Розділ "Концепції" допоможе вам дізнатися про складові системи Kubernetes та абстракції, які використовує Kubernetes для представлення вашого кластера, і допоможе вам краще зрозуміти, як працює Kubernetes.
Це багатосторінковий друкований вигляд цього розділу. Натисність щоб друкувати.
Концепції
- 1: Огляд
- 1.1: Компоненти Kubernetes
- 1.2: Обʼєкти в Kubernetes
- 1.2.1: Управління обʼєктами Kubernetes
- 1.2.2: Назви та Ідентифікатори Обʼєктів
- 1.2.3: Мітки та Селектори
- 1.2.4: Простори імен
- 1.2.5: Анотації
- 1.2.6: Селектори полів
- 1.2.7: Завершувачі
- 1.2.8: Власники та Залежності
- 1.2.9: Рекомендовані Мітки
- 1.3: API Kubernetes
- 2: Архітектура кластера
- 2.1: Вузли
- 2.2: Звʼязок між Вузлами та Панеллю управління
- 2.3: Контролери
- 2.4: Лізинг
- 2.5: Cloud Controller Manager
- 2.6: Про cgroup v2
- 2.7: Інтерфейс середовища виконання контейнерів (CRI)
- 2.8: Збір сміття
- 2.9: Mixed Version Proxy
- 3: Контейнери
- 3.1: Образ контейнера
- 3.2: Середовище контейнера
- 3.3: Клас виконання
- 3.4: Хуки життєвого циклу контейнера
- 4: Робочі навантаження
- 4.1: Podʼи
- 4.1.1: Життєвий цикл Podʼа
- 4.1.2: Контейнери ініціалізації
- 4.1.3: Контейнери sidecar
- 4.1.4: Ефемерні контейнери
- 4.1.5: Розлади
- 4.1.6: Класи якості обслуговування (Quality of Service) Podʼів
- 4.1.7: Простори імен користувачів
- 4.1.8: Downward API
- 4.2: Керування навантаженням
- 4.2.1: Deployment
- 4.2.2: ReplicaSet
- 4.2.3: StatefulSets
- 4.2.4: DaemonSet
- 4.2.5: Job
- 4.2.6: Автоматичне очищення завершених задач
- 4.2.7: CronJob
- 4.2.8: ReplicationController
- 4.3: Автомасштабування робочих навантажень
- 4.4: Управління робочими навантаженнями
- 5: Service, балансування навантаження та мережа
- 5.1: Service
- 5.2: Ingress
- 5.3: Контролери Ingress
- 5.4: Gateway API
- 5.5: EndpointSlices
- 5.6: Мережеві політики
- 5.7: DNS для Service та Podʼів
- 5.8: Подвійний стек IPv4/IPv6
- 5.9: Маршрутизація з урахуванням топології
- 5.10: Мережеві аспекти Windows
- 5.11: Виділення IP-адрес ClusterIP Serviceʼам
- 5.12: Політики внутрішнього трафіку Service
- 6: Зберігання
- 6.1: Томи
- 6.2: Постійні томи
- 6.3: Projected томи
- 6.4: Ефемерні томи
- 6.5: Класи сховищ
- 6.6: Класи атрибутів тома
- 6.7: Динамічне впровадження томів
- 6.8: Знімки томів
- 6.9: Класи знімків томів
- 6.10: Клонування CSI-томів
- 6.11: Обсяг сховища
- 6.12: Обмеження томів на вузлі
- 6.13: Моніторинг справності томів
- 6.14: Зберігання у Windows
- 7: Конфігурація
- 7.1: Поради щодо конфігурації
- 7.2: ConfigMaps
- 7.3: Secrets
- 7.4: Керування ресурсами Podʼів та Контейнерів
- 7.5: Проби життєздатності, готовності та запуску
- 7.6: Організація доступу до кластеру за допомогою файлів kubeconfig
- 7.7: Управління ресурсами для вузлів Windows
- 8: Безпека
- 8.1: Безпека хмарних середовищ та Kubernetes
- 8.2: Стандарти безпеки для Podʼів
- 8.3: Pod Security Admission
- 8.4: Службові облікові записи
- 8.5: Політики безпеки для Podʼів
- 8.6: Захист для вузлів з операційною системою Windows
- 8.7: Керування доступом до API Kubernetes
- 8.8: Поради з безпеки для контролю доступу на основі ролей
- 8.9: Поради використання Secretʼів в Kubernetes
- 8.10: Мультиорендність
- 8.11: Поради з посилення безпеки — Механізми автентифікації
- 8.12: Ризики обходу сервера API Kubernetes
- 8.13: Обмеження безпеки ядра Linux для Podʼів та контейнерів
- 8.14: Список перевірок безпеки
- 8.15: Список перевірки безпеки застосунків
- 9: Політики
- 9.1: Обмеження діапазонів
- 9.2: Квоти ресурсів
- 9.3: Обмеження та резервування ID процесів
- 9.4: Менеджери ресурсів вузлів
- 10: Планування, Випередження та Виселення
- 10.1: Планувальник Kubernetes
- 10.2: Призначення Podʼів до Вузлів
- 10.3: Накладні витрати, повʼязані з роботою Podʼів
- 10.4: Готовність планування Pod
- 10.5: Обмеження поширення топології Podʼів
- 10.6: Заплямованість та Толерантність
- 10.7: Фреймворк планування
- 10.8: Динамічне виділення ресурсів
- 10.9: Налаштування продуктивності планувальника
- 10.10: Пакування ресурсів
- 10.11: Пріоритет та Випередження Podʼів
- 10.12: Виселення внаслідок тиску на вузол
- 10.13: Виселення, ініційоване API
- 11: Адміністрування кластера
- 11.1: Вимикання вузлів
- 11.2: Сертифікати
- 11.3: Мережа в кластері
- 11.4: Архітектура логування
- 11.5: Версія сумісності для компонентів панелі управління Kubernetes
- 11.6: Метрики для компонентів системи Kubernetes
- 11.7: Метрики для станів обʼєктів Kubernetes
- 11.8: Системні логи
- 11.9: Трейси для системних компонентів Kubernetes
- 11.10: Проксі у Kubernetes
- 11.11: API Priority та Fairness
- 11.12: Автомасштабування кластера
- 11.13: Встановлення надбудов
- 11.14: Координовані вибори лідера
- 12: Windows у Kubernetes
- 13: Розширення можливостей Kubernetes
- 13.1: Розширення обчислення, зберігання та мережі
- 13.1.1: Мережеві втулки
- 13.1.2: Втулки пристроїв
- 13.2: Розширючи API Kubernetes
- 13.2.1: Власні Ресурси
- 13.2.2: Шар агрегації API Kubernetes
- 13.3: Шаблон Operator
1 - Огляд
Kubernetes — це переносима, розширювана та відкрита платформа для управління контейнеризованими навантаженнями та службами, яка полегшує як декларативне, так і автоматичне налаштування. Вона має велику та швидко зростаючу екосистему. Сервіси, підтримка та інструменти Kubernetes широко доступні.
Ця сторінка надає огляд основних концепцій Kubernetes.
Назва Kubernetes (/ˌk(j)uːbərˈnɛtɪs, Кубернетіс) походить від грецького слова, що означає особу, що керує кораблем. K8s — це скорочення Kubernetes, яке складається з першої літери «K», потім восьми літер і, нарешті, літери «s». Google зробив Kubernetes проєктом з відкритим кодом у 2014 році. Kubernetes поєднує понад 15 років досвіду Google у роботі з контейнеризованими навантаженнями з найкращими ідеями та практиками спільноти.
Чому вам потрібен Kubernetes та що він може робити?
Контейнери — це гарний спосіб обʼєднати та запустити ваші застосунки. У промисловому середовищі вам потрібно керувати контейнерами, які запускають застосунки, і гарантувати відсутність простоїв. Наприклад, якщо контейнер падає, повинен запуститися інший контейнер. Чи не було б легше, якби такою поведінкою займалася система?
Ось саме тут Kubernetes приходить на допомогу! Kubernetes надає вам фреймворк для надійного запуску розподілених систем. Він піклується про масштабування та відмовостійкість для ваших застосунків, забезпечує шаблони розгортання тощо. Наприклад: Kubernetes може легко керувати розгортанням канарки (canary deployment) для вашої системи.
Kubernetes надає вам:
- Виявлення сервісів та балансування Kubernetes може надати доступ до контейнерів застосунків за допомогою внутрішньої IP-адреси та імені DNS. Якщо навантаження на контейнер зростає, Kubernetes може балансувати навантаження та розподіляти мережевий трафік, що робить роботу розгортання стабільною.
- Оркестрування зберіганням Kubernetes дозволяє автоматично монтувати системи зберігання, такі як локальні пристрої, хмарні ресурси тощо.
- Автоматизоване розгортання та згортання Ви можете описати бажаний стан вашого розгорнутого контейнера використовуючи Kubernetes, а він може змінювати стан вашого контейнера, щоб відповідати бажаному стану з певним рівнем відповідності. Наприклад, ви можете налаштувати Kubernetes так, щоб він автоматично створював контейнери з вашими застосунками для вашого розгортання, вилучав контейнери, які не використовуються та використовував їх ресурси для нових контейнерів.
- Автоматичне пакування Ви надаєте Kubernetes кластер вузлів, які він може використовувати для виконання контейнеризованих завдань. Ви вказуєте Kubernetes, скільки процесорних потужностей та памʼяті (ОЗП) потрібно кожному контейнеру. Kubernetes може помістити контейнери на ваші вузли, щоб найкращим чином використовувати ресурси.
- Самовідновлення Kubernetes перезапускає контейнери, які впали, заміняє контейнери, припиняє роботу контейнерів, які не відповідають визначеному користувачем стану під час перевірки, очікує готовності їх до роботи перш ніж пропонувати їх клієнтам.
- Секрети та керування конфігураціями Kubernetes дозволяє зберігати та керувати чутливими даними, такими як паролі, OAuth-токени та SSH-ключі. Ви можете розгортати та оновлювати конфігурацію та секрети без перезбирання образу вашого контейнера, без розголошення секретів у вашому стеку конфігурації.
- Пакетне виконання На додачу до сервісів, Kubernetes може керувати пакетним виконанням процесів та CI завдань, заміщаючи контейнери, що зазнали збою, за потреби.
- Горизонтальне масштабування Масштабуйте ваші застосунки, збільшуючи чи зменшуючи кількість робочих навантажень, просто командами, за допомогою UI або автоматично залежно від використання ЦП або інших ресурсів.
- Подвійний стек IPv4/IPv6 Виділення адрес IPv4 та IPv6 для Podʼів та Serviceʼів.
- Запланована розширюваність Додавайте нові функції до Kubernetes без зміни основного коду Kubernetes.
Чим не є Kubernetes?
Kubernetes не є традиційною, все-в-одному PaaS-платформою (Platform as a Service). Оскільки Kubernetes працює на рівні контейнерів, а не апаратному рівні, він надає деякі загально прийняті функції PaaS, такі як розгортання, масштабування, балансування навантаження та дозволяє користувачам інтегрувати власні рішення для моніторингу, журналювання тощо. Однак, Kubernetes не є монолітом і ці рішення є підʼєднуваними та необовʼязковими. Kubernetes надає вам будівельні блоки, які можна зʼєднати для створення платформи для розробки, але залишає вами вибір та гнучкість саме там де вам це потрібно.
Kubernetes:
- Не обмежує типи підтримуваних застосунків. Kubernetes прагне підтримувати надзвичайно різноманітні робочі навантаження, включаючи робочі навантаження stateless, stateful та робочі навантаження з обробки даних. Якщо застосунок може працювати в контейнері, він повинен чудово працювати на Kubernetes.
- Не розгортає код і не збирає ваш застосунок. Робочі процеси безперервної інтеграції, доставки та розгортання (CI/CD) визначаються культурою та уподобаннями організації, а також технічними вимогами.
- Не надає служби на рівні застосунків, такі як middleware, проміжне програмне забезпечення (наприклад, шини повідомлень), фреймворки обробки даних (наприклад, Spark), бази даних (наприклад, MySQL), кеші або кластерні системи зберігання (наприклад, Ceph) як вбудовані служби. Такі компоненти можуть працювати на Kubernetes та/або бути доступними застосункам, що працюють в Kubernetes, за допомогою механізмів перенесення, таких як Open Service Broker.
- Не диктує рішення для логування, моніторингу або оповіщення. Він забезпечує деякі інтеграції як доказ концепції та механізми збору та експорту метрик.
- Не надає та не ставить вимог щодо мови/системної конфігурації (наприклад, Jsonnet). Він надає декларативний API, який може використовуватись довільними формами декларативних специфікацій.
- Не забезпечує і не приймає будь-які комплексні системи конфігурації машини, обслуговування, управління або самовідновлення.
- Крім того, Kubernetes — це не просто система оркестрування. Насправді вона усуває необхідність оркестрування. Технічним визначенням оркестрування є виконання визначеного робочого процесу: спочатку зробіть A, потім B, потім C. На відміну від цього, Kubernetes має в собі набір незалежних частин процесів управління, які безперервно рухають поточний стан до вказаного бажаного стану. Не має значення, як ви перейдете від А до С. Централізоване управління також не потрібне. Це призводить до того, що система простіша у використанні та потужніша, надійна, стійка та розширювана.
Назад у минуле
Погляньмо на те, чому Kubernetes настільки корисний, повернувшись в минуле.

Ера традиційного розгортання:
На початку, організації запускали свої застосунки на фізичних серверах. Не було можливості визначити межі ресурсів для застосунків на фізичному сервері, і це спричиняло проблеми з розподілом ресурсів. Наприклад, якщо на фізичному сервері працює кілька програм, можуть бути випадки, коли одна програма займе більшу частину ресурсів, і в результаті інші застосунки будуть працювати не так. Рішенням для цього було б запустити кожну програму на іншому фізичному сервері. Але це не масштабувалося, оскільки ресурси були недостатньо використані, і організаціям було дорого підтримувати багато фізичних серверів.
Ера віртуалізованого розгортання:
Як розвʼязання цієї проблеми виникла віртуалізація. Вона дозволяє запускати кілька віртуальних машин на одному фізичному сервері. Віртуалізація дозволяє ізолювати застосунки в межах віртуальних машин та надає такий рівень безпеки, що інформація з одного застосунку не може бути вільно доступною в іншому застосунку.
Віртуалізація дозволяє краще використовувати ресурси фізичного сервера та означає кращу масштабованість, оскільки застосунки можуть бути легко додані та оновлені разом зі скороченням витрат на апаратне забезпечення. За допомогою віртуалізації ви можете представити набір фізичних ресурсів у вигляді кластера із пулом замінюваних віртуальних машин.
Кожна віртуальна машина є компʼютером, який має всі компоненти, включаючи операційну систему, встановлену на віртуальне апаратне забезпечення.
Ера контейнеризації:
Контейнери подібні до віртуальних машин, але вони мають слабкішу ізоляцію і можуть використовувати спільну операційну систему поміж застосунками. Тому контейнери вважаються легшими, ніж віртуальні машини. Так само як і віртуальні машини, контейнери мають власну файлову систему, спільно використовують ресурси ЦП, памʼять, простір процесів та інше. Оскільки вони відокремлені від базової інфраструктури, їх просто переносити між хмарами та ОС.
Контейнери набули популярності, оскільки вони надають додаткові вигоди, такі як:
- Гнучке створення та розгортання застосунків: підвищено простоту та ефективність створення образу контейнера порівняно з використанням образу віртуальної машини.
- Безперервна розробка, інтеграція та розгортання: забезпечує надійне та часте створення та розгортання образу контейнера зі швидким та ефективним відкатом (через незмінність образу).
- Розділення Dev та Ops: створення образів контейнерів застосунків під час створення/випуску, а не під час розгортання, тим самим застосунки відокремлюються від інфраструктури.
- Спостережуваність: не тільки відображає інформацію та метрики на рівні ОС, але й стан застосунків та інші сигнали.
- Узгодженість оточення розробки, тестування та експлуатації: все працює так само на ноутбуці, як і в хмарі.
- Переносимість між хмарами та ОС: працює на Ubuntu, RHEL, CoreOS, у приватних хмарах, основних публічних хмарах — всюди.
- Управління, орієнтоване на застосунки: підвищує рівень абстракції від запуску ОС на віртуальному обладнанні до запуску застосунків в ОС з використанням логічних ресурсів.
- Вільно повʼязані, розподілені, еластичні, звільнені мікросервіси: застосунки розбиваються на менші, незалежні частини та можуть бути розгорнуті та керовані динамічно — на відміну від монолітного стека, що працює на одній великій спеціально призначеній для цього машині.
- Ізоляція ресурсів: передбачувана продуктивність застосунків.
- Використання ресурсів: висока ефективність та щільність.
Що далі
- Подивіться на Компоненти Kubernetes
- Подивіться на API Kubernetes
- Подивіться на Архітектура кластера
- Готові розпочати?
1.1 - Компоненти Kubernetes
Огляд ключових компонентів, з яких складається кластер Kubernetes.
Ця сторінка містить огляд основних компонентів, з яких складається кластер Kubernetes.

Компоненти кластера Kubernetes
Основні компоненти
Кластер Kubernetes складається з панелі управління та одного або декількох робочих вузлів. Ось короткий огляд основних компонентів:
Компоненти панелі управління
Керують загальним станом кластера:
- kube-apiserver
- Сервер основних компонентів, який надає Kubernetes HTTP API
- etcd
- Узгоджене та високодоступне сховище значень ключів для всіх даних сервера API
- kube-scheduler
- Шукає ще не прикріплені до вузла Podʼи та призначає кожен Pod до відповідного вузла.
- kube-controller-manager
- Запускає контролери для впровадження поведінки API Kubernetes.
- cloud-controller-manager (необовʼязково)
- Інтегрується з інфраструктурою хмарного постачальника.
Компоненти вузлів
Запускаються на кожному вузлі, підтримуючи запущені Podʼи та надаючи середовище виконання Kubernetes:
- kubelet
- Забезпечує роботу Podʼів, включно з їхніми контейнерами.
- kube-proxy
- Підтримує мережеві правила на вузлах для реалізації Services.
- Рушій виконання контейнерів
- Програмне забезпечення для запуску контейнерів. Дивіться Середовище виконання контейнерів, щоб дізнатись більше.
Надбудови
Надбудови розширюють функціональність Kubernetes. Ось кілька важливих прикладів:
- DNS
- Для перетворення адрес на назви на рівні всього кластера.
- Wеb UI (Dashboard)
- Вебінтерфейс для керування кластером Kubernetes.
- Container Resource Monitoring
- Збирає логи контейнерів в централізоване сховище логів.
Гнучкість архітектури
Kubernetes дозволяє гнучко розгортати та керувати цими компонентами. Архітектуру можна адаптувати до різних потреб, від невеликих середовищ розробки до великомасштабних виробничих розгортань.
Для отримання більш детальної інформації про кожен компонент та різні способи налаштування кластерної архітектури, див. сторінку Архітектура кластера.
1.2 - Обʼєкти в Kubernetes
Обʼєкти Kubernetes є постійними сутностями в системі Kubernetes. Kubernetes використовує ці сутності для подання стану вашого кластера. Дізнайтеся про модель обʼєктів Kubernetes та про те, як працювати з цими обʼєктами.
Ця сторінка пояснює, як обʼєкти Kubernetes подаються в API Kubernetes, та як ви можете описати їх у форматі .yaml.
Розуміння обʼєктів Kubernetes
Обʼєкти Kubernetes є постійними сутностями в системі Kubernetes. Kubernetes використовує ці сутності для подання стану вашого кластера. Зокрема, вони можуть описувати:
- Які контейнеризовані застосунки працюють (і на яких вузлах)
- Ресурси, доступні для цих застосунків
- Політики щодо того, як ці застосунки поводяться, такі як політики перезапуску, оновлення та стійкості до відмов
Обʼєкт Kubernetes є "записом про наміри" — після створення обʼєкта система Kubernetes постійно працюватиме, щоб переконатися, що обʼєкт існує. Створюючи обʼєкт, ви фактично повідомляєте системі Kubernetes, ваші побажання щодо того, як має виглядати робоче навантаження вашого кластера; це бажаний стан вашого кластера.
Для роботи з обʼєктами Kubernetes — чи то для створення, зміни чи видалення — вам потрібно використовувати API Kubernetes. Наприклад, коли ви використовуєте інтерфейс командного рядка kubectl, CLI виконує необхідні виклики API Kubernetes за вас. Ви також можете використовувати API Kubernetes безпосередньо у ваших власних програмах за допомогою однієї з Клієнтських бібліотек.
Специфікація та стан обʼєкта
Майже кожен обʼєкт Kubernetes містить два вкладених поля обʼєкта, які керують конфігурацією обʼєкта: spec та status обʼєкта. Для обʼєктів, які мають spec, вам потрібно встановити його при створенні обʼєкта, надаючи опис характеристик, які ви хочете, щоб ресурс мав: його бажаний стан.
status описує поточний стан обʼєкта, який надається та оновлюється системою Kubernetes та її компонентами. Control plane Kubernetes постійно та активно керує фактичним станом кожного обʼєкта, щоб він відповідав бажаному стану, який ви вказали.
Наприклад: в Kubernetes, Deployment є обʼєктом, який може представляти застосунок, який працює на вашому кластері. При створенні Deployment ви можете встановити spec Deployment, щоб вказати, що ви хочете, щоб працювало три репліки застосунку. Система Kubernetes читає spec Deployment та запускає три екземпляри вашого застосунку — оновлюючи status Deployment, щоб віддзеркалювати поточний стан розгорнення. Якщо один цих екземплярів зазнає збою (зміни стану), Kubernetes відреагує на відмінність між spec та status, створивши новий екземпляр, щоб забезпечити, щоб status відповідав spec.
З докладнішою інформацією про spec, status та metadata обʼєктів Kubernetes звертайтесь до Kubernetes API Conventions.
Опис обʼєктів Kubernetes
Коли ви створюєте обʼєкт Kubernetes, ви повинні визначити spec обʼєкта, який описує бажаний стан обʼєкта, а також інші відомості про обʼєкт, наприклад його назву (name). Коли ви використовуєте API Kubernetes для створення обʼєкта, чи безпосередньо, чи за допомогою kubectl, цей запит до API має містити ці відомості у вигляді JSON в тілі запиту. Найчастіше інформація про обʼєкт подається kubectl у вигляді файлу, який називається маніфестом. За домовленістю, маніфести обʼєктів Kubernetes подаються у форматі YAML (ви також можете використовувати JSON). Інструменти, такі як kubectl, перетворюють інформацію з маніфесту у JSON або інший підтримуваний формат серіалізації надсилаючи HTTP-запити до API.
Ось приклад маніфесту, який містить обовʼязкові поля обʼєкта та його spec для Kubernetes Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # вказує Deployment запустити 2 Podʼи, що відповідають шаблону
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Один зі способів створення Deployment за допомогою маніфесту, подібного до показаного вище, — використання команди kubectl apply в інтерфейсі командного рядка kubectl, передаючи файл .yaml як аргумент. Ось так:
kubectl apply -f https://k8s.io/examples/application/deployment.yaml
Вивід буде схожий на цей:
deployment.apps/nginx-deployment created
Обовʼязкові поля
В маніфесті (файл YAML або JSON) обʼєкта Kubernetes, який ви хочете створити, ви повинні вказати значення для наступних обовʼязкових полів:
apiVersion— версія API Kubernetes, яку ви використовуєте для створення обʼєктаkind— тип обʼєкта, який ви хочете створитиmetadata— відомості про обʼєкт, які дозволяють ідентифікувати обʼєкт, включаючи рядокname, який вказує назву обʼєкта,UID, та, необовʼязково,namespacespec— опис бажаного стану обʼєкта
Точний формат spec обʼєкта є різним для кожного типу обʼєкта в Kubernetes та містить вкладені поля, що притаманні конкретному типу обʼєкта. Kubernetes API Reference може допомогти знайти формати для всіх типів обʼєктів, які ви хочете створити використовуючи API Kubernetes.
Наприклад, подивіться на поле spec для обʼєкта Pod. Для кожного Pod, поле .spec вказує на Pod та його бажаний стан (наприклад, назву образу контейнера для кожного контейнера всередині цього Pod). Інший приклад специфікації обʼєкта — поле spec для обʼєкта StatefulSet. Для StatefulSet, поле .spec вказує на StatefulSet та його бажаний стан. У .spec StatefulSet є template для обʼєктів Pod. Цей шаблон описує Pod, які контролер StatefulSet створить, щоб задовольнити специфікацію StatefulSet. Різні типи обʼєктів Kubernetes можуть мати різні .status; дивіться Kubernetes API Reference для отримання відомостей структуру поля .status та його вміст для кожного типу обʼєкта.
Примітка:
Конфігурація – найкращі практики, містить інформацію про те, як писати конфігураційні файли YAML.Перевірка полів на стороні сервера
Починаючи з Kubernetes v1.25, API сервера Kubernetes може виконувати перевірку полів на стороні сервера, що дозволяє виявляти невідомі та задвоєні поля в описі обʼєктів. Це надає функціонал kubectl --validate на стороні сервера.
kubectl використовує прапорець --validate для встановлення рівня перевірки полів маніфесту. Його значенням може бути ignore, warn та strict, також можна вказати true (еквівалент strict) та false (еквівалент ignore). Типове значення перевірки для kubectl — --validate=true.
Strict- Сувора перевірка, повертає збій під час виявлення помилок.
Warn- Перевірка виконується, але виявлення помилок призводить до виведення попереджень, а не збою.
Ignore- Перевірка на стороні сервера не виконується.
Якщо kubectl не може підʼєднатися до API сервера, він використовує локальну перевірку, яка виконується на стороні клієнта. Kubernetes v1.27 та пізніші версії завжди пропонуватимуть перевірку полів; версії до v1.27, скоріш за все — ні. Якщо версія Kubernetes на вашому кластері старіша за v1.27, звіртесь з документацією до вашої версії Kubernetes.
Що далі
Якщо ви тільки починаєте свій шлях з Kubernetes, дізнайтесь більше про:
- Podʼи — найважливіші базові обʼєкти в Kubernetes.
- Deployment — ресурс, який допомагає вам керувати наборами Podʼів.
- Контролери в Kubernetes.
- kubectl та команди
kubectl.
Керування обʼєктами в Kubernetes надає додаткову інформацію про те, як працювати використовувати kubectl для керування обʼєктами. Скоріш за все вам буде потрібно встановити kubectl, якщо тільки ви цього ще не зробили.
Щоб дізнатись про API Kubernetes, зверніться до:
Якщо ви хочете дізнатись про Kubernetes більше, зверніться до інших сторінок в цьому розділі:
1.2.1 - Управління обʼєктами Kubernetes
Інструмент командного рядка kubectl підтримує кілька різних способів створення та управління обʼєктами Kubernetes. Цей документ надає огляд різних підходів. Для отримання деталей щодо управління обʼєктами за допомогою Kubectl читайте Книгу Kubectl.
Техніки управління
Попередження:
Обʼєкт Kubernetes повинен управлятися лише з використанням однієї техніки. Змішування різних технік для того самого обʼєкта призводить до невизначеної поведінки.| Техніка управління | Діє на | Рекомендоване середовище | Підтримувані інструменти | Крива навчання |
|---|---|---|---|---|
| Імперативні команди | Живі обʼєкти | Проєкти розробки | 1+ | Налегша |
| Імперативна конфігурація обʼєктів | Окремі файли | Продуктові проєкти | 1 | Середня |
| Декларативна конфігурація обʼєктів | Теки файлів | Продуктові проєкти | 1+ | Найскладніша |
Імперативні команди
При використанні імперативних команд користувач працює безпосередньо з живими обʼєктами в кластері. Користувач надає операції команді kubectl у вигляді аргументів чи прапорців.
Це рекомендований спосіб початку роботи або виконання одноразового завдання в кластері. Оскільки цей метод працює безпосередньо з живими обʼєктами, він не зберігає жодної історичної конфігурації.
Приклади
Запустіть екземпляр контейнера nginx, створивши обʼєкт розгортання (Deployment):
kubectl create deployment nginx --image nginx
Компроміси
Переваги порівняно із конфігуруванням обʼєктів:
- Команди виражені як одне слово дії.
- Команди вимагають лише одного кроку для внесення змін до кластера.
Недоліки порівняно із конфігуруванням обʼєктів:
- Команди не інтегруються з процесами перегляду змін.
- Команди не надають логів аудиту, повʼязаних зі змінами.
- Команди не надають джерела записів, окрім того, що є на живому сервері.
- Команди не надають шаблону для створення нових обʼєктів.
Імперативне конфігурування обʼєктів
У імперативній конфігурації обʼєктів команда kubectl вказує операцію (створити, замінити інше), необовʼязкові прапорці та принаймні одне імʼя файлу. Зазначений файл повинен містити повне визначення обʼєкта у форматі YAML або JSON.
Див. API-довідник для отримання докладніших відомостей щодо визначення обʼєктів.
Попередження:
Імперативна командаreplace замінює поточну специфікацію на нову, вилучаючи всі зміни обʼєкта, які відсутні в файлі конфігурації. Цей підхід не повинен використовуватися із типами ресурсів, специфікації яких оновлюються незалежно від файлу конфігурації. Наприклад, у служб типу LoadBalancer поле externalIPs оновлюється незалежно від конфігурації кластера.Приклади
Створити обʼєкти, визначені у файлі конфігурації:
kubectl create -f nginx.yaml
Видалити обʼєкти, визначені у двох файлах конфігурації:
kubectl delete -f nginx.yaml -f redis.yaml
Оновити обʼєкти, визначені у файлі конфігурації, перезаписавши живу конфігурацію:
kubectl replace -f nginx.yaml
Компроміси
Переваги порівняно з імперативними командами:
- Конфігурація обʼєктів може зберігатися у системі контролю версій, такій як Git.
- Конфігурація обʼєктів може інтегруватися з процесами, такими як перегляд змін перед публікацією та аудитом.
- Конфігурація обʼєктів надає шаблон для створення нових обʼєктів.
Недоліки порівняно з імперативними командами:
- Конфігурація обʼєктів потребує базового розуміння схеми обʼєкта.
- Конфігурація обʼєктів потребує додаткового кроку у вигляді написання файлу YAML.
Переваги порівняно із декларативною конфігурацією обʼєктів:
- Поведінка імперативної конфігурації обʼєктів простіша та її легше зрозуміти.
- З версії Kubernetes 1.5 імперативна конфігурація обʼєктів більш зріла.
Недоліки порівняно із декларативною конфігурацією обʼєктів:
- Імперативна конфігурація обʼєктів працює краще з файлами, а не з теками.
- Оновлення живих обʼєктів повинно відображатися у файлах конфігурації, або вони будуть втрачені під час наступної заміни.
Декларативна конфігурація обʼєктів
При використанні декларативної конфігурації обʼєктів користувач працює з конфігураційними файлами обʼєктів, збереженими локально, проте користувач не визначає операції, які слід виконати над файлами. Операції створення, оновлення та видалення автоматично визначаються для кожного обʼєкта за допомогою kubectl. Це дозволяє працювати з теками, де для різних обʼєктів можуть бути потрібні різні операції.
Примітка:
Декларативна конфігурація обʼєктів зберігає зміни, внесені іншими учасниками, навіть якщо зміни не зливаються назад у файл конфігурації обʼєкта. Це можливо за допомогою використання операції APIpatch для запису тільки спостережуваних відмінностей, замість використання операції replace для заміни всього файлу конфігурації обʼєкта.Приклади
Обробити всі файли конфігурації обʼєктів у каталозі configs та створити або внести патчі до живих обʼєктів. Спочатку ви можете використовувати diff, щоб побачити, які зміни будуть внесені, а потім застосовувати:
kubectl diff -f configs/
kubectl apply -f configs/
Рекурсивно обробити теки:
kubectl diff -R -f configs/
kubectl apply -R -f configs/
Компроміси
Переваги порівняно з імперативною конфігурацією обʼєктів:
- Зміни, внесені безпосередньо в живі обʼєкти, зберігаються, навіть якщо вони не зливаються назад у файли конфігурації.
- Декларативна конфігурація обʼєктів краще підтримує роботу з теками та автоматично визначає типи операцій (створення, патч, видалення) для кожного обʼєкта.
Недоліки порівняно з імперативною конфігурацією обʼєктів:
- Декларативна конфігурація обʼєктів важко налагоджувати, і результати її роботи важко зрозуміти, коли вони несподівані.
- Часткові оновлення за допомогою відміток створюють складні операції злиття та накладання патчів.
Що далі
- Управління обʼєктами Kubernetes за допомогою імперативних команд
- Імперативне управління обʼєктами Kubernetes за допомогою файлів конфігурації
- Декларативне управління обʼєктами Kubernetes за допомогою файлів конфігурації
- Декларативне управління обʼєктами Kubernetes за допомогою Kustomize
- Довідник команд Kubectl
- Книга Kubectl
- Довідник API Kubernetes
1.2.2 - Назви та Ідентифікатори Обʼєктів
Кожен обʼєкт у вашому кластері має Назву (імʼя), яка є унікальною для цього типу ресурсу. Кожен обʼєкт Kubernetes також має UID, який є унікальним в усьому вашому кластеру.
Наприклад, ви можете мати лише один обʼєкт Pod із назвою myapp-1234 в просторі імен з такою ж назвою, а також ви можете мати один обʼєкт Pod та один Deployment із назвами myapp-1234 кожен.
Для неунікальних атрибутів, наданих користувачем, Kubernetes надає мітки (labels) та анотації (annotations).
Назви
Наданий клієнтом рядок, який посилається на обʼєкт в URL ресурсу, наприклад /api/v1/pods/some-name.
Тільки один обʼєкт вказаного виду (kind) може мати вказану назву одночасно. Проте, якщо ви видаляєте обʼєкт, ви можете створити новий обʼєкт з такою ж назвою.
Назви повинні бути унікальними між усіма версіями API того ж самого ресурсу. Ресурси API відрізняються своєю API-групою, типом ресурсу, простором імен (для ресурсів із просторами імен) та назвою. Іншими словами, версія API не має значення в цьому контексті.
Примітка:
У випадках, коли обʼєкти представляють фізичний обʼєкт, наприклад, Node, що представляє фізичний хост, коли хост перестворюється з тією ж самою назвою без видалення та перестворення Node, Kubernetes розглядає новий хост як старий, що може призвести до неузгодженостей.Сервер може згенерувати імʼя, якщо в запиті на створення ресурсу замість name вказати generateName. Коли використовується generateName, надане значення використовується як префікс імені, до якого сервер додає згенерований суфікс. Навіть якщо імʼя згенеровано, воно може конфліктувати з наявними іменами, що призведе до повторної відповіді HTTP 409. Це стало набагато менш імовірним в Kubernetes v1.31 і пізніших версіях, оскільки сервер зробить до 8 спроб згенерувати унікальне імʼя перед тим, як повернути відповідь HTTP 409.
Нижче наведено чотири типи обмежень на назви ресурсів, які часто використовуються.
Назви DNS-піддоменів
Більшість типів ресурсів потребують назви, яку можна використовувати як DNS-піддомен згідно з RFC 1123. Це означає, що назва повинна:
- містити не більше 253 символів
- містити лише буквено-цифрові символи, '-' чи '.' в нижньому регістрі
- починатися буквено-цифровим символом
- закінчуватися буквено-цифровим символом
Назви міток RFC 1123
Деякі типи ресурсів вимагають, щоб їх назви відповідали стандарту DNS як визначено в RFC 1123. Це означає, що назва повинна:
- містити не більше 63 символів
- містити лише буквено-цифрові символи чи '-' в нижньому регістрі
- починатися буквено-цифровим символом
- закінчуватися буквено-цифровим символом
Назви міток RFC 1035
Деякі типи ресурсів вимагають, щоб їх назви відповідали стандарту DNS як визначено в RFC 1035. Це означає, що назва повинна:
- містити не більше 63 символів
- містити лише буквено-цифрові символи чи '-' в нижньому регістрі
- починатися алфавітним символом
- закінчуватися буквено-цифровим символом
Примітка:
Єдина відмінність між стандартами RFC 1035 та RFC 1123 полягає у тому, що мітки RFC 1123 можуть починатися з цифри, тоді як мітки RFC 1035 можуть починатися лише з літери алфавіту в нижньому регістрі.Назви сегментів шляху
Деякі типи ресурсів вимагають, щоб їх назви можна було безпечно кодувати як сегмент шляху. Іншими словами, назва не може бути "." або "..", і вона не може містити "/" або "%".
Ось приклад маніфесту для Pod із назвою nginx-demo.
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Примітка:
Деякі типи ресурсів мають додаткові обмеження на їх назви.UID
Рядок, створений системами Kubernetes для унікальної ідентифікації обʼєктів.
Кожен обʼєкт, створений протягом усього життя кластера Kubernetes, має відмінний UID. Він призначений для відмінності між історичними випадками схожих сутностей.
UID Kubernetes — це унікальні ідентифікатори, також відомі як UUID (узгоджені універсальні ідентифікатори). UUID стандартизовані згідно з ISO/IEC 9834-8 та ITU-T X.667.
Що далі
- Дізнайтеся більше про мітки (labels) та анотації (annotations) в Kubernetes.
- Перегляньте документ Ідентифікатори та Назви в Kubernetes.
1.2.3 - Мітки та Селектори
Мітки — це пари ключ/значення, які прикріплені до обʼєктів, таких як Pod. Мітки призначені для використання для вказівки визначних атрибутів обʼєктів, які мають значення та стосуються користувачів, але безпосередньо не вбачають семантику для основної системи. Мітки можуть бути використані для організації та вибору підмножини обʼєктів. Мітки можуть бути прикріплені до обʼєктів при їх створенні та пізніше додані та змінені в будь-який час. Кожен обʼєкт може мати набір унікальних міток ключ/значення. Кожен ключ повинен бути унікальним для даного обʼєкта.
"metadata": {
"labels": {
"key1" : "value1",
"key2" : "value2"
}
}
Мітки дозволяють є ефективними для запитів та спостережень та є ідеальними для використання в інтерфейсах користувача та інтерфейсах командного рядка. Інформацію, що не є ідентифікуючою, слід записувати за допомогою анотацій.
Мотивація
Мітки дозволяють користувачам звʼязувати свої власні організаційні структури з обʼєктами системи у вільний спосіб, не вимагаючи зберігання цих звʼязків в клієнтах.
Розгортання Service та конвеєрів обробки пакетів часто є багатомірними сутностями (наприклад, кілька розділів чи розгортань, кілька шляхів релізів, кілька рівнів, кілька мікросервісів на кожному рівні). Управління часто потребує наскрізних операцій, які порушують інкапсуляцію строго ієрархічних уявлень, особливо жорстких ієрархій, визначених інфраструктурою, а не користувачами.
Приклади міток:
"release" : "stable","release" : "canary""environment" : "dev","environment" : "qa","environment" : "production""tier" : "frontend","tier" : "backend","tier" : "cache""partition" : "customerA","partition" : "customerB""track" : "daily","track" : "weekly"
Це приклади загальновживаних міток; ви вільні розробляти свої власні домовленості. Памʼятайте, що ключ мітки повинен бути унікальним для даного обʼєкта.
Синтаксис та набір символів
Мітки — це пари ключ/значення. Дійсні ключі міток мають два сегменти: необовʼязковий префікс та назву, розділені слешем (/). Сегмент назви є обовʼязковим і має бути не більше 63 символів, починатися та закінчуватися буквено-цифровим символом ([a-z0-9A-Z]) з дефісами (-), підкресленнями (_), крапками (.), та буквено-цифровими символами між ними. Префікс є необовʼязковим. Якщо вказаний, префікс повинен бути піддоменом DNS: серією DNS-міток, розділених крапками (.), не довше 253 символів загалом, за яким слідує слеш (/).
Якщо префікс відсутній, ключ мітки вважається приватним для користувача. Автоматизовані компоненти системи (наприклад, kube-scheduler, kube-controller-manager, kube-apiserver, kubectl, або інші засоби автоматизації від інших сторін), які додають мітки до обʼєктів користувача, повинні вказати префікс.
Префікси kubernetes.io/ та k8s.io/ є зарезервованими для основних компонентів Kubernetes.
Дійсне значення мітки:
- повинно бути не більше 63 символів (може бути порожнім),
- крім порожнього значення, повинно починатися та закінчуватися буквено-цифровим символом (
[a-z0-9A-Z]), - може містити дефіси (
-), підкреслення (_), крапки (.), та буквено-цифрові символи між ними.
Наприклад, ось маніфест для Pod із двома мітками environment: production та app: nginx:
apiVersion: v1
kind: Pod
metadata:
name: label-demo
labels:
environment: production
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Селектори міток
На відміну від назв та UID, мітки не забезпечують унікальності. Загалом, ми очікуємо, що багато обʼєктів матимуть ті ж самі мітки.
За допомогою селектора міток користувач може ідентифікувати набір обʼєктів. Селектор міток є основним примітивом гуртування в Kubernetes.
На цей момент API підтримує два типи селекторів: equality-based та set-based. Селектор міток може складатися з кількох вимог, які розділені комами. У випадку кількох вимог всі повинні бути задоволені, таким чином кома виступає логічним
оператором AND (&&).
Примітка:
Для деяких типів API, таких як ReplicaSets, селектори міток двох екземплярів не повинні перетинатися в одному просторі імен, бо контролер може вважати це конфліктною інструкцією та не визначити, скільки реплік повинно бути присутньо.Увага:
Для умов на основі рівності і на основі множини немає логічного оператора OR (||). Переконайтеся, що ваші вирази фільтрації структуровані відповідно.Equality-based вимоги
Вимоги Equality- чи inequality-based дозволяють фільтрувати обʼєкти за ключами та значеннями міток. Відповідні обʼєкти повинні задовольняти всі вказані обмеження міток, хоча вони можуть мати додаткові мітки також. Допускаються три види операторів: =, ==, !=. Перший та другий представляють рівність (equality) і є синонімами, тоді як останній представляє нерівність (inequality).
Наприклад:
environment = production
tier != frontend
Перший вибирає всі ресурси з ключем environment та значенням production. Другий вибирає всі ресурси з ключем tier та значеннями відмінним від frontend, та всі ресурси без міток з ключем tier. Можна використовувати оператор коми для фільтрації ресурсів у production, іншими словами, environment=production,tier!=frontend.
Один зі сценаріїв використання вимог на основі рівності використовується для Podʼів, які вказують критерії вибору вузлів. Наприклад, зразок Podʼа нижче вибирає вузли з міткою accelerator зі значенням "accelerator=nvidia-tesla-p100".
apiVersion: v1
kind: Pod
metadata:
name: cuda-test
spec:
containers:
- name: cuda-test
image: "registry.k8s.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
accelerator: nvidia-tesla-p100
Set-based вимоги
Вимоги на основі множини дозволяють фільтрувати ключі за набором значень. Підтримуються три види операторів: in, notin та exists (тільки ідентифікатор ключа). Наприклад:
environment in (production, qa)
tier notin (frontend, backend)
partition
!partition
- Перший приклад вибирає всі ресурси з ключем, рівним
environmentта значенням рівнимproductionабоqa. - Другий приклад вибирає всі ресурси з ключем, рівним
tierта значеннями іншими ніжfrontendтаbackend, та всі ресурси без міток з ключемtier. - Третій приклад вибирає всі ресурси, включаючи мітку з ключем
partition; значення не перевіряються. - Четвертий приклад вибирає всі ресурси без мітки з ключем
partition; значення не перевіряються.
Так само розділювач коми діє як AND оператор. Таким чином, фільтрування ресурсів з ключем partition (без значення) та з environment відмінним від qa може бути досягнуто за допомогою partition,environment notin (qa). Вимоги на основі множини є загальною формою вимог на основі рівності, оскільки environment=production еквівалентно environment in (production); так само для != та notin.
Вимоги на основі множини можна комбінувати з вимогами на основі рівності. Наприклад: partition in (customerA, customerB),environment!=qa.
API
Фільтрація LIST та WATCH
Для операцій list і watch ви можете вказати селектори міток для фільтрації наборів обʼєктів що повертаються; фільтр задається за допомогою параметра запиту. (Щоб дізнатися докладніше про watch у Kubernetes, прочитайте ефективне виявлення змін). Обидві вимоги дозволені (тут подано так, як вони з'являться у рядку URL-запиту):
- вимоги на основі рівності:
?labelSelector=environment%3Dproduction,tier%3Dfrontend - вимоги на основі множини:
?labelSelector=environment+in+%28production%2Cqa%29%2Ctier+in+%28frontend%29
Обидва стилі селекторів міток можуть бути використані для переліку чи перегляду ресурсів через клієнта REST. Наприклад, спрямовуючись до apiserver за допомогою kubectl та використовуючи вимогу на основі рівності, можна написати:
kubectl get pods -l environment=production,tier=frontend
чи використовуючи вимогу на основі множини:
kubectl get pods -l 'environment in (production),tier in (frontend)'
Як вже зазначалося, вимоги на основі множини є більш виразними. Наприклад, вони можуть реалізувати оператор OR в значеннях:
kubectl get pods -l 'environment in (production, qa)'
чи обмежувати відʼємний збіг за допомогою оператора notin:
kubectl get pods -l 'environment,environment notin (frontend)'
Посилання в API-обʼєктах
Деякі обʼєкти Kubernetes, такі як services та replicationcontrollers, також використовують селектори міток для вказівки наборів інших ресурсів, таких як Podʼи.
Service та ReplicationController
Множина Podʼів, яку service вибирає, визначається селектором міток. Так само, популяція Podʼів, якою replicationcontroller повинен керувати,
також визначається селектором міток.
Селектори міток для обох обʼєктів визначаються в файлах json або yaml за допомогою звʼязування та підтримуються лише equality-based селектори:
"selector": {
"component" : "redis",
}
або
selector:
component: redis
Цей селектор (відповідно у форматі json або yaml) еквівалентний component=redis або component in (redis).
Ресурси, які підтримують вимоги на основі множин
Нові ресурси, такі як Job, Deployment, ReplicaSet, та DaemonSet, також підтримують вимоги на основі множин.
selector:
matchLabels:
component: redis
matchExpressions:
- { key: tier, operator: In, values: [cache] }
- { key: environment, operator: NotIn, values: [dev] }
matchLabels — це звʼязування з парами {key,value}. Одна пара {key,value} у
звʼязці matchLabels еквівалентна елементу matchExpressions, де поле key — це "key", оператор — "In", а масив values містить лише "value". matchExpressions - це список вимог селектора для вибору Podʼів. Допустимі оператори включають In, NotIn, Exists, та DoesNotExist. Масив values повинен бути непорожнім у випадку In та NotIn. Всі вимоги, як з matchLabels, так і з matchExpressions, йдуть разом
з логічною операцією AND — всі вони повинні бути задоволені для збігу.
Вибір множини вузлів
Одним з варіантів використання селекторів на мітках є обмеження множини вузлів, на які може бути заплановано Pod. Дивіться документацію щодо вибору вузла для отримання докладнішої інформації.
Ефективне використання міток
Ви можете застосовувати одну мітку до будь-яких ресурсів, але це не завжди є найкращою практикою. Є багато сценаріїв, де слід використовувати кілька міток для розрізнення наборів ресурсів один від одного.
Наприклад, різні застосунки можуть використовувати різні значення для мітки app,
але багаторівневий застосунок, такий як приклад гостьової книги, додатково повинен відрізняти кожний рівень. Фронтенд може мати наступні мітки:
labels:
app: guestbook
tier: frontend
тоді як Redis master та replica можуть мати різні мітки tier, і, можливо, навіть
додаткову мітку role:
labels:
app: guestbook
tier: backend
role: master
та
labels:
app: guestbook
tier: backend
role: replica
Мітки дозволяють розрізняти ресурси по будь-якому виміру, зазначеному міткою:
kubectl apply -f examples/guestbook/all-in-one/guestbook-all-in-one.yaml
kubectl get pods -Lapp -Ltier -Lrole
NAME READY STATUS RESTARTS AGE APP TIER ROLE
guestbook-fe-4nlpb 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-ght6d 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-jpy62 1/1 Running 0 1m guestbook frontend <none>
guestbook-redis-master-5pg3b 1/1 Running 0 1m guestbook backend master
guestbook-redis-replica-2q2yf 1/1 Running 0 1m guestbook backend replica
guestbook-redis-replica-qgazl 1/1 Running 0 1m guestbook backend replica
my-nginx-divi2 1/1 Running 0 29m nginx <none> <none>
my-nginx-o0ef1 1/1 Running 0 29m nginx <none> <none>
kubectl get pods -lapp=guestbook,role=replica
NAME READY STATUS RESTARTS AGE
guestbook-redis-replica-2q2yf 1/1 Running 0 3m
guestbook-redis-replica-qgazl 1/1 Running 0 3m
Оновлення міток
Іноді вам може знадобитися переозначити наявні Podʼи та інші ресурси перед створенням нових ресурсів. Це можна зробити за допомогою kubectl label. Наприклад, якщо ви хочете позначити всі свої NGINX Podʼи як рівень фронтенду, виконайте:
kubectl label pods -l app=nginx tier=fe
pod/my-nginx-2035384211-j5fhi labeled
pod/my-nginx-2035384211-u2c7e labeled
pod/my-nginx-2035384211-u3t6x labeled
Спочатку фільтруються всі Podʼи з міткою "app=nginx", а потім вони позначаються як "tier=fe". Щоб переглянути Podʼи, які ви позначили, виконайте:
kubectl get pods -l app=nginx -L tier
NAME READY STATUS RESTARTS AGE TIER
my-nginx-2035384211-j5fhi 1/1 Running 0 23m fe
my-nginx-2035384211-u2c7e 1/1 Running 0 23m fe
my-nginx-2035384211-u3t6x 1/1 Running 0 23m fe
Це виводить всі Podʼи "app=nginx", з додатковим стовпчиком міток рівня Podʼів (вказаним за допомогою -L або --label-columns).
Для отримання додаткової інформації, будь ласка, див. kubectl label.
Що далі
- Дізнайтеся, як додати мітку до вузла
- Знайдіть Відомі мітки, Анотації та Ознаки
- Перегляньте Рекомендовані мітки
- Застосовуйте стандарти безпеки для Podʼів з мітками простору імен
- Прочитайте блог про Написання контролера для міток Podʼа
1.2.4 - Простори імен
В Kubernetes простори імен (namespaces) забезпечують механізм для ізоляції груп ресурсів в межах одного кластера. Імена ресурсів повинні бути унікальними в межах простору імен, але не між просторами імен. Засноване на просторах імен обмеження застосовується лише до обʼєктів, які входять до простору імен (наприклад, Deployments, Services тощо), а не до обʼєктів, що поширюються на весь кластер (наприклад, StorageClass, Вузли, PersistentVolumes тощо).
Коли використовувати кілька просторів імен
Простори імен призначені для використання в середовищах з багатьма користувачами, розподіленими в різні команди чи проєкти. Для кластерів з кількома десятками користувачів вам, ймовірно, не потрібно створювати або думати про простори імен. Почніть використовувати простори імен, коли ви потребуєте функції, які вони забезпечують.
Простори імен визначають область імен. Назви ресурсів повинні бути унікальними в межах простору імен, але не між просторами імен. Простори імен не можуть бути вкладені один в одного, і кожен ресурс Kubernetes може бути лише в одному просторі імен.
Простори імен — це спосіб розділити ресурси кластера між кількома користувачами (за допомогою квот ресурсів).
Не обовʼязково використовувати кілька просторів імен для відокремлення трохи відмінних ресурсів, таких як різні версії одного й того ж програмного забезпечення: використовуйте мітки для розрізнення ресурсів в межах одного простору імен.
Примітка:
Для промислового кластера розгляньте можливість не використовувати простір іменdefault. Замість цього створюйте і використовуйте інші простори імен.Початкові простори імен
Після запуску в Kubernetes є чотирьох початкових простори імен:
default- Kubernetes включає цей простір імен, щоб ви могли почати використовувати новий кластер без попереднього створення простору імен.
kube-node-lease- Цей простір імен містить обʼєкти Оренди, повʼязані з кожним вузлом. Обʼєкти оренди дозволяють kubelet відправляти імпульси, щоб панель управління могла виявити відмову вузла.
kube-public- Цей простір імен може бути прочитаний усіма клієнтами (включаючи тих, які не автентифіковані). Цей простір імен в основному призначений для внутрішнього використання кластером, у випадку, коли деякі ресурси повинні бути видимими та доступними публічно по всьому кластеру. Публічний аспект цього простору імен — це лише домовленість, яка не є обовʼязковою.
kube-system- Простір імен для обʼєктів, створених системою Kubernetes.
Робота з просторами імен
Створення та видалення просторів імен описано в документації з адміністрування просторів імен.
Примітка:
Уникайте створення просторів імен із префіксомkube-, оскільки він зарезервований для системних просторів імен Kubernetes.Перегляд просторів імен
Ви можете переглянути поточні простори імен у кластері за допомогою:
kubectl get namespace
NAME STATUS AGE
default Active 1d
kube-node-lease Active 1d
kube-public Active 1d
kube-system Active 1d
Встановлення простору імен для запиту
Щоб встановити простір імен для поточного запиту, використовуйте прапорець --namespace.
Наприклад:
kubectl run nginx --image=nginx --namespace=<insert-namespace-name-here>
kubectl get pods --namespace=<insert-namespace-name-here>
Встановлення обраного простору імен
Ви можете постійно зберігати простір імен для всіх подальших команд kubectl в даному контексті.
kubectl config set-context --current --namespace=<insert-namespace-name-here>
# Перевірте його
kubectl config view --minify | grep namespace:
Простори імен та DNS
При створенні Service, створюється відповідний DNS запис. Цей запис має форму <service-name>.<namespace-name>.svc.cluster.local, що означає,
що якщо контейнер використовує тільки <service-name>, він буде звертатись до сервісу, який є локальним для простору імен. Це корисно для використання одного і того ж конфігураційного файлу в кількох просторах імен, таких як Development, Staging та Production. Якщо вам потрібно досягти обʼєкта в іншому просторі імен, вам слід використовувати повне кваліфіковане доменне імʼя (FQDN).
Отже, всі імена просторів імен повинні бути дійсними DNS-мітками згідно RFC 1123.
Попередження:
Створюючи простори імен із тими ж назвами, що і публічні домени верхнього рівня (TLD), Serviceʼи в цих просторах імен можуть мати короткі імена DNS, які перетинаються з публічними записами DNS. Завдання з будь-якого простору імен, яке виконує DNS-запит без крапки в кінці буде перенаправлено на ці сервіси, отримуючи перевагу над публічним DNS.
Для помʼякшення цього обмеження скоротіть привілеї для створення просторів імен довіреним користувачам. Якщо необхідно, ви можете додатково налаштувати сторонні перевірки на забезпечення безпеки, такі як обробники доступу, щоб блокувати створення будь-якого простору імен з іменем публічних TLD.
Не всі обʼєкти мають простори імен
Більшість ресурсів Kubernetes (наприклад, pods, services, replication controllers та інші) є в деяких просторах імен. Однак ресурси простору імен самі не перебувають в просторі імен. І ресурси низького рівня, такі як nodes та persistentVolumes, не перебувають в жодному просторі імен.
Щоб переглянути, які ресурси Kubernetes є в просторі імен, а які — ні:
# В просторі імен
kubectl api-resources --namespaced=true
# Не в просторі імен
kubectl api-resources --namespaced=false
Автоматичне маркування
СТАН ФУНКЦІОНАЛУ:
Kubernetes 1.22 [stable]Панель управління Kubernetes встановлює незмінювану мітку kubernetes.io/metadata.name для всіх просторів імен. Значення мітки — це назва простору імен.
Що далі
- Дізнайтеся більше про створення нового простору імен.
- Дізнайтеся більше про видалення простору імен.
1.2.5 - Анотації
Ви можете використовувати анотації Kubernetes, щоб додати довільні невизначені метадані до обʼєктів. Клієнти, такі як інструменти та бібліотеки, можуть отримувати ці метадані.
Додавання метаданих до обʼєктів
Ви можете використовувати як мітки, так і анотації для додавання метаданих до обʼєктів Kubernetes. Мітки можна використовувати для вибору обʼєктів та пошуку колекцій обʼєктів, які відповідають певним умовам. На відміну від цього, анотації не використовуються для ідентифікації та вибору обʼєктів. Метадані в анотації можуть бути невеликими або великими, структурованими або неструктурованими, і можуть включати символи, які не дозволяються міткам. Можна використовувати як мітки, так і анотації в метаданих того ж самого обʼєкта.
Анотації, подібно до міток, є парами ключ/значення:
"metadata": {
"annotations": {
"key1" : "value1",
"key2" : "value2"
}
}
Примітка:
Ключі та значення в парі повинні бути рядками. Іншими словами, ви не можете використовувати числові, булеві, спискові або інші типи як для ключів, так і для їх значень.Ось кілька прикладів інформації, яку можна записати в анотаціях:
Поля, керовані декларативним рівнем конфігурації. Додавання цих полів як анотацій відмежовує їх від типових значень, встановлених клієнтами чи серверами, а також від автогенерованих полів та полів, встановлених системами автомасштабування.
Інформація про збірку, реліз чи образ, така як часові мітки, ідентифікатори релізу, гілка git, номера PR, хеші образу та адреса реєстру.
Вказівники на репозиторії логування, моніторингу, аналітики чи аудиту.
Інформація про клієнтську бібліотеку чи інструмент, яку можна використовувати для налагодження: наприклад, назва, версія та інформація про збірку.
Інформація про походження користувача чи інструменту/системи, така як URL-адреси повʼязаних обʼєктів з інших компонентів екосистеми.
Метадані інструменту легкого розгортання: наприклад, конфігурація чи контрольні точки.
Номери телефонів або пейджерів відповідальних осіб, чи записи в каталозі, які вказують, де можна знайти цю інформацію, наприклад, на вебсайті команди.
Директиви від кінцевого користувача до реалізації щодо зміни поведінки чи використання нестандартних функцій.
Замість використання анотацій, ви можете зберігати цей тип інформації у зовнішній базі даних чи каталозі, але це ускладнило б створення загальних бібліотек та інструментів для впровадження, управління, інтроспекції, та подібного.
Синтаксис та набір символів
Анотації — це пари ключ/значення. Допустимі ключі анотацій мають два сегменти: необовʼязковий префікс і назва, розділені косою рискою (/). Назва є обовʼязковою та має містити не більше 63 символів, починаючи та закінчуючись буквено-цифровим символом ([a-z0-9A-Z]), тире (-), підкресленням (_), крапкою (.) та буквено-цифровими символами між ними. Префікс є необовʼязковим. Якщо вказано, префікс повинен бути піддоменом DNS: серією DNS-міток, розділених крапками (.), загальною довжиною не більше 253 символів, за якою слідує коса риска (/).
Якщо префікс відсутній, ключ анотації вважається приватним для користувача. Автоматизовані компоненти системи (наприклад, kube-scheduler, kube-controller-manager, kube-apiserver, kubectl чи інші автоматизовані засоби від сторонніх розробників), які додають анотації до обʼєктів кінцевого користувача, повинні вказати префікс.
Префікси kubernetes.io/ та k8s.io/ зарезервовані для основних компонентів Kubernetes.
Наприклад, ось маніфест для Pod, який має анотацію imageregistry: https://hub.docker.com/:
apiVersion: v1
kind: Pod
metadata:
name: annotations-demo
annotations:
imageregistry: "https://hub.docker.com/"
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Що далі
- Дізнайтеся більше про Мітки та Селектори.
- Подивіться Відомі мітки, Анотації та Позначення
1.2.6 - Селектори полів
Селектори полів дозволяють вам вибирати обʼєкти Kubernetes на основі значень одного або кількох полів ресурсу. Ось кілька прикладів запитань для селекторів полів:
metadata.name=my-servicemetadata.namespace!=defaultstatus.phase=Pending
Ця команда kubectl вибирає всі Podʼи, для яких значення поля status.phase дорівнює Running:
kubectl get pods --field-selector status.phase=Running
Примітка:
Селектори полів, по суті, є фільтрами ресурсів. Типово селектори/фільтри не застосовуються, а це означає, що вибрані всі ресурси вказаного типу. Це робить запити kubectlkubectl get pods та kubectl get pods --field-selector "" еквівалентними.Підтримувані поля
Підтримувані селектори полів варіюються залежно від типу ресурсу Kubernetes. Усі типи ресурсів підтримують поля metadata.name та metadata.namespace. Використання селекторів до полів, що їх не підтримують, призводить до помилки. Наприклад:
kubectl get ingress --field-selector foo.bar=baz
Error from server (BadRequest): Unable to find "ingresses" that match label selector "", field selector "foo.bar=baz": "foo.bar" is not a known field selector: only "metadata.name", "metadata.namespace"
Список підтримуваних полів
| Вид | Поля |
|---|---|
| Pod | spec.nodeNamespec.restartPolicyspec.schedulerNamespec.serviceAccountNamespec.hostNetworkstatus.phasestatus.podIPstatus.nominatedNodeName |
| Event | involvedObject.kindinvolvedObject.namespaceinvolvedObject.nameinvolvedObject.uidinvolvedObject.apiVersioninvolvedObject.resourceVersioninvolvedObject.fieldPathreasonreportingComponentsourcetype |
| Secret | type |
| Namespace | status.phase |
| ReplicaSet | status.replicas |
| ReplicationController | status.replicas |
| Job | status.successful |
| Node | spec.unschedulable |
| CertificateSigningRequest | spec.signerName |
Поля власних ресурсів
Усі власні типи ресурсів підтримують поля metadata.name та metadata.namespace.
Крім того, поле spec.versions[*].selectableFields у CustomResourceDefinition оголошує, які інші поля власного ресурсу можна використовувати у селекторах полів. Дивіться статтю поля, які можна вибрати для власних ресурсів або додаткові відомості про те, як використовувати селектори полів з CustomResourceDefinitions.
Підтримувані оператори
Ви можете використовувати оператори =, == та != з селекторами полів (= та == означають те саме). Наприклад, ця команда kubectl вибирає всі сервіси Kubernetes, які не знаходяться в просторі імен default:
kubectl get services --all-namespaces --field-selector metadata.namespace!=default
Ланцюжки селекторів
Як і з мітками та іншими селекторами, селектори полів можна складати у список, розділений комами. Ця команда kubectl вибирає всі Podʼи, для яких значення status.phase не дорівнює Running, а поле spec.restartPolicy дорівнює Always:
kubectl get pods --field-selector=status.phase!=Running,spec.restartPolicy=Always
Кілька типів ресурсів
Ви можете використовувати селектори полів для кількох типів ресурсів. Ця команда kubectl вибирає всі Statefulsets та Services, які не знаходяться в просторі імен default:
kubectl get statefulsets,services --all-namespaces --field-selector metadata.namespace!=default
1.2.7 - Завершувачі
Завершувачі — це ключі простору імен, які наказують Kubernetes чекати до виконання певних умов перед тим, як повністю видаляти ресурси, позначені для видалення. Завершувачі попереджають контролери про очищення ресурсів, які належать обʼєкту, що вилучається.
Коли ви наказуєте Kubernetes видалити обʼєкт, для якого є завершувачі, API Kubernetes позначає обʼєкт для видалення, заповнюючи поле .metadata.deletionTimestamp, і повертає статус-код 202 (HTTP "Accepted"). Цільовий обʼєкт залишається в стані завершення, поки панель управління чи інші компоненти виконують дії, визначені завершувачами. Після завершення цих дій контролер видаляє відповідні завершувачі з цільового обʼєкта. Коли поле metadata.finalizers порожнє, Kubernetes вважає видалення завершеним і видаляє обʼєкт.
Ви можете використовувати завершувачі для управління збором сміття ресурсів. Наприклад, ви можете визначити завершувач для очищення повʼязаних ресурсів чи інфраструктури перед тим, як контролер видалить цільовий ресурс.
Ви можете використовувати завершувачі для управління збиранням сміття з обʼєктів за допомогою надсилань повідомлень контролерам з вимогою виконати певні завдання з очищення перед видаленням цільового ресурсу.
Зазвичай завершувачі не вказують код для виконання. Замість цього вони являють собою списки ключів для конкретного ресурсу, аналогічні анотаціям. Kubernetes автоматично вказує деякі завершувачі, але ви також можете вказати свої.
Як працюють завершувачі
При створенні ресурсу за допомогою файлу маніфесту ви можете вказати завершувачі у полі metadata.finalizers. Коли ви намагаєтеся видалити ресурс, сервер API, що обробляє запит на видалення, помічає значення у полі finalizers і робить наступне:
- Модифікує обʼєкт, додаючи поле
metadata.deletionTimestampз часом, коли ви почали видалення. - Запобігає видаленню обʼєкта, поки всі елементи не будуть видалені з його поля
metadata.finalizers. - Повертає код статусу
202(HTTP "Accepted")
Контролер, який керує цим завершувачем, помічає оновлення обʼєкта і встановлення metadata.deletionTimestamp, що вказує на те, що було запрошене видалення обʼєкта. Контролер потім намагається виконати вимоги, вказані для цього ресурсу завершувачами. Кожного разу, коли виконується умова завершувача, контролер видаляє цей ключ із поля finalizers ресурсу. Коли поле finalizers порожнє, обʼєкт із встановленим полем deletionTimestamp автоматично видаляється. Ви також можете використовувати завершувачі для запобігання видаленню некерованих ресурсів.
Розповсюджений приклад завершувача — kubernetes.io/pv-protection, який запобігає
випадковому видаленню обʼєктів PersistentVolume. Коли обʼєкт PersistentVolume
використовується у Podʼі, Kubernetes додає завершувач pv-protection. Якщо ви
намагаєтеся видалити PersistentVolume, він потрапляє в стан Terminating, але
контролер не може видалити його через наявність завершувача. Коли Pod перестає
використовувати PersistentVolume, Kubernetes очищує завершувач pv-protection,
і контролер видаляє обʼєкт.
Примітка:
Коли ви видаляєте обʼєкт за допомогою
DELETE, Kubernetes додає відмітку видалення для цього обʼєкта і тут же починає обмежувати зміни в полі.metadata.finalizersдля обʼєкта, який тепер очікує видалення. Ви можете видаляти наявні завершувачі (видаляти запис зі спискуfinalizers), але не можете додати новий завершувач. Ви також не можете модифікуватиdeletionTimestampдля обʼєкта, якщо він вже встановлений.Після запиту на видалення ви не можете відновити цей обʼєкт. Єдиний спосіб — видалити його і створити новий схожий обʼєкт.
Власники, мітки та завершувачі
Так само як і мітки, посилання на власника описують стосунки між обʼєктами в Kubernetes, але використовуються для іншої цілі. Коли контролер керує обʼєктами типу Pod, він використовує мітки для відстеження змін у групах повʼязаних обʼєктів. Наприклад, коли Завдання створює один чи декілька Podʼів, контролер Завдання додає мітки до цих Podʼів та відстежує зміни у будь-яких Podʼах у кластері з такою ж міткою.
Контролер Завдання також додає посилання на власника до цих Podʼів, посилаючись на Завдання, яке створило Podʼи. Якщо ви видаляєте Завдання, поки ці Podʼи працюють, Kubernetes використовує посилання на власника (а не мітки), щоб визначити, які Podʼи в кластері потрібно прибрати.
Kubernetes також обробляє завершувачі, коли визначає посилання на власника ресурсу, призначене для видалення.
У деяких ситуаціях завершувачі можуть блокувати видалення залежних обʼєктів, що може призвести до того, що цільовий обʼєкт-власник залишиться довше, ніж очікувалося, не буде повністю видалений. У таких ситуаціях вам слід перевірити завершувачі та посилання на власника, на цільового власника та залежні обʼєкти для усунення несправностей.
Примітка:
У випадках, коли обʼєкти застрягають в стані видалення, уникайте ручного видалення завершувачів для продовження процесу видалення. Завершувачі, як правило, додаються до ресурсів з певною метою, тому примусове їх видалення може призвести до проблем у вашому кластері. Це слід робити лише тоді, коли призначення завершувача зрозуміло та може бути виконано іншим способом (наприклад, ручне очищення деякого залежного обʼєкта).Що далі
- Прочитайте Using Finalizers to Control Deletion в блозі Kubernetes.
1.2.8 - Власники та Залежності
В Kubernetes деякі обʼєкти є власниками інших обʼєктів. Наприклад, ReplicaSet є власником групи Podʼів. Ці обʼєкти, якими володіють, є залежними від свого власника.
Власність відрізняється від механізму міток та селекторів, який також використовують деякі ресурси. Наприклад, розгляньте Service, який створює обʼєкти EndpointSlice. Service використовує мітки щоби панель управління могла
визначити, які обʼєкти EndpointSlice використовуються для цього Service. Крім того, до міток, кожен EndpointSlice, який керується від імені Service, має
посилання на власника. Посилання на власника допомагають різним частинам Kubernetes уникати втручання в обʼєкти, якими вони не керують.
Посилання на власника в специфікаціях обʼєктів
Залежні обʼєкти мають поле metadata.ownerReferences, яке містить посилання на їх власника. Дійсне посилання на власника складається з назви обʼєкта та UID в межах того ж простору імен, що й залежний обʼєкт. Kubernetes автоматично встановлює значення цього поля для обʼєктів, які є залежностями інших обʼєктів, таких як ReplicaSets, DaemonSets, Deployments, Jobs and CronJobs, та ReplicationControllers. Ви також можете налаштувати ці звʼязки вручну, змінивши значення цього поля. Однак зазвичай цього не потрібно робити, і можна дозволити Kubernetes автоматично керувати цими звʼязками.
Залежні обʼєкти також мають поле ownerReferences.blockOwnerDeletion, яке має булеве значення і контролює, чи можуть певні залежні обʼєкти блокувати збір сміття, що видаляє їх власника. Kubernetes автоматично встановлює це поле в true, якщо контролер (наприклад, контролер Deployment) встановлює значення поля metadata.ownerReferences. Ви також можете встановити значення поля blockOwnerDeletion вручну, щоб контролювати, які залежні обʼєкти блокують збір сміття.
Контролер доступу Kubernetes контролює доступ користувачів для зміни цього поля для залежних ресурсів на основі прав видалення власника. Це керування перешкоджає несанкціонованим користувачам затримувати видалення обʼєкта-власника.
Примітка:
Посилання на власника поза межами простору імен заборонені. Залежні обʼєкти в просторі імен можуть вказувати власників або на рівні кластера, або в тому ж просторі імен. Якщо цього не відбувається, посилання на власника розглядається як відсутнє, і залежний обʼєкт може бути видалений, якщо всі власники визначено як відсутні.
Обʼєкти в просторі імен можуть вказувати тільки власників в межах кластера. У версії v1.20+, якщо обʼєкт в просторі імен вказує обʼєкт кластера як власника, він розглядається як обʼєкт з нерозвʼязаним посиланням на власника і не може бути вилучений.
У v1.20+, якщо збирач сміття виявляє недійсний перехресний простір імен ownerReference або залежний обʼєкт на рівні кластера з ownerReference, що посилається на тип простору імен, зʼявляється повідомлення з попередженням з причиною OwnerRefInvalidNamespace та involvedObject про недійсного залежного. Ви можете перевірити наявність такого роду подій (Event), запустивши kubectl get events -A --field-selector=reason=OwnerRefInvalidNamespace.
Власність та завершувачі
Коли ви наказуєте Kubernetes видалити ресурс, сервер API дозволяє керуючому контролеру обробити будь-які правила завершувача для ресурсу. Завершувачі запобігають випадковому видаленню ресурсів, які вашому кластеру можуть ще бути потрібні для коректної роботи. Наприклад, якщо ви намагаєтеся видалити PersistentVolume, який все ще використовується Podʼом, видалення не відбувається негайно, оскільки PersistentVolume має завершувач kubernetes.io/pv-protection. Замість цього том залишається в стані Terminating до тих пір, поки Kubernetes не очистить завершувач, що відбувається тільки після того, як PersistentVolume більше не привʼязаний до Podʼа.
Kubernetes також додає завершувачів до ресурсу-власника, коли ви використовуєте або переднє або інше каскадне видалення. При передньому видаленні додається завершувач foreground, так що контролер повинен видалити залежні ресурси, які також мають ownerReferences.blockOwnerDeletion=true, перш ніж він видалить власника. Якщо ви вказуєте політику видалення покинутих ресурсів (сиріт), Kubernetes додає завершувач orphan, так що контролер ігнорує залежні ресурси після того, як він видаляє обʼєкт-власника.
Що далі
- Дізнайтеся більше про завершувачі Kubernetes.
- Дізнайтеся про збір сміття.
- Прочитайте API-довідник про метадані обʼєкта.
1.2.9 - Рекомендовані Мітки
Ви можете візуалізувати та керувати обʼєктами Kubernetes за допомогою інших інструментів, ніж kubectl та панель інструментів (dashboard). Загальний набір міток дозволяє інструментам працювати між собою, описуючи обʼєкти спільним чином, який можуть розуміти всі інструменти.
Крім підтримки інструментів, рекомендовані мітки описують застосунки так, що до них можна звертатись.
Метадані організовані навколо концепції застосунку. Kubernetes не є платформою як сервіс (PaaS) і не має формального поняття застосунку або його виконання. Замість цього застосунки є неформальними та описуються метаданими. Визначення того, що включає застосунок, є гнучким.
Примітка:
Це рекомендовані мітки. Вони полегшують управління застосунками, але не обовʼязкові для будь-яких основних інструментів.Спільні мітки та анотації мають спільний префікс: app.kubernetes.io. Мітки без префіксу є приватними для користувачів. Спільний префікс забезпечує, що спільні мітки не втручаються у власні мітки користувача.
Мітки
Щоб повною мірою скористатися цими мітками, їх слід застосовувати до кожного обʼєкта ресурсу.
| Ключ | Опис | Приклад | Тип |
|---|---|---|---|
app.kubernetes.io/name | Назва застосунку | mysql | рядок |
app.kubernetes.io/instance | Унікальна назва, що ідентифікує екземпляр застосунку | mysql-abcxyz | рядок |
app.kubernetes.io/version | Поточна версія застосунку (наприклад, SemVer 1.0, хеш ревізії і т.д.) | 5.7.21 | рядок |
app.kubernetes.io/component | Компонент всередині архітектури | database | рядок |
app.kubernetes.io/part-of | Назва вищого рівня застосунку, частину якого складає цей | wordpress | рядок |
app.kubernetes.io/managed-by | Інструмент, який використовується для управління операцією застосунку | Helm | рядок |
Щоб проілюструвати ці мітки в дії, розгляньте наступний обʼєкт StatefulSet:
# Це уривок
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxyz
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
app.kubernetes.io/managed-by: Helm
Застосунки та екземпляри застосунків
Застосунок можна встановити один або декілька разів в кластер Kubernetes і, у деяких випадках, в тому ж просторі імен. Наприклад, WordPress можна встановити більше одного разу, де різні вебсайти є різними екземплярами WordPress.
Назва застосунку та назва екземпляра записуються окремо. Наприклад, у WordPress є app.kubernetes.io/name — wordpress, тоді як назва екземпляра представлена як app.kubernetes.io/instance зі значенням wordpress-abcxyz. Це дозволяє ідентифікувати застосунок та його екземпляр. Кожен екземпляр застосунку повинен мати унікальну назву.
Приклади
Щоб проілюструвати різні способи використання цих міток, наведено різні приклади складності.
Простий Stateless Service
Розгляньте випадок простого Stateless Serviceʼу, розгорнутого за допомогою обʼєктів Deployment та Service. Наведені нижче два уривки представляють, як можуть бути використані мітки у їх найпростішій формі.
Deployment використовується для нагляду за Podʼами, які виконують сам застосунок.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxyz
...
Service використовується для відкриття доступу до застосунку.
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxyz
...
Вебзастосунок із базою даних
Розгляньмо трохи складніший застосунок: вебзастосунок (WordPress) із базою даних (MySQL), встановлений за допомогою Helm. Наведені нижче уривки ілюструють початок обʼєктів, які використовуються для розгортання цього застосунку.
Початок цього Deployment використовується для WordPress:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxyz
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
Service використовується для відкриття доступу до WordPress:
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxyz
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
MySQL представлено як StatefulSet з метаданими як для нього, так і для застосунку, до якого він належить:
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxyz
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
...
Service використовується для відкриття доступу до MySQL як частини WordPress:
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxyz
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
...
З MySQL StatefulSet та Service ви побачите, що включена інформація як про MySQL, так і про WordPress.
1.3 - API Kubernetes
API Kubernetes дозволяє отримувати та маніпулювати станом обʼєктів в Kubernetes. Основа панелі управління Kubernetes — це сервер API та відкритий API HTTP, який він надає. Користувачі, різні частини вашого кластера та зовнішні компоненти взаємодіють одне з одним через сервер API.
Основа Kubernetes — це панель управління з API server. Сервер API використовує API HTTP, яке дозволяє кінцевим користувачам, різним частинам вашого кластера та зовнішнім компонентам спілкуватися один з одним.
API Kubernetes дозволяє вам отримувати та маніпулювати станом обʼєктів API в Kubernetes (наприклад: Pod, Namespace, ConfigMap та Event).
Більшість операцій можна виконати за допомогою інтерфейсу командного рядка kubectl або інших інструментів командного рядка, таких як kubeadm, які, своєю чергою, використовують API. Однак ви також можете отримати доступ до API безпосередньо за допомогою викликів REST. Розгляньте використання однієї з клієнтських бібліотек, якщо ви пишете застосунок для користування API Kubernetes.
Кожен кластер Kubernetes публікує специфікацію своїх API, якими він оперує. Kubernetes використовує два механізми для публікації цих специфікацій API; обидва корисні для забезпечення автоматичної сумісності. Наприклад, інструмент kubectl отримує та кешує специфікацію API для увімкнення функціонала автозавершення командного рядка та інших функцій. Нижче наведено два підтримуваних механізми:
- Discovery API надає інформацію про API Kubernetes: назви API, ресурси, версії, та операції, які підтримуються. Цей термін є специфічним для Kubernetes, що відділяє API від Kubernetes OpenAPI. Він має на меті надавати опис доступних ресурсів, однак він не надає детальну специфікацію кожного ресурсу. Щоб отримати докладні відомості про схеми ресурсів звертайтесь до документації OpenAPI.
- Документація Kubernetes OpenAPI надає детальну специфікацію схем OpenAPI v2.0 та v3.0 для всіх точок доступу API Kubernetes. OpenAPI v3.0 є бажаним методом для доступу до OpenAPI, оскільки він надає більш докладну та повну специфікацію API. Цей варіант містить всі можливі API-шляхи, так само як і всі ресурси, що використовуються та створюються для кожної операції на кожній точці доступу. Тут також є розширювані компоненти, які підтримуються кластером. Дані містять повну специфікацію та значно перевищують за обсягом те, що надає Discovery API.
Discovery API
Kubernetes публікує перелік всіх груп версій та ресурсів які підтримуються через Discovery API, що включає для кожного ресурсу наступне:
- Назва
- Обсяг досяжності (
NamespaceабоCluster) - URL Endpoint та підтримувані дії
- Альтернативні назви
- Group, version, kind
API доступний як в агрегованому, так і в не агрегованому вигляді. Агреговане виявлення обслуговує дві точки доступу (endpoint), тоді як не агреговане — окрему точку доступу для кожної групи версії.
Агреговане виявлення
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.30 [stable] (стандартно увімкнено: true)Kubernetes надає підтримку агрегованого виявлення, публікуючи всі ресурси, які підтримує кластер, через дві точки доступу (/api та /apis) порівняно з одним для кожної групи версій. Надсилання запиту до цієї точки доступу різко зменшує кількість надісланих запитів для отримання даних про кластер Kubernetes. Ви можете отримати доступ до даних надсилаючи запити до відповідних точок доступу з заголовком Accept, що є агрегованим виявленням ресурсів: Accept: application/json;v=v2;g=apidiscovery.k8s.io;as=APIGroupDiscoveryList.
Без зазначення типу ресурсів використання заголовка Accept стандартна відповідь для /api та /apis буде не агрегованим виявленням ресурсів.
Документ виявлення для вбудованих ресурсів можна знайти в репозиторій Kubernetes GitHub. Цей документ Github можна використовувати як довідник базового набору доступних ресурсів, якщо кластер Kubernetes недоступний для запитів.
Точка доступу також підтримує кодування ETag і protobuf.
Не агреговане виявлення
Без агрегації виявлення інформація публікується рівнями, де кореневі точки доступу публікують дані виявлення для підлеглих документів.
Список усіх версій груп, підтримуваних кластером, публікується в точках доступу /api та /apis. Наприклад:
{
"kind": "APIGroupList",
"apiVersion": "v1",
"groups": [
{
"name": "apiregistration.k8s.io",
"versions": [
{
"groupVersion": "apiregistration.k8s.io/v1",
"version": "v1"
}
],
"preferredVersion": {
"groupVersion": "apiregistration.k8s.io/v1",
"version": "v1"
}
},
{
"name": "apps",
"versions": [
{
"groupVersion": "apps/v1",
"version": "v1"
}
],
"preferredVersion": {
"groupVersion": "apps/v1",
"version": "v1"
}
},
...
]
}
Для отримання документа виявлення для кожної версії групи за адресою /apis/<group>/<version> (наприклад, /apis/rbac.authorization.k8s.io/v1alpha1) потрібні додаткові запити. Ці точки доступу оголошують список ресурсів, що обслуговуються певною версією групи. Ці точки доступу використовуються командою kubectl для отримання списку ресурсів, підтримуваних кластером.
Інтерфейс OpenAPI
Докладніше про специфікації OpenAPI дивіться у документації OpenAPI.
Kubernetes працює як з OpenAPI v2.0, так і з OpenAPI v3.0. OpenAPI v3 є кращим методом доступу до OpenAPI, оскільки він пропонує повніше (без втрат) представлення ресурсів Kubernetes. Через обмеження OpenAPI версії 2 певні поля видалено з опублікованого OpenAPI, включаючи, але не обмежуючись, default, nullable, oneOf.
OpenAPI V2
Сервер API Kubernetes надає агреговану специфікацію OpenAPI v2 через точку доступу /openapi/v2. Ви можете запросити формат відповіді, використовуючи заголовки запиту наступним чином:
| Заголовок | Можливі значення | Примітки |
|---|---|---|
Accept-Encoding | gzip | не надання цього заголовка також допустиме |
Accept | application/com.github.proto-openapi.spec.v2@v1.0+protobuf | головним чином для внутрішньокластерного використання |
application/json | типово | |
* | обслуговує application/json |
Попередження:
Правила валідації, опубліковані як частина схем OpenAPI, можуть бути неповними, і зазвичай не є такими. Додаткова перевірка відбувається на сервері API. Якщо вам потрібна точна і повна перевірка,kubectl apply --dry-run=server виконує всі застосовні перевірки (а також активує перевірку часу допуску).OpenAPI V3
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.27 [stable] (стандартно увімкнено: true)Kubernetes підтримує публікацію опису своїх API у форматі OpenAPI v3.
Надається точка доступу /openapi/v3 для перегляду списку всіх доступних груп/версій. Ця точка повертає лише JSON. Ці групи/версії вказані у наступному форматі:
{
"paths": {
...,
"api/v1": {
"serverRelativeURL": "/openapi/v3/api/v1?hash=CC0E9BFD992D8C59AEC98A1E2336F899E8318D3CF4C68944C3DEC640AF5AB52D864AC50DAA8D145B3494F75FA3CFF939FCBDDA431DAD3CA79738B297795818CF"
},
"apis/admissionregistration.k8s.io/v1": {
"serverRelativeURL": "/openapi/v3/apis/admissionregistration.k8s.io/v1?hash=E19CC93A116982CE5422FC42B590A8AFAD92CDE9AE4D59B5CAAD568F083AD07946E6CB5817531680BCE6E215C16973CD39003B0425F3477CFD854E89A9DB6597"
},
....
}
}
Відносні URL вказують на незмінний опис OpenAPI для поліпшення кешування на стороні клієнта. Також API-сервер встановлює відповідні заголовки кешування HTTP (Expires на 1 рік вперед та Cache-Control на immutable). При використанні застарілого URL API-сервер повертає перенаправлення на новий URL.
API-сервер Kubernetes публікує специфікацію OpenAPI v3 для кожної групи версій Kubernetes через точку доступу /openapi/v3/apis/<group>/<version>?hash=<hash>.
Дивіться таблицю нижче для прийнятних заголовків запиту.
| Заголовок | Можливі значення | Примітки |
|---|---|---|
Accept-Encoding | gzip | не надання цього заголовка також допустиме |
Accept | application/com.github.proto-openapi.spec.v3@v1.0+protobuf | головним чином для внутрішньокластерного використання |
application/json | станадартно/em> | |
* | обслуговує application/json |
Реалізація Golang для отримання OpenAPI V3 надається в пакунку k8s.io/client-go/openapi3.
Kubernetes 1.32 публікує OpenAPI v2.0 та v3.0; найближчим часом підтримка 3.1 не планується.
Серіалізація Protobuf
Kubernetes реалізує альтернативний формат серіалізації на основі Protobuf, який призначений головним чином для комунікації всередині кластера. Докладніше про цей формат читайте в пропозиції дизайну серіалізації Kubernetes Protobuf та файлах мови опису інтерфейсу (IDL) для кожної схеми, які розташовані в пакунках Go, які визначають обʼєкти API.
Постійність
Kubernetes зберігає серіалізований стан обʼєктів, записуючи їх у etcd.
Групи API та версіювання
Щоб полегшити вилучення полів або перебудову представлень ресурсів, Kubernetes підтримує кілька версій API, кожна з різним API-шляхом, таким як /api/v1 або /apis/rbac.authorization.k8s.io/v1alpha1.
Версіювання робиться на рівні API, а не на рівні ресурсу чи поля, щоб забезпечити чіткий, послідовний погляд на ресурси та поведінку системи, а також для можливості керування доступом до застарілих та/або експериментальних API.
Щоб полегшити еволюцію та розширення свого API, Kubernetes реалізує API groups, які можна увімкнути або вимкнути.
Ресурси API розрізняються за їхньою API-групою, типом ресурсу, простором імен (для ресурсів з підтримкою просторів імен) та назвою. Сервер API обробляє конвертацію між версіями API прозоро: всі різні версії фактично є представленням тих самих даних. Сервер API може служити тими самими базовими даними для кількох версій API.
Наприклад, припустимо, є дві версії API, v1 та v1beta1, для того самого ресурсу. Якщо ви спочатку створили обʼєкт, використовуючи версію v1beta1 його API, ви можете згодом читати, оновлювати чи видаляти цей обʼєкт, використовуючи або версію API v1beta1, або версію v1, поки версія v1beta1 не буде застарілою та видаленою. На цьому етапі ви можете продовжувати отримувати доступ та модифікувати обʼєкт, використовуючи API версії v1.
Зміни в API
Будь-яка система, яка досягла успіху, повинна рости та змінюватися, коли зʼявляються нові випадки її використання або змінюються поточні. Тому Kubernetes розробив своє API так, щоб він постійно змінювався та ріс. Проєкт Kubernetes має за мету не порушувати сумісність з наявними клієнтами та забезпечити цю сумісність на тривалий час, щоб інші проєкти мали можливість адаптуватися.
Загалом можна часто та періодично додавати нові ресурси API та нові поля ресурсів. Усунення ресурсів чи полів вимагає дотримання політики застарівання API.
Kubernetes твердо зобовʼязується підтримувати сумісність з офіційними API Kubernetes, як тільки вони досягнуть загальної доступності (GA), як правило, у версії API v1. Крім того, Kubernetes підтримує сумісність з даними, що зберігаються через бета-версії API офіційних API Kubernetes, і гарантує, що дані можуть бути перетворені та доступні через версії GA API, коли функція стане стабільною.
Якщо ви використовуєте бета-версію API, вам слід перейти до наступної бета- або стабільної версії API, якщо це API набуло зрілості. Найкращий час для цього — під час періоду застарівання бета- API, оскільки обʼєкти одночасно доступні через обидві версії API. Як тільки бета- API завершить свій період застарівання і більше не буде обслуговуватися, слід використовувати версію API-замінник.
Примітка:
Попри те, що Kubernetes також ставить перед собою мету зберігати сумісність для версій альфа API, в деяких випадках це неможливо. Якщо ви використовуєте будь-які альфа-версії API, перевірте примітки до випуску Kubernetes при оновленні кластера, в разі змін API, які можуть бути несумісними та вимагати видалення всіх наявних альфа-обʼєктів перед оновленням.Дивіться довідник по версіях API для отримання докладнішої інформації про визначення рівня API.
Розширення API
API Kubernetes можна розширити одним з двох способів:
- Власні ресурси дозволяють декларативно визначити, як API-сервер повинен надавати вибраний вами ресурс API.
- Ви також можете розширити API Kubernetes, реалізовуючи шар агрегації.
Що далі
- Дізнайтеся, як розширити API Kubernetes, додаючи свій власний CustomResourceDefinition.
- Контроль доступу до Kubernetes API описує, як кластер керує автентифікацією та авторизацією для доступу до API.
- Дізнайтеся про точки доступу API, типи ресурсів та зразки з Довідника API.
- Дізнайтеся про те, що є сумісною зміною та як змінити API, в Зміни в API.
2 - Архітектура кластера
Архітектурні концепції в основі Kubernetes.
Кластер Kubernetes складається з панелі управління та набору робочих машин, які називаються вузлами, що запускають контейнеризовані застосунки. Кожен кластер потребує принаймні одного робочого вузла для запуску Podʼів.
Робочі вузли розміщують Podʼи, які є компонентами робочого навантаження застосунку. Панель управління керує робочими вузлами та Podʼами в кластері. В операційних середовищах панель управління зазвичай працює на кількох компʼютерах, а кластер зазвичай має кілька вузлів, забезпечуючи відмовостійкість та високу доступність.
Цей документ описує різні компоненти, які вам потрібні для повноцінного та працездатного кластера Kubernetes.

Схема 1. Компоненти кластера Kubernetes.
Про архітектуру
На схемі 1 представлено приклад еталонної архітектури кластера Kubernetes. Фактичний розподіл компонентів може змінюватися залежно від конкретних налаштувань кластера та вимог.
На схемі на кожному вузлі запущено компонент kube-proxy. Вам потрібен компонент мережевого проксі на кожному вузлі, щоб гарантувати, що Service API та пов'язані з ним дії були доступні у вашій кластерній мережі. Втім, деякі мережеві втулки надають власну, сторонню реалізацію проксі-сервера. Коли ви використовуєте такий мережевий втулок, вузлу не потрібно запускати kube-proxy.
Компоненти панелі управління
Компоненти панелі управління приймають глобальні рішення щодо кластера (наприклад, планування), а також виявляють та реагують на події в кластері (наприклад, запуск нового Podʼа, коли умова поля replicas в Deployment не виконується).
Компоненти панелі управління можуть запускатися на будь-якій машині у кластері. Однак для спрощення, скрипти налаштування зазвичай запускають всі компоненти панелі управління на одній машині та не запускають контейнерів користувача на цій машині. Див. Створення кластерів з високою доступністю за допомогою kubeadm для прикладу налаштування панелі управління, яка працює на кількох машинах.
kube-apiserver
Сервер API є компонентом панелі управління Kubernetes, який надає доступ до API Kubernetes. Сервер API є фронтендом для панелі управління Kubernetes.
Основна реалізація сервера API Kubernetes — kube-apiserver. kube-apiserver спроєктований для горизонтального масштабування, тобто масштабується за допомогою розгортання додаткових екземплярів. Ви можете запустити кілька екземплярів kube-apiserver та балансувати трафік між ними.
etcd
Сумісне та високодоступне сховище ключ-значення, яке використовується як сховище Kubernetes для резервування всіх даних кластера.
Якщо ваш кластер Kubernetes використовує etcd як сховище для резервування, переконайтеся, що у вас є план резервного копіювання даних.
Ви можете знайти докладну інформацію про etcd в офіційній документації.
kube-scheduler
Компонент панелі управління, що відстежує створені Podʼи, які ще не розподілені по вузлах, і обирає вузол, на якому вони працюватимуть.
При виборі вузла враховуються наступні фактори: індивідуальна і колективна потреба у ресурсах, обмеження за апаратним/програмним забезпеченням і політиками, характеристики affinity та anti-affinity, локальність даних, сумісність робочих навантажень і граничні терміни виконання.
kube-controller-manager
Компонент панелі управління, який запускає процеси контролера.
За логікою, кожен контролер є окремим процесом. Однак для спрощення їх збирають в один бінарний файл і запускають як єдиний процес.
Існує багато різних типів контролерів. Деякі приклади:
- Контролер вузлів: відповідає за виявлення та реагування, коли вузли виходять з ладу.
- Контролер завдань: відстежує обʼєкти Job, що представляють одноразові завдання, а потім створює Podʼи для виконання цих завдань, які існують до їх завершення.
- Контролер EndpointSlice: заповнює обʼєкти EndpointSlice (для забезпечення звʼязку між Serviceʼами та Podʼами).
- Контролер службових облікових записів: створює стандартні ServiceAccounts для нових просторів імен.
Наведений вище список не є вичерпним.
cloud-controller-manager
Компонент панелі управління Kubernetes, що інтегрує управління логікою певної хмари. Cloud controller manager дозволяє звʼязувати ваш кластер з API хмарного провайдера та відокремлює компоненти, що взаємодіють з хмарною платформою від компонентів, які взаємодіють тільки в кластері.cloud-controller-manager запускає лише ті контролери, які специфічні для вашого хмарного провайдера. Якщо ви використовуєте Kubernetes у себе на підприємстві або в навчальному середовищі всередині вашого ПК, кластер не матиме cloud-controller-manager.
Як і kube-controller-manager, cloud-controller-manager обʼєднує кілька логічно незалежних циклів керування в один бінарний файл, який ви запускаєте як один процес. Ви можете масштабувати його горизонтально (запускати більше однієї копії) для покращення продуктивності або для підвищення стійкості до збоїв.
Наступні контролери можуть мати залежності від хмарного провайдера:
- Контролер вузлів: перевіряє у хмарного провайдера, чи було видалено вузол у хмарі після того, як він перестав відповідати.
- Контролер маршрутів: налаштовує маршрути в основній хмарній інфраструктурі.
- Контролер сервісів: створює, оновлює та видаляє балансувальників навантаження хмарного провайдера.
Компоненти вузлів
Компоненти вузлів працюють на кожному вузлі, підтримуючи роботу Podʼів та забезпечуючи середовище виконання Kubernetes.
kubelet
Агент, запущений на кожному вузлі кластера. Забезпечує запуск і роботу контейнерів в Podʼах.
kubelet використовує специфікації PodSpecs, які надаються за допомогою різних механізмів, і забезпечує працездатність і справність усіх контейнерів, що описані у PodSpecs. kubelet керує лише тими контейнерами, що були створені Kubernetes.
kube-proxy (опційно)
kube-proxy є мережевим проксі, що запущений на кожному вузлі кластера і реалізує частину концепції Kubernetes Service.
kube-proxy забезпечує підтримання мережевих правил на вузлах. Ці правила обумовлюють підключення мережею до ваших Podʼів всередині чи поза межами кластера.
kube-proxy використовує шар фільтрації пакетів операційної системи, за його наявності. В іншому випадку kube-proxy скеровує трафік самостійно.
Якщо ви використовуєте мережевий втулок, який самостійно реалізує пересилання пакетів для сервісів та надає еквівалентну поведінку kube-proxy, то вам не потрібно запускати kube-proxy на вузлах вашого кластера.
Рушій виконання контейнерів
Основний компонент, який дозволяє Kubernetes ефективно запускати контейнери. Він відповідає за керування виконанням і життєвим циклом контейнерів у середовищі Kubernetes.
Kubernetes підтримує середовища виконання контейнерів, такі як containerd, CRI-O, та будь-яку іншу реалізацію Kubernetes CRI (інтерфейс виконання контейнерів).
Надбудови
Надбудови використовують ресурси Kubernetes (DaemonSet, Deployment тощо) для реалізації функцій кластера. Оскільки вони надають функції на рівні кластера, ресурси, що належать надбудовам, розміщуються в просторі імен kube-system.
Вибрані застосунки описані нижче; для розширеного списку доступних надбудов дивіться Надбудови.
DNS
Хоча інші надбудови не є строго необхідними, всі кластери Kubernetes повинні мати кластерний DNS, оскільки багато прикладів залежать від нього.
Кластерний DNS — це DNS-сервер, який доповнює інші DNS-сервери у вашому середовищі та обслуговує DNS-записи для сервісів Kubernetes.
Контейнери, запущені за допомогою Kubernetes, автоматично включають цей DNS-сервер у свої DNS-запити.
Вебінтерфейс (Dashboard)
Dashboard — це універсальний вебінтерфейс для кластерів Kubernetes. Він дозволяє користувачам керувати та розвʼязувати проблеми з застосунками, що працюють у кластері, а також з самим кластером.
Моніторинг ресурсів контейнерів
Моніторинг ресурсів контейнерів записує загальні метрики часу для контейнерів у центральну базу даних та надає інтерфейс для перегляду цих даних.
Логування на рівні кластера
Механізм логування на рівні кластера відповідає за збереження логів контейнерів в центральному сховищі логів з інтерфейсом пошуку та перегляду.
Мережеві втулки
Мережеві втулки — це програмні компоненти, які реалізують специфікацію інтерфейсу мережі контейнерів (CNI). Вони відповідають за виділення IP-адрес Podʼам та забезпечення їх звʼязку між собою у кластері.
Варіації архітектури
Хоча основні компоненти Kubernetes залишаються незмінними, способи їх розгортання та управління можуть відрізнятися. Розуміння цих варіацій є ключовим для проєктування та підтримки кластерів Kubernetes, що відповідають специфічним операційним потребам.
Варіанти розгортання панелі управління
Компоненти панелі управління можна розгортати кількома способами:
- Традиційне розгортання:
- Компоненти панелі управління працюють безпосередньо на виділених машинах або віртуальних машинах, часто керованих як служби systemd.
- Статичні Podʼи:
- Компоненти панелі управління розгортаються як статичні Podʼи, керовані kubelet на певних вузлах. Це поширений підхід, який використовують такі інструменти, як kubeadm.
- Самообслуговування:
- Панель управління працює як Podʼи у самому кластері Kubernetes, яким керують Deployments та StatefulSets або інші примітиви Kubernetes.
- Керовані сервіси Kubernetes:
- Хмарні провайдери часто абстрагують панель управління, керуючи її компонентами як частиною послуги, яку вони надають.
Розміщення робочих навантажень
Розміщення робочих навантажень, включаючи компоненти панелі управління, може варіюватися залежно від розміру кластера, вимог до продуктивності та операційних політик:
- У менших або розробницьких кластерах компоненти панелі управління та робочі навантаження користувачів можуть працювати на одних і тих же вузлах.
- Великі операційні кластери часто виділяють певні вузли для компонентів панелі управління, відокремлюючи їх від робочих навантажень користувачів.
- Деякі організації запускають критично важливі застосунки або інструменти моніторингу на вузлах панелі управління.
Інструменти управління кластером
Такі інструменти, як kubeadm, kops та Kubespray, пропонують різні підходи до розгортання та управління кластерами, кожен з яких має свій метод розташування та управління компонентами.
Гнучкість архітектури Kubernetes дозволяє організаціям налаштовувати свої кластери відповідно до специфічних потреб, балансуючи фактори, такі як операційна складність, продуктивність та управлінські витрати.
Налаштування та розширюваність
Архітектура Kubernetes дозволяє значну кастомізацію:
- Власні планувальники можна розгортати паралельно зі стандартним планувальником Kubernetes або замінювати його повністю.
- API-сервери можна розширювати за допомогою CustomResourceDefinitions та API Aggregation.
- Хмарні провайдери можуть глибоко інтегруватися з Kubernetes за допомогою cloud-controller-manager.
Гнучкість архітектури Kubernetes дозволяє організаціям налаштовувати свої кластери відповідно до специфічних потреб, балансуючи фактори, такі як операційна складність, продуктивність та управлінські витрати.
Що далі
Дізнайтеся більше про:
- Вузли та їх комунікацію з панеллю управління.
- Контролери Kubernetes.
- kube-scheduler, який є стандартним планувальником для Kubernetes.
- Офіційну документацію Etcd.
- Декілька контейнерних рушіїв у Kubernetes.
- Інтеграцію з хмарними провайдерами за допомогою cloud-controller-manager.
- Команди kubectl.
2.1 - Вузли
Kubernetes виконує ваше навантаження шляхом розміщення контейнерів у Podʼах для запуску на Вузлах. Вузол може бути віртуальною або фізичною машиною, залежно від кластера. Кожен вузол керується панеллю управління і містить необхідні служби для запуску Podʼів.
Зазвичай в кластері є кілька вузлів; в умовах навчання чи обмежених ресурсів може бути всього один вузол.
Компоненти на вузлі включають kubelet, середовище виконання контейнерів та kube-proxy.
Управління
Є два основних способи додавання Вузлів до API-сервера:
- kubelet на вузлі самостійно реєструється в панелі управління.
- Ви (або інший користувач) вручну додаєте обʼєкт Node.
Після створення обʼєкта Node, або якщо kubelet на вузлі самостійно реєструється, панель управління перевіряє, чи новий обʼєкт Node є дійсним. Наприклад, якщо ви спробуєте створити Вузол з наступним JSON-маніфестом:
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}
Kubernetes внутрішньо створює обʼєкт Node. Kubernetes перевіряє чи kubelet зареєструвався в API-сервері, що відповідає полю metadata.name Node. Якщо вузол є справним (тобто всі необхідні служби працюють), то він може запускати Podʼи. В іншому випадку цей вузол ігнорується для будь-якої діяльності кластера доки він не стане справним.
Примітка:
Kubernetes зберігає обʼєкт для недійсного Вузла та продовжує перевіряти, чи він стає справним.
Вам або контролер має явно видалити обʼєкт Node, щоб припинити цю перевірку його справності.
Назва обʼєкта Node повинно бути дійсним імʼям DNS-піддомену.
Унікальність назв Вузлів
Назва ідентифікує Node. Два Вузли не можуть мати однакову назву одночасно. Kubernetes також припускає, що ресурс з такою ж назвою — це той самий обʼєкт. У випадку Вузла припускається неявно, що екземпляр, який використовує ту ж назву, матиме той самий стан (наприклад, мережеві налаштування, вміст кореневого диска) та атрибути, такі як мітки вузла. Це може призвести до невідповідностей, якщо екземпляр був змінений без зміни його назви. Якщо Вузол потрібно замінити або значно оновити, наявний обʼєкт Node повинен бути видалений з API-сервера спочатку і знову доданий після оновлення.
Самореєстрація Вузлів
Коли прапорець kubelet --register-node є true (типово), kubelet спробує зареєструвати себе в API-сервері. Цей підхід використовується більшістю дистрибутивів.
Для самореєстрації kubelet запускається з наступними параметрами:
--kubeconfig— Шлях до облікових даних для автентифікації на API-сервері.--cloud-provider— Як взаємодіяти з хмарним постачальником для отримання метаданих про себе.--register-node— Автоматична реєстрація в API-сервері.--register-with-taints— Реєстрація вузла з заданим списком позначок (розділених комами<ключ>=<значення>:<ефект>).Нічого не відбувається, якщо
register-nodeє false.--node-ip— Необовʼязковий розділений комами список IP-адрес вузла. Можна вказати лише одну адресу для кожного роду адрес. Наприклад, у кластері з одним стеком IPv4 ви встановлюєте це значення як IPv4-адресу, яку повинен використовувати kubelet для вузла. Див. налаштування подвійного стека IPv4/IPv6 для отримання відомостей з запуску кластера з подвійним стеком.Якщо ви не вказали цей аргумент, kubelet використовує стандартну IPv4-адресу вузла, якщо є; якщо у вузла немає адреси IPv4, тоді kubelet використовує стандартну IPv6-адресу вузла.
--node-labels- Мітки для додавання при реєстрації вузла в кластері (див. обмеження міток, що накладаються втулком доступу NodeRestriction).--node-status-update-frequency— Вказує, як часто kubelet публікує свій статус вузла на API-сервері.
Коли увімкнено режим авторизації Вузла та втулок доступу NodeRestriction, kubelets мають право створювати/змінювати лише свій власний ресурс Node.
Примітка:
Як зазначено в розділі Унікальність назв Вузлів, коли потрібно оновити конфігурацію Вузла, добре було б знову зареєструвати вузол в API-сервері. Наприклад, якщо kubelet перезапускається з новим набором --node-labels, але використовується та ж назва Node, зміна не відбудеться, оскільки мітки встановлюються при реєстрації вузла.
Podʼи, вже заплановані на Node, можуть погано поводитися або викликати проблеми, якщо конфігурація Node буде змінена при перезапуску kubelet. Наприклад, вже запущений Pod може бути позначений новими мітками, призначеними Node, тоді як інші Pod, які несумісні з цим Pod, будуть заплановані на основі цієї нової мітки. Перереєстрація вузла гарантує, що всі Podʼи будуть очищені та належним чином переплановані.
Ручне адміністрування Вузлів
Ви можете створювати та змінювати обʼєкти Node за допомогою kubectl.
Коли ви хочете створювати обʼєкти Node вручну, встановіть прапорець kubelet --register-node=false.
Ви можете змінювати обʼєкти Node незалежно від налаштувань --register-node. Наприклад, ви можете встановлювати мітки на наявному Вузлі або позначати його як незапланований.
Ви можете використовувати мітки на Вузлах разом із селекторами вузлів на Podʼах для управління плануванням. Наприклад, ви можете обмежити Pod лише можливістю запуску на підмножині доступних вузлів.
Позначення вузла як незапланованого перешкоджає планувальнику розміщувати нові Podʼи на цьому Вузлі, але не впливає на наявні Podʼи на Вузлі. Це корисно як підготовчий крок перед перезавантаженням вузла чи іншим обслуговуванням.
Щоб позначити Вузол як незапланований, виконайте:
kubectl cordon $NODENAME
Див. Безпечне очищення вузла для деталей.
Примітка:
Podʼи, які є частиною DaemonSet, можуть працювати на незапланованому Вузлі. Зазвичай DaemonSets надають служби, що працюють локально на Вузлі, навіть якщо він очищується від робочих навантажень.Статус Вузла
Статус Вузла містить наступну інформацію:
Ви можете використовувати kubectl, щоб переглядати статус Вузла та інші деталі:
kubectl describe node <вставте-назву-вузла-тут>
Див. Статус Вузла для отримання додаткової інформації.
Сигнали Вузлів
Сигнали, надсилані вузлами Kubernetes, допомагають вашому кластеру визначати доступність кожного вузла та вживати заходів у випадку виявлення відмов.
Для вузлів існують дві форми сигналів:
- Оновлення в
.statusВузла. - Обʼєкти Оренди (Lease) у просторі імен
kube-node-lease. Кожен Вузол має асоційований обʼєкт Lease.
Контролер вузлів
Контролер вузлів — це компонент панелі управління Kubernetes, який керує різними аспектами роботи вузлів.
У контролера вузла є кілька ролей у житті вузла. По-перше, він призначає блок CIDR вузлу при його реєстрації (якщо призначення CIDR увімкнено).
По-друге, він підтримує актуальність внутрішнього списку вузлів контролера зі списком доступних машин хмарного провайдера. У разі, якщо вузол несправний, контролер вузла перевіряє у хмарному провайдері, чи ще доступний віртуальний компʼютер (VM) для цього вузла. Якщо ні, контролер вузла видаляє вузол зі свого списку вузлів.
По-третє, контролер відповідає за моніторинг стану вузлів і:
- У випадку, якщо вузол стає недоступним, оновлення умови
Readyу полі.statusВузла. У цьому випадку контролер вузла встановлює умовуReadyвUnknown. - Якщо вузол залишається недоступним: запускає виселення ініційоване API для всіх Podʼів на недосяжному вузлі. Типово контролер вузла чекає 5 хвилин між позначенням вузла як
Unknownта поданням першого запиту на виселення.
Стандартно контролер вузла перевіряє стан кожного вузла кожні 5 секунд. Цей період можна налаштувати за допомогою прапорця --node-monitor-period у компоненті kube-controller-manager.
Обмеження швидкості виселення
У більшості випадків контролер вузла обмежує швидкість виселення на --node-eviction-rate (типово 0,1) в секунду, що означає, що він не буде виводити Podʼи з більше, ніж 1 вузла кожні 10 секунд.
Поведінка виселення вузла змінюється, коли вузол в певній доступності стає несправним. Контролер вузла перевіряє, яка частина вузлів в зоні є несправною (умова Ready — Unknown або False) у той самий час:
- Якщо частка несправних вузлів становить принаймні
--unhealthy-zone-threshold(типово 0,55), тоді швидкість виселення зменшується. - Якщо кластер малий (тобто має менше або дорівнює
--large-cluster-size-thresholdвузлів — типово 50), тоді виселення припиняється. - У іншому випадку швидкість виселення зменшується до
--secondary-node-eviction-rate(типово 0,01) в секунду.
Причина того, що ці політики реалізовані окремо для кожної зони доступності, полягає в тому, що одна зона може втратити зʼєднання з панеллю управління, тоді як інші залишаються підключеними. Якщо ваш кластер не охоплює кілька зон доступності хмарного провайдера, тоді механізм виселення не враховує доступність поміж зон.
Однією з ключових причин розподілу вузлів за зонами доступності є можливість переміщення навантаження в справні зони, коли одна ціла зона виходить з ладу. Таким чином, якщо всі вузли в зоні несправні, контролер вузла виводить навантаження зі звичайною швидкістю --node-eviction-rate. Крайній випадок — коли всі зони повністю несправні (жоден вузол в кластері не є справним). У такому випадку контролер вузла припускає, що існує якась проблема зі зʼєднанням між панеллю управління та вузлами, і не виконує жодних виселень. (Якщо стався збій і деякі вузли відновились, контролер вузла виводить Podʼи з решти вузлів, які є несправними або недосяжними).
Контролер вузла також відповідає за виселення Podʼів, що працюють на вузлах із позначками NoExecute, якщо ці Podʼи дозволяють таке. Контролер вузла також додає taint, відповідні проблемам вузла, таким як недосяжність вузла або неготовність вузла. Це означає, що планувальник не розміщуватиме Podʼи на несправних вузлах.
Відстеження місткості ресурсів
Обʼєкти Node відстежують інформацію про ресурсну місткість вузла: наприклад, кількість доступної памʼяті та кількість процесорів. Вузли, які реєструються самостійно, повідомляють про свою місткість під час реєстрації. Якщо ви додаєте вузол вручну, то вам потрібно встановити інформацію про місткість вузла при його додаванні.
Планувальник Kubernetes scheduler забезпечує, що на вузлі є достатньо ресурсів для всіх Podʼів. Планувальник перевіряє, що сума запитів контейнерів на вузлі не перевищує місткості вузла. Ця сума запитів включає всі контейнери, керовані kubelet, але не включає жодні контейнери, запущені безпосередньо середовищем виконання контейнерів, а також виключає будь-які процеси, які працюють поза контролем kubelet.
Примітка:
Якщо ви хочете явно зарезервувати ресурси для не-Pod процесів, дивіться резервування ресурсів для системних служб.Топологія вузла
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.27 [stable] (стандартно увімкнено: true)Якщо ви увімкнули функціональну можливість ресурсу TopologyManager, то kubelet може використовувати підказки топології при прийнятті рішень щодо призначення ресурсів. Див. Керування політиками топології на вузлі
для отримання додаткової інформації.
Керування swapʼом
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.30 [beta] (стандартно увімкнено: true)Щоб увімкнути swap на вузлі, feature gate NodeSwap повинен бути активований у kubelet (типово так), і прапорець командного рядка --fail-swap-on або параметр конфігурації failSwapOn повинен бути встановлений в значення false. Для того, щоб дозволити Podʼам використовувати swap, swapBehavior не повинен мати значення NoSwap (яке є стандартним) у конфігурації kubelet.
Попередження:
Коли увімкнено swap, дані Kubernetes, такі як вміст обʼєктів Secret, які були записані у tmpfs, тепер можуть переноситись на диск.Користувач також може налаштувати memorySwap.swapBehavior, щоб вказати, як вузол буде використовувати swap. Наприклад,
memorySwap:
swapBehavior: LimitedSwap
NoSwap(стандартно): Робочі навантаження Kubernetes не використовуватимуть swap.LimitedSwap: Використання робочими навантаженнями Kubernetes swap обмежено. Тільки Podʼи Burstable QoS мають право використовувати swap.
Якщо конфігурація для memorySwap не вказана, і feature gate увімкнено, типово kubelet застосовує ту ж саму поведінку, що й налаштування NoSwap.
З LimitedSwap, Podʼам, які не відносяться до класифікації Burstable QoS (тобто Podʼи QoS BestEffort/Guaranteed), заборонено використовувати swap. Для забезпечення гарантій безпеки і справності вузла цим Podʼам заборонено використовувати swap при включеному LimitedSwap.
Перед тим як розглядати обчислення ліміту swap, необхідно визначити наступне:
nodeTotalMemory: Загальна кількість фізичної памʼяті, доступної на вузлі.totalPodsSwapAvailable: Загальний обсяг swap на вузлі, доступний для використання Podʼами (деякий swap може бути зарезервовано для системного використання).containerMemoryRequest: Запит на памʼять для контейнера.
Ліміт swap налаштовується так: (containerMemoryRequest / nodeTotalMemory) * totalPodsSwapAvailable.
Важливо враховувати, що для контейнерів у Podʼах Burstable QoS можна відмовитися від використання swap, вказавши запити на памʼять, рівні лімітам памʼяті. Контейнери, налаштовані таким чином, не матимуть доступу до swap.
Swap підтримується тільки з cgroup v2, cgroup v1 не підтримується.
Для отримання додаткової інформації, а також для допомоги у тестуванні та надання зворотного звʼязку, будь ласка, перегляньте блог-пост Kubernetes 1.28: NodeSwap виходить у Beta1, KEP-2400 та його проєкт концепції.
Що далі
Дізнайтеся більше про наступне:
- Компоненти, з яких складається вузол.
- Визначення API для вузла.
- Node у документі з дизайну архітектури.
- Відповідне/невідповідне вимкнення вузлів.
- Автомасштабування кластера для керування кількістю та розміром вузлів у вашому кластері.
- Заплямованість та Толерантність.
- Менеджери ресурсів вузла.
- Управління ресурсами для вузлів з операційною системою Windows.
2.2 - Звʼязок між Вузлами та Панеллю управління
Цей документ описує шляхи звʼязку між API-сервером та кластером Kubernetes. Мета — надати користувачам можливість налаштувати їхнє встановлення для зміцнення конфігурації мережі так, щоб кластер можна було запускати в ненадійній мережі (або на повністю публічних IP-адресах у хмарному середовищі).
Звʼязок Вузла з Панеллю управління
У Kubernetes існує шаблон API "hub-and-spoke". Всі використання API вузлів (або Podʼів, які вони виконують) завершуються на API-сервері. Інші компоненти панелі управління не призначені для експонування віддалених служб. API-сервер налаштований для прослуховування віддалених підключень на захищеному порту HTTPS (зазвичай 443) з однією або декількома формами автентифікації клієнта. Рекомендується включити одну чи кілька форм авторизації, особливо якщо анонімні запити або токени облікового запису служби дозволені.
Вузли повинні бути забезпечені загальним кореневим сертифікатом для кластера, щоб вони могли безпечно підключатися до API-сервера разом з дійсними обліковими даними клієнта. Добрим підходом є те, що облікові дані клієнта, які надаються kubelet, мають форму сертифіката клієнта. Див. завантаження TLS kubelet для автоматичного забезпечення облікових даних клієнта kubelet.
Podʼи, які бажають підʼєднатися до API-сервера, можуть це зробити безпечно, використовуючи службовий обліковий запис (service account), так що Kubernetes автоматично вставлятиме загальний кореневий сертифікат та дійсний токен власника у Pod, коли він буде ініціалізований. Служба kubernetes (в просторі імен default) налаштована з віртуальною IP-адресою, яка перенаправляється (через kube-proxy) на точку доступу HTTPS на API-сервері.
Компоненти панелі управління також взаємодіють з API-сервером через захищений порт.
В результаті, типовий режим роботи для зʼєднань від вузлів та Podʼів, що працюють на вузлах, до панелі управління є захищеним і може працювати через ненадійні та/або публічні мережі.
Звʼязок Панелі управління з Вузлом
Існують два основних шляхи звʼязку панелі управління (API-сервера) з вузлами. Перший — від API-сервера до процесу kubelet, який працює на кожному вузлі в кластері. Другий — від API-сервера до будь-якого вузла, Podʼа чи Service через проксі API-сервера.
Звʼязок API-сервер з kubelet
Зʼєднання від API-сервера до kubelet використовуються для:
- Отримання логів для Podʼів.
- Приєднання (зазвичай через
kubectl) до запущених Podʼів. - Забезпечення функціональності перенаправлення портів kubelet.
Ці зʼєднання завершуються на точці доступу HTTPS kubelet. Стандартно API-сервер не перевіряє сертифікат обслуговування kubelet, що робить зʼєднання вразливими до атаки "особа-посередині" і небезпечними для використання через ненадійні та/або публічні мережі.
Щоб перевірити це зʼєднання, використовуйте прапорець --kubelet-certificate-authority, щоб надати API серверу пакет кореневих сертифікатів для перевірки сертифіката обслуговування kubelet.
Якщо це неможливо, скористайтеся тунелюванням SSH між API-сервером та kubelet, якщо необхідно, щоб уникнути підключення через ненадійну або публічну мережу.
Нарешті, автентифікацію та/або авторизацію Kubelet потрібно ввімкнути, щоб захистити API kubelet.
Звʼязок API-сервера з вузлами, Podʼам та Service
Зʼєднання від API-сервера до вузла, Podʼа чи Service типово використовують прості HTTP-зʼєднання і, отже, не автентифікуються або не шифруються. Їх можна використовувати через захищене зʼєднання HTTPS, підставивши https: перед назвою вузла, Podʼа чи Service в URL API, але вони не будуть перевіряти сертифікат, наданий точкою доступу HTTPS, та не надаватимуть облікові дані клієнта. Таким чином, хоча зʼєднання буде зашифрованим, воно не гарантує цілісності. Ці зʼєднання поки не є безпечними для використання через ненадійні або публічні мережі.
Тунелі SSH
Kubernetes підтримує тунелі SSH, щоб захистити канали звʼязку від панелі управління до вузлів. У цій конфігурації API-сервер ініціює тунель SSH до кожного вузла в кластері (підключаючись до SSH-сервера, який прослуховує порт 22) і передає весь трафік, призначений для kubelet, вузла, Podʼа чи Service через тунель. Цей тунель гарантує, що трафік не виходить за межі мережі, в якій працюють вузли.
Примітка:
Тунелі SSH наразі застарілі, тому ви не повинні вибирати їх для використання, якщо не знаєте, що робите. Служба Konnectivity — це заміна для цього каналу звʼязку.Служба Konnectivity
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.18 [beta]Як заміна тунелям SSH, служба Konnectivity надає проксі на рівні TCP для звʼязку панелі управління з кластером. Служба Konnectivity складається з двох частин: сервера Konnectivity в мережі панелі управління та агентів Konnectivity в мережі вузлів. Агенти Konnectivity ініціюють зʼєднання з сервером Konnectivity та утримують мережеві підключення. Після ввімкнення служби Konnectivity весь трафік від панелі управління до вузлів прокладається через ці зʼєднання.
Для налаштування служби Konnectivity у своєму кластері ознайомтесь із завданням служби Konnectivity.
Що далі
- Дізнайтеся більше про компоненти панелі управління Kubernetes
- Дізнайтеся більше про модель "Hubs and Spoke"
- Дізнайтеся, як захистити кластер
- Дізнайтеся більше про API Kubernetes
- Налаштуйте службу Konnectivity
- Використовуйте перенаправлення портів для доступу до застосунку у кластері
- Дізнайтеся, як отримати логи для Podʼів, використовуйте kubectl port-forward
2.3 - Контролери
У робототехніці та автоматизації control loop (цикл керування) — це необмежений цикл, який регулює стан системи.
Ось один приклад control loop — термостат у кімнаті.
Коли ви встановлюєте температуру, це означає, що ви повідомляєте термостату про бажаний стан. Фактична температура в кімнаті — це поточний стан. Термостат діє так, щоб наблизити поточний стан до бажаного стану, вмикаючи чи вимикаючи відповідне обладнання.
У Kubernetes контролери — це цикли управління, які спостерігають за станом вашого кластера, а потім вносять або запитують зміни там, де це необхідно. Кожен контролер намагається наблизити поточний стан кластера до бажаного.Шаблон контролер
Контролер відстежує принаймні один тип ресурсу Kubernetes. Ці обʼєкти мають поле spec, яке представляє бажаний стан. Контролер(и) для цього ресурсу відповідають за наближення поточного стану до цього бажаного стану.
Контролер може виконати дію самостійно; частіше в Kubernetes контролер надсилає повідомлення API-серверу, які мають корисні побічні ефекти. Нижче ви побачите приклади цього.
Управління через API-сервер
Контролер Job — це приклад вбудованого контролера Kubernetes. Вбудовані контролери управляють станом, взаємодіючи з API-сервером кластера.
Job — це ресурс Kubernetes, який запускає Pod, або може кілька Podʼів, щоб виконати завдання і потім зупинитися.
(Після процесу планування, обʼєкти Pod стають частиною бажаного стану для kubelet).
Коли контролер Job бачить нове завдання, він переконується, що десь у вашому кластері kubelet на наборі вузлів виконують потрібну кількість Podʼів. Контролер Job не запускає жодних Podʼів або контейнерів самостійно. Замість цього контролер Job вказує API-серверу створити або видалити Podʼи. Інші компоненти панелі управління працюють з новою інформацією (є нові Podʼи для планування та запуску), і, нарешті, робота виконана.
Після того, як ви створите нове завдання, бажаний стан полягає в тому, щоб це завдання було завершене. Контролер Job робить поточний стан для цього завдання ближче до бажаного стану: створення Podʼів, які виконують роботу, яку ви хотіли для цього завдання, щоб завдання була ближчим до завершення.
Контролери також оновлюють обʼєкти, які їх конфігурують. Наприклад, якщо робота виконана для завдання, контролер Job оновлює обʼєкт Job, щоб позначити його як Finished.
(Це трошки схоже на те, як деякі термостати вимикають світловий індикатор, щоб сповістити, що ваша кімната тепер має температуру, яку ви встановили).
Безпосереднє управління
На відміну від Job, деякі контролери повинні вносити зміни в речі за межами вашого кластера.
Наприклад, якщо ви використовуєте control loop, щоб переконатися, що у вашому кластері є достатньо вузлів, то цей контролер потребує щось поза поточним кластером, щоб налаштувати нові вузли при необхідності.
Контролери, які взаємодіють із зовнішнім станом, отримують свій бажаний стан від API-сервера, а потім безпосередньо спілкуються з зовнішньою системою для наближення поточного стану до бажаного.
(Фактично є контролер що горизонтально масштабує вузли у вашому кластері).
Важливим тут є те, що контролер вносить певні зміни, щоб досягти вашого бажаного стану, а потім повідомляє поточний стан назад на API-сервер вашого кластера. Інші control loop можуть спостерігати за цим звітами та виконувати вже свої дії.
У прикладі з термостатом, якщо в кімнаті дуже холодно, то інший контролер може також увімкнути обігрівач для захисту від морозу. У кластерах Kubernetes панель управління опосередковано працює з інструментами управління IP-адресами, службами сховища, API хмарних провайдерів та іншими службами, розширюючи Kubernetes для їх виконання.
Бажаний стан порівняно з поточним
Kubernetes має хмарний вигляд систем і здатний обробляти постійні зміни.
Ваш кластер може змінюватися в будь-який момент під час роботи, а цикли управління автоматично виправляють збої. Це означає, що, потенційно, ваш кластер ніколи не досягає стабільного стану.
Поки контролери вашого кластера працюють і можуть робити корисні зміни, не має значення, чи є загальний стан сталим, чи ні.
Дизайн
Як принцип дизайну, Kubernetes використовує багато контролерів, кожен з яких керує певним аспектом стану кластера. Найчастіше, певний цикл управління (контролер) використовує один вид ресурсу як свій бажаний стан, і має різні види ресурсу, якими він управляє, щоб задовольнити цей бажаний стан. Наприклад, контролер для ресурсу Job відстежує обʼєкти Job (для виявлення нової роботи) та обʼєкти Pod (для запуску робіт і потім визначення, коли робота закінчена). У цьому випадку щось інше створює роботи, тоді як контролер Job створює Podʼи.
Корисно мати прості контролери, а не один великий набір взаємозалежних циклів управління. Контролери можуть виходити з ладу, тому Kubernetes спроєктовано з урахуванням цього.
Примітка:
У деяких контролерах може бути кілька контролерів, які створюють або оновлюють один і той же тип обʼєкта. За лаштунками контролери Kubernetes переконуються, що вони звертають увагу лише на ресурси, повʼязані з їх контрольним ресурсом.
Наприклад, ви можете мати ресурси Deployments і Jobs; обидва ці ресурси створюють Podʼи. Контролер Job не видаляє Podʼи, які створив ваш Deployment, оскільки є інформація (мітки) яку контролери можуть використовувати для розрізнення цих Podʼів.
Способи використання контролерів
Kubernetes постачається з набором вбудованих контролерів, які працюють всередині kube-controller-manager. Ці вбудовані контролери забезпечують важливі основні функції.
Контролер Deployment та контролер Job — це приклади контролерів, які постачаються разом з Kubernetes (контролери, вбудовані в систему). Kubernetes дозволяє вам запускати надійну панель управління, так що, якщо будь-який з вбудованих контролерів не зможе виконувати завдання, інша частина панелі управління візьме на себе його обовʼязки.
Ви можете знайти контролери, які працюють поза панеллю управління, для розширення Kubernetes. Або, якщо ви хочете, ви можете написати новий контролер самостійно. Ви можете запустити свій власний контролер як набір Podʼів, або поза межами Kubernetes. Те, що найкраще підходить, буде залежати від того, що саме робить цей контролер.
Що далі
- Прочитайте про панель управління Kubernetes
- Дізнайтеся про деякі з основних обʼєктів Kubernetes
- Дізнайтеся більше про API Kubernetes
- Якщо ви хочете написати свій власний контролер, див. Розширювані шаблони Kubernetes та репозиторій sample-controller.
2.4 - Лізинг
Часто в розподілених системах є потреба в лізингу, яка забезпечує механізм блокування спільних ресурсів та координації дій між членами групи. В Kubernetes концепцію лізингу представлено обʼєктами Lease в API Group coordination.k8s.io, які використовуються для критичних для системи можливостей, таких як час роботи вузлів та вибір лідера на рівні компонентів.
Час роботи вузлів
Kubernetes використовує API Lease для звʼязку з пульсом kubelet вузла з API сервером Kubernetes. Для кожного Node існує обʼєкт Lease з відповідним імʼям в просторі імен kube-node-lease. Під капотом кожен сигнал пульсу kubelet — це запит на оновлення цього обʼєкта Lease, який оновлює поле spec.renewTime для оренди. Панель управління Kubernetes використовує відмітку часу цього поля для визначення доступності цього вузла.
Дивіться Обʼєкти Lease вузлів для отримання додаткових деталей.
Вибір лідера
Kubernetes також використовує лізинги для забезпечення того, що в будь-який момент часу працює лише один екземпляр компонента. Це використовується компонентами панелі управління, такими як kube-controller-manager та kube-scheduler в конфігураціях з високою доступністю, де лише один екземпляр компонента має активно працювати, тоді як інші екземпляри перебувають в режимі очікування.
Прочитайте координовані вибори лідера, щоб дізнатися про те, як Kubernetes використовує Lease API для вибору екземпляра компонента, який буде виконувати роль лідера.
Ідентифікація API сервера
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.26 [beta] (стандартно увімкнено: true)Починаючи з Kubernetes v1.26, кожен kube-apiserver використовує API Lease для публікації своєї ідентичності для решти системи. Хоча це само по собі не є особливо корисним, це забезпечує механізм для клієнтів для визначення кількості екземплярів kube-apiserver, які керують панеллю управління Kubernetes. Наявність лізингів kube-apiserver дозволяє майбутнім можливостям, які можуть потребувати координації між кожним kube-apiserver.
Ви можете перевірити лізинги, якими володіє кожен kube-apiserver, перевіривши обʼєкти лізингу в просторі імен kube-system з іменем kube-apiserver-<sha256-hash>. Або ви можете використовувати селектор міток apiserver.kubernetes.io/identity=kube-apiserver:
kubectl -n kube-system get lease -l apiserver.kubernetes.io/identity=kube-apiserver
NAME HOLDER AGE
apiserver-07a5ea9b9b072c4a5f3d1c3702 apiserver-07a5ea9b9b072c4a5f3d1c3702_0c8914f7-0f35-440e-8676-7844977d3a05 5m33s
apiserver-7be9e061c59d368b3ddaf1376e apiserver-7be9e061c59d368b3ddaf1376e_84f2a85d-37c1-4b14-b6b9-603e62e4896f 4m23s
apiserver-1dfef752bcb36637d2763d1868 apiserver-1dfef752bcb36637d2763d1868_c5ffa286-8a9a-45d4-91e7-61118ed58d2e 4m43s
Хеш SHA256, який використовується в назвах лізингу, базується на імені ОС, які бачить цей API сервер. Кожен kube-apiserver повинен бути налаштований на використання унікального імені в межах кластера. Нові екземпляри kube-apiserver, які використовують те саме імʼя хоста, захоплюють наявні лізинги за допомогою нового ідентифікатора власника, замість того щоб створювати нові обʼєкти лізингу. Ви можете перевірити імʼя хоста, використовуючи kube-apisever, перевіривши значення мітки kubernetes.io/hostname:
kubectl -n kube-system get lease apiserver-07a5ea9b9b072c4a5f3d1c3702 -o yaml
apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
creationTimestamp: "2023-07-02T13:16:48Z"
labels:
apiserver.kubernetes.io/identity: kube-apiserver
kubernetes.io/hostname: master-1
name: apiserver-07a5ea9b9b072c4a5f3d1c3702
namespace: kube-system
resourceVersion: "334899"
uid: 90870ab5-1ba9-4523-b215-e4d4e662acb1
spec:
holderIdentity: apiserver-07a5ea9b9b072c4a5f3d1c3702_0c8914f7-0f35-440e-8676-7844977d3a05
leaseDurationSeconds: 3600
renewTime: "2023-07-04T21:58:48.065888Z"
Прострочені лізинги від kube-apiservers, які вже не існують, прибираються новими kube-apiservers через 1 годину.
Ви можете вимкнути лізинги ідентичності API сервера, вимкнувши функціональну можливість APIServerIdentity.
Робочі навантаження
Ваші власні робочі навантаження можуть визначити своє власне використання лізингів. Наприклад, ви можете запускати власний контролер, де первинний член чи лідер виконує операції, які його партнери не виконують. Ви визначаєте лізинг так, щоб репліки контролера могли вибирати чи обирати лідера, використовуючи API Kubernetes для координації. Якщо ви використовуєте лізинг, це гарна практика визначати імʼя лізингу, яке очевидно повʼязано з продуктом чи компонентом. Наприклад, якщо у вас є компонент з іменем Example Foo, використовуйте лізинг з іменем example-foo.
Якщо оператор кластера чи інший кінцевий користувач може розгортати кілька екземплярів компонента, виберіть префікс імʼя і виберіть механізм (такий як хеш від назви Deployment), щоб уникнути конфліктів імен для лізингів.
Ви можете використовувати інший підхід, поки він досягає того самого результату: відсутність конфліктів між різними програмними продуктами.
2.5 - Cloud Controller Manager
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.11 [beta]Технології хмарної інфраструктури дозволяють вам запускати Kubernetes в публічних, приватних та гібридних хмарах. Kubernetes вірить в автоматизовану інфраструктуру, що працює за допомогою API без тісного звʼязку між компонентами.
Сloud-controller-manager це компонент панелі управління Kubernetes, що інтегрує управління логікою певної хмари. Cloud controller manager дозволяє звʼязувати ваш кластер з API хмарного провайдера та відокремлює компоненти, що взаємодіють з хмарною платформою від компонентів, які взаємодіють тільки в кластері.
Відокремлюючи логіку сумісності між Kubernetes і базовою хмарною інфраструктурою, компонент cloud-controller-manager дає змогу хмарним провайдерам випускати функції з іншою швидкістю порівняно з основним проєктом Kubernetes.
Cloud-controller-manager структурується з допомогою механізму втулків, який дозволяє різним постачальникам хмар інтегрувати свої платформи з Kubernetes.
Дизайн
Менеджер контролера хмар працює в панелі управління як реплікований набір процесів (зазвичай це контейнери в Podʼах). Кожен контролер хмар реалізує кілька контролерів в одному процесі.
Примітка:
Ви також можете запускати менеджер контролера хмар як надбудову Kubernetes, а не як частину панелі управління.Функції менеджера контролера хмар
Контролери всередині менеджера контролера хмар складаються з:
Контролер Node
Контролер Node відповідає за оновлення обʼєктів Node при створенні нових серверів у вашій хмарній інфраструктурі. Контролер Node отримує інформацію про хости, які працюють у вашому оточені у хмарному провайдері. Контролер Node виконує наступні функції:
- Оновлення обʼєкта Node відповідним унікальним ідентифікатором сервера, отриманим з API постачальника хмари.
- Анотація та маркування обʼєкта Node хмароспецифічною інформацією, такою як регіон, в якому розгорнуто вузол, та ресурси (CPU, памʼять і т. д.), якими він володіє.
- Отримання імені хосту та мережевих адрес.
- Перевірка стану вузла. У випадку, якщо вузол стає непридатним для відповіді, цей контролер перевіряє за допомогою API вашого постачальника хмари, чи сервер був деактивований / видалений / завершений. Якщо вузол був видалений з хмари, контролер видаляє обʼєкт Node з вашого кластера Kubernetes.
Деякі реалізації від постачальників хмар розділяють це на контролер Node та окремий контролер життєвого циклу вузла.
Контролер Route
Контролер Route відповідає за налаштування маршрутів у хмарі відповідним чином, щоб контейнери на різних вузлах вашого Kubernetes кластера могли спілкуватися один з одним.
Залежно від постачальника хмари, контролер Route може також виділяти блоки IP-адрес для мережі Podʼа.
Контролер Service
Services інтегруються з компонентами хмарної інфраструктури, такими як керовані балансувальники трафіку, IP-адреси, мережеве фільтрування пакетів та перевірка стану цільового обʼєкта. Контролер Service взаємодіє з API вашого постачальника хмари для налаштування балансувальника навантаження та інших компонентів інфраструктури, коли ви оголошуєте ресурс Service, який вимагає їх.
Авторизація
У цьому розділі розглядаються доступи, яких вимагає менеджер контролера хмар для різних обʼєктів API для виконання своїх операцій.
Контролер Node
Контролер Node працює тільки з обʼєктами Node. Він вимагає повного доступу для читання та модифікації обʼєктів Node.
v1/Node:
- get
- list
- create
- update
- patch
- watch
- delete
Контролер Route
Контролер Route відстежує створення обʼєктів Node та налаштовує маршрути відповідним чином. Він вимагає доступу Get до обʼєктів Node.
v1/Node:
- get
Контролер Service
Контролер Service відстежує події create, update та delete обʼєктів та після цього налаштовує Endpoints для цих Service відповідним чином (для EndpointSlices менеджер kube-controller-manager керує ними за запитом).
Для доступу до Service потрібні доступи list та watch. Для оновлення Service потрібен доступ patch та update.
Для налаштування ресурсів Endpoints для Service потрібен доступ до create, list, get, watch та update.
v1/Service:
- list
- get
- watch
- patch
- update
Інші
Реалізація основи менеджера контролера хмар потребує доступу до створення Event та для забезпечення безпечної роботи він потребує доступу до створення ServiceAccounts.
v1/Event:
- create
- patch
- update
v1/ServiceAccount:
- create
RBAC ClusterRole для менеджера контролера хмар виглядає наступним чином:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
Що далі
Адміністрування менеджера контролера хмар містить інструкції щодо запуску та управління менеджером контролера хмар.
Щодо оновлення панелі управління з розділеною доступністю для використання менеджера контролера хмар, див. Міграція реплікованої панелі управління для використання менеджера контролера хмар.
Хочете знати, як реалізувати свій власний менеджер контролера хмар або розширити поточний проєкт?
- Менеджер контролера хмар використовує інтерфейси Go, зокрема, інтерфейс
CloudProvider, визначений уcloud.goз kubernetes/cloud-provider, щоб дозволити використовувати імплементації з будь-якої хмари. - Реалізація загальних контролерів, виділених у цьому документі (Node, Route та Service), разом із загальним інтерфейсом хмарного постачальника, є частиною ядра Kubernetes. Реалізації, специфічні для постачальників хмари, знаходяться поза ядром Kubernetes і реалізують інтерфейс
CloudProvider. - Для отримання додаткової інформації щодо розробки втулків, див. Розробка менеджера контролера хмар.
- Менеджер контролера хмар використовує інтерфейси Go, зокрема, інтерфейс
2.6 - Про cgroup v2
У Linux control groups обмежують ресурси, які виділяються процесам.
kubelet та середовище виконання контейнерів повинні співпрацювати з cgroups для забезпечення управління ресурсами для Podʼів та контейнерів, що включає запити та обмеження на CPU/памʼяті для контейнеризованих навантажень.
Є дві версії cgroups у Linux: cgroup v1 і cgroup v2. cgroup v2 — це нове покоління API cgroup в Linux.
Що таке cgroup v2?
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.25 [stable]cgroup v2 — це наступне покоління API Linux cgroup. cgroup v2 надає єдину систему управління з розширеними можливостями управління ресурсами.
cgroup v2 пропонує кілька поліпшень порівняно з cgroup v1, таких як:
- Один уніфікований дизайн ієрархії в API
- Безпечне делегування піддерева контейнерам
- Нові можливості, такі як Pressure Stall Information
- Розширене управління розподілом ресурсів та ізоляція між різними ресурсами
- Обʼєднаний облік різних типів виділення памʼяті (мережева памʼять, памʼять ядра і т. д.)
- Облік негайних змін ресурсів, таких як запис кешу сторінок
Деякі можливості Kubernetes використовують виключно cgroup v2 для поліпшення управління ресурсами та ізоляцією. Наприклад, можливість MemoryQoS покращує якість обслуговування памʼяті та покладається на примітиви cgroup v2.
Використання cgroup v2
Рекомендованим способом використання cgroup v2 є використання дистрибутиву Linux, який типово має та використовує cgroup v2.
Щоб перевірити, чи ваш дистрибутив використовує cgroup v2, див. Визначення версії cgroup на вузлах Linux.
Вимоги
cgroup v2 має наступні вимоги:
- Дистрибутив ОС включає cgroup v2
- Версія ядра Linux — 5.8 або пізніше
- Середовище виконання контейнерів підтримує cgroup v2. Наприклад:
- containerd v1.4 і новіше
- cri-o v1.20 і новіше
- kubelet та середовище виконання контейнерів налаштовані на використання cgroup-драйвера systemd
Підтримка cgroup v2 дистрибутивами Linux
Для ознайомлення зі списком дистрибутивів Linux, які використовують cgroup v2, див. документацію cgroup v2
- Container Optimized OS (з версії M97)
- Ubuntu (з версії 21.10, рекомендовано 22.04+)
- Debian GNU/Linux (з Debian 11 bullseye)
- Fedora (з версії 31)
- Arch Linux (з квітня 2021)
- RHEL та схожі дистрибутиви (з версії 9)
Щоб перевірити, чи ваш дистрибутив використовує cgroup v2, див. документацію вашого дистрибутиву або скористайтеся інструкціями в Визначенні версії cgroup на вузлах Linux.
Також можна включити cgroup v2 вручну у вашому дистрибутиві Linux, змінивши аргументи завантаження ядра. Якщо ваш дистрибутив використовує GRUB, systemd.unified_cgroup_hierarchy=1 повинно бути додано в GRUB_CMDLINE_LINUX в /etc/default/grub, а потім виконайте sudo update-grub. Однак рекомендованим підходом є використання дистрибутиву, який вже стандартно має cgroup v2.
Міграція на cgroup v2
Щоб перейти на cgroup v2, переконайтеся, що ваша система відповідаєте вимогам, а потім оновіть її до версії ядра, яка стандартно має cgroup v2.
Kubelet автоматично виявляє, що ОС працює з cgroup v2 і виконує відповідно без додаткової конфігурації.
При переході на cgroup v2 не повинно бути помітної різниці в використані, якщо користувачі не звертаються безпосередньо до файлової системи cgroup чи на вузлі, чи зсередини контейнерів.
cgroup v2 використовує інший API, ніж cgroup v1, тому, якщо є застосунки, які безпосередньо отримують доступ до файлової системи cgroup, вони повинні бути оновлені до новіших версій, які підтримують cgroup v2. Наприклад:
- Деякі сторонні агенти моніторингу та безпеки можуть залежати від файлової системи cgroup. Оновіть ці агенти до версій, які підтримують cgroup v2.
- Якщо ви використовуєте cAdvisor як окремий DaemonSet для моніторингу Podʼів та контейнерів, оновіть його до v0.43.0 чи новіше.
- Якщо ви розгортаєте Java-застосунки, віддайте перевагу використанню версій, які повністю підтримують cgroup v2:
- OpenJDK / HotSpot: jdk8u372, 11.0.16, 15 та пізніше
- IBM Semeru Runtimes: 8.0.382.0, 11.0.20.0, 17.0.8.0 та пізніше
- IBM Java: 8.0.8.6 та пізніше
- Якщо ви використовуєте пакунок uber-go/automaxprocs, переконайтеся, що ви використовуєте версію v1.5.1 чи вище.
Визначення версії cgroup на вузлах Linux
Версія cgroup залежить від використаного дистрибутиву Linux та версії cgroup, налаштованої в ОС. Щоб перевірити, яка версія cgroup використовується вашим дистрибутивом, виконайте команду stat -fc %T /sys/fs/cgroup/ на вузлі:
stat -fc %T /sys/fs/cgroup/
Для cgroup v2 вивід — cgroup2fs.
Для cgroup v1 вивід — tmpfs.
Що далі
- Дізнайтеся більше про cgroups
- Дізнайтеся більше про середовище виконання контейнерів
- Дізнайтеся більше про драйвери cgroup
2.7 - Інтерфейс середовища виконання контейнерів (CRI)
CRI — це інтерфейс втулка, який дозволяє kubelet використовувати різноманітні середовища виконання контейнерів, не маючи потреби перекомпілювати компоненти кластера.
Для того, щоб kubelet міг запускати Podʼи та їхні контейнери, потрібне справне середовище виконання контейнерів на кожному вузлі в кластері.
Інтерфейс середовища виконання контейнерів (CRI) — основний протокол для взаємодії між kubelet та середовищем виконання контейнерів.
Інтерфейс виконання контейнерів Kubernetes (CRI) визначає основний gRPC протокол для звʼязку між компонентами вузла kubelet та середовищем виконання контейнерів.
API
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.23 [stable]Kubelet діє як клієнт при підключенні до середовища виконання контейнерів через gRPC. Endpointʼи служби виконання та образів повинні бути доступні в середовищі виконання контейнерів, це може бути налаштовано окремо в kubelet за допомогою прапорців командного рядка --image-service-endpoint command line flags.
Для Kubernetes v1.32, kubelet вибирає CRI v1. Якщо середовище виконання контейнерів не підтримує v1 CRI, то kubelet намагається домовитися про будь-яку підтримувану старішу версію. Kubelet v1.32 також може домовитися про CRI v1alpha2, але ця версія вважається застарілою. Якщо kubelet не може домовитися про підтримувану версію CRI, то kubelet припиняє спроби та не реєструє вузол.
Оновлення
При оновленні Kubernetes kubelet намагається автоматично вибрати останню версію CRI при перезапуску компонента. Якщо це не вдається, то відбувається відновлення згідно з зазначеними вище. Якщо потрібен перезапуск kubelet через gRPC через оновлення середовища виконання контейнерів, то середовище виконання контейнерів також повинне підтримувати вибрану спочатку версію, інакше очікується що відновлення не відбудеться. Це вимагає перезапуску kubelet.
Що далі
- Дізнайтеся більше про визначення протоколу CRI
2.8 - Збір сміття
Збирання сміття — це загальний термін для різних механізмів, які Kubernetes використовує для очищення ресурсів кластера. Це дозволяє очищати ресурси, такі як:
- Припиненні Podʼи
- Завершені завдання (Jobs)
- Обʼєкти без власників
- Невикористані контейнери та образи контейнерів
- Динамічно створені томи PersistentVolumes із політикою вилучення StorageClass Delete
- Застарілі або прострочені запити на підпис сертифікатів (CSRs)
- Видалені вузли в наступних сценаріях:
- У хмарі, коли кластер використовує керування контролером хмари
- На місці, коли кластер використовує надбудову, схожу на контролер хмари
- Обʼєкти Node Lease
Власники та залежності
Багато обʼєктів в Kubernetes повʼязані один з одним через посилання на власника. Посилання на власника повідомляють панелі управління, які обʼєкти залежать від інших. Kubernetes використовує посилання на власника для того, щоб дати панелі управління та іншим клієнтам API можливість очищати повʼязані ресурси перед видаленням обʼєкта. У більшості випадків Kubernetes автоматично керує посиланнями на власника.
Власність відрізняється від механізму міток та селекторів, які також використовують деякі ресурси. Наприклад, розгляньте Service, який створює обʼєкти EndpointSlice. Сервіс використовує мітки, щоб дозволити панелі управління визначити, які обʼєкти EndpointSlice використовуються для цього Сервісу. Кожен обʼєкт EndpointSlice, який керується Сервісом, має власників. Посилання на власника допомагають різним частинам Kubernetes уникати втручання в обʼєкти, якими вони не керують.
Примітка:
Посилання на власника через простір імен заборонені зазначеною концепцією. Обʼєкти, які використовують простори імен можуть вказувати власників загального простору імен або простору імен. Власник простору імен повинен існувати в тому ж просторі імен, що і залежний обʼєкт. Якщо цього не відбувається, таке посилання вважається відсутнім, і залежний обʼєкт підлягає видаленню після перевірки відсутності всіх власників.
Обʼєкти залежні від загального простору імен можуть вказувати тільки загальних власників. У v1.20+, якщо залежний обʼєкт, який залежить від класу, вказує простор імен як власника, йому не вдасться вирішити посилання на власника та його не можна буде прибрати через збирання сміття.
У v1.20+, якщо збирач сміття виявляє недійсний перехресний простір імен ownerReference або кластерний залежний з ownerReference, що посилається на тип простору імен, повідомляється про попереджувальну подію з причиною OwnerRefInvalidNamespace та involvedObject недійсного залежного елемента. Ви можете перевірити наявність такого роду подій, запустивши kubectl get events -A --field-selector=reason=OwnerRefInvalidNamespace.
Каскадне видалення
Kubernetes перевіряє та видаляє обʼєкти, які більше не мають власників, наприклад, Podʼи, які залишилися після видалення ReplicaSet. Коли ви видаляєте обʼєкт, ви можете контролювати, чи автоматично видаляє Kubernetes залежні обʼєкти, у процесі, що називається каскадним видаленням. Існують два типи каскадного видалення:
- Каскадне видалення на передньому плані
- Каскадне видалення у фоні
Ви також можете контролювати те, як і коли збирання сміття видаляє ресурси, які мають посилання на власника, використовуючи завершувачі Kubernetes.
Каскадне видалення на передньому плані
У каскадному видаленні на передньому плані обʼєкт власника, який видаляється, спочатку потрапляє в стан deletion in progress. У цьому стані стається наступне для обʼєкта власника:
- Сервер API Kubernetes встановлює поле
metadata.deletionTimestampобʼєкта на час, коли обʼєкт був позначений на видалення. - Сервер API Kubernetes також встановлює поле
metadata.finalizersвforegroundDeletion. - Обʼєкт залишається видимим через API Kubernetes, поки не буде завершений процес видалення.
Після того як обʼєкт власника потрапляє в стан видалення в процесі, контролер видаляє відомі йому залежні обʼєкти. Після видалення всіх відомих залежних обʼєктів контролер видаляє обʼєкт власника. На цьому етапі обʼєкт більше не є видимим в API Kubernetes.
Під час каскадного видалення на передньому плані, єдиними залежними обʼєктами, які блокують видалення власника, є ті, що мають поле ownerReference.blockOwnerDeletion=true і знаходяться в кеші контролера збірки сміття. Кеш контролера збірки сміття не може містити обʼєкти, тип ресурсу яких не може бути успішно перелічений / переглянутий, або обʼєкти, які створюються одночасно з видаленням обʼєкта-власника. Дивіться Використання каскадного видалення на передньому плані, щоб дізнатися більше.
Каскадне видалення у фоні
При фоновому каскадному видаленні сервер Kubernetes API негайно видаляє обʼєкт-власник, а контролер збирача сміття (ваш власний або стандартний) очищає залежні обʼєкти у фоновому режимі. Якщо існує завершувач, він гарантує, що обʼєкти не будуть видалені, доки не будуть виконані всі необхідні завдання з очищення. Типово Kubernetes використовує каскадне видалення у фоні, якщо ви не використовуєте видалення вручну на передньому плані або не вибираєте залишити залежні обʼєкти.
Дивіться Використання каскадного видалення у фоні, щоб дізнатися більше.
Залишені залежності
Коли Kubernetes видаляє обʼєкт власника, залишені залежні обʼєкти називаються залишеними обʼєктами. Типово Kubernetes видаляє залежні обʼєкти. Щоб дізнатися, як перевизначити цю поведінку, дивіться Видалення власників та залишені залежності.
Збір сміття невикористаних контейнерів та образів
kubelet виконує збір сміття невикористаних образів кожні пʼять хвилин та невикористаних контейнерів кожну хвилину. Ви повинні уникати використання зовнішніх інструментів для збору сміття, оскільки вони можуть порушити поведінку kubelet та видаляти контейнери, які повинні існувати.
Щоб налаштувати параметри для збору сміття невикористаних контейнерів та образів, налаштуйте kubelet за допомогою файлу конфігурації та змініть параметри, повʼязані зі збором сміття, використовуючи ресурс типу KubeletConfiguration.
Життєвий цикл образу контейнера
Kubernetes керує життєвим циклом всіх образів через свій менеджер образів, який є частиною kubelet, співпрацюючи з cadvisor. Kubelet враховує наступні обмеження щодо використання дискового простору при прийнятті рішень про збір сміття:
HighThresholdPercentLowThresholdPercent
Використання дискового простору вище встановленого значення HighThresholdPercent викликає збір сміття, який видаляє образи в порядку їх останнього використання, починаючи з найстаріших. Kubelet видаляє образи до тих пір, поки використання дискового простору не досягне значення LowThresholdPercent.
Збір сміття для невикористаних контейнерних образів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.30 [beta] (стандартно увімкнено: true)Як бета-функцію, ви можете вказати максимальний час, протягом якого локальний образ може бути невикористаний, незалежно від використання дискового простору. Це налаштування kubelet, яке ви вказуєте для кожного вузла.
Щоб налаштувати параметр встановіть значення поля imageMaximumGCAge в файлі конфігурації kubelet.
Значення вказується як тривалість. Дивіться визначення тривалості в глосарії для отримання докладних відомостей
Наприклад, ви можете встановити значення поля конфігурації 12h45m, що означає 12 годин 45 хвилин.
Примітка:
Ця функція не відстежує використання образів kubeletʼами під час перезапуску. Якщо kubelet перезапускається, вік відстежуваного образу скидається, що призводить до того, що kubelet очікує повний проміжок часуimageMaximumGCAge перед тим як кваліфікувати образ для прибирання збирачем сміття на основі віку образу.Збір сміття контейнерів
Kubelet збирає сміття невикористаних контейнерів на основі наступних змінних, які ви можете визначити:
MinAge: мінімальний вік, при якому kubelet може видаляти контейнер. Вимкніть, встановивши на значення0.MaxPerPodContainer: максимальна кількість мертвих контейнерів які кожен Pod може мати. Вимкніть, встановивши менше0.MaxContainers: максимальна кількість мертвих контейнерів у кластері. Вимкніть, встановивши менше0.
Крім цих змінних, kubelet збирає сміття невизначених та видалених контейнерів, як правило, починаючи з найстарших.
MaxPerPodContainer та MaxContainers можуть потенційно конфліктувати одне з одним в ситуаціях, де збереження максимальної кількості контейнерів на кожен Pod (MaxPerPodContainer) вийде за допустиму загальну кількість глобальних мертвих контейнерів (MaxContainers). У цій ситуації kubelet коригує MaxPerPodContainer для вирішення конфлікту. У найгіршому випадку може бути знижений MaxPerPodContainer до 1 та видалені найдавніші контейнери. Крім того, контейнери, які належать Podʼам, які були видалені, видаляються, якщо вони старше MinAge.
Примітка:
Kubelet збирає сміття лише для контейнерів, якими він керує.Налаштування збору сміття
Ви можете налаштовувати збір сміття ресурсів, налаштовуючи параметри, специфічні для контролерів, що керують цими ресурсами. На наступних сторінках показано, як налаштовувати збір сміття:
- Налаштування каскадного видалення обʼєктів Kubernetes
- Налаштування очищення завершених завдань (Jobs)
Що далі
- Дізнайтеся більше про власність обʼєктів Kubernetes.
- Дізнайтеся більше про завершувачі Kubernetes.
- Дізнайтеся про контролер TTL, який очищає завершені завдання.
2.9 - Mixed Version Proxy
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.28 [alpha] (стандартно увімкнено: false)У Kubernetes 1.32 включено альфа-функцію, яка дозволяє API Server проксійовати запити ресурсів до інших рівноправних API-серверів. Це корисно, коли існують кілька API-серверів, що працюють на різних версіях Kubernetes в одному кластері (наприклад, під час тривалого впровадження нового релізу Kubernetes).
Це дозволяє адміністраторам кластерів налаштовувати високодоступні кластери, які можна модернізувати більш безпечно, направляючи запити на ресурси (зроблені під час оновлення) на правильний kube-apiserver. Цей проксі заважає користувачам бачити несподівані помилки 404 Not Found, які випливають з процесу оновлення.
Цей механізм називається Mixed Version Proxy.
Активація Mixed Version Proxy
Переконайтеся, що функціональну можливість UnknownVersionInteroperabilityProxy увімкнено, коли ви запускаєте API Server:
kube-apiserver \
--feature-gates=UnknownVersionInteroperabilityProxy=true \
# обовʼязкові аргументи командного рядка для цієї функції
--peer-ca-file=<шлях до сертифіката CA kube-apiserver>
--proxy-client-cert-file=<шлях до сертифіката агрегатора проксі>,
--proxy-client-key-file=<шлях до ключа агрегатора проксі>,
--requestheader-client-ca-file=<шлях до сертифіката CA агрегатора>,
# requestheader-allowed-names може бути встановлено як порожнє значення, щоб дозволити будь-яке Загальне Імʼя
--requestheader-allowed-names=<дійсні Загальні Імена для перевірки сертифікату клієнта проксі>,
# необовʼязкові прапорці для цієї функції
--peer-advertise-ip=`IP цього kube-apiserver, яке повинно використовуватися рівноправними для проксі-запитів`
--peer-advertise-port=`порт цього kube-apiserver, який повинен використовуватися рівноправними для проксі-запитів`
# …і інші прапорці як зазвичай
Транспорт та автентифікація проксі між API-серверами
Вихідний kube-apiserver повторно використовує наявні прапорці автентифікації клієнта API-сервера
--proxy-client-cert-fileта--proxy-client-key-fileдля представлення своєї ідентичності, яку перевіряє його рівноправний (цільовий kube-apiserver). Цей останній підтверджує підключення рівноправного на основі конфігурації, яку ви вказуєте за допомогою аргументу командного рядка--requestheader-client-ca-file.Для автентифікації сертифікатів серверів призначення вам слід налаштувати пакет сертифіката організації, вказавши аргумент командного рядка
--peer-ca-fileвихідному API-серверу.
Налаштування для зʼєднання з рівноправним API-сервером
Для встановлення мережевого розташування kube-apiserver, яке партнери будуть використовувати для проксі-запитів, використовуйте аргументи командного рядка --peer-advertise-ip та --peer-advertise-port для kube-apiserver або вказуйте ці поля в конфігураційному файлі API-сервера. Якщо ці прапорці не вказані, партнери будуть використовувати значення з аргументів командного рядка --advertise-address або --bind-address для kube-apiserver. Якщо ці прапорці теж не встановлені, використовується типовий інтерфейс хосту.
Mixed version proxying
При активації Mixed version proxying шар агрегації завантажує спеціальний фільтр, який виконує такі дії:
- Коли запит ресурсу надходить до API-сервера, який не може обслуговувати цей API (чи то тому, що він є версією, що передує введенню API, чи тому, що API вимкнено на API-сервері), API-сервер намагається надіслати запит до рівноправного API-сервера, який може обслуговувати затребуваний API. Це відбувається шляхом ідентифікації груп API / версій / ресурсів, які місцевий сервер не визнає, і спроби проксійовати ці запити до рівноправного API-сервера, який може обробити запит.
- Якщо рівноправний API-сервер не відповідає, то source API-сервер відповідає помилкою 503 ("Сервіс недоступний").
Як це працює під капотом
Коли API-сервер отримує запит ресурсу, він спочатку перевіряє, які API-сервери можуть обслуговувати затребуваний ресурс. Ця перевірка відбувається за допомогою внутрішнього API зберігання версії.
Якщо ресурс відомий API-серверу, що отримав запит (наприклад,
GET /api/v1/pods/some-pod), запит обробляється локально.Якщо для запитаного ресурсу не знайдено внутрішнього обʼєкта
StorageVersion(наприклад,GET /my-api/v1/my-resource) і налаштовано APIService на проксі до API-сервера розширення, цей проксі відбувається за звичайного процесу для розширених API.Якщо знайдено дійсний внутрішній обʼєкт
StorageVersionдля запитаного ресурсу (наприклад,GET /batch/v1/jobs) і API-сервер, який намагається обробити запит (API-сервер обробників), має вимкнений APIbatch, тоді API-сервер, який обробляє запит, витягує рівноправні API-сервери, які обслуговують відповідну групу / версію / ресурс (api/v1/batchу цьому випадку) за інформацією у витягнутому обʼєктіStorageVersion. API-сервер, який обробляє запит, потім проксіює запит до одного з вибраних рівноправних kube-apiservers які обізнані з запитаним ресурсом.Якщо немає партнера, відомого для тієї групи API / версії / ресурсу, API-сервер обробників передає запит своєму власному ланцюжку обробки, який, врешті-решт, повинен повернути відповідь 404 ("Не знайдено").
Якщо API-сервер обробників ідентифікував і вибрав рівноправний API-сервер, але цей останній не відповідає (з причин, таких як проблеми з мережевим зʼєднанням або data race між отриманням запиту та реєстрацією інформації партнера в панелі управління), то API-сервер обробників відповідає помилкою 503 ("Сервіс недоступний").
3 - Контейнери
Технологія для упаковки застосунку разом з його залежностями оточення виконання.
На цій сторінці міститься огляд контейнерів та образів контейнерів, а також їх використання для розробки та промислової експлуатації.
Слово контейнер є дуже перевантаженим терміном. Щоразу, коли ви використовуєте це слово, перевіряйте, чи ваша аудиторія використовує те саме визначення.
Кожен контейнер, який ви запускаєте, є повторюваним; стандартизація завдяки включеним залежностям означає, що ви отримуєте однакову поведінку, де б ви його не запускали.
Контейнери відокремлюють застосунки від базової інфраструктури хосту Це полегшує розгортання в різних хмарних або ОС-середовищах.
Кожен вузол в кластері Kubernetes запускає контейнери, які формують Podʼи, призначені цьому вузлу. Контейнери розташовуються та плануються разом, щоб запускатися на тому ж вузлі.
Образи контейнерів
Образ контейнера — це готовий до запуску пакунок програмного забезпечення, який містить все необхідне для запуску застосунку: код та будь-яке середовище виконання, яке він вимагає, бібліотеки застосунку та системи, та типові значення для будь-яких важливих налаштувань.
Контейнери призначені для того, щоб бути stateless та незмінними: ви не повинні змінювати код контейнера, який вже працює. Якщо у вас є контейнеризований застосунок та ви хочете внести зміни, правильний процес полягає в тому, щоб побудувати новий образ, який включає зміни, а потім перебудувати контейнер, щоб запустити оновлений образ.
Середовище виконання контейнерів
Основний компонент, який дозволяє Kubernetes ефективно запускати контейнери. Він відповідає за керування виконанням і життєвим циклом контейнерів у середовищі Kubernetes.
Kubernetes підтримує середовища виконання контейнерів, такі як containerd, CRI-O, та будь-яку іншу реалізацію Kubernetes CRI (інтерфейс виконання контейнерів).
Зазвичай, ви можете дозволити вашому кластеру обрати стандартне середовище виконання для Podʼа. Якщо вам потрібно використовувати більше одного середовища виконання контейнерів у вашому кластері, ви можете вказати RuntimeClass для Podʼа, щоб переконатися, що Kubernetes запускає ці контейнери за допомогою певного середовища виконання.
Ви також можете використовувати RuntimeClass для запуску різних Podʼів з однаковим контейнером, але з різними налаштуваннями.
3.1 - Образ контейнера
Образ контейнера представляє бінарні дані, які інкапсулюють застосунок та всі його програмні залежності. Образи контейнерів — це виконувані пакунки програмного забезпечення, які можуть працювати окремо і роблять дуже чітко визначені припущення щодо свого середовища виконання.
Зазвичай ви створюєте образ контейнера свого застосунку та розміщуєте його в реєстрі перш ніж посилатися на нього у Pod.
Ця сторінка надає огляд концепції образів контейнерів.
Примітка:
Якщо ви шукаєте образи контейнерів для випуску Kubernetes (наприклад, v1.32, остання мінорна версія), відвідайте розділ Завантаження Kubernetes.Назви образів
Образам контейнерів зазвичай дається назва, така як pause, example/mycontainer або kube-apiserver. Образ також може містити імʼя хосту реєстру; наприклад: fictional.registry.example/imagename, а також, можливо, номер порту; наприклад: fictional.registry.example:10443/imagename.
Якщо ви не вказуєте імʼя хосту реєстру, Kubernetes вважає, що ви маєте на увазі публічний реєстр образів Docker. Ви можете змінити цю поведінку, вказавши стандартний реєстр образів у налаштуваннях середовища виконання контейнерів.
Після частини назви образу ви можете додати теґ або даджест (так само, якщо ви використовуєте команди типу docker чи podman). Теґи дозволяють ідентифікувати різні версії одного ряду образів. Даджест — унікальний ідентифікатор конкретної версії образу. Даджести є хешами, які визначаються вмістом образу, і вони не змінюються. Теґи можна змініювати, так щоб вони вказували на різні версії образу, даджйести залишаються незмінними.
Теґи образів складаються з малих і великих літер, цифр, підкреслень (_), крапок (.) та тире (-). Довжина теґу може бути до 128 символів. Теґ має відповідати наступному шаблону: [a-zA-Z0-9_][a-zA-Z0-9._-]{0,127}. Дізнатись більше та знайти інші регулярні вирази для перевірки можна в OCI Distribution Specification. Якщо ви не вказуєте теґ, Kubernetes вважає, що ви маєте на увазі теґ latest.
Хеш-сума образу складається з назви алгоритму хешу (наприклад, sha256) і значення хешу. Наприклад: sha256:1ff6c18fbef2045af6b9c16bf034cc421a29027b800e4f9b68ae9b1cb3e9ae07
Додаткову інформацію про формат хешів можна знайти в OCI Image Specification.
Деякі приклади імен образів, які може використовувати Kubernetes:
busybox— Тільки назва образу, без теґу або хеша. Kubernetes використовує загальний реєстр Docker і теґ latest. (Те саме, що іdocker.io/library/busybox:latest)busybox:1.32.0— назва образу з теґом. Kubernetes використовує загальний реєстр Docker. (Те саме, що іdocker.io/library/busybox:1.32.0)registry.k8s.io/pause:latest— назва образу з власного реєстру і теґом latest.registry.k8s.io/pause:3.5— назва образу з власного реєстру і теґом, який не є останнім.registry.k8s.io/pause@sha256:1ff6c18fbef2045af6b9c16bf034cc421a29027b800e4f9b68ae9b1cb3e9ae07— назва образу з хешем.registry.k8s.io/pause:3.5@sha256:1ff6c18fbef2045af6b9c16bf034cc421a29027b800e4f9b68ae9b1cb3e9ae07— назва образу з теґом і хешем. Тільки хеш буде використаний для завантаження.
Оновлення образів
При першому створенні Deployment, StatefulSet, Pod чи іншого обʼєкта, що включає шаблон Pod, стандартна політика завантаження всіх
контейнерів у цьому Pod буде встановлена в IfNotPresent, якщо вона не вказана явно. Ця політика призводить до того, що kubelet пропускає завантаження образів, якщо вони вже існують.
Політика завантаження образів
imagePullPolicy для контейнера та теґ образу впливають на те, коли kubelet намагається завантажити (стягнути) вказаний образ.
Ось список значень, які можна встановити для imagePullPolicy та їхні ефекти:
IfNotPresent- образ завантажується лише тоді, коли він ще не присутній локально.
Always- кожен раз, коли kubelet запускає контейнер, kubelet зверетається до реєстру образів для пошуку відповідності між назвою та образом (digest). Якщо у kubelet є образ контейнера з цим точним хешем в кеші локально, kubelet використовує свій кеш образів; в іншому випадку kubelet завантажує образ зі знайденим хешем та використовує його для запуску контейнера.
Never- kubelet не намагається отримати образ. Якщо образ вже присутній локально, kubelet намагається запустити контейнер; в іншому випадку запуск закінчується невдачею. Див. попередньо завантажені образи для отримання деталей.
Семантика кешування базового постачальника образів робить навіть imagePullPolicy: Always ефективним, якщо реєстр доступний. Ваше середовище виконання контейнерів може помітити, що шари образів вже існують на вузлі, так що їх не потрібно знову завантажувати.
Примітка:
Ви повинні уникати використання теґу :latest при розгортанні контейнерів в промисловому оточені, оскільки важко відстежити, яка версія образів запущена, і складніше виконати відкат.
Замість цього використовуйте інший значущий теґ, такий як v1.42.0 і/або хеш.
Щоб переконатися, що Pod завжди використовує ту саму версію образів контейнерів, ви можете вказати хеш образів; замініть <image-name>:<tag> на <image-name>@<digest>
(наприклад, image@sha256:45b23dee08af5e43a7fea6c4cf9c25ccf269ee113168c19722f87876677c5cb2).
При використанні теґів образів, якщо реєстр образів змінив код, який представляє теґ вашого образу, ви могли б отримати суміш Podʼів, що запускають старий і новий код. Дайджест образу унікально ідентифікує конкретну версію образу, тому Kubernetes запускає один і той же код кожного разу, коли він запускає контейнер із вказаним імʼям образу та дайджестом. зазначення образу за допомогою дайджесту виправляє код, який ви запускаєте, так що зміна в реєстрі не може призвести до такого змішаного використання версій.
Є сторонні контролери допуску що змінюють Pod (і шаблони pod), коли вони створюються, так що робоче навантаження визначається на основі хешу образу, а не теґу. Це може бути корисно, якщо ви хочете переконатися, що всі ваші робочі навантаження запускають один і той самий код, незалежно від того, які зміни теґів відбуваються в реєстрі.
Стандартні політики завантаження образів
Коли ви (чи контролер) подаєте новий Pod серверу API, ваш кластер встановлює поле imagePullPolicy при виконанні певних умов:
- якщо ви опускаєте поле
imagePullPolicyта вказуєте хеш для образів контейнерів,imagePullPolicyавтоматично встановлюється вIfNotPresent. - якщо ви опускаєте поле
imagePullPolicyта теґ для образів контейнерів є:latest,imagePullPolicyавтоматично встановлюється вAlways; - якщо ви опускаєте поле
imagePullPolicyта не вказуєте теґ для образів контейнерів,imagePullPolicyавтоматично встановлюється вAlways; - якщо ви опускаєте поле
imagePullPolicyта вказуєте теґ для образів контейнерів, який не є:latest,imagePullPolicyавтоматично встановлюється вIfNotPresent.
Примітка:
Значення imagePullPolicy контейнера завжди встановлюється при першому створенні обʼєкта і не оновлюється, якщо теґ чи хеш образів пізніше зміниться.
Наприклад, якщо ви створите Deployment з образом, теґ якого не є :latest, і пізніше оновите образ цього Deployment до теґу :latest, поле imagePullPolicy не зміниться на Always. Вам слід вручну змінити політику завантаження для будь-якого обʼєкта після його початкового створення.
Обовʼязкове завантаження образів
Якщо ви хочете завжди виконувати завантаження, ви можете зробити одне з наступного:
- Встановіть
imagePullPolicyконтейнера вAlways. - Опустіть
imagePullPolicyі використовуйте:latestяк теґ для образів; Kubernetes встановить політику вAlwaysпри подачі Pod. - Опустіть
imagePullPolicyта теґ для використання образів; Kubernetes встановить політику вAlwaysпри подачі Pod. - Увімкніть контролер допуску AlwaysPullImages.
ImagePullBackOff
Коли kubelet починає створювати контейнери для Pod за допомогою середовища виконання контейнерів, можливо, контейнер перебуває у стані Waiting з причини ImagePullBackOff.
Статус ImagePullBackOff означає, що контейнер не може запуститися через те, що Kubernetes не може завантажити образ контейнера (з причин, таких як невірне імʼя образу або спроба завантаження з приватного реєстру без imagePullSecret). Частина BackOff вказує на те, що Kubernetes буде продовжувати пробувати завантажити образ зі збільшенням інтервалів між спробами.
Kubernetes збільшує інтервал між кожною спробою до тих пір, поки не досягне вбудованого обмеження, яке становить 300 секунд (5 хвилин).
Завантаження образу відповідно до класу середовища виконання
СТАН ФУНКЦІОНАЛУ:
У Kubernetes є альфа-підтримка для виконання завантаження образів на основі класу середовища виконання контейнерів Pod.Kubernetes v1.29 [alpha] (стандартно увімкнено: false)Якщо ви увімкнете функціональну можливість RuntimeClassInImageCriApi, kubelet вказує образи контейнерів кортежем (назва образу, обробник), а не лише назва чи хешем образу. Ваше середовище виконання контейнерів може адаптувати свою поведінку залежно від обраного обробника. Завантаження образів на основі класу середовища виконання буде корисним для контейнерів, що використовують віртуальні машини, таких як контейнери Windows Hyper-V.
Послідовне та паралельне завантаження образів
Типово kubelet завантажує образи послідовно. Іншими словами, kubelet надсилає лише один запит на завантаження образу до служби образів одночасно. Інші запити на завантаження образів мають чекати, поки завершиться обробка того, який знаходиться в процесі.
Вузли приймають рішення про завантаження образу незалежно один від одного. Навіть коли ви використовуєте послідовні запити на завантаження образів, два різні вузли можуть завантажувати один і той самий образ паралельно.
Якщо ви хочете увімкнути паралельне завантаження образів, ви можете встановити поле serializeImagePulls у значення false у конфігурації kubelet. Зі значенням serializeImagePulls встановленим у false, запити на завантаження образів будуть надсилатись до служби образів негайно, і кілька образів буде завантажено одночасно.
При увімкненні паралельного завантаження образів, будь ласка, переконайтеся, що служба образів вашого середовища виконання контейнерів може обробляти паралельне завантаження образів.
Kubelet ніколи не завантажує кілька образів паралельно від імені одного Pod. Наприклад, якщо у вас є Pod із контейнером ініціалізації та контейнером застосунку, завантаження образів для цих двох контейнерів не буде виконуватись паралельно. Однак якщо у вас є два Podʼи, які використовують різні образи, kubelet завантажує образи паралельно для цих двох різних Podʼів, коли увімкнено паралельне завантаження образів.
Максимальна кількість паралельних завантажень образів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [beta]Коли serializeImagePulls встановлено в значення false, kubelet стандартно не обмежує максимальну кількість образів, які завантажуються одночасно. Якщо ви хочете обмежити кількість паралельних завантажень образів, ви можете встановити поле maxParallelImagePulls у конфігурації kubelet. Зі значенням maxParallelImagePulls в n, тільки n образів можуть завантажуватися одночасно, і будь-яке завантаження образу за межами n буде чекати, поки завершиться принаймні одне завантаження образу, яке вже триває.
Обмеження кількості паралельних завантажень образів допоможе уникнути зайвого використання пропускної здатності мережі або дискових операцій вводу/виводу, коли увімкнено паралельне завантаження образів.
Ви можете встановити maxParallelImagePulls на позитивне число, яке більше або рівне 1. Якщо ви встановите maxParallelImagePulls більше або рівне 2, ви повинні встановити serializeImagePulls в значення false. Kubelet не буде запущено з недійсними налаштуваннями maxParallelImagePulls.
Мультиархітектурні образи з індексами образів
Окрім надання бінарних образів, реєстр контейнерів також може обслуговувати індекс образу контейнера. Індекс образу може посилатися на кілька маніфестів образу для версій контейнера, специфічних для архітектури. Ідея полягає в тому, що ви можете мати імʼя для образу (наприклад: pause, example/mycontainer, kube-apiserver) та дозволити різним системам отримувати правильний бінарний образ для використання на їхній архітектурі машини.
Сам Kubernetes зазвичай називає образи контейнерів із суфіксом -$(ARCH). З метою забезпечення сумісності з попередніми версіями, будь ласка, генеруйте старіші образи із суфіксами. Ідея полягає в тому, щоб створити, наприклад, образ pause, який має маніфест для всіх архітектур, та скажімо pause-amd64, який є сумісним з попередніми конфігураціями або файлами YAML, які можуть містити жорстко закодовані образи із суфіксами.
Використання приватних реєстрів
Приватні реєстри можуть вимагати ключі для читання образів з них. Облікові дані можна надати кількома способами:
- Налаштування вузлів для автентифікації в приватному реєстрі
- всі Podʼи можуть читати будь-які налаштовані приватні реєстри
- вимагає конфігурації вузла адміністратором кластера
- Постачальник облікових даних Kubelet для динамічного отримання облікових даних для приватних реєстрів
- kubelet може бути налаштований для використання втулка від постачальника облікових даних для відповідного приватного реєстру.
- Попередньо завантажені образи
- всі Podʼи можуть використовувати будь-які образи, кешовані на вузлі
- вимагає доступу до кореня на всіх вузлах для налаштування
- Вказання ImagePullSecrets на Pod
- лише Podʼи, які надають свої власні ключі, можуть отримувати доступ до приватного реєстру
- Постачальник специфічний для вендора або локальні розширення
- якщо ви використовуєте власну конфігурацію вузла, ви (або ваш постачальник хмари) можете реалізувати власний механізм автентифікації вузла в реєстрі контейнерів.
Ці варіанти пояснюються докладніше нижче.
Налаштування вузлів для автентифікації в приватному реєстрі
Конкретні інструкції щодо встановлення облікових даних залежать від середовища виконання контейнерів та реєстру, який ви вибрали для використання. Вам слід звертатися до документації щодо вашого рішення для отримання найточнішої інформації.
Для прикладу конфігурування приватного реєстру образів контейнерів дивіться завдання Завантаження образу з приватного реєстру. У цьому прикладі використовується приватний реєстр в Docker Hub.
Постачальник облікових даних Kubelet для витягування автентифікованих образів
Примітка:
Цей підхід добре підходить, коли kubelet повинен динамічно отримувати облікові дані реєстру. Зазвичай використовується для реєстрів, наданих хмарними провайдерами, де токени автентифікації мають обмежений термін дії.Ви можете налаштувати kubelet для виклику бінарного втулка, щоб динамічно отримувати облікові дані реєстру для образу контейнера. Це найнадійніший та універсальний спосіб отримання облікових даних для приватних реєстрів, але також вимагає конфігурації kubelet для його увімкнення.
Докладніше дивіться Налаштування постачальника облікових даних образу kubelet.
Тлумачення файлу config.json
Тлумачення config.json відрізняється між оригінальною реалізацією Docker та тлумаченням Kubernetes. У Docker ключі auths можуть вказувати тільки кореневі URL-адреси, тоді як Kubernetes дозволяє використовувати глобальні URL-адреси, а також шляхи, які відповідають префіксу. Єдиним обмеженням є те, що глобальні шаблони (*) повинні включати крапку (.) для кожного піддомену. Кількість піддоменів, що мають збіг, повинна дорівнювати кількості глобальних шаблонів (*.), наприклад:
*.kubernetes.ioне збігатиметься зkubernetes.io, але збігатиметься зabc.kubernetes.io*.*.kubernetes.ioне збігатиметься зabc.kubernetes.io, але збігатиметься зabc.def.kubernetes.ioprefix.*.ioзбігатиметься зprefix.kubernetes.io*-good.kubernetes.ioзбігатиметься зprefix-good.kubernetes.io
Це означає, що файл config.json, подібний до цього, є дійсним:
{
"auths": {
"my-registry.io/images": { "auth": "…" },
"*.my-registry.io/images": { "auth": "…" }
}
}
Операції отримання образів тепер будуть передавати облікові дані CRI контейнеру для кожного дійсного шаблону. Наприклад, образи контейнера, вказані нижче, успішно збігатимуться:
my-registry.io/imagesmy-registry.io/images/my-imagemy-registry.io/images/another-imagesub.my-registry.io/images/my-image
Але не:
a.sub.my-registry.io/images/my-imagea.b.sub.my-registry.io/images/my-image
Kubelet виконує операції отримання образів послідовно для кожного знайденого облікового запису. Це означає, що можливі кілька записів у config.json для різних шляхів:
{
"auths": {
"my-registry.io/images": {
"auth": "…"
},
"my-registry.io/images/subpath": {
"auth": "…"
}
}
}
Тепер, якщо контейнер вказує образ my-registry.io/images/subpath/my-image,
то kubelet спробує завантажити його з обох джерел автентифікації, якщо завантеження з одного з них виявиться невдалим.
Попередньо завантажені образи
Примітка:
Цей підхід підходить, якщо ви можете контролювати конфігурацію вузла. Він не буде надійно працювати, якщо ваш постачальник хмари управляє вузлами та автоматично їх замінює.Типово kubelet намагається отримати кожен образ з вказаного реєстру. Однак якщо властивість imagePullPolicy контейнера встановлена на IfNotPresent або Never,
то використовується локальний образ (переважно або виключно, відповідно).
Якщо ви хочете покладатися на попередньо завантажені образи як заміну автентифікації в реєстрі, вам слід переконатися, що всі вузли кластера мають однакові попередньо завантажені образи.
Це може бути використано для попереднього завантаження певних образів для швидкості або як альтернатива автентифікації в приватному реєстрі.
Всі Podʼи матимуть доступ на читання до будь-яких попередньо завантажених образів.
Вказання ImagePullSecrets для Pod
Примітка:
Це рекомендований підхід для запуску контейнерів на основі образів з приватних реєстрів.Kubernetes підтримує вказання ключів реєстру образів контейнерів для Pod. imagePullSecrets повинні бути всі в тому ж просторі імен, що й Pod. Зазначені Secrets повинні бути типу kubernetes.io/dockercfg або kubernetes.io/dockerconfigjson.
Створення Secret з Docker-конфігом
Вам потрібно знати імʼя користувача, пароль реєстру та адресу електронної пошти клієнта для автентифікації в реєстрі, а також його імʼя хосту. Виконайте наступну команду, підставивши відповідні значення замість написів у верхньому регістрі:
kubectl create secret docker-registry <name> \
--docker-server=DOCKER_REGISTRY_SERVER \
--docker-username=DOCKER_USER \
--docker-password=DOCKER_PASSWORD \
--docker-email=DOCKER_EMAIL
Якщо у вас вже є файл облікових даних Docker, ніж використовувати вищезазначену команду, ви можете імпортувати файл облікових даних як Secrets Kubernetes. Створення Secret на основі наявних облікових даних Docker пояснює, як це зробити.
Це особливо корисно, якщо ви використовуєте кілька приватних реєстрів контейнерів, оскільки kubectl create secret docker-registry створює Secret, який працює лише з одним приватним реєстром.
Примітка:
Podʼи можуть посилатися лише на ключі реєстру образів у своєму власному просторі імен, так що цей процес слід виконати один раз для кожного простору імен.Посилання на imagePullSecrets для Pod
Тепер ви можете створювати Podʼи, які посилаються на цей secret, додавши розділ imagePullSecrets до визначення Pod. Кожен елемент у масиві imagePullSecrets може посилатися тільки на Secret у тому ж просторі імен.
Наприклад:
cat <<EOF > pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo
namespace: awesomeapps
spec:
containers:
- name: foo
image: janedoe/awesomeapp:v1
imagePullSecrets:
- name: myregistrykey
EOF
cat <<EOF >> ./kustomization.yaml
resources:
- pod.yaml
EOF
Це слід робити для кожного Podʼа, який використовує приватний реєстр.
Однак налаштування цього поля можна автоматизувати, встановивши imagePullSecrets в ресурс ServiceAccount.
Перевірте Додавання ImagePullSecrets до облікового запису служби для докладних інструкцій.
Ви можете використовувати це разом із .docker/config.json на рівні вузла. Облікові дані обʼєднанні.
Сценарії використання
Існує кілька рішень для конфігурації приватних реєстрів. Ось деякі типові сценарії використання та рекомендовані рішення.
- Кластер, в якому використовуються лише непроприєтарні (наприклад, відкриті) образи. Немає потреби приховувати образи.
- Використовуйте відкриті образи з відкритого реєстру.
- Конфігурація не потрібна.
- Деякі постачальники хмари автоматично кешують або дзеркалюють відкриті образи, що підвищує доступність та скорочує час їх отримання.
- Використовуйте відкриті образи з відкритого реєстру.
- Кластер, в якому використовуються деякі проприєтарні образи, які повинні бути невидимими для інших компаній, але доступними для всіх користувачів кластера.
- Використовуйте приватний реєстр.
- Можлива ручна конфігурація на вузлах, які повинні мати доступ до приватного реєстру.
- Або запустіть внутрішній приватний реєстр за вашим фаєрволом з відкритим доступом на читання.
- Не потрібна конфігурація Kubernetes.
- Використовуйте сервіс реєстрації образів контейнерів, який контролює доступ до образів.
- Він працюватиме краще з автомасштабуванням кластера, ніж ручна конфігурація вузла.
- Або на кластері, де зміна конфігурації вузла незручна, використовуйте
imagePullSecrets.
- Використовуйте приватний реєстр.
- Кластер із проприєтарними образами, кілька з яких вимагають строгого контролю доступу.
- Переконайтеся, що контролер доступу AlwaysPullImages активний. У противному випадку всі Podʼи потенційно мають доступ до всіх образів.
- Перемістіть конфіденційні дані в ресурс "Secret", а не додавайте їх в образ.
- Багатокористувацький кластер, де кожен орендар потребує власного приватного реєстру.
- Переконайтеся, що контролер доступу AlwaysPullImages активний. У противному випадку всі Podʼи всіх орендарів потенційно мають доступ до всіх образів.
- Запустіть приватний реєстр з обовʼязковою авторизацією.
- Створіть обліковий запис реєстру для кожного орендара, розмістіть його в Secret та внесіть Secret в кожний простір імен орендаря.
- Орендар додає цей Secret до imagePullSecrets кожного простору імен.
Якщо вам потрібен доступ до декількох реєстрів, ви можете створити Secret для кожного реєстру.
Застарілий вбудований постачальник облікових даних kubelet
У старших версіях Kubernetes kubelet мав пряму інтеграцію з обліковими даними хмарного постачальника. Це давало йому можливість динамічно отримувати облікові дані для реєстрів образів.
Існувало три вбудовані реалізації інтеграції облікових записів kubelet: ACR (Azure Container Registry), ECR (Elastic Container Registry) та GCR (Google Container Registry).
Докладніше про застарілий механізм можна прочитати в документації версії Kubernetes, яку ви використовуєте. У версіях Kubernetes від v1.26 до v1.32 він відсутній, тому вам потрібно або:
- налаштувати постачальника облікових записів kubelet на кожному вузлі
- вказати облікові дані для отримання образів, використовуючи
imagePullSecretsта принаймні один Secret
Що далі
- Прочитайте Специфікацію маніфеста образу OCI.
- Дізнайтеся про збирання сміття образів контейнерів.
- Дізнайтеся більше про отримання образу з приватного реєстру.
3.2 - Середовище контейнера
Ця сторінка описує ресурси, доступні контейнерам в середовищі контейнера.
Середовище контейнера
Середовище контейнера Kubernetes надає кілька важливих ресурсів контейнерам:
- Файлову систему, яка є комбінацією образу та одного чи декількох томів.
- Інформацію про сам контейнер.
- Інформацію про інші обʼєкти в кластері.
Інформація про контейнер
hostname контейнера є імʼям Pod, в якому він працює. Воно доступне через команду hostname або виклик функції gethostname у бібліотеці libc.
Імʼя та простір імен Pod доступні як змінні середовища через downward API.
Змінні середовища, визначені користувачем у визначенні Pod, також доступні для контейнера, так само як будь-які статично визначені змінні середовища в образі контейнера.
Інформація про кластер
Список всіх служб, які були активні при створенні контейнера, доступний цьому контейнеру як змінні середовища. Цей список обмежений службами в межах того ж простору імен, що й новий Pod контейнера, та службами керування Kubernetes.
Для служби з імʼям foo, яка повʼязана з контейнером із імʼям bar, визначаються наступні змінні:
FOO_SERVICE_HOST=<хост, на якому працює служба>
FOO_SERVICE_PORT=<порт, на якому працює служба>
Служби мають виділені IP-адреси які доступні для контейнера через DNS, якщо увімкнено надбудову DNS.
Що далі
- Дізнайтеся більше про закріплення обробників за подіями життєвого циклу контейнера.
- Отримайте практичний досвід прикріплення обробників до подій життєвого циклу контейнера.
3.3 - Клас виконання
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.20 [stable]Ця сторінка описує ресурс RuntimeClass та механізм вибору середовища виконання.
RuntimeClass — це функція для вибору конфігурації середовища виконання контейнерів. Конфігурація середовища виконання контейнерів використовується для запуску контейнерів у Pod.
Мотивація
Ви можете встановити різне значення RuntimeClass для різних Pod, щоб забезпечити баланс між продуктивністю та безпекою. Наприклад, якщо частина вашого завдання вимагає високого рівня підтвердження захищеності інформації, ви можете вибрати планування цих Pod так, щоб вони працювали в середовищі виконання контейнерів, яке використовує апаратну віртуалізацію. Таким чином ви скористаєтеся додатковою ізоляцією альтернативного середовища коштом деякого додаткового навантаження.
Ви також можете використовувати RuntimeClass для запуску різних Pod з однаковим середовищем виконання, але з різними налаштуваннями.
Налаштування
- Налаштуйте впровадження CRI на вузлах (залежить від середовища виконання).
- Створіть відповідні ресурси RuntimeClass.
1. Налаштуйте впровадження CRI на вузлах
Конфігурації, доступні через RuntimeClass, залежать від конкретної реалізації інтерфейсу контейнера (CRI). Для отримання інструкцій щодо налаштування перегляньте відповідну документацію (нижче) для вашої реалізації CRI.
Примітка:
Стандартно RuntimeClass передбачає однорідну конфігурацію вузла в усьому кластері (що означає, що всі вузли налаштовані однаковим чином щодо контейнерних середовищ). Щоб підтримувати різнорідні конфігурації вузлів, див. Планування нижче.Кожна конфігурація має відповідний handler, на який посилається RuntimeClass. Handler повинен бути дійсним імʼям DNS-мітки.
2. Створіть відповідні ресурси RuntimeClass
Кожна конфігурація, налаштована на кроці 1, повинна мати асоційованій handler, який ідентифікує конфігурацію. Для кожного handler створіть обʼєкт RuntimeClass.
Ресурс RuntimeClass наразі має всього 2 значущі поля: імʼя RuntimeClass (metadata.name) та handler (handler). Визначення обʼєкта виглядає наступним чином:
# RuntimeClass визначений у групі API node.k8s.io
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
# Імʼя, за яким буде викликано RuntimeClass.
# RuntimeClass - ресурс без простору імен.
name: myclass
# Імʼя відповідної конфігурації CRI
handler: myconfiguration
Імʼя обʼєкта RuntimeClass повинно бути дійсним імʼям DNS-піддомену.
Примітка:
Рекомендується обмежити операції запису RuntimeClass (create/update/patch/delete), щоб вони були доступні тільки адміністраторам кластера. Це, як правило, типове значення. Докладніше див. Огляд авторизації.Використання
Після налаштування RuntimeClass для кластера, ви можете вказати runtimeClassName в специфікації Pod, щоб використовувати його. Наприклад:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
runtimeClassName: myclass
# ...
Це доручить kubelet використовувати названий RuntimeClass для запуску цього Podʼа. Якщо зазначений RuntimeClass не існує або CRI не може виконати відповідний handler, Pod увійде в термінальну фазу Failed. Шукайте відповідну подію для отримання повідомлення про помилку.
Якщо runtimeClassName не вказано, буде використовуватися стандартний обробник, що еквівалентно поведінці при вимкненні функції RuntimeClass.
Конфігурація CRI
Докладніше про налаштування CRI див. в Інсталяції CRI.
containerd
Обробники Runtime налаштовуються через конфігурацію containerd за шляхом
/etc/containerd/config.toml. Дійсні обробники налаштовуються в розділі runtimes:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.${HANDLER_NAME}]
Докладніше див. у документації з конфігурації containerd:
CRI-O
Обробники Runtime налаштовуються через конфігурацію CRI-O за шляхом /etc/crio/crio.conf. Дійсні обробники налаштовуються в таблиці crio.runtime:
[crio.runtime.runtimes.${HANDLER_NAME}]
runtime_path = "${PATH_TO_BINARY}"
Докладніше див. у документації з конфігурації CRI-O.
Планування
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.16 [beta]Зазначаючи поле scheduling для RuntimeClass, ви можете встановити обмеження, щоб
забезпечити, що Podʼи, які працюють із цим RuntimeClass, плануються на вузли, які його підтримують. Якщо scheduling не встановлено, припускається, що цей RuntimeClass підтримується всіма вузлами.
Щоб гарантувати, що Podʼи потрапляють на вузли, які підтримують конкретний RuntimeClass, цей набір вузлів повинен мати спільні мітки, які потім обираються полем runtimeclass.scheduling.nodeSelector. NodeSelector RuntimeClass обʼєднується з nodeSelector Pod під час допуску, фактично беручи перетин множини вузлів, обраних кожним.
Якщо підтримувані вузли позначені, щоб завадити запуску інших Podʼів з іншим RuntimeClass на вузлі, ви можете додати tolerations до RuntimeClass. Як із nodeSelector, tolerations обʼєднуються з tolerations Pod у доступі, фактично беручи обʼєднання множини вузлів, які влаштовують всіх.
Щоб дізнатися більше про налаштування селектора вузла і tolerations, див. Призначення Podʼів вузлам.
Надмірність Pod
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]Ви можете вказати ресурси overhead, що повʼязані із запуском Pod. Вказівка надмірності дозволяє кластеру (включаючи планувальник) враховувати це при прийнятті рішень про Podʼи та ресурси.
Надмірність Podʼа визначається через поле overhead в RuntimeClass. За допомогою цього поля ви можете вказати надмірність запуску Podʼів, що використовують цей RuntimeClass, та забезпечити облік цих надмірностей в Kubernetes.
Що далі
3.4 - Хуки життєвого циклу контейнера
На цій сторінці описано, як контейнери, керовані kubelet, можуть використовувати фреймворк хука життєвого циклу контейнера для запуску коду, викликаного подіями під час управління їх життєвим циклом.
Огляд
Аналогічно багатьом фреймворкам програмування, які мають хуки життєвого циклу компонентів, таким як Angular, Kubernetes надає контейнерам хуки життєвого циклу. Ці хуки дозволяють контейнерам бути в курсі подій у своєму циклі управління та виконувати код, реалізований в обробнику, коли відповідний хук життєвого циклу виконується.
Хуки контейнера
До контейнерів виносяться два хуки:
PostStart
Цей хук виконується негайно після створення контейнера. Однак немає гарантії, що хук виконається до ENTRYPOINT контейнера. До обробника не передаються параметри.
PreStop
Цей хук викликається негайно перед тим, як контейнер буде завершено через запит API або подію управління, таку як невдача проби на живучість/запуску, передумови, конфлікт ресурсів та інші. Звернення до хука PreStop не вдасться, якщо контейнер вже перебуває у стані завершення або виконання, і хук повинен завершити виконання до того, як може бути відправлений сигнал TERM для зупинки контейнера. Відлік пільгового періоду припинення Pod починається до виконання хуку PreStop, тому, незалежно від результату обробника, контейнер врешті-решт закінчиться протягом пільгового періоду припинення Pod. Жодні параметри не передаються обробнику.
Докладний опис поведінки припинення роботи Podʼів можна знайти в Припинення роботи Podʼа.
Реалізації обробника хуків
Контейнери можуть мати доступ до хука, реалізувавши та реєструючи обробник для цього хука. Існують три типи обробників хука, які можна реалізувати для контейнерів:
- Exec — Виконує конкретну команду, таку як
pre-stop.sh, всередині cgroups та namespaces контейнера. Ресурси, спожиті командою, зараховуються на рахунок контейнера. - HTTP — Виконує HTTP-запит до конкретного endpoint в контейнері.
