- Kubernetes
- Документація
- Блог
- Навчання
- Карʼєра
- Партнери
- Спільнота
- Версії
- Інформація про випуск
- v1.34
- v1.33
- v1.32
- v1.31
- v1.30
- Українська (Ukrainian)
- English
- বাংলা (Bengali)
- 中文 (Chinese)
- Français (French)
- Deutsch (German)
- Bahasa Indonesia (Indonesian)
- Italiano (Italian)
- 日本語 (Japanese)
- 한국어 (Korean)
- Português (Portuguese)
- Español (Spanish)
- Tiếng Việt (Vietnamese)
Це багатосторінковий друкований вигляд цього розділу. Натисність щоб друкувати.
Блог
- 7 типових помилок Kubernetes (і як я навчився їх уникати)
- Представляємо втулок Headlamp для Karpenter — масштабування та видимість
- Оголошення про підтримку Changed Block Tracking API (альфа)
- Kubernetes v1.34: Ресурси рівня Pod перейшли в стадію бета
- Kubernetes v1.34: Відновлення після збою розширення тому (GA)
- Kubernetes v1.34: Споживча ємність DRA
- Kubernetes v1.34: Звіт про стан ресурсів DRA в Podʼах
- Kubernetes v1.34: Volume Group Snapshots переходить в v1beta2
- Kubernetes v1.34: Виділений Taint Manager тепер Stable
- Kubernetes 1.34: Автоконфігурація для драйвера Node Cgroup переходить у стадію загальної доступності (GA)
- Kubernetes v1.34: Mutable CSI Node Allocatable переходить в Beta
- Kubernetes v1.34: Використання контейнера ініціалізації для визначення змінних середовища застосунку
- Kubernetes v1.34: Кеш сервера API, що підтримує створення знімків стану
- Kubernetes v1.34: VolumeAttributesClass для зміни атрибутів томів тепер GA
- Kubernetes v1.34: Політика заміни Pod для Jobs переходить у GA
- Метрики PSI для Kubernetes переходять у бета-версію
- Kubernetes v1.34: Інтеграція токенів службових облікових записів для витягування образів контейнерів переходить у стадію бета
- Kubernetes v1.34: Впровадження опції статичної політики менеджера CPU для розподілу кешу Uncore
- Kubernetes v1.34: DRA отримав статус GA
- Kubernetes v1.34: Більш точний контроль над перезапуском контейнерів
- Kubernetes v1.34: Налаштування користувача (kuberc) доступні для тестування в kubectl 1.34
- Kubernetes v1.34: Of Wind & Will (O' WaW)
- Налаштування Linux Swap для Kubernetes: детальний огляд
- Попередній огляд Kubernetes v1.34
- Оголошення про випуск etcd v3.6.0
- Kubernetes v1.33: Оновлення в життєвому циклі контейнерів в Kubernetes v1.33
- Kubernetes v1.33: Image Pull Policy працює так, як ви завжди вважали!
- Kubernetes 1.33: Заповнювач томів перейшов у стан загальної доступності (GA)
- Kubernetes v1.33: Томи Image (Image Volumes) переходять в стан бета!
- Kubernetes v1.33: Продовження переходу від Endpoints до EndpointSlices
- Kubernetes v1.33: Octarine
- Попередній огляд Kubernetes v1.33
- Kubernetes v1.32: Penelope
- Попередній огляд Kubernetes v1.32
- DIY: Створіть власну хмару з Kubernetes (Частина 3)
- DIY: Створіть власну хмару з Kubernetes (Частина 2)
- DIY: Створіть власну хмару з Kubernetes (Частина 1)
- Огляд Kubernetes v1.30
7 типових помилок Kubernetes (і як я навчився їх уникати)
Не секрет, що Kubernetes може бути як потужним, так і іноді викликати розчарування. Коли я вперше почав займатися оркеструванням контейнерів, я зробив більше ніж достатньо помилок, щоб скласти цілий список підводних каменів. У цій публікації я хочу розглянути сім основних підводних каменів, з якими я стикався (або бачив, як стикалися інші), і поділитися кількома порадами, як їх уникнути. Незалежно від того, чи ви тільки починаєте знайомитися з Kubernetes, чи вже керуєте кластерами у промисловій експлуатації, сподіваюся, ці поради допоможуть вам уникнути зайвого стресу.
1. Оминання запитів на ресурси та обмежень
Пастка: відсутність вказання вимог до CPU та памʼяті в специфікаціях Pod. Зазвичай це відбувається тому, що Kubernetes не вимагає заповнення цих полів, а робочі навантаження часто можуть запускатися та працювати без них, що робить цей пропуск таким, який легко пропустити на ранніх етапах конфігурації або під час швидких циклів розгортання.
Контекст: У Kubernetes запити та обмеження ресурсів є критично важливими для ефективного управління кластерами. Запити ресурсів гарантують, що планувальник зарезервує відповідну кількість CPU та памʼяті для кожного пода, гарантуючи, що він має необхідні ресурси для роботи. Обмеження ресурсів обмежують кількість CPU та памʼяті, яку може використовувати под, запобігаючи тому, щоб жоден окремий под не споживав надмірні ресурси та потенційно не позбавляв інші поди ресурсів. Коли запити та обмеження ресурсів не встановлені:
- Нестача ресурсів: Поди можуть отримувати недостатньо ресурсів, що призводить до зниження продуктивності або збоїв. Це відбувається тому, що Kubernetes планує поди на основі цих запитів. Без них планувальник може розмістити занадто багато подів на одному вузлі, що призводить до конкуренції за ресурси та вузьких місць у продуктивності.
- Привласнення ресурсів: З іншого боку, без обмежень под може споживати більше, ніж йому належить, впливаючи на продуктивність і стабільність інших подів на тому ж вузлі. Це може призвести до таких проблем, як виселення або знищення інших подів за допомогою Out-Of-Memory (OOM) killer через брак доступної памʼяті.
Як уникнути цього:
- Почніть з помірних
requests(наприклад,100mCPU,128Miпамʼяті) і подивіться, як ваш застосунок поводиться. - Моніторте реальне використання та уточнюйте свої значення; HorizontalPodAutoscaler може допомогти автоматизувати масштабування на основі метрик.
- Слідкуйте за
kubectl top podsабо вашим інструментом логування/моніторингу, щоб підтвердити, що ви не перевищуєте або недопостачаєте ресурси.
Перевірка життям: На початку я ніколи не думав про обмеження памʼяті. Здавалося, що все гаразд на моєму локальному кластері. Потім, у більшому середовищі, Pods отримали OOMKilled зліва і справа. Урок засвоєно. Для отримання детальних інструкцій щодо налаштування запитів і обмежень ресурсів для ваших контейнерів, будь ласка, зверніться до Призначення ресурсів памʼяті для контейнерів і подів (частина офіційної документації Kubernetes).
2. Недооцінка перевірок життєздатності та готовності
Пастка: Розгортання контейнерів без явного визначення того, як Kubernetes повинен перевіряти їхню справність або готовність. Це зазвичай відбувається тому, що Kubernetes вважає контейнер "запущеним", поки процес всередині не завершився. Без додаткових сигналів Kubernetes припускає, що робоче навантаження функціонує, навіть якщо застосунок всередині не відповідає, ініціалізується або застряг.
Контекст: Перевірки життєздатності, готовності та запуску — це механізми, які Kubernetes використовує для моніторингу стану контейнерів та їх доступності.
- Liveness probes визначають, чи все ще працює застосунок. Якщо перевірка життєздатності не проходить, контейнер перезапускається.
- Readiness probes контролюють, чи готовий контейнер обслуговувати трафік. Поки перевірка готовності не пройде, контейнер видаляється з точок доступу Service.
- Startup probes допомагають відрізнити тривалі часи запуску від фактичних збоїв.
Як уникнути цього:
- Додайте просту HTTP
livenessProbe, щоб перевірити точку доступу справності (наприклад,/healthz), щоб Kubernetes міг перезапустити контейнер, якщо він перестане відповідати. - Використовуйте
readinessProbe, щоб забезпечити, те що трафік не досягає вашого застосунку, поки він не буде готовий. - Зберігайте перевірки простими. Надто складні перевірки можуть створити хибні сповіщення та непотрібні перезапуски.
Перевірка життям: Одного разу я забув про перевірку готовності для вебсервісу, який потребував деякого часу для завантаження. Користувачі зверталися до нього передчасно, отримували дивні тайм-аути, і я витратив години на роздуми. Три рядки перевірки готовності врятували б ситуацію.
Детальні інструкції щодо налаштування тестів на життєздатність, готовність та запуск для контейнерів див. у розділі Налаштування проб життєздатності, готовності та запуску в офіційній документації Kubernetes.
3. «Ми просто переглянемо журнали контейнерів» (відомі останні слова)
Пастка: Покладатися виключно на журнали контейнерів, отримані за допомогою kubectl logs. Це часто відбувається тому, що команда є швидкою та зручною, і в багатьох налаштуваннях журнали здаються доступними під час розробки або раннього усунення несправностей. Однак kubectl logs лише отримує журнали з поточних або нещодавно завершених контейнерів, а ці журнали зберігаються на локальному диску вузла. Як тільки контейнер видаляється, виселяється або вузол перезавантажується, файли журналів можуть бути видалені або назавжди втрачені.
Як уникнути цього:
- Централізуйте журнали за допомогою інструментів CNCF, таких як Fluentd або Fluent Bit, щоб агрегувати вихідні дані з усіх Podʼів.
- Використовуйте OpenTelemetry для унфікованого перегляду журналів, метрик і (за потреби) трейсів. Це дозволяє виявляти кореляції між подіями інфраструктури та поведінкою на рівні застосунків.
- Поєднуйте журнали з метриками Prometheus, щоб відстежувати дані на рівні кластера разом із журналами застосунків. Якщо вам потрібне розподілене трасування, розгляньте проекти CNCF, такі як Jaeger.
Перевірка життям: Коли я вперше втратив журнали Pod через швидкий перезапуск, я зрозумів, наскільки ненадійним може бути «kubectl logs» сам по собі. З того часу я налаштував належний конвеєр для кожного кластера, щоб уникнути втрати важливих підказок.
4. Однакове ставлення до оточень розробки та промислової експлуатації
Пастка: Розгортання тих самих маніфестів Kubernetes з ідентичними налаштуваннями в середовищах розробки, тестування та промислової експлуатації. Це часто відбувається, коли команди прагнуть до узгодженості та повторного використання, але не враховують, що специфічні для середовища фактори — такі як шаблони трафіку, доступність ресурсів, потреби в масштабуванні або контроль доступу, які можуть суттєво відрізнятися. Без налаштування конфігурації, оптимізовані для одного середовища, можуть викликати нестабільність, погану продуктивність або прогалини в безпеці в іншому.
Як уникнути цього:
- Використовуйте оверлеї або kustomize, щоб підтримувати спільну базу, налаштовуючи запити ресурсів, репліки або конфігурацію для кожного середовища.
- Витягніть специфічну для середовища конфігурацію в ConfigMaps і / або Secrets. Ви можете використовувати спеціалізований інструмент, такий як Sealed Secrets, для управління конфіденційними даними.
- Плануйте масштабування в промисловому середовищі. Ваш кластер розробки, ймовірно, може обійтися мінімальними ресурсами CPU/памʼяті, але промислове середовище може потребувати значно більше.
Перевірка життям: Одного разу я збільшив replicaCount з 2 до 10 у невеликому середовищі розробки, просто щоб «перевірити». Я швидко вичерпав ресурси і півдня витратив на подолання наслідків. Ой.
5. Коли старі речі залишаються на місці
Пастка: У кластері залишаються невикористані або застарілі ресурси, такі як Deployments, Services, ConfigMaps або PersistentVolumeClaims. Це часто відбувається тому, що Kubernetes не видаляє ресурси автоматично, якщо не вказано явно, і немає вбудованого механізму для відстеження приналежності або терміну придатності. З часом ці забуті обʼєкти можуть накопичуватися, споживаючи ресурси кластера, збільшуючи витрати на хостинг у хмарі та створюючи операційну плутанину, особливо коли застарілі Services або LoadBalancers продовжують маршрутизувати трафік.
Як уникнути цього:
- Позначте все мітками з метою або власником. Таким чином, ви зможете легко знайти ресурси, які вам більше не потрібні.
- Регулярно перевіряйте свій кластер: запустіть
kubectl get all -n <namespace>, щоб побачити, що насправді працює, і підтвердити, що все це так має бути. - Використовуйте збір сміття в Kubernetes: документація K8s показує, як автоматично видаляти залежні обʼєкти.
- Використовуйте автоматизацію політики: Інструменти, такі як Kyverno, можуть автоматично видаляти або блокувати застарілі ресурси після певного періоду, або впроваджувати політики життєвого циклу, щоб вам не доводилося памʼятати про кожен окремий крок очищення.
Перевірка життям: Після хакатону я забув знести “test-svc”, привʼязаний до зовнішнього балансувальника навантаження. Три тижні потому я зрозумів, що платив за цей балансувальник навантаження весь цей час. Facepalm.
6. Занадто глибоке занурення в мережу занадто рано
Пастка: Впровадження розширених мережевих рішень, таких як сервісні мережі, власні втулки CNI або міжкластерна комунікація, до повного розуміння рідних мережевих примітивів Kubernetes. Це часто трапляється, коли команди реалізують такі функції, як маршрутизація трафіку, спостережуваність або mTLS, використовуючи зовнішні інструменти, не освоївши спочатку, як працює основна мережа Kubernetes: включаючи Pod-to-Pod комунікацію, ClusterIP сервіси, DNS-резолюцію та базову обробку вхідного трафіку. В результаті проблеми, повʼязані з мережею, стають важчими для усунення, особливо коли оверлеї вводять додаткові абстракції та точки відмови.
Як уникнути цього:
- Почніть з малого: Deployment, Service та базовий контролер вхідного трафіку, наприклад, на основі NGINX (наприклад, Ingress-NGINX).
- Переконайтеся, що ви розумієте, як трафік проходить у кластері, як працює виявлення сервісів і як налаштована DNS.
- Переходьте до повноцінної мережі або розширених функцій CNI лише тоді, коли це дійсно необхідно, оскільки складна мережа додає накладні витрати.
Перевірка життям: Я спробував Istio на невеликому внутрішньому застосунку, а потім витратив більше часу на налагодження самого Istio, ніж на сам застосунок. Врешті-решт, я відступив, видалив Istio, і все запрацювало нормально.
7. Занадто легковажне ставлення до безпеки та RBAC
Пастка: Розгортання робочих навантажень з ненадійними конфігураціями, такими як запуск контейнерів від імені користувача root, використання теґу обрахів latest, відключення контекстів безпеки або призначення надто широких ролей RBAC, таких як cluster-admin. Ці практики зберігаються, оскільки Kubernetes не забезпечує суворі стандартні налаштування безпеки, а платформа розроблена для гнучкості, а не для жорстких обмежень. Без явних політик безпеки кластери можуть залишатися вразливими до ризиків, таких як втеча контейнерів, несанкціоноване підвищення привілеїв або випадкові зміни в промисловому середовищі через незафіксовані образи.
Як уникнути цього:
- Використовуйте RBAC для визначення ролей і дозволів у Kubernetes. Хоча RBAC є стандартним і найширше підтримуваним механізмом авторизації, Kubernetes також дозволяє використовувати альтернативні авторизатори. Для більш складних або зовнішніх потреб у політиці розгляньте рішення, такі як OPA Gatekeeper (на основі Rego), Kyverno або користувацькі вебхуки з використанням мов політики, таких як CEL або Cedar.
- Привʼяжіть образи до конкретних версій (більше ніякого
:latest!). Це допоможе вам знати, що насправді розгорнуто. - Розгляньте Pod Security Admission (або інші рішення, такі як Kyverno), щоб забезпечити використання контейнерів без прав root, файлових систем лише для читання тощо.
Перевірка життям: Я ніколи не стикався з серйозними порушеннями безпеки, але чув безліч застережливих історій. Якщо не посилити заходи безпеки, то це лише питання часу, коли щось піде не так.
І на останок
Kubernetes дивовижний, але він не є провидцем, він не зробить магічно правильні речі, якщо ви не скажете йому, що вам потрібно. Памʼятаючи про ці пастки, ви уникнете головного болю та марної трати часу. Помилки трапляються (повірте, я зробив свою частку), але кожна з них — це можливість дізнатися більше про те, як Kubernetes насправді працює під капотом. Якщо ви хочете заглибитися, офіційна документація та спільнота Slack є відмінними наступними кроками. І, звичайно, не соромтеся ділитися своїми жахливими історіями або порадами щодо успіху, адже в кінцевому підсумку ми всі разом у цій пригоді з хмарними технологіями.
Щасливої подорожі!
Представляємо втулок Headlamp для Karpenter — масштабування та видимість
Headlamp — це відкритий, розширюваний проєкт Kubernetes SIG UI, призначений для того, щоб ви могли досліджувати, керувати та налагоджувати ресурси кластера.
Karpenter — це проєкт Kubernetes Autoscaling SIG для виділення вузлів, який допомагає кластерам швидко та ефективно масштабуватися. Він запускає нові вузли за лічені секунди, добираючи відповідні типи екземплярів для навантажень і керує повним життєвим циклом вузлів, включаючи зменшення масштабу.
Новий втулок Headlamp Karpenter додає можливість перегляду активності Karpenter у реальному часі безпосередньо з інтерфейсу Headlamp. Він показує, які ресурси Karpenter відповідають обʼєктам Kubernetes, виводить метрики в реальному часі та демонструє події масштабування в міру їх виникнення. Ви можете здійснювати перевірку подів, що очікують на обробку, переглядати рішення щодо масштабування та редагувати ресурси, що керуються Karpenter, за допомогою вбудованої функції перевірки. Втулок Karpenter був створений у рамках проєкту за підтримки LFX.
Втулок Karpenter для Headlamp має на меті спростити розуміння, налагодження та тонке налаштування поведінки автоматичного масштабування в кластерах Kubernetes. Тепер ми проведемо короткий тур по втулку Headlamp.
Мапа ресурсів Karpenter та їх звʼязки з ресурсами Kubernetes
Легко побачити, як ресурси Karpenter, такі як NodeClasses, NodePool і NodeClaims, повʼязані з основними ресурсами Kubernetes, такими як Pods, Nodes тощо.

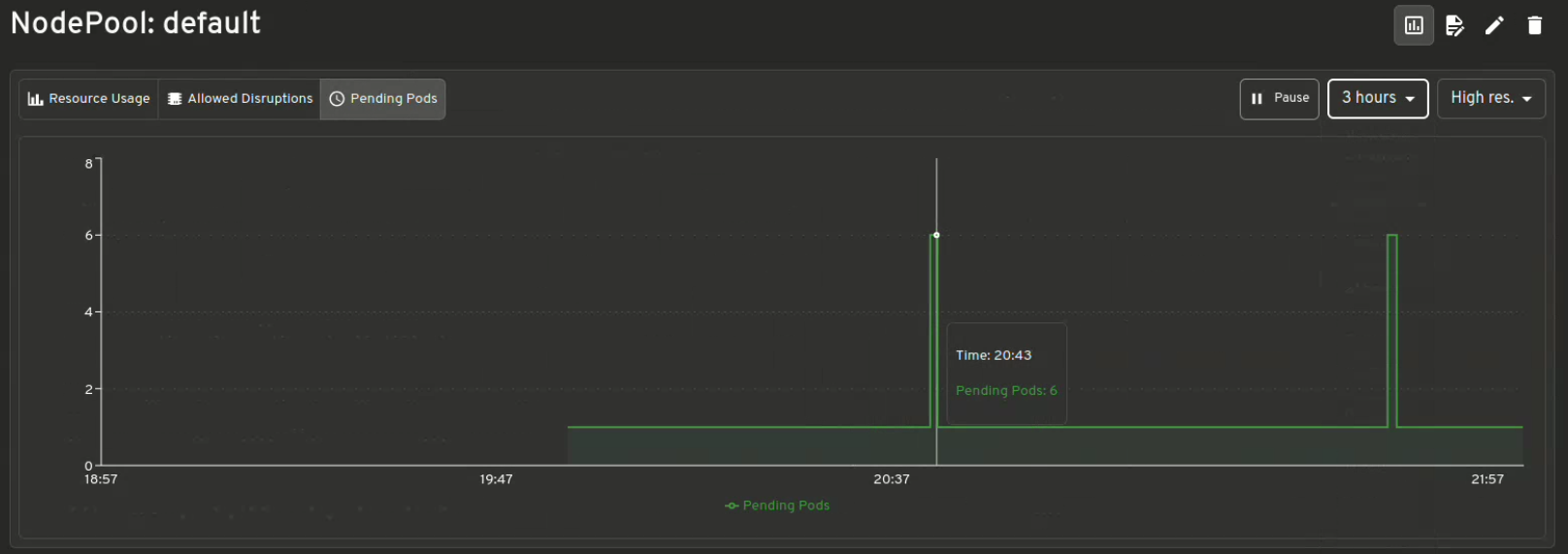
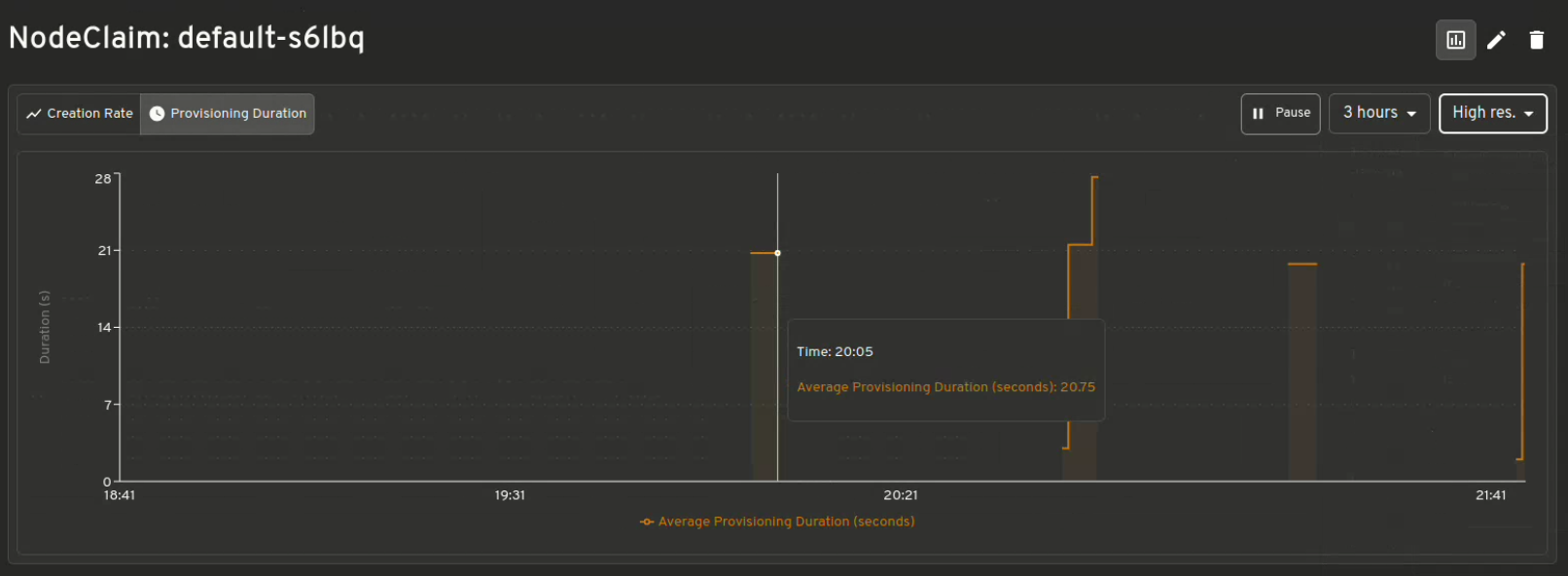
Візуалізація метрик Karpenter
Отримайте миттєву інформацію про Resource Usage v/s Limits, Allowed disruptions, Pending Pods, Provisioning Latency та багато іншого.
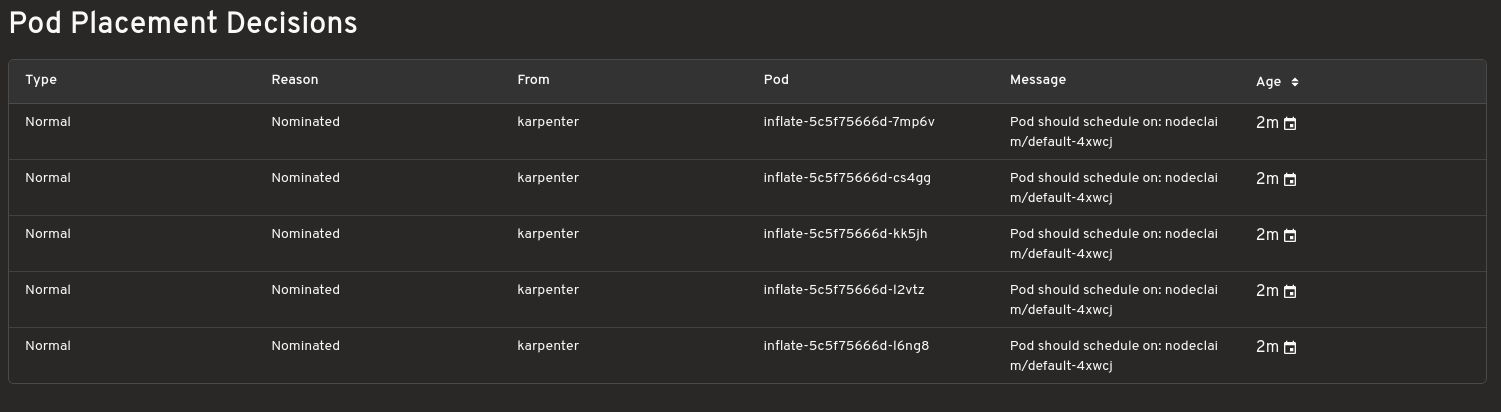
Рішення щодо масштабування
Показує, які екземпляри виділяються для ваших навантажень, і допомагає зрозуміти причину, чому Karpenter прийняв ці рішення. Корисно під час налагодження.

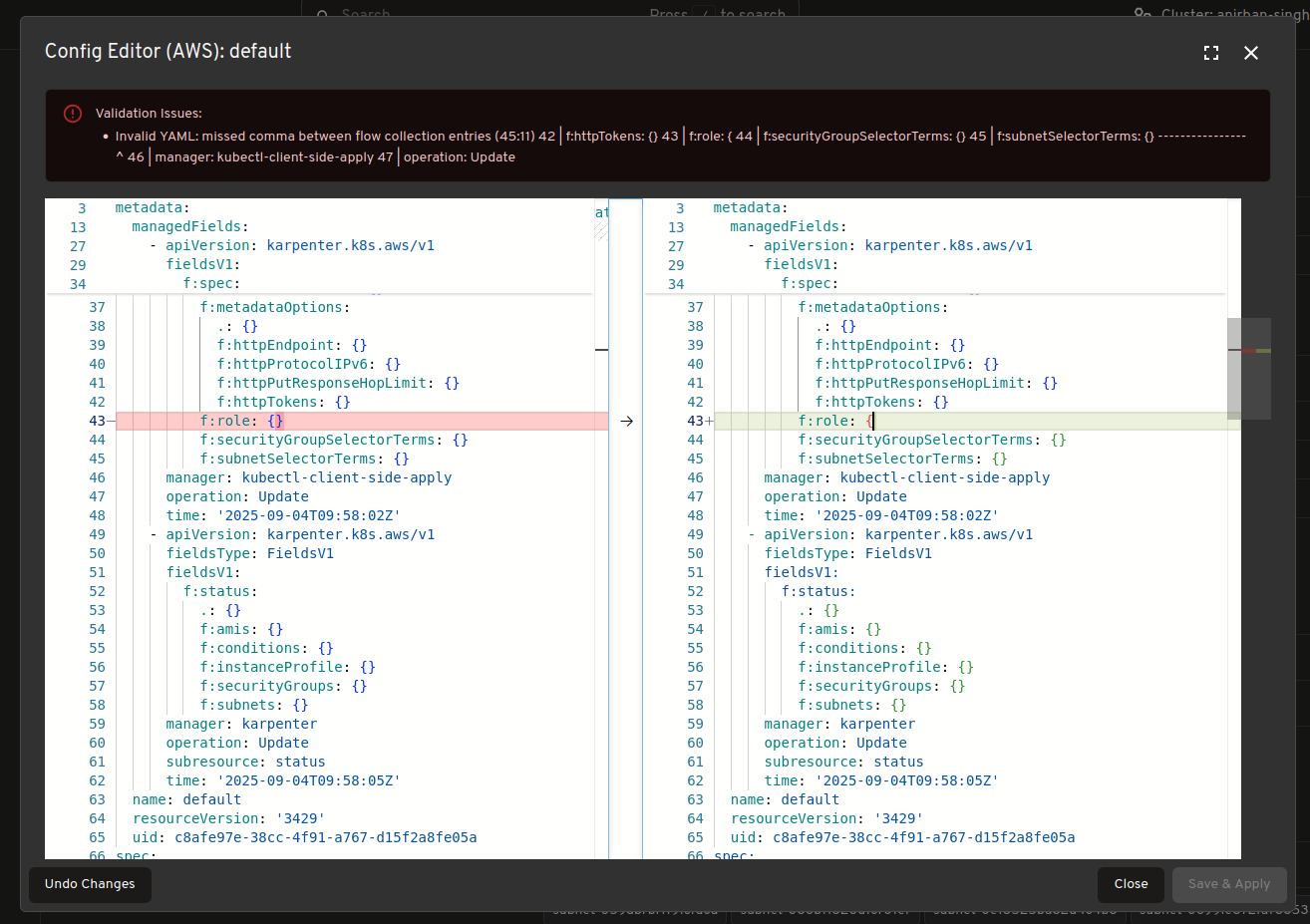
Редактор конфігурацій з підтримкою валідації
Робіть зміни в конфігурації Karpenter в реальному часі. Редактор включає попередній перегляд змін і валідацію ресурсів для безпечніших налаштувань.
Перегляд ресурсів Karpenter у реальному часі
Переглядайте та відстежуйте специфічні ресурси Karpenter у реальному часі, такі як "NodeClaims", коли ваш кластер масштабується вгору та вниз.



