Kubernetes 博客
- Kubernetes v1.32:内存管理器进阶至 GA
- Kubernetes v1.32 预览
- 关于日本的 Kubernetes 上游培训的特别报道
- 公布 2024 年指导委员会选举结果
- SIG Scheduling 访谈
- Kubernetes v1.31:kubeadm v1beta4
- Kubernetes 1.31:kubectl debug 中的自定义模板化配置特性已进入 Beta 阶段
- Kubernetes 1.31:细粒度的 SupplementalGroups 控制
- Kubernetes v1.31:全新的 Kubernetes CPUManager 静态策略:跨核分发 CPU
- Kubernetes 1.31: 节点 Cgroup 驱动程序的自动配置 (beta)
- Kubernetes 1.31:流式传输从 SPDY 转换为 WebSocket
- Kubernetes 1.31:针对 Job 的 Pod 失效策略进阶至 GA
- Kubernetes 1.31:podAffinity 中的 matchLabelKeys 进阶至 Beta
- Kubernetes 1.31:防止无序删除时 PersistentVolume 泄漏
- Kubernetes 1.31:基于 OCI 工件的只读卷 (Alpha)
- Kubernetes 1.31:通过 VolumeAttributesClass 修改卷进阶至 Beta
- Kubernetes 1.31:对 cgroup v1 的支持转为维护模式
- Kubernetes v1.31: Elli
- 向 Client-Go 引入特性门控:增强灵活性和控制力
- 聚焦 SIG API Machinery
- Kubernetes v1.31 中的移除和主要变更
- Kubernetes 的十年
- 完成 Kubernetes 史上最大规模迁移
- Gateway API v1.1:服务网格、GRPCRoute 和更多变化
- Kubernetes 1.30:防止未经授权的卷模式转换进阶到 GA
- Kubernetes 1.30:结构化身份认证配置进阶至 Beta
- Kubernetes 1.30:验证准入策略 ValidatingAdmissionPolicy 正式发布
- Kubernetes 1.30:只读卷挂载终于可以真正实现只读了
- Kubernetes 1.30:对 Pod 使用用户命名空间的支持进阶至 Beta
- SIG Architecture 特别报道:代码组织
- Kubernetes v1.30 初探
- 走进 Kubernetes 读书会(Book Club)
- 镜像文件系统:配置 Kubernetes 将容器存储在独立的文件系统上
- Kubernetes 1.29 中的上下文日志生成:更好的故障排除和增强的日志记录
- Kubernetes 1.29: 解耦污点管理器与节点生命周期控制器
- Kubernetes 1.29:PodReadyToStartContainers 状况进阶至 Beta
- Kubernetes 1.29 新的 Alpha 特性:Service 的负载均衡器 IP 模式
- Kubernetes 1.29:修改卷之 VolumeAttributesClass
- 聚焦 SIG Testing
- Kubernetes 1.29 中的移除、弃用和主要变更
- 介绍 SIG etcd
- Gateway API v1.0:正式发布(GA)
- Kubernetes 中 PersistentVolume 的最后阶段转换时间
- 2023 中国 Kubernetes 贡献者峰会简要回顾
- CRI-O 正迁移至 pkgs.k8s.io
- 聚焦 SIG Architecture: Conformance
- 公布 2023 年指导委员会选举结果
- kubeadm 七周年生日快乐!
- kubeadm:使用 etcd Learner 安全地接入控制平面节点
- 用户命名空间:对运行有状态 Pod 的支持进入 Alpha 阶段!
- 比较本地 Kubernetes 开发工具:Telepresence、Gefyra 和 mirrord
- Kubernetes 旧版软件包仓库将于 2023 年 9 月 13 日被冻结
- Gateway API v0.8.0:引入服务网格支持
- Kubernetes 1.28:用于改进集群安全升级的新(Alpha)机制
- Kubernetes v1.28:介绍原生边车容器
- Kubernetes 1.28:在 Linux 上使用交换内存的 Beta 支持
- Kubernetes 1.28:节点 podresources API 正式发布
- Kubernetes 1.28:Job 失效处理的改进
- Kubernetes v1.28:可追溯的默认 StorageClass 进阶至 GA
- Kubernetes 1.28: 节点非体面关闭进入 GA 阶段(正式发布)
- pkgs.k8s.io:介绍 Kubernetes 社区自有的包仓库
- 聚焦 SIG CLI
- Kubernetes 机密:使用机密虚拟机和安全区来增强你的集群安全性
- 在 CRI 运行时内验证容器镜像签名
- dl.k8s.io 采用内容分发网络(CDN)
- 使用 OCI 工件为 seccomp、SELinux 和 AppArmor 分发安全配置文件
- 在边缘上玩转 seccomp 配置文件
- Kubernetes 1.27: KMS V2 进入 Beta 阶段
- Kubernetes 1.27:关于加快 Pod 启动的进展
- Kubernetes 1.27: 原地调整 Pod 资源 (alpha)
- Kubernetes 1.27:为 NodePort Service 分配端口时避免冲突
- Kubernetes 1.27:kubectl apply 裁剪更安全、更高效
- Kubernetes 1.27:介绍用于磁盘卷组快照的新 API
- Kubernetes 1.27:内存资源的服务质量(QoS)Alpha
- Kubernetes 1.27: StatefulSet PVC 自动删除(beta)
- Kubernetes 1.27:HorizontalPodAutoscaler ContainerResource 类型指标进阶至 Beta
- Kubernetes 1.27: StatefulSet 启动序号简化了迁移
- 官方自动刷新 CVE 订阅源的更新
- Kubernetes 1.27:服务器端字段校验和 OpenAPI V3 进阶至 GA
- Kubernetes 1.27: 使用 Kubelet API 查询节点日志
- Kubernetes 1.27:持久卷的单个 Pod 访问模式升级到 Beta
- Kubernetes 1.27:高效的 SELinux 卷重新标记(Beta 版)
- Kubernetes 1.27:更多精细粒度的 Pod 拓扑分布策略进阶至 Beta
- “使用更新后的 Go 版本保持 Kubernetes 安全”
- Kubernetes 验证准入策略:一个真实示例
- Kubernetes 在 v1.27 中移除的特性和主要变更
- k8s.gcr.io 重定向到 registry.k8s.io - 用户须知
- Kubernetes 的容器检查点分析
- 介绍 KWOK(Kubernetes WithOut Kubelet,没有 Kubelet 的 Kubernetes)
- 免费的 Katacoda Kubernetes 教程即将关闭
- k8s.gcr.io 镜像仓库将从 2023 年 4 月 3 日起被冻结
- 聚光灯下的 SIG Instrumentation
- 考虑所有微服务的脆弱性并对其行为进行监控
- 使用 PriorityClass 确保你的关键任务 Pod 免遭驱逐
- Kubernetes 1.26:PodDisruptionBudget 守护的不健康 Pod 所用的驱逐策略
- Kubernetes v1.26:可追溯的默认 StorageClass
- Kubernetes v1.26:对跨名字空间存储数据源的 Alpha 支持
- Kubernetes v1.26:Kubernetes 中流量工程的进步
- Kubernetes v1.26:CPUManager 正式发布
- Kubernetes 1.26:Pod 调度就绪态
- Kubernetes 1.26: 支持在挂载时将 Pod fsGroup 传递给 CSI 驱动程序
- Kubernetes 1.26:设备管理器正式发布
- Kubernetes 1.26: 节点非体面关闭进入 Beta 阶段
- Kubernetes 1.26: 动态资源分配 Alpha API
- Kubernetes 1.26: 我们现在正在对二进制发布工件进行签名!
- Kubernetes 的取证容器检查点
- Kubernetes 1.26 中的移除、弃用和主要变更
- Kueue 介绍
- “Kubernetes 1.25:对使用用户名字空间运行 Pod 提供 Alpha 支持”
- Kubernetes 1.25:应用滚动上线所用的两个特性进入稳定阶段
- Kubernetes 1.25:Pod 新增 PodHasNetwork 状况
- 宣布自动刷新官方 Kubernetes CVE 订阅源
- Kubernetes 的 iptables 链不是 API
- COSI 简介:使用 Kubernetes API 管理对象存储
- Kubernetes 1.25: cgroup v2 升级到 GA
- Kubernetes 1.25:CSI 内联存储卷正式发布
- PodSecurityPolicy:历史背景
- Kubernetes v1.25: Combiner
- 聚焦 SIG Storage
- 认识我们的贡献者 - 亚太地区(中国地区)
- 逐个 KEP 地增强 Kubernetes
- Kubernetes 1.25 的移除说明和主要变更
- 聚光灯下的 SIG Docs
- Kubernetes Gateway API 进入 Beta 阶段
- 2021 年度总结报告
- Kubernetes 1.24: StatefulSet 的最大不可用副本数
- Kubernetes 1.24 中的上下文日志记录
- Kubernetes 1.24: 避免为 Services 分配 IP 地址时发生冲突
- Kubernetes 1.24: 节点非体面关闭特性进入 Alpha 阶段
- Kubernetes 1.24: 防止未经授权的卷模式转换
- Kubernetes 1.24: 卷填充器功能进入 Beta 阶段
- Kubernetes 1.24:gRPC 容器探针功能进入 Beta 阶段
- Kubernetes 1.24 版本中存储容量跟踪特性进入 GA 阶段
- Kubernetes 1.24:卷扩充现在成为稳定功能
- Dockershim:历史背景
- Kubernetes 1.24: 观星者
- Frontiers, fsGroups and frogs: Kubernetes 1.23 发布采访
- 在 Ingress-NGINX v1.2.0 中提高安全标准
- Kubernetes 1.24 中的移除和弃用
- 你的集群准备好使用 v1.24 版本了吗?
- 认识我们的贡献者 - 亚太地区(澳大利亚-新西兰地区)
- 更新:移除 Dockershim 的常见问题
- SIG Node CI 子项目庆祝测试改进两周年
- 关注 SIG Multicluster
- 确保准入控制器的安全
- 认识我们的贡献者 - 亚太地区(印度地区)
- Kubernetes 即将移除 Dockershim:承诺和下一步
- Security Profiles Operator v0.4.0 中的新功能
- Kubernetes 1.23: StatefulSet PVC 自动删除 (alpha)
- Kubernetes 1.23:树内存储向 CSI 卷迁移工作的进展更新
- Kubernetes 1.23:IPv4/IPv6 双协议栈网络达到 GA
- 公布 2021 年指导委员会选举结果
- 关注 SIG Node
- 更新 NGINX-Ingress 以使用稳定的 Ingress API
- 聚焦 SIG Usability
- 卷健康监控的 Alpha 更新
- 弃用 PodSecurityPolicy:过去、现在、未来
- 一个编排高可用应用的 Kubernetes 自定义调度器
- Kubernetes 1.20:CSI 驱动程序中的 Pod 身份假扮和短时卷
- Kubernetes 1.20: 最新版本
- 别慌: Kubernetes 和 Docker
- 弃用 Dockershim 的常见问题
- 为开发指南做贡献
- 结构化日志介绍
- 警告: 有用的预警
- Docsy 带来更好的 Docs UX
- Kubernetes 1.18: Fit & Finish
- 基于 MIPS 架构的 Kubernetes 方案
- Kubernetes 1.17:稳定
- 使用 Java 开发一个 Kubernetes controller
- 使用 Microk8s 在 Linux 上本地运行 Kubernetes
- Kubernetes 文档最终用户调研
- 圣迭戈贡献者峰会日程公布!
- 2019 指导委员会选举结果
- San Diego 贡献者峰会开放注册!
- 机器可以完成这项工作,一个关于 kubernetes 测试、CI 和自动化贡献者体验的故事
- OPA Gatekeeper:Kubernetes 的策略和管理
- 欢迎参加在上海举行的贡献者峰会
- 壮大我们的贡献者研讨会
- 如何参与 Kubernetes 文档的本地化工作
- 使用 Kubernetes 设备插件和 RuntimeClass 在 Ingress 控制器中实现硬件加速 SSL/TLS 终止
- Kubernetes 1.14 稳定性改进中的进程ID限制
- Raw Block Volume 支持进入 Beta
- 新贡献者工作坊上海站
- Kubernetes 文档更新,国际版
- Kubernetes 2018 年北美贡献者峰会
- 2018 年督导委员会选举结果
- Kubernetes 中的拓扑感知数据卷供应
- Kubernetes v1.12: RuntimeClass 简介
- KubeDirector:在 Kubernetes 上运行复杂状态应用程序的简单方法
- 在 Kubernetes 上对 gRPC 服务器进行健康检查
- 使用 CSI 和 Kubernetes 实现卷的动态扩容
- 使用 Kubernetes 调整 PersistentVolume 的大小
- 动态 Kubelet 配置
- 用于 Kubernetes 集群 DNS 的 CoreDNS GA 正式发布
- 基于 IPVS 的集群内部负载均衡
- Airflow 在 Kubernetes 中的使用(第一部分):一种不同的操作器
- Kubernetes 的动态 Ingress
- Kubernetes 这四年
- 向 Discuss Kubernetes 问好
- 在 Kubernetes 上开发
- Kubernetes 社区 - 2017 年开源排行榜榜首
- “基于容器的应用程序设计原理”
- Kubernetes 1.9 对 Windows Server 容器提供 Beta 版本支持
- Kubernetes 中自动缩放
- Kubernetes 1.8 的五天
- Kubernetes 社区指导委员会选举结果
- 使用 Kubernetes Pet Sets 和 Datera Elastic Data Fabric 的 FlexVolume 扩展有状态的应用程序
- SIG Apps: 为 Kubernetes 构建应用并在 Kubernetes 中进行运维
- Kubernetes 生日快乐。哦,这是你要去的地方!
- 将端到端的 Kubernetes 测试引入 Azure (第二部分)
- Dashboard - Kubernetes 的全功能 Web 界面
- Citrix + Kubernetes = 全垒打
- 容器中运行有状态的应用!? Kubernetes 1.3 说 “是!”
- CoreOS Fest 2016: CoreOS 和 Kubernetes 在柏林(和旧金山)社区见面会
- SIG-ClusterOps: 提升 Kubernetes 集群的可操作性和互操作性
- “SIG-Networking:1.3 版本引入 Kubernetes 网络策略 API”
- 在 Rancher 中添加对 Kuernetes 的支持
- KubeCon EU 2016:伦敦 Kubernetes 社区
- Kubernetes 社区会议记录 - 20160218
- Kubernetes 社区会议记录 - 20160204
- 容器世界现状,2016 年 1 月
- Kubernetes 社区会议记录 - 20160114
- 为什么 Kubernetes 不用 libnetwork
- Kubernetes 和 Docker 简单的 leader election
- 使用 Puppet 管理 Kubernetes Pod、Service 和 Replication Controller
- Kubernetes 1.1 性能升级,工具改进和社区不断壮大
- Kubernetes 社区每周环聊笔记——2015 年 7 月 31 日
- 宣布首个Kubernetes企业培训课程
- 幻灯片:Kubernetes 集群管理,爱丁堡大学演讲
- OpenStack 上的 Kubernetes
- Kubernetes 社区每周聚会笔记- 2015年5月1日
- 通过 RKT 对 Kubernetes 的 AppC 支持
- Kubernetes 社区每周聚会笔记- 2015年4月24日
- Borg: Kubernetes 的前身
- Kubernetes 社区每周聚会笔记- 2015年4月17日
- Kubernetes Release: 0.15.0
- 每周 Kubernetes 社区例会笔记 - 2015 年 4 月 3 日
- Kubernetes 社区每周聚会笔记 - 2015 年 3 月 27 日
- Kubernetes 采集视频
- 欢迎来到 Kubernetes 博客!
Kubernetes v1.32:内存管理器进阶至 GA
随着 Kubernetes 1.32 的发布,内存管理器已进阶至正式发布(GA), 这标志着在为容器化应用实现高效和可预测的内存分配的旅程中迈出了重要的一步。 内存管理器自 Kubernetes v1.22 进阶至 Beta 后,其可靠性、稳定性已得到证实, 是 CPU 管理器的一个良好补充特性。
作为 kubelet 的工作负载准入过程的一部分,内存管理器提供拓扑提示以优化内存分配和对齐。这使得用户能够为 Guaranteed QoS 类的 Pod 分配独占的内存。 有关此过程的细节,参见博客:内存管理器进阶至 Beta。
自 Beta 以来引入的大部分变更是修复 Bug、内部重构以及改进可观测性(例如优化指标和日志)。
改进可观测性
作为提高内存管理器可观测性工作的一部分,新增了一些指标以提供关于内存分配模式的某些统计信息。
memory_manager_pinning_requests_total - 跟踪 Pod 规约要求内存管理器锁定内存页的次数。
memory_manager_pinning_errors_total - 跟踪 Pod 规约要求内存管理器锁定内存页但分配失败的次数。
提高内存管理器可靠性和一致性
kubelet 不保证在 Pod 重启或重新引导后准入 Pod 的顺序。
在某些边缘情况下,这种行为可能导致内存管理器拒绝某些 Pod, 在更极端的情况下,可能导致 kubelet 在重启时失败。
以前,Beta 实现缺乏某些检查和逻辑来防止这些问题的发生。
为了使内存管理器更为稳定,以便为进阶至正式发布(GA)做好准备, 我们对算法进行了小而美的改进,提高了其稳健性和对边缘场景的处理能力。
未来发展
总体而言,未来对拓扑管理器(Topology Manager),特别是内存管理器,会有更多特性推出。 值得一提的是,目前的工作重心是将内存管理器支持扩展到 Windows, 使得在 Windows 操作系统上实现 CPU 和内存亲和性成为可能。
参与其中
此特性由 SIG Node 社区推动。请加入我们,与社区建立联系,分享你对上述特性及其他方面的想法和反馈。 我们期待听到你的声音!
Kubernetes v1.32 预览
随着 Kubernetes v1.32 发布日期的临近,Kubernetes 项目继续发展和成熟。 在这个过程中,某些特性可能会被弃用、移除或被更好的特性取代,以确保项目的整体健康与发展。
本文概述了 Kubernetes v1.32 发布的一些计划变更,发布团队认为你应该了解这些变更, 以确保你的 Kubernetes 环境得以持续维护并跟上最新的变化。以下信息基于 v1.32 发布的当前状态,实际发布日期前可能会有所变动。
Kubernetes API 的移除和弃用流程
Kubernetes 项目对功能特性有一个文档完备的弃用策略。 该策略规定,只有当较新的、稳定的相同 API 可用时,原有的稳定 API 才可能被弃用,每个稳定级别的 API 都有一个最短的生命周期。 弃用的 API 指的是已标记为将在后续发行某个 Kubernetes 版本时移除的 API; 移除之前该 API 将继续发挥作用(从弃用起至少一年时间),但使用时会显示一条警告。 移除的 API 将在当前版本中不再可用,此时你必须迁移以使用替换的 API。
正式发布的(GA)或稳定的 API 版本可被标记为已弃用,但不得在 Kubernetes 主要版本未变时删除。
Beta 或预发布 API 版本,必须保持在被弃用后 3 个发布版本中仍然可用。
Alpha 或实验性 API 版本可以在任何版本中删除,不必提前通知; 如果同一特性已有不同实施方案,则此过程可能会成为撤销。
无论 API 是因为特性从 Beta 升级到稳定状态还是因为未能成功而被移除, 所有移除操作都遵守此弃用策略。每当 API 被移除时, 迁移选项都会在弃用指南中进行说明。
关于撤回 DRA 的旧的实现的说明
增强特性 #3063 在 Kubernetes 1.26 中引入了动态资源分配(DRA)。
然而,在 Kubernetes v1.32 中,这种 DRA 的实现方法将发生重大变化。与原来实现相关的代码将被删除, 只留下 KEP #4381 作为"新"的基础特性。
改变现有方法的决定源于其与集群自动伸缩的不兼容性,因为资源可用性是不透明的, 这使得 Cluster Autoscaler 和控制器的决策变得复杂。 新增的结构化参数模型替换了原有特性。
这次移除将使 Kubernetes 能够更可预测地处理新的硬件需求和资源声明, 避免了与 kube-apiserver 之间复杂的来回 API 调用。
请参阅增强问题 #3063 以了解更多信息。
API 移除
在 Kubernetes v1.32 中,计划仅移除一个 API:
flowcontrol.apiserver.k8s.io/v1beta3版本的 FlowSchema 和 PriorityLevelConfiguration 已被移除。 为了对此做好准备,你可以编辑现有的清单文件并重写客户端软件,使用自 v1.29 起可用的flowcontrol.apiserver.k8s.io/v1API 版本。 所有现有的持久化对象都可以通过新 API 访问。flowcontrol.apiserver.k8s.io/v1beta3中的重要变化包括: 当未指定时,PriorityLevelConfiguration 的spec.limited.nominalConcurrencyShares字段仅默认为 30,而显式设置的 0 值不会被更改为此默认值。有关更多信息,请参阅 API 弃用指南。
Kubernetes v1.32 的抢先预览
以下增强特性有可能会被包含在 v1.32 发布版本中。请注意,这并不是最终承诺,发布内容可能会发生变化。
更多 DRA 增强特性!
在此次发布中,就像上一次一样,Kubernetes 项目继续提出多项对动态资源分配(DRA)的增强。 DRA 是 Kubernetes 资源管理系统的关键组件,这些增强旨在提高对需要专用硬件(如 GPU、FPGA 和网络适配器) 的工作负载进行资源分配的灵活性和效率。此次发布引入了多项改进,包括在 Pod 状态中添加资源健康状态, 具体内容详见 KEP #4680。
在 Pod 状态中添加资源健康状态
当 Pod 使用的设备出现故障或暂时不健康时,很难及时发现。
KEP #4680
提议通过 Pod 的 status 暴露设备健康状态,从而使 Pod 崩溃的故障排除更加容易。
Windows 工作继续
KEP #4802 为 Kubernetes 集群中的 Windows 节点添加了体面关机支持。 在此之前,Kubernetes 为 Linux 节点提供了体面关机特性,但缺乏对 Windows 节点的同等支持。 这一增强特性使 Windows 节点上的 kubelet 能够正确处理系统关机事件,确保在 Windows 节点上运行的 Pod 能够体面终止, 从而允许工作负载在不受干扰的情况下重新调度。这一改进提高了包含 Windows 节点的集群的可靠性和稳定性, 特别是在计划维护或系统更新期间。
允许环境变量中使用特殊字符
随着这一增强特性升级到 Beta 阶段,
Kubernetes 现在允许几乎所有的可打印 ASCII 字符(不包括 =)作为环境变量名称。
这一变化解决了此前对变量命名的限制,通过适应各种应用需求,促进了 Kubernetes 的更广泛采用。
放宽的验证将通过 RelaxedEnvironmentVariableValidation 特性门控默认启用,
确保用户可以轻松使用环境变量而不受严格限制,增强了开发者在处理需要特殊字符配置的应用(如 .NET Core)时的灵活性。
使 Kubernetes 感知到 LoadBalancer 的行为
KEP #1860 升级到 GA 阶段,
为 type: LoadBalancer 类型的 Service 引入了 ipMode 字段,该字段可以设置为 "VIP" 或 "Proxy"。
这一增强旨在改善云提供商负载均衡器与 kube-proxy 的交互方式,对最终用户来说是透明的。
使用 "VIP" 时,kube-proxy 会继续处理负载均衡,保持现有的行为。使用 "Proxy" 时,
流量将直接发送到负载均衡器,提供云提供商对依赖 kube-proxy 的更大控制权;
这意味着对于某些云提供商,你可能会看到负载均衡器性能的提升。
为资源生成名称时重试
这一增强特性改进了使用
generateName 字段创建 Kubernetes 资源时的名称冲突处理。此前,如果发生名称冲突,
API 服务器会返回 409 HTTP 冲突错误,客户端需要手动重试请求。通过此次更新,
API 服务器在发生冲突时会自动重试生成新名称,最多重试七次。这显著降低了冲突的可能性,
确保生成多达 100 万个名称时冲突的概率低于 0.1%,为大规模工作负载提供了更高的弹性。
想了解更多?
新特性和弃用特性也会在 Kubernetes 发布说明中宣布。我们将在此次发布的 Kubernetes v1.32 的 CHANGELOG 中正式宣布新内容。
你可以在以下版本的发布说明中查看变更公告:
关于日本的 Kubernetes 上游培训的特别报道
我们是日本 Kubernetes 上游培训的组织者。 我们的团队由积极向 Kubernetes 做贡献的成员组成,他们在社区中担任了 Member、Reviewer、Approver 和 Chair 等角色。
我们的目标是增加 Kubernetes 贡献者的数量,并促进社区的成长。 虽然 Kubernetes 社区友好协作,但新手可能会发现迈出贡献的第一步有些困难。 我们的培训项目旨在降低壁垒,创造一个即使是初学者也能顺利参与的环境。
日本 Kubernetes 上游培训是什么?

我们的培训始于 2019 年,每年举办 1 到 2 次。 最初,Kubernetes 上游培训曾作为 KubeCon(Kubernetes 贡献者峰会)的同场地活动进行, 后来我们在日本推出了 Kubernetes 上游培训,目的是通过在日本举办类似活动来增加日本的贡献者。
在疫情之前,培训是面对面进行的,但自 2020 年以来,我们已转为在线上进行。 培训为尚未参与过 Kubernetes 贡献的学员提供以下内容:
- Kubernetes 社区简介
- Kubernetes 代码库概述以及如何创建你的第一个 PR
- 各种降低参与壁垒(如语言)的提示和鼓励
- 如何搭建开发环境
- 使用 kubernetes-sigs/contributor-playground 开展实践课程
在培训开始时,我们讲解为什么贡献 Kubernetes 很重要以及谁可以做贡献。 我们强调,贡献 Kubernetes 可以让你产生全球影响,而 Kubernetes 社区期待着你的贡献!
我们还讲解 Kubernetes 社区、SIG(特别兴趣小组)和 WG(工作组)。 接下来,我们讲解 Member、Reviewer、Approver、Tech Lead 和 Chair 的角色与职责。 此外,我们介绍大家所使用的主要沟通工具,如 Slack、GitHub 和邮件列表。 一些讲日语的人可能会觉得用英语沟通是一个障碍。 此外,社区的新人需要理解在哪儿以及如何与人交流。 我们强调迈出第一步的重要性,这是我们培训中最关注的方面!
然后,我们讲解 Kubernetes 代码库的结构、主要的仓库、如何创建 PR 以及使用 Prow 的 CI/CD 流程。 我们详细讲解从创建 PR 到合并 PR 的过程。
经过几节课后,参与者将体验使用 kubernetes-sigs/contributor-playground 开展实践工作,在那里他们可以创建一个简单的 PR。 目标是让参与者体验贡献 Kubernetes 的过程。
在项目结束时,我们还提供关于为贡献 kubernetes/kubernetes 仓库搭建开发环境的详细说明,
包括如何在本地构建代码、如何高效运行测试以及如何搭建集群。
与参与者的访谈
我们对参与我们培训项目的人进行了访谈。 我们询问了他们参加的原因、印象和未来目标。
Keita Mochizuki(NTT DATA 集团公司)
Keita Mochizuki 是一位持续为 Kubernetes 及相关项目做贡献的贡献者。 他还是容器安全领域的专业人士,他最近出版了一本书。此外, 他还发布了一份新贡献者路线图, 对新贡献者非常有帮助。
Junya: 你为什么决定参加 Kubernetes 上游培训?
Keita: 实际上,我分别在 2020 年和 2022 年参加过两次培训。 在 2020 年,我刚开始学习 Kubernetes,想尝试参与工作以外的活动, 所以在 Twitter 上偶然看到活动后报了名参加了活动。 然而,那时我的知识积累还不多,贡献 OSS 感觉超出了我的能力。 因此,在培训后的理解比较肤浅,离开时更多是“嗯,好吧”的感觉。
在 2022 年,我再次参加,那时我认真考虑开始贡献。 我事先进行了研究,并能够在讲座中解决我的问题,那次经历非常有成效。
Junya: 参加后你有什么感受?
Keita: 我觉得培训的意义很大程度上取决于参与者的心态。 培训本身包括常规的讲解和简单的实践练习,但这并不意味着参加培训就会立即会去做贡献。
Junya: 你贡献的目的是什么?
Keita: 我最初的动机是“深入理解 Kubernetes 并生成成绩记录”,也就是说“贡献本身就是目标”。 如今,我还会通过贡献来解决我在工作中发现的 Bug 或约束。 此外,通过贡献,我变得不再那么犹豫,会去直接基于源代码分析了解没有文档记录的特性。
Junya: 贡献中遇到的挑战是什么?
Keita: 最困难的部分是迈出第一步。贡献 OSS 需要一定的知识水平,利用像这样的培训和他人的支持至关重要。
一句让我印象深刻的话是,“一旦你迈出第一步,后续就会变得更容易。”
此外,在作为工作的一部分继续贡献时,最具挑战性的是将输出的结果变为成就感。
要保持长期贡献,将贡献与业务目标和策略对齐非常重要,但上游贡献并不总是能直接产生与表现相关的即时结果。
因此,确保与管理人员的相互理解并获得他们的支持至关重要。
Junya: 你未来的目标是什么?
Keita: 我的目标是对影响更大的领域做出贡献。 到目前为止,我主要通过修复较小的 Bug 来做贡献,因为我的主要关注是生成一份成绩单, 但未来,我希望挑战自己对 Kubernetes 用户产生更大影响的贡献,或解决与我工作相关的问题。 最近,我还在努力将我对代码库所做的更改反映到官方文档中, 我将这视为实现我目标的一步。
Junya: 非常感谢!
Yoshiki Fujikane(CyberAgent, Inc.)
Yoshiki Fujikane 是 CNCF 沙盒项目 PipeCD 的维护者之一。 除了在 PipeCD 中开发对 Kubernetes 支持的新特性外, Yoshiki 还积极参与社区管理,并在各种技术会议上发言。
Junya: 你为什么决定参加 Kubernetes 上游培训?
Yoshiki: 当我参与培训时,我还是一名学生。 我只简短地接触过 EKS,我觉得 Kubernetes 看起来复杂但很酷,我对此有一种随意的兴趣。 当时,OSS 对我来说感觉像是遥不可及,而 Kubernetes 的上游开发似乎非常令人生畏。 虽然我一直对 OSS 感兴趣,但我不知道从哪里开始。 也就在那个时候,我了解到 Kubernetes 上游培训,并决定挑战自己为 Kubernetes 做贡献。
Junya: 参加后你的印象是什么?
Yoshiki: 我发现对于了解如何成为 OSS 社区的一部分,这种培训是一种非常有价值的方式。 当时,我的英语水平不是很好,所以获取主要信息源对我来说是一个很大的障碍。 Kubernetes 是一个非常大的项目,我对整体结构没有清晰的理解,更不用说贡献所需的内容了。 上游培训提供了对社区结构的日文解释,并让我获得了实际贡献的实践经验。 得益于我所得到的指导,我学会了如何接触主要信息源,并将其作为进一步研究的切入点,这对我帮助很大。 这次经历让我意识到组织和评审主要信息源的重要性,现在我经常在 GitHub Issue 和文档中深入研究我感兴趣的内容。 因此,虽然我不再直接向 Kubernetes 做贡献,但这次经历为我在其他项目中做贡献奠定了很好的基础。
Junya: 你目前在哪些领域做贡献?你参与了哪些其他项目?
Yoshiki: 目前,我不再从事 Kubernetes 的工作,而是担任 CNCF 沙盒项目 PipeCD 的维护者。 PipeCD 是一个支持各种应用平台的 GitOps 式部署的 CD 工具。 此工具最初作为 CyberAgent 的内部项目启动。 随着不同团队采用不同的平台,PipeCD 设计为提供一个统一的 CD 平台,确保用户体验一致。 目前,它支持 Kubernetes、AWS ECS、Lambda、Cloud Run 和 Terraform。
Junya: 你在 PipeCD 团队中扮演什么角色?
Yoshiki: 我全职负责团队中与 Kubernetes 相关特性的改进和开发。 由于我们将 PipeCD 作为内部 SaaS 提供,我的主要关注点是添加新特性和改进现有特性, 确保 PipeCD 能够持续良好支持 Kubernetes 等平台。 除了代码贡献外,我还通过在各种活动上发言和管理社区会议来帮助发展 PipeCD 社区。
Junya: 你能讲解一下你对于 Kubernetes 正在进行哪些改进或开发吗?
Yoshiki: PipeCD 支持 Kubernetes 的 GitOps 和渐进式交付,因此我参与这些特性的开发。 最近,我一直在开发简化跨多个集群部署的特性。
Junya: 在贡献 OSS 的过程中,你遇到过哪些挑战?
Yoshiki: 一个挑战是开发在满足用户用例的同时保持通用性的特性。 当我们在运营内部 SaaS 期间收到特性请求时,我们首先考虑添加特性来解决这些问题。 与此同时,我们希望 PipeCD 作为一个 OSS 工具被更广泛的受众使用。 因此,我总是思考为一个用例设计的特性是否可以应用于其他用例,以确保 PipeCD 这个软件保持灵活且广泛可用。
Junya: 你未来的目标是什么?
Yoshiki: 我希望专注于扩展 PipeCD 的功能。 目前,我们正在以“普遍可用的持续交付”(One CD for All)的口号开发 PipeCD。 正如我之前提到的,它支持 Kubernetes、AWS ECS、Lambda、Cloud Run 和 Terraform, 但还有许多其他平台,以及未来可能会出现的新平台。 因此,我们目前正在开发一个插件系统,允许用户自行扩展 PipeCD,我希望将这一努力向前推进。 我也在处理 Kubernetes 的多集群部署特性,目标是继续做出有影响力的贡献。
Junya: 非常感谢!
Kubernetes 上游培训的未来
我们计划继续在日本举办 Kubernetes 上游培训,并期待欢迎更多的新贡献者。 我们的下一次培训定于 11 月底在 CloudNative Days Winter 2024 期间举行。
此外,我们的目标不仅是在日本推广这些培训项目,还希望推广到全球。 今年的 Kubernetes 十周年庆, 以及为了使社区更加活跃,让全球各地的人们持续贡献至关重要。 虽然上游培训已经在多个地区举行,但我们希望将其带到更多地方。
我们希望随着越来越多的人加入 Kubernetes 社区并做出贡献,我们的社区将变得更加生机勃勃!
公布 2024 年指导委员会选举结果
2024 年指导委员会选举现已完成。 Kubernetes 指导委员会由 7 个席位组成,其中 3 个席位于 2024 年进行选举。 新任委员会成员的任期为 2 年,所有成员均由 Kubernetes 社区选举产生。
这个社区机构非常重要,因为它负责监督整个 Kubernetes 项目的治理。 权力越大责任越大,你可以在其 章程中了解有关指导委员会角色的更多信息。
感谢所有在选举中投票的人;你们的参与有助于支持社区的持续健康和成功。
结果
祝贺当选的委员会成员,其两年任期立即开始(按 GitHub 句柄按字母顺序列出):
- Antonio Ojea (@aojea), Google
- Benjamin Elder (@BenTheElder), Google
- Sascha Grunert (@saschagrunert), Red Hat
他们将与以下连任成员一起工作:
- Stephen Augustus (@justaugustus), Cisco
- Paco Xu 徐俊杰 (@pacoxu), DaoCloud
- Patrick Ohly (@pohly), Intel
- Maciej Szulik (@soltysh), Defense Unicorns
Benjamin Elder 是一位回归的指导委员会成员。
十分感谢!
感谢并祝贺本轮选举官员成功完成选举工作:
- Bridget Kromhout (@bridgetkromhout)
- Christoph Blecker (@cblecker)
- Priyanka Saggu (@Priyankasaggu11929)
感谢名誉指导委员会成员,你们的服务受到社区的赞赏:
- Bob Killen (@mrbobbytables)
- Nabarun Pal (@palnabarun)
感谢所有前来竞选的候选人。
参与指导委员会
这个管理机构与所有 Kubernetes 一样,向所有人开放。 你可以关注指导委员会会议记录, 并通过提交 Issue 或针对其 repo 创建 PR 来参与。 他们在太平洋时间每月第一个周一上午 8:00 举行开放的会议。 你还可以通过其公共邮件列表 steering@kubernetes.io 与他们联系。
你可以通过在 YouTube 播放列表上观看过去的会议来了解指导委员会会议的全部内容。
如果你想认识一些新当选的指导委员会成员, 欢迎参加在盐湖城举行的 2024 年北美 Kubernetes 贡献者峰会上的 Steering AMA。
这篇文章是由贡献者通信子项目撰写的。 如果你想撰写有关 Kubernetes 社区的故事,请了解有关我们的更多信息。
SIG Scheduling 访谈
在本次 SIG Scheduling 的访谈中,我们与 Kensei Nakada 进行了交流,他是 SIG Scheduling 的一名 Approver。
介绍
Arvind: 你好,感谢你让我们有机会了解 SIG Scheduling! 你能介绍一下自己,告诉我们你的角色以及你是如何参与 Kubernetes 的吗?
Kensei: 嗨,感谢你给我这个机会!我是 Kensei Nakada (@sanposhiho),是来自 Tetrate.io 的一名软件工程师。 我在业余时间为 Kubernetes 贡献了超过 3 年的时间,现在我是 Kubernetes 中 SIG Scheduling 的一名 Approver。 同时,我还是两个 SIG 子项目的创始人/负责人: kube-scheduler-simulator 和 kube-scheduler-wasm-extension。
关于 SIG Scheduling
AP: 太棒了!你参与这个项目已经很久了。你能简要概述一下 SIG Scheduling,并说明它在 Kubernetes 生态系统中的角色吗?
KN: 正如名字所示,我们的责任是增强 Kubernetes 中的调度特性。 具体来说,我们开发了一些组件,将每个 Pod 调度到最合适的 Node。 在 Kubernetes 中,我们的主要关注点是维护 kube-scheduler, 以及其他调度相关的组件,这些组件是 SIG Scheduling 的子项目。
AP: 明白了!我有点好奇,SIG Scheduling 最近为 Kubernetes 调度引入了哪些创新或发展?
KN: 从特性的角度来看,最近对 PodTopologySpread
进行了几项增强。
PodTopologySpread 是调度器中一个相对较新的特性,我们仍在收集反馈并进行改进。
最近,我们专注于一个内部增强特性,称为 QueueingHint, 这个特性旨在提高调度的吞吐量。吞吐量是我们调度中的关键指标之一。传统上,我们主要关注优化每个调度周期的延迟。 而 QueueingHint 采取了一种不同的方法,它可以优化何时重试调度,从而减少浪费调度周期的可能性。
A: 听起来很有趣!你目前在 SIG Scheduling 中还有其他有趣的主题或项目吗?
KN: 我正在牵头刚刚提到的 QueueingHint 的开发。考虑到这是我们面临的一项重大新挑战,
我们遇到了许多意想不到的问题,特别是在可扩展性方面,我们正在努力解决每一个问题,使这项特性最终能够默认启用。
此外,我认为我去年启动的 kube-scheduler-wasm-extension(SIG 子项目) 对许多人来说也会很有趣。Kubernetes 有各种扩展来自许多组件。传统上,扩展通过 Webhook (调度器中的 extender)或 Go SDK(调度器中的调度框架)提供。 然而,这些方法存在缺点,首先是 Webhook 的性能问题以及需要重建和替换调度器的 Go SDK,这就给那些希望扩展调度器但对其不熟悉的人带来了困难。 此项目尝试引入一种新的解决方案来应对这一普遍挑战,即基于 WebAssembly 的扩展。 Wasm 允许用户轻松构建插件,而无需担心重新编译或替换调度器,还能规避性能问题。
通过这个项目,SIG Scheduling 正在积累 WebAssembly 与大型 Kubernetes 对象交互的宝贵洞察。 我相信我们所获得的经验应该对整个社区都很有用,而不仅限于 SIG Scheduling 的范围。
A: 当然!目前 SIG Scheduling 有 8 个子项目。你想谈谈它们吗?有没有一些你想强调的有趣贡献?
KN: 让我挑选三个子项目:Kueue、KWOK 和 Descheduler。
- Kueue:
- 最近,许多人尝试使用 Kubernetes 管理批处理工作负载,2022 年,Kubernetes 社区成立了 WG-Batch, 以更好地支持 Kubernetes 中的此类批处理工作负载。 Kueue 是一个在其中扮演关键角色的项目。 它是一个作业队列控制器,决定何时一个作业应该等待,何时一个作业应该被准许启动,以及何时一个作业应该被抢占。 Kueue 旨在安装在一个普通的 Kubernetes 集群上, 同时与现有的成熟控制器(调度器、cluster-autoscaler、kube-controller-manager 等)协作。
- KWOK
- KWOK 这个组件可以在几秒钟内创建一个包含数千个节点的集群。它主要用于模拟/测试轻量级集群,实际上另一个 SIG 子项目 kube-scheduler-simulator 就在后端使用了 KWOK。
- Descheduler
- Descheduler 这个组件可以将运行在不理想的节点上的 Pod 重新创建。
在 Kubernetes 中,调度约束(
PodAffinity、NodeAffinity、PodTopologySpread等)仅在 Pod 调度时被考虑, 但不能保证这些约束在之后仍然被满足。Descheduler 会驱逐违反其调度约束(或其他不符合预期状况)的 Pod, 以便这些 Pod 被重新创建和重新调度。
- Descheduling Framework:
- 一个非常有趣的正在进行的项目,类似于调度器中的调度框架, 旨在使去调度逻辑可扩展,并允许维护者们专注于构建 Descheduler 的核心引擎。
AP: 感谢你告诉我们这些!我想问一下,你最喜欢这个 SIG 的哪些方面?
KN: 我真正喜欢这个 SIG 的地方在于每个人都积极参与。 我们来自不同的公司和行业,带来了多样的视角。 这些差异并没有造成分歧,实际上产生了丰富的观点。 每种观点都会受到尊重,这使我们的讨论既丰富又富有成效。
我非常欣赏这种协作氛围,我相信这对我们多年来不断改进组件至关重要。
给 SIG Scheduling 做贡献
AP: Kubernetes 是一个社区驱动的项目。你对新贡献者或希望参与并为 SIG Scheduling 做出贡献的初学者有什么建议?他们应该从哪里开始?
KN: 让我先给出一个关于为任何 SIG 贡献的通用建议:一种常见的方法是寻找 good-first-issue。 然而,你很快就会意识到,世界各地有很多人正在尝试为 Kubernetes 仓库做贡献。
我建议先查看你感兴趣的某个组件的实现。如果你对该组件有任何疑问,可以在相应的 Slack 频道中提问(例如,调度器的 #sig-scheduling,kubelet 的 #sig-node 等)。 一旦你对实现有了大致了解,就可以查看 SIG 中的 Issue (例如,sig-scheduling), 相比 good-first-issue,在这里你会发现更多未分配的 Issue。你可能还想过滤带有 kind/cleanup 标签的 Issue,这通常表示较低优先级的任务,可以作为起点。
具体对于 SIG Scheduling 而言,你应该先了解调度框架, 这是 kube-scheduler 的基本架构。大多数实现都可以在 pkg/scheduler中找到。我建议从 ScheduleOne 函数开始,然后再深入探索。
此外,除了 kubernetes/kubernetes 主仓库外,还可以考虑查看一些子项目。 这些子项目的维护者通常比较少,你有更多的机会来对其产生重大影响。尽管被称为“子”项目, 但许多项目实际上有大量用户,并对社区产生了相当大的影响。
最后但同样重要的是,记住为社区做贡献不仅仅是编写代码。 虽然我谈到了很多关于实现的贡献,但还有许多其他方式可以做贡献,每一种都很有价值。 对某个 Issue 的一条评论,对现有特性的一个反馈,对 PR 的一个审查建议,对文档的一个说明阐述; 每一个小贡献都有助于推动 Kubernetes 生态系统向前发展。
AP: 这些建议非常有用!冒昧问一下,你是如何帮助新贡献者入门的,参与 SIG Scheduling 的贡献者可能会学习到哪些技能?
KN: 我们的维护者在 #sig-scheduling Slack 频道中随时可以回答你的问题。 多多参与,你将深入了解 Kubernetes 的调度,并有机会与来自不同背景的维护者合作和建立联系。 你将学习到的不仅仅是如何编写代码,还有如何维护大型项目、设计和讨论新特性、解决 Bug 等等。
未来方向
AP: 在调度方面,Kubernetes 特有的挑战有哪些?有没有特别的痛点?
KN: 在 Kubernetes 中进行调度可能相当具有挑战性,因为不同组织有不同的业务要求。 在 kube-scheduler 中支持所有可能的使用场景是不可能的。因此,可扩展性是我们关注的核心焦点。 几年前,我们使用调度框架为 kube-scheduler 重新设计了架构,为用户通过插件实现各种调度需求提供了灵活的可扩展性。 这使得维护者们能够专注于核心调度特性和框架运行时。
另一个主要问题是保持足够的调度吞吐量。通常,一个 Kubernetes 集群只有一个 kube-scheduler, 因此其吞吐量直接影响整体调度的可扩展性,从而影响集群的可扩展性。尽管我们有一个内部性能测试 (scheduler_perf), 但不巧的是,我们有时会忽视在不常见场景下的性能下降。即使是与性能无关的小改动也有难度,可能导致性能下降。
AP: 接下来 SIG Scheduling 有哪些即将实现的目标或计划?你如何看待 SIG 的未来发展?
KN: 我们的主要目标始终是构建和维护可扩展的和稳定的调度运行时,我敢打赌这个目标将永远不会改变。
正如之前所提到的,可扩展性是解决调度多样化需求挑战的关键。我们不会尝试直接在 kube-scheduler 中支持每种不同的使用场景, 而是将继续专注于增强可扩展性,以便能够适应各种用例。我提到的 kube-scheduler-wasm-extension 也是这一计划的一部分。
关于稳定性,引入 QueueHint 这类新的优化是我们的一项策略。 此外,保持吞吐量也是面向未来的关键目标。我们计划增强我们的吞吐量监控 (参考), 以便在发布之前尽可能多地发现性能下降问题。但实际上,我们无法覆盖每个可能的场景。 我们非常感谢社区对调度吞吐量的关注,鼓励大家提出反馈,就性能问题提出警示!
结束语
AP: 最后,你想对那些有兴趣了解 SIG Scheduling 的人说些什么?
KN: 调度是 Kubernetes 中最复杂的领域之一,你可能一开始会觉得很困难。但正如我之前分享的, 你可以找到许多贡献的机会,许多维护者愿意帮助你理解各事项。 我们知道你独特的视角和技能是我们的开源项目能够如此强大的源泉 😊
随时可以通过 Slack (#sig-scheduling) 或会议联系我们。 我希望这篇文章能引起大家的兴趣,希望能吸引到新的贡献者!
AP: 非常感谢你抽出时间进行这次访谈!我相信很多人会发现这些信息对理解 SIG Scheduling 和参与 SIG 的贡献非常有价值。
Kubernetes v1.31:kubeadm v1beta4
作为 Kubernetes v1.31 发布的一部分,kubeadm
采用了全新版本(v1beta4)的配置文件格式。
之前 v1beta3 格式的配置现已正式弃用,这意味着尽管之前的格式仍然受支持,但你应迁移到 v1beta4 并停止使用已弃用的格式。
对 v1beta3 配置的支持将在至少 3 次 Kubernetes 次要版本发布后被移除。
在本文中,我将介绍关键的变更;我将解释 kubeadm v1beta4 配置格式,以及如何从 v1beta3 迁移到 v1beta4。
你可以参阅 v1beta4 配置格式的参考文档: kubeadm 配置 (v1beta4)。
自 v1beta3 以来的变更列表
此版本通过修复一些小问题并添加一些新字段来改进 v1beta3 格式。
简单而言,
- 增加了两个新的配置元素:ResetConfiguration 和 UpgradeConfiguration
- 对于 InitConfiguration 和 JoinConfiguration,支持
dryRun模式和nodeRegistration.imagePullSerial - 对于 ClusterConfiguration,新增字段包括
certificateValidityPeriod、caCertificateValidityPeriod、encryptionAlgorithm、dns.disabled和proxy.disabled - 所有控制平面组件支持
extraEnvs extraArgs从映射变更为支持重复的结构化额外参数- 为 init、join、upgrade 和 reset 添加了
timeouts结构
有关细节请参阅以下官方文档:
- 在
ClusterConfiguration下支持控制平面组件的自定义环境变量。 可以使用apiServer.extraEnvs、controllerManager.extraEnvs、scheduler.extraEnvs、etcd.local.extraEnvs。 - ResetConfiguration API 类型现在在 v1beta4 中得到支持。用户可以通过将
--config文件传递给kubeadm reset来重置节点。 dryRun模式现在在 InitConfiguration 和 JoinConfiguration 中可配置。
- 用支持重复的结构化额外参数替换现有的 string/string 额外参数映射。
此变更适用于
ClusterConfiguration-apiServer.extraArgs、controllerManager.extraArgs、scheduler.extraArgs、etcd.local.extraArgs。也适用于nodeRegistrationOptions.kubeletExtraArgs。 - 添加了
ClusterConfiguration.encryptionAlgorithm,可用于设置此集群的密钥和证书所使用的非对称加密算法。 可以是 "RSA-2048"(默认)、"RSA-3072"、"RSA-4096" 或 "ECDSA-P256" 之一。 - 添加了
ClusterConfiguration.dns.disabled和ClusterConfiguration.proxy.disabled, 可用于在集群初始化期间禁用 CoreDNS 和 kube-proxy 插件。 在集群创建期间跳过相关插件阶段将把相同的字段设置为true。
- 在
InitConfiguration和JoinConfiguration中添加了nodeRegistration.imagePullSerial字段, 可用于控制 kubeadm 是顺序拉取镜像还是并行拉取镜像。 - 当将
--config传递给kubeadm upgrade子命令时,现已在 v1beta4 中支持 UpgradeConfiguration kubeadm API。 对于升级子命令,kubelet 和 kube-proxy 的组件配置以及 InitConfiguration 和 ClusterConfiguration 的用法现已弃用, 并将在传递--config时被忽略。 - 在
InitConfiguration、JoinConfiguration、ResetConfiguration和UpgradeConfiguration中添加了timeouts结构,可用于配置各种超时。ClusterConfiguration.timeoutForControlPlane字段被timeouts.controlPlaneComponentHealthCheck替换。JoinConfiguration.discovery.timeout被timeouts.discovery替换。
- 向
ClusterConfiguration添加了certificateValidityPeriod和caCertificateValidityPeriod字段。 这些字段可用于控制 kubeadm 在init、join、upgrade和certs等子命令中生成的证书的有效期。 默认值继续为非 CA 证书 1 年和 CA 证书 10 年。另请注意,只有非 CA 证书可以通过kubeadm certs renew进行续期。
这些变更简化了使用 kubeadm 的工具的配置,并提高了 kubeadm 本身的可扩展性。
如何将 v1beta3 配置迁移到 v1beta4?
如果你的配置未使用最新版本,建议你使用 kubeadm config migrate 命令进行迁移。
此命令读取使用旧格式的现有配置文件,并写入一个使用当前格式的新文件。
示例
使用 kubeadm v1.31,运行 kubeadm config migrate --old-config old-v1beta3.yaml --new-config new-v1beta4.yaml
我该如何参与?
衷心感谢在此特性的设计、实现和评审中提供帮助的所有贡献者:
- Lubomir I. Ivanov (neolit123)
- Dave Chen (chendave)
- Paco Xu (pacoxu)
- Sata Qiu (sataqiu)
- Baofa Fan (carlory)
- Calvin Chen (calvin0327)
- Ruquan Zhao (ruquanzhao)
如果你有兴趣参与 kubeadm 配置的后续讨论,可以通过多种方式与 kubeadm 或 SIG-cluster-lifecycle 联系:
- v1beta4 相关事项在 kubeadm issue #2890 中跟踪。
- Slack: #kubeadm 或 #sig-cluster-lifecycle
- 邮件列表
Kubernetes 1.31:kubectl debug 中的自定义模板化配置特性已进入 Beta 阶段
有很多方法可以对集群中的 Pod 和节点进行故障排查,而 kubectl debug 是最简单、使用最广泛、最突出的方法之一。
它提供了一组静态配置,每个配置适用于不同类型的角色。
例如,从网络管理员的视角来看,调试节点应该像这样简单:
$ kubectl debug node/mynode -it --image=busybox --profile=netadmin
另一方面,静态配置也存在固有的刚性,对某些 Pod 所产生的影响与其易用性是相悖的。 因为各种类型的 Pod(或节点)都有其特定的需求,不幸的是,有些问题仅通过静态配置是无法调试的。
以一个简单的 Pod 为例,此 Pod 由一个容器组成,其健康状况依赖于环境变量:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: example-container
image: customapp:latest
env:
- name: REQUIRED_ENV_VAR
value: "value1"
目前,复制 Pod 是使用 kubectl debug 命令调试此 Pod 的唯一机制。
此外,如果用户需要将 REQUIRED_ENV_VAR 环境变量修改为其他不同值来进行高级故障排查,
当前并没有机制能够实现这一需求。
自定义模板化配置
自定义模板化配置使用 --custom 标志提供的一项新特性,在 kubectl debug 中引入以提供可扩展性。
它需要以 YAML 或 JSON 格式的内容填充 container 规约,
为了通过创建临时容器来调试上面的示例容器,我们只需定义此 YAML:
# partial_container.yaml
env:
- name: REQUIRED_ENV_VAR
value: value2
并且执行:
kubectl debug example-pod -it --image=customapp --custom=partial_container.yaml
下面是另一个在 JSON 中一次修改多个字段(更改端口号、添加资源限制、修改环境变量)的示例:
{
"ports": [
{
"containerPort": 80
}
],
"resources": {
"limits": {
"cpu": "0.5",
"memory": "512Mi"
},
"requests": {
"cpu": "0.2",
"memory": "256Mi"
}
},
"env": [
{
"name": "REQUIRED_ENV_VAR",
"value": "value2"
}
]
}
约束
不受控制的扩展性会损害可用性。因此,某些字段(例如命令、镜像、生命周期、卷设备和容器名称)不允许进行自定义模版化配置。 将来如果需要,可以将更多字段添加到禁止列表中。
限制
kubectl debug 命令有 3 个方面:使用临时容器进行调试、Pod 复制和节点调试。
这些方面最大的交集是 Pod 内的容器规约,因此自定义模版化配置仅支持修改使用 containers 下定义的字段。
这导致了一个限制,如果用户需要修改 Pod 规约中的其他字段,则不受支持。
致谢
特别感谢所有审查和评论此特性(从最初的概念到实际实施)的贡献者(按字母顺序排列):
Kubernetes 1.31:细粒度的 SupplementalGroups 控制
本博客讨论了 Kubernetes 1.31 中的一项新特性,目的是改善处理 Pod 中容器内的附加组。
动机:容器镜像中 /etc/group 中定义的隐式组成员关系
尽管这种行为可能并不受许多 Kubernetes 集群用户/管理员的欢迎,
但 Kubernetes 默认情况下会将 Pod 中的组信息与容器镜像中 /etc/group 中定义的信息进行合并。
让我们看一个例子,以下 Pod 在 Pod 的安全上下文中指定了
runAsUser=1000、runAsGroup=3000 和 supplementalGroups=4000。
apiVersion: v1
kind: Pod
metadata:
name: implicit-groups
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
supplementalGroups: [4000]
containers:
- name: ctr
image: registry.k8s.io/e2e-test-images/agnhost:2.45
command: [ "sh", "-c", "sleep 1h" ]
securityContext:
allowPrivilegeEscalation: false
在 ctr 容器中执行 id 命令的结果是什么?
# 创建 Pod:
$ kubectl apply -f https://k8s.io/blog/2024-08-22-Fine-grained-SupplementalGroups-control/implicit-groups.yaml
# 验证 Pod 的容器正在运行:
$ kubectl get pod implicit-groups
# 检查 id 命令
$ kubectl exec implicit-groups -- id
输出应类似于:
uid=1000 gid=3000 groups=3000,4000,50000
尽管 50000 根本没有在 Pod 的清单中被定义,但附加组中的组 ID 50000(groups 字段)是从哪里来的呢?
答案是容器镜像中的 /etc/group 文件。
检查容器镜像中 /etc/group 的内容应如下所示:
$ kubectl exec implicit-groups -- cat /etc/group
...
user-defined-in-image:x:1000:
group-defined-in-image:x:50000:user-defined-in-image
原来如此!容器的主要用户 1000 属于最后一个条目中的组 50000。
因此,容器镜像中为容器的主要用户定义的组成员关系会被隐式合并到 Pod 的信息中。 请注意,这是当前 CRI 实现从 Docker 继承的设计决策,而社区直到现在才重新考虑这个问题。
这有什么问题?
从容器镜像中的 /etc/group 隐式合并的组信息可能会引起一些担忧,特别是在访问卷时
(有关细节参见 kubernetes/kubernetes#112879),
因为在 Linux 中文件权限是通过 uid/gid 进行控制的。
更糟糕的是,隐式的 gid 无法被任何策略引擎所检测/验证,因为在清单中没有隐式组信息的线索。
这对 Kubernetes 的安全性也可能构成隐患。
Pod 中的细粒度 SupplementalGroups 控制:SupplementaryGroupsPolicy
为了解决上述问题,Kubernetes 1.31 在 Pod 的 .spec.securityContext
中引入了新的字段 supplementalGroupsPolicy。
此字段提供了一种控制 Pod 中容器进程如何计算附加组的方法。可用的策略如下:
Merge:将容器的主要用户在
/etc/group中定义的组成员关系进行合并。 如果不指定,则应用此策略(即为了向后兼容性而保持的原有行为)。Strict:仅将
fsGroup、supplementalGroups或runAsGroup字段中指定的组 ID 挂接为容器进程的附加组。这意味着容器的主要用户在/etc/group中定义的任何组成员关系都不会被合并。
让我们看看 Strict 策略是如何工作的。
apiVersion: v1
kind: Pod
metadata:
name: strict-supplementalgroups-policy
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
supplementalGroups: [4000]
supplementalGroupsPolicy: Strict
containers:
- name: ctr
image: registry.k8s.io/e2e-test-images/agnhost:2.45
command: [ "sh", "-c", "sleep 1h" ]
securityContext:
allowPrivilegeEscalation: false
# 创建 Pod:
$ kubectl apply -f https://k8s.io/blog/2024-08-22-Fine-grained-SupplementalGroups-control/strict-supplementalgroups-policy.yaml
# 验证 Pod 的容器正在运行:
$ kubectl get pod strict-supplementalgroups-policy
# 检查进程身份:
kubectl exec -it strict-supplementalgroups-policy -- id
输出应类似于:
uid=1000 gid=3000 groups=3000,4000
你可以看到 Strict 策略可以将组 50000 从 groups 中排除出去!
因此,确保(通过某些策略机制强制执行的)supplementalGroupsPolicy: Strict 有助于防止 Pod 中的隐式附加组。
说明:
实际上,这还不够,因为具有足够权限/能力的容器可以更改其进程身份。 有关细节参见以下章节。
Pod 状态中挂接的进程身份
此特性还通过 .status.containerStatuses[].user.linux
字段公开挂接到容器的第一个容器进程的进程身份。这将有助于查看隐式组 ID 是否被挂接。
...
status:
containerStatuses:
- name: ctr
user:
linux:
gid: 3000
supplementalGroups:
- 3000
- 4000
uid: 1000
...
说明:
请注意,status.containerStatuses[].user.linux 字段中的值是首次挂接到容器中第一个容器进程的进程身份。
如果容器具有足够的权限调用与进程身份相关的系统调用(例如
setuid(2)、
setgid(2) 或
setgroups(2) 等),
则容器进程可以更改其身份。因此,实际的进程身份将是动态的。
特性可用性
要启用 supplementalGroupsPolicy 字段,必须使用以下组件:
- Kubernetes:v1.31 或更高版本,启用
SupplementalGroupsPolicy特性门控。 截至 v1.31,此门控标记为 Alpha。 - CRI 运行时:
- containerd:v2.0 或更高版本
- CRI-O:v1.31 或更高版本
你可以在 Node 的 .status.features.supplementalGroupsPolicy 字段中查看此特性是否受支持。
apiVersion: v1
kind: Node
...
status:
features:
supplementalGroupsPolicy: true
接下来
Kubernetes SIG Node 希望并期待此特性将在 Kubernetes 后续版本中进阶至 Beta, 并最终进阶至正式发布(GA),以便用户不再需要手动启用特性门控。
当 supplementalGroupsPolicy 未被指定时,将应用 Merge 策略,以保持向后兼容性。
我如何了解更多?
- 为 Pod 或容器配置安全上下文以获取有关
supplementalGroupsPolicy的更多细节 - KEP-3619:细粒度 SupplementalGroups 控制
如何参与?
此特性由 SIG Node 社区推动。请加入我们,与社区保持联系, 分享你对上述特性及其他方面的想法和反馈。我们期待听到你的声音!
Kubernetes v1.31:全新的 Kubernetes CPUManager 静态策略:跨核分发 CPU
在 Kubernetes v1.31 中,我们很高兴引入了对 CPU 管理能力的重大增强:针对
CPUManager 静态策略的
distribute-cpus-across-cores 选项。此特性目前处于 Alpha 阶段,
默认被隐藏,标志着旨在优化 CPU 利用率和改善多核处理器系统性能的战略转变。
理解这一特性
传统上,Kubernetes 的 CPUManager 倾向于尽可能紧凑地分配 CPU,通常将这些 CPU 打包到尽可能少的物理核上。 然而,分配策略很重要,因为同一物理主机上的 CPU 仍然共享一些物理核的资源,例如缓存和执行单元等。
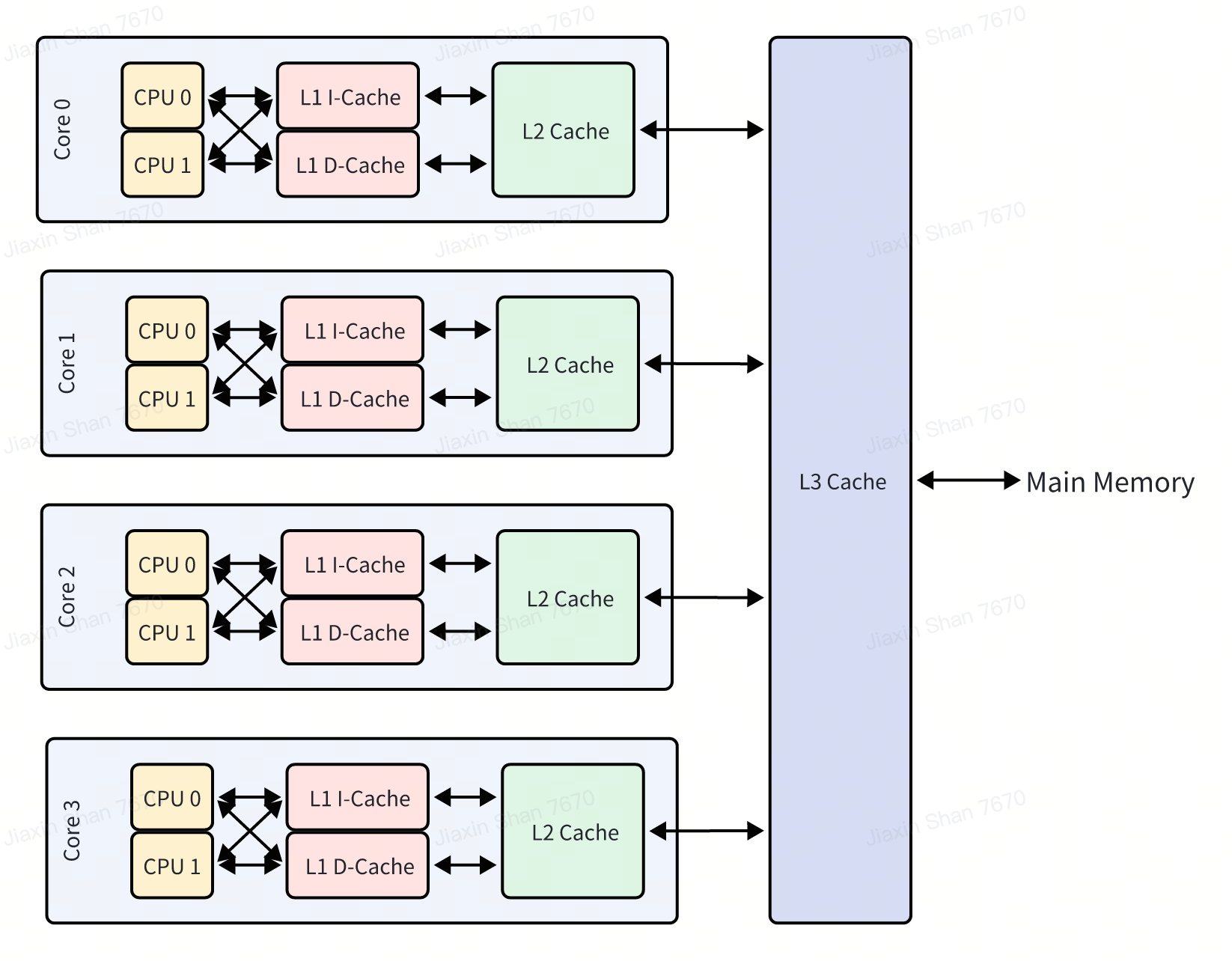
虽然默认方法可以最小化核间通信,并在某些情况下是有益的,但也带来了挑战。 在同一物理核上共享的 CPU 可能导致资源竞争,从而可能造成性能瓶颈,这在 CPU 密集型应用中尤为明显。
全新的 distribute-cpus-across-cores 特性通过修改分配策略来解决这个问题。
当此特性被启用时,此策略选项指示 CPUManager 尽可能将 CPU(硬件线程)分发到尽可能多的物理核上。
这种分发旨在最小化共享同一物理核的 CPU 之间的争用,从而通过为应用提供专用的核资源来潜在提高性能。
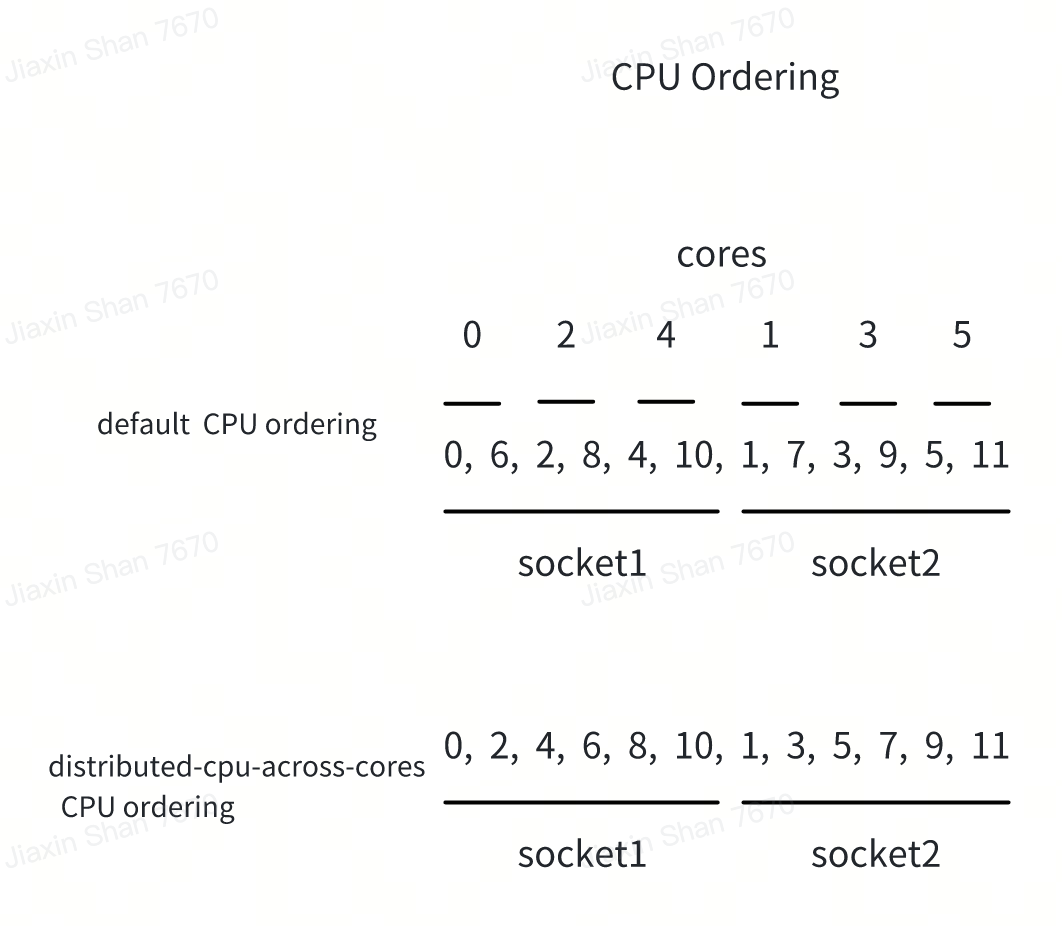
从技术上讲,在这个静态策略中,可用的 CPU 列表按照图示的方式重新排序,旨在从不同的物理核分配 CPU。
启用此特性
要启用此特性,用户首先需要在 kubelet 配置中添加 --cpu-manager-policy=static kubelet 标志或 cpuManagerPolicy: static 字段。
然后用户可以在 Kubernetes 配置中添加 --cpu-manager-policy-options distribute-cpus-across-cores=true 或
distribute-cpus-across-cores=true 到自己的 CPUManager 策略选项中。此设置指示 CPUManager 采用新的分发策略。
需要注意的是,目前此策略选项无法与 full-pcpus-only 或 distribute-cpus-across-numa 选项一起使用。
当前限制和未来方向
与所有新特性一样,尤其是处于 Alpha 阶段的特性,此特性也存在一些限制,很多方面还有待后续改进。
当前一个显著的限制是 distribute-cpus-across-cores 不能与可能在 CPU 分配策略上存在冲突的其他策略选项结合使用。
这一限制可能会影响与(依赖于更专业的资源管理的)某些工作负载和部署场景的兼容性。
展望未来,我们将致力于增强 distribute-cpus-across-cores 选项的兼容性和特性。
未来的更新将专注于解决这些兼容性问题,使此策略能够与其他 CPUManager 策略无缝结合。
我们的目标是提供一个更灵活和强大的 CPU 分配框架,能够适应各种工作负载和性能需求。
结论
在 Kubernetes CPUManager 中引入 distribute-cpus-across-cores 策略是我们持续努力改进资源管理和提升应用性能而向前迈出的一步。
通过减少物理核上的争用,此特性提供了更加平衡的 CPU 资源分配方法,特别有利于运行异构工作负载的环境。
我们鼓励 Kubernetes 用户测试这一新特性并提供反馈,这将对其未来发展至关重要。
本文旨在清晰地解释这一新特性,同时设定对其当前阶段和未来改进的期望。
进一步阅读
请查阅节点上的 CPU 管理策略任务页面, 以了解有关 CPU 管理器的更多信息,以及 CPU 管理器与其他节点级资源管理器的关系。
参与其中
此特性由 SIG Node 推动。 如果你有兴趣帮助开发此特性、分享反馈或参与其他目前 SIG Node 项目的工作,请参加 SIG Node 会议了解更多细节。
Kubernetes 1.31: 节点 Cgroup 驱动程序的自动配置 (beta)
一直以来,为新运行的 Kubernetes 集群配置正确的 cgroup 驱动程序是用户的一个痛点。
在 Linux 系统中,存在两种不同的 cgroup 驱动程序:cgroupfs 和 systemd。
过去,kubelet 和 CRI
实现(如 CRI-O 或 containerd)需要配置为使用相同的 cgroup 驱动程序, 否则 kubelet 会报错并退出。
这让许多集群管理员头疼不已。不过,现在曙光乍现!
自动检测 cgroup 驱动程序
在 v1.28.0 版本中,SIG Node 社区引入了 KubeletCgroupDriverFromCRI 特性门控,
它指示 kubelet 向 CRI 实现询问使用哪个 cgroup 驱动程序。在两个主要的 CRI 实现(containerd
和 CRI-O)增加对该功能的支持这段期间,Kubernetes 经历了几次小版本发布,但从 v1.31.0 版本开始,此功能现已进入 beta 阶段!
除了设置特性门控之外,集群管理员还需要确保 CRI 实现版本足够新:
- containerd:v2.0.0 版本开始支持
- CRI-O:v1.28.0 版本开始支持
然后,他们应该确保配置其 CRI 实现使用他们想要的 cgroup 驱动程序。
未来工作
最终,kubelet 对 cgroupDriver 配置字段的支持将会被移除,如果 CRI 实现的版本不够新,无法支持此功能,kubelet 将无法启动。
Kubernetes 1.31:流式传输从 SPDY 转换为 WebSocket
在 Kubernetes 1.31 中,kubectl 现在默认使用 WebSocket 协议而不是 SPDY 进行流式传输。
这篇文章介绍了这些变化对你意味着什么以及这些流式传输 API 的重要性。
Kubernetes 中的流式 API
在 Kubernetes 中,某些以 HTTP 或 RESTful 接口公开的某些端点会被升级为流式连接,因而需要使用流式协议。 与 HTTP 这种请求-响应协议不同,流式协议提供了一种持久的双向连接,具有低延迟的特点,并允许实时交互。 流式协议支持在客户端与服务器之间通过同一个连接进行双向的数据读写。 这种类型的连接非常有用,例如,当你从本地工作站在某个运行中的容器内创建 shell 并在该容器中运行命令时。
为什么要改变流式传输协议?
在 v1.31 版本发布之前,Kubernetes 默认使用 SPDY/3.1 协议来升级流式连接。
但是 SPDY/3.1 已经被废弃了八年之久,并且从未被标准化,许多现代代理、网关和负载均衡器已经不再支持该协议。
因此,当你尝试通过代理或网关访问集群时,可能会发现像 kubectl cp、kubectl attach、kubectl exec
和 kubectl port-forward 这样的命令无法正常工作。
从 Kubernetes v1.31 版本开始,SIG API Machinery 修改了 Kubernetes
客户端(如 kubectl)中用于这些命令的流式传输协议,将其改为更现代化的
WebSocket 流式传输协议。
WebSocket 协议是一种当前得到支持的标准流式传输协议,
它可以确保与不同组件及编程语言之间的兼容性和互操作性。
相较于 SPDY,WebSocket 协议更为广泛地被现代代理和网关所支持。
流式 API 的工作原理
Kubernetes 通过在原始的 HTTP 请求中添加特定的升级头字段来将 HTTP 连接升级为流式连接。
例如,在集群内的 nginx 容器上运行 date 命令的 HTTP 升级请求类似于以下内容:
$ kubectl exec -v=8 nginx -- date
GET https://127.0.0.1:43251/api/v1/namespaces/default/pods/nginx/exec?command=date…
Request Headers:
Connection: Upgrade
Upgrade: websocket
Sec-Websocket-Protocol: v5.channel.k8s.io
User-Agent: kubectl/v1.31.0 (linux/amd64) kubernetes/6911225
如果容器运行时支持 WebSocket 流式协议及其至少一个子协议版本(例如 v5.channel.k8s.io),
服务器会以代表成功的 101 Switching Protocols 状态码进行响应,并附带协商后的子协议版本:
Response Status: 101 Switching Protocols in 3 milliseconds
Response Headers:
Upgrade: websocket
Connection: Upgrade
Sec-Websocket-Accept: j0/jHW9RpaUoGsUAv97EcKw8jFM=
Sec-Websocket-Protocol: v5.channel.k8s.io
此时,原本用于 HTTP 协议的 TCP 连接已转换为流式连接。 随后,此 Shell 交互中的标准输入(STDIN)、标准输出(STDOUT)和标准错误输出(STDERR)数据 (以及终端重置大小数据和进程退出码数据)会通过这个升级后的连接进行流式传输。
如何使用新的 WebSocket 流式协议
如果你的集群和 kubectl 版本为 1.29 及以上版本,有两个控制面特性门控以及两个 kubectl 环境变量用来控制启用 WebSocket 而不是 SPDY 作为流式协议。 在 Kubernetes 1.31 中,以下所有特性门控均处于 Beta 阶段,并且默认被启用:
- 特性门控
TranslateStreamCloseWebsocketRequests.../exec.../attach
PortForwardWebsockets.../port-forward
- kubectl 特性控制环境变量
KUBECTL_REMOTE_COMMAND_WEBSOCKETSkubectl execkubectl cpkubectl attach
KUBECTL_PORT_FORWARD_WEBSOCKETSkubectl port-forward
如果你正在使用一个较旧的集群但可以管理其特性门控设置,
那么可以通过开启 TranslateStreamCloseWebsocketRequests(在 Kubernetes v1.29 中添加)
和 PortForwardWebsockets(在 Kubernetes v1.30 中添加)来尝试启用 Websocket 作为流式传输协议。
版本为 1.31 的 kubectl 可以自动使用新的行为,但你需要连接到明确启用了服务器端特性的集群。
了解有关流式 API 的更多信息
Kubernetes 1.31:针对 Job 的 Pod 失效策略进阶至 GA
这篇博文阐述在 Kubernetes 1.31 中进阶至 Stable 的 Pod 失效策略,还介绍如何在你的 Job 中使用此策略。
关于 Pod 失效策略
当你在 Kubernetes 上运行工作负载时,Pod 可能因各种原因而失效。 理想情况下,像 Job 这样的工作负载应该能够忽略瞬时的、可重试的失效,并继续运行直到完成。
要允许这些瞬时的失效,Kubernetes Job 需包含 backoffLimit 字段,
此字段允许你指定在 Job 执行期间你愿意容忍的 Pod 失效次数。然而,
如果你为 backoffLimit 字段设置了一个较大的值,并完全依赖这个字段,
你可能会发现,由于在满足 backoffLimit 条件之前 Pod 重启次数太多,导致运营成本发生不必要的增加。
在运行大规模的、包含跨数千节点且长时间运行的 Pod 的 Job 时,这个问题尤其严重。
Pod 失效策略扩展了回退限制机制,帮助你通过以下方式降低成本:
- 让你在出现不可重试的 Pod 失效时控制 Job 失败。
- 允许你忽略可重试的错误,而不增加
backoffLimit字段。
例如,通过忽略由节点体面关闭引起的 Pod 失效,你可以使用 Pod 失效策略在更实惠的临时机器上运行你的工作负载。
此策略允许你基于失效 Pod 中的容器退出码或 Pod 状况来区分可重试和不可重试的 Pod 失效。
它是如何工作的
你在 Job 规约中指定的 Pod 失效策略是一个规则的列表。
对于每个规则,你基于以下属性之一来定义匹配条件:
- 容器退出码:
onExitCodes属性。 - Pod 状况:
onPodConditions属性。
此外,对于每个规则,你要指定在 Pod 与此规则匹配时应采取的动作,可选动作为以下之一:
Ignore:不将失效计入backoffLimit或backoffLimitPerIndex。FailJob:让整个 Job 失败并终止所有运行的 Pod。FailIndex:与失效 Pod 对应的索引失效。
此动作与逐索引回退限制特性一起使用。Count:将失效计入backoffLimit或backoffLimitPerIndex。这是默认行为。
当在运行的 Job 中发生 Pod 失效时,Kubernetes 按所给的顺序将失效 Pod 的状态与 Pod 失效策略规则的列表进行匹配,并根据匹配的第一个规则采取相应的动作。
请注意,在指定 Pod 失效策略时,你还必须在 Job 的 Pod 模板中设置 restartPolicy: Never。
此字段可以防止在对 Pod 失效计数时在 kubelet 和 Job 控制器之间出现竞争条件。
Kubernetes 发起的 Pod 干扰
为了允许将 Pod 失效策略规则与由 Kubernetes 引发的干扰所导致的失效进行匹配,
此特性引入了 DisruptionTarget Pod 状况。
Kubernetes 会将此状况添加到因可重试的干扰场景而失效的所有
Pod,无论其是否由 Job 控制器管理。其中 DisruptionTarget 状况包含与这些干扰场景对应的以下原因之一:
PreemptionByKubeScheduler:由kube-scheduler抢占以接纳更高优先级的新 Pod。DeletionByTaintManager- Pod 因其不容忍的NoExecute污点而被kube-controller-manager删除。EvictionByEvictionAPI- Pod 因为 API 发起的驱逐而被删除。DeletionByPodGC- Pod 被绑定到一个不再存在的节点,并将通过 Pod 垃圾收集而被删除。TerminationByKubelet- Pod 因节点体面关闭、 节点压力驱逐或被系统关键 Pod抢占
在所有其他干扰场景中,例如因超过
Pod 容器限制而驱逐,
Pod 不会收到 DisruptionTarget 状况,因为干扰可能是由 Pod 引起的,并且在重试时会再次发生干扰。
示例
下面的 Pod 失效策略片段演示了一种用法:
podFailurePolicy:
rules:
- action: Ignore
onPodConditions:
- type: DisruptionTarget
- action: FailJob
onPodConditions:
- type: ConfigIssue
- action: FailJob
onExitCodes:
operator: In
values: [ 42 ]
在这个例子中,Pod 失效策略执行以下操作:
- 忽略任何具有内置
DisruptionTarget状况的失效 Pod。这些 Pod 不计入 Job 回退限制。 - 如果任何失效的 Pod 具有用户自定义的、由自定义控制器或 Webhook 添加的
ConfigIssue状况,则让 Job 失败。 - 如果任何容器以退出码 42 退出,则让 Job 失败。
- 将所有其他 Pod 失效计入默认的
backoffLimit(在合适的情况下,计入backoffLimitPerIndex)。
进一步了解
- 有关使用 Pod 失效策略的实践指南, 参见使用 Pod 失效策略处理可重试和不可重试的 Pod 失效
- 阅读文档:Pod 失效策略和逐索引回退限制
- 阅读文档:Pod 干扰状况
- 阅读 KEP:Pod 失效策略
相关工作
基于 Pod 失效策略所引入的概念,正在进行中的进一步工作如下:
- JobSet 集成:可配置的失效策略 API
- 扩展 Pod 失效策略以添加更细粒度的失效原因
- 通过 JobSet 在 Kubeflow Training v2 中支持 Pod 失效策略
- 提案:受干扰的 Pod 应从端点中移除
参与其中
这项工作由 Batch Working Group(批处理工作组) 发起, 与 SIG Apps、 SIG Node 和 SIG Scheduling 社区密切合作。
如果你有兴趣处理这个领域中的新特性,建议你订阅我们的 Slack 频道,并参加定期的社区会议。
感谢
我想感谢在这些年里参与过这个项目的每个人。 这是一段旅程,也是一个社区共同努力的见证! 以下名单是我尽力记住并对此特性产生过影响的人。感谢大家!
- Aldo Culquicondor 在整个过程中提供指导和审查
- Jordan Liggitt 审查 KEP 和 API
- David Eads 审查 API
- Maciej Szulik 从 SIG Apps 角度审查 KEP
- Clayton Coleman 提供指导和 SIG Node 审查
- Sergey Kanzhelev 从 SIG Node 角度审查 KEP
- Dawn Chen 从 SIG Node 角度审查 KEP
- Daniel Smith 从 SIG API Machinery 角度进行审查
- Antoine Pelisse 从 SIG API Machinery 角度进行审查
- John Belamaric 审查 PRR
- Filip Křepinský 从 SIG Apps 角度进行全面审查并修复 Bug
- David Porter 从 SIG Node 角度进行全面审查
- Jensen Lo 进行早期需求讨论、测试和报告问题
- Daniel Vega-Myhre 推进 JobSet 集成并报告问题
- Abdullah Gharaibeh 进行早期设计讨论和指导
- Antonio Ojea 审查测试
- Yuki Iwai 审查并协调相关 Job 特性的实现
- Kevin Hannon 审查并协调相关 Job 特性的实现
- Tim Bannister 审查文档
- Shannon Kularathna 审查文档
- Paola Cortés 审查文档
Kubernetes 1.31:podAffinity 中的 matchLabelKeys 进阶至 Beta
Kubernetes 1.29 在 podAffinity 和 podAntiAffinity 中引入了新的字段 matchLabelKeys 和 mismatchLabelKeys。
在 Kubernetes 1.31 中,此特性进阶至 Beta,并且相应的特性门控(MatchLabelKeysInPodAffinity)默认启用。
matchLabelKeys - 为多样化滚动更新增强了调度
在工作负载(例如 Deployment)的滚动更新期间,集群中可能同时存在多个版本的 Pod。
然而,调度器无法基于 podAffinity 或 podAntiAffinity 中指定的 labelSelector 区分新旧版本。
结果,调度器将并置或分散调度 Pod,不会考虑这些 Pod 的版本。
这可能导致次优的调度结果,例如:
- 新版本的 Pod 与旧版本的 Pod(
podAffinity)并置在一起,这些旧版本的 Pod 最终将在滚动更新后被移除。 - 旧版本的 Pod 被分布在所有可用的拓扑中,导致新版本的 Pod 由于
podAntiAffinity无法找到节点。
matchLabelKeys 是一组 Pod 标签键,可以解决上述问题。
调度器从新 Pod 的标签中查找这些键的值,并将其与 labelSelector 结合,
以便 podAffinity 匹配到具有相同标签键值的 Pod。
通过在 matchLabelKeys 中使用标签
pod-template-hash,
你可以确保对 podAffinity 或 podAntiAffinity 进行评估时仅考虑相同版本的 Pod。
apiVersion: apps/v1
kind: Deployment
metadata:
name: application-server
...
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- database
topologyKey: topology.kubernetes.io/zone
matchLabelKeys:
- pod-template-hash
上述 Pod 中的 matchLabelKeys 将被转换为:
kind: Pod
metadata:
name: application-server
labels:
pod-template-hash: xyz
...
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- database
- key: pod-template-hash # 从 matchLabelKeys 添加; 只有来自同一 ReplicaSet 的 Pod 将与此亲和性匹配
operator: In
values:
- xyz
topologyKey: topology.kubernetes.io/zone
matchLabelKeys:
- pod-template-hash
mismatchLabelKeys - 服务隔离
mismatchLabelKeys 是一组 Pod 标签键,类似于 matchLabelKeys,
它在新 Pod 的标签中查找这些键的值,并将其与 labelSelector 合并为 key notin (value),
以便 podAffinity 不会匹配到具有相同标签键值的 Pod。
假设每个租户的所有 Pod 通过控制器或像 Helm 这样的清单管理工具得到 tenant 标签。
尽管在组合每个工作负载的清单时,tenant 标签的值是未知的,
但集群管理员希望实现租户与域之间形成排他性的 1:1 对应关系,以便隔离租户。
mismatchLabelKeys 适用于这一使用场景;
通过使用变更性质的 Webhook 在全局应用以下亲和性,
集群管理员可以确保来自同一租户的 Pod 将以独占方式落到同一域上,
这意味着来自其他租户的 Pod 不会落到同一域上。
affinity:
podAffinity: # 确保此租户的 Pod 落在同一节点池上
requiredDuringSchedulingIgnoredDuringExecution:
- matchLabelKeys:
- tenant
topologyKey: node-pool
podAntiAffinity: # 确保只有此租户的 Pod 落在同一节点池上
requiredDuringSchedulingIgnoredDuringExecution:
- mismatchLabelKeys:
- tenant
labelSelector:
matchExpressions:
- key: tenant
operator: Exists
topologyKey: node-pool
上述的 matchLabelKeys 和 mismatchLabelKeys 将被转换为:
kind: Pod
metadata:
name: application-server
labels:
tenant: service-a
spec:
affinity:
podAffinity: # 确保此租户的 Pod 落在同一节点池上
requiredDuringSchedulingIgnoredDuringExecution:
- matchLabelKeys:
- tenant
topologyKey: node-pool
labelSelector:
matchExpressions:
- key: tenant
operator: In
values:
- service-a
podAntiAffinity: # 确保只有此租户的 Pod 落在同一节点池上
requiredDuringSchedulingIgnoredDuringExecution:
- mismatchLabelKeys:
- tenant
labelSelector:
matchExpressions:
- key: tenant
operator: Exists
- key: tenant
operator: NotIn
values:
- service-a
topologyKey: node-pool
参与其中
这些特性由 Kubernetes SIG Scheduling 管理。
请加入我们并分享你的反馈。我们期待听到你的声音!
了解更多
Kubernetes 1.31:防止无序删除时 PersistentVolume 泄漏
PersistentVolume(简称 PV)
具有与之关联的回收策略。
回收策略用于确定在删除绑定到 PV 的 PVC 时存储后端需要采取的操作。当回收策略为 Delete 时,
期望存储后端释放为 PV 所分配的存储资源。实际上,在 PV 被删除时就需要执行此回收策略。
在最近发布的 Kubernetes v1.31 版本中,一个 Beta 特性允许你配置集群以这种方式运行并执行你配置的回收策略。
在以前的 Kubernetes 版本中回收是如何工作的?
PersistentVolumeClaim (简称 PVC)是用户对存储的请求。如果新创建了 PV 或找到了匹配的 PV,那么此 PV 和此 PVC 被视为已绑定。 PV 本身是由存储后端所分配的卷支持的。
通常,如果卷要被删除,对应的预期是为一个已绑定的 PV-PVC 对删除其中的 PVC。 不过,对于在删除 PVC 之前可否删除 PV 并没有限制。
首先,我将演示运行旧版本 Kubernetes 的集群的行为。
检索绑定到 PV 的 PVC
检索现有的 PVC example-vanilla-block-pvc:
kubectl get pvc example-vanilla-block-pvc
以下输出显示了 PVC 及其绑定的 PV;此 PV 显示在 VOLUME 列下:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
example-vanilla-block-pvc Bound pvc-6791fdd4-5fad-438e-a7fb-16410363e3da 5Gi RWO example-vanilla-block-sc 19s
删除 PV
当我尝试删除已绑定的 PV 时,kubectl 会话被阻塞,
且 kubectl 工具不会将控制权返回给 Shell;例如:
kubectl delete pv pvc-6791fdd4-5fad-438e-a7fb-16410363e3da
persistentvolume "pvc-6791fdd4-5fad-438e-a7fb-16410363e3da" deleted
^C
检索 PV
kubectl get pv pvc-6791fdd4-5fad-438e-a7fb-16410363e3da
你可以观察到 PV 处于 Terminating 状态:
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-6791fdd4-5fad-438e-a7fb-16410363e3da 5Gi RWO Delete Terminating default/example-vanilla-block-pvc example-vanilla-block-sc 2m23s
删除 PVC
kubectl delete pvc example-vanilla-block-pvc
如果 PVC 被成功删除,则会看到以下输出:
persistentvolumeclaim "example-vanilla-block-pvc" deleted
集群中的 PV 对象也被删除。当尝试检索 PV 时,你会观察到该 PV 已不再存在:
kubectl get pv pvc-6791fdd4-5fad-438e-a7fb-16410363e3da
Error from server (NotFound): persistentvolumes "pvc-6791fdd4-5fad-438e-a7fb-16410363e3da" not found
尽管 PV 被删除,但下层存储资源并未被删除,需要手动移除。
总结一下,与 PersistentVolume 关联的回收策略在某些情况下会被忽略。
对于 Bound 的 PV-PVC 对,PV-PVC 删除的顺序决定了回收策略是否被执行。
如果 PVC 先被删除,则回收策略被执行;但如果在删除 PVC 之前 PV 被删除,
则回收策略不会被执行。因此,外部基础设施中关联的存储资产未被移除。
Kubernetes v1.31 的 PV 回收策略
新的行为确保当用户尝试手动删除 PV 时,下层存储对象会从后端被删除。
如何启用新的行为?
要利用新的行为,你必须将集群升级到 Kubernetes v1.31 版本,并运行
CSI external-provisioner
v5.0.1 或更高版本。
工作方式
对于 CSI 卷,新的行为是通过在新创建和现有的 PV 上添加
Finalizer
external-provisioner.volume.kubernetes.io/finalizer 来实现的。
只有在后端存储被删除后,Finalizer 才会被移除。
下面是一个带 Finalizer 的 PV 示例,请注意 Finalizer 列表中的新 Finalizer:
kubectl get pv pvc-a7b7e3ba-f837-45ba-b243-dec7d8aaed53 -o yaml
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: csi.vsphere.vmware.com
creationTimestamp: "2021-11-17T19:28:56Z"
finalizers:
- kubernetes.io/pv-protection
- external-provisioner.volume.kubernetes.io/finalizer
name: pvc-a7b7e3ba-f837-45ba-b243-dec7d8aaed53
resourceVersion: "194711"
uid: 087f14f2-4157-4e95-8a70-8294b039d30e
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 1Gi
claimRef:
apiVersion: v1
kind: PersistentVolumeClaim
name: example-vanilla-block-pvc
namespace: default
resourceVersion: "194677"
uid: a7b7e3ba-f837-45ba-b243-dec7d8aaed53
csi:
driver: csi.vsphere.vmware.com
fsType: ext4
volumeAttributes:
storage.kubernetes.io/csiProvisionerIdentity: 1637110610497-8081-csi.vsphere.vmware.com
type: vSphere CNS Block Volume
volumeHandle: 2dacf297-803f-4ccc-afc7-3d3c3f02051e
persistentVolumeReclaimPolicy: Delete
storageClassName: example-vanilla-block-sc
volumeMode: Filesystem
status:
phase: Bound
Finalizer 防止此 PersistentVolume 从集群中被移除。如前文所述,Finalizer 仅在从存储后端被成功删除后才会从 PV 对象中被移除。进一步了解 Finalizer, 请参阅使用 Finalizer 控制删除。
同样,Finalizer kubernetes.io/pv-controller 也被添加到动态制备的树内插件卷中。
有关 CSI 迁移的卷
本次修复同样适用于 CSI 迁移的卷。
一些注意事项
本次修复不适用于静态制备的树内插件卷。
参考
我该如何参与?
Kubernetes Slack SIG Storage 交流频道是与 SIG Storage 和迁移工作组团队联系的良好媒介。
特别感谢以下人员的用心评审、周全考虑和宝贵贡献:
- Fan Baofa (carlory)
- Jan Šafránek (jsafrane)
- Xing Yang (xing-yang)
- Matthew Wong (wongma7)
如果你有兴趣参与 CSI 或 Kubernetes Storage 系统任何部分的设计和开发,请加入 Kubernetes Storage SIG。 我们正在快速成长,始终欢迎新的贡献者。
Kubernetes 1.31:基于 OCI 工件的只读卷 (Alpha)
Kubernetes 社区正朝着在未来满足更多人工智能(AI)和机器学习(ML)使用场景的方向发展。 虽然此项目在过去设计为满足微服务架构,但现在是时候听听最终用户的声音并引入更侧重于 AI/ML 的特性了。
其中一项需求是直接支持与开放容器倡议(OCI) 兼容的镜像和工件(称为 OCI 对象)作为原生卷源。 这使得用户能够专注于 OCI 标准,且能够使用 OCI 镜像仓库存储和分发任何内容。 与此类似的特性让 Kubernetes 项目有机会扩大其使用场景,不再局限于运行特定镜像。
在这一背景下,Kubernetes 社区自豪地展示在 v1.31 中引入的一项新的 Alpha 特性: 镜像卷源(KEP-4639)。 此特性允许用户在 Pod 中指定一个镜像引用作为卷,并在容器内将其作为卷挂载进行复用:
…
kind: Pod
spec:
containers:
- …
volumeMounts:
- name: my-volume
mountPath: /path/to/directory
volumes:
- name: my-volume
image:
reference: my-image:tag
上述示例的结果是将 my-image:tag 挂载到 Pod 的容器中的 /path/to/directory。
使用场景
此增强特性的目标是在尽可能贴近 kubelet 中现有的容器镜像实现的同时, 引入新的 API 接口以支持更广泛的使用场景。
例如,用户可以在 Pod 中的多个容器之间共享一个配置文件,而无需将此文件包含在主镜像中, 这样用户就可以将安全风险最小化和并缩减整体镜像大小。用户还可以使用 OCI 镜像打包和分发二进制工件, 并直接将它们挂载到 Kubernetes Pod 中,例如用户这样就可以简化其 CI/CD 流水线。
数据科学家、MLOps 工程师或 AI 开发者可以与模型服务器一起在 Pod 中挂载大语言模型权重或机器学习模型权重数据, 从而可以更高效地提供服务,且无需将这些模型包含在模型服务器容器镜像中。 他们可以将这些模型打包在 OCI 对象中,以利用 OCI 分发机制,还可以确保高效的模型部署。 这一新特性允许他们将模型规约/内容与处理它们的可执行文件分开。
另一个使用场景是安全工程师可以使用公共镜像作为恶意软件扫描器,并将私有的(商业的)恶意软件签名挂载到卷中, 这样他们就可以加载这些签名且无需制作自己的组合镜像(公共镜像的版权要求可能不允许这样做)。 签名数据文件与操作系统或扫描器软件版本无关,总是可以被使用。
但就长期而言,作为此项目的最终用户的你要负责为这一新特性的其他重要使用场景给出规划。 SIG Node 乐于接收与进一步增强此特性以适应更高级的使用场景有关的所有反馈或建议。你可以通过使用 Kubernetes Slack(#sig-node) 频道或 SIG Node 邮件列表提供反馈。
详细示例
你需要在 API 服务器以及
kubelet 上启用
Kubernetes Alpha 特性门控 ImageVolume,
才能使其正常工作。如果启用了此特性,
并且容器运行时支持此特性
(如 CRI-O ≥ v1.31),那就可以创建这样一个示例 pod.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod
spec:
containers:
- name: test
image: registry.k8s.io/e2e-test-images/echoserver:2.3
volumeMounts:
- name: volume
mountPath: /volume
volumes:
- name: volume
image:
reference: quay.io/crio/artifact:v1
pullPolicy: IfNotPresent
此 Pod 使用值为 quay.io/crio/artifact:v1 的 image.reference 声明一个新卷,
该字段值引用了一个包含两个文件的 OCI 对象。pullPolicy 的行为与容器镜像相同,允许以下值:
Always:kubelet 总是尝试拉取引用,如果拉取失败,容器创建将失败。Never:kubelet 从不拉取引用,只使用本地镜像或工件。如果引用不存在,容器创建将失败。IfNotPresent:kubelet 会在引用已不在磁盘上时进行拉取。如果引用不存在且拉取失败,容器创建将失败。
volumeMounts 字段表示名为 test 的容器应将卷挂载到 /volume 路径下。
如果你现在创建 Pod:
kubectl apply -f pod.yaml
然后通过 exec 进入此 Pod:
kubectl exec -it pod -- sh
那么你就能够查看已挂载的内容:
/ # ls /volume
dir file
/ # cat /volume/file
2
/ # ls /volume/dir
file
/ # cat /volume/dir/file
1
你已经成功地使用 Kubernetes 访问了 OCI 工件!
容器运行时拉取镜像(或工件),将其挂载到容器中,并最终使其可被直接使用。 在实现中有很多细节,这些细节与 kubelet 现有的镜像拉取行为密切相关。例如:
- 如果提供给
reference的值包含:latest标签,pullPolicy将默认为Always, 而在任何其他情况下,pullPolicy在未被设置的情况下都默认为IfNotPresent。 - 如果 Pod 被删除并重新创建,卷将被重新解析,这意味着在 Pod 重新创建时将可以访问新的远端内容。 如果在 Pod 启动期间未能解析或未能拉取镜像,将会容器启动会被阻止,并可能显著增加延迟。 如果拉取镜像失败,将使用正常的卷回退机制进行重试,并将在 Pod 的原因和消息中报告出错原因。
- 拉取 Secret 的组装方式与容器镜像所用的方式相同,也是通过查找节点凭据、服务账户镜像拉取 Secret 和 Pod 规约中的镜像拉取 Secret 来完成。
- OCI 对象被挂载到单个目录中,清单层的合并方式与容器镜像相同。
- 卷以只读(
ro)和非可执行文件(noexec)的方式被挂载。
- 容器的子路径挂载不被支持(
spec.containers[*].volumeMounts.subpath)。 - 字段
spec.securityContext.fsGroupChangePolicy对这种卷类型没有影响。 - 如果已启用,此特性也将与
AlwaysPullImages准入插件一起工作。
感谢你阅读到这篇博客文章的结尾!对于将此特性作为 Kubernetes v1.31 的一部分交付,SIG Node 感到很高兴也很自豪。
作为这篇博客的作者,我想特别感谢所有参与者!你们都很棒,让我们继续开发之旅!
进一步阅读
Kubernetes 1.31:通过 VolumeAttributesClass 修改卷进阶至 Beta
在 Kubernetes 中,卷由两个属性描述:存储类和容量。存储类是卷的不可变属性, 而容量可以通过卷调整大小进行动态变更。
这使得使用卷的工作负载的垂直扩缩容变得复杂。 虽然云厂商和存储供应商通常提供了一些允许指定注入 IOPS 或吞吐量等 IO 服务质量(性能)参数的卷,并允许在工作负载运行期间调整这些参数,但 Kubernetes 没有提供用来更改这些参数的 API。
我们很高兴地宣布,自 Kubernetes 1.29 起以 Alpha 引入的 VolumeAttributesClass KEP 将在 1.31 中进入 Beta 阶段。这一机制提供了一个通用的、Kubernetes 原生的 API, 可用来修改诸如所提供的 IO 能力这类卷参数。
类似于 Kubernetes 中所有新的卷特性,此 API 是通过容器存储接口(CSI)实现的。 除了 VolumeAttributesClass 特性门控外,特定于制备器的 CSI 驱动还必须支持此特性在 CSI 一侧的全新的 ModifyVolume API。
有关细节请参阅完整文档。 在这里,我们展示了常见的工作流程。
动态修改卷属性
VolumeAttributesClass 是一个集群范围的资源,用来指定特定于制备器的属性。
这些属性由集群管理员创建,方式上与存储类相同。
例如,你可以为卷创建一系列金、银和铜级别的卷属性类,以区隔不同级别的 IO 能力。
apiVersion: storage.k8s.io/v1alpha1
kind: VolumeAttributesClass
metadata:
name: silver
driverName: your-csi-driver
parameters:
provisioned-iops: "500"
provisioned-throughput: "50MiB/s"
---
apiVersion: storage.k8s.io/v1alpha1
kind: VolumeAttributesClass
metadata:
name: gold
driverName: your-csi-driver
parameters:
provisioned-iops: "10000"
provisioned-throughput: "500MiB/s"
属性类的添加方式与存储类类似。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-pv-claim
spec:
storageClassName: any-storage-class
volumeAttributesClassName: silver
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 64Gi
与存储类不同,卷属性类可以被更改:
kubectl patch pvc test-pv-claim -p '{"spec": "volumeAttributesClassName": "gold"}'
Kubernetes 将与 CSI 驱动协作来更新卷的属性。 PVC 的状态将跟踪当前和所需的属性类。 PV 资源也将依据新的卷属性类完成更新,卷属性类也会被依据 PV 当前活跃的属性完成设置。
Beta 阶段的限制
作为一个 Beta 特性,仍有一些特性计划在 GA 阶段推出,但尚未实现。最大的限制是配额支持,详见 KEP 和 sig-storage 中的讨论。
有关此特性在 CSI 驱动中的最新支持信息,请参阅 Kubernetes CSI 驱动列表。
Kubernetes 1.31:对 cgroup v1 的支持转为维护模式
随着 Kubernetes 不断发展,为了适应容器编排全景图的变化,社区决定在 v1.31 中将对 cgroup v1 的支持转为维护模式。 这一转变与行业更广泛地向 cgroup v2 的迁移保持一致,后者的功能更强, 包括可扩展性和更加一致的接口。在我们深入探讨对 Kubernetes 的影响之前, 先回顾一下 cgroup 的概念及其在 Linux 中的重要意义。
理解 cgroup
控制组(Control Group)也称为 cgroup, 是 Linux 内核的一项特性,允许在进程之间分配、划分优先级、拒绝和管理系统资源(如 CPU、内存、磁盘 I/O 和网络带宽)。 这一功能对于维护系统性能至关重要,确保没有单个进程能够垄断系统资源,这在多租户环境中尤其重要。
cgroup 有两个版本: v1 和 v2。 虽然 cgroup v1 提供了足够的资源管理能力,但其局限性促使了 cgroup v2 的开发。 cgroup v2 在更好的资源控制特性之外提供了更统一且更一致的接口。
Kubernetes 中的 cgroup
对于 Linux 节点,Kubernetes 在管理和隔离 Pod 中运行的容器所消耗的资源方面高度依赖 cgroup。 Kubernetes 中的每个容器都放在其自己的 cgroup 中,这使得 Kubernetes 能够强制执行资源限制、 监控使用情况并确保所有容器之间的资源公平分配。
Kubernetes 如何使用 cgroup
- 资源分配
- 确保容器不超过其分配的 CPU 和内存限制。
- 隔离
- 将容器相互隔离,防止资源争用。
- 监控
- 跟踪每个容器的资源使用情况,以提供洞察数据和指标。
向 cgroup v2 过渡
Linux 社区一直在聚焦于为 cgroup v2 提供新特性和各项改进。 主要的 Linux 发行版和像 systemd 这样的项目正在过渡到 cgroup v2。 使用 cgroup v2 相较于使用 cgroup v1 提供了多个好处,例如统一的层次结构、改进的接口、更好的资源控制, 以及 cgroup 感知的 OOM 杀手、 非 root 支持等。
鉴于这些优势,Kubernetes 也正在更全面地转向 cgroup v2。然而, 这一过渡需要谨慎处理,以避免干扰现有的工作负载,并为用户提供平滑的迁移路径。
对 cgroup v1 的支持转入维护模式
维护模式意味着什么?
当 cgroup v1 在 Kubernetes 中被置于维护模式时,这意味着:
- 特性冻结:不会再向 cgroup v1 添加新特性。
- 安全修复:仍将提供关键的安全修复。
- 尽力而为的 Bug 修复:在可行的情况下可能会修复重大 Bug,但某些问题可能保持未解决。
为什么要转入维护模式?
转入维护模式的原因是为了与更广泛的生态体系保持一致,也为了鼓励采用 cgroup v2,后者提供了更好的性能、安全性和可用性。 通过将 cgroup v1 转入维护模式,Kubernetes 可以专注于增强对 cgroup v2 的支持,并确保其满足现代工作负载的需求。 需要注意的是,维护模式并不意味着弃用;cgroup v1 将继续按需进行关键的安全修复和重大 Bug 修复。
这对集群管理员意味着什么
目前强烈鼓励那些依赖 cgroup v1 的用户做好向 cgroup v2 过渡的计划。这一过渡涉及:
- 升级系统:确保底层操作系统和容器运行时支持 cgroup v2。
- 测试工作负载:验证工作负载和应用程序在 cgroup v2 下正常工作。
进一步阅读
Kubernetes v1.31: Elli
编辑: Matteo Bianchi, Yigit Demirbas, Abigail McCarthy, Edith Puclla, Rashan Smith
Kubernetes v1.31:Elli 宣布发布!
与之前的版本类似,Kubernetes v1.31 的发布中引入了新的稳定版、Beta 版和 Alpha 特性功能。 持续提供高质量的版本彰显了我们开发周期的强劲实力以及社区的大力支持。 此版本包含 45 项增强功能。 在这些增强功能中,11 项已升级到稳定版,22 项正在进入 Beta 版,12 项已升级到 Alpha 版。
发布主题和 logo

