にクラウドコントローラーマネージャーによって初期化する必要があることをkubeletが認識できるようにするためです。クラウドコントローラーマネージャーを使用するようにクラスターを設定するとクラスターの動作がいくつか変わることに注意してください。
--cloud-provider=externalを指定したkubeletは、初期化時にNoScheduleのnode.cloudprovider.kubernetes.io/uninitialized汚染を追加します。これによりノードは作業をスケジュールする前に外部のコントローラーからの2回目の初期化が必要であるとマークされます。クラウドコントローラーマネージャーが使用できない場合クラスター内の新しいノードはスケジュールできないままになることに注意してください。スケジューラーはリージョンやタイプ(高CPU、GPU、高メモリ、スポットインスタンスなど)などのノードに関するクラウド固有の情報を必要とする場合があるためこの汚染は重要です。クラウドコントローラーマネージャーは以下を実装できます。
現在Kubernetesのコアでサポートされているクラウドを使用していて、クラウドコントローラーマネージャーを利用する場合は、kubernetesのコアのクラウドコントローラーマネージャーを参照してください。
Kubernetesのコアリポジトリにないクラウドコントローラーマネージャーの場合、クラウドベンダーまたはsigリードが管理するリポジトリでプロジェクトを見つけることができます。
すでにKubernetesのコアリポジトリにあるプロバイダーの場合、クラスター内でデーモンセットとしてKubernetesリポジトリ内部のクラウドコントローラーマネージャーを実行できます。以下をガイドラインとして使用してください。
# This is an example of how to set up cloud-controller-manager as a Daemonset in your cluster.
# It assumes that your masters can run pods and has the role node-role.kubernetes.io/master
# Note that this Daemonset will not work straight out of the box for your cloud, this is
# meant to be a guideline.
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: cloud-controller-manager
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:cloud-controller-manager
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: cloud-controller-manager
namespace: kube-system
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
k8s-app: cloud-controller-manager
name: cloud-controller-manager
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: cloud-controller-manager
template:
metadata:
labels:
k8s-app: cloud-controller-manager
spec:
serviceAccountName: cloud-controller-manager
containers:
- name: cloud-controller-manager
# for in-tree providers we use registry.k8s.io/cloud-controller-manager
# this can be replaced with any other image for out-of-tree providers
image: registry.k8s.io/cloud-controller-manager:v1.8.0
command:
- /usr/local/bin/cloud-controller-manager
- --cloud-provider=[YOUR_CLOUD_PROVIDER] # Add your own cloud provider here!
- --leader-elect=true
- --use-service-account-credentials
# these flags will vary for every cloud provider
- --allocate-node-cidrs=true
- --configure-cloud-routes=true
- --cluster-cidr=172.17.0.0/16
tolerations:
# this is required so CCM can bootstrap itself
- key: node.cloudprovider.kubernetes.io/uninitialized
value: "true"
effect: NoSchedule
# these tolerations are to have the daemonset runnable on control plane nodes
# remove them if your control plane nodes should not run pods
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
# this is to restrict CCM to only run on master nodes
# the node selector may vary depending on your cluster setup
nodeSelector:
node-role.kubernetes.io/master: ""
クラウドコントローラーマネージャーの実行にはいくつかの制限があります。これらの制限は今後のリリースで対処されますが、本番のワークロードにおいてはこれらの制限を認識することが重要です。
ボリュームの統合にはkubeletとの調整も必要になるためクラウドコントローラーマネージャーはkube-controller-managerにあるボリュームコントローラーを実装しません。CSI(コンテナストレージインターフェース)が進化してFlexボリュームプラグインの強力なサポートが追加されるにつれ、クラウドがボリュームと完全に統合できるようクラウドコントローラーマネージャーに必要なサポートが追加されます。Kubernetesリポジトリの外部にあるCSIボリュームプラグインの詳細についてはこちらをご覧ください。
cloud-controller-managerは、クラウドプロバイダーのAPIにクエリーを送信して、すべてのノードの情報を取得します。非常に大きなクラスターの場合、リソース要件やAPIレートリミットなどのボトルネックの可能性を考慮する必要があります。
クラウドコントローラーマネージャープロジェクトの目標はKubernetesのコアプロジェクトからクラウドに関する機能の開発を切り離すことです。残念ながら、Kubernetesプロジェクトの多くの面でクラウドプロバイダーの機能がKubernetesプロジェクトに緊密に結びついているという前提があります。そのため、この新しいアーキテクチャを採用するとクラウドプロバイダーの情報を要求する状況が発生する可能性がありますが、クラウドコントローラーマネージャーはクラウドプロバイダーへのリクエストが完了するまでその情報を返すことができない場合があります。
これの良い例は、KubeletのTLSブートストラップ機能です。TLSブートストラップはKubeletがすべてのアドレスタイプ(プライベート、パブリックなど)をクラウドプロバイダー(またはローカルメタデータサービス)に要求する能力を持っていると仮定していますが、クラウドコントローラーマネージャーは最初に初期化されない限りノードのアドレスタイプを設定できないためapiserverと通信するためにはkubeletにTLS証明書が必要です。
このイニシアチブが成熟するに連れ、今後のリリースでこれらの問題に対処するための変更が行われます。
独自のクラウドコントローラーマネージャーを構築および開発するにはクラウドコントローラーマネージャーの開発を参照してください。
Kubernetes v1.18 [beta]近年、CPUやハードウェア・アクセラレーターの組み合わせによって、レイテンシーが致命的となる実行や高いスループットを求められる並列計算をサポートするシステムが増えています。このようなシステムには、通信、科学技術計算、機械学習、金融サービス、データ分析などの分野のワークロードが含まれます。このようなハイブリッドシステムは、高い性能の環境で構成されます。
最高のパフォーマンスを引き出すために、CPUの分離やメモリーおよびデバイスの位置に関する最適化が求められます。しかしながら、Kubernetesでは、これらの最適化は分断されたコンポーネントによって処理されます。
トポロジーマネージャー はKubeletコンポーネントの1つで最適化の役割を担い、コンポーネント群を調和して機能させます。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.18. バージョンを確認するには次のコマンドを実行してください:kubectl version.トポロジーマネージャー導入前は、KubernetesにおいてCPUマネージャーやデバイスマネージャーはそれぞれ独立してリソースの割り当てを決定します。 これは、マルチソケットのシステムでは望ましくない割り当てとなり、パフォーマンスやレイテンシーが求められるアプリケーションは、この望ましくない割り当てに悩まされます。 この場合の望ましくない例として、CPUやデバイスが異なるNUMAノードに割り当てられ、それによりレイテンシー悪化を招くことが挙げられます。
トポロジーマネージャーはKubeletコンポーネントであり、信頼できる情報源として振舞います。それによって、他のKubeletコンポーネントはトポロジーに沿ったリソース割り当ての選択を行うことができます。
トポロジーマネージャーは Hint Providers と呼ばれるコンポーネントのインターフェースを提供し、トポロジー情報を送受信します。トポロジーマネージャーは、ノード単位のポリシー群を保持します。ポリシーについて以下で説明します。
トポロジーマネージャーは Hint Providers からトポロジー情報を受け取ります。トポロジー情報は、利用可能なNUMAノードと優先割り当て表示を示すビットマスクです。トポロジーマネージャーのポリシーは、提供されたヒントに対して一連の操作を行い、ポリシーに沿ってヒントをまとめて最適な結果を得ます。もし、望ましくないヒントが保存された場合、ヒントの優先フィールドがfalseに設定されます。現在のポリシーでは、最も狭い優先マスクが優先されます。
選択されたヒントはトポロジーマネージャーの一部として保存されます。設定されたポリシーにしたがい、選択されたヒントに基づいてノードがPodを許可したり、拒否することができます。 トポロジーマネージャーに保存されたヒントは、Hint Providers が使用しリソース割り当てを決定します。
トポロジーマネージャーをサポートするには、TopologyManager フィーチャーゲートを有効にする必要があります。Kubernetes 1.18ではデフォルトで有効です。
トポロジーマネージャは現在:
これらの条件が合致した場合、トポロジーマネージャーは要求されたリソースを調整します。
この調整をどのように実行するかカスタマイズするために、トポロジーマネージャーは2つのノブを提供します: スコープ とポリシーです。
スコープはリソースの配置を行う粒度を定義します(例:podやcontainer)。そして、ポリシーは調整を実行するための実戦略を定義します(best-effort, restricted, single-numa-node等)。
現在利用可能なスコープとポリシーの値について詳細は以下の通りです。
トポロジーマネージャーは、以下の複数の異なるスコープでリソースの調整を行う事が可能です:
container (デフォルト)podいずれのオプションも、--topology-manager-scopeフラグによって、kubelet起動時に選択できます。
containerスコープはデフォルトで使用されます。
このスコープでは、トポロジーマネージャーは連続した複数のリソース調整を実行します。つまり、Pod内の各コンテナは、分離された配置計算がされます。言い換えると、このスコープでは、コンテナを特定のNUMAノードのセットにグループ化するという概念はありません。実際には、トポロジーマネージャーは各コンテナのNUMAノードへの配置を任意に実行します。
コンテナをグループ化するという概念は、以下のスコープで設定・実行されます。例えば、podスコープが挙げられます。
podスコープを選択するには、コマンドラインで--topology-manager-scope=podオプションを指定してkubeletを起動します。
このスコープでは、Pod内全てのコンテナを共通のNUMAノードのセットにグループ化することができます。トポロジーマネージャーはPodをまとめて1つとして扱い、ポッド全体(全てのコンテナ)を単一のNUMAノードまたはNUMAノードの共通セットのいずれかに割り当てようとします。以下の例は、さまざまな場面でトポロジーマネージャーが実行する調整を示します:
Pod全体に要求される特定のリソースの総量は有効なリクエスト/リミットの式に従って計算されるため、この総量の値は以下の最大値となります。
podスコープとsingle-numa-nodeトポロジーマネージャーポリシーを併用することは、レイテンシーが重要なワークロードやIPCを行う高スループットのアプリケーションに対して特に有効です。両方のオプションを組み合わせることで、Pod内の全てのコンテナを単一のNUMAノードに配置できます。そのため、PodのNUMA間通信によるオーバーヘッドを排除することができます。
single-numa-nodeポリシーの場合、可能な割り当ての中に適切なNUMAノードのセットが存在する場合にのみ、Podが許可されます。上の例をもう一度考えてみましょう:
要約すると、トポロジーマネージャーはまずNUMAノードのセットを計算し、それをトポロジーマネージャーのポリシーと照合し、Podの拒否または許可を検証します。
トポロジーマネージャーは4つの調整ポリシーをサポートします。--topology-manager-policyというKubeletフラグを通してポリシーを設定できます。
4つのサポートされるポリシーがあります:
none (デフォルト)best-effortrestrictedsingle-numa-nodeこれはデフォルトのポリシーで、トポロジーの調整を実行しません。
Pod内の各コンテナに対して、best-effort トポロジー管理ポリシーが設定されたkubeletは、各Hint Providerを呼び出してそれらのリソースの可用性を検出します。
トポロジーマネージャーはこの情報を使用し、そのコンテナの推奨されるNUMAノードのアフィニティーを保存します。アフィニティーが優先されない場合、トポロジーマネージャーはこれを保存し、Podをノードに許可します。
Hint Providers はこの情報を使ってリソースの割り当てを決定します。
Pod内の各コンテナに対して、restricted トポロジー管理ポリシーが設定されたkubeletは各Hint Providerを呼び出してそれらのリソースの可用性を検出します。
トポロジーマネージャーはこの情報を使用し、そのコンテナの推奨されるNUMAノードのアフィニティーを保存します。アフィニティーが優先されない場合、トポロジーマネージャーはPodをそのノードに割り当てることを拒否します。この結果、PodはPodの受付失敗となりTerminated 状態になります。
Podが一度Terminated状態になると、KubernetesスケジューラーはPodの再スケジューリングを試み ません 。Podの再デプロイをするためには、ReplicasetかDeploymenを使用してください。Topology Affinityエラーとなったpodを再デプロイするために、外部のコントロールループを実行することも可能です。
Podが許可されれば、 Hint Providers はこの情報を使ってリソースの割り当てを決定します。
Pod内の各コンテナに対して、single-numa-nodeトポロジー管理ポリシーが設定されたkubeletは各Hint Prociderを呼び出してそれらのリソースの可用性を検出します。
トポロジーマネージャーはこの情報を使用し、単一のNUMAノードアフィニティが可能かどうか決定します。
可能な場合、トポロジーマネージャーは、この情報を保存し、Hint Providers はこの情報を使ってリソースの割り当てを決定します。
不可能な場合、トポロジーマネージャーは、Podをそのノードに割り当てることを拒否します。この結果、Pod は Pod の受付失敗となりTerminated状態になります。
Podが一度Terminated状態になると、KubernetesスケジューラーはPodの再スケジューリングを試みません。Podの再デプロイをするためには、ReplicasetかDeploymentを使用してください。Topology Affinityエラーとなったpodを再デプロイするために、外部のコントロールループを実行することも可能です。
以下のようなpodのSpecで定義されるコンテナを考えます:
spec:
containers:
- name: nginx
image: nginx
requestsもlimitsも定義されていないため、このPodはBestEffortQoSクラスで実行します。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
requestsがlimitsより小さい値のため、このPodはBurstableQoSクラスで実行します。
選択されたポリシーがnone以外の場合、トポロジーマネージャーは、これらのPodのSpecを考慮します。トポロジーマネージャーは、Hint Providersからトポロジーヒントを取得します。CPUマネージャーポリシーがstaticの場合、デフォルトのトポロジーヒントを返却します。これらのPodは明示的にCPUリソースを要求していないからです。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
整数値でCPUリクエストを指定されたこのPodは、requestsがlimitsが同じ値のため、GuaranteedQoSクラスで実行します。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
CPUの一部をリクエストで指定されたこのPodは、requestsがlimitsが同じ値のため、GuaranteedQoSクラスで実行します。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
example.com/deviceA: "1"
example.com/deviceB: "1"
requests:
example.com/deviceA: "1"
example.com/deviceB: "1"
CPUもメモリもリクエスト値がないため、このPodは BestEffort QoSクラスで実行します。
トポロジーマネージャーは、上記Podを考慮します。トポロジーマネージャーは、Hint ProvidersとなるCPUマネージャーとデバイスマネージャーに問い合わせ、トポロジーヒントを取得します。
整数値でCPU要求を指定されたGuaranteedQoSクラスのPodの場合、staticが設定されたCPUマネージャーポリシーは、排他的なCPUに関するトポロジーヒントを返却し、デバイスマネージャーは要求されたデバイスのヒントを返します。
CPUの一部を要求を指定されたGuaranteedQoSクラスのPodの場合、排他的ではないCPU要求のためstaticが設定されたCPUマネージャーポリシーはデフォルトのトポロジーヒントを返却します。デバイスマネージャーは要求されたデバイスのヒントを返します。
上記のGuaranteedQoSクラスのPodに関する2ケースでは、noneで設定されたCPUマネージャーポリシーは、デフォルトのトポロジーヒントを返却します。
BestEffortQoSクラスのPodの場合、staticが設定されたCPUマネージャーポリシーは、CPUの要求がないためデフォルトのトポロジーヒントを返却します。デバイスマネージャーは要求されたデバイスごとのヒントを返します。
トポロジーマネージャーはこの情報を使用してPodに最適なヒントを計算し保存します。保存されたヒントは Hint Providersが使用しリソースを割り当てます。
トポロジーマネージャーが許容するNUMAノードの最大値は8です。8より多いNUMAノードでは、可能なNUMAアフィニティを列挙しヒントを生成する際に、生成する状態数が爆発的に増加します。
スケジューラーはトポロジーを意識しません。そのため、ノードにスケジュールされた後に実行に失敗する可能性があります。
このドキュメントでは、Pod同士の通信を制御するネットワークポリシーを定義するための、KubernetesのNetworkPolicy APIを使い始める手助けをします。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.8. バージョンを確認するには次のコマンドを実行してください:kubectl version.ネットワークポリシーをサポートしているネットワークプロバイダーが設定済みであることを確認してください。さまざまなネットワークプロバイダーがNetworkPolicyをサポートしています。次に挙げるのは一例です。
nginx Deploymentを作成してService経由で公開するKubernetesのネットワークポリシーの仕組みを理解するために、まずはnginx Deploymentを作成することから始めましょう。
kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
nginxという名前のService経由でDeploymentを公開します。
kubectl expose deployment nginx --port=80
service/nginx exposed
上記のコマンドを実行すると、nginx Podを持つDeploymentが作成され、そのDeploymentがnginxという名前のService経由で公開されます。nginxのPodおよびDeploymentはdefault名前空間の中にあります。
kubectl get svc,pod
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes 10.100.0.1 <none> 443/TCP 46m
service/nginx 10.100.0.16 <none> 80/TCP 33s
NAME READY STATUS RESTARTS AGE
pod/nginx-701339712-e0qfq 1/1 Running 0 35s
これで、新しいnginxサービスに他のPodからアクセスできるようになったはずです。default名前空間内の他のPodからnginx Serviceにアクセスするために、busyboxコンテナを起動します。
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
シェルの中で、次のコマンドを実行します。
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
nginx Serviceへのアクセスを制限するnginx Serviceへのアクセスを制限するために、access: trueというラベルが付いたPodだけがクエリできるようにします。次の内容でNetworkPolicyオブジェクトを作成してください。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: access-nginx
spec:
podSelector:
matchLabels:
app: nginx
ingress:
- from:
- podSelector:
matchLabels:
access: "true"
NetworkPolicyオブジェクトの名前は、有効なDNSサブドメイン名でなければなりません。
podSelectorが含まれています。このポリシーは、ラベルapp=nginxの付いたPodを選択していることがわかります。このラベルは、nginx Deployment内のPodに自動的に追加されたものです。空のpodSelectorは、その名前空間内のすべてのPodを選択します。kubectlを使って、上記のnginx-policy.yamlファイルからNetworkPolicyを作成します。
kubectl apply -f https://k8s.io/examples/service/networking/nginx-policy.yaml
networkpolicy.networking.k8s.io/access-nginx created
nginx Serviceに正しいラベルが付いていないPodからアクセスを試してみると、リクエストがタイムアウトします。
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
シェルの中で、次のコマンドを実行します。
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
wget: download timed out
正しいラベルが付いたPodを作成すると、リクエストが許可されるようになるのがわかります。
kubectl run busybox --rm -ti --labels="access=true" --image=busybox -- /bin/sh
シェルの中で、次のコマンドを実行します。
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
cloud-controller-managerは クラウド特有の制御ロジックを組み込むKubernetesのcontrol planeコンポーネントです。クラウドコントロールマネージャーは、クラスターをクラウドプロバイダーAPIをリンクし、クラスターのみで相互作用するコンポーネントからクラウドプラットフォームで相互作用するコンポーネントを分離します。
Kubernetesと下のクラウドインフラストラクチャー間の相互運用ロジックを分離することで、cloud-controller-managerコンポーネントはクラウドプロバイダを主なKubernetesプロジェクトと比較し異なるペースで機能をリリース可能にします。
クラウドプロバイダーはKubernetesプロジェクトとは異なる速度で開発しリリースすることから、プロバイダー特有なコードをcloud-controller-managerバイナリから抽象化することで、クラウドベンダーはコアKubernetesコードから独立して発展することができます。
Kubernetesプロジェクトは、(クラウドプロバイダーの)独自実装を組み込めるGoインターフェースを備えたcloud-controller-managerのスケルトンコードを提供しています。これは、クラウドプロバイダーがKubernetesコアからパッケージをインポートすることでcloud-controller-managerを実装できることを意味します。各クラウドプロバイダーは利用可能なクラウドプロバイダーのグローバル変数を更新するためにcloudprovider.RegisterCloudProviderを呼び出し、独自のコードを登録します。
Kubernetesには登録されていない独自のクラウドプロバイダーのクラウドコントローラーマネージャーを構築するには、
main.goをあなたのmain.goのテンプレートとして利用します。上で述べたように、唯一の違いはインポートされるクラウドパッケージのみです。main.go にインポートし、パッケージに cloudprovider.RegisterCloudProvider を実行するための init ブロックがあることを確認します。多くのクラウドプロバイダーはオープンソースとしてコントローラーマネージャーのコードを公開しています。新たにcloud-controller-managerをスクラッチから開発する際には、既存のKubernetesには登録されていない独自クラウドプロバイダーのコントローラーマネージャーを開始地点とすることができます。
Kubernetesに登録されているクラウドプロバイダーであれば、DaemonSetを使ってあなたのクラスターで動かすことができます。詳細についてはKubernetesクラウドコントローラーマネージャーを参照してください。
etcdは 一貫性、高可用性を持ったキーバリューストアで、Kubernetesの全てのクラスター情報の保存場所として利用されています。
etcdをKubernetesのデータストアとして使用する場合、必ずデータのバックアッププランを作成して下さい。
公式ドキュメントでetcdに関する詳細な情報を見つけることができます。
Kubernetesクラスターが必要で、kubectlコマンドラインツールがクラスターと通信できるように設定されている必要があります。 コントロールプレーンノード以外に少なくとも2つのノードを持つクラスターで、このガイドに従うことを推奨します。 まだクラスターを用意していない場合は、minikubeを使用して作成することができます。
etcdは、奇数のメンバーを持つクラスターとして実行します。
etcdはリーダーベースの分散システムです。リーダーが定期的に全てのフォロワーにハートビートを送信し、クラスターの安定性を維持するようにします。
リソース不足が発生しないようにします。
クラスターのパフォーマンスと安定性は、ネットワークとディスクのI/Oに敏感です。 リソース不足はハートビートのタイムアウトを引き起こし、クラスターの不安定化につながる可能性があります。 不安定なetcdは、リーダーが選出されていないことを意味します。 そのような状況では、クラスターは現在の状態に変更を加えることができません。 これは、新しいPodがスケジュールされないことを意味します。
Kubernetesクラスターの安定性には、etcdクラスターの安定性が不可欠です。 したがって、etcdクラスターは専用のマシンまたは保証されたリソース要件を持つ隔離された環境で実行してください。
本番環境で実行するために推奨される最低限のetcdバージョンは、3.4.22以降あるいは3.5.6以降です。
限られたリソースでetcdを運用するのはテスト目的にのみ適しています。 本番環境へのデプロイには、高度なハードウェア構成が必要です。 本番環境へetcdをデプロイする前に、リソース要件を確認してください。
このセクションでは、単一ノードおよびマルチノードetcdクラスターの起動について説明します。
単一ノードetcdクラスターは、テスト目的でのみ使用してください。
以下を実行します:
etcd --listen-client-urls=http://$PRIVATE_IP:2379 \
--advertise-client-urls=http://$PRIVATE_IP:2379
Kubernetes APIサーバーをフラグ--etcd-servers=$PRIVATE_IP:2379で起動します。
PRIVATE_IPがetcdクライアントIPに設定されていることを確認してください。
耐久性と高可用性のために、本番環境ではマルチノードクラスターとしてetcdを実行し、定期的にバックアップを取ります。 本番環境では5つのメンバーによるクラスターが推奨されます。 詳細はFAQドキュメントを参照してください。
etcdクラスターは、静的なメンバー情報、または動的な検出によって構成されます。 クラスタリングに関する詳細は、etcdクラスタリングドキュメントを参照してください。
例として、次のクライアントURLで実行される5つのメンバーによるetcdクラスターを考えてみます。
5つのURLは、http://$IP1:2379、http://$IP2:2379、http://$IP3:2379、http://$IP4:2379、およびhttp://$IP5:2379です。Kubernetes APIサーバーを起動するには、
以下を実行します:
etcd --listen-client-urls=http://$IP1:2379,http://$IP2:2379,http://$IP3:2379,http://$IP4:2379,http://$IP5:2379 --advertise-client-urls=http://$IP1:2379,http://$IP2:2379,http://$IP3:2379,http://$IP4:2379,http://$IP5:2379
フラグ--etcd-servers=$IP1:2379,$IP2:2379,$IP3:2379,$IP4:2379,$IP5:2379を使ってKubernetes APIサーバーを起動します。
IP<n>変数がクライアントのIPアドレスに設定されていることを確認してください。
ロードバランシングされたetcdクラスターを実行するには、次の手順に従います。
$LBとします。--etcd-servers=$LB:2379を使ってKubernetes APIサーバーを起動します。etcdへのアクセスはクラスター内でのルート権限に相当するため、理想的にはAPIサーバーのみがアクセスできるようにするべきです。 データの機密性を考慮して、etcdクラスターへのアクセス権を必要とするノードのみに付与することが推奨されます。
etcdをセキュアにするためには、ファイアウォールのルールを設定するか、etcdによって提供されるセキュリティ機能を使用します。
etcdのセキュリティ機能はx509公開鍵基盤(PKI)に依存します。
この機能を使用するには、キーと証明書のペアを生成して、セキュアな通信チャンネルを確立します。
例えば、etcdメンバー間の通信をセキュアにするためにpeer.keyとpeer.certのキーペアを使用し、etcdとそのクライアント間の通信をセキュアにするためにclient.keyとclient.certを使用します。
クライアント認証用のキーペアとCAファイルを生成するには、etcdプロジェクトによって提供されているサンプルスクリプトを参照してください。
セキュアなピア通信を持つetcdを構成するためには、--peer-key-file=peer.keyおよび--peer-cert-file=peer.certフラグを指定し、URLスキーマとしてHTTPSを使用します。
同様に、セキュアなクライアント通信を持つetcdを構成するためには、--key-file=k8sclient.keyおよび--cert-file=k8sclient.certフラグを指定し、URLスキーマとしてHTTPSを使用します。
セキュアな通信を使用するクライアントコマンドの例は以下の通りです:
ETCDCTL_API=3 etcdctl --endpoints 10.2.0.9:2379 \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
member list
セキュアな通信を構成した後、TLS認証を使用して、etcdクラスターへのアクセスをKubernetes APIサーバーのみに制限します。
例えば、CA etcd.caによって信頼されるキーペアk8sclient.keyとk8sclient.certを考えてみます。
--client-cert-authとTLSを使用してetcdが構成されている場合、etcdは--trusted-ca-fileフラグで渡されたCAまたはシステムのCAを使用してクライアントからの証明書を検証します。
--client-cert-auth=trueおよび--trusted-ca-file=etcd.caフラグを指定することで、証明書k8sclient.certを持つクライアントのみにアクセスを制限します。
etcdが正しく構成されると、有効な証明書を持つクライアントのみがアクセスできます。
Kubernetes APIサーバーにアクセス権を与えるためには、--etcd-certfile=k8sclient.cert、--etcd-keyfile=k8sclient.keyおよび--etcd-cafile=ca.certフラグで構成します。
etcdクラスターは、一部のメンバーの障害を許容することで高可用性を実現します。 しかし、クラスターの全体的な状態を改善するためには、障害が発生したメンバーを直ちに交換することが重要です。 複数のメンバーに障害が発生した場合は、1つずつ交換します。 障害が発生したメンバーを交換するには、メンバーを削除し、新しいメンバーを追加するという2つのステップがあります。
etcdは内部でユニークなメンバーIDを保持していますが、人的なミスを避けるためにも各メンバーにはユニークな名前を使用することが推奨されます。
例えば、3つのメンバーのetcdクラスターを考えてみましょう。
URLがmember1=http://10.0.0.1、member2=http://10.0.0.2、そしてmember3=http://10.0.0.3だとします。
member1に障害が発生した場合、member4=http://10.0.0.4で交換します。
障害が発生したmember1のメンバーIDを取得します:
etcdctl --endpoints=http://10.0.0.2,http://10.0.0.3 member list
次のメッセージが表示されます:
8211f1d0f64f3269, started, member1, http://10.0.0.1:2380, http://10.0.0.1:2379
91bc3c398fb3c146, started, member2, http://10.0.0.2:2380, http://10.0.0.2:2379
fd422379fda50e48, started, member3, http://10.0.0.3:2380, http://10.0.0.3:2379
以下のいずれかを行います:
--etcd-serversフラグから障害が発生したメンバーを削除し、各Kubernetes APIサーバーを再起動します。壊れたノード上のetcdサーバーを停止します。 Kubernetes APIサーバー以外のクライアントからetcdにトラフィックが流れている可能性があり、データディレクトリへの書き込みを防ぐためにすべてのトラフィックを停止することが望ましいです。
メンバーを削除します:
etcdctl member remove 8211f1d0f64f3269
次のメッセージが表示されます:
Removed member 8211f1d0f64f3269 from cluster
新しいメンバーを追加します:
etcdctl member add member4 --peer-urls=http://10.0.0.4:2380
次のメッセージが表示されます:
Member 2be1eb8f84b7f63e added to cluster ef37ad9dc622a7c4
IP 10.0.0.4のマシン上で新たに追加されたメンバーを起動します:
export ETCD_NAME="member4"
export ETCD_INITIAL_CLUSTER="member2=http://10.0.0.2:2380,member3=http://10.0.0.3:2380,member4=http://10.0.0.4:2380"
export ETCD_INITIAL_CLUSTER_STATE=existing
etcd [flags]
以下のいずれかを行います:
--etcd-serversフラグに新たに追加されたメンバーを加え、各Kubernetes APIサーバーを再起動します。クラスターの再構成に関する詳細については、etcd再構成ドキュメントを参照してください。
すべてのKubernetesオブジェクトはetcdに保存されています。 定期的にetcdクラスターのデータをバックアップすることは、すべてのコントロールプレーンノードを失うなどの災害シナリオでKubernetesクラスターを復旧するために重要です。 スナップショットファイルには、すべてのKubernetesの状態と重要な情報が含まれています。 機密性の高いKubernetesデータを安全に保つために、スナップショットファイルを暗号化してください。
etcdクラスターのバックアップは、etcdのビルトインスナップショットとボリュームスナップショットの2つの方法で実現できます。
etcdはビルトインスナップショットをサポートしています。
スナップショットは、etcdctl snapshot saveコマンドを使用してライブメンバーから、あるいはetcdプロセスによって現在使用されていないデータディレクトリからmember/snap/dbファイルをコピーして作成できます。
スナップショットを作成しても、メンバーのパフォーマンスに影響はありません。
以下は、$ENDPOINTによって提供されるキースペースのスナップショットをsnapshot.dbファイルに作成する例です:
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshot.db
スナップショットを確認します:
ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshot.db
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| fe01cf57 | 10 | 7 | 2.1 MB |
+----------+----------+------------+------------+
etcdがAmazon Elastic Block Storeのようなバックアップをサポートするストレージボリューム上で実行されている場合、ストレージボリュームのスナップショットを作成することによってetcdデータをバックアップします。
etcdctlによって提供されるさまざまなオプションを使用してスナップショットを作成することもできます。例えば
ETCDCTL_API=3 etcdctl -h
はetcdctlから利用可能なさまざまなオプションを一覧表示します。 例えば、以下のようにエンドポイント、証明書、キーを指定してスナップショットを作成することができます:
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=<trusted-ca-file> --cert=<cert-file> --key=<key-file> \
snapshot save <backup-file-location>
ここで、trusted-ca-file、cert-file、key-fileはetcd Podの説明から取得できます。
etcdクラスターのスケールアウトは、パフォーマンスとのトレードオフで可用性を高めます。 スケーリングはクラスターのパフォーマンスや能力を高めるものではありません。 一般的なルールとして、etcdクラスターをスケールアウトまたはスケールインすることはありません。 etcdクラスターに自動スケーリンググループを設定しないでください。 公式にサポートされるどんなスケールの本番環境のKubernetesクラスターにおいても、常に静的な5つのメンバーのetcdクラスターを運用することを強く推奨します。
合理的なスケーリングは、より高い信頼性が求められる場合に、3つのメンバーで構成されるクラスターを5つのメンバーにアップグレードすることです。 既存のクラスターにメンバーを追加する方法については、etcdの再構成ドキュメントを参照してください。
etcdは、major.minorバージョンのetcdプロセスから取得されたスナップショットからの復元をサポートしています。 異なるパッチバージョンのetcdからのバージョン復元もサポートされています。 復元操作は、障害が発生したクラスターのデータを回復するために用いられます。
復元操作を開始する前に、スナップショットファイルが存在している必要があります。 これは、以前のバックアップ操作からのスナップショットファイルでも、残っているデータディレクトリからのスナップショットファイルでも構いません。
クラスターを復元する場合は、--data-dirオプションを使用して、クラスターをどのフォルダーに復元するかを指定します:
ETCDCTL_API=3 etcdctl --data-dir <data-dir-location> snapshot restore snapshot.db
ここで、<data-dir-location>は復元プロセス中に作成されるディレクトリです。
もう一つの例としては、まずETCDCTL_API環境変数をエクスポートします:
export ETCDCTL_API=3
etcdctl --data-dir <data-dir-location> snapshot restore snapshot.db
<data-dir-location>が以前と同じフォルダーである場合は、クラスターを復元する前にそれを削除してetcdプロセスを停止します。そうでない場合は、etcdの構成を変更し、復元後にetcdプロセスを再起動して新しいデータディレクトリを使用するようにします。
スナップショットファイルからクラスターを復元する方法と例についての詳細は、etcd災害復旧ドキュメントを参照してください。
復元されたクラスターのアクセスURLが前のクラスターと異なる場合、Kubernetes APIサーバーをそれに応じて再設定する必要があります。
この場合、--etcd-servers=$OLD_ETCD_CLUSTERのフラグの代わりに、--etcd-servers=$NEW_ETCD_CLUSTERのフラグでKubernetes APIサーバーを再起動します。
$NEW_ETCD_CLUSTERと$OLD_ETCD_CLUSTERをそれぞれのIPアドレスに置き換えてください。
etcdクラスターの前にロードバランサーを使用している場合、代わりにロードバランサーを更新する必要があるかもしれません。
etcdメンバーの過半数に永続的な障害が発生した場合、etcdクラスターは故障したと見なされます。 このシナリオでは、Kubernetesは現在の状態に対して変更を加えることができません。 スケジュールされたPodは引き続き実行されるかもしれませんが、新しいPodはスケジュールできません。 このような場合、etcdクラスターを復旧し、必要に応じてKubernetes APIサーバーを再設定して問題を修正します。
クラスター内でAPIサーバーが実行されている場合、etcdのインスタンスを復元しようとしないでください。 代わりに、以下の手順に従ってetcdを復元してください:
また、kube-scheduler、kube-controller-manager、kubeletなどのコンポーネントを再起動することもお勧めします。
これは、これらが古いデータに依存していないことを確認するためです。実際には、復元には少し時間がかかります。
復元中、重要なコンポーネントはリーダーロックを失い、自動的に再起動します。
etcdのアップグレードに関する詳細は、etcdアップグレードのドキュメントを参照してください。
etcdのメンテナンスに関する詳細は、etcdメンテナンスのドキュメントを参照してください。
デフラグメンテーションはコストがかかる操作のため、できるだけ頻繁に実行しないようにしてください。 一方で、etcdメンバーがストレージのクォータを超えないようにする必要もあります。 Kubernetesプロジェクトでは、デフラグメンテーションを行う際には、etcd-defragなどのツールを使用することを推奨しています。
また、デフラグメンテーションを定期的に実行するために、KubernetesのCronJobとしてデフラグメンテーションツールを実行することもできます。
詳細はetcd-defrag-cronjob.yamlを参照してください。
このドキュメントでは、偶発的または悪意のあるアクセスからクラスターを保護するためのトピックについて説明します。 また、全体的なセキュリティに関する推奨事項を提供します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.Kubernetesは完全にAPI駆動であるため、誰がクラスターにアクセスできるか、どのようなアクションを実行できるかを制御・制限することが第一の防御策となります。
Kubernetesは、クラスター内のすべてのAPI通信がデフォルトでTLSにより暗号化されていることを期待しており、大半のインストール方法では、必要な証明書を作成してクラスターコンポーネントに配布することができます。
コンポーネントやインストール方法によっては、HTTP上のローカルポートを有効にする場合があることに注意してください。管理者は、潜在的に保護されていないトラフィックを特定するために、各コンポーネントの設定に精通している必要があります。
クラスターのインストール時に、共通のアクセスパターンに合わせて、APIサーバーが使用する認証メカニズムを選択します。 例えば、シングルユーザーの小規模なクラスターでは、シンプルな証明書や静的なBearerトークンを使用することができます。 大規模なクラスターでは、ユーザーをグループに細分化できる既存のOIDCまたはLDAPサーバーを統合することができます。
ノード、プロキシ、スケジューラー、ボリュームプラグインなど、インフラの一部であるものも含めて、すべてのAPIクライアントを認証する必要があります。 これらのクライアントは通常、service accountsであるか、またはx509クライアント証明書を使用しており、クラスター起動時に自動的に作成されるか、クラスターインストールの一部として設定されます。
詳細については、認証を参照してください。
認証されると、すべてのAPIコールは認可チェックを通過することになります。
Kubernetesには、統合されたRBACコンポーネントが搭載されており、入力されたユーザーやグループを、ロールにまとめられたパーミッションのセットにマッチさせます。 これらのパーミッションは、動詞(get, create, delete)とリソース(pods, services, nodes)を組み合わせたもので、ネームスペース・スコープまたはクラスター・スコープに対応しています。 すぐに使えるロールのセットが提供されており、クライアントが実行したいアクションに応じて、デフォルトで適切な責任の分離を提供します。
NodeとRBACの承認者は、NodeRestrictionのアドミッションプラグインと組み合わせて使用することをお勧めします。
認証の場合と同様に、小規模なクラスターにはシンプルで幅広い役割が適切かもしれません。 しかし、より多くのユーザーがクラスターに関わるようになるとチームを別の名前空間に分け、より限定的な役割を持たせることが必要になるかもしれません。 認可においては、あるオブジェクトの更新が、他の場所でどのようなアクションを起こすかを理解することが重要です。
たとえば、ユーザーは直接Podを作成することはできませんが、ユーザーに代わってPodを作成するDeploymentの作成を許可することで、間接的にそれらのPodを作成することができます。 同様に、APIからノードを削除すると、そのノードにスケジューリングされていたPodが終了し、他のノードに再作成されます。 すぐに使えるロールは、柔軟性と一般的なユースケースのバランスを表していますが、より限定的なロールは、偶発的なエスカレーションを防ぐために慎重に検討する必要があります。 すぐに使えるロールがニーズを満たさない場合は、ユースケースに合わせてロールを作成することができます。
詳しくはauthorization reference sectionに参照してください。
Kubeletsは、ノードやコンテナの強力な制御を可能にするHTTPSエンドポイントを公開しています。 デフォルトでは、KubeletsはこのAPIへの認証されていないアクセスを許可しています。
本番環境のクラスターでは、Kubeletの認証と認可を有効にする必要があります。
詳細は、Kubelet 認証/認可に参照してください。
Kubernetesにおける権限付与は、意図的にハイレベルであり、リソースに対する粗いアクションに焦点を当てています。
より強力なコントロールはpoliciesとして存在し、それらのオブジェクトがクラスターや自身、その他のリソースにどのように作用するかをユースケースによって制限します。
リソースクォータは、ネームスペースに付与されるリソースの数や容量を制限するものです。
これは、ネームスペースが割り当てることのできるCPU、メモリー、永続的なディスクの量を制限するためによく使われますが、各ネームスペースに存在するPod、サービス、ボリュームの数を制御することもできます。
Limit rangesは、上記のリソースの一部の最大または最小サイズを制限することで、ユーザーがメモリーなどの一般的に予約されたリソースに対して不当に高いまたは低い値を要求するのを防いだり、何も指定されていない場合にデフォルトの制限を提供したりします。
Podの定義には、security contextが含まれており、ノード上の特定の Linux ユーザー(rootなど)として実行するためのアクセス、特権的に実行するためのアクセス、ホストネットワークにアクセスするためのアクセス、その他の制御を要求することができます。 Pod security policiesは、危険なセキュリティコンテキスト設定を提供できるユーザーやサービスアカウントを制限することができます。
たとえば、Podのセキュリティポリシーでは、ボリュームマウント、特にhostPathを制限することができ、これはPodの制御すべき側面です。
一般に、ほとんどのアプリケーションワークロードでは、ホストリソースへのアクセスを制限する必要があります。
ホスト情報にアクセスすることなく、ルートプロセス(uid 0)として正常に実行できます。
ただし、ルートユーザーに関連する権限を考慮して、非ルートユーザーとして実行するようにアプリケーションコンテナを記述する必要があります。
Linuxカーネルは、ハードウェアが接続されたときやファイルシステムがマウントされたときなど、特定の状況下で必要となるカーネルモジュールをディスクから自動的にロードします。 特にKubernetesでは、非特権プロセスであっても、適切なタイプのソケットを作成するだけで、特定のネットワークプロトコル関連のカーネルモジュールをロードさせることができます。これにより、管理者が使用されていないと思い込んでいるカーネルモジュールのセキュリティホールを攻撃者が利用できる可能性があります。 特定のモジュールが自動的にロードされないようにするには、そのモジュールをノードからアンインストールしたり、ルールを追加してブロックしたりします。
ほとんどのLinuxディストリビューションでは、/etc/modprobe.d/kubernetes-blacklist.confのような内容のファイルを作成することで実現できます。
# DCCPは必要性が低く、複数の深刻な脆弱性があり、保守も十分ではありません。
blacklist dccp
# SCTPはほとんどのKubernetesクラスターでは使用されておらず、また過去には脆弱性がありました。
blacklist sctp
モジュールのロードをより一般的にブロックするには、SELinuxなどのLinuxセキュリティモジュールを使って、コンテナに対する module_request権限を完全に拒否し、いかなる状況下でもカーネルがコンテナ用のモジュールをロードできないようにすることができます。
(Podは、手動でロードされたモジュールや、より高い権限を持つプロセスに代わってカーネルがロードしたモジュールを使用することはできます)。
名前空間のネットワークポリシーにより、アプリケーション作成者は、他の名前空間のPodが自分の名前空間内のPodやポートにアクセスすることを制限することができます。
サポートされているKubernetes networking providersの多くは、ネットワークポリシーを尊重するようになりました。 クォータやリミットの範囲は、ユーザーがノードポートや負荷分散サービスを要求するかどうかを制御するためにも使用でき、多くのクラスターでは、ユーザーのアプリケーションがクラスターの外で見えるかどうかを制御できます。 ノードごとのファイアウォール、クロストークを防ぐための物理的なクラスターノードの分離、高度なネットワークポリシーなど、プラグインや環境ごとにネットワークルールを制御する追加の保護機能が利用できる場合もあります。
クラウドプラットフォーム(AWS、Azure、GCEなど)では、しばしばメタデータサービスをインスタンスローカルに公開しています。 デフォルトでは、これらのAPIはインスタンス上で実行されているPodからアクセスでき、そのノードのクラウド認証情報や、kubelet認証情報などのプロビジョニングデータを含むことができます。 これらの認証情報は、クラスター内でのエスカレーションや、同じアカウントの他のクラウドサービスへのエスカレーションに使用できます。
クラウドプラットフォーム上でKubernetesを実行する場合は、インスタンスの認証情報に与えられるパーミッションを制限し、ネットワークポリシーを使用してメタデータAPIへのPodのアクセスを制限し、プロビジョニングデータを使用してシークレットを配信することは避けてください。
デフォルトでは、どのノードがPodを実行できるかについての制限はありません。 Kubernetesは、エンドユーザーが利用できるNode上へのPodのスケジューリングとTaintとTolerationを提供します。 多くのクラスターでは、ワークロードを分離するためにこれらのポリシーを使用することは、作者が採用したり、ツールを使って強制したりする慣習になっています。
管理者としては、ベータ版のアドミッションプラグイン「PodNodeSelector」を使用して、ネームスペース内のPodをデフォルトまたは特定のノードセレクタを必要とするように強制することができます。 エンドユーザーがネームスペースを変更できない場合は、特定のワークロード内のすべてのPodの配置を強く制限することができます。
このセクションでは、クラスターを危険から守るための一般的なパターンを説明します。
API用のetcdバックエンドへの書き込みアクセスは、クラスター全体のrootを取得するのと同等であり、読み取りアクセスはかなり迅速にエスカレートするために使用できます。 管理者は、TLSクライアント証明書による相互認証など、APIサーバーからetcdサーバーへの強力な認証情報を常に使用すべきであり、API サーバーのみがアクセスできるファイアウォールの後ろにetcdサーバーを隔離することがしばしば推奨されます。
audit loggerはベータ版の機能で、APIによって行われたアクションを記録し、侵害があった場合に後から分析できるようにするものです。
監査ログを有効にして、ログファイルを安全なサーバーにアーカイブすることをお勧めします。
アルファ版およびベータ版のKubernetesの機能は活発に開発が行われており、セキュリティ上の脆弱性をもたらす制限やバグがある可能性があります。 常に、アルファ版またはベータ版の機能が提供する価値と、セキュリティ体制に起こりうるリスクを比較して評価してください。 疑問がある場合は、使用しない機能を無効にしてください。
秘密やクレデンシャルの有効期間が短いほど、攻撃者がそのクレデンシャルを利用することは難しくなります。 証明書の有効期間を短く設定し、そのローテーションを自動化します。 発行されたトークンの利用可能期間を制御できる認証プロバイダーを使用し、可能な限り短いライフタイムを使用します。 外部統合でサービス・アカウント・トークンを使用する場合、これらのトークンを頻繁にローテーションすることを計画します。 例えば、ブートストラップ・フェーズが完了したら、ノードのセットアップに使用したブートストラップ・トークンを失効させるか、その認証を解除する必要があります。
Kubernetesへの多くのサードパーティの統合は、クラスターのセキュリティプロファイルを変更する可能性があります。 統合を有効にする際には、アクセスを許可する前に、拡張機能が要求するパーミッションを常に確認してください。
例えば、多くのセキュリティ統合は、事実上そのコンポーネントをクラスター管理者にしているクラスター上のすべての秘密を見るためのアクセスを要求するかもしれません。
疑問がある場合は、可能な限り単一の名前空間で機能するように統合を制限してください。
Podを作成するコンポーネントも、kube-system名前空間のような名前空間内で行うことができれば、予想外に強力になる可能性があります。これは、サービスアカウントのシークレットにアクセスしたり、サービスアカウントに寛容なpod security policiesへのアクセスが許可されている場合に、昇格したパーミッションでPodが実行される可能性があるからです。
一般的に、etcdデータベースにはKubernetes APIを介してアクセス可能なあらゆる情報が含まれており、クラスターの状態に対する大きな可視性を攻撃者へ与える可能性があります。 よく吟味されたバックアップおよび暗号化ソリューションを使用して、常にバックアップを暗号化し、可能な場合はフルディスク暗号化の使用を検討してください。
Kubernetesは1.7で導入された機能であるencryption at restをサポートしており、これは1.13からはベータ版となっています。
これは、etcdのSecretリソースを暗号化し、etcdのバックアップにアクセスした人が、それらのシークレットの内容を見ることを防ぎます。
この機能は現在ベータ版ですが、バックアップが暗号化されていない場合や、攻撃者がetcdへの読み取りアクセスを得た場合に、追加の防御レベルを提供します。
kubernetes-announceに参加してください。 グループに参加すると、セキュリティアナウンスに関するメールを受け取ることができます。 脆弱性の報告方法については、security reportingページを参照してください。
このページでは、Kubernetesクラスターをアップグレードする際に従うべき手順の概要を提供します。
クラスターのアップグレード方法は、初期のデプロイ方法やその後の変更によって異なります。
大まかな手順は以下の通りです:
既存のクラスターが必要です。このページではKubernetes 1.31からKubernetes 1.32へのアップグレードについて説明しています。現在のクラスターがKubernetes 1.31を実行していない場合は、アップグレードしようとしているKubernetesバージョンのドキュメントを確認してください。
クラスターがkubeadmツールを使用してデプロイされた場合の詳細なアップグレード方法は、kubeadmクラスターのアップグレードを参照してください。
クラスターをアップグレードしたら、忘れずに最新バージョンのkubectlをインストールしてください。
次の順序でコントロールプレーンを手動で更新する必要があります:
この時点で、最新バージョンのkubectlをインストールしてください。
クラスター内の各ノードに対して、そのノードをドレインし、1.32 kubeletを使用する新しいノードと置き換えるか、そのノードのkubeletをアップグレードして再稼働させます。
クラスターデプロイメントツールのドキュメントを参照して、メンテナンスの推奨手順を確認してください。
クラスターの内部表現でアクティブなKubernetesリソースのためにetcdにシリアル化されるオブジェクトは、特定のAPIバージョンを使用して書き込まれます。
サポートされるAPIが変更されると、これらのオブジェクトは新しいAPIで再書き込みする必要があります。これを行わないと、最終的にはKubernetes APIサーバーによってデコードまたは使用できなくなるリソースが発生する可能性があります。
影響を受ける各オブジェクトについて、最新のサポートされるAPIを使用して取得し、最新のサポートされるAPIを使用して再書き込みします。
新しいKubernetesバージョンへのアップグレードにより、新しいAPIが提供されることがあります。
異なるAPIバージョン間でマニフェストを変換するためにkubectl convertコマンドを使用できます。例えば:
kubectl convert -f pod.yaml --output-version v1
kubectlツールはpod.yamlの内容を、kindがPod(変更なし)で、apiVersionが改訂されたマニフェストに置き換えます。
クラスターがデバイスプラグインを実行しており、ノードを新しいデバイスプラグインAPIバージョンを含むKubernetesリリースにアップグレードする必要がある場合、デバイスプラグインをアップグレードして両方のバージョンをサポートする必要があります。これにより、アップグレード中にデバイスの割り当てが正常に完了し続けることが保証されます。
詳細については、API互換性およびkubeletのデバイスマネージャーAPIバージョンを参照してください。
このページでは、ガベージコレクション中にクラスターで使用するカスケード削除のタイプを指定する方法を示します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
また、さまざまな種類のカスケード削除を試すために、サンプルのDeploymentを作成する必要があります。 タイプごとにDeploymentを再作成する必要があります。
PodにownerReferencesフィールドが存在することを確認します:
kubectl get pods -l app=nginx --output=yaml
出力には、次のようにownerReferencesフィールドがあります。
apiVersion: v1
...
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: nginx-deployment-6b474476c4
uid: 4fdcd81c-bd5d-41f7-97af-3a3b759af9a7
...
デフォルトでは、Kubernetesはバックグラウンドカスケード削除を使用して、オブジェクトの依存関係を削除します。
クラスターが動作しているKubernetesのバージョンに応じて、kubectlまたはKubernetes APIのいずれかを使用して、フォアグラウンドカスケード削除に切り替えることができます。
バージョンを確認するには次のコマンドを実行してください: kubectl version.
kubectlまたはKubernetes APIを使用して、フォアグラウンドカスケード削除を使用してオブジェクトを削除することができます。
kubectlを使用する
以下のコマンドを実行してください:
kubectl delete deployment nginx-deployment --cascade=foreground
Kubernetes APIを使用する
ローカルプロキシセッションを開始します:
kubectl proxy --port=8080
削除のトリガーとしてcurlを使用します:
curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \
-d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Foreground"}' \
-H "Content-Type: application/json"
出力には、次のようにforegroundDeletionファイナライザーが含まれています。
"kind": "Deployment",
"apiVersion": "apps/v1",
"metadata": {
"name": "nginx-deployment",
"namespace": "default",
"uid": "d1ce1b02-cae8-4288-8a53-30e84d8fa505",
"resourceVersion": "1363097",
"creationTimestamp": "2021-07-08T20:24:37Z",
"deletionTimestamp": "2021-07-08T20:27:39Z",
"finalizers": [
"foregroundDeletion"
]
...
kubectlまたはKubernetes APIのいずれかを使用してDeploymentを削除します。
バージョンを確認するには次のコマンドを実行してください: kubectl version.kubectlまたはKubernetes APIを使用して、バックグラウンドカスケード削除を使用してオブジェクトを削除できます。
Kubernetesはデフォルトでバックグラウンドカスケード削除を使用し、--cascadeフラグまたはpropagationPolicy引数なしで以下のコマンドを実行した場合も同様です。
kubectlを使用する
以下のコマンドを実行してください:
kubectl delete deployment nginx-deployment --cascade=background
Kubernetes APIを使用する
ローカルプロキシセッションを開始します:
kubectl proxy --port=8080
削除のトリガーとしてcurlを使用します:
curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \
-d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Background"}' \
-H "Content-Type: application/json"
出力は、次のようになります。
"kind": "Status",
"apiVersion": "v1",
...
"status": "Success",
"details": {
"name": "nginx-deployment",
"group": "apps",
"kind": "deployments",
"uid": "cc9eefb9-2d49-4445-b1c1-d261c9396456"
}
デフォルトでは、Kubernetesにオブジェクトの削除を指示すると、コントローラーは従属オブジェクトも削除します。クラスターが動作しているKubernetesのバージョンに応じて、kubectlまたはKubernetes APIを使用して、これらの従属オブジェクトをKubernetesでorphanにすることができます。
バージョンを確認するには次のコマンドを実行してください: kubectl version.
kubectlを使用する
以下のコマンドを実行してください:
kubectl delete deployment nginx-deployment --cascade=orphan
Kubernetes APIを使用する
ローカルプロキシセッションを開始します:
kubectl proxy --port=8080
削除のトリガーとしてcurlを使用します:
curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \
-d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Orphan"}' \
-H "Content-Type: application/json"
出力には、次のようにfinalizersフィールドにorphanが含まれます。
"kind": "Deployment",
"apiVersion": "apps/v1",
"namespace": "default",
"uid": "6f577034-42a0-479d-be21-78018c466f1f",
"creationTimestamp": "2021-07-09T16:46:37Z",
"deletionTimestamp": "2021-07-09T16:47:08Z",
"deletionGracePeriodSeconds": 0,
"finalizers": [
"orphan"
],
...
