Це багатосторінковий друкований вигляд цього розділу. Натисність щоб друкувати.
Адміністрування кластера
- 1: Адміністрування з kubeadm
- 1.1: Додавання робочих вузлів Linux
- 1.2: Додавання робочих вузлів Windows
- 1.3: Оновлення кластерів з kubeadm
- 1.4: Оновлення вузлів Linux
- 1.5: Оновлення вузлів Windows
- 1.6: Налаштування драйвера cgroup
- 1.7: Управління сертифікатами з kubeadm
- 1.8: Переконфігурація кластера за допомогою kubeadm
- 1.9: Зміна репозиторія пакунків Kubernetes
- 2: Перевищення ємності вузла для кластера
- 3: Міграція з dockershim
- 3.1: Заміна середовища виконання контейнерів на вузлі з Docker Engine на containerd
- 3.2: Перевірте, яке середовище виконання контейнерів використовується на вузлі
- 3.3: Виправлення помилок, повʼязаних з втулками CNI
- 3.4: Перевірка впливу видалення dockershim на ваш кластер
- 3.5: Міграція агентів телеметрії та безпеки з dockershim
- 4: Генерація сертифікатів вручну
- 5: Керування ресурсами памʼяті, CPU та API
- 5.1: Налаштування типових запитів та обмежень памʼяті для простору імен
- 5.2: Налаштування типових запитів та обмежень CPU для простору імен
- 5.3: Налаштування мінімальних та максимальних обмежень памʼяті для простору імен
- 5.4: Налаштування мінімальних та максимальних обмеженнь CPU для простору імен
- 5.5: Налаштування квот памʼяті та CPU для простору імен
- 5.6: Налаштування квоти Podʼів для простору імен
- 6: Встановлення постачальника мережевої політики
- 6.1: Використання Antrea для NetworkPolicy
- 6.2: Використання Calico для NetworkPolicy
- 6.3: Використання Cilium для NetworkPolicy
- 6.4: Використання Kube-router для NetworkPolicy
- 6.5: Використання Romana для NetworkPolicy
- 6.6: Використання Weave Net для NetworkPolicy
- 7: Доступ до кластера через API Kubernetes
- 8: Увімкнення або вимкнення функціональних можливостей
- 9: Оголошення розширених ресурсів для вузла
- 10: Автоматичне масштабування служби DNS в кластері
- 11: Зміна режиму доступу до PersistentVolume на ReadWriteOncePod
- 12: Зміна типового StorageClass
- 13: Перехід від опитування до оновлення стану контейнера на основі подій CRI
- 14: Зміна політики відновлення PersistentVolume
- 15: Адміністрування менеджера хмарного контролера
- 16: Налаштування постачальника облікових даних образів в kubelet
- 17: Налаштування квот для обʼєктів API
- 18: Управління політиками керування ЦП на вузлі
- 19: Керування політиками топології на вузлі
- 20: Налаштування служби DNS
- 21: Налагодження розвʼязання імен DNS
- 22: Оголошення мережевої політики
- 23: Розробка Cloud Controller Manager
- 24: Увімкнення або вимкнення API Kubernetes
- 25: Шифрування конфіденційних даних у спокої
- 26: Розшифровування конфіденційних даних, які вже зашифровані у спокої
- 27: Гарантоване планування для критичних Podʼів надбудов
- 28: Керівництво користувача агента маскування IP
- 29: Обмеження використання сховища
- 30: Міграція реплікованої панелі управління на використання менеджера керування хмарою
- 31: Управління кластерами etcd для Kubernetes
- 32: Резервування обчислювальних ресурсів для системних служб
- 33: Запуск компонентів вузла Kubernetes користувачем без прав root
- 34: Безпечне очищення вузла
- 35: Захист кластера
- 36: Встановлення параметрів Kubelet через файл конфігурації
- 37: Спільне використання кластера з просторами імен
- 38: Оновлення кластера
- 39: Використання каскадного видалення у кластері
- 40: Використання постачальника KMS для шифрування даних
- 41: Використання CoreDNS для виявлення Service
- 42: Використання NodeLocal DNSCache в кластерах Kubernetes
- 43: Використання sysctl в кластері Kubernetes
- 44: Використання NUMA-орієнтованого менеджера памʼяті
- 45: Перевірка підписаних артефактів Kubernetes
1 - Адміністрування з kubeadm
Якщо у вас немає кластера, зверніться до сторінки Запуск кластерів з kubeadm.
Завдання в цьому розділі призначені для адміністрування наявного кластера:
1.1 - Додавання робочих вузлів Linux
Ця сторінка пояснює, як додати робочі вузли Linux до кластера, створеного за допомогою kubeadm.
Перш ніж ви розпочнете
- Кожен робочий вузол, що додається, має встановлені необхідні компоненти з Встановлення kubeadm, такі як kubeadm, kubelet і середовище виконання контейнерів.
- Запущений кластер kubeadm, створений за допомогою
kubeadm initта дотриманням кроків з документа Створення кластера з kubeadm. - Необхідно мати права суперкористувача на вузлі.
Додавання робочих вузлів Linux
Щоб додати нові робочі вузли Linux до кластера, виконайте наступне для кожної машини:
- Підʼєднатесь до машини за допомогою SSH або іншого методу.
- Запустіть команду, яка була виведена
kubeadm init. Наприклад:
sudo kubeadm join \
--token <token> <control-plane-host>:<control-plane-port> \
--discovery-token-ca-cert-hash sha256:<hash>
Додаткова інформація для kubeadm join
Примітка:
Щоб вказати IPv6 адресу для<control-plane-host>:<control-plane-port>, адресу IPv6 потрібно взяти у квадратні дужки, наприклад: [2001:db8::101]:2073.Якщо у вас немає токена, ви можете отримати його, запустивши наступну команду на вузлі панелі управління:
# Запустіть це на вузлі панелі управління
sudo kubeadm token list
Вивід буде приблизно таким:
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
8ewj1p.9r9hcjoqgajrj4gi 23h 2018-06-12T02:51:28Z authentication, The default bootstrap system:
signing token generated by bootstrappers:
'kubeadm init'. kubeadm:
default-node-token
Стандартно токени для приєднання вузлів мають термін дії 24 години. Якщо ви додаєте вузол до кластера після того, як поточний токен закінчився, ви можете створити новий токен, виконавши наступну команду на вузлі панелі управління:
# Запустіть це на вузлі панелі управління
sudo kubeadm token create
Вивід буде приблизно таким:
5didvk.d09sbcov8ph2amjw
Щоб вивести команду kubeadm join і одночасно створити новий токен, можна використати:
sudo kubeadm token create --print-join-command
Якщо у вас немає значення --discovery-token-ca-cert-hash, ви можете отримати його, виконавши наступні команди на вузлі панелі управління:
# Запустіть це на вузлі панелі управління
sudo cat /etc/kubernetes/pki/ca.crt | \
openssl x509 -pubkey | \
openssl rsa -pubin -outform der 2>/dev/null | \
openssl dgst -sha256 -hex | \
sed 's/^.* //'
Вивід буде приблизно таким:
8cb2de97839780a412b93877f8507ad6c94f73add17d5d7058e91741c9d5ec78
Вивід команди kubeadm join має виглядати приблизно так:
[preflight] Running pre-flight checks
... (вивід процесу приєднання) ...
Node join complete:
* Запит на підписання сертифікату надіслано до панелі управління, отримано відповідь.
* Kubelet проінформований про нові деталі безпечного зʼєднання.
Запустіть 'kubectl get nodes' на панелі управління, щоб побачити приєднання цього вузла.
Через кілька секунд ви повинні побачити цей вузол у виводі команди kubectl get nodes. (наприклад, запустіть kubectl на вузлі панелі управління).
Примітка:
Оскільки вузли кластера зазвичай ініціалізуються послідовно, ймовірно, що всі Podʼи CoreDNS працюватимуть на першому вузлі панелі управління. Для забезпечення високої доступності перерозподіліть Podʼи CoreDNS за допомогоюkubectl -n kube-system rollout restart deployment coredns після приєднання хоча б одного нового вузла.Що далі
- Дізнайтеся, як додати робочі вузли Windows.
1.2 - Додавання робочих вузлів Windows
Kubernetes v1.18 [beta]Ця сторінка пояснює, як додати робочі вузли Windows до кластера kubeadm.
Перш ніж ви розпочнете
- Запущений екземпляр Windows Server 2022 (або новіший) з адміністративним доступом.
- Запущений кластер kubeadm, створений за допомогою
kubeadm initта з дотриманням кроків з документа Створення кластера з kubeadm.
Додавання робочих вузлів Windows
Примітка:
Для полегшення додавання робочих вузлів Windows до кластера використовуються скрипти PowerShell з репозиторію https://sigs.k8s.io/sig-windows-tools.Виконайте наступні кроки для кожної машини:
- Відкрийте сесію PowerShell на машині.
- Переконайтеся, що ви є адміністратором або привілейованим користувачем.
Потім виконайте наведені нижче кроки.
Встановлення containerd
Щоб встановити containerd, спочатку виконайте наступну команду:
curl.exe -LO https://raw.githubusercontent.com/kubernetes-sigs/sig-windows-tools/master/hostprocess/Install-Containerd.ps1
Потім виконайте наступну команду, але спочатку замініть CONTAINERD_VERSION на нещодавній реліз з репозиторію containerd. Версія не повинна містити префікс v. Наприклад, використовуйте 1.7.22 замість v1.7.22:
.\Install-Containerd.ps1 -ContainerDVersion CONTAINERD_VERSION
- Налаштуйте будь-які інші параметри для
Install-Containerd.ps1, такі якnetAdapterName, за необхідності. - Встановіть
skipHypervisorSupportCheck, якщо ваша машина не підтримує Hyper-V і не може розміщувати контейнери ізольовані Hyper-V. - Якщо ви змінюєте необовʼязкові параметри
CNIBinPathта/абоCNIConfigPathуInstall-Containerd.ps1, вам потрібно буде налаштувати встановлений втулок CNI Windows з відповідними значеннями.
Встановлення kubeadm і kubelet
Виконайте наступні команди для установки kubeadm і kubelet:
curl.exe -LO https://raw.githubusercontent.com/kubernetes-sigs/sig-windows-tools/master/hostprocess/PrepareNode.ps1
.\PrepareNode.ps1 -KubernetesVersion v1.35.0
- Налаштуйте параметр
KubernetesVersionуPrepareNode.ps1за необхідності.
Запуск kubeadm join
Виконайте команду, з виводу kubeadm init. Наприклад:
kubeadm join --token <token> <control-plane-host>:<control-plane-port> --discovery-token-ca-cert-hash sha256:<hash>
Додаткова інформація про kubeadm join
Примітка:
Щоб вказати кортеж IPv6 для<control-plane-host>:<control-plane-port>, IPv6-адреса повинна бути взята у квадратні дужки, наприклад: [2001:db8::101]:2073.Якщо у вас немає токена, ви можете отримати його, виконавши наступну команду на вузлі панелі управління:
# Виконайте це на вузлі панелі управління
sudo kubeadm token list
Вивід буде подібний до цього:
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
8ewj1p.9r9hcjoqgajrj4gi 23h 2018-06-12T02:51:28Z authentication, The default bootstrap system:
signing token generated by bootstrappers:
'kubeadm init'. kubeadm:
default-node-token
Стандартно, токени приєднання вузлів діють 24 години. Якщо ви приєднуєте вузол до кластера після того, як токен закінчився, ви можете створити новий токен, виконавши наступну команду на вузлі панелі управління:
# Виконайте це на вузлі панелі управління
sudo kubeadm token create
Вивід буде подібний до цього:
5didvk.d09sbcov8ph2amjw
Якщо ви не маєте значення --discovery-token-ca-cert-hash, ви можете отримати його, виконавши наступні команди на вузлі панелі управління:
sudo cat /etc/kubernetes/pki/ca.crt | \
openssl x509 -pubkey | \
openssl rsa -pubin -outform der 2>/dev/null | \
openssl dgst -sha256 -hex | \
sed 's/^.* //'
Вивід буде подібний до:
8cb2de97839780a412b93877f8507ad6c94f73add17d5d7058e91741c9d5ec78
Вивід команди kubeadm join має виглядати приблизно так:
[preflight] Running pre-flight checks
... (вивід журналу процесу приєднання) ...
Приєднання вузла завершено:
* Запит на підпис сертифіката надіслано до панелі управління та отримано відповідь.
* Kubelet поінформований про нові деталі захищеного з'єднання.
Запустіть 'kubectl get nodes' на панелі управління, щоб побачити цей вузол.
Через кілька секунд ви повинні помітити цей вузол у виводі kubectl get nodes. (наприклад, виконайте kubectl на вузлі панелі управління).
Налаштування мережі
Налаштування CNI в кластерах, що містять як Linux, так і вузли Windows, вимагає більше кроків, ніж просто запуск kubectl apply з файлом маніфесту. Крім того, втулок CNI, що працює на вузлах панелі управління, повинен бути підготовлений для підтримки втулка CNI, що працює на робочих вузлах Windows.
Зараз лише кілька втулків CNI підтримують Windows. Нижче наведені інструкції для їх налаштування:
Встановлення kubectl для Windows (необовʼязково)
Дивіться Встановлення та налаштування kubectl у Windows.
Що далі
- Дивіться, як додати робочі вузли Linux.
1.3 - Оновлення кластерів з kubeadm
Ця сторінка пояснює, як оновити кластер Kubernetes, створений за допомогою kubeadm, з версії 1.34.x до версії 1.35.x і з версії 1.35.x до 1.35.y (де y > x). Пропуск МІНОРНИХ версій при оновленні не підтримується. Для отримання додаткових відомостей відвідайте Політику версій зміни.
Щоб переглянути інформацію про оновлення кластерів, створених за допомогою старіших версій kubeadm, зверніться до наступних сторінок:
- Оновлення кластера kubeadm з 1.33 на 1.34
- Оновлення кластера kubeadm з 1.32 на 1.33
- Оновлення кластера kubeadm з 1.31 на 1.32
- Оновлення кластера kubeadm з 1.30 на 1.31
Проєкт Kubernetes рекомендує оперативно оновлюватись до останніх випусків патчів, а також переконатися, що ви використовуєте підтримуваний мінорний випуск Kubernetes. Дотримання цих рекомендацій допоможе вам залишатись захищеними.
Процес оновлення загалом виглядає наступним чином:
- Оновлення первинного вузла панелі управління.
- Оновлення додаткових вузлів панелі управління.
- Оновлення вузлів робочого навантаження.
Перш ніж ви розпочнете
- Переконайтеся, що ви уважно прочитали примітки до випуску.
- Кластер повинен використовувати статичні вузли керування та контейнери etcd або зовнішній etcd.
- Переконайтеся, що ви зробили резервне копіювання важливих компонентів, таких як стан на рівні застосунків, збережений у базі даних.
kubeadm upgradeне торкнеться вашого робочого навантаження, лише компонентів, внутрішніх для Kubernetes, але резервне копіювання завжди є найкращою практикою. - Своп має бути вимкнено.
Додаткова інформація
- Наведені нижче інструкції описують, коли потрібно вивести з експлуатації кожний вузол під час процесу оновлення. Якщо ви виконуєте оновлення для мінорного номера версії для будь-якого kubelet, ви обовʼязково спочатку повинні вивести вузол (або вузли) з експлуатації, які ви оновлюєте. У випадку вузлів панелі управління, на них можуть працювати контейнери CoreDNS або інші критичні робочі навантаження. Для отримання додаткової інформації дивіться Виведення вузлів з експлуатації.
- Проєкт Kubernetes рекомендує щоб версії kubelet і kubeadm збігались. Замість цього ви можете використовувати версію kubelet, яка є старішою, ніж kubeadm, за умови, що вона знаходиться в межах підтримуваних версій. Для отримання додаткових відомостей, будь ласка, відвідайте Відхилення kubeadm від kubelet.
- Всі контейнери перезавантажуються після оновлення, оскільки змінюється значення хешу специфікації контейнера.
- Щоб перевірити, що служба kubelet успішно перезапустилась після оновлення kubelet, ви можете виконати
systemctl status kubeletабо переглянути логи служби за допомогоюjournalctl -xeu kubelet. kubeadm upgradeпідтримує параметр--configіз типом APIUpgradeConfiguration, який можна використовувати для налаштування процесу оновлення.kubeadm upgradeне підтримує переналаштування наявного кластера. Замість цього виконайте кроки, описані в Переналаштування кластера kubeadm.
Що треба враховувати при оновленні etcd
Оскільки статичний Pod kube-apiserver працює постійно (навіть якщо ви вивели вузол з експлуатації), під час виконання оновлення kubeadm, яке включає оновлення etcd, запити до сервера зупиняться, поки новий статичний Pod etcd не перезапуститься. Як обхідний механізм, можна активно зупинити процес kube-apiserver на кілька секунд перед запуском команди kubeadm upgrade apply. Це дозволяє завершити запити, що вже відправлені, і закрити наявні зʼєднання, що знижує наслідки перерви роботи etcd. Це можна зробити на вузлах панелі управління таким чином:
killall -s SIGTERM kube-apiserver # виклик належного припинення роботи kube-apiserver
sleep 20 # зачекайте трохи, щоб завершити запити, які вже були відправлені
kubeadm upgrade ... # виконати команду оновлення kubeadm
Зміна репозиторію пакунків
Якщо ви використовуєте репозиторії пакунків, що керуються спільнотою (pkgs.k8s.io), вам потрібно увімкнути репозиторій пакунків для бажаної мінорної версії Kubernetes. Як це зробити можна дізнатись з документа Зміна репозиторію пакунків Kubernetes.
apt.kubernetes.io та yum.kubernetes.io) визнані
застарілими та заморожені станом на 13 вересня 2023.
Використання нових репозиторіїв пакунків, розміщених за адресою pkgs.k8s.io`,
настійно рекомендується і є обовʼязковим для встановлення версій Kubernetes, випущених після 13 вересня 2023 року.
Застарілі репозиторії та їхні вміст можуть бути видалені у будь-який момент у майбутньому і без попереднього повідомлення.
Нові репозиторії пакунків надають можливість завантаження версій Kubernetes, починаючи з v1.24.0.Визначення версії, на яку потрібно оновитися
Знайдіть останнє патч-видання для Kubernetes 1.35 за допомогою менеджера пакунків ОС:
# Знайдіть останню версію 1.35 у списку.
# Вона має виглядати як 1.35.x-*, де x — останній патч.
sudo apt update
sudo apt-cache madison kubeadm
Для систем з DNF:
# Знайдіть останню версію 1.35 у списку.
# Вона має виглядати як 1.35.x-*, де x — останній патч.
sudo yum list --showduplicates kubeadm --disableexcludes=kubernetes
Для систем з DNF5:
# Знайдіть останню версію 1.35 у списку.
# Вона має виглядати як 1.35.x-*, де x — останній патч.
sudo yum list --showduplicates kubeadm --setopt=disable_excludes=kubernetes
Якщо ви не бачите версію, до якої очікуєте оновитися, перевірте, чи використовуються сховища пакунків Kubernetes.
Оновлення вузлів панелі управління
Процедуру оновлення на вузлах панелі управління слід виконувати по одному вузлу за раз. Виберіть перший вузол панелі управління, який ви хочете оновити. Він повинен мати файл /etc/kubernetes/admin.conf.
Here's the translation:
Виклик "kubeadm upgrade"
Для першого вузла панелі управління
Оновіть kubeadm:
# замініть x на останню версію патча sudo apt-mark unhold kubeadm && \ sudo apt-get update && sudo apt-get install -y kubeadm='1.35.x-*' && \ sudo apt-mark hold kubeadmДля систем з DNF:
# замініть x в 1.35.x-* на останню версію патча sudo yum install -y kubeadm-'1.35.x-*' --disableexcludes=kubernetesДля систем з DNF5:
# замініть x в 1.35.x-* на останню версію патча sudo yum install -y kubeadm-'1.35.x-*' --setopt=disable_excludes=kubernetesПеревірте, що завантаження працює і має очікувану версію:
kubeadm versionПеревірте план оновлення:
sudo kubeadm upgrade planЦя команда перевіряє можливість оновлення вашого кластера та отримує версії, на які ви можете оновитися. Також вона показує таблицю стану версій компонентів.
Примітка:
kubeadm upgradeтакож автоматично оновлює сертифікати, якими він керує на цьому вузлі. Щоб відмовитися від оновлення сертифікатів, можна використовувати прапорець--certificate-renewal=false. Для отримання додаткової інформації див. керівництво з керування сертифікатами.Виберіть версію для оновлення та запустіть відповідну команду. Наприклад:
# замініть x на версію патча, яку ви вибрали для цього оновлення sudo kubeadm upgrade apply v1.35.xПісля завершення команди ви маєте побачити:
[upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.35.x". Enjoy! [upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven't already done so.Примітка:
Для версій, старіших, ніж v1.28, kubeadm типово використовував режим, який оновлює надбудови (включно з CoreDNS та kube-proxy) безпосередньо під часkubeadm upgrade apply, незалежно від того, чи є інші екземпляри вузлів панелі управління, які не були оновлені. Це може викликати проблеми сумісності. Починаючи з v1.28, kubeadm стандартно перевіряє, чи всі екземпляри вузлів панелі управління були оновлені, перед початком оновлення надбудов. Ви повинні виконати оновлення екземплярів вузлів керування послідовно або принаймні забезпечити, що останнє оновлення екземпляра вузла панелі управління не розпочато, поки всі інші екземпляри вузлів панелі управління не будуть повністю оновлені, і оновлення надбудов буде виконано після останнього оновлення екземпляра вузла керування.Вручну оновіть втулок постачальник мережевого інтерфейсу контейнера (CNI).
Ваш постачальник мережевого інтерфейсу контейнера (CNI) може мати власні інструкції щодо оновлення. Перевірте надбудови для знаходження вашого постачальника CNI та перегляньте, чи потрібні додаткові кроки оновлення.
Цей крок не потрібен на додаткових вузлах панелі управління, якщо постачальник CNI працює як DaemonSet.
Для інших вузлів панелі управління
Те саме, що для першого вузла керування, але використовуйте:
sudo kubeadm upgrade node
замість:
sudo kubeadm upgrade apply
Також виклик kubeadm upgrade plan та оновлення постачальника мережевого інтерфейсу контейнера (CNI) вже не потрібні.
Виведення вузла з експлуатації
Готуємо вузол для обслуговування, відмітивши його як непридатний для планування та вивівши з нього робочі навантаження:
# замініть <node-to-drain> іменем вашого вузла, який ви хочете вивести з експлуатації
kubectl drain <node-to-drain> --ignore-daemonsets
Оновлення kubelet та kubectl
Примітка:
На вузлах Linux kubelet стандартно підтримує тільки cgroups v2. Для Kubernetes 1.35 опція конфігурації kubelet FailCgroupV1 типово встановлена на true.
Щоб дізнатися більше, зверніться до документації про виведення з експлуатації Kubernetes cgroup v1.
Оновіть kubelet та kubectl:
# замініть x у 1.35.x-* на останню патч-версію sudo apt-mark unhold kubelet kubectl && \ sudo apt-get update && sudo apt-get install -y kubelet='1.35.x-*' kubectl='1.35.x-*' && \ sudo apt-mark hold kubelet kubectlДля систем з DNF:
# замініть x у 1.35.x-* на останню патч-версію sudo yum install -y kubelet-'1.35.x-*' kubectl-'1.35.x-*' --disableexcludes=kubernetesДля систем з DNF:
# замініть x у 1.35.x-* на останню патч-версію sudo yum install -y kubelet-'1.35.x-*' kubectl-'1.35.x-*' --setopt=disable_excludes=kubernetesПерезапустіть kubelet:
sudo systemctl daemon-reload sudo systemctl restart kubelet
Повернення вузла до експлуатації
Відновіть роботу вузла, позначивши його як доступний для планування:
# замініть <node-to-uncordon> на імʼя вашого вузла
kubectl uncordon <node-to-uncordon>
Оновлення вузлів робочих навантажень
Процедуру оновлення на робочих вузлах слід виконувати один за одним або декільком вузлами одночасно, не посягаючи на мінімально необхідні можливості для виконання вашого навантаження.
Наступні сторінки показують, як оновити робочі вузли у Linux та Windows:
Перевірка стану кластера
Після оновлення kubelet на всіх вузлах перевірте доступність всіх вузлів, виконавши наступну команду з будь-якого місця, де кubectl має доступу до кластера:
kubectl get nodes
У стовпці STATUS повинно бути вказано Ready для всіх ваших вузлів, а номер версії повинен бути оновлений.
Відновлення після несправності
Якщо kubeadm upgrade виявляється несправним і не відновлює роботу, наприклад через неочікуване вимкнення під час виконання, ви можете виконати kubeadm upgrade ще раз. Ця команда є ідемпотентною і, зрештою, переконується, що фактичний стан відповідає заданому вами стану.
Для відновлення з несправного стану ви також можете запустити sudo kubeadm upgrade apply --force без зміни версії, яку використовує ваш кластер.
Під час оновлення kubeadm записує наступні резервні теки у /etc/kubernetes/tmp:
kubeadm-backup-etcd-<дата>-<час>kubeadm-backup-manifests-<дата>-<час>
kubeadm-backup-etcd містить резервну копію даних локального etcd для цього вузла панелі управління. У разі невдачі оновлення etcd і якщо автоматичне відновлення не працює, вміст цієї теки може бути відновлений вручну в /var/lib/etcd. У разі використання зовнішнього etcd ця тека резервного копіювання буде порожньою.
kubeadm-backup-manifests містить резервну копію файлів маніфестів статичних Podʼів для цього вузла панелі управління. У разі невдачі оновлення і якщо автоматичне відновлення не працює, вміст цієї теки може бути відновлений вручну в /etc/kubernetes/manifests. Якщо з будь-якої причини немає різниці між попереднім та файлом маніфесту після оновлення для певного компонента, резервна копія файлу для нього не буде записана.
Примітка:
Після оновлення кластера за допомогою kubeadm, тека резервних копій/etc/kubernetes/tmp залишиться, і ці резервні файли потрібно буде очистити вручну.Як це працює
kubeadm upgrade apply робить наступне:
- Перевіряє, що ваш кластер можна оновити:
- Сервер API доступний
- Всі вузли знаходяться у стані
Ready - Панель управління працює належним чином
- Застосовує політику різниці версій.
- Переконується, що образи панелі управління доступні або доступні для отримання на машині.
- Генерує заміни та/або використовує зміни підготовлені користувачем, якщо компонентні конфігурації вимагають оновлення версії.
- Оновлює компоненти панелі управління або відкочується, якщо будь-який з них не може бути запущений.
- Застосовує нові маніфести
CoreDNSіkube-proxyі переконується, що створені всі необхідні правила RBAC. - Створює нові сертифікати та файли ключів API-сервера і робить резервні копії старих файлів, якщо вони мають закінчитися за 180 днів.
kubeadm upgrade node робить наступне на додаткових вузлах панелі управління:
- Витягує
ClusterConfigurationkubeadm з кластера. - Опційно робить резервні копії сертифіката kube-apiserver.
- Оновлює маніфести статичних Podʼів для компонентів панелі управління.
- Оновлює конфігурацію kubelet для цього вузла.
kubeadm upgrade node робить наступне на вузлах робочих навантажень:
- Витягує
ClusterConfigurationkubeadm з кластера. - Оновлює конфігурацію kubelet для цього вузла.
1.4 - Оновлення вузлів Linux
Ця сторінка пояснює, як оновити вузли робочих навантажень Linux, створені за допомогою kubeadm.
Перш ніж ви розпочнете
Вам потрібен доступ до оболонки на всіх вузлах, а також інструмент командного рядка kubectl повинен бути налаштований для спілкування з вашим кластером. Рекомендується виконувати цю інструкцію у кластері, який має принаймні два вузли, які не виконують функції вузлів панелі управління.
Для перевірки версії введіть kubectl version.
- Ознайомтеся з процесом оновлення решти вузлів панелі управління за допомогою kubeadm. Вам потрібно буде спочатку оновити вузли панелі управління перед оновленням вузлів робочих навантажень Linux.
Зміна репозиторію пакунків
Якщо ви використовуєте репозиторії пакунків (pkgs.k8s.io), вам потрібно увімкнути репозиторій пакунків для потрібного мінорного релізу Kubernetes. Це пояснено в документі Зміна репозиторію пакунків Kubernetes.
apt.kubernetes.io та yum.kubernetes.io) визнані
застарілими та заморожені станом на 13 вересня 2023.
Використання нових репозиторіїв пакунків, розміщених за адресою pkgs.k8s.io`,
настійно рекомендується і є обовʼязковим для встановлення версій Kubernetes, випущених після 13 вересня 2023 року.
Застарілі репозиторії та їхні вміст можуть бути видалені у будь-який момент у майбутньому і без попереднього повідомлення.
Нові репозиторії пакунків надають можливість завантаження версій Kubernetes, починаючи з v1.24.0.Оновлення робочих вузлів
Оновлення kubeadm
Оновіть kubeadm:
# замініть x у 1.35.x-* на останню версію патча
sudo apt-mark unhold kubeadm && \
sudo apt-get update && sudo apt-get install -y kubeadm='1.35.x-*' && \
sudo apt-mark hold kubeadm
Для систем з DNF:
# замініть x у 1.35.x-* на останню версію патча
sudo yum install -y kubeadm-'1.35.x-*' --disableexcludes=kubernetes
Для систем з DNF5:
# замініть x у 1.35.x-* на останню версію патча
sudo yum install -y kubeadm-'1.35.x-*' --setopt=disable_excludes=kubernetes
Виклик "kubeadm upgrade"
Для робочих вузлів це оновлює локальну конфігурацію kubelet:
sudo kubeadm upgrade node
Виведіть вузол з експлуатації
Підготуйте вузол до обслуговування, позначивши його як недоступний для планування та виселивши завдання:
# виконайте цю команду на вузлі панелі управління
# замініть <node-to-drain> імʼям вузла, який ви виводите з експлуатації
kubectl drain <node-to-drain> --ignore-daemonsets
Оновлення kubelet та kubectl
Оновіть kubelet та kubectl:
# замініть x у 1.35.x-* на останню версію патча sudo apt-mark unhold kubelet kubectl && \ sudo apt-get update && sudo apt-get install -y kubelet='1.35.x-*' kubectl='1.35.x-*' && \ sudo apt-mark hold kubelet kubectlДля сисетм з DNF:
# замініть x у 1.35.x-* на останню версію патча sudo yum install -y kubelet-'1.35.x-*' kubectl-'1.35.x-*' --disableexcludes=kubernetesДля сисетм з DNF5:
# замініть x у 1.35.x-* на останню версію патча sudo yum install -y kubelet-'1.35.x-*' kubectl-'1.35.x-*' --setopt=disable_excludes=kubernetesПерезавантажте kubelet:
sudo systemctl daemon-reload sudo systemctl restart kubelet
Відновіть роботу вузла
Поверніть вузол в роботу, позначивши його як придатний для планування:
# виконайте цю команду на вузлі панелі управління
# замініть <node-to-uncordon> імʼям вашого вузла
kubectl uncordon <node-to-uncordon>
Що далі
- Подивіться, як оновити вузли Windows.
1.5 - Оновлення вузлів Windows
Kubernetes v1.18 [beta]Ця сторінка пояснює, як оновити вузол Windows, створений за допомогою kubeadm.
Перш ніж ви розпочнете
Вам потрібен доступ до оболонки на всіх вузлах, а також інструмент командного рядка kubectl повинен бути налаштований для спілкування з вашим кластером. Рекомендується виконувати цю інструкцію у кластері, який має принаймні два вузли, які не виконують функції вузлів панелі управління.
Версія вашого Kubernetes сервера має бути не старішою ніж 1.17.Для перевірки версії введіть kubectl version.
- Ознайомтеся з процесом оновлення інших вузлів вашого кластера kubeadm. Вам слід оновити вузли панелі управління перед оновленням вузлів Windows.
Оновлення робочих вузлів
Оновлення kubeadm
З вузла Windows оновіть kubeadm:
# замініть 1.35.0 на вашу бажану версію curl.exe -Lo <path-to-kubeadm.exe> "https://dl.k8s.io/v1.35.0/bin/windows/amd64/kubeadm.exe"
Виведіть вузол з експлуатації
З машини з доступом до API Kubernetes підготуйте вузол до обслуговування, позначивши його як недоступний для планування та виселивши завдання:
# замініть <node-to-drain> імʼям вашого вузла, який ви виводите з експлуатації kubectl drain <node-to-drain> --ignore-daemonsetsВи повинні побачити подібний вивід:
node/ip-172-31-85-18 cordoned node/ip-172-31-85-18 drained
Оновлення конфігурації kubelet
З вузла Windows викличте наступну команду, щоб синхронізувати нову конфігурацію kubelet:
kubeadm upgrade node
Оновлення kubelet та kube-proxy
З вузла Windows оновіть та перезапустіть kubelet:
stop-service kubelet curl.exe -Lo <path-to-kubelet.exe> "https://dl.k8s.io/v1.35.0/bin/windows/amd64/kubelet.exe" restart-service kubeletЗ вузла Windows оновіть та перезапустіть kube-proxy.
stop-service kube-proxy curl.exe -Lo <path-to-kube-proxy.exe> "https://dl.k8s.io/v1.35.0/bin/windows/amd64/kube-proxy.exe" restart-service kube-proxy
Примітка:
Якщо ви запускаєте kube-proxy в контейнері HostProcess всередині Podʼа, а не як службу Windows, ви можете оновити kube-proxy, застосувавши нову версію ваших маніфестів kube-proxy.Відновіть роботу вузла
З машини з доступом до API Kubernetes, поверніть вузол в роботу, позначивши його як придатний для планування:
# замініть <node-to-drain> імʼям вашого вузла kubectl uncordon <node-to-drain>
Що далі
- Подивіться, як оновити вузли Linux.
1.6 - Налаштування драйвера cgroup
Ця сторінка пояснює, як налаштувати драйвер cgroup kubelet, щоб він відповідав драйверу cgroup контейнера для кластерів kubeadm.
Перш ніж ви розпочнете
Вам слід ознайомитися з вимогами до контейнерних середовищ Kubernetes.
Налаштування драйвера cgroup середовища виконання контейнерів
Сторінка Середовища виконання контейнерів пояснює, що для налаштувань на основі kubeadm рекомендується використовувати драйвер systemd замість типового драйвера cgroupfs kubelet, оскільки kubeadm керує kubelet як сервісом systemd.
На сторінці також наведено деталі щодо того, як налаштувати різні контейнерні середовища зі стандартним використанням драйвера systemd.
Налаштування драйвера cgroup для kubelet
kubeadm дозволяє передавати структуру KubeletConfiguration під час ініціалізації за допомогою kubeadm init. Ця структура KubeletConfiguration може включати поле cgroupDriver, яке контролює драйвер cgroup для kubelet.
Примітка:
Починаючи з v1.22, якщо користувач не встановить поле cgroupDriver у KubeletConfiguration, kubeadm стандартно задає його як systemd.
У Kubernetes v1.28 можна увімкнути автоматичне виявлення драйвера cgroup як експериментальну функцію. Див. Драйвер cgroup системи systemd для отримання детальнішої інформації.
Ось мінімальний приклад, який явним чином вказує значення поля cgroupDriver:
# kubeadm-config.yaml
kind: ClusterConfiguration
apiVersion: kubeadm.k8s.io/v1beta4
kubernetesVersion: v1.21.0
---
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
cgroupDriver: systemd
Такий файл конфігурації можна передати команді kubeadm:
kubeadm init --config kubeadm-config.yaml
Примітка:
Kubeadm використовує ту саму конфігурацію KubeletConfiguration для всіх вузлів у кластері. KubeletConfiguration зберігається в обʼєкті ConfigMap в просторі імен kube-system.
Виконання підкоманд init, join та upgrade призведе до запису kubeadm KubeletConfiguration у файл під /var/lib/kubelet/config.yaml і передачі його до kubelet локального вузла.
На кожному вузлі kubeadm виявляє сокет CRI та зберігає його деталі у файлі /var/lib/kubelet/instance-config.yaml. Коли виконуються підкоманди init, join або upgrade, kubeadm вносить зміни до значення containerRuntimeEndpoint з цієї конфігурації інстансу у /var/lib/kubelet/config.yaml.
Використання драйвера cgroupfs
Для використання cgroupfs і запобігання модифікації драйвера cgroup в KubeletConfiguration під час оновлення kubeadm в поточних налаштуваннях, вам потрібно явно вказати його значення. Це стосується випадку, коли ви не хочете, щоб майбутні версії kubeadm стандартно застосовували драйвер systemd.
Дивіться нижче розділ "Зміна ConfigMap у kubelet" для отримання деталей щодо явного вказання значення.
Якщо ви хочете налаштувати середовище виконання контейнерів на використання драйвера cgroupfs, вам слід звернутися до документації вашого середовища виконання контейнерів.
Міграція на використання драйвера systemd
Щоб змінити драйвер cgroup поточного кластера kubeadm з cgroupfs на systemd на місці, потрібно виконати подібну процедуру до оновлення kubelet. Це повинно включати обидва зазначені нижче кроки.
Примітка:
Також можливо замінити старі вузли в кластері новими, які використовують драйверsystemd. Для цього потрібно виконати лише перший крок нижче перед приєднанням нових вузлів та забезпечити те, що робочі навантаження можуть безпечно переміщатися на нові вузли перед видаленням старих вузлів.Зміна ConfigMap у kubelet
Викличте
kubectl edit cm kubelet-config -n kube-system.Змініть наявне значення
cgroupDriverабо додайте нове поле, яке виглядає наступним чином:cgroupDriver: systemdЦе поле повинно бути присутнє у розділі
kubelet:в ConfigMap.
Оновлення драйвера cgroup на всіх вузлах
Для кожного вузла в кластері:
- Відключіть вузол за допомогою
kubectl drain <імʼя-вузла> --ignore-daemonsets - Зупиніть kubelet за допомогою
systemctl stop kubelet - Зупиніть середовище виконання контейнерів
- Змініть драйвер cgroup середовища виконання контейнерів на
systemd - Встановіть
cgroupDriver: systemdу/var/lib/kubelet/config.yaml - Запустіть середовище виконання контейнерів
- Запустіть kubelet за допомогою
systemctl start kubelet - Увімкніть вузол за допомогою
kubectl uncordon <імʼя-вузла>
Виконайте ці кроки на вузлах по одному, щоб забезпечити достатній час для розміщення робочих навантажень на різних вузлах.
Після завершення процесу переконайтеся, що всі вузли та робочі навантаження є справними.
1.7 - Управління сертифікатами з kubeadm
Kubernetes v1.15 [stable]Клієнтські сертифікати, що генеруються kubeadm, закінчуються через 1 рік. Ця сторінка пояснює, як управляти поновленням сертифікатів за допомогою kubeadm. Вона також охоплює інші завдання, повʼязані з управлінням сертифікатами kubeadm.
Проєкт Kubernetes рекомендує оперативно оновлюватись до останніх випусків патчів, а також переконатися, що ви використовуєте підтримуваний мінорний випуск Kubernetes. Дотримання цих рекомендацій допоможе вам залишатися в безпеці.
Перш ніж ви розпочнете
Ви повинні бути знайомі з сертифікатами PKI та вимогами Kubernetes.
Ви маєте знати, як передати файл configuration командам kubeadm.
Цей посібник описує використання команди openssl (використовується для ручного підписання сертифікатів, якщо ви обираєте цей підхід), але ви можете використовувати інші інструменти, яким надаєте перевагу.
Деякі кроки тут використовують sudo для адміністративного доступу. Ви можете використовувати будь-який еквівалентний інструмент.
Використання власних сертифікатів
Типово, kubeadm генерує всі необхідні сертифікати для роботи кластера. Ви можете перевизначити цю поведінку, надавши власні сертифікати.
Для цього вам потрібно помістити їх у ту теку, яка вказується за допомогою прапорця --cert-dir або поля certificatesDir конфігурації кластера ClusterConfiguration kubeadm. Типово це /etc/kubernetes/pki.
Якщо певна пара сертифікатів і приватний ключ існують до запуску kubeadm init, kubeadm не перезаписує їх. Це означає, що ви можете, наприклад, скопіювати наявний ЦС (Центр сертифікації — Certificate authority) в /etc/kubernetes/pki/ca.crt та /etc/kubernetes/pki/ca.key, і kubeadm використовуватиме цей ЦС для підпису решти сертифікатів.
Вибір алгоритму шифрування
kubeadm дозволяє вибрати алгоритм шифрування, який використовується для створення відкритих і закритих ключів. Це можна зробити за допомогою поля encryptionAlgorithm у конфігурації kubeadm:
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
encryptionAlgorithm: <ALGORITHM>
<ALGORITHM> може бути одним з: RSA-2048 (стандартно), RSA-3072, RSA-4096 або ECDSA-P256.
Вибір терміну дії сертифіката
kubeadm дозволяє вибирати період дії сертифікатів центрів сертифікації та листових сертифікатів. Це можна зробити за допомогою полів certificateValidityPeriod і caCertificateValidityPeriod
в конфігурації kubeadm:
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
certificateValidityPeriod: 8760h # Стандартно: 365 днів × 24 години = 1 рік
caCertificateValidityPeriod: 87600h # Стандартно: 365 днів × 24 години * 10 = 10 років
Значення полів відповідають прийнятому формату для значень Go's time.Duration, при цьому найдовшою одиницею виміру є h (години).
Режим зовнішнього ЦС
Також можливо надати лише файл ca.crt і не файл ca.key (це доступно лише для файлу кореневого ЦС, а не інших пар сертифікатів). Якщо всі інші сертифікати та файли kubeconfig на місці, kubeadm розпізнає цю умову та активує режим "Зовнішній ЦС". kubeadm буде продовжувати без ключа ЦС на диску.
Замість цього, запустіть контролер-менеджер самостійно з параметром --controllers=csrsigner та вкажіть на сертифікат та ключ ЦС.
Існують різні способи підготовки облікових даних компонента при використанні режиму зовнішнього ЦС.
Цей посібник описує використання команди openssl (використовується для ручного підписання сертифікатів, якщо ви обираєте цей підхід), але ви можете використовувати інші інструменти, яким надаєте перевагу.
Ручна підготовка облікових даних компонента
Сертифікати PKI та вимоги містять інформацію про те, як підготувати всі необхідні облікові дані для компонентів, які вимагаються kubeadm, вручну.
Підготовка облікових даних компонента шляхом підпису CSR, що генеруються kubeadm
kubeadm може генерувати файли CSR, які ви можете підписати вручну за допомогою інструментів, таких як openssl, та вашого зовнішнього ЦС. Ці файли CSR будуть включати всі вказівки для облікових даних, які вимагаються компонентами, розгорнутими kubeadm.
Автоматизована підготовка облікових даних компонента за допомогою фаз kubeadm
З іншого боку, можливо використовувати команди фаз kubeadm для автоматизації цього процесу.
- Перейдіть на хост, який ви хочете підготувати як вузол панелі управління kubeadm з зовнішнім ЦС.
- Скопіюйте зовнішні файли ЦС
ca.crtтаca.key, які ви маєте, до/etc/kubernetes/pkiна вузлі. - Підготуйте тимчасовий файл конфігурації kubeadm під назвою
config.yaml, який можна використовувати зkubeadm init. Переконайтеся, що цей файл містить будь-яку відповідну інформацію на рівні кластера або хосту, яка може бути включена в сертифікати, таку як,ClusterConfiguration.controlPlaneEndpoint,ClusterConfiguration.certSANsтаInitConfiguration.APIEndpoint. - На тому ж самому хості виконайте команди
kubeadm init phase kubeconfig all --config config.yamlтаkubeadm init phase certs all --config config.yaml. Це згенерує всі необхідні файли kubeconfig та сертифікати у теці/etc/kubernetes/та її підтеціpki. - Перевірте згенеровані файли. Видаліть
/etc/kubernetes/pki/ca.key, видаліть або перемістіть в безпечне місце файл/etc/kubernetes/super-admin.conf. - На вузлах, де буде викликано
kubeadm join, також видаліть/etc/kubernetes/kubelet.conf. Цей файл потрібний лише на першому вузлі, де буде викликаноkubeadm init. - Зауважте, що деякі файли, такі як
pki/sa.*,pki/front-proxy-ca.*таpki/etc/ca.*, спільно використовуються між вузлами панелі управління, Ви можете згенерувати їх один раз та розподілити їх вручну на вузли, де буде викликаноkubeadm join, або ви можете використовувати функціональність--upload-certskubeadm initта--certificate-keykubeadm joinдля автоматизації цього розподілу.
Після того, як облікові дані будуть підготовлені на всіх вузлах, викличте kubeadm init та kubeadm join для цих вузлів, щоб приєднати їх до кластера. kubeadm використовуватиме наявні файли kubeconfig та сертифікати у теці /etc/kubernetes/ та її підтеці pki.
Закінчення терміну дії сертифікатів та управління ними
Примітка:
kubeadm не може керувати сертифікатами, підписаними зовнішнім ЦС.Ви можете використовувати підкоманду check-expiration, щоб перевірити термін дії сертифікатів:
kubeadm certs check-expiration
Вивід подібний до наступного:
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Dec 30, 2020 23:36 UTC 364d no
apiserver Dec 30, 2020 23:36 UTC 364d ca no
apiserver-etcd-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
apiserver-kubelet-client Dec 30, 2020 23:36 UTC 364d ca no
controller-manager.conf Dec 30, 2020 23:36 UTC 364d no
etcd-healthcheck-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-peer Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-server Dec 30, 2020 23:36 UTC 364d etcd-ca no
front-proxy-client Dec 30, 2020 23:36 UTC 364d front-proxy-ca no
scheduler.conf Dec 30, 2020 23:36 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Dec 28, 2029 23:36 UTC 9y no
etcd-ca Dec 28, 2029 23:36 UTC 9y no
front-proxy-ca Dec 28, 2029 23:36 UTC 9y no
Команда показує час закінчення та залишковий час для сертифікатів клієнта у теці /etc/kubernetes/pki та для сертифіката клієнта, вбудованого у файли kubeconfig, що використовуються kubeadm (admin.conf, controller-manager.conf та scheduler.conf).
Крім того, kubeadm повідомляє користувача, якщо керування сертифікатом відбувається ззовні; у цьому випадку користувачу слід самостійно забезпечити керування поновленням сертифікатів вручну/за допомогою інших інструментів.
Файл конфігурації kubelet.conf не включений у цей список, оскільки kubeadm налаштовує kubelet на автоматичне поновлення сертифікатів зі змінними сертифікатами у теці /var/lib/kubelet/pki. Для відновлення простроченого сертифіката клієнта kubelet див.
Помилка оновлення сертифіката клієнта kubelet.
Примітка:
На вузлах, створених за допомогою kubeadm init, до версії kubeadm 1.17, існує помилка, де вам потрібно вручну змінити зміст kubelet.conf. Після завершення kubeadm init ви повинні оновити kubelet.conf, щоб вказати на змінені сертифікати клієнта kubelet, замінивши client-certificate-data та client-key-data на:
client-certificate: /var/lib/kubelet/pki/kubelet-client-current.pem
client-key: /var/lib/kubelet/pki/kubelet-client-current.pem
Автоматичне поновлення сертифікатів
kubeadm поновлює всі сертифікати під час оновлення панелі управління.
Ця функція призначена для вирішення найпростіших випадків використання; якщо у вас немає конкретних вимог до поновлення сертифікатів і ви регулярно виконуєте оновлення версії Kubernetes (частіше ніж 1 раз на рік між кожним оновленням), kubeadm буде піклуватися про те, щоб ваш кластер був завжди актуальним і досить безпечним.
Якщо у вас є складніші вимоги до поновлення сертифікатів, ви можете відмовитися від стандартної поведінки, передавши --certificate-renewal=false до kubeadm upgrade apply або до kubeadm upgrade node.
Ручне поновлення сертифікатів
Ви можете в будь-який момент вручну оновити свої сертифікати за допомогою команди kubeadm certs renew з відповідними параметрами командного рядка. Якщо ви використовуєте кластер з реплікованою панеллю управління, цю команду потрібно виконати на всіх вузлах панелі управління.
Ця команда виконує поновлення за допомогою сертифіката та ключа ЦС (або front-proxy-CA), збережених у /etc/kubernetes/pki.
kubeadm certs renew використовує поточні сертифікати як авторитетне джерело для атрибутів ( Common Name, Organization, subject alternative name) і не покладається на kubeadm-config ConfigMap. Незважаючи на це, проєкт Kubernetes рекомендує зберігати сертифікат, що обслуговується, та повʼязані з ним значення у цьому файлі ConfigMap синхронізовано, щоб уникнути будь-якого ризику плутанини.
Після виконання команди вам слід перезапустити Podʼи панелі управління. Це необхідно, оскільки
динамічне перезавантаження сертифікатів наразі не підтримується для всіх компонентів та сертифікатів. Статичні Podʼи керуються локальним kubelet і не API-сервером, тому kubectl не може бути використаний для їх видалення та перезапуску. Щоб перезапустити статичний Pod, ви можете тимчасово видалити файл його маніфеста з /etc/kubernetes/manifests/ і зачекати 20 секунд (див. значення fileCheckFrequency у KubeletConfiguration struct). kubelet завершить роботу Pod, якщо він більше не знаходиться в теці маніфестів. Потім ви можете повернути файл назад і після ще одного періоду fileCheckFrequency kubelet знову створить Pod, і поновлення сертифікатів для компонента буде завершено.
kubeadm certs renew може оновити будь-який конкретний сертифікат або, за допомогою підкоманди all, він може оновити всі з них, як показано нижче:
# Якщо ви використовуєте кластер з реплікованою панеллю управління, цю команду
# потрібно виконати на всіх вузлах панеллі управління.
kubeadm certs renew all
Копіювання сертифіката адміністратора (необовʼязково)
Кластери, побудовані за допомогою kubeadm, часто копіюють сертифікат admin.conf у $HOME/.kube/config, як вказано у Створення кластера за допомогою kubeadm. У такій системі, для оновлення вмісту $HOME/.kube/config після поновлення admin.conf, вам треба виконати наступні команди:
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Поновлення сертифікатів за допомогою API сертифікатів Kubernetes
У цьому розділі надаються додаткові відомості про те, як виконати ручне поновлення сертифікатів за допомогою API сертифікатів Kubernetes.
Увага:
Це розширені теми для користувачів, які потребують інтеграції сертифікатної інфраструктури своєї організації в кластер, побудований за допомогою kubeadm. Якщо типово конфігурація kubeadm відповідає вашим потребам, вам слід дозволити kubeadm керувати сертифікатами.Налаштування підписувача
Kubernetes Certificate Authority не працює зразу. Ви можете налаштувати зовнішнього підписувача, такого як cert-manager, або можете використовувати вбудованого підписувача.
Вбудований підписувач є частиною kube-controller-manager.
Для активації вбудованого підписувача вам необхідно передати прапорці --cluster-signing-cert-file та --cluster-signing-key-file.
Якщо ви створюєте новий кластер, ви можете використовувати файл конфігурації kubeadm:
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
controllerManager:
extraArgs:
- name: "cluster-signing-cert-file"
value: "/etc/kubernetes/pki/ca.crt"
- name: "cluster-signing-key-file"
value: "/etc/kubernetes/pki/ca.key"
Створення запитів на підпис сертифікатів (CSR)
Дивіться Створення CertificateSigningRequest для створення CSRs за допомогою API Kubernetes.
Поновлення сертифікатів зовнішнім ЦС
У цьому розділі надаються додаткові відомості про те, як виконати ручне поновлення сертифікатів за допомогою зовнішнього ЦС.
Для кращої інтеграції з зовнішніми ЦС, kubeadm також може створювати запити на підпис сертифікатів (CSR). Запит на підпис сертифіката є запитом до ЦС на підписаний сертифікат для клієнта. За термінологією kubeadm, будь-який сертифікат, який зазвичай підписується ЦС на диску, може бути створений у вигляді CSR. Однак ЦС не може бути створено як CSR.
Поновлення за допомогою запитів на підпис сертифікатів (CSR)
Поновлення сертифікатів можливе шляхом генерації нових CSR і підпису їх зовнішнім ЦС. Для отримання докладнішої інформації щодо роботи з CSR, створеними kubeadm, див. розділ Підпис запитів на підпис сертифікатів (CSR), згенерованих kubeadm.
Оновлення Certificate authority (ЦС)
Kubeadm не підтримує автоматичне оновлення або заміну сертифікатів ЦС зразу.
Для отримання додаткової інформації про ручне оновлення або заміну ЦС дивіться ручне оновлення сертифікатів ЦС.
Ввімкнення підписаних службових сертифікатів kubelet
Типово службовий сертифікат kubelet, розгорнутий за допомогою kubeadm, є самопідписним. Це означає, що зʼєднання зовнішніх служб, наприклад, сервера метрик з kubelet, не може бути захищено TLS.
Щоб налаштувати kubelet в новому кластері kubeadm для отримання належно підписаних службових сертифікатів, ви повинні передати наступну мінімальну конфігурацію до kubeadm init:
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
serverTLSBootstrap: true
Якщо ви вже створили кластер, вам слід адаптувати його, виконавши наступне:
- Знайдіть і відредагуйте ConfigMap
kubelet-configв просторі іменkube-system. У ConfigMap ключkubeletмає документ KubeletConfiguration як своє значення. Відредагуйте документ KubeletConfiguration, щоб встановитиserverTLSBootstrap: true. - На кожному вузлі додайте поле
serverTLSBootstrap: trueу/var/lib/kubelet/config.yamlі перезапустіть kubelet за допомогоюsystemctl restart kubelet.
Поле serverTLSBootstrap: true дозволить ініціювати завантаження службових сертифікатів kubelet, запитуючи їх з API certificates.k8s.io. Одне з відомих обмежень поля serverTLSBootstrap: true — CSRs (запити на підпис сертифікатів) для цих сертифікатів не можуть бути автоматично затверджені типовим підписувачем в kube-controller-manager — kubernetes.io/kubelet-serving. Це потребує дій користувача або стороннього контролера.
Ці CSRs можна переглянути за допомогою:
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-9wvgt 112s kubernetes.io/kubelet-serving system:node:worker-1 Pending
csr-lz97v 1m58s kubernetes.io/kubelet-serving system:node:control-plane-1 Pending
Щоб затвердити їх, ви можете виконати наступне:
kubectl certificate approve <CSR-name>
Типово ці службові сертифікати закінчуються через рік. Kubeadm встановлює поле rotateCertificates в true у KubeletConfiguration, що означає, що близько до закінчення буде створено новий набір CSRs для службових сертифікатів і їх слід затвердити, щоб завершити оновлення. Для отримання додаткової інформації дивіться Оновлення сертифікатів.
Якщо ви шукаєте рішення для автоматичного затвердження цих CSRs, рекомендується звернутися до свого постачальника хмарних послуг і дізнатись, чи він має підписувача CSR, який перевіряє ідентифікацію вузла за допомогою окремого механізму.
Ви можете використовувати власні контролери сторонніх постачальників:
Такий контролер не є безпечним механізмом, якщо він перевіряє лише CommonName в CSR, але також перевіряє запитані IP-адреси та доменні імена. Це запобігло б зловмиснику, який має доступ до сертифіката клієнта kubelet, створювати CSRs, запитуючи службові сертифікати для будь-якої IP-адреси або доменного імені.
Генерація файлів kubeconfig для додаткових користувачів
Під час створення кластера, kubeadm init підписує сертифікат у super-admin.conf, щоб мати Subject: O = system:masters, CN = kubernetes-super-admin. system:masters є групою суперкористувачів, яка обходить рівень авторизації (наприклад, RBAC). Файл admin.conf також створюється за допомогою kubeadm на вузлах панелі управління і містить сертифікат з Subject: O = kubeadm:cluster-admins, CN = kubernetes-admin. kubeadm:cluster-admins це група, яка логічно належить до kubeadm. Якщо ваш кластер використовує RBAC (стандартний параметр kubeadm), група kubeadm:cluster-admins буде привʼязана до ClusterRole групи cluster-admin.
Попередження:
Уникайте спільного доступу до файлівsuper-admin.conf або admin.conf. Замість цього створіть найменш привілейований доступ навіть для людей, які працюють адміністраторами, і використовуйте цю найменш привілейовану альтернативу для будь-чого, крім аварійного (екстреного) доступу.Замість цього, ви можете використовувати команду kubeadm kubeconfig user для генерації файлів kubeconfig для додаткових користувачів. Команда приймає змішаний набір параметрів командного рядка та опцій конфігурації kubeadm. Згенерований kubeconfig буде записаний до stdout і може бути перенаправлений у файл за допомогою kubeadm kubeconfig user ... > somefile.conf.
Приклад конфігураційного файлу, який можна використовувати з --config:
# example.yaml
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
# Буде використано як цільовий "кластер" у kubeconfig
clusterName: "kubernetes"
# Буде використано як "сервер" (IP або DNS-імʼя) цього кластера в kubeconfig
controlPlaneEndpoint: "some-dns-address:6443"
# Ключ і сертифікат ЦС кластера будуть завантажені з цієї локальної теки
certificatesDir: "/etc/kubernetes/pki"
Переконайтеся, що ці параметри відповідають бажаним параметрам цільового кластера. Щоб переглянути параметри поточного кластера, скористайтеся:
kubectl get cm kubeadm-config -n kube-system -o=jsonpath="{.data.ClusterConfiguration}"
Наступний приклад згенерує файл kubeconfig з обліковими даними, дійсними протягом 24 годин, для нового користувача johndoe, який належить до групи appdevs:
kubeadm kubeconfig user --config example.yaml --org appdevs --client-name johndoe --validity-period 24h
Наступний приклад згенерує файл kubeconfig з обліковими даними адміністратора, дійсними протягом 1 тижня:
kubeadm kubeconfig user --config example.yaml --client-name admin --validity-period 168h
Підписування запитів на підпис сертифікатів (CSR), згенерованих kubeadm
Ви можете створювати запити на підпис сертифікатів за допомогою kubeadm certs generate-csr. Виклик цієї команди згенерує пари файлів .csr / .key для звичайних сертифікатів. Для сертифікатів, вбудованих у файли kubeconfig, команда згенерує пару файлів .csr / .conf, де ключ вже вбудований у файл .conf.
Файл CSR містить всю необхідну інформацію для ЦС для підпису сертифіката. kubeadm використовує чітко визначену специфікацію для всіх своїх сертифікатів і CSR.
Типовою текою для сертифікатів є /etc/kubernetes/pki, тоді як типова тека для файлів kubeconfig є /etc/kubernetes. Ці стандартні значення можна змінити за допомогою прапорців --cert-dir та --kubeconfig-dir, відповідно.
Для передачі власних параметрів команді kubeadm certs generate-csr використовуйте прапорець --config, який приймає файл конфігурації kubeadm, так само як і команди, такі як kubeadm init. Будь-яка специфікація, така як додаткові SAN та власні IP-адреси, повинна зберігатися в тому ж файлі конфігурації та використовуватися для всіх відповідних команд kubeadm, передаючи його як --config.
Примітка:
У цьому керівництві буде використано стандартну теку Kubernetes /etc/kubernetes, що вимагає прав доступу суперкористувача. Якщо ви дотримуєтесь цього керівництва та використовуєте теки, в яки ви можете писати, (зазвичай, це означає виконання kubeadm з --cert-dir та --kubeconfig-dir), ви можете пропустити команду sudo.
Потім ви повинні скопіювати створені файли до теки /etc/kubernetes, щоб kubeadm init або kubeadm join могли їх знайти.
Підготовка файлів ЦС та сервісного облікового запису
На головному вузлі панелі управління, де буде виконано команду kubeadm init, виконайте наступні команди:
sudo kubeadm init phase certs ca
sudo kubeadm init phase certs etcd-ca
sudo kubeadm init phase certs front-proxy-ca
sudo kubeadm init phase certs sa
Це заповнить теки /etc/kubernetes/pki та /etc/kubernetes/pki/etcd усіма самопідписними файлами ЦС (сертифікати та ключі) та сервісним обліковим записом (публічні та приватні ключі), які необхідні kubeadm для вузла панелі управління.
Примітка:
Якщо ви використовуєте зовнішній ЦС, вам потрібно згенерувати ті ж самі файли окремо та вручну скопіювати їх на головний вузол панелі управління у /etc/kubernetes.
Після підписання всіх CSR ви можете видалити ключ кореневого ЦС (ca.key), як зазначено у розділі Режим зовнішнього ЦС.
Для другорядних вузлів панелі управління (kubeadm join --control-plane) нема потреби викликати вищезазначені команди. Залежно від того, як ви налаштували Високодоступний кластер, вам або потрібно вручну скопіювати ті ж самі файли з головного вузла панелі управління, або використати автоматизовану функціональність --upload-certs від kubeadm init.
Генерація CSR
Команда kubeadm certs generate-csr генерує CSR для всіх відомих сертифікатів, якими керує kubeadm. Після завершення команди вам потрібно вручну видалити файли .csr, .conf або .key, які вам не потрібні.
Врахування kubelet.conf
Цей розділ стосується як вузлів панелі управління, так і робочих вузлів.
Якщо ви видалили файл ca.key з вузлів панелі управління (Режим зовнішнього ЦС), активний kube-controller-manager у цьому кластері не зможе підписати клієнтські сертифікати kubelet. Якщо у вашій конфігурації не існує зовнішнього методу для підписання цих сертифікатів (наприклад, зовнішній підписувач), ви могли б вручну підписати kubelet.conf.csr, як пояснено в цьому посібнику.
Зверніть увагу, що це також означає, що автоматичне оновлення клієнтського сертифіката kubelet буде відключено. Таким чином, близько до закінчення терміну дії сертифіката, вам потрібно буде генерувати новий kubelet.conf.csr, підписувати сертифікат, вбудовувати його в kubelet.conf і перезапускати kubelet.
