Спостережуваність
В Kubernetes спостережуваність — це процес збору та аналізу метрик, журналів і трейсів, часто їх називають трьома стовпами спостережуваності, з метою отримання кращого розуміння внутрішнього стану, продуктивності та справності кластера.
Панель управління Kubernetes, так само як і багато надбудов, генеруює та надсилає ці сигнали. Обʼєднуючи та корелюючи їх, ви можете отримати єдину картину панелі управління, надбудов і застосунків у вашому кластері.
На малюнку 1 показано, як компоненти кластера формують три основні типи сигналів.
кластера] --> M[Потік метрик] A --> L[Потік журналів] A --> T[Потік трейсів] M --> S[(Збереження та
аналіз)] L --> S T --> S S --> O[Оператори та
автоматизація]
Малюнок 1. Сигнали високого рівня, що надходять від компонентів кластера та їх користувачів.
Метрики
Компоненти Kubernetes генерують метрики у форматі Prometheus на їх точках доступу /metrics, включаючи:
- kube-controller-manager
- kube-proxy
- kube-apiserver
- kube-scheduler
- kubelet
Kubelet також надає метрики на /metrics/cadvisor, /metrics/resource та /metrics/probes, а надбудови, такі як kube-state-metrics, збагачують ці сигнали панелі управління статусом обʼєктів Kubernetes.
Типовий потік метрик Kubernetes періодично зчитує ці точки доступу та зберігає відібрані частинки в базі даних часових рядів (приклад з Prometheus).
Дивіться посібник з системних метрик для отримання додаткової інформації та параметрів конфігурації.
Малюнок 2 показує типовий потік метрик Kubernetes.
кластера] --> P[Збирач
Prometheus] P --> TS[(Сховище
часових рядів)] TS --> D[Панелі моніторингу
та сповіщення] TS --> A[Автоматизовані дії]
Малюнок 2. Компоненти типового потоку метрик Kubernetes.
Для спостережуваності в умовах багатокластерного або багатохмарного середовища розподілені бази даних часових рядів (наприклад, Thanos або Cortex) можуть доповнити Prometheus.
Подивіться Загальні інструменти спостережуваності — інструменти метрик для отримання інформації щодо інструментів збору метрик і баз даних часових рядів.
Дивіться також
- Системні метрики компонентів Kubernetes
- Моніторинг використання ресурсів за допомогою metrics-server
- Концепція kube-state-metrics
- Огляд конвеєра метрик ресурсів
Логи
Логи дозволять отримати хронологічні записи подій всередині застосунків, компонентів системи Kubernetes та діяльності, повʼязаної з безпекою, такої як журнали аудиту.
Середовища виконання контейнерів захоплюють вивід контейнеризованого застосунку з потоків стандартного виводу (stdout) та стандартних виводу помилок (stderr). Хоча середовища виконання реалізують це по-різному, інтеграція з kubelet стандартизована через формат логування CRI, а kubelet робить ці логи доступними через kubectl logs.
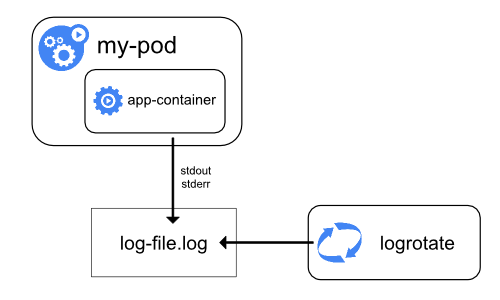
Малюнок 3a. Архітектура отримання логів на рівні вузла.
Логи компонентів системи захоплюють події з кластера і часто корисні для налагодження та усунення несправностей. Ці компоненти класифікуються двома різними способами: ті, що працюють у контейнері, і ті, що працюють поза контейнером. Наприклад, kube-scheduler і kube-proxy зазвичай працюють у контейнерах, тоді як kubelet і середовище виконання контейнерів працюють безпосередньо на хості.
- На машинах з
systemdkubelet і середовище виконання контейнерів пишуть у journald. В іншому випадку вони виконують запис у.logфайли в теці/var/log. - Системні компоненти, які працюють у контейнерах, завжди пишуть у
.logфайли в/var/log, обходячи стандартний механізм ведення журналів контейнерів.
Логи компонентів системи та контейнерів, що зберігаються в теці /var/log, потребують ротації, щоб запобігти неконтрольованому зростанню. Деякі сценарії розгортання кластерів стандартно встановлюють ротацію журналів; перевірте своє середовище та налаштуйте його за потреби. Дивіться довідку щодо системних журналів для отримання додаткової інформації про розташування, формати та параметри конфігурації.