Kubernetes v1.31 的发布主题是 "Elli"。
Kubernetes v1.31 的 Elli 是一只可爱欢快的小狗,戴着一顶漂亮的水手帽,这是对庞大而多样化的 Kubernetes 贡献者家族的一个俏皮致意。
Kubernetes v1.31 标志着该项目成功庆祝其诞生十周年后的首次发布。 自诞生以来,Kubernetes 已经走过了漫长的道路,并且每次发布都在朝着令人兴奋的新方向前进。 十年后,回顾无数 Kubernetes 贡献者为实现这一目标所付出的努力、奉献、技能、智慧和辛勤工作,令人敬畏。
还有,尽管运营项目需要付出巨大的努力,仍然有大量的人不断以热情、微笑和自豪感出现,为社区做出贡献并成为其中的一员。 我们从新老贡献者那里看到的这种"精神"是一个充满活力的社区的标志,我们可以称之为"欢乐"的社区。
Kubernetes v1.31 的 Elli 就是为了庆祝这种美好的精神!让我们为 Kubernetes 的下一个十年干杯!
晋级为稳定版的功能亮点
以下是 v1.31 发布后晋级为稳定版的部分改进。
AppArmor 支持现已稳定
Kubernetes 对 AppArmor 的支持现已正式发布。通过在容器的 securityContext 中设置 appArmorProfile.type 字段,可以使用 AppArmor 保护您的容器。
请注意,在 Kubernetes v1.30 之前,AppArmor 是通过注解控制的;从 v1.30 开始,它是通过字段控制的。
建议您停止使用注解,开始使用 appArmorProfile.type 字段。
要了解更多信息,请阅读 AppArmor 教程。 这项工作是作为 KEP #24 的一部分由 SIG Node 完成的。
改进 kube-proxy 的入站连接可靠性
kube-proxy 改进的入站连接可靠性在 v1.31 中已稳定。
Kubernetes 中负载均衡器的一个常见问题是为避免流量丢失而在不同组件之间进行同步的机制。
此特性在 kube-proxy 中实现了一种机制,用于负载均衡器对 type: LoadBalancer 和 externalTrafficPolicy: Cluster
服务所公开的、进入终止进程的 Node 进行连接排空,并为云提供商和 Kubernetes 负载均衡器实现建立了一些最佳实践。
要使用此特性,kube-proxy 需要在集群上作为默认服务代理运行,并且负载均衡器需要支持连接排空。 使用此特性不需要进行特定的更改,它自 v1.30 以来在 kube-proxy 中默认启用,并在 v1.31 中晋级为稳定版。
有关此特性的更多详细信息,请访问虚拟 IP 和服务代理文档页面。
这项工作是作为 KEP #3836 的一部分由 SIG Network 完成的。
持久卷最近阶段转换时间
持久卷最近阶段转换时间功能在 v1.31 中晋级为正式版(GA)。
此特性添加了一个 PersistentVolumeStatus 字段,用于保存 PersistentVolume 最近转换到不同阶段的时间戳。
启用此特性后,每个 PersistentVolume 对象将有一个新字段 .status.lastTransitionTime 保存卷最近转换阶段的时间戳。
这种变化并不是立即的;新字段将在 PersistentVolume 更新并在升级到 Kubernetes v1.31 后首次在各阶段(Pending、Bound 或 Released)之间转换时填充。
这允许您测量 PersistentVolume 从 Pending 移动到 Bound 之间的时间。这对于提供指标和 SLO 也很有用。
有关此特性的更多详细信息,请访问 PersistentVolume 文档页面。
这项工作是作为 KEP #3762 的一部分由 SIG Storage 完成的。
晋级为 Beta 版的功能亮点
以下是 v1.31 发布后晋级为 Beta 版的部分改进。
kube-proxy 的 nftables 后端
nftables 后端在 v1.31 中晋级为 Beta 版,由 NFTablesProxyMode 特性门控控制,现在默认启用。
nftables API 是 iptables API 的继任者,旨在提供比 iptables 更好的性能和可扩展性。
nftables 代理模式能够比 iptables 模式更快、更高效地处理服务端点的变化,并且在内核中也能更高效地处理数据包(尽管这只有在拥有数万个服务的集群中才会显著)。
截至 Kubernetes v1.31,nftables 模式仍相对较新,可能与某些网络插件不兼容;请查阅您的网络插件文档。 此代理模式仅在 Linux 节点上可用,并且需要内核 5.13 或更高版本。 在迁移之前,请注意某些功能,特别是与 NodePort 服务相关的功能,在 nftables 模式下的实现方式与 iptables 模式不完全相同。 查看迁移指南以了解是否需要覆盖默认配置。
这项工作是作为 KEP #3866 的一部分由 SIG Network 完成的。
PersistentVolumes 回收策略的变更
始终遵循 PersistentVolume 回收策略这一特性在 Kubernetes v1.31 中晋级为 Beta 版。 这项增强确保即使在所关联的 PersistentVolumeClaim (PVC) 被删除后,PersistentVolume (PV) 回收策略也会被遵循,从而防止卷的泄漏。
在此特性之前,与 PV 相关联的回收策略可能在特定条件下被忽视,这取决于 PV 或 PVC 是否先被删除。 因此,即使回收策略设置为 "Delete",外部基础设施中相应的存储资源也可能不会被删除。 这导致了潜在的不一致性和资源泄漏。
随着这项功能的引入,Kubernetes 现在保证 "Delete" 回收策略将被执行,确保底层存储对象从后端基础设施中删除,无论 PV 和 PVC 的删除顺序如何。
这项工作是作为 KEP #2644 的一部分由 SIG Storage 完成的。
绑定服务账户令牌的改进
ServiceAccountTokenNodeBinding 功能在 v1.31 中晋级为 Beta 版。
此特性允许请求仅绑定到节点而不是 Pod 的令牌,在令牌中包含节点信息的声明,并在使用令牌时验证节点的存在。
有关更多信息,请阅读绑定服务账户令牌文档。
这项工作是作为 KEP #4193 的一部分由 SIG Auth 完成的。
多个 Service CIDR
支持具有多个服务 CIDR 的集群在 v1.31 中晋级为 Beta 版(默认禁用)。
Kubernetes 集群中有多个组件消耗 IP 地址: Node、Pod 和 Service。 Node 和 Pod 的 IP 范围可以动态更改,因为它们分别取决于基础设施或网络插件。 然而,Service IP 范围是在集群创建期间作为 kube-apiserver 中的硬编码标志定义的。 IP 耗尽一直是长期存在或大型集群的问题,因为管理员需要扩展、缩小甚至完全替换分配的服务 CIDR 范围。 这些操作从未得到原生支持,并且是通过复杂和精细的维护操作执行的,经常导致集群无法正常服务。 这个新特性允许用户和集群管理员以零中断时间动态修改服务 CIDR 范围。
有关此特性的更多详细信息,请访问虚拟 IP 和服务代理文档页面。
这项工作是作为 KEP #1880 的一部分由 SIG Network 完成的。
Service 的流量分配
Service 的流量分配在 v1.31 中晋级为 Beta 版,并默认启用。
为实现 Service 联网的最佳用户体验和流量工程能力,经过多次迭代后,SIG Networking 在服务规约中实现了
trafficDistribution 字段,作为底层实现在做出路由决策时考虑的指导原则。
有关此特性的更多详细信息,请阅读 1.30 发布博客 或访问 Service 文档页面。
这项工作是作为 KEP #4444 的一部分由 SIG Network 完成的。
Kubernetes VolumeAttributesClass ModifyVolume
VolumeAttributesClass API 在 v1.31 中晋级为 Beta 版。 VolumeAttributesClass 提供了一个通用的、Kubernetes 原生的 API,用于修改动态卷参数,如所提供的 IO 能力。 这允许工作负载在线垂直扩展其卷,以平衡成本和性能(如果提供商支持)。 该功能自 Kubernetes 1.29 以来一直处于 Alpha 状态。
这项工作是作为 KEP #3751 的一部分完成的,由 SIG Storage 领导。
Alpha 版的新功能
以下是 v1.31 发布后晋级为 Alpha 版的部分改进。
用于更好管理加速器和其他硬件的新 DRA API
Kubernetes v1.31 带来了更新的动态资源分配(DRA)API 和设计。 此次更新的主要焦点是结构化参数,因为它们使资源信息和请求对 Kubernetes 和客户端透明,并能够实现集群自动扩缩容等功能。 kubelet 中的 DRA 支持已更新,使得 kubelet 和控制平面之间的版本偏差成为可能。通过结构化参数,调度器在调度 Pod 时分配 ResourceClaims。 通过现在称为"经典 DRA"的方式,仍然支持由 DRA 驱动程序控制器进行分配。
从 Kubernetes v1.31 开始,经典 DRA 有一个单独的特性门控名为 DRAControlPlaneController,您需要显式启用它。
通过这样的控制平面控制器,DRA 驱动程序可以实现尚未通过结构化参数支持的分配策略。
这项工作是作为 KEP #3063 的一部分由 SIG Node 完成的。
对镜像卷的支持
Kubernetes 社区正在朝着在未来满足更多人工智能(AI)和机器学习(ML)用例的方向发展。
满足这些用例的要求之一是直接将开放容器倡议(OCI)兼容的镜像和工件(称为 OCI 对象)作为原生卷源支持。 这允许用户专注于 OCI 标准,并使他们能够使用 OCI 注册表存储和分发任何内容。
鉴于此,v1.31 添加了一个新的 Alpha 特性,允许在 Pod 中使用 OCI 镜像作为卷。
此特性允许用户在 pod 中指定镜像引用作为卷,同时在容器内重用它作为卷挂载。您需要启用 ImageVolume 特性门控才能尝试此特性。
这项工作是作为 KEP #4639 的一部分由 SIG Node 和 SIG Storage 完成的。
通过 Pod 状态暴露设备健康信息
通过 Pod 状态暴露设备健康信息作为新的 Alpha 特性添加到 v1.31 中,默认被禁用。
在 Kubernetes v1.31 之前,了解 Pod 是否与故障设备关联的方法是使用 PodResources API。
通过启用此特性,字段 allocatedResourcesStatus 将添加到每个容器状态中,在每个 Pod 的 .status 内。
allocatedResourcesStatus 字段报告分配给容器的各个设备的健康信息。
这项工作是作为 KEP #4680 的一部分由 SIG Node 完成的。
基于选择算符的细粒度鉴权
此特性允许 Webhook 鉴权组件和未来(但目前尚未设计)的树内鉴权组件允许 list 和 watch 请求,
前提是这些请求使用标签和/或字段选择算符。
例如,现在鉴权组件可以表达:此用户不能列出所有 Pod,但可以列举所有 .spec.nodeName 匹配某个特定值的 Pod。
或者允许用户监视命名空间中所有未标记为 confidential: true 的 Secret。
结合 CRD 字段选择器(在 v1.31 中也晋级为 Beta 版),可以编写更安全的节点级别扩展。
这项工作是作为 KEP #4601 的一部分由 SIG Auth 完成的。
对匿名 API 访问的限制
通过启用特性门控 AnonymousAuthConfigurableEndpoints,用户现在可以使用身份认证配置文件来配置可以通过匿名请求访问的端点。
这允许用户保护自己免受 RBAC 错误配置的影响;错误的配置可能会给匿名用户提供对集群的更多访问权限。
这项工作是作为 KEP #4633 的一部分由 SIG Auth 完成的。
1.31 中的晋级、弃用和移除
晋级为稳定版
以下列出了所有晋级为稳定版(也称为 正式可用 )的功能。有关包括新功能和从 Alpha 晋级到 Beta 的完整列表,请参阅发行说明。
此版本包括总共 11 项晋级为稳定版的增强:
- PersistentVolume 最后阶段转换时间
- Metric 基数强制执行
- Kube-proxy 改进的入站连接可靠性
- 将 CDI 设备添加到设备插件 API
- 将 cgroup v1 支持移入维护模式
- AppArmor 支持
- PodDisruptionBudget 的 PodHealthyPolicy
- Job 的可重试和不可重试 Pod 失败
- 弹性的带索引的 Job
- 允许 StatefulSet 控制起始副本序号编号
- ReplicaSet 缩小时随机选择 Pod
弃用和移除
随着 Kubernetes 的发展和成熟,某些特性可能会被弃用、移除或替换为更好的特性,以确保项目的整体健康。 有关此过程的更多详细信息,请参阅 Kubernetes 弃用和移除策略。
Cgroup v1 进入维护模式
随着 Kubernetes 继续发展并适应容器编排不断变化的格局,社区决定在 v1.31 中将 cgroup v1 支持移入维护模式。 这一转变与行业中普遍向 cgroup v2 迁移的趋势一致, 提供了改进的功能、可扩展性和更一致的接口。 Kubernetes 维护模式意味着不会向 cgroup v1 支持添加新功能。 社区仍将提供关键的安全修复,但是,错误修复现在是尽力而为。 这意味着如果可行,可能会修复重大错误,但某些问题可能保持未解决状态。
建议您尽快开始切换到使用 cgroup v2。 这种转变取决于您的架构,包括确保底层操作系统和容器运行时支持 cgroup v2,以及测试工作负载以验证工作负载和应用程序在 cgroup v2 下是否正常运行。
如果遇到任何问题,请通过提交 issue 进行报告。
这项工作是作为 KEP #4569 的一部分由 SIG Node 完成的。
关于 SHA-1 签名支持的说明
在 go1.18(2022 年 3 月发布)中,crypto/x509 库开始拒绝使用 SHA-1 哈希函数签名的证书。
虽然 SHA-1 已被确定为不安全,并且公共信任的证书颁发机构自 2015 年以来就不再颁发 SHA-1 证书,
但在 Kubernetes 语境中可能仍然存在用户提供的证书通过私有机构使用 SHA-1 哈希函数签名的情况,
这些证书用于聚合 API 服务器或 Webhook。
如果您依赖基于 SHA-1 的证书,必须通过在环境变量中设置 GODEBUG=x509sha1=1 来明确选择重新启用其支持。
鉴于 Go 的 GODEBUG 兼容性策略,x509sha1 GODEBUG 和对 SHA-1
证书的支持将在 go1.24 中完全消失,
而 go1.24 将在 2025 年上半年发布。
如果您依赖 SHA-1 证书,请开始迁移离开它们。
请查看 Kubernetes issue #125689 以了解有关 SHA-1 支持消失的时间线、Kubernetes 发布计划何时采用 go1.24, 以及如何通过指标和审计日志检测 SHA-1 证书使用情况的更多详细信息。
弃用 Node 节点的 status.nodeInfo.kubeProxyVersion 字段 (KEP 4004)
节点的 .status.nodeInfo.kubeProxyVersion 字段在 Kubernetes v1.31 中已被弃用,
并将在以后的版本中删除。
它被弃用是因为这个字段的值不准确(现在也不准确)。
这个字段是由 kubelet 设置的,而 kubelet 没有关于 kube-proxy 版本或 kube-proxy 是否正在运行的可靠信息。
DisableNodeKubeProxyVersion 特性门控将在 v1.31
中默认设置为 true,kubelet 将不再尝试为其关联的节点设置 .status.kubeProxyVersion 字段。
移除所有树内云提供商集成
正如之前的文章中强调的那样,作为 v1.31 发布的一部分,最后剩余的树内云平台集成支持已被移除。 这并不意味着您不能与云平台集成,但是您现在必须使用推荐的方法使用外部集成。一些集成是 Kubernetes 项目的一部分,而其他则是第三方软件。
这一里程碑标志着所有云提供商集成从 Kubernetes 核心外部化过程的完成(KEP-2395),这个过程始于 Kubernetes v1.26。 这一变化有助于 Kubernetes 更接近成为一个真正供应商中立的平台。
有关云提供商集成的更多详细信息,请阅读我们的 v1.29 云提供商集成功能博客。 有关树内代码移除的额外背景,我们邀请您查看(v1.29 弃用博客)。
后者的博客还包含了需要迁移到 v1.29 及更高版本的用户的有用信息。
移除树内供应商特性门控
在 Kubernetes v1.31 中,以下 Alpha 特性门控 InTreePluginAWSUnregister、InTreePluginAzureDiskUnregister、
InTreePluginAzureFileUnregister、InTreePluginGCEUnregister、InTreePluginOpenStackUnregister
和 InTreePluginvSphereUnregister 已被移除。
这些特性门控的引入是为了便于测试从代码库中移除树内卷插件的场景,而无需实际移除它们。
由于 Kubernetes 1.30 已弃用这些树内卷插件,这些特性门控变得多余,不再有用。
唯一仍然存在的 CSI 迁移门控是 InTreePluginPortworxUnregister,它将保持 Alpha 状态,
直到 Portworx 的 CSI 迁移完成,其树内卷插件准备好被移除。
移除 kubelet 的 --keep-terminated-pod-volumes 命令行标志
作为 v1.31 版本的一部分,已移除 kubelet 标志 --keep-terminated-pod-volumes。该标志于 2017 年被弃用。
您可以在拉取请求 #122082 中找到更多详细信息。
移除 CephFS 卷插件
本次发布中移除了 CephFS 卷插件,cephfs 卷类型变为不可用。
建议您改用 CephFS CSI 驱动 作为第三方存储驱动程序。 如果您在将集群版本升级到 v1.31 之前使用了 CephFS 卷插件,则必须重新部署应用程序以使用新的驱动程序。
CephFS 卷插件在 v1.28 中正式标记为废弃。
移除 Ceph RBD 卷插件
v1.31 版本移除了 Ceph RBD volume plugin 及其 CSI 迁移支持,使 rbd 卷类型变为不可用。
建议您在集群中改用 RBD CSI driver。 如果您在将集群版本升级到 v1.31 之前使用了 Ceph RBD 卷插件,则必须重新部署应用程序以使用新的驱动程序。
Ceph RBD 卷插件在 v1.28 中正式标记为废弃。
废弃 kube-scheduler 中的非 CSI 卷限制插件
v1.31 版本将废弃所有非 CSI 卷限制调度器插件,并将从默认插件中移除一些已废弃的插件,包括:
AzureDiskLimitsCinderLimitsEBSLimitsGCEPDLimits
建议您改用 NodeVolumeLimits 插件,因为自从这些卷类型迁移到 CSI 后,该插件可以处理与已移除插件相同的功能。
如果您在调度器配置中明确使用了已废弃的插件,请将它们替换为 NodeVolumeLimits 插件。
AzureDiskLimits、CinderLimits、EBSLimits 和 GCEPDLimits 插件将在未来的版本中被移除。
这些插件自 Kubernetes v1.14 以来已被废弃,将从默认调度器插件列表中移除。
发布说明和所需的升级操作
请在我们的发布说明中查看 Kubernetes v1.31 版本的完整详细信息。
启用 SchedulerQueueingHints 时,调度器现在使用 QueueingHint
社区为调度器添加了支持,以便在启用 SchedulerQueueingHints 功能门控时,开始使用为 Pod/Updated
事件注册的 QueueingHint,以确定对先前不可调度的 Pod 的更新是否使其变得可调度。
以前,当不可调度的 Pod 被更新时,调度器总是将 Pod 放回队列(activeQ / backoffQ)。
然而,并非所有对 Pod 的更新都会使 Pod 变得可调度,特别是考虑到现在许多调度约束是不可变更的。
在新的行为下,一旦不可调度的 Pod 被更新,调度队列会通过 QueueingHint 检查该更新是否可能使 Pod 变得可调度,
并且只有当至少一个 QueueingHint 返回 Queue 时,才将它们重新排队到 activeQ 或 backoffQ。
自定义调度器插件开发者需要采取的操作:
如果插件的拒绝可以通过更新未调度的 Pod 本身来解决,那么插件必须为 Pod/Update 事件实现 QueueingHint。
例如:假设您开发了一个自定义插件,该插件拒绝具有 schedulable=false 标签的 Pod。
鉴于带有 schedulable=false 标签的 Pod 在移除该标签后将变得可调度,这个插件将为 Pod/Update
事件实现 QueueingHint,当在未调度的 Pod 中进行此类标签更改时返回 Queue。
您可以在 pull request #122234 中找到更多详细信息。
移除 kubelet --keep-terminated-pod-volumes 命令行标志
作为 v1.31 版本的一部分,已移除 kubelet 标志 --keep-terminated-pod-volumes。该标志于 2017 年被弃用。
您可以在拉取请求 #122082 中找到更多详细信息。
可用性
Kubernetes v1.31 可在 GitHub 或 Kubernetes 下载页面上下载。
要开始使用 Kubernetes,请查看这些交互式教程或使用 minikube 运行本地 Kubernetes 集群。您还可以使用 kubeadm 轻松安装 v1.31。
发布团队
Kubernetes 的实现离不开社区的支持、投入和辛勤工作。 每个发布团队由致力于构建 Kubernetes 发布版本各个部分的专门社区志愿者组成。 这需要来自我们社区各个角落的人员的专业技能,从代码本身到文档和项目管理。
我们要感谢整个发布团队为向我们的社区交付 Kubernetes v1.31 版本所付出的时间和努力。 发布团队的成员从首次参与的影子成员到经历多个发布周期的回归团队负责人不等。 特别感谢我们的发布负责人 Angelos Kolaitis,他支持我们完成了一个成功的发布周期,为我们发声,确保我们都能以最佳方式贡献,并挑战我们改进发布过程。
项目速度
CNCF K8s DevStats 项目汇总了许多与 Kubernetes 及各个子项目速度相关的有趣数据点。 这包括从个人贡献到贡献公司数量的所有内容,展示了进化这个生态系统所投入的深度和广度。
在为期 14 周的 v1.31 发布周期(5 月 7 日至 8 月 13 日)中,我们看到来自 113 家不同公司和 528 个个人对 Kubernetes 的贡献。
在整个云原生生态系统中,我们有 379 家公司,共计 2268 名贡献者 - 这意味着相比上一个发布周期,个人贡献者数量惊人地增加了 63%!
数据来源:
贡献指的是当某人进行提交、代码审查、评论、创建问题或 PR、审查 PR(包括博客和文档)或对问题和 PR 进行评论。
如果您有兴趣贡献,请访问此页面开始。
查看 DevStats 以了解更多关于 Kubernetes 项目和社区整体速度的信息。
活动更新
探索 2024 年 8 月至 11 月即将举行的 Kubernetes 和云原生活动,包括 KubeCon、KCD 和其他全球知名会议。保持了解并参与 Kubernetes 社区。
2024 年 8 月
- KubeCon + CloudNativeCon + 开源峰会中国 2024:2024 年 8 月 21-23 日 | 中国香港
- KubeDay Japan:2024 年 8 月 27 日 | 东京,日本
2024 年 9 月
- KCD 拉合尔 - 巴基斯坦 2024: 2024 年 9 月 1 日 | 拉合尔,巴基斯坦
- KuberTENes 生日庆典 斯德哥尔摩: 2024 年 9 月 5 日 | 斯德哥尔摩,瑞典
- KCD Sydney ’24: 2024 年 9 月 5-6 日 | 悉尼,澳大利亚
- KCD Washington DC 2024: 2024 年 9 月 24 日 | 华盛顿特区,美国
- KCD Porto 2024: 2024 年 9 月 27-28 日 | 波尔图,葡萄牙
2024 年 10 月
- KCD Austria 2024: 2024 年 10 月 8-10 日 | 维也纳,奥地利
- KubeDay Australia: 2024 年 10 月 15 日 | 墨尔本,澳大利亚
- KCD UK - London 2024: 2024 年 10 月 22-23 日 | 伦敦,英国
2024 年 11 月
- KubeCon + CloudNativeCon North America 2024: 2024 年 11 月 12-15 日 | 盐湖城,美国
- Kubernetes on EDGE Day North America: 2024 年 11 月 12 日 | 盐湖城,美国
即将举行的发布网络研讨会
加入 Kubernetes v1.31 发布团队成员,于 2024 年 9 月 12 日星期四太平洋时间上午 10 点了解此版本的主要特性,以及废弃和移除的内容,以帮助规划升级。 有关更多信息和注册,请访问 CNCF 在线项目网站上的活动页面。
参与其中
参与 Kubernetes 的最简单方式是加入与您兴趣相符的众多特殊兴趣小组(SIG)之一。 您有什么想向 Kubernetes 社区广播的内容吗? 在我们的每周社区会议上分享您的声音,并通过以下渠道。 感谢您持续的反馈和支持。
- 在 X 上关注我们 @Kubernetesio 获取最新更新
- 在 Discuss 上加入社区讨论
- 在 Slack 上加入社区
- 在 Stack Overflow 上发布问题(或回答问题)
- 分享您的 Kubernetes 故事
- 在博客上阅读更多关于 Kubernetes 的最新动态
- 了解更多关于 Kubernetes 发布团队的信息
向 Client-Go 引入特性门控:增强灵活性和控制力
Kubernetes 组件使用称为“特性门控(Feature Gates)”的开关来管理添加新特性的风险, 特性门控机制使特性能够通过 Alpha、Beta 和 GA 阶段逐步升级。
Kubernetes 组件(例如 kube-controller-manager 和 kube-scheduler)使用 client-go 库与 API 交互, 整个 Kubernetes 生态系统使用相同的库来构建控制器、工具、webhook 等。 client-go 现在包含自己的特性门控机制,使开发人员和集群管理员能够更好地控制如何使用客户端特性。
要了解有关 Kubernetes 中特性门控的更多信息,请参阅特性门控。
动机
在没有 client-go 特性门控的情况下,每个新特性都以自己的方式(如果有的话)将特性可用性与特性的启用分开。 某些特性可通过更新到较新版本的 client-go 来启用,其他特性则需要在每个使用它们的程序中进行主动配置, 其中一些可在运行时使用环境变量进行配置。使用 kube-apiserver 公开的特性门控功能时,有时需要客户端回退机制, 以保持与由于版本新旧或配置不同而不支持该特性服务器的兼容性。 如果在这些回退机制中发现问题,则缓解措施需要更新到 client-go 的固定版本或回滚。
这些方法都无法很好地支持为某些(但不是全部)使用 client-go 的程序默认启用特性。 默认设置的更改不会首先仅为单个组件启用新特性,而是会立即影响所有 Kubernetes 组件的默认设置,从而大大扩大影响半径。
client-go 中的特性门控
为了应对这些挑战,大量的 client-go 特性将使用新的特性门控机制来逐步引入。 这一机制将允许开发人员和用户以类似 Kubernetes 组件特性门控的管理方式启用或禁用特性。
作为一种开箱即用的能力,用户只需使用最新版本的 client-go。这种设计带来多种好处。
对于使用通过 client-go 构建的软件的用户:
- 早期采用者可以针对各个进程分别启用默认关闭的 client-go 特性。
- 无需构建新的二进制文件即可禁用行为不当的特性。
- 所有已知的 client-go 特性门控的状态都会被记录到日志中,允许用户检查。
对于开发使用 client-go 构建的软件的人员:
- 默认情况下,client-go 特性门控覆盖是从环境变量中读取的。 如果在 client-go 特性中发现错误,用户将能够禁用它,而无需等待新版本发布。
- 开发人员可以替换程序中基于默认环境变量的覆盖值以更改默认值、从其他源读取覆盖值或完全禁用运行时覆盖值。
Kubernetes 组件使用这种可定制性将 client-go 特性门控与现有的
--feature-gates命令行标志、特性启用指标和日志记录集成在一起。
覆盖 client-go 特性门控
注意:这描述了在运行时覆盖 client-go 特性门控的默认方法,它可以由特定程序的开发人员禁用或自定义。
在 Kubernetes 组件中,client-go 特性门控覆盖由 --feature-gates 标志控制。
可以通过设置以 KUBE_FEATURE 为前缀的环境变量来启用或禁用 client-go 的特性。
例如,要启用名为 MyFeature 的特性,请按如下方式设置环境变量:
KUBE_FEATURE_MyFeature=true
要禁用特性,可将环境变量设置为 false:
KUBE_FEATURE_MyFeature=false
注意:在某些操作系统上,环境变量区分大小写。
因此,KUBE_FEATURE_MyFeature 和 KUBE_FEATURE_MYFEATURE 将被视为两个不同的变量。
自定义 client-go 特性门控
基于环境变量的默认特性门控覆盖机制足以满足 Kubernetes 生态系统中许多程序的需求,无需特殊集成。 需要不同行为的程序可以用自己的自定义特性门控提供程序替换它。 这允许程序执行诸如强制禁用已知运行不良的特性、直接从远程配置服务读取特性门控或通过命令行选项接受特性门控覆盖等操作。
Kubernetes 组件将 client-go 的默认特性门控提供程序替换为现有 Kubernetes 特性门控提供程序的转换层。
在所有实际应用场合中,client-go 特性门控与其他 Kubernetes 特性门控的处理方式相同:
它们连接到 --feature-gates 命令行标志,包含在特性启用指标中,并在启动时记录。
要替换默认的特性门控提供程序,请实现 Gates 接口并在包初始化时调用 ReplaceFeatureGates,如以下简单示例所示:
import (
"k8s.io/client-go/features"
)
type AlwaysEnabledGates struct{}
func (AlwaysEnabledGates) Enabled(features.Feature) bool {
return true
}
func init() {
features.ReplaceFeatureGates(AlwaysEnabledGates{})
}
需要定义的 client-go 特性完整列表的实现可以通过实现 Registry 接口并调用 AddFeaturesToExistingFeatureGates 来获取它。
完整示例请参考
Kubernetes 内部使用。
总结
随着 client-go v1.30 中特性门控的引入,推出新的 client-go 特性变得更加安全、简单。 用户和开发人员可以控制自己采用 client-go 特性的步伐。 通过为跨 Kubernetes API 边界两侧的特性提供一种通用的培育机制,Kubernetes 贡献者的工作得到了简化。
聚焦 SIG API Machinery
我们最近与 SIG API Machinery 的主席 Federico Bongiovanni(Google)和 David Eads(Red Hat)进行了访谈, 了解一些有关这个 Kubernetes 特别兴趣小组的信息。
介绍
Frederico (FSM):你好,感谢你抽时间参与访谈。首先,你能做个自我介绍以及你是如何参与到 Kubernetes 的?
David:我在 2014 年秋天开始在
OpenShift
(Red Hat 的 Kubernetes 发行版)工作,很快就参与到 API Machinery 的工作中。
我的第一个 PR 是修复 kube-apiserver 的错误消息,然后逐渐扩展到 kubectl(kubeconfigs 是我的杰作!),
auth(RBAC
和 *Review API 是从 OpenShift 移植过来的),apps(例如 workqueues 和 sharedinformers)。
别告诉别人,但 API Machinery 仍然是我的最爱 :)
Federico:我加入 Kubernetes 没有 David 那么早,但现在也已经超过六年了。 在我之前的公司,我们开始为自己的产品使用 Kubernetes,当我有机会直接参与 Kubernetes 的工作时, 我放下了一切,登上了这艘船(无意双关)。我在 2018 年初加入 Google 从事 Kubernetes 的相关工作, 从那时起一直参与其中。
SIG Machinery 的范围
FSM:只需快速浏览一下 SIG API Machinery 的章程,就可以看到它的范围相当广泛, 不亚于 Kubernetes 的控制平面。你能用自己的话描述一下这个范围吗?
David:我们全权负责 kube-apiserver 以及如何高效地使用它。
在后端,这包括它与后端存储的契约以及如何让 API 模式随时间演变。
在前端,这包括模式的最佳实践、序列化、客户端模式以及在其之上的控制器模式。
Federico:Kubernetes 有很多不同的组件,但控制平面有一个非常关键的任务: 它是你与集群的通信层,同时也拥有所有使 Kubernetes 如此强大的可扩展机制。 我们不能犯像回归或不兼容变更这样的错误,因为影响范围太大了。
FSM:鉴于这个广度,你们如何管理它的不同方面?
Federico:我们尝试将大量工作组织成较小的领域。工作组和子项目是其中的一部分。 SIG 中的各位贡献者有各自的专长领域,如果一切都失败了,我们很幸运有像 David、Joe 和 Stefan 这样的人, 他们真的是“全能型”,这种方式让我在这些年里一直感到惊叹。但另一方面, 这也是为什么我们需要更多人来帮助我们在版本变迁之时保持 Kubernetes 的质量和卓越。
不断演变的协作模式
FSM:现有的模式一直是这样,还是随着时间的推移而演变的 - 如果是在演变的,你认为主要的变化以及背后的原因是什么?
David:API Machinery 在随着时间的推移不断发展,既有扩展也有收缩。 在尝试满足客户端访问模式时,它很容易在特性和应用方面扩大范围。
一个范围扩大的好例子是我们认识到需要减少客户端写入控制器时的内存使用率而开发了共享通知器。 在开发共享通知器和使用它们的控制器模式(工作队列、错误处理和列举器)时, 我们大大减少了内存使用率,并消除了许多占用资源较多的列表。 缺点是:我们增加了一套新的权能来提供支持,并有效地从 sig-apps 接管了该领域的所有权。
一个更多共享所有权的例子是:构建出合作的资源管理(服务器端应用的目标),
kubectl 扩展为负责利用服务器端应用的权能。这个过渡尚未完成,
但 SIG CLI 管理其使用情况并拥有它。
FSM:对于方法之间的权衡,你们有什么指导方针吗?
David:我认为这很大程度上取决于影响。如果影响在立即见效中是局部的, 我们会给其他 SIG 提出建议并让他们以自己的节奏推进。 如果影响在立即见效中是全局的且没有自然的激励,我们发现需要直接推动采用。
FSM:仍然在这个话题上,SIG Architecture 有一个 API Governance 子项目, 它与 SIG API Machinery 是否完全独立,还是有重要的连接点?
David:这些项目有相似的名称并对彼此产生一些影响,但有不同的使命和范围。 API Machinery 负责“如何做”,而 API Governance 负责“做什么”。 API 约定、API 审批过程以及对单个 k8s.io API 的最终决定权属于 API Governance。 API Machinery 负责 REST 语义和非 API 特定行为。
Federico:我真得很喜欢 David 的说法: “API Machinery 负责‘如何做’,而 API Governance 负责‘做什么’”: 我们并未拥有实际的 API,但实际的 API 依靠我们存在。
Kubernetes 受欢迎的挑战
FSM:随着 Kubernetes 的采用率上升,我们肯定看到了对控制平面的需求增加:你们对这点的感受如何,它如何影响 SIG 的工作?
David:这对 API Machinery 产生了巨大的影响。多年来,我们经常响应并多次促进了 Kubernetes 的发展阶段。 作为几乎所有 Kubernetes 集群上权能的集中编排中心,我们既领导又跟随社区。 从广义上讲,我看到多年来 API Machinery 经历了一些发展阶段,活跃度一直很高。
寻找目标:从
pre-1.0到v1.3(我们达到了第一个 1000+ 节点/命名空间)。 这段时间以快速变化为特征。我们经历了五个不同版本的模式,并满足了需求。 我们优化了快速、树内 API 的演变(有时以牺牲长期目标为代价),并首次定义了模式。满足需求的扩展:
v1.3-1.9(直到控制器中的共享通知器)。 当我们开始尝试满足客户需求时,我们发现了严重的 CPU 和内存规模限制。 这也是为什么我们将 API Machinery 扩展到包含访问模式,但我们仍然非常关注树内类型。 我们构建了 watch 缓存、protobuf 序列化和共享缓存。
- 培育生态系统:
v1.8-1.21(直到 CRD v1)。这是我们设计和编写 CRD(视为第三方资源的替代品)的时间, 满足我们知道即将到来的即时需求(准入 Webhook),以及我们知道需要的最佳实践演变(API 模式)。 这促成了早期采用者的爆发式增长,他们愿意在约束内非常谨慎地工作,以实现服务 Pod 的用例。 采用速度非常快,有时超出了我们的权能,并形成了新的问题。
- 简化部署:
v1.22+。在不久之前, 我们采用扩展机制来响应运行大规模的 Kubernetes 集群的压力,其中包含大量有时会发生冲突的生态系统项目。 我们投入了许多努力,使平台更易于扩展,管理更安全,就算不是很精通 Kubernetes 的人也能做到。 这些努力始于服务器端应用,并在如今延续到 Webhook 匹配状况和验证准入策略等特性。
API Machinery 的工作对整个项目和生态系统有广泛的影响。 对于那些能够长期投入大量时间的人来说,这是一个令人兴奋的工作领域。
未来发展
FSM:考虑到这些不同的发展阶段,你能说说这个 SIG 的当前首要任务是什么吗?
David:大致的顺序为可靠性、效率和权能。
随着 kube-apiserver 和扩展机制的使用增加,我们发现第一套扩展机制虽然在权能方面相当完整,
但在潜在误用方面存在重大风险,影响范围很大。为了减轻这些风险,我们正在致力于减少事故影响范围的特性
(Webhook 匹配状况)以及为大多数操作提供风险配置较低的替代机制(验证准入策略)。
同时,使用量的增加使我们更加意识到我们可以同时改进服务器端和客户端的扩缩限制。 这里的努力包括更高效的序列化(CBOR),减少 etcd 负载(从缓存中一致读取)和减少峰值内存使用量(流式列表)。
最后,使用量的增加突显了一些长期存在的、我们正在设法填补的差距。这些包括针对 CRD 的字段选择算符, Batch Working Group 渴望利用这些选择算符,并最终构建一种新的方法以防止从有漏洞的节点实施“蹦床式”的 Pod 攻击。
加入有趣的我们
FSM:如果有人想要开始贡献,你有什么建议?
Federico:SIG API Machinery 毫不例外也遵循 Kubernetes 的风格:砍柴和挑水(踏实工作,注重细节)。 有多个每周例会对所有人开放,总是有更多的工作要做,人手总是不够。
我承认 API Machinery 并不容易,入门的坡度会比较陡峭。门槛较高,就像我们所讨论的原因:我们肩负着巨大的责任。 当然凭借激情和毅力,多年来有许多人已经跟了上来,我们希望更多的人加入。
具体的机会方面,每两周有一次 SIG 会议。欢迎所有人参会和听会,了解小组在讨论什么,了解这个版本中发生了什么等等。
此外,每周两次,周二和周四,我们有公开的 Bug 分类管理会,在会上我们会讨论上次会议以来的所有新内容。 我们已经保持这种做法 7 年多了。这是一个很好的机会,你可以志愿审查代码、修复 Bug、改进文档等。 周二的会议在下午 1 点(PST),周四是在 EMEA 友好时间(上午 9:30 PST)。 我们总是在寻找改进的机会,希望能够在未来提供更多具体的参与机会。
FSM:太好了,谢谢!你们还有什么想与我们的读者分享吗?
Federico:正如我提到的,第一步可能较难,但回报也更大。 参与 API Machinery 的工作就是在加入一个影响巨大(百万用户?)的领域, 你的贡献将直接影响 Kubernetes 的工作方式和使用方式。对我来说,这已经足够作为回报和动力了!
Kubernetes v1.31 中的移除和主要变更
随着 Kubernetes 的发展和成熟,为了项目的整体健康,某些特性可能会被弃用、删除或替换为更好的特性。 本文阐述了 Kubernetes v1.31 版本的一些更改计划,发行团队认为你应当了解这些更改, 以便持续维护 Kubernetes 环境。 下面列出的信息基于 v1.31 版本的当前状态;这些状态可能会在实际发布日期之前发生变化。
Kubernetes API 删除和弃用流程
Kubernetes 项目针对其功能特性有一个详细说明的弃用策略。 此策略规定,只有当某稳定 API 的更新、稳定版本可用时,才可以弃用该 API,并且 API 的各个稳定性级别都有对应的生命周期下限。 已弃用的 API 标记为在未来的 Kubernetes 版本中删除, 这类 API 将继续发挥作用,直至被删除(从弃用起至少一年),但使用时会显示警告。 已删除的 API 在当前版本中不再可用,因此你必须将其迁移到替换版本。
正式发布的(GA)或稳定的 API 版本可被标记为已弃用,但不得在 Kubernetes 主要版本未变时删除。
Beta 或预发布 API 版本在被弃用后,必须保持 3 个发布版本中仍然可用。
Alpha 或实验性 API 版本可以在任何版本中删除,不必提前通知。
无论 API 是因为某个特性从 Beta 版升级到稳定版,还是因为此 API 未成功而被删除,所有删除都将符合此弃用策略。 每当删除 API 时,迁移选项都会在文档中传达。
关于 SHA-1 签名支持的说明
在 go1.18(2022 年 3 月发布)中,crypto/x509
库开始拒绝使用 SHA-1 哈希函数签名的证书。
虽然 SHA-1 被确定为不安全,并且公众信任的证书颁发机构自 2015 年以来就没有颁发过 SHA-1 证书,
但在 Kubernetes 环境中,仍可能存在用户提供的证书通过私人颁发机构使用 SHA-1 哈希函数签名的情况,
这些证书用于聚合 API 服务器或 Webhook。
如果你依赖基于 SHA-1 的证书,则必须通过在环境中设置 GODEBUG=x509sha1=1 以明确选择重新支持这种证书。
鉴于 Go 的 GODEBUG 兼容性策略,x509sha1 GODEBUG
和对 SHA-1 证书的支持将 在 2025 年上半年发布的 go1.24
中完全消失。
如果你依赖 SHA-1 证书,请开始放弃使用它们。
请参阅 Kubernetes 问题 #125689, 以更好地了解对 SHA-1 支持的时间表,以及 Kubernetes 发布采用 go1.24 的计划时间、如何通过指标和审计日志检测 SHA-1 证书使用情况的更多详细信息。
Kubernetes 1.31 中的弃用和删除
弃用节点的 status.nodeInfo.kubeProxyVersion 字段(KEP 4004)
Node 的 .status.nodeInfo.kubeProxyVersion 字段在 Kubernetes v1.31 中将被弃用,
并将在后续版本中删除。该字段被弃用是因为其取值原来不准确,并且现在也不准确。
该字段由 kubelet 设置,而 kubelet 没有关于 kube-proxy 版本或 kube-proxy 是否正在运行的可靠信息。
在 v1.31 中,DisableNodeKubeProxyVersion
特性门控将默认设置为 true,
并且 kubelet 将不再尝试为其关联的 Node 设置 .status.kubeProxyVersion 字段。
删除所有云驱动的树内集成组件
正如之前一篇文章中所强调的, v1.31 版本将删除云驱动集成的树内支持的最后剩余部分。 这并不意味着你无法与某云驱动集成,只是你现在必须使用推荐的外部集成方法。 一些集成组件是 Kubernetes 项目的一部分,其余集成组件则是第三方软件。
这一里程碑标志着将所有云驱动集成组件从 Kubernetes 核心外部化的过程已经完成 (KEP-2395), 该过程从 Kubernetes v1.26 开始。 这一变化有助于 Kubernetes 进一步成为真正的供应商中立平台。
有关云驱动集成的更多详细信息,请阅读我们的 v1.29 云驱动集成特性的博客。 有关树内代码删除的更多背景信息,请阅读 (v1.29 弃用博客)。
后一个博客还包含对需要迁移到 v1.29 及更高版本的用户有用的信息。
删除 kubelet --keep-terminated-pod-volumes 命令行标志
kubelet 标志 --keep-terminated-pod-volumes 已于 2017 年弃用,将在 v1.31 版本中被删除。
你可以在拉取请求 #122082 中找到更多详细信息。
删除 CephFS 卷插件
CephFS 卷插件已在此版本中删除,
并且 cephfs 卷类型已无法使用。
建议你改用 CephFS CSI 驱动程序 作为第三方存储驱动程序。 如果你在将集群版本升级到 v1.31 之前在使用 CephFS 卷插件,则必须重新部署应用才能使用新驱动。
CephFS 卷插件在 v1.28 中正式标记为已弃用。
删除 Ceph RBD 卷插件
v1.31 版本将删除 Ceph RBD 卷插件及其 CSI 迁移支持,
rbd 卷类型将无法继续使用。
建议你在集群中使用 RBD CSI 驱动。 如果你在将集群版本升级到 v1.31 之前在使用 Ceph RBD 卷插件,则必须重新部署应用以使用新驱动。
Ceph RBD 卷插件在 v1.28 中正式标记为已弃用。
kube-scheduler 中非 CSI 卷限制插件的弃用
v1.31 版本将弃用所有非 CSI 卷限制调度程序插件, 并将从默认插件中删除一些已弃用的插件,包括:
AzureDiskLimitsCinderLimitsEBSLimitsGCEPDLimits
建议你改用 NodeVolumeLimits 插件,因为它可以处理与已删除插件相同的功能,因为这些卷类型已迁移到 CSI。
如果你在调度器配置中显式使用已弃用的插件,
请用 NodeVolumeLimits 插件替换它们。
AzureDiskLimits、CinderLimits、EBSLimits 和 GCEPDLimits 插件将在未来的版本中被删除。
这些插件将从默认调度程序插件列表中删除,因为它们自 Kubernetes v1.14 以来已被弃用。
展望未来
Kubernetes v1.32 计划删除的官方 API 包括:
- 将删除
flowcontrol.apiserver.k8s.io/v1beta3API 版本的 FlowSchema 和 PriorityLevelConfiguration。 为了做好准备,你可以编辑现有清单并重写客户端软件以使用自 v1.29 起可用的flowcontrol.apiserver.k8s.io/v1 API版本。 所有现有的持久化对象都可以通过新 API 访问。flowcontrol.apiserver.k8s.io/v1beta3中需要注意的变化包括优先级配置spec.limited.nominalConcurrencyShares字段仅在未指定时默认为 30,并且显式设置为 0 的话不会被更改为 30。
有关更多信息,请参阅 API 弃用指南。
想要了解更多?
Kubernetes 发行说明中会宣布弃用信息。 我们将在 Kubernetes v1.31 中正式宣布弃用信息,作为该版本的 CHANGELOG 的一部分。
你可以在发行说明中看到待弃用的公告:
Kubernetes 的十年

十年前的 2014 年 6 月 6 日,Kubernetes 的第一次提交被推送到 GitHub。 第一次提交包含了 250 个文件和 47,501 行的 Go、Bash 和 Markdown 代码, 开启了我们今天所拥有的项目。谁能预测到 10 年后,Kubernetes 会成长为迄今为止最大的开源项目之一, 拥有来自超过 8,000 家公司、来自 44 个国家的 88,000 名贡献者。

这一里程碑不仅属于 Kubernetes,也属于由此蓬勃发展的云原生生态系统。 在 CNCF 本身就有近 200 个项目,有来自 240,000 多名个人贡献者, 还有数千名来自更大的生态系统的贡献者的贡献。 如果没有 700 多万开发者和更庞大的用户社区, Kubernetes 就不会达到今天的成就,他们一起帮助塑造了今天的生态系统。
Kubernetes 的起源 - 技术的融合
Kubernetes 背后的理念早在第一次提交之前, 甚至第一个原型(在 2013 年问世之前就已经存在。 在 21 世纪初,摩尔定律仍然成立。计算硬件正以惊人的速度变得越来越强大。 相应地,应用程序变得越来越复杂。硬件商品化和应用程序复杂性的结合表明需要进一步将软件从硬件中抽象出来, 因此解决方案开始出现。
像当时的许多公司一样,Google 正在快速扩张,其工程师对在 Linux 内核中创建一种隔离形式的想法很感兴趣。 Google 工程师 Rohit Seth 在 2006 年的一封电子邮件中描述了这个概念:
我们使用术语 “容器” 来表示一种结构,通过该结构我们可以对负载的系统资源(如内存、任务等)利用情况进行跟踪和计费。

2013 年 3 月,Solomon Hykes 在 PyCon 上进行了一场名为 “Linux容器的未来”的 5 分钟闪电演讲,介绍了名为 “Docker” 的一款即将被推出的开源工具,用于创建和使用 Linux 容器。Docker 提升了 Linux 容器的可用性,使其比以往更容易被更多用户使用,从而使 Docker 和Linux 容器的流行度飙升。随着 Docker 使 Linux 容器的抽象概念可供所有人使用, 以更便于移植且可重复的方式运行应用突然成为可能,但大规模使用的问题仍然存在。
Google 用来管理大规模应用编排的 Borg 系统在 2000 年代中期采用当时所开发的 Linux 容器技术。 此后,该公司还开始研发该系统的一个新版本,名为 “Omega”。 熟悉 Borg 和 Omega 系统的 Google 工程师们看到了 Docker 所推动的容器化技术的流行。 他们意识到对一个开源的容器编排系统的需求,而且意识到这一系统的“必然性”,正如 Brendan Burns 在这篇博文中所描述的。 这一认识在 2013 年秋天激发了一个小团队开始着手一个后来成为 Kubernetes 的项目。该团队包括 Joe Beda、Brendan Burns、Craig McLuckie、Ville Aikas、Tim Hockin、Dawn Chen、Brian Grant 和 Daniel Smith。
Kubernetes 十年回顾

Kubernetes 的历史始于 2014 年 6 月 6 日的那次历史性提交,随后, Google 工程师 Eric Brewer 在 2014 年 6 月 10 日的 DockerCon 2014 上的主题演讲(及其相应的 Google 博客)中由宣布了该项目。
在接下来的一年里,一个由主要来自 Google 和 Red Hat 等公司的贡献者组成的小型社区为该项目付出了辛勤的努力,最终在 2015 年 7 月 21 日发布了 1.0 版本。 在发布 1.0 版本的同时,Google 宣布将 Kubernetes 捐赠给 Linux 基金会下的一个新成立的分支, 即云原生计算基金会 (Cloud Native Computing Foundation,CNCF)。
尽管到了 1.0 版本,但 Kubernetes 项目的使用和理解仍然很困难。Kubernetes 贡献者 Kelsey Hightower 特别注意到了该项目在易用性方面的不足,并于 2016 年 7 月 7 日推出了他著名的 “Kubernetes the Hard Way” 指南的第一次提交。
自从最初的 1.0 版本发布以来,项目经历了巨大的变化,取得了许多重大的成就,例如 在 1.16 版本中正式发布的 Custom Resource Definitions (CRD) , 或者在 1.23 版本中推出的全面双栈支持,以及社区从 1.22 版本中移除广泛使用的 Beta API 和弃用 Dockershim 中吸取的“教训”。
自 1.0 版本以来的一些值得注意的更新、里程碑和事件包括:
- 2016 年 12 月 - Kubernetes 1.5
引入了运行时可插拔性,初步支持 CRI 和 Alpha 版 Windows 节点支持。
OpenAPI 也首次出现,为客户端能够发现扩展 API 铺平了道路。
- 此版本还引入了 Beta 版的 StatefulSet 和 PodDisruptionBudget。
- 2017 年 4 月 — 引入基于角色的访问控制(RBAC)。
- 2017 年 6 月 — 在 Kubernetes 1.7 中,ThirdPartyResources 或 "TPRs" 被 CustomResourceDefinitions(CRD)取代。
- 2017 年 12 月 — Kubernetes 1.9 中, 工作负载 API 成为 GA(正式可用)。发布博客中指出:“Deployment 和 ReplicaSet 是 Kubernetes 中最常用的两个对象, 在经过一年多的实际使用和反馈后,现在已经稳定下来。”
- 2018 年 12 月 — 在 1.13 版本中,容器存储接口(CSI)达到 GA,用于引导最小可用集群的 kubeadm 工具达到 GA,并且 CoreDNS 成为默认的 DNS 服务器。
- 2019 年 9 月 — 自定义资源定义(Custom Resource Definition)在 Kubernetes 1.16 中正式发布。
- 2020 年 8 月 — Kubernetes 1.19 将发布支持窗口增加到 1 年。
- 2020 年 12 月 — Dockershim 在 1.20 版本中被弃用。
- 2021 年 4 月 - Kubernetes 发布节奏变更,从每年发布 4 个版本变为每年发布 3 个版本。
- 2021 年 7 月 - 在 Kubernetes 1.22 中移除了广泛使用的 Beta API。
- 2022 年 5 月 - 在 Kubernetes 1.24 中,Beta API 默认被禁用, 以减少升级冲突,并移除了 Dockershim,导致用户普遍感到困惑 (我们已经改进了我们的沟通方式!)
- 2022 年 12 月 - 在 1.26 版本中,进行了重大的批处理和作业 API 改进, 为更好地支持 AI/ML/批处理工作负载铺平了道路。
附言: 想亲自体会一下这个项目的进展么?可以查看由社区成员 Carlos Santana、Amim Moises Salum Knabben 和 James Spurin 创建的 Kubernetes 1.0 集群搭建教程。
Kubernetes 提供的扩展点多得数不胜数。最初设计用于与 Docker 一起工作,现在你可以插入任何符合 CRI 标准的容器运行时。还有其他类似的接口:用于存储的 CSI 和用于网络的 CNI。 而且这还远远不是全部。在过去的十年中,出现了全新的模式,例如使用自定义资源定义(CRD) 来支持第三方控制器 - 这现在是 Kubernetes 生态系统的重要组成部分。
在过去十年间,参与构建该项目的社区也得到了巨大的扩展。通过使用 DevStats,我们可以看到过去十年中令人难以置信的贡献量,这使得 Kubernetes 成为了全球第二大开源项目:
- 88,474 位贡献者
- 15,121 位代码提交者
- 4,228,347 次贡献
- 158,530 个问题
- 311,787 个拉取请求
Kubernetes 现状

自项目初期以来,项目在技术能力、使用率和贡献方面取得了巨大的增长。 项目仍在积极努力改进并更好地为用户服务。
在即将发布的 1.31 版本中,该项目将庆祝一个重要的长期项目的完成:移除内部云提供商代码。在这个 Kubernetes 历史上最大的迁移中,大约删除了 150 万行代码,将核心组件的二进制文件大小减小了约 40%。在项目早期,很明显可扩展性是成功的关键。 然而,如何实现这种可扩展性并不总是很清楚。此次迁移从核心 Kubernetes 代码库中删除了各种特定于供应商的功能。 现在,特定于供应商的功能可以通过其他可插拔的扩展功能或模式更好地提供,例如自定义资源定义(CRD) 或 Gateway API 等 API 标准。 Kubernetes 在为其庞大的用户群体提供服务时也面临着新的挑战,社区正在相应地进行调整。其中一个例子是将镜像托管迁移到新的、由社区拥有的 registry.k8s.io。为用户提供预编译二进制镜像的出口带宽和成本已经变得非常巨大。这一新的仓库变更使社区能够以更具成本效益和性能高效的方式继续提供这些便利的镜像。 请务必查看此博客文章并更新你必须使用 registry.k8s.io 仓库的任何自动化设施!
Kubernetes 的未来

十年过去了,Kubernetes 的未来依然光明。社区正在优先考虑改进用户体验和增强项目可持续性的变革。 应用程序开发的世界不断演变,Kubernetes 正准备随之变化。
2024 年,人工智能的进展将一种曾经小众的工作负载类型变成了一种非常重要的工作负载类型。 分布式计算和工作负载调度一直与人工智能、机器学习和高性能计算工作负载的资源密集需求密切相关。 贡献者们密切关注新开发的工作负载的需求以及 Kubernetes 如何为它们提供最佳服务。新成立的 Serving 工作组 就是社区组织来解决这些工作负载需求的一个例子。未来几年可能会看到 Kubernetes 在管理各种类型的硬件以及管理跨硬件运行的大型批处理工作负载的调度能力方面的改进。
Kubernetes 周围的生态系统将继续发展壮大。未来,为了保持项目的可持续性, 像内部供应商代码的迁移和仓库变更这样的举措将变得更加重要。
Kubernetes 的未来 10 年将由其用户和生态系统引领,但最重要的是,由为其做出贡献的人引领。 社区对新贡献者持开放态度。你可以在我们的新贡献者课程 https://k8s.dev/docs/onboarding 中找到更多有关贡献的信息。
我们期待与你一起构建 Kubernetes 的未来!