Якщо це не стосується вашої конфігурації, ви можете пропустити обробку kubelet.conf.csr на другорядних вузлах панелі управління та на робочих вузлах (всі вузли, що викликають kubeadm join ...). Це тому, що активний kube-controller-manager буде відповідальний за підписання нових клієнтських сертифікатів kubelet.
Примітка:
Ви повинні обробити файлkubelet.conf.csr на первинному вузлі панелі управління (хост, на якому ви спочатку запустили kubeadm init). Це повʼязано з тим, що kubeadm розглядає цей вузол як вузол, з якого завантажується кластер, і попередньо заповнений файл kubelet.conf потрібен.Вузли панелі управління
Виконайте наступну команду на головному (kubeadm init) та вторинних (kubeadm join --control-plane) вузлах панелі управління, щоб згенерувати всі файли CSR:
sudo kubeadm certs generate-csr
Якщо має використовуватися зовнішній etcd, дотримуйтесь керівництва Зовнішній etcd з kubeadm, щоб зрозуміти, які файли CSR потрібні на вузлах kubeadm та etcd. Інші файли .csr та .key у теці /etc/kubernetes/pki/etcd можна видалити.
Виходячи з пояснення у розділі Врахування kubelet.conf, збережіть або видаліть файли kubelet.conf та kubelet.conf.csr.
Робочі вузли
Згідно з поясненням у розділі Врахування kubelet.conf, за необхідності викличте:
sudo kubeadm certs generate-csr
та залиште лише файли kubelet.conf та kubelet.conf.csr. Альтернативно, повністю пропустіть кроки для робочих вузлів.
Підписання CSR для всіх сертифікатів
Примітка:
Якщо ви використовуєте зовнішній ЦС та вже маєте файли серійних номерів ЦС (.srl) для openssl, ви можете скопіювати такі файли на вузол kubeadm, де будуть оброблятися CSR. Файли .srl, які потрібно скопіювати, це: /etc/kubernetes/pki/ca.srl, /etc/kubernetes/pki/front-proxy-ca.srl та /etc/kubernetes/pki/etcd/ca.srl. Потім файли можна перемістити на новий вузол, де будуть оброблятися файли CSR.
Якщо файл .srl для ЦС відсутній на вузлі, скрипт нижче згенерує новий файл SRL з випадковим початковим серійним номером.
Щоб дізнатися більше про файли .srl, дивіться документацію openssl для прапорця --CAserial.
Повторіть цей крок для всіх вузлів, що мають файли CSR.
Запишіть наступний скрипт у теку /etc/kubernetes, перейдіть до цієї теки та виконайте скрипт. Скрипт згенерує сертифікати для всіх файлів CSR, які присутні в дереві /etc/kubernetes.
#!/bin/bash
# Встановіть термін дії сертифіката в днях
DAYS=365
# Обробіть всі файли CSR, крім тих, що призначені для front-proxy і etcd
find ./ -name "*.csr" | grep -v "pki/etcd" | grep -v "front-proxy" | while read -r FILE;
do
echo "* Обробка ${FILE} ..."
FILE=${FILE%.*} # Відкинути розширення
if [ -f "./pki/ca.srl" ]; then
SERIAL_FLAG="-CAserial ./pki/ca.srl"
else
SERIAL_FLAG="-CAcreateserial"
fi
openssl x509 -req -days "${DAYS}" -CA ./pki/ca.crt -CAkey ./pki/ca.key ${SERIAL_FLAG} \
-in "${FILE}.csr" -out "${FILE}.crt"
sleep 2
done
# Обробіть всі CSR для etcd
find ./pki/etcd -name "*.csr" | while read -r FILE;
do
echo "* Обробка ${FILE} ..."
FILE=${FILE%.*} # Відкинути розширення
if [ -f "./pki/etcd/ca.srl" ]; then
SERIAL_FLAG=-CAserial ./pki/etcd/ca.srl
else
SERIAL_FLAG=-CAcreateserial
fi
openssl x509 -req -days "${DAYS}" -CA ./pki/etcd/ca.crt -CAkey ./pki/etcd/ca.key ${SERIAL_FLAG} \
-in "${FILE}.csr" -out "${FILE}.crt"
done
# Обробіть CSR для front-proxy
echo "* Обробка ./pki/front-proxy-client.csr ..."
openssl x509 -req -days "${DAYS}" -CA ./pki/front-proxy-ca.crt -CAkey ./pki/front-proxy-ca.key -CAcreateserial \
-in ./pki/front-proxy-client.csr -out ./pki/front-proxy-client.crt
Вбудовування сертифікатів у файли kubeconfig
Повторіть цей крок для всіх вузлів, що мають файли CSR.
Запишіть наступний скрипт у теку /etc/kubernetes, перейдіть до цієї теки та виконайте скрипт. Скрипт візьме файли .crt, які були підписані для файлів kubeconfig з CSR на попередньому кроці, та вбудує їх у файли kubeconfig.
#!/bin/bash
CLUSTER=kubernetes
find ./ -name "*.conf" | while read -r FILE;
do
echo "* Обробка ${FILE} ..."
KUBECONFIG="${FILE}" kubectl config set-cluster "${CLUSTER}" --certificate-authority ./pki/ca.crt --embed-certs
USER=$(KUBECONFIG="${FILE}" kubectl config view -o jsonpath='{.users[0].name}')
KUBECONFIG="${FILE}" kubectl config set-credentials "${USER}" --client-certificate "${FILE}.crt" --embed-certs
done
Виконання очищення
Виконайте цей крок на всіх вузлах, які мають файли CSR.
Запишіть наступний скрипт у теці /etc/kubernetes, перейдіть до цієї теки та виконайте скрипт.
#!/bin/bash
# Очищення файлів CSR
rm -f ./*.csr ./pki/*.csr ./pki/etcd/*.csr # Очистка всіх файлів CSR
# Очищення файлів CRT, які вже були вбудовані у файли kubeconfig
rm -f ./*.crt
За бажанням, перемістіть файли .srl на наступний вузол, який буде оброблено.
За бажанням, якщо використовується зовнішній ЦС, видаліть файл /etc/kubernetes/pki/ca.key, як пояснено у розділі Вузол зовнішнього ЦС.
Ініціалізація вузла kubeadm
Як тільки файли CSR підписані і необхідні сертифікати розміщені на хостах, які ви хочете використовувати як вузли, ви можете використовувати команди kubeadm init та kubeadm join для створення Kubernetes кластера з цих вузлів. Під час init та join, kubeadm використовує існуючі сертифікати, ключі шифрування та файли kubeconfig, які він знаходить у дереві /etc/kubernetes у локальній файловій системі хоста.
1.8 - Переконфігурація кластера за допомогою kubeadm
kubeadm не підтримує автоматизованих способів переконфігурації компонентів, що були розгорнуті на керованих вузлах. Один зі способів автоматизації цього — використання власного оператора.
Для зміни конфігурації компонентів вам потрібно вручну редагувати повʼязані обʼєкти кластера та файли на диску.
Цей посібник показує правильну послідовність кроків, які потрібно виконати для досягнення переконфігурації кластера kubeadm.
Перш ніж ви розпочнете
- Вам потрібен кластер, що був розгорнутий за допомогою kubeadm.
- У вас мають бути адміністративні облікові дані (
/etc/kubernetes/admin.conf) та мережеве зʼєднання з робочим kube-apiserver у кластері з хосту, на якому встановлено kubectl. - Мати текстовий редактор встановлений на всіх хостах.
Переконфігурація кластера
kubeadm записує набір параметрів конфігурації компонентів на рівні кластера у ConfigMaps та в інших обʼєктах. Ці обʼєкти потрібно редагувати вручну. Команда kubectl edit може бути використана для цього.
Команда kubectl edit відкриє текстовий редактор, в якому ви можете редагувати та зберегти обʼєкт безпосередньо.
Ви можете використовувати змінні середовища KUBECONFIG та KUBE_EDITOR для вказівки розташування файлу kubeconfig, який використовується kubectl, та обраного текстового редактора.
Наприклад:
KUBECONFIG=/etc/kubernetes/admin.conf KUBE_EDITOR=nano kubectl edit <параметри>
Примітка:
Після збереження будь-яких змін у цих обʼєктах кластера, компоненти, що працюють на вузлах, можуть не оновлюватись автоматично. У нижченаведених кроках вказано, як це зробити вручну.Попередження:
Конфігурація компонентів у ConfigMaps зберігається як неструктуровані дані (рядки YAML). Це означає, що перевірка правильності не буде проводитися при оновленні вмісту ConfigMap. Вам потрібно бути обережними та слідувати документованому формату API для певної конфігурації компонента, а також уникати друкарських помилок та помилок у відступах в YAML.Застосування змін у конфігурації кластера
Оновлення ClusterConfiguration
Під час створення кластера та його оновлення, kubeadm записує ClusterConfiguration у ConfigMap, з назвою kubeadm-config у просторі імен kube-system.
Щоб змінити певну опцію у ClusterConfiguration, ви можете редагувати ConfigMap за допомогою цієї команди:
kubectl edit cm -n kube-system kubeadm-config
Конфігурація знаходиться в ключі data.ClusterConfiguration.
Примітка:
ClusterConfiguration включає різноманітні параметри, які впливають на конфігурацію окремих компонентів, таких як kube-apiserver, kube-scheduler, kube-controller-manager, CoreDNS, etcd та kube-proxy. Зміни в конфігурації повинні бути віддзеркалені в компонентах вузла вручну.Віддзеркалення змін ClusterConfiguration на вузлах панелі управління
kubeadm керує компонентами панелі управління як статичними маніфестами Pod, які розташовані в
теці /etc/kubernetes/manifests. Будь-які зміни у ClusterConfiguration в ключах apiServer, controllerManager, scheduler або etcd повинні віддзеркалюватись у відповідних файлах у теці маніфестів на вузлі панелі управління.
Такі зміни можуть включати:
extraArgs— потребує оновлення списку прапорців, які передаються контейнеру компонентаextraVolumes— потребує оновлення точок монтування для контейнера компонента*SANs— потребує написання нових сертифікатів з Subject Alternative Names.
Перед продовженням цих змін переконайтеся, що ви зробили резервну копію теки /etc/kubernetes/.
Для написання нових сертифікатів ви можете використовувати:
kubeadm init phase certs <component-name> --config <config-file>
Для написання нових файлів маніфестів у теці /etc/kubernetes/manifests ви можете використовувати:
# Для компонентів панелі управління Kubernetes
kubeadm init phase control-plane <component-name> --config <config-file>
# Для локального etcd
kubeadm init phase etcd local --config <config-file>
Зміст <config-file> повинен відповідати оновленням в ClusterConfiguration. Значення <component-name> повинно бути імʼям компонента панелі управління Kubernetes (apiserver, controller-manager або scheduler).
Примітка:
Оновлення файлу у/etc/kubernetes/manifests призведе до перезапуску статичного Podʼа для відповідного компонента. Спробуйте робити ці зміни один за одним на вузлі, щоб не переривати роботу кластера.Застосування змін конфігурації kubelet
Оновлення KubeletConfiguration
Під час створення кластера та оновлення, kubeadm записує KubeletConfiguration у ConfigMap з назвою kubelet-config в просторі імен kube-system.
Ви можете редагувати цей ConfigMap за допомогою такої команди:
kubectl edit cm -n kube-system kubelet-config
Конфігурація розташована в ключі data.kubelet.
Віддзеркалення змін в kubelet
Щоб віддзеркалити зміни на вузлах kubeadm, вам потрібно виконати наступне:
- Увійдіть на вузол kubeadm.
- Виконайте команду
kubeadm upgrade node phase kubelet-config, щоб завантажити свіжий вмістkubelet-configConfigMap в локальний файл/var/lib/kubelet/config.yaml. - Відредагуйте файл
/var/lib/kubelet/kubeadm-flags.env, щоб застосувати додаткову конфігурацію за допомогою прапорців. - Перезапустіть службу kubelet за допомогою
systemctl restart kubelet.
Примітка:
Виконуйте ці зміни по одному вузлу за раз, щоб дозволити належне перепланування робочих навантажень.Примітка:
Під час оновленняkubeadm, kubeadm завантажує KubeletConfiguration з ConfigMap kubelet-config і перезаписує вміст /var/lib/kubelet/config.yaml. Це означає, що локальна конфігурація вузла повинна бути застосована або за допомогою прапорців у /var/lib/kubelet/kubeadm-flags.env, або шляхом ручного оновлення вмісту /var/lib/kubelet/config.yaml після kubeadm upgrade, з подальшим перезапуском kubelet.Застосування змін у конфігурації kube-proxy
Оновлення KubeProxyConfiguration
Під час створення кластера та оновлення, kubeadm записує KubeProxyConfiguration у ConfigMap в просторі імен kube-system з назвою kube-proxy.
Цей ConfigMap використовується DaemonSet kube-proxy в просторі імен kube-system.
Щоб змінити певну опцію в KubeProxyConfiguration, ви можете відредагувати ConfigMap за допомогою цієї команди:
kubectl edit cm -n kube-system kube-proxy
Конфігурація знаходиться в ключі data.config.conf.
Віддзеркалення змін у kube-proxy
Після оновлення ConfigMap kube-proxy, ви можете перезапустити всі Podʼи kube-proxy:
Видаліть Podʼи за допомогою:
kubectl delete po -n kube-system -l k8s-app=kube-proxy
Створюватимуться нові Podʼи, які використовують оновлений ConfigMap.
Примітка:
Оскількиkubeadm розгортає kube-proxy як DaemonSet, конфігурація, специфічна для вузла, не підтримується.Застосування змін конфігурації CoreDNS
Оновлення розгортання CoreDNS та сервісу
kubeadm розгортає CoreDNS як Deployment з назвою coredns та Service з назвою kube-dns, обидва у просторі імен kube-system.
Для оновлення будь-яких налаштувань CoreDNS ви можете редагувати обʼєкти Deployment та Service:
kubectl edit deployment -n kube-system coredns
kubectl edit service -n kube-system kube-dns
Віддзеркалення змін у CoreDNS
Після застосування змін у CoreDNS ви можете перезапустити його deployment:
kubectl rollout restart deployment -n kube-system coredns
Примітка:
kubeadm не дозволяє налаштування CoreDNS під час створення та оновлення кластера. Це означає, що якщо ви виконаєтеkubeadm upgrade apply, ваші зміни в обʼєктах CoreDNS будуть втрачені та мають бути застосовані повторно.Збереження переконфігурації
Під час виконання команди kubeadm upgrade на керованому вузлі kubeadm може перезаписати конфігурацію, яка була застосована після створення кластера (переконфігурація).
Збереження переконфігурації обʼєкту Node
kubeadm записує Labels, Taints, сокенти CRI та іншу інформацію в обʼєкті Node для конкретного вузла Kubernetes. Для зміни будь-якого змісту цього обʼєкта Node ви можете використовувати:
kubectl edit no <імʼя-вузла>
Під час виконання kubeadm upgrade вміст такого Node може бути перезаписаний. Якщо ви бажаєте зберегти свої зміни в обʼєкті Node після оновлення, ви можете підготувати команду патча для kubectl і застосувати її до обʼєкта Node:
kubectl patch no <імʼя-вузла> --patch-file <файл-патча>
Збереження переконфігурації компонента панелі управління
Основним джерелом конфігурації панелі управління є обʼєкт ClusterConfiguration, збережений у кластері. Для розширення конфігурації статичних маніфестів Podʼів можна використовувати патчі.
Ці файли патчів повинні залишатися як файли на вузлах панелі управління, щоб забезпечити можливість їх використання командою kubeadm upgrade ... --patches <directory>.
Якщо переконфігурування виконується для ClusterConfiguration і статичних маніфестів Podʼів на диску, то набір патчів для конкретного вузла повинен бути відповідно оновлений.
Збереження переконфігурації kubelet
Будь-які зміни в KubeletConfiguration, збережені у /var/lib/kubelet/config.yaml, будуть перезаписані під час виконання kubeadm upgrade, завантажуючи вміст конфігурації kubelet-config ConfigMap для всього кластера. Для збереження конфігурації kubelet для Node потрібно або вручну змінити файл /var/lib/kubelet/config.yaml після оновлення, або файл /var/lib/kubelet/kubeadm-flags.env може містити прапорці. Прапорці kubelet перевизначають відповідні параметри KubeletConfiguration, але слід зауважити, що деякі з прапорців є застарілими.
Після зміни /var/lib/kubelet/config.yaml або /var/lib/kubelet/kubeadm-flags.env потрібен перезапуск kubelet.
Що далі
1.9 - Зміна репозиторія пакунків Kubernetes
Ця сторінка пояснює, як увімкнути репозиторій пакунків для бажаного мінорного випуску Kubernetes під час оновлення кластера. Це потрібно лише для користувачів репозиторіїв пакунків, що підтримуються спільнотою та розміщені на pkgs.k8s.io. На відміну від застарілих репозиторіїв пакунків, репозиторії пакунків, що підтримуються спільнотою, структуровані таким чином, що для кожної мінорної версії Kubernetes є окремий репозиторій пакунків.
Примітка:
Цей посібник охоплює лише частину процесу оновлення Kubernetes. Для отримання додаткової інформації про оновлення кластерів Kubernetes див. посібник з оновлення.Примітка:
Цей крок потрібно виконати лише під час оновлення кластера до іншого мінорного випуску. Якщо ви оновлюєтеся до іншого патч-релізу в межах тієї самої мінорної версії (наприклад, з v1.35.5 до v1.35.7), вам не потрібно дотримуватися цього посібника. Однак, якщо ви все ще використовуєте застарілі репозиторії пакунків, вам потрібно перейти на нові репозиторії пакунків, які підтримуються спільнотою, перед оновленням (див. наступний розділ для отримання деталей про те, як це зробити).Перш ніж ви розпочнете
У цьому документі припускається, що ви вже використовуєте репозиторії пакунків, які підтримуються спільнотою (pkgs.k8s.io). Якщо це не так, наполегливо рекомендується перейти на репозиторії пакунків, які підтримуються спільнотою, як описано в офіційному оголошенні.
apt.kubernetes.io та yum.kubernetes.io) визнані
застарілими та заморожені станом на 13 вересня 2023.
Використання нових репозиторіїв пакунків, розміщених за адресою pkgs.k8s.io`,
настійно рекомендується і є обовʼязковим для встановлення версій Kubernetes, випущених після 13 вересня 2023 року.
Застарілі репозиторії та їхні вміст можуть бути видалені у будь-який момент у майбутньому і без попереднього повідомлення.
Нові репозиторії пакунків надають можливість завантаження версій Kubernetes, починаючи з v1.24.0.Перевірка використання репозиторіїв пакунків Kubernetes
Якщо ви не впевнені, чи ви використовуєте репозиторії пакунків, які підтримуються спільнотою, чи застарілі репозиторії пакунків, виконайте наступні кроки для перевірки:
Виведіть вміст файлу, який визначає apt-репозиторій Kubernetes:
# У вашій системі цей файл конфігурації може мати іншу назву
pager /etc/apt/sources.list.d/kubernetes.list
Якщо ви бачите рядок, схожий на:
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.34/deb/ /
Ви використовуєте репозиторії пакунків Kubernetes, і цей посібник стосується вас. Інакше наполегливо рекомендується перейти на репозиторії пакунків Kubernetes, які підтримуються спільнотою, як описано в офіційному оголошенні.
Виведіть вміст файлу, який визначає yum-репозиторій Kubernetes:
# У вашій системі цей файл конфігурації може мати іншу назву
cat /etc/yum.repos.d/kubernetes.repo
Якщо ви бачите baseurl, схожий на baseurl в наведеному нижче виводі:
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.34/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.34/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl
Ви використовуєте репозиторії пакунків Kubernetes, і цей посібник стосується вас. Інакше наполегливо рекомендується перейти на репозиторії пакунків Kubernetes, які підтримуються спільнотою, як описано в офіційному оголошенні.
Виведіть вміст файлу, який визначає zypper-репозиторій Kubernetes:
# У вашій системі цей файл конфігурації може мати іншу назву
cat /etc/zypp/repos.d/kubernetes.repo
Якщо ви бачите baseurl, схожий на baseurl в наведеному нижче виводі:
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.34/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.34/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl
Ви використовуєте репозиторії пакунків Kubernetes, і цей посібник стосується вас. Інакше наполегливо рекомендується перейти на репозиторії пакунків Kubernetes, які підтримуються спільнотою, як описано в офіційному оголошенні.
Примітка:
URL, використаний для репозиторіїв пакунків Kubernetes, не обмежується pkgs.k8s.io, він також може бути одним із наступних:
pkgs.k8s.iopkgs.kubernetes.iopackages.kubernetes.io
Перехід на інший репозиторій пакунків Kubernetes
Цей крок слід виконати при оновленні з одного мінорного випуску Kubernetes на інший для отримання доступу до пакунків бажаної мінорної версії Kubernetes.
Відкрийте файл, який визначає
apt-репозиторій Kubernetes за допомогою текстового редактора на ваш вибір:nano /etc/apt/sources.list.d/kubernetes.listВи повинні побачити один рядок з URL, що містить вашу поточну мінорну версію Kubernetes. Наприклад, якщо ви використовуєте v1.34, ви повинні побачити це:
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.34/deb/ /Змініть версію в URL на наступний доступний мінорний випуск, наприклад:
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.35/deb/ /Збережіть файл і вийдіть з текстового редактора. Продовжуйте дотримуватися відповідних інструкцій щодо оновлення.
Відкрийте файл, який визначає
yum-репозиторій Kubernetes за допомогою текстового редактора на ваш вибір:nano /etc/yum.repos.d/kubernetes.repoВи повинні побачити файл з двома URL, що містять вашу поточну мінорну версію Kubernetes. Наприклад, якщо ви використовуєте v1.34, ви повинні побачити це:
[kubernetes] name=Kubernetes baseurl=https://pkgs.k8s.io/core:/stable:/v1.34/rpm/ enabled=1 gpgcheck=1 gpgkey=https://pkgs.k8s.io/core:/stable:/v1.34/rpm/repodata/repomd.xml.key exclude=kubelet kubeadm kubectl cri-tools kubernetes-cniЗмініть версію в цих URL на наступний доступний мінорний випуск, наприклад:
[kubernetes] name=Kubernetes baseurl=https://pkgs.k8s.io/core:/stable:/v1.35/rpm/ enabled=1 gpgcheck=1 gpgkey=https://pkgs.k8s.io/core:/stable:/v1.35/rpm/repodata/repomd.xml.key exclude=kubelet kubeadm kubectl cri-tools kubernetes-cniЗбережіть файл і вийдіть з текстового редактора. Продовжуйте дотримуватися відповідних інструкцій щодо оновлення.
Що далі
- Подивіться, як оновити вузли Linux.
- Подивіться, як оновити вузли Windows.
2 - Перевищення ємності вузла для кластера
Ця сторінка допоможе вам налаштувати перевищення ємності вузла у вашому кластері Kubernetes. Перевищення ємності вузла — це стратегія, яка проактивно резервує частину обчислювальних ресурсів вашого кластера. Це резервування допомагає зменшити час, необхідний для планування нових podʼів під час подій масштабування, підвищуючи чутливість вашого кластера до раптових сплесків трафіку або навантаження.
Підтримуючи деяку невикористану ємність, ви забезпечуєте негайну доступність ресурсів при створенні нових podʼів, запобігаючи їх переходу в стан очікування під час масштабування кластера.
Перш ніж ви розпочнете
- Вам потрібен кластер Kubernetes, і інструмент командного рядка kubectl має бути налаштований для звʼязку з вашим кластером.
- Ви повинні мати базове розуміння про Deployments, пріоритет podʼів, та PriorityClasses.
- У вашому кластері має бути налаштований з автомасштабувальник, який керує вузлами на основі попиту.
Створіть PriorityClass
Почніть з визначення PriorityClass для podʼів-заповнювачів. Спочатку створіть PriorityClass з негативним значенням пріоритету, який ви незабаром призначите podʼам-заповнювачам. Пізніше ви налаштуєте Deployment, яке використовує цей PriorityClass.
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: placeholder # ці Podʼи передставляють ємність заповнювача
value: -1000
globalDefault: false
description: "Відʼємний пріоритет для pod-заповнювачів, щоб увімкнути надлишкове розміщення."
Потім створіть PriorityClass:
kubectl apply -f https://k8s.io/examples/priorityclass/low-priority-class.yaml
Далі ви визначите Deployment, який використовує PriorityClass з негативним пріоритетом і запускає мінімальний контейнер. Коли ви додасте його до свого кластера, Kubernetes запустить ці podʼи-заповнювачі для резервування ємності. У разі нестачі ємності, панель управління вибере один з цих podʼів-заповнювачів як першого кандидата для випередження.
Запустіть Podʼи, що запитують ємність вузла
Перегляньте зразок маніфесту:
apiVersion: apps/v1
kind: Deployment
metadata:
name: capacity-reservation
# Ви маєте вирішити, в якому просторі імен розгортати
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: capacity-placeholder
template:
metadata:
labels:
app.kubernetes.io/name: capacity-placeholder
annotations:
kubernetes.io/description: "Capacity reservation"
spec:
priorityClassName: placeholder
affinity: # Спробуйте розмістити ці додаткові Podʼи на різних вузлах
# якщо це можливо
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchLabels:
app.kubernetes.io/name: capacity-placeholder
topologyKey: topology.kubernetes.io/hostname
containers:
- name: pause
image: registry.k8s.io/pause:3.6
resources:
requests:
cpu: "50m"
memory: "512Mi"
limits:
memory: "512Mi"
Оберіть простір імен для podʼів-заповнювачів
Виберіть, або створіть, {{ < glossary_tooltip text="простір імен" term_id="namespace" >}}, в якому ви будете запускати podʼи-заповнювачі.
Створіть Deployment-заповнювач
Створіть Deployment на основі цього маніфесту:
# Змініть `example` на простір імен, який ви вибрали
kubectl --namespace example apply -f https://k8s.io/examples/deployments/deployment-with-capacity-reservation.yaml
Налаштуйте запити ресурсів для заповнювачів
Налаштуйте запити та обмеження ресурсів для podʼів-заповнювачів, щоб визначити кількість зарезервованих ресурсів, які ви хочете підтримувати. Це резервування забезпечує наявність певної кількості CPU та памʼяті для нових podʼів.
Щоб редагувати Deployment, змініть розділ resources у файлі маніфесту Deployment, щоб встановити відповідні запити та обмеження. Ви можете завантажити цей файл локально та відредагувати його за допомогою будь-якого текстового редактора.
Ви можете редагувати маніфест Deployment використовуючи kubectl:
kubectl edit deployment capacity-reservation
Наприклад, щоб зарезервувати 0.5 CPU та 1GiB памʼяті для 5 podʼів-заповнювачів, визначте запити та обмеження ресурсів для одного podʼа-заповнювача наступним чином:
resources:
requests:
cpu: "100m"
memory: "200Mi"
limits:
cpu: "100m"
Встановіть бажану кількість реплік
Розрахуйте загальні зарезервовані ресурси
Наприклад, з 5 репліками, кожна з яких резервує 0.1 CPU та 200MiB памʼяті:
Загальна зарезервована емність CPU: 5 × 0.1 = 0.5 (у специфікації podʼа ви напишете кількість 500m)
Загальна зарезервована памʼять: 5 × 200MiB = 1GiB (у специфікації podʼа ви напишете 1 Gi)
Щоб масштабувати Deployment, налаштуйте кількість реплік відповідно до розміру вашого кластера та очікуваного навантаження:
kubectl scale deployment capacity-reservation --replicas=5
Перевірте масштабування:
kubectl get deployment capacity-reservation
Вихідні дані повинні відображати оновлену кількість реплік:
NAME READY UP-TO-DATE AVAILABLE AGE
capacity-reservation 5/5 5 5 2m
Примітка:
Деякі автомасштабувальники, зокрема Karpenter, розглядають правила переважної спорідненості як жорсткі правила при розгляді масштабування вузлів. Якщо ви використовуєте Karpenter або інший автомасштабувальник вузлів, який використовує той самий евристичний підхід, кількість реплік, яку ви встановлюєте тут, також встановлює мінімальну кількість вузлів для вашого кластера.Що далі
- Дізнайтеся більше про PriorityClasses та як вони впливають на планування podʼів.
- Дізнайтеся більше про автомасштабування вузлів, щоб динамічно налаштовувати розмір вашого кластера на основі навантаження.
- Зрозумійте Випередження podʼів, ключовий механізм Kubernetes для обробки конфліктів ресурсів. Та ж сторінка охоплює поняття виселення, що менш актуально для підходу з podʼами-заповнювачами, але також є механізмом для Kubernetes для реагування на конфлікти ресурсів.
3 - Міграція з dockershim
Цей розділ містить інформацію, яку вам потрібно знати при міграції з dockershim на інші оточення виконання контейнерів.
Після оголошення про застарівання dockershim в Kubernetes 1.20, виникли питання, як це вплине на різні робочі навантаження та розгортання самого Kubernetes. Наш Dockershim Removal FAQ допоможе вам краще зрозуміти проблему.
Dockershim був видалений з Kubernetes з випуском v1.24. Якщо ви використовуєте Docker Engine через dockershim як своє оточення виконання контейнерів і хочете оновитись до v1.24, рекомендується або мігрувати на інше оточення виконання, або знайти альтернативний спосіб отримання підтримки Docker Engine. Ознайомтеся з розділом оточення виконання контейнерів, щоб дізнатися про ваші варіанти.
Версія Kubernetes з dockershim (1.23) вийшла з стану підтримки, а v1.24 скоро вийде зі стану підтримки. Переконайтеся, що повідомляєте про проблеми з міграцією, щоб проблеми могли бути вчасно виправлені, і ваш кластер був готовий до видалення dockershim. Після виходу v1.24 зі стану підтримки вам доведеться звертатися до вашого постачальника Kubernetes за підтримкою або оновлювати кілька версій одночасно, якщо є критичні проблеми, які впливають на ваш кластер.
Ваш кластер може мати більше одного типу вузлів, хоча це не є загальною конфігурацією.
Ці завдання допоможуть вам здійснити міграцію:
- Перевірте, чи вас стосується видалення dockershim
- Міграція телеметрії та агентів безпеки з dockershim
Що далі
- Ознайомтеся з оточеннями виконання контейнерів, щоб зрозуміти які з варіантів вам доступні.
- Якщо ви знайшли дефект або іншу технічну проблему, повʼязану з відмовою від dockershim, ви можете повідомити про проблему проєкту Kubernetes.
3.1 - Заміна середовища виконання контейнерів на вузлі з Docker Engine на containerd
Це завдання визначає кроки, необхідні для оновлення вашого середовища виконання контейнерів на containerd з Docker. Воно буде корисним для операторів кластерів, які працюють з Kubernetes 1.23 або старішими версіями. Воно також охоплює приклад сценарію міграції з dockershim на containerd. З цієї сторінки можна вибрати альтернативні середовища виконання контейнерів.
Перш ніж ви розпочнете
Встановіть containerd. Для отримання додаткової інформації дивіться документацію з встановлення containerd і для конкретних передумов виконуйте кроки описані в посібнику containerd.
Виведення вузла з експлуатації
kubectl drain <node-to-drain> --ignore-daemonsets
Замініть <node-to-drain> на імʼя вузла, який ви збираєтеся виводити з експлуатації.
Зупиніть службу Docker
systemctl stop kubelet
systemctl disable docker.service --now
Встановлення Containerd
Дотримуйтесь настанов посібника для отримання детальних кроків з встановлення containerd.
Встановіть пакунок
containerd.ioз офіційних репозиторіїв Docker. Інструкції щодо налаштування репозиторію Docker для вашого конкретного дистрибутиву Linux і встановлення пакункаcontainerd.ioможна знайти у Починаючи з containerd.Налаштуйте containerd:
sudo mkdir -p /etc/containerd containerd config default | sudo tee /etc/containerd/config.tomlПерезапустіть containerd:
sudo systemctl restart containerd
Розпочніть сеанс PowerShell, встановіть значення $Version на бажану версію (наприклад, $Version="1.4.3"), а потім виконайте наступні команди:
Завантажте containerd:
curl.exe -L https://github.com/containerd/containerd/releases/download/v$Version/containerd-$Version-windows-amd64.tar.gz -o containerd-windows-amd64.tar.gz tar.exe xvf .\containerd-windows-amd64.tar.gzРозпакуйте та налаштуйте:
Copy-Item -Path ".\bin\" -Destination "$Env:ProgramFiles\containerd" -Recurse -Force cd $Env:ProgramFiles\containerd\ .\containerd.exe config default | Out-File config.toml -Encoding ascii # Перегляньте конфігурацію. Залежно від налаштувань можливо, ви захочете внести корективи: # - образ sandbox_image (образ pause Kubernetes) # - розташування cni bin_dir та conf_dir Get-Content config.toml # (Необовʼязково, але дуже рекомендується) Виключіть containerd зі сканування Windows Defender Add-MpPreference -ExclusionProcess "$Env:ProgramFiles\containerd\containerd.exe"Запустіть containerd:
.\containerd.exe --register-service Start-Service containerd
Налаштування kubelet для використання containerd як його середовища виконання контейнерів
Відредагуйте файл /var/lib/kubelet/kubeadm-flags.env та додайте середовище виконання контейнерів до прапорців; --container-runtime-endpoint=unix:///run/containerd/containerd.sock.
Використовуючи kubeadm, користувачі повинні знати, що інструмент kubeadm зберігає сокет CRI хоста в файлі /var/lib/kubelet/instance-config.yaml на кожному вузлі. Ви можете створити цей файл /var/lib/kubelet/instance-config.yaml на вузлі.
Файл /var/lib/kubelet/instance-config.yaml дозволяє налаштувати параметр containerRuntimeEndpoint.
Ви можете встановити значення цього параметра на шлях до вибраного вами сокета CRI (наприклад, unix:///run/containerd/containerd.sock).
Перезапустіть kubelet
systemctl start kubelet
Перевірте, що вузол справний
Запустіть kubectl get nodes -o wide, і containerd зʼявиться як середовище виконання для вузла, який ми щойно змінили.
Видаліть Docker Engine
Якщо вузол виглядає справним, видаліть Docker.
sudo yum remove docker-ce docker-ce-cli
sudo apt-get purge docker-ce docker-ce-cli
sudo dnf remove docker-ce docker-ce-cli
sudo apt-get purge docker-ce docker-ce-cli
Попередні команди не видаляють образи, контейнери, томи або налаштовані файли конфігурації на вашому хості. Щоб їх видалити, слідуйте інструкціям Docker щодо Видалення Docker Engine.
Увага:
Інструкції Docker щодо видалення Docker Engine створюють ризик видалення containerd. Будьте обережні при виконанні команд.Введення вузла в експлуатацію
kubectl uncordon <node-to-uncordon>
Замініть <node-to-uncordon> на імʼя вузла, який ви раніше вивели з експлуатації.
3.2 - Перевірте, яке середовище виконання контейнерів використовується на вузлі
На цій сторінці наведено кроки для визначення того, яке середовище виконання контейнерів використовують вузли у вашому кластері.
Залежно від того, як ви запускаєте свій кластер, середовище виконання контейнерів для вузлів може бути попередньо налаштованим або вам потрібно його налаштувати. Якщо ви використовуєте сервіс Kubernetes, що надається вам постачальником послуг, можуть існувати специфічні для нього способи перевірки того, яке середовище виконання контейнерів налаштоване для вузлів. Метод, описаний на цій сторінці, повинен працювати завжди, коли дозволяється виконання kubectl.
Перш ніж ви розпочнете
Встановіть та налаштуйте kubectl. Див. розділ Встановлення інструментів для отримання деталей.
Визначте середовище виконання контейнерів, яке використовується на вузлі
Використовуйте kubectl, щоб отримати та показати інформацію про вузли:
kubectl get nodes -o wide
Вивід подібний до такого. Стовпець CONTAINER-RUNTIME виводить інформацію про середовище та його версію.
Для Docker Engine вивід схожий на цей:
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.16.15 docker://19.3.1
node-2 Ready v1.16.15 docker://19.3.1
node-3 Ready v1.16.15 docker://19.3.1
Якщо ваше середовище показується як Docker Engine, це все одно не означає, що вас точно торкнеться видалення dockershim у Kubernetes v1.24. Перевірте точку доступу середовища, щоб побачити, чи використовуєте ви dockershim. Якщо ви не використовуєте dockershim, вас це не стосується.
Для containerd вивід схожий на цей:
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.19.6 containerd://1.4.1
node-2 Ready v1.19.6 containerd://1.4.1
node-3 Ready v1.19.6 containerd://1.4.1
Дізнайтеся більше інформації про середовища виконання контейнерів на сторінці Середовища виконання контейнерів.
Дізнайтеся, яку точку доступу середовища виконання контейнерів ви використовуєте
Середовище виконання контейнерів спілкується з kubelet через Unix-сокет, використовуючи протокол CRI, який базується на фреймворку gRPC. Kubelet діє як клієнт, а середовище — як сервер. У деяких випадках може бути корисно знати, який сокет використовується на ваших вузлах. Наприклад, з видаленням dockershim у Kubernetes v1.24 і пізніше ви, можливо, захочете знати, чи використовуєте ви Docker Engine з dockershim.
Примітка:
Якщо ви зараз використовуєте Docker Engine на своїх вузлах зcri-dockerd, вас не торкнетеся видалення dockershim.Ви можете перевірити, який сокет ви використовуєте, перевіривши конфігурацію kubelet на своїх вузлах.
Прочитайте початкові команди для процесу kubelet:
tr \\0 ' ' < /proc/"$(pgrep kubelet)"/cmdlineЯкщо у вас немає
trабоpgrep, перевірте командний рядок для процесу kubelet вручну.У виведенні шукайте прапорець
--container-runtimeта прапорець--container-runtime-endpoint.- Якщо ваші вузли використовують Kubernetes v1.23 та старіший, і ці прапори відсутні або прапорець
--container-runtimeне єremote, ви використовуєте сокет dockershim з Docker Engine. Параметр командного рядка--container-runtimeне доступний у Kubernetes v1.27 та пізніше. - Якщо прапорець
--container-runtime-endpointприсутній, перевірте імʼя сокета, щоб дізнатися, яке середовище ви використовуєте. Наприклад,unix:///run/containerd/containerd.sock— це точка доступу containerd.
- Якщо ваші вузли використовують Kubernetes v1.23 та старіший, і ці прапори відсутні або прапорець
Якщо ви хочете змінити середовище виконання контейнерів на вузлі з Docker Engine на containerd, ви можете дізнатися більше інформації про міграцію з Docker Engine на containerd, або, якщо ви хочете продовжити використовувати Docker Engine у Kubernetes v1.24 та пізніше, мігруйте на сумісний з CRI адаптер, наприклад cri-dockerd.
3.3 - Виправлення помилок, повʼязаних з втулками CNI
Щоб уникнути помилок, повʼязаних з втулками CNI, переконайтеся, що ви використовуєте або оновлюєте середовище виконання контейнерів, яке було протестовано й працює коректно з вашою версією Kubernetes.
Про помилки "Incompatible CNI versions" та "Failed to destroy network for sandbox"
Проблеми з Service існують для налаштування та демонтажу мережі CNI для Pod в containerd v1.6.0-v1.6.3, коли втулки CNI не були оновлені та/або версія конфігурації CNI не вказана в файлах конфігурації CNI. Команда containerd повідомляє, що "ці проблеми вирішені в containerd v1.6.4."
З containerd v1.6.0-v1.6.3, якщо ви не оновите втулки CNI та/або не вкажете версію конфігурації CNI, ви можете стикнутися з наступними умовами помилок "Incompatible CNI versions" або "Failed to destroy network for sandbox".
Помилка "Incompatible CNI versions"
Якщо версія вашого втулка CNI не відповідає версії втулка в конфігурації, тому що версія конфігурації є новішою, ніж версія втулка, лог containerd, швидше за все, покаже повідомлення про помилку при запуску Pod подібне до:
incompatible CNI versions; config is \"1.0.0\", plugin supports [\"0.1.0\" \"0.2.0\" \"0.3.0\" \"0.3.1\" \"0.4.0\"]"
Щоб виправити цю проблему, оновіть свої втулки CNI та файли конфігурації CNI.
Помилка "Failed to destroy network for sandbox"
Якщо версія втулка відсутня в конфігурації втулка CNI, Pod може запускатися. Однак припинення Podʼа призводить до помилки, подібної до:
ERROR[2022-04-26T00:43:24.518165483Z] StopPodSandbox for "b" failed
error="failed to destroy network for sandbox \"bbc85f891eaf060c5a879e27bba9b6b06450210161dfdecfbb2732959fb6500a\": invalid version \"\": the version is empty"
Ця помилка залишає Pod у стані "not-ready" з приєднаним простором імен мережі. Щоб відновити роботу після цієї проблеми, відредагуйте файл конфігурації CNI, щоб додати відсутню інформацію про версію. Наступна спроба зупинити Pod повинна бути успішною.
Оновлення ваших втулків CNI та файлів конфігурації CNI
Якщо ви використовуєте containerd v1.6.0-v1.6.3 та зіткнулися з помилками "Incompatible CNI versions" або "Failed to destroy network for sandbox", розгляньте можливість оновлення ваших втулків CNI та редагування файлів конфігурації CNI.
Ось огляд типових кроків для кожного вузла:
Після зупинки ваших служб середовища виконання контейнерів та kubelet виконайте наступні операції оновлення:
- Якщо ви використовуєте втулки CNI, оновіть їх до останньої версії.
- Якщо ви використовуєте не-CNI втулки, замініть їх втулками CNI. Використовуйте останню версію втулків.
- Оновіть файл конфігурації втулка, щоб вказати або відповідати версії специфікації CNI, яку підтримує втулок, як показано у наступному розділі "Приклад файлу конфігурації containerd".
- Для
containerdпереконайтеся, що ви встановили останню версію (v1.0.0 або пізніше) втулка CNI loopback. - Оновіть компоненти вузла (наприклад, kubelet) до Kubernetes v1.24.
- Оновіть або встановіть найновішу версію середовища виконання контейнерів.
Поверніть вузол у ваш кластер, перезапустивши ваше середовище виконання контейнерів та kubelet. Увімкніть вузол (
kubectl uncordon <імʼя_вузла>).
Приклад файлу конфігурації containerd
Наведений нижче приклад показує конфігурацію для середовища виконання контейнерів containerd версії v1.6.x, яке підтримує останню версію специфікації CNI (v1.0.0).
Будь ласка, перегляньте документацію від вашого постачальника втулків та мереж для подальших інструкцій з налаштування вашої системи.
У Kubernetes, середовище виконання контейнерів containerd додає типовий інтерфейс loopback, lo, до Podʼів. Середовище виконання контейнерів containerd налаштовує інтерфейс loopback через втулок CNI, loopback. Втулок loopback розповсюджується як частина пакунків релізу containerd, які мають позначення cni. containerd v1.6.0 та пізніше включає сумісний з CNI v1.0.0 втулок loopback, а також інші типові втулки CNI. Налаштування втулка loopback виконується внутрішньо за допомогою контейнерного середовища containerd і встановлюється для використання CNI v1.0.0. Це також означає, що версія втулка loopback повинна бути v1.0.0 або пізніше при запуску цієї новішої версії containerd.
Наступна команда bash генерує приклад конфігурації CNI. Тут значення 1.0.0 для версії конфігурації призначено для поля cniVersion для використання при запуску containerd втулком bridge CNI.
cat << EOF | tee /etc/cni/net.d/10-containerd-net.conflist
{
"cniVersion": "1.0.0",
"name": "containerd-net",
"plugins": [
{
"type": "bridge",
"bridge": "cni0",
"isGateway": true,
"ipMasq": true,
"promiscMode": true,
"ipam": {
"type": "host-local",
"ranges": [
[{
"subnet": "10.88.0.0/16"
}],
[{
"subnet": "2001:db8:4860::/64"
}]
],
"routes": [
{ "dst": "0.0.0.0/0" },
{ "dst": "::/0" }
]
}
},
{
"type": "portmap",
"capabilities": {"portMappings": true},
"externalSetMarkChain": "KUBE-MARK-MASQ"
}
]
}
EOF
Оновіть діапазони IP-адрес у прикладі відповідно до вашого випадку використання та плану адресації мережі.
3.4 - Перевірка впливу видалення dockershim на ваш кластер
Компонент dockershim Kubernetes дозволяє використовувати Docker як середовище виконання контейнерів Kubernetes. Вбудований компонент dockershim Kubernetes був видалений у випуску v1.24.
Ця сторінка пояснює, як ваш кластер може використовувати Docker як середовище виконання контейнерів, надає деталі щодо ролі, яку відіграє dockershim при використанні, і показує кроки, які можна виконати, щоб перевірити, чи може видалення dockershim впливати на робочі навантаження.
Пошук залежностей вашого застосунку від Docker
Якщо ви використовуєте Docker для побудови контейнерів вашого застосунку, ви все ще можете запускати ці контейнери на будь-якому середовищі виконання контейнерів. Це використання Docker не вважається залежністю від Docker як середовища виконання контейнерів.
Коли використовується альтернативне середовище виконання контейнерів, виконання команд Docker може або не працювати, або призводити до неочікуваного виводу. Ось як ви можете зʼясувати, чи є у вас залежність від Docker:
- Переконайтеся, що привілейовані Podʼи не виконують команди Docker (наприклад,
docker ps), перезапускають службу Docker (команди типуsystemctl restart docker.service) або змінюють файли Docker, такі як/etc/docker/daemon.json. - Перевірте наявність приватних реєстрів або налаштувань дзеркал образів у файлі конфігурації Docker (наприклад,
/etc/docker/daemon.json). Зазвичай їх потрібно повторно налаштувати для іншого середовища виконання контейнерів. - Перевірте, що скрипти та застосунки, які працюють на вузлах поза вашою інфраструктурою Kubernetes, не виконують команди Docker. Це може бути:
- SSH на вузли для усунення несправностей;
- Сценарії запуску вузлів;
- Встановлені безпосередньо на вузлах агенти безпеки та моніторингу.
- Інструменти сторонніх розробників, які виконують вищезгадані привілейовані операції. Див. Міграція телеметрії та агентів безпеки з dockershim для отримання додаткової інформації.
- Переконайтеся, що немає непрямих залежностей від поведінки dockershim. Це крайній випадок і ймовірно не вплине на ваш застосунок. Деякі інструменти можуть бути налаштовані реагувати на специфічну поведінку Docker, наприклад, видаляти сповіщення про певні метрики або шукати певне повідомлення у лозі як частину інструкцій щодо усунення несправностей. Якщо у вас налаштовано такі інструменти, перевірте поведінку на тестовому кластері перед міграцією.
Пояснення залежності від Docker
Середовище виконання контейнерів — це програмне забезпечення, яке може виконувати контейнери, які складаються з Podʼів Kubernetes. Kubernetes відповідає за оркестрування та планування Podʼів; на кожному вузлі kubelet використовує інтерфейс середовища виконання контейнерів як абстракцію, щоб ви могли використовувати будь-яке сумісне середовище виконання контейнерів.
У своїх перших випусках Kubernetes пропонував сумісність з одним середовищем виконання контейнерів — Docker. Пізніше, в історії проєкту Kubernetes, оператори кластерів хотіли б використовувати додаткові середовища виконання контейнерів. CRI було розроблено для того, щоб дозволити такий вид гнучкості — і kubelet почав підтримувати CRI. Однак, оскільки Docker існував до того, як була винайдена специфікація CRI, проєкт Kubernetes створив адаптер dockershim. Адаптер dockershim дозволяє kubelet взаємодіяти з Docker так, ніби Docker був середовищем виконання контейнерів, сумісним з CRI.
Ви можете прочитати про це в блозі Інтеграція Kubernetes Containerd стає загально доступною.
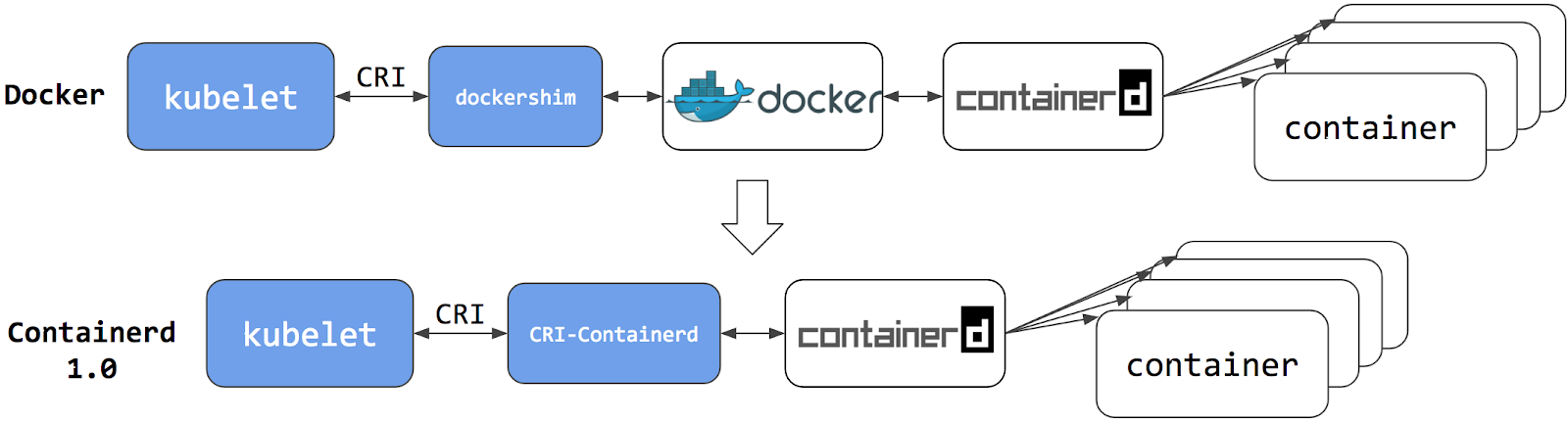
Перехід до Containerd як середовища виконання контейнерів прибирає посередника. Всі ті самі контейнери можуть бути запущені середовищем виконання контейнерів, такими як Containerd, як і раніше. Але тепер, оскільки контейнери розміщуються безпосередньо з середовищем виконання контейнерів, вони не є видимими для Docker. Отже, будь-який інструментарій Docker або стильний інтерфейс користувача, який ви могли використовувати раніше для перевірки цих контейнерів, більше не доступний.
Ви не можете отримати інформацію про контейнери за допомогою команд docker ps або docker inspect. Оскільки ви не можете отримувати перелік контейнерів, ви не можете отримати логи, зупинити контейнери або виконати щось всередині контейнера за допомогою docker exec.
Примітка:
Якщо ви запускаєте робочі навантаження через Kubernetes, найкращий спосіб зупинити контейнер — це через API Kubernetes, а не безпосередньо через середовище виконання контейнерів (ця порада стосується всіх розширень контейнерів, не тільки Docker).Ви все ще можете отримувати образи або будувати їх за допомогою команди docker build. Але образи, побудовані або отримані Docker, не будуть видимі для середовища виконання контейнерів та Kubernetes. Їх потрібно буде розмістити у якомусь реєстрі, щоб їх можна було використовувати в Kubernetes.
Відомі проблеми
Деякі метрики файлової системи відсутні та формат метрик відрізняється
Точка доступу Kubelet /metrics/cadvisor надає метрики Prometheus, як описано в Метрики для системних компонентів Kubernetes. Якщо ви встановите збирач метрик, який залежить від цієї точки доступу, ви можете побачити такі проблеми:
Формат метрик на вузлі Docker - це
k8s_<container-name>_<pod-name>_<namespace>_<pod-uid>_<restart-count>, але формат у іншому середовищі відрізняється. Наприклад, на вузлі containerd він має вигляд<container-id>.Деякі метрики файлової системи відсутні, як описано нижче:
container_fs_inodes_free container_fs_inodes_total container_fs_io_current container_fs_io_time_seconds_total container_fs_io_time_weighted_seconds_total container_fs_limit_bytes container_fs_read_seconds_total container_fs_reads_merged_total container_fs_sector_reads_total container_fs_sector_writes_total container_fs_usage_bytes container_fs_write_seconds_total container_fs_writes_merged_total
Обхідний шлях
Ви можете помʼякшити цю проблему, використовуючи cAdvisor як автономний DaemonSet.
- Знайдіть останній реліз cAdvisor із шаблоном імені
vX.Y.Z-containerd-cri(наприклад,v0.42.0-containerd-cri). - Дотримуйтесь кроків у DaemonSet Kubernetes cAdvisor, щоб створити DaemonSet.
- Drf;Вкажіть збирачу метрик використовувати точку доступу
/metricscAdvisor, яка надає повний набір метрик контейнера в форматі Prometheus.
Альтернативи:
- Використовуйте альтернативне рішення для збору метрик сторонніх розробників.
- Збирайте метрики з Kubelet summary API, який доступний через
/stats/summary.
Що далі
- Прочитайте Міграція з dockershim, щоб зрозуміти наступні кроки
- Прочитайте статтю dockershim deprecation FAQ для отримання додаткової інформації.
3.5 - Міграція агентів телеметрії та безпеки з dockershim
Підтримка Kubernetes прямої інтеграції з Docker Engine є застарілою та була видалена. Більшість застосунків не мають прямої залежності від середовища виконання контейнерів. Однак, є ще багато агентів телеметрії та моніторингу, які мають залежність від Docker для збору метаданих, логів та метрик контейнерів. Цей документ збирає інформацію про те, як виявити ці залежності, а також посилання на те, як перенести ці агенти для використання загальних інструментів або альтернативних середовищ виконання.
Агенти телеметрії та безпеки
У кластері Kubernetes є кілька різних способів запуску агентів телеметрії чи безпеки. Деякі агенти мають пряму залежність від Docker Engine, коли вони працюють як DaemonSets або безпосередньо на вузлах.
Чому деякі агенти телеметрії взаємодіють з Docker Engine?
Історично Kubernetes був спеціально створений для роботи з Docker Engine. Kubernetes займався мережею та плануванням, покладаючись на Docker Engine для запуску та виконання контейнерів (у Podʼах) на вузлі. Деяка інформація, яка стосується телеметрії, наприклад, імʼя Podʼа, доступна лише з компонентів Kubernetes. Інші дані, такі як метрики контейнерів, не є обовʼязком середовища виконання контейнера. Ранні агенти телеметрії мали потребу у запиті середовища виконання контейнера та Kubernetes для передачі точної картини. З часом Kubernetes набув можливості підтримки кількох середовищ виконання контейнерів, і зараз підтримує будь-яке середовище виконання, яке сумісне з інтерфейсом середовища виконання контейнерів.
Деякі агенти телеметрії покладаються тільки на інструменти Docker Engine. Наприклад, агент може виконувати команду, таку як docker ps чи docker top для отримання переліку контейнерів та процесів або docker logs для отримання поточних логів. Якщо вузли у вашому проточному кластері використовують Docker Engine, і ви переходите на інше середовище виконання контейнерів, ці команди більше не працюватимуть.
Виявлення DaemonSets, що залежать від Docker Engine
Якщо Pod хоче викликати dockerd, що працює на вузлі, він повинен або:
- змонтувати файлову систему, що містить привілейований сокет Docker, як том; або
- безпосередньо змонтувати конкретний шлях привілейованого сокета Docker, також як том.
Наприклад: на образах COS Docker відкриває свій Unix сокет у /var/run/docker.sock. Це означає, що специфікація Pod буде містити монтування тому hostPath з /var/run/docker.sock.
Нижче наведено приклад сценарію оболонки для пошуку Podʼів, які мають монтування, які безпосередньо зіставляються з сокетом Docker. Цей сценарій виводить простір імен та імʼя Podʼа. Ви можете видалити grep '/var/run/docker.sock', щоб переглянути інші монтування.
kubectl get pods --all-namespaces \
-o=jsonpath='{range .items[*]}{"\n"}{.metadata.namespace}{":\t"}{.metadata.name}{":\t"}{range .spec.volumes[*]}{.hostPath.path}{", "}{end}{end}' \
| sort \
| grep '/var/run/docker.sock'
Примітка:
Є альтернативні способи для Pod мати доступ до Docker на вузлі. Наприклад, батьківська тека/var/run може бути змонтована замість повного шляху (як у цьому прикладі). Представлений вище сценарій виявляє лише найпоширеніші використання.Виявлення залежності від Docker агентів вузлів
Якщо вузли кластера налаштовані та встановлюють додаткові заходи безпеки та агенти телеметрії на вузлі, перевірте у вендора агента, чи має він будь-які залежності від Docker.
Вендори агентів телеметрії та безпеки
Цей розділ призначений для збирання інформації про різноманітних агентів телеметрії та безпеки, які можуть мати залежність від середовищ виконання контейнерів.
Ми зберігаємо робочу версію інструкцій щодо перенесення для різних вендорів агентів телеметрії та безпеки у документі Google. Будь ласка, звʼяжіться з вендором, щоб отримати актуальні інструкції щодо міграції з dockershim.
Міграція з dockershim
Aqua
Ніяких змін не потрібно: все має працювати без перешкод при перемиканні середовища виконання.
Datadog
Як перенести: Застарівання Docker у Kubernetes Pod, який має доступ до Docker Engine, може мати назву, яка містить будь-що з:
datadog-agentdatadogdd-agent
Dynatrace
Як перенести: Міграція з Docker до загальних метрик контейнера в Dynatrace
Оголошення підтримки Containerd: Автоматична повна видимість у стеку в середовищах Kubernetes на основі containerd
Оголошення підтримки CRI-O: Автоматична повна видимість у ваших контейнерах Kubernetes з CRI-O (бета)
Pod, який має доступ до Docker, може мати назву, яка містить:
dynatrace-oneagent
Falco
Як перенести: Міграція Falco з dockershim. Falco підтримує будь-яке середовище виконання, сумісне з CRI (стандартно використовується containerd); документація пояснює всі деталі. Pod, який має доступ до Docker, може мати назву, яка містить:
falco
Prisma Cloud Compute
Перевірте документацію для Prisma Cloud, в розділі "Встановлення Prisma Cloud в кластер CRI (не Docker)". Pod, який має доступ до Docker, може мати назву, подібну до:
twistlock-defender-ds
SignalFx (Splunk)
Смарт-агент SignalFx (застарілий) використовує кілька різних моніторів для Kubernetes, включаючи kubernetes-cluster, kubelet-stats/kubelet-metrics та docker-container-stats. Монітор kubelet-stats раніше був застарілим вендором на користь kubelet-metrics. Монітор docker-container-stats є одним з тих, що стосуються видалення dockershim. Не використовуйте монітор docker-container-stats з середовищами виконання контейнерів, відмінними від Docker Engine.
Як перейти з агента, залежного від dockershim:
- Видаліть
docker-container-statsзі списку налаштованих моніторів. Зверніть увагу, що залишення цього монітора увімкненим з не-dockershim середовищем виконання призведе до неправильних метрик при встановленні docker на вузлі та відсутності метрик, коли docker не встановлено. - Увімкніть та налаштуйте монітор
kubelet-metrics.
Примітка:
Набір зібраних метрик зміниться. Перегляньте ваші правила сповіщень та інфопанелі.Pod, який має доступ до Docker, може мати назву, подібну до:
signalfx-agent
Yahoo Kubectl Flame
Flame не підтримує середовищ виконання контейнера, відмінні від Docker. Див. https://github.com/yahoo/kubectl-flame/issues/51
4 - Генерація сертифікатів вручну
При використанні автентифікації сертифіката клієнта ви можете генерувати сертифікати вручну за допомогою easyrsa, openssl або cfssl.
easyrsa
З easyrsa ви можете вручну генерувати сертифікати для вашого кластера.
Завантажте, розпакуйте та ініціалізуйте патчену версію
easyrsa3.curl -LO https://dl.k8s.io/easy-rsa/easy-rsa.tar.gz tar xzf easy-rsa.tar.gz cd easy-rsa-master/easyrsa3 ./easyrsa init-pkiЗгенеруйте новий центр сертифікації (CA).
--batchвстановлює автоматичний режим;--req-cnвказує загальну назву (CN, Common Name) для нового кореневого сертифіката CA../easyrsa --batch "--req-cn=${MASTER_IP}@`date +%s`" build-ca nopassЗгенеруйте сертифікат та ключ сервера.
Аргумент
--subject-alt-nameвстановлює можливі IP-адреси та імена DNS, за якими буде доступний сервер API.MASTER_CLUSTER_IPзазвичай є першою IP-адресою з діапазону служб CIDR, який вказаний як аргумент--service-cluster-ip-rangeдля сервера API та компонента керування контролером. Аргумент--daysвикористовується для встановлення кількості днів чинності сертифіката. У прикладі нижче також припускається, що ви використовуєтеcluster.localяк типове імʼя домену DNS../easyrsa --subject-alt-name="IP:${MASTER_IP},"\ "IP:${MASTER_CLUSTER_IP},"\ "DNS:kubernetes,"\ "DNS:kubernetes.default,"\ "DNS:kubernetes.default.svc,"\ "DNS:kubernetes.default.svc.cluster,"\ "DNS:kubernetes.default.svc.cluster.local" \ --days=10000 \ build-server-full server nopassСкопіюйте
pki/ca.crt,pki/issued/server.crtтаpki/private/server.keyу вашу теку.Заповніть та додайте наступні параметри до параметрів запуску сервера API:
--client-ca-file=/yourdirectory/ca.crt --tls-cert-file=/yourdirectory/server.crt --tls-private-key-file=/yourdirectory/server.key
openssl
Ви також можете вручну генерувати сертифікати за допомогою openssl.