Deploymentによって管理されているPodがまだ実行中であることを確認できます。
kubectl get pods -l app=nginx
このページでは、CoreDNSのアップグレードプロセスと、kube-dnsの代わりにCoreDNSをインストールする方法を説明します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.9. バージョンを確認するには次のコマンドを実行してください:kubectl version.CoreDNSは、KubernetesクラスターDNSとして稼働させることができる柔軟で拡張可能なDNSサーバーです。Kubernetesと同様に、CoreDNSプロジェクトはCNCFによってホストされています。
既存のデプロイでkube-dnsを置き換えるか、クラスターのデプロイとアップグレードを代行してくれるkubeadmのようなツールを使用することで、クラスターでkube-dnsの代わりにCoreDNSを使用することができます。
kube-dnsの手動デプロイや置き換えについては、CoreDNS websiteのドキュメントを参照してください。
Kubernetesバージョン1.21でkubeadmはDNSアプリケーションとしてのkube-dnsに対するサポートを削除しました。
kubeadm v1.32に対してサポートされるクラスターDNSアプリケーションはCoreDNSのみです。
kube-dnsを使用しているクラスターをkubeadmを使用してアップグレードするときに、CoreDNSに移行することができます。
この場合、kubeadmは、kube-dns ConfigMapをベースにしてCoreDNS設定("Corefile")を生成し、スタブドメインおよび上流のネームサーバーの設定を保持します。
KubernetesのバージョンごとにkubeadmがインストールするCoreDNSのバージョンは、KubernetesにおけるCoreDNSのバージョンのページで確認することができます。
CoreDNSのみをアップグレードしたい場合や、独自のカスタムイメージを使用したい場合は、CoreDNSを手動でアップグレードすることができます。
スムーズなアップグレードのために役立つガイドラインとウォークスルーが用意されています。
クラスターをアップグレードする際には、既存のCoreDNS設定("Corefile")が保持されていることを確認してください。
kubeadmツールを使用してクラスターをアップグレードしている場合、kubeadmは既存のCoreDNSの設定を自動的に保持する処理を行うことができます。
リソース使用率が問題になる場合は、CoreDNSの設定を調整すると役立つ場合があります。 詳細は、CoreDNSのスケーリングに関するドキュメントを参照してください。
CoreDNSは、設定("Corefile")を変更することで、kube-dnsよりも多くのユースケースをサポートする構成にすることができます。
詳細はKubernetes CoreDNSプラグインのドキュメントを参照するか、CoreDNSブログを参照してください。
Kubernetes v1.18 [stable]Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.NodeLocal DNSキャッシュは、クラスターノード上でDNSキャッシュエージェントをDaemonSetで稼働させることで、クラスターのDNSパフォーマンスを向上させます。現在のアーキテクチャにおいて、ClusterFirstのDNSモードでのPodは、DNSクエリー用にkube-dnsのService IPに疎通します。これにより、kube-proxyによって追加されたiptablesを介してkube-dns/CoreDNSのエンドポイントへ変換されます。この新しいアーキテクチャによって、Podは同じノード上で稼働するDNSキャッシュエージェントに対して疎通し、それによってiptablesのDNATルールとコネクショントラッキングを回避します。ローカルのキャッシュエージェントはクラスターのホスト名(デフォルトではcluster.localというサフィックス)に対するキャッシュミスがあるときはkube-dnsサービスへ問い合わせます。
現在のDNSアーキテクチャでは、ローカルのkube-dns/CoreDNSがないとき、DNSへの秒間クエリー数が最も高いPodは他のノードへ疎通する可能性があります。ローカルでキャッシュを持つことにより、この状況におけるレイテンシーの改善に役立ちます。
iptables DNATとコネクショントラッキングをスキップすることはconntrackの競合を減らし、UDPでのDNSエントリーがconntrackテーブルを満杯にすることを避けるのに役立ちます。
ローカルのキャッシュエージェントからkube-dnsサービスへの接続がTCPにアップグレードされます。タイムアウトをしなくてはならないUDPエントリーと比べ、TCPのconntrackエントリーはコネクションクローズ時に削除されます(デフォルトの nf_conntrack_udp_timeout は30秒です)。
DNSクエリーをUDPからTCPにアップグレードすることで、UDPパケットの欠損や、通常30秒(10秒のタイムアウトで3回再試行する)であるDNSのタイムアウトによるテイルレイテンシーを減少させます。NodeLocalキャッシュはUDPのDNSクエリーを待ち受けるため、アプリケーションを変更する必要はありません。
DNSクエリーに対するノードレベルのメトリクスと可視性を得られます。
DNSの不在応答のキャッシュも再度有効にされ、それによりkube-dnsサービスに対するクエリー数を減らします。
この図はNodeLocal DNSキャッシュが有効にされた後にDNSクエリーがあったときの流れとなります。

この図は、NodeLocal DNSキャッシュがDNSクエリーをどう扱うかを表したものです。
この機能は、下記の手順により有効化できます。
nodelocaldns.yamlと同様のマニフェストを用意し、nodelocaldns.yamlという名前で保存してください。
マニフェスト内の変数を正しい値に置き換えてください。
kubedns=kubectl get svc kube-dns -n kube-system -o jsonpath={.spec.clusterIP}
domain=<cluster-domain>
localdns=<node-local-address>
<cluster-domain>はデフォルトで"cluster.local"です。<node-local-address> はNodeLocal DNSキャッシュ用に確保されたローカルの待ち受けIPアドレスです。
kube-proxyがIPTABLESモードで稼働中のとき:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/__PILLAR__DNS__SERVER__/$kubedns/g" nodelocaldns.yaml
__PILLAR__CLUSTER__DNS__と__PILLAR__UPSTREAM__SERVERS__はnode-local-dnsというPodによって生成されます。
このモードでは、node-local-dns Podは<node-local-address>とkube-dnsのサービスIPの両方で待ち受けるため、PodはIPアドレスでもDNSレコードのルップアップができます。
kube-proxyがIPVSモードで稼働中のとき:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/__PILLAR__DNS__SERVER__//g; s/__PILLAR__CLUSTER__DNS__/$kubedns/g" nodelocaldns.yaml
このモードでは、node-local-dns Podは<node-local-address>上のみで待ち受けます。node-local-dnsのインターフェースはkube-dnsのクラスターIPをバインドしません。なぜならばIPVSロードバランシング用に使われているインターフェースは既にこのアドレスを使用しているためです。
__PILLAR__UPSTREAM__SERVERS__ はnode-local-dns Podにより生成されます。
kubectl create -f nodelocaldns.yamlを実行してください。
kube-proxyをIPVSモードで使用しているとき、NodeLocal DNSキャッシュが待ち受けている<node-local-address>を使用するため、kubeletに対する--cluster-dnsフラグを修正する必要があります。IPVSモード以外のとき、--cluster-dnsフラグの値を修正する必要はありません。なぜならNodeLocal DNSキャッシュはkube-dnsのサービスIPと<node-local-address>の両方で待ち受けているためです。
一度有効にすると、クラスターの各Node上で、kube-systemという名前空間でnode-local-dns Podが、稼働します。このPodはCoreDNSをキャッシュモードで稼働させるため、異なるプラグインによって公開された全てのCoreDNSのメトリクスがNode単位で利用可能となります。
kubectl delete -f <manifest>を実行してDaemonSetを削除することによって、この機能を無効にできます。また、kubeletの設定に対して行った全ての変更をリバートすべきです。
このページはKubernetesのEndpointSliceの有効化の概要を説明します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.EndpointSliceは、KubernetesのEndpointsに対してスケーラブルで拡張可能な代替手段を提供します。Endpointsが提供する機能のベースの上に構築し、スケーラブルな方法で拡張します。Serviceが多数(100以上)のネットワークエンドポイントを持つ場合、それらは単一の大きなEndpointsリソースではなく、複数の小さなEndpointSliceに分割されます。
Kubernetes v1.17 [beta]EndpoitSliceはベータ版の機能です。APIとEndpointSliceコントローラーはデフォルトで有効です。kube-proxyはデフォルトでEndpointSliceではなくEndpointsを使用します。
スケーラビリティと性能向上のため、kube-proxy上でEndpointSliceProxyingフィーチャーゲートを有効にできます。この変更はデータソースをEndpointSliceに移します、これはkube-proxyとKubernetes API間のトラフィックの量を削減します。
クラスター内でEndpointSliceを完全に有効にすると、各Endpointsリソースに対応するEndpointSliceリソースが表示されます。既存のEndpointsの機能をサポートすることに加えて、EndpointSliceはトポロジーなどの新しい情報を含みます。これらにより、クラスター内のネットワークエンドポイントのスケーラビリティと拡張性が大きく向上します。
このページでは、メモリーの 要求 と 制限 をコンテナに割り当てる方法について示します。コンテナは要求されたメモリーを確保することを保証しますが、その制限を超えるメモリーの使用は許可されません。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.クラスターの各ノードには、少なくとも300MiBのメモリーが必要になります。
このページのいくつかの手順では、クラスターにてmetrics-serverサービスを実行する必要があります。すでにmetrics-serverが動作している場合、これらの手順をスキップできます。
Minikubeを動作させている場合、以下のコマンドによりmetrics-serverを有効にできます:
minikube addons enable metrics-server
metrics-serverが実行されているか、もしくはリソースメトリクスAPI (metrics.k8s.io) の別のプロバイダが実行されていることを確認するには、以下のコマンドを実行してください:
kubectl get apiservices
リソースメトリクスAPIが利用可能であれば、出力には metrics.k8s.io への参照が含まれます。
NAME
v1beta1.metrics.k8s.io
この練習で作成するリソースがクラスター内で分離されるよう、namespaceを作成します。
kubectl create namespace mem-example
コンテナにメモリーの要求を指定するには、コンテナのリソースマニフェストにresources:requestsフィールドを追記します。メモリーの制限を指定するには、resources:limitsを追記します。
この練習では、一つのコンテナをもつPodを作成します。コンテナに100MiBのメモリー要求と200MiBのメモリー制限を与えます。Podの設定ファイルは次のようになります:
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: mem-example
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
設定ファイルのargsセクションでは、コンテナ起動時の引数を与えます。"--vm-bytes", "150M"という引数では、コンテナに150MiBのメモリーを割り当てます。
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/resource/memory-request-limit.yaml --namespace=mem-example
Podのコンテナが起動していることを検証してください:
kubectl get pod memory-demo --namespace=mem-example
Podの詳細な情報を確認してください:
kubectl get pod memory-demo --output=yaml --namespace=mem-example
この出力では、Pod内の一つのコンテナに100MiBのメモリー要求と200MiBのメモリー制限があることを示しています。
...
resources:
limits:
memory: 200Mi
requests:
memory: 100Mi
...
kubectl topを実行し、Podのメトリクスを取得してください:
kubectl top pod memory-demo --namespace=mem-example
この出力では、Podが約162,900,000バイト(約150MiB)のメモリーを使用していることを示しています。Podの100MiBの要求を超えていますが、200MiBの制限には収まっています。
NAME CPU(cores) MEMORY(bytes)
memory-demo <something> 162856960
Podを削除してください:
kubectl delete pod memory-demo --namespace=mem-example
ノードに利用可能なメモリーがある場合、コンテナはメモリー要求を超えることができます。しかしながら、メモリー制限を超えて使用することは許可されません。コンテナが制限を超えてメモリーを確保しようとした場合、そのコンテナは終了候補となります。コンテナが制限を超えてメモリーを消費し続ける場合、コンテナは終了されます。終了したコンテナを再起動できる場合、ほかのランタイムの失敗時と同様に、kubeletがコンテナを再起動させます。
この練習では、制限を超えてメモリーを確保しようとするPodを作成します。以下に50MiBのメモリー要求と100MiBのメモリー制限を与えたコンテナを持つ、Podの設定ファイルを示します:
apiVersion: v1
kind: Pod
metadata:
name: memory-demo-2
namespace: mem-example
spec:
containers:
- name: memory-demo-2-ctr
image: polinux/stress
resources:
requests:
memory: "50Mi"
limits:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "250M", "--vm-hang", "1"]
設定ファイルのargsセクションでは、コンテナに250MiBのメモリーを割り当てており、これは100MiBの制限を十分に超えています。
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/resource/memory-request-limit-2.yaml --namespace=mem-example
Podの詳細な情報を確認してください:
kubectl get pod memory-demo-2 --namespace=mem-example
この時点で、コンテナは起動中か強制終了されているでしょう。コンテナが強制終了されるまで上記のコマンドをくり返し実行してください:
NAME READY STATUS RESTARTS AGE
memory-demo-2 0/1 OOMKilled 1 24s
コンテナステータスの詳細な情報を取得してください:
kubectl get pod memory-demo-2 --output=yaml --namespace=mem-example
この出力では、コンテナがメモリー不足 (OOM) により強制終了されたことを示しています。
lastState:
terminated:
containerID: docker://65183c1877aaec2e8427bc95609cc52677a454b56fcb24340dbd22917c23b10f
exitCode: 137
finishedAt: 2017-06-20T20:52:19Z
reason: OOMKilled
startedAt: null
この練習のコンテナはkubeletによって再起動されます。次のコマンドを数回くり返し実行し、コンテナが強制終了と再起動を続けていることを確認してください:
kubectl get pod memory-demo-2 --namespace=mem-example
この出力では、コンテナが強制終了され、再起動され、再度強制終了および再起動が続いていることを示しています:
kubectl get pod memory-demo-2 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-2 0/1 OOMKilled 1 37s
kubectl get pod memory-demo-2 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-2 1/1 Running 2 40s
Podの履歴について詳細な情報を確認してください:
kubectl describe pod memory-demo-2 --namespace=mem-example
この出力では、コンテナの開始とその失敗が繰り返されていることを示しています:
... Normal Created Created container with id 66a3a20aa7980e61be4922780bf9d24d1a1d8b7395c09861225b0eba1b1f8511
... Warning BackOff Back-off restarting failed container
クラスターのノードの詳細な情報を確認してください:
kubectl describe nodes
この出力には、メモリー不足の状態のためコンテナが強制終了された記録が含まれます:
Warning OOMKilling Memory cgroup out of memory: Kill process 4481 (stress) score 1994 or sacrifice child
Podを削除してください:
kubectl delete pod memory-demo-2 --namespace=mem-example
メモリー要求と制限はコンテナと関連づけられていますが、Podにメモリー要求と制限が与えられていると考えるとわかりやすいでしょう。Podのメモリー要求は、Pod内のすべてのコンテナのメモリー要求の合計となります。同様に、Podのメモリー制限は、Pod内のすべてのコンテナのメモリー制限の合計となります。
Podのスケジューリングは要求に基づいています。Podはノード上で動作するうえで、そのメモリー要求に対してノードに十分利用可能なメモリーがある場合のみスケジュールされます。
この練習では、クラスター内のノードのキャパシティを超える大きさのメモリー要求を与えたPodを作成します。以下に1000GiBのメモリー要求を与えた一つのコンテナを持つ、Podの設定ファイルを示します。これは、クラスター内のノードのキャパシティを超える可能性があります。
apiVersion: v1
kind: Pod
metadata:
name: memory-demo-3
namespace: mem-example
spec:
containers:
- name: memory-demo-3-ctr
image: polinux/stress
resources:
limits:
memory: "1000Gi"
requests:
memory: "1000Gi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/resource/memory-request-limit-3.yaml --namespace=mem-example
Podの状態を確認してください:
kubectl get pod memory-demo-3 --namespace=mem-example
この出力では、Podのステータスが待機中であることを示しています。つまり、Podがどのノードに対しても実行するようスケジュールされておらず、いつまでも待機状態のままであることを表しています:
kubectl get pod memory-demo-3 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-3 0/1 Pending 0 25s
イベントを含むPodの詳細な情報を確認してください:
kubectl describe pod memory-demo-3 --namespace=mem-example
この出力では、ノードのメモリー不足のためコンテナがスケジュールされないことを示しています:
Events:
... Reason Message
------ -------
... FailedScheduling No nodes are available that match all of the following predicates:: Insufficient memory (3).
メモリーリソースはバイト単位で示されます。メモリーをE、P、T、G、M、K、Ei、Pi、Ti、Gi、Mi、Kiという接尾辞とともに、整数型または固定小数点整数で表現できます。たとえば、以下はおおよそ同じ値を表します:
128974848, 129e6, 129M , 123Mi
Podを削除してください:
kubectl delete pod memory-demo-3 --namespace=mem-example
コンテナのメモリー制限を指定しない場合、次のいずれかの状態となります:
コンテナのメモリー使用量に上限がない状態となります。コンテナは実行中のノードで利用可能なすべてのメモリーを使用でき、その後OOM Killerが呼び出される可能性があります。さらに、OOM killの場合、リソース制限のないコンテナは強制終了される可能性が高くなります。
メモリー制限を与えられたnamespaceでコンテナを実行されると、コンテナにはデフォルトの制限値が自動的に指定されます。クラスターの管理者はLimitRangeによってメモリー制限のデフォルト値を指定できます。
クラスターで動作するコンテナにメモリー要求と制限を設定することで、クラスターのノードで利用可能なメモリーリソースを効率的に使用することができます。Podのメモリー要求を低く保つことで、Podがスケジュールされやすくなります。メモリー要求よりも大きい制限を与えることで、次の2つを実現できます:
namespaceを削除してください。これにより、今回のタスクで作成したすべてのPodが削除されます:
kubectl delete namespace mem-example
このページでは、CPUの request と limit をコンテナに割り当てる方法について示します。コンテナは設定された制限を超えてCPUを使用することはできません。システムにCPUの空き時間がある場合、コンテナには要求されたCPUを割り当てられます。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.タスク例を実行するには、クラスターに少なくとも利用可能な1 CPUが必要です。
このページのいくつかの手順では、クラスターにてmetrics-serverサービスを実行する必要があります。すでにmetrics-serverが動作している場合、これらの手順をスキップできます。
Minikubeを動作させている場合、以下のコマンドによりmetrics-serverを有効にできます:
minikube addons enable metrics-server
metrics-serverが実行されているか、もしくはリソースメトリクスAPI (metrics.k8s.io) の別のプロバイダーが実行されていることを確認するには、以下のコマンドを実行してください:
kubectl get apiservices
リソースメトリクスAPIが利用可能であれば、出力には metrics.k8s.io への参照が含まれます。
NAME
v1beta1.metrics.k8s.io
この練習で作成するリソースがクラスター内で分離されるよう、Namespaceを作成します。
kubectl create namespace cpu-example
コンテナにCPUの要求を指定するには、コンテナのリソースマニフェストにresources:requestsフィールドを追記します。CPUの制限を指定するには、resources:limitsを追記します。
この練習では、一つのコンテナをもつPodを作成します。コンテナに0.5 CPUの要求と1 CPUの制限を与えます。Podの設定ファイルは次のようになります:
apiVersion: v1
kind: Pod
metadata:
name: cpu-demo
namespace: cpu-example
spec:
containers:
- name: cpu-demo-ctr
image: vish/stress
resources:
limits:
cpu: "1"
requests:
cpu: "0.5"
args:
- -cpus
- "2"
設定ファイルのargsセクションでは、コンテナ起動時の引数を与えます。-cpus "2"という引数では、コンテナに2 CPUを割り当てます。
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/resource/cpu-request-limit.yaml --namespace=cpu-example
Podのコンテナが起動していることを検証してください:
kubectl get pod cpu-demo --namespace=cpu-example
Podの詳細な情報を確認してください:
kubectl get pod cpu-demo --output=yaml --namespace=cpu-example
この出力では、Pod内の一つのコンテナに500ミリCPUの要求と1 CPUの制限があることを示しています。
resources:
limits:
cpu: "1"
requests:
cpu: 500m
kubectl topを実行し、Podのメトリクスを取得してください:
kubectl top pod cpu-demo --namespace=cpu-example
この出力では、Podが974ミリCPUを使用していることを示しています。Podの設定で指定した1 CPUの制限よりわずかに小さい値です。
NAME CPU(cores) MEMORY(bytes)
cpu-demo 974m <something>
-cpu "2"を設定することで、コンテナが2 CPU利用しようとすることを思い出してください。しかしながら、コンテナは約1 CPUしか使用することができません。コンテナが制限よりも多くのCPUリソースを利用しようとしているため、コンテナのCPUの利用が抑制されています。
CPUリソースは CPU の単位で示されます。Kubernetesにおいて1つのCPUは次に等しくなります:
小数値も利用可能です。0.5 CPUを要求するコンテナには、1 CPUを要求するコンテナの半分のCPUが与えられます。mというミリを表す接尾辞も使用できます。たとえば、100m CPU、100 milliCPU、0.1 CPUはすべて同じです。1m以上の精度は指定できません。
CPUはつねに絶対量として要求され、決して相対量としては要求されません。0.1はシングルコア、デュアルコア、48コアCPUのマシンで同じ量となります。
Podを削除してください:
kubectl delete pod cpu-demo --namespace=cpu-example
CPU要求と制限はコンテナと関連づけられていますが、PodにCPU要求と制限が与えられていると考えるとわかりやすいでしょう。PodのCPU要求は、Pod内のすべてのコンテナのCPU要求の合計となります。同様に、PodのCPU制限は、Pod内のすべてのコンテナのCPU制限の合計となります。
Podのスケジューリングはリソースの要求量に基づいています。Podはノード上で動作するうえで、そのCPU要求に対してノードに十分利用可能なCPUリソースがある場合のみスケジュールされます。
この練習では、クラスター内のノードのキャパシティを超える大きさのCPU要求を与えたPodを作成します。以下に100 CPUの要求を与えた一つのコンテナを持つ、Podの設定ファイルを示します。これは、クラスター内のノードのキャパシティを超える可能性があります。
apiVersion: v1
kind: Pod
metadata:
name: cpu-demo-2
namespace: cpu-example
spec:
containers:
- name: cpu-demo-ctr-2
image: vish/stress
resources:
limits:
cpu: "100"
requests:
cpu: "100"
args:
- -cpus
- "2"
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/resource/cpu-request-limit-2.yaml --namespace=cpu-example
Podの状態を確認してください:
kubectl get pod cpu-demo-2 --namespace=cpu-example
この出力では、Podのステータスが待機中であることを示しています。つまり、Podがどのノードに対しても実行するようスケジュールされておらず、いつまでも待機状態のままであることを表しています:
NAME READY STATUS RESTARTS AGE
cpu-demo-2 0/1 Pending 0 7m
イベントを含むPodの詳細な情報を確認してください:
kubectl describe pod cpu-demo-2 --namespace=cpu-example
この出力では、ノードのCPU不足のためコンテナがスケジュールされないことを示しています:
Events:
Reason Message
------ -------
FailedScheduling No nodes are available that match all of the following predicates:: Insufficient cpu (3).
Podを削除してください:
kubectl delete pod cpu-demo-2 --namespace=cpu-example
コンテナのCPU制限を指定しない場合、次のいずれかの状態となります:
コンテナのCPUリソースの使用量に上限がない状態となります。コンテナは実行中のノードで利用可能なすべてのCPUを使用できます。
CPU制限を与えられたnamespaceでコンテナを実行されると、コンテナにはデフォルトの制限値が自動的に指定されます。クラスターの管理者はLimitRangeによってCPU制限のデフォルト値を指定できます。
クラスターで動作するコンテナにCPU要求と制限を設定することで、クラスターのノードで利用可能なCPUリソースを効率的に使用することができます。PodのCPU要求を低く保つことで、Podがスケジュールされやすくなります。CPU要求よりも大きい制限を与えることで、次の2つを実現できます:
namespaceを削除してください:
kubectl delete namespace cpu-example
Kubernetes v1.18 [stable]このページでは、Windowsノード上で動作するPodとコンテナに対するグループ管理サービスアカウント(GMSA)の設定方法を示します。 グループ管理サービスアカウントは特別な種類のActive Directoryアカウントで、パスワードの自動管理、簡略化されたサービスプリンシパル名(SPN)の管理、および管理を他の管理者に委任する機能を複数のサーバーに提供します。
Kubernetesでは、GMSA資格情報仕様は、Kubernetesクラスター全体をスコープとするカスタムリソースとして設定されます。 WindowsのPodおよびPod内の個々のコンテナは、他のWindowsサービスとやり取りする際に、ドメインベースの機能(例えばKerberos認証)に対してGMSAを使用するように設定できます。
Kubernetesクラスターが必要で、kubectlコマンドラインツールがクラスターと通信できるように設定されている必要があります。
クラスターにはWindowsワーカーノードを持つことが求められます。
このセクションでは、各クラスターに対して一度だけ実施する必要がある一連の初期ステップについて説明します:
カスタムリソースタイプGMSACredentialSpecを定義するために、GMSA資格情報仕様リソースに対するCustomResourceDefinition(CRD)をクラスター上で設定する必要があります。
GMSA CRDのYAMLをダウンロードし、gmsa-crd.yamlとして保存します。
次に、kubectl apply -f gmsa-crd.yamlを実行してCRDをインストールします。
Podまたはコンテナレベルで参照するGMSA資格情報仕様を追加および検証するために、Kubernetesクラスター上で2つのWebhookを設定する必要があります:
Mutating Webhookは、(Podの仕様から名前で指定された)GMSAへの参照を、JSON形式の完全な資格情報仕様としてPodのspecの中へ展開します。
Validating Webhookは、すべてのGMSAへの参照に対して、Podサービスアカウントによる利用が認可されているか確認します。
上記Webhookと関連するオブジェクトをインストールするためには、次の手順が必要です:
証明書と鍵のペアを作成します(Webhookコンテナがクラスターと通信できるようにするために使用されます)
上記の証明書を含むSecretをインストールします。
コアとなるWebhookロジックのためのDeploymentを作成します。
Deploymentを参照するValidating WebhookとMutating Webhookの設定を作成します。
上で述べたGMSA Webhookと関連するオブジェクトを展開、構成するためのスクリプトがあります。
スクリプトは、--dry-run=serverオプションをつけることで、クラスターに対して行われる変更内容をレビューすることができます。
Webhookと関連するオプジェクトを(適切なパラメーターを渡すことで)手動で展開するためのYAMLテンプレートもあります。
Windows GMSAのドキュメントに記載されている通り、Kubernetes内のPodがGMSAを使用するために設定できるようにする前に、Active Directory内に目的のGMSAを展開する必要があります。 Windows GMSAのドキュメントに記載されている通り、(Kubernetesクラスターの一部である)Windowsワーカーノードは、目的のGMSAに関連づけられたシークレット資格情報にアクセスできるように、Active Directory内で設定されている必要があります。
(前述の通り)GMSACredentialSpec CRDをインストールすると、GMSA資格情報仕様を含むカスタムリソースを設定できます。 GMSA資格情報仕様には、シークレットや機密データは含まれません。 それは、コンテナランタイムが目的のコンテナのGMSAをWindowsに対して記述するために使用できる情報です。 GMSA資格情報仕様は、PowerShellスクリプトのユーティリティを使用して、YAMLフォーマットで生成することができます。
以下は、GMSA資格情報仕様をJSON形式で手動で生成し、その後それをYAMLに変換する手順です:
CredentialSpecモジュールをインポートします: ipmo CredentialSpec.psm1
New-CredentialSpecを使用してJSONフォーマットの資格情報仕様を作成します。
WebApp1という名前のGMSA資格情報仕様を作成するには、New-CredentialSpec -Name WebApp1 -AccountName WebApp1 -Domain $(Get-ADDomain -Current LocalComputer)を実行します
Get-CredentialSpecを使用して、JSONファイルのパスを表示します。
credspecファイルをJSON形式からYAML形式に変換し、Kubernetesで設定可能なGMSACredentialSpecカスタムリソースにするために、必要なヘッダーフィールドであるapiVersion、kind、metadata、credspecを記述します。
次のYAML設定は、gmsa-WebApp1という名前のGMSA資格情報仕様を記述しています:
apiVersion: windows.k8s.io/v1
kind: GMSACredentialSpec
metadata:
name: gmsa-WebApp1 # これは任意の名前で構いませんが、参照時に使用されます
credspec:
ActiveDirectoryConfig:
GroupManagedServiceAccounts:
- Name: WebApp1 # GMSAアカウントのユーザー名
Scope: CONTOSO # NETBIOSドメイン名
- Name: WebApp1 # GMSAアカウントのユーザー名
Scope: contoso.com # DNSドメイン名
CmsPlugins:
- ActiveDirectory
DomainJoinConfig:
DnsName: contoso.com # DNSドメイン名
DnsTreeName: contoso.com # DNSルートドメイン名
Guid: 244818ae-87ac-4fcd-92ec-e79e5252348a # GUID
MachineAccountName: WebApp1 # GMSAアカウントのユーザー名
NetBiosName: CONTOSO # NETBIOSドメイン名
Sid: S-1-5-21-2126449477-2524075714-3094792973 # GMSAのSID
上記の資格情報仕様リソースはgmsa-Webapp1-credspec.yamlとして保存され、次のコマンドを使用してクラスターに適用されます: kubectl apply -f gmsa-Webapp1-credspec.yml
各GMSA資格情報仕様リソースに対して、クラスターロールを定義する必要があります。
これは特定のGMSAリソース上のuse verbを、通常はサービスアカウントであるsubjectに対して認可します。
次の例は、前述のgmsa-WebApp1資格情報仕様の利用を認可するクラスターロールを示しています。
ファイルをgmsa-webapp1-role.yamlとして保存し、kubectl apply -f gmsa-webapp1-role.yamlを使用して適用します。
# credspecを読むためのロールを作成
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: webapp1-role
rules:
- apiGroups: ["windows.k8s.io"]
resources: ["gmsacredentialspecs"]
verbs: ["use"]
resourceNames: ["gmsa-WebApp1"]
(Podに対して設定される)サービスアカウントを、上で作成したクラスターロールに結びつける必要があります。
これによって、要求されたGMSA資格情報仕様のリソースの利用をサービスアカウントに対して認可できます。
以下は、上で作成した資格情報仕様リソースgmsa-WebApp1を使うために、既定のサービスアカウントに対してクラスターロールwebapp1-roleを割り当てる方法を示しています。
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: allow-default-svc-account-read-on-gmsa-WebApp1
namespace: default
subjects:
- kind: ServiceAccount
name: default
namespace: default
roleRef:
kind: ClusterRole
name: webapp1-role
apiGroup: rbac.authorization.k8s.io
PodのspecのフィールドsecurityContext.windowsOptions.gmsaCredentialSpecNameは、要求されたGMSA資格情報仕様のカスタムリソースに対する参照を、Podのspec内で指定するために使用されます。
これは、Podのspec内の全てのコンテナに対して、指定されたGMSAを使用するように設定します。
gmsa-WebApp1を参照するために追加された注釈を持つPodのspecのサンプルです:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: with-creds
name: with-creds
namespace: default
spec:
replicas: 1
selector:
matchLabels:
run: with-creds
template:
metadata:
labels:
run: with-creds
spec:
securityContext:
windowsOptions:
gmsaCredentialSpecName: gmsa-webapp1
containers:
- image: mcr.microsoft.com/windows/servercore/iis:windowsservercore-ltsc2019
imagePullPolicy: Always
name: iis
nodeSelector:
kubernetes.io/os: windows
Podのspec内の個々のコンテナも、コンテナ毎のsecurityContext.windowsOptions.gmsaCredentialSpecNameフィールドを使用することで、要求されたGMSA credspecを指定することができます。
設定例:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: with-creds
name: with-creds
namespace: default
spec:
replicas: 1
selector:
matchLabels:
run: with-creds
template:
metadata:
labels:
run: with-creds
spec:
containers:
- image: mcr.microsoft.com/windows/servercore/iis:windowsservercore-ltsc2019
imagePullPolicy: Always
name: iis
securityContext:
windowsOptions:
gmsaCredentialSpecName: gmsa-Webapp1
nodeSelector:
kubernetes.io/os: windows
(上記のような)GMSAフィールドが入力されたPod specがクラスターに適用されると、次の一連のイベントが発生します:
Mutating WebhookがGMSA資格情報仕様リソースへの全ての参照を解決し、GMSA資格情報仕様の内容を展開します。
Validating Webhookは、Podに関連付けられたサービスアカウントが、指定されたGMSA資格情報仕様上のuse verbに対して認可されていることを保証します。
コンテナランタイムは、指定されたGMSA資格情報仕様で各Windowsコンテナを設定します。 それによってコンテナはGMSAのIDがActive Directory内にあることを仮定でき、そのIDを使用してドメイン内のサービスにアクセスできます。
PodからSMB共有へのホスト名やFQDNを使用した接続で問題が発生した際に、IPv4アドレスではSMB共有にアクセスすることはできる場合には、次のレジストリキーがWindowsノード上で設定されているか確認してください。
reg add "HKLM\SYSTEM\CurrentControlSet\Services\hns\State" /v EnableCompartmentNamespace /t REG_DWORD /d 1
その後、動作の変更を反映させるために、実行中のPodを再作成する必要があります。 このレジストリキーがどのように使用されるかについてのより詳細な情報は、こちらを参照してください。
自分の環境でGMSAがうまく動作しない時に実行できるトラブルシューティングステップがあります。
まず、credspecがPodに渡されたことを確認します。
そのためには、Podのひとつにexecで入り、nltest.exe /parentdomainコマンドの出力をチェックする必要があります。
以下の例では、Podはcredspecを正しく取得できませんでした:
kubectl exec -it iis-auth-7776966999-n5nzr powershell.exe
nltest.exe /parentdomainの結果は次のようなエラーになります:
Getting parent domain failed: Status = 1722 0x6ba RPC_S_SERVER_UNAVAILABLE
Podが正しくcredspecを取得したら、次にドメインと正しく通信できることを確認します。 まずはPodの中から、ドメインのルートを見つけるために、手短にnslookupを実行します。
これから3つのことがわかります:
DNSと通信のテストをパスしたら、次にPodがドメインとセキュアチャネル通信を構築することができるか確認する必要があります。
そのためには、再びexecを使用してPodの中に入り、nltest.exe /queryコマンドを実行します。
nltest.exe /query
結果は次のように出力されます:
I_NetLogonControl failed: Status = 1722 0x6ba RPC_S_SERVER_UNAVAILABLE
これは、Podがなんらかの理由で、credspec内で指定されたアカウントを使用してドメインにログオンできなかったことを示しています。 次のコマンドを実行してセキュアチャネルを修復してみてください:
nltest /sc_reset:domain.example
コマンドが成功したら、このような出力を確認することができます:
Flags: 30 HAS_IP HAS_TIMESERV
Trusted DC Name \\dc10.domain.example
Trusted DC Connection Status Status = 0 0x0 NERR_Success
The command completed successfully
もし上記によってエラーが解消された場合は、次のライフサイクルフックをPodのspecに追加することで、手順を自動化できます。 エラーが解消されなかった場合は、credspecをもう一度調べ、正しく完全であることを確認する必要があります。
image: registry.domain.example/iis-auth:1809v1
lifecycle:
postStart:
exec:
command: ["powershell.exe","-command","do { Restart-Service -Name netlogon } while ( $($Result = (nltest.exe /query); if ($Result -like '*0x0 NERR_Success*') {return $true} else {return $false}) -eq $false)"]
imagePullPolicy: IfNotPresent
Podのspecに上記のlifecycleセクションを追加すると、nltest.exe /queryコマンドがエラーとならずに終了するまでnetlogonサービスを再起動するために、Podは一連のコマンドを実行します。
このページでは、特定のQuality of Service (QoS)クラスをPodに割り当てるための設定方法を示します。Kubernetesは、Podのスケジューリングおよび退役を決定するためにQoSクラスを用います。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.KubernetesはPodの作成時に次のいずれかのQoSクラスをPodに割り当てます:
この演習で作成するリソースがクラスター内で分離されるよう、namespaceを作成します。
kubectl create namespace qos-example
PodにGuaranteedのQoSクラスを与えるには、以下が必要になります:
以下に1つのコンテナをもつPodの設定ファイルを示します。コンテナには200MiBのメモリー制限とリクエストを与え、700ミリCPUの制限と要求を与えます。
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/qos/qos-pod.yaml --namespace=qos-example
Podの詳細な情報を確認してください:
kubectl get pod qos-demo --namespace=qos-example --output=yaml
この出力では、KubernetesがPodにGuaranteed QoSクラスを与えたことを示しています。Podのコンテナにメモリー制限と一致するメモリー要求があり、CPU制限と一致するCPU要求があることも確認できます。
spec:
containers:
...
resources:
limits:
cpu: 700m
memory: 200Mi
requests:
cpu: 700m
memory: 200Mi
...
status:
qosClass: Guaranteed
Podを削除してください:
kubectl delete pod qos-demo --namespace=qos-example
次のような場合に、Burstable QoSクラスがPodに与えられます:
以下に1つのコンテナをもつPodの設定ファイルを示します。コンテナには200MiBのメモリー制限と100MiBのメモリー要求を与えます。
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-2
namespace: qos-example
spec:
containers:
- name: qos-demo-2-ctr
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/qos/qos-pod-2.yaml --namespace=qos-example
Podの詳細な情報を確認してください:
kubectl get pod qos-demo-2 --namespace=qos-example --output=yaml
この出力では、KubernetesがPodにBurstable QoSクラスを与えたことを示しています。
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: qos-demo-2-ctr
resources:
limits:
memory: 200Mi
requests:
memory: 100Mi
...
status:
qosClass: Burstable
Podを削除してください:
kubectl delete pod qos-demo-2 --namespace=qos-example
PodにBestEffort QoSクラスを与えるには、Pod内のコンテナにはメモリーやCPUの制限や要求を指定してはなりません。
以下に1つのコンテナをもつPodの設定ファイルを示します。コンテナにはメモリーやCPUの制限や要求がありません:
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-3
namespace: qos-example
spec:
containers:
- name: qos-demo-3-ctr
image: nginx
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/qos/qos-pod-3.yaml --namespace=qos-example
Podの詳細な情報を確認してください:
kubectl get pod qos-demo-3 --namespace=qos-example --output=yaml
この出力では、KubernetesがPodにBestEffort QoSクラスを与えたことを示しています。
spec:
containers:
...
resources: {}
...
status:
qosClass: BestEffort
Podを削除してください:
kubectl delete pod qos-demo-3 --namespace=qos-example
以下に2つのコンテナをもつPodの設定ファイルを示します。一方のコンテナは200MiBのメモリー要求を指定し、もう一方のコンテナには要求や制限を指定しません。
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-4
namespace: qos-example
spec:
containers:
- name: qos-demo-4-ctr-1
image: nginx
resources:
requests:
memory: "200Mi"
- name: qos-demo-4-ctr-2
image: redis
このPodがBurstable QoSクラスの基準を満たしていることに注目してください。つまり、Guaranteed QoSクラスの基準に満たしておらず、一方のコンテナにはメモリー要求を与えられています。
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/qos/qos-pod-4.yaml --namespace=qos-example
Podの詳細な情報を確認してください:
kubectl get pod qos-demo-4 --namespace=qos-example --output=yaml
この出力では、KubernetesがPodにBurstable QoSクラスを与えたことを示しています:
spec:
containers:
...
name: qos-demo-4-ctr-1
resources:
requests:
memory: 200Mi
...
name: qos-demo-4-ctr-2
resources: {}
...
status:
qosClass: Burstable
Podを削除してください:
kubectl delete pod qos-demo-4 --namespace=qos-example
namespaceを削除してください:
kubectl delete namespace qos-example
Kubernetes v1.32 [stable]このページでは、拡張リソースをコンテナに割り当てる方法について説明します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.この練習を始める前に、Nodeに拡張リソースをアドバタイズするの練習を行ってください。これにより、Nodeの1つがドングルリソースをアドバタイズするように設定されます。
拡張リソースをリクエストするには、コンテナのマニフェストにresources:requestsフィールドを含めます。拡張リソースは、*.kubernetes.io/以外の任意のドメインで完全修飾されます。有効な拡張リソース名は、example.com/fooという形式になります。ここで、example.comはあなたの組織のドメインで、fooは記述的なリソース名で置き換えます。
1つのコンテナからなるPodの構成ファイルを示します。
apiVersion: v1
kind: Pod
metadata:
name: extended-resource-demo
spec:
containers:
- name: extended-resource-demo-ctr
image: nginx
resources:
requests:
example.com/dongle: 3
limits:
example.com/dongle: 3
構成ファイルでは、コンテナが3つのdongleをリクエストしていることがわかります。
次のコマンドでPodを作成します。
kubectl apply -f https://k8s.io/examples/pods/resource/extended-resource-pod.yaml
Podが起動したことを確認します。
kubectl get pod extended-resource-demo
Podの説明を表示します。
kubectl describe pod extended-resource-demo
dongleのリクエストが表示されます。
Limits:
example.com/dongle: 3
Requests:
example.com/dongle: 3
以下に、1つのコンテナを持つPodの構成ファイルを示します。コンテナは2つのdongleをリクエストします。
apiVersion: v1
kind: Pod
metadata:
name: extended-resource-demo-2
spec:
containers:
- name: extended-resource-demo-2-ctr
image: nginx
resources:
requests:
example.com/dongle: 2
limits:
example.com/dongle: 2
Kubernetesは、2つのdongleのリクエストを満たすことができません。1つ目のPodが、利用可能な4つのdongleのうち3つを使用してしまっているためです。
Podを作成してみます。
kubectl apply -f https://k8s.io/examples/pods/resource/extended-resource-pod-2.yaml
Podの説明を表示します。
kubectl describe pod extended-resource-demo-2
出力にはPodがスケジュールできないことが示されます。2つのdongleが利用できるNodeが存在しないためです。
Conditions:
Type Status
PodScheduled False
...
Events:
...
... Warning FailedScheduling pod (extended-resource-demo-2) failed to fit in any node
fit failure summary on nodes : Insufficient example.com/dongle (1)
Podのステータスを表示します。
kubectl get pod extended-resource-demo-2
出力には、Podは作成されたものの、Nodeにスケジュールされなかったことが示されています。PodはPending状態になっています。
NAME READY STATUS RESTARTS AGE
extended-resource-demo-2 0/1 Pending 0 6m
この練習で作成したPodを削除します。
kubectl delete pod extended-resource-demo
kubectl delete pod extended-resource-demo-2
このページでは、ストレージにボリュームを使用するPodを構成する方法を示します。
コンテナのファイルシステムは、コンテナが存在する間のみ存続します。 そのため、コンテナが終了して再起動すると、ファイルシステムの変更は失われます。 コンテナに依存しない、より一貫したストレージを実現するには、ボリュームを使用できます。 これは、キーバリューストア(Redisなど)やデータベースなどのステートフルアプリケーションにとって特に重要です。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.この演習では、1つのコンテナを実行するPodを作成します。 今回作成するPodには、コンテナが終了して再起動した場合でもPodの寿命が続くemptyDirタイプのボリュームがあります。 これがPodの設定ファイルです:
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: redis-storage
mountPath: /data/redis
volumes:
- name: redis-storage
emptyDir: {}
Podを作成します:
kubectl apply -f https://k8s.io/examples/pods/storage/redis.yaml
Podのコンテナが実行されていることを確認し、Podへの変更を監視します:
kubectl get pod redis --watch
出力は次のようになります:
NAME READY STATUS RESTARTS AGE
redis 1/1 Running 0 13s
別のターミナルで、実行中のコンテナへのシェルを取得します:
kubectl exec -it redis -- /bin/bash
シェルで、/data/redisに移動し、ファイルを作成します:
root@redis:/data# cd /data/redis/
root@redis:/data/redis# echo Hello > test-file
シェルで、実行中のプロセスを一覧表示します:
root@redis:/data/redis# apt-get update
root@redis:/data/redis# apt-get install procps
root@redis:/data/redis# ps aux
出力はこのようになります:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
redis 1 0.1 0.1 33308 3828 ? Ssl 00:46 0:00 redis-server *:6379
root 12 0.0 0.0 20228 3020 ? Ss 00:47 0:00 /bin/bash
root 15 0.0 0.0 17500 2072 ? R+ 00:48 0:00 ps aux
シェルで、Redisプロセスを終了します:
root@redis:/data/redis# kill <pid>
ここで<pid>はRedisプロセスID(PID)です。
元の端末で、Redis Podへの変更を監視します。最終的には、このようなものが表示されます:
NAME READY STATUS RESTARTS AGE
redis 1/1 Running 0 13s
redis 0/1 Completed 0 6m
redis 1/1 Running 1 6m
この時点で、コンテナは終了して再起動しました。
これは、Redis PodのrestartPolicyがAlwaysであるためです。
再起動されたコンテナへのシェルを取得します:
kubectl exec -it redis -- /bin/bash
シェルで/data/redisに移動し、test-fileがまだ存在することを確認します。
root@redis:/data/redis# cd /data/redis/
root@redis:/data/redis# ls
test-file
この演習用に作成したPodを削除します:
kubectl delete pod redis
このページでは、projected(投影)ボリュームを使用して、既存の複数のボリュームソースを同一ディレクトリ内にマウントする方法を説明します。
現在、secret、configMap、downwardAPIおよびserviceAccountTokenボリュームを投影できます。
serviceAccountTokenはボリュームタイプではありません。Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.この課題では、ローカルファイルからユーザーネームおよびパスワードのSecretを作成します。
次に、単一のコンテナを実行するPodを作成し、projectedボリュームを使用してそれぞれのSecretを同じ共有ディレクトリにマウントします。
以下にPodの設定ファイルを示します:
apiVersion: v1
kind: Pod
metadata:
name: test-projected-volume
spec:
containers:
- name: test-projected-volume
image: busybox
args:
- sleep
- "86400"
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: user
- secret:
name: pass
Secretを作成します:
# ユーザーネームおよびパスワードを含むファイルを作成します:
echo -n "admin" > ./username.txt
echo -n "1f2d1e2e67df" > ./password.txt
# これらのファイルからSecretを作成します:
kubectl create secret generic user --from-file=./username.txt
kubectl create secret generic pass --from-file=./password.txt
Podを作成します:
kubectl apply -f https://k8s.io/examples/pods/storage/projected.yaml
Pod内のコンテナが実行されていることを確認するため、Podの変更を監視します:
kubectl get --watch pod test-projected-volume
出力は次のようになります:
NAME READY STATUS RESTARTS AGE
test-projected-volume 1/1 Running 0 14s
別の端末にて、実行中のコンテナへのシェルを取得します:
kubectl exec -it test-projected-volume -- /bin/sh
シェル内にて、投影されたソースを含むprojected-volumeディレクトリが存在することを確認します:
ls /projected-volume/
PodおよびSecretを削除します:
kubectl delete pod test-projected-volume
kubectl delete secret user pass
projectedボリュームについてさらに学ぶセキュリティコンテキストはPod・コンテナの特権やアクセスコントロールの設定を定義します。 セキュリティコンテキストの設定には以下のものが含まれますが、これらに限定はされません。
任意アクセス制御: user ID (UID) と group ID (GID)に基づいて、ファイルなどのオブジェクトに対する許可を行います。
Security Enhanced Linux (SELinux): オブジェクトにセキュリティラベルを付与します。
特権または非特権として実行します。
Linux Capabilities: rootユーザーのすべての特権ではなく、一部の特権をプロセスに与えます。
AppArmor: プロファイルを用いて、個々のプログラムのcapabilityを制限します。
Seccomp: プロセスのシステムコールを限定します。
allowPrivilegeEscalation: あるプロセスが親プロセスよりも多くの特権を得ることができるかを制御します。 この真偽値は、コンテナプロセスに
no_new_privs
フラグが設定されるかどうかを直接制御します。
コンテナが以下の場合、allowPrivilegeEscalationは常にtrueになります。
CAP_SYS_ADMINを持っているreadOnlyRootFilesystem: コンテナのルートファイルシステムが読み取り専用でマウントされます。
上記の項目は全てのセキュリティコンテキスト設定を記載しているわけではありません。 より広範囲なリストはSecurityContextを確認してください。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.Podにセキュリティ設定を行うには、Podの設定にsecurityContextフィールドを追加してください。
securityContextフィールドはPodSecurityContextオブジェクトが入ります。
Podに設定したセキュリティ設定はPod内の全てのコンテナに適用されます。こちらはsecurityContextとemptyDirボリュームを持ったPodの設定ファイルです。
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
supplementalGroups: [4000]
volumes:
- name: sec-ctx-vol
emptyDir: {}
containers:
- name: sec-ctx-demo
image: busybox:1.28
command: [ "sh", "-c", "sleep 1h" ]
volumeMounts:
- name: sec-ctx-vol
mountPath: /data/demo
securityContext:
allowPrivilegeEscalation: false設定ファイルの中のrunAsUserフィールドは、Pod内のコンテナに対して全てのプロセスをユーザーID 1000で実行するように指定します。
runAsGroupフィールドはPod内のコンテナに対して全てのプロセスをプライマリーグループID 3000で実行するように指定します。このフィールドが省略されたときは、コンテナのプライマリーグループIDはroot(0)になります。runAsGroupが指定されている場合、作成されたファイルもユーザー1000とグループ3000の所有物になります。
またfsGroupも指定されているため、全てのコンテナ内のプロセスは補助グループID 2000にも含まれます。/data/demoボリュームとこのボリュームに作成されたファイルはグループID 2000になります。加えて、supplementalGroupsフィールドが指定されている場合、全てのコンテナ内のプロセスは指定されている補助グループIDにも含まれます。もしこのフィールドが指定されていない場合、空を意味します。
Podを作成してみましょう。
kubectl apply -f https://k8s.io/examples/pods/security/security-context.yaml
Podのコンテナが実行されていることを確認します。
kubectl get pod security-context-demo
実行中のコンテナでshellを取ります。
kubectl exec -it security-context-demo -- sh
shellで、実行中のプロセスの一覧を確認します。
ps
runAsUserで指定した値である、ユーザー1000でプロセスが実行されていることが確認できます。
PID USER TIME COMMAND
1 1000 0:00 sleep 1h
6 1000 0:00 sh
...
shellで/dataに入り、ディレクトリの一覧を確認します。
cd /data
ls -l
fsGroupで指定した値であるグループID 2000で/data/demoディレクトリが作成されていることが確認できます。
drwxrwsrwx 2 root 2000 4096 Jun 6 20:08 demo
shellで/data/demoに入り、ファイルを作成します。
cd demo
echo hello > testfile
/data/demoディレクトリでファイルの一覧を確認します。
ls -l
fsGroupで指定した値であるグループID 2000でtestfileが作成されていることが確認できます。
-rw-r--r-- 1 1000 2000 6 Jun 6 20:08 testfile
以下のコマンドを実行してください。
id
出力はこのようになります。
uid=1000 gid=3000 groups=2000,3000,4000
出力からrunAsGroupフィールドと同じくgidが3000になっていることが確認できるでしょう。runAsGroupが省略された場合、gidは0(root)になり、そのプロセスはグループroot(0)とグループroot(0)に必要なグループパーミッションを持つグループが所有しているファイルを操作することができるようになります。また、groupsの出力に、gidに加えて、fsGroups、supplementalGroupsフィールドで指定したグループIDも含まれていることも確認できるでしょう。
shellから抜けましょう。
exit
/etc/groupから暗黙的にマージされるグループ情報Kubernetesは、デフォルトでは、Podで定義された情報に加えて、コンテナイメージ内の/etc/groupのグループ情報をマージします。
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
supplementalGroups: [4000]
containers:
- name: sec-ctx-demo
image: registry.k8s.io/e2e-test-images/agnhost:2.45
command: [ "sh", "-c", "sleep 1h" ]
securityContext:
allowPrivilegeEscalation: false
このPodはsecurity contextでrunAsUser、runAsGroup、supplementalGroupsフィールドが指定されています。しかし、コンテナ内のプロセスには、コンテナイメージ内の/etc/groupに定義されたグループIDが、補助グループとして付与されていることが確認できるでしょう。
Podを作成してみましょう。
kubectl apply -f https://k8s.io/examples/pods/security/security-context-5.yaml
Podのコンテナが実行されていることを確認します。
kubectl get pod security-context-demo
実行中のコンテナでshellを取ります。
kubectl exec -it security-context-demo -- sh
プロセスのユーザー、グループ情報を確認します。
$ id
出力はこのようになります。
uid=1000 gid=3000 groups=3000,4000,50000
groupsにグループID50000が含まれていることが確認できるでしょう。これは、ユーザー(uid=1000)がコンテナイメージで定義されており、コンテナイメージ内の/etc/groupでグループ(gid=50000)に所属しているためです。
コンテナイメージの/etc/groupの内容を確認してみましょう。
$ cat /etc/group
ユーザー1000がグループ50000に所属していることが確認できるでしょう。
...
user-defined-in-image:x:1000:
group-defined-in-image:x:50000:user-defined-in-image
shellから抜けましょう。
exit
Kubernetes v1.31 [alpha] (enabled by default: false)この機能はkubeletとkube-apiseverにSupplementalGroupsPolicy
フィーチャーゲートを設定し、Podの.spec.securityContext.supplementalGroupsPolicyフィールドを指定することで利用できます。
supplementalGroupsPolicyフィールドは、Pod内のコンテナプロセスに付与される補助グループを、どのように決定するかを定義します。有効な値は次の2つです。
Merge: /etc/groupで定義されている、コンテナのプライマリユーザーが所属するグループをマージします。指定されていない場合、このポリシーがデフォルトです。
Strict: fsGroup、supplementalGroups、runAsGroupフィールドで指定されたグループのみ補助グループに指定されます。つまり、/etc/groupで定義された、コンテナのプライマリユーザーのグループ情報はマージされません。
この機能が有効な場合、.status.containerStatuses[].user.linuxフィールドで、コンテナの最初のプロセスに付与されたユーザー、グループ情報が確認出来ます。暗黙的なグループIDが付与されているかどうかを確認するのに便利でしょう。
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
supplementalGroups: [4000]
supplementalGroupsPolicy: Strict
containers:
- name: sec-ctx-demo
image: registry.k8s.io/e2e-test-images/agnhost:2.45
command: [ "sh", "-c", "sleep 1h" ]
securityContext:
allowPrivilegeEscalation: false
このPodマニフェストはsupplementalGroupsPolicy=Strictを指定しています。/etc/groupに定義されているグループ情報が、コンテナ内のプロセスの補助グループにマージされないことが確認できるでしょう。
Podを作成してみましょう。
kubectl apply -f https://k8s.io/examples/pods/security/security-context-6.yaml
Podのコンテナが実行されていることを確認します。
kubectl get pod security-context-demo
プロセスのユーザー、グループ情報を確認します。
kubectl exec -it security-context-demo -- id
出力はこのようになります。
uid=1000 gid=3000 groups=3000,4000
Podのステータスを確認します。
kubectl get pod security-context-demo -o yaml
status.containerStatuses[].user.linuxフィールドでコンテナの最初のプロセスに付与されたユーザー、グループ情報が確認出来ます。
...
status:
containerStatuses:
- name: sec-ctx-demo
user:
linux:
gid: 3000
supplementalGroups:
- 3000
- 4000
uid: 1000
...
status.containerStatuses[].user.linuxフィールドで公開されているユーザー、グループ情報は、コンテナの最初のプロセスに、最初に付与された 情報であることに注意してください。
もしそのプロセスが、自身のユーザー、グループ情報を変更できるシステムコール(例えば setuid(2),
setgid(2),
setgroups(2)等)を実行する権限を持っている場合、プロセス自身で動的に変更が可能なためです。
つまり、実際にプロセスに付与されているユーザー、グループ情報は動的に変化します。下記のコンテナランタイムがfine-grained(きめ細かい) SupplementalGroups controlを実装しています。
CRI実装:
ノードのステータスでこの機能が利用可能かどうか確認出来ます。
apiVersion: v1
kind: Node
...
status:
features:
supplementalGroupsPolicy: true
Kubernetes v1.23 [stable]デフォルトでは、Kubernetesはボリュームがマウントされたときに、PodのsecurityContextで指定されたfsGroupに合わせて再帰的に各ボリュームの中の所有権とパーミッションを変更します。
大きなボリュームでは所有権の確認と変更に時間がかかり、Podの起動が遅くなります。
securityContextの中のfsGroupChangePolicyフィールドを設定することで、Kubernetesがボリュームの所有権・パーミッションの確認と変更をどう行うかを管理することができます。
fsGroupChangePolicy - fsGroupChangePolicyは、ボリュームがPod内部で公開される前に所有権とパーミッションを変更するための動作を定義します。
このフィールドはfsGroupで所有権とパーミッションを制御することができるボリュームタイプにのみ適用されます。このフィールドは以下の2つの値を取ります。
例:
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
fsGroupChangePolicy: "OnRootMismatch"
Kubernetes v1.26 [stable]VOLUME_MOUNT_GROUP NodeServiceCapabilityをサポートしているContainer Storage Interface (CSI)ドライバーをデプロイした場合、securityContextのfsGroupで指定された値に基づいてKubernetesの代わりにCSIドライバーがファイルの所有権とパーミッションの設定処理を行います。
この場合Kubernetesは所有権とパーミッションの設定を行わないためfsGroupChangePolicyは無効となり、CSIで指定されている通りドライバーはfsGroupに従ってボリュームをマウントすると考えられるため、ボリュームはfsGroupに従って読み取り・書き込み可能になります。
コンテナに対してセキュリティ設定を行うには、コンテナマニフェストにsecurityContextフィールドを含めてください。securityContextフィールドにはSecurityContextオブジェクトが入ります。
コンテナに指定したセキュリティ設定は個々のコンテナに対してのみ反映され、Podレベルの設定を上書きします。コンテナの設定はPodのボリュームに対しては影響しません。
こちらは一つのコンテナを持つPodの設定ファイルです。PodもコンテナもsecurityContextフィールドを含んでいます。
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo-2
spec:
securityContext:
runAsUser: 1000
containers:
- name: sec-ctx-demo-2
image: gcr.io/google-samples/node-hello:1.0
securityContext:
runAsUser: 2000
allowPrivilegeEscalation: falsePodを作成します。
kubectl apply -f https://k8s.io/examples/pods/security/security-context-2.yaml
Podのコンテナが実行されていることを確認します。
kubectl get pod security-context-demo-2
実行中のコンテナでshellを取ります。
kubectl exec -it security-context-demo-2 -- sh
shellの中で、実行中のプロセスの一覧を表示します。
ps aux
ユーザー2000として実行されているプロセスが表示されました。これはコンテナのrunAsUserで指定された値です。Podで指定された値である1000を上書きしています。
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
2000 1 0.0 0.0 4336 764 ? Ss 20:36 0:00 /bin/sh -c node server.js
2000 8 0.1 0.5 772124 22604 ? Sl 20:36 0:00 node server.js
...
shellから抜けます。
exit
Linuxケーパビリティを用いると、プロセスに対してrootユーザーの全権を渡すことなく特定の権限を与えることができます。
コンテナに対してLinuxケーパビリティを追加したり削除したりするには、コンテナマニフェストのsecurityContextセクションのcapabilitiesフィールドに追加してください。
まず、capabilitiesフィールドを含まない場合どうなるかを見てみましょう。
こちらはコンテナに対してケーパビリティを渡していない設定ファイルです。
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo-3
spec:
containers:
- name: sec-ctx-3
image: gcr.io/google-samples/node-hello:1.0Podを作成します。
kubectl apply -f https://k8s.io/examples/pods/security/security-context-3.yaml
Podが実行されていることを確認します。
kubectl get pod security-context-demo-3
実行中のコンテナでshellを取ります。
kubectl exec -it security-context-demo-3 -- sh
shellの中で、実行中のプロセスの一覧を表示します。
ps aux
コンテナのプロセスID(PID)が出力されます。
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 4336 796 ? Ss 18:17 0:00 /bin/sh -c node server.js
root 5 0.1 0.5 772124 22700 ? Sl 18:17 0:00 node server.js
shellの中で、プロセス1のステータスを確認します。
cd /proc/1
cat status
プロセスのケーパビリティビットマップが表示されます。
...
CapPrm: 00000000a80425fb
CapEff: 00000000a80425fb
...
ケーパビリティビットマップのメモを取った後、shellから抜けます。
exit
次に、追加のケーパビリティを除いて上と同じ設定のコンテナを実行します。
こちらは1つのコンテナを実行するPodの設定ファイルです。
CAP_NET_ADMINとCAP_SYS_TIMEケーパビリティを設定に追加しました。
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo-4
spec:
containers:
- name: sec-ctx-4
image: gcr.io/google-samples/node-hello:1.0
securityContext:
capabilities:
add: ["NET_ADMIN", "SYS_TIME"]Podを作成します。
kubectl apply -f https://k8s.io/examples/pods/security/security-context-4.yaml
実行中のコンテナでshellを取ります。
kubectl exec -it security-context-demo-4 -- sh
shellの中で、プロセス1のケーパビリティを確認します。
cd /proc/1
cat status
プロセスのケーパビリティビットマップが表示されます。
...
CapPrm: 00000000aa0435fb
CapEff: 00000000aa0435fb
...