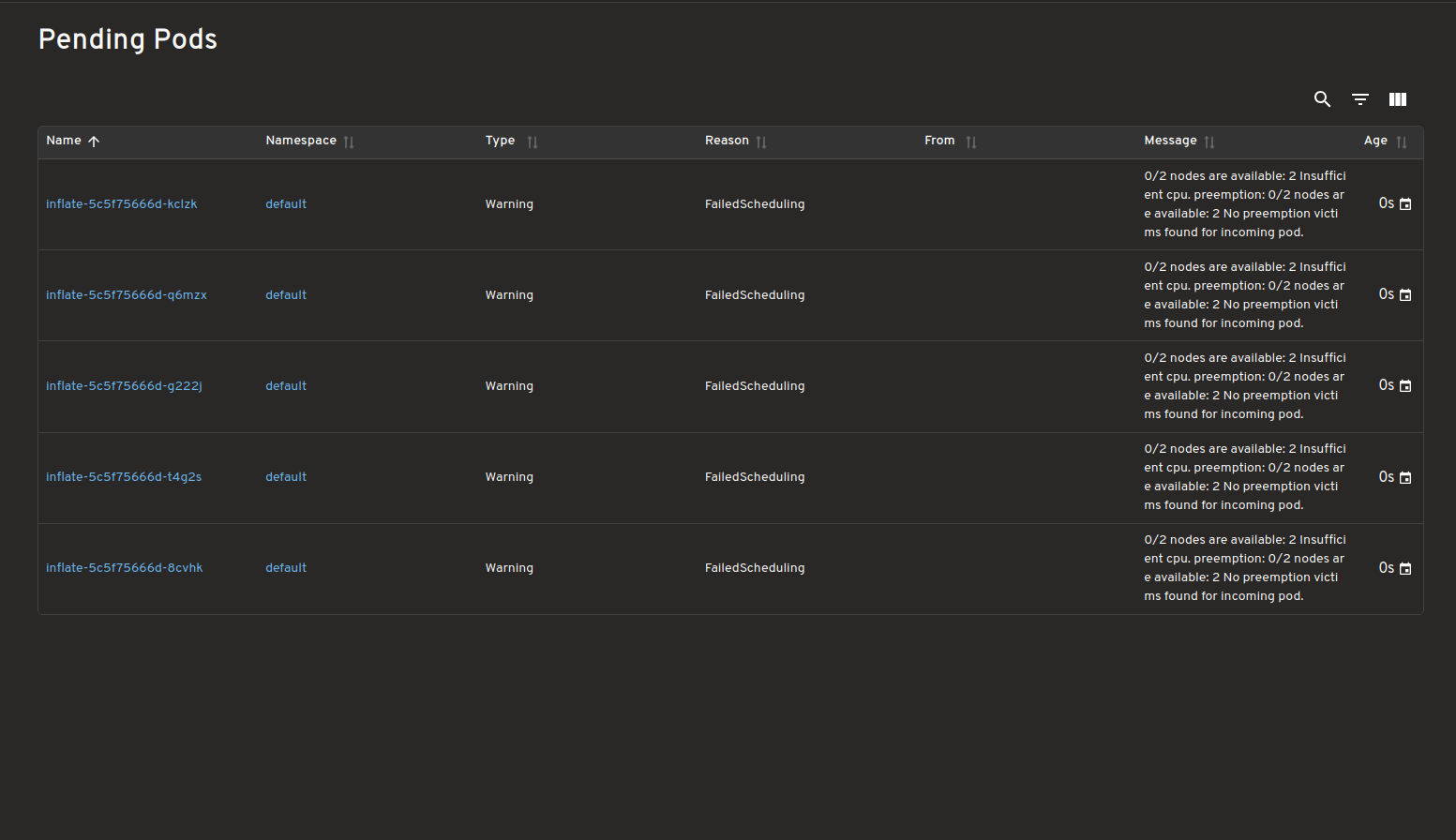
Панель інструментів для подів в очікуванні
Переглядайте всі поди в очікуванні з невиконаними вимогами до планування/не вдалося запланувати, підкреслюючи причини, чому їх не вдалося запланувати.
Karpenter Providers
Цей втулок повинен працювати з більшістю постачальників Karpenter, але наразі був протестований лише на тих, що наведені в таблиці. Крім того, кожен постачальник надає деяку додаткову інформацію, і ті, що наведені в таблиці нижче, відображаються втулком.
| Постачальник | Перевірено | Підтримується додаткова інформація про конкретного постачальника |
|---|---|---|
| AWS | ✅ | ✅ |
| Azure | ✅ | ✅ |
| AlibabaCloud | ❌ | ❌ |
| Bizfly Cloud | ❌ | ❌ |
| Cluster API | ❌ | ❌ |
| GCP | ❌ | ❌ |
| Proxmox | ❌ | ❌ |
| Oracle Cloud Infrastructure (OCI) | ❌ | ❌ |
Будь ласка, стовріть тікет якщо ви протестуєте одного з неперевірених постачальників або якщо ви хочете підтримку для цього постачальника (PRs також з радістю приймаються).
Як користуватися
Будь ласка, ознайомтеся з plugins/karpenter/README.md для отримання інструкцій щодо використання.
Відгуки та запитання
Будь ласка, стовріть тікет якщо ви використовуєте Karpenter і маєте будь-які інші ідеї або відгуки. Або приєднуйтесь до каналу Kubernetes slack headlamp для спілкування.
Оголошення про підтримку Changed Block Tracking API (альфа)
Ми раді оголосити про альфа-підтримку механізму відстеження змінених блоків. Це покращує екосистему зберігання даних Kubernetes, надаючи ефективний спосіб для драйверів зберігання даних CSI ідентифікувати змінені блоки в знімках (snapshot) PersistentVolume. За допомогою драйвера, який може використовувати цю функцію, ви зможете скористатися швидшими та більш ефективними з точки зору використання ресурсів операціями резервного копіювання.
Якщо ви хочете спробувати цю функцію, перейдіть до розділу Початок роботи.
Що таке відстеження змінених блоків?
Відстеження змінених блоків дозволяє системам зберігання даних ідентифікувати та відстежувати зміни на рівні блоків між моментальними знімками, усуваючи необхідність сканування цілих томів під час операцій резервного копіювання. Це вдосконалення є зміною в інтерфейсі Container Storage Interface (CSI), а також у підтримці зберігання даних у самій системі Kubernetes. З увімкненою альфа-функцією ваш кластер може:
- Ідентифікувати виділені блоки в знімку тому CSI
- Визначати змінені блоки між двома знімками одного тому
- Оптимізувати операції резервного копіювання, зосередившись лише на змінених блоках даних
Для користувачів Kubernetes, які керують великими наборами даних, цей API забезпечує значно ефективніші процеси резервного копіювання. Тепер програми резервного копіювання можуть зосередитися лише на змінених блоках, а не обробляти цілі томи.
Примітка:
На даний момент Changed Block Tracking API підтримується тільки для блокових томів, а не для файлових томів. Драйвери CSI, які керують файловими системами зберігання даних, не зможуть реалізувати цю функцію.Переваги підтримки відстеження змінених блоків у Kubernetes
У міру зростання популярності Kubernetes для управління критичними даними зі збереженням стану (stateful), потреба в ефективних рішеннях для резервного копіювання стає все більш важливою. Традиційні підходи до повного резервного копіювання стикаються з такими проблемами:
- Довгі вікна резервного копіювання: повне резервне копіювання великих обсягів даних може займати години, що ускладнює його виконання в межах вікон технічного обслуговування.
- Високе використання ресурсів: операції резервного копіювання споживають значну пропускну здатність мережі та ресурси вводу-виводу, особливо для великих обсягів даних і застосунків, що інтенсивно використовують дані.
- Збільшення витрат на зберігання: Повторні повні резервні копії зберігають надлишкові дані, що призводить до лінійного зростання вимог до зберігання, навіть якщо між резервними копіями фактично змінюється лише невеликий відсоток даних.
Changed Block Tracking API вирішує ці проблеми, надаючи вбудовану підтримку Kubernetes для інкрементних резервних копій через інтерфейс CSI.
Ключові компоненти
Реалізація складається з трьох основних компонентів:
- CSI SnapshotMetadata Service API: API, що пропонується gRPC, який надає знімки томів та дані про змінені блоки.
- SnapshotMetadataService API: Kubernetes CustomResourceDefinition (CRD), який повідомляє про доступність служби метаданих драйвера CSI та деталі підключення до клієнтів кластера.
- External Snapshot Metadata Sidecar: проміжний компонент, який підключає драйвери CSI до застосунків резервного копіювання через стандартизований інтерфейс gRPC.
Вимоги до впровадження
Обовʼязки постачальника послуг зберігання
Якщо ви є автором інтеграції сховища з Kubernetes і хочете підтримати функцію відстеження змінених блоків, ви повинні виконати певні вимоги:
Впровадити CSI RPC: Постачальники систем зберігання даних повинні впровадити сервіс
SnapshotMetadata, як визначено в специфікаціях CSI protobuf. Цей сервіс вимагає впровадження серверного потокового передавання для таких RPC:GetMetadataAllocated: для ідентифікації виділених блоків у знімкуGetMetadataDelta: для визначення змінених блоків між двома знімками
Можливості бекенду сховища: переконайтеся, що бекенд сховища має можливість відстежувати та повідомляти про зміни на рівні блоків.
Розгортання зовнішніх компонентів: інтегруйте з sidecar
external-snapshot-metadata, щоб відкрити доступ до сервісу метаданих знімків.Реєстрація власного ресурсу: зареєструйте ресурс
SnapshotMetadataServiceза допомогою CustomResourceDefinition і створіть власний ресурсSnapshotMetadataService, який повідомляє про доступність служби метаданих і надає деталі підключення.Підтримка обробки помилок: реалізуйте належну обробку помилок для цих RPC відповідно до вимог специфікації CSI.
Відповідальність за рішення щодо резервного копіювання
A backup solution looking to leverage this feature must:
Налаштування автентифікації: Програма резервного копіювання повинна надавати токен Kubernetes ServiceAccount під час використання Kubernetes SnapshotMetadataService API. Необхідно встановити відповідні права доступу, такі як RBAC RoleBindings, щоб авторизувати ServiceAccount програми резервного копіювання для отримання таких токенів.
Впровадити код потокового передавання на стороні клієнта: Розробити клієнти, які впроваджують API потокового передавання gRPC, визначені у файлі schema.proto. Зокрема:
- Впровадити код клієнта для потокового передавання для методів
GetMetadataAllocatedтаGetMetadataDelta. - Ефективно обробляти відповіді сервера для потокового передавання, оскільки метадані надходять частинами.
- Обробляти формат повідомлення
SnapshotMetadataResponseз належним обробленням помилок.
Репозиторій GitHub
external-snapshot-metadataнадає зручний пакет підтримки ітератора для спрощення реалізації клієнта.- Впровадити код клієнта для потокового передавання для методів
Обробка великих потоків даних: Розробка клієнтів для ефективної обробки великих потоків метаданих блоків, які можуть бути повернуті для томів із значними змінами.
Оптимізація процесів резервного копіювання: Модифікація робочих процесів резервного копіювання для використання змінених метаданих блоків з метою ідентифікації та передачі лише змінених блоків, щоб зробити резервне копіювання більш ефективним, скоротивши тривалість резервного копіювання та споживання ресурсів.
Початок роботи
Щоб використовувати відстеження змінених блоків у кластері:
- Переконайтеся, що драйвер CSI підтримує знімки томів і реалізує можливості метаданих знімків за допомогою необхідного sidecar
external-snapshot-metadata. - Переконайтеся, що власний ресурс SnapshotMetadataService зареєстрований за допомогою CRD.
- Перевірте наявність власного ресурсу SnapshotMetadataService для драйвера CSI.
- Створіть клієнтів, які можуть отримати доступ до API за допомогою відповідної автентифікації (через токени Kubernetes ServiceAccount).
API надає дві основні функції:
GetMetadataAllocated: перелічує блоки, виділені в одному знімку.GetMetadataDelta: перелічує блоки, змінені між двома знімками.
Що далі?
Залежно від відгуків та прийняття, розробники Kubernetes сподіваються перевести реалізацію CSI Snapshot Metadata в бета-версію в майбутніх релізах.
Де я можу дізнатися більше?
Для тих, хто зацікавлений у випробуванні цієї нової функції:
- Офіційна документація для розробників Kubernetes CSI
- Пропозиція щодо вдосконалення функції метаданих знімків.
- Репозиторій GitHub для реалізації та статусу випуску
external-snapshot-metadata - Повні визначення протоколу gRPC для API метаданих знімків: schema.proto
- Приклад реалізації клієнта метаданих знімків: snapshot-metadata-lister
- Приклад комплексного рішення з csi-hostpath-driver: документація з прикладом
Як я можу долучитися?
Цей проєкт, як і всі проєкти Kubernetes, є результатом наполегливої праці багатьох учасників з різних сфер, які працювали разом. Від імені SIG Storage я хотів би висловити величезну подяку учасникам, які допомогли переглянути дизайн та реалізацію проєкту, зокрема, але не виключно, наступним особам:
- Ben Swartzlander (bswartz)
- Carl Braganza (carlbraganza)
- Daniil Fedotov (hairyhum)
- Ivan Sim (ihcsim)
- Nikhil Ladha (Nikhil-Ladha)
- Prasad Ghangal (PrasadG193)
- Praveen M (iPraveenParihar)
- Rakshith R (Rakshith-R)
- Xing Yang (xing-yang)
Дякуємо також усім, хто долучився до проєкту, зокрема тим, хто допоміг рецензувати KEP та CSI spec PR.
Ті, хто зацікавлений у розробці та розвитку CSI або будь-якої частини системи зберігання даних Kubernetes, можуть приєднатися до Kubernetes Storage Special Interest Group (SIG). Ми завжди раді новим учасникам.
SIG також проводить регулярні зустрічі Data Protection Working Group. Нові учасники можуть долучитися до наших дискусій.
Kubernetes v1.34: Ресурси рівня Pod перейшли в стадію бета
Від імені спільноти Kubernetes я з радістю повідомляю, що функція Pod Level Resources (Ресурси рівня Pod) перейшла в стадію бета у версії Kubernetes v1.34 і є стандартно увімкненою! Ця важлива подія відкриває нові можливості для визначення та управління розподілом ресурсів для ваших Podʼів. Така гнучкість зумовлена можливістю вказати ресурси CPU та памʼяті для Podʼа в цілому. Ресурси на рівні Podʼа можна поєднувати зі специфікаціями на рівні контейнера, щоб точно визначити вимоги до ресурсів та обмеження, необхідні для вашого застосунку.
Специфікація ресурсів на рівні Podʼа
До недавнього часу специфікації ресурсів, що застосовувалися до Podʼа, визначалися переважно на рівні окремих контейнерів. Хоча такий підхід був ефективним, іноді він вимагав дублювання або ретельного розрахунку потреб у ресурсах для декількох контейнерів в одному Podʼі. У якості бета-функції Kubernetes дозволяє визначати ресурси CPU, памʼяті та hugepages на рівні Podʼа. Це означає, що тепер ви можете визначати запити та обмеження ресурсів для всього Podʼа, що спрощує спільне використання ресурсів без необхідності детального управління цими ресурсами для кожного контейнера, де це не потрібно.
Чому важливі специфікації на рівні Podʼа?
Ця функція покращує управління ресурсами в Kubernetes, пропонуючи гнучке управління ресурсами як на рівні Podʼів, так і на рівні контейнерів.
Вона забезпечує консолідований підхід до оголошення ресурсів, зменшуючи необхідність ретельного управління кожним контейнером окремо, особливо для Podʼів з декількома контейнерами.
Ресурси на рівні Podʼа дозволяють контейнерам у Podʼі обмінюватися між собою невикористаними ресурсами, сприяючи ефективному використанню ресурсів у Podʼі. Наприклад, це запобігає перетворенню контейнерів-sidecar на вузькі місця, що обмежують продуктивність. Раніше sidecar (наприклад, агент логування або проксі сервісної мережі), що досягали свого індивідуального обмеження CPU, могли бути стишені і сповільнювати роботу всього Podʼа, навіть якщо основний контейнер застосунку мав достатньо вільного CPU. За допомогою ресурсів на рівні Podʼа sidecarʼи та основний контейнер можуть спільно використовувати ресурси Podʼа, забезпечуючи безперебійну роботу під час пікових навантажень — або весь Pod стишується, або всі контейнери працюють.
Коли вказані ресурси як на рівні подів, так і на рівні контейнерів, пріоритет мають запити та обмеження на рівні подів. Це надає вам та адміністраторам кластерів потужний засіб для забезпечення загальних обмежень ресурсів для ваших Podʼів.
Для планування, якщо запит на рівні подів явно визначений, планувальник використовує це конкретне значення для пошуку відповідного вузла, а не сукупні запити окремих контейнерів. Під час виконання обмеження на рівні подів діє як жорстка верхня межа для сукупного використання ресурсів усіма контейнерами. Важливо, що це обмеження на рівні подів є абсолютним; навіть якщо сума індивідуальних обмежень контейнерів є вищою, загальне споживання ресурсів ніколи не може перевищити обмеження на рівні подів.
Ресурси на рівні Podʼів мають пріоритет у впливі на клас якості обслуговування (QoS) Podʼа.
Для Podʼів, що працюють на вузлах Linux, при розрахунку коригування показника Out-Of-Memory (OOM) враховуються запити на ресурси як на рівні Podʼа, так і на рівні контейнера.
Ресурси на рівні Pod спроєктовані для сумісності з наявними функціональними можливостями Kubernetes, що забезпечує плавну інтеграцію у ваші робочі процеси.
Як вказати ресурси для всього Pod
Використання функціональної можливості PodLevelResources вимагає Kubernetes v1.34 або новішої версії для всіх компонентів кластера, включаючи панель управління та кожен вузол. Ця функція знаходиться в бета-версії та є стандартно увімкненою у v1.34.
Приклад маніфесту
Ви можете вказати ресурси CPU, памʼяті та hugepages безпосередньо в маніфесті специфікації Podʼа у полі resources для всього Podʼа.
Ось приклад, що демонструє Pod із запитами та обмеженнями CPU та памʼяті, визначеними на рівні Pod:
apiVersion: v1
kind: Pod
metadata:
name: pod-resources-demo
namespace: pod-resources-example
spec:
# Поле 'resources' на рівні специфікації Podʼа визначає загальний
# бюджет ресурсів для всіх контейнерів у цьому Podʼі разом.
resources: # Ресурси на рівні Podʼа
# 'limits' визначає максимальну кількість ресурсів, яку може використовувати Pod.
# Сума обмежень усіх контейнерів у Podʼі не може перевищувати ці значення.
limits:
cpu: "1" # Весь Pod не може використовувати більше 1 ядро процесора.
memory: "200Mi" # Весь Pod не може використовувати більше 200 МБ памʼяті.
# 'requests' визначає мінімальний обсяг ресурсів, гарантований Podʼу.
# Це значення використовується планувальником Kubernetes для пошуку вузла з достатньою ємністю.
requests:
cpu: "1" # Pod гарантовано отримує 1 ядро процесора при плануванні.
memory: "100Mi" # При плануванні Pod гарантується 100 МБ памʼяті.
containers:
- name: main-app-container
image: nginx
...
# Для цього контейнера не вказано жодних запитів на ресурси або обмежень.
- name: auxiliary-container
image: fedora
command: ["sleep", "inf"]
...
# Для цього контейнера не вказано жодних запитів на ресурси або обмежень.
У цьому прикладі Pod pod-resources-demo в цілому запитує 1 CPU і 100 MiB памʼяті, і обмежений 1 CPU і 200 MiB памʼяті. Контейнери всередині будуть працювати в рамках цих загальних обмежень на рівні Podʼа, як пояснено в наступному розділі.
Взаємодія з запитами або обмеженнями ресурсів на рівні контейнера
Коли вказані ресурси як на рівні Podʼа, так і на рівні контейнера, запити та обмеження на рівні podʼа мають пріоритет. Це означає, що вузол розподіляє ресурси на основі специфікацій на рівні pod.
Розглянемо Pod з двома контейнерами, де визначені запити та обмеження на рівні podʼа щодо CPU та памʼяті, і лише один контейнер має власні явні визначення ресурсів:
apiVersion: v1
kind: Pod
metadata:
name: pod-resources-demo
namespace: pod-resources-example
spec:
resources:
limits:
cpu: "1"
memory: "200Mi"
requests:
cpu: "1"
memory: "100Mi"
containers:
- name: main-app-container
image: nginx
resources:
requests:
cpu: "0.5"
memory: "50Mi"
- name: auxiliary-container
image: fedora
command: [ "sleep", "inf"]
# Для цього контейнера не вказано жодних запитів на ресурси або обмежень.
Обмеження на рівні Podʼа: Обмеження на рівні Podʼа (cpu: "1", memory: "200Mi") встановлюють абсолютну межу для всього Podʼа. Сума ресурсів, що споживаються всіма його контейнерами, обмежується цією межею і не може бути перевищена.
Спільне використання та перевищення ресурсів: контейнери можуть динамічно запозичувати будь-яку невикористану потужність, що дозволяє їм перевищувати обмеження за потреби, якщо сукупне використання Podʼа залишається в межах загального обмеження.
Запити на рівні Pod: запити на рівні Pod (cpu: "1", memory: "100Mi") слугують основою для гарантування ресурсів для всього Podʼа. Це значення впливає на рішення планувальника щодо розміщення і представляє мінімальні ресурси, на які Pod може розраховувати під час конфлікту на рівні вузла.
Запити на рівні контейнера: запити на рівні контейнера створюють систему пріоритетів у межах гарантованого бюджету Podʼа. Оскільки main-app-container має явний запит (cpu: "0.5", memory: "50Mi"), йому надається пріоритет у розподілі ресурсів під тиском ресурсів над auxiliary-container, який не має такого явного запиту.
Обмеження
По-перше, зміна на місці розміру ресурсів на рівні pod не підтримується для Kubernetes v1.34 (або раніше). Спроба змінити обмеження або запити ресурсів на рівні podʼа для працюючого Podʼа призводить до помилки: зміна розміру відхиляється. Реалізація ресурсів на рівні Podʼа у версії v1.34 зосереджена на тому, щоб дозволити початкове оголошення загального ресурсного конверту, який застосовується до всього Podʼа. Це відрізняється від зміни розміру на місці, яка (незважаючи на те, що може натякати назва) дозволяє динамічно коригувати запити та обмеження ресурсів контейнера в працюючому Podʼі і, можливо, без перезапуску контейнера. Зміна розміру на місці також ще не є стабільною функцією; вона перейшла в стадію бета у версії v1.33.
На рівні pod можна вказати лише ресурси CPU, памʼяті та великі сторінки (hugepages).
Ресурси на рівні pod не підтримуються для podʼів Windows. Якщо специфікація Podʼа явно націлена на Windows (наприклад, шляхом встановлення spec.os.name: "windows"), сервер API відхилить Pod під час етапу перевірки. Якщо под явно не позначений для Windows, але запланований для вузла Windows (наприклад, за допомогою nodeSelector), Kubelet на цьому вузлі Windows відхилить под під час процесу допуску.
Менеджер топології, менеджер памʼяті та менеджер процесора не вирівнюють под і контейнери на основі ресурсів на рівні пода, оскільки ці менеджери ресурсів наразі не підтримують ресурси на рівні пода.
Початок роботи та надання відгуків
Готові ознайомитися з функцією Pod Level Resources? Вам знадобиться кластер Kubernetes з версією 1.34 або пізнішою. Не забудьте увімкнути функціональну можливість PodLevelResources у вашій панелі управління та на всіх вузлах.
Оскільки ця функція перебуває на стадії бета-тестування, ваші відгуки є надзвичайно цінними. Будь ласка, повідомляйте про будь-які проблеми або діліться своїм досвідом через стандартні канали комунікації Kubernetes:
Kubernetes v1.34: Відновлення після збою розширення тому (GA)
Чи робили ви коли-небудь помилку при розширенні ваших постійних томів у Kubernetes? Хотіли вказати 2TB, але вказали 20TiB? Ця, здавалося б, незначна проблема була досить важкою для виправлення, і проєкту знадобилося майже 5 років, щоб її виправити. Автоматичне відновлення після розширення сховища існує вже деякий час у бета-версії; однак, з випуском v1.34, ми перевели її в загальну доступність.
Хоча завжди було можливо відновитися після збою розширення томів вручну, зазвичай це вимагало доступу адміністратора кластера і було нудно робити (див. вказане посилання для отримання додаткової інформації).
Що, якщо ви зробите помилку, а потім відразу усвідомите це? З Kubernetes v1.34 ви повинні мати можливість зменшити запитуваний розмір PersistentVolumeClaim (PVC) і, якщо розширення до раніше запитуваного розміру не завершилося, ви можете змінити запитуваний розмір. Kubernetes автоматично працюватиме над його виправленням. Будь-яка квота, спожита невдалим розширенням, буде повернена користувачу, а повʼязаний PersistentVolume повинен бути змінений на останній вказаний вами розмір.
Я пройду через приклад того, як все це працює.
Зменшення розміру PVC для відновлення після невдалого розширення
Уявіть, що у вас закінчується місце на диску для одного з ваших серверів бази даних, і ви хочете розширити PVC з раніше вказаного 10TB до 100TB, але ви зробили помилку і вказали 1000TB.
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1000TB # новий вказаний розмір - але неправильний!
Тепер у вас може закінчитися місце на диску в масиві дисків або просто вичерпані виділені квоти у вашого постачальника хмари. Але припустимо, що розширення до 1000TB ніколи не відбудеться.
У Kubernetes v1.34 ви можете просто виправити свою помилку і запитати новий розмір PVC, який менший за помилку, за умови, що він все ще більший за початковий розмір фактичного PersistentVolume.
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100TB # Правильний розмір; має бути більшим за 10TB.
# Ви не можете зменшити обсяг нижче його фактичного розміру.
Це не вимагає втручання адміністратора. Ще краще, будь-яка надлишкова квота Kubernetes, яку ви тимчасово спожили, буде автоматично повернена.
Цей механізм відновлення після збоїв має одну умову: будь-який новий розмір, який ви вказуєте для PVC, повинен бути все ще більшим за початковий розмір у .status.capacity. Оскільки Kubernetes не підтримує зменшення ваших обʼєктів PV, ви ніколи не зможете зменшити їх до розміру, який спочатку був виділений для вашого запиту PVC.
Поліпшене оброблення помилок і спостережуваність розширення томів
Реалізація того, що може виглядати як відносно незначна зміна, також вимагала від нас майже повністю переробити те, як працює розширення томів під капотом у Kubernetes. Існують нові поля API, доступні в обʼєктах PVC, які ви можете контролювати, щоб спостерігати за прогресом розширення томів.
Поліпшена спостережуваність за розширенням у процесі
Ви можете запитати .status.allocatedResourceStatus['storage'] PVC, щоб відстежувати прогрес операції розширення томів. Для типового блочного тому це має переходити між ControllerResizeInProgress, NodeResizePending і NodeResizeInProgress і ставати nil/порожнім, коли розширення томів завершено.
Якщо з якоїсь причини розширення томів до запитаного розміру неможливе, воно повинно відповідно перебувати в станах, таких як ControllerResizeInfeasible або NodeResizeInfeasible.
Ви також можете спостерігати за розміром, до якого Kubernetes працює, спостерігаючи за pvc.status.allocatedResources.
Поліпшене оброблення помилок і звітність
Kubernetes тепер повинен повторно спробувати ваші невдалі розширення томів повільніше, він повинен робити менше запитів як до системи зберігання, так і до Kubernetes apiserver.
Помилки, виявлені під час розширення томів, тепер повідомляються як стан на обʼєктах PVC і повинні зберігатися на відміну від подій. Kubernetes тепер заповнить pvc.status.conditions ключами помилок ControllerResizeError або NodeResizeError, коли розширення томів не вдається.
Виправлення давніх помилок у робочих процесах зміни розміру
Ця функція також дозволила нам виправити давні помилки в робочих процесах зміни розміру, такі як Kubernetes issue #115294. Якщо ви спостерігаєте щось зламане, будь ласка, повідомте про свої помилки на https://github.com/kubernetes/kubernetes/issues, разом з деталями про те, як відтворити проблему.
Робота над цією функцією протягом її життєвого циклу була складною, і було б неможливо досягти GA без зворотного звʼязку від @msau42, @jsafrane і @xing-yang.
Всі учасники, які працювали над цим, також цінують внесок, наданий @thockin і @liggitt на різних самітах контрибʼюторів Kubernetes.
Kubernetes v1.34: Споживча ємність DRA
Динамічне виділення ресурсів (Dynamic Resource Allocation, DRA) — це API Kubernetes для управління дефіцитними ресурсами Podʼів та контейнерів. Він дозволяє гнучкі запити ресурсів, виходячи за межі простого виділення N кількості пристроїв, щоб підтримувати більш детальні сценарії використання. З DRA користувачі можуть запитувати специфічні типи пристроїв на основі їх атрибутів, визначати власні конфігурації, адаптовані до їх робочих навантажень, і навіть ділитися одним і тим же ресурсом між кількома контейнерами або Podʼами.
Тут ми зосередимося на функції спільного використання пристроїв і заглибимось в нову можливість, представлену в Kubernetes 1.34: споживча ємність DRA, яка розширює DRA для підтримки більш тонкого спільного використання пристроїв.
Передумови: спільне використання пристроїв через ResourceClaims
З самого початку DRA представила можливість для кількох Podʼів ділитися пристроєм, посилаючись на один і той же ResourceClaim. Цей дизайн відокремлює виділення ресурсів від конкретного обладнання, що дозволяє більш динамічне та повторне використання пристроїв.
У Kubernetes 1.33 нова підтримка розділювальних пристроїв (partitionable devices) дозволила драйверам ресурсів оголошувати частини пристрою, які доступні, а не виставляти весь пристрій як ресурс "все або нічого". Це дозволило Kubernetes більш точно моделювати обладнання спільного використання.
Але все ще залишалася одна відсутня частина: він ще не підтримував сценарії, коли драйвер пристрою керує тонкими, динамічними частинами ресурсу пристрою, такими як пропускна здатність мережі, на основі запитів користувачів, або для спільного використання цих ресурсів незалежно від ResourceClaims, які обмежені їх специфікацією та простором імен.
Саме тут зʼявляється споживча ємність для DRA.
Переваги підтримки споживчої ємності DRA
Ось короткий огляд того, що ви отримуєте в кластері з увімкненою функціональною можливістю DRAConsumableCapacity.
Спільне використання пристроїв між кількома ResourceClaims або DeviceRequests
Тепер драйвери ресурсів можуть підтримувати спільне використання одного й того ж пристрою, або навіть частини пристрою, між кількома ResourceClaims або між кількома DeviceRequests.
Це означає, що Podʼи з різних просторів імен можуть одночасно ділитися одним і тим же пристроєм, якщо це дозволено та підтримується конкретним драйвером DRA.
Виділення ресурсів пристроїв
Kubernetes розширює алгоритм виділення в планувальнику, щоб підтримувати виділення частини ресурсів пристрою, як визначено в полі capacity. Планувальник забезпечує, щоб загальна виділена ємність для всіх споживачів ніколи не перевищувала загальну ємність пристрою, навіть коли вона ділиться між кількома ResourceClaims або DeviceRequests. Це дуже схоже на те, як планувальник дозволяє Podʼам і контейнерам ділитися виділеними ресурсами на вузлах; в цьому випадку він дозволяє їм ділитися виділеними ресурсами на пристроях.
Ця функція розширює підтримку сценаріїв, де драйвер пристрою може керувати ресурсами всередині пристрою та на основі кожного процесу — наприклад, виділення певної кількості памʼяті (наприклад, 8 ГіБ) з віртуального GPU, або встановлення обмежень пропускної здатності на віртуальні мережеві інтерфейси, виділені конкретним Podʼам. Це має на меті забезпечити безпечне та ефективне спільне використання ресурсів.
Обмеження DistinctAttribute
Ця функція також вводить нове обмеження: DistinctAttribute, яке є доповненням до наявного обмеження MatchAttribute.
Основна мета DistinctAttribute полягає в тому, щоб запобігти багаторазовому виділенню одного й того ж базового пристрою в межах одного ResourceClaim, що може статися, оскільки ми виділяємо частки (або підмножини) пристроїв. Це обмеження забезпечує, щоб кожне виділення посилалося на окремий ресурс, навіть якщо вони належать до одного й того ж класу пристроїв.
Це корисно для таких випадків, як виділення мережевих пристроїв, що підключаються до різних підмереж, щоб розширити покриття або забезпечити резервування в різних зонах відмов.
Як використовувати споживчу ємність?
DRAConsumableCapacity була представлена як альфа-функція в Kubernetes 1.34. Функціональна можливість DRAConsumableCapacity має бути увімкнена в kubelet, kube-apiserver, kube-scheduler і kube-controller-manager.
--feature-gates=...,DRAConsumableCapacity=true
Як розробник драйвера DRA
Як розробник драйвера DRA, що пише на Golang, ви можете зробити пристрій у межах ResourceSlice доступним для кількох ResourceClaims (або devices.requests), встановивши AllowMultipleAllocations на true.
Device {
...
AllowMultipleAllocations: ptr.To(true),
...
}
Додатково, ви можете визначити політику, щоб обмежити те, як кожен DeviceRequest повинен споживати Capacity кожного пристрою, визначивши поле RequestPolicy у DeviceCapacity. Приклад нижче показує, як визначити політику, яка вимагає, щоб GPU з 40 ГіБ памʼяті виділяв щонайменше 5 ГіБ на запит, при цьому кожне виділення має бути кратним 5 ГіБ.
DeviceCapacity{
Value: resource.MustParse("40Gi"),
RequestPolicy: &CapacityRequestPolicy{
Default: ptr.To(resource.MustParse("5Gi")),
ValidRange: &CapacityRequestPolicyRange {
Min: ptr.To(resource.MustParse("5Gi")),
Step: ptr.To(resource.MustParse("5Gi")),
}
}
}
Це буде опубліковано в ResourceSlice, як частково показано нижче:
apiVersion: resource.k8s.io/v1
kind: ResourceSlice
...
spec:
devices:
- name: gpu0
allowMultipleAllocations: true
capacity:
memory:
value: 40Gi
requestPolicy:
default: 5Gi
validRange:
min: 5Gi
step: 5Gi
Віділений пристрій з певною часткою спожитої ємності матиме поле ShareID, встановлене в статусі виділення.
claim.Status.Allocation.Devices.Results[i].ShareID
Цей ShareID дозволяє драйверу розрізняти різні віділення, які посилаються на той самий пристрій або той самий статично виділений сегмент, але походять з різних запитів ResourceClaim. Він діє як унікальний ідентифікатор для кожного спільного сегмента, дозволяючи драйверу незалежно керувати та застосовувати обмеження ресурсів для декількох споживачів.
Як споживач
Як споживач (або користувач), ресурс пристрою можна запитати за допомогою ResourceClaim, як показано нижче:
apiVersion: resource.k8s.io/v1
kind: ResourceClaim
...
spec:
devices:
requests: # для пристроїв
- name: req0
exactly:
deviceClassName: resource.example.com
capacity:
requests: # для ресурсів, які повинні бути надані цими пристроями
memory: 10Gi
Ця конфігурація забезпечує, що запитуваний пристрій може надати щонайменше 10ГіБ памʼяті.
Зокрема, будь-який пристрій resource.example.com, який має щонайменше 10ГіБ памʼяті, може бути виділений. Якщо вибрано пристрій, який не підтримує кілька виділень, виділення використовуватиме весь пристрій. Щоб відфільтрувати лише пристрої, які підтримують кілька виділень, ви можете визначити селектор, як показано нижче:
selectors:
- cel:
expression: |-
device.allowMultipleAllocations == true
Інтеграція зі статусом пристроїв DRA
У спільному використанні пристроїв загальна інформація про пристрій надається через ресурсний зріз. Однак деякі деталі встановлюються динамічно після виділення. Ці дані можна передати за допомогою поля .status.devices у ResourceClaim. Це поле публікується лише в кластерах, де увімкнено DRAResourceClaimDeviceStatus feature gate.
Якщо у вас є підтримка статусу пристроїв, драйвер може надати додаткову інформацію про пристрій, виходячи за межі ShareID. Одним із особливо корисних випадків є віртуальні мережі, де драйвер може включити призначену IP-адресу(и) у статус. Це цінно як для операцій мережевих служб, так і для усунення несправностей.
Ви можете знайти більше інформації, переглянувши нашу запис: KubeCon Japan 2025 — Reimagining Cloud Native Networks: The Critical Role of DRA.
Що ви можете зробити далі?
Перегляньте проєкт CNI DRA Driver для прикладу інтеграції DRA в мережі Kubernetes. Спробуйте інтегруватися з мережевими ресурсами, такими як
macvlan,ipvlanабо смарт NIC.Увімкніть функціональну можливість
DRAConsumableCapacityта експериментуйте з віртуалізованими або роздільними пристроями. Визначте свої робочі навантаження з споживаною ємністю (наприклад: дробова пропускна здатність або памʼять).Дайте нам знати вашу думку:
- ✅ Що спрацювало добре?
- ⚠️ Що не спрацювало?
Якщо ви зіткнулися з проблемами, які потрібно виправити, або можливостями для вдосконалення, будь ласка, створіть новий тікет і посилайтеся та пошліться на KEP-5075 там, або звʼяжіться з нами через Slack (#wg-device-management).
Висновок
Підтримка споживчої ємності покращує можливості спільного використання пристроїв DRA, дозволяючи ефективне спільне використання пристроїв між просторами імен, між запитами та адаптуючи їх до фактичних потреб кожного Podʼа. Це також надає драйверам можливість забезпечувати обмеження ємності, покращує точність планування та відкриває нові випадки використання, такі як обізнаність про пропускну здатність мережі та спільне використання пристроїв у багатокористувацькому середовищі.
Спробуйте це, експериментуйте зі споживаними ресурсами та допоможіть сформувати майбутнє динамічного виділення ресурсів у Kubernetes!
Додатково ознайомтеся з
Kubernetes v1.34: Звіт про стан ресурсів DRA в Podʼах
Зростання популярності штучного інтелекту (AI) та машинного навчання (ML) та інших високопродуктивних робочих навантажень зробило спеціалізоване обладнання, таке як графічні процесори (GPU), процесори для обробки даних (TPU) та програмовані логічні матриці (FPGA), критично важливим компонентом багатьох кластерів Kubernetes. Однак, як обговорювалося в попередньому блозі про пошук збоїв у Podʼах з пристроями, коли це обладнання виходить з ладу, його може бути важко діагностувати, що призводить до значного часу простою. З випуском Kubernetes v1.34 ми раді оголосити про нову альфа-функцію, яка забезпечує необхідну видимість стану цих пристроїв.
Ця робота розширює функціональність KEP-4680, яка вперше представила механізм для звітування про стан пристроїв, що керуються втулками пристроїв. Тепер ця можливість розширюється на Динамічне виділення ресурсів (DRA). Контрольована через функціональну можливість ResourceHealthStatus, це вдосконалення дозволяє драйверам DRA звітувати про стан пристроїв безпосередньо в поле .status Podʼа, надаючи важливу інформацію для операторів і розробників.
Чому важливо показувати стан пристроїв у статусі Podʼа?
Для стану застосунків або тривалих завдань збій пристрою може бути руйнівним і витратним. Експонуючи стан пристроїв у полі .status для Podʼа, Kubernetes надає стандартизований спосіб для користувачів і автоматизованих інструментів швидко діагностувати проблеми. Якщо Pod зазнає збою, ви тепер можете перевірити його статус, щоб дізнатися, чи є несправний пристрій основною причиною, заощаджуючи цінний час, який інакше міг би бути витрачений на налагодження коду застосунку.
Як це працює
Ця функція вводить новий, необовʼязковий канал звʼязку між Kubelet і драйверами DRA, побудований на трьох основних компонентах.
Новий gRPC сервіс перевірки справності
Новий gRPC сервіс, DRAResourceHealth, визначено в групі API dra-health/v1alpha1. Драйвери DRA можуть реалізувати цей сервіс для потокової передачі оновлень стану пристроїв до Kubelet. Сервіс включає серверний стрім RPC NodeWatchResources, який надсилає статус справності (Healthy, Unhealthy або Unknown) для пристроїв, якими він керує.
Інтеграція з Kubelet
Менеджер втулків DRA в Kubelet виявляє, які драйвери реалізують сервіс перевірки справності. Для кожного сумісного драйвера він запускає довготривалий стрім NodeWatchResources, щоб отримувати оновлення стану. Менеджер DRA потім споживає ці оновлення та зберігає їх у постійному кеші healthInfoCache, який може пережити перезавантаження Kubelet.
Заповнення статусу Podʼа
Коли стан пристрою змінюється, менеджер DRA ідентифікує всі Podʼи, на які вплинула зміна, і ініціює оновлення статусу Podʼа. Нове поле, allocatedResourcesStatus, тепер є частиною обʼєкта API v1.ContainerStatus. Kubelet заповнює це поле поточним станом кожного пристрою, виділеного контейнеру.
Практичний приклад
Якщо Pod знаходиться в стані CrashLoopBackOff, ви можете використовувати kubectl describe pod <pod-name>, щоб перевірити його статус. Якщо виділений пристрій зазнав збою, вивід тепер включатиме поле allocatedResourcesStatus, чітко вказуючи на проблему:
status:
containerStatuses:
- name: my-gpu-intensive-container
# ... інші стани контейнерів
allocatedResourcesStatus:
- name: "claim:my-gpu-claim"
resources:
- resourceID: "example.com/gpu-a1b2-c3d4"
health: "Unhealthy"
Цей явний статус чітко вказує на те, що проблема полягає в апаратному забезпеченні, а не в застосунку.
Тепер ви можете вдосконалити логіку виявлення збоїв, щоб реагувати на несправні пристрої, повʼязані з Podʼом, скасування планування Podʼа.
Як використовувати цю функцію
Оскільки це альфа-функція в Kubernetes v1.34, ви повинні виконати такі кроки, щоб використовувати її:
- Увімкніть функціональну можливість
ResourceHealthStatusна вашому kube-apiserver та kubelet. - Переконайтеся, що ви використовуєте драйвер DRA, який реалізує gRPC сервіс
v1alpha1 DRAResourceHealth.
Драйвери DRA
Якщо ви розробляєте драйвер DRA, обовʼязково подумайте про стратегію виявлення збоїв пристроїв і переконайтеся, що ваш драйвер інтегрований з цією функцією. Таким чином, ваш драйвер покращить досвід використання користувачами і спростить налагодження проблем з апаратним забезпеченням.
Що далі?
Це перший крок у більш широких зусиллях щодо покращення обробки збоїв пристроїв у Kubernetes. Збираючи відгуки про цю альфа-функцію, спільнота планує кілька ключових вдосконалень перед переходом до бета-версії:
- Детальні повідомлення про стан справності: Щоб покращити досвід налагодження, ми плануємо додати поле з повідомленням зрозумілими людям до gRPC API. Це дозволить драйверам DRA надавати конкретний контекст для стану справності, наприклад, "Температура GPU перевищує поріг" або "Зʼєднання NVLink втрачено".
- Конфігуровані тайм-аути перевірки справності: Тайм-аут для позначення стану справності пристрою як "Unknown" наразі жорстко прописаним у коді. Ми плануємо зробити це конфігурованим, ймовірно, на основі кожного драйвера, щоб краще врахувати різні характеристики звітності про стан справності різного апаратного забезпечення.
- Покращене усунення несправностей після виходу з ладу: Ми вирішимо відому обмеженість, коли оновлення стану справності можуть не застосовуватися до Podʼів, які вже завершили свою роботу. Це виправлення забезпечить збереження стану справності пристрою на момент збою, що є критично важливим для налагодження пакетних завдань та інших "завдань, що виконуються до завершення".
Ця функція була розроблена в рамках KEP-4680, і відгуки спільноти є критично важливими, оскільки ми працюємо над її переходом до бета-версії. Ми маємо більше вдосконалень обробки збоїв пристроїв у k8s і закликаємо вас спробувати це та поділитися своїм досвідом з спільнотою SIG Node!
Kubernetes v1.34: Volume Group Snapshots переходить в v1beta2
Volume group snapshots було представлено як функцію Alpha у випуску Kubernetes 1.27, зміна у Beta — у випуску Kubernetes 1.32. Останній випуск Kubernetes v1.34 переніс цю підтримку на другий бета-етап. Підтримка знімків групи томів спирається на набір додаткових API для групових знімків. Ці API дозволяють користувачам робити знімки, що відповідають аварійним ситуаціям, для набору томів. За лаштунками Kubernetes використовує селектор міток для групування кількох PersistentVolumeClaims для знімків. Основна мета полягає в тому, щоб дозволити вам відновити цей набір знімків на нові томи та відновити вашу роботу на основі точки відновлення, що відповідає аварійним ситуаціям.
Ця нова функція підтримується лише для CSI драйверів томів.
Що нового в Beta 2?
Під час тестування бета-версії ми зіткнулися з проблемою, коли поле restoreSize не встановлюється для окремих VolumeSnapshotContents і VolumeSnapshots, якщо драйвер CSI не реалізує виклик RPC ListSnapshots. Ми оцінили різні варіанти тут і вирішили внести цю зміну, випустивши нову бета-версію для API.
Конкретно, у v1beta2 додано структуру VolumeSnapshotInfo, яка містить інформацію про окремий знімок тома, що є членом знімка групи томів. VolumeSnapshotInfoList, список VolumeSnapshotInfo, додано до VolumeGroupSnapshotContentStatus, замінюючи VolumeSnapshotHandlePairList. VolumeSnapshotInfoList — це список інформації про знімки, повернутий драйвером CSI для ідентифікації знімків у системі зберігання. VolumeSnapshotInfoList заповнюється бічним контейнером csi-snapshotter на основі відповіді CSI CreateVolumeGroupSnapshotResponse, поверненої викликом CreateVolumeGroupSnapshot драйвера CSI.
Наявні обʼєкти API v1beta1 будуть перетворені на нові обʼєкти API v1beta2 за допомогою вебхука перетворення.
Що далі?
Залежно від відгуків та впровадження, проєкт Kubernetes планує перенести реалізацію знімків групи томів у загальну доступність (GA) у майбутньому випуску.
Як дізнатися більше?
- Дизайн-специфікація для функції знімків групи томів.
- Репозиторій коду для API знімків групи томів та контролера.
- CSI документація про функцію знімків групи.
Як взяти участь?
Цей проєкт, як і весь Kubernetes, є результатом наполегливої роботи багатьох учасників з різним досвідом, які працюють разом. Від імені SIG Storage я хотів би висловити величезну подяку всім учасникам, які допомогли проєкту досягти бета-версії за останні кілька кварталів:
- Ben Swartzlander (bswartz)
- Hemant Kumar (gnufied)
- Jan Šafránek (jsafrane)
- Madhu Rajanna (Madhu-1)
- Michelle Au (msau42)
- Niels de Vos (nixpanic)
- Leonardo Cecchi (leonardoce)
- Saad Ali (saad-ali)
- Xing Yang (xing-yang)
- Yati Padia (yati1998)
Якщо ви зацікавлені взяти участь у проєктуванні та розробці CSI або будь-якої частини системи зберігання Kubernetes, приєднуйтесь до Kubernetes Storage Special Interest Group (SIG). Ми завжди раді новим учасникам.
Ми також проводимо регулярні Data Protection Working Group meetings. Нові учасники завжди можуть приєднатися до наших обговорень.
Kubernetes v1.34: Виділений Taint Manager тепер Stable
Ця функція відокремлює відповідальність за управління життєвим циклом вузлів і виселенням podʼів на два окремі компоненти. Раніше контролер життєвого циклу вузлів обробляв як позначення вузлів як несправних з позначкам (taints) NoExecute, так і виселення podʼів з них. Тепер спеціалізований контролер виселення на основі позначок taint керує процесом, тоді як контролер життєвого циклу вузлів зосереджується виключно на проставлянні taintʼів. Це відокремлення не тільки покращує організацію коду, але й спрощує вдосконалення контролера виселення або створення власних реалізацій виселення на основі позначок.
Що нового?
Функціональна можливість SeparateTaintEvictionController була підвищена до GA в цьому випуску. Користувачі можуть за бажанням вимкнути виселення на основі taintʼів, встановивши --controllers=-taint-eviction-controller в kube-controller-manager.
Як дізнатися більше?
Для отримання додаткової інформації зверніться до KEP та до статті про бета-версію: Kubernetes 1.29: Decoupling taint manager from node lifecycle controller.
Як взяти участь?
Ми висловлюємо величезну подяку всім учасникам, які допомогли з проєктуванням, реалізацією та рецензуванням цієї функції та допомогли перевести її з бета-версії в стабільну:
- Ed Bartosh (@bart0sh)
- Yuan Chen (@yuanchen8911)
- Aldo Culquicondor (@alculquicondor)
- Baofa Fan (@carlory)
- Sergey Kanzhelev (@SergeyKanzhelev)
- Tim Bannister (@lmktfy)
- Maciej Skoczeń (@macsko)
- Maciej Szulik (@soltysh)
- Wojciech Tyczynski (@wojtek-t)
Kubernetes 1.34: Автоконфігурація для драйвера Node Cgroup переходить у стадію загальної доступності (GA)
Історично, налаштування правильного драйвера cgroup було болючою точкою для користувачів, які запускали нові кластери Kubernetes. В системах Linux існують два різні драйвери cgroup: cgroupfs і systemd. У минулому як kubelet, так і реалізація CRI (така як CRI-O або containerd) повинні були бути налаштовані на використання одного й того ж драйвера cgroup, інакше kubelet поводився б неправильно без жодного явного повідомлення про помилку. Це було джерелом головного болю для багатьох адміністраторів кластерів. Тепер ми (майже) поклали край цьому головному болю.
Автоматичне виявлення драйвера cgroup
У v1.28.0 спільнота SIG Node представила функціональну можливість KubeletCgroupDriverFromCRI, яка вказує kubelet запитувати у реалізації CRI, який драйвер cgroup використовувати. Ви можете прочитати більше тут. Після багатьох випусків очікування, поки кожна реалізація CRI випустить основні версії та упакує їх у основні операційні системи, ця функція стала загальнодоступною (GA) з Kubernetes 1.34.0.
На додачу до налаштування функціональної можливості, адміністратори кластерів повинні переконатися, що їх реалізації CRI є достатньо новими:
- containerd: Підтримка була додана в v2.0.0
- CRI-O: Підтримка була додана в v1.28.0
Оголошення: Kubernetes припиняє підтримку containerd v1.y
Хоча CRI-O випускає версії, які відповідають версіям Kubernetes, і, отже, версії CRI-O без цієї поведінки більше не підтримуються, containerd підтримує свій власний цикл випуску. Підтримка containerd для цієї функції доступна лише в v2.0 і пізніших версіях, але Kubernetes 1.34 все ще підтримує containerd 1.7 та інші LTS випуски containerd.
Спільнота Kubernetes SIG Node формально погодилася на остаточний графік підтримки для containerd v1.y. Останній випуск Kubernetes, який запропонує цю підтримку, буде останньою випущеною версією v1.35, а підтримка буде припинена у v1.36.0. Щоб допомогти адміністраторам у керуванні цією майбутньою трансформацією, доступний новий механізм виявлення. Ви можете моніторити метрику kubelet_cri_losing_support, щоб визначити, чи використовують будь-які вузли у вашому кластері версію containerd, яка незабаром стане застарілою. Наявність цієї метрики з міткою версії 1.36.0 вказуватиме на те, що рушій виконання контейнерів вузла недостатньо новий для майбутніх вимог. Відповідно, адміністратору потрібно буде оновити containerd до v2.0 або пізнішої версії до або одночасно з оновленням kubelet до v1.36.0.
Kubernetes v1.34: Mutable CSI Node Allocatable переходить в Beta
Функція для драйверів CSI, що дозволяє оновлювати інформацію про кількість підключених томів на вузлах, вперше представлена в альфа-версії Kubernetes v1.33, перейшла в бета-версію у випуску Kubernetes v1.34! Це є важливою віхою у підвищенні точності планування podʼівв із збереженням стану шляхом зменшення кількості збоїв, спричинених застарілою інформацією про ємність підключених томів.
Background
Традиційно, CSI драйвери Kubernetes повідомляють про статичний максимальний ліміт підключення томів під час ініціалізації. Однак фактичні ємності підключення можуть змінюватися протягом життєвого циклу вузла з різних причин, таких як:
- Ручні або зовнішні операції з підключення/відключення томів поза контролем Kubernetes.
- Динамічно підключені мережеві інтерфейси або спеціалізоване обладнання (GPU, NIC тощо), що споживає доступні слоти.
- Сценарії з кількома драйверами, коли операції одного драйвера CSI впливають на доступну ємність, про яку повідомляє інший.
Статичне звітування може призвести до того, що Kubernetes запланує поди на вузлах, які, здається, мають ємність, але насправді не мають, що призводить до зависання подів у стані ContainerCreating.
Динамічна адаптація лімітів томів CSI
Завдяки цій новій функції Kubernetes дозволяє драйверам CSI динамічно налаштовувати та повідомляти про ємності підключення вузлів під час виконання. Це забезпечує наявність у планувальника, а також інших компонентів, які покладаються на цю інформацію, найбільш точної та актуальної інформації про ємність вузлів.
Як це працює
Kubernetes підтримує два механізми для оновлення інформації про ліміти томів вузлів:
- Періодичні оновлення: Драйвери CSI вказують інтервал для періодичного оновлення виділеної ємності вузла.
- Реактивні оновлення: Негайне оновлення, яке викликається, коли операція підключення тому не вдається через вичерпані ресурси (помилка
ResourceExhausted).
Увімкнення функції
Щоб використовувати цю бета-функцію, необхідно увімкнути функціональну можливість MutableCSINodeAllocatableCount в компонентах:
kube-apiserverkubelet
Приклад конфігурації драйвера CSI
Нижче наведено приклад конфігурації драйвера CSI для увімкнення періодичних оновлень кожні 60 секунд:
apiVersion: storage.k8s.io/v1
kind: CSIDriver
metadata:
name: example.csi.k8s.io
spec:
nodeAllocatableUpdatePeriodSeconds: 60
Ця конфігурація вказує kubelet періодично викликати метод NodeGetInfo драйвера CSI кожні 60 секунд, оновлюючи кількість виділених томів вузла. Kubernetes забезпечує мінімальний інтервал оновлення в 10 секунд, щоб збалансувати точність і використання ресурсів.
Негайні оновлення при збоях підключення
Коли операція підключення тому не вдається через помилку ResourceExhausted (код gRPC 8), Kubernetes негайно оновлює кількість виділених томів замість того, щоб чекати наступного періодичного оновлення. Kubelet потім позначає постраждалі поди як Failed, що дозволяє їх контролерам відтворити їх. Це запобігає зависанню подів у стані ContainerCreating.
Як почати використовувати
Щоб увімкнути цю функцію у вашому кластері Kubernetes v1.34:
- Увімкніть функціональну можливість
MutableCSINodeAllocatableCountв компонентахkube-apiserverтаkubelet. - Оновіть конфігурацію вашого драйвера CSI, встановивши
nodeAllocatableUpdatePeriodSeconds. - Моніторте та спостерігайте за покращеннями в точності планування та надійності розміщення подів.
Наступні кроки
Ця функція наразі знаходиться на стадії бета-тестування, і спільнота Kubernetes вітає ваші відгуки. Тестуйте її, діліться своїм досвідом і допомагайте спрямовувати її еволюцію до стабільності GA.
Приєднуйтесь до обговорень у Kubernetes Storage Special Interest Group (SIG-Storage), щоб сформувати майбутнє можливостей зберігання Kubernetes.
Kubernetes v1.34: Використання контейнера ініціалізації для визначення змінних середовища застосунку
Зазвичай Kubernetes використовує ConfigMaps і Secrets для встановлення змінних середовища, що призводить до додаткових викликів API та складності. Наприклад, вам потрібно окремо керувати Podʼами ваших робочих навантажень і їх конфігураціями, забезпечуючи при цьому впорядковані оновлення як для конфігурацій, так і для Podʼів робочих навантажень.
Альтернативно, ви можете використовувати контейнер, наданий постачальником, який вимагає змінних середовища (таких як ліцензійний ключ або одноразовий токен), але ви не хочете їх жорстко прописувати в коді або монтувати томи лише для того, щоб виконати завдання.
Якщо ви опинилися в такій ситуації, у вас тепер є новий (альфа) спосіб досягти цього. За умови, що у вас увімкнено функціональну можливість EnvFiles у вашому кластері, ви можете вказати kubelet завантажити змінні середовища контейнера з тому (цей том повинен бути частиною Podʼа, до якого належить контейнер). Ця функціональна можливість дозволяє вам завантажувати змінні середовища безпосередньо з файлу з тома emptyDir без фактичного монтування цього файлу в контейнер. Це просте, але елегантне рішення для деяких дивовижно поширених проблем.
Що це все означає?
В основі цієї функціональності лежить можливість вказати контейнеру файл, який генерується initContainer, і дозволити Kubernetes розкласти цей файл на складники для встановлення змінних середовища. Файл розташовується в томі emptyDir (тимчасовому сховищі, яке існує так довго, як існує pod), ваш основний контейнер не потребує монтування тому. Kubelet прочитає файл і впровадить ці змінні, коли контейнер запуститься.
Як це працює
Ось простий приклад:
apiVersion: v1
kind: Pod
spec:
initContainers:
- name: generate-config
image: busybox
command: ['sh', '-c', 'echo "CONFIG_VAR=HELLO" > /config/config.env']
volumeMounts:
- name: config-volume
mountPath: /config
containers:
- name: app-container
image: gcr.io/distroless/static
env:
- name: CONFIG_VAR
valueFrom:
fileKeyRef:
path: config.env
volumeName: config-volume
key: CONFIG_VAR
volumes:
- name: config-volume
emptyDir: {}
Використання цього підходу дуже просте. Ви визначаєте свої змінні середовища в специфікації podʼа, використовуючи поле fileKeyRef, яке вказує Kubernetes, де знайти файл і який ключ витягти. Сам файл нагадує стандарт для синтаксису .env (подумайте про KEY=VALUE), і (принаймні у цій альфа-стадії) ви повинні переконатися, що він записується в том emptyDir. Інші типи томів не підтримуються для цієї функції. Принаймні один контейнер ініціалізації повинен змонтувати цей том emptyDir (щоб записати файл), але основний контейнер не потребує цього — він просто отримує змінні, передані йому під час запуску.
Слово про безпеку
Хоча ця функція підтримує обробку чутливих даних, таких як ключі або токени, слід зазначити, що її реалізація спирається на томи emptyDir, змонтовані в pod. Оператори з доступом до файлової системи вузлів можуть легко отримати ці чутливі дані через шляхи тек podʼа.
Якщо ви зберігаєте чутливі дані, такі як ключі або токени, за допомогою цієї функції, переконайтеся, що політики безпеки вашого кластера ефективно захищають вузли від несанкціонованого доступу, щоб запобігти витоку конфіденційної інформації.
Підсумок
Ця функція усуне ряд складних обхідних шляхів, які використовуються сьогодні, спростивши створення застосунків і відкриваючи нові можливості для використання. Kubernetes залишається гнучким і відкритим для відгуків. Скажіть нам, як ви використовуєте цю функцію або що її бракує.
Kubernetes v1.34: Кеш сервера API, що підтримує створення знімків стану
Роками спільнота Kubernetes працює над поліпшенням стабільності та передбачуваності продуктивності сервера API. Основна увага в цих зусиллях була зосереджена на обробці запитів list, які історично були основним джерелом високого використання памʼяті та великого навантаження на сховище etcd. З кожним випуском ми поступово розвʼязували цю проблему, і сьогодні ми раді оголосити про завершення останнього великого етапу цього процесу.
Функція кешу сервера API, що підтримує створення знімків, перейшла в бета-версію в Kubernetes v1.34, що стало кульмінацією зусиль впродовж кількох випусків, спрямованих на те, щоб практично всі запити на читання могли обслуговуватися безпосередньо з кешу сервера API.
Еволюція кешу для продуктивності та стабільності
Шлях до поточного стану включав кілька ключових вдосконалень у недавніх випусках, які проклали шлях для сьогоднішнього оголошення.
Послідовні читання з кешу (бета в v1.31)
Хоча сервер API вже давно використовує кеш для підвищення продуктивності, ключовим етапом стало забезпечення послідовних читань останніх даних з нього. Це вдосконалення v1.31 дозволило вперше використовувати кеш спостереження для запитів на читання з високою узгодженістю, що стало величезним досягненням, оскільки це дозволило безпечно обслуговувати фільтровані колекції (наприклад, "список подів, привʼязаних до цього вузла") з кешу замість etcd, що різко зменшило навантаження на нього для звичайних робочих навантажень.
Упорядкування великих відповідей за допомогою потокової передачі (бета в v1.33)
Ще одним ключовим вдосконаленням стало вирішення проблеми сплесків памʼяті під час передачі великих відповідей. Потоковий кодувальник, представлений у v1.33, дозволив серверу API надсилати елементи списку по одному, а не буферизувати всю багатогігабайтну відповідь у пам'яті. Це зробило витрати памʼяті на надсилання відповіді передбачуваними та мінімальними, незалежно від її розміру.
Відсутня частина
Незважаючи на ці величезні вдосконалення, критичний розрив залишався. Будь-який запит на історичний LIST, найчастіше використовуваний для пагінації через великі набори результатів, все ще повинен був обійти кеш і безпосередньо запитати etcd. Це означало, що вартість отримання даних все ще була непередбачуваною і могла створити значний тиск на памʼять сервера API.
Kubernetes 1.34: створення знімків довершує картину
Кеш сервера API, що підтримує створення знімків, розвʼязує цю останню частину головоломки. Ця функція покращує кеш спостереження, дозволяючи йому генерувати ефективні, точкові знімки свого стану.
Ось як це працює: для кожного оновлення кеш створює легкий знімок. Ці знімки є "лінивими (lazy) копіями", що означає, що вони не дублюють обʼєкти, а просто зберігають вказівники, що робить їх неймовірно ефективними з точки зору памʼяті.
Коли надходить запит LIST на історичний resourceVersion, сервер API тепер знаходить відповідний знімок і обслуговує відповідь безпосередньо з памʼяті. Це закриває останній великий розрив, дозволяючи обслуговувати запити на пагінацію повністю з кешу.
Нова ера продуктивності сервера API 🚀
З цим останнім елементом на місці синергія цих трьох функцій відкриває нову еру передбачуваності та продуктивності сервера API:
- Отримання даних з кешу: Послідовні читання та кеш, що підтримує створення знімків, працюють разом, щоб забезпечити обслуговування майже всіх запитів на читання, незалежно від того, чи йдеться про останні дані або історичний знімок, безпосередньо з памʼяті сервера API.
- Надсилання даних через потік: Потокова передача спискових відповідей забезпечує мінімальний і постійний обсяг памʼяті при відправці цих даних клієнту.
Результатом є система, в якій ресурсні витрати на операції читання майже повністю передбачувані і набагато більш стійкі до сплесків навантаження запитів. Це означає різке зменшення тиску на памʼять, менше навантаження на etcd і більш стабільну, масштабовану та надійну панель управління для всіх кластерів Kubernetes.
Як почати
З моментом переходу в бета-версію функціональність SnapshottableCache є стандартно увімкненою у Kubernetes v1.34. Необхідних дій для початку використання цих покращень продуктивності та стабільності не потрібно.
Подяки
Особлива подяка за проєктування, впровадження та рецензування цих критичних функцій належить:
- Ahmad Zolfaghari (@ah8ad3)
- Ben Luddy (@benluddy) — Red Hat
- Chen Chen (@z1cheng) — Microsoft
- Davanum Srinivas (@dims) — Nvidia
- David Eads (@deads2k) — Red Hat
- Han Kang (@logicalhan) — CoreWeave
- haosdent (@haosdent) — Shopee
- Joe Betz (@jpbetz) — Google
- Jordan Liggitt (@liggitt) — Google
- Łukasz Szaszkiewicz (@p0lyn0mial) — Red Hat
- Maciej Borsz (@mborsz) — Google
- Madhav Jivrajani (@MadhavJivrajani) — UIUC
- Marek Siarkowicz (@serathius) — Google
- NKeert (@NKeert)
- Tim Bannister (@lmktfy)
- Wei Fu (@fuweid) - Microsoft
- Wojtek Tyczyński (@wojtek-t) — Google
… та багато інших у SIG API Machinery. Ця віха є свідченням відданості спільноти побудові більш масштабованого та надійного Kubernetes.
Kubernetes v1.34: VolumeAttributesClass для зміни атрибутів томів тепер GA
API VolumeAttributesClass, який надає можливість користувачам динамічно змінювати атрибути томів, офіційно перейшов у стадію загальної доступності (GA) у Kubernetes v1.34. Це важлива віхa, яка забезпечує надійний і стабільний спосіб налаштування вашого постійного сховища безпосередньо в Kubernetes.
Що таке VolumeAttributesClass?
По суті, VolumeAttributesClass — це ресурс, що охоплює кластер, який визначає набір змінних параметрів для тому. Розглядайте це як "профіль" для вашого сховища, що дозволяє адміністраторам кластерів експонувати різні рівні якості обслуговування (QoS) або продуктивності.
Користувачі можуть вказати volumeAttributesClassName у своїх PersistentVolumeClaim (PVC), щоб вказати, який клас атрибутів вони бажають. Чарівність відбувається через Container Storage Interface (CSI): коли PVC, що посилається на VolumeAttributesClass, оновлюється, відповідний драйвер CSI взаємодіє з відповідною системою зберігання, щоб застосувати вказані зміни до тому.
Це означає, що ви тепер можете:
- Динамічно масштабувати продуктивність: збільшити IOPS або пропускну здатність для завантаженої бази даних або зменшити її для менш критичного застосунку.
- Оптимізувати витрати: налаштовувати атрибути на льоту, щоб відповідати вашим поточним потребам, уникаючи надмірного постачання.
- Спростити операції: керувати змінами томів безпосередньо в API Kubernetes, а не покладатися на зовнішні інструменти або ручні процеси.
Що нового в GA порівняно з бета
Є два основних вдосконалення порівняно з бета.
Підтримка скасування у разі виникнення помилок
Щоб покращити стійкість і зручність використання, випуск GA вводить явну підтримку скасування, коли під час запиту на зміну тома виникає помилка. Якщо відповідна система зберігання або драйвер CSI вказує, що запитувані зміни не можуть бути застосовані (наприклад, через недійсні аргументи), користувачі можуть скасувати операцію і повернути том до його попередньої стабільної конфігурації, запобігаючи залишенню тому в несумісному стані.
Підтримка квот на основі області дії
Хоча VolumeAttributesClass не додає нового типу квот, панель управління Kubernetes може бути налаштована для примусового дотримання квот на PersistentVolumeClaims, які посилаються на конкретний VolumeAttributesClass.
Це досягається за допомогою поля scopeSelector в ResourceQuota для націлювання на PVC, які мають .spec.volumeAttributesClassName, встановлене на конкретне імʼя VolumeAttributesClass. Будь ласка, дивіться більше деталей тут.
Підтримка драйверами VolumeAttributesClass
- Драйвер Amazon EBS CSI: Драйвер AWS EBS CSI має надійну підтримку VolumeAttributesClass і дозволяє динамічно змінювати такі параметри, як тип тому (наприклад, gp2 на gp3, io1 на io2), IOPS і пропускну здатність томів EBS.
- Драйвер Google Compute Engine (GCE) Persistent Disk CSI (pd.csi.storage.gke.io): цей драйвер також підтримує динамічну зміну атрибутів постійного диска, включаючи IOPS і пропускну здатність, за допомогою VolumeAttributesClass.
Контакти
Якщо у вас є запитання або конкретні запити, повʼязані з VolumeAttributesClass, будь ласка, звертайтеся до SIG Storage community.
Kubernetes v1.34: Політика заміни Pod для Jobs переходить у GA
В Kubernetes v1.34, функція Політика заміни Pod досягла загальної доступності (GA). Ця стаття описує функцію політики заміни Pod і те, як її використовувати у ваших Jobs.
Про політику заміни Pod
Стандартно контролер Job негайно відтворює Podʼи, як тільки вони виходять з ладу або починають завершувати роботу (коли вони мають мітку часу видалення).
В результаті, хоча деякі Podʼи припиняють роботу, загальна кількість працюючих Podʼів для завдання може тимчасово перевищувати заданий рівень паралельності. Для індексованих Jobs це може навіть означати, що кілька Podʼів працюють для одного й того ж індексу одночасно.
Ця поведінка добре працює для багатьох робочих навантажень, але в певних випадках може викликати проблеми.
Наприклад, популярні фреймворки машинного навчання, такі як TensorFlow та JAX, очікують, що для кожного індексу виконавця буде точно один Pod. Якщо два Podʼа працюють одночасно, ви можете зіткнутися з такими помилками:
/job:worker/task:4: Duplicate task registration with task_name=/job:worker/replica:0/task:4
Крім того, запуск замінних Podʼів до повного завершення старих може призвести до:
- Затримок у плануванні з боку kube-scheduler, оскільки вузли залишаються зайнятими.
- Непотрібного масштабування кластера для розміщення замінних Podʼів.
- Тимчасового обходу перевірок квот з боку оркестраторів робочих навантажень, таких як Kueue.
З політикою заміни Podʼів Kubernetes надає вам контроль над тим, коли панель управління замінює Podʼи, що завершуються, допомагаючи уникнути цих проблем.
Як працює політика заміни Pod
Це вдосконалення означає, що Jobs у Kubernetes мають необовʼязкове поле .spec.podReplacementPolicy. Ви можете вибрати одну з двох політик:
TerminatingOrFailed(стандартно): Замінює Podʼи, щойно вони починають завершуватися.Failed: Замінює Podʼи лише після того, як вони повністю завершаться і перейдуть у фазуFailed.
Встановлення політики на Failed забезпечує створення нового Pod лише після повного завершення попереднього.
Для Jobs з політикою відмови Podʼів (Pod Failure Policy), стандартне значення для podReplacementPolicy — Failed, і жодне інше значення не дозволяється. Дивіться Політика відмови Podʼів, щоб дізнатися більше про політики відмови Podʼів для Jobs.
Ви можете перевірити, скільки Podʼів наразі завершуються, перевіривши поле .status.terminating Job:
kubectl get job myjob -o=jsonpath='{.status.terminating}'
Приклад
Ось приклад Job, який виконує завдання двічі (spec.completions: 2) паралельно (spec.parallelism: 2) і замінює Podʼи лише після їх повного завершення (spec.podReplacementPolicy: Failed):
apiVersion: batch/v1
kind: Job
metadata:
name: example-job
spec:
completions: 2
parallelism: 2
podReplacementPolicy: Failed
template:
spec:
restartPolicy: Never
containers:
- name: worker
image: your-image
Якщо Pod отримує сигнал SIGTERM (видалення, виселення, примусове завершення…), він починає завершувати роботу. Коли контейнер обробляє завершення роботи відповідним чином, очищення може зайняти деякий час.
Коли Job починається, ми побачимо два Podʼа, які працюють:
kubectl get pods
NAME READY STATUS RESTARTS AGE
example-job-qr8kf 1/1 Running 0 2s
example-job-stvb4 1/1 Running 0 2s
Видалимо один з Podʼів (example-job-qr8kf).
З політикою TerminatingOrFailed, як тільки один Pod (example-job-qr8kf) починає завершуватися, контролер Job негайно створює новий Pod (example-job-b59zk) для його заміни.
kubectl get pods
NAME READY STATUS RESTARTS AGE
example-job-b59zk 1/1 Running 0 1s
example-job-qr8kf 1/1 Terminating 0 17s
example-job-stvb4 1/1 Running 0 17s
З політикою Failed, новий Pod (example-job-b59zk) не створюється, поки старий Pod (example-job-qr8kf) завершує свою роботу.
kubectl get pods
NAME READY STATUS RESTARTS AGE
example-job-qr8kf 1/1 Terminating 0 17s
example-job-stvb4 1/1 Running 0 17s
Коли Pod, що завершується, повністю переходить у фазу Failed, створюється новий Pod:
kubectl get pods
NAME READY STATUS RESTARTS AGE
example-job-b59zk 1/1 Running 0 1s
example-job-stvb4 1/1 Running 0 25s
Як ви можете дізнатися більше?
- Ознайомтесь з документацією для користувачів про Політику замини Podʼів, Ліміт затримки для кожного індексу, та Політику відмови Podʼів.
- Ознайомтесь з KEP для Політики замини Podʼів, Ліміту затримки для кожного індексу, та Політики відмови Podʼів.
Подяки
Як і з будь-якою функцією Kubernetes, багато людей внесли свій вклад у реалізацію цієї функції, від тестування та подання помилок до перегляду коду.
Оскільки ця функція переходить у стабільний стан після 2 років, ми хотіли б подякувати наступним людям:
- Kevin Hannon - за написання KEP та початкову реалізацію.
- Michał Woźniak - за керівництво, менторство та рецензії.
- Aldo Culquicondor - за керівництво, менторство та рецензії.
- Maciej Szulik - за керівництво, менторство та рецензії.
- Dejan Zele Pejchev - за те, що взяв на себе цю функцію та просував її з Alpha через Beta до GA.
Долучайтесь
Ця робота була підтримана групою batch working group в тісній співпраці з SIG Apps спільнотою.
Якщо ви зацікавлені в роботі над новими функціями в цій області, ми рекомендуємо підписатися на наш Slack канал і відвідувати регулярні зустрічі спільноти.
Метрики PSI для Kubernetes переходять у бета-версію
У міру зростання розміру та складності кластерів Kubernetes розуміння стану та продуктивності окремих вузлів стає все більш важливим. Ми раді оголосити, що з Kubernetes v1.34 Метрики інформації про затримки (PSI) перейшли в бета-версію.
Що таке інформація про затримки (PSI)?
Pressure Stall Information (PSI) є функцією ядра Linux (версія 4.20 і новіші), яка забезпечує канонічний спосіб кількісно оцінити тиск на інфраструктурні ресурси з точки зору того, чи перевищує попит на ресурс поточну пропозицію. Вона виходить за межі простих метрик використання ресурсів і натомість вимірює кількість часу, протягом якого завдання затримуються через конкуренцію за ресурси. Це потужний спосіб виявлення та діагностування вузьких місць у ресурсах, які можуть вплинути на продуктивність застосунків.
PSI надає метрики для CPU, памʼяті та I/O, які класифікуються як some або full pressure:
some- Відсоток часу, протягом якого принаймні одне завдання затримується на ресурсі. Це вказує на певний рівень конкуренції за ресурси.
full- Відсоток часу, протягом якого всі не простоюючі завдання затримуються на ресурсі одночасно. Це вказує на більш серйозне вузьке місце в ресурсах.