Згенеруйте 2048-бітний ca.key :
openssl genrsa -out ca.key 2048Згенеруйте ca.crt для ca.key (використовуйте
-daysдля встановлення кількості днів чинності сертифіката):openssl req -x509 -new -nodes -key ca.key -subj "/CN=${MASTER_IP}" -days 10000 -out ca.crtЗгенеруйте 2048-бітний server.key:
openssl genrsa -out server.key 2048Створіть конфігураційний файл для генерування Certificate Signing Request (CSR).
Переконайтеся, що ви встановили власні значення для параметрів в кутових дужках, наприклад
<MASTER_IP>, замінивши їх на власні значення перед збереженням файлу, наприклад з назвоюcsr.conf. Зауважте, що значення<MASTER_CLUSTER_IP>є IP-адресою API-сервера, як про це йдеться в попередньому розділі. Приклад конфігураційного файлу нижче використовуєcluster.localяк типове імʼя домену DNS.[ req ] default_bits = 2048 prompt = no default_md = sha256 req_extensions = req_ext distinguished_name = dn [ dn ] C = <country> ST = <state> L = <city> O = <organization> OU = <organization unit> CN = <MASTER_IP> [ req_ext ] subjectAltName = @alt_names [ alt_names ] DNS.1 = kubernetes DNS.2 = kubernetes.default DNS.3 = kubernetes.default.svc DNS.4 = kubernetes.default.svc.cluster DNS.5 = kubernetes.default.svc.cluster.local IP.1 = <MASTER_IP> IP.2 = <MASTER_CLUSTER_IP> [ v3_ext ] authorityKeyIdentifier=keyid,issuer:always basicConstraints=CA:FALSE keyUsage=keyEncipherment,dataEncipherment extendedKeyUsage=serverAuth,clientAuth subjectAltName=@alt_namesЗгенеруйте Certificate Signing Request (CSR) на основі конфігураційного файлу:
openssl req -new -key server.key -out server.csr -config csr.confЗгенеруйте сертифікат сервера, використовуючи ca.key, ca.crt та server.csr:
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \ -CAcreateserial -out server.crt -days 10000 \ -extensions v3_ext -extfile csr.conf -sha256Перегляньте запит на підписання сертифіката:
openssl req -noout -text -in ./server.csrПерегляньте сертифікат:
openssl x509 -noout -text -in ./server.crt
Нарешті, додайте ті ж самі параметри до параметрів запуску сервера API.
cfssl
Ви також можете вручну генерувати сертифікати за допомогою cfssl.
Завантажте, розпакуйте та підготуйте інструменти як показано нижче
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl_1.5.0_linux_amd64 -o cfssl chmod +x cfssl curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssljson_1.5.0_linux_amd64 -o cfssljson chmod +x cfssljson curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl-certinfo_1.5.0_linux_amd64 -o cfssl-certinfo chmod +x cfssl-certinfoСтворіть теку для зберігання артифактів та ініціалізації cfssl:
mkdir cert cd cert ../cfssl print-defaults config > config.json ../cfssl print-defaults csr > csr.jsonСтворіть конфігураційний файл JSON для генерації файлу CA, наприклад,
ca-config.json:{ "signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "8760h" } } } }Створіть конфігураційний файл JSON для генерації Certificate Signing Request (CSR), наприклад,
ca-csr.json. Переконайтеся, що ви встановили власні значення для параметрів в кутових дужках.{ "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names":[{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] }Згенеруйте сертифікат CA (
ca.pem) та ключ CA (ca-key.pem):../cfssl gencert -initca ca-csr.json | ../cfssljson -bare caСтворіть конфігураційний файл JSON для генерації ключів та сертифікатів для сервера API, наприклад,
server-csr.json. Переконайтеся, що ви встановили власні значення для параметрів в кутових дужках.<MASTER_CLUSTER_IP>є IP-адресою кластера, як про це йдеться в попередньому розділі. В прикладі нижче також припускається, що ви використовуєтеcluster.localяк типове імʼя домену DNS.{ "CN": "kubernetes", "hosts": [ "127.0.0.1", "<MASTER_IP>", "<MASTER_CLUSTER_IP>", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] }Згенеруйте ключ та сертифікат для сервера API, які типово зберігаються у файлах
server-key.pemтаserver.pem, відповідно:../cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \ --config=ca-config.json -profile=kubernetes \ server-csr.json | ../cfssljson -bare server
Розповсюдження самопідписних сертифікатів CA
Клієнтський вузол може не визнавати самопідписні сертифікати CA. Для оточення, що не є операційним, або для операційного оточення, що працює за корпоративним фаєрволом, ви можете розповсюджувати самопідписні сертифікати CA на всіх клієнтів та оновлювати перелік довірених сертифікатів.
На кожному клієнті виконайте наступні кроки:
sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
API сертифікатів
Ви можете використовувати certificates.k8s.io API для надання сертифікатів x509 для використання для автентифікації, як про це йдеться на сторінці Керування TLS в кластері.
5 - Керування ресурсами памʼяті, CPU та API
5.1 - Налаштування типових запитів та обмежень памʼяті для простору імен
Ця сторінка показує, як налаштувати типові запити та обмеження памʼяті для простору імен.
Кластер Kubernetes може бути розділений на простори імен. Якщо у вас є простір імен, в якому вже є типове обмеження памʼяті limit, і ви спробуєте створити Pod з контейнером, який не вказує своє власне обмеження памʼяті, то панель управління назначає типове обмеження памʼяті цьому контейнеру.
Kubernetes назначає типовий запит памʼяті за певних умов, які будуть пояснені пізніше в цій темі.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У вас має бути доступ до створення просторів імен у вашому кластері.
Кожен вузол у вашому кластері повинен мати принаймні 2 ГіБ памʼяті.
Створення простору імен
Створіть простір імен, щоб ресурси, які ви створюєте у цьому завданні, були ізольовані від решти вашого кластера.
kubectl create namespace default-mem-example
Створення LimitRange та Pod
Ось маніфест для прикладу LimitRange. Маніфест вказує типовий запит памʼяті та типове обмеження памʼяті.
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: Container
Створіть LimitRange у просторі імен default-mem-example:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults.yaml --namespace=default-mem-example
Тепер, якщо ви створите Pod у просторі імен default-mem-example, і будь-який контейнер у цьому Podʼі не вказує свої власні значення для запиту та обмеження памʼяті, то панель управління застосовує типові значення: запит памʼяті 256MiB та обмеження памʼяті 512MiB.
Ось приклад маніфесту для Pod, який має один контейнер. Контейнер не вказує запиту та обмеження памʼяті.
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo
spec:
containers:
- name: default-mem-demo-ctr
image: nginx
Створіть цей Pod.
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod.yaml --namespace=default-mem-example
Перегляньте інформацію про цей Pod:
kubectl get pod memory-defaults-pod --namespace=default-mem-example
Вивід має показати, що контейнер Podʼа має обмеження на запит памʼяті 256MiB та обмеження памʼяті 512MiB. Ці значення були назначені через типові обмеження памʼяті, вказані в LimitRange.
containers:
- image: nginx
imagePullPolicy: Always
name: default-mem-demo-ctr
resources:
limits:
memory: 512Mi
requests:
memory: 256Mi
Видаліть свій Pod:
kubectl delete pod memory-defaults-pod --namespace=default-mem-example
Що якщо ви вказуєте обмеження контейнера, але не його запит?
Ось маніфест для Podʼа з одним контейнером. Контейнер вказує обмеження памʼяті, але не запит:
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-2
spec:
containers:
- name: default-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1Gi"
Створіть Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-2.yaml --namespace=default-mem-example
Перегляньте детальну інформацію про Pod:
kubectl get pod default-mem-demo-2 --output=yaml --namespace=default-mem-example
Вивід показує, що запит памʼяті контейнера встановлено таким чином, щоб відповідати його обмеженню памʼяті. Зверніть увагу, що контейнеру не було назначено типового значення запиту памʼяті 256Mi.
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
Що якщо ви вказуєте запит контейнера, але не його обмеження?
Ось маніфест для Podʼа з одним контейнером. Контейнер вказує запит памʼяті, але не обмеження:
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-3
spec:
containers:
- name: default-mem-demo-3-ctr
image: nginx
resources:
requests:
memory: "128Mi"
Створіть Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-3.yaml --namespace=default-mem-example
Перегляньте специфікацію Podʼа:
kubectl get pod default-mem-demo-3 --output=yaml --namespace=default-mem-example
Вивід показує, що запит памʼяті контейнера встановлено на значення, вказане в маніфесті контейнера. Контейнер обмежений використовувати не більше 512MiB памʼяті, що відповідає типовому обмеженню памʼяті для простору імен.
resources:
limits:
memory: 512Mi
requests:
memory: 128Mi
Примітка:
LimitRange не перевіряє відповідність типових значень, які він застосовує. Це означає, що типове значення для обмеження, встановлене за допомогою LimitRange, може бути меншим за значення запиту, вказане для контейнера в специфікації, яку клієнт подає на сервер API. Якщо це станеться, остаточний Pod не буде можливим для розміщення. Дивіться Обмеження на ресурси лімітів та запитів для отримання додаткової інформації.Мотивація для типових обмежень та запитів памʼяті
Якщо у вашому просторі імен налаштовано квоту ресурсів памʼяті, корисно мати типове значення для обмеження памʼяті. Ось три обмеження, які накладає квота ресурсів на простір імен:
- Для кожного Podʼа, який працює у просторі імен, Pod та кожен з його контейнерів повинні мати обмеження памʼяті. (Якщо ви вказуєте обмеження памʼяті для кожного контейнера у Podʼі, Kubernetes може вивести типове обмеження памʼяті на рівні Podʼа, додавши обмеження для його контейнерів).
- Обмеження памʼяті застосовує резервування ресурсів на вузлі, де запускається відповідний Pod. Загальна кількість памʼяті, зарезервована для всіх Podʼів у просторі імен, не повинна перевищувати вказаного обмеження.
- Загальна кількість памʼяті, що фактично використовується всіма Podʼами у просторі імен, також не повинна перевищувати вказаного обмеження.
Коли ви додаєте обмеження (LimitRange):
Якщо будь-який Pod у цьому просторі імен, що містить контейнер, не вказує своє власне обмеження памʼяті, панель управління застосовує типове обмеження памʼяті для цього контейнера, і Podʼу може бути дозволено запуститися в просторі імен, який обмежено квотою ресурсів памʼяті.
Очищення
Видаліть простір імен:
kubectl delete namespace default-mem-example
Що далі
Для адміністраторів кластера
Налаштування типових запитів та обмежень CPU для простору імен
Налаштування мінімальних та максимальних обмежень памʼяті для простору імен
Налаштування мінімальних та максимальних обмежень CPU для простору імен
Для розробників застосунків
5.2 - Налаштування типових запитів та обмежень CPU для простору імен
Ця сторінка показує, як налаштувати типові запити та обмеження CPU для просторів імен.
Кластер Kubernetes може бути розділений на простори імен. Якщо ви створюєте Pod у просторі імен, який має типове обмеження CPU limit, і будь-який контейнер у цьому Podʼі не вказує своє власне обмеження CPU, то панель управління назначає типове обмеження CPU цьому контейнеру.
Kubernetes назначає типовий запит CPU request, але лише за певних умов, які будуть пояснені пізніше на цій сторінці.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Вам потрібно мати доступ для створення просторів імен у вашому кластері.
Якщо ви ще не знайомі з тим, що означає 1.0 CPU в Kubernetes, прочитайте значення CPU.
Створення простору імен
Створіть простір імен, щоб ресурси, які ви створюєте у цьому завданні, були ізольовані від решти вашого кластера.
kubectl create namespace default-cpu-example
Створення LimitRange та Podʼа
Ось маніфест для прикладу LimitRange. У маніфесті вказано типовий запит CPU та типове обмеження CPU.
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-limit-range
spec:
limits:
- default:
cpu: 1
defaultRequest:
cpu: 0.5
type: Container
Створіть LimitRange у просторі імен default-cpu-example:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults.yaml --namespace=default-cpu-example
Тепер, якщо ви створюєте Pod у просторі імен default-cpu-example, і будь-який контейнер у цьому Podʼі не вказує свої власні значення для запиту та обмеження CPU, то панель управління застосовує типові значення: запит CPU 0.5 та типове обмеження CPU 1.
Ось маніфест для Podʼа з одним контейнером. Контейнер не вказує запит CPU та обмеження.
apiVersion: v1
kind: Pod
metadata:
name: default-cpu-demo
spec:
containers:
- name: default-cpu-demo-ctr
image: nginx
Створіть Pod.
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults-pod.yaml --namespace=default-cpu-example
Перегляньте специфікацію Podʼа :
kubectl get pod default-cpu-demo --output=yaml --namespace=default-cpu-example
Вивід показує, що єдиний контейнер Podʼа має запит CPU 500m cpu (що ви можете читати як “500 millicpu”), і обмеження CPU 1 cpu. Це типові значення, вказані обмеженням.
containers:
- image: nginx
imagePullPolicy: Always
name: default-cpu-demo-ctr
resources:
limits:
cpu: "1"
requests:
cpu: 500m
Що якщо ви вказуєте обмеження контейнера, але не його запит?
Ось маніфест для Podʼа з одним контейнером. Контейнер вказує обмеження CPU, але не запит:
apiVersion: v1
kind: Pod
metadata:
name: default-cpu-demo-2
spec:
containers:
- name: default-cpu-demo-2-ctr
image: nginx
resources:
limits:
cpu: "1"
Створіть Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults-pod-2.yaml --namespace=default-cpu-example
Перегляньте специфікацію Podʼа, який ви створили:
kubectl get pod default-cpu-demo-2 --output=yaml --namespace=default-cpu-example
Вивід показує, що запит CPU контейнера встановлено таким чином, щоб відповідати його обмеженню CPU. Зверніть увагу, що контейнеру не було назначено типове значення запиту CPU 0.5 cpu:
resources:
limits:
cpu: "1"
requests:
cpu: "1"
Що якщо ви вказуєте запит контейнера, але не його обмеження?
Ось приклад маніфесту для Podʼа з одним контейнером. Контейнер вказує запит CPU, але не обмеження:
apiVersion: v1
kind: Pod
metadata:
name: default-cpu-demo-3
spec:
containers:
- name: default-cpu-demo-3-ctr
image: nginx
resources:
requests:
cpu: "0.75"
Створіть Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults-pod-3.yaml --namespace=default-cpu-example
Перегляньте специфікацію Podʼа , який ви створили:
kubectl get pod default-cpu-demo-3 --output=yaml --namespace=default-cpu-example
Вивід показує, що запит CPU контейнера встановлено на значення, яке ви вказали при створенні Podʼа (іншими словами: воно відповідає маніфесту). Однак обмеження CPU цього ж контейнера встановлено на 1 cpu, що є типовим обмеженням CPU для цього простору імен.
resources:
limits:
cpu: "1"
requests:
cpu: 750m
Мотивація для типових обмежень та запитів CPU
Якщо ваш простір імен має налаштовану квоту ресурсів CPU, корисно мати типове значення для обмеження CPU. Ось два обмеження, які накладає квота ресурсів CPU на простір імен:
- Для кожного Podʼа, який працює в просторі імен, кожен з його контейнерів повинен мати обмеження CPU.
- Обмеження CPU застосовує резервування ресурсів на вузлі, де запускається відповідний Pod. Загальна кількість CPU, яка зарезервована для використання всіма Podʼами в просторі імен, не повинна перевищувати вказане обмеження.
Коли ви додаєте LimitRange:
Якщо будь-який Pod у цьому просторі імен, що містить контейнер, не вказує своє власне обмеження CPU, панель управління застосовує типове обмеження CPU цьому контейнеру, і Pod може отримати дозвіл на запуск у просторі імен, який обмежено квотою ресурсів CPU.
Прибирання
Видаліть ваш простір імен:
kubectl delete namespace default-cpu-example
Що далі
Для адміністраторів кластера
Налаштування типових запитів та обмежень памʼяті для простору імен
Налаштування мінімальних та максимальних обмежень памʼяті для простору імен
Налаштування мінімальних та максимальних обмежень CPU для простору імен
Для розробників застосунків
5.3 - Налаштування мінімальних та максимальних обмежень памʼяті для простору імен
Ця сторінка показує, як встановити мінімальні та максимальні значення для памʼяті, яку використовують контейнери, що працюють у просторі імен. Мінімальні та максимальні значення памʼяті ви вказуєте у LimitRange обʼєкті. Якщо Pod не відповідає обмеженням, накладеним LimitRange, його неможливо створити в просторі імен.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У вас повинен бути доступ до створення просторів імен у вашому кластері.
Кожен вузол у вашому кластері повинен мати щонайменше 1 GiB памʼяті для Podʼів.
Створення простору імен
Створіть простір імен, щоб ресурси, які ви створюєте в цьому завданні, були відокремлені від решти вашого кластера.
kubectl create namespace constraints-mem-example
Створення LimitRange та Podʼа
Ось приклад маніфесту для LimitRange:
apiVersion: v1
kind: LimitRange
metadata:
name: mem-min-max-demo-lr
spec:
limits:
- max:
memory: 1Gi
min:
memory: 500Mi
type: Container
Створіть LimitRange:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints.yaml --namespace=constraints-mem-example
Перегляньте докладну інформацію про LimitRange:
kubectl get limitrange mem-min-max-demo-lr --namespace=constraints-mem-example --output=yaml
Вивід показує мінімальні та максимальні обмеження памʼяті як очікувалося. Але зверніть увагу, що, навіть якщо ви не вказали типові значення в конфігураційному файлі для LimitRange, вони були створені автоматично.
limits:
- default:
memory: 1Gi
defaultRequest:
memory: 1Gi
max:
memory: 1Gi
min:
memory: 500Mi
type: Container
Тепер кожного разу, коли ви визначаєте Pod у просторі імен constraints-mem-example, Kubernetes виконує такі кроки:
Якщо будь-який контейнер в цьому Podʼі не вказує свій власний запит памʼяті та обмеження, панель управління надає типовий запит та обмеження памʼяті цьому контейнеру.
Перевірте, що кожний контейнер у цьому Podʼі запитує принаймні 500 MiB памʼяті.
Перевірте, що кожний контейнер у цьому Podʼі запитує не більше 1024 MiB (1 GiB) памʼяті.
Ось маніфест для Podʼа з одним контейнером. У специфікації Podʼа, єдиний контейнер вказує запит памʼяті 600 MiB та обмеження памʼяті 800 MiB. Ці значення задовольняють мінімальні та максимальні обмеження памʼяті, накладені LimitRange.
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo
spec:
containers:
- name: constraints-mem-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "600Mi"
Створіть Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod.yaml --namespace=constraints-mem-example
Перевірте, що Pod працює і його контейнер є справним:
kubectl get pod constraints-mem-demo --namespace=constraints-mem-example
Перегляньте докладну інформацію про Pod:
kubectl get pod constraints-mem-demo --output=yaml --namespace=constraints-mem-example
Вивід показує, що контейнер у цьому Podʼі має запит памʼяті 600 MiB та обмеження памʼяті 800 MiB. Ці значення задовольняють обмеження, накладені LimitRange на цей простір імен:
resources:
limits:
memory: 800Mi
requests:
memory: 600Mi
Видаліть свій Pod:
kubectl delete pod constraints-mem-demo --namespace=constraints-mem-example
Спроба створення Podʼа, який перевищує максимальне обмеження памʼяті
Ось маніфест для Podʼа з одним контейнером. Контейнер вказує запит памʼяті 800 MiB та обмеження памʼяті 1.5 GiB.
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-2
spec:
containers:
- name: constraints-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1.5Gi"
requests:
memory: "800Mi"
Спробуйте створити Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-2.yaml --namespace=constraints-mem-example
Вивід показує, що Pod не було створено, оскільки він визначає контейнер, який запитує більше памʼяті, ніж дозволяється:
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-2.yaml":
pods "constraints-mem-demo-2" is forbidden: maximum memory usage per Container is 1Gi, but limit is 1536Mi.
Спроба створення Podʼа, який не відповідає мінімальному запиту памʼяті
Ось маніфест для Podʼа з одним контейнером. Цей контейнер вказує запит памʼяті 100 MiB та обмеження памʼяті 800 MiB.
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-3
spec:
containers:
- name: constraints-mem-demo-3-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "100Mi"
Спробуйте створити Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-3.yaml --namespace=constraints-mem-example
Вивід показує, що Pod не було створено, оскільки він визначає контейнер який запитує менше памʼяті, ніж вимагається:
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-3.yaml":
pods "constraints-mem-demo-3" is forbidden: minimum memory usage per Container is 500Mi, but request is 100Mi.
Створення Podʼа, який не вказує жодного запиту памʼяті чи обмеження
Ось маніфест для Podʼа з одним контейнером. Контейнер не вказує запиту памʼяті, і він не вказує обмеження памʼяті.
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-4
spec:
containers:
- name: constraints-mem-demo-4-ctr
image: nginx
Створіть Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-4.yaml --namespace=constraints-mem-example
Перегляньте докладну інформацію про Pod:
kubectl get pod constraints-mem-demo-4 --namespace=constraints-mem-example --output=yaml
Вивід показує, що єдиний контейнер у цьому Podʼі має запит памʼяті 1 GiB та обмеження памʼяті 1 GiB. Як цей контейнер отримав ці значення?
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
Тому що ваш Pod не визначає жодного запиту памʼяті та обмеження для цього контейнера, кластер застосував типовий запит памʼяті та обмеження з LimitRange.
Це означає, що визначення цього Podʼа показує ці значення. Ви можете перевірити це за допомогою kubectl describe:
# Подивіться розділ "Requests:" виводу
kubectl describe pod constraints-mem-demo-4 --namespace=constraints-mem-example
На цей момент ваш Pod може працювати або не працювати. Памʼятайте, що передумовою для цього завдання є те, що ваші вузли мають щонайменше 1 GiB памʼяті. Якщо кожен з ваших вузлів має лише 1 GiB памʼяті, тоді недостатньо виділеної памʼяті на будь-якому вузлі для обслуговування запиту памʼяті 1 GiB. Якщо ви використовуєте вузли з 2 GiB памʼяті, то, ймовірно, у вас достатньо місця для розміщення запиту 1 GiB.
Видаліть свій Pod:
kubectl delete pod constraints-mem-demo-4 --namespace=constraints-mem-example
Застосування мінімальних та максимальних обмежень памʼяті
Максимальні та мінімальні обмеження памʼяті, накладені на простір імен LimitRange, діють тільки під час створення або оновлення Podʼа. Якщо ви змінюєте LimitRange, це не впливає на Podʼи, що були створені раніше.
Причини для мінімальних та максимальних обмежень памʼяті
Як адміністратор кластера, вам може знадобитися накладати обмеження на кількість памʼяті, яку можуть використовувати Podʼи. Наприклад:
Кожен вузол у кластері має 2 GiB памʼяті. Ви не хочете приймати будь-який Pod, який запитує більше ніж 2 GiB памʼяті, оскільки жоден вузол у кластері не може підтримати запит.
Кластер використовується як виробництвом, так і розробкою вашими відділами. Ви хочете дозволити навантаженням в експлуатації використовувати до 8 GiB памʼяті, але ви хочете обмежити навантаження в розробці до 512 MiB. Ви створюєте окремі простори імен для експлуатації та розробки і застосовуєте обмеження памʼяті для кожного простору імен.
Прибирання
Видаліть свій простір імен:
kubectl delete namespace constraints-mem-example
Що далі
Для адміністраторів кластера
Налаштувати типові запити та обмеження памʼяті для простору імен
Налаштувати типові запити та обмеження CPU для простору імен
Налаштувати мінімальні та максимальні обмеження CPU для простору імен
Для розробників застосунків
5.4 - Налаштування мінімальних та максимальних обмеженнь CPU для простору імен
Ця сторінка показує, як встановити мінімальні та максимальні значення ресурсів CPU, що використовуються контейнерами та Podʼами в просторі імен. Ви вказуєте мінімальні та максимальні значення CPU в обʼєкті LimitRange. Якщо Pod не відповідає обмеженням, накладеним LimitRange, його не можна створити у просторі імен.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Ви повинні мати доступ до створення просторів імен у своєму кластері.
Кожен вузол у вашому кластері повинен мати щонайменше 1,0 CPU, доступний для Podʼів. Див. значення CPU, щоб дізнатися, що означає в Kubernetes "1 CPU".
Створення простору імен
Створіть простір імен, щоб ресурси, які ви створюєте у цьому завданні, були відокремлені від інших частин вашого кластера.
kubectl create namespace constraints-cpu-example
Створення LimitRange та Podʼа
Ось маніфест для прикладу LimitRange:
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-min-max-demo-lr
spec:
limits:
- max:
cpu: "800m"
min:
cpu: "200m"
type: Container
Створіть LimitRange:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints.yaml --namespace=constraints-cpu-example
Перегляньте детальну інформацію про LimitRange:
kubectl get limitrange cpu-min-max-demo-lr --output=yaml --namespace=constraints-cpu-example
Вивід показує мінімальні та максимальні обмеження CPU, як очікувалося. Але зверніть увагу, що навіть якщо ви не вказали типових значень у конфігураційному файлі для LimitRange, вони були створені автоматично.
limits:
- default:
cpu: 800m
defaultRequest:
cpu: 800m
max:
cpu: 800m
min:
cpu: 200m
type: Container
Тепер, кожного разу, коли ви створюєте Pod у просторі імен constraints-cpu-example (або який-небудь інший клієнт API Kubernetes створює еквівалентний Pod), Kubernetes виконує ці кроки:
Якщо який-небудь контейнер у цьому Podʼі не вказує свої власні CPU-запити та обмеження, панель управління призначає контейнеру типове значення для CPU-запиту та обмеження.
Перевірте, що кожен контейнер у цьому Podʼі вказує CPU-запит, який більший або дорівнює 200 мілі-CPU.
Перевірте, що кожен контейнер у цьому Podʼі вказує обмеження CPU, яке менше або дорівнює 800 мілі-CPU.
Примітка:
При створенні обʼєктаLimitRange можна вказати обмеження на використання великих сторінок або GPU. Однак, коли одночасно вказуються default та defaultRequest для цих ресурсів, два значення повинні бути однаковими.Ось маніфест для Podʼа з одним контейнером. Маніфест контейнера вказує CPU-запит у розмірі 500 мілі-CPU та обмеження CPU у розмірі 800 мілі-CPU. Це задовольняє мінімальні та максимальні обмеження CPU, накладені LimitRange на цей простір імен.
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo
spec:
containers:
- name: constraints-cpu-demo-ctr
image: nginx
resources:
limits:
cpu: "800m"
requests:
cpu: "500m"
Створіть Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod.yaml --namespace=constraints-cpu-example
Перевірте, що Pod працює, а його контейнер є справним:
kubectl get pod constraints-cpu-demo --namespace=constraints-cpu-example
Перегляньте детальну інформацію про Pod:
kubectl get pod constraints-cpu-demo --output=yaml --namespace=constraints-cpu-example
Вивід показує, що єдиний контейнер Podʼа має запит CPU у розмірі 500 мілі-CPU та обмеження CPU 800 мілі-CPU. Це задовольняє обмеження, накладеним LimitRange.
resources:
limits:
cpu: 800m
requests:
cpu: 500m
Видаліть Pod
kubectl delete pod constraints-cpu-demo --namespace=constraints-cpu-example
Спроба створити Pod, який перевищує максимальне обмеження CPU
Ось маніфест для Podʼа з одним контейнером. Контейнер вказує запит CPU у розмірі 500 мілі-CPU та обмеження CPU у розмірі 1,5 CPU.
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo-2
spec:
containers:
- name: constraints-cpu-demo-2-ctr
image: nginx
resources:
limits:
cpu: "1.5"
requests:
cpu: "500m"
Спробуйте створити Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod-2.yaml --namespace=constraints-cpu-example
Вивід показує, що Pod не створено, оскільки визначений контейнер є неприйнятним. Цей контейнер є неприйнятним, оскільки він вказує обмеження CPU, яке занадто велике:
Error from server (Forbidden): error when creating "examples/admin/resource/cpu-constraints-pod-2.yaml":
pods "constraints-cpu-demo-2" is forbidden: maximum cpu usage per Container is 800m, but limit is 1500m.
Спроба створити Pod, який не відповідає мінімальному запиту CPU
Ось маніфест для Podʼа з одним контейнером. Контейнер вказує запит CPU у розмірі 100 мілі-CPU та обмеження CPU у розмірі 800 мілі-CPU.
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo-3
spec:
containers:
- name: constraints-cpu-demo-3-ctr
image: nginx
resources:
limits:
cpu: "800m"
requests:
cpu: "100m"
Спробуйте створити Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod-3.yaml --namespace=constraints-cpu-example
Вивід показує, що Pod не створено, оскільки визначений контейнер є неприйнятним. Цей контейнер є неприйнятним, оскільки він вказує запит CPU, який нижче мінімального:
Error from server (Forbidden): error when creating "examples/admin/resource/cpu-constraints-pod-3.yaml":
pods "constraints-cpu-demo-3" is forbidden: minimum cpu usage per Container is 200m, but request is 100m.
Створення Podʼа, який не вказує жодного запиту або обмеження CPU
Ось маніфест для Podʼа з одним контейнером. Контейнер не вказує запит CPU і не вказує обмеження CPU.
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo-4
spec:
containers:
- name: constraints-cpu-demo-4-ctr
image: vish/stress
Створіть Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod-4.yaml --namespace=constraints-cpu-example
Перегляньте детальну інформацію про Pod:
kubectl get pod constraints-cpu-demo-4 --namespace=constraints-cpu-example --output=yaml
Вивід показує, що у Podʼі єдиний контейнер має запит CPU у розмірі 800 мілі-CPU та обмеження CPU у розмірі 800 мілі-CPU. Як цей контейнер отримав ці значення?
resources:
limits:
cpu: 800m
requests:
cpu: 800m
Тому що цей контейнер не вказав свій власний запит CPU та обмеження, панель управління застосовує стандартні обмеження та запит CPU з LimitRange для цього простору імен.
На цьому етапі ваш Pod може бути запущеним або не запущеним. Згадайте, що передумовою для цієї задачі є те, що у ваших вузлах повинно бути щонайменше 1 CPU для використання. Якщо в кожному вузлі у вас є лише 1 CPU, то, можливо, немає достатньої кількості CPU на будь-якому вузлі для виконання запиту у розмірі 800 мілі-CPU. Якщо ви використовуєте вузли з 2 CPU, то, ймовірно, у вас достатньо CPU для виконання запиту у розмірі 800 мілі-CPU.
Видаліть ваш Pod:
kubectl delete pod constraints-cpu-demo-4 --namespace=constraints-cpu-example
Застосування мінімальних та максимальних обмежень CPU
Максимальні та мінімальні обмеження CPU, накладені на простір імен за допомогою LimitRange, застосовуються лише при створенні або оновленні Podʼа. Якщо ви зміните LimitRange, це не вплине на Podʼи, які були створені раніше.
Причини для мінімальних та максимальних обмежень CPU
Як адміністратор кластера, ви можете бажати накладати обмеження на ресурси CPU, які можуть використовувати Podʼи. Наприклад:
Кожен вузол у кластері має 2 CPU. Ви не хочете приймати жодного Podʼа, який запитує більше, ніж 2 CPU, оскільки жоден вузол у кластері не може підтримати цей запит.
Кластер використовується вашими відділами експлуатації та розробки. Ви хочете дозволити навантаженням в експлуатації споживати до 3 CPU, але ви хочете обмежити навантаження в розробці до 1 CPU. Ви створюєте окремі простори імен для експлуатації та розробки та застосовуєте обмеження CPU до кожного простору імен.
Прибирання
Видаліть ваш простір імен:
kubectl delete namespace constraints-cpu-example
Що далі
Для адміністраторів кластера
Типові налаштування запитів та обмежень памʼяті для простору імен
Типові налаштування запитів та обмежень CPU для простору імен
Налаштування мінімальних та максимальних обмежень памʼяті для простору імен
Для розробників застосунків
5.5 - Налаштування квот памʼяті та CPU для простору імен
На цій сторінці показано, як встановити квоти для загальної кількості памʼяті та CPU, які можуть бути використані всіма Podʼами, що працюють у просторі імен. Ви вказуєте квоти в обʼєкті ResourceQuota.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Вам потрібен доступ до створення просторів імен у вашому кластері.
Кожен вузол у вашому кластері повинен мати принаймні 1 ГБ памʼяті.
Створення простору імен
Створіть простір імен, щоб ресурси, які ви створюєте у цьому завданні, були ізольовані від інших частин вашого кластера.
kubectl create namespace quota-mem-cpu-example
Створення ResourceQuota
Ось маніфест для прикладу ResourceQuota:
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-demo
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
Створіть ResourceQuota:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-mem-cpu.yaml --namespace=quota-mem-cpu-example
Перегляньте детальну інформацію про ResourceQuota:
kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example --output=yaml
ResourceQuota накладає такі вимоги на простір імен quota-mem-cpu-example:
- Для кожного Podʼа у просторі імен кожен контейнер повинен мати запит памʼяті, обмеження памʼяті, запит CPU та обмеження CPU.
- Загальний запит памʼяті для всіх Podʼів у цьому просторі імен не повинен перевищувати 1 ГБ.
- Загальне обмеження памʼяті для всіх Podʼів у цьому просторі імен не повинно перевищувати 2 ГБ.
- Загальний запит CPU для всіх Podʼів у цьому просторі імен не повинен перевищувати 1 CPU.
- Загальне обмеження CPU для всіх Podʼів у цьому просторі імен не повинно перевищувати 2 CPU.
Дивіться значення CPU, щоб дізнатися, що має на увазі Kubernetes, коли говорить про "1 CPU".
Створення Podʼа
Ось маніфест для прикладу Podʼа:
apiVersion: v1
kind: Pod
metadata:
name: quota-mem-cpu-demo
spec:
containers:
- name: quota-mem-cpu-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
cpu: "800m"
requests:
memory: "600Mi"
cpu: "400m"
Створіть Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-mem-cpu-pod.yaml --namespace=quota-mem-cpu-example
Перевірте, що Pod працює, і його (єдиний) контейнер є справним:
kubectl get pod quota-mem-cpu-demo --namespace=quota-mem-cpu-example
Знову перегляньте детальну інформацію про ResourceQuota:
kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example --output=yaml
У виводі вказано квоту разом з тим, скільки з квоти було використано. Ви можете побачити, що запити памʼяті та CPU для вашого Podʼа не перевищують квоту.
status:
hard:
limits.cpu: "2"
limits.memory: 2Gi
requests.cpu: "1"
requests.memory: 1Gi
used:
limits.cpu: 800m
limits.memory: 800Mi
requests.cpu: 400m
requests.memory: 600Mi
Якщо у вас є інструмент jq, ви також можете запитувати (використовуючи JSONPath) лише значення used, і друкувати ці значення з приємним форматуванням. Наприклад:
kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example -o jsonpath='{ .status.used }' | jq .
Спроба створити другий Pod
Ось маніфест для другого Podʼа:
apiVersion: v1
kind: Pod
metadata:
name: quota-mem-cpu-demo-2
spec:
containers:
- name: quota-mem-cpu-demo-2-ctr
image: redis
resources:
limits:
memory: "1Gi"
cpu: "800m"
requests:
memory: "700Mi"
cpu: "400m"
У маніфесті можна побачити, що Pod має запит памʼяті 700 MiB. Зверніть увагу, що сума використаного запиту памʼяті та цього нового запиту памʼяті перевищує квоту запиту памʼяті: 600 MiB + 700 MiB > 1 GiB.
Спробуйте створити Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-mem-cpu-pod-2.yaml --namespace=quota-mem-cpu-example
Другий Pod не створюється. У виводі вказано, що створення другого Podʼа призведе до того, що загальний запит памʼяті перевищить квоту запиту памʼяті.
Error from server (Forbidden): error when creating "examples/admin/resource/quota-mem-cpu-pod-2.yaml":
pods "quota-mem-cpu-demo-2" is forbidden: exceeded quota: mem-cpu-demo,
requested: requests.memory=700Mi,used: requests.memory=600Mi, limited: requests.memory=1Gi
Обговорення
Як ви бачили у цьому завданні, ви можете використовувати ResourceQuota для обмеження загального запиту памʼяті для всіх Podʼів, що працюють у просторі імен. Ви також можете обмежити загальні суми для обмеження памʼяті, запиту CPU та обмеження CPU.
Замість керування загальним використанням ресурсів у просторі імен, ви, можливо, захочете обмежити окремі Podʼи або контейнери у цих Podʼах. Щоб досягти такого обмеження, використовуйте LimitRange.
Прибирання
Видаліть ваш простір імен:
kubectl delete namespace quota-mem-cpu-example
Що далі
Для адміністраторів кластера
Налаштування станадртних запитів та обмежень памʼяті для простору імен
Налаштування станадртних запитів та обмежень CPU для простору імен
Налаштування мінімальних та максимальних обмежень памʼяті для простору імен
Налаштування мінімальних та максимальних обмежень CPU для простору імен
Для розробників застосунків
5.6 - Налаштування квоти Podʼів для простору імен
На цій сторінці показано, як встановити квоту на загальну кількість Podʼів, які можуть працювати в просторі імен. Ви вказуєте квоти в обʼєкті ResourceQuota.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Вам потрібен доступ до створення просторів імен у вашому кластері.
Створення простору імен
Створіть простір імен, щоб ресурси, які ви створюєте у цьому завданні, були ізольовані від інших частин вашого кластера.
kubectl create namespace quota-pod-example
Створення ResourceQuota
Ось приклад маніфесту для ResourceQuota:
apiVersion: v1
kind: ResourceQuota
metadata:
name: pod-demo
spec:
hard:
pods: "2"
Створіть ResourceQuota:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-pod.yaml --namespace=quota-pod-example
Перегляньте детальну інформацію про ResourceQuota:
kubectl get resourcequota pod-demo --namespace=quota-pod-example --output=yaml
У виводі показано, що у просторі імен є квота на два Podʼи, і наразі немає Podʼів; іншими словами, жодна частина квоти не використовується.
spec:
hard:
pods: "2"
status:
hard:
pods: "2"
used:
pods: "0"
Ось приклад маніфесту для Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-quota-demo
spec:
selector:
matchLabels:
purpose: quota-demo
replicas: 3
template:
metadata:
labels:
purpose: quota-demo
spec:
containers:
- name: pod-quota-demo
image: nginx
У цьому маніфесті replicas: 3 повідомляє Kubernetes спробувати створити три нові Podʼи, які всі працюватимуть з одним і тим же застосунком.
Створіть Deployment:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-pod-deployment.yaml --namespace=quota-pod-example
Перегляньте детальну інформацію про Deployment:
kubectl get deployment pod-quota-demo --namespace=quota-pod-example --output=yaml
У виводі показано, що навіть якщо Deployment вказує три репліки, було створено лише два Podʼи через раніше визначену вами квоту:
spec:
...
replicas: 3
...
status:
availableReplicas: 2
...
lastUpdateTime: 2021-04-02T20:57:05Z
message: 'unable to create pods: pods "pod-quota-demo-1650323038-" is forbidden:
exceeded quota: pod-demo, requested: pods=1, used: pods=2, limited: pods=2'
Вибір ресурсу
У цьому завданні ви визначили ResourceQuota, яке обмежує загальну кількість Podʼів, але ви також можете обмежити загальну кількість інших видів обʼєктів. Наприклад, ви можете вирішити обмежити кількість CronJobs, які можуть існувати в одному просторі імен.
Прибирання
Видаліть ваш простір імен:
kubectl delete namespace quota-pod-example
Для адміністраторів кластера
Налаштування стандартних запитів та обмежень памʼяті для простору імен
Налаштування стандартних запитів та обмежень CPU для простору імен
Налаштування мінімальних та максимальних обмежень памʼяті для простору імен
Налаштування мінімальних та максимальних обмежень CPU для простору імен
Для розробників застосунків
6 - Встановлення постачальника мережевої політики
6.1 - Використання Antrea для NetworkPolicy
Ця сторінка показує, як встановити та використовувати втулок Antrea CNI в Kubernetes. Щоб дізнатися більше про проєкт Antrea, прочитайте Вступ до Antrea.
Перш ніж ви розпочнете
Вам потрібно мати кластер Kubernetes. Слідуйте початковому керівництву kubeadm для його створення.
Розгортання Antrea за допомогою kubeadm
Слідуйте керівництву Початок роботи для розгортання Antrea за допомогою kubeadm.
Що далі
Після того, як ваш кластер буде запущений, ви можете перейти до Оголошення мережевої політики, щоб спробувати в дії Kubernetes NetworkPolicy.
6.2 - Використання Calico для NetworkPolicy
Ця сторінка показує кілька швидких способів створення кластера Calico в Kubernetes.
Перш ніж ви розпочнете
Вирішіть, чи ви хочете розгорнути хмарний або локальний кластер.
Створення кластера Calico з Google Kubernetes Engine (GKE)
Передумова: gcloud.
Щоб запустити кластер GKE з Calico, включіть прапорець
--enable-network-policy.Синтаксис
gcloud container clusters create [ІМ'Я_КЛАСТЕРА] --enable-network-policyПриклад
gcloud container clusters create my-calico-cluster --enable-network-policyДля перевірки розгортання використовуйте наступну команду.
kubectl get pods --namespace=kube-systemPodʼи Calico починаються з
calico. Перевірте, щоб кожен з них мав статусRunning.
Створення локального кластера Calico з kubeadm
Щоб отримати локальний кластер Calico для одного хосту за пʼятнадцять хвилин за допомогою kubeadm, див. Швидкий старт Calico.
Що далі
Після того, як ваш кластер буде запущений, ви можете перейти до Оголошення мережевої політики, щоб спробувати в дії Kubernetes NetworkPolicy.
6.3 - Використання Cilium для NetworkPolicy
Ця сторінка показує, як використовувати Cilium для NetworkPolicy.
Щоб ознайомитися з основною інформацією про Cilium, прочитайте Вступ до Cilium.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для перевірки версії введіть kubectl version.
Розгортання Cilium на Minikube для базового тестування
Щоб легко ознайомитися з Cilium, ви можете слідувати Початковому керівництву Cilium Kubernetes для виконання базової інсталяції Cilium як DaemonSet у Minikube.
Щоб запустити Minikube, мінімально необхідна версія >= v1.5.2, виконайте з наступними аргументами:
minikube version
minikube version: v1.5.2
minikube start --network-plugin=cni
Для Minikube ви можете встановити Cilium за допомогою його CLI інструменту. Спочатку завантажте останню версію CLI за допомогою наступної команди:
curl -LO https://github.com/cilium/cilium-cli/releases/latest/download/cilium-linux-amd64.tar.gz
Потім розпакуйте завантажений файл у вашу теку /usr/local/bin за допомогою наступної команди:
sudo tar xzvfC cilium-linux-amd64.tar.gz /usr/local/bin
rm cilium-linux-amd64.tar.gz
Після виконання вищевказаних команд, ви тепер можете встановити Cilium за допомогою наступної команди:
cilium install
Cilium автоматично визначить конфігурацію кластера та створить і встановить відповідні компоненти для успішної інсталяції. Компоненти включають:
- Центр сертифікації (CA) у Secret
cilium-caта сертифікати для Hubble (шар спостереження Cilium). - Сервісні облікові записи.
- Кластерні ролі.
- ConfigMap.
- Agent DaemonSet та Operator Deployment.
Після інсталяції ви можете переглянути загальний статус розгортання Cilium за допомогою команди cilium status. Дивіться очікуваний вивід команди status
тут.
Решта Початкового керівництва пояснює, як застосувати політики безпеки як L3/L4 (тобто IP-адреса + порт), так і L7 (наприклад, HTTP) за допомогою прикладної програми.
Розгортання Cilium для використання в операційному середовищі
Для докладних інструкцій з розгортання Cilium для операційного використання, дивіться: Керівництво з інсталяції Cilium Kubernetes. Ця документація включає докладні вимоги, інструкції та приклади файлів DaemonSet для продуктивного використання.
Розуміння компонентів Cilium
Розгортання кластера з Cilium додає Podʼи до простору імен kube-system. Щоб побачити цей список Podʼів, виконайте:
kubectl get pods --namespace=kube-system -l k8s-app=cilium
Ви побачите список Podʼів, подібний до цього:
NAME READY STATUS RESTARTS AGE
cilium-kkdhz 1/1 Running 0 3m23s
...
Pod cilium працює на кожному вузлі вашого кластера і забезпечує виконання мережевої політики для трафіку до/від Podʼів на цьому вузлі за допомогою Linux BPF.
Що далі
Після того, як ваш кластер буде запущений, ви можете перейти до Оголошення мережевої політики для випробування Kubernetes NetworkPolicy з Cilium. Якщо у вас є запитання, звʼяжіться з нами за допомогою Каналу Cilium у Slack.
6.4 - Використання Kube-router для NetworkPolicy
Ця сторінка показує, як використовувати Kube-router для NetworkPolicy.
Перш ніж ви розпочнете
Вам потрібно мати запущений кластер Kubernetes. Якщо у вас ще немає кластера, ви можете створити його, використовуючи будь-які інсталятори кластерів, такі як Kops, Bootkube, Kubeadm тощо.
Встановлення надбудови Kube-router
Надбудова Kube-router містить контролер мережевих політик, який відстежує сервер API Kubernetes на предмет будь-яких оновлень NetworkPolicy та Podʼів і налаштовує правила iptables та ipsets для дозволу або блокування трафіку відповідно до політик. Будь ласка, слідуйте керівництву спробуйте Kube-router з інсталяторами кластерів для встановлення надбудови Kube-router.
Що далі
Після того, як ви встановили надбудову Kube-router, ви можете перейти до Оголошення мережевої політики для випробування Kubernetes NetworkPolicy.
6.5 - Використання Romana для NetworkPolicy
Ця сторінка показує, як використовувати Romana для NetworkPolicy.
Перш ніж ви розпочнете
Виконайте кроки 1, 2 та 3 з початкового керівництва kubeadm.
Встановлення Romana за допомогою kubeadm
Слідуйте керівництву з контейнеризованого встановлення для kubeadm.
Застосування мережевих політик
Для застосування мережевих політик використовуйте одне з наступного:
- Мережеві політики Romana.
- API NetworkPolicy.
Що далі
Після встановлення Romana ви можете перейти до Оголошення мережевої політики для випробування Kubernetes NetworkPolicy.
6.6 - Використання Weave Net для NetworkPolicy
Ця сторінка показує, як використовувати Weave Net для NetworkPolicy.
Перш ніж ви розпочнете
Вам потрібен Kubernetes кластер. Слідуйте початковому керівництву kubeadm, щоб його налаштувати.
Встановлення надбудови Weave Net
Слідуйте керівництву Інтеграція Kubernetes через надбудову.
Надбудова Weave Net для Kubernetes містить Контролер мережевих політик, який автоматично відстежує всі анотації мережевих політик у Kubernetes у всіх просторах імен і налаштовує правила iptables для дозволу або блокування трафіку відповідно до цих політик.
Тестування встановлення
Перевірте, що Weave працює коректно.
Введіть наступну команду:
kubectl get pods -n kube-system -o wide
Вивід буде схожим на це:
NAME READY STATUS RESTARTS AGE IP NODE
weave-net-1t1qg 2/2 Running 0 9d 192.168.2.10 worknode3
weave-net-231d7 2/2 Running 1 7d 10.2.0.17 worknodegpu
weave-net-7nmwt 2/2 Running 3 9d 192.168.2.131 masternode
weave-net-pmw8w 2/2 Running 0 9d 192.168.2.216 worknode2
На кожному вузлі є Pod Weave, і всі Podʼи Running та 2/2 READY. (2/2 означає, що кожен Pod має weave і weave-npc.)
Що далі
Після встановлення надбудови Weave Net ви можете перейти до Оголошення мережевої політики, щоб спробувати Kubernetes NetworkPolicy. Якщо у вас є запитання, звертайтеся до нас #weave-community у Slack або Weave User Group.
7 - Доступ до кластера через API Kubernetes
Ця сторінка описує, як отримати доступ до кластера через API Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для перевірки версії введіть kubectl version.
Доступ до API Kubernetes
Перший доступ за допомогою kubectl
При першому доступі до API Kubernetes використовуйте інструмент командного рядка Kubernetes, kubectl.
Для отримання доступу до кластера вам потрібно знати його розташування та мати облікові дані для входу. Зазвичай вони встановлюються автоматично, коли ви користуєтесь настановами зі сторінки Початок роботи, або ж ви вже маєте розгорнутий кластер з налаштованим доступом.
Перевірте місце знаходження та облікові дані, про які знає kubectl, за допомогою цієї команди:
kubectl config view
Багато прикладів містять введення в користування kubectl. Повну документацію ви можете знайти в довідці kubectl.
Прямий доступ до REST API
kubectl використовується для знаходження та автентифікації на сервері API. Якщо ви хочете дістатись REST API за допомогою інструментів на кшталт curl або wget, чи вебоглядача, існує кілька способів якими ви можете знайти та автентифікуватись на сервері API.
- Запустіть kubectl у режимі проксі (рекомендовано). Цей метод рекомендується, оскільки він використовує збережене розташування сервера API та перевіряє відповідність сервера API за допомогою самопідписного сертифіката. За допомогою цього методу неможлива атака man-in-the-middle (MITM).
- Крім того, ви можете вказати знаходження та облікові дані безпосередньо http-клієнту. Це працює з клієнтським кодом, який плутають проксі. Щоб захиститися від атак man in the middle, вам потрібно буде імпортувати кореневий сертифікат у свій вебоглядач.
Використання клієнтських бібліотек Go або Python забезпечує доступ до kubectl у режимі проксі.
Використання kubectl proxy
Наступна команда запускає kubectl у режимі, де він діє як зворотний проксі. Він виконує пошук сервера API та автентифікацію.
kubectl proxy --port=8080 &
Дивіться kubectl proxy для отримання додаткової інформації.
Потім ви можете дослідити API за допомогою curl, wget або вебоглядача, наприклад:
curl http://localhost:8080/api/
Вивід має бути схожий на цей:
{
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
Без використання kubectl proxy
Можна уникнути використання kubectl proxy, передаючи токен автентифікації безпосередньо на сервер API, наприклад:
Використовуючи підхід grep/cut:
# Перевірте всі можливі кластери, оскільки ваш .KUBECONFIG може мати кілька контекстів:
kubectl config view -o jsonpath='{"Cluster name\tServer\n"}{range .clusters[*]}{.name}{"\t"}{.cluster.server}{"\n"}{end}'
# Виберіть назву кластера, з яким ви хочете взаємодіяти, з виводу вище:
export CLUSTER_NAME="some_server_name"
# Вкажіть сервер API, посилаючись на імʼя кластера
APISERVER=$(kubectl config view -o jsonpath="{.clusters[?(@.name==\"$CLUSTER_NAME\")].cluster.server}")
# Створіть секрет для зберігання токена для службовоого облікового запису
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: default-token
annotations:
kubernetes.io/service-account.name: default
type: kubernetes.io/service-account-token
EOF
# Зачекайте, поки контролер заповнить секрет токеном:
while ! kubectl describe secret default-token | grep -E '^token' >/dev/null; do
echo "waiting for token..." >&2
sleep 1
done
# Отримайте значення токена
TOKEN=$(kubectl get secret default-token -o jsonpath='{.data.token}' | base64 --decode)
# Дослідіть API скориставшись TOKEN
curl -X GET $APISERVER/api --header "Authorization: Bearer $TOKEN" --insecure
Вивід має бути схожий на цей:
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
У вищенаведеному прикладі використовується прапорець --insecure. Це залишає систему вразливою до атак типу MITM (Man-In-The-Middle). Коли kubectl отримує доступ до кластера, він використовує збережений кореневий сертифікат та сертифікати клієнта для доступу до сервера. (Ці дані знаходяться у теці ~/.kube). Оскільки сертифікати кластера зазвичай самопідписні, може знадобитися спеціальна конфігурація, щоб ваш HTTP-клієнт використовував кореневий сертифікат.
На деяких кластерах сервер API може не вимагати автентифікації; він може обслуговувати локальний хост або бути захищений фаєрволом. Не існує стандарту для цього. Документ Керування доступом до API Kubernetes описує, як ви можете налаштувати це, як адміністратор кластера.
Програмний доступ до API
Kubernetes офіційно підтримує клієнтські бібліотеки для Go, Python, Java, dotnet, JavaScript та Haskell. Існують інші клієнтські бібліотеки, які надаються та підтримуються їхніми авторами, а не командою Kubernetes. Дивіться бібліотеки клієнтів для доступу до API з інших мов програмування та їхнього методу автентифікації.
Go-клієнт
- Щоб отримати бібліотеку, виконайте наступну команду:
go get k8s.io/client-go@kubernetes-<номер-версії-kubernetes>. Дивіться https://github.com/kubernetes/client-go/releases, щоб переглянути підтримувані версії. - Напишіть застосунок поверх клієнтів client-go.
Примітка:
client-go визначає власні обʼєкти API, тому у разі необхідності імпортуйте визначення API з client-go, а не з основного сховища. Наприклад, import "k8s.io/client-go/kubernetes" є правильним.Go-клієнт може використовувати той самий файл kubeconfig, як і kubectl CLI, для пошуку та автентифікації на сервері API. Дивіться цей приклад:
package main
import (
"context"
"fmt"
"k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/clientcmd"
)
func main() {
// використовуємо поточний контекст з kubeconfig
// path-to-kubeconfig -- наприклад, /root/.kube/config
config, _ := clientcmd.BuildConfigFromFlags("", "<path-to-kubeconfig>")
// створює clientset
clientset, _ := kubernetes.NewForConfig(config)
// доступ API до списку Podʼів
pods, _ := clientset.CoreV1().Pods("").List(context.TODO(), v1.ListOptions{})
fmt.Printf("There are %d pods in the cluster\n", len(pods.Items))
}
Якщо застосунок розгорнуто як Pod у кластері, дивіться Доступ до API зсередини Pod.
Python-клієнт
Щоб використовувати Python-клієнт, виконайте наступну команду: pip install kubernetes. Дивіться сторінку бібліотеки Python-клієнта для отримання додаткових варіантів встановлення.
Python-клієнт може використовувати той самий файл kubeconfig, як і kubectl CLI, для пошуку та автентифікації на сервері API. Дивіться цей приклад:
from kubernetes import client, config
config.load_kube_config()
v1=client.CoreV1Api()
print("Listing pods with their IPs:")
ret = v1.list_pod_for_all_namespaces(watch=False)
for i in ret.items:
print("%s\t%s\t%s" % (i.status.pod_ip, i.metadata.namespace, i.metadata.name))
Java-клієнт
Для встановлення Java-клієнта виконайте наступну команду:
# Зколнуйте код білліотеки java
git clone --recursive https://github.com/kubernetes-client/java
# Встановлення артефактів проєкту, POM й так даіл:
cd java
mvn install
Дивіться https://github.com/kubernetes-client/java/releases, щоб переглянути підтримувані версії.
Java-клієнт може використовувати той самий файл kubeconfig, що і kubectl CLI, для пошуку та автентифікації на сервері API. Дивіться цей приклад:
package io.kubernetes.client.examples;
import io.kubernetes.client.ApiClient;
import io.kubernetes.client.ApiException;
import io.kubernetes.client.Configuration;
import io.kubernetes.client.apis.CoreV1Api;
import io.kubernetes.client.models.V1Pod;
import io.kubernetes.client.models.V1PodList;
import io.kubernetes.client.util.ClientBuilder;
import io.kubernetes.client.util.KubeConfig;
import java.io.FileReader;
import java.io.IOException;
/**
* Простий приклад використання Java API з застосунку поза кластером Kubernetes.
*
* Найпростіший спосіб запуску цього: mvn exec:java
* -Dexec.mainClass="io.kubernetes.client.examples.KubeConfigFileClientExample"
*
*/
public class KubeConfigFileClientExample {
public static void main(String[] args) throws IOException, ApiException {
// шлях до файлуу KubeConfig
String kubeConfigPath = "~/.kube/config";
// завантаження конфігурації ззовні кластера, kubeconfig із файлової системи
ApiClient client =
ClientBuilder.kubeconfig(KubeConfig.loadKubeConfig(new FileReader(kubeConfigPath))).build();
// встановлення глобального api-client на того, що працює в межах кластера, як описано вище
Configuration.setDefaultApiClient(client);
// the CoreV1Api завантажує api-client з глобальної конфігурації.
CoreV1Api api = new CoreV1Api();
// виклик клієнта CoreV1Api
V1PodList list = api.listPodForAllNamespaces(null, null, null, null, null, null, null, null, null);
System.out.println("Listing all pods: ");
for (V1Pod item : list.getItems()) {
System.out.println(item.getMetadata().getName());
}
}
}
dotnet-клієнт
Щоб використовувати dotnet-клієнт, виконайте наступну команду: dotnet add package KubernetesClient --version 1.6.1. Дивіться сторінку бібліотеки dotnet-клієнта для отримання додаткових варіантів встановлення. Дивіться https://github.com/kubernetes-client/csharp/releases, щоб переглянути підтримувані версії.
Dotnet-клієнт може використовувати той самий файл kubeconfig, що і kubectl CLI, для пошуку та автентифікації на сервері API. Дивіться цей приклад:
using System;
using k8s;
namespace simple
{
internal class PodList
{
private static void Main(string[] args)
{
var config = KubernetesClientConfiguration.BuildDefaultConfig();
IKubernetes client = new Kubernetes(config);
Console.WriteLine("Starting Request!");
var list = client.ListNamespacedPod("default");
foreach (var item in list.Items)
{
Console.WriteLine(item.Metadata.Name);
}
if (list.Items.Count == 0)
{
Console.WriteLine("Empty!");
}
}
}
}
JavaScript-клієнт
Щоб встановити JavaScript-клієнт, виконайте наступну команду: npm install @kubernetes/client-node. Дивіться сторінку бібліотеки JavaScript-клієнта для отримання додаткових варіантів встановлення. Дивіться https://github.com/kubernetes-client/javascript/releases, щоб переглянути підтримувані версії.
JavaScript-клієнт може використовувати той самий файл kubeconfig, що і kubectl CLI, для пошуку та автентифікації на сервері API. Дивіться цей приклад:
const k8s = require('@kubernetes/client-node');
const kc = new k8s.KubeConfig();
kc.loadFromDefault();
const k8sApi = kc.makeApiClient(k8s.CoreV1Api);
k8sApi.listNamespacedPod({ namespace: 'default' }).then((res) => {
console.log(res);
});
Haskell-клієнт
Дивіться https://github.com/kubernetes-client/haskell/releases, щоб переглянути підтримувані версії.
Haskell-клієнт може використовувати той самий файл kubeconfig, що і kubectl CLI, для пошуку та автентифікації на сервері API. Дивіться цей приклад:
exampleWithKubeConfig :: IO ()
exampleWithKubeConfig = do
oidcCache <- atomically $ newTVar $ Map.fromList []
(mgr, kcfg) <- mkKubeClientConfig oidcCache $ KubeConfigFile "/path/to/kubeconfig"
dispatchMime
mgr
kcfg
(CoreV1.listPodForAllNamespaces (Accept MimeJSON))
>>= print
Що далі
8 - Увімкнення або вимкнення функціональних можливостей
На цій сторінці показано, як увімкнути або вимкнути функціональні можливості для керування певними функціями Kubernetes у вашому кластері. Увімкнення функціональних можливостей дозволяє тестувати та використовувати функції Alpha або Beta до того, як вони стануть загальнодоступними.
Примітка:
Деякі стабільні (GA) можливості також можна вимкнути, зазвичай через один мінорний реліз після GA; однак у цьому випадку ваш кластер може не відповідати вимогам Kubernetes.Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Вам також потрібно:
- Адміністративний доступ до вашого кластера
- Знання про те, яку функцію ви хочете увімкнути (див. [Довідку про функціональні можливості] (/docs/reference/command-line-tools-reference/feature-gates/))
Примітка:
Загально доступні функції (GA) є завжди стандартно увімкненими. Зазвичай ви налаштовуєте можливості для функцій Alpha або Beta.Understand feature gate maturity
Перед увімкненням функціональної можливості перевірте довідку про функціональні можливості щодо рівня зрілості функції:
- Альфа: стандартно вимкнена, може містити помилки. Використовуйте тільки в тестових кластерах.
- Бета: зазвичай стандартно увімкнена, добре протестована.
- GA: завжди стандартно увімкнена; іноді може бути вимкнена для одного випуску після GA.
Визначте, які компоненти вимагають використання функціональної можливості {#identify-which-components-need-the-feature gate}
Різні функціональні можливості впливають на різні компоненти Kubernetes:
- Деякі функції вимагають увімкнення можливості на декількох компонентах (наприклад, API-сервері та менеджері контролерів)
- Інші функції вимагають увімкнення можливості лише на одному компоненті (наприклад, лише kubelet)
У довідці про функціональні можливості зазвичай вказано, на які компоненти впливає кожна функція. Усі компоненти Kubernetes мають однакові визначення функціональних можливостей, тому всі функції відображаються у вікні довідки, але на поведінку кожного компонента впливають лише відповідні функції.
Конфігурація
Під час ініціалізації кластера
Створіть файл конфігурації, щоб увімкнути функціональні можливості для відповідних компонентів:
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
apiServer:
extraArgs:
feature-gates: "FeatureName=true"
controllerManager:
extraArgs:
feature-gates: "FeatureName=true"
scheduler:
extraArgs:
feature-gates: "FeatureName=true"
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
FeatureName: true
Ініціалізуйте кластер:
kubeadm init --config kubeadm-config.yaml
На наявному кластері
Для кластерів kubeadm конфігурацію функціональних можливостей можна налаштувати в декількох місцях, включаючи файли маніфесту, файли конфігурації та конфігурацію kubeadm.