2つのコンテナのケーパビリティを比較します。
00000000a80425fb
00000000aa0435fb
1つ目のコンテナのケーパビリティビットマップでは、12, 25ビット目がクリアされています。2つ目のコンテナでは12, 25ビット目がセットされています。12ビット目はCAP_NET_ADMIN、25ビット目はCAP_SYS_TIMEです。
ケーパビリティの定数の定義はcapability.hを確認してください。
CAP_XXX形式です。
ただしコンテナのマニフェストでケーパビリティを記述する際は、定数のCAP_の部分を省いてください。
例えば、CAP_SYS_TIMEを追加したい場合はケーパビリティにSYS_TIMEを追加してください。コンテナにSeccompプロフィールを設定するには、Pod・コンテナマニフェストのsecurityContextにseccompProfileフィールドを追加してください。
seccompProfileフィールドはSeccompProfileオブジェクトで、typeとlocalhostProfileで構成されています。
typeではRuntimeDefault、Unconfined、Localhostが有効です。
localhostProfileはtype: Localhostのときのみ指定可能です。こちらはノード上で事前に設定されたプロファイルのパスを示していて、kubeletのSeccompプロファイルの場所(--root-dirフラグで設定したもの)からの相対パスです。
こちらはノードのコンテナランタイムのデフォルトプロフィールをSeccompプロフィールとして設定した例です。
...
securityContext:
seccompProfile:
type: RuntimeDefault
こちらは<kubelet-root-dir>/seccomp/my-profiles/profile-allow.jsonで事前に設定したファイルをSeccompプロフィールに設定した例です。
...
securityContext:
seccompProfile:
type: Localhost
localhostProfile: my-profiles/profile-allow.json
コンテナにAppArmorプロフィールを設定するには、securityContextセクションにappAormorProfileフィールドを含めてください。
appAormerProfileフィールドには、typeフィールドとlocalhostProfileフィールドから構成されるAppArmorProfileオブジェクトが入ります。typeフィールドの有効なオプションはRuntimeDefault(デフォルト)、Unconfined、Localhostです。
localhostProfileはtypeがLocalhostのときには必ず設定しなければなりません。この値はノードで事前に設定されたプロフィール名を示します。Podは事前にどのノードにスケジュールされるかわからないため、指定されたプロフィールはPodがスケジュールされ得る全てのノードにロードされている必要があります。カスタムプロフィールをセットアップする方法はSetting up nodes with profilesを参照してください。
注意: containers[*].securityContext.appArmorProfile.typeが明示的にRuntimeDefaultに設定されている場合は、もしノードでAppArmorが有効化されていなければ、Podの作成は許可されません。
しかし、containers[*].securityContext.appArmorProfile.typeが設定されていない場合、AppArmorが有効化されていれば、デフォルト(RuntimeDefault)が適用されます。もし、AppArmorが無効化されている場合は、Podの作成は許可されますが、コンテナにはRuntimeDefaultプロフィールの制限は適用されません。
これは、AppArmorプロフィールとして、ノードのコンテナランタイムのデフォルトプロフィールを設定する例です。
...
containers:
- name: container-1
securityContext:
appArmorProfile:
type: RuntimeDefault
これは、AppArmorプロフィールとして、k8s-apparmor-example-deny-writeという名前で事前に設定されたプロフィールを設定する例です。
...
containers:
- name: container-1
securityContext:
appArmorProfile:
type: Localhost
localhostProfile: k8s-apparmor-example-deny-write
より詳細な内容についてはRestrict a Container's Access to Resources with AppArmorを参照してください。
コンテナにSELinuxラベルをつけるには、Pod・コンテナマニフェストのsecurityContextセクションにseLinuxOptionsフィールドを追加してください。
seLinuxOptionsフィールドはSELinuxOptionsオブジェクトが入ります。
こちらはSELinuxレベルを適用する例です。
...
securityContext:
seLinuxOptions:
level: "s0:c123,c456"
Kubernetes v1.28 [beta] (enabled by default: true)Kubernetes v1.27で、ReadWriteOncePod アクセスモードを使用するボリューム(およびPersistentVolumeClaim)にのみ、この機能の限定的な機能が早期提供されています。
Alphaフィーチャーとして、SELinuxMountフィーチャーゲートを有効にすることで、以下で説明するように、他の種類のPersistentVolumeClaimにもパフォーマンス改善の範囲を広げる事ができます。
デフォルトでは、コンテナランタイムは全てのPodのボリュームの全てのファイルに再帰的にSELinuxラベルを付与します。処理速度を上げるために、Kubernetesはマウントオプションで-o context=<label>を使うことでボリュームのSELinuxラベルを即座に変更することができます。
この高速化の恩恵を受けるには、以下の全ての条件を満たす必要があります。
ReadWriteOncePodとSELinuxMountReadWriteOncePodを有効にすることaccessModesでPersistentVolumeClaimを使うことaccessModes: ["ReadWriteOncePod"]を持ち、フィーチャーゲートSELinuxMountReadWriteOncePodが有効であることSELinuxMountReadWriteOncePodとSELinuxMountの両方が有効であることseLinuxOptionsが設定されていることiscs、rbd、fcボリュームタイプであることspec.seLinuxMount: trueを指定したときに-o contextでマウントを行うとアナウンスしていることそれ以外のボリュームタイプでは、コンテナランタイムはボリュームに含まれる全てのinode(ファイルやディレクトリ)に対してSELinuxラベルを再帰的に変更します。 ボリューム内のファイルやディレクトリが増えるほど、ラベリングにかかる時間は増加します。
/procファイルシステムへのアクセスを管理するKubernetes v1.31 [beta] (enabled by default: false)OCI runtime specificationに準拠するランタイムでは、コンテナはデフォルトで、いくつかの複数のパスはマスクされ、かつ、読み取り専用のモードで実行されます。 その結果、コンテナのマウントネームスペース内にはこれらのパスが存在し、あたかもコンテナが隔離されたホストであるかのように機能しますが、コンテナプロセスはそれらのパスに書き込むことはできません。 マスクされるパスおよび読み取り専用のパスのリストは次のとおりです。
マスクされるパス:
/proc/asound/proc/acpi/proc/kcore/proc/keys/proc/latency_stats/proc/timer_list/proc/timer_stats/proc/sched_debug/proc/scsi/sys/firmware/sys/devices/virtual/powercap読み取り専用のパス:
/proc/bus/proc/fs/proc/irq/proc/sys/proc/sysrq-trigger一部のPodでは、デフォルトでパスがマスクされるのを回避したい場合があります。このようなケースで最も一般的なのは、Kubernetesコンテナ(Pod内のコンテナ)内でコンテナを実行しようとする場合です。
securityContextのprocMountフィールドを使用すると、コンテナの/procをUnmaskedにしたり、コンテナプロセスによって読み書き可能な状態でマウントすることができます。この設定は、/proc以外の/sys/firmwareにも適用されます。
...
securityContext:
procMount: Unmasked
procMountをUnmaskedに設定するには、Podのspec.hostUsersの値がfalseである必要があります。
つまり、Unmaskedな/procやUnmaskedな/sysを使用したいコンテナは、user namespace内で動作している必要があります。
Kubernetes v1.12からv1.29までは、この要件は強制されません。PodのセキュリティコンテキストはPodのコンテナや、適用可能であればPodのボリュームに対しても適用されます。
特にfsGroupとseLinuxOptionsは以下のようにボリュームに対して適用されます。
fsGroup: 所有権管理をサポートしているボリュームはfsGroupで指定されているGIDで所有権・書き込み権限が設定されます。詳しくはOwnership Management design documentを確認してください。
seLinuxOptions: SELinuxラベリングをサポートしているボリュームではseLinuxOptionsで指定されているラベルでアクセス可能になるように貼り直されます。通常、levelセクションのみ設定する必要があります。
これはPod内の全てのボリュームとコンテナに対しMulti-Category Security (MCS)ラベルを設定します。
Podを削除します。
kubectl delete pod security-context-demo
kubectl delete pod security-context-demo-2
kubectl delete pod security-context-demo-3
kubectl delete pod security-context-demo-4
このページでは、Secretを用いるPodを作成するためにイメージをプライベートコンテナイメージレジストリもしくはリポジトリから取得する方法について説明します。 多くのプライベートレジストリが存在しますが、このタスクではDocker Hubをレジストリの一例として使用します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
この演習を行うためには、dockerコマンドラインツールと自身のDocker IDが必要です。
別のプライベートコンテナレジストリを使用している場合は、そのレジストリのコマンドラインツールとログイン情報が必要です。
ラップトップ(ローカル環境)上では、プライベートイメージを取得するためにレジストリに認証する必要があります。
dockerツールを使用してDocker Hubにログインしてください。詳細はDocker IDアカウントの Sign in セクションを参照してください。
docker login
プロンプトが表示されたら、Docker IDと使用したい認証情報(アクセストークンまたはDocker IDのパスワード)を入力してください。
ログインプロセスは、認証トークンを保持するconfig.jsonファイルを作成または更新します。Kubernetesがこのファイルを解釈する方法を確認してください。
以下のようにconfig.jsonファイルを確認します:
cat ~/.docker/config.json
出力には以下のような部分が含まれています:
{
"auths": {
"https://index.docker.io/v1/": {
"auth": "c3R...zE2"
}
}
}
authエントリの代わりに、ストア名を値とするcredsStoreエントリが表示されます。
この場合、Secretを直接作成できます。
コマンドライン上で認証情報を入力してSecretを作成するを参照してください。Kubernetesクラスターはプライベートイメージを取得するためのレジストリとの認証にkubernetes.io/dockerconfigjsonタイプのSecretを使用します。
既にdocker loginを実行済みの場合、その認証情報をKubernetesにコピーできます:
kubectl create secret generic regcred \
--from-file=.dockerconfigjson=<path/to/.docker/config.json> \
--type=kubernetes.io/dockerconfigjson
新しいSecretをカスタマイズする必要がある場合(例えば、新しいSecretにNamespaceやLabelを設定する場合)は、保存する前にSecretをカスタマイズできます。 必ず以下を行ってください:
data項目の名前を.dockerconfigjsonに設定するdata[".dockerconfigjson"]の値として貼り付けるtypeをkubernetes.io/dockerconfigjsonに設定するSecretをカスタマイズする場合のマニフェストの例:
apiVersion: v1
kind: Secret
metadata:
name: myregistrykey
namespace: awesomeapps
data:
.dockerconfigjson: UmVhbGx5IHJlYWxseSByZWVlZWVlZWVlZWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGx5eXl5eXl5eXl5eXl5eXl5eXl5eSBsbGxsbGxsbGxsbGxsbG9vb29vb29vb29vb29vb29vb29vb29vb29vb25ubm5ubm5ubm5ubm5ubm5ubm5ubm5ubmdnZ2dnZ2dnZ2dnZ2dnZ2dnZ2cgYXV0aCBrZXlzCg==
type: kubernetes.io/dockerconfigjson
error: no objects passed to createをエラーメッセージとして受け取った場合、base64エンコードされた文字列が無効である可能性があります。
Secret "myregistrykey" is invalid: data[.dockerconfigjson]: invalid value ...をエラーメッセージとして受け取った場合は、data内のbase64エンコードされた文字列は正常にデコードされたものの、.docker/config.jsonファイルとして読み込むことができなかったことを意味します。
このSecretをregcredという名前で作成します:
kubectl create secret docker-registry regcred --docker-server=<your-registry-server> --docker-username=<your-name> --docker-password=<your-pword> --docker-email=<your-email>
ここでは:
<your-registry-server>は、プライベートDockerレジストリのFQDN(完全修飾ドメイン名)です。
Docker Hubを使用する場合は、https://index.docker.io/v1/を設定して下さい。<your-name>は、Dockerのユーザー名です。<your-pword>は、Dockerのパスワードです。<your-email>は、Dockerのメールアドレスです。Dockerレジストリの認証情報がSecretとしてregcredという名前でクラスターに正常に設定されました。
kubectl実行中はPCの他のユーザーがそれらの認証情報を閲覧できる可能性があります。regcredSecretを確認する作成したregcredSecretの内容を理解するために、まずYAML形式でSecretを表示します:
kubectl get secret regcred --output=yaml
出力は以下のようになります:
apiVersion: v1
kind: Secret
metadata:
...
name: regcred
...
data:
.dockerconfigjson: eyJodHRwczovL2luZGV4L ... J0QUl6RTIifX0=
type: kubernetes.io/dockerconfigjson
.dockerconfigjsonフィールドの値は、Docker認証情報をbase64でエンコードしたものです。
.dockerconfigjsonフィールドの内容を理解するために、認証情報のデータを読解可能な形式に変換します:
kubectl get secret regcred --output="jsonpath={.data.\.dockerconfigjson}" | base64 --decode
出力は以下のようになります:
{"auths":{"your.private.registry.example.com":{"username":"janedoe","password":"xxxxxxxxxxx","email":"jdoe@example.com","auth":"c3R...zE2"}}}
authフィールドの内容を理解するために、base64エンコードされたデータを読解可能な形式に変換します:
echo "c3R...zE2" | base64 --decode
出力はユーザー名とパスワードが:で連結された以下のような形式になります:
janedoe:xxxxxxxxxxx
Secretのdataには、ローカルの~/.docker/config.jsonファイルと同様の認証トークンが含まれていることが分かります。
クラスターにregcredという名前のSecretとしてDockerの認証情報が正常に設定されました。
以下はregcredという名前のDockerの認証情報へのアクセスが必要なPodのマニフェストの例です:
apiVersion: v1
kind: Pod
metadata:
name: private-reg
spec:
containers:
- name: private-reg-container
image: <your-private-image>
imagePullSecrets:
- name: regcred
上記のファイルをあなたのコンピューターにダウンロードします:
curl -L -o my-private-reg-pod.yaml https://k8s.io/examples/pods/private-reg-pod.yaml
my-private-reg-pod.yamlファイル内の<your-private-image>を、以下のようなプライベートレジストリのイメージのパスに置き換えてください:
your.private.registry.example.com/janedoe/jdoe-private:v1
プライベートレジストリからイメージを取得するために、Kubernetesは認証情報を必要とします。
設定ファイル内のimagePullSecretsフィールドは、Kubernetesがregcredという名前のSecretから認証情報を取得することを指定します。
以下のようにして作成したSecretを使用するPodを作成し、Podが実行されていることを確認します:
kubectl apply -f my-private-reg-pod.yaml
kubectl get pod private-reg
また、PodのステータスがImagePullBackOffになり起動に失敗した場合は、Podのイベントを確認してください:
kubectl describe pod private-reg
もしFailedToRetrieveImagePullSecretという理由を持つイベントが表示された場合は、Kubernetesが指定された名前のSecret(この例ではregcred)を見つけることができないことを示します。
指定したSecretが存在し、その名前が正しく記載されていることを確認してください。
Events:
... Reason ... Message
------ -------
... FailedToRetrieveImagePullSecret ... Unable to retrieve some image pull secrets (<regcred>); attempting to pull the image may not succeed.
1つのPodは複数のコンテナを持つことができ、各コンテナのイメージは異なるレジストリから取得できます。
1つのPodで複数のimagePullSecretsを使用でき、それぞれに複数の認証情報を含めることができます。
レジストリに一致する各認証情報を使用してイメージの取得が試行されます。 レジストリに一致する認証情報がない場合、認証なしで、またはカスタムランタイム固有の設定を使用してイメージの取得が試行されます。
imagePullSecretsフィールドを参照する。このページでは、Liveness Probe、Readiness ProbeおよびStartup Probeの使用方法について説明します。
kubeletは、Liveness Probeを使用して、コンテナをいつ再起動するかを認識します。 例えば、アプリケーション自体は起動しているが、処理を継続することができないデッドロック状態を検知することができます。 このような状態のコンテナを再起動することで、バグがある場合でもアプリケーションの可用性を高めることができます。
kubeletは、Readiness Probeを使用して、コンテナがトラフィックを受け入れられる状態であるかを認識します。 Podが準備ができていると見なされるのは、Pod内の全てのコンテナの準備が整ったときです。 一例として、このシグナルはServiceのバックエンドとして使用されるPodを制御するときに使用されます。 Podの準備ができていない場合、そのPodはServiceのロードバランシングから切り離されます。
kubeletは、Startup Probeを使用して、コンテナアプリケーションの起動が完了したかを認識します。 Startup Probeを使用している場合、Startup Probeが成功するまでは、Liveness Probeと Readiness Probeによるチェックを無効にし、これらがアプリケーションの起動に干渉しないようにします。 例えば、これを起動が遅いコンテナの起動チェックとして使用することで、起動する前にkubeletによって 強制終了されることを防ぐことができます。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.長期間実行されているアプリケーションの多くは、再起動されるまで回復できないような異常な状態になることがあります。 Kubernetesはこのような状況を検知し、回復するためのLiveness Probeを提供します。
この演習では、registry.k8s.io/busyboxイメージのコンテナを起動するPodを作成します。
Podの構成ファイルは次の通りです。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: registry.k8s.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
この構成ファイルでは、Podは一つのContainerを起動します。
periodSecondsフィールドは、kubeletがLiveness Probeを5秒おきに行うように指定しています。
initialDelaySecondsフィールドは、kubeletが最初のProbeを実行する前に5秒間待機するように指示しています。
Probeの動作としては、kubeletはcat /tmp/healthyを対象のコンテナ内で実行します。
このコマンドが成功し、リターンコード0が返ると、kubeletはコンテナが問題なく動いていると判断します。
リターンコードとして0以外の値が返ると、kubeletはコンテナを終了し、再起動を行います。
このコンテナは、起動すると次のコマンドを実行します:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600"
コンテナが起動してから初めの30秒間は/tmp/healthyファイルがコンテナ内に存在します。
そのため初めの30秒間はcat /tmp/healthyコマンドは成功し、正常なリターンコードが返ります。
その後30秒が経過すると、cat /tmp/healthyコマンドは異常なリターンコードを返します。
このPodを起動してください:
kubectl apply -f https://k8s.io/examples/pods/probe/exec-liveness.yaml
30秒間以内に、Podのイベントを確認します。
kubectl describe pod liveness-exec
この出力結果は、Liveness Probeがまだ失敗していないことを示しています。
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
24s 24s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "registry.k8s.io/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "registry.k8s.io/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e
35秒後に、Podのイベントをもう一度確認します:
kubectl describe pod liveness-exec
出力結果の最後に、Liveness Probeが失敗していることを示すメッセージが表示されます。これによりコンテナは強制終了し、再作成されました。
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
37s 37s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "registry.k8s.io/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "registry.k8s.io/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e
2s 2s 1 {kubelet worker0} spec.containers{liveness} Warning Unhealthy Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
さらに30秒後、コンテナが再起動していることを確認します:
kubectl get pod liveness-exec
出力結果から、RESTARTSがインクリメントされていることを確認します:
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m
別の種類のLiveness Probeでは、HTTP GETリクエストを使用します。
次の構成ファイルは、registry.k8s.io/e2e-test-images/agnhostイメージを使用したコンテナを起動するPodを作成します。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/e2e-test-images/agnhost:2.40
args:
- liveness
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
この構成ファイルでは、Podは一つのContainerを起動します。
periodSecondsフィールドは、kubeletがLiveness Probeを3秒おきに行うように指定しています。
initialDelaySecondsフィールドは、kubeletが最初のProbeを実行する前に3秒間待機するように指示しています。
Probeの動作としては、kubeletは8080ポートをリッスンしているコンテナ内のサーバーに対してHTTP GETリクエストを送ります。
サーバー内の/healthzパスに対するハンドラーが正常なリターンコードを応答した場合、
kubeletはコンテナが問題なく動いていると判断します。
異常なリターンコードを応答すると、kubeletはコンテナを終了し、再起動を行います。
200以上400未満のコードは成功とみなされ、その他のコードは失敗とみなされます。
server.go にてサーバーのソースコードを確認することができます。
コンテナが生きている初めの10秒間は、/healthzハンドラーが200ステータスを返します。
その後、ハンドラーは500ステータスを返します。
http.HandleFunc("/healthz", func(w http.ResponseWriter, r *http.Request) {
duration := time.Now().Sub(started)
if duration.Seconds() > 10 {
w.WriteHeader(500)
w.Write([]byte(fmt.Sprintf("error: %v", duration.Seconds())))
} else {
w.WriteHeader(200)
w.Write([]byte("ok"))
}
})
kubeletは、コンテナが起動してから3秒後からヘルスチェックを行います。 そのため、初めのいくつかのヘルスチェックは成功します。しかし、10秒経過するとヘルスチェックは失敗し、kubeletはコンテナを終了し、再起動します。
HTTPリクエストのチェックによるLiveness Probeを試すには、以下のようにPodを作成します:
kubectl apply -f https://k8s.io/examples/pods/probe/http-liveness.yaml
10秒後、Podのイベントを表示して、Liveness Probeが失敗し、コンテナが再起動されていることを確認します。
kubectl describe pod liveness-http
v1.13以前(v1.13を含む)のリリースにおいては、Podが起動しているノードに環境変数http_proxy
(または HTTP_PROXY)が設定されている場合、HTTPリクエストのLiveness Probeは設定されたプロキシを使用します。
v1.13より後のリリースにおいては、ローカルHTTPプロキシ環境変数の設定はHTTPリクエストのLiveness Probeに影響しません。
3つ目のLiveness ProbeはTCPソケットを使用するタイプです。 この構成においては、kubeletは指定したコンテナのソケットを開くことを試みます。 コネクションが確立できる場合はコンテナを正常とみなし、失敗する場合は異常とみなします。
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: registry.k8s.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
見ての通り、TCPによるチェックの構成はHTTPによるチェックと非常に似ています。
この例では、Readiness ProbeとLiveness Probeを両方使用しています。
kubeletは、コンテナが起動してから5秒後に最初のReadiness Probeを開始します。
これはgoproxyコンテナの8080ポートに対して接続を試みます。
このProbeが成功すると、Podは準備ができていると通知されます。kubeletはこのチェックを10秒ごとに行います。
この構成では、Readiness Probeに加えてLiveness Probeが含まれています。
kubeletは、コンテナが起動してから15秒後に最初のLiveness Probeを実行します。
Readiness Probeと同様に、これはgoproxyコンテナの8080ポートに対して接続を試みます。
Liveness Probeが失敗した場合、コンテナは再起動されます。
TCPのチェックによるLiveness Probeを試すには、以下のようにPodを作成します:
kubectl apply -f https://k8s.io/examples/pods/probe/tcp-liveness-readiness.yaml
15秒後、Podのイベントを表示し、Liveness Probeが行われていることを確認します:
kubectl describe pod goproxy
HTTPまたはTCPによるProbeにおいて、ContainerPort で定義した名前付きポートを使用することができます。
ports:
- name: liveness-port
containerPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
場合によっては、最初の初期化において追加の起動時間が必要になるようなレガシーアプリケーションを扱う必要があります。 そのような場合、デッドロックに対する迅速な反応を損なうことなくLiveness Probeのパラメーターを設定することは難しい場合があります。
これに対する解決策の一つは、Liveness Probeと同じ構成のコマンドを用いるか、HTTPまたはTCPによるチェックを使用したStartup Probeをセットアップすることです。
その際、failureThreshold * periodSecondsで計算される時間を、起動時間として想定される最も遅いケースをカバーできる十分な長さに設定します。
上記の例は、次のようになります:
ports:
- name: liveness-port
containerPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 1
periodSeconds: 10
startupProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 30
periodSeconds: 10
Startup Probeにより、アプリケーションは起動が完了するまでに最大5分間の猶予(30 * 10 = 300秒)が与えられます。
Startup Probeに一度成功すると、その後はLiveness Probeが引き継ぎ、コンテナのデッドロックに対して迅速に反応します。
Startup Probeが成功しない場合、コンテナは300秒後に終了し、その後はPodのrestartPolicyに従います。
アプリケーションは一時的にトラフィックを処理できないことが起こり得ます。 例えば、アプリケーションは起動時に大きなデータまたは構成ファイルを読み込む必要がある場合や、起動後に外部サービスに依存している場合があります。 このような場合、アプリケーション自体を終了させたくはありませんが、このアプリケーションに対してリクエストも送信したくないと思います。 Kubernetesは、これらの状況を検知して緩和するための機能としてReadiness Probeを提供します。 これにより、準備ができていないことを報告するコンテナを含むPodは、KubernetesのServiceを通してトラフィックを受信しないようになります。
Readiness ProbeはLiveness Probeと同様に構成します。
唯一の違いはreadinessProbeフィールドをlivenessProbeフィールドの代わりに利用することだけです。
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
HTTPおよびTCPによるReadiness Probeの構成もLiveness Probeと同じです。
Readiness ProbeとLiveness Probeは同じコンテナで同時に使用できます。 両方使用することで、準備できていないコンテナへのトラフィックが到達しないようにし、コンテナが失敗したときに再起動することができます。
Probe には、 Liveness ProbeおよびReadiness Probeのチェック動作をより正確に制御するために使用できるフィールドがあります:
initialDelaySeconds: コンテナが起動してから、Liveness ProbeまたはReadiness Probeが開始されるまでの秒数。デフォルトは0秒。最小値は0。periodSeconds: Probeが実行される頻度(秒数)。デフォルトは10秒。最小値は1。
コンテナが起動してから準備が整うまでの間、periodSecondsで指定した間隔とは異なるタイミングでReadiness Probeが実行される場合があります。
これは、Podをより早く準備完了の状態に移行させるためです。timeoutSeconds: Probeがタイムアウトになるまでの秒数。デフォルトは1秒。最小値は1。successThreshold: 一度Probeが失敗した後、次のProbeが成功したとみなされるための最小連続成功数。
デフォルトは1。Liveness ProbeおよびStartup Probeには1を設定する必要があります。最小値は1。failureThreshold: Probeが失敗した場合、KubernetesはfailureThresholdに設定した回数までProbeを試行します。
Liveness Probeにおいて、試行回数に到達することはコンテナを再起動することを意味します。
Readiness Probeの場合は、Podが準備できていない状態として通知されます。デフォルトは3。最小値は1。HTTPによるProbe
には、httpGetにて設定できる追加のフィールドがあります:
host: 接続先ホスト名。デフォルトはPod IP。おそらくはこのフィールドの代わりにhttpHeaders内の"Host"を代わりに使用することになります。scheme: ホストへの接続で使用するスキーマ(HTTP または HTTPS)。デフォルトは HTTP。path: HTTPサーバーへアクセスする際のパスhttpHeaders: リクエスト内のカスタムヘッダー。HTTPでは重複したヘッダーが許可されています。port: コンテナにアクセスする際のポートの名前または番号。ポート番号の場合、1から65535の範囲内である必要があります。HTTPによるProbeの場合、kubeletは指定したパスとポートに対するHTTPリクエストを送ることでチェックを行います。
httpGetのオプションであるhostフィールドでアドレスが上書きされない限り、kubeletはPodのIPアドレスに対してProbeを送ります。
schemeフィールドにHTTPSがセットされている場合、kubeletは証明書の検証を行わずにHTTPSリクエストを送ります。
ほとんどのシナリオにおいては、hostフィールドを使用する必要はありません。次のシナリオは使用する場合の一例です。
仮にコンテナが127.0.0.1をリッスンしており、かつPodのhostNetworkフィールドがtrueだとします。
その場合においては、httpGetフィールド内のhostには127.0.0.1をセットする必要があります。
より一般的なケースにおいてPodが仮想ホストに依存している場合は、おそらくhostフィールドではなく、httpHeadersフィールド内のHostヘッダーを使用する必要があります。
TCPによるProbeの場合、kubeletはPodの中ではなく、ノードに対してコネクションを確立するProbeを実行します。
kubeletはServiceの名前を解決できないため、hostパラメーター内でServiceの名前を使用することはできません。
また、次のAPIリファレンスも参考にしてください:
このページでは、KubernetesのPodをKubernetesクラスター上の特定のノードに割り当てる方法を説明します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.クラスター内のノードのリストをラベル付きで表示します。
kubectl get nodes --show-labels
出力は次のようになります。
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
ノードの1つを選択して、ラベルを追加します。
kubectl label nodes <your-node-name> disktype=ssd
ここで、<your-node-name>は選択したノードの名前です。
選択したノードにdisktype=ssdラベルがあることを確認します。
kubectl get nodes --show-labels
出力は次のようになります。
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,disktype=ssd,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
上の出力を見ると、worker0にdisktype=ssdというラベルがあることがわかります。
以下のPodの構成ファイルには、nodeSelectorにdisktype: ssdを持つPodが書かれています。これにより、Podはdisktype: ssdというラベルを持っているノードにスケジューリングされるようになります。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd
構成ファイルを使用して、選択したノードにスケジューリングされるPodを作成します。
kubectl apply -f https://k8s.io/examples/pods/pod-nginx.yaml
Podが選択したノード上で実行されているをことを確認します。
kubectl get pods --output=wide
出力は次のようになります。
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
nodeNameという設定を使用して、Podを特定のノードにスケジューリングすることもできます。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
nodeName: foo-node # 特定のノードにPodをスケジューリングする
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
構成ファイルを使用して、foo-nodeにだけスケジューリングされるPodを作成します。
このページでは、Node Affinityを利用して、PodをKubernetesクラスター内の特定のノードに割り当てる方法を説明します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.10. バージョンを確認するには次のコマンドを実行してください:kubectl version.クラスター内のノードを一覧表示して、ラベルを確認します。
kubectl get nodes --show-labels
出力は次のようになります。
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
ノードを選択して、ラベルを追加します。
kubectl label nodes <your-node-name> disktype=ssd
ここで、<your-node-name>は選択したノードの名前で置換します。
選択したノードにdisktype=ssdラベルがあることを確認します。
kubectl get nodes --show-labels
出力は次のようになります。
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,disktype=ssd,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
この出力を見ると、worker0ノードにdisktype=ssdというラベルが追加されたことがわかります。
以下に示すマニフェストには、requiredDuringSchedulingIgnoredDuringExecutionにdisktype: ssdというnode affinityを使用したPodが書かれています。このように書くと、Podはdisktype=ssdというラベルを持つノードにだけスケジューリングされるようになります。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
マニフェストを適用して、選択したノード上にスケジューリングされるPodを作成します。
kubectl apply -f https://k8s.io/examples/pods/pod-nginx-required-affinity.yaml
Podが選択したノード上で実行されていることを確認します。
kubectl get pods --output=wide
出力は次のようになります。
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
以下に示すマニフェストには、preferredDuringSchedulingIgnoredDuringExecutionにdisktype: ssdというnode affinityを使用したPodが書かれています。このように書くと、Podはdisktype=ssdというラベルを持つノードに優先的にスケジューリングされるようになります。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
マニフェストを適用して、選択したノード上にスケジューリングされるPodを作成します。
kubectl apply -f https://k8s.io/examples/pods/pod-nginx-preferred-affinity.yaml
Podが選択したノード上で実行されていることを確認します。
kubectl get pods --output=wide
出力は次のようになります。
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
Node Affinityについてさらに学ぶ。
このページでは、アプリケーションコンテナが実行される前に、Initコンテナを使用してPodを初期化する方法を示します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.この演習では、アプリケーションコンテナが1つ、Initコンテナが1つのPodを作成します。 Initコンテナはアプリケーションコンテナが実行される前に完了します。
Podの設定ファイルは次の通りです:
apiVersion: v1
kind: Pod
metadata:
name: init-demo
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
# These containers are run during pod initialization
initContainers:
- name: install
image: busybox
command:
- wget
- "-O"
- "/work-dir/index.html"
- http://kubernetes.io
volumeMounts:
- name: workdir
mountPath: "/work-dir"
dnsPolicy: Default
volumes:
- name: workdir
emptyDir: {}
設定ファイルを確認すると、PodはInitコンテナとアプリケーションコンテナが共有するボリュームを持っています。
Initコンテナは共有ボリュームを/work-dirにマウントし、アプリケーションコンテナは共有ボリュームを/usr/share/nginx/htmlにマウントします。
Initコンテナは以下のコマンドを実行してから終了します:
wget -O /work-dir/index.html http://info.cern.ch
Initコンテナは、nginxサーバーのルートディレクトリのindex.htmlファイルに書き込むことに注意してください。
Podを作成します:
kubectl apply -f https://k8s.io/examples/pods/init-containers.yaml
nginxコンテナが実行中であることを確認します:
kubectl get pod init-demo
次の出力はnginxコンテナが実行中であることを示します:
NAME READY STATUS RESTARTS AGE
init-demo 1/1 Running 0 1m
init-demo Podで実行中のnginxコンテナのシェルを取得します:
kubectl exec -it init-demo -- /bin/bash
シェルで、nginxサーバーにGETリクエストを送信します:
root@nginx:~# apt-get update
root@nginx:~# apt-get install curl
root@nginx:~# curl localhost
出力は、Initコンテナが書き込んだウェブページをnginxが提供していることを示します:
<html><head></head><body><header>
<title>http://info.cern.ch</title>
</header>
<h1>http://info.cern.ch - home of the first website</h1>
...
<li><a href="http://info.cern.ch/hypertext/WWW/TheProject.html">Browse the first website</a></li>
...
このページでは、コンテナのライフサイクルイベントにハンドラーを紐付けする方法を説明します。KubernetesはpostStartとpreStopイベントをサポートしています。Kubernetesはコンテナの起動直後にpostStartイベントを送信し、コンテナの終了直前にpreStopイベントを送信します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.この課題では、1つのコンテナを持つPodを作成します。コンテナには、postStartイベントとpreStopイベントのハンドラーがあります。
これがPodの設定ファイルです:
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"]
設定ファイルでは、postStartコマンドがmessageファイルをコンテナの/usr/shareディレクトリに書き込むことがわかります。preStopコマンドはnginxを適切にシャットダウンします。これは、障害のためにコンテナが終了している場合に役立ちます。
Podを作成します:
kubectl apply -f https://k8s.io/examples/pods/lifecycle-events.yaml
Pod内のコンテナが実行されていることを確認します:
kubectl get pod lifecycle-demo
Pod内で実行されているコンテナでシェルを実行します:
kubectl exec -it lifecycle-demo -- /bin/bash
シェルで、postStartハンドラーがmessageファイルを作成したことを確認します:
root@lifecycle-demo:/# cat /usr/share/message
出力は、postStartハンドラーによって書き込まれたテキストを示しています。
Hello from the postStart handler
コンテナが作成された直後にKubernetesはpostStartイベントを送信します。 ただし、コンテナのエントリーポイントが呼び出される前にpostStartハンドラーが呼び出されるという保証はありません。postStartハンドラーはコンテナのコードに対して非同期的に実行されますが、postStartハンドラーが完了するまでコンテナのKubernetesによる管理はブロックされます。postStartハンドラーが完了するまで、コンテナのステータスはRUNNINGに設定されません。
Kubernetesはコンテナが終了する直前にpreStopイベントを送信します。 コンテナのKubernetesによる管理は、Podの猶予期間が終了しない限り、preStopハンドラーが完了するまでブロックされます。詳細はPodのライフサイクルを参照してください。
ConfigMapを使用すると、設定をイメージのコンテンツから切り離して、コンテナ化されたアプリケーションの移植性を維持できます。このページでは、ConfigMapを作成し、ConfigMapに保存されているデータを使用してPodを構成する一連の使用例を示します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.kubectl create configmapまたはkustomization.yamlのConfigMap generatorを使用すると、ConfigMapを作成できます。kubectlがkustomization.yamlをサポートをしているのは1.14からである点に注意してください。
kubectl create configmapを使用してConfigMapをディレクトリ、ファイル、またはリテラル値から作成します:
kubectl create configmap <map-name> <data-source>
<map-name>の部分はConfigMapに割り当てる名前で、<data-source>はデータを取得するディレクトリ、ファイル、またはリテラル値です。ConfigMapの名前は有効なDNSサブドメイン名である必要があります。
ファイルをベースにConfigMapを作成する場合、<data-source> のキーはデフォルトでファイル名になり、値はデフォルトでファイルの中身になります。
kubectl describeまたは
kubectl getを使用すると、ConfigMapに関する情報を取得できます。
kubectl create configmapを使用すると、同一ディレクトリ内にある複数のファイルから1つのConfigMapを作成できます。ディレクトリをベースにConfigMapを作成する場合、kubectlはディレクトリ内でベース名が有効なキーであるファイルを識別し、それらのファイルを新たなConfigMapにパッケージ化します。ディレクトリ内にある通常のファイルでないものは無視されます(例: サブディレクトリ、シンボリックリンク、デバイス、パイプなど)。
例えば:
# ローカルディレクトリを作成します
mkdir -p configure-pod-container/configmap/
# `configure-pod-container/configmap/`ディレクトリにサンプルファイルをダウンロードします
wget https://kubernetes.io/examples/configmap/game.properties -O configure-pod-container/configmap/game.properties
wget https://kubernetes.io/examples/configmap/ui.properties -O configure-pod-container/configmap/ui.properties
# ConfigMapを作成します
kubectl create configmap game-config --from-file=configure-pod-container/configmap/
上記のコマンドは各ファイルをパッケージ化します。この場合、configure-pod-container/configmap/ ディレクトリのgame.properties と ui.propertiesをgame-config ConfigMapにパッケージ化します。 以下のコマンドを使用すると、ConfigMapの詳細を表示できます:
kubectl describe configmaps game-config
出力結果は以下のようになります:
Name: game-config
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties:
----
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
configure-pod-container/configmap/ ディレクトリのgame.properties と ui.properties ファイルはConfigMapのdataセクションに表示されます。
kubectl get configmaps game-config -o yaml
出力結果は以下のようになります:
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2016-02-18T18:52:05Z
name: game-config
namespace: default
resourceVersion: "516"
uid: b4952dc3-d670-11e5-8cd0-68f728db1985
data:
game.properties: |
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
kubectl create configmapを使用して、個別のファイルまたは複数のファイルからConfigMapを作成できます。
例えば、
kubectl create configmap game-config-2 --from-file=configure-pod-container/configmap/game.properties
は、以下のConfigMapを生成します:
kubectl describe configmaps game-config-2
出力結果は以下のようになります:
Name: game-config-2
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
--from-file引数を複数回渡し、ConfigMapを複数のデータソースから作成できます。
kubectl create configmap game-config-2 --from-file=configure-pod-container/configmap/game.properties --from-file=configure-pod-container/configmap/ui.properties
以下のコマンドを使用すると、ConfigMapgame-config-2の詳細を表示できます:
kubectl describe configmaps game-config-2
出力結果は以下のようになります:
Name: game-config-2
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties:
----
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
--from-env-fileオプションを利用してConfigMapをenv-fileから作成します。例えば:
# Env-filesは環境編集のリストを含んでいます。
# 以下のシンタックスルールが適用されます:
# envファイルの各行はVAR=VALの形式である必要がある。
# #で始まる行 (例えばコメント)は無視される。
# 空の行は無視される。
# クオーテーションマークは特別な扱いは処理をしない(例えばConfigMapの値の一部になる).
# `configure-pod-container/configmap/`ディレクトリにサンプルファイルをダウンロードします
wget https://kubernetes.io/examples/configmap/game-env-file.properties -O configure-pod-container/configmap/game-env-file.properties
# env-file `game-env-file.properties`は以下のようになります
cat configure-pod-container/configmap/game-env-file.properties
enemies=aliens
lives=3
allowed="true"
# このコメントと上記の空の行は無視されます
kubectl create configmap game-config-env-file \
--from-env-file=configure-pod-container/configmap/game-env-file.properties
は、以下のConfigMapを生成します:
kubectl get configmap game-config-env-file -o yaml
出力結果は以下のようになります:
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2017-12-27T18:36:28Z
name: game-config-env-file
namespace: default
resourceVersion: "809965"
uid: d9d1ca5b-eb34-11e7-887b-42010a8002b8
data:
allowed: '"true"'
enemies: aliens
lives: "3"
--from-env-fileを複数回渡してConfigMapを複数のデータソースから作成する場合、最後のenv-fileのみが使用されます。--from-env-fileを複数回渡す場合の挙動は以下のように示されます:
# `configure-pod-container/configmap/`ディレクトリにサンブルファイルをダウンロードします
wget https://kubernetes.io/examples/configmap/ui-env-file.properties -O configure-pod-container/configmap/ui-env-file.properties
# ConfigMapを作成します
kubectl create configmap config-multi-env-files \
--from-env-file=configure-pod-container/configmap/game-env-file.properties \
--from-env-file=configure-pod-container/configmap/ui-env-file.properties
は、以下のConfigMapを生成します:
kubectl get configmap config-multi-env-files -o yaml
出力結果は以下のようになります:
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2017-12-27T18:38:34Z
name: config-multi-env-files
namespace: default
resourceVersion: "810136"
uid: 252c4572-eb35-11e7-887b-42010a8002b8
data:
color: purple
how: fairlyNice
textmode: "true"
--from-file引数を使用する場合、ConfigMapのdata セクションでキーにファイル名以外を定義できます:
kubectl create configmap game-config-3 --from-file=<my-key-name>=<path-to-file>
<my-key-name>の部分はConfigMapで使うキー、<path-to-file> はキーで表示したいデータソースファイルの場所です。
例えば:
kubectl create configmap game-config-3 --from-file=game-special-key=configure-pod-container/configmap/game.properties
は、以下のConfigMapを生成します:
kubectl get configmaps game-config-3 -o yaml
出力結果は以下のようになります:
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2016-02-18T18:54:22Z
name: game-config-3
namespace: default
resourceVersion: "530"
uid: 05f8da22-d671-11e5-8cd0-68f728db1985
data:
game-special-key: |
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
--from-literal引数を指定してkubectl create configmapを使用すると、コマンドラインからリテラル値を定義できます:
kubectl create configmap special-config --from-literal=special.how=very --from-literal=special.type=charm
複数のキーバリューペアを渡せます。CLIに提供された各ペアは、ConfigMapのdataセクションで別のエントリーとして表示されます。
kubectl get configmaps special-config -o yaml
出力結果は以下のようになります:
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2016-02-18T19:14:38Z
name: special-config
namespace: default
resourceVersion: "651"
uid: dadce046-d673-11e5-8cd0-68f728db1985
data:
special.how: very
special.type: charm
kubectlはkustomization.yamlを1.14からサポートしています。
ジェネレーターからConfigMapを作成して適用すると、APIサーバー上でオブジェクトを作成できます。ジェネレーターはディレクトリ内のkustomization.yamlで指定する必要があリます。
例えば、ファイルconfigure-pod-container/configmap/game.propertiesからConfigMapを生成するには、
# ConfigMapGeneratorを含むkustomization.yamlファイルを作成する
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: game-config-4
files:
- configure-pod-container/configmap/game.properties
EOF
ConfigMapを作成するためにkustomizationディレクトリを適用します。
kubectl apply -k .
configmap/game-config-4-m9dm2f92bt created
ConfigMapが作成されたことを以下のようにチェックできます:
kubectl get configmap
NAME DATA AGE
game-config-4-m9dm2f92bt 1 37s
kubectl describe configmaps/game-config-4-m9dm2f92bt
Name: game-config-4-m9dm2f92bt
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","data":{"game.properties":"enemies=aliens\nlives=3\nenemies.cheat=true\nenemies.cheat.level=noGoodRotten\nsecret.code.p...
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
Events: <none>
生成されたConfigMapの名前は、コンテンツをハッシュ化したサフィックスを持つことに注意してください。これにより、コンテンツが変更されるたびに新しいConfigMapが生成されます。
ConfigMapジェネレーターで使用するキーはファイルの名前以外を定義できます。
例えば、ファイルconfigure-pod-container/configmap/game.propertiesからキーgame-special-keyを持つConfigMapを作成する場合
# ConfigMapGeneratorを含むkustomization.yamlファイルを作成する
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: game-config-5
files:
- game-special-key=configure-pod-container/configmap/game.properties
EOF
kustomizationディレクトリを適用してConfigMapを作成します。
kubectl apply -k .
configmap/game-config-5-m67dt67794 created
リテラルspecial.type=charmとspecial.how=veryからConfigMapを作成する場合は、
以下のようにkustomization.yamlのConfigMapジェネレーターで指定できます。
# ConfigMapGeneratorを含むkustomization.yamlファイルを作成します
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: special-config-2
literals:
- special.how=very
- special.type=charm
EOF
kustomizationディレクトリを適用してConfigMapを作成します。
kubectl apply -k .
configmap/special-config-2-c92b5mmcf2 created
ConfigMapに環境変数をキーバリューペアとして定義します:
kubectl create configmap special-config --from-literal=special.how=very
ConfigMapに定義された値special.howをPod specificationの環境変数SPECIAL_LEVEL_KEYに割り当てます。
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "/bin/sh", "-c", "env" ]
env:
# 環境変数を定義します
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
# SPECIAL_LEVEL_KEYに割り当てる値をConfigMapが保持します
name: special-config
# 値に紐付けるキーを指定します
key: special.how
restartPolicy: Never
Podを作成します:
kubectl create -f https://kubernetes.io/examples/pods/pod-single-configmap-env-variable.yaml
すると、Podの出力結果に環境変数SPECIAL_LEVEL_KEY=veryが含まれています。
先ほどの例の通り、まずはConfigMapを作成します。
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
---
apiVersion: v1
kind: ConfigMap
metadata:
name: env-config
namespace: default
data:
log_level: INFO
ConfigMapを作成します:
kubectl create -f https://kubernetes.io/examples/configmap/configmaps.yaml
Pod specificationの環境変数を定義します
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "/bin/sh", "-c", "env" ]
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.how
- name: LOG_LEVEL
valueFrom:
configMapKeyRef:
name: env-config
key: log_level
restartPolicy: Never
Podを作成します:
kubectl create -f https://kubernetes.io/examples/pods/pod-multiple-configmap-env-variable.yaml
すると、Podの出力結果に環境変数SPECIAL_LEVEL_KEY=very and LOG_LEVEL=INFOが含まれています。
複数のキーバリューペアを含むConfigMapを作成します。
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
SPECIAL_LEVEL: very
SPECIAL_TYPE: charm
ConfigMapを作成します:
kubectl create -f https://kubernetes.io/examples/configmap/configmap-multikeys.yaml
envFromを利用して全てのConfigMapのデータをコンテナ環境変数として定義します。ConfigMapからのキーがPodの環境変数名になります。apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "/bin/sh", "-c", "env" ]
envFrom:
- configMapRef:
name: special-config
restartPolicy: Never
Podを作成します:
kubectl create -f https://kubernetes.io/examples/pods/pod-configmap-envFrom.yaml
すると、Podの出力結果は環境変数SPECIAL_LEVEL=veryとSPECIAL_TYPE=charmが含まれています。
ConfigMapに環境変数を定義し、Pod specificationのcommand セクションで$(VAR_NAME)Kubernetes置換構文を介して使用できます。
例えば以下のPod specificationは
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "/bin/echo", "$(SPECIAL_LEVEL_KEY) $(SPECIAL_TYPE_KEY)" ]
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: SPECIAL_LEVEL
- name: SPECIAL_TYPE_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: SPECIAL_TYPE
restartPolicy: Never
以下コマンドの実行で作成され、
kubectl create -f https://kubernetes.io/examples/pods/pod-configmap-env-var-valueFrom.yaml
test-containerコンテナで以下の出力結果を表示します:
kubectl logs dapi-test-pod
very charm
ファイルからConfigMapを作成するで説明したように、--from-fileを使用してConfigMapを作成する場合は、ファイル名がConfigMapのdataセクションに保存されるキーになり、ファイルのコンテンツがキーの値になります。
このセクションの例は以下に示されているspecial-configと名付けれたConfigMapについて言及したものです。
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
SPECIAL_LEVEL: very
SPECIAL_TYPE: charm
ConfigMapを作成します:
kubectl create -f https://kubernetes.io/examples/configmap/configmap-multikeys.yaml
ConfigMap名をPod specificationのvolumesセクション配下に追加します。
これによりConfigMapデータがvolumeMounts.mountPathで指定されたディレクトリに追加されます (このケースでは、/etc/configに)。commandセクションはConfigMapのキーに合致したディレクトリファイルを名前別でリスト表示します。
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "/bin/sh", "-c", "ls /etc/config/" ]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
# コンテナに追加するファイルを含むConfigMapの名前を提供する
name: special-config
restartPolicy: Never
Podを作成します:
kubectl create -f https://kubernetes.io/examples/pods/pod-configmap-volume.yaml
Podが稼働していると、ls /etc/config/は以下の出力結果を表示します:
SPECIAL_LEVEL
SPECIAL_TYPE
/etc/config/ディレクトリに何かファイルがある場合、それらは削除されます。pathフィールドを利用して特定のConfigMapのアイテム向けに希望のファイルパスを指定します。
このケースではSPECIAL_LEVELアイテムが/etc/config/keysのconfig-volumeボリュームにマウントされます。
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "/bin/sh","-c","cat /etc/config/keys" ]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: special-config
items:
- key: SPECIAL_LEVEL
path: keys
restartPolicy: Never
Podを作成します:
kubectl create -f https://kubernetes.io/examples/pods/pod-configmap-volume-specific-key.yaml
Podが稼働していると、 cat /etc/config/keysは以下の出力結果を表示します:
very
/etc/config/ ディレクトリのこれまでのファイルは全て削除されますキーをファイル単位で特定のパスとアクセス許可に投影できます。Secretのユーザーガイドで構文が解説されています。
ボリュームで使用されているConfigMapが更新されている場合、投影されているキーも同じく結果的に更新されます。kubeletは定期的な同期ごとにマウントされているConfigMapが更新されているかチェックします。しかし、これはローカルのttlを基にしたキャッシュでConfigMapの現在の値を取得しています。その結果、新しいキーがPodに投影されてからConfigMapに更新されるまでのトータルの遅延はkubeletで、kubeletの同期期間(デフォルトで1分) + ConfigMapキャッシュのttl(デフォルトで1分)の長さになる可能性があります。Podのアノテーションを1つ更新すると即時のリフレッシュをトリガーできます。
ConfigMap APIリソースは構成情報をキーバリューペアとして保存します。データはPodで利用したり、コントローラーなどのシステムコンポーネントに提供できます。ConfigMapはSecretに似ていますが、機密情報を含まない文字列を含まない操作する手段を提供します。ユーザーとシステムコンポーネントはどちらも構成情報をConfigMapに保存できます。
/etcディレクトリとそのコンテンツのように捉えましょう。例えば、Kubernetes VolumeをConfigMapから作成した場合、ConfigMapのデータアイテムはボリューム内で個別のファイルとして表示されます。ConfigMapのdataフィールドは構成情報を含みます。下記の例のように、シンプルに個別のプロパティーを--from-literalで定義、または複雑に構成ファイルまたはJSON blobsを--from-fileで定義できます。
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2016-02-18T19:14:38Z
name: example-config
namespace: default
data:
# --from-literalを使用してシンプルにプロパティーを定義する例
example.property.1: hello
example.property.2: world
# --from-fileを使用して複雑にプロパティーを定義する例
example.property.file: |-
property.1=value-1
property.2=value-2
property.3=value-3
ConfigMapはPod specificationを参照させる前に作成する必要があります(ConfigMapを"optional"として設定しない限り)。存在しないConfigMapを参照させた場合、Podは起動しません。同様にConfigMapに存在しないキーを参照させた場合も、Podは起動しません。
ConfigMapでenvFromを使用して環境変数を定義した場合、無効と判断されたキーはスキップされます。Podは起動されますが、無効な名前はイベントログに(InvalidVariableNames)と記録されます。ログメッセージはスキップされたキーごとにリスト表示されます。例えば:
kubectl get events
出力結果は以下のようになります:
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON SOURCE MESSAGE
0s 0s 1 dapi-test-pod Pod Warning InvalidEnvironmentVariableNames {kubelet, 127.0.0.1} Keys [1badkey, 2alsobad] from the EnvFrom configMap default/myconfig were skipped since they are considered invalid environment variable names.
ConfigMapは特定のNamespaceに属します。ConfigMapは同じ名前空間に属するPodからのみ参照できます。
static podsはKubeletがサポートしていないため、ConfigMapに使用できません。
Kubernetes v1.17 [stable]このページでは、プロセス名前空間を共有するPodを構成する方法を示します。 プロセス名前空間の共有が有効になっている場合、コンテナ内のプロセスは、そのPod内の他のすべてのコンテナに表示されます。
この機能を使用して、ログハンドラーサイドカーコンテナなどの協調コンテナを構成したり、シェルなどのデバッグユーティリティを含まないコンテナイメージをトラブルシューティングしたりできます。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.10. バージョンを確認するには次のコマンドを実行してください:kubectl version.プロセス名前空間の共有は、v1.PodSpecのshareProcessNamespaceフィールドを使用して有効にします。
例:
クラスターにPod nginxを作成します:
kubectl apply -f https://k8s.io/examples/pods/share-process-namespace.yaml
shellコンテナにアタッチしてpsを実行します:
kubectl exec -it nginx -c shell -- /bin/sh
コマンドプロンプトが表示されない場合は、Enterキーを押してみてください。
/ # ps ax
PID USER TIME COMMAND
1 root 0:00 /pause
8 root 0:00 nginx: master process nginx -g daemon off;
14 101 0:00 nginx: worker process
15 root 0:00 sh
21 root 0:00 ps ax
他のコンテナのプロセスにシグナルを送ることができます。
たとえば、ワーカープロセスを再起動するには、SIGHUPをnginxに送信します。
この操作にはSYS_PTRACE機能が必要です。
/ # kill -HUP 8
/ # ps ax
PID USER TIME COMMAND
1 root 0:00 /pause
8 root 0:00 nginx: master process nginx -g daemon off;
15 root 0:00 sh
22 101 0:00 nginx: worker process
23 root 0:00 ps ax
/proc/$pid/rootリンクを使用して別のコンテナイメージにアクセスすることもできます。
/ # head /proc/8/root/etc/nginx/nginx.conf
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
Podは多くのリソースを共有するため、プロセスの名前空間も共有することになります。 ただし、一部のコンテナイメージは他のコンテナから分離されることが期待されるため、これらの違いを理解することが重要です:
コンテナプロセスは PID 1ではなくなります。
一部のコンテナイメージは、PID 1なしで起動することを拒否し(たとえば、systemdを使用するコンテナ)、kill -HUP 1などのコマンドを実行してコンテナプロセスにシグナルを送信します。
共有プロセス名前空間を持つPodでは、kill -HUP 1はPodサンドボックスにシグナルを送ります。(上の例では/pause)
プロセスはPod内の他のコンテナに表示されます。
これには、引数または環境変数として渡されたパスワードなど、/procに表示されるすべての情報が含まれます。
これらは、通常のUnixアクセス許可によってのみ保護されます。
コンテナファイルシステムは、/proc/$pid/rootリンクを介してPod内の他のコンテナに表示されます。
これによりデバッグが容易になりますが、ファイルシステム内の秘密情報はファイルシステムのアクセス許可によってのみ保護されることも意味します。
Static Podとは、APIサーバーが監視せず、特定のノード上のkubeletデーモンによって直接管理されるPodです。コントロールプレーンに管理されるPod(たとえばDeploymentなど)とは異なり、kubeletがそれぞれのstatic Podを監視(および障害時には再起動)します。
Static Podは、常に特定のノード上の1つのKubeletに紐付けられます。
kubeletは、各static Podに対して、自動的にKubernetes APIサーバー上にミラーPodの作成を試みます。つまり、ノード上で実行中のPodはAPIサーバーから検出されますが、APIサーバー自身から制御されることはないということです。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.このページの説明では、Podを実行するためにDockerを使用しており、ノード上のOSがFedoraであることを前提としています。他のディストリビューションやKubernetesのインストール方法によっては、操作が異なる場合があります。
static Podは、ファイルシステム上でホストされた設定ファイルまたはウェブ上でホストされた設定ファイルを使用して設定できます。
マニフェストは、JSONまたはYAML形式の標準のPod定義で、特定のディレクトリに置きます。kubeletの設定ファイルの中で、staticPodPath: <ディレクトリの場所>というフィールドを使用すると、kubeletがこのディレクトリを定期的にスキャンして、YAML/JSONファイルが作成/削除されるたびに、static Podの作成/削除が行われるようになります。指定したディレクトリをスキャンする際、kubeletはドットから始まる名前のファイルを無視することに注意してください。
例として、単純なウェブサーバーをstatic Podとして実行する方法を示します。
static Podを実行したいノードを選択します。この例では、my-node1です。
ssh my-node1
ディレクトリを選び(ここでは/etc/kubelet.dとします)、ここにウェブサーバーのPodの定義を置きます。たとえば、/etc/kubelet.d/static-web.yamlに置きます。
# このコマンドは、kubeletが実行中のノード上で実行してください
mkdir /etc/kubelet.d/
cat <<EOF >/etc/kubelet.d/static-web.yaml
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
EOF
ノード上のkubeletがこのディレクトリを使用するようにするために、--pod-manifest-path=/etc/kubelet.d/引数を付けてkubeletを実行するように設定します。Fedoraの場合、次の行が含まれるように/etc/kubernetes/kubeletを編集します。
KUBELET_ARGS="--cluster-dns=10.254.0.10 --cluster-domain=kube.local --pod-manifest-path=/etc/kubelet.d/"
あるいは、kubeletの設定ファイルに、staticPodPath: <ディレクトリの場所>フィールドを追加することでも設定できます。
kubeletを再起動します。Fedoraの場合、次のコマンドを実行します。
# このコマンドは、kubeletが実行中のノード上で実行してください
systemctl restart kubelet
kubeletは、--manifest-url=<URL>引数で指定されたファイルを定期的にダウンロードし、Podの定義が含まれたJSON/YAMLファイルとして解釈します。kubeletは、ファイルシステム上でホストされたマニフェストでの動作方法と同じように、定期的にマニフェストを再取得します。static Podのリスト中に変更が見つかると、kubeletがその変更を適用します。
このアプローチを採用する場合、次のように設定します。
YAMLファイルを作成し、kubeletにファイルのURLを渡せるようにするために、ウェブサーバー上に保存する。
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
選択したノード上のkubeletを--manifest-url=<manifest-url>を使用して実行することで、このウェブ上のマニフェストを使用するように設定する。Fedoraの場合、/etc/kubernetes/kubeletに次の行が含まれるように編集します。
KUBELET_ARGS="--cluster-dns=10.254.0.10 --cluster-domain=kube.local --manifest-url=<マニフェストのURL"
kubeletを再起動する。Fedoraの場合、次のコマンドを実行します。
# このコマンドは、kubeletが実行中のノード上で実行してください
systemctl restart kubelet
kubeletが起動すると、定義されたすべてのstatic Podを起動します。ここまででstatic Podを設定してkubeletを再起動したため、すでに新しいstatic Podが実行中になっているはずです。
次のコマンドを(ノード上で)実行することで、(static Podを含む)実行中のコンテナを確認できます。
# このコマンドは、kubeletが実行中のノード上で実行してください
docker ps
出力は次のようになります。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f6d05272b57e nginx:latest "nginx" 8 minutes ago Up 8 minutes k8s_web.6f802af4_static-web-fk-node1_default_67e24ed9466ba55986d120c867395f3c_378e5f3c
APIサーバー上では、ミラーPodを確認できます。
kubectl get pods
NAME READY STATUS RESTARTS AGE
static-web-my-node1 1/1 Running 0 2m
static Podに付けたラベルはミラーPodに伝搬します。ミラーPodに付けたラベルは、通常のPodと同じようにセレクターなどから利用できます。
もしkubectlを使用してAPIサーバーからミラーPodを削除しようとしても、kubeletはstatic Podを削除しません。
kubectl delete pod static-web-my-node1
pod "static-web-my-node1" deleted
Podはまだ実行中であることがわかります。
kubectl get pods
NAME READY STATUS RESTARTS AGE
static-web-my-node1 1/1 Running 0 12s
kubeletが実行中のノードに戻り、Dockerコンテナを手動で停止してみることができます。しばらくすると、kubeletが変化に気づき、Podを自動的に再起動することがわかります。
# このコマンドは、kubeletが実行中のノード上で実行してください
docker stop f6d05272b57e # 実際のコンテナIDと置き換えてください
sleep 20
docker ps
CONTAINER ID IMAGE COMMAND CREATED ...
5b920cbaf8b1 nginx:latest "nginx -g 'daemon of 2 seconds ago ...
実行中のkubeletは設定ディレクトリ(この例では/etc/kubelet.d)の変更を定期的にスキャンし、このディレクトリ内にファイルが追加/削除されると、Podの追加/削除を行います。
# This assumes you are using filesystem-hosted static Pod configuration
# このコマンドは、kubeletが実行中のノード上で実行してください
#
mv /etc/kubernetes/manifests/static-web.yaml /tmp
sleep 20
docker ps
# You see that no nginx container is running
mv /tmp/static-web.yaml /etc/kubernetes/manifests/
sleep 20
docker ps
CONTAINER ID IMAGE COMMAND CREATED ...
e7a62e3427f1 nginx:latest "nginx -g 'daemon of 27 seconds ago
時には物事がうまくいかないこともあります。このガイドは、それらを正すことを目的としています。
2つのセクションから構成されています:
また、使用しているリリースの既知の問題を確認する必要があります。
もしあなたの問題が上記のどのガイドでも解決されない場合は、Kubernetesコミュニティから助けを得るための様々な方法があります。
本サイトのドキュメントは、様々な疑問に対する答えを提供するために構成されています。
コンセプトでは、Kubernetesのアーキテクチャと各コンポーネントの動作について説明し、セットアップでは、使い始めるための実用的な手順を提供しています。
タスク は、よく使われるタスクの実行方法を示し、 チュートリアルは、実世界の業界特有、またはエンドツーエンドの開発シナリオ、より包括的なウォークスルーとなります。
リファレンスセクションでは、Kubernetes APIやkubectlなどのコマンドラインインターフェース(CLI)に関する詳しいドキュメントが提供されています。
コミュニティの誰かがすでに同じような質問をしている可能性があり、あなたの問題を解決できるかもしれません。 KubernetesチームもKubernetesタグが付けられた投稿を監視しています。 もし役立つ既存の質問がない場合は、新しく質問する前に、あなたの質問がStack Overflowのトピックに沿ったものであることを確認し、新しく質問する方法のガイダンスに目を通してください!