- Sleep — Призупиняє контейнер на вказаний час. Обробник "Sleep" є функцією бета-рівня типово увімкненою через функціональну можливість
PodLifecycleSleepAction.
Примітка:
Увімкніть функціональну можливістьPodLifecycleSleepActionAllowZero, якщо ви хочете встановити тривалість сплячого режиму у нуль секунд (фактично бездіяльність) для ваших хуків життєвого циклу Sleep.Виконання обробника хука
Коли викликається хук управління життєвим циклом контейнера, система управління Kubernetes виконує обробник відповідно до дії хука, httpGet, tcpSocket та sleep виконуються процесом kubelet, а exec виконується в контейнері.
Виклик обробника хука PostStart ініціюється при створенні контейнера, тобто точка входу контейнера ENTRYPOINT і хук PostStart спрацьовують одночасно. Однак, якщо хук PostStart виконується занадто довго або зависає, це може завадити контейнеру перейти у стан running.
Хуки PreStop не викликаються асинхронно від сигналу зупинки контейнера; хук повинен завершити своє виконання до того, як може бути відправлений сигнал TERM. Якщо хук PreStop затримується під час виконання, фаза Pod буде Terminating, і залишиться такою, поки Pod не буде вбито після закінчення його terminationGracePeriodSeconds. Цей період припинення роботи застосовується до загального часу, необхідного як для виконання хука PreStop, так і для зупинки контейнера. Якщо, наприклад, terminationGracePeriodSeconds дорівнює 60, і хук займає 55 секунд для завершення, а контейнер зупиняється нормально через 10 секунд після отримання сигналу, то контейнер буде вбитий перш, ніж він зможе завершити роботу, оскільки terminationGracePeriodSeconds менше, ніж загальний час (55+10), необхідний для цих двох подій.
Якщо хук PostStart або PreStop не вдасться, він вбиває контейнер.
Користувачам слід робити свої обробники хуків якомога легкими. Проте є випадки, коли довгострокові команди мають сенс, наприклад, коли потрібно зберегти стан перед зупинкою контейнера.
Гарантії доставки хуків
Постачання хука призначено бути принаймні одноразовим, що означає, що хук може бути викликано кілька разів для будь-якої події, такої як для PostStart чи PreStop. Це залежить від реалізації хука.
Як правило, здійснюються лише разові доставки. Якщо, наприклад, приймач HTTP-хука не працює і не може приймати трафік, спроба повторно надіслати не відбувається. Однак у деяких рідкісних випадках може статися подвійна доставка. Наприклад, якщо kubelet перезапускається посеред надсилання хука, хук може бути повторно відправлений після того, як kubelet повернеться.
Налагодження обробників хуків
Логи обробника хука не відображаються в подіях Pod. Якщо обробник відмовляється з будь-якої причини, він розсилає подію. Для PostStart це подія FailedPostStartHook, а для PreStop це подія FailedPreStopHook. Щоб згенерувати подію FailedPostStartHook, змініть lifecycle-events.yaml файл, щоб змінити команду postStart на "badcommand" та застосуйте його. Ось приклад виводу події, який ви побачите після виконання kubectl describe pod lifecycle-demo:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7s default-scheduler Successfully assigned default/lifecycle-demo to ip-XXX-XXX-XX-XX.us-east-2...
Normal Pulled 6s kubelet Successfully pulled image "nginx" in 229.604315ms
Normal Pulling 4s (x2 over 6s) kubelet Pulling image "nginx"
Normal Created 4s (x2 over 5s) kubelet Created container lifecycle-demo-container
Normal Started 4s (x2 over 5s) kubelet Started container lifecycle-demo-container
Warning FailedPostStartHook 4s (x2 over 5s) kubelet Exec lifecycle hook ([badcommand]) for Container "lifecycle-demo-container" in Pod "lifecycle-demo_default(30229739-9651-4e5a-9a32-a8f1688862db)" failed - error: command 'badcommand' exited with 126: , message: "OCI runtime exec failed: exec failed: container_linux.go:380: starting container process caused: exec: \"badcommand\": executable file not found in $PATH: unknown\r\n"
Normal Killing 4s (x2 over 5s) kubelet FailedPostStartHook
Normal Pulled 4s kubelet Successfully pulled image "nginx" in 215.66395ms
Warning BackOff 2s (x2 over 3s) kubelet Back-off restarting failed container
Що далі
- Дізнайтеся більше про Середовище контейнера.
- Отримайте практичний досвід, прикріплюючи обробників до подій життєвого циклу контейнера.
4 - Робочі навантаження
Отримайте розуміння про Podʼи, найменші обʼєкти виконання в Kubernetes, та вищі рівні абстракції, які допомагають вам їх запускати.
Робоче навантаження є застосунком, який запущено в Kubernetes. Неважливо чи є ваше робоче навантаження одним компонентом, чи кількома, які працюють разом, в Kubernetes ви запускаєте його всередині набору Podʼів. В Kubernetes Pod представляє набір запущених контейнерів у вашому кластері.
Podʼи Kubernetes мають кінцевий життєвий цикл. Наприклад, як тільки Pod запущено у вашому кластері, будь-яка критична помилка на вузлі, де запущено цей Pod, означає, що всі Podʼи на цьому вузлі зазнають збою. Kubernetes розглядає цей рівень збою як кінцевий: вам потрібно створити новий Pod, щоб відновити роботу, навіть якщо вузол пізніше відновить свою роботу.
Однак, керувати кожним Pod окремо може бути складно. Замість цього, ви можете використовувати ресурси робочого навантаження, які керують набором Podʼів за вас. Ці ресурси налаштовують контролери, які переконуються, що правильна кількість Podʼів потрібного виду працює, щоб відповідати стану, який ви вказали.
Kubernetes надає кілька вбудованих ресурсів робочого навантаження:
- Deployment та ReplicaSet (що є заміною застарілого типу ресурсу ReplicationController). Deployment є хорошим вибором для керування робочим навантаженням, яке не зберігає стану, де будь-який Pod у Deployment може бути замінений, якщо це потрібно.
- StatefulSet дозволяє вам запускати один або кілька повʼязаних Podʼів, які відстежують стан певним чином. Наприклад, якщо ваше робоче навантаження постійно записує дані, ви можете запустити StatefulSet, який поєднує кожен Pod з PersistentVolume. Ваш код, який працює в Pod для цього StatefulSet, може реплікувати дані на інші Podʼи в цьому StatefulSet, щоб покращити загальну надійність.
- DaemonSet визначає Podʼи які надають можливості, що локальними для вузлів. Кожного разу, коли ви додаєте вузол до свого кластера, який відповідає специфікації в DaemonSet, панель управління планує Pod для цього DaemonSet на новому вузлі. Кожен Pod в DaemonSet виконує роботу, схожу на роботу системного демона у класичному Unix/POSIX сервері. DaemonSet може бути фундаментальним для роботи вашого кластера, як, наприклад, втулок мережі кластера, він може допомогти вам керувати вузлом, або надати додаткову поведінку, яка розширює платформу контейнерів, яку ви використовуєте.
- Job та CronJob надають різні способи визначення завдань, які виконуються до завершення та зупиняються. Ви можете використовувати Job для визначення завдання, яке виконується до завершення, тільки один раз. Ви можете використовувати CronJob для запуску того ж Job кілька разів згідно з розкладом.
В екосистемі Kubernetes ви можете знайти ресурси робочого навантаження від сторонніх розробників, які надають додаткові можливості. Використовуючи визначення власних ресурсів, ви можете додати ресурс робочого навантаження від стороннього розробника, якщо ви хочете використовувати конкретну функцію, яка не є частиною основної функціональності Kubernetes. Наприклад, якщо ви хочете запустити групу Podʼів для вашого застосунку, але зупинити роботу незалежно від того, чи доступні всі Podʼи (можливо, для якогось розподіленого завдання великого обсягу), ви можете реалізувати або встановити розширення, яке надає цю функцію.
Що далі
Так само як і дізнаючись про кожний різновид API для керування робочим навантаженням, ви можете дізнатись, як виконати конкретні завдання:
- Запуск застосунку stateless використовуючи Deployment
- Запуск застосунку stateful як одиничного екземпляру чи як реплікованого набору
- Викоання автоматизованих завдань з CronJob
Щоб дізнатись про механізми Kubernetes для відокремлення коду від конфігурації, відвідайте сторінку Конфігурація.
Існують два концепти, які надають фонову інформацію про те, як Kubernetes керує Podʼами для застосунків:
- Збір сміття приводить до ладу обʼєкти у вашому кластері після того, як їх власний ресурс був видалений.
- Контролер time-to-live after finished видаляє Jobʼи після того, як визначений час пройшов після їх завершення.
Як тільки ваш застосунок працює, ви, можливо, захочете зробити його доступними в Інтернеті як Service або, для вебзастосунків, використовуючи Ingress.
4.1 - Podʼи
Podʼи — найменші обчислювальні одиниці, які ви можете створити та керувати ними в Kubernetes.
Pod (як у випадку з групою китів або гороховим стручком) — це група з одного або кількох контейнерів, які мають спільні ресурси зберігання та мережі, а також специфікацію щодо того, як запускати контейнери. Вміст Podʼа завжди розташований та запускається разом, та працює в спільному контексті. Pod моделює "логічний хост" для вашого застосунку: він містить один або кілька контейнерів застосунку, які мають відносно тісний звʼязок один з одним. По за контекстом хмар, застосунки, що виконуються на одному фізичному або віртуальному компʼютері, аналогічні застосункам, що виконуються на одному логічному хості.
Так само як і контейнери застосунків, Podʼи можуть містити контейнери ініціалізації, які запускаються під час старту Podʼа. Ви також можете впровадити тимчасові контейнери для налагодження, якщо ваш кластер це підтримує.
Що таке Pod?
Примітка:
Вам потрібно встановити середовище виконання контейнерів на кожному вузлі кластера, щоб контейнери могли працювати там.Спільний контекст Podʼа — це набір Linux-просторів імен, cgroups та, можливо, інших аспектів ізоляції — ті самі речі, які ізолюють контейнер. В межах контексту Podʼа окремі застосунки можуть мати додаткові підізоляції.
Pod схожий на набір контейнерів із спільними просторами імен та спільними ресурсами файлових систем.
Podʼи в кластері Kubernetes використовуються двома основними способами:
- Podʼи, що керують одним контейнером. Модель "один контейнер на Pod" є найпоширенішим використанням в Kubernetes. У цьому випадку Pod можна розглядати як обгортку навколо одного контейнера; Kubernetes керує Podʼами, а не контейнерами безпосередньо.
- Podʼи, що керують кількома контейнерами, які мають працювати разом. Pod може інкапсулювати застосунок, який складається з кількох розміщених разом контейнерів, які тісно повʼязані та мають спільні ресурси. Такі контейнери утворюють єдиний обʼєкт.
Група кількох контейнерів, розміщених разом в одному Podʼі є відносно складним прикладом. Ви повинні використовувати цей шаблон тільки в конкретних випадках, коли ваші контейнери тісно повʼязані.
Вам не треба запускати кілька контейнерів для забезпечення реплікації (для підтримання стійкості чи місткості); якщо вам потрібно кілька реплік, дивіться ресурси робочих навантажень.
Використання Podʼів
Нижче наведено приклад Pod, який складається з контейнера, який запускає образ nginx:1.14.2.
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Для створення Podʼа, показаного вище, виконайте наступну команду:
kubectl apply -f https://k8s.io/examples/pods/simple-pod.yaml
Як правило Podʼи не створюються напряму, навіть одиничні Podʼи. Замість цього, створюйте їх за допомогою ресурсів робочих навантажень. Дивіться Робота з Podʼами для отримання додаткової інформації про те, як Podʼи використовуються разом з ресурсами робочих навантажень.
Ресурси навантаження для керування Podʼами
Зазвичай у вас немає потреби у створенні окремих Pod напряму в Kubernetes, навіть одиничних Podʼів. Натомість створюйте їх за допомогою ресурсів робочих навантажень, таких як Deployment або Job. Якщо ваші Podʼи потребують відстеження стану, розгляньте використання ресурсу StatefulSet.
Кожен Pod призначений для запуску одного екземпляра застосунку. Якщо ви хочете масштабувати свій застосунок горизонтально (щоб надати більше ресурсів, запустивши більше екземплярів), вам слід використовувати кілька Podʼів, по одному для кожного екземпляра. У Kubernetes це зазвичай називається реплікацією. Репліковані Podʼи створюються та керуються як група ресурсів робочих навантажень разом з їх контролером.
Ознайомтесь з Podʼи та контролери для отримання додаткової інформації про те, як Kubernetes використовує ресурси робочих навантажень та їх контролери для реалізації масштабування та автоматичного відновлення роботи застосунку.
Podʼи можуть надавати два види спільних ресурсів для своїх підпорядкованих контейнерів: мережу та зберігання.
Робота з Podʼами
Ви навряд чи створюватимете окремі Pod напряму в Kubernetes, навіть одиничні Podʼи. Це тому, що Podʼи спроєктовано бути відносно ефемерними, одноразовими обʼєктами, які можуть бути втрачені в будь-який момент. Коли Pod створено (чи це зроблено вами, чи це зроблено автоматично за допомогою контролера), новий Pod планується на виконання на вузлі вашого кластера. Pod залишається на цьому вузлі до тих пір, поки він не завершить роботу, обʼєкт Pod видалено, Pod виселено за відсутності ресурсів, або вузол зазнав збою.
Примітка:
Перезапуск контейнера в Pod не слід плутати з перезапуском Podʼа. Pod — це не процес, а середовище для запуску контейнера(ів). Pod існує до тих пір, поки його не видалено.Назва Podʼа має бути дійсним DNS-піддоменом, але це може призвести до неочікуваних результатів для імені хоста Podʼа. Для найкращої сумісності, імʼя має відповідати більш обмеженим правилам для DNS-мітки.
Операційна система Podʼа
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.25 [stable]Ви маєте вказати значення поля .spec.os.name як linux або windows, щоб вказати ОС, на якій ви хочете запустити Pod. Ці дві ОС підтримуються Kubernetes. У майбутньому цей список може бути розширений.
У Kubernetes v1.32, значення .spec.os.name не впливає на те, як kube-scheduler вибирає вузол для запуску Podʼа. У будь-якому кластері, де існує більше однієї операційної системи для запуску вузлів, ви повинні правильно встановити мітку kubernetes.io/os на кожному вузлі та визначити Podʼи з використанням nodeSelector на основі мітки операційної системи. Kube-scheduler призначає вашому Podʼа вузол на основі інших критеріїв і може або не може вдало вибрати відповідне розміщення вузлів, де операційна система вузла відповідає контейнерам в такому Podʼі. Стандарти безпеки Pod також використовують це поле, щоб уникнути застосування політик, які не є відповідними для цієї операційної системи.
Podʼи та контролери
Ви можете використовувати ресурси робочих навантажень для створення та керування Podʼами. Контролери ресурсів опікуються реплікацією та розгортанням Podʼів, а також автоматичним відновленням роботи застосунку в разі відмови. Наприклад, якщо Node впав, контролер помітить, що Pod на цьому вузлі перестав працювати, він створить заміну Podʼа. Планувальник поміщає Pod заміну до нового працездатного вузла.
Ось кілька прикладів ресурсів робочих навантажень, які керують одним чи більше Podʼами:
Pod templates
Контролери ресурсів робочих навантажень створюють Pod з pod template та керують цими Podʼом від вашого імені.
PodTemplate — це специфікація для створення Pod, і вона включена в ресурси робочих навантажень, такі як Deployment, Job та DaemonSet.
Кожен контролер ресурсів робочих навантажень використовує PodTemplate всередині обʼєкта робочого навантаження для створення фактичних Podʼів. PodTemplate є частиною бажаного стану будь-якого ресурсу робочого навантаження, який ви використовуєте для запуску вашого застосунку.
Коли ви створюєте Pod, ви можете додати змінні оточення в шаблон Podʼа для контейнерів, які запускаються в Podʼі.
Приклад нижче — це маніфест простого Job з template, який запускає один контейнер. Контейнер в цьому Podʼі виводить повідомлення, а потім призупиняється.
apiVersion: batch/v1
kind: Job
metadata:
name: hello
spec:
template:
# Це шаблон Podʼа
spec:
containers:
- name: hello
image: busybox:1.28
command: ['sh', '-c', 'echo "Hello, Kubernetes!" && sleep 3600']
restartPolicy: OnFailure
# Кінець щаблону Podʼа
Зміна template або перемикання на новий template не має прямого впливу на Podʼи, які вже існують. Якщо ви змінюєте template Podʼа для ресурсу робочого навантаження, цей ресурс має створити Pod заміну, який використовує оновлений template.
Наприклад, контролер StatefulSet переконується, що запущені Pod відповідають поточному template для кожного обʼєкта StatefulSet. Якщо ви редагуєте StatefulSet, щоб змінити його template, StatefulSet починає створювати нові Pod на основі оновленого template. З часом всі старі Pod замінюються новими і оновлення завершується.
Кожен ресурс робочого навантаження реалізує власні правила для обробки змін у template Podʼа. Якщо ви хочете дізнатися більше про StatefulSet, прочитайте Стратегія оновлення в посібнику StatefulSet Basics.
На вузлах kubelet безпосередньо не спостерігає або керує жодними деталями щодо template Podʼа та оновлень; ці деталі абстраговані. Ця абстракція та розділення відповідальностей спрощує семантику системи та робить можливим розширення поведінки кластера без зміни наявного коду.
Оновлення та заміна Podʼів
Як зазначено в попередньому розділі, коли template Podʼа для ресурсу робочого навантаження змінюється, контролер створює нові Podʼи на основі оновленого template замість оновлення або латання наявних Podʼів.
Kubernetes не забороняє вам керувати Pod напряму. Ви можете оновлювати деякі поля запущеного Pod, на місці. Однак операції оновлення Pod, такі як patch та replace, мають деякі обмеження:
- Більшість метаданих про Pod є незмінними. Наприклад, ви не можете змінити поля
namespace,name,uidабоcreationTimestamp; полеgenerationє унікальним. Воно приймає лише оновлення, які збільшують поточне значення поля. - Якщо
metadata.deletionTimestampвстановлено, новий запис не може бути доданий до спискуmetadata.finalizers. - Оновлення Pod може не змінювати поля, крім
spec.containers[*].image,spec.initContainers[*].image,spec.activeDeadlineSecondsабоspec.tolerations. Дляspec.tolerationsви можете додавати лише нові записи. - Коли ви оновлюєте
spec.activeDeadlineSeconds, дозволені два типи оновлень:- встановлення непризначеному полю позитивного числа;
- оновлення поля з позитивного числа на менше, невідʼємне число.
Спільні ресурси та комунікація
Podʼи дозволяють контейнерам спільно використовувати ресурси та спілкуватися один з одним.
Збереження в Podʼах
Кожен Pod може вказати набір спільних ресурсів зберігання. Всі контейнери в Pod можуть отримати доступ до спільних томів, що дозволяє цим контейнерам спільно використовувати дані. Також томи дозволяють постійним даним в Pod вижити в разі перезапуску одного з контейнерів. Дивіться Зберігання для отримання додаткової інформації про те, як Kubernetes реалізує спільне зберігання та робить його доступним для Podʼів.
Мережі та Pod
Кожен Pod отримує власну унікальну IP-адресу для кожного сімейства адрес. Кожен контейнер в Pod використовує спільний простір імен мережі, включаючи IP-адресу та мережеві порти. В межах Pod (і тільки там) контейнери, які належать до Pod, можуть спілкуватися один з одним, використовуючи localhost. Коли контейнери в Pod спілкуються з іншими обʼєктами по за Podʼом, вони повинні координуватись, як вони використовують спільні мережеві ресурси (такі як порти). В межах Pod контейнери спільно використовують IP-адресу та порти, і можуть знаходити один одного через localhost. Контейнери в різних Podʼах мають власні IP-адреси та не можуть спілкуватися за допомогою міжпроцесового звʼязку ОС без спеціальної конфігурації. Контейнери, які хочуть взаємодіяти з контейнером, що працює в іншому Pod, можуть використовувати IP-мережу для комунікації.
Контейнери в Pod бачать системне імʼя хоста таким самим, як і вказане name для Pod. Більше про це ви можете прочитати в розділі мережі.
Налаштування безпеки Podʼів
Для встановлення обмежень безпеки на Podʼи та контейнери використовуйте поле securityContext у специфікації Podʼа. Це поле дозволяє вам здійснювати докладний контроль над тим, що може робити Pod або окремі контейнери. Наприклад:
- Відкидайте конкретні можливості Linux, щоб уникнути впливу CVE.
- Примусово запускайте всі процеси в Podʼі як користувач не-root або як певний користувач або ідентифікатор групи.
- Встановлюйте конкретний профіль seccomp.
- Встановлюйте параметри безпеки Windows, такі як те, чи працюють контейнери як HostProcess.
Увага:
Ви також можете використовувати контекст безпеки Podʼа, щоб увімкнути privileged mode у контейнерах Linux. Привілейований режим перевизначає багато інших параметрів безпеки у контексті безпеки. Уникайте використання цього параметра, якщо ви можете надати еквівалентні дозволи, використовуючи інші поля в контексті безпеки. У Kubernetes 1.26 та пізніших версіях ви також можете запускати контейнери Windows в схожому привілейованому режимі, встановивши прапорецьwindowsOptions.hostProcess у контексті безпеки специфікації Podʼа. Для отримання деталей та інструкцій див. Створення Podʼа з Windows HostProcess.- Щоб дізнатися про обмеження безпеки на рівні ядра, які ви можете використовувати, див. Обмеження безпеки ядра Linux для Podʼів та контейнерів.
- Для отримання додаткової інформації про контекст безпеки Podʼа див. Налаштування контексту безпеки для Podʼа або контейнера.
Статичні Podʼи
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.22 [stable]Static Pods керуються безпосередньо демоном kubelet на конкретному вузлі, без спостереження з боку сервера API. У той час як більшість Podʼів керуються панеллю управління (наприклад, Deployment), для статичних Podʼів kubelet безпосередньо наглядає за кожним статичним Pod (та перезапускає його, якщо він падає).
Статичні Podʼи завжди привʼязані до одного Kubeletʼу на конкретному вузлі. Основне використання статичних Podʼів — це запуск самостійної панелі управління: іншими словами, використання kubelet для нагляду за окремими компонентами панелі управління.
Kublet автоматично намагається створити mirror Pod на сервері API Kubernetes для кожного статичного Pod. Це означає, що Pod, які працюють на вузлі, видно на сервері API, але ними не можна керувати звідти. Дивіться Створення статичних Podʼів для отримання додаткової інформації.
Примітка:
Розділspec статичного Pod не може посилатися на інші API-обʼєкти (наприклад, ServiceAccount, ConfigMap, Secret тощо).Як Podʼи керують кількома контейнерами
Podʼи спроєктовано для підтримки кількох співпрацюючих процесів (таких як контейнери), які утворюють єдиний обʼєкт служби. Контейнери в Pod автоматично спільно розміщуються та плануються на тому ж фізичному або віртуальному компʼютері в кластері. Контейнери можуть спільно використовувати ресурси та залежності, спілкуватися один з одним та координувати, коли та як вони завершують роботу.
Podʼи в Kubernetes можуть керувати одним або кількома контейнерами двома способами:
- Podʼи, що керують одним контейнером. Модель "один контейнер на Pod" є найпоширенішим використанням в Kubernetes. У цьому випадку Pod можна розглядати як обгортку навколо одного контейнера; Kubernetes керує Podʼами, а не контейнерами безпосередньо.
- Podʼи, що керують кількома контейнерами, які мають працювати разом. Pod може інкапсулювати застосунок, який складається з кількох розміщених разом контейнерів, які тісно повʼязані та мають спільні ресурси. Ці спільно розташовані контейнери утворюють єдину цілісну службу — наприклад, один контейнер обслуговує дані, збережені в спільному томі, для загального доступу, тоді як окремий контейнер sidecar оновлює ці файли. Pod обгортає ці контейнери, ресурси сховища та тимчасову мережеву ідентичність разом як єдину одиницю.
Наприклад, у вас може бути контейнер, який виконує функції вебсервера для файлів у спільному томі, та окремий "sidecar" контейнер, який оновлює ці файли з віддаленого джерела, як показано на наступній діаграмі:

Деякі Podʼи мають контейнери ініціалізації та контейнери застосунку. Типово, контейнери ініціалізації запускаються та завершують роботу перед тим, як почнуть працювати контейнери застосунку.
У вас також може бути "sidecar" контейнер, який виконує додаткові функції для контейнера застосунку, наприклад, реалізує service mesh.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.29 [beta]Типово увімкнена функціональна можливість SidecarContainers дозволяє вам вказати restartPolicy: Always для контейнерів ініціалізації. Встановлення політики перезапуску Always гарантує, що контейнери, там де ви встановили, будуть вважатися як sidecar та працювати протягом усього життєвого циклу Pod. Контейнери, які явно визначені як sidecar контейнери, стартують до запуску основного застосунку Podʼа та працюють допоки Pod не завершить роботу.
Перевірки контейнерів
Probe — це діагностика, яку періодично виконує kubelet на контейнері. Для виконання діагностики kubelet може використовувати різні дії:
ExecAction(виконується за допомогою процесу виконання контейнера)TCPSocketAction(перевіряється безпосередньо the kubelet)HTTPGetAction(перевіряється безпосередньо kubelet)
Ви можете дізнатися більше про перевірки в документації про життєвий цикл Podʼів
Що далі
- Дізнайтесь про життєвий цикл Podʼів.
- Дізнайтесь про RuntimeClass та як ви можете використовувати його для налаштування різних Pod з різними конфігураціями середовища виконання контейнера.
- Дізнайтесь про PodDisruptionBudget та як ви можете використовувати його для керування доступністю застосунку під час збоїв.
- Pod є ресурсом найвищого рівня в Kubernetes REST API. Обʼєкт Pod детально описує його.
- The Distributed System Toolkit: Patterns for Composite Containers пояснює загальні макети для Pod з більш ніж одним контейнером.
- Дізнайтесь про Топологію обмежень розподілу Podʼів
Для розуміння контексту того, чому Kubernetes обгортає загальний API Pod іншими ресурсами (такими як StatefulSets або Deployments), ви можете прочитати про попередні роботи, включаючи:
4.1.1 - Життєвий цикл Podʼа
Ця сторінка описує життєвий цикл Podʼа. Podʼи слідують визначеному життєвому циклу, починаючи з фази Pending, переходячи до фази Running, якщо принаймні один з його основних контейнерів запускається добре, а потім до фаз Succeeded або Failed, залежно від того, чи завершився будь-який контейнер у Pod з помилкою.
Podʼи, подібно окремим контейнерам застосунків, вважаються відносно ефемерними (а не постійними) обʼєктами. Podʼи створюються, отримують унікальний ідентифікатор (UID) і призначаються вузлам, де вони залишаються до моменту завершення (відповідно до політики перезапуску) або видалення. Якщо вузол зазнає збою, Podʼи, призначені до цього вузла, призначаються для видалення після періоду затримки.
Тривалість життя Podʼа
Поки Pod працює, kubelet може перезапускати контейнери, щоб вирішити деякі види несправностей. У межах Podʼа Kubernetes відстежує різні стани контейнера і визначає дії, які слід вжити, щоб знову забезпечити справність Podʼів.
В API Kubernetes у Pod є як специфікація, так і фактичний стан. Стан для обʼєкта Pod складається з набору станів Podʼа. Ви також можете додавати власні дані готовності в дані стани для Podʼів, якщо це корисно для вашого застосунку.
Podʼи плануються лише один раз протягом свого життя; призначення Podʼа до певного вузла називається привʼязка, а процес вибору який вузол використовувати, називається плануванням. Після того, як Pod було заплановано і привʼязано до вузла, Kubernetes намагається запустити цей Pod на цьому вузлі. Pod працює на цьому вузлі, доки не зупиниться, або доки його не буде завершено; якщо Kubernetes не може запустити Pod на вибраному вузлі вузлі (наприклад, якщо вузол аварійно завершить роботу до запуску Podʼа), то цей конкретний Pod ніколи не запуститься.
Ви можете використати Готовність Podʼів до планування щоб затримати планування Podʼа, доки не буде видалено всі його scheduling gates. Наприклад, ви можете визначити набір Podʼів, але запустити планування лише після того, як всі Podʼи будуть створені.
Podʼи та усунення несправностей
Якщо один з контейнерів у Podʼі виходить з ладу, Kubernetes може спробувати перезапустити саме цей контейнер. Щоб дізнатися більше, прочитайте Як Podʼи вирішують проблеми з контейнерами.
Podʼи можуть вийти з ладу таким чином, що кластер не зможе відновитися, і в такому випадку Kubernetes не намагається далі відновлювати Pod; замість цього Kubernetes видаляє Pod і покладається на інші компоненти для забезпечення автоматичного відновлення.
Якщо Pod заплановано на вузол і цей вузол вийшов з ладу, то цей Pod вважається несправним, і Kubernetes зрештою видаляє його. Pod не переживе виселення через нестачу ресурсів або обслуговування вузла.
У Kubernetes використовується абстракція вищого рівня, яка називається контролер, яка відповідає за роботу керуванням відносно одноразовими екземплярами Podʼів.
Даний Pod (визначений UID) ніколи не "переплановується" на інший вузол; замість цього, цей Pod може бути замінений новим, майже ідентичним Podʼом. Якщо ви створюєте новий Pod, він може навіть мати ту саму назву (як у .metadata.name), що й старий Pod, але заміна буде мати інший .metadata.uid, ніж старий Pod.
Kubernetes не гарантує, що заміну існуючого Podʼа буде заплановано на на той самий вузол, де був старий Pod, який замінюється.
Повʼязані терміни служби
Коли говорять, що щось має такий самий термін життя, як і Pod, наприклад volume, це означає, що ця річ існує стільки часу, скільки існує цей конкретний Pod (з таким самим UID). Якщо цей Pod буде видалений з будь-якої причини, і навіть якщо буде створений ідентичний замінник, повʼязана річ (у цьому прикладі — том) також буде знищена і створена знову.
Малюнок 1.
Багатоконтейнерний Pod, який містить механізм отримання файлів sidecar і веб-сервер. Pod використовує ефемерний том emptyDir для спільного сховища для контейнерів.
Фази Pod
Поле status обʼєкта PodStatus Podʼа містить поле phase.
Фази Podʼа — це простий, високорівневий підсумок того, на якому етапі свого життєвого циклу знаходиться Pod. Фаза не призначена бути всеосяжним підсумком спостережень за станом контейнера чи Podʼа, і бути процесом за спостереженням стану.
Кількість та значення фаз Podʼа є строго прописаними. Крім того, що зазначено тут, не слід вважати, що щось відомо про Podʼи з певним значенням phase.
Ось можливі значення для phase:
| Значення | Опис |
|---|---|
Pending | Pod прийнятий кластером Kubernetes, але один чи кілька контейнерів ще не було налаштовано та готові до запуску. Це включає час, який Pod витрачає на очікування планування, а також час, який витрачається на завантаження образів контейнерів з мережі. |
Running | Pod привʼязаний до вузла, і всі контейнери створені. Принаймні один контейнер все ще працює або перебуває у процесі запуску чи перезапуску. |
Succeeded | Всі контейнери в Podʼі завершили роботу успішно і не будуть перезапущені. |
Failed | Всі контейнери в Podʼі завершили роботу, і принаймні один контейнер завершився з помилкою. Іншими словами, контейнер вийшов зі статусом, відмінним від нуля, або його роботу завершила система, і контейнер не налаштований на автоматичний перезапуск. |
Unknown | З якоїсь причини не вдалося отримати стан Podʼа. Ця фаза, як правило, виникає через помилку в комунікації з вузлом, де повинен виконуватися Pod. |
Примітка:
Якщо Podʼу не вдається кілька разів підряд стартувати, у полі Status деяких команд kubectl може зʼявитися відмітка CrashLoopBackOff. Аналогічно, під час видалення Podʼа у полі Status деяких команд kubectl може зʼявитися відмітка Terminating.
Переконайтеся, що ви не плутаєте Status, поле відображення kubectl, призначене для інтуїтивного сприйняття користувача, з phase. Фаза тесту є явною частиною моделі даних Kubernetes і документації Pod API.
NAMESPACE NAME READY STATUS RESTARTS AGE
alessandras-namespace alessandras-pod 0/1 CrashLoopBackOff 200 2d9h
Pod отримує час на відповідне завершення, який типово становить 30 секунд. Ви можете використовувати прапорець --force для примусового завершення роботи Podʼа.
Починаючи з Kubernetes 1.27, kubelet переводить видалені Podʼи, крім статичних Podʼів та примусово видалених Podʼів без завершувача, в термінальну фазу (Failed або Succeeded залежно від статусів exit контейнерів Podʼа) перед їх видаленням із сервера API.
Якщо вузол вмирає або відключається від іншої частини кластера, Kubernetes застосовує політику встановлення phase всіх Podʼів на втраченому вузлі у Failed.
Стани контейнера
Окрім фаз Podʼа загалом Kubernetes відстежує стан кожного контейнера всередині Podʼа. Ви можете використовувати хуки життєвого циклу контейнера, щоб запускати події на певних етапах життєвого циклу контейнера.
Як тільки планувальник призначає Pod вузлу, kubelet починає створювати контейнери для цього Podʼа, використовуючи середовище виконання контейнерів. Існує три можливі стани контейнера: Waiting (Очікування), Running (Виконання) та Terminated (Завершено).
Щоб перевірити стан контейнерів Podʼа, ви можете використовувати kubectl describe pod <імʼя-пода>. Вивід показує стан для кожного контейнера в межах цього Podʼа.
Кожен стан має конкретне значення:
Waiting
Якщо контейнер не перебуває в стані або Running, або Terminated, то він знаходиться в стані Waiting (Очікування). Контейнер в стані Waiting все ще виконує операції, які він потребує для завершення запуску: наприклад, витягує образ контейнера із реєстру образів контейнерів або застосовує Secret. Коли ви використовуєте kubectl для опитування Podʼа із контейнером, який перебуває в стані Waiting, ви також бачите поле Reason, щоб узагальнити причину, чому контейнер знаходиться в цьому стані.
Running
Статус Running вказує на те, що виконання контейнера відбувається без проблем. Якщо існує налаштований хук postStart — його роботу завершено. Коли ви використовуєте kubectl для опитування Podʼа із контейнером, який перебуває в стані Running, ви також бачите інформацію про те, коли контейнер увійшов в стан Running.
Terminated
Контейнер в стані Terminated розпочав виконання і потім або завершив його успішно, або зазнав відмови з певних причин. Коли ви використовуєте kubectl для опитування Podʼа із контейнером, який перебуває в стані Terminated, ви бачите причину, код виходу та час початку та завершення періоду виконання цього контейнера.
Якщо у контейнера є налаштований хук preStop, цей хук запускається перед тим, як контейнер увійде в стан Terminated.
Як Podʼи вирішують проблеми з контейнерами
Kubernetes порається з відмовами контейнерів в межах Podʼів за допомогою політики перезапуску, визначеної в spec Podʼа. Ця політика визначає, як Kubernetes реагує на виходи контейнерів через помилки або інші причини, які складаються з наступних етапів:
- Початковий збій: Kubernetes намагається негайно перезапустити контейнер на основі політики перезапуску Podʼа.
- Повторні збої: Після початкового збою Kubernetes застосовує експоненційну затримку для наступних перезапусків, описано в
restartPolicy. Це запобігає швидким, повторним спробам перезапуску, що може перенавантажити систему. - Стан
CrashLoopBackOff: Це означає, що механізм затримки працює для певного контейнера, який знаходиться в циклі збоїв, невдач і постійного перезапуску. - Скидання затримки: Якщо контейнер успішно працює протягом певного часу (наприклад, 10 хвилин), Kubernetes скидає затримку, розглядаючи будь-який новий збій як перший.
На практиці, CrashLoopBackOff — це стан або подія, яку можна помітити у виводі команди kubectl, при отриманні опису або перегляді списку Podʼів, коли контейнер в Podʼі не запускається належним чином, а потім безперервно намагається запуститися, але безуспішно.
Іншими словами, коли контейнер увійшов у цикл збоїв, Kubernetes застосовує експоненційну затримку, про яку було згадано в політиці перезапуску контейнера. Цей механізм запобігає збійному контейнеру перевантажувати систему безперервними невдалими спробами запуску.
CrashLoopBackOff може бути спричинений проблемами, такими як:
- Помилки застосунків, які призводять до виходу контейнера.
- Помилки конфігурації, такі як неправильні змінні середовища або відсутність конфігураційних файлів.
- Обмеження ресурсів, коли контейнеру може бракувати памʼяті або процесорного часу для правильного запуску.
- Невдалі перевірки готовності, якщо застосунок не починає обслуговувати запити у передбачений час.
- Проблеми контейнерних перевірок готовності або перевірок запуску, що повертають результат
Failure, як згадано у розділі про перевірки.
Щоб розібратися у причинах CrashLoopBackOff проблеми, користувач може:
- Перевірити логи: Використовуйте
kubectl logs <name-of-pod>, щоб перевірити логи контейнера. Це часто є безпосереднім способом діагностики проблеми, що викликає збої. - Перевірити події: Використовуйте
kubectl describe pod <name-of-pod>для перегляду подій для Podʼа, які можуть надати підказки про проблеми конфігурації або ресурсів. - Перевірити конфігурацію: Переконайтеся, що конфігурація Podʼа, включаючи змінні середовища та змонтовані томи, є правильною і що всі необхідні зовнішні ресурси доступні.
- Перевірити обмеження ресурсів: Переконайтеся, що контейнер має достатньо CPU та памʼяті. Іноді збільшення ресурсів у специфікації Podʼа може вирішити проблему.
- Перевірити застосунок: Можуть існувати помилки або неправильні конфігурації в коді застосунку. Запуск цього образу контейнера локально або в середовищі розробки може допомогти діагностувати проблеми, специфічні для застосунку.
Політика перезапуску контейнера
У полі spec Podʼа є поле restartPolicy із можливими значеннями Always, OnFailure та Never. Стандартне значення — Always.
restartPolicy для Podʼа застосовується до контейнерів застосунків в Podʼі та до звичайних контейнерів ініціалізації. Контейнери Sidecar не звертають уваги на поле restartPolicy на рівні Podʼа: в Kubernetes, sidecar визначається як запис всередині initContainers, який має свою політику перезапуску контейнера на рівні контейнера, встановлену на Always. Для контейнерів ініціалізації, які завершують роботу із помилкою, kubelet виконує їх перезапуск, якщо політика перезапуску Podʼа встановлена як OnFailure або Always:
Always: автоматично перезапускає контейнер після його завершення, незалежно від статусу завершення.OnFailure: перезапускає контейнер тільки після його завершення з помилкою (код виходу відмінний від нуля).Never: ніколи автоматично не перезапускає контейнер, що завершив роботу.
Коли kubelet обробляє перезапуск контейнера згідно з налаштованою політикою перезапуску, це стосується лише перезапусків, які призводять до заміни контейнерів всередині того ж Podʼа та на тому ж вузлі. Після завершення контейнерів у Podʼі, kubelet перезапускає їх із затримкою, що зростає експоненційно (10 с, 20 с, 40 с, …), і обмеженою пʼятьма хвилинами (300 секунд). Якщо контейнер виконується протягом 10 хвилин без проблем, kubelet скидає таймер затримки перезапуску для цього контейнера. Контейнери Sidecar та життєвий цикл Podʼа пояснює поведінку контейнерів ініціалізації при вказанні поля restartpolicy для нього.
Налаштовувана затримка перезапуску контейнера
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [alpha] (стандартно увімкнено: false)З увімкненою альфа-функцією KubeletCrashLoopBackOffMax ви можете змінити максимальну затримку між повторними спробами запуску контейнера, яка стандартно становить 300 секунд (5 хвилин). Ця конфігурація встановлюється для кожного вузла за допомогою конфігурації kubelet. У вашій конфігурації kubelet у полі crashLoopBackOff встановіть значення поля maxContainerRestartPeriod між 1s і 300s. Як описано вище у Політиці перезапуску контейнерів, затримки на цьому вузлі все одно починатимуться з 10 секунд і збільшуватимуться експоненціально у 2 рази при кожному перезапуску, але тепер вони будуть обмежені вашим налаштованим максимумом. Якщо значення maxContainerRestartPeriod, яке ви налаштували, менше початкового стандартного значення у 10 секунд, початкова затримка буде встановлена на максимальне значення.
Дивіться наступні приклади налаштування kubelet:
# затримки перезапуску контейнерів починаються з 10 секунд і збільшуються
# в 2 рази при кожному перезапуску, максимум до 100с
kind: KubeletConfiguration
crashLoopBackOff:
maxContainerRestartPeriod: "100s"
# затримки між перезапусками контейнера завжди будуть дорівнювати 2s
kind: KubeletConfiguration
crashLoopBackOff:
maxContainerRestartPeriod: "2s"
Стани Podʼа
У Podʼа є статус, який містить масив PodConditions, через які Pod проходить чи не проходить. Kubelet управляє наступними PodConditions:
PodScheduled: Pod був запланований на вузол.PodReadyToStartContainers: (бета-функція; типово увімкнено) Pod sandbox був успішно створений, і була налаштована мережа.ContainersReady: всі контейнери в Pod готові.Initialized: всі контейнери ініціалізації успішно завершили виконання.Ready: Pod може обслуговувати запити і його слід додати до балансування навантаження всіх відповідних Services.
| Назва поля | Опис |
|---|---|
type | Імʼя цього стану Podʼа. |
status | Вказує, чи застосовується цей стан, з можливими значеннями "True", "False" або "Unknown". |
lastProbeTime | Відмітка часу останнього запиту стану Podʼа. |
lastTransitionTime | Відмітка часу для останнього переходу Podʼа з одного статусу в інший. |
reason | Машиночитаний текст у форматі UpperCamelCase, який вказує причину останньої зміни стану. |
message | Повідомлення, яке вказує подробиці щодо останнього переходу стану, яке може розібрати людина. |
Готовність Podʼа
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.14 [stable]Ваш застосунок може внести додатковий зворотний звʼязок або сигнали в PodStatus: готовність Podʼа. Щоб використовувати це, встановіть readinessGates в spec Podʼа, щоб вказати список додаткових станів, які kubelet оцінює для готовності Podʼа.
Стани готовності визначаються поточним станом полів status.condition для Podʼа. Якщо Kubernetes не може знайти такий стан в полі status.conditions Podʼа, стан подається як "False".
Наприклад:
kind: Pod
...
spec:
readinessGates:
- conditionType: "www.example.com/feature-1"
status:
conditions:
- type: Ready # вбудований стан Podʼа
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
- type: "www.example.com/feature-1" # додатковий стан Podʼа
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
containerStatuses:
- containerID: docker://abcd...
ready: true
...
Стани Podʼа, які ви додаєте, повинні мати імена, які відповідають формату ключа міток Kubernetes.
Стан для готовності Podʼа
Команда kubectl patch не підтримує зміну статусу обʼєкта накладанням патчів. Щоб встановити ці status.conditions для Podʼа, застосунки та оператори повинні використовувати дію PATCH. Ви можете використовувати бібліотеку клієнтів Kubernetes для написання коду, який встановлює власні стани Podʼа для готовності Podʼа.
Для Podʼа, який використовує власні стани, Pod оцінюється як готовий тільки коли застосовуються обидва наступні твердження:
- Всі контейнери в Podʼі готові.
- Всі стани, вказані в
readinessGates, рівніTrue.
Коли контейнери Podʼа готові, але принаймні один власний стан відсутній або False, kubelet встановлює стан Podʼа ContainersReady в True.
Готовність мережі Podʼа
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.29 [beta]Примітка:
На початкових стадіях створення цей стан називалиPodHasNetwork.Після того, як Pod отримує призначення на вузол, йому потрібно бути допущеним до kubelet та мати встановлені всі необхідні томи зберігання. Як тільки ці фази завершаться, kubelet співпрацює з середовищем виконання контейнерів (використовуючи Інтерфейс середовища виконання контейнера), щоб налаштувати ізольоване середовище виконання та налаштувати мережу для Podʼа. Якщо функціональну можливість PodReadyToStartContainersCondition увімкнено (є типово увімкненою для Kubernetes 1.32), стан PodReadyToStartContainers буде додано до поля status.conditions Podʼа.
Стан PodReadyToStartContainers встановлюється в False kubeletʼом, коли він виявляє, що у Podʼа немає ізольованого середовища виконання із налаштованою мережею. Це трапляється в
наступних випадках:
- На початковому етапі життєвого циклу Podʼа, коли kubelet ще не почав налаштовувати середовище виконання для Podʼа за допомогою середовища виконання контейнерів.
- Пізніше в життєвому циклі Podʼа, коли sandbox Podʼа був знищений через:
- перезавантаження вузла без вилучення Podʼа
- для середовищ виконання контейнерів, які використовують віртуальні машини для ізоляції, віртуальна машина Pod sandbox перезавантажується, що потім вимагає створення нового sandbox та свіжої конфігурації мережі контейнера.
Стан PodReadyToStartContainers встановлюється в True kubelet після успішного завершення створення і налаштування ізольованого середовища виконання для Podʼа за допомогою втулка виконання. Kubelet може почати витягувати образ контейнера та створювати контейнери після встановлення стану PodReadyToStartContainers в True.
Для Podʼа з контейнерами ініціалізації kubelet встановлює стан Initialized в True після успішного завершення контейнерів ініціалізації (що відбувається після успішного створення sandbox та налаштування мережі контейнером втулка виконання). Для Podʼа без контейнерів ініціалізації kubelet встановлює стан Initialized в True перед початком створення sandbox та налаштування мережі.
Діагностика контейнера
Проба (probe) — це діагностика, яку періодично виконує kubelet для контейнера. Для виконання діагностики kubelet або виконує код всередині контейнера, або виконує мережевий запит.
Механізми перевірки
Існує чотири різних способи перевірки контейнера за допомогою проб. Кожна проба повинна визначати один з чотирьох цих механізмів:
exec- Виконує вказану команду всередині контейнера. Діагностика вважається успішною, якщо команда виходить з кодом стану 0.
grpc- Виконує віддалений виклик процедури gRPC. Цільовий обʼєкт повинен мати підтримку gRPC health checks. Діагностика вважається успішною, якщо
statusвідповіді рівнийSERVING. httpGet- Виконує HTTP-запит
GETдо IP-адреси Podʼа з вказаним портом та шляхом. Діагностика вважається успішною, якщо код стану відповіді більший або рівний 200 і менше ніж 400. tcpSocket- Виконує перевірку TCP до IP-адреси Podʼа за вказаним портом. Діагностика вважається успішною, якщо порт відкритий. Якщо віддалена система (контейнер) відразу закриває зʼєднання після відкриття, це вважається нормальним.
Увага:
На відміну від інших механізмів, виконання пробиexec передбачає створення/розгалуження кількох процесів при кожному виконанні. В результаті використання проб з exec на кластерах з високою щільністю Pod, низькими інтервалами initialDelaySeconds, periodSeconds, конфігурування будь-якої проби з механізмом exec, може призвести до надмірного навантаження на центральний процесор вузла. У таких сценаріях розгляньте можливість використання альтернативних механізмів проб, щоб уникнути надмірного навантаження.Результат проби
Кожна проба має один із трьох результатів:
Success- Контейнер пройшов діагностику.
Failure- Контейнер не пройшов діагностику.
Unknown- Діагностика не пройшла (не потрібно вживати жодних заходів, і kubelet буде робити подальші перевірки).
Типи проб
Kubelet може опціонально виконувати та реагувати на три типи проб для робочих контейнерів:
livenessProbe- Вказує, чи контейнер працює. Якщо ця проба не проходить, kubelet припиняє роботу контейнера, і він підлягає перезапуску відповідно до своєї політики перезапуску. Якщо в контейнері не впроваджено пробу життєздатності, стандартний стан —
Success. readinessProbe- Вказує, чи готовий контейнер відповідати на запити. Якщо проба готовності завершиться невдачею, контролер endpoint видаляє IP-адресу Podʼа з endpoint усіх служб, які збігаються з Podʼом. Стандартний стан готовності перед початковою затримкою —
Failure. Якщо в контейнері не проваджено пробу готовності, стандартний стан —Success. startupProbe- Вказує, чи запущено застосунок всередині контейнера. Усі інші проби вимкнено, якщо впроваджено пробу запуску, поки вона не стане успішною. Якщо проба запуску завершиться невдачею, kubelet вбиває контейнер, і він підлягає перезапуску відповідно до політики перезапуску. Якщо в контейнері не впроваджено пробу запуску, стандартний стан —
Success.
Для отримання докладнішої інформації щодо налаштування проб життєздатності, готовності або запуску дивіться Налаштування проб життєздатності, готовності та запуску.
Коли слід використовувати пробу життєздатності?
Якщо процес у вашому контейнері може аварійно завершитися, коли виникає проблема або він стає несправним, вам можливо не потрібна проба життєздатності; kubelet автоматично виконає правильну дію згідно з політикою перезапуску Podʼа.
Якщо ви хочете, щоб роботу вашого контейнера було припинено та він був перезапущений у разі невдачі проби, то вказуйте пробу життєздатності та встановлюйте restartPolicy на Always або OnFailure.
Коли слід використовувати пробу готовності?
Якщо ви хочете розпочати надсилання трафіку до Podʼа лише після успішної проби, вказуйте пробу готовності. У цьому випадку проба готовності може бути такою самою, як і проба життєздатності, але наявність проби готовності в специфікації означає, що Pod розпочне роботу без отримання будь-якого трафіку і почне отримувати трафік лише після успішності проби.
Якщо ви хочете, щоб ваш контейнер міг вимкнутися для обслуговування, ви можете вказати пробу готовності, яка перевіряє конкретний endpoint для готовності, відмінний від проби життєздатності.
Якщо ваш застосунок залежить від бекенд сервісів, ви можете реалізувати як пробу життєздатності, так і пробу готовності. Проба життєздатності пройде, коли саме застосунок є справним, але проба готовності додатково перевірить, що кожна необхідна служба доступна. Це допомагає уникнути направлення трафіку до Podʼів, які можуть відповідати лише повідомленнями про помилки.
Якщо вашому контейнеру потрібно працювати з великими даними, файлами конфігурації або міграціями під час запуску, ви можете використовувати пробу запуску. Однак, якщо ви хочете виявити різницю між застосунком, який зазнав невдачі, і застосунком, який все ще обробляє дані запуску, вам може більше підійти проба готовності.
Примітка:
Якщо вам потрібно мати можливість забрати запити при видаленні Podʼа, вам, можливо, не потрібна проба готовності; при видаленні Pod автоматично переводить себе в стан неготовності, незалежно від того, чи існує проба готовності. Pod залишається в стані неготовності, поки контейнери в Podʼі не зупиняться.Коли слід використовувати пробу запуску?
Проби запуску корисні для Podʼів, в яких контейнери потребують багато часу, щоб перейти в режим експлуатації. Замість встановлення довгого інтервалу життєздатності, ви можете налаштувати окрему конфігурацію для спостереження за контейнером при запуску, встановивши час, більший, ніж дозволяв би інтервал життєздатності.
Якщо ваш контейнер зазвичай запускається довше, ніж
initialDelaySeconds + failureThreshold × periodSeconds, вам слід вказати пробу запуску, яка перевіряє той самий endpoint, що й проба життєздатності. Типово для periodSeconds — 10 секунд. Потім ви повинні встановити його failureThreshold настільки великим, щоб дозволити контейнеру запускатися, не змінюючи стандартних значень проби життєздатності. Це допомагає захиститись від блокування роботи.
Завершення роботи Podʼів
Оскільки Podʼи представляють процеси, які виконуються на вузлах кластера, важливо дозволити цим процесам завершувати роботу відповідним чином, коли вони більше не потрібні (замість раптового зупинення за допомогою сигналу KILL і відсутності можливості завершити роботу).
Мета дизайну полягає в тому, щоб ви могли запитувати видалення і знати, коли процеси завершуються, а також мати можливість гарантувати, що видалення врешті-решт завершиться. Коли ви запитуєте видалення Podʼа, кластер реєструє та відстежує призначений строк належного припинення роботи до того, як буде дозволено примусово знищити Pod. З цим відстеженням примусового завершення, kubelet намагається виконати належне завершення роботи Podʼа.
Зазвичай, з цим належним завершенням роботи, kubelet робить запити до середовища виконання контейнера з метою спроби зупинити контейнери у Podʼі, спочатку надсилаючи сигнал TERM (також відомий як SIGTERM) основному процесу в кожному контейнері з таймаутом для належного завершення. Запити на зупинку контейнерів обробляються середовищем виконання контейнера асинхронно. Немає гарантії щодо порядку обробки цих запитів. Багато середовищ виконання контейнерів враховують значення STOPSIGNAL, визначене в образі контейнера і, якщо воно відрізняється, надсилають значення STOPSIGNAL, визначене в образі контейнера, замість TERM. Після закінчення строку належного завершення роботи сигнал KILL надсилається до будь-яких залишкових процесів, а потім Pod видаляється з API Server. Якщо kubelet або служба управління середовищем виконання перезапускається під час очікування завершення процесів, кластер повторює спробу спочатку, включаючи повний початковий строк належного завершення роботи.
Припинення роботи Podʼа проілюстровано у наступному прикладі:
Ви використовуєте інструмент
kubectl, щоб вручну видалити певний Pod, з типовим значення строку належного припинення роботи (30 секунд).В Podʼі в API-сервері оновлюється час, поза яким Pod вважається "мертвим", разом із строком належного припинення роботи. Якщо ви використовуєте
kubectl describeдля перевірки Podʼа, який ви видаляєте, цей Pod показується як "Terminating". На вузлі, на якому виконується Pod: як тільки kubelet бачить, що Pod був позначений як такий, що закінчує роботу (встановлений строк для належного вимкнення), kubelet розпочинає локальний процес вимкнення Podʼа.Якщо один із контейнерів Podʼа визначає
preStopхук, іterminationGracePeriodSecondsв специфікації Podʼа не встановлено на 0, kubelet виконує цей хук всередині контейнера. СтандартноterminationGracePeriodSecondsвстановлено на 30 секунд.Якщо
preStopхук все ще виконується після закінчення строку належного припинення роботи, kubelet запитує невелике подовження строку належного припинення роботи в розмірі 2 секунд.Примітка:
ЯкщоpreStopхук потребує більше часу для завершення, ніж дозволяє стандартний строк належного припинення роботи, вам слід змінитиterminationGracePeriodSecondsвідповідно до цього.Kubelet робить виклик до середовища виконання контейнера для надсилання сигналу TERM процесу 1 всередині кожного контейнера.
Є спеціальний порядок, якщо для Podʼа вказані будь-які контейнери sidecar. В іншому випадку контейнери в Podʼі отримують сигнал TERM у різний час і в довільному порядку. Якщо порядок завершення роботи має значення, розгляньте можливість використання хука
preStopдля синхронізації (або перейдіть на використання контейнерів sidecar).
У той же час, коли kubelet розпочинає належне вимкнення Podʼа, панель управління оцінює, чи слід вилучити цей Pod з обʼєктів EndpointSlice (та Endpoints), де ці обʼєкти представляють Service із налаштованим селектором. ReplicaSets та інші ресурси робочого навантаження більше не розглядають такий Pod як дійсний.
Podʼи, які повільно завершують роботу, не повинні продовжувати обслуговувати звичайний трафік і повинні почати процес завершення роботи та завершення обробки відкритих зʼєднань. Деякі застосунки потребують більше часу для належного завершення роботи, наприклад, сесії піготовки до обслуговування та завершення.
Будь-які endpoint, які представляють Podʼи, що закінчують свою роботу, не вилучаються негайно з EndpointSlices, а статус, який вказує на стан завершення, викладається з EndpointSlice API (та застарілого API Endpoints). Endpointʼи, які завершуть роботу, завжди мають статус
readyякfalse(для сумісності з версіями до 1.26), тому балансувальники навантаження не будуть використовувати його для звичайного трафіку.Якщо трафік на завершуючомуся Podʼі ще потрібний, фактичну готовність можна перевірити як стан
serving. Детальніше про те, як реалізувати очищення зʼєднань, можна знайти в розділі Порядок завершення роботи Podʼів та Endpointʼівkubelet забезпечує завершення та вимкнення Pod
- Коли період очікування закінчується, якщо у Podʼа все ще працює якийсь контейнер, kubelet ініціює примусове завершення роботи. Середовище виконання контейнера надсилає
SIGKILLвсім процесам, які ще працюють у будь-якому контейнері в Podʼі. kubelet також очищає прихований контейнерpause, якщо цей контейнер використовується. - kubelet переводить Pod у термінальну фазу (
FailedабоSucceededзалежно від кінцевого стану його контейнерів). - kubelet ініціює примусове видалення обʼєкта Pod з API-сервера, встановлюючи період очікування на 0 (негайне видалення).
- API-сервер видаляє обʼєкт API Pod, який потім більше не доступний для жодного клієнта.
- Коли період очікування закінчується, якщо у Podʼа все ще працює якийсь контейнер, kubelet ініціює примусове завершення роботи. Середовище виконання контейнера надсилає
Примусове завершення Podʼів
Увага:
Примусове завершення може бути потенційно руйнівним для деяких завдань та їх Podʼів.Типово всі видалення є належними протягом 30 секунд. Команда kubectl delete підтримує опцію --grace-period=<seconds>, яка дозволяє вам перевизначити типове значення своїм.
Встановлення належного завершення роботи в 0 примусово та негайно видаляє Pod з API сервера. Якщо Pod все ще працює на вузлі, це примусове видалення спричинює початок негайного прибирання kubelet.
Використовуючи kubectl, ви повинні вказати додатковий прапорець --force разом із --grace-period=0, щоб виконати примусове видалення.
Під час примусового видалення API-сервер не чекає підтвердження від kubelet, що Pod завершено на вузлі, на якому він працював. Він негайно видаляє Pod в API, щоб можна було створити новий pod з тим самим імʼям. На вузлі Podʼи, які мають бути видалені негайно, все ще отримують невеликий строк для завершення роботи перед примусовим вимиканням.
Увага:
Негайне видалення не чекає підтвердження того, що робочий ресурс було завершено. Ресурс може продовжувати працювати в кластері нескінченно.Якщо вам потрібно примусово видалити Podʼи, які є частиною StatefulSet, дивіться документацію для видалення Podʼів з StatefulSet.
Завершення роботи Podʼа та контейнери sidecar
Якщо ваш Pod містить один або більше контейнерів sidecar (init-контейнерів з політикою перезапуску Always), kubelet затримає надсилання сигналу TERM цим контейнерам sidecar, доки останній основний контейнер повністю не завершить роботу. Контейнери sidecar будуть завершені у зворотному порядку, в якому вони визначені в специфікації Podʼа. Це забезпечує продовження обслуговування контейнерами sidecar інших контейнерів у Podʼі, доки вони не стануть непотрібними.
Це означає, що повільне завершення роботи основного контейнера також затримає завершення роботи контейнерів sidecar. Якщо період очікування закінчиться до завершення процесу завершення, Pod може перейти в стан примусового завершення. У цьому випадку всі залишкові контейнери в Podʼі будуть завершені одночасно з коротким періодом очікування.
Аналогічно, якщо Pod має хук preStop, який перевищує період очікування завершення, може статися аварійне завершення. Загалом, якщо ви використовували хуки preStop для керування порядком завершення без контейнерів sidecar, тепер ви можете видалити їх і дозволити kubelet автоматично керувати завершенням роботи контейнерів sidecar.
Збір сміття Podʼів
Для несправних Podʼів обʼєкти API залишаються в API кластера, поки людина чи контролер явно їх не видалять.
Збірник сміття Podʼів (PodGC), який є контролером панелі управління, прибирає завершені Podʼи (з фазою Succeeded або Failed), коли кількість Podʼів перевищує налаштований поріг (визначений параметром terminated-pod-gc-threshold в kube-controller-manager). Це запобігає витоку ресурсів при створенні та завершенні Podʼів з часом.
Крім того, PodGC очищує будь-які Podʼи, які відповідають одній з наступних умов:
- є осиротілими Podʼами — привʼязаними до вузла, якого вже не існує,
- є незапланованими Podʼами у стані завершення,
- є Podʼами у стані завершення, привʼязаними до непрацюючого вузла з позначкою
node.kubernetes.io/out-of-service.
Разом із прибиранням Podʼів, PodGC також позначає їх як несправнені, якщо вони перебувають в незавершеній фазі. Крім того, PodGC додає стан руйнування Podʼа під час очищення осиротілого Podʼа. Див. стани руйнування Podʼів для отримання докладніших відомостей.
Що далі
Отримайте практичний досвід прикріплення обробників до подій життєвого циклу контейнера.
Отримайте практичний досвід налаштування проб Liveness, Readiness та Startup.
Дізнайтеся більше про обробники життєвого циклу контейнера.
Дізнайтеся більше про контейнери sidecar.
Для докладної інформації про статус Podʼа та контейнера в API, перегляньте документацію API, яка охоплює
statusдля Podʼа.
4.1.2 - Контейнери ініціалізації
Ця сторінка надає загальний огляд контейнерів ініціалізації: спеціалізованих контейнерів, які запускаються перед запуском контейнерів застосунків в Podʼі. Контейнери ініціалізації можуть містити утиліти або сценарії налаштування, які відсутні в образі застосунку.
Ви можете вказати контейнери ініціалізації в специфікації Podʼа разом із масивом containers (який описує контейнери застосунку).
У Kubernetes контейнер sidecar — це контейнер, який запускається перед основним контейнером застосунку і продовжує працювати. Цей документ стосується контейнерів ініціалізації — контейнерів, які завершують свою роботу після ініціалізації Podʼа.
Контейнери ініціалізації
У Pod може бути кілька контейнерів, які виконують застосунки всередині нього, але також може бути один чи кілька контейнерів ініціалізації, які виконуються до того, як стартують контейнери застосунків.
Контейнери ініціалізації абсолютно такі ж, як і звичайні контейнери, окрім того:
- Контейнери ініціалізації завжди завершуються після виконання завдань ініціалізації.
- Кожен контейнер ініціалізації повинен успішно завершити свою роботу, перш ніж почнуть свою роботу наступні.
Якщо контейнер init Pod виходить з ладу, kubelet неодноразово перезапускає цей контейнер, поки він не досягне успіху. Однак якщо у Pod встановлено restartPolicy рівне Never, і контейнер ініціалізації виходить з ладу під час запуску Pod, Kubernetes розглядає весь Pod як неуспішний.
Для зазначення контейнера ініціалізації для Pod додайте поле initContainers у специфікацію Podʼа, у вигляді масиву обʼєктів container (аналогічно полю containers контейнерів застосунку і їх змісту). Дивіться Container в
довідці API для отримання докладнішої інформації.
Стан контейнерів внвціалізації повертається у полі .status.initContainerStatuses у вигляді масиву станів контейнерів (аналогічно полю .status.containerStatuses).
Відмінності від звичайних контейнерів
Контейнери ініціалізації підтримують всі поля та можливості контейнерів застосунків, включаючи обмеження ресурсів, томи та налаштування безпеки. Однак запити та обмеження ресурсів для контейнера ініціалізації обробляються по-іншому, як описано в розділі Спільне використання ресурсів в межах контейнерів.
Звичайні контейнери ініціалізації (іншими словами, виключаючи контейнери sidecar) не підтримують поля lifecycle, livenessProbe, readinessProbe чи startupProbe. Контейнери ініціалізації повинні успішно завершити свою роботу перед тим, як Pod може бути готовий; контейнери sidecar продовжують працювати протягом життєвого циклу Podʼа і підтримують деякі проби. Дивіться контейнер sidecar для отримання додаткової інформації про nfrs контейнери.
Якщо ви вказали кілька контейнерів ініціалізації для Podʼа, kubelet виконує кожен такий контейнер послідовно. Кожен контейнер ініціалізації повинен успішно завершити свою роботу, перш ніж може бути запущено наступний. Коли всі контейнери ініціалізації завершать свою роботу, kubelet ініціалізує контейнери застосунків для Podʼа та запускає їх як зазвичай.
Відмінності від контейнерів sidecar
Контейнери ініціалізації запускаються і завершують свої завдання до того, як розпочнеться робота основного контейнера застосунку. На відміну від контейнерів sidecar, контейнери ініціалізації не продовжують працювати паралельно з основними контейнерами.
Контейнери ініціалізації запускаються і завершують свою роботу послідовно, і основний контейнер не починає свою роботу, доки всі контейнери ініціалізації успішно не завершать свою роботу.
Контейнери ініціалізації не підтримують lifecycle, livenessProbe, readinessProbe чи startupProbe, у той час, як контейнери sidecar підтримують всі ці проби, щоб керувати своїм життєвим циклом.
Контейнери ініціалізації використовують ті ж ресурси (CPU, памʼять, мережу) що й основні контейнери застосунків, але не взаємодіють з ними напряму. Однак вони можуть використовувати спільні томи для обміну даними.
Використання контейнерів ініціалізації
Оскільки контейнери ініціалізації мають окремі образи від контейнерів застосунків, вони мають кілька переваг для коду, повʼязаного із запуском:
- Контейнери ініціалізації можуть містити утиліти або власний код для налаштування, які відсутні в образі застосунку. Наприклад, немає потреби створювати образ
FROMіншого образу лише для використання інструменту, такого якsed,awk,pythonчиdigпід час налаштування. - Ролі створення та розгортання образу застосунку можуть працювати незалежно одна від одної без необхідності спільного створення єдиного образу застосунку.
- Контейнери ініціалізації можуть працювати з різними видами файлових систем порівняно з контейнерами застосунків у тому ж Podʼі. Вони, отже, можуть мати доступ до Secret, до яких контейнери застосунків не можуть отримати доступ.
- Оскільки контейнери ініціалізації завершують свою роботу, перш ніж будь-які контейнери застосунків розпочнуть свою роботу, вони пропонують механізм блокування або затримки запуску контейнера застосунку до виконання певних умов. Після того, як умови виконані, всі контейнери застосунків у Pod можуть стартувати паралельно.
- Контейнери ініціалізації можуть безпечно виконувати утиліти або власний код, який інакше зробив би образ контейнера застосунку менш безпечним. Відокремлюючи непотрібні інструменти, ви можете обмежити область атак для вашого образу контейнера застосунку.
Приклади
Ось кілька ідей, як використовувати контейнери ініціалізації:
Очікування на створення Service, використовуючи команду оболонки у вигляді одного рядка, наприклад:
for i in {1..100}; do sleep 1; if nslookup myservice; then exit 0; fi; done; exit 1Реєстрація Podʼа у віддаленому сервері зі значеннями, отриманими з Downward API за допомогою команди, подібної цій:
curl -X POST http://$MANAGEMENT_SERVICE_HOST:$MANAGEMENT_SERVICE_PORT/register -d 'instance=$(<POD_NAME>)&ip=$(<POD_IP>)'Очікування певного часу перед запуском контейнера застосунку за допомогою команди, подібної цій:
sleep 60Клонування репозиторію Git в Том
Додавання значень у файл конфігурації та виклик інструменту шаблонування для динамічного створення файлу конфігурації для основного контейнера застосунку. Наприклад, додайте значення
POD_IPу конфігурації та створюйте основний файл конфігурації застосунку, що використовує Jinja.
Використання контейнерів ініціалізації
У цьому прикладі визначається простий Pod, який має два контейнери ініціалізації. Перший чекає на myservice, а другий — на mydb. Як тільки обидва контейнери ініціалізації завершаться, Pod запускає контейнер застосунку зі свого розділу spec.
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app.kubernetes.io/name: MyApp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
- name: init-mydb
image: busybox:1.28
command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]
Ви можете запустити цей Pod, використовуючи:
kubectl apply -f myapp.yaml
Вивід подібний до цього:
pod/myapp-pod created
І перевірте його статус за допомогою:
kubectl get -f myapp.yaml
Вивід подібний до цього:
NAME READY STATUS RESTARTS AGE
myapp-pod 0/1 Init:0/2 0 6m
або для отримання більше деталей:
kubectl describe -f myapp.yaml
Вивід подібний до цього:
Name: myapp-pod
Namespace: default
[...]
Labels: app.kubernetes.io/name=MyApp
Status: Pending
[...]
Init Containers:
init-myservice:
[...]
State: Running
[...]
init-mydb:
[...]
State: Waiting
Reason: PodInitializing
Ready: False
[...]
Containers:
myapp-container:
[...]
State: Waiting
Reason: PodInitializing
Ready: False
[...]
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
16s 16s 1 {default-scheduler } Normal Scheduled Successfully assigned myapp-pod to 172.17.4.201
16s 16s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Pulling pulling image "busybox"
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Pulled Successfully pulled image "busybox"
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Created Created container init-myservice
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Started Started container init-myservice
Щоб переглянути логи контейнерів ініціалізації у цьому Podʼі, виконайте:
kubectl logs myapp-pod -c init-myservice # Огляд першого контейнера ініціалізації
kubectl logs myapp-pod -c init-mydb # Огляд другого контейнера ініціалізації
На цей момент ці контейнери ініціалізації будуть чекати виявлення Сервісів з іменами mydb та myservice.
Ось конфігурація, яку ви можете використовувати для того, щоб ці Services зʼявилися:
---
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
---
apiVersion: v1
kind: Service
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
Щоб створити Services mydb та myservice:
kubectl apply -f services.yaml
Вивід подібний до цього:
service/myservice created
service/mydb created
Потім ви побачите, що ці контейнери ініціалізації завершаться, і Pod myapp-pod переходить у стан Running:
kubectl get -f myapp.yaml
Вивід подібний до цього:
NAME READY STATUS RESTARTS AGE
myapp-pod 1/1 Running 0 9m
Цей простий приклад повинен дати вам натхнення для створення ваших власних контейнерів ініціалізації. У розділі Що далі є посилання на більш детальний приклад.
Докладний опис поведінки
Під час запуску Pod kubelet затримує виконання контейнерів ініціалізації (init containers), доки мережеве зʼєднання та сховище не будуть готові. Після цього kubelet виконує контейнери ініціалізації Podʼа в порядку, в якому вони зазначені в специфікації Pod.
Кожен контейнер ініціалізації має успішно завершитися перед тим, як буде запущений наступний контейнер. Якщо контейнер не вдалося запустити через помилку середовища виконання або він завершується з помилкою, його перезапускають згідно з політикою перезапуску Podʼів (restartPolicy). Однак, якщо політика перезапуску Podʼа (restartPolicy) встановлена на Always, контейнери ініціалізації використовують політику перезапуску OnFailure.
Pod не може бути Ready, поки всі контейнери ініціалізації не завершаться успішно. Порти контейнерів ініціалізації не агрегуються в Service. Pod, що ініціалізується, перебуває в стані Pending, але повинен мати умову Initialized, встановлену на false.
Якщо Pod перезапускається або був перезапущений, всі контейнери ініціалізації мають виконатися знову.
Зміни в специфікації контейнерів ініціалізації обмежуються полем образу контейнера. Безпосередня зміна поля image контейнера init не призводить до перезапуску Podʼа або його перестворення. Якщо Pod ще не було запущено, ці зміни можуть вплинути на те, як він завантажиться.
У шаблоні pod template ви можете змінити будь-яке поле початкового контейнера; вплив цих змін залежить від того, де використовується шаблон podʼа.
Оскільки контейнери ініціалізації можуть бути перезапущені, повторно виконані або виконані заново, код контейнерів ініціалізації повинен бути ідемпотентним. Зокрема, код, що записує дані у том emptyDirs, має бути підготовлений до того, що файл виводу вже може існувати.
Контейнери ініціалізації мають усі поля контейнера застосунку. Проте Kubernetes забороняє використання readinessProbe, оскільки контейнери ініціалізації не можуть визначати готовність окремо від завершення. Це забезпечується під час валідації.
Використовуйте activeDeadlineSeconds в Podʼі, щоб запобігти нескінченним збоям контейнерів ініціалізації. Загальний дедлайн включає контейнери ініціалізації. Однак рекомендується використовувати activeDeadlineSeconds лише якщо команди розгортають свій застосунок як Job, оскільки activeDeadlineSeconds впливає навіть після завершення роботи контейнера ініціалізації. Pod, який вже працює правильно, буде зупинений через activeDeadlineSeconds, якщо ви це налаштуєте.
Імʼя кожного контейнера застосунку та контейнера ініціалізації в Pod має бути унікальним; якщо контейнер має імʼя, яке збігається з іншим, буде згенеровано помилку валідації.
Спільне використання ресурсів між контейнерами
З урахуванням порядку виконання контейнерів ініціалізації, обслуговування та застосунків застосовуються наступні правила використання ресурсів:
- Найвищий запит чи обмеження будь-якого конкретного ресурсу, визначеного у всіх контейнерах ініціалізації, вважається ефективним запитом/обмеженням ініціалізації. Якщо для будь-якого ресурсу не вказано обмеження, це вважається найвищим обмеженням.
- Ефективний запит/обмеження Podʼа для ресурсу — більше з:
- сума всіх запитів/обмежень контейнерів застосунків для ресурсу
- ефективний запит/обмеження для ініціалізації для ресурсу
- Планування виконується на основі ефективних запитів/обмежень, що означає, що контейнери ініціалізації можуть резервувати ресурси для ініціалізації, які не використовуються протягом життя Podʼа.
- Рівень якості обслуговування (QoS), рівень QoS Podʼа — є рівнем QoS як для контейнерів ініціалізації, так і для контейнерів застосунків.
Обмеження та ліміти застосовуються на основі ефективного запиту та ліміту Podʼа.
Контейнери ініціалізація та cgroups Linux
У Linux, розподіл ресурсів для контрольних груп рівня Podʼів (cgroups) ґрунтується на ефективному запиті та ліміті рівня Podʼа, так само як і для планувальника.
Причини перезапуску Pod
Pod може перезапускатися, що призводить до повторного виконання контейнерів ініціалізації, з наступних причин:
- Перезапускається контейнер інфраструктури Podʼа. Це рідкісне явище і його має виконати тільки той, хто має root-доступ до вузлів.
- Всі контейнери в Podʼі завершуються, коли
restartPolicyвстановлено вAlways, що примушує до перезапуску, а запис про завершення контейнера ініціалізації був втрачено через збирання сміття.
Pod не буде перезапущено, коли змінюється образ контейнера ініціалізації, або запис про завершення контейнера ініціалізації був втрачений через збирання сміття. Це стосується Kubernetes v1.20 і пізніших версій. Якщо ви використовуєте попередню версію Kubernetes, ознайомтеся з документацією версії, яку ви використовуєте.
Що далі
Дізнайтеся більше про наступне:
- Створення Podʼа з контейнером ініціалізації.
- Налагодження контейнерів ініціалізації.
- Огляд kubelet та kubectl.
- Види проб: liveness, readiness, startup probe.
- Контейнери sidecar.
4.1.3 - Контейнери sidecar
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.29 [beta]Контейнери sidecar — це додаткові контейнери, які працюють разом з основним контейнером застосунку всередині одного Podʼа. Ці контейнери використовуються для розширення чи покращення функціональності основного контейнера застосунку, надаючи додаткові служби чи функціональність, такі як логування, моніторинг, безпеку або синхронізацію даних, не змінюючи безпосередньо код основного застосунку.
Зазвичай в одному Podʼі є лише один контейнер застосунку. Наприклад, якщо у вас є вебзастосунок, який потребує локального вебсервера, локальний вебсервер буде контейнером sidecar, а сам вебзастосунок — це контейнер застосунку.
Контейнери sidecar в Kubernetes
Kubernetes впроваджує контейнери sidecar як особливий випадок контейнерів ініціалізації; контейнери sidecar залишаються запущеними після запуску Podʼа. У цьому документі термін звичайні контейнери ініціалізації використовується для чіткого посилання на контейнери, які працюють лише під час запуску Podʼа.
Припускаючи, що у вашому кластері увімкнено функціональну можливість SidecarContainers, (активна починаючи з Kubernetes v1.29), ви можете вказати restartPolicy для контейнерів, вказаних у полі initContainers Podʼа. Ці контейнери sidecar, які перезапускаються, є незалежними від інших контейнерів ініціалізації та від основних контейнерів застосунку у тому ж Podʼі, і можуть бути запущені, зупинені або перезапущені без впливу на основний контейнер застосунку та інші контейнери ініціалізації.
Ви також можете запустити Pod із декількома контейнерами, які не позначені як контейнери ініціалізації або sidecar. Це доцільно, якщо контейнери в межах Podʼа необхідні для його роботи в цілому, але вам не потрібно керувати тим, які контейнери спочатку запускаються або зупиняються. Ви також можете це зробити, якщо вам потрібно підтримувати старі версії Kubernetes, які не підтримують поле restartPolicy на рівні контейнера.
Приклад застосунку
Нижче наведено приклад Deployment з двома контейнерами, один з яких є sidecar:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
labels:
app: myapp
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: alpine:latest
command: ['sh', '-c', 'while true; do echo "logging" >> /opt/logs.txt; sleep 1; done']
volumeMounts:
- name: data
mountPath: /opt
initContainers:
- name: logshipper
image: alpine:latest
restartPolicy: Always
command: ['sh', '-c', 'tail -F /opt/logs.txt']
volumeMounts:
- name: data
mountPath: /opt
volumes:
- name: data
emptyDir: {}Контейнери sidecar та життєвий цикл Podʼа
Якщо контейнер ініціалізації створено з параметром restartPolicy, встановленим на Always, він розпочне роботу і залишиться запущеним протягом усього життя Podʼа. Це може бути корисно для запуску служб підтримки, відокремлених від основних контейнерів застосунку.
Якщо для цього контейнера ініціалізації вказано readinessProbe, результат буде використовуватися для визначення стану ready Podʼа.
Оскільки ці контейнери визначені як контейнери ініціалізації, вони користуються тими ж гарантіями порядку та послідовності, що й інші контейнери ініціалізації, що дозволяє їх змішувати з іншими контейнерами ініціалізації в складні потоки ініціалізації Podʼа.
В порівнянні зі звичайними контейнерами ініціалізації, контейнери, визначені в initContainers, продовжують роботу після їх запуску. Це важливо, коли в .spec.initContainers для Podʼа є більше одного запису. Після запуску контейнера ініціалізації типу sidecar (kubelet встановлює статус started для цього контейнера в true), kubelet запускає наступний контейнер ініціалізації з упорядкованого списку .spec.initContainers. Цей статус стає true через те, що в контейнері працює процес і немає визначеного startupProbe, або внаслідок успішного виконання startupProbe.
При завершенні роботи Podʼа, kubelet відкладає завершення контейнерів sidecar до повної зупинки основного контейнера застосунку. Після цього контейнери sidecar вимикаються у порядку, протилежному порядку їх появи у специфікації Podʼа. Такий підхід гарантує, що контейнери sidecar залишаються в робочому стані, підтримуючи інші контейнери в Podʼі, до тих пір, поки їх обслуговування більше не буде потрібне.
Завдання з контейнерами sidecar
Якщо ви створюєте Job з контейнерами sidecar, що використовує їх за допомогою контейнерів ініціалізації, контейнери sidecar у кожному Podʼі не перешкоджатимуть завершенню Завдання після завершення роботи основного контейнера.
Ось приклад Job із двома контейнерами, один з яких — це контейнер sidecar:
apiVersion: batch/v1
kind: Job
metadata:
name: myjob
spec:
template:
spec:
containers:
- name: myjob
image: alpine:latest
command: ['sh', '-c', 'echo "logging" > /opt/logs.txt']
volumeMounts:
- name: data
mountPath: /opt
initContainers:
- name: logshipper
image: alpine:latest
restartPolicy: Always
command: ['sh', '-c', 'tail -F /opt/logs.txt']
volumeMounts:
- name: data
mountPath: /opt
restartPolicy: Never
volumes:
- name: data
emptyDir: {}Відмінності від контейнерів застосунків
Контейнери sidecar працюють поруч з контейнерами застосунку в одному Podʼі. Однак вони не виконують основну логіку застосунку; замість цього вони надають додатковий функціонал основному застосунку.
Контейнери sidecar мають власні незалежні життєві цикли. Їх можна запускати, зупиняти та перезапускати незалежно від контейнерів застосунку. Це означає, що ви можете оновлювати, масштабувати чи обслуговувати контейнери sidecar, не впливаючи на основний застосунок.
Контейнери sidecar ділять той самий простір імен мережі та сховища з основним контейнером. Це спільне розташування дозволяє їм тісно взаємодіяти та спільно використовувати ресурси.
З погляду Kubernetes, відповідне завершення для sidecar є менш важливим. Якщо інші контейнери використали весь виділений час для відповідного завершення роботи, то контейнери з sidecar отримають SIGTERM, а потім SIGKILL швидше, ніж можна було б очікувати. Отже, коди виходу, відмінні від 0 (0 означає успішний вихід), для контейнерів з sidecar є нормальним явищем при завершенні роботи Podʼа, і зазвичай їх слід ігнорувати зовнішньому інструментарію.
Відмінності від контейнерів ініціалізації
Контейнери sidecar працюють поруч з основним контейнером, розширюючи його функціональність та надаючи додаткові служби.
Контейнери sidecar працюють паралельно з основним контейнером застосунку. Вони активні протягом усього життєвого циклу Podʼа та можуть бути запущені та зупинені незалежно від основного контейнера. На відміну від контейнерів ініціалізації, контейнери sidecar підтримують проби, щоб контролювати їхній життєвий цикл.
Контейнери sidecar можуть взаємодіяти безпосередньо з основними контейнерами застосунків, оскільки вони, так само як і контейнери ініціалізації, спільно використовують той самий простір імен мережі, файлову систему та змінні оточення.
Контейнери ініціалізації зупиняються до того, як основний контейнер застосунку розпочне роботу, тож контейнер ініціалізації не може обмінюватись повідомленнями з контейнером застосунку в Podʼі. Будь-які дані передаються лише в один бік (наприклад, контейнер ініціалізації може залишити інформацію у томі emptyDir).
Спільне використання ресурсів всередині контейнерів
З урахуванням порядку виконання контейнерів ініціалізації, обслуговування та застосунків застосовуються наступні правила використання ресурсів:
- Найвищий запит чи обмеження будь-якого конкретного ресурсу, визначеного у всіх контейнерах ініціалізації, вважається ефективним запитом/обмеженням ініціалізації. Якщо для будь-якого ресурсу не вказано обмеження, це вважається найвищим обмеженням.
- Ефективний запит/обмеження Podʼа для ресурсу — більше з:
- сума всіх запитів/обмежень контейнерів застосунків для ресурсу
- ефективний запит/обмеження для ініціалізації для ресурсу
- Планування виконується на основі ефективних запитів/обмежень, що означає, що контейнери ініціалізації можуть резервувати ресурси для ініціалізації, які не використовуються протягом життя Podʼа.
- Рівень якості обслуговування (QoS), рівень QoS Podʼа — є рівнем QoS як для контейнерів ініціалізації, так і для контейнерів застосунків.
Обмеження та ліміти застосовуються на основі ефективного запиту та ліміту Podʼа.
Контейнери sidecar та cgroups Linux
У Linux, розподіл ресурсів для контрольних груп рівня Podʼів (cgroups) ґрунтується на ефективному запиті та ліміті рівня Podʼа, так само як і для планувальника.
Що далі
- Дізнайтеся, про те як використовувати контейнери sidecar
- Прочитайте блог-пост про нативні контейнери sidecar.
- Прочитайте про створення Podʼа, який має контейнер ініціалізації.
- Дізнайтеся про види проб: liveness, readiness, startup.
- Дізнайтеся про накладні витрати роботи Podʼа.
4.1.4 - Ефемерні контейнери
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.25 [stable]Ця сторінка надає огляд ефемерних контейнерів: особливого типу контейнера, який працює тимчасово в наявному Pod для виконання дій, ініційованих користувачем, таких як усунення несправностей. Ви можете використовувати ефемерні контейнери для інспектування служб, а не для створення застосунків.
Розуміння ефемерних контейнерів
Podʼи є фундаментальним елементом застосунків Kubernetes. Оскільки Podʼи призначені бути одноразовими та замінними, ви не можете додавати контейнер до Podʼа, якщо він вже був створений. Замість цього ви зазвичай видаляєте та замінюєте Podʼи у контрольований спосіб, використовуючи Deployment.
Іноді, однак, необхідно оглянути стан наявного Podʼа, наприклад, для усунення несправностей, коли важко відтворити помилку. У цих випадках ви можете запустити ефемерний контейнер в Podʼі, щоб оглянути його стан та виконати певні довільні команди.
Що таке ефемерний контейнер?
Ефемерні контейнери відрізняються від інших контейнерів тим, що вони не мають гарантій щодо ресурсів або виконання, і їх ніколи автоматично не перезапускають, тому вони не підходять для створення Застосунків. Ефемерні контейнери описуються за допомогою того ж ContainerSpec, що й звичайні контейнери, але багато полів
несумісні та заборонені для ефемерних контейнерів.
- У ефемерних контейнерів не може бути портів, тому такі поля, як
ports,livenessProbe,readinessProbe, заборонені. - Виділення ресурсів для Podʼа незмінне, тому встановлення
resourcesзаборонене. - Для повного списку дозволених полів дивіться документацію по ефемерним контейнерам (EphemeralContainer).
Ефемерні контейнери створюються за допомогою спеціального обробника ephemeralcontainers в API замість того, щоб додавати їх безпосередньо до pod.spec, тому не можна додавати ефемерний контейнер за допомогою kubectl edit.
Примітка:
Ефемерні контейнери не підтримуються статичними Podʼами.Використання ефемерних контейнерів
Ефемерні контейнери корисні для інтерактивного усунення несправностей, коли kubectl exec недостатній, оскільки контейнер впав або образ контейнера не містить засобів налагодження.
Зокрема образи distroless дозволяють вам розгортати мінімальні образи контейнерів, які зменшують площу атаки та вразливість. Оскільки образи distroless не включають оболонку або будь-які засоби налагодження, складно налагоджувати образи distroless, використовуючи лише kubectl exec.
При використанні ефемерних контейнерів корисно включити спільний простір імен процесу (process namespace sharing), щоб ви могли переглядати процеси в інших контейнерах.
Що далі
- Дізнайтеся, як налагоджувати Podʼи за допомогою ефемерних контейнерів.
4.1.5 - Розлади
Цей посібник призначений для власників застосунків, які хочуть створити високодоступні застосунки та, таким чином, повинні розуміти, які типи розладів можуть трапитися з Podʼами.
Також це стосується адміністраторів кластера, які хочуть виконувати автоматизовані дії з кластером, такі як оновлення та автомасштабування кластерів.
Добровільні та невідворотні розлади
Podʼи не зникають, поки хтось (людина або контролер) не знищить їх, або не трапиться невідворотна помилка обладнання чи системного програмного забезпечення.
Ми називаємо ці невідворотні випадки невідворотними розладами застосунку. Приклади:
- відмова обладнання фізичної машини, яка підтримує вузол
- адміністратор кластера видаляє віртуальну машину (екземпляр) помилково
- відмова хмарного провайдера або гіпервізора призводить до зникнення віртуальної машини
- kernel panic
- вузол зникає з кластера через поділ мережі кластера
- виселення Podʼа через вичерпання ресурсів вузла.
Крім умов, повʼязаних із вичерпанням ресурсів, всі ці умови повинні бути знайомими більшості користувачів; вони не є специфічними для Kubernetes.
Ми називаємо інші випадки добровільними розладами. До них належать як дії, ініційовані власником застосунку, так і ті, які ініціює адміністратор кластера. Типові дії власника застосунку включають:
- видалення розгортання або іншого контролера, який управляє Podʼом
- оновлення шаблону розгортання Podʼа, що призводить до перезапуску
- безпосереднє видалення Podʼа (наприклад, випадково)
Дії адміністратора кластера включають:
- Виведення вузла для ремонту чи оновлення.
- Виведення вузла з кластера для зменшення масштабу кластера (дізнайтеся більше про автомасштабування кластера).
- Видалення Podʼа з вузла, щоб щось інше помістилося на цей вузол.
Ці дії можуть бути виконані безпосередньо адміністратором кластера чи за допомогою автоматизації, запущеної адміністратором кластера, або вашим провайдером хостингу кластера.
Зверніться до адміністратора кластера або проконсультуйтеся з документацією вашого хмарного провайдера або дистрибутиву, щоб визначити, чи увімкнено які-небудь джерела добровільних розладів для вашого кластера. Якщо жодне з них не увімкнено, ви можете пропустити створення бюджетів розладів Podʼів (Pod Disruption Budget).
Увага:
Не всі добровільні розлади обмежені бюджетами розладів Podʼів. Наприклад, видалення Deployment чи Pod обходить бюджети розладів Podʼів.Управління розладами
Ось кілька способів помʼякшення невідворотних розладів:
- Переконайтеся, що ваш Pod звертається по необхідні ресурси.
- Реплікуйте своє застосунки, якщо вам потрібна вища доступність. (Дізнайтеся про запуск реплікованих stateless та stateful застосунків.)
- Для ще більшої доступності при запуску реплікованих застосунків розподіліть їх по стійках (за допомогою anti-affinity) чи по зонах (якщо використовуєте кластер з кількома зонами.)
Частота добровільних розладів різниться. На базовому кластері Kubernetes немає автоматизованих добровільних розладів (тільки ті, які ініціює користувач). Однак адміністратор кластера або постачальник хостингу може запускати деякі додаткові служби, які призводять до добровільних розладів. Наприклад, розгортання оновлень програмного забезпечення вузла може призвести до добровільних розладів. Також деякі реалізації автомасштабування кластера (вузла) можуть призводити до добровільних розладів для дефрагментації та ущільнення вузлів. Адміністратор кластера або постачальник хостингу повинні документувати, на якому рівні добровільних розладів, якщо такі є, можна розраховувати. Деякі параметри конфігурації, такі як використання PriorityClasses у вашій специфікації Podʼа, також можуть призводити до добровільних (і невідворотних) розладів.
Бюджет розладів Podʼів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.21 [stable]Kubernetes пропонує функції, що допомагають запускати застосунки з високою доступністю навіть тоді, коли ви вводите часті добровільні розлади.
Як власник застосунку, ви можете створити Бюджет розладів Podʼів (PodDisruptionBudget або PDB) для кожного застосунку. PDB обмежує кількість Podʼів, які можуть бути одночасно вимкнені через добровільні розлади для реплікованого застосунку. Наприклад, застосунок, який працює на основі кворуму, хоче забезпечити, що кількість реплік ніколи не знизиться нижче необхідної для кворуму. Вебінтерфейс, наприклад, може бажати забезпечити, що кількість реплік, які обслуговують навантаження, ніколи не падатиме нижче певного відсотка від загальної кількості.
Менеджери кластерів та постачальники хостингу повинні використовувати інструменти, які дотримуються бюджетів розладів Podʼів, викликаючи Eviction API замість прямого видалення Podʼа або Deployment.
Наприклад, команда kubectl drain дозволяє вам позначити вузол, як виводиться з експлуатації. Коли ви виконуєте kubectl drain, інструмент намагається витіснити всі Podʼи з вузла, який ви виводите з експлуатації. Запит на виселення, який kubectl робить від вашого імені, може тимчасово бути відхилено, тому інструмент періодично повторює всі невдалі запити, поки всі Podʼи на цільовому вузлі не будуть завершені, або досягне вказаного тайм-ауту.
PDB визначає кількість реплік, які застосунок може терпіти, порівняно з тим, скільки він має намір мати. Наприклад, Deployment, який має .spec.replicas: 5, повинен мати 5 Podʼів в будь-який момент часу. Якщо PDB дозволяє бути 4 Podʼам одночасно, то Eviction API дозволить добровільне відключення одного (але не двох) Podʼів одночасно.
Група Podʼів, з яких складається застосунок, визначається за допомогою селектора міток, такого самого, як і той, який використовується контролером застосунку (deployment, stateful-set і т. д.).
"Очікувана" кількість Podʼів обчислюється з .spec.replicas ресурсу робочого навантаження (Workload), який управляє цими Podʼами. Панель управління визначає ресурс робочого навантаження, оглядаючи .metadata.ownerReferences Podʼа.
Невідворотні розлади не можуть бути усунуті за допомогою PDB; однак вони враховуються в бюджеті.
Podʼи, які видаляються або недоступні через поетапне оновлення застосунку, дійсно враховуються в бюджеті розладів, але ресурси робочого навантаження (такі як Deployment і StatefulSet) не обмежуються PDB під час поетапного оновлення. Замість цього обробка невдач під час оновлення застосунку конфігурується в специфікації конкретного ресурсу робочого навантаження.
Рекомендується встановлювати політику виселення несправних Podʼів AlwaysAllow у ваших PodDisruptionBudgets для підтримки виселення неправильно працюючих застосунків під час виведення вузла. Стандартна поведінка полягає в тому, що очікується, коли Podʼи застосунку стануть справними перед тим, як виведення може продовжитися.
Коли Pod виводиться за допомогою API виселення, він завершується відповідним чином, з урахуванням налаштувань terminationGracePeriodSeconds його PodSpec.
Приклад бюджету розладів поди
Припустимо, що у кластері є 3 вузли: node-1 до node-3.
Кластер виконує кілька застосунків. Один з них має 3 репліки, які спочатку називаються pod-a, pod-b і pod-c. Інший, неповʼязаний з ними Pod без PDB, називається pod-x. Спочатку Podʼи розташовані наступним чином:
| node-1 | node-2 | node-3 |
|---|---|---|
| pod-a доступний | pod-b доступний | pod-c доступний |
| pod-x доступний |
Усі 3 Podʼи є частиною Deployment, і вони разом мають PDB, який вимагає, щоб одночасно було доступними принаймні 2 з 3 Podʼів.
Наприклад, припустимо, що адміністратор кластера хоче запровадити нову версію ядра ОС, щоб виправити помилку в ядрі. Адміністратор кластера спочатку намагається вивести з експлуатації node-1 за допомогою команди kubectl drain. Цей інструмент намагається витіснити pod-a і pod-x. Це відбувається миттєво. Обидві Podʼа одночасно переходять в стан terminating. Це переводить кластер у стан:
| node-1 draining | node-2 | node-3 |
|---|---|---|
| pod-a terminating | pod-b available | pod-c available |
| pod-x terminating |
Deployment помічає, що один з Podʼів виводиться, тому він створює заміну під назвою pod-d. Оскільки node-1 закритий, він опиняється на іншому вузлі. Також, щось створило pod-y як заміну для pod-x.
(Примітка: для StatefulSet, pod-a, який міг би мати назву щось на зразок pod-0, повинен був би повністю завершити свою роботу,
перш ніж його заміна, яка також має назву pod-0, але має інший UID, може бути створений. В іншому випадку приклад застосовується і до StatefulSet.)
Тепер кластер перебуває у такому стані:
| node-1 draining | node-2 | node-3 |
|---|---|---|
| pod-a terminating | pod-b available | pod-c available |
| pod-x terminating | pod-d starting | pod-y |
У якийсь момент Podʼи завершують свою роботу, і кластер виглядає так:
| node-1 drained | node-2 | node-3 |
|---|---|---|
| pod-b available | pod-c available | |
| pod-d starting | pod-y |
На цьому етапі, якщо нетерплячий адміністратор кластера намагається вивести з експлуатації node-2 або node-3, команда виведення буде блокуватися, оскільки доступно тільки 2 Podʼи для Deployment, і його PDB вимагає принаймні 2. Після того, як пройде певний час, pod-d стає доступним.
Тепер стан кластера виглядає так:
| node-1 drained | node-2 | node-3 |
|---|---|---|
| pod-b available | pod-c available | |
| pod-d available | pod-y |
Тепер адміністратор кластера намагається вивести з експлуатації node-2. Команда drain спробує виселити два Podʼи у деякому порядку, скажімо, спочатку pod-b, а потім pod-d. Їй вдасться витіснити pod-b. Але, коли вона спробує витіснити pod-d, отримає відмову через те, що це залишить тільки один доступний Pod для Deployment.
Deployment створює заміну для pod-b з назвою pod-e. Оскільки в кластері недостатньо ресурсів для планування pod-e, виведення знову буде заблоковано. Кластер може опинитися в такому стані:
| node-1 drained | node-2 | node-3 | no node |
|---|---|---|---|
| pod-b terminating | pod-c available | pod-e pending | |
| pod-d available | pod-y |
На цьому етапі адміністратор кластера повинен додати вузол назад до кластера, щоб продовжити оновлення.
Ви можете побачити, як Kubernetes змінює частоту випадків розладів відповідно до:
- скільки реплік потрібно для застосунку
- скільки часу потрібно для відповідного вимикання екземпляра
- скільки часу потрібно для запуску нового екземпляра
- типу контролера
- ресурсів кластера
Умови розладу поду
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [stable] (стандартно увімкнено: true)Спеціальна умова DisruptionTarget додається до Podʼа, що вказує, що Pod має бути видалений через розлад. Поле reason умови додатково вказує на одну з наступних причин завершення роботи Podʼа:
PreemptionByScheduler- Pod має бути випереджений планувальником для надання місця новому Podʼа з вищим пріоритетом. Докладніше дивіться Випередження за пріоритетом Podʼа.
DeletionByTaintManager- Pod має бути видалений Менеджером Taint (який є частиною контролера життєвого циклу вузла в
kube-controller-manager) черезNoExecutetaint, який Pod не толерує; див. виселення на основі taint. EvictionByEvictionAPI- Pod був позначений для виселення за допомогою Kubernetes API.
DeletionByPodGC- Pod, який повʼязаний із вузлом, якого вже не існує, має бути видалений за допомогою збирання сміття Podʼів.
TerminationByKubelet- Pod був примусово завершений kubelet, через виселення через тиск вузла, відповідне вимикання вузла або пріоритет для системно критичних Podʼів.
У всіх інших сценаріях порушення, таких як видалення через перевищення обмежень контейнерів Podʼа, Podʼи не отримують умову DisruptionTarget, оскільки порушення, ймовірно, були спричинені самим Podʼом і можуть повторитися при повторній спробі.
Примітка:
Розлад Podʼа може бути перерваний. Панель управління може повторно намагатися продовжити розлад того ж Podʼа, але це не гарантується. У результаті умоваDisruptionTarget може бути додана до Podʼа, але цей Pod може фактично не бути видалений. У такій ситуації після певного часу умова розладу Pod буде видалена.Разом із видаленням Podʼів, збирач сміття Podʼів (PodGC) також відзначатиме їх як неуспішні, якщо вони не знаходяться в фазі завершення роботи (див. також Збирання сміття Podʼів).
При використанні Job (або CronJob) вам може знадобитися використовувати ці умови розладу Podʼа як частину політики невдачі вашого Job Політики невдачі Podʼа.
Розділення ролей власника кластера та власника застосунку
Часто корисно розглядати Менеджера кластера і Власника застосунку як окремі ролі з обмеженим знанням одне про одного. Це розділення обовʼязків може мати сенс у таких сценаріях:
- коли багато команд розробки застосунків використовують спільний кластер Kubernetes і є природна спеціалізація ролей
- коли використовуються інструменти або сервіси сторонніх розробників для автоматизації управління кластером
Бюджети розладу Podʼів підтримують це розділення ролей, надаючи інтерфейс між цими ролями.
Якщо у вашій організації немає такого розділення обовʼязків, вам може не знадобитися використовувати бюджети розладу Podʼів.
Як виконати дії з розладу у вашому кластері
Якщо ви є адміністратором кластера і вам потрібно виконати дію розладу на всіх вузлах вашого кластера, таку як оновлення вузла чи системного програмного забезпечення, ось кілька варіантів:
- Примиритись з періодом простою під час оновлення.
- Перемикнутися на іншу повну репліку кластера.
- Відсутність простою, але може бути дорогою як для дубльованих вузлів, так і для зусиль людей для оркестрування перемикання.
- Розробляти застосунки, що терплять розлади, і використовувати бюджети розладу Podʼів.
- Відсутність простою.
- Мінімальне дублювання ресурсів.
- Дозволяє більше автоматизації адміністрування кластера.
- Написання застосунків, що терплять розлади, складне, але робота з підтримкою добровільних розладів в основному збігається з роботою з підтримкою автомасштабування і толеруючи інші типи рощладів розлади.
Що далі
Слідкуйте за кроками для захисту вашого застосунку, налаштовуючи бюджет розладу Podʼів.
Дізнайтеся більше про виведення вузлів з експлуатації.
Дізнайтеся про оновлення Deployment, включаючи кроки забезпечення його доступності під час впровадження.
4.1.6 - Класи якості обслуговування (Quality of Service) Podʼів
Ця сторінка вводить класи обслуговування (Quality of Service, QoS) в Kubernetes та пояснює, як Kubernetes присвоює кожному Podʼа клас QoS як наслідок обмежень ресурсів, які ви вказуєте для контейнерів у цьому Podʼі. Kubernetes покладається на цю класифікацію для прийняття рішень про те, які Podʼи виводити при відсутності достатньої кількості ресурсів на вузлі.
Класи обслуговування (QoS)
Kubernetes класифікує Podʼи, які ви запускаєте, і розподіляє кожен Pod в певний клас обслуговування (Quality of Service, QoS). Kubernetes використовує цю класифікацію для впливу на те, як різні Podʼи обробляються. Kubernetes робить цю класифікацію на основі резервів ресурсів контейнерів у цьому Podʼі, а також того, як ці резерви стосуються обмежень ресурсів. Це відомо як клас обслуговування (Quality of Service, QoS). Kubernetes присвоює кожному Podʼу клас QoS на основі запитів та лімітів ресурсів його складових контейнерів. Класи QoS використовуються Kubernetes для вирішення того, які Podʼи виводити з вузла, який переживає високий тиск на вузол. Можливі класи QoS: Guaranteed, Burstable та BestEffort.
Guaranteed
Podʼи, які мають клас Guaranteed, мають найстрогіші обмеження ресурсів і найменшу ймовірність бути виселеними. Гарантується, що їх не буде примусово завершено, доки вони не перевищать свої ліміти або доки не буде інших Podʼів з меншим пріоритетом, які можна витіснити з вузла. Вони можуть не отримувати ресурси поза вказаними лімітами. Ці Podʼи також можуть використовувати виключно власні CPU, використовуючи політику управління CPU типу static.
Критерії
Щоб Pod отримав клас QoS Guaranteed:
- У кожному контейнері Podʼа повинен бути ліміт та запит на памʼять.
- Для кожного контейнера у Podʼі ліміт памʼяті повинен дорівнювати запиту памʼяті.
- У кожному контейнері Podʼа повинен бути ліміт та запит на CPU.
- Для кожного контейнера у Podʼі ліміт CPU повинен дорівнювати запиту CPU.
Burstable
Podʼи, які мають клас Burstable, мають гарантії ресурсів на основі запиту, але не вимагають конкретного ліміту. Якщо ліміт не вказано, він типово встановлюється рівним потужності вузла, що дозволяє Podʼам гнучко збільшувати свої ресурси, якщо це можливо. У разі виселення Podʼа через високий тиск на вузол ці Podʼи виселяються лише після виселення всіх Podʼів з класом BestEffort. Оскільки Burstable Pod може містити контейнер, який не має лімітів чи запитів ресурсів, Pod з класом Burstable може намагатися використовувати будь-яку кількість ресурсів вузла.
Критерії
Pod отримує клас QoS Burstable, якщо:
- Pod не відповідає критеріям класу QoS
Guaranteed. - Принаймні один контейнер у Podʼі має запит або ліміт пам\яті або CPU.
BestEffort
Podʼи в класі BestEffort можуть використовувати ресурси вузла, які не призначені спеціально для Podʼів інших класів QoS. Наприклад, якщо у вузлі є 16 ядер CPU, і ви призначили 4 ядра CPU під Pod із класом Guaranteed, тоді Pod з класом BestEffort може намагатися використовувати будь-яку кількість решти з 12 ядер CPU.
Kubelet віддає перевагу виселенню Podʼів з класом BestEffort, якщо вузол потрапляє в стан тиску на ресурси.
Критерії
Pod має клас QoS BestEffort, якщо він не відповідає критеріям ані Guaranteed, ані Burstable. Іншими словами, Pod має клас BestEffort лише в тому випадку, якщо жоден з контейнерів у Podʼі не має ліміту або запиту памʼяті, і жоден з контейнерів у Podʼі не має ліміту або запиту CPU. Контейнери в Podʼі можуть запитувати інші ресурси (не CPU чи памʼять) і все одно класифікуватися як BestEffort.
QoS памʼяті з cgroup v2
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.22 [alpha] (стандартно увімкнено: false)QoS памʼяті використовує контролер памʼяті cgroup v2 для гарантування ресурсів памʼяті в Kubernetes. Запити та ліміти памʼяті контейнерів у Podʼі використовуються для встановлення конкретних інтерфейсів memory.min та memory.high, які надає контролер памʼяті. Коли memory.min встановлено на запити памʼяті, ресурси памʼяті резервуються і ніколи не звільняються ядром; саме так QoS памʼяті забезпечує наявність памʼяті для Podʼів Kubernetes. Якщо в контейнері встановлено ліміти памʼяті, це означає, що системі потрібно обмежити використання памʼяті контейнера; QoS памʼяті використовує memory.high для обмеження роботи навантаження, що наближається до свого ліміту памʼяті, забезпечуючи, що систему не перевантажено миттєвим виділенням памʼяті.
QoS памʼяті покладається на клас QoS для визначення того, які налаштування застосовувати; проте це різні механізми, які обидва надають контроль за якістю обслуговування.
Деяка поведінка незалежна від класу QoS
Деяка поведінка є незалежною від класу QoS, який визначає Kubernetes. Наприклад:
Будь-який контейнер, що перевищує ліміт ресурсів, буде завершено та перезапущено kubelet без впливу на інші контейнери в цьому Podʼі.
Якщо контейнер перевищує свій запит ресурсу і вузол, на якому він працює, стикається з нестачею ресурсів, Pod, в якому він перебуває, стає кандидатом для виселення. Якщо це станеться, всі контейнери в цьому Podʼі будуть завершені. Kubernetes може створити новий Pod, зазвичай на іншому вузлі.
Запит ресурсів Podʼа дорівнює сумі запитів ресурсів його компонентних контейнерів, а ліміт Podʼа дорівнює сумі лімітів ресурсів його контейнерів.
Планувальник kube-scheduler не враховує клас QoS при виборі того, які Podʼи випереджати. Випередження може відбуватися, коли кластер не має достатньо ресурсів для запуску всіх визначених вами Podʼів.
Що далі
- Дізнайтеся про управління ресурсами для Podʼів та контейнерів.
- Дізнайтеся про виселення через тиск на вузол.
- Дізнайтеся про пріоритет Podʼів та випередження.
- Дізнайтеся про розлад Podʼів.
- Дізнайтеся, як призначати ресурси памʼяті контейнерам та Podʼам.
- Дізнайтеся, як призначати ресурси CPU контейнерам та Podʼам.
- Дізнайтеся, як налаштовувати клас обслуговування для Podʼів.
4.1.7 - Простори імен користувачів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.30 [beta]Ця сторінка пояснює, як використовуються простори імен користувачів у Podʼах Kubernetes. Простір імен користувача ізолює користувача, який працює всередині контейнера, від користувача на хості.
Процес, який працює як root в контейнері, може працювати як інший (не-root) користувач на хості; іншими словами, процес має повні привілеї для операцій всередині простору користувача, але не має привілеїв для операцій за його межами.
Ви можете використовувати цю функцію, щоб зменшити можливий збиток, який може заподіяти скомпрометований контейнер хосту або іншим Podʼам на тому ж вузлі. Є кілька вразливостей безпеки, які оцінено як ВИСОКІ або КРИТИЧНІ, і які не можна було б використати при активних просторах користувачів. Передбачається, що простір користувачів також буде запобігати деяким майбутнім вразливостям.
Перш ніж ви розпочнете
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Це функція, доступна лише для Linux, і потребує підтримки в Linux для монтування idmap на використовуваних файлових системах. Це означає:
- На вузлі файлова система, яку ви використовуєте для
/var/lib/kubelet/pods/, або спеціальна тека, яку ви конфігуруєте для цього, повинна підтримувати монтування idmap. - Всі файлові системи, які використовуються в томах Podʼа, повинні підтримувати монтування idmap.
На практиці це означає, що вам потрібне ядро Linux принаймні версії 6.3, оскільки tmpfs почав підтримувати монтування idmap у цій версії. Це зазвичай потрібно, оскільки кілька функцій Kubernetes використовують tmpfs (токен облікового запису служби, який монтується типово, використовує tmpfs, аналогічно Secrets використовують tmpfs та інше).
Деякі популярні файлові системи, які підтримують монтування idmap в Linux 6.3, — це: btrfs, ext4, xfs, fat, tmpfs, overlayfs.
Крім того, середовище виконання контейнерів та його базове середовище OCI повинні підтримувати простори користувачів. Підтримку надають наступні середовища OCI:
Примітка:
Деякі середовища OCI не включають необхідну підтримку для використання просторів користувачів у Podʼах Linux. Якщо ви використовуєте Kubernetes, що надається постачальником хмарних послуг, або завантажили його з пакунків та встановили, ймовірно, що вузли у вашому кластері використовують середовище, яке не має такої підтримки.Для використання просторів користувачів з Kubernetes також потрібно використовувати CRI середовища виконання контейнерів, щоб мати можливість використовувати цю функцію з Podʼами Kubernetes:
- containerd: версія 2.0 (і новіші) підтримує користувацькі простори імен для контейнерів.
- CRI-O: версія 1.25 (і пізніше) підтримує простори користувачів для контейнерів.
Стан підтримки просторів користувачів в cri-dockerd відстежується у тікеті на GitHub.
Вступ
Простори користувачів — це функція Linux, яка дозволяє зіставляти користувачів у контейнері з користувачами на хості. Крім того, можливості, наданні Pod в просторі користувача, є дійсними лише в просторі та не виходять за його межі.
Pod може обрати використовувати простори користувачів, встановивши поле pod.spec.hostUsers в false.
Kubelet вибере host UID/GID, до якого зіставлено Pod, і зробить це так, щоб гарантувати, що жоден з Podʼів на одному вузлі не використовує те саме зіставлення.
Поля runAsUser, runAsGroup, fsGroup тощо в pod.spec завжди звертаються до користувача всередині контейнера.
Дійсні UID/GID, коли ця функція активована, є у діапазоні 0-65535. Це стосується файлів та процесів (runAsUser, runAsGroup і т. д.).
Файли з UID/GID за межами цього діапазону будуть вважатися належними переповненню ID, яке зазвичай дорівнює 65534 (налаштовано в /proc/sys/kernel/overflowuid та /proc/sys/kernel/overflowgid). Однак їх неможливо змінити, навіть якщо запущено як user/group 65534.
Більшість застосунків, які потребують запуску з правами root, але не мають доступу до інших просторів імен хоста чи ресурсів, повинні продовжувати працювати без змін, якщо простори користувачів активовано.
Розуміння просторів користувачів для Podʼів
Кілька середовищ виконання контейнерів із їхньою типовою конфігурацією (таких як Docker Engine, containerd, CRI-O) використовують простори імен Linux для ізоляції. Існують інші технології, які також можна використовувати з цими середовищами (наприклад, Kata Containers використовує віртуальні машини замість просторів імен Linux). Ця стосується середовищ виконання контейнерів, які використовують простори імен Linux для ізоляції.
При стандартному створенні Podʼа використовуються різні нові простори імен для ізоляції: мережевий простір імен для ізоляції мережі контейнера, простір імен PID для ізоляції виду процесів і т.д. Якщо використовується простір користувачів, це ізолює користувачів у контейнері від користувачів на вузлі.
Це означає, що контейнери можуть працювати як root та зіставлятись з не-root користувачами на хості. Всередині контейнера процес буде вважати себе root (і, отже, інструменти типу apt, yum, ін. працюватимуть нормально), тоді як насправді процес не має привілеїв на хості. Ви можете перевірити це, наприклад, якщо ви перевірите, як користувач запущений у контейнері, виконавши ps aux з хосту. Користувач, якого показує ps, не той самий, що і користувач, якого ви бачите, якщо ви виконаєте команду id всередині контейнера.
Ця абстракція обмежує те, що може трапитися, наприклад, якщо контейнер вдасться перетече на хост. Оскільки контейнер працює як непривілейований користувач на хості, обмежено те, що він може зробити на хості.
Крім того, оскільки користувачі в кожному Podʼі будуть зіставлені з різними користувачами на хості, обмежено те, що вони можуть зробити з іншими Podʼами.
Можливості, надані Podʼа, також обмежуються простором користувача Podʼа і в основному є недійсними поза межами його простору, а деякі навіть абсолютно нечинні. Ось два приклади:
CAP_SYS_MODULEне має жодного ефекту, якщо зіставлено в Podʼі з використанням просторів користувачів, Pod не може завантажити модулі ядра.CAP_SYS_ADMINобмежений простором користувача Podʼа та є недійсним поза його межами.
Без використання просторів користувачів контейнер, який працює як root, у разі втечі контейнера, має привілеї root на вузлі. І якщо контейнеру надано деякі можливості, ці можливості є дійсними на хості. Цього не відбувається, коли ми використовуємо простори користувачів.
Якщо ви хочете дізнатися більше подробиць про те, що змінюється при використанні просторів користувачів, дивіться man 7 user_namespaces.
Налаштування вузла для підтримки просторів користувачів
Типово kubelet призначає UID/GID Podʼам вище діапазону 0-65535, ґрунтуючись на припущенні, що файли та процеси хоста використовують UID/GID у цьому діапазоні, що є стандартним для більшості дистрибутивів Linux. Цей підхід запобігає будь-якому перекриттю між UID/GID хостом та UID/GID Podʼів.
Уникнення перекриття є важливим для помʼякшення впливу вразливостей, таких як CVE-2021-25741, де потенційно Pod може читати довільні файли на хості. Якщо UID/GID Podʼа та хосту не перекриваються, те що може робити Pod обмежено: UID/GID Podʼа не буде відповідати власнику/групі файлів хосту.
kubelet може використовувати власний діапазон для ідентифікаторів користувачів та груп для Podʼів. Для налаштування власного діапазону, вузол повинен мати:
- Користувача
kubeletв системі (ви не можете використовувати інше імʼя користувача тут) - Встановлений бінарний файл
getsubids(частина shadow-utils) таPATHдля бінарного файлу kubelet. - Конфігурацію допоміжних UID/GID для користувача
kubelet(див.man 5 subuidтаman 5 subgid).
Цей параметр лише збирає конфігурацію діапазону UID/GID та не змінює користувача, який виконує kubelet.
Вам потрібно дотримуватися деяких обмежень для допоміжного діапазону ID, який ви призначаєте користувачу kubelet:
Допоміжний ідентифікатор користувача, який визначає початок діапазону UID для Podʼів, має бути кратним 65536 і також повинен бути більшим або рівним 65536. Іншими словами, ви не можете використовувати жодний ідентифікатор з діапазону 0-65535 для Podʼів; kubelet накладає це обмеження, щоб ускладнити створення ненавмисно незахищеної конфігурації.
Кількість допоміжних ID повинна бути кратною 65536. (для Kubernetes 1.32 кількість підпорядкованих ідентифікаторів для кожного Pod жорстко закодовано до 65536).
Кількість допоміжних ID повинна бути щонайменше
65536 x <maxPods>, де<maxPods>— максимальна кількість Podʼів, які можуть запускатися на вузлі.Ви повинні призначити однаковий діапазон як для ідентифікаторів користувача, так і для ідентифікаторів груп. Не має значення, які інші користувачі мають діапазони ідентифікаторів користувача, які не збігаються з діапазонами ідентифікаторів груп.
Жоден з призначених діапазонів не повинен перекриватися з будь-яким іншим призначенням.
Конфігурація допоміжних ID повинна бути лише одним рядком. Іншими словами, ви не можете мати кілька діапазонів.
Наприклад, ви можете визначити /etc/subuid та /etc/subgid, щоб обидва мати такі записи для користувача kubelet:
# Формат такий
# імʼя:першийID:кількість ідентифікаторів
# де
# - першийID - 65536 (мінімально можливt значення)
# - кількість ідентифікаторів - 110 (стандартний ліміт кількості) * 65536
kubelet:65536:7208960
Інтеграція з перевірками безпеки доступу в Podʼи
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.29 [alpha]Для Podʼів Linux, які увімкнули простори користувачів, Kubernetes послаблює застосування Стандартів безпеки Podʼа контрольованим способом. Цю поведінку можна контролювати за допомогою функціональної можливості UserNamespacesPodSecurityStandards, що дозволяє раннє включення для кінцевих користувачів. Адміністраторам слід забезпечити увімкнення просторів користувачів на всіх вузлах в межах кластера при використанні feature gate.
Якщо ви увімкнете відповідний feature gate та створите Pod, який використовує простори користувачів, yfcnegys поля не будуть обмежені навіть в контекстах, які застосовують Baseline чи Restricted Podʼа. Це не становить проблему безпеки, оскільки root всередині Podʼа з просторами користувачів фактично посилається на користувача всередині контейнера, який ніколи не зіставляється з привілейованим користувачем на хості. Ось список полів, які не перевіряються для Podʼів в цих обставинах:
spec.securityContext.runAsNonRootspec.containers[*].securityContext.runAsNonRootspec.initContainers[*].securityContext.runAsNonRootspec.ephemeralContainers[*].securityContext.runAsNonRootspec.securityContext.runAsUserspec.containers[*].securityContext.runAsUserspec.initContainers[*].securityContext.runAsUserspec.ephemeralContainers[*].securityContext.runAsUser
Обмеження
При використанні просторів користувачів для Podʼа заборонено використовувати інші простори імен хосту. Зокрема, якщо ви встановите hostUsers: false, ви не маєте права встановлювати будь-яке з наступного:
hostNetwork: truehostIPC: truehostPID: true
Що далі
- Подивіться Використання простору користувача в Podʼах
4.1.8 - Downward API
Є два способи використання полів обʼєкта Pod та контейнера у працюючому контейнері: як змінні середовища та як файли, які заповнюються спеціальним типом тома. Разом ці два способи використання полів обʼєкта Pod та контейнера називають Downward API.
Іноді корисно, щоб контейнер мав інформацію про себе, не будучи занадто повʼязаним із Kubernetes. downward API дозволяє контейнерам використовувати інформацію про себе чи кластер, не використовуючи клієнт Kubernetes або API-сервер.
Наприклад, поточний застосунок, який передбачає, що відома змінна середовища містить унікальний ідентифікатор. Однією з можливостей є обгортання застосунку, але це нудно та помилкове, і воно суперечить меті вільного звʼязку. Кращий варіант — використовувати імʼя Podʼа як ідентифікатор та впровадити імʼя Podʼа у відому змінну середовища.
В Kubernetes існують два способи використання полів обʼєкта Pod та контейнера:
Разом ці два способи використання полів обʼєкта Pod та контейнера називають downward API.
Доступні поля
Через downward API доступні не всі поля обʼєкта Kubernetes API. У цьому розділі перераховано доступні поля.
Ви можете передавати інформацію з доступних полів рівня Pod, використовуючи fieldRef. На рівні API spec для Pod завжди визначає принаймні один Контейнер. Ви можете передавати інформацію з доступних полів рівня Container, використовуючи
resourceFieldRef.
Інформація, доступна за допомогою fieldRef
Для деяких полів рівня Pod ви можете передати їх контейнеру як змінні середовища або використовуючи том downwardAPI. Поля, доступні через обидва механізми, наступні:
metadata.name- імʼя Pod
metadata.namespace- namespace Pod
metadata.uid- унікальний ідентифікатор Pod
metadata.annotations['<KEY>']- значення аннотації Pod з іменем
<KEY>(наприклад,metadata.annotations['myannotation']) metadata.labels['<KEY>']- текстове значення мітки Pod з іменем
<KEY>(наприклад,metadata.labels['mylabel'])
Наступна інформація доступна через змінні середовища, але не як поле fieldRef тома downwardAPI:
spec.serviceAccountName- імʼя service account Pod
spec.nodeName- імʼя вузла, на якому виконується Pod
status.hostIP- основна IP-адреса вузла, до якого призначено Pod
status.hostIPs- IP-адреси — це версія подвійного стека
status.hostIP, перша завжди така сама, як іstatus.hostIP. status.podIP- основна IP-адреса Pod (зазвичай, його IPv4-адреса)
status.podIPs- IP-адреси — це версія подвійного стека
status.podIP, перша завжди така сама, як іstatus.podIP
Наступна інформація доступна через том downwardAPI fieldRef, але не як змінні середовища:
metadata.labels- всі мітки Pod, в форматі
label-key="escaped-label-value"з однією міткою на рядок metadata.annotations- всі аннотації поду, у форматі
annotation-key="escaped-annotation-value"з однією аннотацією на рядок
Інформація, доступна за допомогою resourceFieldRef
Ці поля рівня контейнера дозволяють надавати інформацію про вимоги та обмеження для ресурсів, таких як CPU та памʼять.
resource: limits.cpu- Обмеження CPU контейнера
resource: requests.cpu- Вимога CPU контейнера
resource: limits.memory- Обмеження памʼяті контейнера
resource: requests.memory- Вимога памʼяті контейнера
resource: limits.hugepages-*- Обмеження hugepages контейнера
resource: requests.hugepages-*- Вимога hugepages контейнера
resource: limits.ephemeral-storage- Обмеження ефемерних сховищ контейнера
resource: requests.ephemeral-storage- Вимога ефемерних сховищ контейнера
Резервні інформаційні обмеження для ресурсів
Якщо ліміти CPU та памʼяті не вказані для контейнера, і ви використовуєте downward API для спроби викриття цієї інформації, тоді kubelet типово використовує значення для CPU та памʼяті на основі розрахунку розподілених вузлів.
Що далі
Ви можете прочитати про томи downwardAPI.
Ви можете спробувати використовувати downward API для поширення інформації на рівні контейнера чи Pod:
4.2 - Керування навантаженням
Kubernetes надає кілька вбудованих API для декларативного керування вашими робочими навантаженнями та їх компонентами.
У кінцевому підсумку ваші застосунки працюють як контейнери всередині Podʼів; однак керувати окремими Podʼами вимагало б багато зусиль. Наприклад, якщо Pod зазнає збою, ви, ймовірно, захочете запустити новий Pod для його заміни. Kubernetes може зробити це за вас.
Ви використовуєте API Kubernetes для створення робочого обʼєкта, який представляє вищий рівень абстракції, ніж Pod, а потім Kubernetes control plane автоматично керує обʼєктами Pod від вашого імені, відповідно до специфікації обʼєкта робочого навантаження, яку ви визначили.
Вбудовані API для керування робочими навантаженнями:
Deployment (і, опосередковано, ReplicaSet), найпоширеніший спосіб запуску застосунку у вашому кластері. Deployment є хорошим вибором для керування робочим навантаженням, яке не зберігає стану, де будь-який Pod у Deployment може бути замінений, якщо це потрібно. (Deployments є заміною застарілого API ReplicationController).
StatefulSet дозволяє вам керувати одним або кількома Pod, які виконують один і той же код застосунку, де Pod мають унікальну ідентичність. Це відрізняється від Deployment, де очікується, що Pod будуть взаємозамінними. Найпоширеніше використання StatefulSet полягає в тому, щоб забезпечити звʼязок між Pod та їх постійним сховищем. Наприклад, ви можете запустити StatefulSet, який асоціює кожен Pod з PersistentVolume. Якщо один з Pod у StatefulSet зазнає збою, Kubernetes створює новий Pod, який підключений до того ж PersistentVolume.
DemonSet визначає Podʼи, які надають можливості, що є локальними для конкретного вузла; наприклад, драйвер, який дозволяє контейнерам на цьому вузлі отримувати доступ до системи сховища. Ви використовуєте DemonSet, коли драйвер або інша служба рівня вузла має працювати на вузлі, де вона корисна. Кожен Pod в DemonSet виконує роль, схожу на системний демон на класичному сервері Unix/POSIX. DemonSet може бути фундаментальним для роботи вашого кластера, наприклад, як втулок мережі кластера, він може допомогти вам керувати вузлом, або надати додаткову поведінку, яка розширює платформу контейнерів, яку ви використовуєте. Ви можете запускати DemonSet (і їх Podʼи) на кожному вузлі вашого кластера, або лише на підмножині (наприклад, встановити драйвер прискорювача GPU лише на вузлах, де встановлено GPU).
Ви можете використовувати Job та / або CronJob для визначення завдань, які виконуються до завершення та зупиняються. Job представляє одноразове завдання, тоді як кожен CronJob повторюється згідно з розкладом.
Інші теми в цьому розділі:
4.2.1 - Deployment
Deployment керує набором екземплярів Podʼів та їх робочими навантаженнями, як правило, тими, що не зберігають стан.
Розгортання (Deployment) забезпечує декларативні оновлення для Podʼів та ReplicaSets.
Ви описуєте бажаний стан у Deployment, і Контролер Deployment змінює фактичний стан на бажаний стан з контрольованою швидкістю. Ви можете визначити Deployment для створення нових ReplicaSets або видалення існуючих Deployment та прийняття всіх їхніх ресурсів новими Deployment.
Примітка:
Не керуйте ReplicaSets, що належать Deployment. Розгляньте можливість створення тікета в основному репозиторії Kubernetes, якщо ваш випадок використання не врахований нижче.Сценарії використання
Наступні сценарії є типовими для Deployment:
- Створення Deployment для розгортання набору ReplicaSet. ReplicaSet створює Podʼи у фоновому режимі. Перевірте стан розгортання, щоб переконатися, чи воно успішне чи ні.
- Оголошення нового стану Podʼів шляхом оновлення PodTemplateSpec в Deployment. Створюється новий ReplicaSet, і Deployment відповідає за переміщення Podʼів зі старого ReplicaSet на новий з контрольованою швидкістю. Кожен новий ReplicaSet оновлює ревізію Deployment.
- Відкат до попередньої ревізії Deployment, якщо поточний стан Deployment нестабільний. Кожен відкат оновлює ревізію Deployment.
- Масштабування Deployment для обробки більшого навантаження.
- Призупинення Deployment, щоб застосувати кілька виправлень до його PodTemplateSpec, а потім відновити його для початку нового розгортання.
- Використання стану Deployment як індикатора того, що розгортання зупинилося.
- Очищення старих ReplicaSets, які вам більше не потрібні.
Створення Deployment
Розглянемо приклад Deployment. Він створює ReplicaSet для запуску трьох Podʼів nginx:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
В цьому прикладі:
Створюється Deployment з назвою
nginx-deployment, назва вказується в полі.metadata.name. Ця назва буде основою для ReplicaSets та Podʼів які буде створено потім. Дивіться Написання Deployment Spec для отримання додаткових відомостей.Deployment створює ReplicaSet, який створює три реплікованих Podʼи, кількість зазначено у полі
.spec.replicas.Поле
.spec.selectorвизначає як створений ReplicaSet відшукує Podʼи для керування. В цьому випадку вибирається мітка, яка визначена в шаблоні Pod,app: nginx. Однак можливі складніші правила вибору, якщо шаблон Pod задовольняє це правило.Примітка:
Поле.spec.selector.matchLabelsє масивом пар {key,value}. Одна пара {key,value} уmatchLabelsеквівалентна елементуmatchExpressions, де полеkey— "key",operator— "In", а масивvaluesмістить лише "value". Всі умови, як відmatchLabels, так і відmatchExpressions, повинні бути виконані для отримання збігу.Поле
templateмає наступні вкладені поля:- Podʼи позначаються міткою
app: nginxз поля.metadata.labels. - Шаблон специфікації Podʼа, поле
.template.spec, вказує на те, що Podʼи використовують один контейнер,nginx, який використовує образnginxз Docker Hub версія якого – 1.14.2. - Створюється один контейнер, який отримує назву
nginx, яка вказана в полі.spec.template.spec.containers[0].name.
- Podʼи позначаються міткою
Перед тим, як почати, переконайтеся, що ваш кластер Kubernetes працює. Дотримуйтесь наведених нижче кроків для створення Deployment:
Створіть Deployment скориставшись командою:
kubectl apply -f https://k8s.io/examples/controllers/nginx-deployment.yamlВиконайте
kubectl get deploymentsдля перевірки створення Deployment.Якщо Deployment все ще створюється, ви побачите вивід подібний цьому:
NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 0/3 0 0 1sКоли ви досліджуєте Deploymentʼи у вашому кластері, показуються наступні поля:
NAME— містить назву Deploymentʼів у просторі імен.READY— показує скільки реплік застосунку доступно користувачам. Значення відповідає шаблону наявно/бажано.UP-TO-DATE— показує кількість реплік, які були оновлені для досягнення бажаного стану.AVAILABLE— показує скільки реплік доступно користувачам.AGE— показує час впродовж якого застосунок працює.
Notice how the number of desired replicas is 3 according to
.spec.replicasfield.Для перевірки стану розгортання Deployment, виконайте
kubectl rollout status deployment/nginx-deployment.Має бути подібний вивід:
Waiting for rollout to finish: 2 out of 3 new replicas have been updated... deployment "nginx-deployment" successfully rolled outЗапустіть
kubectl get deploymentsзнов через кілька секунд. Має бути подібний вивід:NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 18sБачите, що Deployment створив три репліки, і всі репліки актуальні (вони містять останній шаблон Pod) та доступні.
Для перевірки ReplicaSet (
rs), створених Deployment, виконайтеkubectl get rs. Має бути подібний вивід:NAME DESIRED CURRENT READY AGE nginx-deployment-75675f5897 3 3 3 18sВивід ReplicaSet має наступні поля:
NAME— перелік назв ReplicaSets в просторі імен.DESIRED— показує бажану кількість реплік застосунку, яку ви вказали при створенні Deployment. Це — бажаний стан.CURRENT— показує поточну кількість реплік, що працюють на поточний момент.READY— показує скільки реплік застосунку доступно користувачам.AGE— показує час впродовж якого застосунок працює.
Зверніть увагу, що назва ReplicaSet завжди складається як
[DEPLOYMENT-NAME]-[HASH]. Ця назва буде основою для назв Podʼів, які буде створено потім.Рядок
HASHє відповідником міткиpod-template-hashв ReplicaSet.Для ознайомлення з мітками, які було створено для кожного Pod, виконайте
kubectl get pods --show-labels. Вивід буде схожим на це:NAME READY STATUS RESTARTS AGE LABELS nginx-deployment-75675f5897-7ci7o 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897 nginx-deployment-75675f5897-kzszj 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897 nginx-deployment-75675f5897-qqcnn 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897Створений ReplicaSet таким чином переконується, що в наявності є три Podʼи
nginx.
Примітка:
Ви маєте зазначити відповідний селектор та мітки шаблону Pod в Deployment (тут, app: nginx).
Не використовуйте однакові мітки або селектори з іншими контролерами (включаючи інші Deployments та StatefulSets). Kubernetes не завадить вам це зробити, і якщо кілька контролерів мають селектори, що збігаються, ці контролери можуть конфліктувати та поводитись непередбачувано.
Мітка pod-template-hash
Увага:
Не змінюйте цю мітку.Мітка pod-template-hash додається контролером Deployment до кожного ReplicaSet, який створює або бере під нагляд Deployment.
Ця мітка забезпечує унікальність дочірніх ReplicaSets Deploymentʼа. Вона генерується шляхом хешування PodTemplate ReplicaSet, і отриманий хеш використовується як значення мітки, яке додається до селектора ReplicaSet, міток шаблону Podʼа, а також до всіх наявних Podʼів, які можуть бути у ReplicaSet.
Оновлення Deployment
Примітка:
Оновлення Deployment викликається тільки в тому випадку, якщо шаблон Deployment Podʼа (тобто.spec.template) змінився, наприклад, якщо оновлено мітки чи образ контейнера шаблону. Інші оновлення, такі як масштабування Deployment, не викликають розгортання.Дотримуйтеся поданих нижче кроків для оновлення вашого Deployment:
Оновіть Podʼи nginx, щоб використовувати образ
nginx:1.16.1замістьnginx:1.14.2.kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.16.1або використовуйте наступну команду:
kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1де
deployment/nginx-deploymentвказує на Deployment,nginx— на контейнер, який буде оновлено, іnginx:1.16.1— на новий образ та його теґ.Вивід буде схожий на:
deployment.apps/nginx-deployment image updatedАльтернативно, ви можете відредагувати розгортання і змінити
.spec.template.spec.containers[0].imageзnginx:1.14.2наnginx:1.16.1:kubectl edit deployment/nginx-deploymentВивід буде схожий на:
deployment.apps/nginx-deployment editedЩоб перевірити статус розгортання, виконайте:
kubectl rollout status deployment/nginx-deploymentВивід буде схожий на це:
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...або
deployment "nginx-deployment" successfully rolled out
Отримайте більше деталей про ваш оновлений Deployment:
Після успішного розгортання можна переглянути Deployment за допомогою
kubectl get deployments. Вивід буде схожий на це:NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 36sВиконайте
kubectl get rs, щоб перевірити, що Deployment оновив Podʼи, створивши новий ReplicaSet та масштабував його до 3 реплік, а також зменшивши розмір старого ReplicaSet до 0 реплік.kubectl get rsВивід схожий на це:
NAME DESIRED CURRENT READY AGE nginx-deployment-1564180365 3 3 3 6s nginx-deployment-2035384211 0 0 0 36sВиклик
get podsповинен тепер показати лише нові Podʼи:kubectl get podsВивід буде схожий на це:
NAME READY STATUS RESTARTS AGE nginx-deployment-1564180365-khku8 1/1 Running 0 14s nginx-deployment-1564180365-nacti 1/1 Running 0 14s nginx-deployment-1564180365-z9gth 1/1 Running 0 14sНаступного разу, коли вам потрібно буде оновити ці Podʼи, вам достатньо буде знову оновити шаблон Podʼа в Deployment.
Deployment забезпечує, що тільки певна кількість Podʼів буде відключена під час оновлення. Типово це забезпечує, що принаймні 75% відомої кількості Podʼів будуть активними (максимум недоступних 25%).
Deployment також забезпечує, що тільки певна кількість Podʼів буде створена поверх відомої кількості Podʼів. Типово це забезпечує, що як максимум буде активно 125% відомої кількості Podʼів (25% максимального збільшення).
Наприклад, якщо ви ретельно досліджуєте Deployment вище, ви побачите, що спочатку було створено новий Pod, потім видалено старий Pod і створено ще один новий. Старі Podʼи не прибираються допоки не зʼявиться достатня кількість нових, і не створюються нові Podʼи допоки не буде прибрано достатню кількість старих. Deployment переконується, що принаймні 3 Podʼи доступні, і що вони не перевищують 4 Podʼа. У випадку розгортання з 4 репліками кількість Podʼів буде між 3 і 5.
Отримайте деталі вашого розгортання:
kubectl describe deploymentsВивід буде схожий на це:
Name: nginx-deployment Namespace: default CreationTimestamp: Thu, 30 Nov 2017 10:56:25 +0000 Labels: app=nginx Annotations: deployment.kubernetes.io/revision=2 Selector: app=nginx Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge Pod Template: Labels: app=nginx Containers: nginx: Image: nginx:1.16.1 Port: 80/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason ---- ------ ------ Available True MinimumReplicasAvailable Progressing True NewReplicaSetAvailable OldReplicaSets: <none> NewReplicaSet: nginx-deployment-1564180365 (3/3 replicas created) Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ScalingReplicaSet 2m deployment-controller Scaled up replica set nginx-deployment-2035384211 to 3 Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 1 Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 2 Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 2 Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 1 Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 3 Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 0Тут ви бачите, що при створенні Deployment спочатку було створено ReplicaSet (nginx-deployment-2035384211) та масштабовано його до 3 реплік безпосередньо. Коли ви оновили Deployment, було створено новий ReplicaSet (nginx-deployment-1564180365) та масштабовано його до 1, потім Deployment дочекався, коли він запуститься. Потім було зменшено розмір старого ReplicaSet до 2 і масштабовано новий ReplicaSet до 2, таким чином, щоб принаймні 3 Podʼа були доступні, і не більше 4 Podʼів в будь-який момент. Потім було продовжено масштабування нового та старого ReplicaSet, з однаковою стратегією поетапного оновлення. У кінці вас буде 3 доступні репліки в новому ReplicaSet, і старий ReplicaSet зменшений до 0.
Примітка:
Kubernetes не враховує Podʼи, які завершують роботу, коли розраховує кількістьavailableReplicas, яка повинна бути між replicas - maxUnavailable та replicas + maxSurge. Внаслідок цього ви можете помітити, що під час розгортання є більше Podʼів, ніж очікувалося, і що загальні ресурси, які використовує Deployment, перевищують replicas + maxSurge до того моменту, поки не мине terminationGracePeriodSeconds для Podʼів, що завершують роботу.Rollover (або кілька одночасних оновлень)
Кожного разу, коли новий Deployment спостерігається контролером Deployment, ReplicaSet створюється для запуску необхідних Podʼів. Якщо Deployment оновлюється, поточний ReplicaSet, Podʼи якого збігаються з міткам з .spec.selector, але не збігаються з .spec.template, зменшується. Зрештою, новий ReplicaSet масштабується до .spec.replicas, і всі старі ReplicaSets масштабуються в 0.
Якщо ви оновите Deployment під час вже поточного процесу розгортання, Deployment створить новий ReplicaSet відповідно до оновлення і почне масштабувати його, і розвертати ReplicaSet, який він раніше масштабував — він додасть його до списку старих ReplicaSets та почне зменшувати його.
Наприклад, припустимо, ви створюєте Deployment для створення 5 реплік nginx:1.14.2, але потім оновлюєте Deployment для створення 5 реплік nginx:1.16.1, коли вже створено тільки 3 репліки nginx:1.14.2. У цьому випадку Deployment негайно починає
знищувати 3 Podʼи nginx:1.14.2, які вже створено, і починає створювати
Podʼи nginx:1.16.1. Deployment не чекає, доки буде створено 5 реплік nginx:1.14.2, перш ніж змінити напрямок.
Оновлення селектора міток
Зазвичай не рекомендується вносити оновлення до селектора міток, і рекомендується планувати ваші селектори наперед. У будь-якому випадку, якщо вам потрібно виконати оновлення селектора міток, дійте з великою обережністю і переконайтеся, що ви розумієте всі його наслідки.
Примітка:
В API-версіїapps/v1 селектор міток Deployment є незмінним після створення.- Додавання селектора вимагає оновлення міток шаблону Podʼа в специфікації Deployment новою міткою, інакше буде повернуто помилку перевірки. Ця зміна не є такою, що перетинається з наявними мітками, що означає, що новий селектор не вибирає ReplicaSets та Podʼи, створені за допомогою старого селектора, що призводить до залишення всіх старих ReplicaSets та створення нового ReplicaSet.
- Оновлення селектора змінює поточне значення ключа селектора — призводить до такого ж результату, як і додавання.
- Вилучення селектора вилучає наявний ключ з селектора Deployment — не вимагає будь-яких змін у мітках шаблону Podʼа. Наявні ReplicaSets не залишаються сиротами, і новий ReplicaSet не створюється, але слід зауважити, що вилучена мітка все ще існує в будь-яких наявних Podʼах і ReplicaSets.
Відкат Deployment
Іноді вам може знадобитися відкотити Deployment, наприклад, коли Deployment нестабільний, наприклад цикл постійних помилок. Типово, вся історія Deployment зберігається в системі, щоб ви могли відкотити його в будь-який час (ви можете змінити це, змінивши обмеження історії ревізій).
Примітка:
Ревізія Deployment створюється, коли спрацьовує Deployment. Це означає, що нова ревізія створюється тільки тоді, коли змінюється шаблон Podʼа Deployment (.spec.template), наприклад, якщо ви оновлюєте мітки або образи контейнера в шаблоні. Інші оновлення, такі як масштабування Deployment, не створюють ревізію Deployment, щоб ви могли одночасно використовувати ручне або автоматичне масштабування. Це означає, що при відкаті до попередньої ревізії повертається лише частина шаблону Podʼа Deployment.Припустимо, ви припустилися помилки при оновленні Deployment, вказавши назву образу як
nginx:1.161замістьnginx:1.16.1:kubectl set image deployment/nginx-deployment nginx=nginx:1.161Вивід буде подібний до цього:
deployment.apps/nginx-deployment image updatedРозгортання застрягає. Ви можете перевірити це, перевіривши стан розгортання:
kubectl rollout status deployment/nginx-deploymentВивід буде подібний до цього:
Waiting for rollout to finish: 1 out of 3 new replicas have been updated...Натисніть Ctrl-C, щоб зупинити спостереження за станом розгортання. Щодо деталей розгортання, що застрягло, читайте тут.
Ви бачите, що кількість старих реплік (додаючи кількість реплік від
nginx-deployment-1564180365таnginx-deployment-2035384211) — 3, а кількість нових реплік (відnginx-deployment-3066724191) — 1.kubectl get rsВивід буде подібний до цього:
NAME DESIRED CURRENT READY AGE nginx-deployment-1564180365 3 3 3 25s nginx-deployment-2035384211 0 0 0 36s nginx-deployment-3066724191 1 1 0 6sПри перегляді створених Podʼів ви бачите, що 1 Pod, створений новим ReplicaSet, застряг у циклі завантаження образу.
kubectl get podsВивід буде подібний до цього:
NAME READY STATUS RESTARTS AGE nginx-deployment-1564180365-70iae 1/1 Running 0 25s nginx-deployment-1564180365-jbqqo 1/1 Running 0 25s nginx-deployment-1564180365-hysrc 1/1 Running 0 25s nginx-deployment-3066724191-08mng 0/1 ImagePullBackOff 0 6sПримітка:
Контролер Deployment автоматично зупиняє невдале розгортання та припиняє масштабування нового ReplicaSet. Це залежить від параметрів rollingUpdate (maxUnavailable), які ви вказали. Стандартно Kubernetes встановлює значення 25%.Отримання опису розгортання:
kubectl describe deploymentВивід буде подібний до цього:
Name: nginx-deployment Namespace: default CreationTimestamp: Tue, 15 Mar 2016 14:48:04 -0700 Labels: app=nginx Selector: app=nginx Replicas: 3 desired | 1 updated | 4 total | 3 available | 1 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge Pod Template: Labels: app=nginx Containers: nginx: Image: nginx:1.161 Port: 80/TCP Host Port: 0/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason ---- ------ ------ Available True MinimumReplicasAvailable Progressing True ReplicaSetUpdated OldReplicaSets: nginx-deployment-1564180365 (3/3 replicas created) NewReplicaSet: nginx-deployment-3066724191 (1/1 replicas created) Events: FirstSeen LastSeen Count From SubObjectPath Type Reason Message --------- -------- ----- ---- ------------- -------- ------ ------- 1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-2035384211 to 3 22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 1 22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 2 22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 2 21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 1 21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 3 13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 0 13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-3066724191 to 1Для виправлення цього вам потрібно відкотитиcm до попередньої ревізії Deployment, яка є стабільною.
Перевірка історії розгортання Deployment
Виконайте наведені нижче кроки, щоб перевірити історію розгортань:
По-перше, перевірте ревізії цього Deployment:
kubectl rollout history deployment/nginx-deploymentВивід буде подібний до цього:
deployments "nginx-deployment" REVISION CHANGE-CAUSE 1 kubectl apply --filename=https://k8s.io/examples/controllers/nginx-deployment.yaml 2 kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 3 kubectl set image deployment/nginx-deployment nginx=nginx:1.161CHANGE-CAUSEкопіюється з анотації Deploymentkubernetes.io/change-causeдо його ревізій при створенні. Ви можете вказати повідомленняCHANGE-CAUSE:- Анотуючи Deployment командою
kubectl annotate deployment/nginx-deployment kubernetes.io/change-cause="image updated to 1.16.1" - Ручним редагуванням маніфесту ресурсу.
- Анотуючи Deployment командою
Щоб переглянути деталі кожної ревізії, виконайте:
kubectl rollout history deployment/nginx-deployment --revision=2Вивід буде подібний до цього:
deployments "nginx-deployment" revision 2 Labels: app=nginx pod-template-hash=1159050644 Annotations: kubernetes.io/change-cause=kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 Containers: nginx: Image: nginx:1.16.1 Port: 80/TCP QoS Tier: cpu: BestEffort memory: BestEffort Environment Variables: <none> No volumes.
Відкат до попередньої ревізії
Виконайте наведені нижче кроки, щоб відкотити Deployment з поточної версії на попередню версію, яка є версією 2.
Тепер ви вирішили скасувати поточне розгортання та повернутися до попередньої ревізії:
kubectl rollout undo deployment/nginx-deploymentВивід буде подібний до цього:
deployment.apps/nginx-deployment rolled backЗамість цього ви можете виконати відкат до певної ревізії, вказавши її параметром
--to-revision:kubectl rollout undo deployment/nginx-deployment --to-revision=2Вивід буде подібний до цього:
deployment.apps/nginx-deployment rolled backДля отримання додаткових відомостей про команди, повʼязані з розгортаннями, читайте
kubectl rollout.Deployment тепер повернуто до попередньої стабільної ревізії. Як ви можете бачити, контролер розгортань генерує подію
DeploymentRollbackщодо відкату до ревізії 2.Перевірте, чи відкат був успішним і Deployment працює як очікується, виконавши:
kubectl get deployment nginx-deploymentВивід буде подібний до цього:
NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 30mОтримайте опис розгортання:
kubectl describe deployment nginx-deploymentВивід подібний до цього:
Name: nginx-deployment Namespace: default CreationTimestamp: Sun, 02 Sep 2018 18:17:55 -0500 Labels: app=nginx Annotations: deployment.kubernetes.io/revision=4 kubernetes.io/change-cause=kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 Selector: app=nginx Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge Pod Template: Labels: app=nginx Containers: nginx: Image: nginx:1.16.1 Port: 80/TCP Host Port: 0/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason ---- ------ ------ Available True MinimumReplicasAvailable Progressing True NewReplicaSetAvailable OldReplicaSets: <none> NewReplicaSet: nginx-deployment-c4747d96c (3/3 replicas created) Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ScalingReplicaSet 12m deployment-controller Scaled up replica set nginx-deployment-75675f5897 to 3 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 1 Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 2 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 2 Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 1 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 3 Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 0 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-595696685f to 1 Normal DeploymentRollback 15s deployment-controller Rolled back deployment "nginx-deployment" to revision 2 Normal ScalingReplicaSet 15s deployment-controller Scaled down replica set nginx-deployment-595696685f to 0
Масштабування Deployment
Ви можете масштабувати Deployment за допомогою наступної команди:
kubectl scale deployment/nginx-deployment --replicas=10
Вивід буде подібний до цього:
deployment.apps/nginx-deployment scaled
Припускаючи, що горизонтальне автомасштабування Pod увімкнено у вашому кластері, ви можете налаштувати автомасштабування для вашого Deployment і вибрати мінімальну та максимальну кількість Podʼів, які ви хочете запустити на основі використання ЦП вашими поточними Podʼами.
kubectl autoscale deployment/nginx-deployment --min=10 --max=15 --cpu-percent=80
Вивід буде подібний до цього:
deployment.apps/nginx-deployment scaled
Пропорційне масштабування
Deployment RollingUpdate підтримує виконання кількох версій застосунку одночасно. Коли ви або автомасштабування масштабуєте Deployment RollingUpdate, яке знаходиться в процесі розгортання (будь-то в процесі або призупинено), контролер Deployment балансує додаткові репліки в наявних активних ReplicaSets (ReplicaSets з Podʼами), щоб помʼякшити ризик. Це називається пропорційним масштабуванням.
Наприклад, ви використовуєте Deployment з 10 репліками, maxSurge=3 та maxUnavailable=2.
Переконайтеся, що в вашому Deployment працює 10 реплік.
kubectl get deployВивід буде подібний до цього:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx-deployment 10 10 10 10 50sВи оновлюєте образ, який, як виявляється, неможливо знайти в межах кластера.
kubectl set image deployment/nginx-deployment nginx=nginx:sometagВивід подібний до цього:
deployment.apps/nginx-deployment image updatedОновлення образу розпочинає новий rollout з ReplicaSet nginx-deployment-1989198191, але воно блокується через вимогу
maxUnavailable, яку ви вказали вище. Перевірте стан rollout:kubectl get rsВивід буде подібний до цього:
NAME DESIRED CURRENT READY AGE nginx-deployment-1989198191 5 5 0 9s nginx-deployment-618515232 8 8 8 1mПотім надходить новий запит на масштабування для Deployment. Автомасштабування збільшує репліки Deployment до 15. Контролер Deployment повинен вирішити, куди додати цих нових 5 реплік. Якби ви не використовували пропорційне масштабування, всі 5 реплік були б додані в новий ReplicaSet. З пропорційним масштабуванням ви розподіляєте додаткові репліки між всіма ReplicaSets. Більші частки йдуть в ReplicaSets з найбільшою кількістю реплік, а менші частки йдуть в ReplicaSets з меншою кількістю реплік. Залишки додаються до ReplicaSet з найбільшою кількістю реплік. ReplicaSets з нульовою кількістю реплік не масштабуються.
У нашому прикладі вище 3 репліки додаються до старого ReplicaSet, а 2 репліки — до нових ReplicaSet. Процес розгортання повинен остаточно перемістити всі репліки в новий ReplicaSet, за умови, що нові репліки стають справними. Для підтвердження цього виконайте:
kubectl get deploy
Вивід буде подібний до цього:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 15 18 7 8 7m
Статус rollout підтверджує, як репліки були додані до кожного ReplicaSet.
kubectl get rs
Вивід буде подібний до цього:
NAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 7 7 0 7m
nginx-deployment-618515232 11 11 11 7m
Призупинення та відновлення розгортання Deployment
При оновленні Deployment або плануванні оновлення ви можете призупинити розгортання для цього Deployment перед тим, як запустити одне чи кілька оновлень. Коли ви готові застосувати зміни, ви відновлюєте розгортання для Deployment. Цей підхід дозволяє вам застосовувати кілька виправлень між призупиненням та відновленням без зайвих розгортань.
Наприклад, з Deployment, яке було створено:
Отримайте деталі Deployment:
kubectl get deployВивід буде подібний до цього:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx 3 3 3 3 1mОтримайте стан розгортання:
kubectl get rsВивід буде подібний до цього:
NAME DESIRED CURRENT READY AGE nginx-2142116321 3 3 3 1mЗробіть паузу за допомогою наступної команди:
kubectl rollout pause deployment/nginx-deploymentВивід буде подібний до цього:
deployment.apps/nginx-deployment pausedПотім оновіть образ в Deployment:
kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1Вивід буде подібний до цього:
deployment.apps/nginx-deployment image updatedЗверніть увагу, що новий rollout не розпочався:
kubectl rollout history deployment/nginx-deploymentВивід буде подібний до цього:
deployments "nginx" REVISION CHANGE-CAUSE 1 <none>Отримайте стан розгортання, щоб перевірити, що існуючий ReplicaSet не змінився:
kubectl get rsВивід буде подібний до цього:
NAME DESIRED CURRENT READY AGE nginx-2142116321 3 3 3 2mВи можете робити стільки оновлень, скільки вам потрібно, наприклад, оновіть ресурси, які будуть використовуватися:
kubectl set resources deployment/nginx-deployment -c=nginx --limits=cpu=200m,memory=512MiВивід буде подібний до цього:
deployment.apps/nginx-deployment resource requirements updatedПочатковий стан Deployment перед призупиненням його rollout продовжить свою роботу, але нові оновлення до Deployment не матимуть жодного впливу, поки розгортання Deployment призупинено.
У кінці відновіть розгортання Deployment і спостерігайте, як новий ReplicaSet зʼявляється з усіма новими оновленнями:
kubectl rollout resume deployment/nginx-deploymentВивід буде подібний до цього:
deployment.apps/nginx-deployment resumedСпостерігайте за статусом розгортання, доки воно не завершиться.
kubectl get rs --watchВивід буде подібний до цього:
NAME DESIRED CURRENT READY AGE nginx-2142116321 2 2 2 2m nginx-3926361531 2 2 0 6s nginx-3926361531 2 2 1 18s nginx-2142116321 1 2 2 2m nginx-2142116321 1 2 2 2m nginx-3926361531 3 2 1 18s nginx-3926361531 3 2 1 18s nginx-2142116321 1 1 1 2m nginx-3926361531 3 3 1 18s nginx-3926361531 3 3 2 19s nginx-2142116321 0 1 1 2m nginx-2142116321 0 1 1 2m nginx-2142116321 0 0 0 2m nginx-3926361531 3 3 3 20sОтримайте статус останнього розгортання:
kubectl get rsВивід буде подібний до цього:
NAME DESIRED CURRENT READY AGE nginx-2142116321 0 0 0 2m nginx-3926361531 3 3 3 28s
Примітка:
Ви не можете відкотити призупинене розгортання Deployment, доки ви його не відновите.Статус Deployment
Deployment переходить через різні стани протягом свого життєвого циклу. Він може бути d процесі, коли виконується розгортання нового ReplicaSet, може бути завершеним або невдалим.
Deployment в процесі
Kubernetes позначає Deployment як в процесі (progressing), коли виконується одне з наступних завдань:
- Deployment створює новий ReplicaSet.
- Deployment масштабує вгору свій новий ReplicaSet.
- Deployment масштабує вниз свої старі ReplicaSet(s).
- Нові Podʼи стають готовими або доступними (готові принаймні MinReadySeconds).
Коли розгортання стає "в процесі" (progressing), контролер Deployment додає умову із наступними атрибутами до .status.conditions Deployment:
type: Progressingstatus: "True"reason: NewReplicaSetCreated|reason: FoundNewReplicaSet|reason: ReplicaSetUpdated
Ви можете відстежувати хід розгортання за допомогою kubectl rollout status.
Завершений Deployment
Kubernetes позначає Deployment як завершений (complete), коли він має наступні характеристики:
- Всі репліки, повʼязані з Deployment, були оновлені до останньої версії, яку ви вказали. Це означає, що всі запитані вами оновлення були завершені.
- Всі репліки, повʼязані з Deployment, доступні.
- Не працюють жодні старі репліки для Deployment.
Коли розгортання стає "завершеним" (complete), контролер Deployment встановлює умову із наступними атрибутами до .status.conditions Deployment:
type: Progressingstatus: "True"reason: NewReplicaSetAvailable
Ця умова Progressing буде зберігати значення статусу "True" до тих пір, поки не буде запущено нове розгортання. Умова залишається незмінною навіть тоді, коли змінюється доступність реплік (це не впливає на умову Available).
Ви можете перевірити, чи завершено Deployment, використовуючи kubectl rollout status. Якщо Deployment завершився успішно, kubectl rollout status повертає код виходу нуль (успіх).
kubectl rollout status deployment/nginx-deployment
Вивід буде схожий на наступний:
Waiting for rollout to finish: 2 of 3 updated replicas are available...
deployment "nginx-deployment" successfully rolled out
і код виходу з kubectl rollout дорівнює 0 (успіх):
echo $?
0
Невдалий Deployment
Ваш Deployment може застрягти під час намагання розгорнути свій новий ReplicaSet і ніколи не завершитися. Це може статися через наступне:
- Недостатні квоти
- Збій проб readiness
- Помилки підтягування образів
- Недостатні дозволи
- Обмеження лімітів
- Неправильна конфігурація середовища виконання застосунку
Один із способів виявлення цього стану — це вказати параметр граничного терміну в специфікації вашого розгортання: (.spec.progressDeadlineSeconds). .spec.progressDeadlineSeconds вказує кількість секунд, протягом яких контролер Deployment чекатиме, перш ніж вказати (в статусі Deployment), що прогрес розгортання зупинився.
Наступна команда kubectl встановлює специфікацію з progressDeadlineSeconds, щоб змусити контролер повідомляти про відсутність прогресу розгортання для Deployment після 10 хвилин:
kubectl patch deployment/nginx-deployment -p '{"spec":{"progressDeadlineSeconds":600}}'
Вивід буде схожий на наступний:
deployment.apps/nginx-deployment patched
Після того як граничний термін закінчився, контролер Deployment додає DeploymentCondition з наступними атрибутами до .status.conditions Deployment:
type: Progressingstatus: "False"reason: ProgressDeadlineExceeded
Ця умова також може зазнати невдачі на ранніх етапах, і тоді вона встановлюється в значення статусу "False" з причинами, такими як ReplicaSetCreateError. Крім того, термін не враховується більше після завершення розгортання.
Дивіться Домовленості API Kubernetes для отримання додаткової інформації щодо умов статусу.
Примітка:
Kubernetes не вживає ніяких заходів стосовно до зупиненого Deployment, крім як звітувати про умову статусу зreason: ProgressDeadlineExceeded. Оркестратори вищого рівня можуть використовувати це і відповідним чином діяти, наприклад, відкотити Deployment до його попередньої версії.Примітка:
Якщо ви призупините розгортання Deployment, Kubernetes не перевірятиме прогрес відносно вашого вказаного терміну. Ви можете безпечно призупинити розгортання Deployment в середині процесу розгортання та відновити його, не викликаючи умову виходу за граничним терміном.Ви можете зіткнутися з тимчасовими помилками у Deployment, або через низький таймаут, який ви встановили, або через будь-який інший вид помилок, який можна розглядати як тимчасовий. Наприклад, допустімо, що у вас недостатні квоти. Якщо ви опишете Deployment, ви помітите наступний розділ:
kubectl describe deployment nginx-deployment
Вивід буде схожий на наступний:
<...>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True ReplicaSetUpdated
ReplicaFailure True FailedCreate
<...>
Якщо ви виконаєте kubectl get deployment nginx-deployment -o yaml, статус Deployment схожий на це:
status:
availableReplicas: 2
conditions:
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: Replica set "nginx-deployment-4262182780" is progressing.
reason: ReplicaSetUpdated
status: "True"
type: Progressing
- lastTransitionTime: 2016-10-04T12:25:42Z
lastUpdateTime: 2016-10-04T12:25:42Z
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: 2016-10-04T12:25:39Z
last
UpdateTime: 2016-10-04T12:25:39Z
message: 'Error creating: pods "nginx-deployment-4262182780-" is forbidden: exceeded quota:
object-counts, requested: pods=1, used: pods=3, limited: pods=2'
reason: FailedCreate
status: "True"
type: ReplicaFailure
observedGeneration: 3
replicas: 2
unavailableReplicas: 2
В решті решт, коли граничний термін прогресу Deployment буде перевищений, Kubernetes оновить статус і причину умови Progressing:
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing False ProgressDeadlineExceeded
ReplicaFailure True FailedCreate
Ви можете вирішити проблему недостатньої квоти, зменшивши масштаб вашого Deployment, зменшивши масштаб інших контролерів, які ви можете виконувати, або збільшивши квоту у вашому просторі імен. Якщо ви задовольните умови квоти
і контролер Deployment завершить розгортання, ви побачите, що статус Deployment оновлюється успішною умовою (status: "True" та reason: NewReplicaSetAvailable).
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
type: Available з status: "True" означає, що у вас є мінімальна доступність Deployment. Мінімальна доступність визначається параметрами, вказаними в стратегії розгортання. type: Progressing з status: "True" означає, що ваш Deployment або знаходиться в середині розгортання і прогресує, або він успішно завершив свій прогрес, і доступна мінімально необхідна нова кількість реплік (див. причину умови для конкретики — у нашому випадку reason: NewReplicaSetAvailable означає, що Deployment завершено).
Ви можете перевірити, чи Deployment не вдався за допомогою kubectl rollout status. kubectl rollout status повертає код виходу, відмінний від нуля, якщо Deployment перевищив граничний термін виконання.
kubectl rollout status deployment/nginx-deployment
Вивід буде схожий на наступний:
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
error: deployment "nginx" exceeded its progress deadline
і код виходу з kubectl rollout дорівнює 1 (позначає помилку):
echo $?
1
Операції з невдалим Deployment
Всі дії, які застосовуються до завершеного Deployment, також застосовуються до невдалого Deployment. Ви можете масштабувати його вгору/вниз, відкотити на попередню ревізію або навіть призупинити, якщо вам потрібно застосувати кілька корекцій у шаблоні Pod Deployment.
Політика очищення
Ви можете встановити поле .spec.revisionHistoryLimit у Deployment, щоб вказати, скільки старих ReplicaSets для цього Deployment ви хочете зберегти. Решта буде видалена як сміття в фоновому режимі. Типове значення становить 10.
Примітка:
Якщо явно встановити це поле на 0, буде виконано очищення всієї історії вашого Deployment, і цей Deployment не зможе виконати відкат.Canary Deployment
Якщо ви хочете впроваджувати релізи для підмножини користувачів чи серверів, використовуючи Deployment, ви можете створити кілька Deployment, один для кожного релізу, слідуючи шаблону Canary, описаному в управлінні ресурсами.
Написання специфікації Deployment
Як і з усіма іншими конфігураціями Kubernetes, у Deployment потрібні поля .apiVersion, .kind і .metadata. Для загальної інформації щодо роботи з файлами конфігурацій дивіться документи розгортання застосунків, налаштування контейнерів та використання kubectl для управління ресурсами.
Коли панель управління створює нові Podʼи для Deployment, .metadata.name Deployment є частиною основи для найменування цих Podʼів. Назва Deployment повинна бути дійсним значенням DNS-піддомену, але це може призводити до неочікуваних результатів для імен хостів Podʼів. Для найкращої сумісності імʼя повинно відповідати більш обмеженим правилам DNS-мітки.
Deployment також потребує розділу .spec.
Шаблон Pod
.spec.template та .spec.selector — єдині обовʼязкові поля .spec.
.spec.template — це шаблон Pod. Він має точно таку ж схему, як і Pod, за винятком того, що він вкладений і не має apiVersion або kind.
Крім обовʼязкових полів для Pod, шаблон Pod в Deployment повинен вказати відповідні мітки та відповідну політику перезапуску. Щодо міток, переконайтеся, що вони не перекриваються з іншими контролерами. Дивіться селектор.
Дозволяється лише .spec.template.spec.restartPolicy, рівне Always, що є стандартним значенням, якщо не вказано інше.
Репліки
.spec.replicas — це необовʼязкове поле, яке вказує кількість бажаних Podʼів. Стандартно встановлено значення 1.
Якщо ви вручну масштабуєте Deployment, наприклад, через kubectl scale deployment deployment --replicas=X, а потім ви оновлюєте цей Deployment на основі маніфесту (наприклад: виконуючи kubectl apply -f deployment.yaml), то застосування цього маніфесту перезаписує ручне масштабування, яке ви раніше вказали.
Якщо HorizontalPodAutoscaler (або будь-який аналогічний API для горизонтального масштабування) відповідає за масштабування Deployment, не встановлюйте значення в .spec.replicas.
Замість цього дозвольте панелі управління Kubernetes автоматично керувати полем .spec.replicas.
Селектор
.spec.selector — обовʼязкове поле, яке вказує селектор міток для Podʼів, які створює цей Deployment.
.spec.selector повинно відповідати .spec.template.metadata.labels, або воно буде відхилено API.
В API-версії apps/v1 .spec.selector та .metadata.labels не встановлюють стандартні значення на основі .spec.template.metadata.labels, якщо вони не встановлені. Таким чином, їх слід встановлювати явно. Також слід зазначити, що .spec.selector неможливо змінити після створення Deployment в apps/v1.
Deployment може примусово завершити Podʼи, мітки яких відповідають селектору, якщо їх шаблон відмінний від .spec.template або якщо загальна кількість таких Podʼів перевищує .spec.replicas. Запускає нові Podʼи з .spec.template, якщо кількість Podʼів менше, ніж бажана кількість.
Примітка:
Вам не слід створювати інші Podʼи, мітки яких відповідають цьому селектору, або безпосередньо, створюючи інший Deployment, або створюючи інший контролер, такий як ReplicaSet або ReplicationController. Якщо ви це зробите, перший Deployment вважатиме, що він створив ці інші Podʼи. Kubernetes не забороняє вам робити це.Якщо у вас є кілька контролерів із подібними селекторами, контролери будуть конфліктувати між собою і не будуть вести себе коректно.
Стратегія
.spec.strategy визначає стратегію, якою замінюються старі Podʼи новими. .spec.strategy.type може бути "Recreate" або "RollingUpdate". Типовим значенням є "RollingUpdate".
Перестворення Deployment
Всі поточні Podʼи примусово зупиняються та вилучаються, перш ніж створюються нові, коли .spec.strategy.type==Recreate.
Примітка:
Це гарантує тільки завершення роботи Podʼи до створення для оновлення. Якщо ви оновлюєте Deployment, всі Podʼи старої ревізії будуть негайно завершені. Успішне видалення очікується перед створенням будь-якого Podʼи нової ревізії. Якщо ви вручну видаляєте Pod, життєвий цикл керується ReplicaSet, і заміщення буде створено негайно (навіть якщо старий Pod все ще перебуває в стані Terminating). Якщо вам потрібна гарантія "at most" для ваших Podʼів, вам слід розглянути використання StatefulSet.Оновлення Deployment
Deployment оновлює Podʼи в режимі поетапного оновлення, коли .spec.strategy.type==RollingUpdate. Ви можете вказати maxUnavailable та maxSurge, щоб контролювати процес поетапного оновлення.
Максимально недоступний
.spec.strategy.rollingUpdate.maxUnavailable — це необовʼязкове поле, яке вказує максимальну кількість Podʼів, які можуть бути недоступні під час процесу оновлення. Значення може бути абсолютним числом (наприклад, 5) або відсотком від бажаної кількості Podʼів (наприклад, 10%). Абсолютне число обчислюється з відсотком, округленим вниз. Значення не може бути 0, якщо MaxSurge дорівнює 0. Станадартне значення — 25%.
Наприклад, якщо це значення встановлено на 30%, старий ReplicaSet може бути масштабований до 70% від бажаної кількості Podʼів негайно, коли починається поетапне оновлення. Як тільки нові Podʼи готові, старий ReplicaSet може бути ще більше масштабований вниз, а після цього може бути збільшено масштаб нового ReplicaSet, забезпечуючи, що загальна кількість Podʼів, доступних у будь-який час під час оновлення, становить принаймні 70% від бажаної кількості Podʼів.
Максимальний наплив
.spec.strategy.rollingUpdate.maxSurge — це необовʼязкове поле, яке вказує максимальну кількість Podʼів, які можуть бути створені понад бажану кількість Podʼів. Значення може бути абсолютним числом (наприклад, 5) або відсотком від бажаної кількості Podʼів (наприклад, 10%). Абсолютне число обчислюється з відсотком, округленим вгору. Значення не може бути 0, якщо MaxUnavailable дорівнює 0. Станадартне значення - 25%.
Наприклад, якщо це значення встановлено на 30%, новий ReplicaSet може бути масштабований негайно, коли починається поетапне оновлення, таким чином, щоб загальна кількість старих і нових Podʼів не перевищувала 130% від бажаної кількості Podʼів. Як тільки старі Podʼи буде вилучено, новий ReplicaSet може бути масштабований ще більше, забезпечуючи, що загальна кількість Podʼів, які працюють в будь-який час під час оновлення, становить найбільше 130% від бажаної кількості Podʼів.
Ось кілька прикладів оновлення Deployment за допомогою maxUnavailable та maxSurge:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
Час Progress Deadline
.spec.progressDeadlineSeconds — це необовʼязкове поле, яке вказує кількість секунд, протягом яких ви хочете чекати, поки ваш Deployment продовжиться, перш ніж система повідомить, що Deployment має помилку — відображається як умова з type: Progressing, status: "False" та reason: ProgressDeadlineExceeded в статусі ресурсу. Контролер Deployment буде продовжувати
повторювати спроби Deployment. Станадартно це значення становить 600. У майбутньому, коли буде реалізовано автоматичний відкат, контролер Deployment відкотить Deployment, як тільки він виявить таку умову.
Якщо вказано це поле, воно повинно бути більше, ніж значення .spec.minReadySeconds.
Час Min Ready
.spec.minReadySeconds — це необовʼязкове поле, яке вказує мінімальну кількість секунд, протягом яких новий створений Pod повинен бути готовим, і жоден з його контейнерів не повинен виходити з ладу, щоб його вважалим доступним. Стандартно це значення становить 0 (Pod буде вважатися доступним, як тільки він буде готовий). Щоб дізнатися більше про те, коли Pod вважається готовим, див. Проби контейнерів.
Ліміт історії ревізій
Історія ревізій Deployment зберігається в ReplicaSets, якими він керує.
.spec.revisionHistoryLimit — це необовʼязкове поле, яке вказує кількість старих ReplicaSets, які слід зберігати для можливості відкату. Ці старі ReplicaSets витрачають ресурси в etcd та заважають виводу kubectl get rs. Конфігурація кожного ревізії Deployment зберігається в його ReplicaSets; отже, після видалення старого ReplicaSet ви втрачаєте можливість відкотитися до цієї ревізії Deployment. Стандартно буде збережено 10 старих ReplicaSets, але ідеальне значення залежить від частоти та стабільності нових Deployment.
Зокрема, встановлення цього поля рівним нулю означає, що всі старі ReplicaSets з 0 реплік буде очищено. У цьому випадку нове розгортання Deployment не може бути скасовано, оскільки його історія ревізій очищена.
Пауза
.spec.paused — це необовʼязкове булеве поле для призупинення та відновлення Deployment. Єдиний відмінок між призупиненим Deployment і тим, який не призупинений, полягає в тому, що будь-які зміни в PodTemplateSpec призупиненого Deployment не викличуть нових розгортань, поки він призупинений. Deployment типово не призупинений при створенні.
Що далі
- Дізнайтеся більше про Podʼи.
- Запустіть stateless застосунок за допомогою Deployment.
- Прочитайте Deployment, щоб зрозуміти API Deployment.
- Прочитайте про PodDisruptionBudget та як ви можете використовувати його для управління доступністю застосунку під час розладу.
- Використовуйте kubectl для створення Deployment.
4.2.2 - ReplicaSet
Призначення ReplicaSet полягає в забезпеченні стабільного набору реплік Podʼів, які працюють у будь-який момент часу. Зазвичай ви визначаєте Deployment та дозволяєте цьому Deployment автоматично керувати ReplicaSets.
Призначення ReplicaSet полягає в забезпеченні стабільного набору реплік Podʼів, які працюють у будь-який момент часу. Тож, ReplicaSet часто використовується для гарантування наявності вказаної кількості ідентичних Podʼів.
Як працює ReplicaSet
ReplicaSet визначається полями, включаючи селектор, який вказує, як ідентифікувати Podʼи, які він може отримати, кількість реплік, що вказує, скільки Podʼів він повинен підтримувати, і шаблон Podʼа, який вказує дані для нових Podʼів, які слід створити для відповідності критеріям кількості реплік. ReplicaSet виконує своє призначення, створюючи та видаляючи Podʼи за необхідності для досягнення їх бажаної кількості. Коли ReplicaSet потребує створення нових Podʼів, він використовує свій шаблон Podʼа.
ReplicaSet повʼязаний зі своїми Podʼами через поле metadata.ownerReferences Podʼа, яке вказує, яким ресурсом є власник поточного обʼєкта. Усі Podʼи, які отримав ReplicaSet, мають інформацію про ідентифікацію їхнього власного ReplicaSet у полі ownerReferences. Завдяки цим посиланням ReplicaSet знає про стан Podʼів, які він підтримує, і планує дії відповідно.
ReplicaSet визначає нові Podʼи для отримання за допомогою свого селектора. Якщо існує Pod, який не має OwnerReference або OwnerReference не є контролером, і він відповідає селектору ReplicaSet, його негайно отримає вказаний ReplicaSet.
Коли використовувати ReplicaSet
ReplicaSet забезпечує наявність вказаної кількості реплік Podʼів у будь-який момент часу. Проте Deployment є концепцією вищого рівня, яка управляє ReplicaSets і надає декларативні оновлення для Podʼів, разом із багатьма іншими корисними можливостями. Тому ми рекомендуємо використовувати Deployments замість безпосереднього використання ReplicaSets, якщо вам необхідне настроювання оркестрування оновлень або взагалі не потрібні оновлення.
Це означає, що вам можливо навіть не доведеться працювати з обʼєктами ReplicaSet: використовуйте Deployment та визначайте ваш застосунок у розділі spec.
Приклад
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# змініть кількість реплік відповідно до ваших потреб
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: us-docker.pkg.dev/google-samples/containers/gke/gb-frontend:v5
Зберігаючи цей маніфест у файл frontend.yaml та застосовуючи його до кластера Kubernetes ви створите визначений обʼєкт ReplicaSet та Podʼи, якими він керує.
kubectl apply -f https://kubernetes.io/examples/controllers/frontend.yaml
Ви можете переглянути створений ReplicaSet за допомогою команди:
kubectl get rs
І побачите що створено frontend:
NAME DESIRED CURRENT READY AGE
frontend 3 3 3 6s
Ви також можете перевірити стан ReplicaSet:
kubectl describe rs/frontend
Ви побачите вивід подібний до цього:
Name: frontend
Namespace: default
Selector: tier=frontend
Labels: app=guestbook
tier=frontend
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: tier=frontend
Containers:
php-redis:
Image: us-docker.pkg.dev/google-samples/containers/gke/gb-frontend:v5
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 13s replicaset-controller Created pod: frontend-gbgfx
Normal SuccessfulCreate 13s replicaset-controller Created pod: frontend-rwz57
Normal SuccessfulCreate 13s replicaset-controller Created pod: frontend-wkl7w
І нарешті, ви можете перевірити, що Podʼи створені:
kubectl get pods
І побачите щось подібне до цього:
NAME READY STATUS RESTARTS AGE
frontend-gbgfx 1/1 Running 0 10m
frontend-rwz57 1/1 Running 0 10m
frontend-wkl7w 1/1 Running 0 10m
Ви можете також перевірити, що посилання на власника цих Podʼів вказує на ReplicaSet. Для цього отримайте деталі одного з Pod в форматі YAML:
kubectl get pods frontend-gbgfx -o yaml
Вихід буде схожий на цей, з інформацією ReplicaSet, встановленою в полі ownerReferences метаданих:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2024-02-28T22:30:44Z"
generateName: frontend-
labels:
tier: frontend
name: frontend-gbgfx
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: frontend
uid: e129deca-f864-481b-bb16-b27abfd92292
...
Володіння Podʼами без шаблону
Хоча ви можете створювати прості Podʼи без проблем, настійно рекомендується переконатися, що ці прості Podʼи не мають міток, які відповідають селектору одного з ваших ReplicaSets. Причина цього полягає в тому, що ReplicaSet не обмежується володінням Podʼів, зазначених у його шаблоні — він може отримати інші Podʼи у спосіб, визначений в попередніх розділах.
Візьмемо приклад попереднього ReplicaSet для фронтенду та Podʼів, визначених у наступному маніфесті:
apiVersion: v1
kind: Pod
metadata:
name: pod1
labels:
tier: frontend
spec:
containers:
- name: hello1
image: gcr.io/google-samples/hello-app:2.0
---
apiVersion: v1
kind: Pod
metadata:
name: pod2
labels:
tier: frontend
spec:
containers:
- name: hello2
image: gcr.io/google-samples/hello-app:1.0
Оскільки ці Podʼи не мають контролера (або будь-якого обʼєкта) як власника та відповідають селектору ReplicaSet для фронтенду, вони одразу перейдуть у його володіння.
Припустимо, ви створюєте Podʼи після того, як ReplicaSet для фронтенду буде розгорнуто та встановлено свої початкові репліки Podʼів для виконання вимог до кількості реплік:
kubectl apply -f https://kubernetes.io/examples/pods/pod-rs.yaml
Нові Podʼи будуть отримані ReplicaSet та негайно завершені, оскільки ReplicaSet буде мати більше, ніж його бажана кількість.
Отримання Podʼів:
kubectl get pods
Вивід покаже, що нові Podʼи або вже завершено, або в процесі завершення:
NAME READY STATUS RESTARTS AGE
frontend-b2zdv 1/1 Running 0 10m
frontend-vcmts 1/1 Running 0 10m
frontend-wtsmm 1/1 Running 0 10m
pod1 0/1 Terminating 0 1s
pod2 0/1 Terminating 0 1s
Якщо ви створите Podʼи спочатку:
kubectl apply -f https://kubernetes.io/examples/pods/pod-rs.yaml
А потім створите ReplicaSet таким чином:
kubectl apply -f https://kubernetes.io/examples/controllers/frontend.yaml
Ви побачите, що ReplicaSet отримав Podʼи та створив нові лише відповідно до свого опису, доки кількість його нових Podʼів та оригінальних не відповідала його бажаній кількості. Якщо отримати Podʼи:
kubectl get pods
Вивід покаже, що:
NAME READY STATUS RESTARTS AGE
frontend-hmmj2 1/1 Running 0 9s
pod1 1/1 Running 0 36s
pod2 1/1 Running 0 36s
Таким чином, ReplicaSet може володіти неоднорідним набором Podʼів.
Написання маніфесту ReplicaSet
Як і усі інші обʼєкти API Kubernetes, ReplicaSet потребує полів apiVersion, kind та metadata. Для ReplicaSet kind завжди є ReplicaSet.
Коли панель управління створює нові Podʼи для ReplicaSet, .metadata.name ReplicaSet є частиною основи для найменування цих Podʼів. Назва ReplicaSet повинна бути дійсним значенням DNS-піддомену, але це може призвести до неочікуваних результатів для імен хостів Podʼа. Для найкращої сумісності назва має відповідати більш обмеженим правилам для DNS-мітки.
ReplicaSet також потребує розділу .spec.
Шаблон Podʼа
.spec.template — це шаблон Podʼа, який також повинен мати встановлені мітки. У нашому прикладі frontend.yaml ми мали одну мітку: tier: frontend. Будьте обережні, щоб селектори не перекривалися з селекторами інших контролерів, інакше вони можуть намагатися взяти контроль над Podʼом.
Для політики перезапуску шаблону restart policy, .spec.template.spec.restartPolicy, є допустимим тільки значення Always, яке є стандартним значенням.
Селектор Podʼа
Поле .spec.selector є селектором міток. Як обговорювалося раніше, це мітки, які використовуються для ідентифікації потенційних Podʼів для володіння. У нашому прикладі frontend.yaml селектор був:
matchLabels:
tier: frontend
У ReplicaSet .spec.template.metadata.labels має відповідати spec.selector, інакше він буде відхилений API.
Примітка:
Для 2 ReplicaSets, які вказують на однаковий.spec.selector, але різні .spec.template.metadata.labels та .spec.template.spec поля, кожен ReplicaSet ігнорує
Podʼи, створені іншим ReplicaSet.Репліки
Ви можете вказати, скільки Podʼів мають виконуватись одночасно, встановивши значення .spec.replicas. ReplicaSet буде створювати/видаляти свої Podʼи щоб кількість Podʼів відповідала цьому числу. Якщо ви не вказали .spec.Podʼа, то типово значення дорівнює 1.
Робота з ReplicaSets
Видалення ReplicaSet та його Podʼів
Щоб видалити ReplicaSet і всі його Podʼи, використовуйте kubectl delete. Збирач сміття Garbage collector автоматично видаляє всі
залежні Podʼи.
При використанні REST API або бібліотеки client-go, вам потрібно встановити propagationPolicy в Background або Foreground в опції -d. Наприклад:
kubectl proxy --port=8080
curl -X DELETE 'localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend' \
-d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Foreground"}' \
-H "Content-Type: application/json"
Видалення лише ReplicaSet
Ви можете видалити ReplicaSet, не впливаючи на його Podʼи за допомогою
kubectl delete з опцією --cascade=orphan. При використанні REST API або бібліотеки client-go, вам потрібно встановити propagationPolicy в Orphan. Наприклад:
kubectl proxy --port=8080
curl -X DELETE 'localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend' \
-d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Orphan"}' \
-H "Content-Type: application/json"
Після видалення оригіналу ви можете створити новий ReplicaSet для заміни. До тих пір поки старий та новий .spec.selector однакові, новий прийме старі Podʼи. Однак він не буде намагатися повʼязувати наявні Podʼи з новим, відмінним шаблоном Podʼа. Для оновлення Podʼів до нової специфікації у контрольований спосіб використовуйте Deployment, оскільки ReplicaSets безпосередньо не підтримують rolling update.
Ізолювання Podʼів від ReplicaSet
Ви можете видалити Podʼи з ReplicaSet, змінивши їх мітки. Цей метод може бути використаний для вилучення Podʼів з обслуговування з метою налагодження, відновлення даних і т.д. Podʼи, які вилучаються цим способом, будуть автоматично замінені (за умови, що кількість реплік також не змінюється).
Масштабування ReplicaSet
ReplicaSet можна легко масштабувати вгору або вниз, просто оновивши поле .spec.replicas. Контролер ReplicaSet забезпечує, що бажана кількість Podʼів з відповідним селектором міток доступна та працює.
При зменшенні масштабу ReplicaSet контролер ReplicaSet вибирає Podʼи для видалення, сортуючи доступні Podʼи, щоб визначити, які Podʼи видаляти в першу чергу, використовуючи наступний загальний алгоритм:
- Перш за все прибираються Podʼи, що перебувають в очікуванні.
- Якщо встановлено анотацію
controller.kubernetes.io/pod-deletion-cost, то Pod із меншою вартістю буде видалено першим. - Podʼи на вузлах з більшою кількістю реплік йдуть перед Podʼами на вузлах з меншою кількістю реплік.
- Якщо часи створення Podʼів відрізняються, то Pod, створений недавно, йде перед старішим Podʼом (часи створення розділені на цілочисельний логарифмічний масштаб)
Якщо все вище вказане збігається, вибір випадковий.
Вартість видалення Podʼа
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.22 [beta]За допомогою анотації controller.kubernetes.io/pod-deletion-cost користувачі можуть встановити вподобання щодо порядку видалення Podʼів під час зменшення масштабу ReplicaSet.
Анотація повинна бути встановлена на Podʼі, діапазон — [-2147483648, 2147483647]. Вона представляє вартість видалення Podʼа порівняно з іншими Podʼами, які належать тому ж ReplicaSet. Podʼи з меншою вартістю видалення видаляються першими на відміну Podʼами з більшою вартістю видалення.
Неявне значення для цієї анотації для Podʼів, які його не мають, — 0; допустимі відʼємні значення. Неприпустимі значення будуть відхилені API-сервером.
Ця функція є бета-версією та увімкнена типово. Ви можете вимкнути її, використовуючи функціональну можливість PodDeletionCost як в kube-apiserver, так і в kube-controller-manager.
Примітка:
- Цей підхід використовується як найкраще, тому він не пропонує жодних гарантій щодо порядку видалення Podʼів.
- Користувачам слід уникати частого оновлення анотації, такого як оновлення її на основі значення метрики, оскільки це призведе до значного числа оновлень Podʼів на apiserver.
Приклад Використання
Різні Podʼи застосунку можуть мати різний рівень використання. При зменшенні масштабу застосунок може віддавати перевагу видаленню Podʼів з меншим використанням. Щоб уникнути частого оновлення Podʼів, застосунок повинен оновити controller.kubernetes.io/pod-deletion-cost один раз перед зменшенням масштабу
(встановлення анотації в значення, пропорційне рівню використання Podʼа). Це працює, якщо сам застосунок контролює масштабування вниз; наприклад, драйвер розгортання Spark.
ReplicaSet як ціль горизонтального автомасштабування Podʼа
ReplicaSet також може бути ціллю для Горизонтального Автомасштабування Podʼа (HPA). Іншими словами, ReplicaSet може автоматично масштабуватися за допомогою HPA. Ось приклад HPA, який застосовується до ReplicaSet, створеному у попередньому прикладі.
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: frontend-scaler
spec:
scaleTargetRef:
kind: ReplicaSet
name: frontend
minReplicas: 3
maxReplicas: 10
targetCPUUtilizationPercentage: 50
Збереження цього маніфесту в hpa-rs.yaml та його застосування до кластера Kubernetes повинно створити визначене HPA, яке автоматично змінює масштаб цільового ReplicaSet залежно від використання ЦП реплікованими Podʼами.
kubectl apply -f https://k8s.io/examples/controllers/hpa-rs.yaml
Або ви можете використовувати команду kubectl autoscale для досягнення того ж самого (і це простіше!)
kubectl autoscale rs frontend --max=10 --min=3 --cpu-percent=50
Альтернативи ReplicaSet
Deployment (рекомендовано)
Deployment — це обʼєкт, який може володіти ReplicaSets і оновлювати їх та їхні Podʼи через декларативні оновлення на стороні сервера. Хоча ReplicaSets можуть використовуватися незалежно, на сьогодні вони головним чином використовуються Deployments як механізм для
оркестрування створення, видалення та оновлення Podʼів. Коли ви використовуєте Deployments, вам не потрібно турбуватися про керування ReplicaSets, які вони створюють. Deployments володіють і керують своїми ReplicaSets. Таким чином, рекомендується використовувати Deployments, коли вам потрібні ReplicaSets.
Чисті Podʼи
На відміну від випадку, коли користувач безпосередньо створює Podʼи, ReplicaSet замінює Podʼи, які видаляються або завершуються з будь-якої причини, такої як випадок відмови вузла чи розбирання вузла, таке як оновлення ядра. З цього приводу ми рекомендуємо використовувати ReplicaSet навіть якщо ваш застосунок вимагає лише одного Podʼа. Подібно до наглядача процесів, він наглядає за кількома Podʼами на різних вузлах замість окремих процесів на одному вузлі. ReplicaSet делегує перезапуск локальних контейнерів до агента на вузлі, такого як Kubelet.
Job
Використовуйте Job замість ReplicaSet для Podʼів, які повинні завершитися самостійно (тобто пакетні завдання).
DaemonSet
Використовуйте DaemonSet замість ReplicaSet для Podʼів, які надають функції на рівні машини, такі як моніторинг стану машини або реєстрація машини. Ці Podʼи мають термін служби, який повʼязаний з терміном служби машини: Pod повинен працювати на машині перед тим, як інші Podʼи почнуть роботу, і можуть бути безпечно завершені, коли машина готова до перезавантаження/вимкнення.
ReplicationController
ReplicaSets — є наступниками ReplicationControllers. Обидва служать тому ж самому призначенню та поводяться схоже, за винятком того, що ReplicationController не підтримує вимоги вибору на основі множини, як описано в посібнику про мітки. Таким чином, ReplicaSets має перевагу над ReplicationControllers.
Що далі
- Дізнайтеся про Podʼи.
- Дізнайтеся про Deploуments.
- Запустіть Stateless Application за допомогою Deployment, що ґрунтується на роботі ReplicaSets.
ReplicaSet— це ресурс верхнього рівня у Kubernetes REST API. Прочитайте визначення обʼєкта ReplicaSet, щоб розуміти API для реплік.- Дізнайтеся про PodDisruptionBudget та як ви можете використовувати його для управління доступністю застосунку під час перебоїв.
4.2.3 - StatefulSets
StatefulSet — це обʼєкт робочого навантаження API, який використовується для управління застосунками зі збереженням стану. Він запускає групу Podʼів і зберігає стійку ідентичність для кожного з цих Podʼів. Це корисно для керування застосвунками, які потребують постійного сховища або стабільної, унікальної мережевої ідентичності.
StatefulSet — це обʼєкт робочого навантаження API, який використовується для управління застосунками зі збереженням стану.
StatefulSet керує розгортанням і масштабуванням групи Podʼів, і забезпечує гарантії щодо порядку та унікальності цих Podʼів.
Схожий на Deployment, StatefulSet керує Podʼами, які базуються на ідентичній специфікації контейнерів. На відміну від Deployment, StatefulSet зберігає постійну ідентичність для кожного свого Podʼа. Ці Podʼи створюються за однаковою специфікацією, але не є взаємозамінними: у кожного є постійний ідентифікатор, який він утримує при переплануванні.
Якщо ви хочете використовувати томи для забезпечення постійності для вашого завдання, ви можете використовувати StatefulSet як частину рішення. Навіть якщо окремі Podʼи в StatefulSet можуть вийти з ладу, постійні ідентифікатори Podʼів полегшують відповідність наявних томів новим Podʼам, які замінюють ті, що вийшли з ладу.
Використання StatefulSets
StatefulSets є цінним інструментом для застосунків, які потребують однієї або декількох речей з наступного.
- Стабільних, унікальних мережевих ідентифікаторів.
- Стабільного, постійного сховища.
- Упорядкованого, відповідного розгортання та масштабування.
- Упорядкованих, автоматизованих поступових (rolling) оновлень.
У випадку відсутності потреби в стабільних ідентифікаторах або упорядкованому розгортанні, видаленні чи масштабуванні, вам слід розгортати свою програму за допомогою робочого обʼєкта, який забезпечує набір реплік без збереження стану (stateless). Deployment або ReplicaSet можуть бути більш придатними для ваших потреб.
Обмеження
- Місце для зберігання для певного Podʼа повинно буде виділене чи вже виділено PersistentVolume Provisioner на основі запиту storage class, або виділено адміністратором наперед.
- Видалення та/або масштабування StatefulSet вниз не призведе до видалення томів, повʼязаних з StatefulSet. Це зроблено для забезпечення безпеки даних, яка загалом є важливішою, ніж автоматичне очищення всіх повʼязаних ресурсів StatefulSet.
- Наразі для StatefulSets обовʼязково потрібний Headless Service щоб відповідати за мережевий ідентифікатор Podʼів. Вам слід створити цей Сервіс самостійно.
- StatefulSets не надають жодних гарантій щодо припинення роботи Podʼів при видаленні StatefulSet. Для досягнення упорядкованого та відповідного завершення роботи Podʼів у StatefulSet можливо зменшити масштаб StatefulSet до 0 перед видаленням.
- При використанні Поступових Оновлень використовуючи стандартну Політику Керування Podʼів (
OrderedReady), можливе потрапляння в стан, що вимагає ручного втручання для виправлення.
Компоненти
Наведений нижче приклад демонструє компоненти StatefulSet.
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # повинно відповідати .spec.template.metadata.labels
serviceName: "nginx"
replicas: 3 # типово 1
minReadySeconds: 10 # типово 0
template:
metadata:
labels:
app: nginx # повинно відповідати .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: registry.k8s.io/nginx-slim:0.24
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
Примітка:
Цей приклад використовує режим доступуReadWriteOnce, для спрощення. Для
промислового використання проєкт Kubernetes рекомендує використовувати режим доступу
ReadWriteOncePod.У вищенаведеному прикладі:
- Використовується Headless Service, з назвою
nginx, для управління мережевим доменом. - StatefulSet, названий
web, має Spec, який вказує на те, що буде запущено 3 репліки контейнера nginx в унікальних Podʼах. volumeClaimTemplatesбуде забезпечувати стійке зберігання за допомогою PersistentVolumes, виділених PersistentVolume Provisioner.
Назва обʼєкта StatefulSet повинна бути дійсною DNS міткою.
Селектор Podʼів
Вам слід встановити поле .spec.selector StatefulSet, яке збігається з міткам його
.spec.template.metadata.labels. Нездатність вказати відповідний селектор Pod призведе до помилки перевірки під час створення StatefulSet.
Шаблони заявок на місце для зберігання
Ви можете встановити поле .spec.volumeClaimTemplates, щоб створити PersistentVolumeClaim. Це забезпечить стійке зберігання для StatefulSet, якщо:
- Для заявки на том встановлено StorageClass, який налаштований на використання динамічного виділення, або
- Кластер вже містить PersistentVolume з правильним StorageClass та достатньою кількістю доступного місця для зберігання.
Мінімальний час готовності
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.25 [stable].spec.minReadySeconds є необовʼязковим полем, яке вказує мінімальну кількість секунд, протягом яких новий створений Pod повинен працювати та бути готовим, без виходу будь-яких його контейнерів з ладу, щоб вважатися доступним. Це використовується для перевірки прогресу розгортання при використанні стратегії Поступового Оновлення. Це поле станлартно дорівнює 0 (Pod вважатиметься доступним одразу після готовності). Дізнайтеся більше про те, коли
Pod вважається готовим, див. Проби Контейнера.
Ідентичність Podʼа
Podʼи StatefulSet мають унікальну ідентичність, яка складається з порядкового номера, стабільного мережевого ідентифікатора та стійкого сховища. Ця ідентичність залишається прикріпленою до Podʼа, незалежно від того, на якому вузлі він перепланований чи знову запланований.
Порядковий індекс
Для StatefulSet з N реплік кожному Podʼу в StatefulSet буде призначено ціле число, яке є унікальним у наборі. Стандартно Podʼам буде призначено порядкові номери від 0 до N-1. Контролер StatefulSet також додасть мітку Podʼа з цим індексом: apps.kubernetes.io/pod-index.
Початковий порядковий номер
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [stable] (стандартно увімкнено: true).spec.ordinals — це необовʼязкове поле, яке дозволяє налаштувати цілочисельні порядкові номери, призначені кожному Pod. Стандартно воно встановлено в nil. В межах цього поля ви можете налаштувати наступні параметри:
.spec.ordinals.start: Якщо встановлено поле.spec.ordinals.start, Podʼам будуть призначені порядкові номери від.spec.ordinals.startдо.spec.ordinals.start + .spec.replicas - 1.
Стабільний мережевий ідентифікатор
Кожен Pod в StatefulSet виводить назву свого хосту з імені StatefulSet та порядкового номера Podʼа. Шаблон для створеного імені хосту має вигляд $(імʼя statefulset)-$(порядковий номер). У вищезазначеному прикладі буде створено три Podʼа з іменами web-0,web-1,web-2. StatefulSet може використовувати Headless Service
для управління доменом своїх Podʼів. Домен, яким управляє цей сервіс, має вигляд:
$(імʼя сервісу).$(простір імен).svc.cluster.local, де "cluster.local" — це кластерний домен. При створенні кожного Podʼа він отримує відповідний DNS-піддомен, який має вигляд: $(імʼя Podʼа).$(головний домен сервісу), де головний сервіс визначається полем serviceName в StatefulSet.