PSI: Тиск 'Some' та 'Full'
Ці метрики агрегуються за 10-секундними, 1-хвилинними та 5-хвилинними ковзаючими вікнами, що забезпечує всебічний огляд тиску на ресурси з часом.
Метрики PSI в Kubernetes
З увімкненою функціональною можливістю KubeletPSI, kubelet тепер може збирати метрики PSI з ядра Linux і надавати їх через два канали: Summary API та точку доступу /metrics/cadvisor Prometheus. Це дозволяє вам відстежувати та отримувати сповіщення про тиск на ресурси на рівні вузла, пода та контейнера.
Наступні нові метрики доступні у форматі експозиції Prometheus через /metrics/cadvisor:
container_pressure_cpu_stalled_seconds_totalcontainer_pressure_cpu_waiting_seconds_totalcontainer_pressure_memory_stalled_seconds_totalcontainer_pressure_memory_waiting_seconds_totalcontainer_pressure_io_stalled_seconds_totalcontainer_pressure_io_waiting_seconds_total
Ці метрики, разом з даними з Summary API, забезпечують детальний огляд тиску на ресурси, що дозволяє вам точно визначити джерело проблем з продуктивністю та вжити коригувальних заходів. Наприклад, ви можете використовувати ці метрики для:
- Виявлення витоків памʼяті: Постійно зростаючий тиск
someдля памʼяті може вказувати на витік памʼяті в застосунку. - Оптимізація запитів та обмежень ресурсів: Розуміючи тиск на ресурси ваших робочих навантажень, ви можете точніше налаштувати їх запити та обмеження ресурсів.
- Автоматичне масштабування робочих навантажень: Ви можете використовувати метрики PSI для ініціювання подій автоматичного масштабування, забезпечуючи, щоб ваші робочі навантаження мали ресурси, необхідні для оптимальної роботи.
Як увімкнути метрики PSI
Щоб увімкнути метрики PSI у вашому кластері Kubernetes, вам потрібно:
- Переконатися, що ваші вузли працюють на версії ядра Linux 4.20 або новішій та використовують cgroup v2.
- Увімкнути функціональну можливість
KubeletPSIу kubelet.
Після увімкнення ви можете почати збирати дані з точки доступу /metrics/cadvisor за допомогою вашого рішення для моніторингу, сумісного з Prometheus, або запитувати Summary API для збору та візуалізації нових метрик PSI. Зверніть увагу, що PSI є функцією ядра Linux, тому ці метрики недоступні на вузлах Windows. Ваш кластер може містити комбінацію вузлів Linux та Windows, але на вузлах Windows kubelet не надає метрики PSI.
Що далі?
Ми раді представити метрики PSI спільноті Kubernetes і чекаємо на ваші відгуки. Як функція бета-версії, ми активно працюємо над поліпшенням і розширенням цієї функціональності до стабільного випуску GA. Ми закликаємо вас спробувати її та поділитися своїм досвідом з нами.
Щоб дізнатися більше про метрики PSI, ознайомтеся з офіційною документацією Kubernetes. Ви також можете долучитися до обговорення на каналі #sig-node в Slack.
Kubernetes v1.34: Інтеграція токенів службових облікових записів для витягування образів контейнерів переходить у стадію бета
Спільнота Kubernetes продовжує вдосконалювати найкращі практики безпеки, зменшуючи залежність від довготривалих облікових даних. Після успішного випуску альфа-версії в Kubernetes v1.33, Інтеграція токенів службових облікових записів для постачальників облікових даних Kubelet перейшла на бета-версію в Kubernetes v1.34, що наблизило нас до усунення довготривалих секретів витягування образів контейнерів із кластерів Kubernetes.
Це вдосконалення дозволяє постачальникам облікових даних використовувати токени службових облікових записів, специфічні для робочих навантажень, для отримання облікових даних реєстру, забезпечуючи безпечну, короткотривалу ефемерну альтернативу традиційним секретам для витягування образів.
Що нового в бета-версії?
Перехід у бета-версію приносить кілька важливих змін, які роблять цю функцію більш надійною та готовою до промислової експлуатації:
Обовʼязкове поле cacheType
Істотна зміна порівняно з альфа-версією: поле cacheType є обовʼязковим у конфігурації постачальника облікових даних під час використання токенів службового облікового запису. Це поле є новим у бета-версії і має бути вказане для забезпечення належного функціонування кешування.
# УВАГА: це не повний приклад конфігурації, а лише посилання на поле 'tokenAttributes.cacheType'.
tokenAttributes:
serviceAccountTokenAudience: "my-registry-audience"
cacheType: "ServiceAccount" # Required field in beta
requireServiceAccount: true
Обирайте поміж двома стратегіями кешування:
Token: Робіть кешування облікових даних для кожного токена службового облікового запису (використовуйте, коли термін дії облікових даних повʼязаний із токеном). Це корисно, коли постачальник облікових даних перетворює токен службового облікового запису на облікові дані реєстру з таким же терміном дії, як і токен, або коли реєстри безпосередньо підтримують токени службових облікових записів Kubernetes. Примітка: Kubelet не може безпосередньо надсилати токени службових облікових записів до реєстрів; для перетворення токенів у формат імені користувача/пароля, очікуваний реєстрами, потрібні втулки постачальників облікових даних.ServiceAccount: Кешуйте облікові дані для кожної ідентичності службового облікового запису (використовуйте, коли облікові дані дійсні для всіх подів, які використовують один і той же службовий обліковий запис)
Ізольовані облікові дані для витягування образів
Бета-версія забезпечує сильнішу ізоляцію безпеки для образів контейнерів при використанні токенів службових облікових записів для витягування образів. Вона гарантує, що поди можуть отримувати доступ лише до образів, які були витягнуті за допомогою службових облікових записів, до яких вони мають право доступу. Це запобігає несанкціонованому доступу до чутливих образів контейнерів і дозволяє здійснювати детальний контроль доступу, де різні робочі навантаження можуть мати різні дозволи реєстрації на основі їх службового облікового запису.
Коли постачальники облікових даних використовують токени службових облікових записів, система відстежує ідентичність службового облікового запису (простір імен, імʼя та UID) для кожного витягнутого образу. Коли под намагається використовувати кешований образ, система перевіряє, що службовий обліковий запис пода точно збігається з службовим обліковим записом, який був використаний для початкового витягування образу.
Адміністратори можуть відкликати доступ до раніше витягнутих образів, видаливши та створивши наново ServiceAccount, що змінює UID і робить недоступним кешований доступ до образів.
Для отримання додаткової інформації про цю можливість дивіться документацію перевірки облікових даних для витягування образів.
Як це працює
Конфігурація
Постачальники облікових даних використовують токени службових облікових записів за допомогою поля tokenAttributes:
#
# УВАГА: це не повний приклад конфігурації, а лише посилання на поле 'tokenAttributes'.
#
apiVersion: kubelet.config.k8s.io/v1
kind: CredentialProviderConfig
providers:
- name: my-credential-provider
matchImages:
- "*.myregistry.io/*"
defaultCacheDuration: "10m"
apiVersion: credentialprovider.kubelet.k8s.io/v1
tokenAttributes:
serviceAccountTokenAudience: "my-registry-audience"
cacheType: "ServiceAccount" # New in beta
requireServiceAccount: true
requiredServiceAccountAnnotationKeys:
- "myregistry.io/identity-id"
optionalServiceAccountAnnotationKeys:
- "myregistry.io/optional-annotation"
Порядок отримання образів
На високому рівні, kubelet координує свою роботу з постачальником облікових даних та середовищем виконання контейнерів наступним чином:
Коли образ відсутній локально:
kubeletперевіряє свій кеш облікових даних, використовуючи налаштованийcacheType(TokenабоServiceAccount)- Якщо потрібно,
kubeletзапитує токен ServiceAccount для ServiceAccount пода і передає його, а також будь-які необхідні анотації, постачальнику облікових даних - Постачальник обмінює цей токен на облікові дані реєстру і повертає їх
kubelet kubeletкешує облікові дані відповідно до стратегіїcacheTypeі витягує образ з цими обліковими данимиkubeletзаписує координати ServiceAccount (простір імен, імʼя, UID) повʼязані з витягнутим образом для подальших перевірок авторизації
Коли образ вже присутній локально:
kubeletперевіряє координати ServiceAccount пода на відповідність обліковим даним, записаним для кешованого образу- Якщо вони точно збігаються, можна використовувати кешований образ без витягування з реєстру
- Якщо вони відрізняються,
kubeletвиконує нове витягування з використанням облікових даних для нового ServiceAccount
З увімкненою перевіркою облікових даних для витягування образів:
- Авторизація виконується з використанням записаних облікових даних ServiceAccount, що забезпечує використання подами лише образів, витягнутих за допомогою ServiceAccount, до яких вони мають право доступу
- Адміністратори можуть відкликати доступ, видаливши та створивши наново ServiceAccount; UID змінюється, і раніше записана авторизація більше не збігається
Обмеження аудиторії
Бета-реліз базується на обмеженнях аудиторії вузлів службових облікових записів (бета з v1.33), щоб забезпечити можливість kubelet запитувати токени лише для авторизованих аудиторій. Адміністратори налаштовують дозволені аудиторії за допомогою RBAC, щоб дозволити kubelet запитувати токени службових облікових записів для витягування образів:
#
# УВАГА: це лише приклад конфігурації.
# Не використовуйте це для свого кластера!
#
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kubelet-credential-provider-audiences
rules:
- verbs: ["request-serviceaccounts-token-audience"]
apiGroups: [""]
resources: ["my-registry-audience"]
resourceNames: ["registry-access-sa"] # Опціонально: конкретний SA
Початок роботи з бета-версією
Необхідні умови
- Kubernetes v1.34 або пізніше
- Увімкнено функціональні можливості:
KubeletServiceAccountTokenForCredentialProviders=true(бета, стандартно увімкнено) - Підтримка постачальника облікових даних: Update your credential provider to handle ServiceAccount tokens
Міграція з альфа-версії
У випадку, якщо ви вже використовуєте альфа-версію, міграція на бета-версію вимагає мінімальних змін:
- Додайте поле
cacheType: Оновіть конфігурацію вашого постачальника облікових даних, щоб включити необхідне полеcacheType - Перегляньте стратегію кешування:
Виберіть між типами кешу
TokenіServiceAccountна основі поведінки вашого постачальника - Перевірте обмеження аудиторії: Переконайтеся, що ваша конфігурація RBAC або інші правила авторизації кластера правильно обмежують аудиторії токенів
Приклад налаштування
Ось повний приклад налаштування постачальника облікових даних з токенами службових облікових записів (цей приклад передбачає, що ваш кластер використовує авторизацію RBAC):
#
# УВАГА: це лише приклад конфігурації.
# Не використовуйте це для свого кластера!
#
# Service Account з анотаціями реєстру
apiVersion: v1
kind: ServiceAccount
metadata:
name: registry-access-sa
namespace: default
annotations:
myregistry.io/identity-id: "user123"
---
# RBAC для обмеження аудиторії
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: registry-audience-access
rules:
- verbs: ["request-serviceaccounts-token-audience"]
apiGroups: [""]
resources: ["my-registry-audience"]
resourceNames: ["registry-access-sa"] # Опціонально: конкретний ServiceAccount
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubelet-registry-audience
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: registry-audience-access
subjects:
- kind: Group
name: system:nodes
apiGroup: rbac.authorization.k8s.io
---
# Pod що використовує ServiceAccount
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
serviceAccountName: registry-access-sa
containers:
- name: my-app
image: myregistry.example/my-app:latest
Що далі?
Для Kubernetes v1.35 ми, Kubernetes SIG Auth, очікуємо, що функція залишиться в бета-версії, і ми будемо продовжувати збирати відгуки.
Ви можете дізнатися більше про цю функцію на сторінці токена службового облікового запису для витягування зображень в документації Kubernetes.
Ви також можете стежити за KEP-4412, щоб відстежувати прогрес у майбутніх випусках Kubernetes.
Дійте
У цьому блозі ми висвітлили бета-випуск інтеграції токенів службових облікових записів для Kubelet Credential Providers в Kubernetes v1.34. Ми розглянули ключові поліпшення, включаючи необхідне поле cacheType та вдосконалену інтеграцію з Ensure Secret Pull Images.
Ми отримали позитивні відгуки від спільноти під час альфа-фази і хотіли б почути більше, оскільки ми стабілізуємо цю функцію для GA. Зокрема, ми хотіли б отримати відгуки від розробників постачальників облікових даних під час інтеграції з новим бета-API та механізмами кешування. Будь ласка, звʼяжіться з нами в каналі #sig-auth-authenticators-dev на Kubernetes Slack.
Як взяти участь
Якщо ви зацікавлені в участі в розробці цієї функції, поділіться відгуками або візьміть участь в інших поточних проектах SIG Auth, будь ласка, зв'яжіться з нами в каналі #sig-auth на Kubernetes Slack.
Ви також можете приєднатися до двотижневих зборів SIG Auth, які проходять кожну другу середу.
Kubernetes v1.34: Впровадження опції статичної політики менеджера CPU для розподілу кешу Uncore
Нова опція статичної політики менеджера CPU під назвою prefer-align-cpus-by-uncorecache була представлена в Kubernetes v1.32 як альфа-функція, а в Kubernetes v1.34 вона перейшла в бета-стадію. Ця опція політики менеджера CPU призначена для оптимізації продуктивності конкретних робочих навантажень, що працюють на процесорах з архітектурою розділеного кешу uncore. У цій статті пояснюється, що це означає і чому це корисно.
Розуміння функції
Що таке кеш uncore?
До відносно недавнього часу майже всі сучасні компʼютерні процесори мали монолітний кеш останнього рівня, який ділився між усіма ядрами в багатопроцесорному пакеті. Цей монолітний кеш також називається кешем uncore (оскільки він не повʼязаний з конкретним ядром) або кешем третього рівня. Крім кешу третього рівня, існує інший кеш, який зазвичай називають кешем першого і другого рівня, який повʼязаний з конкретним ядром процесора.
Для зменшення затримки доступу між ядрами процесора та їх кешем нещодавно процесори на базі архітектури AMD64 та ARM впровадили архітектуру розділеного кешу uncore, де кеш останнього рівня ділиться на кілька фізичних кешів, які розділені відповідно до конкретних груп ядер у фізичному пакеті. Коротші відстані в межах пакета процесора допомагають зменшити затримку.
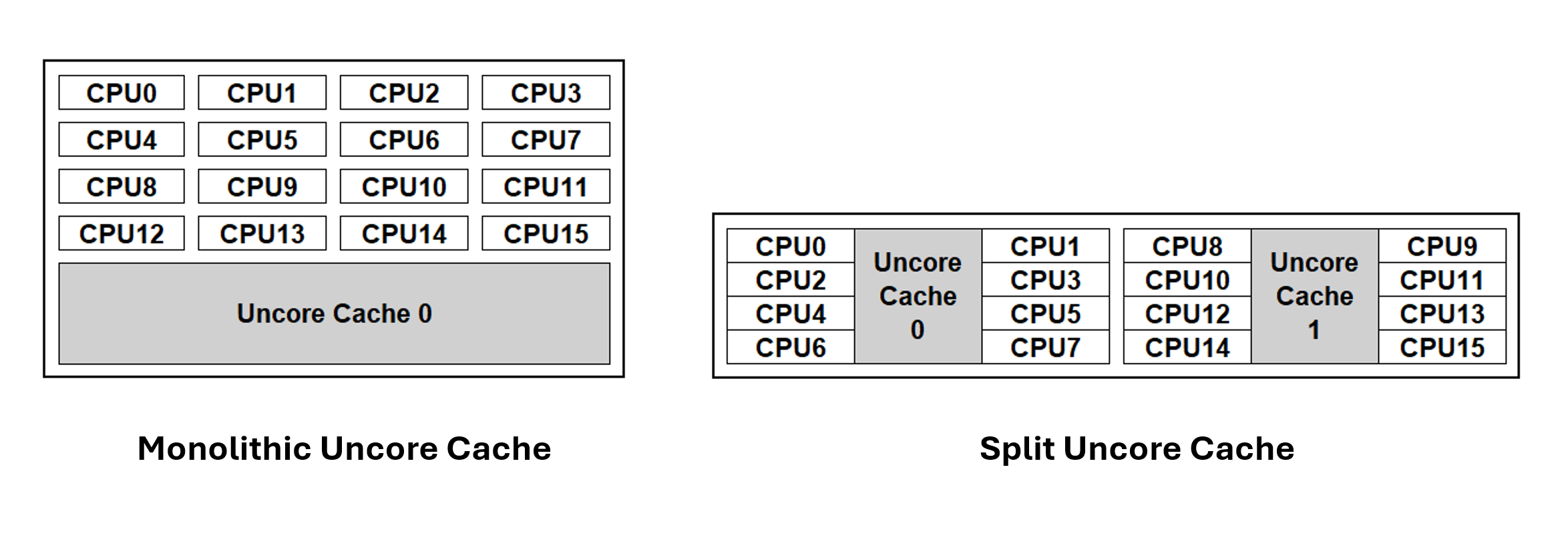
Kubernetes може розміщувати робочі навантаження таким чином, щоб враховувати топологію кешу в межах пакета CPU.
Розміщення робочих навантажень з урахуванням кешу
Матриця нижче показує затримку між CPU, виміряну в наносекундах (менше — краще) при передачі пакета між CPU через протокол когерентності кешу на процесорі, який використовує розділений кеш uncore. У цьому прикладі пакет процесора складається з 2 кешів uncore. Кожен кеш uncore обслуговує 8 ядер CPU.

Сині елементи в матриці представляють затримку між CPU, які ділять один і той же кеш uncore, тоді як сірі елементи вказують на затримку між CPU, які відповідають різним кешам uncore. Затримка між CPU, які відповідають різним кешам, вища, ніж затримка між CPU, які належать до одного і того ж кешу.
З увімкненим prefer-align-cpus-by-uncorecache, статичний Менеджер CPU намагається виділити ресурси CPU для контейнера таким чином, щоб всі CPU, призначені контейнеру, ділили один і той же кеш uncore. Ця політика працює на основі найкращих зусиль, прагнучи мінімізувати розподіл ресурсів CPU контейнера між кешами uncore, виходячи з вимог контейнера та враховуючи ресурси, які можна виділити на вузлі.
Запускаючи робоче навантаження, де це можливо, на наборі CPU, які використовують найменшу можливу кількість кешів uncore, програми отримують вигоду від зменшення затримки кешу (як видно з матриці вище) і зменшення конкуренції з іншими робочими навантаженнями, що може призвести до загального підвищення пропускної здатності. Перевага проявляється лише в тому випадку, якщо ваші вузли використовують топологію розділеного кешу uncore для своїх процесорів.
Наступна діаграма ілюструє розподіл кешу uncore, коли функція увімкнена.
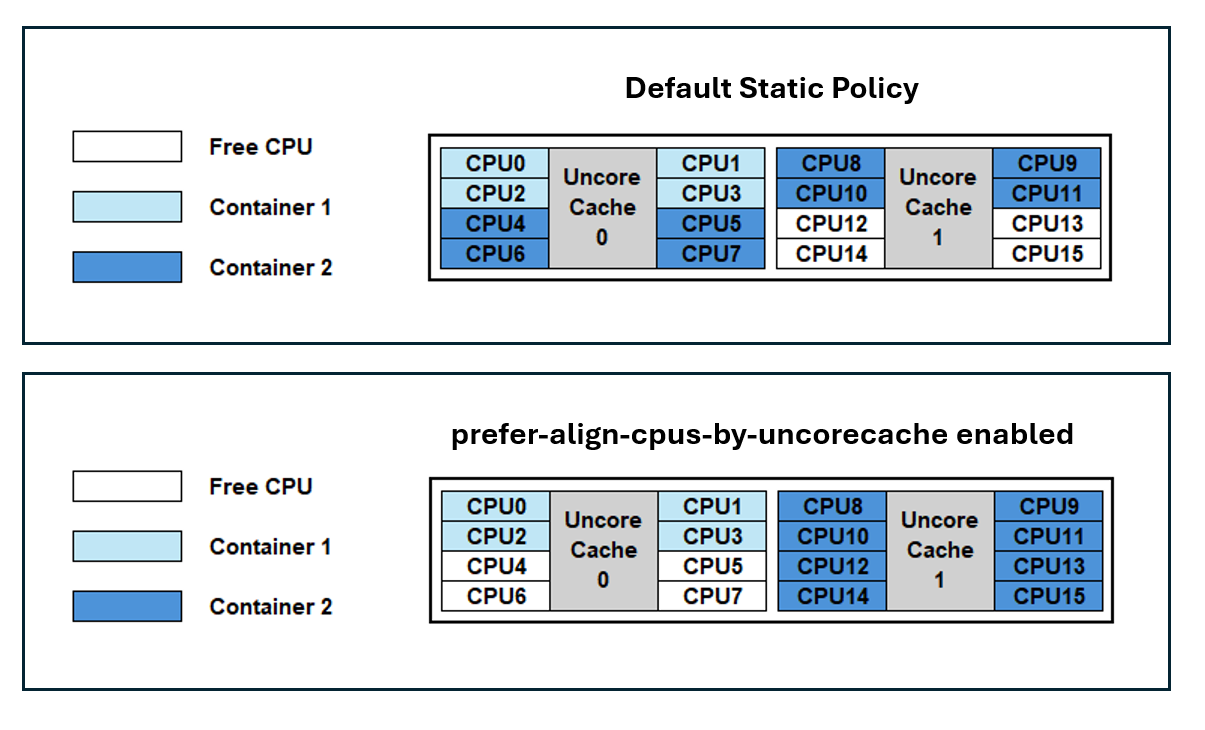
Стандартно Kubernetes не враховує топологію кешу uncore; контейнери отримують ресурси CPU за допомогою методології упаковки. Як наслідок, Контейнер 1 і Контейнер 2 можуть зазнати впливу "галасливого сусіда" через конкуренцію за доступ до кешу на Uncore Cache 0. Крім того, Контейнер 2 матиме CPU, розподілені між обома кешами, що може призвести до затримки між кешами.
З увімкненим prefer-align-cpus-by-uncorecache, кожен контейнер ізольований на окремому кеші. Це вирішує проблему конкуренції за кеш між контейнерами та мінімізує латентність кешу для використовуваних CPU.
Використання
Звичайні випадки використання можуть включати телекомунікаційні програми, такі як vRAN, Mobile Packet Core та брандмауери. Важливо зазначити, що оптимізація, надана prefer-align-cpus-by-uncorecache, може залежати від робочого навантаження. Наприклад, програми, які обмежені пропускною здатністю памʼяті, можуть не отримати вигоду від розподілу кешу uncore, оскільки використання більшої кількості кешів uncore може збільшити доступ до пропускної здатності памʼяті.
Увімкнення функції
Щоб увімкнути цю функцію, потрібно встановити політику менеджера CPU на static та увімкнути параметри політики менеджера CPU за допомогою prefer-align-cpus-by-uncorecache.
Для Kubernetes 1.34 функція знаходиться на стадії бета-тестування і вимагає також увімкнення функціональних можливостей CPUManagerPolicyBetaOptions.
Додайте наступне до файлу конфігурації kubelet:
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
featureGates:
...
CPUManagerPolicyBetaOptions: true
cpuManagerPolicy: "static"
cpuManagerPolicyOptions:
prefer-align-cpus-by-uncorecache: "true"
reservedSystemCPUs: "0"
...
Якщо ви вносите цю зміну до вже наявного вузла, видаліть файл cpu_manager_state, а потім перезапустіть kubelet.
prefer-align-cpus-by-uncorecache може бути увімкнено на вузлах з монолітним кешем uncore. Ця функція імітуватиме ефект розподілу сокетів з найкращими зусиллями та упакує ресурси CPU на сокеті, подібно до стандартної статичної політики менеджера CPU.
Додаткова інформація
Дивіться статтю Менеджери ресурсів вузлів щоб дізнатися більше про менеджер CPU та доступні політики.
Ознайомтеся з документацією до prefer-align-cpus-by-uncorecache.
Дивіться Kubernetes Enhancement Proposal для отримання додаткової інформації про те, як реалізовано prefer-align-cpus-by-uncorecache.
Долучайтеся
Ця функція розробляється SIG Node. Якщо ви зацікавлені в допомозі в розробці цієї функції, наданні відгуків або участі в будь-яких інших поточних проектах SIG Node, будь ласка, відвідайте зустріч SIG Node для отримання додаткової інформації.
Kubernetes v1.34: DRA отримав статус GA
Kubernetes 1.34 вже тут, і він приніс величезну хвилю вдосконалень для Dynamic Resource Allocation (DRA)! Цей реліз знаменує важливу віху: багато API в групі resource.k8s.io отримали статус General Availability (GA), розкриваючи повний потенціал управління пристроями в Kubernetes. Крім того, кілька ключових функцій перейшли до бети, а нова порція альфа-функцій обіцяє ще більше виразності та гнучкості.
Давайте розглянемо, що нового для DRA в Kubernetes 1.34!
Ядро DRA тепер має статус GA
Головною особливістю релізу v1.34 є те, що ядро DRA отримало статус General Availability.
Dynamic Resource Allocation (DRA) у Kubernetes надає гнучкий фреймворк для управління спеціалізованим апаратним та інфраструктурним забезпеченням, таким як GPU або FPGA. DRA надає API, які дозволяють кожному робочому навантаженню вказувати властивості потрібних пристроїв, залишаючи планувальнику завдання розподілу реальних пристроїв, що дозволяє підвищити надійність та покращити використання дорогого обладнання.
З отриманням статусу GA, DRA стає стабільним і буде частиною Kubernetes на довгий час. Спільнота все ще може очікувати постійний потік нових функцій, що додаються до DRA протягом наступних кількох релізів Kubernetes, але вони не внесуть жодних руйнівних змін до DRA. Тож користувачі та розробники драйверів DRA можуть починати впевнено використовувати DRA.
Починаючи з Kubernetes 1.34, DRA є стандартно увімкненими; функції DRA, які досягли бети, також стандартно увімкнені. Це тому, що стандартною версією API для DRA тепер є стабільна версія v1, а не попередні версії (наприклад: v1beta1 або v1beta2), які потребували явного увімкнення функції.
Функції які, перейшли в бета
Кілька потужних функцій були підвищені до бети, додаючи більше контролю, гнучкості та спостережуваності до управління ресурсами з DRA.
Позначення мітками адміністративного доступу було оновлено. У v1.34 ви можете обмежити підтримку пристроїв для людей (або застосунків), уповноважених їх використовувати. Це використовується як спосіб уникнути підвищення привілеїв, якщо драйвер DRA надає додаткові привілеї при запиті адміністративного доступу, та уникнути доступу до пристроїв, які використовуються звичайними застосунками, потенційно в іншому просторі імен. Обмеження працює, гарантуючи, що лише користувачі з доступом до простору імен з міткою resource.k8s.io/admin-access: "true" мають право створювати об'єкти ResourceClaim або ResourceClaimTemplates з полем adminAccess, встановленим як true. Це гарантує, що користувачі без прав адміністратора не зможуть зловживати цією функцією.
Список пріоритетів дозволяє користувачам вказувати список прийнятних пристроїв для їхніх робочих навантажень, а не лише один тип пристрою. Тож хоча робоче навантаження може працювати найкраще на одному високопродуктивному GPU, воно також може працювати на 2 GPU середнього рівня. Планувальник спробує задовольнити альтернативи у списку по порядку, тож робоче навантаження отримає найкращий набір доступних пристроїв на вузлі.
API kubelet було оновлено для звітування про ресурси подів, виділені через DRA. Це дозволяє агентам моніторингу вузлів знати про виділені ресурси DRA для подів на вузлі і робить можливим використання інформації DRA в API PodResources для розробки нових функцій та інтеграцій.
Нові альфа-функції
Kubernetes 1.34 також представляє кілька нових альфа-функцій, які дають нам уявлення про майбутнє управління ресурсами з DRA.
Розподіл розширених ресурсів в DRA дозволяє адміністраторам кластера оголошувати ресурси, керовані DRA, як розширені ресурси, дозволяючи розробникам використовувати їх за допомогою знайомого, простішого синтаксису запитів, все ще отримуючи переваги динамічного розподілу. Це дозволяє наявним робочим навантаженням почати використовувати DRA без модифікацій, спрощуючи перехід до DRA як для розробників застосунків, так і для адміністраторів кластера.
Споживана ємність представляє гнучку модель спільного використання пристроїв, де кілька незалежних запитів ресурсів від неповʼязаних подів можуть отримати частку одного і того ж фізичного пристрою. Ця нова можливість керується через необовʼязкові, визначені адміністратором політики спільного використання, які регулюють, як загальна ємність пристрою розподіляється та контролюється платформою для кожного запиту. Це дозволяє спільно використовувати пристрої в сценаріях, де попередньо визначені розділи не є життєздатними.
Дивіться Kubernetes v1.34: Споживча ємність DRA для отримання додаткової інформації.
Умови прив'язки покращують надійність планування для певних класів пристроїв, дозволяючи планувальнику Kubernetes відкладати привʼязку пода до вузла, доки його необхідні зовнішні ресурси, такі як приєднувані пристрої або FPGA, не будуть підтверджені як повністю підготовлені. Це запобігає передчасному призначенню подів, яке могло б призвести до збоїв, і забезпечує більш надійне, передбачуване планування шляхом явного моделювання готовності ресурсів перед тим, як под буде прив'язаний до вузла.
Статус справності ресурсу для DRA покращує спостережуваність, показуючи статус справності пристроїв, виділених для пода через Pod Status. Це працює незалежно від того, чи пристрій виділено через DRA чи Device Plugin. Це полегшує розуміння причини несправного стану пристрою та відповідне реагування.
Дивіться Kubernetes v1.34: Звіт про стан ресурсів DRA в Podʼах для отримання додаткової інформації.
Що далі?
Хоча DRA отримав статус GA в цьому циклі, наполеглива робота над DRA не припиняється. Є кілька функцій в альфа та бета статусі, які ми плануємо довести до GA в наступних кількох релізах, і ми прагнемо продовжувати покращувати продуктивність, масштабованість та надійність DRA. Тож очікуйте такий же амбітний набір функцій в DRA для релізу 1.35.
Як долучитися
Хорошою відправною точкою є приєднання до Slack-каналу WG Device Management та зустрічей, які відбуваються у зручний для US/EU та EU/APAC час.
Не всі ідеї щодо вдосконалень ще відстежуються як issues, тож приходьте поговорити з нами, якщо хочете допомогти або маєте власні ідеї! У нас є робота на всіх рівнях, від складних основних змін до покращень зручності використання в kubectl, які могли б бути підхоплені новачками.
Подяки
Величезна подяка новим учасникам DRA цього циклу:
- Alay Patel (alaypatel07)
- Gaurav Kumar Ghildiyal (gauravkghildiyal)
- JP (Jpsassine)
- Kobayashi Daisuke (KobayashiD27)
- Laura Lorenz (lauralorenz)
- Sunyanan Choochotkaew (sunya-ch)
- Swati Gupta (guptaNswati)
- Yu Liao (yliaog)
Kubernetes v1.34: Більш точний контроль над перезапуском контейнерів
З виходом Kubernetes 1.34, було представлено нову альфа-функцію, яка надає більш детальний контроль над перезапусками контейнерів у межах Pod. Ця функція, названа Container Restart Policy and Rules, дозволяє вам вказати політику перезапуску для кожного контейнера окремо, перевизначаючи глобальну політику перезапуску Podʼа. Крім того, вона також дозволяє перезапускати окремі контейнери на основі їх кодів виходу. Ця функція доступна за альфа-функціональною можливістю ContainerRestartRules.
Ця функція була давно очікуваною. Розглянемо, як вона працює і як ви можете її використовувати.
Проблема з єдиною політикою перезапуску
До цієї функції restartPolicy встановлювалася на рівні Podʼа. Це означало, що всі контейнери в Podʼі ділили одну й ту ж політику перезапуску (Always, OnFailure або Never). Хоча це підходить для багатьох випадків використання, в інших ситуаціях це може бути обмеженням.
Наприклад, розглянемо Pod з основним контейнером застосунку та ініціалізаційним контейнером, який виконує деякі початкові налаштування. Ви можете захотіти, щоб основний контейнер завжди перезапускався у разі збою, але ініціалізаційний контейнер повинен виконуватися лише один раз і ніколи не перезапускатися. З єдиною політикою перезапуску на рівні Pod це було неможливо.
Введення політик перезапуску для кожного контейнера
З новою функцією ContainerRestartRules ви тепер можете вказати restartPolicy для кожного контейнера в специфікації вашого Podʼа. Ви також можете визначити restartPolicyRules, щоб контролювати перезапуски на основі кодів виходу. Це дає вам детальний контроль, необхідний для обробки складних сценаріїв.
Варіанти використання
Давайте розглянемо деякі реальні випадки використання, де політики перезапуску для кожного контейнера можуть бути корисними.
Перезапуски на місці для завдань навчання моделей
У дослідженнях машинного навчання часто потрібно організовувати велику кількість тривалих навчальних навантажень AI/ML. У цих сценаріях збої навантаження є неминучими. Коли навантаження зазнає збою з кодом виходу, що підлягає повторному виконанню, ви хочете, щоб контейнер швидко перезапускався без повторного планування всього Podʼа, що споживає значну кількість часу та ресурсів. Перезапуск невдалого контейнера "на місці" є критично важливим для кращого використання обчислювальних ресурсів. Контейнер повинен перезапускатися "на місці" лише у разі збою через помилку, що підлягає повторному виконанню; в іншому випадку контейнер і Pod повинні завершити роботу та, можливо, бути повторно запланованими.
Це тепер можна досягти за допомогою правил restartPolicyRules на рівні контейнера. Навантаження може завершитися з різними кодами, щоб представити помилки, що підлягають повторному виконанню, і непідлягають повторному виконанню. Завдяки restartPolicyRules навантаження може бути швидко перезапущено на місці, але лише тоді, коли помилка підлягає повторному виконанню.
Ініціалізаційні контейнери з одноразовим виконанням
Ініціалізаційні контейнери часто використовуються для виконання початкових налаштувань для основного контейнера, таких як налаштування середовищ і облікових даних. Іноді ви хочете, щоб основний контейнер завжди перезапускався, але не хочете повторювати ініціалізацію, якщо вона зазнає збою.
З політикою перезапуску на рівні контейнера це тепер можливо. Ініціалізаційний контейнер може виконуватися лише один раз, і його збій буде вважатися збоєм Podʼа. Якщо ініціалізація проходить успішно, основний контейнер завжди може бути перезапущений.
Podʼи з кількома контейнерами
Для Podʼів, які виконують кілька контейнерів, ви можете мати різні вимоги до перезапуску для кожного контейнера. Деякі контейнери можуть мати чітке визначення успіху і повинні перезапускатися лише у разі збою. Інші можуть потребувати постійного перезапуску.
Це тепер можливо з політикою перезапуску на рівні контейнера, що дозволяє окремим контейнерам мати різні політики перезапуску.
Як це використовувати
Щоб використовувати цю нову функцію, вам потрібно увімкнути функціональну можливість ContainerRestartRules в панелі управління вашого кластера Kubernetes та робочих вузлах, які працюють на Kubernetes 1.34+. Після увімкнення ви можете вказати поля restartPolicy та restartPolicyRules у визначеннях ваших контейнерів.
Ось кілька прикладів:
Приклад 1: Перезапуск на основі конкретних кодів виходу
У цьому прикладі контейнер повинен перезапуститися, якщо і тільки якщо він зазнає збою з помилкою, що підлягає повторному виконанню, що представляється кодом виходу 42.
Щоб досягти цього, контейнер має restartPolicy: Never, і правило політики перезапуску, яке вказує Kubernetes перезапустити контейнер на місці, якщо він завершується з кодом 42.
apiVersion: v1
kind: Pod
metadata:
name: restart-on-exit-codes
annotations:
kubernetes.io/description: "This Pod only restart the container only when it exits with code 42."
spec:
restartPolicy: Never
containers:
- name: restart-on-exit-codes
image: docker.io/library/busybox:1.28
command: ['sh', '-c', 'sleep 60 && exit 0']
restartPolicy: Never # Політика перезапуску контейнера повинна бути вказана, якщо правила вказані
restartPolicyRules: # Тільки перезапустити контейнер, якщо він завершується з кодом 42
- action: Restart
exitCodes:
operator: In
values: [42]
Приклад 2: Ініціалізаційний контейнер з одною спробою запуску
У цьому прикладі Pod повинен завжди перезапускатися після успішної ініціалізації. Однак ініціалізація повинна бути спробована лише один раз.
Щоб досягти цього, Pod має політику перезапуску Always. Ініціалізаційний контейнер init-once спробує запуститися лише один раз. Якщо він зазнає невдачі, Pod зазнає невдачі. Це дозволяє Pod зазнати невдачі, якщо ініціалізація не вдалася, але також продовжувати працювати, як тільки ініціалізація буде успішною.
apiVersion: v1
kind: Pod
metadata:
name: fail-pod-if-init-fails
annotations:
kubernetes.io/description: "This Pod has an init container that runs only once. After initialization succeeds, the main container will always be restarted."
spec:
restartPolicy: Always
initContainers:
- name: init-once # Цей контейнер ініціалізації спробує запуститись лише один раз. Якщо спроба не вдасться, Pod не працюватиме.
image: docker.io/library/busybox:1.28
command: ['sh', '-c', 'echo "Failing initialization" && sleep 10 && exit 1']
restartPolicy: Never
containers:
- name: main-container # Цей контейнер завжди буде перезапущений, як тільки ініціалізація буде успішною.
image: docker.io/library/busybox:1.28
command: ['sh', '-c', 'sleep 1800 && exit 0']
Приклад 3: Контейнери з різними політиками перезапуску
У цьому прикладі є два контейнери з різними вимогами до перезапуску. Один повинен завжди перезапускатися, тоді як інший повинен перезапускатися лише у разі збою.
Це досягається за допомогою різних політик перезапуску на рівні контейнера для кожного з двох контейнерів.
apiVersion: v1
kind: Pod
metadata:
name: on-failure-pod
annotations:
kubernetes.io/description: "This Pod has two containers with different restart policies."
spec:
containers:
- name: restart-on-failure
image: docker.io/library/busybox:1.28
command: ['sh', '-c', 'echo "Not restarting after success" && sleep 10 && exit 0']
restartPolicy: OnFailure
- name: restart-always
image: docker.io/library/busybox:1.28
command: ['sh', '-c', 'echo "Always restarting" && sleep 1800 && exit 0']
restartPolicy: Always
Дізнайтеся більше
- Ознайомтеся з документацією про політику перезапуску контейнерів.
- Ознайомтеся з KEP для правил перезапуску контейнерів
Плани
Більше дій та сигналів для перезапуску Pod і контейнерів зʼявляться незабаром! Зокрема, планується додати підтримку перезапуску всього Podʼа. Планування та обговорення цих функцій тривають. Не соромтеся ділитися відгуками або запитами до спільноти SIG Node!
Ми будемо раді отримати ваші відгуки!
Це альфа-функція, і проєкт Kubernetes хотів би почути ваші відгуки. Будь ласка, спробуйте її. Ця функція керується SIG Node. Якщо ви зацікавлені в допомозі в розробці цієї функції, обміні відгуками або участі в будь-яких інших поточних проєктах SIG Node, будь ласка, звʼяжіться зі спільнотою SIG Node!
Ви можете звʼязатися з SIG Node кількома способами:
Kubernetes v1.34: Налаштування користувача (kuberc) доступні для тестування в kubectl 1.34
Чи хотіли ви будь-коли, щоб ви могли мати стандартно увімкнене інтерактивне видалення у kubectl? Або, можливо, ви хочете визначити власні псевдоніми, але не обовʼязково генерувати сотні з них вручну? Шукайте далі. SIG-CLI наполегливо працює над додаванням налаштувань користувача до kubectl, і ми раді оголосити, що ця функціональність досягає бета-версії в рамках випуску Kubernetes v1.34.
Як це працює
Повний опис цієї функціональності доступний в нашій офіційній документації, але в цьому дописі ми відповімо на обидва питання з початку цієї статті.
Перед тим, як зануритися в деталі, давайте швидко розглянемо, як виглядає файл налаштувань користувача та де його розмістити. Типово kubectl буде шукати файл kuberc у вашій стандартній теці kubeconfig, яка знаходиться за адресою $HOME/.kube. Альтернативно, ви можете вказати це місце за допомогою параметра --kuberc або змінної середовища KUBERC.
Як і кожен маніфест Kubernetes, файл kuberc почнеться з apiVersion та kind:
apiVersion: kubectl.config.k8s.io/v1beta1
kind: Preference
# тут будуть відображатися налаштування користувача
Defaults
Почнемо з налаштування стандартних значень для параметрів команд kubectl. Наша мета — завжди використовувати інтерактивне видалення, що означає, що ми хочемо, щоб параметр --interactive для kubectl delete завжди був встановлений на true. Це можна досягти, додавши наступний фрагмент до нашого файлу kuberc:
defaults:
- command: delete
options:
- name: interactive
default: "true"
В цьому прикладі ми представляємо секцію defaults, яка дозволяє користувачам визначати стандартні значення для параметрів kubectl. У цьому випадку ми встановлюємо параметр інтерактивності для kubectl delete на true. Це значення можна перевизначити, якщо користувач явно надає інше значення, наприклад, kubectl delete --interactive=false, в цьому випадку явний параметр має пріоритет.
Ще одне дуже рекомендоване типове значення від SIG-CLI — це використання Server-Side Apply. Щоб це зробити, ви можете додати наступний фрагмент до ваших налаштувань:
# продовження розділу defaults
- command: apply
options:
- name: server-side
default: "true"
Aliases
Можливість визначати аліаси дозволяє нам заощаджувати дорогоцінні секунди під час введення команд. Я впевнений, що ви, напевно, маєте один визначений для kubectl, оскільки введення семи літер безумовно займає більше часу, ніж просто натискання k.
З цієї причини можливість визначати аліаси була обовʼязковою, коли ми вирішили реалізувати налаштування користувача, поряд з установкою стандартних значень. Щоб визначити аліас для будь-якої з вбудованих команд, розширте свій файл kuberc наступним:
aliases:
- name: gns
command: get
prependArgs:
- namespace
options:
- name: output
default: json
Там багато чого відбувається, тому давайте розберемо це по черзі. По-перше, ми вводимо новий розділ: aliases. Тут ми визначаємо новий аліас gns, який відображається на команду get. Далі ми визначаємо аргументи (namespace ресурс), які будуть вставлені відразу після назви команди. Крім того, ми встановлюємо опцію --output=json для цього аліаса. Структура блоку options ідентична тій, що в розділі defaults.
Ви, напевно, помітили, що ми представили механізм для попереднього додавання аргументів, і ви можете запитати, чи є відповідне налаштування для їх додавання в кінці (іншими словами, додавання в кінець команди, після аргументів, наданих користувачем). Це можна досягти за допомогою блоку appendArgs, який представлений нижче:
# продовження розділу aliases
- name: runx
command: run
options:
- name: image
default: busybox
- name: namespace
default: test-ns
appendArgs:
- --
- custom-arg
Тут ми вводимо ще один аліас: runx, який викликає команду kubectl run, передаючи параметри --image і --namespace з попередньо визначеними значеннями, а також додаючи -- і custom-arg в кінці виклику.
Відлагодження
Ми сподіваємося, що налаштування користувача kubectl відкриє нові можливості для наших користувачів. Коли у вас виникають сумніви, не соромтеся запускати kubectl з підвищеною докладністю виводу. При -v=5 ви повинні отримати всю можливу інформацію для відлагодження з цієї функції, що буде важливо при повідомленні про проблеми.
Щоб дізнатися більше, я закликаю вас ознайомитися з нашою офіційною документацією та фактичною пропозицією.
Долучайтесь
Функція налаштувань користувача Kubectl досягла бета-версії, і ми дуже зацікавлені у ваших відгуках. Нам хотілося б почути, що вам подобається в ній і які проблеми ви хотіли б вирішити. Не соромтеся приєднуватися до каналу SIG-CLI slack, або відкривати тікети в репозиторії kubectl. Ви також можете приєднатися до наших зустрічей спільноти, які відбуваються кожну другу середу, і поділитися своїми історіями з нами.
Kubernetes v1.34: Of Wind & Will (O' WaW)
Редактори: Agustina Barbetta, Alejandro Josue Leon Bellido, Graziano Casto, Melony Qin, Dipesh Rawat
Подібно до попередніх релізів, випуск Kubernetes v1.34 представляє нові стабільні, бета- та альфа-функції. Послідовне надання високоякісних релізів підкреслює силу нашого циклу розробки та активну підтримку нашої спільноти.
Цей реліз складається з 58 покращень. З них 23 перейшли до стабільного стану, 22 входять до бета-версії, а 13 перейшли до альфа-версії.
У цьому релізі також є застарівання та видалення функцій; обовʼязково ознайомтеся з ними.
Тема та логотип релізу