Kubernetesコミュニティの多くの人々は、Kubernetes Slackの#kubernetes-usersチャンネルに集まっています。
Slackは登録が必要です。招待をリクエストすることができ、登録は誰でも可能です。
お気軽にお越しいただき、何でも質問してください。
登録が完了したら、WebブラウザまたはSlackの専用アプリからKubernetes organization in Slackにアクセスします。
登録が完了したら、増え続けるチャンネルリストを見て、興味のある様々なテーマについて調べてみましょう。
たとえば、Kubernetesの初心者は、#kubernetes-noviceに参加してみるのもよいでしょう。
別の例として、開発者は#kubernetes-contributorsチャンネルに参加するとよいでしょう。
また、多くの国別/言語別チャンネルがあります。これらのチャンネルに参加すれば、地域特有のサポートや情報を得ることができます。
| Country | Channels |
|---|---|
| 中国 | #cn-users, #cn-events |
| フィンランド | #fi-users |
| フランス | #fr-users, #fr-events |
| ドイツ | #de-users, #de-events |
| インド | #in-users, #in-events |
| イタリア | #it-users, #it-events |
| 日本 | #jp-users, #jp-events |
| 韓国 | #kr-users |
| オランダ | #nl-users |
| ノルウェー | #norw-users |
| ポーランド | #pl-users |
| ロシア | #ru-users |
| スペイン | #es-users |
| スウェーデン | #se-users |
| トルコ | #tr-users, #tr-events |
Kubernetesの公式フォーラムへの参加は大歓迎ですdiscuss.kubernetes.io。
バグらしきものを発見した場合、または機能要望を出したい場合、GitHub課題追跡システムをご利用ください。 課題を提出する前に、既存の課題を検索して、あなたの課題が解決されているかどうかを確認してください。
バグを報告する場合は、そのバグを再現するための詳細な情報を含めてください。
kubectl versionこのドキュメントには、コンテナ化されたアプリケーションの問題を解決するための、一連のリソースが記載されています。Kubernetesリソース(Pod、Service、StatefulSetなど)に関する一般的な問題や、コンテナ終了メッセージを理解するためのアドバイス、実行中のコンテナをデバッグする方法などが網羅されています。
このガイドは、Kubernetesにデプロイされ、正しく動作しないアプリケーションをユーザーがデバッグするためのものです。 これは、自分のクラスターをデバッグしたい人のためのガイドでは ありません。 そのためには、debug-clusterを確認する必要があります。
トラブルシューティングの最初のステップは切り分けです。何が問題なのでしょうか? Podなのか、レプリケーションコントローラーなのか、それともサービスなのか?
デバッグの第一歩は、Podを見てみることです。 以下のコマンドで、Podの現在の状態や最近のイベントを確認します。
kubectl describe pods ${POD_NAME}
Pod内のコンテナの状態を見てください。
すべてRunningですか? 最近、再起動がありましたか?
Podの状態に応じてデバッグを続けます。
PodがPendingで止まっている場合、それはノードにスケジュールできないことを意味します。
一般に、これはある種のリソースが不十分で、スケジューリングできないことが原因です。
上のkubectl describe ...コマンドの出力を見てください。
なぜあなたのPodをスケジュールできないのか、スケジューラーからのメッセージがあるはずです。 理由は以下の通りです。
リソースが不足しています。 クラスターのCPUまたはメモリーを使い果たしている可能性があります。Podを削除するか、リソースの要求値を調整するか、クラスターに新しいノードを追加する必要があります。詳しくはCompute Resources documentを参照してください。
あなたが使用しているのはhostPortです。 PodをhostPortにバインドすると、そのPodがスケジュールできる場所が限定されます。ほとんどの場合、hostPortは不要なので、Serviceオブジェクトを使ってPodを公開するようにしてください。もしhostPort が必要な場合は、Kubernetesクラスターのノード数だけPodをスケジュールすることができます。
PodがWaiting状態で止まっている場合、ワーカーノードにスケジュールされていますが、そのノード上で実行することができません。この場合も、kubectl describe ...の情報が参考になるはずです。Waiting状態のPodの最も一般的な原因は、コンテナイメージのプルに失敗することです。
確認すべきことは3つあります。
docker pull <image>を実行し、イメージをプルできるかどうか確認してください。Podがスケジュールされると、実行中のPodのデバッグで説明されている方法がデバッグに利用できるようになります。
Podが期待した動作をしない場合、ポッドの記述(ローカルマシンの mypod.yaml ファイルなど)に誤りがあり、Pod作成時にその誤りが黙って無視された可能性があります。Pod記述のセクションのネストが正しくないか、キー名が間違って入力されていることがよくあり、そのようなとき、そのキーは無視されます。たとえば、commandのスペルをcommndと間違えた場合、Podは作成されますが、あなたが意図したコマンドラインは使用されません。
まずPodを削除して、--validate オプションを付けて再度作成してみてください。
例えば、kubectl apply --validate -f mypod.yamlと実行します。
commandのスペルをcommndに間違えると、以下のようなエラーになります。
I0805 10:43:25.129850 46757 schema.go:126] unknown field: commnd
I0805 10:43:25.129973 46757 schema.go:129] this may be a false alarm, see https://github.com/kubernetes/kubernetes/issues/6842
pods/mypod
次に確認することは、apiserver上のPodが、作成しようとしたPod(例えば、ローカルマシンのyamlファイル)と一致しているかどうかです。
例えば、kubectl get pods/mypod -o yaml > mypod-on-apiserver.yaml を実行して、元のポッドの説明であるmypod.yamlとapiserverから戻ってきたmypod-on-apiserver.yamlを手動で比較してみてください。
通常、"apiserver" バージョンには、元のバージョンにはない行がいくつかあります。これは予想されることです。
しかし、もし元のバージョンにある行がapiserverバージョンにない場合、これはあなたのPod specに問題があることを示している可能性があります。
レプリケーションコントローラーはかなり単純なものです。
彼らはPodを作ることができるか、できないか、どちらかです。
もしPodを作成できないのであれば、上記の説明を参照して、Podをデバッグしてください。
また、kubectl describe rc ${CONTROLLER_NAME}を使用すると、レプリケーションコントローラーに関連するイベントを確認することができます。
Serviceは、Podの集合全体でロードバランシングを提供します。 Serviceが正しく動作しない原因には、いくつかの一般的な問題があります。
以下の手順は、Serviceの問題をデバッグするのに役立つはずです。
まず、Serviceに対応するEndpointが存在することを確認します。
全てのServiceオブジェクトに対して、apiserverは endpoints リソースを利用できるようにします。
このリソースは次のようにして見ることができます。
kubectl get endpoints ${SERVICE_NAME}
EndpointがServiceのメンバーとして想定されるPod数と一致していることを確認してください。 例えば、3つのレプリカを持つnginxコンテナ用のServiceであれば、ServiceのEndpointには3つの異なるIPアドレスが表示されるはずです。
Endpointが見つからない場合は、Serviceが使用しているラベルを使用してPodをリストアップしてみてください。 ラベルがあるところにServiceがあると想像してください。
...
spec:
- selector:
name: nginx
type: frontend
セレクタに一致するPodを一覧表示するには、次のコマンドを使用します。
kubectl get pods --selector=name=nginx,type=frontend
リストがServiceを提供する予定のPodと一致することを確認します。
PodのcontainerPortがServiceのtargetPortと一致することを確認します。
詳しくはServiceのデバッグを参照してください。
上記のいずれの方法でも問題が解決しない場合は、以下の手順に従ってください。
Serviceのデバッグに関するドキュメントで、Serviceが実行されていること、Endpointsがあること、Podsが実際にサービスを提供していること、DNSが機能していること、IPtablesルールがインストールされていること、kube-proxyが誤作動を起こしていないようなことを確認してください。
トラブルシューティングドキュメントに詳細が記載されています。
新規にKubernetesをインストールした環境でかなり頻繁に発生する問題は、Serviceが適切に機能しないというものです。Deployment(または他のワークロードコントローラー)を通じてPodを実行し、サービスを作成したにもかかわらず、アクセスしようとしても応答がありません。何が問題になっているのかを理解するのに、このドキュメントがきっと役立つでしょう。
ここでの多くのステップでは、クラスターで実行されているPodが見ているものを確認する必要があります。これを行う最も簡単な方法は、インタラクティブなalpineのPodを実行することです。
kubectl run -it --rm --restart=Never alpine --image=alpine sh
使用したい実行中のPodがすでにある場合は、以下のようにしてそのPod内でコマンドを実行できます。
kubectl exec <POD-NAME> -c <CONTAINER-NAME> -- <COMMAND>
このドキュメントのウォークスルーのために、いくつかのPodを実行しましょう。おそらくあなた自身のServiceをデバッグしているため、あなた自身の詳細に置き換えることもできますし、これに沿って2番目のデータポイントを取得することもできます。
kubectl create deployment hostnames --image=registry.k8s.io/serve_hostname
deployment.apps/hostnames created
kubectlコマンドは作成、変更されたリソースのタイプと名前を出力するため、この後のコマンドで使用することもできます。
Deploymentを3つのレプリカにスケールさせてみましょう。
kubectl scale deployment hostnames --replicas=3
deployment.apps/hostnames scaled
これは、次のYAMLでDeploymentを開始した場合と同じです。
apiVersion: apps/v1
kind: Deployment
metadata:
name: hostnames
labels:
app: hostnames
spec:
selector:
matchLabels:
app: hostnames
replicas: 3
template:
metadata:
labels:
app: hostnames
spec:
containers:
- name: hostnames
image: registry.k8s.io/serve_hostname
"app"ラベルはkubectl create deploymentによって、Deploymentの名前に自動的にセットされます。
Podが実行されていることを確認できます。
kubectl get pods -l app=hostnames
NAME READY STATUS RESTARTS AGE
hostnames-632524106-bbpiw 1/1 Running 0 2m
hostnames-632524106-ly40y 1/1 Running 0 2m
hostnames-632524106-tlaok 1/1 Running 0 2m
Podが機能していることも確認できます。Pod IP アドレスリストを取得し、直接テストできます。
kubectl get pods -l app=hostnames \
-o go-template='{{range .items}}{{.status.podIP}}{{"\n"}}{{end}}'
10.244.0.5
10.244.0.6
10.244.0.7
このウォークスルーに使用されるサンプルコンテナは、ポート9376でHTTPを介して独自のホスト名を提供するだけですが、独自のアプリをデバッグする場合は、Podがリッスンしているポート番号を使用する必要があります。
Pod内から実行します。
for ep in 10.244.0.5:9376 10.244.0.6:9376 10.244.0.7:9376; do
wget -qO- $ep
done
次のように表示されます。
hostnames-632524106-bbpiw
hostnames-632524106-ly40y
hostnames-632524106-tlaok
この時点で期待通りの応答が得られない場合、Podが正常でないか、想定しているポートでリッスンしていない可能性があります。なにが起きているかを確認するためにkubectl logsが役立ちます。Podに直接に入りデバッグする場合はkubectl execが必要になります。
これまでにすべての計画が完了していると想定すると、Serviceが機能しない理由を調査することができます。
賢明な読者は、Serviceをまだ実際に作成していないことにお気付きかと思いますが、これは意図的です。これは時々忘れられるステップであり、最初に確認すべきことです。
存在しないServiceにアクセスしようとするとどうなるでしょうか?このServiceを名前で利用する別のPodがあると仮定すると、次のような結果が得られます。
wget -O- hostnames
Resolving hostnames (hostnames)... failed: Name or service not known.
wget: unable to resolve host address 'hostnames'
最初に確認するのは、そのServiceが実際に存在するかどうかです。
kubectl get svc hostnames
No resources found.
Error from server (NotFound): services "hostnames" not found
Serviceを作成しましょう。前と同様に、これはウォークスルー用です。ご自身のServiceの詳細を使用することもできます。
kubectl expose deployment hostnames --port=80 --target-port=9376
service/hostnames exposed
そして、念のため内容を確認します。
kubectl get svc hostnames
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hostnames ClusterIP 10.0.1.175 <none> 80/TCP 5s
これで、Serviceが存在することがわかりました。
前と同様に、これは次のようなYAMLでServiceを開始した場合と同じです。
apiVersion: v1
kind: Service
metadata:
name: hostnames
spec:
selector:
app: hostnames
ports:
- name: default
protocol: TCP
port: 80
targetPort: 9376
構成の全範囲をハイライトするため、ここで作成したServiceはPodとは異なるポート番号を使用します。多くの実際のServiceでは、これらのポートは同じになる場合があります。
クライアントがサービスを使用する最も一般的な方法の1つは、DNS名を使用することです。同じNamespaceのPodから次のコマンドを実行してください。
nslookup hostnames
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: hostnames
Address 1: 10.0.1.175 hostnames.default.svc.cluster.local
これが失敗した場合、おそらくPodとServiceが異なるNamespaceにあるため、ネームスペースで修飾された名前を試してください。(Podの中からもう一度)
nslookup hostnames.default
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: hostnames.default
Address 1: 10.0.1.175 hostnames.default.svc.cluster.local
これが機能する場合、クロスネームスペース名を使用するようにアプリケーションを調整するか、同じNamespaceでアプリとServiceを実行する必要があります。これでも失敗する場合は、完全修飾名を試してください。
nslookup hostnames.default.svc.cluster.local
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: hostnames.default.svc.cluster.local
Address 1: 10.0.1.175 hostnames.default.svc.cluster.local
ここでのサフィックス"default.svc.cluster.local"に注意してください。"default"は、操作しているNamespaceです。"svc"は、これがServiceであることを示します。"cluster.local"はクラスタードメインであり、あなたのクラスターでは異なる場合があります。
クラスター内のノードからも試すこともできます。
nslookup hostnames.default.svc.cluster.local 10.0.0.10
Server: 10.0.0.10
Address: 10.0.0.10#53
Name: hostnames.default.svc.cluster.local
Address: 10.0.1.175
完全修飾名では検索できるのに、相対名ではできない場合、Podの/etc/resolv.confファイルが正しいことを確認する必要があります。Pod内から実行します。
cat /etc/resolv.conf
次のように表示されます。
nameserver 10.0.0.10
search default.svc.cluster.local svc.cluster.local cluster.local example.com
options ndots:5
nameserver行はクラスターのDNS Serviceを示さなければなりません。これは、--cluster-dnsフラグでkubeletに渡されます。
search行には、Service名を見つけるための適切なサフィックスを含める必要があります。この場合、ローカルのNamespaceでServiceを見つけるためのサフィックス(default.svc.cluster.local)、すべてのNamespacesでServiceを見つけるためのサフィックス(svc.cluster.local)、およびクラスターのサフィックス(cluster.local)です。インストール方法によっては、その後に追加のレコードがある場合があります(合計6つまで)。クラスターのサフィックスは、--cluster-domainフラグを使用してkubeletに渡されます。このドキュメントではそれが"cluster.local"であると仮定していますが、あなたのクラスターでは異なる場合があります。その場合は、上記のすべてのコマンドでクラスターのサフィックスを変更する必要があります。
options行では、DNSクライアントライブラリーが検索パスをまったく考慮しないようにndotsを十分に高く設定する必要があります。Kubernetesはデフォルトでこれを5に設定します。これは、生成されるすべてのDNS名をカバーするのに十分な大きさです。
上記がまだ失敗する場合、DNSルックアップがServiceに対して機能していません。一歩離れて、他の何が機能していないかを確認しましょう。KubernetesマスターのServiceは常に機能するはずです。Pod内から実行します。
nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
これが失敗する場合は、このドキュメントのkube-proxyセクションを参照するか、このドキュメントの先頭に戻って最初からやり直してください。ただし、あなた自身のServiceをデバッグするのではなく、DNSサービスをデバッグします。
DNSサービスが正しく動作できると仮定すると、次にテストするのはIPによってServiceが動作しているかどうかです。上述のkubectl getで確認できるIPに、クラスター内のPodからアクセスします。
for i in $(seq 1 3); do
wget -qO- 10.0.1.175:80
done
次のように表示されます。
hostnames-0uton
hostnames-bvc05
hostnames-yp2kp
Serviceが機能している場合は、正しい応答が得られるはずです。そうでない場合、おかしい可能性のあるものがいくつかあるため、続けましょう。
馬鹿げているように聞こえるかもしれませんが、Serviceが正しく定義されPodのポートとマッチすることを二度、三度と確認すべきです。Serviceを読み返して確認しましょう。
kubectl get service hostnames -o json
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "hostnames",
"namespace": "default",
"uid": "428c8b6c-24bc-11e5-936d-42010af0a9bc",
"resourceVersion": "347189",
"creationTimestamp": "2015-07-07T15:24:29Z",
"labels": {
"app": "hostnames"
}
},
"spec": {
"ports": [
{
"name": "default",
"protocol": "TCP",
"port": 80,
"targetPort": 9376,
"nodePort": 0
}
],
"selector": {
"app": "hostnames"
},
"clusterIP": "10.0.1.175",
"type": "ClusterIP",
"sessionAffinity": "None"
},
"status": {
"loadBalancer": {}
}
}
spec.ports[]のリストのなかに定義されていますか?targetPortはPodに対して適切ですか(いくつかのPodはServiceとは異なるポートを使用します)?targetPortを数値で定義しようとしている場合、それは数値(9376)、文字列"9376"のどちらですか?targetPortを名前で定義しようとしている場合、Podは同じ名前でポートを公開していますか?protocolはPodに適切ですか?ここまで来たということは、Serviceは正しく定義され、DNSによって名前解決できることが確認できているでしょう。ここでは、実行したPodがServiceによって実際に選択されていることを確認しましょう。
以前に、Podが実行されていることを確認しました。再確認しましょう。
kubectl get pods -l app=hostnames
NAME READY STATUS RESTARTS AGE
hostnames-632524106-bbpiw 1/1 Running 0 1h
hostnames-632524106-ly40y 1/1 Running 0 1h
hostnames-632524106-tlaok 1/1 Running 0 1h
-l app=hostnames引数はラベルセレクターで、ちょうど私たちのServiceに定義されているものと同じです。
"AGE"列は、これらのPodが約1時間前のものであることを示しており、それらが正常に実行され、クラッシュしていないことを意味します。
"RESTARTS"列は、これらのポッドが頻繁にクラッシュしたり、再起動されていないことを示しています。頻繁に再起動すると、断続的な接続性の問題が発生する可能性があります。再起動回数が多い場合は、ポッドをデバッグするを参照してください。
Kubernetesシステム内には、すべてのServiceのセレクターを評価し、結果をEndpointsオブジェクトに保存するコントロールループがあります。
kubectl get endpoints hostnames
NAME ENDPOINTS
hostnames 10.244.0.5:9376,10.244.0.6:9376,10.244.0.7:9376
これにより、EndpointsコントローラーがServiceの正しいPodを見つけていることを確認できます。ENDPOINTS列が<none>の場合、Serviceのspec.selectorフィールドが実際にPodのmetadata.labels値を選択していることを確認する必要があります。よくある間違いは、タイプミスやその他のエラー、たとえばDeployment作成にもkubectl runが使われた1.18以前のバージョンのように、Serviceがapp=hostnamesを選択しているのにDeploymentがrun=hostnamesを指定していることです。
この時点で、Serviceが存在し、Podを選択していることがわかります。このウォークスルーの最初に、Pod自体を確認しました。Podが実際に機能していることを確認しましょう。Serviceメカニズムをバイパスして、上記EndpointsにリストされているPodに直接アクセスすることができます。
Pod内から実行します。
for ep in 10.244.0.5:9376 10.244.0.6:9376 10.244.0.7:9376; do
wget -qO- $ep
done
次のように表示されます。
hostnames-632524106-bbpiw
hostnames-632524106-ly40y
hostnames-632524106-tlaok
Endpointsリスト内の各Podは、それぞれの自身のホスト名を返すはずです。そうならない(または、あなた自身のPodの正しい振る舞いにならない)場合は、そこで何が起こっているのかを調査する必要があります。
ここに到達したのなら、Serviceは実行され、Endpointsがあり、Podが実際にサービスを提供しています。この時点で、Serviceのプロキシメカニズム全体が疑わしいです。ひとつひとつ確認しましょう。
Serviceのデフォルト実装、およびほとんどのクラスターで使用されるものは、kube-proxyです。kube-proxyはそれぞれのノードで実行され、Serviceの抽象化を提供するための小さなメカニズムセットの1つを構成するプログラムです。クラスターがkube-proxyを使用しない場合、以下のセクションは適用されず、使用しているServiceの実装を調査する必要があります。
kube-proxyがノード上で実行されていることを確認しましょう。ノードで実行されていれば、以下のような結果が得られるはずです。
ps auxw | grep kube-proxy
root 4194 0.4 0.1 101864 17696 ? Sl Jul04 25:43 /usr/local/bin/kube-proxy --master=https://kubernetes-master --kubeconfig=/var/lib/kube-proxy/kubeconfig --v=2
次に、マスターとの接続など、明らかな失敗をしていないことを確認します。これを行うには、ログを確認する必要があります。ログへのアクセス方法は、ノードのOSに依存します。一部のOSでは/var/log/kube-proxy.logのようなファイルですが、他のOSではjournalctlを使用してログにアクセスします。次のように表示されます。
I1027 22:14:53.995134 5063 server.go:200] Running in resource-only container "/kube-proxy"
I1027 22:14:53.998163 5063 server.go:247] Using iptables Proxier.
I1027 22:14:53.999055 5063 server.go:255] Tearing down userspace rules. Errors here are acceptable.
I1027 22:14:54.038140 5063 proxier.go:352] Setting endpoints for "kube-system/kube-dns:dns-tcp" to [10.244.1.3:53]
I1027 22:14:54.038164 5063 proxier.go:352] Setting endpoints for "kube-system/kube-dns:dns" to [10.244.1.3:53]
I1027 22:14:54.038209 5063 proxier.go:352] Setting endpoints for "default/kubernetes:https" to [10.240.0.2:443]
I1027 22:14:54.038238 5063 proxier.go:429] Not syncing iptables until Services and Endpoints have been received from master
I1027 22:14:54.040048 5063 proxier.go:294] Adding new service "default/kubernetes:https" at 10.0.0.1:443/TCP
I1027 22:14:54.040154 5063 proxier.go:294] Adding new service "kube-system/kube-dns:dns" at 10.0.0.10:53/UDP
I1027 22:14:54.040223 5063 proxier.go:294] Adding new service "kube-system/kube-dns:dns-tcp" at 10.0.0.10:53/TCP
マスターに接続できないことに関するエラーメッセージが表示された場合、ノードの設定とインストール手順をダブルチェックする必要があります。
kube-proxyが正しく実行できない理由の可能性の1つは、必須のconntrackバイナリが見つからないことです。これは、例えばKubernetesをスクラッチからインストールするなど、クラスターのインストール方法に依存して、一部のLinuxシステムで発生する場合があります。これが該当する場合は、conntrackパッケージを手動でインストール(例: Ubuntuではsudo apt install conntrack)する必要があり、その後に再試行する必要があります。
kube-proxyは、いくつかのモードのいずれかで実行できます。上記のログのUsing iptables Proxierという行は、kube-proxyが「iptables」モードで実行されていることを示しています。最も一般的な他のモードは「ipvs」です。古い「ユーザースペース」モードは、主にこれらに置き換えられました。
「iptables」モードでは、ノードに次のようなものが表示されます。
iptables-save | grep hostnames
-A KUBE-SEP-57KPRZ3JQVENLNBR -s 10.244.3.6/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-57KPRZ3JQVENLNBR -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.3.6:9376
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -s 10.244.1.7/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.1.7:9376
-A KUBE-SEP-X3P2623AGDH6CDF3 -s 10.244.2.3/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-X3P2623AGDH6CDF3 -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.2.3:9376
-A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames: cluster IP" -m tcp --dport 80 -j KUBE-SVC-NWV5X2332I4OT4T3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2IHDGP2BOBGZ
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-X3P2623AGDH6CDF3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -j KUBE-SEP-57KPRZ3JQVENLNBR
各サービスのポートごとに、KUBE-SERVICESに1つのルールと1つのKUBE-SVC- <hash>チェーンが必要です。Podエンドポイントごとに、そのKUBE-SVC- <hash>に少数のルールがあり、少数のルールが含まれる1つのKUBE-SEP- <hash>チェーンがあるはずです。正確なルールは、正確な構成(NodePortとLoadBalancerを含む)に基づいて異なります。
「ipvs」モードでは、ノードに次のようなものが表示されます。
ipvsadm -ln
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
...
TCP 10.0.1.175:80 rr
-> 10.244.0.5:9376 Masq 1 0 0
-> 10.244.0.6:9376 Masq 1 0 0
-> 10.244.0.7:9376 Masq 1 0 0
...
各Serviceの各ポートに加えて、NodePort、External IP、およびLoad Balancer IPに対して、kube-proxyは仮想サーバーを作成します。Pod endpointごとに、対応する実サーバーが作成されます。この例では、サービスhostnames(10.0.1.175:80)は3つのendpoints(10.244.0.5:9376、10.244.0.6:9376、10.244.0.7:9376)を持っています。
IPVSプロキシは、各Serviceアドレス(Cluster IP、External IP、NodePort IP、Load Balancer IPなど)毎の仮想サーバーと、Serviceのエンドポイントが存在する場合に対応する実サーバーを作成します。この例では、hostnames Service(10.0.1.175:80)は3つのエンドポイント(10.244.0.5:9376、10.244.0.6:9376、10.244.0.7:9376)を持ち、上と似た結果が得られるはずです。
まれに、「userspace」モードを使用している場合があります。
ノードから実行します。
iptables-save | grep hostnames
-A KUBE-PORTALS-CONTAINER -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames:default" -m tcp --dport 80 -j REDIRECT --to-ports 48577
-A KUBE-PORTALS-HOST -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames:default" -m tcp --dport 80 -j DNAT --to-destination 10.240.115.247:48577
サービスの各ポートには2つのルールが必要です(この例では1つだけ)-「KUBE-PORTALS-CONTAINER」と「KUBE-PORTALS-HOST」です。
「userspace」モードを使用する必要はほとんどないので、ここでこれ以上時間を費やすことはありません。
上記のいずれかが発生したと想定して、いずれかのノードからIPでサービスにアクセスをしています。
curl 10.0.1.175:80
hostnames-632524106-bbpiw
もしこれが失敗し、あなたがuserspaceプロキシを使用している場合、プロキシへの直接アクセスを試してみてください。もしiptablesプロキシを使用している場合、このセクションはスキップしてください。
上記のiptables-saveの出力を振り返り、kube-proxyがServiceに使用しているポート番号を抽出します。上記の例では"48577"です。このポートに接続してください。
curl localhost:48577
hostnames-632524106-tlaok
もしまだ失敗する場合は、kube-proxyログで次のような特定の行を探してください。
Setting endpoints for default/hostnames:default to [10.244.0.5:9376 10.244.0.6:9376 10.244.0.7:9376]
これらが表示されない場合は、-vフラグを4に設定してkube-proxyを再起動してから、再度ログを確認してください。
これはありそうに聞こえないかもしれませんが、実際には起こり、動作するはずです。これはネットワークが"hairpin"トラフィック用に適切に設定されていない場合、通常はkube-proxyがiptablesモードで実行され、Podがブリッジネットワークに接続されている場合に発生します。Kubeletはhairpin-modeフラグを公開します。これにより、Serviceのエンドポイントが自身のServiceのVIPにアクセスしようとした場合に、自身への負荷分散を可能にします。hairpin-modeフラグはhairpin-vethまたはpromiscuous-bridgeに設定する必要があります。
この問題をトラブルシューティングする一般的な手順は次のとおりです。
hairpin-modeがhairpin-vethまたはpromiscuous-bridgeに設定されていることを確認します。次のような表示がされるはずです。この例では、hairpin-modeはpromiscuous-bridgeに設定されています。ps auxw | grep kubelet
root 3392 1.1 0.8 186804 65208 ? Sl 00:51 11:11 /usr/local/bin/kubelet --enable-debugging-handlers=true --config=/etc/kubernetes/manifests --allow-privileged=True --v=4 --cluster-dns=10.0.0.10 --cluster-domain=cluster.local --configure-cbr0=true --cgroup-root=/ --system-cgroups=/system --hairpin-mode=promiscuous-bridge --runtime-cgroups=/docker-daemon --kubelet-cgroups=/kubelet --babysit-daemons=true --max-pods=110 --serialize-image-pulls=false --outofdisk-transition-frequency=0
hairpin-modeを確認します。これを行うには、kubeletログを確認する必要があります。ログへのアクセス方法は、ノードのOSによって異なります。一部のOSでは/var/log/kubelet.logなどのファイルですが、他のOSではjournalctlを使用してログにアクセスします。互換性のために、実際に使われているhairpin-modeが--hairpin-modeフラグと一致しない場合があることに注意してください。kubelet.logにキーワードhairpinを含むログ行があるかどうかを確認してください。実際に使われているhairpin-modeを示す以下のようなログ行があるはずです。I0629 00:51:43.648698 3252 kubelet.go:380] Hairpin mode set to "promiscuous-bridge"
hairpin-modeがhairpin-vethの場合、Kubeletにノードの/sysで操作する権限があることを確認します。すべてが正常に機能している場合、次のようなものが表示されます。for intf in /sys/devices/virtual/net/cbr0/brif/*; do cat $intf/hairpin_mode; done
1
1
1
1
実際に使われているhairpin-modeがpromiscuous-bridgeの場合、Kubeletにノード上のLinuxブリッジを操作する権限があることを確認してください。cbr0ブリッジが使用され適切に構成されている場合、以下が表示されます。
ifconfig cbr0 |grep PROMISC
UP BROADCAST RUNNING PROMISC MULTICAST MTU:1460 Metric:1
ここまでたどり着いたということは、とてもおかしなことが起こっています。Serviceは実行中で、Endpointsがあり、Podは実際にサービスを提供しています。DNSは動作していて、kube-proxyも誤動作していないようです。それでも、あなたのServiceは機能していません。おそらく私たちにお知らせ頂いた方がよいでしょう。調査をお手伝いします!
Slack、ForumまたはGitHubでお問い合わせください。
詳細については、トラブルシューティングドキュメントをご覧ください。
このページでは、コンテナ終了メッセージの読み書き方法を説明します。
終了メッセージは、致命的なイベントに関する情報を、ダッシュボードや監視ソフトウェアなどのツールで簡単に取得して表示できる場所にコンテナが書き込むための手段を提供します。 ほとんどの場合、終了メッセージに入力した情報も一般的なKubernetesログに書き込まれるはずです。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.この課題では、1つのコンテナを実行するPodを作成します。 設定ファイルには、コンテナの開始時に実行されるコマンドを指定します。
apiVersion: v1
kind: Pod
metadata:
name: termination-demo
spec:
containers:
- name: termination-demo-container
image: debian
command: ["/bin/sh"]
args: ["-c", "sleep 10 && echo Sleep expired > /dev/termination-log"]
YAML設定ファイルに基づいてPodを作成します:
kubectl apply -f https://k8s.io/examples/debug/termination.yaml
YAMLファイルのcommandフィールドとargsフィールドで、コンテナが10秒間スリープしてから/dev/termination-logファイルに「Sleep expired」と書いているのがわかります。コンテナが「Sleep expired」メッセージを書き込んだ後、コンテナは終了します。
Podに関する情報を表示します:
kubectl get pod termination-demo
Podが実行されなくなるまで、上記のコマンドを繰り返します。
Podに関する詳細情報を表示します:
kubectl get pod termination-demo --output=yaml
出力には「Sleep expired」メッセージが含まれています:
apiVersion: v1
kind: Pod
...
lastState:
terminated:
containerID: ...
exitCode: 0
finishedAt: ...
message: |
Sleep expired
...
Goテンプレートを使用して、終了メッセージのみが含まれるように出力をフィルタリングします:
kubectl get pod termination-demo -o go-template="{{range .status.containerStatuses}}{{.lastState.terminated.message}}{{end}}"
Kubernetesは、コンテナのterminationMessagePathフィールドで指定されている終了メッセージファイルから終了メッセージを取得します。デフォルト値は/dev/termination-logです。このフィールドをカスタマイズすることで、Kubernetesに別のファイルを使うように指示できます。Kubernetesは指定されたファイルの内容を使用して、成功と失敗の両方についてコンテナのステータスメッセージを入力します。
終了メッセージはアサーションエラーメッセージのように、最終状態を簡潔に示します。kubeletは4096バイトより長いメッセージは切り詰めます。全コンテナの合計メッセージの長さの上限は12キビバイトです。デフォルトの終了メッセージのパスは/dev/termination-logです。Pod起動後に終了メッセージのパスを設定することはできません。
次の例では、コンテナはKubernetesが取得するために終了メッセージを/tmp/my-logに書き込みます:
apiVersion: v1
kind: Pod
metadata:
name: msg-path-demo
spec:
containers:
- name: msg-path-demo-container
image: debian
terminationMessagePath: "/tmp/my-log"
さらに、ユーザーは追加のカスタマイズをするためにContainerのterminationMessagePolicyフィールドを設定できます。このフィールドのデフォルト値はFileです。これは、終了メッセージが終了メッセージファイルからのみ取得されることを意味します。terminationMessagePolicyをFallbackToLogsOnErrorに設定することで、終了メッセージファイルが空でコンテナがエラーで終了した場合に、コンテナログ出力の最後のチャンクを使用するようにKubernetesに指示できます。ログ出力は、2048バイトまたは80行のどちらか小さい方に制限されています。
terminationMessagePathフィールド参照このタスクでは、StatefulSetをデバッグする方法を説明します。
StatefulSetに属し、ラベルapp=myappが設定されているすべてのPodを一覧表示するには、以下のコマンドを利用できます。
kubectl get pods -l app=myapp
Podが長期間UnknownまたはTerminatingの状態になっていることがわかった場合は、それらを処理する方法についてStatefulSetの削除タスクを参照してください。
Podのデバッグガイドを使用して、StatefulSet内の個々のPodをデバッグできます。
このページでは、Initコンテナの実行に関連する問題を調査する方法を説明します。以下のコマンドラインの例では、Podを<pod-name>、Initコンテナを<init-container-1>および<init-container-2>として参照しています。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.Podのステータスを表示します:
kubectl get pod <pod-name>
たとえば、Init:1/2というステータスは、2つのInitコンテナのうちの1つが正常に完了したことを示します。
NAME READY STATUS RESTARTS AGE
<pod-name> 0/1 Init:1/2 0 7s
ステータス値とその意味の例については、Podのステータスを理解するを参照してください。
Initコンテナの実行に関する詳細情報を表示します:
kubectl describe pod <pod-name>
たとえば、2つのInitコンテナを持つPodでは、次のように表示されます:
Init Containers:
<init-container-1>:
Container ID: ...
...
State: Terminated
Reason: Completed
Exit Code: 0
Started: ...
Finished: ...
Ready: True
Restart Count: 0
...
<init-container-2>:
Container ID: ...
...
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Exit Code: 1
Started: ...
Finished: ...
Ready: False
Restart Count: 3
...
また、Pod Specのstatus.initContainerStatusesフィールドを読むことでプログラムでInitコンテナのステータスにアクセスすることもできます。:
kubectl get pod nginx --template '{{.status.initContainerStatuses}}'
このコマンドは生のJSONで上記と同じ情報を返します。
ログにアクセスするには、Initコンテナ名とPod名を渡します。
kubectl logs <pod-name> -c <init-container-2>
シェルスクリプトを実行するInitコンテナは、実行時にコマンドを出力します。たとえば、スクリプトの始めにset -xを実行することでBashで同じことができます。
Init:で始まるPodステータスはInitコンテナの実行ステータスを要約します。以下の表は、Initコンテナのデバッグ中に表示される可能性のあるステータス値の例をいくつか示しています。
| ステータス | 意味 |
|---|---|
Init:N/M | PodはM個のInitコンテナを持ち、これまでにN個完了しました。 |
Init:Error | Initコンテナが実行に失敗しました。 |
Init:CrashLoopBackOff | Initコンテナが繰り返し失敗しました。 |
Pending | PodはまだInitコンテナの実行を開始していません。 |
PodInitializing or Running | PodはすでにInitコンテナの実行を終了しています。 |
このページでは、ノード上で動作している(またはクラッシュしている)Podをデバッグする方法について説明します。
あなたのPodは既にスケジュールされ、実行されているはずです。Podがまだ実行されていない場合は、アプリケーションのトラブルシューティングから始めてください。
いくつかの高度なデバッグ手順では、Podがどのノードで動作しているかを知り、そのノードでコマンドを実行するためのシェルアクセス権を持っていることが必要です。kubectlを使用する標準的なデバッグ手順の実行には、そのようなアクセスは必要ではありません。
kubectl describe podを使ってpodの詳細を取得この例では、先ほどの例と同様に、Deploymentを使用して2つのpodを作成します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 80
以下のコマンドを実行して、Deploymentを作成します:
kubectl apply -f https://k8s.io/examples/application/nginx-with-request.yaml
deployment.apps/nginx-deployment created
以下のコマンドでPodの状態を確認します:
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-1006230814-6winp 1/1 Running 0 11s
nginx-deployment-1006230814-fmgu3 1/1 Running 0 11s
kubectl describe podを使うと、これらのPodについてより多くの情報を得ることができます。
例えば:
kubectl describe pod nginx-deployment-1006230814-6winp
Name: nginx-deployment-1006230814-6winp
Namespace: default
Node: kubernetes-node-wul5/10.240.0.9
Start Time: Thu, 24 Mar 2016 01:39:49 +0000
Labels: app=nginx,pod-template-hash=1006230814
Annotations: kubernetes.io/created-by={"kind":"SerializedReference","apiVersion":"v1","reference":{"kind":"ReplicaSet","namespace":"default","name":"nginx-deployment-1956810328","uid":"14e607e7-8ba1-11e7-b5cb-fa16" ...
Status: Running
IP: 10.244.0.6
Controllers: ReplicaSet/nginx-deployment-1006230814
Containers:
nginx:
Container ID: docker://90315cc9f513c724e9957a4788d3e625a078de84750f244a40f97ae355eb1149
Image: nginx
Image ID: docker://6f62f48c4e55d700cf3eb1b5e33fa051802986b77b874cc351cce539e5163707
Port: 80/TCP
QoS Tier:
cpu: Guaranteed
memory: Guaranteed
Limits:
cpu: 500m
memory: 128Mi
Requests:
memory: 128Mi
cpu: 500m
State: Running
Started: Thu, 24 Mar 2016 01:39:51 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-5kdvl (ro)
Conditions:
Type Status
Initialized True
Ready True
PodScheduled True
Volumes:
default-token-4bcbi:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4bcbi
Optional: false
QoS Class: Guaranteed
Node-Selectors: <none>
Tolerations: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
54s 54s 1 {default-scheduler } Normal Scheduled Successfully assigned nginx-deployment-1006230814-6winp to kubernetes-node-wul5
54s 54s 1 {kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Pulling pulling image "nginx"
53s 53s 1 {kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Pulled Successfully pulled image "nginx"
53s 53s 1 {kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Created Created container with docker id 90315cc9f513
53s 53s 1 {kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Started Started container with docker id 90315cc9f513
ここでは、コンテナ(複数可)とPodに関する構成情報(ラベル、リソース要件など)や、コンテナ(複数可)とPodに関するステータス情報(状態、準備状況、再起動回数、イベントなど)を確認できます。
コンテナの状態は、Waiting(待機中)、Running(実行中)、Terminated(終了)のいずれかです。状態に応じて、追加の情報が提供されます。ここでは、Running状態のコンテナについて、コンテナがいつ開始されたかが表示されています。
Readyは、コンテナが最後のReadiness Probeに合格したかどうかを示す。(この場合、コンテナにはReadiness Probeが設定されていません。Readiness Probeが設定されていない場合、コンテナは準備が完了した状態であるとみなされます)。
Restart Countは、コンテナが何回再起動されたかを示します。この情報は、再起動ポリシーが「always」に設定されているコンテナのクラッシュループを検出するのに役立ちます。
現在、Podに関連する条件は、二値のReady条件のみです。これは、Podがリクエストに対応可能であり、マッチングするすべてのサービスのロードバランシングプールに追加されるべきであることを示します。
最後に、Podに関連する最近のイベントのログが表示されます。このシステムでは、複数の同一イベントを圧縮して、最初に見られた時刻と最後に見られた時刻、そして見られた回数を示します。"From"はイベントを記録しているコンポーネントを示し、"SubobjectPath"はどのオブジェクト(例: Pod内のコンテナ)が参照されているかを示し、"Reason"と "Message"は何が起こったかを示しています。
イベントを使って検出できる一般的なシナリオは、どのノードにも収まらないPodを作成した場合です。例えば、Podがどのノードでも空いている以上のリソースを要求したり、どのノードにもマッチしないラベルセレクターを指定したりする場合です。例えば、各(仮想)マシンが1つのCPUを持つ4ノードのクラスター上で、(2つではなく)5つのレプリカを持ち、500ではなく600ミリコアを要求する前のDeploymentを作成したとします。この場合、Podの1つがスケジュールできなくなります。(なお、各ノードではfluentdやskydnsなどのクラスターアドオンPodが動作しているため、もし1000ミリコアを要求した場合、どのPodもスケジュールできなくなります)
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-1006230814-6winp 1/1 Running 0 7m
nginx-deployment-1006230814-fmgu3 1/1 Running 0 7m
nginx-deployment-1370807587-6ekbw 1/1 Running 0 1m
nginx-deployment-1370807587-fg172 0/1 Pending 0 1m
nginx-deployment-1370807587-fz9sd 0/1 Pending 0 1m
nginx-deployment-1370807587-fz9sdのPodが実行されていない理由を調べるには、保留中のPodに対してkubectl describe podを使用し、そのイベントを見てみましょう
kubectl describe pod nginx-deployment-1370807587-fz9sd
Name: nginx-deployment-1370807587-fz9sd
Namespace: default
Node: /
Labels: app=nginx,pod-template-hash=1370807587
Status: Pending
IP:
Controllers: ReplicaSet/nginx-deployment-1370807587
Containers:
nginx:
Image: nginx
Port: 80/TCP
QoS Tier:
memory: Guaranteed
cpu: Guaranteed
Limits:
cpu: 1
memory: 128Mi
Requests:
cpu: 1
memory: 128Mi
Environment Variables:
Volumes:
default-token-4bcbi:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4bcbi
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 48s 7 {default-scheduler } Warning FailedScheduling pod (nginx-deployment-1370807587-fz9sd) failed to fit in any node
fit failure on node (kubernetes-node-6ta5): Node didn't have enough resource: CPU, requested: 1000, used: 1420, capacity: 2000
fit failure on node (kubernetes-node-wul5): Node didn't have enough resource: CPU, requested: 1000, used: 1100, capacity: 2000
ここでは、理由 FailedScheduling (およびその他の理由)でPodのスケジュールに失敗したという、スケジューラーによって生成されたイベントを見ることができます。このメッセージは、どのノードでもPodに十分なリソースがなかったことを示しています。
この状況を修正するには、kubectl scaleを使用して、4つ以下のレプリカを指定するようにDeploymentを更新します。(あるいは、1つのPodを保留にしたままにしておいても害はありません。)
kubectl describe podの最後に出てきたようなイベントは、etcdに永続化され、クラスターで何が起こっているかについての高レベルの情報を提供します。
すべてのイベントをリストアップするには、次のようにします:
kubectl get events
しかし、イベントは名前空間に所属することを忘れてはいけません。つまり、名前空間で管理されているオブジェクトのイベントに興味がある場合(例: 名前空間 my-namespaceのPods で何が起こったか)、コマンドに名前空間を明示的に指定する必要があります。
kubectl get events --namespace=my-namespace
すべての名前空間からのイベントを見るには、--all-namespaces 引数を使用できます。
kubectl describe podに加えて、(kubectl get pod で提供される以上の)Podに関する追加情報を得るためのもう一つの方法は、-o yaml出力形式フラグを kubectl get podに渡すことです。これにより、kubectl describe podよりもさらに多くの情報、つまりシステムが持っているPodに関するすべての情報をYAML形式で得ることができます。ここでは、アノテーション(Kubernetesのシステムコンポーネントが内部的に使用している、ラベル制限のないキーバリューのメタデータ)、再起動ポリシー、ポート、ボリュームなどが表示されます。
kubectl get pod nginx-deployment-1006230814-6winp -o yaml
apiVersion: v1
kind: Pod
metadata:
annotations:
kubernetes.io/created-by: |
{"kind":"SerializedReference","apiVersion":"v1","reference":{"kind":"ReplicaSet","namespace":"default","name":"nginx-deployment-1006230814","uid":"4c84c175-f161-11e5-9a78-42010af00005","apiVersion":"extensions","resourceVersion":"133434"}}
creationTimestamp: 2016-03-24T01:39:50Z
generateName: nginx-deployment-1006230814-
labels:
app: nginx
pod-template-hash: "1006230814"
name: nginx-deployment-1006230814-6winp
namespace: default
resourceVersion: "133447"
uid: 4c879808-f161-11e5-9a78-42010af00005
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
ports:
- containerPort: 80
protocol: TCP
resources:
limits:
cpu: 500m
memory: 128Mi
requests:
cpu: 500m
memory: 128Mi
terminationMessagePath: /dev/termination-log
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-4bcbi
readOnly: true
dnsPolicy: ClusterFirst
nodeName: kubernetes-node-wul5
restartPolicy: Always
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
volumes:
- name: default-token-4bcbi
secret:
secretName: default-token-4bcbi
status:
conditions:
- lastProbeTime: null
lastTransitionTime: 2016-03-24T01:39:51Z
status: "True"
type: Ready
containerStatuses:
- containerID: docker://90315cc9f513c724e9957a4788d3e625a078de84750f244a40f97ae355eb1149
image: nginx
imageID: docker://6f62f48c4e55d700cf3eb1b5e33fa051802986b77b874cc351cce539e5163707
lastState: {}
name: nginx
ready: true
restartCount: 0
state:
running:
startedAt: 2016-03-24T01:39:51Z
hostIP: 10.240.0.9
phase: Running
podIP: 10.244.0.6
startTime: 2016-03-24T01:39:49Z
例えば、ノード上で動作しているPodのおかしな挙動に気付いたり、Podがノード上でスケジュールされない原因を探ったりと、デバッグ時にノードのステータスを見ることが有用な場合があります。Podと同様に、kubectl describe nodeやkubectl get node -o yamlを使ってノードの詳細情報を取得することができます。例えば、ノードがダウンした場合(ネットワークから切断された、またはkubeletが死んで再起動しないなど)に表示される内容は以下の通りです。ノードがNotReadyであることを示すイベントに注目してください。また、Podが実行されなくなっていることにも注目してください(NotReady状態が5分続くと、Podは退避されます)。
kubectl get nodes
NAME STATUS ROLES AGE VERSION
kubernetes-node-861h NotReady <none> 1h v1.13.0
kubernetes-node-bols Ready <none> 1h v1.13.0
kubernetes-node-st6x Ready <none> 1h v1.13.0
kubernetes-node-unaj Ready <none> 1h v1.13.0
kubectl describe node kubernetes-node-861h
Name: kubernetes-node-861h
Role
Labels: kubernetes.io/arch=amd64
kubernetes.io/os=linux
kubernetes.io/hostname=kubernetes-node-861h
Annotations: node.alpha.kubernetes.io/ttl=0
volumes.kubernetes.io/controller-managed-attach-detach=true
Taints: <none>
CreationTimestamp: Mon, 04 Sep 2017 17:13:23 +0800
Phase:
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
OutOfDisk Unknown Fri, 08 Sep 2017 16:04:28 +0800 Fri, 08 Sep 2017 16:20:58 +0800 NodeStatusUnknown Kubelet stopped posting node status.
MemoryPressure Unknown Fri, 08 Sep 2017 16:04:28 +0800 Fri, 08 Sep 2017 16:20:58 +0800 NodeStatusUnknown Kubelet stopped posting node status.
DiskPressure Unknown Fri, 08 Sep 2017 16:04:28 +0800 Fri, 08 Sep 2017 16:20:58 +0800 NodeStatusUnknown Kubelet stopped posting node status.
Ready Unknown Fri, 08 Sep 2017 16:04:28 +0800 Fri, 08 Sep 2017 16:20:58 +0800 NodeStatusUnknown Kubelet stopped posting node status.
Addresses: 10.240.115.55,104.197.0.26
Capacity:
cpu: 2
hugePages: 0
memory: 4046788Ki
pods: 110
Allocatable:
cpu: 1500m
hugePages: 0
memory: 1479263Ki
pods: 110
System Info:
Machine ID: 8e025a21a4254e11b028584d9d8b12c4
System UUID: 349075D1-D169-4F25-9F2A-E886850C47E3
Boot ID: 5cd18b37-c5bd-4658-94e0-e436d3f110e0
Kernel Version: 4.4.0-31-generic
OS Image: Debian GNU/Linux 8 (jessie)
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://1.12.5
Kubelet Version: v1.6.9+a3d1dfa6f4335
Kube-Proxy Version: v1.6.9+a3d1dfa6f4335
ExternalID: 15233045891481496305
Non-terminated Pods: (9 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
......
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
CPU Requests CPU Limits Memory Requests Memory Limits
------------ ---------- --------------- -------------
900m (60%) 2200m (146%) 1009286400 (66%) 5681286400 (375%)
Events: <none>
kubectl get node kubernetes-node-861h -o yaml
apiVersion: v1
kind: Node
metadata:
creationTimestamp: 2015-07-10T21:32:29Z
labels:
kubernetes.io/hostname: kubernetes-node-861h
name: kubernetes-node-861h
resourceVersion: "757"
uid: 2a69374e-274b-11e5-a234-42010af0d969
spec:
externalID: "15233045891481496305"
podCIDR: 10.244.0.0/24
providerID: gce://striped-torus-760/us-central1-b/kubernetes-node-861h
status:
addresses:
- address: 10.240.115.55
type: InternalIP
- address: 104.197.0.26
type: ExternalIP
capacity:
cpu: "1"
memory: 3800808Ki
pods: "100"
conditions:
- lastHeartbeatTime: 2015-07-10T21:34:32Z
lastTransitionTime: 2015-07-10T21:35:15Z
reason: Kubelet stopped posting node status.
status: Unknown
type: Ready
nodeInfo:
bootID: 4e316776-b40d-4f78-a4ea-ab0d73390897
containerRuntimeVersion: docker://Unknown
kernelVersion: 3.16.0-0.bpo.4-amd64
kubeProxyVersion: v0.21.1-185-gffc5a86098dc01
kubeletVersion: v0.21.1-185-gffc5a86098dc01
machineID: ""
osImage: Debian GNU/Linux 7 (wheezy)
systemUUID: ABE5F6B4-D44B-108B-C46A-24CCE16C8B6E
まず、影響を受けるコンテナのログを見ます。
kubectl logs ${POD_NAME} ${CONTAINER_NAME}
コンテナが以前にクラッシュしたことがある場合、次のコマンドで以前のコンテナのクラッシュログにアクセスすることができます:
kubectl logs --previous ${POD_NAME} ${CONTAINER_NAME}
もしcontainer imageがデバッグユーティリティを含んでいれば、LinuxやWindows OSのベースイメージからビルドしたイメージのように、kubectl execで特定のコンテナ内でコマンドを実行することが可能です:
kubectl exec ${POD_NAME} -c ${CONTAINER_NAME} -- ${CMD} ${ARG1} ${ARG2} ... ${ARGN}
-c ${CONTAINER_NAME}は省略可能です。コンテナを1つだけ含むPodの場合は省略できます。例として、実行中のCassandra Podからログを見るには、次のように実行します。
kubectl exec cassandra -- cat /var/log/cassandra/system.log
例えばkubectl execの-iと-t引数を使って、端末に接続されたシェルを実行することができます:
kubectl exec -it cassandra -- sh
詳しくは、実行中のコンテナへのシェルを取得するを参照してください。
Kubernetes v1.25 [stable]エフェメラルコンテナは、コンテナがクラッシュしたり、コンテナイメージにデバッグユーティリティが含まれていないなどの理由でkubectl execが不十分な場合に、対話的にトラブルシューティングを行うのに便利です(ディストロレスイメージの場合など)。
実行中のPodにエフェメラルコンテナを追加するには、kubectl debugコマンドを使用することができます。
まず、サンプル用のPodを作成します:
kubectl run ephemeral-demo --image=registry.k8s.io/pause:3.1 --restart=Never
このセクションの例では、デバッグユーティリティが含まれていないpauseコンテナイメージを使用していますが、この方法はすべてのコンテナイメージで動作します。
もし、kubectl execを使用してシェルを作成しようとすると、このコンテナイメージにはシェルが存在しないため、エラーが表示されます。
kubectl exec -it ephemeral-demo -- sh
OCI runtime exec failed: exec failed: container_linux.go:346: starting container process caused "exec: \"sh\": executable file not found in $PATH": unknown
代わりに、kubectl debugを使ってデバッグ用のコンテナを追加することができます。
引数に-i/--interactiveを指定すると、kubectlは自動的にエフェメラルコンテナのコンソールにアタッチされます。
kubectl debug -it ephemeral-demo --image=busybox:1.28 --target=ephemeral-demo
Defaulting debug container name to debugger-8xzrl.
If you don't see a command prompt, try pressing enter.
/ #
このコマンドは新しいbusyboxコンテナを追加し、それにアタッチします。--targetパラメーターは、他のコンテナのプロセス名前空間をターゲットにします。これはkubectl runが作成するPodでプロセス名前空間の共有を有効にしないため、指定する必要があります。
--targetパラメーターはContainer Runtimeでサポートされている必要があります。サポートされていない場合、エフェメラルコンテナは起動されないか、psが他のコンテナ内のプロセスを表示しないように孤立したプロセス名前空間を使用して起動されます。新しく作成されたエフェメラルコンテナの状態はkubectl describeを使って見ることができます:
kubectl describe pod ephemeral-demo
...
Ephemeral Containers:
debugger-8xzrl:
Container ID: docker://b888f9adfd15bd5739fefaa39e1df4dd3c617b9902082b1cfdc29c4028ffb2eb
Image: busybox
Image ID: docker-pullable://busybox@sha256:1828edd60c5efd34b2bf5dd3282ec0cc04d47b2ff9caa0b6d4f07a21d1c08084
Port: <none>
Host Port: <none>
State: Running
Started: Wed, 12 Feb 2020 14:25:42 +0100
Ready: False
Restart Count: 0
Environment: <none>
Mounts: <none>
...
終了したらkubectl deleteを使ってPodを削除してください:
kubectl delete pod ephemeral-demo
Podの設定オプションによって、特定の状況でのトラブルシューティングが困難になることがあります。
例えば、コンテナイメージにシェルが含まれていない場合、またはアプリケーションが起動時にクラッシュした場合は、kubectl execを実行してトラブルシューティングを行うことができません。
このような状況では、kubectl debugを使用してデバッグを支援するために設定値を変更したPodのコピーを作ることができます。
新しいコンテナを追加することは、アプリケーションは動作しているが期待通りの動作をせず、トラブルシューティングユーティリティをPodに追加したい場合に便利です。
例えば、アプリケーションのコンテナイメージはbusybox上にビルドされているが、busyboxに含まれていないデバッグユーティリティが必要な場合があります。このシナリオはkubectl runを使ってシミュレーションすることができます。
kubectl run myapp --image=busybox:1.28 --restart=Never -- sleep 1d
このコマンドを実行すると、myappのコピーにmyapp-debugという名前が付き、デバッグ用の新しいUbuntuコンテナが追加されます。
kubectl debug myapp -it --image=ubuntu --share-processes --copy-to=myapp-debug
Defaulting debug container name to debugger-w7xmf.
If you don't see a command prompt, try pressing enter.
root@myapp-debug:/#
kubectl debugは--containerフラグでコンテナ名を選択しない場合、自動的にコンテナ名を生成します。
iフラグを指定すると、デフォルトでkubectl debugが新しいコンテナにアタッチされます。これを防ぐには、--attach=falseを指定します。セッションが切断された場合は、kubectl attachを使用して再接続することができます。
--share-processesを指定すると、このPod内のコンテナが、Pod内の他のコンテナのプロセスを参照することができます。この仕組みについて詳しくは、Pod内のコンテナ間でプロセス名前空間を共有するを参照してください。
デバッグが終わったら、Podの後始末をするのを忘れないでください。
kubectl delete pod myapp myapp-debug
例えば、デバッグフラグを追加する場合や、アプリケーションがクラッシュしている場合などでは、コンテナのコマンドを変更すると便利なことがあります。
アプリケーションのクラッシュをシミュレートするには、kubectl runを使用して、すぐに終了するコンテナを作成します:
kubectl run --image=busybox:1.28 myapp -- false
kubectl describe pod myappを使用すると、このコンテナがクラッシュしていることがわかります:
Containers:
myapp:
Image: busybox
...
Args:
false
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Exit Code: 1
kubectl debugを使うと、コマンドをインタラクティブシェルに変更したこのPodのコピーを作成することができます。
kubectl debug myapp -it --copy-to=myapp-debug --container=myapp -- sh
If you don't see a command prompt, try pressing enter.
/ #
これで、ファイルシステムのパスのチェックやコンテナコマンドの手動実行などのタスクを実行するために使用できる対話型シェルが完成しました。
特定のコンテナのコマンドを変更するには、そのコンテナ名を--containerで指定する必要があります。そうしなければ、指定したコマンドを実行するための新しいコンテナを、kubectl debugが代わりに作成します。
-iフラグは、デフォルトでkubectl debugがコンテナにアタッチされるようにします。これを防ぐには、--attach=falseを指定します。セッションが切断された場合は、kubectl attachを使用して再接続することができます。
デバッグが終わったら、Podの後始末をするのを忘れないでください:
kubectl delete pod myapp myapp-debug
状況によっては、動作不良のPodを通常のプロダクション用のコンテナイメージから、デバッグビルドや追加ユーティリティを含むイメージに変更したい場合があります。
例として、kubectl runを使用してPodを作成します:
kubectl run myapp --image=busybox:1.28 --restart=Never -- sleep 1d
ここで、kubectl debugを使用してコピーを作成し、そのコンテナイメージをubuntuに変更します:
kubectl debug myapp --copy-to=myapp-debug --set-image=*=ubuntu
--set-imageの構文は、kubectl set imageと同じcontainer_name=imageの構文を使用します。*=ubuntuは、全てのコンテナのイメージをubuntuに変更することを意味します。
デバッグが終わったら、Podの後始末をするのを忘れないでください:
kubectl delete pod myapp myapp-debug
いずれの方法でもうまくいかない場合は、Podが動作しているノードを探し出し、ホストの名前空間で動作するデバッグ用のPodを作成します。
ノード上でkubectl debugを使って対話型のシェルを作成するには、以下を実行します:
kubectl debug node/mynode -it --image=ubuntu
Creating debugging pod node-debugger-mynode-pdx84 with container debugger on node mynode.