Залежно від того, як налаштований DNS у вашому кластері, ви можливо не зможете одразу знаходити DNS-імʼя для нового Podʼа. Це можливо, коли інші клієнти в кластері вже відправили запити на імʼя хосту Podʼа до його створення. Негативне кешування (зазвичай для DNS) означає, що результати попередніх невдалих пошуків запамʼятовуються та використовуються, навіть після того, як Pod вже працює, принаймні кілька секунд.
Якщо вам потрібно виявити Podʼи негайно після їх створення, у вас є кілька варіантів:
- Запитуйте API Kubernetes безпосередньо (наприклад, використовуючи режим спостереження), а не покладаючись на DNS-запити.
- Зменште час кешування в вашому постачальнику DNS Kubernetes (зазвичай це означає редагування ConfigMap для CoreDNS, який зараз кешує протягом 30 секунд).
Як зазначено в розділі Обмеження, ви відповідаєте за створення Headless Service, відповідального за мережевий ідентифікатор Podʼів.
Ось деякі приклади варіантів вибору кластерного домену, імені сервісу, імені StatefulSet та того, як це впливає на DNS-імена Podʼів StatefulSet.
| Кластерний домен | Сервіс (ns/імʼя) | StatefulSet (ns/імʼя) | Домен StatefulSet | DNS Podʼа | Імʼя хоста Podʼа |
|---|---|---|---|---|---|
| cluster.local | default/nginx | default/web | nginx.default.svc.cluster.local | web-{0..N-1}.nginx.default.svc.cluster.local | web-{0..N-1} |
| cluster.local | foo/nginx | foo/web | nginx.foo.svc.cluster.local | web-{0..N-1}.nginx.foo.svc.cluster.local | web-{0..N-1} |
| kube.local | foo/nginx | foo/web | nginx.foo.svc.kube.local | web-{0..N-1}.nginx.foo.svc.kube.local | web-{0..N-1} |
Стійке сховище
Для кожного вхідного запису volumeClaimTemplates, визначеного в StatefulSet, кожен Pod отримує один PersistentVolumeClaim. У прикладі з nginx кожен Pod отримує один PersistentVolume з StorageClass my-storage-class та 1 ГБ зарезервованого сховища. Якщо не вказано StorageClass, то використовуватиметься стандартний розмір сховища. Коли Pod переплановується на вузлі, його volumeMounts монтує PersistentVolumes, повʼязані із його PersistentVolume Claims. Зазначте, що PersistentVolumes, повʼязані із PersistentVolume Claims Podʼів, не видаляються при видаленні Podʼів чи StatefulSet. Це слід робити вручну.
Мітка імені Podʼа
Коли StatefulSet контролер створює Pod, він додає мітку statefulset.kubernetes.io/pod-name, яка дорівнює назві Podʼа. Ця мітка дозволяє прикріплювати Service до конкретного Podʼа в StatefulSet.
Мітка індексу Podʼа
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [stable] (стандартно увімкнено: true)Коли StatefulSet контролер створює Pod, новий Pod має мітку apps.kubernetes.io/pod-index. Значення цієї мітки — це порядковий індекс Podʼа. Ця мітка дозволяє спрямовувати трафік до певного індексу під, фільтрувати логи/метрику за допомогою мітки індексу podʼа тощо. Зауважте, що стандартно функціональна можливість PodIndexLabel увімкнена і заблокована для цієї функції, для того, щоб вимкнути її, користувачам доведеться використовувати емуляцію сервера версії v1.31.
Гарантії розгортання та масштабування
- Для StatefulSet із N реплік, при розгортанні Podʼи створюються послідовно, у порядку від {0..N-1}.
- При видаленні Podʼів вони закінчуються у зворотньому порядку, від {N-1..0}.
- Перед тим як застосувати масштабування до Podʼа, всі його попередники повинні бути запущені та готові.
- Перед тим як Pod буде припинено, всі його наступники повинні бути повністю зупинені.
StatefulSet не повинен вказувати pod.Spec.TerminationGracePeriodSeconds рівним 0. Це практика небезпечна і настійно не рекомендується. Для отримання додаткової інформації, зверніться до примусового видалення Podʼів StatefulSet.
Коли створюється приклад nginx вище, три Podʼа будуть розгорнуті в порядку web-0, web-1, web-2. web-1 не буде розгорнуто, поки web-0 не буде запущений і готовий, і web-2 не буде розгорнуто, поки web-1 не буде запущений і готовий. Якщо web-0 виявиться несправним, після того, як web-1 стане запущеним і готовим, але до запуску web-2, web-2 не буде запущено, поки web-0 успішно перезапуститься і стане запущеним і готовим.
Якщо користувач масштабує розгорнутий приклад, застосовуючи патчи до StatefulSet так, так щоб replicas=1, спочатку буде припинено web-2. web-1 не буде припинено, поки web-2 повністю не завершить свою роботу та буде видалено. Якщо web-0 виявиться невдалим після того, як web-2 вже був припинений і повністю завершено, але перед видаленням web-1, web-1 не буде припинено, поки web-0 не стане запущеним і готовим.
Політики управління Podʼами
StatefulSet дозволяє зменшити його гарантії послідовності, зберігаючи при цьому його гарантії унікальності та ідентичності за допомогою поля .spec.podManagementPolicy.
Політика управління Podʼами "OrderedReady"
OrderedReady є типовим значенням політики управління Podʼами для StatefulSet. Вона реалізує поведінку, описану вище.
Політика управління Podʼами "Parallel"
"Parallel" вказує контролеру StatefulSet запускати або припиняти всі Podʼи паралельно, і не чекати, поки Podʼи стануть запущеними та готовими або повністю припиняться перед запуском або видаленням іншого Podʼа. Ця опція впливає лише на поведінку операцій масштабування. Оновлення не підпадають під вплив.
Стратегії оновлення
Поле .spec.updateStrategy обʼєкта StatefulSet дозволяє налаштовувати
та вимикати автоматизовані поетапні оновлення для контейнерів, міток, ресурсів (запити/обмеження) та анотацій для Podʼів у StatefulSet. Є два можливих значення:
OnDelete- Коли поле
.spec.updateStrategy.typeStatefulSet встановлено вOnDelete, контролер StatefulSet не буде автоматично оновлювати Podʼи в StatefulSet. Користувачам необхідно вручну видаляти Podʼи, щоб спричинити створення контролером нових Podʼів, які відображають зміни, внесені в.spec.templateStatefulSet. RollingUpdate- Стратегія оновлення
RollingUpdateреалізує автоматизовані, поточні оновлення для Podʼів у StatefulSet. Це значення є стандартною стратегією оновлення.
Поточні оновлення
Коли поле .spec.updateStrategy.type StatefulSet встановлено на RollingUpdate,
контролер StatefulSet буде видаляти та знову створювати кожен Pod у StatefulSet. Він буде продовжувати в тому ж порядку, як Podʼи завершують роботу (від найбільшого індексу до найменшого), оновлюючи кожен Pod по одному.
Панель управління Kubernetes чекає, доки оновлений Pod буде переведений в стан Running та Ready, перш ніж оновити його попередника. Якщо ви встановили .spec.minReadySeconds (див. Мінімальна кількість секунд готовності), панель управління також чекає вказану кількість секунд після того, як Pod стане готовим, перш ніж перейти далі.
Поточні оновлення частинами
Стратегію оновлення RollingUpdate можна поділити на розділи, вказавши .spec.updateStrategy.rollingUpdate.partition. Якщо вказано розділ, всі Podʼи з індексом, який більший або рівний розділу, будуть оновлені при оновленні .spec.template StatefulSet. Усі Podʼи з індексом, який менший за розділ, не будуть оновлені та, навіть якщо вони будуть видалені, вони будуть відновлені на попередню версію. Якщо .spec.updateStrategy.rollingUpdate.partition StatefulSet більше, ніж .spec.replicas, оновлення .spec.template не буде розповсюджуватися на його Podʼи. У більшості випадків вам не знадобиться використовувати розподіл, але вони корисні, якщо ви хочете розгортати оновлення, робити канаркові оновлення або виконати поетапне оновлення.
Максимальна кількість недоступних Podʼів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [alpha]Ви можете контролювати максимальну кількість Podʼів, які можуть бути недоступні під час оновлення, вказавши поле .spec.updateStrategy.rollingUpdate.maxUnavailable. Значення може бути абсолютним числом (наприклад, 5) або відсотком від бажаних Podʼів (наприклад, 10%). Абсолютне число обчислюється з відсоткового значення заокругленням вгору. Це поле не може бути 0. Стандартне значення — 1.
Це поле застосовується до всіх Podʼів у діапазоні від 0 до replicas - 1. Якщо є будь-який недоступний Pod у діапазоні від 0 до replicas - 1, він буде враховуватися в maxUnavailable.
Примітка:
ПолеmaxUnavailable знаходиться на етапі альфа-тестування і враховується тільки API-серверами, які працюють з увімкненою функціональною можливістю MaxUnavailableStatefulSetПримусовий відкат
При використанні поступових оновлень зі стандартною політикою управління Podʼами (OrderedReady), існує можливість потрапити в становище, яке вимагає ручного втручання для виправлення.
Якщо ви оновлюєте шаблон Podʼа до конфігурації, яка ніколи не стає в стан Running and Ready (наприклад, через поганий бінарний файл або помилку конфігурації на рівні застосунку), StatefulSet припинить розгортання і залишиться у стані очікування.
У цьому стані недостатньо повернути шаблон Podʼа до справної конфігурації. Через відомий дефект, StatefulSet продовжуватиме очікувати, доки неробочий Pod стане готовим (що ніколи не відбувається), перед тим як спробувати повернути його до робочої конфігурації.
Після повернення до шаблону вам також слід видалити будь-які Podʼи, які StatefulSet вже намагався запустити з поганою конфігурацією. Після цього StatefulSet почне перестворювати Podʼи, використовуючи відновлений шаблон.
Збереження PersistentVolumeClaim
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [stable] (стандартно увімкнено: true)Необовʼязкове поле .spec.persistentVolumeClaimRetentionPolicy контролює, чи і як видаляються PVC під час життєвого циклу StatefulSet. Вам потрібно увімкнути функціональну можливість StatefulSetAutoDeletePVC на сервері API та менеджері контролера, щоб використовувати це поле. Після активації ви можете налаштувати дві політики для кожного StatefulSet:
whenDeleted- налаштовує поведінку зберігання тому, яке застосовується при видаленні StatefulSet
whenScaled- налаштовує поведінку зберігання тому, яке застосовується при зменшенні кількості реплік у StatefulSet, наприклад, при масштабуванні вниз.
Для кожної політики, яку ви можете налаштувати, ви можете встановити значення Delete або Retain.
Delete- PVC, створені за допомогою
volumeClaimTemplateStatefulSet, видаляються для кожного Podʼа, який впливає на політику. З політикоюwhenDeletedвсі PVC відvolumeClaimTemplateвидаляються після того, як їх Podʼи були видалені. З політикоююwhenScaled, лише PVC, що відповідають реплікам Podʼа, які зменшуються видаляються після того, як їх Podʼи були видалені. Retain(стандартно)- PVC від
volumeClaimTemplateне змінюються, коли їх Pod видаляється. Це поведінка до цієї нової функції.
Звертайте увагу, що ці політики застосовуються лише при вилученні Podʼів через видалення або масштабування StatefulSet. Наприклад, якщо Pod, повʼязаний із StatefulSet, зазнає відмови через відмову вузла, і панель управління створює замінний Pod, StatefulSet зберігає поточний PVC. Поточний том не піддається впливу, і кластер прикріплює його до вузла, де має запуститися новий Pod.
Станадртно для політик встановлено Retain, відповідно до поведінки StatefulSet до цієї нової функції.
Ось приклад політики.
apiVersion: apps/v1
kind: StatefulSet
...
spec:
persistentVolumeClaimRetentionPolicy:
whenDeleted: Retain
whenScaled: Delete
...
Контролер StatefulSet додає посилання на власника до своїх PVC, які потім видаляються збирачем сміття після завершення Podʼа. Це дозволяє Podʼу чисто демонтувати всі томи перед видаленням PVC (і перед видаленням PV та обсягу, залежно від політики збереження). Коли ви встановлюєте whenDeleted політику Delete, посилання власника на екземпляр StatefulSet поміщається на всі PVC, повʼязані із цим StatefulSet.
Політика whenScaled повинна видаляти PVC тільки при зменшенні розміру Podʼа, а не при видаленні Podʼа з іншої причини. Під час узгодження контролер StatefulSet порівнює очікувану кількість реплік із фактичними Podʼами, що присутні на кластері. Будь-який Pod StatefulSet, ідентифікатор якого більший за кількість реплік, засуджується та позначається для видалення. Якщо політика whenScaled є Delete, засуджені Podʼи спочатку встановлюються власниками для відповідних PVC зразків StatefulSet, перед видаленням Podʼа. Це призводить до того, що PVC видаляються збирачем сміття тільки після видалення таких Podʼів.
Це означає, що якщо контролер виходить з ладу і перезапускається, жоден Pod не буде видалено до того моменту, поки його посилання на власника не буде відповідно оновлено згідно з політикою. Якщо засуджений Pod видаляється примусово, коли контролер вимкнено, посилання на власника може бути або встановлене, або ні, залежно від того, коли відбулася аварія контролера. Для оновлення посилань на власника може знадобитися кілька циклів врегулювання, тому деякі засуджені Podʼи можуть мати встановлені посилання на власника, а інші — ні. З цієї причини ми рекомендуємо зачекати, поки контролер знову запуститься, що перевірить посилання на власника перед завершенням роботи Podʼів. Якщо це неможливо, оператор повинен перевірити посилання на власника на PVC, щоб забезпечити видалення очікуваних обʼєктів при примусовому видаленні Podʼів.
Репліки
.spec.replicas — це необовʼязкове поле, яке вказує кількість бажаних Podʼів. Стандартно воно дорівнює 1.
Якщо ви масштабуєте Deployment вручну, наприклад, через kubectl scale statefulset statefulset --replicas=X, а потім оновлюєте цей StatefulSet на основі маніфесту (наприклад, за допомогою kubectl apply -f statefulset.yaml), то застосування цього маніфесту перезапише попереднє ручне масштабування.
Якщо HorizontalPodAutoscaler (або будь-який подібний API для горизонтального масштабування) керує масштабуванням StatefulSet, не встановлюйте .spec.replicas. Замість цього дозвольте панелі управління Kubernetes автоматично керувати полем .spec.replicas.
Що далі
- Дізнайтеся про Podʼи.
- Дізнайтеся, як використовувати StatefulSets
- Спробуйте приклад розгортання stateful застосунків.
- Спробуйте приклад розгортання Cassandra з Stateful Sets.
- Спробуйте приклад запуску реплікованого stateful застосунку.
- Дізнайтеся, як масштабувати StatefulSet.
- Дізнайтеся, що включає в себе видалення StatefulSet.
- Дізнайтеся, як налаштувати Pod для використання тома для зберігання.
- Дізнайтеся, як налаштувати Pod для використання PersistentVolume для зберігання.
StatefulSetє ресурсом верхнього рівня в API REST Kubernetes. Ознайомтесь з визначеням обʼєкта StatefulSet для розуміння API.- Дізнайтеся про PodDisruptionBudget та як його можна використовувати для управління доступністю застосунків під час відключень.
4.2.4 - DaemonSet
DaemonSet визначає Podʼи, які надають локальні обʼєкти вузлів. Вони можуть бути фундаментальними для роботи вашого кластера, наприклад, допоміжним інструментом для роботи з мережею, або бути частиною надбудови.
DaemonSet переконується, що всі (або деякі) вузли запускають копію Podʼа. При додаванні вузлів до кластера, на них додаються Podʼи. При видаленні вузлів з кластера ці Podʼи видаляються. Видалення DaemonSet призведе до очищення створених ним Podʼів.
Деякі типові використання DaemonSet включають:
- запуск демона кластерного сховища на кожному вузлі
- запуск демона збору логів на кожному вузлі
- запуск демона моніторингу вузла на кожному вузлі
У простому випадку один DaemonSet, який охоплює всі вузли, може використовуватися для кожного типу демона. Складніше налаштування може використовувати кілька DaemonSet для одного типу демона, але з різними прапорцями, або різними запитами памʼяті та CPU для різних типів обладнання.
Створення специфікації DaemonSet
Створення DaemonSet
Ви можете описати DaemonSet у файлі YAML. Наприклад, файл daemonset.yaml нижче описує DaemonSet, який запускає Docker-образ fluentd-elasticsearch:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# ці tolerations дозволяють запускати DaemonSet на вузлах панелі управління
# видаліть їх, якщо ваші вузли панелі управління не повинні запускати Podʼи
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
# можливо, бажано встановити високий пріоритетний клас, щоб забезпечити, що Podʼи DaemonSetʼу
# витіснятимуть Podʼи, що виконуються
# priorityClassName: important
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
Створіть DaemonSet на основі файлу YAML:
kubectl apply -f https://k8s.io/examples/controllers/daemonset.yaml
Обовʼязкові поля
Як і з будь-якою іншою конфігурацією Kubernetes, DaemonSet потребує полів apiVersion, kind та metadata. Для загальної інформації щодо роботи з файлами конфігурації, див. запуск stateless застосунків та управління обʼєктами за допомогою kubectl.
Назва обʼєкта DaemonSet повинна бути дійсним імʼям DNS-піддомену.
DaemonSet також потребує .spec розділу.
Шаблон Podʼа
.spec.template — одне з обовʼязкових полів в .spec.
.spec.template — це шаблон Podʼа. Він має ту саму схему, що і Pod, за винятком того, що він вкладений і не має apiVersion або kind.
Окрім обовʼязкових полів для Podʼа, шаблон Podʼа в DaemonSet повинен вказати відповідні мітки (див. вибір Podʼа).
Шаблон Pod в DaemonSet повинен мати RestartPolicy рівну Always або бути не вказаною, що типово рівнозначно Always.
Селектор Podʼа
.spec.selector — обовʼязкове поле в .spec.
Поле .spec.selector — це селектор Podʼа. Воно працює так само як і .spec.selector в Job.
Ви повинні вказати селектор Podʼа, який відповідає міткам .spec.template. Крім того, після створення DaemonSet, його .spec.selector не може бути змінено. Зміна вибору Podʼа може призвести до навмисного залишення Podʼів сиротами, і це буде плутати користувачів.
.spec.selector — це обʼєкт, що складається з двох полів:
matchLabels- працює так само як і.spec.selectorу ReplicationController.matchExpressions- дозволяє будувати складніші селектори, вказуючи ключ, список значень та оператор, який повʼязує ключ і значення.
Коли вказані обидва, результат є має мати збіг з обома.
.spec.selector повинен відповідати .spec.template.metadata.labels. Конфігурація з цими двома несумісними буде відхилена API.
Запуск Podʼів на вибраних вузлах
Якщо ви вказуєте .spec.template.spec.nodeSelector, тоді контролер DaemonSet буде
створювати Podʼи на вузлах, які відповідають селектору вузла. Так само, якщо ви вказуєте .spec.template.spec.affinity, тоді контролер DaemonSet буде створювати Podʼи на вузлах, які відповідають цій спорідненості вузла. Якщо ви не вказали жодного з них, контролер DaemonSet буде створювати Podʼи на всіх вузлах.
Як заплановані Daemon Podʼи
DaemonSet може бути використаний для того, щоб забезпечити, щоб всі придатні вузли запускали копію Podʼа. Контролер DaemonSet створює Pod для кожного придатного вузла та додає поле spec.affinity.nodeAffinity Podʼа для відповідності цільовому хосту. Після створення Podʼа, зазвичай вступає в дію типовий планувальник і привʼязує Pod до цільового хосту, встановлюючи поле .spec.nodeName. Якщо новий Pod не може поміститися на вузлі, типовий планувальник може здійснити перерозподіл (виселення) деяких наявних Podʼів на основі пріоритету нового Podʼа.
Примітка:
Якщо важливо, щоб Pod DaemonSet запускався на кожному вузлі, часто бажано встановити.spec.template.spec.priorityClassName DaemonSet на PriorityClass з вищим пріоритетом, щоб переконатись, що таке виселення видбувається.Користувач може вказати інший планувальник для Podʼів DaemonSet, встановивши поле .spec.template.spec.schedulerName DaemonSet.
Оригінальна спорідненість вузла, вказана в полі .spec.template.spec.affinity.nodeAffinity (якщо вказано), береться до уваги контролером DaemonSet при оцінці придатних вузлів, але замінюється на спорідненість вузла, що відповідає імені придатного вузла, на створеному Podʼі.
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchFields:
- key: metadata.name
operator: In
values:
- target-host-name
Taint та toleration
Контролер DaemonSet автоматично додає набір toleration до Podʼів DaemonSet:
| Ключ толерантності | Ефект | Деталі |
|---|---|---|
node.kubernetes.io/not-ready | NoExecute | Podʼи DaemonSet можуть бути заплановані на вузли, які не є справними або готовими приймати Podʼи. Будь-які Podʼи DaemonSet, які працюють на таких вузлах, не будуть виселені. |
node.kubernetes.io/unreachable | NoExecute | Podʼи DaemonSet можуть бути заплановані на вузли, які недоступні з контролера вузла. Будь-які Podʼи DaemonSet, які працюють на таких вузлах, не будуть виселені. |
node.kubernetes.io/disk-pressure | NoSchedule | Podʼи DaemonSet можуть бути заплановані на вузли із проблемами дискового тиску. |
node.kubernetes.io/memory-pressure | NoSchedule | Podʼи DaemonSet можуть бути заплановані на вузли із проблемами памʼяті. |
node.kubernetes.io/pid-pressure | NoSchedule | Podʼи DaemonSet можуть бути заплановані на вузли з проблемами процесів. |
node.kubernetes.io/unschedulable | NoSchedule | Podʼи DaemonSet можуть бути заплановані на вузли, які не можна планувати. |
node.kubernetes.io/network-unavailable | NoSchedule | Додається лише для Podʼів DaemonSet, які запитують мережу вузла, тобто Podʼи з spec.hostNetwork: true. Такі Podʼи DaemonSet можуть бути заплановані на вузли із недоступною мережею. |
Ви можете додавати свої толерантності до Podʼів DaemonSet, визначивши їх в шаблоні Podʼа DaemonSet.
Оскільки контролер DaemonSet автоматично встановлює толерантність node.kubernetes.io/unschedulable:NoSchedule, Kubernetes може запускати Podʼи DaemonSet на вузлах, які відзначені як unschedulable.
Якщо ви використовуєте DaemonSet для надання важливої функції на рівні вузла, такої як мережа кластера, то корисно, що Kubernetes розміщує Podʼи DaemonSet на вузлах до того, як вони будуть готові. Наприклад, без цієї спеціальної толерантності ви можете опинитися в тупиковій ситуації, коли вузол не позначений як готовий, тому що мережевий втулок не працює там, і в той самий час мережевий втулок не працює на цьому вузлі, оскільки вузол ще не готовий.
Взаємодія з Daemon Podʼами
Деякі можливі шаблони для взаємодії з Podʼами у DaemonSet:
- Push: Podʼи в DaemonSet налаштовані надсилати оновлення до іншого сервісу, такого як база статистики. У них немає клієнтів.
- NodeIP та відомий порт: Podʼи в DaemonSet можуть використовувати
hostPort, щоб їх можна було знайти за IP-адресою вузла. Клієнти певним чином знають стандартний список IP-адрес вузлів і порти. - DNS: Створіть headless сервіс за таким же вибором Podʼа, а потім виявіть DaemonSet, використовуючи ресурс
endpointsабо отримайте кілька записів A з DNS. - Сервіс: Створіть сервіс із тим самим вибором Podʼа та використовуйте сервіс для зʼєднання з демоном на випадковому вузлі. (Немає способу зʼєднатися напряму з конкретним Podʼом.)
Оновлення DaemonSet
Якщо мітки вузлів змінюються, DaemonSet негайно додає Podʼи на нові відповідні вузли та видаляє Podʼи на нових не відповідних вузлах.
Ви можете змінювати Podʼи, які створює DaemonSet. Проте Podʼи не дозволяють оновлювати всі поля. Крім того, контролер DaemonSet буде використовувати початковий шаблон при наступному створенні вузла (навіть з тим самим імʼям).
Ви можете видалити DaemonSet. Якщо ви вказали --cascade=orphan з kubectl, тоді Podʼи залишаться на вузлах. Якщо ви потім створите новий DaemonSet з тим самим селектором, новий DaemonSet прийме наявні Podʼи. Якщо потрібно замінити які-небудь Podʼи, DaemonSet їх замінює згідно з його updateStrategy.
Ви можете виконати поетапне оновлення DaemonSet.
Альтернативи DaemonSet
Скрипти ініціалізації
Звичайно, можливо запускати процеси демонів, безпосередньо стартуючи їх на вузлі (наприклад, за допомогою init, upstartd або systemd). Це абсолютно прийнятно. Однак існують кілька переваг запуску таких процесів через DaemonSet:
- Можливість моніторингу та управління логами для демонів так само як і для застосунків.
- Однакова мова конфігурації та інструменти (наприклад, шаблони Podʼа,
kubectl) для демонів та застосунків. - Запуск демонів у контейнерах з обмеженням ресурсів підвищує ізоляцію між демонами та контейнерами застосунків. Однак це також можна досягти, запускаючи демонів у контейнері, але не в Podʼі.
Тільки Podʼи
Можливо створити Podʼи безпосередньо, вказуючи певний вузол для запуску. Проте DaemonSet замінює Podʼи, які видаляються або завершуються з будь-якої причини, такої як збій вузла або руйнівне обслуговування вузла, наприклад, оновлення ядра. З цієї причини слід використовувати DaemonSet замість створення тільки Podʼів.
Статичні Podʼи
Можливо створити Podʼи, записавши файл у певну теку, що спостерігається Kubelet. Їх називають статичними Podʼами. На відміну від DaemonSet, статичними Podʼами не можна управляти за допомогою kubectl або інших клієнтів API Kubernetes. Статичні Podʼи не залежать від apiserver, що робить їх корисними в разі початкового налаштування кластера. Однак, статичні Podʼи можуть бути застарілими у майбутньому.
Deployments
DaemonSet схожий на Розгортання (Deployments) тим, що обидва створюють Podʼи, і ці Podʼи мають процеси, які не очікується, що завершаться (наприклад, вебсервери, сервери сховищ).
Використовуйте Розгортання для stateless служб, таких як фронтенди, де важливо збільшувати та зменшувати кількість реплік та розгортати оновлення. Використовуйте DaemonSet, коли важливо, щоб копія Podʼа завжди працювала на всіх або певних вузлах, якщо DaemonSet надає функціональність рівня вузла, яка дозволяє іншим Podʼам правильно працювати на цьому конкретному вузлі.
Наприклад, мережеві втулки часто включають компонент, який працює як DaemonSet. Цей компонент DaemonSet переконується, що вузол, де він працює, має справну кластерну мережу.
Що далі
- Дізнайтеся більше про Podʼи.
- Дізнайтеся про статичні Podʼи, які корисні для запуску компонентів панелі управління Kubernetes.
- Дізнайтеся, як використовувати DaemonSets
- Виконати поетапне оновлення DaemonSet
- Виконати відкат DaemonSet (наприклад, якщо розгортання не працює так, як ви очікували).
- Дізнайтесь як Kubernetes призначає Podʼи вузлам.
- Дізнайтеся про втулки пристроїв та надбудови, які часто працюють як DaemonSets.
DaemonSet— це ресурс верхнього рівня у Kubernetes REST API. Ознайомтесь з визначенням обʼєкта DaemonSet, щоб зрозуміти API для DaemonSet.
4.2.5 - Job
Job – є одноразовим завданням, що виконується до моменту його завершення.
Завдання (Job) створює один або кілька Podʼів і буде продовжувати повторювати виконання Podʼів, доки не буде досягнуто вказану кількість успішних завершень. При успішному завершенні Podʼів завдання відстежує ці успішні завершення. Коли досягнута вказана кількість успішних завершень, завдання (тобто Job) завершується. Видалення завдання буде видаляти Podʼи, які воно створило. При призупиненні завдання буде видаляти активні Podʼи, доки завдання знову не буде відновлене.
У простому випадку можна створити один обʼєкт Job для надійного запуску одного Podʼа до завершення. Обʼєкт Job буде запускати новий Pod, якщо перший Pod зазнає невдачі або видаляється (наприклад, через відмову апаратного забезпечення вузла або перезавантаження вузла).
Також можна використовувати Job для запуску кількох Podʼів паралельно.
Якщо ви хочете запустити завдання (або одне завдання, або декілька паралельно) за розкладом, див. CronJob.
Запуск прикладу Job
Ось конфігурація прикладу Job. Тут обчислюється число π з точністю до 2000 знаків і виконується його вивід. Виконання зазвичай займає близько 10 секунд.
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
Ви можете запустити цей приклад за допомогою наступної команди:
kubectl apply -f https://kubernetes.io/examples/controllers/job.yaml
Вивід буде схожим на це:
job.batch/pi created
Перевірте статус Job за допомогою kubectl:
Name: pi
Namespace: default
Selector: batch.kubernetes.io/controller-uid=c9948307-e56d-4b5d-8302-ae2d7b7da67c
Labels: batch.kubernetes.io/controller-uid=c9948307-e56d-4b5d-8302-ae2d7b7da67c
batch.kubernetes.io/job-name=pi
...
Annotations: batch.kubernetes.io/job-tracking: ""
Parallelism: 1
Completions: 1
Start Time: Mon, 02 Dec 2019 15:20:11 +0200
Completed At: Mon, 02 Dec 2019 15:21:16 +0200
Duration: 65s
Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
Pod Template:
Labels: batch.kubernetes.io/controller-uid=c9948307-e56d-4b5d-8302-ae2d7b7da67c
batch.kubernetes.io/job-name=pi
Containers:
pi:
Image: perl:5.34.0
Port: <none>
Host Port: <none>
Command:
perl
-Mbignum=bpi
-wle
print bpi(2000)
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 21s job-controller Created pod: pi-xf9p4
Normal Completed 18s job-controller Job completed
apiVersion: batch/v1
kind: Job
metadata:
annotations: batch.kubernetes.io/job-tracking: ""
...
creationTimestamp: "2022-11-10T17:53:53Z"
generation: 1
labels:
batch.kubernetes.io/controller-uid: 863452e6-270d-420e-9b94-53a54146c223
batch.kubernetes.io/job-name: pi
name: pi
namespace: default
resourceVersion: "4751"
uid: 204fb678-040b-497f-9266-35ffa8716d14
spec:
backoffLimit: 4
completionMode: NonIndexed
completions: 1
parallelism: 1
selector:
matchLabels:
batch.kubernetes.io/controller-uid: 863452e6-270d-420e-9b94-53a54146c223
suspend: false
template:
metadata:
creationTimestamp: null
labels:
batch.kubernetes.io/controller-uid: 863452e6-270d-420e-9b94-53a54146c223
batch.kubernetes.io/job-name: pi
spec:
containers:
- command:
- perl
- -Mbignum=bpi
- -wle
- print bpi(2000)
image: perl:5.34.0
imagePullPolicy: IfNotPresent
name: pi
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Never
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
active: 1
ready: 0
startTime: "2022-11-10T17:53:57Z"
uncountedTerminatedPods: {}
Щоб переглянути завершені Podʼи Job, використовуйте kubectl get pods.
Щоб вивести всі Podʼи, які належать Job у машинночитаній формі, ви можете використовувати таку команду:
pods=$(kubectl get pods --selector=batch.kubernetes.io/job-name=pi --output=jsonpath='{.items[*].metadata.name}')
echo $pods
Вивід буде схожим на це:
pi-5rwd7
Тут, селектор збігається з селектором, який використовується в Job. Параметр --output=jsonpath зазначає вираз з назвою з кожного Pod зі списку.
kubectl logs $pods
Іншим варіантом є використання kubectl logs для виводу логів з кожного Pod.
kubectl logs job/pi
Вивід буде схожим на це:
3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819644288109756659334461284756482337867831652712019091456485669234603486104543266482133936072602491412737245870066063155881748815209209628292540917153643678925903600113305305488204665213841469519415116094330572703657595919530921861173819326117931051185480744623799627495673518857527248912279381830119491298336733624406566430860213949463952247371907021798609437027705392171762931767523846748184676694051320005681271452635608277857713427577896091736371787214684409012249534301465495853710507922796892589235420199561121290219608640344181598136297747713099605187072113499999983729780499510597317328160963185950244594553469083026425223082533446850352619311881710100031378387528865875332083814206171776691473035982534904287554687311595628638823537875937519577818577805321712268066130019278766111959092164201989380952572010654858632788659361533818279682303019520353018529689957736225994138912497217752834791315155748572424541506959508295331168617278558890750983817546374649393192550604009277016711390098488240128583616035637076601047101819429555961989467678374494482553797747268471040475346462080466842590694912933136770289891521047521620569660240580381501935112533824300355876402474964732639141992726042699227967823547816360093417216412199245863150302861829745557067498385054945885869269956909272107975093029553211653449872027559602364806654991198818347977535663698074265425278625518184175746728909777727938000816470600161452491921732172147723501414419735685481613611573525521334757418494684385233239073941433345477624168625189835694855620992192221842725502542568876717904946016534668049886272327917860857843838279679766814541009538837863609506800642251252051173929848960841284886269456042419652850222106611863067442786220391949450471237137869609563643719172874677646575739624138908658326459958133904780275901
Створення опису Job
Як і з будь-якою іншою конфігурацією Kubernetes, у Job мають бути вказані поля apiVersion, kind та metadata.
При створенні панеллю управління нових Podʼів для Job, поле .metadata.name Job є частиною основи для надання імен цим Podʼам. Імʼя Job повинно бути дійсним значенням DNS-піддомену, але це може призводити до неочікуваних результатів для імен хостів Podʼів. Для найкращої сумісності імʼя повинно відповідати більш обмеженим правилам для DNS-мітки. Навіть якщо імʼя є DNS-піддоменом, імʼя повинно бути не довше 63 символів.
Також у Job повинен бути розділ .spec.
Мітки для Job
Мітки Job повинні мати префікс batch.kubernetes.io/ для job-name та controller-uid.
Шаблон Podʼа
.spec.template — єдине обовʼязкове поле .spec.
.spec.template — це шаблон Podʼа. Він має точно таку ж схему, як Pod, окрім того, що він вкладений і не має apiVersion чи kind.
Окрім обовʼязкових полів для Podʼа , шаблон Podʼа в Job повинен вказати відповідні мітки (див. селектор Podʼа) та відповідну політику перезапуску.
Дозволяється лише RestartPolicy, рівний Never або OnFailure.
Селектор Podʼа
Поле .spec.selector є необовʼязковим. У майже всіх випадках ви не повинні його вказувати. Дивіться розділ вказування вашого власного селектора Podʼа.
Паралельне виконання для Jobs
Існують три основних типи завдань, які підходять для виконання в якості Job:
Непаралельні Jobs
- зазвичай запускається лише один Pod, якщо Pod не вдається.
- Job завершується, як тільки його Pod завершується успішно.
Паралельні Jobs із фіксованою кількістю завершень
- вкажіть ненульове позитивне значення для
.spec.completions. - Job являє собою загальне завдання і завершується, коли є
.spec.completionsуспішних Podʼів. - при використанні
.spec.completionMode="Indexed", кожен Pod отримує різний індекс у діапазоні від 0 до.spec.completions-1.
- вкажіть ненульове позитивне значення для
Паралельні Jobs із чергою завдань
- не вказуйте
.spec.completions, типово встановлюється.spec.parallelism. - Podʼи повинні координувати серед себе або зовнішній сервіс для визначення над чим кожен з них має працювати. Наприклад, Pod може отримати набір з N елементів з черги завдань.
- кожен Pod може незалежно визначити, чи завершилися всі його партнери, і, таким чином, що весь Job завершений.
- коли будь-який Pod з Job завершується успішно, нові Podʼи не створюються.
- як тільки хоча б один Pod завершився успішно і всі Podʼи завершені, тоді Job завершується успішно.
- як тільки будь-який Pod завершився успішно, жоден інший Pod не повинен виконувати роботу для цього завдання чи записувати будь-який вивід. Вони всі мають бути в процесі завершення.
- не вказуйте
Для непаралельного Job ви можете залишити як .spec.completions, так і .spec.parallelism не встановленими. Коли обидва не встановлені, обидва типово встановлюються на 1.
Для Job із фіксованою кількістю завершень вам слід встановити .spec.completions на кількість необхідних завершень. Ви можете встановити .spec.parallelism чи залишити його не встановленим, і він буде встановлено типово на 1.
Для Job із чергою завдань ви повинні залишити .spec.completions не встановленим і встановити .spec.parallelism на не відʼємне ціле число.
За докладною інформацією про використання різних типів Job, див. розділ патерни Job.
Контроль паралелізму
Запитаний паралелізм (.spec.parallelism) може бути встановлений на будь-яке не відʼємне значення. Якщо значення не вказано, стандартно воно дорівнює 1. Якщо вказано як 0, то Job ефективно призупинено до тих пір, поки воно не буде збільшене.
Фактична паралельність (кількість Podʼів, які працюють в будь-який момент) може бути більше чи менше, ніж запитаний паралелізм, з різних причин:
- Для Job із фіксованою кількістю завершень, фактична кількість Podʼів, які працюють паралельно, не буде перевищувати кількість залишених завершень. Значення
.spec.parallelismбільше чи менше ігнорується. - Для Job із чергою завдань, жоден новий Pod не запускається після успішного завершення будь-якого Podʼа — залишені Podʼи мають право завершити роботу.
- Якщо у контролера Job не було часу відреагувати.
- Якщо контролер Job не зміг створити Podʼи з будь-якої причини (нестача
ResourceQuota, відсутність дозволу і т.д.), тоді може бути менше Podʼів, ніж запитано. - Контролер Job може обмежувати створення нових Podʼів через ексцесивні попередні відмови Podʼів у цьому ж Job.
- Коли Pod завершується відповідним чином, на його зупинку потрібен час.
Режим завершення
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]Для завдань з фіксованою кількістю завершень — тобто завдань, які мають не нульове .spec.completions — може бути встановлено режим завершення, який вказується в .spec.completionMode:
NonIndexed(стандартно): завдання вважається завершеним, коли є.spec.completionsуспішно завершених Podʼів. Іншими словами, завершення кожного Podʼа гомологічне одне одному. Зверніть увагу, що завдання, у яких.spec.completionsдорівнює null, неявно єNonIndexed.Indexed: Podʼи завдання отримують асоційований індекс завершення від 0 до.spec.completions-1. Індекс доступний через чотири механізми:- Анотація Podʼа
batch.kubernetes.io/job-completion-index. - Мітка Podʼа
batch.kubernetes.io/job-completion-index(для v1.28 і новіших). Зверніть увагу, що для використання цієї мітки механізм feature gatePodIndexLabelповинен бути увімкнений, і він є типово увімкненим. - Як частина імені хоста Podʼа, за шаблоном
$(job-name)-$(index). Коли ви використовуєте Індексоване Завдання у поєднанні з Service, Podʼи всередині завдання можуть використовувати детерміністичні імена хостів для адресації одне одного через DNS. Докладні відомості щодо того, як налаштувати це, див. Завдання з комунікацією від Podʼа до Podʼа. - З контейнера завдання, в змінній середовища
JOB_COMPLETION_INDEX.
Завдання вважається завершеним, коли є успішно завершений Pod для кожного індексу. Докладні відомості щодо того, як використовувати цей режим, див. Індексоване завдання для паралельної обробки зі статичним призначенням роботи.
- Анотація Podʼа
Примітка:
Хоча це і рідко, може бути запущено більше одного Podʼа для одного і того ж індексу (з різних причин, таких як відмови вузла, перезапуски kubelet чи виселення Podʼа). У цьому випадку лише перший успішно завершений Pod буде враховуватися при підрахунку кількості завершень та оновленні статусу завдання. Інші Podʼи, які працюють чи завершили роботу для того ж самого індексу, будуть видалені контролером завдання, як тільки він їх виявлять.Обробка відмов Podʼа та контейнера
Контейнер у Podʼі може вийти з ладу з ряду причин, таких як завершення процесу з ненульовим кодом виходу або примусове припинення роботи контейнера через перевищення ліміту памʼяті та таке інше. Якщо це стається і .spec.template.spec.restartPolicy = "OnFailure", тоді Pod залишається на вузлі, але контейнер перезапускається. Отже, ваш застосунок повинен обробляти випадок, коли він
перезапускається локально, або вказувати .spec.template.spec.restartPolicy = "Never". Докладні відомості про restartPolicy див. в розділі життєвий цикл Podʼа.
Весь Pod також може вийти з ладу з ряду причин, таких як коли Pod видаляється з вузла (вузол оновлюється, перезавантажується, видаляється тощо), або якщо контейнер Podʼа виходить з ладу і .spec.template.spec.restartPolicy = "Never". Коли Pod виходить з ладу, контролер завдання запускає новий Pod. Це означає, що ваш застосунок повинен обробляти випадок, коли він перезапускається у новому
Podʼі. Зокрема, він повинен обробляти тимчасові файли, блокування, неповний вивід та інше, викликане попередніми запусками.
Типово кожна відмова Podʼа враховується в ліміті .spec.backoffLimit, див. політика відмови Podʼа. Однак ви можете налаштовувати обробку відмов Podʼа, встановлюючи [політику відмови Podʼа] (#pod-failure-policy) для завдання.
Додатково ви можете вирішити враховувати відмови Podʼа незалежно для кожного індексу в Індексованому Завданні, встановлюючи поле .spec.backoffLimitPerIndex (докладні відомості див. ліміт затримки на індекс).
Зверніть увагу, що навіть якщо ви вказали .spec.parallelism = 1 і .spec.completions = 1 і .spec.template.spec.restartPolicy = "Never", той самий програмний код може іноді бути запущений двічі.
Якщо ви вказали як .spec.parallelism, так і .spec.completions більше ніж 1, то може бути запущено кілька Podʼів одночасно. Таким чином, ваші Podʼи також повинні бути стійкими до конкурентності.
Якщо ви вказуєте поле .spec.podFailurePolicy, контролер Job не вважає Pod, який перебуває у стані завершення (Pod з встановленим полем .metadata.deletionTimestamp), за помилку до того, як Pod стане термінальним (його .status.phase є Failed або Succeeded). Однак контролер Job створює замінний Pod, як тільки стає очевидним, що Pod перебуває в процесі завершення. Після того як Pod завершиться, контролер Job оцінює .backoffLimit і .podFailurePolicy для відповідного Job, враховуючи тепер уже завершений Pod.
Якщо хоча б одна з цих вимог не виконана, контролер завдання рахує завершення Podʼа негайною відмовою, навіть якщо цей Pod пізніше завершить фазою "Succeeded".
Політика backoff відмови Podʼа
Є ситуації, коли ви хочете щоб завдання зазнало збою після певної кількості спроб
через логічну помилку в конфігурації тощо. Для цього встановіть .spec.backoffLimit, щоб вказати кількість спроб перед тим, як вважати завдання таким, що не вдалось. Ліміт затримки стандартно встановлено на рівні 6. Помилкові Podʼи, повʼязані з завданням, відновлюються контролером завдань з експоненційною затримкою (10 с, 20 с, 40 с …) з верхнім обмеженням у шість хвилин.
Кількість спроб обчислюється двома способами:
- Кількість Podʼів з
.status.phase = "Failed". - При використанні
restartPolicy = "OnFailure"кількість спроб у всіх контейнерах Podʼів з.status.phase, що дорівнюєPendingабоRunning.
Якщо хоча б один із розрахунків досягне значення .spec.backoffLimit, завдання вважається невдалим.
Примітка:
Якщо ваше завдання маєrestartPolicy = "OnFailure", майте на увазі, що Pod, який виконує завдання, буде припинений, як тільки ліміт затримки завдання буде досягнуто. Це може ускладнити налагодження виконуваного завдання. Ми радимо встановлювати restartPolicy = "Never" під час налагодження завдання або використовувати систему логування, щоб забезпечити, що вивід з невдалого завдання не буде втрачено випадково.Ліміт затримки для кожного індексу
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.29 [beta]Примітка:
Ви можете налаштувати ліміт затримки для кожного індексу для завдання з індексацією, якщо у вас увімкнено функціональну можливістьJobBackoffLimitPerIndex в вашому кластері.Коли ви запускаєте індексоване Завдання, ви можете вибрати обробку спроб для відмов Podʼа незалежно для кожного індексу. Для цього встановіть
.spec.backoffLimitPerIndex, щоб вказати максимальну кількість невдалих спроб Podʼа
для кожного індексу.
Коли ліміт затримки для кожного індексу перевищується для певного індексу, Kubernetes вважає цей індекс невдалим і додає його до поля .status.failedIndexes. Індекси, які виконались успішно, реєструються в полі .status.completedIndexes, незалежно від того, чи ви встановили поле backoffLimitPerIndex.
Зауважте, що невдалий індекс не перериває виконання інших індексів. Щойно всі індекси завершаться для завдання, в якому ви вказали ліміт затримки для кожного індексу, якщо хоча б один з цих індексів виявився невдалим, контролер завдань позначає загальне завдання як невдале, встановлюючи умову Failed в статусі. Завдання отримує позначку "невдало", навіть якщо деякі, можливо, усі індекси були
оброблені успішно.
Ви також можете обмежити максимальну кількість позначених невдалих індексів, встановивши поле .spec.maxFailedIndexes. Коли кількість невдалих індексів перевищує значення поля maxFailedIndexes, контролер завдань запускає завершення всіх залишаються запущеними Podʼами для цього завдання. Щойно всі Podʼи будуть завершені, контролер завдань позначає все Завдання як невдале, встановлюючи умову Failed в статусі Завдання.
Ось приклад маніфесту для завдання, яке визначає backoffLimitPerIndex:
apiVersion: batch/v1
kind: Job
metadata:
name: job-backoff-limit-per-index-example
spec:
completions: 10
parallelism: 3
completionMode: Indexed # обов'язково для функціоналу
backoffLimitPerIndex: 1 # максимальна кількість невдач на один індекс
maxFailedIndexes: 5 # максимальна кількість невдалих індексів перед припиненням виконання Job
template:
spec:
restartPolicy: Never # обов'язково для функціоналу
containers:
- name: example
image: python
command: # Робота завершується невдачею, оскільки є принаймні один невдалий індекс
# (всі парні індекси невдаються), але всі індекси виконуються,
# оскільки не перевищено максимальну кількість невдалих індексів.
- python3
- -c
- |
import os, sys
print("Привіт, світ")
if int(os.environ.get("JOB_COMPLETION_INDEX")) % 2 == 0:
sys.exit(1)
У вищенаведеному прикладі контролер завдань дозволяє один перезапуск для кожного з індексів. Коли загальна кількість невдалих індексів перевищує 5, тоді все завдання припиняються.
Після завершення роботи стан завдання виглядає наступним чином:
kubectl get -o yaml job job-backoff-limit-per-index-example
status:
completedIndexes: 1,3,5,7,9
failedIndexes: 0,2,4,6,8
succeeded: 5 # 1 succeeded pod for each of 5 succeeded indexes
failed: 10 # 2 failed pods (1 retry) for each of 5 failed indexes
conditions:
- message: Job has failed indexes
reason: FailedIndexes
status: "True"
type: FailureTarget
- message: Job has failed indexes
reason: FailedIndexes
status: "True"
type: Failed
Контролер Job додає умову FailureTarget до Job для запуску завершення та очищення Job. Коли всі Podʼи Job завершуються, контролер Job додає умову Failed з тими ж значеннями для reason і message, що й у умови FailureTarget. Для деталей дивіться Завершення Podʼів завдання.
Додатково ви можете використовувати ліміт затримки для кожного індексу разом з
політикою збоїв Podʼа. Коли використовується ліміт затримки для кожного індексу, доступний новій дії FailIndex, який дозволяє вам уникати непотрібних повторів всередині індексу.
Політика збою Podʼа
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [stable] (стандартно увімкнено: true)Політика збою Podʼа, визначена за допомогою поля .spec.podFailurePolicy, дозволяє вашому кластеру обробляти відмови Podʼа на основі кодів виходу контейнера та умов Podʼа.
У деяких ситуаціях вам може знадобитися кращий контроль обробки відмов Podʼа, ніж контроль, який надає політика відмови Podʼа за допомогою затримки збою Podʼа, яка базується на .spec.backoffLimit завдання. Ось деякі приклади використання:
- Для оптимізації витрат на виконання завдань, уникнення непотрібних перезапусків Podʼа, ви можете завершити завдання, як тільки один із його Podʼів відмовить із кодом виходу, що вказує на помилку програмного забезпечення.
- Щоб гарантувати, що ваше завдання завершиться, навіть якщо є розлади, ви можете ігнорувати відмови Podʼа, спричинені розладами (такими як випередження, виселення, ініційоване API або виселення на підставі маркування), щоб вони не враховувалися при досягненні
.spec.backoffLimitліміту спроб.
Ви можете налаштувати політику збою Podʼа в полі .spec.podFailurePolicy, щоб відповідати вищенаведеним використанням. Ця політика може обробляти відмови Podʼа на основі кодів виходу контейнера та умов Podʼа.
Ось маніфест для завдання, яке визначає podFailurePolicy:
apiVersion: batch/v1
kind: Job
metadata:
name: job-pod-failure-policy-example
spec:
completions: 12
parallelism: 3
template:
spec:
restartPolicy: Never
containers:
- name: main
image: docker.io/library/bash:5
command: ["bash"] # приклад команди, що емулює помилку, яка запускає дію FailJob
args:
- -c
- echo "Hello world!" && sleep 5 && exit 42
backoffLimit: 6
podFailurePolicy:
rules:
- action: FailJob
onExitCodes:
containerName: main # опціонально
operator: In # одне з: In, NotIn
values: [42]
- action: Ignore # одне з: Ignore, FailJob, Count
onPodConditions:
- type: DisruptionTarget # вказує на порушення роботи Podʼу
У вищенаведеному прикладі перше правило політики збою Podʼа вказує, що завдання слід позначити як невдале, якщо контейнер main завершиться кодом виходу 42. Наступні правила стосуються саме контейнера main:
- код виходу 0 означає, що контейнер виконався успішно
- код виходу 42 означає, що все завдання виконалося невдало
- будь-який інший код виходу вказує, що контейнер виконався невдало, і, отже, весь Pod буде створений заново, якщо загальна кількість перезапусків менше
backoffLimit. ЯкщоbackoffLimitдосягнуте, все завдання виконалося невдало.
Примітка:
Оскільки в шаблоні Podʼа вказаноrestartPolicy: Never, kubelet не перезапускає контейнер main в тому конкретному Podʼі.Друге правило політики збою Podʼа, що вказує дію Ignore для невдалих Podʼів з умовою DisruptionTarget, виключає Podʼи, які взяли участь в розладах, з хунок ліміту спроб .spec.backoffLimit.
Примітка:
Якщо завдання виявилося невдалим, будь-то через політику збою Podʼа, чи через політику затримки збою Podʼа, і завдання виконується декількома Podʼами, Kubernetes завершує всі Podʼи в цьому завданні, які все ще перебувають у статусах Pending або Running.Ось деякі вимоги та семантика API:
- якщо ви хочете використовувати поле
.spec.podFailurePolicyдля завдання Job, вам також слід визначити шаблон Podʼа цього завдання з.spec.restartPolicy, встановленим наNever. - правила політики збою Podʼа, які ви визначаєте у
spec.podFailurePolicy.rules, оцінюються послідовно. Якщо одне з правил відповідає збою Podʼа, інші правила ігноруються. Якщо жодне правило не відповідає збою Podʼа, застосовується типова обробка. - ви можете бажати обмежити правило певним контейнером, вказавши його імʼя у
spec.podFailurePolicy.rules[*].onExitCodes.containerName. Якщо не вказано, правило застосовується до всіх контейнерів. Якщо вказано, воно повинно відповідати імені одного з контейнерів абоinitContainerу шаблоні Podʼа. - ви можете вказати дію, вживану при відповідності політиці збою Podʼа, у
spec.podFailurePolicy.rules[*].action. Можливі значення:FailJob: використовуйте це, щоб вказати, що завдання Podʼа має бути позначено як Failed та всі запущені Podʼи повинні бути завершені.Ignore: використовуйте це, щоб вказати, що лічильник до.spec.backoffLimitне повинен збільшуватися, і повинен бути створений замінюючий Pod.Count: використовуйте це, щоб вказати, що Pod повинен бути оброблений типовим способом. Лічильник до.spec.backoffLimitповинен збільшитися.FailIndex: використовуйте цю дію разом із лімітом затримки на кожен індекс для уникнення непотрібних повторних спроб в межах індексу невдалого Podʼа.
Примітка:
Коли використовуєтьсяpodFailurePolicy, контролер завдань враховує лише Podʼи у фазі Failed. Podʼи з відміткою про видалення, які не знаходяться в термінальній фазі (Failed чи Succeeded), вважаються таким що примусово припиняють свою роботу. Це означає, що такі Podʼи зберігають завершувачі відстеження доки не досягнуть термінальної фази. З Kubernetes 1.27 Kubelet переводить видалені Podʼи в термінальну фазу (див.: Фаза Podʼа). Це забезпечує видалення завершувачів контролером Job.Примітка:
Починаючи з Kubernetes v1.28, коли використовується політика збою Podʼа, контролер Job відтворює Podʼи, що припиняються примусово, лише тоді, коли ці Podʼи досягли термінальної фазиFailed. Це подібно до політики заміщення Podʼа: podReplacementPolicy: Failed. Для отримання додаткової інформації див. Політика заміщення Podʼа.Коли ви використовуєте podFailurePolicy, і Job зазнає невдачі через Pod, що відповідає правилу з дією FailJob, контролер Job запускає процес завершення Job, додаючи умову FailureTarget. Для деталей дивіться Завершення та очищення Job.
Політика успіху
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [beta] (стандартно увімкнено: true)Примітка:
Ви можете налаштувати політику успіху лише для Індексованого Завдання, якщо у вас увімкнено функціональну можливістьJobSuccessPolicy у вашому кластері.При створенні Індексованого Завдання ви можете визначити, коли завдання може бути визнане успішним за допомогою .spec.successPolicy, на основі успішних Podʼів.
Типово завдання вважається успішним, коли кількість успішних Podʼів дорівнює .spec.completions. Існують ситуації, коли вам може знадобитися додатковий контроль для визначення завдання успішним:
- Під час виконання симуляцій з різними параметрами, вам можуть не знадобитися всі симуляції для успішного завершення загального завдання.
- При використанні шаблону лідер-робітник, успіх лідера визначає успіх чи невдачу завдання. Прикладами цього є фреймворки, такі як MPI та PyTorch тощо.
Ви можете налаштувати політику успіху у полі .spec.successPolicy, щоб задовольнити вищезазначені випадки використання. Ця політика може керувати успіхом завдання на основі успішних Podʼів. Після того, як завдання відповідає політиці успіху, контролер завдань завершує залишкові Podʼи. Політика успіху визначається правилами. Кожне правило може мати одну з наступних форм:
- Коли ви вказуєте лише
succeededIndexes, одразу після успішного завершення всіх індексів, вказаних уsucceededIndexes, контролер завдань позначає завдання як успішне.succeededIndexesповинен бути списком інтервалів між 0 і.spec.completions-1. - Коли ви вказуєте лише
succeededCount, як тільки кількість успішних індексів досягнеsucceededCount, контролер завдань позначає завдання як успішне. - Коли ви вказуєте як
succeededIndexes, так іsucceededCount, як тільки кількість успішних індексів з підмножини індексів, вказаних уsucceededIndexes, досягнеsucceededCount, контролер завдань позначає завдання як успішне.
Зверніть увагу, що коли ви вказуєте кілька правил у .spec.successPolicy.rules, контролер завдань оцінює правила послідовно. Після того, як завдання задовольняє правило, контролер завдань ігнорує решту правил.
Ось приклад маніфеста для завдання із successPolicy:
apiVersion: batch/v1
kind: Job
metadata:
name: job-success
spec:
parallelism: 10
completions: 10
completionMode: Indexed # Обовʼязково для іспішної політики
successPolicy:
rules:
- succeededIndexes: 0,2-3
succeededCount: 1
template:
spec:
containers:
- name: main
image: python
command: # З урахуванням того, що принаймні один із Podʼів з індексами 0, 2 та 3 успішно завершився,
# загальна задача вважатиметься успішною.
- python3
- -c
- |
import os, sys
if os.environ.get("JOB_COMPLETION_INDEX") == "2":
sys.exit(0)
else:
sys.exit(1)
restartPolicy: Never
У вищенаведеному прикладі були вказані як succeededIndexes, так і succeededCount. Тому контролер завдань позначить завдання як успішне і завершить залишкові Podʼи після успіху будь-яких зазначених індексів, 0, 2 або 3. Завдання, яке відповідає політиці успіху, отримує умову SuccessCriteriaMet з причиною SuccessPolicy. Після видалення залишкових Podʼів, завдання отримує стан Complete.
Зверніть увагу, що succeededIndexes представлено як інтервали, розділені дефісом. Номери перераховані у вигляді першого та останнього елементів серії, розділених дефісом.
Примітка:
Коли ви вказуєте як політику успіху, так і деякі політики завершення, такі як.spec.backoffLimit і .spec.podFailurePolicy, одного разу, коли завдання задовольняє будь-яку політику, контролер завдань дотримується політики завершення і ігнорує політику успіху.Завершення завдання та очищення
Коли завдання завершується, Podʼи більше не створюються, але Podʼи зазвичай також не видаляються. Тримання їх допомагає переглядати логи завершених Podʼів для перевірки наявності помилок, попереджень чи іншого діагностичного виводу. Обʼєкт завдання також залишається після завершення, щоб ви могли переглядати його статус. Користувачу слід видаляти старі завдання після перегляду їх статусу. Видаліть завдання за допомогою kubectl (наприклад, kubectl delete jobs/pi або kubectl delete -f ./job.yaml). Коли ви видаляєте завдання за допомогою kubectl, всі його створені Podʼи також видаляються.
Стандартно завдання буде виконуватися без перерви, поки Pod не вийде з ладу (restartPolicy=Never) або контейнер не вийде з ладу з помилкою (restartPolicy=OnFailure), після чого завдання дотримується .spec.backoffLimit, описаного вище. Як тільки досягнуто .spec.backoffLimit, завдання буде позначене як невдале, і будь-які запущені Podʼи будуть завершені.
Іншим способом завершити завдання є встановлення граничного терміну виконання. Це робиться шляхом встановлення поля .spec.activeDeadlineSeconds завдання кількості секунд. activeDeadlineSeconds застосовується до тривалості завдання, незалежно від кількості створених Podʼів. Як тільки Job досягає activeDeadlineSeconds, всі його запущені Podʼи завершуються, і статус завдання стане type: Failed з reason: DeadlineExceeded.
Зауважте, що .spec.activeDeadlineSeconds Job має пріоритет перед його .spec.backoffLimit. Отже, завдання, яке повторює один або кілька невдал х Podʼів, не розпочне розгортання додаткових Podʼів, якщо activeDeadlineSeconds вже досягнуто, навіть якщо backoffLimit не досягнуто. Приклад:
apiVersion: batch/v1 kind: Job
metadata:
name: pi-with-timeout
Стандартноimit: 5
activeDeadlineSeconds: 100
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
Зверніть увагу, що як саме специфікація Job, так і специфікація шаблону Pod у межах завдання мають поле activeDeadlineSeconds. Переконайтеся, що ви встановлюєте це поле на відповідному рівні.
Памʼятайте, що restartPolicy застосовується до Podʼа, а не до самого завдання: автоматичного перезапуску завдання не відбудеться, якщо статус завдання type: Failed. Іншими словами, механізми завершення завдання, активовані за допомогою .spec.activeDeadlineSeconds і .spec.backoffLimit, призводять до постійної невдачі завдання, що вимагає ручного втручання для вирішення.
Умови термінального завдання
Job має два можливих термінальних стани, кожен з яких має відповідну умову завдання:
- Успішне виконання: умова завдання
Complete - Невдача: умова завдання
Failed
Завдання зазнають невдачі з наступних причин:
- Кількість невдач Podʼа перевищила вказане
.spec.backoffLimitу специфікації завдання. Для деталей див. Політика відмови Podʼа. - Час виконання завдання перевищив вказане
.spec.activeDeadlineSeconds. - Індексуєме завдання, яке використовує
.spec.backoffLimitPerIndex, має невдалі індекси. Для деталей див. Ліміт затримки на індекс. - Кількість невдалих індексів у завданні перевищила вказане
spec.maxFailedIndexes. Для деталей див. Ліміт затримки на індекс. - Невдалий Pod відповідає правилу у
.spec.podFailurePolicy, яке має діюFailJob. Для деталей про те, як правила політики невдач Podʼа можуть вплинути на оцінку невдачі, див. Політика невдач Podʼа.
Завдання успішні з наступних причин:
- Кількість успішних Podʼів досягла вказаного
.spec.completions. - Виконані критерії, зазначені у
.spec.successPolicy. Для деталей див. Політика успіху.
У Kubernetes v1.31 та пізніших версіях контролер завдань затримує додавання термінальних умов, Failed або Complete, поки всі Podʼи завдання не будуть завершені.
У Kubernetes v1.30 та раніших версіях контролер завдань додавав термінальні умови Complete або Failed відразу після того, як був запущений процес завершення завдання та всі завершувачі Podʼа були видалені. Однак деякі Podʼи все ще могли працювати або завершуватися в момент додавання термінальної умови.
У Kubernetes v1.31 та пізніших версіях контролер додає термінальні умови завдання лише після завершення всіх Podʼів. Ви можете увімкнути цю поведінку, використовуючи функціональні можливості JobManagedBy та JobPodReplacementPolicy (обидві стандартно увімкнені).
Завершення Podʼів завдання
Контролер Job додає умову FailureTarget або умову SuccessCriteriaMet до завдання, щоб запустити завершення Pod після того, як завдання відповідає критеріям успіху або невдачі.
Фактори, такі як terminationGracePeriodSeconds, можуть збільшити час від моменту додавання контролером завдання умови FailureTarget або умови SuccessCriteriaMet до моменту, коли всі Pod завдання завершаться і контролер Job додасть термінальну умову (Failed або Complete).
Ви можете використовувати умову FailureTarget або умову SuccessCriteriaMet, щоб оцінити, чи завдання зазнало невдачі чи досягло успіху, без необхідності чекати, поки контролер додасть термінальну умову.
Наприклад, ви можете захотіти вирішити, коли створити замінний Job, що замінює невдалий. Якщо ви заміните невдале завдання, коли з’являється умова FailureTarget, ваше замінне завдання запуститься раніше, але це може призвести до того, що Podʼи з невдалого та замінного завдання будуть працювати одночасно, використовуючи додаткові обчислювальні ресурси.
Альтернативно, якщо ваш кластер має обмежену ресурсну ємність, ви можете вибрати чекати, поки з’явиться умова Failed на завданні, що затримає ваше замінне завдання, але забезпечить збереження ресурсів, чекаючи, поки всі невдалі Podʼи не будуть видалені.
Автоматичне очищення завершених завдань
Зазвичай завершені завданя вже не потрібні в системі. Зберігання їх в системі може створювати тиск на сервер API. Якщо завдання керується безпосередньо контролером вищого рівня, таким як CronJobs, завдання можна очищати за допомогою CronJobs на основі визначеної політики очищення з урахуванням місткості.
Механізм TTL для завершених завдань
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.23 [stable]Ще один спосіб автоматично очищати завершені завдання (якщо вони Complete або Failed) — це використовувати механізм TTL, наданий
контролером TTL для завершених ресурсів, вказуючи поле .spec.ttlSecondsAfterFinished у Job.
Коли контролер TTL очищує Job, він каскадно видаляє Job, тобто видаляє його залежні обʼєкти, такі як Podʼи, разом з Job. Зверніть увагу що при видаленні Job будуть дотримані гарантії його життєвого циклу, такі як завершувачі.
Наприклад:
apiVersion: batch/v1
kind: Job
metadata:
name: pi-with-ttl
spec:
ttlSecondsAfterFinished: 100
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
Job pi-with-ttl буде призначено для автоматичного видалення через 100 секунд після завершення.
Якщо поле встановлено в 0, Job буде призначено для автоматичного видалення негайно після завершення. Якщо поле не вказане, це Job не буде очищено контролером TTL після завершення.
Примітка:
Рекомендується встановлювати поле ttlSecondsAfterFinished, оскільки завдання без нагляду (завдання, які ви створили безпосередньо, а не опосередковано через інші API робочого навантаження такі як CronJob) мають станадартну політику видалення orphanDependents, що призводить до того, що Podʼи, створені некерованим Job, залишаються після того, як Job повністю видалено. Навіть якщо панель управління в кінцевому рахунку збирає сміття Podʼів з видаленого Job після того, як вони або не вдались, або завершились, іноді ці залишки Podʼів можуть призводити до погіршання продуктивності кластера або в найгіршому випадку можуть спричинити відключення кластера через це погіршення.
Ви можете використовувати LimitRanges та ResourceQuotas щоб обмежити кількість ресурсів, які певний простір імен може споживати.
Патерни використання завдань (Job)
Обʼєкт завдання (Job) може використовуватися для обробки набору незалежних, але повʼязаних робочих одиниць. Це можуть бути електронні листи для надсилання, кадри для відтворення, файли для транскодування, діапазони ключів у базі даних NoSQL для сканування і так далі.
У складній системі може бути кілька різних наборів робочих одиниць. Тут ми розглядаємо лише один набір робочих одиниць, якими користувач хоче управляти разом — пакетне завдання.
Існує кілька різних патернів для паралельних обчислень, кожен з власними перевагами та недоліками. Компроміси:
- Один обʼєкт Job для кожної робочої одиниці або один обʼєкт Job для всіх робочих одиниць. Один Job на кожну робочу одиницю створює деяку накладну роботу для користувача та системи при управлінні великою кількістю обʼєктів Job. Один Job для всіх робочих одиниць підходить краще для великої кількості одиниць.
- Кількість створених Podʼів дорівнює кількості робочих одиниць або кожен Pod може обробляти кілька робочих одиниць. Коли кількість Podʼів дорівнює кількості робочих одиниць, Podʼи зазвичай вимагають менше змін у наявному коді та контейнерах. Кожен Pod, що обробляє кілька робочих одиниць, підходить краще для великої кількості одиниць.
- Декілька підходів використовують робочу чергу. Це вимагає запуску служби черги та модифікацій існуючої програми чи контейнера, щоб зробити його сумісним із чергою роботи. Інші підходи легше адаптувати до наявного контейнеризованого застосунку.
- Коли Job повʼязаний із headless Service, ви можете дозволити Podʼам у межах Job спілкуватися один з одним для спільної обчислень.
Переваги та недоліки узагальнено у таблиці нижче, де стовпці з 2 по 4 відповідають зазначеним вище питанням. Імена патернів також є посиланнями на приклади та більш детальний опис.
| Патерн | Один обʼєкт Job | Кількість Pods менше за робочі одиниці? | Використовувати застосунок без модифікацій? |
|---|---|---|---|
| Черга з Pod на робочу одиницю | ✓ | іноді | |
| Черга змінної кількості Pod | ✓ | ✓ | |
| Індексоване Завдання із статичним призначенням роботи | ✓ | ✓ | |
| Завдання із спілкуванням від Pod до Pod | ✓ | іноді | іноді |
| Розширення шаблону Job | ✓ |
Коли ви вказуєте завершення з .spec.completions, кожний Pod, створений контролером Job, має ідентичний spec. Це означає, що всі Podʼи для завдання матимуть однакову командну строку та один і той же шаблон, та (майже) ті ж самі змінні середовища. Ці патерни — це різні способи організації Podʼів для роботи над різними завданнями.
Ця таблиця показує обовʼязкові налаштування для .spec.parallelism та .spec.completions для кожного з патернів. Тут W — це кількість робочих одиниць.
| Патерн | .spec.completions | .spec.parallelism |
|---|---|---|
| Черга з Pod на робочу одиницю | W | будь-яка |
| Черга змінної кількості Pod | null | будь-яка |
| Індексоване Завдання із статичним призначенням роботи | W | будь-яка |
| Завдання із спілкуванням від Pod до Pod | W | W |
| Розширення шаблону Job | 1 | повинно бути 1 |
Розширене використання завдань (Job)
Відкладення завдання
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]Коли створюється Job, контролер Job негайно починає створювати Podʼи, щоб відповісти вимогам Job і продовжує це робити, доки Job не завершиться. Однак іноді ви можете хотіти тимчасово призупинити виконання Job та відновити його пізніше, або створити Jobs у призупиненому стані та мати власний контролер, який вирішить, коли їх запустити.
Щоб призупинити Job, ви можете оновити поле .spec.suspend Job на значення true; пізніше, коли ви захочете відновити його, оновіть його на значення false. Створення Job з .spec.suspend встановленим в true створить його в призупиненому стані.
При відновленні Job з призупинення йому буде встановлено час початку .status.startTime в поточний час. Це означає, що таймер .spec.activeDeadlineSeconds буде зупинений і перезапущений, коли Job буде призупинено та відновлено.
Коли ви призупиняєте Job, будь-які запущені Podʼи, які не мають статусу Completed, будуть завершені з сигналом SIGTERM. Буде дотримано період відповідного завершення ваших Podʼів, і вашим Podʼам слід обробити цей сигнал протягом цього періоду. Це може включати в себе збереження прогресу для майбутнього або скасування змін. Podʼи, завершені цим чином, не враховуватимуться при підрахунку completions Job.
Приклад визначення Job в призупиненому стані може виглядати так:
kubectl get job myjob -o yaml
apiVersion: batch/v1
kind: Job
metadata:
name: myjob
spec:
suspend: true
parallelism: 1
completions: 5
template:
spec:
...
Ви також можете перемикати призупинення Job, використовуючи командний рядок.
Призупиніть активний Job:
kubectl patch job/myjob --type=strategic --patch '{"spec":{"suspend":true}}'
Відновіть призупинений Job:
kubectl patch job/myjob --type=strategic --patch '{"spec":{"suspend":false}}'
Статус Job може бути використаний для визначення того, чи Job призупинено чи його було зупинено раніше:
kubectl get jobs/myjob -o yaml
apiVersion: batch/v1
kind: Job
# .metadata and .spec пропущено
status:
conditions:
- lastProbeTime: "2021-02-05T13:14:33Z"
lastTransitionTime: "2021-02-05T13:14:33Z"
status: "True"
type: Suspended
startTime: "2021-02-05T13:13:48Z"
Умова Job типу "Suspended" зі статусом "True" означає, що Job призупинено; поле lastTransitionTime може бути використане для визначення того, як довго Job було призупинено. Якщо статус цієї умови є "False", то Job було раніше призупинено і зараз працює. Якщо такої умови не існує в статусі Job, то Job ніколи не був зупинений.
Також створюються події, коли Job призупинено та відновлено:
kubectl describe jobs/myjob
Name: myjob
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 12m job-controller Created pod: myjob-hlrpl
Normal SuccessfulDelete 11m job-controller Deleted pod: myjob-hlrpl
Normal Suspended 11m job-controller Job suspended
Normal SuccessfulCreate 3s job-controller Created pod: myjob-jvb44
Normal Resumed 3s job-controller Job resumed
Останні чотири події, зокрема події "Suspended" та "Resumed", є прямим наслідком перемикання поля .spec.suspend. Протягом цього часу ми бачимо, що жоден Pods не був створений, але створення Pod розпочалося знову, як тільки Job було відновлено.
Змінні директиви планування
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.27 [stable]У більшості випадків, паралелльні завдання вимагатимуть щоб їхні Podʼи запускались з певними обмеженнями, типу "всі в одній зоні" або "всі на GPU моделі x або y", але не комбінація обох.
Поле призупинення є першим кроком для досягнення цих семантик. Призупинення дозволяє власному контролеру черги вирішити, коли повинне початися завдання; Однак після того, як завдання престає бути призупиненим, власний контролер черги не впливає на те, де насправді буде розташований Pod завдання.
Ця функція дозволяє оновлювати директиви планування Job до запуску, що дає власному контролеру черги змогу впливати на розташування Podʼів, а в той самий час здійснювати власне призначення Podʼів вузлам в kube-scheduler. Це дозволяється тільки для призупинених Завдань, які ніколи не переставали бути призупиненими раніше.
Поля в шаблоні Podʼа Job, які можна оновити, це приналежність до вузла, селектор вузла, толерантності, мітки, анотації та вікно планування.
Вказування власного селектора Podʼа
Зазвичай, коли ви створюєте обʼєкт Job, ви не вказуєте .spec.selector. Логіка системного визначення типових значень додає це поле під час створення Завдання. Вона обирає значення селектора, яке не буде перекриватися з будь-яким іншим завданням.
Однак у деяких випадках вам може знадобитися перевизначити цей автоматично встановлений селектор. Для цього ви можете вказати .spec.selector Job.
Будьте дуже уважні при цьому. Якщо ви вказуєте селектор міток, який не є унікальним для Podʼів цього Завдання, і який відповідає неповʼязаним Podʼам, то Podʼи з неповʼязаним Завданням можуть бути видалені, або це Завдання може вважати інші Podʼи завершеними, або одне чи обидва Завдання можуть відмовитися від створення Podʼів або виконуватись до завершення роботи. Якщо вибираєте неунікальний селектор, то інші контролери (наприклад, ReplicationController) та їхні Podʼи можуть проявляти непередбачувану поведінку також. Kubernetes не зупинить вас від того, що ви можете зробити помилку при зазначені .spec.selector.
Ось приклад ситуації, коли вам може знадобитися використовувати цю функцію.
Скажімо, Завдання old вже запущене. Ви хочете, щоб наявні Podʼи продовжували працювати, але ви хочете, щоб решта Podʼів, які воно створює, використовували інший шаблон Pod і щоб у Завдання було нове імʼя. Ви не можете оновити Завдання, оскільки ці поля не можна оновлювати. Отже, ви видаляєте Завдання old, але залишаєте її Podʼи запущеними, використовуючи kubectl delete jobs/old --cascade=orphan. Перед видаленням ви робите помітку, який селектор використовувати:
kubectl get job old -o yaml
Виввід схожий на цей:
kind: Job
metadata:
name: old
...
spec:
selector:
matchLabels:
batch.kubernetes.io/controller-uid: a8f3d00d-c6d2-11e5-9f87-42010af00002
...
Потім ви створюєте нове Завдання з імʼям new і явно вказуєте той самий селектор. Оскільки існуючі Podʼи мають мітку batch.kubernetes.io/controller-uid=a8f3d00d-c6d2-11e5-9f87-42010af00002, вони також контролюються Завданням new.
Вам потрібно вказати manualSelector: true в новому Завданні, оскільки ви не використовуєте селектор, який система зазвичай генерує автоматично.
kind: Job
metadata:
name: new
...
spec:
manualSelector: true
selector:
matchLabels:
batch.kubernetes.io/controller-uid: a8f3d00d-c6d2-11e5-9f87-42010af00002
...
Саме нове Завдання матиме інший uid від a8f3d00d-c6d2-11e5-9f87-42010af00002. Встановлення manualSelector: true говорить системі, що ви розумієте, що робите, і дозволяє це неспівпадіння.
Відстеження Завдання за допомогою завершувачів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.26 [stable]Панель управління стежить за Podʼами, які належать будь-якого Завдання, і виявляє, чи Pod був видалений з сервера API. Для цього контролер Job створює Podʼи з завершувачем batch.kubernetes.io/job-tracking. Контролер видаляє завершувач тільки після того, як Pod був врахований в стані Завдання, що дозволяє видалити Pod іншими контролерами або користувачами.
Примітка:
Див. Мій Pod залишається в стані завершення, якщо ви спостерігаєте, що Podʼи з Завдання залишаються з завершувачем відстеження.Еластичні Індексовані Завдання
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [stable] (стандартно увімкнено: true)Ви можете масштабувати Indexed Job вгору або вниз, змінюючи як .spec.parallelism, так і .spec.completions разом, так щоб .spec.parallelism == .spec.completions. При масштабуванні вниз Kubernetes видаляє Podʼи з вищими індексами.
Сценарії використання для еластичних Індексованих Завдань включають пакетні робочі навантаження, які вимагають масштабування Індексованого Завдання, такі як MPI, Horovod, Ray, та PyTorch.
Відкладене створення замінних Podʼів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.29 [beta]Примітка:
Ви можете встановитиpodReplacementPolicy для Завдань тільки у випадку, якщо увімкнуто функціональну можливість JobPodReplacementPolicy (стандартно увімкнено).Типово контролер Job створює Podʼи якнайшвидше, якщо вони або зазнають невдачі, або знаходяться в стані завершення (мають відмітку видалення). Це означає, що в певний момент часу, коли деякі з Podʼів знаходяться в стані завершення, кількість робочих Podʼів для Завдання може бути більшою, ніж parallelism або більше, ніж один Pod на індекс (якщо ви використовуєте Індексоване Завданя).
Ви можете вибрати створення замінних Podʼів лише тоді, коли Podʼи, які знаходиться в стані завершення, повністю завершені (мають status.phase: Failed). Для цього встановіть .spec.podReplacementPolicy: Failed. Типова політика заміщення залежить від того, чи Завдання має встановлену політику відмови Podʼів. Якщо для Завдання не визначено політику відмови Podʼів, відсутність поля podReplacementPolicy вибирає політику заміщення TerminatingOrFailed: панель управління створює Podʼи заміни негайно після видалення Podʼів (як тільки панель управління бачить, що Pod для цього Завдання має встановлене значення deletionTimestamp). Для Завдань із встановленою політикою відмови Podʼів стандартне значення podReplacementPolicy — це Failed, інших значень не передбачено. Докладніше про політики відмови Podʼів для Завдань можна дізнатися у розділі Політика відмови Podʼів.
kind: Job
metadata:
name: new
...
spec:
podReplacementPolicy: Failed
...
При увімкненому feature gate у вашому кластері ви можете перевірити поле .status.terminating Завдання. Значення цього поля — це кількість Podʼів, якими володіє Завдання, які зараз перебувають у стані завершення.
kubectl get jobs/myjob -o yaml
apiVersion: batch/v1
kind: Job
# .metadata and .spec omitted
status:
terminating: 3 # три Podʼи, які перебувають у стані завершення і ще не досягли стану Failed
Делегування управління обʼєктом Job зовнішньому контролеру
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [beta] (стандартно увімкнено: true)Примітка:
Ви можете встановити полеmanagedBy для Job лише в разі увімкнення функціональної можливості JobManagedBy (типово увімкнено).Ця функція дозволяє вам вимкнути вбудований контролер Job для конкретного Завдання і делегувати узгодження цього Завдання зовнішньому контролеру.
Ви вказуєте контролер, який узгоджує Завдання, встановлюючи власне значення для поля spec.managedBy — будь-яке значення окрім kubernetes.io/job-controller. Значення поля є незмінним.
Примітка:
При використанні цієї функції переконайтеся, що контролер, вказаний у полі, встановлено, інакше Завдання може не бути узгоджене взагалі.Примітка:
При розробці зовнішнього контролера Job, будьте уважні: ваш контролер повинен працювати відповідно до визначень специфікації API та полів статусу обʼєкта Job.
Докладно ознайомтесь з ними в API Job. Ми також рекомендуємо запустити тести сумісності e2e для обʼєкта Job, щоб перевірити вашу реалізацію.
Нарешті, при розробці зовнішнього контролера Job переконайтеся, що він не використовує завершувач batch.kubernetes.io/job-tracking, зарезервований для вбудованого контролера.
Попередження:
Якщо ви думаєте про вимкенняJobManagedBy, або зниження версії кластера до версії без увімкненого feature gate, перевірте, чи є у вас завдання з власним значенням поля spec.managedBy. Якщо такі завдання існують, існує ризик
того, що після виконання операції вони можуть бути узгоджені двома контролерами: вбудованим контролером Job і зовнішнім контролером, вказаним значенням поля.Альтернативи
Тільки Podʼи
Коли вузол, на якому працює Pod, перезавантажується або виходить з ладу, Pod завершується і не буде перезапущений. Однак Завдання створить нові Podʼи для заміщення завершених. З цієї причини ми рекомендуємо використовувати Завдання замість тільки Podʼів, навіть якщо ваш застосунок вимагає тільки одного Podʼа.
Контролер реплікації
Завдання є компліментарними до контролера реплікації. Контролер реплікації керує Podʼами, які не повинні завершуватися (наприклад, вебсервери), а Завдання керує Podʼами, які очікують завершення (наприклад, пакетні задачі).
Якщо врахувати життєвий цикл Podʼа, Job лише придатний для Podʼів з RestartPolicy, рівним OnFailure або Never. (Примітка: Якщо RestartPolicy не встановлено, стандартне значення — Always.)
Один Job запускає контролер Podʼів
Ще один підхід — це те, що одне Завдання створює Podʼи, які своєю чергою створюють інші Podʼи, виступаючи як свого роду власний контролер для цих Podʼів. Це дає найбільшу гнучкість, але може бути дещо складним для початку використання та пропонує меншу інтеграцію з Kubernetes.
Один приклад такого підходу — це Завдання, яке створює Podʼи, яка виконує сценарій, який з свого боку запускає контролер Spark master (див. приклад Spark), запускає драйвер Spark, а потім робить очищення.
Перевагою цього підходу є те, що загальний процес отримує гарантію завершення обʼєкта Job, але при цьому повністю контролюється те, які Podʼи створюються і яке навантаження їм призначається.
Що далі
- Дізнайтеся про Podʼи.
- Дізнайтеся про різні способи запуску Завдань:
- Груба паралельна обробка за допомогою робочої черги
- Тонка паралельна обробка за допомогою робочої черги
- Використовуйте Індексовані Завдання для паралельної обробки із статичним призначенням навантаження
- Створіть кілька Завдань на основі шаблону: Паралельна обробка з використанням розширень
- Перейдіть за посиланням Автоматичне очищення завершених завдань, щоб дізнатися більше про те, як ваш кластер може очищати завершені та/або невдачливі завдання.
Jobє частиною REST API Kubernetes. Ознайомтесь з визначенням обʼєкта Job, щоб зрозуміти API для завдань.- Прочитайте про
CronJob, який ви можете використовувати для визначення серії Завдань, які будуть виконуватися за розкладом, схожим на інструмент UNIXcron. - Попрактикуйтесь в налаштувані обробки відмовних і невідмовних збоїв Podʼів за допомогою
podFailurePolicyна основі покрокових прикладів.
4.2.6 - Автоматичне очищення завершених задач
Механізм визначення часу життя для автоматичного очищення старих задач, які завершили виконання.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.23 [stable]Коли ваша задача завершилася, корисно залишити цю задачу в API (і не видаляти її відразу), щоб ви могли визначити, чи вдалося, чи не вдалося завдання.
Контролер Kubernetes часу життя після завершення забезпечує механізм TTL (time to live), щоб обмежити термін життя обʼєктів задачі, які завершили виконання.
Очищення завершених задач
Контролер часу життя після завершення підтримується лише для задач. Ви можете використовувати цей механізм для автоматичного очищення завершених завдань (як Complete, так і Failed), автоматично вказавши поле .spec.ttlSecondsAfterFinished задачі, як у цьому прикладі.
Контролер часу життя після завершення передбачає, що задачу можна очистити через TTL секунд після завершення роботи. Відлік починається, коли умова статусу задачі змінюється, щоб показати, що задача є або Complete, або Failed; як тільки TTL закінчився, ця задача стає придатною для каскадного видалення. Коли контролер часу життя після завершення очищає задачу, він видалить її каскадно, іншими словами, він видалить її залежні обʼєкти разом з нею.
Kubernetes дотримується гарантій життєвого циклу обʼєкта для задачі, таких як очікування завершувачів.
Ви можете встановити TTL секунд у будь-який момент. Ось деякі приклади встановлення поля .spec.ttlSecondsAfterFinished задачі:
- Вказуйте це поле в маніфесті задачі, щоб задачу можна було автоматично очистити через певний час після її завершення.
- Вручну встановлюйте це поле вже наявним завершеним завданням, щоб вони стали придатними для очищення.
- Використовуйте змінний вебхук доступу для динамічного встановлення цього поля під час створення задачі. Адміністратори кластера можуть використовувати це, щоб накладати політику TTL для завершених задач.
- Використовуйте змінний вебхук доступу для динамічного встановлення цього поля після завершення задачі та вибору різних значень TTL на основі статусу завдання, міток. У цьому випадку вебзапит повинен виявляти зміни в полі
.statusзадачі та встановлювати TTL лише тоді, коли задача позначається як завершена. - Напишіть свій власний контролер для управління часом життя TTL для задач, які відповідають певному селектору.
Обмеження
Оновлення TTL для завершених задач
Ви можете змінювати період TTL, наприклад, поле .spec.ttlSecondsAfterFinished для задач, після створення або завершення задачі. Якщо ви збільшуєте період TTL після закінчення поточного періоду ttlSecondsAfterFinished, Kubernetes не гарантує збереження цієї задачі, навіть якщо оновлення для збільшення TTL повертає успішну API відповідь.
Зсув часу
Оскільки контролер часу життя після завершення використовує відмітки часу, збережені в задачах Kubernetes, для визначення того, чи TTL минув, чи ні, ця функція чутлива до зсуву часу в кластері, що може призвести до очищення обʼєктів задачі в неправильний час.
Годинники не завжди вірні, але різниця повинна бути дуже мала. Будь ласка, будьте уважні при встановленні ненульового TTL.
Що далі
Прочитайте Автоматичне очищення задач
Зверніться до Пропозиції з покращення Kubernetes (KEP) для додавання цього механізму.
4.2.7 - CronJob
Обʼєкт CronJob запускає Job за повторюваним графіком.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.21 [stable]CronJob створює Jobs за повторюваним графіком.
CronJob призначений для виконання регулярних запланованих дій, таких як резервне копіювання, генерація звітів та інше. Один обʼєкт CronJob подібний до одного рядка файлу crontab (таблиця cron) на системі Unix. Він запускає Job періодично за заданим графіком, записаним у форматі Cron.
У CronJob є обмеження та особливості. Наприклад, в певних обставинах один CronJob може створювати кілька одночасних Jobs. Див. обмеження нижче.
Коли планувальник створює нові Jobs і (відповідно) Podʼи для CronJob, .metadata.name CronJob є частиною основи для імені цих Podʼів. Назва CronJob повинна бути дійсним значенням DNS-піддомену, але це може призводити до неочікуваних результатів для імен хостів Podʼів. Для найкращої сумісності назва повинна відповідати більш обмеженим правилам DNS-мітки. Навіть коли імʼя є DNS-піддоменом, імʼя не повинно бути довше 52 символів. Це тому, що контролер CronJob автоматично додає 11 символів до наданого вами імені, і існує обмеження на довжину імені Job, яке не повинно перевищувати 63 символи.
Приклад
У цьому прикладі маніфест CronJob виводить поточний час та вітання кожну хвилину:
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
(Виконання автоматизованих завдань за допомогою CronJob докладніше описує цей приклад).
Написання специфікації CronJob
Синтаксис розкладу
Поле .spec.schedule є обовʼязковим. Значення цього поля відповідає синтаксису Cron:
# ┌───────────── хвилина (0 - 59)
# │ ┌───────────── година (0 - 23)
# │ │ ┌───────────── день місяця (1 - 31)
# │ │ │ ┌───────────── місяць (1 - 12)
# │ │ │ │ ┌───────────── день тижня (0 - 6) (Неділя - Субота)
# │ │ │ │ │ АБО неділя, понеділок, вівторок, середа, четвер, пʼятниця, субота
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
Наприклад, 0 3 * * 1 означає, що це завдання планується запускати щотижня в понеділок о 3 ранку.
Формат також включає розширені значення кроків "Vixie cron". Як пояснено в документації FreeBSD:
Значення кроків можна використовувати разом із діапазонами. Після діапазону з
/ <number>вказує пропуски значення числа через діапазон. Наприклад,0-23/2можна використовувати в годинах для вказівки виконання команди кожну другу годину (альтернативою в стандарті V7 є0,2,4,6,8,10,12,14,16,18,20,22). Після зірочки також допускаються кроки, тому, якщо ви хочете сказати "кожні дві години", просто використовуйте*/2.
Примітка:
Знак питання (?) у розкладі має той же зміст, що й зірочка *, тобто позначає будь-яке доступне значення для даного поля.Окрім стандартного синтаксису, також можна використовувати деякі макроси, такі як @monthly:
| Запис | Опис | Еквівалентно |
|---|---|---|
| @yearly (або @annually) | Виконувати один раз на рік о півночі 1 січня | 0 0 1 1 * |
| @monthly | Виконувати один раз на місяць о півночі першого дня місяця | 0 0 1 * * |
| @weekly | Виконувати один раз на тиждень о півночі в неділю | 0 0 * * 0 |
| @daily (або @midnight) | Виконувати один раз на день о півночі | 0 0 * * * |
| @hourly | Виконувати один раз на годину на початку години | 0 * * * * |
Для генерації виразів розкладу CronJob можна також використовувати вебінструменти, наприклад crontab.guru.
Шаблон завдання
Поле .spec.jobTemplate визначає шаблон для завдань, які створює CronJob, і воно обовʼязкове. Воно має точно таку ж схему, як Job, за винятком того, що воно вкладене і не має apiVersion або kind. Ви можете вказати загальні метадані для завдань, створених за шаблоном, такі як labels або annotations. Щодо інформації щодо написання .spec завдання, дивіться Написання специфікації завдання.
Термін відстрочення для відкладеного запуску завдання
Поле .spec.startingDeadlineSeconds є необовʼязковим. Це поле визначає термін (в повних секундах) для запуску завдання, якщо це завдання пропускає свій запланований час з будь-якої причини.
Після пропуску терміну CronJob пропускає цей екземпляр завдання (майбутні випадки все ще заплановані). Наприклад, якщо у вас є завдання резервного копіювання, яке запускається двічі на день, ви можете дозволити йому запускатися з запізненням до 8 годин, але не пізніше, оскільки резервна копія, виконана пізніше, буде неактуальною: ви замість цього віддавали б перевагу чекати на наступний запланований запуск.
Для завдань, які пропускають свій термін, налаштований час відстрочення, Kubernetes вважає їх завданнями, що не вдалися. Якщо ви не вказали startingDeadlineSeconds для CronJob, екземпляри завдань не мають терміну.
Якщо поле .spec.startingDeadlineSeconds встановлено (не є нульовим), контролер CronJob вимірює час між тим, коли очікується створення завдання, і зараз. Якщо різниця вище за цей ліміт, він пропускає це виконання.
Наприклад, якщо воно встановлене на 200, це дозволяє створити завдання протягом 200 секунд після фактичного часу.
Політика паралелізму
Також необовʼязкове поле .spec.concurrencyPolicy. Воно визначає, як обробляти паралельні виконання завдання, яке створюється цим CronJob. Специфікація може вказувати лише одну з наступних політик паралельності:
Allow(станадартно): CronJob дозволяє паралельні запуски завданьForbid: CronJob не дозволяє паралельні запуски; якщо настав час для нового запуску завдання і попередній запуск завдання ще не завершився, CronJob пропускає новий запуск завдання. Також слід зауважити, що коли попередній запуск завдання завершиться, враховується.spec.startingDeadlineSecondsі може призвести до нового запуску завдання.Replace: Якщо час для нового запуску завдання і попередній запуск завдання ще не завершився, CronJob замінює поточний запуск завдання новим запуском завдання.
Зверніть увагу, що політика паралелізму застосовується лише до завдань, створених цим самим CronJob. Якщо є кілька CronJob, їхні відповідні завдання завжди можуть виконуватися паралельно.
Призупинення розкладу
Ви можете призупинити виконання завдань для CronJob, встановивши необовʼязкове поле .spec.suspend в значення true. Стандартно поле має значення false.
Це налаштування не впливає на завдання, які CronJob вже розпочав.
Якщо ви встановите це поле в значення true, всі наступні виконання будуть призупинені (вони залишаються запланованими, але контролер CronJob не запускає завдання для виконання завдань), поки ви не призупините CronJob.
Увага:
Виконання, які призупинені під час запланованого часу, вважаються пропущеними завданнями. Коли.spec.suspend змінюється з true на false для наявного CronJob без строку початку, пропущені завдання заплановані негайно.Обмеження історії завдань
Поля .spec.successfulJobsHistoryLimit та .spec.failedJobsHistoryLimit вказують, скільки завершених успішних та невдалих завдань потрібно зберігати. Обидва поля є необовʼязковими.
.spec.successfulJobsHistoryLimit: Це поле вказує кількість успішно завершених завдань, які слід зберігати. Стандартне значення —3. Встановлення цього поля на0не буде зберігати жодних успішних завдань..spec.failedJobsHistoryLimit: Це поле вказує кількість невдало завершених завдань, які слід зберігати. Стандартне значення —1. Встановлення цього поля на0не буде зберігати жодних невдало завершених завдань.
Для іншого способу автоматичного прибирання завершених Завдань, дивіться Автоматичне прибирання завершених завдань.
Часові пояси
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.27 [stable]Для CronJob без вказаного часового поясу kube-controller-manager інтерпретує розклад відносно свого локального часового поясу.
Ви можете вказати часовий пояс для CronJob, встановивши .spec.timeZone на назву дійсного часового поясу. Наприклад, встановлення .spec.timeZone: "Etc/UTC" вказує Kubernetes інтерпретувати графік відносно Координованого універсального часу.
В базових бінарниках включена база даних часових поясів зі стандартної бібліотеки Go і використовується як запасний варіант у разі, якщо зовнішня база даних недоступна на системі.
Обмеження CronJob
Непідтримувані специфікації часових поясів
Зазначення часового поясу за допомогою змінних CRON_TZ або TZ всередині .spec.schedule офіційно не підтримується (і ніколи не підтримувалася).
Починаючи з Kubernetes 1.29, якщо ви намагаєтеся встановити розклад, який включає вказівку часового поясу TZ або CRON_TZ, Kubernetes не зможе створити ресурс і сповістить про помилку. Оновлення CronJobs, які вже використовують TZ або CRON_TZ, продовжать повідомляти клієнта про попередження.
Зміна параметрів CronJob
За концепцією, у CronJob є шаблоном для нових Jobs. Якщо ви модифікуєте наявний CronJob, зміни застосовуватимуться до нових Job, які почнуть виконуватися після завершення вашої модифікації. Job (і їх Podʼи), які вже почали виконуватися, продовжують працювати без змін. Іншими словами, CronJob не оновлює поточні Job, навіть якщо вони ще продовжують виконуватися.
Створення Job
CronJob створює обʼєкт Job приблизно один раз за час виконання свого розкладу. Запуск є приблизним через те, що є обставини, коли може бути створено два Job або жодного. Kubernetes намагається уникати таких ситуацій, але не повністю запобігає їм. Таким чином, Job, які ви визначаєте, повинні бути ідемпотентними.
Починаючи з Kubernetes v1.32, CronJobs застосовує анотацію batch.kubernetes.io/cronjob-scheduled-timestamp до створених завдань. Ця анотація вказує початковий запланований час створення завдання і має формат RFC3339.
Якщо startingDeadlineSeconds встановлено на велике значення або залишено не встановленим (типово), і якщо concurrencyPolicy встановлено на Allow, Jobs завжди будуть запускатися принаймні один раз.
Увага:
ЯкщоstartingDeadlineSeconds встановлено у значення менше ніж 10 секунд, CronJob може не бути заплановано. Це повʼязано з тим, що контролер CronJob перевіряє стан справ кожні 10 секунд.Для кожного CronJob контролер CronJob Контролер перевіряє, скільки розкладів він пропустив протягом часу від його останнього запланованого часу до теперішнього часу. Якщо пропущено понад 100 розкладів, то Job не запускається, і виводиться помилка в лог.
Cannot determine if job needs to be started. Too many missed start time (> 100). Set or decrease .spec.startingDeadlineSeconds or check clock skew.
Важливо відзначити, що якщо поле startingDeadlineSeconds встановлено (не є nil), контролер враховує, скільки пропущених Job сталося від значення startingDeadlineSeconds до теперішнього часу, а не від останнього запланованого часу до теперішнього часу. Наприклад, якщо startingDeadlineSeconds дорівнює 200, контролер враховує, скільки Job було пропущено за останні 200 секунд.
CronJob вважається пропущеним, якщо не вдалося створити Job в запланований час. Наприклад, якщо concurrencyPolicy встановлено на Forbid і CronJob було спробовано запланувати, коли попередній Job все ще працював, то це буде враховуватися як пропущено.
Наприклад, припустимо, що CronJob встановлено для запуску нового Job кожну хвилину, починаючи з 08:30:00, і його поле startingDeadlineSeconds не встановлено. Якщо контролер CronJob випадково був вимкнений з 08:29:00 по 10:21:00, Job не буде запущено, оскільки кількість пропущених Jobs, які пропустили свій розклад, понад 100.
Для того, щоб краще проілюструвати цей концепт, припустимо, що CronJob встановлено для запуску нового Job кожну хвилину, починаючи з 08:30:00, і його поле startingDeadlineSeconds встановлено на 200 секунд. Якщо контролер CronJob випадково був вимкнений протягом того ж періоду, що й у попередньому прикладі (08:29:00 до 10:21:00) Job все одно запуститься о 10:22:00. Це трапляється тому, що тепер контролер перевіряє, скільки пропущених розкладів сталося за останні 200 секунд (тобто 3 пропущені розклади), а не від останнього запланованого часу до теперішнього часу.
CronJob відповідає лише за створення Job, які відповідають його розкладу, а Job, зs свого боку, відповідає за управління Podʼами, які він представляє.
Що далі
- Дізнайтесь про Podʼи та Job, два поняття, які використовуються в CronJobs.
- Дізнайтеся більше про формат поля
.spec.scheduleв CronJob. - Щодо інструкцій зі створення та роботи з CronJobs, а також для прикладу маніфесту CronJob, дивіться Виконання автоматизованих завдань за допомогою CronJobs.
CronJobє частиною Kubernetes REST API. Читайте CronJob API посилання для отримання докладних деталей.
4.2.8 - ReplicationController
Застаріле API для управління навантаженням, яке може горизонтально масштабуватися. Замінено API Deployment та ReplicaSet.
Примітка:
Deployment, який налаштовує ReplicaSet, тепер є рекомендованим способом налаштування реплікації.ReplicationController гарантує, що завжди запущено зазначену кількість реплік Podʼів. Іншими словами, ReplicationController переконується, що Pod або однорідний набір Podʼів завжди працює та доступний.
Як працює ReplicationController
Якщо є занадто багато Podʼів, ReplicationController завершує зайві Podʼи. Якщо Podʼів замало, ReplicationController запускає додаткові. На відміну від вручну створених Podʼів, Podʼи, якими керує ReplicationController, автоматично замінюються, якщо вони відмовляють, видаляються або завершуються. Наприклад, ваші Podʼи перестворюються на вузлі після руйнівного обслуговування, такого як оновлення ядра. З цієї причини ви повинні використовувати ReplicationController навіть якщо ваша програма вимагає лише одного Podʼа. ReplicationController схожий на менеджер процесів, але замість того, щоб наглядати за окремими процесами на одному вузлі, ReplicationController наглядає за кількома Podʼами на різних вузлах.
ReplicationController часто скорочується до "rc" в обговореннях та як скорочення в командах kubectl.
Простим випадком є створення одного обʼєкта ReplicationController для надійного запуску одного екземпляра Pod нескінченно. Складніший випадок — це запуск кількох ідентичних реплік реплікованої служби, такої як вебсервери.
Запуск прикладу ReplicationController
Цей приклад конфігурації ReplicationController запускає три копії вебсервера nginx.
kubectl apply -f https://k8s.io/examples/controllers/replication.yaml
Вивід подібний до такого:
replicationcontroller/nginx created
Перевірте стан ReplicationController за допомогою цієї команди:
kubectl describe replicationcontrollers/nginx
Вивід подібний до такого:
Name: nginx
Namespace: default
Selector: app=nginx
Labels: app=nginx
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 0 Running / 3 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- ---- ------ -------
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-qrm3m
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-3ntk0
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-4ok8v
Тут створено три Podʼи, але жоден ще не працює, можливо, через те, що виконується витягування образу. Трохи пізніше та ж команда може показати:
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Щоб перелічити всі Podʼи, які належать ReplicationController у формі, придатній для машинного читання, можна використовувати команду на зразок:
pods=$(kubectl get pods --selector=app=nginx --output=jsonpath={.items..metadata.name})
echo $pods
Вивід подібний до такого:
nginx-3ntk0 nginx-4ok8v nginx-qrm3m
Тут селектор такий самий, як і селектор для ReplicationController (бачимо у виводі kubectl describe), і в іншій формі у replication.yaml. Опція --output=jsonpath вказує вираз з іменем кожного Podʼа в отриманому списку.
Створення маніфесту ReplicationController
Як і з усіма іншими конфігураціями Kubernetes, для ReplicationController потрібні поля apiVersion, kind і metadata.
Коли панель управління створює нові Podʼи для ReplicationController, .metadata.name ReplicationController є частиною основи для найменування цих Podʼів. Назва ReplicationController повинна бути дійсним значенням DNS-піддомену, але це може призводити до неочікуваних результатів для імен хостів Podʼів. Для забезпечення найкращої сумісності імʼя повинно відповідати більш обмеженим правилам для DNS-мітки.
Для загальної інформації про роботу з файлами конфігурації дивіться управління обʼєктами.
ReplicationController також потребує розділу .spec.
Шаблон Pod
.spec.template — єдине обовʼязкове поле в розділі .spec.
.spec.template — це шаблон pod. Він має точно таку ж схему, як і Pod, за винятком того, що він вкладений і не має apiVersion або kind.
Окрім обовʼязкових полів для Pod, шаблон pod в ReplicationController повинен вказати відповідні мітки та відповідну політику перезапуску. Щодо міток, переконайтеся, що вони не перекриваються з іншими контролерами. Див. селектор pod.
Дозволяється лише .spec.template.spec.restartPolicy, рівна Always, якщо не вказано інше, що є стандартним значенням.
Для локальних перезапусків контейнерів ReplicationControllers делегують агентові на вузлі, наприклад, Kubelet.
Мітки на ReplicationController
ReplicationController може мати власні мітки (.metadata.labels). Зазвичай ви встановлюєте їх так само, як і .spec.template.metadata.labels; якщо .metadata.labels не вказано, то вони cnfylfhnyj встановлюються як .spec.template.metadata.labels. Однак вони можуть бути різними, і .metadata.labels не впливають на поведінку ReplicationController.
Селектор Pod
Поле .spec.selector є селектором міток. ReplicationController керує всіма Podʼами з мітками, які відповідають селектору. Він не робить різниці між Podʼами, які він створив чи видалив, і Podʼами, які створив чи видалив інший процес чи особа. Це дозволяє замінити ReplicationController без впливу на робочі Podʼи.
Якщо вказано, то .spec.template.metadata.labels повинні бути рівні .spec.selector, або вони буде відхилені API. Якщо .spec.selector не вказано, він буде встановлений типово як .spec.template.metadata.labels.
Також, як правило, ви не повинні створювати жодних Podʼів, мітки яких відповідають цьому селектору, безпосередньо, з іншим ReplicationController або з іншим контролером, таким як Job. Якщо ви це зробите, то ReplicationController вважатиме, що він створив інші Podʼами. Kubernetes не забороняє вам це робити.
Якщо у вас все-таки виникає кілька контролерів з однаковими селекторами, вам доведеться керувати видаленням самостійно (див. нижче).
Декілька Реплік
Ви можете вказати, скільки Podʼів повинно працювати одночасно, встановивши .spec.replicas рівним кількості Podʼів, які ви хочете мати одночасно. Кількість, що працює в будь-який момент, може бути більшою або меншою, наприклад, якщо репліки тільки що були збільшені або зменшені, чи якщо Pod коректно зупинено, і запускається його заміна.
Якщо ви не вказали .spec.replicas, то типово встановлюється 1.
Робота з ReplicationControllers
Видалення ReplicationController та його Podʼів
Щоб видалити ReplicationController та всі його Podʼи, використовуйте команду kubectl delete. Kubectl масштабує ReplicationController до нуля і чекає, доки кожний Pod буде видалено, перед видаленням самого ReplicationController. Якщо цю команду kubectl перервати, її можна перезапустити.
При використанні REST API або бібліотеки клієнта, вам потрібно виконати кроки явно (масштабування реплік до 0, очікування видалення Podʼів, а потім видалення самого ReplicationController).
Видалення лише ReplicationController
Ви можете видалити ReplicationController, не впливаючи на його Podʼи.
При використанні kubectl вкажіть опцію --cascade=orphan команді kubectl delete.
При використанні REST API або бібліотеки клієнта ви можете видалити обʼєкт ReplicationController.
Після видалення оригіналу ви можете створити новий ReplicationController, щоб замінити його. Поки старий та новий .spec.selector однакові, то новий прийме старі Podʼи. Однак він не буде вживати жодних зусиль, щоб наявні Podʼи відповідали новому, відмінному від оригінального, шаблону Podʼа. Щоб оновити Podʼи за новою специфікацією у керований спосіб, використовуйте кероване оновлення.
Ізолювання Podʼів від ReplicationController
Podʼи можуть бути вилучені із цільового набору ReplicationController, зміною їх мітки. Цей метод може бути використаний для відокремлення Podʼів від служби для налагодження та відновлення даних. Podʼи, які були виокремлені цим способом, будуть автоматично замінені (за умови, що кількість реплік також не змінюється).
Загальні патерни використання
Перепланування
Як було зазначено вище, чи у вас є 1 Pod, який вам потрібно тримати в роботі, чи 1000, ReplicationController гарантує, що зазначена кількість Podʼів існує, навіть у випадку відмови вузла або завершення Podʼа (наприклад, через дію іншого агента управління).
Масштабування
ReplicationController дозволяє масштабувати кількість реплік вгору або вниз, як вручну, так і за допомогою агента автомасштабування, оновлюючи поле replicas.
Поступові оновлення
ReplicationController призначений для полегшення поступового оновлення служби за допомогою заміни Podʼів один за одним.
Як пояснено в #1353, рекомендований підхід — створити новий ReplicationController з 1 реплікою, масштабувати нові (+1) та старі (-1) контролери по одному, а потім видалити старий контролер після досягнення 0 реплік. Це передбачувано оновлює набір Podʼів незалежно від неочікуваних відмов.
В ідеалі, контролер поступового оновлення мав би враховувати готовність застосунків і гарантувати, що достатня кількість Podʼів завжди працює.
Два ReplicationController повинні створювати Podʼи із принаймні однією відмінною міткою, такою як теґ образу основного контейнера Podʼа, оскільки це зазвичай оновлення образу, що мотивує поступові оновлення.
Кілька треків випуску
Крім того, щоб запустити кілька випусків застосунку під час процесу поступового оновлення, часто використовують кілька треків випуску протягом тривалого періоду часу або навіть постійно, використовуючи кілька треків випуску. Треки можуть бути розрізнені за допомогою міток.
Наприклад, служба може охоплювати всі Podʼи з tier in (frontend), environment in (prod). Тепер скажімо, у вас є 10 реплікованих Podʼів, які складають цей рівень. Але ви хочете мати можливість 'канаркову' нову версію цього компонента. Ви можете налаштувати ReplicationController із replicas, встановленим на 9 для більшості реплік, з мітками tier=frontend, environment=prod, track=stable, та інший ReplicationController із replicas, встановленим на 1 для канарки, з мітками tier=frontend, environment=prod, track=canary. Тепер служба охоплює як канаркові, так і не канаркові Podʼи. Але ви можете окремо взаємодіяти з ReplicationControllers, щоб тестувати речі, відстежувати результати і т.д.
Використання ReplicationControllers з Service
Декілька ReplicationControllers можуть бути розміщені поза одним Service, так що, наприклад, частина трафіку іде до старої версії, а частина до нової.
ReplicationController ніколи не завершиться самостійно, але не очікується, що він буде таким тривалим, як Service. Service можуть складатися з Podʼів, які контролюються кількома ReplicationControllers, і передбачається, що протягом життя Service (наприклад, для виконання оновлення Podʼів, які виконують Service) буде створено і знищено багато ReplicationControllers. Як самі Service, так і їх клієнти повинні залишатися осторонь від ReplicationControllers, які утримують Podʼи Service.
Написання програм для Replication
Створені ReplicationController'ом Podʼи призначені бути взаємозамінними та семантично ідентичними, хоча їх конфігурації можуть ставати різноманітними з часом. Це очевидний вибір для реплікованих stateless серверів, але ReplicationControllers також можна використовувати для забезпечення доступності застосунків, які вибирають майстра, або мають розподілені, або пул робочих задач. Такі застосунки повинні використовувати механізми динамічного призначення роботи, такі як черги роботи RabbitMQ, на відміну від статичної / одноразової настроюваної конфігурації кожного Podʼа, що вважається анти-патерном. Будь-яке настроювання Podʼа, таке як вертикальне автоматичне масштабування ресурсів (наприклад, процесора чи памʼяті), повинно виконуватися іншим процесом контролю в режимі реального часу, подібним до самого ReplicationController.
Обовʼязки ReplicationController
ReplicationController забезпечує відповідність бажаної кількості Podʼів його селектору міток та їхню функціональність. Наразі з його підрахунку виключаються лише завершені Podʼи. У майбутньому можливо буде враховувати інформацію про готовність та інші дані, доступні від системи, можливо буде додано більше елементів керування над політикою заміщення, і планується генерація подій, які можуть використовуватися зовнішніми клієнтами для впровадження довільних складних політик заміщення та / або масштабування вниз.
ReplicationController завжди обмежується цією вузькою відповідальністю. Він самостійно не буде виконувати перевірки готовності або тестів на життєздатність. Замість автоматичного масштабування він призначений для управління зовнішнім автомасштабувальником (як обговорюється в #492), який буде змінювати його поле replicas. Ми не будемо додавати політик планування (наприклад, розподілення) до ReplicationController. Він також не повинен перевіряти, чи відповідають контрольовані Podʼи поточному зазначеному шаблону, оскільки це може заважати автоматичному зміщенню розміру та іншим автоматизованим процесам. Також термінові строки виконання, залежності від порядку, розширення конфігурації та інші функції належать іншим місцям. Навіть планується виділити механізм масового створення Podʼів (#170).
ReplicationController призначений бути базовим примітивом для побудови композиційних структур. Ми очікуємо, що на його основі та інших взаємодіючих примітивів у майбутньому буде побудовано високорівневі API та / або інструменти для зручності користувачів. "Макро" операції, які наразі підтримуються kubectl (run, scale), є прикладами концепції. Наприклад, можемо уявити щось на зразок Asgard, що управляє ReplicationControllers, автомасштабувальниками, сервісами, політиками планування, канарковими розгортаннями та іншими аспектами.
Обʼєкт API
ReplicationController є ресурсом верхнього рівня в Kubernetes REST API. Докладніша інформація про обʼєкт API може бути знайдена за посиланням: Обʼєкт API ReplicationController.
Альтернативи ReplicationController
ReplicaSet
ReplicaSet — це ReplicationController нового покоління, який підтримує нові вимоги щодо вибору міток на основі множин. Він використовується головним чином Deployment як механізм для оркестрування створення, видалення та оновлення Podʼів. Зауважте, що ми рекомендуємо використовувати Deployments замість безпосереднього використання Replica Sets, якщо вам потрібна власне оркестрування оновлення або взагалі не потрібні оновлення.
Deployment (Рекомендовано)
Deployment — це обʼєкт API вищого рівня, який оновлює свої базові Replica Sets та їхні Podʼи. Deployments рекомендуються, якщо вам потрібна функціональність плавного оновлення, оскільки вони є декларативними, виконуються на сервері та мають додаткові функції.
Тільки Podʼи
На відміну від випадку, коли користувач створює Podʼи безпосередньо, ReplicationController замінює Podʼи, які видаляються або завершуються з будь-якого приводу, такого як випадок відмови вузла або руйнівне технічне обслуговування вузла, таке як оновлення ядра. З цієї причини ми рекомендуємо використовувати ReplicationController навіть якщо ваша програма вимагає лише одного Podʼа. Вважайте це подібним наглядачу процесів, тільки він наглядає за кількома Podʼами на кількох вузлах, а не за окремими процесами на одному вузлі. ReplicationController делегує перезапуск контейнерів локальній системі, наприклад Kubelet.
Job
Використовуйте Job замість ReplicationController для Podʼів, які мають завершуватись самі по собі (іншими словами, пакетні завдання).
DaemonSet
Використовуйте DaemonSet замість ReplicationController для Podʼів, які забезпечують функцію рівня машини, таку як моніторинг машини або ведення логу машини. Ці Podʼи мають термін служби, який повʼязаний із терміном служби машини: Pod повинty працювати на машині перед тим, як інші Podʼи почнуть працювати, і може бути безпечно завершений, коли машина готова до перезавантаження або вимкнення.
Що далі
- Більше про Podʼи.
- Дізнайтеся більше про Deployment, альтернативу ReplicationController.
ReplicationController— це частина Kubernetes REST API. Ознайомтесь з визначенням обʼєкта ReplicationController, щоб зрозуміти API для контролерів реплікації.
4.3 - Автомасштабування робочих навантажень
З автомасштабуванням ви можете автоматично оновлювати ваші робочі навантаження різними способами. Це дозволяє вашому кластеру еластичніше та ефективніше реагувати на зміни витрат ресурсів.
У Kubernetes ви можете масштабувати робоче навантаження залежно від поточного попиту на ресурси. Це дозволяє вашому кластеру більш еластично та ефективно реагувати на зміни витрат ресурсів.
При масштабуванні робочого навантаження ви можете збільшувати або зменшувати кількість реплік, які керуються робочим навантаженням, або налаштовувати ресурси, доступні для реплік на місці.
Перший підхід називається горизонтальним масштабуванням, тоді як другий — вертикальним масштабуванням.
Є ручні та автоматичні способи масштабування робочих навантажень, залежно від вашого випадку використання.
Ручне масштабування робочих навантажень
Kubernetes підтримує ручне масштабування робочих навантажень. Горизонтальне масштабування можна виконати за допомогою інтерфейсу командного рядка kubectl. Для вертикального масштабування вам потрібно змінити визначення ресурсів вашого робочого навантаження.
Дивіться нижче приклади обох стратегій.
- Горизонтальне масштабування: Запуск кількох екземплярів вашого застосунку
- Вертикальне масштабування: Зміна обсягів ресурсів CPU та памʼяті, призначених для контейнерів
Автоматичне масштабування робочих навантажень
Kubernetes також підтримує автоматичне масштабування робочих навантажень, що є основною темою цієї сторінки.
Концепція Автомасштабування в Kubernetes стосується можливості автоматичного оновлення обʼєкта, який керує набором Podʼів (наприклад, Deployment).
Горизонтальне масштабування робочих навантажень
У Kubernetes ви можете автоматично масштабувати робоче навантаження горизонтально за допомогою HorizontalPodAutoscaler (HPA).
Він реалізований як ресурс Kubernetes API та controller і періодично налаштовує кількість реплік в робочому навантаженні, щоб відповідати спостереженню за використанням ресурсів, такими як використання CPU чи памʼяті.
Є посібник з інструкціями з налаштування HorizontalPodAutoscaler для Deployment.
Вертикальне масштабування робочих навантажень
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.25 [stable]Ви можете автоматично масштабувати робоче навантаження вертикально за допомогою VerticalPodAutoscaler (VPA). На відміну від HPA, VPA не поставляється стандартно в Kubernetes, але є окремим проєктом, який можна знайти на GitHub.
Після встановлення він дозволяє створювати CustomResourceDefinitions (CRDs) для ваших робочих навантажень, які визначають як і коли масштабувати ресурси керованих реплік.
Примітка:
Вам потрібно мати встановлений Metrics Server в вашому кластері для роботи HPA.На цей час VPA може працювати в чотирьох різних режимах:
| Режим | Опис |
|---|---|
Auto | Наразі Recreate, може змінитися на оновлення на місці у майбутньому |
Recreate | VPA встановлює ресурсні запити при створенні підпорядкованих контейнерів і оновлює їх на наявних контейнерах, витісняючи їх, коли запитані ресурси відрізняються від нової рекомендації |
Initial | VPA встановлює ресурсні запити лише при створенні підпорядкованих контейнерів і ніколи не змінює їх пізніше. |
Off | VPA автоматично не змінює вимоги до ресурсів підпорядкованих контейнерів. Рекомендації обчислюються і можуть бути перевірені в обʼєкті VPA. |
Вимоги для масштабування на місці
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.27 [alpha] (стандартно увімкнено: false)Масштабування робочого навантаження на місці без перезапуску підпорядкованих контейнерів чи їх контейнерів вимагає версії Kubernetes 1.27 чи пізніше. Додатково потрібно ввімкнути властивість InPlaceVerticalScaling.
InPlacePodVerticalScaling: Дозволяє вертикальне масштабування Podʼів на місці.
Автомасштабування на основі розміру кластера
Для робочих навантажень, які потрібно масштабувати залежно від розміру кластера (наприклад, cluster-dns чи інші системні компоненти), ви можете використовувати Cluster Proportional Autoscaler. Так само як і VPA, він не є частиною основного функціонала Kubernetes, але розміщений як окремий проєкт на GitHub.
Cluster Proportional Autoscaler відстежує кількість вузлів які готові приймати Podʼи та ядра та масштабує кількість реплік цільового робочого навантаження відповідно.
Якщо кількість реплік має залишитися незмінною, ви можете масштабувати свої робочі навантаження вертикально залежно від розміру кластера, використовуючи Cluster Proportional Vertical Autoscaler. Проєкт знаходиться наразі у бета-версії та доступний на GitHub.
В той час як Cluster Proportional Autoscaler масштабує кількість реплік робочого навантаження, Cluster Proportional Vertical Autoscaler налаштовує вимоги до ресурсів для робочого навантаження (наприклад, Deployment або DaemonSet) залежно від кількості вузлів та/або ядер у кластері.
Автомасштабування, на підставі подій
Також існує можливість масштабування робочих навантажень на основі подій, наприклад, використовуючи Kubernetes Event Driven Autoscaler (KEDA).
KEDA є проєктом створеним під егідою CNCF, що дозволяє масштабувати ваші робочі навантаження залежно від кількості подій для обробки, наприклад, кількість повідомлень в черзі. Існує широкий спектр адаптерів для різних джерел подій, які можна вибрати.
Автомасштабування на основі розкладу
Ще одна стратегія для масштабування вашого робочого навантаження — це запланувати операції масштабування, наприклад, для зменшення використання ресурсів під час годин неактивності.
Схоже на автомасштабування, спровоковане подіями, таку поведінку можна досягти за допомогою KEDA спільно з його Cron scaler. Scaler Cron дозволяє вам визначати розклади (і часові пояси) для масштабування ваших робочих навантажень вгору чи вниз.
Масштабування інфраструктури кластера
Якщо масштабування робочих навантажень не вистачає для задоволення ваших потреб, ви також можете масштабувати інфраструктуру вашого кластера.
Масштабування інфраструктури кластера, зазвичай, передбачає додавання або видалення вузлів. Дивіться автомасштабування кластера для отримання додаткової інформації.
Що далі
- Дізнайтеся більше про горизонтальне масштабування
- Зміна розміру ресурсів контейнера на місці
- Автомасштабування служби DNS в кластері
- Автомасштабування кластера
4.4 - Управління робочими навантаженнями
Ви розгорнули ваш застосунок та експонували його через Service. Що далі? Kubernetes надає ряд інструментів для допомоги в управлінні розгортанням вашого застосунку, включаючи масштабування та оновлення.
Організація конфігурацій ресурсів
Багато застосунків потребують створення кількох ресурсів, таких як Deployment разом із Service. Управління кількома ресурсами можна спростити, обʼєднавши їх в одному файлі (розділеному --- у YAML). Наприклад:
apiVersion: v1
kind: Service
metadata:
name: my-nginx-svc
labels:
app: nginx
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Кілька ресурсів можна створити так само як і один ресурс:
kubectl apply -f https://k8s.io/examples/application/nginx-app.yaml
service/my-nginx-svc created
deployment.apps/my-nginx created
Ресурси будуть створені в порядку, в якому вони зʼявляються в маніфесті. Тому краще спочатку вказати Service, оскільки це забезпечить, що планувальник зможе розподілити повʼязані з Service podʼи в процесі їх створення контролером(ами), таким як Deployment.
kubectl apply також приймає кілька аргументів -f:
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-svc.yaml \
-f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
Рекомендовано розміщувати ресурси, повʼязані з одним мікросервісом або рівнем застосунку, в одному файлі та групувати всі файли, повʼязані з вашим застосунком, в одній теці. Якщо рівні вашого застосунку звʼязуються один з одним за допомогою DNS, ви можете розгорнути всі компоненти вашого стека разом.
Також можна вказати URL як джерело конфігурації, що зручно для розгортання безпосередньо з маніфестів у вашій системі контролю версій:
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx created
Якщо потрібно визначити більше маніфестів, наприклад, додати ConfigMap, це також можна зробити.
Зовнішні інструменти
У цьому розділі перераховані лише найпоширеніші інструменти, які використовуються для керування навантаженнями в Kubernetes. Щоб переглянути більше інструментів, подивіться Application definition and image build в CNCF Landscape.
Helm
🛇 Цей елемент посилається на сторонній проєкт або продукт, який не є частиною Kubernetes. Докладніше
Helm — це інструмент для управління пакетами попередньо налаштованих ресурсів Kubernetes. Ці пакети відомі як Helm чарти.
Kustomize
Kustomize проходить по маніфестах Kubernetes, щоб додати, видалити або оновити конфігураційні опції. Він доступний як окремий бінарний файл і як вбудована функція kubectl.
Пакетні операції в kubectl
Створення ресурсів — не єдина операція, яку kubectl може виконувати в пакетному режимі. Він також може витягувати імена ресурсів з конфігураційних файлів для виконання інших операцій, зокрема для видалення тих же ресурсів, які ви створили:
kubectl delete -f https://k8s.io/examples/application/nginx-app.yaml
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
У випадку з двома ресурсами ви можете вказати обидва ресурси в командному рядку, використовуючи синтаксис resource/name:
kubectl delete deployments/my-nginx services/my-nginx-svc
Для більшої кількості ресурсів буде зручніше вказати селектор (запит на мітку), використовуючи -l або --selector, щоб відфільтрувати ресурси за їхніми мітками:
kubectl delete deployment,services -l app=nginx
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
Ланцюги та фільтрація
Оскільки kubectl виводить імена ресурсів у тому ж синтаксисі, який він приймає, ви можете робити ланцюги операції, використовуючи $() або xargs:
kubectl get $(kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service/ )
kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service/ | xargs -i kubectl get '{}'
Вивід може бути подібний до:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx-svc LoadBalancer 10.0.0.208 <pending> 80/TCP 0s
Використовуючи вище наведенні команди, спочатку ви створюєте ресурси в examples/application/nginx/ і виводите створені ресурси у форматі виводу -o name (виводите кожен ресурс як resource/name). Потім ви виконуєте grep для вибору Service, а потім виводите його за допомогою kubectl get.
Рекурсивні операції з локальними файлами
Якщо ви організували ваші ресурси в кількох підтеках всередині певної теки, ви можете рекурсивно виконувати операції з ними, вказавши --recursive або -R разом з аргументом --filename/-f.
Наприклад, припустимо, є тека project/k8s/development, яка містить усі маніфести необхідні для середовища розробки, організовані за типом ресурсу:
project/k8s/development
├── configmap
│ └── my-configmap.yaml
├── deployment
│ └── my-deployment.yaml
└── pvc
└── my-pvc.yaml
Стандартно, виконання пакетної операції для project/k8s/development зупиниться на першому рівні теки, не обробляючи жодних вкладених тек. Якщо ви спробували б створити ресурси з цієї теки, використовуючи наступну команду, ви б отримали помилку:
kubectl apply -f project/k8s/development
error: you must provide one or more resources by argument or filename (.json|.yaml|.yml|stdin)
Замість цього, вкажіть аргумент командного рядка --recursive або -R разом з аргументом --filename/-f:
kubectl apply -f project/k8s/development --recursive
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
Аргумент --recursive працює з будь-якою операцією, яка приймає аргумент --filename/-f, такою як: kubectl create, kubectl get, kubectl delete, kubectl describe, або навіть kubectl rollout.
Аргумент --recursive також працює, коли вказані кілька аргументів -f:
kubectl apply -f project/k8s/namespaces -f project/k8s/development --recursive
namespace/development created
namespace/staging created
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
Якщо ви хочете дізнатися більше про kubectl, ознайомтеся зі статею Інструмент командного рядка (kubectl).
Оновлення застосунку без перебоїв у роботі
В якийсь момент вам, ймовірно, доведеться оновити ваш розгорнутий застосунок, зазвичай шляхом зазначення нового образу чи теґу образу. kubectl підтримує кілька операцій оновлення, кожна з яких застосовується до різних сценаріїв.
Ви можете запускати кілька копій вашого застосунку і використовувати rollout для поступового перенаправлення трафіку до нових справних Podʼів. З часом всі запущені Podʼи отримають нове програмне забезпечення.
Цей розділ сторінки проводить вас через процес створення та оновлення застосунків за допомогою Deployments.
Припустимо, ви запускали версію 1.14.2 nginx:
kubectl create deployment my-nginx --image=nginx:1.14.2
deployment.apps/my-nginx created
Переконайтеся, що є 1 репліка:
kubectl scale --replicas 1 deployments/my-nginx --subresource='scale' --type='merge' -p '{"spec":{"replicas": 1}}'
deployment.apps/my-nginx scaled
і дозвольте Kubernetes додавати більше тимчасових реплік під час розгортання, встановивши максимум сплеску на 100%::
kubectl patch --type='merge' -p '{"spec":{"strategy":{"rollingUpdate":{"maxSurge": "100%" }}}}'
deployment.apps/my-nginx patched
Щоб оновитись до версії 1.16.1, змініть .spec.template.spec.containers[0].image з nginx:1.14.2 на nginx:1.16.1, використовуючи kubectl edit:
kubectl edit deployment/my-nginx
# Змініть маніфест на використання новішого образу контейнера, потім збережіть зміни
Ось і все! Deployment оновить розгорнутий застосунок з nginx прогресивно за лаштунками. Він забезпечує, що лише певна кількість старих реплік може бути недоступною під час оновлення, і лише певна кількість нових реплік може бути створена понад бажану кількість podʼів. Щоб дізнатися більше деталей про те, як це відбувається, відвідайте Deployment.
Ви можете використовувати rollouts з DaemonSets, Deployments або StatefulSets.
Управління Rollouts
Ви можете використовувати kubectl rollout для управління прогресивним оновленням поточного застосунку.
Наприклад:
kubectl apply -f my-deployment.yaml
# дочекайтеся завершення rollout
kubectl rollout status deployment/my-deployment --timeout 10m # тайм-аут 10 хвилин
або
kubectl apply -f backing-stateful-component.yaml
# не чекайте завершення rollout, просто перевірте статус
kubectl rollout status statefulsets/backing-stateful-component --watch=false
Ви також можете призупиняти, відновлювати або скасовувати rollout. Відвідайте kubectl rollout для отримання додаткової інформації.
Canary Deployment
Ще один сценарій, коли потрібні кілька міток, це відрізнення розгортання різних версій або конфігурацій одного й того ж компонента. Загальною практикою є розгортання canary нової версії застосунку (зазначеної через теґ образу в шаблоні podʼа) поруч з попередньою версією, щоб нова версія могла отримати реальний трафік перед повним розгортанням.
Наприклад, можна використовувати мітку track для розрізнення різних версій.
Основна, стабільна версія буде мати мітку track зі значенням stable:
name: frontend
replicas: 3
...
labels:
app: guestbook
tier: frontend
track: stable
...
image: gb-frontend:v3
А потім ви можете створити нову версію фронтенду для guestbook, яка має мітку track з іншим значенням (тобто canary), так що два набори podʼів не перетинатимуться:
name: frontend-canary
replicas: 1
...
labels:
app: guestbook
tier: frontend
track: canary
...
image: gb-frontend:v4
Сервіс фронтенду охоплюватиме обидва набори реплік, вибираючи загальну підмножину їх міток (тобто пропускаючи мітку track), так що трафік буде перенаправлено на обидва застосунки:
selector:
app: guestbook
tier: frontend
Ви можете налаштувати кількість реплік стабільних і canary версій, щоб визначити відношення кожного розгортання, яке отримає реальний трафік (в цьому випадку, 3:1). Коли ви будете впевнені, що нова версія стабільна, ви можете оновити стабільний трек до нової версії застосунку і видалити canary версію.
Оновлення анотацій
Іноді ви захочете додати анотації до ресурсів. Анотації є довільними метаданими, що не є ідентифікаційними, для отримання API клієнтами, такими як інструменти або бібліотеки. Це можна зробити за допомогою kubectl annotate. Наприклад:
kubectl annotate pods my-nginx-v4-9gw19 description='my frontend running nginx'
kubectl get pods my-nginx-v4-9gw19 -o yaml
apiVersion: v1
kind: pod
metadata:
annotations:
description: my frontend running nginx
...
Для отримання додаткової інформації дивіться анотації та kubectl annotate.
Масштабування вашого застосунку
Коли навантаження на ваш застосунок зростає або зменшується, використовуйте kubectl, щоб масштабувати ваш застосунок. Наприклад, щоб зменшити кількість реплік nginx з 3 до 1, виконайте:
kubectl scale deployment/my-nginx --replicas=1
deployment.apps/my-nginx scaled
Тепер у вас буде тільки один pod, яким управляє deployment.
kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
my-nginx-2035384211-j5fhi 1/1 Running 0 30m
Щоб система автоматично вибирала кількість реплік nginx в межах від 1 до 3, виконайте:
# Це вимагає існуючого джерела метрик контейнера і Pod
kubectl autoscale deployment/my-nginx --min=1 --max=3
horizontalpodautoscaler.autoscaling/my-nginx autoscaled
Тепер ваші репліки nginx будуть масштабуватися вгору і вниз за потреби автоматично.
Для отримання додаткової інформації перегляньте kubectl scale, kubectl autoscale і horizontal pod autoscaler.
Оновлення ресурсів на місці
Іноді необхідно вносити вузькі оновлення до ресурсів які ви створили, не порушуючи роботи.
kubectl apply
Рекомендується підтримувати набір конфігураційних файлів у системі контролю версій (див. конфігурація як код), щоб їх можна було підтримувати та версіонувати разом з кодом для ресурсів, які вони конфігурують. Тоді ви можете використовувати kubectl apply для того, щоб надіслати зміни конфігурації в кластер.
Ця команда порівнює версію конфігурації, яку ви надсилаєте, з попередньою версією та застосовує внесені вами зміни, не перезаписуючи зміни властивостей, що відбулись автоматичні, які ви не вказали.
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx configured
Щоб дізнатися більше про механізм, що лежить в основі, прочитайте server-side apply.
kubectl edit
Альтернативно, ви також можете оновлювати ресурси за допомогою kubectl edit:
kubectl edit deployment/my-nginx
Це еквівалентно спочатку отриманню get ресурсу, редагуванню його в текстовому редакторі, а потім apply ресурсу з оновленою версією:
kubectl get deployment my-nginx -o yaml > /tmp/nginx.yaml
vi /tmp/nginx.yaml
# зробіть деякі редагування, а потім збережіть файл
kubectl apply -f /tmp/nginx.yaml
deployment.apps/my-nginx configured
rm /tmp/nginx.yaml
Це дозволяє легше вносити більш значні зміни. Зверніть увагу, що ви можете вказати редактор за допомогою змінних середовища EDITOR або KUBE_EDITOR.
Для отримання додаткової інформації дивіться kubectl edit.
kubectl patch
Ви можете використовувати kubectl patch для оновлення API обʼєктів на місці. Ця підкоманда підтримує JSON patch, JSON merge patch і стратегічний merge patch.
Дивіться Оновлення API обʼєктів на місці за допомогою kubectl patch для отримання додаткових деталей.
Оновлення, що порушують стабільність
В деяких випадках може знадобитися оновити поля ресурсу, які не можна оновити після його ініціалізації, або може знадобитися зробити рекурсивну зміну негайно, наприклад, щоб виправити пошкоджені podʼи, створені Deployment. Для зміни таких полів використовуйте replace --force, що видаляє і перезапускає ресурс. У цьому випадку ви можете змінити ваш оригінальний конфігураційний файл:
kubectl replace -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml --force
deployment.apps/my-nginx deleted
deployment.apps/my-nginx replaced
Що далі
5 - Service, балансування навантаження та мережа
Концепції та ресурси, що лежать в основі роботи в мережі в Kubernetes.
Мережева модель Kubernetes
Мережева модель Kubernetes складається з кількох частин:
Кожен pod у кластері отримує власну унікальну кластерну IP-адресу.
- Pod має власний приватний мережевий простір імен, який спільно використовують всі контейнери всередині podʼа. Процеси, що працюють у різних контейнерах в одному podʼі, можуть спілкуватися між собою через
localhost.
- Pod має власний приватний мережевий простір імен, який спільно використовують всі контейнери всередині podʼа. Процеси, що працюють у різних контейнерах в одному podʼі, можуть спілкуватися між собою через
Мережа podʼів (також називається кластерною мережею) керує комунікацією між podʼами. Вона забезпечує, що (за відсутності навмисної сегментації мережі):
Модель мережі Kubernetes складається з кількох компонентів:
Кожен pod у кластері отримує свою унікальну кластерну IP-адресу.
- Pod має власний приватний мережевий простір імен, який спільно використовують усі контейнери в pod. Процеси, що працюють у різних контейнерах в одному pod, можуть спілкуватися між собою через
localhost.
- Pod має власний приватний мережевий простір імен, який спільно використовують усі контейнери в pod. Процеси, що працюють у різних контейнерах в одному pod, можуть спілкуватися між собою через
Мережа pod (також називається кластерною мережею) керує комунікацією між podʼами. Вона забезпечує, що (за відсутності навмисної сегментації мережі):
Усі podʼи можуть спілкуватися з усіма іншими podʼами, незалежно від того, чи знаходяться вони на одному вузлі, чи на різних. Podʼи можуть спілкуватися безпосередньо, без використання проксі-серверів чи трансляції адрес (NAT).
У Windows це правило не застосовується до podʼів з мережею вузла.
Агенти на вузлі (такі як системні демони чи kubelet) можуть спілкуватися з усіма podʼами на цьому вузлі.
API Service дозволяє надати стабільну (довготривалу) IP-адресу або імʼя хосту для сервісу, реалізованого одним або кількома podʼами, при цьому окремі podʼи, що складають сервіс, можуть змінюватися з часом.
Kubernetes автоматично керує обʼєктами EndpointSlice, які надають інформацію про podʼи, що підтримують сервіс.
Реалізація проксі сервісу відстежує набір обʼєктів Service та EndpointSlice і програмує панель даних для маршрутизації трафіку сервісу до його бекендів, використовуючи API операційної системи або хмарних провайдерів для перехоплення або переписування пакетів.
API Gateway (або його попередник Ingress) дозволяє зробити сервіси доступними для клієнтів поза кластером.
- Простішим, але менш гнучким механізмом кластерного ingress є використання API Service з типом
type: LoadBalancer, якщо підтримується відповідним постачальником хмарних послуг.
- Простішим, але менш гнучким механізмом кластерного ingress є використання API Service з типом
NetworkPolicy — це вбудований API Kubernetes, який дозволяє контролювати трафік між podʼами або між podʼами та зовнішнім світом.
У старіших контейнерних системах не було автоматичної зʼєднуваності між контейнерами на різних вузлах, тому часто було необхідно явно створювати посилання між контейнерами або призначати порти контейнерів на порти хосту, щоб зробити їх доступними для інших контейнерів. Це не потрібно в Kubernetes, оскільки модель Kubernetes передбачає, що podʼи можна розглядати подібно до віртуальних машин або фізичних хостів з погляду виділення портів, іменування, виявлення сервісів, балансування навантаження, налаштування застосунків та міграції.
Тільки кілька частин цієї моделі реалізовані безпосередньо Kubernetes. Для решти Kubernetes визначає API, але відповідна функціональність надається зовнішніми компонентами, деякі з яких є опціональними:
Налаштування простору імен мережі pod виконується системним програмним забезпеченням, яке реалізує Container Runtime Interface.
Мережею pod керує реалізація мережі pod. На Linux більшість середовищ виконання контейнерів використовують Container Networking Interface (CNI), щоб взаємодіяти з реалізацією мережі pod, тому ці реалізації часто називаються _CNI втулками.
Kubernetes надає стандартну реалізацію для проксі сервісів, яка називається kube-proxy, але деякі реалізації мережі pod використовують власний сервісний проксі, який тісніше інтегрований з іншими компонентами.
NetworkPolicy зазвичай також реалізується мережею pod. (Деякі простіші реалізації мережі pod не підтримують NetworkPolicy, або адміністратор може вирішити налаштувати мережу pod без підтримки NetworkPolicy. У таких випадках API буде присутній, але не матиме жодного ефекту.)
Існує багато реалізацій Gateway API, деякі з яких специфічні для певних хмарних середовищ, інші більше орієнтовані на середовища "bare metal", а інші є більш універсальними.
Що далі
Підключення застосунків за допомогою Service — це навчальний посібник, який дозволяє дізнатися більше про сервіси та мережу Kubernetes на практичному прикладі.
Стаття Мережа кластера пояснює, як налаштувати мережу для вашого кластера, а також надає огляд задіяних технологій.
5.1 - Service
Надайте доступ до застосунку, що працює в кластері, за допомогою однієї точки доступу, навіть якщо робота розподілена між декількома бекендами.
В Kubernetes, Service — це метод надання доступу ззовні до мережевого застосунку, який працює як один чи кілька Podʼів у вашому кластері.
Ключова мета Service в Kubernetes — це те, що вам не потрібно модифікувати ваш поточний застосунок для використання незнайомого механізму виявлення Service. Ви можете виконувати код в Podʼах, чи це буде код, призначений для світу, орієнтованого на хмари, або старий застосунок, який ви контейнеризували. Ви використовуєте Service, щоб зробити цей набір Podʼіів доступним в мережі, так щоб клієнти могли взаємодіяти з ним.
Якщо ви використовуєте Deployment для запуску вашого застосунку, цей Deployment може динамічно створювати та знищувати Podʼи. З одного моменту і до наступного, ви не знаєте, скільки з цих Podʼів працюють і є справними; ви навіть не можете знати, як називаються ці справні Podʼи. Podʼи Kubernetes створюються та знищуються для відповідності бажаному стану вашого кластера. Podʼи є ефемерними ресурсами (ви не повинні очікувати, що індивідуальний Pod є надійним та довговічним).
Кожен Pod отримує свою власну IP-адресу (Kubernetes очікує, що мережеві втулки гарантують це). Для даного Deployment у вашому кластері набір Podʼів, який працює в один момент часу, може відрізнятися від набору Pod, який працює для цього застосунку наступний момент часу.
Це призводить до проблеми: якщо певний набір Podʼів (назвемо їх "backend") надає функціонал іншим Podʼам (назвемо їх "frontend") всередині вашого кластера, як фронтенд дізнається та відстежує, яку IP-адресу підключати, щоб він міг використовувати частину робочого навантаження?
Познайомтесь з Service.
Service в Kubernetes
API Service, що є частиною Kubernetes, є абстракцією, яка допомагає вам давати групі Podʼів доступ в мережі. Кожен обʼєкт Service визначає логічний набір endpoint (зазвичай endpoint — Pod) разом із політикою того, як робити ці Podʼи доступними.
Наприклад, розгляньте stateless бекенд для обробки зображень, який працює з 3 репліками. Ці репліки замінюються одна одною — фронтендам не важливо, який бекенд вони використовують. Хоча конкретні Podʼи, що складають бекенд, можуть змінюватися, клієнти фронтенду не мають на це звертати уваги, і вони не повинні вести облік набору елементів бекендів самі.
Абстракція Service дозволяє таке відокремлення.
Набір Podʼів, яким призначається Service, зазвичай визначається селектором, який ви визначаєте. Щоб дізнатися про інші способи визначення endpointʼів сервісу, дивіться Сервіси без селекторів.
Якщо ваше навантаження використовує HTTP, ви можете викорисовувати Ingress для контролю над тим, як вебтрафік досягає цього навантаження. Ingress не є типом сервісу, але він діє як точка входу до вашого кластера. Ingress дозволяє обʼєднати ваші правила маршрутизації в один ресурс, щоб ви могли експонувати кілька компонентів вашого навантаження, що працюють окремо в вашому кластері, під одним зовнішнім URL.
API Gateway для Kubernetes надає додаткові можливості, які виходять за межі Ingress і Service. Ви можете додати Gateway до вашого кластера — це родина розширених API, реалізованих за допомогою CustomResourceDefinitions — і потім використовувати їх для налаштування доступу до мережевих сервісів, що працюють у вашому кластері.
Хмарно-нативне виявлення сервісів
Якщо ви можете використовувати API Kubernetes для виявлення сервісів у вашому застосунку, ви можете звертатись до сервера API по відповідні EndpointSlices. Kubernetes оновлює EndpointSlices для сервісу кожного разу, коли набір Podʼів у сервісі змінюється.
Для не-нативних застосунків Kubernetes пропонує способи розміщення мережевого порту чи балансувальника між вашим застосунком та Podʼами бекенду.
В будь-якому випадку ваше навантаження може використовувати ці засоби виявлення сервісів для пошуку цільового сервісу, до якого воно хоче підʼєднатися.
Визначення Сервісу
Service — це обʼєкт (так само як Pod чи ConfigMap є обʼєктами). Ви можете створювати, переглядати або змінювати визначення Service, використовуючи API Kubernetes. Зазвичай для цього ви використовуєте інструмент, такий як kubectl, який звертається до API.
Наприклад, припустимо, у вас є набір Podʼів, які слухають TCP-порт 9376 і мають мітку app.kubernetes.io/name=MyApp. Ви можете визначити Сервіс, щоб
опублікувати цього TCP-слухача:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
Застосування цього маніфесту створює новий Сервіс з назвою "my-service" зі стандартним типом служби ClusterIP. Сервіс обслуговує TCP-порт 9376 на будь-якому Podʼі з міткою app.kubernetes.io/name: MyApp.
Kubernetes призначає цьому Сервісу IP-адресу (так званий кластерний IP), що використовується механізмом віртуалізації IP-адрес. Для отримання докладнішої інформації про цей механізм, читайте Віртуальні IP та Проксі-сервіси.
Контролер для цього Сервісу постійно сканує Podʼи, які відповідають його селектору, а потім вносить будь-які необхідні оновлення до набору EndpointSlices для Сервісу.
Назва обʼєкта Сервісу повинна бути дійсним іменем мітки за стандартом RFC 1035.
Примітка:
Сервіс може повʼязувати будь-який вхіднийport з targetPort. Типово та для зручності, targetPort встановлено на те ж саме значення, що й поле port.Визначення портів
Визначення портів в Podʼах мають назви, і ви можете посилатися на ці назви в атрибуті targetPort Сервісу. Наприклад, ми можемо привʼязати targetPort Сервісу до порту Podʼа таким чином:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app.kubernetes.io/name: proxy
spec:
containers:
- name: nginx
image: nginx:stable
ports:
- containerPort: 80
name: http-web-svc
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app.kubernetes.io/name: proxy
ports:
- name: name-of-service-port
protocol: TCP
port: 80
targetPort: http-web-svc
Це працює навіть у випадку, якщо у Сервісу є суміш Podʼів з використанням одного налаштованого імені, з однаковим мережевим протоколом, доступним через різні номери портів. Це надає багато гнучкості для розгортання та розвитку вашого Сервісу. Наприклад, ви можете змінити номери портів, які Podʼи прослуховують в наступній версії вашого програмного забезпечення бекенду, без руйнівних наслідків для клієнтів.
Станадртним протоколом для Service є TCP; ви також можете використовувати будь-який інший підтримуваний протокол.
Оскільки багато Сервісів повинні працювати більше ніж з одним портом, Kubernetes підтримує визначення кількох портів для одного Сервісу. Кожне визначення порту може мати той же протокол або різні.
Сервіси без селекторів
Сервіси найчастіше абстрагують доступ до Podʼів Kubernetes завдяки селектору, але коли вони використовуються разом із відповідним набором EndpointSlices обʼєктів та без селектора, Сервіс може абстрагувати інші типи бекендів, включаючи ті, які працюють поза кластером.
Наприклад:
- Ви хочете мати зовнішній кластер баз даних у вашому експлуатаційному оточенні, але у своєму тестовому середовищі ви використовуєте свої власні бази даних.
- Ви хочете спрямувати ваш Сервіс на Сервіс в іншому Namespace чи в іншому кластері.
- Ви мігруєте робоче навантаження в Kubernetes. Під час оцінки цього підходу, ви запускаєте лише частину своїх бекендів в Kubernetes.
У будь-якому з цих сценаріїв ви можете визначити Сервіс без вказівки селектора для відповідності Podʼам. Наприклад:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
Оскільки у цього Сервісу немає селектора, відповідні обʼєкти EndpointSlice (та застарілі Endpoints) не створюються автоматично. Ви можете повʼязувати Сервіс з мережевою адресою та портом, де він працює, додавши обʼєкт EndpointSlice вручну. Наприклад:
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: my-service-1 # за звичай, використовуйте назву Сервісу
# як префікс для назви EndpointSlice
labels:
# Ви повинні встановити мітку "kubernetes.io/service-name".
# Встановіть її значення, щоб відповідати назві Сервісу
kubernetes.io/service-name: my-service
addressType: IPv4
ports:
- name: http # Має збігатись з іменем порту у визначенні Service
# визначеному вище
appProtocol: http
protocol: TCP
port: 9376
endpoints:
- addresses:
- "10.4.5.6"
- addresses:
- "10.1.2.3"
Власні EndpointSlices
Коли ви створюєте обʼєкт EndpointSlice для Сервісу, ви можете
використовувати будь-яку назву для EndpointSlice. Кожен EndpointSlice в просторі імен повинен мати унікальну назву. Ви поєднуєте EndpointSlice із Сервісом, встановлюючи label kubernetes.io/service-name на цьому EndpointSlice.
Примітка:
IP-адреси endpoint не повинні бути: локальними (127.0.0.0/8 для IPv4, ::1/128 для IPv6), або (169.254.0.0/16 та 224.0.0.0/24 для IPv4, fe80::/64 для IPv6).
IP-адреси endpoint не можуть бути кластерними IP-адресами інших Сервісів Kubernetes, оскільки kube-proxy не підтримує віртуальні IP-адреси як призначення.
Для EndpointSlice, який ви створюєте самостійно або у своєму власному коді,
вам також слід вибрати значення для мітки endpointslice.kubernetes.io/managed-by. Якщо ви створюєте свій власний код контролера для управління EndpointSlice, розгляньте можливість використання значення, схожого на "my-domain.example/name-of-controller". Якщо ви використовуєте інструмент від стороннього постачальника, використовуйте назву інструменту в нижньому регістрі та замініть пробіли та інші знаки пунктуації на дефіси (-). Якщо ви безпосередньо використовуєте інструмент, такий як kubectl, для управління EndpointSlice, використовуйте назву, яка описує це ручне управління, таку як "staff" або "cluster-admins". Ви повинні уникати використання захищеного значення "controller", яке ідентифікує EndpointSlices, які керуються власною панеллю управління Kubernetes.
Доступ до Сервісу без селектора
Доступ до Сервісу без селектора працює так само, якби він мав селектор. У прикладі Сервісу без селектора, трафік маршрутизується до одного з двох endpoint, визначених у маніфесті EndpointSlice: TCP-зʼєднання до 10.1.2.3 або 10.4.5.6, на порт 9376.
Примітка:
Сервер API Kubernetes не дозволяє проксіювання до endpoint, які не повʼязані з Podʼами. Дії, такі якkubectl port-forward service/<service-name> forwardedPort:servicePort, де сервіс не має селектора, зазнають збою через це обмеження. Це запобігає використанню сервера API Kubernetes як проксі до endpoint, до яких викликач може не мати авторизації на доступ.ExternalName Сервіс — це особливий випадок Сервісу, який не має селекторів і використовує DNS-імена замість них. Для отримання доклдадної інформації, див. розділ
ExternalName.
EndpointSlices
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.21 [stable]EndpointSlices — це обʼєкти, які представляють підмножину (зріз) мережевих endpoint, які підтримують Сервіс.
Ваш кластер Kubernetes відстежує кількість endpointʼів, які представляє кожен EndpointSlice. Якщо для Сервісу є настільки багато endpointʼів, що досягається порогове значення, тоді Kubernetes додає ще один порожній EndpointSlice і зберігає там нову інформацію про endpoint. Типово Kubernetes створює новий EndpointSlice, як тільки наявні EndpointSlice всі містять принаймні 100 endpoint. Kubernetes не створює новий EndpointSlice, поки не буде потрібно додати додатковий endpoint.
Див. EndpointSlices для отримання додаткової інформації про цей API.
Endpoint
В API Kubernetes, Endpoints (тип ресурсу у множині) визначають список мережевих endpointʼів, зазвичай використовується Сервісом для визначення того, до яких Podʼів можна направляти трафік.
API EndpointSlice — це рекомендована заміна для Endpoints.
Endpoints з перевищеним обсягом
Kubernetes обмежує кількість endpointʼів, які можуть поміститися в один обʼєкт Endpoints. Коли є понад 1000 endpointʼів, які підтримують Сервіс, Kubernetes розмішує дані в обʼєкті Endpoints. Оскільки Сервіс може бути повʼязаним з більше ніж одним EndpointSlice, обмеження в 1000 endpointʼів впливає лише на застарілий API Endpoints.
У цьому випадку Kubernetes вибирає не більше 1000 можливих endpointʼів, які слід зберегти в обʼєкті Endpoints, і встановлює анотацію на Endpoints: endpoints.kubernetes.io/over-capacity: truncated. Панель управління також видаляє цю анотацію, якщо кількість бекенд-Podʼів впадає нижче 1000.
Трафік все ще відсилається на бекенди, але будь-який механізм балансування навантаження, який покладається на застарілий API Endpoints, відсилає трафік не більше, ніж до 1000 доступних бекенд-endpointʼів.
Той самий ліміт API означає, що ви не можете вручну оновлювати Endpoints так, щоб у них було понад 1000 endpointʼів.
Протокол застосунку
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.20 [stable]Поле appProtocol надає можливість вказати протокол застосунку для кожного порту Сервісу. Це використовується як підказка для реалізацій для надання розширеної поведінки для протоколів, які вони розуміють. Значення цього поля відображається відповідними обʼєктами Endpoints та EndpointSlice.
Це поле відповідає стандартному синтаксису міток Kubernetes. Дійсні значення — це одне з:
Імплементаційно-визначені префіксовані імена, такі як
mycompany.com/my-custom-protocol.Імена з префіксом, визначені Kubernetes:
| Протокол | Опис |
|---|---|
kubernetes.io/h2c | HTTP/2 поверх чіткого тексту, як описано в RFC 7540 |
kubernetes.io/ws | WebSocket через текст, як описано у RFC 6455 |
kubernetes.io/wss | WebSocket через TLS, як описано у RFC 6455 |
Сервіси з кількома портами
Для деяких Сервісів вам може знадобитися використовувати більше одного порту. Kubernetes дозволяє конфігурувати кілька визначень портів в обʼєкті Service. При використанні кількох портів для Сервісу, вам слід надавати всім портам імена, щоб вони були однозначними. Наприклад:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
Примітка:
Так само як і з іменами в Kubernetes взагалі, імена портів мають містити лише буквено-цифрові символи в нижньому регістрі та -. Імена портів також повинні починатися та закінчуватися буквено-цифровим символом.
Наприклад, імена 123-abc та web є допустимими, але 123_abc та -web - ні.
Тип Сервісу
Для деяких частин вашого застосунку (наприклад, фронтенду) ви можете знадобитись звʼязати Сервіс з зовнішньою IP-адресою, доступну з-поза вашого кластера.
Типи Сервісів Kubernetes дозволяють вам вказати, який тип Сервісу ви потрібен.
Доступні значення type та їхні поведінки:
ClusterIP- Повʼязує Сервіс з внутрішньою IP-адресою кластера. Вибір цього значення робить Сервіс доступним лише зсередини кластера. Це значення використовується стандартно, якщо ви не вказали явно
typeдля Сервісу. Ви можете дати Сервісу доступ в Інтернет за допомогою Ingress або Gateway. NodePort- Повʼязує Сервіс на кожному IP-адресі вузла зі статичним портом (
NodePort). Щоб зробити порт вузла доступним, Kubernetes налаштовує IP-адресу кластера, так само якби ви запросили Сервіс зtype: ClusterIP. LoadBalancer- Повʼязує Сервіс із зовнішніми споживачами за допомогою зовнішнього балансувальника навантаження. Kubernetes не надає безпосередньо компонент балансування навантаження; вам слід надати його, або ви можете інтегрувати свій кластер Kubernetes з постачальником хмарних послуг.
ExternalName- Повʼязує Сервіс зі змістом поля
externalName(наприклад, на імʼя хостаapi.foo.bar.example). Це конфігурує сервер DNS вашого кластера повертати записCNAMEз вказаною зовнішньою назвою хосту. Ніякого проксінгу не налаштовується.
Поле type в API Сервісу розроблене як вкладена функціональність — кожен рівень додається до попереднього. Однак існує виняток з цього вкладеного дизайну. Ви можете визначити Сервіс LoadBalancer, відключивши використання порту вузла для балансування навантаження.
type: ClusterIP
Цей тип Сервісу типово призначає IP-адресу з пулу IP-адрес, який ваш кластер зарезервував для цієї мети.
Кілька інших типів Сервісу базуються на типі ClusterIP.
Якщо ви визначаєте Сервіс, у якому .spec.clusterIP встановлено в "None", тоді Kubernetes не призначає IP-адресу. Див. сервіси headless для отримання додаткової інформації.
Вибір власної IP-адреси
Ви можете вказати власну IP-адресу кластера як частину запиту на створення Service. Для цього встановіть поле .spec.clusterIP. Наприклад, якщо у вас вже є наявний запис DNS, який ви хочете повторно використовувати, або старі системи, які налаштовані на певну IP-адресу і важко переналаштовуються.
IP-адреса, яку ви вибираєте, повинна бути дійсною IPv4 або IPv6 адресою з діапазону CIDR, який налаштований для сервера API за допомогою service-cluster-ip-range. Якщо ви намагаєтеся створити Сервіс із недійсною IP-адресою clusterIP, сервер API поверне HTTP-відповідь зі статус-кодом 422 для позначення проблеми.
Читайте уникнення конфліктів, щоб дізнатися, як Kubernetes допомагає зменшити ризик та вплив двох різних Сервісів, що намагаються використовувати однакову IP-адресу.
type: NodePort
Якщо ви встановлюєте поле type в NodePort, панель управління Kubernetes виділяє порт з діапазону, вказаного прапорцем --service-node-port-range (типово: 30000-32767). Кожен вузол проксіює цей порт (той самий номер порту на кожному вузлі) у ваш Сервіс. Ваш Сервіс повідомляє виділений порт у полі .spec.ports[*].nodePort.
Використання NodePort дає вам свободу налаштувати власне рішення з балансування навантаження, конфігурувати середовища, які не повністю підтримуються Kubernetes, або навіть експонувати один або кілька IP-адрес вузлів безпосередньо.
Для Сервісу з портом вузла Kubernetes додатково виділяє порт (TCP, UDP або SCTP для відповідності протоколу Сервісу). Кожен вузол у кластері конфігурується на прослуховування цього призначеного порту і пересилання трафіку на одну з готових точок доступу, повʼязаних із цим Сервісом. Ви зможете звертатися до Сервісу з type: NodePort, ззовні кластера, підключаючись до будь-якого вузла за відповідним протоколом (наприклад: TCP) та відповідним портом (який призначено цьому Сервісу).
Вибір власного порту
Якщо вам потрібен певний номер порту, ви можете вказати значення у полі nodePort.Панель управління вибере для вас цей порт або повідомить, що транзакція API не вдалася. Це означає, що вам потрібно самостійно дбати про можливі конфлікти портів. Вам також слід використовувати дійсний номер порту, який знаходиться в межах налаштованого діапазону для використання NodePort.
Ось приклад маніфесту для Сервісу з type: NodePort, який вказує значення NodePort (30007 у цьому прикладі):
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector:
app.kubernetes.io/name: MyApp
ports:
- port: 80
# Стандартно та для зручності, `targetPort` встановлено
# в те ж значення, що й поле `port`.
targetPort: 80
# Необовʼязкове поле
# Стандартно та для зручності, панель управління Kubernetes
# виділить порт з діапазону (станадртно: 30000-32767)
nodePort: 30007
Резервування діапазонів NodePort для уникнення конфліктів
Політика виділення портів для NodePort-сервісів застосовується як до автоматичного, так і до ручного виділення. Коли користувач хоче створити NodePort-сервіс, який використовує певний порт, цей цільовий порт може конфліктувати з іншим портом, який вже виділено.
Щоб уникнути цієї проблеми, діапазон портів для NodePort-сервісів розбито на дві частини. Типово для динамічного виділення портів використовується верхній діапазон, і він може використовувати нижній діапазон, якщо верхній діапазон вичерпано. Користувачі можуть виділяти порти з нижнього діапазону з меншим ризиком конфлікту портів.
Налаштування власної IP-адреси для Сервісів type: NodePort
Ви можете налаштувати вузли у своєму кластері використовувати певну IP-адресу для обслуговування сервісів з портом вузла. Ви можете це зробити, якщо кожен вузол підключений до декількох мереж (наприклад: одна мережа для трафіку застосунків, а інша мережа для трафіку між вузлами та панеллю управління).
Якщо ви хочете вказати певні IP-адреси для проксі-порта, ви можете встановити прапорець --nodeport-addresses для kube-proxy або еквівалентне поле nodePortAddresses у файлі конфігурації kube-proxy на конкретні блоки IP.
Цей прапорець приймає список IP-блоків через кому (наприклад, 10.0.0.0/8, 192.0.2.0/25) для вказівки діапазонів IP-адрес, які kube-proxy повинен вважати локальними для цього вузла.
Наприклад, якщо ви запускаєте kube-proxy з прапорцем --nodeport-addresses=127.0.0.0/8, kube-proxy вибирає лише інтерфейс loopback для NodePort-сервісів. Типово для --nodeport-addresses є порожній список. Це означає, що kube-proxy повинен вважати всі доступні мережеві інтерфейси локальними для NodePort. (Це також сумісно з раніше випущеними версіями Kubernetes.)
Примітка:
Цей Сервіс видно як<NodeIP>:spec.ports[*].nodePort та .spec.clusterIP:spec.ports[*].port. Якщо встановлено прапорець --nodeport-addresses для kube-proxy або еквівалентне поле у файлі конфігурації kube-proxy, <NodeIP> буде IP-адресою вузла (або можливо IP-адресами) для фільтрування.type: LoadBalancer
У хмарних постачальників, які підтримують зовнішні балансувальники навантаження, встановлення поле type в LoadBalancer надає балансувальник навантаження для вашого Сервісу. Створення балансувальника навантаження відбувається асинхронно, і інформація про створений балансувальник публікується у поле .status.loadBalancer Сервісу. Наприклад:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
clusterIP: 10.0.171.239
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 192.0.2.127
Трафік від зовнішнього балансувальника навантаження направляється на бекенд-Podʼи. Хмарний постачальник вирішує, як він балансує навантаження.
Для реалізації Сервісу з type: LoadBalancer, Kubernetes зазвичай починає з того, що вносить зміни, які еквівалентні вашим запитам на Сервіс type: NodePort. Компонент cloud-controller-manager потім налаштовує зовнішній балансувальник для пересилання трафіку на цей призначений порт вузла.
Ви можете налаштувати балансований за навантаженням Сервіс для виключення призначення порта вузла, за умови, що реалізація постачальника хмари це підтримує.
Деякі постачальники хмар дозволяють вам вказати loadBalancerIP. У цих випадках балансувальник створюється з вказаною користувачем loadBalancerIP. Якщо поле loadBalancerIP не вказано, то балансувальник налаштовується з ефемерною IP-адресою. Якщо ви вказали loadBalancerIP, але ваш постачальник хмари не підтримує цю функцію, то вказане вами поле loadbalancerIP ігнорується.
Примітка:
Поле .spec.loadBalancerIP для Сервісу було визнане застарілим в Kubernetes v1.24.
Це поле було недостатньо визначеним, і його значення різниться в різних реалізаціях. Воно також не підтримує мережі з подвійним стеком. Це поле може бути вилучено в майбутніх версіях API.
Якщо ви інтегруєтеся з постачальником, який підтримує вказання IP-адреси(в) балансувальника навантаження для Сервісу через анотацію (специфічну для постачальника), вам слід перейти на цей метод.
Якщо ви пишете код для інтеграції балансувальника з Kubernetes, уникайте використання цього поля. Ви можете інтегрувати його з Gateway замість Service, або ви можете визначити власні анотації (специфічні для постачальника) для Сервісу, які визначають еквівалентну деталь.
Вплив життєздатності вузла на трафік балансувальника навантаження
Перевірки стану балансувальника навантаження є критичними для сучасних застосунків. Вони використовуються для визначення того, на який сервер (віртуальна машина або IP-адреса) повинен бути направлений трафік балансувальника навантаження. API Kubernetes не визначає, як мають бути реалізовані перевірки стану для керованих Kubernetes балансувальників навантаження; замість цього це роблять хмарні постачальники (і люди, які створюють код інтеграції), які визначають поведінку. Перевірки стану балансувальника навантаження широко використовуються в контексті підтримки поля externalTrafficPolicy для Service.
Балансувальники з мішаними типами протоколів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.26 [stable] (стандартно увімкнено: true)Типово для Сервісів типу LoadBalancer, коли визначено більше одного порту, всі порти повинні мати один і той же протокол, і цей протокол повинен бути підтримуваний постачальником хмари.
Feature gate MixedProtocolLBService (стандартно увімкнено для kube-apiserver з версії v1.24) дозволяє використовувати різні протоколи для Сервісів типу LoadBalancer, коли визначено більше одного порту.
Примітка:
Набір протоколів, які можна використовувати для балансованих навантажень Сервісів, визначається вашим постачальником хмари; вони можуть накладати обмеження поза тим, що накладає API Kubernetes.Вимкнення виділення порту вузла для балансувальника навантаження
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]Ви можете вимкнути виділення порту вузла для Сервісу з type: LoadBalancer, встановивши поле spec.allocateLoadBalancerNodePorts в false. Це слід використовувати тільки для реалізацій балансувальників, які маршрутизують трафік безпосередньо до Podʼів, а не використовують порти вузла. Стандартно spec.allocateLoadBalancerNodePorts дорівнює true, і Сервіси типу LoadBalancer будуть продовжувати виділяти порти вузла. Якщо spec.allocateLoadBalancerNodePorts встановлено в false для існуючого Сервісу з виділеними портами вузла, ці порти вузла не будуть автоматично видалятися. Вам слід явно видалити запис nodePorts в кожному порту Сервісу для деалокації цих портів вузла.
Вказання класу реалізації балансувальника
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]Для Сервісу з type встановленим на LoadBalancer, поле .spec.loadBalancerClass
дозволяє вам використовувати реалізацію балансувальника, відмінну від тієї, яку типово встановлено постачальником хмари.
Типово .spec.loadBalancerClass не встановлено, і Сервіс з LoadBalancer використовує реалізацію балансувальника що постачається в хмарі, якщо кластер налаштовано постачальником хмари за допомогою прапорця компоненту --cloud-provider. Якщо ви вказуєте .spec.loadBalancerClass, вважається, що реалізація балансувальника, яка відповідає вказаному класу, відстежує Сервіси. Будь-яка стандартн реалізація балансувальника (наприклад, та, яку надає постачальник хмари), ігнорує Сервіси, у яких встановлено це поле. spec.loadBalancerClass може бути встановлено тільки для Сервісу типу LoadBalancer. Після встановлення його не можна змінити. Значення spec.loadBalancerClass повинно бути ідентифікатором у формі мітки, з необовʼязковим префіксом, таким як "internal-vip" або "example.com/internal-vip". Безпрефіксні імена зарезервовані для кінцевих користувачів.
Режим IP-адреси балансувальника навантаження
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [stable] (стандартно увімкнено: true)Для Service з типом type: LoadBalancer, контролер може встановити .status.loadBalancer.ingress.ipMode. .status.loadBalancer.ingress.ipMode вказує, як веде себе IP-адреса балансувальника. Воно може бути вказано лише тоді, коли вказано поле .status.loadBalancer.ingress.ip.
Є два можливі значення для .status.loadBalancer.ingress.ipMode: "VIP" та "Proxy".Типово встановлене значення "VIP", що означає, що трафік подається на вузол з призначенням, встановленим на IP та порт балансувальника. Є два випадки, коли встановлено значення "Proxy", залежно від того, як постачальник хмари балансує трафік:
- Якщо трафік подається на вузол, а потім перенаправляється до Podʼа, призначення буде встановлено на IP та порт вузла;
- Якщо трафік подається безпосередньо до Podʼа, призначення буде встановлено на IP та порт Podʼа.
Реалізації Сервісів можуть використовувати цю інформацію для налаштування маршрутизації трафіку.
Внутрішній балансувальник
У змішаному середовищі іноді необхідно направляти трафік від Сервісів всередині того ж (віртуального) мережевого блоку.
У середовищі DNS із подвійним горизонтом вам може знадобитися два Сервіси для маршрутизації зовнішнього і внутрішнього трафіку до ваших ендпоінтів.
Щоб встановити внутрішній балансувальник, додайте одну з наступних анотацій до Сервісу в залежності від постачальника хмари, який ви використовуєте:
Виберіть одну з вкладок.
metadata:
name: my-service
annotations:
networking.gke.io/load-balancer-type: "Internal"
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-internal: "true"
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/azure-load-balancer-internal: "true"
metadata:
name: my-service
annotations:
service.kubernetes.io/ibm-load-balancer-cloud-provider-ip-type: "private"
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/openstack-internal-load-balancer: "true"
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/cce-load-balancer-internal-vpc: "true"
metadata:
annotations:
service.kubernetes.io/qcloud-loadbalancer-internal-subnetid: subnet-xxxxx
metadata:
annotations:
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-address-type: "intranet"
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/oci-load-balancer-internal: true
type: ExternalName
Сервіси типу ExternalName звʼязують Сервіс з DNS-іменем, а не на типовим селектором, таким як my-service або cassandra. Ви вказуєте ці Сервіси параметром spec.externalName.
Наприклад, це визначення Сервісу звʼязує Сервіс my-service в просторі імен prod з my.database.example.com:
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
Примітка:
Сервіс типу ExternalName приймає рядок IPv4 адреси, але трактує цей рядок як імʼя DNS, що складається з цифр, а не як IP-адресу (інтернет, однак, не дозволяє такі імена в DNS). Сервіси зовнішніх імен, які нагадують IPv4 адреси, не вирішуються DNS-серверами.
Якщо ви хочете звʼязати Сервіс безпосередньо з конкретною IP-адресою, розгляньте можливість використання headless Services.
При пошуку хоста my-service.prod.svc.cluster.local, DNS-сервіс кластера повертає запис CNAME із значенням my.database.example.com. Доступ до my-service працює так само, як і для інших Сервісів, але з важливою різницею в тому, що перенаправлення відбувається на рівні DNS, а не через проксі або переадресацію. Якщо ви пізніше вирішите перемістити свою базу даних в кластер, ви можете запустити його Podʼи, додати відповідні селектори чи endpointʼи та змінити тип Сервісу.
Увага:
Можливі проблеми з використанням ExternalName для деяких загальних протоколів, таких як HTTP та HTTPS. Якщо ви використовуєте ExternalName, імʼя хоста, яке використовують клієнти всередині вашого кластера, відрізняється від імені, на яке посилається ExternalName.
Для протоколів, які використовують імена хостів, ця різниця може призвести до помилок або непередбачуваних відповідей. HTTP-запити матимуть заголовок Host:, який сервер-джерело не визнає; сервери TLS не зможуть надати сертифікат, що відповідає імені хоста, до якого приєдно клієнта.
Headless Services
Іноді вам не потрібен балансувальник навантаження та одна IP-адреса Сервісу. У цьому випадку ви можете створити так звані headless Services, якщо явно вказати "None" для IP-адреси кластера (.spec.clusterIP).
Ви можете використовувати headless Сервіс для взаємодії з іншими механізмами виявлення служб, не будучи привʼязаним до реалізації Kubernetes.
Для headless Сервісів кластерна IP-адреса не видається, kube-proxy не обслуговує ці Сервіси, і для них платформа не виконує балансування навантаження чи проксіюваня.
Headless Сервіси дозволяють клієнту приєднуватись до будь-якого Pod безпосередньо. Ці Сервіси не встановлюють маршрути та перенаправлення пакетів з використанням віртуальних IP-адрес та проксі; натомість вони повідомляють про IP-адреси точок доступу окремих Podʼів через внутрішні записи DNS, які обслуговуються службою DNS кластера. Для визначення headless Сервіса вам потрібно створити Service з .spec.type встановленим на ClusterIP (що також є типовим значенням) та .spec.clusterIP встановленим у None.
Рядкове значення None є спеціальним випадком та не є тотожноми тому, якщо поле .spec.clusterIP не вказане.
Те, як автоматично налаштовано DNS, залежить від того, чи визначені селектори Сервісу:
З селекторами
Для headless Сервісів, які визначають селектори, контролер endpointʼів створює обʼєкти EndpointSlice в Kubernetes API та змінює конфігурацію DNS так, щоб повертати записи A або AAAA (IPv4 або IPv6 адреси), які напрямую вказують на Podʼи, які підтримують Сервіс.
Без селекторів
Для headless Сервісів, які не визначають селектори, панель управління не створює обʼєкти EndpointSlice. Проте система DNS шукає та налаштовує або:
- DNS-записи CNAME для Сервісів з
type: ExternalName. - DNS-записи A / AAAA для всіх IP-адрес Сервісу з готовими endpointʼами, для всіх типів Сервісів, крім
ExternalName.- Для IPv4 endpointʼів система DNS створює A-записи.
- Для IPv6 endpointʼів система DNS створює AAAA-записи.
Коли ви визначаєте headless Сервіс без селектора, поле port повинно відповідати полю targetPort.
Виявлення сервісів
Для клієнтів, що працюють всередині вашого кластера, Kubernetes підтримує два основних способи виявлення Сервісу: змінні середовища та DNS.
Змінні середовища
Коли Pod запускається на вузлі, kubelet додає набір змінних середовища для кожного активного Сервісу. Додаються змінні середовища {SVCNAME}_SERVICE_HOST та {SVCNAME}_SERVICE_PORT, де імʼя Сервісу перетворюється у верхній регістр, а тире конвертуються у підкреслення.
Наприклад, Сервіс redis-primary, який використовує TCP-порт 6379 та має присвоєну IP-адресу кластера 10.0.0.11, створює наступні змінні середовища:
REDIS_PRIMARY_SERVICE_HOST=10.0.0.11
REDIS_PRIMARY_SERVICE_PORT=6379
REDIS_PRIMARY_PORT=tcp://10.0.0.11:6379
REDIS_PRIMARY_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_PRIMARY_PORT_6379_TCP_PROTO=tcp
REDIS_PRIMARY_PORT_6379_TCP_PORT=6379
REDIS_PRIMARY_PORT_6379_TCP_ADDR=10.0.0.11
Примітка:
Коли у вас є Pod, який потребує доступу до Сервісу, і ви використовуєте метод змінної середовища для публікації порту та кластерного IP для Podʼів клієнта, ви повинні створити Сервіс перед створенням Podʼів клієнта. В іншому випадку ці Podʼи клієнта не матимуть заповнених змінних середовища.
Якщо ви використовуєте лише DNS для визначення кластерного IP для Сервісу, вам не потрібно турбуватися про цю проблему порядку.
Kubernetes також підтримує та надає змінні, які сумісні з "legacy container links" Docker Engine. Ви можете переглянути makeLinkVariables щоб побачити, як це реалізовано в Kubernetes.
DNS
Ви можете (і майже завжди повинні) налаштувати службу DNS для вашого кластера Kubernetes, використовуючи надбудову.
Сервер DNS, знається на кластерах, такий як CoreDNS, стежить за Kubernetes API для виявлення нових Сервісів і створює набір DNS-записів для кожного з них. Якщо DNS увімкнено в усьому кластері, то всі Podʼи повинні автоматично мати можливість знаходити Сервіси за їхнім DNS-імʼям.
Наприклад, якщо у вас є Сервіс з назвою my-service в просторі імен Kubernetes my-ns, то разом панель управління та служба DNS створюють DNS-запис для my-service.my-ns. Podʼи в просторі імен my-ns повинні мати можливість знаходити Сервіс, роблячи запит за іменем my-service (my-service.my-ns також працюватиме).
Podʼи в інших просторах імен повинні вказати імʼя як my-service.my-ns. Ці імена будуть розповсюджуватись на призначений кластером IP для Сервісу.
Kubernetes також підтримує DNS SRV (Service) записи для іменованих портів. Якщо Сервіс my-service.my-ns має порт з іменем http і протоколом, встановленим в TCP, ви можете виконати DNS SRV-запит для _http._tcp.my-service.my-ns, щоб дізнатися номер порту для http, а також IP-адресу.
Сервер DNS Kubernetes — єдиний спосіб доступу до Сервісів ExternalName. Ви можете знайти більше інформації про вирішення ExternalName в DNS для Сервісів та Podʼів.
Механізм віртуальних IP-адрес
Прочитайте Віртуальні IP-адреси та сервісні проксі, що пояснює механізм, який Kubernetes надає для експозиції Сервісу з віртуальною IP-адресою.
Політики трафіку
Ви можете встановити поля .spec.internalTrafficPolicy та .spec.externalTrafficPolicy, щоб контролювати, як Kubernetes маршрутизує трафік до справних ("готових") бекендів.
Дивіться Політики трафіку для отримання докладнішої інформації.
Розподіл трафіку
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [beta] (стандартно увімкнено: true)Поле .spec.trafficDistribution надає ще один спосіб впливу на маршрутизацію трафіку в межах Сервісу Kubernetes. Хоча політика трафіку зосереджується на строгих семантичних гарантіях, розподіл трафіку дозволяє виражати уподобання (наприклад, маршрутизацію до топологічно ближчих точок доступу). Це може допомогти оптимізувати продуктивність, вартість або надійність. Це необовʼязкове поле можна використовувати, якщо ви ввімкнули функціональну можливість ServiceTrafficDistribution для вашого кластера та всіх його вузлів. У Kubernetes 1.32, підтримується таке значення поля:
PreferClose- Вказує на уподобання маршрутизації трафіку до точок доступу, які є топологічно близькими до клієнта. Інтерпретація "топологічної близькості" може варіюватися в залежності від реалізацій і може охоплювати точки доступу всередині того самого вузла, стійки, зони або навіть регіони. Встановлення цього значення надає реалізаціям дозвіл на прийняття різних компромісів, наприклад, оптимізацію на користь близькості замість рівномірного розподілу навантаження. Користувачам не слід встановлювати це значення, якщо такі компроміси неприйнятні.
Якщо поле не встановлено, реалізація застосує свою стандартну стратегію маршрутизації.
Дивіться Розподіл трафіку для отримання додаткової інформації.
Збереження сесії
Якщо ви хочете переконатися, що зʼєднання з певного клієнта щоразу передаються до одного і того ж Pod, ви можете налаштувати спорідненість сеансу на основі IP-адреси клієнта. Докладніше читайте спорідненість сесії.
Зовнішні IP
Якщо існують зовнішні IP-адреси, які маршрутизують до одного чи декількох вузлів кластера, Сервіси Kubernetes можна використовувати на цих externalIPs. Коли мережевий трафік потрапляє в кластер із зовнішнім IP (як IP призначення) та портом, який відповідає цьому Сервісу, правила та маршрути, які Kubernetes налаштовує, забезпечують маршрутизацію трафіку до одного з кінцевих пунктів цього Сервісу.
При визначенні Сервісу ви можете вказати externalIPs для будь-якого типу сервісу. У наведеному нижче прикладі Сервіс з іменем "my-service" може отримати доступ від клієнтів за допомогою TCP за адресою "198.51.100.32:80" (розраховано із .spec.externalIPs[] та .spec.ports[].port).
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 49152
externalIPs:
- 198.51.100.32
Примітка:
Kubernetes не керує виділеннямexternalIPs; це відповідальність адміністратора кластера.API Обʼєкт
Сервіс — це ресурс верхнього рівня в Kubernetes REST API. Ви можете знайти більше деталей про обʼєкт API Service.
Що далі
Дізнайтеся більше про Сервіси та те, як вони вписуються в Kubernetes:
- Дізнайтесь про Підключення застосунків за допомогою Service уроку.
- Прочитайте про Ingress, який експонує маршрути HTTP та HTTPS ззовні кластера до Сервісів всередині вашого кластера.
- Прочитайте про Gateway, розширення для Kubernetes, яке надає більше гнучкості, ніж Ingress.
Для отримання додаткового контексту прочитайте наступне:
5.2 - Ingress
Робить вашу мережеву службу HTTP (або HTTPS) доступною за допомогою конфігурації, яка розуміє протокол та враховує вебконцепції, такі як URI, імена хостів, шляхи та інше. Концепція Ingress дозволяє вам направляти трафік на різні бекенди на основі правил, які ви визначаєте через API Kubernetes.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.19 [stable]Обʼєкт API, який управляє зовнішнім доступом до служб в кластері, зазвичай HTTP.
Ingress може надавати балансування навантаження, розшифровування SSL-трафіку та віртуальний хостинг на основі імен.
Примітка:
Ingress заморожений. Нові функції додаються до Gateway API.Термінологія
Для ясності цей посібник визначає наступні терміни:
- Вузол: Робоча машина в Kubernetes, що є частиною кластера.
- Кластер: Набір вузлів, на яких виконуються контейнеризовані застосунки, керовані Kubernetes. У прикладі та в більшості типових розгортань Kubernetes вузли кластера не є частиною відкритої мережі Інтернет.
- Edge маршрутизатор: Маршрутизатор, який застосовує політику брандмауера для вашого кластера. Це може бути шлюз, керований хмарним постачальником, або фізичний пристрій.
- Кластерна мережа: Набір зʼєднань, логічних або фізичних, які сприяють комунікації в межах кластера згідно з мережевою моделлю Kubernetes.
- Service: Service Kubernetes, що ідентифікує набір Podʼів за допомогою селекторів label. Якщо не вказано інше, припускається, що служби мають віртуальні IP-адреси, які можна маршрутизувати лише в межах кластерної мережі.
Що таке Ingress?
Ingress відкриває маршрути HTTP та HTTPS із зовні кластера до Services всередині кластера. Маршрутизацію трафіку контролюють правила, визначені в ресурсі Ingress.
Ось простий приклад, де Ingress спрямовує весь свій трафік на один Service:graph LR;
client([клієнт])-. Балансувальник навантаження
яким керує Ingress .->ingress[Ingress];
ingress-->|правила
маршрутизації|service[Service];
subgraph cluster["Кластер"]
ingress;
service-->pod1[Pod];
service-->pod2[Pod];
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class ingress,service,pod1,pod2 k8s;
class client plain;
class cluster cluster;
Ingress може бути налаштований таким чином, щоб надавати Service зовнішньодоступні URL, балансувати трафік, термінувати SSL/TLS та пропонувати іменований віртуальний хостинг. Контролер Ingress відповідає за виконання Ingress, зазвичай з допомогою балансувальника навантаження, хоча він також може конфігурувати ваш edge маршрутизатор або додаткові фронтенди для допомоги в обробці трафіку.
Ingress не відкриває довільні порти або протоколи. Для експозиції служб, відмінних від HTTP та HTTPS, в Інтернет зазвичай використовується служба типу Service.Type=NodePort або Service.Type=LoadBalancer.
Передумови
Вам потрібно мати контролер Ingress, щоб виконувати Ingress. Лише створення ресурсу Ingress не має ефекту.
Можливо, вам доведеться розгорнути контролер Ingress, такий як ingress-nginx. Ви можете вибрати з-поміж контролерів Ingress.
В ідеалі, всі контролери Ingress повинні відповідати вказаній специфікації. На практиці різні контролери Ingress працюють трошки по-різному.
Примітка:
Переконайтеся, що ви ознайомились з документацією вашого контролера Ingress, щоб зрозуміти його особливості.Ресурс Ingress
Мінімальний приклад ресурсу Ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: minimal-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx-example
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
service:
name: test
port:
number: 80
Для Ingress необхідні поля apiVersion, kind, metadata та spec.
Назва обʼєкта Ingress повинна бути дійсним DNS-піддоменом. Для загальної інформації щодо роботи з файлами конфігурації дивіться розгортання застосунків, налаштування контейнерів, управління ресурсами. Ingress часто використовує анотації для налаштування деяких параметрів залежно від контролера Ingress, прикладом чого є анотація для перезапису. Різні контролери Ingress підтримують різні анотації. Ознайомтеся з документацією контролера Ingress, який ви вибрали, щоб дізнатися, які анотації підтримуються.
У специфікації Ingress міститься вся інформація, необхідна для налаштування балансувальника навантаження чи проксі-сервера. Важливою є наявність списку правил, які порівнюються з усіма вхідними запитами. Ресурс Ingress підтримує правила тільки для направлення трафіку HTTP(S).
Якщо ingressClassName відсутній, має бути визначений типовий клас Ingress.
Є контролери Ingress, які працюють без визначення типового IngressClass. Наприклад, контролер Ingress-NGINX може бути налаштований за допомогою прапора --watch-ingress-without-class. З усім тим, рекомендується вказати типовий IngressClass, як показано нижче.
Правила Ingress
Кожне правило HTTP містить наступну інформацію:
- Необовʼязковий хост. У цьому прикладі хост не вказаний, тому правило застосовується до всього вхідного HTTP-трафіку через вказану IP-адресу. Якщо вказано хост (наприклад, foo.bar.com), правила застосовуються до цього хосту.
- Список шляхів (наприклад,
/testpath), кожен з яких має повʼязаний бекенд, визначений імʼямservice.nameтаservice.port.nameабоservice.port.number. Як хост, так і шлях повинні відповідати вмісту вхідного запиту, перш ніж балансувальник навантаження направить трафік до зазначеного Service. - Бекенд — це комбінація імені Service та порту, як описано в документації Service або ресурсом бекенду користувача за допомогою CRD. HTTP (та HTTPS) запити до Ingress, які відповідають хосту та шляху правила, надсилаються до вказаного бекенду.
Зазвичай в Ingress контролері налаштований defaultBackend, який обслуговує будь-які запити, які не відповідають шляху в специфікації.
DefaultBackend
Ingress без правил спрямовує весь трафік до єдиного стандартного бекенду, і .spec.defaultBackend — це бекенд, який повинен обробляти запити в цьому випадку. Зазвичай defaultBackend — це опція конфігурації контролера Ingress і не вказується в ресурсах вашого Ingress. Якщо не вказано .spec.rules, то повинен бути вказаний .spec.defaultBackend. Якщо defaultBackend не встановлено, обробка запитів, які не відповідають жодному з правил, буде покладена на контролер ingress (звертайтеся до документації свого контролера Ingress, щоб дізнатися, як він обробляє цей випадок).
Якщо жоден із хостів або шляхів не відповідає HTTP-запиту в обʼєктах Ingress, трафік направляється до вашого стандартного бекенду.
Бекенд Resource
Бекенд Resource — це ObjectRef на інший ресурс Kubernetes всередині того ж простору імен, що й обʼєкт Ingress. Resource — є несумісним з Service, перевірка налаштувань виявить помилку, якщо вказані обидва. Звичайне використання для бекенду Resource — це направлення даних в обʼєкт зберігання зі статичними ресурсами.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-resource-backend
spec:
defaultBackend:
resource:
apiGroup: k8s.example.com
kind: StorageBucket
name: static-assets
rules:
- http:
paths:
- path: /icons
pathType: ImplementationSpecific
backend:
resource:
apiGroup: k8s.example.com
kind: StorageBucket
name: icon-assets
Після створення Ingress вище, ви можете переглянути його за допомогою наступної команди:
kubectl describe ingress ingress-resource-backend
Name: ingress-resource-backend
Namespace: default
Address:
Default backend: APIGroup: k8s.example.com, Kind: StorageBucket, Name: static-assets
Rules:
Host Path Backends
---- ---- --------
*
/icons APIGroup: k8s.example.com, Kind: StorageBucket, Name: icon-assets
Annotations: <none>
Events: <none>
Типи шляхів
Для кожного шляху в Ingress обовʼязково повинен бути відповідний тип шляху. Шляхи, які не включають явний pathType, не пройдуть валідацію. Існує три типи шляхів, що підтримуються:
ImplementationSpecific: З цим типом шляху визначення відповідності залежить від IngressClass. Реалізації можуть розглядати це як окремийpathTypeабо обробляти його так само як типи шляхівPrefixабоExact.Exact: Відповідає URL-шляху точно і з урахуванням регістрів.Prefix: Відповідає на основі префіксу URL-шляху, розділеному/. Відповідність визначається з урахуванням регістру і виконується поелементно за кожним елементом шляху. Елемент шляху вказує на список міток у шляху, розділених роздільником/. Запит відповідає шляху p, якщо кожен p є префіксом елемента p запиту.Примітка:
Якщо останній елемент шляху є підрядком останнього елементу в шляху запиту, це не вважається відповідністю (наприклад:/foo/barвідповідає/foo/bar/baz, але не відповідає/foo/barbaz).
Приклади
| Тип | Шлях(и) | Шлях запиту | Відповідає? |
|---|---|---|---|
| Префікс | / | (всі шляхи) | Так |
| Точний | /foo | /foo | Так |
| Точний | /foo | /bar | Ні |
| Точний | /foo | /foo/ | Ні |
| Точний | /foo/ | /foo | Ні |
| Префікс | /foo | /foo, /foo/ | Так |
| Префікс | /foo/ | /foo, /foo/ | Так |
| Префікс | /aaa/bb | /aaa/bbb | Ні |
| Префікс | /aaa/bbb | /aaa/bbb | Так |
| Префікс | /aaa/bbb/ | /aaa/bbb | Так, ігнорує кінцевий слеш |
| Префікс | /aaa/bbb | /aaa/bbb/ | Так, співпадає з кінцевим слешем |
| Префікс | /aaa/bbb | /aaa/bbb/ccc | Так, співпадає з підшляхом |
| Префікс | /aaa/bbb | /aaa/bbbxyz | Ні, не співпадає з префіксом рядка |
| Префікс | /, /aaa | /aaa/ccc | Так, співпадає з префіксом /aaa |
| Префікс | /, /aaa, /aaa/bbb | /aaa/bbb | Так, співпадає з префіксом /aaa/bbb |
| Префікс | /, /aaa, /aaa/bbb | /ccc | Так, співпадає з префіксом / |
| Префікс | /aaa | /ccc | Ні, використовується типовий backend |
| Змішаний | /foo (Префікс), /foo (Точний) | /foo | Так, віддає перевагу Точному |
Декілька збігів
У деяких випадках одночасно можуть збігатися кілька шляхів в межах Ingress. У цих випадках перевага буде надаватися спочатку найдовшому збігу шляху. Якщо два шляхи все ще однаково збігаються, перевага буде надаватися шляхам із точним типом шляху перед префіксним типом шляху.
Шаблони імен хостів
Хости можуть бути точними збігами (наприклад, "foo.bar.com") або містити шаблони (наприклад, "*.foo.com"). Точні збіги вимагають, щоб заголовок HTTP host відповідав полю host. Шаблони вимагають, щоб заголовок HTTP host був рівним суфіксу правила з символами підстановки.
| Хост | Заголовок хоста | Збіг? |
|---|---|---|
*.foo.com | bar.foo.com | Збіг на основі спільного суфіксу |
*.foo.com | baz.bar.foo.com | Немає збігу, символ підстановки охоплює лише одну DNS-мітку |
*.foo.com | foo.com | Немає збігу, символ підстановки охоплює лише одну DNS-мітку |
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-wildcard-host
spec:
rules:
- host: "foo.bar.com"
http:
paths:
- pathType: Prefix
path: "/bar"
backend:
service:
name: service1
port:
number: 80
- host: "*.foo.com"
http:
paths:
- pathType: Prefix
path: "/foo"
backend:
service:
name: service2
port:
number: 80
Клас Ingress
Ingressʼи можуть бути реалізовані різними контролерами, часто з різною конфігурацією. Кожен Ingress повинен вказати клас — посилання на ресурс IngressClass, який містить додаткову конфігурацію, включаючи імʼя контролера, який повинен реалізувати цей клас.
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb
spec:
controller: example.com/ingress-controller
parameters:
apiGroup: k8s.example.com
kind: IngressParameters
name: external-lb
Поле .spec.parameters класу IngressClass дозволяє посилатися на інший ресурс, який надає конфігурацію, повʼязану з цим класом IngressClass.
Конкретний тип параметрів для використання залежить від контролера Ingress, який ви вказуєте в полі .spec.controller IngressClass.
Область застосування IngressClass
Залежно від вашого контролера Ingress, ви можете використовувати параметри, які ви встановлюєте на рівні кластера, або лише для одного простору імен.
Стандартна область застосування параметрів IngressClass — це весь кластер.
Якщо ви встановлюєте поле .spec.parameters і не встановлюєте .spec.parameters.scope, або ви встановлюєте .spec.parameters.scope на Cluster, тоді IngressClass посилається на ресурс, який є на рівні кластера. kind (в поєднанні з apiGroup) параметрів вказує на API на рівні кластера (можливо, власний ресурс), і name параметрів ідентифікує конкретний ресурс на рівні кластера для цього API.
Наприклад:
---
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb-1
spec:
controller: example.com/ingress-controller
parameters:
# Параметри для цього IngressClass вказані в ClusterIngressParameter
# (API group k8s.example.net) імені "external-config-1".
# Це визначення вказує Kubernetes шукати ресурс параметрів на рівні кластера.
scope: Cluster
apiGroup: k8s.example.net
kind: ClusterIngressParameter
name: external-config-1
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.23 [stable]Якщо ви встановлюєте поле .spec.parameters і встановлюєте .spec.parameters.scope на Namespace, тоді IngressClass посилається на ресурс на рівні простору імен. Ви також повинні встановити поле namespace в межах .spec.parameters на простір імен, який містить параметри, які ви хочете використовувати.
kind (в поєднанні з apiGroup) параметрів вказує на API на рівні простору імен (наприклад: ConfigMap), і name параметрів ідентифікує конкретний ресурс у просторі імен, який ви вказали в namespace.
Параметри на рівні простору імен допомагають оператору кластера делегувати контроль над конфігурацією (наприклад: налаштування балансувальника трафіку, визначення шлюзу API) що використовується для робочого навантаження. Якщо ви використовуєте параметр на рівні кластера, то або:
- команда операторів кластера повинна схвалити зміни іншої команди кожен раз, коли застосовується нова конфігураційна зміна.
- оператор кластера повинен визначити конкретні засоби керування доступом, такі як RBAC ролі та привʼязки, що дозволяють команді застосунків вносити зміни в ресурс параметрів на рівні кластера.
Сам API IngressClass завжди має область застосування на рівні кластера.
Ось приклад IngressClass, який посилається на параметри на рівні простору імен:
---
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb-2
spec:
controller: example.com/ingress-controller
parameters:
# Параметри для цього IngressClass вказані в IngressParameter
# (API group k8s.example.com) імені "external-config",
# що знаходиться в просторі імен "external-configuration".
scope: Namespace
apiGroup: k8s.example.com
kind: IngressParameter
namespace: external-configuration
name: external-config
Застарілі анотації
Перед тим, як в Kubernetes 1.18 були додані ресурс IngressClass та поле ingressClassName, класи Ingress вказувалися за допомогою анотації kubernetes.io/ingress.class в Ingress. Ця анотація ніколи не була формально визначена, але отримала широку підтримку контролерами Ingress.
Нове поле ingressClassName в Ingress — це заміна для цієї анотації, але не є прямим еквівалентом. Хоча анотація, як правило, використовувалася для посилання на імʼя контролера Ingress, який повинен реалізувати Ingress, поле є посиланням на ресурс IngressClass, який містить додаткову конфігурацію Ingress, включаючи
імʼя контролера Ingress.
Стандартний IngressClass
Ви можете визначити певний IngressClass як стандартний для вашого кластера. Встановлення анотації ingressclass.kubernetes.io/is-default-class зі значенням true на ресурсі IngressClass забезпечить те, що новим Ingress буде призначений цей типовий IngressClass, якщо в них не вказано поле ingressClassName.
Увага:
Якщо у вас є більше одного IngressClass, відзначеного як стандартного для вашого кластера, контролер доступу завадить створенню нових обʼєктів Ingress, в яких не вказано полеingressClassName. Ви можете вирішити це, забезпечивши, те що в вашому кластері визначено не більше 1 типового IngressClass.Є контролери Ingress, які працюють без визначення типового IngressClass. Наприклад, контролер Ingress-NGINX може бути налаштований з прапорцем
--watch-ingress-without-class. Однак рекомендується визначати типовий IngressClass явно:
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
labels:
app.kubernetes.io/component: controller
name: nginx-example
annotations:
ingressclass.kubernetes.io/is-default-class: "true"
spec:
controller: k8s.io/ingress-nginx
Типи Ingress
Ingress з підтримкою одного Service
Існують концепції в Kubernetes, що дозволяють вам використовувати один Service (див. альтернативи). Ви також можете зробити це за допомогою Ingress, вказавши стандартний бекенд без правил.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: test-ingress
spec:
defaultBackend:
service:
name: test
port:
number: 80
Якщо ви створите його за допомогою kubectl apply -f, ви повинні мати можливість переглядати стан доданого Ingress:
kubectl get ingress test-ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
test-ingress external-lb * 203.0.113.123 80 59s
Де 203.0.113.123 — це IP-адреса, яку надав контролер Ingress для виконання цього Ingress.