Випуск, що рухається силою вітру навколо нас — і силою нашої волі.
Кожен цикл випуску ми успадковуємо вітри, які насправді не контролюємо — стан наших інструментів, документації та історичні особливості нашого проєкту. Іноді ці вітри наповнюють наші вітрила, іноді вони штовхають нас убік або стихають.
Те, що тримає Kubernetes в русі, не ідеальні вітри, а воля наших моряків, які регулюють вітрила, тримають штурвал, прокладають курси і тримають корабель на плаву. Випуск відбувається не тому, що умови завжди ідеальні, а завдяки людям, які його створюють, людям, які його випускають, і ведмедям^, котам, собакам, чарівникам і допитливим умам, які допомагають Kubernetes залишатися на плаву — незалежно від того, в якому напрямку дме вітер.
Цей реліз, Of Wind & Will (O' WaW), вшановує вітри, які сформували нас, і волю, яка штовхає нас вперед.
^ О, і ви здивовані, чому ведмеді? Продовжуйте дивуватися!
Основні оновлення
Kubernetes v1.34 насичений новими функціями та покращеннями. Ось кілька оновлень, які команда випуску хотіла б виділити!
Stable: Ядро DRA тепер GA
Динамічне виділення ресурсів (DRA) дозволяє використовувати потужніші способи вибору, виділення, спільного використання та налаштування GPU, TPU, мережевих карт та інших пристроїв.
Починаючи з релізу v1.30, DRA базується на заявках на пристрої за допомогою структурованих параметрів, які є непрозорими для ядра Kubernetes. Це покращення було натхненне динамічним провізуванням для сховищ. DRA зі структурованими параметрами спирається на набір допоміжних API-видів: ResourceClaim, DeviceClass, ResourceClaimTemplate та ResourceSlice API-типів в рамках resource.k8s.io, одночасно розширюючи .spec для Podʼів новим полем resourceClaims. API resource.k8s.io/v1 стали стабільними і тепер є стандартно доступними.
Ця робота була виконана в рамках KEP #4381, очолюваної WG Device Management.
Beta: Захищені токени ServiceAccount для провайдерів облікових даних образів kubelet
Постачальники облікових даних kubelet, які використовуються для отримання приватних контейнерних образів, традиційно покладалися на довгострокові Secrets, збережені на вузлі або в кластері. Такий підхід збільшував ризики безпеки та ускладнював управління, оскільки ці облікові дані не були привʼязані до конкретного робочого навантаження і не оновлювалися автоматично. Щоб вирішити цю проблему, kubelet тепер може запитувати короткочасні, привʼязані до певної аудиторії токени ServiceAccount для автентифікації в контейнерних реєстрах. Це дозволяє авторизувати отримання образів на основі власної ідентичності Podʼа, а не облікових даних на рівні вузла. Основна перевага полягає в значному поліпшенні безпеки. Це усуває необхідність у довгострокових Secrets для отримання образів, зменшуючи поверхню атаки та спрощуючи управління обліковими даними як для адміністраторів, так і для розробників.
Ця робота була виконана в рамках KEP #4412, очолюваної SIG Auth та SIG Node.
Alpha: Підтримка KYAML, діалекту YAML для Kubernetes
KYAML має бути більш безпечним і менш неоднозначною підмножиною YAML, і був спроектований спеціально для Kubernetes. Незалежно від версії Kubernetes, яку ви використовуєте, починаючи з Kubernetes v1.34 ви можете використовувати KYAML як новий формат виводу для kubectl.
KYAML вирішує специфічні проблеми як з YAML, так і з JSON. Значний пробіл YAML вимагає уважної уваги до відступів та вкладеності, тоді як необовʼязкове взяття рядків в лапки може призвести до неочікуваного приведення типів (наприклад: "The Norway Bug"). Тим часом, JSON не підтримує коментарі та має суворі вимоги до наявності ком та ключів в лапках.
Ви можете писати KYAML та передавати його як вхідні дані будь-якій версії kubectl, оскільки всі файли KYAML також є дійсними YAML. З kubectl v1.34 ви також можете запитувати вивід у форматі KYAML (як у kubectl get -o kyaml …), встановивши змінну середовища KUBECTL_KYAML=true. Якщо ви бажаєте, ви все ще можете запитувати вивід у форматі JSON або YAML.
Ця робота була виконана в рамках KEP #5295, очолюваної SIG CLI.
Функції, що переходять у стабільний стан
Це вибір деяких покращень, які тепер є стабільними після випуску v1.34.
Відкладене створення замінних Podʼів для Job
Стандартно, контролери Job створюють замінні Podʼи негайно, коли Pod починає завершення своєї роботи, що призводить до одночасного виконання обох Podʼів. Це може спричинити конкуренцію за ресурси в обмежених кластерах, де замінний Pod може зіткнутися з труднощами при пошуку доступних вузлів, поки оригінальний Pod повністю не завершиться. Ситуація також може спровокувати небажане збільшення масштабу кластеру. Крім того, деякі фреймворки машинного навчання, такі як TensorFlow та JAX, вимагають, щоб на індекс припадав лише один Pod, що робить одночасне виконання Podʼів проблематичним. Ця функція вводить .spec.podReplacementPolicy у Jobs. Ви можете вибрати створення замінних Podʼів лише тоді, коли Pod повністю завершено (має .status.phase: Failed). Для цього встановіть .spec.podReplacementPolicy: Failed.
Представлена як альфа у v1.28, ця функція стала стабільною у v1.34.
Ця робота була виконана в рамках KEP #3939, очолюваної SIG Apps.
Відновлення після збою розширення тому
Ця функція дозволяє користувачам скасовувати розширення тому, які не підтримуються підляглими постачальниками зберігання, і повторно спробувати розширити том з меншими значеннями, які можуть бути успішними. Представлена як альфа у v1.23, ця функція стала стабільною у v1.34.
Ця робота була виконана в рамках KEP #1790, очолюваної SIG Storage.
VolumeAttributesClass для зміни томів
VolumeAttributesClass став стабільним у v1.34. VolumeAttributesClass — це загальний, рідний для Kubernetes API для зміни параметрів тому, таких як виділений IO. Він дозволяє робочим навантаженням вертикально масштабувати свої томи онлайн для балансування вартості та продуктивності, якщо це підтримується їх провайдером. Як і всі нові функції томів в Kubernetes, цей API реалізується через інтерфейс зберігання контейнерів (CSI). Ваш специфічний для провайдерів CSI драйвер повинен підтримувати новий ModifyVolume API, який є CSI стороною цієї функції.
Ця робота була виконана в рамках KEP #3751, очолюваної SIG Storage.
Структурована конфігурація автентифікації
Kubernetes v1.29 представив формат файлу конфігурації для управління автентифікацією клієнта API сервера, відмовившись від попередньої залежності від великої кількості параметрів командного рядка. AuthenticationConfiguration дозволяє адміністраторам підтримувати кілька автентифікаторів JWT, перевірку виразів CEL та динамічну перезагрузку. Ця зміна суттєво покращує керованість та можливість аудиту налаштувань автентифікації кластеру, і стала стабільною у v1.34.
Ця робота була виконана в рамках KEP #3331, очолюваної SIG Auth.
Більш детальна авторизація на основі селекторів
Авторизатори Kubernetes, включаючи веб-хуки авторизації та вбудований авторизатор вузлів, тепер можуть приймати рішення про авторизацію на основі селекторів полів та міток у вхідних запитах. Коли ви надсилаєте запити list, watch або deletecollection з селекторами, шар авторизації тепер може оцінювати доступ з урахуванням цього додаткового контексту.
Наприклад, ви можете написати політику авторизації, яка дозволяє лише вивід переліку Podʼів, привʼязаних до конкретного .spec.nodeName. Клієнт (можливо, kubelet на певному вузлі) повинен вказати селектор поля, який вимагає політика, в іншому випадку запит заборонено. Ця зміна робить можливим налаштування правил найменшого привілею, за умови, що клієнт знає, як відповідати встановленим вами обмеженням. Kubernetes v1.34 тепер підтримує більш детальний контроль у таких середовищах, як ізоляція на рівні вузлів або спеціальні багатокористувацькі налаштування.
Ця робота була виконана в рамках KEP #4601, очолюваної SIG Auth.
Обмеження анонімних запитів за допомогою детальних налаштувань контролю
Замість повного увімкнення або вимкнення анонімного доступу, ви тепер можете налаштувати суворий список точок доступу, де дозволені неавтентифіковані запити. Це забезпечує більш безпечну альтернативу для кластерів, які покладаються на анонімний доступ до точок доступу, таких як /healthz, /readyz або /livez.
З цією функцією можна уникнути випадкових неправильних налаштувань RBAC, які надають широкий доступ неавтентифікованим користувачам, не вимагаючи змін у зовнішніх пробах або інструментах завантаження.
Ця робота була виконана в рамках KEP #4633, очолюваної SIG Auth.
Більш ефективне повторне додавання в чергу за допомогою зворотних викликів, специфічних для відповідних втулків
kube-scheduler тепер може приймати більш точні рішення про те, коли повторно намагатися запланувати Podʼи, які раніше не вдалося запланувати. Кожен втулок планування тепер може реєструвати функції зворотного виклику, які повідомляють планувальнику, чи ймовірно, що вхідна подія кластера знову зробить Pod, що відхиляється, придатним для планування.
Це зменшує непотрібні повторні спроби та покращує загальну пропускну здатність планування, особливо в кластерах, що використовують динамічне виділення ресурсів. Ця функція також дозволяє певним втулкам пропускати звичайну затримку повторної спроби, коли це безпечно, що прискорює планування в певних випадках.
Ця робота була виконана в рамках KEP #4247, очолюваної SIG Scheduling.
Впорядковане видалення Namespace
Напіввипадковий порядок видалення ресурсів може створювати прогалини в безпеці або непередбачувану поведінку, таку як збереження Podʼів після видалення їх асоційованих NetworkPolicies. Це покращення впроваджує більш структурований процес видалення для просторів імен Kubernetes, щоб забезпечити безпечне та детерміноване видалення ресурсів. Дотримуючись структурованої послідовності видалення, яка враховує логічні та безпекові залежності, цей підхід забезпечує видалення Podʼів перед іншими ресурсами. Ця функція була представлена в Kubernetes v1.33 і стала стабільною в v1.34. Підвищення безпеки та надійності завдяки зменшенню ризиків від недетермінованих видалень, включаючи вразливість, описану в CVE-2024-7598.
Ця робота була виконана в рамках KEP #5080, очолюваної SIG API Machinery.
Потокове передавання list відповідей
Обробка великих list відповідей у Kubernetes раніше становила значну проблему масштабованості. Коли клієнти запитували великі списки ресурсів, такі як тисячі Podʼів або Custom Resources, API серверу потрібно було серіалізувати всю колекцію обʼєктів в один великий буфер памʼяті перед відправленням. Цей процес створював значний тиск на памʼять і міг призвести до погіршення продуктивності, впливаючи на загальну стабільність кластера. Щоб розвʼязати це обмеження, було впроваджено механізм кодування потоків для колекцій (відповідей списку). Цей механізм потокового передавання автоматично активний для форматів відповіді JSON та Kubernetes Protobuf, і відповідна функціональна можливість є стабільною. Основна перевага цього підходу полягає в уникненні великих алокацій памʼяті на API сервері, що призводить до набагато меншої та більш передбачуваної витрати памʼяті. Внаслідок цього кластер стає більш стійким і продуктивним, особливо в середовищах великого масштабу, де часті запити на великі списки ресурсів є звичайними.
Ця робота була виконана в рамках KEP #5116, очолюваної SIG API Machinery.
Ініціалізація стійкого кешу спостереження
Watch cache — це шар кешування всередині kube-apiserver, який підтримує врешті-решт узгоджений кеш стану кластера, збереженого в etcd. У минулому могли виникати проблеми, коли кеш спостереження ще не був ініціалізований під час запуску kube-apiserver або коли він вимагав повторної ініціалізації.
Щоб вирішити ці проблеми, процес ініціалізації кешу спостереження став більш стійким до збоїв, покращуючи надійність панелі управління та забезпечуючи надійне встановлення спостережень для контролерів і клієнтів. Це покращення було представлено як бета у v1.31 і тепер є стабільним.
Ця робота була виконана в рамках KEP #4568, очолюваної SIG API Machinery та SIG Scalability.
Послаблення перевірки шляху пошуку DNS
Раніше сувора перевірка шляху DNS search у Kubernetes часто створювала проблеми інтеграції в складних або застарілих мережевих середовищах. Ця обмеженість могла блокувати конфігурації, які були необхідні для інфраструктури організації, змушуючи адміністраторів впроваджувати складні обхідні шляхи. Щоб вирішити цю проблему, була введена послаблена перевірка DNS як альфа у v1.32, і вона стала стабільною у v1.34. Загальний випадок використання включає Podʼи, які повинні спілкуватися як з внутрішніми службами Kubernetes, так і з зовнішніми доменами. Встановивши одну крапку (.) як перший запис у списку searches поля .spec.dnsConfig Pod, адміністратори можуть запобігти додаванню внутрішніх доменів пошуку кластера до зовнішніх запитів. Це запобігає створенню непотрібних DNS-запитів до внутрішнього DNS-сервера для зовнішніх імен хостів, покращуючи ефективність та запобігаючи потенційним помилкам резолюції.
Ця робота була виконана в рамках KEP #4427, очолюваної SIG Network.
Підтримкадля Direct Service Return (DSR) у Windows kube-proxy
DSR забезпечує оптимізацію продуктивності, дозволяючи поверненню трафіку, що маршрутизується через балансувальники навантаження, обходити балансувальник і безпосередньо відповідати клієнту, зменшуючи навантаження на балансувальник і покращуючи загальну затримку. Для отримання інформації про DSR у Windows читайте Direct Server Return (DSR) in a nutshell. Спочатку представлена у v1.14, ця функція стала стабільною у v1.34.
Ця робота була виконана в рамках KEP #5100, очолюваної SIG Windows.
Дія Sleep для хуків життєвого циклу контейнерів
Дія Sleep для хуків життєвого циклу контейнерів PreStop і PostStart була введена, щоб забезпечити простий спосіб керування процесом відповідного завершення роботи та покращити загальне управління життєвим циклом контейнерів. Дія Sleep дозволяє контейнерам призупинятися на вказаний період після запуску або перед завершенням. Використання негативної або нульової тривалості сну призводить до негайного повернення, що призводить до відсутності операції. Дія Sleep була представлена в Kubernetes v1.29, з підтримкою нульового значення, доданою в v1.32. Обидві функції стали стабільними в v1.34.
Ця робота була виконана в рамках KEP #3960 та KEP #4818, очолюваної SIG Node.
Підтримка свопу на вузлах Linux
Історично, відсутність підтримки свопу в Kubernetes могло призводити до нестабільності робочих навантажень, оскільки вузли під тиском памʼяті часто змушені були примусово завершувати процеси. Це особливо впливало на програми з великими, але рідко використовуваними обсягами памʼяті, і заважало більш мʼякому управлінню ресурсами.
Щоб вирішити цю проблему, підтримка свопу з налаштуваннями на рівні вузлів була представлена у v1.22. Вона пройшла через альфа- та бета-етапи і стала стабільною у v1.34. Основний режим, LimitedSwap, дозволяє Podʼам використовувати своп всередині їх наявних обмежень памʼяті, надаючи безпосереднє розвʼязання проблеми. Стандартно, kubelet налаштований у режимі NoSwap, що означає, що робочі навантаження Kubernetes не можуть використовувати своп.
Ця функція покращує стабільність робочих навантажень і дозволяє більш ефективно використовувати ресурси. Вона дозволяє кластерам підтримувати ширший спектр програм, особливо в умовах обмежених ресурсів, хоча адміністраторам слід враховувати потенційний вплив на продуктивність від використання свопу.
Ця робота була виконана в рамках KEP #2400, очолюваної SIG Node.
Дозвіл на використання спеціальних символів в змінних середовища
Правила валідації змінних середовища в Kubernetes були послаблені, щоб дозволити майже всі друковані символи ASCII в іменах змінних, за винятком =. Ця зміна підтримує сценарії, коли робочі навантаження вимагають нестандартних символів в іменах змінних, наприклад, фреймворки, такі як .NET Core, які використовують : для представлення вкладених ключів конфігурації.
Послаблена валідація застосовується до змінних середовища, визначених безпосередньо в специфікації Pod, а також до тих, що впроваджуються за допомогою посилань envFrom на ConfigMaps і Secrets.
Ця робота була виконана в рамках KEP #4369, очолюваної SIG Node.
Керування позначками taint тепер відокремлено від життєвого циклу вузлів
Історично, логіка TaintManager щодо застосування taints NoSchedule та NoExecute до вузлів на основі їх стану (NotReady, Unreachable тощо) була тісно повʼязана з контролером життєвого циклу вузлів. Це тісне зʼєднання ускладнювало обслуговування та тестування коду, а також обмежувало гнучкість механізму виселення на основі taint. Цей KEP переносить TaintManager у свій власний окремий контролер у межах менеджера контролерів Kubernetes. Це внутрішнє архітектурне покращення, спрямоване на підвищення модульності та підтримуваності коду. Ця зміна дозволяє логіці виселення на основі taint тестуватися та розвиватися незалежно, але не має прямого впливу на користувацький інтерфейс щодо використання taints.
Ця робота була виконана в рамках KEP #3902, очолюваної SIG Scheduling та SIG Node.
Нові Beta функції
Це деякі покращення, які тепер є бета після випуску v1.34.
Запити та обмеження ресурсів на рівні Pod
Визначення потреб у ресурсах для Podʼів з кількома контейнерами було складним, оскільки запити та обмеження могли бути встановлені лише на рівні кожного контейнера. Це змушувало розробників або перевищувати виділені ресурси для кожного контейнера, або ретельно ділити загальні бажані ресурси, ускладнюючи конфігурацію та часто призводячи до неефективного виділення ресурсів. Щоб спростити це, була введена можливість вказувати запити та обмеження ресурсів на рівні Podʼів. Це дозволяє розробникам визначати загальний бюджет ресурсів для Podʼа, який потім ділиться між його контейнерами. Ця функція була представлена як альфа у v1.32 і стала бета у v1.34, при цьому HPA тепер підтримує специфікації ресурсів на рівні подів.
Основна перевага полягає в більш інтуїтивному та простому способі управління ресурсами для Podʼів з кількома контейнерами. Це забезпечує те, щоб загальні ресурси, що використовуються всіма контейнерами, не перевищували визначені обмеження Podʼа, що призводить до кращого планування ресурсів, більш точного розподілу, та більш ефективного використання ресурсів кластера.
Ця робота була виконана в рамках KEP #2837, очолюваної SIG Scheduling та SIG Autoscaling.
Файл .kuberc для налаштувань користувача kubectl
Файл конфігурації .kuberc дозволяє визначити уподобання для kubectl, такі як стандартні параметри та псевдоніми команд. На відміну від файлу kubeconfig, файл конфігурації .kuberc не містить інформації про кластер, імен користувачів або паролів. Ця функція була представлена як альфа у v1.33, під контролем змінної середовища KUBECTL_KUBERC. Вона стала бета у v1.34 і є стандартно увімкненою.
Ця робота була виконана в рамках KEP #3104, очолюваної SIG CLI.
Підписування токенів зовнішніх ServiceAccount
Традиційно, Kubernetes управляє токенами ServiceAccount, використовуючи статичні ключі підпису, які завантажуються з диска під час запуску kube-apiserver. Ця функція впроваджує сервіс gRPC ExternalJWTSigner для підпису поза процесом, що дозволяє дистрибутивам Kubernetes інтегруватися з зовнішніми рішеннями для управління ключами (наприклад, HSM, хмарні KMS) для підпису токенів ServiceAccount замість статичних ключів на диску.
Представлена як альфа у v1.32, ця зовнішня можливість підпису JWT переходить у бета-версію та є стандартно увімкненою у v1.34.
Ця робота була виконана в рамках KEP #740, очолюваної SIG Auth.
Функції DRA у бета-версії
Адміністративний доступ для безпечного моніторингу ресурсів
DRA підтримує контрольований адміністративний доступ через поле adminAccess у ResourceClaims або ResourceClaimTemplates, що дозволяє операторам кластерів отримувати доступ до пристроїв, які вже використовуються іншими, для моніторингу або діагностики. Цей привілейований режим обмежений користувачами, уповноваженими створювати такі обʼєкти в просторах імен, помічених як resource.k8s.io/admin-access: "true", що забезпечує, щоб звичайні робочі навантаження залишалися неушкодженими. Перехід до бета-версії у v1.34 надає цю функцію безпечних інструментів для спостереження, зберігаючи при цьому ізоляцію робочих навантажень через авторизаційні перевірки на основі просторів імен.
Ця робота була виконана в рамках KEP #5018, очолюваної WG Device Management та SIG Auth.
Пріоритетні альтернативи в ResourceClaims та ResourceClaimTemplates
Хоча робоче навантаження може найкраще працювати на одному високопродуктивному GPU, воно також може працювати на двох слабших GPU. З перемикачем функцій DRAPrioritizedList (тепер стандартно увімкнено) ResourceClaims та ResourceClaimTemplates отримують нове поле firstAvailable. Це поле є впорядкованим списком, що дозволяє користувачам вказувати, що запит може бути задоволений різними способами, включаючи виділення нічого, якщо специфічне обладнання недоступне. Планувальник намагатиметься задовольнити альтернативи в списку за порядком, тому робоче навантаження отримає найкращий набір доступних пристроїв у кластері.
Ця робота була виконана в рамках KEP #4816, очолюваної WG Device Management.
kubelet сповіщає про виділені ресурси DRA
API kubelet було оновлено для звіту про ресурси Pod, виділені через DRA. Це дозволяє агентам моніторингу вузлів виявляти виділені ресурси DRA для Podʼів на вузлі. Крім того, це дозволяє вузловим компонентам використовувати PodResourcesAPI та використовувати цю інформацію про DRA при розробці нових функцій та інтеграцій. Починаючи з Kubernetes v1.34, ця функція є стандартно увімкненою.
Ця робота була виконана в рамках KEP #3695, очолюваної WG Device Management.
Неблокуючі виклики API kube-scheduler
kube-scheduler виконує блокуючі API виклики під час циклів планування, створюючи вузькі місця в продуктивності. Ця функція впроваджує асинхронну обробку API через систему пріоритетних черг з дедуплікацією запитів, що дозволяє планувальнику продовжувати обробку Podʼів, поки операції API завершуються у фоновому режимі. Основні переваги включають зменшення затримки планування, запобігання голодування потоків планувальника під час затримок API та негайну можливість повторної спроби для незапланованих Podʼів. Реалізація зберігає зворотну сумісність і додає метрики для моніторингу очікуючих операцій API.
Ця робота була виконана в рамках KEP #5229, очолюваної SIG Scheduling.
Змінювані політики допуску
MutatingAdmissionPolicies пропонують декларативну, внутрішню альтернативу змінюваним веб-хукам допуску. Ця функція використовує інсталяцію обʼєктів CEL та стратегії JSON Patch, в поєднанні з алгоритмами злиття Server Side Apply. Це суттєво спрощує контроль допуску, дозволяючи адміністраторам визначати правила мутації безпосередньо в API сервері. Представлені як альфа у v1.32, політики мутації допуску стали бета у v1.34.
Ця робота була виконана в рамках KEP #3962, очолюваної SIG API Machinery.
Кеш сервера API, доступний для знімків
Механізм кешування kube-apiserver (кеш спостереження) ефективно обслуговує запити на останній спостережуваний стан. Однак, list запити на попередні стани (наприклад, через пагінацію або вказуючи resourceVersion) часто обходять цей кеш і обслуговуються безпосередньо з etcd. Це пряме звернення до etcd значно збільшує витрати на продуктивність і може призвести до проблем зі стабільністю, особливо з великими ресурсами, через тиск на памʼять від передачі великих обсягів даних. Зі стандартно увімкненою функцією ListFromCacheSnapshot kube-apiserver намагатиметься обслуговувати відповідь з моментальних знімків, якщо такий є з resourceVersion, старішим за запитуваний. kube-apiserver починає без знімків, створює новий знімок на кожну подію спостереження і зберігає їх, поки не виявить, що etcd стиснуто, або якщо кеш заповнений подіями старшими за 75 секунд. Якщо вказаний resourceVersion недоступний, сервер повернеться до etcd.
Ця робота була виконана в рамках KEP #4988, очолюваної SIG API Machinery.
Інструменти для декларативної перевірки типів, властивих Kubernetes
Перед цим випуском правила валідації для вбудованих у Kubernetes API писалися повністю вручну, що ускладнює їх виявлення, розуміння, покращення або тестування для супроводжуючих. Не було єдиного способу знайти всі правила валідації, які можуть застосовуватися до API. Декларативна валідація приносить користь супроводжувачам Kubernetes, спрощуючи розробку, обслуговування та перевірку API, одночасно дозволяючи програмну інспекцію для кращого інструментування та документації. Для людей, які використовують бібліотеки Kubernetes для написання свого коду (наприклад: контролера), новий підхід спрощує додавання нових полів через IDL теґи, а не складні функції валідації. Ця зміна допомагає прискорити створення API, автоматизуючи шаблони валідації, та надає більш релевантні повідомлення про помилки, виконуючи валідацію на версійованих типах. Це вдосконалення (яке стало бета у v1.33 і продовжується як бета у v1.34) приносить правила валідації на основі CEL до рідних типів Kubernetes. Це дозволяє визначати більш детальну та декларативну валідацію безпосередньо в визначеннях типів, покращуючи узгодженість API та взаємодію з розробниками.
Ця робота була виконана в рамках KEP #5073, очолюваної SIG API Machinery.
Потокові інформери для запитів list
Функція потокових інформерів, яка була в бета-версії з v1.32, отримує подальші вдосконалення бета-версії в v1.34. Ця можливість дозволяє list запитам повертати дані як безперервний потік обʼєктів з кешу спостереження API сервера, а не збиратися з пагінованих результатів безпосередньо з etcd. Повторюючи ті ж механізми, що використовуються для операцій watch, API сервер може обслуговувати великі набори даних, зберігаючи при цьому стабільне використання памʼяті та уникаючи піків алокації, які можуть вплинути на стабільність.
У цьому релізі kube-apiserver та kube-controller-manager обидва типово використовують новий механізм WatchList. Для kube-apiserver це означає, що запити списку тепер обслуговуються більш ефективно, тоді як kube-controller-manager отримує більш ефективний з точки зору памʼяті та передбачуваний спосіб роботи з інформерами. Разом ці покращення зменшують тиск на памʼять під час великих операцій list та покращують надійність під час тривалого навантаження, роблячи потокову передачу списків більш передбачуваною та ефективною.
Ця робота була виконана в рамках KEP #3157, очолюваної SIG API Machinery та SIG Scalability.
Управління належним вимкненням для вузлів на Windows
kubelet на вузлах Windows тепер може виявляти події завершення системи та починати належне завершення роботи запущених Podʼів. Це відображає існуючу поведінку на Linux і допомагає забезпечити чистий вихід робочих навантажень під час запланованих вимкнень або перезавантажень. Коли система починає вимикатися, kubelet реагує, використовуючи стандартну логіку завершення. Він поважає налаштовані хуки життєвого циклу та періоди належного вимкнення, надаючи Podʼам час на зупинку перед вимкненням вузла. Ця функція покладається на попереджувальні сповіщення Windows для координації цього процесу. Це вдосконалення покращує надійність робочих навантажень під час обслуговування, перезавантажень або оновлень системи. Тепер вона знаходиться в бета-версії та є стандартно увімкненою.
Ця робота була виконана в рамках KEP #4802, очолюваної SIG Windows.
Покращення в зміні розмірів Podʼа на місці
Підвищена до бета-версії та стандартно увімкнена у v1.33, функція зміни розміру Podʼа на місці отримує подальші вдосконалення в v1.34. До них відноситься підтримка зменшення використання памʼяті та інтеграція з ресурсами на рівні Podʼа.
Ця функція залишається в бета-версії в v1.34. Для отримання детальних інструкцій щодо використання та прикладів зверніться до документації: Зміна ресурсів CPU та памʼяті, призначених контейнерам.
Ця робота була виконана в рамках KEP #1287, очолюваної SIG Node та SIG Autoscaling.
Нові функції в Alpha
Це деякі з покращень, які тепер є альфа після випуску v1.34.
Сертифікати Pod для автентифікації mTLS
Автентифікація робочих навантажень всередині кластера, особливо для звʼязку з API сервером, в основному покладалася на токени ServiceAccount. Хоча це ефективно, ці токени не завжди є ідеальними для встановлення сильної, перевіряємої ідентичності для взаємного TLS (mTLS) і можуть створювати проблеми при інтеграції з зовнішніми системами, які очікують автентифікації на основі сертифікатів. Kubernetes v1.34 вводить вбудований механізм для Podʼів для отримання сертифікатів X.509 через PodCertificateRequests. kubelet може запитувати та керувати сертифікатами для Podʼів, які потім можуть використовуватися для автентифікації на сервері API Kubernetes та інших службах за допомогою mTLS. Основна перевага полягає в більш надійному та гнучкому механізмі ідентифікації для Podʼів. Це надає рідний спосіб реалізації надійної автентифікації mTLS без покладання виключно на маркерні токени, узгоджуючи Kubernetes зі стандартними практиками безпеки та спрощуючи інтеграцію з інструментами спостереження та безпеки, які використовують сертифікати.
Ця робота була виконана в рамках KEP #4317, очолюваної SIG Auth.
Стандарт безпеки Pod "Restricted" тепер забороняє віддалені перевірки
Поле host в рамках перевірок та обробників життєвого циклу дозволяє користувачам вказувати іншу сутність, ніж podIP, для перевірки kubelet. Однак, це відкриває шлях для зловживань та атак, які обходять засоби безпеки, оскільки поле host може бути встановлено на будь-яке значення, включаючи чутливі до безпеки зовнішні хости або localhost на вузлі. У Kubernetes v1.34, Podʼи відповідають стандарту безпеки Restricted лише в тому випадку, якщо вони або залишають поле host не налаштованим, або якщо вони навіть не використовують цей тип перевірки. Ви можете використовувати автоматизацію безпеки Pod, або сторонніх рішень, щоб забезпечити відповідність Podʼів цьому стандарту. Оскільки це засоби безпеки, ознайомтеся з документацією, щоб зрозуміти обмеження та поведінку механізму примусового виконання, який ви обираєте.
Ця робота була виконана в рамках KEP #4940, очолюваної SIG Auth.
Використовуйте .status.nominatedNodeName для показу розміщення Podʼа
Коли kube-scheduler затримується з привʼязкою Podʼів до вузлів, кластерні автомасштабувальники можуть не розуміти, що Pod буде привʼязаний до певного вузла. Внаслідок цього вони можуть помилково вважати вузол недовикористаним і видалити його. Щоб вирішити цю проблему, kube-scheduler може використовувати .status.nominatedNodeName не лише для вказівки на триваюче примусове виконання, але й для показу намірів розміщення Pod. Увімкнувши функціональну можливість NominatedNodeNameForExpectation, планувальник використовує це поле, щоб вказати, куди Pod буде призначений. Це відкриває внутрішні резервування, щоб допомогти зовнішнім компонентам приймати обґрунтовані рішення.
Ця робота була виконана в рамках KEP #5278, очолюваної SIG Scheduling.
Функції DRA в альфа-версії
Стан ресурсів для DRA
Може бути важко дізнатися, коли Pod використовує пристрій, який вийшов з ладу або тимчасово не працює, що ускладнює усунення неполадок, повʼязаних з аварією Pod. Стан справності ресурсу для DRA покращує спостережуваність, відкриваючи стан справності пристроїв, виділених Podʼу, у статусі Podʼа. Це полегшує виявлення причин проблем Podʼа, повʼязаних з несправними пристроями, та відповідь на них. Щоб увімкнути цю функціональність, потрібно активувати функціональну можливість ResourceHealthStatus, а драйвер DRA повинен реалізувати сервіс gRPC DRAResourceHealth.
Ця робота була виконана в рамках KEP #4680, очолюваної WG Device Management.
Зіставлення розширених ресурсів
Зіставлення розширених ресурсів надає простіший альтернативний DRA виразний та гнучкий підхід, пропонуючи простий спосіб опису ємності та споживання ресурсів. Ця функція дозволяє адміністраторам кластерів оголошувати ресурси, керовані DRA, як розширені ресурси, що дозволяє розробникам хастосунків та операторам продовжувати використовувати знайомий синтаксис контейнера .spec.resources для їх використання. Це дозволяє наявним робочим навантаженням приймати DRA без модифікацій, спрощуючи перехід на DRA як для розробників застосунків, так і для адміністраторів кластерів.
Ця робота була виконана в рамках KEP #5004, очолюваної WG Device Management.
Споживча спроможність DRA
У Kubernetes v1.33 додано підтримку драйверів ресурсів для оголошення доступних частин пристрою, замість того, щоб виставляти весь пристрій як ресурс «все або нічого». Однак, цей підхід не міг впоратися зі сценаріями, де драйвери пристроїв керують тонкими, динамічними частинами ресурсу пристрою на основі попиту користувача або ділять ці ресурси незалежно від ResourceClaims, які обмежені їх специфікацією та простором іменем. Увімкнення функціональної можливості DRAConsumableCapacity (представленої як альфа у v1.34) дозволяє драйверам ресурсів ділити один й той же пристрій, або навіть частину пристрою, між кількома ResourceClaims або між кількома DeviceRequests. Ця функція також розширює планувальник, щоб підтримувати виділення частин ресурсів пристрою, як визначено в полі capacity. Ця функція DRA покращує спільне використання пристроїв між просторами імен та заявками, налаштовуючи його на потреби Pod. Вона дозволяє драйверам забезпечувати обмеження ємності, покращує планування та підтримує нові випадки використання, такі як обізнаний про пропускну здатність мережевий звʼязок та багатокористувацьке спільне використання.
Ця робота була виконана в рамках KEP #5075, очолюваної WG Device Management.
Умови привʼязки пристроїв
Планувальник Kubernetes стає надійнішим, затримуючи привʼязку Pod до вузла, поки його необхідні зовнішні ресурси, такі як приєднувані пристрої або FPGA, не будуть підтверджені як готові. Цей механізм затримки реалізовано в фазі PreBind фреймворку планування. Під час цієї фази планувальник перевіряє, чи задоволені всі необхідні умови пристрою, перш ніж продовжити привʼязку. Це забезпечує координацію з зовнішніми контролерами пристроїв, забезпечуючи більш надійне та передбачуване планування.
Ця робота була виконана в рамках KEP #5007, очолюваної WG Device Management.
Правила перезапуску контейнерів
В даний час всі контейнери в межах Podʼа будуть дотримуватися однієї й тієї ж політики перезапуску .spec.restartPolicy під час виходу або аварії. Однак, Podʼи, які виконують кілька контейнерів, можуть мати різні вимоги до перезапуску для кожного контейнера. Наприклад, для ініціалізаційних контейнерів, які використовуються для виконання ініціалізації, ви, можливо, не захочете повторювати спроби ініціалізації, якщо вони зазнають невдачі. Аналогічно, в середовищах дослідження ML з тривалими навчальними навантаженнями, контейнери, які зазнають невдачі з кодами виходу, що підлягають повторному спробуванню, повинні швидко перезапускатися на місці, а не викликати відтворення Pod і втрату прогресу. Kubernetes v1.34 вводить перемикач функцій ContainerRestartRules. Коли він увімкнений, політика перезапуску може бути вказана для кожного контейнера в межах Pod. Також можна визначити список restartPolicyRules, щоб переважити restartPolicy на основі останнього коду виходу. Це надає детальний контроль, необхідний для обробки складних сценаріїв та кращого використання обчислювальних ресурсів.
Ця робота була виконана в рамках KEP #5307, очолюваної SIG Node.
Завантаження змінних середовища з файлів, створених під час виконання
Розробники застосунків давно просять про більшу гнучкість у оголошенні змінних середовища. Традиційно, змінні середовища оголошуються на стороні сервера API через статичні значення, ConfigMaps або Secrets.
Під функціональністю EnvFiles Kubernetes v1.34 впроваджує можливість оголошення змінних середовища під час виконання. Один контейнер (зазвичай ініціалізаційний контейнер) може згенерувати змінну та зберегти її у файлі, а наступний контейнер може запуститися зі змінною середовища, завантаженою з цього файлу. Цей підхід усуває необхідність "обгортати" точку входу цільового контейнера, що дозволяє більш гнучку оркестрацію контейнерів у Pod.
Ця функція особливо корисна для навчальних навантажень AI/ML, де кожен Pod у навчальному завданні вимагає ініціалізації з значеннями, визначеними під час виконання.
Ця робота була виконана в рамках KEP #5307, очолюваної SIG Node.
Зміна станів, застарівання та видалення в v1.34
Перехід до стабільного стану
Це список усіх функцій, які стали стабільними (також відомими як загально доступні). Для отримання повного списку оновлень, включаючи нові функції та переходи з альфа- до бета-версії, дивіться примітки до випуску.
Цей реліз включає в себе в цілому 23 вдосконалення, які стали стабільними:
- Дозволити майже всі друковані символи ASCII в змінних середовища
- Дозволити відтворення подів після повного завершення в контролері завдань
- Дозволити нульове значення для дії сну хуків PreStop
- Трасування API сервера
- Підтримка AppArmor
- Авторизація за допомогою селекторів полів та міток
- Послідовні читання з кешу
- Відділення TaintManager від контролера життєвого циклу вузлів
- Виявлення драйвера cgroup з CRI
- DRA: структуровані параметри
- Введення дії сну для хуків PreStop
- Трасування OpenTelemetry для Kubelet
- Модифікація VolumeAttributesClass Kubernetes
- Підтримка свопу на вузлах
- Дозволити анонімну авторизацію лише для налаштованих точок доступу
- Упорядковане видалення просторів імен
- Повторне чергування з точними зворотними викликами в kube-scheduler
- Послаблена валідація рядка пошуку DNS
- Стійка ініціалізація кешу спостереження
- Потокове кодування для відповідей LIST
- Структурована конфігурація автентифікації
- Підтримка Direct Service Return (DSR) та мережевих оверлеїв в Windows kube-proxy
- Відновлення після збою розширення тому
Застарівання та вилучення
Оскільки Kubernetes розвивається та росте, функції можуть застарівати, видалятися або замінюватися кращими для покращення загального стану проєкту. Дивіться політику застарівання та видалення для отримання додаткової інформації про цей процес. Випуск Kubernetes v1.34 містить кілька застарівань.
Ручна конфігурація драйвера cgroup застаріла
Історично, налаштування правильного драйвера cgroup було болючою точкою для користувачів, які використовували кластери Kubernetes. Kubernetes v1.28 додав спосіб для kubelet запитувати реалізацію CRI та дізнаватися, який драйвер cgroup використовувати. Це автоматичне виявлення тепер наполегливо рекомендується і підтримка цього функціоналу стала стабільною у v1.34. Якщо ваш CRI рушій виконання контейнерів не підтримує можливість повідомляти про драйвер cgroup, який йому потрібен, вам слід оновити або змінити його. Налаштування cgroupDriver у файлі конфігурації kubelet тепер застаріло. Відповідна опція командного рядка --cgroup-driver була раніше застаріла, оскільки Kubernetes рекомендує використовувати замість цього файл конфігурації. Як і налаштування конфігурації, так і опція командного рядка будуть видалені в майбутньому релізі, але це видалення не відбудеться раніше, ніж у мінорному релізі випуску v1.36.
Ця робота була виконана в рамках KEP #4033, очолюваної SIG Node.
Kubernetes припинить підтримку containerd 1.x у v1.36
Хоча Kubernetes v1.34 все ще підтримує containerd 1.7 та інші LTS релізи containerd, внаслідок автоматичного виявлення драйвера cgroup, спільнота Kubernetes SIG Node формально погодилася на остаточний графік підтримки для containerd v1.X. Останнім релізом Kubernetes, який запропонує цю підтримку, буде v1.35 (узгоджений з EOL containerd 1.7). Це раннє попередження про те, що якщо ви використовуєте containerd 1.X, розгляньте можливість переходу на 2.0+ найближчим часом. Ви можете моніторити метрику kubelet_cri_losing_support, щоб визначити, чи використовують якісь вузли у вашому кластері версію containerd, яка незабаром стане застарілою.
Ця робота була виконана в рамках KEP #4033, очолюваної SIG Node.
Розподіл трафіку PreferClose є застарілим
Поле spec.trafficDistribution в рамках Kubernetes Service дозволяє користувачам висловлювати переваги щодо того, як трафік повинен маршрутизуватися до точок доступу сервісу.
KEP-3015 визнає застарілим PreferClose і вводить два додаткових значення: PreferSameZone та PreferSameNode. PreferSameZone є псевдонімом для наявного PreferClose, щоб прояснити його семантику. PreferSameNode дозволяє зʼєднанням доставлятися до локальної точки доступу, коли це можливо, з переходом на віддалену точку доступу, коли це неможливо.
Ця функція була представлена у v1.33 під перемикачем функцій PreferSameTrafficDistribution. Вона стала бета у v1.34 і є стандартно увімкненою.
Ця робота була виконана в рамках KEP #3015, очолюваної SIG Network.
Примітки до випуску
Перегляньте всі деталі випуску Kubernetes v1.34 у наших примітках до випуску.
Доступність
Kubernetes v1.34 доступний для завантаження на GitHub або на сторінці Завантаження Kubernetes.
Щоб почати роботу з Kubernetes, ознайомтеся з цими інтерактивними навчальними посібниками або запустіть локальні кластери Kubernetes за допомогою minikube. Ви також можете легко встановити v1.34 за допомогою kubeadm.
Команда випуску
Kubernetes можливий лише завдяки підтримці, відданості та наполегливій праці його спільноти. Кожна команда випуску складається з відданих волонтерів спільноти, які працюють разом, щоб зібрати багато частин, які складають випуски Kubernetes, на які ви покладаєтеся. Це вимагає спеціалізованих навичок людей з усіх куточків нашої спільноти, від самого коду до його документації та управління проєктом.
Ми вшановуємо памʼять Рудольфо "Родо" Мартінеса Веги, відданого учасника, чия пристрасть до технологій та побудови спільноти залишила слід у спільноті Kubernetes. Родо був учасником команди випуску Kubernetes протягом кількох релізів, включаючи v1.22-v1.23 та v1.25-v1.30, демонструючи непохитну відданість успіху та стабільності проєкту. Поза участтю в команді випуску, Родо активно сприяв розвитку спільноти Cloud Native LATAM, допомагаючи подолати мовні та культурні барʼєри в цій сфері. Його робота над іспанською версією документації Kubernetes та глосарію CNCF є прикладом його відданості справі зробити знання доступними для розробників, які говорять іспанською мовою, по всьому світу. Спадщина Родо живе через безліч членів спільноти, яких він наставляв, релізи, які він допоміг випустити, та яскраву спільноту Kubernetes LATAM, яку він допоміг виростити.
Ми хотіли б подякувати всій Команді випуску за години наполегливої праці, витрачені на підготовку релізу Kubernetes v1.34 для нашої спільноти. Членство в команді випуску варіюється від новачків до досвідчених лідерів команд з досвідом, набутих протягом кількох циклів випуску. Особлива подяка нашому лідеру випуску, Вйому Ядаву, за те, що провів нас через успішний цикл випуску, за його практичний підхід до вирішення викликів та за енергію та турботу, які рухають нашу спільноту вперед.
Швидкість проєкту
Проєкт CNCF K8s DevStats агрегує кілька цікавих показників, повʼязаних з швидкістю розвитку Kubernetes та різних підпроєктів. Це включає все, починаючи від індивідуальних внесків до кількості компаній, які роблять свій внесок, і є ілюстрацією глибини та широти зусиль, які вкладаються в розвиток цієї екосистеми.
Під час циклу випуску v1.34, який тривав 15 тижнів з 19 травня 2025 року по 27 серпня 2025 року, Kubernetes отримав внески від 106 різних компаній та 491 особи. У ширшій хмарній екосистемі ця цифра зростає до 370 компаній, враховуючи 2235 загальних учасників.
Зверніть увагу, що "внесок" враховується, коли хтось робить коміт, рецензію коду, коментар, створює тікет або PR, рецензує PR (включаючи блоги та документацію) або коментує тікети та PR. Якщо ви зацікавлені в участі, відвідайте розділ Початок роботи на нашому сайті для учасників.
Джерело цих даних:
Майбутні події
Ознайомтесь з майбутніми подіями Kubernetes та Cloud Native, включаючи KubeCon + CloudNativeCon, KCD та інші помітні конференції по всьому світу. Залишайтеся в курсі та беріть участь у житті спільноти Kubernetes!
Серпень 2025
- KCD — Дні спільноти Kubernetes: Колумбія: 28 серпня 2025 року | Богота, Колумбія
Вересень 2025
- CloudCon Sydney: 9–10 вересня 2025 року | Сідней, Австралія
- KCD — Дні спільноти Kubernetes: Сан-Франциско: 9 вересня 2025 року | Сан-Франциско, США
- KCD — Дні спільноти Kubernetes: Вашингтон: 16 вересня 2025 року | Вашингтон, округ Колумбія, США
- KCD — Дні спільноти Kubernetes: Софія: 18 вересня 2025 року | Софія, Болгарія
- KCD — Дні спільноти Kubernetes: Ель-Сальвадор: 20 вересня 2025 року | Сан-Сальвадор, Ель-Сальвадор
Жовтень 2025
- KCD — Дні спільноти Kubernetes: Варшава: 9 жовтня 2025 року | Варшава, Польща
- KCD — Дні спільноти Kubernetes: Единбург: 21 жовтня 2025 року | Единбург, Сполучене Королівство
- KCD — Дні спільноти Kubernetes: Шрі-Ланка: 26 жовтня 2025 року | Коломбо, Шрі-Ланка
Листопад 2025
- KCD — Дні спільноти Kubernetes: Порту: 3 листопада 2025 року | Порту, Португалія
- KubeCon + CloudNativeCon Північна Америка 2025: 10-13 листопада 2025 року | Атланта, США
- KCD — Дні спільноти Kubernetes: Ханчжоу: 15 листопада 2025 року | Ханчжоу, Китай
Грудень 2025
- KCD — Дні спільноти Kubernetes: Швейцарська Романдія: 4 грудня 2025 року | Женева, Швейцарія
Ви можете знайти останні деталі подій тут.
Вебінар про майбутній реліз
Приєднуйтесь до членів команди випуску Kubernetes v1.34 у середу, 24 вересня 2025 року о 16:00 (UTC), щоб дізнатися про основні моменти цього випуску. Для отримання додаткової інформації та реєстрації відвідайте сторінку події на сайті CNCF Online Programs.
Долучайтесь
Найпростіший спосіб долучитися до Kubernetes — це приєднатися до однієї з багатьох Груп за інтересами (SIG, Special Interest Groups), які відповідають вашим інтересам. Маєте щось, що хочете донести до спільноти Kubernetes? Поділіться своїм голосом на нашій щотижневій зустрічі спільноти, а також через наведені нижче канали. Дякуємо за ваш постійний зворотний звʼязок та підтримку.
- Слідкуйте за нами в Bluesky @Kubernetesio для отримання останніх оновлень
- Приєднуйтесь до обговорення спільноти на Discuss
- Приєднуйтесь до спільноти в Slack
- Публікуйте запитання (або відповідайте на запитання) на Stack Overflow
- Діліться своєю історією про Kubernetes
- Читайте більше про те, що відбувається з Kubernetes в блозі
- Дізнайтеся більше про Команду випуску Kubernetes
Налаштування Linux Swap для Kubernetes: детальний огляд
Функція Kubernetes NodeSwap, яка, ймовірно, отримає статус stable у майбутньому релізі Kubernetes v1.34, дозволяє використання swap: це значна зміна порівняно з традиційною практикою вимкнення swap для передбачуваної продуктивності. Ця стаття зосереджена виключно на налаштуванні swap на вузлах Linux, де ця функція доступна. Дозволяючи вузлам Linux використовувати вторинне сховище для додаткової віртуальної памʼяті, коли фізична RAM вичерпана, підтримка swap на вузлах спрямована на покращення використання ресурсів та зменшення кількості припинень процесів через нестачу памʼяті (OOM kills).
Однак, увімкнення swap не є рішенням "під ключ". Продуктивність та стабільність ваших вузлів під тиском на памʼять критично залежать від набору параметрів ядра Linux. Неправильна конфігурація може призвести до погіршення продуктивності та втручання в логіку виселення Kubelet.
У цьому дописі ми розглянемо критичні параметри ядра Linux, які керують поведінкою swap. Ми дослідимо, як ці параметри впливають на продуктивність робочих навантажень Kubernetes, використання swap та критичні механізми виселення. Також представимо різні результати тестів, що демонструють вплив різних конфігурацій, та поділимось своїми висновками щодо досягнення оптимальних налаштувань для стабільних та високопродуктивних кластерів Kubernetes.
Вступ до Linux swap
На високому рівні, ядро Linux керує памʼяттю через сторінки, зазвичай розміром 4КіБ. Коли фізична памʼять стає обмеженою, алгоритм заміни сторінок ядра вирішує, які сторінки перемістити у swap-простір. Хоча точна логіка є складною оптимізацією, на цей процес прийняття рішень впливають певні ключові фактори:
- Шаблони доступу до сторінок (як часто сторінки використовуються)
- "Забрудненість" сторінок (чи були сторінки модифіковані)
- Тиск на памʼять (наскільки терміново системі потрібна вільна памʼять)
Анонімна памʼять проти памʼяті, що підтримується файлами
Важливо розуміти, що не всі сторінки памʼяті однакові. Ядро розрізняє анонімну памʼять та памʼять з файловою підтримкою.
Анонімна памʼять: Це памʼять, яка не підтримується конкретним файлом на диску, така як купа та стек програми. З точки зору програми це приватна памʼять, і коли ядру потрібно звільнити ці сторінки, воно повинно записати їх на спеціально відведений пристрій swap.
Памʼять з файловою підтримкою: Ця памʼять підтримується файлом у файловій системі. Сюди входять виконуваний код програми, спільні бібліотеки та кеші файлової системи. Коли ядру потрібно звільнити ці сторінки, воно може просто відкинути їх, якщо вони не були модифіковані ("чисті"). Якщо сторінка була модифікована ("брудна"), ядро спочатку повинно записати зміни назад у файл, перш ніж її можна буде відкинути.
Хоча система без swap все ще може звільняти памʼять з чистими файлами під тиском, скидаючи їх, у неї немає способу скинути анонімну памʼять. Увімкнення swap надає цю можливість, дозволяючи ядру переміщати менш часто використовувані сторінки памʼяті на диск, щоб зберегти памʼять і уникнути використання механізму OOM-очищення системи.
Ключові параметри ядра для налаштування swap
Щоб ефективно налаштувати поведінку swap, Linux надає кілька параметрів ядра, якими можна керувати за допомогою sysctl.
vm.swappiness: Це найвідоміший параметр. Це значення від 0 до 200 (100 у старіших ядрах), яке контролює перевагу ядра для обміну анонімними сторінками памʼяті проти відновлення сторінок памʼяті з файловою підтримкою (кеш сторінок).- Високе значення (наприклад, 90+): Ядро буде агресивно переміщувати в своп менш використовувану анонімну памʼять, щоб звільнити місце для кешу файлів.
- Низьке значення (наприклад, < 10): Ядро буде намагатися в першу чергу скинути сторінки кешу файлів, а не робити своп анонімній памʼяті.
vm.min_free_kbytes: Цей параметр вказує ядру зберігати мінімальну кількість памʼяті вільною як буфер. Коли кількість вільної памʼяті падає нижче цього буфера безпеки, ядро починає більш агресивно відновлювати сторінки (робити їх своп, а врешті-решт виконувати OOM-очищення).- Функція: Це діє як запобіжник, щоб забезпечити ядру достатньо памʼяті для критичних запитів на виділення, які не можуть бути відкладені.
- Вплив на swap: Встановлення більшого
min_free_kbytesефективно підвищує мінімальне значення для вільної памʼяті, змушуючи ядро раніше ініціювати своп під час тиску на памʼять.
vm.watermark_scale_factor: Ця настройка контролює проміжок між різними водяними знаками:min,lowтаhigh, які обчислюються на основіmin_free_kbytes.- Пояснення водяних знаків:
low: Коли вільна памʼять нижча за цю позначку, процес ядраkswapdпрокидається, щоб відновити сторінки у фоновому режимі. Саме тоді починається цикл свопу.min: Коли вільна памʼять досягає цього мінімального рівня, агресивне відновлення сторінок блокує виділення процесів. Нездатність відновити сторінки призведе до OOM-очищень.high: Відновлення памʼяті зупиняється, як тільки вільна памʼять досягає цього рівня.
- Вплив: Більший
watermark_scale_factorстворює більший буфер між водяними знакамиlowтаmin. Це даєkswapdбільше часу для поступового відновлення памʼяті, перш ніж система потрапить у критичний стан.
- Пояснення водяних знаків:
У типовому серверному робочому навантаженні у вас може бути довготривалий процес з деякою памʼяттю, яка стає "холодною". Вищий показник swappiness може звільнити RAM, обмінюючи холодну памʼять, для інших активних процесів, які можуть виграти від збереження свого кешу файлів.
Налаштування параметрів min_free_kbytes та watermark_scale_factor для раннього переміщення вікна обміну надасть більше місця для kswapd, щоб скинути памʼять на диск і запобігти OOM-очищенням під час раптових сплесків потреби в памʼяті.
Тести та результати свопу
Щоб зрозуміти реальний вплив цих параметрів, ми провели серію стрес-тестів.
Налаштування тесту
- Середовище: GKE на Google Cloud
- Версія Kubernetes: 1.33.2
- Конфігурація вузла:
n2-standard-2(8GiB RAM, 50GB swap на дискуpd-balanced, без шифрування), Ubuntu 22.04 - Робоче навантаження: Спеціально розроблена програма на Go, призначена для виділення памʼяті з налаштовуваною швидкістю, створення тиску на кеш файлів та імітації різних шаблонів доступу до памʼяті (випадковий проти послідовного).
- Моніторинг: Контейнер-сайдкар, що захоплює системні метрики щосекунди.
- Захист: Критичним системним компонентам (kubelet, середовище запуску контейнерів, sshd) було заборонено використовувати swap, встановивши
memory.swap.max=0у їхніх відповідних cgroups.
Методологія тестування
Був запущений под зі стрес-тестом на вузлах з різними налаштуваннями swappiness (0, 60 та 90) з варіюванням параметрів min_free_kbytes та watermark_scale_factor, щоб спостерігати за результатами під час сильного виділення памʼяті та тиску введення/виведення.
Візуалізація роботи свопу
Графік нижче, з тесту на стрес з швидкістю 100MBps, показує роботу swap. Коли вільна памʼять (на графіку "Використання памʼяті") зменшується, використання swap (Використано swap (GiB)) та активність swap-виводу (Swap Out (MiB/s)) зростають. Критично, оскільки система більше покладається на swap, також зростає I/O активність та відповідний час очікування (IO Wait % на графіку "Використання CPU"), що вказує на навантаження на CPU.