If you don't see a command prompt, try pressing enter.
root@ek8s:/#
ノードでデバッグセッションを作成する場合、以下の点に注意してください:
kubectl debugはノードの名前に基づいて新しいPodの名前を自動的に生成します。/hostにマウントされます。chroot /hostの実行に失敗する場合があります。--profile=sysadminを使用してください。デバッグが終わったら、Podの後始末をするのを忘れないでください:
kubectl delete pod node-debugger-mynode-pdx84
kubectl debugでノードやPodをデバッグする場合、デバッグ用のPod、エフェメラルコンテナ、またはコピーされたPodにデバッグプロファイルを適用できます。
デバッグプロファイルを適用することで、securityContextなど特定のプロパティが設定され、
さまざまなシナリオに適応できるようになります。
デバッグプロファイルにはスタティックプロファイルとカスタムプロファイルの2種類があります。
スタティックプロファイルは事前に定義されたプロパティの組み合わせで構成され、--profileフラグを使用して適用できます。
使用可能なスタティックプロファイルは以下の通りです:
| Profile | Description |
|---|---|
| legacy | v1.22と互換性を保つプロパティのセット |
| general | 各デバッグシナリオに対応する汎用的なプロパティのセット |
| baseline | PodSecurityStandard baseline policy に準拠したプロパティのセット |
| restricted | PodSecurityStandard restricted policyに準拠したプロパティのセット |
| netadmin | ネットワーク管理者権限を含むプロパティのセット |
| sysadmin | システム管理者(root)権限を含むプロパティのセット |
--profileを指定しない場合、デフォルトでlegacyプロファイルが使用されます。
legacyプロファイルは将来的に廃止される予定であるため、generalプロファイルなどの他のプロファイルを使用することを推奨します。例えば、myappという名前のPodを作成し、デバッグを行います:
kubectl run myapp --image=busybox:1.28 --restart=Never -- sleep 1d
エフェメラルコンテナを使用して、Podをデバッグします。
エフェメラルコンテナに特権が必要な場合は、sysadminプロファイルを使用できます:
kubectl debug -it myapp --image=busybox:1.28 --target=myapp --profile=sysadmin
Targeting container "myapp". If you don't see processes from this container it may be because the container runtime doesn't support this feature.
Defaulting debug container name to debugger-6kg4x.
If you don't see a command prompt, try pressing enter.
/ #
コンテナで次のコマンドを実行して、エフェメラルコンテナプロセスのケーパビリティを確認します:
/ # grep Cap /proc/$$/status
...
CapPrm: 000001ffffffffff
CapEff: 000001ffffffffff
...
この結果は、sysadminプロファイルを適用したことで、エフェメラルコンテナプロセスに特権が付与されていることを示しています。
詳細はコンテナにケーパビリティを設定するを参照してください。
エフェメラルコンテナが特権コンテナであることは、次のコマンドからも確認できます:
kubectl get pod myapp -o jsonpath='{.spec.ephemeralContainers[0].securityContext}'
{"privileged":true}
確認が終わったらPodを削除します:
kubectl delete pod myapp
Kubernetes v1.31 [beta]デバッグに使用するコンテナのspecをYAMLまたはJSON形式でカスタムプロファイルとして定義し、--customフラグを使用して適用できます。
name, image, command, lifecycle
および volumeDevicesフィールドの変更は許可されません。
また、Podのspecの変更もサポートされていません。例えば、myappという名前のPodを作成します:
kubectl run myapp --image=busybox:1.28 --restart=Never -- sleep 1d
YAMLまたはJSON形式でカスタムプロファイルを作成します。
ここでは、custom-profile.yamlという名前のYAML形式のファイルを作成します:
env:
- name: ENV_VAR_1
value: value_1
- name: ENV_VAR_2
value: value_2
securityContext:
capabilities:
add:
- NET_ADMIN
- SYS_TIME
次のコマンドを実行することで、エフェメラルコンテナにカスタムプロファイルを適用し、Podをデバッグします:
kubectl debug -it myapp --image=busybox:1.28 --target=myapp --profile=general --custom=custom-profile.yaml
Podにカスタムプロファイルが適用された状態のエフェメラルコンテナが追加されたことを確認できます:
kubectl get pod myapp -o jsonpath='{.spec.ephemeralContainers[0].env}'
[{"name":"ENV_VAR_1","value":"value_1"},{"name":"ENV_VAR_2","value":"value_2"}]
kubectl get pod myapp -o jsonpath='{.spec.ephemeralContainers[0].securityContext}'
{"capabilities":{"add":["NET_ADMIN","SYS_TIME"]}}
確認が終わったらPodを削除します:
kubectl delete pod myapp
このページはkubectl execを使用して実行中のコンテナへのシェルを取得する方法を説明します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
このエクササイズでは、1つのコンテナを持つPodを作成します。 コンテナはnginxのイメージを実行します。以下がそのPodの設定ファイルです:
apiVersion: v1
kind: Pod
metadata:
name: shell-demo
spec:
volumes:
- name: shared-data
emptyDir: {}
containers:
- name: nginx
image: nginx
volumeMounts:
- name: shared-data
mountPath: /usr/share/nginx/html
Podを作成します:
kubectl apply -f https://k8s.io/examples/application/shell-demo.yaml
コンテナが実行中であることを確認します:
kubectl get pod shell-demo
実行中のコンテナへのシェルを取得します:
kubectl exec --stdin --tty shell-demo -- /bin/bash
--)のセパレーターは、コマンドに渡す引数とkubectlの引数を分離します。シェル内で、ルートディレクトリーのファイル一覧を表示します:
# このコマンドをコンテナ内で実行します
ls /
シェル内で、他のコマンドを試しましょう。以下がいくつかの例です:
# これらのサンプルコマンドをコンテナ内で実行することができます
ls /
cat /proc/mounts
cat /proc/1/maps
apt-get update
apt-get install -y tcpdump
tcpdump
apt-get install -y lsof
lsof
apt-get install -y procps
ps aux
ps aux | grep nginx
Podの設定ファイルを再度確認します。PodはemptyDirボリュームを持ち、
コンテナは/usr/share/nginx/htmlボリュームをマウントします。
シェル内で、/usr/share/nginx/htmlディレクトリにindex.htmlを作成します。
# このコマンドをコンテナ内で実行します
echo 'Hello shell demo' > /usr/share/nginx/html/index.html
シェル内で、nginxサーバーにGETリクエストを送信します:
# これらのコマンドをコンテナ内のシェルで実行します
apt-get update
apt-get install curl
curl http://localhost/
出力にindex.htmlファイルに書き込んだ文字列が表示されます:
Hello shell demo
シェルを終了する場合、exitを入力します。
exit # コンテナ内のシェルを終了する
シェルではない通常のコマンドウインドウ内で、実行中のコンテナの環境変数の一覧を表示します:
kubectl exec shell-demo -- env
他のコマンドを試します。以下がいくつかの例です:
kubectl exec shell-demo -- ps aux
kubectl exec shell-demo -- ls /
kubectl exec shell-demo -- cat /proc/1/mounts
Podが1つ以上のコンテナを持つ場合、--containerか-cを使用して、kubectl execコマンド内でコンテナを指定します。
例えば、my-podという名前のPodがあり、そのPodが main-app と helper-app という2つのコンテナを持つとします。
以下のコマンドは main-app のコンテナへのシェルを開きます。
kubectl exec -i -t my-pod --container main-app -- /bin/bash
-iと-tは、ロングオプションの--stdinと--ttyと同様です。このドキュメントはクラスターのトラブルシューティングに関するもので、あなたが経験している問題の根本原因として、アプリケーションをすでに除外していることを前提としています。 アプリケーションのデバッグのコツは、アプリケーションのトラブルシューティングガイドをご覧ください。 また、トラブルシューティングドキュメントにも詳しい情報があります。
kubectlのトラブルシューティングについては、kubectlのトラブルシューティングを参照してください。
クラスターで最初にデバッグするのは、ノードがすべて正しく登録されているかどうかです。
以下を実行します。
kubectl get nodes
そして、期待するノードがすべて存在し、それらがすべて Ready 状態であることを確認します。
クラスター全体の健全性に関する詳細な情報を得るには、以下を実行します。
kubectl cluster-info dump
デバッグを行う際、ノードの状態を見ることが有用なことがあります。
たとえば、そのノード上で動作しているPodが奇妙な挙動を示している場合や、なぜPodがそのノードにスケジュールされないのかを知りたい場合などです。
Podと同様に、kubectl describe nodeやkubectl get node -o yamlを使用してノードに関する詳細情報を取得できます。
例えば、ノードがダウンしている(ネットワークから切断されている、またはkubeletが停止して再起動しないなど)場合に見られる状況は以下の通りです。
ノードがNotReadyであることを示すイベントに注意し、また、Podが動作していないことにも注意してください(NotReady状態が5分間続くとPodは追い出されます)。
kubectl get nodes
NAME STATUS ROLES AGE VERSION
kube-worker-1 NotReady <none> 1h v1.23.3
kubernetes-node-bols Ready <none> 1h v1.23.3
kubernetes-node-st6x Ready <none> 1h v1.23.3
kubernetes-node-unaj Ready <none> 1h v1.23.3
kubectl describe node kube-worker-1
Name: kube-worker-1
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=kube-worker-1
kubernetes.io/os=linux
Annotations: kubeadm.alpha.kubernetes.io/cri-socket: /run/containerd/containerd.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Thu, 17 Feb 2022 16:46:30 -0500
Taints: node.kubernetes.io/unreachable:NoExecute
node.kubernetes.io/unreachable:NoSchedule
Unschedulable: false
Lease:
HolderIdentity: kube-worker-1
AcquireTime: <unset>
RenewTime: Thu, 17 Feb 2022 17:13:09 -0500
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Thu, 17 Feb 2022 17:09:13 -0500 Thu, 17 Feb 2022 17:09:13 -0500 WeaveIsUp Weave pod has set this
MemoryPressure Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
DiskPressure Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
PIDPressure Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
Ready Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
Addresses:
InternalIP: 192.168.0.113
Hostname: kube-worker-1
Capacity:
cpu: 2
ephemeral-storage: 15372232Ki
hugepages-2Mi: 0
memory: 2025188Ki
pods: 110
Allocatable:
cpu: 2
ephemeral-storage: 14167048988
hugepages-2Mi: 0
memory: 1922788Ki
pods: 110
System Info:
Machine ID: 9384e2927f544209b5d7b67474bbf92b
System UUID: aa829ca9-73d7-064d-9019-df07404ad448
Boot ID: 5a295a03-aaca-4340-af20-1327fa5dab5c
Kernel Version: 5.13.0-28-generic
OS Image: Ubuntu 21.10
Operating System: linux
Architecture: amd64
Container Runtime Version: containerd://1.5.9
Kubelet Version: v1.23.3
Kube-Proxy Version: v1.23.3
Non-terminated Pods: (4 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default nginx-deployment-67d4bdd6f5-cx2nz 500m (25%) 500m (25%) 128Mi (6%) 128Mi (6%) 23m
default nginx-deployment-67d4bdd6f5-w6kd7 500m (25%) 500m (25%) 128Mi (6%) 128Mi (6%) 23m
kube-system kube-proxy-dnxbz 0 (0%) 0 (0%) 0 (0%) 0 (0%) 28m
kube-system weave-net-gjxxp 100m (5%) 0 (0%) 200Mi (10%) 0 (0%) 28m
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1100m (55%) 1 (50%)
memory 456Mi (24%) 256Mi (13%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
...
kubectl get node kube-worker-1 -o yaml
apiVersion: v1
kind: Node
metadata:
annotations:
kubeadm.alpha.kubernetes.io/cri-socket: /run/containerd/containerd.sock
node.alpha.kubernetes.io/ttl: "0"
volumes.kubernetes.io/controller-managed-attach-detach: "true"
creationTimestamp: "2022-02-17T21:46:30Z"
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/os: linux
kubernetes.io/arch: amd64
kubernetes.io/hostname: kube-worker-1
kubernetes.io/os: linux
name: kube-worker-1
resourceVersion: "4026"
uid: 98efe7cb-2978-4a0b-842a-1a7bf12c05f8
spec: {}
status:
addresses:
- address: 192.168.0.113
type: InternalIP
- address: kube-worker-1
type: Hostname
allocatable:
cpu: "2"
ephemeral-storage: "14167048988"
hugepages-2Mi: "0"
memory: 1922788Ki
pods: "110"
capacity:
cpu: "2"
ephemeral-storage: 15372232Ki
hugepages-2Mi: "0"
memory: 2025188Ki
pods: "110"
conditions:
- lastHeartbeatTime: "2022-02-17T22:20:32Z"
lastTransitionTime: "2022-02-17T22:20:32Z"
message: Weave pod has set this
reason: WeaveIsUp
status: "False"
type: NetworkUnavailable
- lastHeartbeatTime: "2022-02-17T22:20:15Z"
lastTransitionTime: "2022-02-17T22:13:25Z"
message: kubelet has sufficient memory available
reason: KubeletHasSufficientMemory
status: "False"
type: MemoryPressure
- lastHeartbeatTime: "2022-02-17T22:20:15Z"
lastTransitionTime: "2022-02-17T22:13:25Z"
message: kubelet has no disk pressure
reason: KubeletHasNoDiskPressure
status: "False"
type: DiskPressure
- lastHeartbeatTime: "2022-02-17T22:20:15Z"
lastTransitionTime: "2022-02-17T22:13:25Z"
message: kubelet has sufficient PID available
reason: KubeletHasSufficientPID
status: "False"
type: PIDPressure
- lastHeartbeatTime: "2022-02-17T22:20:15Z"
lastTransitionTime: "2022-02-17T22:15:15Z"
message: kubelet is posting ready status. AppArmor enabled
reason: KubeletReady
status: "True"
type: Ready
daemonEndpoints:
kubeletEndpoint:
Port: 10250
nodeInfo:
architecture: amd64
bootID: 22333234-7a6b-44d4-9ce1-67e31dc7e369
containerRuntimeVersion: containerd://1.5.9
kernelVersion: 5.13.0-28-generic
kubeProxyVersion: v1.23.3
kubeletVersion: v1.23.3
machineID: 9384e2927f544209b5d7b67474bbf92b
operatingSystem: linux
osImage: Ubuntu 21.10
systemUUID: aa829ca9-73d7-064d-9019-df07404ad448
今のところ、クラスターをより深く掘り下げるには、関連するマシンにログインする必要があります。
以下は、関連するログファイルの場所です。
(systemdベースのシステムでは、代わりにjournalctlを使う必要があるかもしれないことに注意してください)
/var/log/kube-apiserver.log - APIの提供を担当するAPIサーバーのログ/var/log/kube-scheduler.log - スケジューリング決定責任者であるスケジューラーのログ/var/log/kube-controller-manager.log - スケジューリングを除く、ほとんどのKubernetes組み込みのコントローラーを実行するコンポーネントのログ(スケジューリングはkube-schedulerが担当します)/var/log/kubelet.log - ノード上でコンテナの実行を担当するKubeletのログ/var/log/kube-proxy.log - サービスのロードバランシングを担うKube Proxyのログこれは、問題が発生する可能性のある事柄と、問題を軽減するためにクラスターのセットアップを調整する方法の不完全なリストです。
対処法: IaaSプロバイダーの自動VM再起動機能をIaaS VMに使用する
対処法: IaaSプロバイダーの信頼できるストレージ(GCE PDやAWS EBSボリュームなど)をapiserver+etcdを使用するVMに使用する
対処法: 高可用性構成を使用します
対処法: apiserver PDs/EBS-volumesを定期的にスナップショットする
対処法:レプリケーションコントローラーとServiceをPodの前に使用する
対処法: 予期せぬ再起動に耐えられるように設計されたアプリケーション(コンテナ)
kubectl debug nodeを使用してKubernetesノードをデバッグするcrictlを使用してKubernetesノードをデバッグするtelepresenceを使用してローカルでサービスを開発・デバッグするこのドキュメントは、kubectl関連の問題の調査と診断に関するものです。
kubectlへのアクセスやクラスターへの接続で問題に直面した場合、このドキュメントではさまざまな一般的なシナリオや考えられる解決策を概説し、問題の特定と対処するのに役立ちます。
kubectlもインストールする必要があります。ツールのインストールを参照してください。kubectlがローカルマシンに正しくインストールされ、構成されていることを確認してください。
kubectlバージョンが最新であり、クラスターと互換性があることを確認してください。
kubectlバージョンを確認します:
kubectl version
以下のような出力が表示されます:
Client Version: version.Info{Major:"1", Minor:"27", GitVersion:"v1.27.4",GitCommit:"fa3d7990104d7c1f16943a67f11b154b71f6a132", GitTreeState:"clean",BuildDate:"2023-07-19T12:20:54Z", GoVersion:"go1.20.6", Compiler:"gc", Platform:"linux/amd64"}
Kustomize Version: v5.0.1
Server Version: version.Info{Major:"1", Minor:"27", GitVersion:"v1.27.3",GitCommit:"25b4e43193bcda6c7328a6d147b1fb73a33f1598", GitTreeState:"clean",BuildDate:"2023-06-14T09:47:40Z", GoVersion:"go1.20.5", Compiler:"gc", Platform:"linux/amd64"}
Server VersionではなくUnable to connect to the server: dial tcp <server-ip>:8443: i/o timeoutと表示された場合、クラスターとのkubectl接続のトラブルシューティングを行う必要があります。
kubectlのインストールについての公式ドキュメントに従ってkubectlがインストールされていること、環境変数$PATHが適切に設定されていることを確認してください。
kubectlがKubernetesクラスターに接続するためにはkubeconfigファイルが必要です。
kubeconfigファイルは通常~/.kube/configディレクトリに配置されています。
有効なkubeconfigファイルがあることを確認してください。
kubeconfigファイルがない場合、Kubernetes管理者から入手するか、Kubernetesコントロールプレーンの/etc/kubernetes/admin.confディレクトリからコピーすることができます。
Kubernetesクラスターをクラウドプラットフォームにデプロイし、kubeconfigファイルを紛失した場合は、クラウドプロバイダーのツールを使用してファイルを再生成できます。
kubeconfigファイルの再生成については、クラウドプロバイダーのドキュメントを参照してください。
環境変数$KUBECONFIGが正しく設定されていることを確認してください。
環境変数$KUBECONFIGを設定するか、kubectlで--kubeconfigパラメーターを使用して、kubeconfigファイルのディレクトリを指定できます。
Kubernetesクラスターにアクセスするために仮想プライベートネットワーク(VPN)を使用している場合は、VPN接続がアクティブで安定していることを確認してください。 しばしば、VPNの切断がクラスターへの接続の問題につながることがあります。 VPNに再接続して、クラスターに再度アクセスしてみてください。
トークンベースの認証を使用していて、kubectlが認証トークンや認証サーバーのアドレスに関するエラーを返している場合は、Kubernetesの認証トークンと認証サーバーのアドレスが正しく設定されていることを確認してください。
kubectlが認可に関するエラーを返している場合は、有効なユーザー資格情報を使用していることを確認してください。 また、リクエストしたリソースにアクセスする権限があることを確認してください。
Kubernetesは複数のクラスターとコンテキストをサポートしています。 クラスターとやり取りするために正しいコンテキストを使用していることを確認してください。
使用可能なコンテキストの一覧を表示します:
kubectl config get-contexts
適切なコンテキストに切り替えます:
kubectl config use-context <context-name>
kube-apiserverサーバーは、Kubernetesクラスターの中心的なコンポーネントです。 APIサーバーや、APIサーバーの前段にあるロードバランサーに到達できない、または応答しない場合、クラスターとのやり取りができません。
APIサーバーのホストに到達可能かどうかを確認するためにpingコマンドを使用します。
クラスターネットワークの接続性とファイアウォールを確認してください。
クラウドプロバイダーを使用してクラスターをデプロイしている場合は、クラスターのAPIサーバーに対して、クラウドプロバイダーのヘルスチェックのステータスを確認してください。
(使用している場合)ロードバランサーのステータスを確認し、ロードバランサーが正常であり、APIサーバーにトラフィックを転送していることを確認してください。
base64およびopensslバージョン3.0以上。KubernetesのAPIサーバーは、デフォルトではHTTPSリクエストのみを処理します。 TLSの問題は、証明書の有効期限切れやトラストチェーンの有効性など、さまざまな原因で発生する可能性があります。
TLS証明書は、~/.kube/configディレクトリにあるkubeconfigファイルに含まれています。
certificate-authority属性にはCA証明書が、client-certificate属性にはクライアント証明書が含まれています。
これらの証明書の有効期限を確認します:
kubectl config view --flatten --output 'jsonpath={.clusters[0].cluster.certificate-authority-data}' | base64 -d | openssl x509 -noout -dates
出力:
notBefore=Feb 13 05:57:47 2024 GMT
notAfter=Feb 10 06:02:47 2034 GMT
kubectl config view --flatten --output 'jsonpath={.users[0].user.client-certificate-data}'| base64 -d | openssl x509 -noout -dates
出力:
notBefore=Feb 13 05:57:47 2024 GMT
notAfter=Feb 12 06:02:50 2025 GMT
一部のkubectl認証ヘルパーは、Kubernetesクラスターへの容易なアクセスを提供します。 そのようなヘルパーを使用して接続性の問題が発生している場合は、必要な構成がまだ存在していることを確認してください。
認証の詳細についてはkubectl構成を確認します:
kubectl config view
以前にヘルパーツール(kubectl-oidc-loginなど)を使用していた場合は、そのツールがまだインストールされ正しく構成されていることを確認してください。
Kubernetesでは、コンテナのCPU使用率やメモリ使用率といったリソース使用量のメトリクスが、メトリクスAPIを通じて提供されています。これらのメトリクスは、ユーザーがkubectl topコマンドで直接アクセスするか、クラスター内のコントローラー(例えばHorizontal Pod Autoscaler)が判断するためにアクセスすることができます。
メトリクスAPIを使用すると、指定したノードやPodが現在使用しているリソース量を取得することができます。 このAPIはメトリックの値を保存しないので、例えば10分前に指定されたノードが使用したリソース量を取得することはできません。
メトリクスAPIは他のAPIと何ら変わりはありません。
/apis/metrics.k8s.io/パスの下で発見できます。メトリクスAPIはk8s.io/metricsリポジトリで定義されています。 メトリクスAPIについての詳しい情報はそちらをご覧ください。
CPUは、一定期間の平均使用量をCPU coresという単位で報告されます。 この値は、カーネルが提供する累積CPUカウンターの比率を取得することで得られます(LinuxとWindowsの両カーネルで)。 kubeletは、比率計算のためのウィンドウを選択します。
メモリは、測定値が収集された時点のワーキングセットとして、バイト単位で報告されます。 理想的な世界では、「ワーキングセット」は、メモリ不足で解放できない使用中のメモリ量です。 しかし、ワーキングセットの計算はホストOSによって異なり、一般に推定値を生成するために経験則を多用しています。 Kubernetesはスワップをサポートしていないため、すべての匿名(非ファイルバックアップ)メモリが含まれます。 ホストOSは常にそのようなページを再請求することができないため、メトリックには通常、一部のキャッシュされた(ファイルバックされた)メモリも含まれます。
メトリクスサーバーは、クラスター全体のリソース使用量データのアグリゲーターです。
デフォルトでは、kube-up.shスクリプトで作成されたクラスターにDeploymentオブジェクトとしてデプロイされます。
別のKubernetesセットアップ機構を使用する場合は、提供されるdeployment components.yamlファイルを使用してデプロイすることができます。
メトリクスサーバーは、Summary APIからメトリクスを収集します。
各ノードのKubeletからKubernetes aggregator経由でメインAPIサーバーに登録されるようになっています。
メトリクスサーバーについては、Design proposalsで詳しく解説しています。
Kubeletは、ノード、ボリューム、Pod、コンテナレベルの統計情報を収集し、Summary APIで省略して消費者が読めるようにするものです。
1.23以前は、これらのリソースは主にcAdvisorから収集されていました。しかし、1.23ではPodAndContainerStatsFromCRIフィーチャーゲートの導入により、コンテナとPodレベルの統計情報をCRI実装で収集することができます。
注意: これはCRI実装によるサポートも必要です(containerd >= 1.6.0, CRI-O >= 1.23.0)。
アプリケーションを拡張し、信頼性の高いサービスを提供するために、デプロイ時にアプリケーションがどのように動作するかを理解する必要があります。 コンテナ、Pod、Service、クラスター全体の特性を調べることにより、Kubernetesクラスターのアプリケーションパフォーマンスを調査することができます。 Kubernetesは、これらの各レベルでアプリケーションのリソース使用に関する詳細な情報を提供します。 この情報により、アプリケーションのパフォーマンスを評価し、ボトルネックを取り除くことで全体のパフォーマンスを向上させることができます。
Kubernetesでは、アプリケーションの監視は1つの監視ソリューションに依存することはありません。 新しいクラスターでは、リソースメトリクスまたはフルメトリクスパイプラインを使用してモニタリング統計を収集することができます。
リソースメトリックパイプラインは、Horizontal Pod Autoscalerコントローラーなどのクラスターコンポーネントや、kubectl topユーティリティに関連する限定的なメトリックセットを提供します。
これらのメトリクスは軽量、短期、インメモリーのmetrics-serverによって収集され、metrics.k8s.io APIを通じて公開されます。
metrics-serverはクラスター上のすべてのノードを検出し 各ノードのkubeletにCPUとメモリーの使用量を問い合わせます。
kubeletはKubernetesマスターとノードの橋渡し役として、マシン上で動作するPodやコンテナを管理する。 kubeletは各Podを構成するコンテナに変換し、コンテナランタイムインターフェースを介してコンテナランタイムから個々のコンテナ使用統計情報を取得します。この情報は、レガシーDocker統合のための統合cAdvisorから取得されます。
そして、集約されたPodリソース使用統計情報を、metrics-server Resource Metrics APIを通じて公開します。
このAPIは、kubeletの認証済みおよび読み取り専用ポート上の /metrics/resource/v1beta1 で提供されます。
フルメトリクスパイプラインは、より豊富なメトリクスにアクセスすることができます。
Kubernetesは、Horizontal Pod Autoscalerなどのメカニズムを使用して、現在の状態に基づいてクラスターを自動的にスケールまたは適応させることによって、これらのメトリクスに対応することができます。
モニタリングパイプラインは、kubeletからメトリクスを取得し、custom.metrics.k8s.io または external.metrics.k8s.io APIを実装してアダプタ経由でKubernetesにそれらを公開します。
CNCFプロジェクトのPrometheusは、Kubernetes、ノード、Prometheus自身をネイティブに監視することができます。
CNCFに属さない完全なメトリクスパイプラインのプロジェクトは、Kubernetesのドキュメントの範囲外です。
以下のような追加のデバッグツールについて学びます:
Node Problem Detectorは、ノードの健全性を監視し、報告するためのデーモンです。
Node Problem DetectorはDaemonSetとして、あるいはスタンドアロンデーモンとして実行することができます。
Node Problem Detectorは様々なデーモンからノードの問題に関する情報を収集し、これらの状態をNodeConditionおよびEventとしてAPIサーバーにレポートします。
Node Problem Detectorのインストール方法と使用方法については、Node Problem Detectorプロジェクトドキュメントを参照してください。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
Node Problem Detectorは、ファイルベースのカーネルログのみをサポートします。
journaldのようなログツールはサポートされていません。
Node Problem Detectorは、カーネルの問題を報告するためにカーネルログフォーマットを使用します。 カーネルログフォーマットを拡張する方法については、Add support for another log format を参照してください。
クラウドプロバイダーによっては、Node Problem DetectorをAddonとして有効にしている場合があります。
また、kubectlを使ってNode Problem Detectorを有効にするか、Addon podを作成することで有効にできます。
kubectlはNode Problem Detectorを最も柔軟に管理することができます。
デフォルトの設定を上書きして自分の環境に合わせたり、カスタマイズしたノードの問題を検出したりすることができます。
例えば:
node-problem-detector.yamlのようなNode Problem Detectorの設定を作成します:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-problem-detector-v0.1
namespace: kube-system
labels:
k8s-app: node-problem-detector
version: v0.1
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
k8s-app: node-problem-detector
version: v0.1
kubernetes.io/cluster-service: "true"
template:
metadata:
labels:
k8s-app: node-problem-detector
version: v0.1
kubernetes.io/cluster-service: "true"
spec:
hostNetwork: true
containers:
- name: node-problem-detector
image: registry.k8s.io/node-problem-detector:v0.1
securityContext:
privileged: true
resources:
limits:
cpu: "200m"
memory: "100Mi"
requests:
cpu: "20m"
memory: "20Mi"
volumeMounts:
- name: log
mountPath: /log
readOnly: true
volumes:
- name: log
hostPath:
path: /var/log/Node Problem Detectorをkubectlで起動します。
kubectl apply -f https://k8s.io/examples/debug/node-problem-detector.yaml
カスタムのクラスターブートストラップソリューションを使用していて、デフォルトの設定を上書きする必要がない場合は、Addon Podを利用してデプロイをさらに自動化できます。
node-problem-detector.yamlを作成し、制御プレーンノードのAddon Podのディレクトリ/etc/kubernetes/addons/node-problem-detectorに設定を保存します。
Node Problem Detectorの Dockerイメージをビルドする際に、default configurationが埋め込まれます。
ConfigMap を使用することで設定を上書きすることができます。
config/ にある設定ファイルを変更します
ConfigMap node-problem-detector-configを作成します。
kubectl create configmap node-problem-detector-config --from-file=config/
node-problem-detector.yamlを変更して、ConfigMapを使用するようにします。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-problem-detector-v0.1
namespace: kube-system
labels:
k8s-app: node-problem-detector
version: v0.1
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
k8s-app: node-problem-detector
version: v0.1
kubernetes.io/cluster-service: "true"
template:
metadata:
labels:
k8s-app: node-problem-detector
version: v0.1
kubernetes.io/cluster-service: "true"
spec:
hostNetwork: true
containers:
- name: node-problem-detector
image: registry.k8s.io/node-problem-detector:v0.1
securityContext:
privileged: true
resources:
limits:
cpu: "200m"
memory: "100Mi"
requests:
cpu: "20m"
memory: "20Mi"
volumeMounts:
- name: log
mountPath: /log
readOnly: true
- name: config # Overwrite the config/ directory with ConfigMap volume
mountPath: /config
readOnly: true
volumes:
- name: log
hostPath:
path: /var/log/
- name: config # Define ConfigMap volume
configMap:
name: node-problem-detector-config新しい設定ファイルでNode Problem Detectorを再作成します。
# If you have a node-problem-detector running, delete before recreating
kubectl delete -f https://k8s.io/examples/debug/node-problem-detector.yaml
kubectl apply -f https://k8s.io/examples/debug/node-problem-detector-configmap.yaml
kubectl で起動された Node Problem Detector にのみ適用されます。ノード問題検出装置がクラスターアドオンとして実行されている場合、設定の上書きはサポートされていません。
Addon Managerは、ConfigMapをサポートしていません。
Kernel MonitorはNode Problem Detectorでサポートされるシステムログ監視デーモンです。
Kernel Monitorはカーネルログを監視し、事前に定義されたルールに従って既知のカーネル問題を検出します。
Kernel Monitorはconfig/kernel-monitor.jsonにある一連の定義済みルールリストに従ってカーネルの問題を照合します。
ルールリストは拡張可能です。設定を上書きすることで、ルールリストを拡張することができます。
新しいNodeConditionをサポートするには、例えばconfig/kernel-monitor.jsonのconditionsフィールド内に条件定義を作成します。
{
"type": "NodeConditionType",
"reason": "CamelCaseDefaultNodeConditionReason",
"message": "arbitrary default node condition message"
}
新しい問題を検出するために、config/kernel-monitor.jsonのrulesフィールドを新しいルール定義で拡張することができます。
{
"type": "temporary/permanent",
"condition": "NodeConditionOfPermanentIssue",
"reason": "CamelCaseShortReason",
"message": "regexp matching the issue in the kernel log"
}
ご使用のオペレーティングシステム(OS)ディストリビューションのカーネルログパスをご確認ください。
Linuxカーネルのログデバイスは通常/dev/kmsgとして表示されます。
しかし、OSのディストリビューションによって、ログパスの位置は異なります。
config/kernel-monitor.jsonのlogフィールドは、コンテナ内のログパスを表します。
logフィールドは、Node Problem Detectorで見たデバイスパスと一致するように設定することができます。
Kernel monitorはTranslatorプラグインを使用して、カーネルログの内部データ構造を変換します。
新しいログフォーマット用に新しいトランスレータを実装することができます。
ノードの健全性を監視するために、クラスターでNode Problem Detectorを実行することが推奨されます。
Node Problem Detectorを実行する場合、各ノードで余分なリソースのオーバーヘッドが発生することが予想されます。
通常これは問題ありません。
詳細はNode Problem Detectorベンチマーク結果を参照してください。
Kubernetes v1.11 [stable]crictlはCRI互換のコンテナランタイム用のコマンドラインインターフェースです。
これを使って、Kubernetesノード上のコンテナランタイムやアプリケーションの検査やデバッグを行うことができます。
crictlとそのソースコードはcri-toolsリポジトリにホストされています。
crictlにはCRIランタイムを搭載したLinuxが必要です。
cri-toolsのリリースページから、いくつかの異なるアーキテクチャ用の圧縮アーカイブcrictlをダウンロードできます。
お使いのKubernetesのバージョンに対応するバージョンをダウンロードしてください。
それを解凍してシステムパス上の/usr/local/bin/などの場所に移動します。
crictlコマンドにはいくつかのサブコマンドとランタイムフラグがあります。
詳細はcrictl helpまたはcrictl <subcommand> helpを参照してください。
crictlはデフォルトではunix:///var/run/dockershim.sockに接続します。
他のランタイムの場合は、複数の異なる方法でエンドポイントを設定することができます:
--runtime-endpointと--image-endpointの設定によりCONTAINER_RUNTIME_ENDPOINTとIMAGE_SERVICE_ENDPOINTの設定により--config=/etc/crictl.yamlでエンドポイントの設定によりまた、サーバーに接続する際のタイムアウト値を指定したり、デバッグを有効/無効にしたりすることもできます。
これには、設定ファイルでtimeoutやdebugを指定するか、--timeoutや--debugのコマンドラインフラグを使用します。
現在の設定を表示または編集するには、/etc/crictl.yamlの内容を表示または編集します。
cat /etc/crictl.yaml
runtime-endpoint: unix:///var/run/dockershim.sock
image-endpoint: unix:///var/run/dockershim.sock
timeout: 10
debug: true
以下の例では、いくつかのcrictlコマンドとその出力例を示しています。
crictlを使ってポッドのサンドボックスやコンテナを作成しても、Kubeletは最終的にそれらを削除します。crictl は汎用のワークフローツールではなく、デバッグに便利なツールです。すべてのポッドをリストアップ:
crictl pods
出力はこのようになります:
POD ID CREATED STATE NAME NAMESPACE ATTEMPT
926f1b5a1d33a About a minute ago Ready sh-84d7dcf559-4r2gq default 0
4dccb216c4adb About a minute ago Ready nginx-65899c769f-wv2gp default 0
a86316e96fa89 17 hours ago Ready kube-proxy-gblk4 kube-system 0
919630b8f81f1 17 hours ago Ready nvidia-device-plugin-zgbbv kube-system 0
Podを名前でリストアップします:
crictl pods --name nginx-65899c769f-wv2gp
出力はこのようになります:
POD ID CREATED STATE NAME NAMESPACE ATTEMPT
4dccb216c4adb 2 minutes ago Ready nginx-65899c769f-wv2gp default 0
Podをラベルでリストアップします:
crictl pods --label run=nginx
出力はこのようになります:
POD ID CREATED STATE NAME NAMESPACE ATTEMPT
4dccb216c4adb 2 minutes ago Ready nginx-65899c769f-wv2gp default 0
すべてのイメージをリストアップします:
crictl images
出力はこのようになります:
IMAGE TAG IMAGE ID SIZE
busybox latest 8c811b4aec35f 1.15MB
k8s-gcrio.azureedge.net/hyperkube-amd64 v1.10.3 e179bbfe5d238 665MB
k8s-gcrio.azureedge.net/pause-amd64 3.1 da86e6ba6ca19 742kB
nginx latest cd5239a0906a6 109MB
イメージをリポジトリでリストアップします:
crictl images nginx
出力はこのようになります:
IMAGE TAG IMAGE ID SIZE
nginx latest cd5239a0906a6 109MB
イメージのIDのみをリストアップします:
crictl images -q
出力はこのようになります:
sha256:8c811b4aec35f259572d0f79207bc0678df4c736eeec50bc9fec37ed936a472a
sha256:e179bbfe5d238de6069f3b03fccbecc3fb4f2019af741bfff1233c4d7b2970c5
sha256:da86e6ba6ca197bf6bc5e9d900febd906b133eaa4750e6bed647b0fbe50ed43e
sha256:cd5239a0906a6ccf0562354852fae04bc5b52d72a2aff9a871ddb6bd57553569
すべてのコンテナをリストアップします:
crictl ps -a
出力はこのようになります:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
1f73f2d81bf98 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 7 minutes ago Running sh 1
9c5951df22c78 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 8 minutes ago Exited sh 0
87d3992f84f74 nginx@sha256:d0a8828cccb73397acb0073bf34f4d7d8aa315263f1e7806bf8c55d8ac139d5f 8 minutes ago Running nginx 0
1941fb4da154f k8s-gcrio.azureedge.net/hyperkube-amd64@sha256:00d814b1f7763f4ab5be80c58e98140dfc69df107f253d7fdd714b30a714260a 18 hours ago Running kube-proxy 0
ランニングコンテナをリストアップします:
crictl ps
出力はこのようになります:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
1f73f2d81bf98 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 6 minutes ago Running sh 1
87d3992f84f74 nginx@sha256:d0a8828cccb73397acb0073bf34f4d7d8aa315263f1e7806bf8c55d8ac139d5f 7 minutes ago Running nginx 0
1941fb4da154f k8s-gcrio.azureedge.net/hyperkube-amd64@sha256:00d814b1f7763f4ab5be80c58e98140dfc69df107f253d7fdd714b30a714260a 17 hours ago Running kube-proxy 0
crictl exec -i -t 1f73f2d81bf98 ls
出力はこのようになります:
bin dev etc home proc root sys tmp usr var
すべてのコンテナログを取得します:
crictl logs 87d3992f84f74
出力はこのようになります:
10.240.0.96 - - [06/Jun/2018:02:45:49 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
10.240.0.96 - - [06/Jun/2018:02:45:50 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
10.240.0.96 - - [06/Jun/2018:02:45:51 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
最新のN行のログのみを取得します:
crictl logs --tail=1 87d3992f84f74
出力はこのようになります:
10.240.0.96 - - [06/Jun/2018:02:45:51 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
crictlを使ってPodサンドボックスを実行することは、コンテナのランタイムをデバッグするのに便利です。
稼働中のKubernetesクラスターでは、サンドボックスは最終的にKubeletによって停止され、削除されます。
以下のようなJSONファイルを作成します:
{
"metadata": {
"name": "nginx-sandbox",
"namespace": "default",
"attempt": 1,
"uid": "hdishd83djaidwnduwk28bcsb"
},
"logDirectory": "/tmp",
"linux": {
}
}
JSONを適用してサンドボックスを実行するには、crictl runpコマンドを使用します:
crictl runp pod-config.json
サンドボックスのIDが返されます。
コンテナの作成にcrictlを使うと、コンテナのランタイムをデバッグするのに便利です。
稼働中のKubernetesクラスターでは、サンドボックスは最終的にKubeletによって停止され、削除されます。
busyboxイメージをプルします:
crictl pull busybox
Image is up to date for busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47
Podとコンテナのコンフィグを作成します:
Pod config:
{
"metadata": {
"name": "nginx-sandbox",
"namespace": "default",
"attempt": 1,
"uid": "hdishd83djaidwnduwk28bcsb"
},
"log_directory": "/tmp",
"linux": {
}
}
Container config:
{
"metadata": {
"name": "busybox"
},
"image":{
"image": "busybox"
},
"command": [
"top"
],
"log_path":"busybox.log",
"linux": {
}
}
先に作成されたPodのID、コンテナの設定ファイル、Podの設定ファイルを渡して、コンテナを作成します。コンテナのIDが返されます。
crictl create f84dd361f8dc51518ed291fbadd6db537b0496536c1d2d6c05ff943ce8c9a54f container-config.json pod-config.json
すべてのコンテナをリストアップし、新しく作成されたコンテナの状態がCreatedに設定されていることを確認します:
crictl ps -a
出力はこのようになります:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
3e025dd50a72d busybox 32 seconds ago Created busybox 0
コンテナを起動するには、そのコンテナのIDをcrictl startに渡します:
crictl start 3e025dd50a72d956c4f14881fbb5b1080c9275674e95fb67f965f6478a957d60
出力はこのようになります:
3e025dd50a72d956c4f14881fbb5b1080c9275674e95fb67f965f6478a957d60
コンテナの状態が「Running」に設定されていることを確認します:
crictl ps
出力はこのようになります:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
3e025dd50a72d busybox About a minute ago Running busybox 0
詳しくはkubernetes-sigs/cri-toolsをご覧ください。
以下のマッピング表の正確なバージョンは、docker cli v1.40とcrictl v1.19.0のものです。
この一覧はすべてを網羅しているわけではないことに注意してください。
たとえば、docker cliの実験的なコマンドは含まれていません。
| docker cli | crictl | 説明 | サポートされていない機能 |
|---|---|---|---|
attach | attach | 実行中のコンテナにアタッチ | --detach-keys, --sig-proxy |
exec | exec | 実行中のコンテナでコマンドの実行 | --privileged, --user, --detach-keys |
images | images | イメージのリストアップ | |
info | info | システム全体の情報の表示 | |
inspect | inspect, inspecti | コンテナ、イメージ、タスクの低レベルの情報を返します | |
logs | logs | コンテナのログを取得します | --details |
ps | ps | コンテナのリストアップ | |
stats | stats | コンテナのリソース使用状況をライブで表示 | Column: NET/BLOCK I/O, PIDs |
version | version | ランタイム(Docker、ContainerD、その他)のバージョン情報を表示します |
| docker cli | crictl | 説明 | サポートされていない機能 |
|---|---|---|---|
create | create | 新しいコンテナを作成します | |
kill | stop (timeout = 0) | 1つ以上の実行中のコンテナを停止します | --signal |
pull | pull | レジストリーからイメージやリポジトリをプルします | --all-tags, --disable-content-trust |
rm | rm | 1つまたは複数のコンテナを削除します | |
rmi | rmi | 1つまたは複数のイメージを削除します | |
run | run | 新しいコンテナでコマンドを実行 | |
start | start | 停止した1つまたは複数のコンテナを起動 | --detach-keys |
stop | stop | 実行中の1つまたは複数のコンテナの停止 | |
update | update | 1つまたは複数のコンテナの構成を更新 | --restart、--blkio-weightとその他 |
| crictl | 説明 |
|---|---|
imagefsinfo | イメージファイルシステムの情報を返します |
inspectp | 1つまたは複数のPodの状態を表示します |
port-forward | ローカルポートをPodに転送します |
runp | 新しいPodを実行します |
rmp | 1つまたは複数のPodを削除します |
stopp | 稼働中の1つまたは複数のPodを停止します |
このページでは、Kubernetesクラスター上で動作しているノードをkubectl debugコマンドを使用してデバッグする方法について説明します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: 1.2. バージョンを確認するには次のコマンドを実行してください:kubectl version.Podを作成し、それらの新しいPodを任意のノードに割り当てる権限が必要です。 また、ホストのファイルシステムにアクセスするPodを作成する権限も必要です。
kubectl debug nodeを用いてノードをデバッグするkubectl debug nodeコマンドを使用して、トラブルシューティングしたいノードにPodをデプロイします。
このコマンドは、SSH接続を使用してノードにアクセスできないシナリオで役に立ちます。
Podが作成されると、そのPodはノード上で対話型シェルを開きます。
mynodeという名前のノード上で対話型シェルを作成するには、次のように実行します。
kubectl debug node/mynode -it --image=ubuntu
mynodeという名前のノード上に、コンテナデバッガーを持つデバッグの用Pod、node-debugger-mynode-pdx84を作成します。
コマンドプロンプトが表示されない場合は、エンターキーを押してみてください。
root@mynode:/#
デバッグコマンドは、情報を収集し、問題をトラブルシューティングするのに役立ちます。
使用する可能性のあるコマンドには、ip、ifconfig、nc、ping、psなどがあります。
また、mtr、tcpdump、curlなどの他のツールもそれぞれのパッケージマネージャーからインストールすることができます。
デバッグ用のPodは、Pod内の/hostにマウントされたノードのルートファイルシステムにアクセスできます。
kubeletをファイルシステムのネームスペースで実行している場合、デバッグ用のPodはそのネームスペースのルートを見ることになり、ノード全体のルートではありません。
典型的なLinuxノードの場合、関連するログを見つけるために以下のパスを確認できます。
/host/var/log/kubelet.logkubeletからのログです。/host/var/log/kube-proxy.logkube-proxyからのログです。/host/var/log/containerd.logcontainerdプロセスからのログです。/host/var/log/syslog/host/var/log/kern.logノード上でデバッグセッションを作成する際には、以下の点を考慮してください。
kubectl debugは、新しいPodの名前をノードの名前に基づいて自動的に生成します。/hostにマウントされます。chroot /hostは失敗します。
特権Podが必要な場合は、手動で作成するか、--profile=sysadminを使用してください。デバッグ用のPodの使用が終了したら、それを削除してください。
kubectl get pods
NAME READY STATUS RESTARTS AGE
node-debugger-mynode-pdx84 0/1 Completed 0 8m1s
# Podの名前は適宜変更してください
kubectl delete pod node-debugger-mynode-pdx84 --now
pod "node-debugger-mynode-pdx84" deleted
kubectl debug nodeコマンドは機能しません。
その場合は、ダウンあるいは到達不能なノードのデバッグを確認してください。Podが"Container Creating"と表示されたまま動かなくなったり、何度も再起動を繰り返します
pauseイメージがWindows OSのバージョンと互換性があることを確認してください。 最新/推奨のpauseイメージや詳細情報については、Pauseコンテナを参照してください。
plugins.plugins.cri.sandbox_imageフィールドで指定されます。PodがErrImgPullまたはImagePullBackOffのステータスを表示します
Podが互換性のあるWindowsノードにスケジュールされていることを確認してください。
Podに対して互換性のあるノードを指定する方法の詳細については、このガイドを参照してください。
Windows Podがネットワークに接続できません
仮想マシンを使用している場合は、すべてのVMのネットワークアダプターでMACスプーフィングが有効になっていることを確認してください。
Windows Podから外部リソースにpingできません
Windows Podには、ICMPプロトコル用にプログラムされたアウトバウンドルールはありません。ただし、TCP/UDPはサポートされています。
クラスター外のリソースへの接続を実証する場合は、ping <IP>を対応するcurl <IP>コマンドに置き換えてください。
それでも問題が解決しない場合は、cni.confのネットワーク設定に問題がある可能性が高いです。 この静的ファイルはいつでも編集できます。 設定の更新は、新しく作成されたすべてのKubernetesリソースに適用されます。
Kubernetesのネットワーク要件の1つ(Kubernetesモデルを参照)は、内部でNATせずにクラスター通信が行われることです。
この要件を満たすために、アウトバウンドのNATを発生させたくないすべての通信のためのExceptionListがあります。
ただしこれは、クエリしようとしている外部IPをExceptionListから除外する必要があることも意味します。
そうして初めて、Windows Podからのトラフィックが正しくSNATされ、外部からの応答を受信できるようになります。
この点について、cni.confのExceptionListは次のようになります:
"ExceptionList": [
"10.244.0.0/16", # クラスターのサブネット
"10.96.0.0/12", # Serviceのサブネット
"10.127.130.0/24" # 管理(ホスト)のサブネット
]
WindowsノードがNodePortタイプのServiceにアクセスできません
ノード自身からのローカルNodePortへのアクセスは失敗します。 これは既知の制限です。 NodePortへのアクセスは、他のノードや外部のクライアントからは動作します。
コンテナのvNICとHNSエンドポイントが削除されています
この問題はhostname-overrideパラメーターがkube-proxy
に渡されていない場合に発生する可能性があります。
これを解決するためには、ユーザーは次のようにkube-proxyにホスト名を渡す必要があります:
C:\k\kube-proxy.exe --hostname-override=$(hostname)
WindowsノードがService IPを使用してサービスにアクセスできません
これはWindows上のネットワークスタックの既知の制限です。 ただし、Windows PodはService IPにアクセスできます。
kubeletの起動時にネットワークアダプターが見つかりません
Windowsのネットワーキングスタックでは、Kubernetesネットワーキングが動作するために仮想アダプターが必要です。 (管理者シェルで)次のコマンドを実行しても結果が返されない場合、kubeletが動作するために必要な前提条件である仮想ネットワークの作成に失敗しています。
Get-HnsNetwork | ? Name -ieq "cbr0"
Get-NetAdapter | ? Name -Like "vEthernet (Ethernet*"
ホストのネットワークアダプターが"Ethernet"ではない場合、start.ps1スクリプトのInterfaceNameパラメーターを修正することが有益です。
それ以外の場合は、start-kubelet.ps1スクリプトの出力結果を参照して、仮想ネットワークの作成中にエラーが発生していないか確認します。
DNS名前解決が正しく動作しません
このセクションのWindowsにおけるDNSの制限について確認してください。
kubectl port-forwardが"unable to do port forwarding: wincat not found"で失敗します
これは、pauseインフラコンテナmcr.microsoft.com/oss/kubernetes/pause:3.6にwincat.exeを含める形で、Kubernetes 1.15にて実装されました。
必ずサポートされたKubernetesのバージョンを使用してください。
独自のpauseインフラコンテナをビルドしたい場合は、必ずwincatを含めるようにしてください。
Windows Serverノードがプロキシの背後にあるため、Kubernetesのインストールに失敗しています
プロキシの背後にある場合は、次のPowerShell環境変数が定義されている必要があります:
[Environment]::SetEnvironmentVariable("HTTP_PROXY", "http://proxy.example.com:80/", [EnvironmentVariableTarget]::Machine)
[Environment]::SetEnvironmentVariable("HTTPS_PROXY", "http://proxy.example.com:443/", [EnvironmentVariableTarget]::Machine)
Flannelを使用すると、クラスターに再参加した後にノードに問題が発生します
以前に削除したノードがクラスターに再参加すると、flanneldはノードに新しいPodサブネットを割り当てようとします。 ユーザーは、次のパスにある古いPodサブネットの設定ファイルを削除する必要があります:
Remove-Item C:\k\SourceVip.json
Remove-Item C:\k\SourceVipRequest.json
Flanneldが"Waiting for the Network to be created"と表示されたままになります
このIssueに関する多数の報告があります;
最も可能性が高いのは、flannelネットワークの管理IPが設定されるタイミングの問題です。
回避策は、start.ps1を再度実行するか、次のように手動で再起動することです:
[Environment]::SetEnvironmentVariable("NODE_NAME", "<Windows_Worker_Hostname>")
C:\flannel\flanneld.exe --kubeconfig-file=c:\k\config --iface=<Windows_Worker_Node_IP> --ip-masq=1 --kube-subnet-mgr=1
/run/flannel/subnet.envが見つからないためにWindows Podが起動しません
これはFlannelが正常に起動できなかったことを示しています。
flanneld.exeを再起動するか、Kubernetesマスター上の/run/flannel/subnet.envをWindowsワーカーノード上のC:\run\flannel\subnet.envに手動でコピーして、FLANNEL_SUBNET行を異なる数値に変更します。
例えば、ノードのサブネットを10.244.4.1/24としたい場合は次のようにします:
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.4.1/24
FLANNEL_MTU=1500
FLANNEL_IPMASQ=true
これらの手順で問題が解決しない場合は、下記からKubernetesのWindowsノード上でWindowsコンテナを実行するためのヘルプを得ることができます:
Kubernetesアプリケーションは通常、複数の独立したサービスから構成され、それぞれが独自のコンテナで動作しています。これらのサービスをリモートのKubernetesクラスター上で開発・デバッグするには、実行中のコンテナへのシェルを取得してリモートシェル内でツールを実行しなければならず面倒な場合があります。
telepresenceは、リモートKubernetesクラスターにサービスをプロキシしながら、ローカルでサービスを開発・デバッグするプロセスを容易にするためのツールです。
telepresence を使用すると、デバッガーやIDEなどのカスタムツールをローカルサービスで使用でき、ConfigMapやsecret、リモートクラスター上で動作しているサービスへのフルアクセスをサービスに提供します。
このドキュメントでは、リモートクラスター上で動作しているサービスをローカルで開発・デバッグするためにtelepresenceを使用する方法を説明します。
kubectl が設定されていることターミナルを開いて、引数なしでtelepresenceを実行すると、telepresenceシェルが表示されます。
このシェルはローカルで動作し、ローカルのファイルシステムに完全にアクセスすることができます。
このtelepresenceシェルは様々な方法で使用することができます。
例えば、ラップトップでシェルスクリプトを書いて、それをシェルから直接リアルタイムで実行することができます。これはリモートシェルでもできますが、好みのコードエディターが使えないかもしれませんし、コンテナが終了するとスクリプトは削除されます。
終了してシェルを閉じるにはexitと入力してください。
Kubernetes上でアプリケーションを開発する場合、通常は1つのサービスをプログラミングまたはデバッグすることになります。 そのサービスは、テストやデバッグのために他のサービスへのアクセスを必要とする場合があります。 継続的なデプロイメントパイプラインを使用することも一つの選択肢ですが、最速のデプロイメントパイプラインでさえ、プログラムやデバッグサイクルに遅延が発生します。
既存のデプロイメントとtelepresenceプロキシを交換するには、--swap-deployment オプションを使用します。
スワップすることで、ローカルでサービスを実行し、リモートのKubernetesクラスターに接続することができます。
リモートクラスター内のサービスは、ローカルで実行されているインスタンスにアクセスできるようになりました。
telepresenceを「--swap-deployment」で実行するには、次のように入力します。
telepresence --swap-deployment $DEPLOYMENT_NAME
ここで、$DEPLOYMENT_NAMEは既存のDeploymentの名前です。
このコマンドを実行すると、シェルが起動します。そのシェルで、サービスを起動します。 そして、ローカルでソースコードの編集を行い、保存すると、すぐに変更が反映されるのを確認できます。 また、デバッガーやその他のローカルな開発ツールでサービスを実行することもできます。
もしハンズオンのチュートリアルに興味があるなら、Google Kubernetes Engine上でGuestbookアプリケーションをローカルに開発する手順を説明したこちらのチュートリアルをチェックしてみてください。
telepresenceには、状況に応じてnumerous proxying optionsがあります。
さらに詳しい情報は、telepresence websiteをご覧ください。
Kubernetesの監査はクラスター内の一連の行動を記録するセキュリティに関連した時系列の記録を提供します。 クラスターはユーザー、Kubernetes APIを使用するアプリケーション、 およびコントロールプレーン自体によって生成されたアクティビティなどを監査します。
監査により、クラスター管理者は以下の質問に答えることができます:
監査記録のライフサイクルはkube-apiserverコンポーネントの中で始まります。 各リクエストの実行の各段階で、監査イベントが生成されます。 ポリシーに従って前処理され、バックエンドに書き込まれます。 ポリシーが何を記録するかを決定し、 バックエンドがその記録を永続化します。現在のバックエンドの実装はログファイルやWebhookなどがあります。
各リクエストは関連する stage で記録されます。 定義されたステージは以下の通りです:
RequestReceived - 監査ハンドラーがリクエストを受信すると同時に生成されるイベントのステージ。
つまり、ハンドラーチェーンに委譲される前に生成されるイベントのステージです。ResponseStarted - レスポンスヘッダーが送信された後、レスポンスボディが送信される前のステージです。
このステージは長時間実行されるリクエスト(watchなど)でのみ発生します。ResponseComplete - レスポンスボディの送信が完了して、それ以上のバイトは送信されません。Panic - パニックが起きたときに発生するイベント。監査ログ機能は、リクエストごとに監査に必要なコンテキストが保存されるため、APIサーバーのメモリー消費量が増加します。 メモリーの消費量は、監査ログ機能の設定によって異なります。
監査ポリシーはどのようなイベントを記録し、どのようなデータを含むべきかについてのルールを定義します。
監査ポリシーのオブジェクト構造は、audit.k8s.io API groupで定義されています。
イベントが処理されると、そのイベントは順番にルールのリストと比較されます。 最初のマッチングルールは、イベントの監査レベルを設定します。
定義されている監査レベルは:
None - ルールに一致するイベントを記録しません。Metadata - リクエストのメタデータ(リクエストしたユーザー、タイムスタンプ、リソース、動作など)を記録しますが、リクエストやレスポンスのボディは記録しません。Request - ログイベントのメタデータとリクエストボディは表示されますが、レスポンスボディは表示されません。
これは非リソースリクエストには適用されません。RequestResponse - イベントのメタデータ、リクエストとレスポンスのボディを記録しますが、
非リソースリクエストには適用されません。audit-policy-fileフラグを使って、ポリシーを記述したファイルを kube-apiserverに渡すことができます。
このフラグが省略された場合イベントは記録されません。
監査ポリシーファイルでは、rulesフィールドが必ず指定されることに注意してください。
ルールがない(0)ポリシーは不当なものとして扱われます。
以下は監査ポリシーファイルの例です:
apiVersion: audit.k8s.io/v1 # This is required.
kind: Policy
# Don't generate audit events for all requests in RequestReceived stage.
omitStages:
- "RequestReceived"
rules:
# Log pod changes at RequestResponse level
- level: RequestResponse
resources:
- group: ""
# Resource "pods" doesn't match requests to any subresource of pods,
# which is consistent with the RBAC policy.
resources: ["pods"]
# Log "pods/log", "pods/status" at Metadata level
- level: Metadata
resources:
- group: ""
resources: ["pods/log", "pods/status"]
# Don't log requests to a configmap called "controller-leader"
- level: None
resources:
- group: ""
resources: ["configmaps"]
resourceNames: ["controller-leader"]
# Don't log watch requests by the "system:kube-proxy" on endpoints or services
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: "" # core API group
resources: ["endpoints", "services"]
# Don't log authenticated requests to certain non-resource URL paths.
- level: None
userGroups: ["system:authenticated"]
nonResourceURLs:
- "/api*" # Wildcard matching.