完成 Kubernetes 史上最大规模迁移
早自 Kubernetes v1.7 起,Kubernetes 项目就开始追求取消集成内置云驱动 (KEP-2395)。 虽然这些集成对于 Kubernetes 的早期发展和增长发挥了重要作用,但它们的移除是由两个关键因素驱动的: 为各云启动维护数百万行 Go 代码的原生支持所带来的日趋增长的复杂度,以及将 Kubernetes 打造为真正的供应商中立平台的愿景。
历经很多发布版本之后,我们很高兴地宣布所有云驱动集成组件已被成功地从核心 Kubernetes 仓库迁移到外部插件中。 除了实现我们最初的目标之外,我们还通过删除大约 150 万行代码,将核心组件的可执行文件大小减少了大约 40%, 极大简化了 Kubernetes。
由于受影响的组件众多,而且关键代码路径依赖于五个初始云驱动(Google Cloud、AWS、Azure、OpenStack 和 vSphere) 的内置集成,因此此次迁移是一项复杂且耗时的工作。 为了成功完成此迁移,我们必须从头开始构建四个新的子系统:
- 云控制器管理器(Cloud controller manager)(KEP-2392)
- API 服务器网络代理(KEP-1281)
- kubelet 凭证提供程序插件(KEP-2133)
- 存储迁移以使用 CSI(KEP-625)
就与内置功能实现完全的特性等价而言,每个子系统都至关重要, 并且需要迭代多个版本才能使每个子系统达到 GA 级别并具有安全可靠的迁移路径。 下面详细介绍每个子系统。
云控制器管理器
云控制器管理器是这项工作中引入的第一个外部组件,取代了 kube-controller-manager 和 kubelet 中直接与云 API 交互的功能。 这个基本组件负责通过施加元数据标签来初始化节点。所施加的元数据标签标示节点运行所在的云区域和可用区, 以及只有云驱动知道的 IP 地址。 此外,它还运行服务控制器,该控制器负责为 LoadBalancer 类型的 Service 配置云负载均衡器。

要进一步了解相关信息,请阅读 Kubernetes 文档中的云控制器管理器。
API 服务器网络代理
API 服务器网络代理项目于 2018 年与 SIG API Machinery 合作启动,旨在取代 kube-apiserver 中的 SSH 隧道功能。 该隧道器原用于安全地代理 Kubernetes 控制平面和节点之间的流量,但它重度依赖于 kube-apiserver 中所嵌入的、特定于提供商的实现细节来建立这些 SSH 隧道。
现在,API 服务器网络代理成为 kube-apiserver 中 GA 级别的扩展点。 提供了一种通用代理机制,可以通过一个安全的代理将流量从 API 服务器路由到节点, 从而使 API 服务器无需了解其运行所在的特定云驱动。 此项目还引入了 Konnectivity 项目,该项目在生产环境中的采用越来越多。
你可以在其 README 中了解有关 API 服务器网络代理的更多信息。
kubelet 的凭据提供程序插件
kubelet 凭据提供程序插件的开发是为了取代 kubelet 的内置功能,用于动态获取用于托管在 Google Cloud、AWS 或 Azure 上的镜像仓库的凭据。 原来所实现的功能很方便,因为它允许 kubelet 无缝地获取短期令牌以从 GCR、ECR 或 ACR 拉取镜像 然而,与 Kubernetes 的其他领域一样,支持这一点需要 kubelet 具有不同云环境和 API 的特定知识。
凭据驱动插件机制于 2019 年推出,为 kubelet 提供了一个通用扩展点用于执行插件的可执行文件, 进而为访问各种云上托管的镜像动态提供凭据。 可扩展性扩展了 kubelet 获取短期令牌的能力,且不受限于最初的三个云驱动。
要了解更多信息,请阅读用于认证镜像拉取的 kubelet 凭据提供程序。
存储插件从树内迁移到 CSI
容器存储接口(Container Storage Interface,CSI)是一种控制平面标准,用于管理 Kubernetes 和其他容器编排系统中的块和文件存储系统,已在 1.13 中进入正式发布状态。 它的设计目标是用可在 Kubernetes 集群中 Pod 内运行的驱动程序替换直接内置于 Kubernetes 中的树内卷插件。 这些驱动程序通过 Kubernetes API 与 kube-controller-manager 存储控制器通信,并通过本地 gRPC 端点与 kubelet 进行通信。 现在,所有主要云和存储供应商一起提供了 100 多个 CSI 驱动,使 Kubernetes 中运行有状态工作负载成为现实。
然而,如何处理树内卷 API 的所有现有用户仍然是一个重大挑战。 为了保持 API 向后兼容性,我们在控制器中构建了一个 API 转换层,把树内卷 API 转换为等效的 CSI API。 这使我们能够将所有存储操作重定向到 CSI 驱动程序,为我们在不删除 API 的情况下删除内置卷插件的代码铺平了道路。
你可以在 Kubernetes 树内卷到 CSI 卷的迁移进入 Beta 阶段。
下一步是什么?
过去几年,这一迁移工程一直是 SIG Cloud Provider 的主要关注点。 随着这一重要里程碑的实现,我们将把努力转向探索新的创新方法,让 Kubernetes 更好地与云驱动集成,利用我们多年来构建的外部子系统。 这包括使 Kubernetes 在混合环境中变得更加智能,其集群中的节点可以运行在公共云和私有云上, 以及为外部驱动的开发人员提供更好的工具和框架,以简化他们的集成工作,提高效率。
在规划所有这些新特性、工具和框架的同时,SIG Cloud Provider 并没有忘记另一项同样重要的工作:测试。 SIG 未来活动的另一个重点领域是改进云控制器测试以涵盖更多的驱动。 这项工作的最终目标是创建一个包含尽可能多驱动的测试框架,以便我们让 Kubernetes 社区对其 Kubernetes 环境充满信心。
如果你使用的 Kubernetes 版本早于 v1.29 并且尚未迁移到外部云驱动,我们建议你查阅我们之前的博客文章 Kubernetes 1.29:云驱动集成现在是单独的组件。 该博客包含与我们所作的变更相关的详细信息,并提供了有关如何迁移到外部驱动的指导。 从 v1.31 开始,树内云驱动将被永久禁用并从核心 Kubernetes 组件中删除。
如果你有兴趣做出贡献,请参加我们的每两周一次的 SIG 会议!
Gateway API v1.1:服务网格、GRPCRoute 和更多变化
![]()
继去年十月正式发布 Gateway API 之后,Kubernetes SIG Network 现在又很高兴地宣布 Gateway API v1.1 版本发布。 在本次发布中,有几个特性已进阶至标准渠道(GA),特别是对服务网格和 GRPCRoute 的支持也已进阶。 我们还引入了一些新的实验性特性,包括会话持久性和客户端证书验证。
新内容
进阶至标准渠道
本次发布有四个备受期待的特性进阶至标准渠道。这意味着它们不再是实验性的概念; 包含在标准发布渠道中的举措展现了大家对 API 接口的高度信心,并提供向后兼容的保证。 当然,与所有其他 Kubernetes API 一样,标准渠道的特性可以随着时间的推移通过向后兼容的方式演进, 我们当然期待未来对这些新特性有进一步的优化和改进。 有关细节请参阅 Gateway API 版本控制政策。
服务网格支持
在 Gateway API 中支持服务网格意味着允许服务网格用户使用相同的 API 来管理 Ingress 流量和网格流量,
能够重用相同的策略和路由接口。在 Gateway API v1.1 中,路由(如 HTTPRoute)现在可以将一个 Service 作为 parentRef,
以控制到特定服务的流量行为。有关细节请查阅
Gateway API 服务网格文档或
Gateway API 实现列表。
例如,你可以使用如下 HTTPRoute 以金丝雀部署深入到应用调用图中的工作负载:
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: color-canary
namespace: faces
spec:
parentRefs:
- name: color
kind: Service
group: ""
port: 80
rules:
- backendRefs:
- name: color
port: 80
weight: 50
- name: color2
port: 80
weight: 50
通过使用一种便于从一个网格迁移到另一个网格的可移植配置,
此 HTTPRoute 对象将把发送到 faces 命名空间中的 color Service 的流量按 50/50
拆分到原始的 color Service 和 color2 Service 上。
GRPCRoute
如果你已经在使用实验性版本的 GRPCRoute,我们建议你暂时不要升级到标准渠道版本的 GRPCRoute, 除非你正使用的控制器已被更新为支持 GRPCRoute v1。 在此之后,你才可以安全地升级到实验性渠道版本的 GRPCRoute v1.1,这个版本同时包含了 v1alpha2 和 v1 的 API。
ParentReference 端口
port 字段已被添加到 ParentReference 中,
允许你将资源挂接到 Gateway 监听器、Service 或其他父资源(取决于实现)。
绑定到某个端口还允许你一次挂接到多个监听器。
例如,你可以将 HTTPRoute 挂接到由监听器 port 而不是监听器 name 字段所指定的一个或多个特定监听器。
有关细节请参阅挂接到 Gateways。
合规性配置文件和报告
合规性报告 API 被扩展了,添加了 mode 字段(用于指定实现的工作模式)以及 gatewayAPIChannel(标准或实验性)。
gatewayAPIVersion 和 gatewayAPIChannel 现在由套件机制自动填充,并附有测试结果的简要描述。
这些报告已通过更加结构化的方式进行重新组织,现在实现可以添加测试是如何运行的有关信息,还能提供复现步骤。
实验性渠道的新增内容
Gateway 客户端证书验证
Gateway 现在可以通过在 tls 内引入的新字段 frontendValidation 来为每个
Gateway 监听器配置客户端证书验证。此字段支持配置可用作信任锚的 CA 证书列表,以验证客户端呈现的证书。
以下示例显示了如何使用存储在 foo-example-com-ca-cert ConfigMap 中的 CACertificate
来验证连接到 foo-https Gateway 监听器的客户端所呈现的证书。
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: client-validation-basic
spec:
gatewayClassName: acme-lb
listeners:
name: foo-https
protocol: HTTPS
port: 443
hostname: foo.example.com
tls:
certificateRefs:
kind: Secret
group: ""
name: foo-example-com-cert
frontendValidation:
caCertificateRefs:
kind: ConfigMap
group: ""
name: foo-example-com-ca-cert
会话持久性和 BackendLBPolicy
会话持久性 通过新的策略(BackendLBPolicy) 引入到 Gateway API 中用于服务级配置,在 HTTPRoute 和 GRPCRoute 内以字段的形式用于路由级配置。 BackendLBPolicy 和路由级 API 提供相同的会话持久性配置,包括会话超时、会话名称、会话类型和 cookie 生命周期类型。
以下是 BackendLBPolicy 的示例配置,为 foo 服务启用基于 Cookie 的会话持久性。
它将会话名称设置为 foo-session,定义绝对超时时间和空闲超时时间,并将 Cookie 配置为会话 Cookie:
apiVersion: gateway.networking.k8s.io/v1alpha2
kind: BackendLBPolicy
metadata:
name: lb-policy
namespace: foo-ns
spec:
targetRefs:
- group: core
kind: service
name: foo
sessionPersistence:
sessionName: foo-session
absoluteTimeout: 1h
idleTimeout: 30m
type: Cookie
cookieConfig:
lifetimeType: Session
其他更新
TLS 术语阐述
为了在整个 API 中让我们的 TLS 术语更加一致以实现更广泛的目标, 我们对 BackendTLSPolicy 做了一些破坏性变更。 这就产生了新的 API 版本(v1alpha3),且将需要这个策略所有现有的实现来正确处理版本升级, 例如通过备份数据并在安装这个新版本之前卸载 v1alpha2 版本。
所有引用了 v1alpha2 BackendTLSPolicy 的字段都将需要更新为 v1alpha3。这些字段的具体变更包括:
targetRef变为targetRefs以允许 BackendTLSPolicy 挂接到多个目标tls变为validationtls.caCertRefs变为validation.caCertificateRefstls.wellKnownCACerts变为validation.wellKnownCACertificates
有关本次发布包含的完整变更列表,请参阅 v1.1.0 发布说明。
Gateway API 背景
Gateway API 的想法最初是在 2019 年 KubeCon San Diego 上作为下一代 Ingress API 提出的。 从那时起,一个令人瞩目的社区逐渐形成,共同开发出了可能成为 Kubernetes 历史上最具合作精神的 API。 到目前为止,已有超过 200 人为该 API 做过贡献,而且这一数字还在不断攀升。
维护者们要感谢为 Gateway API 做出贡献的每一个人, 无论是提交代码、参与讨论、提供创意,还是给予常规支持,我们都在此表示诚挚的感谢。 没有这个专注且活跃的社区的支持,我们不可能走到这一步。
试用一下
与其他 Kubernetes API 不同,你不需要升级到最新版本的 Kubernetes 即可获得最新版本的 Gateway API。 只要你运行的是 Kubernetes 1.26 或更高版本,你就可以使用这个版本的 Gateway API。
要试用此 API,请参阅入门指南。
参与进来
你有很多机会可以参与进来并帮助为 Ingress 和服务网格定义 Kubernetes 路由 API 的未来。
- 查阅用户指南以了解可以解决哪些用例。
- 试用其中一个现有的 Gateway 控制器。
- 或者加入我们的社区,帮助我们一起构建 Gateway API 的未来!
相关的 Kubernetes 博文
- 2023 年 11 月 Gateway API v1.0 中的新实验性特性
- 2023 年 10 月 Gateway API v1.0:正式发布(GA)
- 2023 年 10 月介绍 ingress2gateway;简化 Gateway API 升级
- 2023 年 8 月 Gateway API v0.8.0:引入服务网格支持
Kubernetes 1.30:防止未经授权的卷模式转换进阶到 GA
作者: Raunak Pradip Shah (Mirantis)
译者: Xin Li (DaoCloud)
随着 Kubernetes 1.30 的发布,防止修改从 Kubernetes 集群中现有 VolumeSnapshot 创建的 PersistentVolumeClaim 的卷模式的特性已被升级至 GA!
问题
PersistentVolumeClaim 的卷模式 是指存储设备上的底层卷是被格式化为某文件系统还是作为原始块设备呈现给使用它的 Pod。
用户可以利用自 Kubernetes v1.20 以来一直稳定的 VolumeSnapshot 特性,基于
Kubernetes 集群中现有的 VolumeSnapshot 创建 PersistentVolumeClaim(简称 PVC)。
PVC 规约中包括一个 dataSource 字段,它可以指向现有的 VolumeSnapshot 实例。
有关如何基于 Kubernetes 集群中现有 VolumeSnapshot 创建 PVC 的更多详细信息,
请访问使用卷快照创建 PersistentVolumeClaim。
当利用上述特性时,没有逻辑来验证制作快照的原始卷的模式是否与新创建的卷的模式匹配。
这带来了一个安全漏洞,允许恶意用户潜在地利用主机操作系统中未知的漏洞。
有一个合法的场景允许某些用户执行此类转换。 通常,存储备份供应商会在备份操作过程中转换卷模式,通过检索已被更改的块来提高操作效率。 这使得 Kubernetes 无法完全阻止此类操作,但给区分可信用户和恶意用户带来了挑战。
防止未经授权的用户转换卷模式
在此上下文中,授权用户是有权对 VolumeSnapshotContents(集群级资源)执行 update 或 patch 操作的用户。 集群管理员应仅向受信任的用户或应用程序(例如备份供应商)赋予这些权限。 当从 VolumeSnapshot 创建 PVC 时,除了此类授权用户之外的用户将永远不会被允许修改 PVC 的卷模式。
要转换卷模式,授权用户必须执行以下操作:
标识要用作给定命名空间中新创建的 PVC 的数据源的 VolumeSnapshot。
识别与上述 VolumeSnapshot 绑定的 VolumeSnapshotContent。
kubectl describe volumesnapshot -n <namespace> <name>
在 VolumeSnapshotContent 上添加
snapshot.storage.kubernetes.io/allow-volume-mode-change: "true"注解,VolumeSnapshotContent 注解必须包含类似于以下清单片段:kind: VolumeSnapshotContent metadata: annotations: - snapshot.storage.kubernetes.io/allow-volume-mode-change: "true" ...
注意:对于预配置的 VolumeSnapshotContents,你必须执行额外的步骤,将
spec.sourceVolumeMode 字段设置为 Filesystem 或 Block,
具体取决于用来制作此快照的卷的模式。
一个例子如下所示:
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
annotations:
- snapshot.storage.kubernetes.io/allow-volume-mode-change: "true"
name: <volume-snapshot-content-name>
spec:
deletionPolicy: Delete
driver: hostpath.csi.k8s.io
source:
snapshotHandle: <snapshot-handle>
sourceVolumeMode: Filesystem
volumeSnapshotRef:
name: <volume-snapshot-name>
namespace: <namespace>
对备份或恢复操作期间需要转换卷模式的所有 VolumeSnapshotContent 重复步骤 1 至 3。 这可以通过具有授权用户凭据的软件来完成,也可以由授权用户手动完成。
如果 VolumeSnapshotContent 对象上存在上面显示的注解,Kubernetes 将不会阻止卷模式转换。 用户在尝试将注解添加到任何 VolumeSnapshotContent 之前应记住这一点。
需要采取的行动
默认情况下,在 external-provisioner v4.0.0 和 external-snapshotter v7.0.0
中启用 prevent-volume-mode-conversion 特性标志。
基于 VolumeSnapshot 来创建 PVC 时,卷模式更改将被拒绝,除非已执行上述步骤。
接下来
要确定哪些 CSI 外部 sidecar 版本支持此功能,请前往 CSI 文档页面。 对于任何疑问或问题,请加入 Slack 上的 Kubernetes 并在 #csi 或 #sig-storage 频道中发起讨论。 或者,在 CSI 外部快照仓库中登记问题。
Kubernetes 1.30:结构化身份认证配置进阶至 Beta
在 Kubernetes 1.30 中,我们(SIG Auth)将结构化身份认证配置(Structured Authentication Configuration)进阶至 Beta。
今天的文章是关于身份认证:找出谁在执行任务,核查他们是否是自己所说的那个人。 本文还述及 Kubernetes v1.30 中关于 鉴权(决定某些人能访问什么,不能访问什么)的新内容。
动机
Kubernetes 长期以来都需要一个更灵活、更好扩展的身份认证系统。 当前的系统虽然强大,但有一些限制,使其难以用在某些场景下。 例如,不可能同时使用多个相同类型的认证组件(例如,多个 JWT 认证组件), 也不可能在不重启 API 服务器的情况下更改身份认证配置。 结构化身份认证配置特性是解决这些限制并提供一种更灵活、更好扩展的方式来配置 Kubernetes 中身份认证的第一步。
什么是结构化身份认证配置?
Kubernetes v1.30 针对基于文件来配置身份认证提供实验性支持,这是在 Kubernetes v1.30 中新增的 Alpha 特性。 在此 Beta 阶段,Kubernetes 仅支持配置 JWT 认证组件,这是现有 OIDC 认证组件的下一次迭代。 JWT 认证组件使用符合 JWT 标准的令牌对 Kubernetes 用户进行身份认证。 此认证组件将尝试解析原始 ID 令牌,验证其是否由配置的签发方签名。
Kubernetes 项目新增了基于文件的配置,以便提供比使用命令行选项(命令行依然有效,仍受支持)更灵活的方式。 对配置文件的支持还使得在即将发布的版本中更容易提供更多改进措施。
结构化身份认证配置的好处
以下是使用配置文件来配置集群身份认证的好处:
- 多个 JWT 认证组件:你可以同时配置多个 JWT 认证组件。 这允许你使用多个身份提供程序(例如 Okta、Keycloak、GitLab)而无需使用像 Dex 这样的中间程序来处理多个身份提供程序之间的多路复用。
- 动态配置:你可以在不重启 API 服务器的情况下更改配置。 这允许你添加、移除或修改认证组件而不会中断 API 服务器。
- 任何符合 JWT 标准的令牌:你可以使用任何符合 JWT 标准的令牌进行身份认证。 这允许你使用任何支持 JWT 的身份提供程序的令牌。最小有效的 JWT 载荷必须包含 Kubernetes 文档中结构化身份认证配置页面中记录的申领。
- CEL(通用表达式语言)支持:你可以使用 CEL 来确定令牌的申领是否与 Kubernetes 中用户的属性(例如用户名、组)匹配。 这允许你使用复杂逻辑来确定令牌是否有效。
- 多个受众群体:你可以为单个认证组件配置多个受众群体。
这允许你为多个受众群体使用相同的认证组件,例如为
kubectl和仪表板使用不同的 OAuth 客户端。 - 使用不支持 OpenID 连接发现的身份提供程序:你可以使用不支持
OpenID 连接发现 的身份提供程序。
唯一的要求是将发现文档托管到与签发方不同的位置(例如在集群中本地),并在配置文件中指定
issuer.discoveryURL。
如何使用结构化身份认证配置
要使用结构化身份认证配置,你可以使用 --authentication-config 命令行参数在
API 服务器中指定身份认证配置的路径。此配置文件是一个 YAML 文件,指定认证组件及其配置。
以下是一个配置两个 JWT 认证组件的示例配置文件:
apiVersion: apiserver.config.k8s.io/v1beta1
kind: AuthenticationConfiguration
# 如果某人具有这些 issuer 之一签发的有效令牌,则此人可以在集群上进行身份认证
jwt:
- issuer:
url: https://issuer1.example.com
audiences:
- audience1
- audience2
audienceMatchPolicy: MatchAny
claimValidationRules:
expression: 'claims.hd == "example.com"'
message: "the hosted domain name must be example.com"
claimMappings:
username:
expression: 'claims.username'
groups:
expression: 'claims.groups'
uid:
expression: 'claims.uid'
extra:
- key: 'example.com/tenant'
expression: 'claims.tenant'
userValidationRules:
- expression: "!user.username.startsWith('system:')"
message: "username cannot use reserved system: prefix"
# 第二个认证组件将发现文档公布于与签发方不同的位置
- issuer:
url: https://issuer2.example.com
discoveryURL: https://discovery.example.com/.well-known/openid-configuration
audiences:
- audience3
- audience4
audienceMatchPolicy: MatchAny
claimValidationRules:
expression: 'claims.hd == "example.com"'
message: "the hosted domain name must be example.com"
claimMappings:
username:
expression: 'claims.username'
groups:
expression: 'claims.groups'
uid:
expression: 'claims.uid'
extra:
- key: 'example.com/tenant'
expression: 'claims.tenant'
userValidationRules:
- expression: "!user.username.startsWith('system:')"
message: "username cannot use reserved system: prefix"
从命令行参数迁移到配置文件
结构化身份认证配置特性旨在与基于命令行选项配置 JWT 认证组件的现有方法向后兼容。 这意味着你可以继续使用现有的命令行选项来配置 JWT 认证组件。 但是,我们(Kubernetes SIG Auth)建议迁移到新的基于配置文件的方法,因为这种方法更灵活,更好扩展。
Note
如果你同时指定 --authentication-config 和任何 --oidc-* 命令行参数,这是一种错误的配置。
在这种情况下,API 服务器会报告错误,然后立即退出。
如果你想切换到使用结构化身份认证配置,你必须移除 --oidc-* 命令行参数,并改为使用配置文件。
以下是如何从命令行标志迁移到配置文件的示例:
命令行参数
--oidc-issuer-url=https://issuer.example.com
--oidc-client-id=example-client-id
--oidc-username-claim=username
--oidc-groups-claim=groups
--oidc-username-prefix=oidc:
--oidc-groups-prefix=oidc:
--oidc-required-claim="hd=example.com"
--oidc-required-claim="admin=true"
--oidc-ca-file=/path/to/ca.pem
在配置文件中没有与 --oidc-signing-algs 相对应的配置项。
对于 Kubernetes v1.30,认证组件支持在
oidc.go
中列出的所有非对称算法。
配置文件
apiVersion: apiserver.config.k8s.io/v1beta1
kind: AuthenticationConfiguration
jwt:
- issuer:
url: https://issuer.example.com
audiences:
- example-client-id
certificateAuthority: <取值是 /path/to/ca.pem 文件的内容>
claimMappings:
username:
claim: username
prefix: "oidc:"
groups:
claim: groups
prefix: "oidc:"
claimValidationRules:
- claim: hd
requiredValue: "example.com"
- claim: admin
requiredValue: "true"
下一步是什么?
对于 Kubernetes v1.31,我们预计该特性将保持在 Beta,我们要收集更多反馈意见。 在即将发布的版本中,我们希望调查以下内容:
- 通过 CEL 表达式使分布式申领生效。
- 对
issuer.url和issuer.discoveryURL的调用提供 Egress 选择算符配置支持。
你可以在 Kubernetes 文档的结构化身份认证配置页面上了解关于此特性的更多信息。 你还可以通过 KEP-3331 跟踪未来 Kubernetes 版本中的进展。
试用一下
在本文中,我介绍了结构化身份认证配置特性在 Kubernetes v1.30 中带来的好处。
要使用此特性,你必须使用 --authentication-config 命令行参数指定身份认证配置的路径。
从 Kubernetes v1.30 开始,此特性处于 Beta 并默认启用。
如果你希望继续使用命令行参数而不想用配置文件,原来的命令行参数也将继续按原样起作用。
我们很高兴听取你对此特性的反馈意见。请在 Kubernetes Slack 上的 #sig-auth-authenticators-dev 频道与我们联系(若要获取邀请,请访问 https://slack.k8s.io/)。
如何参与
如果你有兴趣参与此特性的开发、分享反馈意见或参与任何其他 SIG Auth 项目, 请在 Kubernetes Slack 上的 #sig-auth 频道联系我们。
我们也欢迎你参加 SIG Auth 双周会议。
Kubernetes 1.30:验证准入策略 ValidatingAdmissionPolicy 正式发布
我代表 Kubernetes 项目组成员,很高兴地宣布 ValidatingAdmissionPolicy 已经作为 Kubernetes 1.30 发布的一部分正式发布。 如果你还不了解这个全新的声明式验证准入 Webhook 的替代方案, 请参阅有关这个新特性的上一篇博文。 如果你已经对 ValidatingAdmissionPolicy 有所了解并且想要尝试一下,那么现在是最好的时机。
让我们替换一个简单的 Webhook,体验一下 ValidatingAdmissionPolicy。
准入 Webhook 示例
首先,让我们看一个简单 Webhook 的示例。以下是一个强制将
runAsNonRoot、readOnlyRootFilesystem、allowPrivilegeEscalation 和 privileged 设置为最低权限值的 Webhook 代码片段。
func verifyDeployment(deploy *appsv1.Deployment) error {
var errs []error
for i, c := range deploy.Spec.Template.Spec.Containers {
if c.Name == "" {
return fmt.Errorf("container %d has no name", i)
}
if c.SecurityContext == nil {
errs = append(errs, fmt.Errorf("container %q does not have SecurityContext", c.Name))
}
if c.SecurityContext.RunAsNonRoot == nil || !*c.SecurityContext.RunAsNonRoot {
errs = append(errs, fmt.Errorf("container %q must set RunAsNonRoot to true in its SecurityContext", c.Name))
}
if c.SecurityContext.ReadOnlyRootFilesystem == nil || !*c.SecurityContext.ReadOnlyRootFilesystem {
errs = append(errs, fmt.Errorf("container %q must set ReadOnlyRootFilesystem to true in its SecurityContext", c.Name))
}
if c.SecurityContext.AllowPrivilegeEscalation != nil && *c.SecurityContext.AllowPrivilegeEscalation {
errs = append(errs, fmt.Errorf("container %q must NOT set AllowPrivilegeEscalation to true in its SecurityContext", c.Name))
}
if c.SecurityContext.Privileged != nil && *c.SecurityContext.Privileged {
errs = append(errs, fmt.Errorf("container %q must NOT set Privileged to true in its SecurityContext", c.Name))
}
}
return errors.NewAggregate(errs)
}
查阅什么是准入 Webhook?, 或者查看这个 Webhook 的完整代码以便更好地理解下述演示。
策略
现在,让我们尝试使用 ValidatingAdmissionPolicy 来忠实地重新创建验证。
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionPolicy
metadata:
name: "pod-security.policy.example.com"
spec:
failurePolicy: Fail
matchConstraints:
resourceRules:
- apiGroups: ["apps"]
apiVersions: ["v1"]
operations: ["CREATE", "UPDATE"]
resources: ["deployments"]
validations:
- expression: object.spec.template.spec.containers.all(c, has(c.securityContext) && has(c.securityContext.runAsNonRoot) && c.securityContext.runAsNonRoot)
message: 'all containers must set runAsNonRoot to true'
- expression: object.spec.template.spec.containers.all(c, has(c.securityContext) && has(c.securityContext.readOnlyRootFilesystem) && c.securityContext.readOnlyRootFilesystem)
message: 'all containers must set readOnlyRootFilesystem to true'
- expression: object.spec.template.spec.containers.all(c, !has(c.securityContext) || !has(c.securityContext.allowPrivilegeEscalation) || !c.securityContext.allowPrivilegeEscalation)
message: 'all containers must NOT set allowPrivilegeEscalation to true'
- expression: object.spec.template.spec.containers.all(c, !has(c.securityContext) || !has(c.securityContext.Privileged) || !c.securityContext.Privileged)
message: 'all containers must NOT set privileged to true'
使用 kubectl 创建策略。很好,到目前为止没有任何问题。那我们获取此策略对象并查看其状态。
kubectl get -oyaml validatingadmissionpolicies/pod-security.policy.example.com
status:
typeChecking:
expressionWarnings:
- fieldRef: spec.validations[3].expression
warning: |
apps/v1, Kind=Deployment: ERROR: <input>:1:76: undefined field 'Privileged'
| object.spec.template.spec.containers.all(c, !has(c.securityContext) || !has(c.securityContext.Privileged) || !c.securityContext.Privileged)
| ...........................................................................^
ERROR: <input>:1:128: undefined field 'Privileged'
| object.spec.template.spec.containers.all(c, !has(c.securityContext) || !has(c.securityContext.Privileged) || !c.securityContext.Privileged)
| ...............................................................................................................................^
系统根据所匹配的类别 apps/v1.Deployment 对策略执行了检查。
查看 fieldRef 后,发现问题出现在第 3 个表达式上(索引从 0 开始)。
有问题的表达式访问了一个未定义的 Privileged 字段。
噢,看起来是一个复制粘贴错误。字段名应该是小写的。
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionPolicy
metadata:
name: "pod-security.policy.example.com"
spec:
failurePolicy: Fail
matchConstraints:
resourceRules:
- apiGroups: ["apps"]
apiVersions: ["v1"]
operations: ["CREATE", "UPDATE"]
resources: ["deployments"]
validations:
- expression: object.spec.template.spec.containers.all(c, has(c.securityContext) && has(c.securityContext.runAsNonRoot) && c.securityContext.runAsNonRoot)
message: 'all containers must set runAsNonRoot to true'
- expression: object.spec.template.spec.containers.all(c, has(c.securityContext) && has(c.securityContext.readOnlyRootFilesystem) && c.securityContext.readOnlyRootFilesystem)
message: 'all containers must set readOnlyRootFilesystem to true'
- expression: object.spec.template.spec.containers.all(c, !has(c.securityContext) || !has(c.securityContext.allowPrivilegeEscalation) || !c.securityContext.allowPrivilegeEscalation)
message: 'all containers must NOT set allowPrivilegeEscalation to true'
- expression: object.spec.template.spec.containers.all(c, !has(c.securityContext) || !has(c.securityContext.privileged) || !c.securityContext.privileged)
message: 'all containers must NOT set privileged to true'
再次检查状态,你应该看到所有警告都已被清除。
接下来,我们创建一个命名空间进行测试。
kubectl create namespace policy-test
接下来,我将策略绑定到命名空间。但此时我将动作设置为 Warn,
这样此策略将打印出警告而不是拒绝请求。
这对于在开发和自动化测试期间收集所有表达式的结果非常有用。
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionPolicyBinding
metadata:
name: "pod-security.policy-binding.example.com"
spec:
policyName: "pod-security.policy.example.com"
validationActions: ["Warn"]
matchResources:
namespaceSelector:
matchLabels:
"kubernetes.io/metadata.name": "policy-test"
测试策略的执行过程。
kubectl create -n policy-test -f- <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
securityContext:
privileged: true
allowPrivilegeEscalation: true
EOF
Warning: Validation failed for ValidatingAdmissionPolicy 'pod-security.policy.example.com' with binding 'pod-security.policy-binding.example.com': all containers must set runAsNonRoot to true
Warning: Validation failed for ValidatingAdmissionPolicy 'pod-security.policy.example.com' with binding 'pod-security.policy-binding.example.com': all containers must set readOnlyRootFilesystem to true
Warning: Validation failed for ValidatingAdmissionPolicy 'pod-security.policy.example.com' with binding 'pod-security.policy-binding.example.com': all containers must NOT set allowPrivilegeEscalation to true
Warning: Validation failed for ValidatingAdmissionPolicy 'pod-security.policy.example.com' with binding 'pod-security.policy-binding.example.com': all containers must NOT set privileged to true
Error from server: error when creating "STDIN": admission webhook "webhook.example.com" denied the request: [container "nginx" must set RunAsNonRoot to true in its SecurityContext, container "nginx" must set ReadOnlyRootFilesystem to true in its SecurityContext, container "nginx" must NOT set AllowPrivilegeEscalation to true in its SecurityContext, container "nginx" must NOT set Privileged to true in its SecurityContext]
看起来很不错!策略和 Webhook 给出了等效的结果。 又测试了其他几种情形后,当我们对策略有信心时,也许是时候进行一些清理工作了。
- 对于每个表达式,我们重复访问
object.spec.template.spec.containers和每个securityContext; - 有一个检查某字段是否存在然后访问该字段的模式,这种模式看起来有点繁琐。
幸运的是,自 Kubernetes 1.28 以来,我们对这两个问题都有了新的解决方案。 变量组合(Variable Composition)允许我们将重复的子表达式提取到单独的变量中。 Kubernetes 允许为 CEL 使用可选库, 这些库非常适合处理可选的字段,你猜对了。
在了解了这两个特性后,让我们稍微重构一下此策略。
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionPolicy
metadata:
name: "pod-security.policy.example.com"
spec:
failurePolicy: Fail
matchConstraints:
resourceRules:
- apiGroups: ["apps"]
apiVersions: ["v1"]
operations: ["CREATE", "UPDATE"]
resources: ["deployments"]
variables:
- name: containers
expression: object.spec.template.spec.containers
- name: securityContexts
expression: 'variables.containers.map(c, c.?securityContext)'
validations:
- expression: variables.securityContexts.all(c, c.?runAsNonRoot == optional.of(true))
message: 'all containers must set runAsNonRoot to true'
- expression: variables.securityContexts.all(c, c.?readOnlyRootFilesystem == optional.of(true))
message: 'all containers must set readOnlyRootFilesystem to true'
- expression: variables.securityContexts.all(c, c.?allowPrivilegeEscalation != optional.of(true))
message: 'all containers must NOT set allowPrivilegeEscalation to true'
- expression: variables.securityContexts.all(c, c.?privileged != optional.of(true))
message: 'all containers must NOT set privileged to true'
策略现在更简洁、更易读。更新策略后,你应该看到它的功用与之前无异。
现在让我们将策略绑定从警告更改为实际拒绝验证失败的请求。
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionPolicyBinding
metadata:
name: "pod-security.policy-binding.example.com"
spec:
policyName: "pod-security.policy.example.com"
validationActions: ["Deny"]
matchResources:
namespaceSelector:
matchLabels:
"kubernetes.io/metadata.name": "policy-test"
最后,移除 Webhook。现在结果应该只包含来自策略的消息。
kubectl create -n policy-test -f- <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
securityContext:
privileged: true
allowPrivilegeEscalation: true
EOF
The deployments "nginx" is invalid: : ValidatingAdmissionPolicy 'pod-security.policy.example.com' with binding 'pod-security.policy-binding.example.com' denied request: all containers must set runAsNonRoot to true
请注意,根据设计,此策略在第一个导致请求被拒绝的表达式之后停止处理。 这与表达式只生成警告时的情况不同。
设置监控
与 Webhook 不同,策略不是一个可以公开其自身指标的专用进程。 相反,你可以使用源自 API 服务器的指标来代替。
以下是使用 Prometheus 查询语言执行一些常见监控任务的示例。
找到上述策略执行期间的 95 分位值:
histogram_quantile(0.95, sum(rate(apiserver_validating_admission_policy_check_duration_seconds_bucket{policy="pod-security.policy.example.com"}[5m])) by (le))
找到策略评估的速率:
rate(apiserver_validating_admission_policy_check_total{policy="pod-security.policy.example.com"}[5m])
你可以阅读指标参考了解有关上述指标的更多信息。 ValidatingAdmissionPolicy 的指标目前处于 Alpha 阶段,随着稳定性在未来版本中的提升,将会有更多和更好的指标。
Kubernetes 1.30:只读卷挂载终于可以真正实现只读了
作者: Akihiro Suda (NTT)
译者: Xin Li (DaoCloud)
只读卷挂载从一开始就是 Kubernetes 的一个特性。 令人惊讶的是,在 Linux 上的某些条件下,只读挂载并不是完全只读的。 从 v1.30 版本开始,这类卷挂载可以被处理为完全只读;v1.30 为递归只读挂载提供 Alpha 支持。
默认情况下,只读卷装载并不是真正的只读
卷挂载可能看似复杂。
你可能期望以下清单使容器中 /mnt 下的所有内容变为只读:
---
apiVersion: v1
kind: Pod
spec:
volumes:
- name: mnt
hostPath:
path: /mnt
containers:
- volumeMounts:
- name: mnt
mountPath: /mnt
readOnly: true
但是,/mnt 下的任何子挂载可能仍然是可写的!
例如,假设 /mnt/my-nfs-server 在主机上是可写的。
在容器内部,写入 /mnt/* 将被拒绝,但 /mnt/my-nfs-server/* 仍然可写。
新的挂载选项:递归只读
Kubernetes 1.30 添加了一个新的挂载选项 recursiveReadOnly,以使子挂载递归只读。
可以按如下方式启用该选项:
---
apiVersion: v1
kind: Pod
spec:
volumes:
- name: mnt
hostPath:
path: /mnt
containers:
- volumeMounts:
- name: mnt
mountPath: /mnt
readOnly: true
# NEW
# 可能的值为 `Enabled`、`IfPossible` 和 `Disabled`。
# 需要与 `readOnly: true` 一起指定。
recursiveReadOnly: Enabled这是通过使用 Linux 内核 v5.12 中添加的
mount_setattr(2)
应用带有 AT_RECURSIVE 标志的 MOUNT_ATTR_RDONLY 属性来实现的。
为了向后兼容,recursiveReadOnly 字段不是 readOnly 的替代品,而是与其结合使用。
要获得正确的递归只读挂载,你必须设置这两个字段。
特性可用性
要启用 recursiveReadOnly 挂载,必须使用以下组件:
Kubernetes:v1.30 或更新版本,并启用
RecursiveReadOnlyMounts特性门控。 从 v1.30 开始,此特性被标记为 Alpha。CRI 运行时:
- containerd:v2.0 或更新版本
OCI 运行时:
- runc:v1.1 或更新版本
- crun: v1.8.6 或更新版本
Linux 内核: v5.12 或更新版本
接下来
Kubernetes SIG Node 希望并期望该特性将在 Kubernetes 的未来版本中升级为 Beta 版本并最终稳定可用(GA),以便用户不再需要手动启用此特性门控。
为了向后兼容,recursive ReadOnly 的默认值仍将保持 Disabled。
怎样才能了解更多?
请查看文档以获取
recursiveReadOnly 挂载的更多详细信息。
如何参与?
此特性由 SIG Node 社区推动。 请加入我们,与社区建立联系,并分享你对上述特性及其他特性的想法和反馈。 我们期待你的回音!
Kubernetes 1.30:对 Pod 使用用户命名空间的支持进阶至 Beta
Linux 提供了不同的命名空间来将进程彼此隔离。 例如,一个典型的 Kubernetes Pod 运行在一个网络命名空间中可以隔离网络身份,运行在一个 PID 命名空间中可以隔离进程。
Linux 有一个以前一直未被容器化应用所支持的命名空间是用户命名空间。 这个命名空间允许我们将容器内使用的用户标识符和组标识符(UID 和 GID)与主机上的标识符隔离开来。
这是一个强大的抽象,允许我们以 “root” 身份运行容器: 我们在容器内部有 root 权限,可以在 Pod 内执行所有 root 能做的操作, 但我们与主机的交互仅限于非特权用户可以执行的操作。这对于限制容器逃逸的影响非常有用。
容器逃逸是指容器内的进程利用容器运行时或内核中的某些未打补丁的漏洞逃逸到主机上, 并可以访问/修改主机或其他容器上的文件。如果我们以用户命名空间运行我们的 Pod, 容器对主机其余部分的特权将减少,并且此容器可以访问的容器外的文件也将受到限制。
在 Kubernetes v1.25 中,我们仅为无状态 Pod 引入了对用户命名空间的支持。 Kubernetes 1.28 取消了这一限制,目前在 Kubernetes 1.30 中,这个特性进阶到了 Beta!
什么是用户命名空间?
注意:Linux 用户命名空间与 Kubernetes 命名空间是不同的概念。 前者是一个 Linux 内核特性;后者是一个 Kubernetes 特性。
用户命名空间是一个 Linux 特性,它将容器的 UID 和 GID 与主机上的隔离开来。 容器中的标识符可以被映射为主机上的标识符,并且保证不同容器所使用的主机 UID/GID 不会重叠。 此外,这些标识符可以被映射到主机上没有特权的、非重叠的 UID 和 GID。这带来了两个关键好处:
- 防止横向移动:由于不同容器的 UID 和 GID 被映射到主机上的不同 UID 和 GID, 即使这些标识符逃出了容器的边界,容器之间也很难互相攻击。 例如,假设容器 A 在主机上使用的 UID 和 GID 与容器 B 不同。 在这种情况下,它对容器 B 的文件和进程的操作是有限的:只能读取/写入某文件所允许的操作, 因为它永远不会拥有文件所有者或组权限(主机上的 UID/GID 保证对不同容器是不同的)。
- 增加主机隔离:由于 UID 和 GID 被映射到主机上的非特权用户,如果某容器逃出了它的边界, 即使它在容器内部以 root 身份运行,它在主机上也没有特权。 这大大保护了它可以读取/写入的主机文件,它可以向哪个进程发送信号等。 此外,所授予的权能仅在用户命名空间内有效,而在主机上无效,这就限制了容器逃逸的影响。
用户命名空间 ID 分配
如果不使用用户命名空间,容器逃逸时以 root 运行的容器在节点上将具有 root 特权。 如果某些权能授权给了此容器,这些权能在主机上也会有效。 如果使用用户命名空间,就不会是这种情况(当然,除非有漏洞 🙂)。
1.30 的变化
在 Kubernetes 1.30 中,除了将用户命名空间进阶至 Beta,参与此特性的贡献者们还:
- 为 kubelet 引入了一种使用自定义范围进行 UID/GID 映射的方式
- 为 Kubernetes 添加了一种强制执行的方式让运行时支持用户命名空间所需的所有特性。 如果不支持这些特性,Kubernetes 在尝试创建具有用户命名空间的 Pod 时,会显示一个明确的错误。 在 1.30 之前,如果容器运行时不支持用户命名空间,Pod 可能会在没有用户命名空间的情况下被创建。
- 新增了更多的测试,包括在 cri-tools 仓库中的测试。
你可以查阅有关用户命名空间的文档, 了解如何配置映射的自定义范围。
演示
几个月前,CVE-2024-21626 被披露。 这个 漏洞评分为 8.6(高)。它允许攻击者让容器逃逸,并读取/写入节点上的任何路径以及同一节点上托管的其他 Pod。
Rodrigo 创建了一个滥用 CVE 2024-21626 的演示, 演示了此漏洞在没有用户命名空间时的工作方式,而在使用用户命名空间后 得到了缓解。
请注意,使用用户命名空间时,攻击者可以在主机文件系统上执行“其他”权限位所允许的操作。 因此,此 CVE 并没有完全被修复,但影响大大降低。
节点系统要求
使用此特性对 Linux 内核版本和容器运行时有一些要求。
在 Linux 上,你需要 Linux 6.3 或更高版本。 这是因为此特性依赖于一个名为 idmap 挂载的内核特性,而支持 idmap 挂载与 tmpfs 一起使用的特性是在 Linux 6.3 中合并的。
假设你使用 CRI-O 和 crun;就像往常一样,你可以期待 CRI-O 1.30 支持 Kubernetes 1.30。 请注意,你还需要 crun 1.9 或更高版本。如果你使用的是 CRI-O 和 runc,则仍然不支持用户命名空间。
containerd 对此特性的支持目前锁定为 containerd 2.0,同样 crun 也有适用的版本要求。 如果你使用的是 containerd 和 runc,则仍然不支持用户命名空间。
请注意,正如在 Kubernetes 1.25 和 1.26 中实现的那样,containerd 1.7 增加了对用户命名空间的实验性支持。 我们曾在 Kubernetes 1.27 中进行了重新设计,所以容器运行时需要做一些变更。 而 containerd 1.7 并未包含这些变更,所以它仅在 Kubernetes 1.25 和 1.26 中支持使用用户命名空间。
containerd 1.7 的另一个限制是,它需要在 Pod 启动期间变更容器镜像内的每个文件和目录的所有权。 这会增加存储开销,并可能显著影响容器启动延迟。containerd 2.0 可能会包含一个实现,以消除增加的启动延迟和存储开销。 如果你计划在生产环境中使用 containerd 1.7 和用户命名空间,请考虑这一点。
containerd 1.7 的这些限制均不适用于 CRI-O。
如何参与?
你可以通过以下方式联系 SIG Node:
你也可以通过以下方式直接联系我们:
- GitHub:@rata @giuseppe @saschagrunert
- Slack:@rata @giuseppe @sascha
SIG Architecture 特别报道:代码组织
作者: Frederico Muñoz (SAS Institute)
译者: Xin Li (DaoCloud)
这是 SIG Architecture Spotlight 系列的第三次采访,该系列将涵盖不同的子项目。 我们将介绍 SIG Architecture:代码组织。
在本次 SIG Architecture 聚焦中,我与代码组织子项目的成员 Madhav Jivrajani(VMware)进行了交谈。
介绍代码组织子项目
Frederico (FSM):你好,Madhav,感谢你百忙之中接受我们的采访。你能否首先向我们介绍一下你自己、你的角色以及你是如何参与 Kubernetes 的?
Madhav Jivrajani (MJ):你好!我叫 Madhav Jivrajani,担任 SIG 贡献者体验的技术主管和 Kubernetes 项目的 GitHub 管理员。 除此之外,我还为 SIG API Machinery 和 SIG Etcd 做出贡献,但最近,我一直在帮助完成 Kubernetes 保留受支持的 Go 版本 所需的工作, 正是通过这一点,参与到了 SIG Architecture 的代码组织子项目中。
FSM:像 Kubernetes 这样规模的项目在代码组织方面肯定会遇到独特的挑战 -- 这是一个合理的假设吗? 如果是这样,你认为 Kubernetes 特有的一些主要挑战是什么?
MJ:这是一个合理的假设!第一个有趣的挑战来自 Kubernetes 代码库的庞大规模。 我们有大约 220 万行 Go 代码(由于 dims 和这个子项目中的其他人的努力,该代码正在稳步减少!), 而且我们的依赖项(无论是直接还是间接)超过 240 个,这就是为什么拥有一个致力于帮助进行依赖项管理的子项目至关重要: 我们需要知道我们正在引入哪些依赖项,这些依赖项处于什么版本, 以及帮助确保我们能够以一致的方式管理代码库不同部分的依赖关系的工具。 以一致的方式管理代码库不同部分的这些依赖关系。
Kubernetes 的另一个有趣的挑战是,我们在 Kubernetes 发布周期中发布了许多 Go 模块,其中一个例子是
client-go。
然而,作为一个项目,我们也希望将所有内容都放在一个仓库中,便获得使用单一仓库的优势,例如原子性的提交……
因此,代码组织与其他 SIG(例如 SIG Release)合作,以实现将代码从单一仓库发布到下游仓库的自动化过程,
下游仓库更容易使用,因为你就不必导入整个 Kubernetes 代码库!
代码组织和 Kubernetes
FSM:对于刚刚开始为 Kubernetes 代码做出贡献的人来说,在代码组织方面他们应该考虑的主要事项是什么? 你认为有哪些关键概念?
MJ:我认为至少在开始时要记住的关键事情之一是 staging 目录的概念。
在 kubernetes/kubernetes 中,你会遇到一个名为
staging/ 的目录。
该目录中的子文件夹充当一堆伪仓库。
例如,发布 client-go 版本的 kubernetes/client-go
仓库实际上是一个 staging 仓库。
FSM:那么 staging 目录的概念会从根本上影响贡献?
MJ:准确地说,因为如果你想为任何 staging 仓库做出贡献,你需要将 PR 发送到 kubernetes/kubernetes 中相应的 staging 目录。
一旦代码合并到那里,我们就会让一个名为 publishing-bot
的机器人将合并的提交同步到必要的 staging 仓库(例如 kubernetes/client-go)中。
通过这种方式,我们可以获得单一仓库的好处,但我们也可以以模块化的形式发布代码以供下游使用。
PS:publishing-bot 需要更多人的帮助!
FSM:说到贡献,贡献者数量非常多,包括个人和公司,也一定是一个挑战:这个子项目是如何运作的以确保大家都遵循标准呢?
MJ:当涉及到项目中的依赖关系管理时,
有一个专门团队帮助审查和批准依赖关系更改。
这些人为目前 Kubernetes 用于管理依赖的许多工具做了开拓性的工作。
这些工具帮助我们确保贡献者可以以一致的方式更改依赖项。
这个子项目还开发了其他工具来基于被添加或删除的依赖项的统计信息发出通知:
depstat
除了依赖管理之外,这个项目执行的另一项重要任务是管理 staging 仓库。
用于实现此目的的工具(publishing-bot)对贡献者完全透明,
有助于确保就提交给 kubernetes/kubernetes 的贡献而言,各个 staging 仓库获得的视图是一致的。
代码组织还致力于确保 Kubernetes 一直在使用受支持的 Go 版本。 链接所指向的 KEP 中包含更详细的背景信息,用来说明为什么我们需要这样做。 我们与 SIG Release 合作,确保我们在 Go 版本上尽可能严格、尽早地测试 Kubernetes; 作为这些工作的一部分,我们要处理会破坏我们的 CI 的那些变更。 我们如何跟踪此过程的示例可以在此处找到。
发布周期和当前优先级
FSM:在发布周期中有什么变化吗?
MJ:在发布周期内,特别是在代码冻结之前,通常会发生添加、更新、删除依赖项的变更,以及修复需要修复的代码等更改, 这些都是我们继续使用受支持的 Go 版本的努力的一部分。
此外,其中一些更改也可以向后移植 到我们支持的发布分支。
FSM:就子项目中目前正在进行的主要项目或主题而言你有什么要特别强调的吗?
MJ:我认为最近添加的一个非常有趣且非常有用的变更(我借这个机会特别强调 Tim Hockin 在这方面的工作)是引入 Go 工作空间的概念到Kubernetes 仓库中。 我们当前的许多依赖管理和代码发布工具,以及在 Kubernetes 仓库中编辑代码的体验, 都可以通过此更改得到显着改善。
收尾
FSM:对这个主题感兴趣的人要怎样开始帮助这个子项目?
MJ:与 Kubernetes 中任何项目的第一步一样,第一步是加入我们的
Slack:slack.k8s.io,然后加入 #k8s-code-organization 频道,
你还可以选择参加代码组织办公时间。
时区是个困难点,所以请随时查看录音或会议记录并跟进 Slack!
FSM:非常好,谢谢!最后你还有什么想分享的吗?
MJ:代码组织子项目总是需要帮助!特别是像发布机器人这样的领域,所以请不要犹豫,参与到 #k8s-code-organization Slack 频道中。
Kubernetes v1.30 初探
作者: Amit Dsouza, Frederick Kautz, Kristin Martin, Abigail McCarthy, Natali Vlatko
译者: Paco Xu (DaoCloud)
快速预览:Kubernetes v1.30 中令人兴奋的变化
新年新版本,v1.30 发布周期已过半,我们将迎来一系列有趣且令人兴奋的增强功能。 从全新的 alpha 特性,到已有的特性升级为稳定版,再到期待已久的改进,这个版本对每个人都有值得关注的内容!
为了让你在正式发布之前对其有所了解,下面给出我们在这个周期中最为期待的增强功能的预览!
Kubernetes v1.30 的主要变化
动态资源分配(DRA)的结构化参数 (KEP-4381)
动态资源分配(DRA) 在 Kubernetes v1.26 中作为 alpha 特性添加。 它定义了一种替代传统设备插件 device plugin API 的方式,用于请求访问第三方资源。 在设计上,动态资源分配(DRA)使用的资源参数对于核心 Kubernetes 完全不透明。 这种方法对于集群自动缩放器(CA)或任何需要为一组 Pod 做决策的高级控制器(例如作业调度器)都会带来问题。 这一设计无法模拟在不同时间分配或释放请求的效果。 只有第三方 DRA 驱动程序才拥有信息来做到这一点。
动态资源分配(DRA)的结构化参数是对原始实现的扩展,它通过构建一个框架来支持增加请求参数的透明度来解决这个问题。 驱动程序不再需要自己处理所有请求参数的语义,而是可以使用 Kubernetes 预定义的特定“结构化模型”来管理和描述资源。 这一设计允许了解这个“结构化规范”的组件做出关于这些资源的决策,而不再将它们外包给某些第三方控制器。 例如,调度器可以在不与动态资源分配(DRA)驱动程序反复通信的前提下快速完成分配请求。 这个版本的工作重点是定义一个框架来支持不同的“结构化模型”,并实现“命名资源”模型。 此模型允许列出各个资源实例,同时,与传统的设备插件 API 相比,模型增加了通过属性逐一选择实例的能力。
节点交换内存 SWAP 支持 (KEP-2400)
在 Kubernetes v1.30 中,Linux 节点上的交换内存支持机制有了重大改进,其重点是提高系统的稳定性。
以前的 Kubernetes 版本默认情况下禁用了 NodeSwap 特性门控。当门控被启用时,UnlimitedSwap 行为被作为默认行为。
为了提高稳定性,UnlimitedSwap 行为(可能会影响节点的稳定性)将在 v1.30 中被移除。
更新后的 Linux 节点上的交换内存支持仍然是 beta 级别,并且默认情况下开启。
然而,节点默认行为是使用 NoSwap(而不是 UnlimitedSwap)模式。
在 NoSwap 模式下,kubelet 支持在启用了磁盘交换空间的节点上运行,但 Pod 不会使用页面文件(pagefile)。
你仍然需要为 kubelet 设置 --fail-swap-on=false 才能让 kubelet 在该节点上运行。
特性的另一个重大变化是针对另一种模式:LimitedSwap。
在 LimitedSwap 模式下,kubelet 会实际使用节点上的页面文件,并允许 Pod 的一些虚拟内存被换页出去。
容器(及其父 Pod)访问交换内存空间不可超出其内存限制,但系统的确可以使用可用的交换空间。
Kubernetes 的 SIG Node 小组还将根据最终用户、贡献者和更广泛的 Kubernetes 社区的反馈更新文档, 以帮助你了解如何使用经过修订的实现。
阅读之前的博客文章或交换内存管理文档以获取有关 Kubernetes 中 Linux 节点交换支持的更多详细信息。
支持 Pod 运行在用户命名空间 (KEP-127)
用户命名空间 是一个仅在 Linux 上可用的特性,它更好地隔离 Pod, 以防止或减轻几个高/严重级别的 CVE,包括 2024 年 1 月发布的 CVE-2024-21626。 在 Kubernetes 1.30 中,对用户命名空间的支持正在迁移到 beta,并且现在支持带有和不带有卷的 Pod,自定义 UID/GID 范围等等!
结构化鉴权配置(KEP-3221)
对结构化鉴权配置的支持正在晋级到 Beta 版本,并将默认启用。 这个特性支持创建具有明确参数定义的多个 Webhook 所构成的鉴权链;这些 Webhook 按特定顺序验证请求, 并允许进行细粒度的控制,例如在失败时明确拒绝。 配置文件方法甚至允许你指定 CEL 规则,以在将请求分派到 Webhook 之前对其进行预过滤,帮助你防止不必要的调用。 当配置文件被修改时,API 服务器还会自动重新加载鉴权链。
你必须使用 --authorization-config 命令行参数指定鉴权配置的路径。
如果你想继续使用命令行标志而不是配置文件,命令行方式没有变化。
要访问新的 Webhook 功能,例如多 Webhook 支持、失败策略和预过滤规则,需要切换到将选项放在 --authorization-config 文件中。
从 Kubernetes 1.30 开始,配置文件格式约定是 beta 级别的,只需要指定 --authorization-config,因为特性门控默认启用。
鉴权文档
中提供了一个包含所有可能值的示例配置。
有关更多详细信息,请阅读鉴权文档。
基于容器资源指标的 Pod 自动扩缩容 (KEP-1610)
基于 ContainerResource 指标的 Pod 水平自动扩缩容将在 v1.30 中升级为稳定版。
HorizontalPodAutoscaler 的这一新行为允许你根据各个容器的资源使用情况而不是 Pod 的聚合资源使用情况来配置自动伸缩。
有关更多详细信息,请参阅我们的先前文章,
或阅读容器资源指标。
在准入控制中使用 CEL (KEP-3488)
Kubernetes 为准入控制集成了 Common Expression Language (CEL) 。 这一集成引入了一种更动态、表达能力更强的方式来判定准入请求。 这个特性允许通过 Kubernetes API 直接定义和执行复杂的、细粒度的策略,同时增强了安全性和治理能力,而不会影响性能或灵活性。
将 CEL 引入到 Kubernetes 的准入控制后,集群管理员就具有了制定复杂规则的能力, 这些规则可以根据集群的期望状态和策略来评估 API 请求的内容,而无需使用基于 Webhook 的访问控制器。 这种控制水平对于维护集群操作的完整性、安全性和效率至关重要,使 Kubernetes 环境更加健壮,更适应各种用例和需求。 有关使用 CEL 进行准入控制的更多信息,请参阅 API 文档中的 ValidatingAdmissionPolicy。
我们希望你和我们一样对这个版本的发布感到兴奋。请在未来几周内密切关注官方发布博客,以了解其他亮点!
走进 Kubernetes 读书会(Book Club)
学习 Kubernetes 及其整个生态的技术并非易事。在本次采访中,我们的访谈对象是 Carlos Santana (AWS), 了解他是如何创办 Kubernetes 读书会(Book Club)的, 整个读书会是如何运作的,以及大家如何加入其中,进而更好地利用社区学习体验。