Висновки
Мої початкові тести з типовими параметрами ядра (swappiness=60, min_free_kbytes=68MB, watermark_scale_factor=10) швидко призвели до OOM-очищень і навіть несподіваних перезавантажень вузлів під час високого навантаження на памʼять. З вибором відповідних параметрів ядра можна досягти хорошого балансу між стабільністю вузла та продуктивністю.
Вплив swappiness
Параметр swappiness безпосередньо впливає на вибір ядра між відновленням анонімної памʼяті (свопом) та скиданням кешу сторінок. Щоб це спостерігати, я провів тест, у якому один под створював та утримував тиск на кеш файлів, після чого другий под виділяв анонімну памʼять зі швидкістю 100MB/s, щоб спостерігати за налаштуваннями ядра у відновленні:
Мої висновки виявили чіткий компроміс:
swappiness=90: Ядро проактивно робило своп неактивної анонімної памʼяті, щоб зберегти кеш файлів. Це призвело до високого та стабільного використання swap та значної I/O активності ("Blocks Out"), що, в свою чергу, викликало сплески очікування I/O на CPU.swappiness=0: Ядро надавало перевагу скиданню сторінок кешу файлів, затримуючи споживання swap. Однак важливо розуміти, що це не вимикає своп. Коли тиск на памʼять був високим, ядро все ще робило своп анонімної памʼяті на диск.
Вибір залежить від робочого навантаження. Для робочих навантажень, чутливих до затримок введення/виведення, бажано нижче значення swappiness. Для робочих навантажень, які покладаються на великий та часто використовуваний кеш файлів, може бути корисним вищий показник swappiness, за умови, що диск достатньо швидкий, щоб впоратися з навантаженням.
Налаштування водяних знаків для запобігання виселенню та OOM kills
Найбільшою проблемою, з якою я зіткнувся, було взаємодія між швидким виділенням памʼяті та механізмом виселення Kubelet. Коли мій тестовий под, який навмисно був налаштований на перевищення памʼяті, виділяв її високими темпами (наприклад, 300-500 MBps), система швидко залишалася без вільної памʼяті.
Стандартно буфер для відновлення був занадто малим. Перш ніж kswapd встигав звільнити достатньо памʼяті шляхом свопу, вузол потрапляв у критичний стан, що призводило до двох можливих наслідків:
- Виселення Kubelet Якщо менеджер виселення kubelet виявляв, що
memory.availableнижче його порогу, він виселяв под. - OOM-очищення У деяких сценаріях з високою швидкістю OOM-очищення активувалось би раніше, ніж виселення встигало завершитися, іноді вбиваючи поди вищого пріоритету, які не були джерелом тиску.
Щоб помʼякшити це, я налаштував водяні знаки:
- Збільшено
min_free_kbytesдо 512MiB: Це змушує ядро почати відновлення памʼяті набагато раніше, забезпечуючи більший буфер безпеки. - Збільшено
watermark_scale_factorдо 2000: Це розширило проміжок між водяними знакамиlowтаhigh(з ≈337MB до ≈591MB у моєму тестовому вузлі в/proc/zoneinfo), ефективно збільшуючи вікно обміну.
Ця комбінація надала kswapd більшу операційну зону та більше часу для обміну сторінок на диск під час сплесків памʼяті, успішно запобігаючи як передчасним виселенням, так і OOM-очищенням у моїх тестових запусках.
Таблиця порівнює рівні водяних знаків з /proc/zoneinfo (недоступний NUMA-узел):
min_free_kbytes=67584KiB та watermark_scale_factor=10 | min_free_kbytes=524288KiB та watermark_scale_factor=2000 |
|---|---|
| Вузол 0, зона Нормальна вільні сторінки 583273 підвищення 0 мін 10504 низький 13130 високий 15756 охоплено 1310720 присутній 1310720 керується 1265603 | Вузол 0, зона Нормальна вільні сторінки 470539 мін 82109 низький 337017 високий 591925 охоплено 1310720 присутній 1310720 керується 1274542 |
Графік нижче показує, що розмір буфера ядра та коефіцієнт масштабування відіграють вирішальну роль у визначенні того, як система реагує на навантаження на памʼять. З правильним поєднанням цих параметрів система може ефективно використовувати простір swap, щоб уникнути виселення та підтримувати стабільність.

Ризики та рекомендації
Увімкнення swap у Kubernetes є потужним інструментом, але воно повʼязане з ризиками, якими потрібно управляти за допомогою ретельного налаштування.
Ризик погіршення продуктивності Своп значно повільніший, ніж доступ до RAM. Якщо активний робочий набір програми буде переміщено до свопу, її продуктивність різко постраждає через високі часи очікування введення/виведення (thrashing). Своп бажано забезпечити сховищем на базі SSD для покращення продуктивності.
Ризик маскування витоків пам'яті Своп може приховати витоки памʼяті в програмах, які інакше призвели б до швидкого OOM-очищення. З свопом програма з протіканням памʼяті може повільно погіршувати продуктивність вузла з часом, ускладнюючи діагностику першопричини.
Ризик відключення виселень Kubelet активно моніторить вузол на предмет тиску на памʼять та завершує поди, щоб відновити ресурси. Неправильне налаштування може призвести до OOM-очищень до того, як kubelet матиме можливість виселити поди відповідним чином. Правильно налаштований
min_free_kbytesє критично важливим для забезпечення ефективності механізму виселення kubelet.
Kubernetes context
Разом, водяні знаки ядра та поріг виселення kubelet створюють серію зон тиску памʼяті на вузлі. Параметри порогу виселення потрібно відрегулювати, щоб налаштувати керовані Kubernetes виселення, які відбуваються до OOM-очищення.

Як показано на діаграмі, ідеальна конфігурація полягає в тому, щоб створити достатньо велике "вікно обміну" (між водяними знаками high та min), щоб ядро могло обробляти тиск памʼяті шляхом свопу, перш ніж доступна памʼять впаде в зону виселення/прямого відновлення.
Рекомендована точка відліку
На основі цих висновків, я рекомендую наступне як відправну точку для вузлів Linux з увімкненим swap. Вам слід провести тестування продуктивності з вашими власними робочими навантаженнями.
vm.swappiness=60: Linux стандартно є хорошою відправною точкою для загальних робочих навантажень. Однак, ідеальне значення залежить від робочого навантаження, і застосунки, чутливі до swap, можуть потребувати більш ретельного налаштування.vm.min_free_kbytes=500000(500MB): Встановіть це на досить високе значення (наприклад, 2-3% від загальної памʼяті вузла), щоб забезпечити розумний буфер безпеки.vm.watermark_scale_factor=2000: Створіть більше вікно для роботиkswapd, запобігаючи OOM kills під час раптових сплесків виділення памʼяті.
Я рекомендую проводити тести продуктивності з вашими власними робочими навантаженнями в тестових середовищах при першому налаштуванні swap у вашому кластері Kubernetes. Продуктивність swap може бути чутливою до різних особливостей середовища, таких як навантаження на CPU, тип диска (SSD проти HDD) та шаблони введення/виведення.
Попередній огляд Kubernetes v1.34
Kubernetes v1.34 очікукється наприкінці серпня 2025 року. Хоча він не міститиме видалень чи застарівань, у ньому буде велика кількість покращень. Ось деякі з функцій, які нас найбільше зацікавили в цьому циклі!
Зверніть увагу, що ця інформація відображає поточний стан розробки v1.34 і може змінитися до випуску нової версії.
Основні покращення Kubernetes v1.34
Нижче наведено деякі з помітних покращень, які, ймовірно, будуть включені до випуску v1.34, але це не вичерпний перелік усіх запланованих змін, і вміст релізу може змінюватися.
Ядро DRA переходить у стабільний стан
Динамічний розподіл ресурсів (DRA) забезпечує гнучкий спосіб категоризації, подання заявок та використання пристроїв, таких як GPU або спеціалізоване обладнання, у вашому кластері Kubernetes.
З моменту випуску v1.30 DRA базується на заявках на пристрої із структурованими параметрами, які є непрозорими для ядра Kubernetes. Відповідна пропозиція (KEP-4381) щодо покращення, була створена під впливом концепцій динамічного виділення сховищ. DRA зі структурованими параметрами використовує набір допоміжних API-типів: ResourceClaim, DeviceClass, ResourceClaimTemplate та ResourceSlice у групі resource.k8s.io, а також розширює .spec для Pod новим полем resourceClaims. Ядро DRA планує перейти у стабільний стан у Kubernetes v1.34.
З DRA драйвери пристроїв та адміністратори кластерів визначають класи пристроїв, доступні для використання. Робочі навантаження можуть подавати заявки на пристрої із зазначенням класу пристроїв у запитах. Kubernetes виділяє відповідні пристрої для конкретних заявок і розміщує відповідні Podʼи на вузлах, які мають доступ до виділених пристроїв. Ця система забезпечує гнучку фільтрацію пристроїв за допомогою CEL, централізовану категоризацію пристроїв та спрощені запити Podʼів.
Після переходу цієї функції у стабільний стан API resource.k8s.io/v1 буде стандартно доступний.
Токени ServiceAccount для автентифікації для завантаження образів
Інтеграція токенів ServiceAccount для провайдерів облікових даних kubelet ймовірно досягне бета-стадії та буде стандартно увімкнена у Kubernetes v1.34. Це дозволяє kubelet використовувати ці токени для завантаження контейнерних образів з реєстрів, які потребують автентифікації.
Підтримка вже існує як alpha і відстежується у KEP-4412.
Alpha-інтеграція дозволяє kubelet використовувати короткострокові, токени ServiceAccount (з OIDC-сумісною семантикою) з автоматичною ротацією для автентифікації у реєстрі контейнерних образів. Кожен токен прив’язаний до відповідного Podʼа; механізм замінює потребу у довгострокових секретах для завантаження образів.
Впровадження цього підходу знижує ризики безпеки, підтримує ідентичність на рівні робочого навантаження та зменшує операційні витрати. Це наближає автентифікацію при завантаженні образів до сучасних практик.
Політика заміни Pod в Deployment
Після змін в Deployment завершення Podʼів може тривати певний час і споживати додаткові ресурси. У рамках KEP-3973 буде додано поле .spec.podReplacementPolicy (як alpha) для Deployment.
Якщо функція увімкнена у вашому кластері, ви зможете обрати одну з двох політик:
TerminationStarted- Створює нові Podʼи, як тільки старі починають процес завершення роботи, що прискорює оновлення, але може збільшити споживання ресурсів.
TerminationComplete- Чекає повного завершення роботи старих Podʼів перед створенням нових, що забезпечує контрольоване споживання ресурсів.
Ця функція робить поведінку Deployment більш передбачуваною, дозволяючи обирати, коли створювати нові Podʼи, під час оновлення чи масштабування. Це корисно для кластерів із обмеженими ресурсами або для навантажень із тривалим часом завершенням.
Очікується, що функція буде доступна як alpha і може бути увімкнена через функціональні можливості DeploymentPodReplacementPolicy та DeploymentReplicaSetTerminatingReplicas в API-сервері та kube-controller-manager.
Готовий до промислового використання трейсинг для kubelet та API Server
Для вирішення проблеми налагодження на рівні вузла шляхом зіставлення розрізнених логів, KEP-2831 забезпечує глибоке, контекстне розуміння роботи kubelet.
Функція інструментує критичні операції kubelet, особливо gRPC-виклики до Container Runtime Interface (CRI), використовуючи стандарт OpenTelemetry. Це дозволяє операторам візуалізувати весь життєвий цикл подій (наприклад, запуск Podʼів) для визначення джерел затримок та помилок. Найпотужніша частина — передача trace ID у запитах до контейнерного рушія, що дозволяє їм зв’язувати свої власні відрізки.
Це доповнюється паралельним покращенням, KEP-647, яке приносить такі ж можливості трейсингу до API-сервера Kubernetes. Разом ці покращення забезпечують більш цілісний, наскрізний огляд подій, спрощуючи пошук затримок та помилок від панелі управління до вузла. Обидві функції пройшли офіційний процес релізу Kubernetes. KEP-2831 був представлений як alpha у v1.25, а KEP-647 — як alpha у v1.22. Обидва були підвищені до beta у v1.27. У v1.34 планується, що вони перейдуть у стабільний стан.
PreferSameZone та PreferSameNode для розподілу трафіку у Service
Поле spec.trafficDistribution у Service дозволяє вказати переваги щодо маршрутизації трафіку до точок доступу Service.
KEP-3015 визнає застарілим PreferClose та додає два нових значення: PreferSameZone та PreferSameNode. PreferSameZone еквівалентний поточному PreferClose. PreferSameNode надає перевагу надсиланню трафіку до точок доступу на тому ж вузлі, що й клієнт.
Функція була представлена у v1.33 функціональною можливістю PreferSameTrafficDistribution. У v1.34 вона планує перейти у beta зі стандартним її увімкненням.
Підтримка KYAML: діалекту YAML для Kubernetes
KYAML — це безпечніша та менш неоднозначна підмножина YAML, спеціально розроблена для Kubernetes. Незалежно від версії Kubernetes, ви зможете використовувати KYAML для написання маніфестів чи Helm-чартів. Ви можете писати KYAML і передавати його як вхідні дані у будь-яку версію kubectl, оскільки всі KYAML-файли також є валідними YAML. З kubectl v1.34 очікується можливість запитувати вивід у форматі KYAML (kubectl get -o kyaml …). За бажанням, ви можете й надалі отримувати вихід у форматі JSON або YAML.
KYAML вирішує специфічні проблеми YAML та JSON. У YAML значущі пробіли вимагають уважності до відступів та вкладеності, а необов’язкове взяття рядків в лапки може призвести до неочікуваного приведення типів (наприклад, "The Norway Bug"). JSON не підтримує коментарі та має суворі вимоги до ком та ключів в лапках.
KEP-5295 представляє KYAML, який вирішує основні проблеми:
Обовʼязкове використання подвійних лапок для рядкових (string) значень
Не вказувати ключі в лапках, якщо вони не є потенційно неоднозначними
Завжди використовує
{}для відображень (асоціативних масивів)Завжди використовує
[]для списків
Це схоже на JSON, але на відміну від JSON, KYAML підтримує коментарі, дозволяє коми у кінці та не вимагає лапок для ключів.
Очікуємо, що KYAML буде представлений як новий формат виводу для kubectl v1.34. Як і для всіх цих функцій, жодна з них не гарантована; слідкуйте за оновленнями!
KYAML є і залишатиметься строгою підмножиною YAML, що гарантує можливість парсингу KYAML-документів будь-яким YAML-парсером. Kubernetes не вимагає спеціального формату KYAML для вхідних даних, і змінювати це не планується.
Точне регулювання автоматичного масштабування з налаштовуваною толерантністю HPA
KEP-4951 додає можливість налаштовувати толерантність автомасштабування для кожного HPA окремо, замість стандартного кластерного значення 10%, яке часто є занадто грубим для різних навантажень. Покращення додає необов’язкове поле tolerance до секцій spec.behavior.scaleUp та spec.behavior.scaleDown HPA, дозволяючи різні значення толерантності для масштабування вгору та вниз, що особливо корисно, оскільки чутливість до масштабування вгору зазвичай важливіша для обробки піків трафіку.
Функція була випущена як alpha у Kubernetes v1.33 з функціональною можливістю HPAConfigurableTolerance, а у v1.34 планує перейти у beta. Це покращення допомагає вирішити проблеми масштабування для великих розгортань, де толерантність для масштабування вниз на 10% може означати те, що в роботі залишаться сотні зайвих Podʼів. Новий підхід дозволяє оптимізувати поведінку для кожного навантаження окремо.
Хочете дізнатися більше?
Нові функції та застарівання також оголошуються у нотатках до релізу Kubernetes. Офіційний анонс новинок у Kubernetes v1.34 буде частиною CHANGELOG для цього випуску.
Випуск Kubernetes v1.34 заплановано на середу, 27 серпня 2025 року. Слідкуйте за оновленнями!
Долучайтеся
Найпростіший спосіб долучитися до Kubernetes — приєднатися до однієї з багатьох Special Interest Groups (SIG), які відповідають вашим інтересам. Маєте щось, чим хочете поділитися з Kubernetes-спільнотою? Висловіть свою думку на щотижневій community meeting та через канали нижче. Дякуємо за ваші відгуки та підтримку!
- Слідкуйте за нами у Bluesky @kubernetes.io для останніх новин
- Долучайтеся до обговорень на Discuss
- Долучайтеся до спільноти у Slack
- Ставте питання (або відповідайте на них) на Server Fault або Stack Overflow
- Поділіться своєю Kubernetes історією
- Читайте більше про події у Kubernetes на блозі
- Дізнайтеся більше про Kubernetes Release Team
Оголошення про випуск etcd v3.6.0
Це оголошення спочатку було опубліковане в блозі etcd.
Сьогодні ми випускаємо etcd v3.6.0, перший мінорний реліз з моменту випуску etcd v3.5.0 15 червня 2021 року. Цей реліз вводить кілька нових функцій, робить значний прогрес у тривалих зусиллях, таких як підтримка зниження версії та міграція на v3store, і вирішує численні критичні та основні проблеми. Він також включає великі оптимізації в використанні памʼяті, покращуючи ефективність і продуктивність.
На додачу до функцій v3.6.0, etcd приєднався до Kubernetes як SIG (sig-etcd), що дозволяє нам покращити стійкість проєкту. Ми впровадили систематичне тестування на надійність, щоб забезпечити правильність і надійність. За допомоги робочої групи etcd-operator ми плануємо також покращити зручність використання.
Далі наведені найзначніші зміни в etcd v3.6.0, а також обговорення планів майбутнього розвитку. Для детального списку змін, будь ласка, зверніться до CHANGELOG-3.6.
Щира подяка всім учасникам, які зробили цей реліз можливим!
Безпека
etcd ставиться до безпеки серйозно. Щоб підвищити безпеку програмного забезпечення в v3.6.0, ми покращили наші перевірки робочого процесу, інтегрувавши govulncheck для сканування вихідного коду та trivy для сканування контейнерних образів. Ці покращення також були перенесені на підтримувані стабільні релізи.
etcd продовжує дотримуватися процесу безпеки випуску для забезпечення належного управління та вирішення вразливостей.
Функції
Міграція на v3store
v2store був визнаний застарілим з моменту випуску etcd v3.4, але його все ще можна було активувати за допомогою --enable-v2. Він залишався джерелом істини для даних про членство. У etcd v3.6.0 v2store більше не може бути активований, оскільки прапорець --enable-v2 був видалений, а v3store став єдиним джерелом істини для даних про членство.
Хоча v2store все ще існує в v3.6.0, etcd не зможе запуститися, якщо він міститиме будь-які дані, крім інформації про членство. Щоб допомогти з міграцією, etcd v3.5.18+ надає команду etcdutl check v2store, яка перевіряє, чи містить v2store лише дані про членство (див. PR 19113).
У порівнянні з v2store, v3store пропонує кращу продуктивність і транзакційну підтримку. Він також є системою зберігання, що перебуває в стані активної підтримки, що просувається вперед.
Видалення v2store все ще триває і відстежується в issues/12913.
Зниження версії
etcd v3.6.0 — це перша версія, яка повністю підтримує зниження версії. Зусилля для цього завдання зниження версії охоплюють обидві версії 3.5 і 3.6, а вся повʼязана робота відстежується в issues/11716.
На високому рівні процес охоплює міграцію схеми даних до цільової версії (наприклад, v3.5), а потім — поетапне зниження версії.
Переконайтеся, що кластер справний, і зробіть резервну копію знімка. Переконайтеся, що пониження до нижчого рівня є дійсним:
$ etcdctl downgrade validate 3.5
Downgrade validate success, cluster version 3.6
Якщо пониження є валідним, увімкніть режим пониження:
$ etcdctl downgrade enable 3.5
Downgrade enable success, cluster version 3.6
etcd перенесе схему даних у фоновому режимі. Після завершення перейдіть до поетапного оновлення.
За деталями звертайтесь до керівництва Downgrade-3.6.
Функціональні можливості
У etcd v3.6.0 ми впровадили функціональні можливості в стилі Kubernetes для управління новими функціями. Раніше ми вказували на нестабільні функції через префікс --experimental у назвах прапорців функцій. Префікс видалявся після стабілізації функції, що призводило до зламу. Тепер функції починаються з Alpha, переходять в Beta, потім GA або застарівають. Це забезпечує набагато плавніший процес оновлення та зниження версії для користувачів.
Дивіться feature-gates для деталей.
Перевірки livez / readyz
etcd тепер підтримує точки доступу /livez і /readyz, що відповідає перевіркам життєздатності та готовності в Kubernetes. /livez вказує, чи є екземпляр etcd життєздатним, тоді як /readyz вказує, коли він готовий обслуговувати запити. Ця функція також була перенесена на release-3.5 (починаючи з v3.5.11) і release-3.4 (починаючи з v3.4.29). Дивіться livez/readyz для деталей.
Наявна точка доступу /health залишається функціональною. /livez подібна до /health?serializable=true, тоді як /readyz подібна до /health або /health?serializable=false. Очевидно, що точки доступу /livez і /readyz надають чіткішу семантику і легші для розуміння.
v3discovery
В etcd v3.6.0 був представлений новий протокол виявлення v3discovery, заснований на clientv3. Він полегшує виявлення всіх членів кластера під час фази початкового завантаження.
Попередній протокол v2discovery, заснований на clientv2, був визнаний застарілим. Крім того, публічна служба виявлення за адресою https://discovery.etcd.io/, яка покладалася на v2discovery, більше не підтримується.
Продуктивність
Памʼять
У цьому випуску ми зменшили середнє споживання памʼяті щонайменше на 50% (див. Зображення 1). Це покращення в основному зумовлено двома змінами:
- Стандартне значення для
--snapshot-countбуло зменшено з 100 000 у v3.5 до 10 000 у v3.6. В результаті etcd v3.6 тепер зберігає лише 10% історичних записів у порівнянні з v3.5. - Історія Raft стискається частіше, про що йдеться в PR/18825.
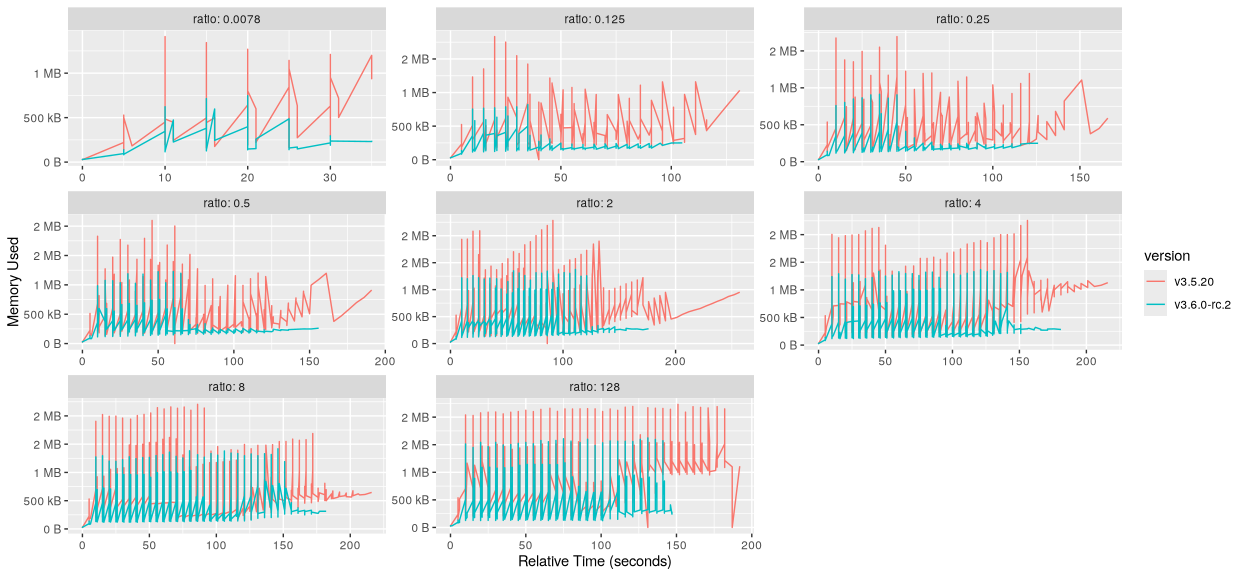
Зображення 1: Порівняння використання памʼяті між etcd v3.5.20 і v3.6.0-rc.2 за різними співвідношеннями читання/запису. Кожен графік показує використання памʼяті з часом з певним співвідношенням читання/запису. Червона лінія представляє etcd v3.5.20, тоді як бірюзова лінія представляє v3.6.0-rc.2. У всіх протестованих співвідношеннях v3.6.0-rc.2 демонструє нижче і більш стабільне використання памʼяті.
Пропускна здатність
У порівнянні з v3.5, etcd v3.6 забезпечує середнє поліпшення продуктивності приблизно на 10% як у читанні, так і в запису (див. Зображення 2, 3, 4 і 5). Це поліпшення не повʼязане з жодною окремою великою зміною, а є кумулятивним ефектом кількох незначних вдосконалень. Одним з таких прикладів є оптимізація запитів до вільних сторінок, введена в PR/419.
Зображення 2: Порівняння пропускної здатності читання між etcd v3.5.20 і v3.6.0-rc.2 за високого коефіцієнта запису. Коефіцієнт читання/запису становить 0.0078, що означає 1 читання на 128 записів. Права смуга показує відсоткове поліпшення пропускної здатності читання v3.6.0-rc.2 в порівнянні з v3.5.20, яке коливається від 3.21% до 25.59%.
Зображення 3: Порівняння пропускної здатності читання між etcd v3.5.20 і v3.6.0-rc.2 за високого коефіцієнта читання. Коефіцієнт читання/запису становить 8, що означає 8 читань на 1 запис. Права смуга показує відсоткове поліпшення пропускної здатності читання v3.6.0-rc.2 в порівнянні з v3.5.20, яке коливається від 4.38% до 27.20%.
Зображення 4: Порівняння пропускної здатності запису між etcd v3.5.20 і v3.6.0-rc.2 за високого коефіцієнта запису. Коефіцієнт читання/запису становить 0.0078, що означає 1 читання на 128 записів. Права смуга показує відсоткове поліпшення пропускної здатності запису v3.6.0-rc.2 в порівнянні з v3.5.20, яке коливається від 2.95% до 24.24%.
Зображення 5: Порівняння пропускної здатності запису між etcd v3.5.20 і v3.6.0-rc.2 за високого коефіцієнта читання. Коефіцієнт читання/запису становить 8, що означає 8 читань на 1 запис. Права смуга показує відсоткове поліпшення пропускної здатності запису v3.6.0-rc.2 в порівнянні з v3.5.20, яке коливається від 3.86% до 28.37%.
Кардинальні зміни
У цьому розділі висвітлено кілька важливих змін. Повний список можна знайти у Оновлення з v3.5 до v3.6 та CHANGELOG-3.6.
Старі бінарні файли несумісні з новими версіями схем
Старі бінарні файли etcd несумісні з новими версіями схем даних. Наприклад, etcd 3.5 не може бути запущений з даними, створеними etcd 3.6, а etcd 3.4 не може бути запущений з даними, створеними як 3.5, так і 3.6.
При пониженні версії etcd важливо дотримуватися задокументованої процедури пониження. Просте заміщення бінарного файлу або образу призведе до проблеми несумісності.
Точки доступу учасників більше не обслуговують запити клієнтів
Точки доступу клієнтів (--advertise-client-urls) призначені лише для обслуговування запитів клієнтів, тоді як точки доступу учасників (--initial-advertise-peer-urls) призначені виключно для звʼязку між учасниками. Однак через недогляд у реалізації точки доступу учасників також могли обробляти запити клієнтів в etcd 3.4 і 3.5. Ця поведінка була оманливою і сприяла неправильним шаблонам використання. У etcd 3.6 ця оманлива поведінка була виправлена за допомогою PR/13565; точки доступу учасників більше не обслуговують запити клієнтів.
Чітка межа між etcdctl і etcdutl
Обидва etcdctl і etcdutl є інструментами командного рядка. etcdutl є офлайн-утилітою, призначеною для роботи безпосередньо з файлами даних etcd, тоді як etcdctl є онлайн-інструментом, який взаємодіє з etcd через мережу. Раніше між ними існували деякі перекриття функціональності, але ці перекриття були усунені в 3.6.0.
Вилучено
etcdctl defrag --data-dir.Команда
etcdctl defragпідтримує лише онлайн-дефрагментацію і більше не підтримує офлайн-дефрагментацію. Щоб виконати офлайн-дефрагментацію, використовуйте командуetcdutl defrag --data-dir.Вилучено
etcdctl snapshot statusetcdctlбільше не підтримує отримання статусу знімка. Використовуйте командуetcdutl snapshot statusзамість цього.Вилучено
etcdctl snapshot restoreetcdctlбільше не підтримує відновлення з знімка. Використовуйте командуetcdutl snapshot restoreзамість цього.
Виправлення критичних помилок
Коректність завжди була основним пріоритетом для проєкту etcd. У процесі розробки 3.6.0 ми знайшли та виправили кілька помітних помилок, які могли призвести до неузгодженості даних у певних випадках. Ці виправлення були перенесені до попередніх версій, але ми вважаємо, що вони заслуговують на окрему згадку тут.
Неузгодженість даних при аварійному завершенні під навантаженням
Раніше, коли etcd використовував дані, він спочатку оновлював індекс узгодженості, а потім фіксував дані. Однак ці операції не були атомарними. Якщо etcd зазнавав аварії між цими операціями, це могло призвести до неузгодженості даних (див. issue/13766). Цю проблему було введено в v3.5.0 і виправлено в v3.5.3 за допомогою PR/13854.
Порушення гарантії довговічності API в кластері, що складається з одного вузла
Коли клієнт записує дані та отримує успішну відповідь, очікується, що дані будуть збережені. Однак дані можуть бути втрачені, якщо etcd зазнає аварії одразу після надсилання успішної відповіді клієнту. Це була стара проблема (див. issue/14370) яка впливала на всі попередні випуски. Вона була вирішена в v3.4.21 і v3.5.5 за допомогою PR/14400, і виправлена на стороні raft в основній гілці (тепер release-3.6) з PR/14413.
Неузгодженість ревізій при аварійному завершенні під час дефрагментації
Якщо etcd зазнавав аварії під час операції дефрагментації, після перезапуску він міг повторно застосувати деякі записи, які вже були застосовані, що призводило до проблеми з неузгодженістю ревізій (див. обговорення в PR/14685). Ця проблема зʼявилась в v3.5.0 і її було виправлено в v3.5.6 за допомогою PR/14730.
Проблема з оновленням
Цей розділ висвітлює загальну проблему issues/19557 в оновленні etcd з v3.5 до v3.6, яка може призвести до збою процесу оновлення. Для отримання докладних інструкцій з оновлення зверніться до Оновлення etcd з v3.5 до v3.6.
Ця проблема зʼявилась в etcd v3.5.1 і її було вирішено в v3.5.20.
Основні висновки: користувачі повинні спочатку оновитися до etcd v3.5.20 (або вищої патч-версії) перед оновленням до etcd v3.6.0; інакше оновлення може зазнати невдачі.
Для отримання додаткової інформації та технічного контексту див. upgrade_from_3.5_to_3.6_issue.
Тестування
Ми впровадили Тестування на стійкість, щоб перевірити коректність, яка завжди була нашим основним пріоритетом. Тест відтворює трафік різних типів і обсягів на кластері etcd, одночасно впроваджуючи випадкову точку відмови, записує всі операції (включаючи запити та відповіді) і, нарешті, виконує перевірку лінійної узгодженості. Він також перевіряє, що гарантії Watch APIs не були порушені. Тест на стійкість підвищує нашу впевненість у забезпеченні якості кожного випуску etcd.
Ми мігрували більшість тестів робочого процесу etcd до інфраструктури тестування Prow Kubernetes, щоб використати її переваги, такі як зручні інформаційні панелі для перегляду результатів тестування та можливість для учасників повторно запускати невдалі тести самостійно.
Платформи
Зберігаючи всі наявні підтримувані платформи, ми підвищили Linux/ARM64 до рівня підтримки Tier 1. Для отримання додаткової інформації зверніться до issues/15951. Для отримання повного списку підтримуваних платформ, див. supported-platform.
Залежності
Посібник з оновлення залежностей
Ми опублікували офіційний посібник з оновлення залежностей для основної гілки та стабільних випусків etcd. У ньому також описано, як оновити версію для Go. Для отримання більш детальної інформації, будь ласка, зверніться до dependency_management. Тепер, коли цей посібник доступний, будь-хто з учасників може допомогти з оновленням залежностей.
Оновлення основних залежностей
bbolt та raft є двома основними залежностями etcd.
Обидва etcd v3.4 і v3.5 залежать від bbolt v1.3, тоді як etcd v3.6 залежить від bbolt v1.4.
Для гілок release-3.4 і release-3.5 raft включено безпосередньо в репозиторій etcd, тому etcd v3.4 і v3.5 не залежать від зовнішнього модуля raft. Починаючи з etcd v3.6, raft було переміщено до окремого репозиторію (raft), а перший самостійний реліз raft — це v3.6.0. Як наслідок, etcd v3.6.0 залежить від raft v3.6.0.
Будь ласка, дивіться таблицю нижче:
| версії etcd | версії bbolt | версії raft |
|---|---|---|
| 3.4.x | v1.3.x | N/A |
| 3.5.x | v1.3.x | N/A |
| 3.6.x | v1.4.x | v3.6.x |
grpc-gateway@v2
Ми оновили grpc-gateway з v1 до v2 через PR/16595 в etcd v3.6.0. Це є важливим кроком до міграції на protobuf-go, другу основну версію реалізації API протоколу буферизації Go.
grpc-gateway@v2 призначений для роботи з protobuf-go. Однак etcd v3.6 все ще залежить від застарілого gogo/protobuf, який насправді є реалізацією протоколу буферизації v1. Щоб вирішити цю несумісність, ми застосували патч до згенерованих *.pb.gw.go файлів, щоб перетворити повідомлення v1 на повідомлення v2.
grpc-ecosystem/go-grpc-middleware/providers/prometheus
Ми перейшли з застарілого (і архівованого) grpc-ecosystem/go-grpc-prometheus на grpc-ecosystem/go-grpc-middleware/providers/prometheus у PR/19195. Ця зміна забезпечує подальшу підтримку та доступ до останніх функцій і вдосконалень в інтеграції gRPC Prometheus.
Спільнота
В спільноті etcd відбуваються захопливі події, які відображають нашу постійну прихильність до зміцнення співпраці, покращення підтримки та еволюції управління проєктом.
etcd стає Kubernetes SIG
etcd офіційно став Kubernetes Special Interest Group: SIG-etcd. Ця зміна відображає критичну роль etcd як основного сховища даних для Kubernetes і встановлює більш структуровану та прозору основу для довгострокового управління та співпраці між проєктами. Нова SIG допоможе спростити процес прийняття рішень, узгодити плани з потребами Kubernetes, і залучити більше учасників.
Нові учасники, підтримувачі та рецензенти
Ми спостерігали активність, що постійно зростає, з боку учасників, що призвело до додавання трьох нових підтримувачів до команди etcd:
Їхні подальші внески були вирішальними для просування проєкту вперед.
Ми також вітаємо двох нових рецензентів у проєкті:
Ми цінуємо їхню відданість якості коду та готовність взяти на себе ширші обовʼязки з рецензування в межах спільноти.
Нова команда випуску
Ми сформували нову команду випуску, очолювану ivanvc та jmhbnz, спростивши процес випуску шляхом автоматизації багатьох раніше ручних етапів. Надихнувшись Kubernetes SIG Release, ми прийняли кілька найкращих практик, включаючи чітко визначені ролі команди випуску та впровадження "тіней випуску" для підтримки обміну знаннями та стійкості команди. Ці зміни зробили наші випуски більш плавними та надійними, дозволяючи нам підходити до кожного випуску з більшою впевненістю та послідовністю.
Представляємо etcd Operator Working Group
Щоб ще більше покращити операційну досконалість etcd, ми сформували нову робочу групу: WG-etcd-operator. Робоча група присвячена питанням забезпечення автоматичної та ефективної роботи кластерів etcd, які працюють у середовищі Kubernetes за допомогою etcd-оператора.
Майбутній розвиток
v2store був визнаний застарілим з моменту виходу etcd v3.4, а прапорець --enable-v2 був повністю видалений у v3.6. Це означає, що починаючи з v3.6, більше немає способу увімкнути або використовувати v2store. Однак etcd все ще ініціалізується з внутрішніх спадкових знімків v2. Щоб вирішити цю несумісність, ми плануємо змінити etcd на bootstrap з v3store і відтворити записи WAL на основі consistent-index. Ця робота відстежується в issues/12913.
Однією з найпостійніших проблем залишаються великі запити діапазону з kube-apiserver, які можуть призвести до аварійних зупинок процесів через їх непередбачувану природу. Функція потокового діапазону, спочатку описана в v3.5 release blog/Future roadmaps, залишається ідеєю, яку варто переглянути, щоб розвʼязати проблеми з великими запитами діапазону.
Для отримання додаткової інформації та майбутніх планів, будь ласка, зверніться до планів розвитку etcd.
Kubernetes v1.33: Оновлення в життєвому циклі контейнерів в Kubernetes v1.33
У Kubernetes v1.33 представлено декілька оновлень життєвого циклу контейнерів. Дія Sleep для хуків життєвого циклу контейнера тепер підтримує нульову тривалість сну (функція стандартно увімкнена). Також зʼявилася альфа-підтримка для налаштування сигналу зупинки, що надсилається контейнерам при завершенні їхньої роботи.
У цій статті ви дізнаєтеся більше про ці нові аспекти життєвого циклу контейнера і про те, як ними користуватися.
Нульове значення для дії Sleep
У Kubernetes v1.29 введено дію Sleep для хуків життєвого циклу контейнерів PreStop і PostStart. Дія Sleep дозволяє вашим контейнерам призупиняти роботу на певний час після запуску контейнера або перед його завершенням. Це було необхідно для забезпечення простого способу керування відповідним завершенням роботи. До появи дії Sleep люди використовували команду sleep за допомогою дії exec у своїх хуках життєвого циклу контейнера. Якщо ви хочете це зробити, вам потрібно мати двійковий файл для команди sleep в образі вашого контейнера. Це важко зробити, якщо ви використовуєте сторонні образи.
Дія sleep, коли її було додано, спочатку не підтримувала тривалість сну у нуль секунд. Параметр time.Sleep, який приховано використовується дією Sleep, підтримує тривалість сну у нуль секунд. Використання відʼємного або нульового значення для часу сну призводить до негайного повернення, що призводить до невиконання дії. Ми хотіли отримати таку саму поведінку для дії sleep. Цю підтримку нульової тривалості було додано у версії 1.32 за допомогою функціональної можливості PodLifecycleSleepActionAllowZero.
Елемент керування PodLifecycleSleepActionAllowZero перейшов до бета-версії у версії 1.33 і тепер стандартно увімкнений. Оригінальна дія Sleep для хуків preStop і postStart стандартно увімкнена, починаючи з Kubernetes v1.30. У кластері під керуванням Kubernetes v1.33 ви можете встановити нульову тривалість для хуків життєвого циклу сну. Для кластера зі стандартною конфігурацією вам не потрібно вмикати жодних функціональних можливостей, щоб зробити це можливим.
Container stop signals
Такі середовища виконання контейнерів, як containerd та CRI-O, враховують інструкцію StopSignal у визначенні образу контейнера. За допомогою цієї інструкції можна вказати власний сигнал зупинки, який буде використано для завершення роботи контейнерів на основі цього образу. Налаштування сигналу зупинки спочатку не було частиною Pod API у Kubernetes. До версії Kubernetes v1.33 єдиним способом перевизначити сигнал зупинки для контейнерів було перебудувати образ контейнера з новим власним сигналом зупинки (наприклад, вказавши STOPSIGNAL у Containerfile або Dockerfile).
Функціональна можливість ContainerStopSignals, яка була додана у Kubernetes v1.33, додає сигнали зупинки до API Kubernetes. Це дозволяє користувачам вказати власний сигнал зупинки в специфікації контейнера. Сигнали зупинки додаються до API як новий життєвий цикл разом з існуючими обробниками життєвого циклу PreStop та PostStart. Для того, щоб використовувати цю функцію, ми очікуємо, що в Pod буде вказана операційна система за допомогою spec.os.name. Це необхідно для того, щоб ми могли перехресно перевірити сигнал зупинки на відповідність операційній системі і переконатися, що контейнери в Pod створюються з правильним сигналом зупинки для операційної системи, для якої планується створення Pod. Для Podʼів, запланованих на вузлах Windows, допустимими сигналами зупинки є лише SIGTERM і SIGKILL. Повний список сигналів, що підтримуються на вузлах Linux, можна знайти тут.
Стандартна поведінка
Якщо у життєвому циклі контейнера визначено власний сигнал зупинки, то для завершення роботи контейнера буде використано сигнал, визначений у життєвому циклі, враховуючи, що середовище виконання контейнера також підтримує власні сигнали зупинки. Якщо у життєвому циклі контейнера не визначено спеціального сигналу зупинки, програма виконання повернеться до сигналу зупинки, визначеного в образі контейнера. Якщо в образі контейнера не визначено жодного сигналу зупинки, буде використано сигнал типовий сигнал зупинки середовища виконання. Стандартним сигналом є SIGTERM як для containerd, так і для CRI-O.
Розбіжності версії
Щоб ця функція працювала належним чином, версії Kubernetes та середовища виконання контейнера повинні підтримувати сигнали зупинки контейнера. Зміни до API Kuberentes та kubelet доступні в альфа-версії, починаючи з v1.33, які можна увімкнути за допомогою функціоналу ContainerStopSignals. Реалізації середовища виконання контейнерів для containerd та CRI-O все ще перебувають у процесі розробки та будуть випущені найближчим часом.
Використання сигналів зупинки контейнера
Щоб увімкнути цю функцію, вам потрібно увімкнути функціональну можливість ContainerStopSignals в kube-apiserver та kubelet. Після того, як у вас є вузли з увімкненим функціоналом, ви можете створювати Podʼи з життєвим циклом StopSignal і правильною назвою ОС, наприклад, таким чином:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
os:
name: linux
containers:
- name: nginx
image: nginx:latest
lifecycle:
stopSignal: SIGUSR1
Зверніть увагу, що сигнал SIGUSR1 у цьому прикладі може бути використаний лише у тому випадку, якщо Pod контейнера заплановано на вузол Linux. Отже, нам потрібно вказати spec.os.name як linux, щоб мати змогу використовувати цей сигнал. Ви зможете налаштувати сигнали SIGTERM і SIGKILL, тільки якщо Pod планується на вузол Windows. Ви також не зможете вказати containers[*].lifecycle.stopSignal, якщо поле spec.os.name дорівнює нулю або не встановлено.
Як долучитися?
Ця функція розроблена SIG Node. Якщо ви зацікавлені в тому, щоб допомогти розвивати цю функцію, поділитися відгуками або взяти участь у будь-яких інших поточних проєктах SIG Node, будь ласка, звʼяжіться з нами!
Ви можете звʼязатися з SIG Node кількома способами:
Ви також можете звʼязатися зі мною напряму:
- GitHub: @sreeram-venkitesh
- Slack: @sreeram.venkitesh
Kubernetes v1.33: Image Pull Policy працює так, як ви завжди вважали!
Image Pull Policy працює так, як ви завжди вважали!
Деякі речі в Kubernetes дивують, і поведінка imagePullPolicy може бути однією з них. Враховуючи, що Kubernetes - це все про запуск podʼів, може бути дивним дізнатися, що вже більш як 10 років існує застереження щодо обмеження доступу podʼів до автентифікованих образів у вигляді issue 18787! Дуже приємно, коли вдається розвʼязати проблему десятирічної давнини.
Примітка:
У цьому блозі ми часто будемо використовувати термін «облікові дані подів». У цьому контексті цей термін, як правило, інкапсулює автентифікаційні дані, які доступні для podʼів, щоб автентифікувати отримання образу контейнера.IfNotPresent, навіть якщо я не повинен його мати
Суть проблеми в тому, що стратегія imagePullPolicy: IfNotPresent робила саме те, що в ній сказано, і нічого більше.
Створімо сценарій. Почнемо з того, що Pod A у Просторі імен X заплановано на Вузол 1 і йому потрібен образ Foo з приватного сховища. Для отримання матеріалу для автентифікації образів pod посилається на Secret 1 у своєму imagePullSecrets. Secret 1 містить необхідні облікові дані для отримання образів з приватного реєстру. Kubelet використає облікові дані з Secret 1, надані Pod A, і отримає образ контейнера Foo з реєстру. Це передбачувана (і безпечна) поведінка. Але тепер все стає цікавіше. Якщо Pod B у Просторі імен Y також заплановано на Вузол 1, трапляються неочікувані (і потенційно небезпечні) речі. Pod B може посилатися на той самий приватний образ, визначаючи політику отримання образу IfNotPresent. Pod B не посилається на Secret 1 (або, у нашому випадку, на будь-який секрет) у своєму imagePullSecrets. Коли Kubelet намагається запустити pod, він дотримується політики IfNotPresent. Kubelet бачить, що образ Foo вже присутній локально, і надасть образ Foo для Pod B. Pod B може запустити образ, навіть якщо він не надав облікових даних, які б дозволили йому спочатку отримати образ.