- "/version"
# Log the request body of configmap changes in kube-system.
- level: Request
resources:
- group: "" # core API group
resources: ["configmaps"]
# This rule only applies to resources in the "kube-system" namespace.
# The empty string "" can be used to select non-namespaced resources.
namespaces: ["kube-system"]
# Log configmap and secret changes in all other namespaces at the Metadata level.
- level: Metadata
resources:
- group: "" # core API group
resources: ["secrets", "configmaps"]
# Log all other resources in core and extensions at the Request level.
- level: Request
resources:
- group: "" # core API group
- group: "extensions" # Version of group should NOT be included.
# A catch-all rule to log all other requests at the Metadata level.
- level: Metadata
# Long-running requests like watches that fall under this rule will not
# generate an audit event in RequestReceived.
omitStages:
- "RequestReceived"
最小限の監査ポリシーファイルを使用して、すべてのリクエストを Metadataレベルで記録することができます。
# Log all requests at the Metadata level.
apiVersion: audit.k8s.io/v1
kind: Policy
rules:
- level: Metadata
独自の監査プロファイルを作成する場合は、Google Container-Optimized OSの監査プロファイルを出発点として使用できます。 監査ポリシーファイルを生成するconfigure-helper.shスクリプトを確認することができます。 スクリプトを直接見ることで、監査ポリシーファイルのほとんどを見ることができます。
また、定義されているフィールドの詳細については、Policy` configuration referenceを参照できます。
監査バックエンドは監査イベントを外部ストレージに永続化します。 kube-apiserverには2つのバックエンドが用意されています。
いずれの場合も、監査イベントはKubernetes APIaudit.k8s.io API groupで定義されている構造に従います。
パッチの場合、リクエストボディはパッチ操作を含むJSON配列であり、適切なKubernetes APIオブジェクトを含むJSONオブジェクトではありません。
例えば、以下のリクエストボディは/apis/batch/v1/namespaces/some-namespace/jobs/some-job-nameに対する有効なパッチリクエストです。
[
{
"op": "replace",
"path": "/spec/parallelism",
"value": 0
},
{
"op": "remove",
"path": "/spec/template/spec/containers/0/terminationMessagePolicy"
}
]
ログバックエンドは監査イベントをJSONlines形式のファイルに書き込みます。
以下の kube-apiserver フラグを使ってログ監査バックエンドを設定できます。
--audit-log-path は、ログバックエンドが監査イベントを書き込む際に使用するログファイルのパスを指定します。
このフラグを指定しないと、ログバックエンドは無効になります。- は標準出力を意味します。--audit-log-maxage は、古い監査ログファイルを保持する最大日数を定義します。audit-log-maxbackupは、保持する監査ログファイルの最大数を定義します。--audit-log-maxsize は、監査ログファイルがローテーションされるまでの最大サイズをメガバイト単位で定義します。クラスターのコントロールプレーンでkube-apiserverをPodとして動作させている場合は、監査記録が永久化されるように、ポリシーファイルとログファイルの場所にhostPathをマウントすることを忘れないでください。
例えば:
- --audit-policy-file=/etc/kubernetes/audit-policy.yaml
- --audit-log-path=/var/log/kubernetes/audit/audit.log
それからボリュームをマウントします:
...
volumeMounts:
- mountPath: /etc/kubernetes/audit-policy.yaml
name: audit
readOnly: true
- mountPath: /var/log/audit.log
name: audit-log
readOnly: false
最後にhostPathを設定します:
...
volumes:
- name: audit
hostPath:
path: /etc/kubernetes/audit-policy.yaml
type: File
- name: audit-log
hostPath:
path: /var/log/audit.log
type: FileOrCreate
Webhook監査バックエンドは、監査イベントをリモートのWeb APIに送信しますが、 これは認証手段を含むKubernetes APIの形式であると想定されます。
Webhook監査バックエンドを設定するには、以下のkube-apiserverフラグを使用します。
--audit-webhook-config-file は、Webhookの設定ファイルのパスを指定します。
webhookの設定は、事実上特化したkubeconfigです。--audit-webhook-initial-backoff は、最初に失敗したリクエストの後、再試行するまでに待つ時間を指定します。
それ以降のリクエストは、指数関数的なバックオフで再試行されます。Webhookの設定ファイルは、kubeconfig形式でサービスのリモートアドレスと接続に使用する認証情報を指定します。
ログバックエンドとwebhookバックエンドの両方がバッチ処理をサポートしています。
webhookを例に、利用可能なフラグの一覧を示します。
ログバックエンドで同じフラグを取得するには、フラグ名のwebhookをlogに置き換えてください。
デフォルトでは、バッチングはwebhookでは有効で、logでは無効です。
同様に、デフォルトではスロットリングは webhook で有効で、logでは無効です。
--audit-webhook-mode は、バッファリング戦略を定義します。以下のいずれかとなります。batch - イベントをバッファリングして、非同期にバッチ処理します。これがデフォルトです。blocking - 個々のイベントを処理する際に、APIサーバーの応答をブロックします。blocking-strict - blockingと同じですが、RequestReceivedステージでの監査ログに失敗した場合は RequestReceivedステージで監査ログに失敗すると、kube-apiserverへのリクエスト全体が失敗します。以下のフラグは batch モードでのみ使用されます:
--audit-webhook-batch-buffer-sizeは、バッチ処理を行う前にバッファリングするイベントの数を定義します。
入力イベントの割合がバッファをオーバーフローすると、イベントはドロップされます。--audit-webhook-batch-max-sizeは、1つのバッチに入れるイベントの最大数を定義します。--audit-webhook-batch-max-waitは、キュー内のイベントを無条件にバッチ処理するまでの最大待機時間を定義します。--audit-webhook-batch-throttle-qpsは、1秒あたりに生成されるバッチの最大平均数を定義します。--audit-webhook-batch-throttle-burstは、許可された QPS が低い場合に、同じ瞬間に生成されるバッチの最大数を定義します。パラメーターは、APIサーバーの負荷に合わせて設定してください。
例えば、kube-apiserverが毎秒100件のリクエストを受け取り、それぞれのリクエストがResponseStartedとResponseCompleteの段階でのみ監査されるとします。毎秒≅200の監査イベントが発生すると考えてください。
1つのバッチに最大100個のイベントがあるの場合、スロットリングレベルを少なくとも2クエリ/秒に設定する必要があります。
バックエンドがイベントを書き込むのに最大で5秒かかる場合、5秒分のイベントを保持するようにバッファーサイズを設定する必要があります。
10バッチ、または1000イベントとなります。
しかし、ほとんどの場合デフォルトのパラメーターで十分であり、手動で設定する必要はありません。 kube-apiserverが公開している以下のPrometheusメトリクスや、ログを見て監査サブシステムの状態を監視することができます。
apiserver_audit_event_totalメトリックには、エクスポートされた監査イベントの合計数が含まれます。apiserver_audit_error_totalメトリックには、エクスポート中にエラーが発生してドロップされたイベントの総数が含まれます。logバックエンドとwebhookバックエンドは、ログに記録されるイベントのサイズを制限することをサポートしています。
例として、logバックエンドで利用可能なフラグの一覧を以下に示します
audit-log-truncate-enabledイベントとバッチの切り捨てを有効にするかどうかです。audit-log-truncate-max-batch-sizeバックエンドに送信されるバッチのバイト単位の最大サイズ。audit-log-truncate-max-event-sizeバックエンドに送信される監査イベントのバイト単位の最大サイズです。デフォルトでは、webhookとlogの両方で切り捨ては無効になっていますが、クラスター管理者は audit-log-truncate-enabledまたはaudit-webhook-truncate-enabledを設定して、この機能を有効にする必要があります。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
SecretはデータベースにアクセスするためにPodが必要とするユーザー資格情報を含めることができます。
たとえば、データベース接続文字列はユーザー名とパスワードで構成されます。
ユーザー名はローカルマシンの./username.txtに、パスワードは./password.txtに保存します。
echo -n 'admin' > ./username.txt
echo -n '1f2d1e2e67df' > ./password.txt
上記の2つのコマンドの-nフラグは、生成されたファイルにテキスト末尾の余分な改行文字が含まれないようにします。
kubectlがファイルを読み取り、内容をbase64文字列にエンコードすると、余分な改行文字もエンコードされるため、これは重要です。
kubectl create secretコマンドはこれらのファイルをSecretにパッケージ化し、APIサーバー上にオブジェクトを作成します。
kubectl create secret generic db-user-pass \
--from-file=./username.txt \
--from-file=./password.txt
出力は次のようになります:
secret/db-user-pass created
ファイル名がデフォルトのキー名になります。オプションで--from-file=[key=]sourceを使用してキー名を設定できます。たとえば:
kubectl create secret generic db-user-pass \
--from-file=username=./username.txt \
--from-file=password=./password.txt
--from-fileに指定したファイルに含まれるパスワードの特殊文字をエスケープする必要はありません。
また、--from-literal=<key>=<value>タグを使用してSecretデータを提供することもできます。
このタグは、複数のキーと値のペアを提供するために複数回指定することができます。
$、\、*、=、!などの特殊文字はシェルによって解釈されるため、エスケープを必要とすることに注意してください。
ほとんどのシェルでは、パスワードをエスケープする最も簡単な方法は、シングルクォート(')で囲むことです。
たとえば、実際のパスワードがS!B\*d$zDsb=の場合、次のようにコマンドを実行します:
kubectl create secret generic db-user-pass \
--from-literal=username=admin \
--from-literal=password='S!B\*d$zDsb='
Secretが作成されたことを確認できます:
kubectl get secrets
出力は次のようになります:
NAME TYPE DATA AGE
db-user-pass Opaque 2 51s
Secretの説明を参照できます:
kubectl describe secrets/db-user-pass
出力は次のようになります:
Name: db-user-pass
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 12 bytes
username: 5 bytes
kubectl getとkubectl describeコマンドはデフォルトではSecretの内容を表示しません。
これは、Secretが不用意に他人にさらされたり、ターミナルログに保存されたりしないようにするためです。
先ほど作成したSecretの内容を見るには、以下のコマンドを実行します:
kubectl get secret db-user-pass -o jsonpath='{.data}'
出力は次のようになります:
{"password":"MWYyZDFlMmU2N2Rm","username":"YWRtaW4="}
passwordのデータをデコードします:
echo 'MWYyZDFlMmU2N2Rm' | base64 --decode
出力は次のようになります:
1f2d1e2e67df
作成したSecretを削除するには次のコマンドを実行します:
kubectl delete secret db-user-pass
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
あらかじめYAMLまたはJSON形式でSecretのマニフェストを作成したうえで、オブジェクトを作成することができます。
Secretリソースには、dataとstringDataの2つのマップが含まれています。
dataフィールドは任意のデータを格納するのに使用され、base64でエンコードされます。
stringDataフィールドは利便性のために用意されており、Secretデータをエンコードされていない文字列として提供することができます。
dataとstringDataのキーは、英数字、-、_、.で構成されている必要があります。
たとえば、dataフィールドを使用して2つの文字列をSecretに格納するには、次のように文字列をbase64に変換します:
echo -n 'admin' | base64
出力は次のようになります:
YWRtaW4=
echo -n '1f2d1e2e67df' | base64
出力は次のようになります:
MWYyZDFlMmU2N2Rm
以下のようなSecret設定ファイルを記述します:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
なお、Secretオブジェクトの名前は、有効なDNSサブドメイン名である必要があります。
base64ユーティリティーを使用する場合、長い行を分割するために-bオプションを使用するのは避けるべきです。
逆に、Linux ユーザーは、base64 コマンドにオプション-w 0を追加するか、-wオプションが利用できない場合には、パイプラインbase64 | tr -d '\n'を追加する必要があります。特定のシナリオでは、代わりにstringDataフィールドを使用できます。
このフィールドでは、base64エンコードされていない文字列を直接Secretに入れることができ、Secretの作成時や更新時には、その文字列がエンコードされます。
たとえば、設定ファイルを保存するためにSecretを使用しているアプリケーションをデプロイする際に、デプロイプロセス中に設定ファイルの一部を入力したい場合などが考えられます。
たとえば、次のような設定ファイルを使用しているアプリケーションの場合:
apiUrl: "https://my.api.com/api/v1"
username: "<user>"
password: "<password>"
次のような定義でSecretに格納できます:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
stringData:
config.yaml: |
apiUrl: "https://my.api.com/api/v1"
username: <user>
password: <password>
kubectl applyでSecretを作成します:
kubectl apply -f ./secret.yaml
出力は次のようになります:
secret/mysecret created
stringDataフィールドは、書き込み専用の便利なフィールドです。Secretを取得する際には決して出力されません。たとえば、次のようなコマンドを実行した場合:
kubectl get secret mysecret -o yaml
出力は次のようになります:
apiVersion: v1
data:
config.yaml: YXBpVXJsOiAiaHR0cHM6Ly9teS5hcGkuY29tL2FwaS92MSIKdXNlcm5hbWU6IHt7dXNlcm5hbWV9fQpwYXNzd29yZDoge3twYXNzd29yZH19
kind: Secret
metadata:
creationTimestamp: 2018-11-15T20:40:59Z
name: mysecret
namespace: default
resourceVersion: "7225"
uid: c280ad2e-e916-11e8-98f2-025000000001
type: Opaque
kubectl getとkubectl describeコマンドはデフォルトではSecretの内容を表示しません。
これは、Secretが不用意に他人にさらされたり、ターミナルログに保存されたりしないようにするためです。
エンコードされたデータの実際の内容を確認するには、Secretのデコードを参照してください。
usernameなどのフィールドがdataとstringDataの両方に指定されている場合は、stringDataの値が使われます。
たとえば、以下のようなSecretの定義の場合:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
stringData:
username: administrator
結果は以下の通りです:
apiVersion: v1
data:
username: YWRtaW5pc3RyYXRvcg==
kind: Secret
metadata:
creationTimestamp: 2018-11-15T20:46:46Z
name: mysecret
namespace: default
resourceVersion: "7579"
uid: 91460ecb-e917-11e8-98f2-025000000001
type: Opaque
YWRtaW5pc3RyYXRvcg==をデコードするとadministratorとなります。
作成したSecretを削除するには次のコマンドを実行します:
kubectl delete secret mysecret
Kubernetes v1.14以降、kubectlはKustomizeを使ったオブジェクト管理をサポートしています。
KustomizeはSecretやConfigMapを作成するためのリソースジェネレーターを提供します。
Kustomizeジェネレーターは、ディレクトリ内のkustomization.yamlファイルで指定します。
Secretを生成したら、kubectl applyでAPIサーバー上にSecretを作成します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
kustomization.yamlファイルの中でsecretGeneratorを定義し、他の既存のファイルを参照することで、Secretを生成することができます。
たとえば、以下のkustomizationファイルは./username.txtと./password.txtを参照しています。
secretGenerator:
- name: db-user-pass
files:
- username.txt
- password.txt
また、kustomization.yamlファイルの中でリテラルを指定してsecretGeneratorを定義することもできます。
たとえば、以下のkustomization.yamlファイルにはusernameとpasswordの2つのリテラルが含まれています。
secretGenerator:
- name: db-user-pass
literals:
- username=admin
- password=1f2d1e2e67df
また、kustomization.yamlファイルに.envファイルを用意してsecretGeneratorを定義することもできます。
たとえば、以下のkustomization.yamlファイルは、.env.secretファイルからデータを取り込みます。
secretGenerator:
- name: db-user-pass
envs:
- .env.secret
なお、いずれの場合も、値をbase64エンコードする必要はありません。
kustomization.yamlを含むディレクトリを適用して、Secretを作成します。
kubectl apply -k .
出力は次のようになります:
secret/db-user-pass-96mffmfh4k created
なお、Secretを生成する際には、データをハッシュ化し、そのハッシュ値を付加することでSecret名を生成します。 これにより、データが変更されるたびに、新しいSecretが生成されます。
Secretが作成されたことを確認できます:
kubectl get secrets
出力は次のようになります:
NAME TYPE DATA AGE
db-user-pass-96mffmfh4k Opaque 2 51s
Secretの説明を参照できます:
kubectl describe secrets/db-user-pass-96mffmfh4k
出力は次のようになります:
Name: db-user-pass-96mffmfh4k
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password.txt: 12 bytes
username.txt: 5 bytes
kubectl getとkubectl describeコマンドはデフォルトではSecretの内容を表示しません。
これは、Secretが不用意に他人にさらされたり、ターミナルログに保存されたりしないようにするためです。
エンコードされたデータの実際の内容を確認するには、Secretのデコードを参照してください。
作成したSecretを削除するには次のコマンドを実行します:
kubectl delete secret db-user-pass-96mffmfh4k
このページでは、Podでコンテナを実行するときにコマンドと引数を定義する方法を説明します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.Podを作成するときに、Pod内で実行するコンテナのコマンドと引数を定義できます。コマンドを定義するには、設定ファイルにcommandフィールドを記述します。コマンドの引数を定義するには、設定ファイルにargsフィールドを記述します。定義したコマンドと引数はPodの作成後に変更することはできません。
設定ファイルで定義したコマンドと引数は、コンテナイメージが提供するデフォルトのコマンドと引数を上書きします。引数を定義し、コマンドを定義しなかった場合、デフォルトのコマンドと新しい引数が使用されます。
commandフィールドは、いくつかのコンテナランタイムではエントリポイントに相当します。この演習では、1つのコンテナを実行するPodを作成します。Podの設定ファイルには、コマンドと2つの引数を定義します。
apiVersion: v1
kind: Pod
metadata:
name: command-demo
labels:
purpose: demonstrate-command
spec:
containers:
- name: command-demo-container
image: debian
command: ["printenv"]
args: ["HOSTNAME", "KUBERNETES_PORT"]
restartPolicy: OnFailure
YAMLの設定ファイルに基づいてPodを作成
kubectl apply -f https://k8s.io/examples/pods/commands.yaml
実行中のPodをリストアップ
kubectl get pods
出力は、command-demo Podで実行されたコンテナが完了したことを示します。
コンテナ内で実行されたコマンドの出力を確認するためにPodのログを見る
kubectl logs command-demo
出力は、HOSTNAMEとKUBERNETES_PORT環境変数の値を示します。
command-demo
tcp://10.3.240.1:443
前述の例では、文字列を指定して引数を直接定義しました。文字列を直接指定する代わりに、環境変数を使用して引数を定義することもできます。
env:
- name: MESSAGE
value: "hello world"
command: ["/bin/echo"]
args: ["$(MESSAGE)"]
つまり、ConfigMapやSecretなど、環境変数を定義するために利用可能な技術のどれを使っても、Podの引数を定義できるということです。
"$(VAR)"という括弧で囲まれて表示されます。これは、commandやargsフィールドで変数を展開するために必要です。シェルでコマンドを実行する必要がある場合もあります。例えば、コマンドが複数のコマンドをパイプでつないだものであったり、シェルスクリプトであったりします。コマンドをシェルで実行するには、次のように記述します。
command: ["/bin/sh"]
args: ["-c", "while true; do echo hello; sleep 10;done"]
このページでは、Kubernetes Podでコンテナの環境変数を定義する方法を説明します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.Podを作成するとき、そのPodで実行するコンテナに環境変数を設定することができます。環境変数を設定するには、設定ファイルに env または envFrom フィールドを含めます。
この演習では、1つのコンテナを実行するPodを作成します。Podの設定ファイルには、名前 DEMO_GREETING、値 "Hello from the environment"を持つ環境変数が定義されています。Podの設定マニフェストを以下に示します:
apiVersion: v1
kind: Pod
metadata:
name: envar-demo
labels:
purpose: demonstrate-envars
spec:
containers:
- name: envar-demo-container
image: gcr.io/google-samples/node-hello:1.0
env:
- name: DEMO_GREETING
value: "Hello from the environment"
- name: DEMO_FAREWELL
value: "Such a sweet sorrow"
マニフェストに基づいてPodを作成します:
kubectl apply -f https://k8s.io/examples/pods/inject/envars.yaml
実行中のPodを一覧表示します:
kubectl get pods -l purpose=demonstrate-envars
出力は以下のようになります:
NAME READY STATUS RESTARTS AGE
envar-demo 1/1 Running 0 9s
Podで実行しているコンテナのシェルを取得します:
kubectl exec -it envar-demo -- /bin/bash
シェルでprintenvコマンドを実行すると、環境変数の一覧が表示されます。
# コンテナ内のシェルで以下のコマンドを実行します
printenv
出力は以下のようになります:
NODE_VERSION=4.4.2
EXAMPLE_SERVICE_PORT_8080_TCP_ADDR=10.3.245.237
HOSTNAME=envar-demo
...
DEMO_GREETING=Hello from the environment
DEMO_FAREWELL=Such a sweet sorrow
シェルを終了するには、exitと入力します。
envまたはenvFromフィールドを使用して設定された環境変数は、コンテナイメージで指定された環境変数を上書きします。Podの設定で定義した環境変数は、Podのコンテナに設定したコマンドや引数など、設定の他の場所で使用することができます。以下の設定例では、環境変数GREETING、HONORORIFIC、NAMEにそれぞれ Warm greetings to、The Most Honorable、Kubernetesを設定しています。これらの環境変数は、env-print-demoコンテナに渡されるCLI引数で使われます。
apiVersion: v1
kind: Pod
metadata:
name: print-greeting
spec:
containers:
- name: env-print-demo
image: bash
env:
- name: GREETING
value: "Warm greetings to"
- name: HONORIFIC
value: "The Most Honorable"
- name: NAME
value: "Kubernetes"
command: ["echo"]
args: ["$(GREETING) $(HONORIFIC) $(NAME)"]
作成されると、コンテナ上でecho Warm greetings to The Most Honorable Kubernetesというコマンドが実行されます。
このページでは、Podが内部で実行しているコンテナに自身の情報を共有する方法を説明します。環境変数ではPodのフィールドとコンテナのフィールドを共有することができます。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.Podとコンテナのフィールドを実行中のコンテナに共有する方法は2つあります:
これら2つの方法を合わせて、Podとコンテナフィールドを共有する方法をDownward APIと呼びます。
この演習では、1つのコンテナを持つPodを作成します。Podの設定ファイルは次のとおりです:
apiVersion: v1
kind: Pod
metadata:
name: dapi-envars-fieldref
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "sh", "-c"]
args:
- while true; do
echo -en '\n';
printenv MY_NODE_NAME MY_POD_NAME MY_POD_NAMESPACE;
printenv MY_POD_IP MY_POD_SERVICE_ACCOUNT;
sleep 10;
done;
env:
- name: MY_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: MY_POD_SERVICE_ACCOUNT
valueFrom:
fieldRef:
fieldPath: spec.serviceAccountName
restartPolicy: Never
設定ファイルには、5つの環境変数があります。envフィールドはEnvVarsの配列です。配列の最初の要素では、環境変数MY_NODE_NAMEの値をPodのspec.nodeNameフィールドから取得することを指定します。同様に、他の環境変数もPodのフィールドから名前を取得します。
Podを作成します:
kubectl apply -f https://k8s.io/examples/pods/inject/dapi-envars-pod.yaml
Podのコンテナが実行されていることを確認します:
kubectl get pods
コンテナのログを表示します:
kubectl logs dapi-envars-fieldref
出力には、選択した環境変数の値が表示されます:
minikube
dapi-envars-fieldref
default
172.17.0.4
default
これらの値がログにある理由を確認するには、設定ファイルのcommandおよびargsフィールドを確認してください。コンテナが起動すると、5つの環境変数の値が標準出力に書き込まれます。これを10秒ごとに繰り返します。
次に、Podで実行しているコンテナへのシェルを取得します:
kubectl exec -it dapi-envars-fieldref -- sh
シェルで環境変数を表示します:
/# printenv
出力は、特定の環境変数にPodフィールドの値が割り当てられていることを示しています:
MY_POD_SERVICE_ACCOUNT=default
...
MY_POD_NAMESPACE=default
MY_POD_IP=172.17.0.4
...
MY_NODE_NAME=minikube
...
MY_POD_NAME=dapi-envars-fieldref
前の演習では、環境変数の値としてPodフィールドを使用しました。次の演習では、環境変数の値としてコンテナフィールドを使用します。これは、1つのコンテナを持つPodの設定ファイルです:
apiVersion: v1
kind: Pod
metadata:
name: dapi-envars-resourcefieldref
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox:1.24
command: [ "sh", "-c"]
args:
- while true; do
echo -en '\n';
printenv MY_CPU_REQUEST MY_CPU_LIMIT;
printenv MY_MEM_REQUEST MY_MEM_LIMIT;
sleep 10;
done;
resources:
requests:
memory: "32Mi"
cpu: "125m"
limits:
memory: "64Mi"
cpu: "250m"
env:
- name: MY_CPU_REQUEST
valueFrom:
resourceFieldRef:
containerName: test-container
resource: requests.cpu
- name: MY_CPU_LIMIT
valueFrom:
resourceFieldRef:
containerName: test-container
resource: limits.cpu
- name: MY_MEM_REQUEST
valueFrom:
resourceFieldRef:
containerName: test-container
resource: requests.memory
- name: MY_MEM_LIMIT
valueFrom:
resourceFieldRef:
containerName: test-container
resource: limits.memory
restartPolicy: Never
設定ファイルには、4つの環境変数があります。envフィールドはEnvVarsの配列です。配列の最初の要素では、環境変数MY_CPU_REQUESTの値をtest-containerという名前のコンテナのrequests.cpuフィールドから取得することを指定します。同様に、他の環境変数もコンテナのフィールドから値を取得します。
Podを作成します:
kubectl apply -f https://k8s.io/examples/pods/inject/dapi-envars-container.yaml
Podのコンテナが実行されていることを確認します:
kubectl get pods
コンテナのログを表示します:
kubectl logs dapi-envars-resourcefieldref
出力には、選択した環境変数の値が表示されます:
1
1
33554432
67108864
このページでは、パスワードや暗号化キーなどの機密データをPodに安全に注入する方法を紹介します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.6. バージョンを確認するには次のコマンドを実行してください:kubectl version.ユーザー名my-appとパスワード39528$vdg7Jbの2つの機密データが必要だとします。
まず、base64エンコーディングツールを使って、ユーザ名とパスワードをbase64表現に変換します。
ここでは、手軽に入手できるbase64プログラムを使った例を紹介します:
echo -n 'my-app' | base64
echo -n '39528$vdg7Jb' | base64
出力結果によると、ユーザ名のbase64表現はbXktYXBwで、パスワードのbase64表現はMzk1MjgkdmRnN0piです。
以下はユーザー名とパスワードを保持するSecretを作成するために使用できる設定ファイルです:
apiVersion: v1
kind: Secret
metadata:
name: test-secret
data:
username: bXktYXBw
password: Mzk1MjgkdmRnN0pi
Secret を作成する
kubectl apply -f https://k8s.io/examples/pods/inject/secret.yaml
Secretの情報を取得する
kubectl get secret test-secret
出力:
NAME TYPE DATA AGE
test-secret Opaque 2 1m
Secretの詳細な情報を取得する:
kubectl describe secret test-secret
出力:
Name: test-secret
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 13 bytes
username: 7 bytes
base64エンコードの手順を省略したい場合は、kubectl create secretコマンドで同じSecretを作成することができます。
例えば:
kubectl create secret generic test-secret --from-literal='username=my-app' --from-literal='password=39528$vdg7Jb'
先ほどの詳細なアプローチでは 各ステップを明示的に実行し、何が起こっているかを示していますが、kubectl create secretの方が便利です。
これはPodの作成に使用できる設定ファイルです。
apiVersion: v1
kind: Pod
metadata:
name: secret-test-pod
spec:
containers:
- name: test-container
image: nginx
volumeMounts:
# name must match the volume name below
- name: secret-volume
mountPath: /etc/secret-volume
# The secret data is exposed to Containers in the Pod through a Volume.
volumes:
- name: secret-volume
secret:
secretName: test-secret
Podを作成する:
kubectl apply -f https://k8s.io/examples/pods/inject/secret-pod.yaml
PodのSTATUSがRunningであるのを確認する:
kubectl get pod secret-test-pod
出力:
NAME READY STATUS RESTARTS AGE
secret-test-pod 1/1 Running 0 42m
Podの中にあるコンテナにシェルを実行する
kubectl exec -i -t secret-test-pod -- /bin/bash
機密データは /etc/secret-volume にマウントされたボリュームを介してコンテナに公開されます。
ディレクトリ /etc/secret-volume 中のファイルの一覧を確認する:
# Run this in the shell inside the container
ls /etc/secret-volume
passwordとusername 2つのファイル名が出力される:
password username
username と password ファイルの中身を表示する:
# Run this in the shell inside the container
echo "$( cat /etc/secret-volume/username )"
echo "$( cat /etc/secret-volume/password )"
出力:
my-app
39528$vdg7Jb
Secretの中でkey-valueペアで環境変数を定義する:
kubectl create secret generic backend-user --from-literal=backend-username='backend-admin'
Secretで定義されたbackend-usernameの値をPodの環境変数SECRET_USERNAMEに割り当てます。
apiVersion: v1
kind: Pod
metadata:
name: env-single-secret
spec:
containers:
- name: envars-test-container
image: nginx
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: backend-user
key: backend-username
Podを作成する:
kubectl create -f https://k8s.io/examples/pods/inject/pod-single-secret-env-variable.yaml
コンテナの環境変数SECRET_USERNAMEの中身を表示する:
kubectl exec -i -t env-single-secret -- /bin/sh -c 'echo $SECRET_USERNAME'
出力:
backend-admin
前述の例と同様に、まずSecretを作成します:
kubectl create secret generic backend-user --from-literal=backend-username='backend-admin'
kubectl create secret generic db-user --from-literal=db-username='db-admin'
Podの中で環境変数を定義する:
apiVersion: v1
kind: Pod
metadata:
name: envvars-multiple-secrets
spec:
containers:
- name: envars-test-container
image: nginx
env:
- name: BACKEND_USERNAME
valueFrom:
secretKeyRef:
name: backend-user
key: backend-username
- name: DB_USERNAME
valueFrom:
secretKeyRef:
name: db-user
key: db-username
Podを作成する:
kubectl create -f https://k8s.io/examples/pods/inject/pod-multiple-secret-env-variable.yaml
コンテナの環境変数を表示する:
kubectl exec -i -t envvars-multiple-secrets -- /bin/sh -c 'env | grep _USERNAME'
出力:
DB_USERNAME=db-admin
BACKEND_USERNAME=backend-admin
複数のkey-valueペアを含むSecretを作成する
kubectl create secret generic test-secret --from-literal=username='my-app' --from-literal=password='39528$vdg7Jb'
envFromを使用してSecretのすべてのデータをコンテナの環境変数として定義します。SecretのキーがPodの環境変数名になります。
apiVersion: v1
kind: Pod
metadata:
name: envfrom-secret
spec:
containers:
- name: envars-test-container
image: nginx
envFrom:
- secretRef:
name: test-secret
Podを作成する:
kubectl create -f https://k8s.io/examples/pods/inject/pod-secret-envFrom.yaml
usernameとpasswordコンテナの環境変数を表示する
kubectl exec -i -t envfrom-secret -- /bin/sh -c 'echo "username: $username\npassword: $password\n"'
出力:
username: my-app
password: 39528$vdg7Jb
このページでは、Kubernetes Deploymentオブジェクトを使用してアプリケーションを実行する方法を説明します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.9. バージョンを確認するには次のコマンドを実行してください:kubectl version.Kubernetes Deploymentオブジェクトを作成することでアプリケーションを実行できます。また、YAMLファイルでDeploymentを記述できます。例えば、このYAMLファイルはnginx:1.14.2 Dockerイメージを実行するデプロイメントを記述しています:
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
YAMLファイルに基づいてDeploymentを作成します:
kubectl apply -f https://k8s.io/examples/application/deployment.yaml
Deploymentに関する情報を表示します:
kubectl describe deployment nginx-deployment
出力はこのようになります:
Name: nginx-deployment
Namespace: default
CreationTimestamp: Tue, 30 Aug 2016 18:11:37 -0700
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=1
Selector: app=nginx
Replicas: 2 desired | 2 updated | 2 total | 2 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 1 max unavailable, 1 max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.14.2
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-1771418926 (2/2 replicas created)
No events.
Deploymentによって作成されたPodを一覧表示します:
kubectl get pods -l app=nginx
出力はこのようになります:
NAME READY STATUS RESTARTS AGE
nginx-deployment-1771418926-7o5ns 1/1 Running 0 16h
nginx-deployment-1771418926-r18az 1/1 Running 0 16h
Podに関する情報を表示します:
kubectl describe pod <pod-name>
ここで<pod-name>はPodの1つの名前を指定します。
新しいYAMLファイルを適用してDeploymentを更新できます。このYAMLファイルは、Deploymentを更新してnginx 1.16.1を使用するように指定しています。
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1 # Update the version of nginx from 1.14.2 to 1.16.1
ports:
- containerPort: 80
新しいYAMLファイルを適用します:
kubectl apply -f https://k8s.io/examples/application/deployment-update.yaml
Deploymentが新しい名前でPodを作成し、古いPodを削除するのを監視します:
kubectl get pods -l app=nginx
新しいYAMLファイルを適用することで、Deployment内のPodの数を増やすことができます。このYAMLファイルはreplicasを4に設定します。これはDeploymentが4つのPodを持つべきであることを指定します:
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 4 # Update the replicas from 2 to 4
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1
ports:
- containerPort: 80
新しいYAMLファイルを適用します:
kubectl apply -f https://k8s.io/examples/application/deployment-scale.yaml
Deploymentに4つのPodがあることを確認します:
kubectl get pods -l app=nginx
出力はこのようになります:
NAME READY STATUS RESTARTS AGE
nginx-deployment-148880595-4zdqq 1/1 Running 0 25s
nginx-deployment-148880595-6zgi1 1/1 Running 0 25s
nginx-deployment-148880595-fxcez 1/1 Running 0 2m
nginx-deployment-148880595-rwovn 1/1 Running 0 2m
Deploymentを名前を指定して削除します:
kubectl delete deployment nginx-deployment
複製アプリケーションを作成するための好ましい方法はDeploymentを使用することです。そして、DeploymentはReplicaSetを使用します。 DeploymentとReplicaSetがKubernetesに追加される前は、ReplicationControllerを使用して複製アプリケーションを構成していました。
このページでは、PersistentVolumeとDeploymentを使用して、Kubernetesで単一レプリカのステートフルアプリケーションを実行する方法を説明します。アプリケーションはMySQLです。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.ここで使用されているPersistentVolumeClaimsの要件を満たすには、デフォルトのStorageClassを使用して動的PersistentVolumeプロビジョナーを作成するか、PersistentVolumesを静的にプロビジョニングする必要があります。
Kubernetes Deploymentを作成し、PersistentVolumeClaimを使用して既存のPersistentVolumeに接続することで、ステートフルアプリケーションを実行できます。 たとえば、以下のYAMLファイルはMySQLを実行し、PersistentVolumeClaimを参照するDeploymentを記述しています。 このファイルは/var/lib/mysqlのボリュームマウントを定義してから、20Gのボリュームを要求するPersistentVolumeClaimを作成します。 この要求は、要件を満たす既存のボリューム、または動的プロビジョナーによって満たされます。
注:パスワードはYAMLファイル内に定義されており、これは安全ではありません。安全な解決策についてはKubernetes Secretを参照してください 。
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- port: 3306
selector:
app: mysql
clusterIP: None
---
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: mysql:5.6
name: mysql
env:
# Use secret in real usage
- name: MYSQL_ROOT_PASSWORD
value: password
ports:
- containerPort: 3306
name: mysql
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
kind: PersistentVolume
apiVersion: v1
metadata:
name: mysql-pv-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
YAMLファイルに記述されたPVとPVCをデプロイします。
kubectl create -f https://k8s.io/examples/application/mysql/mysql-pv.yaml
YAMLファイルの内容をデプロイします。
kubectl create -f https://k8s.io/examples/application/mysql/mysql-deployment.yaml
作成したDeploymentの情報を表示します。
kubectl describe deployment mysql
Name: mysql
Namespace: default
CreationTimestamp: Tue, 01 Nov 2016 11:18:45 -0700
Labels: app=mysql
Annotations: deployment.kubernetes.io/revision=1
Selector: app=mysql
Replicas: 1 desired | 1 updated | 1 total | 0 available | 1 unavailable
StrategyType: Recreate
MinReadySeconds: 0
Pod Template:
Labels: app=mysql
Containers:
mysql:
Image: mysql:5.6
Port: 3306/TCP
Environment:
MYSQL_ROOT_PASSWORD: password
Mounts:
/var/lib/mysql from mysql-persistent-storage (rw)
Volumes:
mysql-persistent-storage:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: mysql-pv-claim
ReadOnly: false
Conditions:
Type Status Reason
---- ------ ------
Available False MinimumReplicasUnavailable
Progressing True ReplicaSetUpdated
OldReplicaSets: <none>
NewReplicaSet: mysql-63082529 (1/1 replicas created)
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
33s 33s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set mysql-63082529 to 1
Deploymentによって作成されたPodを一覧表示します。
kubectl get pods -l app=mysql
NAME READY STATUS RESTARTS AGE
mysql-63082529-2z3ki 1/1 Running 0 3m
PersistentVolumeClaimを確認します。
kubectl describe pvc mysql-pv-claim
Name: mysql-pv-claim
Namespace: default
StorageClass:
Status: Bound
Volume: mysql-pv-volume
Labels: <none>
Annotations: pv.kubernetes.io/bind-completed=yes
pv.kubernetes.io/bound-by-controller=yes
Capacity: 20Gi
Access Modes: RWO
Events: <none>
前述のYAMLファイルは、クラスター内の他のPodがデータベースにアクセスできるようにするServiceを作成します。
ServiceのオプションでclusterIP: Noneを指定すると、ServiceのDNS名がPodのIPアドレスに直接解決されます。
このオプションは、ServiceのバックエンドのPodが1つのみであり、Podの数を増やす予定がない場合に適しています。
MySQLクライアントを実行してサーバーに接続します。
kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -ppassword
このコマンドは、クラスター内にMySQLクライアントを実行する新しいPodを作成し、Serviceを通じてMySQLサーバーに接続します。 接続できれば、ステートフルなMySQLデータベースが稼働していることが確認できます。
Waiting for pod default/mysql-client-274442439-zyp6i to be running, status is Pending, pod ready: false
If you don't see a command prompt, try pressing enter.
mysql>
イメージまたはDeploymentの他の部分は、kubectl applyコマンドを使用して通常どおりに更新できます。
ステートフルアプリケーションに固有のいくつかの注意事項を以下に記載します。
strategy: type: Recreateを使用して下さい。
この設定はKubernetesにローリングアップデートを使用 しない ように指示します。
同時に複数のPodを実行することはできないため、ローリングアップデートは使用できません。
Recreate戦略は、更新された設定で新しいPodを作成する前に、最初のPodを停止します。名前を指定してデプロイしたオブジェクトを削除します。
kubectl delete deployment,svc mysql
kubectl delete pvc mysql-pv-claim
kubectl delete pv mysql-pv-volume
PersistentVolumeを手動でプロビジョニングした場合は、PersistentVolumeを手動で削除し、また、下層にあるリソースも解放する必要があります。 動的プロビジョニング機能を使用した場合は、PersistentVolumeClaimを削除すれば、自動的にPersistentVolumeも削除されます。 一部の動的プロビジョナー(EBSやPDなど)は、PersistentVolumeを削除すると同時に下層にあるリソースも解放します。
Deploymentオブジェクトについてもっと学ぶ
アプリケーションのデプロイについてもっと学ぶ
このページでは、StatefulSet コントローラーを使用して、レプリカを持つステートフルアプリケーションを実行する方法を説明します。 ここでの例は、非同期レプリケーションを行う複数のスレーブを持つ、単一マスターのMySQLです。
この例は本番環境向けの構成ではないことに注意してください。 具体的には、MySQLの設定が安全ではないデフォルトのままとなっています。 これはKubernetesでステートフルアプリケーションを実行するための一般的なパターンに焦点を当てるためです。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.ここで使用されているPersistentVolumeClaimsの要件を満たすには、デフォルトのStorageClassを使用して動的PersistentVolumeプロビジョナーを作成するか、PersistentVolumesを静的にプロビジョニングする必要があります。
このMySQLのデプロイの例は、1つのConfigMap、2つのService、および1つのStatefulSetから構成されます。
次のYAML設定ファイルからConfigMapを作成します。
kubectl apply -f https://k8s.io/examples/application/mysql/mysql-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
app.kubernetes.io/name: mysql
data:
primary.cnf: |
# Apply this config only on the primary.
[mysqld]
log-bin
replica.cnf: |
# Apply this config only on replicas.
[mysqld]
super-read-only
このConfigMapは、MySQLマスターとスレーブの設定を独立して制御するために、
それぞれのmy.cnfを上書きする内容を提供します。
この場合、マスターはスレーブにレプリケーションログを提供するようにし、
スレーブはレプリケーション以外の書き込みを拒否するようにします。
ConfigMap自体に特別なことはありませんが、ConfigMapの各部分は異なるPodに適用されます。 各Podは、StatefulSetコントローラーから提供される情報に基づいて、 初期化時にConfigMapのどの部分を見るかを決定します。
以下のYAML設定ファイルからServiceを作成します。
kubectl apply -f https://k8s.io/examples/application/mysql/mysql-services.yaml
# Headless service for stable DNS entries of StatefulSet members.
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None
selector:
app: mysql
---
# Client service for connecting to any MySQL instance for reads.
# For writes, you must instead connect to the master: mysql-0.mysql.
apiVersion: v1
kind: Service
metadata:
name: mysql-read
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
selector:
app: mysql
ヘッドレスサービスは、StatefulSetコントローラーが
StatefulSetの一部であるPodごとに作成するDNSエントリーのベースエントリーを提供します。
この例ではヘッドレスサービスの名前はmysqlなので、同じKubernetesクラスターの
同じ名前空間内の他のPodは、<pod-name>.mysqlを名前解決することでPodにアクセスできます。
mysql-readと呼ばれるクライアントサービスは、独自のクラスターIPを持つ通常のServiceであり、
Ready状態のすべてのMySQL Podに接続を分散します。
Serviceのエンドポイントには、MySQLマスターとすべてのスレーブが含まれる可能性があります。
読み込みクエリーのみが、負荷分散されるクライアントサービスを使用できることに注意してください。 MySQLマスターは1つしかいないため、クライアントが書き込みを実行するためには、 (ヘッドレスサービス内のDNSエントリーを介して)MySQLのマスターPodに直接接続する必要があります。
最後に、次のYAML設定ファイルからStatefulSetを作成します。
kubectl apply -f https://k8s.io/examples/application/mysql/mysql-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
serviceName: mysql
replicas: 3
template:
metadata:
labels:
app: mysql
spec:
initContainers:
- name: init-mysql
image: mysql:5.7
command:
- bash
- "-c"
- |
set -ex
# Generate mysql server-id from pod ordinal index.
[[ $HOSTNAME =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# Add an offset to avoid reserved server-id=0 value.
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# Copy appropriate conf.d files from config-map to emptyDir.
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/master.cnf /mnt/conf.d/
else
cp /mnt/config-map/slave.cnf /mnt/conf.d/
fi
volumeMounts:
- name: conf
mountPath: /mnt/conf.d
- name: config-map
mountPath: /mnt/config-map
- name: clone-mysql
image: gcr.io/google-samples/xtrabackup:1.0
command:
- bash
- "-c"
- |
set -ex
# Skip the clone if data already exists.
[[ -d /var/lib/mysql/mysql ]] && exit 0
# Skip the clone on master (ordinal index 0).
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
# Clone data from previous peer.
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
# Prepare the backup.
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ALLOW_EMPTY_PASSWORD
value: "1"
ports:
- name: mysql
containerPort: 3306
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 500m
memory: 1Gi
livenessProbe:
exec:
command: ["mysqladmin", "ping"]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
exec:
# Check we can execute queries over TCP (skip-networking is off).
command: ["mysql", "-h", "127.0.0.1", "-e", "SELECT 1"]
initialDelaySeconds: 5
periodSeconds: 2
timeoutSeconds: 1
- name: xtrabackup
image: gcr.io/google-samples/xtrabackup:1.0
ports:
- name: xtrabackup
containerPort: 3307
command:
- bash
- "-c"
- |
set -ex
cd /var/lib/mysql
# Determine binlog position of cloned data, if any.
if [[ -f xtrabackup_slave_info && "x$(<xtrabackup_slave_info)" != "x" ]]; then
# XtraBackup already generated a partial "CHANGE MASTER TO" query
# because we're cloning from an existing slave. (Need to remove the tailing semicolon!)
cat xtrabackup_slave_info | sed -E 's/;$//g' > change_master_to.sql.in
# Ignore xtrabackup_binlog_info in this case (it's useless).
rm -f xtrabackup_slave_info xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
# We're cloning directly from master. Parse binlog position.
[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm -f xtrabackup_binlog_info xtrabackup_slave_info
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
# Check if we need to complete a clone by starting replication.
if [[ -f change_master_to.sql.in ]]; then
echo "Waiting for mysqld to be ready (accepting connections)"
until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
mysql -h 127.0.0.1 \
-e "$(<change_master_to.sql.in), \
MASTER_HOST='mysql-0.mysql', \
MASTER_USER='root', \
MASTER_PASSWORD='', \
MASTER_CONNECT_RETRY=10; \
START SLAVE;" || exit 1
# In case of container restart, attempt this at-most-once.
mv change_master_to.sql.in change_master_to.sql.orig
fi
# Start a server to send backups when requested by peers.
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 100m
memory: 100Mi
volumes:
- name: conf
emptyDir: {}
- name: config-map
configMap:
name: mysql
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
次のコマンドを実行して起動の進行状況を確認できます。
kubectl get pods -l app=mysql --watch
しばらくすると、3つのPodすべてがRunning状態になるはずです。
NAME READY STATUS RESTARTS AGE
mysql-0 2/2 Running 0 2m
mysql-1 2/2 Running 0 1m
mysql-2 2/2 Running 0 1m
Ctrl+Cを押してウォッチをキャンセルします。 起動が進行しない場合は、始める前にで説明されているように、 PersistentVolumeの動的プロビジョニング機能が有効になっていることを確認してください。
このマニフェストでは、StatefulSetの一部としてステートフルなPodを管理するためにさまざまな手法を使用しています。 次のセクションでは、これらの手法のいくつかに焦点を当て、StatefulSetがPodを作成するときに何が起こるかを説明します。
StatefulSetコントローラーは、序数インデックスの順にPodを一度に1つずつ起動します。 各PodがReady状態を報告するまで待機してから、その次のPodの起動が開始されます。
さらに、コントローラーは各Podに <statefulset-name>-<ordinal-index>という形式の一意で不変の名前を割り当てます。
この例の場合、Podの名前はmysql-0、mysql-1、そしてmysql-2となります。
上記のStatefulSetマニフェスト内のPodテンプレートは、これらのプロパティーを利用して、 MySQLレプリケーションの起動を順序正しく実行します。
Podスペック内のコンテナを起動する前に、Podは最初に 初期化コンテナを定義された順序で実行します。
最初の初期化コンテナはinit-mysqlという名前で、序数インデックスに基づいて特別なMySQL設定ファイルを生成します。
スクリプトは、hostnameコマンドによって返されるPod名の末尾から抽出することによって、自身の序数インデックスを特定します。
それから、序数を(予約された値を避けるために数値オフセット付きで)MySQLのconf.dディレクトリーのserver-id.cnfというファイルに保存します。
これは、StatefulSetコントローラーによって提供される一意で不変のIDを、同じ特性を必要とするMySQLサーバーIDの領域に変換します。
さらに、init-mysqlコンテナ内のスクリプトは、master.cnfまたはslave.cnfのいずれかを、
ConfigMapから内容をconf.dにコピーすることによって適用します。
このトポロジー例は単一のMySQLマスターと任意の数のスレーブで構成されているため、
スクリプトは単に序数の0がマスターになるように、それ以外のすべてがスレーブになるように割り当てます。
StatefulSetコントローラーによる
デプロイ順序の保証と組み合わせると、
スレーブが作成される前にMySQLマスターがReady状態になるため、スレーブはレプリケーションを開始できます。
一般に、新しいPodがセットにスレーブとして参加するときは、 MySQLマスターにはすでにデータがあるかもしれないと想定する必要があります。 また、レプリケーションログが期間の先頭まで全て揃っていない場合も想定する必要があります。 これらの控えめな仮定は、実行中のStatefulSetのサイズを初期サイズに固定するのではなく、 時間の経過とともにスケールアップまたはスケールダウンできるようにするために重要です。
2番目の初期化コンテナはclone-mysqlという名前で、スレーブPodが空のPersistentVolumeで最初に起動したときに、
クローン操作を実行します。
つまり、実行中の別のPodから既存のデータをすべてコピーするので、
そのローカル状態はマスターからレプリケーションを開始するのに十分な一貫性があります。
MySQL自体はこれを行うためのメカニズムを提供していないため、この例ではPercona XtraBackupという人気のあるオープンソースツールを使用しています。
クローンの実行中は、ソースとなるMySQLサーバーのパフォーマンスが低下する可能性があります。
MySQLマスターへの影響を最小限に抑えるために、スクリプトは各Podに序数インデックスが自分より1低いPodからクローンするように指示します。
StatefulSetコントローラーは、N+1のPodを開始する前には必ずNのPodがReady状態であることを保証するので、この方法が機能します。
初期化コンテナが正常に完了すると、通常のコンテナが実行されます。
MySQLのPodは実際にmysqldサーバーを実行するmysqlコンテナと、
サイドカー
として機能するxtrabackupコンテナから成ります。
xtrabackupサイドカーはクローンされたデータファイルを見て、
スレーブ上でMySQLレプリケーションを初期化する必要があるかどうかを決定します。
もし必要がある場合、mysqldが準備できるのを待ってから、
XtraBackupクローンファイルから抽出されたレプリケーションパラメーターでCHANGE MASTER TOとSTART SLAVEコマンドを実行します。
スレーブがレプリケーションを開始すると、スレーブはMySQLマスターを記憶し、
サーバーが再起動した場合または接続が停止した場合に、自動的に再接続します。
また、スレーブはその不変のDNS名(mysql-0.mysql)でマスターを探すため、
再スケジュールされたために新しいPod IPを取得したとしても、自動的にマスターを見つけます。
最後に、レプリケーションを開始した後、xtrabackupコンテナはデータのクローンを要求する他のPodからの接続を待ち受けます。
StatefulSetがスケールアップした場合や、次のPodがPersistentVolumeClaimを失ってクローンをやり直す必要がある場合に備えて、
このサーバーは無期限に起動したままになります。
テストクエリーをMySQLマスター(ホスト名 mysql-0.mysql)に送信するには、
mysql:5.7イメージを使って一時的なコンテナを実行し、mysqlクライアントバイナリを実行します。
kubectl run mysql-client --image=mysql:5.7 -i --rm --restart=Never --\
mysql -h mysql-0.mysql <<EOF
CREATE DATABASE test;
CREATE TABLE test.messages (message VARCHAR(250));
INSERT INTO test.messages VALUES ('hello');
EOF
Ready状態を報告したいずれかのサーバーにテストクエリーを送信するには、ホスト名mysql-readを使用します。
kubectl run mysql-client --image=mysql:5.7 -i -t --rm --restart=Never --\
mysql -h mysql-read -e "SELECT * FROM test.messages"
次のような出力が得られるはずです。
Waiting for pod default/mysql-client to be running, status is Pending, pod ready: false
+---------+
| message |
+---------+
| hello |
+---------+
pod "mysql-client" deleted
mysql-readサービスがサーバー間で接続を分散させることを実証するために、
ループでSELECT @@server_idを実行することができます。
kubectl run mysql-client-loop --image=mysql:5.7 -i -t --rm --restart=Never --\
bash -ic "while sleep 1; do mysql -h mysql-read -e 'SELECT @@server_id,NOW()'; done"
接続の試行ごとに異なるエンドポイントが選択される可能性があるため、
報告される@@server_idはランダムに変更されるはずです。
+-------------+---------------------+
| @@server_id | NOW() |
+-------------+---------------------+
| 100 | 2006-01-02 15:04:05 |
+-------------+---------------------+
+-------------+---------------------+
| @@server_id | NOW() |
+-------------+---------------------+
| 102 | 2006-01-02 15:04:06 |
+-------------+---------------------+
+-------------+---------------------+
| @@server_id | NOW() |
+-------------+---------------------+
| 101 | 2006-01-02 15:04:07 |
+-------------+---------------------+
ループを止めたいときはCtrl+Cを押すことができますが、別のウィンドウで実行したままにしておくことで、 次の手順の効果を確認できます。
単一のサーバーではなくスレーブのプールから読み取りを行うことによって可用性が高まっていることを実証するため、
Podを強制的にReadyではない状態にする間、上記のSELECT @@server_idループを実行したままにしてください。
mysqlコンテナに対する
readiness probe
は、mysql -h 127.0.0.1 -e 'SELECT 1'コマンドを実行することで、サーバーが起動していてクエリーが実行できることを確認します。
このreadiness probeを失敗させる1つの方法は、そのコマンドを壊すことです。
kubectl exec mysql-2 -c mysql -- mv /usr/bin/mysql /usr/bin/mysql.off
ここでは、mysql-2 Podの実際のコンテナのファイルシステムにアクセスし、
mysqlコマンドの名前を変更してreadiness probeがコマンドを見つけられないようにしています。
数秒後、Podはそのコンテナの1つがReadyではないと報告するはずです。以下を実行して確認できます。
kubectl get pod mysql-2
READY列の1/2を見てください。
NAME READY STATUS RESTARTS AGE
mysql-2 1/2 Running 0 3m
この時点で、SELECT @@server_idループは実行され続け、しかしもう102が報告されないことが確認できるはずです。
init-mysqlスクリプトがserver-idを100+$ordinalとして定義したことを思い出して下さい。
そのため、サーバーID102はPodのmysql-2に対応します。
それではPodを修復しましょう。すると数秒後にループ出力に再び現れるはずです。
kubectl exec mysql-2 -c mysql -- mv /usr/bin/mysql.off /usr/bin/mysql
StatefulSetは、Podが削除された場合にPodを再作成します。 これはReplicaSetがステートレスなPodに対して行うのと同様です。
kubectl delete pod mysql-2
StatefulSetコントローラーはmysql-2 Podがもう存在しないことに気付き、
同じ名前で同じPersistentVolumeClaimにリンクされた新しいPodを作成します。
サーバーID102がしばらくの間ループ出力から消えて、また元に戻るのが確認できるはずです。
Kubernetesクラスターに複数のノードがある場合は、 drainを発行して ノードのダウンタイム(例えばノードのアップグレード時など)をシミュレートできます。
まず、あるMySQL Podがどのノード上にいるかを確認します。
kubectl get pod mysql-2 -o wide
ノード名が最後の列に表示されるはずです。
NAME READY STATUS RESTARTS AGE IP NODE
mysql-2 2/2 Running 0 15m 10.244.5.27 kubernetes-minion-group-9l2t
その後、次のコマンドを実行してノードをdrainします。
これにより、新しいPodがそのノードにスケジュールされないようにcordonされ、そして既存のPodは強制退去されます。
<node-name>は前のステップで確認したノードの名前に置き換えてください。
この操作はノード上の他のアプリケーションに影響を与える可能性があるため、 テストクラスターでのみこの操作を実行するのが最善です。
kubectl drain <node-name> --force --delete-local-data --ignore-daemonsets
Podが別のノードに再スケジュールされる様子を確認しましょう。
kubectl get pod mysql-2 -o wide --watch
次のような出力が見られるはずです。
NAME READY STATUS RESTARTS AGE IP NODE
mysql-2 2/2 Terminating 0 15m 10.244.1.56 kubernetes-minion-group-9l2t
[...]
mysql-2 0/2 Pending 0 0s <none> kubernetes-minion-group-fjlm
mysql-2 0/2 Init:0/2 0 0s <none> kubernetes-minion-group-fjlm
mysql-2 0/2 Init:1/2 0 20s 10.244.5.32 kubernetes-minion-group-fjlm
mysql-2 0/2 PodInitializing 0 21s 10.244.5.32 kubernetes-minion-group-fjlm
mysql-2 1/2 Running 0 22s 10.244.5.32 kubernetes-minion-group-fjlm
mysql-2 2/2 Running 0 30s 10.244.5.32 kubernetes-minion-group-fjlm
また、サーバーID102がSELECT @@server_idループの出力からしばらくの消えて、
そして戻ることが確認できるはずです。
それでは、ノードをuncordonして正常な状態に戻しましょう。
kubectl uncordon <node-name>
MySQLレプリケーションでは、スレーブを追加することで読み取りクエリーのキャパシティーをスケールできます。 StatefulSetを使用している場合、単一のコマンドでこれを実行できます。
kubectl scale statefulset mysql --replicas=5
次のコマンドを実行して、新しいPodが起動してくるのを確認します。
kubectl get pods -l app=mysql --watch
新しいPodが起動すると、サーバーID103と104がSELECT @@server_idループの出力に現れます。
また、これらの新しいサーバーが、これらのサーバーが存在する前に追加したデータを持っていることを確認することもできます。
kubectl run mysql-client --image=mysql:5.7 -i -t --rm --restart=Never --\
mysql -h mysql-3.mysql -e "SELECT * FROM test.messages"
Waiting for pod default/mysql-client to be running, status is Pending, pod ready: false
+---------+
| message |
+---------+
| hello |
+---------+
pod "mysql-client" deleted
元の状態へのスケールダウンもシームレスに可能です。
kubectl scale statefulset mysql --replicas=3
ただし、スケールアップすると新しいPersistentVolumeClaimが自動的に作成されますが、 スケールダウンしてもこれらのPVCは自動的には削除されないことに注意して下さい。 このため、初期化されたPVCをそのまま置いておいくことで再スケールアップを速くしたり、 PVを削除する前にデータを抽出するといった選択が可能になります。
次のコマンドを実行してこのことを確認できます。
kubectl get pvc -l app=mysql
StatefulSetを3にスケールダウンしたにもかかわらず、5つのPVCすべてがまだ存在しています。
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
data-mysql-0 Bound pvc-8acbf5dc-b103-11e6-93fa-42010a800002 10Gi RWO 20m
data-mysql-1 Bound pvc-8ad39820-b103-11e6-93fa-42010a800002 10Gi RWO 20m
data-mysql-2 Bound pvc-8ad69a6d-b103-11e6-93fa-42010a800002 10Gi RWO 20m
data-mysql-3 Bound pvc-50043c45-b1c5-11e6-93fa-42010a800002 10Gi RWO 2m
data-mysql-4 Bound pvc-500a9957-b1c5-11e6-93fa-42010a800002 10Gi RWO 2m
余分なPVCを再利用するつもりがないのであれば、削除することができます。
kubectl delete pvc data-mysql-3
kubectl delete pvc data-mysql-4
SELECT @@server_idループを実行している端末でCtrl+Cを押すか、
別の端末から次のコマンドを実行して、ループをキャンセルします。
kubectl delete pod mysql-client-loop --now
StatefulSetを削除します。これによってPodの終了も開始されます。
kubectl delete statefulset mysql
Podが消えたことを確認します。 Podが終了処理が完了するのには少し時間がかかるかもしれません。
kubectl get pods -l app=mysql
上記のコマンドから以下の出力が戻れば、Podが終了したことがわかります。
No resources found.