Більшість кластерів запускають агента ведення журналів на рівні вузла (наприклад, Fluent Bit або Fluentd), який стежить за цими файлами та пересилає записи до центрального сховища журналів. Посібник з архітектури ведення журналів пояснює, як проєктувати такі конвеєри, застосовувати утримання та реєструвати потоки в бекендах.
Малюнок 3 описує типовий конвеєр агрегації логів.
в stdout / stderr] B[Логи
панелі
управління] C[Записи аудиту] end A --> N[Агент
ведення журналів
на рівні вузла] B --> N C --> N N --> L[Центральне
сховище
журналів] L --> Q[Дашборди,
сповіщення,
SIEM]
Малюнок 3. Компоненти стандартного конвеєра журналів Kubernetes.
Подивіться Загальні інструменти спостережуваності — інструменти ведення журналів для отримання відомостей про агентів ведення журналів та центральні сховища журналів.
Дивіться також
- Архітектура ведення журналів
- Системні журнали
- Завдання та посібники з ведення журналів
- Налаштування ведення журналів аудиту
Трейси
Трейси фіксують, як запити переміщуються між компонентами та застосунками Kubernetes, повʼязуючи затримки, час та взаємозвʼязки між операціями. Збираючи трейси, ви можете візуалізувати потік запитів від початку до кінця, діагностувати проблеми з продуктивністю та виявляти вузькі місця або несподівані взаємодії в панелі управління, надбудовах або застосунках.
Kubernetes 1.35 може експортувати відрізки (span) використовуючи OpenTelemetry Protocol (OTLP), або безпосередньо через вбудовані gRPC експортери, або пересилаючи їх через OpenTelemetry Collector.
OpenTelemetry Collector отримує відрізки від компонентів та застосунків, обробляє їх (наприклад, застосовуючи відбір або редагування) і пересилає їх до бекенду трасування для зберігання та аналізу.
Малюнок 4 описує типовий конвеєр розподіленого трасування.
панелі управління] B[Відрізки
застосунків] end A --> X[OTLP exporter] B --> X X --> COL[OpenTelemetry
Collector] COL --> TS[(Бекенд
трасування)] TS --> V[Візуалізація
та аналіз]
Малюнок 4. Компоненти стандартного конвеєра трасування Kubernetes.
Подивіться Загальні інструменти спостережуваності — інструменти трасування для отримання відомостей про колектори трасування та бекенди.
Дивіться також
- Системні відрізки для компонентів Kubernetes
- Посібник з налаштування OpenTelemetry Collector
- Завдання з моніторингу та трасування
Загальні інструменти спостережуваності
Інструменти метрик
- Cortex пропонує горизонтально масштабоване, довгострокове сховище Prometheus.
- Grafana Mimir — проєкт Grafana Labs, який надає багатокористувацьке, горизонтально масштабоване сховище, сумісне з Prometheus.
- Prometheus — це система моніторингу, яка збирає та зберігає метрики з компонентів Kubernetes.
- Thanos розширює Prometheus механізмом глобальних запитів, зменшуючи дисковий простір та додаючи підтримку обʼєктного зберігання.
Інструменти журналювання
- Elasticsearch забезпечує розподілену індексацію та пошук в журналах.
- Fluent Bit збирає та пересилає журнали контейнерів і вузлів з низьким споживанням ресурсів.
- Fluentd маршрутизує та трансформує журнали до кількох місць призначення.
- Grafana Loki зберігає журнали у форматі, на основі міток, подібному до Prometheus.
- OpenSearch інструмент з відкритим кодом, що надає індексування та пошук в логах, сумісний з API Elasticsearch.
Інструменти трасування
- Grafana Tempo пропонує масштабоване, розподілене зберігання трасувань, що не потребує високих витрат.
- Jaeger збирає та візуалізує розподілені трасування для мікросервісів.
- OpenTelemetry Collector отримує, обробляє та експортує телеметричні дані, включаючи трасування.
- Zipkin забезпечує збір та візуалізацію розподілених трасувань.
Що далі
- Дізнайтесь як збирати метрики використання ресурсів за допомогою metrics-server
- Подивіться завдання та посібники з журналювання
- Спробуйте виконати завдання з моніторингу та трасування
- Ознайомтесь з посібником по системних метриках для отримання відомостей про точки доступу компонентів та їх стабільність
- Ознайомтесь з розділом загальні інструменти спостережуваності для перевірених сторонніх варіантів