Примітка:
Для контролерів Ingress та балансувальників навантаження це може тривати хвилину або дві для виділення IP-адреси. Тож ви часто можете побачити, що адреса вказана як<pending>.Простий розподіл
Конфігурація розподілу дозволяє маршрутизувати трафік з одної IP-адреси до більше ніж одного сервісу, виходячи з HTTP URI, що запитується. Ingress дозволяє зберігати кількість балансувальників на мінімальному рівні. Наприклад, налаштування як:
graph LR;
client([клієнт])-. Балансувальник навантаження
яким керує Ingress .->ingress[Ingress, 178.91.123.132];
ingress-->|/foo|service1[Service service1:4200];
ingress-->|/bar|service2[Service service2:8080];
subgraph cluster["Кластер"]
ingress;
service1-->pod1[Pod];
service1-->pod2[Pod];
service2-->pod3[Pod];
service2-->pod4[Pod];
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class ingress,service1,service2,pod1,pod2,pod3,pod4 k8s;
class client plain;
class cluster cluster;
Для цього потрібно мати Ingress, наприклад:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: simple-fanout-example
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
pathType: Prefix
backend:
service:
name: service1
port:
number: 4200
- path: /bar
pathType: Prefix
backend:
service:
name: service2
port:
number: 8080
Коли ви створюєте Ingress за допомогою kubectl apply -f:
kubectl describe ingress simple-fanout-example
Name: simple-fanout-example
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:4200 (10.8.0.90:4200)
/bar service2:8080 (10.8.0.91:8080)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 22s loadbalancer-controller default/test
Контролер Ingress надає реалізаційно-специфічний балансувальник що влаштовує Ingress, за умови, що існують сервіси (service1, service2). Коли це сталося, ви можете побачити адресу балансувальника в полі Address.
Примітка:
Залежно від контролера Ingress, який ви використовуєте, можливо, вам доведеться створити сервіс default-http-backend Service.Віртуальний хостинг на основі імен
Віртуальні хости на основі імен підтримують маршрутизацію HTTP-трафіку до кількох імен хостів за однією IP-адресою.
graph LR;
client([клієнт])-. Балансувальник навантаження
яким керує Ingress .->ingress[Ingress, 178.91.123.132];
ingress-->|Host: foo.bar.com|service1[Service service1:80];
ingress-->|Host: bar.foo.com|service2[Service service2:80];
subgraph cluster["Кластер"]
ingress;
service1-->pod1[Pod];
service1-->pod2[Pod];
service2-->pod3[Pod];
service2-->pod4[Pod];
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class ingress,service1,service2,pod1,pod2,pod3,pod4 k8s;
class client plain;
class cluster cluster;
Наступний Ingress вказує балансувальнику направляти запити на основі заголовка Host.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: name-virtual-host-ingress
spec:
rules:
- host: foo.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service1
port:
number: 80
- host: bar.foo.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service2
port:
number: 80
Якщо ви створюєте ресурс Ingress без визначених хостів в правилах, то будь-який вебтрафік на IP-адресу вашого контролера Ingress може відповідати без необхідності в імені заснованому віртуальному хості.
Наприклад, наступний Ingress маршрутизує трафік спрямований для first.bar.com до service1, second.bar.com до service2, і будь-який трафік, який має заголовок запиту хоста, який не відповідає first.bar.com і second.bar.com до service3.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: name-virtual-host-ingress-no-third-host
spec:
rules:
- host: first.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service1
port:
number: 80
- host: second.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service2
port:
number: 80
- http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service3
port:
number: 80
TLS
Ви можете захистити Ingress, вказавши Secret, що містить приватний ключ TLS та сертифікат. Ресурс Ingress підтримує лише один TLS-порт, 443, та передбачає термінування TLS на точці входу (трафік до Service та його Podʼів передається у вигляді звичайного тексту). Якщо розділ конфігурації TLS в Ingress вказує різні хости, вони мультиплексуються на одному порту відповідно до імені хоста, вказаного через розширення TLS з SNI (за умови, що контролер Ingress підтримує SNI). TLS-секрет повинен містити ключі з іменами tls.crt та tls.key, які містять сертифікат та приватний ключ для використання TLS. Наприклад:
apiVersion: v1
kind: Secret
metadata:
name: testsecret-tls
namespace: default
data:
tls.crt: base64 encoded cert
tls.key: base64 encoded key
type: kubernetes.io/tls
Посилання на цей секрет в Ingress дозволяє контролеру Ingress захистити канал, що йде від клієнта до балансувальника навантаження за допомогою TLS. Вам потрібно переконатися, що TLS-секрет, який ви створили, містить сертифікат, який містить Common Name (CN), також Fully Qualified Domain Name (FQDN) для https-example.foo.com.
Примітка:
Майте на увазі, що TLS не працюватиме типове для правил, оскільки сертифікати повинні бути видані для всіх можливих піддоменів. Таким чином,hosts в розділі tls повинні явно відповідати host в розділі rules.apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: tls-example-ingress
spec:
tls:
- hosts:
- https-example.foo.com
secretName: testsecret-tls
rules:
- host: https-example.foo.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service1
port:
number: 80
Примітка:
Є різниця між можливостями TLS, які підтримуються різними Ingress контролерами. Будь ласка, зверніться до документації nginx, GCE, або будь-якого іншого платформозалежного контролера Ingress, щоб зрозуміти, як TLS працює в вашому середовищі.Балансування навантаження
Контролер Ingress створюється з певними параметрами політики балансування навантаження, які він застосовує до всіх Ingress, таких як алгоритм балансування навантаження, схема коефіцієнтів ваги бекенду та інші. Більш розширені концепції балансування навантаження (наприклад, постійні сесії, динамічні коефіцієнти ваги) наразі не експонуються через Ingress. Замість цього ви можете отримати ці функції через балансувальник, що використовується для Service.
Також варто зазначити, що навіть якщо перевірки стану не експоновані безпосередньо через Ingress, існують паралельні концепції в Kubernetes, такі як перевірки готовності, що дозволяють досягти того ж самого результату. Будь ласка, ознайомтеся з документацією конкретного контролера, щоб переглянути, як вони обробляють перевірки стану (наприклад: nginx або GCE).
Оновлення Ingress
Щоб оновити існуючий Ingress і додати новий хост, ви можете відредагувати ресурс таким чином:
kubectl describe ingress test
Name: test
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:80 (10.8.0.90:80)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 35s loadbalancer-controller default/test
kubectl edit ingress test
Це відкриє редактор з поточною конфігурацією у форматі YAML. Змініть її, щоб додати новий хост:
spec:
rules:
- host: foo.bar.com
http:
paths:
- backend:
service:
name: service1
port:
number: 80
path: /foo
pathType: Prefix
- host: bar.baz.com
http:
paths:
- backend:
service:
name: service2
port:
number: 80
path: /foo
pathType: Prefix
..
Після збереження змін, kubectl оновлює ресурс у API-сервері, що повідомляє Ingress-контролеру переконфігурувати балансувальник.
Перевірте це:
kubectl describe ingress test
Name: test
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:80 (10.8.0.90:80)
bar.baz.com
/foo service2:80 (10.8.0.91:80)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 45s loadbalancer-controller default/test
Ви можете досягти того самого результату, викликавши kubectl replace -f із зміненим файлом YAML для Ingress.
Збій у різних зонах доступності
Методи розподілу трафіку між доменами відмови відрізняються між хмарними провайдерами. Будь ласка, перевірте документацію відповідного контролера Ingress для отримання деталей.
Альтернативи
Ви можете використовувати різні способи надання доступу до Service, які безпосередньо не стосуються ресурсу Ingress:
- Використовуйте Service.Type=LoadBalancer
- Використовуйте Service.Type=NodePort
Що далі
- Дізнайтеся про API Ingress
- Дізнайтеся про контролери Ingress
- Налаштуйте Ingress на Minikube з контролером NGINX
5.3 - Контролери Ingress
Для того, щоб ресурс Ingress працював у вашому кластері, повинен бути запущений контролер Ingress. Вам потрібно вибрати принаймні один контролер Ingress та переконатися, що він налаштований у вашому кластері. На цій сторінці перелічені поширені контролери Ingress, які ви можете встановити.
Для того, щоб ресурс Ingress працював, у кластері повинен бути запущений контролер Ingress.
На відміну від інших типів контролерів, які працюють як частина бінарного файлу kube-controller-manager, контролери Ingress не запускаються автоматично разом з кластером. Використовуйте цю сторінку, щоб вибрати реалізацію контролера Ingress, яка найкраще підходить для вашого кластера.
Проєкт Kubernetes підтримує контролери Ingress для AWS, GCE та nginx.
Додаткові контролери
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
- AKS Application Gateway Ingress Controller — це контролер Ingress, який налаштовує Azure Application Gateway.
- Alibaba Cloud MSE Ingress — це контролер Ingress, який налаштовує Alibaba Cloud Native Gateway, який також є комерційною версією Higress.
- Apache APISIX Ingress Controller — це контролер Ingress, заснований на Apache APISIX.
- Avi Kubernetes Operator забезпечує балансування навантаження рівня 4-7, використовуючи VMware NSX Advanced Load Balancer.
- BFE Ingress Controller — це контролер Ingress, заснований на BFE.
- Cilium Ingress Controller — це контролер Ingress, який працює на основі Cilium.
- Контролер Ingress Citrix співпрацює з контролером доставки програм Citrix.
- Contour — це контролер Ingress на основі Envoy.
- Emissary-Ingress API Gateway — це контролер Ingress на основі Envoy.
- EnRoute — це шлюз API на основі Envoy, який може працювати як контролер Ingress.
- Easegress IngressController — це шлюз API на основі Easegress, який може працювати як контролер Ingress.
- F5 BIG-IP Container Ingress Services for Kubernetes дозволяє використовувати Ingress для конфігурації віртуальних серверів F5 BIG-IP.
- FortiADC Ingress Controller підтримує ресурси Kubernetes Ingress та дозволяє керувати обʼєктами FortiADC з Kubernetes
- Gloo — це відкритий контролер Ingress на основі Envoy, який пропонує функціональність воріт API.
- HAProxy Ingress — це контролер Ingress для HAProxy.
- Higress — це шлюз API на основі Envoy, який може працювати як контролер Ingress.
- Контролер Ingress HAProxy для Kubernetes також є контролером Ingress для HAProxy.
- Istio Ingress — це контролер Ingress на основі Istio.
- Контролер Ingress Kong для Kubernetes — це контролер Ingress, який керує Kong Gateway.
- Kusk Gateway — це контролер Ingress, орієнтований на OpenAPI, на основі Envoy.
- Контролер Ingress NGINX для Kubernetes працює з вебсервером NGINX (як проксі).
- ngrok Kubernetes Ingress Controller — це контролер Ingress з відкритим кодом для надання безпечного публічного доступу до ваших служб K8s за допомогою платформи ngrok.
- Контролер Ingress OCI Native — це контролер Ingress для Oracle Cloud Infrastructure, який дозволяє керувати OCI Load Balancer.
- OpenNJet Ingress Controller є ingress-контролером на основі OpenNJet.
- Контролер Ingress Pomerium — це контролер Ingress на основі Pomerium, який пропонує політику доступу з урахуванням контексту.
- Skipper — це HTTP-маршрутизатор та зворотний проксі для композиції служб, включаючи випадки використання, такі як Kubernetes Ingress, розроблений як бібліотека для побудови вашого власного проксі.
- Контролер Ingress Traefik Kubernetes provider — це контролер Ingress для проксі Traefik.
- Tyk Operator розширює Ingress за допомогою власних ресурсів для надання можливостей управління API Ingress. Tyk Operator працює з відкритими шлюзами Tyk та хмарною системою управління Tyk.
- Voyager — це контролер Ingress для HAProxy.
- Контролер Ingress Wallarm — це контролер Ingress, який надає можливості WAAP (WAF) та захисту API.
Використання кількох контролерів Ingress
Ви можете розгортати будь-яку кількість контролерів Ingress за допомогою класу Ingress у межах кластера. Зверніть увагу на значення .metadata.name вашого ресурсу класу Ingress. При створенні Ingress вам слід вказати це імʼя для визначення поля ingressClassName в обʼєкті Ingress (див. специфікацію IngressSpec v1). ingressClassName є заміною застарілого методу анотації.
Якщо ви не вказуєте IngressClass для Ingress, і у вашому кластері рівно один IngressClass відзначений як типовий, тоді Kubernetes застосовує типовий IngressClass кластера до Ingress. Ви вказуєте IngressClass як типовий, встановлюючи анотацію ingressclass.kubernetes.io/is-default-class для цього IngressClass, зі значенням "true".
В ідеалі, всі контролери Ingress повинні відповідати цій специфікації, але різні контролери Ingress працюють трошки по-різному.
Примітка:
Переконайтеся, що ви ознайомилися з документацією вашого контролера Ingress, щоб зрозуміти особливості вибору.Що далі
- Дізнайтеся більше про Ingress.
- Налаштуйте Ingress на Minikube з контролером NGINX.
5.4 - Gateway API
Gateway API є різновидом видів API, які забезпечують динамічне надання інфраструктури та розширений маршрутизації трафіку.
Забезпечте доступ до мережевих служб за допомогою розширюваного, орієнтованого на ролі та протокол обізнаного механізму конфігурації. Gateway API є надбудовою, що містить види API, які надають динамічну інфраструктуру надання та розширену маршрутизацію трафіку.
Принципи дизайну
Наведені нижче принципи визначили дизайн та архітектуру Gateway API:
Орієнтований на ролі: Види Gateway API моделюються за організаційними ролями, які відповідають за управління мережевою службою Kubernetes:
- Постачальник інфраструктури: Управляє інфраструктурою, яка дозволяє кільком ізольованим кластерам обслуговувати кілька орендарів, наприклад, хмарний постачальник.
- Оператор кластера: Управляє кластерами та зазвичай цікавиться політиками, мережевим доступом, дозволами застосунків тощо.
- Розробник застосунків: Управляє застосунком, який працює в кластері та, як правило, цікавиться конфігурацією рівня застосунку та складом Service.
Переносний: Специфікації Gateway API визначаються як власні ресурси та підтримуються багатьма реалізаціями.
Експресивний: Види Gateway API підтримують функціональність для загальних випадків маршрутизації трафіку, таких як відповідність на основі заголовків, визначенні пріоритету трафіку та інших, які були можливі тільки в Ingress за допомогою власних анотацій.
Розширюваний: Gateway дозволяє повʼязувати власні ресурси на різних рівнях API. Це робить можливим докладне налаштування на відповідних рівнях структури API.
Модель ресурсів
Gateway API має три стабільні види API:
GatewayClass: Визначає набір шлюзів зі спільною конфігурацією та керується контролером, який реалізує цей клас.
Gateway: Визначає екземпляр інфраструктури обробки трафіку, такої як хмарний балансувальник.
HTTPRoute: Визначає правила, специфічні для HTTP, для передачі трафіку з Gateway listener на мережеві точки доступу бекенду. Ці точки доступу часто представлені як Service.
Gateway API організовано за різними видами API, які мають взаємозалежні відносини для підтримки організаційно орієнтованої природи організацій. Обʼєкт Gateway повʼязаний із саме одним GatewayClass; GatewayClass описує контролер шлюзу, відповідального за керування шлюзами цього класу. Один чи кілька видів маршрутів, таких як HTTPRoute, потім повʼязуються з Gateways. Gateway може фільтрувати маршрути, які можуть бути прикріплені до його слухачів, утворюючи двоспрямовану довірчу модель з маршрутами.
Наступна схема ілюструє звʼязок між трьома стабільними видами Gateway API:
graph LR;
subgraph cluster["Кластер"]
direction LR
HTTPRoute --> Gateway;
Gateway --> GatewayClass;
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class HTTPRoute,Gateway,GatewayClass k8s;
class cluster cluster;
GatewayClass
Шлюзи можуть бути реалізовані різними контролерами, часто з різними конфігураціями. Шлюз має посилатися на GatewayClass, який містить імʼя контролера, що реалізує цей клас.
Мінімальний приклад GatewayClass:
apiVersion: gateway.networking.k8s.io/v1
kind: GatewayClass
metadata:
name: example-class
spec:
controllerName: example.com/gateway-controller
У цьому прикладі контролер, який реалізував Gateway API, налаштований для управління GatewayClasses з іменем контролера example.com/gateway-controller. Шлюзи цього класу будуть керуватися контролером реалізації.
Дивіться специфікацію GatewayClass для повного визначення цього виду API.
Gateway
Gateway описує екземпляр інфраструктури обробки трафіку. Він визначає мережеву точку доступу з використанням якої можна обробляти трафік, тобто фільтрувати, балансувати, розділяти тощо для таких бекендів як Service. Наприклад, шлюз може представляти хмарний балансувальник навантаження або внутрішній проксі-сервер, налаштований для отримання HTTP-трафіку.
Мінімальний приклад ресурсу Gateway:
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: example-gateway
spec:
gatewayClassName: example-class
listeners:
- name: http
protocol: HTTP
port: 80
У цьому прикладі екземпляр інфраструктури обробки трафіку програмується на прослуховування HTTP-трафіку на порту 80. Оскільки поле addresses не вказано, адреса чи імʼя хосту надається Gateway контролером реалізації. Ця адреса використовується як мережева точка доступу для обробки трафіку бекенду, визначеного в маршрутах.
Дивіться специфікацію Gateway для повного визначення цього виду API.
HTTPRoute
Вид HTTPRoute визначає поведінку маршрутизації HTTP-запитів від слухача Gateway до бекенду мережевих точок доступу. Для бекенду Service реалізація може представляти мережеву точку доступу як IP-адресу Service чи поточні Endpointʼи Service. HTTPRoute представляє конфігурацію, яка застосовується до внутрішньої реалізації Gateway. Наприклад, визначення нового HTTPRoute може призвести до налаштування додаткових маршрутів трафіку в хмарному балансувальнику або внутрішньому проксі-сервері.
Мінімальний приклад HTTPRoute:
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: example-httproute
spec:
parentRefs:
- name: example-gateway
hostnames:
- "www.example.com"
rules:
- matches:
- path:
type: PathPrefix
value: /login
backendRefs:
- name: example-svc
port: 8080
У цьому прикладі HTTP-трафік від Gateway example-gateway із заголовком Host: www.example.com та вказаним шляхом запиту /login буде направлений до Service example-svc на порт 8080.
Дивіться специфікацію HTTPRoute для повного визначення цього виду API.
Потік запитів
Ось простий приклад маршрутизації HTTP-трафіку до Service за допомогою Gateway та HTTPRoute:
graph LR;
client([клієнт])-. HTTP
запит .->Gateway; Gateway-->HTTPRoute; HTTPRoute-->|Правила
маршрутизації|Service; Service-->pod1[Pod]; Service-->pod2[Pod]; classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000; classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff; classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5; class Gateway,HTTPRoute,Service,pod1,pod2 k8s; class client plain; class cluster cluster;
запит .->Gateway; Gateway-->HTTPRoute; HTTPRoute-->|Правила
маршрутизації|Service; Service-->pod1[Pod]; Service-->pod2[Pod]; classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000; classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff; classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5; class Gateway,HTTPRoute,Service,pod1,pod2 k8s; class client plain; class cluster cluster;
У цьому прикладі потік запиту для Gateway, реалізованого як зворотний проксі, є таким:
- Клієнт починає готувати HTTP-запит для URL
http://www.example.com - DNS-resolver клієнта запитує імʼя призначення та дізнається про звʼязок між однією чи кількома IP-адресами, повʼязаними з Gateway.
- Клієнт надсилає запит на IP-адресу Gateway; зворотній проксі отримує HTTP запит і використовує заголовок Host: заголовок має збігатись з налаштуваннями, які були отримані від Gateway та прикріпленого HTTPRoute. Опційно зворотній проксі може виконати порівняння заголовків або шляху запиту на основі правил відповідності HTTPRoute.
- Опційно зворотній проксі може змінювати запит; наприклад, додавати чи видаляти заголовки, відповідно до правил фільтрації HTTPRoute.
- Наприкінці зворотній проксі пересилає запит на один чи кілька бекендів.
Відповідність
Gateway API охоплює широкий набір функцій та має широке впровадження. Ця комбінація вимагає чітких визначень відповідності та тестів, щоб гарантувати, що API забезпечує однаковий підхід, де б він не використовувався.
Дивіться документацію щодо відповідності для розуміння деталей, таких як канали випусків, рівні підтримки та виконання тестів відповідності.
Міграція з Ingress
Gateway API є наступником Ingress API. Однак він не включає вид Ingress. Внаслідок цього необхідно провести одноразове перетворення з наявних ресурсів Ingress на ресурси Gateway API.
Дивіться посібник з міграції з Ingress для отримання деталей щодо міграції ресурсів Ingress на ресурси Gateway API.
Що далі
Замість того, щоб ресурси Gateway API були реалізовані нативно в Kubernetes, специфікації визначаються як Власні ресурси та підтримуються широким спектром реалізацій. Встановіть CRD Gateway API або виконайте інструкції щодо встановлення обраної реалізації. Після встановлення реалізації скористайтесь розділом Початок роботи для швидкого початку роботи з Gateway API.
Примітка:
Обовʼязково ознайомтесь з документацією обраної вами реалізації, щоб розуміти можливі обмеження.Дивіться специфікацію API для отримання додаткових деталей про всі види API Gateway API.
5.5 - EndpointSlices
API EndpointSlice — це механізм, який Kubernetes використовує, щоб ваш Service масштабувався для обробки великої кількості бекендів і дозволяє кластеру ефективно оновлювати свій список справних бекендів.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.21 [stable]EndpointSlice API Kubernetes надає можливість відстежувати мережеві точки доступу в межах кластера Kubernetes. EndpointSlices пропонують більш масштабований та розширюваний альтернативний варіант Endpoints.
EndpointSlice API
У Kubernetes, EndpointSlice містить посилання на набір мережевих точок доступу. Панель управління автоматично створює EndpointSlices для будь-якої служби Kubernetes, яка має вказаний селектор. Ці EndpointSlices містять посилання на всі Podʼи, які відповідають селектору Service. EndpointSlices групують мережеві точки доступу за унікальними комбінаціями протоколу, номеру порту та імені Service. Імʼя обʼєкта EndpointSlice повинно бути дійсним імʼям піддомену DNS.
Наприклад, ось приклад обʼєкта EndpointSlice, яким володіє Service Kubernetes з імʼям example.
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: example-abc
labels:
kubernetes.io/service-name: example
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
hostname: pod-1
nodeName: node-1
zone: us-west2-a
Типово, панель управління створює та керує EndpointSlices так, щоб в кожному з них було не більше 100 мережевих точок доступу. Це можна налаштувати за допомогою прапорця --max-endpoints-per-slice kube-controller-manager, до максимуму 1000.
EndpointSlices можуть виступати джерелом правди для kube-proxy щодо того, як маршрутизувати внутрішній трафік.
Типи адрес
EndpointSlices підтримують три типи адрес:
- IPv4
- IPv6
- FQDN (Fully Qualified Domain Name — Повністю Кваліфіковане Доменне Імʼя)
Кожен обʼєкт EndpointSlice представляє конкретний тип IP-адреси. Якщо у вас
є Service, який доступний через IPv4 та IPv6, буде принаймні два обʼєкти EndpointSlice (один для IPv4 та один для IPv6).
Стани
API EndpointSlice зберігає стани точок доступу, які можуть бути корисні для споживачів. Три стани: ready, serving та terminating.
Ready
ready — це стан, який відповідає стану Ready Pod. Запущений Pod зі станом Ready встановленим в True повинен мати стан ready також встановлений в true. З міркувань сумісності, ready НІКОЛИ не буває true, коли Pod видаляється. Споживачі повинні звертатися до стану serving, щоб перевірити готовність Podʼів, які видаляються. Єдиний виняток є для Services з spec.publishNotReadyAddresses, встановленим в true. Podʼи для цих служб завжди матимуть стан ready, встановлений в true.
Serving
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.26 [stable]Стан serving майже ідентичний стану ready. Різниця полягає в тому, що
споживачі API EndpointSlice повинні перевіряти стан serving, якщо їм важливо перевірити готовність Podʼів в той час, коли Pod також примусово припиняє свою роботу.
Примітка:
Хочаserving майже ідентичний ready, його додано для того, щоб не порушувати поточне значення ready. Для наявних клієнтів може бути неочікуваним, якщо ready може бути true для точок доступу, що припиняють роботу, оскільки історично точки доступу, що припиняють роботу ніколи не включалися в Endpoints або
EndpointSlice API. З цієї причини ready завжди false для таких точок доступу, і новий стан serving було додано у версії v1.20, щоб клієнти могли відстежувати готовність Podʼів, що примусово припиняють роботу, від наявної семантики ready.Terminating
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.22 [beta]Terminating — це стан, що вказує, чи Pod видаляється. Для Podʼів це буде будь-який Pod з встановленою часовою міткою видалення.
Інформація про топологію
Кожна точка доступу в межах EndpointSlice може містити відповідну інформацію про топологію. Інформація про топологію включає місцезнаходження точки доступу та інформацію про відповідний вузол та зону. Ця інформація доступна в наступних полях на кожній кінцевій точці в EndpointSlices:
nodeName— Назва вузла, на якому знаходиться ця точка доступу.zone— Зона, в якій знаходиться ця точка доступу.
Примітка:
В API v1 поле топології на кожній кінцевій точці було фактично видалено на користь
спеціальних полів nodeName та zone.
Встановлення довільних полів топології в поле endpoint ресурсу EndpointSlice було визнане застарілим і не підтримується в API v1. Замість цього, API v1 підтримує встановлення окремих полів nodeName та zone. Ці поля автоматично перемикаються між версіями API. Наприклад, значення ключа "topology.kubernetes.io/zone" у полі topology в v1beta1 API є доступним як поле zone в API v1.
Управління
Зазвичай обʼєкти EndpointSlice створюються та керуються панеллю управління зокрема, контролером EndpointSlice. Є різноманітні інші випадки використання EndpointSlices, такі як реалізації Service mesh, які можуть призвести до інших сутностей або контролерів, які керують додатковими наборами EndpointSlices.
Щоб забезпечити можливість кількох сутностей керувати EndpointSlices без взаємодії одна з одною, Kubernetes визначає label endpointslice.kubernetes.io/managed-by, яка вказує сутність, яка керує EndpointSlice. Контролер встановлює значення endpointslice-controller.k8s.io для цієї мітки на всіх точках доступу, якими він керує. Інші сутності, які керують EndpointSlices, також повинні встановити унікальне значення для цієї мітки.
Власність
У більшості випадків EndpointSlices належать Service, за яким обʼєкт EndpointSlices стежить для виявлення точок доступу. Право власності вказується власником
посиланням на кожен EndpointSlice, а також міткою kubernetes.io/service-name
для простого пошуку всіх EndpointSlices, які належать Service.
Віддзеркалення EndpointSlice
У деяких випадках застосунки створюють власні ресурси Endpoints. Щоб забезпечити що ці застосунки не повинні одночасно записувати як в ресурси Endpoints, так і в ресурси EndpointSlice, панель управління кластера віддзеркалює більшість ресурсів Endpoints на відповідні ресурси EndpointSlices.
Панель управління віддзеркалює ресурси Endpoints, якщо:
- ресурс Endpoints має мітку
endpointslice.kubernetes.io/skip-mirrorвстановлену вtrue. - ресурс Endpoints має анотацію
control-plane.alpha.kubernetes.io/leader. - відповідний ресурс Service не існує.
- відповідний ресурс Service має ненульовий селектор.
Окремі ресурси Endpoints можуть транслюватись в кілька ресурсів EndpointSlices. Це може відбуватись, якщо ресурс Endpoints має кілька підмножин або включає точки доступу з кількома сімействами IP (IPv4 та IPv6). Максимально 1000 адрес на підмножину буде віддзеркалено на EndpointSlices.
Розподіл EndpointSlices
Кожен EndpointSlice має набір портів, які застосовуються до всіх точок доступу ресурсу. При використанні іменованих портів для Service, Podʼи можуть мати різні номери цільового порту для того самого іменованого порту, що вимагає різних EndpointSlices. Це схоже на логіку того, як підмножини групуються з Endpoints.
Панель управління намагається заповнити EndpointSlices так повно, як це можливо, але не активно перерозподіляє їх. Логіка досить проста:
- Пройдіться по наявних EndpointSlices, вилучіть точки доступу, які вже не потрібні, і оновіть відповідні точки, які змінилися.
- Пройдіться по EndpointSlices, які були змінені на першому етапі, і заповніть їх будь-якими новими точками доступу, які потрібно додати.
- Якщо ще залишилися нові точки доступу для додавання, спробуйте додати їх в раніше не змінений EndpointSlice та/або створіть новий.
Важливо, що третій крок надає пріоритет обмеженню оновлень EndpointSlice над ідеально повним розподілом EndpointSlices. Наприклад, якщо є 10 нових точок доступу для додавання та 2 EndpointSlices з простором для ще 5 точок доступу кожна, цей підхід створить новий EndpointSlice замість заповнення 2 наявних EndpointSlices. Іншими словами, одне створення EndpointSlice краще, ніж кілька оновлень EndpointSlice.
З kube-proxy, який працює на кожному вузлі та слідкує за EndpointSlices, кожна зміна EndpointSlice стає відносно дорогою, оскільки вона буде передана кожному вузлу в кластері. Цей підхід призначений для обмеження кількості змін, які потрібно надіслати кожному вузлу, навіть якщо це може призвести до декількох EndpointSlices, які не є повністю заповненими.
На практиці це рідко трапляється. Більшість змін опрацьовуються контролером EndpointSlice буде достатньо малою, щоб поміститися в наявний EndpointSlice, і якщо ні, новий EndpointSlice, ймовірно, буде потрібен невдовзі. Поступові оновлення Deploymentʼів також надають природню перепаковку EndpointSlices з всіма Podʼами та їх відповідними точками доступу, що заміняються.
Дублікати endpoints
Через характер змін EndpointSlice точки доступу можуть бути представлені в більш ніж одному EndpointSlice одночасно. Це, природно, відбувається, оскільки зміни до різних обʼєктів EndpointSlice можуть надходити до клієнта Kubernetes watch / cache в різний час.
Примітка:
Клієнти API EndpointSlice повинні переглянути всі наявні EndpointSlices повʼязані з Service та побудувати повний список унікальних мережевих точок доступу. Важливо зазначити, що мережеві точки доступу можуть бути дубльовані в різних EndpointSlices.
Ви можете знайти посилання на референтну реалізацію того, як виконати це агрегування точок доступу та вилучення дублікатів як частину коду EndpointSliceCache всередині kube-proxy.
Порівняння з Endpoints
Оригінальний API Endpoints надавав простий і зрозумілий спосіб відстеження мережевих точок доступу в Kubernetes. Однак з ростом кластерів Kubernetes та Serviceʼів, які обробляють більше трафіку і надсилають трафік до більшої кількості підзадач, обмеження оригінального API стали більш помітними. Зокрема, до них входили проблеми масштабування до більшої кількості мережевих точок доступу.
Оскільки всі мережеві точки доступу для Service зберігалися в одному ресурсі Endpoints, ці обʼєкти Endpoints могли бути досить великими. Для служб, які залишалися стабільними (тобто тим самим набором точок доступу протягом тривалого періоду часу), вплив був менше помітний; навіть тоді деякі випадки використання Kubernetes працювали не дуже добре.
Коли у Service було багато точок доступу бекенду, а робочі навантаження або часто масштабуються, або до них часто вносилися нові зміни, кожне оновлення єдиного обʼєкта Endpoints для цього Service означало багато трафіку між компонентами кластера Kubernetes (в межах панелі управління, а також між вузлами та сервером API). Цей додатковий трафік також мав вартість у термінах використання ЦП.
З EndpointSlices додавання або видалення одного окремого Podʼа призводить до такого ж кількості оновлень для клієнтів, які спостерігають за змінами, але розмір цих оновлень на багато менший на великій кількості точок доступу.
EndpointSlices також включили інновації щодо нових можливостей, таких як мережі з подвійним стеком і маршрутизація з урахуванням топології.
Що далі
- Ознайомтесь з Підключенням застосунків до Service
- Прочитайте довідку API EndpointSlice
- Прочитайте довідку API Endpoints
5.6 - Мережеві політики
Якщо ви хочете контролювати потік трафіку на рівні IP-адреси чи порту (рівень OSI 3 або 4), мережеві політики Kubernetes дозволяють вам визначати правила потоку трафіку всередині вашого кластера, а також між Podʼами та зовнішнім світом. Ваш кластер повинен використовувати мережевий втулок, який підтримує NetworkPolicy.
Якщо ви хочете контролювати потік трафіку на рівні IP-адреси чи порту для протоколів TCP, UDP та SCTP, то вам, можливо, варто розглянути використання NetworkPolicies Kubernetes для конкретних застосунків у вашому кластері. NetworkPolicies — це конструкт, орієнтований на застосунок, який дозволяє вам визначати, як Pod може взаємодіяти з різними мережевими "сутностями" (ми використовуємо тут слово "сутність", щоб уникнути перевантаження більш загальноприйнятими термінами, такими як "Endpoints" та "Services", які мають конкретні конотації Kubernetes) мережею. NetworkPolicies – застосовується до зʼєднання з Pod на одному або обох кінцях і не має відношення до інших зʼєднань.
Сутності, з якими може взаємодіяти Pod, ідентифікуються за допомогою комбінації наступних трьох ідентифікаторів:
- Інші дозволені Podʼи (виняток: Pod не може блокувати доступ до себе самого)
- Дозволені простори імен
- IP-блоки (виняток: трафік до та від вузла, де працює Pod, завжди дозволений, незалежно від IP-адреси Podʼа чи вузла)
При визначенні мережевої політики на основі Podʼа чи простору імен ви використовуєте селектор для визначення, який трафік дозволений до та від Podʼа(ів), які відповідають селектору.
Тим часом при створенні мережевих політик на основі IP ми визначаємо політику на основі IP-блоків (діапазони CIDR).
Передумови
Мережеві політики впроваджуються мережевим втулком. Для використання мережевих політик вам слід використовувати рішення з підтримкою NetworkPolicy. Створення ресурсу NetworkPolicy без контролера, який його реалізує, не матиме ефекту.
Два види ізоляції для Podʼів
Існують два види ізоляції для Podʼа: ізоляція для вихідного трафіку (egress) та ізоляція для вхідного трафіку (ingress). Це стосується того, які зʼєднання можуть бути встановлені. Тут "ізоляція" не є абсолютною, але означає "діють деякі обмеження". Альтернатива, "non-isolated for $direction", означає, що в зазначеному напрямку обмеження відсутні. Два види ізоляції (або ні) декларуються незалежно та є важливими для підключення від одного Podʼа до іншого.
Типово Pod не є ізольованим для вихідного трафіку (egress); всі вихідні зʼєднання дозволені. Pod ізольований для вихідного трафіку, якщо є будь-яка мережева політика, яка одночасно вибирає Pod і має "Egress" у своєму policyTypes; ми кажемо, що така політика застосовується до Podʼа для вихідного трафіку. Коли Pod ізольований для вихідного трафіку, єдині дозволені зʼєднання з Podʼа — ті, які дозволені списком egress деякої мережевої політики, яка застосовується до Podʼа для вихідного трафіку. Також буде неявно дозволений вихідний трафік для цих дозволених зʼєднань. Ефекти цих списків egress обʼєднуються адитивно.
Типово Pod не є ізольованим для вхідного трафіку (ingress); всі вхідні зʼєднання дозволені. Pod ізольований для вхідного трафіку, якщо є будь-яка мережева політика, яка одночасно вибирає Pod і має "Ingress" у своєму policyTypes; ми кажемо, що така політика застосовується до Podʼа для вхідного трафіку. Коли Pod ізольований для вхідного трафіку, єдині дозволені зʼєднання до Podʼа - ті, що з вузла Podʼа та ті, які дозволені списком ingress деякої мережевої політики, яка застосовується до Podʼа для вхідного трафіку. Також буде неявно дозволений вхідний трафік для цих дозволених зʼєднань. Ефекти цих списків ingress обʼєднуються адитивно.
Мережеві політики не конфліктують; вони є адитивними. Якщо будь-яка політика чи політики застосовуються до певного Podʼа для певного напрямку, то зʼєднання, які дозволяються в цьому напрямку від цього Podʼа, — це обʼєднання того, що дозволяють відповідні політики. Таким чином, порядок оцінки не впливає на результат політики.
Для того, щоб зʼєднання від джерела до призначення було дозволено, обидві політики, вихідна на джерелі та вхідна на призначенні, повинні дозволяти зʼєднання. Якщо хоча б одна сторона не дозволяє зʼєднання, воно не відбудеться.
Ресурс NetworkPolicy
Для повного визначення ресурсу дивіться посилання на NetworkPolicy.
Приклад NetworkPolicy може виглядати наступним чином:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
Примітка:
Надсилання (POST) цього до сервера API вашого кластера не матиме жодного ефекту, якщо ваше обране мережеве рішення не підтримує мережеву політику.Обовʼязкові поля: Як і з усіма іншими конфігураціями Kubernetes, для NetworkPolicy потрібні поля apiVersion, kind та metadata. Для загальної інформації щодо роботи з конфігураційними файлами дивіться Налаштування Pod для використання ConfigMap та Управління обʼєктами.
spec: Специфікація мережевої політики spec містить всю інформацію, необхідну для визначення конкретної мережевої політики в заданому просторі імен.
podSelector: Кожна NetworkPolicy включає podSelector, який вибирає групу Podʼів, до яких застосовується політика. У прикладі політики вибираються Podʼи з міткою "role=db". Порожній podSelector вибирає всі Podʼи в просторі імен.
policyTypes: Кожна NetworkPolicy включає список policyTypes, який може містити або Ingress, або Egress, або обидва. Поле policyTypes вказує, чи політика застосовується, чи ні до трафіку ingress до вибраних Podʼів, трафіку egress від вибраних Podʼів чи обох. Якщо на NetworkPolicy не вказано жодних policyTypes, то станадартно буде завжди встановлено Ingress, а Egress буде встановлено, якщо у NetworkPolicy є хоча б одне правило egress.
ingress: Кожна NetworkPolicy може включати список дозволених правил ingress. Кожне правило дозволяє трафіку, який відповідає як from, так і секції ports. У прикладі політики є одне правило, яке відповідає трафіку на одному порту від одного з трьох джерел: перше вказано через ipBlock, друге через namespaceSelector, а третє через podSelector.
egress: Кожна NetworkPolicy може включати список дозволених правил egress. Кожне правило дозволяє трафіку, який відповідає як секції to, так і ports. У прикладі політики є одне правило, яке відповідає трафіку на одному порту до будь-якого призначення в 10.0.0.0/24.
Отже, приклад NetworkPolicy:
ізолює Podʼи
role=dbв просторі іменdefaultдля трафіку як ingress, так і egress (якщо вони ще не були ізольовані)(Правила Ingress) дозволяє підключення до всіх Podʼів в просторі імен
defaultз міткоюrole=dbна TCP-порт 6379 від:- будь-якого Pod в просторі імен
defaultз міткоюrole=frontend - будь-якого Pod в просторі імені з міткою
project=myproject - IP-адреси в діапазонах
172.17.0.0–172.17.0.255nf172.17.2.0–172.17.255.255(тобто, усе172.17.0.0/16, за винятком172.17.1.0/24)
- будь-якого Pod в просторі імен
(Правила Egress) дозволяє підключення з будь-якого Pod в просторі імен
defaultз міткоюrole=dbдо CIDR10.0.0.0/24на TCP-порт 5978
Дивіться Оголошення мережевої політики для ознайомлення з додатковими прикладами.
Поведінка селекторів to та from
Існує чотири види селекторів, які можна вказати в розділі from для ingress або to для egress:
podSelector: Вибирає певні Podʼи в тому ж просторі імен, що і NetworkPolicy, які мають бути допущені як джерела ingress або призначення egress.
namespaceSelector: Вибирає певні простори імен, для яких всі Podʼи повинні бути допущені як джерела ingress або призначення egress.
namespaceSelector та podSelector: Один елемент to/from, який вказує як namespaceSelector, так і podSelector, вибирає певні Podʼи в певних просторах імен. Будьте уважні при використанні правильного синтаксису YAML. Наприклад:
...
ingress:
- from:
- namespaceSelector:
matchLabels:
user: alice
podSelector:
matchLabels:
role: client
...
Ця політика містить один елемент from, який дозволяє підключення від Podʼів з міткою role=client в просторах імен з міткою user=alice. Але наступна політика відрізняється:
...
ingress:
- from:
- namespaceSelector:
matchLabels:
user: alice
- podSelector:
matchLabels:
role: client
...
Вона містить два елементи у масиві from та дозволяє підключення від Podʼів у локальному просторі імен з міткою role=client, або від будь-якого Podʼа в будь-якому просторі імен з міткою user=alice.
У випадку невизначеності використовуйте kubectl describe, щоб переглянути, як Kubernetes інтерпретував політику.
ipBlock: Вибирає певні діапазони IP CIDR для дозволу їх як джерел ingress або призначення egress. Це повинні бути зовнішні для кластера IP, оскільки IP Podʼів є ефемерними та непередбачуваними.
Механізми ingress та egress кластера часто вимагають переписування IP джерела або IP призначення пакетів. У випадках, коли це відбувається, не визначено, чи це відбувається до, чи після обробки NetworkPolicy, і поведінка може бути різною для різних комбінацій мережевого втулка, постачальника хмарних послуг, реалізації Service тощо.
У випадку ingress це означає, що у деяких випадках ви можете фільтрувати вхідні пакети на основі фактичної вихідної IP, тоді як в інших випадках "вихідна IP-адреса", на яку діє NetworkPolicy, може бути IP LoadBalancer або вузла Podʼа тощо.
Щодо egress це означає, що підключення з Podʼів до IP Service, які переписуються на зовнішні IP кластера, можуть або не можуть підпадати під політику на основі ipBlock.
Стандартні політики
Типово, якщо в просторі імен відсутні будь-які політики, то трафік ingress та egress дозволено до та від Podʼів в цьому просторі імен. Наступні приклади дозволяють змінити стандартну поведінку в цьому просторі імені.
Стандартна заборона всього вхідного трафіку
Ви можете створити політику стандартної ізоляції вхідного трафіку для простору імен, створивши NetworkPolicy, яка вибирає всі Podʼи, але не дозволяє будь-який вхідний трафік для цих Podʼів.
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
Це забезпечить ізоляцію вхідного трафіку навіть для Podʼів, які не вибрані жодною іншою NetworkPolicy. Ця політика не впливає на ізоляцію egress трафіку з будь-якого Podʼа.
Дозвіл на весь вхідний трафік
Якщо ви хочете дозволити всі вхідні підключення до всіх Podʼів в просторі імен, ви можете створити політику, яка явно це дозволяє.
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-ingress
spec:
podSelector: {}
ingress:
- {}
policyTypes:
- Ingress
З цією політикою ніяка додаткова політика або політики не можуть призвести до відмови у ingress підключенні до цих Podʼів. Ця політика не впливає на ізоляцію вихідного трафіку з будь-якого Podʼа.
Стандартна заборона всього вихідного трафіку
Ви можете створити стандартну політику ізоляції вихідного трафіку для простору імен, створивши NetworkPolicy, яка вибирає всі Podʼи, але не дозволяє будь-який egress трафік від цих Podʼів.
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-egress
spec:
podSelector: {}
policyTypes:
- Egress
Це забезпечить те, що навіть Podʼи, які не вибрані жодною іншою NetworkPolicy, не матимуть дозволу на вихідний трафік. Ця політика не змінює ізоляційну поведінку egress трафіку з будь-якого Podʼа.
Дозвіл на весь вихідний трафік
Якщо ви хочете дозволити всі підключення з усіх Podʼів в просторі імен, ви можете створити політику, яка явно дозволяє всім вихідним зʼєднанням з Podʼів в цьому просторі імені.
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress
spec:
podSelector: {}
egress:
- {}
policyTypes:
- Egress
З цією політикою ніяка додаткова політика або політики не можуть призвести до відмови у вихідному підключенні з цих Podʼів. Ця політика не впливає на ізоляцію ingress трафіку до будь-якого Podʼа.
Стандартна заборона всього вхідного та всього вихідного трафіку
Ви можете створити "стандартну" політику для простору імен, яка забороняє весь ingress та egress трафік, створивши наступний NetworkPolicy в цьому просторі імені.
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
Це забезпечить те, що навіть Podʼи, які не вибрані жодною іншою NetworkPolicy, не матимуть дозволу на трафік ingress та egress напрямку.
Фільтрація мережевого трафіку
NetworkPolicy визначений для зʼєднань layer 4 (TCP, UDP та за необхідності SCTP). Для всіх інших протоколів поведінка може варіюватися залежно від мережевих втулків.
Примітка:
Вам потрібно використовувати втулок CNI, який підтримує мережеві політики для протоколу SCTP.Коли визначена мережева політика deny all, гарантується тільки відмова в TCP, UDP та SCTP зʼєднаннях. Для інших протоколів, таких як ARP чи ICMP, поведінка невизначена. Те ж саме стосується правил дозволу (allow): коли певний Pod дозволений як джерело ingress або призначення egress, не визначено, що відбувається з (наприклад) пакетами ICMP. Такі протоколи, як ICMP, можуть бути дозволені одними мережевими втулками та відхилені іншими.
Спрямування трафіку на діапазон портів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.25 [stable]При написанні NetworkPolicy ви можете спрямовувати трафік на діапазон портів, а не на один окремий порт.
Це можливо завдяки використанню поля endPort, як показано в наступному прикладі:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: multi-port-egress
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 32000
endPort: 32768
Вищевказане правило дозволяє будь-якому Podʼа з міткою role=db в просторі імен default спілкуватися з будь-яким IP в діапазоні 10.0.0.0/24 по протоколу TCP, при умові, що цільовий порт знаходиться в діапазоні від 32000 до 32768.
Застосовуються наступні обмеження при використанні цього поля:
- Поле
endPortповинно бути рівним або більшим за полеport. endPortможе бути визначено тільки в тому випадку, якщо також визначеноport.- Обидва порти повинні бути числовими значеннями.
Примітка:
Ваш кластер повинен використовувати втулок CNI, який підтримує полеendPort в специфікаціях NetworkPolicy. Якщо ваш мережевий втулок не підтримує поле endPort, і ви вказуєте NetworkPolicy з таким полем, політика буде застосована лише для одного поля port.Спрямування трафіку на кілька просторів імен за допомогою міток
У цім сценарії ця ваша Egress NetworkPolicy спрямована на більше ніж один простір імен, використовуючи їх мітки. Для цього необхідно додати мітки до цільових просторів імен. Наприклад:
kubectl label namespace frontend namespace=frontend
kubectl label namespace backend namespace=backend
Додайте мітки до namespaceSelector в вашому документі NetworkPolicy. Наприклад:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: egress-namespaces
spec:
podSelector:
matchLabels:
app: myapp
policyTypes:
- Egress
egress:
- to:
- namespaceSelector:
matchExpressions:
- key: namespace
operator: In
values: ["frontend", "backend"]
Примітка:
Неможливо безпосередньо вказати імʼя простору імен в NetworkPolicy. Ви повинні використовуватиnamespaceSelector з matchLabels або matchExpressions, щоб вибрати простори імен на основі їх міток.Спрямування трафіку на простір імен за його іменем
Керівництво Kubernetes встановлює незмінювану мітку kubernetes.io/metadata.name на всі простори імен, значення мітки — це імʼя простору імен.
Хоча NetworkPolicy не може спрямовуватися на простір імен за його іменем з допомогою поля обʼєкта, ви можете використовувати стандартизовану мітку для спрямування на конкретний простір імен.
Життєвий цикл Podʼа
Примітка:
Наведене нижче стосується кластерів із сумісним мережевим втулком та сумісною реалізацією NetworkPolicy.При створенні нового обʼєкта NetworkPolicy може знадобитися певний час для обробки нового обʼєкта мережевим втулком. Якщо Pod, який стосується NetworkPolicy, створено до того, як мережевий втулок завершить обробку NetworkPolicy, цей Pod може бути запущений в незахищеному стані, і правила ізоляції будуть застосовані, коли обробка NetworkPolicy буде завершена.
Щойно NetworkPolicy оброблено мережевим втулком,
Усі нові Podʼи, які стосуються даної NetworkPolicy, будуть ізольовані перед тим, як їх запустять. Реалізації NetworkPolicy повинні забезпечити, що фільтрація є ефективною впродовж усього життєвого циклу Podʼа, навіть з моменту першого запуску будь-якого контейнера у цьому Podʼі. Оскільки вони застосовуються на рівні Podʼа, NetworkPolicies однаково застосовуються до init-контейнерів, контейнерів-супутників та звичайних контейнерів.
Правила дозволів будуть застосовані, остаточно після правил ізоляції (або можуть бути застосовані одночасно). У найгіршому випадку новий Pod може не мати жодного мережевого зʼєднання взагалі при першому запуску, якщо правила ізоляції вже були застосовані, але правила дозволів ще не були застосовані.
Кожна створена NetworkPolicy буде врешті-решт застосована мережевим втулком, але немає способу визначити з API Kubernetes, коли саме це станеться.
Отже, Podʼи повинні бути стійкими до того, що їх можуть запускати з різним ступенем мережевого зʼєднання, ніж очікувалося. Якщо вам потрібно переконатися, що Pod може досягти певних місць перед тим, як його запустять, ви можете використовувати init контейнер чекати, доки ці місця стануть доступними, перш ніж kubelet запустить контейнери застосунків.
Кожна NetworkPolicy буде застосована до всіх вибраних Podʼів врешті-решт. Оскільки мережевий втулок може реалізовувати NetworkPolicy розподіленим чином, можливо, що Podʼи можуть бачити трохи неузгоджений вид мережевих політик при першому створенні Podʼа або при зміні Podʼів або політик. Наприклад, новий створений Pod, який повинен бути в змозі досягти як Podʼа на вузлі 1, так і Podʼа на вузлі 2, може знайти, що він може досягати Podʼа А негайно, але не може досягати Podʼа B впродовж кількох секунд.
NetworkPolicy та Podʼи з hostNetwork
Поведінка NetworkPolicy для Podʼів із hostNetwork є невизначеною, але вона повинна обмежуватися двома можливостями:
- Мережевий втулок може відрізняти трафік Podʼів з
hostNetworkвід усього іншого трафіку (включаючи можливість відрізняти трафік від різних Podʼів зhostNetworkна тому ж вузлі) та застосовувати NetworkPolicy до Podʼів ізhostNetwork, , так само як і до Podʼів мережі Podʼа. - Мережевий втулок не може належним чином відрізняти трафік Podʼів із
hostNetwork, тому він ігнорує Podʼи зhostNetworkпри відповідностіpodSelectorтаnamespaceSelector. Трафік до/від Podʼів ізhostNetworkобробляється так само як і весь інший трафік до/від IP-адреси вузла. (Це найбільш поширена реалізація.)
Це стосується випадків, коли
Pod із
hostNetworkвибирається за допомогоюspec.podSelector.... spec: podSelector: matchLabels: role: client ...Pod із
hostNetworkвибирається за допомогоюpodSelectorчиnamespaceSelectorв правиліingressчиegress.... ingress: - from: - podSelector: matchLabels: role: client ...
В той самий час, оскільки Podʼи з hostNetwork мають ті ж IP-адреси, що й вузли, на яких вони розташовані, їх зʼєднання буде вважатися зʼєднанням до вузла. Наприклад, ви можете дозволити трафік з Podʼа із hostNetwork за допомогою правила ipBlock.
Що ви не можете зробити за допомогою мережевих політик (принаймні, зараз) {#what-you-can't-do-with-network-policies-at-least-not-yet}
В Kubernetes 1.32, наступна функціональність відсутня в API NetworkPolicy, але, можливо, ви зможете реалізувати обходні шляхи, використовуючи компоненти операційної системи (такі як SELinux, OpenVSwitch, IPTables та інші) або технології Layer 7 (контролери Ingress, реалізації Service Mesh) чи контролери допуску. У випадку, якщо ви новачок в мережевому захисті в Kubernetes, варто відзначити, що наступні випадки не можна (ще) реалізувати за допомогою API NetworkPolicy.
- Примусова маршрутизація внутрішньокластерного трафіку через загальний шлюз (це, можливо, найкраще реалізувати за допомогою сервіс-мешу чи іншого проксі).
- Будь-яка функціональність, повʼязана з TLS (для цього можна використовувати сервіс-меш чи контролер ingress).
- Політики, специфічні для вузла (ви можете використовувати нотацію CIDR для цього, але ви не можете визначати вузли за їхніми ідентифікаторами Kubernetes).
- Спрямування трафіку на service за іменем (проте ви можете спрямовувати трафік на Podʼи чи простори імен за їх мітками, що часто є прийнятним обхідним варіантом).
- Створення або управління "Policy request", які виконуються третьою стороною.
- Типові політики, які застосовуються до всіх просторів імен чи Podʼів (є деякі дистрибутиви Kubernetes від сторонніх постачальників та проєкти, які можуть це робити).
- Розширені засоби надсилання запитів та інструменти перевірки досяжності політики.
- Можливість ведення логу подій з мережевої безпеки (наприклад, заблоковані чи прийняті зʼєднання).
- Можливість явно відмовляти в політиках (наразі модель для NetworkPolicy — це типова відмова, з можливістю додавання тільки правил дозволу).
- Можливість уникнення loopback чи вхідного трафіку від хоста (Podʼи наразі не можуть блокувати доступ до localhost, і вони не мають можливості блокувати доступ від їхнього вузла-резидента).
Вплив мережевих політик на існуючі зʼєднання
Коли набір мережевих політик, які застосовуються до існуючого зʼєднання, змінюється — це може трапитися через зміну мережевих політик або якщо відповідні мітки обраних просторів імен/Podʼів, обраних політикою (як субʼєкт і peers), змінюються під час існуючого зʼєднання — не визначено в реалізації, чи буде врахована зміна для цього існуючого зʼєднання чи ні. Наприклад: створено політику, яка призводить до відмови в раніше дозволеному зʼєднанні, реалізація базового мережевого втулка відповідальна за визначення того, чи буде ця нова політика закривати існуючі зʼєднання чи ні. Рекомендується утримуватися від змін політик/Podʼів/просторів імен таким чином, що може вплинути на існуючі зʼєднання.
Що далі
- Перегляньте оголошення мережевої політики для отримання додаткових прикладів.
- Дивіться більше рецептів для звичайних сценаріїв, які підтримує ресурс NetworkPolicy.
5.7 - DNS для Service та Podʼів
Ваше робоче навантаження може виявляти Serviceʼи всередині вашого кластеру за допомогою DNS; ця сторінка пояснює, як це працює.
Kubernetes створює DNS-записи для Service та Podʼів. Ви можете звертатися до Service за допомогою стійких імен DNS замість IP-адрес.
Kubernetes публікує інформацію про Podʼи та Serviceʼи, яка використовується для налаштування DNS. Kubelet конфігурує DNS Podʼів так, щоб запущені контейнери могли знаходити Service за іменем, а не за IP.
Service, визначеним у кластері, призначаються імена DNS. Типово список пошуку DNS клієнта Pod включає власний простір імен Pod та стандартний домен кластера.
Простори імен Serviceʼів
DNS-запит може повертати різні результати залежно від простору імен Podʼа, який його створив. DNS-запити, які не вказують простір імен, обмежені простором імен Podʼа. Для доступу до Service в інших просторах імен, вказуйте його в DNS-запиті.
Наприклад, розгляньте Pod в просторі імен test. Service data перебуває в просторі імен prod.
Запит для data не повертає результатів, оскільки використовує простір імен Podʼа test.
Запит для data.prod повертає бажаний результат, оскільки вказує простір імен.
DNS-запити можуть бути розширені за допомогою /etc/resolv.conf Podʼа. Kubelet налаштовує цей файл для кожного Podʼа. Наприклад, запит лише для data може бути розширений до data.test.svc.cluster.local. Значення опції search використовуються для розширення запитів. Щоб дізнатися більше про DNS-запити, див. сторінку довідки resolv.conf.
nameserver 10.32.0.10
search <namespace>.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
Отже, узагальнюючи, Pod у просторі імен test може успішно знаходити як data.prod, так і data.prod.svc.cluster.local.
DNS-записи
Для яких обʼєктів створюються DNS-записи?
- Serviceʼи
- Podʼи
У наступних розділах детально розглядаються підтримувані типи записів DNS та структура, яка їх підтримує. Будь-яка інша структура, імена чи запити, які випадково працюють, вважаються реалізаційними деталями та можуть змінюватися без попередження. Для отримання більш актуальної специфікації див. Виявлення Serviceʼів на основі DNS у Kubernetes.
Serviceʼи
Записи A/AAAA
"Звичайні" (не headless) Serviceʼи отримують DNS-запис A та/або AAAA, залежно від IP-сімейства або сімейств Serviceʼів, з імʼям у вигляді my-svc.my-namespace.svc.cluster-domain.example. Це розгортається в кластерний IP Serviceʼу.
Headless Services
(без кластерного IP) теж отримують DNS-записи A та/або AAAA, з імʼям у вигляді my-svc.my-namespace.svc.cluster-domain.example. На відміну від звичайних Serviceʼів, це розгортається в набір IP-адрес всіх Podʼів, вибраних Serviceʼом. Очікується, що клієнти будуть використовувати цей набір або використовувати стандартний round-robin вибір із набору.
Записи SRV
Записи SRV створюються для іменованих портів, які є частиною звичайних або headless сервісів. Для кожного іменованого порту запис SRV має вигляд _port-name._port-protocol.my-svc.my-namespace.svc.cluster-domain.example. Для звичайного Serviceʼу це розгортається в номер порту та доменне імʼя: my-svc.my-namespace.svc.cluster-domain.example. Для headless Serviceʼу це розгортається в кілька відповідей, по одній для кожного Podʼа, які підтримує Service, і містить номер порту та доменне імʼя Podʼа у вигляді hostname.my-svc.my-namespace.svc.cluster-domain.example.
Podʼи
Записи A/AAAA
Версії Kube-DNS, до впровадження специфікації DNS, мали наступне DNS-подання:
pod-ipv4-address.my-namespace.pod.cluster-domain.example.
Наприклад, якщо Pod в просторі імен default має IP-адресу 172.17.0.3, а доменне імʼя вашого кластера — cluster.local, то у Podʼа буде DNS-імʼя:
172-17-0-3.default.pod.cluster.local.
Будь-які Podʼи, на які поширюється Service, мають наступний доступ через DNS:
pod-ipv4-address.service-name.my-namespace.svc.cluster-domain.example.
Поля hostname та subdomain Podʼа
Наразі, при створенні Podʼа, його імʼя (як його видно зсередини Podʼа) визначається як значення metadata.name Podʼа.
У специфікації Podʼа є необовʼязкове поле hostname, яке можна використовувати для вказівки відмінного від імʼя Podʼа імені хосту. Коли вказано, воно має пріоритет над іменем Podʼа та стає імʼям хосту Podʼа (знову ж таки, в спостереженнях зсередини Podʼа). Наприклад, якщо у Podʼа вказано spec.hostname зі значенням "my-host", то у Podʼа буде імʼя хосту "my-host".
Специфікація Podʼа також має необовʼязкове поле subdomain, яке може використовуватися для вказівки того, що Pod є частиною підгрупи простору імен. Наприклад, Pod з spec.hostname встановленим на "foo", та spec.subdomain встановленим на "bar", у просторі імен "my-namespace", матиме імʼя хосту "foo" та повністю визначене доменне імʼя (FQDN) "foo.bar.my-namespace.svc.cluster.local" (знову ж таки, в спостереженнях зсередини Podʼа).
Якщо існує headless Service в тому ж просторі імен, що і Pod, із тим самим імʼям, що і піддомен, DNS-сервер кластера також поверне записи A та/або AAAA для повної доменної назви Podʼа.
Приклад:
apiVersion: v1
kind: Service
metadata:
name: busybox-subdomain
spec:
selector:
name: busybox
clusterIP: None
ports:
- name: foo # імʼя не є обовʼязковим для Serviceʼів з одним портом
port: 1234
---
apiVersion: v1
kind: Pod
metadata:
name: busybox1
labels:
name: busybox
spec:
hostname: busybox-1
subdomain: busybox-subdomain
containers:
- image: busybox:1.28
command:
- sleep
- "3600"
name: busybox
---
apiVersion: v1
kind: Pod
metadata:
name: busybox2
labels:
name: busybox
spec:
hostname: busybox-2
subdomain: busybox-subdomain
containers:
- image: busybox:1.28
command:
- sleep
- "3600"
name: busybox
У вище наведеному Прикладі, із Service "busybox-subdomain" та Podʼами, які встановлюють spec.subdomain на "busybox-subdomain", перший Pod побачить своє власне FQDN як "busybox-1.busybox-subdomain.my-namespace.svc.cluster-domain.example". DNS повертає записи A та/або AAAA під цим іменем, що вказують на IP-адресу Podʼа. Обидва Podʼа "busybox1" та "busybox2" матимуть свої власні записи адрес.
EndpointSlice може визначати DNS-hostname для будь-якої адреси endpoint, разом з його IP.
Примітка:
Записи A та AAAA не створюються для назв Pod'ів, оскільки для них відсутнійhostname. Pod без hostname, але з subdomain, створить запис A або AAAA лише для headless Service (busybox-subdomain.my-namespace.svc.cluster-domain.example), що вказує на IP-адреси Podʼів. Крім того, Pod повинен бути готовий, щоб мати запис, якщо не встановлено publishNotReadyAddresses=True для Service.Поле setHostnameAsFQDN Podʼа
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.22 [stable]Коли Pod налаштовано так, що він має повне доменне імʼя (FQDN), його імʼя хосту — це коротке імʼя хосту. Наприклад, якщо у вас є Pod із повним доменним імʼям busybox-1.busybox-subdomain.my-namespace.svc.cluster-domain.example, то стандартно команда hostname в цьому Podʼі повертає busybox-1, а команда hostname --fqdn повертає FQDN.
Коли ви встановлюєте setHostnameAsFQDN: true у специфікації Podʼа, kubelet записує FQDN Podʼа в імʼя хосту для простору імен цього Podʼа. У цьому випадку як hostname, так і hostname --fqdn повертають FQDN Podʼа.
Примітка:
У Linux поле hostname ядра (поле nodename структури struct utsname) обмежено 64 символами.
Якщо Pod активує цю функцію і його FQDN довше за 64 символи, запуск буде неуспішним. Pod залишиться у статусі Pending (ContainerCreating, як це бачить kubectl), генеруючи події помилок, такі як "Не вдалося побудувати FQDN з імені хосту Podʼа та домену кластера, FQDN long-FQDN занадто довгий (максимально 64 символи, запитано 70)". Один зі способів поліпшення досвіду користувача у цьому сценарії — створення контролера admission webhook для контролю розміру FQDN при створенні користувачами обʼєктів верхнього рівня, наприклад, Deployment.
Політика DNS Podʼа
Політику DNS можна встановлювати для кожного Podʼа окремо. Наразі Kubernetes підтримує наступні політики DNS, вказані у полі dnsPolicy в специфікації Podʼа:
- "
Default": Pod успадковує конфігурацію розпізнавання імені від вузла, на якому працюють Podʼи. Деталі можна переглянути у відповідному описі. - "
ClusterFirst": Будь-який DNS-запит, який не відповідає налаштованому суфіксу домену кластера, такому як "www.kubernetes.io", пересилається на вихідний DNS-сервер DNS-сервером. Адміністратори кластера можуть мати додаткові налаштовані піддомени та вихідні DNS-сервери. Деталі щодо обробки DNS-запитів у цих випадках можна знайти відповідному дописі. - "
ClusterFirstWithHostNet": Для Podʼів, які працюють ізhostNetwork, ви повинні явно встановити для них політику DNS "ClusterFirstWithHostNet". В іншому випадку Podʼи, що працюють ізhostNetworkта "ClusterFirst", будуть використовувати поведінку політики "Default".- Примітка: Це не підтримується в Windows. Деталі дивіться нижче.
- "
None": Це дозволяє Podʼу ігнорувати налаштування DNS з оточення Kubernetes. Всі налаштування DNS повинні надаватися за допомогою поляdnsConfigу специфікації Podʼа. Деталі дивіться у підрозділі DNS-конфігурація Podʼа нижче.
Примітка:
"Default" — це не стандартно політика DNS. Якщо полеdnsPolicy не вказано явно, то використовується "ClusterFirst".Наведений нижче приклад показує Pod із встановленою політикою DNS "ClusterFirstWithHostNet", оскільки у нього встановлено hostNetwork в true.
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- image: busybox:1.28
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
restartPolicy: Always
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
Конфігурація DNS для Podʼа
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.14 [stable]Конфігурація DNS для Podʼа дозволяє користувачам мати більше контролю над налаштуваннями DNS для конкретного Podʼа.
Поле dnsConfig є необовʼязковим і може використовуватися з будь-якими налаштуваннями dnsPolicy. Однак, коли поле dnsPolicy Podʼа встановлено в "None", поле dnsConfig повинно бути вказано.
Нижче наведені значення, які користувач може вказати у полі dnsConfig:
nameservers: список IP-адрес, які будуть використовуватися як DNS-сервери для Podʼа. Можна вказати не більше 3 IP-адрес, але коли політика DNS Podʼа встановлена на "None", список повинен містити принаймні одну IP-адресу, інакше ця властивість є необовʼязковою. Зазначені сервери будуть обʼєднані з базовими серверами, згенерованими з вказаною політикою DNS, з вилученням дубльованих адрес.searches: список доменів пошуку DNS для пошуку імен в хостах у Podʼі. Ця властивість є необовʼязковою. При вказанні, вказаний список буде обʼєднаний з базовими доменами пошуку, згенерованими з вибраної політики DNS. Дубльовані доменні імена вилучаються. Kubernetes дозволяє до 32 доменів пошуку.options: необовʼязковий список обʼєктів, де кожний обʼєкт може мати властивістьname(обовʼязкова) і властивістьvalue(необовʼязкова). Зміст цієї властивості буде обʼєднаний з параметрами, згенерованими з вказаної політики DNS. Дубльовані елементи вилучаються.
Тут наведено приклад Podʼа з власними налаштуваннями DNS:
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: dns-example
spec:
containers:
- name: test
image: nginx
dnsPolicy: "None"
dnsConfig:
nameservers:
- 192.0.2.1 # тут адреса для прикладу
searches:
- ns1.svc.cluster-domain.example
- my.dns.search.suffix
options:
- name: ndots
value: "2"
- name: edns0
Коли створюється Pod, контейнер test отримує наступний зміст у своєму файлі /etc/resolv.conf:
nameserver 192.0.2.1
search ns1.svc.cluster-domain.example my.dns.search.suffix
options ndots:2 edns0
Для налаштування IPv6 шляху пошуку та сервера імен слід встановити:
kubectl exec -it dns-example -- cat /etc/resolv.conf
Вивід буде подібний до наступного:
nameserver 2001:db8:30::a
search default.svc.cluster-domain.example svc.cluster-domain.example cluster-domain.example
options ndots:5
Обмеження списку доменів пошуку DNS
СТАН ФУНКЦІОНАЛУ:
Kubernetes 1.28 [stable]Kubernetes сам по собі не обмежує конфігурацію DNS до тих пір, поки довжина списку доменів пошуку не перевищить 32 або загальна довжина всіх доменів пошуку не перевищить 2048. Це обмеження стосується файлу конфігурації резолвера вузла, конфігурації DNS Podʼа та обʼєднаної конфігурації DNS відповідно.
Примітка:
Деякі середовища виконання контейнерів раніших версій можуть мати власні обмеження щодо кількості доменів пошуку DNS. Залежно від середовища виконання контейнерів, Podʼи з великою кількістю доменів пошуку DNS можуть залишатися в стані очікування.
Відомо, що containerd версії 1.5.5 або раніше та CRI-O версії 1.21 або раніше мають цю проблему.
DNS на вузлах з операційною системою Windows
- ClusterFirstWithHostNet не підтримується для Podʼів, які працюють на вузлах з операційною системою Windows. У Windows всі імена з крапкою
.розглядаються як повністю кваліфіковані та пропускають розгортання FQDN. - На Windows існують кілька резолверів DNS, які можна використовувати. Оскільки вони мають трохи відмінну поведінку, рекомендується використовувати
Resolve-DNSNameдля отримання імені. - У Linux у вас є список суфіксів DNS, який використовується після того, як розгортання імені як повністю кваліфіковане не вдалося. У Windows можна вказати лише 1 суфікс DNS, який є суфіксом DNS, повʼязаним з простором імен цього Podʼа (наприклад,
mydns.svc.cluster.local). Windows може розгортати FQDN, служби або мережеве імʼя, яке може бути розгорнуто за допомогою цього єдиного суфікса. Наприклад, Pod, створений у просторі іменdefault, матиме суфікс DNSdefault.svc.cluster.local. Всередині Windows імʼя Podʼа можна розгортати якkubernetes.default.svc.cluster.local, так іkubernetes, але не в частково кваліфіковані імена (kubernetes.defaultабоkubernetes.default.svc).
Що далі
Для керівництва щодо адміністрування конфігурацій DNS дивіться Налаштування служби DNS
5.8 - Подвійний стек IPv4/IPv6
Kubernetes дозволяє налаштувати мережеве зʼєднання з одним стеком IPv4, з одним стеком IPv6 або з подвійним стеком з обома сімействами мереж. Ця сторінка пояснює, як це зробити.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.23 [stable]Двостекова мережа IPv4/IPv6 дозволяє виділяти як адреси IPv4, так і IPv6 для Podʼів та Serviceʼів.
Двостекова мережа IPv4/IPv6 є стандартно увімкненою у вашому кластері Kubernetes починаючи з версії 1.21, що дозволяє одночасно призначати адреси як IPv4, так і IPv6.
Підтримувані функції
Двостекова мережа IPv4/IPv6 у вашому кластері Kubernetes надає наступні можливості:
- Мережа Pod із двома стеками (призначення адреси IPv4 і IPv6 на один Pod)
- Serviceʼи з підтримкою IPv4 і IPv6
- Маршрутизація egress Pod за межі кластера (наприклад, в Інтернет) через інтерфейси IPv4 та IPv6
Передумови
Для використання двостекових кластерів Kubernetes IPv4/IPv6 потрібні наступні передумови:
Kubernetes 1.20 або новіше
Для отримання інформації щодо використання двостекових Serviceʼів із попередніми версіями Kubernetes, дивіться документацію для відповідної версії Kubernetes.
Підтримка постачальником двостекової мережі (постачальник хмари або інший повинен забезпечити вузлам Kubernetes маршрутизовані мережеві інтерфейси IPv4/IPv6)
Мережевий втулок, який підтримує двостекову мережу.
Налаштування двостекової мережі IPv4/IPv6
Щоб налаштувати подвійний стек IPv4/IPv6, встановіть призначення мережі кластера з подвійним стеком:
- kube-apiserver:
--service-cluster-ip-range=<CIDR IPv4>,<CIDR IPv6>
- kube-controller-manager:
--cluster-cidr=<CIDR IPv4>,<CIDR IPv6>--service-cluster-ip-range=<CIDR IPv4>,<CIDR IPv6>--node-cidr-mask-size-ipv4|--node-cidr-mask-size-ipv6типово /24 для IPv4 та /64 для IPv6
- kube-proxy:
--cluster-cidr=<CIDR IPv4>,<CIDR IPv6>
- kubelet:
--node-ip=<IP IPv4>,<IP IPv6>- Ця опція є обовʼязковою для bare metal двостекових вузлів (вузлів, які не визначають постачальника хмари прапорцем
--cloud-provider). Якщо ви використовуєте постачальника хмари та вирішили перевизначити IP-адреси вузлів, визначені постачальником хмари, встановіть опцію--node-ip. - (Вбудовані застарілі постачальники хмари не підтримують двостековий параметр
--node-ip.)
- Ця опція є обовʼязковою для bare metal двостекових вузлів (вузлів, які не визначають постачальника хмари прапорцем
Примітка:
Приклад CIDR IPv4: 10.244.0.0/16 (хоча ви повинні вказати свій власний діапазон адрес)
Приклад CIDR IPv6: fdXY:IJKL:MNOP:15::/64 (це показує формат, але не є дійсною адресою — дивіться RFC 4193)
Serviceʼи
Ви можете створювати Serviceʼи, які можуть використовувати адреси IPv4, IPv6 або обидві.
Сімейство адрес Service типово відповідає сімейству адрес першого діапазону IP Service кластера (налаштованого через прапорець --service-cluster-ip-range у kube-apiserver).
При визначенні Service ви можете конфігурувати його як двостековий за власним бажанням. Щоб вказати потрібну поведінку, ви встановлюєте в поле .spec.ipFamilyPolicy одне з наступних значень:
SingleStack: Service з одним стеком. Панель управління виділяє IP кластера для Service, використовуючи перший налаштований діапазон IP кластера для Service.PreferDualStack: Виділяє IP-адреси кластерів IPv4 та IPv6 для Service, коли ввімкнено подвійний стек. Якщо подвійний стек не ввімкнено або не підтримується, він повертається до одностекового режиму.RequireDualStack: Виділяє IP-адреси Service.spec.clusterIPз діапазонів адрес IPv4 та IPv6, якщо увімкнено подвійний стек. Якщо подвійний стек не ввімкнено або не підтримується, створення обʼєкта Service API завершиться невдачею.- Вибирає
.spec.clusterIPзі списку.spec.clusterIPsна основі сімейства адрес першого елемента у масиві.spec.ipFamilies.
- Вибирає
Якщо ви хочете визначити, яке сімейство IP використовувати для одностекової конфігурації або визначити порядок IP для двостекової, ви можете вибрати сімейства адрес, встановивши необовʼязкове поле .spec.ipFamilies в Service.
Примітка:
Поле.spec.ipFamilies умовно змінюване: ви можете додавати або видаляти вторинне
сімейство IP-адрес, але не можете змінювати основне сімейство IP-адрес наявного Service.Ви можете встановити .spec.ipFamilies в будь-яке з наступних значень масиву:
["IPv4"]["IPv6"]["IPv4","IPv6"](два стеки)["IPv6","IPv4"](два стеки)
Перше сімейство, яке ви перераховуєте, використовується для легасі-поля .spec.clusterIP.
Сценарії конфігурації двостекового Service
Ці приклади демонструють поведінку різних сценаріїв конфігурації двостекового Service.
Параметри подвійного стека в нових Service
Специфікація цього Service явно не визначає
.spec.ipFamilyPolicy. Коли ви створюєте цей Service, Kubernetes виділяє кластерний IP для Service з першого налаштованогоservice-cluster-ip-rangeта встановлює значення.spec.ipFamilyPolicyнаSingleStack. (Service без селекторів та headless Services із селекторами будуть працювати так само.)apiVersion: v1 kind: Service metadata: name: my-service labels: app.kubernetes.io/name: MyApp spec: selector: app.kubernetes.io/name: MyApp ports: - protocol: TCP port: 80Специфікація цього Service явно визначає
PreferDualStackв.spec.ipFamilyPolicy. Коли ви створюєте цей Service у двостековому кластері, Kubernetes призначає як IPv4, так і IPv6 адреси для Service. Панель управління оновлює.specдля Service, щоб зафіксувати адреси IP. Поле.spec.clusterIPsє основним полем і містить обидві призначені адреси IP;.spec.clusterIPє вторинним полем зі значенням, обчисленим з.spec.clusterIPs.- Для поля
.spec.clusterIPпанель управління записує IP-адресу, яка є з того ж самого сімейства адрес, що й перший діапазон кластерних IP Service. - У одностековому кластері поля
.spec.clusterIPsта.spec.clusterIPмістять лише одну адресу. - У кластері з увімкненими двома стеками вказання
RequireDualStackв.spec.ipFamilyPolicyпрацює так само як іPreferDualStack.
apiVersion: v1 kind: Service metadata: name: my-service labels: app.kubernetes.io/name: MyApp spec: ipFamilyPolicy: PreferDualStack selector: app.kubernetes.io/name: MyApp ports: - protocol: TCP port: 80- Для поля
Специфікація цього Service явно визначає
IPv6таIPv4в.spec.ipFamilies, а також визначаєPreferDualStackв.spec.ipFamilyPolicy. Коли Kubernetes призначає IPv6 та IPv4 адреси в.spec.clusterIPs,.spec.clusterIPвстановлюється на IPv6 адресу, оскільки це перший елемент у масиві.spec.clusterIPs, що перевизначає типові значення.apiVersion: v1 kind: Service metadata: name: my-service labels: app.kubernetes.io/name: MyApp spec: ipFamilyPolicy: PreferDualStack ipFamilies: - IPv6 - IPv4 selector: app.kubernetes.io/name: MyApp ports: - protocol: TCP port: 80
Параметри подвійного стека в наявних Service
Ці приклади демонструють типову поведінку при увімкненні двостековості в кластері, де вже існують Service. (Оновлення наявного кластера до версії 1.21 або новіше вмикає двостековість.)
Коли двостековість увімкнена в кластері, наявні Service (безперебійно
IPv4абоIPv6) конфігуруються панеллю управління так, щоб встановити.spec.ipFamilyPolicyнаSingleStackта встановити.spec.ipFamiliesна сімейство адрес наявного Service. Кластерний IP наявного Service буде збережено в.spec.clusterIPs.apiVersion: v1 kind: Service metadata: name: my-service labels: app.kubernetes.io/name: MyApp spec: selector: app.kubernetes.io/name: MyApp ports: - protocol: TCP port: 80Ви можете перевірити цю поведінку за допомогою kubectl, щоб переглянути наявний Service.
kubectl get svc my-service -o yamlapiVersion: v1 kind: Service metadata: labels: app.kubernetes.io/name: MyApp name: my-service spec: clusterIP: 10.0.197.123 clusterIPs: - 10.0.197.123 ipFamilies: - IPv4 ipFamilyPolicy: SingleStack ports: - port: 80 protocol: TCP targetPort: 80 selector: app.kubernetes.io/name: MyApp type: ClusterIP status: loadBalancer: {}Коли двостековість увімкнена в кластері, наявні headless Services з селекторами конфігуруються панеллю управління так, щоб встановити
.spec.ipFamilyPolicyнаSingleStackта встановити.spec.ipFamiliesна сімейство адрес першого діапазону кластерних IP Service (налаштованого за допомогою прапорця--service-cluster-ip-rangeдля kube-apiserver), навіть якщо.spec.clusterIPвстановлено вNone.apiVersion: v1 kind: Service metadata: name: my-service labels: app.kubernetes.io/name: MyApp spec: selector: app.kubernetes.io/name: MyApp ports: - protocol: TCP port: 80Ви можете перевірити цю поведінку за допомогою kubectl, щоб переглянути наявний headless Service з селекторами.
kubectl get svc my-service -o yamlapiVersion: v1 kind: Service metadata: labels: app.kubernetes.io/name: MyApp name: my-service spec: clusterIP: None clusterIPs: - None ipFamilies: - IPv4 ipFamilyPolicy: SingleStack ports: - port: 80 protocol: TCP targetPort: 80 selector: app.kubernetes.io/name: MyApp
Перемикання Service між одностековим та двостековим режимами
Service можна перемикати з одностекового режиму на двостековий та навпаки.
Для того щоби перемикнути Service з одностекового режиму на двостековий, змініть
.spec.ipFamilyPolicyзSingleStackнаPreferDualStackабоRequireDualStackза необхідності. Коли ви змінюєте цей Service з одностекового режиму на двостековий, Kubernetes призначає відсутнє адресне сімейство, так що тепер Service має адреси IPv4 та IPv6.Відредагуйте специфікацію Service, оновивши
.spec.ipFamilyPolicyзSingleStackнаPreferDualStack.До:
spec: ipFamilyPolicy: SingleStackПісля:
spec: ipFamilyPolicy: PreferDualStackДля того щоби змінити Service з двостекового режиму на одностековий, змініть
.spec.ipFamilyPolicyзPreferDualStackабоRequireDualStackнаSingleStack. Коли ви змінюєте цей Service з двостекового режиму на одностековий, Kubernetes залишає лише перший елемент у масиві.spec.clusterIPs, і встановлює.spec.clusterIPна цю IP-адресу і встановлює.spec.ipFamiliesна адресне сімейство.spec.clusterIPs.
Headless Services без селекторів
Для Headless Services без селекторів і без явно вказаного .spec.ipFamilyPolicy, поле .spec.ipFamilyPolicy має типове значення RequireDualStack.
Тип Service — LoadBalancer
Щоб налаштувати двостековий балансувальник навантаження для вашого Service:
- Встановіть значення поля
.spec.typeвLoadBalancer - Встановіть значення поля
.spec.ipFamilyPolicyвPreferDualStackабоRequireDualStack
Примітка:
Для використання двостекового Service типуLoadBalancer, ваш постачальник хмари повинен підтримувати балансувальники навантаження IPv4 та IPv6.Трафік Egress
Якщо ви хочете увімкнути трафік Egress, щоб досягти призначення за межами кластера (наприклад, публічний Інтернет) з Podʼа, який використовує непублічно марковані адреси IPv6, вам потрібно увімкнути Pod для використання публічно-маршрутизованих адрес IPv6 за допомогою механізму, такого як прозорий проксі або IP маскування. Проєкт ip-masq-agent підтримує IP-маскування у двохстекових кластерах.
Примітка:
Переконайтеся, що ваш постачальник CNI підтримує IPv6.Підтримка Windows
Kubernetes на Windows не підтримує одностекову мережу "лише IPv6". Однак підтримується двохстекова мережа IPv4/IPv6 для Podʼів та вузлів з одностековими Service.
Ви можете використовувати двохстекову мережу IPv4/IPv6 з мережами l2bridge.
Примітка:
Мережі VXLAN на Windows не підтримують двохстекову мережу.Ви можете дізнатися більше про різні режими мережі для Windows в розділі Мережа у Windows.
Що далі
5.9 - Маршрутизація з урахуванням топології
Маршрутизацію з урахуванням топології надає механізм для збереження мережевого трафіку в межах зони, з якої він походить. Віддача переваги трафіку в межах однієї зони між Podʼами в вашому кластері може допомогти з надійністю, продуктивністю (мережевою затримкою та пропускною здатністю) або вартістю.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.23 [beta]Примітка:
До Kubernetes 1.27 ця функція відома як Topology Aware Hints.Маршрутизація з урахуванням топології налаштовує поведінку маршрутизації для того, щоб надавати перевагу зберіганню трафіку в межах тієї зони, з якої він походить. У деяких випадках це може допомогти зменшити витрати або покращити мережеву продуктивність.
Мотивація
Кластери Kubernetes все частіше розгортаються в багатозональних середовищах. Маршрутизацію з урахуванням топології забезпечує механізм для збереження трафіку в межах зони, з якої він походить. При розрахунку точок доступу для Service, контролер EndpointSlice враховує топологію (регіон і зону) кожної точки доступу та заповнює поле підказок для виділення її в зону. Компоненти кластера, такі як kube-proxy, можуть використовувати ці підказки для впливу на маршрутизацію трафіку (надання переваги точкам доступу, які знаходяться в топологічно ближчих зонах).
Увімкнення маршрутизації з урахуванням топології
Примітка:
До Kubernetes 1.27 така поведінка контролювалася за допомогою анотаціїservice.kubernetes.io/topology-aware-hints.Ви можете увімкнути маршрутизацію з урахуванням топології, для Service, встановивши анотацію service.kubernetes.io/topology-mode в значення Auto. Коли є достатня кількість точок доступу у кожній зоні, в EndpointSlice будуть заповнені підказки щодо топології для виділення окремих точок доступу конкретним зонам, що призводить до того, що трафік буде маршрутизуватися ближче до місця, звідки він походить.
Найкращий випадок застосування
Ця функція працює найкраще, коли:
1. Вхідний трафік рівномірно розподілений
Якщо значна частина трафіку походить з однієї зони, цей трафік може перенавантажити підмножину точок доступу, які були виділені для цієї зони. Не рекомендується використовувати цю функцію, коли очікується, що вхідний трафік буде походити з однієї зони.
2. У Service є 3 чи більше точок доступу на зону
У кластері з трьома зонами це означає 9 чи більше точок доступу. Якщо кількість точок доступу менше ніж 3 на зону, існує висока (≈50%) ймовірність, що контролер EndpointSlice не зможе рівномірно розподілити точки доступу та повернеться до застосування типового підходу до маршрутизації на рівні кластера.
Як це працює
Характеристика "Auto" намагається пропорційно виділити кількість точок доступу кожній зоні. Зверніть увагу, що цей підхід працює найкраще для сервісів зі значною кількістю точок доступу.
Контролер EndpointSlice
Контролер EndpointSlice відповідає за встановлення підказок на EndpointSlice, коли цей евристичний підхід увімкнено. Контролер виділяє пропорційну кількість точок доступу кожній зоні. Ця пропорція ґрунтується на виділеному обсязі ядер ЦП для вузлів, що працюють в цій зоні. Наприклад, якщо в одній зоні є 2 ядра ЦП, а в іншій зоні лише 1 ядро ЦП, контролер виділить подвійну кількість точок доступу для зони з 2 ядрами ЦП.
Нижче наведено приклад того, як виглядає EndpointSlice, коли підказки вже заповнено:
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: example-hints
labels:
kubernetes.io/service-name: example-svc
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
hostname: pod-1
zone: zone-a
hints:
forZones:
- name: "zone-a"
kube-proxy
Компонент kube-proxy фільтрує точки доступу, до яких він направляє трафік, на підставі підказок, встановлених контролером EndpointSlice. У більшості випадків це означає, що kube-proxy може направляти трафік до точок доступу в тій самій зоні. Іноді контролер вибирає точки доступу з іншої зони, щоб забезпечити більш рівномірний розподіл точок доступу між зонами. Це може призвести до того, що деякий трафік буде направлятися до інших зон.
Запобіжники
Панель управління Kubernetes та kube-proxy на кожному вузлі застосовують деякі правила захисту перед використанням Topology Aware Hints. Якщо ці перевірки не пройдуть, kube-proxy вибирає точки доступу з будь-якої частини вашого кластера, незалежно від зони.
Недостатня кількість точок доступу: Якщо точок доступу менше, ніж зон в кластері, контролер не буде додавати жодних підказок.
Неможливо досягнути збалансованого розподілу: У деяких випадках може бути неможливо досягти збалансованого розподілу точок доступу між зонами. Наприклад, якщо zone-a удвічі більша, ніж zone-b, але є лише 2 точки доступу, точка доступу, призначена zone-a, може отримати вдвічі більше трафіку, ніж zone-b. Контролер не призначає підказок, якщо він не може знизити це значення "очікуваного перевантаження" нижче прийнятного порогу для кожної зони. Важливо, що це не ґрунтується на зворотньому звʼязку в режимі реального часу. Можливе перенавантаження окремих точок доступу.
Один чи декілька вузлів має недостатню інформацію: Якщо який-небудь вузол не має мітки
topology.kubernetes.io/zoneабо не повідомляє значення виділеного ЦП, панель управління не встановлює жодних підказок точок доступу з відомостями про зони, і, отже, kube-proxy не фільтрує точки доступу за зоною.Одна чи декілька точок доступу не має підказки щодо зони: Коли це трапляється, kube-proxy припускає, що відбувається перехід до або з Topology Aware Hints. Фільтрація точок доступу для Serviceʼу в цьому стані була б небезпечною, тому kube-proxy використовує всі точки доступу.
Зона не представлена в підказках: Якщо kube-proxy не може знайти принаймні одну точку доступу із підказкою для зони, в якій він працює, він припускається до використання точок доступу з усіх зон. Це ймовірніше станеться, коли ви додаєте нову зону до вашого наявного кластера.
Обмеження
Topology Aware Hints не використовуються, коли
internalTrafficPolicyвстановлено вLocalдля Service. Можливе використання обох функцій у тому ж кластері для різних Serviceʼів, просто не на одному і тому ж Service.Цей підхід не дуже підходить для Serviceʼів, від яких значна частина трафіку походить від підмножини зон. Замість цього передбачається, що вхідний трафік буде приблизно пропорційним місткості Вузлів у кожній зоні.
Контролер EndpointSlice ігнорує непридатні вузли під час розрахунку пропорцій для кожної зони. Це може мати неочікувані наслідки, якщо велика частина вузлів непридатна.
Контролер EndpointSlice ігнорує вузли з мітками
node-role.kubernetes.io/control-planeабоnode-role.kubernetes.io/master. Це може бути проблематичним, якщо також на цих вузлах працюють робочі навантаження.Контролер EndpointSlice не враховує tolerations при розгортанні або розрахунку пропорцій для кожної зони. Якщо Podʼи, які підтримують Service, обмежені у підмножині вузлів у кластері, це не буде враховано.
Це може не добре працювати з автомасштабуванням. Наприклад, якщо багато трафіку походить з однієї зони, тільки точки доступу, виділені для цієї зони, будуть обробляти цей трафік. Це може призвести до того, що Horizontal Pod Autoscaler або не помічає такої події, або нові Podʼи стартують в іншій зоні.
Власні евристики
Kubernetes може розгортатися різними способами, і для кожного випадку не існує єдиної евристики, яка працюватиме для виділення точок доступу в зони. Одна з ключових цілей цього функціоналу — надання можливості розробки власних евристик, якщо вбудована евристика не працює для вашого випадку використання. Перші кроки для увімкнення власних евристик були включені у випуск 1.27. Це обмежена реалізація, яка може ще не враховувати деякі актуальні та вірогідні ситуації.
Що далі
- Скористайтесь довідником Підключення застосунків за допомогою Service.
- Дізнайтесь про поле trafficDistribution, що тісно повʼязане з анотацією
service.kubernetes.io/topology-modeта надає гнучкість управління маршрутизацією трафіку в Kubernetes.
5.10 - Мережеві аспекти Windows
Kubernetes підтримує використання як вузлів Linux, так і Windows, і можливе одночасне використання обох типів вузлів у межах одного кластеру. Ця сторінка надає огляд мережевих аспектів, специфічних для операційної системи Windows.
Мережева взаємодія контейнерів у Windows
Мережевий стек для контейнерів у Windows використовує CNI-втулки. Контейнери у Windows працюють схоже до віртуальних машин з погляду мережі. Кожен контейнер має віртуальний мережевий адаптер (vNIC), який підключений до віртуального комутатора Hyper-V (vSwitch). Host Networking Service (HNS) та Host Compute Service (HCS) спільно працюють для створення контейнерів і підключення віртуальних мережевих адаптерів контейнера до мереж. HCS відповідає за управління контейнерами, тоді як HNS відповідає за управління ресурсами мережі, такими як:
- Віртуальні мережі (включаючи створення vSwitches)
- Endpoint / vNIC
- Namespaces
- Політика, включаючи інкапсуляцію пакетів, правила балансування навантаження, ACL, та правила NAT.
Windows HNS та vSwitch реалізують простір імен та можуть створювати віртуальні мережеві адаптери за потреби для Podʼів чи контейнерів. Однак багато конфігурацій,
таких як DNS, маршрути та метрики, зберігаються в базі даних реєстру Windows, а не як файли в /etc, як це робить Linux. Реєстр Windows для контейнера відрізняється від реєстру хосту, тому концепції, такі як передавання /etc/resolv.conf з хосту в контейнер, не мають такого ж ефекту, як у Linux. Їх потрібно налаштовувати за допомогою API Windows, що виконуються в контексті контейнера. Таким чином, реалізації CNI повинні викликати HNS, а не покладатися на доступ до файлів для передачі мережевих деталей у Pod чи контейнер.
Режими мережі
Windows підтримує пʼять різних драйверів/режимів мережі: L2bridge, L2tunnel, Overlay (Beta), Transparent та NAT. У гетерогенному кластері з вузлами Windows і Linux необхідно вибрати мережеве рішення, яке сумісне як з Windows, так і з Linux. У таблиці нижче наведено втулки, що не є частиною Kubernetes, які підтримуються у Windows, з рекомендаціями щодо використання кожного CNI:
| Драйвер мережі | Опис | Модифікації контейнерних пакетів | Втулки мережі | Характеристики втулків мережі |
|---|---|---|---|---|
| L2bridge | Контейнери підключені до зовнішнього vSwitch. Контейнери підключені до мережі нижнього рівня, хоча фізична мережа не повинна знати MAC-адреси контейнера, оскільки вони переписуються при вході/виході. | MAC переписується на MAC хосту, IP може бути переписаний на IP хосту за допомогою політики HNS OutboundNAT. | win-bridge, Azure-CNI, Flannel host-gateway використовує win-bridge | win-bridge використовує режим мережі L2bridge, підключаючи контейнери до нижнього рівня хостів, пропонуючи найкращу продуктивність. Вимагає маршрутів, визначених користувачем (UDR) для міжвузлової звʼязності. |
| L2Tunnel | Це спеціальний випадок l2bridge, але використовується тільки на Azure. Всі пакети відсилаються на віртуальний хост, де застосовується політика SDN. | MAC переписується, IP видно в мережі нижнього рівня | Azure-CNI | Azure-CNI дозволяє інтегрувати контейнери з Azure vNET та використовувати набір можливостей, які Azure Virtual Network надає. Наприклад, безпечно підключатися до служб Azure або використовувати NSG Azure. Див. azure-cni для прикладів |
| Overlay | Контейнерам надається vNIC, підключений до зовнішнього vSwitch. Кожна мережа має власну підмережу IP, визначену власним IP-префіксом. Драйвер мережі використовує інкапсуляцію VXLAN. | Інкапсульований в зовнішній заголовок. | win-overlay, Flannel VXLAN (використовує win-overlay) | win-overlay слід використовувати, коли потрібна ізоляція віртуальних мереж контейнерів від нижнього рівня хостів (наприклад, з міркувань безпеки). Дозволяє використовувати однакові IP для різних віртуальних мереж (які мають різні теґи VNID), якщо у вас обмеження на IP в вашому датацентрі. Цей варіант вимагає KB4489899 у Windows Server 2019. |
| Transparent (спеціальний випадок для ovn-kubernetes) | Вимагає зовнішнього vSwitch. Контейнери підключені до зовнішнього vSwitch, що дозволяє взаємодію всередині Podʼа за допомогою логічних мереж (логічні свічі та маршрутизатори). | Пакет капсулюється через GENEVE або STT для доступу до Podʼів, які не знаходяться на тому самому хості. Пакети пересилаються чи відкидаються через інформацію про тунель, яку надає контролер мережі ovn. NAT виконується для комунікації північ-південь. | ovn-kubernetes | Розгортається за допомогою ansible. Розподілені ACL можна застосовувати за допомогою політик Kubernetes. Підтримка IPAM. Балансування навантаження можливе без використання kube-proxy. NAT виконується без використання iptables/netsh. |
| NAT (не використовується в Kubernetes) | Контейнерам надається віртуальний мережевий адаптер (vNIC), підключений до внутрішнього vSwitch. DNS/DHCP надається за допомогою внутрішнього компонента, називається WinNAT | MAC та IP переписуються на MAC/IP хосту. | nat | Включено тут для повноти. |
Як вказано вище, Flannel CNI plugin також підтримується у Windows через VXLAN мережевий бекенд (Бета-підтримка; делегує до win-overlay) та host-gateway мережевий бекенд (стабільна підтримка; делегує до win-bridge).
Цей втулок підтримує делегування до одного з втулків CNI за вибором користувача (win-overlay, win-bridge), для співпраці з демоном Flannel у Windows (Flanneld) для автоматичного присвоєння лізингу підмережі вузлу та створення мережі HNS. Цей втулок читає власний файл конфігурації (cni.conf) та агрегує його зі змінними середовища зі створеного FlannelD файлу subnet.env. Потім він делегує одному з втулків CNI для роботи з мережею, надсилаючи правильну конфігурацію, що містить призначену вузлом підмережу до IPAM-втулку (наприклад: host-local).
Для обʼєктів Node, Pod та Service підтримуються наступні потоки даних мережі для TCP/UDP-трафіку:
- Pod → Pod (IP)
- Pod → Pod (Імʼя)
- Pod → Сервіс (Кластерний IP)
- Pod → Сервіс (PQDN, але тільки якщо немає ".")
- Pod → Сервіс (FQDN)
- Pod → зовнішній (IP)
- Pod → зовнішній (DNS)
- Node → Pod
- Pod → Node
Управління IP-адресами (IPAM)
У Windows підтримуються наступні параметри IPAM:
- host-local
- azure-vnet-ipam (тільки для azure-cni)
- IPAM Windows Server (запасна опція, якщо не встановлено IPAM)
Балансування навантаження та Service
Service Kubernetes є абстракцією, яка визначає логічний набір Podʼів та засіб доступу до них мережею. У кластері, який включає вузли Windows, можна використовувати наступні типи Service:
NodePortClusterIPLoadBalancerExternalName
Мережева взаємодія контейнерів у Windows відрізняється в деяких важливих аспектах від мережі Linux. Документація Microsoft з мережевої взаємодії контейнерів у Windows надає додаткові відомості та контекст.
У Windows можна використовувати наступні налаштування для конфігурації Service та поведінки балансування навантаження:
| Функція | Опис | Мінімальна підтримувана версія Windows OS | Як ввімкнути |
|---|---|---|---|
| Подібність сесій (Session affinity) | Забезпечує, що підключення від певного клієнта передається тому самому Podʼу кожен раз. | Windows Server 2022 | Встановіть у service.spec.sessionAffinity значення "ClientIP" |
| Direct Server Return (DSR) | Режим балансування навантаження, де виправлення IP-адреси та LBNAT відбуваються на порту vSwitch контейнера напряму; трафік служби приходить з набору вихідних IP, встановленого як IP походження Podʼа. | Windows Server 2019 | Встановіть наступні прапорці в kube-proxy: --feature-gates="WinDSR=true" --enable-dsr=true |
| Збереження-Призначення | Пропускає DNAT-трафік Servicʼу, тим самим зберігаючи віртуальну IP цільового Service в пакетах, що досягають фронтенду Podʼа. Також вимикає пересилання вузол-вузол. | Windows Server, версія 1903 | Встановіть "preserve-destination": "true" в анотаціях служби та увімкніть DSR в kube-proxy. |
| Подвійний мережевий стек IPv4/IPv6 | Нативна підтримка IPv4-до-IPv4 поряд з IPv6-до-IPv6 комунікацією до, з і всередині кластера | Windows Server 2019 | Див. Підтримка подвійного стеку IPv4/IPv6 |
| Збереження IP клієнта | Забезпечує збереження джерела ingress трафіку. Також вимикає пересилання вузол-вузол. | Windows Server 2019 | Встановіть service.spec.externalTrafficPolicy у "Local" та увімкніть DSR в kube-proxy |
Попередження:
Існують відомі проблеми з Serviceʼами NodePort в мережі оверлея, якщо вузол призначення працює під управлінням Windows Server 2022. Щоб уникнути проблеми повністю, ви можете налаштувати Service з externalTrafficPolicy: Local.
Існують відомі проблеми зі зʼєднаннями Pod-Pod в режимі мережі l2bridge у Windows Server 2022 з KB5005619 або вище. Для усунення проблеми та відновлення зʼєднаності Pod-Pod ви можете вимкнути функцію WinDSR в kube-proxy.
Ці проблеми потребують виправлень в операційній системі. Будь ласка, слідкуйте за https://github.com/microsoft/Windows-Containers/issues/204 для отримання оновлень.
Обмеження
Наступні функції мережі не підтримуються на вузлах Windows:
- Режим мережі хосту
- Локальний доступ NodePort з вузла (працює для інших вузлів або зовнішніх клієнтів)
- Більше 64 бекенд-Podʼів (або унікальних адрес призначення) для одного Service
- Звʼязок IPv6 між Pods Windows, підключеними до мереж оверлея
- Local Traffic Policy в режимі без DSR
- Вихідна комунікація за допомогою протоколу ICMP через
win-overlay,win-bridge, або використовуючи втулок Azure-CNI. Зокрема панель даних Windows (VFP) не підтримує ICMP-перетворення пакетів, і це означає:- Пакети ICMP, спрямовані до пунктів призначення в одній мережі (наприклад, звʼязок Pod-Pod за допомогою ping), працюють належним чином;
- TCP/UDP-пакети працюють, як очікується;
- Пакети ICMP, спрямовані на проходження через віддалену мережу (наприклад, Pod-зовнішньої точки в інтернет через ping), не можуть бути перенесені та, таким чином, не будуть перенаправлені назад до свого джерела;
- Оскільки TCP/UDP-пакети все ще можуть бути перетворені, ви можете замінити
ping <destination>наcurl <destination>при налагодженні зʼєднаності з зовнішнім світом.
Інші обмеження:
- Референсні мережеві втулки Windows, такі як win-bridge та win-overlay, не мають реалізації специфікації CNI v0.4.0, через відсутність реалізації
CHECK. - Втулок Flannel VXLAN має наступні обмеження на Windows:
- Зʼєднаність Node-Pod можлива лише для локальних Podʼів з Flannel v0.12.0 (або вище).
- Flannel обмежений використанням VNI 4096 та UDP-порту 4789. Див. офіційну Flannel VXLAN документацію про бекенд Flannel VXLAN щодо цих параметрів.
5.11 - Виділення IP-адрес ClusterIP Serviceʼам
У Kubernetes Service — це абстракція для експозиції застосунку, який працює на наборі Podʼів. Serviceʼи можуть мати віртуальну IP-адресу, доступну на рівні кластера (за допомогою Service з type: ClusterIP). Клієнти можуть підключатися за допомогою цієї віртуальної IP-адреси, і Kubernetes балансує трафік до цього Service між його Podʼами.
Як виділяються IP-адреси ClusterIP Сервісу?
Коли Kubernetes потрібно призначити віртуальну IP-адресу для Service, це відбувається одним із двох способів:
- динамічно
- панель управління кластера автоматично вибирає вільну IP-адресу з налаштованого діапазону IP для Service з
type: ClusterIP. - статично
- ви вказуєте IP-адресу за своїм вибором, з налаштованого діапазону IP для Service.
Для всього вашого кластера кожен Service ClusterIP повинен бути унікальним. Спроба створення Service із конкретним ClusterIP, що вже був призначений, призведе до помилки.
З чого випливає необхідність резервування IP-адрес для ClusterIP Service?
Іноді вам може знадобитися мати Serviceʼи, які працюють на відомих IP-адресах, щоб інші компоненти та користувачі в кластері могли їх використовувати.
Найкращим прикладом є Service DNS для кластера. Як мʼяка конвенція, деякі встановлювачі Kubernetes відводять 10-ту IP-адресу з діапазону IP-адрес Service для служби DNS. Припустимо, ви налаштували кластер із діапазоном IP-адрес Service 10.96.0.0/16 і хочете, щоб ваша IP-адреса Service DNS була 10.96.0.10, вам доведеться створити Service, подібний до цього:
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: CoreDNS
name: kube-dns
namespace: kube-system
spec:
clusterIP: 10.96.0.10
ports:
- name: dns
port: 53
protocol: UDP
targetPort: 53
- name: dns-tcp
port: 53
protocol: TCP
targetPort: 53
selector:
k8s-app: kube-dns
type: ClusterIP
Але, як це було пояснено раніше, IP-адреса 10.96.0.10 не була зарезервована. Якщо інші Service створюються перед або паралельно з динамічним виділенням, існує шанс, що вони можуть зайняти цю IP-адресу, тому ви не зможете створити Service DNS, оскільки це призведе до конфлікту.
Як уникнути конфліктів IP-адрес ClusterIP Сервісу?
Стратегія виділення, реалізована в Kubernetes для виділення ClusterIPs Service, зменшує ризик колізій.
ClusterIP діапазон поділений на основі формули min(max(16, cidrSize / 16), 256), описано як ніколи менше ніж 16 або більше за 256 із поступовим кроком між ними.
Динамічне призначення IP типово використовує верхній діапазон, якщо цей діапазон вичерпано, то буде використано нижній діапазон. Це дозволить користувачам використовувати статичні виділення в нижньому діапазоні із низьким ризиком колізій.
Приклади
Приклад 1
У цьому прикладі використовується діапазон IP-адрес: 10.96.0.0/24 (нотація CIDR) для IP-адрес Serviceʼів.
Розмір діапазону: 28 - 2 = 254
Зсув діапазону: min(max(16, 256/16), 256) = min(16, 256) = 16
Початок статичного діапазону: 10.96.0.1
Кінець статичного діапазону: 10.96.0.16
Кінець діапазону: 10.96.0.254
pie showData
title 10.96.0.0/24
"Статичний" : 16
"Динамічний" : 238
Приклад 2
У цьому прикладі використовується діапазон IP-адрес: 10.96.0.0/20 (нотація CIDR) для IP-адрес Service.
Розмір діапазону: 212 - 2 = 4094
Зсув діапазону: min(max(16, 4096/16), 256) = min(256, 256) = 256
Початок статичного діапазону: 10.96.0.1
Кінець статичного діапазону: 10.96.1.0
Кінець діапазону: 10.96.15.254
pie showData
title 10.96.0.0/20
"Статичний" : 256
"Динамічний" : 3838
Приклад 3
У цьому прикладі використовується діапазон IP-адрес: 10.96.0.0/16 (нотація CIDR) для IP-адрес Service.
Розмір діапазону: 216 - 2 = 65534
Зсув діапазону: min(max(16, 65536/16), 256) = min(4096, 256) = 256
Початок статичного діапазону: 10.96.0.1
Кінець статичного діапазону: 10.96.1.0
Кінець діапазону: 10.96.255.254
pie showData
title 10.96.0.0/16
"Статичний" : 256
"Динамічний" : 65278
Що далі
- Дізнайтеся про Політики зовнішнього трафіку Service
- Дізнайтеся про Підключення застосунків за допомогою Service
- Дізнайтеся про Service
5.12 - Політики внутрішнього трафіку Service
Якщо два Podʼа в вашому кластері хочуть взаємодіяти, і вони обидва фактично працюють на одному й тому ж вузлі, використовуйте Політики внутрішнього трафіку Service, щоб утримувати мережевий трафік в межах цього вузла. Уникнення зворотного зв’язку через кластерну мережу може допомогти підвищити надійність, продуктивність (затримку мережі та пропускну здатність) або вартість.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.26 [stable]Політика внутрішнього трафіку Service дозволяє обмежувати внутрішній трафік, маршрутизуючи його лише до endpoint у межах вузла, з якого походить трафік. Тут "внутрішній" трафік означає трафік, який виник з Podʼів у поточному кластері. Це може допомогти зменшити витрати та покращити продуктивність.
Використання політики внутрішнього трафіку Service
Ви можете увімкнути політику тільки для внутрішнього трафіку для Service, встановивши його .spec.internalTrafficPolicy в Local. Це вказує kube-proxy використовувати лише вузлові локальні endpoint для внутрішнього трафіку кластера.
Примітка:
Для Podʼів на вузлах без endpoint для певного Service, Service буде працювати так, ніби в нього немає endpoint (для Podʼів на цьому вузлі), навіть якщо у Service є endpointʼи на інших вузлах.У наступному прикладі показано, як виглядає Service, коли ви встановлюєте
.spec.internalTrafficPolicy в Local:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
internalTrafficPolicy: Local
Як це працює
Kube-proxy фільтрує endpointʼи, до яких він виконує маршрутизацію, на основі налаштувань spec.internalTrafficPolicy. Коли вона встановлена в Local, розглядаються тільки вузлові локальні endpointʼи. Коли вона встановлена в Cluster (стандартно), або не встановлена взагалі, Kubernetes розглядає всі endpointʼи.
Що далі
- Дізнайтеся про Маршрутизацію з урахуванням топології
- Дізнайтеся про Політики зовнішнього трафіку Service
- Скористайтесь довідником Підключенням застосунків за допомогою Service.
6 - Зберігання
Способи надання як довгострокового, так і тимчасового зберігання даних для
Podів у вашому кластері.6.1 - Томи
Файли на диску в контейнері є ефемерними, що викликає певні проблеми для складних застосунків при їх виконанні в контейнерах. Одна з проблем виникає під час аварії або зупинки контейнера. Стан контейнера не зберігається, тому всі файли, що були створені чи змінені під час життя контейнера, втрачаються. Під час аварії kubelet перезапускає контейнер в його первісному стані. Ще одна проблема виникає, коли кілька контейнерів працюють у Pod та потребують спільного доступу до файлів. Створення та отримання доступу до спільної файлової системи для всіх контейнерів може бути не простим завданням. Абстракція volume у Kubernetes дозволяє розвʼязати обидві ці проблеми. Рекомендується вже мати уявлення про Podʼи.
Контекст
Kubernetes підтримує багато типів томів. Pod може використовувати одночасно будь-яку кількість типів томів. Типи ефемеральних томів існують протягом життєвого циклу Podʼа, але постійні томи існують поза життєвим циклом Podʼа. Коли Pod припиняє існування, Kubernetes знищує ефемеральні томи; проте Kubernetes не знищує постійні томи. Для будь-якого виду тому в певному Podʼі дані зберігаються при перезапуску контейнера.
У своєму основному визначенні том — це каталог, можливо, з деякими даними в ньому, який доступний контейнерам в Podʼі. Те, як цей каталог стає наявним, носій, який його підтримує, і його вміст визначаються конкретним типом тому.
Для використання тому вказуйте томи, які надаються для Podʼа в .spec.volumes і зазначте, куди монтувати ці томи в контейнери в .spec.containers[*].volumeMounts. Процес в контейнері бачить перегляд файлової системи, створений з початкового вмісту образу контейнера, а також томи (якщо визначено), змонтовані всередині контейнера. Процес бачить кореневу файлову систему, яка спочатку відповідає вмісту образу контейнера. Будь-які записи всередині ієрархії файлової системи, якщо дозволено, впливають на те, що цей процес бачить при виконанні наступного доступу до файлової системи. Томи монтуються за вказаними шляхами всередині образу. Для кожного контейнера, визначеного в Podʼі, ви повинні незалежно вказати, куди монтувати кожен том, яким користується контейнер.
Томи не можуть монтуватися всередині інших томів (але див. Використання subPath для повʼязаного механізму). Також том не може містити жорстке посилання на будь-що в іншому томі.
Типи томів
Kubernetes підтримує кілька типів томів.
awsElasticBlockStore (застаріло)
У Kubernetes 1.32, всі операції з типом awsElasticBlockStore будуть перенаправлені на драйвер ebs.csi.aws.com CSI.
Вбудований драйвер сховища AWSElasticBlockStore був застарілим у випуску Kubernetes v1.19 і потім був повністю вилучений у випуску v1.27.
Проєкт Kubernetes рекомендує використовувати сторонній драйвер сховища AWS EBS замість.
azureDisk (застаріло)
У Kubernetes 1.32, всі операції з типом azureDisk будуть перенаправлені на драйвер disk.csi.azure.com CSI.
Вбудований драйвер сховища AzureDisk був застарілим у випуску Kubernetes v1.19 і потім був повністю вилучений у випуску v1.27.
Проєкт Kubernetes рекомендує використовувати сторонній драйвер сховища Azure Disk замість.
azureFile (застаріло)
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.21 [deprecated]Тип тому azureFile монтує том файлу Microsoft Azure (SMB 2.1 і 3.0) в Pod.
Для отримання докладнішої інформації див. Втулок томів azureFile.
Міграція до CSI для azureFile
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.26 [stable]Функція CSIMigration для azureFile, якщо увімкнена, перенаправляє всі операції втулка з наявного вбудованого втулка до драйвера інтерфейсу зберігання (Container Storage Interface, CSI) file.csi.azure.com контейнера. Для використання цієї функції необхідно встановити Драйвер CSI для Azure File у кластері, і функціональна можливість CSIMigrationAzureFile має бути увімкненою.
Драйвер CSI для Azure File не підтримує використання одного й того ж тому з різними fsgroups. Якщо CSIMigrationAzureFile увімкнено, використання одного й того ж тому з різними fsgroups взагалі не підтримується.
Завершення міграції до CSI для azureFile
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.21 [alpha]Щоб вимкнути завантаження втулка сховища azureFile контролером і менеджером kubelet, встановіть прапорець InTreePluginAzureFileUnregister в значення true.
cephfs (видалено)
Kubernetes 1.32 не містить типу тому cephfs.
Драйвер вбудованої системи зберігання cephfs був застарілий у випуску Kubernetes v1.28, а потім повністю видалений у випуску v1.31.
cinder (застаріло)
У Kubernetes 1.32, всі операції з типом cinder будуть перенаправлені на драйвер cinder.csi.openstack.org CSI.
Вбудований драйвер сховища Cinder для OpenStack був застарілим ще у випуску Kubernetes v1.11 і потім був повністю вилучений у випуску v1.26.
Проєкт Kubernetes рекомендує натомість використовувати сторонній драйвер сховища OpenStack Cinder.
configMap
ConfigMap надає можливість вводити конфігураційні дані у Podʼи. Дані, збережені в ConfigMap, можуть бути використані у томі типу configMap і потім використовуватись контейнеризованими застосунками, що працюють у Podʼі.
При посиланні на ConfigMap ви вказуєте імʼя ConfigMap у томі. Ви можете налаштувати шлях для конкретного запису в ConfigMap. Наведена нижче конфігурація показує, як замонтувати ConfigMap з імʼям log-config у Pod з імʼям configmap-pod:
apiVersion: v1
kind: Pod
metadata:
name: configmap-pod
spec:
containers:
- name: test
image: busybox:1.28
command: ['sh', '-c', 'echo "The app is running!" && tail -f /dev/null']
volumeMounts:
- name: config-vol
mountPath: /etc/config
volumes:
- name: config-vol
configMap:
name: log-config
items:
- key: log_level
path: log_level.conf
ConfigMap log-config змонтовано як том, і весь вміст, збережений у його запису log_level, змонтовано в Pod за шляхом /etc/config/log_level.conf. Зверніть увагу, що цей шлях виводиться з mountPath тому та path з ключем log_level.
Примітка:
Ви повинні створити ConfigMap, перш ніж ви зможете його використовувати.
ConfigMap завжди монтується як
readOnly.Контейнер, який використовує ConfigMap як том з
subPathмонтування тому, не буде отримувати оновлення ConfigMap.Текстові дані використовуються як файли за допомогою кодування UTF-8. Для інших кодувань символів використовуйте
binaryData.
downwardAPI
Том downwardAPI робить дані downward API доступними для застосунків. У межах тому ви можете знайти відкриті дані, викладені у вигляді файлів у форматі звичайного тексту, доступні для читання.
Примітка:
Контейнер, який використовує downward API як монтування тому зsubPath, не отримує оновлень при зміні значень полів.Дивіться Передавання інформації про Podʼи контейнерам через файли для отримання докладнішої інформації.
emptyDir
Для Podʼа, який визначає том emptyDir, том створюється, коли Pod призначається до вузла. Як і зазначено в назві, том emptyDir спочатку є порожнім. Всі контейнери в Pod можуть читати та записувати ті самі файли у томі emptyDir, хоча цей том може бути змонтований на той самий чи різні шляхи в кожному контейнері. При видаленні Podʼа з вузла з будь-якої причини дані в томі emptyDir видаляються назавжди.
Примітка:
Крах контейнера не призводить до видалення Podʼа з вузла. Дані в томіemptyDir зберігаються при аваріях контейнера.Деякі використання тому emptyDir:
- робочий простір, наприклад, для сортування залишків на основі диска
- контрольна точка для тривалого обчислення для відновлення після аварії
- утримання файлів, якими управляє контейнер вмісту, поки контейнер вебсервер обслуговує дані
Поле emptyDir.medium контролює, де зберігаються томи emptyDir. Типово томи emptyDir зберігаються у томі, який підтримує вузол такому як диск, SSD або мережеве сховище, залежно від вашого середовища. Якщо ви встановите поле emptyDir.medium в "Memory", Kubernetes автоматично монтує tmpfs (віртуальна файлова система в памʼяті) замість цього. Хоча tmpfs дуже швидкий, слід памʼятати, що, на відміну від дисків, файли, які ви записуєте, враховуються у ліміті памʼяті контейнера, який їх записав.
Можна вказати обмеження розміру для типового носія, яке обмежує місткість тому emptyDir. Простір виділяється з ефемерного сховища вузла. Якщо він заповнюється з іншого джерела (наприклад, файли логів чи образи), том emptyDir може вийти з ладу через це обмеження.
Якщо розмір не вказаний, том, що розмішується в памʼяті, буде обмежений обсягом доступної памʼяті вузла.
Увага:
Будь ласка, перевірте тут пункти, які слід врахувати з точки зору управління ресурсами при використанніemptyDir, що зберігаються в памʼяті.Приклад налаштування emptyDir
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir:
sizeLimit: 500Mi
Приклад конфігурації памʼяті emptyDir
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir:
sizeLimit: 500Mi
medium: Memory
fc (fibre channel)
Тип тому fc дозволяє монтувати наявний том з блочного зберігання по каналу звʼязку в Pod. Ви можете вказати одне чи кілька імен шляхів цілей (world wide name, WWN) за допомогою параметра targetWWNs у конфігурації вашого тому. Якщо вказано кілька WWN, targetWWNs очікує, що ці WWN належать до зʼєднань з багатьма шляхами.
Примітка:
Ви повинні налаштувати зону FC SAN, щоб виділити та приховати ці LUN (томи) для WWN цілей заздалегідь, щоб хости Kubernetes могли до них отримувати доступ.Дивіться приклад fibre channel для отримання докладнішої інформації.
gcePersistentDisk (застаріло)
У Kubernetes 1.32, всі операції з типом gcePersistentDisk будуть перенаправлені на драйвер pd.csi.storage.gke.io CSI.
Драйвер вбудованого сховища gcePersistentDisk був застарілим ще у випуску Kubernetes v1.17 і потім був повністю вилучений у випуску v1.28.
Проєкт Kubernetes рекомендує натомість використовувати сторонній драйвер сховища Google Compute Engine Persistent Disk CSI.
gitRepo (застаріло)
Попередження:
Тип тому gitRepo застарів. Щоб забезпечити те, що Pod має змонтований репозиторій git, ви можете змонтувати том EmptyDir, який монтується в init container, що клонує репозиторій за допомогою git, а потім монтує EmptyDir в контейнер Podʼа.
Ви можете обмежити використання томів gitRepo у вашому кластері, використовуючи політики, такі як ValidatingAdmissionPolicy. Ви можете використовувати наступний вираз мови виразів загального виразу (Common Expression Language, CEL) як частину політики для відхилення використання томів gitRepo: !has(object.spec.volumes) || !object.spec.volumes.exists(v, has(v.gitRepo)).
Том gitRepo є прикладом втулка тому. Цей втулок монтує порожній каталог і клонує репозиторій git у цей каталог
для використання вашим Podʼом.
Ось приклад тому gitRepo:
apiVersion: v1
kind: Pod
metadata:
name: server
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- mountPath: /mypath
name: git-volume
volumes:
- name: git-volume
gitRepo:
repository: "git@somewhere:me/my-git-repository.git"
revision: "22f1d8406d464b0c0874075539c1f2e96c253775"
glusterfs (вилучено)
Тип тому glusterfs не включено в Kubernetes 1.32.
Вбудований драйвер сховища GlusterFS був застарілим ще у випуску Kubernetes v1.25 і потім був повністю вилучений у випуску v1.26.
hostPath
Том hostPath монтує файл або каталог з файлової системи вузла хосту у ваш Pod. Це не є необхідним для більшості Podʼів, але це надає потужний аварійний вихід для деяких застосунків.
Попередження:
Використання типу тому hostPath призводить до багатьох ризиків з погляду безпеки. Якщо ви можете уникнути використання тому hostPath, то слід це зробити. Наприклад, визначте local PersistentVolume та використовуйте натомість його.
Якщо ви обмежуєте доступ до конкретних каталогів на вузлі за допомогою перевірки прийняття часу валідації, це обмеження є ефективним лише тоді, коли ви додатково вимагаєте, щоб будь-які монтування тому hostPath були тільки для читання. Якщо ви дозволяєте монтування тому hostPath на читання та запис для ненадійного Podʼа, контейнери в цьому Podʼі можуть порушувати монтування хосту для читання та запису.
Будьте обережні при використанні томів hostPath, незалежно від того, чи вони монтуються як тільки для читання, чи для читання та запису, оскільки:
- Доступ до файлової системи вузла може викрити привілейовані системні облікові дані (такі як для kubelet) або привілейовані API (такі як сокет середовища виконання контейнера), які можуть бути використані для втечі з контейнера або для атаки інших частин кластера.
- Podʼи з однаковою конфігурацією (такою як створені за допомогою PodTemplate) можуть поводитися по-різному на різних вузлах через різні файли на вузлах.
- Використання тома
hostPathне розглядається як використання ефемерного сховища. Ви маєте самостійно стежити за використанням диска, оскільки надмірне використання диска `hostPath призведе до тиску на диск на вузлі.
Деякі використання тому hostPath:
- виконання контейнера, який потребує доступу до системних компонентів рівня вузла (такого як контейнер, який передає системні логи до центрального сховища, з доступом до цих логів за допомогою монтування
/var/logтільки для читання) - надання конфігураційного файлу, збереженого на хост-системі, доступного тільки для читання для статичного Podʼа; на відміну від звичайних Podʼів, статичні Podʼи не можуть отримувати доступ до ConfigMaps.
Типи томів hostPath
Крім обовʼязкової властивості path, ви можете вказати необовʼязковий параметр type для тому hostPath.
Доступні значення для type:
| Значення | Поведінка |
|---|---|
"" | Порожній рядок (стандартно) призначений для забезпечення сумісності з попередніми версіями, що означає, що перед монтуванням тому hostPath не виконуватимуться перевірки. |
DirectoryOrCreate | Якщо нічого не існує за вказаним шляхом, буде створено порожній каталог за необхідності з правами на виконання, встановленими на 0755, з тією ж групою і власником, що й Kubelet. |
Directory | Повинен існувати каталог за вказаним шляхом |
FileOrCreate | Якщо нічого не існує за вказаним шляхом, буде створено порожній файл за необхідності з правами на виконання, встановленими на 0644, з тією ж групою і власником, що й Kubelet. |
File | Повинен існувати файл за вказаним шляхом |
Socket | Має існувати UNIX-сокет за вказаним шляхом |
CharDevice | (Лише вузли Linux) Має існувати символьний пристрій за вказаним шляхом |
BlockDevice | (Лише вузли Linux) Має існувати блочний пристрій за вказаним шляхом |
Увага:
РежимFileOrCreate не створює батьківський каталог файлу. Якщо батьківський каталог змонтуваного файлу не існує, Pod не вдасться запуститися. Щоб забезпечити роботу цього режиму, можна спробувати монтувати каталоги та файли окремо, як показано в прикладі FileOrCreate для hostPath.Деякі файли або каталоги, створені на базових вузлах, можуть бути доступні лише користувачу root. В такому випадку вам слід або запускати свій процес як root у привілейованому контейнері або змінювати права доступу до файлів на вузлі щоб мати змогу читати (або записувати) у том hostPath.
Приклад конфігурації hostPath
---
# Цей маніфест монтує /data/foo на вузлі як /foo всередині
# єдиного контейнера, який працює в межах Podʼа hostpath-example-linux
#
# Монтування в контейнер тільки для читання
apiVersion: v1
kind: Pod
metadata:
name: hostpath-example-linux
spec:
os: { name: linux }
nodeSelector:
kubernetes.io/os: linux
containers:
* name: example-container
image: registry.k8s.io/test-webserver
volumeMounts:
* mountPath: /foo
name: example-volume
readOnly: true
volumes:
* name: example-volume
# монтувати /data/foo, але тільки якщо цей каталог вже існує
hostPath:
path: /data/foo # розташування каталогу на вузлі
type: Directory # це поле є необовʼязковим
---
# Цей маніфест монтує C:\Data\foo на вузлі як C:\foo всередині
# єдиного контейнера, який працює в межах Podʼа hostpath-example-windows
#
# Монтування в контейнер тільки для читання
apiVersion: v1
kind: Pod
metadata:
name: hostpath-example-windows
spec:
os: { name: windows }
nodeSelector:
kubernetes.io/os: windows
containers:
* name: example-container
image: microsoft/windowsservercore:1709
volumeMounts:
* name: example-volume
mountPath: "C:\\foo"
readOnly: true
volumes:
# монтувати C:\Data\foo з вузла, але тільки якщо цей каталог вже існує
* name: example-volume
hostPath:
path: "C:\\Data\\foo" # розташування каталогу на вузлі
type: Directory # це поле є необовʼязковим
Приклад конфігурації hostPath для FileOrCreate
У наступному маніфесті визначено Pod, який монтує /var/local/aaa всередині єдиного контейнера в Podʼі. Якщо на вузлі не існує шляху /var/local/aaa, kubelet створює його як каталог і потім монтує його в Pod.
Якщо /var/local/aaa вже існує, але не є каталогом, Pod зазнає невдачі. Крім того, kubelet намагається створити файл із назвою /var/local/aaa/1.txt всередині цього каталогу (як бачить його вузол); якщо щось вже існує за цим шляхом і це не є звичайним файлом, Pod також зазнає невдачі.
Ось приклад маніфесту:
apiVersion: v1
kind: Pod
metadata:
name: test-webserver
spec:
os: { name: linux }
nodeSelector:
kubernetes.io/os: linux
containers:
- name: test-webserver
image: registry.k8s.io/test-webserver:latest
volumeMounts:
- mountPath: /var/local/aaa
name: mydir
- mountPath: /var/local/aaa/1.txt
name: myfile
volumes:
- name: mydir
hostPath:
# Забезпечте створення каталогу файлів.
path: /var/local/aaa
type: DirectoryOrCreate
- name: myfile
hostPath:
path: /var/local/aaa/1.txt
type: FileOrCreate
image
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [alpha] (стандартно увімкнено: false)Джерело тому image представляє обʼєкт OCI (образ контейнера або артефакт), який доступний на хост-машині kubelet.
Ось приклад використання джерела тому image:
apiVersion: v1
kind: Pod
metadata:
name: image-volume
spec:
containers:
- name: shell
command: ["sleep", "infinity"]
image: debian
volumeMounts:
- name: volume
mountPath: /volume
volumes:
- name: volume
image:
reference: quay.io/crio/artifact:v1
pullPolicy: IfNotPresent
Том визначається при запуску Podʼа в залежності від значення pullPolicy:
Always- kubelet завжди намагається завантажити посилання. Якщо завантаження не вдається, kubelet встановлює статус Podʼа як
Failed. Never- kubelet ніколи не завантажує посилання і використовує лише локальний образ або артефакт. Pod стає
Failed, якщо будь-які шари образу не присутні локально або якщо маніфест для цього образу не закешований. IfNotPresent- kubelet завантажує образ, якщо посилання не присутнє на диску. Pod стає
Failed, якщо посилання не присутнє і завантаження не вдалося.
Том буде знову визначено, якщо Pod буде видалено і перезавантажено, що означає, що новий віддалений контент стане доступним після відновлення Podʼа. Невдача у визначені або завантаженні образу під час запуску Podʼа заблокує запуск контейнерів і може спричинити значну затримку. Невдалі спроби будуть повторені з використанням звичайного механізму відновлення тому і буде повідомлено в причини та повідомленні Podʼа.
Типи обʼєктів, які можуть бути змонтовані цим томом, визначені реалізацією середовища виконання контейнерів на хост-машині і повинні включати всі дійсні типи, підтримувані полем образу контейнера. Обʼєкт OCI монтується в одну теку (spec.containers[*].volumeMounts.mountPath) і буде змонтований в режимі тільки для читання. В Linux, середовище виконання контейнерів зазвичай також монтує том з блокуванням виконання файлів (noexec).
Крім того:
- Субшляхи монтування контейнерів не підтримуються (
spec.containers[*].volumeMounts.subpath). - Поле
spec.securityContext.fsGroupChangePolicyне має жодного ефекту для цього типу тому. - Admission Controller
AlwaysPullImagesтакож працює для цього джерела тому, як і для образів контейнерів.
Доступні наступні поля для типу image:
reference- Посилання на артефакт, який слід використовувати. Наприклад, ви можете вказати
registry.k8s.io/conformance:v1.32.0для завантаження файлів з образу тестування Kubernetes. Працює так само, якpod.spec.containers[*].image. Секрети завантаження образів будуть зібрані так само, як для образу контейнера, шукаючи облікові дані вузла, секрети службового облікового запису завантаження образів та секрети завантаження образів з специфікації Podʼа. Це поле є необовʼязковим, щоб дозволити вищому рівню управління конфігурацією використовувати стандартні або перевизначати образи контейнерів у контролерах навантаження, таких як Deployments і StatefulSets. Більше інформації про образи контейнерів pullPolicy- Політика завантаження обʼєктів OCI. Можливі значення:
Always,NeverабоIfNotPresent. Стандартно встановлюєтьсяAlways, якщо вказано теґ:latest, абоIfNotPresentв іншому випадку.
Дивіться приклад Використання образу тому з Podʼом для більш детальної інформації про те, як використовувати джерело тому.
iscsi
Обʼєкт iscsi дозволяє монтувати наявний том iSCSI (SCSI через IP) у ваш Pod. На відміну від emptyDir, який видаляється, коли Pod видаляється, вміст тому iscsi зберігається, і том просто розмонтується. Це означає, що том iSCSI можна наперед наповнити даними, і ці дані можна спільно використовувати між Podʼами.
Примітка:
Вам потрібно мати власний сервер iSCSI, на якому створено том, перш ніж ви зможете його використовувати.Особливістю iSCSI є те, що його можна монтувати як тільки для читання одночасно багатьма споживачами. Це означає, що ви можете наперед наповнити том своїми даними та потім обслуговувати їх паралельно зі стількох Podʼів, скільки вам потрібно. На жаль, томи iSCSI можна монтувати тільки одним споживачем у режимі читання-запису. Одночасні операції запису не допускаються.
Докладніше дивіться у прикладі iSCSI.
local
Обʼєкт local представляє собою підключений локальний пристрій зберігання, такий як диск, розділ чи каталог.
Локальні томи можна використовувати лише як статично створені PersistentVolume. Динамічне розгортання не підтримується.
У порівнянні з томами hostPath, томи local використовуються в надійний та переносимий спосіб, не потрібно вручну планувати Podʼи на вузли. Система обізнана з обмеженнями вузла тому, переглядаючи приналежність вузла до PersistentVolume.
Однак томи local є предметом доступності підключеного вузла і не підходять для всіх застосунків. Якщо вузол стає несправним, то том local стає недоступним для Podʼи. Pod, що використовує цей том, не може працювати. Застосунки, які використовують томи local, повинні бути здатні терпіти це зменшення доступності, а також можливу втрату даних, залежно від характеристик стійкості підключеного диска.
У наступному прикладі показано PersistentVolume з використанням тому local і nodeAffinity:
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-pv
spec:
capacity:
storage: 100Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /mnt/disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- example-node
Вам потрібно встановити nodeAffinity для PersistentVolume при використанні томів local. Планувальник Kubernetes використовує nodeAffinity PersistentVolume для планування цих Podʼів на відповідний вузол.
PersistentVolume volumeMode може бути встановлено на "Block" (замість станадартного значення "Filesystem") для експозиції локального тому як чистого (raw) блокового пристрою.
При використанні локальних томів рекомендується створити StorageClass із встановленим volumeBindingMode в WaitForFirstConsumer. Докладніше дивіться у прикладі StorageClass для локальних томів. Затримка вибору тому дозволяє переконатися, що рішення щодо привʼязки PersistentVolumeClaim буде оцінено разом із будь-якими іншими обмеженнями вузла, які може мати Pod, такими як вимоги до ресурсів вузла, вибір вузла, спорідненість Podʼа та анти-спорідненість Podʼа.
Можна використовувати зовнішнього статичного постачальника для кращого управління циклом життя локального тому. Зазначте, що цей постачальник не підтримує динамічне постачання. Для прикладу того, як запустити зовнішнього постачальника локального тому, дивіться посібник користувача постачальника локального тому.
Примітка:
Локальний PersistentVolume вимагає вручного очищення та видалення користувачем, якщо зовнішній статичний постачальник не використовується для управління циклом життя тому.nfs
Обʼєкт nfs дозволяє приєднати наявний розділ NFS (Network File System) до Podʼа. На відміну від emptyDir, який видаляється, коли Pod видаляється, вміст тому nfs зберігається, і том просто відмонтується. Це означає, що том NFS можна попередньо наповнити даними, і ці дані можна спільно використовувати між Podʼами. Том NFS може бути приєднаний одночасно кількома записувачами.
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /my-nfs-data
name: test-volume
volumes:
- name: test-volume
nfs:
server: my-nfs-server.example.com
path: /my-nfs-volume
readOnly: true
Примітка:
Перед його використанням, вам потрібно мати власний сервер NFS, на якому експортовано розділ.
Також враховуйте, що ви не можете вказувати параметри монтування NFS у специфікації Podʼаа. Ви можете встановлювати параметри монтування на боці сервера або використовувати /etc/nfsmount.conf. Ви також можете монтувати томи NFS через PersistentVolumes, які дозволяють вам встановлювати параметри монтування.
Дивіться приклад NFS для прикладу монтування томів NFS з PersistentVolumes.
persistentVolumeClaim
Обʼєкт persistentVolumeClaim використовується для монтування PersistentVolume в Pod. PersistentVolumeClaim є способом для користувачів "вимагати" надійне сховище (наприклад, том iSCSI) без знання деталей конкретного хмарного середовища.
Дивіться інформацію щодо PersistentVolumes для отримання додаткових деталей.
portworxVolume (застаріло)
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.25 [deprecated]Обʼєкт portworxVolume — це еластичний рівень блочного сховища, який працює в режимі гіперконвергенції з Kubernetes. Portworx визначає сховище на сервері, розділяє його за можливостями і агрегує місткість на кількох серверах. Portworx працює в гостьовій операційній системі віртуальних машин або на bare metal серверах з ОС Linux.
Обʼєкт portworxVolume можна динамічно створити через Kubernetes або його можна попередньо налаштувати та вказати в Podʼі. Тут наведено приклад Podʼа, який посилається на попередньо налаштований том Portworx:
apiVersion: v1
kind: Pod
metadata:
name: test-portworx-volume-pod
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /mnt
name: pxvol
volumes:
- name: pxvol
# Цей том Portworx повинен вже існувати.
portworxVolume:
volumeID: "pxvol"
fsType: "<fs-type>"
Примітка:
Переконайтеся, що існує том Portworx з іменемpxvol, перш ніж використовувати його в Podʼі.Докладніше дивіться приклади томів Portworx.
Міграція на Portworx CSI
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.25 [beta]Стандартно Kubernetes 1.32 намагається мігрувати старі томи Portworx для використання CSI. (Міграція CSI для Portworx була доступна з Kubernetes v1.23, але стала стандатно увімкненою лише з випуску v1.31). Якщо ви хочете вимкнути автоматичну міграцію, ви можете встановити функціональну можливість CSIMigrationPortworx у false; це необхідно зробити як для kube-controller-manager, так і для кожного відповідного kubelet.
Це перенаправляє всі операції втулка з існуючого втулка вбудованої системи до драйвера Container Storage Interface (CSI) pxd.portworx.com. Portworx CSI Driver повинен бути встановлений в кластері.
projected
Том projected підʼєднує кілька існуючих джерел томів в одну теку. Докладніше дивіться projected томи.
rbd (вилучено)
Kubernetes 1.32 не включає тип тому rbd.
Драйвер зберігання Rados Block Device (RBD) і підтримка його міграції CSI були визнані застарілими у випуску Kubernetes v1.28 і повністю видалені в випуску v1.31.
secret
Том secret використовується для передачі конфіденційної інформації, такої як паролі, у Podʼи. Ви можете зберігати секрети в API Kubernetes і монтувати їх як файли для використання Podʼами без привʼязки безпосередньо до Kubernetes. Томи secret підтримуються tmpfs (файлова система, яка знаходиться в оперативній памʼяті), тому їх ніколи не записують на постіний носій.
Примітка:
Ви повинні створити Secret в API Kubernetes, перш ніж ви зможете його використовувати.
Секрет завжди монтується як
readOnly.Контейнер, який використовує Secret як том
subPath, не отримує оновлення Secret.
Для отримання додаткової інформації дивіться Налаштування Secret.
vsphereVolume (застаріло)
Примітка:
Проєкт Kubernetes рекомендує використовувати vSphere CSI зовнішній драйвер сховища замість цього.vsphereVolume використовується для монтування тому vSphere VMDK у ваш Pod. Зміст тому зберігається при його демонтажі. Підтримуються обидва типи сховища VMFS та VSAN.
Для отримання додаткової інформації дивіться приклади томів vSphere.
Міграція на vSphere CSI
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.26 [stable]У Kubernetes 1.32, всі операції для типу vsphereVolume, що використовується в інтегрованому стеку, перенаправляються на драйвер csi.vsphere.vmware.com CSI.
Для цього має бути встановлений драйвер CSI для vSphere на кластері. Додаткові поради щодо міграції з інтегрованого стеку vsphereVolume можна знайти на сторінці документації VMware Migrating In-Tree vSphere Volumes to vSphere Container Storage Plug-in. Якщо драйвер vSphere CSI не встановлено, не буде можливості виконати операції з томами, створеними за допомогою типу vsphereVolume з інтегрованим стеком.
Для успішної міграції до драйвера vSphere CSI вам слід використовувати vSphere версії 7.0u2 або пізніше.
Якщо ви використовуєте версію Kubernetes відмінну від v1.32, перевірте документацію для цієї версії Kubernetes.
Примітка:
Наступні параметри StorageClass вбудованого втулка vsphereVolume не підтримуються драйвером vSphere CSI:
diskformathostfailurestotolerateforceprovisioningcachereservationdiskstripesobjectspacereservationiopslimit
Наявні томи, створені з використанням цих параметрів, будуть перенесені на драйвер vSphere CSI, але нові томи, створені драйвером vSphere CSI, не будуть враховувати ці параметри.
Завершення міграція до vSphere CSI
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.19 [beta]Щоб вимкнути завантаження втулка vsphereVolume контролер-менеджером та kubelet, потрібно встановити прапорець InTreePluginvSphereUnregister в значення true. Драйвер csi.vsphere.vmware.com CSI повинен бути встановлений на всіх вузлах робочого навантаження.
Використання subPath
Іноді корисно ділити один том для кількох цілей у одному Podʼі. Властивість volumeMounts[*].subPath вказує підшлях всередині посилання на том, а не його корінь.
У наступному прикладі показано, як налаштувати Pod із стеком LAMP (Linux Apache MySQL PHP) за допомогою одного загального тому. Ця конфігурація subPath у прикладі не рекомендується для використання в операційному середовищі.
Код та ресурси PHP-застосунку відображаються на томі у папці html, а база даних MySQL зберігається у папці mysql на цьому томі. Наприклад:
apiVersion: v1
kind: Pod
metadata:
name: my-lamp-site
spec:
containers:
- name: mysql
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "rootpasswd"
volumeMounts:
- mountPath: /var/lib/mysql
name: site-data
subPath: mysql
- name: php
image: php:7.0-apache
volumeMounts:
- mountPath: /var/www/html
name: site-data
subPath: html
volumes:
- name: site-data
persistentVolumeClaim:
claimName: my-lamp-site-data
Використання subPath із розширеними змінними середовища
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.17 [stable]Використовуйте поле subPathExpr для створення імен каталогів subPath із змінних середовища downward API. Властивості subPath та subPathExpr є взаємовиключними.
У цьому прикладі Pod використовує subPathExpr для створення каталогу pod1 всередині тома hostPath /var/log/pods. Том hostPath отримує імʼя Pod із downwardAPI. Директорія хоста /var/log/pods/pod1 монтується у /logs в контейнері.
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
containers:
- name: container1
env:
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
image: busybox:1.28
command: [ "sh", "-c", "while [ true ]; do echo 'Hello'; sleep 10; done | tee -a /logs/hello.txt" ]
volumeMounts:
- name: workdir1
mountPath: /logs
# Для змінних використовуються круглі дужки (не фігурні).
subPathExpr: $(POD_NAME)
restartPolicy: Never
volumes:
- name: workdir1
hostPath:
path: /var/log/pods
Ресурси
Носій інформації (такий як диск чи SSD) тома emptyDir визначається середовищем файлової системи, яке утримує кореневий каталог kubelet (зазвичай /var/lib/kubelet). Немає обмежень щодо того, скільки місця може використовувати том emptyDir чи hostPath, і відсутня ізоляція між контейнерами чи між Podʼами.
Щоб дізнатися про те, як запросити місце за допомогою специфікації ресурсів, дивіться як управляти ресурсами.
Сторонні втулки томів
До стороннії втулків томів належать Container Storage Interface (CSI), а також FlexVolume (який є застарілим). Ці втулки дозволяють виробникам засобів для зберігання створювати власні зовнішні втулки томів без додавання їх вихідного коду до репозиторію Kubernetes.
Раніше всі втулки томів були "вбудованими". "Вбудовані" втулки збиралися, звʼязувалися, компілювалися і входили до базових бінарних файлів Kubernetes. Це означало, що для додавання нової системи зберігання до Kubernetes (втулка тому) потрібно було додавати код у основний репозиторій коду Kubernetes.
Як CSI, так і FlexVolume дозволяють розробляти втулки томів незалежно від кодової бази Kubernetes і встановлювати їх (інсталювати) на кластерах Kubernetes як розширення.
Для виробників засобів для зберігання, які прагнуть створити зовнішній втулок тома, будь ласка, звертайтеся до Поширених питань щодо втулків томів.
csi
Інтерфейс зберігання контейнерів (Container Storage Interface) (CSI) визначає стандартний інтерфейс для систем оркестрування контейнерів (таких як Kubernetes), щоб вони могли надавати доступ до різних систем зберігання своїм робочим навантаженням контейнерів.
Будь ласка, прочитайте пропозицію щодо дизайну CSI для отримання додаткової інформації.
Примітка:
Підтримка версій специфікації CSI 0.2 та 0.3 є застарілою в Kubernetes v1.13 і буде видалена у майбутньому релізі.Примітка:
Драйвери CSI можуть бути несумісними у всіх версіях Kubernetes. Перевірте документацію конкретного драйвера CSI для підтримуваних кроків розгортання для кожного релізу Kubernetes та матриці сумісності.Після розгортання сумісного з CSI драйвера тому у кластері Kubernetes, користувачі можуть використовувати тип тома csi, щоб долучати чи монтувати томи, які надаються драйвером CSI.
Том csi можна використовувати в Pod трьома різними способами:
- через посилання на PersistentVolumeClaim
- з загальним ефемерним томом
- з CSI ефемерним томом, якщо драйвер підтримує це
Для налаштування постійного тому CSI адміністраторам доступні такі поля:
driver: Рядкове значення, яке вказує імʼя драйвера тома, яке треба використовувати. Це значення повинно відповідати значенню, що повертається відповіддюGetPluginInfoResponseдрайвера CSI, як це визначено в специфікації CSI. Воно використовується Kubernetes для ідентифікації того, який драйвер CSI слід викликати, і драйверами CSI для ідентифікації того, які обʼєкти PV належать драйверу CSI.volumeHandle: Рядкове значення, яке унікально ідентифікує том. Це значення повинно відповідати значенню, що повертається в поліvolume.idвідповіддюCreateVolumeResponseдрайвера CSI, як це визначено в специфікації CSI. Значення передається якvolume_idу всі виклики драйвера тома CSI при посиланні на том.readOnly: Необовʼязкове булеве значення, яке вказує, чи повинен бути том «ControllerPublished» (приєднаний) як тільки для читання. Станадртно — false. Це значення передається драйверу CSI через полеreadonlyуControllerPublishVolumeRequest.fsType: ЯкщоVolumeModePV —Filesystem, тоді це поле може бути використано для вказівки файлової системи, яку слід використовувати для монтування тому. Якщо том не був відформатований і підтримується форматування, це значення буде використано для форматування тому. Це значення передається драйверу CSI через полеVolumeCapabilityуControllerPublishVolumeRequest,NodeStageVolumeRequestтаNodePublishVolumeRequest.volumeAttributes: Масив зі строк, що вказує статичні властивості тому. Цей масив має відповідати масиву, що повертається в поліvolume.attributesвідповіддюCreateVolumeResponseдрайвера CSI, як це визначено в специфікації CSI. Масив передається драйверу CSI через полеvolume_contextуControllerPublishVolumeRequest,NodeStageVolumeRequestтаNodePublishVolumeRequest.controllerPublishSecretRef: Посилання на обʼєкт secret, який містить конфіденційну інформацію для передачі драйверу CSI для завершення викликівControllerPublishVolumeтаControllerUnpublishVolumeCSI. Це поле є необовʼязковим і може бути порожнім, якщо не потрібно жодного secretʼу. Якщо Secret містить більше одного secret, передаються всі secretʼи.nodeExpandSecretRef: Посилання на secret, який містить конфіденційну інформацію для передачі драйверу CSI для завершення викликуNodeExpandVolume. Це поле є необовʼязковим і може бути порожнім, якщо не потрібен жоден secret. Якщо обʼєкт містить більше одного secret, передаються всі secretʼи. Коли ви налаштовуєте конфіденційні дані secret для розширення тому, kubelet передає ці дані через викликNodeExpandVolume()драйверу CSI. Усі підтримувані версії Kubernetes пропонують полеnodeExpandSecretRefі мають його стандартно доступним. Випуски Kubernetes до v1.25 не включали цю підтримку.- Увімкніть функціональну можливість з назвою
CSINodeExpandSecretдля кожного kube-apiserver та для kubelet на кожному вузлі. З версії Kubernetes 1.27 цю функцію типово ввімкнено і не потрібно явно використовувати функціональну можливість. Також вам потрібно використовувати драйвер CSI, який підтримує або вимагає конфіденційні дані secret під час операцій зміни розміру зберігання, ініційованих вузлом. nodePublishSecretRef: Посилання на обʼєкт secret, який містить конфіденційну інформацію для передачі драйверу CSI для завершення викликуNodePublishVolume. Це поле є необовʼязковим і може бути порожнім, якщо не потрібен жоден secret. Якщо обʼєкт secret містить більше одного secret, передаються всі secretʼи.nodeStageSecretRef: Посилання на обʼєкт secret, який містить конфіденційну інформацію для передачі драйверу CSI для завершення викликуNodeStageVolume. Це поле є необовʼязковим і може бути порожнім, якщо не потрібен жоден secret. Якщо Secret містить більше одного secret, передаються всі secretʼи.
Підтримка CSI для блочних томів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.18 [stable]Виробники зовнішніх драйверів CSI можуть реалізувати підтримку блочних томів безпосередньо в робочих навантаженнях Kubernetes.
Ви можете налаштувати ваш PersistentVolume/PersistentVolumeClaim із підтримкою блочний томів як зазвичай, без будь-яких конкретних змін CSI.
Ефемерні томи CSI
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.25 [stable]Ви можете безпосередньо налаштувати томи CSI в межах специфікації Pod. Такі томи є ефемерними і не зберігаються після перезапуску Podʼів. Див. Ефемерні томи для отримання додаткової інформації.
Для отримання додаткової інформації про те, як розробити драйвер CSI, див. документацію kubernetes-csi
Проксі CSI для Windows
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.22 [stable]Драйвери вузла CSI повинні виконувати різні привілейовані операції, такі як сканування пристроїв диска та монтування файлових систем. Ці операції відрізняються для кожної операційної системи хоста. Для робочих вузлів Linux, контейнеризовані вузли CSI зазвичай розгортуто як привілейовані контейнери. Для робочих вузлів Windows, підтримка привілеїрованих операцій для контейнеризованих вузлів CSI підтримується за допомогою csi-proxy, бінарного файлц, що розробляється спільнотою, який повинен бути встановлений на кожному вузлі Windows.
Докладніше див. в посібнику з розгортання втулку CSI, який ви хочете розгортати.
Міграція на драйвери CSI з вбудованих втулків
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.25 [stable]Функція CSIMigration направляє операції щодо існуючих вбудованих втулків до відповідних втулків CSI (які очікується, що вони будуть встановлені та налаштовані). Внаслідок цього операторам не потрібно робити жодних змін конфігурації існуючих класів сховища, стійких томів або заявок на стійкі томи (які посилаються на вбудовані втулки) при переході до драйвера CSI, який заміщає вбудований ввтулок.
Примітка:
Існуючі постійні томи (PV), створені вбудованим втулком томів, можна продовжувати використовувати у майбутньому без будь-яких змін конфігурації, навіть після завершення міграції до драйвера CSI для цього типу тома і навіть після оновлення до версії Kubernetes, у якій вже немає вбудованої підтримки для цього типу сховища.
Для здійснення цієї міграції вам або іншому адміністратору кластера необхідно встановити та налаштувати відповідний драйвер CSI для цього типу сховища. Основна частина Kubernetes не встановлює це програмне забезпечення за вас.
Після завершення цієї міграції ви також можете визначати нові заявки на стійкі томи (PVC) та постійні томи (PV), які посилаються на старі, вбудовані інтеграції сховищ. Забезпечивши встановлення та налаштування відповідного драйвера CSI, створення постійних томів продовжує працювати, навіть для зовсім нових томів. Фактичне управління сховищем тепер відбувається через драйвер CSI.
Підтримувані операції та функції включають: створення/видалення, приєднання/відʼєднання, монтування/розмонтовування та зміна розміру томів.
Вбудовані втулки, які підтримують CSIMigration і мають відповідний реалізований драйвер CSI перераховуються в Типи томів.
Підтримуються також вбудовані втулки, які підтримують постійне сховище на вузлах Windows:
flexVolume (застаріло)
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.23 [deprecated]FlexVolume — це інтерфейс зовнішнього втулка, який використовує модель на основі викликів exec для взаємодії із засобами сховища. Виконувані файли драйверів FlexVolume повинні бути встановлені в попередньо визначений шлях для втулків томів на кожному вузлі і, в деяких випадках, на вузлах панелі упраіління.
Podʼи взаємодіють із драйверами FlexVolume через вбудований втулок тому flexVolume. Докладні відомості див. у документі FlexVolume README.
Наступні втулки FlexVolume, розгорнуті як сценарії PowerShell на хості, підтримують вузли Windows:
Примітка:
FlexVolume застарів. Рекомендований спосіб інтеграції зовнішнього сховища з Kubernetes — використовувати сторонній драйвер CSI.
Розробники драйвера FlexVolume повинні реалізувати драйвер CSI та допомагати переходити користувачам драйверів FlexVolume на CSI. Користувачі FlexVolume повинні переміщати свої робочі навантаження на еквівалентний драйвер CSI.
Поширення монтування
Увага:
Поширення монтування є низькорівневою функцією, яка не працює послідовно на всіх типах томів. Рекомендується використовувати її тільки з томами типуhostPath або з томами emptyDir, що розміщені в памʼяті. Більше деталей можна знайти в цьому обговоренні.Поширення монтування дозволяє обʼєднувати томи, змонтовані контейнером, іншим контейнерам у тому ж Podʼі або навіть іншим Podʼам на тому самому вузлі.
Поширення монтування тому керується полем mountPropagation в containers[*].volumeMounts. Його значення такі:
None— Це монтування тома не отримає жодних подальших монтувань, які монтуються на цей том або будь-які його підкаталоги хостом. Також ніякі монтування, створені контейнером, не будуть видимими на хості. Це стандартний режим.Цей режим еквівалентний поширенню монтування
rprivate, як описано вmount(8)Однак CRI runtime може вибрати поширення монтування
rslave(тобто,HostToContainer), коли поширенняrprivateне може бути використано. Відомо, що cri-dockerd (Docker) обирає поширення монтуванняrslave, коли джерело монтування містить кореневий каталог демона Docker (/var/lib/docker).HostToContainer— Це монтування тома отримає всі подальші монтування, які монтуються на цей том або будь-які його підкаталоги.Іншими словами, якщо хост монтує будь-що всередині тома, контейнер побачить, що щось змонтовано там.
Також, якщо будь-який Pod із поширенням монтування
Bidirectionalна той же том монтує будь-що там, контейнер із монтуваннямHostToContainerбуде це бачити.Цей режим еквівалентний поширенню монтування
rslave, як описано вmount(8)Bidirectional— Це монтування тома веде себе так само, як монтуванняHostToContainer. Крім того, всі монтування тома, створені контейнером, будуть поширені назад на хост і на всі контейнери всіх Podʼів, які використовують той самий том.Типовим використанням для цього режиму є Pod із драйвером FlexVolume або CSI або Pod, який повинен щось змонтувати на хості за допомогою тома типу
hostPath.Цей режим еквівалентний поширенню монтування
rshared, як описано вmount(8)Попередження:
Поширення монтуванняBidirectionalможе бути небезпечним. Воно може пошкодити операційну систему хоста і тому дозволяється тільки в привілейованих контейнерах. Рекомендується ретельне знайомство з поведінкою ядра Linux. Крім того, всі монтування томів, створені контейнерами в Podʼах, повинні бути знищені (розмонтовані) контейнерами під час їх завершення.
Монтування тільки для читання
Монтування може бути зроблено тільки для читання, втсановленням у поле .spec.containers[].volumeMounts[].readOnly значення true. Це не робить том сам по собі тільки для читання, але конкретний контейнер не зможе записувати в нього. Інші контейнери в Podʼі можуть монтувати той самий том з правами читання-запису.
У Linux, монтування тільки для читання стандартно не є рекурсивними. Наприклад, розгляньте Pod, який монтує /mnt хостів як том hostPath. Якщо існує інша файлова система, яка монтується для читання-запису на /mnt/<SUBMOUNT> (така як tmpfs, NFS або USB-сховище), то том, змонтований у контейнерах, також буде мати запис для /mnt/<SUBMOUNT>, навіть якщо монтування само було вказано як тільки для читання.
Рекурсивне монтування тільки для читання
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [beta] (стандартно увімкнено: true)Рекурсивне монтування тільки для читання може бути увімкнено встановленням функціональної можливості RecursiveReadOnlyMounts для kubelet та kube-apiserver, і встановленням поля .spec.containers[].volumeMounts[].recursiveReadOnly для Podʼа.
Допустимі значення:
Disabled(стандартно): без ефекту.Enabled: робить монтування рекурсивно тільки для читання. Потрібно задовольняти всі наступні вимоги:readOnlyвстановлено наtruemountPropagationне встановлено або встановлено наNone- Хост працює з ядром Linux v5.12 або пізніше
- Середовище виконання контейнерів рівня CRI підтримує рекурсивне монтування тільки для читання
- Середовище виконання контейнерів рівня OCI підтримує рекурсивне монтування тільки для читання. Це не спрацює якщо хоча б одна з цих умов не виконується.
IfPossible: намагається застосуватиEnabledі повертається доDisabled, якщо функція не підтримується ядром або класом середовища виконання.
Приклад:
apiVersion: v1
kind: Pod
metadata:
name: rro
spec:
volumes:
- name: mnt
hostPath:
# tmpfs змонтовано у /mnt/tmpfs
path: /mnt
containers:
- name: busybox
image: busybox
args: ["sleep", "infinity"]
volumeMounts:
# /mnt-rro/tmpfs не має права на запис
- name: mnt
mountPath: /mnt-rro
readOnly: true
mountPropagation: None
recursiveReadOnly: Enabled
# /mnt-ro/tmpfs має право на запис
- name: mnt
mountPath: /mnt-ro
readOnly: true
# /mnt-rw/tmpfs має право на запис
- name: mnt
mountPath: /mnt-rw
Коли ця властивість розпізнається kubelet та kube-apiserver, поле .status.containerStatuses[].volumeMounts[].recursiveReadOnly буде встановлено на Enabled або Disabled.
Реалізації
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Відомо, що наступні середовища виконання контейнерів підтримують рекурсивне монтування тільки для читання.
Рівень CRI:
- containerd, починаючи з v2.0
- CRI-O, починаючи з v1.30
Рівень OCI:
Що далі
Ознайомтесь з прикладом розгортання WordPress та MySQL з Persistent Volume.
6.2 - Постійні томи
Цей документ описує постійні томи (persistent volumes) в Kubernetes. Рекомендується вже мати уявлення про томи, StorageClasses та VolumeAttributesClasses.
Вступ
Управління зберіганням — це задача, що є відокремленою від управління обчислювальними ресурсами. Підсистема PersistentVolume надає API для користувачів та адміністраторів, яке абстрагує деталі того, як забезпечується зберігання від того, як воно використовується. Для цього ми вводимо два нових ресурси API: PersistentVolume та PersistentVolumeClaim.
PersistentVolume (PV) — це частина системи зберігання в кластері, яка була надана адміністратором або динамічно надана за допомогою Storage Classes. Це ресурс в кластері, так само як вузол — це ресурс кластера. PV — це втулки томів, так само як Volumes, але вони мають життєвий цикл, незалежний від будь-якого окремого Podʼа, який використовує PV. Цей обʼєкт API охоплює деталі реалізації зберігання, такі як NFS, iSCSI або система зберігання, специфічна для постачальника хмарних послуг.
PersistentVolumeClaim (PVC) — це запит на зберігання від користувача. Він схожий на Pod. Podʼи використовують ресурси вузла, а PVC використовують ресурси PV. Podʼи можуть запитувати конкретні рівні ресурсів (CPU та памʼять). Claims можуть запитувати конкретний розмір та режими доступу (наприклад, їх можна монтувати в режимі ReadWriteOnce, ReadOnlyMany, ReadWriteMany або ReadWriteOncePod, див. AccessModes).
Хоча PersistentVolumeClaims дозволяють користувачам споживати абстрактні ресурси зберігання, часто користувачам потрібні PersistentVolumes з різними властивостями, такими як продуктивність для різних завдань. Адміністратори кластера повинні мати можливість надавати різноманітні PersistentVolumes, які відрізняються не тільки розміром і режимами доступу, але й іншими характеристиками, не розголошуючи користувачам деталей того, як реалізовані ці томи. Для цих потреб існує ресурс StorageClass.
Дивіться докладний огляд із робочими прикладами.
Життєвий цикл тому та запиту
PV (PersistentVolume) — це ресурс в кластері. PVC (PersistentVolumeClaim) — це запити на ці ресурси та також діють як перевірки запитів ресурсів. Взаємодія між PV та PVC слідує такому життєвому циклу:
Виділення
Існує два способи надання PV: статичне чи динамічне.
Статичне
Адміністратор кластера створює кілька PV. Вони містять деталі реального зберігання, яке доступне для використання користувачами кластера. Вони існують в API Kubernetes і доступні для споживання.
Динамічне
Коли жоден зі статичних PV, які створив адміністратор, не відповідає PersistentVolumeClaim користувача, кластер може спробувати динамічно надати том спеціально для PVC. Це надання ґрунтується на StorageClasses: PVC повинен запитати клас зберігання, а адміністратор повинен створити та налаштувати цей клас для динамічного надання. Заявки, які запитують клас "", ефективно вимикають динамічне надання для себе.
Для активації динамічного надання сховища на основі класу зберігання адміністратор кластера повинен увімкнути контролер допуску DefaultStorageClass на API-сервері. Це можна зробити, наприклад, забезпечивши, що DefaultStorageClass знаходиться серед значень, розділених комами, у впорядкованому списку для прапорця --enable-admission-plugins компонента API-сервера. Для отримання додаткової інформації щодо прапорців командного рядка API-сервера перевірте документацію kube-apiserver.
Звʼязування
Користувач створює, або, у разі динамічного надання, вже створив, PersistentVolumeClaim із конкретним обсягом запитаного сховища та з певними режимами доступу. Цикл керування в панелі управління бачить нові PVC, знаходить відповідний PV (якщо це можливо), і звʼязує їх один з одним. Якщо PV був динамічно наданий для нового PVC, цикл завжди буде привʼязувати цей PV до PVC. В іншому випадку користувач завжди отримає принаймні те, про що вони просили, але том може бути більшим, ніж те, що було запитано. Як тільки звʼязування виконане, привʼязки PersistentVolumeClaim є ексклюзивними, незалежно від того, як вони були звʼязані. Привʼязка PVC до PV — це відображення один до одного, використовуючи ClaimRef, яке є двонапрямним звʼязуванням між PersistentVolume і PersistentVolumeClaim.
Заявки залишатимуться непривʼязаними нескінченно довго, якщо відповідного тому не існує. Заявки будуть привʼязані, в міру того як стають доступні відповідні томи. Наприклад, кластер, який має багато PV розміром 50Gi, не буде відповідати PVC розміром 100Gi. PVC може бути привʼязаний, коли до кластера додається PV розміром 100Gi.
Використання
Podʼи використовують заявки як томи. Кластер перевіряє заявку, щоб знайти привʼязаний том і монтує цей том для Podʼа. Для томів, які підтримують кілька режимів доступу, користувач вказує бажаний режим при використанні своєї заявки як тому в Podʼі.
Якщо у користувача є заявка, і ця заявка привʼязана, привʼязаний PV належить користувачеві стільки, скільки він йому потрібний. Користувачі планують Podʼи та отримують доступ до своїх заявлених PV, включивши розділ persistentVolumeClaim в блок volumes Podʼа. Див. Заявки як томи для отримання докладнішої інформації щодо цього.
Захист обʼєкта зберігання, що використовується
Мета функції захисту обʼєктів зберігання — це забезпечити, що PersistentVolumeClaims (PVC), які активно використовуються Podʼом, та PersistentVolume (PV), які привʼязані до PVC, не видаляються з системи, оскільки це може призвести до втрати даних.
Примітка:
PVC активно використовується Podʼом, коли існує обʼєкт Pod, який використовує PVC.Якщо користувач видаляє PVC, що активно використовується Podʼом, PVC не видаляється негайно. Видалення PVC відкладається до тих пір, поки PVC більше активно не використовується жодними Podʼами. Також, якщо адміністратор видаляє PV, який привʼязаний до PVC, PV не видаляється негайно. Видалення PV відкладається до тих пір, поки PV більше не є привʼязаним до PVC.
Ви можете перевірити, що PVC захищено, коли статус PVC — «Terminating», а список Finalizers включає kubernetes.io/pvc-protection:
kubectl describe pvc hostpath
Name: hostpath
Namespace: default
StorageClass: example-hostpath
Status: Terminating
Volume:
Labels: <none>
Annotations: volume.beta.kubernetes.io/storage-class=example-hostpath
volume.beta.kubernetes.io/storage-provisioner=example.com/hostpath
Finalizers: [kubernetes.io/pvc-protection]
...
Ви можете перевірити, що PV захищено, коли статус PV — «Terminating», а список Finalizers також включає kubernetes.io/pv-protection:
kubectl describe pv task-pv-volume
Name: task-pv-volume
Labels: type=local
Annotations: <none>
Finalizers: [kubernetes.io/pv-protection]
StorageClass: standard
Status: Terminating
Claim:
Reclaim Policy: Delete
Access Modes: RWO
Capacity: 1Gi
Message:
Source:
Type: HostPath (bare host directory volume)
Path: /tmp/data
HostPathType:
Events: <none>
Повторне використання
Коли користувач закінчує використання свого тому, він може видалити обʼєкти PVC з API, що дозволяє відновлення ресурсу. Політика відновлення для PersistentVolume повідомляє кластеру, що робити з томом після звільнення заявки на нього. Наразі томи можуть бути Retained, Recycled, або Deleted
Retain
Політика повторного використання Retain дозволяє ручне повторне використання ресурсу. Коли видаляється PersistentVolumeClaim, PersistentVolume все ще існує, і том вважається "звільненим". Але він ще не доступний для іншої заявки через те, що дані попередньої заявки залишаються на томі. Адміністратор може вручну відновити том виконавши наступні кроки.
- Видаліть PersistentVolume. Повʼязаний актив в зовнішній інфраструктурі все ще існує після видалення PV.
- Вручну очистіть дані на повʼязаному активі відповідно.
- Вручну видаліть повʼязаний актив.
Якщо ви хочете використовувати той самий актив, створіть новий PersistentVolume з тим же описом активу.
Delete
Для втулків томів, які підтримують політику відновлення Delete, видалення видаляє як обʼєкт PersistentVolume з Kubernetes, так і повʼязаний актив зовнішньої інфраструктури. Томи, які були динамічно виділені, успадковують політику пвоторного використання їх StorageClass, яка типово встановлена в Delete. Адміністратор повинен налаштувати StorageClass відповідно до очікувань користувачів; в іншому випадку PV повинен бути відредагований або виправлений після створення. Див.
Змінення політики повторного використання PersistentVolume.
Recycle
Попередження:
Політика повторного використанняRecycle є застарілою. Замість цього рекомендований підхід — використовувати динамічне виділення.Якщо підтримується відповідний втулок томів, політика повторного використання Recycle виконує базове очищення (rm -rf /thevolume/*) тому та знову робить його доступним для нової заявки.
Однак адміністратор може налаштувати власний шаблон Podʼа для повторного використання тому за допомогою аргументів командного рядка контролера Kubernetes, як описано в довідці. Власний шаблон Podʼа повторного використання тому повинен містити специфікацію volumes, як показано у прикладі нижче:
apiVersion: v1
kind: Pod
metadata:
name: pv-recycler
namespace: default
spec:
restartPolicy: Never
volumes:
- name: vol
hostPath:
path: /any/path/it/will/be/replaced
containers:
- name: pv-recycler
image: "registry.k8s.io/busybox"
command: ["/bin/sh", "-c", "test -e /scrub && rm -rf /scrub/..?* /scrub/.[!.]* /scrub/* && test -z \"$(ls -A /scrub)\" || exit 1"]
volumeMounts:
- name: vol
mountPath: /scrub
Проте конкретний шлях, вказаний у власному шаблоні Podʼа для повторного використання тому, в частині volumes, замінюється конкретним шляхом тому, який використовується.
Завершувач захисту від видалення PersistentVolume
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [beta] (стандартно увімкнено: true)До PersistentVolume можна додавати завершувачі, щоб забезпечити, що PersistentVolume з політикою відновлення Delete буде видалено лише після видалення сховища, яке він забезпечував.
Завершувач external-provisioner.volume.kubernetes.io/finalizer (введений у v1.31) додається як до динамічно, так і до статично виділених томів CSI.
Завершувач kubernetes.io/pv-controller (введений у v1.31) додається до динамічно виділених томів внутрішнього втулка і пропускається для статично виділених томів внутрішнього втулка.
Ось приклад динамічно виділеного тому внутрішнього втулка:
kubectl describe pv pvc-74a498d6-3929-47e8-8c02-078c1ece4d78
Name: pvc-74a498d6-3929-47e8-8c02-078c1ece4d78
Labels: <none>
Annotations: kubernetes.io/createdby: vsphere-volume-dynamic-provisioner
pv.kubernetes.io/bound-by-controller: yes
pv.kubernetes.io/provisioned-by: kubernetes.io/vsphere-volume
Finalizers: [kubernetes.io/pv-protection kubernetes.io/pv-controller]
StorageClass: vcp-sc
Status: Bound
Claim: default/vcp-pvc-1
Reclaim Policy: Delete
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 1Gi
Node Affinity: <none>
Message:
Source:
Type: vSphereVolume (a Persistent Disk resource in vSphere)
VolumePath: [vsanDatastore] d49c4a62-166f-ce12-c464-020077ba5d46/kubernetes-dynamic-pvc-74a498d6-3929-47e8-8c02-078c1ece4d78.vmdk
FSType: ext4
StoragePolicyName: vSAN Default Storage Policy
Events: <none>
Завершувач external-provisioner.volume.kubernetes.io/finalizer додається для томів CSI. Наприклад:
Name: pvc-2f0bab97-85a8-4552-8044-eb8be45cf48d
Labels: <none>
Annotations: pv.kubernetes.io/provisioned-by: csi.vsphere.vmware.com
Finalizers: [kubernetes.io/pv-protection external-provisioner.volume.kubernetes.io/finalizer]
StorageClass: fast
Status: Bound
Claim: demo-app/nginx-logs
Reclaim Policy: Delete
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 200Mi
Node Affinity: <none>
Message:
Source:
Type: CSI (a Container Storage Interface (CSI) volume source)
Driver: csi.vsphere.vmware.com
FSType: ext4
VolumeHandle: 44830fa8-79b4-406b-8b58-621ba25353fd
ReadOnly: false
VolumeAttributes: storage.kubernetes.io/csiProvisionerIdentity=1648442357185-8081-csi.vsphere.vmware.com
type=vSphere CNS Block Volume
Events: <none>
Коли прапорець функції CSIMigration{provider} увімкнено для конкретного внутрішнього втулка, завершувач kubernetes.io/pv-controller замінюється завершувачем external-provisioner.volume.kubernetes.io/finalizer.
Завершувачі забезпечують, що обʼєкт PV видаляється лише після того, як том буде видалений з бекенду зберігання, якщо політика відновлення PV є Delete. Це також гарантує, що том буде видалений з бекенду зберігання незалежно від порядку видалення PV і PVC.
Резервування PersistentVolume
Панель управління може привʼязувати PersistentVolumeClaims до PersistentVolume в кластері. Однак, якщо вам потрібно, щоб PVC привʼязувався до певного PV, вам слід заздалегідь їх привʼязувати.
Вказавши PersistentVolume в PersistentVolumeClaim, ви оголошуєте привʼязку між цим конкретним PV та PVC. Якщо PersistentVolume існує і не зарезервував PersistentVolumeClaim через своє поле claimRef, тоді PersistentVolume і PersistentVolumeClaim будуть привʼязані.
Привʼязка відбувається попри деякі критерії відповідності, включаючи спорідненість вузла. Панель управління все ще перевіряє, що клас сховища, режими доступу та розмір запитаного сховища є дійсними.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-pvc
namespace: foo
spec:
storageClassName: "" # Порожній рядок повинен бути явно встановлений, інакше буде встановлено типовий StorageClass
volumeName: foo-pv
...
Цей метод не гарантує жодних привʼязок для PersistentVolume. Якщо інші PersistentVolumeClaims можуть використовувати PV, який ви вказуєте, вам слід заздалегідь резервувати цей обсяг сховища. Вкажіть відповідний PersistentVolumeClaim у поле claimRef PV, щоб інші PVC не могли привʼязатися до нього.
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-pv
spec:
storageClassName: ""
claimRef:
name: foo-pvc
namespace: foo
...
Це корисно, якщо ви хочете використовувати PersistentVolumes з політикою повторного використання Retain, включаючи випадки, коли ви повторно використовуєте наявний PV.
Розширення Persistent Volume Claims
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]Підтримка розширення PersistentVolumeClaims (PVCs) є типово увімкненою. Ви можете розширити наступні типи томів:
- azureFile (застарілий)
- csi
- flexVolume (застарілий)
- rbd (застарілий)
- portworxVolume (застарілий)
Ви можете розширити PVC лише в тому випадку, якщо поле allowVolumeExpansion його класу сховища має значення true.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: example-vol-default
provisioner: vendor-name.example/magicstorage
parameters:
resturl: "http://192.168.10.100:8080"
restuser: ""
secretNamespace: ""
secretName: ""
allowVolumeExpansion: true
Для запиту більшого тому для PVC відредагуйте обʼєкт PVC та вказуйте більший розмір. Це спричинює розширення тому, який стоїть за основним PersistentVolume. Новий PersistentVolume ніколи не створюється для задоволення вимоги. Замість цього, змінюється розмір поточного тому.
Попередження:
Пряме редагування розміру PersistentVolume може запобігти автоматичному зміненню розміру цього тому. Якщо ви редагуєте обсяг PersistentVolume, а потім редагуєте.spec відповідного PersistentVolumeClaim, щоб розмір PersistentVolumeClaim відповідав PersistentVolume, то зміна розміру сховища не відбудеться. Панель управління Kubernetes побачить, що бажаний стан обох ресурсів збігається, і робить висновок, що розмір обʼєкта був збільшений вручну і розширення не потрібне.Розширення томів CSI
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]Підтримка розширення томів CSI типово увімкнена, але вона також вимагає, щоб конкретний драйвер CSI підтримував розширення тому. Зверніться до документації відповідного драйвера CSI для отримання додаткової інформації.
Зміна розміру тому, що містить файлову систему
Ви можете змінювати розмір томів, що містять файлову систему, тільки якщо файлова система є XFS, Ext3 або Ext4.
Коли том містить файлову систему, розмір файлової системи змінюється тільки тоді, коли новий Pod використовує PersistentVolumeClaim у режимі ReadWrite. Розширення файлової системи виконується при запуску нового Pod або коли Pod працює, і базова файлова система підтримує онлайн-розширення.
FlexVolumes (застарілий починаючи з Kubernetes v1.23) дозволяє змінювати розмір, якщо драйвер налаштований із можливістю RequiresFSResize встановленою в true. FlexVolume може бути змінений при перезапуску Pod.
Зміна розміру використовуваного PersistentVolumeClaim
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]В цьому випадку вам не потрібно видаляти та перестворювати Pod або Deployment, який використовує наявний PVC. Будь-який PVC, який знаходиться у використанні, автоматично стає доступним для свого Pod, як тільки його файлова система буде розширена. Ця функція не впливає на PVC, які не використовуються Pod або Deployment. Ви повинні створити Pod, який використовує PVC, перш ніж розширення може завершитися.
Аналогічно іншим типам томів — томи FlexVolume також можуть бути розширені в разі використання Podʼом.
Примітка:
Змінювати розмір FlexVolume можливо лише тоді, коли зміна розміру підтримується драйвером.Відновлення після невдалих спроб розширення томів
Якщо користувач вказав новий розмір, який надто великий для задоволення базовою системою зберігання, розширення PVC буде намагатися робити спроби його задовольнити, доки користувач або адміністратор кластера не вживе будь-яких заходів. Це може бути небажаним, і, отже, Kubernetes надає наступні методи відновлення після таких невдач.
Якщо розширення базового сховища не вдається, адміністратор кластера може вручну відновити стан Persistent Volume Claim (PVC) та скасувати запити на зміну розміру. Інакше запити на зміну розміру буде продовжено автоматично контролером без втручання адміністратора.
- Позначте Persistent Volume (PV), який привʼязаний до Persistent Volume Claim (PVC), політикою вилучення
Retain. - Видаліть PVC. Оскільки PV має політику вилучення
Retain, ми не втратимо жодних даних під час повторного створення PVC. - Видаліть запис
claimRefз характеристик PV, щоб новий PVC міг привʼязатися до нього. Це повинно зробити PVAvailable. - Створіть заново PVC з меншим розміром, ніж у PV, і встановіть в поле
volumeNamePVC імʼя PV. Це повинно привʼязати новий PVC до наявного PV. - Не забудьте відновити політику вилучення PV.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [beta] (стандартно увімкнено: true)Примітка:
Відновлення після невдалого розширення PVC користувачами (RecoverVolumeExpansionFailure) доступне у бета-версії Kubernetes 1.32 і має бути стандартно увімкнено. Докладнішу інформацію наведено у документації функціональної можливості.Коли використовується функціональна можливість RecoverVolumeExpansionFailure, і розширення не вдалося для PVC, ви можете повторити спробу розширення з меншим розміром, ніж раніше запитаний. Щоб запросити нову спробу розширення з новим запропонованим розміром, відредагуйте .spec.resources для цього PVC і виберіть значення, яке менше за попереднє значення. Це корисно, якщо розширення до більшого значення не вдалося через обмеження місткості. Якщо це трапилося або ви підозрюєте, що це може трапитися, ви можете повторити спробу розширення, вказавши розмір, який знаходиться в межах обмежень місткості базового постачальника сховища. Ви можете слідкувати за станом операції зміни розміру, спостерігаючи за .status.allocatedResourceStatuses та подіями на PVC.
Зверніть увагу, що, навіть якщо ви можете вказати менше обсягу зберігання, ніж запитано раніше, нове значення все ще повинно бути вищим за .status.capacity. Kubernetes не підтримує зменшення PVC до меншого розміру, ніж його поточний розмір.
Типи Persistent Volume
Типи PersistentVolume реалізовані у вигляді втулків. Kubernetes наразі підтримує наступні втулки:
csi— Інтерфейс зберігання контейнерів (Container Storage Interface, CSI)fc— Сховище Fibre Channel (FC)hostPath— Том HostPath (для тестування на одному вузлі лише; НЕ ПРАЦЮВАТИМЕ в кластері з декількома вузлами; розгляньте використання томуlocalзамість цього)iscsi— Сховище iSCSI (SCSI через IP)local— Локальні пристрої зберігання, підключені до вузлів.nfs— Сховище в мережевій файловій системі (NFS)
Наступні типи PersistentVolume застарілі, але все ще доступні. Якщо ви використовуєте ці типи томів, окрім flexVolume, cephfs та rbd, будь ласка, встановіть відповідні драйвери CSI.
awsElasticBlockStore— AWS Elastic Block Store (EBS) (міграція типово увімкнена починаючи з v1.23)azureDisk— Azure Disk (міграція типово увімкнена починаючи з v1.23)azureFile— Azure File (міграція типово увімкнена починаючи з v1.24)cinder— Cinder (блочне сховище OpenStack) (міграція типово увімкнена починаючи з v1.21)flexVolume— FlexVolume (застаріло починаючи з версії v1.23, план міграції відсутній, планів припинення підтримки немає)gcePersistentDisk— GCE Persistent Disk (застаріло починаючи з v1.23, план міграції відсутній, планів припинення підтримки немає)portworxVolume— Том Portworx (міграція типово увімкнена починаючи з v1.31)vsphereVolume- vSphere VMDK volume (міграція типово увімкнена починаючи з v1.25)
Старші версії Kubernetes також підтримували наступні типи вбудованих PersistentVolume:
cephfs(недоступно починаючи з версії v1.31)flocker— Flocker storage. (недоступно починаючи з версії v1.25)photonPersistentDisk— Photon controller persistent disk. (недоступно починаючи з версії v1.15)quobyte— Том Quobyte. (недоступно починаючи з версії v1.25)rbd— Rados Block Device (RBD) volume (недоступно починаючи з версії v1.31)scaleIO— Том ScaleIO. (недоступно починаючи з версії v1.21)storageos— Том StorageOS. (недоступно починаючи з версії v1.25)
Persistent Volumes
Кожен PersistentVolume (PV) містить специфікацію та статус, які являють собою характеристики та стан тому. Імʼя обʼєкта PersistentVolume повинно бути дійсним DNS імʼям субдомену.
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /tmp
server: 172.17.0.2
Примітка:
Можливо, для використання PersistentVolume у кластері будуть потрібні допоміжні програми. У цьому прикладі PersistentVolume має тип NFS, і для підтримки монтування файлових систем NFS необхідна допоміжна програма /sbin/mount.nfs.Обсяг
Зазвичай у PV є конкретний обсяг зберігання. Він встановлюється за допомогою атрибута capacity PV, який є значенням кількості обсягу.
Наразі розмір — це єдиний ресурс, який можна встановити або вимагати. Майбутні атрибути можуть включати IOPS, пропускну здатність тощо.
Режим тому
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.18 [stable]Kubernetes підтримує два режими volumeModes для PersistentVolumes: Filesystem та Block.
volumeMode є необовʼязковим параметром API. Filesystem є типовим режимом, який використовується, коли параметр volumeMode пропущено.
Том з volumeMode: Filesystem монтується в Podʼах в каталог. Якщо том підтримується блоковим пристроєм, і пристрій порожній, Kubernetes створює файлову систему на пристрої перед його першим монтуванням.
Ви можете встановити значення volumeMode в Block, щоб використовувати том як блоковий пристрій. Такий том представляється в Podʼі як блоковий пристрій, без будь-якої файлової системи на ньому. Цей режим корисний, щоб надати Podʼу найшвидший можливий спосіб доступу до тому, без будь-якого рівня файлової системи між Podʼом і томом. З іншого боку, застосунок, який працює в Podʼі, повинен знати, як взаємодіяти з блоковим пристроєм. Дивіться Підтримка блокового тому для прикладу використання тому з volumeMode: Block в Podʼі.
Режими доступу
PersistentVolume може бути підключений до вузла будь-яким способом, який підтримує постачальник ресурсів. Як показано в таблиці нижче, постачальники матимуть різні можливості, і кожному PV присвоюється набір режимів доступу, які описують можливості саме цього PV.
Режими доступу такі:
ReadWriteOnce- том може бути підключений як для читання-запису одним вузлом. Режим доступу ReadWriteOnce все ще може дозволяти доступ до тому для кількох Podʼів, коли Podʼи працюють на тому самому вузлі. Для доступу одного Podʼа, див. ReadWriteOncePod.
ReadOnlyMany- том може бути підключений як для читання лише багатьма вузлами.
ReadWriteMany- том може бути підключений як для читання-запису багатьма вузлами.
ReadWriteOncePod- СТАН ФУНКЦІОНАЛУ:том може бути підключений як для читання-запису одним Podʼом. Використовуйте режим доступу ReadWriteOncePod, якщо ви хочете забезпечити, що тільки один Pod по всьому кластеру може читати цей PVC або писати в нього.
Kubernetes v1.29 [stable]
Примітка:
Режим доступу ReadWriteOncePod підтримується лише для CSI томів та Kubernetes версії 1.22+. Щоб використовувати цю функцію, вам потрібно оновити наступні CSI sidecars до цих версій або новіших:
У командному рядку режими доступу скорочено так:
- RWO — ReadWriteOnce
- ROX — ReadOnlyMany
- RWX — ReadWriteMany
- RWOP — ReadWriteOncePod
Примітка:
Kubernetes використовує режими доступу до тому для відповідності PersistentVolumeClaims та PersistentVolumes. У деяких випадках режими доступу до тому також обмежують місця, де може бути підключений PersistentVolume. Режими доступу до тому не накладають захист від запису після підключення сховища. Навіть якщо режими доступу вказані як ReadWriteOnce, ReadOnlyMany або ReadWriteMany, вони не встановлюють жодних обмежень на том. Наприклад, навіть якщо PersistentVolume створено як ReadOnlyMany, це не гарантує, що він буде доступний лише для читання. Якщо режими доступу вказані як ReadWriteOncePod, том обмежений і може бути підключений лише до одного пода.Важливо! Том може бути підключений лише одним режимом доступу одночасно, навіть якщо він підтримує багато.
| Тип тому | ReadWriteOnce | ReadOnlyMany | ReadWriteMany | ReadWriteOncePod |
|---|---|---|---|---|
| AzureFile | ✓ | ✓ | ✓ | - |
| CephFS | ✓ | ✓ | ✓ | - |
| CSI | залежить від драйвера | залежить від драйвера | залежить від драйвера | залежить від драйвера |
| FC | ✓ | ✓ | - | - |
| FlexVolume | ✓ | ✓ | залежить від драйвера | - |
| HostPath | ✓ | - | - | - |
| iSCSI | ✓ | ✓ | - | - |
| NFS | ✓ | ✓ | ✓ | - |
| RBD | ✓ | ✓ | - | - |
| VsphereVolume | ✓ | - | - (працює, коли Podʼи розташовані разом) | - |
| PortworxVolume | ✓ | - | ✓ | - |
Class
PV може мати клас, який вказується, встановленням атрибуту storageClassName на імʼя StorageClass. PV певного класу може бути призначений лише до PVC, що запитує цей клас. PV без storageClassName не має класу і може бути призначений тільки до PVC, які не запитують жодного конкретного класу.
У минулому для цього використовувався атрибут volume.beta.kubernetes.io/storage-class замість storageClassName. Ця анотація все ще працює; однак вона повністю застаріє в майбутньому релізі Kubernetes.
Політика повторного використання
Поточні політики повторного використання:
- Retain — ручне відновлення
- Recycle — базова очистка (
rm -rf /thevolume/*) - Delete — видалити том
Для Kubernetes 1.32 підтримують повторнн використання лише типи томів nfs та hostPath.
Параметри монтування
Адміністратор Kubernetes може вказати додаткові параметри монтування для випадку, коли постійний том монтується на вузлі.
Примітка:
Не всі типи постійних томів підтримують параметри монтування.Наступні типи томів підтримують параметри монтування:
azureFilecephfs(застаріло в v1.28)cinder(застаріло в v1.18)iscsinfsrbd(застаріло в v1.28)vsphereVolume
Параметри монтування не перевіряються на валідність. Якщо параметр монтування недійсний, монтування не вдасться.
У минулому для цього використовувалася анотація volume.beta.kubernetes.io/mount-options замість атрибуту mountOptions. Ця анотація все ще працює; однак вона повністю застаріє в майбутньому релізі Kubernetes.
Node Affinity
Примітка:
Для більшості типів томів вам не потрібно встановлювати це поле. Вам слід явно встановити його для локальних томів.Постійний том може вказувати властивості спорідненості вузла для визначення обмежень, які обмежують доступ до цього тому з визначених вузлів. Podʼи, які використовують PV, будуть заплановані тільки на ті вузли, які вибрані за допомогою спорідненості вузла. Щоб вказати спорідненість вузла, встановіть nodeAffinity в .spec PV. Деталі поля можна знайти у референсі API PersistentVolume.
Фаза
PersistentVolume може перебувати в одній з наступних фаз:
Available- вільний ресурс, який ще не призначений запиту
Bound- том призначено запиту
Released- запит було видалено, але повʼязане сховища ще не вилучено кластером
Failed- том не вдалося вилучити (автоматично)
Ви можете бачити імʼя PVC, призначеного для PV, використовуючи kubectl describe persistentvolume <імʼя>.
Час переходу фази
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [stable] (стандартно увімкнено: true)Поле .status для PersistentVolume може включати альфа-поле lastPhaseTransitionTime. Це поле фіксує відмітку часу, коли том востаннє перейшов у свою фазу. Для новостворених томів фаза встановлюється як Pending, а lastPhaseTransitionTime встановлюється на поточний час.
PersistentVolumeClaims
Кожен PVC містить специфікацію та статус, які визначають вимоги та стан заявок. Імʼя обʼєкта PersistentVolumeClaim повинно бути дійсним DNS-піддоменом.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 8Gi
storageClassName: slow
selector:
matchLabels:
release: "stable"
matchExpressions:
- {key: environment, operator: In, values: [dev]}
Режим доступу
Заявки використовують ті ж самі конвенції, що й томи, коли вони вимагають зберігання з конкретними режимами доступу.
Режим тому
Заявки використовують ту ж саму конвенцію, що і томи, щоб вказати споживання тому як файлової системи чи блокового пристрою.
Імʼя тому
Заявки можуть використовувати поле volumeName, щоб явно привʼязатись до певного PersistentVolume. Ви також можете залишити volumeName невстановленим, вказавши, що ви хочете, щоб Kubernetes налаштував новий PersistentVolume, який відповідає заявці. Якщо вказаний PV вже привʼязаний до іншого PVC, привʼязка залишиться в очікуванні.
Ресурси
Заявки, подібно до Podʼів, можуть вимагати конкретну кількість ресурсів. У цьому випадку запит стосується зберігання. До заявок застосовується та ж модель ресурсів, що і до томів.
Селектор
Заявки можуть вказати селектор міток, щоб додатково фільтрувати набір томів. До заявки може бути привʼязано лише ті томи, мітки яких відповідають селектору. Селектор може складатися з двох полів:
matchLabels— том повинен містити мітку з таким значеннямmatchExpressions— список вимог, які визначаються за допомогою ключа, списку значень та оператора, який повʼязує ключ і значення. Допустимі оператори включають In, NotIn, Exists та DoesNotExist.
Всі вимоги як з matchLabels, так і з matchExpressions обʼєднуються за допомогою ЛОГІЧНОГО «І» — всі вони повинні бути задоволені, щоб мати збіг.
Class
Заявка може вимагати певний клас, вказавши імʼя StorageClass за допомогою атрибута storageClassName. Тільки Томи з запитаним класом, тобто ті, у яких storageClassName збігається з PVC, можуть бути привʼязані до PVC.
PVC не обоʼязково повинен вимагати клас. PVC зі своїм storageClassName, встановленим рівним "", завжди інтерпретується як PVC, який вимагає PV без класу, тобто він може бути привʼязаний лише до PV без класу (без анотації або з анотацією, встановленою рівною ""). PVC без storageClassName не зовсім те ж саме і відзначається по-іншому кластером, залежно від того, чи включений втулок доступу DefaultStorageClass.
- Якщо втулок доступу увімкнено, адміністратор може вказати типовий StorageClass. Усі PVC, у яких немає
storageClassName, можуть бути привʼязані лише до PV з цим типовим StorageClass. Вказання типового StorageClass виконується, встановивши анотаціюstorageclass.kubernetes.io/is-default-classрівноюtrueв обʼєкті StorageClass. Якщо адміністратор не вказав типовий StorageClass, кластер відповідає на створення PVC так, ніби втулок доступу був вимкнений. Якщо вказано більше одного типового StorageClass, для привʼязки PVC використовується остання версія типового StorageClass, коли PVC динамічно виділяється. - Якщо втулок доступу вимкнено, немає поняття типового StorageClass. Усі PVC, у яких
storageClassNameвстановлено рівно"", можуть бути привʼязані лише до PV, у якихstorageClassNameтакож встановлено рівно"". Однак PVC з відсутнімstorageClassNameможна буде оновити пізніше, коли стане доступним типовий StorageClass. Якщо PVC оновлюється, він більше не буде привʼязуватися до PV зstorageClassName, також встановленим рівно"".
Дивіться ретроактивне призначення типового StorageClass для отримання докладнішої інформації.
Залежно від методу встановлення, типовий StorageClass може бути розгорнутий в кластер Kubernetes менеджером надбудов під час встановлення.
Коли PVC вказує selector, крім вимоги типового StorageClass, вимоги використовують ЛОГІЧНЕ «І»: лише PV вказаного класу і з вказаними мітками може бути привʼязаний до PVC.
Примітка:
На даний момент PVC з непорожнімselector не може мати PV, динамічно виділеного для нього.У минулому анотація volume.beta.kubernetes.io/storage-class використовувалася замість атрибута storageClassName. Ця анотація все ще працює; однак вона не буде підтримуватися в майбутньому релізі Kubernetes.
Ретроактивне призначення типового StorageClass
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.28 [stable]Ви можете створювати PersistentVolumeClaim без вказівки storageClassName для нового PVC, і ви можете це робити навіть тоді, коли в кластері немає типового StorageClass. У цьому випадку новий PVC створюється так, як ви його визначили, і storageClassName цього PVC залишається невизначеним, доки не стане доступним типовий StorageClass.
Коли стає доступним типовий StorageClass, панель управління ідентифікує всі наявні PVC без storageClassName. Для PVC, у яких або встановлено порожнє значення для storageClassName, або цей ключ взагалі відсутній, панель управління оновлює ці PVC, встановлюючи storageClassName, щоб відповідати новому типовому StorageClass. Якщо у вас є наявний PVC, у якого storageClassName дорівнює "", і ви налаштовуєте типовий StorageClass, то цей PVC не буде оновлено.
Щоб продовжувати привʼязувати до PV з storageClassName, встановленим рівно "" (коли присутній типовий StorageClass), вам потрібно встановити storageClassName асоційованого PVC рівно "".
Це поведінка допомагає адміністраторам змінювати типовий StorageClass, видаляючи спочатку старий, а потім створюючи або встановлюючи інший. Це короткочасне вікно, коли немає типового StorageClass, призводить до того, що PVC без storageClassName, створені в цей час, не мають жодного типового значення, але завдяки ретроактивному призначенню типового StorageClass цей спосіб зміни типових значень є безпечним.
Заявки як томи
Podʼи отримують доступ до сховища, використовуючи заявки як томи. Заявки повинні існувати в тому ж просторі імен, що і Pod, який її використовує. Кластер знаходить заявку в просторі імен Pod і використовує її для отримання PersistentVolume, який підтримує заявку. Потім том монтується на хост та у Pod.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: myfrontend
image: nginx
volumeMounts:
- mountPath: "/var/www/html"
name: mypd
volumes:
- name: mypd
persistentVolumeClaim:
claimName: myclaim
Примітка щодо просторів імен
Привʼязки PersistentVolumes є ексклюзивними, і оскільки PersistentVolumeClaims є обʼєктами з простором імен, монтування заявк з режимами "Many" (ROX, RWX) можливе лише в межах одного простору імен.
PersistentVolumes типу hostPath
PersistentVolume типу hostPath використовує файл або каталог на вузлі для емуляції мережевого сховища. Див. приклад тому типу hostPath.
Підтримка блокового тому
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.18 [stable]Наступні втулки томів підтримують блокові томи, включаючи динамічне надання, де це можливо:
- CSI
- FC (Fibre Channel)
- iSCSI
- Локальний том
- OpenStack Cinder
- RBD (застаріло)
- RBD (Ceph Block Device; застаріло)
- VsphereVolume
PersistentVolume, що використовує блоковий том
apiVersion: v1
kind: PersistentVolume
metadata:
name: block-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
volumeMode: Block
persistentVolumeReclaimPolicy: Retain
fc:
targetWWNs: ["50060e801049cfd1"]
lun: 0
readOnly: false
PersistentVolumeClaim, який запитує блоковий том
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: block-pvc
spec:
accessModes:
- ReadWriteOnce
volumeMode: Block
resources:
requests:
storage: 10Gi
Специфікація Pod з додаванням шляху блокового пристрою в контейнер
apiVersion: v1
kind: Pod
metadata:
name: pod-with-block-volume
spec:
containers:
- name: fc-container
image: fedora:26
command: ["/bin/sh", "-c"]
args: [ "tail -f /dev/null" ]
volumeDevices:
- name: data
devicePath: /dev/xvda
volumes:
- name: data
persistentVolumeClaim:
claimName: block-pvc
Примітка:
При додаванні блокового пристрою для Pod ви вказуєте шлях до пристрою в контейнері замість шляху монтування.Привʼязка блокових томів
Якщо користувач вимагає блокового тому, вказавши це за допомогою поля volumeMode у специфікації PersistentVolumeClaim, правила привʼязки трохи відрізняються від попередніх версій, які не враховували цей режим як частину специфікації. У таблиці наведено можливі комбінації, які користувач і адміністратор можуть вказати для запиту блокового пристрою. Таблиця показує, чи буде привʼязаний том чи ні, враховуючи ці комбінації: Матриця привʼязки томів для статично виділених томів:
| PV volumeMode | PVC volumeMode | Результат |
|---|---|---|
| не вказано | не вказано | ПРИВ'ЯЗАНИЙ |
| не вказано | Блоковий | НЕ ПРИВ'ЯЗАНИЙ |
| не вказано | Файлова система | ПРИВ'ЯЗАНИЙ |
| Блоковий | не вказано | НЕ ПРИВ'ЯЗАНИЙ |
| Блоковий | Блоковий | ПРИВ'ЯЗАНИЙ |
| Блоковий | Файлова система | НЕ ПРИВ'ЯЗАНИЙ |
| Файлова система | Файлова система | ПРИВ'ЯЗАНИЙ |
| Файлова система | Блоковий | НЕ ПРИВ'ЯЗАНИЙ |
| Файлова система | не вказано | ПРИВ'ЯЗАНИЙ |
Примітка:
Підтримуються лише статично виділені томи для альфа-релізу. Адміністраторам слід бути обережними, враховуючи ці значення при роботі з блоковими пристроями.Підтримка знімків томів та відновлення тому зі знімка
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.20 [stable]Знімки томів підтримують лише зовнішні втулки томів CSI. Докладні відомості див. у Знімках томів. Втулки томів, які входять до складу Kubernetes, є застарілими. Про застарілі втулки томів можна прочитати в ЧаПи втулків томів.