ConfigMap、Services、およびPersistentVolumeClaimを削除します。
kubectl delete configmap,service,pvc -l app=mysql
PersistentVolumeを手動でプロビジョニングした場合は、それらを手動で削除し、 また、下層にあるリソースも解放する必要があります。 動的プロビジョニング機能を使用した場合は、PersistentVolumeClaimを削除すれば、自動的にPersistentVolumeも削除されます。 一部の動的プロビジョナー(EBSやPDなど)は、PersistentVolumeを削除すると同時に下層にあるリソースも解放します。
このタスクは、StatefulSetをスケールする方法を示します。StatefulSetをスケーリングするとは、レプリカの数を増減することです。
StatefulSetはKubernetesバージョン1.5以降でのみ利用可能です。
Kubernetesのバージョンを確認するには、kubectl versionを実行してください。
すべてのステートフルアプリケーションがうまくスケールできるわけではありません。StatefulSetがスケールするかどうかわからない場合は、StatefulSetの概念またはStatefulSetのチュートリアルを参照してください。
ステートフルアプリケーションクラスターが完全に健全であると確信できる場合にのみ、スケーリングを実行してください。
まず、スケールしたいStatefulSetを見つけます。
kubectl get statefulsets <stateful-set-name>
StatefulSetのレプリカ数を変更します:
kubectl scale statefulsets <stateful-set-name> --replicas=<new-replicas>
コマンドライン上でレプリカ数を変更する代わりに、StatefulSetにインプレースアップデートが可能です。
StatefulSetが最初に kubectl applyで作成されたのなら、StatefulSetマニフェストの.spec.replicasを更新してから、kubectl applyを実行します:
kubectl apply -f <stateful-set-file-updated>
そうでなければ、kubectl editでそのフィールドを編集してください:
kubectl edit statefulsets <stateful-set-name>
あるいはkubectl patchを使ってください:
kubectl patch statefulsets <stateful-set-name> -p '{"spec":{"replicas":<new-replicas>}}'
管理するステートフルPodのいずれかが異常である場合、StatefulSetをスケールダウンすることはできません。それらのステートフルPodが実行され準備ができた後にのみ、スケールダウンが行われます。
spec.replicas > 1の場合、Kubernetesは不健康なPodの理由を判断できません。それは、永続的な障害または一時的な障害の結果である可能性があります。一時的な障害は、アップグレードまたはメンテナンスに必要な再起動によって発生する可能性があります。
永続的な障害が原因でPodが正常でない場合、障害を修正せずにスケーリングすると、StatefulSetメンバーシップが正しく機能するために必要な特定の最小レプリカ数を下回る状態になる可能性があります。これにより、StatefulSetが利用できなくなる可能性があります。
一時的な障害によってPodが正常でなくなり、Podが再び使用可能になる可能性がある場合は、一時的なエラーがスケールアップまたはスケールダウン操作の妨げになる可能性があります。一部の分散データベースでは、ノードが同時に参加および脱退するときに問題があります。このような場合は、アプリケーションレベルでスケーリング操作を考えることをお勧めします。また、ステートフルアプリケーションクラスターが完全に健全であることが確実な場合にのみスケーリングを実行してください。
このタスクでは、StatefulSetを削除する方法を説明します。
Kubernetesで他のリソースを削除するのと同じ方法でStatefulSetを削除することができます。つまり、kubectl deleteコマンドを使い、StatefulSetをファイルまたは名前で指定します。
kubectl delete -f <file.yaml>
kubectl delete statefulsets <statefulset-name>
StatefulSet自体が削除された後で、関連するヘッドレスサービスを個別に削除する必要があるかもしれません。
kubectl delete service <service-name>
kubectlを使ってStatefulSetを削除すると0にスケールダウンされ、すべてのPodが削除されます。PodではなくStatefulSetだけを削除したい場合は、--cascade=orphanを使用してください。
kubectl delete -f <file.yaml> --cascade=orphan
--cascade=orphanをkubectl deleteに渡すことで、StatefulSetオブジェクト自身が削除された後でも、StatefulSetによって管理されていたPodは残ります。Podにapp.kubernetes.io/name=MyAppというラベルが付いている場合は、次のようにして削除できます:
kubectl delete pods -l app.kubernetes.io/name=MyApp
StatefulSet内のPodを削除しても、関連付けられているボリュームは削除されません。これは、削除する前にボリュームからデータをコピーする機会があることを保証するためです。Podが終了した後にPVCを削除すると、ストレージクラスと再利用ポリシーによっては、背後にある永続ボリュームの削除がトリガーされることがあります。決してクレーム削除後にボリュームにアクセスできると想定しないでください。
関連付けられたPodを含むStatefulSet内のすべてのものを単純に削除するには、次のような一連のコマンドを実行します:
grace=$(kubectl get pods <stateful-set-pod> --template '{{.spec.terminationGracePeriodSeconds}}')
kubectl delete statefulset -l app.kubernetes.io/name=MyApp
sleep $grace
kubectl delete pvc -l app.kubernetes.io/name=MyApp
上の例では、Podはapp.kubernetes.io/name=MyAppというラベルを持っています。必要に応じてご利用のラベルに置き換えてください。
StatefulSet内の一部のPodが長期間TerminatingまたはUnknown状態のままになっていることが判明した場合は、手動でapiserverからPodを強制的に削除する必要があります。これは潜在的に危険な作業です。詳細はStatefulSet Podの強制削除を参照してください。
このページでは、StatefulSetの一部であるPodを削除する方法と、削除する際に考慮すべき事項について説明します。
StatefulSetの通常の操作では、StatefulSet Podを強制的に削除する必要はまったくありません。StatefulSetコントローラーは、StatefulSetのメンバーの作成、スケール、削除を行います。それは序数0からN-1までの指定された数のPodが生きていて準備ができていることを保証しようとします。StatefulSetは、クラスター内で実行されている特定のIDを持つ最大1つのPodがいつでも存在することを保証します。これは、StatefulSetによって提供される最大1つのセマンティクスと呼ばれます。
手動による強制削除は、StatefulSetに固有の最大1つのセマンティクスに違反する可能性があるため、慎重に行う必要があります。StatefulSetを使用して、安定したネットワークIDと安定した記憶域を必要とする分散型およびクラスター型アプリケーションを実行できます。これらのアプリケーションは、固定IDを持つ固定数のメンバーのアンサンブルに依存する構成を持つことがよくあります。同じIDを持つ複数のメンバーを持つことは悲惨なことになり、データの損失につながる可能性があります(例:定足数ベースのシステムでのスプリットブレインシナリオ)。
次のコマンドで正常なPod削除を実行できます:
kubectl delete pods <pod>
上記がグレースフルターミネーションにつながるためには、pod.Spec.TerminationGracePeriodSecondsに0を指定してはいけません。pod.Spec.TerminationGracePeriodSecondsを0秒に設定することは安全ではなく、StatefulSet Podには強くお勧めできません。グレースフル削除は安全で、kubeletがapiserverから名前を削除する前にPodが適切にシャットダウンすることを保証します。
Kubernetes(バージョン1.5以降)は、Nodeにアクセスできないという理由だけでPodを削除しません。到達不能なNodeで実行されているPodは、タイムアウトの後にTerminatingまたはUnknown状態になります。到達不能なNode上のPodをユーザーが適切に削除しようとすると、Podはこれらの状態に入ることもあります。そのような状態のPodをapiserverから削除することができる唯一の方法は以下の通りです:
推奨されるベストプラクティスは、1番目または2番目のアプローチを使用することです。Nodeが死んでいることが確認された(例えば、ネットワークから恒久的に切断された、電源が切られたなど)場合、Nodeオブジェクトを削除します。Nodeがネットワークパーティションに苦しんでいる場合は、これを解決するか、解決するのを待ちます。パーティションが回復すると、kubeletはPodの削除を完了し、apiserverでその名前を解放します。
通常、PodがNode上で実行されなくなるか、管理者によってそのNodeが削除されると、システムは削除を完了します。あなたはPodを強制的に削除することでこれを無効にすることができます。
強制削除はPodが終了したことをkubeletから確認するまで待ちません。強制削除がPodの削除に成功したかどうかに関係なく、apiserverから名前をすぐに解放します。これにより、StatefulSetコントローラーは、同じIDを持つ交換Podを作成できます。これは、まだ実行中のPodの複製につながる可能性があり、そのPodがまだStatefulSetの他のメンバーと通信できる場合、StatefulSetが保証するように設計されている最大1つのセマンティクスに違反します。
StatefulSetのPodを強制的に削除するということは、問題のPodがStatefulSet内の他のPodと再び接触することはなく、代わりのPodを作成するために名前が安全に解放されることを意味します。
バージョン1.5以上のkubectlを使用してPodを強制的に削除する場合は、次の手順を実行します:
kubectl delete pods <pod> --grace-period=0 --force
バージョン1.4以下のkubectlを使用している場合、--forceオプションを省略する必要があります:
kubectl delete pods <pod> --grace-period=0
これらのコマンドを実行した後でもPodがUnknown状態のままになっている場合は、次のコマンドを使用してPodをクラスターから削除します:
kubectl patch pod <pod> -p '{"metadata":{"finalizers":null}}'
StatefulSet Podの強制削除は、常に慎重に、関連するリスクを完全に把握して実行してください。
Kubernetesでは、 HorizontalPodAutoscaler は自動的にワークロードリソース(DeploymentやStatefulSetなど)を更新し、ワークロードを自動的にスケーリングして需要に合わせることを目指します。
水平スケーリングとは、負荷の増加に対応するために、より多くのPodをデプロイすることを意味します。これは、Kubernetesの場合、既に稼働しているワークロードのPodに対して、より多くのリソース(例:メモリーやCPU)を割り当てることを意味する 垂直 スケーリングとは異なります。
負荷が減少し、Podの数が設定された最小値より多い場合、HorizontalPodAutoscalerはワークロードリソース(Deployment、StatefulSet、または他の類似のリソース)に対してスケールダウンするよう指示します。
水平Pod自動スケーリングは、スケーリングできないオブジェクト(例:DaemonSet)には適用されません。
HorizontalPodAutoscalerは、Kubernetes APIリソースとコントローラーとして実装されています。リソースはコントローラーの動作を決定します。Kubernetesコントロールプレーン内で稼働している水平Pod自動スケーリングコントローラーは、平均CPU利用率、平均メモリー利用率、または指定した任意のカスタムメトリクスなどの観測メトリクスに合わせて、ターゲット(例:Deployment)の理想的なスケールを定期的に調整します。
水平Pod自動スケーリングの使用例のウォークスルーがあります。
図1. HorizontalPodAutoscalerはDeploymentとそのReplicaSetのスケールを制御します。
Kubernetesは水平Pod自動スケーリングを断続的に動作する制御ループとして実装しています(これは連続的なプロセスではありません)。その間隔はkube-controller-managerの--horizontal-pod-autoscaler-sync-periodパラメーターで設定します(デフォルトの間隔は15秒です)。
各期間中に1回、コントローラーマネージャーはHorizontalPodAutoscalerの定義のそれぞれに指定されたメトリクスに対するリソース使用率を照会します。コントローラーマネージャーはscaleTargetRefによって定義されたターゲットリソースを見つけ、ターゲットリソースの.spec.selectorラベルに基づいてPodを選択し、リソースメトリクスAPI(Podごとのリソースメトリクスの場合)またはカスタムメトリクスAPI(他のすべてのメトリクスの場合)からメトリクスを取得します。
Podごとのリソースメトリクス(CPUなど)の場合、コントローラーはHorizontalPodAutoscalerによってターゲットとされた各PodのリソースメトリクスAPIからメトリクスを取得します。その後、使用率の目標値が設定されている場合、コントローラーは各Pod内のコンテナの同等のリソース要求に対する割合として使用率を算出します。生の値の目標値が設定されている場合、生のメトリクス値が直接使用されます。次に、コントローラーはすべてのターゲットとなるPod間で使用率または生の値(指定されたターゲットのタイプによります)の平均を取り、理想のレプリカ数でスケールするために使用される比率を生成します。
Podのコンテナの一部に関連するリソース要求が設定されていない場合、PodのCPU利用率は定義されず、オートスケーラーはそのメトリクスに対して何も行動を起こしません。オートスケーリングアルゴリズムの動作についての詳細は、以下のアルゴリズムの詳細をご覧ください。
Podごとのカスタムメトリクスについては、コントローラーはPodごとのリソースメトリクスと同様に機能しますが、使用率の値ではなく生の値で動作します。
オブジェクトメトリクスと外部メトリクスについては、問題となるオブジェクトを表す単一のメトリクスが取得されます。このメトリクスは目標値と比較され、上記のような比率を生成します。autoscaling/v2 APIバージョンでは、比較を行う前にこの値をPodの数で割ることもできます。
HorizontalPodAutoscalerを使用する一般的な目的は、集約API(metrics.k8s.io、custom.metrics.k8s.io、またはexternal.metrics.k8s.io)からメトリクスを取得するように設定することです。metrics.k8s.io APIは通常、別途起動する必要があるMetrics Serverというアドオンによって提供されます。リソースメトリクスについての詳細は、Metrics Serverをご覧ください。
メトリクスAPIのサポートは、これらの異なるAPIの安定性の保証とサポート状況を説明します。
HorizontalPodAutoscalerコントローラーは、スケーリングをサポートするワークロードリソース(DeploymentやStatefulSetなど)にアクセスします。これらのリソースはそれぞれscaleというサブリソースを持っており、これはレプリカの数を動的に設定し、各々の現在の状態を調べることができるインターフェースを提供します。Kubernetes APIのサブリソースに関する一般的な情報については、Kubernetes API Conceptsをご覧ください。
最も基本的な観点から言えば、HorizontalPodAutoscalerコントローラーは、理想のメトリクス値と現在のメトリクス値との間の比率で動作します:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
たとえば、現在のメトリクス値が200mで、理想の値が100mの場合、レプリカの数は倍増します。なぜなら、200.0 / 100.0 == 2.0だからです。現在の値が50mの場合、レプリカの数は半分になります。なぜなら、50.0 / 100.0 == 0.5だからです。コントロールプレーンは、比率が十分に1.0に近い場合(全体的に設定可能な許容範囲内、デフォルトでは0.1)には、任意のスケーリング操作をスキップします。
targetAverageValueまたはtargetAverageUtilizationが指定されている場合、currentMetricValueは、HorizontalPodAutoscalerのスケールターゲット内のすべてのPodで指定されたメトリクスの平均を取ることで計算されます。
許容範囲を確認し、最終的な値を決定する前に、コントロールプレーンは、メトリクスが欠けていないか、また何個のPodがReady状態であるかを考慮します。削除タイムスタンプが設定されているすべてのPod(削除タイムスタンプがあるオブジェクトはシャットダウンまたは削除の途中です)は無視され、失敗したPodはすべて破棄されます。
特定のPodがメトリクスを欠いている場合、それは後で検討するために取っておかれます。メトリクスが欠けているPodは、最終的なスケーリング量の調整に使用されます。
CPUに基づいてスケーリングする場合、任意のPodがまだReadyになっていない(まだ初期化中か、おそらくunhealthy)、またはPodがReadyになる前の最新のメトリクスポイントがある場合、そのPodも取り置かれます。
技術的な制約により、HorizontalPodAutoscalerコントローラーは特定のCPUメトリクスを取り置くかどうかを判断する際に、Podが初めてReadyになる時間を正確に決定することができません。その代わり、Podが起動してから設定可能な短い時間内にReadyに遷移した場合、それを「まだReadyになっていない」とみなします。この値は、--horizontal-pod-autoscaler-initial-readiness-delayフラグで設定し、デフォルトは30秒です。Podが一度Readyになると、起動してから設定可能な長い時間内に発生した場合、それが最初のReadyへの遷移だとみなします。この値は、--horizontal-pod-autoscaler-cpu-initialization-periodフラグで設定し、デフォルトは5分です。
次に、上記で取り置かれたり破棄されたりしていない残りのPodを使用して、currentMetricValue / desiredMetricValueの基本スケール比率が計算されます。
メトリクスが欠けていた場合、コントロールプレーンは平均値をより保守的に再計算し、スケールダウンの場合はそのPodが理想の値の100%を消費していたと仮定し、スケールアップの場合は0%を消費していたと仮定します。これにより、潜在的なスケールの大きさが抑制されます。
さらに、まだReadyになっていないPodが存在し、欠けているメトリクスやまだReadyになっていないPodを考慮せずにワークロードがスケールアップした場合、コントローラーは保守的にまだReadyになっていないPodが理想のメトリクスの0%を消費していると仮定し、スケールアップの大きさをさらに抑制します。
まだReadyになっていないPodと欠けているメトリクスを考慮に入れた後、コントローラーは使用率の比率を再計算します。新しい比率がスケールの方向を逆転させるか、許容範囲内である場合、コントローラーはスケーリング操作を行いません。その他の場合、新しい比率がPodの数の変更を決定するために使用されます。
新しい使用率の比率が使用されたときであっても、平均使用率の元の値は、まだReadyになっていないPodや欠けているメトリクスを考慮せずに、HorizontalPodAutoscalerのステータスを通じて報告されることに注意してください。
HorizontalPodAutoscalerに複数のメトリクスが指定されている場合、この計算は各メトリクスに対して行われ、その後、理想のレプリカ数の最大値が選択されます。これらのメトリクスのいずれかを理想のレプリカ数に変換できない場合(例えば、メトリクスAPIからのメトリクスの取得エラーが原因)、そして取得可能なメトリクスがスケールダウンを提案する場合、スケーリングはスキップされます。これは、1つ以上のメトリクスが現在の値よりも大きなdesiredReplicasを示す場合でも、HPAはまだスケーリングアップ可能であることを意味します。
最後に、HPAがターゲットを減らす直前に、減らす台数の推奨値が記録されます。コントローラーは、設定可能な時間内のすべての推奨値を考慮し、その時間内で最も高い推奨値を選択します。この値は、--horizontal-pod-autoscaler-downscale-stabilizationフラグを使用して設定でき、デフォルトは5分です。これは、スケールダウンが徐々に行われ、急速に変動するメトリクス値の影響を滑らかにすることを意味します。
Horizontal Pod Autoscalerは、Kubernetesのautoscaling APIグループのAPIリソースです。現行の安定バージョンは、メモリーおよびカスタムメトリクスに対するスケーリングのサポートを含むautoscaling/v2 APIバージョンに見つけることができます。autoscaling/v2で導入された新たなフィールドは、autoscaling/v1で作業する際にアノテーションとして保持されます。
HorizontalPodAutoscaler APIオブジェクトを作成するときは、指定された名前が有効なDNSサブドメイン名であることを確認してください。APIオブジェクトについての詳細は、HorizontalPodAutoscaler Objectで見つけることができます。
HorizontalPodAutoscalerを使用してレプリカ群のスケールを管理する際、評価されるメトリクスの動的な性質により、レプリカの数が頻繁に変動する可能性があります。これは、スラッシング または フラッピング と呼ばれることがあります。これは、サイバネティクス における ヒステリシス の概念に似ています。
Kubernetesでは、Deploymentに対してローリングアップデートを行うことができます。その場合、Deploymentが基礎となるReplicaSetを管理します。Deploymentに自動スケーリングを設定すると、HorizontalPodAutoscalerを単一のDeploymentに結びつけます。HorizontalPodAutoscalerはDeploymentのreplicasフィールドを管理します。Deploymentコントローラーは、ロールアウト時およびその後も適切な数になるように、基礎となるReplicaSetのreplicasを設定する責任があります。
自動スケールされたレプリカ数を持つStatefulSetのローリングアップデートを実行する場合、StatefulSetは直接そのPodのセットを管理します(ReplicaSetのような中間リソースは存在しません)。
HPAの任意のターゲットは、スケーリングターゲット内のPodのリソース使用状況に基づいてスケールすることができます。Podの仕様を定義する際には、cpuやmemoryなどのリソース要求を指定する必要があります。これはリソースの使用状況を決定するために使用され、HPAコントローラーがターゲットをスケールアップまたはスケールダウンするために使用されます。リソース使用状況に基づくスケーリングを使用するには、以下のようなメトリクスソースを指定します:
type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
このメトリクスを使用すると、HPAコントローラーはスケーリングターゲット内のPodの平均使用率を60%に保ちます。使用率は、Podの要求したリソースに対する現在のリソース使用量の比率です。使用率がどのように計算され、平均化されるかの詳細については、アルゴリズムを参照してください。
Kubernetes v1.27 [beta]HorizontalPodAutoscaler APIは、コンテナメトリクスソースもサポートしています。これは、ターゲットリソースをスケールするために、HPAが一連のPod内の個々のコンテナのリソース使用状況を追跡できるようにするものです。これにより、特定のPodで最も重要なコンテナのスケーリング閾値を設定することができます。例えば、Webアプリケーションとロギングサイドカーがある場合、サイドカーのコンテナとそのリソース使用を無視して、Webアプリケーションのリソース使用に基づいてスケーリングすることができます。
ターゲットリソースを新しいPodの仕様に修正し、異なるコンテナのセットを持つようにした場合、新たに追加されたコンテナもスケーリングに使用されるべきであれば、HPAの仕様も修正すべきです。メトリクスソースで指定されたコンテナが存在しないか、または一部のPodのみに存在する場合、それらのPodは無視され、推奨が再計算されます。計算に関する詳細は、アルゴリズムを参照してください。コンテナリソースを自動スケーリングに使用するためには、以下のようにメトリクスソースを定義します:
type: ContainerResource
containerResource:
name: cpu
container: application
target:
type: Utilization
averageUtilization: 60
上記の例では、HPAコントローラーはターゲットをスケールし、すべてのPodのapplicationコンテナ内のCPUの平均使用率が60%になるようにします。
HorizontalPodAutoscalerが追跡しているコンテナの名前を変更する場合、特定の順序でその変更を行うことで、変更が適用されている間も、スケーリングが利用可能で有効なままであることが保証されます。コンテナを定義するリソース(Deploymentなど)を更新する前に、関連するHPAを更新して新旧のコンテナ名を両方追跡するようにします。これにより、HPAはアップデートプロセス全体でスケーリングの推奨を計算することができます。
コンテナ名の変更をワークロードリソースにロールアウトしたら、HPAの仕様から古いコンテナ名を削除して片付けます。
Kubernetes v1.23 [stable](以前のautoscaling/v2beta2 APIバージョンでは、これをベータ機能として提供していました)
autoscaling/v2 APIバージョンを使用することで、HorizontalPodAutoscalerをカスタムメトリクス(KubernetesまたはKubernetesのコンポーネントに組み込まれていない)に基づいてスケールするように設定することができます。その後、HorizontalPodAutoscalerコントローラーはこれらのカスタムメトリクスをKubernetes APIからクエリします。
要件については、メトリクスAPIのサポートを参照してください。
Kubernetes v1.23 [stable](以前のautoscaling/v2beta2 APIバージョンでは、これをベータ機能として提供していました)
autoscaling/v2 APIバージョンを使用することで、HorizontalPodAutoscalerがスケールするための複数のメトリクスを指定することができます。その後、HorizontalPodAutoscalerコントローラーは各メトリクスを評価し、そのメトリクスに基づいた新しいスケールを提案します。HorizontalPodAutoscalerは、各メトリクスで推奨される最大のスケールを取得し、そのサイズにワークロードを設定します(ただし、これが設定した全体の最大値を超えていないことが前提です)。
デフォルトでは、HorizontalPodAutoscalerコントローラーは一連のAPIからメトリクスを取得します。これらのAPIにアクセスするためには、クラスター管理者が以下を確認する必要があります:
API集約レイヤーが有効になっていること。
対応するAPIが登録されていること:
リソースメトリクスの場合、これは一般的にmetrics-serverによって提供されるmetrics.k8s.io APIです。クラスターの追加機能として起動することができます。
カスタムメトリクスの場合、これはcustom.metrics.k8s.io APIです。これはメトリクスソリューションベンダーが提供する「アダプター」APIサーバーによって提供されます。利用可能なKubernetesメトリクスアダプターがあるかどうかは、メトリクスパイプラインで確認してください。
外部メトリクスの場合、これはexternal.metrics.k8s.io APIです。これは上記のカスタムメトリクスアダプターによって提供される可能性があります。
これらの異なるメトリクスパスとその違いについての詳細は、HPA V2、custom.metrics.k8s.io、およびexternal.metrics.k8s.ioの関連デザイン提案をご覧ください。
これらの使用方法の例については、カスタムメトリクスの使用方法と外部メトリクスの使用方法をご覧ください。
Kubernetes v1.23 [stable](以前のautoscaling/v2beta2 APIバージョンでは、これをベータ機能として提供していました)
v2 HorizontalPodAutoscaler APIを使用する場合、behaviorフィールド(APIリファレンスを参照)を使用して、スケールアップとスケールダウンの振る舞いを個別に設定することができます。これらの振る舞いは、behaviorフィールドの下でscaleUpおよび/またはscaleDownを設定することにより指定します。
スケーリングターゲットのレプリカ数のフラッピングを防ぐための 安定化ウィンドウ を指定することができます。また、スケーリングポリシーにより、スケーリング中のレプリカの変化率を制御することもできます。
1つ以上のスケーリングポリシーをspecのbehaviorセクションで指定することができます。複数のポリシーが指定された場合、デフォルトで最も多くの変更を許可するポリシーが選択されます。次の例は、スケールダウンする際のこの振る舞いを示しています:
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60
periodSecondsは、ポリシーが真でなければならない過去の時間を示します。最初のポリシー(Pods)では、1分間で最大4つのレプリカをスケールダウンできます。2つ目のポリシー(Percent)では、1分間で現在のレプリカの最大10%をスケールダウンできます。
デフォルトでは、最も多くの変更を許可するポリシーが選択されるため、2つ目のポリシーはPodのレプリカの数が40を超える場合にのみ使用されます。40レプリカ以下の場合、最初のポリシーが適用されます。例えば、レプリカが80あり、ターゲットを10レプリカにスケールダウンしなければならない場合、最初のステップでは8レプリカが減少します。次のイテレーションでは、レプリカの数が72で、ポッドの10%は7.2ですが、数値は8に切り上げられます。オートスケーラーコントローラーの各ループで、変更するべきPodの数は現在のレプリカの数に基づいて再計算されます。レプリカの数が40以下になると、最初のポリシー(Pods)が適用され、一度に4つのレプリカが減少します。
ポリシーの選択は、スケーリング方向のselectPolicyフィールドを指定することで変更できます。この値をMinに設定すると、レプリカ数の最小変化を許可するポリシーが選択されます。この値をDisabledに設定すると、その方向へのスケーリングが完全に無効になります。
安定化ウィンドウは、スケーリングに使用されるメトリクスが常に変動する場合のレプリカ数のフラッピングを制限するために使用されます。自動スケーリングアルゴリズムは、このウィンドウを使用して以前の望ましい状態を推測し、ワークロードスケールへの望ましくない変更を避けます。
例えば、次の例のスニペットでは、scaleDownに対して安定化ウィンドウが指定されています。
behavior:
scaleDown:
stabilizationWindowSeconds: 300
メトリクスがターゲットをスケールダウンすべきであることを示すと、アルゴリズムは以前に計算された望ましい状態を探し、指定された間隔から最高値を使用します。上記の例では、過去5分間のすべての望ましい状態が考慮されます。
これは移動最大値を近似し、スケーリングアルゴリズムが頻繁にPodを削除して、わずかな時間後に同等のPodの再作成をトリガーするのを防ぎます。
カスタムスケーリングを使用するためには、全てのフィールドを指定する必要はありません。カスタマイズが必要な値のみを指定することができます。これらのカスタム値はデフォルト値とマージされます。デフォルト値はHPAアルゴリズムの既存の動作と一致します。
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max
スケールダウンの場合、安定化ウィンドウは300秒(--horizontal-pod-autoscaler-downscale-stabilizationフラグが指定されている場合はその値)です。スケールダウンのための単一のポリシーがあり、現在稼働しているレプリカの100%を削除することが許可されています。これは、スケーリングターゲットが最小許容レプリカ数まで縮小されることを意味します。スケールアップの場合、安定化ウィンドウはありません。メトリクスがターゲットをスケールアップするべきであることを示すと、ターゲットはすぐにスケールアップされます。2つのポリシーがあり、HPAが安定状態に達するまで、最大で15秒ごとに4つのポッドまたは現在稼働しているレプリカの100%が追加されます。
1分間のカスタムダウンスケール安定化ウィンドウを提供するには、HPAに以下の動作を追加します:
behavior:
scaleDown:
stabilizationWindowSeconds: 60
HPAによるPodの除去率を毎分10%に制限するには、HPAに以下の動作を追加します:
behavior:
scaleDown:
policies:
- type: Percent
value: 10
periodSeconds: 60
1分あたりに削除されるPodが5つを超えないようにするために、固定サイズ5の2番目のスケールダウンポリシーを追加し、selectPolicyを最小に設定することができます。selectPolicyをMinに設定すると、オートスケーラーは最少数のPodに影響を与えるポリシーを選択します:
behavior:
scaleDown:
policies:
- type: Percent
value: 10
periodSeconds: 60
- type: Pods
value: 5
periodSeconds: 60
selectPolicy: Min
selectPolicyの値がDisabledの場合、指定された方向のスケーリングをオフにします。したがって、スケールダウンを防ぐには、次のようなポリシーが使われます:
behavior:
scaleDown:
selectPolicy: Disabled
HorizontalPodAutoscalerは、他のすべてのAPIリソースと同様にkubectlによって標準的にサポートされています。kubectl createコマンドを使用して新しいオートスケーラーを作成することができます。kubectl get hpaを使用してオートスケーラーを一覧表示したり、kubectl describe hpaを使用して詳細な説明を取得したりできます。最後に、kubectl delete hpaを使用してオートスケーラーを削除することができます。
さらに、HorizontalPodAutoscalerオブジェクトを作成するための特別なkubectl autoscaleコマンドがあります。例えば、kubectl autoscale rs foo --min=2 --max=5 --cpu-percent=80を実行すると、ReplicaSet fooのオートスケーラーが作成され、ターゲットのCPU使用率が80%に設定され、レプリカ数は2から5の間になります。
HPAの設定自体を変更することなく、ターゲットのHPAを暗黙的に非活性化することができます。ターゲットの理想のレプリカ数が0に設定され、HPAの最小レプリカ数が0より大きい場合、HPAはターゲットの調整を停止します(そして、自身のScalingActive条件をfalseに設定します)。これは、ターゲットの理想のレプリカ数またはHPAの最小レプリカ数を手動で調整して再活性化するまで続きます。
HPAが有効になっている場合、Deploymentおよび/またはStatefulSetのspec.replicasの値をそのマニフェストから削除することが推奨されます。これを行わない場合、たとえばkubectl apply -f deployment.yamlを介してそのオブジェクトに変更が適用されるたびに、これはKubernetesに現在のPodの数をspec.replicasキーの値にスケールするよう指示します。これは望ましくない場合があり、HPAがアクティブなときに問題になる可能性があります。
spec.replicasの削除は、このキーのデフォルト値が1であるため(参照: Deploymentのレプリカ数)、一度だけPod数が低下する可能性があることに注意してください。更新時に、1つを除くすべてのPodが終了手順を開始します。その後の任意のDeploymentアプリケーションは通常どおり動作し、望む通りのローリングアップデート設定を尊重します。Deploymentをどのように変更しているかによって、以下の2つの方法から1つを選択することでこの低下を回避することができます:
kubectl apply edit-last-applied deployment/<deployment_name>spec.replicasを削除します。保存してエディターを終了すると、kubectlが更新を適用します。このステップではPod数に変更はありません。spec.replicasを削除できます。ソースコード管理を使用している場合は、変更をコミットするか、更新の追跡方法に適したソースコードの改訂に関するその他の手順を行います。kubectl apply -f deployment.yamlを実行できます。サーバーサイド適用を使用する場合は、この具体的なユースケースをカバーしている所有権の移行ガイドラインに従うことができます。
クラスターでオートスケーリングを設定する場合、Cluster Autoscalerのようなクラスターレベルのオートスケーラーを実行することも検討してみてください。
HorizontalPodAutoscalerに関する詳細情報:
kubectl autoscaleのドキュメンテーションを読む。Horizontal Pod Autoscalerは、Deployment、ReplicaSetまたはStatefulSetといったレプリケーションコントローラー内のPodの数を、観測されたCPU使用率(もしくはベータサポートの、アプリケーションによって提供されるその他のメトリクス)に基づいて自動的にスケールさせます。
このドキュメントはphp-apacheサーバーに対しHorizontal Pod Autoscalerを有効化するという例に沿ってウォークスルーで説明していきます。Horizontal Pod Autoscalerの動作についてのより詳細な情報を知りたい場合は、Horizontal Pod Autoscalerユーザーガイドをご覧ください。
この例ではバージョン1.2以上の動作するKubernetesクラスターおよびkubectlが必要です。 Metrics APIを介してメトリクスを提供するために、Metrics serverによるモニタリングがクラスター内にデプロイされている必要があります。 Horizontal Pod Autoscalerはメトリクスを収集するためにこのAPIを利用します。metrics-serverをデプロイする方法を知りたい場合はmetrics-server ドキュメントをご覧ください。
Horizontal Pod Autoscalerで複数のリソースメトリクスを利用するためには、バージョン1.6以上のKubernetesクラスターおよびkubectlが必要です。カスタムメトリクスを使えるようにするためには、あなたのクラスターがカスタムメトリクスAPIを提供するAPIサーバーと通信できる必要があります。 最後に、Kubernetesオブジェクトと関係のないメトリクスを使うにはバージョン1.10以上のKubernetesクラスターおよびkubectlが必要で、さらにあなたのクラスターが外部メトリクスAPIを提供するAPIサーバーと通信できる必要があります。 詳細についてはHorizontal Pod Autoscaler user guideをご覧ください。
Horizontal Pod Autoscalerのデモンストレーションのために、php-apacheイメージをもとにしたカスタムのDockerイメージを使います。 このDockerfileは下記のようになっています。
FROM php:5-apache
COPY index.php /var/www/html/index.php
RUN chmod a+rx index.php
これはCPU負荷の高い演算を行うindex.phpを定義しています。
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "OK!";
?>
まず最初に、イメージを動かすDeploymentを起動し、Serviceとして公開しましょう。 下記の設定を使います。
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
以下のコマンドを実行してください。
kubectl apply -f https://k8s.io/examples/application/php-apache.yaml
deployment.apps/php-apache created
service/php-apache created
サーバーが起動したら、kubectl autoscaleを使ってautoscalerを作成しましょう。以下のコマンドで、最初のステップで作成したphp-apache deploymentによって制御されるPodレプリカ数を1から10の間に維持するHorizontal Pod Autoscalerを作成します。
簡単に言うと、HPAは(Deploymentを通じて)レプリカ数を増減させ、すべてのPodにおける平均CPU使用率を50%(それぞれのPodはkubectl runで200 milli-coresを要求しているため、平均CPU使用率100 milli-coresを意味します)に保とうとします。
このアルゴリズムについての詳細はこちらをご覧ください。
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
horizontalpodautoscaler.autoscaling/php-apache autoscaled
以下を実行して現在のAutoscalerの状況を確認できます。
kubectl get hpa
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 18s
現在はサーバーにリクエストを送っていないため、CPU使用率が0%になっていることに注意してください(TARGETカラムは対応するDeploymentによって制御される全てのPodの平均値を示しています。)。
Autoscalerがどのように負荷の増加に反応するか見てみましょう。 コンテナを作成し、クエリの無限ループをphp-apacheサーバーに送ってみます(これは別のターミナルで実行してください)。
kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
数分以内に、下記を実行することでCPU負荷が高まっていることを確認できます。
kubectl get hpa
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 305% / 50% 1 10 1 3m
ここでは、CPU使用率はrequestの305%にまで高まっています。 結果として、Deploymentはレプリカ数7にリサイズされました。
kubectl get deployment php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 7/7 7 7 19m
ユーザー負荷を止めてこの例を終わらせましょう。
私たちがbusyboxイメージを使って作成したコンテナ内のターミナルで、<Ctrl> + Cを入力して負荷生成を終了させます。
そして結果の状態を確認します(数分後)。
kubectl get hpa
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 11m
kubectl get deployment php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 1/1 1 1 27m
ここでCPU使用率は0に下がり、HPAによってオートスケールされたレプリカ数は1に戻ります。
autoscaling/v2beta2 APIバージョンと使うと、php-apache Deploymentをオートスケーリングする際に使う追加のメトリクスを導入することが出来ます。
まず、autoscaling/v2beta2内のHorizontalPodAutoscalerのYAMLファイルを入手します。
kubectl get hpa.v2beta2.autoscaling -o yaml > /tmp/hpa-v2.yaml
/tmp/hpa-v2.yamlファイルをエディタで開くと、以下のようなYAMLファイルが見えるはずです。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
status:
observedGeneration: 1
lastScaleTime: <some-time>
currentReplicas: 1
desiredReplicas: 1
currentMetrics:
- type: Resource
resource:
name: cpu
current:
averageUtilization: 0
averageValue: 0
targetCPUUtilizationPercentageフィールドはmetricsと呼ばれる配列に置換されています。
CPU使用率メトリクスは、Podコンテナで定められたリソースの割合として表されるため、リソースメトリクスです。CPU以外のリソースメトリクスを指定することもできます。デフォルトでは、他にメモリだけがリソースメトリクスとしてサポートされています。これらのリソースはクラスター間で名前が変わることはなく、そしてmetrics.k8s.io APIが利用可能である限り常に利用可能です。
さらにtarget.typeにおいてUtilizationの代わりにAverageValueを使い、target.averageUtilizationフィールドの代わりに対応するtarget.averageValueフィールドを設定することで、リソースメトリクスをrequest値に対する割合に代わり、直接的な値に設定することも可能です。
PodメトリクスとObjectメトリクスという2つの異なる種類のメトリクスが存在し、どちらもカスタムメトリクスとみなされます。これらのメトリクスはクラスター特有の名前を持ち、利用するにはより発展的なクラスター監視設定が必要となります。
これらの代替メトリクスタイプのうち、最初のものがPodメトリクスです。これらのメトリクスはPodを説明し、Podを渡って平均され、レプリカ数を決定するためにターゲット値と比較されます。
これらはほとんどリソースメトリクス同様に機能しますが、targetの種類としてはAverageValueのみをサポートしている点が異なります。
Podメトリクスはmetricブロックを使って以下のように指定されます。
type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
2つ目のメトリクスタイプはObjectメトリクスです。これらのメトリクスはPodを説明するかわりに、同一Namespace内の異なったオブジェクトを説明します。このメトリクスはオブジェクトから取得される必要はありません。単に説明するだけです。Objectメトリクスはtargetの種類としてValueとAverageValueをサポートします。Valueでは、ターゲットはAPIから返ってきたメトリクスと直接比較されます。AverageValueでは、カスタムメトリクスAPIから返ってきた値はターゲットと比較される前にPodの数で除算されます。以下の例はrequests-per-secondメトリクスのYAML表現です。
type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
target:
type: Value
value: 2k
もしこのようなmetricブロックを複数提供した場合、HorizontalPodAutoscalerはこれらのメトリクスを順番に処理します。 HorizontalPodAutoscalerはそれぞれのメトリクスについて推奨レプリカ数を算出し、その中で最も多いレプリカ数を採用します。
例えば、もしあなたがネットワークトラフィックについてのメトリクスを収集する監視システムを持っているなら、kubectl editを使って指定を次のように更新することができます。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
target:
type: Value
value: 10k
status:
observedGeneration: 1
lastScaleTime: <some-time>
currentReplicas: 1
desiredReplicas: 1
currentMetrics:
- type: Resource
resource:
name: cpu
current:
averageUtilization: 0
averageValue: 0
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
current:
value: 10k
この時、HorizontalPodAutoscalerはそれぞれのPodがCPU requestの50%を使い、1秒当たり1000パケットを送信し、そしてmain-route Ingressの裏にあるすべてのPodが合計で1秒当たり10000パケットを送信する状態を保持しようとします。
多くのメトリクスパイプラインは、名前もしくは labels と呼ばれる追加の記述子の組み合わせによって説明することができます。全てのリソースメトリクス以外のメトリクスタイプ(Pod、Object、そして下で説明されている外部メトリクス)において、メトリクスパイプラインに渡す追加のラベルセレクターを指定することができます。例えば、もしあなたがhttp_requestsメトリクスをverbラベルとともに収集しているなら、下記のmetricブロックを指定してGETリクエストにのみ基づいてスケールさせることができます。
type: Object
object:
metric:
name: http_requests
selector: {matchLabels: {verb: GET}}
このセレクターは完全なKubernetesラベルセレクターと同じ文法を利用します。もし名前とセレクターが複数の系列に一致した場合、この監視パイプラインはどのようにして複数の系列を一つの値にまとめるかを決定します。このセレクターは付加的なもので、ターゲットオブジェクト(Podsタイプの場合は対象Pod、Objectタイプの場合は説明されるオブジェクト)ではないオブジェクトを説明するメトリクスを選択することは出来ません。
Kubernetes上で動いているアプリケーションを、Kubernetes Namespaceと直接的な関係がないサービスを説明するメトリクスのような、Kubernetesクラスター内のオブジェクトと明確な関係が無いメトリクスを基にオートスケールする必要があるかもしれません。Kubernetes 1.10以降では、このようなユースケースを外部メトリクスによって解決できます。
外部メトリクスを使うにはあなたの監視システムについての知識が必要となります。この設定はカスタムメトリクスを使うときのものに似ています。外部メトリクスを使うとあなたの監視システムのあらゆる利用可能なメトリクスに基づいてクラスターをオートスケールできるようになります。上記のようにmetricブロックでnameとselectorを設定し、ObjectのかわりにExternalメトリクスタイプを使います。
もし複数の時系列がmetricSelectorにより一致した場合は、それらの値の合計がHorizontalPodAutoscalerに使われます。
外部メトリクスはValueとAverageValueの両方のターゲットタイプをサポートしています。これらの機能はObjectタイプを利用するときとまったく同じです。
例えばもしあなたのアプリケーションがホストされたキューサービスからのタスクを処理している場合、あなたは下記のセクションをHorizontalPodAutoscalerマニフェストに追記し、未処理のタスク30個あたり1つのワーカーを必要とすることを指定します。
- type: External
external:
metric:
name: queue_messages_ready
selector: "queue=worker_tasks"
target:
type: AverageValue
averageValue: 30
可能なら、クラスター管理者がカスタムメトリクスAPIを保護することを簡単にするため、外部メトリクスのかわりにカスタムメトリクスを用いることが望ましいです。外部メトリクスAPIは潜在的に全てのメトリクスへのアクセスを許可するため、クラスター管理者はこれを公開する際には注意が必要です。
autoscaling/v2beta2形式のHorizontalPodAutoscalerを使っている場合は、KubernetesによるHorizontalPodAutoscaler上のstatus conditionsセットを見ることができます。status conditionsはHorizontalPodAutoscalerがスケール可能かどうか、そして現時点でそれが何らかの方法で制限されているかどうかを示しています。
このconditionsはstatus.conditionsフィールドに現れます。HorizontalPodAutoscalerに影響しているconditionsを確認するために、kubectl describe hpaを利用できます。
kubectl describe hpa cm-test
Name: cm-test
Namespace: prom
Labels: <none>
Annotations: <none>
CreationTimestamp: Fri, 16 Jun 2017 18:09:22 +0000
Reference: ReplicationController/cm-test
Metrics: ( current / target )
"http_requests" on pods: 66m / 500m
Min replicas: 1
Max replicas: 4
ReplicationController pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale the last scale time was sufficiently old as to warrant a new scale
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_requests
ScalingLimited False DesiredWithinRange the desired replica count is within the acceptable range
Events:
このHorizontalPodAutoscalerにおいて、いくつかの正常な状態のconditionsを見ることができます。まず最初に、AbleToScaleは、HPAがスケール状況を取得し、更新させることが出来るかどうかだけでなく、何らかのbackoffに関連した状況がスケーリングを妨げていないかを示しています。2番目に、ScalingActiveは、HPAが有効化されているかどうか(例えば、レプリカ数のターゲットがゼロでないこと)や、望ましいスケールを算出できるかどうかを示します。もしこれがFalseの場合、大体はメトリクスの取得において問題があることを示しています。最後に、一番最後の状況であるScalingLimitedは、HorizontalPodAutoscalerの最大値や最小値によって望ましいスケールがキャップされていることを示しています。この指標を見てHorizontalPodAutoscaler上の最大・最小レプリカ数制限を増やす、もしくは減らす検討ができます。
全てのHorizontalPodAutoscalerおよびメトリクスAPIにおけるメトリクスはquantityとして知られる特殊な整数表記によって指定されます。例えば、10500mという数量は10進数表記で10.5と書くことができます。メトリクスAPIは可能であれば接尾辞を用いない整数を返し、そうでない場合は基本的にミリ単位での数量を返します。これはメトリクス値が1と1500mの間で、もしくは10進法表記で書かれた場合は1と1.5の間で変動するということを意味します。
kubectl autoscaleコマンドを使って命令的にHorizontalPodAutoscalerを作るかわりに、下記のファイルを使って宣言的に作成することができます。
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
下記のコマンドを実行してAutoscalerを作成します。
kubectl create -f https://k8s.io/examples/application/hpa/php-apache.yaml
horizontalpodautoscaler.autoscaling/php-apache created
CronJobは、Kubernetes v1.21で一般利用(GA)に昇格しました。古いバージョンのKubernetesを使用している場合、正確な情報を参照できるように、使用しているバージョンのKubernetesのドキュメントを参照してください。古いKubernetesのバージョンでは、batch/v1 CronJob APIはサポートされていません。
CronJobを使用すると、Jobを時間ベースのスケジュールで実行できるようになります。この自動化されたJobは、LinuxまたはUNIXシステム上のCronのように実行されます。
CronJobは、バックアップやメールの送信など、定期的なタスクや繰り返しのタスクを作成する時に便利です。CronJobはそれぞれのタスクを、たとえばアクティビティが少ない期間など、特定の時間にスケジューリングすることもできます。
CronJobには制限と特性があります。たとえば、特定の状況下では、1つのCronJobが複数のJobを作成する可能性があるため、Jobは冪等性を持つようにしなければいけません。
制限に関する詳しい情報については、CronJobを参照してください。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
CronJobには設定ファイルが必要です。次の例のCronJobの.specは、現在の時刻とhelloというメッセージを1分ごとに表示します。
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
次のコマンドで例のCronJobを実行します。
kubectl create -f https://k8s.io/examples/application/job/cronjob.yaml
出力は次のようになります。
cronjob.batch/hello created
CronJobを作成したら、次のコマンドで状態を取得します。
kubectl get cronjob hello
出力は次のようになります。
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 <none> 10s
コマンドの結果からわかるように、CronJobはまだスケジュールされておらず、まだ何のJobも実行していません。約1分以内にJobが作成されるのを見てみましょう。
kubectl get jobs --watch
出力は次のようになります。
NAME COMPLETIONS DURATION AGE
hello-4111706356 0/1 0s
hello-4111706356 0/1 0s 0s
hello-4111706356 1/1 5s 5s
"hello"CronJobによってスケジュールされたJobが1つ実行中になっていることがわかります。Jobを見るのをやめて、再度CronJobを表示して、Jobがスケジュールされたことを確認してみます。
kubectl get cronjob hello
出力は次のようになります。
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 50s 75s
CronJobhelloが、LAST SCHEDULEで指定された時間にJobを正しくスケジュールしたことが確認できるはずです。現在、activeなJobの数は0です。つまり、Jobは完了または失敗したことがわかります。
それでは、最後にスケジュールされたJobの作成と、Podの1つの標準出力を表示してみましょう。
# "hello-4111706356" の部分は、あなたのシステム上のJobの名前に置き換えてください。
pods=$(kubectl get pods --selector=job-name=hello-4111706356 --output=jsonpath={.items[*].metadata.name})
Podのログを表示します。
kubectl logs $pods
出力は次のようになります。
Fri Feb 22 11:02:09 UTC 2019
Hello from the Kubernetes cluster
CronJobが必要なくなったときは、kubectl delete cronjob <cronjob name>で削除します。
kubectl delete cronjob hello
CronJobを削除すると、すべてのJobと、そのJobが作成したPodが削除され、追加のJobの作成が停止されます。Jobの削除について詳しく知りたい場合は、ガベージコレクションを読んでください。
すべてのKubernetesの設定と同じように、CronJobにもapiVersion、kind、metadataのフィールドが必要です。設定ファイルの扱い方についての一般的な情報については、アプリケーションのデプロイとkubectlを使用してリソースを管理するを読んでください。
CronJobの設定には、.specセクションも必要です。
specへのすべての修正は、それ以降の実行にのみ適用されます。.spec.scheduleは、.specには必須のフィールドです。0 * * * *や@hourlyなどのCron形式の文字列を取り、Jobの作成と実行のスケジュール時間を指定します。
フォーマットにはVixie cronのステップ値(step value)も指定できます。FreeBSDのマニュアルでは次のように説明されています。
ステップ値は範囲指定と組み合わせて使用できます。範囲の後ろに
/<number>を付けると、範囲全体で指定したnumberの値ごとにスキップすることを意味します。たとえば、0-23/2をhoursフィールドに指定すると、2時間毎にコマンド実行を指定することになります(V7標準では代わりに0,2,4,6,8,10,12,14,16,18,20,22と指定する必要があります)。ステップはアスタリスクの後ろにつけることもできます。そのため、「2時間毎に実行」したい場合は、単純に*/2と指定できます。
?はアスタリスク*と同じ意味を持ちます。つまり、与えられたフィールドには任意の値が使えるという意味になります。.spec.jobTemplateはJobのテンプレートであり、必須です。Jobと完全に同一のスキーマを持ちますが、フィールドがネストされている点と、apiVersionとkindが存在しない点だけが異なります。Jobの.specを書くための情報については、JobのSpecを書くを参照してください。
.spec.startingDeadlineSecondsフィールドはオプションです。何かの理由でスケジュールに間に合わなかった場合に適用される、Jobの開始のデッドライン(締め切り)を秒数で指定します。デッドラインを過ぎると、CronJobはJobを開始しません。この場合にデッドラインに間に合わなかったJobは、失敗したJobとしてカウントされます。もしこのフィールドが指定されなかった場合、Jobはデッドラインを持ちません。
.spec.startingDeadlineSecondsフィールドがnull以外に設定された場合、CronJobコントローラーはJobの作成が期待される時間と現在時刻との間の時間を計測します。もしその差が制限よりも大きかった場合、その実行はスキップされます。
たとえば、この値が200に設定された場合、実際のスケジュールの最大200秒後までに作成されるJobだけが許可されます。
.spec.concurrencyPolicyフィールドもオプションです。このフィールドは、このCronJobで作成されたJobの並列実行をどのように扱うかを指定します。specには以下のconcurrency policyのいずれかを指定します。
Allow (デフォルト): CronJobがJobを並列に実行することを許可します。Forbid: CronJobの並列実行を禁止します。もし新しいJobの実行時に過去のJobがまだ完了していなかった場合、CronJobは新しいJobの実行をスキップします。Replace: もし新しいJobの実行の時間になっても過去のJobの実行が完了していなかった場合、CronJobは現在の実行中のJobを新しいJobで置換します。concurrency policyは、同じCronJobが作成したJobにのみ適用されます。もし複数のCronJobがある場合、それぞれのJobの並列実行は常に許可されます。
.spec.suspendフィールドもオプションです。このフィールドをtrueに設定すると、すべての後続の実行がサスペンド(一時停止)されます。この設定はすでに実行開始したJobには適用されません。デフォルトはfalseです。
.spec.suspendがtrueからfalseに変更されると、見逃されたJobは即座にスケジュールされます。.spec.successfulJobsHistoryLimitと.spec.failedJobsHistoryLimitフィールドはオプションです。これらのフィールドには、完了したJobと失敗したJobをいくつ保持するかを指定します。デフォルトでは、それぞれ3と1に設定されます。リミットを0に設定すると、対応する種類のJobを実行完了後に何も保持しなくなります。
Kubernetes v1.21 [alpha]この例では、複数の並列ワーカープロセスを使用するKubernetesのJobを実行します。各ワーカーは、それぞれが自分のPod内で実行される異なるコンテナです。Podはコントロールプレーンが自動的に設定するインデックス値を持ち、この値を利用することで、各Podは処理するタスク全体のどの部分を処理するのかを特定できます。
Podのインデックスは、アノテーション内のbatch.kubernetes.io/job-completion-indexを整数値の文字列表現として利用できます。コンテナ化されたタスクプロセスがこのインデックスを取得できるようにするために、このアノテーションの値はdownward APIの仕組みを利用することで公開できます。利便性のために、コントロールプレーンは自動的にdownward APIを設定して、JOB_COMPLETION_INDEX環境変数にインデックスを公開します。
以下に、この例で実行するステップの概要を示します。
あらかじめ基本的な非並列のJobの使用に慣れている必要があります。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.21. バージョンを確認するには次のコマンドを実行してください:kubectl version.インデックス付きJobを作成できるようにするには、APIサーバーとコントローラーマネージャー上でIndexedJobフィーチャーゲートを有効にしていることを確認してください。
ワーカープログラムから処理アイテムにアクセスするには、いくつかの選択肢があります。
JOB_COMPLETION_INDEX環境変数を読み込む。Jobコントローラーは、この変数をcompletion indexを含むアノテーションに自動的にリンクします。この例では、3番目のオプションを選択肢して、revユーティリティを実行したいと考えているとしましょう。このプログラムはファイルを引数として受け取り、内容を逆さまに表示します。
rev data.txt
revツールはbusyboxコンテナイメージから利用できます。
これは単なる例であるため、各Podはごく簡単な処理(短い文字列を逆にする)をするだけです。現実のワークロードでは、たとえば、シーンデータをもとに60秒の動画を生成するというようなタスクを記述したJobを作成するかもしれません。ビデオレンダリングJobの各処理アイテムは、ビデオクリップの特定のフレームのレンダリングを行うものになるでしょう。その場合、インデックス付きの完了が意味するのは、クリップの最初からフレームをカウントすることで、Job内の各Podがレンダリングと公開をするのがどのフレームであるかがわかるということです。
以下は、completion modeとしてIndexedを使用するJobのマニフェストの例です。
apiVersion: batch/v1
kind: Job
metadata:
name: 'indexed-job'
spec:
completions: 5
parallelism: 3
completionMode: Indexed
template:
spec:
restartPolicy: Never
initContainers:
- name: 'input'
image: 'docker.io/library/bash'
command:
- "bash"
- "-c"
- |
items=(foo bar baz qux xyz)
echo ${items[$JOB_COMPLETION_INDEX]} > /input/data.txt
volumeMounts:
- mountPath: /input
name: input
containers:
- name: 'worker'
image: 'docker.io/library/busybox'
command:
- "rev"
- "/input/data.txt"
volumeMounts:
- mountPath: /input
name: input
volumes:
- name: input
emptyDir: {}
上記の例では、Jobコントローラーがすべてのコンテナに設定する組み込みのJOB_COMPLETION_INDEX環境変数を使っています。initコンテナがインデックスを静的な値にマッピングし、その値をファイルに書き込み、ファイルをemptyDir volumeを介してワーカーを実行しているコンテナと共有します。オプションとして、インデックスとコンテナに公開するためにdownward APIを使用して独自の環境変数を定義することもできます。環境変数やファイルとして設定したConfigMapから値のリストを読み込むという選択肢もあります。
他には、以下の例のように、直接downward APIを使用してアノテーションの値をボリュームファイルとして渡すこともできます。
apiVersion: batch/v1
kind: Job
metadata:
name: 'indexed-job'
spec:
completions: 5
parallelism: 3
completionMode: Indexed
template:
spec:
restartPolicy: Never
containers:
- name: 'worker'
image: 'docker.io/library/busybox'
command:
- "rev"
- "/input/data.txt"
volumeMounts:
- mountPath: /input
name: input
volumes:
- name: input
downwardAPI:
items:
- path: "data.txt"
fieldRef:
fieldPath: metadata.annotations['batch.kubernetes.io/job-completion-index']次のコマンドでJobを実行します。
# このコマンドでは1番目のアプローチを使っています ($JOB_COMPLETION_INDEX に依存しています)
kubectl apply -f https://kubernetes.io/examples/application/job/indexed-job.yaml
このJobを作成したら、コントロールプレーンは指定した各インデックスごとに一連のPodを作成します。.spec.parallelismの値が同時に実行できるPodの数を決定し、.spec.completionsの値がJobが作成するPodの合計数を決定します。
.spec.parallelismは.spec.completionsより小さいため、コントロールプレーンは別のPodを開始する前に最初のPodの一部が完了するまで待機します。
Jobを作成したら、少し待ってから進行状況を確認します。
kubectl describe jobs/indexed-job
出力は次のようになります。
Name: indexed-job
Namespace: default
Selector: controller-uid=bf865e04-0b67-483b-9a90-74cfc4c3e756
Labels: controller-uid=bf865e04-0b67-483b-9a90-74cfc4c3e756
job-name=indexed-job
Annotations: <none>
Parallelism: 3
Completions: 5
Start Time: Thu, 11 Mar 2021 15:47:34 +0000
Pods Statuses: 2 Running / 3 Succeeded / 0 Failed
Completed Indexes: 0-2
Pod Template:
Labels: controller-uid=bf865e04-0b67-483b-9a90-74cfc4c3e756
job-name=indexed-job
Init Containers:
input:
Image: docker.io/library/bash
Port: <none>
Host Port: <none>
Command:
bash
-c
items=(foo bar baz qux xyz)
echo ${items[$JOB_COMPLETION_INDEX]} > /input/data.txt
Environment: <none>
Mounts:
/input from input (rw)
Containers:
worker:
Image: docker.io/library/busybox
Port: <none>
Host Port: <none>
Command:
rev
/input/data.txt
Environment: <none>
Mounts:
/input from input (rw)
Volumes:
input:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 4s job-controller Created pod: indexed-job-njkjj
Normal SuccessfulCreate 4s job-controller Created pod: indexed-job-9kd4h
Normal SuccessfulCreate 4s job-controller Created pod: indexed-job-qjwsz
Normal SuccessfulCreate 1s job-controller Created pod: indexed-job-fdhq5
Normal SuccessfulCreate 1s job-controller Created pod: indexed-job-ncslj
この例では、各インデックスごとにカスタムの値を使用してJobを実行します。次のコマンドでPodの1つの出力を確認できます。
kubectl logs indexed-job-fdhq5 # これを対象のJobのPodの名前に一致するように変更してください。
出力は次のようになります。
xuq
ダッシュボードは、WebベースのKubernetesユーザーインターフェースです。 ダッシュボードを使用して、コンテナ化されたアプリケーションをKubernetesクラスターにデプロイしたり、 コンテナ化されたアプリケーションをトラブルシューティングしたり、クラスターリソースを管理したりすることができます。 ダッシュボードを使用して、クラスター上で実行されているアプリケーションの概要を把握したり、 個々のKubernetesリソース(Deployments、Jobs、DaemonSetsなど)を作成または修正したりすることができます。 たとえば、Deploymentのスケール、ローリングアップデートの開始、Podの再起動、 デプロイウィザードを使用した新しいアプリケーションのデプロイなどが可能です。
ダッシュボードでは、クラスター内のKubernetesリソースの状態や、発生した可能性のあるエラーに関する情報も提供されます。
ダッシュボードUIはデフォルトではデプロイされていません。デプロイするには、以下のコマンドを実行します:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml
クラスターデータを保護するために、ダッシュボードはデフォルトで最小限のRBAC構成でデプロイします。 現在、ダッシュボードはBearer Tokenによるログインのみをサポートしています。 このデモ用のトークンを作成するには、 サンプルユーザーの作成ガイドに従ってください。
以下のコマンドを実行することで、kubectlコマンドラインツールを使ってダッシュボードにアクセスすることができます:
kubectl proxy
kubectlは、ダッシュボードを http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/ で利用できるようにします。
UIはコマンドを実行しているマシンから のみ アクセスできます。オプションについてはkubectl proxy --helpを参照してください。
空のクラスターでダッシュボードにアクセスすると、ウェルカムページが表示されます。
このページには、このドキュメントへのリンクと、最初のアプリケーションをデプロイするためのボタンが含まれています。
さらに、クラスターのkube-system名前空間でデフォルトで実行されているシステムアプリケーション、たとえばダッシュボード自体を見ることができます。
ダッシュボードを使用すると、簡単なウィザードでコンテナ化されたアプリケーションをDeploymentとオプションのServiceとして作成してデプロイすることができます。 アプリケーションの詳細を手動で指定するか、アプリケーションの設定を含むYAMLまたはJSONファイルをアップロードすることができます。
任意のページの右上にあるCREATEボタンをクリックして開始します。
デプロイウィザードでは、以下の情報を入力する必要があります:
App name (必須): アプリケーションの名前です。 その名前のlabelは、デプロイされるDeploymentとServiceに追加されます。
アプリケーション名は、選択したKubernetes名前空間内で一意である必要があります。 小文字で始まり、小文字または数字で終わり、小文字、数字、ダッシュ(-)のみを含む必要があります。文字数は24文字に制限されています。先頭と末尾のスペースは無視されます。
Container image (必須): 任意のレジストリ上の公開Dockerコンテナイメージ、またはプライベートイメージ(一般的にはGoogle Container RegistryやDocker Hub上でホストされている)のURLです。 コンテナイメージの指定はコロンで終わらせる必要があります。
クラスター全体で必要な数のPodを維持するために、Deploymentが作成されます。
Service (任意): アプリケーションのいくつかの部分(たとえばフロントエンド)では、 Serviceをクラスター外の外部、おそらくパブリックIPアドレス(外部サービス)に公開したいと思うかもしれません。
クラスター内部からしか見えないその他のサービスは、内部サービスと呼ばれます。
サービスの種類にかかわらず、サービスを作成し、コンテナがポート(受信)をリッスンする場合は、 2つのポートを指定する必要があります。 サービスは、ポート(受信)をコンテナから見たターゲットポートにマッピングして作成されます。 このサービスは、デプロイされたPodにルーティングされます。サポートされるプロトコルはTCPとUDPです。 このサービスの内部DNS名は、上記のアプリケーション名として指定した値になります。
必要に応じて、高度なオプションセクションを展開して、より多くの設定を指定することができます:
Description: ここで入力したテキストは、 アノテーションとしてDeploymentに追加され、アプリケーションの詳細に表示されます。
Labels: アプリケーションに使用するデフォルトのラベルは、アプリケーション名とバージョンです。 リリース、環境、ティア、パーティション、リリーストラックなど、Deployment、Service(存在する場合)、Podに適用する追加のラベルを指定できます。