Відредагуйте маніфести компонентів панелі управління в /etc/kubernetes/manifests/:
Для kube-apiserver, kube-controller-manager або kube-scheduler додайте прапорець до команди:
spec: containers: - command: - kube-apiserver - --feature-gates=FeatureName=true # ... інші прапорціЗбережіть файл. Pod автоматично перезапуститься.
Для kubelet, відредагуйте
/var/lib/kubelet/config.yaml:apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration featureGates: FeatureName: trueПерезапустіть kubelet:
sudo systemctl restart kubeletДля kube-proxy, змініть ConfigMap:
kubectl -n kube-system edit configmap kube-proxyДодайте функціональні можливості до конфігурації:
featureGates: FeatureName: trueПерезапустіть DaemonSet:
kubectl -n kube-system rollout restart daemonset kube-proxy
Налаштування декількох функціональних можливостей
Використовуйте списки, розділені комами, для прапорців командного рядка:
--feature-gates=FeatureA=true,FeatureB=false,FeatureC=true
Для компонентів, що підтримують файли конфігурації (kubelet, kube-proxy):
featureGates:
FeatureA: true
FeatureB: false
FeatureC: true
Примітка:
У кластерах kubeadm компоненти панелі управління (kube-apiserver, kube-controller-manager та kube-scheduler) зазвичай налаштовуються за допомогою прапорців командного рядка в їх маніфестах статичних подів, розташованих у/etc/kubernetes/manifests/. Хоча ці компоненти підтримують файли конфігурації за допомогою прапорця --config, kubeadm в основному використовує прапорці командного рядка.Перевірка конфігурації функціональних можливостей
Після налаштування перевірте, чи функціональні можливості активні. Наступні методи застосовуються до кластерів kubeadm, де компоненти панелі управління працюють як статичні поди.
Перевірка маніфестів компонентів панелі управління
Перегляньте функціональні можливості, налаштовані в маніфесті статичного пода:
kubectl -n kube-system get pod kube-apiserver-<node-name> -o yaml | grep feature-gates
Перевірка конфігурації kubelet
Використовуйте точку доступу configz kubelet:
kubectl proxy --port=8001 &
curl -sSL «http://localhost:8001/api/v1/nodes/<node-name>/proxy/configz» | grep featureGates -A 5
Або перевірте файл конфігурації безпосередньо на вузлі:
cat /var/lib/kubelet/config.yaml | grep -A 10 featureGates
Перевірка через точку доступу метрик
Статус функціональної можливості виводиться в метриках у стилі Prometheus компонентами Kubernetes (доступно в Kubernetes 1.26+). Запитайте точку доступу метрик, щоб перевірити, які функціональні можливості включені:
kubectl get --raw /metrics | grep kubernetes_feature_enabled
Щоб перевірити конкретну функціональну можливість:
kubectl get --raw /metrics | grep kubernetes_feature_enabled | grep FeatureName
Метрика показує 1 для увімкнених можливостей і 0 для вимкнених можливостей.
Примітка:
У кластерах kubeadm перевірте всі відповідні місця, де можуть бути налаштовані функціональні можливості, оскільки конфігурація розподілена між декількома файлами та місцями.Перевірка через точку доступу /flagz
Якщо ви маєте доступ до точок доступу для налагодження компонента і для цього компонента ввімкнено функціональну можливість ComponentFlagz, ви можете перевірити прапорці командного рядка, які використовувалися для запуску компонента, відвідавши точку доступу /flagz. Функціональні можливості, налаштовані за допомогою прапорців командного рядка, відображаються в цьому виводі.
Точка доступу /flagz є частиною Kubernetes z-pages, які надають зрозумілу для людини інформацію про налагодження під час виконання для основних компонентів.
Для отримання додаткової інформації див. документацію z-pages.
Розуміння вимог до конкретних компонентів
Деякі приклади функціональних можливостей, специфічних для компонентів:
- Орієнтовані на API-сервер: такі функції, як
StructuredAuthenticationConfiguration, в першу чергу впливають на kube-apiserver - Орієнтовані на Kubelet: такі функції, як
GracefulNodeShutdown, в першу чергу впливають на kubelet - Кілька компонентів: деякі функції вимагають координації між компонентами
Увага:
Якщо для функції потрібно кілька компонентів, необхідно ввімкнути можливість на всіх відповідних компонентах. Увімкнення можливості лише на деяких компонентах може призвести до несподіваної поведінки або помилок.Завжди спочатку тестуйте функціональні можливості на тестових середовищах. Функції Alpha можуть бути видалені без попередження.
Що далі
- Прочитайте довідку про функціональні можливості
- Дізнайтеся про стадії функцій
- Перегляньте kubeadm configuration
9 - Оголошення розширених ресурсів для вузла
Ця сторінка показує, як вказати розширені ресурси для вузла. Розширені ресурси дозволяють адміністраторам кластера оголошувати ресурси на рівні вузла, які інакше були б невідомі для Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для перевірки версії введіть kubectl version.
Отримання імен ваших вузлів
kubectl get nodes
Виберіть один з ваших вузлів для цього завдання.
Оголошення нового розширеного ресурсу на одному з ваших вузлів
Щоб оголосити новий розширений ресурс на вузлі, відправте HTTP PATCH запит до сервера API Kubernetes. Наприклад, припустимо, що один з ваших вузлів має чотири підключені dongle. Ось приклад запиту PATCH, який оголошує чотири ресурси dongle для вашого вузла.
PATCH /api/v1/nodes/<your-node-name>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "add",
"path": "/status/capacity/example.com~1dongle",
"value": "4"
}
]
Зверніть увагу, що Kubernetes не потрібно знати, що таке dongle або для чого він призначений. Попередній запит PATCH повідомляє Kubernetes, що ваш вузол має чотири речі, які ви називаєте dongle.
Запустіть проксі, щоб відправляти запити на сервер API Kubernetes:
kubectl proxy
У іншому вікні термінала відправте HTTP PATCH запит. Замініть <your-node-name> на імʼя вашого вузла:
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1dongle", "value": "4"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
Примітка:
У запиті~1 — це кодування символу / у шляху патча. Значення шляху операцій в JSON-Patch трактується як JSON-вказівник. Докладніше дивіться
IETF RFC 6901, розділ 3.Вивід показує, що вузол має потужність 4 dongle:
"capacity": {
"cpu": "2",
"memory": "2049008Ki",
"example.com/dongle": "4",
Опишіть свій вузол:
kubectl describe node <your-node-name>
Ще раз, вивід показує ресурс dongle:
Capacity:
cpu: 2
memory: 2049008Ki
example.com/dongle: 4
Тепер розробники застосунків можуть створювати Podʼи, які вимагають певну кількість dongle. Див. Призначення розширених ресурсів контейнеру.
Обговорення
Розширені ресурси схожі на памʼять та ресурси CPU. Наприклад, так само як на вузлі є певна кількість памʼяті та CPU для спільного використання всіма компонентами, що працюють на вузлі, він може мати певну кількість dongle для спільного використання всіма компонентами, що працюють на вузлі. І так само як розробники застосунків можуть створювати Podʼи, які вимагають певної кількості памʼяті та CPU, вони можуть створювати Podʼи, які вимагають певну кількість dongle.
Розширені ресурси є непрозорими для Kubernetes; Kubernetes не знає нічого про їх призначення. Kubernetes знає лише, що у вузла є їх певна кількість. Розширені ресурси мають оголошуватись у цілих числах. Наприклад, вузол може оголошувати чотири dongle, але не 4,5 dongle.
Приклад зберігання
Припустимо, що вузол має 800 ГіБ особливого типу дискового простору. Ви можете створити назву для спеціального сховища, скажімо, example.com/special-storage. Потім ви можете оголошувати його в частинах певного розміру, скажімо, 100 ГіБ. У цьому випадку, ваш вузол буде повідомляти, що в ньому є вісім ресурсів типу example.com/special-storage.
Capacity:
...
example.com/special-storage: 8
Якщо ви хочете дозволити довільні запити на спеціальне зберігання, ви можете оголошувати спеціальне сховище частками розміром 1 байт. У цьому випадку ви оголошуєте 800Gi ресурсів типу example.com/special-storage.
Capacity:
...
example.com/special-storage: 800Gi
Потім контейнер може запросити будь-яку кількість байтів спеціального сховища, до 800Gi.
Очищення
Ось запит PATCH, який видаляє оголошення dongle з вузла.
PATCH /api/v1/nodes/<your-node-name>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "remove",
"path": "/status/capacity/example.com~1dongle",
}
]
Запустіть проксі, щоб відправляти запити на сервер API Kubernetes:
kubectl proxy
У іншому вікні термінала відправте HTTP PATCH запит. Замініть <your-node-name> на імʼя вашого вузла:
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "remove", "path": "/status/capacity/example.com~1dongle"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
Перевірте, що оголошення dongle було видалено:
kubectl describe node <your-node-name> | grep dongle
(ви не повинні бачити жодного виводу)
Що далі
Для розробників застосунків
Для адміністраторів кластера
10 - Автоматичне масштабування служби DNS в кластері
Ця сторінка показує, як увімкнути та налаштувати автоматичне масштабування служби DNS у вашому кластері Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для перевірки версії введіть
kubectl version.Цей посібник передбачає, що ваші вузли використовують архітектуру процесора AMD64 або Intel 64.
Переконайтеся, що DNS Kubernetes увімкнений.
Визначте, чи вже увімкнуто горизонтальне автоматичне масштабування DNS
Перегляньте Deploymentʼи у вашому кластері у просторі імен kube-system:
kubectl get deployment --namespace=kube-system
Вивід схожий на такий:
NAME READY UP-TO-DATE AVAILABLE AGE
...
kube-dns-autoscaler 1/1 1 1 ...
...
Якщо ви бачите "kube-dns-autoscaler" у виводі, горизонтальне автоматичне масштабування DNS вже увімкнено, і ви можете перейти до Налаштування параметрів автоматичного масштабування.
Отримайте імʼя вашого Deployment DNS
Перегляньте Deployment DNS у вашому кластері у просторі імен kube-system:
kubectl get deployment -l k8s-app=kube-dns --namespace=kube-system
Вивід схожий на такий:
NAME READY UP-TO-DATE AVAILABLE AGE
...
coredns 2/2 2 2 ...
...
Якщо ви не бачите Deployment для DNS-служб, ви також можете знайти його за імʼям:
kubectl get deployment --namespace=kube-system
і пошукайте Deployment з назвою coredns або kube-dns.
Ваша ціль масштабування:
Deployment/<імʼя вашого розгортання>
де <імʼя вашого розгортання> — це імʼя вашого Deployment DNS. Наприклад, якщо імʼя вашого Deployment для DNS — coredns, ваша ціль масштабування — Deployment/coredns.
Примітка:
CoreDNS — це стандартна служба DNS в Kubernetes. CoreDNS встановлює міткуk8s-app=kube-dns, щоб вона могла працювати в кластерах, які спочатку використовували kube-dns.Увімкніть горизонтальне автоматичне масштабування DNS
У цьому розділі ви створюєте нове Deployment. Podʼи в Deployment працюють з контейнером на основі образу cluster-proportional-autoscaler-amd64.
Створіть файл з назвою dns-horizontal-autoscaler.yaml з таким вмістом:
kind: ServiceAccount
apiVersion: v1
metadata:
name: kube-dns-autoscaler
namespace: kube-system
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: system:kube-dns-autoscaler
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["list", "watch"]
- apiGroups: [""]
resources: ["replicationcontrollers/scale"]
verbs: ["get", "update"]
- apiGroups: ["apps"]
resources: ["deployments/scale", "replicasets/scale"]
verbs: ["get", "update"]
# Remove the configmaps rule once below issue is fixed:
# kubernetes-incubator/cluster-proportional-autoscaler#16
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get", "create"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: system:kube-dns-autoscaler
subjects:
- kind: ServiceAccount
name: kube-dns-autoscaler
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:kube-dns-autoscaler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-dns-autoscaler
namespace: kube-system
labels:
k8s-app: kube-dns-autoscaler
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
k8s-app: kube-dns-autoscaler
template:
metadata:
labels:
k8s-app: kube-dns-autoscaler
spec:
priorityClassName: system-cluster-critical
securityContext:
seccompProfile:
type: RuntimeDefault
supplementalGroups: [ 65534 ]
fsGroup: 65534
nodeSelector:
kubernetes.io/os: linux
containers:
- name: autoscaler
image: registry.k8s.io/cpa/cluster-proportional-autoscaler:1.8.4
resources:
requests:
cpu: "20m"
memory: "10Mi"
command:
- /cluster-proportional-autoscaler
- --namespace=kube-system
- --configmap=kube-dns-autoscaler
# Should keep target in sync with cluster/addons/dns/kube-dns.yaml.base
- --target=<SCALE_TARGET>
# When cluster is using large nodes(with more cores), "coresPerReplica" should dominate.
# If using small nodes, "nodesPerReplica" should dominate.
- --default-params={"linear":{"coresPerReplica":256,"nodesPerReplica":16,"preventSinglePointFailure":true,"includeUnschedulableNodes":true}}
- --logtostderr=true
- --v=2
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
serviceAccountName: kube-dns-autoscaler
У файлі замініть <SCALE_TARGET> на вашу ціль масштабування.
Перейдіть в теку, яка містить ваш файл конфігурації, та введіть цю команду для створення Deployment:
kubectl apply -f dns-horizontal-autoscaler.yaml
Вивід успішної команди:
deployment.apps/kube-dns-autoscaler created
Тепер горизонтальне автоматичне масштабування DNS увімкнено.
Налаштування параметрів автоматичного масштабування DNS
Перевірте, що існує ConfigMap kube-dns-autoscaler:
kubectl get configmap --namespace=kube-system
Вивід схожий на такий:
NAME DATA AGE
...
kube-dns-autoscaler 1
...
...
Змініть дані в ConfigMap:
kubectl edit configmap kube-dns-autoscaler --namespace=kube-system
Знайдіть цей рядок:
linear: '{"coresPerReplica":256,"min":1,"nodesPerReplica":16}'
Змініть поля відповідно до ваших потреб. Поле "min" вказує на мінімальну кількість резервних DNS. Фактична кількість резервних копій обчислюється за цією формулою:
replicas = max( ceil( cores × 1/coresPerReplica ) , ceil( nodes × 1/nodesPerReplica ) )
Зверніть увагу, що значення як coresPerReplica, так і nodesPerReplica — це числа з комою.
Ідея полягає в тому, що, коли кластер використовує вузли з багатьма ядрами, coresPerReplica домінує. Коли кластер використовує вузли з меншою кількістю ядер, домінує nodesPerReplica.
Існують інші підтримувані шаблони масштабування. Докладні відомості див. у cluster-proportional-autoscaler.
Вимкніть горизонтальне автоматичне масштабування DNS
Існують декілька варіантів налаштування горизонтального автоматичного масштабування DNS. Який варіант використовувати залежить від різних умов.
Опція 1: Зменшити масштаб розгортання kube-dns-autoscaler до 0 резервних копій
Цей варіант працює для всіх ситуацій. Введіть цю команду:
kubectl scale deployment --replicas=0 kube-dns-autoscaler --namespace=kube-system
Вивід:
deployment.apps/kube-dns-autoscaler scaled
Перевірте, що кількість резервних копій дорівнює нулю:
kubectl get rs --namespace=kube-system
Вивід показує 0 в колонках DESIRED та CURRENT:
NAME DESIRED CURRENT READY AGE
...
kube-dns-autoscaler-6b59789fc8 0 0 0 ...
...
Опція 2: Видаліть розгортання kube-dns-autoscaler
Цей варіант працює, якщо kube-dns-autoscaler знаходиться під вашим контролем, що означає, що його ніхто не буде знову створювати:
kubectl delete deployment kube-dns-autoscaler --namespace=kube-system
Вивід:
deployment.apps "kube-dns-autoscaler" deleted
Опція 3: Видаліть файл маніфесту kube-dns-autoscaler з майстер-вузла
Цей варіант працює, якщо kube-dns-autoscaler знаходиться під контролем (застарілий) Addon Manager, і ви маєте права запису на майстер-вузол.
Увійдіть на майстер-вузол та видаліть відповідний файл маніфесту. Загальний шлях для цього kube-dns-autoscaler:
/etc/kubernetes/addons/dns-horizontal-autoscaler/dns-horizontal-autoscaler.yaml
Після видалення файлу маніфесту Addon Manager видалить розгортання kube-dns-autoscaler.
Розуміння того, як працює горизонтальне автоматичне масштабування DNS
Застосунок cluster-proportional-autoscaler розгортається окремо від служби DNS.
Pod автомасштабування працює клієнтом, який опитує сервер API Kubernetes для отримання кількості вузлів та ядер у кластері.
Обчислюється та застосовується бажана кількість резервних копій на основі поточних запланованих вузлів та ядер та заданих параметрів масштабування.
Параметри масштабування та точки даних надаються через ConfigMap Podʼа автомасштабування, і він оновлює свою таблицю параметрів щоразу під час періодичного опитування, щоб вона була актуальною з найновішими бажаними параметрами масштабування.
Зміни параметрів масштабування дозволені без перебудови або перезапуску Podʼа автомасштабування.
Автомасштабування надає інтерфейс контролера для підтримки двох шаблонів керування: linear та ladder.
Що далі
- Дізнайтеся більше про Гарантоване планування для Podʼів критичних надбудов.
- Дізнайтеся більше про реалізацію cluster-proportional-autoscaler.
11 - Зміна режиму доступу до PersistentVolume на ReadWriteOncePod
Ця сторінка показує, як змінити режим доступу наявного PersistentVolume на ReadWriteOncePod.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.22.Для перевірки версії введіть kubectl version.
Примітка:
Режим доступуReadWriteOncePod став стабільним у релізі Kubernetes v1.29. Якщо ви використовуєте версію Kubernetes старішу за v1.29, можливо, вам доведеться увімкнути feature gate. Перевірте документацію для вашої версії Kubernetes.Примітка:
Режим доступу ReadWriteOncePod підтримується тільки для CSI томів. Щоб застосувати цей режим доступу до тому, вам потрібно оновити наступні CSI sidecars до цих версій або вище:
Чому слід використовувати ReadWriteOncePod?
До версії Kubernetes v1.22 часто використовувався режим доступу ReadWriteOnce, щоб обмежити доступ до PersistentVolume для робочих навантажень, яким потрібен доступ одноосібного запису до сховища. Однак цей режим доступу мав обмеження: він обмежував доступ до тому одним вузлом, дозволяючи кільком Podʼам на одному вузлі одночасно читати та записувати в один і той же том. Це могло становити ризик для застосунків, які вимагають строгого доступу одноосібного запису для безпеки даних.
Якщо забезпечення доступу одноосібного запису є критичним для ваших робочих навантажень, розгляньте можливість міграції ваших томів на ReadWriteOncePod.
Міграція наявних PersistentVolumes
Якщо у вас є наявні PersistentVolumes, їх можна мігрувати на використання ReadWriteOncePod. Підтримується тільки міграція з ReadWriteOnce на ReadWriteOncePod.
У цьому прикладі вже є ReadWriteOnce "cat-pictures-pvc" PersistentVolumeClaim, який привʼязаний до "cat-pictures-pv" PersistentVolume, і "cat-pictures-writer" Deployment, який використовує цей PersistentVolumeClaim.
Примітка:
Якщо ваш втулок сховища підтримує Динамічне впровадження, "cat-pictures-pv" буде створено для вас, але його назва може відрізнятися. Щоб дізнатися назву вашого PersistentVolume, виконайте:
kubectl get pvc cat-pictures-pvc -o jsonpath='{.spec.volumeName}'
І ви можете переглянути PVC перед тим, як робити зміни. Перегляньте маніфест локально або виконайте kubectl get pvc <name-of-pvc> -o yaml. Вивід буде схожий на:
# cat-pictures-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: cat-pictures-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
Ось приклад Deployment, який залежить від цього PersistentVolumeClaim:
# cat-pictures-writer-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: cat-pictures-writer
spec:
replicas: 3
selector:
matchLabels:
app: cat-pictures-writer
template:
metadata:
labels:
app: cat-pictures-writer
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
volumeMounts:
- name: cat-pictures
mountPath: /mnt
volumes:
- name: cat-pictures
persistentVolumeClaim:
claimName: cat-pictures-pvc
readOnly: false
На першому етапі вам потрібно відредагувати spec.persistentVolumeReclaimPolicy вашого PersistentVolume і встановити його на Retain. Це забезпечить, що ваш PersistentVolume не буде видалений, коли ви видалите відповідний PersistentVolumeClaim:
kubectl patch pv cat-pictures-pv -p '{"spec":{"persistentVolumeReclaimPolicy":"Retain"}}'
Потім вам потрібно зупинити будь-які робочі навантаження, які використовують PersistentVolumeClaim, повʼязаний з PersistentVolume, який ви хочете мігрувати, а потім видалити PersistentVolumeClaim. Уникайте вносити будь-які інші зміни до PersistentVolumeClaim, такі як зміна розміру тому, поки міграція не буде завершена.
Якщо це зроблено, вам потрібно очистити spec.claimRef.uid вашого PersistentVolume, щоб забезпечити можливість звʼязування PersistentVolumeClaims з ним під час перестворення:
kubectl scale --replicas=0 deployment cat-pictures-writer
kubectl delete pvc cat-pictures-pvc
kubectl patch pv cat-pictures-pv -p '{"spec":{"claimRef":{"uid":""}}}'
Після цього замініть список дійсних режимів доступу до PersistentVolume, щоб був (тільки) ReadWriteOncePod:
kubectl patch pv cat-pictures-pv -p '{"spec":{"accessModes":["ReadWriteOncePod"]}}'
Примітка:
Режим доступуReadWriteOncePod не може бути поєднаний з іншими режимами доступу. Переконайтеся, що ReadWriteOncePod — єдиний режим доступу до PersistentVolume при оновленні, в іншому випадку запит буде невдалим.Після цього вам потрібно змінити ваш PersistentVolumeClaim, щоб встановити ReadWriteOncePod як єдиний режим доступу. Ви також повинні встановити spec.volumeName PersistentVolumeClaim на назву вашого PersistentVolume, щоб забезпечити його привʼязку саме до цього конкретного PersistentVolume.
Після цього ви можете перестворити ваш PersistentVolumeClaim та запустити ваші робочі навантаження:
# ВАЖЛИВО: Переконайтеся, що ви відредагували свій PVC в cat-pictures-pvc.yaml перед застосуванням. Вам потрібно:
# - Встановити ReadWriteOncePod як єдиний режим доступу
# - Встановити spec.volumeName на "cat-pictures-pv"
kubectl apply -f cat-pictures-pvc.yaml
kubectl apply -f cat-pictures-writer-deployment.yaml
Нарешті, ви можете відредагувати spec.persistentVolumeReclaimPolicy вашого PersistentVolume і встановити його знову на Delete, якщо ви раніше змінювали його.
kubectl patch pv cat-pictures-pv -p '{"spec":{"persistentVolumeReclaimPolicy":"Delete"}}'
Що далі
- Дізнайтеся більше про PersistentVolumes.
- Дізнайтеся більше про PersistentVolumeClaims.
- Дізнайтеся більше про Конфігурацію Pod для використання PersistentVolume для зберігання
12 - Зміна типового StorageClass
Ця сторінка показує, як змінити типовий StorageClass, який використовується для створення томів для PersistentVolumeClaims, які не мають особливих вимог.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для перевірки версії введіть kubectl version.
Чому змінювати типовий StorageClass?
Залежно від методу встановлення, ваш кластер Kubernetes може бути розгорнутий з наявним StorageClass, який позначений як типовий. Цей типовий StorageClass потім використовується для динамічного створення сховищ для PersistentVolumeClaims, які не вимагають будь-якого конкретного класу сховища. Див. документацію по PersistentVolumeClaim для деталей.
Попередньо встановлений типовий StorageClass може не відповідати вашим очікуваним навантаженням; наприклад, він може створювати занадто дороге сховище. У цьому випадку ви можете змінити типовий StorageClass або повністю вимкнути його, щоб уникнути динамічного створення сховища.
Видалення типового StorageClass може бути недійсним, оскільки він може бути автоматично створений знову менеджером надбудов, що працює в вашому кластері. Будь ласка, перегляньте документацію для вашого встановлення для деталей про менеджера надбудов та способи вимкнення окремих надбудов.
Зміна типового StorageClass
Перегляньте StorageClasses у вашому кластері:
kubectl get storageclassВивід буде схожий на це:
NAME PROVISIONER AGE standard (default) kubernetes.io/gce-pd 1d gold kubernetes.io/gce-pd 1dТиповий StorageClass позначений як
(default).Зніміть позначку default з типового StorageClass:
У типового StorageClass є анотація
storageclass.kubernetes.io/is-default-class, встановлена наtrue. Будь-яке інше значення або відсутність анотації розглядається якfalse.Щоб позначити StorageClass як не типовий, вам потрібно змінити його значення на
false:kubectl patch storageclass standard -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'де
standard— це назва вашого вибраного StorageClass.Позначте StorageClass як типовий:
Аналогічно попередньому кроку, вам потрібно додати/встановити анотацію
storageclass.kubernetes.io/is-default-class=true.kubectl patch storageclass gold -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'Зверніть увагу, що ви можете позначити декілька
StorageClassяк стандартні. Якщо позначено більше одногоStorageClassяк стандартного,PersistentVolumeClaimбез явно визначеногоstorageClassNameбуде створено з використанням останнього створеного стандартногоStorageClass. КолиPersistentVolumeClaimстворено із зазначенимvolumeName, він залишається у стані очікування, якщоstorageClassNameстатичного тому не збігається зStorageClassуPersistentVolumeClaim.Перевірте, що ваш вибраний StorageClass є default:
kubectl get storageclassВивід буде схожий на це:
NAME PROVISIONER AGE standard kubernetes.io/gce-pd 1d gold (default) kubernetes.io/gce-pd 1d
Що далі
- Дізнайтеся більше про PersistentVolumes.
13 - Перехід від опитування до оновлення стану контейнера на основі подій CRI
Kubernetes v1.26 [alpha](стандартно вимкнено)Ця сторінка показує, як мігрувати вузли для використання оновлення стану контейнера на основі подій. Реалізація на основі подій зменшує використання ресурсів вузла kubeletʼом порівняно зі старим підходом, який ґрунтується на опитуванні. Ви можете знати цю функцію як evented Pod lifecycle event generator (PLEG). Це назва, яка використовується внутрішньо в проєкті Kubernetes для основних деталей реалізації.
Підхід на основі опитування відомий як generic PLEG.
Перш ніж ви розпочнете
- Ви повинні запускати версію Kubernetes, яка надає цю функцію. Kubernetes v1.27 включає підтримку бета-версії оновлення стану контейнера на основі подій. Функція є бета-версією, але стандартно вимкнена, оскільки вона потребує підтримки від середовища виконання контейнерів.
- Версія вашого Kubernetes сервера має бути не старішою ніж 1.26.
Для перевірки версії введіть
Якщо ви використовуєте іншу версію Kubernetes, перевірте документацію для цього релізу.kubectl version. - Використане контейнерне середовище повинно підтримувати події життєвого циклу контейнера. Kubelet автоматично повертається до старого механізму опитування generic PLEG, якщо контейнерне середовище не оголошує підтримку подій життєвого циклу контейнера, навіть якщо у вас увімкнено цей функціонал.
Навіщо переходити на Evented PLEG?
- Generic PLEG викликає значне навантаження через часте опитування стану контейнерів.
- Це навантаження загострюється паралельним опитуванням стану контейнерів kublet, що обмежує його масштабованість та призводить до проблем з поганим функціонуванням та надійністю.
- Мета Evented PLEG — зменшити непотрібну роботу під час бездіяльності шляхом заміни періодичного опитування.
Перехід на Evented PLEG
Запустіть Kubelet з увімкненою функціональною можливістю
EventedPLEG. Ви можете керувати feature gate kubelet редагуючи файл конфігурації kubelet і перезапустіть службу kubelet. Вам потрібно зробити це на кожному вузлі, де ви використовуєте цю функцію.Переконайтеся, що вузол виведено з експлуатації перед продовженням.
Запустіть контейнерне середовище з увімкненою генерацією подій контейнера.
Версія вашого Kubernetes сервера має бути не старішою ніж 1.26.Версія 1.7+
Версія 1.26+
Перевірте, чи CRI-O вже налаштований на відправлення CRI-подій, перевіривши конфігурацію,
crio config | grep enable_pod_eventsЯкщо він увімкнений, вивід повинен бути схожий на наступний:
enable_pod_events = trueЩоб увімкнути його, запустіть демон CRI-O з прапорцем
--enable-pod-events=trueабо використовуйте конфігурацію dropin з наступними рядками:[crio.runtime] enable_pod_events: trueДля перевірки версії введіть
kubectl version.Перевірте, що kubelet використовує моніторинг стану контейнера на основі подій. Щоб перевірити це, шукайте термін
EventedPLEGв журналах kubelet.Вивід буде схожий на це:
I0314 11:10:13.909915 1105457 feature_gate.go:249] feature gates: &{map[EventedPLEG:true]}Якщо ви встановили
--vу значення 4 і вище, ви можете побачити більше записів, що підтверджують, що kubelet використовує моніторинг стану контейнера на основі подій.I0314 11:12:42.009542 1110177 evented.go:238] "Evented PLEG: Generated pod status from the received event" podUID=3b2c6172-b112-447a-ba96-94e7022912dc I0314 11:12:44.623326 1110177 evented.go:238] "Evented PLEG: Generated pod status from the received event" podUID=b3fba5ea-a8c5-4b76-8f43-481e17e8ec40 I0314 11:12:44.714564 1110177 evented.go:238] "Evented PLEG: Generated pod status from the received event" podUID=b3fba5ea-a8c5-4b76-8f43-481e17e8ec40
Що далі
- Дізнайтеся більше про дизайн у пропозиції покращення Kubernetes (KEP): Kubelet Evented PLEG for Better Performance.
14 - Зміна політики відновлення PersistentVolume
Ця сторінка показує, як змінити політику відновлення PersistentVolume в Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для перевірки версії введіть kubectl version.
Навіщо змінювати політику відновлення PersistentVolume
У PersistentVolume можуть бути різні політики відновлення, включаючи "Retain", "Recycle" та "Delete". Для динамічно створених PersistentVolume типовою політикою відновлення є "Delete". Це означає, що динамічно створений том автоматично видаляється, коли користувач видаляє відповідний PersistentVolumeClaim. Ця автоматична поведінка може бути неприйнятною, якщо том містить важливі дані. У цьому випадку більш відповідною буде політика "Retain". З політикою "Retain", якщо користувач видаляє PersistentVolumeClaim, відповідний PersistentVolume не буде видалено. Замість цього він переміщується до фази Released, де всі його дані можуть бути вручну відновлені.
Зміна політики відновлення PersistentVolume
Виведіть список PersistentVolume в вашому кластері:
kubectl get pvВивід буде схожий на такий:
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-b6efd8da-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim1 manual 10s pvc-b95650f8-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim2 manual 6s pvc-bb3ca71d-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim3 manual 3sЦей список також включає імена заявок, які привʼязані до кожного тому для полегшення ідентифікації динамічно створених томів.
Виберіть один з ваших PersistentVolume та змініть його політику відновлення:
kubectl patch pv <your-pv-name> -p '{"spec":{"persistentVolumeReclaimPolicy":"Retain"}}'де
<your-pv-name>— це імʼя вашого обраного PersistentVolume.Примітка:
У Windows ви повинні двічі взяти в лапки будь-який шаблон JSONPath, що містить пробіли (не подвійні лапки як вказано вище для bash). Це своєю чергою означає, що ви повинні використовувати одинарні лапки або екрановані подвійні лапки навколо будь-яких літералів в шаблоні. Наприклад:
kubectl patch pv <your-pv-name> -p "{\"spec\":{\"persistentVolumeReclaimPolicy\":\"Retain\"}}"Перевірте, що ваш обраний PersistentVolume має відповідну політику:
kubectl get pvВивід буде схожий на такий:
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-b6efd8da-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim1 manual 40s pvc-b95650f8-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim2 manual 36s pvc-bb3ca71d-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Retain Bound default/claim3 manual 33sУ попередньому виводі ви можете побачити, що том, привʼязаний до заявки
default/claim3, має політику відновленняRetain. Він не буде автоматично видалений, коли користувач видаляє заявкуdefault/claim3.
Що далі
- Дізнайтеся більше про PersistentVolumes.
- Дізнайтеся більше про PersistentVolumeClaims.
Посилання
- PersistentVolume
- Зверніть увагу на
.spec.persistentVolumeReclaimPolicyполя PersistentVolume.
- Зверніть увагу на
- PersistentVolumeClaim
15 - Адміністрування менеджера хмарного контролера
Kubernetes v1.11 [beta]Оскільки хмарні провайдери розвиваються та випускають нові функції в іншому темпі порівняно з проєктом Kubernetes, абстрагування провайдеро-залежного коду у бінарний файл cloud-controller-manager дозволяє хмарним постачальникам розвиватися незалежно від основного коду Kubernetes.
cloud-controller-manager може бути повʼязаний з будь-яким хмарним провайдером, який відповідає вимогам cloudprovider.Interface. Для забезпечення зворотної сумісності, cloud-controller-manager, що постачається у складі основного проєкту Kubernetes, використовує ті ж хмарні бібліотеки, що і kube-controller-manager. Очікується, що хмарні постачальники, які вже підтримуються у ядрі Kubernetes, використовуватимуть вбудований cloud-controller-manager для передачі даних з ядра Kubernetes.
Адміністрування
Вимоги
Кожна хмара має свій власний набір вимог для запуску своєї інтеграції з власним провайдером, це не повинно суттєво відрізнятися від вимог до запуску kube-controller-manager. Загалом вам знадобиться:
- автентифікація/авторизація в хмарі: вашій хмарі може знадобитися токен або правила IAM, щоб дозволити доступ до їхніх API
- автентифікація/авторизація в Kubernetes: cloud-controller-manager може потребувати налаштування RBAC правила для звʼязку з apiserver Kubernetes
- висока доступність: як і kube-controller-manager, вам може знадобитися налаштування високої доступності для cloud controller manager з використанням вибору лідера (стандартно увімкнено).
Робота cloud-controller-manager
Успішне виконання cloud-controller-manager вимагає деяких змін у конфігурації кластера.
kubelet,kube-apiserverтаkube-controller-managerповинні бути налаштовані відповідно до використання користувачем зовнішнього CCM. Якщо користувач має зовнішній CCM (не внутрішні цикли управління хмарою в Kubernetes Controller Manager), то--cloud-provider=externalповинен бути вказаний. В іншому випадку це не повинно бути вказано.
Майте на увазі, що налаштування кластера на використання контролера хмарного провайдера змінить поведінку вашого кластера:
- Компоненти, що вказують
--cloud-provider=external, додають спеціальний taintnode.cloudprovider.kubernetes.io/uninitializedз ефектомNoScheduleпід час ініціалізації. Це помічає вузол як такий, що потребує другої ініціалізації з зовнішнього контролера перед тим, як він зможе розпочати роботу. Зверніть увагу, що в разі недоступності cloud-controller-manager, нові вузли у кластері залишаться незапланованими. Taint важливий, оскільки планувальник може вимагати специфічної для хмари інформації про вузли, такої як їхній регіон чи тип (high cpu, gpu, high memory, spot instance тощо). - інформація про вузли в кластері більше не буде вибиратися з локальних метаданих, а замість цього всі виклики API для вибору інформації про вузли будуть проходити через cloud controller manager. Це може означати, що ви можете обмежити доступ до вашого API хмари на kubelet для кращої безпеки. Для великих кластерів вам може бути доцільно розглянути можливість обмеження швидкості викликів API cloud controller manager, оскільки він тепер відповідальний майже за всі виклики API вашої хмари зсередини кластера.
Контролер хмарного провайдера може надавати:
- контролер Node — відповідає за оновлення вузлів Kubernetes з використанням API хмари та видалення вузлів Kubernetes, які були видалені у вашій хмарі.
- контролер Service — відповідає за балансування навантаження у вашій хмарі для сервісів типу LoadBalancer.
- контролер Route — відповідає за налаштування мережевих маршрутів у вашій хмарі
- будь-які інші функції, які ви хочете реалізувати, якщо ви використовуєте провайдера не з ядра Kubernetes.
Приклади
Якщо ви використовуєте хмару, яка наразі підтримується в ядрі Kubernetes і хочете використовувати контролер хмарного провайдера, див. контролер хмарного провайдера в ядрі Kubernetes.
Для контролерів хмарних провайдерів, які не входять у ядро Kubernetes, ви можете знайти відповідні проєкти у репозиторіях, підтримуваних хмарними постачальниками або SIGs.
Для провайдерів, які вже є в ядрі Kubernetes, ви можете запускати вбудований контролер хмарного провайдера як DaemonSet у вашому кластері, використовуючи наступне як рекомендацію:
# Це приклад налаштування cloud-controller-manager як Daemonset у вашому кластері.
# Він передбачає, що ваші мастери можуть запускати Podʼи та мають роль node-role.kubernetes.io/master.
# Зверніть увагу, що цей Daemonset не працюватиме безпосередньо з коробки для вашого хмарного середовища, це
# призначено як рекомендація.
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: cloud-controller-manager
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:cloud-controller-manager
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: cloud-controller-manager
namespace: kube-system
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
k8s-app: cloud-controller-manager
name: cloud-controller-manager
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: cloud-controller-manager
template:
metadata:
labels:
k8s-app: cloud-controller-manager
spec:
serviceAccountName: cloud-controller-manager
containers:
- name: cloud-controller-manager
# for in-tree providers we use registry.k8s.io/cloud-controller-manager
# this can be replaced with any other image for out-of-tree providers
image: registry.k8s.io/cloud-controller-manager:v1.8.0
command:
- /usr/local/bin/cloud-controller-manager
- --cloud-provider=[YOUR_CLOUD_PROVIDER] # Add your own cloud provider here!
- --leader-elect=true
- --use-service-account-credentials
# these flags will vary for every cloud provider
- --allocate-node-cidrs=true
- --configure-cloud-routes=true
- --cluster-cidr=172.17.0.0/16
tolerations:
# this is required so CCM can bootstrap itself
- key: node.cloudprovider.kubernetes.io/uninitialized
value: "true"
effect: NoSchedule
# these tolerations are to have the daemonset runnable on control plane nodes
# remove them if your control plane nodes should not run pods
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
# this is to restrict CCM to only run on master nodes
# the node selector may vary depending on your cluster setup
nodeSelector:
node-role.kubernetes.io/master: ""
Обмеження
Запуск контролера хмарного провайдера супроводжується кількома можливими обмеженнями. Хоча ці обмеження вирішуються у майбутніх релізах, важливо, щоб ви були обізнані з цими обмеженнями для операційних робочих навантажень.
Підтримка томів
Контролер хмарного провайдера не реалізує жодного з контролерів томів, що знаходяться в kube-controller-manager, оскільки інтеграція томів також потребує координації з kubelet. Під час розвитку CSI (інтерфейс контейнерного сховища) та додавання більш надійної підтримки втулків flex томів буде додано необхідну підтримку до контролера хмарного провайдера, щоб хмари могли повністю інтегруватися з томами. Дізнайтеся більше про зовнішні втулки томів CSI тут.
Масштабованість
Контролер хмарного провайдера запитує API вашого хмарного постачальника для отримання інформації про всі вузли. Для дуже великих кластерів розгляньте можливі вузькі місця, такі як вимоги до ресурсів та обмеження швидкості API.
Курча і яйце
Метою проєкту контролера хмарного провайдера є відділення розробки хмарних функцій від розробки проєкту ядра Kubernetes. На жаль, багато аспектів проєкту Kubernetes мають припущення, що функції хмарного провайдера тісно інтегровані у проєкт. Внаслідок цього, прийняття цієї нової архітектури може створити кілька ситуацій, коли робиться запит інформації від хмарного постачальника, але контролер хмарного провайдера може не мати можливості повернути цю інформацію без завершення початкового запиту.
Хорошим прикладом цього є функція TLS bootstrapping в Kubelet. TLS bootstrapping передбачає, що Kubelet має можливість запитати у хмарного провайдера (або локального сервісу метаданих) всі його типи адрес (приватні, публічні і т. д.), але контролер хмарного провайдера не може встановити типи адрес вузла без попередньої ініціалізації, що потребує, щоб kubelet мав TLS-сертифікати для звʼязку з apiserver.
Під час розвитку цієї ініціативи будуть внесені зміни для розвʼязання цих питань у майбутніх релізах.
Що далі
Щоб створити та розробити свій власний контролер хмарного провайдера, прочитайте Розробка контролера хмарного провайдера.
16 - Налаштування постачальника облікових даних образів в kubelet
Kubernetes v1.26 [stable]Починаючи з Kubernetes v1.20, kubelet може динамічно отримувати облікові дані для реєстру образів контейнерів за допомогою використання втулків. Kubelet та втулок спілкуються через stdio (stdin, stdout та stderr), використовуючи версійні API Kubernetes. Ці втулки дозволяють kubelet запитувати облікові дані для реєстру контейнерів динамічно, на відміну від зберігання статичних облікових даних на диску. Наприклад, втулок може звертатися до локального сервера метаданих, щоб отримати облікові дані з обмеженим терміном дії для образу, який завантажується kubelet.
Ви можете бути зацікавлені у використанні цієї можливості, якщо будь-яке з нижче перерахованих тверджень є правдивим:
- Потрібні виклики API до служби хмарного постачальника для отримання інформації для автентифікації реєстру.
- Облікові дані мають короткий термін дії, і потрібно часто запитувати нові облікові дані.
- Зберігання облікових даних реєстру на диску або в imagePullSecrets неприпустиме.
Цей посібник демонструє, як налаштувати механізм втулка постачальника облікових даних зображення kubelet.
Токен службового облікового запису для витягування образів
Kubernetes v1.34 [beta](стандартно увімкнено)Починаючи з Kubernetes v1.33, kubelet можна налаштувати так, щоб надсилати токен службового облікового запису, привʼязаного до того podʼу, для якого виконується отримання образу, до втулка постачальника облікових даних.
Це дозволить втулку обміняти токен на облікові дані для доступу до реєстру образів.
Щоб увімкнути цю можливість, в kubelet має бути увімкнено функціональну можливість KubeletServiceAccountTokenForCredentialProviders, а у файлі CredentialProviderConfig для втулка має бути задано поле tokenAttributes.
Поле tokenAttributes містить інформацію про токен службового облікового запису, який буде передано втулку, включаючи цільову аудиторію для токена і те, чи вимагає втулок, щоб pod мав службовий обліковий запис.
Використання облікових даних службового облікового запису може забезпечити наступні варіанти використання:
- Уникнення необхідності використання ідентифікатора на основі kubelet/node для отримання образів з реєстру.
- Дозволити робочим навантаженням отримувати образи на основі їхніх власних ідентифікаторів часу виконання без довготривалих/стійких секретів.
Перш ніж ви розпочнете
- Вам потрібен кластер Kubernetes з вузлами, які підтримують втулки постачальника облікових даних kubelet. Ця підтримка доступна у Kubernetes 1.35; Kubernetes v1.24 та v1.25 мали це як бета-функцію, яка є типово увімкненою.
- Якщо ви налаштовуєте втулок постачальника облікових даних, якому потрібен токен службового облікового запису, вам потрібен кластер Kubernetes з вузлами під керуванням Kubernetes v1.33 або новішої версії та ввімкненим на kubelet функціоналом
KubeletServiceAccountTokenForCredentialProviders. - Робоча реалізація втулка постачальника облікових даних. Ви можете створити власний втулок або використовувати той що, наданий хмарним постачальником.
Для перевірки версії введіть kubectl version.
Встановлення втулків на вузлах
Втулок постачальника облікових даних — це виконавчий бінарний файл, який kubelet буде використовувати. Переконайтеся, що бінарний файл втулка існує на кожному вузлі вашого кластера і зберігається в відомій теці. Ця тека буде потрібна пізніше при налаштуванні прапорців kubelet.
Налаштування Kubelet
Для використання цієї функції kubelet очікує встановлення двох прапорців:
--image-credential-provider-config— шлях до файлу конфігурації втулка постачальника облікових даних.--image-credential-provider-bin-dir— шлях до теки, де знаходяться бінарні файли втулка постачальника облікових даних.
Налаштування постачальника облікових даних kubelet
Файл конфігурації, переданий в --image-credential-provider-config, зчитується kubelet для визначення, які виконавчі втулки слід викликати для яких образів контейнерів. Нижче наведено приклад файлу конфігурації, який ви, можливо, будете використовувати, якщо використовуєте втулок, оснований на ECR:
apiVersion: kubelet.config.k8s.io/v1
kind: CredentialProviderConfig
# providers — це список допоміжних втулків постачальників облікових даних, які будуть активовані
# kubelet. Одному образу може відповідати декілька постачальників, в такому випадку облікові дані
# від усіх постачальників будуть повернуті kubelet. Якщо для одного образу є кілька
# постачальників, результати будуть обʼєднані. Якщо постачальники повертають ключі автентифікації,
# що перекриваються, використовується значення від постачальника, який знаходиться раніше в цьому
# списку.
providers:
# name — це обовʼязкове імʼя постачальника облікових даних. Воно повинно відповідати імені
# виконавчого файлу постачальника, яке бачить kubelet. Виконавчий файл повинен знаходитися в
# теці bin kubelet (встановлено за допомогою прапорця --image-credential-provider-bin-dir).
- name: ecr-credential-provider
# matchImages - обовʼязковий список рядків, які використовуються для порівняння з образами, щоб
# визначити, чи потрібно викликати цього постачальника. Якщо один із рядків відповідає
# запитаному образу від kubelet, втулок буде викликаний і отримає шанс надати облікові дані.
# Очікується, що образи містять домен реєстру та URL-шлях.
#
# Кожний запис в matchImages — це шаблон, який може необовʼязково містити порт та шлях.
# Можна використовувати шаблони для домену, але не для порту або шляху. Шаблони підтримуються
# як піддомени, наприклад, '*.k8s.io' або 'k8s.*.io', так і верхніх рівнів доменів, наприклад,
# 'k8s.*'. Підтримується також частковий збіг піддоменів, наприклад, 'app*.k8s.io'. Кожен
# шаблон може відповідати лише одному сегменту піддомену, тому `*.io` **не** відповідає
# `*.k8s.io`.
#
# Збіг існує між образами та matchImage, коли виконуються всі наведені нижче умови:
# - Обидва мають однакову кількість частин домену і кожна частина має збіг.
# - URL-шлях matchImages повинен бути префіксом URL-шляху цільового образу.
# - Якщо matchImages містить порт, то порт також повинен мати збіг в образі.
# Приклади значент matchImages:
# - 123456789.dkr.ecr.us-east-1.amazonaws.com
# - *.azurecr.io
# - gcr.io
# - *.*.registry.io
# - registry.io:8080/path
matchImages:
- "*.dkr.ecr.*.amazonaws.com"
- "*.dkr.ecr.*.amazonaws.com.cn"
- "*.dkr.ecr-fips.*.amazonaws.com"
- "*.dkr.ecr.us-iso-east-1.c2s.ic.gov"
- "*.dkr.ecr.us-isob-east-1.sc2s.sgov.gov"
# defaultCacheDuration — це типовий час, протягом якої втулок буде кешувати облікові дані у памʼяті,
# якщо тривалість кешу не надана у відповіді втулку. Це поле є обовʼязковим.
defaultCacheDuration: "12h"
# Вхідна версія CredentialProviderRequest є обовʼязковою. Відповідь CredentialProviderResponse
# ПОВИННА використовувати ту ж версію кодування, що й вхідна. Поточні підтримувані значення:
# - credentialprovider.kubelet.k8s.io/v1
apiVersion: credentialprovider.kubelet.k8s.io/v1
# Аргументи, що перндаються команді під час її виконання.
# +optional
# args:
# - --example-argument
# Env визначає додаткові змінні середовища, які слід надати процесу. Ці
# змінні обʼєднуються з оточенням хоста, а також змінними, які використовує client-go
# для передачі аргументів до втулка.
# +optional
env:
- name: AWS_PROFILE
value: example_profile
# tokenAttributes - конфігурація токену службового облікового запису, який буде передано втулку.
# За допомогою цього поля постачальник облікових даних погоджується на використання токенів службових облікових записів для отримання образів.
# якщо це поле встановлено без увімкненої функціональної можливості `KubeletServiceAccountTokenForCredentialProviders`, # kubelet не зможе запуститися з помилкою конфігурації.
# +optional
tokenAttributes:
# serviceAccountTokenAudience — це очікувана аудиторія для спроєцьованих токенів службових облікових запісів.
# +required
serviceAccountTokenAudience: "<audience for the token>"
# cacheType вказує тип ключа кешу, що використовується для кешування облікових даних, повернених втулком
# коли використовується токен службового облікового запису.
# Найбільш консервативний варіант - встановити його на "Token", що означає, що kubelet буде кешувати
# повернуті облікові дані на основі кожного токена. Це слід встановити, якщо термін дії повернутого облікового запису
# обмежений терміном дії токена службового облікового запису.
# Якщо логіка отримання облікових даних втулка залежить лише від службового облікового запису, а не від
# заявок pod-specific, тоді втулок може встановити це значення на "ServiceAccount". У цьому випадку
# kubelet буде кешувати повернуті облікові дані на основі кожного службового облікового запису. Використовуйте це, коли
# повернуті облікові дані дійсні для всіх podʼів, які використовують той самий службовий обліковий запис.
# +required
cacheType: "<Token or ServiceAccount>"
# requireServiceAccount вказує чи вимагає втулок, щоб pod мав службовий обліковий запис.
# Якщов становлено true, kubelet буде викликати втулок тільки якщо pod має службовий обліковий запис.
# Якщо встановлено false, kubelet буде викликати втулок навіть, тоді, коли pod не має службового облікового запису
# та не вклбчатиме токен у CredentialProviderRequest. Це корисно для втулків,
# які використовуються для отримання образів для podʼів без службових облікових записів (напр., статичні podʼи).
# +required
requireServiceAccount: true
# requiredServiceAccountAnnotationKeys є переліком ключів анотацій потрібних для втулків
# та які мають бути присутні в службових облікових записах.
# Ключі визначені в переліку будуть отримані з відповідного службового облікового запису та передані
# до втулку як частина CredentialProviderRequest. Якщо будь-яких з ключів, з цього переліку
# не знаходиться в службового обліковому записі, kubelet не викликатиме втулок та поверне помилку.
# Це поле є опціональним та може бути пустим. Втулки можуть використовувати це поле для отримання додаткової інформації,
# потрібної для отримання облікових даних або для дозволу робочому навантаженю використовувати токен службового облікового запису для отримання образів.
# Якщо це не пусте значення, requireServiceAccount має бути рівним true.
# Ключі визначені в цьому переліку мають бути унікальними та не перетинатись з ключами визначених в
# переліку optionalServiceAccountAnnotationKeys.
# +optional
requiredServiceAccountAnnotationKeys:
- "example.com/required-annotation-key-1"
- "example.com/required-annotation-key-2"
# optionalServiceAccountAnnotationKeys це перелік ключів анотації потрібні для втулку
# та наявність яких в службового обліковому записі є опціональною.
# Ключі визначені в цьому переліку будуть отримані з відповідного службового облікового запису та передані
# втулку як частина CredentialProviderRequest. Перевірка наявності анотацій та їх значень покладається на втулок
# Це поле є опціональним і може бути порожнім.
# Втулки можуть використовувати це поле для отримання додаткової інформації для отримання облікових даних.
# Ключі визначені в цьому переліку мають бути унікальними та не перетинатись з ключами з перелку
# requiredServiceAccountAnnotationKeys.
# +optional
optionalServiceAccountAnnotationKeys:
- "example.com/optional-annotation-key-1"
- "example.com/optional-annotation-key-2"
Поле providers — це список увімкнених втулків, які використовує kubelet. Кожен запис має кілька обовʼязкових полів:
name: назва втулка, яка ПОВИННА відповідати назві виконавчого бінарного файлу, який існує в теці, вказаній у--image-credential-provider-bin-dir.matchImages: список рядків, які використовуються для порівняння образів з метою визначення, чи слід викликати цього постачальника для конкретного образу контейнера. Докладніше про це нижче.defaultCacheDuration: термін, протягом якого kubelet буде кешувати облікові дані в памʼяті, якщо втулок не надав термін кешування.apiVersion: версія API, яку використовуватимуть kubelet і виконавчий втулок під час спілкування.
Кожен постачальник облікових даних також може мати додаткові аргументи та змінні середовища. Перегляньте реалізацію втулків, щоб визначити, який набір аргументів та змінних середовища потрібний для певного втулка.
Якщо ви використовуєте функціональну можливість KubeletServiceAccountTokenForCredentialProviders та налаштовуєте втулок для використання токена службового облікового запису через встановлення поля tokenAttributes, наступні поля є обовʼязковими:
serviceAccountTokenAudience: передбачувана аудиторія для спроєцьованого токена службового облікового запису . Це не може бути порожній рядок.cacheType: тип ключа кешу, що використовується для кешування облікових даних, повернених втулком, коли використовується токен службового облікового запису. Найбільш консервативний варіант — встановити його вToken, що означає, що kubelet буде кешувати повернені облікові дані на основі кожного токена. Це слід встановити, якщо термін дії повернутого облікового запису обмежений терміном дії токена службового облікового запису. Якщо логіка отримання облікових даних втулка залежить лише від службового облікового запису, а не від специфічних для пода вимог, то втулок може встановити це вServiceAccount. У цьому випадку kubelet буде кешувати повернені облікові дані на основі кожного службового облікового запису. Використовуйте це, коли повернений обліковий запис дійсний для всіх подів, які використовують один і той же службовий обліковий запис.requireServiceAccount: чи потребує втулок, щоб pod мав службовий обліковий запис.- Якщо —
true, kubelet викликатиме втулок коли pod має службовий обліковий запис. - Якщо —
false, kubelet викликатиме втулок навіть тоді, коли pod не має службового облікового запису та не включатиме токен уCredentialProviderRequest.
- Якщо —
Це є корисним для втулків, які використовуються для отримання образів для podʼів без службових облікових записів (напр., статичні podʼи).
Налаштування збігу образів
Поле matchImages для кожного постачальника облікових даних використовується kubelet для визначення того, чи слід викликати втулок для певного образу, що використовується в Podʼі. Кожний запис у matchImages — це шаблон образу, який може опціонально містити порт та шлях. Символи підстановки дозволяють використовувати шаблони для піддоменів, такі як *.k8s.io або k8s.*.io, а також для доменів верхнього рівня, такі як k8s.*. Збіг між імʼям образу та записом matchImage існує тоді, коли виконуються всі умови:
- Обидва містять однакову кількість частин домену, і кожна частина має збіг.
- Шлях URL
matchImageповинен бути префіксом шляху URL цільового образу. - Якщо
matchImagesмістить порт, то порт також повинен мати збіг в образі.
Деякі приклади значень шаблонів matchImages:
123456789.dkr.ecr.us-east-1.amazonaws.com*.azurecr.iogcr.io*.*.registry.iofoo.registry.io:8080/path
Що далі
- Ознайомтесь із деталями
CredentialProviderConfigв довідці API конфігурації kubelet (v1). - Прочитайте довідник API постачальника облікових даних kubelet (v1).
17 - Налаштування квот для обʼєктів API
Ця сторінка показує, як налаштувати квоти для обʼєктів API, включаючи PersistentVolumeClaims та Services. Квота обмежує кількість обʼєктів певного типу, які можуть бути створені в просторі імен. Ви вказуєте квоти в обʼєкті ResourceQuota.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для перевірки версії введіть kubectl version.
Створення простору імен
Створіть простір імен, щоб ресурси, які ви створюєте у цьому завданні, були ізольовані від решти вашого кластера.
kubectl create namespace quota-object-example
Створення ResourceQuota
Ось файл конфігурації для обʼєкта ResourceQuota:
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-quota-demo
spec:
hard:
persistentvolumeclaims: "1"
services.loadbalancers: "2"
services.nodeports: "0"
Створіть ResourceQuota:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-objects.yaml --namespace=quota-object-example
Перегляньте докладну інформацію про ResourceQuota:
kubectl get resourcequota object-quota-demo --namespace=quota-object-example --output=yaml
У виводі показано, що в просторі імен quota-object-example може бути максимум один PersistentVolumeClaim, максимум два Services типу LoadBalancer та жодного Services типу NodePort.
status:
hard:
persistentvolumeclaims: "1"
services.loadbalancers: "2"
services.nodeports: "0"
used:
persistentvolumeclaims: "0"
services.loadbalancers: "0"
services.nodeports: "0"
Створення PersistentVolumeClaim
Ось файл конфігурації для обʼєкта PersistentVolumeClaim:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-quota-demo
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
Створіть PersistentVolumeClaim:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-objects-pvc.yaml --namespace=quota-object-example
Перевірте, що PersistentVolumeClaim було створено:
kubectl get persistentvolumeclaims --namespace=quota-object-example
У виводі показано, що PersistentVolumeClaim існує і має статус Pending:
NAME STATUS
pvc-quota-demo Pending
Спроба створити другий PersistentVolumeClaim
Ось файл конфігурації для другого PersistentVolumeClaim:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-quota-demo-2
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 4Gi
Спробуйте створити другий PersistentVolumeClaim:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-objects-pvc-2.yaml --namespace=quota-object-example
У виводі показано, що другий PersistentVolumeClaim не був створений, оскільки це перевищило квоту для простору імен.
persistentvolumeclaims "pvc-quota-demo-2" is forbidden:
exceeded quota: object-quota-demo, requested: persistentvolumeclaims=1,
used: persistentvolumeclaims=1, limited: persistentvolumeclaims=1
Примітки
Ці рядки використовуються для ідентифікації обʼєктів API, які можуть бути обмежені за допомогою квот:
| Рядок | Обʼєкт API |
|---|---|
| "pods" | Pod |
| "services" | Service |
| "replicationcontrollers" | ReplicationController |
| "resourcequotas" | ResourceQuota |
| "secrets" | Secret |
| "configmaps" | ConfigMap |
| "persistentvolumeclaims" | PersistentVolumeClaim |
| "services.nodeports" | Service типу NodePort |
| "services.loadbalancers" | Service типу LoadBalancer |
Очищення
Видаліть свій простір імен:
kubectl delete namespace quota-object-example
Що далі
Для адміністраторів кластера
Налаштуйте типові запити та ліміти памʼяті для простору імен
Налаштуйте типові запити та ліміти центрального процесора для простору імен
Налаштуйте мінімальні та максимальні обмеження памʼяті для простору імен
Налаштуйте мінімальні та максимальні обмеження центрального процесора для простору імен
Налаштуйте квоти памʼяті та центрального процесора для простору імен
Для розробників застосунків
18 - Управління політиками керування ЦП на вузлі
Kubernetes v1.26 [stable]Kubernetes зберігає багато аспектів того, як Podʼи виконуються на вузлах, абстрагованими від користувача. Це зроблено навмисно. Проте деякі завдання вимагають більших гарантій з погляду часу реакції та/або продуктивності, щоб працювати задовільно. Kubelet надає методи для включення складніших політик розміщення завдань, зберігаючи абстракцію вільною від явних директив розміщення.
Для отримання докладної інформації щодо управління ресурсами, будь ласка, зверніться до документації Управління ресурсами для Podʼів та контейнерів.
Для отримання детальної інформації про те, як у kubelet реалізовано управління ресурсами, зверніться до документації Node ResourceManagers.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.26.Для перевірки версії введіть kubectl version.
Якщо ви використовуєте старішу версію Kubernetes, будь ласка, перегляньте документацію для версії, яку ви фактично використовуєте.
Налаштування політик керування CPU
Стандартно, kubelet використовує квоту CFS, щоб обмежувати ЦП для Podʼів. Коли вузол виконує багато Podʼів, залежних від ЦП, навантаження може переміщуватися на різні ядра ЦП залежно від того, чи обмежений Pod, і які ядра ЦП доступні на момент планування. Багато завдань не чутливі до цього переміщення і, отже, працюють нормально без будь-якого втручання.
Проте, в завданнях, де спорідненість кешу ЦП та затримка планування значно впливають на продуктивність робочого завдання, kubelet дозволяє використовувати альтернативні політики керування ЦП для визначення деяких вподобань розміщення на вузлі.
Підтримка Windows
Kubernetes v1.32 [alpha](стандартно вимкнено)Підтримку диспетчера процесорів можна увімкнути у Windows за допомогою WindowsCPUAndMemoryAffinity, і вона потребує підтримки під час виконання контейнера. Після увімкнення функціональної можливості виконайте наведені нижче кроки для налаштування політики диспетчера CPU.
Налаштування
Політика керування ЦП встановлюється прапорцем kubelet --cpu-manager-policy або полем cpuManagerPolicy в KubeletConfiguration. Підтримуються дві політики:
none: стандартна політика.static: дозволяє контейнерам з певними характеристиками ресурсів отримувати збільшену спорідненість ЦП та ексклюзивність на вузлі.
Керування ЦП періодично записує оновлення ресурсів через CRI, щоб звести до мінімуму проблеми сумісності памʼяті та виправити їх. Частота зведення встановлюється за допомогою нового значення конфігурації Kubelet --cpu-manager-reconcile-period. Якщо вона не вказана, стандартно вона дорівнює тому ж часу, що й --node-status-update-frequency.
Поведінку статичної політики можна налаштувати за допомогою прапорця --cpu-manager-policy-options. Прапорець приймає список параметрів політики у вигляді ключ=значення. Якщо ви вимкнули функціональну можливість CPUManagerPolicyOptions, то ви не зможете налаштувати параметри політик керування ЦП. У цьому випадку керування ЦП працюватиме лише зі своїми стандартними налаштуваннями.