Frederico Muñoz (FSM):你好 Carlos,非常感谢你能接受我们的采访。首先,你能介绍一下自己吗?
Carlos Santana (CS):当然可以。六年前,我在生产环境中部署 Kubernetes 的经验为我加入 Knative 并通过 Release Team 为 Kubernetes 贡献代码打开了大门。 为上游 Kubernetes 工作是我在开源领域最好的经历之一。在过去的两年里,作为 AWS 的高级专业解决方案架构师, 我一直在帮助大型企业在 Kubernetes 之上构建他们的内部开发平台(IDP)。 未来我的开源贡献将主要集中在 CNOE 和 CNCF 项目,如 Argo、Crossplane 和 Backstage。
创办读书会
FSM:所以你的职业道路把你引向了 Kubernetes,那么是什么动机促使你开始创办读书会呢?
CS:Kubernetes 读书会的想法源于一次 TGIK 直播中的一个临时建议。 对我来说,这不仅仅是读一本书,更是创办一个学习社区。这个社区平台不仅是知识的来源,也是一个支持系统, 特别是在疫情期间陪我度过了艰难时刻。读书会的这项倡议后来帮助许多成员学会了应对和成长,这让我感到很欣慰。 我们在 2021 年 3 月 5 日开始第一本书 Production Kubernetes, 花了 36 周时间。目前,一本书不会再花那么长时间了,如今每周会完成一到两章。
FSM:你能介绍一下 Kubernetes 读书会是如何运作的吗?你们如何选书以及如何阅读它们?
CS:我们根据小组的兴趣和需求以集体的方式选书。这种实用的方法有助于成员们(特别是初学者)更容易地掌握复杂的概念。 我们每周有两次读书会应对不同的时区,一个针对 EMEA(欧洲、中东及非洲)时区,另一个是由我自己负责的美国时区。 每位组织者与他们的联合主持人在 Slack 上甄选一本书,然后安排几个主持人用几周时间讨论每一章。
FSM:如果我没记错的话,Kubernetes 读书会如今已经进行到了第 17 本书。这很了不起:有什么秘诀可以让读书这件事保持活跃吗?
CS:保持俱乐部活跃和吸引人参与的秘诀在于几个关键因素。
首先,一贯性至关重要。我们努力保持定期聚会,只有在重大事件如节假日或 KubeCon 时才会取消聚会。 这种规律性有助于成员保持惯性参与,有助于建立一个可靠的社区。
其次,让聚会有趣生动也非常重要。例如,我经常在聚会期间引入提问测验,不仅检测成员们的理解程度,还增加了一些乐趣。 这种方法使读书内容更加贴近实际,并帮助成员们理解理论概念在现实世界中的运用方式。
读书会涵盖的话题
FSM:书籍的主要话题包括 Kubernetes、GitOps、安全、SRE 和可观测性: 这是否也反映了云原生领域的现状,特别是在受欢迎程度方面?
CS:我们的旅程始于《Production Kubernetes》,为我们专注于实用、生产就绪的解决方案定下了基调。 从那时起,我们深入探讨了 CNCF 领域的各个方面,根据不同的主题去选书。 每个主题,无论是安全性、可观测性还是服务网格,都是根据其相关性和社区需求来选择的。 例如,在我们最近关于 Kubernetes 考试认证的主题中,我们邀请了书籍的作者作为活跃现场的主持人,用他们的专业知识丰富了我们的讨论。
FSM:我了解到此项目最近有一些变化,即被整合到了 CNCF 作为云原生社区组(Cloud Native Community Group)的一部分。你能谈谈这个变化吗?
CS:CNCF 慷慨地接受了读书会作为云原生社区组的一部分。 这是读书会发展过程中的重要一步,优化了读书会的运作并扩大了读书会的影响力。 这种拉齐对于增强读书会的管理能力至关重要,这点很像 Kubernetes Community Days (KCD) 聚会。 现在,读书会有了更稳健的会员结构、活动安排、邮件列表、托管的网络会议和录播系统。
FSM:在过去的六个月里,你参与 CNCF 这件事对 Kubernetes 读书会的成长和参与度产生了什么影响?
CS:自从六个月前成为 CNCF 社区的一部分以来,我们在 Kubernetes 读书会中看到了一些显著的变化。 我们的会员人数激增至 600 多人,并在此期间成功组织并举办了超过 40 场活动。 更令人鼓舞的是,每场活动的出席人数都很稳定,平均约有 30 人参加。 这种增长和参与度清楚地表明了我们与 CNCF 的合作让 Kubernetes 读书会在社区中增强了影响力。
加入读书会
FSM:若有人想加入读书会,他们应该怎么做?
CS:加入读书会只需三步:
- 首先加入 Kubernetes 读书会社区
- 然后注册参与在社区页面上列出的活动
- 最后加入 CNCF Slack 频道 #kubernetes-book-club。
FSM:太好了,谢谢你!最后你还有什么想法要跟大家分享吗?
CS:Kubernetes 读书会不仅仅是一个讨论书籍的专业小组,它是一个充满活力的社区, 有许多令人敬佩的志愿者帮助组织和主持聚会。我想借这次机会感谢几位志愿者: Neependra Khare、 Eric Smalling、 Sevi Karakulak、 Chad M. Crowell 和 Walid (CNJ) Shaari。 欢迎来 KubeCon 与我们相聚,还能领取你的 Kubernetes 读书会贴纸!
镜像文件系统:配置 Kubernetes 将容器存储在独立的文件系统上
作者: Kevin Hannon (Red Hat)
译者: Michael Yao
磁盘空间不足是运行或操作 Kubernetes 集群时的一个常见问题。
在制备节点时,你应该为容器镜像和正在运行的容器留足够的存储空间。
容器运行时通常会向 /var 目录写入数据。
此目录可以位于单独的分区或根文件系统上。CRI-O 默认将其容器和镜像写入 /var/lib/containers,
而 containerd 将其容器和镜像写入 /var/lib/containerd。
在这篇博文中,我们想要关注的是几种不同方式,用来配置容器运行时将其内容存储到别的位置而非默认分区。 这些配置允许我们更灵活地配置 Kubernetes,支持在保持默认文件系统不受影响的情况下为容器存储添加更大的磁盘。
需要额外讲述的是 Kubernetes 向磁盘在写入数据的具体位置及内容。
了解 Kubernetes 磁盘使用情况
Kubernetes 有持久数据和临时数据。kubelet 和特定于 Kubernetes 的本地存储的基础路径是可配置的,
但通常假定为 /var/lib/kubelet。在 Kubernetes 文档中,
这一位置有时被称为根文件系统或节点文件系统。写入的数据可以大致分类为:
- 临时存储
- 日志
- 容器运行时
与大多数 POSIX 系统不同,这里的根/节点文件系统不是 /,而是 /var/lib/kubelet 所在的磁盘。
临时存储
Pod 和容器的某些操作可能需要临时或瞬态的本地存储。 临时存储的生命周期短于 Pod 的生命周期,且临时存储不能被多个 Pod 共享。
日志
默认情况下,Kubernetes 将每个运行容器的日志存储为 /var/log 中的文件。
这些日志是临时性质的,并由 kubelet 负责监控以确保不会在 Pod 运行时变得过大。
你可以为每个节点自定义日志轮换设置, 以管控这些日志的大小,并(使用第三方解决方案)配置日志转储以避免对节点本地存储形成依赖。
容器运行时
容器运行时针对容器和镜像使用两个不同的存储区域。
- 只读层:镜像通常被表示为只读层,因为镜像在容器处于运行状态期间不会被修改。 只读层可以由多个层组成,这些层组合到一起形成最终的只读层。 如果容器要向文件系统中写入数据,则在容器层之上会存在一个薄层为容器提供临时存储。
- 可写层:取决于容器运行时的不同实现,本地写入可能会用分层写入机制来实现
(例如 Linux 上的
overlayfs或 Windows 上的 CimFS)。这一机制被称为可写层。 本地写入也可以使用一个可写文件系统来实现,该文件系统使用容器镜像的完整克隆来初始化; 这种方式适用于某些基于 Hypervisor 虚拟化的运行时。
容器运行时文件系统包含只读层和可写层。在 Kubernetes 文档中,这一文件系统被称为 imagefs。
容器运行时配置
CRI-O
CRI-O 使用 TOML 格式的存储配置文件,让你控制容器运行时如何存储持久数据和临时数据。
CRI-O 使用了 containers-storage 库。
某些 Linux 发行版为 containers-storage 提供了帮助手册条目(man 5 containers-storage.conf)。
存储的主要配置位于 /etc/containers/storage.conf 中,你可以控制临时数据和根目录的位置。
根目录是 CRI-O 存储持久数据的位置。
[storage]
# 默认存储驱动
driver = "overlay"
# 临时存储位置
runroot = "/var/run/containers/storage"
# 容器存储的主要读/写位置
graphroot = "/var/lib/containers/storage"
graphroot- 存储来自容器运行时的持久数据
- 如果 SELinux 被启用,则此项必须是
/var/lib/containers/storage
runroot- 容器的临时读/写访问
- 建议将其放在某个临时文件系统上
以下是为你的 graphroot 目录快速重新打标签以匹配 /var/lib/containers/storage 的方法:
semanage fcontext -a -e /var/lib/containers/storage <你的存储路径>
restorecon -R -v <你的存储路径>
containerd
containerd 运行时使用 TOML 配置文件来控制存储持久数据和临时数据的位置。
配置文件的默认路径位于 /etc/containerd/config.toml。
与 containerd 存储的相关字段是 root 和 state。
root- containerd 元数据的根目录
- 默认为
/var/lib/containerd - 如果你的操作系统要求,需要为根目录设置 SELinux 标签
state- containerd 的临时数据
- 默认为
/run/containerd
Kubernetes 节点压力驱逐
Kubernetes 将自动检测容器文件系统是否与节点文件系统分离。 当你分离文件系统时,Kubernetes 负责同时监视节点文件系统和容器运行时文件系统。 Kubernetes 文档将节点文件系统称为 nodefs,将容器运行时文件系统称为 imagefs。 如果 nodefs 或 imagefs 中有一个磁盘空间不足,则整个节点被视为有磁盘压力。 这种情况下,Kubernetes 先通过删除未使用的容器和镜像来回收空间,之后会尝试驱逐 Pod。 在同时具有 nodefs 和 imagefs 的节点上,kubelet 将在 imagefs 上对未使用的容器镜像执行垃圾回收, 并从 nodefs 中移除死掉的 Pod 及其容器。 如果只有 nodefs,则 Kubernetes 垃圾回收将包括死掉的容器、死掉的 Pod 和未使用的镜像。
Kubernetes 提供额外的配置方法来确定磁盘是否已满。kubelet 中的驱逐管理器有一些让你可以控制相关阈值的配置项。
对于文件系统,相关测量值有 nodefs.available、nodefs.inodesfree、imagefs.available 和
imagefs.inodesfree。如果容器运行时没有专用磁盘,则 imagefs 被忽略。
用户可以使用现有的默认值:
memory.available< 100MiBnodefs.available< 10%imagefs.available< 15%nodefs.inodesFree< 5%(Linux 节点)
Kubernetes 允许你在 kubelet 配置文件中将 EvictionHard 和 EvictionSoft 设置为用户定义的值。
EvictionHard- 定义限制;一旦超出这些限制,Pod 将被立即驱逐,没有任何宽限期。
EvictionSoft- 定义限制;一旦超出这些限制,Pod 将在按各信号所设置的宽限期后被驱逐。
如果你为 EvictionHard 指定了值,所设置的值将取代默认值。
这意味着在你的配置中设置所有信号非常重要。
例如,以下 kubelet 配置可用于配置驱逐信号和宽限期选项。
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
address: "192.168.0.8"
port: 20250
serializeImagePulls: false
evictionHard:
memory.available: "100Mi"
nodefs.available: "10%"
nodefs.inodesFree: "5%"
imagefs.available: "15%"
imagefs.inodesFree: "5%"
evictionSoft:
memory.available: "100Mi"
nodefs.available: "10%"
nodefs.inodesFree: "5%"
imagefs.available: "15%"
imagefs.inodesFree: "5%"
evictionSoftGracePeriod:
memory.available: "1m30s"
nodefs.available: "2m"
nodefs.inodesFree: "2m"
imagefs.available: "2m"
imagefs.inodesFree: "2m"
evictionMaxPodGracePeriod: 60s
问题
Kubernetes 项目建议你针对 Pod 驱逐要么使用其默认设置,要么设置与之相关的所有字段。
你可以使用默认设置或指定你自己的 evictionHard 设置。 如果你漏掉一个信号,那么 Kubernetes 将不会监视该资源。
管理员或用户可能会遇到的一个常见误配是将新的文件系统挂载到 /var/lib/containers/storage 或 /var/lib/containerd。
Kubernetes 将检测到一个单独的文件系统,因此你要确保 imagefs.inodesfree 和 imagefs.available 符合你的需要。
另一个令人困惑的地方是,如果你为节点定义了镜像文件系统,则临时存储报告不会发生变化。
镜像文件系统(imagefs)用于存储容器镜像层;如果容器向自己的根文件系统写入,
那么这种本地写入不会计入容器镜像的大小。容器运行时存储这些本地修改的位置是由运行时定义的,但通常是镜像文件系统。
如果 Pod 中的容器正在向基于文件系统的 emptyDir 卷写入,所写入的数据将使用 nodefs 文件系统的空间。
kubelet 始终根据 nodefs 所表示的文件系统来报告临时存储容量和分配情况;
当临时写入操作实际上是写到镜像文件系统时,这种差别可能会让人困惑。
后续工作
为了解决临时存储报告相关的限制并为容器运行时提供更多配置选项,SIG Node 正在处理 KEP-4191。在 KEP-4191 中, Kubernetes 将检测可写层是否与只读层(镜像)分离。 这种检测使我们可以将包括可写层在内的所有临时存储放在同一磁盘上,同时也可以为镜像使用单独的磁盘。
参与其中
如果你想参与其中,可以加入 Kubernetes Node 特别兴趣小组(SIG)。
如果你想分享反馈,可以分享到我们的 #sig-node Slack 频道。 如果你还没有加入该 Slack 工作区,可以访问 https://slack.k8s.io/ 获取邀请。
特别感谢所有提供出色评审、分享宝贵见解或建议主题想法的贡献者。
- Peter Hunt
- Mrunal Patel
- Ryan Phillips
- Gaurav Singh
Kubernetes 1.29 中的上下文日志生成:更好的故障排除和增强的日志记录
作者:Mengjiao Liu (DaoCloud), Patrick Ohly (Intel)
译者:Mengjiao Liu (DaoCloud)
代表结构化日志工作组和 SIG Instrumentation, 我们很高兴地宣布在 Kubernetes v1.24 中引入的上下文日志记录功能现已成功迁移了两个组件(kube-scheduler 和 kube-controller-manager) 以及一些目录。该功能旨在为 Kubernetes 提供更多有用的日志以更好地进行故障排除,并帮助开发人员增强 Kubernetes。
上下文日志记录是什么?
上下文日志记录基于 go-logr API。 关键思想是调用者将一个日志生成器实例传递给库,并使用它进行日志记录而不是访问全局日志生成器。 二进制文件而不是库负责选择日志记录的实现。go-logr API 围绕结构化日志记录而设计,并支持向日志生成器提供额外信息。
这一设计可以支持某些额外的使用场景:
调用者可以为日志生成器提供额外的信息:
- WithName 添加一个 “logger” 键, 并用句点(.)将名称的各个部分串接起来作为取值
- WithValues 添加键/值对
当将此经过扩展的日志生成器传递到函数中,并且该函数使用它而不是全局日志生成器时, 所有日志条目中都会包含所给的额外信息,而无需修改生成日志条目的代码。 这一特点在高度并行的应用中非常有用。在这类应用中,很难辨识某操作的所有日志条目,因为不同操作的输出是交错的。
运行单元测试时,日志输出可以与当前测试相关联。且当测试失败时,go test 仅显示失败测试的日志输出。 默认情况下,该输出也可能更详细,因为它不会在成功的测试中显示。测试可以并行运行,而无需交错输出。
上下文日志记录的设计决策之一是允许将日志生成器作为值附加到 context.Context 之上。
由于日志生成器封装了调用所预期的、与日志记录相关的所有元素,
因此它是 context 的一部分,而不仅仅是使用它。这一设计的一个比较实际的优点是,
许多 API 已经有一个 ctx 参数,或者可以添加一个 ctx 参数。
进而产生的额外好处还包括比如可以去掉函数内的 context.TODO() 调用。
如何使用它
从 Kubernetes v1.24 开始,上下文日志记录功能处于 Alpha 状态,因此它需要启用
ContextualLogging 特性门控。
如果你想在该功能处于 Alpha 状态时对其进行测试,则需要在 kube-controller-manager 和 kube-scheduler 上启用此特性门控。
对于 kube-scheduler,有一点需要注意,除了启用 ContextualLogging 特性门控之外,
插桩行为还取决于日志的详细程度设置。
为了避免因 1.29 添加的上下文日志记录工具而降低调度程序的速度,请务必仔细选择何时添加额外的信息:
- 在
-v3或更低日志级别中,每个调度周期仅使用一次WithValues("pod")。 这样做可以达到预期效果,即该周期的所有日志消息都包含 Pod 信息。 一旦上下文日志记录特性到达 GA 阶段,就可以从所有日志调用中删除 “pod” 键值对。 - 在
-v4或更高日志级别中,会生成更丰富的日志条目,其中WithValues也用于节点(如果适用),WithName用于当前操作和插件。
下面的示例展示了这一效果:
I1113 08:43:37.029524 87144 default_binder.go:53] "Attempting to bind pod to node" logger="Bind.DefaultBinder" pod="kube-system/coredns-69cbfb9798-ms4pq" node="127.0.0.1"
这一设计的直接好处是在 logger 中可以看到操作和插件名称。pod 和 node 已作为参数记录在
kube-scheduler 代码中的各个日志调用中。一旦 kube-scheduler 之外的其他包也支持上下文日志记录,
在这些包(例如,client-go)中也可以看到操作和插件名称。
一旦上下文日志记录特性到达 GA 阶段,就可以简化日志调用以避免重复这些值。
在 kube-controller-manager 中,WithName 被用来在日志中输出用户可见的控制器名称,例如:
I1113 08:43:29.284360 87141 graph_builder.go:285] "garbage controller monitor not synced: no monitors" logger="garbage-collector-controller"
logger=”garbage-collector-controller” 是由 kube-controller-manager
核心代码在实例化该控制器时添加的,会出现在其所有日志条目中——只要它所调用的代码支持上下文日志记录。
转换像 client-go 这样的共享包还需要额外的工作。
性能影响
在包中支持上下文日志记录,即接受来自调用者的记录器,成本很低。
没有观察到 kube-scheduler 的性能影响。如上所述,添加 WithName 和 WithValues 需要更加小心。
在 Kubernetes 1.29 中,以生产环境日志详细程度(-v3 或更低)启用上下文日志不会导致 kube-scheduler 速度出现明显的减慢,
并且 kube-controller-manager 速度也不会出现明显的减慢。在 debug 级别,考虑到生成的日志使调试更容易,某些测试用例减速 28% 仍然是合理的。
详细信息请参阅有关将该特性升级为 Beta 版的讨论。
对下游用户的影响
日志输出不是 Kubernetes API 的一部分,并且经常在每个版本中都会出现更改, 无论是因为开发人员修改代码还是因为不断转换为结构化和上下文日志记录。
如果下游用户对特定日志有依赖性,他们需要了解此更改如何影响他们。
进一步阅读
如何参与
如果你有兴趣参与,我们始终欢迎新的贡献者加入我们。上下文日志记录为你参与 Kubernetes 开发做出贡献并产生有意义的影响提供了绝佳的机会。 通过加入 Structured Logging WG, 你可以积极参与 Kubernetes 的开发并做出你的第一个贡献。这是学习和参与社区并获得宝贵经验的好方法。
我们鼓励你探索存储库并熟悉正在进行的讨论和项目。这是一个协作环境,你可以在这里交流想法、提出问题并与其他贡献者一起工作。
如果你有任何疑问或需要指导,请随时与我们联系,你可以通过我们的公共 Slack 频道联系我们。 如果你尚未加入 Slack 工作区,可以访问 https://slack.k8s.io/ 获取邀请。
我们要向所有提供精彩评论、分享宝贵见解并协助实施此功能的贡献者表示感谢(按字母顺序排列):
- Aldo Culquicondor (alculquicondor)
- Andy Goldstein (ncdc)
- Feruzjon Muyassarov (fmuyassarov)
- Freddie (freddie400)
- JUN YANG (yangjunmyfm192085)
- Kante Yin (kerthcet)
- Kiki (carlory)
- Lucas Severo Alve (knelasevero)
- Maciej Szulik (soltysh)
- Mengjiao Liu (mengjiao-liu)
- Naman Lakhwani (Namanl2001)
- Oksana Baranova (oxxenix)
- Patrick Ohly (pohly)
- songxiao-wang87 (songxiao-wang87)
- Tim Allclai (tallclair)
- ZhangYu (Octopusjust)
- Ziqi Zhao (fatsheep9146)
- Zac (249043822)
Kubernetes 1.29: 解耦污点管理器与节点生命周期控制器
作者: Yuan Chen (Apple), Andrea Tosatto (Apple)
译者: Allen Zhang
这篇博客讨论在 Kubernetes 1.29 中基于污点的 Pod 驱逐处理的新特性。
背景
在 Kubernetes 1.29 中引入了一项改进,以加强节点上基于污点的 Pod 驱逐处理。 本文将讨论对节点生命周期控制器(node-lifecycle-controller)所做的更改,以分离职责并提高代码的整体可维护性。
变动摘要
节点生命周期控制器之前组合了两个独立的功能:
- 基于节点的条件为节点新增了一组预定义的污点
NoExecute。 - 对有
NoExecute污点的 Pod 执行驱逐操作。
在 Kubernetes 1.29 版本中,基于污点的驱逐实现已经从节点生命周期控制器中移出, 成为一个名为污点驱逐控制器(taint-eviction-controller)的独立组件。 旨在拆分代码,提高代码的可维护性,并方便未来对这两个组件进行扩展。
以下新指标可以帮助你监控基于污点的 Pod 驱逐:
pod_deletion_duration_seconds表示当 Pod 的污点被激活直到这个 Pod 被污点驱逐控制器删除的延迟时间。pod_deletions_total表示自从污点驱逐控制器启动以来驱逐的 Pod 总数。
如何使用这个新特性?
名为 SeparateTaintEvictionController 的特性门控已被添加。该特性在 Kubernetes 1.29 Beta 版本中默认开启。
详情请参阅特性门控。
当这项特性启用时,用户可以通过在 kube-controller-manager 通过手动设置
--controllers=-taint-eviction-controller 的方式来禁用基于污点的驱逐功能。
如果想禁用该特性并在节点生命周期中使用旧版本污点管理器,用户可以通过设置 SeparateTaintEvictionController=false 来禁用。
使用案例
该特性将允许集群管理员扩展、增强默认的污点驱逐控制器,并且可以使用自定义的实现方式替换默认的污点驱逐控制器以满足不同的需要。 例如:更好地支持在本地磁盘的持久卷中的有状态工作负载。
FAQ
该特性是否会改变现有的基于污点的 Pod 驱逐行为?
不会,基于污点的 Pod 驱逐行为保持不变。如果特性门控 SeparateTaintEvictionController 被关闭,
将继续使用之前的节点生命周期管理器中的污点管理器。
启用/使用此特性是否会导致现有 SLI/SLO 中任何操作的用时增加?
不会。
启用/使用此特性是否会导致资源利用量(如 CPU、内存、磁盘、IO 等)的增加?
运行单独的 taint-eviction-controller 所增加的资源利用量可以忽略不计。
了解更多
更多细节请参考 KEP。
特别鸣谢
与任何 Kubernetes 特性一样,从撰写 KEP 到实现新控制器再到审核 KEP 和代码,多名社区成员都做出了贡献,特别感谢:
- Aldo Culquicondor (@alculquicondor)
- Maciej Szulik (@soltysh)
- Filip Křepinský (@atiratree)
- Han Kang (@logicalhan)
- Wei Huang (@Huang-Wei)
- Sergey Kanzhelevi (@SergeyKanzhelev)
- Ravi Gudimetla (@ravisantoshgudimetla)
- Deep Debroy (@ddebroy)
Kubernetes 1.29:PodReadyToStartContainers 状况进阶至 Beta
作者:Zefeng Chen (independent), Kevin Hannon (Red Hat)
译者:Michael Yao
随着最近发布的 Kubernetes 1.29,PodReadyToStartContainers
状况默认可用。
kubelet 在 Pod 的整个生命周期中管理该状况的值,将其存储在 Pod 的状态字段中。
kubelet 将通过容器运行时从 Pod 沙箱创建和网络配置的角度使用 PodReadyToStartContainers
状况准确地展示 Pod 的初始化状态,
这个特性的动机是什么?
集群管理员以前没有明确且轻松访问的方式来查看 Pod 沙箱创建和初始化的完成情况。
从 1.28 版本开始,Pod 中的 Initialized 状况跟踪 Init 容器的执行情况。
然而,它在准确反映沙箱创建完成和容器准备启动的方面存在一些限制,无法适用于集群中的所有 Pod。
在多租户集群中,这种区别尤为重要,租户拥有包括 Init 容器集合在内的 Pod 规约,
而集群管理员管理存储插件、网络插件和容器运行时处理程序。
因此,需要改进这个机制,以便为集群管理员提供清晰和全面的 Pod 沙箱创建完成和容器就绪状态的视图。
这个特性有什么好处?
- 改进可见性:集群管理员可以更清晰和全面地查看 Pod 沙箱的创建完成和容器的就绪状态。 这种增强的可见性使他们能够做出更明智的决策,并更有效地解决问题。
- 指标收集和监控:监控服务可以利用与
PodReadyToStartContainers状况相关的字段来报告沙箱创建状态和延迟。 可以按照每个 Pod 的基数进行指标收集,或者根据 Pod 的各种属性进行聚合,例如volumes、runtimeClassName、CNI 和 IPAM 插件的自定义注解, 以及任意标签和注解,以及 PersistentVolumeClaims 的storageClassName。 这样可以全面监控和分析集群中 Pod 的就绪状态。
- 增强故障排查能力:通过更准确地表示 Pod 沙箱的创建和容器的就绪状态, 集群管理员可以快速识别和解决初始化过程中可能出现的任何问题。 这将提高故障排查能力,并减少停机时间。
后续事项
鉴于反馈和采用情况,Kubernetes 团队在 1.29 版本中将 PodReadyToStartContainersCondition
进阶至 Beta版。你的评论将有助于确定该状况是否继续并晋升至 GA,请针对此特性提交更多反馈!
如何了解更多?
请查看关于 PodReadyToStartContainersCondition
的文档,
以了解其更多信息及其与其他 Pod 状况的关系。
如何参与?
该特性由 SIG Node 社区推动。请加入我们,与社区建立联系,分享你对这一特性及更多内容的想法和反馈。 我们期待倾听你的建议!
Kubernetes 1.29 新的 Alpha 特性:Service 的负载均衡器 IP 模式
作者: Aohan Yang
译者: Allen Zhang
本文介绍 Kubernetes 1.29 中一个新的 Alpha 特性。 此特性提供了一种可配置的方式用于定义 Service 的实现方式,本文中以 kube-proxy 为例介绍如何处理集群内从 Pod 到 Service 的流量。
背景
在 Kubernetes 早期版本中,kube-proxy 会拦截指向 type: LoadBalancer Service 关联
IP 地址的流量。这与你为 kube-proxy 所使用的哪种模式无关。
这种拦截实现了预期行为(流量最终会抵达服务后挂载的端点)。这种机制取决于 kube-proxy 的模式,在 Linux 中,运行于 iptables 模式下的 kube-proxy 会重定向数据包到后端端点;在 ipvs 模式下, kube-proxy 会将负载均衡器的 IP 地址配置到节点的一个网络接口上。采用这种拦截有两个原因:
- 流量路径优化: 高效地重定向 Pod 流量 - 当 Pod 中的容器发送指向负载均衡器 IP 地址的出站包时, 会绕过负载均衡器直接重定向到后端服务。
- 处理负载均衡数据包: 有些负载均衡器发送的数据包设置目标 IP 为负载均衡器的 IP 地址。 因此,这些数据包需要被直接路由到正确的后端(可能不在该节点本地),以避免回环。
问题
然而,上述行为存在几个问题:
- 源 IP(Source IP):
一些云厂商在传输数据包到节点时使用负载均衡器的 IP 地址作为源 IP。在 kube-proxy 的 ipvs 模式下,
存在负载均衡器健康检查永远不会返回的问题。原因是回复的数据包被转发到本地网络接口
kube-ipvs0(绑定负载均衡器 IP 的接口)上并被忽略。
- 负载均衡器层功能缺失: 某些云厂商在负载均衡器层提供了部分特性(例如 TLS 终结、协议代理等)。 绕过负载均衡器会导致当数据包抵达后端服务时这些特性不会生效(导致协议错误等)。
即使新的 Alpha 特性默认关闭,也有临时解决方案,
即为 Service 设置 .status.loadBalancer.ingress.hostname 以绕过 kube-proxy 绑定。
但这终究只是临时解决方案。
解决方案
总之,为云厂商提供选项以禁用当前这种行为大有裨益。
Kubernetes 1.29 版本为 Service 引入新的 Alpha 字段 .status.loadBalancer.ingress.ipMode 以解决上述问题。
该字段指定负载均衡器 IP 的运行方式,并且只有在指定 .status.loadBalancer.ingress.ip 字段时才能指定。
.status.loadBalancer.ingress.ipMode 可选值为:"VIP" 和 "Proxy"。
默认值为 VIP,即目标 IP 设置为负载均衡 IP 和端口并发送到节点的流量会被 kube-proxy 重定向到后端服务。
这种方式保持 kube-proxy 现有行为模式。Proxy 用于阻止 kube-proxy 在 ipvs 和 iptables 模式下绑定负载均衡 IP 地址到节点。
此时,流量会直达负载均衡器然后被重定向到目标节点。转发数据包的目的值配置取决于云厂商的负载均衡器如何传输流量。
- 如果流量被发送到节点然后通过目标地址转换(
DNAT)的方式到达 Pod,目的地应当设置为节点和 IP 和端口; - 如果流量被直接转发到 Pod,目的地应当被设置为 Pod 的 IP 和端口。
用法
开启该特性的必要步骤:
- 下载 Kubernetes 最新版本(
v1.29.0或更新)。 - 通过命令行参数
--feature-gates=LoadBalancerIPMode=true在 kube-proxy、kube-apiserver 和 cloud-controller-manager 开启特性门控。 - 对于
type: LoadBalancer类型的 Service,将ipMode设置为合适的值。 这一步可能由你在EnsureLoadBalancer过程中选择的 cloud-controller-manager 进行处理。
更多信息
- 阅读指定负载均衡器状态的 IPMode。
- 阅读 KEP-1860 - 让 Kubernetes 感知负载均衡器的行为 (sic)。
联系我们
通过 Slack 频道 #sig-network, 或者通过邮件列表联系我们。
特别鸣谢
非常感谢 @Sh4d1 的原始提案和最初代码实现。 我中途接手并完成了这项工作。同样我们也向其他帮助设计、实现、审查特性代码的贡献者表示感谢(按首字母顺序排列):
Kubernetes 1.29:修改卷之 VolumeAttributesClass
译者:Baofa Fan (DaoCloud)
Kubernetes v1.29 版本引入了一个 Alpha 功能,支持通过变更 PersistentVolumeClaim(PVC)的
volumeAttributesClassName 字段来修改卷。启用该功能后,Kubernetes 可以处理除容量以外的卷属性的更新。
允许更改卷属性,而无需通过不同提供商的 API 对其进行管理,这直接简化了当前流程。
你可以在 Kubernetes 文档中,阅读有关 VolumeAttributesClass 的详细使用信息,或者继续阅读了解 Kubernetes 项目为什么支持此功能。
VolumeAttributesClass
新的 storage.k8s.io/v1alpha1 API 组提供了两种新类型:
VolumeAttributesClass
表示由 CSI 驱动程序定义的可变卷属性的规约。你可以在 PersistentVolumeClaim 动态制备时指定它, 并且允许在制备完成后在 PersistentVolumeClaim 规约中进行更改。
ModifyVolumeStatus
表示 ControllerModifyVolume 操作的状态对象。
启用此 Alpha 功能后,PersistentVolumeClaim 的 spec.VolumeAttributesClassName 字段指明了在 PVC 中使用的 VolumeAttributesClass。
在制备卷时,CreateVolume 操作将应用 VolumeAttributesClass 中的参数以及 StorageClass 中的参数。
当 PVC 的 spec.VolumeAttributesClassName 发生变化时,external-resizer sidecar 将会收到一个 informer 事件。
基于当前的配置状态,resizer 将触发 CSI ControllerModifyVolume。更多细节可以在
KEP-3751 中找到。
如何使用它
如果你想在 Alpha 版本中测试该功能,需要在 kube-controller-manager 和 kube-apiserver 中启用相关的特性门控。
使用 --feature-gates 命令行参数:
--feature-gates="...,VolumeAttributesClass=true"
它还需要 CSI 驱动程序实现 ModifyVolume API。
用户流程
如果你想看到该功能的运行情况,并验证它在你的集群中是否正常工作,可以尝试以下操作:
定义 StorageClass 和 VolumeAttributesClass
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: csi-sc-example provisioner: pd.csi.storage.gke.io parameters: type: "hyperdisk-balanced" volumeBindingMode: WaitForFirstConsumerapiVersion: storage.k8s.io/v1alpha1 kind: VolumeAttributesClass metadata: name: silver driverName: pd.csi.storage.gke.io parameters: provisioned-iops: "3000" provisioned-throughput: "50"
定义并创建 PersistentVolumeClaim
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: test-pv-claim spec: storageClassName: csi-sc-example volumeAttributesClassName: silver accessModes: - ReadWriteOnce resources: requests: storage: 64Gi
验证 PersistentVolumeClaim 是否已正确制备:
kubectl get pvc
创建一个新的名为 gold 的 VolumeAttributesClass:
apiVersion: storage.k8s.io/v1alpha1 kind: VolumeAttributesClass metadata: name: gold driverName: pd.csi.storage.gke.io parameters: iops: "4000" throughput: "60"
使用新的 VolumeAttributesClass 更新 PVC 并应用:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: test-pv-claim spec: storageClassName: csi-sc-example volumeAttributesClassName: gold accessModes: - ReadWriteOnce resources: requests: storage: 64Gi
验证 PersistentVolumeClaims 是否具有更新的 VolumeAttributesClass 参数:
kubectl describe pvc <PVC_NAME>
后续步骤
- 有关设计的更多信息,请参阅 VolumeAttributesClass KEP
- 你可以在项目看板上查看或评论 VolumeAttributesClass
- 为了将此功能推向 Beta 版本,我们需要社区的反馈,因此这里有一个行动倡议:为 CSI 驱动程序添加支持, 尝试此功能,考虑它如何帮助解决你的用户遇到的问题...
参与其中
我们始终欢迎新的贡献者。因此,如果你想参与其中,可以加入我们的 Kubernetes 存储特别兴趣小组 (SIG)。
如果你想分享反馈意见,可以在我们的公共 Slack 频道 上留言。
特别感谢所有为此功能提供了很好的评论、分享了宝贵见解并帮助实现此功能的贡献者(按字母顺序):
- Baofa Fan (calory)
- Ben Swartzlander (bswartz)
- Connor Catlett (ConnorJC3)
- Hemant Kumar (gnufied)
- Jan Šafránek (jsafrane)
- Joe Betz (jpbetz)
- Jordan Liggitt (liggitt)
- Matthew Cary (mattcary)
- Michelle Au (msau42)
- Xing Yang (xing-yang)
聚焦 SIG Testing
作者: Sandipan Panda
译者: Michael Yao
欢迎阅读又一期的 “SIG 聚光灯” 系列博客,这些博客重点介绍 Kubernetes 项目中各个特别兴趣小组(SIG)所从事的令人赞叹的工作。这篇博客将聚焦 SIG Testing, 这是一个致力于有效测试 Kubernetes,让此项目的繁琐工作实现自动化的兴趣小组。 SIG Testing 专注于创建和运行工具和基础设施,使社区更容易编写和运行测试,并对测试结果做贡献、分析和处理。
为了深入了解 SIG Testing 的情况, Sandipan Panda 采访了 Google 高级软件工程师兼 SIG Testing 主席 Michelle Shepardson 以及英特尔软件工程师、架构师兼 SIG Testing 技术负责人 Patrick Ohly。
会见贡献者
Sandipan: 你能简单介绍一下自己吗,谈谈你的职责角色以及你是如何参与 Kubernetes 项目和 SIG Testing 的?
Michelle: 嗨!我是 Michelle,是 Google 高级软件工程师。 我最初是为 SIG Testing 开发工具(如 TestGrid 的外部实例)而参与到 Kubernetes 项目的。 我是 TestGrid 和 Prow 的轮值人员,现在也是这个 SIG 的主席。
Patrick: 你好!我在英特尔的一个团队中担任软件工程师和架构师,专注于开源云原生项目。 当我开始学习 Kubernetes 开发存储驱动时,我最初的问题是“如何在集群中进行测试以及如何记录信息?” 这个兴趣点引发了各种增强提案,直到我(重新)编写了足够多的代码,也正式担任了 SIG Testing 技术负责人 (负责 E2E 框架)兼结构化日志工作组负责人。
测试实践和工具
Sandipan: 测试是一个存在多种方法和工具的领域,你们是如何形成现有实践方式的?
Patrick: 我没法谈论早期情况,因为那时我还未参与其中 😆,但回顾一些提交历史可以明显看出, 当时开发人员只是看看有什么可用的工具并开始使用这些工具。对于 E2E 测试来说,使用的是 Ginkgo + Gomega。集成一些黑科技是必要的, 例如在测试运行后进行清理和对测试进行分类。最终形成了 Ginkgo v2 和重新修订的 E2E 测试最佳实践。 关于单元测试,意见非常多样化:一些维护者倾向于只使用 Go 标准库和手动检查。 而其他人使用 stretchr/testify 这类辅助工具包。这种多样性是可以接受的,因为单元测试是自包含的: 贡献者只需在处理许多不同领域时保持灵活。集成测试介于二者之间,它基于 Go 单元测试, 但需要复杂的辅助工具包来启动 API 服务器和其他组件,然后运行更像是 E2E 测试的测试。
SIG Testing 拥有的子项目
Sandipan: SIG Testing 非常多样化。你能简要介绍一下 SIG Testing 拥有的各个子项目吗?
Michelle: 广义上来说,我们拥有与测试框架相关的子项目和基础设施,尽管它们肯定存在重叠。 我们的子项目包括:
- e2e-framework(外部使用)
- test/e2e/framework (用于 Kubernetes 本身)
- kubetest2(用于端到端测试)
- boskos(用于 e2e 测试的资源租赁)
- KIND(在 Docker 中运行 Kubernetes,用于本地测试和开发)
- 以及 KIND 的云驱动。
我们的基础设施包括:
- Prow(基于 K8s 的 CI/CD 和 chatops)
- test-infra 仓库中用于分类、分析、覆盖率、Prow/TestGrid 配置生成等的其他工具和实用程序。
如果你有兴趣了解更多并参与到 SIG Testing 的任何子项目中,查阅 SIG Testing 的 README。
主要挑战和成就
Sandipan: 你们面临的一些主要挑战是什么?
Michelle: Kubernetes 从贡献者到代码再到用户等各方面看都是一个庞大的项目。 测试和基础设施必须满足这种规模,跟上 Kubernetes 每个仓库的所有变化, 同时尽可能地促进开发、改进和发布项目,尽管当然我们并不是唯一参与其中的 SIG。 我认为另一个挑战是子项目的人员配置。SIG Testing 有一些已经存在多年的子项目, 但其中许多最初的维护者已经转到其他领域或者没有时间继续维护它们。 我们需要在这些子项目中培养长期的专业知识和 Owner。
Patrick: 正如 Michelle 所说,规模本身可能就是一个挑战。 不仅基础设施要与之匹配,我们的流程也必须与贡献者数量相匹配。 记录最佳实践是好的,但还不够好:我们有许多新的贡献者,这是好事, 但是让 Reviewer 靠人工解释最佳实践并不可行,这前提是 Reviewer 了解这些最佳实践! 如果现有代码不能被立即更新也无济于事,因为代码实在太多了,特别是对于 E2E 测试来说更是如此。 在接受现有代码无法通过同样的 linter 检查的同时, 为新代码或代码修改应用更严格的 lint 检查对于改善情况会有所帮助。
Sandipan: 有没有一些 SIG 成就使你感到自豪,想要重点说一下?
Patrick: 我有一些拙见,因为我一直在推动这个项目,但我认为现在 E2E 框架和 lint 机制比以前好得多。 我们可能很快就能在启用竞争检测的情况下运行集成测试,这很重要, 因为目前我们只能对单元测试进行竞争检测,而那些往往不太复杂。
Sandipan: 测试始终很重要,但在 Kubernetes 发布过程中,你的工作是否有任何特殊之处?
Patrick: 测试不稳定…… 如果我们有太多这样的不稳定测试,开发速度就会下降,因为我们无法在没有干净测试运行环境的情况下合并 PR, 并且这些环境会越来越少。开发者也会失去对测试的信任,只是“重新测试”直到有了一个干净的运行环境为止, 而不会检查失败是否确实与当前更改中的回归有关。
人员和范围
Sandipan: 这个 SIG 中有哪些让你热爱的?
Michelle: 当然是人 🙂。除此之外,我喜欢 SIG Testing 的宽广范围。 我觉得即使是小的改动也可以对其他贡献者产生重大影响,即使随着时间的推移我的兴趣发生变化, 我也永远不会缺少项目可供我参与。
Patrick: 我的工作是为了让我和其他开发人员的工作变得更好, 比如建设在其他地方开发新特性时每天必须使用的工具。
Sandipan: 你们有没有任何好玩/酷炫/日常趣事可以告诉我们?
Patrick: 五年前,我开始致力于 E2E 框架的增强,然后在一段时间内参与活动较少。 当我回来并想要测试一些新的增强功能时,我询问如何为新代码编写单元测试, 并被指向了一些看起来有些熟悉的、好像以前见过的现有测试。 我查看了提交历史,发现这些测试是我自己编写的! 你可以决定这是否说明了我的长期记忆力衰退还是这很正常... 无论如何,伙计们,要谨记让每个 Commit 的消息和注释明确、友好; 某一刻会有人需要看这些消息和注释 - 甚至可能就是你自己!
展望未来
Sandipan: 在哪些领域和/或子项目上,你们的 SIG 需要帮助?
Michelle: 目前有一些子项目没有人员配置,需要有意愿了解更多的人参与进来。 boskos 和 kubetest2 对我来说尤其突出, 因为它们对于测试非常重要,但却缺乏专门的负责人。
Sandipan: 新的 SIG Testing 贡献者可以带来哪些有用的技能? 如果他们的背景与编程没有直接关联,有哪些方面可以帮助到这个 SIG?
Michelle: 我认为具备用户共情、清晰反馈和识别模式的能力非常有用。 有人使用测试框架或工具,并能用清晰的示例概述痛点,或者能够识别项目中的更广泛的问题并提供数据来支持解决方案。
Sandipan: SIG Testing 的下一步是什么?
Patrick: 对于新代码,更严格的 lint 检查很快将成为强制要求。 如果有人愿意承担这项工作,我们可以对一些 E2E 框架的子工具包进行现代化改造。 我还看到一个机会,可以统一一些 E2E 和集成测试的辅助代码,但这需要更多的思考和讨论。
Michelle: 我期待为我们的工具和基础设施进行一些可用性改进, 并支持更多长期贡献者的贡献和成长,使他们在 SIG 中担任长期角色。如果你有兴趣,请联系我们!
展望未来,SIG Testing 有令人兴奋的计划。你可以通过他们的 Slack 频道与 SIG Testing 的人员取得联系, 或参加他们定期举行的每两周的周二会议。 如果你有兴趣为社区更轻松地运行测试并贡献测试结果,确保 Kubernetes 在各种集群配置和云驱动中保持稳定,请立即加入 SIG Testing 社区!
Kubernetes 1.29 中的移除、弃用和主要变更
作者: Carol Valencia, Kristin Martin, Abigail McCarthy, James Quigley, Hosam Kamel
译者: Michael Yao (DaoCloud)
和其他每次发布一样,Kubernetes v1.29 将弃用和移除一些特性。 一贯以来生成高质量发布版本的能力是开发周期稳健和社区健康的证明。 下文列举即将发布的 Kubernetes 1.29 中的一些弃用和移除事项。
Kubernetes API 移除和弃用流程
Kubernetes 项目对特性有一个文档完备的弃用策略。此策略规定,只有当同一 API 有了较新的、稳定的版本可用时, 原有的稳定 API 才可以被弃用,各个不同稳定级别的 API 都有一个最短的生命周期。 弃用的 API 指的是已标记为将在后续某个 Kubernetes 发行版本中被移除的 API; 移除之前该 API 将继续发挥作用(从被弃用起至少一年时间),但使用时会显示一条警告。 被移除的 API 将在当前版本中不再可用,此时你必须转为使用替代的 API。
- 正式发布(GA)或稳定的 API 版本可能被标记为已弃用,但只有在 Kubernetes 主版本变化时才会被移除。
- 测试版(Beta)或预发布 API 版本在弃用后必须在后续 3 个版本中继续支持。
- Alpha 或实验性 API 版本可以在任何版本中被移除,不另行通知。
无论一个 API 是因为某特性从 Beta 进阶至稳定阶段而被移除,还是因为该 API 根本没有成功, 所有移除均遵从上述弃用策略。无论何时移除一个 API,文档中都会列出迁移选项。
k8s.gcr.io 重定向到 registry.k8s.io 相关说明
Kubernetes 项目为了托管其容器镜像,使用社区自治的一个名为 registry.k8s.io 的镜像仓库。 从最近的 3 月份起,所有流向 k8s.gcr.io 旧仓库的请求开始被重定向到 registry.k8s.io。 已弃用的 k8s.gcr.io 仓库最终将被淘汰。有关这一变更的细节或若想查看你是否受到影响,参阅 k8s.gcr.io 重定向到 registry.k8s.io - 用户须知。
Kubernetes 社区自治软件包仓库相关说明
在 2023 年年初,Kubernetes 项目引入了 pkgs.k8s.io,
这是 Debian 和 RPM 软件包所用的社区自治软件包仓库。这些社区自治的软件包仓库取代了先前由 Google 管理的仓库
(apt.kubernetes.io 和 yum.kubernetes.io)。在 2023 年 9 月 13 日,这些老旧的仓库被正式弃用,其内容被冻结。
有关这一变更的细节或你若想查看是否受到影响, 请参阅弃用公告。
Kubernetes v1.29 的弃用和移除说明
有关 Kubernetes v1.29 计划弃用的完整列表, 参见官方 API 移除列表。
移除与云驱动的内部集成(KEP-2395)
对于 Kubernetes v1.29,默认特性门控 DisableCloudProviders 和 DisableKubeletCloudCredentialProviders
都将被设置为 true。这个变更将要求当前正在使用内部云驱动集成(Azure、GCE 或 vSphere)的用户启用外部云控制器管理器,
或者将关联的特性门控设置为 false 以选择传统的集成方式。
启用外部云控制器管理器意味着你必须在集群的控制平面中运行一个合适的云控制器管理器;
同时还需要为 kubelet(在每个相关节点上)及整个控制平面(kube-apiserver 和 kube-controller-manager)
设置命令行参数 --cloud-provider=external。
有关如何启用和运行外部云控制器管理器的细节, 参阅管理云控制器管理器和 迁移多副本的控制面以使用云控制器管理器。
有关云控制器管理器的常规信息,请参阅 Kubernetes 文档中的云控制器管理器。
移除 v1beta2 流量控制 API 组
在 Kubernetes v1.29 中,将不再提供 FlowSchema 和 PriorityLevelConfiguration 的 flowcontrol.apiserver.k8s.io/v1beta2 API 版本。
为了做好准备,你可以编辑现有的清单(Manifest)并重写客户端软件,以使用自 v1.26 起可用的
flowcontrol.apiserver.k8s.io/v1beta3 API 版本。所有现有的持久化对象都可以通过新的 API 访问。
flowcontrol.apiserver.k8s.io/v1beta3 中的显著变化包括将 PriorityLevelConfiguration 的
spec.limited.assuredConcurrencyShares 字段更名为 spec.limited.nominalConcurrencyShares。
弃用针对 Node 的 status.nodeInfo.kubeProxyVersion 字段
在 v1.29 中,针对 Node 对象的 .status.kubeProxyVersion 字段将被
标记为弃用,
准备在未来某个发行版本中移除。这是因为此字段并不准确,它由 kubelet 设置,
而 kubelet 实际上并不知道 kube-proxy 版本,甚至不知道 kube-proxy 是否在运行。
了解更多
弃用信息是在 Kubernetes 发布说明(Release Notes)中公布的。你可以在以下版本的发布说明中看到待弃用的公告:
我们将在 Kubernetes v1.29 的 CHANGELOG 中正式宣布与该版本相关的弃用信息。
有关弃用和移除流程的细节,参阅 Kubernetes 官方弃用策略文档。
介绍 SIG etcd
作者:Han Kang (Google), Marek Siarkowicz (Google), Frederico Muñoz (SAS Institute)
译者:Xin Li (Daocloud)
特殊兴趣小组(SIG)是 Kubernetes 项目的基本组成部分,很大一部分的 Kubernetes 社区活动都在其中进行。 当有需要时,可以创建新的 SIG, 而这正是最近发生的事情。
SIG etcd 是 Kubernetes SIG 列表中的最新成员。在这篇文章中,我们将更好地认识它,了解它的起源、职责和计划。
etcd 的关键作用
如果我们查看 Kubernetes 集群的控制平面内部,我们会发现 etcd, 一个一致且高可用的键值存储,用作 Kubernetes 所有集群数据的后台数据库 -- 仅此描述就突出了 etcd 所扮演的关键角色,以及它在 Kubernetes 生态系统中的重要性。
由于 etcd 在生态中的关键作用,其项目和社区的健康成为了一个重要的考虑因素, 并且人们 2022 年初对项目状态的担忧 并没有被忽视。维护团队的变化以及其他因素导致了一些情况需要被解决。
为什么要设立特殊兴趣小组
考虑到 etcd 的关键作用,有人提出未来的方向是创建一个新的特殊兴趣小组。 如果 etcd 已经成为 Kubernetes 的核心,创建专门的 SIG 不仅是对这一角色的认可, 还会使 etcd 成为 Kubernetes 社区的一等公民。
SIG etcd 的成立为明确 etcd 和 Kubernetes API 机制之间的契约关系创造了一个专门的空间, 并防止在 etcd 级别上发生违反此契约的更改。此外,etcd 将能够采用 Kubernetes 提供的 SIG 流程(KEP、 PRR、 分阶段特性门控以及其他流程) 以提高代码库的一致性和可靠性,这将为 etcd 社区带来巨大的好处。
作为 SIG,etcd 还能够从 Kubernetes 获得贡献者的支持:Kubernetes 维护者对 etcd 的积极贡献将通过增加潜在审核者数量以及与现有测试框架的集成来降低破坏 Kubernetes 更改的可能性。 这不仅有利于 Kubernetes,由于它能够更好地参与并塑造 etcd 所发挥的关键作用,从而也将有利于整个 etcd。
关于 SIG etcd
最近创建的 SIG 已经在努力实现其章程 和愿景中定义的目标。 其目的很明确:确保 etcd 是一个可靠、简单且可扩展的生产就绪存储,用于构建云原生分布式系统并通过 Kubernetes 等编排器管理云原生基础设施。
SIG etcd 的范围不仅仅涉及将 etcd 作为 Kubernetes 组件,还涵盖将 etcd 作为标准解决方案。 我们的目标是使 etcd 成为可在任何地方使用的最可靠的键值存储,不受任何 kubernetes 特定限制的约束,并且可以扩展以满足许多不同用例的需求。
我们相信,SIG etcd 的创建将成为项目生命周期中的一个重要里程碑,同时改进 etcd 本身以及 etcd 与 Kubernetes 的集成。我们欢迎所有对 etcd 感兴趣的人访问我们的页面、 加入我们的 Slack 频道,并参与 etcd 生命的新阶段。
Gateway API v1.0:正式发布(GA)
作者: Shane Utt (Kong), Nick Young (Isovalent), Rob Scott (Google)
译者: Xin Li (Daocloud)
我们代表 Kubernetes SIG Network 很高兴地宣布 Gateway API v1.0 版本发布!此版本是该项目的一个重要里程碑。几个关键的 API 正在逐步进入 GA(正式发布)阶段, 同时其他重要特性已添加到实验(Experimental)通道中。
新增内容
升级到 v1
此版本将 Gateway、 GatewayClass 和 HTTPRoute 升级到 v1 版本, 这意味着它们现在是正式发布(GA)的版本。这个 API 版本表明我们对 API 的可感知方面具有较强的信心,并提供向后兼容的保证。 需要注意的是,虽然标准(Standard)通道中所包含的这个版本的 API 集合现在被认为是稳定的,但这并不意味着它们是完整的。 即便这些 API 已满足毕业标准,仍将继续通过实验(Experimental)通道接收新特性。要了解相关工作的组织方式的进一步信息,请参阅 Gateway API 版本控制策略。
Gateway API 现在有了自己的 Logo!这个 Logo 是通过协作方式设计的, 旨在表达这是一组用于路由南北向和东西向流量的 Kubernetes API:
![]()
CEL 验证
过去,Gateway API 在安装 API 时绑定了一个验证性质(Validation)的 Webhook。 从 v1.0 开始,Webhook 的安装是可选的,仅建议在 Kubernetes 1.24 版本上使用。 Gateway API 现在将 CEL 验证规则包含在 CRD 中。Kubernetes 1.25 及以上版本支持这种新形式的验证,因此大多数安装中不再需要验证性质的 Webhook。
标准(Standard)通道
此发行版本主要侧重于确保现有 Beta 级别 API 定义良好且足够稳定,可以升级为 GA。 其背后意味着为了提高与 Gateway API 交互时的整体用户体验而作的各种规范的澄清以及一些改进。
实验(Experimental)通道
此发行版本中包含的大部分更改都限于实验通道。这些更改包括 HTTPRoute 超时、用于 Gateway 访问后端的 TLS 配置、WebSocket 支持、Gateway 基础设施的标签等等。 请继续关注后续博客,我们将详细介绍这些新特性。
其他内容
有关此版本中包含的所有更改的完整列表,请参阅 v1.0.0 版本说明。
发展历程
Gateway API 的想法最初是在 4 年前的 KubeCon 圣地亚哥提出的, 下一代 Ingress API。那次会议之后,诞生了一个令人难以置信的社区,致力于开发一种可能是 Kubernetes 历史上协作关系最密切的 API。 迄今为止,已有超过 170 人为此 API 做出了贡献,而且这个数字还在不断增长。
特别感谢 20 多位愿意在项目中担任正式角色的社区成员, 他们付出了时间进行评审并分担项目维护的负担!
我们特别要强调那些在项目早期发展中起到关键作用的荣誉维护者:
尝试一下
与其他 Kubernetes API 不同,你无需升级到最新版本的 Kubernetes 即可获取最新版本的 Gateway API。只要运行的是 Kubernetes 最新的 5 个次要版本之一(1.24+), 就可以使用最新版本的 Gateway API。
要尝试此 API,请参照我们的入门指南。
下一步
此版本只是 Gateway API 更广泛前景的开始,将来的 API 版本中还有很多新特性和新想法。
我们未来的一个关键目标是努力稳定和升级 API 的其他实验级特性。 这些特性包括支持服务网格、 额外的路由类型(GRPCRoute、 TCPRoute、 TLSRoute、 UDPRoute)以及各种实验级特性。
我们还致力于将 ReferenceGrant 移入内置的 Kubernetes API 中,使其不仅仅可用于网关 API。在 Gateway API 中,我们使用这个资源来安全地实现跨命名空间引用, 而这个概念现在被其他 SIG 采纳。这个 API 的新版本将归 SIG Auth 所有,在移到内置的 Kubernetes API 时可能至少包含一些修改。
Gateway API 现身于 KubeCon + CloudNativeCon
在 KubeCon 北美(芝加哥) 和同场的贡献者峰会上, 有几个与 Gateway API 相关的演讲将详细介绍这些主题。如果你今年要参加其中的一场活动, 请考虑将它们添加到你的日程安排中。
贡献者峰会:
KubeCon 主要活动:
KubeCon 办公时间:
如果你想就相关主题发起讨论或参与头脑风暴,请参加 Gateway API 维护人员在 KubeCon 上举行办公时间会议。
要获取有关这些会议的最新更新,请加入 Kubernetes Slack
上的 #sig-network-gateway-api 频道。
参与其中
我们只是初步介绍了 Gateway API 正在进行的工作。 有很多机会参与并帮助定义 Ingress 和 Mesh 的 Kubernetes 路由 API 的未来。
如果你对此感兴趣,请加入我们的社区并帮助我们共同构建 Gateway API 的未来!
Kubernetes 中 PersistentVolume 的最后阶段转换时间
作者: Roman Bednář (Red Hat)
译者: Xin Li (DaoCloud)
在最近的 Kubernetes v1.28 版本中,我们(SIG Storage)引入了一项新的 Alpha 级别特性,
旨在改进 PersistentVolume(PV)存储管理并帮助集群管理员更好地了解 PV 的生命周期。
通过将 lastPhaseTransitionTime 字段添加到 PV 的状态中,集群管理员现在可以跟踪
PV 上次转换到不同阶段的时间,
从而实现更高效、更明智的资源管理。
我们为什么需要新的 PV 字段?
Kubernetes 中的 PersistentVolume 在为集群中运行的工作负载提供存储资源方面发挥着至关重要的作用。
然而,有效管理这些 PV 可能具有挑战性,特别是在确定 PV 在不同阶段(Pending、Bound 或 Released)之间转换的最后时间时。
管理员通常需要知道 PV 上次使用或转换到某些阶段的时间;例如,实施保留策略、执行清理或监控存储运行状况时。
过去,Kubernetes 用户在使用 Delete 保留策略时面临数据丢失问题,不得不使用更安全的 Retain 策略。
当我们计划引入新的 lastPhaseTransitionTime 字段时,我们希望提供一个更通用的解决方案,
可用于各种用例,包括根据卷上次使用时间进行手动清理或根据状态转变时间生成警报。
lastPhaseTransitionTime 如何提供帮助
如果你已启用特性门控(请参阅如何使用它),则每次 PV 从一个阶段转换到另一阶段时,
PersistentVolume(PV)的新字段 .status.lastPhaseTransitionTime 都会被更新。
无论是从 Pending 转换到 Bound、Bound 到 Released,还是任何其他阶段转换,都会记录 lastPhaseTransitionTime。
对于新创建的 PV,将被声明为处于 Pending 阶段,并且 lastPhaseTransitionTime 也将被记录。
此功能允许集群管理员:
实施保留政策
通过
lastPhaseTransitionTime,管理员可以跟踪 PV 上次使用或转换到Released阶段的时间。 此信息对于实施保留策略以清理在特定时间内处于Released阶段的资源至关重要。 例如,现在编写一个脚本或一个策略来删除一周内处于Released阶段的所有 PV 是很简单的。
监控存储运行状况
通过分析 PV 的相变时间,管理员可以更有效地监控存储运行状况。 例如,他们可以识别处于
Pending阶段时间异常长的 PV,这可能表明存储配置程序存在潜在问题。
如何使用它
从 Kubernetes v1.28 开始,lastPhaseTransitionTime 为 Alpha 特性字段,因此需要启用
PersistentVolumeLastPhaseTransitionTime 特性门控。
如果你想在该特性处于 Alpha 阶段时对其进行测试,则需要在 kube-controller-manager
和 kube-apiserver 上启用此特性门控。
使用 --feature-gates 命令行参数:
--feature-gates="...,PersistentVolumeLastPhaseTransitionTime=true"
请记住,该特性启用后不会立即生效;而是在 PV 更新以及阶段之间转换时,填充新字段。 然后,管理员可以通过查看 PV 状态访问新字段,此状态可以使用标准 Kubernetes API 调用或通过 Kubernetes 客户端库进行检索。
以下示例展示了如何使用 kubectl 命令行工具检索特定 PV 的 lastPhaseTransitionTime:
kubectl get pv <pv-name> -o jsonpath='{.status.lastPhaseTransitionTime}'
未来发展
此特性最初是作为 Alpha 特性引入的,位于默认情况下禁用的特性门控之下。 在 Alpha 阶段,我们(Kubernetes SIG Storage)将收集最终用户的反馈并解决发现的任何问题或改进。
一旦收到足够的反馈,或者没有收到投诉,该特性就可以进入 Beta 阶段。 Beta 阶段将使我们能够进一步验证实施并确保其稳定性。
在该字段升级到 Beta 级别和将该字段升级为通用版 (GA) 的版本之间,至少会经过两个 Kubernetes 版本。 这意味着该字段 GA 的最早版本是 Kubernetes 1.32,可能计划于 2025 年初发布。
欢迎参与
我们始终欢迎新的贡献者,因此如果你想参与其中,可以加入我们的 Kubernetes 存储特殊兴趣小组(SIG)。
如果你想分享反馈,可以在我们的 公共 Slack 频道上分享。 如果你尚未加入 Slack 工作区,可以访问 https://slack.k8s.io/ 获取邀请。
特别感谢所有提供精彩评论、分享宝贵意见并帮助实现此特性的贡献者(按字母顺序排列):
2023 中国 Kubernetes 贡献者峰会简要回顾
作者: Paco Xu 和 Michael Yao (DaoCloud)
2023 年 9 月 26 日,即 KubeCon + CloudNativeCon + Open Source Summit China 2023 第一天,近 50 位社区贡献者济济一堂,在上海聚首 Kubernetes 贡献者峰会。

2023 Kubernetes 贡献者峰会与会者集体合影
这是疫情三年之后,首次在中国本土召开的面对面线下聚会。
开心遇见
首先是本次 KubeCon 活动的联席主席、来自华为云的 Kevin Wang 和来自 Gaint Swarm 的 Puja 做了欢迎致辞。
随后在座的几十位贡献者分别做了简单的自我介绍,80% 以上的与会者来自中国,还有一些贡献者专程从欧美飞到上海参会。 其中不乏来自微软、Intel、华为的技术大咖,也有来自 DaoCloud 这样的新锐中坚力量。 欢声笑语齐聚一堂,无论是操着欧美口音的英语,还是地道的中国话,都在诠释着舒心与欢畅,表达着尊敬和憧憬。 是曾经做出的贡献拉近了彼此,是互相的肯定和成就赋予了这次线下聚会的可能。

Face to face meeting in Shanghai
与会的贡献者不再是简单的 GitHub ID,而是进阶为一个个鲜活的面孔, 从静坐一堂,到合照留影,到寻觅彼此辨别 Who is Who 的那一刻起,我们事实上已形成了一个松散的集体。 这个 team 结构松散、自由开放,却是为了追逐梦想而成立。
一分耕耘一分收获,每一份努力都已清晰地记录在 Kubernetes 社区贡献中。 无论时光如何流逝,社区中不会抹去那些发光的痕迹,璀璨可能是你的 PR、Issue 或 comments, 也可能是某次 Meetup 的合影笑脸,还可能是贡献者口口相传的故事。
技术分享和讨论
接下来是 3 个技术分享:
- sig-multi-cluster: Karmada 的维护者 Hongcai Ren 介绍了这个 SIG 的职责和作用。 这个 SIG 负责设计、讨论、实现和维护多集群管理相关的 API、工具和文档。 其中涉及的 Cluster Federation 也是 Karmada 的核心概念之一。
- helmfile:来自极狐 GitLab 的 yxxhero 介绍了如何声明式部署 Kubernetes 清单,如何自定义配置, 如何使用 Helm 的最新特性 Helmfile 等内容。
- sig-scheduling: 来自华为云的 william-wang 介绍了 SIG Scheduling 最近更新的特性以及未来的规划。SIG Scheduling 负责设计、开发和测试 Pod 调度相关的组件。

有关 sig-multi-cluster 的技术主题演讲
随后播放了来自 SIG-Node Chair Sergey Kanzhelev 的贡献者招募视频,希望更多贡献者参与到 Kubernetes 社区,特别是社区热门的 SIG-Node 方向。
最后,Kevin 主持了 Unconference 的集体讨论活动,主要涉及到多集群、调度、弹性、AI 等方向。 有关 Unconference 会议纪要,参阅 https://docs.qq.com/doc/DY3pLWklzQkhjWHNT
中国贡献者数据
本次贡献者峰会在上海举办,有 90% 的与会者为华人。而在 CNCF 生态体系中,来自中国的贡献数据也在持续增长,目前:
- 中国贡献者占比 9%
- 中国贡献量占比 11.7%
- 全球贡献排名第 2
说明:
以上数据来自 CNCF 首席技术官 Chris Aniszczyk 在 2023 年 9 月 26 日 KubeCon 的主题演讲。 另外,由于大量中国贡献者使用 VPN 连接社区,这些统计数据可能与真实数据有所差异。
Kubernetes 贡献者峰会是一个自由开放的 Meetup,欢迎社区所有贡献者参与:
- 新人
- 老兵
- 文档
- 代码
- 社区管理
- 子项目 Owner 和参与者
- 特别兴趣小组(SIG)或工作小组(WG)人员
- 活跃的贡献者
- 临时贡献者
致谢
感谢本次活动的组织者:
- Kevin Wang 是本次 KubeCon 活动的联席主席,也是贡献者峰会的负责人
- Paco Xu 积极联络场地餐食,联系和邀请国内外贡献者,建立微信群征集议题, 会前会后公示活动细节等
- Mengjiao Liu 负责组织协调和联络事宜
我们衷心感谢所有参加在上海举办的中国 Kubernetes 贡献者峰会的贡献者们。 你们对 Kubernetes 社区的奉献和承诺是无价之宝。 让我们携手共进,继续推动云原生技术的边界,塑造这个生态系统的未来。
CRI-O 正迁移至 pkgs.k8s.io
作者:Sascha Grunert
译者:Wilson Wu (DaoCloud)
Kubernetes 社区最近宣布旧的软件包仓库已被冻结, 现在这些软件包将被迁移到由 OpenBuildService(OBS) 提供支持的社区自治软件包仓库中。 很久以来,CRI-O 一直在利用 OBS 进行软件包构建, 但到目前为止,所有打包工作都是手动完成的。
CRI-O 社区非常喜欢 Kubernetes,这意味着他们很高兴地宣布:
所有未来的 CRI-O 包都将作为在 pkgs.k8s.io 上托管的官方支持的 Kubernetes 基础设施的一部分提供!
现有软件包将进入一个弃用阶段,目前正在
CRI-O 社区中讨论。
新的基础设施将仅支持 CRI-O >= v1.28.2 的版本以及比 release-1.28 新的版本分支。
如何使用新软件包
与 Kubernetes 社区一样,CRI-O 提供 deb 和 rpm 软件包作为 OBS 中专用子项目的一部分,
被称为 isv:kubernetes:addons:cri-o。
这个项目是一个集合,提供 stable(针对 CRI-O 标记)以及 prerelease(针对 CRI-O release-1.y 和 main 分支)版本的软件包。
稳定版本:
isv:kubernetes:addons:cri-o:stable:稳定软件包isv:kubernetes:addons:cri-o:stable:v1.29:v1.29.z标记isv:kubernetes:addons:cri-o:stable:v1.28:v1.28.z标记
预发布版本:
v1.29 仓库中尚无可用的稳定版本,因为 v1.29.0 将于 12 月发布。
CRI-O 社区也不支持早于 release-1.28 的版本分支,
因为已经有 CI 需求合并到 main 中,只有通过适当的努力才能向后移植到 release-1.28。
例如,如果最终用户想要安装 CRI-O main 分支的最新可用版本,
那么他们可以按照与 Kubernetes 相同的方式添加仓库。
基于 rpm 的发行版
对于基于 rpm 的发行版,您可以以 root
用户身份运行以下命令来将 CRI-O 与 Kubernetes 一起安装:
添加 Kubernetes 仓库
cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.28/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.28/rpm/repodata/repomd.xml.key
EOF
添加 CRI-O 仓库
cat <<EOF | tee /etc/yum.repos.d/cri-o.repo
[cri-o]
name=CRI-O
baseurl=https://pkgs.k8s.io/addons:/cri-o:/prerelease:/main/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/addons:/cri-o:/prerelease:/main/rpm/repodata/repomd.xml.key
EOF
安装官方包依赖
dnf install -y \
conntrack \
container-selinux \
ebtables \
ethtool \
iptables \
socat
从添加的仓库中安装软件包
dnf install -y --repo cri-o --repo kubernetes \
cri-o \
kubeadm \
kubectl \
kubelet
基于 deb 的发行版
对于基于 deb 的发行版,您可以以 root 用户身份运行以下命令:
安装用于添加仓库的依赖项
apt-get update
apt-get install -y software-properties-common curl
添加 Kubernetes 仓库
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.28/deb/Release.key |
gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.28/deb/ /" |
tee /etc/apt/sources.list.d/kubernetes.list
添加 CRI-O 仓库
curl -fsSL https://pkgs.k8s.io/addons:/cri-o:/prerelease:/main/deb/Release.key |
gpg --dearmor -o /etc/apt/keyrings/cri-o-apt-keyring.gpg
echo "deb [signed-by=/etc/apt/keyrings/cri-o-apt-keyring.gpg] https://pkgs.k8s.io/addons:/cri-o:/prerelease:/main/deb/ /" |
tee /etc/apt/sources.list.d/cri-o.list
安装软件包
apt-get update
apt-get install -y cri-o kubelet kubeadm kubectl
启动 CRI-O
systemctl start crio.service
如果使用的是另一个包序列,CRI-O 包路径中项目的 prerelease:/main
前缀可以替换为 stable:/v1.28、stable:/v1.29、prerelease:/v1.28 或 prerelease :/v1.29。
你可以使用 kubeadm init 命令来引导集群,
该命令会自动检测后台正在运行 CRI-O。还有适用于
Fedora 38
以及 Ubuntu 22.04
的 Vagrantfile 示例,可在使用 kubeadm 的场景中测试下载的软件包。
它是如何工作的
与这些包相关的所有内容都位于新的 CRI-O 打包仓库中。
它包含 Daily Reconciliation GitHub 工作流,
支持所有发布分支以及 CRI-O 标签。
OBS 工作流程中的测试管道确保包在发布之前可以被正确安装和使用。
所有包的暂存和发布都是在 Kubernetes 发布工具箱(krel)的帮助下完成的,
这一工具箱也被用于官方 Kubernetes deb 和 rpm 软件包。
包构建的输入每天都会被动态调整,并使用 CRI-O 的静态二进制包。
这些包是基于 CRI-O CI 中的每次提交来构建和签名的,
并且包含 CRI-O 在特定架构上运行所需的所有内容。静态构建是可重复的,
由 nixpkgs 提供支持,
并且仅适用于 x86_64、aarch64 以及 ppc64le 架构。
CRI-O 维护者将很乐意听取有关新软件包工作情况的任何反馈或建议! 感谢您阅读本文,请随时通过 Kubernetes Slack 频道 #crio 联系维护人员或在打包仓库中创建 Issue。
聚焦 SIG Architecture: Conformance
作者:Frederico Muñoz (SAS Institute)
译者:Michael Yao (DaoCloud)
这是 SIG Architecture 焦点访谈系列的首次采访,这一系列访谈将涵盖多个子项目。 我们从 SIG Architecture:Conformance 子项目开始。
在本次 SIG Architecture 访谈中,我们与 Riaan Kleinhans (ii.nz) 进行了对话,他是 Conformance 子项目的负责人。
关于 SIG Architecture 和 Conformance 子项目
Frederico (FSM):你好 Riaan,欢迎!首先,请介绍一下你自己,你的角色以及你是如何参与 Kubernetes 的。
Riaan Kleinhans (RK):嗨!我叫 Riaan Kleinhans,我住在南非。 我是新西兰 ii.nz 的项目经理。在我加入 ii 时,本来计划在 2020 年 4 月搬到新西兰, 然后新冠疫情爆发了。幸运的是,作为一个灵活和富有活力的团队,我们能够在各个不同的时区以远程方式协作。
ii 团队负责管理 Kubernetes Conformance 测试的技术债务,并编写测试内容来消除这些技术债务。 我担任项目经理的角色,成为监控、测试内容编写和社区之间的桥梁。通过这项工作,我有幸在最初的几个月里结识了 Dan Kohn,他对我们的工作充满热情,给了我很大的启发。
FSM:谢谢!所以,你参与 SIG Architecture 是因为合规性的工作?
RK:SIG Architecture 负责管理 Kubernetes Conformance 子项目。 最初,我大部分时间直接与 SIG Architecture 交流 Conformance 子项目。 然而,随着我们开始按 SIG 来组织工作任务,我们开始直接与各个 SIG 进行协作。 与拥有未被测试的 API 的这些 SIG 的协作帮助我们加快了工作进度。
FSM:你如何描述 Conformance 子项目的主要目标和介入的领域?
RM: Kubernetes Conformance 子项目专注于通过开发和维护全面的合规性测试套件来确保兼容性并遵守 Kubernetes 规范。其主要目标包括确保不同 Kubernetes 实现之间的兼容性,验证 API 规范的遵守情况, 通过鼓励合规性认证来支持生态体系,并促进 Kubernetes 社区内的合作。 通过提供标准化的测试并促进一致的行为和功能, Conformance 子项目为开发人员和用户提供了一个可靠且兼容的 Kubernetes 生态体系。
关于 Conformance Test Suite 的更多内容
FSM:我认为,提供这些标准化测试的一部分工作在于 Conformance Test Suite。 你能解释一下它是什么以及其重要性吗?
RK:Kubernetes Conformance Test Suite 检查 Kubernetes 发行版是否符合项目的规范, 确保在不同的实现之间的兼容性。它涵盖了诸如 API、联网、存储、调度和安全等各个特性。 能够通过测试,则表示实现合理,便于推动构建一致且可移植的容器编排平台。
FSM:是的,这些测试很重要,因为它们定义了所有 Kubernetes 集群必须支持的最小特性集合。 你能描述一下决定将哪些特性包含在内的过程吗?在最小特性集的思路与其他 SIG 提案之间是否有所冲突?
RK:SIG Architecture 针对经受合规性测试的每个端点的要求,都有明确的定义。 API 端点只有正式发布且不是可选的特性,才会被(进一步)考虑是否合规。 多年来,关于合规性配置文件已经进行了若干讨论, 探讨将被大多数终端用户广泛使用的可选端点(例如 RBAC)纳入特定配置文件中的可能性。 然而,这一方面仍在不断改进中。
不满足合规性标准的端点被列在 ineligible_endpoints.yaml 中, 该文件放在 Kubernetes 代码仓库中,是被公开访问的。 随着这些端点的状态或要求发生变化,此文件可能会被更新以添加或删除端点。 不合格的端点也可以在 APISnoop 上看到。
对于 SIG Architecture 来说,确保透明度并纳入社区意见以确定端点的合格或不合格状态是至关重要的。
FSM:为新特性编写测试内容通常需要某种强制执行方式。 你如何看待 Kubernetes 中这方面的演变?是否有人在努力改进这个流程, 使得必须具备测试成为头等要务,或许这从来都不是一个问题?
RK:在 2018 年开始围绕 Kubernetes 合规性计划进行讨论时,只有大约 11% 的端点被测试所覆盖。 那时,CNCF 的管理委员会提出一个要求,如果要提供资金覆盖缺失的合规性测试,Kubernetes 社区应采取一个策略, 即如果新特性没有包含稳定 API 的合规性测试,则不允许添加此特性。
SIG Architecture 负责监督这一要求,APISnoop 在此方面被证明是一个非常有价值的工具。通过自动化流程,APISnoop 在每个周末生成一个 PR, 以突出 Conformance 覆盖范围的变化。如果有端点在没有进行合规性测试的情况下进阶至正式发布, 将会被迅速识别发现。这种方法有助于防止积累新的技术债务。
此外,我们计划在不久的将来创建一个发布通知任务,作用是添加额外一层防护,以防止产生新的技术债务。
FSM:我明白了,工具化和自动化在其中起着重要的作用。 在你看来,就合规性而言,还有哪些领域需要做一些工作? 换句话说,目前标记为优先改进的领域有哪些?
RK:在 1.27 版本中,我们已完成了 “100% 合规性测试” 的里程碑!
当时,社区重新审视了所有被列为不合规的端点。这个列表是收集多年的社区意见后填充的。 之前被认为不合规的几个端点已被挑选出来并迁移到一个新的专用列表中, 该列表中包含目前合规性测试开发的焦点。同样,可以在 apisnoop.cncf.io 上查阅此列表。
为了确保在合规性项目中避免产生新的技术债务,我们计划建立一个发布通知任务作为额外的预防措施。
虽然 APISnoop 目前被托管在 CNCF 基础设施上,但此项目已慷慨地捐赠给了 Kubernetes 社区。 因此,它将在 2023 年底之前转移到社区自治的基础设施上。
FSM:这是个好消息!对于想要提供帮助的人们,你能否重点说明一下协作的价值所在? 参与贡献是否需要对 Kubernetes 有很扎实的知识,或否有办法让一些新人也能为此项目做出贡献?
RK:参与合规性测试就像 "洗碗" 一样,它可能不太显眼,但仍然非常重要。 这需要对 Kubernetes 有深入的理解,特别是在需要对端点进行测试的领域。 这就是为什么与负责测试 API 端点的每个 SIG 进行协作会如此重要。
我们的承诺是让所有人都能参与测试内容编写,作为这一承诺的一部分, ii 团队目前正在开发一个 “点击即部署(click and deploy)” 的解决方案。 此解决方案旨在使所有人都能在几分钟内快速创建一个在真实硬件上工作的环境。 我们将在准备好后分享有关此项开发的更新。
FSM:那会非常有帮助,谢谢。最后你还想与我们的读者分享些什么见解吗?
RK:合规性测试是一个协作性的社区工作,涉及各个 SIG 之间的广泛合作。 SIG Architecture 在推动倡议并提供指导方面起到了领头作用。然而, 工作的进展在很大程度上依赖于所有 SIG 在审查、增强和认可测试方面的支持。
我要衷心感谢 ii 团队多年来对解决技术债务的坚定承诺。 特别要感谢 Hippie Hacker 的指导和对愿景的引领作用,这是非常宝贵的。 此外,我还要特别表扬 Stephen Heywood 在最近几个版本中承担了大部分测试内容编写工作而做出的贡献, 还有 Zach Mandeville 对 APISnoop 也做了很好的贡献。
FSM:非常感谢你参加本次访谈并分享你的深刻见解,我本人从中获益良多,我相信读者们也会同样受益。
公布 2023 年指导委员会选举结果
作者:Kaslin Fields
译者:Xin Li(DaoCloud)
2023 年指导委员会选举现已完成。 Kubernetes 指导委员会由 7 个席位组成,其中 4 个席位于 2023 年进行选举。 新任委员会成员的任期为 2 年,所有成员均由 Kubernetes 社区选举产生。
这个社区机构非常重要,因为它负责监督整个 Kubernetes 项目的治理。 权力越大责任越大,你可以在其 章程中了解有关指导委员会角色的更多信息。
感谢所有在选举中投票的人;你们的参与有助于支持社区的持续健康和成功。
结果
祝贺当选的委员会成员,其两年任期立即开始(按 GitHub 名称字母顺序列出):
- Stephen Augustus (@justaugustus), Cisco
- Paco Xu 徐俊杰 (@pacoxu), DaoCloud
- Patrick Ohly (@pohly), Intel
- Maciej Szulik (@soltysh), Red Hat
他们将与一下连任成员一起工作:
- Benjamin Elder (@bentheelder), Google
- Bob Killen (@mrbobbytables), Google
- Nabarun Pal (@palnabarun), VMware
Stephen Augustus 是回归的指导委员会成员。
十分感谢!
感谢并祝贺本轮选举官员成功完成选举工作:
- Bridget Kromhout (@bridgetkromhout)
- Davanum Srinavas (@dims)
- Kaslin Fields (@kaslin)
感谢名誉指导委员会成员,你们的服务受到社区的赞赏:
感谢所有前来竞选的候选人。
参与指导委员会
你可以关注指导委员会积压的项目, 并通过提交 Issue 或针对其 repo 创建 PR 来参与。 他们在太平洋时间每月第一个周一上午 9:30 举行开放的会议。 你还可以通过其公共邮件列表 steering@kubernetes.io 与他们联系。
你可以通过在 YouTube 播放列表上观看过去的会议来了解指导委员会会议的全部内容。
如果你想认识一些新当选的指导委员会成员,请参加我们在芝加哥 Kubernetes 贡献者峰会举行的 Steering AMA。
这篇文章是由贡献者通信子项目撰写的。 如果你想撰写有关 Kubernetes 社区的故事,请了解有关我们的更多信息。
kubeadm 七周年生日快乐!
作者: Fabrizio Pandini (VMware)
译者: Michael Yao (DaoCloud)
回首向来萧瑟处,七年光阴风雨路!
从 2016 年 9 月发表第一篇博文 How we made Kubernetes insanely easy to install 开始,kubeadm 经历了令人激动的成长旅程,两年后随着 Production-Ready Kubernetes Cluster Creation with kubeadm 这篇博文的发表进阶为正式发布。
此后,持续、稳定且可靠的系列小幅改进一直延续至今。
什么是 kubeadm?(简要回顾)
kubeadm 专注于在现有基础设施上启动引导 Kubernetes 集群并执行一组重要的维护任务。
kubeadm 接口的核心非常简单:通过运行
kubeadm init
创建新的控制平面节点,通过运行
kubeadm join
将工作节点加入控制平面。此外还有用于管理已启动引导的集群的实用程序,例如控制平面升级、令牌和证书续订等。
为了使 kubeadm 精简、聚焦且与供应商/基础设施无关,以下任务不包括在其范围内:
- 基础设施制备
- 第三方联网
- 例如监视、日志记录和可视化等非关键的插件
- 特定云驱动集成
例如,基础设施制备留给 SIG Cluster Lifecycle 等其他项目来处理, 比如 Cluster API。 kubeadm 仅涵盖每个 Kubernetes 集群中的共同要素: 控制平面。 用户可以在集群创建后安装其偏好的联网方案和其他插件。
kubeadm 在幕后做了大量工作。它确保你拥有所有关键组件:etcd、API 服务器、调度器、控制器管理器。 你可以加入更多的控制平面节点以提高容错性,或者加入工作节点以运行你的工作负载。 kubeadm 还为你设置好了集群 DNS 和 kube-proxy;在各组件之间启用 TLS 用于传输加密。
庆祝 kubeadm 的过去、现在和未来!
总之,kubeadm 的故事与 Kubernetes 深度耦合,也离不开这个令人惊叹的社区。
因此庆祝 kubeadm 首先是庆祝这个社区,一群人共同努力寻找一个共同点,一个最小可行工具,用于启动引导 Kubernetes 集群。
kubeadm 这个工具对 Kubernetes 的成功起到了关键作用,其价值主张可以概括为两点:
极致的简单:只需两个命令 kubeadm init 和 kubeadm join 即可完成初始化和接入集群的操作!让大多数用户轻松上手。
明确定义的问题范围:专注于在现有基础设施上启动引导 Kubernetes 集群。正如我们的口号所说:保持简单,保持可扩展!
这个明确的约定是整个 kubeadm 用户群体所依赖的基石,同时本文也是为了与 kubeadm 的使用者们共同欢庆。
我们由衷感谢用户给予的反馈,感谢他们通过 Slack、GitHub、社交媒体、博客、每次 KubeCon 会面以及各种聚会上持续展现的热情。来看看后续的发展!
这么多年来,对人们基于 kubeadm 构建的诸多项目我感到惊叹。迄今已经有很多强大而活跃的项目,例如:
- minikube
- kind
- Cluster API
- Kubespray
- 还有更多;如果你正在使用 Kubernetes,很可能你甚至不知道自己正在使用 kubeadm 😜
这个社区、kubeadm 的用户以及基于 kubeadm 构建的项目,是 kubeadm 七周年庆典的亮点,也是未来怎么发展的基础!
请继续关注我们,并随时与我们联系!
- 现在尝试使用 kubeadm 安装 Kubernetes
- 在 GitHub 参与 Kubernetes 项目
- 在 Slack 与社区交流
- 关注我们的 Twitter 账号 @Kubernetesio,获取最近更新信息
kubeadm:使用 etcd Learner 安全地接入控制平面节点
作者: Paco Xu (DaoCloud)
译者: Michael Yao (DaoCloud)
kubeadm 工具现在支持 etcd learner 模式,
借助 etcd 3.4 版本引入的
learner 模式特性,
可以提高 Kubernetes 集群的弹性和稳定性。本文将介绍如何在 kubeadm 中使用 etcd learner 模式。
默认情况下,kubeadm 在每个控制平面节点上运行一个本地 etcd 实例。
在 v1.27 中,kubeadm 引入了一个新的特性门控 EtcdLearnerMode。
启用此特性门控后,在加入新的控制平面节点时,一个新的 etcd 成员将被创建为 learner,
只有在 etcd 数据被完全对齐后此成员才会晋升为投票成员。
使用 etcd learner 模式的优势是什么?
在 Kubernetes 集群中采用 etcd learner 模式具有以下几个优点:
- 增强了弹性:etcd learner 节点是非投票成员,在完全进入角色之前会追随领导者的日志。 这样可以防止新的集群成员干扰投票结果或引起领导者选举,从而使集群在成员变更期间更具弹性。
- 减少了集群不可用时间:传统的添加新成员的方法通常会造成一段时间集群不可用,特别是在基础设施迟缓或误配的情况下更为明显。 而 etcd learner 模式可以最大程度地减少此类干扰。
- 简化了维护:learner 节点提供了一种更安全、可逆的方式来添加或替换集群成员。 这降低了由于误配或在成员添加过程中出错而导致集群意外失效的风险。
- 改进了网络容错性:在涉及网络分区的场景中,learner 模式允许更优雅的处理。 根据新成员所落入的分区,它可以无缝地与现有集群集成,而不会造成中断。
总之,etcd learner 模式可以在成员添加和变更期间提高 Kubernetes 集群的可靠性和可管理性, 这个特性对集群运营人员很有价值。
节点如何接入使用这种新模式的集群
创建以 etcd learner 模式支撑的 Kubernetes 集群
关于使用 kubeadm 创建高可用集群的通用说明, 请参阅使用 kubeadm 创建高可用集群。
要使用 kubeadm 创建一个后台是 learner 模式的 etcd 的 Kubernetes 集群,按照以下步骤操作:
# kubeadm init --feature-gates=EtcdLearnerMode=true ...
kubeadm init --config=kubeadm-config.yaml
kubeadm 配置文件如下:
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
featureGates:
EtcdLearnerMode: true
这里,kubeadm 工具部署单节点 Kubernetes 集群,其中的 etcd 被设置为 learner 模式。
将节点接入 Kubernetes 集群
在将控制平面节点接入新的 Kubernetes 集群之前,确保现有的控制平面节点和所有 etcd 成员都健康。
使用 etcdctl 检查集群的健康状况。如果 etcdctl 不可用,你可以运行在容器镜像内的这个工具。
你可以直接使用 crictl run 这类容器运行时工具而不是通过 Kubernetes 来执行此操作。
以下是一个使用安全通信来检查 etcd 集群健康状况的客户端命令示例:
ETCDCTL_API=3 etcdctl --endpoints 127.0.0.1:2379 \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
member list
...
dc543c4d307fadb9, started, node1, https://10.6.177.40:2380, https://10.6.177.40:2379, false
要检查 Kubernetes 控制平面是否健康,运行 kubectl get node -l node-role.kubernetes.io/control-plane=
并检查节点是否就绪。
说明:
建议在 etcd 集群中的成员个数为奇数。
在将工作节点接入新的 Kubernetes 集群之前,确保控制平面节点健康。
接下来的步骤
- 特性门控
EtcdLearnerMode在 v1.27 中为 Alpha,预计会在 Kubernetes 的下一个小版本发布(v1.29)中进阶至 Beta。 - etcd 社区有一个开放问题,目的是使这个过程更加自动化: 支持自动将 learner 成员晋升为投票成员。
- 更多细节参阅 kubeadm 配置格式。
反馈
本文对你有帮助吗?如果你有任何反馈或遇到任何问题,请告诉我们。 非常欢迎你提出反馈!你可以参加 SIG Cluster Lifecycle 双周例会 或 kubeadm 每周讨论会。 你还可以通过 Slack(频道 #kubeadm)或 SIG 邮件列表联系我们。
用户命名空间:对运行有状态 Pod 的支持进入 Alpha 阶段!
作者: Rodrigo Campos Catelin (Microsoft), Giuseppe Scrivano (Red Hat), Sascha Grunert (Red Hat)
译者: Xin Li (DaoCloud)
Kubernetes v1.25 引入用户命名空间(User Namespace)特性,仅支持无状态(Stateless)Pod。 Kubernetes 1.28 在 1.27 的基础上中进行了一些改进后,取消了这一限制。
此特性的精妙之处在于:
- 使用起来很简单(只需在 Pod 规约(spec)中设置一个 bool)
- 大多数应用程序不需要任何更改
- 通过大幅度加强容器的隔离性以及应对评级为高(HIGH)和关键(CRITICAL)的 CVE 来提高安全性。
这篇文章介绍了用户命名空间的基础知识,并展示了:
- 最近的 Kubernetes v1.28 版本中出现的变化
- 一个评级为高(HIGH)的漏洞的演示(Demo),该漏洞无法在用户命名空间中被利用
- 使用此特性的运行时要求
- 关于用户命名空间的未来版本中可以期待的内容
用户命名空间是什么?
用户命名空间是 Linux 的一项特性,它将容器的用户和组标识符(UID 和 GID)与宿主机上的标识符隔离开来。 容器中的标识符可以映射到宿主机上的标识符,其中用于不同容器的主机 UID/GID 从不重叠。 更重要的是,标识符可以映射到宿主机上的非特权、非重叠的 UID 和 GID。这基本上意味着两件事:
- 由于不同容器的 UID 和 GID 映射到宿主机上不同的 UID 和 GID,因此即使它们逃逸出了容器的边界,也很难相互攻击。 例如,如果容器 A 在宿主机上使用与容器 B 不同的 UID 和 GID 运行,则它可以对容器 B 的文件和进程执行的操作受到限制:只能读/写允许其他人使用的文件, 因为它永远不会拥有所有者或组的权限(宿主机上的 UID/GID 保证对于不同的容器是不同的)。
- 由于 UID 和 GID 映射到宿主机上的非特权用户,如果容器逃逸出了容器边界, 即使它在容器内以 root 身份运行,它在宿主机上也没有特权。 这极大地保护了它可以读/写哪些宿主机文件、可以向哪个进程发送信号等。
此外,所授予的权能(Capability)仅在用户命名空间内有效,而在宿主机上无效。
在不使用用户命名空间的情况下,以 root 身份运行的容器在发生逃逸的情况下会获得节点上的 root 权限。如果某些权能被授予容器,那么这些权能在主机上也有效。 当使用用户命名空间时,这些情况都会被避免(当然,除非存在漏洞 🙂)。
1.28 版本的变化
正如之前提到的,从 1.28 版本开始,Kubernetes 支持有状态的 Pod 的用户命名空间。 这意味着具有用户命名空间的 Pod 可以使用任何类型的卷,不再仅限于以前的部分卷类型。
从 1.28 版本开始,用于激活此特性的特性门控已被重命名,不再是 UserNamespacesStatelessPodsSupport,
而应该使用 UserNamespacesSupport。此特性经历了许多更改,
对节点主机的要求也发生了变化。因此,Kubernetes 1.28 版本将该特性标志重命名以反映这一变化。
演示
Rodrigo 创建了一个利用 CVE 2022-0492 的演示, 用以展现如何在没有用户命名空间的情况下利用该漏洞。 他还展示了在容器使用了此特性的 Pod 中无法利用此漏洞的情况。
此漏洞被评为高危,允许一个没有特殊特权的容器读/写宿主机上的任何路径,并在宿主机上以 root 身份启动进程。
如今,容器中的大多数应用程序都以 root 身份运行,或者以半可预测的非 root 用户身份运行(用户 ID 65534 是一个比较流行的选择)。 当你运行某个 Pod,而其中带有使用用户名命名空间(userns)的容器时,Kubernetes 以非特权用户身份运行这些容器,无需在你的应用程序中进行任何更改。
这意味着两个以用户 65534 身份运行的容器实际上会被映射到宿主机上的不同用户, 从而限制了它们在发生逃逸的情况下能够对彼此执行的操作,如果它们以 root 身份运行, 宿主机上的特权也会降低到非特权用户的权限。
节点系统要求
要使用此功能,对 Linux 内核版本以及容器运行时有一定要求。
在 Linux上,你需要 Linux 6.3 或更高版本。这是因为该特性依赖于一个名为 idmap mounts 的内核特性,而 Linux 6.3 中合并了针对 tmpfs 使用 idmap mounts 的支持
如果你使用 CRI-O 与 crun,这一特性在 CRI-O 1.28.1 和 crun 1.9 或更高版本中受支持。 如果你使用 CRI-O 与 runc,目前仍不受支持。
containerd 对此的支持目前设定的目标是 containerd 2.0;不管你是否与 crun 或 runc 一起使用,或许都不重要。
请注意,containerd 1.7 添加了对用户命名空间的实验性支持,正如在 Kubernetes 1.25 和 1.26 中实现的那样。1.27 版本中进行的重新设计不受 containerd 1.7 支持, 因此它在用户命名空间支持方面仅适用于 Kubernetes 1.25 和 1.26。
containerd 1.7 存在的一个限制是,在 Pod 启动期间需要更改容器镜像中每个文件和目录的所有权。 这意味着它具有存储开销,并且可能会显著影响容器启动延迟。containerd 2.0 可能会包括一个实现,可以消除增加的启动延迟和存储开销。如果计划在生产中使用 containerd 1.7 与用户命名空间,请考虑这一点。
这些 Containerd 限制均不适用于 [CRI-O 1.28][CRIO 版本]。
接下来?
展望 Kubernetes 1.29,计划是与 SIG Auth 合作,将用户命名空间集成到 Pod 安全标准(PSS)和 Pod 安全准入中。
目前的计划是在使用用户命名空间时放宽 Pod 安全标准(PSS)策略中的检查。这意味着如果使用用户命名空间,那么字段
spec[.*].securityContext、runAsUser、runAsNonRoot、allowPrivilegeEscalation和capabilities
将不会触发违规,此行为可能会通过使用 API Server 特性门控来控制,比如 UserNamespacesPodSecurityStandards 或其他类似的。
我该如何参与?
你可以通过以下方式与 SIG Node 联系:
你还可以直接联系我们:
- GitHub:@rata @giuseppe @saschagrunert
- Slack:@rata @giuseppe @sascha
比较本地 Kubernetes 开发工具:Telepresence、Gefyra 和 mirrord
作者: Eyal Bukchin (MetalBear)
译者: Michael Yao (DaoCloud)
Kubernetes 的开发周期是一个不断演化的领域,有许多工具在寻求简化这个过程。 每个工具都有其独特的方法,具体选择通常取决于各个项目的要求、团队的专业知识以及所偏好的工作流。
在各种解决方案中,我们称之为“本地 K8S 开发工具”的一个类别已渐露端倪, 这一类方案通过将本地运行的组件连接到 Kubernetes 集群来提升 Kubernetes 开发体验。 这样可以在云环境中快速测试新代码,避开了 Docker 化、CI 和部署这样的传统周期。
在本文中,我们将比较这个类别中的三个解决方案:Telepresence、Gefyra 和我们自己的挑战者 mirrord。
Telepresence
Telepresence 是这类工具中最早也最成熟的解决方案,
它使用 VPN(或更具体地说,一个 tun 设备)将用户的机器(或本地运行的容器)与集群的网络相连。
它支持拦截发送到集群中特定服务的传入流量,并将其重定向到本地端口。
被重定向的流量还可以被过滤,以避免完全破坏远程服务。
它还提供了一些补充特性,如支持文件访问(通过本地挂载卷将其挂载到 Pod 上)和导入环境变量。
Telepresence 需要在用户的机器上安装一个本地守护进程(需要 root 权限),并在集群上运行一个
Traffic Manager 组件。此外,它在 Pod 上以边车的形式运行一个 Agent 来拦截所需的流量。
Gefyra
Gefyra 与 Telepresence 类似,也采用 VPN 连接到集群。 但 Gefyra 只支持将本地运行的 Docker 容器连接到集群。 这种方法增强了在不同操作系统和本地设置环境之间的可移植性。 然而,它的缺点是不支持原生运行非容器化的代码。
Gefyra 主要关注网络流量,不支持文件访问和环境变量。 与 Telepresence 不同,Gefyra 不会改变集群中的工作负载, 因此如果发生意外情况,清理过程更加简单明了。
mirrord
作为这三个工具中最新的工具,mirrord采用了一种不同的方法,
它通过将自身注入到本地二进制文件中(在 Linux 上利用 LD_PRELOAD,在 macOS 上利用 DYLD_INSERT_LIBRARIES),
并重写 libc 函数调用,然后代理到在集群中运行的临时代理。
例如,当本地进程尝试读取一个文件时,mirrord 会拦截该调用并将其发送到该代理,
该代理再从远程 Pod 读取文件。这种方法允许 mirrord 覆盖进程的所有输入和输出,统一处理网络访问、文件访问和环境变量。
通过在进程级别工作,mirrord 支持同时运行多个本地进程,每个进程都在集群中的相应 Pod 上下文中运行, 无需将这些进程容器化,也无需在用户机器上获取 root 权限。
摘要
| Telepresence | Gefyra | mirrord | |
|---|---|---|---|
| 集群连接作用域 | 整台机器或容器 | 容器 | 进程 |
| 开发者操作系统支持 | Linux、macOS、Windows | Linux、macOS、Windows | Linux、macOS、Windows (WSL) |
| 传入的流量特性 | 拦截 | 拦截 | 拦截或镜像 |
| 文件访问 | 已支持 | 不支持 | 已支持 |
| 环境变量 | 已支持 | 不支持 | 已支持 |
| 需要本地 root | 是 | 否 | 否 |
| 如何使用 |
|
|
|
结论
Telepresence、Gefyra 和 mirrord 各自提供了独特的方法来简化 Kubernetes 开发周期, 每个工具都有其优缺点。Telepresence 功能丰富但复杂,mirrord 提供无缝体验并支持各种功能, 而 Gefyra 则追求简单和稳健。
你的选择应取决于项目的具体要求、团队对工具的熟悉程度以及所需的开发工作流。 无论你选择哪个工具,我们相信本地 Kubernetes 开发方法都可以提供一种简单、有效和低成本的解决方案, 来应对 Kubernetes 开发周期中的瓶颈,并且随着这些工具的不断创新和发展,这种本地方法将变得更加普遍。
Kubernetes 旧版软件包仓库将于 2023 年 9 月 13 日被冻结
作者:Bob Killen (Google), Chris Short (AWS), Jeremy Rickard (Microsoft), Marko Mudrinić (Kubermatic), Tim Bannister (The Scale Factory)
译者:Mengjiao Liu (DaoCloud)
2023 年 8 月 15 日,Kubernetes 项目宣布社区拥有的 Debian 和 RPM
软件包仓库在 pkgs.k8s.io 上正式提供。新的软件包仓库将取代旧的由
Google 托管的软件包仓库:apt.kubernetes.io 和 yum.kubernetes.io。
pkgs.k8s.io 的公告博客文章强调我们未来将停止将软件包发布到旧仓库。
今天,我们正式弃用旧软件包仓库(apt.kubernetes.io 和 yum.kubernetes.io),
并且宣布我们计划在 2023 年 9 月 13 日 冻结仓库的内容。
请继续阅读以了解这对于作为用户或分发商的你意味着什么, 以及你可能需要采取哪些步骤。
作为 Kubernetes 最终用户,这对我有何影响?
此更改影响直接安装 Kubernetes 的上游版本的用户, 无论是按照官方手动安装 和升级说明, 还是通过使用 Kubernetes 安装工具,该安装工具使用 Kubernetes 项目提供的软件包。
如果你在自己的 PC 上运行 Linux 并使用旧软件包仓库安装了 kubectl,则此更改也会影响你。
我们稍后将解释如何检查是否你会受到影响。
如果你使用完全托管的 Kubernetes,例如从云提供商获取服务,
那么只有在你还使用旧仓库中的软件包在你的 Linux PC 上安装 kubectl 时,
你才会受到此更改的影响。云提供商通常使用他们自己的 Kubernetes 发行版,
因此他们不使用 Kubernetes 项目提供的软件包;更重要的是,如果有其他人为你管理 Kubernetes,
那么他们通常会负责该检查。
如果你使用的是托管的控制平面 但你负责自行管理节点,并且每个节点都运行 Linux, 你应该检查你是否会受到影响。
如果你按照官方的安装和升级说明自己管理你的集群, 请按照本博客文章中的说明迁移到(新的)社区拥有的软件包仓库。
如果你使用的 Kubernetes 安装程序使用 Kubernetes 项目提供的软件包, 请检查安装程序工具的通信渠道,了解有关你需要采取的步骤的信息,最后如果需要, 请与维护人员联系,让他们了解此更改。
下图以可视化形式显示了谁受到此更改的影响(单击图表可查看大图):