Використання приватного образу, отриманого іншим подом
Хоча IfNotPresent не повинен витягувати образ Foo, якщо він вже присутній на вузлі, це неправильна позиція безпеки — дозволяти всім podʼам, запланованим на вузлі, мати доступ до раніше отриманих приватних образів, хоча ці поди ніколи не були уповноважені на отримання образу.
IfNotPresent, але тільки якщо я повинен його мати
У Kubernetes v1.33 ми, SIG Auth і SIG Node, нарешті почали вирішувати цю (дійсно стару) проблему і робити перевірку правильно! Основна очікувана поведінка не змінилася. Якщо образ відсутній, Kubelet спробує отримати його. Для цього будуть використані облікові дані, які надаються кожним подом. Це відповідає поведінці до версії 1.33.
Якщо образ присутній, поведінка Kubelet зміниться. Тепер Kubelet перевірятиме облікові дані подів перед тим, як дозволити поду використовувати образ.
Під час доопрацювання цієї функції було враховано продуктивність та стабільність роботи. Поди, що використовують ті самі облікові дані, не потребуватимуть повторної автентифікації. Це також стосується випадків, коли под отримує облікові дані з одного і того ж обʼєкта Kubernetes Secret, навіть коли облікові дані змінюються.
Ніколи не витягувати, а використовувати, якщо дозволено
Опція imagePullPolicy: Never не витягує образи. Однак, якщо образ контейнера вже присутній на вузлі, будь-який pod, який намагатиметься використати приватний образ, повинен буде надати облікові дані, і ці дані потребуватимуть перевірки.
Від подів, які використовують ті самі облікові дані, повторна автентифікація не вимагатиметься. Якщо ви не надасте облікові дані, які раніше використовувалися для успішного отримання образу, вам не буде дозволено використовувати приватний образ.
Завжди витягувати, якщо це дозволено
Політика imagePullPolicy: Always завжди працювала належним чином. Кожного разу, коли запитується образ, запит надсилається до реєстру, і реєстр виконує перевірку автентичності.
У минулому примусове застосування політики витягування образів Always через допуск подів було єдиним способом гарантувати, що ваші приватні образи контейнерів не будуть повторно використані іншими подами на вузлах, які вже витягли образи.
На щастя, це було досить ефективно. Витягувався лише маніфест образу, а не сам образ. Однак, це все одно було повʼязано з певними витратами і ризиками. Під час нового розгортання, масштабування або перезапуску вузла, реєстр образів, який надав образ, ПОВИНЕН бути доступним для перевірки автентичності, що ставить реєстр образів на критичний шлях для стабільності сервісів, запущених всередині кластера.
Як це все працює
Ця функція базується на постійних файлових кешах, які присутні на кожному з вузлів. Нижче наведено спрощений опис роботи цієї функції. Повну версію можна знайти у KEP-2535.
Процес першого запиту образу виглядає наступним чином:
- На вузлі заплановано под, який запитує образ з приватного реєстру.
- Образ відсутній на вузлі.
- Kubelet робить запис про намір отримати образ.
- Kubelet витягує облікові дані з Секрету Kubernetes, на який посилається вузол як на секрет для отримання образу, і використовує їх для отримання образу з приватного реєстру.
- Після того, як образ успішно отримано, Kubelet робить запис про успішне отримання. Цей запис містить деталі про використані облікові дані (у вигляді хешу), а також Секрет, з якого вони були отримані.
- Kubelet видаляє початковий запис про наміри.
- Kubelet зберігає запис про успішне витягування для подальшого використання.
Коли майбутні поди, заплановані на той самий вузол, запитують раніше витягнутий приватний образ:
- Kubelet перевіряє облікові дані, які надає для витягування новий под.
- Якщо хеш цих облікових даних або Секрет джерела облікових даних збігається з хешем або Секретом джерела, які були записані для попереднього успішного витягування, поду дозволяється використовувати раніше витягнутий образ.
- Якщо облікові дані або їх Секрет джерела не знайдено у записах успішних витягувань для цього образу, Kubelet спробує використати ці нові облікові дані для запиту витягування з віддаленого реєстру, запускаючи потік авторизації.
Спробуйте
У Kubernetes v1.33 ми випустили альфа-версію цієї можливості. Щоб випробувати її, увімкніть функціональну можливість KubeletEnsureSecretPulledImages для вашого Kubelet версії 1.33.
Ви можете дізнатися більше про цю можливість та додаткові опціональні налаштування на сторінці концепції Образ контейнера в офіційній документації Kubernetes.
Що далі?
У наступних випусках ми збираємося:
- Зробити так, щоб ця можливість працювала разом з Projected service account tokens for Kubelet image credentials providers, який додає нове, специфічне для робочого навантаження джерело облікових даних для витягування образів.
- Написати набір для проведення тестування, щоб виміряти продуктивність цієї функції та оцінити вплив будь-яких майбутніх змін.
- Реалізувати рівень кешування у памʼяті, щоб нам не потрібно було читати файли для кожного запиту на отримання образів.
- Додати підтримку закінчення терміну дії облікових даних, таким чином змушуючи раніше підтверджені облікові дані проходити повторну автентифікацію.
Як долучитися
Ознайомитись з KEP-2535 — це чудовий спосіб глибше зрозуміти ці зміни.
Якщо ви зацікавлені в подальшій участі, звʼяжіться з нами у каналі #sig-auth-authenticators-dev в Slack (щоб отримати запрошення, відвідайте https://slack.k8s.io/). Ви також можете приєднатися до зустрічей SIG Auth meetings, що відбуваються двічі на тиждень, кожну другу середу.
Kubernetes 1.33: Заповнювач томів перейшов у стан загальної доступності (GA)
Заповнювачі томів у Kubernetes тепер загальнодоступні (GA)! Функціональна можливість AnyVolumeDataSource вважається увімкненою у Kubernetes v1.33, що означає, що користувачі можуть вказати будь-який відповідний власний ресурс в якості джерела даних для PersistentVolumeClaim (PVC).
Приклад використання dataSourceRef у PVC:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc1
spec:
...
dataSourceRef:
apiGroup: provider.example.com
kind: Provider
name: provider1
Що нового
У порівнянні з бета-версією є чотири основні покращення.
Заповнювач Pod є опціональним
Під час бета-версії учасники проєкту Kubernetes виявили потенційні витоки ресурсів при видаленні PersistentVolumeClaim (PVC) під час заповнення тома; ці витоки траплялися через обмеження в роботі з завершувачами. Напередодні переходу до стану загальної доступності проєкт Kubernetes додав підтримку видалення тимчасових ресурсів (PVC prime тощо), якщо видалено первинний PVC.
Для цього ми створили три нові функції на основі втулків:
PopulateFn(): Виконує логіку заповнення даних, специфічну для провайдера.PopulateCompleteFn(): Перевіряє, чи успішно завершилася операція поповнення бази даних.PopulateCleanupFn(): Очищає тимчасові ресурси, створені функціями, специфічними для провайдера, після завершення заповнення даних
Приклад для провайдера додано до lib-volume-populator/example.
Функції-мутатори для модифікації ресурсів Kubernetes
Для GA, код контролера CSI для керування заповненням томів отримав MutatorConfig, що дозволяє визначати функції-мутатори для модифікації ресурсів Kubernetes. Наприклад, якщо прайм PVC не є точною копією PVC і вам потрібна інформація для драйвера, специфічна для провайдера, ви можете включити цю інформацію у додатковий MutatorConfig. Це дозволить вам налаштовувати обʼєкти Kubernetes у заповнювачі томів.
Гнучка обробка метрик для постачальників
Наша бета-версія виявила нову вимогу: необхідність агрегувати метрики не лише з lib-volume-populator, але й з інших компонентів у кодовій базі провайдера.
Щоб розвʼязати цю проблему, SIG Storage запровадила менеджер метрик провайдера. Це вдосконалення делегує реалізацію логіки метрик самому провайдеру, а не покладається виключно на lib-volume-populator. Ця зміна забезпечує більшу гнучкість і контроль над збором та агрегацією метрик, що дає змогу отримати більш повне уявлення про продуктивність провайдера.
Очищення для тимчасових ресурсів
Під час бета-версії ми виявили потенційні протікання ресурсів при видаленні PersistentVolumeClaim (PVC) під час заповнення тому через обмеження в роботі з завершувачем. Ми вдосконалили заповнювач в цьому випуску GA, щоб він підтримував видалення тимчасових ресурсів (PVC prime тощо), якщо початковий PVC видалено.
Як користуватися
Щоб спробувати, будь ласка, дотримуйтесь інструкцій з попереднього допису в блозі.
Майбутні напрямки та потенційні функціональні запити
На наступному кроці є кілька потенційних запитів на доопрацювання заповнювача томів:
- Багаторазова синхронізація: поточна реалізація передбачає одноразову односпрямовану синхронізацію від джерела до місця призначення. Її можна розширити для підтримки багаторазової синхронізації, увімкнувши періодичну синхронізацію або дозволивши користувачам виконувати синхронізацію на вимогу
- Двонапрямна синхронізація: розширення багаторазової синхронізації, описаної вище, але з двонапрямною синхронізацією між джерелом і пунктом призначення
- Заповнення даних з пріоритетами: зі списком різних dataSourceRef, заповнення на основі пріоритетів
- Заповнення даних з декількох джерел одного постачальника: заповнення декількох різних джерел до одного місця призначення
- Заповнення даних з декількох джерел різних постачальників: заповнення з декількох різних джерел до одного місця призначення, обʼєднуючи заповнення з різних ресурсів в один конвеєр
Щоб переконатися, що ми створюємо щось справді цінне, Kubernetes SIG Storage буде радий почути про будь-які конкретні випадки використання цієї функції, які ви маєте на увазі. Якщо у вас виникли запитання або конкретні проблеми, повʼязані з заповнювачем томів, звертайтеся до спільноти SIG Storage.
Kubernetes v1.33: Томи Image (Image Volumes) переходять в стан бета!
Томи Image було представлено як альфа фіункціонал в Kubernetes v1.31, як частину KEP-4639. В Kubernetes v1.33, ця функція переходить в стан бета.
Зверніть увагу, що стандартно цю можливість все ще вимкнено, оскільки не всі контейнерні середовища мають повну підтримку цієї можливості. CRI-O підтримує початкову можливість, починаючи з версії v1.31, а у версії v1.33 буде додано підтримку Томів Image як бета-версію. containerd додав підтримку можливості як альфа-версію, яка буде частиною випуску v2.1.0, і працює над бета-версією в рамках PR #11578.
Що нового
Основною зміною у бета-версії Томів Image є підтримка монтувань subPath і subPathExpr для контейнерів за допомогою spec.containers[*].volumeMounts.[subPath,subPathExpr]. Це дозволяє кінцевим користувачам змонтувати певну теку тому image, яку досі змонтовано у режимі лише для читання (noexec). Це означає, що відсутні теки не можуть бути стандартно змонтовані. Що стосується інших значень subPath та subPathExpr, то Kubernetes переконається, що у вказаному шляху немає компонентів абсолютного шляху або відносного шляху, що входять до складу підшляху. З міркувань безпеки, середовища виконання контейнерів також зобовʼязані перевіряти ці вимоги двічі. Якщо вказана тека не існує у томі, то середовище виконання не зможе створити контейнер і надасть користувачеві відгук, використовуючи події kubelet.
Крім того, для томів образів додано три нові метрики для kubelet-зображень:
kubelet_image_volume_requested_total: Показує кількість запитаних томів образів.kubelet_image_volume_mounted_succeed_total: Підраховує кількість успішних змонтованих томів образів.kubelet_image_volume_mounted_errors_total: Підраховує кількість невдалих монтувань томів образів.
Для використання наявної теки для конкретного тому image, використовуйте її як значення subPath (чи subPathExpr) параметра volumeMounts:
apiVersion: v1
kind: Pod
metadata:
name: image-volume
spec:
containers:
- name: shell
command: ["sleep", "infinity"]
image: debian
volumeMounts:
- name: volume
mountPath: /volume
subPath: dir
volumes:
- name: volume
image:
reference: quay.io/crio/artifact:v2
pullPolicy: IfNotPresent
Потім створіть pod у вашому кластері:
kubectl apply -f image-volumes-subpath.yaml
Тепер ви можете приєднатись до контейнера:
kubectl attach -it image-volume bash
І перевірте вміст файлу з теки dir у цьому томі:
cat /volume/file
На виході ми отримаємо приблизно таке:
1
Дякуємо, що дочитали цю статтю до кінця! SIG Node з гордістю і радістю представляє цей перехід функції в стан бета в рамках Kubernetes v1.33.
Як автор цієї статті, я хотів би підкреслити свою особливу подяку всім залученим особам, які брали участь у розробці!
Якщо ви хочете залишити відгук або пропозиції, не соромтеся звертатися до SIG Node, використовуючи канал Kubernetes Slack (#sig-node) або список розсилки SIG Node.
Ознайомтесь також
Kubernetes v1.33: Продовження переходу від Endpoints до EndpointSlices
Відтоді як EndpointSlices (KEP-752) з’явились у версії v1.15 як alpha, а згодом стали стабільними (GA) у v1.21, API Endpoints у Kubernetes поступово втрачало актуальність. Нові можливості Service, як-от dual-stack networking та traffic distribution, підтримуються лише через API EndpointSlice, тож усі проксі-сервери сервісів, реалізації Gateway API та подібні контролери мусили перейти від використання Endpoints до EndpointSlices. Станом на сьогодні API Endpoints зберігається здебільшого задля сумісності — щоб не ламати робочі навантаження та скрипти користувачів, які досі його використовують.
Починаючи з Kubernetes 1.33, API Endpoints офіційно оголошено застарілим, і API-сервер повертатиме попередження користувачам, які читають або записують ресурси Endpoints замість використання EndpointSlices.
Зрештою, згідно з KEP-4974, план полягає в тому, щоб змінити критерії Kubernetes Conformance, вилучивши з вимог обов’язкове використання контролера Endpoints (який генерує об’єкти Endpoints на основі Services і Pods), аби уникнути зайвої роботи в більшості сучасних кластерів.
Отже, хоча згідно з політикою застарівання Kubernetes тип Endpoints, ймовірно, ніколи не буде повністю вилучено, користувачам, які досі мають робочі навантаження або скрипти, що використовують API Endpoints, слід починати їх перенесення на EndpointSlices.
Примітки щодо міграції з Endpoints до EndpointSlices
Використання EndpointSlices замість Endpoints
Для кінцевих користувачів найбільшою відмінністю між API Endpoints та API EndpointSlice є те, що кожен Service із selector має рівно один об’єкт Endpoints (з такою ж назвою, як і сам Service), тоді як у нього може бути будь-яка кількість пов’язаних EndpointSlice:
$ kubectl get endpoints myservice
Warning: v1 Endpoints is deprecated in v1.33+; use discovery.k8s.io/v1 EndpointSlice
NAME ENDPOINTS AGE
myservice 10.180.3.17:443 1h
$ kubectl get endpointslice -l kubernetes.io/service-name=myservice
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
myservice-7vzhx IPv4 443 10.180.3.17 21s
myservice-jcv8s IPv6 443 2001:db8:0123::5 21s
У цьому прикладі сервіс є двостековим (dual-stack), тому має два EndpointSlice: один для IPv4-адрес, інший — для IPv6. (Endpoints не підтримує dual-stack, тому виводить адреси лише у головному стеку кластера.)
Хоча будь-який Service з кількома endpointʼами може мати кілька EndpointSlice, є три основні випадки, коли ви точно побачите це:
EndpointSlice може представляти лише одну IP-сім’ю, тож dual-stack-сервіси матимуть окремі EndpointSlice для IPv4 та IPv6.
Усі endpoints в одному EndpointSlice повинні мати однакові порти. Наприклад, якщо під час оновлення Podsʼи змінюють порт з 80 на 8080, то на час розгортання Service матиме два EndpointSlice: один для порту 80, інший — для 8080.
Якщо в Service більше 100 endpointʼів, контролер EndpointSlice розділить їх на кілька об’єктів, щоб уникнути створення надто великого ресурсу — на відміну від Endpoints.
Оскільки немає передбачуваного співвідношення 1:1 між Service і EndpointSlice, неможливо заздалегідь знати імена пов’язаних EndpointSlice. Натомість, слід фільтрувати їх за міткою kubernetes.io/service-name, що вказує на назву сервісу:
$ kubectl get endpointslice -l kubernetes.io/service-name=myservice
Подібні зміни потрібні й у Go-коді. Для Endpoints це виглядало так:
// Отримати Endpoints з назвою `name` у просторі імен `namespace`.
endpoint, err := client.CoreV1().Endpoints(namespace).Get(ctx, name, metav1.GetOptions{})
if err != nil {
if apierrors.IsNotFound(err) {
// Endpoints для сервісу ще не існує
...
}
// обробка інших помилок
...
}
// обробка `endpoint`
...
Для EndpointSlice це буде:
// Отримати всі EndpointSlice для сервісу `name` у просторі `namespace`.
slices, err := client.DiscoveryV1().EndpointSlices(namespace).List(ctx,
metav1.ListOptions{LabelSelector: discoveryv1.LabelServiceName + "=" + name})
if err != nil {
// обробка помилок
...
} else if len(slices.Items) == 0 {
// EndpointSlices для сервісу ще не існує
...
}
// обробка `slices.Items`
...
Генерація EndpointSlices замість Endpoints
Для користувачів або контролерів, які створюють об’єкти Endpoints, перехід на EndpointSlices зазвичай є простішим, оскільки в більшості випадків не потрібно опрацьовувати кілька sliceʼів. Достатньо оновити YAML або Go-код, щоб використовувати новий тип (із трохи зміненою структурою).
Наприклад, цей об’єкт Endpoints:
apiVersion: v1
kind: Endpoints
metadata:
name: myservice
subsets:
- addresses:
- ip: 10.180.3.17
nodeName: node-4
- ip: 10.180.5.22
nodeName: node-9
- ip: 10.180.18.2
nodeName: node-7
notReadyAddresses:
- ip: 10.180.6.6
nodeName: node-8
ports:
- name: https
protocol: TCP
port: 443
можна переписати як:
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: myservice
labels:
kubernetes.io/service-name: myservice
addressType: IPv4
endpoints:
- addresses:
- 10.180.3.17
nodeName: node-4
- addresses:
- 10.180.5.22
nodeName: node-9
- addresses:
- 10.180.18.12
nodeName: node-7
- addresses:
- 10.180.6.6
nodeName: node-8
conditions:
ready: false
ports:
- name: https
protocol: TCP
port: 443
Основні моменти:
У цьому прикладі явно вказано
name, але можна використатиgenerateName, і API-сервер сам додасть унікальний суфікс. Назва об’єкта не має значення — важлива мітка"kubernetes.io/service-name", що вказує на Service.Необхідно явно вказати
addressType: IPv4(абоIPv6).Один EndpointSlice відповідає одному елементу масиву
"subsets"в Endpoints. Якщо Endpoints мав кількаsubsets, треба створити кілька EndpointSlice з різними"ports".Поля
endpointsіaddresses— масиви, але зазвичайaddressesмістить лише один елемент. Якщо сервіс має кілька endpointʼів — це мають бути окремі елементи масивуendpoints, кожен з однимaddresses.В Endpoints "готові" й "не готові" адреси розділено, тоді як в EndpointSlice кожен endpoint може мати атрибут
conditions(наприклад,ready: false).
І, звісно, після переходу на EndpointSlice, можна використовувати специфічні для нього можливості, наприклад, topology hints чи terminating endpoints. Докладніше в документації до API EndpointSlice.
Kubernetes v1.33: Octarine
Редактори: Agustina Barbetta, Aakanksha Bhende, Udi Hofesh, Ryota Sawada, Sneha Yadav
Як і у попередніх випусках, у Kubernetes v1.33 представлено нові стабільні, бета та альфа-версії. Послідовний випуск високоякісних випусків підкреслює силу нашого циклу розробки та активну підтримку нашої спільноти.
Цей випуск складається з 64 покращень. З них 18 отримали статус Stable, 20 переходять до бета-версії, 24 — до альфа-версії, а 2 функції вважаються застарілими або вилученими.
У цьому випуску також є кілька помітних застарілостей і вилучень; обовʼязково прочитайте про них, якщо ви вже використовуєте старішу версію Kubernetes.
Тема та логотип релізу

Тема для Kubernetes v1.33 — Октарин: Колір магії1, натхненням для якої стала серія Дискосвіт Террі Пратчетта. Цей випуск підкреслює магію відкритого вихідного коду2, яку Kubernetes використовує в усій екосистемі.
Якщо ви знайомі зі світом Дискосвіту, ви можете впізнати маленького болотного дракона, що сидить на вежі Небаченого Університету, дивлячись на місяць Кубернетес над містом Анх-Морпорк з 64 зірками3 на задньому плані.
Оскільки Kubernetes вступає у своє друге десятиліття, ми відзначаємо майстерність його супровідників, допитливість нових учасників та дух співпраці, який живить проєкт. Випуск v1.33 є нагадуванням про те, що, як писав Пратчетт, «це все одно магія, навіть якщо ви знаєте, як це робиться». Навіть якщо ви знаєте всі тонкощі кодової бази Kubernetes, відійшовши на крок назад в кінці циклу випуску, ви зрозумієте, що Kubernetes залишається чарівним.
Kubernetes v1.33 — це свідчення незмінної сили інновацій з відкритим вихідним кодом, де сотні учасників3 з усього світу працюють разом, щоб створити щось справді надзвичайне. За кожною новою функцією стоїть робота спільноти Kubernetes над підтримкою та вдосконаленням проєкту, гарантуючи, що він залишається безпечним, надійним та випускається вчасно. Кожен реліз спирається на інший, створюючи щось більше, ніж ми могли б досягти поодинці.
1. Октарин — це міфічний восьмий колір, який бачать лише ті, хто має певний стосунок до таємничого: маги, чаклунки та, звісно, коти. І іноді хтось, хто занадто довго витріщається на правила IPtable.
2. Будь-яка достатньо прогресивна технологія не відрізняється від магії...?
3. Це не випадково, що 64 KEP (Kubernetes Enhancement Proposals) також включені в v1.33.
4. Див. розділ «Швидкість проєкту» для версії 1.33 🚀
У центрі уваги ключові оновлення
Kubernetes v1.33 містить багато нових можливостей та покращень. Ось кілька особливо важливих оновлень, на які команда розробників хотіла б звернути увагу!
Stable: контейнери Sidecar
Шаблон використання sidecar передбачає розгортання окремих допоміжних контейнерів для роботи з додатковими можливостями в таких сферах, як мережа, ведення журналів і збір показників. У версії 1.33 контейнери Sidecar переходять у статус Stable.
Kubernetes впроваджує sidecar як спеціальний клас контейнерів ініціалізації що мають restartPolicy: Always, це гарантує, що sidecars запускаються перед контейнерами застосунків, залишаються запущеними протягом усього життєвого циклу podʼа і автоматично завершують свою роботу після завершення роботи основних контейнерів.
Крім того, sidecarʼи можуть використовувати проби (запуску, готовності, життєздатності) для повідомлення про свій робочий стан, а їхні показники Out-Of-Memory (OOM) узгоджуються з основними контейнерами, щоб запобігти передчасному завершенню роботи під тиском обмеження використання памʼяті.
Щоб дізнатися більше, читайте Контейнери Sidecar.
Ця робота була виконана в рамках KEP-753: Sidecar Containers під керівництвом SIG Node.
Beta: Зміна розміру ресурсів на місці для вертикального масштабування Podʼів
Робочі навантаження можна визначити за допомогою API, таких як Deployment, StatefulSet тощо. Вони описують шаблон для Podʼів, які мають бути запущені, включаючи ресурси памʼяті та процесора, а також кількість реплік Podʼів, які мають бути запущені. Робочі навантаження можна масштабувати горизонтально, оновлюючи кількість реплік Podʼів, або вертикально, оновлюючи ресурси, необхідні в контейнері (контейнерах) Podʼів. До цього вдосконалення ресурси контейнера, визначені в spec, були незмінними, і оновлення будь-якої з цих деталей у шаблоні Pod призводило до заміни Podʼа.
Але що, якби ви могли динамічно оновлювати конфігурацію ресурсів для наявних Podʼів, не перезапускаючи їх?
KEP-1287 було створено саме для того, щоб дозволити такі оновлення на місці. Він був випущений як альфа-версія у версії v1.27, а у версії v1.33 перейшов до бета-версії. Це відкриває різні можливості для вертикального масштабування процесів зі станом без простоїв, плавного зменшення масштабу, коли трафік низький, і навіть виділення більших ресурсів під час запуску, які потім можуть бути зменшені після завершення початкового налаштування.
Цю роботу було виконано в рамках KEP-1287: In-Place Update of Pod Resources під керівництвом SIG Node та SIG Autoscaling.
Alpha: Новий параметр конфігурації kubectl за допомогою .kuberc для налаштувань користувача
У версії 1.33 у kubectl зʼявилася нова альфа-версія з опціональним конфігураційним файлом .kuberc для налаштувань користувача. Цей файл може містити аліаси та перевизначення kubectl (наприклад, стандартне використання server-side apply), водночас залишаючи облікові дані кластера та інформацію про хост у kubeconfig. Таке розділення дозволяє використовувати однакові параметри взаємодії з kubectl, незалежно від цільового кластера і використовуваного kubeconfig.
Щоб увімкнути цю альфа-версію, користувачі можуть встановити змінну середовища KUBECTL_KUBERC=true і створити файл конфігурації .kuberc. Зазвичай kubectl шукає цей файл у ~/.kube/kuberc. Ви також можете вказати альтернативне розташування за допомогою прапорця --kuberc, наприклад: kubectl --kuberc /var/kube/rc.
Цю роботу було виконано у рамках KEP-3104: Відокремлення налаштувань користувача kubectl від конфігів кластера під керівництвом SIG CLI.
Функції, що переходять до статусу Stable
Це добірка деяких поліпшень, які тепер мають статус стабільних після релізу v1.33.
Ліміти повторних спроб для індексів в Індексованих Завданнях (Indexed Job)
У цьому випуску реалізовано функцію, яка дозволяє встановлювати ліміти повторних спроб на основі кожного індексу для індексованих завдань. Традиційно параметр backoffLimit у Завданнях Kubernetes задає кількість повторних спроб, після яких завдання вважається невдалим. Це вдосконалення дозволяє кожному індексу в Індексованому Завданні мати власний ліміт повторних спроб, забезпечуючи більш детальний контроль над поведінкою повторних спроб для окремих завдань. Це гарантує, що збій певних індексів не призведе до передчасного завершення всього Завдання, дозволяючи іншим індексам продовжувати обробку незалежно.
Ця робота була виконана в рамках KEP-3850: Backoff Limit Per Index For Indexed Jobs під керівництвом SIG Apps.
Політика успіху Job
Використовуючи .spec.successPolicy, користувачі можуть вказати, які індекси завдань мають бути успішними (succeededIndexes), скільки завдань мають бути успішними (succeededCount), або комбінацію обох параметрів. Ця функція корисна для різних робочих навантажень, включаючи симуляції, де достатньо часткового завершення, і моделі «лідер-працівник», де тільки успіх лідера визначає загальний результат роботи.
Ця робота була виконана в рамках KEP-3998: Job success/completion policy під керівництвом SIG Apps.
Покращення безпеки токенів повʼязаних ServiceAccount
Це вдосконалення впровадило такі функції, як включення унікального ідентифікатора токена (наприклад, JWT ID Claim, також відомий як JTI) та інформації про вузол в токенах, що дозволяє більш точно перевіряти та проводити аудит. Крім того, він підтримує обмеження для конкретних вузлів, гарантуючи, що токени можуть бути використані тільки на визначених вузлах, тим самим знижуючи ризик зловживання токенами і потенційних порушень безпеки. Ці покращення, які тепер є загальнодоступними, мають на меті покращити загальний стан безпеки токенів службових облікових записів у кластерах Kubernetes.
Ця робота була виконана в рамках KEP-4193: Bound service account token improvements під керівництвом SIG Auth.
Підтримка субресурсів у kubectl
Аргумент --subresource тепер є загальнодоступним для таких команд kubectl, як get, patch, edit, apply і replace, що дозволяє користувачам отримувати та оновлювати субресурси для всіх ресурсів, які їх підтримують. Щоб дізнатися більше про підтримувані субресурси, відвідайте довідник kubectl.
Цю роботу було виконано у рамках KEP-2590: Add subresource support to kubectl під керівництвом SIG CLI.
Кілька CIDR Сервісів
Це покращення запровадило нову реалізацію логіки розподілу IP-адрес Service. У всьому кластері кожен сервіс типу type: ClusterIP повинен мати унікальну IP-адресу, призначену йому. Спроба створити Сервіс з певною кластерною IP-адресою, яку вже було призначено, призведе до помилки. Оновлена логіка розподільника IP-адрес використовує два нових стабільних обʼєкти API: ServiceCIDR і IPAddress. Тепер ці API є загальнодоступними і дозволяють адміністраторам кластерів динамічно збільшувати кількість IP-адрес, доступних для `type: ClusterIP' (шляхом створення нових обʼєктів ServiceCIDR).
Ця робота була виконана в рамках KEP-1880: Multiple Service CIDRs під керівництвом SIG Network.
Бекенд nftables для kube-proxy
Бекенд nftables для kube-proxy тепер стабільний, додано нову реалізацію, яка значно покращує продуктивність і масштабованість для реалізації Сервісів у кластерах Kubernetes. З міркувань сумісності, iptables залишається стандартним на вузлах Linux. Ознайомтеся з посібником з міграції, якщо ви хочете спробувати.
Ця робота була виконана в рамках KEP-3866: nftables kube-proxy backend під керівництвом SIG Network.
Маршрутизація з урахуванням топології за допомогою trafficDistribution: PreferClose
У цьому випуску маршрутизація з урахуванням топології та розподілення трафіку переходить до рівня GA, що дозволить нам оптимізувати службовий трафік у багатозонних кластерах. Підказки з урахуванням топології в EndpointSlices дозволять таким компонентам, як kube-proxy, визначати пріоритети маршрутизації трафіку до точок доступу в межах однієї зони, тим самим зменшуючи затримки і витрати на передачу даних між зонами. На основі цього до специфікації Service додано поле trafficDistribution, а опція PreferClose спрямовує трафік до найближчих доступних точок доступу, виходячи з топології мережі. Така конфігурація підвищує продуктивність та економічну ефективність за рахунок мінімізації міжзонового звʼязку.
Ця робота була виконана в рамках KEP-4444: Traffic Distribution for Services та KEP-2433: Topology Aware Routing під керівництвом SIG Network.
Опції для відхилення не узгодженого з SMT навантаження
Ця функція додає параметри політики до CPU Manager, що дозволяє відхиляти робочі навантаження, які не відповідають конфігурації одночасної багатопоточності (Simultaneous Multithreading, SMT). Це вдосконалення, яке тепер є загальнодоступним, гарантує, що коли pod запитує ексклюзивне використання ядер процесора, диспетчер процесорів може примусово розподіляти цілі пари ядер (що складаються з основного і дочірнього потоків) на системах з підтримкою SMT, таким чином запобігаючи сценаріям, коли робочі навантаження використовують ресурси процесора у непередбачуваний спосіб.
Цю роботу було виконано у рамках KEP-2625: node: cpumanager: add options to reject non SMT-aligned workloads під керівництвом SIG Node.
Визначення спорідненості або неспорідненості Pod за допомогою matchLabelKeys та mismatchLabelKeys
Поля matchLabelKeys і mismatchLabelKeys доступні у термінах спорідненості Pod, що дозволяє користувачам точно контролювати область, в якій очікується співіснування Podʼів (Affinity) чи ні (AntiAffinity). Ці нові стабільні опції доповнюють наявний механізм labelSelector. Поля спорідненості полегшують планування універсальних циклічних оновлень, а також ізоляцію сервісів, керованих інструментами або контролерами на основі глобальних конфігурацій.
Цю роботу було виконано в рамках проекту KEP-3633: Introduce MatchLabelKeys to Pod Affinity and Pod Anti Affinity під керівництвом SIG Scheduling.
Врахування позначок taint та toleration при обчисленні відхилення поширення топології Pod
Це покращило PodTopologySpread, додавши два поля: nodeAffinityPolicy та nodeTaintsPolicy. Ці поля дозволяють користувачам вказати, чи слід враховувати правила спорідненості вузлів та плями вузлів при обчисленні розподілу podʼів між вузлами. Стандартно nodeAffinityPolicy має значення Honor, що означає, що до розрахунку розподілу включаються лише вузли, які відповідають правилам спорідненості або селектору вузла. Значення nodeTaintsPolicy стандартно дорівнює Ignore, що вказує на те, що заплямованість вузлів не враховується, якщо це не вказано. Це покращення забезпечує кращий контроль за розміщенням podʼів, гарантуючи, що podʼи будуть заплановані на вузлах, які відповідають вимогам спорідненості та толерантності щодо заплямованості, таким чином запобігаючи сценаріям, коли podʼи залишаються нерозподіленими через незадовільнення обмежень.
Ця робота була виконана у рамках KEP-3094: Take taint/tolerances into consideration when calculating PodTopologySpread skew під керівництвом SIG Scheduling.
Заповнювачі тома
Після випуску бета-версії у v1.24, заповнювачі томів стали доступними у GA у v1.33. Ця нова стабільна функція дозволяє користувачам попередньо заповнювати томи даними з різних джерел, а не лише з клонів PersistentVolumeClaim (PVC) або знімків томів. Механізм ґрунтується на полі dataSourceRef у запиті PersistentVolumeClaim. Це поле забезпечує більшу гнучкість, ніж поточне поле dataSource, і дозволяє використовувати власні ресурси як джерела даних.
Спеціальний контролер, volume-data-source-validator, перевіряє ці посилання на джерела даних, разом з новим стабільним CustomResourceDefinition (CRD) для API типу VolumePopulator. API VolumePopulator дозволяє контролерам заповнвачів тому реєструвати типи джерел даних, які вони підтримують. Вам потрібно налаштувати ваш кластер з відповідним CRD, щоб користуватися заповнювачами томів.
Цю роботу було виконано в рамках KEP-1495: Generic data populators під керівництвом SIG Storage.
Завжди дотримуватися політики повторного використання PersistentVolume
Це вдосконалення вирішило проблему, коли політика повторного використання постійних томів (Persistent Volume, PV) не завжди виконується, що призводить до потенційних витоків ресурсів сховища. Зокрема, якщо постійний том видаляється раніше, ніж повʼязана з ним заявка на постійний том (Persistent Volume Claim, PVC), політика повторного використання "Delete" може не виконуватися, залишаючи базові ресурси сховища недоторканими. Щоб запобігти цьому, Kubernetes тепер встановлює завершувачі на відповідні PV, гарантуючи, що політика повторного використання буде застосована незалежно від послідовності видалення. Це покращення запобігає ненавмисному збереженню ресурсів сховища та підтримує узгодженість в управлінні життєвим циклом PV.
Ця робота була виконана в рамках проекту KEP-2644: Always Honor PersistentVolume Reclaim Policy під керівництвом SIG Storage.
Нові можливості у Бета
Це добірка деяких покращень, які зараз є бета-версією після випуску v1.33._.
Підтримка Прямого Повернення Сервісу (DSR, Direct Service Return) у Windows kube-proxy
DSR забезпечує оптимізацію продуктивності, дозволяючи зворотному трафіку, що проходить через балансувальники навантаження, оминати балансувальник навантаження і відповідати безпосередньо клієнту; зменшуючи навантаження на балансувальник навантаження, а також загальну затримку. Для отримання інформації про DSR в Windows, прочитайте Direct Server Return (DSR) in a nutshell.
Підтримка DSR, вперше представлена в версії 1.14, була доведена SIG Windows до бета-версії в рамках KEP-5100: Support for Direct Service Return (DSR) and overlay networking in Windows kube-proxy.
Підтримка структурованих параметрів
Хоча підтримка структурованих параметрів залишається бета-версією Kubernetes v1.33, ця основна частина динамічного розподілу ресурсів (DRA) зазнала значних покращень. Нова версія v1beta2 спрощує API resource.k8s.io, і звичайні користувачі з роллю edit кластера з простором імен тепер можуть використовувати DRA.
У kubelet додано підтримку безперебійного оновлення, що дозволяє драйверам, розгорнутим як DaemonSets, використовувати механізм постійного оновлення. Для реалізацій DRA це запобігає видаленню і повторному створенню ResourceSlices, дозволяючи їм залишатися незмінними під час оновлень. Крім того, було введено 30-секундний пільговий період перед очищенням kubelet після скасування реєстрації драйвера, що забезпечує кращу підтримку для драйверів, які не користуються механізмом rolling updates.
Ця робота була виконана в рамках KEP-4381: DRA: структуровані параметри робочою групою з управління пристроями, до складу якої входять представники SIG Node, SIG Scheduling і SIG Autoscaling.
Динамічний розподіл ресурсів (DRA) для мережевих інтерфейсів
Стандартизоване звітування про дані мережевих інтерфейсів за допомогою DRA, запроваджене у версії 1.32, перейшло до бета-версії у версії 1.33. Це уможливлює більш природну інтеграцію з мережею Kubernetes, спрощуючи розробку та керування мережевими пристроями. Раніше про це було написано у блозі з анонсом випуску v1.32.
Ця робота була виконана в рамках KEP-4817: DRA: Resource Claim Status with possible standardized network interface data під керівництвом SIG Network, SIG Node та WG Device Management.
Обробка незапланованих podʼів раніше, коли планувальник не має жодного pod у activeQ
Ця функція покращує поведінку планування черги. За лаштунками планувальник досягає цього, вибираючи з backoffQ pods, які не було відкладено через помилки, коли activeQ порожній. Раніше планувальник простоював, навіть якщо activeQ було порожнім; це вдосконалення покращує ефективність планування, запобігаючи цьому.
Ця робота була виконана у рамках KEP-5142: Pop pod from backoffQ when activeQ is empty під керівництвом SIG Scheduling.
Асинхронне випередження у планувальнику Kubernetes
Випередження гарантує, що більш пріоритетні podʼи отримають необхідні їм ресурси, виселивши менш пріоритетні. Асинхронне випередження, представлене у версії 1.32 як альфа-версія, у версії 1.33 перейшло у бета-версію. Завдяки цьому вдосконаленню, важкі операції, такі як виклики API для видалення podʼів, обробляються паралельно, що дозволяє планувальнику продовжувати планувати інші podʼи без затримок. Це покращення особливо корисне для кластерів з високим рівнем відтоку Podʼів або частими збоями в плануванні, забезпечуючи більш ефективний та стійкий процес планування.
Ця робота була виконана в рамках KEP-4832: Asynchronous preemption in the scheduler під керівництвом SIG Scheduling.
ClusterTrustBundle
ClusterTrustBundle, кластерний ресурс, призначений для зберігання довірчих якорів X.509 (кореневих сертифікатів), перейшов у бета-версію 1.33. Цей API полегшує підписантам кластерних сертифікатів публікацію та передачу довірчих якорів X.509 кластерним робочим навантаженням.
Ця робота була виконана в рамках KEP-3257: ClusterTrustBundles (раніше Trust Anchor Sets) під керівництвом SIG Auth.
Детальний контроль SupplementalGroups
Вперше зʼявившись у v1.31, ця можливість перейшла у бета-версію у v1.33 і тепер є стандартно увімкненою. За умови, що у вашому кластері увімкнено функціональну можливість SupplementalGroupsPolicy, поле SupplementalGroupsPolicy у securityContext у Pod підтримує дві політики: стандартна політика Merge підтримує зворотну сумісність, обʼєднуючи вказані групи з групами з файлу /etc/group образу контейнера, в той час як нова політика Strict застосовується тільки до явно визначених груп.
Це покращення допомагає вирішити проблеми безпеки, коли неявна приналежність до груп з образів контейнерів може призвести до непередбачуваних дозволів на доступ до файлів і обходу засобів керування політикою.
Ця робота була виконана в рамках KEP-3619: Fine-grained SupplementalGroups control під керівництвом SIG Node.
Підтримка монтування образів як томів
Підтримка використання образів Open Container Initiative (OCI) як томів у Podʼах, що зʼявилася у версії 1.31, перейшла у стан бета-версії. Ця функція дозволяє користувачам вказувати посилання на образ як том у Pod, а також повторно використовувати його як монтування томів у контейнерах. Це відкриває можливість пакувати дані тома окремо і розподіляти їх між контейнерами в Pod, не включаючи їх до основного образу, тим самим зменшуючи вразливості і спрощуючи створення образів.
Ця робота була виконана в рамках KEP-4639: VolumeSource: OCI Artifact and/or Image під керівництвом SIG Node та SIG Storage.
Підтримка просторів імен користувачів у Linux Podʼах
Одним із найстаріших відкритих KEP на момент написання цієї статті є KEP-127, Покращення безпеки Pod за допомогою використання Просторів імен користувачів Linux для Pods. Цей KEP був вперше відкритий наприкінці 2016 року і після декількох ітерацій отримав альфа-реліз у версії 1.25, початкову бета-версію у версії 1.30 (де він був стандартно вимкнений), а у версії 1.33 перейшов у режим стандартно увімкненої бета-версії.
Ця підтримка не вплине на наявні Podʼи, якщо ви вручну не вкажете pod.spec.hostUsers, щоб увімкнути її. Як зазначено у v1.30 sneak peek blog, це важлива віха для усунення вразливостей.
Ця робота була виконана в рамках KEP-127: Support User Namespaces in pods під керівництвом SIG Node.
Опція procMount для Pod
Параметр procMount, представлений як альфа-версія у версії 1.12 і стандартно вимкнений у бета-версії 1.31, у версії 1.33 став увімкненим у бета-версії 1.33. Це вдосконалення покращує ізоляцію Pod, дозволяючи користувачам тонко налаштовувати доступ до файлової системи /proc. Зокрема, воно додає поле до securityContext, яке дозволяє перевизначити стандартну поведінку маскування та позначення певних шляхів до /proc як таких, що доступні лише для читання. Це особливо корисно у випадках, коли користувачі хочуть запускати непривілейовані контейнери всередині Kubernetes Pod з використанням просторів імен користувачів. Зазвичай, середовище виконання контейнера (через реалізацію CRI) запускає зовнішній контейнер із суворими параметрами монтування /proc. Однак, для успішного запуску вкладених контейнерів з непривілейованим Pod, користувачам потрібен механізм для послаблення цих стандартних налаштувань, і ця функція надає саме це.
Цю роботу було виконано у рамках проекту KEP-4265: add ProcMount option під керівництвом SIG Node.
Політика CPUManager для розподілу CPU між вузлами NUMA
Цей параметр додає нову опцію політики для CPU Manager, яка дозволяє розподіляти CPU між вузлами з нерівномірним доступом до памʼяті (NUMA, Non-Uniform Memory Access), замість того, щоб концентрувати їх на одному вузлі. Він оптимізує розподіл ресурсів CPU, балансуючи робочі навантаження між декількома вузлами NUMA, тим самим покращуючи продуктивність і використання ресурсів у багатопроцесорних системах з NUMA.
Цю роботу було виконано у рамках KEP-2902: Add a CPUManager policy option to distribute CPUs between NUMA nodes instead of packing them під керівництвом SIG Node.
Нуль-секундний сон для хуків PreStop контейнера
У Kubernetes 1.29 було введено дію Sleep для хука життєвого циклу preStop у Podʼах, яка дозволяє контейнерам призупиняти роботу на певний час перед завершенням. Це забезпечує простий спосіб затримки вимкнення контейнера, полегшуючи виконання таких завдань, як очищення зʼєднань або операцій очищення.
Дія Sleep у хуку preStop тепер може приймати нульову тривалість як бета-версію. Це дає змогу визначати хук preStop без затримки, що є корисним у випадках, коли хук preStop потрібен, але затримка не бажана.
Ця робота була виконана в рамках KEP-3960: Introducing Sleep Action for PreStop Hook та KEP-4818: Allow zero value for Sleep Action of PreStop Hook під керівництвом SIG Node.
Внутрішній інструментарій для декларативної валідації нативних типів Kubernetes
За лаштунками, внутрішні механізми Kubernetes починають використовувати новий механізм валідації обʼєктів та змін до обʼєктів. У Kubernetes v1.33 представлено внутрішній інструмент validation-gen, який учасники Kubernetes використовують для створення декларативних правил валідації. Загальна мета полягає у підвищенні надійності та зручності підтримки валідації API, надаючи розробникам можливість декларативно вказувати обмеження валідації, зменшуючи кількість помилок ручного кодування та забезпечуючи узгодженість у кодовій базі.
Ця робота була виконана у рамках проекту KEP-5073: Declarative Validation Of Kubernetes Native Types With validation-gen під керівництвом SIG API Machinery.
Нові можливості в альфа-версії
Це добірка деяких покращень, які тепер доступні у альфа-версії після випуску v1.33.
Налаштовуване допустиме відхилення для HorizontalPodAutoscalers
Ця функція вводить настроюване відхилення для HorizontalPodAutoscalers, яке помʼякшує реакцію масштабування на невеликі зміни метрики.
Цю роботу було виконано як частину KEP-4951: Configurable tolerance for Horizontal Pod Autoscalers під керівництвом SIG Autoscaling.
Настроювана затримка перезапуску контейнера
Представлена у версії 1.32 як alpha1, ця функція надає набір конфігурацій на рівні kubelet, які дозволяють налаштування способу обробки CrashLoopBackOff.
Цю роботу було виконано у рамках KEP-4603: Tune CrashLoopBackOff під керівництвом SIG Node.
Власні сигнали зупинки контейнера
До версії Kubernetes 1.33 сигнали зупинки можна було встановити лише у визначенні образу контейнера (наприклад, за допомогою конфігураційного поля StopSignal у метаданих образу). Якщо ви хочете змінити поведінку завершення, вам потрібно створити власний образ контейнера. Увімкнувши (альфа-версію) ContainerStopSignals у Kubernetes v1.33, ви можете визначати власні сигнали зупинки безпосередньо у специфікаціях Pod. Вони визначаються у полі lifecycle.stopSignal контейнера і вимагають наявності поля spec.os.name у специфікації Pod. Якщо його не вказано, контейнери повертаються до визначеного образом сигналу зупинки (якщо він присутній) або до стандартного сигналу виконання контейнера (зазвичай це SIGTERM для Linux).
Цю роботу було виконано у рамках KEP-4960: Сигнали зупинки контейнерів під керівництвом SIG Node.
Покращення DRA!
У Kubernetes v1.33 продовжено розробку динамічного розподілу ресурсів (DRA) з функціями, призначеними для сучасних складних інфраструктур. DRA — це інтерфейс API для запиту і розподілу ресурсів між podʼами і контейнерами всередині podʼів. Зазвичай такими ресурсами є пристрої, такі як графічні процесори, FPGA та мережеві адаптери.
Нижче перераховані всі можливості альфа-версії DRA, представлені у версії 1.33:
- Подібно до забруднень Вузлів, увімкнувши функціональну можливість
DRADeviceTaints, пристрої підтримують taints та tolerations. Адміністратор або компонент панелі управління може позначити пристрої, щоб обмежити їхнє використання. Планування podʼів, які залежать від цих пристроїв, може бути призупинено, поки існує taint, і/або podʼи, які використовують пристрій з taint, можуть бути виселені. - Увімкнувши функціональну можливість
DRAPrioritizedList, DeviceRequests отримують нове поле, з назвоюfirstAvailable. Це поле є впорядкованим списком, який дозволяє користувачеві вказати, що запит може бути задоволено різними способами, зокрема не виділяти нічого, якщо певне обладнання недоступне. - З активованою функціональною можливістю
DRAAdminAccessлише користувачі, які мають право створювати обʼєкти ResourceClaim або ResourceClaimTemplate у просторах імен, позначенихresource.k8s.io/admin-access: "true"можуть використовувати полеadminAccess. Це гарантує, що користувачі, які не мають прав адміністратора, не зможуть зловживати функцієюadminAccess. - Починаючи з версії 1.31 стало можливим використовувати розділи пристроїв, але виробникам доводилося попередньо розбивати пристрої на розділи і оголошувати про це відповідним чином. Увімкнувши функціональну можливість
DRAPartitionableDevicesу версії 1.33, постачальники пристроїв можуть оголошувати декілька розділів, у тому числі ті, що перетинаються. Планувальник Kubernetes вибере розділ на основі запитів робочого навантаження і запобігатиме одночасному виділенню конфліктуючих розділів. Ця функція дає постачальникам можливість динамічно створювати розділи під час їх виділення. Виділення та динамічне створення розділів відбувається автоматично і є прозорим для користувачів, що сприяє кращому використанню ресурсів.
Ці елементи не матимуть ефекту, якщо ви не увімкнете функціональну можливість DynamicResourceAllocation.
Цю роботу було виконано в рамках KEP-5055: DRA: device taints and tolerations, KEP-4816: DRA: Prioritized Alternatives in Device Requests, KEP-5018: DRA: AdminAccess for ResourceClaims and ResourceClaimsTemplates та KEP-4815: DRA: Add support for partitionable devices, під керівництвом SIG Node, SIG Scheduling та SIG Auth.
Надійна політика отримання образів для автентифікації образів для IfNotPresent та Never
Ця можливість дозволяє користувачам переконатися, що kubelet вимагає перевірки автентичності образів для кожного нового набору облікових даних, незалежно від того, чи образ вже присутній на вузлі.
Цю роботу було виконано у рамках KEP-2535: Ensure secret pulled images під керівництвом SIG Auth.
Мітки топології вузлів доступні через низхідний API
Ця функція дозволяє показувати мітки топології вузлів за допомогою низхідного API. До версії Kubernetes v1.33 обхідний шлях передбачав використання контейнера init для запиту API Kubernetes для базового вузла; ця альфа-версія спрощує доступ робочих навантажень до інформації про топологію вузла.
Цю роботу було виконано у рамках KEP-4742: Expose Node labels via downward API під керівництвом SIG Node.
Покращення статусу podʼів з генерацією та спостережуваною генерацією
До цієї зміни поле metadata.generation не використовувалося у podʼах. Разом з розширенням підтримки metadata.generation, ця функція додасть status.observedGeneration, щоб забезпечити більш чіткий статус підкадру.
Цю роботу було виконано у рамках KEP-5067: Pod Generation під керівництвом SIG Node.
Підтримка архітектури розділеного кешу 3-го рівня з менеджером процесорів kubelet
Попередній менеджер процесорів kubelet не знав про архітектуру розділеного кешу L3 (також відомого як кеш останнього рівня, або LLC), і потенційно міг розподіляти призначення CPU без урахування розділеного кешу L3, що призводило до виникнення проблеми шумних сусідів. Ця альфа-версія вдосконалює диспетчер процесорів, щоб краще призначати ядра CPU для кращої продуктивності.
Ця робота була виконана в рамках KEP-5109: Split L3 Cache Topology Awareness in CPU Manager під керівництвом SIG Node.
Метрики PSI (Pressure Stall Information) для покращень планування
Ця можливість додає підтримку на вузлах Linux для надання статистики та метрик PSI за допомогою cgroupv2. Вона може виявляти дефіцит ресурсів і надавати вузлам більш детальний контроль за плануванням podʼів.
Цю роботу було виконано у рамках KEP-4205: Support PSI based on cgroupv2 під керівництвом SIG Node.
Витягування образів без секретів за допомогою kubelet
Постачальник облікових даних на диску kubelet тепер підтримує додаткову можливість отримання токенів Kubernetes ServiceAccount (SA). Це спрощує автентифікацію за допомогою реєстрів образів, дозволяючи хмарним провайдерам краще інтегруватися з OIDC-сумісними рішеннями для ідентифікації.
Ця робота була виконана в рамках KEP-4412: Projected service account tokens for Kubelet image credentials providers під керівництвом SIG Auth.
Перехід до стабільного стану, застарівання та вилучення у v1.33
Переведення до стабільного стану
Тут перелічено усі компоненти, які перейшли до стабільного стану (також відомого як загальна доступність). Повний список оновлень, включно з новими функціями та переходами з альфа-версії до бета-версії, наведено у примітках до випуску.
Цей випуск містить загалом 18 покращень, які було підвищено до стабільного стану:
- Take taints/tolerations into consideration when calculating PodTopologySpread skew
- Introduce
MatchLabelKeysto Pod Affinity and Pod Anti Affinity - Bound service account token improvements
- Generic data populators
- Multiple Service CIDRs
- Topology Aware Routing
- Portworx file in-tree to CSI driver migration
- Always Honor PersistentVolume Reclaim Policy
- nftables kube-proxy backend
- Deprecate status.nodeInfo.kubeProxyVersion field
- Add subresource support to kubectl
- Backoff Limit Per Index For Indexed Jobs
- Job success/completion policy
- Sidecar Containers
- CRD Validation Ratcheting
- node: cpumanager: add options to reject non SMT-aligned workload
- Traffic Distribution for Services
- Recursive Read-only (RRO) mounts
Застарівання та видалення
У міру розвитку та зрілості Kubernetes деякі функції можуть ставати застарілими, вилучатися або замінюватися на кращі, щоб покращити загальний стан проєкту. Детальніше про цей процес можна дізнатися у документі Kubernetes [політика застарівання та вилучення] (/docs/reference/using-api/deprecation-policy/). Про багато з цих застарівань і вилучень було оголошено у блозі про застарівання і вилучення.
Застарівання стабільного API Endpoints
API EndpointSlices є стабільним з версії 1.21, яка фактично замінила оригінальний API Endpoints. Хоча оригінальний API Endpoints був простим і зрозумілим, він також створював деякі проблеми при масштабуванні на велику кількість точок доступу в мережі. API EndpointSlices представив нові функції, такі як двостекова мережа, що робить оригінальний API Endpoints готовим до застарівання.
Це застарівання впливає тільки на тих, хто використовує API Endpoints безпосередньо з робочих навантажень або скриптів; ці користувачі повинні перейти на використання EndpointSlices. Буде опублікована спеціальна стаття в блозі з більш детальною інформацією про наслідки застарівання і плани міграції.
Ви можете знайти більше інформації в KEP-4974: Deprecate v1.Endpoints.
Видалення інформації про версію kube-proxy зі статусу вузла {#removal-of-kube-proxy-version-information-in-node-status}.
Після застарівання у v1.31, як зазначено в [анонсі випуску] v1.31 (/blog/2024/07/19/kubernetes-1-31-upcoming-changes/#deprecation-of-status-nodeinfo-kubeproxyversion-field-for-nodes-kep-4004-https-github-com-kubernetes-enhancements-issues-4004), у v1.33 було вилучено поле .status.nodeInfo.kubeProxyVersion для вузлів.
Це поле встановлювалося kubelet, але його значення не було стабільно точним. Оскільки воно було стандартно вимкнено з версії 1.31, у версії 1.33 це поле було повністю вилучено.
Ви можете знайти більше інформації у KEP-4004: Deprecate status.nodeInfo.kubeProxyVersion field.
Видалення внутрішнього драйвера тома gitRepo
Тип тома gitRepo був застарілим з версії 1.11, майже 7 років тому. Після його застарівання виникли проблеми з безпекою, зокрема, як типи томів gitRepo можуть бути використані для віддаленого виконання коду від імені користувача root на вузлах. У версії 1.33 код внутрішнього драйвера було вилучено.
Існують альтернативи, такі як git-sync та initContainers. gitVolumes в API Kubernetes які не вилучено, а отже, podʼи з томами gitRepo будуть прийматися kube-apiserverʼом, але kubeletʼи з функціональною можливістю GitRepoVolumeDriver, встановленою в false, не запускатимуть їх і повертатимуть користувачеві відповідну помилку. Це дозволяє користувачам вибрати повторне ввімкнення драйвера для 3 версій, щоб мати достатньо часу для виправлення робочих навантажень.
Функціональну можливість у kubelet та внутрішньому втулку планується вилучити у випуску v1.39.
Ви можете знайти більше інформації в KEP-5040: Видалити драйвер тома gitRepo.
Видалення підтримки хост-мережі для Windows podʼів
Мережа Windows Pod мала на меті досягти паритету можливостей з Linux і забезпечити кращу щільність кластера, дозволивши контейнерам використовувати мережевий простір імен вузла. Початкова реалізація була випущена як альфа-версія у версії 1.26, але оскільки вона зіткнулася з неочікуваною поведінкою контейнерів і були доступні альтернативні рішення, проєкт Kubernetes вирішив відкликати повʼязаний з нею KEP. Підтримка була повністю вилучена у v1.33.
Зверніть увагу, що це не впливає на HostProcess контейнери, які надають доступ до мережі хоста, а також на рівні хоста. KEP, вилучений у версії 1.33, надавав доступ лише до мережі хоста, що ніколи не було стабільним через технічні обмеження мережевої логіки Windows.
Ви можете знайти більше інформації у KEP-3503: Host network support for Windows pods.
Примітки до випуску
Ознайомтеся з повною інформацією про випуск Kubernetes v1.33 у наших примітках до випуску.
Доступність
Kubernetes v1.33 доступний для завантаження на GitHub або на сторінці завантаження Kubernetes.
Щоб розпочати роботу з Kubernetes, перегляньте ці інтерактивні підручники або запустіть локальні кластери Kubernetes за допомогою minikube. Ви також можете легко встановити версію 1.33 за допомогою kubeadm.
Команда випуску
Kubernetes можливий лише завдяки підтримці, відданості та наполегливій праці його спільноти. Команда випуску складається з відданих волонтерів спільноти, які працюють разом над створенням багатьох частин, з яких складаються випуски Kubernetes, на які ви покладаєтесь. Це вимагає спеціальних навичок людей з усіх куточків нашої спільноти, від самого коду до його документації та управління проєктом.
Ми хотіли б подякувати всій Команді випуску за години, проведені за важкою роботою над випуском Kubernetes v1.33 для нашої спільноти. Членство в команді Release Team варіюється від новачків до досвідчених лідерів команд, які повернулися з досвідом, отриманим протягом декількох циклів випуску релізів. У цьому циклі було прийнято нову структуру команди, яка полягає в обʼєднанні підкоманд Release Notes і Docs в єдину підкоманду Docs. Завдяки ретельним зусиллям з організації відповідної інформації та ресурсів від нової команди Docs, перехід до відстеження релізів та Docs пройшов гладко і успішно. Нарешті, особлива подяка нашому керівнику релізу, Ніні Полшаковій, за її підтримку протягом усього успішного циклу релізу, її адвокацію, зусилля, спрямовані на те, щоб кожен міг зробити ефективний внесок, а також за її виклики, спрямовані на покращення процесу релізу.
Швидкість проєкту
Проєкт CNCF K8s DevStats обʼєднує декілька цікавих даних, повʼязаних зі швидкістю розвитку Kubernetes та різних підпроєктів. Це включає все, від індивідуальних внесків до кількості компаній, що беруть участь, і ілюструє глибину і широту зусиль, які докладаються для розвитку цієї екосистеми.
Під час циклу випуску v1.33, який тривав 15 тижнів з 13 січня по 23 квітня 2025 року, Kubernetes отримав внески від 121 компанії та 570 приватних осіб (на момент написання статті, за кілька тижнів до дати випуску). У ширшій хмарній екосистемі ця цифра зростає до 435 компаній, що налічує 2400 учасників. Ви можете знайти джерело даних на цій інформаційній панелі. У порівнянні з даними про швидкість з попереднього випуску, v1.32, ми бачимо аналогічний рівень внеску компаній і приватних осіб, що свідчить про сильний інтерес і залученість спільноти.
Зверніть увагу, що «внесок» зараховується, коли хтось робить комміти, рецензує код, коментує, створює випуск або PR, переглядає PR (включаючи блоги і документацію) або коментує випуски і PR. Якщо ви зацікавлені у внеску, відвідайте Початок роботи на нашому веб-сайті для учасників.
Check out DevStats, щоб дізнатися більше про загальну швидкість проекту та спільноти Kubernetes.
Інформація про події
Дізнайтеся про майбутні події, повʼязані з Kubernetes та хмарними технологіями, включаючи KubeCon + CloudNativeCon, KCD та інші визначні конференції по всьому світу. Будьте в курсі подій та долучайтеся до спільноти Kubernetes!
Травень 2025
- KCD - Дні спільноти Kubernetes: Коста-Ріка: 3 травня 2025 року | Ередіа, Коста-Ріка
- KCD - Дні спільноти Кубернетес: Гельсінкі: 6 травня 2025 | Гельсінкі, Фінляндія
- KCD - Дні спільноти Кубернетес: Техаський Остін: 15 травня 2025 | Остін, США
- KCD - Дні спільноти Kubernetes: Сеул: 22 травня 2025 | Сеул, Південна Корея
- KCD - Дні спільноти Kubernetes: Стамбул, Туреччина: 23 травня 2025 | Стамбул, Туреччина
- KCD - Дні спільноти Kubernetes: район затоки Сан-Франциско: 28 травня 2025 року | Сан-Франциско, США
червень 2025
- KCD - Дні спільноти Kubernetes: Нью-Йорк: 4 червня 2025 року | Нью-Йорк, США
- KCD - Дні спільноти Кубернетес: чеська та словацька мови: 5 червня 2025 | Братислава, Словаччина
- KCD - Дні спільноти Кубернетес: Бенгалуру: 6 червня 2025 | Бангалор, Індія
- KubeCon + CloudNativeCon China 2025: 10-11 червня 2025 року | Гонконг
- KCD - Kubernetes Community Days: Антигуа Гватемала: 14 червня 2025 року | Антигуа Гватемала, Гватемала
- KubeCon + CloudNativeCon Japan 2025: 16-17 червня 2025 року | Токіо, Японія
- KCD - Kubernetes Community Days: Нігерія, Африка: 19 червня 2025 року | Нігерія, Африка
липень 2025
- KCD - Дні спільноти Kubernetes: Утрехт: 4 липня 2025 року | Утрехт, Нідерланди
- KCD - Дні спільноти Kubernetes: Тайбей: 5 липня 2025 | Тайбей, Тайвань
- KCD - Дні спільноти Kubernetes: Ліма, Перу: 19 липня 2025 року | Ліма, Перу
Серпень 2025
- KubeCon + CloudNativeCon India 2025: 6-7 серпня 2025 року | Хайдарабад, Індія
- KCD - Kubernetes Community Days: Колумбія: 29 серпня 2025 року | Богота, Колумбія
Ви можете знайти найновішу інформацію про KCD тут.
Вебінар про випуск нового релізу
Приєднуйтесь до команди розробників Kubernetes v1.33 у пʼятницю, 16 травня 2025 року о 16:00 (UTC), щоб дізнатися про основні моменти цього випуску, а також про застарілі та вилучені компоненти, які допоможуть спланувати оновлення. Для отримання додаткової інформації та реєстрації відвідайте сторінку події на сайті Онлайн-програм CNCF.
Долучайтеся
Найпростіший спосіб долучитися до Kubernetes — приєднатися до однієї з численних Special Interest Groups (SIG), які відповідають вашим інтересам. Маєте щось, про що хотіли б розповісти спільноті Kubernetes? Поділіться своєю думкою на нашій щотижневій зустрічі спільноти, а також за допомогою каналів нижче. Дякуємо за ваші відгуки та підтримку.
- Слідкуйте за нами у Bluesky @kubernetes.io, щоб бути в курсі останніх оновлень
- Приєднуйтесь до обговорення спільноти на Discuss
- Приєднуйтесь до спільноти на Slack
- Задавайте питання (або відповідайте на питання) на Server Fault або Stack Overflow
- Поділіться своєю історією про Kubernetes
- Дізнайтеся більше про те, що відбувається з Kubernetes у блозі
- Дізнайтеся більше про команду розробників Kubernetes
Попередній огляд Kubernetes v1.33
З наближенням релізу Kubernetes v1.33 проєкт Kubernetes продовжує розвиватися. Функції можуть застарівати вилучатись або замінятись для покращення загального стану проєкту. У цьому дописі описано деякі заплановані зміни для релізу v1.33, про які, на думку команди релізу, вам слід знати, щоб забезпечити безперебійну роботу вашого середовища Kubernetes та залишатися в курсі останніх розробок. Інформація нижче базується на поточному статусі релізу v1.33 і може змінитися до дати фінального випуску.
Процес видалення та застарівання API Kubernetes
Проєкт Kubernetes має добре задокументовану політику застарівання для функцій. Ця політика передбачає, що стабільні API можуть бути застарілими лише тоді, коли доступна новіша, стабільна версія того ж API, і що API мають мінімальний термін служби для кожного рівня стабільності. Застарілий API позначається для видалення в майбутніх релізах Kubernetes. Він продовжуватиме функціонувати до видалення (принаймні через рік після застарівання), але його використання призведе до показу попередження. Видалені API більше недоступні в поточній версії, і в цьому випадку вам потрібно перейти на використання заміни.
Загальнодоступні (GA) або стабільні версії API можуть бути позначені як застарілі, але не повинні бути видалені в межах основної версії Kubernetes.
Бета-версії або попередні версії API повинні підтримуватися протягом 3 релізів після застарівання.
Альфа-версії або експериментальні API можуть бути видалені в будь-якому релізі без попереднього повідомлення про застарівання; цей процес може стати відкликанням у випадках, коли вже існує інша реалізація для тієї ж функції.
Незалежно від того, чи API видаляється в результаті переходу функції з бета-версії до стабільної, чи тому, що цей API просто не досяг успіху, усі видалення відповідають цій політиці застарівання. Щоразу, коли API видаляється, варіанти міграції повідомляються в керівництві з застарівання.
Застарівання та видалення у Kubernetes v1.33
Застарівання стабільного API Endpoints
API EndpointSlices є стабільним з v1.21, що фактично замінило оригінальний API Endpoints. Хоча оригінальний API Endpoints був простим і зрозумілим, він також створював певні проблеми при масштабуванні до великої кількості мережевих точок доступу. API EndpointSlices запровадив нові функції, такі як двостекова мережа, що робить оригінальний API Endpoints готовим до застарівання.
Це застарівання впливає лише на тих, хто використовує API Endpoints безпосередньо з робочих навантажень або скриптів; таким користувачам слід перейти на використання EndpointSlices. У найближчі тижні буде опубліковано окремий допис у блозі з детальнішою інформацією про наслідки застарівання та плани міграції.
Детальніше дивіться в KEP-4974: Deprecate v1.Endpoints.
Видалення інформації про версію kube-proxy у статусі вузла
Після застарівання у v1.31, як зазначено в анонсі релізу, поле status.nodeInfo.kubeProxyVersion буде видалено у v1.33. Це поле встановлювалося kubelet, але його значення не завжди було точним. Оскільки воно було стандартно вимкнене з v1.31, у релізі v1.33 це поле буде повністю видалене.
Детальніше дивіться в KEP-4004: Deprecate status.nodeInfo.kubeProxyVersion field.
Видалення підтримки мережі хосту для Windows-подів
Мережа Windows-подів мала на меті досягти паритету функцій із Linux і забезпечити кращу щільність кластерів, дозволяючи контейнерам використовувати мережевий простір імен вузла. Оригінальна реалізація з’явилася як альфа у v1.26, але через несподівану поведінку containerd і наявність альтернативних рішень проєкт Kubernetes вирішив відкликати пов’язаний KEP. Очікується, що підтримка буде повністю видалена у v1.33.
Детальніше дивіться в KEP-3503: Host network support for Windows pods.
Основне покращення Kubernetes v1.33
Як автори цієї статті, ми обрали одне покращення як найважливішу зміну, яку варто відзначити!
Підтримка просторів імен користувача у Linux-подах
Одним із найстаріших відкритих KEP сьогодні є KEP-127, покращення безпеки подів за допомогою просторів імен користувача у Linux. Цей KEP був вперше відкритий наприкінці 2016 року, і після кількох ітерацій мав альфа-реліз у v1.25, початкову бета-версію у v1.30 (де він був стандартно вимкнений), і тепер має стати частиною v1.33, де функція буде стандартно доступна.
Ця підтримка не вплине на наявні поди, якщо ви вручну не вкажете pod.spec.hostUsers, щоб увімкнути її. Як зазначено в блозі про попередній огляд v1.30, це важливий етап для усунення вразливостей.
Детальніше дивіться в KEP-127: Support User Namespaces in pods.
Інші покращення Kubernetes v1.33
Зміна розміру ресурсів на місці для вертикального масштабування подів
Під час створення поду ви можете використовувати різні ресурси, такі як Deployment, StatefulSet тощо. Вимоги до масштабованості можуть вимагати горизонтального масштабування шляхом оновлення кількості реплік подів або вертикального масштабування шляхом оновлення ресурсів, виділених контейнерам поду. До цього покращення ресурси контейнера, визначені в spec поду, були незмінними, і оновлення будь-яких із цих деталей у шаблоні поду призводило до заміни поду.
Але що, якби ви могли динамічно оновлювати конфігурацію ресурсів для ваших поточних подів без їх перезапуску?
KEP-1287 був створений саме для того, щоб дозволити такі оновлення подів на місці. Це відкриває різні можливості вертикального масштабування для станів процесів без простоїв, безперебійного зменшення масштабу, коли трафік низький, і навіть виділення більших ресурсів під час запуску, які згодом зменшуються після завершення початкового налаштування. Це було випущено як альфа у v1.27 і очікується, що стане бета-версією у v1.33.
Детальніше дивіться в KEP-1287: In-Place Update of Pod Resources.
Статус пристрою ResourceClaim DRA переходить до бета-версії
Поле devices у статусі ResourceClaim, яке було вперше введено у релізі v1.32, ймовірно, перейде до бета-версії у v1.33. Це поле дозволяє драйверам повідомляти дані про статус пристрою, покращуючи як можливості спостереження, так і усунення несправностей.
Наприклад, повідомлення імені інтерфейсу, MAC-адреси та IP-адрес мережевих інтерфейсів у статусі ResourceClaim може значно допомогти в налаштуванні та керуванні мережевими службами, а також у налагодженні мережевих проблем. Ви можете прочитати більше про статус пристрою ResourceClaim у документі Dynamic Resource Allocation: ResourceClaim Device Status.
Також ви можете дізнатися більше про заплановане покращення в KEP-4817: DRA: Resource Claim Status with possible standardized network interface data.
Впорядковане видалення просторів імен
Цей KEP запроваджує більш структурований процес видалення просторів імен Kubernetes для забезпечення безпечного та детермінованого видалення ресурсів. Поточний напіввипадковий порядок видалення може створювати прогалини в безпеці або непередбачену поведінку, наприклад, поди, що залишаються після видалення пов’язаних із ними NetworkPolicies. Запроваджуючи структуровану послідовність видалення, яка враховує логічні та безпекові залежності, цей підхід забезпечує видалення подів перед іншими ресурсами. Дизайн покращує безпеку та надійність Kubernetes, зменшуючи ризики, пов’язані з недетермінованими видаленнями.
Детальніше дивіться в KEP-5080: Ordered namespace deletion.
Покращення для керування індексованими завданнями
Ці два KEP мають перейти до GA, щоб забезпечити кращу надійність обробки завдань, зокрема для індексованих завдань. KEP-3850 забезпечує обмеження відкату для кожного індексу для індексованих завдань, що дозволяє кожному індексу бути повністю незалежним від інших індексів. Також KEP-3998 розширює Job API, щоб визначити умови для успішного завершення індексованого завдання, якщо не всі індекси було успішно виконано.
Детальніше дивіться в KEP-3850: Backoff Limit Per Index For Indexed Jobs та KEP-3998: Job success/completion policy.
Хочете дізнатися більше?
Нові функції та застарівання також оголошуються в примітках до релізу Kubernetes. Ми офіційно оголосимо, що нового в Kubernetes v1.33 як частину CHANGELOG для цього релізу.
Реліз Kubernetes v1.33 заплановано на середу, 23 квітня 2025 року. Слідкуйте за оновленнями!
Ви також можете побачити оголошення про зміни в примітках до релізу для:
Долучайтеся
Найпростіший спосіб долучитися до Kubernetes – це приєднатися до однієї з багатьох груп спеціальних інтересів (SIG), які відповідають вашим інтересам. Хочете щось повідомити спільноті Kubernetes? Поділіться своєю думкою на нашій щотижневій зустрічі спільноти та через канали нижче. Дякуємо за ваші постійні відгуки та підтримку.
- Слідкуйте за нами на Bluesky @kubernetes.io для останніх оновлень
- Приєднуйтесь до обговорення спільноти на Discuss
- Приєднуйтесь до спільноти у Slack
- Публікуйте запитання (або відповідайте на запитання) на Server Fault або Stack Overflow
- Поділіться своєю історією про Kubernetes
- Читайте більше про те, що відбувається з Kubernetes в блозі
- Дізнайтеся більше про команду релізу Kubernetes
Kubernetes v1.32: Penelope
Редактори: Matteo Bianchi, Edith Puclla, William Rizzo, Ryota Sawada, Rashan Smith
Анонсуємо випуск Kubernetes v1.32: Penelope!
Як і у попередніх випусках, у Kubernetes v1.32 представлено нові стабільні, бета- та альфа-версії. Послідовний випуск високоякісних випусків підкреслює силу нашого циклу розробки та активну підтримку нашої спільноти. Цей випуск складається з 44 покращень. З них 13 перейшли до стабільного стану, 12 — до бета-версії, а 19 — до альфа-версії.
Тема та логотип релізу