Окрім верхнього рівня CPUManagerPolicyOptions, параметри політики розділені на дві групи: якість альфа (типово прихована) та якість бета (типово видима). Відмінно від стандарту Kubernetes, ці feature gate захищають групи параметрів, оскільки було б надто складно додати feature gate для кожного окремого параметра.
Зміна політики керування ЦП
Оскільки політику керування ЦП можна застосовувати лише коли kubelet створює нові Podʼи, просте змінення з "none" на "static" не застосується до наявних Podʼів. Тому, щоб правильно змінити політику керування ЦП на вузлі, виконайте наступні кроки:
- Виведіть з експлуатації вузол.
- Зупиніть kubelet.
- Видаліть старий файл стану керування ЦП. Типовий шлях до цього файлу
/var/lib/kubelet/cpu_manager_state. Це очищує стан, що зберігається CPUManager, щоб множини ЦП, налаштовані за новою політикою, не конфліктували з нею. - Відредагуйте конфігурацію kubelet, щоб змінити політику керування ЦП на потрібне значення.
- Запустіть kubelet.
Повторіть цей процес для кожного вузла, який потребує зміни політики керування ЦП. Пропуск цього процесу призведе до постійної аварійної роботи kubelet з такою помилкою:
could not restore state from checkpoint: configured policy "static" differs from state checkpoint policy "none", please drain this node and delete the CPU manager checkpoint file "/var/lib/kubelet/cpu_manager_state" before restarting Kubelet
Примітка:
Якщо на вузлі змінюється набір доступних процесорів, то вузол необхідно спустошити та вручну перезавантажити CPU manager, видаливши файл стануcpu_manager_state у кореневій теці kubelet.Налаштування політики none
Ця політика не має додаткових елементів конфігурації.
Налаштування політики static
Ця політика керує спільним пулом ЦП, який на початку містить всі ЦП на вузлі. Кількість ексклюзивно виділених ЦП дорівнює загальній кількості ЦП на вузлі мінус будь-які резерви ЦП за допомогою параметрів kubelet --kube-reserved або --system-reserved. З версії 1.17 список резервувань ЦП може бути вказаний явно за допомогою параметру kubelet --reserved-cpus. Явний список ЦП, вказаний за допомогою --reserved-cpus, має пріоритет над резервуванням ЦП, вказаним за допомогою --kube-reserved та --system-reserved. ЦП, зарезервовані цими параметрами, беруться, у цілочисельній кількості, зі спільного пулу на основі фізичного ідентифікатора ядра. Цей спільний пул — це множина ЦП, на яких працюють контейнери в Podʼах з BestEffort та Burstable. Контейнери у Podʼах з гарантованою продуктивністю з цілими requests ЦП також працюють на ЦП у спільному пулі. Ексклюзивні ЦП призначаються лише контейнерам, які одночасно належать до Podʼа з гарантованою продуктивністю та мають цілочисельні requests ЦП.
Примітка:
Kubelet потребує, щоб було зарезервовано не менше одного ЦП за допомогою параметрів--kube-reserved і/або --system-reserved або --reserved-cpus, коли включена статична політика. Це тому, що нульове резервування ЦП дозволить спільному пулу стати порожнім.Параметри політики static
Ви можете включати та виключати групи параметрів на основі їх рівня зрілості, використовуючи наступні feature gate:
CPUManagerPolicyBetaOptions— стандартно увімкнено. Вимкніть, щоб приховати параметри рівня бета.CPUManagerPolicyAlphaOptions— стандартно вимкнено. Увімкніть, щоб показати параметри рівня альфа. Ви все ще повинні увімкнути кожен параметр за допомогою опції kubeletCPUManagerPolicyOptions.
Для політики static CPUManager існують наступні параметри:
full-pcpus-only(GA, типово видимий) (1.33 або вище)distribute-cpus-across-numa(бета, типово видимий) (1.33 або вище)align-by-socket(альфа, типово прихований) (1.25 або вище)distribute-cpus-across-cores(альфа, типово прихований) (1.31 або вище)strict-cpu-reservation(GA, типово видимий) (1.35 або вище)prefer-align-cpus-by-uncorecache(бета, типово видимий) (1.34 або вище)
Параметр full-pcpus-only можна включити, додавши full-pcpus-only=true до параметрів політики CPUManager. Так само параметр distribute-cpus-across-numa можна включити, додавши distribute-cpus-across-numa=true до параметрів політики CPUManager. Якщо обидва встановлені, вони "адитивні" у тому сенсі, що ЦП будуть розподілені по вузлах NUMA в шматках повних фізичних ядер, а не окремих ядер. Параметр політики align-by-socket можна увімкнути, додавши align-by-socket=true до параметрів політики CPUManager. Він також адитивний до параметрів політики full-pcpus-only та distribute-cpus-across-numa.
Опцію distribute-cpus-across-cores можна увімкнути, додавши distribute-cpus-across-cores=true до параметрів політики CPUManager. Зараз її не можна використовувати разом з параметрами політики full-pcpus-only або distribute-cpus-across-numa.
Опцію strict-cpu-reservation можна увімкнути, додавши strict-cpu-reservation=true до параметрів політики CPUManager, після чого видалити файл /var/lib/kubelet/cpu_manager_state і перезапустити kubelet.
Параметр prefer-align-cpus-by-uncorecache можна увімкнути, додавши prefer-align-cpus-by-uncorecache до параметрів політики CPUManager. Якщо буде використано несумісні опції, kubelet не запуститься з помилкою, яку буде вказано у журналах.
Докладні відомості про поведінку окремих параметрів, які ви можете налаштувати, наведено у документації Node ResourceManagers.
19 - Керування політиками топології на вузлі
Kubernetes v1.27 [stable]Зростаюча кількість систем використовує комбінацію ЦП та апаратних прискорювачів для підтримки виконання, критичного з погляду затримок, та високопродуктивних паралельних обчислень. Ці системи включають робочі навантаження у таких галузях, як телекомунікації, наукові обчислення, машинне навчання, фінансові послуги та аналітика даних. Такі гібридні системи складають високопродуктивне середовище.
Для досягнення найкращої продуктивності потрібні оптимізації, що стосуються ізоляції ЦП, памʼяті та локальності пристроїв. Проте, в Kubernetes ці оптимізації обробляються роздільним набором компонентів.
Topology Manager — це компонент kubelet, який має на меті координацію набору компонентів, відповідальних за ці оптимізації.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.18.Для перевірки версії введіть kubectl version.
Як працює Topology Manager
Перед введенням Topology Manager, CPU та Device Manager в Kubernetes приймають рішення про розподіл ресурсів незалежно одне від одного. Це може призводити до небажаних розподілів на системах з кількома сокетами, де застосунки, що чутливі до продуктивності/затримки, будуть страждати через ці небажані розподіли. Небажані в цьому випадку означає, наприклад, виділення ЦП та пристроїв з різних вузлів NUMA, що призводить до додаткової затримки.
Topology Manager — це компонент kubelet, який діє як джерело правди, щоб інші компоненти kubelet могли робити вибір щодо розподілу ресурсів з урахуванням топології.
Topology Manager надає інтерфейс для компонентів, званих Hint Providers, для надсилання та отримання інформації про топологію. У Topology Manager є набір політик рівня вузла, які пояснюються нижче.
Topology manager отримує інформацію про топологію від Hint Providers у вигляді бітової маски, яка позначає доступні вузли NUMA та попередній показник виділення. Політики Topology Manager виконують набір операцій з наданими підказками та сходяться на підказці, визначеній політикою, щоб дати оптимальний результат, якщо зберігається небажана підказка, бажане поле для підказки буде встановлено у false. У поточних політиках найприйнятніше — це найвужча попередня маска. Обрана підказка зберігається як частина Topology Manager. Залежно від налаштованої політики, Pod може бути прийнятий або відхилений на вузлі на основі обраної підказки. Підказка потім зберігається в Topology Manager для використання Hint Providers під час прийняття рішень про розподіл ресурсів.
Потік можна побачити на наступній діаграмі.
Підтримка Windows
Kubernetes v1.32 [alpha](стандартно вимкнено)Підтримку Topology Manager можна увімкнути у Windows за допомогою функціональної можливості WindowsCPUAndMemoryAffinity, і вона потребує підтримки під час виконання контейнера.
Scope та Policy в Topology Manager
Topology Manager наразі:
- узгоджує Podʼи усіх класів QoS.
- узгоджує запитані ресурси, які Hint Provider надає підказки топології.
Якщо ці умови виконані, Topology Manager узгоджує запитані ресурси.
Для того, щоб налаштувати, як це вирівнювання виконується, Topology Manager надає два відмінні параметри: scope та policy.
scope визначає гранулярність, на якій ви хочете, щоб виконувалось вирівнювання ресурсів, наприклад, на рівні pod або container. А policy визначає фактичну стратегію, яка використовується для виконання вирівнювання, наприклад, best-effort, restricted, single-numa-node і т.д. Деталі щодо різних scopes та policies, доступних на сьогодні, можна знайти нижче.
Примітка:
Щоб вирівняти ресурси ЦП з іншими запитаними ресурсами у специфікації Pod, потрібно включити CPU Manager та налаштувати відповідну політику CPU Manager на вузлі. Див. Управління політиками керування ЦП на вузлі.Примітка:
Щоб вирівняти памʼять (та великі сторінки) з іншими запитаними ресурсами у специфікації Pod, слід увімкнути Memory Manager та налаштувати відповідну політику Memory Manager на вузлі. Див. документацію Memory Manager.Scope в Topology Manager
Topology Manager може вирівнювати ресурси у кількох різних сферах:
container(стандартно)pod
Будь-яку з цих опцій можна вибрати під час запуску kubelet, налаштувавши параметр topologyManagerScope у файлі конфігурації kubelet.
Scope container
Scope container використовується стандартно. Ви також можете явно встановити параметр topologyManagerScope в container у файлі конфігурації kubelet.
У цьому scope Topology Manager виконує кілька послідовних вирівнювань ресурсів, тобто для кожного контейнера (у Pod) окреме вирівнювання. Іншими словами, відсутнє поняття групування контейнерів у певний набір вузлів NUMA, для цього конкретного scope. Фактично Topology Manager виконує довільне вирівнювання окремих контейнерів на вузли NUMA.
Ідея групування контейнерів була затверджена та реалізована навмисно в наступному scope, наприклад, у scope pod.
Scope pod
Для вибору scope pod, встановіть параметр topologyManagerScope у файлі конфігурації kubelet на pod.
Цей scope дозволяє групувати всі контейнери у Podʼі у спільний набір вузлів NUMA. Іншими словами, Topology Manager розглядає Pod як ціле та намагається виділити весь Pod (всі контейнери) на один вузол NUMA або спільний набір вузлів NUMA. Нижче наведено приклади вирівнювання, які виробляє Topology Manager у різні моменти:
- всі контейнери можуть бути та виділені на один вузол NUMA;
- всі контейнери можуть бути та виділені на спільний набір вузлів NUMA.
Загальна кількість певного ресурсу, запитаного для всього Podʼа, розраховується за формулою ефективні запити/обмеження, і, таким чином, це загальне значення дорівнює максимуму з:
- сума всіх запитів контейнерів застосунку,
- максимум запитів контейнерів ініціалізації,
для ресурсу.
Використання scope pod разом з політикою Topology Manager single-numa-node особливо цінне для робочих навантажень, які чутливі до затримок, або для високопродуктивних застосунків, які виконують міжпроцесну комунікацію (IPC). Поєднуючи обидва варіанти, ви можете помістити всі контейнери в Pod на один вузол NUMA; отже, можливість між-NUMA комунікації може бути усунена для цього Pod.
У випадку політики single-numa-node Pod приймається лише в тому разі, якщо серед можливих виділень є відповідний набір вузлів NUMA. Перегляньте приклад вище:
- набір, що містить лише один вузол NUMA — це призводить до допуску Podʼа,
- тоді як набір, що містить більше вузлів NUMA — це призводить до відхилення Podʼа (тому, що для задоволення виділення потрібен один вузол NUMA).
У підсумку, Topology Manager спочатку розраховує набір вузлів NUMA, а потім перевіряє його з політикою Topology Manager, яка призводить до відхилення або допуску Podʼа.
Політики Topology Manager
Topology Manager підтримує чотири політики виділення. Ви можете встановити політику за допомогою прапорця kubelet --topology-manager-policy. Існують чотири підтримувані політики:
none(стандартно)best-effortrestrictedsingle-numa-node
Примітка:
Якщо Topology Manager налаштований зі scope Pod, контейнер, який розглядається політикою, відображає вимоги всього Podʼа, і тому кожний контейнер з Podʼа буде мати одне і те ж рішення про вирівнювання топології.Політика none
Це стандартна політика і вона не виконує жодного вирівнювання топології.
Політика best-effort
Для кожного контейнера у Pod kubelet з політикою керування топологією best-effort викликає кожен Hint Provider, щоб дізнатися їхню доступність ресурсів. Використовуючи цю інформацію, Topology Manager зберігає привʼязку до найближчого вузла NUMA для цього контейнера. Якщо привʼязка не є бажаною, Topology Manager також зберігає це і допускає Pod до вузла не зважаючи на це.
Hint Providers можуть використовувати цю інформацію при прийнятті рішення про розподіл ресурсів.
Політика restricted
Для кожного контейнера у Pod kubelet з політикою керування топологією restricted викликає кожен Hint Provider, щоб дізнатися їхню доступність ресурсів. Використовуючи цю інформацію, Topology Manager зберігає привʼязку до вузла NUMA для цього контейнера. Якщо привʼязка не є бажаною, Topology Manager відхиляє Pod від вузла. Це призводить до того, що Pod переходить в стан Terminated з помилкою допуску Podʼа.
Якщо Pod перебуває в стані Terminated, планувальник Kubernetes не буде намагатися знову запланувати його. Рекомендується використовувати ReplicaSet або Deployment для того, щоб викликати повторне розгортання Podʼа. Зовнішній цикл керування також може бути реалізований для того, щоб викликати повторне розгортання Podʼів, які мають помилку Topology Affinity.
Якщо Pod прийнято, Hint Providers можуть використовувати цю інформацію при прийнятті рішення про розподіл ресурсів.
Політика single-numa-node
Для кожного контейнера у Pod kubelet з політикою керування топологією single-numa-node викликає кожен Hint Provider, щоб дізнатися їхню доступність ресурсів. Використовуючи цю інформацію, Topology Manager визначає, чи можлива привʼязка до одного вузла NUMA. Якщо можливо, Topology Manager зберігає це і Hint Providers можуть використовувати цю інформацію при прийнятті рішення про розподіл ресурсів. Якщо привʼязка не можлива, Topology Manager відхиляє Pod від вузла. Це призводить до того, що Pod перебуває в стані Terminated з помилкою прийняття Podʼа.
Якщо Pod перебуває в стані Terminated, планувальник Kubernetes не буде намагатися знову запланувати його. Рекомендується використовувати ReplicaSet або Deployment для того, щоб викликати повторне розгортання Podʼа. Зовнішній цикл керування також може бути реалізований для того, щоб викликати повторне розгортання Podʼів, які мають помилку Topology Affinity.
Параметри політики керування топологією
Підтримка параметрів політики керування топологією вимагає активації функціональної можливості TopologyManagerPolicyOptions, щоб бути ввімкненими (типово увімкнено).
Ви можете увімкнути та вимкнути групи параметрів на основі їхнього рівня зрілості за допомогою наступних feature gate:
TopologyManagerPolicyBetaOptionsтипово увімкнено. Увімкніть, щоб показати параметри рівня бета.TopologyManagerPolicyAlphaOptionsтипово вимкнено. Увімкніть, щоб показати параметри рівня альфа.
Ви все ще повинні активувати кожний параметр за допомогою опції kubelet TopologyManagerPolicyOptions.
prefer-closest-numa-nodes
Опція prefer-closest-numa-nodes є загально доступною з версії Kubernetes 1.32. У версії Kubernetes 1.35 ця політика стандартно доступна, якщо увімкнено функціональні можливості TopologyManagerPolicyOptions та TopologyManagerPolicyBetaOptions.
Типово менеджер топології не враховує відстані між NUMA вузлами та не бере їх до уваги при прийнятті рішень про допуск Pod. Це обмеження проявляється в системах з кількома сокетами, а також у системах з одним сокетом і кількома NUMA вузлами, і може спричинити значне погіршення продуктивності у виконанні з критичною затримкою та високим пропуском даних, якщо менеджер топології вирішить розмістити ресурси на не сусідніх NUMA вузлах.
Якщо вказано параметр політики prefer-closest-numa-nodes, політики best-effort та restricted будуть віддавати перевагу наборам вузлів NUMA з коротшими відстанями між ними при прийнятті рішень про прийняття.
Стандартно (без цієї опції) менеджер топології розміщує ресурси або на одному NUMA вузлі, або, у випадку, коли потрібно більше одного NUMA вузла, використовує мінімальну кількість NUMA вузлів.
max-allowable-numa-nodes
Опція max-allowable-numa-nodes є загально доступною (GA) починаючи з версії Kubernetes 1.35. У версії Kubernetes 1.35 ця політика стандартно доступна, якщо увімкнено функціональні можливості TopologyManagerPolicyOptions.
Час на прийняття Podʼа повʼязаний з кількістю NUMA вузлів на фізичній машині. стандартно, Kubernetes не запускає kubelet з увімкненим менеджером топології на жодному (Kubernetes) вузлі, де виявлено більше ніж 8 NUMA вузлів.
Примітка:
Якщо ви виберете політикуmax-allowable-numa-nodes, вузли з більше ніж 8 NUMA вузлами можуть бути дозволені для роботи з увімкненим менеджером топології. Проєкт Kubernetes має обмежені дані про вплив використання менеджера топології на вузли (Kubernetes) з більше ніж 8 NUMA вузлами. Через відсутність даних, використання цієї політики з Kubernetes 1.35 не рекомендується і здійснюється на ваш власний ризик.Ви можете увімкнути цю опцію, додавши max-allowable-numa-nodes=true до параметрів політики Topology Manager.
Встановлення значення max-allowable-numa-nodes не впливає безпосередньо на затримку допуску Pod, але привʼязка Pod до вузла (Kubernetes) з великою кількістю NUMA вузлів має вплив. Майбутні можливі поліпшення в Kubernetes можуть покращити продуктивність допуску Podʼів і зменшити високу затримку, яка виникає зі збільшенням кількості NUMA вузлів.
Взаємодія точок доступу Pod з політиками Topology Manager
Розгляньте контейнери у наступному маніфесті Podʼа:
spec:
containers:
- name: nginx
image: nginx
Цей Pod працює в класі QoS BestEffort, оскільки не вказано жодних ресурсів requests або limits.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
Цей Pod працює в класі QoS Burstable, оскільки запити менше, ніж ліміти.
Якщо вибрана політика відрізняється від none, Topology Manager враховуватиме ці специфікації Pod. Topology Manager буде консультувати Hint Provider для отримання підказок топології. У випадку static політики CPU Manager поверне типову підказку топології, оскільки ці Podʼи не мають явних запитів ресурсів CPU.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
Цей Pod із цілим запитом CPU працює в класі QoS Guaranteed, оскільки requests дорівнює limits.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
Цей Pod з спільним запитом CPU працює в класі QoS Guaranteed, оскільки requests дорівнює limits.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
example.com/deviceA: "1"
example.com/deviceB: "1"
requests:
example.com/deviceA: "1"
example.com/deviceB: "1"
Цей Pod працює в класі QoS BestEffort, оскільки немає запитів CPU та памʼяті.
Topology Manager враховуватиме вищезазначені Podʼи. Topology Manager буде консультувати Hint Provider, які є CPU та Device Manager, для отримання підказок топології для Pod.
У випадку Guaranteed Pod із цілим запитом CPU, політика CPU Manager static поверне підказки топології, що стосуються виключно CPU, а Device Manager надішле підказки для запитаного пристрою.
У випадку Guaranteed Pod з спільним запитом CPU, політика CPU Manager static поверне типову підказку топології, оскільки немає виключного запиту CPU, а Device Manager надішле підказки для запитаних пристроїв.
У вищезазначених двох випадках Guaranteed Pod політика CPU Manager none поверне типову підказку топології.
У випадку BestEffort Pod, політика CPU Manager static поверне типову підказку топології, оскільки немає запиту CPU, а Device Manager надішле підказки для кожного запитаного пристрою.
На основі цієї інформації Topology Manager обчислить оптимальну підказку для Pod і збереже цю інформацію, яка буде використовуватися постачальниками підказок при призначенні ресурсів.
Відомі обмеження
Максимальна кількість вузлів NUMA, яку дозволяє Topology Manager, — 8. З більш ніж 8 вузлами NUMA відбудеться вибух стану при спробі перерахувати можливі спорідненості NUMA та генерувати їх підказки. Дивіться
max-allowable-numa-nodes(бета) для отримання додаткової інформації.Планувальник не знає топології, тому його можна запланувати на вузлі, а потім вивести з ладу на вузлі через Topology Manager.
20 - Налаштування служби DNS
На цій сторінці пояснюється, як налаштувати ваші DNS Pod та настроїти процес розвʼязання імен DNS у вашому кластері.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Ваш кластер повинен працювати з надбудовою CoreDNS.
Версія вашого Kubernetes сервера має бути не старішою ніж v1.12.
Для перевірки версії введіть kubectl version.
Вступ
DNS — це вбудована служба Kubernetes, яка автоматично запускається з допомогою менеджера надбудов cluster add-on.
Примітка:
Служба CoreDNS називаєтьсяkube-dns у полі metadata.name. Метою є забезпечення більшої сумісності з навантаженнями, які покладалися на старе імʼя служби kube-dns для розвʼязання адрес в межах кластера. Використання служби з іменем kube-dns абстрагує деталі реалізації
за цим загальним імʼям DNS-провайдера.Якщо ви працюєте з CoreDNS як з Deployment, його зазвичай викладають як Service Kubernetes зі статичною IP-адресою. Kubelet передає інформацію про резолвер DNS кожному контейнеру з прапорцем --cluster-dns=<ір-адреса-dns-служби>.
DNS-імена також потребують доменів. Ви налаштовуєте локальний домен в kubelet з прапорцем --cluster-domain=<типовий-локальний-домен>.
DNS-сервер підтримує прямий пошук (записи A та AAAA), пошук портів (записи SRV), зворотній пошук IP-адрес (записи PTR) та інші. Для отримання додаткової інформації дивіться DNS для Service та Pod.
Якщо для Pod dnsPolicy встановлено значення default, він успадковує конфігурацію розвʼязку імен від вузла, на якому працює Pod. Розвʼязок імен Pod повинен поводитися так само як і на вузлі. Проте див. Відомі проблеми.
Якщо вам це не потрібно, або якщо ви хочете іншу конфігурацію DNS для Podʼів, ви можете використовувати прапорець --resolv-conf kubelet. Встановіть цей прапорець у "" для того, щоб запобігти успадкуванню DNS від Podʼів. Встановіть його на дійсний шлях до файлу, щоб вказати файл, відмінний від /etc/resolv.conf для успадкування DNS.
CoreDNS
CoreDNS — це універсальний авторитетний DNS-сервер, який може служити як кластерний DNS, відповідаючи специфікаціям DNS.
Опції ConfigMap CoreDNS
CoreDNS — це DNS-сервер, який є модульним та розширюваним, з допомогою втулків, які додають нові можливості. Сервер CoreDNS може бути налаштований за допомогою збереження Corefile, який є файлом конфігурації CoreDNS. Як адміністратор кластера, ви можете змінювати ConfigMap для Corefile CoreDNS для зміни того, як поводитися служба виявлення служби DNS для цього кластера.
У Kubernetes CoreDNS встановлюється з наступною стандартною конфігурацією Corefile:
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
Конфігурація Corefile включає наступні втулки CoreDNS:
- errors: Помилки реєструються в stdout.
- health: Справність CoreDNS повідомляється за адресою
http://localhost:8080/health. У цьому розширеному синтаксисіlameduckзробить процес несправним, а потім зачекає 5 секунд, перш ніж процес буде вимкнено. - ready: HTTP-точка на порту 8181 поверне 200 ОК, коли всі втулки, які можуть сигналізувати готовність, зроблять це.
- kubernetes: CoreDNS відповість на DNS-запити на основі IP-адрес Service та Pod. Ви можете знайти більше деталей про цей втулок на вебсайті CoreDNS.
ttlдозволяє встановити власний TTL для відповідей. Стандартно — 5 секунд. Мінімальний дозволений TTL — 0 секунд, а максимальний обмежений 3600 секундами. Встановлення TTL на 0 запобіжить кешуванню записів.- Опція
pods insecureнадається для сумісності зkube-dns. - Ви можете використовувати опцію
pods verified, яка поверне запис A лише у випадку, якщо існує Pod в тому ж просторі імен зі потрібним IP. - Опцію
pods disabledможна використовувати, якщо ви не використовуєте записи Podʼів.
- prometheus: Метрики CoreDNS доступні за адресою
http://localhost:9153/metricsу форматі Prometheus (також відомий як OpenMetrics). - forward: Будь-які запити, які не належать до домену Kubernetes кластера, будуть переслані на попередньо визначені резолвери (/etc/resolv.conf).
- cache: Це увімкнення кешу фронтенду.
- loop: Виявлення простих переспрямовуваннь та припинення процесу CoreDNS у випадку виявлення циклу.
- reload: Дозволяє автоматичне перезавантаження зміненого Corefile. Після редагування конфігурації ConfigMap дайте дві хвилини для того, щоб ваші зміни набули чинності.
- loadbalance: Це round-robin DNS-балансувальник, який випадковим чином змінює порядок записів A, AAAA та MX в відповіді.
Ви можете змінити типову поведінку CoreDNS, змінивши ConfigMap.
Конфігурація Stub-домену та віддаленого сервера імен за допомогою CoreDNS
CoreDNS має можливість налаштувати stub-домени та віддалені сервери імен за допомогою втулку forward.
Приклад
Якщо оператор кластера має сервер домену Consul за адресою "10.150.0.1", і всі імена Consul мають суфікс ".consul.local". Для його налаштування в CoreDNS адміністратор кластера створює наступний запис в ConfigMap CoreDNS.
consul.local:53 {
errors
cache 30
forward . 10.150.0.1
}
Щоб явно пересилати всі не-кластерні DNS-пошуки через конкретний сервер імен за адресою 172.16.0.1, вказуйте forward на сервер імен замість /etc/resolv.conf.
forward . 172.16.0.1
Кінцевий ConfigMap разом з типовою конфігурацією Corefile виглядає так:
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . 172.16.0.1
cache 30
loop
reload
loadbalance
}
consul.local:53 {
errors
cache 30
forward . 10.150.0.1
}
Примітка:
CoreDNS не підтримує FQDN для піддоменів та серверів імен (наприклад: "ns.foo.com"). Під час обробки всі імена серверів імен FQDN будуть виключені з конфігурації CoreDNS.Що далі
- Прочитайте Налагодження розвʼязку адрес DNS
21 - Налагодження розвʼязання імен DNS
Ця сторінка надає вказівки щодо діагностування проблем DNS.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Ваш кластер повинен бути налаштований на використання надбудови CoreDNS або її попередника, kube-dns.
Версія вашого Kubernetes сервера має бути не старішою ніж v1.6.
Для перевірки версії введіть kubectl version.
Створіть простий Pod для використання як тестове середовище
apiVersion: v1
kind: Pod
metadata:
name: dnsutils
namespace: default
spec:
containers:
- name: dnsutils
image: registry.k8s.io/e2e-test-images/agnhost:2.39
imagePullPolicy: IfNotPresent
restartPolicy: Always
Примітка:
У цьому прикладі створюється Pod у просторі іменdefault. Розпізнавання DNS-імені для сервісів залежить від простору імен Podʼа. Для отримання додаткової інформації перегляньте DNS для Service and Pod.Використайте цей маніфест, щоб створити Pod:
kubectl apply -f https://k8s.io/examples/admin/dns/dnsutils.yaml
pod/dnsutils created
…і перевірте його статус:
kubectl get pods dnsutils
NAME READY STATUS RESTARTS AGE
dnsutils 1/1 Running 0 <some-time>
Після того, як цей Pod працює, ви можете виконати nslookup в цьому середовищі. Якщо ви бачите щось схоже на наступне, DNS працює правильно.
kubectl exec -i -t dnsutils -- nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10
Name: kubernetes.default
Address 1: 10.0.0.1
Якщо команда nslookup не вдається, перевірте наступне:
Спочатку перевірте локальну конфігурацію DNS
Подивіться всередину файлу resolv.conf. (Див. Налаштування служби DNS та Відомі проблеми нижче для отримання додаткової інформації)
kubectl exec -ti dnsutils -- cat /etc/resolv.conf
Перевірте, що шлях пошуку та імʼя сервера налаштовані так, як показано нижче (зверніть увагу, що шлях пошуку може відрізнятися для різних постачальників хмарних послуг):
search default.svc.cluster.local svc.cluster.local cluster.local google.internal c.gce_project_id.internal
nameserver 10.0.0.10
options ndots:5
Помилки, такі як наведені нижче, вказують на проблему з CoreDNS (або kube-dns) або з повʼязаними службами:
kubectl exec -i -t dnsutils -- nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10
nslookup: can't resolve 'kubernetes.default'
або
kubectl exec -i -t dnsutils -- nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
nslookup: can't resolve 'kubernetes.default'
Перевірте, чи працює Pod DNS
Використайте команду kubectl get pods, щоб перевірити, що Pod DNS працює.
kubectl get pods --namespace=kube-system -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
...
coredns-7b96bf9f76-5hsxb 1/1 Running 0 1h
coredns-7b96bf9f76-mvmmt 1/1 Running 0 1h
...
Примітка:
Значення для міткиk8s-app — kube-dns для розгортання як CoreDNS, так і kube-dns.Якщо ви бачите, що жоден Pod CoreDNS не працює або що Pod несправний/завершено, надбудова DNS може не бути типово розгорнута у вашому поточному середовищі та вам доведеться розгорнути його вручну.
Перевірка помилок у Podʼі DNS
Використайте команду kubectl logs, щоб переглянути логи контейнерів DNS.
Для CoreDNS:
kubectl logs --namespace=kube-system -l k8s-app=kube-dns
Ось приклад здорових журналів CoreDNS:
.:53
2018/08/15 14:37:17 [INFO] CoreDNS-1.2.2
2018/08/15 14:37:17 [INFO] linux/amd64, go1.10.3, 2e322f6
CoreDNS-1.2.2
linux/amd64, go1.10.3, 2e322f6
2018/08/15 14:37:17 [INFO] plugin/reload: Running configuration MD5 = 24e6c59e83ce706f07bcc82c31b1ea1c
Перегляньте, чи є будь-які підозрілі або несподівані повідомлення у логах.
Чи працює служба DNS?
Перевірте, чи працює служба DNS за допомогою команди kubectl get service.
kubectl get svc --namespace=kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP 1h
...
Примітка:
Назва служби —kube-dns як для розгортання CoreDNS, так і для kube-dns.Якщо ви створили Service або у випадку, якщо вона повинна типово створюватися, але вона не зʼявляється, див. налагодження Service для отримання додаткової інформації.
Чи відкриті точки доступу DNS?
Ви можете перевірити, чи викриті точки доступу DNS, використовуючи команду kubectl get endpointslice.
kubectl get endpointslice -l k8s.io/service-name=kube-dns --namespace=kube-system
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
kube-dns-zxoja IPv4 53 10.180.3.17,10.180.3.17 1h
Якщо ви не бачите точки доступу, дивіться розділ про точки доступу у документації налагодження Service.
Чи надходять/обробляються DNS-запити?
Ви можете перевірити, чи надходять запити до CoreDNS, додавши втулок log до конфігурації CoreDNS (тобто файлу Corefile). Файл CoreDNS Corefile зберігається у ConfigMap з назвою coredns. Щоб редагувати його, використовуйте команду:
kubectl -n kube-system edit configmap coredns
Потім додайте log у розділ Corefile, як показано у прикладі нижче:
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
log
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
Після збереження змін може знадобитися до хвилини або двох, щоб Kubernetes поширив ці зміни на Podʼи CoreDNS.
Далі зробіть кілька запитів і перегляньте логи, як показано у попередніх розділах цього документа. Якщо Podʼи CoreDNS отримують запити, ви повинні побачити їх в логах.
Ось приклад запиту у логах:
.:53
2018/08/15 14:37:15 [INFO] CoreDNS-1.2.0
2018/08/15 14:37:15 [INFO] linux/amd64, go1.10.3, 2e322f6
CoreDNS-1.2.0
linux/amd64, go1.10.3, 2e322f6
2018/09/07 15:29:04 [INFO] plugin/reload: Running configuration MD5 = 162475cdf272d8aa601e6fe67a6ad42f
2018/09/07 15:29:04 [INFO] Reloading complete
172.17.0.18:41675 - [07/Sep/2018:15:29
:11 +0000] 59925 "A IN kubernetes.default.svc.cluster.local. udp 54 false 512" NOERROR qr,aa,rd,ra 106 0.000066649s
Чи має CoreDNS достатні дозволи?
CoreDNS повинен мати можливість переглядати повʼязані Service та endpointslice ресурси для правильного розпізнавання імен служб.
Приклад повідомлення про помилку:
2022-03-18T07:12:15.699431183Z [INFO] 10.96.144.227:52299 - 3686 "A IN serverproxy.contoso.net.cluster.local. udp 52 false 512" SERVFAIL qr,aa,rd 145 0.000091221s
Спочатку отримайте поточну ClusterRole system:coredns:
kubectl describe clusterrole system:coredns -n kube-system
Очікуваний вивід:
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
endpoints [] [] [list watch]
namespaces [] [] [list watch]
pods [] [] [list watch]
services [] [] [list watch]
endpointslices.discovery.k8s.io [] [] [list watch]
Якщо відсутні будь-які дозволи, відредагуйте ClusterRole, щоб додати їх:
kubectl edit clusterrole system:coredns -n kube-system
Приклад вставки дозволів для EndpointSlices:
...
- apiGroups:
- discovery.k8s.io
resources:
- endpointslices
verbs:
- list
- watch
...
Чи ви у правильному просторі імен для служби?
DNS-запити, які не вказують простір імен, обмежені простором імен Podʼа.
Якщо простір імен Podʼа та Service відрізняються, DNS-запит повинен включати простір імен Service.
Цей запит обмежений простором імен Podʼа:
kubectl exec -i -t dnsutils -- nslookup <service-name>
Цей запит вказує простір імен:
kubectl exec -i -t dnsutils -- nslookup <service-name>.<namespace>
Щоб дізнатися більше про розпізнавання імен, дивіться DNS для Service та Pod.
Відомі проблеми
Деякі дистрибутиви Linux (наприклад, Ubuntu) стандартно використовують локальний резолвер DNS (systemd-resolved). Systemd-resolved переміщує та замінює /etc/resolv.conf на файл-заглушку, що може спричинити фатальний цикл переспрямовування при розпізнаванні імен на вихідних серверах. Це можна виправити вручну, використовуючи прапорець --resolv-conf kubelet, щоб вказати правильний resolv.conf (з systemd-resolved це /run/systemd/resolve/resolv.conf). kubeadm автоматично визначає systemd-resolved та налаштовує відповідні прапорці kubelet.
Установки Kubernetes не налаштовують файли resolv.conf вузлів для використання кластерного DNS стандартно, оскільки цей процес властивий для певного дистрибутиву. Це, можливо, має бути реалізовано надалі.
У Linux бібліотека libc (відома як glibc) має обмеження для записів nameserver DNS на 3 стандартно, і Kubernetes потрібно використовувати 1 запис nameserver. Це означає, що якщо локальна установка вже використовує 3 nameserver, деякі з цих записів будуть втрачені. Щоб обійти це обмеження, вузол може запускати dnsmasq, який надасть більше записів nameserver. Ви також можете використовувати прапорець --resolv-conf kubelet.
Якщо ви використовуєте Alpine версії 3.17 або раніше як базовий образ, DNS може працювати неправильно через проблему з дизайном Alpine. До версії musl 1.24 не включено резервне перемикання на TCP для stub-резолвера DNS, що означає, що будь-який виклик DNS понад 512 байтів завершиться невдачею. Будь ласка, оновіть свої образи до версії Alpine 3.18 або вище.
Що далі
- Дивіться Автомасштабування служби DNS в кластері.
- Читайте DNS для Service та Pod
22 - Оголошення мережевої політики
Цей документ допоможе вам розпочати використання API мережевої політики Kubernetes NetworkPolicy API, щоб оголосити політики мережі, які керують тим, як Podʼи спілкуються один з одним.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.8.Для перевірки версії введіть kubectl version.
Переконайтеся, що ви налаштували постачальника мережі з підтримкою політики мережі. Існує кілька постачальників мережі, які підтримують NetworkPolicy, включаючи:
Створення nginx deployment та надання доступу через Service
Щоб переглянути, як працює політика мережі Kubernetes, почніть зі створення Deployment nginx.
kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
Експонуйте Deployment через Service під назвою nginx.
kubectl expose deployment nginx --port=80
service/nginx exposed
Вищезазначені команди створюють Deployment з Podʼом nginx і експонують Deployment через Service під назвою nginx. Pod nginx та Deployment знаходяться в просторі імен default.
kubectl get svc,pod
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes 10.100.0.1 <none> 443/TCP 46m
service/nginx 10.100.0.16 <none> 80/TCP 33s
NAME READY STATUS RESTARTS AGE
pod/nginx-701339712-e0qfq 1/1 Running 0 35s
Перевірте роботу Service, звернувшись до неї з іншого Podʼа
Ви повинні мати можливість звернутися до нового Service nginx з інших Podʼів. Щоб отримати доступ до Service nginx з іншого Podʼа в просторі імен default, запустіть контейнер busybox:
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
У вашій оболонці запустіть наступну команду:
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
Обмеження доступу до Service nginx
Щоб обмежити доступ до Service nginx так, щоб запити до неї могли робити лише Podʼи з міткою access: true, створіть обʼєкт NetworkPolicy наступним чином:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: access-nginx
spec:
podSelector:
matchLabels:
app: nginx
ingress:
- from:
- podSelector:
matchLabels:
access: "true"
Назва обʼєкта NetworkPolicy повинна бути дійсним піддоменом DNS.
Примітка:
NetworkPolicy включаєpodSelector, який вибирає групу Podʼів, до яких застосовується політика. Ви можете побачити, що ця політика вибирає Podʼи з міткою app=nginx. Мітка автоматично додавалася до Podʼа в Deployment nginx. Порожній podSelector вибирає всі Podʼи в просторі імен.Назначте політику для Service
Використовуйте kubectl для створення NetworkPolicy з файлу nginx-policy.yaml вище:
kubectl apply -f https://k8s.io/examples/service/networking/nginx-policy.yaml
networkpolicy.networking.k8s.io/access-nginx created
Перевірте доступ до Service, коли мітка доступу не визначена
Коли ви намагаєтеся отримати доступ до Service nginx з Podʼа без відповідних міток, запит завершується тайм-аутом:
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
У вашій оболонці виконайте команду:
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
wget: download timed out
Визначте мітку доступу і перевірте знову
Ви можете створити Pod із відповідними мітками, щоб переконатися, що запит дозволено:
kubectl run busybox --rm -ti --labels="access=true" --image=busybox -- /bin/sh
У вашій оболонці запустіть команду:
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
23 - Розробка Cloud Controller Manager
Kubernetes v1.11 [beta]Cloud Controller Manager (cloud-controller-manager) є компонент панелі управління Kubernetes, що інтегрує управління логікою певної хмари. Cloud controller manager дозволяє звʼязувати ваш кластер з API хмарного провайдера та відокремлює компоненти, що взаємодіють з хмарною платформою від компонентів, які взаємодіють тільки в кластері.
Відокремлюючи логіку сумісності між Kubernetes і базовою хмарною інфраструктурою, компонент cloud-controller-manager дає змогу хмарним провайдерам випускати функції з іншою швидкістю порівняно з основним проєктом Kubernetes.
Контекст
Оскільки постачальники хмар розвиваються та випускаються іншим темпом порівняно з проєктом Kubernetes, абстрагування специфічного для постачальників коду в окремий бінарний файл cloud-controller-manager дозволяє хмарним постачальникам еволюціонувати незалежно від основного коду Kubernetes.
Проєкт Kubernetes надає кістяк коду cloud-controller-manager з інтерфейсами Go, щоб дозволити вам (або вашому постачальнику хмар) додати свої власні реалізації. Це означає, що постачальник хмар може реалізувати cloud-controller-manager, імпортуючи пакунки з ядра Kubernetes; кожен постачальник хмар буде реєструвати свій власний код, викликаючи cloudprovider.RegisterCloudProvider, щоб оновити глобальну змінну доступних постачальників хмар.
Розробка
Зовнішня реалізація
Для створення зовнішнього cloud-controller-manager для вашої хмари:
- Створіть пакунок Go з реалізацією, яка задовольняє cloudprovider.Interface.
- Використовуйте
main.goу cloud-controller-managerр з ядра Kubernetes як шаблон для свогоmain.go. Як зазначено вище, єдина відмінність полягатиме у пакунку хмари, який буде імпортуватися. - Імпортуйте свій пакунок хмари в
main.go, переконайтеся, що ваш пакунок має блокinitдля запускуcloudprovider.RegisterCloudProvider.
Багато постачальників хмар публікують свій код контролера як відкритий код. Якщо ви створюєте новий cloud-controller-manager з нуля, ви можете взяти наявний зовнішній cloud-controller-manager як вашу вихідну точку.
У коді Kubernetes
Для внутрішніх постачальників хмар ви можете запустити cloud-controller-managerу, що працює у внутрішньому коді, як DaemonSet у вашому кластері. Див. Адміністрування Cloud Controller Manager для отримання додаткової інформації.
24 - Увімкнення або вимкнення API Kubernetes
На цій сторінці показано, як увімкнути або вимкнути версію API зі вузла панелі управління вашого кластера.
Конкретні версії API можна увімкнути або вимкнути, передаючи --runtime-config=api/<version> як аргумент командного рядка до сервера API. Значення для цього аргументу є розділеним комами списком версій API. Пізніші значення перекривають попередні.
Аргумент командного рядка runtime-config також підтримує 2 спеціальні ключі:
api/all, що представляє всі відомі API.api/legacy, що представляє лише застарілі API. Застарілі API — це будь-які API, які були явно визнані застарілими.
Наприклад, щоб вимкнути всі версії API, крім v1, передайте --runtime-config=api/all=false,api/v1=true до kube-apiserver.
Що далі
Прочитайте повну документацію для компонента kube-apiserver.
25 - Шифрування конфіденційних даних у спокої
Усі API в Kubernetes, які дозволяють записувати постійні дані ресурсів API, підтримують шифрування у спокої. Наприклад, ви можете увімкнути шифрування у спокої для Secret. Це шифрування у спокої є додатковим до будь-якого шифрування на рівні системи для кластера etcd або для файлових систем на вузлах, де ви запускаєте kube-apiserver.
На цій сторінці показано, як увімкнути та налаштувати шифрування даних API у спокої.
Примітка:
Це завдання охоплює шифрування даних ресурсів, збережених за допомогою Kubernetes API. Наприклад, ви можете шифрувати обʼєкти Secret, включаючи дані у формі ключ-значення.
Якщо ви хочете зашифрувати дані в файлових системах, які підключаються до контейнерів, вам замість цього потрібно або:
- використовуйте інтеграцію зберігання, яка забезпечує шифровані томи
- шифрувати дані всередині вашого власного застосунку
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Це завдання передбачає, що ви запускаєте сервер API Kubernetes як статичний Pod на кожному вузлі панелі управління.
Панель управління кластера обовʼязково має використовувати etcd версії 3.x (головна версія 3, будь-яка мінорна версія).
Для шифрування власного ресурсу ваш кластер повинен працювати на Kubernetes v1.26 або новіше.
Щоб використовувати символ підстановки для відповідності ресурсів, ваш кластер повинен працювати на Kubernetes v1.27 або новіше.
Для перевірки версії введіть kubectl version.
Визначте, чи вже увімкнено шифрування у спокої
Стандартно, сервер API зберігає текстові представлення ресурсів у etcd без шифрування у спокої.
Процес kube-apiserver приймає аргумент --encryption-provider-config, який вказує шлях до конфігураційного файлу. Зміст цього файлу, якщо ви його вказали, контролює спосіб шифрування даних API Kubernetes у etcd. Якщо ви запускаєте kube-apiserver без аргументу командного рядка --encryption-provider-config, то у вас немає увімкненого шифрування у спокої. Якщо ви запускаєте kube-apiserver з аргументом командного рядка --encryption-provider-config, і файл, на який він посилається, вказує на постачальника шифрування identity як першого постачальника шифрування у списку, то у вас немає увімкненого шифрування у спокої (типовий постачальник identity не надає захисту конфіденційності.)
Якщо ви запускаєте kube-apiserver з аргументом командного рядка --encryption-provider-config, і файл, на який він посилається, вказує на іншого постачальника, а не identity, як першого постачальника шифрування у списку, то ви вже маєте увімкнене шифрування у спокої. Однак ця перевірка не показує, чи вдалася попередня міграція до зашифрованого сховища. Якщо ви не впевнені, переконайтеся, що всі відповідні дані зашифровані.
Розуміння конфігурації шифрування у спокої
---
#
# УВАГА: це приклад конфігурації.
# Не використовуйте його для вашого кластера!
#
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
- configmaps
- pandas.awesome.bears.example # a custom resource API
providers:
# Ця конфігурація не забезпечує конфіденційність даних. Перший
# налаштований постачальник вказує механізм "identity", який
# зберігає ресурси як простий текст.
#
- identity: {} # простий текст, іншими словами, шифрування НЕМАЄ
- aesgcm:
keys:
- name: key1
secret: c2VjcmV0IGlzIHNlY3VyZQ==
- name: key2
secret: dGhpcyBpcyBwYXNzd29yZA==
- aescbc:
keys:
- name: key1
secret: c2VjcmV0IGlzIHNlY3VyZQ==
- name: key2
secret: dGhpcyBpcyBwYXNzd29yZA==
- secretbox:
keys:
- name: key1
secret: YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4eXoxMjM0NTY=
- resources:
- events
providers:
- identity: {} # не шифрувати Events навіть якщо *.* вказаний нижче
- resources:
- '*.apps' # використання символу підстановки потребує Kubernetes 1.27 або пізніше
providers:
- aescbc:
keys:
- name: key2
secret: c2VjcmV0IGlzIHNlY3VyZSwgb3IgaXMgaXQ/Cg==
- resources:
- '*.*' # використання символу підстановки потребує Kubernetes 1.27 або пізніше
providers:
- aescbc:
keys:
- name: key3
secret: c2VjcmV0IGlzIHNlY3VyZSwgSSB0aGluaw==Кожен елемент масиву resources — це окрема конфігурація і містить повну конфігурацію. Поле resources.resources — це масив імен ресурсів Kubernetes (resource або resource.group), які мають бути зашифровані, наприклад, Secrets, ConfigMaps або інші ресурси.
Якщо ви додаєте власні ресурси до EncryptionConfiguration, і версія кластера — 1.26 або новіша, то будь-які нові створені власні ресурси, зазначені в EncryptionConfiguration, будуть зашифровані. Будь-які власні ресурси, які існували в etcd до цієї версії та конфігурації, залишаться незашифрованими до тих пір, поки вони наступного разу не будуть записані у сховище. Така ж поведінка застосовується й до вбудованих ресурсів. Дивіться розділ Переконайтеся, що всі секрети зашифровані.
Масив providers — це упорядкований список можливих постачальників шифрування, які можна використовувати для перелічених вами API. Кожен постачальник підтримує кілька ключів — ключі перевіряються по черзі для розшифрування, і якщо постачальник є першим, перший ключ використовується для шифрування.
Для кожного елементу може бути вказано лише один тип постачальника (identity або aescbc може бути наданий, але не обидва в одному елементі). Перший постачальник у списку використовується для шифрування ресурсів, записаних у сховище. При читанні ресурсів зі сховища кожен постачальник, який відповідає збереженим даним, намагається по черзі розшифрувати дані. Якщо жоден постачальник не може прочитати збережені дані через несумісність формату або секретного ключа, повертається помилка, яка перешкоджає клієнтам отримати доступ до цього ресурсу.
EncryptionConfiguration підтримує використання символів підстановки для вказівки ресурсів, які мають бути зашифровані. Використовуйте '*.<group>', щоб зашифрувати всі ресурси у групі (наприклад, '*.apps' у вищезазначеному прикладі) або '*.*' для шифрування всіх ресурсів. '*.' може бути використаний для шифрування всіх ресурсів у групі ядра. '*.*' зашифрує всі ресурси, навіть власні ресурси, які додаються після запуску сервера API.
Примітка:
Використання символів підстановки, які перекриваються в тому ж списку ресурсів або між кількома елементами, не дозволяється, оскільки частина конфігурації буде неефективною. Порядок обробки та пріоритет спискуresources визначаються порядком його вказання в конфігурації.Якщо у вас є символ підстановки, який охоплює ресурси, і ви хочете відмовитися від шифрування у спокої певного типу ресурсу, ви можете досягати цього, додавши окремий елемент масиву resources з іменем ресурсу, який ви хочете виключити, за яким слідує елемент масиву providers, де ви вказуєте постачальника identity. Ви додаєте цей елемент до списку так, щоб він зʼявився раніше, ніж конфігурація, де ви вказуєте шифрування (постачальник, який не є identity).
Наприклад, якщо ввімкнено '*.*', і ви хочете відмовитися від шифрування для Events та ConfigMaps, додайте новий раніший елемент до resources, за яким слідує елемент масиву постачальників з identity як постачальник. Більш конкретний запис повинен зʼявитися перед записом з символом підстановки.
Новий елемент буде схожий на:
...
- resources:
- configmaps. # спеціально з ядра API групи,
# через крапку в кінці
- events
providers:
- identity: {}
# а потім інші записи в resources
Переконайтеся, що виключення перераховане до позначки символу підстановки '*.*' в масиві ресурсів, щоб надати йому пріоритет.
Для отримання більш детальної інформації про структуру EncryptionConfiguration, зверніться до API конфігурації шифрування.
Увага:
Якщо будь-який ресурс не може бути прочитаний через конфігурацію шифрування (через зміну ключів) та ви не можете відновити робочу конфігурацію, єдиним виходом буде видалити цей ключ безпосередньо з підтримуваного etcd.
Будь-які виклики до API Kubernetes, які намагаються прочитати цей ресурс, завершаться невдачею, поки він не буде видалений або надано дійсний ключ для розшифрування.
Доступні постачальники
Перш ніж налаштувати шифрування у спокої для даних у Kubernetes API вашого кластера, вам потрібно вибрати, які постачальники ви будете використовувати.
Наступна таблиця описує кожного доступного постачальника.
| Назва | Шифрування | Стійкість | Швидкість | Довжина ключа |
|---|---|---|---|---|
| identity | Відсутнє | Н/Д | Н/Д | Н/Д |
| Ресурси зберігаються як є без шифрування. Коли встановлено як перший постачальник, ресурс буде розшифрований при записі нових значень. Існуючі зашифровані ресурси автоматично не перезаписуються даними у відкритому тексті. Постачальник `identity` є типовим, якщо ви не вказали інше. | ||||
| aescbc | AES-CBC з використанням padding PKCS#7 | Слабка | Швидка | 16, 24 або 32 байти |
| Не рекомендується через вразливість CBC до атаки padding oracle attacks. Вміст ключа доступний з хоста панелі управління. | ||||
| aesgcm | AES-GCM з випадковим нонсом | Потрібно оновлювати через кожні 200,000 записів | Найшвидший | 16, 24 або 32 байти |
| Не рекомендується для використання, крім як у випадку, коли реалізована автоматизована схема оновлення ключів. Вміст ключа доступний з хоста панелі управління. | ||||
| kms v1 (застарілий з Kubernetes v1.28) | Використовує схему шифрування конвертів із DEK для кожного ресурсу. | Найміцніший | Повільний (порівняно з kms версією 2) | 32 байти |
| Дані шифруються за допомогою ключів шифрування даних (DEK) з використанням AES-GCM;
DEK шифруються ключами шифрування ключів (KEKs) згідно з
конфігурацією в Службі управління ключами (KMS).
Просте оновлення ключа, з новим DEK, що генерується для кожного шифрування, та
оновлення KEK, контрольоване користувачем. Прочитайте, як налаштувати постачальника KMS V1. | ||||
| kms v2 | Використовує схему шифрування конвертів із DEK для кожного сервера API. | Найміцніший | Швидкий | 32 байти |
| Дані шифруються за допомогою ключів шифрування даних (DEKs) з використанням AES-GCM; DEKs
шифруються ключами шифрування ключів (KEKs) згідно з конфігурацією
в Службі управління ключами (KMS).
Kubernetes генерує новий DEK для кожного шифрування з секретного насіння.
Насіння змінюється кожного разу, коли змінюється KEK. Добрий вибір, якщо використовується сторонній інструмент для управління ключами. Доступний як стабільний з Kubernetes v1.29. Прочитайте, як налаштувати постачальника KMS V2. | ||||
| secretbox | XSalsa20 і Poly1305 | Найміцніший | Швидший | 32 байти |
| Використовує відносно нові технології шифрування, які можуть не бути прийнятними в середовищах, які вимагають високого рівня перегляду. Вміст ключа доступний з хоста панелі управління. | ||||
Постачальник identity є типовим, якщо ви не вказали інше. Постачальник identity не шифрує збережені дані та не надає жодного додаткового захисту конфіденційності.
Зберігання ключів
Локальне зберігання ключів
Шифрування конфіденційних даних за допомогою локально керованих ключів захищає від компрометації etcd, але не забезпечує захисту від компрометації хосту. Оскільки ключі шифрування зберігаються на хості у файлі EncryptionConfiguration YAML, кваліфікований зловмисник може отримати доступ до цього файлу і витягнути ключі шифрування.
Зберігання ключів сервісом KMS
Постачальник KMS використовує шифрування конвертів: Kubernetes шифрує ресурси за допомогою ключа даних, а потім шифрує цей ключ даних за допомогою служби керування шифруванням. Kubernetes генерує унікальний ключ даних для кожного ресурсу. API-сервер зберігає зашифровану версію ключа даних в etcd поряд із шифротекстом; при читанні ресурсу API-сервер викликає служби керування шифруванням і надає як шифротекст, так і (зашифрований) ключ даних. У межах служби керування шифруванням, постачальник використовує ключ шифрування ключа, щоб розшифрувати ключ даних, розшифровує ключ даних і, нарешті, відновлює звичайний текст. Комунікація між панеллю управління та KMS вимагає захисту під час передачі, такого як TLS.
Використання шифрування конвертів створює залежність від ключа шифрування ключа, який не зберігається в Kubernetes. У випадку KMS зловмиснику, який намагається отримати несанкціонований доступ до значень у відкритому тексті, необхідно скомпрометувати etcd та стороннього постачальника KMS.
Захист для ключів шифрування
Вам слід прийняти належні заходи для захисту конфіденційної інформації, що дозволяє розшифрування, чи то це локальний ключ шифрування, чи то токен автентифікації, який дозволяє API-серверу викликати KMS.
Навіть коли ви покладаєтесь на постачальника для керування використанням та життєвим циклом основного ключа шифрування (або ключів), ви все одно відповідаєте за те, щоб контроль доступу та інші заходи безпеки для служби керування шифруванням були відповідними для ваших потреб у безпеці.
Зашифруйте ваші дані
Згенеруйте ключ шифрування
Наступні кроки передбачають, що ви не використовуєте KMS, тому кроки також передбачають, що вам потрібно згенерувати ключ шифрування. Якщо у вас вже є ключ шифрування, перейдіть до Написання файлу конфігурації шифрування.
Увага:
Зберігання сирого ключа шифрування у конфігурації шифрування забезпечує помірний рівень безпеки, порівняно з відсутністю шифрування.
Для додаткової секретності розгляньте використання постачальника kms, оскільки це ґрунтується на ключах, що зберігаються поза вашим кластером Kubernetes. Реалізації kms можуть працювати з модулями апаратного забезпечення для збереження ключів або з службами шифрування, які керуються вашим постачальником хмарних послуг.
Щоб дізнатися, як налаштувати шифрування в стані спокою з використанням KMS, див. Використання постачальника KMS для шифрування даних. Втулок постачальника KMS, який ви використовуєте, також може постачатися з додатковою конкретною документацією.
Розпочніть з генерації нового ключа шифрування, а потім закодуйте його за допомогою base64:
Згенеруйте випадковий ключ з 32 байтів і закодуйте його у форматі base64. Ви можете використовувати цю команду:
head -c 32 /dev/urandom | base64
Ви можете використовувати /dev/hwrng замість /dev/urandom, якщо ви хочете використовувати вбудований апаратний генератор ентропії вашого ПК. Не всі пристрої з Linux надають апаратний генератор випадкових чисел.
Згенеруйте випадковий ключ з 32 байтів і закодуйте його у форматі base64. Ви можете використовувати цю команду:
head -c 32 /dev/urandom | base64
Згенеруйте випадковий ключ з 32 байтів і закодуйте його у форматі base64. Ви можете використовувати цю команду:
# Не запускайте це в сесії, де ви встановили насіння генератора випадкових чисел.
[Convert]::ToBase64String((1..32|%{[byte](Get-Random -Max 256)}))
Примітка:
Зберігайте ключ шифрування конфіденційно, включаючи його час генерації та, якщо можливо, після того, як ви більше активно його не використовуєте.Реплікація ключа шифрування
Використовуючи безпечний механізм передачі файлів, зробіть копію цього ключа шифрування доступною кожному іншому вузлу керування.
Як мінімум використовуйте шифрування під час передачі даних — наприклад, захищену оболонку (SSH). Для більшої безпеки використовуйте асиметричне шифрування між вузлами або змініть підхід, який ви використовуєте, щоб ви покладалися на шифрування KMS.
Створіть файл конфігурації шифрування
Увага:
Файл конфігурації шифрування може містити ключі, які можуть розшифрувати вміст в etcd. Якщо файл конфігурації містить будь-який вміст ключа, вам слід належним чином обмежити дозволи на всіх ваших вузлах керування так, щоб лише користувач, який запускає kube-apiserver, міг читати цю конфігурацію.Створіть новий файл конфігурації шифрування. Зміст повинен бути подібним до:
---
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
- configmaps
- pandas.awesome.bears.example
providers:
- aescbc:
keys:
- name: key1
# Див. наступний текст для отримання додаткової інформації про секретне значення
secret: <BASE 64 ENCODED SECRET>
- identity: {} # цей резервний варіант дозволяє читати незашифровані секрети;
# наприклад, під час початкової міграції
Щоб створити новий ключ шифрування (який не використовує KMS), див. Згенеруйте ключ шифрування.
Використовуйте новий файл конфігурації шифрування
Вам потрібно буде приєднати новий файл конфігурації шифрування до статичного Podʼа kube-apiserver. Ось приклад того, як це зробити:
Збережіть новий файл конфігурації шифрування у
/etc/kubernetes/enc/enc.yamlна вузлі панелі управління.Відредагуйте маніфест для статичного Podʼа
kube-apiserver:/etc/kubernetes/manifests/kube-apiserver.yaml, щоб він був подібний до:--- # # Це фрагмент маніфеста для статичного Podʼа. # Перевірте, чи це правильно для вашого кластера та для вашого API-сервера. # apiVersion: v1 kind: Pod metadata: annotations: kubeadm.kubernetes.io/kube-apiserver.advertise-address.endpoint: 10.20.30.40:443 creationTimestamp: null labels: app.kubernetes.io/component: kube-apiserver tier: control-plane name: kube-apiserver namespace: kube-system spec: containers: - command: - kube-apiserver ... - --encryption-provider-config=/etc/kubernetes/enc/enc.yaml # додайте цей рядок volumeMounts: ... - name: enc # додайте цей рядок mountPath: /etc/kubernetes/enc # додайте цей рядок readOnly: true # додайте цей рядок ... volumes: ... - name: enc # додайте цей рядок hostPath: # додайте цей рядок path: /etc/kubernetes/enc # додайте цей рядок type: DirectoryOrCreate # додайте цей рядок ...Перезапустіть свій API-сервер.
Увага:
Ваш файл конфігурації містить ключі, які можуть розшифрувати вміст в etcd, тому вам слід належним чином обмежити дозволи на вузлах керування так, щоб лише користувач, який запускаєkube-apiserver, міг читати його.Тепер у вас є шифрування для одного вузла панелі управління. У типовому кластері Kubernetes є кілька вузлів керування, тому зробіть це на інших вузлах.
Переконфігуруйте інші вузли керування
Якщо у вашому кластері є кілька API-серверів, вам слід розгорнути зміни по черзі на кожному API-сервері.
Увага:
Для конфігурацій кластеру з двома або більше вузлами панелі управління, конфігурація шифруванняповинна бути ідентичною на кожному вузлі панелі управління.
Якщо існує різниця в конфігурації постачальника шифрування між вузлами панелі управління, ця різниця може означати, що kube-apiserver не може розшифрувати дані.
Коли ви плануєте оновлення конфігурації шифрування вашого кластера, сплануйте це так, щоб API-сервери у вашій панелі управління завжди могли розшифрувати збережені дані (навіть під час часткового впровадження змін).
Переконайтеся, що ви використовуєте однакову конфігурацію шифрування на кожному вузлі керування.
Перевірте, що нові дані записані зашифровано
Дані зашифровуються під час запису в etcd. Після перезапуску вашого kube-apiserver будь-який новий створений або оновлений Secret (або інші види ресурсів, налаштовані в EncryptionConfiguration), повинні бути зашифровані при зберіганні.
Щоб перевірити це, ви можете використовувати інтерфейс командного рядка etcdctl, щоб отримати вміст вашого секретного ключа.
Цей приклад показує, як це перевірити для шифрування Secret API.