Створення PersistentVolumeClaim із знімка тому
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: restore-pvc
spec:
storageClassName: csi-hostpath-sc
dataSource:
name: new-snapshot-test
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
Клонування томів
Клонування томів доступне лише для втулків томів CSI.
Створення PersistentVolumeClaim із існуючого PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cloned-pvc
spec:
storageClassName: my-csi-plugin
dataSource:
name: existing-src-pvc-name
kind: PersistentVolumeClaim
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
Наповнювачі томів та джерела даних
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [beta]Kubernetes підтримує користувацькі заповнювачі томів. Для використання користувацьких заповнювачів томів слід увімкнути функціональну можливість AnyVolumeDataSource для kube-apiserver та kube-controller-manager.
Наповнювачі томів використовують поле специфікації PVC, що називається dataSourceRef. На відміну від поля dataSource, яке може містити тільки посилання на інший PersistentVolumeClaim або на VolumeSnapshot, поле dataSourceRef може містити посилання на будь-який обʼєкт у тому ж просторі імен, за винятком основних обʼєктів, окрім PVC. Для кластерів, які мають увімкнутий feature gate, використання dataSourceRef бажано перед dataSource.
Джерела даних зі змішаними просторами імен
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.26 [alpha]Kubernetes підтримує джерела даних томів зі змішаними просторами імен. Для використання джерел даних томів із змішаними просторами імен слід увімкнути функціональну можливість AnyVolumeDataSource та CrossNamespaceVolumeDataSource для kube-apiserver та kube-controller-manager. Також вам слід увімкнути CrossNamespaceVolumeDataSource для csi-provisioner.
Увімкнення CrossNamespaceVolumeDataSource дозволяє вам вказати простір імен у полі dataSourceRef.
Примітка:
Коли ви вказуєте простір імен для джерела даних тому, Kubernetes перевіряє наявність ReferenceGrant у іншому просторі імен перед прийняттям посилання. ReferenceGrant є частиною розширених APIgateway.networking.k8s.io. Докладні відомості див. в документації API Gateway за посиланням ReferenceGrant. Це означає, що вам слід розширити свій кластер Kubernetes принаймні за допомогою ReferenceGrant зі
специфікації API Gateway, перш ніж ви зможете використовувати цей механізм.Посилання на джерела даних
Поле dataSourceRef поводиться майже так само, як і поле dataSource. Якщо в одне задано, а інше — ні, сервер API надасть обом полям одне й те ж значення. Жодне з цих полів не можна змінити після створення, і спроба вказати різні значення для обох полів призведе до помилки перевірки правильності. Таким чином, обидва поля завжди матимуть однаковий вміст.
Є дві різниці між полем dataSourceRef і полем dataSource, які користувачам слід знати:
- Поле
dataSourceігнорує неправильні значення (мовби поле було порожнім), тоді як полеdataSourceRefніколи не ігнорує значення і призведе до помилки, якщо використано неправильне значення. Неправильними значеннями є будь-які обʼєкти основних обʼєктів (обʼєкти без apiGroup), окрім PVC. - Поле
dataSourceRefможе містити обʼєкти різних типів, тоді як полеdataSourceдозволяє лише PVC та VolumeSnapshot.
Коли увімкнено CrossNamespaceVolumeDataSource, є додаткові відмінності:
- Поле
dataSourceдозволяє лише локальні обʼєкти, тоді як полеdataSourceRefдозволяє обʼєкти у будь-яких просторах імен. - Коли вказано простір імен,
dataSourceіdataSourceRefне синхронізуються.
Користувачам завжди слід використовувати dataSourceRef в кластерах, де увімкнено feature gate, і використовувати dataSource в кластерах, де він вимкнений. В будь-якому випадку необхідно дивитися на обидва поля. Дубльовані значення із трошки різними семантиками існують лише з метою забезпечення сумісності з попередніми версіями. Зокрема, старі й нові контролери можуть взаємодіяти, оскільки поля однакові.
Використання засобів наповнення томів
Засоби наповнення томів — це контролери, які можуть створювати томи з не порожнім вмістом, де вміст тому визначається за допомогою Custom Resource. Користувачі створюють наповнений том, посилаючись на Custom Resource із використанням поля dataSourceRef:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: populated-pvc
spec:
dataSourceRef:
name: example-name
kind: ExampleDataSource
apiGroup: example.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
Оскільки засоби наповнення томів — це зовнішні компоненти, спроби створити PVC, який використовує їх, можуть завершитися неуспішно, якщо встановлені не всі необхідні компоненти. Зовнішні контролери повинні генерувати події на PVC для надання зворотного звʼязку щодо стану створення, включаючи попередження, якщо PVC не може бути створено через відсутність деякого компонента.
Ви можете встановити альфа-контролер перевірки джерела даних тому у вашому кластері. Цей контролер генерує події попередження на PVC у випадку, якщо не зареєстровано жодного засобу наповнення для обробки цього виду джерела даних. Коли для PVC встановлюється відповідний засіб наповнення, це відповідальність цього контролера наповнення повідомляти про події, що стосуються створення тому та проблем під час цього процесу.
Використання джерела даних томів зі змішаними просторами імен
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.26 [alpha]Створіть ReferenceGrant, щоб дозволити власнику простору імен приймати посилання. Ви визначаєте наповнений том, вказавши джерело даних тому між просторами імен за допомогою поля dataSourceRef. Вам вже повинен бути дійсний ReferenceGrant у вихідному просторі імен:
apiVersion: gateway.networking.k8s.io/v1beta1
kind: ReferenceGrant
metadata:
name: allow-ns1-pvc
namespace: default
spec:
from:
- group: ""
kind: PersistentVolumeClaim
namespace: ns1
to:
- group: snapshot.storage.k8s.io
kind: VolumeSnapshot
name: new-snapshot-demo
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-pvc
namespace: ns1
spec:
storageClassName: example
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
dataSourceRef:
apiGroup: snapshot.storage.k8s.io
kind: VolumeSnapshot
name: new-snapshot-demo
namespace: default
volumeMode: Filesystem
Написання переносимої конфігурації
Якщо ви пишете шаблони конфігурації або приклади, які повинні працювати на широкому спектрі кластерів і вам потрібне постійний сховище, рекомендується використовувати такий підхід:
- Включайте обʼєкти PersistentVolumeClaim у ваш набір конфігурації (нарізі з Deployment, ConfigMap і т. д.).
- Не включайте обєкти PersistentVolume в конфігурацію, оскільки користувач, який створює конфігурацію, може не мати прав на створення PersistentVolumes.
- Дайте користувачеві можливість надавати імʼя класу сховища при створенні шаблону.
- Якщо користувач вказує імʼя класу сховища, вставте це значення в поле
persistentVolumeClaim.storageClassName. Це призведе до збігу PVC з відповідним класом сховища, якщо в адміністратора увімкнені класи сховища. - Якщо користувач не вказує імʼя класу сховища, залиште поле
persistentVolumeClaim.storageClassNameнульовим. Це призведе до автоматичного надання користувачеві PV в кластері. Багато середовищ кластеру мають типовий клас сховища, або адміністратори можуть створити свій типовий клас сховища.
- Якщо користувач вказує імʼя класу сховища, вставте це значення в поле
- В інструментах спостерігайте за PVC, які не привʼязуються протягом певного часу та виводьте це користувачеві, оскільки це може вказувати на те, що у кластері відсутня підтримка динамічного сховища (у цьому випадку користувач повинен створити відповідний PV) або у кластері відсутня система сховища (у цьому випадку користувач не може розгортати конфігурацію, що вимагає PVC).
Що далі
- Дізнайтеся більше про створення PersistentVolume.
- Дізнайтеся більше про створення PersistentVolumeClaim.
- Прочитайте документ з дизайну постійного сховища.
API references
Дізнайтеся більше про описані на цій сторінці API:
6.3 - Projected томи
У цьому документі описано спроєцьовані томи в Kubernetes. Рекомендується ознайомитися з томами для кращого розуміння.
Вступ
Том projected відображає кілька наявних джерел томів в один каталог.
Зараз наступні типи джерел томів можуть бути спроєцьовані:
Всі джерела повинні бути в тому ж просторі імен, що й Pod. Для отримання додаткових відомостей дивіться документ з дизайну все-в-одному томі.
Приклад конфігурації з secret, downwardAPI та configMap
apiVersion: v1
kind: Pod
metadata:
name: volume-test
spec:
containers:
- name: container-test
image: busybox:1.28
command: ["sleep", "3600"]
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: mysecret
items:
- key: username
path: my-group/my-username
- downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "cpu_limit"
resourceFieldRef:
containerName: container-test
resource: limits.cpu
- configMap:
name: myconfigmap
items:
- key: config
path: my-group/my-config
Приклад конфігурації: secret з встановленим нестандартним режимом дозволу
apiVersion: v1
kind: Pod
metadata:
name: volume-test
spec:
containers:
- name: container-test
image: busybox:1.28
command: ["sleep", "3600"]
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: mysecret
items:
- key: username
path: my-group/my-username
- secret:
name: mysecret2
items:
- key: password
path: my-group/my-password
mode: 511
Кожне спроєцьоване джерело тому перераховане в специфікації в розділі sources. Параметри майже такі ж, за винятком двох пунктів:
- Для секретів поле
secretNameбуло змінено наname, щоб бути послідовним з назвою ConfigMap. defaultModeможна вказати тільки на рівні спроєцьованого тому, а не для кожного джерела тому. Однак, як показано вище, ви можете явно встановитиmodeдля кожної окремої проєкції.
Спроєцьовані томи serviceAccountToken
Ви можете впровадити токен для поточного service accountʼу в Pod за вказаним шляхом. Наприклад:
apiVersion: v1
kind: Pod
metadata:
name: sa-token-test
spec:
containers:
- name: container-test
image: busybox:1.28
command: ["sleep", "3600"]
volumeMounts:
- name: token-vol
mountPath: "/service-account"
readOnly: true
serviceAccountName: default
volumes:
- name: token-vol
projected:
sources:
- serviceAccountToken:
audience: api
expirationSeconds: 3600
path: token
Pod в прикладі має project том, що містить впроваджений токен service account. Контейнери в цьому Pod можуть використовувати цей токен для доступу до сервера API Kubernetes, автентифікуючись за відомостями service accountʼу Pod. Поле audience містить призначену аудиторію токена. Отримувач токена повинен ідентифікувати себе за ідентифікатором, вказаним в аудиторії токена, інакше він повинен відхилити токен. Це поле є необовʼязковим, але стандартним для ідентифікації в API сервері.
Поле expirationSeconds містить час, через який токен стане недійсним. Типовим є час в одну годину, але він має бути принаймні 10 хвилин (600 секунд). Адміністратор може обмежити максимальне значення вказавши параметр --service-account-max-token-expiration в API сервері. Поле path містить відносний шлях до точки монтування тому.
Примітка:
Контейнер, що використовує джерела project томів якsubPath для монтування тому не отримуватиме оновлення для цих джерел.Спроєцьовані томи clusterTrustBundle
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.29 [alpha]Примітка:
Для використання цієї функції в Kubernetes {{ skew currentVersion }} вам потрібно увімкнути підтримку обʼєктів ClusterTrustBundle з функціональною можливістюClusterTrustBundle та прапорецем --runtime-config=certificates.k8s.io/v1alpha1/clustertrustbundles=true в kube-apiserver, а потім увімкнути функцію ClusterTrustBundleProjection.Спроєцьований том clusterTrustBundle дозволяє впроваджувати контент одного чи більше обʼєктів ClusterTrustBundle як автоматично оновлюваний файл у файловій системі контейнера.
ClusterTrustBundle може бути обраний за допомогою name або signer name.
Для вибору за імʼям використовуйте поле name, щоб вказати один обʼєкт ClusterTrustBundle.
Для вибору за імʼям підписанта використовуйте поле signerName (і, за необхідності, поле labelSelector), щоб вказати набір обʼєктів ClusterTrustBundle, які використовують задане імʼя підписанта. Якщо labelSelector відсутнє, то вибираються всі ClusterTrustBundle для цього підписанта.
Kubelet виконує відсіювання дублікатів сертифікатів у вибраних обʼєктах ClusterTrustBundle, нормалізує представлення PEM (видаляючи коментарі та заголовки), перегруповує сертифікати та записує їх у файл, вказаний полем path. При зміні набору вибраних обʼєктів ClusterTrustBundle або їх вмісту kubelet підтримує актуальність файлу.
Типово kubelet запобігає запуску Podʼа, якщо заданий обʼєкт ClusterTrustBundle не знайдено, або якщо signerName / labelSelector не відповідає жодному обʼєкту ClusterTrustBundle. Якщо ця поведінка не відповідає вашим вимогам, встановіть поле optional в true, і Pod буде запущено з порожнім файлом за шляхом path.
apiVersion: v1
kind: Pod
metadata:
name: sa-ctb-name-test
spec:
containers:
- name: container-test
image: busybox
command: ["sleep", "3600"]
volumeMounts:
- name: token-vol
mountPath: "/root-certificates"
readOnly: true
serviceAccountName: default
volumes:
- name: token-vol
projected:
sources:
- clusterTrustBundle:
name: example
path: example-roots.pem
- clusterTrustBundle:
signerName: "example.com/mysigner"
labelSelector:
matchLabels:
version: live
path: mysigner-roots.pem
optional: true
Взаємодія SecurityContext
Пропозиція щодо обробки дозволів файлів у розширенні projected service account volume представляє, що projected файли мають відповідні набори дозволів власника.
Linux
У Podʼах Linux, які мають projected том та RunAsUser вказано у SecurityContext, projected файли мають правильно встановлені права власності, включаючи власника контейнера.
Коли у всіх контейнерах в Podʼі встановлено одне й те ж runAsUser у їх
PodSecurityContext або SecurityContext, то kubelet гарантує, що вміст тому serviceAccountToken належить цьому користувачеві, а файл токена має режим дозволів, встановлений в 0600.
Примітка:
ефемерні контейнери додані до Podʼа після його створення не змінюють прав доступу до тому, які були встановлені при створенні Podʼа.
Якщо права доступу до тому serviceAccountToken Podʼа були встановлені на 0600, тому що всі інші контейнери в Podʼі мають одне і те ж runAsUser, ефемерні контейнери повинні використовувати той самий runAsUser, щоб мати змогу читати токен.
Windows
У Windows Podʼах, які мають projected том та RunAsUsername вказано в SecurityContext Podʼа, права власності не забезпечуються через спосіб управління користувачами у Windows. Windows зберігає та управляє локальними обліковими записами користувачів і груп у файлі бази даних, який називається Security Account Manager (SAM). Кожен контейнер підтримує свій власний екземпляр бази даних SAM, до якого хост не має доступу під час роботи контейнера. Контейнери Windows призначені для запуску режиму користувача операційної системи в ізоляції від хосту, тому не зберігають динамічну конфігурацію власності файлів хосту для облікових записів віртуалізованих контейнерів. Рекомендується розміщувати файли, які слід спільно використовувати з контейнером на машині-хості, в окремому змісті поза C:\.
Типово у projected файлах буде встановлено наступні права, як показано для прикладу projected файлу тома:
PS C:\> Get-Acl C:\var\run\secrets\kubernetes.io\serviceaccount\..2021_08_31_22_22_18.318230061\ca.crt | Format-List
Path : Microsoft.PowerShell.Core\FileSystem::C:\var\run\secrets\kubernetes.io\serviceaccount\..2021_08_31_22_22_18.318230061\ca.crt
Owner : BUILTIN\Administrators
Group : NT AUTHORITY\SYSTEM
Access : NT AUTHORITY\SYSTEM Allow FullControl
BUILTIN\Administr
ators Allow FullControl
BUILTIN\Users Allow ReadAndExecute, Synchronize
Audit :
Sddl : O:BAG:SYD:AI(A;ID;FA;;;SY)(A;ID;FA;;;BA)(A;ID;0x1200a9;;;BU)
Це означає, що всі адміністратори, такі як ContainerAdministrator, матимуть доступ на читання, запис та виконання, тоді як не-адміністратори матимуть доступ на читання та
виконання.
Примітка:
Загалом не рекомендується надавати контейнеру доступ до хосту, оскільки це може відкрити можливості для потенційних використань дірок безпеки.
Створення Windows Podʼа з RunAsUser в його SecurityContext призведе до того, що Pod буде застрягати на стадії ContainerCreating назавжди. Таким чином, рекомендується не використовувати опцію RunAsUser, яка призначена лише для Linux, з Windows Podʼами.
6.4 - Ефемерні томи
Цей документ описує ефемерні томи в Kubernetes. Рекомендується мати знайомство з томами, зокрема з PersistentVolumeClaim та PersistentVolume.
Деякі застосунки потребують додаткових ресурсів зберігання, але їм не важливо, чи зберігаються ці дані постійно між перезавантаженнями. Наприклад, служби кешування часто обмежені обсягом памʼяті та можуть переміщувати рідко використовувані дані в ресурси зберігання, які є повільнішими за памʼять з мінімальним впливом на загальну продуктивність.
Інші застосунки очікують, що деякі дані тільки-для-читання будуть присутні в файлах, таких як конфігураційні дані або секретні ключі.
Ефемерні томи призначені для таких сценаріїв використання. Оскільки томи слідкують за життєвим циклом Podʼа та створюються і видаляються разом з Podʼом, Podʼи можуть бути зупинені та перезапущені, не обмежуючись тим, чи доступний будь-який постійний том.
Ефемерні томи вказуються inline в специфікації Podʼа, що спрощує розгортання та управління застосунками.
Типи ефемерних томів
Kubernetes підтримує кілька різновидів ефемерних томів для різних цілей:
- emptyDir: порожній при запуску Podʼа, зберігання здійснюється локально з базового каталогу kubelet (зазвичай кореневий диск) або в ОЗП
- configMap, downwardAPI, secret: впровадження різних видів даних Kubernetes в Podʼі
- image: дозволяє монтувати файли образів контейнерів або артефактів, безпосередньо у Pod.
- CSI ефемерні томи: схожі на попередні види томів, але надаються спеціальними драйверами CSI, які спеціально підтримують цю функцію
- загальні ефемерні томи, які можуть бути надані всіма драйверами зберігання, які також підтримують постійні томи
emptyDir, configMap, downwardAPI, secret надаються як локальне ефемерне сховище. Вони керуються kubelet на кожному вузлі.
CSI ефемерні томи обовʼязково повинні надаватися сторонніми драйверами зберігання CSI.
Загальні ефемерні томи можуть надаватися сторонніми драйверами зберігання CSI, але також будь-яким іншим драйвером зберігання, який підтримує динамічне виділення томів. Деякі драйвери CSI написані спеціально для ефемерних томів CSI та не підтримують динамічного виділення: їх тоді не можна використовувати для загальних ефемерних томів.
Перевагою використання сторонніх драйверів є те, що вони можуть пропонувати функціональність, яку Kubernetes сам не підтримує, наприклад сховища з іншими характеристиками продуктивності, ніж диск, яким керує kubelet, або впровадження різних даних.
Ефемерні томи CSI
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.25 [stable]Примітка:
CSI ефемерні томи підтримуються лише певною підмножиною драйверів CSI. Список драйверів CSI Kubernetes показує, які драйвери підтримують ефемерні томи.Концептуально, ефемерні томи CSI схожі на типи томів configMap, downwardAPI та secret: ресурси зберігання керується локально на кожному вузлі та створюються разом з іншими локальними ресурсами після того, як Pod було
заплановано на вузол. Kubernetes не має поняття про перепланування Podʼів на цьому етапі. Створення тому має бути малоймовірним, інакше запуск Podʼа застрягне. Зокрема, планування Podʼів з урахуванням потужності ресурсів зберігання не підтримується для цих томів. Наразі вони також не входять до обмежень використання томів зберігання Podʼа, оскільки це є чимось, що kubelet може забезпечити лише для ресурсу зберігання, яким він управляє самостійно.
Ось приклад маніфесту для Podʼа, який використовує ефемерне зберігання CSI:
kind: Pod
apiVersion: v1
metadata:
name: my-csi-app
spec:
containers:
- name: my-frontend
image: busybox:1.28
volumeMounts:
- mountPath: "/data"
name: my-csi-inline-vol
command: [ "sleep", "1000000" ]
volumes:
- name: my-csi-inline-vol
csi:
driver: inline.storage.kubernetes.io
volumeAttributes:
foo: bar
Атрибути тому визначають, який том підготовлює драйвер. Ці атрибути є специфічними для кожного драйвера і не стандартизовані. Дивіться документацію кожного драйвера CSI для отримання додаткових інструкцій.
Обмеження драйверів CSI
Ефемерні томи CSI дозволяють користувачам передавати volumeAttributes прямо до драйвера CSI як частину специфікації Podʼа. Драйвер CSI, який дозволяє використання volumeAttributes, які зазвичай обмежені для адміністраторів, НЕ підходить для використання в ефемерному томі всередині Podʼа. Наприклад, параметри, які зазвичай визначаються в StorageClass, не повинні використовуватися користувачами через ефемерні томи всередині.
Адміністратори кластера, яким потрібно обмежити драйвери CSI, які дозволяють використання вбудованих томів всередині специфікації Podʼа, можуть зробити це, виконавши наступне:
- Видаліть
EphemeralізvolumeLifecycleModesв специфікації CSIDriver, що перешкоджає використанню драйвера в якості вбудованого ефемерного тому. - Використання admission webhook для обмеження того, як цей драйвер використовується.
Загальні ефемерні томи
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.23 [stable]Загальні ефемерні томи схожі на томи emptyDir в тому сенсі, що вони надають директорію на кожен Pod для тимчасових даних, які, як правило, порожні після створення. Але вони також можуть мати додаткові функції:
- Зберігання може бути локальним або мережевим.
- Томи можуть мати фіксований розмір, який Podʼи не можуть перевищити.
- У томів може бути певні початкові дані, залежно від драйвера та параметрів.
- Підтримуються типові операції з томами, за умови, що драйвер їх підтримує, включаючи створення знімків, клонування, зміну розміру та відстеження місткості томів.
Приклад:
kind: Pod
apiVersion: v1
metadata:
name: my-app
spec:
containers:
- name: my-frontend
image: busybox:1.28
volumeMounts:
- mountPath: "/scratch"
name: scratch-volume
command: [ "sleep", "1000000" ]
volumes:
- name: scratch-volume
ephemeral:
volumeClaimTemplate:
metadata:
labels:
type: my-frontend-volume
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "scratch-storage-class"
resources:
requests:
storage: 1Gi
Життєвий цикл та PersistentVolumeClaim
Ключова концепція дизайну полягає в тому, що параметри для вимог тому дозволені всередині джерела тому Podʼа. Підтримуються мітки, анотації та весь набір полів для PersistentVolumeClaim. Коли такий Pod створюється, контролер ефемерних томів створює фактичний обʼєкт PersistentVolumeClaim в тому ж просторі імен, що і Pod, та забезпечує видалення PersistentVolumeClaim при видаленні Podʼа.
Це викликає привʼязку та/або резервування тому, або негайно, якщо StorageClass використовує негайне звʼязування тому, або коли Pod тимчасово запланований на вузол (WaitForFirstConsumer volume binding mode). Останній варіант рекомендований для загальних ефемерних томів, оскільки тоді планувальник може вибрати відповідний вузол для Podʼа. При негайному звʼязуванні планувальник змушений вибрати вузол, який має доступ до тому, якщо він доступний.
З погляду прав власності на ресурси, Pod, який має загальний ефемерний том, є власником PersistentVolumeClaim(s), які забезпечують цей ефемерний том. При видаленні Podʼа, збирач сміття Kubernetes видаляє PVC, що, як правило, спричиняє видалення тому через типову політику повторного використання класів зберігання — видалення томів. Ви можете створити квазі-ефемерне локальне зберігання за допомогою StorageClass з політикою повторного використання retain: ресурс зберігання існує поза життєвим циклом Podʼа, і в цьому випадку потрібно забезпечити, що очищення тому відбувається окремо.
Поки ці PVC існують, їх можна використовувати, подібно до будь-якого іншого PVC. Зокрема, їх можна вказати як джерело даних для клонування томів або створення знімків. Обʼєкт PVC також містить поточний статус тому.
Найменування PersistentVolumeClaim
Найменування автоматично створених PVC є детермінованим: назва є комбінацією назви Podʼа і назви тому, з дефісом (-) посередині. У вищезазначеному прикладі назва PVC буде my-app-scratch-volume. Це детерміноване найменування полегшує
взаємодію з PVC, оскільки не потрібно шукати її, якщо відомі назва Podʼа та назва тому.
Детерміноване найменування також вводить потенційний конфлікт між різними Podʼами (Pod "pod-a" з томом "scratch" і інший Pod з імʼям "pod" і томом "a-scratch" обидва отримають однакове найменування PVC "pod-a-scratch") і між Podʼами та PVC, створеними вручну.
Такі конфлікти виявляються: PVC використовується лише для ефемерного тому, якщо він був створений для Podʼа. Ця перевірка базується на стосунках власності на ресурси. Наявний PVC не перезаписується або не змінюється. Проте це не вирішує конфлікт, оскільки без відповідного PVC Pod не може стартувати.
Увага:
Будьте уважні при найменуванні Podʼів та томів в тому ж просторі імен, щоб уникнути таких конфліктів.Безпека
Використання загальних ефемерних томів дозволяє користувачам створювати PVC непрямо, якщо вони можуть створювати Podʼи, навіть якщо у них немає дозволу на створення PVC безпосередньо. Адміністраторам кластера слід бути обізнаними щодо цього. Якщо це не відповідає їхньому зразку безпеки, вони повинні використовувати admission webhook, який відхиляє обʼєкти, такі як Podʼи, які мають загальний ефемерний том.
Звичайне обмеження квоти для PVC в просторі імен все ще застосовується, тому навіть якщо користувачам дозволено використовувати цей новий механізм, вони не можуть використовувати його для оминання інших політик.
Що далі
Ефемерні томи, керовані kubelet
Див. локальне ефемерне сховище.
Ефемерні томи CSI
- Докладніша інформація про дизайн доступна у Ефемерних Inline CSI томах KEP.
- Для отримання докладнішої інформації про подальший розвиток цієї функції див. тікет #596.
Загальні ефемерні томи
- Для отримання докладнішої інформації про дизайн див. Ефемерні загальні томи з потоковим доступом KEP.
6.5 - Класи сховищ
Цей документ описує концепцію StorageClass в Kubernetes. Рекомендується мати знайомство з томами та постійними томами.
StorageClass надає можливість адміністраторам описати класи сховищ, які вони надають. Різні класи можуть відповідати рівням обслуговування, політикам резервного копіювання або будь-яким політикам, визначеним адміністраторами кластера. Kubernetes сам не визначає, що являють собою класи.
Концепція Kubernetes StorageClass схожа на "профілі" в деяких інших дизайнах систем збереження.
Обʼєкти StorageClass
Кожен StorageClass містить поля provisioner, parameters та reclaimPolicy, які використовуються, коли PersistentVolume, який належить до класу, має бути динамічно резервований для задоволення PersistentVolumeClaim (PVC).
Імʼя обʼєкта StorageClass має значення, і саме воно дозволяє користувачам запитувати певний клас. Адміністратори встановлюють імʼя та інші параметри класу під час першого створення обʼєктів StorageClass.
Як адміністратор, ви можете вказати типовий StorageClass, який застосовується до будь-яких PVC, які не вимагають конкретного класу. Докладніше див. концепцію PersistentVolumeClaim.
Тут наведено приклад StorageClass:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: low-latency
annotations:
storageclass.kubernetes.io/is-default-class: "false"
provisioner: csi-driver.example-vendor.example
reclaimPolicy: Retain # типове значення — Delete
allowVolumeExpansion: true
mountOptions:
- discard # Це може увімкнути UNMAP / TRIM на рівні зберігання блоків
volumeBindingMode: WaitForFirstConsumer
parameters:
guaranteedReadWriteLatency: "true" # залежить від постачальника
Типовий StorageClass
Ви можете визначити StorageClass як типовий для вашого кластера. Щоб дізнатися, як встановити типовий StorageClass, див. Зміна типового StorageClass.
Якщо PVC не вказує storageClassName, буде використовуватися типовий StorageClass.
Якщо ви встановите анотацію storageclass.kubernetes.io/is-default-class у значення true для більше ніж одного StorageClass у вашому кластері, і потім створите PersistentVolumeClaim без вказання storageClassName, Kubernetes використовуватиме найновіший типовий StorageClass.
Примітка:
Спробуйте мати лише один типовий StorageClass у вашому кластері. Причина, чому Kubernetes дозволяє вам мати кілька типових StorageClass, — це можливість безшовної міграції.Ви можете створити PersistentVolumeClaim, не вказуючи storageClassName для нового PVC, і ви можете це зробити навіть тоді, коли у вашому кластері немає типового StorageClass. У цьому випадку новий PVC створюється так, як ви його визначили, і storageClassName цього PVC залишається невизначеним до тих пір, поки не стане доступний типовий StorageClass.
Ви можете мати кластер без типового StorageClass. Якщо ви не встановлюєте жодного StorageClass як типового (і його не визначено, наприклад, постачальником хмари), то Kubernetes не може застосовувати ці типові класи до PersistentVolumeClaims, які йому потрібні.
Якщо або коли стає доступний типовий StorageClass, система керування визначає будь-які наявні PVC без storageClassName. Для PVC, які або мають порожнє значення для storageClassName, або не мають цього ключа, система керування потім оновлює ці PVC, щоб встановити storageClassName відповідно до нового типового StorageClass. Якщо у вас є наявний PVC з storageClassName "", і ви налаштовуєте типовий StorageClass, то цей PVC не буде оновлено.
Щоб продовжити привʼязку до PV із storageClassName, встановленим як "" (при наявності типового StorageClass), вам потрібно встановити storageClassName асоційованого PVC як "".
Постачальник
У кожного StorageClass є постачальник, який визначає, який модуль обробника тому використовується для надання PV. Це поле повинно бути визначено.
| Модуль обробника тому | Внутрішній постачальник | Приклад конфігурації |
|---|---|---|
| AzureFile | ✓ | Azure File |
| CephFS | - | - |
| FC | - | - |
| FlexVolume | - | - |
| iSCSI | - | - |
| Local | - | Local |
| NFS | - | NFS |
| PortworxVolume | ✓ | Portworx Volume |
| RBD | - | Ceph RBD |
| VsphereVolume | ✓ | vSphere |
Ви не обмежені вказанням "внутрішніх" постачальників, вказаних тут (імена яких починаються з "kubernetes.io" і входять до складу Kubernetes). Ви також можете запускати і вказувати зовнішні постачальники, які є незалежними програмами і слідують специфікації, визначеній Kubernetes. Автори зовнішніх постачальників мають на власний розсуд поводитись щодо того, де розташований їх код, як постачальник надається, як його слід запускати, який модуль обробника тому він використовує (включаючи Flex) тощо. У репозиторії kubernetes-sigs/sig-storage-lib-external-provisioner знаходиться бібліотека для написання зовнішніх постачальників, яка реалізує більшість специфікації. Деякі зовнішні постачальники перелічені у репозиторії kubernetes-sigs/sig-storage-lib-external-provisioner.
Наприклад, NFS не надає внутрішнього постачальника, але можна використовувати зовнішній. Існують також випадки, коли сторонні виробники систем зберігання надають свій власний зовнішній постачальник.
Політика повторного використання
PersistentVolumes, які динамічно створюються за допомогою StorageClass, матимуть політику повторного використання вказану в полі reclaimPolicy класу, яке може бути або Delete, або Retain. Якщо поле reclaimPolicy не вказано при створенні обʼєкта StorageClass, то типово воно буде Delete.
PersistentVolumes, які створені вручну та управляються за допомогою StorageClass, матимуть таку політику повторного використання, яку їм було призначено при створенні.
Розширення тому
PersistentVolumes можуть бути налаштовані на розширення. Це дозволяє змінювати розмір тому, редагуючи відповідний обʼєкт PVC і запитуючи новий, більший том зберігання.
Наступні типи томів підтримують розширення тому, коли базовий StorageClass має поле allowVolumeExpansion, встановлене в значення true.
| Тип тому | Потрібна версія Kubernetes для розширення тому |
|---|---|
| Azure File | 1.11 |
| CSI | 1.24 |
| FlexVolume | 1.13 |
| Portworx | 1.11 |
| rbd | 1.11 |
Примітка:
Ви можете використовувати функцію розширення тому лише для збільшення тому, але не для його зменшення.Опції монтування
PersistentVolumes, які динамічно створюються за допомогою StorageClass, матимуть опції монтування, вказані в полі mountOptions класу.
Якщо обʼєкт тому не підтримує опції монтування, але вони вказані, створення тому завершиться невдачею. Опції монтування не перевіряються ні на рівні класу, ні на рівні PV. Якщо опція монтування є недійсною, монтування PV не вдасться.
Режим привʼязки тому
Поле volumeBindingMode керує тим, коли привʼязка тому та динамічне створення повинно відбуватися. Коли воно не встановлене, типово використовується режим Immediate.
Режим Immediate вказує, що привʼязка тому та динамічне створення відбувається після створення PersistentVolumeClaim. Для сховищ, які обмежені топологією і не доступні з усіх вузлів в кластері, PersistentVolumes буде привʼязаний або створений без знання про планування Podʼа. Це може призвести до неможливості планування Podʼів.
Адміністратор кластера може розвʼязати цю проблему, вказавши режим WaitForFirstConsumer, який затримає привʼязку та створення PersistentVolume до створення Podʼа з PersistentVolumeClaim. PersistentVolumes будуть обрані або створені відповідно до топології, яку визначають обмеження планування Podʼа. Сюди входять, але не обмежуються вимоги до ресурсів, селектори вузлів, affinity та anti-affinity Podʼа, і taint та toleration.
Наступні втулки підтримують WaitForFirstConsumer разом із динамічним створенням:
- CSI-томи, за умови, що конкретний драйвер CSI підтримує це
Наступні втулки підтримують WaitForFirstConsumer разом із попередньо створеною привʼязкою PersistentVolume:
- CSI-томи, за умови, що конкретний драйвер CSI підтримує це
local
Примітка:
Якщо ви вирішили використовувати WaitForFirstConsumer, не використовуйте nodeName в специфікації Podʼа, щоб вказати спорідненість (affinity) вузла. Якщо в цьому випадку використовується nodeName, планувальника буде оминати PVC і вона залишиться в стані pending.
Замість цього ви можете використовувати селектор вузла для kubernetes.io/hostname:
apiVersion: v1
kind: Pod
metadata:
name: task-pv-pod
spec:
nodeSelector:
kubernetes.io/hostname: kube-01
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: task-pv-claim
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: task-pv-storage
Дозволені топології
Коли оператор кластера вказує режим привʼязки тому WaitForFirstConsumer, в більшості випадків не потрібно обмежувати забезпечення конкретних топологій. Однак, якщо це все ще необхідно, можна вказати allowedTopologies.
У цьому прикладі показано, як обмежити топологію запроваджених томів конкретними зонами та використовувати як заміну параметрам zone та zones для підтримуваних втулків.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: example.com/example
parameters:
type: pd-standard
volumeBindingMode: WaitForFirstConsumer
allowedTopologies:
- matchLabelExpressions:
- key: topology.kubernetes.io/zone
values:
- us-central-1a
- us-central-1b
Параметри
У StorageClasses є параметри, які описують томи, які належать класу сховища. Різні параметри можуть прийматися залежно від provisioner. Коли параметр відсутній, використовується який-небудь типове значення.
Може бути визначено не більше 512 параметрів для StorageClass. Загальна довжина обʼєкта параметрів разом із ключами та значеннями не може перевищувати 256 КіБ.
AWS EBS
У Kubernetes 1.32 не включено тип тому awsElasticBlockStore.
Драйвер зберігання AWSElasticBlockStore у вузлі був відзначений як застарілий у релізі Kubernetes v1.19 і повністю видалений у релізі v1.27.
Проєкт Kubernetes рекомендує використовувати AWS EBS замість вбудованого драйвера зберігання.
Нижче подано приклад StorageClass для драйвера CSI AWS EBS:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ebs-sc
provisioner: ebs.csi.aws.com
volumeBindingMode: WaitForFirstConsumer
parameters:
csi.storage.k8s.io/fstype: xfs
type: io1
iopsPerGB: "50"
encrypted: "true"
tagSpecification_1: "key1=value1"
tagSpecification_2: "key2=value2"
allowedTopologies:
- matchLabelExpressions:
- key: topology.ebs.csi.aws.com/zone
values:
- us-east-2c
tagSpecification: Теґи з цим префіксом застосовуються до динамічно наданих томів EBS.
AWS EFS
Щоб налаштувати сховище AWS EFS, можна використовувати сторонній драйвер AWS_EFS_CSI_DRIVER.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: efs-sc
provisioner: efs.csi.aws.com
parameters:
provisioningMode: efs-ap
fileSystemId: fs-92107410
directoryPerms: "700"
provisioningMode: Тип тому, що створюється за допомогою Amazon EFS. Наразі підтримується лише створення на основі точки доступу (efs-ap).fileSystemId: Файлова система, під якою створюється точка доступу.directoryPerms: Дозволи на теки для кореневої теки, створеної точкою доступу.
Для отримання додаткової інформації зверніться до документації AWS_EFS_CSI_Driver Dynamic Provisioning.
NFS
Для налаштування NFS-сховища можна використовувати вбудований драйвер або драйвер CSI для NFS в Kubernetes (рекомендовано).
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: example-nfs
provisioner: example.com/external-nfs
parameters:
server: nfs-server.example.com
path: /share
readOnly: "false"
server: Server — це імʼя хосту або IP-адреса сервера NFS.path: Шлях, який експортується сервером NFS.readOnly: Прапорець, який вказує, чи буде сховище змонтовано тільки для читання (типово – false).
Kubernetes не включає внутрішній NFS-провайдер. Вам потрібно використовувати зовнішній провайдер для створення StorageClass для NFS. Ось деякі приклади:
vSphere
Існують два типи провайдерів для класів сховища vSphere:
- CSI провайдер:
csi.vsphere.vmware.com - vCP провайдер:
kubernetes.io/vsphere-volume
Вбудовані провайдери застарілі. Для отримання додаткової інформації про провайдера CSI, див. Kubernetes vSphere CSI Driver та міграцію vSphereVolume CSI.
CSI провайдер
Постачальник сховища StorageClass для vSphere CSI працює з кластерами Tanzu Kubernetes. Для прикладу див. репозитарій vSphere CSI.
vCP провайдер
У наступних прикладах використовується постачальник сховища VMware Cloud Provider (vCP).
Створіть StorageClass із зазначенням формату диска користувачем.
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: fast provisioner: kubernetes.io/vsphere-volume parameters: diskformat: zeroedthickdiskformat:thin,zeroedthickтаeagerzeroedthick. Стандартно:"thin".Створіть StorageClass із форматуванням диска на зазначеному користувачем сховищі.
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: fast provisioner: kubernetes.io/vsphere-volume parameters: diskformat: zeroedthick datastore: VSANDatastoredatastore: Користувач також може вказати сховище в StorageClass. Том буде створено на сховищі, вказаному в StorageClass, у цьому випадку —VSANDatastore. Це поле є необовʼязковим. Якщо сховище не вказано, том буде створено у сховищі, вказаному в конфігураційному файлі vSphere, який використовується для ініціалізації хмарного провайдера vSphere.Керування політикою сховища в Kubernetes
Використання наявної політики SPBM vCenter
Однією з найважливіших функцій vSphere для керування сховищем є керування на основі політики сховища (SPBM). Система управління сховищем на основі політики (SPBM) — це каркас політики сховища, який надає єдину уніфіковану панель управління для широкого спектра служб обробки даних та рішень зберігання. SPBM дозволяє адміністраторам vSphere подолати виклики щодо передбачуваного виділення сховища, такі як планування потужності, різні рівні обслуговування та управління потужністю.
Політики SPBM можна вказати в StorageClass за допомогою параметра
storagePolicyName.Підтримка політики Virtual SAN всередині Kubernetes
Адміністратори Vsphere Infrastructure (VI) будуть мати можливість вказувати власні віртуальні можливості сховища SAN під час динамічного виділення томів. Тепер ви можете визначити вимоги до сховища, такі як продуктивність та доступність, у вигляді можливостей сховища під час динамічного виділення томів. Вимоги до можливостей сховища перетворюються в політику Virtual SAN, яка потім передається на рівень віртуального SAN при створенні постійного тому (віртуального диска). Віртуальний диск розподіляється по сховищу віртуального SAN для відповідності вимогам.
Детальнішу інформацію щодо використання політик сховища для управління постійними томами можна переглянути в Керуванні політикою на основі зберігання для динамічного виділення томів.
Є кілька прикладів для vSphere, які можна спробувати для керування постійним томом в Kubernetes для vSphere.
Ceph RBD (застарілий)
Примітка:
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.28 [deprecated]Цей внутрішній провайдер Ceph RBD застарів. Будь ласка, використовуйте CephFS RBD CSI driver.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/rbd # Цей провізор є застарілим
parameters:
monitors: 198.19.254.105:6789
adminId: kube
adminSecretName: ceph-secret
adminSecretNamespace: kube-system
pool: kube
userId: kube
userSecretName: ceph-secret-user
userSecretNamespace: default
fsType: ext4
imageFormat: "2"
imageFeatures: "layering"
monitors: Монітори Ceph, розділені комою. Цей параметр є обовʼязковим.adminId: Ідентифікатор клієнта Ceph, який може створювати образи в пулі. Типово — "admin".adminSecretName: Імʼя секрету дляadminId. Цей параметр є обовʼязковим. Наданий секрет повинен мати тип "kubernetes.io/rbd".adminSecretNamespace: Простір імен дляadminSecretName. Типово — "default".pool: Ceph RBD pool. Типово — "rbd".userId: Ідентифікатор клієнта Ceph, який використовується для зіставлення образу RBD. Типово — такий самий, як іadminId.userSecretName: Імʼя Ceph Secret дляuserIdдля зіставлення образу RBD. Він повинен існувати в тому ж просторі імен, що і PVC. Цей параметр є обовʼязковим. Наданий секрет повинен мати тип "kubernetes.io/rbd", наприклад, створений таким чином:kubectl create secret generic ceph-secret --type="kubernetes.io/rbd" \ --from-literal=key='QVFEQ1pMdFhPUnQrSmhBQUFYaERWNHJsZ3BsMmNjcDR6RFZST0E9PQ==' \ --namespace=kube-systemuserSecretNamespace: Простір імен дляuserSecretName.fsType: fsType, який підтримується Kubernetes. Типово:"ext4".imageFormat: Формат образу Ceph RBD, "1" або "2". Типово — "2".imageFeatures: Цей параметр є необовʼязковим і слід використовувати тільки в разі якщо ви встановилиimageFormatна "2". Зараз підтримуються тільки функціїlayering. Типово — "", і жодна функція не включена.
Azure Disk
У Kubernetes 1.32 не включено типу тому azureDisk.
Внутрішній драйвер зберігання azureDisk був застарілий у випуску Kubernetes v1.19 і потім був повністю вилучений у випуску v1.27.
Проєкт Kubernetes рекомендує використовувати замість цього сторонній драйвер зберігання Azure Disk.
Azure File (застаріло)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: azurefile
provisioner: kubernetes.io/azure-file
parameters:
skuName: Standard_LRS
location: eastus
storageAccount: azure_storage_account_name # значення для прикладу
skuName: Рівень SKU облікового запису Azure Storage. Типово відсутній.location: Місце розташування облікового запису Azure Storage. Типово відсутнє.storageAccount: Назва облікового запису Azure Storage. Типово відсутня. Якщо обліковий запис зберігання не наданий, весь обліковий запис, повʼязаний із групою ресурсів, перевіряється на наявність збігуskuNameтаlocation. Якщо обліковий запис зберігання надано, він повинен перебувати в тій самій групі ресурсів, що й кластер, і значенняskuNameтаlocationігноруються.secretNamespace: простір імен секрету, що містить імʼя та ключ облікового запису Azure Storage. Типово такий самий, як у Pod.secretName: імʼя секрету, що містить імʼя та ключ облікового запису Azure Storage. Типовоazure-storage-account-<accountName>-secret.readOnly: прапорець, що вказує, чи буде ресурс зберігання монтуватися лише для читання. Типовоfalse, що означає монтування для читання/запису. Це значення впливає також на налаштуванняReadOnlyвVolumeMounts.
Під час надання ресурсів зберігання, для монтованих облікових даних створюється секрет з імʼям secretName. Якщо кластер активував як RBAC, так і Ролі контролера, додайте дозвіл create ресурсу secret для clusterrole контролера
system:controller:persistent-volume-binder.
У контексті multi-tenancy настійно рекомендується явно встановлювати значення для secretNamespace, інакше дані облікового запису для зберігання можуть бути прочитані іншими користувачами.
Portworx volume (застаріло)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: portworx-io-priority-high
provisioner: kubernetes.io/portworx-volume # Цей провізор є застарілим
parameters:
repl: "1"
snap_interval: "70"
priority_io: "high"
fs: файлова система для створення:none/xfs/ext4(типово:ext4).block_size: розмір блоку у кілобайтах (типово:32).repl: кількість синхронних реплік у формі коефіцієнта реплікації1..3(типово:1). Тут потрібен рядок, наприклад"1", а не1.priority_io: визначає, чи буде том створений з використанням зберігання високої чи низької пріоритетностіhigh/medium/low(типово:low).snap_interval: інтервал годинника/часу у хвилинах для того, щоб запускати моментальні знімки. Моментальні знімки є інкрементальними на основі різниці з попереднім знімком, 0 вимикає знімки (типово:0). Тут потрібен рядок, наприклад"70", а не70.aggregation_level: вказує кількість частин, на які розподілений том, 0 вказує на нерозподілений том (типово:0). Тут потрібен рядок, наприклад"0", а не0.ephemeral: вказує, чи слід очищати том після відмонтовування, чи він повинен бути постійним. Використання випадкуemptyDirможе встановлювати для цього значенняtrue, а випадок використанняпостійних томів, таких як для баз даних, наприклад Cassandra, повинен встановлюватиfalse,true/false(типовоfalse). Тут потрібен рядок, наприклад"true", а неtrue.
Локальне сховище
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner # вказує на те, що цей StorageClass не підтримує автоматичне виділення ресурсів
volumeBindingMode: WaitForFirstConsumer
Локальні томи не підтримують динамічне впровадження в Kubernetes 1.32; однак все одно слід створити StorageClass, щоб відкласти звʼязування тому до моменту фактичного планування Podʼа на відповідний вузол. Це вказано параметром звʼязування тому WaitForFirstConsumer.
Відкладення звʼязування тому дозволяє планувальнику враховувати всі обмеження планування Podʼа при виборі відповідного PersistenVolume для PersistenVolumeClaim.
6.6 - Класи атрибутів тома
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [beta] (стандартно увімкнено: false)Ця сторінка передбачає, що ви знайомі з StorageClasses, томами та постійними томами в Kubernetes.
Клас VolumeAttributesClass надає адміністраторам можливість описати змінні "класи" сховищ, які вони пропонують. Різні класи можуть відповідати різним рівням якості обслуговування. Kubernetes сам по собі не виражає думки про те, що представляють ці класи.
Це бета-функція, її типово вимкнено.
Якщо ви хочете протестувати функцію, поки вона бета, вам потрібно ввімкнути функціональну можливість VolumeAttributesClass для kube-controller-manager, kube-scheduler та kube-apiserver. Використовуйте аргумент командного рядка --feature-gates:
--feature-gates="...,VolumeAttributesClass=true"
Вам також потрібно буде увімкнути API групу storage.k8s.io/v1beta1 через kube-apiserver runtime-config. Для цього використовуйте наступний аргумент командного рядка:
--runtime-config=storage.k8s.io/v1beta1=true
Ви також можете використовувати VolumeAttributesClass лише зі сховищем, підтримуваним Container Storage Interface, і лише там, де відповідний драйвер CSI реалізує API ModifyVolume.
API VolumeAttributesClass
Кожен клас VolumeAttributesClass містить driverName та parameters, які використовуються, коли потрібно динамічно створити або змінити PersistentVolume (PV), що належить до цього класу.
Назва обʼєкта VolumeAttributesClass має значення, і вона використовується користувачами для запиту конкретного класу. Адміністратори встановлюють імʼя та інші параметри класу при створенні обʼєктів VolumeAttributesClass. Хоча імʼя обʼєкта VolumeAttributesClass в PersistentVolumeClaim може змінюватися, параметри в наявному класі є незмінними.
apiVersion: storage.k8s.io/v1beta1
kind: VolumeAttributesClass
metadata:
name: silver
driverName: pd.csi.storage.gke.io
parameters:
provisioned-iops: "3000"
provisioned-throughput: "50"
Постачальник
Кожен клас VolumeAttributesClass має постачальника, який визначає, який втулок тому використовується для надання PV. Поле driverName повинно бути вказане.
Підтримка функції для VolumeAttributesClass реалізована у kubernetes-csi/external-provisioner.
Ви не обмежені вказанням kubernetes-csi/external-provisioner. Ви також можете використовувати та вказувати зовнішні постачальники, які є незалежними програмами та відповідають специфікації, визначеною Kubernetes. Автори зовнішніх постачальників мають повну свободу в тому, де знаходиться їх код, як постачальник надається, як його потрібно запускати, який втулок тому він використовує та інше.
Модифікатор розміру
Кожен клас VolumeAttributesClass має модифікатор розміру, який визначає, який втулок тому використовується для модифікації PV. Поле driverName повинно бути вказане.
Підтримка функції модифікації розміру тому для VolumeAttributesClass реалізована у kubernetes-csi/external-resizer.
Наприклад, наявний запит PersistentVolumeClaim використовує клас VolumeAttributesClass з іменем silver:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-pv-claim
spec:
…
volumeAttributesClassName: silver
…
В кластері доступний новий клас VolumeAttributesClass з імʼям gold:
apiVersion: storage.k8s.io/v1beta1
kind: VolumeAttributesClass
metadata:
name: gold
driverName: pd.csi.storage.gke.io
parameters:
iops: "4000"
throughput: "60"
Користувач може оновити PVC за допомогою нового класу VolumeAttributesClass gold та застосувати зміни:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-pv-claim
spec:
…
volumeAttributesClassName: gold
…
Параметри
Класи VolumeAttributesClass мають параметри, які описують томи, які до них належать. Різні параметри можуть бути прийняті залежно від обраного провайдера або модифікатора розміру. Наприклад, значення 4000 для параметра iops, та параметр throughput є специфічними для GCE PD. Якщо параметр опущено, використовуються стандартні значення під час створення тому. Якщо користувач застосовує PVC із використанням іншого VolumeAttributesClass з пропущеними параметрами, стандартні значення може використовуватися залежно від реалізації драйвера CSI. Будь ласка, звертайтесь до відповідної документації драйвера CSI для отримання деталей.
Може бути визначено не більше 512 параметрів для класу VolumeAttributesClass. Загальна довжина обʼєкта параметрів, включаючи ключі та значення, не може перевищувати 256 КіБ.
6.7 - Динамічне впровадження томів
Динамічне впровадження томів дозволяє створювати томи сховища при потребі. Без динамічного впровадження адміністратори кластера повинні вручну звертатися до свого хмарного або постачальника сховища, щоб створити нові томи сховища, а потім створювати обʼєкти PersistentVolume, щоб мати їх в Kubernetes. Функція динамічного впровадження томів усуває необхідність для адміністраторів кластера попередньо впровадження сховища. Замість цього воно автоматично впроваджує сховище, коли користувачі створюють обʼєкти PersistentVolumeClaim.
Причини
Реалізація динамічного впровадження томів базується на API-обʼєкті StorageClass з групи API storage.k8s.io. Адміністратор кластера може визначити стільки обʼєктів StorageClass, скільки потрібно, кожен з них вказуючи провайдера тому (також відомий як provisioner) для впровадження тому та набір параметрів, які слід передати цьому провайдеру. Адміністратор кластера може визначити та надавати кілька варіантів сховища (з того ж або різних систем сховищ) в межах кластера, кожен зі своїм набором параметрів. Цей дизайн також забезпечує те, що кінцеві користувачі не повинні турбуватися про складнощі та нюанси впровадження сховища, але все ще мають можливість вибрати з різних варіантів сховища.
Додаткову інформацію про класи сховища можна знайти тут.
Увімкнення динамічного впровадження
Для увімкнення динамічного впровадження адміністратор кластера повинен передбачити один або декілька обʼєктів StorageClass для користувачів. Обʼєкти StorageClass визначають, який провайдер повинен використовуватися та які параметри повинні йому передаватися під час виклику динамічного впровадження. Імʼя обʼєкта StorageClass повинно бути дійсним імʼям DNS-піддомену.
Наступний маніфест створює клас сховища "slow", який надає стандартні диски, схожі на постійні диски.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
Наступний маніфест створює клас сховища "fast", який надає диски, схожі на SSD.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
Використання динамічного впровадження
Користувачі можуть запитувати динамічно впроваджене сховище, включаючи клас сховища у свій PersistentVolumeClaim. До версії Kubernetes v1.6 це робилося за допомогою анотації volume.beta.kubernetes.io/storage-class. Однак ця анотація застаріла з версії v1.9. Тепер користувачі можуть і повинні використовувати поле storageClassName обʼєкта PersistentVolumeClaim. Значення цього поля повинно відповідати імені StorageClass, налаштованому адміністратором (див. нижче).
Наприклад, щоб вибрати клас сховища "fast", користувач створює наступний PersistentVolumeClaim:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: claim1
spec:
accessModes:
- ReadWriteOnce
storageClassName: fast
resources:
requests:
storage: 30Gi
Цей запит призводить до автоматичного впровадження тому, схожого на SSD. Після видалення заявки том знищується.
Стандартна поведінка
Динамічне впровадження може бути увімкнено в кластері так, що всі заявки будуть динамічно надані, якщо не вказано жоден клас сховища. Адміністратор кластера може увімкнути цю поведінку шляхом:
- Визначення одного обʼєкта
StorageClassяк типового; - Переконайтеся, що контролер дозволів
DefaultStorageClassувімкнений на API-сервері.
Адміністратор може визначити певний StorageClass як типовий, додавши анотацію storageclass.kubernetes.io/is-default-class до нього. Коли в кластері існує типовий StorageClass, і користувач створює PersistentVolumeClaim із невказаним storageClassName, контролер DefaultStorageClass автоматично додає поле storageClassName, що вказує на типовий клас сховища.
Зверніть увагу, що якщо ви встановите анотацію storageclass.kubernetes.io/is-default-class в true для більше одного StorageClass у вашому кластері, а потім створите PersistentVolumeClaim із не встановленим storageClassName, Kubernetes використовує найновіший створений типовий StorageClass.
Врахування топології
У кластерах з кількома зонами можуть розташовуватися Podʼи в різних зонах одного регіону. Томи сховища в одній зоні повинні надаватися в ті зони, де заплановані Podʼи. Це можна здійснити, встановивши режим звʼязування тому.
6.8 - Знімки томів
У Kubernetes VolumeSnapshot представляє знімок тому в системі зберігання. Цей документ передбачає, що ви вже знайомі з постійними томами Kubernetes — persistent volumes.
Вступ
Так само як ресурси API PersistentVolume та PersistentVolumeClaim використовуються для створення томів для користувачів та адміністраторів, API-ресурси VolumeSnapshotContent та VolumeSnapshot надаються для створення знімків томів для користувачів та адміністраторів.
VolumeSnapshotContent — це знімок, зроблений з тому в кластері, який був створений адміністратором. Це ресурс в кластері, так само як PersistentVolume — це ресурс кластера.
VolumeSnapshot — це запит на знімок тому від користувача. Він схожий на PersistentVolumeClaim.
VolumeSnapshotClass дозволяє вам вказати різні атрибути, що належать до VolumeSnapshot. Ці атрибути можуть відрізнятися серед знімків, зроблених з того ж тому в системі зберігання, і тому не можуть бути виражені, використовуючи той самий StorageClass PersistentVolumeClaim.
Знімки томів надають користувачам Kubernetes стандартизований спосіб копіювання вмісту тому в певний момент часу без створення цілком нового тому. Ця функціональність, наприклад, дозволяє адміністраторам баз даних робити резервні копії баз даних перед внесенням змін або видаленням.
Користувачі повинні знати про наступне при використанні цієї функції:
- API-обʼєкти
VolumeSnapshot,VolumeSnapshotContentтаVolumeSnapshotClassє CRDs, а не частиною основного API. - Підтримка
VolumeSnapshotдоступна лише для драйверів CSI. - В рамках процесу розгортання
VolumeSnapshotкоманда Kubernetes надає контролер знімків для розгортання в панелі управління та допоміжний контейнер csi-snapshotter, який розгортається разом із драйвером CSI. Контролер знімків відстежує обʼєктиVolumeSnapshotтаVolumeSnapshotContentта відповідає за створення та видалення обʼєктаVolumeSnapshotContent. Допоміжний контейнер (sidecar) csi-snapshotter відстежує обʼєктиVolumeSnapshotContentта виконує операціїCreateSnapshotтаDeleteSnapshotдля точки доступу CSI. - Також існує сервер перевірки вебзапитів, який надає затвердження обʼєктів знімків. Його слід встановити дистрибутивами Kubernetes разом із контролером знімків та CRDs, а не драйверами CSI. Він повинен бути встановлений в усіх кластерах Kubernetes, в яких увімкнено функцію створення знімків.
- Драйвери CSI можуть або не втілювати функціональність знімка тому. Драйвери CSI, які надали підтримку знімків тому, скоріш за все, використовуватимуть csi-snapshotter. Див. Документацію драйвера CSI для отримання деталей.
- Встановлення CRDs та контролера знімків є обовʼязком дистрибутиву Kubernetes.
Для розширених випадків використання, таких як створення групових знімків кількох томів, див. додаткову документацію CSI Volume Group Snapshot documentation.
Життєвий цикл знімка тому та змісту знімка тому
VolumeSnapshotContents — це ресурси в кластері. VolumeSnapshots – це запити на отримання цих ресурсів. Взаємодія між VolumeSnapshotContents та VolumeSnapshots відповідає життєвому циклу:
Впровадження знімків томів
Існує два способи впровадження знімків: статичне попереднє впровадження або динамічне попереднє впровадження.
Статичне
Адміністратор кластера створює кілька VolumeSnapshotContents. Вони містять деталі реального знімка тому на системі зберігання, який доступний для використання користувачами кластера. Вони існують в API Kubernetes і доступні для використання.
Динамічне
Замість використання попередньо наявного знімка, можна запросити динамічне створення знімка з PersistentVolumeClaim. VolumeSnapshotClass вказує параметри, специфічні для постачальника зберігання, які слід використовувати при створенні знімка.
Звʼязування
Контролер знімків відповідає за звʼязування обʼєкта VolumeSnapshot з відповідним обʼєктом VolumeSnapshotContent, як у випадку попереднього впровадження, так і у випадку динамічного провадження. Звʼязування є зіставлення один до одного.
У випадку попереднього впровадження, обʼєкт VolumeSnapshot залишається незвʼязаним до тих пір, доки не буде створено запитаний обʼєкт VolumeSnapshotContent.
Persistent Volume Claim як захист джерела знімка
Метою цього захисту є забезпечення того, що обʼєкти API PersistentVolumeClaim використовуються і не видаляються з системи, поки відбувається створення знімка з нього (оскільки це може призвести до втрати даних).
Під час створення знімка з PersistentVolumeClaim, цей PersistentVolumeClaim знаходиться в стані використання. Якщо видалити обʼєкт API PersistentVolumeClaim, який активно використовується як джерело знімка, то обʼєкт PersistentVolumeClaim не видаляється негайно. Замість цього видалення обʼєкта PersistentVolumeClaim відкладається до готовності або анулювання знімка.
Видалення
Видалення спровоковане видаленням обʼєкта VolumeSnapshot, і буде дотримано DeletionPolicy. Якщо DeletionPolicy — це Delete, тоді підлеглий знімок сховища буде видалено разом з обʼєктом VolumeSnapshotContent. Якщо DeletionPolicy — це Retain, то як сховища, так і VolumeSnapshotContent залишаться.
VolumeSnapshots
Кожен том VolumeSnapshot містить специфікацію та стан.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: new-snapshot-test
spec:
volumeSnapshotClassName: csi-hostpath-snapclass
source:
persistentVolumeClaimName: pvc-test
persistentVolumeClaimName — це назва обʼєкта PersistentVolumeClaim, який є джерелом даних для знімка. Це поле є обовʼязковим для динамічного створення знімка.
Обʼєкт знімка тому може запитати певний клас, вказавши назву VolumeSnapshotClass за допомогою атрибута volumeSnapshotClassName. Якщо нічого не встановлено, то використовується типовий клас, якщо він доступний.
Для знімків, що були створені наперед, вам потрібно вказати volumeSnapshotContentName як джерело для знімка, як показано в наступному прикладі. Поле volumeSnapshotContentName як джерело є обовʼязковим для наперед створених знімків.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: test-snapshot
spec:
source:
volumeSnapshotContentName: test-content
Вміст знімків томів
Кожен обʼєкт VolumeSnapshotContent містить специфікацію та стан. При динамічному створенні знімків загальний контролер створює обʼєкти VolumeSnapshotContent. Ось приклад:
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
name: snapcontent-72d9a349-aacd-42d2-a240-d775650d2455
spec:
deletionPolicy: Delete
driver: hostpath.csi.k8s.io
source:
volumeHandle: ee0cfb94-f8d4-11e9-b2d8-0242ac110002
sourceVolumeMode: Filesystem
volumeSnapshotClassName: csi-hostpath-snapclass
volumeSnapshotRef:
name: new-snapshot-test
namespace: default
uid: 72d9a349-aacd-42d2-a240-d775650d2455
volumeHandle – це унікальний ідентифікатор тому, створеного на сховищі та поверненого драйвером CSI під час створення тому. Це поле обовʼязкове для динамічного створення знімка. Воно вказує джерело тому для знімка.
Для наперед створених знімків ви (як адміністратор кластера) відповідаєте за створення обʼєкта VolumeSnapshotContent наступним чином.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
name: new-snapshot-content-test
spec:
deletionPolicy: Delete
driver: hostpath.csi.k8s.io
source:
snapshotHandle: 7bdd0de3-aaeb-11e8-9aae-0242ac110002
sourceVolumeMode: Filesystem
volumeSnapshotRef:
name: new-snapshot-test
namespace: default
snapshotHandle — це унікальний ідентифікатор знімка тому, створеного в сховищі. Це поле є обовʼязковим для наперед створених знімків. Воно вказує ідентифікатор CSI знімка у сховищі, який представляє цей VolumeSnapshotContent.
sourceVolumeMode — це режим тому, з якого був зроблений знімок. Значення поля sourceVolumeMode може бути або Filesystem, або Block. Якщо режим джерела тому не вказано, Kubernetes розглядає знімок так, ніби режим джерела тому невідомий.
volumeSnapshotRef — це посилання на відповідний VolumeSnapshot. Зверніть увагу, що коли VolumeSnapshotContent створюється як наперед створений знімок, то VolumeSnapshot, на який посилається volumeSnapshotRef, може ще не існувати.
Зміна режиму тому знімка
Якщо API VolumeSnapshots, встановлене на вашому кластері, підтримує поле sourceVolumeMode, то API має можливість запобігати несанкціонованим користувачам зміни режиму тому.
Щоб перевірити, чи має ваш кластер цю функціональність, виконайте наступну команду:
kubectl get crd volumesnapshotcontent -o yaml
Якщо ви хочете дозволити користувачам створювати PersistentVolumeClaim з наявного VolumeSnapshot, але з іншим режимом тому, ніж у джерела, слід додати анотацію snapshot.storage.kubernetes.io/allow-volume-mode-change: "true" до VolumeSnapshotContent, який відповідає VolumeSnapshot.
Для наперед створених знімків spec.sourceVolumeMode повинно бути заповнено адміністратором кластера.
Приклад ресурсу VolumeSnapshotContent із включеною цією функцією виглядатиме так:
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
name: new-snapshot-content-test
annotations:
- snapshot.storage.kubernetes.io/allow-volume-mode-change: "true"
spec:
deletionPolicy: Delete
driver: hostpath.csi.k8s.io
source:
snapshotHandle: 7bdd0de3-aaeb-11e8-9aae-0242ac110002
sourceVolumeMode: Filesystem
volumeSnapshotRef:
name: new-snapshot-test
namespace: default
Створення томів зі знімків
Ви можете створити новий том, наперед заповнений даними зі знімка, використовуючи поле dataSource в обʼєкті PersistentVolumeClaim.
Докладніше дивіться в Знімок тому та відновлення тому зі знімка.
6.9 - Класи знімків томів
У цьому документі описано концепцію VolumeSnapshotClass в Kubernetes. Рекомендується мати відомості про знімки томів та класи сховищ.
Вступ
Так само як StorageClass надає можливість адміністраторам описувати "класи" сховищ, які вони пропонують при виділенні тому, VolumeSnapshotClass надає можливість описувати "класи" сховищ при виділенні знімка тому.
Ресурс VolumeSnapshotClass
Кожен VolumeSnapshotClass містить поля driver, deletionPolicy та parameters, які використовуються, коли потрібно динамічно виділити том для VolumeSnapshot, який належить до цього класу.
Назва обʼєкта VolumeSnapshotClass має значення і вказує, як користувачі можуть запитувати певний клас. Адміністратори встановлюють назву та інші параметри класу при створенні обʼєктів VolumeSnapshotClass, і їх не можна оновлювати після створення.
Примітка:
Встановлення CRDs є відповідальністю розподілу Kubernetes. Без наявних необхідних CRDs створення VolumeSnapshotClass закінчується невдачею.apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-hostpath-snapclass
driver: hostpath.csi.k8s.io
deletionPolicy: Delete
parameters:
Адміністратори можуть вказати типовий VolumeSnapshotClass для тих VolumeSnapshots, які не вимагають конкретний клас для привʼязки, додавши анотацію snapshot.storage.kubernetes.io/is-default-class: "true":
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-hostpath-snapclass
annotations:
snapshot.storage.kubernetes.io/is-default-class: "true"
driver: hostpath.csi.k8s.io
deletionPolicy: Delete
parameters:
Driver
Класи знімків томів мають власника, який визначає, який CSI втулок тому використовується для виділення VolumeSnapshots. Це поле обовʼязкове.
DeletionPolicy
Класи знімків томів мають DeletionPolicy. Вона дозволяє налаштувати, що відбудеться з VolumeSnapshotContent, коли буде видалено обʼєкт VolumeSnapshot, з яким він повʼязаний. DeletionPolicy класу знімків томів може бути або Retain, або Delete. Це поле обовʼязкове.
Якщо DeletionPolicy має значення Delete, тоді разом з обʼєктом VolumeSnapshotContent буде видалено знімок тому у сховищі. Якщо DeletionPolicy має значення Retain, то знімок тому та VolumeSnapshotContent залишаються.
Параметри
Класи знімків томів мають параметри, які описують знімки томів, що належать до класу знімків томів. Різні параметри можуть бути прийняті залежно від driver.
6.10 - Клонування CSI-томів
У цьому документі описано концепцію клонування наявних томів CSI в Kubernetes. Рекомендується мати уявлення про томи.
Вступ
Функція клонування томів CSI додає підтримку вказання наявних PVC у полі dataSource для позначення бажання користувача клонувати Том.
Клон визначається як дублікат наявного тому Kubernetes, який можна використовувати як будь-який стандартний том. Єдина відмінність полягає в тому, що після підготовки, а не створення "нового" порожнього тому, пристрій, що відповідає за підтримку томів, створює точний дублікат вказаного тому.
Реалізація клонування, з погляду API Kubernetes, додає можливість вказати наявний PVC як джерело даних під час створення нового PVC. Джерело PVC має бути повʼязане та доступне (не у використанні).
Користувачі повинні знати наступне при використанні цієї функції:
- Підтримка клонування (
VolumePVCDataSource) доступна лише для драйверів CSI. - Підтримка клонування доступна лише для динамічних постачальників.
- Драйвери CSI можуть чи не можуть реалізувати функціонал клонування томів.
- Ви можете клонувати тільки PVC, коли вони існують у тому ж просторі імен, що і PVC призначення (джерело та призначення повинні бути в одному просторі імен).
- Клонування підтримується з різним Storage Class.
- Призначений том може мати той самий або інший клас сховища, ніж джерело.
- Можна використовувати типовий клас сховища, і вказування storageClassName можна пропустити в специфікації.
- Клонування може бути виконане лише між двома томами, які використовують одне і те саме налаштування VolumeMode (якщо ви запитуєте том в блоковому режимі, то джерело ТАКОЖ повинно бути в блоковому режимі).
Впровадження
Клони забезпечуються так само як і інші PVC, за винятком додавання dataSource, яке посилається на поточний PVC у тому ж самому просторі імен.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: clone-of-pvc-1
namespace: myns
spec:
accessModes:
- ReadWriteOnce
storageClassName: cloning
resources:
requests:
storage: 5Gi
dataSource:
kind: PersistentVolumeClaim
name: pvc-1
Примітка:
Ви повинні вказати значення місткості дляspec.resources.requests.storage, і значення, яке ви вказуєте, повинно бути таким самим або більшим, ніж місткість вихідного тому.Результатом є новий PVC з імʼям clone-of-pvc-1, який має точно такий самий зміст, як і вказане джерело pvc-1.
Використання
При доступності нового PVC клонований PVC використовується так само як і інші PVC. Також на цьому етапі очікується, що новий створений PVC є незалежним обʼєктом. Його можна використовувати, клонувати, створювати знімки чи видаляти незалежно та без врахування вихідного джерела PVC. Це також означає, що джерело ніяк не повʼязане з новим створеним клоном, його також можна модифікувати чи видалити, не впливаючи на новий клон.
6.11 - Обсяг сховища
Обсяг сховища обмежений і може відрізнятися залежно від вузла, на якому працює Pod: мережеве сховище, можливо, не буде доступним для всіх вузлів, або зберігання буде локальним для вузла з початку.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]Ця сторінка описує, як Kubernetes відстежує обсяг сховища та як планувальник використовує цю інформацію для планування Podʼів на вузлах, які мають доступ до достатнього обсягу сховища для томів, що залишились пропущеними. Без відстеження обсягу сховища планувальник може вибрати вузол, у якого немає достатнього обсягу для виділення тому, і буде потрібно кілька повторних спроб планування.
Перш ніж ви розпочнете
Kubernetes v1.32 включає підтримку API на рівні кластера для відстеження обсягу сховища. Для використання цього ви також повинні використовувати драйвер CSI, який підтримує відстеження обсягу. Консультуйтесь з документацією драйверів CSI, які ви використовуєте, щоб дізнатися, чи ця підтримка доступна, і як її використовувати. Якщо ви не використовуєте Kubernetes v1.32, перевірте документацію для цієї версії Kubernetes.
API
Існують дві API-розширення для цієї функції:
- Обʼєкти CSIStorageCapacity: їх виробляє драйвер CSI в просторі імен, де встановлено драйвер. Кожен обʼєкт містить інформацію про обсяг для одного класу сховища і визначає, які вузли мають доступ до цього сховища.
- Поле
CSIDriverSpec.StorageCapacity: якщо встановлено значенняtrue, планувальник Kubernetes буде враховувати обсяг сховища для томів, які використовують драйвер CSI.
Планування
Інформація про обсяг сховища використовується планувальником Kubernetes у випадку, якщо:
- Pod використовує том, який ще не був створений,
- цей том використовує StorageClass, який посилається на драйвер CSI та використовує режим привʼязки тому
WaitForFirstConsumer, і - обʼєкт
CSIDriverдля драйвера маєStorageCapacityзі значеннямtrue.
У цьому випадку планувальник розглядає тільки вузли для Podʼів, які мають достатньо вільного обсягу сховища. Ця перевірка є дуже спрощеною і порівнює тільки розмір тому з обсягом, вказаним в обʼєктах CSIStorageCapacity з топологією, що включає вузол.
Для томів з режимом привʼязки Immediate драйвер сховища вирішує де створити том, незалежно від Podʼів, які використовуватимуть том. Планувальник потім планує Podʼи на вузли, де том доступний після створення.
Для ефемерних томів CSI планування завжди відбувається без врахування обсягу сховища. Це ґрунтується на припущенні, що цей тип тому використовується лише спеціальними драйверами CSI, які є локальними для вузла та не потребують значних ресурсів там.
Перепланування
Коли вузол був обраний для Pod з томами WaitForFirstConsumer, це рішення все ще є попереднім. Наступним кроком є те, що драйверу зберігання CSI буде запропоновано створити том з підказкою, що том повинен бути доступний на вибраному вузлі.
Оскільки Kubernetes може вибрати вузол на підставі застарілої інформації про обсяг, існує можливість, що том насправді не може бути створений. Вибір вузла скидається, і планувальник Kubernetes спробує знову знайти вузол для Podʼа.
Обмеження
Відстеження обсягу сховища збільшує ймовірність успішного планування з першої спроби, але не може гарантувати цього, оскільки планувальник повинен вирішувати на підставі можливо застарілої інформації. Зазвичай той самий механізм повторної спроби, що і для планування без будь-якої інформації про обсяг сховища, обробляє відмови в плануванні.
Одна ситуація, коли планування може назавжди зазнати відмови, це коли Pod використовує кілька томів: один том вже може бути створений в сегменті топології, в якому не залишилося достатньо обсягу для іншого тому. Потрібне ручне втручання для відновлення, наприклад, збільшення обсягу або видалення вже створеного тому.
Що далі
- Докладніша інформація щодо концепції дизайну доступна у Storage Capacity Constraints for Pod Scheduling KEP.
6.12 - Обмеження томів на вузлі
Ця сторінка описує максимальну кількість томів, які можна прикріпити до вузла для різних хмарних постачальників.
Хмарні постачальники, такі як Google, Amazon і Microsoft, зазвичай мають обмеження на те, скільки томів можна прикріпити до вузла. Важливо, щоб Kubernetes дотримувався цих обмежень. В іншому випадку Podʼи, заплановані на вузлі, можуть застрягти в очікуванні прикріплення томів.
Типові обмеження Kubernetes
У планувальнику Kubernetes є типові обмеження на кількість томів, які можна прикріпити до вузла:
| Хмарний сервіс | Максимальна кількість томів на вузол |
|---|---|
| Amazon Elastic Block Store (EBS) | 39 |
| Google Persistent Disk | 16 |
| Microsoft Azure Disk Storage | 16 |
Власні обмеження
Ви можете змінити ці обмеження, встановивши значення змінної середовища KUBE_MAX_PD_VOLS, а потім запустивши планувальник. Драйвери CSI можуть мати іншу процедуру, дивіться їх документацію щодо налаштування обмежень.
Будьте обережні, якщо ви встановлюєте ліміт, який перевищує стандартний ліміт. Зверніться до документації хмарного постачальника, щоб переконатися, що Nodes дійсно може підтримувати встановлений вами ліміт.
Обмеження застосовується до всього кластера, тому воно впливає на всі вузли.
Обмеження динамічних томів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.17 [stable]Обмеження динамічних томів підтримуються для наступних типів.
- Amazon EBS
- Google Persistent Disk
- Azure Disk
- CSI
Для томів, керованих вбудованими втулками томів, Kubernetes автоматично визначає тип вузла і накладає відповідне максимальне обмеження кількості томів для вузла. Наприклад:
У Google Compute Engine, до вузла може бути приєднано до 127 томів, залежно від типу вузла.
Для дисків Amazon EBS на типах екземплярів M5,C5,R5,T3 та Z1D Kubernetes дозволяє приєднувати тільки 25 томів до вузла. Для інших типів інстансів на Amazon Elastic Compute Cloud (EC2), Kubernetes дозволяє приєднувати 39 томів до вузла.
На Azure до вузла може бути приєднано до 64 дисків, залежно від типу вузла. Докладніше див. Sizes for virtual machines in Azure.
Якщо драйвер сховища CSI рекламує максимальну кількість томів для вузла (використовуючи
NodeGetInfo), kube-scheduler дотримується цього обмеження. Див. специфікації CSI для отримання додаткових деталей.Для томів, керованих вбудованими втулками, які були перенесені у драйвер CSI, максимальна кількість томів буде тією, яку повідомив драйвер CSI.
6.13 - Моніторинг справності томів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.21 [alpha]Моніторинг справності томів CSI дозволяє драйверам CSI виявляти ненормальні умови тому у підлеглих систем збереження та повідомляти про них як події у PVCs або Podʼи.
Моніторинг справності томів
Моніторинг справності томів Kubernetes є частиною того, як Kubernetes реалізує Container Storage Interface (CSI). Функція моніторингу справності томів реалізована у двох компонентах: контролері зовнішнього монітора справності та kubelet.
Якщо драйвер CSI підтримує функцію моніторингу справності томів зі сторони контролера, подія буде повідомлена у відповідний PersistentVolumeClaim (PVC) при виявленні ненормальної умови тому CSI.
Зовнішній контролер монітора справності також слідкує за подіями відмови вузла. Ви можете увімкнути моніторинг відмови вузла, встановивши прапорець enable-node-watcher в значення true. Коли зовнішній монітор справності виявляє подію відмови вузла, контролер повідомляє про подію PVC, щоб вказати, що Podʼи, які використовують цей PVC, розташовані на несправних вузлах.
Якщо драйвер CSI підтримує функцію моніторингу справності томів зі сторони вузла, подія буде повідомлена на кожному Pod, який використовує PVC, при виявленні ненормальної умови тому CSI. Крім того, інформація про справність томів викладена у вигляді метрик Kubelet VolumeStats. Додано нову метрику kubelet_volume_stats_health_status_abnormal. Ця метрика має дві мітки: namespace та persistentvolumeclaim. Лічильник приймає значення 1 або 0. 1 вказує на те, що том є несправним, 0 вказує на те, що том — справний. Докладніше див. у KEP.
Примітка:
Вам потрібно увімкнути функціональну можливістьCSIVolumeHealth для використання цієї функції зі сторони вузла.Що далі
Див. документацію драйвера CSI, щоб дізнатися, які драйвери CSI реалізували цю функцію.
6.14 - Зберігання у Windows
Ця сторінка надає огляд зберігання, специфічного для операційної системи Windows.
Постійне зберігання
У Windows є багатошаровий файловий драйвер для монтування контейнерних шарів і створення копії файлової системи на основі NTFS. Всі шляхи файлів у контейнері вирішуються лише в межах контексту цього контейнера.
- З Docker точки монтування томів можуть націлюватися лише на каталог у контейнері, а не на окремий файл. Це обмеження не стосується containerd.
- Томи не можуть проєцювати файли або каталоги на файлову систему хосту.
- Файлові системи тільки-читання не підтримуються, оскільки завжди потрібен доступ для запису до реєстру Windows та бази даних SAM. Однак томи тільки-читання підтримуються.
- Маски користувача і дозволи для томів недоступні. Оскільки SAM не спільний між хостом і контейнером, немає зіставлення між ними. Всі дозволи вирішуються в межах контексту контейнера.
В результаті на вузлах Windows не підтримуються наступні можливості зберігання:
- Монтування томів за підкаталогами: у Windows контейнер може монтувати лише весь том
- Монтування томів за підкаталогами для секретів
- Проєцювання монтування хосту
- Коренева файлова система тільки-читання (зіставлені томи все ще підтримують
readOnly) - Зіставлення блокового пристрою
- Памʼять як носій зберігання (наприклад,
emptyDir.mediumвстановлено наMemory) - Функції файлової системи, такі як uid/gid; дозволи Linux файлової системи для кожного користувача
- Встановлення дозволів секрета з DefaultMode (залежність від UID/GID)
- Підтримка зберігання/томів на основі NFS
- Розширення змонтованого тому (resizefs)
Томи Kubernetes дозволяють розгортання складних застосунків, які вимагають постійності даних та вимог до спільного використання томів Pod, розгорнутих у Kubernetes. Управління постійними томами, повʼязаними із конкретним сховищем або протоколом, включає дії, такі як надання/відміна надання/зміна розміру томів, приєднання/відʼєднання тому від/до вузла Kubernetes та монтування/відмонтування тому від/до окремих контейнерів у Podʼі, які повинні зберігати дані.
Компоненти управління томами постачаються як втулок томів Kubernetes. У Windows підтримуються наступні широкі класи втулків томів Kubernetes:
- Втулки FlexVolume
- Зауважте, що FlexVolume були застарілі з версії 1.23
- Втулки CSI
Вбудовані втулки томів
На вузлах Windows підтримуються наступні вбудовані втулки, які підтримують постійне зберігання:
7 - Конфігурація
Ресурси, які Kubernetes надає для конфігурації
Podів.7.1 - Поради щодо конфігурації
Цей документ виділяє та консолідує найкращі практики конфігурації, які представлені в документації користувача, документації для початківців та прикладах.
Це живий документ. Якщо ви подумаєте про щось, що не включено до цього списку, але може бути корисним іншим користувачам, будь ласка, не соромтеся подати тікет або надіслати PR.
Загальні поради щодо конфігурації
При створенні конфігурацій вкажіть останню стабільну версію API.
Файли конфігурації повинні зберігатися у системі контролю версій, перш ніж бути перенесеними в кластер. Це дозволяє швидко відкочувати зміну конфігурації у разі необхідності. Це також сприяє перестворенню та відновленню кластера.
Пишіть файли конфігурації за допомогою YAML, а не JSON. Хоча ці формати можна використовувати взаємозамінно практично в усіх сценаріях, YAML зазвичай є більш зручним для користувачів.
Гуртуйте повʼязані обʼєкти в один файл, якщо це має сенс. Одним файлом часто легше керувати, ніж кількома. Podʼивіться на файл guestbook-all-in-one.yaml як приклад використання цього синтаксису.
Також зверніть увагу, що багато команд
kubectlможна виконувати з теками. Наприклад, ви можете застосуватиkubectl applyв теці з файлами конфігурації.Не вказуйте типові значення без потреби: проста, мінімальна конфігурація зменшить ймовірність помилок.
Додайте описи обʼєктів в анотації, щоб забезпечити кращий самоаналіз.
Примітка:
У специфікації булевих значень в YAML 1.2 була введена переломну зміну у порівнянні з YAML 1.1. Це відома проблема в Kubernetes. YAML 1.2 визнає лише true та false як дійсні булеві значення, тоді як YAML 1.1 також приймає yes, no, on, та off як булеві значення. Хоча Kubernetes використовує YAML парсери, які в основному сумісні з YAML 1.1, однак використання yes або no замість true або false у маніфесті YAML може призвести до непередбачених помилок або поведінки. Щоб уникнути цієї проблеми, рекомендується завжди використовувати true або false для булевих значень у маніфестах YAML, та використовувати лапки для будь-яких рядків, які можуть бути сплутані з булевими значеннями, таких як "yes" або "no".
Крім булевих значень, є додаткові зміни у специфікаціях між версіями YAML. Будь ласка, зверніться до Зміни в специфікації YAML документації для отримання повного списку.
"Чисті" Podʼи проти ReplicaSets, Deployments та Jobs
Не використовуйте "чисті" Podʼи (тобто Podʼи, не повʼязані з ReplicaSet або Deployment), якщо можна уникнути цього. "Чисті" Podʼи не будуть переплановані в разі відмови вузла.
Використання Deployment, який як створює ReplicaSet для забезпечення того, що потрібна кількість Podʼів завжди доступна, так і вказує стратегію для заміни Podʼів (таку як RollingUpdate), майже завжди є переважним варіантом на відміну від створення Podʼів безпосередньо, за винятком деяких явних сценаріїв
restartPolicy: Never. Також може бути прийнятним використання Job.
Services
Створіть Service перед створенням відповідного робочого навантаження (Deployments або ReplicaSets), і перед будь-якими створенням робочих навантажень, які мають до нього доступ. Коли Kubernetes запускає контейнер, він надає змінні середовища, які вказують на всі Serviceʼи, які працювали під час запуску контейнера. Наприклад, якщо існує Service з іменем
foo, то всі контейнери отримають наступні змінні у своєму початковому середовищі:FOO_SERVICE_HOST=<хост, на якому працює Service> FOO_SERVICE_PORT=<порт, на якому працює Service>Це передбачає вимоги щодо черговості — будь-який
Service, до якогоPodхоче отримати доступ, повинен бути створений перед створенням цьогоPodʼу, бо змінні середовища не будуть заповнені. DNS не має такого обмеження.Необовʼязкова (хоча настійно рекомендована) надбудова для кластера — це DNS-сервер. DNS-сервер спостерігає за Kubernetes API за появою нових
Serviceʼівта створює набір DNS-записів для кожного з них. Якщо DNS було активовано в усьому кластері, то всіPodʼиповинні мати можливість автоматичного використовувати назвиServiceʼів.Не вказуйте
hostPortдля Podʼа, якщо це не є абсолютно необхідним. Коли ви привʼязуєте Pod доhostPort, це обмежує місця, де може бути запланований Pod, оскільки кожна комбінація <hostIP,hostPort,protocol> повинна бути унікальною. Якщо ви не вказуєте явноhostIPтаprotocol, Kubernetes використовуватиме0.0.0.0як типовийhostIPтаTCPяк типовийprotocol.Якщо вам потрібен доступ до порту лише для налагодження, ви можете використовувати apiserver proxy або
kubectl port-forward.Якщо вам дійсно потрібно використовувати порт Подʼа на вузлі, розгляньте можливість використання NodePort Service перед використанням
hostPort.Уникайте використання
hostNetwork, з тих самих причин, що йhostPort.Використовуйте headless Service (які мають
ClusterIPNone) для виявлення Service, коли вам не потрібен балансувальник навантаженняkube-proxy.
Використання міток
Визначайте та використовуйте мітки, які ідентифікують семантичні атрибути вашого застосунку або Deployment, такі як
{ app.kubernetes.io/name: MyApp, tier: frontend, phase: test, deployment: v3 }. Ви можете використовувати ці мітки для вибору відповідних Podʼів для інших ресурсів; наприклад, Service, який вибирає всі Podʼи зtier: frontend, або всі складовіphase: testзapp.kubernetes.io/name: MyApp. Подивіться застосунок гостьова книга для прикладів застосування такого підходу.Service може охоплювати кілька Deploymentʼів, пропускаючи мітки, специфічні для релізу, від його селектора. Коли вам потрібно оновити робочий Service без простою, використовуйте Deployment.
Бажаний стан обʼєкта описується Deploymentʼом, і якщо зміни до його специфікації будуть застосовані, контролер Deployment змінює фактичний стан на бажаний з контрольованою швидкістю.
Використовуйте загальні мітки Kubernetes для загальних випадків використання. Ці стандартизовані мітки збагачують метадані таким чином, що дозволяють інструментам, включаючи
kubectlта інфопанель (dashboard), працювати в сумісний спосіб.Ви можете маніпулювати мітками для налагодження. Оскільки контролери Kubernetes (такі як ReplicaSet) та Service отримують збіг з Podʼами за допомогою міток селектора, видалення відповідних міток з Podʼа зупинить його від обробки контролером або від обслуговування трафіку Serviceʼом. Якщо ви видалите мітки наявного Podʼа, його контролер створить новий Pod, щоб зайняти його місце. Це корисний спосіб налагоджувати раніше "справний" Pod в "карантинному" середовищі. Щоб інтерактивно видаляти або додавати мітки, використовуйте
kubectl label.
Використання kubectl
Використовуйте
kubectl apply -f <directory>. Виконання цієї команди шукає конфігурацію Kubernetes у всіх файлах.yaml,.ymlта.jsonу<directory>та передає її доapply.Використовуйте селектори міток для операцій
getтаdeleteзамість конкретних назв обʼєктів. Подивіться розділи про селектори міток та ефективне використання міток.Використовуйте
kubectl create deploymentтаkubectl expose, щоб швидко створити Deployment з одним контейнером та Service. Подивіться Використання Service для доступу до застосунку в кластері для прикладу.
7.2 - ConfigMaps
ConfigMap це обʼєкт API, призначений для зберігання неконфіденційних даних у вигляді пар ключ-значення. Podʼи можуть використовувати ConfigMap як змінні середовища, аргументи командного рядка чи файли конфігурації у томі.
ConfigMap дозволяє відділити конфігурацію, специфічну для середовища, від образів контейнерів, щоб ваші застосунки були легко переносимими.
Увага:
ConfigMap не забезпечує конфіденційності або шифрування. Якщо дані, які ви хочете зберегти, конфіденційні, використовуйте Secret замість ConfigMap, або використовуйте додаткові (зовнішні) інструменти для збереження ваших даних в таємниці.Мотивація
Використовуйте ConfigMap для визначення конфігураційних даних окремо від коду застосунку.
Наприклад, уявіть, що ви розробляєте застосунок, який ви можете запускати на своєму власному компʼютері (для розробки) і в хмарі (для обробки реального трафіку). Ви пишете код, який переглядає змінну середовища з назвою DATABASE_HOST. Локально ви встановлюєте цю змінну як localhost. У хмарі ви встановлюєте її так, щоб вона посилалася на Service, який надає доступ до компонент бази даних вашому кластеру. Це дозволяє вам отримати образ контейнера, який працює в хмарі, і в разі потреби налагоджувати той самий код локально.
Примітка:
ConfigMap не призначено для зберігання великих обсягів даних. Дані, збережені в ConfigMap, не можуть перевищувати 1 MiB. Якщо потрібно зберегти налаштування, які перевищують це обмеження, варто розглянути можливість монтування тому або використання окремої бази даних або файлової служби.Обʼєкт ConfigMap
ConfigMap — це обʼєкт API, який дозволяє зберігати конфігураційні дані для використання іншими обʼєктами. На відміну від більшості обʼєктів Kubernetes, у яких є spec, ConfigMap має поля data та binaryData. Ці поля приймають пари ключ-значення як свої значення. Обидва поля data і binaryData є необовʼязковими. Поле data призначене для зберігання рядків UTF-8, тоді як поле binaryData призначене для зберігання бінарних даних у вигляді рядків, закодованих у base64.
Назва ConfigMap повинна бути дійсним піддоменом DNS.
Кожний ключ у полі data або binaryData повинен складатися з алфавітно-цифрових символів, -, _ або .. Ключі, збережені в data, не повинні перетинатися з ключами у полі binaryData.
Починаючи з версії v1.19, ви можете додати поле immutable до визначення ConfigMap,
щоб створити незмінний ConfigMap.
ConfigMaps та Podʼи
Ви можете написати spec Podʼа, який посилається на ConfigMap і конфігурує контейнер(и) в цьому Podʼі на основі даних з ConfigMap. Pod і ConfigMap повинні бути в тому самому namespace.
Ось приклад ConfigMap, який має деякі ключі з одними значеннями, та інші ключі, де значення виглядає як фрагмент формату конфігурації.
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# ключі у вигляді властивостей; кожен ключ зіставляється з простим значенням
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
# ключі у формі файлів
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
Є чотири різних способи використання ConfigMap для конфігурації контейнера всередині Podʼа:
- В команді та аргументах контейнера
- В змінних середовища для контейнера
- Додайте файл до тому тільки для читання, щоб застосунок міг його читати
- Напишіть код для виконання всередині Podʼа, який використовує Kubernetes API для читання ConfigMap
Ці різні методи підходять для різних способів моделювання даних, які споживаються. Для перших трьох методів kubelet використовує дані з ConfigMap при запуску контейнер(ів) для Podʼа.
Четвертий метод означає, що вам потрібно написати код для читання ConfigMap та його даних. Однак, оскільки ви використовуєте прямий доступ до Kubernetes API, ваш застосунок може підписатися на отримання оновлень, коли змінюється ConfigMap, і реагувати на це. Завдяки прямому доступу до Kubernetes API цей технічний підхід також дозволяє вам отримувати доступ до ConfigMap в іншому namespace.
Ось приклад Podʼа, який використовує значення з game-demo для конфігурації Podʼа:
apiVersion: v1
kind: Pod
metadata:
name: configmap-demo-pod
spec:
containers:
- name: demo
image: alpine
command: ["sleep", "3600"]
env:
# Визначення змінної середовища
- name: PLAYER_INITIAL_LIVES # Зверніть увагу, що регістр відрізняється тут
# від назви ключа в ConfigMap.
valueFrom:
configMapKeyRef:
name: game-demo # ConfigMap, з якого отримується це значення.
key: player_initial_lives # Ключ для отримання значення.
- name: UI_PROPERTIES_FILE_NAME
valueFrom:
configMapKeyRef:
name: game-demo
key: ui_properties_file_name
volumeMounts:
- name: config
mountPath: "/config"
readOnly: true
volumes:
# Ви встановлюєте томи на рівні Pod, а потім монтуєте їх в контейнери всередині цього Pod
- name: config
configMap:
# Вкажіть назву ConfigMap, який ви хочете змонтувати.
name: game-demo
# Масив ключів з ConfigMap, які треба створити як файли
items:
- key: "game.properties"
path: "game.properties"
- key: "user-interface.properties"
path: "user-interface.properties"
ConfigMap не розрізняє значення властивостей з окремих рядків та багаторядкові файлоподібні значення. Важливо, як Podʼи та інші обʼєкти використовують ці значення.
У цьому прикладі визначення тому та монтування його всередину контейнера demo як /config створює два файли, /config/game.properties та /config/user-interface.properties, навіть якщо в ConfigMap є чотири ключі. Це тому, що визначення Podʼа вказує на масив items в розділі volumes. Якщо ви взагалі опустите масив items, кожен ключ у ConfigMap стане файлом з тією ж навою, що й ключ, і ви отримаєте 4 файли.
Використання ConfigMap
ConfigMap можуть бути змонтовані як томи з даними. ConfigMap також можуть бути використані іншими частинами системи, не піддаючись безпосередньому впливу Podʼа. Наприклад, ConfigMap можуть містити дані, які повинні використовуватися іншими частинами системи для конфігурації.
Найпоширеніший спосіб використання ConfigMap — це конфігурація налаштувань для контейнерів, які запускаються в Podʼі в тому ж namespace. Ви також можете використовувати ConfigMap окремо.
Наприклад, ви можете зустріти надбудови або оператори, які налаштовують свою поведінку на основі ConfigMap.
Використання ConfigMaps як файлів в Pod
Щоб використовувати ConfigMap в томі в Podʼі:
- Створіть ConfigMap або використовуйте наявний. Декілька Podʼів можуть посилатися на один ConfigMap.
- Змініть ваше визначення Podʼа, щоб додати том в
.spec.volumes[]. Назвіть том будь-яким імʼям, та встановіть поле.spec.volumes[].configMap.nameдля посилання на ваш обʼєкт ConfigMap. - Додайте
.spec.containers[].volumeMounts[]до кожного контейнера, який потребує ConfigMap. Вкажіть.spec.containers[].volumeMounts[].readOnly = trueта.spec.containers[].volumeMounts[].mountPathв невикористану назву каталогу, де ви хочете, щоб зʼявився ConfigMap. - Змініть ваш образ або командний рядок так, щоб програма шукала файли у цьому каталозі. Кожен ключ в ConfigMap
dataстає імʼям файлу вmountPath.
Ось приклад Podʼа, який монтує ConfigMap в том:
apiVersion: v1
kind:ʼPod {#configmap-object}
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
configMap:
name: myconfigmap
Кожен ConfigMap, який ви хочете використовувати, слід зазначити в .spec.volumes.
Якщо в Podʼі є кілька контейнерів, то кожен контейнер потребує свого власного блоку volumeMounts, але потрібно лише одне полу .spec.volumes на ConfigMap.
Змонтовані ConfigMaps оновлюються автоматично
Коли ConfigMap, що наразі використовується в томі, оновлюється, ключі, що зіставляються, в кінцевому підсумку також оновлюються. Kubelet перевіряє, чи змонтований ConfigMap є свіжим під час кожної синхронізації. Однак Kubelet використовує свій локальний кеш для отримання поточного значення ConfigMap. Тип кешу настроюється за допомогою поля configMapAndSecretChangeDetectionStrategy в структурі KubeletConfiguration. ConfigMap можна поширити за допомогою watch (типово), на основі ttl або шляхом перенаправлення всіх запитів безпосередньо до сервера API. Отже, загальна затримка від моменту оновлення ConfigMap до моменту коли нові ключі зʼявляться в Pod може становити стільки, скільки й періодична затримка kubelet + затримка поширення кешу, де затримка поширення кешу залежить від обраного типу кешу (вона дорівнює затримці поширення watch, ttl кешу або нулю відповідно).
ConfigMap, що використовуються як змінні оточення, не оновлюються автоматично і потребують перезапуску Podʼа.
Примітка:
Контейнер, який використовує ConfigMap як том з монтуванням subPath, не отримує оновлення ConfigMap.Використання ConfigMaps як змінних середовища
Щоб використовувати ConfigMap у змінних середовища в Podʼі:
- Для кожного контейнера у вашій специфікації Podʼа додайте змінну середовища для кожного ключа ConfigMap, який ви хочете використовувати, до поля
env[].valueFrom.configMapKeyRef. - Змініть ваш образ та/або командний рядок так, щоб програма шукала значення у вказаних змінних середовища.
Ось приклад визначення ConfigMap як змінної середовища Podʼа:
Цей ConfigMap (myconfigmap.yaml) містить дві властивості: username та access_level:
apiVersion: v1
kind: ConfigMap
metadata:
name: myconfigmap
data:
username: k8s-admin
access_level: "1"
Наступна команда створить обʼєкт ConfigMap:
kubectl apply -f myconfigmap.yaml
Наступний Pod використовує вміст ConfigMap як змінні середовища:
apiVersion: v1
kind: Pod
metadata:
name: env-configmap
spec:
containers:
- name: app
command: ["/bin/sh", "-c", "printenv"]
image: busybox:latest
envFrom:
- configMapRef:
name: myconfigmap
Поле envFrom вказує Kubernetes створити змінні середовища з джерел, вкладених у нього. Внутрішній configMapRef посилається на ConfigMap за його імʼям і вибирає всі його пари ключ-значення. Додайте Pod до свого кластера, а потім перегляньте його логи, щоб побачити виведення команди printenv. Це має підтвердити, що дві пари ключ-значення з ConfigMap були встановлені як змінні середовища:
kubectl apply -f env-configmap.yaml
kubectl logs pod/ env-configmap
Вивід буде подібний до цього:
...
username: "k8s-admin"
access_level: "1"
...
Іноді Pod не потребуватиме доступу до всіх значень у ConfigMap. Наприклад, можна мати інший Pod, який використовує тільки значення username з ConfigMap. Для цього випадку можна використовувати синтаксис env.valueFrom, який дозволяє вибирати окремі ключі в ConfigMap. Імʼя змінної середовища також може відрізнятися від ключа в ConfigMap. Наприклад:
apiVersion: v1
kind: Pod
metadata:
name: env-configmap
spec:
containers:
- name: envars-test-container
image: nginx
env:
- name: CONFIGMAP_USERNAME
valueFrom:
configMapKeyRef:
name: myconfigmap
key: username
У Podʼі, створеному з цього маніфесту, ви побачите, що змінна середовища CONFIGMAP_USERNAME встановлена на значення username з ConfigMap. Інші ключі з даних ConfigMap не будуть скопійовані у середовище.
Важливо зауважити, що діапазон символів, дозволених для назв змінних середовища в Podʼах, обмежений. Якщо будь-які ключі не відповідають правилам, ці ключі не будуть доступні вашому контейнеру, хоча Pod може бути запущений.
Незмінні ConfigMap
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.21 [stable]Функція Kubernetes Immutable Secrets та ConfigMaps надає опцію встановлення індивідуальних Secret та ConfigMap як незмінних. Для кластерів, що інтенсивно використовують ConfigMap (принаймні десятки тисяч унікальних монтувань ConfigMap до Podʼів), запобігання змінам їх даних має наступні переваги:
- захищає від випадкових (або небажаних) оновлень, які можуть призвести до відмов застосунків
- покращує продуктивність кластера шляхом значного зниження навантаження на kube-apiserver, закриваючи спостереження за ConfigMap, які позначені як незмінні.
Ви можете створити незмінний ConfigMap, встановивши поле immutable в true.
Наприклад:
apiVersion: v1
kind: ConfigMap
metadata:
...
data:
...
immutable: true
Після того як ConfigMap позначено як незмінний, змінити цю властивість або змінити вміст поля data або binaryData неможливо. Ви можете лише видалити та створити ConfigMap знову. Тому що поточні Podʼи підтримують точку монтування для видаленого ConfigMap, рекомендується перестворити ці Podʼи.
Що далі
- Дізнайтеся більше про Secret.
- Прочитайте про Налаштування Podʼа для використання ConfigMap.
- Дізнайтеся про зміну ConfigMap (або будь-якого іншого обʼєкту Kubernetes)
- Прочитайте про 12-факторні застосунки, щоб зрозуміти мотивацію для відокремлення коду від конфігурації.
7.3 - Secrets
Secret — це обʼєкт, який містить невелику кількість конфіденційних даних, таких як пароль, токен або ключ. Така інформація також може бути включена до специфікації Pod або в образ контейнера. Використання Secret означає, що вам не потрібно включати конфіденційні дані у ваш код.
Оскільки Secret можуть бути створені незалежно від Podʼів, які їх використовують, існує менше ризику того, що Secret (і його дані) буде викрито під час процесу створення, перегляду та редагування Podʼів. Kubernetes та програми, які працюють у вашому кластері, також можуть вживати додаткових заходів безпеки щодо Secretʼів, наприклад, уникання запису конфіденційних даних у енергонезалежне сховище.
Secretʼи схожі на ConfigMap, але призначені для зберігання конфіденційних даних.
Увага:
Керовані Kubernetes Secretʼи, стандартно, зберігаються незашифрованими у базі даних API-сервера (etcd). Будь-хто з доступом до API може отримати або змінити Secret, так само як будь-хто з доступом до etcd. Крім того, будь-хто, хто має дозвіл на створення Podʼа у просторі імен, може використовувати цей доступ для читання будь-якого Secretʼу у цьому просторі імен; це включає і непрямий доступ, такий як можливість створення Deployment.
Щоб безпечно використовувати Secretʼи, виконайте принаймні наступні кроки:
- Увімкніть шифрування у стані спокою для Secret.
- Увімкніть або налаштуйте правила RBAC з найменшими правами доступу до Secret.
- Обмежте доступ до Secret для конкретних контейнерів.
- Розгляньте використання зовнішніх постачальників сховища для Secret.
Для отримання додаткових рекомендацій щодо керування та покращення безпеки ваших Secret, ознайомтесь з Належними практиками для Secret Kubernetes.
Дивіться Інформаційна безпека для Secret для отримання додаткових відомостей.
Застосування Secretʼів
Ви можете використовувати Secrets для таких цілей:
- Встановлення змінних оточення для контейнера.
- Надання облікових даних, таких як SSH-ключі або паролі, Podʼам.
- Дозвіл kubelet отримувати образи контейнера з приватних реєстрів.
Панель управління Kubernetes також використовує Secretʼи; наприклад, Secret токену реєстрації вузлів — це механізм, що допомагає автоматизувати реєстрацію вузлів.
Сценарій використання: dotfiles у томі Secret
Ви можете зробити ваші дані "прихованими", визначивши ключ, який починається з крапки. Цей ключ являє собою dotfile або "прихований" файл. Наприклад, коли наступний Secret підключається до тому secret-volume, том буде містити один файл, з назвою .secret-file, і контейнер dotfile-test-container матиме цей файл присутнім у шляху /etc/secret-volume/.secret-file.
Примітка:
Файли, які починаються з крапок, приховані від виводуls -l; для того, щоб побачити їх під час перегляду вмісту каталогу використовуйте ls -la.apiVersion: v1
kind: Secret
metadata:
name: dotfile-secret
data:
.secret-file: dmFsdWUtMg0KDQo=
---
apiVersion: v1
kind: Pod
metadata:
name: secret-dotfiles-pod
spec:
volumes:
- name: secret-volume
secret:
secretName: dotfile-secret
containers:
- name: dotfile-test-container
image: registry.k8s.io/busybox
command:
- ls
- "-l"
- "/etc/secret-volume"
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"Сценарій використання: Secret видимий для одного контейнера в Pod
Припустимо, що у вас є програма, яка потребує обробки HTTP-запитів, виконання складної бізнес-логіки та підписування деяких повідомлень HMAC. Оскільки у неї складна логіка застосунків, може бути непоміченою вразливість на віддалене читання файлів з сервера, що може дати доступ до приватного ключа зловмиснику.
Це можна розділити на два процеси у двох контейнерах: контейнер інтерфейсу, який обробляє взаємодію з користувачем та бізнес-логіку, але не може бачити приватний ключ; і контейнер що перевіряє підписи, який може бачити приватний ключ, та відповідає на прості запити на підпис від фронтенду (наприклад, через мережу localhost).
З цим розділеним підходом зловмиснику зараз потрібно обманути сервер застосунків, щоб зробити щось досить довільне, що може бути складніше, ніж змусити його прочитати файл.
Альтернативи Secretʼам
Замість використання Secret для захисту конфіденційних даних, ви можете вибрати з альтернатив.
Ось деякі з варіантів:
- Якщо ваш хмарно-орієнтований компонент потребує автентифікації від іншого застосунку, який, ви знаєте, працює в межах того ж кластера Kubernetes, ви можете використовувати ServiceAccount та його токени, щоб ідентифікувати вашого клієнта.
- Існують сторонні інструменти, які ви можете запускати, як в межах, так і поза вашим кластером, які керують чутливими даними. Наприклад, Service, до якого Podʼи мають доступ через HTTPS, який використовує Secret, якщо клієнт правильно автентифікується (наприклад, з токеном ServiceAccount).
- Для автентифікації ви можете реалізувати спеціальний підписувач для сертифікатів X.509, і використовувати CertificateSigningRequests, щоб дозволити цьому спеціальному підписувачу видавати сертифікати Podʼам, які їх потребують.
- Ви можете використовувати втулок пристрою, щоб використовувати апаратне забезпечення шифрування, яке локалізоване на вузлі, для певного Podʼа. Наприклад, ви можете розмістити довірені Podʼи на вузлах, які надають Trusted Platform Module.
Ви також можете комбінувати два або більше з цих варіантів, включаючи варіант використання Secret самостійно.
Наприклад: реалізуйте (або розгорніть) оператор, що отримує тимчасові токени сеансів від зовнішнього Service, а потім створює Secretʼи на основі цих тимчасових токенів. Podʼи, що працюють у вашому кластері, можуть використовувати токени сеансів, а оператор забезпечує їхню дійсність. Це розподілення означає, що ви можете запускати Podʼи, які не знають точних механізмів створення та оновлення цих токенів сеансів.
Типи Secret
При створенні Secret ви можете вказати його тип, використовуючи поле type ресурсу Secret, або певні еквівалентні прапорці командного рядка kubectl (якщо вони доступні). Тип Secret використовується для сприяння програмному обробленню даних Secret.
Kubernetes надає кілька вбудованих типів для деяких типових сценаріїв використання. Ці типи відрізняються за умовами перевірки та обмеженнями, які Kubernetes накладає на них.
| Вбудований Тип | Використання |
|---|---|
Opaque | довільні користувацькі дані |
kubernetes.io/service-account-token | токен ServiceAccount |
kubernetes.io/dockercfg | серіалізований файл ~/.dockercfg |
kubernetes.io/dockerconfigjson | серіалізований файл ~/.docker/config.json |
kubernetes.io/basic-auth | облікові дані для базової автентифікації |
kubernetes.io/ssh-auth | облікові дані для SSH автентифікації |
kubernetes.io/tls | дані для TLS клієнта або сервера |
bootstrap.kubernetes.io/token | дані bootstrap token |
Ви можете визначити та використовувати власний тип Secret, присвоївши непорожній рядок як значення type обʼєкту Secret (порожній рядок розглядається як тип Opaque).
Kubernetes не накладає жодних обмежень на назву типу. Однак, якщо ви використовуєте один з вбудованих типів, ви повинні задовольнити всі вимоги, визначені для цього типу.
Якщо ви визначаєте тип Secret, призначений для загального використання, дотримуйтесь домовленостей та структуруйте тип Secret так, щоб він мав ваш домен перед назвою, розділений знаком /. Наприклад: cloud-hosting.example.net/cloud-api-credentials.
Opaque Secrets
Opaque — це стандартний тип Secret, якщо ви не вказуєте явно тип у маніфесті Secret. При створенні Secret за допомогою kubectl вам потрібно використовувати команду generic, щоб вказати тип Secret Opaque. Наприклад, наступна команда створює порожній Secret типу Opaque:
kubectl create secret generic empty-secret
kubectl get secret empty-secret
Вивід виглядає наступним чином:
NAME TYPE DATA AGE
empty-secret Opaque 0 2m6s
У стовпчику DATA показується кількість елементів даних, збережених у Secret. У цьому випадку 0 означає, що ви створили порожній Secret.
Secret токенів ServiceAccount
Тип Secret kubernetes.io/service-account-token використовується для зберігання
токену, який ідентифікує ServiceAccount. Це старий механізм, який забезпечує довгострокові облікові дані ServiceAccount для Podʼів.
У Kubernetes v1.22 та пізніших рекомендований підхід полягає в тому, щоб отримати короткостроковий, токен ServiceAccount який автоматично змінюється за допомогою API [TokenRequest](/docs/reference/kubernetes-api/authentication-resources/ token-request-v1/) замість цього. Ви можете отримати ці короткострокові токени, використовуючи наступні методи:
- Викликайте API
TokenRequestабо використовуйте клієнт API, такий якkubectl. Наприклад, ви можете використовувати командуkubectl create token. - Запитуйте монтований токен в томі projected у вашому маніфесті Podʼа. Kubernetes створює токен і монтує його в Pod. Токен автоматично анулюється, коли Pod, в якому він монтується, видаляється. Докладні відомості див. в розділі Запуск Podʼа за допомогою токена ServiceAccount.
Примітка:
Ви повинні створювати Secret токена ServiceAccount лише в тому випадку, якщо ви не можете використовувати APITokenRequest для отримання токена, і вам прийнятно з погляду безпеки зберігання постійного токена доступу у читабельному обʼєкті API. Для інструкцій див. Створення довгострокового API-токена для ServiceAccount вручну.При використанні цього типу Secret вам потрібно переконатися, що анотація kubernetes.io/service-account.name встановлена на наявне імʼя ServiceAccount. Якщо ви створюєте як Secret, так і обʼєкти ServiceAccount, ви повинні спочатку створити обʼєкт ServiceAccount.
Після створення Secret контролер Kubernetes заповнює деякі інші поля, такі як анотація kubernetes.io/service-account.uid, та ключ token в полі data, який заповнюється токеном автентифікації.
У наступному прикладі конфігурації оголошується Secret токена ServiceAccount:
apiVersion: v1
kind: Secret
metadata:
name: secret-sa-sample
annotations:
kubernetes.io/service-account.name: "sa-name"
type: kubernetes.io/service-account-token
data:
extra: YmFyCg==Після створення Secret дочекайтеся, коли Kubernetes заповнить ключ token в полі data.
Для отримання додаткової інформації про роботу ServiceAccounts перегляньте документацію по ServiceAccount. Ви також можете перевірити поле automountServiceAccountToken та поле serviceAccountName у Pod для отримання інформації про посилання на облікові дані ServiceAccount з Podʼів.
Secret конфігурації Docker
Якщо ви створюєте Secret для зберігання облікових даних для доступу до реєстру образів контейнерів, ви повинні використовувати одне з наступних значень type для цього Secret:
kubernetes.io/dockercfg: збереже серіалізований~/.dockercfg, який є старим форматом налаштування командного рядка Docker. У поліdataSecret міститься ключ.dockercfg, значення якого — це вміст файлу~/.dockercfg, закодованого у форматі base64.kubernetes.io/dockerconfigjson: збереже серіалізований JSON, який слідує тим же правилам формату, що й файл~/.docker/config.json, який є новим форматом для~/.dockercfg. У поліdataSecret має міститися ключ.dockerconfigjson, значення якого – це вміст файлу~/.docker/config.json, закодованого у форматі base64.
Нижче наведено приклад для Secret типу kubernetes.io/dockercfg:
apiVersion: v1
kind: Secret
metadata:
name: secret-dockercfg
type: kubernetes.io/dockercfg
data:
.dockercfg: |
eyJhdXRocyI6eyJodHRwczovL2V4YW1wbGUvdjEvIjp7ImF1dGgiOiJvcGVuc2VzYW1lIn19fQo= Примітка:
Якщо ви не хочете виконувати кодування у формат base64, ви можете вибрати використання поляstringData замість цього.При створенні Secret конфігурації Docker за допомогою маніфесту, API сервер перевіряє, чи існує відповідний ключ у полі data, і перевіряє, чи надане значення можна розпізнати як дійсний JSON. API сервер не перевіряє, чи є цей JSON фактично файлом конфігурації Docker.
Ви також можете використовувати kubectl для створення Secret для доступу до реєстру контейнерів, наприклад, коли у вас немає файлу конфігурації Docker:
kubectl create secret docker-registry secret-tiger-docker \
--docker-email=tiger@acme.example \
--docker-username=tiger \
--docker-password=pass1234 \
--docker-server=my-registry.example:5000
Ця команда створює Secret типу kubernetes.io/dockerconfigjson.
Отримайте поле .data.dockerconfigjson з цього нового Secret та розкодуйте дані:
kubectl get secret secret-tiger-docker -o jsonpath='{.data.*}' | base64 -d
Вихід еквівалентний наступному JSON-документу (який також є дійсним файлом конфігурації Docker):
{
"auths": {
"my-registry.example:5000": {
"username": "tiger",
"password": "pass1234",
"email": "tiger@acme.example",
"auth": "dGlnZXI6cGFzczEyMzQ="
}
}
}
Увага:
Значення auth закодовано у формат base64; воно зашифроване, але не є Secretним. Будь-хто, хто може прочитати цей Secret, може дізнатися токен доступу до реєстру.
Рекомендується використовувати постачальників облікових записів для динамічного і безпечного надання Secretʼів на запит.
Secret базової автентифікації
Тип kubernetes.io/basic-auth наданий для зберігання облікових даних, необхідних для базової автентифікації. При використанні цього типу Secret, поле data Secret повинно містити один з двох наступних ключів:
username: імʼя користувача для автентифікаціїpassword: пароль або токен для автентифікації
Обидва значення для цих ключів закодовані у формат base64. Ви також можете надати чіткий текст, використовуючи поле stringData у маніфесті Secret.
Наступний маніфест є прикладом Secret для базової автентифікації:
apiVersion: v1
kind: Secret
metadata:
name: secret-basic-auth
type: kubernetes.io/basic-auth
stringData:
username: admin # обовʼязкове поле для kubernetes.io/basic-auth
password: t0p-Secret # обовʼязкове поле для kubernetes.io/basic-authПримітка:
ПолеstringData для Secret не дуже підходить для застосування на боці сервера.Тип Secret для базової автентифікації наданий лише для зручності. Ви можете створити тип Opaque для облікових даних, які використовуються для базової автентифікації. Однак використання визначеного та публічного типу Secret (kubernetes.io/basic-auth) допомагає іншим людям зрозуміти призначення вашого Secret та встановлює домовленості для очікуваних назв ключів.
Secret для автентифікації SSH
Вбудований тип kubernetes.io/ssh-auth наданий для зберігання даних, що використовуються в автентифікації SSH. При використанні цього типу Secret, вам потрібно вказати пару ключ-значення ssh-privatekey в полі data (або stringData) як SSH-автентифікаційні дані для використання.
Наступний маніфест є прикладом Secret, який використовується для автентифікації SSH з використанням пари публічного/приватного ключів:
apiVersion: v1
kind: Secret
metadata:
name: secret-ssh-auth
type: kubernetes.io/ssh-auth
data:
# в цьомум прикладі поле data скорочене
ssh-privatekey: |
UG91cmluZzYlRW1vdGljb24lU2N1YmE= Тип Secret для автентифікації SSH наданий лише для зручності. Ви можете створити тип Opaque для облікових даних, які використовуються для автентифікації SSH. Однак використання визначеного та публічного типу Secret (kubernetes.io/ssh-auth) допомагає іншим людям зрозуміти призначення вашого Secret та встановлює домовленості для очікуваних назв ключів. API Kubernetes перевіряє, чи встановлені необхідні ключі для Secret цього типу.
Увага:
Приватні ключі SSH не встановлюють довіру між клієнтом SSH та сервером хосту самі по собі. Для зменшення ризику атак "man-in-the-middle" потрібен додатковий спосіб встановлення довіри, наприклад, файлknown_hosts, доданий до ConfigMap.TLS Secrets
Тип Secret kubernetes.io/tls призначений для зберігання сертифіката та його повʼязаного ключа, які зазвичай використовуються для TLS.
Одним з поширених використань TLS Secret є налаштування шифрування під час передачі для
Ingress, але ви також можете використовувати його з іншими ресурсами або безпосередньо у вашій роботі. При використанні цього типу Secret ключі tls.key та tls.crt повинні бути надані в полі data (або stringData) конфігурації Secret, хоча сервер API фактично не перевіряє значення кожного ключа.
Як альтернативу використанню stringData, ви можете використовувати поле data для надання сертифіката та приватного ключа у вигляді base64-кодованого тексту. Докладніше див. Обмеження для назв і даних Secret.
Наступний YAML містить приклад конфігурації TLS Secret:
apiVersion: v1
kind: Secret
metadata:
name: secret-tls
type: kubernetes.io/tls
data:
# значення закодовані в форматі base64, що приховує їх, але НЕ забезпечує
# жодного рівня конфіденційності
tls.crt: |
LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUNVakNDQWJzQ0FnMytNQTBHQ1NxR1NJYjNE
UUVCQlFVQU1JR2JNUXN3Q1FZRFZRUUdFd0pLVURFT01Bd0cKQTFVRUNCTUZWRzlyZVc4eEVEQU9C
Z05WQkFjVEIwTm9kVzh0YTNVeEVUQVBCZ05WQkFvVENFWnlZVzVyTkVSRQpNUmd3RmdZRFZRUUxF
dzlYWldKRFpYSjBJRk4xY0hCdmNuUXhHREFXQmdOVkJBTVREMFp5WVc1ck5FUkVJRmRsCllpQkRR
VEVqTUNFR0NTcUdTSWIzRFFFSkFSWVVjM1Z3Y0c5eWRFQm1jbUZ1YXpSa1pDNWpiMjB3SGhjTk1U
TXcKTVRFeE1EUTFNVE01V2hjTk1UZ3dNVEV3TURRMU1UTTVXakJMTVFzd0NRWURWUVFHREFKS1VE
RVBNQTBHQTFVRQpDQXdHWEZSdmEzbHZNUkV3RHdZRFZRUUtEQWhHY21GdWF6UkVSREVZTUJZR0Ex
VUVBd3dQZDNkM0xtVjRZVzF3CmJHVXVZMjl0TUlHYU1BMEdDU3FHU0liM0RRRUJBUVVBQTRHSUFE
Q0JoQUo5WThFaUhmeHhNL25PbjJTbkkxWHgKRHdPdEJEVDFKRjBReTliMVlKanV2YjdjaTEwZjVN
Vm1UQllqMUZTVWZNOU1vejJDVVFZdW4yRFljV29IcFA4ZQpqSG1BUFVrNVd5cDJRN1ArMjh1bklI
QkphVGZlQ09PekZSUFY2MEdTWWUzNmFScG04L3dVVm16eGFLOGtCOWVaCmhPN3F1TjdtSWQxL2pW
cTNKODhDQXdFQUFUQU5CZ2txaGtpRzl3MEJBUVVGQUFPQmdRQU1meTQzeE15OHh3QTUKVjF2T2NS
OEtyNWNaSXdtbFhCUU8xeFEzazlxSGtyNFlUY1JxTVQ5WjVKTm1rWHYxK2VSaGcwTi9WMW5NUTRZ
RgpnWXcxbnlESnBnOTduZUV4VzQyeXVlMFlHSDYyV1hYUUhyOVNVREgrRlowVnQvRGZsdklVTWRj
UUFEZjM4aU9zCjlQbG1kb3YrcE0vNCs5a1h5aDhSUEkzZXZ6OS9NQT09Ci0tLS0tRU5EIENFUlRJ
RklDQVRFLS0tLS0K
# У цьому прикладі, дані не є справжнім приватним ключем в форматі PEM
tls.key: |
RXhhbXBsZSBkYXRhIGZvciB0aGUgVExTIGNydCBmaWVsZA== Тип TLS Secret наданий лише для зручності. Ви можете створити тип Opaque для облікових даних, які використовуються для TLS-автентифікації. Однак використання визначеного та публічного типу Secret (kubernetes.io/tls) допомагає забезпечити однорідність формату Secret у вашому проєкті. Сервер API перевіряє, чи встановлені необхідні ключі для Secret цього типу.
Для створення TLS Secret за допомогою kubectl використовуйте підкоманду tls:
kubectl create secret tls my-tls-secret \
--cert=path/to/cert/file \
--key=path/to/key/file
Пара публічного/приватного ключа повинна бути створена заздалегідь. Публічний ключ сертифіката для --cert повинен бути закодований у .PEM форматі і повинен відповідати наданому приватному ключу для --key.
Secret bootstrap-токенів
Тип Secret bootstrap.kubernetes.io/token призначений для токенів, що використовуються під час процесу ініціалізації вузла. Він зберігає токени, які використовуються для підпису відомих ConfigMaps.
Secret токена ініціалізації зазвичай створюється в просторі імен kube-system і називається у формі bootstrap-token-<token-id>, де <token-id> — це 6-символьний
рядок ідентифікатора токена.
Як Kubernetes маніфест, Secret токена ініціалізації може виглядати наступним чином:
apiVersion: v1
kind: Secret
metadata:
name: bootstrap-token-5emitj
namespace: kube-system
type: bootstrap.kubernetes.io/token
data:
auth-extra-groups: c3lzdGVtOmJvb3RzdHJhcHBlcnM6a3ViZWFkbTpkZWZhdWx0LW5vZGUtdG9rZW4=
expiration: MjAyMC0wOS0xM1QwNDozOToxMFo=
token-id: NWVtaXRq
token-secret: a3E0Z2lodnN6emduMXAwcg==
usage-bootstrap-authentication: dHJ1ZQ==
usage-bootstrap-signing: dHJ1ZQ==У Secret токена ініціалізації вказані наступні ключі в data:
token-id: Випадковий рядок з 6 символів як ідентифікатор токена. Обовʼязковий.token-secret: Випадковий рядок з 16 символів як сам Secret токена. Обовʼязковий.description: Рядок, що призначений для користувачів, що описує, для чого використовується токен. Необовʼязковий.expiration: Абсолютний час UTC, відповідно до RFC3339, що вказує, коли дія токена має бути закінчена. Необовʼязковий.usage-bootstrap-<usage>: Логічний прапорець, який вказує додаткове використання для токена ініціалізації.auth-extra-groups: Список імен груп, розділених комами, які будуть автентифікуватися як додатково до групиsystem:bootstrappers.
Ви також можете надати значення в полі stringData Secret без їх base64 кодування:
apiVersion: v1
kind: Secret
metadata:
# Зверніть увагу, як названий Secret
name: bootstrap-token-5emitj
# Зазвичай, Secret з bootstrap token знаходиться в просторі імен kube-system
namespace: kube-system
type: bootstrap.kubernetes.io/token
stringData:
auth-extra-groups: "system:bootstrappers:kubeadm:default-node-token"
expiration: "2020-09-13T04:39:10Z"
# Цей ідентифікатор токена використовується в назві
token-id: "5emitj"
token-secret: "kq4gihvszzgn1p0r"
# Цей токен може бути використаний для автентифікації
usage-bootstrap-authentication: "true"
# і він може бути використаний для підпису
usage-bootstrap-signing: "true"Примітка:
ПолеstringData для Secret погано працює на боці сервера.Робота з Secret
Створення Secret
Є кілька способів створення Secret:
Обмеження щодо імен і даних Secret
Імʼя обʼєкта Secret повинно бути дійсним імʼям DNS-піддомену.
Ви можете вказати поля data і/або stringData при створенні файлу конфігурації для Secret. Поля data і stringData є необовʼязковими. Значення для всіх ключів у полі data повинні бути base64-кодованими рядками. Якщо перетворення у рядок base64 не є бажаним, ви можете вибрати поле stringData, яке приймає довільні рядки як значення.
Ключі data і stringData повинні складатися з буквено-цифрових символів, -, _ або .. Усі пари ключ-значення в полі stringData внутрішньо обʼєднуються в поле data. Якщо ключ зустрічається як у полі data, так і у полі stringData, значення, вказане у полі stringData, має пріоритет.
Обмеження розміру
Індивідуальні Secretʼи обмежені розміром 1 МБ. Це зроблено для того, щоб уникнути створення дуже великих Secret, які можуть вичерпати памʼять API-сервера та kubelet. Однак створення багатьох менших Secret також може вичерпати памʼять. Ви можете використовувати квоту ресурсів для обмеження кількості Secret (або інших ресурсів) в просторі імен.
Редагування Secret
Ви можете редагувати наявний Secret, якщо він не є незмінним. Для редагування Secret скористайтеся одним із наступних методів:
Ви також можете редагувати дані у Secret за допомогою інструменту Kustomize. Проте цей метод створює новий обʼєкт Secret з відредагованими даними.
Залежно від того, як ви створили Secret, а також від того, як Secret використовується в ваших Podʼах, оновлення існуючих обʼєктів Secret автоматично поширюються на Podʼи, які використовують дані. Для отримання додаткової інформації звертайтеся до розділу Використання Secret як файлів у Podʼі.
Використання Secret
Secret можна монтувати як томи даних або використовувати як змінні оточення для використання контейнером в Podʼі. Secret також можна використовувати іншими частинами системи, не надаючи прямого доступу до Podʼа. Наприклад, Secret можуть містити автентифікаційні дані, які інші частини системи повинні використовувати для взаємодії зовнішніми системами від вашого імені.
Джерела томів Secret перевіряються на наявність для того, щоб переконатися, що вказано посилання на обʼєкт дійсно вказує на обʼєкт типу Secret. Тому Secret повинен бути створений перед будь-якими Podʼами, які залежать від нього.
Якщо Secret не може бути отриманий (можливо, через те, що він не існує, або через тимчасову відсутність зʼєднання з сервером API), kubelet періодично повторює спробу запуску цього Podʼа. Крім того, kubelet також реєструє подію для цього Podʼа, включаючи деталі проблеми отримання Secret.
Необовʼязкові Secret
Коли ви посилаєтеся на Secret у Podʼі, ви можете позначити Secret як необовʼязковий, як у наступному прикладі. Якщо необовʼязковий Secret не існує, Kubernetes ігнорує його.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
optional: trueТипово Secret є обовʼязковими. Жоден з контейнерів Podʼа не розпочне роботу, доки всі обовʼязкові Secret не будуть доступні.
Якщо Pod посилається на певний ключ у необовʼязковому Secret і цей Secret існує, але відсутній зазначений ключ, Pod не запускається під час старту.
Використання Secret у вигляді файлів у Pod
Якщо ви хочете отримати доступ до даних з Secret у Podʼі, один із способів зробити це — це дозволити Kubernetes робити значення цього Secret доступним як файл у файловій системі одного або декількох контейнерів Podʼа.
Щоб це зробити, дивіться Створення Podʼа, який має доступ до секретних даних через Volume.
Коли том містить дані з Secret, а цей Secret оновлюється, Kubernetes відстежує це і оновлює дані в томі, використовуючи підхід з подальшою згодою.
Примітка:
Контейнер, який використовує Secret як том subPath, не отримує автоматичних оновлень Secret.Kubelet зберігає кеш поточних ключів та значень для Secret, які використовуються у томах для Podʼів на цьому вузлі. Ви можете налаштувати спосіб, яким kubelet виявляє зміни від кешованих значень. Поле configMapAndSecretChangeDetectionStrategy в конфігурації kubelet контролює стратегію, яку використовує kubelet. Стандартною стратегією є Watch.
Оновлення Secret можуть бути передані за допомогою механізму спостереження за API (стандартно), на основі кешу з визначеним часом життя або отримані зі API-сервера кластера в кожнному циклі синхронізації kubelet.
Як результат, загальна затримка від моменту оновлення Secret до моменту, коли нові ключі зʼявляються в Podʼі, може бути такою ж тривалою, як період синхронізації kubelet + затримка розповсюдження кешу, де затримка розповсюдження кешу залежить від обраного типу кешу (перший у списку це затримка розповсюдження спостереження, налаштований TTL кешу або нуль для прямого отримання).
Використання Secret як змінних оточення
Для використання Secret в змінних оточення в Podʼі:
- Для кожного контейнера у вашому описі Podʼа додайте змінну оточення для кожного ключа Secret, який ви хочете використовувати, у поле
env[].valueFrom.secretKeyRef. - Змініть свій образ і/або командний рядок так, щоб програма шукала значення у вказаних змінних оточення.
Для отримання інструкцій дивіться Визначення змінних оточення контейнера за допомогою даних Secret.
Важливо зауважити, що діапазон символів, дозволених для назв змінних середовища в Podʼах, обмежений. Якщо будь-які ключі не відповідають правилам, ці ключі не будуть доступні вашому контейнеру, хоча Pod може бути запущений.
Використання Secret для витягування образів контейнерів
Якщо ви хочете отримувати образи контейнерів з приватного репозиторію, вам потрібен спосіб автентифікації для kubelet на кожному вузлі для доступу до цього репозиторію. Ви можете налаштувати Secret для витягування образів для досягнення цієї мети. Ці Secret налаштовані на рівні Pod.
Використання imagePullSecrets
Поле imagePullSecrets є списком посилань на Secret в тому ж просторі імен. Ви можете використовувати imagePullSecrets, щоб передати Secret, який містить пароль Docker (або іншого) репозиторію образів, в kubelet. Kubelet використовує цю інформацію для витягування приватного образу від імені вашого Podʼа. Для отримання додаткової інформації про поле imagePullSecrets, дивіться PodSpec API.
Ручне вказання imagePullSecret
Ви можете дізнатися, як вказати imagePullSecrets, переглянувши документацію про образи контейнерів.
Організація автоматичного приєднання imagePullSecrets
Ви можете вручну створити imagePullSecrets та посилатися на них з ServiceAccount. Будь-які Podʼи, створені з цим ServiceAccount або створені з цим ServiceAccount, отримають своє поле imagePullSecrets, встановлене на відповідне для сервісного облікового запису. Дивіться Додавання ImagePullSecrets до Service Account для детального пояснення цього процесу.
Використання Secret зі статичними Podʼами
Ви не можете використовувати ConfigMaps або Secrets зі статичними Podʼами.
Незмінні Secret
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.21 [stable]Kubernetes дозволяє вам позначати певні Secret (і ConfigMaps) як незмінні. Запобігання змінам даних існуючого Secret має наступні переваги:
- захищає вас від випадкових (або небажаних) оновлень, які можуть призвести до відмов застосунків
- (для кластерів, що широко використовують Secret — щонайменше десятки тисяч унікальних монтувань Secret у Podʼи), перехід до незмінних Secret покращує продуктивність вашого кластера шляхом значного зменшення навантаження на kube-apiserver. kubeletʼу не потрібно підтримувати [watch] за будь-якими Secret, які позначені як незмінні.
Позначення Secret як незмінного
Ви можете створити незмінний Secret, встановивши поле immutable в true. Наприклад,
apiVersion: v1
kind: Secret
metadata: ...
data: ...
immutable: true
Ви також можете оновити будь-який наявний змінний Secret, щоб зробити його незмінним.
Примітка:
Як тільки Secret або ConfigMap позначений як незмінний, цю зміну неможливо скасувати чи змінити зміст поляdata. Ви можете тільки видалити і знову створити Secret. Наявні Podʼи зберігають точку монтування для видаленого Secret — рекомендується перестворити ці Podʼи.Інформаційна безпека для Secret
Хоча ConfigMap і Secret працюють схоже, Kubernetes застосовує додаткові заходи захисту для обʼєктів Secret.
Secret часто містять значення, які охоплюють широкий спектр важливостей, багато з яких можуть викликати ескалації всередині Kubernetes (наприклад, токени облікових записів служби) та зовнішніх систем. Навіть якщо окремий застосунок може мати на меті використання Secret, з якими він очікує взаємодіяти, інші застосунки в тому ж просторі імен можуть зробити ці припущення недійсними.
Secret буде відправлений на вузол тільки у випадку, якщо на цьому вузлі є Pod, якому він потрібен. Для монтування Secret Podʼи kubelet зберігає копію даних у tmpfs, щоб конфіденційні дані не записувалися у носії з довгостроковим зберіганням. Коли Pod, який залежить від Secret, видаляється, kubelet видаляє свою локальну копію конфіденційних даних з Secret.
У Podʼі може бути кілька контейнерів. Типово контейнери, які ви визначаєте, мають доступ тільки до службового стандартного облікового запису та повʼязаного з ним Secret. Вам потрібно явно визначити змінні середовища або відобразити том у контейнері, щоб надати доступ до будь-якого іншого Secret.
Може бути Secret для кількох Podʼів на тому ж вузлі. Проте тільки Secretʼи, які запитує Pod, можливо бачити всередині його контейнерів. Таким чином, один Pod не має доступу до Secretʼів іншого Podʼа.
Налаштування доступу за принципом найменшого дозволу до Secret
Щоб посилити заходи безпеки навколо Secrets, використовуйте окремі простори імен для ізоляції доступу до змонтованих секретів.
Попередження:
Будь-які контейнери, які працюють з параметромprivileged: true на вузлі, можуть отримати доступ до всіх Secret, що використовуються на цьому вузлі.Що далі
- Для настанов щодо керування та покращення безпеки ваших Secret перегляньте Рекомендаціх щодо Secret в Kubernetes.
- Дізнайтеся, як керувати Secret за допомогою
kubectl - Дізнайтеся, як керувати Secret за допомогою конфігураційного файлу
- Дізнайтеся, як керувати Secret за допомогою kustomize
- Прочитайте довідник API для
Secret.
7.4 - Керування ресурсами Podʼів та Контейнерів
Коли ви визначаєте Pod, ви можете додатково вказати, скільки кожного ресурсу потребує контейнер. Найпоширеніші ресурси для вказання — це процесор та памʼять (RAM); є й інші.
Коли ви вказуєте запит ресурсів для контейнерів в Podʼі, kube-scheduler використовує цю інформацію для вибору вузла, на який розмістити Pod. Коли ви вказуєте обмеження ресурсів для контейнера, kubelet забезпечує виконання цих обмежень, щоб запущений контейнер не міг використовувати більше цього ресурсу, ніж обмеження, яке ви встановили. Крім того, kubelet резервує принаймні ту кількість запитуваних ресурсів спеціально для використання цим контейнером.
Запити та обмеження
Якщо вузол, на якому запущений Pod, має достатньо вільного ресурсу, то можливе (і дозволено), щоб контейнер використовував більше ресурсу, ніж його запит для цього ресурсу вказує.
Наприклад, якщо ви встановите запит memory 256 МіБ для контейнера, і цей контейнер буде в Pod, запланованому на вузол з 8 ГіБ памʼяті та без інших Pod, то контейнер може спробувати використати більше оперативної памʼяті.
Обмеження, то вже інша справа. Обидва обмеження cpu та memory застосовуються kubletʼом (та середовищем виконання контейнерів), і, зрештою, застосовуються ядром. На вузлах Linux, ядро накладає обмеження за допомогою cgroups. Поведінка застосування обмежень cpu та memory відрізняється.
Застосування обмеження cpu виконується через зниження частоти доступу до процесора. Коли контейенер надближається до свого обмеження, ядро обмежує доступ до процесора, відповідно до обмеженнь контейнера. Тож, обмеження cpu є жорстким обмеженням, що застосовує ядро.
Застосування обмеження memory виконується ядром за допомогою припинення процесів через механізм браку памʼяті (OOM — Out Of Memory kills). Якщо контейнер намагається використати більше памʼяті, ніж його обмеження, ядро може припинити його роботу. Однак, припинення роботи контейнера відбувається тільки тоді, коли ядро виявляє тиск на памʼять. Це означає, що обмеження memory застосовується реактивно. Контенер може використовувати більше памʼяті, ніж його обмеження, однак, якщо він перевищує ліміт, то його робота може бути припинена.
Примітка:
Альфа версіяMemoryQoS є спробою додати більш витісняюче обмеження для памʼяті (на противагу реактивному обмеженню пам'яті за допомогою OOM killer). Однак роботу в цьому напрямку зупинено через можливу ситуацію з блокуванням, яку може спричинити контейнер із високим споживанням пам’яті.Примітка:
Якщо ви вказали обмеження для ресурсу, але не вказали жодного запиту, і жодний механізм часу входу не застосував стандартного значення запиту для цього ресурсу, то Kubernetes скопіює обмеження яке ви вказали та використовує його як запитане значення для ресурсу.Типи ресурсів
ЦП та памʼять кожен є типом ресурсу. Тип ресурсу має базові одиниці вимірювання. ЦП представляє обчислювальні ресурси та вказується в одиницях ЦП Kubernetes. Памʼять вказується в байтах. Для робочих завдань на Linux ви можете вказати huge page ресурсів. Huge page є функцією, специфічною для Linux, де ядро вузла виділяє блоки памʼяті, що значно більше, ніж розмір стандартної сторінки.
Наприклад, у системі, де розмір стандартної сторінки становить 4 КіБ, ви можете вказати обмеження hugepages-2Mi: 80Mi. Якщо контейнер намагається виділити більше ніж 40 2МіБ великих сторінок (всього 80 МіБ), то це виділення не вдасться.
Примітка:
Ви не можете перевищити ресурсиhugepages-*. Це відрізняється від ресурсів memory та cpu.ЦП та памʼять спільно називаються обчислювальними ресурсами або ресурсами. Обчислювальні ресурси – це вимірювальні величини, які можна запитувати, виділяти та використовувати. Вони відрізняються від ресурсів API. Ресурси API, такі як Pod та Service, є обʼєктами, які можна читати та змінювати за допомогою сервера API Kubernetes.
Запити та обмеження ресурсів для Podʼа та контейнера
Для кожного контейнера ви можете вказати обмеження та запити ресурсів, включаючи наступне:
spec.containers[].resources.limits.cpuspec.containers[].resources.limits.memoryspec.containers[].resources.limits.hugepages-<size>spec.containers[].resources.requests.cpuspec.containers[].resources.requests.memoryspec.containers[].resources.requests.hugepages-<size>
Хоча ви можете вказувати запити та обмеження тільки для окремих контейнерів, також корисно думати про загальні запити та обмеження ресурсів для Podʼа. Для певного ресурсу запит/обмеження ресурсів Podʼа — це сума запитів/обмежень цього типу для кожного контейнера в Podʼі.
Специфікація ресурсів на рівні Podʼів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [alpha] (стандартно увімкнено: false)Починаючи з Kubernetes 1.32, ви також можете вказувати запити на ресурси та ліміти на рівні Pod. На рівні Pod, Kubernetes 1.32 підтримує запити на ресурси або ліміти лише для певних типів ресурсів: cpu та/або memory. Наразі ця можливість знаходиться у альфа-версії і з увімкненою функцією Kubernetes дозволяє вам декларувати загальний бюджет ресурсів для Pod, що є особливо корисним при роботі з великою кількістю контейнерів, де може бути важко точно визначити індивідуальні потреби у ресурсах. Крім того, це дає змогу контейнерам в рамках Podʼа ділитися один з одним ресурсами, що простоюють, покращуючи використання ресурсів.
Для Podʼа ви можете вказати ліміти ресурсів і запити на процесор і памʼять, включивши наступне:
spec.resources.limits.cpuspec.resources.limits.memoryspec.resources.requests.cpuspec.resources.requests.memory
Одиниці виміру ресурсів в Kubernetes
Одиниці виміру ресурсів процесора
Обмеження та запити ресурсів процесора вимірюються в одиницях cpu. У Kubernetes 1 одиниця CPU еквівалентна 1 фізичному ядру процесора або 1 віртуальному ядру, залежно від того, чи є вузол фізичним хостом або віртуальною машиною, яка працює всередині фізичної машини.
Допускаються дробові запити. Коли ви визначаєте контейнер з spec.containers[].resources.requests.cpu встановленою на 0.5, ви просите вдвічі менше часу CPU порівняно з тим, якщо ви запросили 1.0 CPU. Для одиниць ресурсів процесора вираз кількості 0.1 еквівалентний виразу 100m, що може бути прочитано як "сто міліпроцесорів". Деякі люди кажуть "сто міліядер", і це розуміється так само.
Ресурс CPU завжди вказується як абсолютна кількість ресурсу, ніколи як відносна кількість. Наприклад, 500m CPU представляє приблизно ту саму обчислювальну потужність, не важливо чи цей контейнер працює на одноядерній, двоядерній або 48-ядерній машині.
Примітка:
Kubernetes не дозволяє вказувати ресурси CPU з точністю вище 1m або 0.001 CPU. Щоб уникнути випадкового використання неприпустимої кількості CPU, корисно вказувати одиниці CPU, використовуючи форму міліCPU замість десяткової форми при використанні менше ніж 1 одиниця CPU.
Наприклад, у вас є Pod, який використовує 5m або 0.005 CPU, і ви хочете зменшити його ресурси CPU. Використовуючи десяткову форму, важко помітити, що 0.0005 CPU є неприпустимим значенням, тоді як використовуючи форму міліCPU, легше помітити, що 0.5m є неприпустимим значенням.
Одиниці виміру ресурсів памʼяті
Обмеження та запити для memory вимірюються в байтах. Ви можете вказувати памʼять як звичайне ціле число або як число з плаваючою комою, використовуючи один з наступних суфіксів кількості: E, P, T, G, M, k. Ви також можете використовувати еквіваленти степенів двійки: Ei, Pi, Ti, Gi, Mi, Ki. Наприклад, наступне приблизно представляє те ж саме значення:
128974848, 129e6, 129M, 128974848000m, 123Mi
Звертайте увагу на регістр суфіксів. Якщо ви запитуєте 400m памʼяті, це запит на 0.4 байта. Той, хто вводить це, ймовірно, мав на увазі запросити 400 мебібайтів (400Mi)
або 400 мегабайтів (400M).
Приклад ресурсів контейнера
У наступному Podʼі є два контейнери. Обидва контейнери визначені з запитом на 0,25 CPU і 64 МіБ (226 байт) памʼяті. Кожен контейнер має обмеження в 0,5 CPU та 128 МіБ памʼяті. Можна сказати, що у Podʼі є запит на 0,5 CPU та 128 МіБ памʼяті, та обмеження в 1 CPU та 256 МіБ памʼяті.
---
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
Приклад ресурсів Podʼа
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [alpha] (стандартно увімкнено: false)Наступний Pod має явний запит на 1 CPU та 100 MiB памʼяті, а також явний ліміт на 1 CPU та 200 MiB памʼяті. Контейнер pod-resources-demo-ctr-1 має явні запити та обмеження. Однак, контейнер pod-resources-demo-ctr-2 буде просто ділити ресурси, доступні в межах ресурсу Pod, оскільки він не має явних запитів і обмежень.
apiVersion: v1
kind: Pod
metadata:
name: pod-resources-demo
namespace: pod-resources-example
spec:
resources:
limits:
cpu: "1"
memory: "200Mi"
requests:
cpu: "1"
memory: "100Mi"
containers:
- name: pod-resources-demo-ctr-1
image: nginx
resources:
limits:
cpu: "0.5"
memory: "100Mi"
requests:
cpu: "0.5"
memory: "50Mi"
- name: pod-resources-demo-ctr-2
image: fedora
command:
- sleep
- inf
Як Podʼи з запитаними ресурсами плануються
Коли ви створюєте Pod, планувальник Kubernetes вибирає вузол, на якому Pod буде запущено. Кожен вузол має максимальну місткість для кожного з типів ресурсів: кількість процесорних ядер (CPU) та обсяг памʼяті, які він може надати для Podʼів. Планувальник забезпечує, що для кожного типу ресурсів сума запитів ресурсів запланованих контейнерів буде менше, ніж місткість вузла. Зверніть увагу, що навіть якщо фактичне використання ресурсів CPU або памʼяті на вузлі дуже низьке, планувальник все одно відмовляється розміщувати Pod на вузлі, якщо перевірка місткості не пройшла успішно. Це захищає від нестачі ресурсів на вузлі, коли пізніше збільшується використання ресурсів, наприклад, під час денного піка запитів.
Як Kubernetes застосовує запити на ресурси та обмеження
Коли kubelet запускає контейнер як частину Podʼа, він передає запити та обмеження для памʼяті та CPU цього контейнера до середовища виконання контейнера.
У Linux середовище виконання контейнера зазвичай налаштовує контрольні групи (cgroups) ядра, які застосовують і виконують обмеження, що ви визначили.
- Обмеження CPU встановлює жорсткий ліміт на те, скільки часу процесора контейнер може використовувати. Протягом кожного інтервалу планування (часового відрізка) ядро Linux перевіряє, чи перевищується це обмеження; якщо так, ядро чекає, перш ніж дозволити цій групі продовжити виконання.
- Запит CPU зазвичай визначає вагу. Якщо кілька різних контейнерів (cgroups) хочуть працювати на конкуруючій системі, робочі навантаження з більшими запитами CPU отримують більше часу CPU, ніж робочі навантаження з малими запитами.
- Запит памʼяті в основному використовується під час планування Podʼа (Kubernetes). На вузлі, що використовує cgroups v2, середовище виконання контейнера може використовувати запит памʼяті як підказку для встановлення
memory.minтаmemory.low. - Обмеження памʼяті встановлює обмеження памʼяті для цієї контрольної групи. Якщо контейнер намагається виділити більше памʼяті, ніж це обмеження, підсистема управління памʼяттю Linux активується і, зазвичай, втручається, зупиняючи один з процесів у контейнері, який намагався виділити памʼять. Якщо цей процес є PID 1 контейнера, і контейнер позначений як можливий до перезапуску, Kubernetes перезапускає контейнер.
- Обмеження памʼяті для Podʼа або контейнера також може застосовуватися до сторінок в памʼяті, резервованих томами, як от
emptyDir. Kubelet відстежуєtmpfsтомиemptyDirяк використання памʼяті контейнера, а не як локальне ефемерне сховище. При використанніemptyDirв памʼяті, обовʼязково ознайомтеся з примітками нижче.
Якщо контейнер перевищує свій запит на памʼять і вузол, на якому він працює, стикається з браком памʼяті взагалі, ймовірно, що Pod, якому належить цей контейнер, буде виселено.
Контейнер може або не може дозволяти перевищувати своє обмеження CPU протягом тривалого часу. Однак середовища виконання контейнерів не припиняють роботу Podʼа або контейнерів через надмірне використання CPU.
Щоб визначити, чи не можна розмістити контейнер або, чи його роботи примусово припиняється через обмеження ресурсів, див. Налагодження.
Моніторинг використання обчислювальних ресурсів та ресурсів памʼяті
kubelet повідомляє про використання ресурсів Podʼа як частину статусу Podʼа.
Якщо в вашому кластері доступні інструменти для моніторингу, то використання ресурсів Podʼа можна отримати або безпосередньо з Metrics API, або з вашого інструменту моніторингу.
Міркування щодо томів emptyDir, що зберігаються в памʼяті
Увага:
Якщо ви не вказуєтеsizeLimit для emptyDir тому, цей том може використовувати до граничного обсягу памʼяті цього Podʼа (Pod.spec.containers[].resources.limits.memory). Якщо ви не встановлюєте граничний обсяг памʼяті, Pod не має верхньої межі на споживання памʼяті і може використовувати всю доступну памʼять на вузлі. Kubernetes планує Podʼи на основі запитів на ресурси (Pod.spec.containers[].resources.requests) і не враховує використання памʼяті понад запит при вирішенні, чи може інший Pod розміститися на даному вузлі. Це може призвести до відмови в обслуговуванні та змусити ОС виконати обробку нестачі памʼяті (OOM). Можливо створити будь-яку кількість emptyDir, які потенційно можуть використовувати всю доступну памʼять на вузлі, що робить OOM більш ймовірним.З точки зору управління памʼяттю, є деякі подібності між використанням памʼяті як робочої області процесу і використанням памʼяті для emptyDir, що зберігається в памʼяті. Але при використанні памʼяті як том, як у випадку з emptyDir, що зберігається в памʼяті, є додаткові моменти, на які слід звернути увагу:
- Файли, збережені в томі, що зберігається в памʼяті, майже повністю управляються застосунком користувча. На відміну від використання памʼяті як робочої області процесу, ви не можете покладатися на такі речі, як збір сміття на рівні мови програмування.
- Мета запису файлів в том полягає в збереженні даних або їх передачі між застосунками. Ні Kubernetes, ні ОС не можуть автоматично видаляти файли з тому, тому памʼять, яку займають ці файли, не може бути відновлена, коли система або Pod відчувають нестачу памʼяті.
- Томи
emptyDir, що зберігаються в памʼяті, корисні через свою продуктивність, але памʼять зазвичай набагато менша за розміром і набагато дорожча за інші носії, такі як диски або SSD. Використання великої кількості памʼяті для томівemptyDirможе вплинути на нормальну роботу вашого Podʼа або всього вузла, тому їх слід використовувати обережно.
Якщо ви адмініструєте кластер або простір імен, ви також можете встановити ResourceQuota, що обмежує використання памʼяті; також може бути корисно визначити LimitRange для додаткового забезпечення обмежень. Якщо ви вказуєте spec.containers[].resources.limits.memory для кожного Podʼа, то максимальний розмір тому emptyDir буде дорівнювати граничному обсягу памʼяті Podʼа.
Як альтернатива, адміністратор кластера може забезпечити дотримання обмежень на розмір томів emptyDir в нових Podʼах, використовуючи механізм політики, такий як ValidationAdmissionPolicy.
Локальне тимчасове сховище
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.25 [stable]На вузлах існує локальне тимчасове сховище, яке підтримується локально приєднаними пристроями для запису або іноді ОЗУ. "Тимчасове" означає, що не існує гарантії тривалості.
Podʼи використовують тимчасове локальне сховище для тимчасового простору, кешування та для логів. kubelet може надавати тимчасовий простір Podʼам, використовуючи локальне тимчасове сховище для підключення emptyDir
тому до контейнерів.
Крім того, kubelet використовує цей тип сховища для збереження логів контейнерів на рівні вузла, образів контейнерів та шарів з можливістю запису запущених контейнерів.
Увага:
Якщо вузол виходить з ладу, дані у його тимчасовому сховищі можуть бути втрачені. Ваші програми не можуть розраховувати на будь-які SLA щодо продуктивності (наприклад, IOPS диска) з локального тимчасового сховища.Примітка:
Щоб квота ресурсів працювала на тимчасовому сховищі, потрібно зробити дві речі:
- Адміністратор встановлює обмеження ресурсів для тимчасового сховища в просторі імен.
- Користувач повинен вказати обмеження для ресурсу тимчасового сховища в специфікації Podʼа.
Якщо користувач не вказує обмеження ресурсу тимчасового сховища в специфікації Podʼа, то обмеження ресурсу не накладається на тимчасове сховище.
Kubernetes дозволяє відстежувати, резервувати та обмежувати обсяг тимчасового локального сховища, яке може використовувати Pod.
Налаштування для локального тимчасового сховища
Kubernetes підтримує два способи налаштування локального тимчасового сховища на вузлі:
У цій конфігурації ви розміщуєте всі різновиди тимчасових локальних даних (таких як тимчасові томи emptyDir, шари з можливістю запису, образи контейнерів, логи) в одній файловій системі. Найефективніший спосіб налаштування kubelet — призначити цю файлову систему для даних Kubernetes (kubelet).
Kubelet також записує логи контейнерів на рівні вузла та обробляє їх аналогічно до тимчасового локального сховища.
Kubelet записує логи в файли всередині свого налаштованого каталогу журналів (/var/log типово); та має базовий каталог для інших локально збережених даних (/var/lib/kubelet типово).
Зазвичай як /var/lib/kubelet, так і /var/log знаходяться на кореневій файловій системі системи, і kubelet розроблений з урахуванням цієї структури.
Ваш вузол може мати стільки інших файлових систем, не використовуваних для Kubernetes, скільки вам потрібно.
Ви маєте файлову систему на вузлі, яку використовуєте для тимчасових даних, які надходять від запущених Podʼів: логи та томи emptyDir. Ви можете використовувати цю файлову систему для інших даних (наприклад: системні логи, не повʼязані з Kubernetes); це може навіть бути кореневою файловою системою.
Kubelet також записує логи контейнерів на рівні вузла у першу файлову систему та обробляє їх аналогічно до тимчасового локального сховища.
Ви також використовуєте окрему файлову систему, яка базується на іншому логічному пристрої зберігання. У цій конфігурації каталог, де ви вказуєте kubelet розміщувати шари образів контейнерів та шари з можливістю запису, знаходиться на цій другій файловій системі.
Перша файлова система не містить жодних шарів образів або шарів з можливістью запису.
Ваш вузол може мати стільки інших файлових систем, не використовуваних для Kubernetes, скільки вам потрібно.
Kubelet може вимірювати, скільки локального сховища він використовує. Він робить це, якщо ви налаштували вузол за однією з підтримуваних конфігурацій для локального тимчасового сховища.
Якщо у вас інша конфігурація, то kubelet не застосовує обмеження ресурсів для тимчасового локального сховища.
Примітка:
Kubelet відстежує тимчасові томиtmpfs як використання памʼяті контейнера, а не як локальне тимчасове сховище.Примітка:
Kubelet відстежує тільки кореневу файлову систему для тимчасового сховища. Розкладки ОС, які монтували окремий диск у/var/lib/kubelet або /var/lib/containers, не будуть правильно відображати тимчасове сховище.Налаштування запитів та обмежень для локального тимчасового сховища
Ви можете вказати ephemeral-storage для керування локальним тимчасовим сховищем. Кожен контейнер Podʼа може вказати одне або обидва з наступного:
spec.containers[].resources.limits.ephemeral-storagespec.containers[].resources.requests.ephemeral-storage
Обмеження та запити для ephemeral-storage вимірюються в кількості байтів. Ви можете виражати сховище як звичайне ціле число або як число з плаваючою точкою, використовуючи один з наступних суфіксів: E, P, T, G, M, k. Ви також можете використовувати еквіваленти степенів двійки: Ei, Pi, Ti, Gi, Mi, Ki. Наприклад, наступні кількості приблизно представляють одне й те ж значення:
128974848129e6129M123Mi
Звертайте увагу на регістр суфіксів. Якщо ви запитуєте 400m тимчасового сховища, це запит на 0,4 байти. Хтось, хто вводить це, мабуть, мав на меті запросити 400 мебібайтів (400Mi) або 400 мегабайтів (400M).
У наступному прикладі Pod має два контейнери. Кожен контейнер має запит на 2 гігабайти локального тимчасового сховища. Кожен контейнер має обмеження на 4 гігабайти локального тимчасового сховища. Отже, у Podʼа запит на 4 гігабайти локального тимчасового сховища, і обмеження на 8 ГіБ локального тимчасового сховища. З цього обмеження 500 Мі може бути витрачено на тимчасовий том emptyDir.
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
ephemeral-storage: "2Gi"
limits:
ephemeral-storage: "4Gi"
volumeMounts:
- name: ephemeral
mountPath: "/tmp"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
ephemeral-storage: "2Gi"
limits:
ephemeral-storage: "4Gi"
volumeMounts:
- name: ephemeral
mountPath: "/tmp"
volumes:
- name: ephemeral
emptyDir:
sizeLimit: 500Mi
Як розміщуються Podʼи з запитами на локальне тимчасове сховище
При створенні Podʼа планувальник Kubernetes вибирає вузол, на якому буде виконуватися Под. Кожен вузол має максимальну кількість локального тимчасового сховища, яке він може надати для Podʼів. Для отримання додаткової інформації дивіться розділ Виділення ресурсів вузла.
Планувальник забезпечує те, щоб сума запитів ресурсів запланованих контейнерів була меншою за потужність вузла.
Керування використанням локального тимчасового сховища
Якщо kubelet керує локальним тимчасовим сховищем як ресурсом, тоді kubelet вимірює використання сховища у таких областях:
emptyDirтоми, за винятком tmpfsemptyDirтомів- каталоги, де зберігаються логи на рівні вузла
- шари контейнера з можливістю запису
Якщо Pod використовує більше тимчасового сховища, ніж дозволяється, kubelet встановлює сигнал виселення, який викликає виселення Podʼа.
Для ізоляції на рівні контейнера, якщо записуваний шар контейнера та використання логу перевищують обмеження щодо сховища, то kubelet позначає Pod для виселення.
Для ізоляції на рівні Podʼа kubelet визначає загальне обмеження сховища для Podʼа, підсумовуючи обмеження для контейнерів у цьому Podʼі. У цьому випадку, якщо сума використання локального тимчасового сховища з усіх контейнерів та emptyDir томів Podʼа перевищує загальне обмеження сховища для Podʼа, то kubelet також позначає Pod для виселення.
Увага:
Якщо kubelet не вимірює локальне тимчасове сховище, тоді Pod, який перевищує своє обмеження локального сховища, не буде виселено за порушення обмежень ресурсів локального сховища.
Проте, якщо простір файлової системи для записуваних шарів контейнерів, журналів на рівні вузла або emptyDir томів стає малим, вузол встановлює для себе позначку недостатності місця у локальному сховищі, і ця позначка викликає виселення будь-яких Podʼів, які не толерують цю позначку. Дивіться підтримані конфігурації для локального тимчасового сховища.
kubelet підтримує різні способи вимірювання використання сховища Podʼа:
kubelet виконує регулярні заплановані перевірки, які сканують кожний emptyDir том, каталог логів контейнера та записуваний шар контейнера.
Під час сканування вимірюється обсяг використаного простору.
Примітка:
У цьому режимі kubelet не відстежує відкриті дескриптори файлів для видалених файлів.
Якщо ви (або контейнер) створюєте файл всередині emptyDir тому, потім щось відкриває цей файл, і ви видаляєте файл, поки він ще відкритий, то inode для видаленого файлу залишається до тих пір, поки ви не закриєте цей файл, але kubelet не класифікує цей простір як використаний.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [beta] (стандартно увімкнено: false)Квоти проєктів — це функціональність на рівні операційної системи для управління використанням сховища у файлових системах. У Kubernetes ви можете ввімкнути квоти проєктів для моніторингу використання сховища. Переконайтеся, що файлова система, яка підтримує emptyDir томи, на вузлі надає підтримку квот проєктів. Наприклад, XFS та ext4fs пропонують квоти проєктів.
Примітка:
Квоти проєктів дозволяють вам відслідковувати використання сховища, вони не встановлюють обмеження.Kubernetes використовує ідентифікатори проєктів, що починаються з 1048576. Використані ідентифікатори зареєстровані в /etc/projects та /etc/projid. Якщо ідентифікатори проєктів у цьому діапазоні використовуються для інших цілей у системі, ці ідентифікатори проєктів повинні бути зареєстровані в /etc/projects та /etc/projid, щоб Kubernetes не використовував їх.
Квоти є швидкими та точними, ніж сканування каталогів. Коли каталог призначений для проєкту, всі файли, створені в каталозі, створюються в цьому проєкті, і ядро просто відстежує, скільки блоків використовується файлами в цьому проєкті. Якщо файл створений і видалений, але має відкритий файловий дескриптор, він продовжує споживати місце. Відстеження квот точно відображає цей простір, тоді як сканування каталогів не враховує місце, використане видаленими файлами.
Щоб використовувати квоти для відстеження використання ресурсів Podʼів, Pod повинен знаходитися в просторі імен користувача. У просторах імен користувачів ядро обмежує зміни ідентифікаторів проєктів у файловій системі, забезпечуючи надійність зберігання метрик, розрахованих за квотами.
Якщо ви хочете використовувати квоти проєктів, вам потрібно:
Увімкнути функціональну можливість
LocalStorageCapacityIsolationFSQuotaMonitoring=trueвикористовуючи полеfeatureGatesв конфігурації kubelet.Переконайтеся, що функціональну можливість
UserNamespacesSupportувімкнено, і що ядро, реалізація CRI та середовище виконання OCI підтримують простори імен користувачів.Переконайтеся, що коренева файлова система (або додаткова файлова система запуску) має увімкнену підтримку квот проєктів. Всі файлові системи XFS підтримують квоти проєктів. Для файлових систем ext4fs вам потрібно увімкнути функцію відстеження квот проєктів допоки файлова система не змонтована.
# Для ext4, з /dev/block-device, не змонтовано sudo tune2fs -O project -Q prjquota /dev/block-deviceПереконайтеся, що коренева файлова система (або додаткова файлова система запуску) змонтована з увімкненими квотами проєктів. Для XFS та ext4fs параметр монтування має назву
prjquota.
Якщо ви не хочете використовувати квоти проєкту, вам слід зробити так:
- Вимкнути функціональну можливість
LocalStorageCapacityIsolationFSQuotaMonitoringвикористовуючи полеfeatureGatesв kubelet configuration.
Розширені ресурси
Розширені ресурси — це повністю кваліфіковані імена ресурсів поза доменом kubernetes.io. Вони дозволяють операторам кластера оголошувати, а користувачам використовувати ресурси, які не вбудовані в Kubernetes.
Щоб скористатися Розширеними ресурсами, потрібно виконати два кроки. По-перше, оператор кластера повинен оголошувати Розширений Ресурс. По-друге, користувачі повинні запитувати Розширений Ресурс в Podʼах.
Керування розширеними ресурсами
Ресурси на рівні вузла
Ресурси на рівні вузла повʼязані з вузлами.
Керовані ресурси втулків пристроїв
Дивіться Втулок пристроїв щодо того, як оголошувати ресурси, що керуються втулком пристроїв на кожному вузлі.
Інші ресурси
Щоб оголошувати новий розширений ресурс на рівні вузла, оператор кластера може надіслати HTTP-запит типу PATCH до API-сервера, щоб вказати доступну кількість в полі status.capacity для вузла у кластері. Після цієї операції поле status.capacity вузла буде містити новий ресурс. Поле status.allocatable оновлюється автоматично з новим ресурсом асинхронно за допомогою kubelet.
Оскільки планувальник використовує значення status.allocatable вузла при оцінці придатності Podʼа, планувальник враховує нове значення лише після цього асинхронного оновлення. Між моментом зміни потужності вузла новим ресурсом і часом, коли перший Pod, який запитує ресурс, може бути запланований на цьому вузлі, може відбуватися коротка затримка.
Приклад:
Нижче наведено приклад використання curl для формування HTTP-запиту, який оголошує пʼять ресурсів "example.com/foo" на вузлі k8s-node-1, майстер якого k8s-master.
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1foo", "value": "5"}]' \
http://k8s-master:8080/api/v1/nodes/k8s-node-1/status
Примітка:
У запиті~1 — це кодування символу / в шляху патча. Значення операційного шляху у JSON-Patch інтерпретується як JSON-вказівник. Для отримання докладнішої інформації дивіться RFC 6901, розділ 3.Ресурси на рівні кластера
Ресурси на рівні кластера не повʼязані з вузлами. Зазвичай ними керують розширювачі планувальника, які відповідають за споживання ресурсів і квоту ресурсів.
Ви можете вказати розширені ресурси, які обробляються розширювачами планувальника, в конфігурації планувальника.
Приклад:
Наступна конфігурація для політики планувальника вказує на те, що ресурс на рівні кластера "example.com/foo" обробляється розширювачем планувальника.
- Планувальник відправляє Pod до розширювача планувальника тільки у випадку, якщо Pod запитує "example.com/foo".
- Поле
ignoredBySchedulerвказує, що планувальник не перевіряє ресурс "example.com/foo" в своєму предикатіPodFitsResources.
{
"kind": "Policy",
"apiVersion": "v1",
"extenders": [
{
"urlPrefix":"<extender-endpoint>",
"bindVerb": "bind",
"managedResources": [
{
"name": "example.com/foo",
"ignoredByScheduler": true
}
]
}
]
}
Використання розширених ресурсів
Користувачі можуть використовувати розширені ресурси у специфікаціях Podʼа, подібно до CPU та памʼяті. Планувальник відповідає за облік ресурсів, щоб одночасно не виділялося більше доступної кількості ресурсів для Podʼів.
Сервер API обмежує кількість розширених ресурсів цілими числами. Приклади дійсних значень: 3, 3000m та 3Ki. Приклади недійсних значень: 0.5 та 1500m (томущо 1500m буде давати в результаті 1.5).
Примітка:
Розширені ресурси замінюють Opaque Integer Resources. Користувачі можуть використовувати будь-який префікс доменного імені, крімkubernetes.io, який зарезервований.Щоб використовувати розширений ресурс у Podʼі, включіть імʼя ресурсу як ключ у масив spec.containers[].resources.limits у специфікації контейнера.
Примітка:
Розширені ресурси не можуть бути перевищені, тому запити та обмеження мають бути рівними, якщо обидва присутні у специфікації контейнера.Pod є запланованим лише у випадку, якщо всі запити ресурсів задовольняються, включаючи CPU, памʼять та будь-які розширені ресурси. Pod залишається у стані PENDING, поки запит ресурсу не може бути задоволений.
Приклад:
Нижче наведено Pod, який запитує 2 CPU та 1 "example.com/foo" (розширений ресурс).
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: myimage
resources:
requests:
cpu: 2
example.com/foo: 1
limits:
example.com/foo: 1
Обмеження PID
Обмеження ідентифікаторів процесів (PID) дозволяють налаштувати kubelet для обмеження кількості PID, яку може використовувати певний Pod. Див. Обмеження PID для отримання інформації.
Усунення несправностей
Мої Podʼи знаходяться в стані очікування з повідомленням події FailedScheduling
Якщо планувальник не може знайти жодного вузла, де може розмістити Pod, Pod залишається
незапланованим, поки не буде знайдено місце. Кожного разу, коли планувальник не може знайти місце для Podʼа, створюється подія. Ви можете використовувати kubectl для перегляду подій Podʼа; наприклад:
kubectl describe pod frontend | grep -A 9999999999 Events
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 23s default-scheduler 0/42 nodes available: insufficient cpu
У прикладі Pod під назвою "frontend" не вдалося запланувати через недостатній ресурс CPU на будь-якому вузлі. Схожі повідомлення про помилку також можуть вказувати на невдачу через недостатню памʼять (PodExceedsFreeMemory). Загалом, якщо Pod знаходиться в стані очікування з таким типом повідомлення, є кілька речей, які варто спробувати:
- Додайте більше вузлів у кластер.
- Завершіть непотрібні Podʼи, щоб звільнити місце для очікуваних Podʼів.
- Перевірте, що Pod не є більшим, ніж усі вузли. Наприклад, якщо всі вузли мають місткість
cpu: 1, то Pod з запитомcpu: 1.1ніколи не буде запланованим. - Перевірте наявність "taint" вузла. Якщо більшість ваших вузлів мають "taint", і новий Pod не толерує цей "taint", планувальник розглядає розміщення лише на залишкових вузлах, які не мають цього "taint".
Ви можете перевірити місткості вузлів та виділені обсяги ресурсів за допомогою команди kubectl describe nodes. Наприклад:
kubectl describe nodes e2e-test-node-pool-4lw4
Name: e2e-test-node-pool-4lw4
[ ... lines removed for clarity ...]
Capacity:
cpu: 2
memory: 7679792Ki
pods: 110
Allocatable:
cpu: 1800m
memory: 7474992Ki
pods: 110
[ ... lines removed for clarity ...]
Non-terminated Pods: (5 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
kube-system fluentd-gcp-v1.38-28bv1 100m (5%) 0 (0%) 200Mi (2%) 200Mi (2%)
kube-system kube-dns-3297075139-61lj3 260m (13%) 0 (0%) 100Mi (1%) 170Mi (2%)
kube-system kube-proxy-e2e-test-... 100m (5%) 0 (0%) 0 (0%) 0 (0%)
kube-system monitoring-influxdb-grafana-v4-z1m12 200m (10%) 200m (10%) 600Mi (8%) 600Mi (8%)
kube-system node-problem-detector-v0.1-fj7m3 20m (1%) 200m (10%) 20Mi
(0%) 100Mi (1%)
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
CPU Requests CPU Limits Memory Requests Memory Limits
------------ ---------- --------------- -------------
680m (34%) 400m (20%) 920Mi (11%) 1070Mi (13%)
У виводі ви можете побачити, що якщо Pod запитує більше 1,120 CPU або більше 6,23 ГБ памʼяті, то цей Pod не поміститься на вузлі.
Дивлячись на розділ "Podʼи", ви можете побачити, які Podʼи займають місце на вузлі.
Обсяг ресурсів, доступних для Podʼів, менший за місткість вузла, оскільки системні служби використовують частину доступних ресурсів. У Kubernetes API, кожен вузол має поле .status.allocatable (див. NodeStatus для деталей).
Поле .status.allocatable описує обсяг ресурсів, доступних для Podʼів на цьому вузлі (наприклад: 15 віртуальних ЦП та 7538 МіБ памʼяті). Для отримання додаткової інформації про виділені ресурси вузла в Kubernetes дивіться Резервування обчислювальних ресурсів для системних служб.
Ви можете налаштувати квоти ресурсів для обмеження загального обсягу ресурсів, який може споживати простір імен. Kubernetes забезпечує дотримання квот для обʼєктів в конкретному просторі імен, коли існує ResourceQuota в цьому просторі імен. Наприклад, якщо ви призначаєте конкретні простори імен різним командам, ви можете додавати ResourceQuotas в ці простори імен. Встановлення квот ресурсів допомагає запобігти використанню однією командою так багато будь-якого ресурсу, що це впливає на інші команди.
Вам також варто розглянути, який доступ ви надаєте в цьому просторі імен: повний дозвіл на запис у простір імен дозволяє тому, хто має такий доступ, видаляти будь-який ресурс, включаючи налаштований ResourceQuota.
Робота мого контейнера завершується примусово
Робота вашого контейнера може бути завершена через нестачу ресурсів. Щоб перевірити, чи контейнер був завершений через досягнення обмеження ресурсів, викличте kubectl describe pod для цікавого вас Podʼа:
kubectl describe pod simmemleak-hra99
Вивід буде схожий на:
Name: simmemleak-hra99
Namespace: default
Image(s): saadali/simmemleak
Node: kubernetes-node-tf0f/10.240.216.66
Labels: name=simmemleak
Status: Running
Reason:
Message:
IP: 10.244.2.75
Containers:
simmemleak:
Image: saadali/simmemleak:latest
Limits:
cpu: 100m
memory: 50Mi
State: Running
Started: Tue, 07 Jul 2019 12:54:41 -0700
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Fri, 07 Jul 2019 12:54:30 -0700
Finished: Fri, 07 Jul 2019 12:54:33 -0700
Ready: False
Restart Count: 5
Conditions:
Type Status
Ready False
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 42s default-scheduler Successfully assigned simmemleak-hra99 to kubernetes-node-tf0f
Normal Pulled 41s kubelet Container image "saadali/simmemleak:latest" already present on machine
Normal Created 41s kubelet Created container simmemleak
Normal Started 40s kubelet Started container simmemleak
Normal Killing 32s kubelet Killing container with id ead3fb35-5cf5-44ed-9ae1-488115be66c6: Need to kill Pod
У прикладі Restart Count: 5 вказує на те, що контейнер simmemleak у Podʼі був завершений та перезапущений пʼять разів (до цього моменту). Причина OOMKilled показує, що контейнер намагався використовувати більше памʼяті, ніж встановлений йому ліміт.
Наступним кроком може бути перевірка коду програми на витік памʼяті. Якщо ви встановите, що програма працює так, як очікувалося, розгляньте встановлення вищого ліміту памʼяті (і, можливо, запит) для цього контейнера.
Що далі
- Отримайте практичний досвід призначення ресурсів памʼяті контейнерам та Podʼам.
- Отримайте практичний досвід призначення ресурсів ЦП контейнерам та Podʼам.
- Прочитайте, як API-довідка визначає контейнер та його вимоги до ресурсів
- Прочитайте про квоти ресурсів проєкту в XFS
- Дізнайтеся більше про конфігурацію планувальника kube-scheduler (v1)
- Дізнайтеся більше про класи якості обслуговування для Podʼів
7.5 - Проби життєздатності, готовності та запуску
Kubernetes має різні типи проб:
Проба життєздатності
Проби життєздатності (Liveness) визначають, коли перезапустити контейнер. Наприклад, проби життєздатності можуть виявити тупик, коли додаток працює, але не може виконувати роботу.
Якщо контейнеру не вдається пройти пробу життєздатності, kubelet перезапускає контейнер.
Проби життєздатності не чекають, поки проби готовності будуть успішними. Якщо ви хочете почекати перед виконанням проби життєздатності, ви можете визначити initialDelaySeconds або використовувати пробу запуску.
Проба готовності
Проби готовності (Readiness) визначають, коли контейнер готовий приймати трафік. Це корисно, коли потрібно зачекати, поки застосунок виконає тривалі початкові завдання, такі як встановлення мережевих зʼєднань, завантаження файлів та наповнення кешів.
Якщо проба готовності повертає неуспішний стан, Kubernetes видаляє Pod з усіх відповідних точок доступу сервісу.
Проби готовності виконуються в контейнері протягом всього його життєвого циклу.
Проба запуску
Проба запуску (Startup) перевіряє, чи застосунок у контейнері запущено. Це можна використовувати для виконання перевірок життєздатності на повільних контейнерах, уникнення їхнього примусового завершення kubelet до того, як вони будуть запущені.
Якщо така проба налаштована, вона вимикає перевірки життєздатності та готовності, поки вона не буде успішною.
Цей тип проби виконується лише при запуску, на відміну від проб життєздатності та готовності, які виконуються періодично.
- Докладніше про Налаштування проб життєздатності, готовності та запуску.
7.6 - Організація доступу до кластеру за допомогою файлів kubeconfig
Використовуйте файли kubeconfig для організації інформації про кластери, користувачів, простори імен та механізми автентифікації. kubectl використовує файли kubeconfig, щоб знайти інформацію, необхідну для вибору кластера та звʼязку з сервером API кластера.
Примітка:
Файл, який використовується для налаштування доступу до кластерів, називається файлом kubeconfig. Це загальний спосіб посилання на файли конфігурації. Це не означає, що існує файл з іменемkubeconfig.Попередження:
Використовуйте файли kubeconfig лише з надійних джерел. Використання спеціально створеного файлу kubeconfig може призвести до виконання зловмисного коду або розголошення файлів. Якщо вам все ж потрібно використовувати ненадійний файл kubeconfig, уважно перевірте його, так само як ви це зробили б з файлом скрипту оболонки.Типово kubectl шукає файл з імʼям config у каталозі $HOME/.kube. Ви можете вказати інші файли kubeconfig, встановивши змінну середовища KUBECONFIG або встановивши прапорець --kubeconfig.
Для покрокових інструкцій щодо створення та вказівки файлів kubeconfig див. Налаштування доступу до кількох кластерів.
Підтримка кількох кластерів, користувачів та механізмів автентифікації
Припустимо, у вас є декілька кластерів, і ваші користувачі та компоненти автентифікуються різними способами. Наприклад:
- Робочий kubelet може автентифікуватися за допомогою сертифікатів.
- Користувач може автентифікуватися за допомогою токенів.
- Адміністратори можуть мати набори сертифікатів, які вони надають окремим користувачам.
За допомогою файлів kubeconfig ви можете організувати ваші кластери, користувачів та простори імен. Ви також можете визначити контексти, щоб швидко та легко перемикатися між кластерами та просторами імен.
Контекст
Елемент context в файлі kubeconfig використовується для групування параметрів доступу під зручною назвою. Кожен контекст має три параметри: кластер, простір імен та користувач. Типово, інструмент командного рядка kubectl використовує параметри з поточного контексту для звʼязку з кластером.
Щоб обрати поточний контекст:
kubectl config use-context
Змінна середовища KUBECONFIG
Змінна середовища KUBECONFIG містить список файлів kubeconfig. Для Linux та Mac список розділяється двокрапкою. Для Windows список розділяється крапкою з комою. Змінна середовища KUBECONFIG не є обовʼязковою. Якщо змінна середовища KUBECONFIG не існує, kubectl використовує стандартний файл kubeconfig, $HOME/.kube/config.
Якщо змінна середовища KUBECONFIG існує, kubectl використовує ефективну конфігурацію, яка є результатом обʼєднання файлів, перерахованих у змінній середовища KUBECONFIG.
Обʼєднання файлів kubeconfig
Щоб переглянути вашу конфігурацію, введіть цю команду:
kubectl config view
Як описано раніше, вихідні дані можуть бути з одного файлу kubeconfig або бути результатом обʼєднання кількох файлів kubeconfig.
Ось правила, які використовує kubectl під час обʼєднання файлів kubeconfig:
Якщо встановлено прапорець
--kubeconfig, використовуйте лише вказаний файл. Обʼєднання не здійснюється. Дозволяється лише один екземпляр цього прапорця.У іншому випадку, якщо встановлена змінна середовища
KUBECONFIG, використовуйте її як список файлів, які потрібно обʼєднати. Обʼєднайте файли, перераховані у змінній середовищаKUBECONFIG, згідно з наступними правилами:- Ігноруйте порожні імена файлів.
- Виводьте помилки для файлів з вмістом, який не може бути десеріалізований.
- Перший файл, що встановлює певне значення або ключ зіставлення, має перевагу.
- Ніколи не змінюйте значення або ключ зіставлення. Наприклад: Зберігайте контекст першого файлу, який встановлює
current-context. Наприклад: Якщо два файли вказують наred-user, використовуйте лише значення зred-userпершого файлу. Навіть якщо другий файл має несумісні записи підred-user, відкиньте їх.
Для прикладу встановлення змінної середовища
KUBECONFIGдивіться Встановлення змінної середовища KUBECONFIG.В іншому випадку використовуйте стандартний файл kubeconfig,
$HOME/.kube/config, без обʼєднання.Визначте контекст, який буде використовуватися на основі першого збігу в цьому ланцюжку:
- Використовуйте прапорець командного рядка
--context, якщо він існує. - Використовуйте
current-contextз обʼєднаних файлів kubeconfig.
Порожній контекст допускається на цьому етапі.
- Використовуйте прапорець командного рядка
Визначте кластер та користувача. На цьому етапі може бути або не бути контексту. Визначте кластер та користувача на основі першого збігу в цьому ланцюжку, який запускається двічі: один раз для користувача та один раз для кластера:
- Використовуйте прапорці командного рядка, якщо вони існують:
--userабо--cluster. - Якщо контекст не порожній, беріть користувача або кластер з контексту.
Користувач та кластер можуть бути порожніми на цьому етапі.
- Використовуйте прапорці командного рядка, якщо вони існують:
Визначте фактичну інформацію про кластер, яку слід використовувати. На цьому етапі може бути або не бути інформації про кластер. Побудуйте кожен елемент інформації про кластер на основі цього ланцюжка; перший збіг перемагає:
- Використовуйте прапорці командного рядка, якщо вони існують:
--server,--certificate-authority,--insecure-skip-tls-verify. - Якщо існують будь-які атрибути інформації про кластер з обʼєднаних файлів kubeconfig, використовуйте їх.
- Якщо немає розташування сервера, відмовтеся.
- Використовуйте прапорці командного рядка, якщо вони існують:
Визначте фактичну інформацію про користувача, яку слід використовувати. Побудуйте інформацію про користувача, використовуючи ті ж правила, що і для інформації про кластер, за винятком того, що дозволяється лише одна техніка автентифікації для кожного користувача:
- Використовуйте прапорці командного рядка, якщо вони існують:
--client-certificate,--client-key,--username,--password,--token. - Використовуйте поля
userз обʼєднаних файлів kubeconfig. - Якщо є дві суперечливі техніки, відмовтеся.
- Використовуйте прапорці командного рядка, якщо вони існують:
Для будь-якої інформації, що все ще відсутня, використовуйте стандартні значення і, можливо, запитайте інформацію для автентифікації.
Посилання на файли
Посилання на файли та шляхи в файлі kubeconfig є відносними до місця розташування файлу kubeconfig. Посилання на файли в командному рядку є відносними до поточного робочого каталогу. У файлі $HOME/.kube/config відносні шляхи зберігаються відносно, абсолютні шляхи зберігаються абсолютно.
Проксі
Ви можете налаштувати kubectl використовувати проксі для кожного кластера за допомогою proxy-url у вашому файлі kubeconfig, на зразок такого:
apiVersion: v1
kind: Config
clusters:
- cluster:
proxy-url: http://proxy.example.org:3128
server: https://k8s.example.org/k8s/clusters/c-xxyyzz
name: development
users:
- name: developer
contexts:
- context:
name: development
Що далі
7.7 - Управління ресурсами для вузлів Windows
Ця сторінка надає огляд різниці у способах управління ресурсами між Linux та Windows.
На Linux-вузлах використовуються cgroups як межа Pod для керування ресурсами. Контейнери створюються в межах цих груп для ізоляції мережі, процесів та файлової системи. API cgroup для Linux може використовуватися для збору статистики використання процесора, введення/виведення та памʼяті.
Натомість, у Windows використовує job object на кожен контейнер з фільтром системного простору імен, щоб обмежити всі процеси в контейнері та забезпечити логічну ізоляцію від хосту. (Обʼєкти завдань є механізмом ізоляції процесів Windows і відрізняються від того, що Kubernetes називає завданням).
Не існує можливості запуску контейнера Windows без фільтрації простору імен. Це означає, що системні привілеї не можуть бути встановлені в контексті хосту, і, отже, привілейовані контейнери не доступні в Windows. Контейнери не можуть припускати ідентичність хосту, оскільки менеджер облікових записів безпеки (Security Account Manager, SAM) є окремим.
Управління памʼяттю
Windows не має спеціального процесу припинення процесів з обмеженням памʼяті, як у Linux. Windows завжди трактує всі виділення памʼяті в режимі користувача як віртуальні, і сторінкові файли є обовʼязковими.
Вузли Windows не перевантажують памʼять для процесів. Основний ефект полягає в тому, що Windows не досягне умов нестачі памʼяті так само як Linux, і процеси будуть перенесені на диск замість виявлення випадків нестачі памʼяті (OOM). Якщо памʼять перевантажена, і всю фізичну памʼять вичерпано, то запис на диск може знизити продуктивність.
Управління CPU
Windows може обмежувати кількість часу CPU, виділену для різних процесів, але не може гарантувати мінімальну кількість часу CPU.
На Windows kubelet підтримує прапорець командного рядка для встановлення пріоритету планування процесу kubelet: --windows-priorityclass. Цей прапорець дозволяє процесу kubelet отримувати більше часових сегментів процесора порівняно з іншими процесами, які виконуються на хості Windows. Додаткову інформацію про допустимі значення та їх значення можна знайти за посиланням Класи пріоритетів Windows. Щоб переконатися, що запущені Podʼи не голодують kubelet між циклами CPU, встановіть цей прапорець на значення ABOVE_NORMAL_PRIORITY_CLASS або вище.
Резервування ресурсів
Для обліку памʼяті та процесора, що використовуються операційною системою, контейнерною системою та процесами хосту Kubernetes, можна (і потрібно) резервувати ресурси памʼяті та процесора за допомогою прапорців kubelet --kube-reserved та/або --system-reserved. У Windows ці значення використовуються лише для розрахунку доступних ресурсів вузла.
Увага:
При розгортанні навантажень встановлюйте ліміти ресурсів памʼяті та процесора на контейнери. Це також віднімає від NodeAllocatable та допомагає глобальному планувальнику кластера визначити, які Podʼи розмістити на яких вузлах.
Планування Podʼів без лімітів може перевантажити вузли Windows, і в екстремальних випадках може призвести до того, що вузли стануть несправними.
У Windows доброю практикою є резервування принаймні 2ГБ памʼяті.
Щоб визначити, скільки CPU резервувати, ідентифікуйте максимальну щільність Podʼів для кожного вузла та відстежуйте використання процесора системними службами, що працюють там, а потім виберіть значення, яке відповідає потребам вашої робочого навантаження.
8 - Безпека
Концепції для забезпечення безпеки ваших хмарних робочих навантажень.
Цей розділ документації Kubernetes призначений, щоб допомогти вам дізнатись, як запускати робочі навантаження безпечніше, а також про основні аспекти забезпечення безпеки кластера Kubernetes.
Kubernetes базується на архітектурі, орієнтованій на хмару, та використовує поради від CNCF щодо найкращих практик з безпеки інформації в хмарних середовищах.
Для отримання загального контексту щодо того, як забезпечити безпеку вашого кластера та застосунків, які ви на ньому запускаєте, прочитайте Безпека хмарних середовищ та Kubernetes.
Механізми безпеки Kubernetes
Kubernetes включає кілька API та елементів керування безпекою, а також способи визначення політик, які можуть бути частиною вашого управління інформаційною безпекою.
Захист панелі управління
Ключовий механізм безпеки для будь-якого кластера Kubernetes — це контроль доступу до API Kubernetes.
Kubernetes очікує, що ви налаштуєте та використовуватимете TLS для забезпечення шифрування даних під час їх руху у межах панелі управління та між панеллю управління та її клієнтами. Ви також можете активувати шифрування в стані спокою для даних, збережених у панелі управління Kubernetes; це відокремлено від використання шифрування в стані спокою для даних ваших власних робочих навантажень, що також може бути хорошою ідеєю.
Secrets
API Secret надає базовий захист для конфіденційних значень конфігурації.
Захист робочого навантаження
Забезпечуйте дотримання стандартів безпеки Pod, щоб переконатися, що Pod та їх контейнери ізольовані належним чином. Ви також можете використовувати RuntimeClasses, щоб визначити власну ізоляцію, якщо це потрібно.
Мережеві політики дозволяють вам контролювати мережевий трафік між Podʼами, або між Podʼами та мережею поза вашим кластером.
Ви можете розгортати компоненти керування безпекою з ширшої екосистеми для впровадження компонентів для запобігання або виявлення небезпеки навколо Pod, їх контейнерів та образів, що запускаються у них.
Аудит
Audit logging Kubernetes забезпечує безпековий, хронологічний набір записів, що документують послідовність дій в кластері. Кластер перевіряє дії, породжені користувачами, застосунками, які використовують API Kubernetes, та самою панеллю управління.
Безпека хмарних провайдерів
Примітка: Items on this page refer to vendors external to Kubernetes. The Kubernetes project authors aren't responsible for those third-party products or projects. To add a vendor, product or project to this list, read the content guide before submitting a change. More information.
Якщо ви запускаєте кластер Kubernetes на власному обладнанні або в іншого хмарного провайдера, зверніться до вашої документації для ознайомлення з найкращими практиками безпеки. Ось посилання на документацію з безпеки деяких популярних хмарних провайдерів:
| IaaS провайдер | Посилання |
|---|---|
| Alibaba Cloud | https://www.alibabacloud.com/trust-center |
| Amazon Web Services | https://aws.amazon.com/security |
| Google Cloud Platform | https://cloud.google.com/security |
| Huawei Cloud | https://www.huaweicloud.com/intl/en-us/securecenter/overallsafety |
| IBM Cloud | https://www.ibm.com/cloud/security |
| Microsoft Azure | https://docs.microsoft.com/en-us/azure/security/azure-security |
| Oracle Cloud Infrastructure | https://www.oracle.com/security |
| VMware vSphere | https://www.vmware.com/security/hardening-guides |
Політики
Ви можете визначати політики безпеки за допомогою механізмів, вбудованих у Kubernetes, таких як NetworkPolicy (декларативний контроль над фільтрацією мережевих пакетів) або ValidatingAdmissionPolicy (декларативні обмеження на те, які зміни може вносити кожен за допомогою API Kubernetes).
Однак ви також можете покладатися на реалізації політик з ширшої екосистеми навколо Kubernetes. Kubernetes надає механізми розширення, щоб ці проєкти екосистеми могли впроваджувати власні елементи керування політиками щодо перегляду вихідного коду, затвердження контейнерних образів, контролю доступу до API, мережевого звʼязку та інших аспектів.
Для отримання додаткової інформації про механізми політики та Kubernetes, читайте Політики.
Що далі
Дізнайтеся про повʼязані теми безпеки Kubernetes:
- Захист вашого кластера
- Відомі уразливості в Kubernetes (та посилання на додаткову інформацію)
- Шифрування даних під час їх обміну для панелі управління
- Шифрування даних в спокої
- Контроль доступу до API Kubernetes
- Мережеві політики для Pods
- Secret в Kubernetes
- Стандарти безпеки Pod
- RuntimeClasses
Дізнайтеся контекст:
Отримайте сертифікацію:
- Спеціаліст з безпеки Kubernetes сертифікація та офіційний навчальний курс.
Докладніше в цьому розділі:
8.1 - Безпека хмарних середовищ та Kubernetes
Концепції забезпечення безпеки вашого робочого навантаження в хмарному середовищі.
Kubernetes базується на архітектурі, орієнтованій на хмару, та використовує поради від CNCF щодо найкращих практик з безпеки інформації в хмарних середовищах.
Прочитайте далі цю сторінку для отримання огляду того, як Kubernetes призначений допомагати вам розгортати безпечну хмарну платформу.
Інформаційна безпека хмарних середовищ
У документів CNCF white paper про безпеку хмарних середовищ визначаються компоненти та практики безпеки, які відповідають різним фазам життєвого циклу.
Фаза життєвого циклу Розробка
- Забезпечте цілісність середовищ розробки.
- Проєктуйте застосунки відповідно до найкращих практик інформаційної безпеки, які відповідають вашому контексту.
- Враховуйте безпеку кінцевого користувача як частину проєктного рішення.
Для досягнення цього ви можете:
- Використовуйте архітектуру, таку як нульова довіра, яка мінімізує сферу атак, навіть для внутрішніх загроз.
- Визначте процес перевірки коду, який враховує питання безпеки.
- Створіть модель загроз вашої системи або застосунку, яка ідентифікує межі довіри. Використовуйте цю модель, щоб ідентифікувати ризики та допомогти знайти способи їх вирішення.
- Включіть розширену безпекову автоматизацію, таку як fuzzing та інжиніринг безпеки хаосу, де це обґрунтовано.
Фаза життєвого циклу Розповсюдження
- Забезпечте безпеку ланцюга постачання образів контейнерів, які ви виконуєте.
- Забезпечте безпеку ланцюга постачання кластера та інших компонентів, що виконують ваш застосунок. Прикладом іншого компонента може бути зовнішня база даних, яку ваше хмарне застосування використовує для стійкості.
Для досягнення цього:
- Скануйте образи контейнерів та інші артефакти на наявність відомих уразливостей.
- Забезпечте, що розповсюдження програмного забезпечення використовує шифрування у русі, з ланцюгом довіри до джерела програмного забезпечення.
- Ухвалюйте та дотримуйтесь процесів оновлення залежностей, коли оновлення доступні особливо повʼязані з оголошеннями про безпеку.
- Використовуйте механізми перевірки, такі як цифрові сертифікати для гарантій безпеки ланцюга постачання.
- Підписуйтесь на стрічки та інші механізми, щоб отримувати сповіщення про безпекові ризики.
- Обмежуйте доступ до артефактів. Розміщуйте образи контейнерів у приватному реєстрі, який дозволяє тільки авторизованим клієнтам отримувати образи.
Фаза життєвого циклу Розгортання
Забезпечте відповідні обмеження на те, що можна розгортати, хто може це робити, та куди це може бути розгорнуто. Ви можете застосовувати заходи з фази розповсюдження, такі як перевірка криптографічної ідентичності артефактів образів контейнерів.
При розгортанні Kubernetes ви також створюєте основу для робочого середовища ваших застосунків: кластер Kubernetes (або кілька кластерів). Ця ІТ-інфраструктура повинна забезпечувати гарантії безпеки на найвищому рівні.
Фаза життєвого циклу Виконання
Фаза Виконання включає три критичні області: доступ, обчислення та зберігання.
Захист під час виконання: доступ
API Kubernetes — це те, що робить ваш кластер робочим. Захист цього API є ключовим для забезпечення ефективної безпеки кластера.
Інші сторінки документації Kubernetes містять більше деталей щодо того, як налаштувати конкретні аспекти контролю доступу. Перелік перевірок безпеки містить набір рекомендованих базових перевірок для вашого кластера.
Поза цим, захист вашого кластера означає впровадження ефективних способів автентифікації та авторизації для доступу до API. Використовуйте ServiceAccounts, щоб забезпечити та керувати перевірками безпеки для робочих навантажень та компонентів кластера.