这对我作为 Kubernetes 分发商有何影响?
如果你将旧仓库用作项目的一部分(例如 Kubernetes 安装程序工具), 则应尽快迁移到社区拥有的仓库,并告知用户此更改以及他们需要采取哪些步骤。
变更时间表
- 2023 年 8 月 15 日:
Kubernetes 宣布推出一个新的社区管理的 Kubernetes 组件 Linux 软件包源 - 2023 年 8 月 31 日:
(本公告) Kubernetes 正式弃用旧版软件包仓库 - 2023 年 9 月 13 日(左右):
Kubernetes 将冻结旧软件包仓库(apt.kubernetes.io和yum.kubernetes.io)。 冻结将计划于 2023 年 9 月发布补丁版本后立即进行。
计划于 2023 年 9 月发布的 Kubernetes 补丁(v1.28.2、v1.27.6、v1.26.9、v1.25.14) 将把软件包发布到社区拥有的仓库和旧仓库。
在发布 9 月份的补丁版本后,我们将冻结旧仓库,这意味着届时我们将完全停止向旧仓库发布软件包。
对于 2023 年 10 月及以后的 v1.28、v1.27、v1.26 和 v1.25 补丁版本,
我们仅将软件包发布到新的软件包仓库 (pkgs.k8s.io)。
未来的次要版本怎么样?
Kubernetes 1.29 及以后的版本将仅发布软件包到社区拥有的仓库(pkgs.k8s.io)。
我可以继续使用旧软件包仓库吗?
旧仓库中的现有软件包将在可预见的未来内保持可用。然而,
Kubernetes 项目无法对这会持续多久提供任何保证。
已弃用的旧仓库及其内容可能会在未来随时删除,恕不另行通知。
更新: 旧版软件包预计将于 2024 年 1 月被删除。
Kubernetes 项目强烈建议尽快迁移到新的社区拥有的仓库。
鉴于在 2023 年 9 月 13 日截止时间点之后不会向旧仓库发布任何新版本, 你将无法升级到自该日期起发布的任何补丁或次要版本。
尽管该项目会尽一切努力发布安全软件,但有一天 Kubernetes 可能会出现一个高危性漏洞, 因此需要升级到一个重要版本。我们所公开的建议将帮助你为未来的所有安全更新(无论是微不足道的还是紧急的)做好准备。
如何检查我是否正在使用旧仓库?
检查你是否使用旧仓库的步骤取决于你在集群中使用的是基于 Debian 的发行版(Debian、Ubuntu 等)还是基于 RPM 的发行版(CentOS、RHEL、Rocky Linux 等)。
在集群中的一个节点上运行以下指令。
基于 Debian 的 Linux 发行版
在基于 Debian 的发行版上,仓库定义(源)位于/etc/apt/sources.list
和 /etc/apt/sources.list.d/中。检查这两个位置并尝试找到如下所示的软件包仓库定义:
deb [signed-by=/etc/apt/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main
如果你发现像这样的仓库定义,则你正在使用旧仓库并且需要迁移。
如果仓库定义使用 pkgs.k8s.io,则你已经在使用社区托管的仓库,无需执行任何操作。
在大多数系统上,此仓库定义应位于 /etc/apt/sources.list.d/kubernetes.list
(按照 Kubernetes 文档的建议),但在某些系统上它可能位于不同的位置。
如果你找不到与 Kubernetes 相关的仓库定义, 则很可能你没有使用软件包管理器来安装 Kubernetes,因此不需要执行任何操作。
基于 RPM 的 Linux 发行版
如果你使用的是 yum 软件包管理器,则仓库定义位于
/etc/yum.repos.d,或者 /etc/dnf/dnf.conf 和 /etc/dnf/repos.d/
如果你使用的是 dnf 软件包管理器。检查这些位置并尝试找到如下所示的软件包仓库定义:
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-\$basearch
enabled=1
gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
如果你发现像这样的仓库定义,则你正在使用旧仓库并且需要迁移。
如果仓库定义使用 pkgs.k8s.io,则你已经在使用社区托管的仓库,无需执行任何操作。
在大多数系统上,该仓库定义应位于 /etc/yum.repos.d/kubernetes.repo
(按照 Kubernetes 文档的建议),但在某些系统上它可能位于不同的位置。
如果你找不到与 Kubernetes 相关的仓库定义,则很可能你没有使用软件包管理器来安装 Kubernetes,那么你不需要执行任何操作。
我如何迁移到新的社区运营的仓库?
有关如何迁移到新的社区管理软件包的更多信息,请参阅
pkgs.k8s.io的公告博客文章 。
为什么 Kubernetes 项目要做出这样的改变?
自 Kubernetes v1.5 或过去七年以来,Kubernetes 一直只将软件包发布到
Google 托管的仓库!继迁移到社区管理的注册表 registry.k8s.io 之后,
我们现在正在将 Kubernetes 软件包仓库迁移到我们自己的社区管理的基础设施。
我们感谢 Google 这些年来持续的托管和支持,
但这一转变标志着该项目迁移到完全由社区拥有的基础设施的目标的又一个重要里程碑。
有 Kubernetes 工具可以帮助我迁移吗?
关于迁移工具方面,我们目前没有任何公告。作为 Kubernetes 用户, 你必须手动修改配置才能使用新仓库。自动从旧仓库迁移到社区拥有的仓库在技术上具有挑战性, 我们希望避免与此相关的任何潜在风险。
致谢
首先,我们要感谢 Alphabet 的贡献。Google 的员工投入了他们的时间; 作为一家企业,谷歌既提供了服务于软件包的基础设施,也提供了为这些软件包提供可信数字签名的安全上下文。 这些对于 Kubernetes 的采用和成长非常重要。
发布软件可能并不那么引人注目,但很重要。Kubernetes 贡献者社区中的许多人都为我们作为一个项目构建和发布软件包的新方法做出了贡献。
最后,我们要再次感谢 SUSE 的帮助。SUSE 的 OpenBuildService 为新的社区管理的软件包仓库提供支持的技术。
Gateway API v0.8.0:引入服务网格支持
作者: Flynn (Buoyant), John Howard (Google), Keith Mattix (Microsoft), Michael Beaumont (Kong), Mike Morris (independent), Rob Scott (Google)
译者: Xin Li (Daocloud)
我们很高兴地宣布 Gateway API 的 v0.8.0 版本发布了! 通过此版本,Gateway API 对服务网格的支持已达到实验性(Experimental)状态。 我们期待你的反馈!
我们很高兴地宣布 Kuma 2.3+、Linkerd 2.14+ 和 Istio 1.16+ 都是 Gateway API 服务网格支持的完全一致实现。
Gateway API 中的服务网格支持
虽然 Gateway API 最初的重点一直是入站(南北)流量,但几乎从最开始就比较明确, 相同的基本路由概念也应适用于服务网格(东西)流量。2022 年,Gateway API 子项目启动了 GAMMA 计划,这是一个专门的供应商中立的工作流, 旨在专门研究如何最好地将服务网格支持纳入 Gateway API 资源的框架中, 而不需要 Gateway API 的用户重新学习他们了解的有关 API 的一切。
在过去的一年中,GAMMA 深入研究了使用 Gateway API 用于服务网格的挑战和可能的解决方案。 最终结果是少量的增强提案,其中包含了很长时间的思考和辩论,并提供允许使用 Gateway API 用于服务网格的最短可行路径。
当使用 Gateway API 时,网格路由将如何工作?
你可以在 Gateway API Mesh 路由文档和 GEP-1426 中找到所有详细信息,
但对于 Gateway API v0.8.0 的简短的版本是现在 HTTPRoute 可以设置 parentRef,
它是一个 Service,而不仅仅是一个网关。随着我们对服务网格用例的经验不断丰富,我们预计在这个领域会出现更多
GEP -- 绑定到 Service 使得将 Gateway API 与服务网格结合使用成为可能,但仍有几个有趣的用例难以覆盖。
例如,你可以使用 HTTPRoute 在网格中进行 A-B 测试,如下所示:
apiVersion: gateway.networking.k8s.io/v1beta1
kind: HTTPRoute
metadata:
name: bar-route
spec:
parentRefs:
- group: ""
kind: Service
name: demo-app
port: 5000
rules:
- matches:
- headers:
- type: Exact
name: env
value: v1
backendRefs:
- name: demo-app-v1
port: 5000
- backendRefs:
- name: demo-app-v2
port: 5000
任何对 demo-app Service 5000 端口且具有 env: v1 表头的请求都将被路由到 demo-app-v1,
而没有该标头的请求都将被路由到 demo-app-v2 -- 并且由于这是由服务网格而不是
Ingress 控制器处理的,A/B 测试可以发生在应用程序的调用图中的任何位置。
如何确定这种方案的可移植性是真的?
Gateway API 一直在其支持的所有功能的一致性测试上投入大量资源,网格也不例外。 GAMMA 面临的挑战之一是,许多测试都认为一个给定实现会提供 Ingress 控制器。 许多服务网格不提供 Ingress 控制器,要求符合 GAMMA 标准的网格同时实现 Ingress 控制器似乎并不切实际。 这导致在 Gateway API 一致性配置文件的工作重新启动,如 GEP-1709 中所述。
一致性配置文件的基本思想是,我们可以定义 Gateway API 的子集,并允许实现选择(并记录)他们符合哪些子集。
GAMMA 正在添加一个名为 Mesh 的新配置文件,其描述在 GEP-1686 中,仅检查由 GAMMA 定义的网格功能。
此时,Kuma 2.3+、Linkerd 2.14+ 和 Istio 1.16+ 都符合 Mesh 配置文件的标准。
Gateway API v0.8.0 中还有什么?
这个版本的发布都是为了即将到来的 v1.0 版本做准备,其中 HTTPRoute、Gateway 和 GatewayClass 将进级为 GA。与此相关的有两个主要更改: CEL 验证和 API 版本更改。
CEL 验证
第一个重大变化是,Gateway API v0.8.0 起从 Webhook 验证转向使用内置于 CRD 中的信息的 CEL 验证。取决于你使用的 Kubernetes 版本,这一转换的影响有些不同:
Kubernetes 1.25+
CEL 验证得到了完全支持,并且几乎所有验证都是在 CEL 中实现的。 (唯一的例外是,标头修饰符过滤器中的标头名称只能进行不区分大小写的验证, 更多的相关信息,请参见 issue 2277。)
我们建议在这些 Kubernetes 版本上不使用验证 Webhook。
Kubernetes 1.23 和 1.24
不支持 CEL 验证,但仍可以安装 Gateway API v0.8.0 CRD。 当你升级到 Kubernetes 1.25+ 时,这些 CRD 中包含的验证将自动生效。
我们建议在这些 Kubernetes 版本上继续使用验证 Webhook。
Kubernetes 1.22 及更早版本
Gateway API 只承诺支持最新的 5 个 Kubernetes 版本。 因此,Gateway API 不再支持这些版本,不幸的是,在这些集群版本中无法安装 Gateway API v0.8.0, 因为包含 CEL 验证的 CRD 将被拒绝。
API 版本更改
在我们所准备的 v1.0 版本中,Gateway、GatewayClass 和 HTTPRoute 都会从
v1beta1 升级到 v1 API 版本,对于已升级到 v1beta1 的资源,我们将继续从 v1alpha2 迁移的过程。
有关此更改以及此版本中包含的所有其他内容的更多信息,请参见 v0.8.0 发布说明。
如何开始使用 Gateway API?
Gateway API 代表了 Kubernetes 中负载平衡、路由和服务网格 API 的未来。 已经有超过 20 个实现可用(包括入口控制器和服务网格),而这一列表还在不断增长。
如果你有兴趣开始使用 Gateway API,请查阅 API 概念文档 和一些指南以尝试使用它。 因为这是一个基于 CRD 的 API,所以你可以在任何 Kubernetes 1.23+ 集群上安装最新版本。
如果你有兴趣为 Gateway API 做出贡献,我们非常欢迎你! 请随时在仓库中报告问题,或加入讨论。 另请查看社区页面,其中包含 Slack 频道和社区会议的链接。 我们期待你的光临!!
进一步阅读:
- GEP-1324 提供了 GAMMA 目标和一些重要定义的概述。这个 GEP 值得一读,因为它讨论了问题空间。
- GEP-1426 定义了如何使用 Gateway API 路由资源(如 HTTPRoute)管理服务网格内的流量。
- GEP-1686 在 GEP-1709 的工作基础上,为声明符合 Gateway API 的服务网格定义了一个一致性配置文件。
虽然这些都是实验特性,但请注意,它们可在 standard 发布频道使用, 因为 GAMMA 计划迄今为止不需要引入新的资源或字段。
Kubernetes 1.28:用于改进集群安全升级的新(Alpha)机制
作者: Richa Banker (Google)
译者: Xin Li (DaoCloud)
本博客介绍了混合版本代理(Mixed Version Proxy),这是 Kubernetes 1.28 中的一个新的 Alpha 级别特性。当集群中存在多个不同版本的 API 服务器时,混合版本代理使对资源的 HTTP 请求能够被正确的 API 服务器处理。例如,在集群升级期间或当发布集群控制平面的运行时配置时此特性非常有用。
这解决了什么问题?
当集群进行升级时,集群中不同版本的 kube-apiserver 为不同的内置资源集(组、版本、资源)提供服务。 在这种情况下资源请求如果由任一可用的 apiserver 提供服务,请求可能会到达无法解析此请求资源的 apiserver 中;因此,它会收到 404("Not Found")的响应报错,这是不正确的。 此外,返回 404 的错误服务可能会导致严重的后果,例如命名空间的删除被错误阻止或资源对象被错误地回收。
如何解决此问题?

"混合版本代理"新特性为 kube-apiserver 提供了将请求代理到对等的、 能够感知所请求的资源并因此能够服务请求的 kube-apiserver。 为此,一个全新的过滤器已被添加到 API
- 处理程序链中的新过滤器检查请求是否为 apiserver 无法解析的 API 组/版本/资源(使用现有的 StorageVersion API)。 如果是,它会将请求代理到 ServerStorageVersion 对象中列出的 apiserver 之一。 如果所选的对等 apiserver 无法响应(由于网络连接、收到的请求与在 ServerStorageVersion 对象中注册 apiserver-resource 信息的控制器之间的竞争等原因),则会出现 503("Service Unavailable")错误响应。
- 为了防止无限期地代理请求,一旦最初的 API 服务器确定无法处理该请求,就会在原始请求中添加一个
(v1.28 新增)HTTP 请求头
X-Kubernetes-APIServer-Rerouted: true。将其设置为 true 意味着原始 API 服务器无法处理该请求,需要对其进行代理。如果目标侧对等 API 服务器看到此标头,则不会对该请求做进一步的代理操作。 - 要设置 kube-apiserver 的网络位置,以供对等服务器来代理请求,将使用
--advertise-address或(当未指定--advertise-address时)--bind-address标志所设置的值。 如果网络配置中不允许用户在对等 kube-apiserver 之间使用这些标志中指定的地址进行通信, 可以选择将正确的对等地址配置在此特性引入的--peer-advertise-ip和--peer-advertise-port参数中。
如何启用此特性?
以下是启用此特性的步骤:
- 下载Kubernetes 项目的最新版本(版本
v1.28.0或更高版本) - 在 kube-apiserver 上使用命令行标志
--feature-gates=UnknownVersionInteroperabilityProxy=true打开特性门控 - 使用 kube-apiserver 的
--peer-ca-file参数为源 kube-apiserver 提供 CA 证书, 用以验证目标 kube-apiserver 的服务证书。注意:这是此功能正常工作所必需的参数。 此参数没有默认值。 - 为本地 kube-apiserver 设置正确的 IP 和端口,在代理请求时,对等方将使用该 IP 和端口连接到此
--peer-advertise-port命令行参数来配置 kube-apiserver。--peer-advertise-port命令行参数。 如果未设置这两个参数,则默认使用--advertise-address或--bind-address命令行参数的值。 如果这些也未设置,则将使用主机的默认接口。
少了什么东西?
目前,我们仅在确定时将资源请求代理到对等 kube-apiserver。 接下来我们需要解决如何在这种情况下处理发现请求。 目前我们计划在测试版中提供以下特性:
- 合并所有 kube-apiserver 的发现数据
- 使用出口拨号器(egress dialer)与对等 kube-apiserver 进行网络连接
如何进一步了解?
如何参与其中?
通过 Slack:#sig-api-machinery 或邮件列表 联系我们。
非常感谢帮助设计、实施和评审此特性的贡献者: Daniel Smith、Han Kang、Joe Betz、Jordan Liggit、Antonio Ojea、David Eads 和 Ben Luddy!
Kubernetes v1.28:介绍原生边车容器
作者:Todd Neal (AWS), Matthias Bertschy (ARMO), Sergey Kanzhelev (Google), Gunju Kim (NAVER), Shannon Kularathna (Google)
本文介绍了如何使用新的边车(Sidecar)功能,该功能支持可重新启动的 Init 容器, 并且在 Kubernetes 1.28 以 Alpha 版本发布。我们希望得到你的反馈,以便我们尽快完成此功能。
“边车”的概念几乎从一开始就是 Kubernetes 的一部分。在 2015 年, 一篇关于复合容器的博客文章(英文)将边车描述为“扩展和增强 ‘main’ 容器”的附加容器。 边车容器已成为一种常见的 Kubernetes 部署模式,通常用于网络代理或作为日志系统的一部分。 到目前为止,边车已经成为 Kubernetes 用户在没有原生支持情况下使用的概念。 缺乏原生支持导致了一些使用摩擦,此增强功能旨在解决这些问题。
在 Kubernetes 1.28 中的边车容器是什么?
Kubernetes 1.28 在 Init 容器中添加了一个新的 restartPolicy 字段,
该字段在 SidecarContainers 特性门控启用时可用。
apiVersion: v1
kind: Pod
spec:
initContainers:
- name: secret-fetch
image: secret-fetch:1.0
- name: network-proxy
image: network-proxy:1.0
restartPolicy: Always
containers:
...
该字段是可选的,如果对其设置,则唯一有效的值为 Always。设置此字段会更改 Init 容器的行为,如下所示:
- 如果容器退出则会重新启动
- 任何后续的 Init 容器在 startupProbe 成功完成后立即启动,而不是等待可重新启动 Init 容器退出
- 由于可重新启动的 Init 容器资源现在添加到主容器的资源请求总和中,所以 Pod 使用的资源计算发生了变化。
Pod 终止继续仅依赖于主容器。
restartPolicy 为 Always 的 Init 容器(称为边车)不会阻止 Pod 在主容器退出后终止。
可重新启动的 Init 容器的以下属性使其非常适合边车部署模式:
- 无论你是否设置
restartPolicy,初始化容器都有一个明确定义的启动顺序, 因此你可以确保你的边车在其所在清单中声明的后续任何容器之前启动。 - 边车容器不会延长 Pod 的生命周期,因此你可以在短生命周期的 Pod 中使用它们,而不会对 Pod 生命周期产生改变。
- 边车容器在退出时将被重新启动,这提高了弹性,并允许你使用边车来为主容器提供更可靠地服务。
何时要使用边车容器
你可能会发现内置边车容器对于以下工作负载很有用:
- 批量或 AI/ML 工作负载,或已运行完成的其他 Pod。这些工作负载将获得最显着的好处。
- 任何在清单中其他容器之前启动的网络代理。所有运行的其他容器都可以使用代理容器的服务。 有关说明,请参阅在 Istio 中使用 Kubernetes 原生 Sidecar。
- 日志收集容器,现在可以在任何其他容器之前启动并运行直到 Pod 终止。这提高了 Pod 中日志收集的可靠性。
- Job,可以将边车用于任何目的,而 Job 完成不会被正在运行的边车阻止。无需额外配置即可确保此行为。
1.28 之前用户如何获得 Sidecar 行为?
在边车功能出现之前,可以使用以下选项来根据边车容器的所需生命周期来实现边车行为:
- 边车的生命周期小于 Pod 生命周期:使用 Init 容器,它提供明确定义的启动顺序。 然而,边车必须退出才能让其他 Init 容器和主 Pod 容器启动。
- 边车的生命周期等于 Pod 生命周期:使用与 Pod 中的工作负载容器一起运行的主容器。 此方法无法让你控制启动顺序,并让边车容器可能会在工作负载容器退出后阻止 Pod 终止。
内置的边车功能解决了其生命周期与 Pod 生命周期相同的用例,并具有以下额外优势:
- 提供对启动顺序的控制
- 不阻碍 Pod 终止
将现有边车过渡到新模式
我们建议仅在 Alpha 阶段的短期测试集群中使用边车功能。
如果你有一个现有的边车,被配置为主容器,以便它可以在 Pod 的生命周期内运行,
则可以将其移至 Pod 规范的 initContainers 部分,并将 restartPolicy 指定为 Always。
在许多情况下,边车应该像以前一样工作,并具有定义启动顺序且不会延长 Pod 生命周期的额外好处。
已知问题
内置边车容器的 Alpha 版本具有以下已知问题,我们将在该功能升级为 Beta 之前解决这些问题:
- CPU、内存、设备和拓扑管理器不知道边车容器的生命周期和额外的资源使用情况,并且会像 Pod 的资源请求低于实际情况的方式运行。
- 使用边车时,
kubectl describe node的输出不正确。输出显示的资源使用量低于实际使用量, 因为它没有对边车容器使用新的资源使用计算方式。
我们需要你的反馈!
在 Alpha 阶段,我们希望你在环境中尝试边车容器,并在遇到错误或摩擦点时提出问题。我们对以下方面的反馈特别感兴趣:
- 关闭顺序,尤其是多个边车运行时
- 碰撞边车的退避超时调整
- 边车运行时 Pod 就绪性和活性探测的行为
要提出问题,请参阅 Kubernetes GitHub 存储库。
接下来是什么?
除了将要解决的已知问题之外,我们正在努力为边车和主容器添加终止顺序。这将确保边车容器仅在 Pod 主容器退出后终止。
我们很高兴看到 Kubernetes 引入了边车功能,并期望得到反馈。
致谢
自从最初的 KEP 编写以来已经过去了很多年,因此如果我们遗漏了多年来致力于此功能的任何人,我们将深表歉意。 这也是识别该功能参与者的最大限度努力。
- mrunalp 对于设计的探讨和评论
- thockin 多年来对于 API 的讨论和支持
- bobbypage 的审查工作
- smarterclayton 进行详细审查和反馈
- howardjohn 多年来进行的反馈以及在实施过程中的早期尝试
- derekwaynecarr 和 dchen1107 的领导力
- jpbetz 对 API 和终止排序的设计以及代码审查
- Joseph-Irving 和 rata 对于多年前的早期迭代设计和审查
- swatisehgal 和 ffromani 对于有关资源管理器影响的早期反馈
- alculquicondor 对于解决调度程序版本偏差的相关反馈
- wojtek-t 对于 KEP 的 PRR 进行审查
- ahg-g 对于 KEP 的调度程序部分进行审查
- adisky 处理了 Job 完成问题
更多内容
Kubernetes 1.28:在 Linux 上使用交换内存的 Beta 支持
作者:Itamar Holder (Red Hat)
译者:Wilson Wu (DaoCloud)
Kubernetes 1.22 版本为交换内存引入了一项 Alpha 支持, 用于为在 Linux 节点上运行的 Kubernetes 工作负载逐个节点地配置交换内存使用。 现在,在 1.28 版中,对 Linux 节点上的交换内存的支持已升级为 Beta 版,并有许多新的改进。
在 1.22 版之前,Kubernetes 不提供对 Linux 系统上交换内存的支持。 这是由于在涉及交换内存时保证和计算 Pod 内存利用率的固有困难。 因此,交换内存支持被认为超出了 Kubernetes 的初始设计范围,并且如果在节点上检测到交换内存, kubelet 的默认行为是无法启动。
在 1.22 版中,Linux 的交换特性以 Alpha 阶段初次引入。 这代表着一项重大进步,首次为 Linux 用户提供了尝试交换内存特性的机会。 然而,作为 Alpha 版本,它尚未开发完成,并存在一些问题, 包括对 cgroup v2 支持的不足、指标和 API 统计摘要不足、测试不足等等。
Kubernetes 中的交换内存有许多用例, 并适用于大量用户。因此,Kubernetes 项目内的节点特别兴趣小组投入了大量精力来支持 Linux 节点上的交换内存特性的 Beta 版本。 与 Alpha 版本相比,启用交换内存后 kubelet 的运行更加稳定和健壮,更加用户友好,并且解决了许多已知缺陷。 这次升级到 Beta 版代表朝着实现在 Kubernetes 中完全支持交换内存的目标迈出了关键一步。
如何使用此特性?
通过激活 kubelet 上的 NodeSwap 特性门控,可以在已配置交换内存的节点上使用此特性。
此外,你必须禁用 failSwapOn 设置,或者停用已被弃用的 --fail-swap-on 命令行标志。
可以配置 memorySwap.swapBehavior 选项来定义节点使用交换内存的方式。例如:
# 将此段内容放入 kubelet 配置文件
memorySwap:
swapBehavior: UnlimitedSwap
swapBehavior 的可用配置选项有:
UnlimitedSwap(默认):Kubernetes 工作负载可以根据请求使用尽可能多的交换内存,最多可达到系统限制。LimitedSwap:Kubernetes 工作负载对交换内存的使用受到限制。 只有 Burstable QoS Pod 才允许使用交换内存。
如果未指定 memorySwap 的配置并且启用了特性门控,则默认情况下,
kubelet 将应用与 UnlimitedSwap 设置相同的行为。
请注意,仅 cgroup v2 支持 NodeSwap。针对 Kubernetes v1.28,不再支持将交换内存与 cgroup v1 一起使用。
使用 kubeadm 安装支持交换内存的集群
开始之前
此演示需要安装 kubeadm 工具, 安装过程按照 kubeadm 安装指南中描述的步骤进行操作。 如果节点上已启用交换内存,则可以继续创建集群。如果未启用交换内存,请参阅提供的启用交换内存说明。
创建交换内存文件并开启交换内存功能
我将演示创建 4GiB 的未加密交换内存。
dd if=/dev/zero of=/swapfile bs=128M count=32
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
swapon -s # 仅在该节点被重新启动后启用该交换内存文件
要在引导时启动交换内存文件,请将诸如 /swapfile swap swap defaults 0 0 的内容添加到 /etc/fstab 文件中。
在 Kubernetes 集群中设置开启交换内存的节点
清晰起见,这里给出启用交换内存特性的集群的 kubeadm 配置文件示例 kubeadm-config.yaml。
---
apiVersion: "kubeadm.k8s.io/v1beta3"
kind: InitConfiguration
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
failSwapOn: false
featureGates:
NodeSwap: true
memorySwap:
swapBehavior: LimitedSwap
接下来使用 kubeadm init --config kubeadm-config.yaml 创建单节点集群。
在初始化过程中,如果 kubelet failSwapOn 设置为 true,则会出现一条警告,告知节点上启用了交换内存特性。
我们计划在未来的版本中删除此警告。
如何通过 LimitedSwap 确定交换内存限额?
交换内存的配置(包括其局限性)是一项挑战。不仅容易出现配置错误,而且作为系统级属性, 任何错误配置都可能危及整个节点而不仅仅是特定的工作负载。 为了减轻这种风险并确保节点的健康,我们在交换内存的 Beta 版本中实现了对缺陷的自动配置。
使用 LimitedSwap,不属于 Burstable QoS 类别的 Pod(即 BestEffort/Guaranteed QoS Pod)被禁止使用交换内存。
BestEffort QoS Pod 表现出不可预测的内存消耗模式,并且缺乏有关其内存使用情况的信息,
因此很难完成交换内存的安全分配。相反,Guaranteed QoS Pod 通常用于根据工作负载的设置精确分配资源的应用,
其中的内存资源立即可用。
为了维持上述安全和节点健康保证,当 LimitedSwap 生效时,这些 Pod 将不允许使用交换内存。
在详细计算交换内存限制之前,有必要定义以下术语:
nodeTotalMemory:节点上可用的物理内存总量。totalPodsSwapAvailable:节点上可供 Pod 使用的交换内存总量(可以保留一些交换内存供系统使用)。containerMemoryRequest:容器的内存请求。
交换内存限制配置为:(containerMemoryRequest / nodeTotalMemory) × totalPodsSwapAvailable
换句话说,容器能够使用的交换内存量与其内存请求、节点的总物理内存以及节点上可供 Pod 使用的交换内存总量呈比例关系。
值得注意的是,对于 Burstable QoS Pod 中的容器,可以通过设置内存限制与内存请求相同来选择不使用交换内存。 以这种方式配置的容器将无法访问交换内存。
此特性如何工作?
我们可以想象可以在节点上使用交换内存的多种可能方式。当节点上提供了交换内存并可用时, SIG 节点建议 kubelet 应该能够遵循如下的配置:
- 在交换内存特性被启用时能够启动。
- 默认情况下,kubelet 将指示容器运行时接口(CRI)不为 Kubernetes 工作负载分配交换内存。
节点上的交换内存配置通过 KubeletConfiguration 中的 memorySwap 向集群管理员公开。
作为集群管理员,你可以通过设置 memorySwap.swapBehavior 来指定存在交换内存时节点的行为。
kubelet 使用 CRI
(容器运行时接口)API 来指示 CRI 配置特定的 cgroup v2 参数(例如 memory.swap.max),
配置方式要支持容器所期望的交换内存配置。接下来,CRI 负责将这些设置写入容器级的 cgroup。
如何对交换内存进行监控?
Alpha 版本的一个显著缺陷是无法监控或检视交换内存的使用情况。 这个问题已在 Kubernetes 1.28 引入的 Beta 版本中得到解决,该版本现在提供了通过多种不同方法监控交换内存使用情况的能力。
kubelet 的 Beta 版本现在支持收集节点级指标统计信息,
可以通过 /metrics/resource 和 /stats/summary kubelet HTTP 端点进行访问。
这些信息使得客户端能够在使用 LimitedSwap 时直接访问 kubelet 来监控交换内存使用情况和剩余交换内存情况。
此外,cadvisor 中还添加了 machine_swap_bytes 指标,以显示机器上总的物理交换内存容量。
注意事项
在系统上提供可用交换内存会降低可预测性。由于交换内存的性能比常规内存差, 有时差距甚至在多个数量级,因而可能会导致意外的性能下降。此外,交换内存会改变系统在内存压力下的行为。 由于启用交换内存允许 Kubernetes 中的工作负载使用更大的内存量,而这一用量是无法预测的, 因此也会增加嘈杂邻居和非预期的装箱配置的风险,因为调度程序无法考虑交换内存使用情况。
启用交换内存的节点的性能取决于底层物理存储。当使用交换内存时,与固态硬盘或 NVMe 等更较快的存储介质相比, 在每秒 I/O 操作数(IOPS)受限的环境(例如具有 I/O 限制的云虚拟机)中,性能会明显变差。
因此,我们不提倡针对有性能约束的工作负载或环境使用交换内存。
此外,建议使用 LimitedSwap,因为这可以显著减轻给节点带来的风险。
集群管理员和开发人员应该在生产场景中使用交换内存之前对其节点和应用进行基准测试, 我们需要你的帮助!
安全风险
在没有加密的系统上启用交换内存会带来安全风险,因为关键信息(例如代表 Kubernetes Secret 的卷) 可能会被交换到磁盘。 如果未经授权的个人访问磁盘,他们就有可能获得这些机密数据。为了减轻这种风险, Kubernetes 项目强烈建议你对交换内存空间进行加密。但是,处理加密交换内存不是 kubelet 的责任; 相反,它其实是操作系统配置通用问题,应在该级别解决。管理员有责任提供加密交换内存来减轻这种风险。
此外,如前所述,启用 LimitedSwap 模式时,用户可以选择通过设置内存限制与内存请求相同来完全禁止容器使用交换内存。
这种设置会阻止相应的容器访问交换内存。
展望未来
Kubernetes 1.28 版本引入了对 Linux 节点上交换内存的 Beta 支持, 我们将继续为这项特性的正式发布而努力。 我希望这将包括:
- 添加根据 kubelet 在主机上检测到的内容来设置系统预留交换内存量的功能。
- 添加对通过 cgroup 在 Pod 级别控制交换内存用量的支持。
- 这一点仍在讨论中。
- 收集测试用例的反馈。
- 我们将考虑引入新的交换内存配置模式,例如在节点层面为工作负载设置交换内存限制。
如果进一步学习?
你可以查看当前文档以了解如何在 Kubernetes 中使用交换内存。
如需了解更多信息,以及协助测试和提供反馈,请参阅 KEP-2400 及其设计提案。
参与其中
随时欢迎你的反馈!SIG Node 定期举行会议并可以通过 Slack(#sig-node 频道) 或 SIG 的 邮件列表 进行联系。 Slack 还提供了专门讨论交换内存的 #sig-node-swap 频道。
如果你想提供帮助或提出进一步的问题,请随时联系 Itamar Holder(Slack 和 GitHub 账号为 @iholder101)。
Kubernetes 1.28:节点 podresources API 正式发布
作者:Francesco Romani (Red Hat)
译者:Wilson Wu (DaoCloud)
podresources API 是由 kubelet 提供的节点本地 API,它用于公开专门分配给容器的计算资源。 随着 Kubernetes 1.28 的发布,该 API 现已正式发布。
它解决了什么问题?
kubelet 可以向容器分配独占资源,例如 CPU,授予对完整核心的独占访问权限或内存,包括内存区域或巨页。 需要高性能或低延迟(或者两者都需要)的工作负载可以利用这些特性。 kubelet 还可以将设备分配给容器。 总的来说,这些支持独占分配的特性被称为“资源管理器(Resource Managers)”。
如果没有像 podresources 这样的 API,了解资源分配的唯一可能选择就是读取资源管理器使用的状态文件。 虽然这样做是出于必要,但这种方法的问题是这些文件的路径和格式都是内部实现细节。 尽管非常稳定,但项目保留自由更改它们的权利。因此,使用状态文件内容的做法是不可靠的且不受支持的, 建议这样做的项目考虑迁移到使用 podresources API 或其他受支持的 API。
API 概述
podresources API 最初被提出是为了实现设备监控。
为了支持监控代理,一个关键的先决条件是启用由 kubelet 执行的设备分配自省(Introspection)。
API 的最初目标就是服务于此目的。API 的第一次迭代仅实现了一个函数 List,用于返回有关设备分配给容器的信息。
该 API 由 multus CNI
和 GPU 监控工具使用。
自推出以来,podresources API 扩大了其范围,涵盖了设备管理器之外的其他资源管理器。
从 Kubernetes 1.20 开始,List API 还报告 CPU 核心和内存区域(包括巨页);
在能够从系统中推断 CPU 和内存的位置时,API 还报告设备的 NUMA 位置。
在 Kubernetes 1.21 中,API 增加了
GetAllocatableResources 函数。这个较新的 API 补充了现有的 List API,
并使监控代理能够辨识尚未分配的资源,从而支持在 podresources API 之上构建新的特性,
例如 NUMA 感知的调度器插件。
最后,在 Kubernetes 1.27 中,引入了另一个函数 Get,以便对 CNI 元插件(Meta-Plugins)更加友好,
简化对已分配给特定 Pod 的资源的访问,而不必过滤节点上所有 Pod 的资源。Get 函数目前处于 Alpha 级别。
使用 API
podresources API 由本地 kubelet 提供,位于 kubelet 运行所在的同一节点上。
在 Unix 风格的系统上,通过 Unix 域套接字提供端点;默认路径是 /var/lib/kubelet/pod-resources/kubelet.sock。
在 Windows 上,通过命名管道提供端点;默认路径是 npipe://\\.\pipe\kubelet-pod-resources。
为了让容器化监控应用使用 API,套接字应挂载到容器内。 一个好的做法是挂载 podresources 套接字端点所在的目录,而不是直接挂载套接字。 这种做法将确保 kubelet 重新启动后,容器化监视器应用能够重新连接到套接字。
在下面的 DaemonSet 示例清单中,包含一个假想的使用 podresources API 的监控代理:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: podresources-monitoring-app
namespace: monitoring
spec:
selector:
matchLabels:
name: podresources-monitoring
template:
metadata:
labels:
name: podresources-monitoring
spec:
containers:
- args:
- --podresources-socket=unix:///host-podresources/kubelet.sock
command:
- /bin/podresources-monitor
image: podresources-monitor:latest # 仅作为样例
volumeMounts:
- mountPath: /host-podresources
name: host-podresources
serviceAccountName: podresources-monitor
volumes:
- hostPath:
path: /var/lib/kubelet/pod-resources
type: Directory
name: host-podresources
我希望你发现以编程方式使用 podresources API 很简单。kubelet API包提供了协议文件和 Go 类型定义; 但是,该项目尚未提供客户端包,并且你也不应直接使用现有代码。 推荐方法是在你自己的项目中重新实现客户端, 复制并粘贴相关功能,就像 multus 项目所做的那样。
在操作使用 podresources API 的容器化监控应用程序时,有几点值得强调,以防止出现“陷阱”:
- 尽管 API 仅公开数据,并且设计上不允许客户端改变 kubelet 状态,
但 gRPC 请求/响应模型要求能对 podresources API 套接字进行读写访问。
换句话说,将容器挂载限制为
ReadOnly是不可能的。 - 让多个客户端连接到 podresources 套接字并使用此 API 是允许的,因为 API 是无状态的。
- kubelet 具有内置限速机制, 用以缓解来自行为不当或恶意用户的本地拒绝服务攻击。API 的使用者必须容忍服务器返回的速率限制错误。 速率限制目前是硬编码的且作用于全局的,因此行为不当的客户端可能会耗光所有配额,进而导致行为正确的客户端挨饿。
未来的增强
由于历史原因,podresources API 的规范不如典型的 kubernetes API(例如 Kubernetes HTTP API 或容器运行时接口)精确。 这会导致在极端情况下出现未指定的行为。我们正在努力纠正这种状态并制定更精确的规范。
动态资源分配(DRA)基础设施是对资源管理的重大改革。 与 podresources API 的集成已经在进行中。
我们正在努力推荐或创建可供使用的参考客户端包。
参与其中
此功能由 SIG Node 驱动。 请加入我们,与社区建立联系,并分享你对上述功能及其他功能的想法和反馈。我们期待你的回音!
Kubernetes 1.28:Job 失效处理的改进
作者: Kevin Hannon (G-Research), Michał Woźniak (Google)
译者: Xin Li (Daocloud)
本博客讨论 Kubernetes 1.28 中的两个新特性,用于为批处理用户改进 Job: Pod 更换策略 和基于索引的回退限制。
这些特性延续了 Pod 失效策略 为开端的工作,用来改进对 Job 中 Pod 失效的处理。
Pod 更换策略
默认情况下,当 Pod 进入终止(Terminating)状态(例如由于抢占或驱逐机制)时,Kubernetes
会立即创建一个替换的 Pod,因此这时会有两个 Pod 同时运行。就 API 而言,当 Pod 具有
deletionTimestamp 字段并且处于 Pending 或 Running 阶段时会被视为终止。
对于一些流行的机器学习框架来说,在给定时间运行两个 Pod 的情况是有问题的, 例如 TensorFlow 和 JAX, 对于给定的索引,它们最多同时运行一个 Pod。如果两个 Pod 使用同一个索引来运行, Tensorflow 会抛出以下错误:
/job:worker/task:4: Duplicate task registration with task_name=/job:worker/replica:0/task:4
可参考问题报告进一步了解细节。
在前一个 Pod 完全终止之前创建替换的 Pod 也可能会导致资源或预算紧张的集群出现问题,例如:
- 对于待调度的 Pod 来说,很难分配到集群资源,导致 Kubernetes 需要很长时间才能找到可用节点, 直到现有 Pod 完全终止。
- 如果启用了集群自动扩缩器(Cluster Autoscaler),可能会产生不必要的集群规模扩增。
如何使用?
这是一项 Alpha 级别特性,你可以通过在集群中启用 JobPodReplacementPolicy
特性门控
来启用该特性。
kind: Job
metadata:
name: new
...
spec:
podReplacementPolicy: Failed
...
在此 Job 中,Pod 仅在达到 Failed 阶段时才会被替换,而不是在它们处于终止过程中(Terminating)时被替换。
此外,你可以检查 Job 的 .status.termination 字段。该字段的值表示终止过程中的
Job 所关联的 Pod 数量。
kubectl get jobs/myjob -o=jsonpath='{.items[*].status.terminating}'
3 # three Pods are terminating and have not yet reached the Failed phase
这一特性对于外部排队控制器(例如 Kueue)特别有用, 它跟踪作业的运行 Pod 的配额,直到从当前终止过程中的 Job 资源被回收为止。
请注意,使用自定义 Pod 失败策略时,
podReplacementPolicy: Failed 是默认值。
逐索引的回退限制
默认情况下,带索引的 Job(Indexed Job)的
Pod 失败情况会被统计下来,受 .spec.backoffLimit 字段所设置的全局重试次数限制。
这意味着,如果存在某个索引值的 Pod 一直持续失败,则会 Pod 会被重新启动,直到重试次数达到限制值。
一旦达到限制值,整个 Job 将被标记为失败,并且对应某些索引的 Pod 甚至可能从不曾被启动。
对于你想要独立处理不同索引值的 Pod 的失败的场景而言,这是有问题的。 例如,如果你使用带索引的 Job(Indexed Job)来运行集成测试,其中每个索引值对应一个测试套件。 在这种情况下,你可能需要考虑可能发生的脆弱测试(Flake Test),允许每个套件重试 1 次或 2 次。 可能存在一些有缺陷的套件,导致对应索引的 Pod 始终失败。在这种情况下, 你或许更希望限制有问题的套件的重试,而允许其他套件完成。
此特性允许你:
- 尽管某些索引值的 Pod 失败,但仍完成执行所有索引值的 Pod。
- 通过避免对持续失败的、特定索引值的 Pod 进行不必要的重试,更好地利用计算资源。
可以如何使用它?
这是一个 Alpha 特性,你可以通过启用集群的 JobBackoffLimitPerIndex
特性门控来启用此特性。
在集群中启用该特性后,你可以在创建带索引的 Job(Indexed Job)时指定 .spec.backoffLimitPerIndex 字段。
示例
下面的示例演示如何使用此功能来确保 Job 执行所有索引值的 Pod(前提是没有其他原因导致 Job 提前终止,
例如达到 activeDeadlineSeconds 超时,或者被用户手动删除),以及按索引控制失败次数。
apiVersion: batch/v1
kind: Job
metadata:
name: job-backoff-limit-per-index-execute-all
spec:
completions: 8
parallelism: 2
completionMode: Indexed
backoffLimitPerIndex: 1
template:
spec:
restartPolicy: Never
containers:
- name: example # 当此示例容器作为任何 Job 中的第二个或第三个索引运行时(即使在重试之后),它会返回错误并失败
image: python
command:
- python3
- -c
- |
import os, sys, time
id = int(os.environ.get("JOB_COMPLETION_INDEX"))
if id == 1 or id == 2:
sys.exit(1)
time.sleep(1)
现在,在 Job 完成后检查 Pod:
kubectl get pods -l job-name=job-backoff-limit-per-index-execute-all
返回的输出类似与:
NAME READY STATUS RESTARTS AGE
job-backoff-limit-per-index-execute-all-0-b26vc 0/1 Completed 0 49s
job-backoff-limit-per-index-execute-all-1-6j5gd 0/1 Error 0 49s
job-backoff-limit-per-index-execute-all-1-6wd82 0/1 Error 0 37s
job-backoff-limit-per-index-execute-all-2-c66hg 0/1 Error 0 32s
job-backoff-limit-per-index-execute-all-2-nf982 0/1 Error 0 43s
job-backoff-limit-per-index-execute-all-3-cxmhf 0/1 Completed 0 33s
job-backoff-limit-per-index-execute-all-4-9q6kq 0/1 Completed 0 28s
job-backoff-limit-per-index-execute-all-5-z9hqf 0/1 Completed 0 28s
job-backoff-limit-per-index-execute-all-6-tbkr8 0/1 Completed 0 23s
job-backoff-limit-per-index-execute-all-7-hxjsq 0/1 Completed 0 22s
此外,你可以查看该 Job 的状态:
kubectl get jobs job-backoff-limit-per-index-fail-index -o yaml
输出内容以 status 结尾,类似于:
status:
completedIndexes: 0,3-7
failedIndexes: 1,2
succeeded: 6
failed: 4
conditions:
- message: Job has failed indexes
reason: FailedIndexes
status: "True"
type: Failed
这里,索引为 1 和 2 的 Pod 都被重试了一次。这两个 Pod 在第二次失败后都超出了指定的
.spec.backoffLimitPerIndex,因此停止重试。相比之下,如果禁用了基于索引的回退,
那么有问题的、特定索引的 Pod 将被重试,直到超出全局 backoffLimit,之后在启动一些索引值较高的 Pod 之前,
整个 Job 将被标记为失败。
如何进一步了解
参与其中
这些功能由 SIG Apps 赞助。 社区正在为批处理工作组中的 Kubernetes 用户积极改进批处理场景。 工作组是相对短暂的举措,专注于特定目标。WG Batch 的目标是改善批处理工作负载的用户体验、 提供对批处理场景的支持并增强常见场景下的 Job API。 如果你对此感兴趣,请通过订阅我们的邮件列表或通过 Slack 加入进来。
致谢
与其他 Kubernetes 特性一样,从测试、报告缺陷到代码审查,很多人为此特性做出了贡献。
如果没有 Aldo Culquicondor(Google)提供出色的领域知识和跨整个 Kubernetes 生态系统的知识, 我们可能无法实现这些特性。
Kubernetes v1.28:可追溯的默认 StorageClass 进阶至 GA
作者: Roman Bednář (Red Hat)
译者: Michael Yao (DaoCloud)
可追溯的默认 StorageClass 赋值(Retroactive Default StorageClass Assignment)在 Kubernetes v1.28 中宣布进阶至正式发布(GA)!
Kubernetes SIG Storage 团队非常高兴地宣布,在 Kubernetes v1.25 中作为 Alpha 特性引入的 “可追溯默认 StorageClass 赋值” 现已进阶至 GA, 并正式成为 Kubernetes v1.28 发行版的一部分。 这项增强特性极大地改进了默认的 StorageClasses 为 PersistentVolumeClaim (PVC) 赋值的方式。
启用此特性后,你不再需要先创建默认的 StorageClass,再创建 PVC 来指定存储类。 现在,未分配 StorageClass 的所有 PVC 都将被自动更新为包含默认的 StorageClass。 此项增强特性确保即使默认的 StorageClass 在 PVC 创建时未被定义, PVC 也不会再滞留在未绑定状态,存储制备工作可以无缝进行。
有什么变化?
PersistentVolume (PV) 控制器已修改为:当未设置 storageClassName 时,自动向任何未绑定的
PersistentVolumeClaim 分配一个默认的 StorageClass。此外,API 服务器中的 PersistentVolumeClaim
准入验证机制也已调整为允许将值从未设置状态更改为实际的 StorageClass 名称。
如何使用?
由于此特性已进阶至 GA,所以不再需要启用特性门控。 只需确保你运行的是 Kubernetes v1.28 或更高版本,此特性即可供使用。
有关更多细节,可以查阅 Kubernetes 文档中的默认 StorageClass 赋值。 你也可以阅读以前在 v1.26 中宣布进阶至 Beta 的博客文章。
要提供反馈,请加入我们的 Kubernetes 存储特别兴趣小组 (SIG) 或参与公共 Slack 频道上的讨论。
Kubernetes 1.28: 节点非体面关闭进入 GA 阶段(正式发布)
作者: Xing Yang (VMware) 和 Ashutosh Kumar (Elastic)
译者: Xin Li (Daocloud)
Kubernetes 节点非体面关闭特性现已在 Kubernetes v1.28 中正式发布。
此特性在 Kubernetes v1.24 中作为 Alpha 特性引入,并在 Kubernetes v1.26 中转入 Beta 阶段。如果原始节点意外关闭或最终处于不可恢复状态(例如硬件故障或操作系统无响应), 此特性允许有状态工作负载在不同节点上重新启动。
什么是节点非体面关闭
在 Kubernetes 集群中,节点可能会按计划正常关闭,也可能由于断电或其他外部原因而意外关闭。 如果节点在关闭之前未腾空,则节点关闭可能会导致工作负载失败。节点关闭可以是正常关闭,也可以是非正常关闭。
节点体面关闭特性允许 kubelet 在实际关闭之前检测节点关闭事件、正确终止该节点上的 Pod 并释放资源。
当节点关闭但 kubelet 的节点关闭管理器未检测到时,将造成节点非体面关闭。 对于无状态应用程序来说,节点非体面关闭通常不是问题,但是对于有状态应用程序来说,这是一个问题。 如果 Pod 停留在关闭节点上并且未在正在运行的节点上重新启动,则有状态应用程序将无法正常运行。
在节点非体面关闭的情况下,你可以在 Node 上手动添加 out-of-service 污点。
kubectl taint nodes <node-name> node.kubernetes.io/out-of-service=nodeshutdown:NoExecute
如果 Pod 上没有与之匹配的容忍规则,则此污点会触发节点上的 Pod 被强制删除。 挂接到关闭中的节点的持久卷将被解除挂接,新的 Pod 将在不同的运行节点上成功创建。
注意: 在应用 out-of-service 污点之前,你必须验证节点是否已经处于关闭或断电状态(而不是在重新启动中)。
与 out-of-service 节点有关联的所有工作负载的 Pod 都被移动到新的运行节点, 并且所关闭的节点已恢复之后,你应该删除受影响节点上的污点。
稳定版中有哪些新内容
随着非正常节点关闭功能提升到稳定状态,特性门控
NodeOutOfServiceVolumeDetach 在 kube-controller-manager 上被锁定为 true,并且无法禁用。
Pod GC 控制器中的指标 force_delete_pods_total 和 force_delete_pod_errors_total
得到增强,以考虑所有 Pod 的强制删除情况。
指标中会添加一个 "reason",以指示 Pod 是否因终止、孤儿、因 out-of-service
污点而终止或因未计划终止而被强制删除。
Attach Detach Controller 中的指标 attachdetach_controller_forced_detaches
中还会添加一个 "reason",以指示强制解除挂接是由 out-of-service 污点还是超时引起的。
接下来
此特性要求用户手动向节点添加污点以触发工作负载故障转移,并在节点恢复后删除污点。 未来,我们计划找到方法来自动检测和隔离关闭/失败的节点,并自动将工作负载故障转移到另一个节点。
如何了解更多?
在此处可以查看有关此特性的其他文档。
我们非常感谢所有帮助设计、实现和审查此功能并帮助其从 Alpha、Beta 到稳定版的贡献者:
- Michelle Au (msau42)
- Derek Carr (derekwaynecarr)
- Danielle Endocrimes (endocrimes)
- Baofa Fan (carlory)
- Tim Hockin (thockin)
- Ashutosh Kumar (sonasingh46)
- Hemant Kumar (gnufied)
- Yuiko Mouri (YuikoTakada)
- Mrunal Patel (mrunalp)
- David Porter (bobbypage)
- Yassine Tijani (yastij)
- Jing Xu (jingxu97)
- Xing Yang (xing-yang)
此特性是 SIG Storage 和 SIG Node 之间的协作。对于那些有兴趣参与 Kubernetes 存储系统任何部分的设计和开发的人,请加入 Kubernetes 存储特别兴趣小组(SIG)。 对于那些有兴趣参与支持 Pod 和主机资源之间受控交互的组件的设计和开发,请加入 Kubernetes Node SIG。
pkgs.k8s.io:介绍 Kubernetes 社区自有的包仓库
作者:Marko Mudrinić (Kubermatic)
译者:Wilson Wu (DaoCloud)
我很高兴代表 Kubernetes SIG Release 介绍 Kubernetes
社区自有的 Debian 和 RPM 软件仓库:pkgs.k8s.io!
这些全新的仓库取代了我们自 Kubernetes v1.5 以来一直使用的托管在
Google 的仓库(apt.kubernetes.io 和 yum.kubernetes.io)。
这篇博文包含关于这些新的包仓库的信息、它对最终用户意味着什么以及如何迁移到新仓库。
ℹ️ 更新(2024 年 1 月 12 日):旧版托管在 Google 的仓库已被弃用,并将于 2024 年 1 月开始被冻结。 查看弃用公告了解有关此更改的更多详细信息。
关于新的包仓库,你需要了解哪些信息?
(更新于 2024 年 1 月 12 日)
- 这是一个明确同意的更改;你需要手动从托管在 Google 的仓库迁移到 Kubernetes 社区自有的仓库。请参阅本公告后面的如何迁移, 了解迁移信息和说明。
- 旧版托管在 Google 的包仓库于 2024 年 1 月停用。
这些仓库自 2023 年 8 月 31 日起被弃用 ,并自 2023 年 9 月 13 日被冻结 。
有关此变更的更多细节请查阅弃用公告。
旧仓库中的现有包将在可预见的未来一段时间内可用。 然而,Kubernetes 项目无法保证这会持续多久。 已弃用的旧仓库及其内容可能会在未来随时被删除,恕不另行通知。旧版包仓库于 2024 年 1 月停用。
- 鉴于在 2023 年 9 月 13 日这个截止时间点之后不会向旧仓库发布任何新版本, 如果你不在该截止时间点迁移至新的 Kubernetes 仓库, 你将无法升级到该日期之后发布的任何补丁或次要版本。 也就是说,我们建议尽快迁移到新的 Kubernetes 仓库。
- 新的 Kubernetes 仓库中包含社区开始接管包构建以来仍在支持的 Kubernetes 版本的包。 这意味着 v1.24.0 之前的任何内容都只存在于托管在 Google 的仓库中。 这意味着新的包仓库将为从 v1.24.0 开始的所有 Kubernetes 版本提供 Linux 包。
- Kubernetes 没有为早期版本提供官方的 Linux 包;然而,你的 Linux 发行版可能会提供自己的包。
- 每个 Kubernetes 次要版本都有一个专用的仓库。 当升级到不同的次要版本时,你必须记住,仓库详细信息也会发生变化。
为什么我们要引入新的包仓库?
随着 Kubernetes 项目的不断发展,我们希望确保最终用户获得最佳体验。 托管在 Google 的仓库多年来一直为我们提供良好的服务, 但我们开始面临一些问题,需要对发布包的方式进行重大变更。 我们的另一个目标是对所有关键组件使用社区拥有的基础设施,其中包括仓库。
将包发布到托管在 Google 的仓库是一个手动过程, 只能由名为 Google 构建管理员的 Google 员工团队来完成。 Kubernetes 发布管理员团队是一个非常多元化的团队, 尤其是在我们工作的时区方面。考虑到这一限制,我们必须对每个版本进行非常仔细的规划, 确保我们有发布经理和 Google 构建管理员来执行发布。
另一个问题是由于我们只有一个包仓库。因此,我们无法发布预发行版本
(Alpha、Beta 和 RC)的包。这使得任何有兴趣测试的人都更难测试 Kubernetes 预发布版本。
我们从测试这些版本的人员那里收到的反馈对于确保版本的最佳质量至关重要,
因此我们希望尽可能轻松地测试这些版本。最重要的是,只有一个仓库限制了我们对
cri-tools 和 kubernetes-cni 等依赖进行发布,
尽管存在这些问题,我们仍非常感谢 Google 和 Google 构建管理员这些年来的参与、支持和帮助!
新的包仓库如何工作?
新的 Debian 和 RPM 仓库托管在 pkgs.k8s.io。
目前,该域指向一个 CloudFront CDN,其后是包含仓库和包的 S3 存储桶。
然而,我们计划在未来添加更多的镜像站点,让其他公司有可能帮助我们提供软件包服务。
包通过 OpenBuildService(OBS)平台构建和发布。 经过长时间评估不同的解决方案后,我们决定使用 OpenBuildService 作为管理仓库和包的平台。 首先,OpenBuildService 是一个开源平台,被大量开源项目和公司使用, 如 openSUSE、VideoLAN、Dell、Intel 等。OpenBuildService 具有许多功能, 使其非常灵活且易于与我们现有的发布工具集成。 它还允许我们以与托管在 Google 的仓库类似的方式构建包,从而使迁移过程尽可能无缝。
SUSE 赞助 Kubernetes 项目并且支持访问其引入的 OpenBuildService 环境
(build.opensuse.org),
还提供将 OBS 与我们的发布流程集成的技术支持。
我们使用 SUSE 的 OBS 实例来构建和发布包。构建新版本后,
我们的工具会自动将所需的制品和包设置推送到 build.opensuse.org。
这将触发构建过程,为所有支持的架构(AMD64、ARM64、PPC64LE、S390X)构建包。
最后,生成的包将自动推送到我们社区拥有的 S3 存储桶,以便所有用户都可以使用它们。
我们想借此机会感谢 SUSE 允许我们使用 build.opensuse.org
以及他们的慷慨支持,使这种集成成为可能!
托管在 Google 的仓库和 Kubernetes 仓库之间有哪些显著差异?
你应该注意三个显著差异:
- 每个 Kubernetes 次要版本都有一个专用的仓库。例如,
名为
core:/stable:/v1.28的仓库仅托管稳定 Kubernetes v1.28 版本的包。 这意味着你可以从此仓库安装 v1.28.0,但无法安装 v1.27.0 或 v1.28 之外的任何其他次要版本。 升级到另一个次要版本后,你必须添加新的仓库并可以选择删除旧的仓库
- 每个 Kubernetes 仓库中可用的
cri-tools和kubernetes-cni包版本有所不同- 这两个包是
kubelet和kubeadm的依赖项 - v1.24 到 v1.27 的 Kubernetes 仓库与托管在 Google 的仓库具有这些包的相同版本
- v1.28 及更高版本的 Kubernetes 仓库将仅发布该 Kubernetes 次要版本
- 就 v1.28 而言,Kubernetes v1.28 的仓库中仅提供 kubernetes-cni 1.2.0 和 cri-tools v1.28
- 与 v1.29 类似,我们只计划发布 cri-tools v1.29 以及 Kubernetes v1.29 将使用的 kubernetes-cni 版本
- 这两个包是
- 包版本的修订部分(
1.28.0-00中的-00部分)现在由 OpenBuildService 平台自动生成,并具有不同的格式。修订版本现在采用-x.y格式,例如1.28.0-1.1
这是否会影响现有的托管在 Google 的仓库?
托管在 Google 的仓库以及发布到其中的所有包仍然可用,与之前一样。 我们构建包并将其发布到托管在 Google 仓库的方式没有变化, 所有新引入的更改仅影响发布到社区自有仓库的包。
然而,正如本文开头提到的,我们计划将来停止将包发布到托管在 Google 的仓库。
如何迁移到 Kubernetes 社区自有的仓库?
使用 apt/apt-get 的 Debian、Ubuntu 一起其他操作系统
替换
apt仓库定义,以便apt指向新仓库而不是托管在 Google 的仓库。 确保将以下命令中的 Kubernetes 次要版本替换为你当前使用的次要版本:echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.28/deb/ /" | sudo tee /etc/apt/sources.list.d/kubernetes.list
下载 Kubernetes 仓库的公共签名密钥。所有仓库都使用相同的签名密钥, 因此你可以忽略 URL 中的版本:
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.28/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
更新
apt包索引:sudo apt-get update
使用 rpm/dnf 的 CentOS、Fedora、RHEL 以及其他操作系统
替换
yum仓库定义,使yum指向新仓库而不是托管在 Google 的仓库。 确保将以下命令中的 Kubernetes 次要版本替换为你当前使用的次要版本:cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://pkgs.k8s.io/core:/stable:/v1.28/rpm/ enabled=1 gpgcheck=1 gpgkey=https://pkgs.k8s.io/core:/stable:/v1.28/rpm/repodata/repomd.xml.key exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni EOF
迁移到 Kubernetes 仓库后是否可以回滚到托管在 Google 的仓库?
一般来说,可以。只需执行与迁移时相同的步骤,但使用托管在 Google 的仓库参数。 你可以在“安装 kubeadm”等文档中找到这些参数。
为什么没有固定的域名/IP 列表?为什么我无法限制包下载?
我们对 pkgs.k8s.io 的计划是使其根据用户位置充当一组后端(包镜像)的重定向器。
此更改的本质意味着下载包的用户可以随时重定向到任何镜像。
鉴于架构和我们计划在不久的将来加入更多镜像,我们无法提供给你可以添加到允许列表中的
IP 地址或域名列表。
限制性控制机制(例如限制访问特定 IP/域名列表的中间人代理或网络策略)将随着此更改而中断。 对于这些场景,我们鼓励你将包的发布版本与你可以严格控制的本地仓库建立镜像。
如果我发现新的仓库有异常怎么办?
如果你在新的 Kubernetes 仓库中遇到任何问题,
请在 kubernetes/release 仓库中提交问题。
聚焦 SIG CLI
作者:Arpit Agrawal
译者:Xin Li (Daocloud)
在 Kubernetes 的世界中,大规模管理容器化应用程序需要强大而高效的工具。 命令行界面(CLI)是任何开发人员或操作人员工具包不可或缺的一部分, 其提供了一种方便灵活的方式与 Kubernetes 集群交互。
SIG CLI 通过专注于 Kubernetes 主要命令行工具 kubectl 的开发和增强,
在改善 Kubernetes CLI
体验方面发挥着至关重要的作用。
在本次 SIG CLI 聚焦中,SIG ContribEx-Comms 团队成员 Arpit Agrawal 与 SIG CLI 技术主管兼主席 Katrina Verey 和 SIG CLI Batch 主管 Maciej Szulik 讨论了 SIG CLI 当前项目状态和挑战以及如何参与其中。
因此,无论你是经验丰富的 Kubernetes 爱好者还是刚刚入门,了解 SIG CLI 的重要性无疑将增强你的 Kubernetes 之旅。
简介
Arpit:你们能否向我们介绍一下你自己、你的角色以及你是如何参与 SIG CLI 的?
Maciej:我是 SIG-CLI 的技术负责人之一。自 2014 年以来,我一直在多个领域从事 Kubernetes 工作,并于 2018 年被任命为负责人。
Katrina:自 2016 年以来,我一直作为最终用户使用 Kubernetes,但直到 2019 年底, 我才发现 SIG CLI 与我在内部项目中的经验非常吻合。我开始定期参加会议并提交了一些小型 PR, 到 2021 年,我专门与 Kustomize 团队进行了更深入的合作。同年晚些时候,我被任命担任目前的职务,担任 Kustomize 和 KRM Functions 的子项目 owner 以及 SIG CLI 技术主管和负责人。
关于 SIG CLI
Arpit:谢谢!你们能否与我们分享一下 SIG CLI 的宗旨和目标?
Maciej:我们的章程有最详细的描述, 但简而言之,我们处理所有 CLI 工具,帮助你管理 Kubernetes 资源清单以及与 Kubernetes 集群进行交互。
Arpit:我明白了。请问 SIG CLI 如何致力于推广云原生生态系统中 CLI 开发和使用的最佳实践?
Maciej:在 kubectl 中,我们正在进行多项努力,试图鼓励新的贡献者将现有命令与新标准保持一致。
我们发布了几个库,希望能够更轻松地编写与 Kubernetes API 交互的 CLI,例如 cli-runtime 和
kyaml。
Katrina:我们还维护一些 CLI 工具的互操作性规范,例如 KRM 函数规范(GA) 和新的 ApplySet 规范(Alpha)。
当前的项目和挑战
Arpit:阅读了一遍 README 文件,发现 SIG CLI 有许多子项目,你能突出讲一些重要的子项目吗?
Maciej:在我看来,值得你投入时间的四个最活跃的子项目是:
kubectl:规范的 Kubernetes CLI。- Kustomize:Kubernetes yaml 清单文件的无模板定制工具。
- KUI - 一个针对 Kubernetes 的 GUI 界面,可以将其视为增强版的
kubectl。 krew:kubectl的插件管理器。
Arpit:SIG CLI 是否有任何正在开展或即将开展的计划或开发工作?
Maciej:在任何给定的时间点,我们总是在开展多项举措。 最好加入我们的一个电话会议来了解当前的情况。
对于主要功能,你可以查看我们的开放 KEP。
例如,在 1.27 中,我们为 kubectl apply 中的新裁剪模式
引入了新的 Alpha 特性,并为 kubectl 添加了插件。
目前正在讨论的令人兴奋的想法包括 kubectl 删除的交互模式(KEP 3895)和
kuberc 用户首选项文件(KEP 3104)。
Arpit:你们能否说说 SIG CLI 在改善云本地技术的 CLI 时面临的任何挑战?未来将采取哪些措施来解决这些问题?
Katrina:我们每个决定面临的最大挑战是向后兼容性并确保我们不会影响现有用户。
经常发生的情况是,修复表面上的内容似乎很简单,但即使修复 bug 也可能对某些用户造成破坏性更改,
这意味着我们需要经历一个较长的弃用过程来更改它,或者在某些情况下我们不能完全改变它。
另一个挑战是我们需要在工具上公开 flag 的平衡定制和可用性。例如,我们收到了许多关于新标志的建议,
这些建议肯定对某些用户有用,但没有足够大的子集来证明,将它们添加到工具中对每个用户来说都会增加复杂性。
kuberc 提案可能会帮助个人用户设置或覆盖我们无法更改的默认值,甚至通过别名创建自定义子命令,
从而帮助解决其中一些问题。
Arpit:随着 Kubernetes 的每个新版本的发布,保持一致性和完整性无疑是一项挑战: SIG CLI 团队如何解决这个问题?
Maciej:这与上一个问题中提到的主题非常相似:每一个新的更改,尤其是对现有命令的更改, 都会经过大量的审查,以确保我们不会影响现有用户。在任何时候我们都必须在功能和不影响用户之间保持合理的平衡。
未来计划及贡献
Arpit:你们如何看待 CLI 工具在未来云原生生态系统中的作用?
Maciej:我认为 CLI 工具曾经并将永远是生态系统的重要组成部分。 无论是管理员在没有 GUI 的远程计算机上还是在每个 CI/CD 管道中使用,它们都是不可替代的。
Arpit:Kubernetes 是一个社区驱动的项目。对于想要参与 SIG CLI 工作的人有什么建议吗? 他们应该从哪里开始?有什么先决条件吗?
Maciej:除了有一点空闲时间和学习新东西的意愿之外,没有任何先决条件 :-)
Katrina:Go 的实用知识通常会有所帮助,但我们也有需要非代码贡献的领域, 例如 Kustomize 文档整合项目。
Kubernetes 机密:使用机密虚拟机和安全区来增强你的集群安全性
作者:Fabian Kammel (Edgeless Systems), Mikko Ylinen (Intel), Tobin Feldman-Fitzthum (IBM)
译者:顾欣
在这篇博客文章中,我们将介绍机密计算(Confidential Computing,简称 CC)的概念, 以增强任何计算环境的安全和隐私属性。此外,我们将展示云原生生态系统, 特别是 Kubernetes,如何从新的计算范式中受益。
机密计算是一个先前在云原生领域中引入的概念。 机密计算联盟(Confidential Computing Consortium,简称 CCC) 是 Linux 基金会中的一个项目社区, 致力于定义和启用机密计算。 在白皮书中, 他们为使用机密计算提供了很好的动机。
数据存在于三种状态:传输中、静态存储和使用中。保护所有状态下的敏感数据比以往任何时候都更加关键。 现在加密技术常被部署以提供数据机密性(阻止未经授权的查看)和数据完整性(防止或检测未经授权的更改)。 虽然现在通常部署了保护传输中和静态存储中的数据的技术,但保护使用中的数据是新的前沿。
机密计算主要通过引入硬件强制执行的可信执行环境(TEE)来解决保护使用中的数据的问题。
可信执行环境
在过去的十多年里,可信执行环境(Trusted Execution Environments,简称 TEEs) 以硬件安全模块(Hardware Security Modules,简称 HSMs) 和可信平台模块(Trusted Platform Modules,简称 TPMs) 的形式在商业计算硬件中得以应用。这些技术提供了可信的环境来进行受保护的计算。 它们可以存储高度敏感的加密密钥,并执行关键的加密操作,如签名或加密数据。
TPMs 的优化为降低成本,使它们能够集成到主板中并充当系统的物理根信任。 为了保持低成本,TPMs 的范围受到限制,即它们只能存储少量的密钥,并且仅能执行一小部分的加密操作。
相比之下,HSMs 的优化为提高性能,为更多的密钥提供安全存储,并提供高级物理攻击检测机制。 此外,高端 HSMs 可以编程,以便可以编译和执行任意代码。缺点是它们的成本非常高。 来自 AWS 的托管 CloudHSM 的费用大约是每小时 1.50 美元, 或者约每年 13,500 美元。
近年来,一种新型的 TEE 已经变得流行。 像 AMD SEV、 Intel SGX 和 Intel TDX 这样的技术提供了与用户空间紧密集成的 TEE。与支持特定的低功耗或高性能设备不同, 这些 TEE 保护普通进程或虚拟机,并且可以以相对较低的开销执行此操作。 这些技术各有不同的设计目标、优点和局限性, 并且在不同的环境中可用,包括消费者笔记本电脑、服务器和移动设备。
此外,我们应该提及 ARM TrustZone, 它针对智能手机、平板电脑和智能电视等嵌入式设备进行了优化, 以及 AWS Nitro Enclaves, 它们只在 Amazon Web Services 上可用, 并且与 Intel 和 AMD 的基于 CPU 的解决方案相比,具有不同的威胁模型。
IBM Secure Execution for Linux 允许你在 IBM Z 系列硬件的可信执行环境内以 KVM 客户端的形式运行 Kubernetes 集群的节点。 你可以使用这种硬件增强的虚拟机隔离机制为集群中的租户之间提供稳固的隔离, 并通过硬件验证提供关于(虚拟)节点完整性的信息。
安全属性和特性功能
下文将回顾这些新技术所带来的安全属性和额外功能。 只有部分解决方案会提供所有属性;我们将在各自的小节中更详细地讨论每项技术。
机密性属性确保在使用 TEE 时信息无法被查看。这为我们提供了非常需要的的功能以保护使用中的数据。 根据使用的特定 TEE,代码和数据都可能受到外部查看者的保护。 TEE 架构的差异以及它们在云原生环境中的使用是在设计端到端安全性时的重要考虑因素, 目的是为敏感工作负载提供最小的可信计算基础(Trusted Computing Base, 简称 TCB)。 CCC 最近致力于通用术语和支持材料,以帮助解释在不同的 TEE 架构下机密性边界的划分, 以及这如何影响 TCB 的大小。
机密性是一个很好的特性,但攻击者仍然可以操纵或注入任意代码和数据供 TEE 执行, 因此,很容易泄露关键信息。完整性保证 TEE 拥有者在运行关键计算时,代码和数据都不能被篡改。
可用性是在信息安全背景下经常讨论的一项基本属性。然而,这一属性超出了大多数 TEE 的范围。 通常,它们可以被一些更高级别的抽象控制(关闭、重启...)。这可以是 CPU 本身、虚拟机监视器或内核。 这是为了保持整个系统的可用性,而不是 TEE 本身。在云环境中运行时, 可用性通常由云提供商以服务级别协议(Service Level Agreements,简称 SLAs)的形式保证, 并且不能通过加密强制执行。
仅凭机密性和完整性在某些情况下是有帮助的。例如,考虑一个在远程云中运行的 TEE。 你如何知道 TEE 是真实的并且正在运行你预期的软件?一旦你发送数据, 它可能是一个冒名顶替者窃取你的数据。这个根本问题通过可验证性得到解决。 验证允许我们基于硬件本身签发的加密证书来验证 TEE 的身份、机密性和完整性。 这个功能也可以以远程验证的形式提供给机密计算硬件之外的客户端使用。
TEEs 可以保存和处理早于或超出可信环境存在时间的信息。这可能意味着重启、跨不同版本或平台迁移的信息。 因此,可恢复性是一个重要的特性。在将数据和 TEE 的状态写入持久性存储之前,需要对它们进行封装, 以维护保证机密性和完整性。对这种封装数据的访问需要明确定义。在大多数情况下, 解封过程与 TEE 绑定的身份有关。因此,确保恢复只能在相同的机密环境中进行。
这不必限制整个系统的灵活性。 AMD SEV-SNP 的迁移代理 (MA) 允许用户将机密虚拟机迁移到不同的主机系统,同时保持 TEE 的安全属性不变。
功能比较
本文的这部分将更深入地探讨具体的实现,比较支持的功能并分析它们的安全属性。
AMD SEV
AMD 的安全加密虚拟化 (SEV)技术是一组功能, 用于增强 AMD 服务器 CPU 上虚拟机的安全性。SEV 透明地用唯一密钥加密每个 VM 的内存。 SEV 还可以计算内存内容的签名,该签名可以作为证明初始客户机内存没有被篡改的依据发送给 VM 的所有者。
SEV 的第二代,称为加密状态 或 SEV-ES,通过在发生上下文切换时加密所有 CPU 寄存器内容,提供了对虚拟机管理程序的额外保护。
SEV 的第三代,安全嵌套分页 或 SEV-SNP,旨在防止基于软件的完整性攻击并降低受损内存完整性相关的风险。 SEV-SNP 完整性的基本原则是,如果虚拟机可以读取私有(加密)内存页, 那么它必须始终读取它最后写入的值。
此外,通过允许客户端动态获取远程验证声明,SNP 增强了 SEV 的远程验证能力。
AMD SEV 是以增量方式实施的。每个新的 CPU 代都增加了新功能和改进。 Linux 社区将这些功能作为 KVM 虚拟机管理程序的一部分提供,适用于主机和客户机内核。 第一批 SEV 功能在 2016 年被讨论并实施 - 参见 2016 年 Usenix 安全研讨会的 AMD x86 内存加密技术。 最新的重大补充是 Linux 5.19 中的 SEV-SNP 客户端支持。
自 2022 年 7 月以来,Microsoft Azure 提供基于 AMD SEV-SNP 的机密虚拟机。 类似地,Google Cloud Platform (GCP) 提供基于 AMD SEV-ES 的机密虚拟机。
Intel SGX
Intel 的软件防护扩展 自 2015 年起便已推出,并在 Skylake 架构中首次亮相。
SGX 是一套指令集,它使用户能够创建一个叫做 Enclave 的受保护且隔离的进程。 它提供了一个反沙箱机制,保护 Enclave 不受操作系统、固件以及任何其他特权执行上下文的影响。
Enclave 内存无法从 Enclave 外部读取或写入,无论当前的权限级别和 CPU 模式如何。 调用 Enclave 功能的唯一方式是通过一条执行多个保护检查的新指令。Enclave 的内存是加密的。 窃听内存或将 DRAM 模块连接到另一个系统只会得到加密数据。内存加密密钥在每次上电周期时随机更改。 密钥存储在 CPU 内部,无法访问。
由于 Enclave 是进程隔离的,操作系统的库不能直接使用; 因此,需要 SGX Enclave SDK 来编译针对 SGX 的程序。 这也意味着应用程序需要在设计和实现时考虑受信任/不受信任的隔离边界。 另一方面,应用程序的构建具有非常小的 TCB。
一种新兴的方法,利用库操作系统(library OSes)来轻松过渡到基于进程的机密计算并避免需要构建自定义应用程序。 这些操作系统有助于在 SGX 安全 Enclave 内运行原生的、未经修改的 Linux 应用程序。 操作系统库会拦截应用对宿主机操作系统的所有请求,并在应用不知情的情况下安全地处理它们, 而应用实际上是在一个受信执行环境(TEE)中运行。
第三代 Xeon 处理器(又称为 Ice Lake 服务器 - "ICX")及其后续版本采用了一种名为 全内存加密 - 多密钥(TME-MK)的技术, 该技术使用 AES-XTS,从消费者和 Xeon E 处理器使用的内存加密引擎中脱离出来。 这可能增加了 Enclave 页面缓存 (EPC)大小(每个 CPU 高达 512 GB)并提高了性能。关于多插槽平台上的 SGX 的更多信息可以在 白皮书中找到。
可以从 Intel 获取支持的平台列表。
SGX 在 Azure、 阿里云、 IBM 以及更多平台上可用。
Intel TDX
Intel SGX 旨在保护单个进程的上下文,而 Intel 的可信域扩展保护整个虚拟机, 因此,它与 AMD SEV 最为相似。
与 SEV-SNP 一样,对 TDX 的客户端支持已经在 Linux Kernel 5.19版本中合并。 然而,硬件支持将在 2023 年与 Sapphire Rapids 一同发布: 阿里云提供 邀请预览实例,同时,Azure 已经宣布 其 TDX 预览机会。
开销分析
通过强隔离和增强的安全性,机密计算技术为客户数据和工作负载提供的好处并非免费。 量化这种影响是具有挑战性的,并且取决于许多因素:TEE 技术,基准测试, 度量标准以及工作负载的类型都对预期的性能开销有巨大的影响。
基于 Intel SGX 的 TEE 很难进行基准测试, 正如不同的论文所 展示的一样。 所选择的 SDK/操作系统库,应用程序本身以及资源需求(特别是大内存需求)对性能有巨大的影响。 如果应用程序非常适合在 Enclave 内运行,那么通常可以预期会有一个个位数的百分比的开销。
基于 AMD SEV-SNP 的机密虚拟机不需要对执行的程序和操作系统进行任何更改, 因此更容易进行基准测试。一个来自 Azure 和 AMD 的基准测试显示, SEV-SNP VM 的开销 < 10%,有时甚至低至 2%。
尽管存在性能开销,但它应该足够低,以便使真实世界的工作负载能够在这些受保护的环境中运行, 并提高我们数据的安全性和隐私性。
机密计算与 FHE、ZKP 和 MPC 的比较
全同态加密(FHE),零知识证明/协议(ZKP)和多方计算(MPC)都是加密或密码学协议的形式, 提供与机密计算类似的安全保证,但不需要硬件支持。
全同态加密(也包括部分和有限同态加密)允许在加密数据上执行计算,例如加法或乘法。 这提供了在使用中加密的属性,但不像机密计算那样提供完整性保护或认证。因此,这两种技术可以 互为补充。
零知识证明或协议是一种隐私保护技术(PPT),它允许一方证明其数据的事实而不泄露关于数据的任何其他信息。 ZKP 可以替代或与机密计算一起使用,以保护相关方及其数据的隐私。同样, 多方计算使多个参与方能够共同进行计算,即每个参与方提供其数据以得出结果, 但不会泄露给任何其他参与方。
机密计算的应用场景
前面介绍的机密计算平台表明,既可以实现单个容器进程的隔离,从而最小化可信计算单元, 也可以实现整个虚拟机的隔离。这已经促使很多有趣且安全的项目涌现:
机密容器
机密容器 (CoCo) 是一个 CNCF 沙箱项目,它在机密虚拟机内隔离 Kubernetes Pod。
CoCo 可以通过 operator 安装在 Kubernetes 集群上。operator 将创建一组运行时类, 这些类可以用于在多个不同的平台上的 Enclave 内部署 Pod, 包括 AMD SEV,Intel TDX,IBM Z 的安全执行和 Intel SGX。
CoCo 通常与签名和/或加密的容器镜像一起使用,这些镜像在 Enclave 内部被拉取、验证和解密。 密钥信息,比如镜像解密密钥,经由受信任的 Key Broker 服务有条件地提供给 Enclave, 这个服务在释放任何敏感信息之前验证 TEE 的硬件认证。
CoCo 有几种部署模型。由于 Kubernetes 控制平面在 TCB 之外,因此 CoCo 适合于受管理的环境。 在不支持嵌套的虚拟环境中,CoCo 可以借助 API 适配器运行,该适配器在云中启动 Pod VM。 CoCo 还可以在裸机上运行,在多租户环境中提供强大的隔离。
受管理的机密 Kubernetes
Azure 和 GCP 都支持将机密虚拟机用作其受管理的 Kubernetes 的工作节点。
这两项服务通过启用容器工作负载的内存加密,旨在提供更好的工作负载保护和安全保证。 然而,它们并没有寻求完全隔离集群或工作负载以防止服务提供者或基础设施的访问。 具体来说,它们不提供专用的机密控制平面,也不为机密集群/节点提供可验证的能力。
Azure 在其托管的 Kubernetes 服务中也启用了 机密容器。 他们支持基于 Intel SGX Enclave 和基于 AMD SEV 虚拟机 创建的机密容器。
Constellation
Constellation 是一个旨在提供最佳数据安全的 Kubernetes 引擎。 Constellation 将整个 Kubernetes 集群包装到一个机密上下文中,使其免受底层云基础设施的影响。 其中的所有内容始终是加密的,包括在内存中的运行时数据。它保护工作节点和控制平面节点。 此外,它已经与流行的 CNCF 软件(如 Cilium,用于安全网络)集成, 并提供扩展的 CSI 动程序来安全地写入数据。
Occlum 和 Gramine
Occlum 和 Gramine 是两个开源的操作系统库项目,它们允许在 SGX 信任执行环境(Enclave)中运行未经修改的应用程序。 它们是 CCC(Confidential Computing Consortium)下的成员项目, 但也存在由公司维护的类似项目和产品。通过使用这些操作系统库项目, 现有的容器化应用可以轻松转换为支持机密计算的容器。还有许多经过筛选的预构建容器可供使用。
我们现在处于哪个阶段?供应商、局限性和开源软件生态
正如我们希望你从前面的章节中看到的,机密计算是一种强大的新概念, 用于提高安全性,但我们仍处于(早期)阶段。新产品开始涌现,以利用这些独特的属性。
谷歌和微软是首批能够让客户在一个受保护的环境内运行未经修改的应用程序的机密计算服务的主要云提供商。 然而,这些服务仅限于计算,而对于机密数据库、集群网络和负载均衡器的端到端解决方案则需要自行管理。
这些技术为极其敏感的工作负载部署到云中提供了可能,并使其能够充分利用 CNCF 领域中的各种工具。
号召行动
如果你目前正在开发一个高安全性的产品,但由于法律要求在公共云上运行面临困难, 或者你希望提升你的云原生项目的隐私和安全性:请联系我们强调的所有出色项目! 每个人都渴望提高我们生态系统的安全性,而你可以在这个过程中扮演至关重要的角色。
在 CRI 运行时内验证容器镜像签名
作者: Sascha Grunert
译者: Michael Yao (DaoCloud)
Kubernetes 社区自 v1.24 版本开始对基于容器镜像的工件进行签名。在 v1.26 中,
相应的增强特性从 alpha 进阶至 beta,引入了针对二进制工件的签名。
其他项目也采用了类似的方法,为其发布版本提供镜像签名。这意味着这些项目要么使用 GitHub actions
在自己的 CI/CD 流程中创建签名,要么依赖于 Kubernetes 的镜像推广流程,
通过向 k/k8s.io 仓库提交 PR 来自动签名镜像。
使用此流程的前提要求是项目必须属于 kubernetes 或 kubernetes-sigs GitHub 组织,
这样能够利用社区基础设施将镜像推送到暂存桶中。
假设一个项目现在生成了已签名的容器镜像工件,那么如何实际验证这些签名呢? 你可以按照 Kubernetes 官方文档所述来手动验证。但是这种方式的问题在于完全没有自动化, 应仅用于测试目的。在生产环境中,sigstore policy-controller 这样的工具有助于进行自动化处理。这些工具使用自定义资源定义(CRD)提供了更高级别的 API, 并且利用集成的准入控制器和 Webhook来验证签名。
基于准入控制器的验证的一般使用流程如下:

这种架构的一个主要优点是简单:集群中的单个实例会先验证签名,然后才在节点上的容器运行时中执行镜像拉取操作, 镜像拉取是由 kubelet 触发的。这个优点也带来了分离的问题:应拉取容器镜像的节点不一定是执行准入控制的节点。 这意味着如果控制器受到攻击,那么无法在整个集群范围内强制执行策略。
解决此问题的一种方式是直接在与容器运行时接口(CRI)兼容的容器运行时中进行策略评估。 这种运行时直接连接到节点上的 kubelet,执行拉取镜像等所有任务。 CRI-O 是可用的运行时之一,将在 v1.28 中完全支持容器镜像签名验证。
容器运行时是如何工作的呢?CRI-O 会读取一个名为 policy.json 的文件,
其中包含了为容器镜像定义的所有规则。例如,你可以定义一个策略,
只允许带有以下标记或摘要的已签名镜像 quay.io/crio/signed:
{
"default": [{ "type": "reject" }],
"transports": {
"docker": {
"quay.io/crio/signed": [
{
"type": "sigstoreSigned",
"signedIdentity": { "type": "matchRepository" },
"fulcio": {
"oidcIssuer": "https://github.com/login/oauth",
"subjectEmail": "sgrunert@redhat.com",
"caData": "LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUI5ekNDQVh5Z0F3SUJBZ0lVQUxaTkFQRmR4SFB3amVEbG9Ed3lZQ2hBTy80d0NnWUlLb1pJemowRUF3TXcKS2pFVk1CTUdBMVVFQ2hNTWMybG5jM1J2Y21VdVpHVjJNUkV3RHdZRFZRUURFd2h6YVdkemRHOXlaVEFlRncweQpNVEV3TURjeE16VTJOVGxhRncwek1URXdNRFV4TXpVMk5UaGFNQ294RlRBVEJnTlZCQW9UREhOcFozTjBiM0psCkxtUmxkakVSTUE4R0ExVUVBeE1JYzJsbmMzUnZjbVV3ZGpBUUJnY3Foa2pPUFFJQkJnVXJnUVFBSWdOaUFBVDcKWGVGVDRyYjNQUUd3UzRJYWp0TGszL09sbnBnYW5nYUJjbFlwc1lCcjVpKzR5bkIwN2NlYjNMUDBPSU9aZHhleApYNjljNWlWdXlKUlErSHowNXlpK1VGM3VCV0FsSHBpUzVzaDArSDJHSEU3U1hyazFFQzVtMVRyMTlMOWdnOTJqCll6QmhNQTRHQTFVZER3RUIvd1FFQXdJQkJqQVBCZ05WSFJNQkFmOEVCVEFEQVFIL01CMEdBMVVkRGdRV0JCUlkKd0I1ZmtVV2xacWw2ekpDaGt5TFFLc1hGK2pBZkJnTlZIU01FR0RBV2dCUll3QjVma1VXbFpxbDZ6SkNoa3lMUQpLc1hGK2pBS0JnZ3Foa2pPUFFRREF3TnBBREJtQWpFQWoxbkhlWFpwKzEzTldCTmErRURzRFA4RzFXV2cxdENNCldQL1dIUHFwYVZvMGpoc3dlTkZaZ1NzMGVFN3dZSTRxQWpFQTJXQjlvdDk4c0lrb0YzdlpZZGQzL1Z0V0I1YjkKVE5NZWE3SXgvc3RKNVRmY0xMZUFCTEU0Qk5KT3NRNHZuQkhKCi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0="
},
"rekorPublicKeyData": "LS0tLS1CRUdJTiBQVUJMSUMgS0VZLS0tLS0KTUZrd0V3WUhLb1pJemowQ0FRWUlLb1pJemowREFRY0RRZ0FFMkcyWSsydGFiZFRWNUJjR2lCSXgwYTlmQUZ3cgprQmJtTFNHdGtzNEwzcVg2eVlZMHp1ZkJuaEM4VXIvaXk1NUdoV1AvOUEvYlkyTGhDMzBNOStSWXR3PT0KLS0tLS1FTkQgUFVCTElDIEtFWS0tLS0tCg=="
}
]
}
}
}
CRI-O 必须被启动才能将策略用作全局的可信源:
> sudo crio --log-level debug --signature-policy ./policy.json
CRI-O 现在可以在验证镜像签名的同时拉取镜像。例如,可以使用 crictl(cri-tools)
来完成此操作:
> sudo crictl -D pull quay.io/crio/signed
DEBU[…] get image connection
DEBU[…] PullImageRequest: &PullImageRequest{Image:&ImageSpec{Image:quay.io/crio/signed,Annotations:map[string]string{},},Auth:nil,SandboxConfig:nil,}
DEBU[…] PullImageResponse: &PullImageResponse{ImageRef:quay.io/crio/signed@sha256:18b42e8ea347780f35d979a829affa178593a8e31d90644466396e1187a07f3a,}
Image is up to date for quay.io/crio/signed@sha256:18b42e8ea347780f35d979a829affa178593a8e31d90644466396e1187a07f3a
CRI-O 的调试日志也会表明签名已成功验证:
DEBU[…] IsRunningImageAllowed for image docker:quay.io/crio/signed:latest
DEBU[…] Using transport "docker" specific policy section quay.io/crio/signed
DEBU[…] Reading /var/lib/containers/sigstore/crio/signed@sha256=18b42e8ea347780f35d979a829affa178593a8e31d90644466396e1187a07f3a/signature-1
DEBU[…] Looking for sigstore attachments in quay.io/crio/signed:sha256-18b42e8ea347780f35d979a829affa178593a8e31d90644466396e1187a07f3a.sig
DEBU[…] GET https://quay.io/v2/crio/signed/manifests/sha256-18b42e8ea347780f35d979a829affa178593a8e31d90644466396e1187a07f3a.sig
DEBU[…] Content-Type from manifest GET is "application/vnd.oci.image.manifest.v1+json"
DEBU[…] Found a sigstore attachment manifest with 1 layers
DEBU[…] Fetching sigstore attachment 1/1: sha256:8276724a208087e73ae5d9d6e8f872f67808c08b0acdfdc73019278807197c45
DEBU[…] Downloading /v2/crio/signed/blobs/sha256:8276724a208087e73ae5d9d6e8f872f67808c08b0acdfdc73019278807197c45
DEBU[…] GET https://quay.io/v2/crio/signed/blobs/sha256:8276724a208087e73ae5d9d6e8f872f67808c08b0acdfdc73019278807197c45
DEBU[…] Requirement 0: allowed
DEBU[…] Overall: allowed
策略中定义的 oidcIssuer 和 subjectEmail 等所有字段都必须匹配,
而 fulcio.caData 和 rekorPublicKeyData 是来自上游 fulcio(OIDC PKI)
和 rekor(透明日志) 实例的公钥。
这意味着如果你现在将策略中的 subjectEmail 作废,例如更改为 wrong@mail.com:
> jq '.transports.docker."quay.io/crio/signed"[0].fulcio.subjectEmail = "wrong@mail.com"' policy.json > new-policy.json
> mv new-policy.json policy.json
然后移除镜像,因为此镜像已存在于本地:
> sudo crictl rmi quay.io/crio/signed
现在当你拉取镜像时,CRI-O 将报错所需的 email 是错的:
> sudo crictl pull quay.io/crio/signed
FATA[…] pulling image: rpc error: code = Unknown desc = Source image rejected: Required email wrong@mail.com not found (got []string{"sgrunert@redhat.com"})
你还可以对未签名的镜像进行策略测试。为此,你需要将键 quay.io/crio/signed
修改为类似 quay.io/crio/unsigned:
> sed -i 's;quay.io/crio/signed;quay.io/crio/unsigned;' policy.json
如果你现在拉取容器镜像,CRI-O 将报错此镜像不存在签名:
> sudo crictl pull quay.io/crio/unsigned
FATA[…] pulling image: rpc error: code = Unknown desc = SignatureValidationFailed: Source image rejected: A signature was required, but no signature exists
需要强调的是,CRI-O 将签名中的 .critical.identity.docker-reference 字段与镜像仓库进行匹配。
例如,如果你要验证镜像 registry.k8s.io/kube-apiserver-amd64:v1.28.0-alpha.3,
则相应的 docker-reference 须是 registry.k8s.io/kube-apiserver-amd64:
> cosign verify registry.k8s.io/kube-apiserver-amd64:v1.28.0-alpha.3 \
--certificate-identity krel-trust@k8s-releng-prod.iam.gserviceaccount.com \
--certificate-oidc-issuer https://accounts.google.com \
| jq -r '.[0].critical.identity."docker-reference"'
…
registry.k8s.io/kubernetes/kube-apiserver-amd64
Kubernetes 社区引入了 registry.k8s.io 作为各种镜像仓库的代理镜像。
在 kpromo v4.0.2 版本发布之前,镜像已使用实际镜像签名而不是使用
registry.k8s.io 签名:
> cosign verify registry.k8s.io/kube-apiserver-amd64:v1.28.0-alpha.2 \
--certificate-identity krel-trust@k8s-releng-prod.iam.gserviceaccount.com \
--certificate-oidc-issuer https://accounts.google.com \
| jq -r '.[0].critical.identity."docker-reference"'
…
asia-northeast2-docker.pkg.dev/k8s-artifacts-prod/images/kubernetes/kube-apiserver-amd64
将 docker-reference 更改为 registry.k8s.io 使最终用户更容易验证签名,
因为他们不需要知道所使用的底层基础设施的详细信息。设置镜像签名身份的特性已通过
sign --sign-container-identity 标志添加到 cosign,并将成为即将发布的版本的一部分。
最近在 Kubernetes 中添加了镜像拉取错误码 SignatureValidationFailed,
将从 v1.28 版本开始可用。这个错误码允许最终用户直接从 kubectl CLI 了解镜像拉取失败的原因。
例如,如果你使用要求对 quay.io/crio/unsigned 进行签名的策略同时运行 CRI-O 和 Kubernetes,
那么 Pod 的定义如下:
apiVersion: v1
kind: Pod
metadata:
name: pod
spec:
containers:
- name: container
image: quay.io/crio/unsigned
将在应用 Pod 清单时造成 SignatureValidationFailed 错误:
> kubectl apply -f pod.yaml
pod/pod created
> kubectl get pods
NAME READY STATUS RESTARTS AGE
pod 0/1 SignatureValidationFailed 0 4s
> kubectl describe pod pod | tail -n8
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 58s default-scheduler Successfully assigned default/pod to 127.0.0.1
Normal BackOff 22s (x2 over 55s) kubelet Back-off pulling image "quay.io/crio/unsigned"
Warning Failed 22s (x2 over 55s) kubelet Error: ImagePullBackOff
Normal Pulling 9s (x3 over 58s) kubelet Pulling image "quay.io/crio/unsigned"
Warning Failed 6s (x3 over 55s) kubelet Failed to pull image "quay.io/crio/unsigned": SignatureValidationFailed: Source image rejected: A signature was required, but no signature exists
Warning Failed 6s (x3 over 55s) kubelet Error: SignatureValidationFailed
这种整体行为提供了更符合 Kubernetes 原生体验的方式,并且不依赖于在集群中安装的第三方软件。
还有一些特殊情况需要考虑:例如,如果你希望像策略控制器那样允许按命名空间设置策略,怎么办?
好消息是,CRI-O 在 v1.28 版本中即将推出这个特性!CRI-O 将支持 --signature-policy-dir /
signature_policy_dir 选项,为命名空间隔离的签名策略的 Pod 定义根路径。
这意味着 CRI-O 将查找该路径,并组装一个类似 <SIGNATURE_POLICY_DIR>/<NAMESPACE>.json
的策略,在镜像拉取时如果存在则使用该策略。如果(通过沙盒配置)
在镜像拉取时未提供 Pod 命名空间,或者串接的路径不存在,则 CRI-O 的全局策略将用作后备。
另一个需要考虑的特殊情况对于容器运行时中正确的签名验证至关重要:kubelet 仅在磁盘上不存在镜像时才调用容器镜像拉取。这意味着来自 Kubernetes 命名空间 A 的不受限策略可以允许拉取一个镜像,而命名空间 B 则无法强制执行该策略, 因为它已经存在于节点上了。最后,CRI-O 必须在容器创建时验证策略,而不仅仅是在镜像拉取时。 这一事实使情况变得更加复杂,因为 CRI 在容器创建时并没有真正传递用户指定的镜像引用, 而是传递已经解析过的镜像 ID 或摘要。对 CRI 进行小改动 有助于解决这个问题。
现在一切都发生在容器运行时中,大家必须维护和定义策略以提供良好的用户体验。 策略控制器的 CRD 非常出色,我们可以想象集群中的一个守护进程可以按命名空间为 CRI-O 编写策略。 这将使任何额外的回调过时,并将验证镜像签名的责任移交给实际拉取镜像的实例。 我已经评估了在纯 Kubernetes 中实现更好的容器镜像签名验证的其他可能途径, 但我没有找到一个很好的原生 API 解决方案。这意味着我相信 CRD 是正确的方法, 但用户仍然需要一个实际有作用的实例。
感谢阅读这篇博文!如果你对更多内容感兴趣,想提供反馈或寻求帮助,请随时通过 Slack (#crio) 或 SIG Node 邮件列表直接联系我。
dl.k8s.io 采用内容分发网络(CDN)
作者:Arnaud Meukam (VMware), Hannah Aubry (Fast Forward), Frederico Muñoz (SAS Institute)
译者:Xin Li (Daocloud)
我们很高兴地宣布,官方 Kubernetes 二进制文件的主页 dl.k8s.io 很快将由 Fastly 提供支持。
Fastly 以其高性能内容分发网络(CDN)而闻名, 该网络旨在全球范围内快速可靠地分发内容。凭借其强大的网络,Fastly 将帮助我们实现比以往更快、更可靠地向用户分发官方 Kubernetes 二进制文件。
使用 Fastly 是在经过广泛的评估过程后做出的决定, 在该过程中我们仔细评估了几个潜在的内容分发网络提供商。最终,我们选择 Fastly 是因为他们对开放互联网的承诺以及在为一些著名的开源项目(通过他们的 Fast Forward 计划)提供快速和安全的数字体验方面的良好记录。
关于本次更改你需要了解的信息
- 7 月 24 日星期一,与 dl.k8s.io 域名关联的 IP 地址和后端存储将发生变化。
- 由于域名将保持不变,因此更改不会影响绝大多数用户。
- 如果你限制对特定 IP 范围的访问,则对 dl.k8s.io 域的访问可能会停止工作。
如果你认为你可能会受到影响或想了解有关此次更改的更多信息,请继续阅读。
我们为什么要进行此更改
官方 Kubernetes 二进制文件网站 dl.k8s.io 被全世界成千上万的用户使用, 目前每月提供超过 5 PB 的二进制文件服务。本次更改将通过充分利用全球 CDN 来改善对这些资源的访问。
这只影响 dl.k8s.io,还是其他域也受到影响?
只有 dl.k8s.io 会受到本次变更的影响。
我公司规定了允许我们访问的域名,此更改会影响域名吗?
不,域名(dl.k8s.io)将保持不变:无需更改,不会影响对 Kubernetes
发布二进制文件站点的访问。
我的公司使用某种形式的 IP 过滤,此更改会影响对站点的访问吗?
如果已经存在基于 IP 的过滤,则当新 IP 地址变为活动状态时,对站点的访问可能会受到影响。
如果我的公司不使用 IP 地址来限制网络流量,我们需要做些什么吗?
不,切换到 CDN 的过程应该是透明的。
会有双运行期吗?
不,这是切换。 但是,你现在可以测试你的网络,检查它们是否可以从 Fastly
路由到新的公共 IP 地址。 你应该在 7 月 24 日之前将新 IP 添加到你网络的 allowlist(白名单)中。
切换完成后,确保你的网络使用新的 IP 地址连接到 dl.k8s.io 服务。
新 IP 地址是什么?
如果你需要管理下载允许列表,你可以从 Fastly API 中获取需要匹配的范围, JSON 格式地址:公共 IP 地址范围。
你不需要任何凭据即可下载该范围列表。
推荐哪些后续操作?
如果你已经有了基于 IP 的过滤,我们建议你在 7 月 24 日之前采取以下行动:
- 将新的 IP 地址添加到你的白名单。
- 对你的网络/防火墙进行测试,以确保你的网络可以路由到新的 IP 地址。
进行更改后,我们建议仔细检查 HTTP 调用是否正在使用新 IP 地址访问 dl.k8s.io。
切换后发现异常怎么办?
如果你在二进制文件下载过程中遇到任何异常, 请提交 Issue。
使用 OCI 工件为 seccomp、SELinux 和 AppArmor 分发安全配置文件
作者: Sascha Grunert
译者: Michael Yao (DaoCloud)
Security Profiles Operator (SPO) 使得在 Kubernetes 中管理 seccomp、SELinux 和 AppArmor 配置文件变得更加容易。 它允许集群管理员在预定义的自定义资源 YAML 中定义配置文件,然后由 SPO 分发到整个集群中。 安全配置文件的修改和移除也由 Operator 以同样的方式进行管理,但这只是其能力的一小部分。
SPO 的另一个核心特性是能够组合 seccomp 配置文件。这意味着用户可以在 YAML
规约中定义 baseProfileName,然后 Operator 会自动解析并组合系统调用规则。
如果基本配置文件有另一个 baseProfileName,那么 Operator 将以递归方式解析配置文件到一定深度。
常见的使用场景是为低级容器运行时(例如 runc 或 crun)定义基本配置文件,
在这些配置文件中包含各种情况下运行容器所需的系统调用。另外,应用开发人员可以为其标准分发容器定义
seccomp 基本配置文件,并在其上组合针对应用逻辑的专用配置文件。
这样开发人员就可以专注于维护更简单且范围限制为应用逻辑的 seccomp 配置文件,
而不需要考虑整个基础设施的设置。
但是如何维护这些基本配置文件呢? 例如,运行时所需的系统调用数量可能会像主应用一样在其发布周期内发生变化。 基本配置文件必须在同一集群中可用,否则主 seccomp 配置文件将无法部署。 这意味着这些基本配置文件与主应用配置文件紧密耦合,因此违背了基本配置文件的核心理念。 将基本配置文件作为普通文件分发和管理感觉像是需要解决的额外负担。
OCI 工件成为救命良方
Security Profiles Operator 的 v0.8.0 版本支持将基本配置文件作为 OCI 工件进行管理!将 OCI 工件假想为轻量级容器镜像,采用与镜像相同的方式在各层中存储文件, 但没有要执行的进程。这些工件可以用于像普通容器镜像一样在兼容的镜像仓库中存储安全配置文件。 这意味着这些工件可以被版本化、作用于命名空间并类似常规容器镜像一样添加注解。
若要查看具体的工作方式,可以在 seccomp 配置文件 CRD 内以前缀 oci://
指定 baseProfileName,例如:
apiVersion: security-profiles-operator.x-k8s.io/v1beta1
kind: SeccompProfile
metadata:
name: test
spec:
defaultAction: SCMP_ACT_ERRNO
baseProfileName: oci://ghcr.io/security-profiles/runc:v1.1.5
syscalls:
- action: SCMP_ACT_ALLOW
names:
- uname
Operator 将负责使用 oras 拉取内容,并验证工件的 sigstore (cosign) 签名。
如果某些工件未经签名,则 SPO 将拒绝它们。随后生成的配置文件 test 将包含来自远程
runc 配置文件的所有基本系统调用加上额外允许的 uname 系统调用。
你还可以通过摘要(SHA256)来引用基本配置文件,使要被拉取的工件更为确定,
例如通过引用 oci://ghcr.io/security-profiles/runc@sha256: 380…。
Operator 在内部缓存已拉取的工件,最多可缓存 1000 个配置文件 24 小时, 这意味着如果缓存已满、Operator 守护进程重启或超出给定时段后这些工件将被刷新。
因为总体生成的系统调用对用户不可见
(我只列出了 SeccompProfile 中的 baseProfileName,而没有列出系统调用本身),
所以我为该 SeccompProfile 的最终 syscalls 添加了额外的注解。
以下是我注解后的 SeccompProfile:
> kubectl describe seccompprofile test
Name: test
Namespace: security-profiles-operator
Labels: spo.x-k8s.io/profile-id=SeccompProfile-test
Annotations: syscalls:
[{"names":["arch_prctl","brk","capget","capset","chdir","clone","close",...
API Version: security-profiles-operator.x-k8s.io/v1beta1
SPO 维护者们作为 “Security Profiles” GitHub 组织 的成员提供所有公开的基本配置文件。
管理 OCI 安全配置文件
好的,官方的 SPO 提供了许多基本配置文件,但是我如何定义自己的配置文件呢? 首先,我们必须选择一个可用的镜像仓库。有许多镜像仓库都已支持 OCI 工件:
- CNCF Distribution
- Azure Container Registry
- Amazon Elastic Container Registry
- Google Artifact Registry
- GitHub Packages container registry
- Docker Hub
- Zot Registry
Security Profiles Operator 交付一个新的名为 spoc 的命令行界面,
这是一个用于管理 OCI 配置文件的小型辅助工具,该工具提供的各项能力不在这篇博文的讨论范围内。
但 spoc push 命令可以用于将安全配置文件推送到镜像仓库:
> export USERNAME=my-user
> export PASSWORD=my-pass
> spoc push -f ./examples/baseprofile-crun.yaml ghcr.io/security-profiles/crun:v1.8.3
16:35:43.899886 Pushing profile ./examples/baseprofile-crun.yaml to: ghcr.io/security-profiles/crun:v1.8.3
16:35:43.899939 Creating file store in: /tmp/push-3618165827
16:35:43.899947 Adding profile to store: ./examples/baseprofile-crun.yaml
16:35:43.900061 Packing files
16:35:43.900282 Verifying reference: ghcr.io/security-profiles/crun:v1.8.3
16:35:43.900310 Using tag: v1.8.3
16:35:43.900313 Creating repository for ghcr.io/security-profiles/crun
16:35:43.900319 Using username and password
16:35:43.900321 Copying profile to repository
16:35:46.976108 Signing container image
Generating ephemeral keys...
Retrieving signed certificate...
Note that there may be personally identifiable information associated with this signed artifact.
This may include the email address associated with the account with which you authenticate.
This information will be used for signing this artifact and will be stored in public transparency logs and cannot be removed later.
By typing 'y', you attest that you grant (or have permission to grant) and agree to have this information stored permanently in transparency logs.
Your browser will now be opened to:
https://oauth2.sigstore.dev/auth/auth?access_type=…
Successfully verified SCT...
tlog entry created with index: 16520520
Pushing signature to: ghcr.io/security-profiles/crun
你可以看到该工具自动签署工件并将 ./examples/baseprofile-crun.yaml 推送到镜像仓库中,
然后直接可以在 SPO 中使用此文件。如果需要验证用户名和密码,则可以使用 --username、
-u 标志或导出 USERNAME 环境变量。要设置密码,可以导出 PASSWORD 环境变量。
采用 KEY:VALUE 的格式多次使用 --annotations / -a 标志,
可以为安全配置文件添加自定义注解。目前这些对安全配置文件没有影响,
但是在后续某个阶段,Operator 的其他特性可能会依赖于它们。
spoc 客户端还可以从兼容 OCI 工件的镜像仓库中拉取安全配置文件。
要执行此操作,只需运行 spoc pull:
> spoc pull ghcr.io/security-profiles/runc:v1.1.5
16:32:29.795597 Pulling profile from: ghcr.io/security-profiles/runc:v1.1.5
16:32:29.795610 Verifying signature
Verification for ghcr.io/security-profiles/runc:v1.1.5 --
The following checks were performed on each of these signatures:
- Existence of the claims in the transparency log was verified offline
- The code-signing certificate was verified using trusted certificate authority certificates
[{"critical":{"identity":{"docker-reference":"ghcr.io/security-profiles/runc"},…}}]
16:32:33.208695 Creating file store in: /tmp/pull-3199397214
16:32:33.208713 Verifying reference: ghcr.io/security-profiles/runc:v1.1.5
16:32:33.208718 Creating repository for ghcr.io/security-profiles/runc
16:32:33.208742 Using tag: v1.1.5
16:32:33.208743 Copying profile from repository
16:32:34.119652 Reading profile
16:32:34.119677 Trying to unmarshal seccomp profile
16:32:34.120114 Got SeccompProfile: runc-v1.1.5
16:32:34.120119 Saving profile in: /tmp/profile.yaml
现在可以在 /tmp/profile.yaml 或 --output-file / -o 所指定的输出文件中找到该配置文件。
我们可以像 spoc push 一样指定用户名和密码。
spoc 使得以 OCI 工件的形式管理安全配置文件变得非常容易,这些 OCI 工件可以由 Operator 本身直接使用。
本文简要介绍了通过 Security Profiles Operator 能够达成的各种最新可能性! 如果你有兴趣了解更多,无论是提出反馈还是寻求帮助, 请通过 Slack (#security-profiles-operator) 或邮件列表直接与我们联系。
在边缘上玩转 seccomp 配置文件
作者: Sascha Grunert
译者: Michael Yao (DaoCloud)
[Security Profiles Operator (SPO)][spo] 是一个功能丰富的 Kubernetes [operator][operator], 相比以往可以简化 seccomp、SELinux 和 AppArmor 配置文件的管理。 从头开始记录这些配置文件是该 Operator 的关键特性之一,这通常涉及与大型 CI/CD 系统集成。 在边缘场景中测试 Operator 的记录能力是 SPO 的最新开发工作之一, 非常有助于轻松玩转 seccomp 配置文件。
使用 spoc record 记录 seccomp 配置文件
v0.8.0 版本的 Security Profiles Operator 附带一个名为 spoc 的全新命令行接口,
是一个能够用来记录和回放 seccomp 配置文件的工具,该工具还有一些其他能力不在这篇博文的讨论范围内。
记录 seccomp 配置文件需要执行一个二进制文件,这个二进制文件可以是一个仅只调用
uname(2) 的简单 Golang 应用程序:
package main
import (
"syscall"
)
func main() {
utsname := syscall.Utsname{}
if err := syscall.Uname(&utsname); err != nil {
panic(err)
}
}
可通过以下命令从代码构建一个二进制文件:
> go build -o main main.go
> ldd ./main
not a dynamic executable
现在可以从 GitHub 下载最新的 spoc 二进制文件,
并使用它在 Linux 上运行应用程序:
> sudo ./spoc record ./main
10:08:25.591945 Loading bpf module
10:08:25.591958 Using system btf file
libbpf: loading object 'recorder.bpf.o' from buffer
…
libbpf: prog 'sys_enter': relo #3: patched insn #22 (ALU/ALU64) imm 16 -> 16
10:08:25.610767 Getting bpf program sys_enter
10:08:25.610778 Attaching bpf tracepoint
10:08:25.611574 Getting syscalls map
10:08:25.611582 Getting pid_mntns map
10:08:25.613097 Module successfully loaded
10:08:25.613311 Processing events
10:08:25.613693 Running command with PID: 336007
10:08:25.613835 Received event: pid: 336007, mntns: 4026531841
10:08:25.613951 No container ID found for PID (pid=336007, mntns=4026531841, err=unable to find container ID in cgroup path)
10:08:25.614856 Processing recorded data
10:08:25.614975 Found process mntns 4026531841 in bpf map
10:08:25.615110 Got syscalls: read, close, mmap, rt_sigaction, rt_sigprocmask, madvise, nanosleep, clone, uname, sigaltstack, arch_prctl, gettid, futex, sched_getaffinity, exit_group, openat
10:08:25.615195 Adding base syscalls: access, brk, capget, capset, chdir, chmod, chown, close_range, dup2, dup3, epoll_create1, epoll_ctl, epoll_pwait, execve, faccessat2, fchdir, fchmodat, fchown, fchownat, fcntl, fstat, fstatfs, getdents64, getegid, geteuid, getgid, getpid, getppid, getuid, ioctl, keyctl, lseek, mkdirat, mknodat, mount, mprotect, munmap, newfstatat, openat2, pipe2, pivot_root, prctl, pread64, pselect6, readlink, readlinkat, rt_sigreturn, sched_yield, seccomp, set_robust_list, set_tid_address, setgid, setgroups, sethostname, setns, setresgid, setresuid, setsid, setuid, statfs, statx, symlinkat, tgkill, umask, umount2, unlinkat, unshare, write
10:08:25.616293 Wrote seccomp profile to: /tmp/profile.yaml
10:08:25.616298 Unloading bpf module
我必须以 root 用户身份执行 spoc,因为它将在内部通过复用 Security Profiles Operator
自身的相同代码,运行一个 ebpf 程序。
我可以看到 bpf 模块已成功加载,并且 spoc 已将所需的跟踪点附加到该模块。
随后该模块将使用其挂载命名空间跟踪主应用程序并处理记录的系统调用数据。
ebpf 程序的本质是监视整个内核的上下文,这意味着 spoc 跟踪系统的所有系统调用,但不会干涉其执行过程。
这些日志表明 spoc 发现了包括 uname 在内的 read、close、mmap 等系统调用。
除 uname 之外的所有系统调用都来自 Golang 运行时及其垃圾回收,这已经为我们演示中的简单应用增加了开销。
我还可以从日志行 Adding base syscalls: … 中看到 spoc 将一堆基本系统调用添加到了生成的配置文件中。
这些系统调用由 OCI 运行时(如 runc 或 crun)使用以便能够运行容器。
这意味着 spoc 可用于记录可直接被容器化的 seccomp 配置文件。
这种行为可以通过在 spoc 中使用 --no-base-syscalls/-n 禁用,或通过
--base-syscalls/-b 命令行标志进行自定义。这对于使用除了 crun 和 runc 之外的不同 OCI
运行时或者如果我只想记录应用的 seccomp 配置文件并将其与另一个基本配置文件组合时非常有帮助。
生成的配置文件现在位于 /tmp/profile.yaml,
但可以使用 --output-file value/-o 标志更改默认位置:
> cat /tmp/profile.yaml
apiVersion: security-profiles-operator.x-k8s.io/v1beta1
kind: SeccompProfile
metadata:
creationTimestamp: null
name: main
spec:
architectures:
- SCMP_ARCH_X86_64
defaultAction: SCMP_ACT_ERRNO
syscalls:
- action: SCMP_ACT_ALLOW
names:
- access
- arch_prctl
- brk
- …
- uname
- …
status: {}
seccomp 配置文件 CRD 可直接与 Security Profiles Operator 一起使用,统一在 Kubernetes 中进行管理。
spoc 还可以通过使用 --type/-t raw-seccomp 标志生成原始的 seccomp 配置文件(格式为 JSON):
> sudo ./spoc record --type raw-seccomp ./main
…
52.628827 Wrote seccomp profile to: /tmp/profile.json
> jq . /tmp/profile.json
{
"defaultAction": "SCMP_ACT_ERRNO",
"architectures": ["SCMP_ARCH_X86_64"],
"syscalls": [
{
"names": ["access", "…", "write"],
"action": "SCMP_ACT_ALLOW"
}
]
}
实用程序 spoc record 允许我们直接在任何能够在内核中运行 ebpf 代码的 Linux
系统上记录复杂的 seccomp 配置文件。但它还可以做更多事情:
例如修改 seccomp 配置文件并使用 spoc run 进行测试。
使用 spoc run 运行 seccomp 配置文件
spoc 还能够使用 seccomp 配置文件来运行二进制文件,轻松测试对其所做的任何修改。
要执行此操作,只需运行:
> sudo ./spoc run ./main
10:29:58.153263 Reading file /tmp/profile.yaml
10:29:58.153311 Assuming YAML profile
10:29:58.154138 Setting up seccomp
10:29:58.154178 Load seccomp profile
10:29:58.154189 Starting audit log enricher
10:29:58.154224 Enricher reading from file /var/log/audit/audit.log
10:29:58.155356 Running command with PID: 437880
>
看起来应用程序已成功退出,这是符合预期的,因为我尚未修改先前记录的配置文件。
我还可以使用 --profile/-p 标志指定配置文件的自定义位置,但这并不是必需的,
因为我没有修改默认输出位置。spoc 将自动确定它是基于原始的(JSON)还是基于 CRD 的
(YAML)seccomp 配置文件,然后将其应用于该进程。
Security Profiles Operator 支持 log enricher 特性,
通过解析审计日志提供与 seccomp 相关的额外信息。
spoc run 以同样的方式使用 enricher 向最终用户提供更多数据以调试 seccomp 配置文件。
现在我不得不修改配置文件来查看输出中有价值的信息。
例如,我可以移除允许的 uname 系统调用:
> jq 'del(.syscalls[0].names[] | select(. == "uname"))' /tmp/profile.json > /tmp/no-uname-profile.json
然后尝试用新的配置文件 /tmp/no-uname-profile.json 来运行:
> sudo ./spoc run -p /tmp/no-uname-profile.json ./main
10:39:12.707798 Reading file /tmp/no-uname-profile.json
10:39:12.707892 Setting up seccomp
10:39:12.707920 Load seccomp profile
10:39:12.707982 Starting audit log enricher
10:39:12.707998 Enricher reading from file /var/log/audit/audit.log
10:39:12.709164 Running command with PID: 480512
panic: operation not permitted
goroutine 1 [running]:
main.main()
/path/to/main.go:10 +0x85
10:39:12.713035 Unable to run: launch runner: wait for command: exit status 2
好的,这符合预期!应用的 seccomp 配置文件阻止了 uname 系统调用,导致出现
"operation not permitted" 错误。此错误提示过于宽泛,没有提供关于 seccomp 阻止了什么的任何提示。
通常情况下,如果 seccomp 禁止某个系统调用,很难预测应用程序会做出什么行为。
可能应用程序像这个简单演示一样终止,但也可能导致奇怪的异常行为使得应用程序根本无法停止。
现在,如果我将配置文件的默认 seccomp 操作从 SCMP_ACT_ERRNO 更改为 SCMP_ACT_LOG,就像这样:
> jq '.defaultAction = "SCMP_ACT_LOG"' /tmp/no-uname-profile.json > /tmp/no-uname-profile-log.json
那么 log enricher 将提示我们 uname 系统调用在使用 spoc run 时被阻止:
> sudo ./spoc run -p /tmp/no-uname-profile-log.json ./main
10:48:07.470126 Reading file /tmp/no-uname-profile-log.json
10:48:07.470234 Setting up seccomp
10:48:07.470245 Load seccomp profile
10:48:07.470302 Starting audit log enricher
10:48:07.470339 Enricher reading from file /var/log/audit/audit.log
10:48:07.470889 Running command with PID: 522268
10:48:07.472007 Seccomp: uname (63)
应用程序现在不会再终止,但 seccomp 将行为记录到 /var/log/audit/audit.log 中,
而 spoc 会解析数据以将其直接与我们的程序相关联。将日志消息生成到审计子系统中会带来巨大的性能开销,
在生产系统中应小心处理。当在生产环境中以审计模式运行不受信任的应用时,也会带来安全风险。
本文的演示希望让你了解如何使用 Security Profiles Operator
各项特性所赋予的全新辅助工具来调试应用程序的 seccomp 配置文件问题。
spoc 是一个灵活且可移植的二进制文件,适用于资源有限的边缘场景,
甚至是 Kubernetes 本身可能无法提供其全部功能的场景中。
感谢阅读这篇博文!如果你有兴趣了解更多,想提出反馈或寻求帮助,请通过 Slack (#security-profiles-operator) 或邮件列表直接与我们联系。
Kubernetes 1.27: KMS V2 进入 Beta 阶段
作者: Anish Ramasekar, Mo Khan, and Rita Zhang (Microsoft)
译者: Xin Li (DaoCloud)
在 Kubernetes 1.27 中,我们(SIG Auth)将密钥管理服务(KMS)v2 API 带入 Beta 阶段。
KMS 是什么?
保护 Kubernetes 集群时首先要考虑的事情之一是加密静态的 etcd 数据。 KMS 为供应商提供了一个接口,以便利用存储在外部密钥服务中的密钥来执行此加密。
KMS v1 自 1.10 版以来一直是 Kubernetes 的一项功能特性,该特性从 v1.12 版开始处于 Beta 阶段。KMS v2 在 v1.25 中作为 Alpha 特性引入。
Note
KMS v2 API 与实现在 v1.25 的 Alpha 版本和 v1.27 的 Beta 版本之间发生了一些不兼容的变化。 自上一篇博文撰写以来, KMS v2 的设计发生了变化,与本博文中的设计不兼容。如果尝试从启用了 Alpha 特性的旧版本升级到 Beta 版本,将会导致数据丢失。
v2beta1 有什么新内容?
KMS 加密驱动使用信封加密方式来加密 etcd 中的数据,使用数据加密密钥(DEK)对数据进行加密。 DEK 使用在远程 KMS 中存储和管理的密钥加密密钥(KEK)进行加密。 使用 KMS v1,每次加密都会生成一个新的 DEK。 使用 KMS v2,只有在服务器启动时且 KMS 插件通知 API 服务器发生 KEK 轮换时才会生成新的 DEK。
警告
如果你运行的是虚拟机(VM)节点,其中启用此特性的节点使用了 VM 的状态存储, 则不得使用 KMS v2。
对于 KMS v2,API 服务器使用带有 12 字节随机数(8 字节原子计数器和 4 字节随机数据)的 AES-GCM 进行加密。在保存和恢复虚拟机时,可能会出现以下问题:
- 如果 VM 的保存状态不一致或其恢复不正确,计数器值可能会丢失或损坏。 这可能会导致系统再次使用同一计数器值,进而在两个不同的消息中使用相同的随机数。
- 如果 VM 恢复到以前的状态,则计数器值可能会设置回其以前的值, 导致再次使用相同的随机数。
虽然这两种情况都可以通过 4 字节随机数部分缓解,但这仍可能会危及加密的安全性。
时序图
加密请求

解密请求

状态请求

生成数据加密密钥(DKE)

性能改进
在 KMS v2 中,我们对 KMS 加密提供程序的性能进行了重大改进。对于 KMS v1, 每次加密都会生成一个新的 DEK。这意味着对于每个写入请求,API 服务器都会调用 KMS 插件以使用远程 KEK 加密 DEK。为避免每个读取请求都会调用 KMS 插件, API 服务器必须缓存 DEK。当 API 服务器重新启动时, 它必须根据缓存大小为 etcd 存储中的每个 DEK 调用 KMS 插件来填充缓存。 这对 API 服务器来说是一个很大的开销。使用 KMS v2,API 服务器在启动时生成一个 DEK 并将其缓存。 API 服务器还调用 KMS 插件以使用远程 KEK 加密 DEK。这是启动时和 KEK 轮换时的一次性调用。 在此之后,API 服务器使用缓存的 DEK 来加密资源。这样做减少了对 KMS 插件的调用次数, 并改善了 API 服务器请求的整体延迟。
我们进行了一项创建 12,000 个 Secret 的测试,并检测了 API
服务器加密资源所花费的时间。使用的指标是
apiserver_storage_transformation_duration_seconds。
对于 KMS v1,测试在具有 2 个节点的托管 Kubernetes v1.25 集群上运行。
测试期间集群上没有额外的负载。对于 KMS v2,
测试是在具有以下集群配置的
Kubernetes CI 环境中运行的
| KMS 驱动 | 95 分位请求所用时间 |
|---|---|
| KMS v1 | 160ms |
| KMS v2 | 80μs |
结果表明,KMS v2 加密驱动比 KMS v1 快三个数量级。
下一步计划
对于 Kubernetes v1.28,我们预计该功能仍处于测试阶段。在即将发布的版本中,我们将致力于:
- 修改加密程序以消除对 VM 状态存储的限制。
- 针对密钥轮换,修改 Kubernetes REST API 以实现更强大的特性。
- 处理无法解密的资源,更多细节参考:KEP
你可以通过阅读使用 KMS 驱动进行数据加密, 还可以关注 KEP 来跟踪即将发布的 Kubernetes 版本进度。
行动号召
在这篇博文中,我们介绍了 Kubernetes v1.27 中对 KMS 加密驱动所做的改进。 我们还讨论了新的 KMS v2 API 及其工作原理。我们很想听听你对此功能的反馈, 特别是,我们希望 Kubernetes KMS 插件实现者在构建与这个新 API 的集成过程中得到反馈。 请通过 Kubernetes Slack 上的 #sig-auth-kms-dev 频道与我们联系。
如何参与
如果你有兴趣参与此功能的开发、分享反馈或参与任何其他正在进行的 SIG Auth 项目, 请联系 Kubernetes Slack 上的 [#sig-auth](https://kubernetes.slack.com/archives /C0EN96KUY) 频道。
也欢迎你加入每两周举行一次的 SIG Auth 会议, 每隔一个星期三举行一次。
致谢
此功能是由来自几家不同公司的贡献者推动的,我们非常感谢所有贡献时间和精力帮助实现这一目标的人。
Kubernetes 1.27:关于加快 Pod 启动的进展
作者:Paco Xu (DaoCloud), Sergey Kanzhelev (Google), Ruiwen Zhao (Google) 译者:Michael Yao (DaoCloud)
如何在大型集群中加快节点上的 Pod 启动?这是集群管理员可能面临的常见问题。
本篇博文重点介绍了从 kubelet 一侧加快 Pod 启动的方法。它不涉及通过 kube-apiserver 由 controller-manager 创建 Pod 所用的时间, 也不包括 Pod 的调度时间或在其上执行 Webhook 的时间。
我们从 kubelet 的角度考虑,在本文提到了一些重要的影响因素,但这并不是详尽罗列。 随着 Kubernetes v1.27 的发布,本文强调了在 v1.27 中有助于加快 Pod 启动的重大变更。
并行容器镜像拉取
拉取镜像总是需要一些时间的,更糟糕的是,镜像拉取默认是串行作业。 换句话说,kubelet 一次只会向镜像服务发送一个镜像拉取请求。 其他的镜像拉取请求必须等到正在处理的拉取请求完成。
要启用并行镜像拉取,请在 kubelet 配置中将 serializeImagePulls 字段设置为 false。
当 serializeImagePulls 被禁用时,将立即向镜像服务发送镜像拉取请求,并可以并行拉取多个镜像。
设定并行镜像拉取最大值有助于防止节点因镜像拉取而过载
我们在 kubelet 中引入了一个新特性,可以在节点级别设置并行镜像拉取的限值。 此限值限制了可以同时拉取的最大镜像数量。如果有个镜像拉取请求超过了这个限值, 该请求将被阻止,直到其中一个正在进行的镜像拉取完成为止。 在启用此特性之前,请确保容器运行时的镜像服务可以有效处理并行镜像拉取。
要限制并行镜像拉取的数量,你可以在 kubelet 中配置 maxParallelImagePulls 字段。
将 maxParallelImagePulls 的值设置为 n 后,并行拉取的镜像数将不能超过 n 个。
超过此限值的任何其他镜像拉取请求都需要等到至少一个正在进行的拉取被完成为止。
你可以在关联的 KEP 中找到更多细节: Kubelet 并行镜像拉取数限值 (KEP-3673)。
提高了 kubelet 默认 API 每秒查询限值
为了在节点上具有多个 Pod 的场景中加快 Pod 启动,特别是在突然扩缩的情况下, kubelet 需要同步 Pod 状态并准备 ConfigMap、Secret 或卷。这就需要大带宽访问 kube-apiserver。
在 v1.27 之前的版本中,kubeAPIQPS 的默认值为 5,kubeAPIBurst 的默认值为 10。
然而在 v1.27 中,kubelet 为了提高 Pod 启动性能,将这些默认值分别提高到了 50 和 100。
值得注意的是,这并不是我们提高 kubelet 的 API QPS 限值的唯一原因。
- 现在的情况是 API 请求可能会被过度限制(默认 QPS = 5)
- 在大型集群中,API 请求仍然可能产生相当大的负载,因为数量很多
- 我们现在可以轻松控制一个专门为此设计的 PriorityLevel 和 FlowSchema
以前在具有 50 个以上 Pod 的节点中,我们经常在 Pod 启动期间在 kubelet 上遇到 volume mount timeout。
特别是在使用裸金属节点时,我们建议集群操作员将 kubeAPIQPS 提高到 20,kubeAPIBurst 提高到 40。
更多细节请参阅 KEP https://kep.k8s.io/1040 和 PR#116121。
事件驱动的容器状态更新
在 v1.27 中,Evented PLEG
(PLEG 是英文 Pod Lifecycle Event Generator 的缩写,表示 “Pod 生命周期事件生成器”)
进阶至 Beta 阶段。Kubernetes 为 kubelet 提供了两种方法来检测 Pod 的生命周期事件,
例如容器中最后一个进程关闭。在 Kubernetes v1.27 中,基于事件的 机制已进阶至 Beta,
但默认被禁用。如果你显式切换为基于事件的生命周期变更检测,则 kubelet
能够比依赖轮询的默认方法更快地启动 Pod。默认的轮询生命周期变化机制会增加明显的开销,
这会影响 kubelet 处理不同任务的并行能力,并导致性能和可靠性问题。
出于这些原因,我们建议你将节点切换为使用基于事件的 Pod 生命周期变更检测。
更多细节请参阅 KEP https://kep.k8s.io/3386 和容器状态从轮询切换为基于 CRI 事件更新。
必要时提高 Pod 资源限值
某些 Pod 在启动过程中可能会耗用大量的 CPU 或内存。 如果 CPU 限值较低,则可能会显著降低 Pod 启动过程的速度。 为了改善内存管理,Kubernetes v1.22 引入了一个名为 MemoryQoS 的特性门控。 该特性使 kubelet 能够在容器、Pod 和 QoS 级别上设置内存 QoS,以便更好地保护和确保在运行 CGroup V2 时的内存质量。尽管此特性门控有一定的好处,但如果 Pod 启动消耗大量内存, 启用此特性门控可能会影响 Pod 的启动速度。
Kubelet 配置现在包括 memoryThrottlingFactor。该因子乘以内存限制或节点可分配内存,
可以设置 cgroupv2 memory.high 值来执行 MemoryQoS。
减小该因子将为容器 cgroup 设置较低的上限,同时增加了回收压力。
提高此因子将减少回收压力。默认值最初为 0.8,并将在 Kubernetes v1.27 中更改为 0.9。
调整此参数可以减少此特性对 Pod 启动速度的潜在影响。
更多细节请参阅 KEP https://kep.k8s.io/2570。
更多说明
在 Kubernetes v1.26 中,新增了一个名为 pod_start_sli_duration_seconds 的直方图指标,
用于显示 Pod 启动延迟 SLI/SLO 详情。此外,kubelet 日志现在会展示更多与 Pod 启动相关的时间戳信息,如下所示:
Dec 30 15:33:13.375379 e2e-022435249c-674b9-minion-group-gdj4 kubelet[8362]: I1230 15:33:13.375359 8362 pod_startup_latency_tracker.go:102] "Observed pod startup duration" pod="kube-system/konnectivity-agent-gnc9k" podStartSLOduration=-9.223372029479458e+09 pod.CreationTimestamp="2022-12-30 15:33:06 +0000 UTC" firstStartedPulling="2022-12-30 15:33:09.258791695 +0000 UTC m=+13.029631711" lastFinishedPulling="0001-01-01 00:00:00 +0000 UTC" observedRunningTime="2022-12-30 15:33:13.375009262 +0000 UTC m=+17.145849275" watchObservedRunningTime="2022-12-30 15:33:13.375317944 +0000 UTC m=+17.146157970"
SELinux 挂载选项重标记功能在 v1.27 中升至 Beta 版本。 该特性通过挂载具有正确 SELinux 标签的卷来加快容器启动速度, 而不是递归地更改卷上的每个文件。更多细节请参阅 KEP https://kep.k8s.io/1710。
为了确定 Pod 启动缓慢的原因,分析指标和日志可能会有所帮助。 其他可能会影响 Pod 启动的因素包括容器运行时、磁盘速度、节点上的 CPU 和内存资源。
SIG Node 负责确保 Pod 快速启动,而解决大型集群中的问题则属于 SIG Scalability 的范畴。
Kubernetes 1.27: 原地调整 Pod 资源 (alpha)
作者: Vinay Kulkarni (Kubescaler Labs)
译者:Paco Xu (Daocloud)
如果你部署的 Pod 设置了 CPU 或内存资源,你就可能已经注意到更改资源值会导致 Pod 重新启动。 以前,这对于运行的负载来说是一个破坏性的操作。
在 Kubernetes v1.27 中,我们添加了一个新的 alpha 特性,允许用户调整分配给 Pod 的
CPU 和内存资源大小,而无需重新启动容器。 首先,API 层面现在允许修改 Pod 容器中的
resources 字段下的 cpu 和 memory 资源。资源修改只需 patch 正在运行的 pod
规约即可。
这也意味着 Pod 定义中的 resource 字段不能再被视为 Pod 实际资源的指标。监控程序必须
查看 Pod 状态中的新字段来获取实际资源状况。Kubernetes 通过 CRI(Container Runtime
Interface,容器运行时接口)API 调用运行时(例如 containerd)来查询实际的 CPU 和内存
的请求和限制。容器运行时的响应会反映在 Pod 的状态中。
此外,Pod 中还添加了对应于资源调整的新字段 restartPolicy。这个字段使用户可以控制在资
源调整时容器的行为。
1.27 版本有什么新内容?
除了在 Pod 规范中添加调整策略之外,还在 Pod 状态中的 containerStatuses 中添加了一个名为
allocatedResources 的新字段。该字段反映了分配给 Pod 容器的节点资源。
此外,容器状态中还添加了一个名为 resources 的新字段。该字段反映的是如同容器运行时所报告的、
针对正运行的容器配置的实际资源 requests 和 limits。
最后,Pod 状态中添加了新字段 resize。resize 字段显示上次请求待处理的调整状态。
此字段可以具有以下值:
- Proposed:此值表示请求调整已被确认,并且请求已被验证和记录。
- InProgress:此值表示节点已接受调整请求,并正在将其应用于 Pod 的容器。
- Deferred:此值意味着在此时无法批准请求的调整,节点将继续重试。 当其他 Pod 退出并释放节点资源时,调整可能会被真正实施。
- Infeasible:此值是一种信号,表示节点无法承接所请求的调整值。 如果所请求的调整超过节点可分配给 Pod 的最大资源,则可能会发生这种情况。
何时使用此功能?
以下是此功能可能有价值的一些示例:
- 正在运行的 Pod 资源限制或者请求过多或过少。
- 一些过度预配资源的 Pod 调度到某个节点,会导致资源利用率较低的集群上因为 CPU 或内存不足而无法调度 Pod。
- 驱逐某些需要较多资源的有状态 Pod 是一项成本较高或破坏性的操作。 这种场景下,缩小节点中的其他优先级较低的 Pod 的资源,或者移走这些 Pod 的成本更低。
如何使用这个功能
在 v1.27 中使用此功能,必须启用 InPlacePodVerticalScaling 特性门控。
可以如下所示启动一个启用了此特性的本地集群:
root@vbuild:~/go/src/k8s.io/kubernetes# FEATURE_GATES=InPlacePodVerticalScaling=true ./hack/local-up-cluster.sh
go version go1.20.2 linux/arm64
+++ [0320 13:52:02] Building go targets for linux/arm64
k8s.io/kubernetes/cmd/kubectl (static)
k8s.io/kubernetes/cmd/kube-apiserver (static)
k8s.io/kubernetes/cmd/kube-controller-manager (static)
k8s.io/kubernetes/cmd/cloud-controller-manager (non-static)
k8s.io/kubernetes/cmd/kubelet (non-static)
...
...
Logs:
/tmp/etcd.log
/tmp/kube-apiserver.log
/tmp/kube-controller-manager.log
/tmp/kube-proxy.log
/tmp/kube-scheduler.log
/tmp/kubelet.log
To start using your cluster, you can open up another terminal/tab and run:
export KUBECONFIG=/var/run/kubernetes/admin.kubeconfig
cluster/kubectl.sh
# Alternatively, you can write to the default kubeconfig:
export KUBERNETES_PROVIDER=local
cluster/kubectl.sh config set-cluster local --server=https://localhost:6443 --certificate-authority=/var/run/kubernetes/server-ca.crt
cluster/kubectl.sh config set-credentials myself --client-key=/var/run/kubernetes/client-admin.key --client-certificate=/var/run/kubernetes/client-admin.crt
cluster/kubectl.sh config set-context local --cluster=local --user=myself
cluster/kubectl.sh config use-context local
cluster/kubectl.sh
一旦本地集群启动并运行,Kubernetes 用户就可以调度带有资源配置的 pod,并通过 kubectl 调整 pod 的资源。 以下演示视频演示了如何使用此功能的示例。
示例用例
云端开发环境
在这种场景下,开发人员或开发团队在本地编写代码,但在和生产环境资源配置相同的 Kubernetes pod 中的 构建和测试代码。当开发人员编写代码时,此类 Pod 需要最少的资源,但在构建代码或运行一系列测试时需要 更多的 CPU 和内存。 这个用例可以利用原地调整 pod 资源的功能(在 eBPF 的一点帮助下)快速调整 pod 资源的大小,并避免内核 OOM(内存不足)Killer 终止其进程。
KubeCon North America 2022 会议演讲中详细介绍了上述用例。
Java进程初始化CPU要求
某些 Java 应用程序在初始化期间 CPU 资源使用量可能比正常进程操作期间所需的 CPU 资源多很多。 如果此类应用程序指定适合正常操作的 CPU 请求和限制,会导致程序启动时间很长。这样的 pod 可以在创建 pod 时请求更高的 CPU 值。在应用程序完成初始化后,降低资源配置仍然可以正常运行。
已知问题
该功能在 v1.27 中仍然是 alpha 阶段. 以下是用户可能会遇到的一些已知问题:
- containerd v1.6.9 以下的版本不具备此功能的所需的 CRI 支持,无法完成端到端的闭环。
尝试调整 Pod 大小将显示为卡在
InProgress状态,并且 Pod 状态中的resources字段永远不会更新,即使新资源配置可能已经在正在运行的容器上生效了。 - Pod 资源调整可能会遇到与其他 Pod 更新的冲突,导致 pod 资源调整操作被推迟。
- 可能需要一段时间才能在 Pod 的状态中反映出调整后的容器资源。
- 此特性与静态 CPU 管理策略不兼容。
致谢
此功能是 Kubernetes 社区高度协作努力的结果。这里是对在这个功能实现过程中,贡献了很多帮助的一部分人的一点点致意。
- @thockin 如此细致的 API 设计和严密的代码审核。
- @derekwaynecarr 设计简化和 API & Node 代码审核。
- @dchen1107 介绍了 Borg 的大量知识,帮助我们避免落入潜在的陷阱。
- @ruiwen-zhao 增加 containerd 支持,使得 E2E 能够闭环。
- @wangchen615 实现完整的 E2E 测试并推进调度问题修复。
- @bobbypage 提供宝贵的帮助,让 CI 准备就绪并快速排查问题,尤其是在我休假时。
- @Random-Liu kubelet 代码审查以及定位竞态条件问题。
- @Huang-Wei, @ahg-g, @alculquicondor 帮助完成调度部分的修改。
- @mikebrow @marosset 帮助我在 v1.25 代码审查并最终合并 CRI 部分的修改。
- @endocrimes, @ehashman 帮助确保经常被忽视的测试处于良好状态。
- @mrunalp cgroupv2 部分的代码审查并保证了 v1 和 v2 的清晰处理。
- @liggitt, @gjkim42 在合并代码后,帮助追踪遗漏的重要问题的根因。
- @SergeyKanzhelev 在冲刺阶段支持和解决各种问题。
- @pdgetrf 完成了第一个原型。
- @dashpole 让我快速了解 Kubernetes 的做事方式。
- @bsalamat, @kgolab 在早期阶段提供非常周到的见解和建议。
- @sftim, @tengqm 确保文档易于理解。
- @dims 无所不在并帮助在关键时刻进行合并。
- 发布团队确保了项目保持健康。
非常感谢我非常支持的管理层 Xiaoning Ding 博士 和 Ying Xiong 博士,感谢他们的耐心和鼓励。
参考
应用程序开发者参考
集群管理员参考
Kubernetes 1.27:为 NodePort Service 分配端口时避免冲突
作者: Xu Zhenglun (Alibaba)
译者: Michael Yao (DaoCloud)
在 Kubernetes 中,对于以一组 Pod 运行的应用,Service 可以为其提供统一的流量端点。
客户端可以使用 Service 提供的虚拟 IP 地址(或 VIP)进行访问,
Kubernetes 为访问不同的后端 Pod 的流量提供负载均衡能力,
但 ClusterIP 类型的 Service 仅限于供集群内的节点来访问,
而来自集群外的流量无法被路由。解决这个难题的一种方式是使用 type: NodePort Service,
这种服务会在集群所有节点上为特定端口建立映射关系,从而将来自集群外的流量重定向到集群内。
Kubernetes 如何为 Services 分配节点端口?
当 type: NodePort Service 被创建时,其所对应的端口将以下述两种方式之一分配:
动态分配:如果 Service 类型是
NodePort且你没有为 Service 显式设置nodePort值, Kubernetes 控制面将在创建时自动为其分配一个未使用的端口。静态分配:除了上述动态自动分配,你还可以显式指定 nodeport 端口范围配置内的某端口。
你手动分配的 nodePort 值在整个集群范围内一定不能重复。
如果尝试在创建 type: NodePort Service 时显式指定已分配的节点端口,将产生错误。
为什么需要保留 NodePort Service 的端口?
有时你可能想要 NodePort Service 运行在众所周知的端口上, 便于集群内外的其他组件和用户可以使用这些端口。
在某些复杂的集群部署场景中在同一网络上混合了 Kubernetes 节点和其他服务器,
可能有必要使用某些预定义的端口进行通信。尤为特别的是,某些基础组件无法使用用来支撑
type: LoadBalancer Service 的 VIP,因为针对集群实现的虚拟 IP 地址映射也依赖这些基础组件。
现在假设你需要在 Kubernetes 上将一个 Minio 对象存储服务暴露给运行在 Kubernetes 集群外的客户端,
协商后的端口是 30009,我们需要创建以下 Service:
apiVersion: v1
kind: Service
metadata:
name: minio
spec:
ports:
- name: api
nodePort: 30009
port: 9000
protocol: TCP
targetPort: 9000
selector:
app: minio
type: NodePort
然而如前文所述,如果 minio Service 所需的端口 (30009) 未被预留,
且另一个 type: NodePort(或者也包括 type: LoadBalancer)Service
在 minio Service 之前或与之同时被创建、动态分配,TCP 端口 30009 可能被分配给了这个 Service;
如果出现这种情况,minio Service 的创建将由于节点端口冲突而失败。
如何才能避免 NodePort Service 端口冲突?
Kubernetes 1.24 引入了针对 type: ClusterIP Service 的变更,将集群 IP 地址的 CIDR
范围划分为使用不同分配策略的两块来减少冲突的风险。
在 Kubernetes 1.27 中,作为一个 Alpha 特性,你可以为 type: NodePort Service 采用类似的策略。
你可以启用新的特性门控
ServiceNodePortStaticSubrange。开启此门控将允许你为
type: NodePort Service 使用不同的端口分配策略,减少冲突的风险。
NodePort 的端口范围将基于公式 min(max(16, 节点端口数 / 32), 128) 进行划分。
这个公式的结果将是一个介于 16 到 128 的数字,随着节点端口范围变大,步进值也会变大。
此公式的结果决定了静态端口范围的大小。当端口范围小于 16 时,静态端口范围的大小将被设为 0,
这意味着所有端口都将被动态分配。
动态端口分配默认使用数值较高的一段,一旦用完,它将使用较低范围。 这将允许用户在冲突风险较低的较低端口段上使用静态分配。
示例
默认范围:30000-32767
| 范围属性 | 值 |
|---|---|
| service-node-port-range | 30000-32767 |
| 分段偏移量 | min(max(16, 2768/32), 128)= min(max(16, 86), 128)= min(86, 128)= 86 |
| 起始静态段 | 30000 |
| 结束静态段 | 30085 |
| 起始动态段 | 30086 |
| 结束动态段 | 32767 |
超小范围:30000-30015
| 范围属性 | 值 |
|---|---|
| service-node-port-range | 30000-30015 |
| 分段偏移量 | 0 |
| 起始静态段 | - |
| 结束静态段 | - |
| 起始动态段 | 30000 |
| 动态动态段 | 30015 |
小(下边界)范围:30000-30127
| 范围属性 | 值 |
|---|---|
| service-node-port-range | 30000-30127 |
| 分段偏移量 | min(max(16, 128/32), 128)= min(max(16, 4), 128)= min(16, 128)= 16 |
| 起始静态段 | 30000 |
| 结束静态段 | 30015 |
| 起始动态段 | 30016 |
| 结束动态段 | 30127 |
大(上边界)范围:30000-34095
| 范围属性 | 值 |
|---|---|
| service-node-port-range | 30000-34095 |
| 分段偏移量 | min(max(16, 4096/32), 128)= min(max(16, 128), 128)= min(128, 128)= 128 |
| 起始静态段 | 30000 |
| 结束静态段 | 30127 |
| 起始动态段 | 30128 |
| 结束动态段 | 34095 |
超大范围:30000-38191
| 范围属性 | 值 |
|---|---|
| service-node-port-range | 30000-38191 |
| 分段偏移量 | min(max(16, 8192/32), 128)= min(max(16, 256), 128)= min(256, 128)= 128 |
| 起始静态段 | 30000 |
| 结束静态段 | 30127 |
| 起始动态段 | 30128 |
| 结束动态段 | 38191 |
Kubernetes 1.27:kubectl apply 裁剪更安全、更高效
作者: Katrina Verey(独立个人)和 Justin Santa Barbara (Google)
译者: Michael Yao (DaoCloud)
通过 kubectl apply 命令执行声明式配置管理是创建或修改 Kubernetes 资源的黄金标准方法。
但这种方法也带来了一个挑战,那就是删除不再需要的资源。
在 Kubernetes 1.5 版本中,引入了 --prune 标志来解决此问题,
允许 kubectl apply 自动清理从当前配置中删除的先前应用的资源。
然而,现有的 --prune 实现存在设计缺陷,会降低性能并导致意外行为。
主要问题源于先前的 apply 操作未对已应用的集合进行显式编码,有必要进行易错的动态发现。
对象泄漏、意外过度选择资源以及与自定义资源的有限兼容性是这种实现的一些明显缺点。
此外,其与客户端 apply 的耦合阻碍了用户升级到更优秀的服务器端 apply 方式。
kubectl 的 1.27 版本引入了 Alpha 版本的重构裁剪实现,解决了这些问题。
这个基于 ApplySet 概念的新实现承诺能够提供更好的性能和更好的安全性。
ApplySet 是一个与集群上的父对象相关联的资源组,通过标准化的标签和注解进行标识和配置。 附加的标准化元数据允许准确标识集群内的 ApplySet 成员对象,简化了裁剪等操作。
为了充分利用基于 ApplySet 的裁剪,设置 KUBECTL_APPLYSET=true 环境变量,
并在 kubectl apply 调用中包括标志 --prune 和 --applyset:
KUBECTL_APPLYSET=true kubectl apply -f <目录> --prune --applyset=<name>
默认情况下,ApplySet 使用 Secret 作为父对象。
但是,你也可以通过格式 --applyset=configmaps/<name> 来使用 ConfigMap。
如果所需的 Secret 或 ConfigMap 对象尚不存在,则 kubectl 将为你创建它。
此外,可以启用自定义资源以用作 ApplySet 父对象。
ApplySet 实现基于新的底层规约,可以通过提高其互操作性来支持更高层次的生态系统工具。
这种规约的轻量性使得这些工具可以继续使用现有的对象分组系统,
同时选用 ApplySet 的元数据约定以防被其他工具(例如 kubectl)意外更改。
基于 ApplySet 的裁剪提供了一种方法,保证有效解决之前 kubectl 中 --prune 实现的缺陷,
还可以帮助优化 Kubernetes 资源管理。请使用这个新特性并与社区分享你的经验。
ApplySet 正处于积极开发中,你的反馈至关重要!
更多资源
- 想了解如何使用基于 ApplySet 的裁剪,请阅读 Kubernetes 文档中的 使用配置文件以声明方式管理 Kubernetes 对象。
- 如需更深入地了解此特性的技术设计或了解如何用你自己工具实现 ApplySet 规范,
请参阅 KEP-3659:
ApplySet:
kubectl apply --prune重新设计和进阶策略。
如何参与
如果你想参与 ApplySet 的开发,可以联系 SIG CLI 的开发人员。
如需提供有关此特性的反馈,请在 kubernetes/kubectl
代码库上提交 bug
或提出增强请求。
Kubernetes 1.27:介绍用于磁盘卷组快照的新 API
Author: Xing Yang (VMware)
译者: 顾欣
磁盘卷组快照在 Kubernetes v1.27 中作为 Alpha 特性被引入。
此特性引入了一个 Kubernetes API,允许用户对多个卷进行快照,以保证在发生故障时数据的一致性。
它使用标签选择器来将多个 PersistentVolumeClaims (持久卷申领)分组以进行快照。
这个新特性仅支持 CSI 卷驱动器。
磁盘卷组快照概述
一些存储系统提供了创建多个卷的崩溃一致性快照的能力。 卷组快照表示在同一时间点从多个卷中生成的“副本”。 卷组快照可以用来重新填充新的卷(预先填充快照数据)或者将现有卷恢复到以前的状态(由快照代表)。
为什么要在 Kubernetes 中添加卷组快照?
Kubernetes 的卷插件系统已经提供了一个强大的抽象层, 可以自动化块存储和文件存储的制备、挂接、挂载、调整大小和快照等操作。
所有这些特性的出发点是 Kubernetes 对工作负载可移植性的目标: Kubernetes 致力于在分布式应用和底层集群之间创建一个抽象层, 使应用可以对承载它们的集群的特殊属性无感,应用部署不需要特定于某集群的知识。
Kubernetes 已经提供了一个 VolumeSnapshot API, 这个 API 提供对持久性卷进行快照的能力,可用于防止数据丢失或数据损坏。然而, 还有一些其他的快照功能并未被 VolumeSnapshot API 所覆盖。
一些存储系统支持一致性的卷组快照,允许在同一时间点在多个卷上生成快照,以实现写入顺序的一致性。 这对于包含多个卷的应用非常有用。例如,应用可能在一个卷中存储数据,在另一个卷中存储日志。 如果数据卷和日志卷的快照在不同的时间点进行,应用将不会保持一致, 当灾难发生时从这些快照中恢复,应用将无法正常工作。
确实,你可以首先使应用静默,然后依次为构成应用的每个卷中生成一个独立的快照, 等所有的快照都已逐个生成后,再取消应用的静止状态。这样你就可以得到应用一致性的快照。
然而,有时可能无法使应用静默,或者使应用静默的代价过高,因此你希望较少地进行这个操作。 相较于生成一致性的卷组快照,依次生成单个快照可能需要更长的时间。 由于这些原因,有些用户可能不希望经常使应用静默。例如, 用户可能希望每周进行一次需要应用静默的备份,而在每晚进行不需应用静默但带有卷组一致性支持的备份, 这种一致性支持将确保组中所有卷的崩溃一致性。
Kubernetes 卷组快照 API
Kubernetes 卷组快照引入了 三个新的 API 对象 用于管理快照:
VolumeGroupSnapshot:由 Kubernetes 用户(或由你的自动化系统)创建,
以请求为多个持久卷申领创建卷组快照。它包含了关于卷组快照操作的信息,
如卷组快照的生成时间戳以及是否可直接使用。
此对象的创建和删除代表了创建或删除集群资源(一个卷组快照)的意愿。
VolumeGroupSnapshotContent:由快照控制器动态生成的 VolumeGroupSnapshot 所创建。
它包含了关于卷组快照的信息,包括卷组快照 ID。此对象代表了集群上制备的一个资源(一个卷组快照)。
VolumeGroupSnapshotContent 对象与其创建时所对应的 VolumeGroupSnapshot 之间存在一对一的映射。
VolumeGroupSnapshotClass:由集群管理员创建,用来描述如何创建卷组快照,
包括驱动程序信息、删除策略等。
这三种 API 类型被定义为自定义资源(CRD)。 这些 CRD 必须在 Kubernetes 集群中安装,以便 CSI 驱动程序支持卷组快照。
如何使用 Kubernetes 卷组快照
卷组快照是在 external-snapshotter 仓库中实现的。实现卷组快照意味着添加或更改几个组件:
- 添加了新的 CustomResourceDefinition 用于 VolumeGroupSnapshot 和两个辅助性 API。
- 向通用快照控制器中添加卷组快照控制器的逻辑。
- 向通用快照验证 webhook 中添加卷组快照验证 webhook 的逻辑。
- 添加逻辑以便在快照 sidecar 控制器中进行 CSI 调用。
每个集群只部署一次卷快照控制器、CRD 和验证 webhook, 而 sidecar 则与每个 CSI 驱动程序一起打包。
因此,将卷快照控制器、CRD 和验证 webhook 作为集群插件部署是合理的。 我强烈建议 Kubernetes 发行版的厂商将卷快照控制器、 CRD 和验证 webhook 打包并作为他们的 Kubernetes 集群管理过程的一部分(独立于所有 CSI 驱动)。
使用 Kubernetes 创建新的卷组快照
一旦定义了一个 VolumeGroupSnapshotClass 对象,并且你有想要一起生成快照的卷, 就可以通过创建一个 VolumeGroupSnapshot 对象来请求一个新的卷组快照。
卷组快照的源指定了底层的卷组快照是应该动态创建, 还是应该使用预先存在的 VolumeGroupSnapshotContent。
预先存在的 VolumeGroupSnapshotContent 由集群管理员创建。 其中包含了在存储系统上实际卷组快照的细节,这些卷组快照可供集群用户使用。
在卷组快照源中,必须设置以下成员之一。
selector- 针对要一起生成快照的 PersistentVolumeClaims 的标签查询。 该 labelSelector 将用于匹配添加到 PVC 上的标签。volumeGroupSnapshotContentName- 指定一个现有的 VolumeGroupSnapshotContent 对象的名称,该对象代表着一个已存在的卷组快照。
在以下示例中,有两个 PVC。
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
pvc-0 Bound pvc-a42d7ea2-e3df-11ed-b5ea-0242ac120002 1Gi RWO 48s
pvc-1 Bound pvc-a42d81b8-e3df-11ed-b5ea-0242ac120002 1Gi RWO 48s
标记 PVC。
% kubectl label pvc pvc-0 group=myGroup
persistentvolumeclaim/pvc-0 labeled
% kubectl label pvc pvc-1 group=myGroup
persistentvolumeclaim/pvc-1 labeled
对于动态制备,必须设置一个选择算符,以便快照控制器可以找到带有匹配标签的 PVC,一起进行快照。
apiVersion: groupsnapshot.storage.k8s.io/v1alpha1
kind: VolumeGroupSnapshot
metadata:
name: new-group-snapshot-demo
namespace: demo-namespace
spec:
volumeGroupSnapshotClassName: csi-groupSnapclass
source:
selector:
matchLabels:
group: myGroup
在 VolumeGroupSnapshot 的规约中,用户可以指定 VolumeGroupSnapshotClass, 其中包含应使用哪个 CSI 驱动程序来创建卷组快照的信息。
作为创建卷组快照的一部分,将创建两个单独的卷快照。
snapshot-62abb5db7204ac6e4c1198629fec533f2a5d9d60ea1a25f594de0bf8866c7947-2023-04-26-2.20.4
snapshot-2026811eb9f0787466171fe189c805a22cdb61a326235cd067dc3a1ac0104900-2023-04-26-2.20.4
如何在 Kubernetes 中使用卷组快照进行恢复
在恢复时,用户可以请求某 VolumeGroupSnapshot 的一部分,即某个 VolumeSnapshot 对象, 创建一个新的 PersistentVolumeClaim。这将触发新卷的制备过程, 并使用指定快照中的数据进行预填充。用户应该重复此步骤,直到为卷组快照的所有部分创建了所有卷。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc0-restore
namespace: demo-namespace
spec:
storageClassName: csi-hostpath-sc
dataSource:
name: snapshot-62abb5db7204ac6e4c1198629fec533f2a5d9d60ea1a25f594de0bf8866c7947-2023-04-26-2.20.4
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
作为一个存储供应商,我应该如何为我的 CSI 驱动程序添加对卷组快照的支持?
要实现卷组快照功能,CSI 驱动必须:
- 实现一个新的组控制器服务。
- 实现组控制器的 RPC:
CreateVolumeGroupSnapshot,DeleteVolumeGroupSnapshot和GetVolumeGroupSnapshot。 - 添加组控制器的特性
CREATE_DELETE_GET_VOLUME_GROUP_SNAPSHOT。
更多详情请参阅 CSI规范 和 Kubernetes-CSI驱动程序开发指南。
对于 CSI 卷驱动程序,它提供了一种建议采用的机制来部署容器化的 CSI 驱动程序以简化流程。
作为所推荐的部署过程的一部分,Kubernetes 团队提供了许多 sidecar(辅助)容器, 包括已经更新以支持卷组快照的 external-snapshotter sidecar 容器。
external-snapshotter 会监听 Kubernetes API 服务器上的 VolumeGroupSnapshotContent 对象,
并对 CSI 端点触发 CreateVolumeGroupSnapshot 和 DeleteVolumeGroupSnapshot 操作。
有哪些限制?
Kubernetes 的卷组快照的 Alpha 版本具有以下限制:
- 不支持将现有的 PVC 还原到由快照表示的较早状态(仅支持从快照创建新的卷)。
- 除了存储系统提供的保证(例如崩溃一致性)之外,不提供应用一致性保证。 请参阅此文档, 了解有关应用一致性的更多讨论。
下一步是什么?
根据反馈和采用情况,Kubernetes 团队计划在 1.28 或 1.29 版本中将 CSI 卷组快照实现推进到 Beta 阶段。 我们有兴趣支持的一些功能包括卷复制、复制组、卷位置选择、应用静默、变更块跟踪等等。
如何获取更多信息?
如何参与其中?
这个项目,就像 Kubernetes 的所有项目一样,是许多不同背景的贡献者共同努力的结果。 我代表 SIG Storage, 向在过去几个季度中积极参与项目并帮助项目达到 Alpha 版本的贡献者们表示衷心的感谢:
- Alex Meade (ameade)
- Ben Swartzlander (bswartz)
- Humble Devassy Chirammal (humblec)
- James Defelice (jdef)
- Jan Šafránek (jsafrane)
- Jing Xu (jingxu97)
- Michelle Au (msau42)
- Niels de Vos (nixpanic)
- Rakshith R (Rakshith-R)
- Raunak Shah (RaunakShah)
- Saad Ali (saad-ali)
- Thomas Watson (rbo54)
- Xing Yang (xing-yang)
- Yati Padia (yati1998)
我们还要感谢其他为该项目做出贡献的人, 包括帮助审核 KEP和 CSI 规约 PR的其他人员。
对于那些对参与 CSI 设计和开发或 Kubernetes 存储系统感兴趣的人, 欢迎加入 Kubernetes存储特别兴趣小组(SIG)。 我们随时欢迎新的贡献者。
我们还定期举行数据保护工作组会议。 欢迎新的与会者加入我们的讨论。
Kubernetes 1.27:内存资源的服务质量(QoS)Alpha
作者:Dixita Narang (Google)
译者:Wilson Wu (DaoCloud)
Kubernetes v1.27 于 2023 年 4 月发布,引入了对内存 QoS(Alpha)的更改,用于提高 Linux 节点中的内存管理功能。
对内存 QoS 的支持最初是在 Kubernetes v1.22 中添加的,后来发现了关于计算 memory.high
公式的一些不足。
这些不足在 Kubernetes v1.27 中得到解决。
背景
Kubernetes 允许你在 Pod 规约中设置某容器对每类资源的需求。通常要设置的资源是 CPU 和内存。
例如,定义容器资源需求的 Pod 清单可能如下所示:
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
containers:
- name: nginx
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "64Mi"
cpu: "500m"
spec.containers[].resources.requests当你为 Pod 中的容器设置资源请求时, Kubernetes 调度器使用此信息来决定将 Pod 放置在哪个节点上。 调度器确保对于每种资源类型,已调度容器的资源请求总和小于节点上可分配资源的总量。
spec.containers[].resources.limits当你为 Pod 中的容器设置资源限制时,kubelet 会强制实施这些限制, 以便运行的容器使用的资源不得超过你设置的限制。
当 kubelet 将容器作为 Pod 的一部分启动时,kubelet 会将容器的 CPU 和内存请求和限制传递给容器运行时。 容器运行时将 CPU 请求和 CPU 限制设置到容器上。如果系统有空闲的 CPU 时间, 就保证为容器分配它们请求的 CPU 数量。容器使用的 CPU 数量不能超过配置的限制, 即,如果容器在给定时间片内使用的 CPU 数量超过指定的限制,则容器的 CPU 使用率将受到限制。
在内存 QoS 特性出现之前,容器运行时仅使用内存限制并忽略内存的 request
(请求值从前到现在一直被用于影响调度)。
如果容器使用的内存超过所配置的限制,则会调用 Linux 内存不足(OOM)杀手机制。
让我们比较一下在有和没有内存 QoS 特性时,Linux 上的容器运行时通常如何在 cgroup 中配置内存请求和限制:
内存请求
内存请求主要由 kube-scheduler 在(Kubernetes)Pod 调度时使用。 在 cgroups v1 中,没有任何控件来设置 cgroup 必须始终保留的最小内存量。 因此,容器运行时不使用 Pod 规约中设置的内存请求值。
cgroups v2 中引入了一个
memory.min设置,用于设置给定 cgroup 中的进程确定可用的最小内存量。 如果 cgroup 的内存使用量在其有效最小边界内,则该 cgroup 的内存在任何情况下都不会被回收。 如果内核无法为 cgroup 中的进程维护至少memory.min字节的内存,内核将调用其 OOM 杀手机制。 换句话说,内核保证至少有这么多内存可用,或者终止进程(可能在 cgroup 之外)以腾出更多内存。 MemoryQoS 机制将memory.min映射到spec.containers[].resources.requests.memory, 以确保 Kubernetes Pod 中容器的内存可用性。
内存限制
memory.limit指定内存限制,如果容器尝试分配更多内存,超出该限制, Linux 内核将通过 OOM(内存不足)来杀死并终止进程。如果终止的进程是容器内的主 (或唯一)进程,则容器可能会退出。在 cgroups v1 中,
memory.limit_in_bytes接口用于设置内存用量限制。 然而,与 CPU 不同的是,内存用量是无法抑制的:一旦容器超过内存限制,它就会被 OOM 杀死。在 cgroups v2 中,
memory.max类似于 cgroupv1 中的memory.limit_in_bytes。 MemoryQoS 机制将memory.max映射到spec.containers[].resources.limits.memory以设置内存用量的硬性限制。如果内存消耗超过此水平,内核将调用其 OOM 杀手机制。cgroups v2 中还添加了
memory.high配置。MemoryQoS 机制使用memory.high来设置内存用量抑制上限。 如果超出了memory.high限制,则违规的 cgroup 会受到抑制,并且内核会尝试回收内存,这可能会避免 OOM 终止。
如何工作
Cgroups v2 内存控制器接口和 Kubernetes 容器资源映
MemoryQoS 机制使用 cgroups v2 的内存控制器来保证 Kubernetes 中的内存资源。 此特性使用的 cgroupv2 接口有:
memory.maxmemory.minmemory.high

