这篇文章已经一年多了,较旧的文章可能包含过时的内容。请检查从发表以来,页面中的信息是否变得不正确。
Kubernetes 1.30:对 Pod 使用用户命名空间的支持进阶至 Beta
Linux 提供了不同的命名空间来将进程彼此隔离。 例如,一个典型的 Kubernetes Pod 运行在一个网络命名空间中可以隔离网络身份,运行在一个 PID 命名空间中可以隔离进程。
Linux 有一个以前一直未被容器化应用所支持的命名空间是用户命名空间。 这个命名空间允许我们将容器内使用的用户标识符和组标识符(UID 和 GID)与主机上的标识符隔离开来。
这是一个强大的抽象,允许我们以 “root” 身份运行容器: 我们在容器内部有 root 权限,可以在 Pod 内执行所有 root 能做的操作, 但我们与主机的交互仅限于非特权用户可以执行的操作。这对于限制容器逃逸的影响非常有用。
容器逃逸是指容器内的进程利用容器运行时或内核中的某些未打补丁的漏洞逃逸到主机上, 并可以访问/修改主机或其他容器上的文件。如果我们以用户命名空间运行我们的 Pod, 容器对主机其余部分的特权将减少,并且此容器可以访问的容器外的文件也将受到限制。
在 Kubernetes v1.25 中,我们仅为无状态 Pod 引入了对用户命名空间的支持。 Kubernetes 1.28 取消了这一限制,目前在 Kubernetes 1.30 中,这个特性进阶到了 Beta!
什么是用户命名空间?
注意:Linux 用户命名空间与 Kubernetes 命名空间是不同的概念。 前者是一个 Linux 内核特性;后者是一个 Kubernetes 特性。
用户命名空间是一个 Linux 特性,它将容器的 UID 和 GID 与主机上的隔离开来。 容器中的标识符可以被映射为主机上的标识符,并且保证不同容器所使用的主机 UID/GID 不会重叠。 此外,这些标识符可以被映射到主机上没有特权的、非重叠的 UID 和 GID。这带来了两个关键好处:
- 防止横向移动:由于不同容器的 UID 和 GID 被映射到主机上的不同 UID 和 GID, 即使这些标识符逃出了容器的边界,容器之间也很难互相攻击。 例如,假设容器 A 在主机上使用的 UID 和 GID 与容器 B 不同。 在这种情况下,它对容器 B 的文件和进程的操作是有限的:只能读取/写入某文件所允许的操作, 因为它永远不会拥有文件所有者或组权限(主机上的 UID/GID 保证对不同容器是不同的)。
- 增加主机隔离:由于 UID 和 GID 被映射到主机上的非特权用户,如果某容器逃出了它的边界, 即使它在容器内部以 root 身份运行,它在主机上也没有特权。 这大大保护了它可以读取/写入的主机文件,它可以向哪个进程发送信号等。 此外,所授予的权能仅在用户命名空间内有效,而在主机上无效,这就限制了容器逃逸的影响。
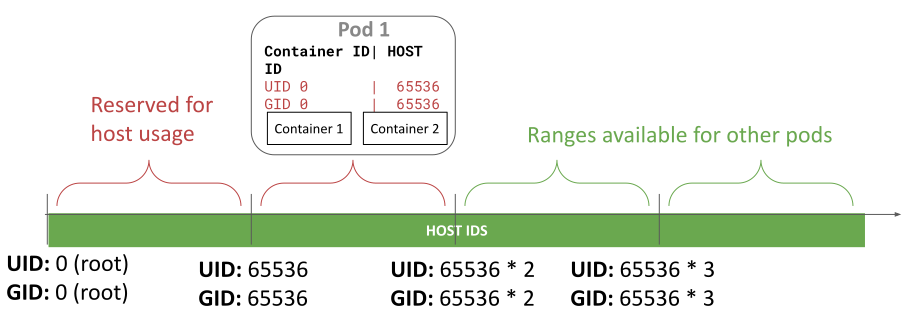
用户命名空间 ID 分配
如果不使用用户命名空间,容器逃逸时以 root 运行的容器在节点上将具有 root 特权。 如果某些权能授权给了此容器,这些权能在主机上也会有效。 如果使用用户命名空间,就不会是这种情况(当然,除非有漏洞 🙂)。
1.30 的变化
在 Kubernetes 1.30 中,除了将用户命名空间进阶至 Beta,参与此特性的贡献者们还:
- 为 kubelet 引入了一种使用自定义范围进行 UID/GID 映射的方式
- 为 Kubernetes 添加了一种强制执行的方式让运行时支持用户命名空间所需的所有特性。 如果不支持这些特性,Kubernetes 在尝试创建具有用户命名空间的 Pod 时,会显示一个明确的错误。 在 1.30 之前,如果容器运行时不支持用户命名空间,Pod 可能会在没有用户命名空间的情况下被创建。
- 新增了更多的测试,包括在 cri-tools 仓库中的测试。
你可以查阅有关用户命名空间的文档, 了解如何配置映射的自定义范围。
演示
几个月前,CVE-2024-21626 被披露。 这个 漏洞评分为 8.6(高)。它允许攻击者让容器逃逸,并读取/写入节点上的任何路径以及同一节点上托管的其他 Pod。
Rodrigo 创建了一个滥用 CVE 2024-21626 的演示, 演示了此漏洞在没有用户命名空间时的工作方式,而在使用用户命名空间后 得到了缓解。
请注意,使用用户命名空间时,攻击者可以在主机文件系统上执行“其他”权限位所允许的操作。 因此,此 CVE 并没有完全被修复,但影响大大降低。
节点系统要求
使用此特性对 Linux 内核版本和容器运行时有一些要求。
在 Linux 上,你需要 Linux 6.3 或更高版本。 这是因为此特性依赖于一个名为 idmap 挂载的内核特性,而支持 idmap 挂载与 tmpfs 一起使用的特性是在 Linux 6.3 中合并的。
假设你使用 CRI-O 和 crun;就像往常一样,你可以期待 CRI-O 1.30 支持 Kubernetes 1.30。 请注意,你还需要 crun 1.9 或更高版本。如果你使用的是 CRI-O 和 runc,则仍然不支持用户命名空间。
containerd 对此特性的支持目前锁定为 containerd 2.0,同样 crun 也有适用的版本要求。 如果你使用的是 containerd 和 runc,则仍然不支持用户命名空间。
请注意,正如在 Kubernetes 1.25 和 1.26 中实现的那样,containerd 1.7 增加了对用户命名空间的实验性支持。 我们曾在 Kubernetes 1.27 中进行了重新设计,所以容器运行时需要做一些变更。 而 containerd 1.7 并未包含这些变更,所以它仅在 Kubernetes 1.25 和 1.26 中支持使用用户命名空间。
containerd 1.7 的另一个限制是,它需要在 Pod 启动期间变更容器镜像内的每个文件和目录的所有权。 这会增加存储开销,并可能显著影响容器启动延迟。containerd 2.0 可能会包含一个实现,以消除增加的启动延迟和存储开销。 如果你计划在生产环境中使用 containerd 1.7 和用户命名空间,请考虑这一点。
containerd 1.7 的这些限制均不适用于 CRI-O。
如何参与?
你可以通过以下方式联系 SIG Node:
你也可以通过以下方式直接联系我们:
- GitHub:@rata @giuseppe @saschagrunert
- Slack:@rata @giuseppe @sascha