Kubernetes використовує TLS для захисту трафіку API; переконайтеся, що кластер розгорнуто за допомогою TLS (включаючи трафік між вузлами та панеллю управління), та захистіть ключі шифрування. Якщо ви використовуєте власний API Kubernetes для CertificateSigningRequests, приділіть особливу увагу обмеженню зловживань там.
Захист під час виконання: обчислення
Контейнери надають дві речі: ізоляцію між різними застосунками та механізм для комбінування цих ізольованих застосунків для запуску на одному і тому ж хост-компʼютері. Ці два аспекти, ізоляція та агрегація, означають, що безпека під час виконання передбачає визначення компромісів та знаходження відповідного балансу.
Kubernetes покладається на програмне забезпечення виконання контейнерів, щоб фактично налаштувати та запустити контейнери. Проєкт Kubernetes не рекомендує конкретне програмне забезпечення виконання контейнерів, і вам слід переконатися, що вибране вами середовище виконання контейнерів відповідає вашим потребам у сфері інформаційної безпеки.
Для захисту обчислень під час виконання ви можете:
Застосовувати стандарти безпеки для Pod для застосунків, щоб забезпечити їх запуск лише з необхідними привілеями.
Запускати спеціалізовану операційну систему на ваших вузлах, яка призначена конкретно для виконання контейнеризованих робочих навантажень. Зазвичай це базується на операційній системі з доступом тільки для читання (незмінні образи), яка надає тільки послуги, необхідні для виконання контейнерів.
Операційні системи, спеціально призначені для контейнерів, допомагають ізолювати компоненти системи та представляють зменшену осяг елементів для атаки в разі "втечі" з контейнера.
Визначати ResourceQuotas для справедливого розподілу спільних ресурсів та використовувати механізми, такі як LimitRanges для забезпечення того, що Podʼи вказують свої вимоги до ресурсів.
Розподіляти робочі навантаження по різних вузлах. Використовуйте механізми ізоляції вузлів, як від самого Kubernetes, так і від екосистеми, щоб гарантувати, що Pod з різними контекстами довіри виконуються на окремих наборах вузлів.
Використовуйте програмне забезпечення виконання контейнерів, яке надає обмеження для підтримання безпеки.
На вузлах Linux використовуйте модуль безпеки Linux, такий як AppArmor або seccomp.
Захист під час виконання: зберігання
Для захисту сховища для вашого кластера та застосунків, що працюють там:
- Інтегруйте свій кластер з зовнішнім втулком сховища, який надає шифрування в стані спокою для томів.
- Увімкніть шифрування в стані спокою для обʼєктів API.
- Захистіть стійкість даних за допомогою резервних копій. Перевірте, що ви можете відновити їх, коли це необхідно.
- Автентифікуйте зʼєднання між вузлами кластера та будь-яким мережевим сховищем, на яке вони спираються.
- Впровадить шифрування даних у межах вашого власного застосунку.
Для ключів шифрування, їх генерація у спеціалізованому обладнанні забезпечує найкращий захист від ризиків розголошення. Апаратний модуль безпеки може дозволити виконувати криптографічні операції без можливості копіювання ключа безпеки в інше місце.
Мережа та безпека
Ви також повинні врахувати заходи мережевої безпеки, такі як NetworkPolicy або сервісна мережа. Деякі мережеві втулки для Kubernetes надають шифрування для вашої мережі кластера, використовуючи технології, такі як прошарок віртуальної приватної мережі (VPN). За концепцією, Kubernetes дозволяє використовувати власний мережевий втулок для вашого кластера (якщо ви використовуєте керований Kubernetes, особа або організація, яка керує вашим кластером, може вибрати мережевий втулок за вас).
Мережевий втулок, який ви виберете, та спосіб його інтеграції можуть сильно вплинути на безпеку інформації під час її передачі.
Спостережність та безпека виконання
Kubernetes дозволяє розширювати ваш кластер додатковими інструментами. Ви можете налаштувати сторонні рішення, щоб допомогти вам моніторити або усувати несправності ваших застосунків та кластерів, на яких вони працюють. Ви також отримуєте деякі базові можливості спостережуваності, вбудовані в сам Kubernetes. Ваш код, що працює в контейнерах, може генерувати логи, публікувати метрики або надавати інші дані спостережуваності; при розгортанні вам потрібно переконатися, що ваш кластер забезпечує відповідний рівень захисту там.
Якщо ви налаштовуєте інформаційну панель метрик (дашбоард) або щось схоже, перегляньте ланцюжок компонентів, які передають дані в цю панель метрик, а також саму панель метрик. Переконайтеся, що весь ланцюжок розроблено з достатньою стійкістю та достатнім захистом цілісності, щоб ви могли покластися на нього навіть під час інциденту, коли ваш кластер може деградувати.
У відповідних випадках розгорніть заходи безпеки нижче рівня самого Kubernetes, такі як криптографічно захищений початок роботи або автентифікований розподіл часу (що допомагає забезпечити відповідність логів та записів аудиту).
Для середовища з високим рівнем безпеки розгорніть криптографічний захист, щоб переконатися, що логи є як захищеними від несанкціонованого доступу, так і конфіденційними.
Що далі
Безпека хмарного середовища
- CNCF white paper
- Біла книга CNCF з належними практиками забезпечення безпеки ланцюга постачання програмного забезпечення.
- Виправлення хаосу Kubernetes: розуміння безпеки починаючи від ядра і далі (FOSDEM 2020)
- Найкращі практики з безпеки Kubernetes (Kubernetes Forum Seoul 2019)
- Шлях до вимірюваного завантаження з коробки (Linux Security Summit 2016)
Kubernetes та інформаційна безпека
8.2 - Стандарти безпеки для Podʼів
Детальний огляд різних рівнів політики, визначених у стандартах безпеки для Podʼів.
Стандарти безпеки для Podʼів визначають три різні політики, щоб покрити широкий спектр безпеки. Ці політики є кумулятивними та охоплюють широкий діапазон від все дозволено до все обмежено. У цьому керівництві наведено вимоги кожної політики.
| Профіль | Опис |
|---|---|
| Privileged | Необмежена політика, яка забезпечує найширший можливий рівень дозволів. Ця політика дозволяє відомі підвищення привілеїв. |
| Baseline | Мінімально обмежена політика, яка запобігає відомим підвищенням привілеїв. Дозволяє стандартну (мінімально визначену) конфігурацію Pod. |
| Restricted | Дуже обмежена політика, яка відповідає поточним найкращим практикам забезпечення безпеки Pod. |
Деталі профілю
Privileged
Політика Privileged спеціально є відкритою і цілковито необмеженою. Цей тип політики зазвичай спрямований на робочі навантаження рівня системи та інфраструктури, які керуються привілейованими, довіреними користувачами.
Політика Privileged визначається відсутністю обмежень. Якщо ви визначаєте Pod, до якого застосовується політика безпеки Privileged, визначений вами Pod може обходити типові механізми ізоляції контейнерів. Наприклад, ви можете визначити Pod, який має доступ до мережі хоста вузла.
Baseline
Політика Baseline спрямована на полегшення впровадження загальних контейнеризованих робочих навантажень та запобіганням відомим ескалаціям привілеїв. Ця політика призначена для операторів застосунків та розробників не критичних застосунків. Наведені нижче параметри мають бути виконані/заборонені:
Примітка:
У цій таблиці зірочки (*) позначають всі елементи в списку. Наприклад,
spec.containers[*].securityContext стосується обʼєкта Контексту Безпеки для усіх визначених контейнерів. Якщо будь-який із перерахованих контейнерів не відповідає вимогам, весь Pod не пройде перевірку.| Елемент | Політика |
|---|---|
| HostProcess | Для Podʼів Windows надається можливість запуску HostProcess контейнерів, що дозволяє привілейований доступ до машини хосту Windows. Привілеї на вузлs заборонені політикою baseline. СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.26 [stable]Заборонені поля
Дозволені значення
|
| Host Namespaces | Доступ до просторів імен вузла має бути заборонений. Заборонені поля
Дозволені значення
|
| Привілейовані контейнери | Привілейовані Podʼи відключають більшість механізмів безпеки і повинні бути відключені. Заборонені поля
Дозволені значення
|
| Capabilities | Додавання додаткових можливостей, крім перерахованих нижче, має бути заборонене. Заборонені поля
Дозволені значення
|
| Томи HostPath | Томи HostPath мають бути заборонені. Заборонені поля
Дозволені значення
|
| Порти хосту | HostPort повинні бути заборонені повністю (рекомендовано) або обмежені до відомого списку Заборонені поля
Дозволені значення
|
| AppArmor | На підтримуваних вузлах стандартно застосовується профіль AppArmor Заборонені поля
Дозволені значення
Дозволені значення
|
| SELinux | Встановлення типу SELinux обмежено, а встановлення користувацького SELinux або ролі заборонено. Заборонені поля
Дозволені значення
Заборонені поля
Дозволені значення
|
/proc Тип монтування | Типові маски Заборонені поля
Дозволені значення
|
| Seccomp | Профіль Seccomp не повинен явно встановлюватися на значення Заборонені поля
Дозволені значення
|
| Sysctls | Sysctls можуть вимкнути механізми безпеки або вплинути на всі контейнери на вузлі, тому вони мають бути заборонені за виключенням дозволеного "безпечного" піднабору. Sysctl вважається безпечним, якщо він знаходиться в просторі імен в контейнері чи Podʼі, і він ізольований від інших Podʼів або процесів на тому ж Вузлі. Заборонені поля
Дозволені значення
|
Restricted
Політика Restricted призначена для забезпечення поточних кращих практик у забезпеченні безпеки Pod, за рахунок деякої сумісності. Вона спрямована на операторів та розробників критичних з точки зору безпеки застосунків, а також на користувачів з меншою довірою. Нижче наведено перелік контролів, які слід дотримуватися/забороняти:
Примітка:
У цій таблиці зірочки (*) позначають всі елементи списку. Наприклад, spec.containers[*].securityContext вказує на обʼєкт Контексту безпеки для всіх визначених контейнерів. Якщо хоча б один з наведених контейнерів не відповідає вимогам, весь підпроцес не пройде валідацію.| Елемент | Політика |
| Все з політики Baseline. | |
| Типи томів | В політиці Restricted дозволяються лише наступні типи томів. Заборонені поля
Дозволені значення Кожен елемент спискуspec.volumes[*] повинен встановлювати одне з наступних полів на ненульове значення:
|
| Підвищення привілеїв (v1.8+) | Підвищення привілеїв (наприклад, через файловий режим set-user-ID або set-group-ID) не повинно бути дозволено. Це політика лише для Linux у v1.25+ Заборонені поля
Дозволені значення
|
| Запуск як не-root | Контейнери мають запускатися як не-root користувачі. Заборонені поля
Дозволені значення
nil, якщо рівень контейнера на рівні підпроцесу
spec.securityContext.runAsNonRoot встановлено на true. |
| Запуск як не-root (v1.23+) | Контейнери не повинні встановлювати runAsUser на 0 Заборонені поля
Дозволені значення
|
| Seccomp (v1.19+) | Профіль Seccomp повинен бути явно встановлений на одне з дозволених значень. Обидва, Заборонені поля
Дозволені значення
nil, якщо на рівні підпроцесу spec.securityContext.seccompProfile.type встановлено відповідне значення. Навпаки, поле на рівні підпроцесу може бути undefined/nil, якщо _всі_ поля рівня контейнера встановлені. |
| Capabilities (v1.22+) | Контейнери повинні скидати Заборонені поля
Дозволені значення
Заборонені поля
Дозволені значення
|
Інстанціювання політики
Відокремлення визначення політики від її інстанціювання дозволяє отримати спільне розуміння та послідовне використання політик у кластерах, незалежно від механізму їх виконання.
Після того як механізми стануть більш зрілими, вони будуть визначені нижче на основі кожної політики. Методи виконання окремих політик тут не визначені.
Контролер Pod Security Admission
Альтернативи
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Інші альтернативи для виконання політик розробляються в екосистемі Kubernetes, такі як:
Поле ОС Podʼа
У Kubernetes ви можете використовувати вузли, які працюють на операційних системах Linux або Windows. Ви можете комбінувати обидва типи вузлів в одному кластері. Windows в Kubernetes має деякі обмеження та відмінності від навантаженнь на базі Linux. Зокрема, багато з полів securityContext для контейнерів Pod не мають ефекту у Windows.
Примітка:
Kubelet до версії v1.24 не здійснює контроль над полем OS для Pod, і якщо в кластері є вузли з версіями під номерами менше v1.24, політики Restricted повинні бути привʼязані до версії до v1.25.Зміни в стандарті обмеження безпеки Pod
Ще одна важлива зміна, внесена в Kubernetes v1.25, полягає в тому, що Restricted політики були оновлені для використання поля pod.spec.os.name. Залежно від назви ОС, деякі політики, які специфічні для певної ОС, можуть бути послаблені для іншої ОС.
Елементи політики, специфічні для ОС
Обмеження для наступних елементів є обовʼязковими лише в разі, якщо .spec.os.name не є windows:
- Підвищення привілеїв
- Seccomp
- Linux Capabilities
Простори імен користувачів
Простори імен користувачів — це функція лише для операційних систем Linux, яка дозволяє запускати завдання з підвищеним рівнем ізоляції. Як вони працюють разом зі стандартами безпеки Pod описано в документації Podʼів, що використовують простори імен користувачів.
ЧаПи
Чому відсутній профіль між Privileged та Baseline?
Три профілі, що визначені тут, мають чітку лінійну прогресію від найбільш безпечного (Restricted) до найменш безпечного (Privileged) і охоплюють широкий набір завдань. Привілеї, необхідні вище baseline, зазвичай є дуже специфічними для застосунку, тому ми не пропонуємо стандартний профіль у цій області. Це не означає, що профіль privileged завжди має використовуватися в цьому випадку, але політику в цій області потрібно визначати індивідуально для кожного випадку.
SIG Auth може переосмислити цю позицію у майбутньому, якщо зʼявиться чітка потреба у інших профілях.
В чому різниця між профілем безпеки та контекстом безпеки?
Контексти безпеки налаштовують Podʼи та контейнери під час виконання. Контексти безпеки визначаються як частина специфікації Podʼа та контейнера в маніфесті Podʼа і представляють параметри для контейнерного середовища виконання.
Профілі безпеки — це механізми керування панелі управління для забезпечення певних налаштувань у контексті безпеки, а також інших повʼязаних параметрів поза контекстом безпеки. На даний момент, з липня 2021 року, Політики безпеки Podʼів є застарілими на користь вбудованого Контролера Pod Security Admission.
Що на рахунок Podʼів у пісочниці?
Наразі не існує стандартного API, що контролює, чи знаходиться Pod у пісочниці, чи ні. Podʼи у пісочниці можуть бути ідентифіковані за допомогою використання середовища виконання пісочниці (такого як gVisor або Kata Containers), але немає стандартного визначення того, що таке середовище виконання пісочниці.
Захист, необхідний для робочих навантажень у пісочниці, може відрізнятися від інших. Наприклад, необхідність обмежити привілейовані дозволи менше, коли робоче навантаження ізольоване від базового ядра. Це дозволяє робочим навантаженням, що потребують підвищених дозволів, залишатися ізольованими.
Крім того, захист робочих навантажень у пісочниці сильнго залежить від методу розташування у пісочниці. Таким чином, для всіх робочих навантажень у пісочниці не надається один рекомендований профіль.
8.3 - Pod Security Admission
Огляд контролера Pod Security Admission, який може застосовувати Стандарти Безпеки Podʼів.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.25 [stable]Стандарти безпеки Podʼів Kubernetes визначають різні рівні ізоляції для Podʼів. Ці стандарти дозволяють визначити, як ви хочете обмежувати поведінку Podʼів в чіткий, послідовний спосіб.
У Kubernetes є вбудований контролер допуску безпеки Pod, щоб застосовувати Стандарти Безпеки Podʼів. Обмеження безпеки Podʼів застосовуються на рівні просторі імен під час створення Podʼів.
Вбудоване забезпечення Pod Security admission
Ця сторінка є частиною документації Kubernetes v1.32. Якщо ви використовуєте іншу версію Kubernetes, перегляньте документацію для цієї версії.
Рівні безпеки Podʼів
Забезпечення Pod Security admission ставить вимоги до Контексту Безпеки Podʼа та інших повʼязаних полів відповідно до трьох рівнів, визначених Стандартами безпеки Podʼів: privileged (привілейований), baseline (базовий) та restricted (обмежений). Для докладного огляду цих вимог дивіться сторінку Стандартів безпеки Podʼів.
Мітки Pod Security Admission для просторів імен
Після активації функції або встановлення вебхука ви можете налаштувати простори імен, щоб визначити режим контролю допуску, який ви хочете використовувати для безпеки Podʼа в кожному просторі імен. Kubernetes визначає набір міток, які можна встановити, щоб визначити, який з попередньо визначених рівнів стандартів безпеки Podʼів ви хочете використовувати для простору імен. Вибрана вами мітка визначає дію, яку панель управління виконує, якщо виявлено потенційне порушення:
| Режим | Опис |
|---|---|
| enforce | Порушення політики призведе до відмови обслуговування Podʼа. |
| audit | Порушення політики спричинить додавання аудит-анотації до події, записаної в аудит-лог, але в іншому випадку буде дозволено. |
| warn | Порушення політики спричинить попередження для користувача, але в іншому випадку буде дозволено. |
Простір імен може налаштувати будь-який або всі режими, або навіть встановити різний рівень для різних режимів.
Для кожного режиму існують дві позначки, які визначають використовувану політику:
# Мітка рівня режиму вказує, який рівень політики застосовується для режиму.
#
# РЕЖИМ повинен бути одним з `enforce`, `audit` або `warn`.
# РІВЕНЬ повинен бути одним з `privileged`, `baseline` або `restricted`.
pod-security.kubernetes.io/<РЕЖИМ>: <РІВЕНЬ>
# Опціонально: позначка версії режиму, яку можна використовувати для привʼязки політики до
# версії, що поставляється з певною мінорною версією Kubernetes (наприклад, v1.32).
#
# РЕЖИМ повинен бути одним з `enforce`, `audit` або `warn`.
# ВЕРСІЯ повинна бути дійсною мінорною версією Kubernetes або `latest`.
pod-security.kubernetes.io/<РЕЖИМ>-version: <ВЕРСІЯ>
Перегляньте Застосування стандартів безпеки Podʼів з використанням міток просторів імен, щоб побачити приклад використання.
Ресурси робочого навантаження та шаблони Podʼа
Podʼи часто створюються не безпосередньо, а шляхом створення обʼєкта робочого навантаження, такого як Deployment або Job. Обʼєкт робочого навантаження визначає шаблон Podʼа та контролер для ресурсу робочого навантаження, який створює Podʼи на основі цього шаблону. Щоб вчасно виявляти порушення, обидва режими аудиту та попередження застосовуються до ресурсів робочого навантаження. Проте режим виконання не застосовується до ресурсів робочого навантаження, а лише до отриманих обʼєктів Podʼа.
Виключення
Ви можете визначити Виключення з виконання політики безпеки Podʼа, щоб дозволити створення Podʼів, які інакше були б заборонені через політику, повʼязану з певним простором імен.
Виключення можна статично налаштувати в конфігурації контролера допуску.
Виключення повинні бути явно перераховані. Запити, які відповідають критеріям винятків, ігноруються контролером допуску (всі поведінки enforce, audit та warn пропускаються). Винятків включають:
- Usernames: запити від користувачів за виключеним автентифікованих (або знеособлених) користувачів ігноруються.
- RuntimeClassNames: Podʼи та ресурси робочого навантаження, які вказують виключене імʼя класу runtime, ігноруються.
- Namespaces: Podʼи та ресурси робочого навантаження у виключеному просторі імен ігноруються.
Увага:
Більшість Podʼів створюються контролером у відповідь ресурсу робочого навантаження, що означає, що виключення кінцевого користувача буде застосовуватися лише до нього при створенні Podʼів безпосередньо, але не при створенні ресурсу робочого навантаження. Облікові записи служби контролера (наприклад,system:serviceaccount:kube-system:replicaset-controller) зазвичай не повинні бути виключені, оскільки це неявно виключить будь-якого користувача, який може створювати відповідний ресурс робочого навантаження.Оновлення наступних полів Podʼа виключаються з перевірки політики, що означає, що якщо запит на оновлення Podʼа змінює лише ці поля, його не буде відхилено, навіть якщо Pod порушує поточний рівень політики:
- Будь-які оновлення метаданих виключають зміну анотацій seccomp або AppArmor:
seccomp.security.alpha.kubernetes.io/pod(застарілий)container.seccomp.security.alpha.kubernetes.io/*(застарілий)container.apparmor.security.beta.kubernetes.io/*(застарілий)
- Дійсні оновлення
.spec.activeDeadlineSeconds - Дійсні оновлення
.spec.tolerations
Метрики
Ось метрики Prometheus, які надаються kube-apiserver:
pod_security_errors_total: Ця метрика показує кількість помилок, які перешкоджають нормальній оцінці. Нефатальні помилки можуть призвести до використання останнього обмеженого профілю для виконання.pod_security_evaluations_total: Ця метрика показує кількість оцінок політики, що відбулися, не враховуючи ігнорованих або запитів винятків під час експортування.pod_security_exemptions_total: Ця метрика показує кількість запитів винятків, не враховуючи ігноровані або запити, що не входять в область застосування.
Що далі
- Стандарти безпеки Podʼів
- Застосування стандартів безпеки Podʼів
- Застосування стандартів безпеки Podʼів за допомогою вбудованого контролера допуску
- Застосування стандартів безпеки Podʼів з мітками простору імен
Якщо ви використовуєте старішу версію Kubernetes і хочете оновитися до версії Kubernetes, яка не містить політик безпеки Podʼа, прочитайте перехід від PodSecurityPolicy до вбудованого контролера допуску для безпеки Podʼа.
8.4 - Службові облікові записи
Дізнайтеся про обʼєкти ServiceAccount в Kubernetes.
Ця сторінка розповідає про обʼєкт ServiceAccount в Kubernetes, надаючи інформацію про те, як працюють службові облікові записи, використання, обмеження, альтернативи та посилання на ресурси для додаткової допомоги.
Що таке службові облікові записи?
Службовий обліковий запис — це тип облікового запису, що використовується компонентами системи (не людьми), який в Kubernetes забезпечує окремий ідентифікатор у кластері Kubernetes. Podʼи застосунків, системні компоненти та сутності всередині та поза кластером можуть використовувати облікові дані конкретного ServiceAccount, щоб ідентифікуватися як цей ServiceAccount. Це корисно в різних ситуаціях, включаючи автентифікацію в API-сервері або впровадження політик безпеки на основі ідентичності.
Службові облікові записи існують як обʼєкти ServiceAccount в API-сервері. Службові облікові записи мають наступні властивості:
Привʼязані до простору імен: Кожен службовий обліковий запис привʼязаний до namespace Kubernetes. Кожен простір імен отримує
defaultServiceAccount при створенні.Легкі: Службові облікові записи існують в кластері та визначені в API Kubernetes. Ви можете швидко створювати службові облікові записи для увімкнення певних завдань.
Переносні: Набір конфігурацій для складного контейнеризованого завдання може включати визначення службових облікових записів для системних компонентів. Легкість службових облікових записів та ідентичності в межах простору імен роблять конфігурації переносними.
Службові облікові записи відрізняються від облікових записів користувачів, які є автентифікованими користувачами-людьми у кластері. Типово облікові записи користувачів не існують в API-сервері Kubernetes; замість цього сервер API розглядає ідентичності користувачів як непрозорі дані. Ви можете автентифікуватися як обліковий запис користувача за допомогою кількох методів. Деякі дистрибутиви Kubernetes можуть додавати власні розширені API для представлення облікових записів користувачів в API-сервері.
| Опис | ServiceAccount | Користувач або група |
|---|---|---|
| Місцезнаходження | Kubernetes API (обʼєкт ServiceAccount) | Зовнішній |
| Контроль доступу | Керування доступом за допомогою RBAC Kubernetes або іншими механізмами авторизації | Керування доступом за допомогою RBAC Kubernetes або іншими механізмами управління ідентичністю та доступом |
| Призначене використання | Робочі завдання, автоматизація | Люди |
Стандартні службові облікові записи
При створенні кластера Kubernetes автоматично створює обʼєкт ServiceAccount з імʼям default для кожного простору імен у вашому кластері. Стандартні службові облікові записи у кожному просторі імен типово не мають прав, окрім стандартних дозволів на знаходження API, які Kubernetes надає всім автентифікованим субʼєктам, якщо увімкнено контроль доступу на основі ролей (RBAC). Якщо ви видаляєте обʼєкт ServiceAccount з імʼям default в просторі імен, панель управління замінює його новим.
Якщо ви розгортаєте Pod у просторі імен, і ви не вручну призначаєте ServiceAccount для Podʼа, Kubernetes призначає ServiceAccount default для цього простору імен Podʼа.
Використання службових облікових записів Kubernetes
Загалом, ви можете використовувати службові облікові записи для надання ідентичності в таких сценаріях:
- Вашим Podʼам потрібно спілкуватися з сервером API Kubernetes, наприклад у таких ситуаціях:
- Надання доступу лише для читання конфіденційної інформації, збереженої у Secret.
- Надання доступу між просторами імен, наприклад дозволу на читання, перелік та перегляд обʼєктів Lease в просторі імен
exampleв просторі іменkube-node-lease.
- Вашим Podʼам потрібно спілкуватися з зовнішнім сервісом. Наприклад, Podʼам робочого навантаження потрібна ідентичність для комерційного хмарного API, а комерційний постачальник дозволяє налаштувати відповідні довірчі стосунки.
- Автентифікація в приватному реєстрі образів за допомогою
imagePullSecret. - Зовнішньому сервісу потрібно спілкуватися з сервером API Kubernetes. Наприклад, автентифікація у кластері як частина конвеєра CI/CD.
- Ви використовуєте стороннє програмне забезпечення безпеки у своєму кластері, яке покладається на ідентичність службового облікового запису різних Podʼів, щоб згрупувати ці Podʼи у різні контексти.
Як використовувати службові облікові записи
Щоб скористатися службовим обліковим записом Kubernetes, виконайте наступне:
Створіть обʼєкт ServiceAccount за допомогою клієнта Kubernetes, такого як
kubectl, або за допомогою маніфесту, який визначає обʼєкт.Надайте дозволи обʼєкту ServiceAccount за допомогою механізму авторизації, такого як RBAC.
Призначте обʼєкт ServiceAccount Podʼам під час створення Podʼа.
Якщо ви використовуєте ідентифікацію з зовнішнього сервісу, отримайте токен ServiceAccount та використовуйте його з цього сервісу.
Щоб дізнатися, як це зробити, перегляньте Налаштування службових облікових записів для Podʼів.
Надання дозволів обліковому запису ServiceAccount
Ви можете використовувати вбудований механізм керування доступом на основі ролей (RBAC) Kubernetes, щоб надати мінімальні дозволи, необхідні кожному службовому обліковому запису. Ви створюєте роль, яка надає доступ, а потім привʼязуєте роль до вашого ServiceAccount. RBAC дозволяє визначити мінімальний набір дозволів, щоб дозволи облікового запису слідували принципу найменших прав. Podʼи, які використовують цей службовий обліковий запис, не отримують більше дозволів, ніж необхідно для правильної роботи.
Для інструкцій дивіться Дозволи ServiceAccount.
Крос-простірний доступ за допомогою облікового запису ServiceAccount
Ви можете використовувати RBAC, щоб дозволити службовим обліковим записам в одному просторі імен виконувати дії з ресурсами в іншому просторі імен в кластері. Наприклад, розгляньте ситуацію, коли у вас є службовий обліковий запис та Pod у просторі імен dev, і ви хочете, щоб ваш Pod бачив Job, які виконуються в просторі імен maintenance. Ви можете створити обʼєкт Role, який надає дозволи на перелік обʼєктів Job. Потім створіть обʼєкт RoleBinding у просторі імен maintenance, щоб привʼязати Role до ServiceAccount. Тепер Podʼи у просторі імен dev можуть бачити перелік обʼєктів Job у просторі імен maintenance, використовуючи цей службовий обліковий запис.
Додавання ServiceAccount для Pod
Щоб додати ServiceAccount для Pod, ви встановлюєте поле spec.serviceAccountName у специфікації Pod. Kubernetes автоматично надає облікові дані для цього ServiceAccount для Pod. У версії v1.22 і пізніше Kubernetes отримує короткостроковий, автоматично змінюваний токен за допомогою API TokenRequest та монтує його як том projected.
Типово Kubernetes надає Podʼу облікові дані для призначеного ServiceAccount, хай то default ServiceAccount або спеціальний ServiceAccount, який ви вказуєте.
Щоб запобігти автоматичному впровадженню Kubernetes облікових даних для вказаного ServiceAccount або default ServiceAccount, встановіть поле automountServiceAccountToken у вашій специфікації Pod в значення false.
У версіях раніше 1.22 Kubernetes надає Pod довгостроковий статичний токен як Secret.
Отримання облікових даних ServiceAccount вручну
Якщо вам потрібні облікові дані для ServiceAccount, щоб вони монтувалися у нестандартне місце або для аудиторії, яка не є API-сервером, скористайтеся одним із наступних методів:
- API TokenRequest (рекомендовано): Запитайте короткостроковий токен ServiceAccount безпосередньо з вашого власного коду застосунку. Токен автоматично закінчується і може змінюватись при закінченні строку дії. Якщо у вас є застаріла програма, яка не враховує Kubernetes, ви можете використовувати контейнер sidecar у тому ж самому Podʼі, щоб отримати ці токени та зробити їх доступними для робочого навантаження застосунку.
- Token Volume Projection (також рекомендовано): У Kubernetes v1.20 і пізніше скористайтеся специфікацією Pod, щоб вказати kubelet додати токен ServiceAccount до Pod як projected том. Токени projected автоматично закінчуються, а kubelet змінює токен до закінчення строку дії.
- Service Account Token Secrets (не рекомендується): Ви можете монтувати токени службового облікового запису як Secret Kubernetes у Podʼах. Ці токени не мають терміну дії та не ротуються. У версіях до v1.24 для кожного службового облікового запису автоматично створювався постійний токен. Цей метод більше не рекомендується, особливо у великому масштабі, через ризики, повʼязані зі статичними, довготривалими обліковими даними. Feature gate LegacyServiceAccountTokenNoAutoGeneration (який був стандартно увімкнений в Kubernetes з v1.24 по v1.26), перешкоджав автоматичному створенню цих токенів для службових облікових записів. Його було вилучено у версії v1.27, оскільки він був піднятий до статусу GA; ви все ще можете вручну створювати нескінченні токени службового облікового запису, але повинні враховувати наслідки для безпеки.
Примітка:
Для застосунків, які працюють поза вашим кластером Kubernetes, ви, можливо, розглядаєте можливість створення довгострокового токена ServiceAccount, який зберігається в Secret. Це дозволяє автентифікацію, але проєкт Kubernetes рекомендує уникати такого підходу. Довгострокові мітки-наміри є ризиком безпеки, оскільки після розкриття токен може бути використаний не за призначенням. Замість цього розгляньте альтернативу. Наприклад, ваш зовнішній застосунок може автентифікуватися за допомогою добре захищеного приватного ключа та сертифікату або за допомогою спеціального механізму, такого як webhook автентифікації токенів, який ви реалізуєте самостійно.
Ви також можете використовувати TokenRequest для отримання короткострокових токенів для вашого зовнішнього застосунку.
Обмеження доступу до Secret (застаріло)
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [deprecated]Примітка:
kubernetes.io/enforce-mountable-secrets є застарілим, починаючи з Kubernetes v1.32. Використовуйте окремі простори імен для ізоляції доступу до змонтованих секретів.У Kubernetes існує анотація з назвою kubernetes.io/enforce-mountable-secrets, яку ви можете додати до своїх ServiceAccounts. Коли ця анотація застосовується, Secret ServiceAccount можна монтувати лише на вказані типи ресурсів, покращуючи безпеку вашого кластера.
Ви можете додати анотацію до ServiceAccount за допомогою маніфесту:
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
kubernetes.io/enforce-mountable-secrets: "true"
name: my-serviceaccount
namespace: my-namespace
Коли ця анотація встановлена в "true", панель управління Kubernetes переконується, що Secret з цього ServiceAccount піддаються певним обмеженням монтування.
- Назва кожного Secret, який монтується як том Podʼа, повинна зʼявитися в полі
secretsServiceAccount Podʼа. - Назва кожного Secret, на який посилається за допомогою
envFromу Podʼі, також повинна зʼявитися в поліsecretsServiceAccount Podʼа. - Назва кожного Secret, на який посилається за допомогою
imagePullSecretsу Podʼі, також повинна зʼявитися в поліsecretsServiceAccount Podʼа.
Розуміючи та дотримуючись цих обмежень, адміністратори кластера можуть підтримувати жорсткіший профіль безпеки та забезпечити, що Secret доступні лише відповідним ресурсам.
Автентифікація службових облікових записів
ServiceAccount використовують підписані JSON Web Tokens (JWT) для автентифікації в API-сервері Kubernetes та будь-якій іншій системі, де існує довіра. Залежно від того, як був виданий токен (або обмежений за часом за допомогою TokenRequest, або використовуючи застарілий механізм із Secret), токен ServiceAccount може також мати час дії, аудиторію та час, коли токен починає бути дійсним. Коли клієнт, який діє як ServiceAccount, намагається спілкуватися з API-сервером Kubernetes, клієнт включає заголовок Authorization: Bearer <token> з HTTP-запитом. API-сервер перевіряє чинність цього токена наступним чином:
- Перевіряє підпис токена.
- Перевіряє, чи не закінчився строк дії токена.
- Перевіряє, чи наразі дійсні посилання на обʼєкти у твердженнях токена.
- Перевіряє, чи наразі дійсний токен.
- Перевіряє аудиторію тверджень.
API TokenRequest створює звʼязані токени для ServiceAccount. Ця звʼязка повʼязана з життєвим циклом клієнта, такого як Pod, який діє як цей ServiceAccount. Дивіться Token Volume Projection для прикладу схеми та полів JWT звʼязаного токена службового облікового запису.
Для токенів, виданих за допомогою API TokenRequest, API-сервер також перевіряє, чи існує зараз конкретне посилання на обʼєкт, яке використовує ServiceAccount, відповідно до унікального ідентифікатора цього обʼєкта. Для застарілих токенів, які монтувалися як Secretʼи в Podʼах, API-сервер перевіряє токен за допомогою Secret.
Для отримання додаткової інформації про процес автентифікації, див. Автентифікація.
Автентифікація службових облікових записів у вашому власному коді
Якщо у вас є власні служби, яким потрібно перевіряти облікові дані служби Kubernetes, ви можете використовувати наступні методи:
- API TokenReview (рекомендовано)
- Відкриття OIDC
Проєкт Kubernetes рекомендує використовувати API TokenReview, оскільки цей метод анулює токени, які привʼязані до обʼєктів API, таких як Secrets, ServiceAccounts, Podʼи або Вузли, коли ці обʼєкти видаляються. Наприклад, якщо ви видаляєте Pod, що містить projected токен ServiceAccount, кластер негайно анулює цей токен, і перевірка TokenReview негайно зазнає невдачі. Якщо ви використовуєте перевірку OIDC замість цього, ваші клієнти продовжують розглядати токен як дійсний, доки токен не досягне часу закінчення дії.
Ваш застосунок повинен завжди визначати аудиторію, яку він приймає, і перевіряти, що аудиторії токена відповідають аудиторіям, які очікує ваш застосунок. Це допомагає зменшити обсяг застосування токена так, що він може бути використаний лише у вашому застосунку і ніде більше.
Альтернативи
- Видавайте свої власні токени, використовуючи інший механізм, а потім використовуйте Автентифікацію токенів за допомогою веб-хуків, щоб перевіряти токени розробника за допомогою власної служби перевірки.
- Надавайте свої власні ідентифікатори для Podʼів.
Використовуйте SPIFFE CSI driver, щоб надавати SPIFFE SVIDs як пари сертифікатів X.509 для Podʼів.
🛇 Цей елемент посилається на сторонній проєкт або продукт, який не є частиною Kubernetes. ДокладнішеВикористовуйте сервісний механізм, такий як Istio, для надання сертифікатів Podʼів.
- Автентифікуйтеся ззовні кластера до API-сервера без використання токенів службового облікового запису:
- Налаштуйте API-сервер для прийняття токенів OpenID Connect (OIDC) від вашого постачальника ідентифікації.
- Використовуйте службові облікові записи або облікові записи користувачів, створені за допомогою зовнішньої служби управління доступом та ідентифікації (IAM), наприклад від постачальника хмарних послуг, для автентифікації в вашому кластері.
- Використовуйте API-інтерфейс CertificateSigningRequest з клієнтськими сертифікатами.
- Налаштуйте kubelet для отримання облікових даних з реєстру зображень.
- Використовуйте втулок пристрою, щоб отримати доступ до віртуального Trusted Platform Module (TPM), що дозволяє потім автентифікуватися за допомогою приватного ключа.
Що далі
- Дізнайтеся, як керувати ServiceAccounts як адміністратор кластера.
- Дізнайтеся, як призначити ServiceAccounts для Podʼів.
- Прочитайте довідку API ServiceAccount.
8.5 - Політики безпеки для Podʼів
Видалена функція
PodSecurityPolicy було визнано застарілим у Kubernetes v1.21, і видалено з Kubernetes у v1.25.Замість використання PodSecurityPolicy, ви можете застосовувати схожі обмеження до Podʼів, використовуючи один чи обидва варіанти:
- Pod Security Admission
- втулок допуску від стороннього розробника, який ви розгортаєте та налаштовуєте самостійно
Для практичного керівництва з міграції дивіться Міграція з PodSecurityPolicy до вбудованого контролера Pod Security Admission. Для отримання додаткової інформації про вилучення цього API, дивіться Застарівання PodSecurityPolicy: минуле, сьогодення та майбутнє.
Якщо ви не використовуєте Kubernetes v1.32, перевірте документацію для вашої версії Kubernetes.
8.6 - Захист для вузлів з операційною системою Windows
На цій сторінці описано питання безпеки та найкращі практики, специфічні для операційної системи Windows.
Захист конфіденційних даних на вузлах
У Windows дані з Secret записуються у відкритому вигляді у локальне сховище вузла (на відміну від використання tmpfs / файлових систем у памʼяті в Linux). Як оператору кластера, вам слід вжити обидва наступні додаткові заходи:
- Використовуйте контроль доступу до файлів (file ACLs), щоб захистити місце розташування файлів Secrets.
- Застосовуйте шифрування на рівні тому за допомогою BitLocker.
Користувачі контейнерів
RunAsUsername може бути вказано для Podʼів Windows або контейнерів, щоб виконувати процеси контейнера як конкретний користувач. Це приблизно еквівалентно RunAsUser.
В контейнерах Windows доступні два типові облікових записів користувачів: ContainerUser та ContainerAdministrator. Різниця між цими двома обліковими записами користувачів описана у When to use ContainerAdmin and ContainerUser user accounts в документації Microsoft Secure Windows containers.
Локальні користувачі можуть бути додані до образів контейнерів під час процесу створення контейнера.
Примітка:
- Образи на основі Nano Server запускаються як
ContainerUser - Образи на основі Server Core запускаються як
ContainerAdministrator
Контейнери Windows також можуть працювати як облікові записи активного каталогу за допомогою Group Managed Service Accounts
Ізоляція на рівні Podʼа
Механізми контексту безпеки Podʼів, специфічні для Linux (такі як SELinux, AppArmor, Seccomp або власні POSIX можливості), не підтримуються на вузлах з Windows.
Привілейовані контейнери не підтримуються на вузлах з Windows. Замість цього на вузлах з Windows можна використовувати HostProcess контейнери для виконання багатьох завдань, які виконуються привілейованими контейнерами у Linux.
8.7 - Керування доступом до API Kubernetes
Ця сторінка надає загальний огляд керування доступом до API Kubernetes.
Користувачі отримують доступ до API Kubernetes за допомогою kubectl, клієнтських бібліотек або за допомогою запитів REST. Як користувачі-люди, так і облікові записи служб Kubernetes можуть бути авторизовані для доступу до API. Коли запит досягає API, він проходить кілька етапів, які ілюструються на
наступній діаграмі:

Транспортна безпека
Стандартно сервер API Kubernetes прослуховує порт 6443 на першому нелокальному мережевому інтерфейсі, захищеному за допомогою TLS. У типовому промисловому кластері Kubernetes, API працює на порту 443. Порт можна змінити за допомогою прапорця --secure-port, а IP-адресу прослуховування – за допомогою --bind-address.
Сервер API представляє сертифікат. Цей сертифікат може бути підписаний за допомогою приватного центру сертифікації (ЦС), або на основі інфраструктури відкритих ключів, повʼязаної з загалом визнаним ЦС. Сертифікат та відповідний приватний ключ можна встановити за допомогою прапорців --tls-cert-file та --tls-private-key-file.
Якщо ваш кластер використовує приватний ЦС, вам потрібна копія цього сертифіката ЦС, налаштована в вашому ~/.kube/config на клієнті, щоб ви могли довіряти зʼєднанню і бути впевненими, що воно не було перехоплено.
На цьому етапі ваш клієнт може представити сертифікат клієнта TLS.
Автентифікація
Якщо TLS-зʼєднання встановлено, HTTP-запит переходить до кроку автентифікації. Це показано як крок 1 на діаграмі. Скрипт створення кластера або адміністратор кластера налаштовує сервер API на виконання одного або декількох модулів автентифікації. Модулі автентифікації детально описані в документації про Автентифікацію.
Вхідними даними для кроку автентифікації є весь HTTP-запит; проте, зазвичай перевіряються заголовки та/або сертифікат клієнта.
Модулі автентифікації включають клієнтські сертифікати, паролі та прості токени, токени ініціалізації та токени JSON Web Tokens (використовується для облікових записів служб).
Можна вказати кілька модулів автентифікації, при цьому кожен з них використовується послідовно, доки спроба не буде успішною.
Якщо запит не може бути автентифікований, він буде відхилений з HTTP-статусом 401. Інакше користувач автентифікується як конкретний username, та імʼя користувача доступне для наступних кроків для використання у їхніх рішеннях. Деякі автентифікатори також надають групові приналежності користувача, в той час, як інші автентифікатори цього не роблять.
Хоча Kubernetes використовує імена користувачів для прийняття рішень про контроль доступу та в логах запитів, в нього немає обʼєкта User, і він не зберігає імена користувачів чи іншу інформацію про користувачів у своєму API.
Авторизація
Після того як запит автентифікується як такий, що надійшов від певного користувача, йому потрібно пройти авторизацію. Це показано як крок 2 на діаграмі.
Запит повинен містити імʼя користувача, який робить запит, запитану дію та обʼєкт, на якому відбувається дія. Запит авторизується, якщо наявна політика вказує, що користувач має дозвіл на виконання запитаної дії.
Наприклад, якщо у Боба є така політика, то він може лише читати обʼєкти у просторі імен projectCaribou:
{
"apiVersion": "abac.authorization.kubernetes.io/v1beta1",
"kind": "Policy",
"spec": {
"user": "bob",
"namespace": "projectCaribou",
"resource": "pods",
"readonly": true
}
}
Якщо Боб зробить такий запит, то він буде авторизований, оскільки він має дозвіл на читання обʼєктів у просторі імен projectCaribou:
{
"apiVersion": "authorization.k8s.io/v1beta1",
"kind": "SubjectAccessReview",
"spec": {
"resourceAttributes": {
"namespace": "projectCaribou",
"verb": "get",
"group": "unicorn.example.org",
"resource": "pods"
}
}
}
Якщо Боб зробить запит на запис (create або update) обʼєктів у просторі імен
projectCaribou, то йому буде відмовлено в авторизації. Якщо Боб зробить запит на
читання (get) обʼєктів у іншому просторі імен, наприклад, projectFish, то йому
буде відмовлено в авторизації.
Для авторизації в Kubernetes потрібно використовувати загальні атрибути REST для взаємодії з наявними системами керування доступом на рівні всієї організації або постачальника хмарних послуг. Важливо використовувати форматування REST, оскільки ці системи керування можуть взаємодіяти з іншими API, крім API Kubernetes.
Kubernetes підтримує кілька модулів авторизації, таких як режим ABAC, режим RBAC та режим Webhook. Коли адміністратор створює кластер, він налаштовує модулі авторизації, які повинні використовуватися в сервері API. Якщо налаштовано більше одного модуля авторизації, Kubernetes перевіряє кожен модуль, і якщо будь-який модуль авторизує запит, то запит може бути виконаний. Якщо всі модулі відхиляють запит, то запит відхиляється (HTTP-статус код 403).
Щоб дізнатися більше про авторизацію в Kubernetes, включно з деталями щодо створення політик з використанням підтримуваних модулів авторизації, див. Авторизація.
Контроль доступу
Модулі контролю доступу — це програмні модулі, які можуть змінювати або відхиляти запити. Крім атрибутів, доступних модулям авторизації, модулі контролю доступу можуть отримувати доступ до вмісту обʼєкта, який створюється або змінюється.
Контролери доступу діють на запити, які створюють, змінюють, видаляють або підключаються (проксі) до обʼєкта. Контролери доступу не діють на запити, які лише читають обʼєкти. Коли налаштовано кілька контролерів доступу, вони викликаються по черзі.
Це показано як крок 3 на діаграмі.
На відміну від модулів автентифікації та авторизації, якщо будь-який модуль контролю доступу відхиляє запит, то запит негайно відхиляється.
Крім відхилення обʼєктів, контролери доступу також можуть встановлювати складні стандартні значення для полів.
Доступні модулі контролю доступу описані в Контролерах доступу.
Після того як запит пройшов усі контролери доступу, він перевіряється за допомогою процедур валідації для відповідного обʼєкта API, і потім записується в сховище обʼєктів (показано як крок 4).
Аудит
Аудит Kubernetes забезпечує безпеку, хронологічний набір записів, що документують послідовність дій у кластері. Кластер аудитує активності, що генеруються користувачами, застосунками, які використовують API Kubernetes, і самою панелі управління.
Для отримання додаткової інформації див. Аудит.
Що далі
Прочитайте додаткову документацію щодо автентифікації, авторизації та контролю доступу до API:
- Автентифікація
- Контролери допуску
- Авторизація
- Запити на підписання сертифікатів
- Сервісні облікові записи
Ви можете дізнатися про:
- як Podʼи можуть використовувати Secret для отримання API-даних для доступу.
8.8 - Поради з безпеки для контролю доступу на основі ролей
Принципи та практики для належного про'ктування RBAC для операторів кластерів.
Kubernetes RBAC є ключовим елементом безпеки, який забезпечує те, що користувачі та робочі навантаження кластера мають доступ лише до ресурсів, необхідних для виконання їх ролей. Важливо переконатися, що при проєктуванні дозволів для користувачів кластера адміністратор кластера розуміє області, де може відбуватися ескалація привілеїв, щоб зменшити ризик надмірного доступу, що може призвести до інцидентів безпеки.
Рекомендації, викладені тут, слід читати разом із загальною документацією з RBAC.
Загальні рекомендації
Принцип найменших привілеїв
Ідеально, мінімальні права RBAC повинні бути надані користувачам та службовим обліковим записам. Використовуйте лише дозволи, які явно потрібні для їхньої роботи. Хоча кожен кластер буде відрізнятися, деякі загальні правила, які можна застосувати, включають наступне:
- Надавайте дозволи на рівні простору імен, де це можливо. Використовуйте RoleBindings замість ClusterRoleBindings, щоб дати користувачам права лише в межах конкретного простору імен.
- Уникайте надання дозволів за допомогою шаблонів (wildcard) при можливості, особливо для всіх ресурсів. Оскільки Kubernetes є розширюваною системою, надання доступу за допомогою шаблонів надає права не лише на всі типи обʼєктів, які наразі існують у кластері, а й на всі типи обʼєктів, які будуть створені у майбутньому.
- Адміністратори не повинні використовувати облікові записи
cluster-admin, крім випадків, коли це дійсно потрібно. Надання облікового запису з низькими привілеями з правами знеособлення може запобігти випадковій модифікації ресурсів кластера. - Уникайте додавання користувачів до групи
system:masters. Будь-який користувач, який є членом цієї групи, обходить всі перевірки прав RBAC та завжди матиме необмежений доступ суперкористувача, який не може бути скасований шляхом видалення RoleBindings або ClusterRoleBindings. До речі, якщо кластер використовує вебхук авторизації, членство в цій групі також обходить цей вебхук (запити від користувачів, які є членами цієї групи, ніколи не відправляються вебхуку).
Мінімізація розповсюдження привілейованих токенів
В ідеалі, службові облікові записи не повинні бути призначені Podʼам, які мають надані потужні дозволи (наприклад, будь-які з перерахованих прав підвищення привілеїв). У випадках, коли робоче навантаження вимагає потужних дозволів, розгляньте такі практики:
- Обмежте кількість вузлів, на яких запущені потужні Podʼи. Переконайтеся, що всі DaemonSets, які ви запускаєте, необхідні та запускаються з мінімальними привілеями, щоб обмежити зону поширення випадкових виходів з контейнера.
- Уникайте запуску потужних Podʼів поруч з ненадійними або публічно-експонованими. Розгляньте використання Taints and Toleration, NodeAffinity або PodAntiAffinity, щоб переконатися, що Podʼи не запускаються поруч з ненадійними або менш надійними Podʼами. Особливу увагу слід приділяти ситуаціям, де менш надійні Podʼи не відповідають стандарту Restricted для безпеки Podʼів.
Зміцнення захисту
Kubernetes типово надає доступ, який може бути непотрібним у кожному кластері. Перегляд прав RBAC, які надаються типово, може створити можливості для зміцнення безпеки. Загалом, зміни не повинні вноситися до прав, наданих system: обліковим записам, але існують деякі опції для зміцнення прав кластера:
- Перегляньте звʼязки для групи
system:unauthenticatedта видаліть їх, де це можливо, оскільки це надає доступ всім, хто може звертатися до сервера API на мережевому рівні. - Уникайте автоматичного монтування токенів службового облікового запису типово, встановивши
automountServiceAccountToken: false. Докладніше дивіться використання токенів стандартного службового облікового запису. Встановлення цього значення для Podʼа перезапише налаштування службового облікового запису, робочі навантаження які потребують токени службового облікового запису, все ще можуть монтувати їх.
Періодичний огляд
Важливо періодично переглядати налаштування Kubernetes RBAC для виявлення зайвих записів та можливих ескалацій привілеїв. Якщо зловмисник може створити обліковий запис користувача з такою ж назвою, як видалений користувач, він автоматично може успадкувати всі права видаленого користувача, зокрема права, призначені цьому користувачу.
Ризики ескалації привілеїв RBAC у Kubernetes
У Kubernetes RBAC існує кілька привілеїв, які, якщо надані, можуть дозволити користувачеві або обліковому запису служби здійснити ескалацію своїх привілеїв у кластері або вплинути на системи за межами кластера.
Цей розділ призначений для того, щоб надати видимість тим областям, де оператори кластерів повинні бути уважними, щоб переконатися, що вони не надають більше доступу до кластерів, ніж було задумано.
Отримання Secret
Зазвичай зрозуміло, що надання доступу до отримання (get) Secret дозволить користувачеві переглядати їх вміст. Також важливо зауважити, що доступ до списку (list) та перегляду (watch) також фактично дозволяє користувачам розкривати вміст Secret. Наприклад, коли повертається відповідь списку (наприклад, за допомогою kubectl get secrets -A -o yaml), вона містить вміст усіх Secret.
Створення робочого навантаження
Дозвіл на створення робочих навантажень (будь-то Podʼи чи ресурси робочих навантажень, що керують Podʼами) у просторі імен неявно надає доступ до багатьох інших ресурсів у цьому просторі імен, таких як Secret, ConfigMap та PersistentVolume, які можна монтувати в Podʼах. Крім того, оскільки Podʼи можуть працювати як будь-який ServiceAccount, надання дозволу на створення робочих навантажень також неявно надає рівні доступу до API будь-якого облікового запису служби у цьому просторі імен.
Користувачі, які можуть запускати привілейовані Podʼи, можуть використовувати цей доступ для отримання доступу до вузла і, можливо, подальшого підвищення своїх привілеїв. Якщо ви не повністю довіряєте користувачеві або іншому принципалу з можливістю створювати відповідні заходи безпеки та ізоляції Podʼів, вам слід застосувати стандарт безпеки Podʼів Baseline або Restricted. Ви можете використовувати Pod Security admission або інші (сторонні) механізми для впровадження цього контролю.
З цих причин простори імен слід використовувати для розділення ресурсів, які потребують різних рівнів довіри або оренди. Вважається за кращу практику дотримуватися принципів найменших привілеїв і надавати мінімальний набір дозволів, але межі у межах простору імен слід розглядати як слабкі.
Створення постійного тому
Якщо дозволяється комусь, або застосунку, створювати довільні постійні томи (PersistentVolumes), цей доступ включає створення томів типу hostPath, що означає, що Pod отримає доступ до базової файлової системи (файлових систем) вузла, з яким повʼязаний цей том. Надання такої можливості — це ризик безпеки.
Існує багато способів, за допомогою яких контейнер з необмеженим доступом до файлової системи вузла може підвищити свої привілеї, включаючи читання даних з інших контейнерів та зловживання обліковими записами служб системи, такими як Kubelet.
Дозволяйте доступ до створення обʼєктів PersistentVolume (постійного тому) лише для:
- Користувачів (операторів кластера), які потребують цього доступу для своєї роботи, і яким ви довіряєте.
- Компонентів управління Kubernetes, які створюють обʼєкти PersistentVolume на основі PersistentVolumeClaims, які налаштовані для автоматичного розподілу. Зазвичай це налаштовано постачальником Kubernetes або оператором при встановленні драйвера CSI.
Де потрібен доступ до постійного сховища, довірені адміністратори повинні створювати PersistentVolumes, а обмежені користувачі повинні використовувати PersistentVolumeClaims для доступу до цього сховища.
Доступ до субресурсу proxy обʼєктів вузлів
Користувачі, які мають доступ до субресурсу proxy обʼєктів вузлів, мають права на використання API Kubelet, що дозволяє виконувати команди на кожному Podʼі на вузлі (вузлах), до якого вони мають права доступу. Цей доступ обходить логування подій та контроль допуску, тому слід бути обережним перед наданням прав на цей ресурс.
Escalate
Загалом, система RBAC запобігає користувачам створювати clusterroles з більшими правами, ніж має користувач. Виняток становить дієслово escalate. Як вказано в документації з RBAC, користувачі з цим правом можуть ефективно підвищувати свої привілеї.
Bind
Схоже до дієслова escalate, надання користувачам цього права дозволяє обхід вбудованих захистів Kubernetes від підвищення привілеїв, що дозволяє користувачам створювати привʼязки до ролей з правами, яких вони ще не мають.
Impersonate
Це дієслово дозволяє користувачам підміняти та отримувати права інших користувачів у кластері. Слід бути обережним при наданні цього права, щоб переконатися, що через один з знеособлених облікових записів не можна отримати занадто багато прав.
Запити на підпис сертифікатів (CSRs) і видача сертифікатів
API CSRs дозволяє користувачам з правами create на CSRs та update на certificatesigningrequests/approval з підписантом kubernetes.io/kube-apiserver-client створювати нові клієнтські сертифікати, що дозволяють користувачам автентифікуватися в кластері. Ці клієнтські сертифікати можуть мати довільні імена, включаючи дублікати компонентів системи Kubernetes. Це фактично дозволить підвищення привілеїв.
Запити токенів
Користувачі з правами create на serviceaccounts/token можуть створювати запити на токени для наявних сервісних облікових записів.
Керування вебхуками допуску
Користувачі з контролем над validatingwebhookconfigurations або mutatingwebhookconfigurations можуть керувати вебхуками, які можуть читати будь-який обʼєкт, допущений до кластера, і, у разі мутаційних вебхуків, також змінювати допущені обʼєкти.
Зміна Namespace
Користувачі, які можуть виконувати операції patch на обʼєктах Namespace (через привʼязку до ролі (RoleBinding) з таким доступом), можуть змінювати мітки цього Namespaceʼу. У кластерах, де використовується Pod Security Admission, це може дозволити користувачу налаштувати простір імен для більш дозволених політик, ніж передбачено адміністратором. Для кластерів, де використовується NetworkPolicy, користувачам можуть бути встановлені мітки, які опосередковано дозволяють доступ до служб, доступ до яких адміністратор не мав на меті давати.
Ризики відмови в обслуговуванні в Kubernetes RBAC
Відмова у створенні обʼєктів
Користувачі, які мають права на створення обʼєктів у кластері, можуть створювати достатньо великі обʼєкти або велику кількість обʼєктів, що може призвести до умов відмови в обслуговуванні, як обговорюється в etcd, що використовується в Kubernetes, піддається атакам типу OOM. Це може бути особливо актуальним у кластерах з кількома орендаторами, якщо користувачі з частковою довірою або користувачі без довіри мають обмежений доступ до системи.
Один зі способів попередження цієї проблеми — використовувати обмеження ресурсів для обмеження кількості обʼєктів, які можна створити.
Що далі
- Дізнайтеся більше про RBAC, переглянувши документацію з RBAC.
8.9 - Поради використання Secretʼів в Kubernetes
Принципи та практики керування Secretʼами для адміністраторів кластера та розробників застосунків.
У Kubernetes, Secret — це обʼєкт, який зберігає конфіденційну інформацію, таку як паролі, токени OAuth та ключі SSH.
Секрети дають вам більше контролю над тим, як використовується конфіденційна інформація і зменшують ризик випадкового її розголошення. Значення Secret кодуються як рядки base64 і зазвичай зберігаються в незашифрованому вигляді, але можуть бути налаштовані для шифрування в стані покою.
Pod може посилатися на Secret різними способами, такими як монтування тому, чи як змінна середовища. Secretʼи призначені для конфіденційних даних, а ConfigMaps призначені для неконфіденційних даних.
Наведені нижче поради призначені як для адміністраторів кластера, так і для розробників застосунків. Використовуйте ці рекомендації, щоб підвищити безпеку вашої конфіденційної інформації у Secret, а також ефективніше керувати вашими Secretʼами.
Адміністратори кластера
У цьому розділі наведені кращі практики, які адміністратори кластера можуть використовувати для покращення безпеки конфіденційної інформації в кластері.
Налаштування шифрування даних у спокої
Стандартно обʼєкти Secret зберігаються у кластері в etcd у незашифрованому вигляді. Вам слід налаштувати шифрування конфіденційної інформації з Secret в etcd. Для отримання інструкцій дивіться Шифрування конфіденційних даних у Secret у спокої.
Налаштування доступу з мінімальними привілеями до Secret
Плануючи механізм керування доступом, такий як Керування доступом на основі ролей Kubernetes (RBAC), слід врахувати наступні рекомендації щодо доступу до обʼєктів Secret. Також слід дотримуватися рекомендацій використання RBAC.
- Компоненти: Обмежте доступ до
watchабоlistтільки для найпривілейованіших системних компонентів. Дозвольте доступ лише для отримання Secret, якщо це необхідно для звичайної роботи компонента. - Люди: Обмежте доступ до Secrets на рівні
get,watchабоlist. Дозвольте адміністраторам кластера отримувати доступ доetcd. Це включає доступ тільки для читання. Для складнішого керування доступом, такого як обмеження доступу до Secrets з конкретними анотаціями, слід розглянути використання механізмів авторизації сторонніх постачальників.
Увага:
Надання доступу доlist Secrets неявно дозволяє субʼєкту отримувати значення Secrets.Користувач, який може створити Pod, який використовує Secret, також може побачити значення цього Secret. Навіть якщо політика кластера не дозволяє користувачу читати Secret безпосередньо, той же користувач може мати доступ до запуску Pod, який потім розкриває Secret. Ви можете виявити або обмежити вплив викриття даних Secret, як умисно, так і неумисно, користувачем з цим доступом. Деякі рекомендації включають:
- Використовуйте Secret з коротким терміном дії
- Реалізуйте правила аудиту, які сповіщають про певні події, такі як одночасне читання кількох Secret одним користувачем
Обмеження доступу для Secrets
Використовуйте окремі простори імен для ізоляції доступу до змонтованих секретів.
Покращення політик управління etcd
Розгляньте очищення або знищення надійного сховища, використаного etcd, якщо воно більше не використовується.
Якщо є кілька екземплярів etcd, налаштуйте зашифровану SSL/TLS комунікацію між екземплярами для захисту конфіденційних даних Secret під час передачі.
Налаштування доступу до зовнішніх Secrets
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Ви можете використовувати сторонніх постачальників систем збереження Secret, щоб зберігати вашу конфіденційну інформацію поза кластером, а потім налаштувати Podʼі для доступу до цієї інформації. Драйвер Kubernetes Secrets Store CSI — це DaemonSet, який дозволяє kubelet отримувати Secrets з зовнішніх сховищ та монтувати Secretʼи як томи у певні Podʼи, які ви авторизуєте для доступу до даних.
Для списку підтримуваних постачальників дивіться Постачальники для драйвера сховища Secret Store CSI.
Розробники
У цьому розділі наведено рекомендації для розробників щодо покращення безпеки конфіденційних даних при створенні та розгортанні ресурсів Kubernetes.
Обмежте доступ до Secret до певних контейнерів
Якщо ви визначаєте декілька контейнерів у Pod, і тільки один з цих контейнерів потребує доступу до Secret, визначте настройки монтування томів або змінних середовища так, щоб інші контейнери не мали доступ до цього Secret.
Захист даних Secret після їх зчитування
Застосунки все ще повинні захищати значення конфіденційної інформації після їх зчитування зі змінної середовища або тому. Наприклад, вашому застосунку слід уникати логування конфіденційних даних у відкритому вигляді або передачі їх ненадійній стороні.
Уникайте спільного використання маніфестів Secret
Якщо ви налаштовуєте Secret через маніфест, де дані Secret кодуються у base64, то обмінюючись цим файлом або включаючи його до репозиторію, цей Secret буде доступний всім, хто може читати маніфест.
Увага:
Кодування у base64 — це не метод шифрування, воно не надає додаткової конфіденційності порівняно зі звичайним текстом.8.10 - Мультиорендність
Ця сторінка надає огляд наявних параметрів конфігурації та найкращих практик для мультиорендності (multi-tenancy) кластера.
Спільне використання кластерів зменшує витрати та спрощує адміністрування. Однак спільне використання кластерів також ставить перед собою виклики, такі як безпека, справедливість та керування шумними сусідами.
Кластери можуть бути спільно використані багатьма способами. У деяких випадках різні програми можуть працювати у тому ж кластері. У інших випадках у тому ж кластері може працювати кілька екземплярів тієї самої програми, один для кожного кінцевого користувача. Усі ці типи спільного використання часто описуються за допомогою терміну мультиорендність.
Хоча Kubernetes не має концепцій кінцевих користувачів або орендарів першого класу, він надає кілька можливостей для керування різними вимогами до оренди. Про них буде нижче.
Сценарії використання
Першим кроком для визначення того, як ділити ваш кластер, є розуміння вашого сценарію використання, щоб ви могли оцінити доступні шаблони та інструменти. Загалом, мульторендність в кластерах Kubernetes може бути узагальнена у дві широкі категорії, хоча можливі також багато варіантів та гібриди.
Декілька команд
Одна з поширених форм мульторендності — це спільне використання кластера кількома командами у межах однієї організації, кожна з яких може працювати з одним або кількома робочими навантаженнями. Ці робочі навантаження часто потребують взаємодії між собою та з іншими робочими навантаженнями, що розташовані на тому самому або різних кластерах.
У цьому сценарії учасники команд часто мають прямий доступ до ресурсів Kubernetes за допомогою інструментів, таких як kubectl, або опосередкований доступ через контролери GitOps або інші типи інструментів автоматизації релізу. Часто існує певний рівень довіри між учасниками різних команд, але політики Kubernetes, такі як RBAC, квоти та мережеві політики, є невіддільним для безпечного та справедливого спільного використання кластерів.
Кілька клієнтів
Інша основна форма багатоорендності часто охоплює постачальника програмного забезпечення як сервісу (SaaS), який запускає кілька екземплярів робочого навантаження для клієнтів. Ця бізнес-модель настільки сильно повʼязана з цим стилем розгортання, що багато хто називає її "SaaS tenancy". Однак, кращим терміном може бути "багатоклієнтська оренда", оскільки постачальники SaaS також можуть використовувати інші моделі розгортання, і цю модель розгортання також можна використовувати поза межами SaaS.
У цьому сценарії клієнти не мають доступу до кластера; Kubernetes невидимий з їх точки погляду і використовується лише постачальником для керування робочими навантаженнями. Оптимізація витрат часто є критичною проблемою, і політики Kubernetes використовуються для забезпечення того, що робочі навантаження міцно ізольовані одне від одного.
Термінологія
Орендарі
При обговоренні мультиорендності в Kubernetes не існує єдиного визначення "орендаря" (tenant). Замість цього визначення орендаря буде залежати від того, чи обговорюється багатокомандна або багатоклієнтська мультиорендність.
У використанні багатокомандної моделі орендарем, як правило, є команда, при цьому кожна команда, як правило, розгортає невелику кількість робочих навантажень, яка зростає зі складністю сервісу. Однак визначення "команди" саме по собі може бути нечітким, оскільки команди складатись з високорівневих підрозділів або розділені на менші команди.
Натомість якщо кожна команда розгортає відокремлені робочі навантаження для кожного нового клієнта, вони використовують багатоклієнтську модель мультиорендності. У цьому випадку "орендарем" є просто група користувачів, які спільно використовують одне робоче навантаження. Це може бути як ціла компанія, так і одна команда в цій компанії.
У багатьох випадках одна й та ж організація може використовувати обидва визначення "орендарів" у різних контекстах. Наприклад, команда платформи може пропонувати спільні послуги, такі як інструменти безпеки та бази даних, кільком внутрішнім "клієнтам", і постачальник SaaS також може мати кілька команд, які спільно використовують кластер, який використовується для розробки. Нарешті, можливі також гібридні архітектури, такі як постачальник SaaS, який використовує комбінацію робочих навантажень для кожного клієнта для конфіденційних даних, спільно з багатокористувацькими спільними службами.
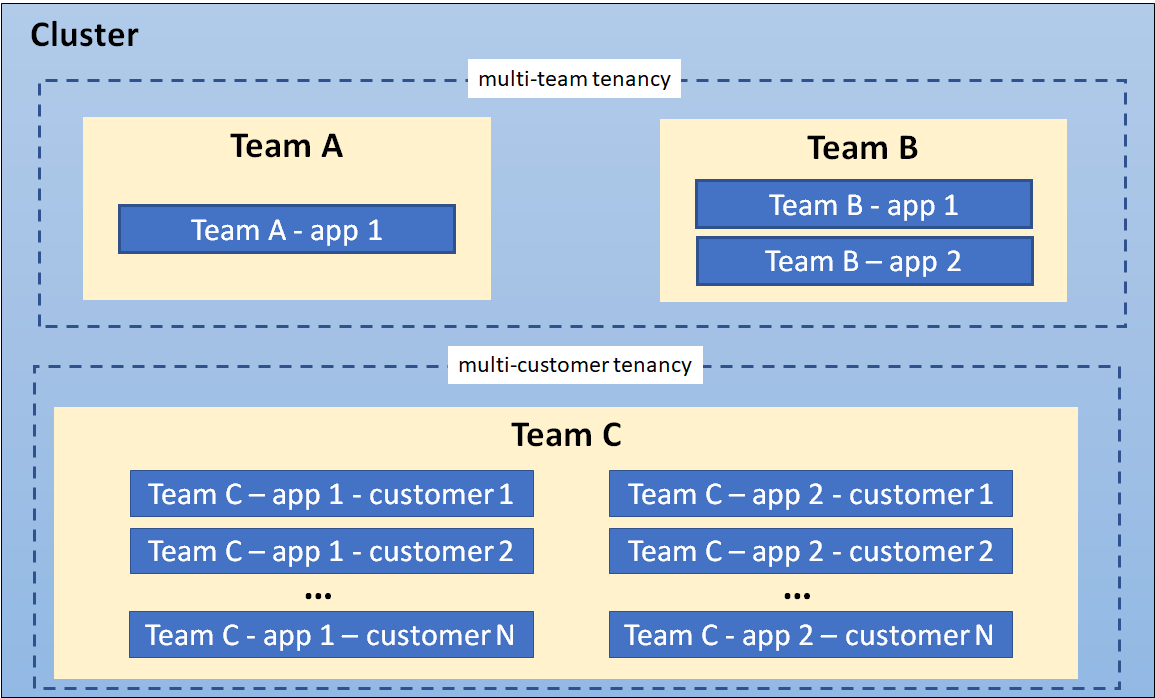
Кластер, на якому показані співіснуючі моделі оренди
Ізоляція
Існує кілька способів проєктування та побудови багатокористувацьких рішень з використанням Kubernetes. Кожен з цих методів має свій набір компромісів, які впливають на рівень ізоляції, складність реалізації, операційну складність та вартість обслуговування.
Кластер Kubernetes складається з панелі управління, на якій працює програмне забезпечення Kubernetes, та панелі даних, яка складається з робочих вузлів, де виконуються робочі навантаження орендарів у вигляді Podʼів. Ізоляція орендарів може бути застосована як в панелі управління, так і в панелі даних залежно від вимог організації.
Рівень ізоляції, який пропонується, іноді описується за допомогою термінів, таких як "жорстка" багатоорендність, що має на увазі міцну ізоляцію, і "мʼяка" багатоорендність, що означає слабшу ізоляцію. Зокрема, "жорстка" багатоорендність часто використовується для опису випадків, коли орендарі не довіряють один одному, часто з погляду безпеки та обміну ресурсами (наприклад, захист від атак, таких як ексфільтрація даних або DoS). Оскільки панелі даних зазвичай мають набагато більші площі атаки, "жорстка" багатоорендність часто вимагає додаткової уваги до ізоляції панелі даних, хоча ізоляція панелі управління також залишається критичною.
Однак терміни "жорстка" та "мʼяка" часто можуть бути плутаними, оскільки немає однозначного визначення, яке б підходило для всіх користувачів. Краще розуміти "жорсткість" або "мʼякість" як широкий спектр, у якому можна використовувати багато різних технік для забезпечення різних типів ізоляції у ваших кластерах, залежно від ваших вимог.
У більш екстремальних випадках може бути легше або необхідно відмовитися від будь-якого рівня спільного використання на рівні кластера та надати кожному орендареві його власний кластер, можливо, навіть запущений на власному обладнанні, якщо віртуальні машини не розглядаються як належний рівень безпеки. Це може бути легше з використанням кластерів Kubernetes, що розгортаються та керуються постачальником, де накладні витрати на створення та експлуатацію кластерів хоча б певною мірою беруться на себе провайдером хмарних послуг. Перевага більшої ізоляції орендарів повинна оцінюватися порівняно з витратами та складністю управління кількома кластерами. Група Multi-cluster SIG відповідає за вирішення цих типів використання.
Решта цієї сторінки присвячена технікам ізоляції, які використовуються для спільних кластерів Kubernetes. Однак, навіть якщо ви розглядаєте власні кластери, може бути корисно переглянути ці рекомендації, оскільки це дозволить вам гнучко змінювати свої потреби або можливості у майбутньому.
Ізоляція панелі управління
Ізоляція панелі управління забезпечує те, що різні орендарі не можуть отримати доступ або вплинути на ресурси Kubernetes API інших орендарів.
Простори імен
У Kubernetes Namespace надає механізм для ізоляції груп ресурсів API в межах одного кластера. Ця ізоляція має дві ключові виміри:
Назви обʼєктів в межах простору імен можуть перекриватися з назвами в інших просторах імен, схоже на файли у теках. Це дозволяє орендарям називати свої ресурси, не переймаючись тим, що роблять інші орендарі.
Багато політик безпеки Kubernetes мають обмеження на простори імен. Наприклад, ресурси RBAC Roles та Network Policies мають обмеження на простори імен. За допомогою RBAC користувачі та облікові записи служб можуть бути обмежені в просторі імен.
У середовищі з кількома орендарями простір імен допомагає сегментувати робоче навантаження орендаря на логічний та окремий підрозділ управління. Насправді поширена практика полягає в тому, щоб ізолювати кожне робоче навантаження у власному просторі імен, навіть якщо кількома робочими навантаженнями керує один і той же орендар. Це гарантує, що кожне робоче навантаження має власну ідентичність і може бути налаштоване з відповідною політикою безпеки.
Модель ізоляції простору імен вимагає конфігурації кількох інших ресурсів Kubernetes, мережевих застосунків та дотримання найкращих практик з безпеки для належної ізоляції робочих навантажень орендарів. Ці важливі аспекти обговорюються нижче.
Контроль доступу
Найважливіший тип ізоляції для панелі управління — це авторизація. Якщо команди або їх робочі навантаження можуть отримати доступ або модифікувати ресурси API інших, вони можуть змінювати або вимикати всі інші види політик, тим самим анулюючи будь-який захист, який ці політики можуть пропонувати. Тому критично забезпечити, що кожен орендар має відповідний доступ тільки до необхідних просторів імен, і ні до яких більше. Це відомо як "принцип найменших привілеїв".
Контроль доступу на основі ролей (RBAC) часто використовується для забезпечення авторизації в панелі управління Kubernetes, як для користувачів, так і для робочих навантажень (облікові записи служб). Role та RoleBinding — це обʼєкти Kubernetes, які використовуються на рівні простору імен для забезпечення контролю доступу у вашій програмі; аналогічні обʼєкти існують для авторизації доступу до обʼєктів на рівні кластера, хоча вони менш корисні для багатоорендних кластерів.
У багатокомандному середовищі RBAC має бути використаний для обмеження доступу орендарів до відповідних просторів імен, а також для забезпечення того, що ресурси на рівні кластера можуть бути отримані або змінені тільки привілейованими користувачами, такими як адміністратори кластера.
Якщо політика виявляється такою, що надає користувачеві більше дозволів, ніж йому потрібно, це найімовірніше сигнал того, що простір імен, який містить відповідні ресурси, повинен бути перероблений у більш деталізовані простори імен. Інструменти управління просторами імен можуть спростити управління цими більш деталізованими просторами імен за допомогою застосування загальних політик RBAC до різних просторів імен, дозволяючи при цьому використовувати детальніші політики за потреби.
Квоти
Робочі навантаження Kubernetes використовують ресурси вузла, такі як CPU та памʼять. У багатоорендному середовищі ви можете використовувати Квоти ресурсів для управління використанням ресурсів робочих навантажень орендарів. Для випадку з декількома командами, де орендарі мають доступ до API Kubernetes, ви можете використовувати квоти ресурсів, щоб обмежити кількість ресурсів API (наприклад: кількість Podʼів або кількість ConfigMap), яку може створити орендар. Обмеження на кількість обʼєктів забезпечують справедливість і спрямовані на уникнення проблем шумного сусіда, які можуть впливати на інших орендарів, які використовують спільну панель управління.
Квоти ресурсів — це обʼєкти, які мають область видимості простору імен. Шляхом зіставлення орендарів з просторами імен адміністратори кластера можуть використовувати квоти, щоб забезпечити, що орендар не може монополізувати ресурси кластера або перевантажувати його панель управління. Інструменти управління просторами імен спрощують адміністрування квот. Крім того, хоча квоти Kubernetes застосовуються лише у межах одного простору імен, деякі інструменти управління просторами імен дозволяють групам просторів імен використовувати спільні квоти, що дає адміністраторам набагато більше гнучкості з меншими зусиллями, ніж вбудовані квоти.
Квоти запобігають тому, щоб один орендар використовував більше, ніж йому призначено ресурсів, що мінімізує проблему "шумного сусіда", коли один орендар негативно впливає на продуктивність робочих навантажень інших орендарів.
При застосуванні квоти до простору імен Kubernetes вимагає вказати також запити та ліміти ресурсів для кожного контейнера. Ліміти — це верхня межа для кількості ресурсів, яку контейнер може використовувати. Контейнери, які намагаються використовувати ресурси, що перевищують налаштовані ліміти, будуть або обмежені, або примусово зупинені, залежно від типу ресурсу. Якщо запити ресурсів встановлені нижче лімітів, кожному контейнеру гарантується запитаний обсяг, але все ще може бути деякий потенціал для впливу на робочі навантаження.
Квоти не можуть надати захист для всіх видів ресурсів спільного використання, наприклад, таких як мережевий трафік. Для цієї проблеми може бути кращим рішенням ізоляція вузла (див. нижче).
Ізоляція панелі даних
Ізоляція панелі даних забезпечує достатню ізоляцію між Podʼами та робочими навантаженнями для різних орендарів.
Мережева ізоляція
Типово всі Podʼи в кластері Kubernetes можуть спілкуватися один з одним, і весь мережевий трафік не є зашифрованим. Це може призвести до вразливостей безпеки, де трафік випадково або зловмисно надсилається до непередбаченого призначення, або перехоплюється робочим навантаженням на скомпрометованому вузлі.
Комунікацію між Podʼами можна контролювати за допомогою мережевих політик, які обмежують комунікацію між Podʼами за допомогою міток простору імен або діапазонів IP-адрес. У багатоорендному середовищі, де потрібна строга мережева ізоляція між орендарями, рекомендується почати зі стандартної політики, яка відхиляє комунікацію між Podʼами, разом з іншим правилом, яке дозволяє всім Podʼам звертатись до сервера DNS для перевірки імен. З такою стандартною політикою ви можете почати додавати дозвільні правила, які дозволяють комунікацію всередині простору імен. Також рекомендується не використовувати порожній селектор мітки '{}' для поля namespaceSelector в визначенні мережевої політики, в разі потреби дозволу на трафік між просторами імен. Цю схему можна подальшим чином удосконалювати за потребою. Зверніть увагу, що це стосується лише Podʼів всередині однієї панелі управління; Podʼи, які належать до різних віртуальних панелей управління, не можуть спілкуватися один з одним в мережі Kubernetes.
Інструменти управління просторами імен можуть спростити створення стандартних або загальних мережевих політик. Крім того, деякі з цих інструментів дозволяють забезпечити послідовний набір міток просторів імен у вашому кластері, що гарантує їх справжність як основу для ваших політик.
Попередження:
Мережеві політики потребують втулка CNI, який підтримує впровадження мережевих політик. В іншому випадку ресурси NetworkPolicy будуть ігноруватися.Розширена мережева ізоляція може бути надана службовими мережами, які впроваджують політики OSI рівня 7 на основі ідентифікації робочих навантажень, крім просторів імен. Ці політики на вищому рівні можуть полегшити управління багатоорендними просторами імен, особливо коли декількох просторів імен призначених для одного орендаря. Вони часто також пропонують шифрування за допомогою взаємного TLS, захищаючи ваші дані навіть у випадку компрометованого вузла, і працюють на виділених або віртуальних кластерах. Однак вони можуть бути значно складнішими у керуванні і можуть бути недоречними для всіх користувачів.
Ізоляція сховищ
Kubernetes пропонує кілька типів томів, які можуть бути використані як постійне сховище для робочих навантажень. Для забезпечення безпеки та ізоляції даних рекомендується динамічне надання томів, а також варто уникати типів томів, які використовують ресурси вузла.
StorageClasses дозволяють описувати власні "класи" сховищ, які пропонуються вашим кластером, на основі рівнів якості обслуговування, політик резервного копіювання або власних політик, визначених адміністраторами кластера.
Podʼи можуть запитувати сховище за допомогою PersistentVolumeClaim. PersistentVolumeClaim є ресурсом, який належить до простору імен, що дозволяє ізолювати частину системи сховищ та призначати її орендарям у спільному кластері Kubernetes. Однак важливо зауважити, що PersistentVolume є ресурсом, доступним у всьому кластері, і має життєвий цикл, незалежний від робочих навантажень та просторів імен.
Наприклад, ви можете налаштувати окремий StorageClass для кожного орендаря і використовувати його для підсилення ізоляції. Якщо StorageClass є загальним, вам слід встановити політику повторного використання Delete, щоб забезпечити, що PersistentVolume не може бути використаний повторно в різних просторах імен.
Утримання контейнерів у пісочниці
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Podʼи Kubernetes складаються з одного або декількох контейнерів, які виконуються на робочих вузлах. Контейнери використовують віртуалізацію на рівні ОС і, отже, пропонують слабку межу ізоляції порівняно з віртуальними машинами, які використовують апаратну віртуалізацію.
У спільному середовищі не виправлені вразливості на рівні застосунків та систем можуть бути використані зловмисниками для виходу контейнера за межі та виконання віддаленого коду, що дозволяє отримати доступ до ресурсів хосту. У деяких застосунках, наприклад, системах управління вмістом (CMS), користувачам може бути надана можливість завантажувати та виконувати ненадійні скрипти або код. В будь-якому випадку, механізми подальшої ізоляції та захисту робочих навантажень за допомогою сильної ізоляції бажані.
Утримання в пісочниці забезпечує спосіб ізоляції робочих навантажень, які запускаються в спільному кластері. Зазвичай це передбачає запуск кожного Podʼа в окремому середовищі виконання, такому як віртуальна машина або ядро простору рівня користувача. Утримання в пісочниці часто рекомендується, коли ви запускаєте ненадійний код, де робочі навантаження вважаються зловмисними. Частково це обумовлено тим, що контейнери — це процеси, які працюють на спільному ядрі; вони підключають файлові системи, такі як /sys та /proc, з базового хосту, що робить їх менш безпечними, ніж застосунок, який працює на віртуальній машині з власним ядром. Хоча такі контрольні механізми, як seccomp, AppArmor та SELinux, можуть бути використані для підвищення безпеки контейнерів, складно застосувати універсальний набір правил до всіх робочих навантажень, які запускаються в спільному кластері. Запуск робочих навантажень в середовищі пісочниці допомагає ізолювати хост від виходу контейнерів за межі, де зловмисник використовує вразливість, щоб отримати доступ до системи хосту та всіх процесів/файлів, що працюють на цьому хості.
Віртуальні машини та ядра користувацького простору — це два популярні підходи до пісочниці. Доступні наступні реалізації пісочниці:
- gVisor перехоплює системні виклики з контейнерів та передає їх простору користувацького рівня ядра, написане на Go, з обмеженим доступом до базового хосту.
- Kata Containers надають безпечний контейнерне середовище, що дозволяє виконувати контейнери в віртуальній машині. Апаратна віртуалізація, доступна в Kata, надає додатковий рівень безпеки для контейнерів, які запускають ненадійний код.
Ізоляція вузлів
Ізоляція вузлів — це ще один прийом, який можна використовувати для ізоляції робочих навантажень окремих орендарів один від одного. За допомогою ізоляції вузлів набір вузлів призначається для виконання Podʼів певного орендаря, і спільне розміщення Podʼів орендарів забороняється. Ця конфігурація зменшує проблему шумного орендаря, оскільки всі Podʼи, що працюють на вузлі, належать до одного орендаря. Ризик розкриття інформації трохи менше з ізоляцією вузлів, оскільки зловмисник, якому вдається вислизнути з контейнера, матиме доступ лише до контейнерів та томів, підключених до цього вузла.
Хоча робочі навантаження від різних орендарів працюють на різних вузлах, важливо памʼятати, що kubelet та (якщо використовується віртуальне керування) служба API все ще є спільними сервісами. Кваліфікований зловмисник може використовувати дозволи, надані kubelet або іншим Podʼам, що працюють на вузлі, для переміщення в межах кластера та отримання доступу до робочих навантажень орендарів, що працюють на інших вузлах. Якщо це є серйозною проблемою, розгляньте можливість впровадження компенсаційних заходів, таких як seccomp, AppArmor або SELinux, або дослідіть можливість використання Podʼів в пісочниці або створення окремих кластерів для кожного орендаря.
Ізоляція вузлів є трохи простішою з точки зору розрахунку, ніж утримання контейнерів у пісочниці, оскільки ви можете стягувати плату за кожен вузол, а не за кожен Pod. Вона також має менше проблем сумісності та продуктивності і може бути легше впроваджена, ніж утримання контейнерів у пісочниці. Наприклад, для кожного орендаря вузли можна налаштувати з taintʼами, щоб на них могли працювати лише Podʼи з відповідним toleration. Потім мутуючий веб-хук можна використовувати для автоматичного додавання толерантності та спорідненості вузлів до Podʼів, розгорнутих у просторах імен орендарів, щоб вони працювали на певному наборі вузлів, призначених для цього орендаря.
Ізоляцію вузлів можна реалізувати за допомогою селекторів вузла Podʼа або Virtual Kubelet.
На що також треба звертати увагу
У цьому розділі обговорюються інші конструкції та шаблони Kubernetes, які є важливими для багатоорендарних середовищ.
API Priority and Fairness
API Priority and Fairness — це функціональність Kubernetes, яка дозволяє призначити пріоритет певним Podʼам, що працюють у кластері. Коли застосунок викликає API Kubernetes, сервер API оцінює пріоритет, призначений для Podʼа. Виклики з Podʼів із вищим пріоритетом виконуються перш ніж ті, що мають нижчий пріоритет. Коли розбіжності високі, виклики з нижчим пріоритетом можуть бути поставлені в чергу до того часу, коли сервер стане менш зайнятим, або ви можете відхилити запити.
Використання API Priority and Fairness буде не дуже поширеним у середовищах SaaS, якщо ви не дозволяєте клієнтам запускати застосунки, які взаємодіють з API Kubernetes, наприклад, контролером.
Якість обслуговування (QoS)
Коли ви запускаєте застосунок SaaS, вам може знадобитися можливість надавати різні рівні якості обслуговування (QoS) для різних орендарів. Наприклад, ви можете мати безкоштовну службу з меншими гарантіями продуктивності та можливостями, або платну службу зі специфічними гарантіями продуктивності. На щастя, існують кілька конструкцій Kubernetes, які можуть допомогти вам досягти цього у спільному кластері, включаючи мережевий QoS, класи сховищ та пріоритети і випредження виконання Podʼів. Ідея полягає в тому, щоб надавати орендарям якість обслуговування, за яку вони заплатили. Давайте спочатку розглянемо мережевий QoS.
Зазвичай всі Podʼи на вузлі використовують один мережевий інтерфейс. Без мережевого QoS деякі Podʼи можуть споживати завелику частину доступної пропускної здатності, що шкодить іншим Podʼам. Kubernetes bandwidth plugin створює розширений ресурс для мережі, який дозволяє використовувати конструкції ресурсів Kubernetes, тобто запити/обмеження, щоб застосовувати обмеження швидкості до Podʼів за допомогою черг Linux tc. Варто зазначити, що втулок вважається експериментальним згідно з документацією про мережеві втулки і його слід ретельно перевірити перед використанням в продуктових середовищах.
Для керування QoS сховища вам, ймовірно, захочеться створити різні класи сховищ або профілі з різними характеристиками продуктивності. Кожен профіль сховища може бути повʼязаний з різним рівнем обслуговування, який оптимізований для різних завдань, таких як IO, надійність або пропускна здатність. Можливо, буде потрібна додаткова логіка для надання дозволу орендарю асоціювати відповідний профіль сховища з їхнім завданням.
Нарешті, є пріоритети та випредження виконання Podʼів, де ви можете призначити значення пріоритету Podʼів. При плануванні Podʼів планувальник спробує видаляти Podʼи з нижчим пріоритетом, коли недостатньо ресурсів для планування Podʼів із вищим пріоритетом. Якщо у вас є випадок використання, де орендарі мають різні рівні обслуговування в спільному кластері, наприклад, безкоштовні та платні, ви можете надати вищий пріоритет певним рівням за допомогою цієї функції.
DNS
У кластерах Kubernetes є служба системи доменних імен (DNS), щоб забезпечити переклад імен у IP-адреси для всіх Serviceʼів та Podʼів. Стандартно служба DNS Kubernetes дозволяє пошук у всіх просторах імен кластера.
У мультиорендних середовищах, де орендарі можуть отримувати доступ до Podʼів та інших ресурсів Kubernetes, або де потрібна сильніша ізоляція, може бути необхідно заборонити Podʼам здійснювати пошук служб в інших просторах імен. Ви можете обмежити пошук DNS між просторами імен, налаштувавши правила безпеки для служби DNS. Наприклад, CoreDNS (типова служба DNS для Kubernetes) може використовувати метадані Kubernetes для обмеження запитів до Podʼів та Serviceʼів в межах простору імен. Для отримання додаткової інформації подивіться приклад налаштування в документації CoreDNS.
Коли використовується модель віртуальної панелі управління для орендаря, службу DNS потрібно налаштувати для кожного орендара окремо або використовувати багатоорендну службу DNS. Ось приклад CoreDNS у зміненому вигляді, що підтримує кількох орендарів.
Оператори
Оператори — це контролери Kubernetes, які керують застосунками. Оператори можуть спростити управління кількома екземплярами програми, такими як служба баз даних, що робить їх загальним будівельним блоком у багатокористувацькому (SaaS) варіанті використання.
Оператори, які використовуються в середовищі з кількома орендарями, повинні дотримуватися більш суворого набору керівних принципів. Зокрема, Оператор повинен:
- Підтримувати створення ресурсів у різних просторах імен орендарів, а не лише у просторі імен, в якому розгорнуто оператор.
- Переконатись, що Podʼи налаштовані з запитами та обмеженнями ресурсів, щоб забезпечити планування та справедливість.
- Підтримувати налаштування Podʼів для технік ізоляції панелі даних, таких як ізоляція вузла та контейнери в пісочниці.
Реалізації
Існують два основних способи поділу кластера Kubernetes для багатоорендності: використання просторів імен (тобто простір імен на орендаря) або віртуалізація панелі управління (тобто віртуальна панель управління на орендаря).
У обох випадках рекомендується також ізоляція панелі даних та керування додатковими аспектами, такими як API Priority and Fairness.
Ізоляція простору імен добре підтримується Kubernetes, має незначні витрати ресурсів і надає механізми, які дозволяють орендарям взаємодіяти належним чином, наприклад, дозволяючи комунікацію між Servicʼами. Однак її може бути складно налаштувати, і вона не застосовується до ресурсів Kubernetes, які не можуть розташовуватись в просоторах імен, таких як визначення спеціальних ресурсів, класи сховищ та веб-хуки.
Віртуалізація панелі управління дозволяє ізолювати ресурси, які не мають просторів імені, за рахунок трохи більшого використання ресурсів та складнішим спільним використанням між орендарями. Це хороший варіант, коли ізоляція простору імен недостатня, але виділені, окремі кластери небажані через великі витрати на їх утримання (особливо на місці) або через їх вищі накладні витрати та відсутність спільного використання ресурсів. Однак навіть у віртуальному плані управління ви, швидше за все, побачите переваги від використання просторів імен.
Два варіанти обговорюються докладніше у наступних розділах.
Простір імен на орендаря
Як вже зазначалося, варто розглянути ізоляцію кожного навантаження у власному просторі імен, навіть якщо ви використовуєте виключно спеціальні кластери або віртуалізовані панелі управління. Це забезпечує доступ кожного навантаження лише до власних ресурсів, таких як ConfigMap та Secret, і дозволяє налаштувати індивідуальні політики безпеки для кожного навантаження. Крім того, краще застосовувати унікальні назви для кожного простору імен у всьому вашому флоті (навіть якщо вони знаходяться у різних кластерах), оскільки це дозволяє вам в майбутньому переходити між спеціальними та спільними кластерами або використовувати багатокластерні інструменти, такі як сервісні мережі.
З іншого боку, є також переваги у призначенні просторів імен на рівні орендаря, а не лише на рівні навантаження, оскільки часто існують політики, що застосовуються до всіх навантажень, що належать одному орендарю. Однак це виникає власні проблеми. По-перше, це робить складним або неможливим налаштування політик для окремих навантажень, і, по-друге, може бути складно визначити єдиний рівень "оренди", який повинен мати простір імен. Наприклад, у організації можуть бути відділи, команди та підкоманди, які з них повинні бути призначені простору імен?
Для вирішення цього Kubernetes надає Контролер ієрархічних просторів імен (HNC), який дозволяє організовувати ваші простори імен у ієрархії та спільно використовувати певні політики та ресурси між ними. Він також допомагає вам керувати мітками просторів імен, життєвим циклом просторів імен та делегованим керуванням, а також спільно використовувати квоти ресурсів між повʼязаними просторами імен. Ці можливості можуть бути корисні як у багатокомандних, так і у багатокористувацьких сценаріях.
Інші проєкти, які надають подібні можливості та допомагають у керуванні просторами імен, перераховані нижче.
Багатокомандна оренда
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Багатокористувацька оренда
Рушії політики
Рушії політики надають можливості для перевірки та генерації конфігурацій орендарів:
Віртуальна панель управління на орендаря
Ще один вид ізоляції панелі управління полягає у використанні розширень Kubernetes для надання кожному орендарю віртуальної панелі управління, що дозволяє сегментацію ресурсів API на рівні кластера. Техніки ізоляції панелі даних можна використовувати з цією моделлю для безпечного управління робочими вузлами між орендарями.
Модель багатокористувацької панелі управління на основі віртуального контролю розширює ізоляцію на основі простору імен шляхом надання кожному орендарю окремих компонентів панелі управління, а отже, повного контролю над ресурсами кластера і додатковими сервісами. Робочі вузли спільно використовуються всіма орендарями і керуються кластером Kubernetes, який зазвичай недоступний орендарям. Цей кластер часто називають суперкластером (іноді — хост кластер). Оскільки панель управління орендаря не прямо повʼязана з підлеглими обчислювальними ресурсами, її називають віртуальною панеллю управління.
Віртуальна панель управління зазвичай складається з сервера API Kubernetes, менеджера контролера та сховища даних etcd. Вона взаємодіє з суперкластером через контролер синхронізації метаданих, який координує зміни між панелями управління орендарів та панеллю управління суперкластера.
З використанням окремих віртуальних панелей управління для кожного орендаря вирішуються більшість проблем ізоляції, повʼязаних із тим, що всі орендарі використовують один сервер API. Прикладами є шумні сусіди в панелі управління, необмежений радіус вибуху неправильних налаштувань політики та конфлікти між обʼєктами на рівні кластера, такими як вебхуки та CRD. Таким чином, модель віртуальної панелі управління особливо підходить для випадків, коли кожен орендар потребує доступу до сервера API Kubernetes та очікує повного керування кластером.
Покращена ізоляція відбувається за рахунок запуску та підтримки окремих віртуальних панелей управління для кожного орендаря. Крім того, віртуальні панелі управління орендаря не вирішують проблеми ізоляції на рівні панелі даних, такі як шумні сусіди на рівні вузла або загрози безпеці. Ці проблеми все ще потрібно вирішувати окремо.
Проєкт Kubernetes Cluster API — Nested (CAPN) надає реалізацію віртуальних панелей управління.
Інші реалізації
8.11 - Поради з посилення безпеки — Механізми автентифікації
Інформація про варіанти автентифікації в Kubernetes та їх властивості безпеки.
Вибір відповідного механізму автентифікації — це ключовий аспект забезпечення безпеки вашого кластера. Kubernetes надає кілька вбудованих механізмів, кожен з власними перевагами та недоліками, які потрібно ретельно розглядати при виборі найкращого механізму автентифікації для вашого кластера.
Загалом рекомендується увімкнути як можливо менше механізмів автентифікації для спрощення управління користувачами та запобігання ситуаціям, коли користувачі мають доступ до кластера, який вже не потрібен.
Важливо зауважити, що Kubernetes не має вбудованої бази даних користувачів у межах кластера. Замість цього він бере інформацію про користувача з налаштованої системи автентифікації та використовує це для прийняття рішень щодо авторизації. Тому для аудиту доступу користувачів вам потрібно переглянути дані автентифікації з кожного налаштованого джерела автентифікації.
Для операційних кластерів з кількома користувачами, які безпосередньо отримують доступ до API Kubernetes, рекомендується використовувати зовнішні джерела автентифікації, такі як OIDC. Внутрішні механізми автентифікації, такі як сертифікати клієнта та токени службових облікових записів, описані нижче, не підходять для цього випадку використання.
Автентифікація сертифіката клієнта X.509
Kubernetes використовує автентифікацію сертифіката клієнта X.509 для системних компонентів, наприклад, коли Kubelet автентифікується на сервері API. Хоча цей механізм також можна використовувати для автентифікації користувачів, він може бути непридатним для операційного використання через кілька обмежень:
- Сертифікати клієнта не можуть бути індивідуально скасовані. Після компрометації сертифікат може бути використаний зловмисником до тих пір, поки не закінчиться строк його дії. Для зменшення цього ризику рекомендується налаштувати короткі строки дії для автентифікаційних даних користувача, створених за допомогою клієнтських сертифікатів.
- Якщо сертифікат потрібно анулювати, то потрібно змінити ключ сертифікації, що може призвести до ризиків доступності для кластера.
- В кластері відсутній постійний запис про створені клієнтські сертифікати. Тому всі видані сертифікати повинні бути зафіксовані, якщо вам потрібно відстежувати їх.
- Приватні ключі, що використовуються для автентифікації за допомогою клієнтського сертифіката, не можуть бути захищені паролем. Хто завгодно, хто може прочитати файл із ключем, зможе його використовувати.
- Використання автентифікації за допомогою клієнтського сертифіката потребує прямого зʼєднання від клієнта до API-сервера без будь-яких проміжних точок TLS, що може ускладнити архітектуру мережі.
- Групові дані вбудовані в значення
Oклієнтського сертифіката, що означає, що членство користувача в групах не може бути змінено впродовж дії сертифіката.
Статичний файл токенів
Хоча Kubernetes дозволяє завантажувати облікові дані зі статичного файлу токенів, розташованого на дисках вузлів управління, цей підхід не рекомендується для операційних серверів з кількох причин:
- Облікові дані зберігаються у відкритому вигляді на дисках вузлів управління, що може представляти ризик для безпеки.
- Зміна будь-яких облікових даних потребує перезапуску процесу API-сервера для набуття чинності, що може вплинути на доступність.
- Не існує механізму, доступного для того, щоб дозволити користувачам змінювати свої облікові дані. Для зміни облікових даних адміністратор кластера повинен змінити токен на диску та розповсюдити його серед користувачів.
- Відсутність механізму блокування, який би запобігав атакам методом підбору.
Токени bootstrap
Токени bootstrap використовуються для приєднання вузлів до кластерів і не рекомендуються для автентифікації користувачів з кількох причин:
- Вони мають затверджені членства у групах, які не підходять для загального використання, що робить їх непридатними для цілей автентифікації.
- Ручне створення токенів bootstrap може призвести до створення слабких токенів, які може вгадати зловмисник, що може бути ризиком для безпеки.
- Відсутність механізму блокування, який би запобігав атакам методом підбору, спрощує завдання зловмисникам для вгадування або підбору токена.
Secret токени ServiceAccount
Secret облікових записів служб доступні як опція для того, щоб дозволити робочим навантаженням, що працюють в кластері, автентифікуватися на сервері API. У версіях Kubernetes < 1.23 вони були типовою опцією, однак, їх замінюють токени API TokenRequest. Хоча ці Secretʼи можуть бути використані для автентифікації користувачів, вони, як правило, не підходять з кількох причин:
- Їм неможливо встановити терміном дії, і вони залишатимуться чинними до тих пір, поки повʼязаний з ними обліковий запис служби не буде видалений.
- Токени автентифікації видимі будь-якому користувачеві кластера, який може читати Secretʼи в просторі імен, в якому вони визначені.
- Облікові записи служб не можуть бути додані до довільних груп, ускладнюючи управління RBAC там, де вони використовуються.
Токени API TokenRequest
API TokenRequest є корисним інструментом для генерації обмежених за часом існування автентифікаційних даних для автентифікації служб на сервері API або сторонніх системах. Проте, загалом не рекомендується використовувати їх для автентифікації користувачів, оскільки не існує методу скасування, і розподіл облікових даних користувачам у безпечний спосіб може бути складним.
При використанні токенів TokenRequest для автентифікації служб рекомендується встановити короткий термін їх дії, щоб зменшити можливі наслідки скомпрометованих токенів.
Автентифікація з використанням токенів OpenID Connect
Kubernetes підтримує інтеграцію зовнішніх служб автентифікації з API Kubernetes, використовуючи OpenID Connect (OIDC). Існує велика кількість програмного забезпечення, яке можна використовувати для інтеграції Kubernetes з постачальником ідентифікації. Однак, при використанні автентифікації OIDC для Kubernetes, важливо враховувати такі заходи з забезпечення безпеки:
- Програмне забезпечення, встановлене в кластері для підтримки автентифікації OIDC, повинно бути відокремлене від загальних робочих навантажень, оскільки воно буде працювати з високими привілеями.
- Деякі керовані Kubernetes сервіси обмежені в постачальниках OIDC, які можна використовувати.
- Як і у випадку з токенами TokenRequest, токени OIDC повинні мати короткий термін дії, щоб зменшити наслідки скомпрометованих токенів.
Автентифікація з використанням вебхуків
Автентифікація з використанням вебхуків є ще одним варіантом інтеграції зовнішніх постачальників автентифікації в Kubernetes. Цей механізм дозволяє звертатися до служби автентифікації, яка працює в кластері або зовнішньо, для прийняття рішення щодо автентифікації через вебхук. Важливо зазначити, що придатність цього механізму, ймовірно, залежатиме від програмного забезпечення, використаного для служби автентифікації, і є деякі специфічні для Kubernetes аспекти, які варто врахувати.
Для налаштування автентифікації за допомогою вебхуків потрібний доступ до файлових систем серверів керування. Це означає, що це не буде можливо з керованим Kubernetes, якщо постачальник не зробить це специфічно доступним. Крім того, будь-яке програмне забезпечення, встановлене в кластері для підтримки цього доступу, повинно бути відокремлене від загальних робочих навантажень, оскільки воно буде працювати з високими привілеями.
Автентифікуючий проксі
Ще один варіант інтеграції зовнішніх систем автентифікації в Kubernetes — використання автентифікуючого проксі. У цьому механізмі Kubernetes очікує отримати запити від проксі з встановленими конкретними значеннями заголовків, які вказують імʼя користувача та членство в групах для призначення для цілей авторизації. Важливо зазначити, що існують певні аспекти, які слід врахувати при використанні цього механізму.
По-перше, для зменшення ризику перехоплення трафіку або атак типу sniffing між проксі та сервером API Kubernetes між ними має бути використане безпечне налаштування TLS. Це забезпечить безпеку комунікації між проксі та сервером API Kubernetes.
По-друге, важливо знати, що зловмисник, який може змінити заголовки запиту, може отримати неавторизований доступ до ресурсів Kubernetes. Тому важливо забезпечити належний захист заголовків та переконатися, що їх не можна підробити.
Що далі
8.12 - Ризики обходу сервера API Kubernetes
Інформація про архітектуру безпеки, що стосується сервера API та інших компонентів
Сервер API Kubernetes є головним входом до кластера для зовнішніх сторін (користувачів та сервісів), що з ним взаємодіють.
У рамках цієї ролі сервер API має кілька ключових вбудованих елементів безпеки, таких як ведення логів аудити та контролери допуску. Однак існують способи модифікації конфігурації або вмісту кластера, які обминають ці елементи.
Ця сторінка описує способи обходу вбудованих в сервер API Kubernetes засобів контролю безпеки, щоб оператори кластера та архітектори безпеки могли переконатися, що ці обхідні механізми адекватно обмежені.
Статичні Podʼи
Kubelet на кожному вузлі завантажує та безпосередньо керує будь-якими маніфестами, що зберігаються в іменованій теці або завантажуються з конкретної URL-адреси як статичні Podʼи у вашому кластері. Сервер API не керує цими статичними Podʼами. Зловмисник з правами на запис у цьому місці може змінити конфігурацію статичних Podʼів, завантажених з цього джерела, або внести нові статичні Podʼи.
Статичним Podʼам заборонено доступ до інших обʼєктів у Kubernetes API. Наприклад, ви не можете налаштувати статичний Pod для монтування Secretʼу з кластера. Однак ці Podʼи можуть виконувати інші дії, що стосуються безпеки, наприклад, використовувати монтування з hostPath з підлеглого вузла.
Типово kubelet створює дзеркальний Pod, щоб статичні Podʼи були видимими у Kubernetes API. Однак якщо зловмисник використовує недійсне імʼя простору імен при створенні Podʼа, він не буде видимим у Kubernetes API та може бути виявлений лише інструментами, які мають доступ до пошкоджених вузлів.
Якщо статичний Pod не пройшов контроль допуску, kubelet не зареєструє Pod у сервері API. Однак Pod все ще працює на вузлі. Для отримання додаткової інформації зверніться до тікету kubeadm #1541.
Зменшення ризиків
- Увімкніть функціональність маніфесту статичних Podʼів kubelet лише в разі необхідності для вузла.
- Якщо вузол використовує функціональність статичних Podʼів, обмежте доступ до файлової системи до теки маніфестів статичних Podʼів або URL для користувачів, які потребують такого доступу.
- Обмежте доступ до параметрів та файлів конфігурації kubelet, щоб запобігти зловмиснику встановлення шляху або URL статичного Podʼа.
- Регулярно перевіряйте та централізовано звітуйте про всі доступи до тек або місць зберігання вебсайтів, які містять маніфести статичних Podʼів та файли конфігурації kubelet.
API kubelet
kubelet надає HTTP API, який, як правило, відкритий на TCP-порту 10250 на вузлах робочих груп кластера. API також може бути відкритим на вузлах панелі управління залежно від дистрибутиву Kubernetes, що використовується. Прямий доступ до API дозволяє розкривати інформацію про Podʼи, що працюють на вузлі, журнали з цих Podʼів та виконання команд у кожному контейнері, що працює на вузлі.
Коли у користувачів кластера Kubernetes є доступ RBAC до ресурсів обʼєкта Node, цей доступ слугує авторизацією для взаємодії з API kubelet. Точний доступ залежить від того, який доступ цим ресурсам був наданий, про що детально описано в авторизації kubelet.
Прямий доступ до API kubelet не є предметом уваги контролю допуску та не реєструється системою аудиту Kubernetes. Зловмисник з прямим доступом до цього API може здійснити обхід елементів захисту, що виявляють або запобігають певним діям.
API kubelet можна налаштувати для автентифікації запитів за допомогою кількох способів. Типово конфігурація kubelet дозволяє анонімний доступ. Більшість постачальників Kubernetes змінюють це на використання автентифікації за допомогою вебхуків та сертифікатів. Це дозволяє панелі управління перевірити, чи авторизований той хто надсилає запит має доступ до ресурсу API nodes або його ресурсів. Анонімний доступ типово не дає цього підтвердження панелі управління.
Зменшення ризиків
- Обмежте доступ до ресурсів обʼєкта API
nodes, використовуючи механізми, такі як RBAC. Надавайте цей доступ лише за необхідності, наприклад, для служб моніторингу. - Обмежте доступ до порту kubelet. Дозволяйте доступ до порту лише зазначеним та довіреним діапазонам IP-адрес.
- Переконайтеся, що автентифікація kubelet налаштована на режим webhook або сертифікату.
- Переконайтеся, що неавтентифікований "тільки для читання" порт kubelet не ввімкнено в кластері.
API etcd
Кластери Kubernetes використовують etcd як сховище даних. Сервіс etcd прослуховує TCP-порт 2379. Доступ до нього необхідний лише для сервера API Kubernetes та будь-яких інструментів резервного копіювання, які ви використовуєте. Прямий доступ до цього API дозволяє розголошення або зміну будь-яких даних, що зберігаються в кластері.
Доступ до API etcd зазвичай керується автентифікацією за допомогою сертифікатів клієнта. Будь-який сертифікат, виданий центром сертифікації, якому довіряє etcd, дозволяє повний доступ до даних, збережених всередині etcd.
Прямий доступ до etcd не підлягає контролю допуску Kubernetes і не реєструється журналом аудиту Kubernetes. Нападник, який має доступ до приватного ключа сертифіката клієнта etcd сервера API (або може створити новий довірений сертифікат клієнта), може отримати права адміністратора кластера, отримавши доступ до секретів кластера або зміни прав доступу. Навіть без підвищення привілеїв RBAC Kubernetes нападник, який може змінювати etcd, може отримати будь-який обʼєкт API або створювати нові робочі навантаження всередині кластера.
Багато постачальників Kubernetes налаштовують etcd для використання взаємного TLS (обидва, клієнт і сервер перевіряють сертифікати один одного для автентифікації). Наразі не існує загальноприйнятої реалізації авторизації для API etcd, хоча функція існує. Оскільки немає моделі авторизації, будь-який сертифікат з доступом клієнта до etcd може бути використаний для повного доступу до etcd. Зазвичай сертифікати клієнта etcd, які використовуються лише для перевірки стану, також можуть надавати повний доступ на читання та запис.
Зменшення ризиків
- Переконайтеся, що центр сертифікації, якому довіряє etcd, використовується лише для цілей автентифікації цього сервісу.
- Керуйте доступом до приватного ключа сертифіката сервера etcd, а також до сертифіката і ключа клієнта сервера API.
- Призначте обмеження доступу до порту etcd на рівні мережі, щоб дозволити доступ лише зазначеним і довіреним діапазонам IP-адрес.
Сокет контейнера
На кожному вузлі в кластері Kubernetes доступ до взаємодії з контейнерами контролюється відносно контейнерного середовища (або середовищ, якщо ви налаштували більше одного). Зазвичай контейнерне середовище відкриває сокет Unix, до якого може отримати доступ kubelet. Нападник з доступом до цього сокету може запускати нові контейнери або взаємодіяти з працюючими контейнерами.
На рівні кластера вплив цього доступу залежить від того, чи мають контейнери, що працюють на скомпрометованому вузлі, доступ до Secretʼів або інших конфіденційних даних, які нападник може використати для підвищення привілеїв на інші вузли або для управління компонентами панелі управління.
Зменшення ризиків
- Переконайтеся, що ви щільно контролюєте доступ до файлової системи для сокетів контейнерного середовища. Коли це можливо, обмежте цей доступ до користувача
root. - Ізолюйте kubelet від інших компонентів, що працюють на вузлі, використовуючи механізми, такі як простори імен ядра Linux.
- Переконайтеся, що ви обмежуєте або забороняєте використання монтуванню
hostPath, які охоплюють робочий порт контейнерного середовища, або безпосередньо, або монтуванням батьківського каталогу. Крім того, монтуванняhostPathмає бути встановлено тільки для читання для зменшення ризиків обходу обмежень каталогу. - Обмежте доступ користувачів до вузлів, особливо обмежте доступ суперкористувача до вузлів.
8.13 - Обмеження безпеки ядра Linux для Podʼів та контейнерів
Огляд модулів безпеки ядра Linux та обмежень, які можна використовувати для зміцнення вашого Podʼа та контейнерів.
Ця сторінка описує деякі з функцій безпеки, які вбудовані в ядро Linux і які ви можете використовувати у вашій роботі з Kubernetes. Щоб дізнатися, як застосувати ці функції до ваших Podʼів та контейнерів, див. Налаштування контексту безпеки для Podʼа або контейнера. Ви вже маєте бути знайомі з Linux та основами роботи з робочими навантаженням Kubernetes.
Запуск робочих навантажень без привілеїв адміністратора
Коли ви розгортаєте робоче навантаження в Kubernetes, використовуйте специфікацію Podʼа, щоб обмежити це навантаження від можливості запуску від імені користувача root на вузлі. Ви можете використовувати securityContext Podʼа, щоб визначити конкретного користувача та групу Linux для процесів у Podʼі, і явно обмежувати контейнери від запуску користувачем root. Встановлення цих значень у маніфесті Podʼа переважає аналогічні значення в образі контейнера, що особливо корисно, якщо ви запускаєте образи, які не належать вам.
Увага:
Переконайтеся, що користувач або група, яку ви призначаєте робочому навантаженню, має необхідні дозволи для правильної роботи застосунку. Зміна користувача або групи на того, у якого немає необхідних дозволів, може призвести до проблем з доступом до файлів або збою операцій.Налаштування функцій безпеки ядра на цій сторінці надає деталізоване керування діями, які можуть виконувати процеси у вашому кластері, проте управління цими налаштуваннями може бути складним у великому масштабі. Запуск контейнерів від імені не-root користувача, або у просторах імен користувачів, якщо вам потрібні привілеї адміністратора, допомагає зменшити ймовірність того, що вам доведеться застосовувати встановлені функції безпеки ядра.
Функції безпеки в ядрі Linux
Kubernetes дозволяє вам налаштовувати та використовувати функції ядра Linux для покращення ізоляції та зміцнення ваших робочих навантажень у контейнерах. Серед загальних функцій:
- Безпечний режим обчислення (seccomp): Фільтруйте, які системні виклики може робити процес
- AppArmor: Обмежуйте привілеї доступу окремих програм
- SELinux (Security Enhanced Linux): Назначайте мітки безпеки обʼєктам для простішого застосування політики безпеки
Для налаштування параметрів для однієї з цих функцій операційна система, яку ви обираєте для ваших вузлів, повинна увімкнути функцію у ядрі. Наприклад, Ubuntu 7.10 та пізніші версії стандартно увімкнені для AppArmor. Щоб дізнатися, чи увімкнено у вашій ОС певні функції, перегляньте документацію ОС.
Ви використовуєте поле securityContext у специфікації Podʼа, щоб визначити обмеження, які застосовуються до цих процесів. Поле securityContext також підтримує інші налаштування безпеки, такі як конкретні можливості Linux або дозволи на доступ до файлів за допомогою UID та GID. Докладніше див. Налаштування контексту безпеки для Podʼа або контейнера.
seccomp
Деякі з ваших робочих навантажень можуть потребувати привілеїв для виконання певних дій від імені користувача root на хостовій машині вашого вузла. Linux використовує можливості для розділення доступних привілеїв на категорії, щоб процеси могли отримати привілеї, необхідні для виконання певних дій без надання всіх привілеїв. Кожна можливість має набір системних викликів (syscalls), які може робити процес. seccomp дозволяє обмежувати ці окремі syscalls. Це може бути використано для ізоляції привілеїв процесу, обмежуючи виклики, які він може робити з простору користувача в ядро.
У Kubernetes ви використовуєте середовище виконання контейнерів на кожному вузлі для запуску ваших контейнерів. Прикладами середовища є CRI-O, Docker або containerd. Кожне середовище стандартно дозволяє лише певну підмножину можливостей Linux. Ви можете обмежити дозволені syscalls індивідуально за допомогою профілю seccomp. Зазвичай середовища виконання контейнерів містять стандартний профіль seccomp. Kubernetes дозволяє автоматично застосовувати профілі seccomp, завантажені на вузол, до ваших Podʼів та контейнерів.
Примітка:
В Kubernetes також є налаштуванняallowPrivilegeEscalation для Podʼів та контейнерів. Якщо воно встановлене в false, це запобігає процесам отримувати нові можливості та обмежує непривілейованих користувачів у зміні застосованого профілю seccomp на більш дозвільний профіль.Щоб дізнатись, як застосувати seccomp в Kubernetes, див. Обмеження системних викликів контейнера за допомогою seccomp або Довідку по вузлах Seccomp.
Для отримання додаткової інформації про seccomp див. Seccomp BPF у документації ядра Linux.
Загальні положення щодо seccomp
seccomp — це конфігурація безпеки на низькому рівні, яку ви маєте налаштувати тільки у разі потреби в детальному контролі над системними викликами Linux. Використання seccomp, особливо на великих масштабах, має наступні ризики:
- Конфігурації можуть ламатись під час оновлення програмного забезпечення
- Зловмисники все ще можуть використовувати дозволені syscalls для використання вразливостей
- Управління профілями для окремих застосунків стає складним на великих масштабах
Рекомендація: Використовуйте стандартний профіль seccomp, який поставляється разом із вашим середовищем виконання контейнерів. Якщо вам потрібна більш ізольоване середовище, розгляньте використання пісочниці, такої як gVisor. Пісочниці вирішують ризики, повʼязані з власними профілями seccomp, але вимагають більшого обсягу обчислювальних ресурсів на ваших вузлах та можуть мати проблеми сумісності з GPU та іншим спеціалізованим обладнанням.
AppArmor та SELinux: політика обовʼязкового контролю доступу
Ви можете використовувати механізми політики обовʼязкового контролю доступу (MAC) Linux, такі як AppArmor та SELinux, для зміцнення ваших робочих навантажень у Kubernetes.
AppArmor
AppArmor — це модуль безпеки ядра Linux, який доповнює стандартні дозволи на основі прав користувачів та груп Linux для обмеження доступу програм до обмеженого набору ресурсів. AppArmor може бути налаштований для будь-якого застосунку з метою зменшення його потенційної площини атаки та забезпечення глибшого захисту. Його налаштовують через профілі, настроєні на надання доступу, необхідного для конкретної програми або контейнера, такі як можливості Linux, мережевий доступ та дозволи на файли. Кожен профіль може працювати у режимі обовʼязкового виконання, який блокує доступ до заборонених ресурсів, або у режимі скарг, який лише реєструє порушення.
AppArmor може допомогти вам запустити більш безпечне розгортання, обмежуючи те, що контейнери мають право робити, або надавати кращі можливості аудиту через системні логи. Середовище виконання контейнерів, яке ви використовуєте, може поставлятися зі стандартним профілем AppArmor, або ви можете використовувати власний профіль.
Щоб дізнатись, як використовувати AppArmor у Kubernetes, див. Обмеження доступу контейнера до ресурсів за допомогою AppArmor.
SELinux
SELinu — це модуль безпеки ядра Linux, який дозволяє обмежувати доступ, який має певний субʼєкт, такий як процес, до файлів у вашій системі. Ви визначаєте політики безпеки, які застосовуються до субʼєктів з певними мітками SELinux. Коли процес, який має мітку SELinux, намагається отримати доступ до файлу, сервер SELinux перевіряє, чи дозволяє ця політика доступ та приймає рішення про авторизацію.
У Kubernetes ви можете встановити мітку SELinux у полі securityContext вашого маніфесту. Вказані мітки назначаються цим процесам. Якщо ви налаштували політики безпеки, які стосуються цих міток, ядро ОС хосту застосовує ці політики.
Щоб дізнатись, як використовувати SELinux у Kubernetes, див. Призначення міток SELinux контейнеру.
Різниця між AppArmor та SELinux
Операційна система на ваших вузлах Linux зазвичай містить один з механізмів захисту, або AppArmor, або SELinux. Обидва механізми забезпечують схожий тип захисту, але мають різниці, такі як:
- Налаштування: AppArmor використовує профілі для визначення доступу до ресурсів. SELinux використовує політики, які застосовуються до певних міток.
- Застосування політики: В AppArmor ви визначаєте ресурси за допомогою шляхів до файлів. SELinux використовує індексний вузол (inode) ресурсу для ідентифікації ресурсу.
Підсумок функцій
У таблиці нижче наведено використання та область застосування кожного контролю безпеки. Ви можете використовувати всі їх разом для створення більш захищеної системи.
| Функція безпеки | Опис | Як використовувати | Приклад |
|---|---|---|---|
| seccomp | Обмежуйте окремі виклики ядра в просторі користувача. Зменшує ймовірність того, що вразливість, яка використовує обмежений системний виклик, скомпрометує систему. | Вказуйте завантажений профіль seccomp у специфікації Podʼа або контейнера, щоб застосувати його обмеження до процесів у Podʼі. | Відхиляйте системні виклики unshare, які використовувались у [CVE-2022-0185](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-0185). |
| AppArmor | Обмежуйте доступ програм до певних ресурсів. Зменшує поверхню атаки програми. Покращує аудит. | Вкажіть завантажений профіль AppArmor у специфікації контейнера. | Обмежити програму, яка працює тільки для читання, в записі будь-якого шляху до файлу у системі. |
| SELinux | Обмежуйте доступ до ресурсів, таких як файли, застосунки, порти та процеси за допомогою міток та політик безпеки. | Вкажіть обмеження доступу для конкретних міток. Позначте процеси цими мітками, щоб застосувати обмеження доступу, повʼязані з міткою. | Обмежити контейнер у доступі до файлів поза його власною файловою системою. |
Примітка:
Механізми, такі як AppArmor та SELinux, можуть забезпечувати захист, який виходить за межі контейнера. Наприклад, ви можете використовувати SELinux для допомоги в запобіганні CVE-2019-5736.Загальні відомості щодо керування власними конфігураціями
seccomp, AppArmor та SELinux зазвичай мають стандартну конфігурацію, яка надає базовий захист. Ви також можете створити власні профілі та політики, які відповідають вимогам ваших робочих навантажень. Управління та розповсюдження цих власних конфігурацій на великому масштабі може бути складним, особливо якщо ви використовуєте всі три функції разом. Щоб допомогти вам керувати цими конфігураціями на великому масштабі, використовуйте інструмент, такий як Kubernetes Security Profiles Operator.
Функції безпеки на рівні ядра та привілейовані контейнери
Kubernetes дозволяє вам вказувати, що деякі довірені контейнери можуть працювати у привілейованому режимі. Будь-який контейнер у Podʼі може працювати у привілейованому режимі для використання адміністративних можливостей операційної системи, які інакше були б недоступні. Це доступно як для Windows, так і для Linux.
Привілейовані контейнери явно перевизначають деякі обмеження ядра Linux, які ви можливо використовуєте у ваших робочих навантаженнях, наступним чином:
- seccomp: Привілейовані контейнери працюють як профіль
Unconfinedseccomp, перевизначаючи будь-який профіль seccomp, який ви вказали у своєму маніфесті. - AppArmor: Привілейовані контейнери ігнорують будь-які застосовані профілі AppArmor.
- SELinux: Привілейовані контейнери працюють як домен
unconfined_t.
Привілейовані контейнери
Будь-який контейнер у Podʼі може увімкнути привілейований режим, якщо ви встановите поле privileged: true у securityContext поле для контейнера. Привілейовані контейнери перевизначають або скасовують багато інших налаштувань зміцнення захисту, таких як застосований профіль seccomp, профіль AppArmor або обмеження SELinux. Привілейовані контейнери отримують всі можливості Linux, включаючи можливості, яких їм не потрібно. Наприклад, користувач root у привілейованому контейнері може мати можливість використовувати можливості CAP_SYS_ADMIN та CAP_NET_ADMIN на вузлі, оминання конфігурації часу виконання seccomp та інших обмежень.
У більшості випадків ви повинні уникати використання привілейованих контейнерів і натомість надавати конкретні можливості, необхідні для вашого контейнера, використовуючи поле capabilities у полі securityContext. Використовуйте привілейований режим лише у випадках, коли у вас є можливість, яку ви не можете надати за допомогою securityContext. Це корисно для контейнерів, які хочуть використовувати адміністративні можливості операційної системи, такі як керування мережевим стеком або доступ до апаратного забезпечення.
У версії Kubernetes 1.26 та пізніше ви також можете запускати контейнери Windows у подібному привілейованому режимі, встановивши прапорець windowsOptions.hostProcess у контексті безпеки специфікації Podʼа. Для отримання докладної інформації та інструкцій див. Створення Podʼа HostProcess для Windows.
Рекомендації та поради
- Перш ніж налаштовувати можливості безпеки на рівні ядра, вам слід розглянути впровадження ізоляції на рівні мережі. Для отримання додаткової інформації прочитайте Перелік заходів безпеки.
- Крім того, якщо це необхідно, запускайте робочі навантаження Linux як непривілейовані, вказавши конкретні ідентифікатори користувача та групи у вашому маніфесті Podʼа та, вказавши
runAsNonRoot: true.
Крім того, ви можете запускати робочі навантаження в просторах користувачів, встановивши hostUsers: false у вашому маніфесті Podʼа. Це дозволяє запускати контейнери від імені користувачів root у просторі користувачів, але як не-root користувача в просторі користувачів на вузлі. Це все ще знаходиться на ранніх етапах розробки та може не мати необхідного рівня підтримки, який вам потрібно. Для отримання інструкцій див. Використання простору користувачів з Podʼом.
Що далі
8.14 - Список перевірок безпеки
Базовий список для забезпечення безпеки в кластерах Kubernetes.
Цей список має на меті надати базовий перелік рекомендацій з посиланнями на більш комплексну документацію з кожної теми. Він не претендує на повноту і може змінюватись.
Як користуватись цим документом:
- Порядок тем не відображає порядок пріоритетів.
- Деякі пункти списку розкриваються в абзац нижче переліку кожної секції.
Увага:
Списки не є достатніми для досягнення хорошої позиції у справах безпеки самі по собі. Для забезпечення відповідної безпеки потрібна постійна увага і вдосконалення, але список може бути першим кроком на нескінченному шляху до безпеки. Деякі рекомендації у цьому списку можуть бути занадто обмежувальними або надто слабкими для вашої конкретної потреби у безпеці. Оскільки безпека Kubernetes не є "однорозмірною", кожна категорія пунктів списку повинна оцінюватися відповідно.Автентифікація та авторизація
- Група
system:mastersне використовується для автентифікації користувачів чи компонентів після першого налаштування. - Компонент kube-controller-manager працює з увімкненим параметром
--use-service-account-credentials. - Кореневий сертифікат захищений (або офлайн CA, або керований онлайн CA з ефективними елементами керування доступом).
- Проміжний та листовий сертифікати мають строк дії не більше ніж 3 роки вперед.
- Існує процес періодичного перегляду доступу, і перегляди проводяться не рідше ніж через кожні 24 місяці.
- Дотримуються рекомендації щодо контролю доступу на основі ролей щодо автентифікації та авторизації.
Після першої налаштування ні користувачі, ні компоненти не повинні автентифікуватися в API Kubernetes як system:masters. Так само, варто уникати використання всіх компонентів kube-controller-manager як system:masters. Фактично, system:masters повинен використовуватися лише як механізм для виходу з аварійної ситуації, а не як адміністративний користувач.
Безпека мережі
- Використані CNI-втулки підтримують політики мережі.
- Політики мережі вхідного та вихідного трафіку застосовані до всіх навантажень в кластері.
- У кожному просторі імен встановлені типові політики мережі, які вибирають всі Podʼи та забороняють все.
- У разі необхідності використано сервісну сітку (service mesh) для шифрування всіх зʼєднань всередині кластера.
- API Kubernetes, API kubelet та etcd не викладені публічно в Інтернеті.
- Доступ від навантажень до API хмарних метаданих фільтрується.
- Використання LoadBalancer та ExternalIPs обмежено.
Багато втулків мережевого інтерфейсу контейнера (CNI) забезпечують функціональність обмеження ресурсів мережі, з якими можуть спілкуватися Podʼи. Найчастіше це робиться за допомогою мережевих політик, які надають ресурс з простором імен для визначення правил. Типові політики мережі, які блокують вхідний та вихідний трафік, у кожному просторі імен, вибираючи всі Podʼи, можуть бути корисні для прийняття списку дозволів, щоб переконатися, що жодне навантаження не пропущене.
Не всі CNI-втулки надають шифрування під час транзиту. Якщо обраний втулок не має цієї функції, альтернативним рішенням може бути використання сервісної сітки для надання цієї функціональності.
Дані etcd панелі управління повинні мати елементи для обмеження доступу і не повинні бути публічно викладені в Інтернеті. Крім того, для безпечного звʼязку з нею має використовуватись взаємний TLS (mTLS). Центр сертифікації для цього повинен бути унікальним для etcd.
Зовнішній Інтернет-доступ до сервера API Kubernetes повинен бути обмежений, щоб не викладати API публічно. Будьте обережні, оскільки багато дистрибутивів Kubernetes, що надаються постачальниками послуг, стандартно викладають сервер API публічно. Потім можна використовувати хост-бастион для доступу до сервера.
Доступ до API kubelet повинен бути обмежений і не викладений публічно, стандартні налаштування автентифікації та авторизації, коли не вказаний файл конфігурації з прапорцем --config, є занадто дозвільними.
Якщо для розміщення Kubernetes використовується хмарний провайдер, доступ від навантажень до API хмарних метаданих 169.254.169.254 також повинен бути обмежений або заблокований, якщо він не потрібний, оскільки це може робити можливим витік інформації.
Для обмеженого використання LoadBalancer та ExternalIPs див. CVE-2020-8554: Man in the middle using LoadBalancer or ExternalIPs та контролер відмови ExternalIPs для отримання додаткової інформації.
Безпека Podʼів
- Права RBAC
create,update,patch,deleteнавантажень надаються лише за необхідності. - Для всіх просторів імен застосована та використовується відповідна політика стандартів безпеки Podʼів.
- Ліміт памʼяті встановлено для навантажень з обмеженням, рівним або меншим за запит.
- Ліміт CPU може бути встановлено для чутливих навантажень.
- Для вузлів, що його підтримують, увімкнено Seccomp з відповідними профілями syscalls для програм.
- Для вузлів, що його підтримують, увімкнено AppArmor або SELinux з відповідним профілем для програм.
Авторизація RBAC є важливою, але не може бути достатньо гранульованою для надання авторизації ресурсам Podʼів (або будь-якому ресурсу, який керує Podʼами). Єдиною гранулярністю є дії API на сам ресурс, наприклад, створення Podʼів. Без додаткового допуску, авторизація на створення цих ресурсів дозволяє прямий необмежений доступ до призначених для планування вузлів кластера.
Стандарти безпеки Podʼів визначають три різних політики: privileged, baseline та restricted, які обмежують, як поля можуть бути встановлені в PodSpec щодо безпеки. Ці стандарти можуть бути накладені на рівні простору імен за допомогою нового допуску безпеки Podʼів, ввімкненого стандартно, або за допомогою стороннього вебхуку допуску. Зауважте, що, на відміну від видаленого PodSecurityPolicy, яке він замінює, допуск безпеки Podʼів може легко поєднуватися з вебхуками допусків та зовнішніми службами.
Політика restricted безпеки Podʼів, найбільш обмежувальна політика зі стандартного набору безпеки Podʼів, може працювати у кількох режимах, warn, audit або enforce, щоб поступово застосовувати найбільш відповідний контекст безпеки відповідно до найкращих практик з безпеки. З усім тим, контекст безпеки Podʼів повинен окремо досліджуватися для обмеження привілеїв та доступу, які можуть мати Podʼи, крім попередньо визначених стандартів безпеки, для конкретних випадків використання.
Для підручника з безпеки Podʼів див. блог пост Kubernetes 1.23: Політика безпеки Podʼів переходить до бета-версії.
Ліміти памʼяті та CPU повинні бути встановлені для обмеження памʼяті та CPU, які може споживати Pod на вузлі, та, отже, запобігають можливим атакам DoS від зловмисних або порушених робочих навантажень. Така політика може бути накладена контролером допуску. Зверніть увагу, що ліміти CPU будуть обмежувати використання і можуть мати непередбачені наслідки для функцій автоматичного масштабування або ефективності, тобто виконання процесу з найкращими спробами з доступними ресурсами CPU.
Увага:
Обмеження памʼяті, що перевищує запит, може піддати весь вузол проблемам OOM.Увімкнення Seccomp
Seccomp (secure computing mode) є функцією ядра Linux з версії 2.6.12. Він може бути використаний для ізоляції привілеїв процесу, обмежуючи виклики, які він може зробити з простору користувача в ядро. Kubernetes дозволяє автоматично застосовувати профілі seccomp, завантажені на вузол, до ваших Podʼів і контейнерів.
Seccomp може покращити безпеку вашого навантаження, зменшуючи доступну для атак на ядро Linux поверхню викликів системного виклику всередині контейнерів. Режим фільтрації seccomp використовує BPF для створення списку дозволених або заборонених конкретних системних викликів, які називаються профілями.
Починаючи з Kubernetes 1.27, ви можете увімкнути використання RuntimeDefault як типового профілю seccomp для всіх навантажень. Існує посібник з безпеки на цю тему. Крім того, Оператор профілів безпеки Kubernetes — це проєкт, який сприяє управлінню та використанню seccomp в кластерах.
Примітка:
Seccomp доступний тільки на вузлах Linux.Увімкнення AppArmor або SELinux
AppArmor
AppArmor — це модуль безпеки ядра Linux, який може забезпечити простий спосіб реалізації обовʼязкового контролю доступу (MAC, Mandatory Access Control) та кращого аудиту через системні логи. На вузлах, які його підтримують, застосовується стандартний профіль AppArmor, або може бути налаштований власний профіль. Як і seccomp, AppArmor також налаштовується через профілі, де кожен профіль працює в посиленому режимі, який блокує доступ до заборонених ресурсів, або в режимі скарг, який лише повідомляє про порушення. Профілі AppArmor застосовуються на рівні контейнера з анотацією, що дозволяє процесам отримати лише необхідні привілеї.
Примітка:
AppArmor доступний тільки на вузлах Linux і увімкнений в деяких дистрибутивах Linux.SELinux
SELinux також є модулем безпеки ядра Linux, який може забезпечити механізм для підтримки політик безпеки контролю доступу, включаючи обовʼязковий контроль доступу (MAC). Мітки SELinux можуть бути призначені для контейнерів або Podʼів через їх розділ securityContext.
Примітка:
SELinux доступний тільки на вузлах Linux і увімкнений в деяких дистрибутивах Linux.Логи та аудит
- Логи аудиту, якщо вони увімкнені, захищені від загального доступу.
Розташування Podʼів
- Розташування Podʼів виконане відповідно до рівнів чутливості застосунку.
- Чутливі застосунки працюють в ізольованому вигляді на вузлах або зі специфічними середовищами виконання, розміщеними в пісочниці.
Podʼи, які належать до різних рівнів чутливості, наприклад, Podʼи застосунку та сервера Kubernetes API, повинні бути розгорнуті на окремих вузлах. Метою ізоляції вузла є запобігання виходу з контейнера застосунку до прямого надання доступу до застосунків з вищим рівнем чутливості для легкого перехоплення у кластері. Це розділення повинно бути накладене для запобігання помилкового розгортання Podʼів на той самий вузол. Це можна забезпечити за допомогою таких функцій:
- Селектори вузла
- Пари ключ-значення, як частина специфікації Podʼів, що вказують, на які вузли їх розгорнути. Це може бути встановлено на рівні простору імен та кластера за допомогою контролера допуску PodNodeSelector.
- PodTolerationRestriction
- Контролер допуску, який дозволяє адміністраторам обмежувати дозволені толерантності в межах простору імен. Podʼів в межах простору імен можуть використовувати тільки толерантності, вказані в ключах анотацій обʼєктів простору імен, які надають типовий та дозволений набір толерантностей.
- RuntimeClass
- RuntimeClass — це функція для вибору конфігурації контейнера для запуску. Конфігурація контейнера використовується для запуску контейнерів Podʼів і може забезпечувати більшу або меншу ізоляцію від хосту коштом продуктивності.
Secret
- ConfigMap не використовуються для зберігання конфіденційних даних.
- Шифрування у спокої для Secret API налаштоване.
- Якщо це необхідно, механізм для вбудовування Secret, збережених у сторонньому сховищі, розгорнуто та доступний.
- Токени облікового запису служби не монтується в Podʼах, які не потребують їх.
- Використовується привʼязанний том токенів облікового запису служби замість нескінченних токенів.
Secret, необхідні для Podʼів, повинні зберігатися у Secretʼах Kubernetes, на відміну від альтернатив, таких як ConfigMap. Ресурси Secret, збережені в etcd, повинні бути зашифровані у спокої.
Podʼи, що потребують Secret, повинні автоматично мати їх змонтовані через томи, попередньо збережені у памʼяті, наприклад, за допомогою опції emptyDir.medium. Механізм може бути використаний також для введення Secret зі сторонніх сховищ як томів, наприклад, Secrets Store CSI Driver. Це слід робити переважно порівняно з наданням Podʼам облікових записів служб доступу RBAC до Secret. Це дозволить додавати Secret до Podʼів як змінні середовища або файли. Зверніть увагу, що метод змінних середовища може бути більш схильним до витоку через аварійні записи в логах та неконфіденційний характер змінної середовища в Linux, на відміну від механізму дозволу на файли.
Токени облікових записів служби не повинні монтуватися в Podʼи, які не потребують їх. Це можна налаштувати, встановивши automountServiceAccountToken в значення false або для облікового запису служби, щоб застосувати це на всі простори імен або конкретно для Podʼа. Для Kubernetes v1.22 і новіше використовуйте привʼязані облікові записи служб для часово обмежених облікових записів служби.
Образи
- Мінімізувати непотрібний вміст у образах контейнера.
- Контейнерні образи налаштовані на запуск з правами непривілейованого користувача.
- Посилання на контейнерні образи виконуються за допомогою хешів sha256 (замість міток), або походження образу перевіряється шляхом перевірки цифрового підпису образу під час розгортання через контролер допуску.
- Контейнерні образи регулярно скануються під час створення та розгортання, і відоме вразливе програмне забезпечення піддається патчингу.
Контейнерний образ має містити мінімум необхідного для запуску програми, яку він упаковує. Найкраще, тільки програму та її залежності, створюючи образи з мінімально можливою базою. Зокрема, образи, які використовуються в операційній діяльності, не повинні містити оболонки або засоби налагодження, оскільки для усунення несправностей може використовуватися ефемерний контейнер для налагодження.
Побудуйте образи для прямого запуску від непривілейованого користувача, використовуючи інструкцію USER у Dockerfile. Контекст безпеки дозволяє запускати контейнерні образи з певним користувачем та групою за допомогою параметрів runAsUser та runAsGroup, навіть якщо вони не вказані у маніфесті образу. Однак дозволи на файли у шарах образів можуть зробити неможливим просто запуск процесу з новим непривілейованим користувачем без модифікації образу.
Уникайте використання міток для посилання на образи, особливо мітки latest, образи з міткою можуть бути легко змінені у реєстрі. Краще використовувати повний хеш sha256, який унікальний для маніфесту образу. Цю політику можна накладати за допомогою ImagePolicyWebhook. Підписи образів також можуть бути автоматично перевірені контролером допуску під час розгортання для перевірки їх автентичності та цілісності.
Сканування контейнерних образів може запобігти розгортанню критичних вразливостей у кластері разом з контейнерним образом. Сканування образів повинно бути завершено перед розгортанням контейнерного образу в кластері та, як правило, виконується як частина процесу розгортання у CI/CD конвеєрі. Метою сканування образу є отримання інформації про можливі вразливості та їх запобігання в контейнерному образі, такої як оцінка Загальної системи оцінки вразливостей (CVSS). Якщо результати сканування образів поєднуються з правилами відповідності конвеєра, операційне середовище буде використовувати лише належно виправлені контейнерні образи.
Контролери допуску
- Включено відповідний вибір контролерів допуску.
- Політика безпеки підпорядкована контролеру допуску про безпеку або/і вебхуку контролера допуску.
- Втулки ланцюжка допуску та вебхуки надійно налаштовані.
Контролери допуску можуть допомогти покращити безпеку кластера. Однак вони можуть представляти ризики самі по собі, оскільки розширюють API-сервер і повинні бути належним чином захищені.
У наступних списках наведено кілька контролерів допуску, які можуть бути розглянуті для покращення безпеки вашого кластера та застосунків. Вони включають контролери, на які є посилання в інших частинах цього документа.
Ця перша група контролерів допуску включає втулки, типово увімкнені, розгляньте можливість залишити їх увімкненими, якщо ви розумієте, що робите:
CertificateApproval- Здійснює додаткові перевірки авторизації, щоб переконатися, що користувач, який затверджує, має дозвіл на затвердження запиту на отримання сертифіката.
CertificateSigning- Здійснює додаткові перевірки авторизації, щоб переконатися, що користувач, який підписує, має дозвіл на підписування запитів на отримання сертифіката.
CertificateSubjectRestriction- Відхиляє будь-який запит на сертифікат, який вказує 'групу' (або 'організаційний атрибут')
system:masters. LimitRanger- Застосовує обмеження API-контролера обмежень.
MutatingAdmissionWebhook- Дозволяє використання власних контролерів через вебхуки, ці контролери можуть змінювати запити, які вони переглядають.
PodSecurity- Заміна політики безпеки контейнера, обмежує контексти безпеки розгорнутих контейнерів.
ResourceQuota- Застосовує обмеження ресурсів для запобігання перевикористанню ресурсів.
ValidatingAdmissionWebhook- Дозволяє використання власних контролерів через вебхуки, ці контролери не змінюють запити, які вони переглядають.
Друга група включає втулки, які типово не увімкнені, але знаходяться в стані загальної доступності та рекомендуються для покращення вашої безпеки:
DenyServiceExternalIPs- Відхиляє всю нову мережеву взаємодію з полем
Service.spec.externalIPs. Це захист від CVE-2020-8554: Man in the middle using LoadBalancer or ExternalIPs. NodeRestriction- Обмежує дозволи kubelet тільки на модифікацію ресурсів API для точок доступу керування мережевими підключеннями, якими він володіє або ресурсу API вузла, які представляють себе. Він також заважає використанню kubelet анотації
node-restriction.kubernetes.io/, яку може використовувати зловмисник з доступом до облікових даних kubelet, щоб вплинути на розміщення Podʼа на вузлі.
Третя група включає втулки, які за стандартно не увімкнені, але можуть бути розглянуті для певних випадків використання:
AlwaysPullImages- Застосовує використання останньої версії мітки образу та перевіряє, чи дозволи використання образ має той, хто здійснює розгортання.
ImagePolicyWebhook- Дозволяє застосовувати додаткові контролери для образів через вебхуки.
Що далі
- Підвищення привілеїв через створення Podʼа попереджає вас про конкретний ризик контролю доступу; перевірте, як ви управляєте цією загрозою.
- Якщо ви використовуєте use Kubernetes RBAC ознайомтьесь з Порадами з використання RBAC для додаткової інформації щодо авторизації.
- Захист кластера для інформації щодо захисту кластера від випадкового або зловмисного доступу.
- Керівництво з мультиорендності кластера для рекомендацій та найкращих практик щодо конфігурації опцій та багатоорендності.
- Стаття в блозі "Докладніше про рекомендації посилення безпеки Kubernetes від NSA/CISA" для додаткових ресурсів з посилення безпеки кластерів Kubernetes.
8.15 - Список перевірки безпеки застосунків
Базові рекомендації щодо забезпечення безпеки застосунків у Kubernetes, орієнтовані на розробників застосунків.
Цей список перевірки спрямований на надання основних рекомендацій з безпеки застосунків, що працюють у Kubernetes, з погляду розробника. Цей список не є вичерпним і має на меті з часом змінюватись.
Як читати та використовувати цей документ:
- Порядок тем не відображає пріоритетність.
- Деякі пункти списку детально описані в абзаці нижче списку кожного розділу.
- Цей список припускає, що
розробникє користувачем кластера Kubernetes, який взаємодіє з обʼєктами в межах області імен.
Увага:
Списки не є достатніми для досягнення хорошого рівня безпеки самі по собі. Хороша безпека вимагає постійної уваги та вдосконалення, але список може бути першим кроком на нескінченному шляху до готовності до забезпечення безпеки. Деякі з рекомендацій у цьому списку можуть бути занадто обмежувальними або, навпаки, недостатніми для ваших конкретних потреб у безпеці. Оскільки безпека в Kubernetes не є універсальною, кожну категорію елементів списку слід оцінювати за її значенням.Базове посилення безпеки
Наведений нижче список містить рекомендації з базового посилення безпеки, які можуть застосовуватися до більшості застосунків, що розгортаються в Kubernetes.
Дизайн застосунків
- Дотримання відповідних принципів безпеки при розробці застосунків.
- Застосунок налаштований з відповідним класом QoS через запити ресурсів і обмеження.
- Встановлено обмеження памʼяті для робочих навантажень з обмеженням, яке дорівнює або менше запиту.
- Обмеження процесора може бути встановлено для чутливих робочих навантажень.
Службові облікові записи
- Уникайте використання ServiceAccount
default. Створюйте ServiceAccount для кожного робочого навантаження або мікросервісу. -
automountServiceAccountTokenповинен бути встановлений уfalse, якщо Pod не потребує доступу до API Kubernetes для роботи.
Рекомендації для securityContext на рівні Podʼа
- Встановіть
runAsNonRoot: true. - Налаштуйте контейнер для виконання як менш привілейований користувач (наприклад, використовуючи
runAsUserіrunAsGroup), а також налаштуйте відповідні дозволи на файли або теки в образі контейнера. - Додатково можна додати допоміжну групу з
fsGroupдля доступу до постійних томів. - Застосунок розгортається в області імен, де застосовується відповідний стандарт безпеки Podʼів. Якщо ви не можете контролювати це примусове виконання для кластера(-ів), у якому розгортається застосунок, врахуйте це через документацію або додатковий захист у глибину.
Рекомендації для securityContext на рівні контейнера
- Вимкніть підвищення привілеїв за допомогою
allowPrivilegeEscalation: false. - Налаштуйте кореневу файлову систему як тільки для читання з
readOnlyRootFilesystem: true. - Уникайте запуску привілейованих контейнерів (встановіть
privileged: false). - Вимкніть усі можливості у контейнерах і додайте лише конкретні, необхідні для роботи контейнера.
Контроль доступу на основі ролей (RBAC)
- Дозволи, такі як create, patch, update і delete, слід надавати лише за потребою.
- Уникайте створення дозволів RBAC для створення або оновлення ролей, що може призвести до підвищення привілеїв.
- Перегляньте привʼязки для групи
system:unauthenticatedі видаліть їх, якщо можливо, оскільки це надає доступ будь-кому, хто може підʼєднатися до API-сервера на мережевому рівні.
Дії create, update і delete слід дозволяти обачно. Дія patch, якщо дозволена для області імен, може дозволити користувачам оновлювати мітки у namespace чи deployment, що може збільшити поверхню атаки.
Для чутливих робочих навантажень розгляньте можливість надання рекомендованої ValidatingAdmissionPolicy, яка додатково обмежує дозволені дії запису.
Безпека образів
- Використовуйте інструменту для сканування образів перед розгортанням контейнерів у кластері Kubernetes.
- Використовуйте підписування контейнерів для перевірки підпису образу контейнера перед розгортанням у кластері Kubernetes.
Мережеві політики
- Налаштуйте NetworkPolicies, щоб дозволити лише очікуваний вхідний та вихідний трафік з Podʼів.
Переконайтеся, що ваш кластер надає та вимагає виконання NetworkPolicy. Якщо ви пишете застосунок, який користувачі будуть розгортати в різних кластерах, розгляньте, чи можете ви припустити, що NetworkPolicy доступний і виконується.
Розширене посилення безпеки
Цей розділ цього посібника охоплює деякі розширені моменти посилення безпеки, які можуть бути корисні залежно від налаштувань середовища Kubernetes.
Безпека контейнерів Linux
Налаштуйте Security Context для pod-container.
- Встановіть профілі Seccomp для контейнерів.
- Обмежте доступ контейнера до ресурсів за допомогою AppArmor.
- Призначте відповідні мітки SELinux контейнерам.
Класи виконання
- Налаштуйте відповідні класи виконання для контейнерів.
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Деяким контейнерам може знадобитися інший рівень ізоляції, ніж стандартно впроваджений у кластері. runtimeClassname можна використовувати у podspec для визначення іншого класу виконання.
Для чутливих робочих навантажень розгляньте використання інструментів емуляції ядра, таких як gVisor, або віртуалізованої ізоляції за допомогою механізму, такого як kata-containers.
У високонадійних середовищах розгляньте використання конфіденційних віртуальних машин для подальшого підвищення безпеки чутливих робочих навантажень.
9 - Політики
Керування безпекою та найкращі практики застосування політик.
Політики Kubernetes — це конфігурації, які керують поведінкою інших конфігурацій чи ресурсів. Kubernetes надає кілька різних рівнів політик, про які можна дізнатися в цьому розділі.
Застосування політик за допомогою обʼєктів API
Деякі обʼєкти API виступають як політики. Ось деякі приклади:
- NetworkPolicies можуть бути використані для обмеження вхідного та вихідного трафіку для робочого навантаження.
- LimitRanges керують обмеженнями розподілу ресурсів між різними типами обʼєктів.
- ResourceQuotas обмежують споживання ресурсів для простору імен.
Застосування політик за допомогою admission-контролерів
Admission контролер працює в API-сервері та може перевіряти або змінювати запити до API. Деякі admission-контролери виступають як політики. Наприклад, admission-контролер AlwaysPullImages змінює новий обʼєкт Pod, щоб встановити політику завантаження образу на Always.
У Kubernetes є кілька вбудованих admission-контролерів, які можна налаштувати за допомогою прапорця --enable-admission-plugins API-сервера.
Детальні відомості про admission-контролери, з повним списком доступних admission-контролерів, ви знайдете в окремому розділі:
Застосування політик за допомогою ValidatingAdmissionPolicy
Перевірка політик допуску дозволяє виконувати налаштовані перевірки в API-сервері за допомогою мови виразів Common Expression Language (CEL). Наприклад, ValidatingAdmissionPolicy може бути використаний для заборони використання образів з теґом latest.
ValidatingAdmissionPolicy працює з запитом до API та може бути використаний для блокування, аудиту та попередження користувачів про невідповідні конфігурації.
Детальні відомості про API ValidatingAdmissionPolicy з прикладами ви знайдете в окремому розділі:
Застосування політик за допомогою динамічного контролю допуску
Контролери динамічного допуску (або вхідні вебхуки) працюють поза API-сервером як окремі застосунки, які реєструються для отримання запитів вебхуків для виконання перевірки або зміни запитів до API.
Контролери динамічного допуску можуть бути використані для застосування політик до запитів до API та спрацьовувати інші робочі процеси на основі політик. Контролер динамічного допуску може виконувати складні перевірки, включаючи ті, які вимагають отримання інших ресурсів кластера та зовнішніх даних. Наприклад, звірка перевірки образу може виконувати пошук даних у реєстрах OCI для перевірки підписів та атестації образу контейнерів.
Детальні відомості про динамічний контроль допуску ви знайдете в окремому розділі:
Реалізації
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Контролери динамічного допуску, які виступають як гнучкі рушії політик, розробляються в екосистемі Kubernetes, серед них:
Застосування політик за конфігурацій Kubelet
Kubeletʼи дозволяють налаштовувати політики для кожного робочого вузла. Деякі конфігурації Kubeletʼів працюють як політики:
- Резурвування та ліміти Process ID використовуються для обмеження та резервування PID.
- Менеджер ресурсів вузлів може бути використаний для керування обчислювальними ресурсами, ресурсами памʼяті та ресурсами пристроїв для високопропускних та критичних до затримок робочих навантажень.
9.1 - Обмеження діапазонів
Типово контейнери запускаються з необмеженими обчислювальними ресурсами у кластері Kubernetes. Використовуючи квоти ресурсів Kubernetes, адміністратори (оператори кластера) можуть обмежити споживання та створення ресурсів кластера (таких як час ЦП, памʼять та постійне сховище) у визначеному namespace. У межах простору імен Pod може використовувати стільки ЦП та памʼяті, скільки дозволяють ResourceQuotas, що застосовуються до цього простору імен. Як оператору кластера або адміністратору на рівні простору імен вам також може бути важливо переконатися, що один обʼєкт не може монополізувати всі доступні ресурси у просторі імен.
LimitRange — це політика обмеження виділення ресурсів (ліміти та запити), яку можна вказати для кожного відповідного типу обʼєкта (такого як Pod або PersistentVolumeClaim) у просторі імен.
LimitRange надає обмеження, які можуть:
- Застосовувати мінімальні та максимальні витрати обчислювальних ресурсів на Pod або Контейнер у просторі імен.
- Застосовувати мінімальний та максимальний запит на сховище для PersistentVolumeClaim у просторі імен.
- Застосовувати співвідношення між запитом та лімітом для ресурсу у просторі імен.
- Встановлювати стандартний запит/ліміт для обчислювальних ресурсів у просторі імен та автоматично вставляти їх у контейнери під час виконання.
Kubernetes обмежує виділення ресурсів для Podʼів у певному просторі імен якщо у цьому просторі назв є хоча б один обʼєкт LimitRange.
Назва обʼєкта LimitRange повинна бути дійсним піддоменом DNS.
Обмеження на ліміти ресурсів та запити
- Адміністратор створює обмеження діапазону у просторі імен.
- Користувачі створюють (або намагаються створити) обʼєкти у цьому просторі імен, такі як Podʼи або PersistentVolumeClaims.
- По-перше, контролер допуску LimitRange застосовує типове значення запиту та ліміту для всіх Podʼів (та їхніх контейнерів), які не встановлюють вимоги щодо обчислювальних ресурсів.
- По-друге, LimitRange відстежує використання, щоб забезпечити, що воно не перевищує мінімальне, максимальне та співвідношення ресурсів, визначених в будь-якому LimitRange, присутньому у просторі імен.
- Якщо ви намагаєтеся створити або оновити обʼєкт (Pod або PersistentVolumeClaim), який порушує обмеження LimitRange, ваш запит до сервера API буде відхилено з HTTP-кодом стану
403 Forbiddenта повідомленням, що пояснює порушене обмеження. - Якщо додати LimitRange в простір імен, який застосовується до обчислювальних ресурсів, таких як
cpuтаmemory, необхідно вказати запити або ліміти для цих значень. В іншому випадку система може відхилити створення Podʼа. - Перевірка LimitRange відбувається тільки на етапі надання дозволу Podʼу, а не на працюючих Podʼах. Якщо ви додаєте або змінюєте LimitRange, Podʼи, які вже існують у цьому просторі імен, залишаються без змін.
- Якщо у просторі імен існує два або більше обʼєкти LimitRange, то не визначено, яке типове значення буде застосовано.
LimitRange та перевірки допуску для Podʼів
LimitRange не перевіряє типово послідовність застосованих значень. Це означає, що стандартні значення для limit, встановлене LimitRange, може бути меншим за значення request, вказане для контейнера в специфікації, яку клієнт надсилає на сервер API. Якщо це станеться, Pod не буде запланованим.
Наприклад, ви визначаєте LimitRange цим маніфестом:
Примітка:
Наступні приклади працюють у просторі імен default вашого кластера, оскільки параметр namespace не визначено, а діапазон LimitRange обмежено рівнем простору імен. Це означає, що будь-які посилання або операції у цих прикладах будуть взаємодіяти з елементами у просторі імен default вашого кластера. Ви можете перевизначити робочий простір імен, налаштувавши простір імен у поліmetadata.namespace.apiVersion: v1
kind: LimitRange
metadata:
name: cpu-resource-constraint
spec:
limits:
- default: # ця секція визначає типові обмеження
cpu: 500m
defaultRequest: # ця секція визначає типові запити
cpu: 500m
max: # max та min визначают діапазон обмеження
cpu: "1"
min:
cpu: 100m
type: Container
разом з Podʼом, який вказує на запит ресурсу ЦП 700m, але не на ліміт:
apiVersion: v1
kind: Pod
metadata:
name: example-conflict-with-limitrange-cpu
spec:
containers:
- name: demo
image: registry.k8s.io/pause:3.8
resources:
requests:
cpu: 700m
тоді цей Pod не буде запланованим, і він відмовиться з помилкою, схожою на:
Pod "example-conflict-with-limitrange-cpu" is invalid: spec.containers[0].resources.requests: Invalid value: "700m": must be less than or equal to cpu limit
Якщо ви встановите як request, так і limit, то цей новий Pod буде успішно запланований, навіть з тим самим LimitRange:
apiVersion: v1
kind: Pod
metadata:
name: example-no-conflict-with-limitrange-cpu
spec:
containers:
- name: demo
image: registry.k8s.io/pause:3.8
resources:
requests:
cpu: 700m
limits:
cpu: 700m
Приклади обмежень ресурсів
Приклади політик, які можна створити за допомогою LimitRange, такі:
- У кластері з 2 вузлами з місткістю 8 ГБ ОЗП та 16 ядрами обмежте Podʼи в просторі імен на роботу з 100m CPU з максимальним лімітом 500m для CPU та запит 200Mi для памʼяті з максимальним лімітом 600Mi для памʼяті.
- Визначте стандартний ліміт та запит CPU на 150m та стандартний запит памʼяті на 300Mi для контейнерів, що запускаються без запитів ЦП та памʼяті у своїх специфікаціях.
У випадку, коли загальні ліміти простору імен менше суми лімітів Podʼів/Контейнерів, може виникнути конфлікт для ресурсів. У цьому випадку контейнери або Podʼи не будуть створені.
Ні конфлікт, ні зміни LimitRange не впливають на вже створені ресурси.
Що далі
Для прикладів використання обмежень дивіться:
- як налаштувати мінімальні та максимальні обмеження CPU на простір імен.
- як налаштувати мінімальні та максимальні обмеження памʼяті на простір імен.
- як налаштувати стандартні запити та ліміти CPU на простір імен.
- як налаштувати стандартні запити та ліміти памʼяті на простір імен.
- як налаштувати мінімальні та максимальні обмеження використання сховища на простір імен.
- детальний приклад налаштування квот на простір імен.
Звертайтеся до документа проєкту LimitRanger для контексту та історичної інформації.
9.2 - Квоти ресурсів
Коли декілька користувачів або команд спільно використовують кластер з фіксованою кількістю вузлів, є можливість, що одна команда може використовувати більше, ніж свою справедливу частку ресурсів.
Квоти ресурсів є інструментом для адміністраторів для розвʼязання цієї проблеми.
Квота ресурсів, визначена обʼєктом ResourceQuota, надає обмеження, які обмежують загальне споживання ресурсів у просторі імен. Вона може обмежувати кількість обʼєктів, які можуть бути створені в просторі імен за типом, а також загальний обсяг обчислювальних ресурсів, які можуть бути спожиті ресурсами у цьому просторі імен.
Квоти ресурсів працюють наступним чином:
Різні команди працюють у різних просторах імен. Це може бути забезпечено з використанням RBAC.
Адміністратор створює одну квоту ресурсів для кожного простору імен.
Користувачі створюють ресурси (Podʼи, Serviceʼи тощо) у просторі імен, і система квот відстежує використання, щоб забезпечити, що воно не перевищує жорсткі обмеження ресурсів, визначені в ResourceQuota.
Якщо створення або оновлення ресурсу порушує обмеження квоти, запит буде відхилено з HTTP кодом стану
403 FORBIDDENз повідомленням, яке пояснює обмеження, що було б порушено.Якщо квота включена в простір імен для обчислювальних ресурсів, таких як
cpuтаmemory, користувачі повинні вказати запити або ліміти для цих значень; інакше, система квот може відхилити створення Podʼа. Підказка: Використовуйте контролер допускуLimitRanger, щоб надати для Podʼів, які не мають вимог до обчислювальних ресурсів, стандартні обсяги ресурсів.Дивіться посібник для прикладу того, як уникнути цієї проблеми.
Примітка:
- Для ресурсів
cpuтаmemory, квоти ресурсів забезпечують, що кожен (новий) Pod у цьому просторі імен встановлює ліміт для цього ресурсу. Якщо ви встановлюєте квоту ресурсів у просторі імен дляcpuабоmemory, ви, і інші клієнти, повинні вказати абоrequests, абоlimitsдля цього ресурсу, для кожного нового Podʼа, який ви створюєте. Якщо ви цього не робите, панель управління може відхилити допуск для цього Podʼа. - Для інших ресурсів: ResourceQuota працює та ігнорує Podʼи в просторі імен, які не встановлюють ліміт або запит для цього ресурсу. Це означає, що ви можете створити новий Pod без обмеження/запиту тимчасового сховища, якщо квота ресурсів обмежує тимчасове сховище цього простору імен. Ви можете використовувати LimitRange для автоматичного встановлення стандартних запитів для цих ресурсів.
Назва обʼєкта ResourceQuota повинна бути дійсним піддоменом DNS.
Приклади політик, які можна створити за допомогою просторів імен та квот, такі:
- У кластері з місткістю 32 ГБ ОЗП та 16 ядрами, дозвольте команді A використовувати 20 ГБ та 10 ядер, дозвольте команді B використовувати 10 ГБ та 4 ядра, і залиште 2 ГБ та 2 ядра у резерві на майбутнє.
- Обмежте простір імен "testing" використанням 1 ядра та 1 ГБ ОЗП. Дозвольте простору імен "production" використовувати будь-який обсяг.
У випадку, коли загальна місткість кластера менше суми квот просторів імен, може виникнути конфлікт за ресурси. Це обробляється за принципом "хто перший прийшов, той і молотить" (FIFO).
Ні конфлікт, ні зміни квоти не впливають на вже створені ресурси.
Увімкнення квоти ресурсів
Підтримка квоти ресурсів є типово увімкненою для багатьох дистрибутивів Kubernetes. Вона увімкнена, коли прапорець --enable-admission-plugins= API serverʼа має ResourceQuota серед своїх аргументів.
Квота ресурсів застосовується в певному просторі імен, коли у цьому просторі імен є ResourceQuota.
Квота обчислювальних ресурсів
Ви можете обмежити загальну суму обчислювальних ресурсів, які можуть бути запитані в певному просторі імен.
Підтримуються наступні типи ресурсів:
| Назва ресурсу | Опис |
|---|---|
limits.cpu | У всіх Podʼах у незавершеному стані сума лімітів CPU не може перевищувати це значення. |
limits.memory | У всіх Podʼах у незавершеному стані сума лімітів памʼяті не може перевищувати це значення. |
requests.cpu | У всіх Podʼах у незавершеному стані сума запитів CPU не може перевищувати це значення. |
requests.memory | У всіх Podʼах у незавершеному стані сума запитів памʼяті не може перевищувати це значення. |
hugepages-<size> | У всіх Podʼах у незавершеному стані кількість запитів великих сторінок зазначеного розміру не може перевищувати це значення. |
cpu | Те саме, що і requests.cpu |
memory | Те саме, що і requests.memory |
Квота для розширених ресурсів
Крім ресурсів, згаданих вище, в релізі 1.10 було додано підтримку квоти для розширених ресурсів.
Оскільки перевищення не дозволяється для розширених ресурсів, немає сенсу вказувати як requests, так і limits для одного й того ж розширеного ресурсу у квоті. Таким чином, для розширених ресурсів дозволяються лише елементи квоти з префіксом requests..
Візьмімо ресурс GPU як приклад. Якщо імʼя ресурсу — nvidia.com/gpu, і ви хочете обмежити загальну кількість запитаних GPU в просторі імен до 4, ви можете визначити квоту так:
requests.nvidia.com/gpu: 4
Дивіться Перегляд та встановлення квот для більш детальної інформації.
Квота ресурсів зберігання
Ви можете обмежити загальну суму ресурсів зберігання, які можуть бути запитані в певному просторі імен.
Крім того, ви можете обмежити споживання ресурсів зберігання на основі повʼязаного класу зберігання.
| Назва ресурсу | Опис |
|---|---|
requests.storage | У всіх запитах на постійний том, сума запитів зберігання не може перевищувати це значення. |
persistentvolumeclaims | Загальна кількість PersistentVolumeClaims, які можуть існувати у просторі імен. |
<storage-class-name>.storageclass.storage.k8s.io/requests.storage | У всіх запитах на постійний том, повʼязаних з <storage-class-name>, сума запитів зберігання не може перевищувати це значення. |
<storage-class-name>.storageclass.storage.k8s.io/persistentvolumeclaims | У всіх запитах на постійний том, повʼязаних з <storage-class-name>, загальна кількість запитів на постійні томи, які можуть існувати у просторі імен. |
Наприклад ви хочете обмежити зберігання з StorageClass gold окремо від StorageClass bronze, ви можете визначити квоту так:
gold.storageclass.storage.k8s.io/requests.storage: 500Gibronze.storageclass.storage.k8s.io/requests.storage: 100Gi
У релізі 1.8, підтримка квоти для локального тимчасового сховища додана як альфа-функція:
| Назва ресурсу | Опис |
|---|---|
requests.ephemeral-storage | У всіх Podʼах у просторі імен, сума запитів на локальне тимчасове сховище не може перевищувати це значення. |
limits.ephemeral-storage | У всіх Podʼах у просторі імен, сума лімітів на локальне тимчасове сховище не може перевищувати це значення. |
ephemeral-storage | Те саме, що і requests.ephemeral-storage. |
Примітка:
При використанні середовища виконання контейнерів CRI, логи контейнера будуть зараховуватися до квоти тимчасового сховища. Це може призвести до неочікуваного видалення Podʼів, які вичерпали свої квоти на сховище. Дивіться Архітектура логів для деталей.Квота на кількість обʼєктів
Ви можете встановити квоту на загальну кількість одного конкретного типу ресурсів у API Kubernetes, використовуючи наступний синтаксис:
count/<resource>.<group>для ресурсів з груп non-corecount/<resource>для ресурсів з групи core
Нижче наведено приклад набору ресурсів, які користувачі можуть хотіти обмежити квотою на кількість обʼєктів:
count/persistentvolumeclaimscount/servicescount/secretscount/configmapscount/replicationcontrollerscount/deployments.appscount/replicasets.appscount/statefulsets.appscount/jobs.batchcount/cronjobs.batch
Якщо ви визначаєте квоту таким чином, вона застосовується до API Kubernetes, які є частиною сервера API, а також до будь-яких власних ресурсів, підтримуваних CustomResourceDefinition. Якщо ви використовуєте агрегацію API, щоб додати додаткові, власні API, які не визначені як CustomResourceDefinitions, основна панель управління Kubernetes не застосовує квоту для агрегованого API. Очікується, що розширений сервер API забезпечить виконання квот, якщо це відповідає потребам власного API. Наприклад, щоб створити квоту на власний ресурс widgets у групі API example.com, використовуйте count/widgets.example.com.
При використанні такої квоти ресурсів (практично для всіх видів обʼєктів), обʼєкт враховується у квоті, якщо вид обʼєкта існує (визначений) у панелі управління. Ці типи квот корисні для захисту від вичерпання ресурсів зберігання. Наприклад, ви можете хотіти обмежити кількість Secretʼів на сервері, враховуючи їх великий розмір. Занадто багато Secretʼів у кластері може фактично завадити запуску серверів і контролерів. Ви можете встановити квоту для Job, щоб захиститися від погано налаштованого CronJob. CronJobs, які створюють занадто багато Job у просторі імен, можуть призвести до заподіяння відмови в обслуговуванні.
Існує інший синтаксис, який дозволяє встановити такий же тип квоти для певних ресурсів. Підтримуються наступні типи:
| Назва ресурсу | Опис |
|---|---|
configmaps | Загальна кількість ConfigMaps, які можуть існувати в просторі імен. |
persistentvolumeclaims | Загальна кількість PersistentVolumeClaims, які можуть існувати в просторі імен. |
pods | Загальна кількість Podʼів у просторі імен, що не перебувають в стані завершення роботи. Pod вважається таким, якщо .status.phase in (Failed, Succeeded) є true. |
replicationcontrollers | Загальна кількість ReplicationControllers, які можуть існувати в просторі імен. |
resourcequotas | Загальна кількість ResourceQuotas, які можуть існувати в просторі імен. |
services | Загальна кількість Services, які можуть існувати в просторі імен. |
services.loadbalancers | Загальна кількість Services типу LoadBalancer, які можуть існувати в просторі імен. |
services.nodeports | Загальна кількість NodePorts, виділених Services типу NodePort чи LoadBalancer, які можуть існувати в просторі імен. |
secrets | Загальна кількість Secrets, які можуть існувати в просторі імен. |
Наприклад, квота pods рахує та обмежує максимальну кількість Podʼів, створених у одному просторі імен, що не перебувають в стані завершення роботи. Ви можете встановити квоту pods у просторі імен, щоб уникнути випадку, коли користувач створює багато невеликих Podʼів і вичерпує запаси IP-адрес Podʼів кластері.
Ви можете знайти більше прикладів у розділі Перегляд і налаштування квот.
Області дії квоти
Кожна квота може мати повʼязаний набір scopes. Квота вимірюватиме використання ресурсу лише в тому випадку, якщо вона відповідає перетину перерахованих областей.
Коли до квоти додається область, вона обмежує кількість ресурсів, які вона підтримує, тими, які стосуються цієї області. Ресурси, вказані у квоті поза дозволеним набором, призводять до помилки перевірки.
| Область | Опис |
|---|---|
Terminating | Відповідає Podʼам, де .spec.activeDeadlineSeconds >= 0 |
NotTerminating | Відповідає Podʼам, де .spec.activeDeadlineSeconds is nil |
BestEffort | Відповідає Podʼам, які мають найкращий рівень якості обслуговування. |
NotBestEffort | Відповідає Podʼам, які не мають найкращого рівня якості обслуговування. |
PriorityClass | Відповідає Podʼам, які посилаються на вказаний клас пріоритету. |
CrossNamespacePodAffinity | Відповідає Podʼам, які мають міжпросторові (anti)affinity. |
Область BestEffort обмежує квоту відстеження наступним ресурсом:
pods
Області Terminating, NotTerminating, NotBestEffort та PriorityClass обмежують квоту відстеження наступними ресурсами:
podscpumemoryrequests.cpurequests.memorylimits.cpulimits.memory
Зверніть увагу, що ви не можете вказати як Terminating, так і NotTerminating області в одній й тій же квоті, і ви також не можете вказати як BestEffort, так і NotBestEffort області в одній й тій же квоті.
Селектор області підтримує наступні значення у полі operator:
InNotInExistsDoesNotExist
При використанні одного з наступних значень як scopeName при визначенні scopeSelector, оператор повинен бути Exists.
TerminatingNotTerminatingBestEffortNotBestEffort
Якщо оператором є In або NotIn, поле values повинно мати щонайменше одне значення. Наприклад:
scopeSelector:
matchExpressions:
- scopeName: PriorityClass
operator: In
values:
- middle
Якщо оператором є Exists або DoesNotExist, поле values НЕ повинно бути
вказане.
Квота ресурсів за PriorityClass
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.17 [stable]Podʼи можуть бути створені з певним пріоритетом. Ви можете контролювати використання ресурсів системи для Podʼів з урахуванням їх пріоритету, використовуючи поле scopeSelector у специфікації квоти.
Квота має збіг та використовується лише якщо scopeSelector у специфікації квоти вибирає Pod.
Коли квота обмежена класом пріоритету за допомогою поля scopeSelector, обʼєкт квоти обмежується відстеженням лише наступних ресурсів:
podscpumemoryephemeral-storagelimits.cpulimits.memorylimits.ephemeral-storagerequests.cpurequests.memoryrequests.ephemeral-storage
У цьому прикладі створюється обʼєкт квоти та відповідною до нього підходить до Podʼів з певними пріоритетами. Приклад працює наступним чином:
- Podʼи в кластері мають один з трьох класів пріоритету: "низький", "середній", "високий".
- Для кожного пріоритету створюється один обʼєкт квоти.
Збережіть наступний YAML у файл quota.yml.
apiVersion: v1
kind: List
items:
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-high
spec:
hard:
cpu: "1000"
memory: 200Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["high"]
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-medium
spec:
hard:
cpu: "10"
memory: 20Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["medium"]
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-low
spec:
hard:
cpu: "5"
memory: 10Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["low"]
Застосуйте YAML за допомогою kubectl create.
kubectl create -f ./quota.yml
resourcequota/pods-high created
resourcequota/pods-medium created
resourcequota/pods-low created
Перевірте, що значення Used квоти дорівнює 0 за допомогою kubectl describe quota.
kubectl describe quota
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 1k
memory 0 200Gi
pods 0 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 5
memory 0 10Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 20Gi
pods 0 10
Створіть Pod із пріоритетом "high". Збережіть наступний YAML у файл high-priority-pod.yml.
apiVersion: v1
kind: Pod
metadata:
name: high-priority
spec:
containers:
- name: high-priority
image: ubuntu
command: ["/bin/sh"]
args: ["-c", "while true; do echo hello; sleep 10;done"]
resources:
requests:
memory: "10Gi"
cpu: "500m"
limits:
memory: "10Gi"
cpu: "500m"
priorityClassName: high
Застосуйте його за допомогою kubectl create.
kubectl create -f ./high-priority-pod.yml
Перевірте, що статистика "Used" для квоти пріоритету "high", pods-high, змінилася і що для інших двох квот стан не змінився.
kubectl describe quota
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 500m 1k
memory 10Gi 200Gi
pods 1 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 5
memory 0 10Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 20Gi
pods 0 10
Квота Pod Affinity між просторами імен
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]Оператори можуть використовувати область квоти CrossNamespacePodAffinity, щоб обмежити, які простори імен можуть мати Podʼи з термінами спорідненості, які перетинають простори імен. Зокрема, вона контролює, яким Podʼам дозволено встановлювати поля namespaces або namespaceSelector у термінах спорідненості (Pod Affinity).
Бажано уникати використання термінів спорідненості, які перетинають простори імен, оскільки Pod з обмеженнями анти-спорідненості може заблокувати Podʼи з усіх інших просторів імен від планування в області відмов.
За допомогою цієї області оператори можуть запобігти певним просторам імен (наприклад, foo-ns у наведеному нижче прикладі) використання Podʼів, які використовують спорідненість між просторами імен, створивши обʼєкт квоти ресурсів в цьому просторі імен з областю CrossNamespacePodAffinity та жорстким обмеженням 0:
apiVersion: v1
kind: ResourceQuota
metadata:
name: disable-cross-namespace-affinity
namespace: foo-ns
spec:
hard:
pods: "0"
scopeSelector:
matchExpressions:
- scopeName: CrossNamespacePodAffinity
operator: Exists
Якщо оператори хочуть заборонити стандартне використання namespaces та namespaceSelector, і дозволити це лише для певних просторів імен, вони можуть налаштувати CrossNamespacePodAffinity як обмежений ресурс, встановивши прапорець kube-apiserver --admission-control-config-file на шлях до наступного конфігураційного файлу:
apiVersion: apiserver.config.k8s.io/v1
kind: AdmissionConfiguration
plugins:
- name: "ResourceQuota"
configuration:
apiVersion: apiserver.config.k8s.io/v1
kind: ResourceQuotaConfiguration
limitedResources:
- resource: pods
matchScopes:
- scopeName: CrossNamespacePodAffinity
operator: Exists
За такої конфігурації Podʼи можуть використовувати namespaces та namespaceSelector у термінах спорідненості тільки якщо простір імен, в якому вони створені, має обʼєкт квоти ресурсів з областю CrossNamespacePodAffinity та жорстким обмеженням, більшим або рівним кількості Podʼів, що використовують ці поля.
Запити порівняно з лімітами
При розподілі обчислювальних ресурсів кожен контейнер може вказати значення запиту та ліміту для CPU або памʼяті. Квоту можна налаштувати для обмеження будь-якого значення.
Якщо для квоти вказано значення для requests.cpu або requests.memory, то це вимагає, щоб кожен вхідний контейнер явно вказував запити для цих ресурсів. Якщо для квоти вказано значення для limits.cpu або limits.memory, то це вимагає, щоб кожен вхідний контейнер вказував явний ліміт для цих ресурсів.
Перегляд і налаштування квот
Kubectl підтримує створення, оновлення та перегляд квот:
kubectl create namespace myspace
cat <<EOF > compute-resources.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
requests.nvidia.com/gpu: 4
EOF
kubectl create -f ./compute-resources.yaml --namespace=myspace
cat <<EOF > object-counts.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
pods: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
services.loadbalancers: "2"
EOF
kubectl create -f ./object-counts.yaml --namespace=myspace
kubectl get quota --namespace=myspace
NAME AGE
compute-resources 30s
object-counts 32s
kubectl describe quota compute-resources --namespace=myspace
Name: compute-resources
Namespace: myspace
Resource Used Hard
-------- ---- ----
limits.cpu 0 2
limits.memory 0 2Gi
requests.cpu 0 1
requests.memory 0 1Gi
requests.nvidia.com/gpu 0 4
kubectl describe quota object-counts --namespace=myspace
Name: object-counts
Namespace: myspace
Resource Used Hard
-------- ---- ----
configmaps 0 10
persistentvolumeclaims 0 4
pods 0 4
replicationcontrollers 0 20
secrets 1 10
services 0 10
services.loadbalancers 0 2
Kubectl також підтримує квоту на кількість обʼєктів для всіх стандартних обʼєктів в просторі імен за допомогою синтаксису count/<resource>.<group>:
kubectl create namespace myspace
kubectl create quota test --hard=count/deployments.apps=2,count/replicasets.apps=4,count/pods=3,count/secrets=4 --namespace=myspace
kubectl create deployment nginx --image=nginx --namespace=myspace --replicas=2
kubectl describe quota --namespace=myspace
Name: test
Namespace: myspace
Resource Used Hard
-------- ---- ----
count/deployments.apps 1 2
count/pods 2 3
count/replicasets.apps 1 4
count/secrets 1 4
Квоти та місткість кластера
ResourceQuotas є незалежними від місткості кластера. Вони виражені в абсолютних одиницях. Таким чином, якщо ви додаєте вузли до свого кластера, це автоматично не надає кожному простору імен можливість використовувати більше ресурсів.
Іноді бажані складніші політики, такі як:
- Пропорційне розподілення спільних ресурсів кластера серед кількох команд.
- Дозвіл кожному орендареві збільшувати використання ресурсів за потреби, але мати щедру квоту, щоб уникнути випадкового вичерпання ресурсів.
- Виявлення попиту з одного простору імен, додавання вузли та збільшення квоти.
Такі політики можна реалізувати, використовуючи ResourceQuotas як будівельні блоки, написавши "контролер", який спостерігає за використанням квоти та налаштовує межі квоти кожного простору імен згідно з іншими сигналами.
Зверніть увагу, що квота ресурсів розподіляє загальні ресурси кластера, але не створює обмежень щодо вузлів: Podʼи з кількох просторів імен можуть працювати на одному вузлі.
Типове обмеження споживання Priority Class
Може бути бажаним, щоб Podʼи з певного пріоритету, наприклад, "cluster-services", дозволялися в просторі імен, лише якщо існує відповідний обʼєкт квоти.
За допомогою цього механізму оператори можуть обмежувати використання певних високопріоритетних класів до обмеженої кількості просторів імен, і не кожний простір імен зможе стандартно споживати ці класи пріоритету.
Для цього потрібно використовувати прапорець --admission-control-config-file kube-apiserver для передачі шляху до наступного конфігураційного файлу:
apiVersion: apiserver.config.k8s.io/v1
kind: AdmissionConfiguration
plugins:
- name: "ResourceQuota"
configuration:
apiVersion: apiserver.config.k8s.io/v1
kind: ResourceQuotaConfiguration
limitedResources:
- resource: pods
matchScopes:
- scopeName: PriorityClass
operator: In
values: ["cluster-services"]
Потім створіть обʼєкт квоти ресурсів у просторі імен kube-system:
apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-cluster-services
spec:
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["cluster-services"]kubectl apply -f https://k8s.io/examples/policy/priority-class-resourcequota.yaml -n kube-system
resourcequota/pods-cluster-services created
У цьому випадку створення Podʼа буде дозволено, якщо:
- Параметр
priorityClassNamePodʼа не вказано. - Параметр
priorityClassNamePodʼа вказано на значення, відмінне відcluster-services. - Параметр
priorityClassNamePodʼа встановлено наcluster-services, він має бути створений в просторі іменkube-systemі пройти перевірку обмеження ресурсів.
Запит на створення Podʼа буде відхилено, якщо його priorityClassName встановлено на cluster-services і він має бути створений в просторі імен, відмінному від kube-system.
Що далі
- Дивіться документ з проєктування ResourceQuota для отримання додаткової інформації.
- Перегляньте детальний приклад використання квоти ресурсів.
- Прочитайте документ з проєктування підтримки квот для класу пріоритету.
- Дивіться LimitedResources.
9.3 - Обмеження та резервування ID процесів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.20 [stable]Kubernetes дозволяє обмежувати кількість ідентифікаторів процесів (PID), які може використовувати Pod. Також можна зарезервувати певну кількість доступних PID для кожного вузла для використання операційною системою та службами (на відміну від Podʼів).
Ідентифікатори процесів (PID) є фундаментальним ресурсом на вузлах. Досить легко досягти обмеження на кількість завдань без досягнення будь-яких інших обмежень ресурсів, що може призвести до нестабільності роботи хосту.
Адміністраторам кластерів потрібні механізми, щоб гарантувати, що Podʼи, що працюють у кластері, не зможуть спричинити вичерпання PID, що перешкоджає роботі системних служб (таких як kubelet або kube-proxy), а також, можливо, і контейнерного середовища. Крім того, важливо забезпечити обмеження PID серед Podʼів, щоб гарантувати, що вони мають обмежений вплив на інші робочі навантаження на тому ж вузлі.
Примітка:
У деяких встановленнях Linux операційна система стандартно встановлює обмеження PID на низьке значення, наприклад,32768. Розгляньте можливість збільшення значення /proc/sys/kernel/pid_max.Ви можете налаштувати kubelet для обмеження кількості PID, які може споживати конкретний Pod. Наприклад, якщо ОС вашого вузла налаштовано на використання максимуму 262144 PID та очікується, що буде зберігатися менше 250 Podʼів, кожному Podʼу можна надати бюджет в розмірі 1000 PID, щоб запобігти використанню загальної кількості доступних PID на вузлі. Якщо адміністратор хоче надати можливість перевищення ліміту PID, схожий на CPU чи памʼять, він може зробити це, але з певними додатковими ризиками. У будь-якому випадку, одиничний Pod не зможе зруйнувати весь вузол. Цей вид обмеження ресурсів допомагає запобігти простим форк-бомбам впливати на роботу всього кластера.
Обмеження PID на рівні Pod дозволяє адміністраторам захистити один Pod від іншого, але не гарантує, що всі Podʼи, заплановані на цей вузол, не зможуть вплинути на вузол загалом. Обмеження PID на рівні Pod також не захищає системні агенти від вичерпання PID.
Ви також можете зарезервувати певну кількість PID для накладних витрат вузла, окремо від виділених для Podʼів. Це аналогічно тому, як ви можете резервувати CPU, памʼять чи інші ресурси для використання операційною системою та іншими засобами поза Podʼами та їх контейнерами.
Обмеження PID є важливим компонентом наряду з ресурсами обчислення. Однак ви вказуєте його по-іншому: замість визначення ліміту ресурсу для Podʼів у .spec для Pod, ви налаштовуєте ліміт як параметр kubelet. Обмеження PID, визначене на рівні Podʼа, наразі не підтримується.
Увага:
Це означає, що обмеження, яке застосовується до Podʼа, може відрізнятися залежно від того, де запланований Pod. Щоб уникнути складнощів, найкраще, якщо всі вузли використовують однакові обмеження та резервування ресурсів PID.Обмеження PID вузла
Kubernetes дозволяє зарезервувати певну кількість ідентифікаторів процесів для системного використання. Для налаштування резервування використовуйте параметр pid=<кількість> у командних параметрах --system-reserved та --kube-reserved для kubelet. Зазначена вами кількість ідентифікаторів процесів оголошує, що вказана кількість ідентифікаторів процесів буде зарезервована для системи в цілому та для служб Kubernetes відповідно.
Обмеження PID на рівні Podʼа
Kubernetes дозволяє обмежити кількість процесів, які запущені в Podʼі. Ви вказуєте це обмеження на рівні вузла, а не налаштовуєте його як обмеження ресурсів для певного Podʼа. Кожен вузол може мати власний ліміт PID. Для налаштування ліміту ви можете вказати параметр командного рядка --pod-max-pids для kubelet або встановити PodPidsLimit в конфігураційному файлі kubelet.
Виселення на основі PID
Ви можете налаштувати kubelet для початку завершення роботи Podʼа, коли він працює некоректно та споживає аномальну кількість ресурсів. Ця функція називається виселення (eviction). Ви можете Налаштувати обробку випадків нестачі ресурсів для різних сигналів виселення. Використовуйте сигнал виселення pid.available, щоб налаштувати поріг кількості PID, використаних Podʼом. Ви можете встановити мʼякі та жорсткі політики виселення. Однак навіть з жорсткою політикою виселення, якщо кількість PID швидко зростає, вузол все ще може потрапити в нестабільний стан через досягнення обмеження PID вузла. Значення сигналу виселення обчислюється періодично і НЕ забезпечує його виконання.
Обмеження PID — на рівні Podʼа і вузла встановлює жорсткий ліміт. Як тільки ліміт буде досягнуто, робота почне стикатись з помилками при спробі отримати новий PID. Це може або не може призвести до перепланування Pod, залежно від того, як робоче навантаження реагує на ці помилки та як налаштовано проби на працездатність та готовність для Podʼа. Однак, якщо ліміти були налаштовані правильно, ви можете гарантувати, що інші робочі навантаження Podʼів та системні процеси не будуть вичерпувати PID, коли один Pod працює некоректно.
Що далі
- Дивіться Покращеннями обмеження використання PID для отримання додаткової інформації.
- Для історичного контексту прочитайте Обмеження PID для покращення стабільності у Kubernetes 1.14.
- Прочитайте Управління ресурсами для контейнерів.
- Дізнайтеся, як Налаштувати обробку випадків нестачі ресурсів.
9.4 - Менеджери ресурсів вузлів
Для підтримки критичних до затримки та високопродуктивних робочих навантажень Kubernetes пропонує набір менеджерів ресурсів. Менеджери прагнуть координувати та оптимізувати вирівнювання ресурсів вузла для Podʼів, налаштованих з конкретною вимогою до ресурсів процесорів, пристроїв та памʼяті (величезних сторінок).
Політики вирівнювання топології апаратного забезпечення
Topology Manager — це компонент kubelet, який прагне координувати набір компонентів, відповідальних за ці оптимізації. Загальний процес управління ресурсами регулюється за допомогою політики, яку ви вказуєте. Щоб дізнатися більше, прочитайте Контроль політик управління топологією на вузлі.
Політики призначення CPU для Podʼів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.26 [stable] (стандартно увімкнено: true)Після привʼязки Podʼа до вузла, kubelet на цьому вузлі може або мультиплексувати наявне апаратне забезпечення (наприклад, розподіляти процесори між кількома Podʼами), або виділяти апаратне забезпечення, присвячуючи деякі ресурси (наприклад, призначаючи один або більше процесорів для виключного використання Pod).
Стандартно kubelet використовує CFS квоту для забезпечення обмежень на використання процесорів Podʼом. Коли вузол запускає багато Podʼів, що вимагають процесорних ресурсів, робоче навантаження може переміщатися на різні ядра процесора залежно від того, чи обмежено Pod і які ядра процесора доступні на момент планування. Багато робочих навантажень не чутливі до цієї міграції й тому працюють нормально без будь-якого втручання.
Однак у робочих навантаженнях, де спорідненість кешу процесора та затримка планування значно впливають на продуктивність, kubelet дозволяє використовувати альтернативні політики управління процесорами для визначення деяких переваг розміщення на вузлі. Це реалізовано за допомогою CPU Manager та його політики. Є дві доступні політики:
none: політикаnoneявно включає стандартну наявну схему спорідненості процесорів, не надаючи додаткової спорідненості, крім того, що автоматично робить планувальник ОС. Обмеження на використання процесорів для Гарантованих Podʼів та Podʼів Burstable забезпечуються за допомогою CFS квоти.static: політикаstaticдозволяє контейнерам уГарантованихPodʼах з цілими числамиrequestsдоступ до ексклюзивних процесорів на вузлі. Ця ексклюзивність забезпечується за допомогою контролера cpuset cgroup.
Примітка:
Системні служби, такі як середовище виконання контейнерів та сам kubelet, можуть продовжувати працювати на цих ексклюзивних процесорах. Ексклюзивність поширюється лише на інші Pod.CPU Manager не підтримує відключення та включення процесорів під час виконання.
Статична політика
Статична політика дозволяє більш детальне управління процесорами та ексклюзивне призначення процесорів. Ця політика керує спільним пулом процесорів, який спочатку містить усі процесори на вузлі. Кількість ексклюзивно виділених процесорів дорівнює загальній кількості процесорів на вузлі мінус будь-які резерви процесорів, встановлені конфігурацією kubelet. Процесори, зарезервовані цими параметрами, беруться, у цілому числі, з початкового спільного пулу у висхідному порядку за фізичним ідентифікатором ядра. Цей спільний пул є набором процесорів, на яких працюють будь-які контейнери у BestEffort та Burstable Pod. Контейнери у Гарантованих Podʼах з дробовими requests також працюють на процесорах у спільному пулі. Лише контейнери, які є частиною Гарантованого Podʼа і мають цілі числа requests процесорів, призначаються
ексклюзивні процесори.
Примітка:
Kubelet вимагає резервування процесорів більше нуля, коли увімкнена статична політика. Це тому, що нульове резервування процесорів дозволило б спільному пулу стати порожнім.Коли Гарантовані Podʼи, контейнери яких відповідають вимогам для статичного призначення, плануються на вузол, процесори видаляються зі спільного пулу та розміщуються у cpuset для контейнера. CFS квота не використовується для обмеження використання процесорів цими контейнерами, оскільки їх використання обмежується самим доменом планування. Іншими словами, кількість процесорів у cpuset контейнера дорівнює цілому числу limit процесорів, зазначеному у специфікації Pod. Це статичне призначення збільшує спорідненість процесорів та зменшує кількість перемикань контексту через обмеження для робочого навантаження, що вимагає процесорних ресурсів.
Розглянемо контейнери у наступних специфікаціях Pod:
spec:
containers:
- name: nginx
image: nginx
Pod вище працює у класі QoS BestEffort, оскільки не вказано жодних requests або limits ресурсів. Він працює у спільному пулі.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
Pod вище працює у класі QoS Burstable, оскільки requests ресурсів не дорівнюють limits і кількість cpu не вказана. Він працює у спільному пулі.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
requests:
memory: "100Mi"
cpu: "1"
Pod вище працює у класі QoS Burstable, оскільки requests ресурсів не дорівнюють limits. Він працює у спільному пулі.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
requests:
memory: "200Mi"
cpu: "2"
Pod вище працює у класі QoS Гарантований, оскільки requests дорівнюють limits. І обмеження ресурсу контейнера для процесора є цілим числом, більшим або дорівнює одному. Контейнер nginx отримує 2 ексклюзивні процесори.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "1.5"
requests:
memory: "200Mi"
cpu: "1.5"
Pod вище працює у класі QoS Гарантований, оскільки requests дорівнюють limits. Але обмеження ресурсу контейнера для процесора є дробовим числом. Він працює у спільному пулі.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
Pod вище працює у класі QoS Гарантований, оскільки вказані лише limits і requests встановлюються рівними limits, коли не вказані явно. І обмеження ресурсу контейнера для процесора є цілим числом, більшим або дорівнює одному. Контейнер nginx отримує 2 ексклюзивні процесори.
Опції статичної політики
Поведінку статичної політики можна налаштувати за допомогою опцій політики CPU Manager. Наступні опції політики існують для статичної політики управління процесорами: {{/* опції в алфавітному порядку */}}
align-by-socket(alpha, стандартно приховано)- Вирівнювання процесорів за фізичним пакетом / межами сокета, а не за логічними межами NUMA (доступно з Kubernetes v1.25)
distribute-cpus-across-cores(alpha, стандартно приховано) - Розподіл віртуальних ядер, іноді званих апаратними потоками, між різними фізичними ядрами (доступно з Kubernetes v1.31)
distribute-cpus-across-numa(alpha, стандартно приховано) - Розподіл процесорів між різними доменами NUMA, прагнучи до рівномірного балансу між вибраними доменами (доступно з Kubernetes v1.23)
full-pcpus-only(beta, стандартно видно) - Завжди виділяти повні фізичні ядра (доступно з Kubernetes v1.22)
strict-cpu-reservation(alpha, стандартно приховано) - Запобігання всім Pod, незалежно від їх класу якості обслуговування, працювати на зарезервованих процесорах (доступно з Kubernetes v1.32)
prefer-align-cpus-by-uncorecache(alpha, стандартно приховано) - Вирівнювання процесорів за межами кешу uncore (останнього рівня) на основі найкращих зусиль (доступно з Kubernetes v1.32)
Ви можете вмикати та вимикати групи опцій на основі їх рівня зрілості за допомогою наступних воріт функцій:
CPUManagerPolicyBetaOptions(стандартно увімкнено). Вимкніть, щоб приховати опції рівня бета.CPUManagerPolicyAlphaOptions(стандартно вимкнено). Увімкніть, щоб показати опції рівня альфа. Ви все одно повинні увімкнути кожну опцію за допомогою поляcpuManagerPolicyOptionsу файлі конфігурації kubelet.