Створіть новий Secret під назвою
secret1у просторі іменdefault:kubectl create secret generic secret1 -n default --from-literal=mykey=mydataВикористовуючи інтерфейс командного рядка
etcdctl, прочитайте цей Секрет з etcd:ETCDCTL_API=3 etcdctl get /registry/secrets/default/secret1 [...] | hexdump -Cде
[...]повинно бути додатковими аргументами для приєднання до сервера etcd.Наприклад:
ETCDCTL_API=3 etcdctl \ --cacert=/etc/kubernetes/pki/etcd/ca.crt \ --cert=/etc/kubernetes/pki/etcd/server.crt \ --key=/etc/kubernetes/pki/etcd/server.key \ get /registry/secrets/default/secret1 | hexdump -CВивід подібний до цього (скорочено):
00000000 2f 72 65 67 69 73 74 72 79 2f 73 65 63 72 65 74 |/registry/secret| 00000010 73 2f 64 65 66 61 75 6c 74 2f 73 65 63 72 65 74 |s/default/secret| 00000020 31 0a 6b 38 73 3a 65 6e 63 3a 61 65 73 63 62 63 |1.k8s:enc:aescbc| 00000030 3a 76 31 3a 6b 65 79 31 3a c7 6c e7 d3 09 bc 06 |:v1:key1:.l.....| 00000040 25 51 91 e4 e0 6c e5 b1 4d 7a 8b 3d b9 c2 7c 6e |%Q...l..Mz.=..|n| 00000050 b4 79 df 05 28 ae 0d 8e 5f 35 13 2c c0 18 99 3e |.y..(..._5.,...>| [...] 00000110 23 3a 0d fc 28 ca 48 2d 6b 2d 46 cc 72 0b 70 4c |#:..(.H-k-F.r.pL| 00000120 a5 fc 35 43 12 4e 60 ef bf 6f fe cf df 0b ad 1f |..5C.N`..o......| 00000130 82 c4 88 53 02 da 3e 66 ff 0a |...S..>f..| 0000013aПеревірте, що збережений Secret має префікс
k8s:enc:aescbc:v1:, що вказує на те, що провайдерaescbcзашифрував результати. Переконайтеся, що імʼя ключа, вказане вetcd, відповідає імені ключа, вказаному вEncryptionConfigurationвище. У цьому прикладі ви бачите, що ключ шифрування під назвоюkey1використовується вetcdі вEncryptionConfiguration.Перевірте, що Secret правильно розшифровується під час отримання через API:
kubectl get secret secret1 -n default -o yamlВивід повинен містити
mykey: bXlkYXRh, з вмістомmydata, закодованим за допомогою base64; прочитайте декодування Secret, щоб дізнатися, як повністю декодувати Secret.
Забезпечте шифрування всіх відповідних даних
Часто недостатньо лише переконатися, що нові обʼєкти зашифровані: ви також хочете, щоб шифрування застосовувалося до обʼєктів, які вже збережені.
У цьому прикладі ви налаштували свій кластер таким чином, що Secret зашифровані при записі. Виконання операції заміни для кожного Secret зашифрує цей вміст в спокої, де обʼєкти залишаються незмінними.
Ви можете виконати цю зміну для всіх Secret у вашому кластері:
# Виконайте це в якості адміністратора, який може читати і записувати всі Secret
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
Команда вище зчитує всі Secret, а потім оновлює їх з тими самими даними, щоб застосувати шифрування на стороні сервера.
Примітка:
Якщо виникає помилка через конфлікт запису, повторіть команду. Це безпечно виконати цю команду більше одного разу.
Для великих кластерів ви можете бажати розділити Secret за просторами імен або сценарію оновлення.
Запобігання отриманню відкритого тексту
Якщо ви хочете переконатися, що доступ до певного виду API здійснюється тільки за допомогою шифрування, ви можете позбавити API-сервер можливості читати дані, що підтримують це API, у вигляді простого тексту.
Попередження:
Ця зміна заважає API-серверу отримувати ресурси, які позначені як зашифровані в спокої, але насправді зберігаються у відкритому вигляді.
Коли ви налаштували шифрування у спокої для API (наприклад: вид API Secret, який представляє ресурси secrets в основній групі API), вам необхідно переконатися, що всі ці ресурси у цьому кластері дійсно зашифровані у спокої. Перевірте це, перш ніж продовжувати з наступними кроками.
Після того, як всі Secret у вашому кластері зашифровані, ви можете видалити identity частину конфігурації шифрування. Наприклад:
---
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: <BASE 64 ENCODED SECRET>
- identity: {} # ВИДАЛІТЬ ЦЮ СТРОКУ… а потім перезапустіть кожен API-сервер по черзі. Ця зміна запобігає API-серверу отримувати доступ до Secret у відкритому текстовому форматі, навіть випадково.
Ротація ключа розшифрування
Зміна ключа шифрування для Kubernetes без простою вимагає багатокрокової операції, особливо в умовах високодоступного розгортання, де працюють кілька процесів kube-apiserver.
- Згенеруйте новий ключ і додайте його як другий запис ключа для поточного провайдера на всіх вузлах панелі управління.
- Перезапустіть усі процеси
kube-apiserver, щоб кожен сервер міг розшифрувати будь-які дані, які зашифровані новим ключем. - Зробіть безпечне резервне копіювання нового ключа шифрування. Якщо ви втратите всі копії цього ключа, вам доведеться видалити всі ресурси, які були зашифровані загубленим ключем, і робочі навантаження можуть не працювати як очікується протягом часу, коли шифровання у спокої зламане.
- Зробіть новий ключ першим записом у масиві
keys, щоб він використовувався для шифрування у спокої для нових записів. - Перезапустіть всі процеси
kube-apiserver, щоб кожен хост панелі управління тепер шифрував за допомогою нового ключа. - Як привілейований користувач виконайте команду
kubectl get secrets --all-namespaces -o json | kubectl replace -f -, щоб зашифрувати всі наявні секрети новим ключем. - Після того, як ви оновили всі наявні секрети, щоб вони використовували новий ключ, і зробили безпечне резервне копіювання нового ключа, видаліть старий ключ розшифрування з конфігурації.
Розшифрування всіх даних
У цьому прикладі показано, як зупинити шифрування API Secret у спокої. Якщо ви шифруєте інші види API, адаптуйте кроки відповідно.
Щоб вимкнути шифрування у спокої, розмістіть провайдера identity як перший запис у вашому файлі конфігурації шифрування:
---
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
# перерахуйте тут будь-які інші ресурси, які ви раніше
# шифрували у спокої
providers:
- identity: {} # додайте цей рядок
- aescbc:
keys:
- name: key1
secret: <BASE 64 ENCODED SECRET> # залиште це на місці
# переконайтеся, що воно йде після "identity"
Потім виконайте таку команду, щоб примусити розшифрування всіх Secrets:
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
Після того, як ви замінили всі наявні зашифровані ресурси резервними даними, які не використовують шифрування, ви можете видалити налаштування шифрування з kube-apiserver.
Налаштування автоматичного перезавантаження
Ви можете налаштувати автоматичне перезавантаження конфігурації провайдера шифрування. Ця настройка визначає, чи має API server завантажувати файл, який ви вказали для --encryption-provider-config тільки один раз при запуску, або автоматично кожного разу, коли ви змінюєте цей файл. Увімкнення цієї опції дозволяє змінювати ключі для шифрування у спокої без перезапуску API server.
Щоб дозволити автоматичне перезавантаження, налаштуйте API server для запуску з параметром: --encryption-provider-config-automatic-reload=true. Коли ввімкнено, зміни файлів перевіряються кожну хвилину для спостереження за модифікаціями. Метрика apiserver_encryption_config_controller_automatic_reload_last_timestamp_seconds визначає час, коли нова конфігурація набирає чинності. Це дозволяє виконувати ротацію ключів шифрування без перезапуску API-сервера.
Що далі
- Дізнайтеся більше про розшифрування даних, які вже збережені у спокої
- Дізнайтеся більше про API конфігурацію EncryptionConfiguration (v1).
26 - Розшифровування конфіденційних даних, які вже зашифровані у спокої
Усі API в Kubernetes, що дозволяють записувати постійні дані ресурсів, підтримують шифрування у спокої. Наприклад, ви можете увімкнути шифрування у спокої для Secret. Це шифрування у спокої додається до будь-якого шифрування системного рівня для кластера etcd або файлових систем на вузлах, де запущений kube-apiserver.
Ця сторінка показує, як перейти від шифрування даних API у спокої, щоб дані API зберігалися у незашифрованому вигляді. Ви можете зробити це для покращення продуктивності; проте, якщо шифрування було раціональним рішенням для деяких даних, то його також варто залишити.
Примітка:
Це завдання охоплює шифрування даних ресурсів, збережених за допомогою Kubernetes API. Наприклад, ви можете шифрувати обʼєкти Secret, включно з даними ключ-значення, які вони містять.
Якщо вам потрібно керувати шифруванням даних у файлових системах, які монтувалися у контейнери, вам потрібно використовувати або:
- інтеграцію зберігання, яка надає зашифровані томи
- шифрувати дані у вашому власному застосунку
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Це завдання передбачає, що Kubernetes API server працює як статичний Pod на кожному вузлі панелі управління.
Панель управління вашого кластера має використовувати etcd v3.x (основна версія 3, будь-яка мінорна версія).
Щоб зашифрувати власний ресурс, ваш кластер повинен працювати на Kubernetes v1.26 або новіше.
У вас повинні бути деякі дані API, які вже зашифровані.
Для перевірки версії введіть kubectl version.
Визначте, чи вже увімкнене шифрування у спокої
Стандартно API server використовує провайдера identity, який зберігає представлення ресурсів у текстовому вигляді. Стандартний провайдер identity не надає жодного захисту конфіденційності.
Процес kube-apiserver приймає аргумент --encryption-provider-config, який вказує шлях до файлу конфігурації. Вміст цього файлу, якщо ви вказали його, керує тим, як дані API Kubernetes шифруються в etcd. Якщо він не вказаний, у вас не увімкнене шифрування у спокої.
Форматом цього файлу конфігурації є YAML, який представляє конфігурацію API-ресурсу під назвою EncryptionConfiguration. Приклад конфігурації ви можете побачити в Шифрування конфіденційних даних у спокої.
Якщо встановлено --encryption-provider-config, перевірте, які ресурси (наприклад, secrets) налаштовані для шифрування, і який провайдер використовується. Переконайтеся, що вподобаний провайдер для цього типу ресурсу не є identity; ви встановлюєте лише identity (без шифрування) як типовий, коли хочете вимкнути шифрування у спокої. Перевірте, чи перший провайдер, зазначений для ресурсу, щось інше, ніж identity, що означає, що будь-яка нова інформація, записана до ресурсів цього типу, буде зашифрована, як налаштовано. Якщо ви бачите, що identity — перший провайдер для якого-небудь ресурсу, це означає, що ці ресурси записуються в etcd без шифрування.
Розшифруйте всі дані
Цей приклад показує, як зупинити шифрування API Secret у спокої. Якщо ви шифруєте інші види API, адаптуйте кроки відповідно.
Визначте файл конфігурації шифрування
Спочатку знайдіть файли конфігурації API server. На кожному вузлі панелі управління маніфест статичного Pod для kube-apiserver вказує аргумент командного рядка --encryption-provider-config. Ймовірно, цей файл монтується у статичний Pod за допомогою томуhostPath. Після того, як ви знайдете том, ви можете знайти файл у файловій системі вузла і перевірити його.
Налаштуйте API server для розшифрування обʼєктів
Щоб вимкнути шифрування у спокої, розмістіть провайдера identity як перший запис у вашому файлі конфігурації шифрування.
Наприклад, якщо ваш наявний файл EncryptionConfiguration виглядає так:
---
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
# Не використовуйте цей (недійсний) приклад ключа для шифрування
- name: example
secret: 2KfZgdiq2K0g2YrYpyDYs9mF2LPZhQ==
то змініть його на:
---
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- identity: {} # додайте цей рядок
- aescbc:
keys:
- name: example
secret: 2KfZgdiq2K0g2YrYpyDYs9mF2LPZhQ==
і перезапустіть kube-apiserver Pod на цьому вузлі.
Переконфігуруйте інші вузли панелі управління
Якщо у вашому кластері є кілька серверів API, ви повинні по черзі впроваджувати зміни на кожен з серверів API.
Переконайтеся, що ви використовуєте однакову конфігурацію шифрування на кожному вузлі панелі управління.
Примусове розшифрування
Потім виконайте таку команду, щоб примусити розшифрування всіх Secrets:
# Якщо ви розшифровуєте інший тип обʼєкта, змініть "secrets" відповідно.
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
Після того, як ви замінили всі наявні зашифровані ресурси резервними даними, які не використовують шифрування, ви можете видалити налаштування шифрування з kube-apiserver.
Параметри командного рядка, які потрібно видалити:
--encryption-provider-config--encryption-provider-config-automatic-reload
Знову перезапустіть kube-apiserver Pod, щоб застосувати нову конфігурацію.
Переконфігуруйте інші вузли панелі управління
Якщо у вашому кластері є кілька серверів API, ви знову повинні по черзі впроваджувати зміни на кожен з серверів API.
Переконайтеся, що ви використовуєте однакову конфігурацію шифрування на кожному вузлі панелі управління.
Що далі
- Дізнайтеся більше про API конфігурацію EncryptionConfiguration (v1).
27 - Гарантоване планування для критичних Podʼів надбудов
Основні компоненти Kubernetes, такі як сервер API, планувальник і контролер-менеджер, працюють на вузлі панелі управління. Однак надбудови мають працювати на звичайному вузлі кластера. Деякі з цих надбудов є критичними для повноцінного функціонування кластера, наприклад, metrics-server, DNS та інтерфейс користувача. Кластер може перестати правильно працювати, якщо критичний Pod надбудови буде видалений (або вручну, або як побічний ефект іншої операції, такої як оновлення) і перейде в стан очікування (наприклад, коли кластер високо завантажений і інші очікувані Podʼи заплановані на місце, звільнене видаленим критичним Podʼом надбудови, або кількість доступних ресурсів на вузлі змінилася з якоїсь іншої причини).
Зверніть увагу, що позначення Podʼа як критичного не означає повного запобігання його видаленню; це лише запобігає тому, що Pod стає постійно недоступним. Статичний Pod, позначений як критичний, не може бути видалений. Однак, нестатичні Podʼи, позначені як критичні, завжди будуть переплановані.
Позначення Podʼа як критичного
Щоб позначити Pod як критичний, встановіть для цього Podʼа priorityClassName у system-cluster-critical або system-node-critical. system-node-critical має найвищий доступний пріоритет, вищий навіть, ніж system-cluster-critical.
28 - Керівництво користувача агента маскування IP
Ця сторінка показує, як налаштувати та ввімкнути ip-masq-agent.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для перевірки версії введіть kubectl version.
Керівництво користувача агента маскування IP
ip-masq-agent налаштовує правила iptables для приховування IP-адреси Podʼа за IP-адресою вузла кластера. Це зазвичай робиться, коли трафік надсилається до пунктів призначення за межами діапазону CIDR Podʼів кластера.
Основні терміни
- NAT (Network Address Translation): Це метод переназначення однієї IP-адреси на іншу шляхом модифікації інформації адреси відправника та/або одержувача у заголовку IP. Зазвичай виконується пристроєм, що здійснює маршрутизацію IP.
- Маскування (Masquerading): Форма NAT, яка зазвичай використовується для здійснення трансляції багатьох адрес в одну, де декілька початкових IP-адрес маскуються за однією адресою, яка зазвичай є адресою пристрою, що виконує маршрутизацію. У Kubernetes це IP-адреса вузла.
- CIDR (Classless Inter-Domain Routing): Заснований на маскуванні підмереж змінної довжини, дозволяє вказувати префікси довільної довжини. CIDR ввів новий метод представлення IP-адрес, тепер відомий як нотація CIDR, у якій адреса або маршрутизаційний префікс записується з суфіксом, що вказує кількість бітів префікса, наприклад 192.168.2.0/24.
- Локальне посилання: Локальна адреса посилання — це мережева адреса, яка є дійсною лише для комунікацій у межах сегмента мережі або домену розсилки, до якого підʼєднано хост. Локальні адреси для IPv4 визначені в блоку адрес 169.254.0.0/16 у нотації CIDR.
ip-masq-agent налаштовує правила iptables для обробки маскування IP-адрес вузлів/Podʼів при надсиланні трафіку до пунктів призначення за межами IP вузла кластера та діапазону IP кластера. Це по суті приховує IP-адреси Podʼів за IP-адресою вузла кластера. У деяких середовищах, трафік до "зовнішніх" адрес має походити з відомої адреси машини. Наприклад, у Google Cloud будь-який трафік до Інтернету має виходити з IP VM. Коли використовуються контейнери, як у Google Kubernetes Engine, IP Podʼа не буде мати виходу. Щоб уникнути цього, ми повинні приховати IP Podʼа за IP адресою VM — зазвичай відомою як "маскування". Типово агент налаштований так, що три приватні IP-діапазони, визначені RFC 1918, не вважаються діапазонами маскування CIDR. Ці діапазони — 10.0.0.0/8, 172.16.0.0/12 і 192.168.0.0/16. Агент також типово вважає локальне посилання (169.254.0.0/16) CIDR не-маскуванням. Агент налаштований на перезавантаження своєї конфігурації з розташування /etc/config/ip-masq-agent кожні 60 секунд, що також можна налаштувати.
Файл конфігурації агента повинен бути написаний у синтаксисі YAML або JSON і може містити три необовʼязкові ключі:
nonMasqueradeCIDRs: Список рядків у форматі CIDR, які визначають діапазони без маскування.masqLinkLocal: Булеве значення (true/false), яке вказує, чи маскувати трафік до локального префіксу169.254.0.0/16. Типово — false.resyncInterval: Інтервал часу, через який агент намагається перезавантажити конфігурацію з диска. Наприклад: '30s', де 's' означає секунди, 'ms' — мілісекунди.
Трафік до діапазонів 10.0.0.0/8, 172.16.0.0/12 і 192.168.0.0/16 НЕ буде маскуватися. Будь-який інший трафік (вважається Інтернетом) буде маскуватися. Прикладом локального пункту призначення з Podʼа може бути IP-адреса його вузла, а також адреса іншого вузла або одна з IP-адрес у діапазоні IP кластера. Будь-який інший трафік буде стандартно маскуватися. Нижче наведено стандартний набір правил, які застосовує агент ip-masq:
iptables -t nat -L IP-MASQ-AGENT
target prot opt source destination
RETURN all -- anywhere 169.254.0.0/16 /* ip-masq-agent: клієнтський трафік в межах кластера не повинен піддаватися маскуванню */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 10.0.0.0/8 /* ip-masq-agent: клієнтський трафік в межах кластера не повинен піддаватися маскуванню */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 172.16.0.0/12 /* ip-masq-agent: клієнтський трафік в межах кластера не повинен піддаватися маскуванню */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 192.168.0.0/16 /* ip-masq-agent: клієнтський трафік в межах кластера не повинен піддаватися маскуванню */ ADDRTYPE match dst-type !LOCAL
MASQUERADE all -- anywhere anywhere /* ip-masq-agent: вихідний трафік повинен піддаватися маскуванню (ця відповідність повинна бути після відповідності клієнтським CIDR у межах кластера) */ ADDRTYPE match dst-type !LOCAL
Стандартно, в середовищі GCE/Google Kubernetes Engine, якщо ввімкнуто мережеву політику або ви використовуєте CIDR кластера не в діапазоні 10.0.0.0/8, агент ip-masq-agent буде запущений у вашому кластері. Якщо ви працюєте в іншому середовищі, ви можете додати DaemonSet ip-masq-agent до свого кластера.
Створення агента маскування IP
Щоб створити агента маскування IP, виконайте наступну команду kubectl:
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/ip-masq-agent/master/ip-masq-agent.yaml
Також вам потрібно застосувати відповідну мітку вузла на будь-яких вузлах вашого кластера, на яких ви хочете запустити агента.
kubectl label nodes my-node node.kubernetes.io/masq-agent-ds-ready=true
Додаткову інформацію можна знайти в документації агента маскування IP тут.
У більшості випадків стандартний набір правил має бути достатнім; однак, якщо це не так для вашого кластера, ви можете створити та застосувати ConfigMap, щоб налаштувати діапазони IP-адрес, що залучаються. Наприклад, щоб дозволити розгляд тільки діапазону 10.0.0.0/8 ip-masq-agent, ви можете створити наступний ConfigMap у файлі з назвою "config".
Примітка:
Важливо, що файл називається config, оскільки стандартно це буде використано як ключ для пошуку агентом ip-masq-agent:
nonMasqueradeCIDRs:
- 10.0.0.0/8
resyncInterval: 60s
Виконайте наступну команду, щоб додати configmap до вашого кластера:
kubectl create configmap ip-masq-agent --from-file=config --namespace=kube-system
Це оновить файл, розташований у /etc/config/ip-masq-agent, який періодично перевіряється кожен resyncInterval та застосовується до вузла кластера. Після закінчення інтервалу синхронізації ви повинні побачити, що правила iptables відображають ваші зміни:
iptables -t nat -L IP-MASQ-AGENT
Chain IP-MASQ-AGENT (1 references)
target prot opt source destination
RETURN all -- anywhere 169.254.0.0/16 /* ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 10.0.0.0/8 /* ip-masq-agent: cluster-local
MASQUERADE all -- anywhere anywhere /* ip-masq-agent: outbound traffic should be subject to MASQUERADE (this match must come after cluster-local CIDR matches) */ ADDRTYPE match dst-type !LOCAL
Стандартно, діапазон локальних посилань (169.254.0.0/16) також обробляється агентом ip-masq, який налаштовує відповідні правила iptables. Щоб агент ip-masq ігнорував локальні посилання, ви можете встановити masqLinkLocal як true у ConfigMap.
nonMasqueradeCIDRs:
- 10.0.0.0/8
resyncInterval: 60s
masqLinkLocal: true
29 - Обмеження використання сховища
Цей приклад демонструє, як обмежити обсяг використання сховища в просторі імен.
У демонстрації використовуються наступні ресурси: ResourceQuota, LimitRange, та PersistentVolumeClaim.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для перевірки версії введіть
kubectl version.
Сценарій: Обмеження використання сховища
Адміністратор кластера керує кластером від імені користувачів і хоче контролювати, скільки сховища може використати один простір імен, щоб контролювати витрати.
Адміністратор хоче обмежити:
- Кількість заявок на постійні томи в просторі імен
- Обсяг сховища, який може бути запитаний кожною заявкою
- Загальний обсяг сховища, який може мати простір імен
LimitRange для обмеження запитів на сховище
Додавання LimitRange до простору імен забезпечує встановлення мінімального і максимального розміру запитів на сховище. Сховище запитується через PersistentVolumeClaim. Контролер допуску, який забезпечує дотримання лімітів, відхилить будь-яку PVC, яка перевищує або не досягає встановлених адміністратором значень.
У цьому прикладі, PVC, що запитує 10Gi сховища, буде відхилено, оскільки це перевищує максимум у 2Gi.
apiVersion: v1
kind: LimitRange
metadata:
name: storagelimits
spec:
limits:
- type: PersistentVolumeClaim
max:
storage: 2Gi
min:
storage: 1Gi
Мінімальні запити на сховище використовуються, коли провайдер сховища вимагає певних мінімумів. Наприклад, диски AWS EBS мають мінімальну вимогу у 1Gi.
ResourceQuota для обмеження кількості PVC та загальної місткості сховища
Адміністратори можуть обмежити кількість PVC в просторі імен, а також загальну місткість цих PVC. Нові PVC, які перевищують будь-яке максимальне значення, будуть відхилені.
У цьому прикладі, шоста PVC у просторі імен буде відхилена, оскільки вона перевищує максимальну кількість у 5. Альтернативно, максимальна квота у 5Gi при поєднанні з максимальним лімітом у 2Gi вище, не може мати 3 PVC, де кожна має по 2Gi. Це було б 6Gi, запитані для простору імен з лімітом у 5Gi.
apiVersion: v1
kind: ResourceQuota
metadata:
name: storagequota
spec:
hard:
persistentvolumeclaims: "5"
requests.storage: "5Gi"
Підсумок
Limit range може встановити максимальний поріг для запитів на сховище, тоді як квота на ресурси може ефективно обмежити обсяг сховища, використовуваного простором імен через кількість заявок та загальну місткість. Це дозволяє адміністратору кластера планувати бюджет на сховище кластера без ризику перевитрати будь-якого проєкту.
30 - Міграція реплікованої панелі управління на використання менеджера керування хмарою
Менеджер керування хмарою — компонент панелі управління Kubernetes, що інтегрує управління логікою певної хмари. Cloud controller manager дозволяє звʼязувати ваш кластер з API хмарного провайдера та відокремлює компоненти, що взаємодіють з хмарною платформою від компонентів, які взаємодіють тільки в кластері.
Відокремлюючи логіку сумісності між Kubernetes і базовою хмарною інфраструктурою, компонент cloud-controller-manager дає змогу хмарним провайдерам випускати функції з іншою швидкістю порівняно з основним проєктом Kubernetes.
Контекст
У рамках зусиль щодо виокремлення хмарного провайдера, всі контролери, специфічні для хмари, повинні бути виокремлені з kube-controller-manager. Усі поточні кластери, які використовують контролери хмари в kube-controller-manager, повинні перейти на запуск контролерів за допомогою специфічному для хмарного провайдера cloud-controller-manager.
Міграція лідера надає механізм, за допомогою якого високодоступні кластери можуть безпечно мігрувати у "хмароспецифічні" контролери між kube-controller-manager та cloud-controller-manager за допомогою загального замикання ресурсів між двома компонентами під час оновлення реплікованої панелі управління. Для панелі управління з одним вузлом або якщо недоступність менеджерів контролерів може бути терпимим під час оновлення, міграція лідера не потрібна, і цей посібник можна ігнорувати.
Міграція лідера може бути увімкнена, встановленням --enable-leader-migration у kube-controller-manager або cloud-controller-manager. Міграція лідера застосовується лише під час оновлення і може бути безпечно вимкнена або залишена увімкненою після завершення оновлення.
Цей посібник на крок за кроком показує вам процес оновлення вручну панелі управління з kube-controller-manager із вбудованим хмарним провайдером до запуску як kube-controller-manager, так і cloud-controller-manager. Якщо ви використовуєте інструмент для розгортання та управління кластером, будь ласка, зверніться до документації інструменту та хмарного провайдера для конкретних інструкцій щодо міграції.
Перш ніж ви розпочнете
Припускається, що панель управління працює на версії Kubernetes N і планується оновлення до версії N + 1. Хоча можливе мігрування в межах однієї версії, ідеально міграцію слід виконати як частину оновлення, щоб зміни конфігурації можна було узгодити з кожним випуском. Точні версії N та N + 1 залежать від кожного хмарного провайдера. Наприклад, якщо хмарний провайдер створює cloud-controller-manager для роботи з Kubernetes 1.24, то N може бути 1.23, а N + 1 може бути 1.24.
Вузли панелі управління повинні запускати kube-controller-manager з увімкненим вибором лідера, що є стандартною поведінкою. З версії N, вбудований хмарний провайдер має бути налаштований за допомогою прапорця --cloud-provider, а cloud-controller-manager ще не повинен бути розгорнутим.
Зовнішній хмарний провайдер повинен мати cloud-controller-manager зібраний з реалізацією міграції лідера. Якщо хмарний провайдер імпортує k8s.io/cloud-provider та k8s.io/controller-manager версії v0.21.0 або пізніше, міграція лідера буде доступною. Однак для версій до v0.22.0 міграція лідера є альфа-версією та потребує увімкнення ControllerManagerLeaderMigration в cloud-controller-manager.
Цей посібник передбачає, що kubelet кожного вузла панелі управління запускає kube-controller-manager та cloud-controller-manager як статичні контейнери, визначені їх маніфестами. Якщо компоненти працюють в іншому середовищі, будь ласка, відповідно скорегуйте дії.
Щодо авторизації цей посібник передбачає, що кластер використовує RBAC. Якщо інший режим авторизації надає дозволи на компоненти kube-controller-manager та cloud-controller-manager, будь ласка, надайте необхідний доступ таким чином, що відповідає режиму.
Надання доступу до Лізингу Міграції
Стандартні дозволи менеджера керування дозволяють доступ лише до їхнього основного Лізингу. Для того, щоб міграція працювала, потрібен доступ до іншого Лізингу.
Ви можете надати kube-controller-manager повний доступ до API лізингів, змінивши роль system::leader-locking-kube-controller-manager. Цей посібник передбачає, що назва лізингу для міграції — cloud-provider-extraction-migration.
kubectl patch -n kube-system role 'system::leader-locking-kube-controller-manager' -p '{"rules": [ {"apiGroups":[ "coordination.k8s.io"], "resources": ["leases"], "resourceNames": ["cloud-provider-extraction-migration"], "verbs": ["create", "list", "get", "update"] } ]}' --type=merge`
Зробіть те саме для ролі system::leader-locking-cloud-controller-manager.
kubectl patch -n kube-system role 'system::leader-locking-cloud-controller-manager' -p '{"rules": [ {"apiGroups":[ "coordination.k8s.io"], "resources": ["leases"], "resourceNames": ["cloud-provider-extraction-migration"], "verbs": ["create", "list", "get", "update"] } ]}' --type=merge`
Початкова конфігурація міграції лідера
Міграція лідера опціонально використовує файл конфігурації, що представляє стан призначення контролерів до менеджера. На цей момент, з вбудованим хмарним провайдером, kube-controller-manager запускає route, service, та cloud-node-lifecycle. Наведений нижче приклад конфігурації показує призначення.
Міграцію лідера можна увімкнути без конфігурації. Будь ласка, див. Станадартну конфігурацію для отримання деталей.
kind: LeaderMigrationConfiguration
apiVersion: controllermanager.config.k8s.io/v1
leaderName: cloud-provider-extraction-migration
resourceLock: leases
controllerLeaders:
- name: route
component: kube-controller-manager
- name: service
component: kube-controller-manager
- name: cloud-node-lifecycle
component: kube-controller-manager
Альтернативно, оскільки контролери можуть працювати з менеджерами контролера, налаштування component на * для обох сторін робить файл конфігурації збалансованим між обома сторонами міграції.
# версія з підстановкою
kind: LeaderMigrationConfiguration
apiVersion: controllermanager.config.k8s.io/v1
leaderName: cloud-provider-extraction-migration
resourceLock: leases
controllerLeaders:
- name: route
component: *
- name: service
component: *
- name: cloud-node-lifecycle
component: *
На кожному вузлі панелі управління збережіть вміст у /etc/leadermigration.conf, та оновіть маніфест kube-controller-manager, щоб файл був змонтований всередині контейнера за тим самим шляхом. Також, оновіть цей маніфест, щоб додати наступні аргументи:
--enable-leader-migrationдля увімкнення міграції лідера у менеджері керування--leader-migration-config=/etc/leadermigration.confдля встановлення файлу конфігурації
Перезапустіть kube-controller-manager на кожному вузлі. Тепер, kube-controller-manager має увімкнену міграцію лідера і готовий до міграції.
Розгортання менеджера керування хмарою
У версії N + 1, бажаний стан призначення контролерів до менеджера може бути представлений новим файлом конфігурації, який показано нижче. Зверніть увагу, що поле component кожного controllerLeaders змінюється з kube-controller-manager на cloud-controller-manager. Альтернативно, використовуйте версію з підстановкою, згадану вище, яка має той самий ефект.
kind: LeaderMigrationConfiguration
apiVersion: controllermanager.config.k8s.io/v1
leaderName: cloud-provider-extraction-migration
resourceLock: leases
controllerLeaders:
- name: route
component: cloud-controller-manager
- name: service
component: cloud-controller-manager
- name: cloud-node-lifecycle
component: cloud-controller-manager
Під час створення вузлів панелі управління версії N + 1, вміст повинен бути розгорнутим в /etc/leadermigration.conf. Маніфест cloud-controller-manager повинен бути оновлений для монтування файлу конфігурації так само як і kube-controller-manager версії N. Також, додайте --enable-leader-migration та --leader-migration-config=/etc/leadermigration.conf до аргументів cloud-controller-manager.
Створіть новий вузол панелі управління версії N + 1 з оновленим маніфестом cloud-controller-manager, та з прапорцем --cloud-provider, встановленим на external для kube-controller-manager. kube-controller-manager версії N + 1 НЕ МУСИТЬ мати увімкненої міграції лідера, оскільки, зовнішній хмарний провайдер вже не запускає мігровані контролери, і, отже, він не бере участі в міграції.
Будь ласка, зверніться до Адміністрування менеджера керування хмарою для отримання детальнішої інформації щодо розгортання cloud-controller-manager.
Оновлення панелі управління
Панель управління тепер містить вузли як версії N, так і N + 1. Вузли версії N запускають лише kube-controller-manager, а вузли версії N + 1 запускають як kube-controller-manager, так і cloud-controller-manager. Мігровані контролери, зазначені у конфігурації, працюють під менеджером управління хмарою версії N або cloud-controller-manager версії N + 1 залежно від того, який менеджер управління утримує лізинг міграції. Жоден контролер ніколи не працюватиме під обома менеджерами управління одночасно.
Поступово створіть новий вузол панелі управління версії N + 1 та вимкніть один вузол версії N до тих пір, поки панель управління не буде містити лише вузли версії N + 1. Якщо потрібно відкотитись з версії N + 1 на версію N, додайте вузли версії N з увімкненою міграцією лідера для kube-controller-manager назад до панелі управління, замінюючи один вузол версії N + 1 кожен раз, поки не залишаться лише вузли версії N.
(Необовʼязково) Вимкнення міграції лідера
Тепер, коли панель управління була оновлена для запуску як kube-controller-manager, так і cloud-controller-manager версії N + 1, міграція лідера завершила свою роботу і може бути безпечно вимкнена для збереження ресурсу лізингу. У майбутньому можна безпечно повторно увімкнути міграцію лідера для відкату.
Поступово у менеджері оновіть маніфест cloud-controller-manager, щоб скасувати встановлення як --enable-leader-migration, так і --leader-migration-config=, також видаліть підключення /etc/leadermigration.conf, а потім видаліть /etc/leadermigration.conf. Щоб повторно увімкнути міграцію лідера, створіть знову файл конфігурації та додайте його монтування та прапорці, які увімкнуть міграцію лідера назад до cloud-controller-manager.
Стандартна конфігурація
Починаючи з Kubernetes 1.22, Міграція лідера надає стандартну конфігурацію, яка підходить для стандартного призначення контролерів до менеджера. Стандартну конфігурацію можна увімкнути, встановивши --enable-leader-migration, але без --leader-migration-config=.
Для kube-controller-manager та cloud-controller-manager, якщо немає жодних прапорців, що увімкнуть будь-якого вбудованого хмарного провайдера або змінять володільця контролерів, можна використовувати стандартну конфігурацію, щоб уникнути ручного створення файлу конфігурації.
Спеціальний випадок: міграція контролера Node IPAM
Якщо ваш хмарний провайдер надає реалізацію контролера Node IPAM, вам слід перейти до реалізації в cloud-controller-manager. Вимкніть контролер Node IPAM в kube-controller-manager версії N + 1, додавши --controllers=*,-nodeipam до його прапорців. Потім додайте nodeipam до списку мігрованих контролерів.
# версія з підстановкою, з nodeipam
kind: LeaderMigrationConfiguration
apiVersion: controllermanager.config.k8s.io/v1
leaderName: cloud-provider-extraction-migration
resourceLock: leases
controllerLeaders:
- name: route
component: *
- name: service
component: *
- name: cloud-node-lifecycle
component: *
- name: nodeipam
component: *
Що далі
- Прочитайте пропозицію щодо покращення Міграції лідера менеджера управління.
31 - Управління кластерами etcd для Kubernetes
etcd — це надійне та високодоступне сховище ключ-значення, яке використовується як сховище Kubernetes для всіх даних кластера.
Якщо ваш кластер Kubernetes використовує etcd як основне сховище, переконайтеся, що у вас є план резервного копіювання даних.
Ви можете знайти докладну інформацію про etcd в офіційній документації.
Перш ніж ви розпочнете
Перш ніж слідувати інструкціям на цій сторінці щодо розгортання, керування, резервного копіювання або відновлення etcd, необхідно зрозуміти типові очікування при експлуатації кластера etcd. Зверніться до документації etcd для отримання додаткової інформації.
Основні деталі включають:
Мінімальні рекомендовані версії etcd для використання в операційній діяльності:
3.4.22+і3.5.6+.etcd є розподіленою системою з визначенням лідера. Забезпечте, щоб лідер періодично надсилав своєчасні сигнали всім підлеглим для підтримки стабільності кластера.
Ви повинні запускати etcd як кластер з непарною кількістю членів.
Намагайтеся уникати виснаження ресурсів.
Продуктивність і стабільність кластера чутлива до наявності ресурсів мережі та введення/виведення даних на диск. Будь-яка нестача ресурсів може призвести до вичерпання тайм-ауту пульсу, що призводить до нестабільності кластера. Нестабільність etcd означає, що лідер не обраний. У таких обставинах кластер не може вносити зміни до свого поточного стану, що означає, що нові Podʼи не можуть бути заплановані.
Вимоги до ресурсів для etcd
Експлуатація etcd з обмеженими ресурсами підходить тільки для тестових цілей. Для розгортання в операційній діяльності потрібна розширена конфігурація обладнання. Перед розгортанням etcd в операційній діяльності дивіться довідник щодо вимог до ресурсів.
Підтримання стабільності кластерів etcd є критичним для стабільності кластерів Kubernetes. Тому запускайте кластери etcd на виділених машинах або в ізольованих середовищах для гарантованих вимог до ресурсів.
Інструменти
Залежно від конкретного завдання, яке ви виконуєте, вам знадобиться інструмент etcdctl або etcdutl (можливо, обидва).
Розуміння etcdctl і etcdutl
etcdctl і etcdutl — це інструменти командного рядка для взаємодії з кластерами etcd, але вони виконують різні завдання:
etcdctl— це основний клієнт командного рядка для взаємодії з etcd через мережу. Використовується для повсякденних операцій, таких як керування ключами та значеннями, адміністрування кластера, перевірка справності та багато іншого.etcdutl— це утиліта адміністратора, призначена для роботи безпосередньо з файлами даних etcd, включаючи міграцію даних між версіями etcd, дефрагментацію бази даних, відновлення знімків і перевірку цілісності даних. Для мережевих операцій слід використовуватиetcdctl.
Для отримання додаткової інформації про etcdutl, ви можете звернутися до документації з відновлення etcd.
Запуск кластерів etcd
У цьому розділі розглядається запуск одно- та багатовузлового кластерів etcd.
Це керівництво передбачає, що etcd встановлено.
Одновузловий кластер etcd
Використовуйте одновузловий кластер etcd лише для тестування.
Виконайте наступне:
etcd --listen-client-urls=http://$PRIVATE_IP:2379 \ --advertise-client-urls=http://$PRIVATE_IP:2379Запустіть сервер API Kubernetes з прапорцем
--etcd-servers=$PRIVATE_IP:2379.Переконайтеся, що
PRIVATE_IPвстановлено на вашу IP-адресу клієнта etcd.
Багатовузловий кластер etcd
Для забезпечення надійності та високої доступності запускайте etcd як багатовузловий кластер для операційної діяльності та періодично робіть резервні копії. В операційній діяльності рекомендується використовувати кластер з пʼятьма членами. Для отримання додаткової інформації див. ЧаПи.
Оскільки ви використовуєте Kubernetes, у вас є можливість запускати etcd як контейнер всередині одного або декількох Podʼів. Інструмент kubeadm типово налаштовує etcd як статичні Podʼи, або ви можете розгорнути окремий кластер і вказати kubeadm використовувати цей кластер etcd як сховище для панелі управління.
Ви можете налаштувати кластер etcd або за допомогою статичної інформації про учасників, або за допомогою динамічного виявлення. Для отримання додаткової інформації про кластеризацію дивіться документацію з кластеризації etcd.
Наприклад, розглянемо кластер etcd з пʼятьох членів, що працює з наступними URL-адресами клієнта: http://$IP1:2379, http://$IP2:2379, http://$IP3:2379, http://$IP4:2379 та http://$IP5:2379. Щоб запустити сервер API Kubernetes:
Виконайте наступне:
etcd --listen-client-urls=http://$IP1:2379,http://$IP2:2379,http://$IP3:2379,http://$IP4:2379,http://$IP5:2379 --advertise-client-urls=http://$IP1:2379,http://$IP2:2379,http://$IP3:2379,http://$IP4:2379,http://$IP5:2379Запустіть сервери API Kubernetes з прапорцем
--etcd-servers=$IP1:2379,$IP2:2379,$IP3:2379,$IP4:2379,$IP5:2379.Переконайтеся, що змінні
IP<n>встановлені на ваші IP-адреси клієнтів.
Багатовузловий кластер etcd з балансувальником навантаження
Для запуску кластера etcd з балансувальником навантаження:
- Налаштуйте кластер etcd.
- Налаштуйте балансувальник навантаження перед кластером etcd. Наприклад, адреса балансувальника навантаження може бути
$LB. - Запустіть сервери API Kubernetes з прапорцем
--etcd-servers=$LB:2379.
Захист кластерів etcd
Доступ до etcd еквівалентний правам користувача root в кластері, тому ідеально, щоб доступ до нього мав лише сервер API. З урахуванням чутливості даних рекомендується надавати дозвіл лише тим вузлам, які потребують доступу до кластерів etcd.
Для захисту etcd налаштуйте правила брандмауера або використовуйте засоби безпеки, надані etcd. Функції безпеки etcd залежать від інфраструктури відкритого ключа x509 (PKI). Для початку налаштуйте безпечні канали звʼязку, згенерувавши пару ключа та сертифікату. Наприклад, використовуйте пари ключів peer.key та peer.cert для захисту звʼязку між членами etcd та client.key та client.cert для захисту звʼязку між etcd та його клієнтами. Див. приклади скриптів, надані проєктом etcd, для генерації пар ключів та файлів ЦС для автентифікації клієнтів.
Захист комунікації
Для налаштування etcd з безпечною взаємодією між членами вкажіть прапорці --peer-key-file=peer.key та --peer-cert-file=peer.cert, та використовуйте протокол HTTPS у схемі URL.
Аналогічно, для налаштування etcd з безпечною взаємодією клієнтів вкажіть прапорці --key=k8sclient.key та --cert=k8sclient.cert, та використовуйте протокол HTTPS у схемі URL. Ось приклад команди клієнта, яка використовує безпечну комунікацію:
ETCDCTL_API=3 etcdctl --endpoints 10.2.0.9:2379 \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
member list
Обмеження доступу до кластерів etcd
Після налаштування безпечної комунікації обмежте доступ до кластера etcd лише для серверів API Kubernetes, використовуючи автентифікацію TLS.
Наприклад, розгляньте пари ключів k8sclient.key та k8sclient.cert, яким довіряє ЦС etcd.ca. Коли etcd налаштовано з параметром --client-cert-auth разом з TLS, він перевіряє сертифікати від клієнтів, використовуючи системні ЦС або ЦС, передані за допомогою прапорця --trusted-ca-file. Вказівка прапорців --client-cert-auth=true та --trusted-ca-file=etcd.ca обмежить доступ до клієнтів з сертифікатом k8sclient.cert.
Після коректного налаштування etcd до нього можуть отримувати доступ лише клієнти з дійсними сертифікатами. Щоб дати серверам API Kubernetes доступ, налаштуйте їх з прапорцями --etcd-certfile=k8sclient.cert, --etcd-keyfile=k8sclient.key та --etcd-cafile=ca.cert.
Примітка:
Автентифікація etcd не планується для Kubernetes.Заміна несправного члена etcd
Кластер etcd досягає високої доступності, толеруючи невеликі відмови членів. Однак, для покращення загального стану кластера, замінюйте несправних членів негайно. Коли відмовляють декілька членів, замінюйте їх по одному. Заміна несправного члена включає два кроки: видалення несправного члена та додавання нового члена.
Хоча etcd зберігає унікальні ідентифікатори членів всередині, рекомендується використовувати унікальне імʼя для кожного члена, щоб уникнути фактора людської помилки. Наприклад, розгляньте кластер etcd з трьох членів. Нехай URL буде таким: member1=http://10.0.0.1, member2=http://10.0.0.2, і member3=http://10.0.0.3. Коли відмовляє member1, замініть його на member4=http://10.0.0.4.
Отримайте ідентифікатор несправного
member1:etcdctl --endpoints=http://10.0.0.2,http://10.0.0.3 member listПоказується наступне повідомлення:
8211f1d0f64f3269, started, member1, http://10.0.0.1:2380, http://10.0.0.1:2379 91bc3c398fb3c146, started, member2, http://10.0.0.2:2380, http://10.0.0.2:2379 fd422379fda50e48, started, member3, http://10.0.0.3:2380, http://10.0.0.3:2379Виконайте одне з наступного:
- Якщо кожен сервер API Kubernetes налаштований на спілкування з усіма членами etcd, видаліть несправного члена з прапорця
--etcd-servers, а потім перезапустіть кожен сервер API Kubernetes. - Якщо кожен сервер API Kubernetes спілкується з одним членом etcd, зупиніть сервер API Kubernetes, який спілкується з несправним etcd.
- Якщо кожен сервер API Kubernetes налаштований на спілкування з усіма членами etcd, видаліть несправного члена з прапорця
Зупиніть сервер etcd на несправному вузлі. Можливо, інші клієнти окрім сервера API Kubernetes створюють трафік до etcd, і бажано зупинити весь трафік, щоб запобігти записам до теки з даними.
Видаліть несправного члена:
etcdctl member remove 8211f1d0f64f3269Показується наступне повідомлення:
Removed member 8211f1d0f64f3269 from clusterДодайте нового члена:
etcdctl member add member4 --peer-urls=http://10.0.0.4:2380Показується наступне повідомлення:
Member 2be1eb8f84b7f63e added to cluster ef37ad9dc622a7c4Запустіть новододаного члена на машині з IP
10.0.0.4:export ETCD_NAME="member4" export ETCD_INITIAL_CLUSTER="member2=http://10.0.0.2:2380,member3=http://10.0.0.3:2380,member4=http://10.0.0.4:2380" export ETCD_INITIAL_CLUSTER_STATE=existing etcd [flags]Виконайте одне з наступного:
- Якщо кожен сервер API Kubernetes налаштований на спілкування з усіма членами etcd, додайте новододаного члена до прапорця
--etcd-servers, а потім перезапустіть кожен сервер API Kubernetes. - Якщо кожен сервер API Kubernetes спілкується з одним членом etcd, запустіть сервер API Kubernetes, який був зупинений на кроці 2. Потім налаштуйте клієнти сервера API Kubernetes знову маршрутизувати запити до сервера API Kubernetes, який був зупинений. Це часто можна зробити, налаштувавши балансувальник навантаження.
- Якщо кожен сервер API Kubernetes налаштований на спілкування з усіма членами etcd, додайте новододаного члена до прапорця
За додатковою інформацією про налаштування кластера etcd див. документацію з переналаштування etcd.
Резервне копіювання кластера etcd
Усі обʼєкти Kubernetes зберігаються в etcd. Періодичне резервне копіювання даних кластера etcd важливо для відновлення кластерів Kubernetes у випадку катастрофи, такої як втрата всіх вузлів панелі управління. Файл знімка містить весь стан Kubernetes та критичну інформацію. Для збереження конфіденційних даних Kubernetes в безпеці зашифруйте файли знімків.
Резервне копіювання кластера etcd можна виконати двома способами: вбудованим засобами знімків etcd та знімком тому.
Вбудовані засоби знімків
etcd підтримує вбудовані засоби знімків. Знімок можна створити з активного члена за допомогою команди etcdctl snapshot save або скопіювавши файл member/snap/db з теки даних etcd, яка в цей момент не використовується процесом etcd. Створення знімка не вплине на продуктивність члена.
Нижче наведено приклад створення знімка простору ключів, який обслуговується за адресою $ENDPOINT, у файл snapshot.db:
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshot.db
Перевірте знімок:
Приклад нижче показує, як використовувати etcdutl для перевірки знімка:
etcdutl --write-out=table snapshot status snapshot.db
Це повинно згенерувати результат, подібний до наведеного нижче прикладу:
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| fe01cf57 | 10 | 7 | 2.1 MB |
+----------+----------+------------+------------+
Примітка:
Використанняetcdctl snapshot status є застарілим починаючи з версії etcd v3.5.x і планується до вилучення у версії v3.6. Натомість рекомендується використовувати etcdutl.Приклад нижче показує, як використовувати etcdctl для перевірки знімка:
export ETCDCTL_API=3
etcdctl --write-out=table snapshot status snapshot.db
Це повинно згенерувати результат, подібний до наведеного нижче прикладу:
Застаріло: Використовуйте `etcdutl snapshot status` натомість.
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| fe01cf57 | 10 | 7 | 2.1 MB |
+----------+----------+------------+------------+
Знімок тому
Якщо etcd працює за томом сховища, який підтримує резервне копіювання, наприклад, Amazon Elastic Block Store, зробіть резервну копію даних etcd, створивши знімок тому сховища.
Знімок за допомогою параметрів etcdctl
Ми також можемо створити знімок, використовуючи різноманітні параметри, надані etcdctl. Наприклад:
ETCDCTL_API=3 etcdctl -h
покаже різні параметри, доступні з etcdctl. Наприклад, ви можете створити знімок, вказавши точку доступу, сертифікати та ключ, як показано нижче:
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=<trusted-ca-file> --cert=<cert-file> --key=<key-file> \
snapshot save <backup-file-location>
де trusted-ca-file, cert-file та key-file можна отримати з опису модуля etcd.
Масштабування кластерів etcd
Масштабування кластерів etcd підвищує доступність шляхом зниження продуктивності. Масштабування не збільшує продуктивність або можливості кластера. Загальне правило — не масштабуйте кластери etcd. Не налаштовуйте жодних автоматичних груп масштабування для кластерів etcd. Наполегливо рекомендується завжди запускати статичний кластер etcd з 5-ти членів для операційних кластерів Kubernetes будь-якого офіційно підтримуваного масштабу.
Доречне масштабування — це оновлення кластера з трьох до пʼяти членів, коли потрібно більше надійності. Див. документацію з переконфігурації etcd для інформації про те, як додавати учасників у наявний кластер.
Відновлення кластера etcd
Увага:
Якщо будь-які API-сервери працюють у вашому кластері, ви не повинні намагатися відновлювати екземпляри etcd. Замість цього дотримуйтесь цих кроків для відновлення etcd:
- зупиніть усі екземпляри API-сервера
- відновіть стан у всіх екземплярах etcd
- перезапустіть усі екземпляри API-сервера
Проєкт Kubernetes також рекомендує перезапускати компоненти Kubernetes (kube-scheduler, kube-controller-manager, kubelet), щоб гарантувати, що вони не покладаються на застарілі дані. На практиці відновлення займає деякий час. Під час відновлення критичні компоненти втратять блокування лідера і перезапустяться.
etcd підтримує відновлення зі знімків, які були створені з процесу etcd версії major.minor. Відновлення версії з іншої версії патча etcd також підтримується. Операція відновлення використовується для відновлення даних несправного кластера.
Перед початком операції відновлення повинен бути наявний файл знімка. Це може бути файл знімка з попередньої операції резервного копіювання або теки даних, що залишилась.
Під час відновлення кластера використовуючи etcdutl використовуйте опцію --data-dir, щоб вказати, у яку теку слід відновити кластер:
etcdutl --data-dir <data-dir-location> snapshot restore snapshot.db
де <data-dir-location> — це тека, яка буде створена під час процесу відновлення.
Примітка:
Використанняetcdctl для відновлення застаріло починаючи з версії etcd v3.5.x і планується до вилучення у версії v3.6. Натомість рекомендується використовувати etcdutl.У наведеному нижче прикладі показано використання інструмента etcdctl для операції відновлення:
export ETCDCTL_API=3
etcdctl --data-dir <data-dir-location> snapshot restore snapshot.db
Якщо <data-dir-location> є тою самою текою, що й раніше, видаліть її та зупиніть процес etcd перед відновленням кластера. В іншому випадку, змініть конфігурацію etcd і перезапустіть процес etcd після відновлення, щоб він використовував нову теку даних: спочатку змініть /etc/kubernetes/manifests/etcd.yaml у volumes.hostPath.path для name: etcd-data на <data-dir-location>, потім виконайте kubectl -n kube-system delete pod <name-of-etcd-pod> або ystemctl restart kubelet.service (або обидві команди).
Для отримання додаткової інформації та прикладів відновлення кластера з файлу знімка, див. документацію з відновлення після збою etcd.
Якщо доступні URL-адреси відновленого кластера відрізняються від попереднього кластера, сервер API Kubernetes повинен бути відповідно переконфігурований. У цьому випадку перезапустіть сервери API Kubernetes з прапорцем --etcd-servers=$NEW_ETCD_CLUSTER замість прапорця --etcd-servers=$OLD_ETCD_CLUSTER. Замініть $NEW_ETCD_CLUSTER та $OLD_ETCD_CLUSTER на відповідні IP-адреси. Якщо перед кластером etcd використовується балансувальник навантаження, можливо, потрібно оновити балансувальник навантаження.
Якщо більшість членів etcd є остаточно несправними, кластер etcd вважається несправним. У цьому сценарії Kubernetes не може вносити зміни у свій поточний стан. Хоча заплановані Podʼи можуть продовжувати працювати, нові Podʼи не можуть бути заплановані. У таких випадках відновіть кластер etcd та, можливо, переконфігуруйте сервери API Kubernetes, щоб усунути проблему.
Оновлення кластерів etcd
Увага:
Перш ніж ви розпочнете оновлення, будь ласка, спочатку зробіть резервне копіювання свого кластера etcd.Для отримання додаткових відомостей щодо оновлення etcd дивіться документацію з оновлення etcd.
Обслуговування кластерів etcd
Для отримання додаткових відомостей щодо обслуговування etcd дивіться документацію з обслуговування etcd.
Дефрагментація кластера
Дефрагментація є дорогою операцією, тому її слід виконувати якомога рідше. З іншого боку, також необхідно переконатися, що жоден з учасників etcd не перевищить квоту зберігання. Проєкт Kubernetes рекомендує, що при виконанні дефрагментації ви використовували інструмент, такий як etcd-defrag.
Ви також можете запускати інструмент дефрагментації як Kubernetes CronJob, щоб переконатися, що дефрагментація відбувається регулярно. Дивіться etcd-defrag-cronjob.yaml для отримання деталей.
32 - Резервування обчислювальних ресурсів для системних служб
Вузли Kubernetes можуть бути заплановані на Capacity. Podʼи можуть використовувати типово всю доступну місткість на вузлі. Це проблема, оскільки на вузлах зазвичай працює досить багато системних служб, які забезпечують операційну систему та сам Kubernetes. Якщо не виділити ресурси для цих системних служб, Podʼи та системні служби конкурують за ресурси, що призводить до проблем з вичерпання ресурсів на вузлі.
kubelet надає можливість під назвою 'Node Allocatable', яка допомагає резервувати обчислювальні ресурси для системних служб. Kubernetes рекомендує адміністраторам кластера налаштовувати 'Node Allocatable' на основі щільності робочого навантаження на кожному вузлі.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Ви можете налаштувати kubelet за допомогою параметрів конфігурації використовуючи конфігураційний файл kubelet.
Node Allocatable

'Виділення' (Allocatable) на вузлі Kubernetes визначається як обсяг обчислювальних ресурсів, які доступні для Podʼів. Планувальник не надає перевищення обсягу 'Виділення'. Зараз підтримуються 'CPU', 'memory' та 'ephemeral-storage'.
Node Allocatable експонується як частина обʼєкта v1.Node в API та як частина kubectl describe node в CLI.
Ресурси можуть бути зарезервовані для двох категорій системних служб в kubelet.
Увімкнення QoS та cgroups на рівні Pod
Для належного застосування обмежень на вузлі виділення ресурсів вузлові вам потрібно увімкнути нову ієрархію cgroup за допомогою параметру налаштувань cgroupsPerQOS. Цей параметр є типово увімкненим. Коли він увімкнений, kubelet буде розташовувати всі Podʼи кінцевих користувачів в ієрархії cgroup, керованій kubelet.
Налаштування драйвера cgroup
kubelet підтримує маніпулювання ієрархією cgroup на хості за допомогою драйвера cgroup. Драйвер налаштовується за допомогою параметра cgroupDriver.
Підтримувані значення наступні:
cgroupfs— це типовий драйвер, який виконує пряме маніпулювання файловою системою cgroup на хості для управління пісочницями cgroup.systemd— це альтернативний драйвер, який управляє пісочницями cgroup за допомогою тимчасових сегментів для ресурсів, які підтримуються цією системою ініціалізації.
Залежно від конфігурації відповідного контейнерного середовища, оператори можуть вибрати певний драйвер cgroup, щоб забезпечити належну роботу системи. Наприклад, якщо оператори використовують драйвер cgroup systemd, наданий контейнерним середовищем containerd, kubelet повинен бути налаштований на використання драйвера cgroup systemd.
Kube Reserved
- KubeletConfiguration Setting:
kubeReserved: {}. Example value{cpu: 100m, memory: 100Mi, ephemeral-storage: 1Gi, pid=1000} - KubeletConfiguration Setting:
kubeReservedCgroup: ""
kubeReserved призначено для захоплення резервування ресурсів для системних демонів Kubernetes, таких як kubelet, container runtime тощо. Він не призначений для резервування ресурсів для системних служб, які запускаються як Podʼи. kubeReserved зазвичай є функцією pod density на вузлах.
Крім cpu, memory та ephemeral-storage, можна вказати pid, щоб зарезервувати вказану кількість ідентифікаторів процесів для системних демонів Kubernetes.
Для необовʼязкового застосування kubeReserved до системних демонів Kubernetes вкажіть батьківську контрольну групу для демонів kube як значення параметра kubeReservedCgroup та додайте kube-reserved до enforceNodeAllocatable.
Рекомендується розміщувати системні демони Kubernetes під верхньою контрольною групою (runtime.slice на машинах з systemd, наприклад). Кожен системний демон повинен ідеально працювати у власній дочірній контрольній групі. Докладнішу інформацію про рекомендовану ієрархію контрольних груп дивіться у пропозиції дизайну.
Зверніть увагу, що Kubelet не створює kubeReservedCgroup, якщо він не існує. Kubelet не запуститься, якщо вказано недійсну контрольну групу. З драйвером cgroup systemd вам слід дотримуватися певного шаблону для імені контрольної групи, яку ви визначаєте: імʼя повинно бути значенням, яке ви встановлюєте для kubeReservedCgroupp, з додаванням .slice.
System Reserved
- KubeletConfiguration Setting:
systemReserved: {}. Example value{cpu: 100m, memory: 100Mi, ephemeral-storage: 1Gi, pid=1000} - KubeletConfiguration Setting:
systemReservedCgroup: ""
systemReserved призначено для захоплення резервування ресурсів для системних служб операційної системи, таких як sshd, udev і т. д. systemReserved повинно резервувати memory для kernel, оскільки памʼять kernel наразі не враховується для Podʼів у Kubernetes. Рекомендується також резервувати ресурси для сеансів входу користувача (user.slice у світі systemd).
Крім cpu, memory та ephemeral-storage, можна вказати pid, щоб зарезервувати вказану кількість ідентифікаторів процесів для системних служб операційної системи.
Для необовʼязкового застосування systemReserved до системних служб вкажіть батьківську контрольну групу для системних служб операційної системи як значення параметра systemReservedCgroup та додайте system-reserved до enforceNodeAllocatable.
Рекомендується розміщувати системні служби операційної системи під верхньою контрольною групою (system.slice на машинах з systemd, наприклад).
Зверніть увагу, що kubelet не створює systemReservedCgroup, якщо він не існує. kubelet відмовить у запуску, якщо вказано недійсну контрольну групу. З драйвером cgroup systemd вам слід дотримуватися певного шаблону для імені контрольної групи, яку ви визначаєте: імʼя повинно бути значенням, яке ви встановлюєте для systemReservedCgroup, з додаванням .slice.
Явно зарезервований список CPU
Kubernetes v1.17 [stable]Параметр KubeletConfiguration Setting: reservedSystemCPUs:. Наприклад: 0-3
reservedSystemCPUs призначено для визначення явного набору CPU для системних служб операційної системи та системних служб Kubernetes. reservedSystemCPUs призначений для систем, які не мають наміру визначати окремі верхні рівні контрольні групи для системних служб операційної системи та системних служб Kubernetes з урахуванням ресурсу cpuset. Якщо Kubelet не має kubeReservedCgroup та systemReservedCgroup, явний набір cpuset, наданий reservedSystemCPUs, переважатиме над CPU, визначеними параметрами kubeReservedCgroup та systemReservedCgroup.
Ця опція спеціально розроблена для випадків використання в телекомунікаціях/NFV, де неконтрольовані переривання/таймери можуть впливати на продуктивність робочого навантаження. Ви можете використовувати цю опцію для визначення явного набору cpuset для системних/кластерних служб та переривань/таймерів, щоб решта процесорів у системі могли використовуватися виключно для робочих навантажень, з меншим впливом неконтрольованих переривань/таймерів. Щоб перенести системні служби, системні служби Kubernetes та переривання/таймери до явного набору cpuset, визначеного цією опцією, слід використовувати інші механізми поза Kubernetes. Наприклад: у CentOS це можна зробити за допомогою інструменту tuned.