内存 QoS 级别
memory.max 映射到 Pod 规约中指定的 limits.memory。
kubelet 和容器运行时在对应的 cgroup 中配置限制值。内核强制执行限制机制以防止容器用量超过所配置的资源限制。
如果容器中的进程尝试消耗的资源超过所设置的限制值,内核将终止进程并报告内存不足(OOM)错误。

memory.max 映射到 limit.memory
memory.min 被映射到 requests.memory,这会导致内存资源被预留而永远不会被内核回收。
这就是 MemoryQoS 机制确保 Kubernetes Pod 内存可用性的方式。
如果没有不受保护的、可回收的内存,则内核会调用 OOM 杀手以提供更多可用内存。

memory.min 映射到 requests.memory
对于内存保护,除了原来的限制内存用量的方式之外,MemoryQoS 机制还会对用量接近其内存限制的工作负载进行抑制,
确保系统不会因内存使用的零星增加而不堪重负。当你启用 MemoryQoS 特性时,
KubeletConfiguration 中将提供一个新字段 memoryThrottlingFactor。默认设置为 0.9。
memory.high 被映射到通过 memoryThrottlingFactor、requests.memory 和 limits.memory
计算得出的抑制上限,计算方法如下式所示,所得的值向下舍入到最接近的页面大小:

memory.high 公式
注意:如果容器没有指定内存限制,则 limits.memory 将被替换为节点可分配内存的值。
总结:
| 文件 | 描述 |
|---|---|
| memory.max | memory.max 指定允许容器使用的最大内存限制。
如果容器内的进程尝试使用的内存量超过所配置的限制值,内核将终止该进程并显示内存不足(OOM)错误。此配置映射到 Pod 清单中指定的容器内存限制。 |
| memory.min | memory.min 指定 cgroup 必须始终保留的最小内存量,
即系统永远不应回收的内存。如果没有可用的未受保护的可回收内存,则会调用 OOM 终止程序。此配置映射到 Pod 清单中指定的容器的内存请求。 |
| memory.high | memory.high 指定内存用量抑制上限。这是控制 cgroup 内存用量的主要机制。
如果 cgroups 内存使用量超过此处指定的上限,则 cgroups 进程将受到抑制并标记回收压力较大。Kubernetes 使用公式来计算 memory.high,具体取决于容器的内存请求、
内存限制或节点可分配内存(如果容器的内存限制为空)和抑制因子。有关公式的更多详细信息,
请参阅 KEP。 |
注意:memory.high 仅可在容器级别的 cgroups 上设置,
而 memory.min 则可在容器、Pod 和节点级别的 cgroups 上设置。
针对 cgroup 层次结构的 memory.min 计算
当发出容器内存请求时,kubelet 在创建容器期间通过 CRI 中的 Unified 字段将 memory.min
传递给后端 CRI 运行时(例如 containerd 或 CRI-O)。容器级别 cgroup 中的 memory.min 将设置为:
$memory.min = pod.spec.containers[i].resources.requests[memory]$
对于 Pod 中每个 ith 容器
由于 memory.min 接口要求祖先 cgroups 目录全部被设置,
因此需要正确设置 Pod 和节点的 cgroups 目录。
Pod 级别 cgroup 中的 memory.min:
$memory.min = \sum_{i=0}^{no. of pods}pod.spec.containers[i].resources.requests[memory]$
对于 Pod 中每个 ith 容器
节点级别 cgroup 中的 memory.min:
$memory.min = \sum_{i}^{no. of nodes}\sum_{j}^{no. of pods}pod[i].spec.containers[j].resources.requests[memory]$
对于节点中每个 ith Pod 中的每个 jth 容器
Kubelet 将直接使用 libcontainer 库(来自 runc 项目)管理 Pod 级别和节点级别 cgroups 的层次结构,而容器 cgroups 限制由容器运行时管理。
支持 Pod QoS 类别
根据用户对 Kubernetes v1.22 中 Alpha 特性的反馈,一些用户希望在 Pod 层面选择不启用 MemoryQoS, 以确保不会出现早期内存抑制现象。因此,在 Kubernetes v1.27 中 MemoryQoS 还支持根据 服务质量(QoS)对 Pod 类设置 memory.high。以下是按 QoS 类设置 memory.high 的几种情况:
- Guaranteed Pods:根据其 QoS 定义,要求 Pod 的内存请求等于其内存限制,并且不允许超配。 因此,通过不设置 memory.high,MemoryQoS 特性会针对这些 Pod 被禁用。 这样做可以确保 Guaranteed Pod 充分利用其内存请求,也就是其内存限制,并且不会被抑制。
Burstable Pod:根据其 QoS 定义,要求 Pod 中至少有一个容器具有 CPU 或内存请求或限制设置。
- 当 requests.memory 和 limits.memory 都被设置时,公式按原样使用:

当请求和限制被设置时的 memory.high
- 当设置了 requests.memory 但未设置 limits.memory 时,公式中的 limits.memory 替换为节点可分配内存:

当请求和限制未被设置时的 memory.high
BestEffort Pod:根据其 QoS 定义,不需要设置内存或 CPU 限制或请求。对于这种情况, kubernetes 设置 requests.memory = 0 并将公式中的 limits.memory 替换为节点可分配内存:

BestEffort Pod 的 memory.high
总结:只有 Burstable 和 BestEffort QoS 类别中的 Pod 才会设置 memory.high。
Guaranteed QoS 的 Pod 不会设置 memory.high,因为它们的内存是有保证的。
我该如何使用它?
在 Linux 节点上启用 MemoryQoS 特性的先决条件是:
验证是否满足 Kubernetes 对 cgroup v2 支持的相关要求。
确保 CRI 运行时支持内存 QoS。在撰写本文时, 只有 Containerd 和 CRI-O 提供与内存 QoS(alpha)兼容的支持。是在以下 PR 中实现的:
MemoryQoS 在 Kubernetes v1.27 中仍然是 Alpha 特性。
你可以通过在 kubelet 配置文件中设置 MemoryQoS=true 来启用该特性:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
MemoryQoS: true
我如何参与?
非常感谢所有帮助设计、实施和审查此功能的贡献者:
- Dixita Narang (ndixita)
- Tim Xu (xiaoxubeii)
- Paco Xu (pacoxu)
- David Porter(bobbypage)
- Mrunal Patel(mrunalp)
对于那些有兴趣参与未来内存 QoS 特性讨论的人,你可以通过多种方式联系 SIG Node:
Kubernetes 1.27: StatefulSet PVC 自动删除(beta)
作者:Matthew Cary (Google)
译者:顾欣 (ICBC)
Kubernetes v1.27 将一种新的策略机制升级到 Beta 阶段,这一策略用于控制
StatefulSets
的 PersistentVolumeClaims(PVCs)的生命周期。
这种新的 PVC 保留策略允许用户指定当删除 StatefulSet 或者缩减 StatefulSet 中的副本时,
是自动删除还是保留从 StatefulSet 规约模板生成的 PVC。
所解决的问题
StatefulSet 规约可以包含 Pod 和 PVC 模板。
当首次创建副本时,Kubernetes 控制平面会为该副本创建一个 PVC (如果不存在)。
在 PVC 保留策略出现之前,控制平面不会清理为 StatefulSets 创建的 PVC,
该任务通常由集群管理员负责,或者通过一些附加的自动化工具来处理。
你需要寻找这些工具,并检查其适用性,然后进行部署。
通常管理 PVC 的常见模式,无论是手动管理还是通过诸如 Helm 等工具进行管理,
都是由负责管理它们的工具跟踪,具有明确的生命周期。
使用 StatefulSets 的工作流必须自行确定由 StatefulSet 创建的 PVC,
并确定其生命周期。
在引入这个新特性之前,当一个由 StatefulSet 管理的副本消失时,
无论是因为 StatefulSet 正在减少其副本数量,还是因为其 StatefulSet 被删除,
PVC 及其支持卷仍然存在,必须手动删除。尽管在数据至关重要时这种行为是合适的,
但在许多情况下,这些 PVC 中的持久数据要么是临时的,要么可以从其他来源重建。
在这些情况下,删除 StatefulSet 或副本后仍保留 PVC 及其支持卷是不必要的,
这会产生成本,并且需要手动清理。
新的 StatefulSet PVC 保留策略
新的 StatefulSet PVC 保留策略用于控制是否以及何时删除从 StatefulSet
的 volumeClaimTemplate 创建的 PVC。有两种情况可能需要就此作出决定。
第一种是当删除 StatefulSet 资源时(意味着所有副本也会被删除)。
这时的行为由 whenDeleted 策略控制。第二种场景由 whenScaled 控制,
即当 StatefulSet 缩减规模时,它会移除一部分而不是全部副本。在这两种情况下,
策略可以是 Retain,表示相应的 PVC 不受影响,或者是 Delete,表示 PVC 将被删除。
删除操作是通过普通的对象删除完成的,
这样可以确保对底层 PV 的所有保留策略都得到遵守。
这个策略形成了一个矩阵,包括四种情况。接下来,我将逐一介绍每种情况并给出一个示例。
whenDeleted和whenScaled都是Retain。这与现有的
StatefulSets行为相匹配,所有 PVC 都不会被删除。这也是默认的保留策略。 当StatefulSet卷上的数据可能是不可替代的,并且应该仅在手动情况下删除时,这种策略是适当的。
whenDeleted是Delete,whenScaled是Retain。在这种情况下,只有在整个
StatefulSet被删除时,PVC 才会被删除。 如果StatefulSet进行缩减操作,PVC 将不会受到影响,这意味着如果缩减后再进行扩展, 并且使用了来自之前副本的任何数据,PVC 可以被重新关联。这种情况适用于临时的StatefulSet, 例如在 CI 实例或 ETL 流水线中,StatefulSet上的数据只在其生命周期内需要, 但在任务运行时,数据不容易重建。对于先被缩容后被扩容的副本而言,所有已保留的状态都是需要的。
whenDeleted和whenScaled都是Delete。当副本不再需要时,PVC 会立即被删除。需要注意的是, 这不包括当删除一个 Pod 并重新调度一个新版本时的情况, 例如当一个节点被排空并且 Pods 需要迁移到其他地方时。只有在副本不再被需要时, 即通过缩减规模或删除
StatefulSet时,PVC 才会被删除。 这种情况适用于数据不需要在其副本的生命周期之外存在的情况。也许数据很容易重建, 删除未使用的 PVC 可以节省成本比快速扩展更重要,或者当创建一个新副本时, 来自前一个副本的任何数据都无法使用,必须进行重建。
whenDeleted是Retain,whenScaled是Delete。这与前面的情况类似,保留 PVC 以便在扩容时进行快速重用的好处微乎其微。 一个使用这种策略的例子是 Elasticsearch 集群。通常,你会根据需求调整该工作负载的规模, 同时确保有一定数量的副本(例如:3个)一直存在。在缩容时,数据会从被删除的副本迁移走, 保留这些 PVC 没有好处。然而,如果需要临时关闭整个 Elasticsearch 集群进行维护, 可以通过暂时删除
StatefulSet然后重建StatefulSet来恢复 Elasticsearch 集群。 持有 Elasticsearch 数据的 PVC 仍然存在,新的副本将自动使用它们。
请访问文档 以查看所有详细信息。
下一步是什么?
试一试吧!在 Kubernetes 1.27 的集群中,StatefulSetAutoDeletePVC 特性门控是 Beta 阶段,
使用新的策略创建一个 StatefulSet,进行测试并告诉我们你的想法!
我非常好奇这个所有者引用机制在实践中是否运行良好。例如,
我意识到在 Kubernetes 中没有机制可以知道是谁设置了引用,
因此 StatefulSet 控制器可能会与设置自己引用的自定义控制器产生冲突。
幸运的是,保持现有的保留行为不涉及任何新的所有者引用,因此默认行为将是兼容的。
请在你报告的任何 issue 上标记标签 sig/apps, 并将它们指派给 Matthew Cary (@mattcary at GitHub)。
祝您使用愉快!
Kubernetes 1.27:HorizontalPodAutoscaler ContainerResource 类型指标进阶至 Beta
作者: Kensei Nakada (Mercari)
译者: Michael Yao (DaoCloud)
Kubernetes 1.20 在 HorizontalPodAutoscaler (HPA) 中引入了
ContainerResource 类型指标。
在 Kubernetes 1.27 中,此特性进阶至 Beta,相应的特性门控 (HPAContainerMetrics) 默认被启用。
什么是 ContainerResource 类型指标
ContainerResource 类型指标允许我们根据各个容器的资源使用量来配置自动扩缩。
在下面的示例中,HPA 控制器扩缩目标,以便所有 Pod 的应用程序容器的 CPU 平均利用率约为 60% (请参见算法详情以了解预期副本数的确切计算方式)。
type: ContainerResource
containerResource:
name: cpu
container: application
target:
type: Utilization
averageUtilization: 60
与 Resource 类型指标的区别
HPA 已具有 Resource 类型指标。
你可以定义如下的目标资源利用率,然后 HPA 将基于当前利用率扩缩副本。
type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
但这个 Resource 类型指标指的是 Pod 的平均利用率。
如果一个 Pod 有多个容器,则利用率计算公式为:
sum{每个容器的资源使用量} / sum{每个容器的资源请求}
每个容器的资源利用率可能没有直接关系,或可能随着负载变化而以不同的速度增长。
例如:
- 边车容器仅提供日志传输这类辅助服务。 如果应用程序不经常记录日志或在其频繁执行的路径中不生成日志,则日志发送器的使用量不会增长。
- 提供身份验证的边车容器。由于重度缓存,当主要容器的负载增加时,使用量只会略微增加。 在当前的混合用量计算方法中,这通常导致 HPA 不会对 Deployment 向上扩容,因为混合的使用量仍然很低。
- 边车可能在未设置资源的情况下被注入,这会阻止基于利用率进行扩缩。 在当前的逻辑中,当未设置资源请求时,HPA 控制器只能根据 Pod 的绝对资源使用量进行扩缩。
在这种情况下,如果仅有一个容器的资源利用率增加,则 Resource 类型指标可能不会建议扩容。
因此,为了实现准确的自动扩缩,你可能需要改为使用 ContainerResource 类型指标来替代这些 Pod。
Beta 版本有哪些新内容?
在 Kubernetes v1.27 中,正如本文开头所述,ContainerResource 类型指标默认可用。
(你仍然可以通过 HPAContainerMetrics 特性门禁用它。)
另外,我们已通过从 kube-controller-manager 中公开一些指标来改进 HPA 控制器的可观测性:
metric_computation_total:指标计算的数量。metric_computation_duration_seconds:HPA 控制器计算一个指标所需的时间。reconciliations_total:HPA 控制器的协调次数。reconciliation_duration_seconds:HPA 控制器协调一次 HPA 对象所需的时间。
这些指标具有 action(scale_up、scale_down、none)和
error(spec、internal、none)标签。
除此之外,前两个指标还具有 metric_type 标签,该标签对应于
HorizontalPodAutoscaler 的 .spec.metrics[*].type。
所有指标都可用于 HPA 控制器的常规监控,你可以深入洞察哪部分存在问题,在哪里耗时, 集群在哪个时间倾向于发生多少次扩缩等问题。
另一件小事是,我们已更改了 SuccessfulRescale 事件的消息,
这样每个人都可以检查事件是否来自资源指标或容器资源指标
(请参见相关 PR)。
参与其中
此特性由 SIG Autoscaling 进行管理。请加入我们分享反馈。我们期待聆听你的声音!
了解更多
Kubernetes 1.27: StatefulSet 启动序号简化了迁移
作者: Peter Schuurman (Google)
译者: Xin Li (DaoCloud)
Kubernetes v1.26 为 StatefulSet 引入了一个新的 Alpha 级别特性,可以控制 Pod 副本的序号。 从 Kubernetes v1.27 开始,此特性进级到 Beta 阶段。序数可以从任意非负数开始, 这篇博文将讨论如何使用此功能。
背景
StatefulSet 序号为 Pod 副本提供顺序标识。当使用
OrderedReady Pod 管理策略时,
Pod 是从序号索引 0 到 N-1 顺序创建的。
如今使用 Kubernetes 跨集群编排 StatefulSet 迁移具有挑战性。 虽然存在备份和恢复解决方案,但这些解决方案需要在迁移之前将应用程序的副本数缩为 0。 在当今这个完全互联的世界中,即使是计划内的应用停机可能也无法实现你的业务目标。
你可以使用级联删除或 OnDelete 策略来迁移单个 Pod, 但是这很容易出错并且管理起来很乏味。 当你的 Pod 出现故障或被逐出时,你将失去 StatefulSet 控制器的自我修复优势。
Kubernetes v1.26 使 StatefulSet 能够负责 {0..N-1} 范围内的一系列序数(序数 0、1、... 直到 N-1)。 有了它,你可以缩小源集群中的范围 {0..k-1},并扩大目标集群中的互补范围 {k..N-1},同时保证应用程序可用性。 这使你在编排跨集群迁移时保留至多一个语义(意味着最多有一个具有给定身份的 Pod 在 StatefulSet 中运行)和[滚动更新](/zh-cn/docs/tutorials/stateful-application/basic-stateful-set/#rolling-update)行为。
我为什么要使用此功能?
假设你在一个集群中运行 StatefulSet,并且需要将其迁移到另一个集群。你需要这样做的原因有很多:
- 可扩展性:你的 StatefulSet 对于你的集群而言规模过大,并且已经开始破坏集群中其他工作负载的服务质量。
- 隔离性:你在一个供多个用户访问的集群中运行 StatefulSet,而命名空间隔离是不够的。
- 集群配置:你想将 StatefulSet 迁移到另一个集群,以使用在当前集群上不存在的某些环境。
- 控制平面升级:你想将 StatefulSet 迁移到运行着较高版本控制平面, 并且无法处承担就地升级控制平面所产生的风险或预留停机时间。
我该如何使用它?
在集群上启用 StatefulSetStartOrdinal 特性门控,并使用自定义的
.spec.ordinals.start 创建一个 StatefulSet。
试试看吧
在此演示中,我将使用新机制将 StatefulSet 从一个 Kubernetes 集群迁移到另一个。 redis-cluster Bitnami Helm chart 将用于安装 Redis。
所需工具:
先决条件
为此,我需要两个可以访问公共网络和存储的 Kubernetes 集群;
我已将集群命名为 source 和 destination。具体来说,我需要:
- 在两个集群上都启用
StatefulSetStartOrdinal特性门控。 kubectl的客户端配置允许我以管理员身份访问这两个集群。- 两个集群上都安装了相同的
StorageClass,并设置为两个集群的默认StorageClass。 这个StorageClass应该提供可从一个或两个集群访问的底层存储。 - 一种扁平的网络拓扑,允许 Pod 向任一集群中的 Pod 发送数据包和从中接收数据包。 如果你在云提供商上创建集群,则此配置可能被称为私有云或私有网络。
在两个集群上创建一个用于演示的命名空间:
kubectl create ns kep-3335
在
source集群中部署一个有六个副本的 Redis 集群:helm repo add bitnami https://charts.bitnami.com/bitnami helm install redis --namespace kep-3335 \ bitnami/redis-cluster \ --set persistence.size=1Gi \ --set cluster.nodes=6
检查
source集群中的副本状态:kubectl exec -it redis-redis-cluster-0 -- /bin/bash -c \ "redis-cli -c -h redis-redis-cluster -a $(kubectl get secret redis-redis-cluster -o jsonpath="{.data.redis-password}" | base64 -d) CLUSTER NODES;"2ce30362c188aabc06f3eee5d92892d95b1da5c3 10.104.0.14:6379@16379 myself,master - 0 1669764411000 3 connected 10923-16383 7743661f60b6b17b5c71d083260419588b4f2451 10.104.0.16:6379@16379 slave 2ce30362c188aabc06f3eee5d92892d95b1da5c3 0 1669764410000 3 connected 961f35e37c4eea507cfe12f96e3bfd694b9c21d4 10.104.0.18:6379@16379 slave a8765caed08f3e185cef22bd09edf409dc2bcc61 0 1669764411000 1 connected 7136e37d8864db983f334b85d2b094be47c830e5 10.104.0.15:6379@16379 slave 2cff613d763b22c180cd40668da8e452edef3fc8 0 1669764412595 2 connected a8765caed08f3e185cef22bd09edf409dc2bcc61 10.104.0.19:6379@16379 master - 0 1669764411592 1 connected 0-5460 2cff613d763b22c180cd40668da8e452edef3fc8 10.104.0.17:6379@16379 master - 0 1669764410000 2 connected 5461-10922
在
destination集群中部署一个零副本的 Redis 集群:helm install redis --namespace kep-3335 \ bitnami/redis-cluster \ --set persistence.size=1Gi \ --set cluster.nodes=0 \ --set redis.extraEnvVars\[0\].name=REDIS_NODES,redis.extraEnvVars\[0\].value="redis-redis-cluster-headless.kep-3335.svc.cluster.local" \ --set existingSecret=redis-redis-cluster
将源集群中的
redis-redis-clusterStatefulSet 副本数缩小 1, 以删除副本redis-redis-cluster-5:kubectl patch sts redis-redis-cluster -p '{"spec": {"replicas": 5}}'
将依赖从
source集群迁移到destionation集群: 以下命令将依赖资源从source复制到destionation,其中与destionation集群无关的详细信息已被删除(例如:uid、resourceVersion、status)。说明:如果使用配置了
reclaimPolicy: Delete的StorageClass, 你应该在删除之前使用reclaimPolicy: Retain修补source中的 PV, 以保留destination中使用的底层存储。 有关详细信息,请参阅更改 PersistentVolume 的回收策略。kubectl get pvc redis-data-redis-redis-cluster-5 -o yaml | yq 'del(.metadata.uid, .metadata.resourceVersion, .metadata.annotations, .metadata.finalizers, .status)' > /tmp/pvc-redis-data-redis-redis-cluster-5.yaml kubectl get pv $(yq '.spec.volumeName' /tmp/pvc-redis-data-redis-redis-cluster-5.yaml) -o yaml | yq 'del(.metadata.uid, .metadata.resourceVersion, .metadata.annotations, .metadata.finalizers, .spec.claimRef, .status)' > /tmp/pv-redis-data-redis-redis-cluster-5.yaml kubectl get secret redis-redis-cluster -o yaml | yq 'del(.metadata.uid, .metadata.resourceVersion)' > /tmp/secret-redis-redis-cluster.yamldestination集群中的步骤说明:对于 PV/PVC,此过程仅在你的 PV 使用的底层存储系统支持复制到
destination集群时才有效。可能不支持与特定节点或拓扑关联的存储。此外,某些存储系统可能会在 PV 对象之外存储有关卷的附加元数据,并且可能需要更专门的序列来导入卷。kubectl create -f /tmp/pv-redis-data-redis-redis-cluster-5.yaml kubectl create -f /tmp/pvc-redis-data-redis-redis-cluster-5.yaml kubectl create -f /tmp/secret-redis-redis-cluster.yaml
将
destination集群中的redis-redis-clusterStatefulSet 扩容 1,起始序号为 5:kubectl patch sts redis-redis-cluster -p '{"spec": {"ordinals": {"start": 5}, "replicas": 1}}'
检查
destination集群中的副本状态:kubectl exec -it redis-redis-cluster-5 -- /bin/bash -c \ "redis-cli -c -h redis-redis-cluster -a $(kubectl get secret redis-redis-cluster -o jsonpath="{.data.redis-password}" | base64 -d) CLUSTER NODES;"我应该看到新副本(标记为
myself)已加入 Redis 集群(IP 地址与source集群中的副本归属于不同的 CIDR 块)。2cff613d763b22c180cd40668da8e452edef3fc8 10.104.0.17:6379@16379 master - 0 1669766684000 2 connected 5461-10922 7136e37d8864db983f334b85d2b094be47c830e5 10.108.0.22:6379@16379 myself,slave 2cff613d763b22c180cd40668da8e452edef3fc8 0 1669766685609 2 connected 2ce30362c188aabc06f3eee5d92892d95b1da5c3 10.104.0.14:6379@16379 master - 0 1669766684000 3 connected 10923-16383 961f35e37c4eea507cfe12f96e3bfd694b9c21d4 10.104.0.18:6379@16379 slave a8765caed08f3e185cef22bd09edf409dc2bcc61 0 1669766683600 1 connected a8765caed08f3e185cef22bd09edf409dc2bcc61 10.104.0.19:6379@16379 master - 0 1669766685000 1 connected 0-5460 7743661f60b6b17b5c71d083260419588b4f2451 10.104.0.16:6379@16379 slave 2ce30362c188aabc06f3eee5d92892d95b1da5c3 0 1669766686613 3 connected
- 对剩余的副本重复 #5 到 #7 的步骤,直到
source集群中的 Redis StatefulSet 副本缩放为 0, 并且destination集群中的 Redis StatefulSet 健康,总共有 6 个副本。
接下来?
此特性为跨集群拆分 StatefulSet 提供了一项基本支撑技术,但没有规定 StatefulSet 的迁移机制。 迁移需要对 StatefulSet 副本的协调,以及对存储和网络层的编排。这取决于使用 StatefulSet 安装的应用程序的存储和网络连接要求。此外,许多 StatefulSet 由 operator 管理,这也增加了额外的迁移复杂性。
如果你有兴趣构建增强功能以简化这些过程,请参与 SIG Multicluster 做出贡献!
官方自动刷新 CVE 订阅源的更新
作者:Cailyn Edwards (Shopify), Mahé Tardy (Isovalent), Pushkar Joglekar
译者:Wilson Wu (DaoCloud)
自从在 1.25 版本中将官方自动刷新 CVE 订阅源作为 Alpha 功能启用以来,我们已经做了一些重大改进和更新。我们很高兴宣布该订阅源的 Beta 版现已发布。这篇博文将列举收到的反馈、所做的更改, 还讨论了在未来 Kubernetes 版本中准备使其进阶成为一个稳定功能时你可以如何提供帮助。
来自最终用户的反馈
SIG Security 收到了一些最终用户的反馈:
- JSON CVE Feed 的名称与在 JSON Feed 规范中所建议的不符。
- 除了 JSON Feed 格式之外,订阅源还可以支持 RSS 格式。
- 可以添加一些元数据来表示整体订阅的实时性, 或者特殊 CVE 内容。 另一个建议是希望指出哪个 Prow 作业最近对订阅源进行了更新。 可以直接在问题汇总中查看更多想法。
- 网站上的订阅源 Markdown 表应按照 CVE 发布的时间顺序由近到远排列。
变更摘要
在回应中,SIG 对生成 JSON 格式订阅源的脚本进行了修改,
让生成的内容符合 JSON Feed 规范,并添加 last_updated 根字段表示整体实时性。此重新设计需要
Kubernetes 网站的相应修复,以便 CVE 订阅源页面基于新格式继续工作。
之后,完全透明的添加了 RSS 订阅源支持,以便最终用户使用订阅源时可以将其作为首选格式。
总而言之,基于 JSON Feed 规范的重新设计(打破了向后兼容性)将允许后续进行更新以解决其余问题,同时令其更加透明且对最终用户的干扰做到较小。
更新
| 标题 | Issue | 状态 |
|---|---|---|
| CVE Feed: JSON feed should pass jsonfeed spec validator | kubernetes/webite#36808 | 已关闭,详见:kubernetes/sig-security#76 |
| CVE Feed: Add lastUpdatedAt as a metadata field | kubernetes/sig-security#72 | 已关闭,详见:kubernetes/sig-security#76 |
| Support RSS feeds by generating data in Atom format | kubernetes/sig-security#77 | 已关闭,详见:kubernetes/website#39513 |
| CVE Feed: Sort Markdown Table from most recent to least recently announced CVE | kubernetes/sig-security#73 | 已关闭,详见:kubernetes/sig-security#76 |
| CVE Feed: Include a timestamp field for each CVE indicating when it was last updated | kubernetes/sig-security#63 | 已关闭,详见:kubernetes/sig-security#76 |
| CVE Feed: Add Prow job link as a metadata field | kubernetes/sig-security#71 | 已关闭,详见:kubernetes/sig-security#83 |
接下来要做什么?
为了此订阅源进阶至稳定阶段做准备,
即 General Availability 阶段,SIG Security 仍将从最终用户持续收集他们使用最新 Beta 版订阅源后的反馈。
为了帮助我们在未来的 Kubernetes 版本中继续改进订阅源,请通过对此跟踪 Issue 添加评论来分享反馈,或者通过 #sig-security-tooling Kubernetes Slack 频道让我们获得更多信息,由此加入 Kubernetes Slack。
Kubernetes 1.27:服务器端字段校验和 OpenAPI V3 进阶至 GA
作者:Jeffrey Ying (Google), Antoine Pelisse (Google)
译者:Michael Yao (DaoCloud)
在 Kubernetes v1.8 之前,YAML 文件中的拼写错误、缩进错误或其他小错误可能会产生灾难性后果
(例如像在 replica: 1000 中忘记了结尾的字母 “s”,可能会导致宕机。
因为该值会被忽略并且丢失,并强制将副本重置回 1)。当时解决这个问题的办法是:
在 kubectl 中获取 OpenAPI v2 并在应用之前使用 OpenAPI v2 来校验字段是否正确且存在。
不过当时没有自定义资源定义 (CRD),相关代码是在当时那样的假设下编写的。
之后引入了 CRD,发现校验代码缺乏灵活性,迫使 CRD 在公开其模式定义时做出了一些艰难的决策,
使得我们进入了不良校验造成不良 OpenAPI,不良 OpenAPI 无法校验的循环。
随着新的 OpenAPI v3 和服务器端字段校验在 1.27 中进阶至 GA,我们现在已经解决了这两个问题。
服务器端字段校验针对通过 create、update 和 patch 请求发送到 apiserver 上的资源进行校验, 此特性是在 Kubernetes v1.25 中添加的,在 v1.26 时进阶至 Beta, 如今在 v1.27 进阶至 GA。它在服务器端提供了 kubectl 校验的所有功能。
OpenAPI 是一个标准的、与编程语言无关的接口, 用于发现 Kubernetes 集群支持的操作集和类型集。 OpenAPI v3 是 OpenAPI 的最新标准,它是自 Kubernetes 1.5 开始支持的 OpenAPI v2 的改进版本。对 OpenAPI v3 的支持是在 Kubernetes v1.23 中添加的, v1.24 时进阶至 Beta,如今在 v1.27 进阶至 GA。
OpenAPI v3
OpenAPI v3 相比 v2 提供了什么?
插件类型
Kubernetes 对 OpenAPI v2 中不能表示或有时在 Kubernetes 生成的 OpenAPI v2 中未表示的某些字段提供了注解。最明显地,OpenAPI v3 发布了 “default” 字段, 而在 OpenAPI v2 中被省略。表示多种类型的单个类型也能在 OpenAPI v3 中使用 oneOf 字段被正确表达。这包括针对 IntOrString 和 Quantity 的合理表示。
CRD
在 Kubernetes 中,自定义资源定义 (CRD) 使用结构化的 OpenAPI v3 模式定义, 无法在不损失某些字段的情况下将其表示为 OpenAPI v2。这些包括 nullable、default、anyOf、oneOf、not 等等。OpenAPI v3 是 CustomResourceDefinition 结构化模式定义的完全无损表示。
如何使用?
Kubernetes API 服务器的 /openapi/v3 端点包含了 OpenAPI v3 的根发现文档。
为了减少传输的数据量,OpenAPI v3 文档以 group-version 的方式进行分组,
不同的文档可以通过 /openapi/v3/apis/<group>/<version> 和 /openapi/v3/api/v1
(表示旧版 group)进行访问。有关此端点的更多信息请参阅
Kubernetes API 文档。
众多使用 OpenAPI 的客户侧组件已更新到了 v3,包括整个 kubectl 和服务器端应用。 在 client-go 中也提供了 OpenAPI V3 Golang 客户端。
服务器端字段校验
查询参数 fieldValidation 可用于指示服务器应执行的字段校验级别。
如果此参数未被传递,服务器端字段校验默认采用 Warn 模式。
- Strict:严格的字段校验,在验证失败时报错
- Warn:执行字段校验,但错误会以警告的形式给出,而不是使请求失败
- Ignore:不执行服务器端的字段校验
kubectl 将跳过客户端校验,并将自动使用 Strict 模式下的服务器端字段校验。
控制器默认使用 Warn 模式进行服务器端字段校验。
使用客户端校验时,由于 OpenAPI v2 中缺少某些字段,所以我们必须更加宽容, 以免拒绝可能有效的对象。而在服务器端校验中,所有这些问题都被修复了。 可以在此处找到更多文档。
未来展望
随着服务器端字段校验和 OpenAPI v3 以 GA 发布,我们引入了更准确的 Kubernetes 资源表示。 建议使用服务器端字段校验而非客户端校验,但是通过 OpenAPI v3, 客户端可以在必要时自行实现其自身的校验(“左移”),我们保证 OpenAPI 发布的是完全无损的模式定义。
现在的一些工作将进一步改善通过 OpenAPI 提供的信息,例如 CEL 校验和准入以及对内置类型的 OpenAPI 注解。
使用在 OpenAPI v3 中的类型信息还可以构建许多其他工具来编写和转换资源。
如何参与?
这两个特性由 SIG API Machinery 社区驱动,欢迎加入 Slack 频道 #sig-api-machinery, 请查阅邮件列表, 我们每周三 11:00 AM PT 在 Zoom 上召开例会。
我们对所有曾帮助设计、实现和审查这两个特性的贡献者们表示衷心的感谢。
- Alexander Zielenski
- Antoine Pelisse
- Daniel Smith
- David Eads
- Jeffrey Ying
- Jordan Liggitt
- Kevin Delgado
- Sean Sullivan
Kubernetes 1.27: 使用 Kubelet API 查询节点日志
作者: Aravindh Puthiyaparambil (Red Hat)
译者: Xin Li (DaoCloud)
Kubernetes 1.27 引入了一个名为节点日志查询的新功能, 可以查看节点上运行的服务的日志。
它解决了什么问题?
集群管理员在调试节点上运行的表现不正常的服务时会遇到问题。 他们通常必须通过 SSH 或 RDP 进入节点以查看服务日志以调试问题。 节点日志查询功能通过允许集群管理员使用 kubectl 查看日志的方式来帮助解决这种情况。这对于 Windows 节点特别有用, 在 Windows 节点中,你会遇到节点进入就绪状态但由于 CNI 错误配置和其他不易通过查看 Pod 状态来辨别的问题而导致容器无法启动的情况。
它是如何工作的?
kubelet 已经有一个 /var/log/ 查看器,可以通过节点代理端点访问。
本功能特性通过一个隔离层对这个端点进行增强,在 Linux 节点上通过
journalctl Shell 调用获得日志,在 Windows 节点上通过 Get-WinEvent CmdLet 获取日志。
然后它使用命令提供的过滤器来过滤日志。kubelet 还使用启发式方法来检索日志。
如果用户不知道给定的系统服务是记录到文件还是本机系统记录器,
启发式方法首先检查本机操作系统记录器,如果不可用,它会尝试先从 /var/log/<servicename>
或 /var/log/<servicename>.log 或 /var/log/<servicename>/<servicename>.log 检索日志。
在 Linux 上,我们假设服务日志可通过 journald 获得,
并且安装了 journalctl。 在 Windows 上,我们假设服务日志在应用程序日志提供程序中可用。
另请注意,只有在你被授权的情况下才能获取节点日志(在 RBAC 中,
这是对 nodes/proxy 的 get 和 create 访问)。
获取节点日志所需的特权也允许特权提升攻击(elevation-of-privilege),
因此请谨慎管理它们。
该如何使用它
要使用该功能,请确保为该节点启用了 NodeLogQuery
特性门控,
并且 kubelet 配置选项 enableSystemLogHandler 和 enableSystemLogQuery 都设置为 true。
然后,你可以查询所有节点或部分节点的日志。下面是一个从节点检索 kubelet 服务日志的示例:
# Fetch kubelet logs from a node named node-1.example
kubectl get --raw "/api/v1/nodes/node-1.example/proxy/logs/?query=kubelet"
你可以进一步过滤查询以缩小结果范围:
# Fetch kubelet logs from a node named node-1.example that have the word "error"
kubectl get --raw "/api/v1/nodes/node-1.example/proxy/logs/?query=kubelet&pattern=error"
你还可以从 Linux 节点上的 /var/log/ 获取文件:
kubectl get --raw "/api/v1/nodes/<insert-node-name-here>/proxy/logs/?query=/<insert-log-file-name-here>"
你可以阅读文档获取所有可用选项。
如何提供帮助
请使用该功能并通过在 GitHub 上登记问题或通过 Kubernetes Slack 的 #sig-windows 频道 或 SIG Windows 邮件列表 联系我们来提供反馈。
Kubernetes 1.27:持久卷的单个 Pod 访问模式升级到 Beta
作者:Chris Henzie (Google)
译者:顾欣 (ICBC)
随着 Kubernetes v1.27 的发布,ReadWriteOncePod 功能已经升级为 Beta 版。 在这篇博客文章中,我们将更详细地介绍这个功能,作用以及在 Beta 版本中的发展。
什么是 ReadWriteOncePod
ReadWriteOncePod 是 Kubernetes 在 v1.22 中引入的一种新的访问模式, 适用于 PersistentVolume(PVs) 和 PersistentVolumeClaim(PVCs)。 此访问模式使你能够将存储卷访问限制在集群中的单个 Pod 上,确保一次只有一个 Pod 可以写入存储卷。 这可能对需要单一写入者访问存储的有状态工作负载特别有用。
要了解有关访问模式和 ReadWriteOncePod 如何工作的更多背景信息, 请阅读 2021 年介绍 PersistentVolume 的单个 Pod 访问模式的文章中的什么是访问模式和为什么它们如此重要?。
ReadWriteOncePod 的 Beta 版中变化
ReadWriteOncePod Beta 版为使用 ReadWriteOncePod PVC 的 Pod 添加调度器抢占。
调度器抢占允许更高优先级的 Pod 抢占较低优先级的 Pod,以便它们可以在同一节点上运行。 在此版本中,如果更高优先级的 Pod 需要相同的 PVC,使用 ReadWriteOncePod PVCs 的 Pod 也可以被抢占。
如何开始使用 ReadWriteOncePod?
随着 ReadWriteOncePod 现已升级为 Beta 版,在 v1.27 及更高版本的集群中将默认启用该功能。
请注意,ReadWriteOncePod 仅支持 CSI 卷。 在使用此功能之前,你需要将以下 CSI Sidecars更新至以下版本或更高版本:
要开始使用 ReadWriteOncePod,请创建具有 ReadWriteOncePod 访问模式的 PVC:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: single-writer-only
spec:
accessModes:
- ReadWriteOncePod #仅允许一个容器访问且独占写入权限。
resources:
requests:
storage: 1Gi
如果你的存储插件支持动态制备, 新创建的持久卷将应用 ReadWriteOncePod 访问模式。
阅读迁移现有持久卷 以了解如何迁移现有卷以使用 ReadWriteOncePod。
如何了解更多信息?
请查看 Alpha 版博客和 KEP-2485 以了解关于 ReadWriteOncePod 访问模式的更多详细信息以及对 CSI 规约作更改的动机。
如何参与?
Kubernetes #csi Slack频道以及任何常规的 SIG 存储沟通渠道 都是联系 SIG 存储和 CSI 团队的最佳途径。
特别感谢以下人士的仔细的审查和反馈,帮助完成了这个功能:
- Abdullah Gharaibeh (ahg-g)
- Aldo Culquicondor (alculquicondor)
- Antonio Ojea (aojea)
- David Eads (deads2k)
- Jan Šafránek (jsafrane)
- Joe Betz (jpbetz)
- Kante Yin (kerthcet)
- Michelle Au (msau42)
- Tim Bannister (sftim)
- Xing Yang (xing-yang)
如果您有兴趣参与 CSI 或 Kubernetes 存储系统的任何部分的设计和开发, 请加入 Kubernetes 存储特别兴趣小组(SIG)。 我们正在迅速发展,始终欢迎新的贡献者。
Kubernetes 1.27:高效的 SELinux 卷重新标记(Beta 版)
作者:Jan Šafránek (Red Hat)
译者:Wilson Wu (DaoCloud)
问题
在启用了 Security-Enhancled Linux(SELinux)系统上,传统做法是让容器运行时负责为
Pod 及所有卷应用 SELinux 标签。
Kubernetes 仅将 SELinux 标签从 Pod 的 securityContext 字段传递给容器运行时。
然后,容器运行时以递归的方式更改 Pod 容器可见的所有文件上的 SELinux 标签。 如果卷上有许多文件,这一过程可能会非常耗时,尤其是当卷位于远程文件系统上时。
Note
如果容器使用卷的 subPath,则系统仅重新标记整个卷的 subPath。
这样,使用不同 SELinux 标签的两个 Pod 可以使用同一卷,只要它们使用该卷的不同子路径即可。
如果 Pod 没有从 Kubernetes API 中获得任何 SELinux 标签,则容器运行时会分配一个唯一的随机标签, 因此可能逃离容器边界的进程将无法访问主机上任何其他容器的数据。 容器运行时仍然使用此随机 SELinux 标签递归地重新标记所有 Pod 卷。
使用挂载选项进行改进
如果 Pod 及其卷满足以下所有条件,Kubernetes 将直接使用正确的 SELinux 标签挂载该卷。 这种挂载将在确定时间内完成,容器运行时不需要递归地重新标记其上的任何文件。
操作系统必须支持 SELinux。
如果没有检测到 SELinux 支持,kubelet 和容器运行时不会对 SELinux 执行任何操作。
必须启用特性门控
ReadWriteOncePod和SELinuxMountReadWriteOncePod。这些特性门控在 Kubernetes 1.27 中是 Beta 版,在 1.25 中是 Alpha 版。禁用这些功能中任何一个后,SELinux 标签将始终由容器运行时通过递归遍历卷(或其 subPath)来应用。
Pod 必须在其 Pod 安全上下文中至少设置
seLinuxOptions.level,或者所有 Pod 容器必须在安全上下文中对其进行设置。 否则 Kubernetes 将从操作系统默认值(通常是system_u、system_r和container_t)中读取默认的user、role和type。如果 Kubernetes 不了解任何 SELinux
level,容器运行时将在卷挂载后为其分配一个随机级别。 在这种情况下,容器运行时仍会递归地对卷进行重新标记。
存储卷必须是访问模式 为
ReadWriteOncePod的持久卷。这是最初的实现的限制。如上所述,两个 Pod 可以具有不同的 SELinux 标签,但仍然使用相同的卷, 只要它们使用不同的
subPath即可。对于已挂载的带有 SELinux 标签的卷,此场景是无法支持的, 因为整个卷已挂载,并且大多数文件系统不支持使用不同的 SELinux 标签多次挂载同一个卷。如果在你的环境中需要使用两个不同的 SELinux 上下文运行两个 Pod 并使用同一卷的不同
subPath, 请在 KEP 问题中发表评论(或对任何现有评论进行投票 - 最好不要重复)。 当此特性扩展到覆盖所有卷访问模式时,这类 Pod 可能无法运行。
卷插件或负责卷的 CSI 驱动程序支持使用 SELinux 挂载选项进行挂载。
这些树内卷插件支持使用 SELinux 挂载选项进行挂载:
fc、iscsi和rbd。支持使用 SELinux 挂载选项挂载的 CSI 驱动程序必须通过设置
seLinuxMount字段在其 CSIDriver 实例中声明这一点。由其他未设置
seLinuxMount: true的卷插件或 CSI 驱动程序管理的卷将由容器运行时递归地重新标记。
使用 SELinux 上下文挂载
当满足所有上述条件时,kubelet 会将 -o context=<SELinux label> 挂载选项传递给卷插件或 CSI 驱动程序。
CSI 驱动程序提供者必须确保其 CSI 驱动程序支持此安装选项,并且如有必要,CSI 驱动程序要附加
-o context 所需的其他安装选项。
例如,NFS 可能需要 -o context=<SELinux label>,nosharecache,这样来自同一
NFS 服务器的多个卷被挂载时可以具有不同的 SELinux 标签值。
类似地,CIFS 可能需要 -o context=<SELinux label>,nosharesock。
在 CSIDriver 实例中设置 seLinuxMount: true 之前,CSI 驱动程序提供者需要在启用 SELinux
的环境中测试其 CSI 驱动程序。
如何了解更多?
容器中的 SELinux:请参阅 Daniel J Walsh 撰写的可视化 SELinux 指南(英文)。 请注意,该指南早于 Kubernetes,它以虚拟机为例描述了多类别安全(MCS)模式,但是,类似的概念也适用于容器。
请参阅以下系列博客文章,详细了解容器运行时如何将 SELinux 应用于容器:
阅读 KEP:使用挂载加速 SELinux 卷重新标记
Kubernetes 1.27:更多精细粒度的 Pod 拓扑分布策略进阶至 Beta
作者: Alex Wang (Shopee), Kante Yin (DaoCloud), Kensei Nakada (Mercari)
译者: Michael Yao (DaoCloud)
在 Kubernetes v1.19 中, Pod 拓扑分布约束进阶至正式发布 (GA)。
随着时间的流逝,SIG Scheduling 收到了许多用户的反馈, 随后通过 3 个 KEP 积极改进了 Topology Spread(拓扑分布)特性。 所有这些特性在 Kubernetes v1.27 中已进阶至 Beta 且默认被启用。
这篇博文介绍了这些特性及其背后的使用场景。
KEP-3022:Pod 拓扑分布中的最小域数
Pod 拓扑分布使用 maxSkew 参数来定义 Pod 可以不均匀分布的程度。
但还有没有一种方式可以控制应分布到的域数。 一些用户想要强制在至少指定个数的若干域内分布 Pod;并且如果目前存在的域个数还不够, 则使用 cluster-autoscaler 制备新的域。
Kubernetes v1.24 以 Alpha 特性的形式为 Pod 拓扑分布约束引入了 minDomains 参数。
通过 minDomains 参数,你可以定义最小域数。
例如,假设有 3 个 Node 具有足够的容量,
且新建的 ReplicaSet 在其 Pod 模板中带有以下 topologySpreadConstraints。
...
topologySpreadConstraints:
- maxSkew: 1
minDomains: 5 # 需要至少 5 个 Node(因为每个 Node 都有唯一的 hostname)
whenUnsatisfiable: DoNotSchedule # 只有使用 DoNotSchedule 时 minDomains 才有效
topologyKey: kubernetes.io/hostname
labelSelector:
matchLabels:
foo: bar
在这个场景中,3 个 Pod 将被分别调度到这 3 个 Node 上, 但 ReplicaSet 中的其它 2 个 Pod 在更多 Node 接入到集群之前将无法被调度。
你可以想象集群自动扩缩器基于这些不可调度的 Pod 制备新的 Node, 因此这些副本最后将分布到 5 个 Node 上。
KEP-3094:计算 podTopologySpread 偏差时考虑污点/容忍度
在本次增强之前,当你部署已经配置了 topologySpreadConstraints 的 Pod 时,kube-scheduler
将在过滤和评分时考虑满足 Pod 的 nodeAffinity 和 nodeSelector 的节点,
但不关心传入的 Pod 是否容忍节点污点。这可能会导致具有不可容忍污点的节点成为唯一的分布候选,
因此如果 Pod 不容忍污点,则该 Pod 将卡在 Pending 状态。
为了能够在计算分布偏差时针对要考虑的节点作出粒度更精细的决策,Kubernetes 1.25
在 topologySpreadConstraints 中引入了两个新字段 nodeAffinityPolicy
和 nodeTaintPolicy 来定义节点包含策略。
应用这些策略的清单如下所示:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# 配置拓扑分布约束
topologySpreadConstraints:
- maxSkew: <integer>
# ...
nodeAffinityPolicy: [Honor|Ignore]
nodeTaintsPolicy: [Honor|Ignore]
# 在此处添加其他 Pod 字段
nodeAffinityPolicy 字段指示 Kubernetes 如何处理 Pod 的 nodeAffinity 或 nodeSelector
以计算 Pod 拓扑分布。如果是 Honor,则 kube-scheduler 在计算分布偏差时会过滤掉不匹配
nodeAffinity/nodeSelector 的节点。如果是 Ignore,则会包括所有节点,不会管它们是否与
Pod 的 nodeAffinity/nodeSelector 匹配。
为了向后兼容,nodeAffinityPolicy 默认为 Honor。
nodeTaintsPolicy 字段定义 Kubernetes 计算 Pod 拓扑分布时如何对待节点污点。
如果是 Honor,则只有配置了污点的节点上的传入 Pod 带有容忍标签时该节点才会被包括在分布偏差的计算中。
如果是 Ignore,则在计算分布偏差时 kube-scheduler 根本不会考虑节点污点,
因此带有未容忍污点的 Pod 的节点也会被包括进去。
为了向后兼容,nodeTaintsPolicy 默认为 Ignore。
该特性在 v1.25 中作为 Alpha 引入。默认被禁用,因此如果要在 v1.25 中使用此特性,
则必须显式启用特性门控 NodeInclusionPolicyInPodTopologySpread。
在接下来的 v1.26 版本中,相关特性进阶至 Beta 并默认被启用。
KEP-3243:滚动升级后关注 Pod 拓扑分布
Pod 拓扑分布使用 labelSelector 字段来标识要计算分布的 Pod 组。
在针对 Deployment 进行拓扑分布时,通常会使用 Deployment 的
labelSelector 作为拓扑分布约束中的 labelSelector。
但这意味着 Deployment 的所有 Pod 都参与分布计算,与这些 Pod 是否属于不同的版本无关。
因此,在发布新版本时,分布将同时应用到新旧 ReplicaSet 的 Pod,
并在新的 ReplicaSet 完全发布且旧的 ReplicaSet 被下线时,我们留下的实际分布可能与预期不符,
这是因为旧 ReplicaSet 中已删除的 Pod 将导致剩余 Pod 的分布不均匀。
为了避免这个问题,过去用户需要向 Deployment 添加修订版标签,并在每次滚动升级时手动更新
(包括 Pod 模板上的标签和 topologySpreadConstraints 中的 labelSelector)。
为了通过更简单的 API 解决这个问题,Kubernetes v1.25 引入了一个名为 matchLabelKeys
的新字段到 topologySpreadConstraints 中。matchLabelKeys 是一个 Pod 标签键列表,
用于选择计算分布方式的 Pod。这些键用于查找 Pod 被调度时的标签值,
这些键值标签与 labelSelector 进行逻辑与运算,为新增 Pod 计算分布方式选择现有 Pod 组。
借助 matchLabelKeys,你无需在修订版变化时更新 pod.spec。
控制器或 Operator 管理滚动升级时只需针对不同修订版为相同的标签键设置不同的值即可。
调度程序将基于 matchLabelKeys 自动完成赋值。例如,如果你正配置 Deployment,
则可以使用由 Deployment 控制器自动添加的
pod-template-hash
的标签键来区分单个 Deployment 中的不同修订版。
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: foo
matchLabelKeys:
- pod-template-hash
参与其中
这些特性归 Kubernetes SIG Scheduling 管理。
请加入我们分享反馈。我们期待聆听你的声音!
了解更多
“使用更新后的 Go 版本保持 Kubernetes 安全”
作者:Jordan Liggitt (Google)
译者:顾欣 (ICBC)
问题
从 2020 年发布的 v1.19 版本以来,Kubernetes 项目为每个次要版本提供 12-14 个月的补丁维护期。 这使得用户可以按照年度升级周期来评估和选用 Kubernetes 版本,并持续一年获得安全修复。
Go 项目每年发布两个新的次要版本, 并为最近的两个版本提供安全修复,每个 Go 版本的维护期约为一年。 尽管每个新的 Kubernetes 次要版本在最初发布时都是使用受支持的 Go 版本编译构建的, 但在这一 Kubernetes 次要版本被停止支持之前,对应的 Go 版本就已经不被支持, 并且由于 Kubernetes 从 v1.19 开始延长了补丁支持期,这个差距被进一步扩大。
在编写本文时,包含了可能对安全产生影响的问题修复的 Go 补丁发布版本 刚刚过半(88/171)。尽管这些问题中很多都与 Kubernetes 无关,但有些确实相关, 因此使用受支持的、已包含了这类修复的 Go 版本是非常重要的。
显而易见的解决方案之一是直接更新 Kubernetes 的发布分支,使用 Go 的新次要版本。 然而,Kubernetes 避免在补丁发布中引入破坏稳定性的变更, 过去,因为这些变更被认为包含过高的复杂性、风险或破坏性,不适合包含在补丁发布中, 所以不能将现有发布分支更新到 Go 的新次要版本。 示例包括:
- Go 1.6: 默认支持 http/2
- Go 1.14: EINTR 问题处理
- Go 1.17: 取消 x509 CN 支持, ParseIP 更改
- Go 1.18: 默认禁用 x509 SHA-1 证书支持
- Go 1.19: 取消当前目录 LookPath 行为
其中一些更改可以基本不会影响 Kubernetes 代码,
有些只能通过用户指定的 GODEBUG 环境变量来选择放弃更新,
而其他变更则需要侵入式的代码变更或完全无法避免。
由于这种不一致性,Kubernetes 的发布分支通常保持使用某个固定的 Go 次要版本,
并在每个 Kubernetes 次要版本支持生命周期的最后几个月内,面临无法得到重要的 Go 安全修复的风险。
当某项重要的 Go 安全修复仅出现在较新的 Kubernetes 次要版本时, 用户必须在旧的 Kubernetes 次要版本的 12-14 个月支持期结束之前完成升级,以获取这些修复。 如果用户没有准备好升级,可能导致 Kubernetes 集群的安全漏洞。 即使用户可以接受这种意外升级,这种不确定性也使得 Kubernetes 在年度支持从规划角度看变得不太可靠。
解决方案
我们很高兴地宣布,自2023年1月起,受支持的 Kubernetes 版本与受支持的 Go 版本之间的差距已得到解决。
在过去的一年里,我们与 Go 团队密切合作,以解决采用新的 Go 版本的困难。 这些工作推动了一场讨论、 提案、 GopherCon 演讲和设计, 以提高 Go 的向后兼容性, 确保新的 Go 版本至少在两年(四个 Go 版本)内能够与之前的 Go 版本保持兼容的运行时行为。 这使得像 Kubernetes 这样的项目能够将发布分支更新到受支持的 Go 版本, 而不是将行为上的变更暴露给用户。
所提议的改进正按计划包含在 Go 1.21 中, 而且 Go 团队已经在 2022 年底的 Go 1.19 补丁发布中提供了针对兼容性的改进。 这些更改使 Kubernetes 1.23+ 在 2023 年 1 月升级到 Go 1.19,并避免了任何用户可见的配置或行为变化。 现在所有受支持的 Kubernetes 发布分支都使用受支持的 Go 版本, 并且可以使用包含可用的安全修复的、新的 Go 补丁发布。
展望未来,Kubernetes 维护者仍致力于使 Kubernetes 补丁发布尽可能安全且不会造成破坏, 因此在现有的 Kubernetes 发布分支更新使用新的 Go 次要版本之前,新的 Go 次要版本必须满足几个要求:
- 新的 Go 版本必须至少已经推出 3 个月。 这给了 Go 社区足够的时间进行报告并解决问题。
- 新的 Go 版本在新的 Kubernetes 次要版本中至少已经使用了 1 个月。 这确保 Kubernetes 所有可能阻塞发布的测试都需要能在新的 Go 版本下通过, 并在早期为 Kubernetes 社区对发布候选版本和新次要版本提供反馈时间。
- 与先前的 Go 版本相比,不能出现新的已知会影响 Kubernetes 的问题。
- 默认情况下必须保持运行时行为,而无需 Kubernetes 用户/管理员采取任何操作。
- Kubernetes 库,如
k8s.io/client-go必须与每个次要版本最初使用的 Go 版本保持兼容, 以便在获取库补丁时,用户不必更新 Go 版本(不过还是鼓励他们使用受支持的 Go 版本构建, 因为 Go 1.21 计划中的兼容性改进会使得这一操作变简单)。
所有这些工作的目标是在不引人注意的情况下使 Kubernetes 补丁发布更加安全可靠, 并确保在整个支持周期内 Kubernetes 次要版本用起来都是安全的。
非常感谢 Go 团队,尤其是 Russ Cox,他们推动了这些改进, 使所有 Go 用户受益,而不仅仅是 Kubernetes。
Kubernetes 验证准入策略:一个真实示例
作者:Craig Box (ARMO), Ben Hirschberg (ARMO)
译者:Xiaoyang Zhang (Huawei)
准入控制是 Kubernetes 控制平面的重要组成部分,在向服务器提交请求时,可根据批准或更改 API 对象的能力来实现多项内部功能。 对于管理员来说,定义有关哪些对象可以进入集群的业务逻辑或策略是很有用的。为了更好地支持该场景, Kubernetes 在 v1.7 中引入了外部准入控制。
除了众多的自定义内部实现外,许多开源项目和商业解决方案还使用用户指定的策略实现准入控制器,包括 Kyverno 和 Open Policy Agent 的 Gatekeep。
虽然针对策略的准入控制器已经被人采用,但其广泛使用仍存在障碍。 Webhook 基础设施必须作为生产服务进行维护,且包含所有相关内容。 如果准入控制 Webhook 失败,则要么必须关闭,从而降低集群的可用性;要么打开,使该功能在策略执行中的使用失效。 例如,在 “serverless” 环境中,当 Pod 启动以响应网络请求时,网络跳跃和评估时间使准入控制成为处理延迟的重要组成部分。
验证准入策略和通用表达语言
Kubernetes 1.26 版本引入了一个折中的、Alpha 状态的解决方案。 验证准入策略是一种声明式的、 进程内的方案,用来替代验证准入 Webhook。使用通用表达语言 (Common Expression Language,CEL) 来声明策略的验证规则。
CEL 是由 Google 根据 Firebase 实时数据库的经验,针对安全和策略用例而开发的。 它的设计使得它可以安全地嵌入到应用程序中,执行时间在微秒量级,对计算和内存的影响很小。 v1.23 版本中,针对 CRD 的验证规则将 CEL 引入了 Kubernetes 生态系统,当时人们注意到该语言将适合实现通过准入控制进行更通用的验证。
让 CEL 发挥作用——一个实际例子
Kubescape 是一个 CNCF 项目, 已成为用户改善 Kubernetes 集群安全状况并验证其合规性的最流行方法之一。 它的控件——针对 API 对象的多组测试——是用 Open Policy Agent 的策略语言 Rego 构建的。
Rego 以复杂性著称,这主要是因为它是一种声明式查询语言(如 SQL)。 它被考虑在 Kubernetes 中使用,但它没有提供与 CEL 相同的沙箱约束。
该项目的一个常见功能要求是能够根据 Kubescape 的发现和输出来实现策略。例如,在扫描 Pod 是否存在云凭据文件的已知路径后, 用户希望能够执行完全不允许这些 Pod 进入的策略。 Kubescape 团队认为这是一个绝佳的机会,可以尝试将现有的控制措施移植到 CEL,并将其应用为准入策略。
策略展示
我们很快就转换了许多控件并建立了一个验证准入策略的库。让我们看一个例子。
Kubescape 的 control C-0017 涵盖了容器具有不可变(只读)根文件系统的要求。 根据 NSA Kubernetes 强化指南, 这是最佳实践,但目前不要求将其作为任何 Pod 安全标准的一部分。
以下是我们用 CEL 的实现方式:
apiVersion: admissionregistration.k8s.io/v1alpha1
kind: ValidatingAdmissionPolicy
metadata:
name: "kubescape-c-0017-deny-resources-with-mutable-container-filesystem"
spec:
failurePolicy: Fail
matchConstraints:
resourceRules:
- apiGroups: [""]
apiVersions: ["v1"]
operations: ["CREATE", "UPDATE"]
resources: ["pods"]
- apiGroups: ["apps"]
apiVersions: ["v1"]
operations: ["CREATE", "UPDATE"]
resources: ["deployments","replicasets","daemonsets","statefulsets"]
- apiGroups: ["batch"]
apiVersions: ["v1"]
operations: ["CREATE", "UPDATE"]
resources: ["jobs","cronjobs"]
validations:
- expression: "object.kind != 'Pod' || object.spec.containers.all(container, has(container.securityContext) && has(container.securityContext.readOnlyRootFilesystem) && container.securityContext.readOnlyRootFilesystem == true)"
message: "Pods having containers with mutable filesystem not allowed! (see more at https://hub.armosec.io/docs/c-0017)"
- expression: "['Deployment','ReplicaSet','DaemonSet','StatefulSet','Job'].all(kind, object.kind != kind) || object.spec.template.spec.containers.all(container, has(container.securityContext) && has(container.securityContext.readOnlyRootFilesystem) && container.securityContext.readOnlyRootFilesystem == true)"
message: "Workloads having containers with mutable filesystem not allowed! (see more at https://hub.armosec.io/docs/c-0017)"
- expression: "object.kind != 'CronJob' || object.spec.jobTemplate.spec.template.spec.containers.all(container, has(container.securityContext) && has(container.securityContext.readOnlyRootFilesystem) && container.securityContext.readOnlyRootFilesystem == true)"
message: "CronJob having containers with mutable filesystem not allowed! (see more at https://hub.armosec.io/docs/c-0017)"
此策略为三个可能的 API 组提供匹配约束:Pod 的 core/v1 组、负载控制器的 apps/v1
和作业控制器的 batch/v1。
说明:
matchConstraints 会为你将 API 对象转换为匹配的版本。例如,如果 API 请求的对象是 apps/v1beta1,
而你在 matchConstraints 中要匹配 apps/v1,那么 API 请求就会从 apps/v1beta1 转换为 apps/v1 然后进行验证。
这样做的好处是可以确保验证规则不会被引入新版本的 API 所破坏,否则 API 请求就会通过使用新引入的版本而躲过验证规则的检查。
其中 validations 包括对象的 CEL 规则。有三种不同的表达方式,以满足 Pod spec
可以位于对象的根部(独立的 Pod)、
在 template 下(负载控制器或作业)或位于 jobTemplate(CronJob)下的情况。
如果任何一个 spec 没有将 readOnlyRootFilesystem 设为 true,则该对象将不会被接受。
说明:
在最初的版本中,我们将这三个表达式分组到同一个策略对象中。这意味着可以原子性地启用和禁用它们,
因此不会出现以下情况:用户启用一个 API 组的策略而未启用其他组的策略,从而不小心留下合规性漏洞。
将它们分成单独的策略将使我们能够使用针对 1.27 版本所作的改进,包括类型检查。
我们正在与 SIG API Machinery 讨论如何在 API 达到 v1 之前最好地解决这个问题。
在集群中使用 CEL 库
策略以 Kubernetes 对象的形式提供,并通过选择算符绑定到某些资源。
Minikube 是一种安装和配置 Kubernetes 集群以进行测试的快速简便的方法。
安装 Kubernetes v1.26 并启用特性门控
ValidatingAdmissionPolicy:
minikube start --kubernetes-version=1.26.1 --extra-config=apiserver.runtime-config=admissionregistration.k8s.io/v1alpha1 --feature-gates='ValidatingAdmissionPolicy=true'
要在集群中安装策略:
# 安装配置 CRD
kubectl apply -f https://github.com/kubescape/cel-admission-library/releases/latest/download/policy-configuration-definition.yaml
# 安装基础配置
kubectl apply -f https://github.com/kubescape/cel-admission-library/releases/latest/download/basic-control-configuration.yaml
# 安装策略
kubectl apply -f https://github.com/kubescape/cel-admission-library/releases/latest/download/kubescape-validating-admission-policies.yaml
要将策略应用到对象,请创建一个 ValidatingAdmissionPolicyBinding 资源。
让我们把上述 Kubescape C-0017 控件应用到所有带有标签 policy=enforced 的命名空间:
# 创建绑定
kubectl apply -f - <<EOT
apiVersion: admissionregistration.k8s.io/v1alpha1
kind: ValidatingAdmissionPolicyBinding
metadata:
name: c0017-binding
spec:
policyName: kubescape-c-0017-deny-mutable-container-filesystem
matchResources:
namespaceSelector:
matchLabels:
policy: enforced
EOT
# 创建用于运行示例的命名空间
kubectl create namespace policy-example
kubectl label namespace policy-example 'policy=enforced'
现在,如果尝试创建一个对象但不指定 readOnlyRootFilesystem,该对象将不会被创建。
# 如下命令会失败
kubectl -n policy-example run nginx --image=nginx --restart=Never
输出错误信息:
The pods "nginx" is invalid: : ValidatingAdmissionPolicy 'kubescape-c-0017-deny-mutable-container-filesystem' with binding 'c0017-binding' denied request: Pods having containers with mutable filesystem not allowed! (see more at https://hub.armosec.io/docs/c-0017)
配置
策略对象可以包括在不同对象中提供的配置。许多 Kubescape 控件需要配置: 需要哪些标签、允许或拒绝哪些权能、允许从哪些镜像库部署容器等。 这些控件的默认值在 ControlConfiguration 对象中定义。
要使用这个配置对象,或者以相同的格式使用你自己的对象,在你绑定对象中添加一个 paramRef.name 值:
apiVersion: admissionregistration.k8s.io/v1alpha1
kind: ValidatingAdmissionPolicyBinding
metadata:
name: c0001-binding
spec:
policyName: kubescape-c-0001-deny-forbidden-container-registries
paramRef:
name: basic-control-configuration
matchResources:
namespaceSelector:
matchLabels:
policy: enforced
总结
在大多数情况下,将我们的控件转换为 CEL 很简单。我们无法移植整个 Kubescape 库,因为有些控件会检查 Kubernetes 集群外部的事物,有些控件需要访问准入请求对象中不可用的数据。 总的来说,我们很高兴将这个库贡献给 Kubernetes 社区,并将继续为 Kubescape 和 Kubernetes 用户开发它。 我们希望它能成为有用的工具,既可以作为你自己使用的工具,也可以作为你编写自己的策略的范例。
至于验证准入策略功能本身,我们很高兴看到 Kubernetes 引入这一原生功能。 我们期待看到它进入 Beta 版,然后进入 GA 版,希望能在今年年底前完成。 值得注意的是,该功能目前还处于 Alpha 阶段,这意味着这是在 Minikube 等环境中试用该功能的绝佳机会。 然而,它尚未被视为生产就绪且稳定,且不会在大多数托管的 Kubernetes 环境中启用。 底层功能变得稳定之前,我们不会建议 Kubescape 用户在生产环境中使用这些策略。 请密切关注 KEP, 当然还有此博客,以获取最终的发布公告。
Kubernetes 在 v1.27 中移除的特性和主要变更
作者:Harshita Sao
译者:Michael Yao (DaoCloud)
随着 Kubernetes 发展和成熟,为了此项目的整体健康,某些特性可能会被弃用、移除或替换为优化过的特性。 基于目前在 v1.27 发布流程中获得的信息,本文将列举并描述一些计划在 Kubernetes v1.27 发布中的变更, 发布工作目前仍在进行中,可能会引入更多变更。
k8s.gcr.io 重定向到 registry.k8s.io 相关说明
Kubernetes 项目为了托管其容器镜像,使用社区拥有的一个名为 registry.k8s.io. 的镜像仓库。 从 3 月 20 日起,所有来自过期 k8s.gcr.io 仓库的流量将被重定向到 registry.k8s.io。 已弃用的 k8s.gcr.io 仓库最终将被淘汰。
这次变更意味着什么?
- 如果你是一个子项目的 Maintainer,你必须更新自己的清单和 Helm Chart 来使用新的仓库。
- Kubernetes v1.27 版本不会发布到旧的仓库。
- 从 4 月份起,针对 v1.24、v1.25 和 v1.26 的补丁版本将不再发布到旧的仓库。
我们曾发布了一篇博文, 讲述了此次变更有关的所有信息,以及影响到你时应该采取的措施。
Kubernetes API 移除和弃用流程
Kubernetes 项目对特性有一个文档完备的弃用策略。 该策略规定,只有当较新的、稳定的相同 API 可用时,原有的稳定 API 才可以被弃用, 每个稳定级别的 API 都有一个最短的生命周期。弃用的 API 指的是已标记为将在后续发行某个 Kubernetes 版本时移除的 API;移除之前该 API 将继续发挥作用(从弃用起至少一年时间), 但使用时会显示一条警告。被移除的 API 将在当前版本中不再可用,此时你必须迁移以使用替换的 API。
- 正式发布(GA)或稳定的 API 版本可能被标记为已弃用,但只有在 Kubernetes 大版本更新时才会被移除。
- 测试版(Beta)或预发布 API 版本在弃用后必须在后续 3 个版本中继续支持。
- Alpha 或实验性 API 版本可以在任何版本中被移除,不另行通知。
无论一个 API 是因为某特性从 Beta 进阶至稳定阶段而被移除,还是因为该 API 根本没有成功, 所有移除均遵从上述弃用策略。无论何时移除一个 API,文档中都会列出迁移选项。
针对 Kubernetes v1.27 移除的 API 和其他变更
从 CSIStorageCapacity 移除 storage.k8s.io/v1beta1
CSIStorageCapacity
API 支持通过 CSIStorageCapacity 对象来暴露当前可用的存储容量,并增强在后续绑定时使用 CSI 卷的 Pod 的调度。
CSIStorageCapacity 的 storage.k8s.io/v1beta1 API 版本在 v1.24 中已被弃用,将在 v1.27 中被移除。
迁移清单和 API 客户端以使用自 v1.24 起可用的 storage.k8s.io/v1 API 版本。
所有现有的已持久保存的对象都可以通过这个新的 API 进行访问。
更多信息可以参阅 Storage Capacity Constraints for Pod Scheduling KEP。
Kubernetes v1.27 没有移除任何其他 API;但还有其他若干特性将被移除。请继续阅读下文。
对弃用的 seccomp 注解的支持
在 Kubernetes v1.19 中, seccomp (安全计算模式)支持进阶至正式发布 (GA)。 此特性通过限制 Pod(应用到所有容器)或单个容器可执行的系统调用可以提高工作负载安全性。
对 Alpha 状态的 seccomp 注解 seccomp.security.alpha.kubernetes.io/pod 和
container.seccomp.security.alpha.kubernetes.io 的支持自 v1.19 起被弃用,
现在已完全移除。当创建具有 seccomp 注解的 Pod 时 seccomp 字段将不再被自动填充。
Pod 应转为使用相应的 Pod 或容器 securityContext.seccompProfile 字段。
移除针对卷扩展的若干特性门控
针对卷扩展
GA 特性的以下特性门控将被移除,且不得再在 --feature-gates 标志中引用:
ExpandCSIVolumes- 启用 CSI 卷的扩展。
ExpandInUsePersistentVolumes- 启用扩展正使用的 PVC。
ExpandPersistentVolumes- 启用持久卷的扩展。
移除 --master-service-namespace 命令行参数
kube-apiserver 接受一个已弃用的命令行参数 --master-service-namespace,
该参数指定在何处创建名为 kubernetes 的 Service 来表示 API 服务器。
Kubernetes v1.27 将移除自 v1.26 版本已被弃用的该参数。
移除 ControllerManagerLeaderMigration 特性门控
Leader Migration
提供了一种机制,让 HA 集群在升级多副本的控制平面时通过在 kube-controller-manager 和
cloud-controller-manager 这两个组件之间共享的资源锁,安全地迁移“特定于云平台”的控制器。
ControllerManagerLeaderMigration 特性自 v1.24 正式发布,被无条件启用,
在 v1.27 版本中此特性门控选项将被移除。
如果你显式设置此特性门控,你将需要从命令行参数或配置文件中将其移除。
移除 --enable-taint-manager 命令行参数
kube-controller-manager 命令行参数 --enable-taint-manager 已被弃用,
将在 Kubernetes v1.27 中被移除。
该参数支持的特性基于污点的驱逐已被默认启用,
且在标志被移除时也将继续被隐式启用。
移除 --pod-eviction-timeout 命令行参数
弃用的命令行参数 --pod-eviction-timeout 将被从 kube-controller-manager 中移除。
移除 CSI Migration 特性门控
CSI migration
程序允许从树内卷插件移动到树外 CSI 驱动程序。
CSI 迁移自 Kubernetes v1.16 起正式发布,关联的 CSIMigration 特性门控将在 v1.27 中被移除。
移除 CSIInlineVolume 特性门控
CSI Ephemeral Volume
特性允许在 Pod 规约中直接指定 CSI 卷作为临时使用场景。这些 CSI 卷可用于使用挂载的卷直接在
Pod 内注入任意状态,例如配置、Secret、身份、变量或类似信息。
此特性在 v1.25 中进阶至正式发布。因此,此特性门控 CSIInlineVolume 将在 v1.27 版本中移除。
移除 EphemeralContainers 特性门控
临时容器在 v1.25 中进阶至正式发布。
这些是具有临时持续周期的容器,在现有 Pod 的命名空间内执行。
临时容器通常由用户发起,以观察其他 Pod 和容器的状态进行故障排查和调试。
对于 Kubernetes v1.27,对临时容器的 API 支持被无条件启用;EphemeralContainers 特性门控将被移除。
移除 LocalStorageCapacityIsolation 特性门控
Local Ephemeral Storage Capacity Isolation
特性在 v1.25 中进阶至正式发布。此特性支持 emptyDir 卷这类 Pod 之间本地临时存储的容量隔离,
因此可以硬性限制 Pod 对共享资源的消耗。如果本地临时存储的消耗超过了配置的限制,kubelet 将驱逐 Pod。
特性门控 LocalStorageCapacityIsolation 将在 v1.27 版本中被移除。
移除 NetworkPolicyEndPort 特性门控
Kubernetes v1.25 版本将 NetworkPolicy 中的 endPort 进阶至正式发布。
支持 endPort 字段的 NetworkPolicy 提供程序可用于指定一系列端口以应用 NetworkPolicy。
以前每个 NetworkPolicy 只能针对一个端口。因此,此特性门控 NetworkPolicyEndPort 将在此版本中被移除。
请注意,endPort 字段必须得到 NetworkPolicy 提供程序的支持。
如果你的提供程序不支持 endPort,并且此字段在 NetworkPolicy 中指定,
则将创建仅涵盖端口字段(单个端口)的 NetworkPolicy。
移除 StatefulSetMinReadySeconds 特性门控
对于作为 StatefulSet 一部分的 Pod,只有当 Pod 至少在
minReadySeconds
中指定的持续期内可用(并通过检查)时,Kubernetes 才会将此 Pod 标记为只读。
该特性在 Kubernetes v1.25 中正式发布,StatefulSetMinReadySeconds
特性门控将锁定为 true,并在 v1.27 版本中被移除。
移除 IdentifyPodOS 特性门控
你可以为 Pod 指定操作系统,此项特性支持自 v1.25 版本进入稳定。
IdentifyPodOS 特性门控将在 Kubernetes v1.27 中被移除。
移除 DaemonSetUpdateSurge 特性门控
Kubernetes v1.25 版本还稳定了对 DaemonSet Pod 的浪涌支持,
其实现是为了最大限度地减少部署期间 DaemonSet 的停机时间。
DaemonSetUpdateSurge 特性门控将在 Kubernetes v1.27 中被移除。
移除 --container-runtime 命令行参数
kubelet 接受一个已弃用的命令行参数 --container-runtime,
并且在移除 dockershim 代码后,唯一有效的值将是 remote。
Kubernetes v1.27 将移除该参数,该参数自 v1.24 版本以来已被弃用。
前瞻
Kubernetes 1.29 计划移除的 API 官方列表包括:
- FlowSchema 和 PriorityLevelConfiguration 的
flowcontrol.apiserver.k8s.io/v1beta2API 版本将不再在 v1.29 中提供。
了解更多
Kubernetes 发行说明中宣告了弃用信息。你可以在以下版本的发行说明中看到待弃用的公告:
我们将在 Kubernetes v1.27 的 CHANGELOG 中正式宣布该版本的弃用信息。
有关弃用和移除流程信息,请查阅正式的 Kubernetes 弃用策略文档。
k8s.gcr.io 重定向到 registry.k8s.io - 用户须知
作者:Bob Killen (Google)、Davanum Srinivas (AWS)、Chris Short (AWS)、Frederico Muñoz (SAS Institute)、Tim Bannister (The Scale Factory)、Ricky Sadowski (AWS)、Grace Nguyen (Expo)、Mahamed Ali (Rackspace Technology)、Mars Toktonaliev(独立个人)、Laura Santamaria (Dell)、Kat Cosgrove (Dell)
译者:Michael Yao (DaoCloud)
3 月 20 日星期一,k8s.gcr.io 仓库被重定向到了社区拥有的仓库: registry.k8s.io 。
长话短说:本次变更须知
- 3 月 20 日星期一,来自 k8s.gcr.io 旧仓库的流量被重定向到了 registry.k8s.io, 最终目标是逐步淘汰 k8s.gcr.io。
- 如果你在受限的环境中运行,且你为 k8s.gcr.io 限定采用了严格的域名或 IP 地址访问策略, 那么 k8s.gcr.io 开始重定向到新仓库之后镜像拉取操作将不起作用。
- 少量非标准的客户端不会处理镜像仓库的 HTTP 重定向,将需要直接指向 registry.k8s.io。
- 本次重定向只是一个协助用户进行切换的权宜之计。弃用的 k8s.gcr.io 仓库将在某个时间点被淘汰。 请尽快更新你的清单,尽快指向 registry.k8s.io。
- 如果你托管自己的镜像仓库,你可以将需要的镜像拷贝到自己的仓库,这样也能减少到社区所拥有仓库的流量压力。
如果你认为自己可能受到了影响,或如果你想知道本次变更的更多相关信息,请继续阅读下文。
若我受到影响该怎样检查?
若要测试到 registry.k8s.io 的连通性,测试是否能够从 registry.k8s.io 拉取镜像, 可以在你所选的命名空间中执行类似以下的命令:
kubectl run hello-world -ti --rm --image=registry.k8s.io/busybox:latest --restart=Never -- date
当你执行上一条命令时,若一切工作正常,预期的输出如下:
$ kubectl run hello-world -ti --rm --image=registry.k8s.io/busybox:latest --restart=Never -- date
Fri Feb 31 07:07:07 UTC 2023
pod "hello-world" deleted
若我受到影响会看到哪种错误?
出现的错误可能取决于你正使用的容器运行时类别以及你被路由到的端点,
通常会出现 ErrImagePull、ImagePullBackOff 这类错误,
也可能容器创建失败时伴随着警告 FailedCreatePodSandBox。
以下举例的错误消息显示了由于未知的证书使得代理后的部署拉取失败:
FailedCreatePodSandBox: Failed to create pod sandbox: rpc error: code = Unknown desc = Error response from daemon: Head “https://us-west1-docker.pkg.dev/v2/k8s-artifacts-prod/images/pause/manifests/3.8”: x509: certificate signed by unknown authority
哪些镜像会受影响?
k8s.gcr.io 上的 所有 镜像都会受到本次变更的影响。
k8s.gcr.io 除了 Kubernetes 各个版本外还托管了许多镜像。
大量 Kubernetes 子项目也在其上托管了自己的镜像。
例如 dns/k8s-dns-node-cache、ingress-nginx/controller 和
node-problem-detector/node-problem-detector 这些镜像。
我受影响了。我该怎么办?
若受影响的用户在受限的环境中运行,最好的办法是将必需的镜像拷贝到私有仓库,或在自己的仓库中配置一个直通缓存。
在仓库之间拷贝镜像可使用若干工具:
crane
就是其中一种工具,通过使用 crane copy SRC DST 可以将镜像拷贝到私有仓库。还有一些供应商特定的工具,例如 Google 的
gcrane,
这个工具实现了类似的功能,但针对其平台自身做了一些精简。
我怎样才能找到哪些镜像正使用旧仓库,如何修复?
方案 1: 试试上一篇博文中所述的一条 kubectl 命令:
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" |\
tr -s '[[:space:]]' '\n' |\
sort |\
uniq -c
方案 2:kubectl krew 的一个插件已被开发完成,名为
community-images,
它能够使用 k8s.gcr.io 端点扫描和报告所有正使用 k8s.gcr.io 的镜像。
如果你安装了 krew,你可以运行以下命令进行安装:
kubectl krew install community-images
并用以下命令生成一个报告:
kubectl community-images
对于安装和示例输出的其他方法,可以查阅代码仓库: kubernetes-sigs/community-images。
方案 3:如果你不能直接访问集群,或如果你管理了许多集群,最好的方式是在清单(manifest)和 Chart 中搜索 "k8s.gcr.io"。
方案 4:如果你想预防基于 k8s.gcr.io 的镜像在你的集群中运行,可以在 AWS EKS 最佳实践代码仓库中找到针对 Gatekeeper 和 Kyverno 的示例策略,这些策略可以阻止镜像被拉取。 你可以在任何 Kubernetes 集群中使用这些第三方策略。
方案 5:作为 最后一个 备选方案, 你可以使用修改性质的准入 Webhook 来动态更改镜像地址。在更新你的清单之前这只应视为一个权宜之计。你可以在 k8s-gcr-quickfix 中找到(第三方)可变性质的 Webhook 和 Kyverno 策略。
为什么 Kubernetes 要换到一个全新的镜像仓库?
k8s.gcr.io 托管在一个 Google Container Registry (GCR) 自定义的域中,这是专为 Kubernetes 项目搭建的域。自 Kubernetes 项目启动以来, 这个仓库一直运作良好,我们感谢 Google 提供这些资源,然而如今还有其他云提供商和供应商希望托管这些镜像, 以便为他们自己云平台上的用户提供更好的体验。除了去年 Google 捐赠 300 万美金的续延承诺来支持本项目的基础设施外, Amazon Web Services (AWS) 也在底特律召开的 Kubecon NA 2022 上发言公布了相当的捐赠金额。 AWS 能为用户提供更好的体验(距离用户更近的服务器 = 更快的下载速度),同时还能减轻 GCR 的出站带宽和成本。
有关此次变更的更多详情,请查阅 registry.k8s.io:更快、成本更低且正式发布 (GA)。
为什么要设置重定向?
本项目在去年发布 1.25 时切换至 registry.k8s.io; 然而,大多数镜像拉取流量仍被重定向到旧端点 k8s.gcr.io。 从项目角度看,这对我们来说是不可持续的,因为这样既没有完全利用其他供应商捐赠给本项目的资源, 也由于流量服务成本而使我们面临资金耗尽的危险。
重定向将使本项目能够利用这些新资源的优势,从而显著降低我们的出站带宽成本。 我们预计此次更改只会影响一小部分用户,他们可能在受限环境中运行 Kubernetes, 或使用了老旧到无法处理重定向行为的客户端。
k8s.gcr.io 将会怎样?
除了重定向之外,k8s.gcr.io 将被冻结,
且在 2023 年 4 月 3 日之后将不会随着新的镜像而更新。
k8s.gcr.io 将不再获取任何新的版本、补丁或安全更新。
这个旧仓库将继续保持可用,以帮助人们迁移,但在以后将会被彻底淘汰。
我仍有疑问,我该去哪儿询问?
有关 registry.k8s.io 及其为何开发这个新仓库的更多信息,请参见 registry.k8s.io:更快、成本更低且正式发布。
如果你想了解镜像冻结以及最后一版可用镜像的更多信息,请参见博文: k8s.gcr.io 镜像仓库将从 2023 年 4 月 3 日起被冻结。
有关 registry.k8s.io 架构及其请求处理决策树的信息, 请查阅 kubernetes/registry.k8s.io 代码仓库。
若你认为自己在使用新仓库和重定向时遇到 bug,请在 kubernetes/registry.k8s.io 代码仓库中提出 Issue。 请先检查是否有人提出了类似的 Issue,再行创建新 Issue。
Kubernetes 的容器检查点分析
作者:Adrian Reber (Red Hat)
译者:Paco Xu (DaoCloud)
我之前在 Kubernetes 中的取证容器检查点 一文中,介绍了检查点以及如何创建和使用它。 该特性的名称是取证容器检查点,但我没有详细介绍如何对 Kubernetes 创建的检查点进行实际分析。 在本文中,我想提供如何分析检查点的详细信息。
检查点仍然是 Kubernetes 中的一个 Alpha 特性,本文将展望该特性未来可能的工作方式。
准备
有关如何配置 Kubernetes 和底层 CRI 实现以启用检查点支持的详细信息, 请参阅 Kubernetes 中的取证容器检查点一文。
作为示例,我准备了一个容器镜像(quay.io/adrianreber/counter:blog),我想对其设定检查点,
然后在本文中进行分析。这个容器允许我在容器中创建文件,并将信息存储在内存中,稍后我想在检查点中找到这些信息。
要运行该容器,我需要一个 Pod,在本例中我使用以下 Pod 清单:
apiVersion: v1
kind: Pod
metadata:
name: counters
spec:
containers:
- name: counter
image: quay.io/adrianreber/counter:blog
这会导致一个名为 counter 的容器在名为 counters 的 Pod 中运行。
容器运行后,我将对该容器执行以下操作:
$ kubectl get pod counters --template '{{.status.podIP}}'
10.88.0.25
$ curl 10.88.0.25:8088/create?test-file
$ curl 10.88.0.25:8088/secret?RANDOM_1432_KEY
$ curl 10.88.0.25:8088
- 第一次访问时在容器中创建一个名为
test-file的文件,其内容为test-file; - 第二次访问时将我的 Secret 信息(
RANDOM_1432_KEY)存储在容器内存中的某处; - 最后一次访问时在内部日志文件中添加了一行。
在分析检查点之前的最后一步是告诉 Kubernetes 创建检查点。
如上一篇文章所述,这需要访问 kubelet 唯一的 checkpoint API 端点。
对于 default 命名空间中 counters Pod 中名为 counter 的容器, 可通过以下方式访问 kubelet API 端点:
# 在运行 Pod 的节点上运行这条命令
curl -X POST "https://localhost:10250/checkpoint/default/counters/counter"
为了完整起见,以下 curl 命令行选项对于让 curl 接受 kubelet 的自签名证书并授权使用
kubelet 检查点 API 是必要的:
--insecure --cert /var/run/kubernetes/client-admin.crt --key /var/run/kubernetes/client-admin.key
检查点操作完成后,检查点应该位于 /var/lib/kubelet/checkpoints/checkpoint-<pod-name>_<namespace-name>-<container-name>-<timestamp>.tar
在本文的以下步骤中,我将在分析检查点归档时使用名称 checkpoint.tar。
使用 checkpointctl 进行检查点归档分析
我使用工具 checkpointctl 获取有关检查点容器的一些初始信息,如下所示:
$ checkpointctl show checkpoint.tar --print-stats
+-----------+----------------------------------+--------------+---------+---------------------+--------+------------+------------+-------------------+
| CONTAINER | IMAGE | ID | RUNTIME | CREATED | ENGINE | IP | CHKPT SIZE | ROOT FS DIFF SIZE |
+-----------+----------------------------------+--------------+---------+---------------------+--------+------------+------------+-------------------+
| counter | quay.io/adrianreber/counter:blog | 059a219a22e5 | runc | 2023-03-02T06:06:49 | CRI-O | 10.88.0.23 | 8.6 MiB | 3.0 KiB |
+-----------+----------------------------------+--------------+---------+---------------------+--------+------------+------------+-------------------+
CRIU dump statistics
+---------------+-------------+--------------+---------------+---------------+---------------+
| FREEZING TIME | FROZEN TIME | MEMDUMP TIME | MEMWRITE TIME | PAGES SCANNED | PAGES WRITTEN |
+---------------+-------------+--------------+---------------+---------------+---------------+
| 100809 us | 119627 us | 11602 us | 7379 us | 7800 | 2198 |
+---------------+-------------+--------------+---------------+---------------+---------------+
这展示了有关该检查点归档中与检查点有关的一些信息。我们可以看到容器的名称、有关容器运行时和容器引擎的信息。
它还列出了检查点的大小(CHKPT SIZE)。
这主要是检查点中包含的内存页的大小,同时也包含有关容器中所有已更改文件的大小信息(ROOT FS DIFF SIZE)。
使用附加参数 --print-stats 可以解码检查点归档中的信息并将其显示在第二个表中(CRIU 转储统计信息)。
此信息是在检查点创建期间收集的,并概述了 CRIU 对容器中的进程生成检查点所需的时间以及在检查点创建期间分析和写入了多少内存页。
深入挖掘
借助 checkpointctl,我可以获得有关检查点归档的一些高级信息。为了能够进一步分析检查点归档,
我必须将其提取。检查点归档是 tar 归档文件,可以借助 tar xf checkpoint.tar 进行解压。
展开检查点存档时,将创建以下文件和目录:
bind.mounts- 该文件包含有关绑定挂载的信息,并且需要在恢复期间将所有外部文件和目录挂载到正确的位置checkpoint/- 该目录包含 CRIU 创建的实际检查点config.dump和spec.dump- 这些文件包含恢复期间所需的有关容器的元数据dump.log- 该文件包含在检查点期间创建的 CRIU 的调试输出stats-dump- 此文件包含checkpointctl用于通过--print-stats显示转储统计信息的数据rootfs-diff.tar- 该文件包含容器文件系统上所有已更改的文件
更改文件系统 - rootfs-diff.tar
进一步分析容器检查点的第一步是查看容器内已更改的文件。这可以通过查看 rootfs-diff.tar 文件来完成。
$ tar xvf rootfs-diff.tar
home/counter/logfile
home/counter/test-file
现在你可以检查容器内已更改的文件。
$ cat home/counter/logfile
10.88.0.1 - - [02/Mar/2023 06:07:29] "GET /create?test-file HTTP/1.1" 200 -
10.88.0.1 - - [02/Mar/2023 06:07:40] "GET /secret?RANDOM_1432_KEY HTTP/1.1" 200 -
10.88.0.1 - - [02/Mar/2023 06:07:43] "GET / HTTP/1.1" 200 -
$ cat home/counter/test-file
test-file
与该容器所基于的容器镜像(quay.io/adrianreber/counter:blog)相比,
我可以看到文件 logfile 包含了访问该容器所提供服务相关的所有信息,
并且文件 test-file 如预期一样被创建了。
在 rootfs-diff.tar 的帮助下,可以根据容器的基本镜像检查所有创建或修改的文件。
分析检查点进程 - checkpoint/
目录 checkpoint/ 包含 CRIU 在容器内对进程进行检查点时创建的数据。
目录 checkpoint/ 的内容由各种镜像文件 组成,可以使用作为 CRIU
一部分分发的 CRIT 工具进行分析。
首先,我们先概览了解一下容器内的进程。
$ crit show checkpoint/pstree.img | jq .entries[].pid
1
7
8
此输出意味着容器的 PID 命名空间内有 3 个进程(PID 为 1、7 和 8)。
这只是容器 PID 命名空间的内部视图。这些 PID 在恢复过程中会准确地被重新创建。 从容器的 PID 命名空间外部,PID 将在恢复后更改。
下一步是获取有关这三个进程的更多信息。
$ crit show checkpoint/core-1.img | jq .entries[0].tc.comm
"bash"
$ crit show checkpoint/core-7.img | jq .entries[0].tc.comm
"counter.py"
$ crit show checkpoint/core-8.img | jq .entries[0].tc.comm
"tee"
这意味着容器内的三个进程是 bash、counter.py(Python 解释器)和 tee。
有关这些进程的父子关系,可以参阅 checkpoint/pstree.img 所分析的更多数据。
让我们将目前为止收集到的信息与仍在运行的容器进行比较。
$ crictl inspect --output go-template --template "{{(index .info.pid)}}" 059a219a22e56
722520
$ ps auxf | grep -A 2 722520
fedora 722520 \_ bash -c /home/counter/counter.py 2>&1 | tee /home/counter/logfile
fedora 722541 \_ /usr/bin/python3 /home/counter/counter.py
fedora 722542 \_ /usr/bin/coreutils --coreutils-prog-shebang=tee /usr/bin/tee /home/counter/logfile
$ cat /proc/722520/comm
bash
$ cat /proc/722541/comm
counter.py
$ cat /proc/722542/comm
tee
在此输出中,我们首先获取容器中第一个进程的 PID。在运行容器的系统上,它会查找其 PID 和子进程。
你应该看到三个进程,第一个进程是 bash,容器 PID 命名空间中的 PID 为 1。
然后查看 /proc/<PID>/comm,可以找到与检查点镜像完全相同的值。
需要记住的重点是,检查点包含容器的 PID 命名空间内的视图。因为这些信息对于恢复进程非常重要。
crit 告诉我们有关容器的最后一个例子是有关 UTS 命名空间的信息。
$ crit show checkpoint/utsns-12.img
{
"magic": "UTSNS",
"entries": [
{
"nodename": "counters",
"domainname": "(none)"
}
]
}
这里输出表示 UTS 命名空间中的主机名是 counters。
对于检查点创建期间收集的每个资源 CRIU,checkpoint/ 目录包含相应的镜像文件,
你可以借助 crit 来分析该镜像文件。
查看内存页面
除了可以借助 CRIT 解码的 CRIU 信息之外,还有包含 CRIU 写入磁盘的原始内存页的文件:
$ ls checkpoint/pages-*
checkpoint/pages-1.img checkpoint/pages-2.img checkpoint/pages-3.img
当我最初使用该容器时,我在内存中的某个位置存储了一个随机密钥。让我看看是否能找到它:
$ grep -ao RANDOM_1432_KEY checkpoint/pages-*
checkpoint/pages-2.img:RANDOM_1432_KEY
确实有我的数据。通过这种方式,我可以轻松查看容器中进程的所有内存页面的内容, 但需要注意的是,你只要能访问检查点存档,就可以访问存储在容器进程内存中的所有信息。
使用 gdb 进一步分析
查看检查点镜像的另一种方法是 gdb。CRIU 存储库包含脚本 coredump,
它可以将检查点转换为 coredump 文件:
$ /home/criu/coredump/coredump-python3
$ ls -al core*
core.1 core.7 core.8
运行 coredump-python3 脚本会将检查点镜像转换为容器中每个进程一个的 coredump 文件。
使用 gdb 我还可以查看进程的详细信息:
$ echo info registers | gdb --core checkpoint/core.1 -q
[New LWP 1]
Core was generated by `bash -c /home/counter/counter.py 2>&1 | tee /home/counter/logfile'.
#0 0x00007fefba110198 in ?? ()
(gdb)
rax 0x3d 61
rbx 0x8 8
rcx 0x7fefba11019a 140667595587994
rdx 0x0 0
rsi 0x7fffed9c1110 140737179816208
rdi 0xffffffff 4294967295
rbp 0x1 0x1
rsp 0x7fffed9c10e8 0x7fffed9c10e8
r8 0x1 1
r9 0x0 0
r10 0x0 0
r11 0x246 582
r12 0x0 0
r13 0x7fffed9c1170 140737179816304
r14 0x0 0
r15 0x0 0
rip 0x7fefba110198 0x7fefba110198
eflags 0x246 [ PF ZF IF ]
cs 0x33 51
ss 0x2b 43
ds 0x0 0
es 0x0 0
fs 0x0 0
gs 0x0 0
在这个例子中,我可以看到所有寄存器的值,因为它们在检查点,我还可以看到容器的 PID 1 进程的完整命令行:
bash -c /home/counter/counter.py 2>&1 | tee /home/counter/logfile。
总结
借助容器检查点,可以在不停止容器且在容器不知情的情况下,为正在运行的容器创建检查点。
在 Kubernetes 中对容器创建一个检查点的结果是检查点存档文件;
使用诸如 checkpointctl、tar、crit 和 gdb 等不同的工具,可以分析检查点。
即使使用像 grep 这样的简单工具,也可以在检查点存档中找到信息。
我在本文所展示的如何分析检查点的不同示例只是一个起点。 根据你的需求,可以更详细地查看某些内容,本文向你介绍了如何开始进行检查点分析。
如何参与?
你可以通过多种方式联系到 SIG Node:
- Slack:#sig-node
- Slack:#sig-security
- 邮件列表
介绍 KWOK(Kubernetes WithOut Kubelet,没有 Kubelet 的 Kubernetes)
作者: Shiming Zhang (DaoCloud), Wei Huang (Apple), Yibo Zhuang (Apple)
译者: Michael Yao (DaoCloud)