Для отримання більш детальної інформації про окремі опції, які ви можете налаштувати, читайте далі.
full-pcpus-only
Якщо вказано опцію політики full-pcpus-only, статична політика завжди виділятиме повні фізичні ядра. Стандартно, без цієї опції, статична політика виділяє процесори, використовуючи топологічно обізнане найкраще підходяще розміщення. На системах з увімкненим SMT політика може виділяти окремі віртуальні ядра, які відповідають апаратним потокам. Це може призвести до того, що різні контейнери будуть ділити одні й ті ж фізичні ядра; ця поведінка, своєю чергою, сприяє проблемі шумних сусідів. З увімкненою опцією kubelet прийме Pod лише якщо запит на процесори всіх його контейнерів може бути виконаний шляхом виділення повних фізичних ядер. Якщо Pod не пройде допуску, він буде переведений у стан Failed з повідомленням SMTAlignmentError.
distribute-cpus-across-numa
Якщо вказано опцію політики distribute-cpus-across-numa, статична політика рівномірно розподілятиме процесори між вузлами NUMA у випадках, коли більше ніж один вузол NUMA потрібен для задоволення виділення. Стандартно, CPUManager буде пакувати процесори на один вузол NUMA, поки він не буде заповнений, з будь-якими залишковими процесорами, що просто переходять на наступний вузол NUMA. Це може спричинити небажані вузькі місця у паралельному коді, що покладається на барʼєри (та подібні примітиви синхронізації), оскільки цей тип коду зазвичай працює лише так швидко, як його найповільніший робітник (який сповільнюється через те, що на принаймні одному вузлі NUMA доступно менше процесорів). Розподіляючи процесори рівномірно між вузлами NUMA, розробники застосунків можуть легше забезпечити, що жоден робітник не страждає від ефектів NUMA більше, ніж будь-який інший, покращуючи загальну продуктивність таких типів застосунків.
align-by-socket
Якщо вказано опцію політики align-by-socket, процесори будуть вважатися вирівняними на межі сокета при вирішенні, як виділяти процесори для контейнера. Стандартно, CPUManager вирівнює виділення процесорів на межі NUMA, що може призвести до зниження продуктивності, якщо процесори потрібно буде взяти з більш ніж одного вузла NUMA для задоволення виділення. Хоча він намагається забезпечити, щоб усі процесори були виділені з мінімальної кількості вузлів NUMA, немає гарантії, що ці вузли NUMA будуть на одному сокеті. Спрямовуючи CPUManager явно вирівнювати процесори на межі сокета замість межі NUMA, ми можемо уникнути таких проблем. Зверніть увагу, що ця опція політики не сумісна з політикою TopologyManager single-numa-node і не застосовується до апаратного забезпечення, де кількість сокетів більша ніж кількість вузлів NUMA.
distribute-cpus-across-cores
Якщо вказано опцію політики distribute-cpus-across-cores, статична політика спробує виділити віртуальні ядра (апаратні потоки) між різними фізичними ядрами. Стандартно, CPUManager має тенденцію пакувати процесори на якомога меншу кількість фізичних ядер, що може призвести до конфліктів між процесорами на одному фізичному ядрі та спричинити вузькі місця продуктивності. Увімкнувши опцію політики distribute-cpus-across-cores, статична політика забезпечує, що процесори розподіляються між якомога більшою кількістю фізичних ядер, зменшуючи конфлікти на одному фізичному ядрі та тим самим покращуючи загальну продуктивність. Однак важливо зазначити, що ця стратегія може бути менш ефективною, коли система сильно завантажена. За таких умов користь від зменшення конфліктів зменшується. Навпаки, стандартна поведінка може допомогти зменшити накладні витрати на міжядерну комунікацію, потенційно забезпечуючи кращу продуктивність за умов високого навантаження.
strict-cpu-reservation
Параметр reservedSystemCPUs у KubeletConfiguration, або застарілий параметр командного рядка kubelet --reserved-cpus, визначає явний набір процесорів для системних демонів ОС та системних демонів kubernetes. Більш детальну інформацію про цей параметр можна знайти на сторінці Явно зарезервований список процесорів. Стандартно ця ізоляція реалізована лише для гарантованих podʼів з цілочисельними запитами на процесор, але не для podʼів burstable та best-effort (а також гарантованих podʼів з дробовими запитами на процесор). Допуск полягає лише у порівнянні запитів на процесор з виділеним процесором. Оскільки ліміт процесорів вищий за кількість запитів, стандартна поведінка дозволяє podʼам burstable та best-effort використати весь потенціал зарезервованих системних процесорів reservedSystemCPUs, що призводить до «голодування» служб ОС у реальних умовах розгортання. Якщо увімкнено параметр політики strict-cpu-reservation, статична політика не дозволить будь-якому робочому навантаженню використовувати ядра процесора, вказані у reservedSystemCPUs.
prefer-align-cpus-by-uncorecache
Якщо вказано політику prefer-align-cpus-by-uncorecache, статична політика розподілятиме ресурси процесора для окремих контейнерів таким чином, щоб усі процесори, призначені для контейнера, використовували один і той самий блок кешу ядра (також відомий як кеш останнього рівня або LLC). Стандартно CPUManager щільно пакує призначення CPU, що може призвести до того, що контейнерам буде призначено процесори з декількох кешів основного ядра. Цей параметр дозволяє CPUManager розподіляти процесори таким чином, щоб максимально ефективно використовувати кеш-памʼять ядра. Розподіл виконується за принципом best-effort, з метою привʼязки якомога більшої кількості процесорів до одного і того ж кешу. Якщо потреба контейнера у процесорах перевищує потужність одного кешу, CPUManager мінімізує кількість використовуваних кешів, щоб підтримувати оптимальне вирівнювання кешів. Конкретні робочі навантаження можуть виграти у продуктивності завдяки зменшенню міжкешових затримок та шумних сусідів на рівні кешу. Якщо CPUManager не може вирівняти оптимально, хоча вузол має достатньо ресурсів, контейнер все одно буде прийнято з використанням стандартної поведінки пакування.
Політики керування памʼяттю
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [stable] (стандартно увімкнено: true)Менеджер памʼяті Kubernetes Memory Manager уможливлює функцію гарантованого виділення памʼяті (та hugepages) для podʼів у класі Guaranteed QoS class.
Диспетчер памʼяті використовує протокол генерації підказок, щоб отримати найбільш відповідну спорідненість NUMA для кожного з podʼів. Менеджер памʼяті передає ці підказки центральному менеджеру (Topology Manager). На основі підказок і політики менеджера топології, pod відхиляється або приймається до вузла.
Крім того, менеджер пам'яті гарантує, що пам'ять, яку запитує вузол виділяється з мінімальної кількості вузлів NUMA.
Інші менеджери ресурсів
Налаштування окремих менеджерів описано у окремих документах:
10 - Планування, Випередження та Виселення
У Kubernetes планування означає забезпечення відповідності Podʼів вузлам (Nodes), щоб kubelet міг їх запустити. Випередження — це процес припинення роботи Podʼів з низьким пріоритетом, щоб Podʼи з вищим пріоритетом могли розміщуватися на вузлах. Виселення — це процес проактивного припинення роботи одного або кількох Podʼів на вузлах.
Планування
- Планувальник Kubernetes
- Призначення Podʼів вузлам
- Витрати ресурсів на Pod
- Обмеження поширення топології Podʼів
- Заплямованість та Толерантність
- Фреймворк планування
- Динамічне виділення ресурсів
- Налаштування продуктивності планувальника
- Пакування ресурсів для розширених ресурсів
- Готовність планування Pod
- Descheduler
Переривання роботи Podʼа
Розлад в роботі Podʼа — це процес, за якого Podʼи на вузлах припиняють роботу добровільно, або примусово.
Добровільні розлади запускаються навмисно власниками застосунків або адміністраторами кластера. Примусові розлади є ненавмисними та можуть бути спричинені невідворотними проблемами, такими як вичерпання ресурсів вузлів, або випадковими видаленнями.
10.1 - Планувальник Kubernetes
У Kubernetes планування означає забезпечення того, що Podʼи відповідно призначаються вузлам, щоб їх можна було запустити за допомогою Kubelet.
Огляд планування
Планувальник відстежує новостворені Podʼи, які не мають призначеного Вузла. Планувальник відповідає за знаходження найкращого Вузла для кожного виявленого Podʼа, на якому можна запустити цей Pod. Планувальник приймає рішення про розташування Podʼа, враховуючи принципи планування, описані нижче.
Якщо ви хочете зрозуміти, чому Podʼи розміщуються на певному Вузлі, або якщо ви плануєте реалізувати власний планувальник, ця сторінка допоможе вам дізнатися більше про планування.
kube-scheduler
kube-scheduler є стандартним планувальником для Kubernetes і працює як частина панелі управління. kube-scheduler розроблено так, що, якщо ви хочете і вам треба, ви можете написати власний компонент планування і використовувати його замість стандартного.
Kube-scheduler вибирає оптимальний вузол для запуску нових або ще не запланованих Podʼів. Оскільки контейнери в Podʼах, і самі Podʼи, можуть мати різні вимоги, планувальник фільтрує будь-які вузли, які не відповідають конкретним потребам планування Podʼа. Зазвичай через API можна вказати вузол для Podʼа при його створенні, але це робиться тільки у виняткових випадках.
У кластері Вузли, які відповідають вимогам планування для Podʼа, називаються feasible (придатними) вузлами. Якщо жоден з вузлів не підходить, Pod залишається незапланованим до тих пір, поки планувальник не зможе розмістити його.
Планувальник знаходить придатні Вузли для Podʼів, а потім виконує набір функцій для оцінки таких Вузлів і вибирає Вузол з найвищим рейтингом серед придатних для запуску Podʼа. Планувальник потім повідомляє сервер API про це рішення в процесі, який називається binding (привʼязкою).
Фактори, які потрібно враховувати при прийнятті рішень про планування, включають індивідуальні та загальні вимоги до ресурсів, обмеження апаратного та програмного забезпечення / політики, (анти)спорідненість (affinity), розташування даних, взаємовплив між робочими навантаженнями та інше.
Вибір вузла в kube-scheduler
kube-scheduler вибирає вузол для Podʼа в два етапи:
- Фільтрація.
- Оцінювання.
На етапі фільтрації визначається набір Вузлів, на яких можна розмістити Pod. Наприклад, фільтр PodFitsResources перевіряє, чи має Вузол-кандидат достатньо доступних ресурсів, щоб задовольнити конкретні вимоги до ресурсів Podʼа. Після цього етапу список вузлів містить придатні вузли; часто їх буде більше одного. Якщо список порожній, цей Pod не є (поки що) можливим для планування.
На етапі оцінювання планувальник ранжує вузли, що були обрані, щоб вибрати найбільш придатне розміщення для Podʼа. Планувальник надає кожному вузлу, який залишився після фільтрації, оцінку, базуючись на активних правилах оцінки.
На останньому етапі kube-scheduler призначає Pod вузлу з найвищим рейтингом. Якщо є більше одного вузла з однаковими рейтингами, kube-scheduler вибирає один з них випадковим чином.
Є два підтримуваних способи налаштування поведінки фільтрації та оцінювання планувальника:
- Політики планування дозволяють налаштувати Предикати для фільтрації та Пріоритети для оцінювання.
- Профілі планування дозволяють налаштувати Втулки, які реалізують різні етапи планування, включаючи:
QueueSort,Filter,Score,Bind,Reserve,Permitта інші. Ви також можете налаштувати kube-scheduler для запуску різних профілів.
Що далі
- Дізнайтеся про налаштування продуктивності планувальника
- Дізнайтеся про обмеження розподілу топології Podʼа
- Прочитайте довідку для kube-scheduler
- Прочитайте посилання на конфігурацію kube-scheduler (v1)
- Дізнайтеся про налаштування кількох планувальників
- Дізнайтеся про політики управління топологією
- Дізнайтеся про накладні витрати Podʼа
- Дізнайтеся про планування Podʼів, які використовують томи в:
10.2 - Призначення Podʼів до Вузлів
Ви можете обмежити Pod так, щоб він був обмежений для запуску на конкретних вузлах, або віддавав перевагу запуску на певних вузлах. Існують кілька способів як це зробити, а рекомендовані підходи використовують усі селектори міток для полегшення вибору. Зазвичай вам не потрібно встановлювати жодні обмеження такого роду; планувальник автоматично робить розумне розміщення (наприклад, розподіл Podʼів по вузлах так, щоб не розміщувати Podʼи на вузлі з недостатньою кількістю вільних ресурсів). Однак є деякі обставини, коли ви можете контролювати, на якому вузлі розгортається Pod, наприклад, щоб переконатися, що Pod потрапляє на вузол з прикріпленим до нього SSD, або спільно розміщувати Podʼи з двох різних служб, які багато спілкуються в одній зоні доступності.
Ви можете використовувати будь-який з наступних методів для вибору місця, де Kubernetes планує конкретні Podʼи:
- Поле nodeSelector, яке відповідає міткам вузлів
- Спорідненість та антиспорідненість
- Поле nodeName
- Обмеження розподілу топології Podʼа
Мітки вузлів
Як і багато інших обʼєктів Kubernetes, вузли мають мітки. Ви можете додавати мітки вручну. Kubernetes також заповнює стандартний набір міток на всіх вузлах кластера.
Примітка:
Значення цих міток специфічне для хмарного середовища і не може бути надійним. Наприклад, значенняkubernetes.io/hostname може бути таким самим, як імʼя вузла у деяких середовищах, і різним в інших середовищах.Ізоляція/обмеження вузлів
Додавання міток до вузлів дозволяє вам позначати Podʼи для розміщення на конкретних вузлах або групах вузлів. Ви можете використовувати цю функціональність, щоб забезпечити, що певні Podʼи працюватимуть тільки на вузлах із певною ізоляцією, безпекою або регуляторними властивостями.
Якщо ви використовуєте мітки для ізоляції вузлів, обирайте ключі міток, які kubelet не може змінювати. Це заважає скомпрометованому вузлу встановлювати ці мітки на себе, щоб планувальник планував навантаження на скомпрометований вузол.
Втулок допуску NodeRestriction перешкоджає kubelet встановлювати або змінювати мітки з префіксом node-restriction.kubernetes.io/.
Щоб скористатися цим префіксом міток для ізоляції вузлів:
- Переконайтеся, що ви використовуєте авторизатор вузлів і ввімкнули втулок допуску
NodeRestriction. - Додайте мітки з префіксом
node-restriction.kubernetes.io/на ваші вузли, і використовуйте ці мітки у ваших селекторах вузлів. Наприклад,example.com.node-restriction.kubernetes.io/fips=trueабоexample.com.node-restriction.kubernetes.io/pci-dss=true.
Вибір вузла з використанням nodeSelector
nodeSelector є найпростішим рекомендованим способом обмеження вибору вузла. Ви можете додати поле nodeSelector до специфікації вашого Podʼа і вказати мітки вузла, які має мати цільовий вузол. Kubernetes розміщує Pod лише на тих вузлах, які мають всі мітки, які ви вказали.
Дивіться Призначення Podʼів на вузли для отримання додаткової інформації.
Спорідненість та антиспорідненість
nodeSelector є найпростішим способом обмежити Podʼи вузлами з певними мітками. Спорідненість та антиспорідненість розширюють типи обмежень, які ви можете визначити. Деякі з переваг спорідненості та антиспорідненості включають:
- Мова (анти)спорідненості є більш виразною.
nodeSelectorвибирає лише вузли з усіма вказаними мітками. (Анти)спорідненіcть дає вам більший контроль над логікою вибору. - Ви можете вказати, що правило є soft або preferred, таким чином, планувальник все ще розміщує Pod навіть якщо не може знайти відповідного вузла.
- Ви можете обмежити Pod, використовуючи мітки на інших Podʼах, які працюють на вузлі (або іншій топологічній області), а не лише мітки вузла, що дозволяє визначати правила для того, які Podʼи можуть бути розташовані на одному вузлі.
Функція affinity складається з двох типів значень:
- Спорідненість вузла працює подібно до поля
nodeSelector, але є більш виразним і дозволяє вказувати мʼякі правила. - Між-Podʼова (анти)спорідненість дозволяє обмежувати Podʼи проти міток інших Podʼів.
Спорідненість вузла
Спорідненість вузла концептуально подібне до nodeSelector і дозволяє вам обмежувати, на яких вузлах може бути запланований ваш Pod на основі міток вузла. Існують два типи спорідненості вузла:
requiredDuringSchedulingIgnoredDuringExecution: Планувальник не може запланувати Pod, якщо правило не виконується. Це працює подібно доnodeSelector, але з більш виразним синтаксисом.preferredDuringSchedulingIgnoredDuringExecution: Планувальник намагається знайти вузол, який відповідає правилу. Якщо відповідний вузол недоступний, планувальник все одно планує Pod.
Примітка:
У попередніх типахIgnoredDuringExecution означає, що якщо мітки вузла змінюються після того, як Kubernetes запланував Pod, Pod продовжує працювати.Ви можете вказати спорідненість вузла, використовуючи поле .spec.affinity.nodeAffinity в специфікації вашого Podʼа.
Наприклад, розгляньте наступну специфікацію Podʼа:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:3.8
У цьому прикладі застосовуються наступні правила:
- Вузол повинен мати мітку з ключем
topology.kubernetes.io/zone, а значення цієї мітки повинно бути абоantarctica-east1, абоantarctica-west1. - Вузол переважно має мати мітку з ключем
another-node-label-key, а значенняanother-node-label-value.
Ви можете використовувати поле operator, щоб вказати логічний оператор, який Kubernetes буде використовувати при інтерпретації правил. Ви можете використовувати In, NotIn, Exists, DoesNotExist, Gt і Lt.
Прочитайте розділ Оператори, щоб дізнатися більше про те, як вони працюють.
NotIn та DoesNotExist дозволяють визначати поведінку антиспорідненості. Альтернативно, ви можете використовувати node taints для відштовхування Podʼів від конкретних вузлів.
Примітка:
Якщо ви вказуєте як nodeSelector, так і nodeAffinity, обидва вони повинні задовольнятися для того, щоб Pod був запланований на вузол.
Якщо ви вказуєте кілька умов в nodeSelectorTerms, повʼязаних з типами nodeAffinity, то Pod може бути запланований на вузол, якщо одна з вказаних умов може бути задоволеною (умови зʼєднуються логічним OR).
Якщо ви вказуєте кілька виразів в одному полі matchExpressions, повʼязаному з умовою в nodeSelectorTerms, то Pod може бути запланований на вузол лише в тому випадку, якщо всі вирази задовольняються (вирази зʼєднуються логічним AND).
Дивіться Призначення Podʼів вузлам з використанням Node Affinity для отримання додаткової інформації.
Вага спорідненості вузла
Ви можете вказати weight (вагу) від 1 до 100 для кожного випадку спорідненості типу preferredDuringSchedulingIgnoredDuringExecution. Коли планувальник знаходить вузли, які відповідають усім іншим вимогам планування Podʼа, планувальник проходить по кожному правилу preferred, якому задовольняє вузол, і додає значення weight для цього виразу до суми.
Кінцева сума додається до загального балу інших функцій пріоритету для вузла. Вузли з найвищим загальним балом пріоритету отримують пріоритет у виборі планувальника при прийнятті рішення щодо планування Podʼа.
Наприклад, розгляньте наступну специфікацію Podʼа:
apiVersion: v1
kind: Pod
metadata:
name: with-affinity-preferred-weight
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: label-1
operator: In
values:
- key-1
- weight: 50
preference:
matchExpressions:
- key: label-2
operator: In
values:
- key-2
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:3.8
Якщо існують два можливих вузли, які відповідають правилу preferredDuringSchedulingIgnoredDuringExecution, один з міткою label-1:key-1, а інший з міткою label-2:key-2, планувальник бере до уваги weight кожного вузла і додає вагу до інших балів для цього вузла, і планує Pod на вузол з найвищим кінцевим балом.
Примітка:
Якщо ви хочете, щоб Kubernetes успішно запланував Podʼи в цьому прикладі, вам потрібно мати наявні вузли з міткоюkubernetes.io/os=linux.Спорідненість вузла для кожного профілю планування
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.20 [beta]При налаштуванні кількох профілів планування ви можете повʼязати профіль зі спорідненістю вузла, що є корисним, якщо профіль застосовується лише до певного набору вузлів. Для цього додайте addedAffinity до поля args втулка NodeAffinity у конфігурації планувальника. Наприклад:
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
- schedulerName: foo-scheduler
pluginConfig:
- name: NodeAffinity
args:
addedAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: scheduler-profile
operator: In
values:
- foo
addedAffinity застосовується до всіх Podʼів, які встановлюють .spec.schedulerName в foo-scheduler, на додачу до NodeAffinity, вказаного в PodSpec. Тобто для збігу вузла з Podʼом потрібно задовольнити збіг між addedAffinity та .spec.NodeAffinity Podʼа.
Оскільки addedAffinity не є видимим для кінцевих користувачів, його поведінка може бути неочікуваною для них. Використовуйте мітки вузлів, які мають чіткий взаємозвʼязок з іменем профілю планування.
Примітка:
Контролер DaemonSet, який створює Podʼи для DaemonSet, не підтримує профілі планування. Коли контролер DaemonSet створює Podʼи, стандартний планувальник Kubernetes розміщує ці Podʼи та дотримується будь-яких правилnodeAffinity в контролері DaemonSet.Між-Podʼова спорідненість та антиспорідненість
Між-Podʼова спорідненість та антиспорідненість дозволяють обмежити, на яких вузлах ваші Podʼи можуть бути заплановані на основі міток Podʼів, які вже працюють на цьому вузлі, а не міток вузлів.
Правила між-Podʼової спорідненості та антиспорідненості мають наступний вигляд: "цей Pod повинен (або, у випадку антиспорідненості, не повинен) працювати у X, якщо на цьому X вже працюють один або декілька Podʼів, які задовольняють правилу Y", де X є областю топології, такою як вузол, стійка, зона або регіон постачальника хмарних послуг, або щос подібне, а Y — це правило, яке Kubernetes намагається задовольнити.
Ви виражаєте ці правила (Y) як селектори міток з опційним повʼязаним списком просторів імен. Podʼи є обʼєктами з простором імен в Kubernetes, тому мітки Podʼів також неявно мають простори імен. Будь-які селектори міток для міток Podʼа повинні вказувати простори імен, в яких Kubernetes має переглядати ці мітки.
Ви виражаєте область топології (X), використовуючи topologyKey, який є ключем для мітки вузла, яку система використовує для позначення домену. Для прикладу дивіться у Відомі мітки, анотації та позначення.
Примітка:
Між-Podʼові спорідненість та антиспорідненість потребують значних обсягів обчислень, що може значно сповільнити планування великих кластерів. Ми не рекомендуємо їх використовувати в кластерах розміром більше декількох сотень вузлів.Примітка:
Антиспорідненість Podʼа вимагає, щоб вузли систематично позначались, іншими словами, кожен вузол в кластері повинен мати відповідну мітку, яка відповідаєtopologyKey. Якщо деякі або всі вузли не мають вказаної мітки topologyKey, це може призвести до непередбачуваної поведінки.Типи між-Podʼової спорідненості та антиспорідненості
Подібно до Node affinnity, існують два типи спорідненості та антиспорідненості Podʼа:
requiredDuringSchedulingIgnoredDuringExecutionpreferredDuringSchedulingIgnoredDuringExecution
Наприклад, ви можете використовувати спорідненість requiredDuringSchedulingIgnoredDuringExecution,
щоб повідомити планувальник про те, що потрібно розташувати Podʼи двох служб в тій самій зоні постачальника хмарних послуг, оскільки вони взаємодіють між собою дуже часто. Так само ви можете використовувати антиспорідненість
preferredDuringSchedulingIgnoredDuringExecution, щоб розподілити Podʼи служби по різних зонах постачальника хмарних послуг.
Для використання між-Podʼової спорідненості використовуйте поле affinity.podAffinity в специфікації Podʼа. Для між-Podʼової антиспорідненості використовуйте поле affinity. podAntiAffinity в специфікації Podʼа.
Планування групи Podʼів з між-Podʼовою спорідненістю
Якщо поточний Pod, який планується, є першим у серії, який має спорідненість один до одного, його можна планувати, якщо він проходить всі інші перевірки спорідненості. Це визначається тим, що не існує іншого Podʼа в кластері, який відповідає простору імен та селектору цього Podʼа, що Pod відповідає власним умовам і обраний вузол відповідає всім запитаним топологіям. Це забезпечує відсутність блокування навіть у випадку, якщо всі Podʼи мають вказану між-Podʼову спорідненість.
Приклад спорідненості Podʼа
Розгляньте наступну специфікацію Podʼа:
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: registry.k8s.io/pause:3.8
У цьому прикладі визначено одне правило спорідненості Podʼа та одне правило антиспорідненості Podʼа. Правило спорідненості Podʼа використовує "hard" requiredDuringSchedulingIgnoredDuringExecution, тоді як правило антиспорідненості використовує "soft" preferredDuringSchedulingIgnoredDuringExecution.
Правило спорідненості вказує, що планувальник може розмістити Pod лише на вузлі, який належить до певної зони, де інші Podʼи мають мітку security=S1. Наприклад, якщо у нас є кластер із призначеною зоною, скажімо, "Zone V", що складається з вузлів з міткою topology.kubernetes.io/zone=V, планувальник може призначити Pod на будь-який вузол у Zone V, якщо принаймні один Pod у Zone V вже має мітку security=S1. Зворотно, якщо в Zone V немає Podʼів з мітками security=S1, планувальник не призначить Pod з прикладц ні на один вузол в цій зоні.
Правило антиспорідненості вказує, що планувальник повинен уникати призначення Podʼа на вузол, якщо цей вузол належить до певної зони, де інші Podʼи мають мітку security=S2. Наприклад, якщо у нас є кластер із призначеною зоною, скажімо, "Zone R", що складається з вузлів з міткою topology.kubernetes.io/zone=R, планувальник повинен уникати призначення Podʼа на будь-який вузол у Zone R, якщо принаймні один Pod у Zone R вже має мітку security=S2. Зворотно, правило антиспорідненості не впливає на планування у Zone R, якщо немає Podʼів з мітками security=S2.
Щоб ближче ознайомитися з прикладами спорідненості та антиспорідненості Podʼів, зверніться до проєктної документації.
В полі operator для спорідненості та антиспорідненості Podʼа можна використовувати значення In, NotIn, Exists та DoesNotExist.
Для отримання додаткової інформації про те, як це працює, перегляньте Оператори.
У принципі, topologyKey може бути будь-яким допустимим ключем мітки з такими винятками з причин продуктивності та безпеки:
- Для спорідненості та антиспорідненості Podʼа пусте поле
topologyKeyне дозволяється як дляrequiredDuringSchedulingIgnoredDuringExecution, так і дляpreferredDuringSchedulingIgnoredDuringExecution. - Для правил антиспорідненості Podʼа
requiredDuringSchedulingIgnoredDuringExecutionконтролер допускуLimitPodHardAntiAffinityTopologyобмежуєtopologyKeyдоkubernetes.io/hostname. Ви можете змінити або вимкнути контролер допуску, якщо хочете дозволити власні топології.
Крім labelSelector та topologyKey, ви можете опціонально вказати список просторів імен, з якими labelSelector повинен зіставлятися, використовуючи поле namespaces на тому ж рівні, що й labelSelector та topologyKey. Якщо відсутнє або порожнє, namespaces типово відноситься до простору імен Podʼа, де зʼявляється визначення спорідненості/антиспорідненості.
Селектор простору імен
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]Ви також можете вибирати відповідні простори імен за допомогою namespaceSelector, який є запитом міток до набору просторів імен. Умова спорідненості застосовується до просторів імен, вибраних як namespaceSelector, так і полем namespaces. Зверніть увагу, що порожній namespaceSelector ({}) відповідає всім просторам імен, тоді як нульовий або порожній список namespaces і нульовий namespaceSelector відповідає простору імен Podʼа, де визначена правило.
matchLabelKeys
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [beta] (стандартно увімкнено: true)Примітка:
Поле matchLabelKeys знаходиться на рівні бета-версії та є стандартно увімкненим в Kubernetes 1.32. Якщо ви бажаєте його вимкнути, вам потрібно зробити це явним чином за допомогою вимкнення функціональної можливості MatchLabelKeysInPodAffinity.
У Kubernetes є опціональне поле matchLabelKeys для спорідненості або антиспорідненості Podʼа. Це поле вказує ключі для міток, які повинні відповідати міткам вхідного Podʼа під час задоволення спорідненості (антиспорідненості) Podʼа.
Ці ключі використовуються для отримання значень з міток Podʼа; ці ключ-значення міток поєднуються (використовуючи AND) з обмеженнями відповідно до поля labelSelector. Обʼєднане фільтрування вибирає набір наявниї Podʼів, які будуть враховуватися при розрахунку спорідненості (антиспорідненості) Podʼа.
Частим використанням є використання matchLabelKeys разом із pod-template-hash (встановленим у Podʼах, керованих як частина Deployment, де значення унікальне для кожного покоління). Використання pod-template-hash в matchLabelKeys дозволяє вам спрямовувати Podʼи, які належать тому ж поколінню, що й вхідний Pod, так щоб поступове оновлення не руйнувало споріденість.
apiVersion: apps/v1
kind: Deployment
metadata:
name: application-server
...
spec:
template:
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- database
topologyKey: topology.kubernetes.io/zone
# Тільки Podʼи з певного розгортання беруться до уваги при обчисленні спорідненості Podʼа.
# Якщо ви оновите Deployment, підмінні Podʼи дотримуватимуться своїх власних правил спорідненості
# (якщо вони визначені в новому шаблоні Podʼа).
matchLabelKeys:
- pod-template-hash
mismatchLabelKeys
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [beta] (стандартно увімкнено: true)Примітка:
Поле mismatchLabelKeys знаходиться на рівні бета-версії та є стандартно увімкненим в Kubernetes 1.32. Якщо ви бажаєте його вимкнути, вам потрібно зробити це явним чином за допомогою вимкнення функціональної можливості MatchLabelKeysInPodAffinity.
Kubernetes включає додаткове поле mismatchLabelKeys для спорідненості або антиспорідненості Podʼа. Це поле вказує ключі для міток, які не повинні мати збігу з мітками вхідного Podʼа, при задоволенні спорідненості чи антиспорідненості Podʼа.
Один з прикладів використання — це забезпечення того, що Podʼи будуть розміщені в топологічному домені (вузол, зона і т. д.), де розміщені лише Podʼи від того ж орендаря або команди. Іншими словами, ви хочете уникнути запуску Podʼів від двох різних орендарів в одному топологічному домені одночасно.
apiVersion: v1
kind: Pod
metadata:
labels:
# Припустимо, що всі відповідні Podʼи мають встановлену мітку "tenant"
tenant: tenant-a
...
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
# переконаємось, що Podʼи, повʼязані з цим орендарем, потрапляють у відповідний пул вузлів
- matchLabelKeys:
- tenant
topologyKey: node-pool
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
# переконаємось, що Podʼи, повʼязані з цим орендарем, не можуть розміщуватися на вузлах,
# які використовуються для іншого орендаря
- mismatchLabelKeys:
- tenant # незалежно від значення мітки "tenant" для цього Podʼа, заборонити
# розміщення на вузлах у будь-якому пулі, де працює будь-який Pod
# від іншого орендаря.
labelSelector:
# Ми повинні мати labelSelector, який вибирає лише Podʼи з міткою орендатора,
# інакше цей Pod буде ворогувати Podʼам з DaemonSetʼів, наприклад,
# які не повинні мати мітку орендаря.
matchExpressions:
- key: tenant
operator: Exists
topologyKey: node-pool
Ще кілька практичних прикладів
Між-Podʼові спорідненість та антиспорідненість можуть бути навіть більш корисними, коли вони використовуються з колекціями вищого рівня, такими як ReplicaSets, StatefulSets, Deployments і т. д. Ці правила дозволяють налаштувати спільне розташування набору робочих навантажень у визначеній топології; наприклад, віддаючи перевагу розміщенню двох повʼязаних Podʼів на одному вузлі.
Наприклад: уявіть кластер з трьох вузлів. Ви використовуєте кластер для запуску вебзастосунку та також сервіс кешування в памʼяті (наприклад, Redis). Нехай для цього прикладу також буде фіксований максимальний рівень затримки між вебзастосунком та цим кешем, як це практично можливо. Ви можете використовувати між-Podʼові спорідненість та антиспорідненість, щоб спільні вебсервери з кешем, як це можна точніше, розташовувалися поруч.
У наступному прикладі Deployment для кешування Redis, репліки отримують мітку app=store. Правило podAntiAffinity повідомляє планувальникові уникати розміщення декількох реплік з міткою app=store на одному вузлі. Це створює кожен кеш на окремому вузлі.
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine
У наступному прикладі Deployment для вебсерверів створює репліки з міткою app=web-store. Правило спорідненості Podʼа повідомляє планувальнику розмістити кожну репліку на вузлі, де є Pod з міткою app=store. Правило антиспорідненості Podʼа повідомляє планувальнику ніколи не розміщати декілька серверів app=web-store на одному вузлі.
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: web-store
replicas: 3
template:
metadata:
labels:
app: web-store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-store
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: nginx:1.16-alpine
Створення цих двох попередніх Deploymentʼів призводить до наступного структури кластера, де кожен вебсервер знаходиться поруч з кешем, на трьох окремих вузлах.
| вузол-1 | вузол-2 | вузол-3 |
|---|---|---|
| webserver-1 | webserver-2 | webserver-3 |
| cache-1 | cache-2 | cache-3 |
Загальний ефект полягає в тому, що кожен екземпляр кешу ймовірно використовується одним клієнтом, який працює на тому ж самому вузлі. Цей підхід спрямований на мінімізацію як перекосу (нерівномірного навантаження), так і затримки.
У вас можуть бути інші причини використання антиспорідненості Podʼа. Дивіться посібник по ZooKeeper для прикладу StatefulSet, налаштованого з антиспорідненостю для забезпечення високої доступності, використовуючи ту ж саму техніку, що й цей приклад.
nodeName
nodeName є більш прямим способом вибору вузла, ніж спорідненісь або nodeSelector. nodeName — це поле в специфікації Pod. Якщо поле nodeName не порожнє, планувальник ігнорує Pod, і kubelet на названому вузлі намагається розмістити Pod на цьому вузлі. Використання nodeName переважає використання nodeSelector або правил спорідненості та антиспорідненості.
Деякі з обмежень використання nodeName для вибору вузлів:
- Якщо зазначений вузол не існує, Pod не буде запущено, і у деяких випадках його може бути автоматично видалено.
- Якщо зазначений вузол не має достатньо ресурсів для розміщення Podʼа, Pod зазнає збою, про що буде повідомлено, наприклад, OutOfmemory або OutOfcpu.
- Назви вузлів у хмарних середовищах не завжди передбачувані або стабільні.
Попередження:
nodeName призначений для використання власними планувальниками або у більш складних випадках, де вам потрібно обійти будь-які налаштовані планувальники. Обхід планувальників може призвести до збійних Podʼів, якщо призначені вузли переповнені. Ви можете використовувати спорідненісь вузлів або поле nodeSelector, щоб призначити Pod до певного вузла без обходу планувальників.Нижче наведено приклад специфікації Pod з використанням поля nodeName:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: kube-01
Вищевказаний Pod буде запущено лише на вузлі kube-01.
Обмеження розподілу топології Pod
Ви можете використовувати обмеження розподілу топології для керування тим, як Podʼи розподіляються по вашому кластеру серед недоступних доменів, таких як регіони, зони, вузли або будь-які інші топологічні домени, які ви визначаєте. Ви можете це зробити, щоб покращити продуктивність, очікувану доступність або загальне використання.
Докладніше про роботу з обмеженнями розподілу топології Podʼів читайте тут.
Оператори
Наступні логічні оператори можна використовувати в полі operator для nodeAffinity та podAffinity, згаданих вище.
| Оператор | Поведінка |
|---|---|
In | Значення мітки присутнє у заданому наборі рядків |
NotIn | Значення мітки не міститься у заданому наборі рядків |
Exists | Мітка з цим ключем існує на обʼєкті |
DoesNotExist | На обʼєкті не існує мітки з цим ключем |
Наступні оператори можна використовувати лише з nodeAffinity.
| Оператор | Поведінка |
|---|---|
Gt | Значення поля буде розібране як ціле число, і це ціле число менше цілого числа, яке отримується при розборі значення мітки, названої цим селектором |
Lt | Значення поля буде розібране як ціле число, і це ціле число більше цілого числа, яке отримується при розборі значення мітки, названої цим селектором |
Примітка:
ОператориGt та Lt не працюватимуть з нецілими значеннями. Якщо дане значення не вдається розібрати як ціле число, Pod не вдасться запланувати. Крім того, Gt та Lt не доступні для podAffinity.Що далі
- Дізнайтеся більше про taint та toleration.
- Прочитайте документи про спорідненісь вузлів та про між-Podʼову (анти)спорідненість.
- Дізнайтеся, як менеджер топології бере участь у рішеннях з розподілу ресурсів на рівні вузлів.
- Навчиться використовувати nodeselector.
- Навчиться використовувати спорідненісь та антиспорідненісь.
10.3 - Накладні витрати, повʼязані з роботою Podʼів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]Коли ви запускаєте Pod на вузлі, сам Pod потребує певної кількості системних ресурсів. Ці ресурси додаються до ресурсів, необхідних для запуску контейнерів всередині Pod. У Kubernetes Pod Overhead — це спосіб обліку ресурсів, які використовуються інфраструктурою Pod, понад запити та обмеження контейнерів.
У Kubernetes накладні витрати Pod встановлюються під час допуску з урахуванням перевищення, повʼязаного з RuntimeClass Pod.
Накладні витрати Pod вважаються додатковими до суми запитів ресурсів контейнера при плануванні Pod. Так само, kubelet включатиме накладні витрати Pod при визначенні розміру cgroup Podʼа і при виконанні ранжування виселення Podʼа.
Налаштування накладних витрат Pod
Вам потрібно переконатися, що використовується RuntimeClass, який визначає поле overhead.
Приклад використання
Для роботи з накладними витратами Podʼів вам потрібен RuntimeClass, який визначає поле overhead. Наприклад, ви можете використати таке визначення RuntimeClass з контейнерним середовищем віртуалізації (в цьому прикладі використовується Kata Containers поєднане з монітором віртуальної машини Firecracker), яке використовує приблизно 120MiB на Pod для віртуальної машини та гостьової ОС:
# Вам треба внести зміни в цей приклад, щоб назва відповідала вашому контейнерному середовищу
# та ресурси overhead були додани до вашого кластера.
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: kata-fc
handler: kata-fc
overhead:
podFixed:
memory: "120Mi"
cpu: "250m"
Робочі навантаження, які створюються з використанням обробника RuntimeClass з іменем kata-fc, беруть участь в обчисленнях квот ресурсів, плануванні вузла, а також розмірі групи контейнерів Pod для памʼяті та CPU.
Розгляньте виконання поданого прикладу робочого навантаження, test-pod:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
runtimeClassName: kata-fc
containers:
- name: busybox-ctr
image: busybox:1.28
stdin: true
tty: true
resources:
limits:
cpu: 500m
memory: 100Mi
- name: nginx-ctr
image: nginx
resources:
limits:
cpu: 1500m
memory: 100Mi
Примітка:
Якщо в визначенні Podʼа вказані лишеlimits, kubelet виведе requests з цих обмежень і встановить їх такими ж, як і визначені limits.Під час обробки допуску (admission) контролер admission controller RuntimeClass оновлює PodSpec робочого навантаження, щоб включити overhead, що є в RuntimeClass. Якщо PodSpec вже має це поле визначеним, Pod буде відхилено. У поданому прикладі, оскільки вказано лише імʼя RuntimeClass, контролер обробки допуску змінює Pod, щоб включити overhead.
Після того, як контролер обробки допуску RuntimeClass вніс зміни, ви можете перевірити оновлене значення overhead Pod:
kubectl get pod test-pod -o jsonpath='{.spec.overhead}'
Вивід:
map[cpu:250m memory:120Mi]
Якщо визначено ResourceQuota, то обчислюється сума запитів контейнера, а також поля overhead.
Коли kube-scheduler вирішує, на якому вузлі слід запускати новий Pod, він бере до уваги overhead цього Pod, а також суму запитів контейнера для цього Pod. Для цього прикладу планувальник додає запити та overhead, а потім шукає вузол, на якому є 2,25 CPU та 320 MiB вільної памʼяті.
Після того, як Pod запланований на вузол, kubelet на цьому вузлі створює нову cgroup для Pod. Це саме той Pod, в межах якого контейнерне середовище створює контейнери.
Якщо для кожного контейнера визначено ліміт ресурсу (Guaranteed QoS або Burstable QoS з визначеними лімітами), то kubelet встановлює верхній ліміт для групи контейнерів Pod, повʼязаних з цим ресурсом (cpu.cfs_quota_us для CPU та memory.limit_in_bytes для памʼяті). Цей верхній ліміт базується на сумі лімітів контейнера плюс поле overhead, визначене в PodSpec.
Для CPU, якщо Pod має Guaranteed або Burstable QoS, то kubelet встановлює cpu.shares на основі суми запитів контейнера плюс поле overhead, визначене в PodSpec.
Подивіться приклад, перевірте запити контейнера для робочого навантаження:
kubectl get pod test-pod -o jsonpath='{.spec.containers[*].resources.limits}'
Загальні запити контейнера становлять 2000m CPU та 200MiB памʼяті:
map[cpu: 500m memory:100Mi] map[cpu:1500m memory:100Mi]
Перевірте це у порівнянні з тим, що спостерігається вузлом:
kubectl describe node | grep test-pod -B2
Вивід показує запити для 2250m CPU та 320MiB памʼяті. Запити включають перевищення Pod:
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default test-pod 2250m (56%) 2250m (56%) 320Mi (1%) 320Mi (1%) 36m
Перевірка обмежень cgroup для Pod
Перевірте cgroup памʼяті для Pod на вузлі, де запускається робоче навантаження. У наступному прикладі використовується crictl на вузлі, який надає інтерфейс командного рядка для сумісних з CRI контейнерних середовищ. Це передбачається для демонстрації поведінки overhead Podʼа, і не очікується, що користувачі повинні безпосередньо перевіряти cgroups на вузлі.
Спочатку, на конкретному вузлі, визначте ідентифікатор Pod:
# Виконайте це на вузлі, де запущено Pod
POD_ID="$(sudo crictl pods --name test-pod -q)"
З цього можна визначити шлях cgroup для Pod:
# Виконайте це на вузлі, де запущено Pod
sudo crictl inspectp -o=json $POD_ID | grep cgroupsPath
Результати шляху cgroup включають контейнер pause для Pod. Рівень cgroup на рівні Pod знаходиться на один каталог вище.
"cgroupsPath": "/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/7ccf55aee35dd16aca4189c952d83487297f3cd760f1bbf09620e206e7d0c27a"
У цьому конкретному випадку, шлях cgroup для Pod — kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2. Перевірте налаштування рівня cgroup для памʼяті на рівні Pod:
# Виконайте це на вузлі, де запущено Pod.
# Також, змініть назву cgroup, щоб відповідати призначеному вашому pod cgroup.
cat /sys/fs/cgroup/memory/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/memory.limit_in_bytes
Це 320 МіБ, як і очікувалося:
335544320
Спостережуваність
Деякі метрики kube_pod_overhead_* доступні у kube-state-metrics для ідентифікації використання накладних витрат Pod та спостереження стабільності робочих навантажень, які працюють з визначеним overhead.
Що далі
- Дізнайтеся більше про RuntimeClass
- Прочитайте пропозицію щодо PodOverhead для додаткового контексту
10.4 - Готовність планування Pod
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.30 [stable]Podʼи вважалися готовими до планування відразу після створення. Планувальник Kubernetes виконує всі необхідні дії для знаходження вузлів для розміщення всіх Podʼів, що очікують. Однак на практиці деякі Podʼи можуть перебувати в стані "відсутні ресурси" ("miss-essential-resources") протягом тривалого періоду. Ці Podʼи фактично спричиняють зайве навантаження на планувальник (та інтегратори, по ходу далі, такі як Cluster AutoScaler), що є непотрібним.
Шляхом вказання/видалення поля .spec.schedulingGates для Podʼа ви можете контролювати, коли Pod готовий до розгляду для планування.
Налаштування schedulingGates Podʼа
Поле schedulingGates містить список рядків, і кожний рядок сприймається як критерій, який повинен бути задоволений перед тим, як Pod буде вважатися придатним для планування. Це поле можна ініціалізувати лише при створенні Podʼа (або клієнтом, або під час змін під час допуску). Після створення кожен schedulingGate можна видалити у довільному порядку, але додавання нового scheduling gate заборонено.
stateDiagram-v2
s1: Pod створено
s2: Планування Pod очікується
s3: Планування Pod готову
s4: Pod виконується
if: є порожні слоти планування?
[*] --> s1
s1 --> if
s2 --> if: обмеження
планування
зняте if --> s2: ні if --> s3: так s3 --> s4 s4 --> [*] classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff; class s1,s2,s3,s4,if k8s
планування
зняте if --> s2: ні if --> s3: так s3 --> s4 s4 --> [*] classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff; class s1,s2,s3,s4,if k8s
Приклад використання
Щоб позначити Pod як не готовий до планування, ви можете створити його з одним або кількома шлюзами планування так:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
schedulingGates:
- name: example.com/foo
- name: example.com/bar
containers:
- name: pause
image: registry.k8s.io/pause:3.6
Після створення Podʼа ви можете перевірити його стан за допомогою:
kubectl get pod test-pod
Вивід показує, що він знаходиться в стані SchedulingGated:
NAME READY STATUS RESTARTS AGE
test-pod 0/1 SchedulingGated 0 7s
Ви також можете перевірити його поле schedulingGates, запустивши:
kubectl get pod test-pod -o jsonpath='{.spec.schedulingGates}'
Вивід:
[{"name":"example.com/foo"},{"name":"example.com/bar"}]
Щоб повідомити планувальник, що цей Pod готовий до планування, ви можете повністю видалити його schedulingGates шляхом повторного застосування зміненого маніфесту:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: pause
image: registry.k8s.io/pause:3.6
Ви можете перевірити, чи очищено schedulingGates, виконавши:
kubectl get pod test-pod -o jsonpath='{.spec.schedulingGates}'
Очікується, що вивід буде порожнім. І ви можете перевірити його останній стан, запустивши:
kubectl get pod test-pod -o wide
Враховуючи те, що test-pod не запитує жодних ресурсів CPU/памʼяті, очікується, що стан цього Podʼа перейде з попереднього SchedulingGated в Running:
NAME READY STATUS RESTARTS AGE IP NODE
test-pod 1/1 Running 0 15s 10.0.0.4 node-2
Спостережуваність
Метрика scheduler_pending_pods має нову мітку "gated", щоб відрізняти, чи були спроби планувати Podʼа, але він був визначений як непридатний для планування, чи він явно позначений як не готовий для планування. Ви можете використовувати scheduler_pending_pods{queue="gated"} для перевірки результату метрики.
Змінні директиви планування Podʼа
Ви можете змінювати директиви планування Podʼа, коли вони мають шлюзи планування, з певними обмеженнями. Узагальнено, ви можете тільки робити директиви планування Podʼа жорсткішими. Іншими словами, оновлені директиви призведуть до можливості розміщення Podʼів тільки на підмножині вузлів, з якими вони раніше мали збіг. Конкретніше, правила для оновлення директив планування Podʼа такі:
Для
.spec.nodeSelectorдозволяються лише додавання. Якщо відсутнє, його можна встановити.Для
spec.affinity.nodeAffinity, якщо nil, тоді дозволяється встановлення будь-чого.Якщо
NodeSelectorTermsбув пустим, дозволено встановлення. Якщо не пустий, тоді дозволяються лише додаванняNodeSelectorRequirementsдоmatchExpressionsабоfieldExpressions, а зміни наявнихmatchExpressionsіfieldExpressionsне будуть дозволені. Це через те, що терміни в.requiredDuringSchedulingIgnoredDuringExecution.NodeSelectorTerms, оцінюються через OR тоді як вирази вnodeSelectorTerms[].matchExpressionsтаnodeSelectorTerms[].fieldExpressionsоцінюються через AND.Для
.preferredDuringSchedulingIgnoredDuringExecutionвсі оновлення дозволені. Це повʼязано з тим, що бажані умови не є авторитетними, і тому контролери політики не підтверджують ці умови.
Що далі
- Прочитайте PodSchedulingReadiness KEP для отримання більш детальної інформації
10.5 - Обмеження поширення топології Podʼів
Ви можете використовувати обмеження поширення топології для контролю того, як Podʼи розподіляються по вашому кластеру серед доменів відмов, таких як регіони, зони, вузли та інші користувацькі топологічні домени. Це може допомогти забезпечити високу доступність, а також ефективне використання ресурсів.
Ви можете встановлювати типові обмеження на рівні кластера або налаштовувати обмеження поширення топології для окремих навантажень.
Мотивація
Уявіть, що у вас є кластер, в якому до двадцяти вузлів, і ви хочете запустити навантаження, яке автоматично масштабує кількість реплік, які використовує. Тут може бути як два Podʼи, так і пʼятнадцять. Коли є лише два Podʼи, ви б хотіли, щоб обидва ці Podʼи не працювали на одному вузлі: ви ризикуєте, що відмова одного вузла призведе до зникнення доступу до вашого навантаження.
Крім цього основного використання, є деякі приклади використання, які дозволяють вашим навантаженням отримувати переваги високої доступності та використання кластера.
При масштабуванні та запуску більшої кількості Podʼів важливим стає інша проблема. Припустімо, що у вас є три вузли, на яких працюють по пʼять Podʼів кожен. У вузлах достатньо потужності для запуску такої кількості реплік; проте клієнти, які взаємодіють з цим навантаженням, розподілені по трьох різних центрах обробки даних (або зонах інфраструктури). Тепер ви менше хвилюєтеся про відмову одного вузла, але ви помічаєте, що затримка вища, ніж ви хотіли б, і ви платите за мережеві витрати, повʼязані з передачею мережевого трафіку між різними зонами.
Ви вирішуєте, що при нормальній роботі ви б хотіли, щоб у кожній інфраструктурній зоні була приблизно однакова кількість реплік, і ви хотіли б, щоб кластер самостійно відновлювався у разі виникнення проблеми.
Обмеження поширення топології Podʼів пропонують вам декларативний спосіб налаштування цього.
Поле topologySpreadConstraints
У API Pod є поле spec.topologySpreadConstraints. Використання цього поля виглядає так:
---
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# Налаштувати обмеження поширення топології
topologySpreadConstraints:
- maxSkew: <ціле число>
minDomains: <ціле число> # необовʼязково
topologyKey: <рядок>
whenUnsatisfiable: <рядок>
labelSelector: <обʼєкт>
matchLabelKeys: <список> # необовʼязково; бета з v1.27
nodeAffinityPolicy: [Honor|Ignore] # необовязково; бета з v1.26
nodeTaintsPolicy: [Honor|Ignore] # необовязково; бета з v1.26
### інші поля Pod тут
Додаткову інформацію про це поле можна отримати, запустивши команду kubectl explain Pod.spec.topologySpreadConstraints або звернувшись до розділу планування довідки API для Pod.
Визначення обмежень поширення топології
Ви можете визначити один або кілька записів topologySpreadConstraints, щоб вказати kube-scheduler, як розмістити кожний вхідний Pod у відповідно до наявних Podʼів у всьому кластері. Ці поля включають:
maxSkew описує ступінь нерівномірного поширення Pod. Ви повинні вказати це поле, і число повинно бути більше нуля. Його семантика відрізняється залежно від значення
whenUnsatisfiable:- якщо ви виберете
whenUnsatisfiable: DoNotSchedule, тодіmaxSkewвизначає максимально допустиму різницю між кількістю відповідних Podʼів у цільовій топології та глобальним мінімумом (мінімальна кількість відповідних Podʼів у прийнятній області або нуль, якщо кількість прийнятних областей менше, ніж MinDomains). Наприклад, якщо у вас є 3 зони з 2, 2 та 1 відповідно відповідних Podʼів,MaxSkewвстановлено на 1, тоді глобальний мінімум дорівнює 1. - якщо ви виберете
whenUnsatisfiable: ScheduleAnyway, планувальник надає вищий пріоритет топологіям, які допомагають зменшити розрив.
- якщо ви виберете
minDomains вказує мінімальну кількість прийнятних областей. Це поле є необовʼязковим. Домен — це певний екземпляр топології. Прийнятний домен — це домен, чиї вузли відповідають селектору вузлів.
Примітка:
До Kubernetes v1.30 полеminDomainsбуло доступним, якщо функціональну можливістьMinDomainsInPodTopologySpreadбуло увімкнено (типово увімкнено починаючи з v1.28). В старіших кластерах Kubernetes воно може бути явно відключеним або поле може бути недоступним.- Значення
minDomainsповинно бути більше ніж 0, коли вказано. Ви можете вказатиminDomainsлише разом зwhenUnsatisfiable: DoNotSchedule. - Коли кількість прийнятних доменів з відповідними ключами топології менше
minDomains, розподіл топології Pod розглядає глобальний мінімум як 0, а потім виконується розрахунокskew. Глобальний мінімум — це мінімальна кількість відповідних Podʼів у прийнятному домені, або нуль, якщо кількість прийнятних доменів менше, ніжminDomains. - Коли кількість прийнятних доменів з відповідними ключами топології дорівнює або більше
minDomains, це значення не впливає на планування. - Якщо ви не вказуєте
minDomains, обмеження поводиться так, як якбиminDomainsдорівнював 1.
- Значення
topologyKey — ключ міток вузла. Вузли, які мають мітку з цим ключем і ідентичними значеннями, вважаються присутніми в тій самій топології. Кожен екземпляр топології (іншими словами, пара <ключ, значення>) називається доменом. Планувальник спробує помістити вирівняну кількість Podʼів в кожен домен. Також ми визначаємо прийнятний домен як домен, вузли якої відповідають вимогам nodeAffinityPolicy та nodeTaintsPolicy.
whenUnsatisfiable вказує, як розвʼязувати проблему з Pod, якщо він не відповідає обмеженню поширення:
DoNotSchedule(типово) вказує планувальнику не планувати його.ScheduleAnywayвказує планувальнику все одно його планувати, проте з пріоритетом вибору вузлів, що мінімізують розрив.
labelSelector використовується для знаходження відповідних Podʼів. Podʼи, які відповідають цьому селектору міток, враховуються для визначення кількості Podʼів у відповідному домені топології. Дивіться селектори міток для отримання додаткових відомостей.
matchLabelKeys — це список ключів міток Podʼа для вибору Podʼів, відносно яких буде розраховано поширення. Ключі використовуються для вибору значень з міток Podʼів, ці ключі-значення міток AND
labelSelectorвибирають групу наявних Podʼів, відносно яких буде розраховано поширення для вхідного Podʼа. Існування однакового ключа заборонене як уmatchLabelKeys, так і вlabelSelector.matchLabelKeysне може бути встановлено, колиlabelSelectorне встановлено. Ключі, яких не існує в мітках Podʼа, будуть проігноровані. Порожній або нульовий список означає, що збіг буде відповідати лишеlabelSelector.З
matchLabelKeysвам не потрібно оновлюватиpod.specміж різними версіями. Контролер/оператор просто повинен встановити різні значення для того самого ключа мітки для різних версій. Планувальник автоматично припускає значення на основіmatchLabelKeys. Наприклад, якщо ви налаштовуєте Deployment, ви можете використовувати мітку за ключем pod-template-hash, яка додається автоматично контролером Deployment, для розрізнення різних версій в одному Deployment.topologySpreadConstraints: - maxSkew: 1 topologyKey: kubernetes.io/hostname whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: app: foo matchLabelKeys: - pod-template-hashПримітка:
ПолеmatchLabelKeysє полем на рівні бета-версії та включено стандартно у 1.27. Ви можете відключити його, вимкнувши функціональну можливістьMatchLabelKeysInPodTopologySpread.nodeAffinityPolicy вказує, як ми будемо обробляти nodeAffinity/nodeSelector Pod, коли розраховуємо розрив поширення топології Podʼів. Опції:
- Honor: до розрахунків включаються лише вузли, які відповідають nodeAffinity/nodeSelector.
- Ignore: nodeAffinity/nodeSelector ігноруються. Включаються всі вузли.
Якщо це значення є null, поведінка еквівалентна політиці Honor.
Примітка:
ПолеnodeAffinityPolicyє полем на рівні бета-версії та включено стандартно у 1.26. Ви можете відключити його, вимкнувши функціональну можливістьNodeInclusionPolicyInPodTopologySpread.nodeTaintsPolicy вказує, як ми будемо обробляти заплямованість вузлів при розрахунку розриву поширення топології Podʼів. Опції:
- Honor: включаються вузли без заплямованості, разом з заплямованими вузлами, для яких вхідний Pod має толерантність.
- Ignore: заплямованість вузла ігноруються. Включаються всі вузли.
Якщо це значення є null, поведінка еквівалентна політиці Ignore.
Примітка:
ПолеnodeTaintsPolicyє полем на рівні бета-версії та включено стандартно у 1.26. Ви можете відключити його, вимкнувши функціональну можливістьNodeInclusionPolicyInPodTopologySpread.
Коли Pod визначає більше одного topologySpreadConstraint, ці обмеження комбінуються за допомогою операції AND: kube-scheduler шукає вузол для вхідного Podʼа, який задовольняє всі налаштовані обмеження.
Мітки вузлів
Обмеження поширення топології ґрунтуються на мітках вузлів для ідентифікації доменів топології, в яких знаходиться кожен вузол. Наприклад, вузол може мати такі мітки:
region: us-east-1
zone: us-east-1a
Примітка:
У цьому прикладі не використовуються відомі ключі міток topology.kubernetes.io/zone та topology.kubernetes.io/region. Однак, рекомендується використовувати саме ці зареєстровані ключі міток, а не приватні (непідтверджені) ключі міток region та zone, які використовуються тут.
Не можна надійно припускати про наявність значення приватного ключа мітки в різних контекстах.
Припустимо, у вас є кластер з 4 вузлами з наступними мітками:
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready <none> 4m26s v1.16.0 node=node1,zone=zoneA
node2 Ready <none> 3m58s v1.16.0 node=node2,zone=zoneA
node3 Ready <none> 3m17s v1.16.0 node=node3,zone=zoneB
node4 Ready <none> 2m43s v1.16.0 node=node4,zone=zoneB
Тоді кластер логічно виглядає так:
graph TB
subgraph "zoneB"
n3(Node3)
n4(Node4)
end
subgraph "zoneA"
n1(Node1)
n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4 k8s;
class zoneA,zoneB cluster;
Узгодженість
Вам слід встановити однакові обмеження поширення топології Podʼів для всіх Podʼів у групі.
Зазвичай, якщо ви використовуєте контролер робочого навантаження, такий як Deployment, шаблон Podʼа забезпечує це за вас. Якщо ви комбінуєте різні обмеження поширення, то Kubernetes дотримується визначення API поля; однак, це більш ймовірно призведе до плутанини в поведінці, а усунення несправностей буде менш прямолінійним.
Вам потрібен механізм для забезпечення того, що всі вузли в домені топології (наприклад, регіон хмарного постачальника) мають однакові мітки. Щоб уникнути необхідності ручного маркування вузлів, більшість кластерів автоматично заповнюють відомі мітки, такі як kubernetes.io/hostname. Перевірте, чи підтримує ваш кластер це.
Приклад обмеження розподілу топології
Приклад: одне обмеження розподілу топології
Припустимо, у вас є кластер із чотирма вузлами, де 3 Podʼа з міткою foo: bar знаходяться на вузлах node1, node2 та node3 відповідно:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class zoneA,zoneB cluster;
Якщо ви хочете, щоб новий Pod рівномірно розподілявся з наявними Podʼами по зонах, ви можете використовувати маніфест Podʼів, схожий на такий:
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: registry.k8s.io/pause:3.1У цьому маніфесті topologyKey: zone означає, що рівномірне поширення буде застосовуватися лише до вузлів, які мають мітку zone: <будь-яке значення> (вузли, які не мають мітки zone, будуть пропущені). Поле whenUnsatisfiable: DoNotSchedule повідомляє планувальнику, що потрібно залишити новий Pod у стані очікування, якщо планувальник не може знайти спосіб задовольнити обмеження.
Якщо планувальник розмістить цей новий Pod у зоні A, розподіл Podʼів стане [3, 1]. Це означає, що фактичне відхилення складає 2 (розраховане як 3 - 1), що порушує maxSkew: 1. Щоб задовольнити умови обмеження та контекст для цього прикладу, новий Pod може бути розміщений лише на вузлі в зоні B.
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
або
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n3
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
Ви можете змінити специфікацію Podʼа, щоб вона відповідала різним вимогам:
- Змініть
maxSkewна більше значення, наприклад2, щоб новий Pod також можна було розмістити в зоніA. - Змініть
topologyKeyнаnode, щоб рівномірно розподілити Podʼи по вузлах, а не зонам. У вищезазначеному прикладі, якщоmaxSkewзалишиться1, новий Pod може бути розміщений лише на вузліnode4. - Змініть
whenUnsatisfiable: DoNotScheduleнаwhenUnsatisfiable: ScheduleAnyway, щоб гарантувати, що новий Pod завжди можна розмістити (якщо інші API планування задовольняються). Однак перевага надається розміщенню в області топології, яка має менше відповідних Podʼів. (Памʼятайте, що ця перевага спільно нормалізується з іншими внутрішніми пріоритетами планування, такими як відношення використання ресурсів).
Приклад: декілька обмежень поширення топології
Цей приклад будується на попередньому. Припустимо, у вашому кластері з 4 вузлами є 3 Podʼа, позначених як foo: bar, що знаходяться на вузлі node1, node2 і node3 відповідно:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
Ви можете поєднати два обмеження поширення топології, щоб контролювати розподіл Podʼів як за вузлами, так і за зонами:
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
- maxSkew: 1
topologyKey: node
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: registry.k8s.io/pause:3.1У цьому випадку для збігу з першим обмеженням новий Pod може бути розміщений лише на вузлах у зоні B; тоді як для відповідності другому обмеженню новий Pod може бути розміщений лише на вузлі node4. Планувальник розглядає лише варіанти, які задовольняють всі визначені обмеження, тому єдине допустиме розташування — це на вузлі node4.
Приклад: конфліктуючі обмеження розподілу топології
Кілька обмежень може призвести до конфліктів. Припустимо, у вас є кластер з 3 вузлами у 2 зонах:
graph BT
subgraph "zoneB"
p4(Pod) --> n3(Node3)
p5(Pod) --> n3
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n1
p3(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3,p4,p5 k8s;
class zoneA,zoneB cluster;
Якщо ви застосуєте two-constraints.yaml (файл маніфесту з попереднього прикладу) до цього кластера, ви побачите, що Pod mypod залишається у стані Pending. Це трапляється тому, що для задоволення першого обмеження Pod mypod може бути розміщений лише у зоні B; тоді як для відповідності другому обмеженню Pod mypod може бути розміщений лише на вузлі node2. Перетин двох обмежень повертає порожній набір, і планувальник не може розмістити Pod.
Щоб подолати цю ситуацію, ви можете або збільшити значення maxSkew, або змінити одне з обмежень, щоб використовувати whenUnsatisfiable: ScheduleAnyway. Залежно від обставин, ви також можете вирішити видалити наявний Pod вручну — наприклад, якщо ви розвʼязуєте проблему, чому розгортання виправлення помилки не виконується.
Взаємодія з селектором вузла та спорідненістю вузла
Планувальник пропустить вузли, що не відповідають, з обчислень нерівності, якщо у вхідного Podʼа визначено spec.nodeSelector або spec.affinity.nodeAffinity.
Приклад: обмеження поширення топології зі спорідненістю вузла
Припустимо, у вас є 5-вузловий кластер, розташований у зонах A до C:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
graph BT
subgraph "zoneC"
n5(Node5)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n5 k8s;
class zoneC cluster;
і ви знаєте, що зону C потрібно виключити. У цьому випадку ви можете скласти маніфест, як наведено нижче, щоб Pod mypod був розміщений у зоні B, а не у зоні C. Так само Kubernetes також враховує spec.nodeSelector.
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: NotIn
values:
- zoneC
containers:
- name: pause
image: registry.k8s.io/pause:3.1Неявні домовленості
Тут є кілька неявних домовленостей, на які варто звернути увагу:
Відповідними кандидатами можуть бути лише ті Podʼи, що мають той самий простір імен, що й вхідний Pod.
Планувальник розглядає лише ті вузли, у яких одночасно присутні всі
topologySpreadConstraints[*].topologyKey. Вузли, у яких відсутній будь-який з цихtopologyKey, обминаються. Це означає, що:- будь-які Podʼи, що розташовані на цих обхідних вузлах, не впливають на обчислення
maxSkew— в прикладі вище, припустимо, що вузолnode1не має мітки "zone", тоді 2 Podʼи будуть проігноровані, тому вхідний Pod буде заплановано в зонуA. - вхідний Pod не має шансів бути запланованим на такі вузли — у вищенаведеному прикладі, припустимо, що вузол
node5має невірно введену міткуzone-typo: zoneC(і не має жодної встановленої міткиzone). Після приєднання вузлаnode5до кластера, він буде обходитися, і Podʼи для цього робочого навантаження не будуть плануватися туди.
- будь-які Podʼи, що розташовані на цих обхідних вузлах, не впливають на обчислення
Будьте уважні, якщо
topologySpreadConstraints[*].labelSelectorвхідного Podʼа не відповідає його власним міткам. У вищенаведеному прикладі, якщо ви видалите мітки вхідного Podʼа, він все ще може бути розміщений на вузлах у зоніB, оскільки обмеження все ще виконуються. Проте, після цього розміщення ступінь незбалансованості кластера залишається без змін — зонаAвсе ще має 2 Podʼи з міткамиfoo: bar, а зонаBмає 1 Pod з міткоюfoo: bar. Якщо це не те, що ви очікуєте, оновітьtopologySpreadConstraints[*].labelSelectorробочого навантаження, щоб відповідати міткам в шаблоні Podʼа.
Типові обмеження на рівні кластера
Можливо встановити типові обмеження поширення топології для кластера. Типово обмеження поширення топології застосовуються до Podʼа лише в тому випадку, якщо:
- Він не визначає жодних обмежень у своєму
.spec.topologySpreadConstraints. - Він належить до Service, ReplicaSet, StatefulSet або ReplicationController.
Типові обмеження можна встановити як частину аргументів втулка PodTopologySpread в профілі планувальника. Обмеження вказуються з тими ж API вище, за винятком того, що labelSelector повинен бути пустим. Селектори обчислюються з Service, ReplicaSet, StatefulSet або ReplicationControllers, до яких належить Pod.
Приклад конфігурації може виглядати наступним чином:
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
defaultingType: List
Вбудовані типові обмеження
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]Якщо ви не налаштовуєте жодних типових обмежень для поширення топології Podʼа на рівні кластера, то kube-scheduler діє так, ніби ви вказали наступні обмеження:
defaultConstraints:
- maxSkew: 3
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: ScheduleAnyway
- maxSkew: 5
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: ScheduleAnyway
Також, типово відключений застарілий втулок SelectorSpread, який забезпечує еквівалентну поведінку.
Примітка:
Втулок PodTopologySpread не оцінює вузли, які не мають вказаних ключів топології в обмеженнях поширення. Це може призвести до іншої типової поведінки порівняно з застарілим втулком SelectorSpread, коли використовуються типові обмеження поширення топології.
Якщо ви не очікуєте, що ваші вузли матимуть обидві мітки kubernetes.io/hostname та topology.kubernetes.io/zone встановлені, визначте свої власні обмеження замість використання стандартних значень Kubernetes.
Якщо ви не хочете використовувати типові обмеження поширення топології Podʼа для вашого кластера, ви можете відключити ці типові значення, встановивши defaultingType у List і залишивши порожніми defaultConstraints у конфігурації втулка PodTopologySpread:
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints: []
defaultingType: List
Порівняння з podAffinity та podAntiAffinity
У Kubernetes, між-Podʼова (анти)спорідненість контролює те, як Podʼи розміщуються відносно один одного — чи ущільнені, чи розріджені.
podAffinity- притягує Podʼи; ви можете намагатися упакувати будь-яку кількість Podʼів в кваліфікуючі топологічні домени.
podAntiAffinity- відштовхує Podʼи. Якщо ви встановите це у режим
requiredDuringSchedulingIgnoredDuringExecution, тоді тільки один Pod може бути запланований в один топологічний домен; якщо ви виберетеpreferredDuringSchedulingIgnoredDuringExecution, то ви втратите можливість змусити виконання обмеження.
Для більш точного контролю ви можете вказати обмеження поширення топології для розподілу podʼів по різним топологічним доменам — для досягнення як високої доступності, так і економії коштів. Це також може допомогти в роботі з оновленнями без відмов та плавному масштабуванні реплік.
Для отримання більш детальної інформації, див. розділ Motivation пропозиції щодо покращення про обмеження поширення топології Podʼів.
Відомі обмеження
Немає гарантії, що обмеження залишаться задоволеними при видаленні Podʼів. Наприклад, зменшення масштабування Deployment може призвести до нерівномірного розподілу Podʼів.
Ви можете використовувати інструменти, такі як Descheduler, для перебалансування розподілу Podʼів.
Podʼи, що відповідають заплямованим вузлам, враховуються. Див. Issue 80921.
Планувальник не має попереднього знання всіх зон або інших топологічних доменів, які має кластер. Вони визначаються на основі наявних вузлів у кластері. Це може призвести до проблем у автоматизованих кластерах, коли вузол (або група вузлів) масштабується до нуля вузлів, і ви очікуєте масштабування кластера, оскільки в цьому випадку ці топологічні домени не будуть враховуватися, поки в них є хоча б один вузол.
Ви можете обійти це, використовуючи інструменти автоматичного масштабування кластера, які враховують обмеження розподілу топології Podʼів та також знають загальний набір топологічних доменів.
Що далі
- У статті блогу Introducing PodTopologySpread докладно пояснюється
maxSkew, а також розглядаються деякі приклади використання. - Прочитайте розділ scheduling з довідки API для Pod.
10.6 - Заплямованість та Толерантність
Спорідненість вузла (node affinity) це властивість Podʼа, яка привертає Pod до набору вузлів (або як перевага, або як жорстка вимога). Заплямованість (taint) є протилежною властивістю — вона дозволяє вузлу відштовхувати набір Podʼів.
Толерантність застосовуються до Podʼів. Толерантність дозволяє планувальнику розміщувати Podʼи, що збігаються з відповідними позначками заплямованості. Толерантність дозволяє планування, але не гарантує його: планувальник також оцінює інші параметри в межах свого функціонала.
Заплямованість та толерантність працюють разом, щоб забезпечити те, щоб Podʼи не розміщувались на непридатних вузлах. Одна або декілька позначок заплямованості застосовуються до вузла; це дозволяє позначити, що вузол не повинен приймати жодних Podʼів, які не толерують цих позначок заплямованості.
Концепції
Ви додаєте позначку taint до вузла за допомогою kubectl taint. Наприклад,
kubectl taint nodes node1 key1=value1:NoSchedule
додає taint до вузла node1. Taint має ключ key1, значення value1 і ефект taint NoSchedule. Це означає, що жодний Pod не зможе розміститись на node1, якщо він не має відповідної толерантності.
Щоб видалити taint, доданий командою вище, можна виконати:
kubectl taint nodes node1 key1=value1:NoSchedule-
Ви вказуєте толерантність для Podʼа в PodSpec. Обидві наступні толерантності "відповідають" taint, створеному за допомогою команди kubectl taint вище, і, отже, Pod з будь-якою з толерантностей зможе розміститись на node1:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
Основний планувальник Kubernetes бере до уваги taint та толерантності при виборі вузла для запуску певного Podʼа. Проте, якщо ви вручну вказуєте .spec.nodeName для Podʼа, ця дія оминає планувальник; Pod тоді привʼязується до вузла, на який ви його призначили, навіть якщо на цьому вузлі є taint типу NoSchedule, які ви обрали. Якщо це трапиться і на вузлі також встановлено taint типу NoExecute, kubelet видалятиме Pod, якщо не буде встановлено відповідну толерантність.
Ось приклад Podʼа, у якого визначено деякі толерантності:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "example-key"
operator: "Exists"
effect: "NoSchedule"
Типово значення для operator є Equal.
Толерантність має "збіг" з taint, якщо ключі є однаковими та ефекти є однаковими також, і:
- оператор —
Exists(у цьому випадку не слід вказуватиvalue), або - оператор —
Equal, а значення повинні бути рівні.
Примітка:
Є два спеціальних випадки:
Якщо key порожній, то operator має бути Exists, що відповідає всім ключам і значенням. Зверніть увагу, що effect все одно має збігатися з ключем.
Порожній effect відповідає всім ефектам з ключем key1.
У вищенаведеному прикладі використовувався effect NoSchedule. Також можна використовувати effect PreferNoSchedule.
Дозволені значення для поля effect:
NoExecute- Це впливає на Podʼи, які вже запущені на вузлі наступним чином:
- Podʼи, які не толерують taint, негайно виселяються
- Podʼи, які толерують taint, не вказуючи
tolerationSecondsв їхній специфікації толерантності, залишаються привʼязаними назавжди - Podʼи, які толерують taint з вказаним
tolerationSecondsзалишаються привʼязаними протягом зазначеного часу. Після закінчення цього часу контролер життєвого циклу вузла виводить Podʼи з вузла.
NoSchedule- На позначеному taint вузлі не буде розміщено нові Podʼи, якщо вони не мають відповідної толерантності. Podʼи, які вже працюють на вузлі, не виселяються.
PreferNoSchedulePreferNoSchedule— це "preference" або "soft" варіантNoSchedule. Планувальник спробує уникнути розміщення Podʼа, який не толерує taint на вузлі, але це не гарантовано.
На один вузол можна накласти декілька taint і декілька толерантностей на один Pod. Спосіб, яким Kubernetes обробляє декілька taint і толерантностей, схожий на фільтр: починаючи з усіх taint вузла, потім ігнорує ті, для яких Pod має відповідну толерантність; залишаються невідфільтровані taint, які мають зазначені ефекти на Pod. Зокрема,
- якщо є принаймні один невідфільтрований taint з ефектом
NoSchedule, тоді Kubernetes не буде планувати Pod на цей вузол - якщо немає невідфільтрованих taint з ефектом
NoSchedule, але є принаймні один невідфільтрований taint з ефектомPreferNoSchedule, тоді Kubernetes спробує не планувати Pod на цей вузол - якщо є принаймні один невідфільтрований taint з ефектом
NoExecute, тоді Pod буде виселено з вузла (якщо він вже працює на вузлі), і він не буде плануватися на вузол (якщо він ще не працює на вузлі).
Наприклад, уявіть, що ви накладаєте taint на вузол таким чином
kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value1:NoExecute
kubectl taint nodes node1 key2=value2:NoSchedule
І Pod має дві толерантності:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
У цьому випадку Pod не зможе плануватися на вузол, оскільки відсутня толерантність, яка відповідає третьому taint. Але він зможе продовжувати працювати, якщо він вже працює на вузлі, коли до нього додається taint, оскільки третій taint — єдиний з трьох, який не толерується Podʼом.
Зазвичай, якщо до вузла додається taint з ефектом NoExecute, то будь-які Podʼи, які не толерують taint, будуть негайно виселені, а Podʼи, які толерують taint, ніколи не будуть виселені. Однак толерантність з ефектом NoExecute може вказати необовʼязкове поле tolerationSeconds, яке визначає, як довго Pod буде привʼязаний до вузла після додавання taint. Наприклад,
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
означає, що якщо цей Pod працює і до вузла додається відповідний taint, то Pod залишиться привʼязаним до вузла протягом 3600 секунд, а потім буде виселений. Якщо taint видаляється до цього часу, то Pod не буде виселений.
Приклади використання
Заплямованість та Толерантність є гнучким способом відвадити Podʼи від вузлів або виселення Podʼів, які не повинні працювати. Деякі з варіантів використання:
Призначені вузли: Якщо ви хочете призначити певний набір вузлів для виключного використання конкретним набором користувачів, ви можете додати taint на ці вузли (наприклад,
kubectl taint nodes nodename dedicated=groupName:NoSchedule) і потім додати відповідну толерантність до їхніх Podʼів (це найкраще робити за допомогою власного контролера допуску). Podʼам з толерантностями буде дозволено використовувати позначені (призначені) вузли, а також будь-які інші вузли в кластері. Якщо ви хочете призначити вузли виключно для них та забезпечити, що вони використовують лише призначені вузли, то ви також повинні додатково додати мітку, аналогічну taint, до того ж набору вузлів (наприклад,dedicated=groupName), і контролер допуску повинен додатково додати спорідненість вузла, щоб вимагати, щоб Podʼи могли плануватися лише на вузли з міткоюdedicated=groupName.Вузли зі спеціальним обладнанням: У кластері, де невелика підмножина вузлів має спеціалізоване обладнання (наприклад, GPU), бажано утримувати Podʼи, які не потребують спеціалізованого обладнання, поза цими вузлами, щоб залишити місце для Podʼів, які дійсно потребують спеціалізованого обладнання. Це можна зробити, накладаючи taint на вузли зі спеціалізованим обладнанням (наприклад,
kubectl taint nodes nodename special=true:NoScheduleабоkubectl taint nodes nodename special=true:PreferNoSchedule) і додавання відповідної толерантності до Podʼів, які використовують спеціалізоване обладнання. Як і у випадку з призначеними вузлами, найпростіше застосовувати толерантності за допомогою власного контролера допуску. Наприклад, рекомендується використовувати Розширені ресурси для представлення спеціального обладнання, позначайте вузли зі спеціальним обладнанням розширеним імʼям ресурсу і запускайте контролер допуску ExtendedResourceToleration. Тепер, оскільки вузли позначені, жоден Pod без толерантності не буде плануватися на них. Але коли ви надсилаєте Pod, який запитує розширений ресурс, контролер допускуExtendedResourceTolerationавтоматично додасть правильну толерантність до Podʼа і цей Pod буде плануватися на вузли зі спеціальним обладнанням. Це забезпечить, що ці вузли зі спеціальним обладнанням призначені для Podʼів, які запитують таке обладнання, і вам не потрібно вручну додавати толерантності до ваших Podʼів.Виселення на основі taint: Поведінка виселення, що налаштовується для кожного Podʼа, коли є проблеми з вузлом, яка описана в наступному розділі.
Виселення на основі taint
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.18 [stable]Контролер вузла автоматично накладає taint на вузол, коли виконуються певні умови. Наступні taint є вбудованими:
node.kubernetes.io/not-ready: Вузол не готовий. Це відповідає тому, що стан NodeCondition "Ready" є "False".node.kubernetes.io/unreachable: Вузол недоступний з контролера вузла. Це відповідає тому, що стан NodeCondition "Ready" є "Unknown".node.kubernetes.io/memory-pressure: Вузол має проблеми з памʼяттю.node.kubernetes.io/disk-pressure: Вузол має проблеми з диском.node.kubernetes.io/pid-pressure: Вузол має проблеми з PID.node.kubernetes.io/network-unavailable: Мережа вузла недоступна.node.kubernetes.io/unschedulable: Вузол не піддається плануванню.node.cloudprovider.kubernetes.io/uninitialized: Коли kubelet запускається з "зовнішнім" хмарним провайдером, цей taint накладається на вузол для позначення його як невикористовуваного. Після того як контролер з cloud-controller-manager ініціалізує цей вузол, kubelet видаляє цей taint.
У разі, якщо потрібно спорожнити вузол, контролер вузла або kubelet додає відповідні taint з ефектом NoExecute. Цей ефект типово додається для taint node.kubernetes.io/not-ready та node.kubernetes.io/unreachable. Якщо умова несправності повертається до нормального стану, kubelet або контролер вузла можуть видалити відповідні taint.
У деяких випадках, коли вузол недоступний, сервер API не може спілкуватися з kubelet на вузлі. Рішення про видалення Podʼів не може бути передане до kubelet до тих пір, поки звʼязок з сервером API не буде відновлено. Протягом цього часу Podʼи, які заплановані для видалення, можуть продовжувати працювати на розділеному вузлі.
Примітка:
Панель управління обмежує швидкість додавання нових taint на вузли. Це обмеження швидкості керує кількістю видалень, які спричиняються, коли одночасно недоступно багато вузлів (наприклад, якщо відбувається збій мережі).Ви можете вказати tolerationSeconds для Podʼа, щоб визначити, як довго цей Pod залишається привʼязаним до несправного або вузла, ще не відповідає.
Наприклад, ви можете довго зберігати застосунок з великою кількістю локального стану, привʼязаного до вузла, у разі розділу мережі, сподіваючись, що розділ відновиться, і, таким чином, можна уникнути виселення Podʼа. Толерантність, яку ви встановили для цього Pod, може виглядати так:
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000
Примітка:
Kubernetes автоматично додає толерантність для node.kubernetes.io/not-ready та node.kubernetes.io/unreachable з tolerationSeconds=300, якщо ви або контролер встановили ці толерантності явно.
Ці автоматично додані толерантності означають, що Podʼи залишаються привʼязаними до вузлів протягом 5 хвилин після виявлення однієї з цих проблем.
Podʼи DaemonSet створюються з толерантностями NoExecute для наступних taint без tolerationSeconds:
node.kubernetes.io/unreachablenode.kubernetes.io/not-ready
Це забезпечує, що Podʼи DaemonSet ніколи не будуть видалені через ці проблеми.
Позначення вузлів taint за умовами
Панель управління, використовуючи контролер вузла, автоматично створює taint з ефектом NoSchedule для умов вузла.
Планувальник перевіряє taint, а не умови вузла, коли він приймає рішення про планування. Це забезпечує те, що умови вузла не впливають безпосередньо на планування. Наприклад, якщо умова вузла DiskPressure активна, панель управління додає taint node.kubernetes.io/disk-pressure і не планує нові Podʼи на уражений вузол. Якщо умова вузла MemoryPressure активна, панель управління додає taint node.kubernetes.io/memory-pressure.
Ви можете ігнорувати умови вузла для новостворених Podʼів, додавши відповідні толерантності Podʼів. Панель управління також додає толерантність node.kubernetes.io/memory-pressure на Podʼи, які мають клас QoS інший, ніж BestEffort. Це тому, що Kubernetes вважає Podʼи у класах QoS Guaranteed або Burstable (навіть Podʼи без встановленого запиту на памʼять) здатними впоратися з тиском на памʼять, тоді як нові Podʼи BestEffort не плануються на уражений вузол.
Контролер DaemonSet автоматично додає наступні толерантності NoSchedule для всіх демонів, щоб запобігти порушенню роботи DaemonSet.
node.kubernetes.io/memory-pressurenode.kubernetes.io/disk-pressurenode.kubernetes.io/pid-pressure(1.14 або пізніше)node.kubernetes.io/unschedulable(1.10 або пізніше)node.kubernetes.io/network-unavailable(тільки для мережі хосту)
Додавання цих толерантностей забезпечує сумісність з попередніми версіями. Ви також можете додавати довільні толерантності до DaemonSets.
Що далі
- Дізнайтеся про Виселення через тиск на вузол та як його налаштувати
- Ознайомтесь з Пріоритетом Podʼа
10.7 - Фреймворк планування
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.19 [stable]Фреймворк планування — це розширювана архітектура для планувальника Kubernetes. Вона складається з набору "втулків" API, які компілюються безпосередньо в планувальник. Ці API дозволяють реалізувати більшість функцій планування у вигляді втулків, зберігаючи при цьому основне ядро планування легким та зручним у використанні. Для отримання більш технічної інформації про дизайн цієї архітектури зверніться до пропозиції проєкту дизайну системи планування.
Робота фреймворку
Фреймворк планування визначає кілька точок розширення. Втулки планувальника реєструються для виклику в одній або кількох таких точках розширення. Деякі з цих втулків можуть змінювати рішення щодо планування, а деякі надають тільки інформаційний вміст.
Кожна спроба запланувати один Pod розділяється на два етапи: цикл планування та цикл привʼязки.
Цикл планування та цикл привʼязки
Цикл планування вибирає вузол для Podʼа, а цикл привʼязки застосовує це рішення до кластера. Разом цикл планування та цикл привʼязки називаються "контекстом планування".
Цикли планування виконуються послідовно, тоді як цикли привʼязки можуть виконуватися паралельно.
Цикл планування або привʼязки може бути перерваний, якщо виявлено, що Pod не може бути запланованим або якщо відбувається внутрішня помилка. Pod буде повернуто у чергу і спроба буде повторена.
Інтерфейси
Наступне зображення показує контекст планування Podʼа та інтерфейси, які надає фреймворк планування.
Один втулок може реалізовувати кілька інтерфейсів для виконання складніших завдань або завдань зі збереженням стану.
Деякі інтерфейси відповідають точкам розширення планувальника, які можна налаштувати через Конфігурацію Планувальника.
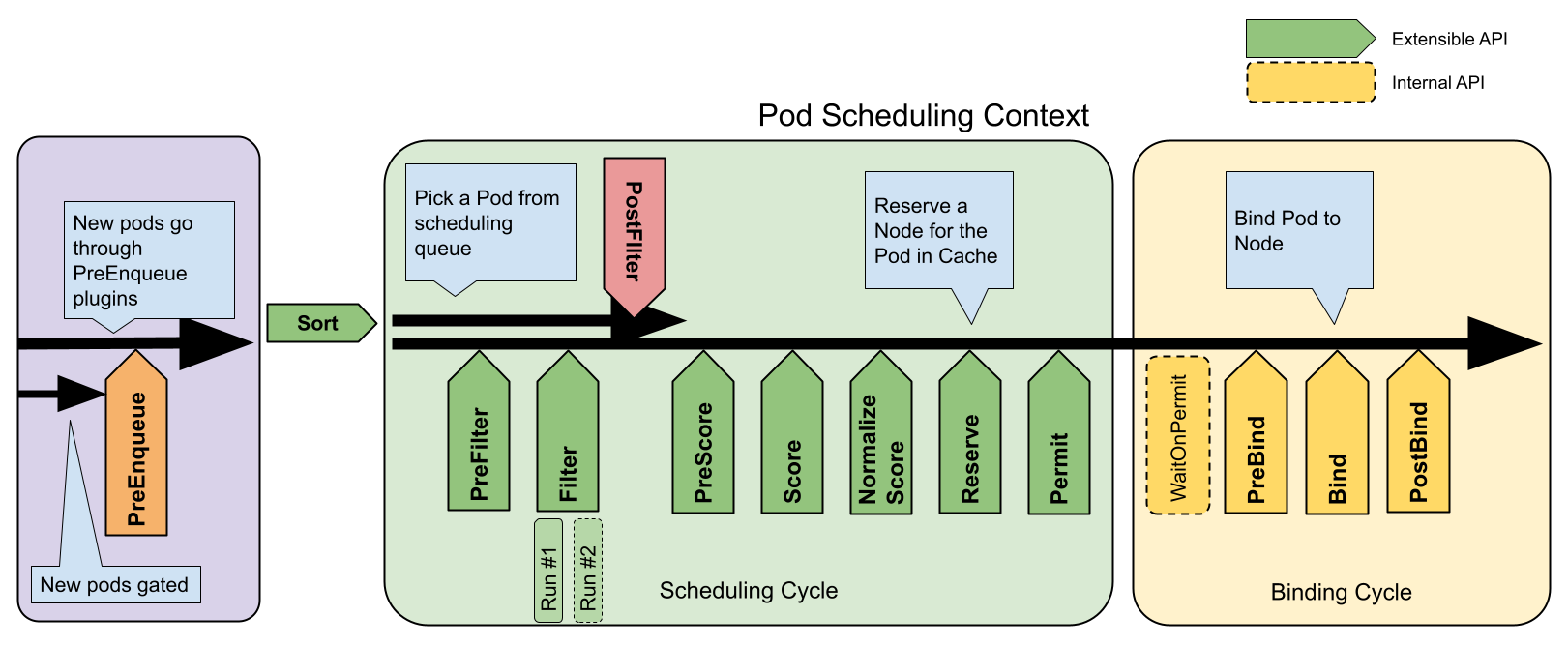
Точки розширення фреймворку планування
PreEnqueue
Ці втулки викликаються перед додаванням Podʼів до внутрішньої активної черги, де Podʼи відзначаються як готові до планування.
Тільки коли всі втулки PreEnqueue повертають Success, Pod допускається до внутрішньої активної черги. В іншому випадку він поміщається у відсортований список незапланованих Podʼів і не отримує умову Unschedulable.
Для отримання докладнішої інформації про те, як працюють внутрішні черги планувальника, прочитайте Черга планування в kube-scheduler.
EnqueueExtension
EnqueueExtension — це інтерфейс, де втулок може контролювати, чи потрібно повторно спробувати планування Podʼів, відхилені цим втулком, на основі змін у кластері. Втулки, які реалізують PreEnqueue, PreFilter, Filter, Reserve або Permit, повинні реалізувати цей інтерфейс.
QueueingHint
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [beta]QueueingHint — це функція зворотного виклику для вирішення того, чи можна повторно включити Pod до активної черги або черги відстрочки. Вона виконується кожного разу, коли в кластері відбувається певний вид події або зміна. Коли QueueingHint виявляє, що подія може зробити Pod запланованим, Pod поміщається в активну чергу або чергу відстрочки, щоб планувальник повторно спробував спланувати Pod.
Примітка:
У Kubernetes 1.32 ця функціональна можливість увімкнена стандартно, і ви можете вимкнути її за допомогою функціональної можливостіSchedulerQueueingHints.QueueSort
Ці втулки використовуються для сортування Podʼів у черзі планування. Втулок сортування черги надає функцію Less(Pod1, Pod2). Одночасно може бути включений лише один втулок сортування черги.
PreFilter
Ці втулки використовуються для попередньої обробки інформації про Pod, або для перевірки певних умов, яким мають відповідати кластер або Pod. Якщо втулок PreFilter повертає помилку, цикл планування переривається.
Filter
Ці втулки використовуються для відфільтрування вузлів, на яких не можна запустити Pod. Для кожного вузла планувальник буде викликати втулки фільтрації в налаштованому порядку. Якщо будь-який втулок фільтра позначає вузол як неспроможний, для цього вузла не буде викликано інші втулки. Оцінка вузлів може відбуватися паралельно.
PostFilter
Ці втулки викликаються після фази фільтрації, але лише тоді, коли не було знайдено жодного можливого вузла для Podʼа. Втулки викликаються в налаштованому порядку. Якщо будь-який втулок postFilter позначає вузол як Schedulable, інші втулки не будуть викликані. Типовою реалізацією PostFilter є preemption, яка намагається зробити Pod запланованим, випереджаючи інші Pods.
PreScore
Ці втулки використовуються для виконання "попередньої оцінки", яка генерує загальний стан для використання втулками Score. Якщо втулок попередньої оцінки повертає помилку, цикл планування переривається.
Score
Ці втулки використовуються для ранжування вузлів, які пройшли фазу фільтрації. Планувальник викликає кожен втулок оцінювання для кожного вузла. Існує чіткий діапазон цілих чисел, який представляє мінімальні та максимальні оцінки. Після фази NormalizeScore, планувальник поєднує оцінки вузла з усіх втулків згідно з налаштованими коефіцієнтами втулків.
NormalizeScore
Ці втулки використовуються для модифікації оцінок перед тим, як планувальник обчислить кінцеве ранжування Вузлів. Втулок, який реєструється для цієї точки розширення, буде викликаний з результатами Score від того ж втулка. Це робиться один раз для кожного втулка на один цикл планування.
Наприклад, припустимо, що втулок BlinkingLightScorer ранжує вузли на основі того, скільки лампочок, що блимають, в них є.
func ScoreNode(_ *v1.pod, n *v1.Node) (int, error) {
return getBlinkingLightCount(n)
}
Однак максимальна кількість лампочок, що блимають, може бути невеликою порівняно з NodeScoreMax. Щоб виправити це, BlinkingLightScorer також повинен реєструватися для цієї точки розширення.
func NormalizeScores(scores map[string]int) {
highest := 0
for _, score := range scores {
highest = max(highest, score)
}
for node, score := range scores {
scores[node] = score*NodeScoreMax/highest
}
}
Якщо будь-який втулок NormalizeScore повертає помилку, цикл планування припиняється.
Примітка:
Втулки, які бажають виконати "pre-reserve", повинні використовувати точку розширення NormalizeScore.Reserve
Втулок, який реалізує інтерфейс Reserve, має два методи, а саме Reserve та Unreserve, які підтримують дві інформаційні фази планування, які називаються Reserve та Unreserve, відповідно. Втулки, які підтримують стан виконання (так звані "статичні втулки"), повинні використовувати ці фази для повідомлення планувальнику про те, що ресурси на вузлі резервуються та скасовуються для вказаного Podʼа.
Фаза резервування (Reserve) відбувається перед тим, як планувальник фактично привʼязує Pod до призначеного вузла. Це робиться для запобігання виникненню умов перегонів (race condition) під час очікування на успішне привʼязування. Метод Reserve кожного втулка Reserve може бути успішним або невдалим; якщо один виклик методу Reserve не вдасться, наступні втулки не виконуються, і фаза резервування вважається невдалою. Якщо метод Reserve всіх втулків успішний, фаза резервування вважається успішною, виконується решта циклу планування та циклу привʼязки.
Фаза скасування резервування (Unreserve) спрацьовує, якщо фаза резервування або пізніша фаза виявиться невдалою. У такому випадку метод Unreserve всіх втулків резервування буде виконано у порядку зворотному виклику методів Reserve. Ця фаза існує для очищення стану, повʼязаного з зарезервованим Podʼом.
Увага:
Реалізація методуUnreserve у втулках Reserve повинна бути ідемпотентною і не може зазнавати невдачі.Permit
Втулки Permit викликаються в кінці циклу планування для кожного Podʼа, щоб запобігти або затримати привʼязку до вузла-кандидата. Втулок дозволу може робити одну з трьох речей:
approve
Якщо всі втулки Permit схвалюють Pod, він відправляється для привʼязки.deny
Якщо будь-який втулок Permit відхиляє Pod, він повертається до черги планування. Це спричинить запуск фази Unreserve у втулках Reserve.wait (із таймаутом)
Якщо втулок Permit повертає "wait", тоді Pod залишається у внутрішньому списком "очікуючих" Podʼів, і цикл привʼязки цього Podʼа починається, але безпосередньо блокується, поки він не буде схвалений. Якщо виникає таймаут, wait стає deny і Pod повертається до черги планування, спричиняючи запуск фази Unreserve у втулках Reserve.
Примітка:
Хоча будь-який втулок може мати доступ до списку "очікуючих" Podʼів та схвалювати їх (див.FrameworkHandle), ми очікуємо, що лише втулки Permit схвалюватимуть привʼязку зарезервованих Podʼів, які перебувають у стані "wait". Після схвалення Podʼа він відправляється до фази PreBind.PreBind
Ці втулки використовуються для виконання будь-яких необхідних операцій перед привʼязкою Podʼа. Наприклад, втулок PreBind може надавати мережевий том і монтувати його на цільовому вузлі перед тим, як дозволити Podʼа запускатися там.
Якщо будь-який втулок PreBind повертає помилку, Pod відхиляється і повертається до черги планування.
Bind
Ці втулки використовуються для привʼязки Podʼа до Вузла. Втулки Bind не будуть викликані, поки всі втулки PreBind не завершаться. Кожен втулок привʼязки викликається в налаштованому порядку. Втулок привʼязки може вибрати, чи обробляти вказаний Pod. Якщо втулок привʼязки обирає Pod для опрацювання, решта втулків привʼязки пропускаються.
PostBind
Це інформаційний інтерфейс. Втулки PostBind викликаються після успішної привʼязки Podʼа. Це завершення циклу привʼязки та може бути використано для очищення повʼязаних ресурсів.
API втулку
Існують два кроки в API втулку. По-перше, втулки повинні зареєструватися та отримати налаштування, а потім вони використовують інтерфейси точок розширення. Інтерфейси точок розширення мають наступну форму.
type Plugin interface {
Name() string
}
type QueueSortPlugin interface {
Plugin
Less(*v1.pod, *v1.pod) bool
}
type PreFilterPlugin interface {
Plugin
PreFilter(context.Context, *framework.CycleState, *v1.pod) error
}
// ...
Налаштування втулків
Ви можете увімкнути або вимкнути втулки у конфігурації планувальника. Якщо ви використовуєте Kubernetes v1.18 або пізнішу версію, більшість втулків планування використовуються та є стандартно увімкненими.
Окрім стандартних втулків, ви також можете реалізувати власні втулки планування та налаштувати їх разом з стандартними втулками. Ви можете дізнатися більше на scheduler-plugins.
Якщо ви використовуєте Kubernetes v1.18 або пізнішу версію, ви можете налаштувати набір втулків як профіль планувальника, а потім визначити кілька профілів для різних видів робочих навантажень. Дізнайтеся більше за про декілька профілів.
10.8 - Динамічне виділення ресурсів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [beta] (стандартно увімкнено: false)Динамічне виділення ресурсів — це API для запиту та спільного використання ресурсів між Podʼами та контейнерами всередині Podʼа. Це узагальнення API для постійних томів для загальних ресурсів. Зазвичай ці ресурси є пристроями, такими як GPU.
Драйвери сторонніх ресурсів відповідають за відстеження та підготовку ресурсів, а виділення ресурсів здійснюється Kubernetes за допомогою структурованих параметрів (введених у Kubernetes 1.30). Різні види ресурсів підтримують довільні параметри для визначення вимог та ініціалізації.
У версіях Kubernetes від 1.26 до 1.31 була реалізована (альфа) версія classic DRA, яка більше не підтримується. Ця документація для Kubernetes v1.32, пояснює поточний підхід до динамічного розподілу ресурсів у Kubernetes.
Перш ніж ви розпочнете
Kubernetes v1.32 включає підтримку API на рівні кластера для динамічного виділення ресурсів, але це потрібно включити явно. Ви також повинні встановити драйвер ресурсів для конкретних ресурсів, які мають бути керовані за допомогою цього API. Якщо ви не використовуєте Kubernetes v1.32, перевірте документацію для цієї версії Kubernetes.
API
Група API resource.k8s.io/v1beta1 надає наступні типи:
- ResourceClaim
- Визначає запит на доступ до ресурсів у кластері для використання робочими навантаженнями. Наприклад, якщо робоче навантаження потребує пристрою прискорювача з певними властивостями, саме так виражається цей запит. Розділ статусу відстежує, чи було виконано цей запит і які конкретні ресурси було виділено.
- ResourceClaimTemplate
- Визначає специфікацію та деякі метадані для створення ResourceClaims. Створюється користувачем під час розгортання робочого навантаження. Kubernetes автоматично створює та видаляє ResourceClaims для кожного Podʼа.
- DeviceClass
- Містить заздалегідь визначені критерії вибору для певних пристроїв та їх конфігурацію. DeviceClass створюється адміністратором кластера під час встановлення драйвера ресурсів. Кожен запит на виділення пристрою в ResourceClaim повинен посилатися на один конкретний DeviceClass.
- ResourceSlice
- Використовується драйверами DEA для публікації інформації про ресурси, які доступні у кластері.
Всі параметри які використовуються для вибору пристроїв визначаються ResourceClaim та DeviceClass за вбудованими типами. Параметри конфігурації можна вбудувати тут. Який параметр є валідним визначається драйвером DRA, Kubernetes лише передає їх без їх інтерпретації.
PodSpec core/v1 визначає ResourceClaims, які потрібні для Podʼа в полі resourceClaims. Записи в цьому списку посилаються або на ResourceClaim, або на ResourceClaimTemplate. При посиланні на ResourceClaim всі Podʼи, які використовують цей PodSpec (наприклад, всередині Deployment або StatefulSet), спільно використовують один екземпляр ResourceClaim. При посиланні на ResourceClaimTemplate, кожен Pod отримує свій власний екземпляр.
Список resources.claims для ресурсів контейнера визначає, чи отримує контейнер доступ до цих екземплярів ресурсів, що дозволяє спільне використання ресурсів між одним або кількома контейнерами.
Нижче наведено приклад для умовного драйвера ресурсів. Для цього Podʼа буде створено два обʼєкти ResourceClaim, і кожен контейнер отримає доступ до одного з них.
apiVersion: resource.k8s.io/v1beta1
kind: DeviceClass
name: resource.example.com
spec:
selectors:
- cel:
expression: device.driver == "resource-driver.example.com"
---
apiVersion: resource.k8s.io/v1beta1
kind: ResourceClaimTemplate
metadata:
name: large-black-cat-claim-template
spec:
spec:
devices:
requests:
- name: req-0
deviceClassName: resource.example.com
selectors:
- cel:
expression: |-
device.attributes["resource-driver.example.com"].color == "black" &&
device.attributes["resource-driver.example.com"].size == "large"
–--
apiVersion: v1
kind: Pod
metadata:
name: pod-with-cats
spec:
containers:
- name: container0
image: ubuntu:20.04
command: ["sleep", "9999"]
resources:
claims:
- name: cat-0
- name: container1
image: ubuntu:20.04
command: ["sleep", "9999"]
resources:
claims:
- name: cat-1
resourceClaims:
- name: cat-0
resourceClaimTemplateName: large-black-cat-claim-template
- name: cat-1
resourceClaimTemplateName: large-black-cat-claim-template
Планування
Планувальник відповідає за виділення ресурсів для ResourceClaim, коли Pod потребує їх. Він робить це, отримуючи повний список доступних ресурсів з обʼєктів ResourceSlice, відстежуючи, які з цих ресурсів вже були виділені наявним ResourceClaim, а потім вибираючи з тих ресурсів, що залишилися.
Єдиний тип підтримуваних ресурсів зараз — це пристрої. Пристрій має імʼя та кілька атрибутів та можливостей. Вибір пристроїв здійснюється за допомогою виразів CEL, які перевіряють ці атрибути та можливості. Крім того, набір вибраних пристроїв також може бути обмежений наборами, які відповідають певним обмеженням.
Обраний ресурс фіксується у статусі ResourceClaim разом з будь-якими вендор-специфічними налаштуваннями, тому коли Pod збирається запуститися на вузлі, драйвер ресурсу на вузлі має всю необхідну інформацію для підготовки ресурсу.
За допомогою структурованих параметрів планувальник може приймати рішення без спілкування з будь-якими драйверами ресурсів DRA. Він також може швидко планувати кілька Podʼів, зберігаючи інформацію про виділення ресурсів для ResourceClaim у памʼяті та записуючи цю інформацію в обʼєкти ResourceClaim у фоні, одночасно з привʼязкою Podʼа до вузла.
Моніторинг ресурсів
Kubelet надає службу gRPC для забезпечення виявлення динамічних ресурсів запущених Podʼів. Для отримання додаткової інформації про точки доступу gRPC дивіться звіт про виділення ресурсів.
Попередньо заплановані Podʼи
Коли ви, або інший клієнт API, створюєте Pod із вже встановленим spec.nodeName, планувальник пропускається. Якщо будь-який ResourceClaim, потрібний для цього Podʼа, ще не існує, не виділений або не зарезервований для Podʼа, то kubelet не зможе запустити Pod і періодично перевірятиме це, оскільки ці вимоги можуть бути задоволені пізніше.
Така ситуація також може виникнути, коли підтримка динамічного виділення ресурсів не була увімкнена в планувальнику на момент планування Podʼа (різниця версій, конфігурація, feature gate і т. д.). kube-controller-manager виявляє це і намагається зробити Pod працюючим, шляхом отримання потрібних ResourceClaims. Однак, це працює якщо вони були виділені планувальником для якогось іншого podʼа.
Краще уникати цього оминаючи планувальник, оскільки Pod, який призначений для вузла, блокує нормальні ресурси (ОЗП, ЦП), які потім не можуть бути використані для інших Podʼів, поки Pod є застряглим. Щоб запустити Pod на певному вузлі, при цьому проходячи через звичайний потік планування, створіть Pod із селектором вузла, який точно відповідає бажаному вузлу:
apiVersion: v1
kind: Pod
metadata:
name: pod-with-cats
spec:
nodeSelector:
kubernetes.io/hostname: назва-призначеного-вузла
...
Можливо, ви також зможете змінити вхідний Pod під час допуску, щоб скасувати поле .spec.nodeName і використовувати селектор вузла замість цього.
Адміністративний доступ
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [alpha] (стандартно увімкнено: false)Ви можете позначити запит у ResourceClaim або ResourceClaimTemplate як такий, що має привілейовані можливості. Запит з правами адміністратора надає доступ до пристроїв, які використовуються, і може увімкнути додаткові дозволи, якщо зробити пристрій доступним у контейнері:
apiVersion: resource.k8s.io/v1beta1
kind: ResourceClaimTemplate
metadata:
name: large-black-cat-claim-template
spec:
spec:
devices:
requests:
- name: req-0
deviceClassName: resource.example.com
adminAccess: true
Якщо цю функцію вимкнено, поле adminAccess буде видалено автоматично при створенні такої вимоги до ресурсу.
Доступ адміністратора є привілейованим режимом, який не слід надавати звичайним користувачам у багатокористувацькому кластері. Адміністратори кластера можуть обмежити використання цієї функції, встановивши політику перевірки допуску, подібну до наступного прикладу. Адміністратори кластера повинні адаптувати принаймні імена і замінити "dra.example.com".
# Дозвіл на використання доступу адміністратора надається лише у просторах імен, які мають мітку
# "admin-access.dra.example.com". Інші способи прийняття цього рішення
# також можливі.
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionPolicy
metadata:
name: resourceclaim-policy.dra.example.com
spec:
failurePolicy: Fail
matchConstraints:
resourceRules:
- apiGroups: ["resource.k8s.io"]
apiVersions: ["v1alpha3", "v1beta1"]
operations: ["CREATE", "UPDATE"]
resources: ["resourceclaims"]
validations:
- expression: '! object.spec.devices.requests.exists(e, has(e.adminAccess) && e.adminAccess)'
reason: Forbidden
messageExpression: '"admin access to devices not enabled"'
---
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionPolicyBinding
metadata:
name: resourceclaim-binding.dra.example.com
spec:
policyName: resourceclaim-policy.dra.example.com
validationActions: [Deny]
matchResources:
namespaceSelector:
matchExpressions:
- key: admin-access.dra.example.com
operator: DoesNotExist
---
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionPolicy
metadata:
name: resourceclaimtemplate-policy.dra.example.com
spec:
failurePolicy: Fail
matchConstraints:
resourceRules:
- apiGroups: ["resource.k8s.io"]
apiVersions: ["v1alpha3", "v1beta1"]
operations: ["CREATE", "UPDATE"]
resources: ["resourceclaimtemplates"]
validations:
- expression: '! object.spec.spec.devices.requests.exists(e, has(e.adminAccess) && e.adminAccess)'
reason: Forbidden
messageExpression: '"admin access to devices not enabled"'
---
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionPolicyBinding
metadata:
name: resourceclaimtemplate-binding.dra.example.com
spec:
policyName: resourceclaimtemplate-policy.dra.example.com
validationActions: [Deny]
matchResources:
namespaceSelector:
matchExpressions:
- key: admin-access.dra.example.com
operator: DoesNotExist
Статус пристрою ResourceClaim
Драйвери можуть повідомляти дані про стан конкретного пристрою для кожного виділеного пристрою у вимозі на ресурс. Наприклад, IP-адреси, призначені пристрою мережевого інтерфейсу, можуть бути вказані у статусі ResourceClaim.
Драйвери встановлюють статус, точність інформації залежить від реалізації цих драйверів DRA. Тому стан пристрою, про який повідомляється, не завжди може відображати зміни стану пристрою в реальному часі.
Якщо цю функцію вимкнено, це поле автоматично очищується при збереженні ResourceClaim.
Статус пристрою в ResourceClaim підтримується, коли з драйвера DRA можна оновити існуючий ResourceClaim, в якому встановлено поле status.devices.
Увімкнення динамічного виділення ресурсів
Динамічне виділення ресурсів є бета-функцією, яка стандартно вимкнена, та увімкнена коли увімкнуто функціональну можливість DynamicResourceAllocation та групу API resource.k8s.io/v1beta1. Для отримання деталей щодо цього дивіться параметри kube-apiserver --feature-gates та --runtime-config. Також варто увімкнути цю функцію в kube-scheduler, kube-controller-manager та kubelet.
Коли драйвер ресурсу повідомляє про стан пристроїв, то слід увімкнути функцію DRAResourceClaimDeviceStatus на додаток до DynamicResourceAllocation.
Швидка перевірка того, чи підтримує кластер Kubernetes цю функцію, полягає у виведенні обʼєктів DeviceClass за допомогою наступної команди:
kubectl get deviceclasses
Якщо ваш кластер підтримує динамічне виділення ресурсів, відповідь буде або список обʼєктів DeviceClass, або:
No resources found
Якщо це не підтримується, буде виведено помилку:
error: the server doesn't have a resource type "deviceclasses"
Типова конфігурація kube-scheduler вмикає втулок "DynamicResources" лише в разі увімкнення функціональної можливості та при використанні конфігурації API v1. Налаштування конфігурації може змінюватися, щоб включити його.
Крім увімкнення функції в кластері, також потрібно встановити драйвер ресурсів. Для отримання додаткової інформації звертайтеся до документації драйвера.
Увімкнення адміністративного доступу
Адміністративний доступ є альфа-функцією і вмикається лише тоді, коли у kube-apiserver та kube-планувальнику увімкнено функціональну можливість DRAAdminAccess.
Увімкнення Device Status
ResourceClaim Device Status є альфа-функцією і вмикається лише тоді, коли функціональну можливість DRAResourceClaimDeviceStatus увімкнено у kube-apiserver.
Що далі
- Для отримання додаткової інформації про дизайн дивіться KEP: Dynamic Resource Allocation with Structured Parameters.
10.9 - Налаштування продуктивності планувальника
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.14 [beta]kube-scheduler — стандартний планувальник для Kubernetes. Він відповідає за розміщення Podʼів на вузлах кластера.
Вузли кластера, які відповідають вимогам планування Podʼа, називаються відповідними вузлами для Podʼа. Планувальник знаходить відповідні вузли для Podʼа, а потім виконує набір функцій для оцінки цих вузлів, вибираючи вузол з найвищим балом серед відповідних для запуску Podʼа. Планувальник потім повідомляє API-серверу про це рішення в процесі, що називається звʼязування.
На цій сторінці пояснюються оптимізації налаштування продуктивності, які є актуальними для великих кластерів Kubernetes.
У великих кластерах ви можете налаштувати роботу планувальника, збалансовуючи результати планування між часом відгуку (нові Podʼи розміщуються швидко) та точністю (планувальник рідко приймає погані рішення про розміщення).
Ви можете налаштувати це налаштування через параметр kube-scheduler percentageOfNodesToScore. Це налаштування KubeSchedulerConfiguration визначає поріг для планування вузлів у вашому кластері.
Налаштування порога
Опція percentageOfNodesToScore приймає цілі числові значення від 0 до 100. Значення 0 є спеціальним числом, яке позначає, що kube-scheduler повинен використовувати типовав вбудоване значення. Якщо ви встановлюєте percentageOfNodesToScore більше 100, kube-scheduler діє так, ніби ви встановили значення 100.
Щоб змінити значення, відредагуйте файл конфігурації kube-scheduler і перезапустіть планувальник. У багатьох випадках файл конфігурації можна знайти за шляхом /etc/kubernetes/config/kube-scheduler.yaml.
Після внесення цих змін ви можете виконати
kubectl get pods -n kube-system | grep kube-scheduler
щоб перевірити, що компонент kube-scheduler працює належним чином.
Поріг оцінки вузлів
Для поліпшення продуктивності планування kube-scheduler може припинити пошук відповідних вузлів, як тільки він знайде їх достатню кількість. У великих кластерах це заощаджує час порівняно з підходом, який би враховував кожен вузол.
Ви вказуєте поріг для того, яка кількість вузлів є достатньою, у відсотках від усіх вузлів у вашому кластері. Kube-scheduler перетворює це в ціле число вузлів. Під час планування, якщо kube-scheduler визначив достатню кількість відповідних вузлів, щоб перевищити налаштований відсоток, він припиняє пошук додаткових відповідних вузлів і переходить до фази оцінки.
У розділі Як планувальник проходиться по вузлах детально описано цей процес.
Стандартний поріг
Якщо ви не вказуєте поріг, Kubernetes розраховує значення за допомогою лінійної формули, яка дає 50% для кластера зі 100 вузлами та 10% для кластера з 5000 вузлів. Нижня межа для автоматичного значення — 5%.
Це означає, що kube-scheduler завжди оцінює принаймні 5% вашого кластера, незалежно від розміру кластера, якщо ви явно не встановили percentageOfNodesToScore менше ніж 5.
Якщо ви хочете, щоб планувальник оцінював всі вузли у вашому кластері, встановіть percentageOfNodesToScore на 100.
Приклад
Нижче наведено приклад конфігурації, яка встановлює percentageOfNodesToScore на 50%.
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
algorithmSource:
provider: DefaultProvider
...
percentageOfNodesToScore: 50
Налаштування percentageOfNodesToScore
percentageOfNodesToScore повинен бути значенням від 1 до 100, а стандартне значення розраховується на основі розміру кластера. Також існує зашите мінімальне значення в 100 вузлів.
Примітка:
У кластерах з менш ніж 100 можливими вузлами планувальник все ще перевіряє всі вузли, тому що недостатньо можливих вузлів для того, щоб рано зупинити пошук планувальника.
У великому кластері, якщо ви встановите низьке значення для percentageOfNodesToScore, ваші зміни майже не матимуть ефекту, зі схожої причини.
Якщо у вашому кластері кілька сотень вузлів або менше, залиште цю опцію конфігурації у стандартному значенні. Ймовірно, внесення змін не суттєво покращить продуктивність планувальника.
Важливою деталлю, яку слід врахувати при встановленні цього значення, є те, що при меншій кількості вузлів у кластері, які перевіряються на придатність, деякі вузли не надсилаються для оцінки для вказаного Podʼа. В результаті вузол, який можливо міг би набрати більший бал для запуску вказаного Podʼа, може навіть не надійти до фази оцінки. Це призведе до менш ідеального розміщення Podʼа.
Вам слід уникати встановлення percentageOfNodesToScore дуже низьким, щоб kube-scheduler не часто приймав неправильні рішення щодо розміщення Podʼа. Уникайте встановлення відсотка нижче 10%, якщо продуктивність планувальника критична для вашого застосунку та оцінка вузлів не є важливою. Іншими словами, ви віддаєте перевагу запуску Podʼа на будь-якому вузлі, який буде придатним.
Як планувальник проходиться по вузлах
Цей розділ призначений для тих, хто бажає зрозуміти внутрішні деталі цієї функції.
Щоб всі вузли кластера мали рівні можливості бути враховані для запуску Podʼів, планувальник проходиться по вузлах по колу. Ви можете уявити, що вузли знаходяться у масиві. Планувальник починає з початку масиву вузлів і перевіряє придатність вузлів, поки не знайде достатню кількість відповідних вузлів, як вказано у percentageOfNodesToScore. Для наступного Podʼа планувальник продовжує з точки в масиві вузлів, де він зупинився при перевірці придатності вузлів для попереднього Podʼа.
Якщо вузли знаходяться в кількох зонах, планувальник проходиться по вузлах у різних зонах, щоб забезпечити, що враховуються вузли з різних зон. Наприклад, розгляньте шість вузлів у двох зонах:
Zone 1: Node 1, Node 2, Node 3, Node 4
Zone 2: Node 5, Node 6
Планувальник оцінює придатність вузлів у такому порядку:
Node 1, Node 5, Node 2, Node 6, Node 3, Node 4
Після переходу усіх вузлів він повертається до Вузла 1.
Що далі
- Перегляньте довідку конфігурації kube-scheduler (v1)
10.10 - Пакування ресурсів
У scheduling-plugin NodeResourcesFit kube-scheduler є дві стратегії оцінювання, які підтримують пакування ресурсів: MostAllocated та RequestedToCapacityRatio.
Включення пакування ресурсів за допомогою стратегії MostAllocated
Стратегія MostAllocated оцінює вузли на основі використання ресурсів, віддаючи перевагу тим, у яких використання вище. Для кожного типу ресурсів ви можете встановити коефіцієнт, щоб змінити його вплив на оцінку вузла.
Щоб встановити стратегію MostAllocated для втулка NodeResourcesFit, використовуйте конфігурацію планувальника подібну до наступної:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- args:
scoringStrategy:
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
- name: intel.com/foo
weight: 3
- name: intel.com/bar
weight: 3
type: MostAllocated
name: NodeResourcesFit
Щоб дізнатися більше про інші параметри та їх стандартну конфігурацію, див. документацію API для NodeResourcesFitArgs.
Включення пакування ресурсів за допомогою стратегії RequestedToCapacityRatio
Стратегія RequestedToCapacityRatio дозволяє користувачам вказати ресурси разом з коефіцієнтами для кожного ресурсу для оцінювання вузлів на основі відношення запиту до потужності. Це дозволяє користувачам пакувати розширені ресурси, використовуючи відповідні параметри для покращення використання рідкісних ресурсів у великих кластерах. Вона віддає перевагу вузлам згідно з налаштованою функцією виділених ресурсів. Поведінку RequestedToCapacityRatio в функції оцінювання NodeResourcesFit можна керувати за допомогою поля scoringStrategy. У межах поля scoringStrategy ви можете налаштувати два параметри: requestedToCapacityRatio та resources. Параметр shape в requestedToCapacityRatio дозволяє користувачу налаштувати функцію як найменш чи найбільш затребувані на основі значень utilization та score. Параметр resources охоплює як name ресурсу, що оцінюється, так і weight для кожного ресурсу.
Нижче наведено приклад конфігурації, яка встановлює поведінку пакування ресурсів intel.com/foo та intel.com/bar за допомогою поля requestedToCapacityRatio.
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- args:
scoringStrategy:
resources:
- name: intel.com/foo
weight: 3
- name: intel.com/bar
weight: 3
requestedToCapacityRatio:
shape:
- utilization: 0
score: 0
- utilization: 100
score: 10
type: RequestedToCapacityRatio
name: NodeResourcesFit
Посилання на файл KubeSchedulerConfiguration з прапорцем kube-scheduler --config=/path/to/config/file передасть конфігурацію планувальнику.
Щоб дізнатися більше про інші параметри та їх стандартну конфігурацію, див. документацію API для NodeResourcesFitArgs.
Налаштування функції оцінювання
Параметр shape використовується для вказівки поведінки функції RequestedToCapacityRatio.
shape:
- utilization: 0
score: 0
- utilization: 100
score: 10
Вищезазначені аргументи надають вузлу score 0, якщо utilization дорівнює 0%, та 10 для utilization 100%, що дозволяє пакування ресурсів. Щоб увімкнути найменш затребувані значення оцінки, значення оцінки має бути оберненим наступним чином.
shape:
- utilization: 0
score: 10
- utilization: 100
score: 0
resources є необовʼязковим параметром, який типово має значення:
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
Він може бути використаний для додавання розширених ресурсів наступними чином:
resources:
- name: intel.com/foo
weight: 5
- name: cpu
weight: 3
- name: memory
weight: 1
Параметр weight є необовʼязковим та встановлений у 1, якщо він не вказаний. Також, він може бути встановлений у відʼємне значення.
Оцінка вузла для розподілу потужностей
Цей розділ призначений для тих, хто бажає зрозуміти внутрішні деталі цієї функціональності. Нижче наведено приклад того, як обчислюється оцінка вузла для заданого набору значень.
Запитані ресурси:
intel.com/foo : 2
memory: 256MB
cpu: 2
Коефіцієнти ресурсів:
intel.com/foo : 5
memory: 1
cpu: 3
FunctionShapePoint {{0, 0}, {100, 10}}
Специфікація вузла 1:
Available:
intel.com/foo: 4
memory: 1 GB
cpu: 8
Used:
intel.com/foo: 1
memory: 256MB
cpu: 1
Оцінка вузла:
intel.com/foo = resourceScoringFunction((2+1),4)
= (100 - ((4-3)*100/4)
= (100 - 25)
= 75 # запитано + використано = 75% * доступно
= rawScoringFunction(75)
= 7 # floor(75/10)
memory = resourceScoringFunction((256+256),1024)
= (100 -((1024-512)*100/1024))
= 50 # запитано + використано = 50% * доступно
= rawScoringFunction(50)
= 5 # floor(50/10)
cpu = resourceScoringFunction((2+1),8)
= (100 -((8-3)*100/8))
= 37.5 # запитано + використано = 37.5% * доступно
= rawScoringFunction(37.5)
= 3 # floor(37.5/10)
NodeScore = ((7 * 5) + (5 * 1) + (3 * 3)) / (5 + 1 + 3)
= 5
Специфікація вузла 2:
Available:
intel.com/foo: 8
memory: 1GB
cpu: 8
Used:
intel.com/foo: 2
memory: 512MB
cpu: 6
Оцінка вузла:
intel.com/foo = resourceScoringFunction((2+2),8)
= (100 - ((8-4)*100/8)
= (100 - 50)
= 50
= rawScoringFunction(50)
= 5
memory = resourceScoringFunction((256+512),1024)
= (100 -((1024-768)*100/1024))
= 75
= rawScoringFunction(75)
= 7
cpu = resourceScoringFunction((2+6),8)
= (100 -((8-8)*100/8))
= 100
= rawScoringFunction(100)
= 10
NodeScore = ((5 * 5) + (7 * 1) + (10 * 3)) / (5 + 1 + 3)
= 7
Що далі
- Дізнайтеся більше про фреймворк планування
- Дізнайтеся більше про конфігурацію планувальника
10.11 - Пріоритет та Випередження Podʼів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.14 [stable]Podʼи можуть мати пріоритети. Пріоритети вказують на порівняну важливість одних Podʼів порівняно з іншими. Якщо Pod не може бути запланованим, планувальник намагається випередити (виселити) Pod з меншим пріоритетом, щоб зробити можливим планування Podʼів, які перебуваються в стані очікування.
Попередження:
У кластері, де не всі користувачі є довіреними, зловмисник може створити Podʼи з найвищими можливими пріоритетами, що призведе до виселення інших Podʼів або неможливості їх планування. Адміністратор може використовувати ResourceQuota, щоб запобігти користувачам створювати Podʼи з високими пріоритетами.
Детальніше дивіться типові обмеження в споживанні Priority Class.
Як використовувати пріоритет та випередження
Для використання пріоритету та випередження:
Додайте один чи декілька PriorityClasses.
Створіть Podʼи з параметром
priorityClassName, встановленим на один з доданих PriorityClasses. Звісно, вам не потрібно створювати Podʼи безпосередньо; зазвичай ви додаєтеpriorityClassNameдо шаблону Podʼа обʼєкта колекції, такого як Deployment.
Продовжуйте читати для отримання додаткової інформації про ці кроки.
Примітка:
Kubernetes вже поставляється з двома PriorityClasses:system-cluster-critical та system-node-critical. Ці спільні класи використовуються для забезпечення того, що критичні компоненти завжди плануються першими.PriorityClass
PriorityClassє є обʼєктом, що не належить до простору імен, і визначає зіставлення імені класу пріоритету з цілим значенням пріоритету. Імʼя вказується в полі name метаданих обʼєкта PriorityClass. Значення вказується в обовʼязковому полі value. Чим вище значення, тим вищий пріоритет. Імʼя обʼєкта PriorityClass повинно бути дійсним піддоменом DNS, і воно не може мати префікс system-.
Обʼєкт PriorityClass може мати будь-яке 32-розрядне ціле значення, яке менше або дорівнює 1 мільярду. Це означає, що діапазон значень для обʼєкта PriorityClass становить від -2147483648 до 1000000000 включно. Більші числа зарезервовані для вбудованих PriorityClass, які представляють критичні системні Podʼів. Адміністратор кластера повинен створити один обʼєкт PriorityClass для кожного такого зіставлення.
PriorityClass також має два необовʼязкові поля: globalDefault та description. Поле globalDefault вказує, що значення цього класу пріоритету повинно використовуватися для Podʼів без priorityClassName. В системі може існувати лише один обʼєкт PriorityClass з globalDefault, встановленим в true. Якщо обʼєкт PriorityClass з globalDefault не встановлено, пріоритет Podʼів без priorityClassName буде рівний нулю.
Поле description є довільним рядком. Воно призначене для сповіщення користувачів кластера про те, коли вони повинні використовувати цей PriorityClass.
Примітки щодо PodPriority та наявних кластерів
Якщо ви оновлюєте наявний кластер без цієї функції, пріоритет ваших поточних Podʼів фактично дорівнює нулю.
Додавання PriorityClass з
globalDefault, встановленим вtrue, не змінює пріоритети поточних Podʼів. Значення такого PriorityClass використовується тільки для Podʼів, створених після додавання PriorityClass.Якщо ви видаляєте PriorityClass, поточні Podʼи, які використовують імʼя видаленого PriorityClass, залишаються незмінними, але ви не можете створювати більше Podʼів, які використовують імʼя видаленого PriorityClass.
Приклад PriorityClass
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."
Невипереджаючий PriorityClass
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [stable]Podʼи з preemptionPolicy: Never будуть розміщені в черзі планування перед Podʼами з меншим пріоритетом, але вони не можуть випереджати інші Podʼи. Pod, який очікує на планування, залишиться в черзі планування, доки не буде достатньо вільних ресурсів, і його можна буде запланувати. Невипереджаючі Podʼи, подібно до інших Podʼів, підлягають відстроченню планування. Це означає, що якщо планувальник спробує запланувати ці Podʼи, і вони не можуть бути заплановані, спроби їх планування будуть здійснені з меншою частотою, що дозволяє іншим Podʼам з нижчим пріоритетом бути запланованими перед ними.
Невипереджаючі Podʼи все ще можуть бути випереджені іншими, Podʼами з високим пріоритетом. Типове значення preemptionPolicy — PreemptLowerPriority, що дозволяє Podʼам цього PriorityClass випереджати Podʼи з нижчим пріоритетом (бо це поточна типова поведінка). Якщо preemptionPolicy встановлено в Never, Podʼи в цьому PriorityClass будуть невипереджаючими.
Прикладом використання є робочі навантаження для роботи з дослідження даних. Користувач може надіслати завдання, якому він хоче дати пріоритет перед іншими робочими навантаженнями, але не бажає скасувати поточне робоче навантаження, випереджаючи запущені Podʼи. Завдання з високим пріоритетом із preemptionPolicy: Never буде заплановано перед іншими Podʼами в черзі, як тільки будуть наявні вільні ресурси кластера.
Приклад невипереджаючого PriorityClass
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority-nonpreempting
value: 1000000
preemptionPolicy: Never
globalDefault: false
description: "This priority class will not cause other pods to be preempted."
Пріоритет Podʼа
Після того, як у вас є один або кілька PriorityClasses, ви можете створювати Podʼи, які вказують одне з імен цих PriorityClass у їх специфікаціях. Контролер допуску пріоритетів використовує поле priorityClassName і заповнює ціле значення пріоритету. Якщо клас пріоритету не знайдено, Pod відхиляється.
Наведений нижче YAML — це приклад конфігурації Podʼа, який використовує PriorityClass, створений у попередньому прикладі. Контролер допуску пріоритетів перевіряє специфікацію та розраховує пріоритет Podʼа як 1000000.
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
Вплив пріоритету Podʼа на порядок планування
Коли пріоритет Podʼа увімкнено, планувальник впорядковує Podʼи, що перебувають в очікуванні за їх пріоритетом, і такий Pod розташовується попереду інших очікуючих Podʼів з меншим пріоритетом в черзі планування. В результаті Pod з вищим пріоритетом може бути запланований швидше, ніж Podʼи з нижчим пріоритетом, якщо відповідні вимоги до планування виконуються. Якщо такий Pod не може бути запланований, планувальник продовжить спроби запланувати інші Podʼи з меншим пріоритетом.
Випередження
Коли Podʼи створюються, вони потрапляють у чергу та очікують на планування. Планувальник вибирає Pod з черги та намагається запланувати його на вузлі. Якщо не знайдено жодного вузла, який задовольняє всі вказані вимоги Podʼа, для очікуючого Podʼа спрацьовує логіка випередження в черзі. Назвімо очікуючий Pod P. Логіка випередження спробує знайти вузол, де видалення одного або декількох Podʼів з нижчим пріоритетом, ніж P, дозволить запланувати P на цьому вузлі. Якщо такий вузол знайдено, один або декілька Podʼів з нижчим пріоритетом будуть виселені з вузла. Після того, як Podʼи підуть, P може бути запланований на вузлі.
Інформація, доступна користувачеві
Коли Pod P випереджає один або кілька Podʼів на вузлі N, поле nominatedNodeName статусу Podʼа P встановлюється на імʼя вузла N. Це поле допомагає планувальнику відстежувати ресурси, зарезервовані для Podʼа P, і також надає користувачам інформацію про випередження в їх кластерах.
Зверніть увагу, що Pod P не обовʼязково планується на "назначений вузол". Планувальник завжди спочатку спробує "назначений вузол", перед тим як перевіряти будь-які інші вузли. Після того, як Podʼи жертви випереджуються, вони отримують свій період належної зупинки. Якщо під час очікування на завершення роботи Podʼів жертв зʼявляється інший вузол, планувальник може використати інший вузол для планування Podʼа P. В результаті поля nominatedNodeName та nodeName специфікації Podʼа не завжди збігаються. Крім того, якщо планувальник випереджає Podʼи на вузлі N, а потім прибуває Pod вищого пріоритету, ніж Pod P, планувальник може надати вузол N новому Podʼу вищого пріоритету. У такому випадку планувальник очищає nominatedNodeName Podʼа P. Цим самим планувальник робить Pod P придатним для випередження Podʼів на іншому вузлі.
Обмеження випередження
Відповідне завершення роботи жертв випередження
Коли Podʼи випереджаються, жертви отримують свій період належного завершення роботи. У них є стільки часу, скільки вказано в цьому періоді, для завершення своєї роботи та виходу. Якщо вони цього не роблять, їх робота завершується примусово. Цей період належного завершення створює проміжок часу між моментом, коли планувальник випереджає Podʼи, і моментом, коли Pod (P), який перебуває в очікування, може бути запланований на вузол (N). Тим часом планувальник продовжує планувати інші Podʼи, що чекають. Поки жертви завершують роботу самі або примусово, планувальник намагається запланувати Podʼи з черги очікування. Тому, зазвичай є проміжок часу між моментом, коли планувальник випереджає жертв, і моментом, коли Pod P стає запланований. Щоб зменшити цей проміжок, можна встановити період належного завершення для Podʼів з низьким пріоритетом на нуль або мале число.
PodDisruptionBudget підтримується, але не гарантується
PodDisruptionBudget (PDB) дозволяє власникам застосунків обмежувати кількість Podʼів реплікованого застосунку, які одночасно вимикаються через добровільні розлади. Kubernetes підтримує PDB при випередженні Podʼів, але гарантоване дотримання PDB не забезпечується. Планувальник намагається знайти жертв, PDB яких не порушується в результаті випередження, але якщо жодної такої жертви не знайдено, випередження все одно відбудеться, і Podʼи з низьким пріоритетом будуть видалені, попри порушення їх PDB.
Між-Podʼова спорідненість для Podʼів з низьким пріоритетом
Вузол розглядається для випередження тільки тоді, коли відповідь на це питання ствердна: "Якщо всі Podʼи з меншим пріоритетом, ніж очікуваний Pod, будуть видалені з вузла, чи може очікуваний Pod бути запланованим на вузлі?"
Примітка:
Випередження не обовʼязково видаляє всі Podʼи з меншим пріоритетом. Якщо очікуваний Pod може бути запланований, видаливши менше, ніж всі Podʼи з меншим пріоритетом, то видаляється лише частина Podʼів з меншим пріоритетом. З усім тим, відповідь на попереднє питання повинна бути ствердною. Якщо відповідь негативна, то вузол не розглядається для випередження.Якщо очікуваний Pod має між-Podʼову спорідненість з одним або декількома Podʼами з низьким пріоритетом на вузлі, правило між-Podʼової спорідненості не може бути виконане у відсутності цих Podʼів з низьким пріоритетом. У цьому випадку планувальник не випереджає жодних Podʼів на вузлі. Замість цього він шукає інший вузол. Планувальник може знайти відповідний вузол або може і не знайти. Немає гарантії, що очікуваний Pod може бути запланований.
Рекомендованим рішенням для цієї проблеми є створення між-Podʼової спорідненості лише для Podʼів з рівним або вищим пріоритетом.
Міжвузлове випередження
Припустимо, що вузол N розглядається для випередження, щоб запланувати очікуваний Pod P на N. Pod P може стати можливим на вузлі N лише у випадку випередження Podʼа на іншому вузлі. Ось приклад:
- Pod P розглядається для вузла N.
- Pod Q запущений на іншому вузлі в тій же зоні, що й вузол N.
- Pod P має антиспорідненість по всій зоні з Podʼом Q (з
topologyKey: topology.kubernetes.io/zone). - Інших випадків антиспорідненості між Podʼом P та іншими Podʼами в зоні немає.
- Щоб запланувати Pod P на вузлі N, Pod Q може бути випереджений, але планувальник не виконує міжвузлове випередження. Отже, Pod P буде вважатися незапланованим на вузлі N.
Якщо Pod Q буде видалено зі свого вузла, порушення антиспорідненості Podʼа буде усунено, і Pod P, можливо, можна буде запланувати на вузлі N.
Ми можемо розглянути додавання міжвузлового випередження в майбутніх версіях, якщо буде достатньо попиту і якщо ми знайдемо алгоритм з прийнятною продуктивністю.
Розвʼязання проблем
Пріоритет та випередження Podʼа можуть мати небажані побічні ефекти. Ось кілька прикладів потенційних проблем і способів їх вирішення.
Podʼи випереджаються безпідставно
Випередження видаляє наявні Podʼи з кластера в умовах недостатнього ресурсу для звільнення місця для високопріоритетних очікуваних Podsʼів. Якщо ви помилково встановили високі пріоритети для певних Podʼів, ці Podʼи можуть призвести до випередження в кластері. Пріоритет Podʼа вказується, встановленням поля priorityClassName в специфікації Podʼа. Потім ціле значення пріоритету розраховується і заповнюється у поле priority podSpec.
Щоб розвʼязати цю проблему, ви можете змінити priorityClassName для цих Podʼів, щоб використовувати класи з меншим пріоритетом, або залишити це поле порожнім. Порожній priorityClassName типово вважається нулем.
Коли Pod випереджається, для такого Podʼа будуть записані події. Випередження повинно відбуватися лише тоді, коли в кластері недостатньо ресурсів для Podʼа. У таких випадках випередження відбувається лише тоді, коли пріоритет очікуваного Podʼа (випереджаючого) вище, ніж у Podʼів жертв. Випередження не повинно відбуватися, коли немає очікуваного Podʼа, або коли очікувані Podʼи мають рівні або нижчі пріоритети, ніж у жертв. Якщо випередження відбувається в таких сценаріях, будь ласка, сповістіть про це для розвʼязання проблеми.
Podʼи випереджаються, але кандидат не планується
Коли Podʼи випереджаються, вони отримують запитаний період належного завершення, який типово становить 30 секунд. Якщо використовувані Podʼи не завершуються протягом цього періоду, вони завершуються примусово. Після того, як всі жертви зникають, Pod кандидат, може бути запланований.
Поки Pod кандидат, чекає, поки жертви зникнуть, може бути створений Pod з вищим пріоритетом, який підходить на той самий вузол. У цьому випадку планувальник запланує Pod з вищим пріоритетом замість кандидата.
Це очікувана поведінка: Pod з вищим пріоритетом повинен зайняти місце Podʼа з нижчим пріоритетом.
Podʼи з вищим пріоритетом припиняють роботу перед Podʼами з нижчим пріоритетом
Планувальник намагається знайти вузли, на яких можна запустити очікуваний Pod. Якщо вузол не знайдено, планувальник намагається видалити Podʼи з меншим пріоритетом з довільного вузла, щоб звільнити місце для очікуваного Podʼа. Якщо вузол з Podʼами низького пріоритету не може бути використаний для запуску очікуваного Podʼа, планувальник може вибрати інший вузол з Podʼами вищого пріоритету (порівняно з Podʼами на іншому вузлі) для випередження. Жертви все ще повинні мати нижчий пріоритет, ніж Pod кандидат.
Коли є доступні кілька вузлів для випередження, планувальник намагається вибрати вузол з набором Podʼів з найнижчим пріоритетом. Однак якщо такі Podʼи мають PodDisruptionBudget, який буде порушений, якщо вони будуть випереджені, то планувальник може вибрати інший вузол з Podʼами вищого пріоритету.
Коли є кілька вузлів для випередження і жоден з вищезазначених сценаріїв не застосовується, планувальник вибирає вузол з найнижчим пріоритетом.
Взаємодія між пріоритетом Podʼа та якістю обслуговування
Пріоритет Podʼа та клас QoS є двома протилежними функціями з невеликою кількістю взаємодій та без типових обмежень щодо встановлення пріоритету Podʼа на основі його класів QoS. Логіка випередження планувальника не враховує QoS при виборі цілей випередження. Випередження враховує пріоритет Podʼа і намагається вибрати набір цілей з найнижчим пріоритетом. Podʼи вищого пріоритету розглядаються для випередження лише тоді, коли видалення Podʼів з найнижчим пріоритетом не є достатнім для того, щоб дозволити планувальнику розмістити Pod кандидат, або якщо Podʼи з найнижчим пріоритетом захищені PodDisruptionBudget.
kubelet використовує пріоритет для визначення порядку Podʼів для виселення через тиск на вузол. Ви можете використовувати клас QoS для оцінки порядку, в якому ймовірно будуть виселятись Podʼи. kubelet ранжує Podʼи для виселення на основі наступних факторів:
- Чи використання, якому недостатньо ресурсів, перевищує запити
- Пріоритет Podʼа
- Обсяг використання ресурсів в порівнянні із запитами
Дивіться Вибір Podʼа для виселення kubelet для отримання додаткової інформації.
Виселення kubeletʼом через тиск на вузол не виселяє Podʼи, коли їх використання не перевищує їх запити. Якщо Pod з нижчим пріоритетом не перевищує свої запити, він не буде виселений. Інший Pod з вищим пріоритетом, який перевищує свої запити, може бути виселений.
Що далі
- Дізнайтеся про використання ResourceQuotas у звʼязці з PriorityClasses: типове обмеження споживання класу пріоритету
- Дізнайтеся про Розлади Podʼів
- Дізнайтеся про Виселення ініційоване API
- Дізнайтеся про Виселення через тиск на вузол
10.12 - Виселення внаслідок тиску на вузол
Виселення через тиск на вузол — це процес, при якому kubelet активно завершує роботу Podʼів для звільнення ресурсів на вузлах.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [beta] (стандартно увімкнено: true)Примітка:
Функція split image filesystem, яка забезпечує підтримку файлової системиcontainerfs, додає кілька нових сигналів виселення, порогів та метрик. Щоб використовувати containerfs, у випуску Kubernetes v1.32 потрібно увімкнути функціональну можливість KubeletSeparateDiskGC. Наразі підтримка файлової системи containerfs доступна лише в CRI-O (версія 1.29 або вище).The kubelet моніторить ресурси, такі як памʼять, простір на диску та i-nodeʼи файлової системи на вузлах вашого кластера. Коли один або декілька з цих ресурсів досягають певних рівнів використання, kubelet може проактивно припинити роботу одного або кількох Podʼів на вузлі, щоб відновити ресурси та запобігти голодуванню.
Під час виселення внаслідок тиску на вузол, kubelet встановлює фазу для вибраних Podʼів в значення Failed та завершує роботу Podʼа.
Виселення внаслідок тиску на вузол, не є тим самим, що й виселення, ініційоване API.
kubelet не дотримується вашого налаштованого PodDisruptionBudget або параметру terminationGracePeriodSeconds Podʼа. Якщо ви використовуєте порогові значення мʼякого виселення, kubelet дотримується вашого налаштованого eviction-max-pod-grace-period. Якщо ви використовуєте порогові значення жорсткого виселення, kubelet використовує граничний період 0s (негайне завершення) для завершення роботи Podʼа.
Самовідновлення
kubelet намагається відновлювати ресурси на рівні вузла перед тим, як він завершує роботу Podʼів кінцевих користувачів. Наприклад, він видаляє не використані образи контейнерів, коли дискових ресурсів недостатньо.
Якщо Podʼи управляються обʼєктом workload (таким як StatefulSet або Deployment), який заміщує несправні Podʼи, панель управління (kube-controller-manager) створює нові Podʼи на місці виселених Podʼів.
Самовідновлення статичних Podʼів
Якщо ви запускаєте статичний Pod на вузлі, який перебуває під тиском нестачі ресурсів, kubelet може виселити цей статичний Pod. Потім kubelet намагається створити заміну, оскільки статичні Podʼи завжди представляють намір запустити Pod на цьому вузлі.
Kubelet враховує пріоритет статичного Podʼа при створенні заміни. Якщо маніфест статичного Podʼа вказує низький пріоритет, і в межах панелі управління кластера визначені Podʼи з вищим пріоритетом, і вузол перебуває під тиском нестачі ресурсів, то kubelet може не мати можливості звільнити місце для цього статичного Podʼа. Kubelet продовжує намагатися запустити всі статичні Podʼи навіть тоді, коли на вузлі є тиск на ресурси.
Сигнали та пороги виселення
Kubelet використовує різні параметри для прийняття рішень щодо виселення, такі як:
- Сигнали виселення
- Пороги виселення
- Інтервали моніторингу
Сигнали виселення
Сигнали виселення — це поточний стан певного ресурсу в конкретний момент часу. Kubelet використовує сигнали виселення для прийняття рішень про виселення, порівнюючи їх з порогами виселення, які є мінімальною кількістю ресурсу, яка повинна бути доступна на вузлі.
Лubelet використовує такі сигнали виселення:
| Сигнал виселення | Опис | Linux Only |
|---|---|---|
memory.available | memory.available := node.status.capacity[memory] - node.stats.memory.workingSet | |
nodefs.available | nodefs.available := node.stats.fs.available | |
nodefs.inodesFree | nodefs.inodesFree := node.stats.fs.inodesFree | • |
imagefs.available | imagefs.available := node.stats.runtime.imagefs.available | |
imagefs.inodesFree | imagefs.inodesFree := node.stats.runtime.imagefs.inodesFree | • |
containerfs.available | containerfs.available := node.stats.runtime.containerfs.available | |
containerfs.inodesFree | containerfs.inodesFree := node.stats.runtime.containerfs.inodesFree | • |
pid.available | pid.available := node.stats.rlimit.maxpid - node.stats.rlimit.curproc | • |
У цій таблиці стовпець Опис показує, як kubelet отримує значення сигналу. Кожен сигнал підтримує відсоткове або літеральне значення. Kubelet обчислює відсоткове значення відносно загальної потужності, повʼязаної з сигналом.
Сигнали памʼяті
На вузлах Linux, значення для memory.available походить з cgroupfs замість таких інструментів, як free -m. Це важливо, оскільки free -m не працює у контейнері, і якщо користувачі використовують можливість виділення ресурсів для вузла, рішення про відсутність ресурсів
приймаються локально для Podʼа кінцевого користувача, який є частиною ієрархії cgroup, а також кореневого вузла. Цей скрипт або скрипт cgroupv2 відтворює той самий набір кроків, які kubelet виконує для обчислення memory.available. Kubelet виключає зі свого обчислення inactive_file (кількість байтів памʼяті, що резервується файлами, у списку неактивних LRU) на основі припущення, що памʼять можна вилучити під час натиску.
На Windows-вузлах значення memory.available отримується з глобального рівня комітів памʼяті вузла (запитується через системний виклик GetPerformanceInfo()) шляхом віднімання глобального значення CommitTotal від CommitLimit вузла. Зверніть увагу, що значення CommitLimit може змінюватися, якщо змінюється розмір файлу підкачки вузла!
Сигнали файлової системи
Kubelet розпізнає три конкретні ідентифікатори файлової системи, які можна використовувати зі сигналами виселення (<identifier>.inodesFree або <identifier>.available):
nodefs: Основна файлова система вузла, використовується для локальних дискових томів, томівemptyDir, які не підтримуються памʼяттю, зберігання логів, ефемерного зберігання та іншого. Наприклад,nodefsмістить/var/lib/kubelet.imagefs: Опціональна файлова система, яку середовище виконання контейнерів може використовувати для зберігання образів контейнерів (що є тільки для читання) і записуваних шарів контейнерів.containerfs: Опціональна файлова система, яку середовище виконання контейнерів може використовувати для зберігання записуваних шарів. Подібно до основної файлової системи (див.nodefs), вона використовується для зберігання локальних дискових томів, томівemptyDir, які не підтримуються памʼяттю, зберігання логів і ефемерного зберігання, за винятком образів контейнерів. Коли використовуєтьсяcontainerfs, файлова системаimagefsможе бути розділена так, щоб зберігати лише образи (шари тільки для читання) і більше нічого.
Таким чином, kubelet зазвичай підтримує три варіанти файлових систем для контейнерів:
Все зберігається на єдиній файловій системі
nodefs, також відомій як "rootfs" або просто "root", і немає окремої файлової системи для образів.Зберігання контейнерів (див.
nodefs) на окремому диску, аimagefs(записувані та лише для читання шари) відокремлені від кореневої файлової системи. Це часто називають "split disk" (або "separate disk") файловою системою.Файлова система контейнерів
containerfs(така ж, якnodefs, плюс записувані шари) знаходиться на root, а образи контейнерів (шари лише для читання) зберігаються на окремійimagefs. Це часто називають "split image" файловою системою.
Kubelet спробує автоматично виявити ці файлові системи з їхньою поточною конфігурацією безпосередньо з підсистеми контейнерів і ігноруватиме інші локальні файлові системи вузла.
Kubelet не підтримує інші файлові системи контейнерів або конфігурації зберігання і наразі не підтримує кілька файлових систем для образів і контейнерів.
Застарілі функції збору сміття kubelet
Деякі функції сміттєзбірника kubelet застаріли на користь процесу виселення:
| Наявний Прапорець | Обґрунтування |
|---|---|
--maximum-dead-containers | застаріло, коли старі журнали зберігаються поза контекстом контейнера |
--maximum-dead-containers-per-container | застаріло, коли старі журнали зберігаються поза контекстом контейнера |
--minimum-container-ttl-duration | застаріло, коли старі журнали зберігаються поза контекстом контейнера |
Пороги виселення
Ви можете вказати спеціальні пороги виселення для kubelet, які він буде використовувати під час прийняття рішень про виселення. Ви можете налаштувати мʼякі та жорсткі пороги виселення.
Пороги виселення мають формат [eviction-signal][operator][quantity], де:
eviction-signal— це сигнал виселення, який використовується.operator— це оператор відношення, який ви хочете використати, наприклад,<(менше ніж).quantity— це кількість порогу виселення, наприклад,1Gi. Значенняquantityповинно відповідати представленню кількості, яке використовується в Kubernetes. Ви можете використовувати як літеральні значення, так і відсотки (%).
Наприклад, якщо вузол має загальний обсяг памʼяті 10ГіБ і ви хочете спровокувати виселення, якщо доступна памʼять знизиться до менше ніж 1ГіБ, ви можете визначити поріг виселення як memory.available<10% або memory.available<1Gi (використовувати обидва варіанти одночасно не можна).
Мʼякі пороги виселення
Мʼякий поріг виселення поєднує в собі поріг виселення з обовʼязковим пільговим періодом, вказаним адміністратором. Kubelet не виселяє Podʼи до закінчення пільгового періоду. Kubelet повертає помилку при запуску, якщо ви не вказали пільговий період.
Ви можете вказати як пільговий період для мʼякого порогу виселення, так і максимально дозволений пільговий період для завершення Podʼів, який kubelet використовуватиме під час виселення. Якщо ви вказали максимально дозволений пільговий період і мʼякий поріг виселення досягнутий, kubelet використовує менший із двох пільгових періодів. Якщо ви не вказали максимально дозволений пільговий період, kubelet негайно завершує роботу виселених Podʼів без очікування належного завершення їх роботи.
Ви можете використовувати наступні прапорці для налаштування мʼяких порогів виселення:
eviction-soft: Набір порогів виселення, наприклад,memory.available<1.5Gi, які можуть спровокувати виселення Podʼів, якщо вони утримуються протягом вказаного пільгового періоду.eviction-soft-grace-period: Набір пільгових періодів для виселення, наприклад,memory.available=1m30s, які визначають, як довго мʼякий поріг виселення повинен утримуватися, перш ніж буде спровоковане виселення Podʼа.eviction-max-pod-grace-period: Максимально дозволений пільговий період (у секундах) для використання при завершенні Podʼів у відповідь на досягнення мʼякого порогу виселення.
Жорсткі пороги виселення
Жорсткий поріг виселення не має пільгового періоду. Коли досягнуто жорсткого порогу виселення, kubelet негайно завершує роботу Podʼів без очікування належного завершення їх роботи, щоб повернути ресурси, яких бракує.
Ви можете використовувати прапорець eviction-hard для налаштування набору жорстких порогів виселення, наприклад memory.available<1Gi.
Kubelet має наступні стандартні жорсткі пороги виселення:
memory.available<100Mi(для вузлів Linux)memory.available<50Mi(для вузлів Windows)nodefs.available<10%imagefs.available<15%nodefs.inodesFree<5%(для вузлів Linux)imagefs.inodesFree<5%(для вузлів Linux)
Ці стандартні значення жорстких порогів виселення будуть встановлені лише у випадку, якщо жоден з параметрів не змінено. Якщо ви зміните значення будь-якого параметра, то значення інших параметрів не будуть успадковані як стандартні та будуть встановлені в нуль. Щоб надати власні значення, ви повинні вказати всі пороги відповідно.
Порогові стандартні значення для containerfs.available і containerfs.inodesFree (для Linux-вузлів) будуть встановлені наступним чином:
Якщо для всього використовується одна файлова система, то порогові значення для
containerfsвстановлюються такими ж, як і дляnodefs.Якщо налаштовані окремі файлові системи для образів і контейнерів, то порогові значення для
containerfsвстановлюються такими ж, як і дляimagefs.
Наразі налаштування власниї порогових значень, повʼязаних із containerfs, не підтримується, і буде видано попередження, якщо спробувати це зробити; будь-які надані власні значення будуть ігноровані.
Інтервал моніторингу виселення
Kubelet оцінює пороги виселення, виходячи з налаштованого інтервалу прибирання (housekeeping-interval), який типово становить 10с.
Стани вузла
Kubelet повідомляє про стан вузла, показуючи, що вузол перебуває під тиском через досягнення порогу жорсткого або мʼякого виселення, незалежно від налаштованих пільгових періодів для належного завершення роботи.
Kubelet зіставляє сигнали виселення зі станами вузла наступним чином:
| Умова вузла | Сигнал виселення | Опис |
|---|---|---|
MemoryPressure | memory.available | Доступна памʼять на вузлі досягла порогового значення для виселення |
DiskPressure | nodefs.available, nodefs.inodesFree, imagefs.available, imagefs.inodesFree, containerfs.available, або containerfs.inodesFree | Доступний диск і вільні іноди на кореневій файловій системі вузла, файловій системі образів або файловій системі контейнерів досягли порогового значення для виселення |
PIDPressure | pid.available | Доступні ідентифікатори процесів на (Linux) вузлі зменшилися нижче порогового значення для виселення |
Панель управління також зіставляє ці стани вузла у вигляді taint.
Kubelet оновлює стани вузла відповідно до налаштованої частоти оновлення стану вузла (--node-status-update-frequency), яка за типово становить 10с.
Коливання стану вузла
У деяких випадках вузли коливаються вище та нижче мʼяких порогів виселення без затримки на визначених пільгових періодах. Це призводить до того, що звітний стан вузла постійно перемикається між true та false, що призводить до поганих рішень щодо виселення.
Для захисту від коливань можна використовувати прапорець eviction-pressure-transition-period, який контролює, як довго kubelet повинен чекати перед переходом стану вузла в інший стан. Період переходу має стандартне значення 5 хв.
Повторне використання ресурсів на рівні вузла
Kubelet намагається повторно використовувати ресурси на рівні вузла перед виселенням контейнерів кінцевих користувачів.
Коли вузол повідомляє про умову DiskPressure, kubelet відновлює ресурси на рівні вузла на основі файлових систем на вузлі.
Без imagefs або containerfs
Якщо на вузлі є лише файлова система nodefs, яка відповідає пороговим значенням для виселення, kubelet звільняє диск у наступному порядку:
- Виконує збір сміття для померлих Podʼів і контейнерів.
- Видаляє непотрібні образи.
З використанням imagefs
Якщо на вузлі є окрема файлова система imagefs, яку використовують інструменти управління контейнерами, то kubelet робить наступне:
- Якщо файлова система
nodefsвідповідає пороговим значенням для виселення, то kubelet видаляє мертві Podʼи та мертві контейнери. - Якщо файлова система
imagefsвідповідає пороговим значенням для виселення, то kubelet видаляє всі невикористані образи.
З imagefs та containerfs
Якщо на вузлі налаштовані окремі файлові системи containerfs разом із файловою системою imagefs, яку використовують середовища виконання контейнерів, то kubelet намагатиметься відновити ресурси наступним чином:
Якщо файлова система
containerfsдосягає порогових значень для виселення, kubelet виконує збір сміття метрвих Podʼів і контейнерів.Якщо файлова система
imagefsдосягає порогових значень для виселення, kubelet видаляє всі непотрібні образи.
Вибір Podʼів для виселення kubelet
Якщо спроби kubelet відновити ресурси на рівні вузла не знижують сигнал виселення нижче порогового значення, kubelet починає виселяти Podʼи кінцевих користувачів.
Kubelet використовує наступні параметри для визначення порядку виселення Podʼів:
- Чи перевищує використання ресурсів Podʼа їх запити
- Пріоритет Podʼа
- Використання ресурсів Podʼа в порівнянні з запитами
В результаті kubelet ранжує та виселяє Podʼи в наступному порядку:
- Podʼи
BestEffortабоBurstable, де використання перевищує запити. Ці Podʼи виселяються на основі їх пріоритету, а потім на те, наскільки їхнє використання перевищує запит. - Podʼи
GuaranteedтаBurstable, де використання менше за запити, виселяються останніми, на основі їх пріоритету.
Примітка:
Kubelet не використовує клас QoS Podʼа для визначення порядку виселення. Ви можете використовувати клас QoS для оцінки найбільш ймовірного порядку виселення Podʼа при відновленні ресурсів, таких як памʼять. Класифікація QoS не застосовується до запитів EphemeralStorage, тому вищезазначений сценарій не буде застосовуватися, якщо вузол, наприклад, перебуває підDiskPressure.Podʼи Guaranteed гарантовані лише тоді, коли для всіх контейнерів вказано запити та обмеження, і вони є однаковими. Ці Podʼи ніколи не будуть виселятися через споживання ресурсів іншим Podʼом. Якщо системний демон (наприклад, kubelet та journald) споживає більше ресурсів, ніж було зарезервовано за допомогою розподілів system-reserved або kube-reserved, і на вузлі залишилися лише Guaranteed або Burstable Podʼи, які використовують менше ресурсів, ніж запити, то kubelet повинен вибрати Pod для виселення для збереження стабільності вузла та обмеження впливу нестачі ресурсів на інші Podʼи. У цьому випадку він вибере Podʼи з найнижчим пріоритетом першими.
Якщо ви використовуєте статичний Pod і хочете уникнути його виселення під час нестачі речурсів, встановіть поле priority для цього Podʼа безпосередньо. Статичні Podʼи не підтримують поле priorityClassName.
Коли kubelet виселяє Podʼи у відповідь на вичерпання inode або ідентифікаторів процесів, він використовує відносний пріоритет Podʼів для визначення порядку виселення, оскільки для inode та PID не існує запитів.
Kubelet сортує Podʼи по-різному залежно від того, чи є на вузлі відведений файловий ресурс imagefs чи containerfs:
Без imagefs або containerfs (nodefs і imagefs використовують одну і ту ж файлову систему)
- Якщо
nodefsініціює виселення, kubelet сортує Podʼи на основі їх загального використання диска (локальні томи + логи та записуваний шар усіх контейнерів).
З imagefs (nodefs і imagefs — окремі файлові системи)
Якщо
nodefsініціює виселення, kubelet сортує Podʼи на основі використанняnodefs(локальні томи + логи всіх контейнерів).Якщо
imagefsініціює виселення, kubelet сортує Podʼи на основі використання записуваного шару всіх контейнерів.
З imagefs та containerfs (imagefs та containerfs розділені)
Якщо
containerfsініціює виселення, kubelet сортує Podʼи на основі використанняcontainerfs(локальні томи + логи та записуваний шар усіх контейнерів).Якщо
imagefsініціює виселення, kubelet сортує Podʼи на основі ранжуванняstorage of images, яке відображає використання диска для даного образу.
Мінімальна кількість ресурсів для відновлення після виселення
Примітка:
У Kubernetes v1.32, ви не можете встановити власне значення для метрикиcontainerfs.available. Конфігурація для цієї конкретної метрики буде встановлена автоматично, щоб відображати значення, задані для nodefs або imagefs, залежно від конфігурації.У деяких випадках виселення підтримує лише невелику кількість виділеного ресурсу. Це може призвести до того, що kubelet постійно стикається з пороговими значеннями для виселення та виконує кілька виселень.
Ви можете використовувати прапорець --eviction-minimum-reclaim або файл конфігурації kubelet для налаштування мінімальної кількості відновлення для кожного ресурсу. Коли kubelet помічає нестачу ресурсу, він продовжує відновлення цього ресурсу до тих пір, поки не відновить кількість, яку ви вказали.
Наприклад, наступна конфігурація встановлює мінімальні кількості відновлення:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
evictionHard:
memory.available: "500Mi"
nodefs.available: "1Gi"
imagefs.available: "100Gi"
evictionMinimumReclaim:
memory.available: "0Mi"
nodefs.available: "500Mi"
imagefs.available: "2Gi"
У цьому прикладі, якщо сигнал nodefs.available досягає порога виселення, kubelet відновлює ресурс до тих пір, поки сигнал не досягне порога в 1 ГіБ, а потім продовжує відновлення мінімальної кількості 500 МіБ до тих пір, поки доступне значення nodefs збереження не досягне 1,5 ГіБ.
Аналогічно, kubelet намагається відновити ресурс imagefs до тих пір, поки значення imagefs.available не досягне 102 ГіБ, що представляє 102 ГіБ доступного сховища для образів контейнерів. Якщо кількість сховища, яку може відновити kubelet, менше за 2 ГіБ, kubelet нічого не відновлює.
Стандартно eviction-minimum-reclaim є 0 для всіх ресурсів.
Поведінка в разі вичерпання памʼяті на вузлі
Якщо вузол зазнає події out of memory (OOM) до того, як kubelet зможе відновити памʼять, вузол залежить від реагування oom_killer.
Kubelet встановлює значення oom_score_adj для кожного контейнера на основі QoS для Podʼа.
| Якість обслуговування | oom_score_adj |
|---|---|
Guaranteed | -997 |
BestEffort | 1000 |
Burstable | мін(макс(2, 1000 - (1000 × memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
Примітка:
Kubelet також встановлює значенняoom_score_adj рівне -997 для будь-яких контейнерів у Podʼах, які мають пріоритет system-node-critical.Якщо kubelet не може відновити памʼять до того, як вузол зазнає OOM, oom_killer обчислює оцінку oom_score на основі відсотка памʼяті, яку він використовує на вузлі, а потім додає oom_score_adj, щоб отримати ефективну оцінку oom_score для кожного контейнера. Потім він примусово завершує роботу контейнера з найвищим показником.
Це означає, що спочатку припиняється робота контейнерів у Podʼах низького QoS, які споживають велику кількість памʼяті в порівнянні з їх запитами на планування.
На відміну від виселення Podʼа, якщо роботу контейнера було припинено через вичерпання памʼяті, kubelet може перезапустити його відповідно до його restartPolicy.
Поради
У наступних розділах описано найкращі практики конфігурації виселення.
Ресурси, доступні для планування, та політики виселення
При конфігурації kubelet з політикою виселення слід переконатися, що планувальник не буде розміщувати Podʼи, які спричинять виселення через те, що вони безпосередньо викликають тиск на памʼять.
Розгляньте такий сценарій:
- Обсяг памʼяті вузла: 10 ГіБ
- Оператор бажає зарезервувати 10% обсягу памʼяті для системних служб (ядро,
kubelet, тощо) - Оператор бажає виселяти Podʼи при використанні памʼяті на рівні 95%, щоб зменшити випадки виснаження системи.
Для цього kubelet запускається наступним чином:
--eviction-hard=memory.available<500Mi
--system-reserved=memory=1.5Gi
У цій конфігурації прапорець --system-reserved резервує 1,5 ГіБ памʼяті для системи, що становить 10% від загальної памʼяті + кількість порогу виселення.
Вузол може досягти порогу виселення, якщо Pod використовує більше, ніж його запит, або якщо система використовує більше 1 ГіБ памʼяті, що знижує значення memory.available нижче 500 МіБ і спричиняє спрацювання порогу.
DaemonSets та виселення через тиск на вузол
Пріоритет Podʼа — це основний фактор при прийнятті рішень про виселення. Якщо вам не потрібно, щоб kubelet виселяв Podʼи, які належать до DaemonSet, встановіть цим Podʼам достатньо високий пріоритет, вказавши відповідний priorityClassName в специфікації Podʼа. Ви також можете використовувати менший пріоритет або типове значення, щоб дозволити запускати Podʼи з цього DaemonSet тільки тоді, коли є достаньо ресурсів.
Відомі проблеми
У наступних розділах описані відомі проблеми, повʼязані з обробкою вичерпання ресурсів.
kubelet може не сприймати тиск на памʼять одразу
Стандартно, kubelet опитує cAdvisor, щоб регулярно збирати статистику використання памʼяті. Якщо використання памʼяті збільшується протягом цього інтервалу швидко, kubelet може не помітити MemoryPressure настільки швидко, і буде викликаний OOM killer.
Ви можете використовувати прапорець --kernel-memcg-notification, щоб увімкнути API сповіщення memcg в kubelet і отримувати повідомлення негайно, коли перетинається поріг.
Якщо ви не намагаєтеся досягти екстремального використання, але не перескочити розумний рівень перевикористання, розумним обходом для цієї проблеми є використання прапорців --kube-reserved та --system-reserved для виділення памʼяті для системи.
active_file памʼять не вважається доступною памʼяттю
В Linux ядро відстежує кількість байтів файлової памʼяті в активному списку останніх використаних (LRU) як статистику active_file. Kubelet розглядає області памʼяті active_file як непіддаються вилученню. Для робочих навантажень, що інтенсивно використовують локальне сховище з блоковою підтримкою, включаючи ефемерне локальне сховище, кеші ядра файлів та блоків означає, що багато недавно доступних сторінок кеша, ймовірно, будуть враховані як active_file. Якщо достатньо цих буферів блоків ядра перебувають на активному списку LRU, kubelet може сприйняти це як високе використання ресурсів та позначити вузол як такий, що страждає від тиску на памʼять — спровокувавши виселення Podʼів.
Для отримання додаткової інформації дивіться https://github.com/kubernetes/kubernetes/issues/43916.
Ви можете обійти цю проблему, встановивши для контейнерів, які ймовірно виконують інтенсивну діяльність з операцій введення/виведення, однакове обмеження памʼяті та запит памєяті. Вам потрібно оцінити або виміряти оптимальне значення обмеження памʼяті для цього контейнера.
Що далі
- Дізнайтеся про Виселення, ініційоване API
- Дізнайтеся про Пріоритет та випередження Podʼів
- Дізнайтеся про PodDisruptionBudgets
- Дізнайтеся про Якість обслуговування (QoS)
- Подивіться на Eviction API
10.13 - Виселення, ініційоване API
Виселення, ініційоване API — процес, під час якого використовується Eviction API для створення обʼєкта Eviction, який викликає належне завершення роботи Podʼа.
Ви можете ініціювати виселення, викликавши Eviction API безпосередньо або програмно,
використовуючи клієнт API-сервера, наприклад, команду kubectl drain. Це створює обʼєкт Eviction, що призводить до завершення роботи Podʼа через API-сервер.
Виселення ініційовані API дотримуються вашого налаштованого PodDisruptionBudgets та terminationGracePeriodSeconds.
Використання API для створення обʼєкта Eviction для Podʼа схоже на виконання контрольованої політикою операції DELETE на Podʼі.
Виклик Eviction API
Ви можете використовувати клієнт кластера Kubernetes, щоб отримати доступ до API Kubernetes та створити обʼєкт Eviction. Для цього ви надсилаєте POST-запит на виконання операції, схожий на наступний приклад:
Примітка:
policy/v1 Eviction доступний в v1.22+. Використовуйте policy/v1beta1 для попередніх версій.{
"apiVersion": "policy/v1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
Примітка:
Застаріло в v1.22 на користьpolicy/v1{
"apiVersion": "policy/v1beta1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
Також ви можете спробувати виконати операцію виселення, звернувшись до API за допомогою
curl або wget, схожою на наступний приклад:
curl -v -H 'Content-type: application/json' https://your-cluster-api-endpoint.example/api/v1/namespaces/default/pods/quux/eviction -d @eviction.json
Як працює виселення, ініційоване через API
Коли ви запитуєте виселення за допомогою API, сервер API виконує перевірки допуску і відповідає одним із таких способів:
200 ОК: виселення дозволено, субресурсEvictionстворюється, і Pod видаляється, подібно до надсиланняDELETE-запиту на URL Podʼа.429 Забагато запитів: виселення на цей момент не дозволено через налаштований PodDisruptionBudget. Можливо, ви зможете спробувати виселення пізніше. Ви також можете отримати цю відповідь через обмеження швидкості API.500 Внутрішня помилка сервера: виселення не дозволено через помилкову конфігурацію, наприклад, якщо декілька PodDisruptionBudget посилаються на той самий Pod.
Якщо Pod, який ви хочете виселити, не є частиною робочого навантаження, яке має PodDisruptionBudget, сервер API завжди повертає 200 OK та дозволяє виселення.
Якщо сервер API дозволяє виселення, Pod видаляється наступним чином:
- Ресурс
Podв сервері API оновлюється з часовою міткою видалення, після чого сервер API вважає ресурсPodтаким, що завершив роботу. РесурсPodтакож позначений для відповідного звершення роботи. - Kubelet на вузлі, на якому запущений локальний Pod, помічає, що ресурс
Podпозначений для припинення та починає видаляти локальний Pod. - Під час вимкнення Podʼа kubelet видаляє Pod з обʼєктів Endpoint та EndpointSlice. В результаті контролери більше не вважають Pod за дійсний обʼєкт.
- Після закінчення періоду належного завершення роботи для Podʼа kubelet примусово вимикає локальний Pod.
- kubelet повідомляє сервер API про видалення ресурсу
Pod. - Сервер API видаляє ресурс
Pod.
Виправлення застряглих виселень
У деяких випадках ваші застосунки можуть потрапити в непрацездатний стан, де Eviction API буде повертати лише відповіді 429 або 500, поки ви не втрутитеся. Це може відбуватися, наприклад, якщо ReplicaSet створює Podʼи для вашого застосунку, але нові Podʼи не переходять в стан Ready. Ви також можете помітити це поведінку у випадках, коли останній виселений Pod мав довгий період належного завершення роботи при примусовому завершенні роботи.
Якщо ви помічаєте застряглі виселення, спробуйте одне з таких рішень:
- Скасуйте або призупиніть автоматизовану операцію, що викликає проблему. Дослідіть застряглий застосунок, перш ніж перезапустити операцію.
- Почекайте трохи, а потім безпосередньо видаліть Pod з панелі управління вашого кластера замість використання API виселення.
Що далі
- Дізнайтеся, як захистити ваші застосунки за допомогою Бюджету відмови Podʼів.
- Дізнайтеся про Виселення внаслідок тиску на вузол.
- Дізнайтеся про Пріоритет та випередження Podʼів.
11 - Адміністрування кластера
Деталі низького рівня, що стосуються створення та адміністрування кластера Kubernetes.
Огляд адміністрування кластера призначений для всіх, хто створює або адмініструє кластер Kubernetes. Він передбачає певний рівень знайомства з основними концепціями.
Планування кластера
Ознайомтеся з посібниками в розділі Встановлення для прикладів планування, налаштування та конфігурації кластерів Kubernetes. Рішення, перераховані в цій статті, називаються distros.
Примітка:
Не всі distros активно підтримуються. Вибирайте distros, які були протестовані з останньою версією Kubernetes.Перед вибором посібника врахуйте наступні моменти:
- Чи хочете ви спробувати Kubernetes на своєму компʼютері, чи хочете побудувати кластер високої доступності з кількома вузлами? Вибирайте distros, які найкраще підходять для ваших потреб.
- Чи будете ви використовувати кластер Kubernetes, розміщений на хостингу, такому як Google Kubernetes Engine, чи створюватимете свій власний кластер?
- Чи буде ваш кластер на місці, чи в хмарі (IaaS)? Kubernetes напряму не підтримує гібридні кластери. Замість цього ви можете налаштувати кілька кластерів.
- Якщо ви налаштовуєте Kubernetes на місці, розгляньте, яка модель мережі підходить найкраще.
- Чи будете ви запускати Kubernetes на "bare metal" обладнанні чи на віртуальних машинах (VMs)?
- Ви хочете мати робочий кластер, чи плануєте активний розвиток коду проєкту Kubernetes? Якщо останнє, вибирайте distros, які активно розвиваються. Деякі distros використовують лише бінарні релізи, але пропонують більшу різноманітність вибору.
- Ознайомтеся з компонентами, необхідними для запуску кластера.
Адміністрування кластера
Дізнайтеся, як керувати вузлами.
- Ознайомтеся з автомасштабуванням кластера.
Дізнайтеся, як налаштовувати та керувати квотою ресурсів для спільних кластерів.
Захист кластера
Генерація сертифікатів описує кроки генерації сертифікатів використовуючи різні інструменти.
Оточення контейнерів Kubernetes описує оточення для контейнерів, які керуються за допомогою kubelet на вузлах кластера.
Керування доступом до API Kubernetes описує, як Kubernetes реал керування доступом до API.
Автентифікація пояснює принципи автентифікації в Kubernetes, включаючи різні методи автентифікації та налаштування.
Авторизація відрізняється від автентифікації, контролює як обробляються HTTP-запити.
Використання admission-контролерів описує втулки, які перехоплюють запити до API Kubernetes після автентифікації та авторизації.
Використання Sysctls в кластері Kubernetes описує, як використовувати інструмент командного рядка
sysctlдля налаштування параметрів ядра.Аудит описує, як взаємодіяти з аудитом подій в Kubernetes.
Захист kubelеt
Додаткові служби кластера
Інтеграція DNS описує, як надавати DNS-імена безпосередньо службам Kubernetes.
Логування та моніторинг активності кластера пояснює, як працює логування в Kubernetes та як його реалізувати.
11.1 - Вимикання вузлів
У кластері Kubernetes вузол може бути вимкнутий плановим відповідним способом або несподівано через такі причини, як відключення електропостачання або інші зовнішні обставини. Вимкнення вузла може призвести до відмови робочого навантаження, якщо вузол не буде виводитись з обслуговування перед вимкненням. Вимкнення вузла може бути відповідним або невідповідним (graceful or non-graceful).
Належне вимикання вузла
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.21 [beta] (стандартно увімкнено: true)Kubelet намагається виявити вимикання системи вузла та завершує виконання Podʼів на вузлі.
Kubelet забезпечує виконання нормального процесу завершення роботи Podʼа під час вимикання вузла. Під час вимикання вузла kubelet не приймає нові Podʼи (навіть якщо ці Podʼи вже призначені вузлу).
Можливість належного вимикання вузла (graceful node shutdown) залежить від systemd, оскільки вона використовує блокування інгібіторів systemd для затримки вимкнення вузла на певний час.
Вимикання вузла керується функціональною можливістю GracefulNodeShutdown, що є типово увімкненим з версії 1.21.
Зауважте, що типово обидва налаштування конфігурації, описані нижче, shutdownGracePeriod та shutdownGracePeriodCriticalPods, встановлені на нуль, таким чином, не активуючи функціональність належного вимикання вузла. Для активації цієї функції, обидва налаштування конфігурації kubelet повинні бути належним чином налаштовані та встановлені на значення, відмінні від нуля.
Як тільки systemd виявляє або повідомляє про вимикання вузла, kubelet встановлює умову NotReady на вузлі з причиною "node is shutting down". Kube-scheduler дотримується цієї умови та не планує жодних Podʼів на цьому вузлі; очікується, що інші планувальники сторонніх постачальників дотримуватимуться такої ж логіки. Це означає, що нові Podʼи не будуть плануватися на цьому вузлі, і, отже, жоден із них не розпочне роботу.
Kubelet також відхиляє Podʼи під час фази PodAdmission, якщо виявлено поточне вимикання вузла, так що навіть Podʼи з toleration для node.kubernetes.io/not-ready:NoSchedule не почнуть виконання там.
Коли kubelet встановлює цю умову на своєму вузлі через API, kubelet також починає завершення будь-яких Podʼів, які виконуються локально.
Під час вимикання kubelet завершує Podʼи у два етапи:
- Завершує роботу звичайних Podʼів, які виконуються на вузлі.
- Завершує роботу критичних Podʼів, які виконуються на вузлі.
Функція належного вимикання вузла налаштовується двома параметрами конфігурації kubelet:
shutdownGracePeriod:- Визначає загальний час, протягом якого вузол повинен затримати вимикання. Це загальний термін допомагає завершити Podʼи як звичайні, так і критичні.
shutdownGracePeriodCriticalPods:- Визначає термін, який використовується для завершення критичних Podʼів під час вимикання вузла. Це значення повинно бути менше за
shutdownGracePeriod.
- Визначає термін, який використовується для завершення критичних Podʼів під час вимикання вузла. Це значення повинно бути менше за
Примітка:
Є випадки, коли вимкнення вузла було скасовано системою (або, можливо, вручну адміністратором). У будь-якому з цих випадків вузол повернеться до стануReady. Однак Podʼи, які вже розпочали процес завершення, не будуть відновлені kubelet і їх потрібно буде перепланувати.Наприклад, якщо shutdownGracePeriod=30s, а shutdownGracePeriodCriticalPods=10s, kubelet затримає вимикання вузла на 30 секунд. Під час вимикання перші 20 (30-10) секунд будуть зарезервовані для належного завершення звичайних Podʼів, а останні 10 секунд будуть зарезервовані для завершення критичних Podʼів.
Примітка:
Коли Podʼи були виселені під час належного вимикання вузла, вони позначаються як вимкнені. Виклик kubectl get pods показує стан виселених Podʼів як Terminated. І kubectl describe pod вказує, що Pod був виселений через вимикання вузла:
Reason: Terminated
Message: Pod was terminated in response to imminent node shutdown.
Належне вимикання вузла на основі пріоритету Podʼа
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.24 [beta] (стандартно увімкнено: true)Щоб забезпечити більше гнучкості під час належного вимикання вузла щодо порядку Podʼів під час вимикання, належне вимикання вузла враховує PriorityClass для Podʼів, за умови, що ви активували цю функцію у своєму кластері. Функція дозволяє адміністраторам кластера явно визначити порядок Podʼів під час належного вимикання вузла на основі priority classes.
Функція належного вимикання вузла, яка описана вище, вимикає Podʼи у дві фази: звичайні Podʼи, а потім критичні Podʼи. Якщо потрібна додаткова гнучкість для явного визначення порядку Podʼа під час вимикання в більш деталізований спосіб, можна використовувати належне (graceful) вимикання вузла на основі пріоритету Podʼа.
Коли вимикання вузла враховує пріоритет Podʼів, це дозволяє виконувати вимикання вузла у кілька етапів, кожен етап — це завершення роботи Podʼів певного класу пріоритету. Kubelet можна налаштувати з точним числом етапів та часом вимикання для кожного етапу.
Припустимо, що в кластері існують наступні власні класи пріоритету Podʼів:
| Назва класу пріоритету Podʼа | Значення класу пріоритету Podʼа |
|---|---|
custom-class-a | 100000 |
custom-class-b | 10000 |
custom-class-c | 1000 |
regular/unset | 0 |
В межах конфігурації kubelet налаштування для shutdownGracePeriodByPodPriority може виглядати так:
| Значення класу пріоритету Podʼа | Період вимкнення |
|---|---|
| 100000 | 10 seconds |
| 10000 | 180 seconds |
| 1000 | 120 seconds |
| 0 | 60 seconds |
Відповідна конфігурація YAML kubelet виглядатиме так:
shutdownGracePeriodByPodPriority:
- priority: 100000
shutdownGracePeriodSeconds: 10
- priority: 10000
shutdownGracePeriodSeconds: 180
- priority: 1000
shutdownGracePeriodSeconds: 120
- priority: 0
shutdownGracePeriodSeconds: 60
Вищеописана таблиця означає, що будь-який Pod зі значенням priority >= 100000 отримає лише 10 секунд на вимкнення, будь-який Pod зі значенням >= 10000 і < 100000 отримає 180 секунд для вимкнення, будь-який Pod зі значенням >= 1000 і < 10000 отримає 120 секунд для вимкнення. Нарешті, всі інші Podʼи отримають 60 секунд для вимкнення.
Не обовʼязково вказувати значення, відповідні всім класам. Наприклад, можна використовувати ці налаштування:
| Значення класу пріоритету Podʼа | Період вимкнення |
|---|---|
| 100000 | 300 seconds |
| 1000 | 120 seconds |
| 0 | 60 seconds |
У вищезазначеному випадку Podʼи з custom-class-b потраплять в ту ж саму групу, що й custom-class-c для вимкнення.
Якщо в певному діапазоні відсутні Podʼи, то kubelet не чекатиме на Podʼи у цьому діапазоні пріоритетів. Замість цього, kubelet безпосередньо перейде до наступного діапазону значень пріоритету.
Якщо ця функція увімкнена, а жодна конфігурація не надана, то дії з упорядкування не будуть виконані.
Використання цієї функції передбачає активацію функціональної можливості GracefulNodeShutdownBasedOnPodPriority, та встановлення ShutdownGracePeriodByPodPriority в kubelet config до потрібної конфігурації, яка містить значення класу пріоритету Podʼа та відповідні періоди вимкнення.
Примітка:
Можливість враховування пріоритетів Podʼів під час належного вимикання вузла була введена як альфа-функція в Kubernetes v1.23. У Kubernetes 1.32 функція є бета-версією та є типово активованою.Метрики graceful_shutdown_start_time_seconds та graceful_shutdown_end_time_seconds публікуються у підсистему kubelet для моніторингу вимкнень вузлів.
Обробка неналежних вимкнень вузлів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.28 [stable] (стандартно увімкнено: true)Дія вимкнення вузла може бути не виявленою Node Shutdown Manager вузла kubelet, чи то через те, що команда не активує механізм блокування інгібітора, який використовується kubelet, чи через помилку користувача, тобто ShutdownGracePeriod та ShutdownGracePeriodCriticalPods налаштовані неправильно. Будь ласка, зверніться до вищезазначеної секції Належне вимикання вузла для отримання докладнішої інформації.
Коли вузол вимикається, але це не виявляється Node Shutdown Manager вузла kubelet, Podʼи, які є частиною StatefulSet, залишаться в стані завершення на вимкненому вузлі та не зможуть перейти до нового робочого вузла. Це тому, що kubelet на вимкненому вузлі недоступний для видалення Podʼів, і StatefulSet не може створити новий Pod із такою ж назвою. Якщо є томи, які використовуються Podʼами, то VolumeAttachments не буде видалено з оригінального вимкненого вузла, і тому томи використовувані цими Podʼами не можуть бути приєднані до нового робочого вузла. В результаті застосунок, що виконується з StatefulSet, не може працювати належним чином. Якщо оригінальний вимкнений вузол вмикається, Podʼи будуть видалені kubelet, і нові Podʼи будуть створені на іншому робочому вузлі. Якщо оригінальний вимкнений вузол не повертається, ці Podʼи залишаться в стані завершення на вимкненому вузлі назавжди.
Для помʼякшення вищезазначеної ситуації користувач може вручну додати позначку (taint) node.kubernetes.io/out-of-service з ефектом NoExecute чи NoSchedule до вузла, вказавши, що він вийшов із ладу. Якщо вузол відзначений як такий, що вийшов з ладу з такою позначкою, Podʼи на вузлі будуть примусово видалені, якщо на них немає відповідних toleration, і операції відʼєднання томів для завершення Podʼів на вузлі відбудуться негайно. Це дозволяє Podʼам на вузлі, що вийшов з ладу, швидко відновитися на іншому вузлі.
Під час такого (non-graceful) вимикання робота Podʼів завершується у дві фази:
- Насильно видаляються Podʼи, які не мають відповідних toleration
out-of-service. - Негайно виконується операція відʼєднання томів для таких Podʼів.
Примітка:
- Перш ніж додавати позначку
node.kubernetes.io/out-of-service, слід перевірити, що вузол вже перебуває в стані припинення роботи чи вимикання (не в середині процесу перезапуску). - Користувач повинен вручну видалити позначку out-of-service після того, як Podʼи будуть переміщені на новий вузол, і користувач перевірив, що вимкнений вузол відновився, оскільки саме користувач додав позначку на початку.
Примусове відʼєднання сховища при перевищенні часу очікування
У будь-якій ситуації, де видалення Podʼа не вдалося протягом 6 хвилин, Kubernetes примусово відʼєднає томи, які розмонтувалися, якщо в цей момент вузол несправний. Будь-яке робоче навантаження, що все ще працює на вузлі та використовує том, який примусово відʼєднується, спричинить порушення специфікації CSI, яка стверджує, що ControllerUnpublishVolume "повинен бути викликаний після всіх викликів NodeUnstageVolume та NodeUnpublishVolume в томі, і вони успішно завершилися". В таких обставинах томи на такому вузлі можуть зіткнутися з пошкодженням даних.
Поведінка примусового відʼєднання сховища є необовʼязковою; користувачі можуть вибрати використання функції "Non-graceful node shutdown" замість цього.
Примусове відʼєднання сховища при перевищенні часу очікування можна вимкнути, встановивши поле конфігурації disable-force-detach-on-timeout в kube-controller-manager. Вимкнення функції примусового відʼєднання при перевищенні часу очікування означає, що у тому, який розміщено на вузлі, який несправний протягом понад 6 хвилин, не буде видалено його повʼязаний VolumeAttachment.
Після застосування цього налаштування, несправні Podʼи, які все ще приєднані до томів, повинні бути відновлені за допомогою процедури Обробки неналежних вимкнень вузлів, згаданої вище.
Примітка:
- Під час використання процедури Обробки неналежних вимкнень вузлів слід бути обережним.
- Відхилення від документованих вище кроків може призвести до пошкодження даних.
Належне припинення роботи вузла Windows
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [alpha] (стандартно увімкнено: false)Функція Windows graceful node shutdown залежить від того, чи працює kubelet як служба Windows, тоді він матиме зареєстрований service control handler для затримки події вимкнення на задану тривалість.
Керування вимкненням вузла Windows здійснюється за допомогою функціональної можливості WindowsGracefulNodeShutdown, яку було представлено у 1.32 як альфа-версію.
Належне завершення роботи вузла у Windows не може бути скасовано.
Якщо kubelet не запущено як службу Windows, він не зможе встановити та відстежувати подію Preshutdown, вузол буде змушений пройти через процедуру Non-Graceful Node Shutdown, згадану вище.
У випадку, якщо у Windows увімкнено функцію належного завершення роботи вузла, але kubelet не запущено як службу Windows, kubelet продовжить роботу, а не завершить її. Однак, він буде реєструвати помилку, яка вказує на те, що його потрібно запустити як службу Windows.
Що далі
Дізнайтеся більше про наступне:
- Допис в Блозі — Non-Graceful Node Shutdown.
- Архітектура кластера: Вузли.
11.2 - Сертифікати
Щоб дізнатись, як генерувати сертифікати для вашого кластера, дивіться розділ Завдань — Сертифікати.
11.3 - Мережа в кластері
Мережі є центральною частиною Kubernetes, але часто важко зрозуміти, як саме вони мають працювати. Існують 4 відмінних мережевих проблеми, які потрібно вирішити:
- Взаємодія контейнерів між собою: цю проблему вирішує використання Podʼів та взаємодія з
localhost. - Взаємодія між Podʼами: це основна ціль даного документа.
- Взаємодія між Podʼом та Service: ця проблема описана у Service.
- Взаємодія Service із зовнішнім світом: це також описано в контексті Service.
Kubernetes — це система розподілу машин між застосунками. Зазвичай для розподілу машин потрібно переконатися, що два застосунки не намагаються використовувати одні й ті самі порти. Координацію портів між кількома розробниками дуже важко зробити в масштабі та наражає користувачів на проблеми на рівні кластера, що знаходяться поза їхнім контролем.
Динамічне призначення портів приносить багато ускладнень в систему — кожен застосунок має приймати порти як прапорці, серверам API потрібно знати, як вставляти динамічні номери портів у блоки конфігурації, сервісам потрібно знати, як знаходити один одного тощо. Замість цього Kubernetes обирає інший підхід.
Ознайомтесь докладніше з мережевою моделлю Kubernetes.
Діапазони IP-адрес Kubernetes
Кластери Kubernetes потребують виділення IP-адрес, які не перекриваються, для Podʼів, Service та Вузлів, з діапазону доступних адрес, налаштованих у наступних компонентах:
- Втулок мережі налаштований для призначення IP-адрес Podʼам.
- Kube-apiserver налаштований для призначення IP-адрес Service.
- Kubelet або cloud-controller-manager налаштовані для призначення IP-адрес Вузлам.

Типи мереж в кластері
Кластери Kubernetes, залежно від налаштованих типів IP адрес, можуть бути категоризовані на:
- Лише IPv4: Втулок мережі, kube-apiserver та kubelet/cloud-controller-manager налаштовані для призначення лише IPv4-адрес.
- Лише IPv6: Втулок мережі, kube-apiserver та kubelet/cloud-controller-manager налаштовані для призначення лише IPv6-адрес.
- IPv4/IPv6 або IPv6/IPv4 подвійний стек:
- Втулок мережі налаштований для призначення IPv4 та IPv6-адрес.
- Kube-apiserver налаштований для призначення IPv4 та IPv6-адрес.
- Kubelet або cloud-controller-manager налаштовані для призначення IPv4 та IPv6-адрес.
- Усі компоненти повинні узгоджуватися щодо налаштованої основного типу IP адрес.
Кластери Kubernetes враховують лише типи IP, які присутні в обʼєктах Podʼів, Service та Вузлів, незалежно від наявних IP-адрес представлених обʼєктів. Наприклад, сервер або Pod може мати кілька IP-адрес на своїх інтерфейсах, але для реалізації мережевої моделі Kubernetes та визначення типу кластера беруться до уваги лише IP-адреси в node.status.addresses або pod.status.ips.
Як реалізувати мережеву модель Kubernetes
Модель мережі реалізується середовищем виконання контейнерів на кожному вузлі. Найпоширеніші середовища використовують Інтерфейс мережі контейнера (CNI) для керування своєю мережею та забезпечення безпеки. Існує багато різних CNI-втулків від різних вендорів. Деякі з них надають лише базові можливості додавання та видалення мережевих інтерфейсів, тоді як інші надають складніші рішення, такі як інтеграція з іншими системами оркестрування контейнерів, запуск кількох CNI-втулків, розширені функції IPAM та інше.
Див. цю сторінку для неповного переліку мережевих надбудов, які підтримуються в Kubernetes.
Що далі
Ранній дизайн мережевої моделі та її обґрунтування докладно описані у документі дизайну мережі. Щодо майбутніх планів та деяких поточних зусиль, спрямованих на поліпшення мережевих функцій Kubernetes, будь ласка, звертайтеся до SIG-Network KEPs.
11.4 - Архітектура логування
Логи застосунків можуть допомогти вам зрозуміти, що відбувається у нього всередині. Логи особливо корисні для виправлення проблем та моніторингу активності кластера. Більшість сучасних застосунків мають деякий механізм логування. Так само, рушії виконання контейнерів розроблені з підтримкою логування. Найпростіший і найбільш прийнятий метод логування для контейнеризованих застосунків — це запис у стандартні потоки виводу та помилок.
Однак, природня функціональність, яку надає рушій виконання контейнерів або середовище виконання, зазвичай недостатня для повного вирішення завдань логування.
Наприклад, вам може бути необхідно дістатись до логів вашого застосунку, якщо контейнер зазнає збою, Pod видаляється, або вузол припиняє роботу.
У кластері логи повинні мати окреме сховище та життєвий цикл незалежно від вузлів, Podʼів або контейнерів. Ця концепція називається логування на рівні кластера.
Архітектури логування на рівні кластера вимагають окремого бекенду для зберігання, аналізу, та отримання логів. Kubernetes не надає власного рішення для зберігання даних логів. Натомість існує багато рішень для логування, які інтегруються з Kubernetes. Наступні розділи описують, як обробляти та зберігати логи на вузлах.
Логи Podʼів та контейнерів
Kubernetes збирає логи з кожного контейнера в запущеному Podʼі.
Цей приклад використовує маніфест для Podʼу з контейнером, який записує текст у стандартний потік виводу, раз на секунду.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Для запуску цього Podʼа використовуйте наступну команду:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
Вивід буде таким:
pod/counter created
Для отримання логів використовуйте команду kubectl logs, як показано нижче:
kubectl logs counter
Вивід буде схожим на:
0: Fri Apr 1 11:42:23 UTC 2022
1: Fri Apr 1 11:42:24 UTC 2022
2: Fri Apr 1 11:42:25 UTC 2022
Ви можете використовувати kubectl logs --previous для отримання логів з попереднього запуску контейнера. Якщо ваш Pod має кілька контейнерів, вкажіть, логи якого контейнера ви хочете переглянути, додавши назву контейнера до команди з прапорцем -c, ось так:
kubectl logs counter -c count
Потоки логів контейнерів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [alpha] (стандартно увімкнено: false)Як альфа-функція, kubelet може розділяти логи з двох стандартних потоків, що створюються контейнером: стандартний вивід та стандартна помилка. Щоб скористатися такою поведінкою, вам слід увімкнути функціональну можливість PodLogsQuerySplitStreams. З її увімкненням Kubernetes 1.32 надає доступ до цих потоків логів безпосередньо за допомогою Pod API. Ви можете отримати конкретний потік, вказавши назву потоку (або Stdout, або Stderr) за допомогою рядка запиту stream. Ви повинні мати доступ до читання підресурсу log цього Pod.
Щоб продемонструвати цю можливість, ви можете створити Pod, який періодично записуватиме текст як до стандартного потоку виводу, так і до потоку помилок.
apiVersion: v1
kind: Pod
metadata:
name: counter-err
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; echo "$i: err" >&2 ; i=$((i+1)); sleep 1; done']
Для запуску цього podʼа скористайтесь наступною командою:
kubectl apply -f https://k8s.io/examples/debug/counter-pod-err.yaml
Щоб отримати лише потік логу stderr, ви можете виконати команду:
kubectl get --raw "/api/v1/namespaces/default/pods/counter-err/log?stream=Stderr"
Дивіться документацію kubectl logs для отримання додаткових деталей.
Як вузли обробляють логи контейнерів
Система управління контейнерами обробляє та перенаправляє будь-який вивід, створений потоками stdout та stderr контейнеризованого застосунку. Різні системи управління контейнерами реалізують це по-різному; однак, інтеграція з kubelet стандартизована як формат логування CRI.
Стандартно, якщо контейнер перезапускається, kubelet зберігає один зупинений контейнер з його логами. Якщо Pod видаляється з вузла, всі відповідні контейнери також видаляються разом з їхніми логами.
Kubelet надає доступ до логів клієнтам через спеціальну функцію Kubernetes API. Зазвичай доступ до неї здійснюється за допомогою команди kubectl logs.
Ротація логів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.21 [stable]Kubelet відповідає за ротацію логів контейнерів та управління структурою тек логів. Kubelet передає цю інформацію до системи управління контейнерами (використовуючи CRI), а середовище виконання записує логи контейнерів у вказане місце.
Ви можете налаштувати два параметри конфігурації kubelet containerLogMaxSize (типово 10Mi) та containerLogMaxFiles (типово 5), використовуючи файл конфігурації kubelet. Ці параметри дозволяють вам налаштувати максимальний розмір для кожного файлу лога та максимальну кількість файлів, дозволених для кожного контейнера відповідно.
Для ефективної ротації логів у кластерах, де обсяг логів, згенерованих робочим навантаженням, великий, kubelet також надає механізм налаштування ротації логів з погляду кількості одночасних ротацій логів та інтервалу, з яким логи відстежуються та ротуються за потребою. Ви можете налаштувати два параметри конфігурації kubelet, containerLogMaxWorkers та containerLogMonitorInterval за допомогою файлу конфігурації kubelet.
Коли ви виконуєте kubectl logs як у прикладі базового логування, kubelet на вузлі обробляє запит і безпосередньо читає з файлу лога. Kubelet повертає вміст файлу лога.
Примітка:
Через kubectl logs доступний лише вміст останнього файлу лога.
Наприклад, якщо Pod пише 40 MiB логів і kubelet ротує логи після 10 MiB, виконання kubectl logs поверне максимум 10MiB даних.
Логи системних компонентів
Існують два типи системних компонентів: ті, які зазвичай працюють у контейнерах, та ті компоненти, які безпосередньо відповідають за запуск контейнерів. Наприклад:
- Kubelet та система управління контейнерами не працюють у контейнерах. Kubelet виконує ваші контейнери (згруповані разом у Podʼи).
- Планувальник Kubernetes, менеджер контролерів та сервер API працюють у Podʼах (зазвичай статичних Podʼах). Компонент etcd працює у планувальнику, і зазвичай також як статичний Pod. Якщо ваш кластер використовує kube-proxy, зазвичай ви запускаєте його як
DaemonSet.
Знаходження логів
Спосіб, яким kubelet та система управління контейнерами записують логи, залежить від операційної системи, яку використовує вузол:
На вузлах Linux, які використовують systemd, типово kubelet та система управління контейнерами записують логи у журнал systemd. Ви можете використовувати journalctl для читання журналу systemd; наприклад: journalctl -u kubelet.
Якщо systemd відсутній, kubelet та система управління контейнерами записують логи у файли .log в директорії /var/log. Якщо ви хочете, щоб логи були записані в інше місце, ви можете опосередковано запустити kubelet через допоміжний інструмент, kube-log-runner, та використовувати цей інструмент для перенаправлення логів kubelet у вибрану вами теку.
Типово, kubelet спрямовує систему управління контейнерами на запис логів у теці всередині /var/log/pods.
Для отримання додаткової інформації про kube-log-runner, читайте Системні логи.
Типово kubelet записує логи у файли всередині теки C:\var\logs (⚠️ зверніть увагу, що це не C:\var\log).
Хоча C:\var\log є типовим місцем для цих логів Kubernetes, деякі інструменти розгортання кластера налаштовують вузли Windows так, щоб логи записувались у C:\var\log\kubelet.
Якщо ви хочете, щоб логи були записані в інше місце, ви можете опосередковано запустити kubelet через допоміжний інструмент, kube-log-runner, та використовувати цей інструмент для перенаправлення логів kubelet у вибрану вами директорію.