Темою випуску Kubernetes v1.32 є «Penelope».
Якщо Kubernetes з давньогрецької означає «лоцман», то в цьому випуску ми відштовхуємося від цього походження і розмірковуємо про останні 10 років Kubernetes і наші досягнення: кожен цикл випуску - це подорож, і як Пенелопа в «Одіссеї» ткала 10 років, щоночі видаляючи частину того, що вона зробила за день, так і кожен випуск додає нові можливості і видаляє інші, хоча в даному випадку з набагато чіткішою метою — постійно покращувати Kubernetes. Оскільки v1.32 є останнім випуском у році, коли Kubernetes відзначає своє перше десятиріччя, ми хотіли б відзначити всіх тих, хто був частиною глобальної команди Kubernetes, яка блукає хмарними морями, долаючи небезпеки та виклики: нехай ми продовжуємо творити майбутнє Kubernetes разом.
Оновлення останніх ключових функцій
Примітка про вдосконалення DRA
У цьому випуску, як і в попередньому, проєкт Kubernetes продовжує пропонувати ряд удосконалень динамічного розподілу ресурсів (DRA), ключового компонента системи керування ресурсами Kubernetes. Ці вдосконалення спрямовані на підвищення гнучкості та ефективності розподілу ресурсів для робочих навантажень, які потребують спеціалізованого обладнання, такого як графічні процесори, FPGA та мережеві адаптери. Ці функції особливо корисні для таких сценаріїв використання, як машинне навчання або високопродуктивні обчислювальні застосунки. Основна частина, що забезпечує підтримку структурованих параметрів DRA перейшла у бета-версію.
Покращення якості життя на вузлах та оновлення контейнерів sidecar
SIG Node має наступні основні моменти, які виходять за рамки KEPs:
Функція сторожового таймера systemd тепер використовується для перезапуску kubelet, коли перевірка стану не вдається, одночасно обмежуючи максимальну кількість перезапусків протягом певного періоду часу. Це підвищує надійність роботи kubelet. Більш детальну інформацію можна знайти в pull request #127566.
У випадках, коли виникає помилка витягування образу, повідомлення, що відображається у статусі podʼів, було покращено, щоб зробити його більш зручним для користувача і вказати деталі про те, чому pod перебуває у такому стані. Коли виникає помилка витягування образу, вона додається до поля
status.containerStatuses[*].state.waiting.messageу специфікації Pod зі значеннямImagePullBackOffу поліreason. Ця зміна надає вам більше контексту і допомагає визначити першопричину проблеми. Докладніші відомості наведено у pull request #127918.Функція контейнерів sidecar планується до випуску у статусі Stable у версії 1.33. Щоб переглянути решту робочих елементів та відгуки користувачів, дивіться коментарі у тікеті #753.
Функції, що перейшли у стан Stable
Це добірка деяких поліпшень, які тепер стабільно працюють після випуску v1.32.
Перемикачі полів Custom Resource
Селектор полів власних ресурсів дозволяє розробникам додавати селектори полів до власних ресурсів, відображаючи функціональність, доступну для вбудованих обʼєктів Kubernetes. Це дозволяє ефективніше і точніше фільтрувати власні ресурси, сприяючи кращому проєктуванню API.
Ця робота була виконана в рамках KEP #4358, силами SIG API Machinery.
Підтримка зміни розміру томів у памʼяті
Ця функція дозволяє динамічно змінювати розмір томів, що зберігаються в памʼяті, на основі обмежень на ресурси Pod, покращуючи перенесення робочого навантаження та загальне використання ресурсів вузла.
Ця робота була виконана в рамках KEP #1967, силами SIG Node.
Покращення токену привʼязаного службового облікового запису
Включення імені вузла до вимог токенів службових облікових записів дозволяє користувачам використовувати цю інформацію під час авторизації та допуску (ValidatingAdmissionPolicy). Крім того, це покращення унеможливлює використання облікових даних службових облікових записів для підвищення привілеїв для вузлів.
Ця робота була виконана в рамках KEP #4193 силами SIG Auth.
Структурована конфігурація авторизації
На сервері API можна налаштувати декілька авторизаторів, щоб забезпечити структуровані рішення щодо авторизації, з підтримкою умов відповідності CEL у веб-хуках.
Ця робота була виконана в рамках KEP #3221 силами SIG Auth.
Автоматичне видалення PVC, створених StatefulSet
PersistentVolumeClaims (PVC), створені StatefulSet, автоматично видаляються, коли вони більше не потрібні, забезпечуючи при цьому збереження даних під час оновлень StatefulSet і обслуговування вузлів. Ця функція спрощує керування сховищем для StatefulSets і зменшує ризик появи «осиротілих» PVC.
Ця робота була виконана в рамках KEP #1847 силами SIG Apps.
Функції, що перейшли в стан Beta
Це добірка деяких покращень, які зараз є в бета версії після релізу v1.32.
Механізм керованого Job API
Поле managedBy для Jobs було підвищено до рівня бета-версії у випуску v1.32. Ця можливість дозволяє зовнішнім контролерам (наприклад, Kueue) керувати синхронізацією завдань, пропонуючи більшу гнучкість та інтеграцію з сучасними системами керування робочим навантаженням.
Ця робота була виконана в рамках KEP #4368, силами SIG Apps.
Дозволити анонімний вхід лише для налаштованих точок доступу
Ця функція дозволяє адміністраторам вказати, які точки доступу дозволено використовувати для анонімних запитів. Наприклад, адміністратор може дозволити анонімний доступ лише до таких точок контролю справності, як /healthz, /livez і /readyz, при цьому не допускаючи анонімного доступу до інших точок доступу або ресурсів кластера, навіть якщо користувач невірно налаштував RBAC.
Ця робота була виконана в рамках KEP #4633, силами SIG Auth.
Функції зворотного виклику для кожного втулку для точного повторного запиту в розширеннях kube-scheduler
Ця функція підвищує продуктивність планування завдяки ефективнішим рішенням щодо повторних спроб планування за допомогою функцій зворотного виклику для кожного втулка (QueueingHint). Тепер усі втулки мають підказки QueueingHints.
Ця робота була виконана в рамках KEP #4247, силами SIG Scheduling.
Відновлення після збою збільшення тому
Ця функція дозволяє користувачам відновитися після невдалої спроби розширення тома, повторивши спробу з меншим розміром. Ця функція гарантує, що розширення тома буде більш стійким і надійним, зменшуючи ризик втрати або пошкодження даних під час цього процесу.
Ця робота була виконана в рамках KEP #1790, силами SIG Storage.
Знімок групи томів
Ця функція представляє API VolumeGroupSnapshot, який дозволяє користувачам робити знімки кількох томів разом, забезпечуючи узгодженість даних у всіх томах.
Ця робота була виконана в рамках KEP #3476, силами SIG Storage.
Підтримка структурованих параметрів
Основна частина Dynamic Resource Allocation (DRA, динамічний розподіл ресурсів), підтримка структурованих параметрів, перейшла в бета-версію. Це дозволяє kube-scheduler та кластерному автомасштабувальнику імітувати розподіл запитів безпосередньо, без використання сторонніх драйверів. Тепер ці компоненти можуть передбачати, чи можуть запити на ресурси бути виконані на основі поточного стану кластера, без фактичної фіксації розподілу. Усуваючи необхідність у сторонньому драйвері для перевірки або тестування розподілів, ця функція покращує планування і прийняття рішень щодо розподілу ресурсів, роблячи процеси планування і масштабування більш ефективними.
Ця робота була виконана в рамках KEP #4381, силами WG Device Management (командою, що складється з SIG Node, SIG Scheduling та SIG Autoscaling).
Авторизація міток і селекторів полів
Селектори міток і полів можна використовувати у рішеннях щодо авторизації. Авторизатор вузла автоматично використовує це, щоб обмежити вузли лише переглядом або переліком їхніх podʼів. Авторизатори вебхуків можна оновити, щоб обмежити запити на основі міток або селекторів полів, що використовуються.
Ця робота була виконана в рамках KEP #4601 силами SIG Auth.
Фцнкції, що перейшли в стан Alpha
Це добірка деяких покращень, які зараз є в альфа версії після релізу v1.32.
Асинхронне витіснення у планувальнику Kubernetes
Планувальник Kubernetes було вдосконалено за допомогою функції асинхронного витіснення, яка покращує пропускну здатність планувальника, обробляючи операції витіснення асинхронно. Витіснення гарантує, що більш пріоритетні podʼи отримують необхідні їм ресурси, витісняючи менш пріоритетні, але раніше цей процес включав важкі операції, такі як виклики API для видалення podʼів, що сповільнювало роботу планувальника. Завдяки цьому вдосконаленню такі завдання тепер обробляються паралельно, що дозволяє планувальнику без затримок продовжувати планувати інші podʼів. Це покращення особливо корисне для кластерів з високим рівнем відтоку Podʼів або частими збоями в плануванні, забезпечуючи більш ефективний та відмовостійкий процес планування.
Ця робота була виконана в рамках KEP #4832 силами SIG Scheduling.
Змінювані політики допуску за допомогою CEL-виразів
Ця функція використовує обʼєктну конкретизацію CEL та стратегії JSON Patch у поєднанні з алгоритмами злиття Server Side Apply. Це спрощує визначення політик, зменшує конфлікти мутацій і підвищує продуктивність контролю доступу, закладаючи основу для більш надійних, розширюваних фреймворків політик в Kubernetes.
Сервер Kubernetes API тепер підтримує мутацію політик допуску на основі Common Expression Language (CEL), що забезпечує легку та ефективну альтернативу мутації веб-хуків допуску. Завдяки цьому вдосконаленню адміністратори можуть використовувати CEL для оголошення змін, таких як встановлення міток, стандартних значень полів або додавання sidecars, за допомогою простих декларативних виразів. Такий підхід зменшує операційну складність, усуває потребу у веб-хуках та інтегрується безпосередньо з kube-apiserver, пропонуючи швидшу та надійнішу обробку мутацій у процесі роботи.
Ця робота була виконана в рамках KEP #3962 силами SIG API Machinery.
Специфікації ресурсів на рівні podʼів
Це вдосконалення спрощує управління ресурсами в Kubernetes, надаючи можливість встановлювати запити на ресурси та ліміти на рівні Pod, створюючи спільний пул, який можуть динамічно використовувати всі контейнери в Pod. Це особливо цінно для робочих навантажень з контейнерами, які мають нестабільні або різкі потреби в ресурсах, оскільки це мінімізує надлишкове резервування і покращує загальну ефективність використання ресурсів.
Використовуючи налаштування Linux cgroup на рівні Pod, Kubernetes гарантує дотримання цих обмежень на ресурси, дозволяючи тісно повʼязаним контейнерам ефективніше співпрацювати без штучних обмежень. Важливо, що ця функція підтримує зворотну сумісність з існуючими налаштуваннями ресурсів на рівні контейнерів, дозволяючи користувачам адаптувати їх поступово, не порушуючи поточні робочі процеси або існуючі конфігурації.
Це значне покращення для багатоконтейнерних подів, оскільки зменшує операційну складність управління розподілом ресурсів між контейнерами. Це також забезпечує приріст продуктивності для тісно інтегрованих застосунків, таких як архітектури sidecar, де контейнери розподіляють робочі навантаження або залежать від доступності один одного для оптимальної роботи.
Ця робота була виконана в рамках KEP #2837 силами SIG Node.
Дозвіл нульового значення для дії sleep хука PreStop
Це вдосконалення надає можливість встановити нульову тривалість сплячого режиму для хука життєвого циклу PreStop у Kubernetes, пропонуючи гнучкіший варіант перевірки та налаштування ресурсів, який не потребує зупинки. Раніше спроба визначити нульове значення для дії переходу в режим сну призводила до помилок валідації, що обмежувало його використання. З цим оновленням користувачі можуть налаштувати нульову тривалість як допустимий параметр переходу в режим сну, що дозволяє негайне виконання і завершення дій, де це необхідно.
Це вдосконалення є сумісним з попередніми версіями, його впроваджено як додаткову функцію, керовану за допомогою функції PodLifecycleSleepActionAllowZero. Ця зміна особливо корисна для сценаріїв, що вимагають використання хуків PreStop для перевірки або обробки веб-хуків допуску, не вимагаючи фактичної тривалості сплячого режиму. Завдяки узгодженню з можливостями функції time.After Go, це оновлення спрощує конфігурацію і розширює зручність використання для робочих навантажень Kubernetes.
Ця робота була виконана в рамках KEP #4818 силами SIG Node.
DRA: Стандартизовані дані мережевого інтерфейсу для статусу заявки на ресурс
Це вдосконалення додає нове поле, яке дозволяє драйверам повідомляти конкретні дані про стан пристрою для кожного виділеного обʼєкта в ResourceClaim. Воно також встановлює стандартизований спосіб представлення інформації про мережеві пристрої.
Ця робота була виконана в рамках KEP #4817, силами SIG Network.
Нові точки доступу statusz та flagz для основних компонентів
Ви можете ввімкнути дві нові HTTP точки доступу /statusz і /flagz, для основних компонентів. Це покращує налагоджуваність кластера за рахунок отримання інформації про те, з якою версією (наприклад, Golang) працює компонент, а також про час його роботи і з якими прапорцями командного рядка він був запущений; це полегшує діагностику як проблем виконання, так і проблем конфігурації.
Ця робота була виконана в рамках KEP #4827 та KEP #4828 силами SIG Instrumentation.
Windows дає відсіч!
Додано підтримку належного завершення роботи Windows-вузлів у кластерах Kubernetes. До цього випуску Kubernetes надавав функціональність належноо завершення роботи для вузлів Linux, але не мав еквівалентної підтримки для Windows. Це покращення дозволяє kubelet на Windows-вузлах правильно обробляти події вимкнення системи. Це гарантує, що Podʼи, запущені на Windows-вузлах, будуть належно завершені, що дозволить перепланувати робочі навантаження без збоїв. Це покращення підвищує надійність і стабільність кластерів, що включають вузли Windows, особливо під час планового обслуговування або будь-яких оновлень системи.
Крім того, додано підтримку спорідненості процесорів і памʼяті для вузлів Windows з вузлами, з поліпшеннями в диспетчері процесорів, диспетчері памʼяті і диспетчері топології.
Ця робота була виконана в рамках KEP #4802 та KEP #4885 силами SIG Windows.
Випуск, списання та ліквідація у 1.32
Перехід у Stable
Тут перераховані всі функції, які перейшли до стабільного стану (також відомого як загальна доступність). Повний список оновлень, включно з новими функціями та переходами з альфа-версії до бета-версії, наведено у примітках до випуску.
Цей випуск містить загалом 13 покращень, які було підвищено до рівня стабільності:
- Structured Authorization Configuration
- Bound service account token improvements
- Custom Resource Field Selectors
- Retry Generate Name
- Make Kubernetes aware of the LoadBalancer behaviour
- Field
status.hostIPsadded for Pod - Custom profile in kubectl debug
- Memory Manager
- Support to size memory backed volumes
- Improved multi-numa alignment in Topology Manager
- Add job creation timestamp to job annotations
- Add Pod Index Label for StatefulSets and Indexed Jobs
- Auto remove PVCs created by StatefulSet
Застарівання та вилучення
У міру розвитку та зрілості Kubernetes, функції можуть бути застарілими, вилученими або заміненими на кращі для покращення загального стану проєкту. Детальніше про цей процес див. у документі Kubernetes політика застарівання та видалення.
Відмова від старої імплементації DRA
Удосконалення #3063 запровадило динамічний розподіл ресурсів (DRA) у Kubernetes 1.26.
Однак, у Kubernetes v1.32 цей підхід до DRA буде суттєво змінено. Код, повʼязаний з оригінальною реалізацією, буде видалено, залишивши KEP #4381 як «нову» базову функціональність.
Рішення про зміну існуючого підходу було прийнято через його несумісність з кластерним автомасштабуванням, оскільки доступність ресурсів була непрозорою, що ускладнювало прийняття рішень як для кластерного автомасштабувальника, так і для контролерів. Нещодавно додана модель структурованих параметрів замінює цю функціональність.
Це видалення дозволить Kubernetes більш передбачувано обробляти нові вимоги до апаратного забезпечення та запити на ресурси, оминаючи складнощі зворотних викликів API до kube-apiserver.
Щоб дізнатися більше, дивіться тікет #3063.
Вилічення API
У [Kubernetes v1.32] (/docs/reference/using-api/deprecation-guide/#v1-32) вилучено один API:
- Видалено версію
flowcontrol.apiserver.k8s.io/v1beta3API FlowSchema та PriorityLevelConfiguration. Щоб підготуватися до цього, ви можете відредагувати наявні маніфести та переписати клієнтське програмне забезпечення для використання версіїflowcontrol.apiserver.k8s.io/v1 API, доступної починаючи з v1.29. Всі існуючі збережені обʼєкти доступні через новий API. Серед помітних змін у flowcontrol.apiserver.k8s.io/v1beta3 - поле PriorityLevelConfigurationspec.limited.nominalConcurrencySharesстає типово рівним 30, якщо його не вказано, а явне значення 0 не змінюється на 30.
Для отримання додаткової інформації зверніться до Посібника із застарівання API.
Примітки до випуску та необхідні дії для оновлення
Ознайомтеся з повною інформацією про випуск Kubernetes v1.32 у наших примітках до випуску.
Доступність
Kubernetes v1.32 доступний для завантаження на GitHub або на сторінці завантаження Kubernetes.
Щоб розпочати роботу з Kubernetes, перегляньте ці інтерактивні підручники або запустіть локальні кластери Kubernetes за допомогою minikube. Ви також можете легко встановити v1.32 за допомогою kubeadm.
Команда випуску
Kubernetes можливий лише завдяки підтримці, відданості та наполегливій праці його спільноти. Кожна команда розробників складається з відданих волонтерів спільноти, які працюють разом над створенням багатьох частин, що складають випуски Kubernetes, на які ви покладаєтесь. Це вимагає спеціалізованих навичок людей з усіх куточків нашої спільноти, від самого коду до його документації та управління проектом.
Ми хотіли б подякувати всій команді розробників за години, проведені за напруженою роботою над випуском Kubernetes v1.32 для нашої спільноти. Членство в команді варіюється від новачків до досвідчених лідерів команд, які повернулися з досвідом, отриманим протягом декількох циклів випуску. Особлива подяка нашому керівнику релізу, Фредеріко Муньосу, за те, що він керує командою розробників так витончено і вирішує будь-які питання з максимальною ретельністю, гарантуючи, що цей реліз буде виконано гладко і ефективно. І останнє, але не менш важливе: велика подяка всім учасникам релізу, як ведучим, так і помічникам, а також наступним SIG за приголомшливу роботу і результати, досягнуті за ці 14 тижнів роботи над релізом:
- SIG Docs — за фундаментальну підтримку в документації та рецензування блогів, а також за постійну співпрацю з командами випуску та документації;
- SIG k8s Infra та SIG Testing — за видатну роботу з підтримки фреймворку тестування, а також усіх необхідних інфра-компонентів;
- SIG Release та усім менеджерам релізу — за неймовірну підтримку, надану протягом усього процесу створення релізу, вирішення навіть найскладніших питань у витончений та своєчасний спосіб.
Швидкість реалізації проекту
CNCF K8s проєкт DevStats обʼєднує низку цікавих даних, повʼязаних зі швидкістю розвитку Kubernetes та різних підпроєктів. Це включає в себе все, від індивідуальних внесків до кількості компаній, які беруть участь, і є ілюстрацією глибини і широти зусиль, які докладаються для розвитку цієї екосистеми.
У циклі випуску v1.32, який тривав 14 тижнів (з 9 вересня по 11 грудня), ми бачили внески в Kubernetes від 125 різних компаній і 559 приватних осіб на момент написання цієї статті.
У всій екосистемі Cloud Native ця цифра зросла до 433 компаній, що налічує 2441 учасника. Це на 7% більше загального внеску порівняно з циклом попереднього випуску, а кількість залучених компаній зросла на 14%, що свідчить про значний інтерес до проектів Cloud Native та наявність спільноти.
Джерело цих даних:
Під внеском ми маємо на увазі, коли хтось робить комміти, рецензує код, коментує, створює випуск або PR, переглядає PR (включаючи блоги і документацію) або коментує випуски і PR.
Якщо ви зацікавлені у внеску, відвідайте Початок роботи на нашому сайті для учасників.
Перевірити DevStats, щоб дізнатися більше про загальну швидкість роботи проєкту та спільноти Kubernetes.
Оновлені події
Ознайомтеся з майбутніми подіями з Kubernetes та хмарних технологій з березня по червень 2025 року, зокрема з KubeCon та KCD Залишайтеся в курсі подій та долучайтеся до спільноти Kubernetes.
Березень 2025
- KCD - Kubernetes Community Days: Beijing, China: У березні | Пекін, Китай
- KCD - Kubernetes Community Days: Guadalajara, Mexico: 16 березня 2025 року | Гвадалахара, Мексика
- KCD - Kubernetes Community Days: Rio de Janeiro, Brazil: 22 березня 2025 року | Ріо-де-Жанейро, Бразилія
Квітень 2025
- KubeCon + CloudNativeCon Europe 2025: 1-4 квітня 2025 року | Лондон, Велика Британія
- KCD - Kubernetes Community Days: Budapest, Hungary: 23 квітня 2025 | Будапешт, Угорщина
- KCD - Kubernetes Community Days: Chennai, India: 26 квітня 2025 | Ченнаї, Індія
- KCD - Kubernetes Community Days: Auckland, New Zealand: 28 квітня 2025 | Окленд, Нова Зеландія
Травень 2025
- KCD - Kubernetes Community Days: Helsinki, Finland: 6 травня 2025 року | Гельсінкі, Фінляндія
- KCD - Kubernetes Community Days: San Francisco, USA: 8 травня 2025 року | Сан-Франциско, США
- KCD - Kubernetes Community Days: Austin, USA: 15 травня 2025 | Остін, США
- KCD - Kubernetes Community Days: Seoul, South Korea: 22 травня 2025 | Сеул, Південна Корея
- KCD - Kubernetes Community Days: Istanbul, Turkey: 23 травня 2025 | Стамбул, Туреччина
- KCD - Kubernetes Community Days: Heredia, Costa Rica: 31 травня 2025 | Ередія, Коста-Ріка
- KCD - Kubernetes Community Days: New York, USA: У травні | Нью-Йорк, США
Червень 2025
- KCD - Kubernetes Community Days: Bratislava, Slovakia: June 5, 2025 | Bratislava, Slovakia
- KCD - Kubernetes Community Days: Bangalore, India: June 6, 2025 | Bangalore, India
- KubeCon + CloudNativeCon China 2025: 10-11 червня 2025 року | Гонконг
- KCD - Kubernetes Community Days: Antigua Guatemala, Guatemala: 14 червня 2025 | Антигуа Гватемала, Гватемала
- KubeCon + CloudNativeCon Japan 2025: 16-17 червня 2025 | Токіо, Японія
- KCD - Kubernetes Community Days: Nigeria, Africa: 19 червня 2025 | Нігерія, Африка
Найближчий вебінар про випуск
Приєднуйтесь до команди розробників Kubernetes v1.32 у четвер, 9 січня 2025 року о 17:00 (UTC), щоб дізнатися про основні моменти цього випуску, а також про застарілі та вилучені компоненти, які допоможуть спланувати оновлення. Для отримання додаткової інформації та реєстрації відвідайте сторінку події на сайті Онлайн-програм CNCF.
Долучайтеся
Найпростіший спосіб долучитися до Kubernetes - приєднатися до однієї з багатьох [ Special Interest Groups] (https://www.kubernetes.dev/community/community-groups/#special-interest-groups) (SIG), які відповідають вашим інтересам. Маєте щось, про що хотіли б розповісти спільноті Kubernetes? Поділіться своєю думкою на нашій щотижневій зустрічі спільноти, а також за допомогою каналів нижче. Дякуємо за ваші постійні відгуки та підтримку.
- Слідкуйте за нами у Bluesky @Kubernetes.io для отримання останніх оновлень
- Приєднуйтесь до обговорення спільноти на Discuss
- Приєднуйтесь до спільноти у Slack
- Ставте питання (або відповідайте) на Stack Overflow
- Поділіться своєю історією про Kubernetes
- Дізнайтеся більше про те, що відбувається з Kubernetes у блозі
- Дізнайтеся більше про команду розробників Kubernetes
Попередній огляд Kubernetes v1.32
Чим ближче до дати випуску Kubernetes v1.32, тим більше проєкт розвивається та вдосконалюється. Функції можуть бути визнані застарілими, видалені або замінені на кращі для загального покращення проєкту.
Тут описані деякі заплановані зміни для випуску Kubernetes v1.32, які, на думку команди випуску, вам слід знати для продовження обслуговування вашого середовища Kubernetes та підтримки в актуальному стані з останніми змінами. Інформація, наведена нижче, базується на поточному стані випуску v1.32 і може змінитися до фактичної дати випуску.
Процес видалення та застарівання API Kubernetes
Проєкт Kubernetes має добре задокументовану політику застарівання для функцій. Ця політика зазначає, що стабільні API можуть бути застарілими лише тоді, коли доступна новіша, стабільна версія цього API, і що API мають мінімальний термін служби для кожного рівня стабільності. Застарілий API, який був позначений для видалення в майбутньому випуску Kubernetes, продовжуватиме функціонувати до видалення (принаймні один рік з моменту застарівання). Його використання призведе до показу попередження. Видалені API більше не доступні в поточній версії, тому вам потрібно перейти на використання заміни.
Загальнодоступні (GA) або стабільні версії API можуть бути позначені як застарілі, але не повинні бути видалені в межах основної версії Kubernetes.
Бета або попередні версії API повинні підтримуватися протягом 3 випусків після застарівання.
Альфа або експериментальні версії API можуть бути видалені в будь-якому випуску без попереднього повідомлення про застарівання; цей процес може стати відкликанням у випадках, коли вже існує інша реалізація для тієї ж функції.
Незалежно від того, чи видаляється API через перехід функції з бета-версії до стабільної, чи через те, що цей API не вдався, всі видалення відповідають цій політиці застарівання. Коли API видаляється, варіанти міграції повідомляються в керівництві по застаріванню.
Примітка щодо відкликання старої реалізації DRA
Покращення #3063 ввело Динамічне виділення ресурсів (DRA — Dynamic Resource Allocation) в Kubernetes 1.26.
Однак у Kubernetes v1.32 цей підхід до DRA буде значно змінено. Код, повʼязаний з початковою реалізацією, буде видалено, залишаючи KEP #4381 як "нову" базову функціональність.
Рішення змінити поточний підхід виникло через його несумісність з автоматичним масштабуванням кластера, оскільки доступність ресурсів була непрозорою, ускладнюючи прийняття рішень як для Cluster Autoscaler, так і для контролерів. Нова додана модель Структурованих Параметрів замінює функціональність.
Це видалення дозволить Kubernetes обробляти нові апаратні вимоги та запити на ресурси більш передбачувано, обходячи складнощі зворотних викликів API до kube-apiserver.
Будь ласка, також перегляньте #3063 для отримання додаткової інформації.
Видалення API
Заплановано лише одне видалення API для Kubernetes v1.32:
- Версія API
flowcontrol.apiserver.k8s.io/v1beta3для FlowSchema та PriorityLevelConfiguration була видалена. Щоб підготуватися до цього, ви можете відредагувати свої поточні маніфести та переписати клієнтське програмне забезпечення для використання версії APIflowcontrol.apiserver.k8s.io/v1, доступної з v1.29. Всі поточні збережені обʼєкти доступні через новий API. Помітні зміни вflowcontrol.apiserver.k8s.io/v1beta3включають те, що поле PriorityLevelConfigurationspec.limited.nominalConcurrencySharesстандартно встановлюється на 30, якщо не вказано явне значення 0, яке не змінюється на 30.
Для отримання додаткової інформації, будь ласка, зверніться до керівництва по застаріванню API.
Попередній огляд Kubernetes v1.32
Наступний список покращень, ймовірно, буде включений у випуск v1.32. Це не є зобовʼязанням, і вміст випуску може змінитися.
Ще більше покращень DRA!
У цьому випуску, як і в попередньому, проєкт Kubernetes продовжує пропонувати ряд покращень для Динамічного виділення ресурсів (DRA), ключового компонента системи управління ресурсами Kubernetes. Ці покращення спрямовані на підвищення гнучкості та ефективності виділення ресурсів для робочих навантажень, які потребують спеціалізованого обладнання, такого як GPU, FPGA та мережеві адаптери. Цей випуск вводить покращення, включаючи додавання статусу справності ресурсів у статус Pod, як описано в KEP #4680.
Додавання статусу справності ресурсів до статусу Pod
Важко дізнатися, коли Pod використовує пристрій, який вийшов з ладу або тимчасово несправний. KEP #4680 пропонує показувати справність пристрою через статус Pod, що полегшує усунення несправностей при аваріях Pod.
Windows повертається!
KEP #4802 додає підтримку для належного завершення роботи вузлів Windows у кластерах Kubernetes. До цього випуску Kubernetes надавав функціональність належного завершення роботи вузлів для вузлів Linux, але не мав еквівалентної підтримки для Windows. Це покращення дозволяє kubelet на вузлах Windows правильно обробляти події завершення роботи системи. Таким чином, забезпечується належне завершення роботи Podʼів на вузлах Windows, дозволяючи робочим навантаженням бути перенесеними без простоїв. Це покращення підвищує надійність та стабільність кластерів, які включають вузли Windows, особливо під час планового обслуговування або будь-яких оновлень системи.
Дозвіл на використання спеціальних символів в змінних середовища
З переходом цього покращення у стан бета-версії, Kubernetes тепер дозволяє використовувати майже всі друковані символи ASCII (за винятком "=") в іменах змінних середовища. Ця зміна усуває обмеження, які раніше накладалися на імена змінних, сприяючи ширшому прийняттю Kubernetes, задовольняючи різні потреби застосунків. Функціональна можливість RelaxedEnvironmentVariableValidation буде стандартно увімкнена, надаючи користувачам можливість легко використовувати змінні середовища без суворих обмежень, підвищуючи гнучкість для розробників, які працюють з застосунками, такими як
.NET Core, які потребують спеціальних символів у своїх конфігураціях.
Kubernetes буде обізнаним про поведінку LoadBalancer
KEP #1860 переходить до GA, вводячи поле ipMode для Service типу LoadBalancer, яке може бути встановлено на "VIP" або "Proxy". Це покращення спрямоване на покращення взаємодії балансувальників навантаження хмарних провайдерів з kube-proxy і є зміною, прозорою для кінцевого користувача. Поточна поведінка kube-proxy зберігається при використанні "VIP", де kube-proxy обробляє балансування навантаження. Використання "Proxy" призводить до того, що трафік надсилається безпосередньо до балансувальника навантаження, надаючи хмарним провайдерам більший контроль над залежністю від kube-proxy;
це означає, що ви можете побачити покращення продуктивності вашого балансувальника навантаження для деяких хмарних провайдерів.
Повторна генерація імен для ресурсів
Це покращення покращує обробку конфліктів імен для ресурсів Kubernetes, створених з полем generateName. Раніше, якщо виникав конфлікт імен, API сервер повертав помилку 409 HTTP Conflict, і клієнти мали вручну повторювати запит. З цим оновленням, API сервер автоматично повторює генерацію нового імені до семи разів у разі конфлікту. Це значно знижує ймовірність зіткнення, забезпечуючи чітку генерацію до 1 мільйона імен з ймовірністю конфлікту менше 0,1%, забезпечуючи більшу стійкість для великих робочих навантажень.
Хочете дізнатися більше?
Нові функції та застарівання також оголошуються в примітках до випуску Kubernetes. Ми офіційно оголосимо, що нового в Kubernetes v1.32 як частину CHANGELOG для цього випуску.
Ви можете побачити оголошення про зміни в примітках до випуску для:
DIY: Створіть власну хмару з Kubernetes (Частина 3)
Наближаючись до найцікавішої фази, ця стаття розглядає запуск Kubernetes всередині Kubernetes. Висвітлюються такі технології, як Kamaji та Cluster API, а також їх інтеграція з KubeVirt.
Попередні обговорення охоплювали підготовку Kubernetes на "голому" обладнанні та як перетворити Kubernetes на систему управління віртуальними машинами. Ця стаття завершує серію, пояснюючи, як, використовуючи все вищезазначене, ви можете створити повноцінний керований Kubernetes і запускати віртуальні кластери Kubernetes одним дотиком.
Почнемо з Cluster API.
Cluster API
Cluster API — це розширення для Kubernetes, яке дозволяє керувати кластерами Kubernetes як власними ресурсами користувача всередині іншого кластеру Kubernetes.
Основна мета Cluster API — забезпечити єдиний інтерфейс для опису основних сутностей кластера Kubernetes і управління їх життєвим циклом. Це дозволяє автоматизувати процеси створення, оновлення та видалення кластерів, спрощуючи масштабування та управління інфраструктурою.
У контексті Cluster API є два терміни: кластер управління та кластери користувачів.
- Кластер управління — це кластер Kubernetes, що використовується для розгортання та управління іншими кластерами. Цей кластер містить всі необхідні компоненти Cluster API та відповідає за опис, створення та оновлення кластерів користувачів. Він часто використовується тільки для цієї мети.
- Кластери користувачів — це кластери користувачів або кластери, що розгортаються за допомогою Cluster API. Вони створюються шляхом опису відповідних ресурсів у кластері управління. Вони використовуються для розгортання застосунків та сервісів кінцевими користувачами.
Важливо розуміти, що фізично кластери користувачів не обовʼязково повинні працювати на тій же інфраструктурі, що і кластер управління; частіше за все вони розгортаються в іншому місці.