Пороги виселення
Параметр KubeletConfiguration: evictionHard: {memory.available: "100Mi", nodefs.available: "10%", nodefs.inodesFree: "5%", imagefs.available: "15%"}. Наприклад: {memory.available: "<500Mi"}
Нестача памʼяті на рівні вузла призводить до System OOMs, що впливає на весь вузол та всі Podʼи, що працюють на ньому. Вузли можуть тимчасово вийти з ладу, поки памʼять не буде відновлена. Щоб уникнути (або зменшити ймовірність) System OOMs, kubelet надає управління ресурсами. Виселення підтримується тільки для memory та ephemeral-storage. Резервуючи певний обсяг памʼяті за допомогою параметра evictionHard, kubelet намагається виселити Podʼи, коли доступність памʼяті на вузлі впаде нижче зарезервованого значення. Гіпотетично, якщо системні служби не існують на вузлі, Podʼи не можуть використовувати більше, ніж capacity - eviction-hard. З цієї причини ресурси, зарезервовані для виселень, не доступні для Podʼів.
Застосування Node Allocatable
KubeletConfiguration setting: enforceNodeAllocatable: [pods]. Наприклад: [pods,system-reserved,kube-reserved]
Планувальник розглядає 'Allocatable' як доступну capacity для Podʼів.
kubelet типово застосовує 'Allocatable' на всіх Podʼах. Застосування виконується шляхом видалення Podʼів, коли загальне використання у всіх Podʼах перевищує 'Allocatable'. Додаткові відомості про політику виселення можна знайти на сторінці Виселення внаслідок тиску на вузол. Це застосування контролюється, вказуючи значення pods для параметра enforceNodeAllocatable.
Необовʼязково, kubelet можна змусити застосовувати kubeReserved та systemReserved, вказавши значення kube-reserved та system-reserved у в одному і тому ж параметрі. Зверніть увагу, що для застосування kubeReserved або systemReserved, потрібно вказати kubeReservedCgroup або ystemReservedCgroup відповідно.
Загальні настанови
Очікується, що системні служби будуть оброблятися аналогічно гарантованим Podʼам. Системні служби можуть розширюватися в межах своїх обмежувальних контрольних груп, і цією поведінкою потрібно керувати як частиною розгортань Kubernetes. Наприклад, kubelet повинен мати свою власну контрольну групу і ділити ресурси kubeReserved з контейнерним середовищем. Однак Kubelet не може розширюватися і використовувати всі доступні ресурси вузла, якщо застосовується kubeReserved.
Будьте особливо обережні при застосуванні резервування systemReserved, оскільки це може призвести до нестачі ресурсів CPU для критичних системних служб, припинення роботи через нестачу памʼяті (OOM) або неможливості форка на вузлі. Рекомендація полягає в застосуванні systemReserved лише у випадку, якщо користувач детально проаналізував свої вузли, щоб надати точні оцінки та має впевненість у своїй здатності відновитися, якщо будь-який процес у цій групі буде примусово завершений через брак памʼяті.
- Спочатку застосовуйте 'Allocatable' на
Pod. - Як тільки буде встановлено достатньо моніторингу та попереджень для відстеження системних служб kube, спробуйте застосувати
kubeReservedна основі використання евристик. - Якщо це абсолютно необхідно, з часом застосуйте
systemReserved.
Вимоги до ресурсів системних служб kube можуть зростати з часом з введенням все більшої кількості функцій. З часом проєкт Kubernetes буде намагатися знизити використання системних служб вузла, але зараз це не пріоритет. Так що очікуйте зниження доступної місткості Allocatable у майбутніх версіях.
Приклад сценарію
Ось приклад для ілюстрації обчислення виділення ресурсів вузла:
- Вузол має
32Гбпамʼяті,16 ЦПі100Гбсховища kubeReservedвстановлено у{cpu: 1000m, memory: 2Gi, ephemeral-storage: 1Gi}systemReservedвстановлено у{cpu: 500m, memory: 1Gi, ephemeral-storage: 1Gi}evictionHardвстановлено у{memory.available: "<500Mi", nodefs.available: "<10%"}
У цьому сценарії "Allocatable" складатиме 14,5 ЦП, 28,5Гб памʼяті та 88Гб локального сховища. Планувальник забезпечує, що загальна памʼять запитів у всіх Podʼів на цьому вузлі не перевищує 28,5Гб, а сховище не перевищує 88Гб. Kubelet виселяє Podʼи, коли загальне використання памʼяті у всіх Podʼах перевищує 28,5Гб, або якщо загальне використання диска перевищує 88Гб. Якщо всі процеси на вузлі використовують як можна більше ЦП, Podʼи разом не можуть використовувати більше ніж 14,5 ЦП.
Якщо kubeReserved та/або systemReserved не застосовується, і системні служби перевищують своє резервування, kubelet виводить Podʼи, коли загальне використання памʼяті вузла вище 31,5Гб або storage перевищує 90Гб.
33 - Запуск компонентів вузла Kubernetes користувачем без прав root
Kubernetes v1.22 [alpha]У цьому документі описано, як запустити компоненти вузла Kubernetes, такі як kubelet, CRI, OCI та CNI, без прав root, використовуючи простір імен користувача.
Ця техніка також відома як rootless mode.
Примітка:
У цьому документі описано, як запустити компоненти вузла Kubernetes (і відповідно Podʼи), як не-root користувач.
Якщо ви шукаєте лише як запустити Pod як не-root користувача, див. SecurityContext.
Перш ніж ви розпочнете
Версія вашого Kubernetes сервера має бути не старішою ніж 1.22.
Для перевірки версії введіть kubectl version.
- Увімкніть Cgroup v2
- Увімкніть systemd з сеансом користувача
- Налаштуйте кілька значень sysctl, залежно від розподілу Linux хосту
- Переконайтеся, що ваш не привілейований користувач вказаний у
/etc/subuidта/etc/subgid - Увімкніть функціональну можливість
KubeletInUserNamespace
Запуск Kubernetes в Rootless Docker або Rootless Podman
kind
kind підтримує запуск Kubernetes в середовищі Rootless Docker або Rootless Podman.
Див. Запуск kind з Rootless Docker.
minikube
minikube також підтримує запуск Kubernetes в середовищі Rootless Docker або Rootless Podman.
Див. документацію Minikube:
Запуск Kubernetes всередині непривілейованих контейнерів
sysbox
Sysbox — це відкрите програмне забезпечення для виконання контейнерів (подібне до "runc"), яке підтримує запуск робочих навантажень на рівні системи, таких як Docker та Kubernetes, всередині непривілейованих контейнерів, ізольованих за допомогою просторів користувачів Linux.
Дивіться Sysbox Quick Start Guide: Kubernetes-in-Docker для отримання додаткової інформації.
Sysbox підтримує запуск Kubernetes всередині непривілейованих контейнерів без потреби в Cgroup v2 і без використання KubeletInUserNamespace. Він досягає цього за допомогою розкриття спеціально створених файлових систем /proc та /sys всередині контейнера, а також кількох інших передових технік віртуалізації операційної системи.
Запуск Rootless Kubernetes безпосередньо на хості
K3s
K3s експериментально підтримує режим без root-прав.
Дивіться Запуск K3s у режимі Rootless для використання.
Usernetes
Usernetes — це референсний дистрибутив Kubernetes, який може бути встановлений у теці $HOME без привілеїв root.
Usernetes підтримує як containerd, так і CRI-O як середовище виконання контейнерів CRI. Usernetes підтримує багатовузлові кластери з використанням Flannel (VXLAN).
Дивіться репозиторій Usernetes для використання.
Ручне розгортання вузла, який використовує kubelet в просторі користувача
У цьому розділі надаються вказівки для запуску Kubernetes у просторі користувача вручну.
Примітка:
Цей розділ призначений для розробників дистрибутивів Kubernetes, а не кінцевими користувачами.Створення простору користувача
Першим кроком є створення простору користувача.
Якщо ви намагаєтеся запустити Kubernetes в контейнері з простором користувача, такому як Rootless Docker/Podman або LXC/LXD, ви готові та можете перейти до наступного підрозділу.
Інакше вам доведеться створити простір користувача самостійно, викликавши unshare(2) з CLONE_NEWUSER.
Простір користувача також можна відокремити за допомогою інструментів командного рядка, таких як:
Після відокремлення простору користувача вам також доведеться відокремити інші простори імен, такі як простір імен монтування.
Вам не потрібно викликати chroot() або pivot_root() після відокремлення простору імен монтування, однак вам потрібно буде монтувати записувані файлові системи у кількох теках в просторі імен.
Принаймні, наступні теки повинні бути записуваними в просторі імен (не поза простором імен):
/etc/run/var/logs/var/lib/kubelet/var/lib/cni/var/lib/containerd(для containerd)/var/lib/containers(для CRI-O)
Створення делегованого дерева cgroup
Крім простору користувача, вам також потрібно мати записуване дерево cgroup з cgroup v2.
Примітка:
Підтримка Kubernetes для запуску компонентів вузла у просторах користувача передбачає використання cgroup v2. Cgroup v1 не підтримується.Якщо ви намагаєтеся запустити Kubernetes у Rootless Docker/Podman або LXC/LXD на хості на основі systemd, у вас все готове.
У противному вам доведеться створити службу systemd з властивістю Delegate=yes, щоб делегувати дерево cgroup з правами на запис.
На вашому вузлі система systemd вже повинна бути налаштована на дозвіл делегування; для отримання докладнішої інформації дивіться cgroup v2 в документації Rootless Containers.
Налаштування мережі
Простір імен мережі компонентів вузла повинен мати не-loopback інтерфейс, який, наприклад, може бути налаштований з використанням slirp4netns, VPNKit, або lxc-user-nic(1).
Простори імен мережі Podʼів можна налаштувати за допомогою звичайних втулків CNI. Для мережі з багатьма вузлами відомо, що Flannel (VXLAN, 8472/UDP) працює.
Порти, такі як порт kubelet (10250/TCP) і порти служби NodePort, повинні бути викриті з простору імен мережі вузла на хост зовнішнім перенаправлювачем портів, таким як RootlessKit, slirp4netns, або socat(1).
Ви можете використовувати перенаправлювач портів від K3s. Див. Запуск K3s в режимі без root-прав для отримання докладнішої інформації. Реалізацію можна знайти в пакунку pkg/rootlessports k3s.
Налаштування CRI
Kubelet покладається на середовище виконання контейнерів. Ви повинні розгорнути середовище виконання контейнерів, таке як containerd або CRI-O, і переконатися, що воно працює у просторі користувача до запуску kubelet.
Запуск CRI втулка containerd в просторі користувача підтримується з версії containerd 1.4.
Запуск containerd у просторі користувача вимагає наступних налаштувань.
version = 2
[plugins."io.containerd.grpc.v1.cri"]
# Вимкнути AppArmor
disable_apparmor = true
# Ігнорувати помилку під час встановлення oom_score_adj
restrict_oom_score_adj = true
# Вимкнути контролер hugetlb cgroup v2 (тому що systemd не підтримує делегування контролера hugetlb)
disable_hugetlb_controller = true
[plugins."io.containerd.grpc.v1.cri".containerd]
# Можливий також використання non-fuse overlayfs для ядра >= 5.11, але потребує вимкненого SELinux
snapshotter = "fuse-overlayfs"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
# Ми використовуємо cgroupfs, який делегується системою systemd, тому ми не використовуємо драйвер SystemdCgroup
# (якщо ви не запускаєте іншу систему systemd у просторі імен)
SystemdCgroup = false
Типовий шлях конфігураційного файлу — /etc/containerd/config.toml. Шлях можна вказати з containerd -c /шлях/до/конфігураційного/файлу.toml.
Запуск CRI-O у просторі користувача підтримується з версії CRI-O 1.22.
CRI-O вимагає, щоб була встановлена змінна середовища _CRIO_ROOTLESS=1.
Також рекомендуються наступні налаштування:
[crio]
storage_driver = "overlay"
# Можливий також використання non-fuse overlayfs для ядра >= 5.11, але потребує вимкненого SELinux
storage_option = ["overlay.mount_program=/usr/local/bin/fuse-overlayfs"]
[crio.runtime]
# Ми використовуємо cgroupfs, який делегується системою systemd, тому ми не використовуємо драйвер "systemd"
# (якщо ви не запускаєте іншу систему systemd у просторі імен)
cgroup_manager = "cgroupfs"
Типовий шлях конфігураційного файлу — /etc/crio/crio.conf.
Шлях можна вказати з crio --config /шлях/до/конфігураційного/файлу/crio.conf.
Налаштування kubelet
Запуск kubelet у просторі користувача вимагає наступної конфігурації:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
KubeletInUserNamespace: true
# Ми використовуємо cgroupfs, який делегується системою systemd, тому ми не використовуємо драйвер "systemd"
# (якщо ви не запускаєте іншу систему systemd у просторі імен)
cgroupDriver: "cgroupfs"
Коли увімкнено KubeletInUserNamespace, kubelet ігнорує помилки, які можуть виникнути під час встановлення наступних значень sysctl на вузлі.
vm.overcommit_memoryvm.panic_on_oomkernel.panickernel.panic_on_oopskernel.keys.root_maxkeyskernel.keys.root_maxbytes.
У просторі користувача kubelet також ігнорує будь-яку помилку, яка виникає при спробі відкрити /dev/kmsg. Цей feature gate також дозволяє kube-proxy ігнорувати помилку під час встановлення RLIMIT_NOFILE.
KubeletInUserNamespace був введений у Kubernetes v1.22 зі статусом "alpha".
Запуск kubelet у просторі користувача без використання цього feature gate також можливий, шляхом монтування спеціально створеного файлової системи proc (як це робить Sysbox), але це не є офіційно підтримуваним.
Налаштування kube-proxy
Запуск kube-proxy у просторі користувача вимагає наступної конфігурації:
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "iptables" # або "userspace"
conntrack:
# Пропустити встановлення значення sysctl "net.netfilter.nf_conntrack_max"
maxPerCore: 0
# Пропустити встановлення "net.netfilter.nf_conntrack_tcp_timeout_established"
tcpEstablishedTimeout: 0s
# Пропустити встановлення "net.netfilter.nf_conntrack_tcp_timeout_close"
tcpCloseWaitTimeout: 0s
Застереження
Більшість "нелокальних" драйверів томів, таких як
nfsтаiscsi, не працюють. Відомо, що працюють локальні томи, такі якlocal,hostPath,emptyDir,configMap,secretтаdownwardAPI.Деякі втулки CNI можуть не працювати. Відомо, що працює Flannel (VXLAN).
Для отримання додаткової інформації з цього питання, див. сторінку Застереження та майбутня робота на веб-айті rootlesscontaine.rs.
Дивіться також
34 - Безпечне очищення вузла
Ця сторінка показує, як безпечно очистити вузол, опційно дотримуючись PodDisruptionBudget, який ви визначили.
Перш ніж ви розпочнете
Це завдання передбачає, що ви виконали такі попередні умови:
- Вам не потрібно, щоб ваші застосунки були високодоступними під час очищення вузла, або
- Ви прочитали про концепцію PodDisruptionBudget та налаштували PodDisruptionBudget для застосунків, які їх потребують.
(Необовʼязково) Налаштування бюджету відмови
Щоб забезпечити доступність ваших робочих навантажень під час технічного обслуговування, ви можете налаштувати PodDisruptionBudget.
Якщо доступність важлива для будь-яких застосунків, які запускаються або можуть запускатися на вузлах, які ви очищуєте, спочатку налаштуйте PodDisruptionBudget, а потім продовжуйте виконувати цей посібник.
Рекомендується встановити AlwaysAllow Політика виселення несправного Podʼа для PodDisruptionBudgets, щоб підтримувати виселення погано працюючих застосунків під час очищення вузла. Стандартна поведінка полягає в очікуванні на те, щоб Podʼи застосунків стали справними, перш ніж можна буде продовжити очищення.
Використання kubectl drain для очищення вузла
Ви можете використовувати kubectl drain для безпечного виселення всіх ваших Podʼів з вузла перед тим, як ви будете виконувати обслуговування вузла (наприклад, оновлення ядра, обслуговування обладнання тощо). Безпечні виселення дозволяють контейнерам Podʼів належним чином завершувати роботу і дотримуватись PodDisruptionBudgets, які ви визначили.
Примітка:
Типовоkubectl drain ігнорує певні системні Podʼи на вузлі, роботу яких не можна завершити примусово; докладніше див. документацію kubectl drain.Коли kubectl drain успішно завершується, це означає, що всі Podʼи (крім тих, які виключені, як описано в попередньому абзаці) безпечно виселені (дотримуючись бажаного періоду належного завершення роботи та PodDisruptionBudget, який ви визначили). Тоді безпечно вимкніть вузол, вимкнувши його фізичний компʼютер або, якщо ви працюєте на хмарній платформі, видаливши його віртуальну машину.
Примітка:
Якщо нові Podʼи толерують taint node.kubernetes.io/unschedulable, то ці Podʼи можуть бути заплановані на вузол, який ви очистили. Уникайте толерування цього taint, крім як для DaemonSets.
Якщо ви або інший користувач API безпосередньо встановили поле nodeName для Podʼа (в обхід планувальника), то Pod буде привʼязаний до вказаного вузла і буде працювати там, навіть якщо ви його очистили та позначили як не придатний для планування.
Спочатку визначте імʼя вузла, який ви хочете очистити. Ви можете перелічити всі вузли у своєму кластері за допомогою
kubectl get nodes
Далі скажіть Kubernetes очистити вузол:
kubectl drain --ignore-daemonsets <імʼя вузла>
Якщо є Podʼи, керовані DaemonSet, вам потрібно вказати --ignore-daemonsets в kubectl, щоб успішно очистити вузол. Підкоманда kubectl drain сама по собі насправді не очищує вузол від його Podʼів DaemonSet: контролер DaemonSet (частина контролера управління) негайно замінює відсутні Podʼи новими еквівалентними Podʼами. Контролер DaemonSet також створює Podʼи, які ігнорують taint, що перешкоджають плануванню, що дозволяє новим Podʼам запуститися на вузлі, який ви очистили.
Після того, як процес завершиться (без помилки), ви можете безпечно вимкнути вузол (або еквівалентно, якщо ви працюєте на хмарній платформі, видалити віртуальну машину, на якій працює вузол). Якщо ви залишите вузол у кластері під час операції обслуговування, вам потрібно виконати
kubectl uncordon <імʼя вузла>
після того, як ви дасте цю команду Kubernetes, він може продовжити планування нових Podʼів на вузол.
Очищення кількох вузлів паралельно
Команду kubectl drain слід використовувати тільки для одного вузла за раз. Однак ви можете запускати кілька команд kubectl drain для різних вузлів паралельно, в різних терміналах або у фоні. Декілька команд очищення, які працюють паралельно, все одно дотримуються PodDisruptionBudget, який ви вказуєте.
Наприклад, якщо у вас є StatefulSet із трьома репліками та ви встановили PodDisruptionBudget для цього набору, вказуючи minAvailable: 2, kubectl drain видаляє тільки Pod з StatefulSet, якщо всі три репліки Pod є справними; якщо дати декілька команд паралельно, Kubernetes дотримується PodDisruptionBudget та забезпечує, що в будь-який момент часу лише один (обчислюється як replicas - minAvailable) Pod недоступний. Будь-які очищення, які призведуть до того, що кількість справних реплік падає нижче визначеного бюджету, блокуються.
API Eviction
Якщо ви не бажаєте використовувати kubectl drain (наприклад, для уникнення виклику зовнішньої команди або для отримання більш детального керування процесом виселення Podʼа), ви також можете програмно викликати виселення, використовуючи API Eviction.
Для отримання додаткової інформації див. Виселення, ініційоване API.
Що далі
- Дотримуйтеся кроків для захисту вашого застосунку, налаштувавши Обмеження переривання роботи Podʼів.
35 - Захист кластера
У цьому документі розглядаються теми, повʼязані з захистом кластера від випадкового або зловмисного доступу та надаються загальні рекомендації безпеки.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для перевірки версії введіть
kubectl version.
Контроль доступу до API Kubernetes
Оскільки Kubernetes повністю заснований на API, контроль та обмеження, хто може мати доступ до кластера та які дії вони можуть виконувати, є першою лінією захисту.
Використання Transport Layer Security (TLS) для всього трафіку API
Kubernetes очікує, що всі комунікації API в кластері будуть типово зашифровані за допомогою TLS, і більшість методів встановлення дозволять створювати необхідні сертифікати та розподіляти їх між компонентами кластера. Зверніть увагу, що деякі компоненти та методи встановлення можуть дозволяти локальні порти через HTTP, і адміністраторам варто ознайомитися з налаштуваннями кожного компонента для ідентифікації потенційно незахищеного трафіку.
Автентифікація API
Виберіть механізм автентифікації для використання API-серверами, який відповідає загальним сценаріям доступу при встановленні кластера. Наприклад, невеликі, однокористувацькі кластери можуть бажати використовувати простий підхід з використанням сертифікатів або статичних токенів Bearer. Більші кластери можуть бажати інтегрувати наявний сервер OIDC або LDAP, який дозволяє розподіляти користувачів на групи.
Всі клієнти API повинні бути автентифіковані, навіть ті, що є частиною інфраструктури, такі як вузли, проксі, планувальник та втулки томів. Зазвичай ці клієнти є сервісними обліковими записами або використовують сертифікати клієнта x509, і вони створюються автоматично при запуску кластера або налаштовуються як частина встановлення кластера.
Для отримання додаткової інформації звертайтеся до документації з автентифікації.
Авторизація API
Після автентифікації кожен виклик API також повинен пройти перевірку авторизації. Kubernetes має вбудований компонент контролю доступу на основі ролей (Role-Based Access Control (RBAC)), який зіставляє користувача або групу набору дозволів, згрупованих за ролями. Ці дозволи поєднують дії (отримати, створити, видалити) з ресурсами (Podʼи, служби, вузли) і можуть бути обмежені простором імен або розгортанням кластера. Доступні набори стандартних ролей, які надають розумне розділення відповідальності залежно від дій, які може бажати виконати клієнт. Рекомендується використовувати авторизатори Node та RBAC разом з втулком входу NodeRestriction.
Так само як і з автентифікацією, для менших кластерів можуть бути відповідні прості та загальні ролі, але зі збільшенням кількості користувачів, які взаємодіють з кластером, може знадобитися розділити команди на окремі простори імен з більш обмеженими ролями.
При авторизації важливо розуміти, як оновлення одного обʼєкта може призвести до дій в інших місцях. Наприклад, користувач не зможе створити Podʼи безпосередньо, але дозволивши їм створювати Deployment, що створює Podʼи для них, дозволить їм створювати ці Podʼи опосередковано. Так само, видалення вузла з API призведе до припинення роботи Podʼів, запланованих на цей вузол, і їх повторного створення на інших вузлах. Стандартні ролі являють собою компроміс між гнучкістю та загальними випадками використання, але більш обмежені ролі повинні бути уважно переглянуті, щоб запобігти випадковому підвищенню привілеїв. Якщо стандартні ролі не відповідають вашим потребам, ви можете створити ролі, специфічні для вашого випадку використання.
Для отримання додаткової інформації звертайтеся до розділу довідки з авторизації.
Контроль доступу до Kubelet
Kubelet експонує HTTPS-точки доступу, які надають потужний контроль над вузлом та контейнерами. Типово Kubelet дозволяє неавтентифікований доступ до цього API.
Операційні кластери повинні увімкнути автентифікацію та авторизацію Kubelet.
Для отримання додаткової інформації звертайтеся до розділу довідки з автентифікації/авторизації Kubelet.
Керування можливостями робочого навантаження або користувача під час виконання
Авторизація в Kubernetes має високий рівень, спрямований на грубі дії з ресурсами. Більш потужні елементи керування існують як політики для обмеження за випадком використання того, як ці обʼєкти діють на кластер, себе та інші ресурси.
Обмеження використання ресурсів у кластері
Квоти ресурсів обмежують кількість або потужність виділених ресурсів для простору імен. Це найчастіше використовується для обмеження обсягу процесора, памʼяті або постійного дискового простору, який може виділятися простору імен, але також може контролювати кількість Podʼів, Serviceʼів або томів, що існують у кожному просторі імен.
Діапазони обмежень обмежують максимальний або мінімальний розмір деяких з вищезазначених ресурсів, щоб уникнути можливості користувачів запитувати надмірно високі або низькі значення для часто зарезервованих ресурсів, таких як памʼять, або надавати типові значення, коли вони не вказані.
Керування привілеями, з якими працюють контейнери
В описі Podʼа міститься контекст безпеки, який дозволяє запитувати доступ до виконання від імені конкретного користувача Linux на вузлі (наприклад, root), доступ до виконання з підвищеними привілеями або доступ до мережі хосту та інші елементи керування, які інакше дозволили б йому працювати без обмежень на вузлі хосту.
Ви можете налаштувати допуски безпеки Pod, щоб забезпечити використання певного стандарту безпеки Pod у просторі імен або виявити порушення.
Загалом, більшість робочих навантажень застосунків потребують обмеженого доступу до ресурсів хосту, щоб вони могли успішно працювати як процес root (uid 0) без доступу до інформації про хост. Однак, враховуючи привілеї, повʼязані з користувачем root, слід робити контейнери застосунків такими, що не вимагають прав root для виконання. Так само адміністратори, які бажають запобігти втечі клієнтських застосунків з їхніх контейнерів, повинні застосувати стандарт безпеки Pod Baseline або Restricted.
Запобігання завантаженню небажаних модулів ядра контейнерами
Ядро Linux автоматично завантажує модулі ядра з диска за потребою в певних обставинах, наприклад, коли пристрій приєднаний або файлова система змонтована. Особливо актуальним для Kubernetes є те, що навіть непривілейовані процеси можуть спричинити завантаження певних модулів, повʼязаних з мережевими протоколами, просто створюючи сокет відповідного типу. Це може дозволити зловмиснику використовувати дірку в безпеці ядра, щодо якої адміністратор має припущення, що вона не використовується.
Щоб запобігти автоматичному завантаженню конкретних модулів, ви можете деінсталювати їх з вузла або додати правила для їх блокування. У більшості дистрибутивів Linux ви можете це зробити, створивши файл, наприклад, /etc/modprobe.d/kubernetes-blacklist.conf, з таким вмістом:
# DCCP майже не потрібен, має кілька серйозних вразливостей
# і не знаходиться у доброму стані обслуговування.
blacklist dccp
# SCTP не використовується в більшості кластерів Kubernetes, і також мав
# вразливості в минулому.
blacklist sctp
Для більш загального блокування завантаження модулів можна використовувати Linux Security Module (наприклад, SELinux), щоб абсолютно відмовити контейнерам у дозволі module_request, запобігаючи ядру завантажувати модулі для контейнерів у будь-яких обставинах. (Podʼи все ще можуть використовувати модулі, які були завантажені вручну або модулі, які були завантажені ядром від імені якогось більш привілейованого процесу.)
Обмеження доступу до мережі
Мережеві політики для простору імен дозволяють авторам застосунків обмежувати, які Podʼи в інших просторах імен можуть отримувати доступ до Podʼів і портів у їхніх просторах імен. Багато з підтримуваних постачальників мережі Kubernetes зараз враховують мережеві політики.
Також можна використовувати квоти та діапазони обмежень, щоб контролювати, чи можуть користувачі запитувати порти вузла або послуги з балансування навантаження, що у багатьох кластерах може контролювати видимість застосунків цих користувачів поза межами кластера.
Додаткові захисти можуть бути доступні, які контролюють правила мережі на рівні втулка чи середовища, такі як брандмауери на рівні вузла, фізичне розділення вузлів кластера для запобігання звʼязку між ними або розширена політика мережевого зʼєднання.
Обмеження доступу до API метаданих хмари
Хмарні платформи (AWS, Azure, GCE і т. д.) часто надають доступ до служб метаданих локально на екземплярах обчислювальних потужностей. Типово ці API доступні Podʼам, що працюють на екземплярі, і можуть містити облікові дані хмари для цього вузла або дані про створення, такі як облікові дані kubelet. Ці облікові дані можуть бути використані для підвищення привілеїв всередині кластера або до інших хмарних служб за тим самим обліковим записом.
При запуску Kubernetes на хмарній платформі обмежуйте дозволи, надані обліковим записам екземплярів, використовуйте мережеві політики для обмеження доступу Podʼів до API метаданих та уникайте використання даних про створення для передачі секретів.
Керування того, до яких вузлів мають доступ Podʼи
Стандартно не має обмежень, щодо того, на яких вузлах може запускатися Pod. Kubernetes пропонує широкий набір політик для керування розміщенням Podʼів на вузлах та політику розміщення та виселення Podʼів на основі позначок, доступні для кінцевих користувачів. Для багатьох кластерів використання цих політик для розділення робочих навантажень може бути домовленістю, якої автори дотримуються або впроваджують через інструментарій.
Як адміністратор, бета-втулок обробки доспуску PodNodeSelector може бути використаний для примусового призначення Podʼів у межах стандартного простору імен або для вимоги до вказання певного селектора вузла, і якщо кінцеві користувачі не можуть змінювати простори імен, це може суттєво обмежити розміщення всіх Podʼів в певному робочому навантаженні.
Захист компонентів кластера від компрометації
У цьому розділі описані деякі загальні шаблони для захисту кластерів від компрометації.
Обмеження доступу до etcd
Права на запис до бази даних etcd для API еквівалентні отриманню root-прав на весь кластер, а доступ на читання може бути використаний для ескалації досить швидко. Адміністратори повинні завжди використовувати надійні облікові дані від серверів API до сервера etcd, такі як взаємна автентифікація за допомогою сертифікатів TLS клієнта, і часто рекомендується ізолювати сервери etcd за допомогою брандмауера, до яких можуть отримувати доступ лише сервери API.
Увага:
Дозвіл іншим компонентам в межах кластера доступу до головного екземпляра etcd з правами на читання або запис повного простору ключів еквівалентний наданню прав адміністратора кластера. Рекомендується використовувати окремі екземпляри etcd для компонентів, які не є головними, або використовувати ACL etcd для обмеження доступу на читання та запис до підмножини простору ключів.Увімкнення логування аудиту
Audit logger є бета-функцією, яка записує дії, виконані API, для подальшого аналізу в разі компрометації. Рекомендується увімкнути логування аудиту та архівувати файл аудиту на захищеному сервері.
Обмеження доступу до альфа- або бета-функцій
Альфа- і бета-функції Kubernetes знаходяться в активній розробці і можуть мати обмеження або помилки, які призводять до вразливостей безпеки. Завжди оцінюйте цінність, яку можуть надати альфа- або бета-функції, у порівнянні з можливим ризиком для вашої безпеки. У разі сумнівів вимикайте функції, які ви не використовуєте.
Часто змінюйте облікові дані інфраструктури
Чим коротший термін дії Secret або облікового запису, тим складніше для зловмисника використати цей обліковий запис. Встановлюйте короткі терміни дії на сертифікати та автоматизуйте їх ротацію. Використовуйте постачальника автентифікації, який може контролювати терміни дії виданих токенів та використовуйте короткі терміни дії, де це можливо. Якщо ви використовуєте токени службового облікового запису в зовнішніх інтеграціях, плануйте часту ротацію цих токенів. Наприклад, як тільки завершиться фаза запуску, токен запуску, використаний для налаштування вузлів, повинен бути відкликаний або його запис авторизації скасований.
Перегляд інтеграцій сторонніх розробників перед їх включенням
Багато сторонніх інтеграцій до Kubernetes можуть змінювати профіль безпеки вашого кластера. При включенні інтеграції завжди переглядайте дозволи, які запитує розширення, перед наданням доступу. Наприклад, багато інтеграцій з безпеки можуть запитувати доступ до перегляду всіх секретів у вашому кластері, що фактично робить цей компонент адміністратором кластера. У разі сумнівів обмежте інтеграцію на роботу в одному просторі імен, якщо це можливо.
Компоненти, які створюють Podʼи, також можуть мати неочікувану потужність, якщо вони можуть робити це всередині просторів імен, таких як простір імен kube-system, оскільки ці Podʼи можуть отримати доступ до секретів службових облікових записів або працювати з підвищеними привілеями, якщо цим службовим обліковим записам надано доступ до дозвольних PodSecurityPolicies.
Якщо ви використовуєте Pod Security admission та дозволяєте будь-якому компоненту створювати Podʼи в межах простору імен, що дозволяє привілейовані Podʼи, ці Podʼи можуть мати здатність втікати зі своїх контейнерів і використовувати цей розширений доступ для підвищення своїх привілеїв.
Ви не повинні дозволяти ненадійним компонентам створювати Podʼи в будь-якому системному просторі імен (те, що починається з kube-) або в будь-якому просторі імен, де цей доступ дозволяє можливість підвищення привілеїв.
Шифрування секретів у спокої
Загалом, база даних etcd буде містити будь-яку інформацію, доступну через API Kubernetes і може надати зловмиснику значний обсяг інформації про стан вашого кластера. Завжди шифруйте свої резервні копії за допомогою розглянутого рішення для резервного копіювання та шифрування, і розгляньте можливість використання повного шифрування диска, де це можливо.
Kubernetes підтримує необовʼязкове шифрування у спокої для інформації в API Kubernetes. Це дозволяє вам забезпечити те, що при збереженні Kubernetes даних для обʼєктів (наприклад, обʼєктів Secret або ConfigMap), сервер API записує зашифроване представлення обʼєкта. Це шифрування означає, що навіть у того, хто має доступ до даних резервних копій etcd, не має можливості переглянути вміст цих обʼєктів. У Kubernetes 1.35 ви також можете шифрувати власні ресурси; шифрування в спокої для розширених API, визначених у визначеннях CustomResourceDefinitions, було додано в Kubernetes як частина випуску v1.26.
Отримання сповіщень про оновлення безпеки та повідомлення про вразливості
Приєднуйтесь до групи kubernetes-announce, щоб отримувати електронні листи про оголошення з питань безпеки. Див. сторінку повідомлень про безпеку для отримання додаткової інформації щодо повідомлення про вразливості.
Що далі
- Контрольний список безпеки для отримання додаткової інформації щодо керівництва з безпеки Kubernetes.
- Довідка Seccomp вузлів
36 - Встановлення параметрів Kubelet через файл конфігурації
Перш ніж ви розпочнете
Деякі кроки на цій сторінці використовують інструмент jq. Якщо у вас немає jq, ви можете встановити його через отримання оновлень програм вашої операційної системи або завантажити з https://jqlang.github.io/jq/.
Деякі кроки також включають встановлення curl, який також можна встановити засобами встановлення програмного забезпечення вашої операційної системи.
Частину параметрів конфігурації kubelet можна встановити за допомогою конфігураційного файлу на диску, як альтернативу командним прапорцям.
Надання параметрів через файл конфігурації є рекомендованим підходом, оскільки це спрощує розгортання вузлів та управління конфігурацією.
Створіть файл конфігурації
Підмножина конфігурації kubelet, яку можна налаштувати через файл, визначається структурою KubeletConfiguration.
Файл конфігурації повинен бути у форматі JSON або YAML, який представляє параметри цієї структури. Переконайтеся, що у kubelet є права для читання файлу.
Ось приклад того, як може виглядати цей файл:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
address: "192.168.0.8"
port: 20250
serializeImagePulls: false
evictionHard:
memory.available: "100Mi"
nodefs.available: "10%"
nodefs.inodesFree: "5%"
imagefs.available: "15%"
imagefs.inodesFree: "5%"
У цьому прикладі kubelet налаштовано з наступними параметрами:
address: Kubelet буде доступний за IP-адресою192.168.0.8.port: Kubelet буде слухати порт20250.serializeImagePulls: Завантаження образів виконуватиметься паралельно.evictionHard: Kubelet буде виселяти Podʼи за однією з наступних умов:- Коли доступна памʼять вузла впаде нижче 100 МіБ.
- Коли доступний простір основної файлової системи вузла менше 10%.
- Коли доступний простір файлової системи образів менше 15%.
- Коли більше ніж 95% inodes основної файлової системи вузла використано.
Примітка:
У прикладі, змінюючи лише один типовий параметр дляevictionHard, типові значення інших параметрів не будуть успадковані та будуть встановлені в нуль. Щоб надати власні значення, вам слід надати всі порогові значення відповідно. Крім того, ви можете встановити MergeDefaultEvictionSettings в true у файлі конфігурації kubelet, якщо будь-який параметр буде змінено, то інші параметри успадкують стандартне значення замість 0.imagefs — це опціональна файлова система, яку середовища виконання контейнерів використовують для зберігання образів контейнерів та записуваних шарів контейнерів.
Запуск процесу kubelet, налаштованого через файл конфігурації
Примітка:
Якщо ви використовуєте kubeadm для ініціалізації кластера, використовуйте kubelet-config під час створення вашого кластера за допомогоюkubeadm init. Дивіться налаштування kubelet за допомогою kubeadm для деталей.Запустіть kubelet з параметром --config, вказавши шлях до файлу конфігурації kubelet. Після цього kubelet завантажить свою конфігурацію з цього файлу.
Зверніть увагу, що параметри командного рядка, які стосуються того ж значення, що й файл конфігурації, перекриватимуть це значення. Це допомагає забезпечити зворотну сумісність з API командного рядка.
Також зверніть увагу, що відносні шляхи файлів у файлі конфігурації kubelet розглядаються відносно місця розташування файлу конфігурації kubelet, тоді як відносні шляхи в параметрах командного рядка розглядаються відносно поточної робочої теки kubelet.
Зауважте, що деякі типові значення відрізняються між параметрами командного рядка та файлом конфігурації kubelet. Якщо наданий параметр --config і значення не вказані через командний рядок, то застосовуються типові значення для версії KubeletConfiguration. У згаданому вище прикладі ця версія є kubelet.config.k8s.io/v1beta1.
Тека для файлів конфігурації kubelet
Ви можете вказати теку конфігурації drop-in для kubelet. Стандартно kubelet не шукає файли конфігурації drop-in — ви повинні вказати шлях. Наприклад: --config-dir=/etc/kubernetes/kubelet.conf.d
Для Kubernetes v1.28 по v1.29 ви можете вказати лише --config-dir, якщо також встановите змінну середовища KUBELET_CONFIG_DROPIN_DIR_ALPHA для процесу kubelet (значення цієї змінної не має значення).
Примітка:
Суфікс дійсного файлу конфігурації drop-in для kubelet має бути.conf. Наприклад: 99-kubelet-address.confKubelet обробляє файли у своїй теці конфігурації drop-in, сортуючи по повному імені файлу. Наприклад, 00-kubelet.conf обробляється першим, а потім перезаписується файлом з назвою 01-kubelet.conf.
Ці файли можуть містити часткові конфігурації, але не повинні бути не валідними та обовʼязково повинні включати метадані типу, зокрема apiVersion та kind. Перевірка виконується лише на кінцевій результівній структурі конфігурації, збереженій внутрішньо в kubelet. Це надає гнучкість в управлінні та злитті конфігурацій kubelet з різних джерел, запобігаючи небажаній конфігурації. Однак важливо зазначити, що поведінка варіюється залежно від типу даних поля конфігурації.
Різні типи даних у структурі конфігурації kubelet обʼєднуються по-різному. Дивіться посилання на довідку для отримання додаткової інформації.
Порядок обʼєднання конфігурації kubelet
При запуску kubelet обʼєднує конфігурацію з:
- Feature gate, вказаних через командний рядок (найнижчий пріоритет).
- Конфігурація kubelet.
- Файли конфігурації drop-in, відповідно до порядку сортування.
- Аргументи командного рядка, за винятком feature gate (найвищий пріоритет).
Примітка:
Механізм теки конфігурації drop-in для kubelet схожий, але відрізняється від того, як інструментkubeadm дозволяє вам патчити конфігурацію. Інструмент kubeadm використовує конкретну стратегію застосування патчів для своєї конфігурації, тоді як єдина стратегія накладання патчів для файлів конфігурації drop-in kubelet це replace. Kubelet визначає порядок обʼєднання на основі сортування суфіксів алфавітно-цифровим чином, і замінює кожне поле, присутнє у файлі вищого пріоритету.Перегляд конфігурації kubelet
Оскільки конфігурація тепер може бути розподілена у декілька файлів за допомогою цієї функції, якщо хтось хоче переглянути остаточну активовану конфігурацію, то вони можуть скористатися цими кроками для перегляду конфігурації kubelet:
Запустіть проксі-сервер за допомогою команди
kubectl proxyу вашому терміналі.kubectl proxyЦе дозволить отримати вивід подібний до:
Starting to serve on 127.0.0.1:8001Відкрийте інше вікно термінала і скористайтесь
curl, щоб отримати конфігурацію kubelet. Замініть<node-name>на фактичне імʼя вашого вузла:curl -X GET http://127.0.0.1:8001/api/v1/nodes/<node-name>/proxy/configz | jq .{ "kubeletconfig": { "enableServer": true, "staticPodPath": "/var/run/kubernetes/static-pods", "syncFrequency": "1m0s", "fileCheckFrequency": "20s", "httpCheckFrequency": "20s", "address": "192.168.1.16", "port": 10250, "readOnlyPort": 10255, "tlsCertFile": "/var/lib/kubelet/pki/kubelet.crt", "tlsPrivateKeyFile": "/var/lib/kubelet/pki/kubelet.key", "rotateCertificates": true, "authentication": { "x509": { "clientCAFile": "/var/run/kubernetes/client-ca.crt" }, "webhook": { "enabled": true, "cacheTTL": "2m0s" }, "anonymous": { "enabled": true } }, "authorization": { "mode": "AlwaysAllow", "webhook": { "cacheAuthorizedTTL": "5m0s", "cacheUnauthorizedTTL": "30s" } }, "registryPullQPS": 5, "registryBurst": 10, "eventRecordQPS": 50, "eventBurst": 100, "enableDebuggingHandlers": true, "healthzPort": 10248, "healthzBindAddress": "127.0.0.1", "oomScoreAdj": -999, "clusterDomain": "cluster.local", "clusterDNS": [ "10.0.0.10" ], "streamingConnectionIdleTimeout": "4h0m0s", "nodeStatusUpdateFrequency": "10s", "nodeStatusReportFrequency": "5m0s", "nodeLeaseDurationSeconds": 40, "imageMinimumGCAge": "2m0s", "imageMaximumGCAge": "0s", "imageGCHighThresholdPercent": 85, "imageGCLowThresholdPercent": 80, "volumeStatsAggPeriod": "1m0s", "cgroupsPerQOS": true, "cgroupDriver": "systemd", "cpuManagerPolicy": "none", "cpuManagerReconcilePeriod": "10s", "memoryManagerPolicy": "None", "topologyManagerPolicy": "none", "topologyManagerScope": "container", "runtimeRequestTimeout": "2m0s", "hairpinMode": "promiscuous-bridge", "maxPods": 110, "podPidsLimit": -1, "resolvConf": "/run/systemd/resolve/resolv.conf", "cpuCFSQuota": true, "cpuCFSQuotaPeriod": "100ms", "nodeStatusMaxImages": 50, "maxOpenFiles": 1000000, "contentType": "application/vnd.kubernetes.protobuf", "kubeAPIQPS": 50, "kubeAPIBurst": 100, "serializeImagePulls": true, "evictionHard": { "imagefs.available": "15%", "memory.available": "100Mi", "nodefs.available": "10%", "nodefs.inodesFree": "5%", "imagefs.inodesFree": "5%" }, "evictionPressureTransitionPeriod": "1m0s", "mergeDefaultEvictionSettings": false, "enableControllerAttachDetach": true, "makeIPTablesUtilChains": true, "iptablesMasqueradeBit": 14, "iptablesDropBit": 15, "featureGates": { "AllAlpha": false }, "failSwapOn": false, "memorySwap": {}, "containerLogMaxSize": "10Mi", "containerLogMaxFiles": 5, "configMapAndSecretChangeDetectionStrategy": "Watch", "enforceNodeAllocatable": [ "pods" ], "volumePluginDir": "/usr/libexec/kubernetes/kubelet-plugins/volume/exec/", "logging": { "format": "text", "flushFrequency": "5s", "verbosity": 3, "options": { "json": { "infoBufferSize": "0" } } }, "enableSystemLogHandler": true, "enableSystemLogQuery": false, "shutdownGracePeriod": "0s", "shutdownGracePeriodCriticalPods": "0s", "enableProfilingHandler": true, "enableDebugFlagsHandler": true, "seccompDefault": false, "memoryThrottlingFactor": 0.9, "registerNode": true, "localStorageCapacityIsolation": true, "containerRuntimeEndpoint": "unix:///var/run/crio/crio.sock" } }
Що далі
- Дізнайтеся більше про конфігурацію kubelet, переглянувши
довідник
KubeletConfiguration. - Дізнайтеся більше про обʼєднання конфігурації kubelet у довідці.
37 - Спільне використання кластера з просторами імен
Ця сторінка показує, як переглядати, працювати та видаляти простори імен. На сторінці також розказується, як використовувати простори імен Kubernetes для розділення вашого кластера.
Перш ніж ви розпочнете
- Вам потрібен кластер Kubernetes.
- Ви маєте базове розуміння про Pod, Service, та Deployment в Kubernetes.
Перегляд просторів імен
Перелік поточних просторів імен у кластері можна отримати за допомогою команди:
kubectl get namespaces
NAME STATUS AGE
default Active 11d
kube-node-lease Active 11d
kube-public Active 11d
kube-system Active 11d
Kubernetes запускається з чотирма просторами імен:
default— стандартний простір імен для обʼєктів без іншого простору імен.kube-node-lease— цей простір імен містить обʼєкти Lease, повʼязані з кожним вузлом. Лізинги вузлів дозволяють kubelet надсилати пульси, щоб панель управління було в змозі виявляти збої вузлів.kube-public— цей простір імен створюється автоматично і доступний для читання всіма користувачами (включаючи неавтентифікованих). Цей простір імен зазвичай зарезервований для використання у межах кластера, у випадках коли деякі ресурси мають бути відкриті та доступні для загального огляду у всьому кластері. Публічний аспект цього простору імен є лише конвенцією, а не вимогою.kube-system— простір імен для обʼєктів, створених системою Kubernetes.
Також ви можете отримати інформацію про певний простір імен за допомогою команди:
kubectl get namespaces <name>
Або отримати детальну інформацію за допомогою:
kubectl describe namespaces <name>
Name: default
Labels: <none>
Annotations: <none>
Status: Active
No resource quota.
Resource Limits
Type Resource Min Max Default
---- -------- --- --- -------
Container cpu - - 100m
Зверніть увагу, що ці деталі включають інформацію про квоти ресурсів (якщо вони є) та обмеження діапазону ресурсів.
Квота ресурсів відстежує загальне використання ресурсів у просторі імен та дозволяє операторам кластера встановлювати жорсткі ліміти використання ресурсів, які може споживати простір імен.
Обмеження діапазону визначає мінімальні/максимальні обмеження на кількість ресурсів, які може споживати одиниця у просторі імен.
Див. Контроль допуску: Limit Range
Простір імен може перебувати в одному з двох станів:
Active— простір імен використовуєтьсяTerminating— простір імен видаляється і не може бути використаний для нових обʼєктів
Для отримання додаткової інформації дивіться Простір імен в довідковій документації API.
Створення нового простору імен
Примітка:
Уникайте створення просторів імен з префіксомkube-, оскільки він зарезервований для системних просторів імен Kubernetes.Створіть новий файл YAML з назвою my-namespace.yaml з таким вмістом:
apiVersion: v1
kind: Namespace
metadata:
name: <вставте-назву-простору-імен-тут>
Потім виконайте:
kubectl create -f ./my-namespace.yaml
Або ви можете створити простір імен за допомогою такої команди:
kubectl create namespace <вставте-назву-простору-імен-тут>
Назва вашого простору імен повинна бути дійсною DNS-міткою.
Є необовʼязкове поле finalizers, яке дозволяє спостережувачам очищати ресурси кожного разу, коли простір імен видаляється. Майте на увазі, що якщо ви вказуєте неіснуючий finalizer, простір імен буде створений, але залишиться в стані Terminating, якщо користувач спробує його видалити.
Більше інформації про finalizers можна знайти в документі про проєктування просторів імен.
Видалення простору імен
Видаліть простір імен за допомогою команди:
kubectl delete namespaces <вставте-назву-простору-імен-тут>
Попередження:
Це видаляє все у просторі імен!Ця операція видалення є асинхронною, тому протягом певного часу ви будете бачити простір імен у стані Terminating.
Поділ кластера за допомогою просторів імен Kubernetes
Типово кластер Kubernetes створює простір імен default при його розгортанні, щоб утримувати стандартний набір Podʼів, Serviceʼів та Deploymentʼів, які використовуються в кластері.
Припускаючи, що у вас є новий кластер, ви можете перевірити наявні простори імен, виконавши наступне:
kubectl get namespaces
NAME STATUS AGE
default Active 13m
Створення нових просторів імен
У цьому завданні ми створимо два додаткових простори імен Kubernetes, щоб утримувати наш контент.
У випадку, коли організація використовує спільний кластер Kubernetes для розробки та операційної діяльності:
Команда розробників хотіла б мати простір у кластері, де вони можуть переглядати список Podʼів, Serviceʼів та Deploymentʼів, які вони використовують для створення та запуску свого застосунку. У цьому просторі ресурси Kubernetes зʼявляються та зникають, і обмеження на те, хто може або не може змінювати ресурси є слабкими для забезпечення гнучкої розробки.
Команда операторів хотіла б мати простір у кластері, де вони можуть використовувати строгі процедури на те, хто може або не може маніпулювати набором Podʼів, Serviceʼів та Deploymentʼів, що працюють в операційному середовищі.
Одним з можливих варіантів для цієї організації є розподіл кластера Kubernetes на два простори імен: development та production. Створімо два нових простори імен для нашої роботи.
Створіть простір імен development за допомогою kubectl:
kubectl create -f https://k8s.io/examples/admin/namespace-dev.json
А потім створімо простір імен production за допомогою kubectl:
kubectl create -f https://k8s.io/examples/admin/namespace-prod.json
Щоб переконатися, що все в порядку, виведемо список всіх просторів імен у нашому кластері.
kubectl get namespaces --show-labels
NAME STATUS AGE LABELS
default Active 32m <none>
development Active 29s name=development
production Active 23s name=production
Створення Podʼів в кожному просторі імен
Простір імен Kubernetes забезпечує область для Podʼів, Serviceʼів та Deploymentʼів у кластері. Користувачі, що взаємодіють з одним простором імен, не бачать вмісту іншого простору імен. Щоб продемонструвати це, створімо простий Deployment та Podʼи в просторі імен development.
kubectl create deployment snowflake \
--image=registry.k8s.io/serve_hostname \
-n=development --replicas=2
Ми створили Deployment з 2 реплік, що запускає Pod з назвою snowflake з базовим контейнером, який обслуговує імʼя хосту.
kubectl get deployment -n=development
NAME READY UP-TO-DATE AVAILABLE AGE
snowflake 2/2 2 2 2m
kubectl get pods -l app=snowflake -n=development
NAME READY STATUS RESTARTS AGE
snowflake-3968820950-9dgr8 1/1 Running 0 2m
snowflake-3968820950-vgc4n 1/1 Running 0 2m
Це чудово, розробники можуть робити те, що вони хочуть, і їм не потрібно хвилюватися про те, як це вплине на контент у просторі імен production.
Перейдімо до простору імен production і покажемо, як ресурси в одному просторі імен приховані від іншого. Простір імен production повинен бути порожнім, і наступні команди не повинні повертати нічого.
kubectl get deployment -n=production
kubectl get pods -n=production
Операційна діяльність вимагає догляду за худобою, тому створімо кілька Podʼів для худоби.
kubectl create deployment cattle --image=registry.k8s.io/serve_hostname -n=production
kubectl scale deployment cattle --replicas=5 -n=production
kubectl get deployment -n=production
NAME READY UP-TO-DATE AVAILABLE AGE
cattle 5/5 5 5 10s
kubectl get pods -l app=cattle -n=production
NAME READY STATUS RESTARTS AGE
cattle-2263376956-41xy6 1/1 Running 0 34s
cattle-2263376956-kw466 1/1 Running 0 34s
cattle-2263376956-n4v97 1/1 Running 0 34s
cattle-2263376956-p5p3i 1/1 Running 0 34s
cattle-2263376956-sxpth 1/1 Running 0 34s
На цьому етапі має бути зрозуміло, що ресурси, які користувачі створюють в одному просторі імен, приховані від іншого простору імен.
Поки політика підтримки в Kubernetes розвивається, ми розширимо цей сценарій, щоб показати, як можна надавати різні правила авторизації для кожного простору імен.
Розуміння мотивації використання просторів імен
Один кластер повинен задовольняти потреби кількох користувачів або груп користувачів (далі в цьому документі спільнота користувачів).
Простори імен Kubernetes допомагають різним проєктам, командам або клієнтам спільно використовувати кластер Kubernetes.
Це робиться за допомогою такого:
- Області для імен.
- Механізму для прикріплення авторизації та політики до підрозділу кластера.
Використання кількох просторів імен не є обовʼязковим.
Кожна спільнота користувачів хоче мати можливість працювати в ізоляції від інших спільнот користувачів. У кожної спільноти користувачів свої:
- ресурси (pods, services, replication controllers тощо)
- політики (хто може або не може виконувати дії у своїй спільноті)
- обмеження (цій спільноті дозволено стільки квоти тощо)
Оператор кластера може створити простір імен для кожної унікальної спільноти користувачів.
Простір імен забезпечує унікальну область для:
- іменованих ресурсів (щоб уникнути базових конфліктів імен)
- делегування прав управління довіреним користувачам
- здатності обмежувати використання ресурсів спільнотою
Сценарії використання включають такі:
- Як оператор кластера, я хочу підтримувати кілька спільнот користувачів на одному кластері.
- Як оператор кластера, я хочу делегувати владу управління підрозділам кластера довіреним користувачам у цих спільнотах.
- Як оператор кластера, я хочу обмежити кількість ресурсів, які кожна спільнота може споживати, щоб обмежити вплив на інші спільноти, що використовують кластер.
- Як користувач кластера, я хочу взаємодіяти з ресурсами, які є важливими для моєї спільноти користувачів в ізоляції від того, що роблять інші спільноти користувачів на кластері.
Розуміння просторів імен та DNS
Коли ви створюєте Service, він створює відповідний DNS-запис. Цей запис має вигляд <імʼя-сервісу>.<імʼя-простору-імен>.svc.cluster.local, що означає, що якщо контейнер використовує <імʼя-сервісу>, воно буде розпізнано як сервіс, який знаходиться в межах простору імен. Це корисно для використання однакової конфігурації в кількох просторах імен, таких як Development, Staging та Production. Якщо ви хочете отримати доступ за межі просторів імен, вам потрібно використовувати повністю кваліфіковане доменне імʼя (FQDN).
Що далі
- Дізнайтеся більше про налаштування простору імен.
- Дізнайтеся більше про налаштування простору імен для запиту
- Перегляньте проєкт дизайну просторів імен.
38 - Оновлення кластера
Ця сторінка надає огляд кроків, які вам слід виконати для оновлення кластера Kubernetes.
Проєкт Kubernetes рекомендує оперативно оновлюватись до останніх випусків патчів, а також переконатися, що ви використовуєте підтримуваний мінорний випуск Kubernetes. Дотримання цих рекомендацій допоможе вам залишатися в безпеці.
Спосіб оновлення кластера залежить від того, як ви спочатку розгорнули його та від будь-яких наступних змін.
На високому рівні кроки, які ви виконуєте, такі:
- Оновити панель управління
- Оновити вузли в вашому кластері
- Оновити клієнтів, такі як kubectl
- Відредагувати маніфести та інші ресурси на основі змін API, які супроводжують нову версію Kubernetes
Перш ніж ви розпочнете
Вам потрібно мати кластер. Ця сторінка присвячена оновленню з Kubernetes 1.34 до Kubernetes 1.35. Якщо ваш кластер зараз працює на Kubernetes 1.34, тоді, будь ласка, перевірте документацію для версії Kubernetes, на яку ви плануєте оновити.
Примітка:
На вузлах Linux kubelet стандартно підтримує тільки cgroups v2. Для Kubernetes 1.35 опція конфігурації kubelet FailCgroupV1 типово встановлена на true.
Щоб дізнатися більше, зверніться до документації про виведення з експлуатації Kubernetes cgroup v1.
Підходи до оновлення
kubeadm
Якщо ваш кластер був розгорнутий за допомогою інструменту kubeadm, дивіться Оновлення кластерів kubeadm для докладної інформації щодо оновлення кластера.
Після того, як ви оновили кластер, не забудьте встановити останню версію kubectl.
Ручне розгортання
Увага:
Ці кроки не враховують розширень сторонніх сторін, таких як мережеві втулки та втулки сховищ.Вам слід вручну оновити панель управління наступним чином:
- etcd (всі екземпляри)
- kube-apiserver (всі хости панелі управління)
- kube-controller-manager
- kube-scheduler
- контролер управління хмари, якщо ви використовуєте його
На цьому етапі вам слід встановити останню версію kubectl.
Для кожного вузла в вашому кластері, очистіть цей вузол, а потім або замініть його новим вузлом, який використовує 1.35 kubelet, або оновіть kubelet на цьому вузлі та відновіть його Service.
Увага:
Jxbotyyz вузлів перед оновленням kubelet забезпечує повторний вхід Podʼів та перезапуск контейнерів, що може бути необхідно для розвʼязання деяких проблем безпеки або інших важливих помилок.Інші розгортання
Дивіться документацію для вашого інструменту розгортання кластера, щоб дізнатися рекомендовані кроки для підтримки.
Завдання після оновлення
Перемикання версії API зберігання кластера
Обʼєкти, які серіалізуються в etcd для внутрішнього представлення кластера ресурсів Kubernetes, записуються за допомогою певної версії API.
Коли підтримуване API змінюється, ці обʼєкти можуть потребувати перезаписування в новому API. Невиконання цього призведе до того, що ресурси не можна буде декодувати або використовувати за допомогою сервера API Kubernetes.
Для кожного ураженого обʼєкта, отримайте його, використовуючи останню підтримувану версію API, а потім записуйте його також, використовуючи останню підтримувану версію API.
Оновлення маніфестів
Оновлення до нової версії Kubernetes може надати нові API.
Ви можете використовувати команду kubectl convert для конвертації маніфестів між різними версіями API. Наприклад:
kubectl convert -f pod.yaml --output-version v1
Інструмент kubectl замінює вміст pod.yaml на маніфест, який встановлює kind на Pod (незмінно), але з оновленим apiVersion.
Втулки пристроїв
Якщо ваш кластер використовує втулки пристроїв і вузол потребує оновлення до випуску Kubernetes з новішою версією API втулка пристроїв, втулки пристроїв повинні бути оновлені для підтримки обох версій перед оновленням вузла, щоб гарантувати, що виділення пристроїв продовжує успішно завершуватися під час оновлення.
Дивіться Сумісність API та Версії API керуючого пристрою Kubelet для отримання додаткової інформації.
39 - Використання каскадного видалення у кластері
Ця сторінка показує, як вказати тип каскадного видалення у вашому кластері під час збору сміття.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Вам також потрібно створити приклад Deployment, щоб експериментувати з різними типами каскадного видалення. Вам доведеться перестворити Deployment для кожного типу.
Перевірка власників у ваших Podʼах
Перевірте, що поле ownerReferences присутнє у ваших Podʼах:
kubectl get pods -l app=nginx --output=yaml
Вивід має поле ownerReferences, схоже на це:
apiVersion: v1
...
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: nginx-deployment-6b474476c4
uid: 4fdcd81c-bd5d-41f7-97af-3a3b759af9a7
...
Використання каскадного видалення на видності
Стандартно Kubernetes використовує фонове каскадне видалення для видалення залежностей обʼєкта. Ви можете переключитися на каскадне видалення на видноті за допомогою kubectl або за допомогою API Kubernetes, залежно від версії Kubernetes вашого кластера.
Для перевірки версії введіть kubectl version.
Ви можете видаляти обʼєкти за допомогою каскадного видалення, використовуючи kubectl або API Kubernetes.
За допомогою kubectl
Виконайте наступну команду:
kubectl delete deployment nginx-deployment --cascade=foreground
За допомогою API Kubernetes
Запустіть локальний проксі:
kubectl proxy --port=8080Використовуйте
curlдля виклику видалення:curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \ -d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Foreground"}' \ -H "Content-Type: application/json"Вивід містить
foregroundDeletionfinalizer подібно до цього:"kind": "Deployment", "apiVersion": "apps/v1", "metadata": { "name": "nginx-deployment", "namespace": "default", "uid": "d1ce1b02-cae8-4288-8a53-30e84d8fa505", "resourceVersion": "1363097", "creationTimestamp": "2021-07-08T20:24:37Z", "deletionTimestamp": "2021-07-08T20:27:39Z", "finalizers": [ "foregroundDeletion" ] ...
Використання фонового каскадного видалення
- Створіть приклад Deployment.
- Використовуйте або
kubectl, або API Kubernetes для видалення Deployment, залежно від версії Kubernetes вашого кластера.Для перевірки версії введіть
kubectl version.
Ви можете видаляти обʼєкти за допомогою фонового каскадного видалення за допомогою kubectl
або API Kubernetes.
Kubernetes типово використовує фонове каскадне видалення, і робить це навіть якщо ви виконуєте наступні команди без прапорця --cascade або аргументу propagationPolicy.
За допомогою kubectl
Виконайте наступну команду:
kubectl delete deployment nginx-deployment --cascade=background
За допомогою API Kubernetes
Запустіть локальний проксі:
kubectl proxy --port=8080Використовуйте
curlдля виклику видалення:curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \ -d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Background"}' \ -H "Content-Type: application/json"Вивід подібний до цього:
"kind": "Status", "apiVersion": "v1", ... "status": "Success", "details": { "name": "nginx-deployment", "group": "apps", "kind": "deployments", "uid": "cc9eefb9-2d49-4445-b1c1-d261c9396456" }
Видалення власних обʼєктів та загублених залежностей
Типово, коли ви вказуєте Kubernetes видалити обʼєкт, controller також видаляє залежні обʼєкти. Ви можете загубити залежності використовуючи kubectl або API Kubernetes, залежно від версії Kubernetes вашого кластера.