Проте, типово kubelet скеровує систему управління контейнерами на запис логів у теці всередині C:\var\log\pods.
Для отримання додаткової інформації про kube-log-runner, читайте Системні логи.
Для компонентів кластера Kubernetes, які працюють у Podʼах, логи записуються у файли всередині директорії /var/log, оминаючи типовий механізм логування (компоненти не записуються у журнал systemd). Ви можете використовувати механізми зберігання Kubernetes для відображення постійного зберігання у контейнері, який виконує компонент.
Kubelet дозволяє змінювати теку логів Podʼів зі стандартної /var/log/pods на власну. Це можна зробити за допомогою параметра podLogsDir у конфігураційному файлі kubelet.
Увага:
Важливо зазначити, що стандартне розташування /var/log/pods використовувалося протягом тривалого часу, і певні процеси можуть неявно використовувати цей шлях. Тому до зміни цього параметра слід підходити з обережністю і на власний ризик.
Ще одним застереженням є те, що kubelet підтримує розташування на тому ж диску, що і /var. В іншому випадку, якщо логи знаходяться в окремій від /var файловій системі, то kubelet не буде відстежувати використання цієї файлової системи, що може призвести до проблем, якщо вона заповниться.
Для отримання детальної інформації про etcd та його логи, перегляньте документацію etcd. Знову ж таки, ви можете використовувати механізми зберігання Kubernetes для відображення постійного зберігання у контейнері, який виконує компонент.
Примітка:
Якщо ви розгортаєте компоненти кластера Kubernetes (наприклад, планувальник) для запису у спільний том від батьківського вузла, вам потрібно враховувати та забезпечувати, що ці логи ротуються. Kubernetes не керує цією ротацією логів.
Ваша операційна система може автоматично здійснювати деяку ротацію логів — наприклад, якщо ви ділитеся текою /var/log у статичному Podʼі для компонента, обробка ротації логів на рівні вузла обробляє файл у цій теці так с так само як записаний будь-яким компонентом поза Kubernetes.
Деякі інструменти розгортання враховують цю ротацію логів та автоматизують її; інші залишають це на вашу відповідальність.
Архітектури логування на рівні кластера
Хоча Kubernetes не надає власного рішення для логування на рівні кластера, існують кілька загальних підходів, які ви можете розглянути. Ось деякі варіанти:
- Використання агента логування на рівні вузла, який працює на кожному вузлі.
- Додавання в Pod з застосунком в спеціального sidecaar-контейнера для логування.
- Пряме надсилання логів безпосередньо до бекенду з застосунка.
Використання агента логування на рівні вузла
Ви можете реалізувати логування на рівні кластера, включивши агента логування на рівні вузла на кожному вузлі. Агент логування — це спеціальний інструмент, який надає логи або надсилає їх до бекенду. Зазвичай агент логування є контейнером, який має доступ до теки з файлами логів з усіх контейнерів застосунків на цьому вузлі.
Оскільки агент логування повинен працювати на кожному вузлі, рекомендується запускати агента
як DaemonSet.
Логування на рівні вузла створює лише одного агента на вузол і не вимагає жодних змін в застосунках, що працюють на вузлі.
Контейнери пишуть у stdout та stderr, але без узгодженого формату. Агент на рівні вузла збирає ці логи та пересилає їх для агрегації.
Використання sidecar контейнера з агентом логування
Ви можете використовувати sidecar контейнер у такий спосіб:
- sidecar контейнер транслює логи застосунку у свій власний
stdout. - sidecar контейнер запускає агента логування, який налаштований на збір логів з контейнера застосунку.
Sidecar контейнер для трансляції
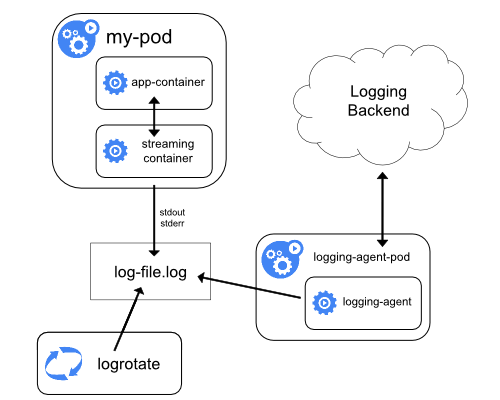
Маючи свої sidecar контейнери які пишуть у власні stdout та stderr, ви можете скористатися kubelet та агентом логування, які вже працюють на кожному вузлі. Sidecar контейнери читають логи з файлу, сокета або журналу. Кожен sidecar контейнер виводить лог у свій власний потік stdout або stderr.
Цей підхід дозволяє вам розділити кілька потоків логів з різних частин вашого застосунку деякі з яких можуть не підтримувати запис у stdout або stderr. Логіка перенаправлення логів мінімальна, тому це не становить значного навантаження. Крім того, оскільки stdout та stderr обробляються kubelet, ви можете використовувати вбудовані інструменти, такі як kubectl logs.
Наприклад, Pod запускає один контейнер, і контейнер записує до двох різних файлів логів з використанням двох різних форматів. Ось маніфест для Podʼа:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Не рекомендується записувати записи логів з різними форматами у той самий потік логу, навіть якщо вам вдалося перенаправити обидва компоненти до потоку stdout контейнера. Замість цього ви можете створити два додаткових sidecar контейнери. Кожен додатковий sidecar контейнер може перехоплювати певний файл логів зі спільного тома та перенаправляти логи до власного потоку stdout.
Ось маніфест для Podʼа, в якому є два sidecar контейнери:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Тепер, коли ви запускаєте цей Pod, ви можете отримати доступ до кожного потоку логів окремо, запустивши такі команди:
kubectl logs counter count-log-1
Результат буде подібним до:
0: Fri Apr 1 11:42:26 UTC 2022
1: Fri Apr 1 11:42:27 UTC 2022
2: Fri Apr 1 11:42:28 UTC 2022
...
kubectl logs counter count-log-2
Результат буде подібним до:
Fri Apr 1 11:42:29 UTC 2022 INFO 0
Fri Apr 1 11:42:30 UTC 2022 INFO 0
Fri Apr 1 11:42:31 UTC 2022 INFO 0
...
Якщо ви встановили агент на рівні вузла у свій кластер, цей агент автоматично перехоплює ці потоки логів без будь-якої додаткової конфігурації. Якщо вам цікаво, ви можете налаштувати агента для розбору рядків логів залежно від вихідного контейнера.
Навіть для Podʼів, які використовують низьке використання CPU та памʼяті (наприклад, декілька мілікорів (millicore) для CPU та кілька мегабайтів для памʼяті), запис логів до файлу та їх трансляція до stdout можуть подвоїти обсяг памʼяті, необхідний на вузлі. Якщо у вас є застосунок, який записує у єдиний файл, рекомендується встановити /dev/stdout як призначення, а не впроваджувати підхід з sidecar контейнером для трансляції.
Sidecar контейнери також можуть використовуватися для ротації файлів логів, ротація яких не може бути зроблена самим застосунком. Прикладом такого підходу є малий контейнер, який періодично запускає logrotate. Однак набагато простіше використовувати stdout та stderr безпосередньо і
залишити ротації та політику зберігання kubelet.
Sidecar контейнер з агентом логування
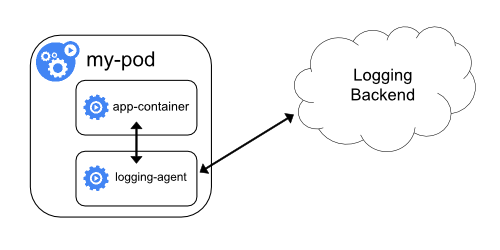
Якщо агент логування на рівні вузла не має достатньої гнучкості для вашої ситуації, ви можете створити sidecar контейнер з окремим агентом логування, який ви налаштували спеціально для роботи з вашим застосунком.
Примітка:
Використання агента логування у sidecar контейнері може призвести до значного використання ресурсів. Щобільше, ви не зможете отримати доступ до цих логів за допомогоюkubectl logs, оскільки вони не керуються kubelet.Ось два приклади маніфестів, які ви можете використати для впровадження sidecar контейнера з агентом логування. Перший маніфест містить ConfigMap, щоб налаштувати fluentd.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Примітка:
У конфігураціях з прикладів ви можете замінити fluentd на будь-який агент логування, який читає з будь-якого джерела всередині контейнера застосунку.Другий маніфест описує Pod, в якому є sidecar контейнер, що запускає fluentd. Pod монтує том, де fluentd може отримати свої дані конфігурації.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
Викладення логів безпосередньо з застосунку
Кластерне логування, яке викладає або надсилає логи безпосередньо з кожного застосунку, виходить за межі цілей Kubernetes.
Що далі
- Дізнайтеся про системні журнали Kubernetes
- Дізнайтеся про Trace для компонентів системи Kubernetes
- Дізнайтеся, як налаштувати повідомлення про припинення роботи яке Kubernetes записує, коли Pod зазнає збою.
11.5 - Версія сумісності для компонентів панелі управління Kubernetes
Починаючи з версії 1.32, ми додали до компонентів панелі управління Kubernetes параметри сумісності версій та емуляції, що налаштовуються, щоб зробити оновлення безпечнішими, надаючи більше контролю та збільшуючи деталізацію кроків, доступних адміністраторам кластерів.
Емульована версія
Параметр емуляції задається прапорцем --emulated-version компонентів панелі управління. Він дозволяє компоненту емулювати поведінку (API, функції ...) більш ранньої версії Kubernetes.
При його використанні доступні можливості будуть відповідати емульованій версії:
- Будь-які можливості, присутні в двійковій версії, які були додані після версії емуляції, будуть недоступні.
- Будь-які можливості, вилучені після версії емуляції, будуть доступними.
Це дозволяє двійковій версії певного випуску Kubernetes емулювати поведінку попередньої версії з достатньою точністю, щоб можна було визначити сумісність з іншими компонентами системи у термінах емульованої версії.
Значення --emulated-version має бути <= binaryVersion. Діапазон підтримуваних емульованих версій див. у довідці до прапорця --emulated-version.
11.6 - Метрики для компонентів системи Kubernetes
Метрики системних компонентів можуть краще показати, що відбувається всередині. Метрики особливо корисні для побудови інформаційних панелей та сповіщень.
Компоненти Kubernetes видають метрики у форматі Prometheus. Цей формат являє собою структурований звичайний текст, призначений для зручного сприйняття як людьми, так і машинами.
Метрики в Kubernetes
У більшості випадків метрики доступні на точці доступу /metrics HTTP сервера. Для компонентів, які типово не показують цю точку, її можна активувати за допомогою прапорця --bind-address.
Приклади таких компонентів:
У промисловому середовищі ви, можливо, захочете налаштувати Prometheus Server або інший інструмент збору метрик для їх періодичного отримання і доступу у якомусь виді бази даних часових рядів.
Зверніть увагу, що kubelet також викладає метрики на /metrics/cadvisor, /metrics/resource та /metrics/probes. Ці метрики не мають того самого життєвого циклу.
Якщо ваш кластер використовує RBAC, для читання метрик потрібна авторизація через користувача, групу або ServiceAccount з ClusterRole, що дозволяє доступ до /metrics. Наприклад:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- nonResourceURLs:
- "/metrics"
verbs:
- get
Життєвий цикл метрик
Метрики альфа → Стабільні метрики → Застарілі метрики → Приховані метрики → Видалені метрики
Альфа метрики не мають гарантій щодо їх стабільності. Ці метрики можуть бути змінені або навіть вилучені в будь-який момент.
Стабільні метрики гарантують, що їх формат залишиться незмінним. Це означає що:
- Стабільні метрики, які не мають позначки "DEPRECATED", не будуть змінені чи вилучені.
- Тип стабільних метрик не буде змінений.
Метрики, які позначені як застарілі, заплановані для видалення, але все ще доступні для використання. Ці метрики мають анотацію щодо версії, у якій вони стали застарілими.
Наприклад:
Перед застарінням
# HELP some_counter this counts things # TYPE some_counter counter some_counter 0Після застаріння
# HELP some_counter (Deprecated since 1.15.0) this counts things # TYPE some_counter counter some_counter 0
Приховані метрики більше не публікуються для збирання, але все ще доступні для використання. Щоб використовувати приховану метрику, будь ласка, звертайтесь до розділу Показ прихованих метрик.
Видалені метрики більше не публікуються і не можуть бути використані.
Показ прихованих метрик
Як описано вище, адміністратори можуть увімкнути приховані метрики через прапорець командного рядка для конкретного бінарного файлу. Це призначено для використання адміністраторами, якщо вони пропустили міграцію метрик, які стали застарілими в останньому релізі.
Прапорець show-hidden-metrics-for-version приймає версію, для якої ви хочете показати метрики, які стали застарілими у цьому релізі. Версія зазначається як x.y, де x — головна версія, y — мінорна версія. Версія патчу не потрібна, хоча метрика може бути застарілою в патч-релізі, причина в тому, що політика застарілих метрик працює з мінорними релізами.
Прапорець може приймати тільки попередню мінорну версію як своє значення. Усі метрики, які були приховані в попередній версії, будуть доступні, якщо адміністратори встановлять попередню версію на show-hidden-metrics-for-version. Занадто стара версія не дозволяється, оскільки це порушує політику застарілих метрик.
Візьміть метрику A як приклад, тут припускається, що A застаріла в 1.n. Згідно з політикою застарілих метрик, ми можемо зробити наступні висновки:
- У випуску
1.n, метрика застаріла і може бути типово доступною. - У випуску
1.n+1, метрика є типово прихованою і може бути доступна через параметр командного рядкаshow-hidden-metrics-for-version=1.n. - У випуску
1.n+2, метрику слід видалити з кодової бази. Більше немає можливості її отримання.
Якщо ви оновлюєтеся з випуску 1.12 до 1.13, але все ще залежите від метрики A, яка застаріла в 1.12, ви повинні встановити приховані метрики через командний рядок: --show-hidden-metrics=1.12 і памʼятати про те, щоб видалити цю залежність від метрики до оновлення до 1.14.
Метрики компонентів
Метрики kube-controller-manager
Метрики менеджера контролера надають важливі відомості про продуктивність та стан контролера. Ці метрики включають загальні метрики часу виконання мови програмування Go, такі як кількість go_routine, а також специфічні для контролера метрики, такі як час виконання запитів до etcd або час виконання API Cloudprovider (AWS, GCE, OpenStack), які можна використовувати для оцінки стану кластера.
Починаючи з Kubernetes 1.7, доступні докладні метрики Cloudprovider для операцій зберігання для GCE, AWS, Vsphere та OpenStack. Ці метрики можуть бути використані для моніторингу стану операцій з постійними томами.
Наприклад, для GCE ці метрики називаються:
cloudprovider_gce_api_request_duration_seconds { request = "instance_list"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_insert"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_delete"}
cloudprovider_gce_api_request_duration_seconds { request = "attach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "detach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "list_disk"}
Метрики kube-scheduler
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.21 [beta]Планувальник надає опціональні метрики, які повідомляють про запитані ресурси та бажані обмеження всіх запущених Podʼів. Ці метрики можна використовувати для побудови панелей управління ресурсами, оцінки поточних або історичних обмежень планування, швидкого виявлення навантажень, які не можуть бути розміщені через відсутність ресурсів, і порівняння фактичного використання з запитом Podʼа.
kube-scheduler ідентифікує ресурсні запити та обмеження для кожного Podʼа; коли запит або обмеження не дорівнює нулю, kube-scheduler повідомляє про метричні часові ряди. Часові ряди мають мітки:
- простір імен
- імʼя Podʼа
- вузол, на якому запущений Pod, або пустий рядок, якщо він ще не запущений
- пріоритет
- призначений планувальник для цього Podʼа
- назва ресурсу (наприклад,
cpu) - одиниця ресурсу, якщо відома (наприклад,
core)
Як тільки Pod досягає завершення (має restartPolicy Never або OnFailure і перебуває в стані Succeeded або Failed, або був видалений і всі контейнери мають стан завершення), часова послідовність більше не повідомляється, оскільки тепер планувальник вільний для розміщення інших Podʼів для запуску. Дві метрики називаються kube_pod_resource_request та kube_pod_resource_limit.
Метрики доступні за адресою HTTP /metrics/resources та вимагають такої ж авторизації, що і точка доступу /metrics планувальника. Вам потрібно використовувати прапорець --show-hidden-metrics-for-version=1.20, щоб показати ці альфа-метрики.
Вимкнення метрик
Ви можете явно вимкнути метрики за допомогою прапорця командного рядка --disabled-metrics. Це може бути бажано, наприклад, якщо метрика викликає проблеми з продуктивністю. Вхідні дані — це список вимкнених метрик (тобто --disabled-metrics=метрика1,метрика2).
Забезпечення послідовності метрик
Метрики з нескінченними розмірами можуть викликати проблеми з памʼяттю в компонентах, які їх інструментують. Щоб обмежити використання ресурсів, ви можете використовувати опцію командного рядка --allow-metric-labels, щоб динамічно налаштувати список дозволених значень міток для метрики.
На стадії альфа, цей прапорець може приймати лише серію зіставлень як список дозволених міток метрики. Кожне зіставлення має формат <metric_name>,<label_name>=<allowed_labels>, де <allowed_labels> — це розділені комами допустимі назви міток.
Загальний формат виглядає так:
--allow-metric-labels <metric_name>,<label_name>='<allow_value1>, <allow_value2>...', <metric_name2>,<label_name>='<allow_value1>, <allow_value2>...', ...
Ось приклад:
--allow-metric-labels number_count_metric,odd_number='1,3,5', number_count_metric,even_number='2,4,6', date_gauge_metric,weekend='Saturday,Sunday'
Крім того, що це можна вказати з командного рядка, теж саме можна зробити за допомогою конфігураційного файлу. Ви можете вказати шлях до цього файлу конфігурації, використовуючи аргумент командного рядка --allow-metric-labels-manifest для компонента. Ось приклад вмісту цього конфігураційного файлу:
"metric1,label2": "v1,v2,v3"
"metric2,label1": "v1,v2,v3"
Додатково, метрика cardinality_enforcement_unexpected_categorizations_total записує кількість неочікуваних категоризацій під час вказання послідовності, тобто кожного разу, коли значення мітки зустрічається, що не дозволяється з урахуванням обмежень списку дозволених значень.
Що далі
- Дізнайтеся про текстовий формат Prometheus для метрик
- Перегляньте список стабільних метрик Kubernetes
- Прочитайте про політику застаріння Kubernetes
11.7 - Метрики для станів обʼєктів Kubernetes
kube-state-metrics — це агент-надбудова для генерації та надання метрик на рівні кластера.
Стан обʼєктів Kubernetes у Kubernetes API може бути поданий у вигляді метрик. Агент-надбудова kube-state-metrics може підключатися до сервера Kubernetes API та надавати доступ до точки доступу з метриками, що генеруються зі стану окремих обʼєктів у кластері. Він надає різні дані про стан обʼєктів, такі як мітки та анотації, час запуску та завершення, статус або фазу, в яких обʼєкт знаходиться зараз. Наприклад, контейнери, що працюють у Podʼах, створюють метрику kube_pod_container_info. Вона включає імʼя контейнера, імʼя Podʼа, до якого він належить, простір імен, в якому працює Pod, імʼя образу контейнера, ідентифікатор образу, імʼя образу з опису контейнера, ідентифікатор працюючого контейнера та ідентифікатор Podʼа як мітки.
🛇 Цей елемент посилається на сторонній проєкт або продукт, який не є частиною Kubernetes. Докладніше
Зовнішній компонент, який може зчитувати точку доступу kube-state-metrics (наприклад, за допомогою Prometheus), можна використовувати для активації наступних варіантів використання.
Приклад: використання метрик з kube-state-metrics для запиту стану кластера
Серії метрик, що генеруються kube-state-metrics, допомагають отримати додаткові уявлення про кластер, оскільки їх можна використовувати для запитів.
Якщо ви використовуєте Prometheus або інструмент, який використовує ту саму мову запитів, наступний запит PromQL поверне кількість Podʼів, які не готові:
count(kube_pod_status_ready{condition="false"}) by (namespace, pod)
Приклад: сповіщення на основі kube-state-metrics
Метрики, що генеруються з kube-state-metrics, також дозволяють сповіщати про проблеми в кластері.
Якщо ви використовуєте Prometheus або схожий інструмент, який використовує ту саму мову правил сповіщень, наступне сповіщення буде активовано, якщо є Podʼи, які перебувають у стані Terminating протягом понад 5 хвилин:
groups:
- name: Pod state
rules:
- alert: PodsBlockedInTerminatingState
expr: count(kube_pod_deletion_timestamp) by (namespace, pod) * count(kube_pod_status_reason{reason="NodeLost"} == 0) by (namespace, pod) > 0
for: 5m
labels:
severity: page
annotations:
summary: Pod {{$labels.namespace}}/{{$labels.pod}} blocked in Terminating state.
11.8 - Системні логи
Логи компонентів системи фіксують події, які відбуваються в кластері, що може бути дуже корисним для налагодження. Ви можете налаштувати рівень деталізації логів, щоб бачити більше або менше деталей. Логи можуть бути настільки грубими, що вони показують лише помилки у компоненті, або настільки дрібними, що вони показують крок за кроком слідування за подіями (наприклад, логи доступу HTTP, зміни стану події, дії контролера або рішення планувальника).
Попередження:
На відміну від описаних тут прапорців командного рядка, вивід логу сам по собі не підпадає під гарантії стійкості API Kubernetes: окремі записи логу та їх форматування можуть змінюватися від одного релізу до наступного!Klog
klog — це бібліотека реєстрації подій для системних компонентів Kubernetes. klog генерує повідомлення логу для системних компонентів Kubernetes.
Kubernetes знаходиться в процесі спрощення реєстрації подій у своїх компонентах. Наступні прапорці командного рядка klog є застарілими починаючи з Kubernetes v1.23 і будуть видалені у Kubernetes v1.26:
--add-dir-header--alsologtostderr--log-backtrace-at--log-dir--log-file--log-file-max-size--logtostderr--one-output--skip-headers--skip-log-headers--stderrthreshold
Вивід буде завжди записуватися у stderr, незалежно від формату виводу. Очікується, що перенаправлення виводу буде оброблено компонентом, який викликає компонент Kubernetes. Це може бути оболонка POSIX або інструмент, такий як systemd.
У деяких випадках, наприклад, у контейнері distroless або службі Windows, ці параметри недоступні. У цьому випадку можна використовувати бінарний файл kube-log-runner як обгортку навколо компонента Kubernetes для перенаправлення виводу. Вже скомпільований бінарний файл включено в декілька базових образів Kubernetes під його традиційною назвою /go-runner та як kube-log-runner в архівах випусків сервера та вузла.
Ця таблиця показує відповідність викликів kube-log-runner перенаправленню оболонки:
| Використання | POSIX оболонка (напр. bash) | kube-log-runner <options> <cmd> |
|---|---|---|
| Обʼєднати stderr і stdout, записати у stdout | 2>&1 | kube-log-runner (типова поведінка) |
| Перенаправити обидва в лог | 1>>/tmp/log 2>&1 | kube-log-runner -log-file=/tmp/log |
| Скопіювати в лог і до stdout | 2>&1 | tee -a /tmp/log | kube-log-runner -log-file=/tmp/log -also-stdout |
| Перенаправити лише stdout в лог | >/tmp/log | kube-log-runner -log-file=/tmp/log -redirect-stderr=false |
Вивід klog
Приклад традиційного формату виводу klog:
I1025 00:15:15.525108 1 httplog.go:79] GET /api/v1/namespaces/kube-system/pods/metrics-server-v0.3.1-57c75779f-9p8wg: (1.512ms) 200 [pod_nanny/v0.0.0 (linux/amd64) kubernetes/$Format 10.56.1.19:51756]
Рядок повідомлення може містити перенесення рядків:
I1025 00:15:15.525108 1 example.go:79] This is a message
which has a line break.
Структуроване ведення логів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.23 [beta]Попередження:
Перехід до структурованого формату ведення логів є поточним процесом. Не всі повідомлення логів мають структурований формат у цій версії. Під час обробки логів вам також доведеться працювати з неструктурованими повідомленнями логів.
Форматування логів та серіалізація значень можуть змінюватися.
Структуроване ведення логів вводить єдину структуру в повідомлення логів, що дозволяє програмно отримувати інформацію. Ви можете зберігати та обробляти структуровані логи з меншими зусиллями та витратами. Код, який генерує повідомлення логів, визначає, чи використовує він традиційний неструктурований вивід klog, чи структуроване ведення логів.
Формат структурованих повідомлень логів є типово текстовим, у форматі, який зберігає сумісність з традиційним klog:
<klog заголовок> "<повідомлення>" <ключ1>="<значення1>" <ключ2>="<значення2>" ...
Приклад:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
Рядки беруться в лапки. Інші значення форматуються за допомогою %+v, що може призводити до того, що повідомлення логів продовжуватимуться на наступному рядку залежно від даних.
I1025 00:15:15.525108 1 example.go:116] "Example" data="This is text with a line break\nand \"quotation marks\"." someInt=1 someFloat=0.1 someStruct={StringField: First line,
second line.}
Контекстне ведення логів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.30 [beta]Контекстне ведення логів базується на структурованому веденні логів. Це переважно стосується того, як розробники використовують системні виклики ведення логів: код, побудований на цьому концепті, є більш гнучким і підтримує додаткові варіанти використання, як описано в KEP щодо контекстного ведення логів.
Якщо розробники використовують додаткові функції, такі як WithValues або WithName, у своїх компонентах, то записи в журнал міститимуть додаткову інформацію, яка передається у функції своїм абонентам.
Для Kubernetes Kubernetes 1.32, це керується через функціональну можливість ContextualLogging, що є типово увімкненою. Інфраструктура для цього була додана в 1.24 без модифікації компонентів. Команда component-base/logs/example показує, як використовувати нові виклики ведення логів та як компонент поводиться, якщо він підтримує контекстне ведення логів.
$ cd $GOPATH/src/k8s.io/kubernetes/staging/src/k8s.io/component-base/logs/example/cmd/
$ go run . --help
...
--feature-gates mapStringBool Набір пар ключ=значення, які описують feature gate для експериментальних функцій. Опції:
AllAlpha=true|false (ALPHA - стандартно=false)
AllBeta=true|false (BETA - стандартно=false)
ContextualLogging=true|false (BETA - default=true)
$ go run . --feature-gates ContextualLogging=true
...
I0222 15:13:31.645988 197901 example.go:54] "runtime" logger="example.myname" foo="bar" duration="1m0s"
I0222 15:13:31.646007 197901 example.go:55] "another runtime" logger="example" foo="bar" duration="1h0m0s" duration="1m0s"
Ключ logger та foo="bar" були додані абонентом функції, яка записує повідомлення runtime та значення duration="1m0s", без необхідності модифікувати цю функцію.
Коли контекстне ведення логів вимкнене, функції WithValues та WithName нічого не роблять, а виклики ведення логів пройшли через глобальний реєстратор klog. Отже, ця додаткова інформація більше не виводиться в журнал:
$ go run . --feature-gates ContextualLogging=false
...
I0222 15:14:40.497333 198174 example.go:54] "runtime" duration="1m0s"
I0222 15:14:40.497346 198174 example.go:55] "another runtime" duration="1h0m0s" duration="1m0s"
Формат логу у форматі JSON
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.19 [alpha]Попередження:
Вивід у форматі JSON не підтримує багато стандартних прапорців klog. Для списку непідтримуваних прапорців klog дивіться Посібник командного рядка.
Не всі логи гарантовано будуть записані у форматі JSON (наприклад, під час запуску процесу). Якщо ви плануєте розбирати логи, переконайтеся, що можете обробити також рядки логу, які не є JSON.
Назви полів та серіалізація JSON можуть змінюватися.
Прапорець --logging-format=json змінює формат логу з власного формату klog на формат JSON. Приклад формату логу у форматі JSON (форматований для зручності):
{
"ts": 1580306777.04728,
"v": 4,
"msg": "Pod status updated",
"pod":{
"name": "nginx-1",
"namespace": "default"
},
"status": "ready"
}
Ключі з особливим значенням:
ts— відмітка часу у форматі Unix (обовʼязково, дійсне число)v— деталізація (тільки для інформаційних повідомлень, а не для повідомлень про помилки, ціле число)err— рядок помилки (необовʼязково, рядок)msg— повідомлення (обовʼязково, рядок)
Список компонентів, що наразі підтримують формат JSON:
Рівень деталізації логів
Прапорець -v керує рівнем деталізації логу. Збільшення значення збільшує кількість зареєстрованих подій. Зменшення значення зменшує кількість зареєстрованих подій. Збільшення рівнів деталізації записує все менш важливі події. На рівні деталізації 0 журнал реєструє лише критичні події.
Розташування логів
Існують два типи системних компонентів: ті, які працюють у контейнері, та ті, які не працюють у контейнері. Наприклад:
- Планувальник Kubernetes та kube-proxy працюють у контейнері.
- kubelet та середовище виконання контейнерів не працюють у контейнерах.
На машинах з systemd, kubelet та середовище виконання контейнерів записують логи в journald. В іншому випадку вони записуються в файли .log в теці /var/log. Системні компоненти всередині контейнерів завжди записуються в файли .log у теці /var/log, обходячи типовий механізм ведення логу. Аналогічно логам контейнерів, вам слід регулярно виконувати ротацію логів системних компонентів у теці /var/log. У кластерах Kubernetes, створених сценарієм kube-up.sh, ротація логів налаштована за допомогою інструменту logrotate. Інструмент logrotate виконує ротацію логів щоденно або якщо розмір логу перевищує 100 МБ.
Отримання логів
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.30 [beta] (стандартно увімкнено: false)Для допомоги у розвʼязанні проблем на вузлах Kubernetes версії v1.27 введено функцію, яка дозволяє переглядати логи служб, що працюють на вузлі. Щоб скористатися цією функцією, переконайтеся, що для цього вузла увімкнути функціональну можливість NodeLogQuery, а також що параметри конфігурації kubelet enableSystemLogHandler та enableSystemLogQuery обидва встановлені в значення true. На Linux ми припускаємо, що логи служб доступні через journald. На Windows ми припускаємо, що логи служб доступні в постачальнику логів застосунків. В обох операційних системах логи також доступні за допомогою читання файлів у теці /var/log/.
Якщо у вас є дозвіл на взаємодію з обʼєктами Node, ви можете спробувати цю функцію на всіх ваших вузлах або лише на їх підмножині. Ось приклад отримання логу служби kubelet з вузла:
# Отримати логи kubelet з вузла під назвою node-1.example
kubectl get --raw "/api/v1/nodes/node-1.example/proxy/logs/?query=kubelet"
Ви також можете отримувати файли, за умови, що файли знаходяться в теці, для якої kubelet дозволяє читання логів. Наприклад, ви можете отримати лог з /var/log/ на вузлі Linux:
kubectl get --raw "/api/v1/nodes/<назва-вузла>/proxy/logs/?query=/<назва-файлу-логу>"
Kubelet використовує евристику для отримання логів. Це допомагає, якщо ви не знаєте, чи даний системний сервіс записує логи до стандартного реєстратора операційної системи, такого як journald, чи до файлу логу у /var/log/. Спочатку евристика перевіряє стандартний реєстратор, а якщо його немає, вона намагається отримати перші логи з /var/log/<імʼя-служби> або /var/log/<назва-служби>.log або /var/log/<назва-служби>/<назва-служби>.log.
Повний перелік параметрів, які можна використовувати:
| Опція | Опис |
|---|---|
boot | показує повідомлення про завантаження з певного завантаження системи |
pattern | фільтрує записи логу за заданим регулярним виразом, сумісним з Perl |
query | вказує службу(и) або файли, з яких слід повернути логи (обовʼязково) |
sinceTime | час відображення логу, починаючи з RFC3339 (включно) |
untilTime | час до якого показувати логи, за RFC3339 (включно) |
tailLines | вказує, скільки рядків з кінця логу отримати; типово отримується весь журнал |
Приклад складнішого запиту:
# Отримати логи kubelet з вузла під назвою node-1.example, у яких є слово "error"
kubectl get --raw "/api/v1/nodes/node-1.example/proxy/logs/?query=kubelet&pattern=error"
Що далі
- Дізнайтеся про Архітектуру логів Kubernetes
- Дізнайтеся про Структуроване ведення логу
- Дізнайтеся про Контекстне ведення логу
- Дізнайтеся про застарілі прапорці klog
- Дізнайтеся про Умови ведення логу за важливістю
- Дізнайтеся про Log Query
11.9 - Трейси для системних компонентів Kubernetes
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.27 [beta]Трейси системних компонентів реєструють затримку та звʼязки між операціями у кластері.
Компоненти Kubernetes відправляють трейси за допомогою Протоколу OpenTelemetry з експортером gRPC і можуть бути зібрані та направлені до різних систем відслідковування за допомогою OpenTelemetry Collector.
Збір трейсів
Компоненти Kubernetes мають вбудовані експортери gRPC для OTLP для експорту трейсів, або через OpenTelemetry Collector, або без нього.
Для повного посібника зі збору трейсів та використання колектора див. Початок роботи з OpenTelemetry Collector. Однак є кілька речей, на які варто звернути увагу, що є специфічними для компонентів Kubernetes.
Типово компоненти Kubernetes експортують трейси за допомогою експортера grpc для OTLP на порт IANA OpenTelemetry, 4317. Наприклад, якщо колектор працює як sidecar контейнер для компонента Kubernetes, наступна конфігурація приймача збере спани (spans) та відправить їх у стандартний вивід:
receivers:
otlp:
protocols:
grpc:
exporters:
# Замініть цей експортер на експортер для вашої системи
logging:
logLevel: debug
service:
pipelines:
traces:
receivers: [otlp]
exporters: [logging]
Для безпосереднього надсилання трейсів до бекенду без використання колектора, вкажіть поле endpoint у конфігурації Kubernetes з адресою бекенду. Цей метод усуває потребу в колекторі та спрощує загальну структуру.
Для конфігурації заголовків backend trace, включаючи дані автентифікації, можна використовувати змінні середовища з OTEL_EXPORTER_OTLP_HEADERS, див. Конфігурація Експортера OTLP.
Додатково, для конфігурації атрибутів ресурсів trace, таких як назва кластера Kubernetes, простір імен, імʼя Pod і т. д., також можна використовувати змінні середовища з OTEL_RESOURCE_ATTRIBUTES, див. Ресурс Kubernetes OTLP.
Трейси компонентів
Трейси kube-apiserver
Kube-apiserver генерує спани для вхідних HTTP-запитів та для вихідних запитів до веб-хуків, etcd та повторних запитів. Він передає W3C Trace Context з вихідними запитами, але не використовує контекст трейса, доданий до вхідних запитів, оскільки kube-apiserver часто є загальнодоступною точкою доступу.
Увімкнення трейсів в kube-apiserver
Щоб увімкнути трейси, надайте kube-apiserver файл конфігурації тресів з --tracing-config-file=<шлях-до-конфігу>. Це приклад конфігурації, яка записує спани для 1 з 10000 запитів та використовує типову точку доступу OpenTelemetry:
apiVersion: apiserver.config.k8s.io/v1beta1
kind: TracingConfiguration
# типове значення
#endpoint: localhost:4317
samplingRatePerMillion: 100
Для отримання додаткової інформації про структуру TracingConfiguration, див. API сервера конфігурації (v1beta1).
Трейси kubelet
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.27 [beta] (стандартно увімкнено: true)Інтерфейс CRI kubelet та автентифіковані http-сервери інструментовані для генерації спанів трейсів. Як і apiserver, адресу та частоту зразків можна налаштувати. Контекст трейсів також налаштований. Рішення про зразок батьківського спану завжди береться до уваги. Частота зразків трейсів, надана в конфігурації, застосовуватиметься до спанів без батьків. Ввімкнено без налаштованої точки доступу, типова адреса приймача OpenTelemetry Collector — "localhost:4317".
Увімкнення трейсів в kubelet
Щоб увімкнути трейси, застосуйте конфігурацію. Це приклад шматка конфігурації kubelet, що записує спани для 1 з 10000 запитів та використовує типову точку доступу OpenTelemetry:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
KubeletTracing: true
tracing:
# типове значення
#endpoint: localhost:4317
samplingRatePerMillion: 100
Якщо samplingRatePerMillion встановлено на мільйон (1000000), то кожен спан буде відправлений до експортера.
Kubelet у Kubernetes v1.32 збирає спани зі збирання сміття, процесів синхронізації Podʼів, а також кожного методу gRPC. Kubelet передає контекст трейсів із запитами gRPC, щоб контейнерні середовища з інструментованими трейсами, такі як CRI-O та containerd, могли асоціювати їх експортовані спани з контекстом трейсів від kubelet. Отримані трейси будуть мати посилання батько-дитина між спанами kubelet та контейнерним середовищем, надаючи корисний контекст при налагодженні вузла.
Зверніть увагу, що експортування спанів завжди супроводжується невеликим перевантаженням мережі та CPU, залежно від загальної конфігурації системи. Якщо в кластері, в якому увімкнено трейси, виникає будь-яка проблема, така як ця, то помʼякшіть проблему шляхом зменшення samplingRatePerMillion або повністю вимкніть трейси, видаливши конфігурацію.
Стабільність
Інструментування трейсів все ще перебуває в активній розробці та може змінюватися різними способами. Це стосується назв спанів, приєднаних атрибутів, інструментованих точок доступу та інших. До того часу, поки ця функція не стане стабільною, не надається жодних гарантій зворотної сумісності для інструментів трейсів.
Що далі
- Прочитайте про Початок роботи з OpenTelemetry Collector
- Прочитайте про Конфігурацію Експортера OTLP
11.10 - Проксі у Kubernetes
На цій сторінці пояснюються проксі, що використовуються з Kubernetes.
Проксі
У вас можуть зустрітися декілька різних проксі, коли ви використовуєте Kubernetes:
- працює на робочому столі користувача або в контейнері
- забезпечує проксі з локальної адреси до apiserver Kubernetes
- клієнт до проксі використовує HTTP
- проксі до apiserver використовує HTTPS
- знаходить apiserver
- додає заголовки автентифікації
- є бастіоном, вбудованим в apiserver
- зʼєднує користувача поза кластером з IP-адресами кластера, які інакше можуть бути недоступними
- працює в процесах apiserver
- клієнт до проксі використовує HTTPS (або http, якщо apiserver налаштовано так)
- проксі до цілі може використовувати HTTP або HTTPS, як вибрав проксі за наявною інформацією
- може бути використаний для доступу до Node, Pod або Service
- виконує балансування навантаження при використанні для доступу до Service
- працює на кожному вузлі
- забезпечує проксі UDP, TCP та SCTP
- не розуміє HTTP
- надає балансування навантаження
- використовується лише для доступу до Service
Проксі/балансувальник перед apiserver(s):
- існування та реалізація різниться від кластера до кластера (наприклад, nginx)
- розташований між всіма клієнтами та одним або кількома apiservers
- діє як балансувальник навантаження, якщо є кілька apiservers.
Хмарні балансувальники навантаження на зовнішньому Service:
- надаються деякими хмарними провайдерами (наприклад, AWS ELB, Google Cloud Load Balancer)
- створюються автоматично, коли у Service Kubernetes тип —
LoadBalancer - зазвичай підтримують лише UDP/TCP
- підтримка SCTP залежить від реалізації балансувальника навантаження хмарного провайдера
- реалізація відрізняється від провайдера хмарних послуг.
Зазвичай користувачі Kubernetes не повинні турбуватися про щось, крім перших двох типів. Зазвичай адміністратор кластера забезпечує правильне налаштування останніх типів.
Запит на перенаправлення
Проксі замінили можливості перенаправлення. Перенаправлення були визнані застарілими.
11.11 - API Priority та Fairness
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.29 [stable]Контроль поведінки сервера API Kubernetes у ситуації перевантаження є основним завданням для адміністраторів кластера. У kube-apiserver є деякі елементи керування (тобто прапорці командного рядка --max-requests-inflight та --max-mutating-requests-inflight), щоб обмежити обсяг невиконаної роботи, яка буде прийнята, запобігаючи перевантаженню потоку вхідних запитів та потенційному збою сервера API, але цих прапорців недостатньо для забезпечення проходження найважливіших запитів у період високого навантаження.
Елементи API Priority та Fairness (APF) є альтернативою, яка покращує зазначені обмеження щодо максимального числа невиконаних завдань. APF класифікує та ізолює запити більш деталізованим способом. Вони також вводять обмеження на черги, щоб ніякі запити не були відхилені в разі дуже коротких вибухів. Запити надсилаються з черг за допомогою техніки справедливих черг, так що, наприклад, контролер, який погано поводиться не має вичерпати інші ресурси (навіть на тому ж рівні пріоритету).
Ця функція розроблена для співпраці зі стандартними контролерами, які використовують інформатори та реагують на невдачі запитів API з експоненційним збільшенням часу очікування, та іншими клієнтами, які також працюють таким чином.
Увага:
Деякі запити, класифіковані як "тривалі", такі як виконання віддалених команд або отримання останніх записів з логів, не є предметом фільтрації API Priority та Fairness. Це також стосується прапорця командного рядка--max-requests-inflight без увімкненої функціональності API Priority та Fairness. API Priority та Fairness застосовується до watch запитів. Коли функціональність API Priority та Fairness вимкнена, watch запити не підлягають обмеженню --max-requests-inflight.Увімкнення/вимкнення API Priority та Fairness
API Priority та Fairness контролюється прапорцем командного рядка та є типово увімкненим. Див. Опції для загального пояснення доступних опцій командного рядка kube-apiserver та того, як їх увімкнути та вимкнути. Назва параметра командного рядка для APF — "--enable-priority-and-fairness". Ця функція також включає API Group, яка має: (a) стабільну версію v1, введена у версії 1.29, і типово увімкнена, (b) версію v1beta3, типово увімкнена та застаріла у версії v1.29. Ви можете вимкнути бета-версію групи API v1beta3, додавши наступні параметри командного рядка до запуску kube-apiserver:
kube-apiserver \
--runtime-config=flowcontrol.apiserver.k8s.io/v1beta3=false \
# …і інші прапорці, як завжди
Параметр командного рядка --enable-priority-and-fairness=false вимкне API Priority та Fairness.
Рекурсивні сценарії сервера
API Priority and Fairness повинні використовуватися обережно в рекурсивних сценаріях сервера. Це сценарії, в яких сервер A, обробляючи запит, надсилає допоміжний запит на сервер B. Можливо, сервер B може навіть зробити подальший допоміжний виклик назад до сервера A. У ситуаціях, коли контроль Пріоритету і Справедливості застосовується як до оригінального запиту, так і до деяких допоміжних, незалежно від глибини рекурсії, існує небезпека пріоритетних інверсій та/або взаємоблокувань.
Прикладом рекурсії є випадок, коли kube-apiserver робить виклик admission webhook на сервер B, і під час обробки цього виклику сервер B робить подальший допоміжний запит назад до kube-apiserver. Інший приклад рекурсії — коли обʼєкт APIService спрямовує kube-apiserver делегувати запити щодо певної групи API на власний зовнішній сервер B користувача (це один з аспектів, які називаються "агрегацією").
Коли відомо, що оригінальний запит належить до певного рівня пріоритету, і допоміжні контрольовані запити класифікуються на вищі рівні пріоритету, це може бути одним з можливих рішень. Коли оригінальні запити можуть належати до будь-якого рівня пріоритету, допоміжні контрольовані запити повинні бути звільнені від обмежень Priority and Fairness. Один із способів це зробити — за допомогою обʼєктів, які налаштовують класифікацію та обробку, обговорених нижче. Інший спосіб — повністю відключити Priority and Fairness на сервері B, використовуючи техніки, обговорені вище. Третій спосіб, який найпростіше використовувати, коли сервер B не є kube-apiserver, це побудувати сервер B з відключеним у коді Priority and Fairness.
Концепції
API Priority та Fairness включає кілька різних функцій. Вхідні запити класифікуються за атрибутами запиту за допомогою FlowSchemas, і призначаються пріоритетним рівням. Пріоритетні рівні додають ступінь ізоляції, підтримуючи окремі обмеження паралелізму, так що запити, які призначені для різних пріоритетних рівнів, не можуть позбавляти ресурсів один одного. У межах пріоритетного рівня алгоритм справедливого чергування не дозволяє запитам з різних потоків позбавляти ресурсів один одного, і дозволяє чергувати запити, щоб запобігти відмовам від запитів у випадках, коли середнє навантаження прийнятно низьке.
Рівні пріоритету
Без увімкненої функції APF загальний паралелізм в API-сервері обмежується прапорцями --max-requests-inflight та --max-mutating-requests-inflight у kube-apiserver. З увімкненою функцією APF ліміти паралелізму, визначені цими прапорцями, сумуються, а потім сума розподіляється серед налаштованого набору рівнів пріоритету. Кожен вхідний запит призначається одному з рівнів пріоритету, і кожен рівень пріоритету буде обробляти лише стільки одночасних запитів, скільки дозволяє його конкретний ліміт.
Наприклад, у типовій конфігурації існують окремі рівні пріоритету для запитів на вибір лідера, запитів від вбудованих контролерів і запитів від Podʼів. Це означає, що Podʼи, які поводяться погано і завалюють API-сервер запитами, не можуть перешкодити вибору лідера або виконанню дій вбудованими контролерами.
Межі паралелізму рівнів пріоритету періодично коригуються, що дозволяє недостатньо використовуваним рівням пріоритету тимчасово надавати паралелізм сильно використовуваних рівнів. Ці обмеження базуються на номінальних обмеженнях та межах того, скільки паралелізму може позичити рівень пріоритету та скільки він може позичити, всі отримані з обʼєктів конфігурації, згаданих нижче.
Місця, зайняті за запитом
Наведений вище опис управління паралелізмом є базовою поведінкою. Запити мають різну тривалість, але враховуються однаково в будь-який момент при порівнянні з лімітом паралелізму на рівні пріоритету. У базовій поведінці кожен запит займає одну одиницю паралелізму. Слово "місце" (seat) використовується для позначення однієї одиниці паралелізму, під впливом від того, як кожен пасажир у поїзді або літаку займає одне з фіксованих місць.
Але деякі запити займають більше, ніж одне місце. Деякі з них — це запити list, які сервер оцінює, що повертають велику кількість обʼєктів. Вони виявилися надзвичайно важкою ношею для сервера. З цієї причини сервер оцінює кількість обʼєктів, які будуть повернуті, і вважає, що запит займає кількість місць, пропорційну цій оцінці.
Коригування часу виконання для запитів watch
API Priority та Fairness керує запитами watch, але це передбачає ще кілька відступів від базової поведінки. Перше стосується того, як довго запит watch вважається таким, що займає своє місце. Залежно від параметрів запиту, відповідь на запит на watch може або не може розпочинатися зі сповіщень create для всіх відповідних попередніх обʼєктів. API Priority та Fairness вважає, що запит watch завершено зі своїм місцем, як тільки цей початковий вибух сповіщень, якщо такі є, закінчився.
Нормальні сповіщення надсилаються у паралельному сплеску на всі потрібні потоки відповіді на watch, коли сервер отримує сповіщення про створення/оновлення/видалення обʼєкта. Для врахування цієї роботи API Priority та Fairness вважає, що кожен записний запит витрачає додатковий час, займаючи місця після завершення фактичного запису. Сервер оцінює кількість сповіщень, які будуть надіслані, і коригує кількість місць та час зайнятості місця для записного запиту, щоб врахувати цю додаткову роботу.
Черги
Навіть на рівні пріоритету може бути велика кількість різних джерел трафіку. У ситуації перевантаження важливо запобігти тому, щоб один потік вичерпував ресурси інших (зокрема, у відносно поширеному випадку, коли один помилковий клієнт переповнює kube-apiserver запитами, цей помилковий клієнт в ідеалі взагалі не мав би помітного впливу на інших клієнтів). Це обробляється за допомогою алгоритму справедливої черги для обробки запитів, яким присвоєно однаковий рівень пріоритету. Кожен запит присвоюється потоку, ідентифікованому за назвою відповідної FlowSchema плюс розрізнювач потоку - який є або запитуючим користувачем, або простором імен цільового ресурсу, або нічим - і система намагається надати приблизно однакову вагу запитам у різних потоках одного і того ж рівня пріоритету. Щоб забезпечити чітку обробку різних екземплярів, контролери, які мають багато екземплярів, повинні автентифікуватися за допомогою різних імен користувачів
Це забезпечується за допомогою алгоритму справедливих черг обробки запитів, які призначені для того ж рівня пріоритету. Кожен запит призначається для потоку, ідентифікованого імʼям відповідного FlowSchema плюс розрізнювач потоку — яким є або користувач-абонент, або простір імен цільового ресурсу, або нічого — і система намагається надати приблизно рівну вагу запитам в різних потоках того ж рівня пріоритету.
Після класифікації запиту у потік, API Priority та Fairness може призначити запит до черги. Це призначення використовує техніку, відому як shuffle sharding, яка досить ефективно використовує черги для ізоляції потоків низької інтенсивності від потоків високої інтенсивності.
Деталі алгоритму черг налаштовуються для кожного рівня пріоритету і дозволяють адміністраторам збалансувати використання памʼяті, справедливість (властивість того, що незалежні потоки всі рухатимуться вперед, коли загальний трафік перевищує потужність), толерантність до бурхливого трафіку та доданий час очікування, що виникає через черги.
Ексклюзивні запити
Деякі запити вважаються достатньо важливими, щоб не підлягати жодним обмеженням, які накладає ця функція. Ці винятки запобігають тому, щоб неправильно налаштована конфігурація керування потоком повністю вимкнула API-сервер.
Ресурси
API керування потоком включає два види ресурсів. Конфігурації рівня пріоритету визначають доступні рівні пріоритету, частку доступного бюджету паралелізму, яку кожен може обробити, та дозволяють налаштовувати поведінку черги. FlowSchemas використовуються для класифікації окремих вхідних запитів, відповідність кожного з PriorityLevelConfiguration.
PriorityLevelConfiguration
PriorityLevelConfiguration представляє один рівень пріоритету. Кожен PriorityLevelConfiguration має незалежні обмеження на кількість невиконаних запитів та обмеження на кількість запитів у черзі.
Номінальне обмеження паралелізму для PriorityLevelConfiguration не визначається в абсолютній кількості місць, а в "номінальних частках паралелізму". Загальне обмеження паралелізму для API-сервера розподіляється серед наявних конфігурацій рівня пріоритету пропорційно цим часткам, щоб кожен рівень отримав своє номінальне обмеження у вигляді місць. Це дозволяє адміністратору кластера збільшувати або зменшувати загальний обсяг трафіку до сервера, перезапускаючи kube-apiserver з іншим значенням для --max-requests-inflight (або --max-mutating-requests-inflight), і всі PriorityLevelConfiguration побачать, що їх максимально допустимий паралелізм збільшиться (або зменшиться) на ту саму частку.
Увага:
У версіях доv1beta3 відповідне поле PriorityLevelConfiguration має назву "assured concurrency shares" замість "nominal concurrency shares". Також у версії Kubernetes 1.25 та раніше не проводилося періодичних налаштувань: номінальні/забезпечені обмеження застосовувалися завжди без коригування.Межі того, скільки паралелізму може надати рівень пріоритету та скільки він може позичити, виражені в PriorityLevelConfiguration у відсотках від номінального обмеження рівня. Ці значення перетворюються на абсолютні числа місць, множачи їх на номінальне обмеження / 100.0 та округлюючи. Динамічно кориговане обмеження паралелізму рівня пріоритету обмежене нижньою межею його номінального обмеження мінус кількість місць, які він може позичити, та верхньою межею його номінального обмеження плюс місця, які він може позичити. Під час кожного налаштування динамічні межі визначаються кожним рівнем пріоритету, відновлюючи будь-які позичені місця, на які востаннє зʼявлявся попит, та спільно відповідаючи на попит за місцями на рівнях пріоритету в межах вищезазначених меж.
Увага:
При увімкненні функції Priority та Fairness загальне обмеження паралелізму для сервера встановлюється як сума--max-requests-inflight та --max-mutating-requests-inflight. Більше не робиться різниці між змінними та незмінними запитами; якщо ви хочете обробляти їх окремо для певного ресурсу, створіть окремі FlowSchemas, які відповідають відповідним діям.Коли обсяг вхідних запитів, які призначені для одного PriorityLevelConfiguration, перевищує його дозволений рівень паралелізму, поле type його специфікації визначає, що відбудеться з додатковими запитами. Тип Reject означає, що зайвий трафік буде негайно відхилено з помилкою HTTP 429 (Too Many Requests). Тип Queue означає, що запити, які перевищують поріг, будуть ставитися у чергу, із використанням технік випадкового розміщення та справедливої черги для збалансування прогресу між потоками запитів.
Конфігурація черги дозволяє налаштувати алгоритм справедливої черги для рівня пріоритету. Деталі алгоритму можна знайти у пропозиції про вдосконалення, ось скорочено:
Збільшення
queuesзменшує швидкість зіткнень між різними потоками, коштом збільшення використання памʼяті. Значення 1 тут фактично вимикає логіку справедливої черги, але все ще дозволяє ставити запити в чергу.Збільшення
queueLengthLimitдозволяє підтримувати більші потоки трафіку без відкидання будь-яких запитів, коштом збільшення затримки та використання памʼяті.Зміна
handSizeдозволяє вам налаштувати ймовірність зіткнень між різними потоками та загальний паралелізм, доступний для одного потоку в ситуації перевантаження.Примітка:
Більше значенняhandSizeдає менше ймовірності, що два окремі потоки зіткнуться (і, отже, один зможе відібрати ресурси в іншого), але більше ймовірності того, що невелика кількість потоків може домінувати в apiserver. Більше значенняhandSizeтакож потенційно збільшує кількість затримок, які може спричинити один потік з високим трафіком. Максимальна кількість запитів, які можна поставити в чергу від одного потоку, становитьhandSize * queueLengthLimit.
Нижче наведена таблиця з цікавою колекцією конфігурацій випадкового розміщення, що показує для кожної ймовірність те, що певна миша (потік низької інтенсивності) буде розчавлена слонами (потоками високої інтенсивності) для ілюстративної колекції числа слонів. Див. https://play.golang.org/p/Gi0PLgVHiUg, який обчислює цю таблицю.
| HandSize | Черги | 1 слон | 4 слони | 16 слонів |
|---|---|---|---|---|
| 12 | 32 | 4.428838398950118e-09 | 0.11431348830099144 | 0.9935089607656024 |
| 10 | 32 | 1.550093439632541e-08 | 0.0626479840223545 | 0.9753101519027554 |
| 10 | 64 | 6.601827268370426e-12 | 0.00045571320990370776 | 0.49999929150089345 |
| 9 | 64 | 3.6310049976037345e-11 | 0.00045501212304112273 | 0.4282314876454858 |
| 8 | 64 | 2.25929199850899e-10 | 0.0004886697053040446 | 0.35935114681123076 |
| 8 | 128 | 6.994461389026097e-13 | 3.4055790161620863e-06 | 0.02746173137155063 |
| 7 | 128 | 1.0579122850901972e-11 | 6.960839379258192e-06 | 0.02406157386340147 |
| 7 | 256 | 7.597695465552631e-14 | 6.728547142019406e-08 | 0.0006709661542533682 |
| 6 | 256 | 2.7134626662687968e-12 | 2.9516464018476436e-07 | 0.0008895654642000348 |
| 6 | 512 | 4.116062922897309e-14 | 4.982983350480894e-09 | 2.26025764343413e-05 |
| 6 | 1024 | 6.337324016514285e-16 | 8.09060164312957e-11 | 4.517408062903668e-07 |
FlowSchema
FlowSchema — це визначення, яке відповідає деяким вхідним запитам і призначає їх певному рівню пріоритету. Кожний вхідний запит перевіряється на відповідність FlowSchemas, починаючи з тих, що мають найменше числове значення matchingPrecedence, і працюючи вгору. Перший збіг перемагає.
Увага:
Лише перший збіг FlowSchema для даного запиту має значення. Якщо для одного вхідного запиту відповідає декілька FlowSchema, він буде призначений відповідно до того, що має найвищийmatchingPrecedence. Якщо кілька FlowSchema з рівним matchingPrecedence відповідають тому ж запиту, переможе та, яка має лексикографічно менший name, але краще не покладатися на це, а замість цього переконатися, що жодні дві FlowSchema не мають одного й того ж matchingPrecedence.FlowSchema відповідає даному запиту, якщо принаймні одне з rules має збіг. Правило має збіг, якщо принаймні один з його subjects та принаймні один з його resourceRules або nonResourceRules (залежно від того, чи є вхідний запит для ресурсу, чи нересурсного URL) відповідає запиту.
Для поля name в підсумках та полів verbs, apiGroups, resources, namespaces та nonResourceURLs правил ресурсів та нересурсних правил можна вказати маску *, щоб відповідати всім значенням для вказаного поля, яке фактично видаляє його з використання.
Тип distinguisherMethod.type FlowSchema визначає, як запити, які відповідають цій схемі, будуть розділені на потоки. Це може бути ByUser, коли один користувач має можливість позбавити інших користувачів можливості використовувати ресурси; ByNamespace, коли запити до ресурсів в одному просторі імен не можуть позбавити запити до ресурсів в інших просторах імен можливості використовувати їх; або порожнє значення (або distinguisherMethod може бути пропущений повністю), коли всі запити, які відповідають цій FlowSchema, будуть вважатися частиною одного потоку. Правильний вибір для даної FlowSchema залежить від ресурсу та вашого конкретного середовища.
Стандартні
Кожен kube-apiserver підтримує два різновиди обʼєктів API Priority та Fairnes: обовʼязкові та рекомендовані.
Обовʼязкові обʼєкти конфігурації
Чотири обовʼязкові обʼєкти конфігурації відображають фіксовану вбудовану поведінку обмежень безпеки. Це поведінка, яку сервери мають до того, як ці обʼєкти почнуть існувати, і коли ці обʼєкти існують, їх специфікації відображають цю поведінку. Чотири обовʼязкові обʼєкти є такими:
Обовʼязковий пріоритетний рівень
exemptвикористовується для запитів, які взагалі не підлягають контролю потоку: вони завжди будуть надсилатися негайно. Обовʼязкова FlowSchemaexemptкласифікує всі запити з групиsystem:mastersу цей рівень пріоритету. Ви можете визначити інші FlowSchemas, які направляють інші запити на цей рівень пріоритету, якщо це доцільно.Обовʼязковий пріоритетний рівень
catch-allвикористовується в поєднанні з обовʼязковою FlowSchemacatch-all, щоб переконатися, що кожен запит отримує якийсь вид класифікації. Зазвичай ви не повинні покладатися на цю універсальнуcatch-allконфігурацію і повинні створити свою власну FlowSchema та PriorityLevelConfiguration для обробки всіх запитів. Оскільки очікується, що він не буде використовуватися нормально, обовʼязковий рівень пріоритетуcatch-allмає дуже невелику частку паралелізму і не ставить запити в чергу.
Рекомендовані обʼєкти конфігурації
Рекомендовані FlowSchema та PriorityLevelConfigurations складають обґрунтовану типову конфігурацію. Ви можете змінювати їх або створювати додаткові обʼєкти конфігурації за необхідності. Якщо ваш кластер може зазнати високого навантаження, то варто розглянути, яка конфігурація працюватиме краще.
Рекомендована конфігурація групує запити в шість рівнів пріоритету:
Рівень пріоритету
node-highпризначений для оновлень стану вузлів.Рівень пріоритету
systemпризначений для запитів, які не стосуються стану справності, з групиsystem:nodes, тобто Kubelets, які повинні мати можливість звʼязатися з сервером API, щоб завдання могли плануватися на них.Рівень пріоритету
leader-electionпризначений для запитів на вибір лідера від вбудованих контролерів (зокрема, запити наendpoints,configmapsабоleases, що надходять від користувачів та облікових записів служб з групиsystem:kube-controller-managerабоsystem:kube-schedulerв просторі іменkube-system). Ці запити важливо ізолювати від іншого трафіку, оскільки невдачі у виборі лідера призводять до збоїв їх контролерів і перезапуску, що в свою чергу призводить до більших витрат трафіку, оскільки нові контролери синхронізують свої сповіщувачі.Рівень пріоритету
workload-highпризначений для інших запитів від вбудованих контролерів.Рівень пріоритету
workload-lowпризначений для запитів від будь-якого іншого облікового запису служби, що зазвичай включає всі запити від контролерів, що працюють в капсулах.Рівень пріоритету
global-defaultобробляє весь інший трафік, наприклад, інтерактивні командиkubectl, запущені непривілейованими користувачами.
Рекомендовані FlowSchema служать для направлення запитів на вищезазначені рівні пріоритету, і тут вони не перераховані.
Підтримка обовʼязкових та рекомендованих обʼєктів конфігурації
Кожен kube-apiserver незалежно підтримує обовʼязкові та рекомендовані обʼєкти конфігурації, використовуючи початкову та періодичну поведінку. Отже, в ситуації з сумішшю серверів різних версій може відбуватися турбулентність, поки різні сервери мають різні погляди на відповідний вміст цих обʼєктів.
Кожен kube-apiserver робить початковий обхід обовʼязкових та рекомендованих обʼєктів конфігурації, а після цього здійснює періодичну обробку (один раз на хвилину) цих обʼєктів.
Для обовʼязкових обʼєктів конфігурації підтримка полягає в тому, щоб забезпечити наявність обʼєкта та, якщо він існує, мати правильну специфікацію. Сервер відмовляється дозволити створення або оновлення зі специфікацією, яка не узгоджується з поведінкою огородження сервера.
Підтримка рекомендованих обʼєктів конфігурації призначена для того, щоб дозволити перевизначення їх специфікації. Видалення, з іншого боку, не враховується: підтримка відновить обʼєкт. Якщо вам не потрібен рекомендований обʼєкт конфігурації, то вам потрібно залишити його, але встановити його специфікацію так, щоб мінімально впливати на систему. Підтримка рекомендованих обʼєктів також призначена для підтримки автоматичної міграції при виході нової версії kube-apiserver, хоча, можливо, з турбулентністю при змішаній популяції серверів.
Підтримка рекомендованого обʼєкта конфігурації включає його створення, зі специфікацією, яку пропонує сервер, якщо обʼєкт не існує. З іншого боку, якщо обʼєкт вже існує, поведінка підтримка залежить від того, чи контролюють обʼєкт kube-apiservers чи користувачі. У першому випадку сервер забезпечує, що специфікація обʼєкта відповідає тому, що пропонує сервер; у другому випадку специфікація залишається без змін.
Питання про те, хто контролює обʼєкт, вирішується спочатку шляхом пошуку анотації з ключем apf.kubernetes.io/autoupdate-spec. Якщо така анотація є і її значення true, то обʼєкт контролюється kube-apiservers. Якщо така анотація існує і її значення false, то обʼєкт контролюють користувачі. Якщо жодна з цих умов не виконується, тоді перевіряється metadata.generation обʼєкта. Якщо вона дорівнює 1, то обʼєкт контролюють kube-apiservers. В іншому випадку обʼєкт контролюють користувачі. Ці правила були введені у версії 1.22, і врахування ними metadata.generation призначена для міграції з більш простої попередньої поведінки. Користувачі, які хочуть контролювати рекомендований обʼєкт конфігурації, повинні встановити анотацію apf.kubernetes.io/autoupdate-spec в false.
Підтримка обовʼязкового або рекомендованого обʼєкта конфігурації також включає забезпечення наявності анотації apf.kubernetes.io/autoupdate-spec, яка точно відображає те, чи контролюють kube-apiservers обʼєкт.
Підтримка також включає видалення обʼєктів, які не є обовʼязковими або рекомендованими, анотованих як apf.kubernetes.io/autoupdate-spec=true.
Звільнення від паралелізму перевірки справності
Запропонована конфігурація не надає спеціального поводження запитам на перевірку стану здоровʼя на kube-apiservers від їхніх локальних kubelets, які зазвичай використовують захищений порт, але не надають жодних облікових даних. Запити цього типу вказаної конфігурації призначаються до FlowSchema global-default і відповідного пріоритетного рівня global-default, де інші запити можуть їх перенавантажувати.
Якщо ви додасте наступний додатковий FlowSchema, це звільнить ці запити від обмежень.
Увага:
Ці зміни, також дозволяють будь-якому, навіть зловмисникам надсилати запити перевірки стану справності, які відповідають цьій FlowSchema, у будь-якому обсязі. Якщо у вас є фільтр вебтрафіку або подібний зовнішній механізм безпеки для захисту сервера API вашого кластера від загального зовнішнього трафіку, ви можете налаштувати правила для блокування будь-яких запитів на перевірку стану справності, які походять ззовні вашого кластера.apiVersion: flowcontrol.apiserver.k8s.io/v1
kind: FlowSchema
metadata:
name: health-for-strangers
spec:
matchingPrecedence: 1000
priorityLevelConfiguration:
name: exempt
rules:
- nonResourceRules:
- nonResourceURLs:
- "/healthz"
- "/livez"
- "/readyz"
verbs:
- "*"
subjects:
- kind: Group
group:
name: "system:unauthenticated"
Спостережуваність
Метрики
Примітка:
У версіях Kubernetes перед v1.20 міткиflow_schema та priority_level мали нестабільні назви flowSchema та priorityLevel, відповідно. Якщо ви використовуєте версії Kubernetes v1.19 та раніше, вам слід звертатися до документації для вашої версії.Після увімкнення функції API Priority та Fairness, kube-apiserver експортує додаткові метрики. Моніторинг цих метрик може допомогти вам визначити, чи правильно ваша конфігурація обробляє важливий трафік, або знайти проблемні робочі навантаження, які можуть шкодити справності системи.
Рівень зрілості BETA
apiserver_flowcontrol_rejected_requests_total— це вектор лічильника (накопичувальний з моменту запуску сервера) запитів, які були відхилені, розбитий за міткамиflow_schema(показує той, який підходить до запиту),priority_level(показує той, до якого був призначений запит) іreason. Міткаreasonбуде мати одне з наступних значень:queue-full, що вказує на те, що занадто багато запитів вже було в черзі.concurrency-limit, що вказує на те, що конфігурація PriorityLevelConfiguration налаштована відхиляти замість того, щоб ставити в чергу зайві запити.time-out, що вказує на те, що запит все ще перебував в черзі, коли його обмеження часу в черзі закінчилося.cancelled, що вказує на те, що запит не закріплений і викинутий з черги.
apiserver_flowcontrol_dispatched_requests_total— це вектор лічильника (накопичувальний з моменту запуску сервера) запитів, які почали виконуватися, розбитий заflow_schemaтаpriority_level.apiserver_flowcontrol_current_inqueue_requests— це вектор мітки миттєвого числа запитів, які знаходяться в черзі (не виконуються), розбитий заpriority_levelтаflow_schema.apiserver_flowcontrol_current_executing_requests— це вектор мітки миттєвого числа виконуваних (не очікуючих в черзі) запитів, розбитий заpriority_levelтаflow_schema.apiserver_flowcontrol_current_executing_seats— це вектор мітки миттєвого числа зайнятих місць, розбитий заpriority_levelтаflow_schema.apiserver_flowcontrol_request_wait_duration_seconds— це вектор гістограми того, скільки часу запити провели в черзі, розбитий за міткамиflow_schema,priority_levelтаexecute. Міткаexecuteвказує, чи почалося виконання запиту.Примітка:
Оскільки кожна FlowSchema завжди призначає запити для одного PriorityLevelConfiguration, ви можете додати гістограми для всіх FlowSchemas для одного рівня пріоритету, щоб отримати ефективну гістограму для запитів, призначених для цього рівня пріоритету.apiserver_flowcontrol_nominal_limit_seats— це вектор вектор, що містить номінальну межу паралелізму кожного рівня пріоритету, обчислювану з загального ліміту паралелізму сервера API та налаштованих номінальних спільних ресурсів паралелізму рівня пріоритету.
Рівень зрілості ALPHA
apiserver_current_inqueue_requests— це вектор вимірювання останніх найвиших значень кількості запитів, обʼєднаних міткоюrequest_kind, значення якої можуть бутиmutatingабоreadOnly. Ці величини описують найбільше значення спостереження в односекундному вікні процесів, що недавно завершилися. Ці дані доповнюють старий графікapiserver_current_inflight_requests, що містить високу точку кількості запитів в останньому вікні, які активно обслуговуються.apiserver_current_inqueue_seats— це вектор мітки миттєвого підсумку запитів, які будуть займати найбільшу кількість місць, згрупованих за мітками з назвамиflow_schemaтаpriority_level.apiserver_flowcontrol_read_vs_write_current_requests— це гістограма спостережень, зроблених в кінці кожної наносекунди, кількості запитів, розбита за міткамиphase(приймає значенняwaitingтаexecuting) таrequest_kind(приймає значенняmutatingтаreadOnly). Кожне спостереження є коефіцентом, від 0 до 1, кількості запитів, поділеним на відповідний ліміт кількості запитів (обмеження обсягу черги для очікування та обмеження паралелізму для виконання).apiserver_flowcontrol_request_concurrency_in_use— це вектор мітки миттєвого числа зайнятих місць, розбитий заpriority_levelтаflow_schema.apiserver_flowcontrol_priority_level_request_utilization— це гістограма спостережень, зроблених в кінці кожної наносекунди, кількості запитів, розбита за міткамиphase(яка приймає значенняwaitingтаexecuting) таpriority_level. Кожне спостереження є відношенням, від 0 до 1, кількості запитів поділеної на відповідний ліміт кількості запитів (обмеження обсягу черги для очікування та обмеження паралелізму для виконання).apiserver_flowcontrol_priority_level_seat_utilization— це гістограма спостережень, зроблених в кінці кожної наносекунди, використання обмеження пріоритету паралелізму, розбита заpriority_level. Це використання є часткою (кількість зайнятих місць) / (обмеження паралелізму). Цей показник враховує всі етапи виконання (як нормальні, так і додаткові затримки в кінці запису для відповідного сповіщення про роботу) всіх запитів, крім WATCH; для них він враховує лише початковий етап, що доставляє сповіщення про попередні обʼєкти. Кожна гістограма в векторі також має міткуphase: executing(для фази очікування не існує обмеження на кількість місць).apiserver_flowcontrol_request_queue_length_after_enqueue— це гістограма вектора довжини черги для черг, розбита заpriority_levelтаflow_schema, як вибірка за запитом у черзі. Кожен запит, який потрапив в чергу, вносить один зразок в свою гістограму, що вказує довжину черги негайно після додавання запиту. Зверніть увагу, що це дає інші показники, ніж неупереджене опитування.Примітка:
Сплеск у значенні гістограми тут означає, що ймовірно, один потік (тобто запити від одного користувача або для одного простору імен, в залежності від конфігурації) затоплює сервер API та піддається обмеженню. На відміну, якщо гістограма одного рівня пріоритету показує, що всі черги для цього рівня пріоритету довші, ніж ті для інших рівнів пріоритету, може бути доцільно збільшити частки паралелізму цієї конфігурації пріоритету.apiserver_flowcontrol_request_concurrency_limitтакий же, якapiserver_flowcontrol_nominal_limit_seats. До введення пралелізму запозичення між рівнями пріоритету, це завжди дорівнювалоapiserver_flowcontrol_current_limit_seats(який не існував як окремий метричний показник).apiserver_flowcontrol_lower_limit_seats— це вектор мітки миттєвої нижньої межі динамічного обмеження паралелізму для кожного рівня пріоритету.apiserver_flowcontrol_upper_limit_seats— це вектор мітки миттєвої верхньої межі динамічного обмеження паралелізму для кожного рівня пріоритету.apiserver_flowcontrol_demand_seats— це гістограма вектора підрахунку спостережень, в кінці кожної наносекунди, відношення кожного рівня пріоритету до (вимоги місць) / (номінального обмеження паралелізму). Вимога місць на рівні пріоритету — це сума, як віконаних запитів, так і тих, які перебувають у початковій фазі виконання, максимум кількості зайнятих місць у початкових та кінцевих фазах виконання запиту.apiserver_flowcontrol_demand_seats_high_watermark— це вектор мітки миттєвого максимального запиту на місця, що спостерігався протягом останнього періоду адаптації до позичання паралелізму для кожного рівня пріоритету.apiserver_flowcontrol_demand_seats_average- це вектор мітки миттєвого часового середнього значення вимог місць для кожного рівня пріоритету, що спостерігався протягом останнього періоду адаптації до позичання паралелізму.apiserver_flowcontrol_demand_seats_stdev- це вектор мітки миттєвого стандартного відхилення популяції вимог місць для кожного рівня пріоритету, що спостерігався протягом останнього періоду адаптації до позичання паралелізму.apiserver_flowcontrol_demand_seats_smoothed- це вектор мітки миттєвого вирівняного значення вимог місць для кожного рівня пріоритету, визначений на останній період адаптації.apiserver_flowcontrol_target_seats- це вектор мітки миттєвого усередненого значення вимог місць для кожного рівня пріоритету, яке виходить в алокації позичання.apiserver_flowcontrol_seat_fair_frac- це мітка миттєвого значення частки справедливого розподілу, визначеного при останній адаптації позичання.apiserver_flowcontrol_current_limit_seats- це вектор мітки миттєвого динамічного обмеження паралелізму для кожного рівня пріоритету, яке було виведено в останню корекцію.apiserver_flowcontrol_request_execution_seconds- це гістограма, яка показує, скільки часу займає виконання запитів, розбита заflow_schemaтаpriority_level.apiserver_flowcontrol_watch_count_samples- це гістограма вектора кількості активних WATCH-запитів, що стосуються певного запису, розбита заflow_schemaтаpriority_level.apiserver_flowcontrol_work_estimated_seats- це гістограма вектора кількості оцінених місць (максимум початкової та кінцевої стадії виконання) для запитів, розбита заflow_schemaтаpriority_level.apiserver_flowcontrol_request_dispatch_no_accommodation_total- це лічильник вектора кількості подій, які в принципі могли призвести до відправки запиту, але не зробили цього через відсутність доступного паралелізму, розбитий заflow_schemaтаpriority_level.apiserver_flowcontrol_epoch_advance_total- це лічильник вектора кількості спроб зрушити вимірювач прогресу рівня пріоритету назад, щоб уникнути переповнення числових значень, згрупований заpriority_levelтаsuccess.
Поради щодо використання API Priority та Fairness
Коли певний рівень пріоритету перевищує свій дозволений паралелізм, запити можуть зазнавати збільшеного часу очікування або бути відкинуті з HTTP 429 (Забагато запитів) помилкою. Щоб запобігти цим побічним ефектам APF, ви можете змінити ваше навантаження або налаштувати ваші налаштування APF, щоб забезпечити достатню кількість місць для обслуговування ваших запитів.
Щоб виявити, чи відкидаються запити через APF, перевірте наступні метрики:
- apiserver_flowcontrol_rejected_requests_total — загальна кількість відкинутих запитів за FlowSchema та PriorityLevelConfiguration.
- apiserver_flowcontrol_current_inqueue_requests — поточна кількість запитів в черзі за FlowSchema та PriorityLevelConfiguration.
- apiserver_flowcontrol_request_wait_duration_seconds — затримка, додана до запитів, що очікують у черзі.
- apiserver_flowcontrol_priority_level_seat_utilization — використання місць на рівні пріоритету за PriorityLevelConfiguration.
Зміни в навантаженні
Щоб запобігти встановленню запитів у чергу та збільшенню затримки або їх відкиданню через APF, ви можете оптимізувати ваші запити шляхом:
- Зменшення швидкості виконання запитів. Менша кількість запитів протягом фіксованого періоду призведе до меншої потреби у місцях в будь-який момент часу.
- Уникання видачі великої кількості дороговартісних запитів одночасно. Запити можна оптимізувати, щоб вони використовували менше місць або мали меншу затримку, щоб ці запити утримували ці місця протягом коротшого часу. Запити списку можуть займати більше 1 місця в залежності від кількості обʼєктів, отриманих під час запиту. Обмеження кількості обʼєктів, отриманих у запиті списку, наприклад, за допомогою розбиття на сторінки (pagination), буде використовувати менше загальних місць протягом коротшого періоду. Крім того, заміна запитів списку запитами перегляду потребуватиме менше загальних часток паралелізму, оскільки запити перегляду займають лише 1 місце під час свого початкового потоку повідомлень. Якщо використовується потоковий перегляд списків у версіях 1.27 і пізніше, запити перегляду займатимуть таку ж кількість місць, як і запит списку під час його початкового потоку повідомлень, оскільки всі стани колекції мають бути передані по потоку. Зауважте, що в обох випадках запит на перегляд не буде утримувати жодних місць після цієї початкової фази.
Памʼятайте, що встановлення запитів у чергу або їх відкидання через APF можуть бути викликані як збільшенням кількості запитів, так і збільшенням затримки для існуючих запитів. Наприклад, якщо запити, які зазвичай виконуються за 1 секунду, починають виконуватися за 60 секунд, це може призвести до того, що APF почне відкидати запити, оскільки вони займають місця протягом тривалого часу через це збільшення затримки. Якщо APF починає відкидати запити на різних рівнях пріоритету без значного змінення навантаження, можливо, існує проблема з продуктивністю контролера, а не з навантаженням або налаштуваннями APF.
Налаштування Priority та fairness
Ви також можете змінити типові обʼєкти FlowSchema та PriorityLevelConfiguration або створити нові обʼєкти цих типів, щоб краще врахувати ваше навантаження.
Налаштування APF можна змінити для:
- Надання більшої кількості місць для запитів високого пріоритету.
- Ізоляція необовʼязкових або дорогих запитів, які можуть забрати рівень паралелізму, якщо він буде спільно використовуватися з іншими потоками.
Надання більшої кількості місць для запитів високого пріоритету
- У разі можливості кількість місць, доступних для всіх рівнів пріоритету для конкретного
kube-apiserver, можна збільшити, збільшивши значення прапорцівmax-requests-inflightтаmax-mutating-requests-inflight. Іншим варіантом є горизонтальне масштабування кількості екземплярівkube-apiserver, що збільшить загальну одночасність на рівень пріоритету по всьому кластеру за умови належного балансування навантаження запитів. - Ви можете створити новий FlowSchema, який посилається на PriorityLevelConfiguration з більшим рівнем паралелізму. Ця нова PriorityLevelConfiguration може бути існуючим рівнем або новим рівнем зі своїм набором номінальних поширень паралелізму. Наприклад, новий FlowSchema може бути введений для зміни PriorityLevelConfiguration для ваших запитів з global-default на workload-low з метою збільшення кількості місць, доступних для ваших користувачів. Створення нової PriorityLevelConfiguration зменшить кількість місць, призначених для існуючих рівнів. Нагадаємо, що редагування типових FlowSchema або PriorityLevelConfiguration потребує встановлення анотації
apf.kubernetes.io/autoupdate-specв значення false. - Ви також можете збільшити значення NominalConcurrencyShares для PriorityLevelConfiguration, що обслуговує ваші запити високого пріоритету. Як альтернативу, для версій 1.26 та пізніших, ви можете збільшити значення LendablePercent для конкуруючих рівнів пріоритету, щоб даний рівень пріоритету мав вищий пул місць, які він може позичати.
Ізоляція неважливих запитів, для попередження виснаження інших потоків
Для ізоляції запитів можна створити FlowSchema, чий субʼєкт збігається з користувачеві, що робить ці запити, або створити FlowSchema, яка відповідає самому запиту (відповідає resourceRules). Далі цю FlowSchema можна зіставити з PriorityLevelConfiguration з низьким пулом місць.
Наприклад, припустимо, що запити на перегляд подій з Podʼів, що працюють в стандартному просторі імен, використовують по 10 місць кожен і виконуються протягом 1 хвилини. Щоб запобігти впливу цих дорогих запитів на інші запити від інших Podʼів, які використовують поточну FlowSchema для сервісних облікових записів, можна застосувати таку FlowSchema для ізоляції цих викликів списків від інших запитів.
Приклад обʼєкта FlowSchema для ізоляції запитів на перегляд подій:
apiVersion: flowcontrol.apiserver.k8s.io/v1
kind: FlowSchema
metadata:
name: list-events-default-service-account
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 8000
priorityLevelConfiguration:
name: catch-all
rules:
- resourceRules:
- apiGroups:
- '*'
namespaces:
- default
resources:
- events
verbs:
- list
subjects:
- kind: ServiceAccount
serviceAccount:
name: default
namespace: default- FlowSchema захоплює всі виклики списків подій, виконані типовим сервісним обліковим записом у стандартному просторі імен. Пріоритет відповідності 8000 менший за значення 9000, що використовується поточною FlowSchema для сервісних облікових записів, тому ці виклики списків подій будуть відповідати list-events-default-service-account, а не service-accounts.
- Використовується конфігурація пріоритету catch-all для ізоляції цих запитів. Пріоритетний рівень catch-all має дуже малий пул місць і не ставить запитів в чергу.
Що далі
- Ви можете переглянути довідку з контролювання потоків для отримання додаткової інформації для розвʼязання проблем.
- Для отримання довідкової інформації про деталі дизайну для пріоритету та справедливості API див. пропозицію про вдосконалення.
- Ви можете надсилати пропозиції та запити на функціонал через SIG API Machinery або через канал у Slack.
11.12 - Автомасштабування кластера
Автоматичне керування вузлами кластера для адаптації до попиту.
Kubernetes потрібні вузли у вашому кластері для роботи Podʼів. Це означає, що потрібно забезпечити місце для робочих Podʼів та для самого Kubernetes.
Ви можете автоматично налаштувати кількість ресурсів, доступних у вашому кластері: автомасштабування вузлів. Ви можете змінювати кількість вузлів або змінювати потужність, яку надають вузли. Перший підхід називається горизонтальним масштабуванням, а другий — вертикальним масштабуванням.
Kubernetes може навіть забезпечити багатовимірне автоматичне масштабування для вузлів.
Керування вузлами вручну
Ви можете вручну керувати потужністю на рівні вузла, де ви налаштовуєте фіксовану кількість вузлів; ви можете використовувати цей підхід навіть якщо забезпечення (процес встановлення, управління та виведення з експлуатації) для цих вузлів автоматизоване.
Ця сторінка присвячена наступному кроку, а саме автоматизації управління обсягом потужності вузла (ЦП, памʼяті та інших ресурсів вузла), доступним у вашому кластері.
Автоматичне горизонтальне масштабування
Автомасштабувальник
Ви можете використовувати Автомасштабувальник, щоб автоматично керувати масштабуванням ваших вузлів. Автомасштабувальник може інтегруватися з хмарним постачальником або з кластерним API Kubernetes, щоб забезпечити фактичне управління вузлами, яке потрібно.
Автомасштабувальник додає вузли, коли неможливо розмістити потоки, і видаляє вузли, коли ці вузли порожні.
Інтеграції з хмарними постачальниками
README для кластерного масштабувальника містить список деяких доступних інтеграцій з хмарними постачальниками.
Багатовимірне масштабування з урахуванням вартості
Karpenter
Karpenter підтримує пряме керування вузлами через втулки, які інтегруються з конкретними хмарними постачальниками та можуть керувати вузлами для вас, оптимізуючи загальну вартість.
Karpenter автоматично запускає саме ті обчислювальні ресурси, які потрібні вашим застосункам. Його спроєктовано, щоб ви могли повною мірою скористатись можливостями хмари з швидким та простим розгортанням обчислювальних ресурсів для вашого кластера Kubernetes.
Інструмент Karpenter призначений для інтеграції з хмарним постачальником, який надає управління серверами через API, і де інформація про ціни на доступні сервери також доступна через веб-API.
Наприклад, якщо ви маєте декілька Podʼів у вашому кластері, інструмент Karpenter може купити новий вузол, який більший за один з вузлів, які ви вже використовуєте, а потім вимкнути наявний вузол, як тільки новий вузол буде готовий до використання.
Інтеграції з постачальниками хмарних послуг
Примітка: Items on this page refer to vendors external to Kubernetes. The Kubernetes project authors aren't responsible for those third-party products or projects. To add a vendor, product or project to this list, read the content guide before submitting a change. More information.
Існують інтеграції між ядром Karpenter та наступними постачальниками хмарних послуг:
Повʼязані компоненти
Descheduler
Descheduler може допомогти консолідувати Podʼи на меншій кількості вузлів, щоб впоратись з автоматичним масштабуванням, коли у кластера зʼявляються вільні потужності.
Визначення розміру навантаження на основі розміру кластера
Пропорційне автомасштабування кластера
Для навантажень, які потрібно масштабувати залежно від розміру кластера, таких як cluster-dns або інші системні компоненти, ви можете використовувати Cluster Proportional Autoscaler.
Cluster Proportional Autoscaler спостерігає за кількістю придатних до планування вузлів та ядер, і масштабує кількість реплік цільового навантаження відповідно.
Вертикальний пропорційний автомасштабувальник кластера
Якщо кількість реплік має залишитися незмінною, ви можете масштабувати ваші робочі навантаження вертикально відповідно до розміру кластера, використовуючи Cluster Proportional Vertical Autoscaler. Цей проєкт перебуває в бета-версії та знаходиться на GitHub.
У той час, як Cluster Proportional Autoscaler масштабує кількість реплік робочого навантаження, Cluster Proportional Vertical Autoscaler налаштовує запити ресурсів для робочого навантаження (наприклад, Deployment або DaemonSet) на основі кількості вузлів та/або ядер у кластері.
Що далі
- Дізнайтеся більше про автомасштабування на рівні робочого навантаження
- Дізнайтеся більше про перевищення ємності вузла для кластера
11.13 - Встановлення надбудов
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Надбудови розширюють функціональність Kubernetes.
Ця сторінка містить список доступних надбудов та посилання на відповідні інструкції з встановлення. Список не намагається бути вичерпним.
Мережа та політика мережі
- ACI надає інтегровану мережу контейнерів та мережеву безпеку з Cisco ACI.
- Antrea працює на рівні 3/4, щоб надати мережеві та служби безпеки для Kubernetes, використовуючи Open vSwitch як мережеву панель даних. Antrea є проєктом CNCF на рівні Sandbox.
- Calico є постачальником мережі та мережевої політики. Calico підтримує гнучкий набір мережевих опцій, щоб ви могли вибрати найефективнішу опцію для вашої ситуації, включаючи мережі з та без оверлею, з або без BGP. Calico використовує однаковий рушій для забезпечення мережевої політики для хостів, Podʼів та (якщо використовуєте Istio та Envoy) застосунків на рівні шару сервісної мережі.
- Canal обʼєднує Flannel та Calico, надаючи мережу та мережеву політику.
- Cilium: це рішення для мережі, спостереження та забезпечення безпеки з eBPF-орієнтованою панеллю даних. Cilium надає просту мережу Layer 3 з можливістю охоплення декількох кластерів в режимі маршрутизації або режимі налагодження/інкапсуляції та може застосовувати політики мережі на рівнях L3-L7 з використанням моделі безпеки на основі ідентифікації, що відʼєднана від мережевого адресування. Cilium може діяти як заміна для kube-proxy; він також пропонує додаткові функції спостереження та безпеки.
- CNI-Genie: Дозволяє Kubernetes безперешкодно підключатися до вибору втулків CNI, таких як Calico, Canal, Flannel або Weave.
- Contiv: надає налаштовану мережу (L3 з використанням BGP, оверлей за допомогою vxlan, класичний L2 та Cisco-SDN/ACI) для різних варіантів використання та повнофункціональний фреймворк політик. Проєкт Contiv є проєктом з повністю відкритими сирцями. Встановлювач надає як варіанти установки, як з, так і без, kubeadm.
- Contrail: оснований на Tungsten Fabric, це відкритою платформою мережевої віртуалізації та управління політикою для кількох хмар. Contrail і Tungsten Fabric інтегровані з системами оркестрування, такими як Kubernetes, OpenShift, OpenStack і Mesos, і надають режими ізоляції для віртуальних машин, контейнерів/Podʼів та обробки робочих навантажень на bare metal.
- Flannel: постачальник мережі на основі оверлеїв, який можна використовувати з Kubernetes.
- Gateway API: відкритий проєкт, керований SIG Network, який надає виразний, розширюваний та рольовий API для моделювання сервісних мереж.
- Knitter є втулком для підтримки кількох мережевих інтерфейсів в Podʼі Kubernetes.
- Multus: мультивтулок для підтримки кількох мереж у Kubernetes для підтримки всіх втулків CNI (наприклад, Calico, Cilium, Contiv, Flannel), а також навантаження SRIOV, DPDK, OVS-DPDK та VPP у Kubernetes.
- OVN-Kubernetes: постачальник мережі для Kubernetes на основі OVN (Open Virtual Network), віртуальної мережевої реалізації, яка вийшла з проєкту Open vSwitch (OVS). OVN-Kubernetes забезпечує реалізацію мережі на основі оверлеїв для Kubernetes, включаючи реалізацію балансування навантаження на основі OVS та політики мережі.
- Nodus: втулок контролера CNI на основі OVN для надання хмарних послуг на основі послуг хмарної обробки (SFC).
- NSX-T Container Plug-in (NCP): забезпечує інтеграцію між VMware NSX-T та оркестраторами контейнерів, такими як Kubernetes, а також інтеграцію між NSX-T та контейнерними платформами CaaS/PaaS, такими як Pivotal Container Service (PKS) та OpenShift.
- Nuage: платформа SDN, яка забезпечує мережеву політику між кластерами Kubernetes Pods та некластерними середовищами з можливістю моніторингу видимості та безпеки.
- Romana: рішення мережі рівня Layer 3 для мережевих мереж Podʼів, яке також підтримує NetworkPolicy API.
- Spiderpool: рішення мережі основи та RDMA для Kubernetes. Spiderpool підтримується на bare metal, віртуальних машинах та публічних хмарних середовищах.
- Weave Net: надає мережу та політику мережі, буде продовжувати працювати з обох боків розділу мережі та не потребує зовнішньої бази даних.
Виявлення служб
- CoreDNS — це гнучкий, розширюваний DNS-сервер, який може бути встановлений як DNS в кластері для Podʼів.
Візуалізація та управління
- Dashboard — це вебінтерфейс для управління Kubernetes.
Інфраструктура
- KubeVirt — це додатковий інструмент для запуску віртуальних машин на Kubernetes. Зазвичай використовується на кластерах на bare metal.
- Виявлення проблем вузла — працює на вузлах Linux та повідомляє про проблеми системи як події або стан вузла.
Інструментування
Старі надбудови
Існують ще кілька інших надбудов, які документуються в застарілій теці cluster/addons.
Добре підтримувані мають бути вказані тут. Приймаються запити на включення!
11.14 - Координовані вибори лідера
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [alpha] (стандартно увімкнено: false)Kubernetes 1.32 включає альфа-функцію, яка дозволяє компонентам панелі управління детерміновано обирати лідера через координовані вибори лідера. Це корисно для задоволення обмежень щодо несумісності версій Kubernetes під час оновлення кластера. Наразі єдина вбудована стратегія вибору — це OldestEmulationVersion, що надає перевагу лідеру з найнижчою версією емуляції, за яким йде бінарна версія, а потім позначка часу створення.
Увімкнення координованих виборів лідера
Переконайтеся, що функціональну можливість CoordinatedLeaderElection увімкнено під час запуску API Server та що група API coordination.k8s.io/v1alpha1 увімкнена також.
Це можна зробити, встановивши прапорці --feature-gates="CoordinatedLeaderElection=true" та --runtime-config="coordination.k8s.io/v1alpha1=true".
Конфігурація компонентів
За умови, що ви увімкнули функціональну можливість CoordinatedLeaderElection та увімкнули групу API coordination.k8s.io/v1alpha1, сумісні компоненти панелі управління автоматично використовують LeaseCandidate та Lease API для вибору лідера за потреби.
Для Kubernetes 1.32 два компоненти панелі управління (kube-controller-manager і kube-scheduler) автоматично використовують координовані вибори лідера, коли функціональну можливість та група API увімкнені.
12 - Windows у Kubernetes
Kubernetes підтримує роботу вузлів на яких запущено Microsoft Windows.
Kubernetes підтримує робочі вузли які запущених на Linux або Microsoft Windows.
🛇 Цей елемент посилається на сторонній проєкт або продукт, який не є частиною Kubernetes. Докладніше
CNCF та батьківська організація Linux Foundation використовують вендор-нейтральний підхід до сумісності. Це означає, що можна додати ваш Windows сервер як робочий вузол до кластера Kubernetes.
Ви можете встановити та налаштувати kubectl на Windows незалежно від операційної системи, яку ви використовуєте в своєму кластері.
Якщо ви використовуєте вузли Windows, ви можете прочитати:
- Мережа на Windows
- Зберігання на Windows в Kubernetes
- Керування ресурсами для вузлів Windows
- Налаштування RunAsUserName для Pod та контейнерів Windows
- Створення Pod Windows HostProcess
- Налаштування облікових записів служби з груповим керуванням для Pod та контейнерів Windows
- Безпека для вузлів Windows
- Поради з налагодження Windows
- Посібник з планування контейнерів Windows в Kubernetes
або, для ознайомлення, подивіться:
12.1 - Контейнери Windows у Kubernetes
Застосунки Windows становлять значну частину сервісів та застосунків, що працюють у багатьох організаціях. Контейнери Windows забезпечують спосіб інкапсуляції процесів та пакування залежностей, що спрощує використання практик DevOps та слідування хмарним рідним патернам для застосунків Windows.
Організації, що вклались у застосунки на базі Windows та Linux, не мають шукати окремі оркестратори для управління своїми навантаженнями, що призводить до збільшення оперативної ефективності у їх розгортаннях, незалежно від операційної системи.
Windows-вузли у Kubernetes
Для увімкнення оркестрування контейнерів Windows у Kubernetes, додайте Windows-вузли до вашого поточного Linux-кластера. Планування розміщення контейнерів Windows у Podʼах на Kubernetes подібне до планування розміщення контейнерів на базі Linux.
Для запуску контейнерів Windows ваш Kubernetes кластер має включати декілька операційних систем. Хоча панель управління можна запускати лише на Linux, ви можете розгортати робочі вузли, що працюють як на Windows, так і на Linux.
Windows вузли є підтримуваними, за умови, що операційна система є Windows Server 2019 або Windows Server 2022.
Цей документ використовує термін контейнери Windows для позначення контейнерів Windows з ізоляцією на рівні процесу. Kubernetes не підтримує запуск контейнерів Windows з ізоляцією Hyper-V.
Сумісність та обмеження
Деякі функції вузла доступні лише при використанні певного середовища для виконання контейнерів; інші не доступні на Windows-вузлах, зокрема:
- HugePages: не підтримуються для контейнерів Windows
- Привілейовані контейнери: не підтримуються для контейнерів Windows. Контейнери HostProcess пропонують схожий функціонал.
- TerminationGracePeriod: вимагає containerD
Не всі функції спільних просторів імен підтримуються. Дивіться Сумісність API для детальнішої інформації.
Дивіться Сумісність версій Windows OS для деталей щодо версій Windows, з якими Kubernetes протестовано.
З точки зору API та kubectl, контейнери Windows поводяться майже так само, як і контейнери на базі Linux. Проте, існують деякі помітні відмінності у ключовому функціоналі, які окреслені в цьому розділі.
Порівняння з Linux
Ключові елементи Kubernetes працюють однаково в Windows, як і в Linux. Цей розділ описує кілька ключових абстракцій робочих навантажень та їх співвідносяться у Windows.
Pod є базовим будівельним блоком Kubernetes — найменшою та найпростішою одиницею в моделі об’єктів Kubernetes, яку ви створюєте або розгортаєте. Ви не можете розгортати Windows та Linux контейнери в одному Podʼі. Всі контейнери в Podʼі плануються на один вузол, де кожен вузол представляє певну платформу та архітектуру. Наступні можливості, властивості та події Podʼа підтримуються з контейнерами Windows:
Один або кілька контейнерів на Pod з ізоляцією процесів та спільним використанням томів
Поля
statusPodʼаПроби готовності, життєздатності та запуску
Хуки життєвого циклу контейнера postStart & preStop
ConfigMap, Secrets: як змінні оточення або томи
Томи
emptyDirМонтування іменованих каналів хоста
Ліміти ресурсів
Поле OS:
Значення поля
.spec.os.nameмає бути встановлено уwindows, щоб вказати, що поточний Pod використовує контейнери Windows.Якщо ви встановлюєте поле
.spec.os.nameуwindows, вам не слід встановлювати наступні поля в.specцього Podʼа:spec.hostPIDspec.hostIPCspec.securityContext.seLinuxOptionsspec.securityContext.seccompProfilespec.securityContext.fsGroupspec.securityContext.fsGroupChangePolicyspec.securityContext.sysctlsspec.shareProcessNamespacespec.securityContext.runAsUserspec.securityContext.runAsGroupspec.securityContext.supplementalGroupsspec.containers[*].securityContext.seLinuxOptionsspec.containers[*].securityContext.seccompProfilespec.containers[*].securityContext.capabilitiesspec.containers[*].securityContext.readOnlyRootFilesystemspec.containers[*].securityContext.privilegedspec.containers[*].securityContext.allowPrivilegeEscalationspec.containers[*].securityContext.procMountspec.containers[*].securityContext.runAsUserspec.containers[*].securityContext.runAsGroup
У вищезазначеному списку, символи зірочки (
*) вказують на всі елементи у списку. Наприклад,spec.containers[*].securityContextстосується обʼєкта SecurityContext для всіх контейнерів. Якщо будь-яке з цих полів вказано, Pod не буде прийнято API сервером.
[Ресурси робочих навантажень]](/docs/concepts/workloads/controllers/):
- ReplicaSet
- Deployment
- StatefulSet
- DaemonSet
- Job
- CronJob
- ReplicationController
Service. Дивіться Балансування навантаження та Service для деталей.
Podʼи, ресурси робочого навантаження та Service є критичними елементами для управління Windows навантаженнями у Kubernetes. Однак, самі по собі вони недостатні для забезпечення належного управління життєвим циклом Windows навантажень у динамічному хмарному середовищі.
kubectl exec- Метрики Podʼів та контейнерів
- Горизонтальне автомасштабування Podʼів
- Квоти ресурсів
- Випередження планувальника
Параметри командного рядка для kubelet
Деякі параметри командного рядка для kubelet ведуть себе по-іншому у Windows, як описано нижче:
- Параметр
--windows-priorityclassдозволяє встановлювати пріоритет планування процесу kubelet (див. Управління ресурсами процесора) - Прапорці
--kube-reserved,--system-reservedта--eviction-hardоновлюють NodeAllocatable - Виселення за допомогою
--enforce-node-allocableне реалізовано - При запуску на вузлі Windows kubelet не має обмежень памʼяті або процесора.
--kube-reservedта--system-reservedвіднімаються лише відNodeAllocatableі не гарантують ресурсів для навантаження. Дивіться Управління ресурсами для вузлів Windows для отримання додаткової інформації. - Умова
PIDPressureне реалізована - Kubelet не вживає дій щодо виселення з приводу OOM (Out of memory)
Сумісність API
Існують важливі відмінності в роботі API Kubernetes для Windows через ОС та середовище виконання контейнерів. Деякі властивості навантаження були розроблені для Linux, і їх не вдається виконати у Windows.
На високому рівні концепції ОС відрізняються:
- Ідентифікація — Linux використовує ідентифікатор користувача (UID) та ідентифікатор групи (GID), які представлені як цілі числа. Імена користувачів і груп не є канонічними — це просто псевдоніми у
/etc/groupsабо/etc/passwdдо UID+GID. Windows використовує більший бінарний ідентифікатор безпеки (SID), який зберігається в базі даних Windows Security Access Manager (SAM). Ця база даних не використовується спільно між хостом та контейнерами або між контейнерами. - Права доступу до файлів — Windows використовує список управління доступом на основі (SID), тоді як POSIX-системи, такі як Linux, використовують бітову маску на основі дозволів обʼєкта та UID+GID, плюс опціональні списки управління доступом.
- Шляхи до файлів — у Windows зазвичай використовується
\замість/. Бібліотеки вводу-виводу Go зазвичай приймають обидва і просто забезпечують їх роботу, але коли ви встановлюєте шлях або командний рядок, що інтерпретується всередині контейнера, можливо, буде потрібен символ\. - Сигнали — інтерактивні програми Windows обробляють завершення по-іншому і можуть реалізувати одне або декілька з цього:
- UI-потік обробляє чітко визначені повідомлення, включаючи
WM_CLOSE. - Консольні програми обробляють Ctrl-C або Ctrl-break за допомогою обробника керування.
- Служби реєструють функцію обробника керування службами, яка може приймати коди керування
SERVICE_CONTROL_STOP.
- UI-потік обробляє чітко визначені повідомлення, включаючи
Коди виходу контейнера дотримуються тієї ж самої конвенції, де 0 є успіхом, а ненульове значення є помилкою. Конкретні коди помилок можуть відрізнятися між Windows та Linux. Однак коди виходу, передані компонентами Kubernetes (kubelet, kube-proxy), залишаються незмінними.
Сумісність полів для специфікацій контейнера
Наступний список документує відмінності у роботі специфікацій контейнерів Podʼа між Windows та Linux:
- Великі сторінки не реалізовані в контейнері Windows та недоступні. Вони потребують встановлення привілеїв користувача, які не налаштовуються для контейнерів.
requests.cpuтаrequests.memory— запити віднімаються від доступних ресурсів вузла, тому вони можуть використовуватися для уникнення перевстановлення вузла. Проте вони не можуть гарантувати ресурси в перевстановленому вузлі. Їх слід застосовувати до всіх контейнерів як найкращу практику, якщо оператор хоче уникнути перевстановлення повністю.securityContext.allowPrivilegeEscalation— неможливо на Windows; жодна з можливостей не підключенаsecurityContext.capabilities— можливості POSIX не реалізовані у WindowssecurityContext.privileged— Windows не підтримує привілейовані контейнери, замість них використовуйте Контейнери HostProcesssecurityContext.procMount— Windows не має файлової системи/procsecurityContext.readOnlyRootFilesystem— неможливо на Windows; запис доступу необхідний для реєстру та системних процесів, щоб виконуватися всередині контейнераsecurityContext.runAsGroup— неможливо на Windows, оскільки відсутня підтримка GIDsecurityContext.runAsNonRoot— це налаштування перешкоджатиме запуску контейнерів якContainerAdministrator, який є найближчим еквівалентом користувача root у Windows.securityContext.runAsUser— використовуйтеrunAsUserNameзамість цьогоsecurityContext.seLinuxOptions— неможливо у Windows, оскільки SELinux специфічний для LinuxterminationMessagePath— у цьому є деякі обмеження, оскільки Windows не підтримує зіставлення одного файлу. Стандартне значення —/dev/termination-log, що працює, оскільки воно стандартно не існує у Windows.
Сумісність полів для специфікацій Podʼа
Наступний список документує відмінності у роботі специфікацій Podʼа між Windows та Linux:
hostIPCтаhostpid— спільне використання простору імен хосту неможливе у WindowshostNetwork— див. нижчеdnsPolicy— встановленняdnsPolicyPodʼа наClusterFirstWithHostNetне підтримується у Windows, оскільки мережа хосту не надається. Podʼи завжди працюють з мережею контейнера.podSecurityContextдив. нижчеshareProcessNamespace— це бета-функція, яка залежить від просторів імен Linux, які не реалізовані у Windows. Windows не може ділитися просторами імен процесів або кореневою файловою системою контейнера. Можлива лише спільна мережа.terminationGracePeriodSeconds— це не повністю реалізовано в Docker у Windows, див. тікет GitHub. Поведінка на сьогодні полягає в тому, що процес ENTRYPOINT отримує сигнал CTRL_SHUTDOWN_EVENT, потім Windows типово чекає 5 секунд, і нарешті вимикає всі процеси за допомогою звичайної поведінки вимкнення Windows. Значення 5 секунд визначаються в реєстрі Windows всередині контейнера, тому їх можна перевизначити при збиранні контейнера.volumeDevices— це бета-функція, яка не реалізована у Windows. Windows не може підключати блочні пристрої безпосередньо до Podʼів.volumes- Якщо ви визначаєте том
emptyDir, ви не можете встановити його джерело тома наmemory.
- Якщо ви визначаєте том
- Ви не можете активувати
mountPropagationдля монтування томів, оскільки це не підтримується у Windows.
Сумісність полів для hostNetwork
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.26 [alpha]Тепер kubelet може вимагати, щоб Podʼи, що працюють на вузлах Windows, використовували мережевий простір імен хоста замість створення нового простору імен мережі Podʼа. Щоб увімкнути цю функціональність, передайте --feature-gates=WindowsHostNetwork=true в kubelet.
Примітка:
Ця функціональність потребує контейнерного середовища, яке підтримує цю функціональність.Сумісність полів для контексту безпеки Podʼа
Тільки поля securityContext.runAsNonRoot та securityContext.windowsOptions з поля Podʼа securityContext працюють у Windows.
Виявлення проблем вузла
Механізм виявлення проблем вузла (див. Моніторинг справності вузла) має попередню підтримку для Windows. Для отримання додаткової інформації відвідайте сторінку проєкту на GitHub.
Контейнер паузи
У кластері Kubernetes спочатку створюється інфраструктурний або контейнер "пауза", щоб вмістити інший контейнер. У Linux, групи керування та простори імен, що утворюють з Pod, потребують процесу для підтримки їхнього подальшого існування; процес паузи забезпечує це. Контейнери, які належать до одного Podʼа, включаючи інфраструктурні та робочі контейнери, мають спільну мережеву точку доступу (з тою ж самою IPv4 та / або IPv6 адресою, тими самими просторами портів мережі). Kubernetes використовує контейнери паузи для того, щоб дозволити робочим контейнерам виходити з ладу або перезапускатися без втрати будь-якої конфігурації мережі.
Kubernetes підтримує багатоархітектурний образ, який включає підтримку для Windows. Для Kubernetes v1.32.0 рекомендований образ паузи — registry.k8s.io/pause:3.6. Вихідний код доступний на GitHub.
Microsoft підтримує інший багатоархітектурний образ, з підтримкою Linux та Windows amd64, це mcr.microsoft.com/oss/kubernetes/pause:3.6. Цей образ побудований з того ж вихідного коду, що й образ, підтримуваний Kubernetes, але всі виконавчі файли Windows підписані authenticode Microsoft. Проєкт Kubernetes рекомендує використовувати образ, підтримуваний Microsoft, якщо ви розгортаєте в операційному середовищі або середовищі подібному до операційного, яке вимагає підписаних виконавчих файлів.
Середовища виконання контейнерів
Вам потрібно встановити середовище виконання контейнерів на кожний вузол у кластері, щоб Podʼи могли там працювати.
Наступні середовища виконання контейнерів ппрацюютьу Windows:
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
ContainerD
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.20 [stable]Ви можете використовувати ContainerD версії 1.4.0+ як середовище виконання контейнера для вузлів Kubernetes, які працюють на Windows.
Дізнайтеся, як встановити ContainerD на вузол Windows.
Примітка:
Є відоме обмеження при використанні GMSA з containerd для доступу до мережевих ресурсів Windows, яке потребує патча ядра.Mirantis Container Runtime
Mirantis Container Runtime (MCR) є доступним середовищем виконання контейнерів для всіх версій Windows Server 2019 та пізніших.
Для отримання додаткової інформації дивіться Встановлення MCR на серверах Windows.
Сумісність версій операційної системи Windows
На вузлах Windows діють строгі правила сумісності, де версія операційної системи хосту повинна відповідати версії операційної системи базового образу контейнера. Повністю підтримуються лише Windows контейнери з операційною системою контейнера Windows Server 2019.
Для Kubernetes v1.32, сумісність операційної системи для вузлів Windows (та Podʼів) виглядає так:
- Випуск LTSC Windows Server
- Windows Server 2019
- Windows Server 2022
- Випуск SAC Windows Server
- Windows Server версії 20H2
Також застосовується політика відхилення версій Kubernetes.
Рекомендації та важливі аспекти апаратного забезпечення
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Примітка:
Наведені тут апаратні характеристики слід розглядати як розумні стандартні значення. Вони не призначені представляти мінімальні вимоги або конкретні рекомендації для операційних середовищ. Залежно від вимог вашого навантаження ці значення можуть потребувати коригування.- 64-бітний процесор з 4 ядрами CPU або більше, здатний підтримувати віртуалізацію
- 8 ГБ або більше оперативної памʼяті
- 50 ГБ або більше вільного місця на диску
Для отримання найновішої інформації про мінімальні апаратні вимоги дивіться Вимоги апаратного забезпечення для Windows Server у документації Microsoft. Для керівництва у виборі ресурсів для операційних робочих вузлів дивіться Робочі вузли для операційного середовища в документації Kubernetes.
Для оптимізації ресурсів системи, якщо не потрібний графічний інтерфейс, бажано використовувати операційну систему Windows Server, яка не включає опцію встановлення Windows Desktop Experience, оскільки така конфігурація зазвичай звільняє більше ресурсів системи.
При оцінці дискового простору для робочих вузлів Windows слід враховувати, що образи контейнера Windows зазвичай більші за образи контейнера Linux, розмір образів контейнерів може становити
від 300 МБ до понад 10 ГБ для одного образу. Додатково, слід зауважити, що типово диск C: в контейнерах Windows являє собою віртуальний вільний розмір 20 ГБ, це не фактично використаний простір, а лише розмір диска, який може займати один контейнер при використанні локального сховища на хості. Дивіться Контейнери на Windows — Документація зберігання контейнерів для отримання більш детальної інформації.
Отримання допомоги та усунення несправностей
Для усунення несправностей звертайтесь до відповідного розділу цієї документації, він стане вашим головним джерелом в отриманні потрібних відомостей.
Додаткова допомога з усунення несправностей, специфічна для Windows, є в цьому розділі. Логи є важливою складовою усунення несправностей у Kubernetes. Переконайтеся, що ви додаєте їх кожного разу, коли звертаєтеся за допомогою у розвʼязані проблем до інших учасників. Дотримуйтесь інструкцій у керівництві щодо збору логів від SIG Windows.
Повідомлення про проблеми та запити нових функцій
Якщо у вас є підозра на помилку або ви хочете подати запит на нову функцію, будь ласка, дотримуйтесь настанов з участі від SIG Windows, щоб створити новий тікет. Спочатку вам слід переглянути список проблем у разі, якщо вона вже була повідомлена раніше, і додавати коментар зі своїм досвідом щодо проблеми та додавати додаткові логи. Канал SIG Windows у Slack Kubernetes також є чудовим способом отримати підтримку та ідеї для усунення несправностей перед створенням тікету.
Перевірка правильності роботи кластера Windows
Проєкт Kubernetes надає специфікацію Готовності до роботи у середовищі Windows разом з структурованим набором тестів. Цей набір тестів розділений на два набори тестів: базовий та розширений, кожен з яких містить категорії, спрямовані на тестування конкретних областей. Його можна використовувати для перевірки всіх функцій системи Windows та гібридної системи (змішана з Linux вузлами) з повним охопленням.
Щоб налаштувати проєкт на новому створеному кластері, дивіться інструкції у посібнику проєкту.
Інструменти розгортання
Інструмент kubeadm допомагає вам розгортати кластер Kubernetes, надаючи панель управління для управління кластером та вузли для запуску ваших робочих навантажень.
Проєкт кластерного API Kubernetes також надає засоби для автоматизації розгортання вузлів Windows.
Канали поширення Windows
Для докладного пояснення каналів поширення Windows дивіться документацію Microsoft.
Інформацію про різні канали обслуговування Windows Server, включаючи їх моделі підтримки, можна знайти на сторінці каналів обслуговування Windows Server.
12.2 - Посібник з запуску контейнерів Windows у Kubernetes
Ця сторінка надає покроковий опис, які ви можете виконати, щоб запустити контейнери Windows за допомогою Kubernetes. На сторінці також висвітлені деякі специфічні для Windows функції в Kubernetes.
Важливо зауважити, що створення та розгортання служб і робочих навантажень у Kubernetes працює практично однаково для контейнерів Linux та Windows. Команди kubectl, щоб працювати з кластером, ідентичні. Приклади на цій сторінці надаються для швидкого старту з контейнерами Windows.
Цілі
Налаштувати приклад розгортання для запуску контейнерів Windows на вузлі з операційною системою Windows.
Перш ніж ви розпочнете
Ви вже повинні мати доступ до кластера Kubernetes, який містить робочий вузол з операційною системою Windows Server.
Початок роботи: Розгортання робочого навантаження Windows
Наведений нижче приклад файлу YAML розгортає простий вебсервер, який працює в контейнері Windows.
Створіть файл маніфесту з назвою win-webserver.yaml з наступним вмістом:
---
apiVersion: v1
kind: Service
metadata:
name: win-webserver
labels:
app: win-webserver
spec:
ports:
# порт, на якому має працювати ця служба
- port: 80
targetPort: 80
selector:
app: win-webserver
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: win-webserver
name: win-webserver
spec:
replicas: 2
selector:
matchLabels:
app: win-webserver
template:
metadata:
labels:
app: win-webserver
name: win-webserver
spec:
containers:
- name: windowswebserver
image: mcr.microsoft.com/windows/servercore:ltsc2019
command:
- powershell.exe
- -command
- "<#code used from https://gist.github.com/19WAS85/5424431#> ; $$listener = New-Object System.Net.HttpListener ; $$listener.Prefixes.Add('http://*:80/') ; $$listener.Start() ; $$callerCounts = @{} ; Write-Host('Listening at http://*:80/') ; while ($$listener.IsListening) { ;$$context = $$listener.GetContext() ;$$requestUrl = $$context.Request.Url ;$$clientIP = $$context.Request.RemoteEndPoint.Address ;$$response = $$context.Response ;Write-Host '' ;Write-Host('> {0}' -f $$requestUrl) ; ;$$count = 1 ;$$k=$$callerCounts.Get_Item($$clientIP) ;if ($$k -ne $$null) { $$count += $$k } ;$$callerCounts.Set_Item($$clientIP, $$count) ;$$ip=(Get-NetAdapter | Get-NetIpAddress); $$header='<html><body><H1>Windows Container Web Server</H1>' ;$$callerCountsString='' ;$$callerCounts.Keys | % { $$callerCountsString+='<p>IP {0} callerCount {1} ' -f $$ip[1].IPAddress,$$callerCounts.Item($$_) } ;$$footer='</body></html>' ;$$content='{0}{1}{2}' -f $$header,$$callerCountsString,$$footer ;Write-Output $$content ;$$buffer = [System.Text.Encoding]::UTF8.GetBytes($$content) ;$$response.ContentLength64 = $$buffer.Length ;$$response.OutputStream.Write($$buffer, 0, $$buffer.Length) ;$$response.Close() ;$$responseStatus = $$response.StatusCode ;Write-Host('< {0}' -f $$responseStatus) } ; "
nodeSelector:
kubernetes.io/os: windows
Примітка:
Зіставлення портів також підтримується, але для спрощення цей приклад використовує прямий доступ до порту 80 контейнера у Service.Перевірте, що всі вузли справні:
kubectl get nodesРозгорніть Service та спостерігайте за оновленнями робочих навантажень:
kubectl apply -f win-webserver.yaml kubectl get pods -o wide -wКоли служба розгорнута правильно, обидва робочі навантаження позначаються як готові. Щоб вийти з команди спостереження, натисніть Ctrl+C.
Перевірте успішність розгортання. Для перевірки:
- Кілька Podʼів показуються з вузла керування Linux, скористайтеся
kubectl get pods - Комунікація від вузла до Podʼа через мережу, за допомогою
curlперевірте доступність порту 80 за IP-адресою Podʼів з вузла керування Linux, щоб перевірити відповідь вебсервера - Комунікація від Podʼа до Podʼа, пінг між Podʼами (і між хостами, якщо у вас більше одного вузла Windows) за допомогою
kubectl exec - Комунікація Service-Pod, за допомогою
curlперевірте віртуальний IP-адрес служби (вказаний уkubectl get services) з вузла керування Linux і з окремих Podʼів - Виявлення Service, за допомогою
curlперевірте імʼя Service з типовим суфіксом DNS Kubernetes - Вхідне підключення, за допомогою
curlперевірте NodePort з вузла керування Linux або зовнішніх машин поза кластером - Вихідне підключення, за допомогою
curlперевірте зовнішні IP-адреси зсередини Podʼа за допомогоюkubectl exec
- Кілька Podʼів показуються з вузла керування Linux, скористайтеся
Примітка:
Хости контейнерів Windows не можуть отримати доступ до IP-адрес служб, запланованих на них через поточні обмеження платформи мережі Windows. Здатність до доступу до IP-адрес служб мають лише Podʼи Windows.Спостережуваність
Збір логів з навантажень
Логи — важливий елемент спостереження; вони дозволяють користувачам отримувати інформацію про роботу навантажень та є ключовим інгредієнтом для розвʼязання проблем. Оскільки контейнери Windows та робочі навантаження всередині контейнерів Windows поводяться по-іншому ніж контейнери в Linux, користувачі мали проблеми зі збором логів, що обмежувало операційну видимість. Робочі навантаження Windows, наприклад, зазвичай налаштовані на ведення логу подій ETW (Event Tracing for Windows) або надсилання записів в журнал подій програми. LogMonitor, відкритий інструмент від Microsoft, є рекомендованим способом моніторингу налаштованих джерел логів всередині контейнера Windows. LogMonitor підтримує моніторинг логів подій, провайдерів ETW та власних логів програм, перенаправляючи їх у STDOUT для використання за допомогою kubectl logs <pod>.
Дотримуйтеся інструкцій на сторінці GitHub LogMonitor, щоб скопіювати його бінарні файли та файли конфігурації до всіх ваших контейнерів та додати необхідні точки входу для LogMonitor, щоб він міг надсилати ваші логи у STDOUT.
Налаштування користувача для роботи контейнера
Використання налаштовуваних імен користувача контейнера
Контейнери Windows можуть бути налаштовані для запуску своїх точок входу та процесів з іншими іменами користувачів, ніж ті, що типово встановлені в образі. Дізнайтеся більше про це тут.
Управління ідентифікацією робочого навантаження за допомогою групових керованих облікових записів служб
Робочі навантаження контейнерів Windows можна налаштувати для використання облікових записів керованих служб групи (Group Managed Service Accounts — GMSA). Облікові записи керованих служб групи є конкретним типом облікових записів Active Directory, які забезпечують автоматичне керування паролями, спрощене керування іменами службових принципалів (service principal name — SPN) та можливість делегування управління іншим адміністраторам на кількох серверах. Контейнери, налаштовані з GMSA, можуть отримувати доступ до зовнішніх ресурсів домену Active Directory, надаючи тим самим ідентифікацію, налаштовану за допомогою GMSA. Дізнайтеся більше про налаштування та використання GMSA для контейнерів Windows тут.
Заплямованість та Толерантність
Користувачам необхідно використовувати певну комбінацію taintʼів та селекторів вузлів, щоб розміщувати робочі навантаження Linux та Windows на відповідних вузлах з операційними системами. Рекомендований підхід викладений нижче, однією з його головних цілей є те, що цей підхід не повинен порушувати сумісність для наявних робочих навантажень Linux.
Ви можете (і повинні) встановлювати значення .spec.os.name для кожного Pod, щоб вказати операційну систему, для якої призначені контейнери у цьому Pod. Для Podʼів, які запускають контейнери Linux, встановіть .spec.os.name на linux. Для Podʼів, які запускають контейнери Windows, встановіть .spec.os.name на windows.
Примітка:
Якщо ви використовуєте версію Kubernetes старішу за 1.24, вам може знадобитися увімкнути функціональну можливістьIdentifyPodOS, щоб мати можливість встановлювати значення для .spec.pod.os.Планувальник не використовує значення .spec.os.name при призначенні Podʼів вузлам. Ви повинні використовувати звичайні механізми Kubernetes для призначення Podʼів вузлам, щоб забезпечити, що панель управління вашого кластера розміщує Podʼи на вузлах, на яких працюють відповідні операційні системи.
Значення .spec.os.name не впливає на планування Podʼів Windows, тому все ще потрібні taint та толерантності (або селектори вузлів), щоб забезпечити, що Podʼи Windows розміщуються на відповідних вузлах Windows.
Забезпечення того, що навантаження, специфічні для ОС, розміщуються на відповідний хост
Користувачі можуть забезпечувати, що Windows контейнери можуть бути заплановані на відповідний хост за допомогою taint та толерантностей. Усі вузли Kubernetes, які працюють під керуванням Kubernetes 1.32, типово мають такі мітки:
- kubernetes.io/os = [windows|linux]
- kubernetes.io/arch = [amd64|arm64|...]
Якщо специфікація Pod не вказує селектор вузла, такий як "kubernetes.io/os": windows, це може означати можливість розміщення Pod на будь-якому хості, Windows або Linux. Це може бути проблематичним, оскільки Windows контейнер може працювати лише на Windows, а Linux контейнер може працювати лише на Linux. Найкраща практика для Kubernetes 1.32 — використовувати селектор вузлів.
Однак у багатьох випадках користувачі мають вже наявну велику кількість розгортань для Linux контейнерів, а також екосистему готових конфігурацій, таких як Helm-чарти створені спільнотою, і випадки програмної генерації Podʼів, такі як оператори. У таких ситуаціях ви можете мати сумнів що до того, щоб внести зміну конфігурації для додавання полів nodeSelector для всіх Podʼів і шаблонів Podʼів. Альтернативою є використання taint. Оскільки kubelet може встановлювати taint під час реєстрації, його можна легко змінити для автоматичного додавання taint при запуску лише на Windows.
Наприклад: --register-with-taints='os=windows:NoSchedule'
Додавши taint до всіх вузлів Windows, на них нічого не буде заплановано (це стосується наявних Podʼів Linux). Щоб запланувати Pod Windows на вузлі Windows, для цього потрібно вказати як nodeSelector, так і відповідну толерантність для вибору Windows.
nodeSelector:
kubernetes.io/os: windows
node.kubernetes.io/windows-build: '10.0.17763'
tolerations:
- key: "os"
operator: "Equal"
value: "windows"
effect: "NoSchedule"
Робота з кількома версіями Windows в одному кластері
Версія Windows Server, що використовується кожним Pod, повинна відповідати версії вузла. Якщо ви хочете використовувати кілька версій Windows Server в одному кластері, то вам слід встановити додаткові мітки вузлів та поля nodeSelector.
Kubernetes автоматично додає мітку,
node.kubernetes.io/windows-build для спрощення цього.
Ця мітка відображає основний, додатковий і номер збірки Windows, які повинні збігатись для сумісності. Ось значення, що використовуються для кожної версії Windows Server:
| Назва продукту | Версія |
|---|---|
| Windows Server 2019 | 10.0.17763 |
| Windows Server 2022 | 10.0.20348 |
Спрощення за допомогою RuntimeClass
RuntimeClass може бути використаний для спрощення процесу використання taints та tolerations. Адміністратор кластера може створити обʼєкт RuntimeClass, який використовується для інкапсуляції цих taint та toleration.
Збережіть цей файл як
runtimeClasses.yml. Він містить відповіднийnodeSelectorдля ОС Windows, архітектури та версії.--- apiVersion: node.k8s.io/v1 kind: RuntimeClass metadata: name: windows-2019 handler: example-container-runtime-handler scheduling: nodeSelector: kubernetes.io/os: 'windows' kubernetes.io/arch: 'amd64' node.kubernetes.io/windows-build: '10.0.17763' tolerations: - effect: NoSchedule key: os operator: Equal value: "windows"Виконайте команду
kubectl create -f runtimeClasses.ymlз правами адміністратора кластера.Додайте
runtimeClassName: windows-2019відповідно до специфікацій Pod.Наприклад:
--- apiVersion: apps/v1 kind: Deployment metadata: name: iis-2019 labels: app: iis-2019 spec: replicas: 1 template: metadata: name: iis-2019 labels: app: iis-2019 spec: runtimeClassName: windows-2019 containers: - name: iis image: mcr.microsoft.com/windows/servercore/iis:windowsservercore-ltsc2019 resources: limits: cpu: 1 memory: 800Mi requests: cpu: .1 memory: 300Mi ports: - containerPort: 80 selector: matchLabels: app: iis-2019 --- apiVersion: v1 kind: Service metadata: name: iis spec: type: LoadBalancer ports: - protocol: TCP port: 80 selector: app: iis-2019
13 - Розширення можливостей Kubernetes
Різні способи зміни поведінки вашого кластера Kubernetes.
Kubernetes добре налаштовується та розширюється. Тому випадки, коли вам потрібно робити форки та накладати патчі на Kubernetes, щоб змінити його поведінку, дуже рідкісні.
Цей розділ описує різні способи зміни поведінки вашого кластера Kubernetes. Він призначений для операторів, які хочуть зрозуміти, як адаптувати кластер до своїх потреб свого робочого оточення. Розробники, які є потенційними розробниками платформ чи учасники проєкту Kubernetes, також знайдуть цей розділ корисним як вступ до того, які точки та шаблони розширення існують, а також їх компроміси та обмеження.
Підходи до налаштувань можна взагалі розділити на конфігурацію, яка включає лише зміну аргументів командного рядка, локальних конфігураційних файлів або ресурсів API; та розширення, яке передбачає виконання додаткових програм, додаткових мережевих служб або обох. Цей документ в основному присвячений розширенням.
Конфігурація
Конфігураційні файли та аргументи командного рядка описані в розділі Довідник онлайн-документації, де кожен файл має свою сторінку:
Аргументи команд та файли конфігурації не завжди можуть бути змінені в службі Kubernetes, що надається постачальником, або дистрибутиві з керованою установкою. Коли їх можна змінювати, вони, як правило, змінюються лише оператором кластера. Крім того, вони можуть бути змінені в майбутніх версіях Kubernetes, і для їх налаштування може знадобитися перезапуск процесів. З цих причин їх слід використовувати лише тоді, коли немає інших варіантів.
Вбудовані API політики, такі як ResourceQuota, NetworkPolicy та доступ на основі ролей (RBAC), є вбудованими API Kubernetes, які надають можливості декларативного налаштування політик. API є доступними та в кластерах, які надаються провайдером, і в кластерах, якими ви керуєте самостійно. Вбудовані API політик використовують ті ж самі конвенції, що й інші ресурси Kubernetes, такі як Podʼи. Коли ви використовуєте стабільний API політик, ви отримуєте зиск від визначеної підтримки політик так само як й інші API Kubernetes. З цих причин використання API політик рекомендується на перевагу до конфігураційних файлів та аргументів командного рядка, де це можливо.
Розширення
Розширення — це компонент програмного забезпечення, який глибоко інтегрується з Kubernetes. Вони використовуються для додавання нових типів ресурсів та видів апаратного забезпечення.
Багато адміністраторів класів Kubernetes використовують кластери, що надаються провайдерами, чи встановленими з дистрибутивів. Ці кластери вже йдуть з розширеннями. В результаті, більшість користувачів Kubernetes не потребують встановлення розширень та дуже невелика частка потребує їх створення.
Шаблони розширень
Kubernetes спроєктовано так, щоб він був автоматизований шляхом створення клієнтських застосунків. Будь-яка програма, яка може писати та читати з API Kubernetes, може надавати корисні функції автоматизації. Ці функції можуть працювати як всередині кластера, так і ззовні. Слідуючи настановам з цього посібника, ви зможете створити надійні та високопродуктивні розширення. Автоматизація, як правило, працює з будь-яким кластером Kubernetes, незалежно від того, як він був встановлений.
Існує конкретний патерн написання клієнтських програм, які ефективно взаємодіють із Kubernetes, відомий як патерн контролера. Зазвичай контролери читають .spec обʼєкта, можливо виконують певні операції, а потім оновлюють .status обʼєкта.
Контролери є клієнтами API Kubernetes. Коли Kubernetes сам є клієнтом та звертається до віддаленого сервісу, виклики Kubernetes є вебхуками. Віддалений сервіс називається вебхук-бекендом. Так само як і стороні контролери, вебхуки додають ще одну точку вразливості.
Примітка:
Поза Kubernetes, термін «вебхук» зазвичай означає механізм асинхронного сповіщення, де вебхук звертається до сервісу з одностороннім сповіщенням до іншої системи чи компонента. В екосистемі Kubernetes, навіть асинхронний HTTP-запит часто описується як «вебхук».В моделі вебхуків, Kubernetes надсилає мережеві запити до віддалених сервісів. Альтернативою є модель бінарних втулків, коли Kubernetes виконує бінарник (застосунок). Бінарні втулки використовуються в kublet (наприклад, втулок зберігання CSI та втулок мережі CNI), а також в kubeсtl (дивітьс розширення kubectl за допомогою втулків).
Точки розширення
На цій діаграмі показано точки розширення в кластері Kubernetes та клієнти з доступом до них.
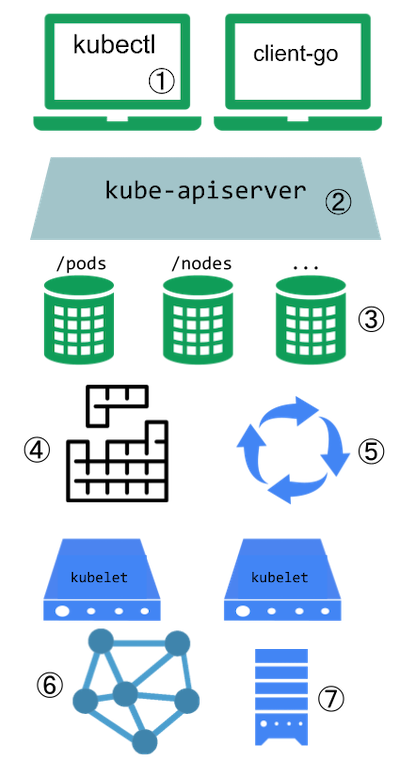
Точки розширення Kubernetes
Пояснення до діаграми
Користувачі часто взаємодіють з API Kubernetes через
kubectl. Втулки підлаштовують поведінку клієнтів. Існують загальні розширення, які можна використовувати з будь-якими клієнтами, так само як і специфічні розширення дляkubectl.API сервер обробляє запити. Різні типи точок розширення на сервері API дозволяють автентифікувати запити або блокувати їх на основі їх вмісту, редагувати вміст та обробляти видалення. Про це в розділі розширення API доступу.
API сервер також обслуговує різні типи ресурсів. Вбудовані типи ресурсі, такі як
Pod, визначені проєктом Kubernetes та не можуть бути змінені. Дивіться розширення API щоб дізнатися про можливості розширення API.Планувальник вирішує на якому вузлі запустити кожний Pod. Існує кілька способів розширити планування, про це в розділі розширення планувальника.
Більшість варіантів поведінки Kubernetes реалізовано через контролери, які є клієнтами API сервера. Контролери часто використовуються разом з нестандартними ресурсами. Дивіться поєднання нових API з автоматизаціями та зміна вбудованих ресурсів, щоб дізнатися більше.
Kublet виконує контейнери на вузлах, та допомагає Podʼами виглядати як віртуальні сервери з їх власними IP в мережі кластера. Мережеві втулки дозволяють реалізувати різні мережеві моделі.
Ви можете використовувати втулки пристроїв для використання спеціалізованих пристроїв або інших розташованих на вузлах ресурсів, та робити їх доступними для Podʼів у вашому кластері. Kublent містить підтримку для роботи з втулками пристроїв.
Kublet також монтує томи для Podʼів та їх контейнерів. Втулки зберігання дозволяють реалізувати різні моделі зберігання.
Вибір точки розширення
Якщо ви вагаєтесь звідки розпочати, ця діаграма може допомогти вам. Зауважте, що деякі рішення можуть включати кілька типів розширень.

Діаграма-посібник для вибору методу розширення.
Розширення клієнта
Втулки до kubectl дозволяють є окремими програмами, які можуть додавати чи замінувати поведінку певних команд. kubectl може інтегруватись з втулком облікових даних. Ці розширення впливають лише на локальне оточення користувача і не можуть додавати нові політики до кластера.
Якщо ви бажаєте розширити kubectl, ознаиомтесь з розширення kubectl за допомогою втулків.
Розширення API
Визначення власних ресурсів
Зважте на додавання власних ресурсів у Kubernetes, якщо ви бажаєте визначити нові контролери, обʼєкти налаштування застосунків або інші декларативні API, та керувати ними використовуючи інструменти подібні до kubectl.
Докладніше про Custom Resource дивіться в розділі Custom Resources.
Шар агрегації API
Ви можете використовувати шар агрегації API Kubernetes, щоб додати нові ресурси до API Kubernetes разом з додатковими службами, такими як метрики.
Поєднання нових API з автоматизаціями
Поєднання API власних ресурсів та циклів управління називається шаблонами контролерів. Якщо ваш контролер виконує функції оператора-людини, та розгортає інфраструктуру на основі бажаного стану, то, можливо, він також дотримується шаблону оператора. Шаблон Оператор використовується для управління конкретними застосунками; зазвичай це застосунки, які підтримують стан та вимагають уважного управління.
Ви також можете створювати власні API та цикли управління, які керують іншими ресурсами, такими як сховище, або визначають політики (наприклад, обмеження контролю доступу).
Зміна вбудованих ресурсів
Коли ви розширюєте API Kubernetes шляхом додавання власних ресурсів, ці ресурси завжди потрапляють до нової групи API. Ви не можете замінити чи змінити наявні групи API. Додавання API напряму не впливає на поведінку наявних API (таких як Podʼи), однак мають вплив на розширення API доступу.
Розширення API доступу
Коли запит потрапляє до API сервера Kubernetes, він спочатку автентифікується, потім авторизується, і потім він потрапляє до перевірки допуску (admission control) (по факту деякі запити є неавтентифікованими та отримують особливу обробку). Дивіться розділ про керування доступу до API Kubernetes для отримання деталей.
Кожен крок в процесі автентифікації/авторизації пропонує точки розширення.
Автентифікація
Автентифікація зіставляє заголовки або сертифікати усіх запитів з користувачами, які зробили запит.
Kubernetes має кілька вбудованих методів автентифікації. Крім того, він може знаходитись поза проксі-сервером автентифікації та може надсилати токени з заголовком Authorization до інших віддалених служб для перевірки (вебхуки автентифікації), якщо вбудовані методи не підходять.
Авторизація
Авторизація визначає, чи має користувач право читати, писати чи виконувати інші дії з ресурсами API. Це відбувається на рівні всього ресурсу, а не на рівні окремих обʼєктів.
Якщо вбудовані методи авторизації не підходять, Kubernetes може використовувати вебхуки авторизації, що дозволяють викликати власний код для визначення, чи має користувач право виконувати дію.
Динамічний контроль допуску
Після того, як запит пройшов та авторизацію, і якщо це операція запису, він також проходить через крок контролю допуску. На додачу до вбудованих кроків, є кілька розширень:
- Вебхуки політик образів дозволяють визначити, які образи можуть бути запущені в контейнерах.
- Для прийняття довільних рішень щодо допуску можуть використовуватись загальні вебхуки допуску. Деякі з вебхуків допуску змінюють дані вхідних запитів до того, як вони будуть опрацьовані Kubernetes.
Розширення інфраструктури
Втулки пристроїв
Втулки пристроїв дозволяють вузлам знаходити нові ресурси Node (на додачу до вбудованих, таких як ЦП та памʼять) за допомогою Втулків пристроїв.
Втулки зберігання
Втулок Container Storage Interface (CSI) надає спосіб розширювати Kubernetes шляхом підтримки нових типів сховищ. Томи можуть знаходитись в надійних зовнішніх системах зберігання, або впроваджувати ефемерні пристрої зберігання, або можуть надавити read-only інтерфейс до інформації використовуючи парадигму роботи з файловою системою.
Kubernetes має підтримку втулків FlexVolume, які вже визнані застаріилими у v1.23 (на користь CSI).
FlexVolume дозволяв користувачам монтувати типи томів які не підтримувались самим Kubernetes. Коли ви запускали Pod, що вимагав FlexVolume, kublet викликав відповідний FlexVolume драйвер, який виконував монтування томів. Архівована пропозиція з проєктування FlexVolume містить більше докладної інформації про те, як все мало відбуватись.
ЧаПи про втулки роботи з томами в Kubernetes для постачальників рішень містить загальні відомості про втулки роботи з томами в Kubernetes.
Мережеві втулки
Ваш кластер Kubernetes потребує мережеві втулки для того, щоб мати робочу мережу для ваших Podʼів та підтримки аспектів мережевої моделі Kubernetes.
Мережеві втулки дозволяють Kubernetes працювати з різними мережевими топологіями та технологіями.
Втулки kublet image credential provider
СТАН ФУНКЦІОНАЛУ:
Kubernetes 1.26 [stable]Втулки kublet image credential provider дозволяють динамічно отримувати облікові дані для образів контейнерів з різних джерел. Облікові дані можуть бути використані для отримання образів контейнерів, які відповідають поточній конфігурації.
Втулки можуть спілкуватись з зовнішніми службами чи використовувати локальні файли для отримання облікових даних. В такому разу kublet не треба мати статичні облікові дані для кожного реєстру, і він може підтримувати різноманітні методи та протоколи автентифікації.
Щоб дізнатись про параметри налаштування втулка дивіться налаштування kubelet image credential provider.
Розширення планувальника
Планувальник є спеціальним типом контролера, який вирішує, на якому вузлі запустити який Pod. Стандартний планувальник можна повністю замінити, продовжуючи використовувати інші компоненти Kubernetes, або ж кілька планувальників можуть працювати разом.
Це значне завдання, і майже всі користувачі Kubernetes вважають, що їм не потрібно змінювати планувальник.
Ви можете контролювати активність втулків планувальника або асоціювати набори втулків з різними іменованими профілями планування. Ви також можете створювати свої власні втулки, які інтегруються з однією або кількома точками розширення kube-scheduler.
Зрештою, вбудований компонент kube-scheduler підтримує вебхуки, що дозволяє віддаленому HTTP-бекенду (розширенню планувальника) фільтрувати та/або пріоритизувати вузли, які kube-scheduler обирає для Podʼів.
Примітка:
Ви можете впливати лише на фільтрування вузлів та їх пріоритизацію за допомогою вебхуків розширювача планувальника; інші точки розширення через інтеграцію вебхука не доступні.Що далі
- Дізнайтеся більше про розширення інфраструктури
- Дізнайтеся про втулки kubectl
- Дізнайтеся більше про власні ресурси
- Дізнайтеся більше про розширення API сервера
- Дізнайтеся про Динамічний контроль допуску
- Дізнайтеся про шаблон Оператора
13.1 - Розширення обчислення, зберігання та мережі
Цей розділ охоплює розширення вашого кластера, які не входять до складу Kubernetes. Ви можете використовувати ці розширення для розширення функціональності вузлів у вашому кластері або для створення основи для мережі, яка зʼєднує Podʼи.
Втулки зберігання CSI та FlexVolume
Втулки Container Storage Interface (CSI) надають можливість розширити Kubernetes підтримкою нових типів томів. Томи можуть спиратись на надійні зовнішні сховища, або надавати тимчасові сховища, або можуть надавати доступ до інформації лише для читання використовуючи парадигму файлової системи.
Kubernetes також включає підтримку втулків FlexVolume, які є застарілими з моменту випуску Kubernetes v1.23 (використовуйте CSI замість них).
Втулки FlexVolume дозволяють користувачам монтувати типи томів, які не підтримуються нативно Kubernetes. При запуску Pod, який залежить від сховища FlexVolume, kubelet викликає бінарний втулок для монтування тому. В заархівованій пропозиції про дизайн FlexVolume є більше деталей щодо цього підходу.
Kubernetes Volume Plugin FAQ для постачальників зберігання містить загальну інформацію про втулки зберігання.
Втулки пристроїв дозволяють вузлу виявляти нові можливості Node (на додаток до вбудованих ресурсів вузла, таких як
cpuтаmemory) та надавати ці додаткові локальні можливості вузла для Podʼів, які їх запитують.Втулки мережі дозволяють Kubernetes працювати з різними топологіями та технологіями мереж. Вашому кластеру Kubernetes потрібен втулок мережі для того, щоб мати працюючу мережу для Podʼів та підтримувати інші аспекти мережевої моделі Kubernetes.
Kubernetes 1.32 сумісний з втулками CNI мережі.
13.1.1 - Мережеві втулки
Kubernetes (з версії 1.3 і до останньої версії 1.32 та можливо й потім) дозволяє використовувати мережевий інтерфейс контейнерів (CNI, Container Network Interface) для втулків мережі кластера. Вам потрібно використовувати втулок CNI, який сумісний з вашим кластером та відповідає вашим потребам. В екосистемі Kubernetes доступні різні втулки (як з відкритим, так і закритим кодом).
Для імплементації мережевої моделі Kubernetes необхідно використовувати втулок CNI.
Вам потрібно використовувати втулок CNI, який сумісний з v0.4.0 або більш пізніми версіями специфікації CNI. Проєкт Kubernetes рекомендує використовувати втулок, який сумісний з v1.0.0 специфікації CNI (втулки можуть бути сумісними з кількома версіями специфікації).
Встановлення
Середовище виконання контейнерів (Container Runtime) у контексті мережі — це служба на вузлі, налаштована для надання сервісів CRI для kubelet. Зокрема, середовище виконання контейнерів повинно бути налаштоване для завантаження втулків CNI, необхідних для реалізації мережевої моделі Kubernetes.
Примітка:
До Kubernetes 1.24 втулками CNI також можна було керувати через kubelet за допомогою параметрів командного рядка cni-bin-dir та network-plugin. Ці параметри командного рядка були видалені в Kubernetes 1.24, і управління CNI більше не входить до сфери обовʼязків kubelet.
Дивіться Вирішення помилок, повʼязаних з втулками CNI якщо ви стикаєтеся з проблемами після видалення dockershim.
Для конкретної інформації про те, як середовище виконання контейнерів керує втулками CNI, дивіться документацію для цього середовища виконання контейнерів, наприклад:
Для конкретної інформації про те, як встановити та керувати втулком CNI, дивіться документацію для цього втулка або постачальника мережі.
Вимоги до мережевих втулків
Loopback CNI
Крім втулка CNI, встановленого на вузлах для реалізації мережевої моделі Kubernetes, Kubernetes також вимагає, щоб середовища виконання контейнерів надавали loopback інтерфейс lo, який використовується для кожної пісочниці (пісочниці Podʼів, пісочниці віртуальних машин тощо). Реалізацію інтерфейсу loopback можна виконати, використовуючи втулок loopback CNI або розробивши власний код для досягнення цього (дивіться цей приклад від CRI-O).
Підтримка hostPort
Втулок мережі CNI підтримує hostPort. Ви можете використовувати офіційний втулок portmap, який пропонується командою втулків CNI, або використовувати свій власний втулок з функціональністю portMapping.
Якщо ви хочете ввімкнути підтримку hostPort, вам потрібно вказати capability portMappings у вашому cni-conf-dir. Наприклад:
{
"name": "k8s-pod-network",
"cniVersion": "0.4.0",
"plugins": [
{
"type": "calico",
"log_level": "info",
"datastore_type": "kubernetes",
"nodename": "127.0.0.1",
"ipam": {
"type": "host-local",
"subnet": "usePodCidr"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "portmap",
"capabilities": {"portMappings": true},
"externalSetMarkChain": "KUBE-MARK-MASQ"
}
]
}
Підтримка формування трафіку
Експериментальна функція
Втулок мережі CNI також підтримує формування вхідного та вихідного трафіку для Podʼів. Ви можете використовувати офіційний втулок bandwidth, що пропонується командою втулків CNI, або використовувати власний втулок з функціональністю контролю ширини смуги.
Якщо ви хочете ввімкнути підтримку формування трафіку, вам потрібно додати втулок bandwidth до вашого файлу конфігурації CNI (типово /etc/cni/net.d) та забезпечити наявність відповідного виконавчого файлу у вашій теці виконавчих файлів CNI (типово /opt/cni/bin).
{
"name": "k8s-pod-network",
"cniVersion": "0.4.0",
"plugins": [
{
"type": "calico",
"log_level": "info",
"datastore_type": "kubernetes",
"nodename": "127.0.0.1",
"ipam": {
"type": "host-local",
"subnet": "usePodCidr"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "bandwidth",
"capabilities": {"bandwidth": true}
}
]
}
Тепер ви можете додати анотації kubernetes.io/ingress-bandwidth та kubernetes.io/egress-bandwidth до вашого Podʼа. Наприклад:
apiVersion: v1
kind: Pod
metadata:
annotations:
kubernetes.io/ingress-bandwidth: 1M
kubernetes.io/egress-bandwidth: 1M
...
Що далі
- Дізнайтеся більше про мережі в кластерах
- Дізнайтеся більше про мережеві політики
- Ознайомтеся з Вирішення помилок, повʼязаних з втулками CNI
13.1.2 - Втулки пристроїв
Втулки пристроїв дозволяють налаштувати кластер із підтримкою пристроїв або ресурсів, які вимагають налаштування від постачальника, наприклад GPU, NIC, FPGA або енергонезалежної основної памʼяті.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.26 [stable]Kubernetes надає фреймворк втулків пристроїв, який ви можете використовувати для оголошення системних апаратних ресурсів Kubelet.
Замість того, щоб вносити зміни в код самого Kubernetes, вендори можуть реалізувати втулки пристроїв, які ви розгортаєте або вручну, або як DaemonSet. Цільові пристрої включають GPU, мережеві інтерфейси високої продуктивності, FPGA, адаптери InfiniBand, та інші подібні обчислювальні ресурси, які можуть вимагати ініціалізації та налаштування від вендора.
Реєстрація втулка пристрою
kubelet надає службу Registration через gRPC:
service Registration {
rpc Register(RegisterRequest) returns (Empty) {}
}
Втулок пристрою може зареєструвати себе в kubelet через цю службу gRPC. Під час реєстрації втулок пристрою повинен надіслати:
- Назву свого Unix сокету.
- Версію API втулка пристрою, під яку він був зібраний.
ResourceName, яке він хоче оголошувати. ТутResourceNameповинно відповідати розширеній схемі найменування ресурсів у виглядіvendor-domain/resourcetype. (Наприклад, NVIDIA GPU рекламується якnvidia.com/gpu.)
Після успішної реєстрації втулок пристрою надсилає kubelet список пристроїв, якими він керує, і тоді kubelet стає відповідальним за оголошення цих ресурсів на сервері API як частини оновлення стану вузла. Наприклад, після того, як втулок пристрою зареєструє hardware-vendor.example/foo в kubelet і повідомить про наявність двох пристроїв на вузлі, статус вузла оновлюється для оголошення того, що на вузлі встановлено 2 пристрої "Foo" і вони доступні для використання.
Після цього користувачі можуть запитувати пристрої як частину специфікації Podʼа (див. container). Запит розширених ресурсів схожий на те, як ви керуєте запитами та лімітами для інших ресурсів, з такими відмінностями:
- Розширені ресурси підтримуються лише як цілочисельні ресурси та не можуть бути перевищені.
- Пристрої не можуть бути спільно використані між контейнерами.
Приклад
Припустимо, що в кластері Kubernetes працює втулок пристрою, який оголошує ресурс hardware-vendor.example/foo на певних вузлах. Ось приклад Podʼа, який використовує цей ресурс для запуску демонстраційного завдання:
---
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
spec:
containers:
- name: demo-container-1
image: registry.k8s.io/pause:3.8
resources:
limits:
hardware-vendor.example/foo: 2
#
# Цей Pod потребує 2 пристроїв hardware-vendor.example/foo
# і може бути розміщений тільки на Вузлі, який може задовольнити
# цю потребу.
#
# Якщо на Вузлі доступно більше 2 таких пристроїв, то
# залишок буде доступний для використання іншими Podʼами.
Імплементація втулка пристрою
Загальний робочий процес втулка пристрою включає наступні кроки:
Ініціалізація. Під час цієї фази втулок пристрою виконує ініціалізацію та налаштування, специфічні для вендора, щоб забезпечити те, що пристрої перебувають в готовому стані.
Втулок запускає службу gRPC з Unix сокетом за шляхом хоста
/var/lib/kubelet/device-plugins/, що реалізує наступні інтерфейси:service DevicePlugin { // GetDevicePluginOptions повертає параметри, що будуть передані до Менеджера пристроїв. rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {} // ListAndWatch повертає потік списку пристроїв // Кожного разу, коли змінюється стан пристрою або пристрій зникає, ListAndWatch // повертає новий список rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {} // Allocate викликається під час створення контейнера, щоб втулок // пристрою міг виконати операції, специфічні для пристрою, та підказати kubelet // кроки для доступу до пристрою в контейнері rpc Allocate(AllocateRequest) returns (AllocateResponse) {} // GetPreferredAllocation повертає набір пріоритетних пристроїв для виділення // зі списку доступних. Остаточне пріоритетне виділення не гарантується, // це буде зроблене devicemanager. Це призначено лише для допомоги devicemanager у // прийнятті більш обізнаних рішень про виділення, коли це можливо. rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {} // PreStartContainer викликається, якщо це вказано втулком пристрою під час фази реєстрації, // перед кожним запуском контейнера. Втулок пристроїв може виконати певні операції // такі як перезаватаження пристрою перед забезпеченням доступу до пристроїв в контейнері. rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {} }Примітка:
Втулки не обовʼязково повинні надавати корисні реалізації дляGetPreferredAllocation()абоPreStartContainer(). Прапорці, що вказують на доступність цих викликів, якщо такі є, повинні бути встановлені в повідомленніDevicePluginOptions, відправленому через викликGetDevicePluginOptions().kubeletзавжди викликаєGetDevicePluginOptions(), щоб побачити, які необовʼязкові функції доступні, перед тим як викликати будь-яку з них безпосередньо.Втулок реєструється з kubelet через Unix сокет за шляхом хосту
/var/lib/kubelet/device-plugins/kubelet.sock.Примітка:
Послідовність робочого процесу є важливою. Втулок МАЄ почати обслуговування служби gRPC перед реєстрацією з kubelet для успішної реєстрації.Після успішної реєстрації втулок працює в режимі обслуговування, під час якого він постійно відстежує стан пристроїв та повідомляє kubelet про будь-які зміни стану пристрою. Він також відповідальний за обслуговування запитів gRPC
Allocate. Під часAllocateвтулок пристрою може виконувати підготовку, специфічну для пристрою; наприклад, очищення GPU або ініціалізація QRNG. Якщо операції успішно виконуються, втулок повертає відповідьAllocateResponse, яка містить конфігурації контейнера для доступу до виділених пристроїв. Kubelet передає цю інформацію середовищу виконання контейнерів.AllocateResponseмістить нуль або більше обʼєктівContainerAllocateResponse. У цих обʼєктах втулок визначає зміни, які потрібно внести в опис контейнера для забезпечення доступу до пристрою. Ці зміни включають:- анотації
- вузли пристроїв
- змінні середовища
- монтування
- повні імена пристроїв CDI
Примітка:
Обробка повних імен пристроїв CDI Менеджером пристроїв потребує, щоб функціональну можливістьDevicePluginCDIDevicesбуло увімкнено як для kubelet, так і для kube-apiserver. Це було додано як альфа-функція в Kubernetes v1.28 і було підняте до бета у v1.29 та GA у v1.31.
Обробка перезапусків kubelet
Очікується, що втулок пристрою виявлятиме перезапуски kubelet і повторно реєструватиметься з новим екземпляром kubelet. Новий екземпляр kubelet видаляє всі наявні Unix-сокети під /var/lib/kubelet/device-plugins, коли він стартує. Втулок пристрою може відстежувати вилучення своїх Unix-сокетів та повторно реєструватися після цієї події.
Втулок пристроїв та несправні пристрої
Існують випадки, коли пристрої виходять з ладу або вимикаються. Відповідальність втулку пристроїв у такому випадку полягає в тому, щоб повідомити kubelet про ситуацію за допомогою API ListAndWatchResponse.
Після того, як пристрій позначено як несправний, kubelet зменшить кількість виділених ресурсів для цього ресурсу на Вузлі, щоб відобразити, скільки пристроїв можна використовувати для планування нових Podʼів. Загальна величина кількості для ресурсу не змінюватиметься.
Podʼи, які були призначені несправним пристроям, залишаться призначеними до цього пристрою. Зазвичай код, що покладається на пристрій, почне виходити з ладу, і Pod може перейти у фазу Failed, якщо restartPolicy для Podʼа не був Always, або увійти в цикл збоїв в іншому випадку.
До Kubernetes v1.31, щоб дізнатися, чи повʼязаний Pod із несправним пристроєм, потрібно було використовувати PodResources API.
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.31 [alpha] (стандартно увімкнено: false)Увімкнувши функціональну можливість ResourceHealthStatus, до кожного статусу контейнера в полі .status для кожного Pod буде додано поле allocatedResourcesStatus. Поле allocatedResourcesStatus надає інформацію про стан справності для кожного пристрою, призначеного контейнеру.
Для несправного Pod або коли ви підозрюєте несправність, ви можете використовувати цей статус, щоб зрозуміти, чи може поведінка Podʼа бути повʼязаною з несправністю пристрою. Наприклад, якщо прискорювач повідомляє про подію перегріву, поле allocatedResourcesStatus може відобразити цю інформацію.
Розгортання втулка пристрою
Ви можете розгорнути втулок пристрою як DaemonSet, як пакунок для операційної системи вузла або вручну.
Канонічна тека /var/lib/kubelet/device-plugins потребує привілейованого доступу, тому втулок пристрою повинен працювати у привілейованому контексті безпеки. Якщо ви розгортаєте втулок пристрою як DaemonSet, тека /var/lib/kubelet/device-plugins має бути змонтована як Том у PodSpec втулка.
Якщо ви обираєте підхід з використанням DaemonSet, ви можете розраховувати на Kubernetes щодо: розміщення Podʼа втулка пристрою на Вузлах, перезапуску Podʼа демона після відмови та автоматизації оновлень.
Сумісність API
Раніше схема керування версіями вимагала, щоб версія API втулка пристрою точно відповідала версії Kubelet. З моменту переходу цієї функції до бета-версії у версії 1.12 це більше не є жорсткою вимогою. API має версію і є стабільним з моменту випуску бета-версії цієї функції. Через це оновлення kubelet повинні бути безперебійними, але все ще можуть бути зміни в API до стабілізації, що робить оновлення не гарантовано непорушними.
Примітка:
Хоча компонент Kubernetes, Device Manager, є загальнодоступною функцією, API втулка пристроїв не є стабільним. Щоб отримати інформацію про API втулка пристрою та сумісність версій, прочитайте Версії API втулка пристрою.Як проєкт, Kubernetes рекомендує розробникам втулка пристрою:
- Слідкувати за змінами API втулка пристрою у майбутніх релізах.
- Підтримувати кілька версій API втулка пристрою для забезпечення зворотної/майбутньої сумісності.
Для запуску втулка пристрою на вузлах, які потрібно оновити до випуску Kubernetes з новішою версією API втулка пристрою, оновіть ваші втулки пристроїв, щоб підтримувати обидві версії перед оновленням цих вузлів. Такий підхід забезпечить безперервну роботу виділення пристроїв під час оновлення.
Моніторинг ресурсів втулка пристрою
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.28 [stable]Для моніторингу ресурсів, наданих втулками пристроїв, агенти моніторингу повинні мати змогу виявляти набір пристроїв, які використовуються на вузлі, та отримувати метадані, щоб описати, з яким контейнером повʼязаний показник метрики. Метрики Prometheus, експоновані агентами моніторингу пристроїв, повинні відповідати Рекомендаціям щодо інструментування Kubernetes, ідентифікуючи контейнери за допомогою міток prometheus pod, namespace та container.
Kubelet надає gRPC-сервіс для виявлення використовуваних пристроїв та надання метаданих для цих пристроїв:
// PodResourcesLister — це сервіс, який надається kubelet, який надає інформацію про
// ресурси вузла, використані контейнерами та Podʼами на вузлі
service PodResourcesLister {
rpc List(ListPodResourcesRequest) returns (ListPodResourcesResponse) {}
rpc GetAllocatableResources(AllocatableResourcesRequest) returns (AllocatableResourcesResponse) {}
rpc Get(GetPodResourcesRequest) returns (GetPodResourcesResponse) {}
}
Точка доступу gRPC List
Точка доступу List надає інформацію про ресурси запущених Podʼів, з деталями, такими як ідентифікатори виключно виділених ЦП, ідентифікатор пристрою так, як він був повідомлений втулками пристроїів, і ідентифікатор NUMA-вузла, де ці пристрої розміщені. Крім того, для машин, що базуються на NUMA, вона містить інформацію про памʼять та великі сторінки, призначені для контейнера.
Починаючи з Kubernetes v1.27, точка доступу List може надавати інформацію про ресурси запущених Podʼів, виділені в ResourceClaims за допомогою API DynamicResourceAllocation. Щоб увімкнути цю функцію, kubelet повинен бути запущений з наступними прапорцями:
--feature-gates=DynamicResourceAllocation=true,KubeletPodResourcesDynamicResources=true
// ListPodResourcesResponse — це відповідь, повернута функцією List
message ListPodResourcesResponse {
repeated PodResources pod_resources = 1;
}
// PodResources містить інформацію про ресурси вузла, призначені для Podʼа
message PodResources {
string name = 1;
string namespace = 2;
repeated ContainerResources containers = 3;
}
// ContainerResources містить інформацію про ресурси, призначені для контейнера
message ContainerResources {
string name = 1;
repeated ContainerDevices devices = 2;
repeated int64 cpu_ids = 3;
repeated ContainerMemory memory = 4;
repeated DynamicResource dynamic_resources = 5;
}
// ContainerMemory містить інформацію про памʼять та великі сторінки, призначені для контейнера
message ContainerMemory {
string memory_type = 1;
uint64 size = 2;
TopologyInfo topology = 3;
}
// Topology описує апаратну топологію ресурсу
message TopologyInfo {
repeated NUMANode nodes = 1;
}
// NUMA представлення NUMA-вузла
message NUMANode {
int64 ID = 1;
}
// ContainerDevices містить інформацію про пристрої, призначені для контейнера
message ContainerDevices {
string resource_name = 1;
repeated string device_ids = 2;
TopologyInfo topology = 3;
}
// DynamicResource містить інформацію про пристрої, призначені для контейнера за допомогою Dynamic Resource Allocation
message DynamicResource {
string class_name = 1;
string claim_name = 2;
string claim_namespace = 3;
repeated ClaimResource claim_resources = 4;
}
// ClaimResource містить інформацію про ресурси у втулках
message ClaimResource {
repeated CDIDevice cdi_devices = 1 [(gogoproto.customname) = "CDIDevices"];
}
// CDIDevice визначає інформацію про пристрій CDI
message CDIDevice {
// Повністю кваліфіковане імʼя пристрою CDI
// наприклад: vendor.com/gpu=gpudevice1
// див. більше деталей в специфікації CDI:
// https://github.com/container-orchestrated-devices/container-device-interface/blob/main/SPEC.md
string name = 1;
}
Примітка:
cpu_ids у ContainerResources у точці доступу List відповідають виключно виділеним ЦП, призначеним для певного контейнера. Якщо мета — оцінити ЦП, які належать до загального пула, точку доступу List необхідно використовувати разом з точкою доступуGetAllocatableResources, як пояснено
нижче:
- Викликайте
GetAllocatableResources, щоб отримати список всіх доступних для виділення ЦП. - Викликайте
GetCpuIdsна всіContainerResourcesу системі. - Відніміть всі ЦП з викликів
GetCpuIdsз викликуGetAllocatableResources.
Точка доступу gRPC GetAllocatableResources
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.28 [stable]Точка доступу GetAllocatableResources надає інформацію про ресурси, що спочатку доступні на робочому вузлі. Вона надає більше інформації, ніж kubelet експортує в APIServer.
Примітка:
GetAllocatableResources слід використовувати лише для оцінки виділених ресурсів на вузлі. Якщо мета - оцінити вільні/невикористані ресурси, її слід використовувати разом з точкою доступу List(). Результат, отриманий за допомогою GetAllocatableResources, залишиться таким самим, якщо ресурси, які експонуються для kubelet, не змінюються. Це відбувається рідко, але коли це відбувається (наприклад: hotplug/hotunplug, зміни стану пристроїв), очікується, що клієнт викличе точку доступу GetAllocatableResources.
Однак виклик точки доступу GetAllocatableResources не є достатнім у випадку оновлення ЦП та/або памʼяті, і для відображення правильної кількості та виділення ресурсів Kubelet повинен бути перезавантажений.
// AllocatableResourcesResponses містить інформацію про всі пристрої, відомі kubelet
message AllocatableResourcesResponse {
repeated ContainerDevices devices = 1;
repeated int64 cpu_ids = 2;
repeated ContainerMemory memory = 3;
}
ContainerDevices дійсно викладають інформацію про топологію, що вказує, до яких NUMA-клітин пристрій прикріплений. NUMA-клітини ідентифікуються за допомогою прихованого цілочисельного ідентифікатора, значення якого відповідає тому, що втулки пристроїв повідомляють коли вони реєструються у kubelet.
Сервіс gRPC обслуговується через unix-сокет за адресою /var/lib/kubelet/pod-resources/kubelet.sock. Агенти моніторингу для ресурсів втулків пристроїв можуть бути розгорнуті як демони, або як DaemonSet. Канонічна тека /var/lib/kubelet/pod-resources вимагає привілейованого доступу, тому агенти моніторингу повинні працювати у привілейованому контексті безпеки. Якщо агент моніторингу пристроїв працює як DaemonSet, /var/lib/kubelet/pod-resources має бути підключена як Том у PodSpec агента моніторингу пристроїв PodSpec.
Примітка:
При доступі до /var/lib/kubelet/pod-resources/kubelet.sock з DaemonSet або будь-якого іншого застосунку, розгорнутого як контейнер на вузлі, який монтує сокет як том, це є доброю практикою монтувати теку /var/lib/kubelet/pod-resources/ замість /var/lib/kubelet/pod-resources/kubelet.sock. Це забезпечить можливість перепідключення контейнера до цього сокету після перезавантаження kubelet.
Записи контейнера керуються за допомогою inode, що посилається на сокет або теку, залежно від того, що було змонтовано. Після перезапуску kubelet сокет видаляється і створюється новий сокет, тоді як тека залишається недоторканою. Таким чином, оригінальний inode для сокета стає непридатним для використання. inode для теки продовжить працювати.
Точка доступу gRPC Get
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.27 [alpha]Точка доступу Get надає інформацію про ресурси робочого Pod. Вона експонує інформацію, аналогічну тій, що описана в точці доступу List. Точка доступу Get вимагає PodName і PodNamespace робочого Pod.
// GetPodResourcesRequest містить інформацію про Pod
message GetPodResourcesRequest {
string pod_name = 1;
string pod_namespace = 2;
}
Для включення цієї функції вам потрібно запустити ваші служби kubelet з такими прапорцями:
--feature-gates=KubeletPodResourcesGet=true
Точка доступу Get може надавати інформацію про Pod, повʼязану з динамічними ресурсами, виділеними за допомогою API динамічного виділення ресурсів. Для включення цієї функції вам потрібно забезпечити, щоб ваші служби kubelet були запущені з наступними прапорцями:
--feature-gates=KubeletPodResourcesGet=true,DynamicResourceAllocation=true,KubeletPodResourcesDynamicResources=true
Інтеграція втулка пристрою з Менеджером Топології
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.27 [stable]Менеджер Топології (Topology Manager) є компонентом Kubelet, який дозволяє координувати ресурси в манері, орієнтованій на топологію. Для цього API втулка пристрою (Device Plugin API) було розширено, щоб включити структуру TopologyInfo.
message TopologyInfo {
repeated NUMANode nodes = 1;
}
message NUMANode {
int64 ID = 1;
}
Втулки пристроїв, які хочуть використовувати Менеджер Топології, можуть надсилати заповнену структуру TopologyInfo як частину реєстрації пристрою, разом з ідентифікаторами пристроїв та станом справності пристрою. Менеджер пристроїв потім використовуватиме цю інформацію для консультації з Менеджером Топології та прийняття рішень щодо призначення ресурсів.
TopologyInfo підтримує встановлення поля nodes або у nil, або у список вузлів NUMA. Це дозволяє Втулку Пристрою оголошувати пристрій, який охоплює кілька вузлів NUMA.
Встановлення TopologyInfo в nil або надання порожнього списку вузлів NUMA для даного пристрою вказує на те, що Втулок Пристрою не має переваги щодо спорідненості NUMA для цього пристрою.
Приклад структури TopologyInfo, заповненої для пристрою Втулком Пристрою:
pluginapi.Device{ID: "25102017", Health: pluginapi.Healthy, Topology:&pluginapi.TopologyInfo{Nodes: []*pluginapi.NUMANode{&pluginapi.NUMANode{ID: 0,},}}}
Приклади втулків пристроїв
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Ось деякі приклади реалізації втулків пристроїв:
- Akri дозволяє легко використовувати різнорідні пристрої вузла (такі як IP-камери та USB-пристрої).
- Втулок пристрою AMD GPU
- Загальний втулок пристрою для загальних пристроїв Linux та USB пристроїв
- HAMi для гетерогенного проміжного програмного забезпечення для віртуалізації обчислень ШІ (наприклад, NVIDIA, Cambricon, Hygon, Iluvatar, MThreads, Ascend, Metax)
- Втулки пристроїв Intel для пристроїв Intel GPU, FPGA, QAT, VPU, SGX, DSA, DLB і IAA
- Втулки пристроїв KubeVirt для апаратної підтримки віртуалізації
- The Втулок пристрою NVIDIA GPU, Офіційний втулок для пристроїв від NVIDIA, який експонує графічні процесори NVIDIA та відстежує стан графічних процесорів
- Втулок пристрою NVIDIA GPU для Container-Optimized OS
- Втулок пристрою RDMA
- Втулок пристрою SocketCAN
- Втулок пристрою Solarflare
- Втулок мережевого пристрою SR-IOV
- Втулки пристроїв Xilinx FPGA для пристроїв Xilinx FPGA
Що далі
- Дізнайтеся про планування ресурсів GPU за допомогою втулків пристроїв
- Дізнайтеся про оголошення розширених ресурсів на вузлі
- Дізнайтеся про Менеджер Топології
- Прочитайте про використання апаратного прискорення для TLS ingress з Kubernetes
13.2 - Розширючи API Kubernetes
Власні ресурси користувача є розширенням API Kubernetes. Kubernetes надає два способи додавання власних ресурсів до вашого кластера:
- Механізм CustomResourceDefinition (CRD) дозволяє вам декларативно визначити новий власний API з API-групою, видом (kind) та схемою, які ви вказуєте. Панель управління Kubernetes обслуговує та обробляє зберіганням вашого власного ресурсу. CRD дозволяє створювати нові типи ресурсів для вашого кластера без написання та запуску власного API-сервера.
- Шар агрегації розташований за основним API-сервером, який діє як проксі. Таке розташування називається агрегацією API (AA), яка дозволяє вам надавати спеціалізовані реалізації для ваших власних ресурсів, написавши та розгорнувши власний API-сервер. Основний API-сервер делегує запити до вашого API-сервера для власних API, які ви вказуєте, зробивши їх доступними для всіх своїх клієнтів.
13.2.1 - Власні Ресурси
Власні ресурси є розширеннями API Kubernetes. Ця сторінка обговорює, коли додавати власний ресурс до вашого кластера Kubernetes та коли використовувати як самостійний сервіс. Вона описує два методи додавання власних ресурсів і як вибрати між ними.
Власні ресурси
Ресурс — це точка доступу в API Kubernetes, яка зберігає колекцію обʼєктів API певного виду; наприклад, вбудований ресурс pods містить колекцію обʼєктів Pod.
Власний ресурс — це розширення API Kubernetes, яке не обовʼязково доступне в типовій установці Kubernetes. Він представляє собою налаштування конкретного встановлення Kubernetes. Однак багато основних функцій Kubernetes тепер побудовані з використанням власних ресурсів, що робить Kubernetes більш модульним.
Власні ресурси можуть зʼявлятися та зникають в працюючому кластері через динамічну реєстрацію, і адміністратори кластера можуть оновлювати власні ресурси незалежно від самого кластера. Як тільки власний ресурс встановлено, користувачі можуть створювати та отримувати доступ до його обʼєктів за допомогою kubectl, так само як для вбудованих ресурсів, таких як Pod.
Власні контролери
Самі по собі власні ресурси дозволяють зберігати та отримувати структуровані дані. Коли ви поєднуєте власний ресурс з власним контролером, власні ресурси надають справжній декларативний API.
Декларативний API Kubernetes забезпечує розділення обовʼязків. Ви оголошуєте бажаний стан вашого ресурсу. Контролер Kubernetes підтримує поточний стан обʼєктів Kubernetes відповідно до вашого оголошеного бажаного стану. Це відрізняється від імперативного API, де ви вказуєте серверу, що робити.
Ви можете розгортати та оновлювати власний контролер на робочому кластері, незалежно від життєвого циклу кластера. Власні контролери можуть працювати з будь-яким видом ресурсів, але вони особливо ефективні, коли поєднуються з власними ресурсами. Шаблон Оператора поєднує власні ресурси та власні контролери. Ви можете використовувати власні контролери для включення доменного знання для конкретних застосунків у розширення API Kubernetes.
Чи слід додавати власний ресурс до мого кластера Kubernetes?
При створенні нового API розгляньте можливість агрегування вашого API з API кластера Kubernetes або дозвольте вашому API залишитися незалежним.
| Розгляньте агрегацію API, якщо: | Віддайте перевагу незалежному API, якщо: |
|---|---|
| Ваш API є Декларативним. | Ваш API не відповідає моделі Декларативного API. |
Ви хочете, щоб ваші нові типи були доступні для читання та запису за допомогою kubectl. | Підтримка kubectl не є необхідною. |
| Ви хочете бачити свої нові типи в UI Kubernetes, такому як панель управління, поряд з вбудованими типами. | Підтримка UI Kubernetes не є необхідною. |
| Ви розробляєте новий API. | Ви вже маєте програму, яка обслуговує ваш API та працює добре. |
| Ви готові прийняти обмеження формату, які Kubernetes накладає на шляхи REST ресурсів, такі як групи API та простори імен. (Дивіться Огляд API.) | Вам потрібні специфічні шляхи REST для сумісності з уже визначеним REST API. |
| Ваші ресурси природно обмежені кластером або просторами імен кластера. | Ресурси, обмежені кластером або простором імен, погано підходять; вам потрібен контроль над специфікою шляхів ресурсів. |
| Ви хочете повторно використовувати функції підтримки API Kubernetes. | Вам не потрібні ці функції. |
Декларативні API
У декларативному API зазвичай:
- Ваш API складається з відносно невеликої кількості відносно невеликих обʼєктів (ресурсів).
- Обʼєкти визначають конфігурацію застосунків або інфраструктури.
- Обʼєкти оновлюються відносно рідко.
- Люди часто мають читати та записувати обʼєкти.
- Основні операції з обʼєктами — це CRUD (створення, читання, оновлення та видалення).
- Транзакції між обʼєктами не потрібні: API представляє бажаний стан, а не точний стан.
Імперативні API не є декларативними. Ознаки того, що ваш API може не бути декларативним, включають:
- Клієнт каже "зробіть це", і потім отримує синхронну відповідь, коли це виконано.
- Клієнт каже "зробіть це", а потім отримує ідентифікатор операції назад і повинен перевірити окремий обʼєкт операції, щоб визначити завершення запиту.
- Ви говорите про виклики віддалених процедур (RPC).
- Пряме зберігання великої кількості даних; наприклад, > кілька кБ на обʼєкт, або > 1000 обʼєктів.
- Потрібен високий доступ до пропускної здатності (десятки запитів на секунду тривалий час).
- Збереження даних кінцевого користувача (наприклад, зображень, PII тощо) або інших великих обсягів даних, оброблених застосунками.
- Природні операції з обʼєктами не є CRUD-подібними.
- API не легко моделюється як обʼєкти.
- Ви вибрали представлення очікуючих операцій за допомогою ідентифікатора операції або обʼєкта операції.
Чи слід використовувати ConfigMap або власний ресурс?
Використовуйте ConfigMap, якщо застосовується будь-який з наступних пунктів:
- Існує вже відомий, добре задокументований формат файлу конфігурації, такий як
mysql.cnfабоpom.xml. - Ви хочете помістити всю конфігурацію в один ключ ConfigMap.
- Основне використання файлу конфігурації — для програми, що працює у Pod у вашому кластері, для використання файлу для самоналаштування.
- Споживачі файлу вважають за краще отримувати його через файл у Pod або змінну оточення у Pod, а не через Kubernetes API.
- Ви хочете виконувати послідовне оновлення за допомогою Deployment тощо, коли файл оновлюється.
Примітка:
Використовуйте Secret для конфіденційних даних, який є схожим на ConfigMap, але безпечнішим.Використовуйте власний ресурс (CRD або Aggregated API), якщо застосовується більшість з наступних пунктів:
- Ви хочете використовувати бібліотеки та CLI Kubernetes для створення та оновлення нового ресурсу.
- Ви хочете отримати підтримку на вищому рівні від
kubectl; наприклад,kubectl get my-object object-name. - Ви хочете побудувати нову автоматизацію, яка стежить за оновленнями нового обʼєкта, а потім виконує CRUD інших обʼєктів, або навпаки.
- Ви хочете написати автоматизацію, яка обробляє оновлення обʼєкта.
- Ви хочете використовувати конвенції Kubernetes API, такі як
.spec,.status, та.metadata. - Ви хочете, щоб обʼєкт був абстракцією над колекцією контрольованих ресурсів або узагальненням інших ресурсів.
Додавання власних ресурсів
Kubernetes надає два способи додавання власних ресурсів до вашого кластера:
- CRD (Custom Resource Definition) є простим і може бути створений без будь-якого програмування.
- API Aggregation потребує програмування, але надає більший контроль над поведінкою API, такою як зберігання даних та конвертація між версіями API.
Kubernetes надає ці два варіанти, щоб задовольнити потреби різних користувачів, щоб ні зручність використання, ні гнучкість не зазнавали утисків.
Агреговані API є підлеглими API-серверами, які розташовані позаду основного API-сервера, який діє як проксі. Ця організація називається API Aggregation(AA). Для користувачів API Kubernetes виглядає розширеним.
CRD дозволяють користувачам створювати нові типи ресурсів без додавання іншого API-сервера. Вам не потрібно розуміти API Aggregation, щоб використовувати CRD.
Незалежно від того, як вони встановлені, нові ресурси називаються Custom Resources, щоб відрізняти їх від вбудованих ресурсів Kubernetes (наприклад, Pod).
Примітка:
Уникайте використання Custom Resource як сховища даних для застосунків, користувачів або моніторингу: архітектурні рішення, які зберігають дані застосунків в API Kubernetes, зазвичай представляють занадто тісно повʼязану конструкцію.
З архітектурного погляду хмарні архітектура застосунків надає перевагу вільному звʼязуванню між компонентами. Якщо частина вашого завдання вимагає сервісу підтримки для його рутинної роботи, запускайте цей сервіс як компонент або використовуйте його як зовнішній сервіс. Таким чином, ваше робоче навантаження не залежить від API Kubernetes для його нормальної роботи.
CustomResourceDefinitions
API-ресурс CustomResourceDefinition дозволяє вам визначати власні ресурси. Визначення обʼєкта CRD створює новий власний ресурс з імʼям і схемою, яку ви вказуєте. API Kubernetes обслуговує та обробляє зберігання вашого власного ресурсу. Назва самого обʼєкта CRD повинна бути дійсною назвою піддомену DNS, утвореною від визначеної назви ресурсу та його API групи; для детальнішої інформації дивіться як створити CRD. Крім того, назва обʼєкта, чий тип/ресурс визначається CRD, також повинна бути дійсною назвою піддомену DNS.
Це звільняє вас від написання власного API-сервера для обробки власного ресурсу, але загальна природа реалізації означає, що у вас менше гнучкості, ніж з агрегацією сервера API.
Для прикладу того, як зареєструвати новий власний ресурс, для роботи з екземплярами вашого нового типу ресурсу та використовувати контролер для обробки подій, дивіться приклад власного контролера.
Агрегація сервера API
Зазвичай кожен ресурс в API Kubernetes вимагає коду, який обробляє REST-запити та керує постійним зберіганням обʼєктів. Основний сервер API Kubernetes обробляє вбудовані ресурси, такі як Pod та Service, а також узагальнено може керувати власними ресурсами через CRD.
Шар агрегації дозволяє вам надати спеціалізовані реалізації для ваших власних ресурсів, написавши та розгорнувши власний сервер API. Основний сервер API делегує запити до вашого сервера API для власних ресурсів, які ви обробляєте, роблячи їх доступними для всіх його клієнтів.
Вибір методу для додавання власних ресурсів
CRD простіші у використанні. Агреговані API більш гнучкі. Виберіть метод, який найкраще відповідає вашим потребам.
Зазвичай CRD підходять, якщо:
- У вас багато полів.
- Ви використовуєте ресурс у своїй компанії або як частину невеликого відкритого проєкту (на відміну від комерційного продукту).
Порівняння простоти використання
Створення CRD простіше, ніж Aggregated APIs.
| CRD | Aggregated API |
|---|---|
| Не потребує програмування. Користувачі можуть вибрати будь-яку мову для контролера CRD. | Вимагає програмування та створення бінарного файлу та образу. |
| Немає додаткової служби для запуску; CRD обробляються сервером API. | Додаткова служба для створення, яка може зазнати невдачі. |
| Немає підтримки після створення CRD. Будь-які виправлення помилок виконуються як частина звичайних оновлень майстра Kubernetes. | Може вимагати періодичного отримування виправлення помилок від постачальника та перебудови та оновлення сервера Aggregated API. |
| Не потрібно керувати декількома версіями вашого API; наприклад, коли ви контролюєте клієнта для цього ресурсу, ви можете оновлювати його синхронно з API. | Потрібно керувати декількома версіями вашого API; наприклад, коли розробляєте розширення для спільного використання. |
Розширені функції та гнучкість
Агреговані API пропонують більше розширених можливостей API та налаштування інших функцій; наприклад, рівень зберігання.
| Функція | Опис | CRD | Aggregated API |
|---|---|---|---|
| Валідація | Допомагає користувачам уникати помилок та дозволяє вам самостійно розвивати ваше API незалежно від ваших клієнтів. Ці функції найбільш корисні, коли є багато клієнтів, які не можуть всі одночасно оновлюватися. | Так. Більшість валідацій можуть бути вказані у CRD за допомогою валідації OpenAPI v3.0. Можливість CRDValidationRatcheting дозволяє ігнорувати валідації, вказані за допомогою OpenAPI, якщо збійна частина ресурсу не була змінена. Будь-яка інша валідація підтримується за допомогою Вебхука валідації. | Так, довільні перевірки валідації |
| Стандартне значення | Див. вище | Так, або через валідацію OpenAPI v3.0 за допомогою ключового слова default (GA в 1.17), або через Вебхук мутації (хоча це не буде виконано при зчитуванні з etcd для старих обʼєктів). | Так |
| Мультиверсіонність | Дозволяє обслуговувати той самий обʼєкт через дві версії API. Може допомогти спростити зміни API, такі як перейменування полів. Менш важливо, якщо ви контролюєте версії вашого клієнта. | Так | Так |
| Власне сховище | Якщо вам потрібне сховище з іншим режимом продуктивності (наприклад, база даних часових рядів замість сховища ключ-значення) або ізоляція для безпеки (наприклад, шифрування конфіденційної інформації тощо). | Немає | Так |
| Власна бізнес-логіка | Виконуйте довільні перевірки або дії при створенні, читанні, оновленні або видаленні обʼєкта | Так, за допомогою Вебхуків. | Так |
| Масштабування Subresource | Дозволяє системам, таким як HorizontalPodAutoscaler та PodDisruptionBudget, взаємодіяти з вашим новим ресурсом | Так | Так |
| Статус Subresource | Дозволяє деталізований контроль доступу, де користувач записує розділ spec, а контролер записує розділ status. Дозволяє інкрементувати Generation обʼєкту при мутації даних власного ресурсу (вимагає окремих розділів spec та status у ресурсі). | Так | Так |
| Інші Subresources | Додавання операцій крім CRUD, таких як "logs" або "exec". | Немає | Так |
| strategic-merge-patch | Нові точки доступу підтримують PATCH з Content-Type: application/strategic-merge-patch+json. Корисно для оновлення обʼєктів, які можуть бути змінені як локально, так і сервером. Докладніше див. "Оновлення обʼєктів API на місці за допомогою kubectl patch" | Немає | Так |
| Protocol Buffers | Новий ресурс підтримує клієнтів, які хочуть використовувати Protocol Buffers | Немає | Так |
| Схема OpenAPI | Чи є схема OpenAPI (swagger) для типів, які можуть бути динамічно завантажені з сервера? Чи захищений користувач від помилок у написанні назв полів, забезпечуючи, що лише дозволені поля встановлені? Чи використовуються типи (іншими словами, не розміщуйте int в string полі?) | Так, на основі схеми валідації OpenAPI v3.0 (GA в 1.16). | Так |
| Назва екземпляра | Чи накладає цей механізм розширення будь-які обмеження на назви обʼєктів, тип/ресурс яких визначено таким чином? | Так, назва такого обʼєкта повинна бути дійсною назвою піддомену DNS. | Ні |
Загальні функції
При створенні власного ресурсу, будь-то через CRD або AA, ви отримуєте багато функцій для вашого API порівняно з його втіленням поза платформою Kubernetes:
| Функція | Опис |
|---|---|
| CRUD | Нові точки доступу підтримують CRUD базові операції через HTTP та kubectl |
| Watch | Нові точки доступу підтримують операції Watch Kubernetes через HTTP |
| Discovery | Клієнти, такі як kubectl та інтерфейс, автоматично пропонують операції list, display та edit для полів у ваших ресурсах |
| json-patch | Нові точки доступу підтримують PATCH з Content-Type: application/json-patch+json |
| merge-patch | Нові точки доступу підтримують PATCH з Content-Type: application/merge-patch+json |
| HTTPS | Нові точки доступу використовують HTTPS |
| Вбудована автентифікація | Доступ до розширення використовує ядро сервера API (рівень агрегації) для автентифікації |
| Вбудована авторизація | Доступ до розширення може використовувати авторизацію, яка використовується ядром сервера API; наприклад, RBAC. |
| Finalizers | Блокування видалення ресурсів розширення до тих пір, поки не відбудеться зовнішнє очищення. |
| Admission Webhooks | Встановлення стандартних значень та валідація ресурсів розширення під час будь-якої операції створення/оновлення/видалення. |
| Відображення в інтерфейсі/CLI | Kubectl, інтерфейс можуть відображати ресурси розширення. |
| Не встановлено чи Порожньо | Клієнти можуть розрізняти невстановлені поля від полів з нульовим значенням. |
| Генерація бібліотек клієнтів | Kubernetes надає загальні бібліотеки клієнтів, а також інструменти для генерації бібліотек клієнтів для конкретних типів даних. |
| Мітки та анотації | Загальні метадані між обʼєктами, для яких інструменти знають, як їх редагувати для основних та власних ресурсів. |
Підготовка до встановлення власного ресурсу
Перш ніж додавати власний ресурс до вашого кластера, слід врахувати кілька моментів.
Код від сторонніх розробників та нові точки відмов
Створення CRD не автоматично додає будь-які нові точки відмов (наприклад, за допомогою запуску коду сторонніх розробників на вашому сервері API), проте пакети (наприклад, Charts) або інші збірники для встановлення часто включають CRD, а також Deployment з кодом сторонніх розробників, який реалізує бізнес-логіку для нового власного ресурсу.
Встановлення агрегованого сервера API завжди передбачає запуск нового Deployment.
Зберігання
Власні ресурси споживають місце зберігання так само як і ConfigMaps. Створення занадто великих власних ресурсів може перевантажити простір зберігання сервера API.
Агреговані сервери API можуть використовувати те саме зберігання, що і головний сервер API, в такому разі застосовуються ті самі попередження.
Автентифікація, авторизація та аудит
CRD завжди використовують ту саму автентифікацію, авторизацію та ведення аудиту, що й вбудовані ресурси вашого сервера API.
Якщо ви використовуєте RBAC для авторизації, більшість ролей RBAC не надають доступ до нових ресурсів (окрім ролі cluster-admin або будь-якої ролі, створеної з шаблонами). Вам потрібно явно надати доступ до нових ресурсів. CRD та агреговані сервери API часто постачаються з новими визначеннями ролей для типів, які вони додають.
Агреговані сервери API можуть або не можуть використовувати ту саму автентифікацію, авторизацію та ведення аудиту, що й основний сервер API.
Доступ до власного ресурсу
Бібліотеки клієнтів Kubernetes можна використовувати для доступу до власних ресурсів. Не всі бібліотеки клієнтів підтримують власні ресурси. Go та Python бібліотеки клієнтів це роблять.
Після додавання власного ресурсу ви можете отримати до нього доступ за допомогою:
kubectl- Динамічного клієнта Kubernetes.
- REST-клієнта, який ви напишете.
- Клієнта, згенерованого за допомогою інструментів генерації клієнта Kubernetes (генерація є складним завданням, але деякі проєкти можуть постачати клієнтів разом з CRD або AA).
Селектори полів власних ресурсів
Селектори полів дозволяють клієнтам вибирати власні ресурси за значенням полів одного чи більше ресурсів.
Всі власні ресурси підтримують селектори полів metadata.name та metadata.namespace.
Поля оголошені у CustomResourceDefinition можуть бути використані з селекторами полів, коли вони вказані у полі spec.versions[*].selectableFields в CustomResourceDefinition.
Поля власних ресурсів, які підтримуються селекторами
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [stable] (стандартно увімкнено: true)Поле spec.versions[*].selectableFields в CustomResourceDefinition може бути використане для вказівки, які інші поля в власному ресурсі можуть бути використані в полях селекторів.
Наступний приклад додає поля .spec.color та .spec.size, як поля які можна вибирати.
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: shirts.stable.example.com
spec:
group: stable.example.com
scope: Namespaced
names:
plural: shirts
singular: shirt
kind: Shirt
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
color:
type: string
size:
type: string
selectableFields:
- jsonPath: .spec.color
- jsonPath: .spec.size
additionalPrinterColumns:
- jsonPath: .spec.color
name: Color
type: string
- jsonPath: .spec.size
name: Size
type: string
За допомогою полів селекторів можна отримати лише ресурси color зі значенням blue:
kubectl get shirts.stable.example.com --field-selector spec.color=blue
Вивід повинен бути наступним:
NAME COLOR SIZE
example1 blue S
example2 blue M
Що далі
- Дізнайтеся, як розширити API Kubernetes за допомогою агрегаційного рівня.
- Дізнайтеся, як розширити API Kubernetes за допомогою CustomResourceDefinition.
13.2.2 - Шар агрегації API Kubernetes
Шар агрегації дозволяє розширювати можливості Kubernetes за допомогою додаткових API, поза тим, що пропонується ядром основних API Kubernetes. Додаткові API можуть бути як готові рішення, такі як сервер метрик, так і API, які ви розробляєте самостійно.
Шар агрегації відрізняється від Custom Resource Definitions, які є способом зробити так, щоб kube-apiserver визнавав нові види обʼєктів.
Шар агрегації
Шар агрегації працює в процесі разом з kube-apiserver. До того, як розширений ресурс буде зареєстровано, шар агрегації не виконуватиме жодних дій. Для реєстрації API ви додаєте обʼєкт APIService, який "запитує" URL-шлях у Kubernetes API. На цьому етапі шар агрегації буде передавати будь-що, що надійде на цей API-шлях (наприклад, /apis/myextension.mycompany.io/v1/…), зареєстрованому APIService.
Найпоширеніший спосіб реалізації APIService — це запуск розширеного API-сервера в Podʼах, які працюють у вашому кластері. Якщо ви використовуєте розширений API-сервер для управління ресурсами у своєму кластері, розширений API-сервер (також пишеться як "extension-apiserver") зазвичай сполучається з одним або кількома контролерами. Бібліотека apiserver-builder надає кістяк як для розширених API-серверів, так і для відповідних контролерів.
Затримки відповіді
Розширені API-сервери повинні мати малі затримки мережевого звʼязку до та від kube-apiserver. Запити на виявлення повинні долати шлях до та від kube-apiserver до пʼяти секунд або менше.
Якщо ваш розширений API-сервер не може досягти цієї вимоги щодо затримки, розгляньте внесення змін, які дозволять вам відповідати їй.
Що далі
- Щоб отримати робочий агрегатор у вашому середовищі, налаштуйте шар агрегації.
- Потім, налаштуйте розширений API-сервер для роботи з шаром агрегації.
- Прочитайте про APIService у довідці API.
Альтернативно: дізнайтеся, як розширити API Kubernetes, використовуючи визначення власних ресурсів.
13.3 - Шаблон Operator
Оператори — це розширення програмного забезпечення для Kubernetes, які використовують власні ресурси для управління застосунками та їх компонентами. Оператори дотримуються принципів Kubernetes, зокрема control loop.
Мотивація
Шаблон operator спрямований на досягнення ключової мети людини-оператора, яка керує сервісом або набором сервісів. Люди-оператори, які відповідають за конкретні застосунки та сервіси, мають глибокі знання про те, як система повинна себе вести, як її розгорнути та як реагувати у разі проблем.
Люди, які запускають робочі навантаження в Kubernetes, часто хочуть використовувати автоматизацію для виконання повторюваних завдань. Шаблон operator показує, як ви можете написати код для автоматизації завдання, яке виходить за межі того, що надає сам Kubernetes.
Оператори в Kubernetes
Kubernetes створений для автоматизації. З коробки ви отримуєте багато вбудованої автоматизації від ядра Kubernetes. Ви можете використовувати Kubernetes для автоматизації розгортання та запуску робочих навантажень, та ви можете автоматизувати те, як це робить Kubernetes.
Концепція шаблону operator Kubernetes дозволяє розширити поведінку кластера без зміни коду самого Kubernetes, звʼязавши контролери з одним або кількома власними ресурсами. Оператори є клієнтами API Kubernetes, які діють як контролери для власного ресурсу.
Приклад оператора
Деякі завдання, які можна автоматизувати за допомогою оператора, включають:
- розгортання застосунку за запитом
- створення та відновлення резервних копій стану цього застосунку
- керування оновленнями коду застосунку разом з повʼязаними змінами, такими як схеми баз даних або додаткові налаштування
- публікація Serviceʼів для застосунків, які не підтримують Kubernetes API, для їх виявлення
- емуляція відмови в усьому або частині кластера для перевірки його стійкості
- обрання лідера для розподіленого застосунку без внутрішнього процесу такого вибору.
Яким може бути оператор у більш детальному вигляді? Ось приклад:
- Власний ресурс з назвою SampleDB, який можна налаштувати в кластері.
- Deployment, який запускає Pod, що містить частину контролера оператора.
- Образ контейнера з кодом оператора.
- Код контролера, який надсилає запити до панелі управління, щоб дізнатися, яким чином налаштовано ресурси SampleDB.
- Ядром оператора є код, який говорить API серверу, які дії потрібно виконати, щоб поточний стан ресурсу SampleDB відповідав бажаному стану ресурсів.
- Якщо ви додаєте новий ресурс SampleDB, оператор створює PersistentVolumeClaim для забезпечення місця для надійного зберігання даних, StatefulSet — для запуску SampleDB, та завдання (Job) для ініціалізації бази даних.
- Якщо ви видаляєте ресурс SampleDB, оператор зробить зліпок з усіх даних, потім переконається, що ресурси StatefulSet та Volume також видалені.
- Оператор також керує процесом створення резервних копій бази даних. Для кожного ресурсу SampleDB оператор визначає, коли потрібно створити Pod, який підʼєднається до бази даних, та зробить резервну копію. Ці Podʼи можуть використовувати ConfigMap чи Secret, що містять облікові дані для підʼєднання до бази даних.
- Оскільки оператор призначений для надання високого рівня автоматизації для керування ресурсами, тож для цього може використовуватись додатковий код. Наприклад, код, що визначає, чи база даних працює на старій версії, та якщо так, то створює Job для оновлення бази даних.
Розгортання операторів
Найпоширеніший спосіб розгортання операторів — це додавання CustomResourceDefinition (CRD) та контролера для них до вашого кластера. Контролери мають зазвичай запускатись за межами панелі управління кластера, так само як ви запускаєте будь-який інший контейнеризований застосунок. Наприклад, ви можете запустити ваш контролер як Deployment.
Використання операторів
Після того, як ви розгорнете оператора, ви будете використовувати його, додаючи, змінюючи або видаляючи тип ресурсу, який використовує оператор. Наслідуючи наведений вище приклад, ви б налаштували розгортання для самого оператора, а потім:
kubectl get SampleDB # пошук налаштованої бази даних
kubectl edit SampleDB/example-database # ручна заміна деяких параметрів
…і все! Оператор візьме на себе роботу застосування змін, а такою як і підтримання сервісу у відповідному стані.
Створення власних операторів
Якщо в екосистемі немає оператора, який реалізує потрібну вам поведінку, ви можете створити власний.
Ви також можете створити оператор (тобто, Контролер) використовуючи мову або рушій виконання, який працює як клієнт API Kubernetes.
Нижче наведено кілька бібліотек та інструментів, які ви можете використовувати для написання власного хмарного оператора.
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
- Charmed Operator Framework
- Java Operator SDK
- Kopf (Kubernetes Operator Pythonic Framework)
- kube-rs (Rust)
- kubebuilder
- KubeOps (.NET operator SDK)
- Mast
- Metacontroller along with WebHooks that you implement yourself
- Operator Framework
- shell-operator
Що далі
- Ознайомтесь з CNCF Operator White Paper.
- Дізнайтесь більше про Custom Resources
- Пошукайте готові оператори в OperatorHub, що можуть відповідати вашому випадку
- Опублікуйте свій оператор для використання іншими
- Подивіться оригінальну статтю від CoreOS, що розповідає про шаблон оператора (тут посилання на архівну версію статті)
- Ознайомтесь зі статтею від Google Cloud про найкращі практики створення операторів