Діаграма, що показує взаємодію кластеру управління Kubernetes та кластерів користувачів Kubernetes за допомогою Cluster API
Для своєї роботи Cluster API використовує концепцію провайдерів, які є окремими контролерами, що відповідають за конкретні компоненти створюваного кластера. В межах Cluster API існує кілька типів провайдерів. Основні з них:
- Провайдер інфраструктури, який відповідає за надання обчислювальної інфраструктури, такої як віртуальні машини або фізичні сервери.
- Провайдер панелі управління, який надає панель управління Kubernetes, а саме компоненти kube-apiserver, kube-scheduler та kube-controller-manager.
- Провайдер Bootstrapping, який використовується для створення конфігурацій cloud-init для віртуальних машин та серверів, що створюються.
Щоб почати, вам потрібно буде встановити сам Cluster API та одного провайдера кожного типу. Повний список підтримуваних провайдерів можна знайти в документації проєкту Cluster API.
Для встановлення можна використовувати утиліту clusterctl або Cluster API Operator як більш декларативний метод.
Вибір провайдерів
Провайдер інфраструктури
Для запуску кластерів Kubernetes за допомогою KubeVirt, необхідно встановити Infrastructure Provider KubeVirt. Він дозволяє розгортання віртуальних машин для робочих вузлів у тому ж кластері управління, де працює Cluster API.
Провайдер панелі управління
Проєкт Kamaji пропонує готове рішення для запуску панелі управління Kubernetes для кластерів користувачів як контейнерів у кластері управління. Цей підхід має кілька суттєвих переваг:
- Економічність: Запуск панелі управління в контейнерах запобігає використанню окремих вузлів панелі управління для кожного кластеру, що суттєво знижує витрати на інфраструктуру.
- Стабільність: Спрощення архітектури шляхом усунення складних багатошарових схем розгортання. Замість послідовного запуску віртуальної машини, а потім встановлення компонентів etcd та Kubernetes всередині неї, є проста панель управління, яка розгортається і працює як звичайний застосунок всередині Kubernetes та управляється оператором.
- Безпека: Панель управління кластера прихована від кінцевого користувача, що знижує можливість компрометації її компонентів, а також усуває доступ користувачів до сховища сертифікатів кластера. Такий підхід до організації панелі управління, невидимої для користувача, часто використовують постачальники хмарних послуг.
Провайдер Bootstrapping
Kubeadm як Bootstrapping Provider — стандартний метод підготовки кластерів у Cluster API. Цей провайдер розроблений як частина самого Cluster API. Він вимагає лише підготовленого системного образу з встановленими kubelet і kubeadm і дозволяє генерувати конфігурації у форматах cloud-init та ignition.
Слід зазначити, що Talos Linux також підтримує виділення ресурсів через Cluster API та має провайдерів для цього. Хоча попередні статті обговорювали використання Talos Linux для налаштування кластера управління на вузлах bare-metal, для створення клієнтських кластерів підхід Kamaji+Kubeadm має більше переваг. Він полегшує розгортання панелей управління Kubernetes у контейнерах, усуваючи необхідність окремих віртуальних машин для екземплярів панелі управління. Це спрощує управління та знижує витрати.
Як це працює
Основний обʼєкт у Cluster API — це ресурс Cluster, який виступає як батьківський для всіх інших. Зазвичай цей ресурс посилається на два інші: ресурс, що описує панель управління, та ресурс, що описує інфраструктуру, кожен з яких управляється окремим провайдером.
На відміну від Cluster, ці два ресурси не є стандартизованими, і їх тип залежить від конкретного провайдера, якого ви використовуєте:

Діаграма, що показує взаємозвʼязок ресурсу Cluster та ресурсів, до яких він посилається в Cluster API
У межах Cluster API також існує ресурс з назвою MachineDeployment, який описує групу вузлів, хоч то фізичні сервери, хоч віртуальні машини. Цей ресурс функціонує подібно до стандартних ресурсів Kubernetes, таких як Deployment, ReplicaSet та Pod, надаючи механізм для декларативного опису групи вузлів і автоматичного масштабування.
Іншими словами, ресурс MachineDeployment дозволяє вам декларативно описати вузли для вашого кластера, автоматизуючи їх створення, видалення та оновлення відповідно до заданих параметрів і запитуваної кількості реплік.

Діаграма, що показує взаємозвʼязок ресурсу MachineDeployment та його дочірніх ресурсів в Cluster API
Для створення машин MachineDeployment посилається на шаблон для генерації самої машини та шаблон для генерації її конфігурації cloud-init:

Діаграма, що показує взаємозвʼязок ресурсу MachineDeployment та ресурсів, до яких він посилається в Cluster API
Щоб розгорнути новий кластер Kubernetes за допомогою Cluster API, вам потрібно буде підготувати наступний набір ресурсів:
- Загальний ресурс Cluster
- Ресурс KamajiControlPlane, відповідальний за панель управління, що управляється Kamaji
- Ресурс KubevirtCluster, що описує конфігурацію кластера в KubeVirt
- Ресурс KubevirtMachineTemplate, відповідальний за шаблон віртуальної машини
- Ресурс KubeadmConfigTemplate, відповідальний за генерацію токенів і cloud-init
- Щонайменше один MachineDeployment для створення деяких робочих ресурсів (workers)
Шліфування кластера
У більшості випадків цього достатньо, але залежно від використаних провайдерів, вам можуть знадобитися й інші ресурси. Ви можете знайти приклади ресурсів, створених для кожного типу провайдера, в документації проєкту Kamaji.
На цьому етапі ви вже маєте готовий клієнтський кластер Kubernetes, але наразі він містить лише API-робітників і кілька основних втулків, що стандартно включені в установку будь-якого кластера Kubernetes: kube-proxy та CoreDNS. Для повної інтеграції вам потрібно буде встановити ще кілька компонентів:
Щоб встановити додаткові компоненти, ви можете використовувати окремий Cluster API Add-on Provider для Helm, або той же FluxCD, про який згадувалося в попередніх статтях.
При створенні ресурсів у FluxCD, можна вказати цільовий кластер, звертаючись до kubeconfig, згенерованого Cluster API. Тоді установка буде виконана безпосередньо в нього. Таким чином, FluxCD стає універсальним інструментом для управління ресурсами як у кластері управління, так і в клієнтських кластерах.

Діаграма, що показує схему взаємодії fluxcd, який може встановлювати компоненти як у кластері управління, так і в орендарських кластерах Kubernetes
Які компоненти обговорюються тут? Загалом, набір включає наступні:
Втулок CNI
Щоб забезпечити комунікацію між podʼами в клієнтському кластері Kubernetes, необхідно розгорнути втулок CNI. Цей втулок створює віртуальну мережу, яка дозволяє podʼам взаємодіяти один з одним і традиційно розгортається як Daemonset на робочих вузлах кластера. Ви можете вибрати та встановити будь-який втулок CNI, який вважаєте відповідним.

Діаграма, що показує втулок CNI, встановлений всередині клієнтського кластера Kubernetes на схемі вкладених кластерів Kubernetes
Cloud Controller Manager
Основне завдання Cloud Controller Manager (CCM) — інтеграція Kubernetes з середовищем провайдера хмари (в вашому випадку це кластер управління Kubernetes, в якому створюються всі робітники клієнтського Kubernetes). Ось деякі з його завдань:
- Коли створюється сервіс типу LoadBalancer, CCM ініціює процес створення хмарного балансувальника навантаження, який направляє трафік до вашого кластера Kubernetes.
- Якщо вузол видаляється з хмарної інфраструктури, CCM забезпечує його видалення з вашого кластера також, підтримуючи поточний стан кластера.
- При використанні CCM вузли додаються до кластера з особливим taint,
node.cloudprovider.kubernetes.io/uninitialized, який дозволяє обробку додаткової бізнес-логіки, якщо це необхідно. Після успішної ініціалізації цей taint видаляється з вузла.
Залежно від постачальника хмари, CCM може працювати як всередині, так і зовні клієнтського кластера.
Провайдер хмари KubeVirt розроблений для установки у зовнішньому батьківському кластері управління. Таким чином, створення сервісів типу LoadBalancer в клієнтському кластері ініціює створення сервісів LoadBalancer у батьківському кластері, які направляють трафік в клієнтський кластер.

Діаграма, що показує Cloud Controller Manager, встановлений зовні клієнтського кластера Kubernetes на схемі вкладених кластерів Kubernetes та відображення сервісів, якими він управляє з батьківського кластера в дочірньому кластері Kubernetes
Драйвер CSI
Container Storage Interface (CSI) розділений на дві основні частини для взаємодії зі зберіганням у Kubernetes:
- csi-controller: Цей компонент відповідає за взаємодію з API постачальника хмари для створення, видалення, підключення, відключення та зміни розміру томів.
- csi-node: Цей компонент працює на кожному вузлі та полегшує монтування томів до podʼів на запит kubelet.
У контексті використання CSI драйвера KubeVirt виникає унікальна можливість. Оскільки віртуальні машини в KubeVirt працюють всередині кластеру управління Kubernetes, де доступне повноцінний API Kubernetes, це відкриває шлях для запуску csi-controller ззовні клієнтського кластера. Цей підхід є популярним у спільноті KubeVirt і має кілька ключових переваг:
- Безпека: Цей метод приховує внутрішнє API хмари від кінцевого користувача, надаючи доступ до ресурсів виключно через інтерфейс Kubernetes. Таким чином, зменшується ризик прямого доступу до кластера управління з клієнтських кластерів.
- Простота і зручність: Користувачам не потрібно управляти додатковими контролерами у своїх кластерах, спрощуючи архітектуру і зменшуючи навантаження управління.
Однак, csi-node обовʼязково повинен працювати всередині клієнтського кластера, оскільки він безпосередньо взаємодіє з kubelet на кожному вузлі. Цей компонент відповідає за монтування та демонтування томів у podʼах, вимагаючи тісної інтеграції з процесами, що відбуваються безпосередньо на вузлах кластера.
CSI-драйвер KubeVirt діє як проксі для замовлення томів. Коли PVC створюється всередині клієнтського кластера, PVC створюється в кластері управління, а потім створений PV підключається до віртуальної машини.

Діаграма, що показує компоненти плагіна CSI, встановлені як всередині, так і ззовні клієнтського кластера Kubernetes на схемі вкладених кластерів Kubernetes та відображення постійних томів, якими він управляє з батьківського до дочірнього кластера Kubernetes
Автоматичний масштабувальник кластера
Cluster Autoscaler є універсальним компонентом, який може працювати з різними API хмари, а його інтеграція з Cluster-API є лише однією з доступних функцій. Для правильного налаштування він потребує доступу до двох кластерів: клієнтського кластера, щоб відстежувати podʼи та визначати необхідність додавання нових вузлів, і кластеру управління Kubernetes (кластер управління), де він взаємодіє з ресурсом MachineDeployment та регулює кількість реплік.
Хоча Cluster Autoscaler зазвичай працює всередині кластера Kubernetes клієнта, у цьому випадку рекомендується встановити його зовні з тих же причин, що і раніше. Цей підхід простіший в обслуговуванні та більш безпечний, оскільки запобігає доступу користувачів клієнтських кластерів до API управління кластером.

Діаграма, що показує Cluster Autoscaler, встановлений зовні клієнтського кластера Kubernetes на схемі вкладених кластерів Kubernetes
Konnectivity
Є ще один додатковий компонент, про який я хотів би згадати — Konnectivity. Ймовірно, він вам знадобиться пізніше, щоб налаштувати вебхуки та шар агрегації API в вашому клієнтському кластері Kubernetes. Це питання детально висвітлене в одній з моїх попередніх статей.
На відміну від наведених вище компонентів, Kamaji дозволяє легко увімкнути Konnectivity та управляти ним як одним з основних компонентів вашого клієнтського кластера, поряд з kube-proxy і CoreDNS.
Висновок
Тепер у вас є повністю функціональний кластер Kubernetes з можливістю динамічного масштабування, автоматичного постачання томів та балансувальників навантаження.
Далі ви можете розглянути збір метрик і логів з ваших клієнтських кластерів, але це вже виходить за межі цієї статті.
Звичайно, всі компоненти, необхідні для розгортання кластера Kubernetes, можна упакувати в один Helm chart і розгорнути як єдиний застосунок. Саме так ми організовуємо розгортання керованих кластерів Kubernetes одним натисканням кнопки на нашій відкритій платформі PaaS, Cozystack, де ви можете безкоштовно випробувати всі технології, описані в статті.
DIY: Створіть власну хмару з Kubernetes (Частина 2)
Продовжуємо нашу серію публікацій про те, як побудувати власну хмару, використовуючи лише екосистему Kubernetes. У попередній статті ми пояснили, як підготувати базовий дистрибутив Kubernetes на основі Talos Linux та Flux CD. У цій статті ми покажемо вам кілька різних технологій віртуалізації в Kubernetes та підготуємо все необхідне для запуску віртуальних машин у Kubernetes, зокрема сховища і мережі.
Ми будемо говорити про такі технології, як KubeVirt, LINSTOR і Kube-OVN.
Але спочатку пояснімо, навіщо потрібні віртуальні машини та чому не можна просто використовувати docker-контейнери для побудови хмари? Причина в тому, що контейнери не забезпечують достатнього рівня ізоляції. Хоча ситуація з кожним роком покращується, ми часто стикаємося з вразливостями, які дозволяють вийти з контейнерного середовища і підвищити привілеї в системі.
З іншого боку, Kubernetes спочатку не був призначений для багатокористувацької системи, тобто базовий шаблон використання передбачає створення окремого кластера Kubernetes для кожного незалежного проєкту та команди розробників.
Віртуальні машини є основним засобом ізоляції орендарів один від одного в хмарному середовищі. У віртуальних машинах користувачі можуть виконувати код і програми з адміністративними привілеями, але це не впливає на інших орендарів або саму інфраструктуру. Іншими словами, віртуальні машини дозволяють досягти жорсткої ізоляції орендарів та запуску в середовищах, де орендарі не довіряють один одному.
Технології віртуалізації в Kubernetes
Існує кілька різних технологій, які приносять віртуалізацію у світ Kubernetes: KubeVirt та Kata Containers є найпопулярнішими з них. Але варто знати, що вони працюють по-різному.
Kata Containers реалізує CRI (Container Runtime Interface) та забезпечує додатковий рівень ізоляції для стандартних контейнерів, запускаючи їх у віртуальних машинах. Але вони працюють в одному кластері Kubernetes.

Схема, що показує, як забезпечується ізоляція контейнерів шляхом запуску контейнерів у віртуальних машинах за допомогою Kata Containers
KubeVirt дозволяє запускати традиційні віртуальні машини за допомогою API Kubernetes. Віртуальні машини KubeVirt запускаються як звичайні процеси Linux у контейнерах. Іншими словами, у KubeVirt контейнер використовується як середовище для запуску процесів віртуальної машини (QEMU). Це чітко видно на малюнку нижче, якщо подивитися, як реалізовано живу міграцію віртуальних машин у KubeVirt. Коли міграція потрібна, віртуальна машина переміщується з одного контейнера до іншого.

Схема, що показує живу міграцію віртуальної машини з одного контейнера до іншого у KubeVirt
Існує також альтернативний проєкт — Virtink, який реалізує легку віртуалізацію за допомогою Cloud-Hypervisor і спочатку орієнтований на запуск віртуальних кластерів Kubernetes за допомогою Cluster API.
Враховуючи наші цілі, ми вирішили використати KubeVirt як найпопулярніший проєкт у цій галузі. Крім того, ми маємо великий досвід і вже зробили чималий внесок у KubeVirt.
KubeVirt легко встановлюється і дозволяє запускати віртуальні машини безпосередньо з коробки, використовуючи containerDisk — ця функція дозволяє зберігати та розповсюджувати образи VM безпосередньо як образи OCI з реєстру образів контейнерів. Віртуальні машини з containerDisk добре підходять для створення робочих вузлів Kubernetes та інших віртуальних машин, які не потребують збереження стану.
Для управління постійними даними KubeVirt пропонує окремий інструмент, Containerized Data Importer (CDI). Він дозволяє клонувати PVC і наповнювати їх даними з базових образів. CDI необхідний, якщо ви хочете автоматично виділяти постійні томи для ваших віртуальних машин, і він також потрібен для драйвера KubeVirt CSI, який використовується для обробки запитів на постійні томи з кластерів Kubernetes орендарів.
Але спочатку вам потрібно вирішити, де і як ви будете зберігати ці дані.
Сховище для VM в Kubernetes
З впровадженням CSI (Container Storage Interface) став доступний широкий спектр технологій, які інтегруються з Kubernetes. Насправді KubeVirt повністю використовує інтерфейс CSI, узгоджуючи вибір сховища для віртуалізації з вибором сховища для самого Kubernetes. Однак є нюанси, які вам потрібно врахувати. На відміну від контейнерів, які зазвичай використовують стандартну файлову систему, блокові пристрої є більш ефективними для віртуальних машин.
Хоча інтерфейс CSI в Kubernetes дозволяє запитувати обидва типи томів: файлові системи та блокові пристрої, важливо перевірити, чи підтримує це ваш бекенд сховища.
Використання блокових пристроїв для віртуальних машин усуває необхідність в додатковому шарі абстракції, такому як файлова система, що робить його більш продуктивним і в більшості випадків дозволяє використовувати режим ReadWriteMany. Цей режим дозволяє одночасно звертатися до тому з декількох вузлів, що є критично важливою функцією для забезпечення живої міграції віртуальних машин у KubeVirt.
Система зберігання може бути зовнішньою або внутрішньою (у випадку гіперконвергованої інфраструктури). Використання зовнішнього сховища в багатьох випадках робить всю систему більш стабільною, оскільки ваші дані зберігаються окремо від обчислювальних вузлів.

Схема, що показує взаємодію зовнішнього сховища даних з обчислювальними вузлами
Зовнішні рішення для зберігання даних часто є популярними в корпоративних системах, оскільки таке сховище часто надається зовнішнім постачальником, який займається його експлуатацією. Інтеграція з Kubernetes включає лише невеликий компонент, встановлений у кластері — драйвер CSI. Цей драйвер відповідає за виділення томів у цьому сховищі та підключення їх до podʼів, які запускає Kubernetes. Втім, подібні рішення для зберігання даних можуть бути реалізовані й з використанням технологій з відкритим вихідним кодом. Одним з популярних рішень є TrueNAS на основі драйвера democratic-csi.

Діаграма, що показує локальне зберігання даних на обчислювальних вузлах
З іншого боку, гіперконвергентні системи часто реалізуються з використанням локального сховища (коли не потрібна реплікація) та програмно визначених сховищ, які часто встановлюються безпосередньо в Kubernetes, таких як Rook/Ceph, OpenEBS, Longhorn, LINSTOR та інші.

Діаграма, що показує кластеризоване зберігання даних на обчислювальних вузлах
Гіперконвергентна система має свої переваги. Наприклад, локальність даних: коли ваші дані зберігаються локально, доступ до таких даних є швидшим. Але є і недоліки, оскільки така система зазвичай складніша в управлінні та обслуговуванні.
В Ænix ми прагнули надати готове до використання рішення, яке можна було б використовувати без необхідності купувати та налаштовувати додаткове зовнішнє сховище, і яке було б оптимальним з погляду швидкості та використання ресурсів. LINSTOR став цим рішенням. Перевірені часом та популярні в промисловості технології, такі як LVM і ZFS, як бекенд, дають упевненість у тому, що дані надійно зберігаються. Реплікація на основі DRBD неймовірно швидка і споживає невелику кількість обчислювальних ресурсів.
Для встановлення LINSTOR в Kubernetes існує проєкт Piraeus, який вже надає готове блокове сховище для використання з KubeVirt.
Примітка:
У випадку, якщо ви використовуєте Talos Linux, як ми описали в попередній статті, вам потрібно буде заздалегідь активувати необхідні модулі ядра і налаштувати piraeus, як описано в інструкції.Мережа для віртуальних машин Kubernetes
Попри схожий інтерфейс — CNI, мережева архітектура в Kubernetes насправді є набагато складнішою та зазвичай складається з багатьох незалежних компонентів, які не повʼязані безпосередньо один з одним. Насправді ви можете розділити мережу Kubernetes на чотири рівні, які описані нижче.
Мережева інфраструктура вузлів (мережа дата-центру)
Мережа, якою вузли зʼєднуються один з одним. Ця мережа зазвичай не управляється Kubernetes, але є важливою, оскільки без неї нічого не працюватиме. На практиці фізична інфраструктура зазвичай має більше ніж одну таку мережу, наприклад, одну для комунікації між вузлами, другу для реплікації сховища, третю для зовнішнього доступу тощо.

Діаграма, що показує роль мережі вузлів (мережі дата-центру) у схемі мережі Kubernetes
Налаштування фізичної мережевої взаємодії між вузлами виходить за межі цієї статті, оскільки в більшості ситуацій Kubernetes використовує вже наявну мережеву інфраструктуру.
Мережа Podʼів
Це мережа, яку забезпечує ваш CNI-втулок. Завдання CNI-втулка полягає в забезпеченні прозорого зʼєднання між усіма контейнерами та вузлами в кластері. Більшість CNI-втулків реалізують пласку мережу, з якої окремі блоки IP-адрес виділяються для використання на кожному вузлі.

Діаграма, що показує роль мережі контейнерів (CNI-втулок) у схемі мережі Kubernetes
На практиці ваш кластер може мати кілька CNI-втулків, керованих Multus. Цей підхід часто використовується у рішеннях віртуалізації на основі KubeVirt — Rancher та OpenShift. Основний CNI-втулок використовується для інтеграції з сервісами Kubernetes, тоді як додаткові CNI-втулки використовуються для реалізації приватних мереж (VPC) та інтеграції з фізичними мережами вашого дата-центру.
Стандартні CNI-втулки можуть бути використані для підключення концентраторів (bridge) або фізичних інтерфейсів. Крім того, існують спеціалізовані втулки, такі як macvtap-cni, які розроблені для забезпечення більшої продуктивності.
Ще одним аспектом, який слід враховувати при запуску віртуальних машин у Kubernetes, є потреба в управлінні IP-адресами (IPAM), особливо для вторинних інтерфейсів, які надає Multus. Це зазвичай керується DHCP-сервером, що працює у вашій інфраструктурі. Додатково, призначення MAC-адрес для віртуальних машин може керуватись за допомогою Kubemacpool.
Проте на нашій платформі ми вирішили піти іншим шляхом і повністю покладаємося на Kube-OVN. Цей CNI-втулок базується на OVN (Open Virtual Network), який спочатку був розроблений для OpenStack і надає повне мережеве рішення для віртуальних машин у Kubernetes, з можливістю управління IP-адресами та MAC-адресами через Custom Resources, підтримує живу міграцію зі збереженням IP-адрес між вузлами, і дозволяє створювати VPC для фізичного розділення мереж між орендарями.
У Kube-OVN ви можете призначати окремі підмережі всьому namespace або підключати їх як додаткові мережеві інтерфейси за допомогою Multus.
Мережа сервісів (Services Network)
Окрім CNI-втулка, Kubernetes також має мережу сервісів, яка в основному потрібна для виявлення сервісів. На відміну від традиційних віртуальних машин, Kubernetes спочатку розроблений для запуску контейнерів із випадковою адресою. І мережа сервісів забезпечує зручну абстракцію (стабільні IP-адреси та DNS-імена), яка завжди буде спрямовувати трафік до правильного контейнера. Такий підхід також часто використовується з віртуальними машинами в хмарах, хоча їх IP-адреси зазвичай є статичними.

Діаграма, що показує роль мережі сервісів (втулок мережі сервісів) у схемі мережі Kubernetes
Реалізацію мережі сервісів у Kubernetes здійснює втулок мережі сервісів. Стандартною реалізацією є kube-proxy, який використовується в більшості кластерів. Але наразі ця функціональність може бути забезпечена як частина CNI-втулка. Найбільш передову реалізацію пропонує проєкт Cilium, який може працювати в режимі заміни kube-proxy.
Cilium базується на технології eBPF, яка дозволяє ефективно розвантажувати мережевий стек Linux, що підвищує продуктивність і безпеку в порівнянні з традиційними методами на основі iptables.
На практиці Cilium і Kube-OVN можуть бути легко інтегровані для забезпечення єдиного рішення, що пропонує безшовну багатокористувацьку мережу для віртуальних машин, а також досконалі мережеві політики та обʼєднану функціональність мережі сервісів.
Зовнішній балансувальник навантаження
На цьому етапі у вас вже є все необхідне для запуску віртуальних машин у Kubernetes. Але насправді є ще одна річ. Вам все ще потрібно отримати доступ до ваших сервісів із зовнішнього середовища, і зовнішній балансувальник навантаження допоможе вам з організацією цього.
Для bare-metal кластерів Kubernetes доступні кілька балансувальників навантаження: MetalLB, kube-vip, LoxiLB, також Cilium та Kube-OVN забезпечують вбудовану реалізацію.
Роль зовнішнього балансувальника навантаження полягає в наданні стабільної адреси, доступної зовні, і спрямуванні зовнішнього трафіку до мережі сервісів. Втулок мережі сервісів направить його до ваших контейнерів та віртуальних машин, як зазвичай.

Діаграма, що показує роль зовнішнього балансувальника навантаження у схемі мережі Kubernetes
У більшості випадків налаштування балансувальника навантаження на bare-metal досягається шляхом створення плаваючої IP-адреси на вузлах у кластері та її оголошення назовні за допомогою протоколів ARP/NDP або BGP.
Вивчивши різні варіанти, ми вирішили, що MetalLB є найпростішим і найнадійнішим рішенням, хоча ми не вимагаємо суворого використання лише його.
Ще однією перевагою є те, що в режимі L2 спікери MetalLB постійно перевіряють стан сусідів, виконуючи перевірки на живучість за допомогою протоколу memberlist. Це дозволяє реалізувати автоматичне перемикання у разі відмови, яке працює незалежно від панелі управління Kubernetes.
Висновок
Цим завершується наш огляд віртуалізації, зберігання та мереж в Kubernetes. Усі згадані технології доступні та вже налаштовані на платформі Cozystack, де ви можете їх спробувати без обмежень.
У наступній статті я розповім, як на основі цього ви можете реалізувати створення повнофункціональних кластерів Kubernetes одним дотиком.
DIY: Створіть власну хмару з Kubernetes (Частина 1)
У Ænix ми дуже любимо Kubernetes і мріємо, що всі сучасні технології незабаром почнуть використовувати його чудові патерни.
Чи думали ви коли-небудь про створення власної хмари? Я впевнений, що так. Але чи можливо це зробити, використовуючи лише сучасні технології та підходи, не виходячи за межі затишної екосистеми Kubernetes? Наш досвід у розробці Cozystack змусив нас глибоко заглибитись у це питання.
Ви можете стверджувати, що Kubernetes не призначений для цього, і чому б просто не використовувати OpenStack на "звичайних" серверах та запускати Kubernetes всередині нього, як це задумано. Але в цьому випадку ви просто передаєте відповідальність зі своїх рук у руки адміністраторів OpenStack. Це додасть ще одну велику та складну систему до вашої екосистеми.
Навіщо ускладнювати речі? — адже Kubernetes вже має все необхідне для запуску кластерів орендаря Kubernetes на цьому етапі.
Я хочу поділитися з вами нашим досвідом у розробці хмарної платформи на основі Kubernetes, виділивши відкриті проєкти, які ми використовуємо самі та вважаємо, що вони заслуговують вашої уваги.
У цій серії статей я розповім вам нашу історію про те, як ми готуємо керовані кластери Kubernetes на "голому" залізі, використовуючи лише відкриті технології. Починаючи з базового рівня підготовки дата-центру, запуску віртуальних машин, ізоляції мереж, налаштування відмовостійкого сховища до забезпечення повнофункціональних кластерів Kubernetes з динамічним розподілом томів, балансувальниками навантаження та автомасштабуванням.
Цією статтею я починаю серію, яка складатиметься з кількох частин:
- Частина 1: Підготовка основи для вашої хмари. Виклики, з якими стикаються під час підготовки та експлуатації Kubernetes на "голому" залізі, та готовий рецепт для забезпечення інфраструктури.
- Частина 2: Мережі, сховища та віртуалізація. Як перетворити Kubernetes на інструмент для запуску віртуальних машин і що для цього потрібно.
- Частина 3: Cluster API і як почати розгортання кластерів Kubernetes натисканням однієї кнопки. Як працює автомасштабування, динамічний розподіл томів і балансувальники навантаження.
Я спробую описати різні технології якнайбільше незалежно, але водночас поділюся нашим досвідом і поясню, чому ми прийшли до того чи іншого рішення.
Почнемо з розуміння основної переваги Kubernetes та того, як він змінив підхід до використання хмарних ресурсів.
Важливо розуміти, що використання Kubernetes у хмарі та на "голому" залізі відрізняється.
Kubernetes у хмарі
Коли ви оперуєте Kubernetes у хмарі, ви не хвилюєтеся про постійні томи, хмарні балансувальники навантаження або процес виділення вузлів. Усе це робить ваш хмарний провайдер, який приймає ваші запити у вигляді обʼєктів Kubernetes. Іншими словами, серверна сторона повністю прихована від вас, і вам не дуже цікаво знати, як саме хмарний провайдер реалізує це, оскільки це не ваша зона відповідальності.

Діаграма, що показує Kubernetes у хмарі, де балансування навантаження та зберігання виконуються поза кластером
Kubernetes пропонує зручні абстракції, які працюють однаково всюди, дозволяючи розгортати ваші застосунки на будь-якому Kubernetes у будь-якій хмарі.
У хмарі дуже часто є кілька окремих сутностей: панель управління Kubernetes, віртуальні машини, постійні томи та балансувальники навантаження як окремі сутності. Використовуючи ці сутності, ви можете створювати дуже динамічні середовища.
Завдяки Kubernetes, віртуальні машини тепер розглядаються лише як інструмент для використання хмарних ресурсів. Ви більше не зберігаєте дані всередині віртуальних машин. Ви можете видалити всі ваші віртуальні машини в будь-який момент і відтворити їх без порушення роботи вашого застосунку. панель управління Kubernetes продовжуватиме зберігати інформацію про те, що має працювати у вашому кластері. Балансувальник навантаження продовжить направляти трафік до вашого робочого навантаження, просто змінюючи точку доступу для передачі трафіку на новий вузол. А ваші дані будуть безпечно зберігатися у зовнішніх постійних томах, наданих хмарою.
Такий підхід є базовим при використанні Kubernetes у хмарах. Причина цього досить очевидна: чим простіша система, тим вона стабільніша, і саме за цю простоту ви купуєте Kubernetes у хмарі.
Kubernetes на "голому" залізі
Використання Kubernetes у хмарах дійсно просте та зручне, чого не можна сказати про установки на "голому" залізі. У світі "голого" заліза Kubernetes, навпаки, стає нестерпно складним. По-перше, тому що вся мережа, сховище даних, балансувальники навантаження тощо зазвичай працюють не зовні, а всередині вашого кластера. У результаті така система набагато складніша для оновлення та підтримки.

Діаграма, що показує Kubernetes на "голому" залізі, де балансування навантаження та зберігання виконуються всередині кластера
Судіть самі: у хмарі, щоб оновити вузол, ви зазвичай видаляєте віртуальну машину (або навіть використовуєте команду kubectl delete node) і дозволяєте вашому інструменту керування вузлами створити новий на основі незмінного образу. Новий вузол приєднається до кластера і "просто працюватиме" як вузол; дотримуючись дуже простого та поширеного шаблону у світі Kubernetes. Багато кластерів замовляють нові віртуальні машини кожні кілька хвилин, просто тому, що вони можуть використовувати дешевші spot-екземпляри. Однак коли у вас є фізичний сервер, ви не можете просто видалити та відтворити його, по-перше, тому що він часто запускає деякі кластерні служби, зберігає дані, і процес його оновлення значно складніший.
Існують різні підходи до розвʼязання цієї проблеми, починаючи від оновлень на місці, як це роблять kubeadm, kubespray та k3s, до повної автоматизації забезпечення фізичних вузлів за допомогою Cluster API та Metal3.
Мені подобається гібридний підхід, який пропонує Talos Linux, де вся ваша система описується в одному конфігураційному файлі. Більшість параметрів цього файлу можна застосувати без перезавантаження або перестворення вузла, включаючи версію компонентів панелі управління Kubernetes. При цьому зберігається максимальна декларативність Kubernetes. Такий підхід мінімізує непотрібний вплив на кластерні сервіси при оновленні «голих» вузлів. У більшості випадків вам не потрібно буде мігрувати віртуальні машини та перебудовувати файлову систему кластера при незначних оновленнях.
Підготовка бази для майбутньої хмари
Отже, ви вирішили створити власну хмару. Щоб почати, потрібно створити базовий шар. Вам слід подумати не лише про те, як ви встановите Kubernetes на свої сервери, а й про те, як ви будете його оновлювати та підтримувати. Врахуйте, що вам доведеться думати про такі речі, як оновлення ядра, встановлення необхідних модулів, а також пакунків і оновлень безпеки. Тепер вам потрібно подумати про набагато більше, ніж зазвичай при використанні готового Kubernetes у хмарі.
Звісно, ви можете використовувати стандартні дистрибутиви, такі як Ubuntu або Debian, або ж розглянути спеціалізовані, як Flatcar Container Linux, Fedora Core і Talos Linux. Кожен з них має свої переваги та недоліки.
Що стосується нас, в Ænix, ми використовуємо досить специфічні модулі ядра, такі як ZFS, DRBD і OpenvSwitch, тому вирішили піти шляхом створення системного образу з усіма необхідними модулями заздалегідь. У цьому випадку Talos Linux виявився найбільш зручним для нас. Наприклад, достатньо такої конфігурації, щоб створити системний образ з усіма необхідними модулями ядра:
arch: amd64
platform: metal
secureboot: false
version: v1.6.4
input:
kernel:
path: /usr/install/amd64/vmlinuz
initramfs:
path: /usr/install/amd64/initramfs.xz
baseInstaller:
imageRef: ghcr.io/siderolabs/installer:v1.6.4
systemExtensions:
- imageRef: ghcr.io/siderolabs/amd-ucode:20240115
- imageRef: ghcr.io/siderolabs/amdgpu-firmware:20240115
- imageRef: ghcr.io/siderolabs/bnx2-bnx2x:20240115
- imageRef: ghcr.io/siderolabs/i915-ucode:20240115
- imageRef: ghcr.io/siderolabs/intel-ice-firmware:20240115
- imageRef: ghcr.io/siderolabs/intel-ucode:20231114
- imageRef: ghcr.io/siderolabs/qlogic-firmware:20240115
- imageRef: ghcr.io/siderolabs/drbd:9.2.6-v1.6.4
- imageRef: ghcr.io/siderolabs/zfs:2.1.14-v1.6.4
output:
kind: installer
outFormat: raw
Потім ми використовуємо командний рядок docker для створення образу ОС:
cat config.yaml | docker run --rm -i -v /dev:/dev --privileged "ghcr.io/siderolabs/imager:v1.6.4" -
І в результаті ми отримуємо контейнерний образ Docker з усім необхідним, який можна використовувати для встановлення Talos Linux на наші сервери. Ви можете зробити те саме; цей образ міститиме всі необхідні прошивки та модулі ядра.
Але виникає питання: як доставити свіжостворений образ на ваші вузли?
Я давно розмірковував над ідеєю завантаження через PXE. Наприклад, проєкт Kubefarm, про який я писав в статті два роки тому, був повністю побудований на цьому підході. Але, на жаль, він не допомагає розгорнути ваш перший батьківський кластер, який міститиме інші. Тож зараз у вас є рішення, яке допоможе зробити це саме за допомогою підходу PXE.
По суті, все, що вам потрібно зробити, це запустити тимчасово DHCP і PXE сервери всередині контейнерів. Тоді ваші вузли завантажаться з вашого образу, і ви можете використовувати простий сценарій, схожий на Debian, щоб допомогти вам ініціалізувати вузли.

Вихідний код для цього сценарію talos-bootstrap доступний на GitHub.
Цей сценарій дозволяє розгорнути Kubernetes на "голому" залізі за п’ять хвилин і отримати kubeconfig для доступу до нього. Однак попереду ще багато невирішених питань.
Доставка системних компонентів
На цьому етапі у вас вже є кластер Kubernetes, здатний запускати різні робочі навантаження. Однак він ще не повністю функціональний. Іншими словами, вам потрібно налаштувати мережу та зберігання, а також встановити необхідні розширення кластера, такі як KubeVirt для запуску віртуальних машин, а також стек моніторингу та інші системні компоненти.
Традиційно це вирішується шляхом встановлення Helm чартів у ваш кластер. Ви можете зробити це, виконуючи команди helm install локально, але цей підхід стає незручним, коли ви хочете відстежувати оновлення, і якщо у вас кілька кластерів і ви хочете, щоб вони залишалися однорідними. Насправді існує багато способів зробити це декларативно. Для подолання цієї задачі я рекомендую використовувати найкращі практики GitOps. Я маю на увазі інструменти, такі як ArgoCD та FluxCD.
Хоча ArgoCD зручніший для розробки завдяки графічному інтерфейсу та централізованій панелі управління, FluxCD, з іншого боку, краще підходить для створення дистрибутивів Kubernetes. За допомогою FluxCD ви можете вказати, які чарти з якими параметрами повинні бути запущені, і описати залежності. Після цього FluxCD подбає про все.
Пропонується одноразово встановити FluxCD у ваш новостворений кластер і надати йому конфігурацію. Це дозволить встановити все необхідне, щоб привести кластер до очікуваного стану.
Здійснивши одноразову інсталяцію FluxCD у вашому новому кластері та налаштувавши його відповідним чином, ви дозволяєте йому автоматично розгорнути всі необхідні компоненти. Це дозволить вашому кластеру оновити себе до потрібного стану. Наприклад, після встановлення нашої платформи ви побачите такі попередньо налаштовані Helm чарти з системними компонентами:
NAMESPACE NAME AGE READY STATUS
cozy-cert-manager cert-manager 4m1s True Release reconciliation succeeded
cozy-cert-manager cert-manager-issuers 4m1s True Release reconciliation succeeded
cozy-cilium cilium 4m1s True Release reconciliation succeeded
cozy-cluster-api capi-operator 4m1s True Release reconciliation succeeded
cozy-cluster-api capi-providers 4m1s True Release reconciliation succeeded
cozy-dashboard dashboard 4m1s True Release reconciliation succeeded
cozy-fluxcd cozy-fluxcd 4m1s True Release reconciliation succeeded
cozy-grafana-operator grafana-operator 4m1s True Release reconciliation succeeded
cozy-kamaji kamaji 4m1s True Release reconciliation succeeded
cozy-kubeovn kubeovn 4m1s True Release reconciliation succeeded
cozy-kubevirt-cdi kubevirt-cdi 4m1s True Release reconciliation succeeded
cozy-kubevirt-cdi kubevirt-cdi-operator 4m1s True Release reconciliation succeeded
cozy-kubevirt kubevirt 4m1s True Release reconciliation succeeded
cozy-kubevirt kubevirt-operator 4m1s True Release reconciliation succeeded
cozy-linstor linstor 4m1s True Release reconciliation succeeded
cozy-linstor piraeus-operator 4m1s True Release reconciliation succeeded
cozy-mariadb-operator mariadb-operator 4m1s True Release reconciliation succeeded
cozy-metallb metallb 4m1s True Release reconciliation succeeded
cozy-monitoring monitoring 4m1s True Release reconciliation succeeded
cozy-postgres-operator postgres-operator 4m1s True Release reconciliation succeeded
cozy-rabbitmq-operator rabbitmq-operator 4m1s True Release reconciliation succeeded
cozy-redis-operator redis-operator 4m1s True Release reconciliation succeeded
cozy-telepresence telepresence 4m1s True Release reconciliation succeeded
cozy-victoria-metrics-operator victoria-metrics-operator 4m1s True Release reconciliation succeeded
Висновок
Як результат, ви досягаєте високо відтворюваного середовища, яке можна надати будь-кому, знаючи, що воно працює саме так, як потрібно. Це, власне, і є метою проєкту Cozystack, який ви можете спробувати абсолютно вільно.
У наступних статтях я розповім про те як підготувати Kubernetes для запуску віртуальних машин та як запускати кластери Kubernetes натисканням кнопки.
Залишайтеся з нами, буде цікаво!
Огляд Kubernetes v1.30
Швидкий огляд: зміни у Kubernetes v1.30
Новий рік, новий реліз Kubernetes. Ми на половині релізного циклу і маємо чимало цікавих та чудових поліпшень у версії v1.30. Від абсолютно нових можливостей у режимі альфа до вже сталих функцій, які переходять у стабільний режим, а також довгоочікуваних поліпшень — цей випуск має щось для усіх, на що варто звернути увагу!
Щоб підготувати вас до офіційного випуску, ось короткий огляд удосконалень, про які ми найбільше хочемо розповісти!
Основні зміни для Kubernetes v1.30
Структуровані параметри для динамічного розподілу ресурсів (KEP-4381)
Динамічний розподіл ресурсів було додано до Kubernetes у версії v1.26 у режимі альфа. Він визначає альтернативу традиційному API пристроїв для запиту доступу до ресурсів сторонніх постачальників. За концепцією, динамічний розподіл ресурсів використовує параметри для ресурсів, що є абсолютно непрозорими для ядра Kubernetes. Цей підхід створює проблему для Cluster Autoscaler (CA) чи будь-якого контролера вищого рівня, який повинен приймати рішення для групи Podʼів (наприклад, планувальник завдань). Він не може симулювати ефект виділення чи звільнення заявок з плином часу. Інформацію для цього можуть надавати лише драйвери DRA сторонніх постачальників.
Структуровані параметри для динамічного розподілу ресурсів — це розширення оригінальної реалізації, яке розвʼязує цю проблему, створюючи фреймворк для підтримки параметрів заявок, що є більш прозорими. Замість обробки семантики всіх параметрів заявок самостійно, драйвери можуть керувати ресурсами та описувати їх, використовуючи конкретну "структуровану модель", заздалегідь визначену Kubernetes. Це дозволить компонентам, які обізнані з цією "структурованою моделлю", приймати рішення щодо цих ресурсів без залучення зовнішнього контролера. Наприклад, планувальник може швидко обробляти заявки без зайвої комунікації з драйверами динамічного розподілу ресурсів. Робота, виконана для цього релізу, зосереджена на визначенні необхідного фреймворку для активації різних "структурованих моделей" та реалізації моделі "пойменованих ресурсів". Ця модель дозволяє перераховувати окремі екземпляри ресурсів та, на відміну від традиційного API пристроїв, додає можливість вибору цих екземплярів індивідуально за атрибутами.
Підтримка своп-памʼяті на вузлах (KEP-2400)
У Kubernetes v1.30 підтримка своп-памʼяті на вузлах Linux отримує значущі зміни в способі її функціонування, з основним акцентом на покращенні стабільності системи. В попередніх версіях Kubernetes функція NodeSwap була типово вимкненою, а при увімкненні використовувала поведінку UnlimitedSwap. З метою досягнення кращої стабільності, поведінка UnlimitedSwap (яка може компрометувати стабільність вузла) буде видалена у версії v1.30.
Оновлена, все ще бета-версія підтримки своп на вузлах Linux буде стандартно доступною. Однак типовою поведінкою буде запуск вузла в режимі NoSwap (а не UnlimitedSwap). У режимі NoSwap kubelet підтримує роботу на вузлі, де активний простір своп, але Podʼи не використовують жодного page-файлу. Для того, щоб kubelet працював на цьому вузлі, вам все ще потрібно встановити --fail-swap-on=false. Однак велика зміна стосується іншого режиму: LimitedSwap. У цьому режимі kubelet фактично використовує page-файл на вузлі та дозволяє Podʼам виділяти деяку частину їхньої віртуальної памʼяті. Контейнери (і їхні батьківські Podʼи) не мають доступу до своп поза їхнім обмеженням памʼяті, але система все ще може використовувати простір своп, якщо він доступний.
Група Kubernetes Node (SIG Node) також оновить документацію, щоб допомогти вам зрозуміти, як використовувати оновлену реалізацію, на основі відгуків від кінцевих користувачів, учасників та широкої спільноти Kubernetes.
Для отримання додаткових відомостей про підтримку своп на вузлах Linux в Kubernetes, прочитайте попередній пост блогу чи документацію про своп на вузлах.
Підтримка просторів імен користувачів в Pod (KEP-127)
Простори імен користувачів — це функція лише для Linux, яка краще ізолює Podʼи для запобігання або помʼякшення кількох важливих CVEs із високим/критичним рейтингом, включаючи CVE-2024-21626, опубліковану у січні 2024 року. У Kubernetes 1.30 підтримка просторів імен користувачів переходить у бета-версію і тепер підтримує Podʼи з томами та без них, власні діапазони UID/GID та багато іншого!
Конфігурація структурованої авторизації (KEP-3221)
Підтримка конфігурації структурованої авторизації переходить у бета-версію та буде типово увімкненою. Ця функція дозволяє створювати ланцюги авторизації з кількома вебхуками із чітко визначеними параметрами, які перевіряють запити в певному порядку та надають деталізований контроль — такий, як явна відмова у випадку невдач. Використання конфігураційного файлу навіть дозволяє вказати правила CEL для попередньої фільтрації запитів, перш ніж вони будуть відправлені до вебхуків, допомагаючи вам запобігти непотрібним викликам. Сервер API також автоматично перезавантажує ланцюг авторизатора при зміні конфігураційного файлу.
Вам необхідно вказати шлях до конфігурації авторизації, використовуючи аргумент командного рядка --authorization-config. Якщо ви хочете продовжувати використовувати аргументи командного рядка замість конфігураційного файлу, вони продовжать працювати як є. Щоб отримати доступ до нових можливостей вебхуків авторизації, таких як кілька вебхуків, політика невдачі та правила попередньої фільтрації, перейдіть до використання параметрів у файлі --authorization-config. З версії Kubernetes 1.30 формат конфігураційного файлу є бета-рівнем, і потрібно вказувати лише --authorization-config, оскільки feature gate вже увімкнено. Приклад конфігурації із всіма можливими значеннями наведено в документації з авторизації. Докладніше читайте в документації з авторизації.
Автомасштабування Podʼів на основі ресурсів контейнера (KEP-1610)
Горизонтальне автомасштабування Podʼів на основі метрик ContainerResource перейде у стабільний стан у версії v1.30. Це нова функціональність для HorizontalPodAutoscaler дозволяє налаштовувати автоматичне масштабування на основі використання ресурсів для окремих контейнерів, а не загального використання ресурсів для всіх контейнерів у Podʼіві. Докладні відомості можна знайти у нашій попередній статті або в метриках ресурсів контейнера.
CEL для керування допуском (KEP-3488)
Інтеграція Common Expression Language (CEL) для керування допуском у Kubernetes вводить більш динамічний та виразний спосіб оцінки запитів на допуск. Ця функція дозволяє визначати та застосовувати складні, деталізовані політики безпосередньо через API Kubernetes, підвищуючи безпеку та здатність до управління без втрати продуктивності чи гнучкості.
Додавання CEL до керування допуском у Kubernetes дає адміністраторам кластерів можливість створювати складні правила, які можуть оцінювати вміст API-запитів на основі бажаного стану та політик кластера, не вдаючись до вебхуків, які використовують контролери доступу. Цей рівень контролю є важливим для забезпечення цілісності, безпеки та ефективності операцій у кластері, роблячи середовища Kubernetes більш надійними та адаптованими до різних сценаріїв використання та вимог. Для отримання докладної інформації щодо використання CEL для керування допуском дивіться документацію API для ValidatingAdmissionPolicy.
Ми сподіваємося, що ви так само нетерпляче чекаєте на цей випуск, як і ми. Стежте за блогом, щоб дізнатись про офіційний випуск через кілька тижнів, де буде представлено ще більше відомостей!