Для перевірки версії введіть kubectl version.
За допомогою kubectl
Виконайте наступну команду:
kubectl delete deployment nginx-deployment --cascade=orphan
За допомогою API Kubernetes
Запустіть локальний проксі:
kubectl proxy --port=8080Використовуйте
curlдля виклику видалення:curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \ -d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Orphan"}' \ -H "Content-Type: application/json"Вивід містить
orphanу поліfinalizers, подібно до цього:"kind": "Deployment", "apiVersion": "apps/v1", "namespace": "default", "uid": "6f577034-42a0-479d-be21-78018c466f1f", "creationTimestamp": "2021-07-09T16:46:37Z", "deletionTimestamp": "2021-07-09T16:47:08Z", "deletionGracePeriodSeconds": 0, "finalizers": [ "orphan" ], ...
Ви можете перевірити, що Podʼи, керовані Deployment, все ще працюють:
kubectl get pods -l app=nginx
Що далі
- Дізнайтеся про власників та залежності у Kubernetes.
- Дізнайтеся про завершувачів в Kubernetes.
- Дізнайтеся про збирання сміття.
40 - Використання постачальника KMS для шифрування даних
Ця сторінка показує, як налаштувати постачальника Служби керування ключами (KMS) та втулок для шифрування конфіденційних даних. У Kubernetes 1.35 існують дві версії шифрування даних за допомогою KMS у спокої. Якщо це можливо, вам слід використовувати KMS v2, оскільки KMS v1 застарів (починаючи з Kubernetes v1.28) та є типово вимкненим (починаючи з Kubernetes v1.29). KMS v2 пропонує значно кращі характеристики продуктивності, ніж KMS v1.
Увага:
Ця документація стосується загальновживаної реалізації KMS v2 (і застарілої реалізації версії 1). Якщо ви використовуєте будь-які компоненти панелі управління старші за Kubernetes v1.29, будь ласка, перевірте відповідну сторінку в документації для версії Kubernetes, яку використовує ваш кластер. Ранні версії Kubernetes мали різну поведінку, яка може бути важливою для інформаційної безпеки.Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія Kubernetes, яка вам потрібна, залежить від того, яку версію API KMS ви вибрали. Kubernetes рекомендує використовувати KMS v2.
- Якщо ви вибрали KMS API v1 для підтримки кластерів до версії v1.27 або якщо у вас є застарілий плагін KMS, який підтримує лише KMS v1, будь-яка підтримувана версія Kubernetes буде працювати. Цей API є застарілим починаючи з Kubernetes v1.28. Kubernetes не рекомендує використовувати цей API.
Для перевірки версії введіть kubectl version.
KMS v1
Kubernetes v1.28 [deprecated]Потрібна версія Kubernetes 1.10.0 або пізніше.
Починаючи з версії 1.29, реалізація v1 KMS типово вимкнена. Щоб увімкнути функцію, встановіть
--feature-gates=KMSv1=true, щоб налаштувати постачальника KMS v1.Ваш кластер повинен використовувати etcd v3 або пізніше.
KMS v2
Kubernetes v1.29 [stable]- Ваш кластер повинен використовувати etcd v3 або пізніше.
Шифрування KMS та ключі для кожного обʼєкта
Постачальник шифрування KMS використовує схему шифрування конвертів для шифрування даних в etcd. Дані шифруються за допомогою ключа шифрування даних (data encryption key — DEK). DEK шифруються за допомогою ключа шифрування ключа (key encryption key — KEK), який зберігається та обслуговується на віддаленому KMS.
Якщо ви використовуєте (застарілу) реалізацію v1 KMS, для кожного шифрування генерується новий DEK.
З KMS v2 для кожного шифрування генерується новий DEK: API-сервер використовує функцію похідного ключа для генерації ключів шифрування даних з одноразовим використанням секретного початкового елемента (seed — насіння) у поєднанні з випадковими даними. Ротація насіння відбувається при кожній зміні KEK (див. розділ Розуміння key_id та Ротація ключів нижче для докладніших відомостей).
Постачальник KMS використовує gRPC для звʼязку з певним втулком KMS через сокет UNIX-домену. Втулок KMS, який реалізований як сервер gRPC та розгорнутий на тих самих вузлах що і панель управління Kubernetes, відповідає за всі комунікації з віддаленим KMS.
Налаштування постачальника KMS
Для налаштування постачальника KMS на API-сервері включіть постачальника типу kms у масиві providers у файлі конфігурації шифрування і встановіть наступні властивості:
KMS v1
apiVersion: Версія API для постачальника KMS. Залиште це значення порожнім або встановіть його наv1.name: Показує назву втулка KMS. Не може бути змінено після встановлення.endpoint: Адреса прослуховування сервера gRPC (втулка KMS). Точка доступу — це сокет UNIX-домену.cachesize: Кількість ключів шифрування даних (DEK), які будуть збережені в кеші у відкритому вигляді. Коли ключі DEK збережені в кеші, вони можуть бути використані без додаткового звертання до KMS; тоді як ключі DEK, які не збережені в кеші, потребують звертання до KMS для розшифрування.timeout: Скільки часуkube-apiserverмає чекати на відповідь від втулка kms, перш ніж сповістити про помилку (типово — 3 секунди).
KMS v2
apiVersion: Версія API для постачальника KMS. Встановіть це наv2.name:Показує назву втулка KMS. Не може бути змінено після встановлення.endpoint: Адреса прослуховування сервера gRPC (втулка KMS). Точка доступу — це сокет UNIX-домену.timeout: Скільки часуkube-apiserverмає чекати на відповідь від втулка kms, перш ніж сповістити про помилку (типово — 3 секунди).
KMS v2 не підтримує властивість cachesize. Всі ключі шифрування даних (DEK) будуть збережені в кеші у відкритому вигляді, як тільки сервер розкриє їх за допомогою звертання до KMS. Після збереження в кеші, ключі DEK можуть бути використані для виконання розшифрування нескінченно довго без звертання до KMS.
Дивіться Розуміння налаштування шифрування в спокої.
Реалізація втулка KMS
Для реалізації втулка KMS ви можете розробити новий сервер gRPC втулка або увімкнути втулок KMS, який вже надається вашим постачальником хмарних послуг. Потім ви інтегруєте втулок з віддаленим KMS та розгортаєте його на панелі управління Kubernetes.
Увімкнення KMS, що підтримується вашим постачальником хмарних послуг
Зверніться до вашого постачальника хмарних послуг для отримання інструкцій щодо увімкнення втулка KMS, який він надає.
Розробка сервера gRPC втулка KMS
Ви можете розробити сервер gRPC втулка KMS, використовуючи файл шаблону, доступний для мови програмування Go. Для інших мов програмування ви можете використовувати файл proto для створення файлу шаблону, який ви можете використовувати для написання коду сервера gRPC.
KMS v1
Використовуючи Go: Використовуйте функції та структури даних у файлі шаблону: api.pb.go для написання коду сервера gRPC.
Використовуючи інших мов програмування: Використовуйте компілятор protoc з файлом proto: api.proto для генерації файлу шаблону для конкретної мови програмування.
KMS v2
Використовуючи Go: Надається високорівнева бібліотека для спрощення процесу. Низькорівневі реалізації можуть використовувати функції та структури даних у файлі шаблону: api.pb.go для написання коду сервера gRPC.
Використовуючи інших мов програмування: Використовуйте компілятор protoc з файлом proto: api.proto для генерації файлу шаблону для конкретної мови програмування.
Потім використовуйте функції та структури даних у файлі шаблону для написання коду сервера.
Примітки
KMS v1
Версія втулка kms:
v1beta1У відповідь на виклик процедури Version сумісний втулок KMS повинен повернути
v1beta1якVersionResponse.version.Версія повідомлення:
v1beta1Усі повідомлення від постачальника KMS мають поле версії встановлене на
v1beta1.Протокол: UNIX доменний сокет (
unix)Втулок реалізований як сервер gRPC, який слухає UNIX доменний сокет. Розгортання втулка повинно створити файл у файловій системі для запуску зʼєднання gRPC unix domain socket. API-сервер (клієнт gRPC) налаштований на постачальника KMS (сервер gRPC) за допомогою точки доступу UNIX доменного сокета для звʼязку з ним. Може використовуватися абстрактний Linux сокет, точка доступу якого починається з
/@, наприклад,unix:///@foo. Слід бути обережним при використанні цього типу сокета, оскільки вони не мають концепції ACL (на відміну від традиційних файлових сокетів). Однак вони підпадають під простір імен мережі Linux, тому будуть доступні лише контейнерам у тому ж самому Podʼі, якщо не використовується мережа хосту.
KMS v2
Версія втулка KMS:
v2У відповідь на віддалений виклик процедури
Statusсумісний втулок KMS повинен повернути свою версію сумісності KMS якStatusResponse.version. У цій відповіді на статус також повинен бути включений "ok" якStatusResponse.healthzіkey_id(ідентифікатор KEK віддаленого KMS) якStatusResponse.key_id. Проєкт Kubernetes рекомендує зробити ваш втулок сумісним зі стабільнимv2API KMS. Kubernetes 1.35 також підтримуєv2beta1API для KMS; майбутні релізи Kubernetes, швидше за все, будуть продовжувати підтримувати цю бета-версію.API-сервер надсилає віддалений виклик процедури
Statusприблизно кожну хвилину, коли все в справному стані, і кожні 10 секунд, коли втулок не справний. Втулки повинні пильнувати за оптимізацією цього виклику, оскільки він буде під постійним навантаженням.Шифрування
Виклик процедури
EncryptRequestнадає текст для шифрування та UID для цілей логування. У відповіді повинен бути включений шифротекст,key_idдля використаного KEK та, опціонально, будь-які метадані, які потрібні втулку KMS для допомоги в майбутніх викликахDecryptRequest(через полеannotations). Втулок повинен гарантувати, що будь-який різний текст призводить до різної відповіді(шифротекст, key_id, annotations).Якщо втулок повертає непорожній масив
annotations, всі ключі масиву повинні бути повністю кваліфікованими доменними іменами, такими якexample.com. Приклад використанняannotations—{"kms.example.io/remote-kms-auditid":"<audit ID використаний віддаленим KMS>"}API-сервер не виконує виклик процедури
EncryptRequestна високому рівні. Реалізації втулків повинні все ж старатися, щоб зберегти час очікування кожного запиту менше 100 мілісекунд.Розшифрування
Виклик процедури
DecryptRequestнадає(ciphertext, key_id, annotations)зEncryptRequestта UID для цілей логування. Як і очікується, це протилежне викликуEncryptRequest. Втулки повинні перевірити, щоkey_idє тим, що вони розуміють — вони не повинні намагатися розшифрувати дані, якщо вони не впевнені, що вони були зашифровані ними раніше.API-сервер може виконати тисячі викликів процедури
DecryptRequestпід час запуску для заповнення свого кешу перегляду. Таким чином, реалізації втулків повинні виконати ці виклики якнайшвидше, і повинні старатися зберегти час очікування кожного запиту менше 10 мілісекунд.Розуміння
key_idта Ротації ключаkey_idє публічним, незасекреченим імʼям віддаленого KEK KMS, який в цей момент використовується. Він може бути зареєстрований під час регулярної роботи API-сервера та, отже, не повинен містити ніяких приватних даних. Реалізації втулків повинні використовувати хеш, щоб уникнути витоку будь-яких даних. Метрики KMS v2 пильнують за хешуванням цього значення перед показом його через точку доступу/metrics.API-сервер вважає, що
key_id, отриманий з виклику процедуриStatus, є авторитетним. Отже, зміна цього значення сигналізує API-серверу, що віддалений KEK змінився, і дані, зашифровані старим KEK, повинні бути позначені як застарілі при виконанні операція запису без операції (як описано нижче). Якщо виклик процедуриEncryptRequestповертаєkey_id, який відрізняється відStatus, відповідь відкидається, і втулок вважається несправним. Таким чином, реалізації повинні гарантувати, щоkey_id, що повертається зіStatus, буде таким самим, як той, що повертається зEncryptRequest. Крім того, втулки повинні забезпечити стабільністьkey_idі не допускати перемикання між значеннями (тобто під час ротації віддаленого KEK).Втулки не повинні повторно використовувати
key_id, навіть у ситуаціях, коли раніше використаний віддалений KEK був відновлений. Наприклад, якщо втулок використовувавkey_id=A, перемикнувся наkey_id=B, а потім повернувся доkey_id=A— замість того, щоб повідомитиkey_id=A, втулок повинен повідомити якесь похідне значення, таке якkey_id=A_001або використовувати нове значення, наприкладkey_id=C.Оскільки API-сервер опитує
Statusприблизно кожну хвилину, ротаціяkey_idне є миттєвою. Крім того, API-сервер буде користуватися останнім дійсним станом протягом приблизно трьох хвилин. Таким чином, якщо користувач хоче здійснити пасивний підхід до міграції зберігання (тобто, чекаючи), він повинен запланувати міграцію на3 + N + Mхвилин після ротації віддаленого KEK (N— це час, необхідний для того, щоб втулок помітив змінуkey_id, іM— бажаний буфер, щоб дозволити обробку змін конфігурації, рекомендується мінімальне значенняMв пʼять хвилин). Зазначте, що для виконання ротації KEK перезапуск API-сервера не потрібен.Увага:
Оскільки ви не контролюєте кількість записів, виконаних з DEK, проєкт Kubernetes рекомендує робити ротацію KEK принаймні кожні 90 днів.Протокол: UNIX доменний сокет (
unix)Втулок реалізований як сервер gRPC, який слухає UNIX доменний сокет. Розгортання втулка повинно створити файл у файловій системі для запуску зʼєднання gRPC unix domain socket. API-сервер (клієнт gRPC) налаштований на постачальника KMS (сервер gRPC) за допомогою точки доступу UNIX доменного сокета для звʼязку з ним. Може використовуватися абстрактний Linux сокет, точка доступу якого починається з
/@, наприклад,unix:///@foo. Слід бути обережним при використанні цього типу сокета, оскільки вони не мають концепції ACL (на відміну від традиційних файлових сокетів). Однак вони підпадають під простір імен мережі Linux, тому будуть доступні лише контейнерам у тому ж самому Podʼі, якщо не використовується мережа хосту.
Інтеграція втулка KMS з віддаленим KMS
Втулок KMS може спілкуватися з віддаленим KMS за допомогою будь-якого протоколу, який підтримується KMS. Усі дані конфігурації, включаючи облікові дані автентифікації, які використовує втулок KMS для спілкування з віддаленим KMS, зберігаються і керуються втулком KMS незалежно. Втулок KMS може кодувати шифротекст з додатковими метаданими, які можуть бути потрібні перед відправленням його в KMS для розшифрування (KMS v2 робить цей процес простішим, надаючи спеціальне поле annotations).
Розгортання втулка KMS
Переконайтеся, що втулок KMS працює на тих самих хостах, що і сервер(и) API Kubernetes.
Шифрування даних за допомогою постачальника KMS
Для шифрування даних виконайте наступні кроки:
Створіть новий файл
EncryptionConfiguration, використовуючи відповідні властивості для постачальникаkms, щоб шифрувати ресурси, такі як Secrets та ConfigMaps. Якщо ви хочете зашифрувати розширення API, яке визначено у визначенні CustomResourceDefinition, ваш кластер повинен працювати на Kubernetes v1.26 або новіше.Встановіть прапорець
--encryption-provider-configна kube-apiserver, щоб вказати місце розташування файлу конфігурації.Аргумент
--encryption-provider-config-automatic-reloadтипу boolean визначає, чи слід автоматично перезавантажувати файл, встановлений за допомогою--encryption-provider-config, у разі зміни вмісту на диску.Перезапустіть свій API-сервер.
KMS v1
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
- configmaps
- pandas.awesome.bears.example
providers:
- kms:
name: myKmsPluginFoo
endpoint: unix:///tmp/socketfile-foo.sock
cachesize: 100
timeout: 3s
- kms:
name: myKmsPluginBar
endpoint: unix:///tmp/socketfile-bar.sock
cachesize: 100
timeout: 3s
KMS v2
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
- configmaps
- pandas.awesome.bears.example
providers:
- kms:
apiVersion: v2
name: myKmsPluginFoo
endpoint: unix:///tmp/socketfile-foo.sock
timeout: 3s
- kms:
apiVersion: v2
name: myKmsPluginBar
endpoint: unix:///tmp/socketfile-bar.sock
timeout: 3s
Встановлення --encryption-provider-config-automatic-reload в true обʼєднує всі перевірки стану в одну точку доступу перевірки стану. Індивідуальні перевірки стану доступні тільки тоді, коли використовуються постачальники KMS v1 і конфігурація шифрування не перезавантажується автоматично.
Наступна таблиця містить підсумки точок доступу перевірки стану для кожної версії KMS:
| Конфігурації KMS | Без автоматичного перезавантаження | З автоматичним перезавантаженням |
|---|---|---|
| Тільки KMS v1 | Індивідуальні перевірки | Одна перевірка |
| Тільки KMS v2 | Одна перевірка | Одна перевірка |
| KMS v1 та KMS v2 | Індивідуальні перевірки | Одна перевірка |
| Без KMS | Немає | Одна перевірка |
Одна перевірка означає, що єдиною точкою доступу перевірки стану є /healthz/kms-providers.
Індивідуальні перевірки означає, що для кожного втулка KMS є асоційована точка доступу перевірки стану на основі його місця в конфігурації шифрування: /healthz/kms-provider-0, /healthz/kms-provider-1 тощо.
Ці шляхи точок доступу перевірки стану жорстко закодовані та генеруються/контролюються сервером. Індекси для індивідуальних перевірок відповідають порядку, у якому обробляється конфігурація шифрування KMS.
До виконання кроків, визначених у Забезпечення шифрування всіх секретів, список providers повинен закінчуватися постачальником identity: {}, щоб можна було читати незашифровані дані. Після шифрування всіх ресурсів постачальника identity слід видалити, щоб запобігти обробці незашифрованих даних сервером API.
Для отримання деталей про формат EncryptionConfiguration, будь ласка, перегляньте
довідник API шифрування API сервера.
Перевірка того, що дані зашифровані
Коли шифрування даних у стані спокою правильно налаштовано, ресурси шифруються під час запису. Після перезапуску вашого kube-apiserver, будь-які новостворені або оновлені Secret чи інші типи ресурсів, налаштовані в EncryptionConfiguration, мають бути зашифровані при зберіганні. Щоб перевірити, ви можете використовувати програму командного рядка etcdctl для отримання вмісту ваших секретних даних.
Створіть новий Secret з назвою
secret1в просторі іменdefault:kubectl create secret generic secret1 -n default --from-literal=mykey=mydataВикористовуючи командний рядок
etcdctl, прочитайте цей Secret з etcd:ETCDCTL_API=3 etcdctl get /kubernetes.io/secrets/default/secret1 [...] | hexdump -Cде
[...]містить додаткові аргументи для підключення до сервера etcd.Переконайтеся, що збережений Secret починається з префікса
k8s:enc:kms:v1:для KMS v1 або з префіксаk8s:enc:kms:v2:для KMS v2, що вказує на те, що постачальникkmsзашифрував результати даних.Перевірте, що Secret правильно розшифровується при отриманні через API:
kubectl describe secret secret1 -n defaultSecret повинен містити
mykey: mydata.
Забезпечення шифрування всіх секретів
Коли шифрування даних у стані спокою правильно налаштовано, ресурси шифруються під час запису. Таким чином, ми можемо виконати оновлення без змін на місці, щоб переконатися, що дані зашифровані.
Наведена нижче команда читає всі Secret, а потім оновлює їх для застосування шифрування на сервері. У разі помилки через конфліктний запис, повторіть команду. Для більших кластерів вам може знадобитися поділити Secret за просторами імен або написати скрипт для оновлення.
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
Перехід від локального постачальника шифрування до постачальника KMS
Щоб перейти від локального постачальника шифрування до постачальника kms та перешифрувати всі секрети:
Додайте постачальника
kmsяк перший запис у файлі конфігурації, як показано в наступному прикладі.apiVersion: apiserver.config.k8s.io/v1 kind: EncryptionConfiguration resources: - resources: - secrets providers: - kms: apiVersion: v2 name: myKmsPlugin endpoint: unix:///tmp/socketfile.sock - aescbc: keys: - name: key1 secret: <BASE 64 ENCODED SECRET>Перезапустіть усі процеси
kube-apiserver.Виконайте наступну команду, щоб змусити всі секрети перешифруватися за допомогою постачальника
kms.kubectl get secrets --all-namespaces -o json | kubectl replace -f -
Що далі
Якщо ви більше не хочете використовувати шифрування для даних, збережених в API Kubernetes, прочитайте розшифровування даних, які вже зберігаються у спокої.
41 - Використання CoreDNS для виявлення Service
Ця сторінка описує процес оновлення CoreDNS та як встановити CoreDNS замість kube-dns.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.9.Для перевірки версії введіть kubectl version.
Про CoreDNS
CoreDNS — це гнучкий, розширюваний DNS-сервер, який може обслуговувати DNS кластера Kubernetes. Як і Kubernetes, проєкт CoreDNS є проєктом CNCF.
Ви можете використовувати CoreDNS замість kube-dns у своєму кластері, замінивши kube-dns у наявному розгортанні, або використовуючи інструменти, такі як kubeadm, які встановлюють і оновлюють кластер за вас.
Встановлення CoreDNS
Для ручного розгортання або заміни kube-dns, дивіться документацію на вебсайті CoreDNS.
Міграція на CoreDNS
Оновлення наявного кластера за допомогою kubeadm
У версії Kubernetes 1.21, kubeadm припинив підтримку kube-dns як застосунку DNS. Для kubeadm v1.35, єдиний підтримуваний DNS застосунок кластера —
це CoreDNS.
Ви можете перейти на CoreDNS, використовуючи kubeadm для оновлення кластера, який використовує kube-dns. У цьому випадку, kubeadm генерує конфігурацію CoreDNS ("Corefile") на основі ConfigMap kube-dns, зберігаючи конфігурації для stub доменів та сервера імен вище в ієрархії.
Оновлення CoreDNS
Ви можете перевірити версію CoreDNS, яку kubeadm встановлює для кожної версії Kubernetes на сторінці Версія CoreDNS у Kubernetes.
CoreDNS можна оновити вручну, якщо ви хочете тільки оновити CoreDNS або використовувати власний кастомізований образ. Є корисні рекомендації та посібник, доступні для забезпечення плавного оновлення. Переконайтеся, що поточна конфігурація CoreDNS ("Corefile") зберігається при оновленні вашого кластера.
Якщо ви оновлюєте свій кластер за допомогою інструменту kubeadm, kubeadm може самостійно зберегти поточну конфігурацію CoreDNS.
Налаштування CoreDNS
Коли використання ресурсів є проблемою, може бути корисним налаштувати конфігурацію CoreDNS. Для детальнішої інформації перевірте документацію зі збільшення масштабу CoreDNS.
Що далі
Ви можете налаштувати CoreDNS для підтримки багатьох інших сценаріїв, ніж kube-dns, змінивши конфігурацію CoreDNS ("Corefile"). Для отримання додаткової інформації дивіться документацію для втулка kubernetes CoreDNS, або читайте Власні DNS записи для Kubernetes в блозі CoreDNS.
42 - Використання NodeLocal DNSCache в кластерах Kubernetes
Kubernetes v1.18 [stable]Ця сторінка надає огляд функції NodeLocal DNSCache в Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для перевірки версії введіть kubectl version.
Вступ
NodeLocal DNSCache поліпшує продуктивність кластерного DNS, запускаючи агента кешування DNS на вузлах кластера як DaemonSet. За поточної архітектури, Podʼи в режимі DNS ClusterFirst звертаються до serviceIP kube-dns для DNS-запитів. Вони переводяться в точку доступу kube-dns/CoreDNS за допомогою прав iptables, доданих kube-proxy. За цією новою архітектурою Podʼи звертаються до агента кешування DNS, що працює на тому ж вузлі, тим самим уникнувши прав iptables DNAT та відстеження зʼєднань. Локальний агент кешування буде запитувати службу kube-dns про пропуски кешування для імен кластера (типовий суфікс "cluster.local").
Мотивація
За поточної архітектури DNS, є можливість того, що Podʼи з найвищим QPS DNS повинні звертатися до іншого вузла, якщо на цьому вузлі немає локального екземпляра kube-dns/CoreDNS. Наявність локального кешу допоможе покращити час відгуку в таких сценаріях.
Пропускаючи iptables DNAT та відстеження зʼєднань допоможе зменшити перегони з відстеженням зʼєднань та уникнути заповнення таблиці conntrack UDP DNS-записами.
Зʼєднання від локального агента кешування до служби kube-dns можуть бути підвищені до TCP. Записи conntrack для TCP будуть видалені при закритті зʼєднання, на відміну від записів UDP, які мусять перейти у режим очікування (типово
nf_conntrack_udp_timeoutстановить 30 секунд)Перехід DNS-запитів з UDP до TCP зменшить хвостовий час відповіді, спричинений втратою пакетів UDP та зазвичай таймаутами DNS до 30 секунд (3 повтори + 10 секунд таймауту). Оскільки кеш NodeLocal прослуховує UDP DNS-запити, застосунки не потребують змін.
Метрики та видимість DNS-запитів на рівні вузла.
Відʼємне кешування можна повторно включити, тим самим зменшивши кількість запитів до служби kube-dns.
Діаграма архітектури
Це шлях, яким йдуть DNS-запити після ввімкнення NodeLocal DNSCache:

Потік NodeLocal DNSCache
Ця картинка показує, як NodeLocal DNSCache обробляє DNS-запити.
Конфігурація
Примітка:
Локальна IP-адреса прослуховування для NodeLocal DNSCache може бути будь-якою адресою, яка гарантовано не перетинається з будь-яким наявним IP у вашому кластері. Рекомендується використовувати адресу з місцевою областю, наприклад, з діапазону 'link-local' '169.254.0.0/16' для IPv4 або з діапазону 'Unique Local Address' у IPv6 'fd00::/8'.Цю функцію можна ввімкнути за допомогою таких кроків:
Підготуйте маніфест, схожий на зразок
nodelocaldns.yamlта збережіть його якnodelocaldns.yaml.Якщо використовуєте IPv6, файл конфігурації CoreDNS потрібно закрити всі IPv6-адреси у квадратні дужки, якщо вони використовуються у форматі 'IP:Port'. Якщо ви використовуєте зразок маніфесту з попереднього пункту, це потребує зміни рядка конфігурації L70 таким чином: "
health [__PILLAR__LOCAL__DNS__]:8080"Підставте змінні в маніфест з правильними значеннями:
kubedns=`kubectl get svc kube-dns -n kube-system -o jsonpath={.spec.clusterIP}` domain=<cluster-domain> localdns=<node-local-address><cluster-domain>типово "cluster.local".<node-local-address>— це локальна IP-адреса прослуховування, обрана для NodeLocal DNSCache.Якщо kube-proxy працює в режимі IPTABLES:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/__PILLAR__DNS__SERVER__/$kubedns/g" nodelocaldns.yaml__PILLAR__CLUSTER__DNS__та__PILLAR__UPSTREAM__SERVERS__будуть заповнені під час роботи підсистемиnode-local-dns. У цьому режимі підсистемиnode-local-dnsпрослуховують як IP-адресу служби kube-dns, так і<node-local-address>, тому Podʼи можуть шукати записи DNS, використовуючи будь-яку з цих IP-адрес.Якщо kube-proxy працює в режимі IPVS:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/,__PILLAR__DNS__SERVER__//g; s/__PILLAR__CLUSTER__DNS__/$kubedns/g" nodelocaldns.yamlУ цьому режимі підсистеми
node-local-dnsпрослуховують лише<node-local-address>. Інтерфейсnode-local-dnsне може привʼязати кластерну IP kube-dns, оскільки інтерфейс, що використовується для IPVS-балансування навантаження, вже використовує цю адресу.__PILLAR__UPSTREAM__SERVERS__буде заповнено підсистемамиnode-local-dns.
Запустіть
kubectl create -f nodelocaldns.yaml.Якщо використовуєте kube-proxy в режимі IPVS, прапорець
--cluster-dnsдля kubelet потрібно змінити на<node-local-address>, який прослуховує NodeLocal DNSCache. В іншому випадку не потрібно змінювати значення прапорця--cluster-dns, оскільки NodeLocal DNSCache прослуховує як IP-адресу служби kube-dns, так і<node-local-address>.
Після ввімкнення, Podʼи node-local-dns будуть працювати у просторі імен kube-system на кожному з вузлів кластера. Цей Pod працює з CoreDNS у режимі кешування, тому всі метрики CoreDNS, що надаються різними втулками, будуть доступні на рівні кожного вузла.
Цю функцію можна вимкнути, видаливши DaemonSet, використовуючи kubectl delete -f <manifest>. Також слід скасувати будь-які зміни, внесені до конфігурації kubelet.
Конфігурація StubDomains та Upstream серверів
StubDomains та upstream сервери, вказані в ConfigMap kube-dns в просторі імен kube-system автоматично використовуються підсистемами node-local-dns. Вміст ConfigMap повинен відповідати формату, показаному у прикладі. ConfigMap node-local-dns також можна змінити безпосередньо з конфігурацією stubDomain у форматі Corefile. Деякі хмарні постачальники можуть не дозволяти змінювати ConfigMap node-local-dns безпосередньо. У цьому випадку ConfigMap kube-dns можна оновити.
Налаштування обмежень памʼяті
Podʼи node-local-dns використовують памʼять для зберігання записів кешу та обробки запитів. Оскільки вони не стежать за обʼєктами Kubernetes, розмір кластера або кількість Service / EndpointSlice не впливає на використання памʼяті безпосередньо. Використання памʼяті впливає на шаблон DNS-запитів. З документації CoreDNS:
Типовий розмір кешу — 10000 записів, що використовує приблизно 30 МБ, коли повністю заповнений.
Це буде використання памʼяті для кожного блоку сервера (якщо кеш буде повністю заповнений). Використання памʼяті можна зменшити, вказавши менші розміри кешу.
Кількість одночасних запитів повʼязана з попитом памʼяті, оскільки кожен додатковий goroutine, використаний для обробки запиту, потребує певної кількості памʼяті. Ви можете встановити верхню межу за допомогою опції max_concurrent у втулку forward.
Якщо Pod node-local-dns намагається використовувати більше памʼяті, ніж доступно (через загальні системні ресурси або через налаштовані обмеження ресурсів), операційна система може вимкнути контейнер цього Podʼа. У разі цього, контейнер, якого вимкнено ("OOMKilled"), не очищає власні правила фільтрації пакетів, які він раніше додавав під час запуску. Контейнер node-local-dns повинен бути перезапущений (оскільки він керується як частина DaemonSet), але це призведе до короткої перерви у роботі DNS кожного разу, коли контейнер зазнає збою: правила фільтрації пакетів направляють DNS-запити до локального Podʼа, який не є справним.
Ви можете визначити прийнятне обмеження памʼяті, запустивши Podʼи node-local-dns без обмеження
та вимірявши максимальне використання. Ви також можете налаштувати та використовувати VerticalPodAutoscaler у recommender mode, а потім перевірити його рекомендації.
43 - Використання sysctl в кластері Kubernetes
Kubernetes v1.21 [stable]У цьому документі описано, як налаштовувати та використовувати параметри ядра в межах кластера Kubernetes, використовуючи інтерфейс sysctl.
Примітка:
Починаючи з версії Kubernetes 1.23, kubelet підтримує використання/ або . як роздільники для назв sysctl. Починаючи з версії Kubernetes 1.25, налаштування Sysctls для контейнера підтримує встановлення sysctl зі слешами. Наприклад, ви можете представити ту саму назву sysctl як kernel.shm_rmid_forced, використовуючи крапку як роздільник, або як kernel/shm_rmid_forced, використовуючи слеш як роздільник. Для отримання додаткових відомостей щодо методу конвертації параметра sysctl див. сторінку sysctl.d(5) проєкту Linux man-pages.Перш ніж ви розпочнете
Примітка:
sysctl — це інструмент командного рядка, специфічний для Linux, який використовується для налаштування різних параметрів ядра, і він недоступний в операційних системах, що не базуються на Linux.Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для деяких кроків вам також потрібно мати змогу змінювати параметри командного рядка для kubelet, що працюють на вашому кластері.
Перелік всіх параметрів Sysctl
У Linux інтерфейс sysctl дозволяє адміністратору змінювати параметри ядра під час виконання. Параметри доступні через віртуальну файлову систему /proc/sys/. Параметри охоплюють різні підсистеми, такі як:
- ядро (загальний префікс:
kernel.) - мережа (загальний префікс:
net.) - віртуальна памʼять (загальний префікс:
vm.) - MDADM (загальний префікс:
dev.) - Більше підсистем описано у документації ядра.
Щоб отримати список всіх параметрів, ви можете виконати команду:
sudo sysctl -a
Безпечні та Небезпечні Sysctl
Kubernetes класифікує sysctl як безпечні або небезпечні. Крім належного просторового розмежування, безпечний sysctl повинен бути належним чином ізольованим між Podʼами на тому ж вузлі. Це означає, що встановлення безпечного sysctl для одного Podʼа
- не повинно мати жодного впливу на інші Podʼи на вузлі
- не повинно дозволяти шкодити справності вузла
- не повинно дозволяти отримувати CPU або ресурси памʼяті поза межами обмежень ресурсів Podʼа.
Наразі більшість просторово розмежованих (по просторах імен) sysctl не обовʼязково вважаються безпечними. До набору безпечних sysctl входять наступні параметри:
kernel.shm_rmid_forced;net.ipv4.ip_local_port_range;net.ipv4.tcp_syncookies;net.ipv4.ping_group_range(починаючи з Kubernetes 1.18);net.ipv4.ip_unprivileged_port_start(починаючи з Kubernetes 1.22);net.ipv4.ip_local_reserved_ports(починаючи з Kubernetes 1.27, потрібне ядро 3.16+);net.ipv4.tcp_keepalive_time(починаючи з Kubernetes 1.29, потрібне ядро 4.5+);net.ipv4.tcp_fin_timeout(починаючи з Kubernetes 1.29, потрібне ядро 4.6+);net.ipv4.tcp_keepalive_intvl(починаючи з Kubernetes 1.29, потрібне ядро 4.5+);net.ipv4.tcp_keepalive_probes(починаючи з Kubernetes 1.29, потрібне ядро 4.5+).net.ipv4.tcp_rmem(починаючи Kubernetes 1.32, потрібне ядро 4.15+).net.ipv4.tcp_wmem(починаючи Kubernetes 1.32, потрібне ядро 4.15+).
Примітка:
Є деякі винятки зі списку безпечних sysctl:
- Параметри sysctl
net.*не дозволені з увімкненою мережею вузла. - Параметр sysctl
net.ipv4.tcp_syncookiesне має просторового розмежування в ядрах Linux версії 4.5 або нижче.
Цей список буде розширюватися у майбутніх версіях Kubernetes, коли kubelet буде підтримувати кращі механізми ізоляції.
Увімкнення небезпечних Sysctl
Всі безпечні sysctl є типово увімкненими.
Всі небезпечні sysctl типово вимкнені та повинні бути дозволені вручну адміністратором кластера на кожному вузлі окремо. Podʼи з вимкненими небезпечними sysctl будуть заплановані, але їх не вдасться запустити.
З врахуванням попередження вище, адміністратор кластера може дозволити певні небезпечні sysctl для дуже спеціальних ситуацій, таких як налаштування високопродуктивних або застосунків реального часу. Небезпечні sysctl вмикаються на основі вузла з прапорцем kubelet; наприклад:
kubelet --allowed-unsafe-sysctls \
'kernel.msg*,net.core.somaxconn' ...
Для Minikube, це можна зробити за допомогою прапорця extra-config:
minikube start --extra-config="kubelet.allowed-unsafe-sysctls=kernel.msg*,net.core.somaxconn"...
Таким чином можна увімкнути лише просторово розмежовані sysctl.
Налаштування Sysctl для Podʼа
Численні sysctl просторово розмежовані в сучасних ядрах Linux. Це означає, що їх можна налаштовувати незалежно для кожного Pod на вузлі. Лише просторово розмежовані sysctl можна налаштовувати через securityContext Podʼа в межах Kubernetes.
Відомо, що наступні sysctl мають просторове розмежування. Цей список може змінитися в майбутніх версіях ядра Linux.
kernel.shm*kernel.msg*kernel.semfs.mqueue.*- Ті
net.*, які можна налаштувати в просторі імен мережі контейнера. Однак є винятки (наприклад,net.netfilter.nf_conntrack_maxтаnet.netfilter.nf_conntrack_expect_maxможуть бути налаштовані в просторі імен мережі контейнера, але не мають просторового розмежування до Linux 5.12.2).
Sysctl без просторового розмежування називають вузловими sysctl. Якщо вам потрібно налаштувати їх, ви повинні вручну налаштувати їх в операційній системі кожного вузла або за допомогою DaemonSet з привілейованими контейнерами.
Використовуйте securityContext Podʼа для налаштування просторово розмежованих sysctl. securityContext застосовується до всіх контейнерів у тому ж Podʼі.
У цьому прикладі використовується securityContext Podʼа для встановлення безпечного sysctl kernel.shm_rmid_forced та двох небезпечних sysctl net.core.somaxconn та kernel.msgmax. В специфікації немає розрізнення між безпечними та небезпечними sysctl.
Попередження:
Змінюйте параметри sysctl лише після розуміння їхніх наслідків, щоб уникнути дестабілізації вашої операційної системи.apiVersion: v1
kind: Pod
metadata:
name: sysctl-example
spec:
securityContext:
sysctls:
- name: kernel.shm_rmid_forced
value: "0"
- name: net.core.somaxconn
value: "1024"
- name: kernel.msgmax
value: "65536"
...
Попередження:
Через їхню природу бути небезпечними, використання небезпечних sysctl здійснюється на ваш власний ризик і може призвести до серйозних проблем, таких як неправильна поведінка контейнерів, нестача ресурсів або повний розлад вузла.Хорошою практикою є вважати вузли з особливими налаштуваннями sysctl як позначені taint в межах кластера і планувати на них лише ті Podʼи, яким потрібні ці налаштування sysctl. Рекомендується використовувати функцію Заплямованість та Толерантність кластера Kubernetes, щоб реалізувати це.
Pod з небезпечними sysctl не вдасться запустити на будь-якому вузлі, на якому не були явно увімкнені ці два небезпечні sysctl. Як і з вузловими sysctl, рекомендується використовувати функцію Заплямованість та Толерантність або заплямованість вузлів для планування цих Podʼів на відповідні вузли.
44 - Використання NUMA-орієнтованого менеджера памʼяті
Kubernetes v1.32 [stable](стандартно увімкнено)Менеджер памʼяті Kubernetes дозволяє функцію гарантованого виділення памʼяті (та великих сторінок) для Podʼів QoS класу Guaranteed.
Менеджер памʼяті використовує протокол генерації підказок для вибору найбільш відповідної спорідненості NUMA для точки доступу. Менеджер памʼяті передає ці підказки центральному менеджеру (Менеджеру топології). На основі як підказок, так і політики Менеджера топології, Pod відхиляється або допускається на вузол.
Крім того, Менеджер памʼяті забезпечує, що памʼять, яку запитує Pod, виділяється з мінімальної кількості NUMA-вузлів.
Менеджер памʼяті має відношення тільки до хостів на базі Linux.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.32.Для перевірки версії введіть kubectl version.
Для вирівнювання ресурсів памʼяті з іншими запитаними ресурсами у специфікації Podʼа:
- Менеджер CPU повинен бути увімкнений, і на вузлі повинна бути налаштована відповідна політика Менеджера CPU. Див. управління політиками керування CPU;
- Менеджер топології повинен бути увімкнений, і на вузлі повинна бути налаштована відповідна політика Менеджера топології. Див. управління політиками керування топологією.
Починаючи з версії v1.22, Менеджер памʼяті типово увімкнено за допомогою функціональної можливості MemoryManager.
Для версій до v1.22, kubelet повинен бути запущений з наступним прапорцем:
--feature-gates=MemoryManager=true
щоб увімкнути функцію Менеджера памʼяті.
Як працює Менеджер памʼяті?
Зараз Менеджер памʼяті пропонує виділення гарантованої памʼяті (та великих сторінок) для Podʼів у класі QoS Guaranteed. Щоб негайно ввести Менеджер памʼяті в роботу, слідкуйте вказівкам у розділі Налаштування Менеджера памʼяті, а потім підготуйте та розгорніть Pod Guaranteed, як показано в розділі Розміщення Podʼів класу QoS Guaranteed.
Менеджер памʼяті є постачальником підказок і надає підказки топології для Менеджера топології, який потім вирівнює запитані ресурси згідно з цими підказками топології. На Linux, він також застосовує cgroups (тобто cpuset.mems) для Podʼів. Повна схематична діаграма щодо процесу допуску та розгортання Podʼа показано у Memory Manager KEP: Design Overview та нижче:

Під час цього процесу Менеджер памʼяті оновлює свої внутрішні лічильники, що зберігаються в Node Map та Memory Maps, для управління гарантованим виділенням памʼяті.
Менеджер памʼяті оновлює Node Map під час запуску та виконання наступним чином.
Запуск
Це відбувається один раз, коли адміністратор вузла використовує --reserved-memory (розділ
Прапорець зарезервованої памʼяті). У цьому випадку Node Map оновлюється, щоб відображати це резервування, як показано в Memory Manager KEP: Memory Maps at start-up (with examples).
Адміністратор повинен надати прапорець --reserved-memory при налаштуванні політики Static.
Робота
Посилання Memory Manager KEP: Memory Maps at runtime (with examples) ілюструє, як успішне розгортання Podʼа впливає на Node Map, і також повʼязано з тим, як потенційні випадки вичерпання памʼяті (OOM) далі обробляються Kubernetes або операційною системою.
Важливою темою в контексті роботи Менеджера памʼяті є керування NUMA-групами. Кожного разу, коли запит памʼяті Podʼа перевищує місткість одного NUMA-вузла, Менеджер памʼяті намагається створити групу, яка включає декілька NUMA-вузлів і має розширений обсяг памʼяті. Проблему вирішено, як про це йдеться у Memory Manager KEP: How to enable the guaranteed memory allocation over many NUMA nodes?. Також, посилання Memory Manager KEP: Simulation - how the Memory Manager works? (by examples) показує, як відбувається управління групами.
Підтримка Windows
Kubernetes v1.32 [alpha](стандартно вимкнено)Підтримку Windows можна увімкнути за допомогою функціональної можливості WindowsCPUAndMemoryAffinity і вона потребує підтримки під час виконання контейнера. У Windows підтримується лише політика BestEffort Policy.
Налаштування Менеджера памʼяті
Інші Менеджери повинні бути спочатку попередньо налаштовані. Далі, функцію Менеджера памʼяті слід увімкнути та запустити з політикою Static (розділ Політика Static). Опційно можна зарезервувати певну кількість памʼяті для системи або процесів kubelet, щоб збільшити стабільність вузла (розділ Прапорець зарезервованої памʼяті).
Політики
Менеджер памʼяті підтримує дві політики. Ви можете вибрати політику за допомогою прапорця kubelet --memory-manager-policy:
None(типово)Static(тільки Linux)BestEffort(тільки Windows)
Політика None
Це типова політика і вона не впливає на виділення памʼяті жодним чином. Вона працює так само як і коли Менеджер памʼяті взагалі відсутній.
Політика None повертає типову підказку топології. Ця спеціальна підказка позначає, що Hint Provider (в цьому випадку Менеджер памʼяті) не має переваги щодо спорідненості NUMA з будь-яким ресурсом.
Політика Static
У випадку Guaranteed Podʼа політика Менеджера памʼяті Static повертає підказки топології, що стосуються набору NUMA-вузлів, де памʼять може бути гарантованою, та резервує памʼять, оновлюючи внутрішній обʼєкт NodeMap.
У випадку Podʼа BestEffort або Burstable політика Менеджера памʼяті Static повертає назад типову підказку топології, оскільки немає запиту на гарантовану памʼять, і не резервує памʼять внутрішнього обʼєкта NodeMap.
Ця політика підтримується тільки в Linux.
Політика BestEffort
Kubernetes v1.32 [alpha](стандартно вимкнено)Ця політика підтримується лише у Windows.
У Windows призначення вузлів NUMA працює інакше, ніж у Linux. Не існує механізму, який би гарантував, що доступ до памʼяті надається лише з певного вузла NUMA. Замість цього планувальник Windows вибере найоптимальніший вузол NUMA на основі призначень процесора(ів). Можливо, Windows може використовувати інші вузли NUMA, якщо планувальник Windows вважатиме їх оптимальними.
Політика відстежує кількість доступної та запитуваної памʼяті за допомогою внутрішньої NodeMap. Менеджер памʼяті докладе максимум зусиль для забезпечення достатнього обсягу памʼяті навузлі NUMA перед тим, як призначити пам'ять. Це означає, що у більшості випадків розподіл памʼяті має відбуватися як очікується.
Прапорець зарезервованої памʼяті
Механізм виділення ресурсів вузла (Node Allocatable) зазвичай використовується адміністраторами вузлів для резервування системних ресурсів вузла K8S для kubelet або процесів операційної системи, щоб підвищити стабільність вузла. Для цього можна використовувати відповідний набір прапорців, щоб вказати загальну кількість зарезервованої памʼяті для вузла. Це попередньо налаштоване значення далі використовується для розрахунку реальної кількості "виділеної" памʼяті вузла, доступної для Podʼів.
Планувальник Kubernetes використовує "виділену" памʼять для оптимізації процесу планування Podʼів. Для цього використовуються прапорці --kube-reserved, --system-reserved та --eviction-threshold. Сума їх значень враховує загальну кількість зарезервованої памʼяті.
Новий прапорець --reserved-memory було додано до Memory Manager, щоб дозволити цю загальну зарезервовану памʼять розділити (адміністратором вузла) і відповідно зарезервувати для багатьох вузлів NUMA.
Прапорець визначається як розділений комами список резервування памʼяті різних типів на NUMA-вузол. Резервації памʼяті по кількох NUMA-вузлах можна вказати, використовуючи крапку з комою як роздільник. Цей параметр корисний лише в контексті функції Менеджера памʼяті. Менеджер памʼяті не використовуватиме цю зарезервовану памʼять для виділення контейнерних робочих навантажень.
Наприклад, якщо у вас є NUMA-вузол "NUMA0" з доступною памʼяттю 10 ГБ, і було вказано --reserved-memory, щоб зарезервувати 1 ГБ памʼяті в "NUMA0", Менеджер памʼяті припускає, що для контейнерів доступно тільки 9 ГБ.
Ви можете не вказувати цей параметр, але слід памʼятати, що кількість зарезервованої памʼяті з усіх NUMA-вузлів повинна дорівнювати кількості памʼяті, вказаній за допомогою функції виділення ресурсів вузла. Якщо принаймні один параметр виділення вузла не дорівнює нулю, вам слід вказати --reserved-memory принаймні для одного NUMA-вузла. Фактично, порогове значення eviction-hard типово становить 100 Mi, отже, якщо використовується політика Static, --reserved-memory є обовʼязковим.
Також слід уникати наступних конфігурацій:
- дублікатів, тобто того самого NUMA-вузла або типу памʼяті, але з іншим значенням;
- встановлення нульового ліміту для будь-якого типу памʼяті;
- ідентифікаторів NUMA-вузлів, які не існують в апаратному забезпеченні машини;
- назв типів памʼяті відмінних від
memoryабоhugepages-<size>(великі сторінки певного розміру<size>також повинні існувати).
Синтаксис:
--reserved-memory N:memory-type1=value1,memory-type2=value2,...
N(ціле число) — індекс NUMA-вузла, наприклад0memory-type(рядок) — представляє тип памʼяті:memory— звичайна памʼятьhugepages-2Miабоhugepages-1Gi— великі сторінки
value(рядок) - кількість зарезервованої памʼяті, наприклад1Gi.
Приклад використання:
--reserved-memory 0:memory=1Gi,hugepages-1Gi=2Gi
або
--reserved-memory 0:memory=1Gi --reserved-memory 1:memory=2Gi
або
--reserved-memory '0:memory=1Gi;1:memory=2Gi'
При вказанні значень для прапорця --reserved-memory слід дотримуватися налаштування, яке ви вказали раніше за допомогою прапорців функції виділення вузла. Іншими словами, слід дотримуватися такого правила для кожного типу памʼяті:
sum(reserved-memory(i)) = kube-reserved + system-reserved + eviction-threshold,
де i - це індекс NUMA-вузла.
Якщо ви не дотримуєтесь вищезазначеної формули, Менеджер памʼяті покаже помилку при запуску.
Іншими словами, у вищезазначеному прикладі показано, що для звичайної памʼяті (type=memory) ми загалом резервуємо 3 ГБ, а саме:
sum(reserved-memory(i)) = reserved-memory(0) + reserved-memory(1) = 1 ГБ + 2 ГБ = 3 ГБ
Приклад командних аргументів kubelet, що стосуються конфігурації виділення вузла:
--kube-reserved=cpu=500m,memory=50Mi--system-reserved=cpu=123m,memory=333Mi--eviction-hard=memory.available<500Mi
Примітка:
Типове значення для жорсткого порога виселення становить 100MiB, а не нуль. Не забудьте збільшити кількість памʼяті, яку ви резервуєте, встановивши--reserved-memory на величину цього жорсткого порога виселення. В іншому випадку kubelet не запустить Менеджер памʼяті та покаже помилку.Нижче наведено приклад правильної конфігурації:
--kube-reserved=cpu=4,memory=4Gi
--system-reserved=cpu=1,memory=1Gi
--memory-manager-policy=Static
--reserved-memory '0:memory=3Gi;1:memory=2148Mi'
Перед версією Kubernetes 1.32 вам також потрібно додавати
--feature-gates=MemoryManager=true
Перевірмо цю конфігурацію:
kube-reserved + system-reserved + eviction-hard(за замовчуванням) = reserved-memory(0) + reserved-memory(1)4GiB + 1GiB + 100MiB = 3GiB + 2148MiB5120MiB + 100MiB = 3072MiB + 2148MiB5220MiB = 5220MiB(що є правильним)
Розміщення Podʼа в класі QoS Guaranteed
Якщо вибрана політика відрізняється від None, Менеджер памʼяті ідентифікує Podʼи, які належать до класу обслуговування Guaranteed. Менеджер памʼяті надає конкретні підказки топології Менеджеру топології для кожного Podʼа з класом обслуговування Guaranteed. Для Podʼів, які належать до класу обслуговування відмінного від Guaranteed, Менеджер памʼяті надає Менеджеру топології типові підказки топології.
Наведені нижче уривки з маніфестів Podʼа призначають Pod до класу обслуговування Guaranteed.
Pod з цілим значенням CPU працює в класі обслуговування Guaranteed, коли requests дорівнюють limits:
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
Також Pod, який спільно використовує CPU, працює в класі обслуговування Guaranteed, коли requests дорівнюють limits.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
Зверніть увагу, що для Podʼа потрібно вказати як запити CPU, так і памʼяті, щоб він належав до класу обслуговування Guaranteed.
Розвʼязання проблем
Для виявлення причин, чому Pod не вдалося розгорнути або він був відхилений на вузлі, можуть бути використані наступні засоби:
- статус Podʼа — вказує на помилки топологічної спорідненості
- системні логи — містять цінну інформацію для налагодження, наприклад, про згенеровані підказки
- файл стану — вивід внутрішнього стану Менеджера памʼяті (включає Node Map та Memory Map)
- починаючи з v1.22, можна використовувати API втулка ресурсів пристроїв, щоб отримати інформацію про памʼять, зарезервовану для контейнерів.
Статус Podʼа (TopologyAffinityError)
Ця помилка зазвичай виникає у наступних ситуаціях:
- вузол не має достатньо ресурсів, щоб задовольнити запит Podʼа
- запит Podʼа відхилено через обмеження певної політики Менеджера топології
Помилка показується у статусі Podʼа:
kubectl get pods
NAME READY STATUS RESTARTS AGE
guaranteed 0/1 TopologyAffinityError 0 113s
Використовуйте kubectl describe pod <id> або kubectl get events, щоб отримати докладне повідомлення про помилку:
Warning TopologyAffinityError 10m kubelet, dell8 Resources cannot be allocated with Topology locality
Системні логи
Шукайте системні логи для певного Podʼа.
У логах можна знайти набір підказок, які згенерував Менеджер памʼяті для Podʼа. Також у логах повинен бути присутній набір підказок, згенерований Менеджером CPU.
Менеджер топології обʼєднує ці підказки для обчислення єдиної найкращої підказки. Найкраща підказка також повинна бути присутня в логах.
Найкраща підказка вказує, куди виділити всі ресурси. Менеджер топології перевіряє цю підказку за своєю поточною політикою і, залежно від вердикту, або допускає Pod до вузла, або відхиляє його.
Також шукайте логи для випадків, повʼязаних з Менеджером памʼяті, наприклад, для отримання інформації про оновлення cgroups та cpuset.mems.
Аналіз стану менеджера памʼяті на вузлі
Спочатку розгляньмо розгорнутий зразок Guaranteed Podʼа, специфікація якого виглядає так:
apiVersion: v1
kind: Pod
metadata:
name: guaranteed
spec:
containers:
- name: guaranteed
image: consumer
imagePullPolicy: Never
resources:
limits:
cpu: "2"
memory: 150Gi
requests:
cpu: "2"
memory: 150Gi
command: ["sleep","infinity"]
Потім увійдімо на вузол, де він був розгорнутий, і розглянемо файл стану у /var/lib/kubelet/memory_manager_state:
{
"policyName":"Static",
"machineState":{
"0":{
"numberOfAssignments":1,
"memoryMap":{
"hugepages-1Gi":{
"total":0,
"systemReserved":0,
"allocatable":0,
"reserved":0,
"free":0
},
"memory":{
"total":134987354112,
"systemReserved":3221225472,
"allocatable":131766128640,
"reserved":131766128640,
"free":0
}
},
"nodes":[
0,
1
]
},
"1":{
"numberOfAssignments":1,
"memoryMap":{
"hugepages-1Gi":{
"total":0,
"systemReserved":0,
"allocatable":0,
"reserved":0,
"free":0
},
"memory":{
"total":135286722560,
"systemReserved":2252341248,
"allocatable":133034381312,
"reserved":29295144960,
"free":103739236352
}
},
"nodes":[
0,
1
]
}
},
"entries":{
"fa9bdd38-6df9-4cf9-aa67-8c4814da37a8":{
"guaranteed":[
{
"numaAffinity":[
0,
1
],
"type":"memory",
"size":161061273600
}
]
}
},
"checksum":4142013182
}
З цього файлу стану можна дізнатись, що Pod був привʼязаний до обох NUMA вузлів, тобто:
"numaAffinity":[
0,
1
],
Термін "привʼязаний" означає, що споживання памʼяті Podʼом обмежено (через конфігурацію cgroups) цими NUMA вузлами.
Це автоматично означає, що Менеджер памʼяті створив нову групу, яка обʼєднує ці два NUMA вузли, тобто вузли з індексами 0 та 1.
Зверніть увагу, що управління групами виконується досить складним способом, і подальші пояснення надані в Memory Manager KEP в цьому та цьому розділах.
Для аналізу ресурсів памʼяті, доступних у групі, потрібно додати відповідні записи з NUMA вузлів, які належать до групи.
Наприклад, загальна кількість вільної "звичайної" памʼяті в групі може бути обчислена шляхом додавання вільної памʼяті, доступної на кожному NUMA вузлі в групі, тобто в розділі "memory" NUMA вузла 0 ("free":0) та NUMA вузла 1 ("free":103739236352). Таким чином, загальна кількість вільної "звичайної" памʼяті в цій групі дорівнює 0 + 103739236352 байт.
Рядок "systemReserved":3221225472 вказує на те, що адміністратор цього вузла зарезервував 3221225472 байти (тобто 3Gi) для обслуговування процесів kubelet та системи на NUMA вузлі 0, використовуючи прапорець --reserved-memory.
API втулка ресурсів пристроїв
Kubelet надає службу gRPC PodResourceLister для включення виявлення ресурсів та повʼязаних метаданих. Використовуючи його точку доступу List gRPC, можна отримати інформацію про зарезервовану памʼять для кожного контейнера, яка міститься у protobuf повідомленні ContainerMemory. Цю інформацію можна отримати лише для Podʼів у класі якості обслуговування Guaranteed.
Що далі
- Memory Manager KEP: Design Overview
- Memory Manager KEP: Memory Maps at start-up (with examples)
- Memory Manager KEP: Memory Maps at runtime (with examples)
- Memory Manager KEP: Simulation - how the Memory Manager works? (by examples)
- Memory Manager KEP: The Concept of Node Map and Memory Maps
- Memory Manager KEP: How to enable the guaranteed memory allocation over many NUMA nodes?
45 - Перевірка підписаних артефактів Kubernetes
Kubernetes v1.26 [beta]Перш ніж ви розпочнете
Вам знадобиться мати встановлені наступні інструменти:
cosign(інструкція щодо встановлення)curl(часто надається вашою операційною системою)jq(завантажте jq)
Перевірка підписів бінарних файлів
В процесі підготовки випуску Kubernetes підписує всі бінарні артефакти (tarballs, файли SPDX, окремі бінарні файли) за допомогою безключового підписування cosign. Щоб перевірити певний бінарний файл, отримайте його разом з підписом та сертифікатом:
URL=https://dl.k8s.io/release/v1.35.0/bin/linux/amd64
BINARY=kubectl
FILES=(
"$BINARY"
"$BINARY.sig"
"$BINARY.cert"
)
for FILE in "${FILES[@]}"; do
curl -sSfL --retry 3 --retry-delay 3 "$URL/$FILE" -o "$FILE"
done
Потім перевірте блоб, використовуючи cosign verify-blob:
cosign verify-blob "$BINARY" \
--signature "$BINARY".sig \
--certificate "$BINARY".cert \
--certificate-identity krel-staging@k8s-releng-prod.iam.gserviceaccount.com \
--certificate-oidc-issuer https://accounts.google.com
Примітка:
Cosign 2.0 вимагає опції --certificate-identity та --certificate-oidc-issuer.
Для отримання додаткової інформації щодо безключового підписування, див. Безключові Підписи.
Попередні версії Cosign вимагали встановлення COSIGN_EXPERIMENTAL=1.
Для отримання додаткової інформації зверніться до Блогу sigstore
Перевірка підписів образів
Для повного списку образів, які підписані, дивіться Випуски.
Оберіть один образ з цього списку та перевірте його підпис, використовуючи команду cosign verify:
cosign verify registry.k8s.io/kube-apiserver-amd64:v1.35.0 \
--certificate-identity krel-trust@k8s-releng-prod.iam.gserviceaccount.com \
--certificate-oidc-issuer https://accounts.google.com \
| jq .
Перевірка образів для всіх компонентів панелі управління
Щоб перевірити всі підписані образи компонентів панелі управління для останньої стабільної версії (v1.35.0), запустіть наступні команди:
curl -Ls "https://sbom.k8s.io/$(curl -Ls https://dl.k8s.io/release/stable.txt)/release" \
| grep "SPDXID: SPDXRef-Package-registry.k8s.io" \
| grep -v sha256 | cut -d- -f3- | sed 's/-/\//' | sed 's/-v1/:v1/' \
| sort > images.txt
input=images.txt
while IFS= read -r image
do
cosign verify "$image" \
--certificate-identity krel-trust@k8s-releng-prod.iam.gserviceaccount.com \
--certificate-oidc-issuer https://accounts.google.com \
| jq .
done < "$input"
Після перевірки образу можна вказати його за його дайджестом у вашому маніфесті Podʼа, як у цьому прикладі:
registry-url/image-name@sha256:45b23dee08af5e43a7fea6c4cf9c25ccf269ee113168c19722f87876677c5cb2
Для отримання додаткової інформації, див. Розділ Політика отримання образів.
Перевірка підписів образів за допомогою контролера допуску
Для образів, що не є частиною компонентів панелі управління (наприклад, образ conformance), підписи також можна перевірити під час розгортання за допомогою контролера допуску sigstore policy-controller.
Ось кілька корисних ресурсів для початку роботи з policy-controller:
Перевірка специфікації на програмне забезпечення
Ви можете перевірити Kubernetes Software Bill of Materials (SBOM), використовуючи сертифікат та підпис sigstore, або відповідні файли SHA:
# Отримайте останню доступну версію релізу Kubernetes
VERSION=$(curl -Ls https://dl.k8s.io/release/stable.txt)
# Перевірте суму SHA512
curl -Ls "https://sbom.k8s.io/$VERSION/release" -o "$VERSION.spdx"
echo "$(curl -Ls "https://sbom.k8s.io/$VERSION/release.sha512") $VERSION.spdx" | sha512sum --check
# Перевірте суму SHA256
echo "$(curl -Ls "https://sbom.k8s.io/$VERSION/release.sha256") $VERSION.spdx" | sha256sum --check
# Отримайте підпис та сертифікат sigstore
curl -Ls "https://sbom.k8s.io/$VERSION/release.sig" -o "$VERSION.spdx.sig"
curl -Ls "https://sbom.k8s.io/$VERSION/release.cert" -o "$VERSION.spdx.cert"
# Перевірте підпис sigstore
cosign verify-blob \
--certificate "$VERSION.spdx.cert" \
--signature "$VERSION.spdx.sig" \
--certificate-identity krel-staging@k8s-releng-prod.iam.gserviceaccount.com \
--certificate-oidc-issuer https://accounts.google.com \
"$VERSION.spdx"