例:
release=1.0
tier=frontend
environment=pod
track=stable
Namespace: Kubernetesは、同じ物理クラスターを基盤とする複数の仮想クラスターをサポートしています。 これらの仮想クラスターは名前空間 と呼ばれます。 これにより、リソースを論理的に名前のついたグループに分割することができます。
ダッシュボードでは、利用可能なすべての名前空間がドロップダウンリストに表示され、新しい名前空間を作成することができます。 名前空間名には、最大63文字の英数字とダッシュ(-)を含めることができますが、大文字を含めることはできません。 名前空間名は数字だけで構成されるべきではありません。 名前が10などの数値として設定されている場合、Podはデフォルトの名前空間に配置されます。
名前空間の作成に成功した場合は、デフォルトで選択されます。 作成に失敗した場合は、最初の名前空間が選択されます。
Image Pull Secret: 指定されたDockerコンテナイメージが非公開の場合、 pull secretの認証情報が必要になる場合があります。
ダッシュボードでは、利用可能なすべてのSecretがドロップダウンリストに表示され、新しいSecretを作成できます。
Secret名は DNSドメイン名の構文に従う必要があります。たとえば、new.image-pull.secretです。
Secretの内容はbase64エンコードされ、.dockercfgファイルで指定されている必要があります。
Secret名は最大253文字で構成されます。
イメージプルシークレットの作成に成功した場合は、デフォルトで選択されています。作成に失敗した場合は、シークレットは適用されません。
CPU requirement (cores)とMemory requirement (MiB): コンテナの最小リソース制限を指定することができます。デフォルトでは、PodはCPUとメモリの制限がない状態で実行されます。
Run commandとRun command arguments: デフォルトでは、コンテナは指定されたDockerイメージのデフォルトのentrypointコマンドを実行します。 コマンドのオプションと引数を使ってデフォルトを上書きすることができます。
Run as privileged: この設定は、特権コンテナ内のプロセスが、ホスト上でrootとして実行されているプロセスと同等であるかどうかを決定します。特権コンテナは、 ネットワークスタックの操作やデバイスへのアクセスなどの機能を利用できます。
Environment variables: Kubernetesは環境変数を介してServiceを公開しています。
環境変数を作成したり、環境変数の値を使ってコマンドに引数を渡したりすることができます。
環境変数の値はServiceを見つけるためにアプリケーションで利用できます。
値は$(VAR_NAME)構文を使用して他の変数を参照できます。
Kubernetesは宣言的な設定をサポートしています。 このスタイルでは、すべての設定は Kubernetes APIリソーススキーマを使用してYAMLまたは JSON設定ファイルに格納されます。
デプロイウィザードでアプリケーションの詳細を指定する代わりに、 YAMLまたはJSONファイルでアプリケーションを定義し、ダッシュボードを使用してファイルをアップロードできます。
以下のセクションでは、Kubernetes Dashboard UIのビュー、それらが提供するものとその使用方法について説明します。
クラスターにKubernetesオブジェクトが定義されている場合、ダッシュボードではそれらのオブジェクトが初期表示されます。 デフォルトでは default 名前空間のオブジェクトのみが表示されますが、これはナビゲーションメニューにある名前空間セレクターで変更できます。
ダッシュボードにはほとんどのKubernetesオブジェクトの種類が表示され、いくつかのメニューカテゴリーにグループ化されています。
クラスターと名前空間の管理者向けに、ダッシュボードにはノード、名前空間、永続ボリュームが一覧表示され、それらの詳細ビューが用意されています。 ノードリストビューには、すべてのノードにわたって集計されたCPUとメモリーのメトリクスが表示されます。 詳細ビューには、ノードのメトリクス、仕様、ステータス、割り当てられたリソース、イベント、ノード上で実行されているPodが表示されます。
選択した名前空間で実行されているすべてのアプリケーションを表示します。 このビューでは、アプリケーションがワークロードの種類(例:Deployment、ReplicaSet、StatefulSetなど)ごとに一覧表示され、各ワークロードの種類を個別に表示することができます。 リストには、ReplicaSetの準備ができたPodの数やPodの現在のメモリ使用量など、ワークロードに関する実用的な情報がまとめられています。
ワークロードの詳細ビューには、ステータスや仕様情報、オブジェクト間の表面関係が表示されます。 たとえば、ReplicaSetが制御しているPodや、新しいReplicaSet、DeploymentのためのHorizontal Pod Autoscalerなどです。
外部の世界にサービスを公開し、クラスター内でサービスを発見できるようにするKubernetesリソースを表示します。 そのため、ServiceとIngressのビューには、それらが対象とするPod、クラスター接続の内部エンドポイント、外部ユーザーの外部エンドポイントが表示されます。
ストレージビューには、アプリケーションがデータを保存するために使用するPersistentVolumeClaimリソースが表示されます。
クラスターで実行されているアプリケーションのライブ設定に使用されているすべてのKubernetesリソースを表示します。 このビューでは、設定オブジェクトの編集と管理が可能で、デフォルトで非表示になっているSecretを表示します。
Podのリストと詳細ページは、ダッシュボードに組み込まれたログビューアーにリンクしています。 このビューアーでは、単一のPodに属するコンテナからログをドリルダウンすることができます。
詳細についてはKubernetes Dashboardプロジェクトページをご覧ください。
ここでは、設定ファイルを使って複数のクラスターにアクセスする方法を紹介します。クラスター、ユーザー、コンテキストの情報を一つ以上の設定ファイルにまとめることで、kubectl config use-contextのコマンドを使ってクラスターを素早く切り替えることができます。
kubeconfigという名前のファイルが存在するわけではありません。Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
kubectlがインストールされているか確認するため、kubectl version --clientを実行してください。kubectlのバージョンは、クラスターのAPIサーバーの1つのマイナーバージョン内である必要があります。
例として、開発用のクラスターが一つ、実験用のクラスターが一つ、計二つのクラスターが存在する場合を考えます。developmentと呼ばれる開発用のクラスター内では、フロントエンドの開発者はfrontendというnamespace内で、ストレージの開発者はstorageというnamespace内で作業をします。scratchと呼ばれる実験用のクラスター内では、開発者はデフォルトのnamespaceで作業をするか、状況に応じて追加のnamespaceを作成します。開発用のクラスターは証明書を通しての認証を必要とします。実験用のクラスターはユーザーネームとパスワードを通しての認証を必要とします。
config-exerciseというディレクトリを作成してください。config-exerciseディレクトリ内に、以下を含むconfig-demoというファイルを作成してください:
apiVersion: v1
kind: Config
preferences: {}
clusters:
- cluster:
name: development
- cluster:
name: scratch
users:
- name: developer
- name: experimenter
contexts:
- context:
name: dev-frontend
- context:
name: dev-storage
- context:
name: exp-scratch
設定ファイルには、クラスター、ユーザー、コンテキストの情報が含まれています。上記のconfig-demo設定ファイルには、二つのクラスター、二人のユーザー、三つのコンテキストの情報が含まれています。
config-exerciseディレクトリに移動してください。クラスター情報を設定ファイルに追加するために、以下のコマンドを実行してください:
kubectl config --kubeconfig=config-demo set-cluster development --server=https://1.2.3.4 --certificate-authority=fake-ca-file
kubectl config --kubeconfig=config-demo set-cluster scratch --server=https://5.6.7.8 --insecure-skip-tls-verify
ユーザー情報を設定ファイルに追加してください:
kubectl config --kubeconfig=config-demo set-credentials developer --client-certificate=fake-cert-file --client-key=fake-key-seefile
kubectl config --kubeconfig=config-demo set-credentials experimenter --username=exp --password=some-password
kubectl --kubeconfig=config-demo config unset users.<name>を実行すると、ユーザーを削除することができます。
kubectl --kubeconfig=config-demo config unset clusters.<name>を実行すると、クラスターを除去することができます。
kubectl --kubeconfig=config-demo config unset contexts.<name>を実行すると、コンテキスト情報を除去することができます。コンテキスト情報を設定ファイルに追加してください:
kubectl config --kubeconfig=config-demo set-context dev-frontend --cluster=development --namespace=frontend --user=developer
kubectl config --kubeconfig=config-demo set-context dev-storage --cluster=development --namespace=storage --user=developer
kubectl config --kubeconfig=config-demo set-context exp-scratch --cluster=scratch --namespace=default --user=experimenter
追加した情報を確認するために、config-demoファイルを開いてください。config-demoファイルを開く代わりに、config viewのコマンドを使うこともできます。
kubectl config --kubeconfig=config-demo view
出力には、二つのクラスター、二人のユーザー、三つのコンテキストが表示されます:
apiVersion: v1
clusters:
- cluster:
certificate-authority: fake-ca-file
server: https://1.2.3.4
name: development
- cluster:
insecure-skip-tls-verify: true
server: https://5.6.7.8
name: scratch
contexts:
- context:
cluster: development
namespace: frontend
user: developer
name: dev-frontend
- context:
cluster: development
namespace: storage
user: developer
name: dev-storage
- context:
cluster: scratch
namespace: default
user: experimenter
name: exp-scratch
current-context: ""
kind: Config
preferences: {}
users:
- name: developer
user:
client-certificate: fake-cert-file
client-key: fake-key-file
- name: experimenter
user:
password: some-password
username: exp
上記のfake-ca-file、fake-cert-file、fake-key-fileは、証明書ファイルの実際のパスのプレースホルダーです。環境内にある証明書ファイルの実際のパスに変更してください。
証明書ファイルのパスの代わりにbase64にエンコードされたデータを使用したい場合は、キーに-dataの接尾辞を加えてください。例えば、certificate-authority-data、client-certificate-data、client-key-dataとできます。
それぞれのコンテキストは、クラスター、ユーザー、namespaceの三つ組からなっています。例えば、dev-frontendは、developerユーザーの認証情報を使ってdevelopmentクラスターのfrontendnamespaceへのアクセスを意味しています。
現在のコンテキストを設定してください:
kubectl config --kubeconfig=config-demo use-context dev-frontend
これ以降実行されるkubectlコマンドは、dev-frontendに設定されたクラスターとnamespaceに適用されます。また、dev-frontendに設定されたユーザーの認証情報を使用します。
現在のコンテキストの設定情報のみを確認するには、--minifyフラグを使用してください。
kubectl config --kubeconfig=config-demo view --minify
出力には、dev-frontendの設定情報が表示されます:
apiVersion: v1
clusters:
- cluster:
certificate-authority: fake-ca-file
server: https://1.2.3.4
name: development
contexts:
- context:
cluster: development
namespace: frontend
user: developer
name: dev-frontend
current-context: dev-frontend
kind: Config
preferences: {}
users:
- name: developer
user:
client-certificate: fake-cert-file
client-key: fake-key-file
今度は、実験用のクラスター内でしばらく作業する場合を考えます。
現在のコンテキストをexp-scratchに切り替えてください:
kubectl config --kubeconfig=config-demo use-context exp-scratch
これ以降実行されるkubectlコマンドは、scratchクラスター内のデフォルトnamespaceに適用されます。また、exp-scratchに設定されたユーザーの認証情報を使用します。
新しく切り替えたexp-scratchの設定を確認してください。
kubectl config --kubeconfig=config-demo view --minify
最後に、developmentクラスター内のstoragenamespaceでしばらく作業する場合を考えます。
現在のコンテキストをdev-storageに切り替えてください:
kubectl config --kubeconfig=config-demo use-context dev-storage
新しく切り替えたdev-storageの設定を確認してください。
kubectl config --kubeconfig=config-demo view --minify
config-exerciseディレクトリ内に、以下を含むconfig-demo-2というファイルを作成してください:
apiVersion: v1
kind: Config
preferences: {}
contexts:
- context:
cluster: development
namespace: ramp
user: developer
name: dev-ramp-up
上記の設定ファイルは、dev-ramp-upというコンテキストを表します。
KUBECONFIGという環境変数が存在するかを確認してください。もし存在する場合は、後で復元できるようにバックアップしてください。例えば:
export KUBECONFIG_SAVED=$KUBECONFIG
$Env:KUBECONFIG_SAVED=$ENV:KUBECONFIG
KUBECONFIG環境変数は、設定ファイルのパスのリストです。リスト内のパスはLinuxとMacではコロンで区切られ、Windowsではセミコロンで区切られます。KUBECONFIG環境変数が存在する場合は、リスト内の設定ファイルの内容を確認してください。
一時的にKUBECONFIG環境変数に以下の二つのパスを追加してください。例えば:
export KUBECONFIG=$KUBECONFIG:config-demo:config-demo-2
$Env:KUBECONFIG=("config-demo;config-demo-2")
config-exerciseディレクトリ内から、以下のコマンドを実行してください:
kubectl config view
出力には、KUBECONFIG環境変数に含まれる全てのファイルの情報がまとめて表示されます。config-demo-2ファイルに設定されたdev-ramp-upの情報と、config-demoに設定された三つのコンテキストの情報がまとめてあることに注目してください:
contexts:
- context:
cluster: development
namespace: frontend
user: developer
name: dev-frontend
- context:
cluster: development
namespace: ramp
user: developer
name: dev-ramp-up
- context:
cluster: development
namespace: storage
user: developer
name: dev-storage
- context:
cluster: scratch
namespace: default
user: experimenter
name: exp-scratch
kubeconfigファイルに関するさらなる情報を参照するには、kubeconfigファイルを使ってクラスターへのアクセスを管理するを参照してください。
既にクラスターを所持していて、kubectlを使ってクラスターを操作できる場合は、$HOME/.kubeディレクトリ内にconfigというファイルが存在する可能性が高いです。
$HOME/.kubeに移動して、そこに存在するファイルを確認してください。configという設定ファイルが存在するはずです。他の設定ファイルも存在する可能性があります。全てのファイルの中身を確認してください。
もし$HOME/.kube/configファイルが存在していて、既にKUBECONFIG環境変数に追加されていない場合は、KUBECONFIG環境変数に追加してください。例えば:
export KUBECONFIG=$KUBECONFIG:$HOME/.kube/config
$Env:KUBECONFIG="$Env:KUBECONFIG;$HOME/.kube/config"
KUBECONFIG環境変数内のファイルからまとめられた設定情報を確認してください。config-exerciseディレクトリ内から、以下のコマンドを実行してください:
kubectl config view
KUBECONFIG環境変数を元に戻してください。例えば:
export KUBECONFIG=$KUBECONFIG_SAVED
$Env:KUBECONFIG=$ENV:KUBECONFIG_SAVED
ここでは、クラスター内で稼働しているアプリケーションに外部からアクセスするために、KubernetesのServiceオブジェクトを作成する方法を紹介します。 例として、2つのインスタンスから成るアプリケーションへのロードバランシングを扱います。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.アプリケーションDeploymentの設定ファイルは以下の通りです:
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-world
spec:
selector:
matchLabels:
run: load-balancer-example
replicas: 2
template:
metadata:
labels:
run: load-balancer-example
spec:
containers:
- name: hello-world
image: gcr.io/google-samples/node-hello:1.0
ports:
- containerPort: 8080
protocol: TCP
クラスターでHello Worldアプリケーションを稼働させます: 上記のファイルを使用し、アプリケーションのDeploymentを作成します:
kubectl apply -f https://k8s.io/examples/service/access/hello-application.yaml
このコマンドはDeploymentオブジェクトとそれに紐付くReplicaSetオブジェクトを作成します。ReplicaSetは、Hello Worldアプリケーションが稼働している2つのPodから構成されます。
Deploymentの情報を表示します:
kubectl get deployments hello-world
kubectl describe deployments hello-world
ReplicaSetオブジェクトの情報を表示します:
kubectl get replicasets
kubectl describe replicasets
Deploymentを公開するServiceオブジェクトを作成します:
kubectl expose deployment hello-world --type=NodePort --name=example-service
Serviceに関する情報を表示します:
kubectl describe services example-service
出力例は以下の通りです:
Name: example-service
Namespace: default
Labels: run=load-balancer-example
Annotations: <none>
Selector: run=load-balancer-example
Type: NodePort
IP: 10.32.0.16
Port: <unset> 8080/TCP
TargetPort: 8080/TCP
NodePort: <unset> 31496/TCP
Endpoints: 10.200.1.4:8080,10.200.2.5:8080
Session Affinity: None
Events: <none>
NodePortの値を記録しておきます。上記の例では、31496です。
Hello Worldアプリーションが稼働しているPodを表示します:
kubectl get pods --selector="run=load-balancer-example" --output=wide
出力例は以下の通りです:
NAME READY STATUS ... IP NODE
hello-world-2895499144-bsbk5 1/1 Running ... 10.200.1.4 worker1
hello-world-2895499144-m1pwt 1/1 Running ... 10.200.2.5 worker2
Hello World podが稼働するNodeのうち、いずれか1つのパブリックIPアドレスを確認します。
確認方法は、使用している環境により異なります。
例として、Minikubeの場合はkubectl cluster-info、Google Compute Engineの場合はgcloud compute instances listによって確認できます。
選択したノード上で、NodePortの値でのTCP通信を許可するファイヤーウォールを作成します。 NodePortの値が31568の場合、31568番のポートを利用したTCP通信を許可するファイヤーウォールを作成します。 クラウドプロバイダーによって設定方法が異なります。
Hello World applicationにアクセスするために、Nodeのアドレスとポート番号を使用します:
curl http://<public-node-ip>:<node-port>
ここで <public-node-ip> はNodeのパブリックIPアドレス、
<node-port> はNodePort Serviceのポート番号の値を表しています。
リクエストが成功すると、下記のメッセージが表示されます:
Hello Kubernetes!
kubectl exposeコマンドの代わりに、
service configuration file
を使用してServiceを作成することもできます。
Serviceを削除するには、以下のコマンドを実行します:
kubectl delete services example-service
Hello Worldアプリケーションが稼働しているDeployment、ReplicaSet、Podを削除するには、以下のコマンドを実行します:
kubectl delete deployment hello-world
詳細は serviceを利用してアプリケーションと接続する を確認してください。
このタスクでは、フロントエンドとバックエンドのマイクロサービスを作成する方法を示します。 バックエンドのマイクロサービスは挨拶です。 フロントエンドとバックエンドは、Kubernetes Serviceオブジェクトを使用して接続されます。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.このタスクではServiceで外部ロードバランサーを使用しますが、外部ロードバランサーの使用がサポートされている環境である必要があります。 ご使用の環境がこれをサポートしていない場合は、代わりにタイプNodePortのServiceを使用できます。
バックエンドは、単純な挨拶マイクロサービスです。 バックエンドのDeploymentの構成ファイルは次のとおりです:
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello
spec:
selector:
matchLabels:
app: hello
tier: backend
track: stable
replicas: 7
template:
metadata:
labels:
app: hello
tier: backend
track: stable
spec:
containers:
- name: hello
image: "gcr.io/google-samples/hello-go-gke:1.0"
ports:
- name: http
containerPort: 80
バックエンドのDeploymentを作成します:
kubectl apply -f https://k8s.io/examples/service/access/hello.yaml
バックエンドのDeploymentに関する情報を表示します:
kubectl describe deployment hello
出力はこのようになります:
Name: hello
Namespace: default
CreationTimestamp: Mon, 24 Oct 2016 14:21:02 -0700
Labels: app=hello
tier=backend
track=stable
Annotations: deployment.kubernetes.io/revision=1
Selector: app=hello,tier=backend,track=stable
Replicas: 7 desired | 7 updated | 7 total | 7 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 1 max unavailable, 1 max surge
Pod Template:
Labels: app=hello
tier=backend
track=stable
Containers:
hello:
Image: "gcr.io/google-samples/hello-go-gke:1.0"
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: hello-3621623197 (7/7 replicas created)
Events:
...
フロントエンドをバックエンドに接続する鍵は、バックエンドServiceです。 Serviceは、バックエンドマイクロサービスに常に到達できるように、永続的なIPアドレスとDNS名のエントリを作成します。 Serviceはセレクターを使用して、トラフィックをルーティングするPodを見つけます。
まず、Service構成ファイルを調べます:
kind: Service
apiVersion: v1
metadata:
name: hello
spec:
selector:
app: hello
tier: backend
ports:
- protocol: TCP
port: 80
targetPort: http
設定ファイルで、Serviceがapp:helloおよびtier:backendというラベルを持つPodにトラフィックをルーティングしていることがわかります。
hello Serviceを作成します:
kubectl apply -f https://k8s.io/examples/service/access/hello-service.yaml
この時点で、バックエンドのDeploymentが実行され、そちらにトラフィックをルーティングできるServiceがあります。
バックエンドができたので、バックエンドに接続するフロントエンドを作成できます。
フロントエンドは、バックエンドServiceに指定されたDNS名を使用して、バックエンドワーカーPodに接続します。
DNS名はhelloです。これは、前のサービス設定ファイルのnameフィールドの値です。
フロントエンドDeploymentのPodは、helloバックエンドServiceを見つけるように構成されたnginxイメージを実行します。 これはnginx設定ファイルです:
upstream hello {
server hello;
}
server {
listen 80;
location / {
proxy_pass http://hello;
}
}
バックエンドと同様に、フロントエンドにはDeploymentとServiceがあります。
Serviceの設定にはtype:LoadBalancerがあります。これは、Serviceがクラウドプロバイダーのデフォルトのロードバランサーを使用することを意味します。
apiVersion: v1
kind: Service
metadata:
name: frontend
spec:
selector:
app: hello
tier: frontend
ports:
- protocol: "TCP"
port: 80
targetPort: 80
type: LoadBalancer
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
spec:
selector:
matchLabels:
app: hello
tier: frontend
track: stable
replicas: 1
template:
metadata:
labels:
app: hello
tier: frontend
track: stable
spec:
containers:
- name: nginx
image: "gcr.io/google-samples/hello-frontend:1.0"
lifecycle:
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"]
フロントエンドのDeploymentとServiceを作成します:
kubectl apply -f https://k8s.io/examples/service/access/frontend.yaml
出力結果から両方のリソースが作成されたことを確認します:
deployment.apps/frontend created
service/frontend created
LoadBalancerタイプのServiceを作成したら、このコマンドを使用して外部IPを見つけることができます:
kubectl get service frontend --watch
これによりfrontend Serviceの設定が表示され、変更が監視されます。
最初、外部IPは<pending>としてリストされます:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend LoadBalancer 10.51.252.116 <pending> 80/TCP 10s
ただし、外部IPがプロビジョニングされるとすぐに、EXTERNAL-IPという見出しの下に新しいIPが含まれるように構成が更新されます:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend LoadBalancer 10.51.252.116 XXX.XXX.XXX.XXX 80/TCP 1m
このIPを使用して、クラスターの外部からfrontend Serviceとやり取りできるようになりました。
フロントエンドとバックエンドが接続されました。 フロントエンドServiceの外部IPに対してcurlコマンドを使用して、エンドポイントにアクセスできます。
curl http://${EXTERNAL_IP} # これを前に見たEXTERNAL-IPに置き換えます
出力には、バックエンドによって生成されたメッセージが表示されます:
{"message":"Hello"}
Serviceを削除するには、このコマンドを入力してください:
kubectl delete services frontend hello
バックエンドとフロントエンドアプリケーションを実行しているDeploymentとReplicaSetとPodを削除するために、このコマンドを入力してください:
kubectl delete deployment frontend hello
このページでは、kubectlを使用して、クラスターで実行されているPodのすべてのコンテナイメージを一覧表示する方法を説明します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.この演習では、kubectlを使用してクラスターで実行されているすべてのPodを取得し、出力をフォーマットしてそれぞれのコンテナの一覧を取得します。
kubectl get pods --all-namespacesを使用して、すべての名前空間のPodを取得します-o jsonpath={.. image}を使用して、コンテナイメージ名のリストのみが含まれるように出力をフォーマットします。これは、返されたjsonのimageフィールドを再帰的に解析します。tr、sort、uniqなどの標準ツールを使用して出力をフォーマットします。trを使用してスペースを改行に置換します。sortを使用して結果を並べ替えます。uniqを使用してイメージ数を集計します。kubectl get pods --all-namespaces -o jsonpath="{..image}" |\
tr -s '[[:space:]]' '\n' |\
sort |\
uniq -c
上記のコマンドは、返されるすべてのアイテムについて、imageという名前のすべてのフィールドを再帰的に返します。
別の方法として、Pod内のimageフィールドへの絶対パスを使用することができます。これにより、フィールド名が繰り返されている場合でも正しいフィールドが取得されます。多くのフィールドは与えられたアイテム内でnameと呼ばれます:
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}"
jsonpathは次のように解釈されます:
.items[*]: 各戻り値.spec: 仕様の取得.containers[*]: 各コンテナ.image: イメージの取得kubectl get pod nginxのように名前を指定して単一のPodを取得する場合、アイテムのリストではなく単一のPodが返されるので、パスの.items[*]部分は省略してください。rangeを使用して要素を個別に繰り返し処理することにより、フォーマットをさらに制御できます。
kubectl get pods --all-namespaces -o jsonpath='{range .items[*]}{"\n"}{.metadata.name}{":\t"}{range .spec.containers[*]}{.image}{", "}{end}{end}' |\
sort
特定のラベルに一致するPodのみを対象とするには、-lフラグを使用します。以下は、app=nginxに一致するラベルを持つPodのみに一致します。
kubectl get pods --all-namespaces -o jsonpath="{..image}" -l app=nginx
特定の名前空間のPodのみを対象とするには、namespaceフラグを使用します。以下はkube-system名前空間のPodのみに一致します。
kubectl get pods --namespace kube-system -o jsonpath="{..image}"
jsonpathの代わりに、kubectlはgo-templatesを使用した出力のフォーマットをサポートしています:
kubectl get pods --all-namespaces -o go-template --template="{{range .items}}{{range .spec.containers}}{{.image}} {{end}}{{end}}"
Ingressとは、クラスター内のServiceに外部からのアクセスを許可するルールを定義するAPIオブジェクトです。IngressコントローラーはIngress内に設定されたルールを満たすように動作します。
このページでは、簡単なIngressをセットアップして、HTTPのURIに応じてwebまたはweb2というServiceにリクエストをルーティングする方法を説明します。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.Launch Terminalをクリックします。
(オプション) Minikubeをローカル環境にインストールした場合は、次のコマンドを実行します。
minikube start
NGINX Ingressコントローラーを有効にするために、次のコマンドを実行します。
minikube addons enable ingress
NGINX Ingressコントローラーが起動したことを確認します。
kubectl get pods -n kube-system
このコマンドの実行には数分かかる場合があります。
出力は次のようになります。
NAME READY STATUS RESTARTS AGE
default-http-backend-59868b7dd6-xb8tq 1/1 Running 0 1m
kube-addon-manager-minikube 1/1 Running 0 3m
kube-dns-6dcb57bcc8-n4xd4 3/3 Running 0 2m
kubernetes-dashboard-5498ccf677-b8p5h 1/1 Running 0 2m
nginx-ingress-controller-5984b97644-rnkrg 1/1 Running 0 1m
storage-provisioner 1/1 Running 0 2m
次のコマンドを実行して、Deploymentを作成します。
kubectl create deployment web --image=gcr.io/google-samples/hello-app:1.0
出力は次のようになります。
deployment.apps/web created
Deploymentを公開します。
kubectl expose deployment web --type=NodePort --port=8080
出力は次のようになります。
service/web exposed
Serviceが作成され、NodePort上で利用できるようになったことを確認します。
kubectl get service web
出力は次のようになります。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
web NodePort 10.104.133.249 <none> 8080:31637/TCP 12m
NodePort経由でServiceを訪問します。
minikube service web --url
出力は次のようになります。
http://172.17.0.15:31637
Katacoda環境の場合のみ: 上部のterminalパネルでプラスのアイコンをクリックして、**Select port to view on Host 1**(Host 1を表示するポートを選択)をクリックします。NodePort(上の例では`31637`)を入力して、**Display Port**(ポートを表示)をクリックしてください。
出力は次のようになります。
Hello, world!
Version: 1.0.0
Hostname: web-55b8c6998d-8k564
これで、MinikubeのIPアドレスとNodePort経由で、サンプルアプリにアクセスできるようになりました。次のステップでは、Ingressリソースを使用してアプリにアクセスできるように設定します。
以下に示すファイルは、hello-world.info経由で送られたトラフィックをServiceに送信するIngressリソースです。
以下の内容でexample-ingress.yamlを作成します。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
spec:
ingressClassName: nginx
rules:
- host: hello-world.info
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: web
port:
number: 8080次のコマンドを実行して、Ingressリソースを作成します。
kubectl apply -f https://kubernetes.io/examples/service/networking/example-ingress.yaml
出力は次のようになります。
ingress.networking.k8s.io/example-ingress created
次のコマンドで、IPアドレスが設定されていることを確認します。
kubectl get ingress
このコマンドの実行には数分かかる場合があります。
NAME CLASS HOSTS ADDRESS PORTS AGE
example-ingress <none> hello-world.info 172.17.0.15 80 38s
次の行を/etc/hostsファイルの最後に書きます。
Minikubeをローカル環境で実行している場合、`minikube ip`コマンドを使用すると外部のIPが取得できます。Ingressのリスト内に表示されるIPアドレスは、内部のIPになるはずです。
172.17.0.15 hello-world.info
この設定により、リクエストがhello-world.infoからMinikubeに送信されるようになります。
Ingressコントローラーがトラフィックを制御していることを確認します。
curl hello-world.info
出力は次のようになります。
Hello, world!
Version: 1.0.0
Hostname: web-55b8c6998d-8k564
Minikubeをローカル環境で実行している場合、ブラウザからhello-world.infoにアクセスできます。
次のコマンドを実行して、v2のDeploymentを作成します。
kubectl create deployment web2 --image=gcr.io/google-samples/hello-app:2.0
出力は次のようになります。
deployment.apps/web2 created
Deploymentを公開します。
kubectl expose deployment web2 --port=8080 --type=NodePort
出力は次のようになります。
service/web2 exposed
既存のexample-ingress.yamlを編集して、以下の行を追加します。
- path: /v2
pathType: Prefix
backend:
service:
name: web2
port:
number: 8080
次のコマンドで変更を適用します。
kubectl apply -f example-ingress.yaml
出力は次のようになります。
ingress.networking/example-ingress configured
Hello Worldアプリの1番目のバージョンにアクセスします。
curl hello-world.info
出力は次のようになります。
Hello, world!
Version: 1.0.0
Hostname: web-55b8c6998d-8k564
Hello Worldアプリの2番目のバージョンにアクセスします。
curl hello-world.info/v2
出力は次のようになります。
Hello, world!
Version: 2.0.0
Hostname: web2-75cd47646f-t8cjk
Minikubeをローカル環境で実行している場合、ブラウザからhello-world.infoおよびhello-world.info/v2にアクセスできます。
このページでは、ボリュームを使用して、同じPodで実行されている2つのコンテナ間で通信する方法を示します。 コンテナ間でプロセス名前空間を共有することにより、プロセスが通信できるようにする方法も参照してください。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。 このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。 まだクラスターがない場合、minikubeを使って作成するか、 以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください:kubectl version.この演習では、2つのコンテナを実行するPodを作成します。 2つのコンテナは、通信に使用できるボリュームを共有します。 これがPodの設定ファイルです:
apiVersion: v1
kind: Pod
metadata:
name: two-containers
spec:
restartPolicy: Never
volumes:
- name: shared-data
emptyDir: {}
containers:
- name: nginx-container
image: nginx
volumeMounts:
- name: shared-data
mountPath: /usr/share/nginx/html
- name: debian-container
image: debian
volumeMounts:
- name: shared-data
mountPath: /pod-data
command: ["/bin/sh"]
args: ["-c", "echo Hello from the debian container > /pod-data/index.html"]
設定ファイルで、Podにshared-dataという名前のボリュームがあることがわかります。
設定ファイルにリストされている最初のコンテナは、nginxサーバーを実行します。
共有ボリュームのマウントパスは/usr/share/nginx/htmlです。
2番目のコンテナはdebianイメージをベースとしており、/pod-dataのマウントパスを持っています。
2番目のコンテナは次のコマンドを実行してから終了します。
echo Hello from the debian container > /pod-data/index.html
2番目のコンテナがnginxサーバーのルートディレクトリにindex.htmlファイルを書き込むことに注意してください。
Podと2つのコンテナを作成します:
kubectl apply -f https://k8s.io/examples/pods/two-container-pod.yaml
Podとコンテナに関する情報を表示します:
kubectl get pod two-containers --output=yaml
こちらは出力の一部です:
apiVersion: v1
kind: Pod
metadata:
...
name: two-containers
namespace: default
...
spec:
...
containerStatuses:
- containerID: docker://c1d8abd1 ...
image: debian
...
lastState:
terminated:
...
name: debian-container
...
- containerID: docker://96c1ff2c5bb ...
image: nginx
...
name: nginx-container
...
state:
running:
...
debianコンテナが終了し、nginxコンテナがまだ実行されていることがわかります。
nginxコンテナへのシェルを取得します:
kubectl exec -it two-containers -c nginx-container -- /bin/bash
シェルで、nginxが実行されていることを確認します:
root@two-containers:/# apt-get update
root@two-containers:/# apt-get install curl procps
root@two-containers:/# ps aux
出力はこのようになります:
USER PID ... STAT START TIME COMMAND
root 1 ... Ss 21:12 0:00 nginx: master process nginx -g daemon off;
debianコンテナがnginxルートディレクトリにindex.htmlファイルを作成したことを思い出してください。
curlを使用して、GETリクエストをnginxサーバーに送信します:
root@two-containers:/# curl localhost
出力は、nginxがdebianコンテナによって書かれたWebページを提供することを示しています:
Hello from the debian container
Podが複数のコンテナを持つことができる主な理由は、プライマリアプリケーションを支援するヘルパーアプリケーションをサポートするためです。 ヘルパーアプリケーションの典型的な例は、データプラー、データプッシャー、およびプロキシです。 多くの場合、ヘルパーアプリケーションとプライマリアプリケーションは互いに通信する必要があります。 通常、これは、この演習に示すように共有ファイルシステムを介して、またはループバックネットワークインターフェースであるlocalhostを介して行われます。 このパターンの例は、新しい更新のためにGitリポジトリをポーリングするヘルパープログラムを伴うWebサーバーです。
この演習のボリュームは、コンテナがポッドの寿命中に通信する方法を提供します。 Podを削除して再作成すると、共有ボリュームに保存されているデータはすべて失われます。
このページでは、kubeletの証明書のローテーションを設定する方法を説明します。
Kubernetes v1.8 [beta]kubeletは、Kubernetes APIへの認証のために証明書を使用します。デフォルトでは、証明書は1年間の有効期限付きで発行されるため、頻繁に更新する必要はありません。
Kubernetes 1.8にはベータ機能のkubelet certificate rotationが含まれているため、現在の証明書の有効期限が近づいたときに自動的に新しい鍵を生成して、Kubernetes APIに新しい証明書をリクエストできます。新しい証明書が利用できるようになると、Kubernetes APIへの接続の認証に利用されます。
kubeletプロセスは--rotate-certificatesという引数を受け付けます。この引数によって、現在使用している証明書の有効期限が近づいたときに、kubeletが自動的に新しい証明書をリクエストするかどうかを制御できます。証明書のローテーションはベータ機能であるため、--feature-gates=RotateKubeletClientCertificate=trueを使用してフィーチャーフラグを有効にする必要もあります。
kube-controller-managerプロセスは、--experimental-cluster-signing-durationという引数を受け付け、この引数で証明書が発行される期間を制御できます。
kubeletが起動すると、ブートストラップが設定されている場合(--bootstrap-kubeconfigフラグを使用した場合)、初期証明書を使用してKubernetes APIに接続して、証明書署名リクエスト(certificate signing request、CSR)を発行します。証明書署名リクエストのステータスは、次のコマンドで表示できます。
kubectl get csr
ノード上のkubeletから発行された証明書署名リクエストは、初めはPending状態です。証明書署名リクエストが特定の条件を満たすと、コントローラーマネージャーに自動的に承認され、Approved状態になります。次に、コントローラーマネージャーは--experimental-cluster-signing-durationパラメーターで指定された有効期限で発行された証明書に署名を行い、署名された証明書が証明書署名リクエストに添付されます。
kubeletは署名された証明書をKubernetes APIから取得し、ディスク上の--cert-dirで指定された場所に書き込みます。その後、kubeletは新しい証明書を使用してKubernetes APIに接続するようになります。
署名された証明書の有効期限が近づくと、kubeletはKubernetes APIを使用して新しい証明書署名リクエストを自動的に発行します。再び、コントローラーマネージャーは証明書のリクエストを自動的に承認し、署名された証明書を証明書署名リクエストに添付します。kubeletは新しい署名された証明書をKubernetes APIから取得してディスクに書き込みます。その後、kubeletは既存のコネクションを更新して、新しい証明書でKubernetes APIに再接続します。
Podの/etc/hostsファイルにエントリーを追加すると、DNSやその他の選択肢を利用できない場合に、Podレベルでホスト名の名前解決を上書きできるようになります。このようなカスタムエントリーは、PodSpecのHostAliasesフィールドに追加できます。
HostAliasesを使用せずにファイルを修正することはおすすめできません。このファイルはkubeletが管理しており、Podの作成や再起動時に上書きされる可能性があるためです。
Nginx Podを実行すると、Pod IPが割り当てられます。
kubectl run nginx --image nginx
pod/nginx created
Pod IPを確認します。
kubectl get pods --output=wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
hostsファイルの内容は次のようになります。
kubectl exec nginx -- cat /etc/hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.200.0.4 nginx
デフォルトでは、hostsファイルには、localhostやPod自身のホスト名などのIPv4とIPv6のボイラープレートだけが含まれています。
デフォルトのボイラープレートに加えて、hostsファイルに追加エントリーを追加できます。たとえば、foo.localとbar.localを127.0.0.1に、foo.remoteとbar.remoteを10.1.2.3にそれぞれ解決するためには、PodのHostAliasesを.spec.hostAliases以下に設定します。
apiVersion: v1
kind: Pod
metadata:
name: hostaliases-pod
spec:
restartPolicy: Never
hostAliases:
- ip: "127.0.0.1"
hostnames:
- "foo.local"
- "bar.local"
- ip: "10.1.2.3"
hostnames:
- "foo.remote"
- "bar.remote"
containers:
- name: cat-hosts
image: busybox
command:
- cat
args:
- "/etc/hosts"
この設定を使用したPodを開始するには、次のコマンドを実行します。
kubectl apply -f https://k8s.io/examples/service/networking/hostaliases-pod.yaml
pod/hostaliases-pod created
Podの詳細情報を表示して、IPv4アドレスと状態を確認します。
kubectl get pod --output=wide
NAME READY STATUS RESTARTS AGE IP NODE
hostaliases-pod 0/1 Completed 0 6s 10.200.0.5 worker0
hostsファイルの内容は次のようになります。
kubectl logs hostaliases-pod
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.200.0.5 hostaliases-pod
# Entries added by HostAliases.
127.0.0.1 foo.local bar.local
10.1.2.3 foo.remote bar.remote
ファイルの最後に追加エントリーが指定されています。
kubeletがPodの各コンテナのhostsファイルを管理するのは、コンテナ起動後にDockerがファイルを編集するのを防ぐためです。
コンテナ内部でhostsファイルを手動で変更するのは控えてください。
hostsファイルを手動で変更すると、コンテナが終了したときに変更が失われてしまいます。
このドキュメントでは、IPv4/IPv6デュアルスタックが有効化されたKubernetesクラスターを検証する方法について共有します。
kubectl version.各デュアルスタックのノードは、1つのIPv4ブロックと1つのIPv6ブロックを割り当てる必要があります。IPv4/IPv6のPodアドレスの範囲が設定されていることを検証するには、次のコマンドを実行します。例の中のノード名は、自分のクラスターの有効なデュアルスタックのノードの名前に置換してください。この例では、ノードの名前はk8s-linuxpool1-34450317-0になっています。
kubectl get nodes k8s-linuxpool1-34450317-0 -o go-template --template='{{range .spec.podCIDRs}}{{printf "%s\n" .}}{{end}}'
10.244.1.0/24
2001:db8::/64
IPv4ブロックとIPv6ブロックがそれぞれ1つずつ割り当てられているはずです。
ノードが検出されたIPv4とIPv6のインターフェースを持っていることを検証します。ノード名は自分のクラスター内の有効なノード名に置換してください。この例では、ノード名はk8s-linuxpool1-34450317-0になっています。
kubectl get nodes k8s-linuxpool1-34450317-0 -o go-template --template='{{range .status.addresses}}{{printf "%s: %s\n" .type .address}}{{end}}'
Hostname: k8s-linuxpool1-34450317-0
InternalIP: 10.0.0.5
InternalIP: 2001:db8:10::5
PodにIPv4とIPv6のアドレスが割り当てられていることを検証します。Podの名前は自分のクラスター内の有効なPodの名前と置換してください。この例では、Podの名前はpod01になっています。
kubectl get pods pod01 -o go-template --template='{{range .status.podIPs}}{{printf "%s\n" .ip}}{{end}}'
10.244.1.4
2001:db8::4
Downward APIを使用して、status.podIPsのfieldPath経由でPod IPを検証することもできます。次のスニペットは、Pod IPをMY_POD_IPSという名前の環境変数経由でコンテナ内に公開する方法を示しています。
env:
- name: MY_POD_IPS
valueFrom:
fieldRef:
fieldPath: status.podIPs
次のコマンドを実行すると、MY_POD_IPS環境変数の値をコンテナ内から表示できます。値はカンマ区切りのリストであり、PodのIPv4とIPv6のアドレスに対応しています。
kubectl exec -it pod01 -- set | grep MY_POD_IPS
MY_POD_IPS=10.244.1.4,2001:db8::4
PodのIPアドレスは、コンテナ内の/etc/hostsにも書き込まれます。次のコマンドは、デュアルスタックのPod上で/etc/hostsに対してcatコマンドを実行します。出力を見ると、Pod用のIPv4およびIPv6のIPアドレスの両方が確認できます。
kubectl exec -it pod01 -- cat /etc/hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.244.1.4 pod01
2001:db8::4 pod01
.spec.isFamilyPolicyを明示的に定義していない、以下のようなServiceを作成してみます。Kubernetesは最初に設定したservice-cluster-ip-rangeの範囲からServiceにcluster IPを割り当てて、.spec.ipFamilyPolicyをSingleStackに設定します。
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app: MyApp
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
kubectlを使ってServiceのYAMLを表示します。
kubectl get svc my-service -o yaml
Serviceの.spec.ipFamilyPolicyはSingleStackに設定され、.spec.clusterIPにはkube-controller-manager上の--service-cluster-ip-rangeフラグで最初に設定した範囲から1つのIPv4アドレスが設定されているのがわかります。
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: default
spec:
clusterIP: 10.0.217.164
clusterIPs:
- 10.0.217.164
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- port: 80
protocol: TCP
targetPort: 9376
selector:
app: MyApp
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
.spec.ipFamilies内の配列の1番目の要素にIPv6を明示的に指定した、次のようなServiceを作成してみます。Kubernetesはservice-cluster-ip-rangeで設定したIPv6の範囲からcluster IPを割り当てて、.spec.ipFamilyPolicyをSingleStackに設定します。
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app: MyApp
spec:
ipFamilies:
- IPv6
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
kubectlを使ってServiceのYAMLを表示します。
kubectl get svc my-service -o yaml
Serviceの.spec.ipFamilyPolicyはSingleStackに設定され、.spec.clusterIPには、kube-controller-manager上の--service-cluster-ip-rangeフラグで指定された最初の設定範囲から1つのIPv6アドレスが設定されているのがわかります。
apiVersion: v1
kind: Service
metadata:
labels:
app: MyApp
name: my-service
spec:
clusterIP: 2001:db8:fd00::5118
clusterIPs:
- 2001:db8:fd00::5118
ipFamilies:
- IPv6
ipFamilyPolicy: SingleStack
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: MyApp
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
.spec.ipFamiliePolicyにPreferDualStackを明示的に指定した、次のようなServiceを作成してみます。Kubernetesは(クラスターでデュアルスタックを有効化しているため)IPv4およびIPv6のアドレスの両方を割り当て、.spec.ClusterIPsのリストから、.spec.ipFamilies配列の最初の要素のアドレスファミリーに基づいた.spec.ClusterIPを設定します。
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app: MyApp
spec:
ipFamilyPolicy: PreferDualStack
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
kubectl get svcコマンドは、CLUSTER-IPフィールドにプライマリーのIPだけしか表示しません。
kubectl get svc -l app=MyApp
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-service ClusterIP 10.0.216.242 <none> 80/TCP 5s
kubectl describeを使用して、ServiceがIPv4およびIPv6アドレスのブロックからcluster IPを割り当てられていることを検証します。その後、ServiceにIPアドレスとポートを使用してアクセスできることを検証することもできます。
kubectl describe svc -l app=MyApp
Name: my-service
Namespace: default
Labels: app=MyApp
Annotations: <none>
Selector: app=MyApp
Type: ClusterIP
IP Family Policy: PreferDualStack
IP Families: IPv4,IPv6
IP: 10.0.216.242
10.0.216.242,2001:db8:fd00::af55
Port: <unset> 80/TCP
TargetPort: 9376/TCP
Endpoints: <none>
Session Affinity: None
Events: <none>
クラウドプロバイダーがIPv6を有効化した外部ロードバランサーのプロビジョニングをサポートする場合、.spec.ipFamilyPolicyにPreferDualStackを指定し、.spec.ipFamiliesの最初の要素をIPv6にして、typeフィールドにLoadBalancerを指定したServiceを作成できます。
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app: MyApp
spec:
ipFamilyPolicy: PreferDualStack
ipFamilies:
- IPv6
type: LoadBalancer
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
Serviceを確認します。
kubectl get svc -l app=MyApp
ServiceがIPv6アドレスブロックからCLUSTER-IPのアドレスとEXTERNAL-IPを割り当てられていることを検証します。その後、IPとポートを用いたServiceへのアクセスを検証することもできます。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-service LoadBalancer 2001:db8:fd00::7ebc 2603:1030:805::5 80:30790/TCP 35s
Kubernetes v1.10 [beta]Kubernetesには、複数ノードに搭載されたAMDおよびNVIDIAのGPU(graphical processing unit)を管理するための実験的なサポートが含まれています。
このページでは、異なるバージョンのKubernetesを横断してGPUを使用する方法と、現時点での制限について説明します。
Kubernetesでは、GPUなどの特別なハードウェアの機能にPodがアクセスできるようにするために、デバイスプラグインが実装されています。
管理者として、ノード上に対応するハードウェアベンダーのGPUドライバーをインストールして、以下のような対応するGPUベンダーのデバイスプラグインを実行する必要があります。
上記の条件を満たしていれば、Kubernetesはamd.com/gpuまたはnvidia.com/gpuをスケジュール可能なリソースとして公開します。
これらのGPUをコンテナから使用するには、cpuやmemoryをリクエストするのと同じように<vendor>.com/gpuというリソースをリクエストするだけです。ただし、GPUを使用するときにはリソースのリクエストの指定方法にいくつか制限があります。
limitsセクションでのみ指定されることが想定されている。この制限は、次のことを意味します。requestsを省略してlimitsを指定できる。limitsとrequestsの両方で指定できるが、これら2つの値は等しくなければならない。limitsを省略してrequestsだけを指定することはできない。以下に例を示します。
apiVersion: v1
kind: Pod
metadata:
name: cuda-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
# https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile
image: "registry.k8s.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1 # 1 GPUをリクエストしています
AMD公式のGPUデバイスプラグインには以下の要件があります。
クラスターが起動して上記の要件が満たされれば、以下のコマンドを実行することでAMDのデバイスプラグインをデプロイできます。
kubectl create -f https://raw.githubusercontent.com/RadeonOpenCompute/k8s-device-plugin/v1.10/k8s-ds-amdgpu-dp.yaml
このサードパーティーのデバイスプラグインに関する問題は、RadeonOpenCompute/k8s-device-pluginで報告できます。
現在、NVIDIAのGPU向けのデバイスプラグインの実装は2種類あります。
NVIDIA公式のGPUデバイスプラグインには以下の要件があります。
nvidia-container-runtimeを設定しなければならない。クラスターが起動して上記の要件が満たされれば、以下のコマンドを実行することでNVIDIAのデバイスプラグインがデプロイできます。
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/1.0.0-beta4/nvidia-device-plugin.yml
このサードパーティーのデバイスプラグインに関する問題は、NVIDIA/k8s-device-pluginで報告できます。
GCEで使用されるNVIDIAのGPUデバイスプラグインは、nvidia-dockerを必要としないため、KubernetesのContainer Runtime Interface(CRI)と互換性のある任意のコンテナランタイムで動作するはずです。このデバイスプラグインはContainer-Optimized OSでテストされていて、1.9以降ではUbuntu向けの実験的なコードも含まれています。
以下のコマンドを実行すると、NVIDIAのドライバーとデバイスプラグインをインストールできます。
# NVIDIAドライバーをContainer-Optimized OSにインストールする
kubectl create -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/stable/daemonset.yaml
# NVIDIAドライバーをUbuntuにインストールする(実験的)
kubectl create -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/stable/nvidia-driver-installer/ubuntu/daemonset.yaml
# デバイスプラグインをインストールする
kubectl create -f https://raw.githubusercontent.com/kubernetes/kubernetes/release-1.14/cluster/addons/device-plugins/nvidia-gpu/daemonset.yaml
このサードパーティーのデバイスプラグインの使用やデプロイに関する問題は、GoogleCloudPlatform/container-engine-acceleratorsで報告できます。
Googleは、GKE上でNVIDIAのGPUを使用するための手順も公開しています。
クラスター上の別のノードに異なる種類のGPUが搭載されている場合、NodeラベルとNodeセレクターを使用することで、Podを適切なノードにスケジューリングできます。
以下に例を示します。
# アクセラレーターを搭載したノードにラベルを付けます。
kubectl label nodes <node-with-k80> accelerator=nvidia-tesla-k80
kubectl label nodes <node-with-p100> accelerator=nvidia-tesla-p100
AMDのGPUデバイスを使用している場合、Node Labellerをデプロイできます。Node Labellerはコントローラーの1種で、GPUデバイスのプロパティを持つノードに自動的にラベルを付けてくれます。
現在は、このコントローラーは以下のプロパティに基づいてラベルを追加できます。
kubectl describe node cluster-node-23
Name: cluster-node-23
Roles: <none>
Labels: beta.amd.com/gpu.cu-count.64=1
beta.amd.com/gpu.device-id.6860=1
beta.amd.com/gpu.family.AI=1
beta.amd.com/gpu.simd-count.256=1
beta.amd.com/gpu.vram.16G=1
beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/hostname=cluster-node-23
Annotations: kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock
node.alpha.kubernetes.io/ttl: 0
…
Node Labellerを使用すると、GPUの種類をPodのspec内で指定できます。
apiVersion: v1
kind: Pod
metadata:
name: cuda-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
# https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile
image: "registry.k8s.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
accelerator: nvidia-tesla-p100 # または nvidia-tesla-k80 など
これにより、指定した種類のGPUを搭載したノードにPodがスケジューリングされることを保証できます。
Kubernetes v1.32 [stable]Kubernetesでは、事前割り当てされたhuge pageをPod内のアプリケーションに割り当てたり利用したりすることをサポートしています。このページでは、ユーザーがhuge pageを利用できるようにする方法について説明します。
ノードは、すべてのhuge pageリソースを、スケジュール可能なリソースとして自動的に探索・報告してくれます。
huge pageはコンテナレベルのリソース要求でhugepages-<size>という名前のリソースを指定することで利用できます。ここで、<size>は、特定のノード上でサポートされている整数値を使った最も小さなバイナリ表記です。たとえば、ノードが2048KiBと1048576KiBのページサイズをサポートしている場合、ノードはスケジュール可能なリソースとして、hugepages-2Miとhugepages-1Giの2つのリソースを公開します。CPUやメモリとは違い、huge pageはオーバーコミットをサポートしません。huge pageリソースをリクエストするときには、メモリやCPUリソースを同時にリクエストしなければならないことに注意してください。
1つのPodのspec内に書くことで、Podから複数のサイズのhuge pageを利用することもできます。その場合、すべてのボリュームマウントでmedium: HugePages-<hugepagesize>という表記を使う必要があります。
apiVersion: v1
kind: Pod
metadata:
name: huge-pages-example
spec:
containers:
- name: example
image: fedora:latest
command:
- sleep
- inf
volumeMounts:
- mountPath: /hugepages-2Mi
name: hugepage-2mi
- mountPath: /hugepages-1Gi
name: hugepage-1gi
resources:
limits:
hugepages-2Mi: 100Mi
hugepages-1Gi: 2Gi
memory: 100Mi
requests:
memory: 100Mi
volumes:
- name: hugepage-2mi
emptyDir:
medium: HugePages-2Mi
- name: hugepage-1gi
emptyDir:
medium: HugePages-1Gi
Podで1種類のサイズのhuge pageをリクエストするときだけは、medium: HugePagesという表記を使うこともできます。
apiVersion: v1
kind: Pod
metadata:
name: huge-pages-example
spec:
containers:
- name: example
image: fedora:latest
command:
- sleep
- inf
volumeMounts:
- mountPath: /hugepages
name: hugepage
resources:
limits:
hugepages-2Mi: 100Mi
memory: 100Mi
requests:
memory: 100Mi
volumes:
- name: hugepage
emptyDir:
medium: HugePages
shmget()にSHM_HUGETLBを指定して取得したhuge pageを使用するアプリケーションは、/proc/sys/vm/hugetlb_shm_groupに一致する補助グループ(supplemental group)を使用して実行する必要があります。cpuやmemoryのような他の計算リソースと同じようにhugepages-<size>というトークンを使用することで制御できます。HugePageStorageMediumSizeフィーチャーゲートを使用すると有効にできます(--feature-gates=HugePageStorageMediumSize=true)。