你是否曾想过在几秒钟内搭建一个由数千个节点构成的集群,如何用少量资源模拟真实的节点, 如何不耗费太多基础设施就能大规模地测试你的 Kubernetes 控制器?
如果你曾有过这些想法,那你可能会对 KWOK 有兴趣。 KWOK 是一个工具包,能让你在几秒钟内创建数千个节点构成的集群。
什么是 KWOK?
KWOK 是 Kubernetes WithOut Kubelet 的缩写,即没有 Kubelet 的 Kubernetes。 到目前为止,KWOK 提供了两个工具:
kwokkwok是这个项目的基石,负责模拟伪节点、Pod 和其他 Kubernetes API 资源的生命周期。kwokctlkwokctl是一个 CLI 工具,设计用于简化创建和管理由kwok模拟节点组成的集群。
为什么使用 KWOK?
KWOK 具有下面几点优势:
- 速度:你几乎可以实时创建和删除集群及节点,无需等待引导或制备过程。
- 兼容性:KWOK 能够与兼容 Kubernetes API 的所有工具或客户端(例如 kubectl、helm、kui)协同作业。
- 可移植性:KWOK 没有特殊的软硬件要求。一旦安装了 Docker 或 Nerdctl,你就可以使用预先构建的镜像来运行 KWOK。 另外,二进制文件包适用于所有平台,安装简单。
- 灵活:你可以配置不同类型的节点、标签、污点、容量、状况等,还可以配置不同的 Pod 行为和状态来测试不同的场景和边缘用例。
- 性能:你在自己的笔记本电脑上就能模拟数千个节点,无需大量消耗 CPU 或内存资源。
使用场景是什么?
KWOK 可用于各种用途:
- 学习:你可以使用 KWOK 学习 Kubernetes 概念和特性,无需顾虑资源浪费或其他后果。
- 开发:你可以使用 KWOK 为 Kubernetes 开发新特性或新工具,无需接入真实的集群,也不需要其他组件。
- 测试:
- 你可以衡量自己的应用程序或控制器在使用不同数量节点和 Pod 时的扩缩表现如何。
- 你可以用不同的资源请求或限制创建大量 Pod 或服务,在集群上营造高负载的环境。
- 你可以通过更改节点状况或随机删除节点来模拟节点故障或网络分区。
- 你可以通过启用不同的特性门控或 API 版本来测试控制器如何与其他组件交互。
有哪些限制?
KWOK 并非试图完整替代其他什么。当然也有一些限制需要你多加注意:
- 功能性:KWOK 不是 kubelet。KWOK 在 Pod 生命周期管理、卷挂载和设备插件方面所展现的行为与 kubelet 不同。 KWOK 的主要功能是模拟节点和 Pod 状态的更新。
- 准确性:需要重点注意 KWOK 还不能确切地反映各种工作负载或环境下真实节点的性能或行为。 KWOK 只能使用一些公式来逼近真实的节点行为。
- 安全性:KWOK 没有对模拟的节点实施任何安全策略或安全机制。 KWOK 假定来自 kube-apiserver 的所有请求都是经过授权且是有效的。
入门
如果你对试用 KWOK 感兴趣,请查阅 KWOK 文档了解详情。

使用 kwokctl 管理模拟的集群
欢迎参与
如果你想参与讨论 KWOK 的未来或参与开发,可通过以下几种方式参与进来:
- Slack #kwok 讨论一般用法,Slack #kwok-dev 讨论开发问题(访问 slack.k8s.io 获取 KWOK 工作空间的邀请链接)
- 在 sigs.k8s.io/kwok 上提出 Issue/PR/Discussion
我们欢迎所有想要加入这个项目的贡献者,欢迎任何形式的反馈和贡献。
免费的 Katacoda Kubernetes 教程即将关闭
作者:Natali Vlatko,Kubernetes SIG Docs 联合主席
译者:Michael Yao (DaoCloud)
Katacoda 是 O’Reilly 开设的热门学习平台, 帮助人们学习 Java、Docker、Kubernetes、Python、Go、C++ 和其他更多内容, 这个学习平台于 2022 年 6 月停止对公众开放。 但是,从 Kubernetes 网站为相关项目用户和贡献者关联的 Kubernetes 专门教程在那次变更后仍然可用并处于活跃状态。 遗憾的是,接下来情况将发生变化,Katacoda 上有关学习 Kubernetes 的教程将在 2023 年 3 月 31 日之后彻底关闭。
Kubernetes 项目感谢 O'Reilly Media 多年来通过 Katacoda 学习平台对 Kubernetes 社区的支持。 你可以在 O'Reilly 自有的网站上阅读 the decision to shutter katacoda.com 有关的更多信息。此次变更之后,我们将专注于移除指向 Katacoda 各种教程的链接。 我们通过 Issue #33936 和 GitHub 讨论跟踪此主题相关的常规问题。 我们也有兴趣调研其他哪些学习平台可能对 Kubernetes 社区有益,尝试将 Katacoda 链接替换为具有类似用户体验的平台或服务。 然而,这项调研需要时间,因此我们正在积极寻觅志愿者来协助完成这项工作。 如果找到替代的平台,需要得到 Kubernetes 领导层的支持,特别是 SIG Contributor Experience、SIG Docs 和 Kubernetes Steering Committee。
Katacoda 的关闭会影响 25 个英文教程页面、对应的多语言页面以及 Katacoda Scenario仓库: github.com/katacoda-scenarios/kubernetes-bootcamp-scenarios。 我们建议你立即更新指向 Katacoda 学习平台的所有链接、指南或文档,以反映这一变化。 虽然我们还没有找到替代这个学习平台的解决方案,但 Kubernetes 网站本身就包含了大量有用的文档可助你继续学习和成长。 你可以在 https://k8s.io/docs/tutorials/ 找到所有可用的 Kubernetes 文档教程。
如果你对 Katacoda 关闭或后续从 Kubernetes 教程页面移除相关链接有任何疑问, 请在 general issue tracking the shutdown 上发表评论,或加入 Kubernetes Slack 的 #sig-docs 频道。
k8s.gcr.io 镜像仓库将从 2023 年 4 月 3 日起被冻结
作者:Mahamed Ali (Rackspace Technology)
译者:Michael Yao (Daocloud)
Kubernetes 项目运行一个名为 registry.k8s.io、由社区管理的镜像仓库来托管其容器镜像。
2023 年 4 月 3 日,旧仓库 k8s.gcr.io 将被冻结,Kubernetes 及其相关子项目的镜像将不再推送到这个旧仓库。
registry.k8s.io 这个仓库代替了旧仓库,这个新仓库已正式发布七个月。
我们也发布了一篇博文阐述新仓库给社区和
Kubernetes 项目带来的好处。这篇博客再次宣布后续版本的 Kubernetes 将不可用于旧仓库。这个时刻已经到来。
这次变更对贡献者意味着:
- 如果你是某子项目的 Maintainer,你将需要更新清单 (manifest) 和 Helm Chart 才能使用新仓库。
这次变更对终端用户意味着:
- Kubernetes 1.27 版本将不会发布到旧仓库。
- 1.24、1.25 和 1.26 版本的补丁从 4 月份起将不再发布到旧仓库。请阅读以下时间线,了解旧仓库最终补丁版本的详情。
- 从 1.25 开始,默认的镜像仓库已设置为
registry.k8s.io。kubeadm和kubelet中的这个镜像仓库地址是可覆盖的,但设置为k8s.gcr.io将在 4 月份之后的新版本中失败, 因为旧仓库将没有这些版本了。 - 如果你想提高集群的可靠性,不想再依赖社区管理的镜像仓库,或你正在外部流量受限的网络中运行 Kubernetes, 你应该考虑托管本地镜像仓库的镜像。一些云供应商可能会为此提供托管解决方案。
变更时间线
k8s.gcr.io将于 2023 年 4 月 3 日被冻结- 1.27 预计于 2023 年 4 月 12 日发布
k8s.gcr.io上的最后一个 1.23 版本将是 1.23.18(1.23 在仓库冻结前进入不再支持阶段)k8s.gcr.io上的最后一个 1.24 版本将是 1.24.12k8s.gcr.io上的最后一个 1.25 版本将是 1.25.8k8s.gcr.io上的最后一个 1.26 版本将是 1.26.3
下一步
请确保你的集群未依赖旧的镜像仓库。例如,你可以运行以下命令列出 Pod 使用的镜像:
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" |\
tr -s '[[:space:]]' '\n' |\
sort |\
uniq -c
旧的镜像仓库可能存在其他依赖项。请确保你检查了所有潜在的依赖项,以保持集群健康和最新。
致谢
改变是艰难的,但只有镜像服务平台演进才能确保 Kubernetes 项目可持续的未来。 我们努力为 Kubernetes 的每个使用者提供更好的服务。从社区各个角落汇聚而来的众多贡献者长期努力工作, 确保我们能够做出尽可能最好的决策、履行计划并尽最大努力传达这些计划。
衷心感谢:
- 来自 SIG K8s Infra 的 Aaron Crickenberger、Arnaud Meukam、Benjamin Elder、Caleb Woodbine、Davanum Srinivas、Mahamed Ali 和 Tim Hockin
- 来自 SIG Node 的 Brian McQueen 和 Sergey Kanzhelev
- 来自 SIG Cluster Lifecycle 的 Lubomir Ivanov
- 来自 SIG Release 的 Adolfo García Veytia、Jeremy Rickard、Sascha Grunert 和 Stephen Augustus
- 来自 SIG Contribex 的 Bob Killen 和 Kaslin Fields
- 来自 Security Response Committee(安全响应委员会)的 Tim Allclair
此外非常感谢负责联络各个云提供商合作伙伴的朋友们:来自 Amazon 的 Jay Pipes 和来自 Google 的 Jon Johnson Jr.
聚光灯下的 SIG Instrumentation
作者: Imran Noor Mohamed (Delivery Hero)
译者: Kevin Yang
可观测性需要在合适的时间提供合适的数据,以便合适的消费者(人员或软件)做出正确的决策。 在 Kubernetes 的环境中,拥有跨所有 Kubernetes 组件的集群可观测性最佳实践是至关重要的。
SIG Instrumentation 通过提供最佳实践和工具来解决这个问题, 所有其他 SIG 都可以使用它们来对如 API 服务器、kubelet 和 kube-controller-manager 这类 Kubernetes 组件进行插桩。
在这次 SIG Instrumentation 采访报道中,SIG ContribEx-Comms 技术主管 Imran Noor Mohamed 与 SIG Instrumentation 的两位主席 Elana Hashman 和 Han Kang 讨论了 SIG 的组织结构、当前的挑战以及大家如何参与并贡献。
关于 SIG Instrumentation
Imran (INM): 你好,感谢你给我这个机会进一步了解关于 SIG Instrumentation 的情况。 你能否介绍一下你自己、你的角色以及你是如何参与 SIG Instrumentation 的?
Han (HK): 我在 2018 年开始参与 SIG Instrumentation,并于 2020 年成为主席。 我参与 SIG Instrumentation 主要是因为一些上游的指标问题对 GKE 造成了不好的影响。 因此我们发起了一个活动,目的是让我们的指标更稳定并将这些指标打造成一个合适的 API 。
Elana (EH): 我也是在 2018 年加入了 SIG Instrumentation,并与 Han 同时成为主席。 当时我是一名负责裸金属 Kubernetes 集群的站点可靠性工程师(site reliability engineer,SRE), 致力于构建我们的可观测性堆栈。我在标签关联方面遇到了一些问题,具体来说是 Kubernetes 的指标与 kube-state-metrics(KSM)不匹配, 因此我开始参加 SIG 会议以改进这些方面。我帮助测试了 kube-state-metrics 的性能改进, 并最终共同撰写了一个关于在 1.14 版本中彻底改进指标以提高其可用性的 KEP 提案。
Imran (INM): 有趣!这是否意味着 SIG Instrumentation 涉及很多的钻研工作?
Han (HK): 我不会说它涉及大量的钻研工作,但它确实触及了基本上每个代码库。 我们有专门的目录用于我们的 metrics、logs 和 tracing 框架,这些是我们要完成的主要工作。 我们必须与其他 SIG 进行互动以推动我们的变更,这使我们更加成为一个横向的 SIG。
Imran (INM): 谈到与其他 SIG 的互动和协调,你能描述一下 SIG 是如何组织的吗?
Elana (EH): 在 SIG Instrumentation 中,我们有两位主席:Han 和我自己,还有两位技术负责人: David Ashpole 和 Damien Grisonnet。作为 SIG 的领导者,我们一起工作,负责组织会议、分类问题和 PR、审查和批准 KEP、规划每个发布版本、在 KubeCon 和社区会议上演讲,以及撰写我们的年度报告。 在 SIG 内部,我们还有许多重要的子项目,每个子项目都有负责人来指导。例如,Marek Siarkowicz 是 metrics-server 这个子项目的负责人。
由于我们是一个横向的 SIG,我们的一些项目的牵涉面很广,需要由一组专门的贡献者来协调。 例如,为了指导 Kubernetes 向结构化日志的迁移,我们成立了由 Marek 和 Patrick Ohly 组织的 Structured Logging 工作组(Working Group,WG)。这个工作组没有自己的代码,但会帮助各个组件(如 kubelet、scheduler 等)迁移它们的代码以使用结构化日志。
Imran (INM): 从章程(charter)来看, SIG Instrumentation 显然有许多子项目。你能重点说一下其中一些重要的项目吗?
Han (HK): 我们有许多不同的子项目,我们急需能够来协助推动它们的人员。我们最重要的树内(in-tree)项目(即在 kubernetes/kubernetes 代码仓库中)是 metrics、tracing 和 structured logging。 我们最重要的树外(out-of-tree)项目是:(a)KSM(kube-state-metrics)和(b)metrics-server。
Elana (EH): 与上面所说的相呼应,我们希望为 kube-state-metrics 和 metrics-server 引入更多的维护者。我们在 Structure Logging 工作组的朋友也在寻找贡献者。其他子项目包括 klog、prometheus-Adapter, 以及我们刚刚启动的一个用于收集高保真度、可伸缩利用率指标的新子项目,称为 usage-metrics-collector ,它们都在寻找新的贡献者!
现状和持续的挑战
Imran (INM): 在 1.26 版本中,我们可以在流水线中看到有相当数量的关于 metrics、logs 和 tracing 方面的 KEPs。您可否谈谈上个版本中的重要事项 (例如 alpha 和 stable 里程碑的候选项?)
Han (HK): 现在我们可以为 Kubernetes 的 main 代码库中的所有监控指标生成文档! 我们有一个相当不错的静态分析流水线,使这一功能成为可能。 我们还添加了 feature 指标,这样你可以查看这个指标来确定在给定时间内集群中启用了哪些特性。 最后,我们添加了一个 component-sli 端点,它应该使人们为控制平面(control-plane) 组件制定可用性 SLOs 变得容易。
Elana (EH): 我们还在做关于 API 服务器 和 kubelet 的 tracing 方面的 KEPs 工作, 尽管它们都没有在 1.26 版本中毕业。我对于 Han 与可靠性工作组合作,来扩展和改进我们的指标稳定性框架的工作也感到非常兴奋。
Imran (INM): 您认为 SIG Instrumentation 所应对的 Kubernetes 特有挑战有哪些?未来打算如何来解决它们?
Han (HK): SIG Instrumentation 作为一个横向的 SIG 曾经遇到一些困难,我们没有明确的位置来存放我们的代码, 也没有一个良好的机制来审核随意添加的指标。经过多年努力我们已经解决了这个问题,现在我们有了专门的代码存放位置, 并且有可靠的机制来审核新的指标。我们现在还为指标提供稳定性保证。我们希望在 Kubernetes 堆栈上下游进行全面的跟踪, 并通过示例提供指标支持。
Elana (EH): 我认为 SIG Instrumentation 是一个非常有趣的 SIG,因为与其他 SIG 相比,它提供了不同类型的参与机会。您不必是一名软件开发人员就可以为我们的 SIG 做出贡献! 我们的所有组件和子项目都专注于更好地了解 Kubernetes 及其在生产环境中的性能, 这也使得我当时能参与进来并成为少数几个 SRE 身份的 SIG 主席。 我喜欢我们通过使用、测试和提供反馈意见的方式来为新人提供贡献机会,这降低了加入的门槛。 由于这些项目中许多都是 out-of-tree 的,我认为我们面临的挑战之一是确定 Kubernetes 核心 SIGs Instrumentation 子项目的范围并找出缺失的部分,然后填补这些空白。
社区和贡献
Imran (INM): Kubernetes 重视社区胜过重视产品。如果有人想参与 SIG Instrumentation 的工作, 您有什么建议?他们应该从哪里开始(在 SIG 中适合新贡献者的领域?)
Han(HK) and Elana (EH): 参加我们的双周分类会议! 这些会议不会被录制,它们是一个很好的提问的地方并可以了解我们正在进行的工作。我们致力于打造一个友好的社区, 同时也是最容易入门的 SIG 之一。你可以查看我们最新的 KubeCon NA 2022 SIG Instrumentation Deep Dive, 以更深入地了解我们的工作。我们还邀请你加入我们的 Slack 频道 #sig-instrumentation,并随时与我们的 SIG 负责人或子项目所有者直接联系。
非常感谢你抽出宝贵时间并深入了解了 SIG Instrumentation 的工作!
考虑所有微服务的脆弱性并对其行为进行监控
作者:David Hadas (IBM Research Labs)
译者:Wilson Wu (DaoCloud)
本文对 DevOps 产生的错误安全意识做出提醒。开发和配置微服务时遵循安全最佳实践并不能让微服务不易被攻击。 本文说明,即使所有已部署的微服务都容易被攻击,但仍然可以采取很多措施来确保微服务不被利用。 本文解释了如何从安全角度对客户端和服务的行为进行分析,此处称为 “安全行为分析” , 可以对已部署的易被攻击的微服务进行保护。本文会引用 Guard, 一个开源项目,对假定易被攻击的 Kubernetes 微服务的安全行为提供监测与控制。
随着网络攻击的复杂性不断加剧,部署云服务的组织持续追加网络安全投资,旨在提供安全且不易被攻击的服务。 然而,网络安全投资的逐年增长并没有造成网络安全事件的同步减少。相反,网络安全事件的数量每年都在持续增长。 显然,这些组织在这场斗争中注定会失败——无论付出多大努力来检测和消除已部署服务中的网络安全弱点,攻击者似乎总是占据上风。
考虑到当前广泛传播的攻击工具、复杂的攻击者以及攻击者们不断增长的网络安全经济收益, 在 2023 年,任何依赖于构建无漏洞、无弱点服务的网络安全战略显然都过于天真。看来唯一可行的策略是:
➥ 承认你的服务容易被攻击!
换句话说,清醒地接受你永远无法创建完全无懈可击服务的事实。 如果你的对手找到哪怕一个弱点作为切入点,你就输了!承认尽管你尽了最大努力, 你的所有服务仍然容易被攻击,这是重要的第一步。接下来,本文将讨论你可以对此做些什么......
如何保护微服务不被利用
容易被攻击并不一定意味着你的服务将被利用。尽管你的服务在某些方面存在你不知道的漏洞, 但攻击者仍然需要识别这些漏洞并利用它们。如果攻击者无法利用你服务的漏洞,你就赢了! 换句话说,拥有无法利用的漏洞就意味着拥有无法坐实的风险。

图 1:攻击者在易被攻击的服务中取得立足点
如上图所示,攻击者尚未在服务中取得立足点;也就是说,假设你的服务在第一天没有运行由攻击者控制的代码。 在我们的示例中,该服务暴露给客户端的 API 中存在漏洞。为了获得初始立足点, 攻击者使用恶意客户端尝试利用服务 API 的其中一个漏洞。恶意客户端发送一个操作触发服务的一些计划外行为。
更具体地说,我们假设该服务容易受到 SQL 注入攻击。开发人员未能正确过滤用户输入, 从而允许客户端发送会改变预期行为的值。在我们的示例中,如果客户端发送键为“username”且值为 “tom or 1=1” 的查询字符串, 则客户端将收到所有用户的数据。要利用此漏洞需要客户端发送不规范的字符串作为值。 请注意,良性用户不会发送带有空格或等号字符的字符串作为用户名,相反,他们通常会发送合法的用户名, 例如可以定义为字符 a-z 的短序列。任何合法的用户名都不会触发服务计划外行为。
在这个简单的示例中,人们已经可以识别检测和阻止开发人员故意(无意)留下的漏洞被尝试利用的很多机会, 从而使该漏洞无法被利用。首先,恶意客户端的行为与良性客户端的行为不同,因为它发送不规范的请求。 如果检测到并阻止这种行为变化,则该漏洞将永远不会到达服务。其次,响应于漏洞利用的服务行为不同于响应于常规请求的服务行为。 此类行为可能包括对其他服务(例如数据存储)进行后续不规范调用、消耗不确定的时间来响应和/或以非正常的响应来回应恶意客户端 (例如,在良性客户端定期发出请求的情况下,包含比正常发送更多的数据)。 如果检测到服务行为变化,也将允许在利用尝试的不同阶段阻止利用。
更一般而言:
- 监控客户端的行为可以帮助检测和阻止针对服务 API 漏洞的利用。事实上, 部署高效的客户端行为监控会使许多漏洞无法被利用,而剩余漏洞则很难实现。 为了成功,攻击者需要创建一个无法从常规请求中检测到的利用方式。
- 监视服务的行为可以帮助检测通过任何攻击媒介正在被利用的服务。 由于攻击者需要确保服务行为无法从常规服务行为中被检测到,所以有效的服务行为监控限制了攻击者可能实现的目的。
结合这两种方法可以为已部署的易被攻击的服务添加一个保护层,从而大大降低任何人成功利用任何已部署的易被攻击服务的可能性。 接下来,让我们来确定需要使用安全行为监控的四个使用场景。
使用场景
从安全的角度来看,我们可以识别任何服务生命周期中的以下四个不同阶段。 每个阶段都需要安全行为监控来应对不同的挑战:
| 服务状态 | 使用场景 | 为了应对这个使用场景,你需要什么? |
|---|---|---|
| 正常的 | 无已知漏洞: 服务所有者通常不知道服务镜像或配置中存在任何已知漏洞。然而,可以合理地假设该服务存在弱点。 | 针对任何未知漏洞、零日漏洞、服务本身漏洞提供通用保护 - 检测/阻止作为发送给客户端请求的可能被用作利用的部分不规则模式。 |
| 存在漏洞的 | 相关的 CVE 已被公开: 服务所有者需要发布该服务的新的无漏洞修订版。研究表明,实际上,消除已知漏洞的过程可能需要数周才能完成(平均 2 个月)。 | 基于 CVE 分析添加保护 - 检测/阻止包含可用于利用已发现漏洞特定模式的请求。尽管该服务存在已知漏洞,但仍然继续提供服务。 |
| 可被利用的 | 可利用漏洞已被公开: 服务所有者需要一种方法来过滤包含已知可利用漏洞的传入请求。 | 基于已知的可利用漏洞签名添加保护 - 检测/阻止携带识别可利用漏洞签名的传入客户端请求。尽管存在可利用漏洞,但仍继续提供服务。 |
| 已被不当使用的 | 攻击者不当使用服务背后的 Pod: 攻击者可以遵循某种攻击模式,从而使他/她能够对 Pod 进行不当使用。服务所有者需要重新启动任何受损的 Pod,同时使用未受损的 Pod 继续提供服务。请注意,一旦 Pod 重新启动,攻击者需要重复进行攻击,然后才能再次对其进行不当使用。 | 识别并重新启动被不当使用的组件实例 - 在任何给定时间,某些后端的 Pod 可能会受到损害和不当使用,而其他后端 Pod 则按计划运行。检测/删除被不当使用的 Pod,同时允许其他 Pod 继续为客户端请求提供服务。 |
而幸运的是,微服务架构非常适合接下来讨论的安全行为监控。
微服务与单体的安全行为对比
Kubernetes 通常提供用于支持微服务架构设计的工作负载。在设计上,微服务旨在遵循“做一件事并将其做好”的 UNIX 哲学。 每个微服务都有一个有边界的上下文和一个清晰的接口。换句话说,你可以期望微服务客户端发送相对规范的请求, 并且微服务呈现相对规范的行为作为对这些请求的响应。因此,微服务架构是安全行为监控的绝佳候选者。

图 2:微服务非常适合安全行为监控
上图阐明了将单体服务划分为一组微服务是如何提高我们执行安全行为监测和控制的能力。 在单体服务方法中,不同的客户端请求交织在一起,导致识别不规则客户端行为的能力下降。 在没有先验知识的情况下,观察者将发现很难区分交织在一起的客户端请求的类型及其相关特征。 此外,内部客户端请求不会暴露给观察者。最后,单体服务的聚合行为是其组件的许多不同内部行为的复合体,因此很难识别不规范的服务行为。
在微服务环境中,每个微服务在设计上都期望提供定义更明确的服务,并服务于定义更明确的请求类型。 这使得观察者更容易识别不规范的客户端行为和不规范的服务行为。此外,微服务设计公开了内部请求和内部服务, 从而提供更多安全行为数据来识别观察者的违规行为。总的来说,这使得微服务设计模式更适合安全行为监控。
Kubernetes 上的安全行为监控
寻求添加安全行为的 Kubernetes 部署可以使用在 CNCF Knative 项目下开发的 Guard。 Guard 集成到在 Kubernetes 之上运行的完整 Knative 自动化套件中。或者, 你可以将 Guard 作为独立工具部署,以保护 Kubernetes 上任何基于 HTTP 的工作负载。
查看:
- Github 上的 Guard,用于将 Guard 用作独立工具。
- Knative 自动化套件 - 在博客文章 Opinionated Kubernetes 中了解 Knative, 其中描述了 Knative 如何简化和统一 Web 服务在 Kubernetes 上的部署方式。
- 你可以在 SIG Security
或 Knative 社区 Security Slack 频道上联系 Guard 维护人员。
Knative 社区频道将很快转移到 CNCF Slack,其名称为
#knative-security。
本文的目标是邀请 Kubernetes 社区采取行动,并引入安全行为监测和控制, 以帮助保护基于 Kubernetes 的部署。希望社区后续能够:
- 分析不同 Kubernetes 使用场景带来的网络挑战
- 为用户添加适当的安全文档,介绍如何引入安全行为监控。
- 考虑如何与帮助用户监测和控制其易被攻击服务的工具进行集成。
欢迎参与
欢迎你参与到对 Kubernetes 的开发安全行为监控的工作中;以代码或文档的形式分享反馈或做出贡献;并以任何形式完成或提议相关改进。
使用 PriorityClass 确保你的关键任务 Pod 免遭驱逐
作者:Sunny Bhambhani (InfraCloud Technologies)
译者:Wilson Wu (DaoCloud)
Kubernetes 已被广泛使用,许多组织将其用作事实上的编排引擎,用于运行需要频繁被创建和删除的工作负载。
因此,是否能对 Pod 进行合适的调度是确保应用 Pod 在 Kubernetes 集群中正常启动并运行的关键。 本文深入探讨围绕资源管理的使用场景,利用 PriorityClass 对象来保护关键或高优先级 Pod 免遭驱逐并确保应用 Pod 正常启动、运行以及提供流量服务。
Kubernetes 中的资源管理
控制平面由多个组件组成,其中调度程序(通常是内置的 kube-scheduler 是一个负责为 Pod 分配节点的组件。
当 Pod 被创建时,它就会进入“Pending”状态,之后调度程序会确定哪个节点最适合放置这个新 Pod。
在后台,调度程序以无限循环的方式运行,并寻找没有设置 nodeName
且准备好进行调度的 Pod。
对于每个需要调度的 Pod,调度程序会尝试决定哪个节点应该运行该 Pod。
如果调度程序找不到任何节点,Pod 就会保持在这个不理想的挂起状态下。
说明:
举几个例子,可以用 nodeSelector、污点与容忍度、nodeAffinity、
基于可用资源(例如 CPU 和内存)的节点排序以及其他若干判别标准来确定将 Pod 放到哪个节点。
下图从第 1 点到第 4 点解释了请求流程:

Kubernetes 中的调度
典型使用场景
以下是一些可能需要控制 Pod 调度和驱逐的真实场景。
假设你计划部署的 Pod 很关键,并且你有一些资源限制。比如 Grafana Loki 等基础设施组件的 DaemonSet。 Loki Pod 必须先于每个节点上的其他 Pod 运行。在这种情况下,你可以通过手动识别并删除不需要的 Pod 或向集群添加新节点来确保资源可用性。 但是这两种方法都不合适,因为前者执行起来很乏味,而后者可能需要花费时间和金钱。
另一个使用场景是包含若干 Pod 的单个集群,其中对于以下环境有着不同的优先级 :
- 生产环境(
prod):最高优先级 - 预生产环境(
preprod):中等优先级 - 开发环境(
dev):最低优先级
当集群资源消耗较高时,节点上会出现 CPU 和内存资源的竞争。虽然集群自动缩放可能会添加更多节点,但这需要时间。 在此期间,如果没有更多节点来扩展集群,某些 Pod 可能会保持 Pending 状态,或者服务可能会因争夺资源而被降级。 如果 kubelet 决定从节点中驱逐一个 Pod,那么该驱逐将是随机的,因为 kubelet 不具有关于要驱逐哪些 Pod 以及要保留哪些 Pod 的任何特殊信息。
- 生产环境(
第三个示例是后端存在队列或数据库的微服务,当遇到资源紧缩并且队列或数据库被驱逐。 在这种情况下,所有其他服务都将变得毫无用处,直到数据库可以再次提供流量。
还可能存在你希望控制 Pod 调度顺序或驱逐顺序的其他场景。
Kubernetes 中的 PriorityClass
PriorityClass 是 Kubernetes 中集群范围的 API 对象,也是 scheduling.k8s.io/v1 API 组的一部分。
它包含 PriorityClass 名称(在 .metadata.name 中定义)和一个整数值(在 .value 中定义)之间的映射。
整数值表示调度程序用来确定 Pod 相对优先级的值。
此外,当你使用 kubeadm 或托管 Kubernetes 服务(例如 Azure Kubernetes Service)创建集群时, Kubernetes 使用 PriorityClass 来保护控制平面节点上托管的 Pod。这种设置可以确保即使资源有限, CoreDNS 和 kube-proxy 等关键集群组件仍然可以运行。
Pod 的这种可用性是通过使用特殊的 PriorityClass 来实现的,该 PriorityClass 可确保 Pod 正常运行并且整个集群不受影响。
$ kubectl get priorityclass
NAME VALUE GLOBAL-DEFAULT AGE
system-cluster-critical 2000000000 false 82m
system-node-critical 2000001000 false 82m
下图通过一个示例展示其确切工作原理,下一节详细介绍这一原理。

Pod 调度和抢占
Pod 优先级和抢占
Pod 抢占是 Kubernetes 的一项功能, 允许集群基于优先级抢占 Pod(删除现有 Pod 以支持新 Pod)。 Pod 优先级表示调度时 Pod 相对于其他 Pod 的重要性。 如果没有足够的资源来运行当前所有 Pod,调度程序会尝试驱逐优先级较低的 Pod,而不是优先级高的 Pod。
此外,当健康集群遇到节点故障时,通常情况下,较低优先级的 Pod 会被抢占,以便在可用节点上为较高优先级的 Pod 腾出空间。 即使集群可以自动创建新节点,也会发生这种情况,因为 Pod 创建通常比创建新节点快得多。
PriorityClass 的前提条件
在配置 PriorityClass 之前,需要考虑一些事项。
- 决定哪些 PriorityClass 是需要的。例如,基于环境、Pod 类型、应用类型等。
- 集群中默认的 PriorityClass 资源。当 Pod 没有设置
priorityClassName时,优先级将被视为 0。 - 对所有 PriorityClass 使用一致的命名约定。
- 确保工作负载的 Pod 正在使用正确的 PriorityClass。
PriorityClass 的动手示例
假设有 3 个应用 Pod:一个用于生产(prod),一个用于预生产(prepord),一个用于开发(development)。 下面是这三个示例的 YAML 清单文件。
---
# 开发环境(dev)
apiVersion: v1
kind: Pod
metadata:
name: dev-nginx
labels:
env: dev
spec:
containers:
- name: dev-nginx
image: nginx
resources:
requests:
memory: "256Mi"
cpu: "0.2"
limits:
memory: ".5Gi"
cpu: "0.5"
---
# 预生产环境(prepord)
apiVersion: v1
kind: Pod
metadata:
name: preprod-nginx
labels:
env: preprod
spec:
containers:
- name: preprod-nginx
image: nginx
resources:
requests:
memory: "1.5Gi"
cpu: "1.5"
limits:
memory: "2Gi"
cpu: "2"
---
# 生产环境(prod)
apiVersion: v1
kind: Pod
metadata:
name: prod-nginx
labels:
env: prod
spec:
containers:
- name: prod-nginx
image: nginx
resources:
requests:
memory: "2Gi"
cpu: "2"
limits:
memory: "2Gi"
cpu: "2"
你可以使用 kubectl create -f <FILE.yaml> 命令创建这些 Pod,然后使用 kubectl get pods 命令检查它们的状态。
你可以查看它们是否已启动并准备好提供流量:
$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
dev-nginx 1/1 Running 0 55s env=dev
preprod-nginx 1/1 Running 0 55s env=preprod
prod-nginx 0/1 Pending 0 55s env=prod
坏消息是生产环境的 Pod 仍处于 Pending 状态,并且不能提供任何流量。
让我们看看为什么会发生这种情况:
$ kubectl get events
...
...
5s Warning FailedScheduling pod/prod-nginx 0/2 nodes are available: 1 Insufficient cpu, 2 Insufficient memory.
在此示例中,只有一个工作节点,并且该节点存在资源紧缩。
现在,让我们看看在这种情况下 PriorityClass 如何提供帮助,因为生产环境应该比其他环境具有更高的优先级。
PriorityClass 的 API
在根据这些需求创建 PriorityClass 之前,让我们看看 PriorityClass 的基本清单是什么样的, 并给出一些先决条件:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: PRIORITYCLASS_NAME
value: 0 # -1000000000 到 1000000000 之间的任何整数值
description: >-
(可选)描述内容!
globalDefault: false # 或 true。只有一个 PriorityClass 可以作为全局默认值。
以下是 PriorityClass 的一些先决条件:
- PriorityClass 的名称必须是有效的 DNS 子域名。
- 当你创建自己的 PriorityClass 时,名称不应以
system-开头,因为这类名称是被 Kubernetes 本身保留的(例如,它们被用于两个内置的 PriorityClass)。 - 其绝对值应在 -1000000000 到 1000000000(10 亿)之间。
- 较大的数值由 PriorityClass 保留,例如
system-cluster-critical(此 Pod 对集群至关重要)以及system-node-critical(节点严重依赖此 Pod)。system-node-critical的优先级高于system-cluster-critical,因为集群级别关键 Pod 只有在其运行的节点满足其所有节点级别关键要求时才能正常工作。 - 额外两个可选字段:
globalDefault:当为 true 时,此 PriorityClass 用于未设置priorityClassName的 Pod。 集群中只能存在一个globalDefault设置为 true 的 PriorityClass。 如果没有 PriorityClass 的 globalDefault 设置为 true,则所有未定义 priorityClassName 的 Pod 都将被视为 0 优先级(即最低优先级)。description:具备有意义值的字符串,以便人们知道何时使用此 PriorityClass。
说明:
添加一个将 globalDefault 设置为 true 的 PriorityClass 并不意味着它将同样应用于已在运行的现有 Pod。
这仅适用于创建 PriorityClass 之后出现的 Pod。
PriorityClass 的实际应用
这里有一个例子。接下来,创建一些针对环境的 PriorityClass:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: dev-pc
value: 1000000
globalDefault: false
description: >-
(可选)此 PriorityClass 只能用于所有开发环境(dev)Pod。
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: preprod-pc
value: 2000000
globalDefault: false
description: >-
(可选)此 PriorityClass 只能用于所有预生产环境(preprod)Pod。
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: prod-pc
value: 4000000
globalDefault: false
description: >-
(可选)此 PriorityClass 只能用于所有生产环境(prod)Pod。
使用 kubectl create -f <FILE.YAML> 命令创建 PriorityClass 并使用 kubectl get pc 检查其状态。
$ kubectl get pc
NAME VALUE GLOBAL-DEFAULT AGE
dev-pc 1000000 false 3m13s
preprod-pc 2000000 false 2m3s
prod-pc 4000000 false 7s
system-cluster-critical 2000000000 false 82m
system-node-critical 2000001000 false 82m
新的 PriorityClass 现已就位。需要对 Pod 清单或 Pod 模板(在 ReplicaSet 或 Deployment 中)进行一些小的修改。
换句话说,你需要在 .spec.priorityClassName(这是一个字符串值)中指定 PriorityClass 名称。
首先更新之前的生产环境 Pod 清单文件以分配 PriorityClass,然后删除生产环境 Pod 并重新创建它。你无法编辑已存在 Pod 的优先级类别。
在我的集群中,当我尝试此操作时,发生了以下情况。首先,这种改变似乎是成功的;Pod 的状态已被更新:
$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
dev-nginx 1/1 Terminating 0 55s env=dev
preprod-nginx 1/1 Running 0 55s env=preprod
prod-nginx 0/1 Pending 0 55s env=prod
dev-nginx Pod 即将被终止。一旦成功终止并且有足够的资源用于 prod Pod,控制平面就可以对 prod Pod 进行调度:
Warning FailedScheduling pod/prod-nginx 0/2 nodes are available: 1 Insufficient cpu, 2 Insufficient memory.
Normal Preempted pod/dev-nginx by default/prod-nginx on node node01
Normal Killing pod/dev-nginx Stopping container dev-nginx
Normal Scheduled pod/prod-nginx Successfully assigned default/prod-nginx to node01
Normal Pulling pod/prod-nginx Pulling image "nginx"
Normal Pulled pod/prod-nginx Successfully pulled image "nginx"
Normal Created pod/prod-nginx Created container prod-nginx
Normal Started pod/prod-nginx Started container prod-nginx
执行
配置 PriorityClass 时,它们会按照你所定义的方式存在。 但是,对集群进行变更的人员(和工具)可以自由设置任意 PriorityClass, 或者根本不设置任何 PriorityClass。然而,你可以使用其他 Kubernetes 功能来确保你想要的优先级被实际应用起来。
作为一项 Alpha 级别功能,你可以定义一个 ValidatingAdmissionPolicy
和一个 ValidatingAdmissionPolicyBinding,例如,进入 prod 命名空间的 Pod 必须使用 prod-pc PriorityClass。
通过另一个 ValidatingAdmissionPolicyBinding,你可以确保 preprod 命名空间使用 preprod-pc PriorityClass,依此类推。
在任何集群中,你可以使用外部项目,例如 Kyverno 或 Gatekeeper 通过验证准入 Webhook 实施类似的控制。
无论你如何操作,Kubernetes 都会为你提供选项,确保 PriorityClass 的用法如你所愿, 或者只是当用户选择不合适的选项时做出警告。
总结
上面的示例及其事件向你展示了 Kubernetes 此功能带来的好处,以及可以使用此功能的几种场景。 重申一下,这一机制有助于确保关键任务 Pod 启动并可用于提供流量,并在资源紧张的情况下确定集群行为。
它赋予你一定的权力来决定 Pod 的调度顺序和抢占顺序。
因此,你需要明智地定义 PriorityClass。例如,如果你有一个集群自动缩放程序来按需添加节点,
请确保使用 system-cluster-critical PriorityClass 运行它。你不希望遇到自动缩放器 Pod 被抢占导致没有新节点上线的情况。
如果你有任何疑问或反馈,可以随时通过 LinkedIn 与我联系。
Kubernetes 1.26:PodDisruptionBudget 守护的不健康 Pod 所用的驱逐策略
作者: Filip Křepinský (Red Hat), Morten Torkildsen (Google), Ravi Gudimetla (Apple)
译者: Michael Yao (DaoCloud)
确保对应用的干扰不影响其可用性不是一个简单的任务。 上个月发布的 Kubernetes v1.26 允许针对 PodDisruptionBudget (PDB) 指定不健康 Pod 驱逐策略,这有助于在节点执行管理操作期间保持可用性。
这解决什么问题?
API 发起的 Pod 驱逐尊重 PodDisruptionBudget (PDB) 约束。这意味着因驱逐 Pod
而请求的自愿干扰不应干扰守护的应用且
PDB 的 .status.currentHealthy 不应低于 .status.desiredHealthy。
如果正在运行的 Pod 状态为 Unhealthy,
则该 Pod 不计入 PDB 状态,只有在应用不受干扰时才可以驱逐这些 Pod。
这有助于尽可能确保受干扰或还未启动的应用的可用性,不会因驱逐造成额外的停机时间。
不幸的是,对于想要腾空节点但又不进行任何手动干预的集群管理员而言,这种机制是有问题的。
若一些应用因 Pod 处于 CrashLoopBackOff 状态(由于漏洞或配置错误)或 Pod 无法进入就绪状态而行为异常,
会使这项任务变得更加困难。当某应用的所有 Pod 均不健康时,所有驱逐请求都会因违反 PDB 而失败。
在这种情况下,腾空节点不会有任何作用。
另一方面,有些用户依赖于现有行为,以便:
- 防止因删除守护基础资源或存储的 Pod 而造成数据丢失
- 让应用达到最佳可用性
Kubernetes 1.26 为 PodDisruptionBudget API 引入了新的实验性字段:
.spec.unhealthyPodEvictionPolicy。启用此字段后,将允许你支持上述两种需求。
工作原理
API 发起的驱逐是触发 Pod 优雅终止的一个进程。
这个进程可以通过直接调用 API 发起,也能使用 kubectl drain 或集群中的其他主体来发起。
在这个过程中,移除每个 Pod 时将与对应的 PDB 协商,确保始终有足够数量的 Pod 在集群中运行。
以下策略允许 PDB 作者进一步控制此进程如何处理不健康的 Pod。
有两个策略可供选择:IfHealthyBudget 和 AlwaysAllow。
前者,IfHealthyBudget 采用现有行为以达到你默认可获得的最佳的可用性。
不健康的 Pod 只有在其应用中可用的 Pod 个数达到 .status.desiredHealthy 即最小可用个数时才会被干扰。
通过将 PDB 的 spec.unhealthyPodEvictionPolicy 字段设置为 AlwaysAllow,
可以表示尽可能为应用选择最佳的可用性。采用此策略时,始终能够驱逐不健康的 Pod。
这可以简化集群的维护和升级。
我们认为 AlwaysAllow 通常是一个更好的选择,但是对于某些关键工作负载,
你可能仍然倾向于防止不健康的 Pod 被从节点上腾空或其他形式的 API 发起的驱逐。
如何使用?
这是一个 Alpha 特性,意味着你必须使用命令行参数 --feature-gates=PDBUnhealthyPodEvictionPolicy=true
为 kube-apiserver 启用 PDBUnhealthyPodEvictionPolicy
特性门控。
以下是一个例子。假设你已在集群中启用了此特性门控且你已定义了运行普通 Web 服务器的 Deployment。
你已为 Deployment 的 Pod 打了标签 app: nginx。
你想要限制可避免的干扰,你知道对于此应用而言尽力而为的可用性也是足够的。
你决定即使这些 Web 服务器 Pod 不健康也允许驱逐。
你创建 PDB 守护此应用,使用 AlwaysAllow 策略驱逐不健康的 Pod:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: nginx-pdb
spec:
selector:
matchLabels:
app: nginx
maxUnavailable: 1
unhealthyPodEvictionPolicy: AlwaysAllow
查阅更多资料
- 阅读 KEP:Unhealthy Pod Eviction Policy for PDBs
- 阅读针对 PodDisruptionBudget 的不健康 Pod 驱逐策略文档
- 参阅 PodDisruptionBudget、 腾空节点和驱逐等 Kubernetes 文档
我如何参与?
如果你有任何反馈,请通过 Slack #sig-apps 频道 (如有需要,请访问 https://slack.k8s.io/ 获取邀请)或通过 SIG Apps 邮件列表 kubernetes-sig-apps@googlegroups.com 联系我们。
Kubernetes v1.26:可追溯的默认 StorageClass
作者: Roman Bednář (Red Hat)
译者: Michael Yao (DaoCloud)
Kubernetes v1.25 引入了一个 Alpha 特性来更改默认 StorageClass 被分配到 PersistentVolumeClaim (PVC) 的方式。 启用此特性后,你不再需要先创建默认 StorageClass,再创建 PVC 来分配类。 此外,任何未分配 StorageClass 的 PVC 都可以在后续被更新。此特性在 Kubernetes v1.26 中已进阶至 Beta。
有关如何使用的更多细节,请参阅 Kubernetes 文档可追溯的默认 StorageClass 赋值, 你还可以阅读了解为什么 Kubernetes 项目做了此项变更。
为什么 StorageClass 赋值需要改进
用户可能已经熟悉在创建时将默认 StorageClasses 分配给新 PVC 的这一类似特性。 这个目前由准入控制器处理。
但是,如果在创建 PVC 时没有定义默认 StorageClass 会怎样? 那用户最终将得到一个永远不会被赋予存储类的 PVC。结果是没有存储会被制备,而 PVC 有时也会“卡在”这里。 一般而言,两个主要场景可能导致 PVC “卡住”,并在后续造成更多问题。让我们仔细看看这两个场景。
更改默认 StorageClass
启用这个 Alpha 特性后,管理员想要更改默认 StorageClass 时会有两个选项:
- 在移除与 PVC 关联的旧 StorageClass 之前,创建一个新的 StorageClass 作为默认值。
这将导致在短时间内出现两个默认值。此时,如果用户要创建一个 PersistentVolumeClaim,
并将 storageClassName 设置为
null(指代默认 StorageClass), 则最新的默认 StorageClass 将被选中并指定给这个 PVC。
- 先移除旧的默认值再创建一个新的默认 StorageClass。这将导致短时间内没有默认值。
接下来如果用户创建一个 PersistentVolumeClaim,并将 storageClassName 设置为
null(指代默认 StorageClass),则 PVC 将永远处于Pending状态。 一旦默认 StorageClass 可用,用户就不得不通过删除并重新创建 PVC 来修复这个问题。
集群安装期间的资源顺序
如果集群安装工具需要创建镜像仓库这种有存储要求的资源,很难进行合适地排序。 这是因为任何有存储要求的 Pod 都将依赖于默认 StorageClass 的存在与否。 如果默认 StorageClass 未被定义,Pod 创建将失败。
发生了什么变化
我们更改了 PersistentVolume (PV) 控制器,以便将默认 StorageClass 指定给
storageClassName 设置为 null 且未被绑定的所有 PersistentVolumeClaim。
我们还修改了 API 服务器中的 PersistentVolumeClaim 准入机制,允许将取值从未设置值更改为实际的 StorageClass 名称。
Null storageClassName 与 storageClassName: "" - 有什么影响?
此特性被引入之前,这两种赋值就其行为而言是相同的。storageClassName 设置为 null 或 ""
的所有 PersistentVolumeClaim 都会被绑定到 storageClassName 也设置为 null 或
"" 的、已有的 PersistentVolume 资源。
启用此新特性时,我们希望保持此行为,但也希望能够更新 StorageClass 名称。
考虑到这些限制,此特性更改了 null 的语义。
具体而言,如果有一个默认 StorageClass,null 将可被理解为 “给我一个默认值”,
而 "" 表示 “给我 StorageClass 名称也是 "" 的 PersistentVolume”,
所以行为将保持不变。
综上所述,我们更改了 null 的语义,使其行为取决于默认 StorageClass 定义的存在或缺失。
下表显示了所有这些情况,更好地描述了 PVC 何时绑定及其 StorageClass 何时被更新。
PVC storageClassName = "" | PVC storageClassName = null | ||
|---|---|---|---|
| 未设置默认存储类 | PV storageClassName = "" | binds | binds |
| PV without storageClassName | binds | binds | |
| 设置了默认存储类 | PV storageClassName = "" | binds | 存储类更新 |
| PV without storageClassName | binds | 存储类更新 | |
如何使用
如果你想测试这个 Alpha 特性,你需要在 kube-controller-manager 和 kube-apiserver 中启用相关特性门控。
你可以使用 --feature-gates 命令行参数:
--feature-gates="...,RetroactiveDefaultStorageClass=true"
测试演练
如果你想看到此特性发挥作用并验证它在集群中是否正常工作,你可以尝试以下步骤:
定义一个基本的 PersistentVolumeClaim:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pvc-1 spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi
在没有默认 StorageClass 时创建 PersistentVolumeClaim。 PVC 不会制备或绑定(除非当前已存在一个合适的 PV),PVC 将保持在
Pending状态。kubectl get pvc输出类似于:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE pvc-1 Pending
将某个 StorageClass 配置为默认值。
kubectl patch sc -p '{"metadata":{"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'输出类似于:
storageclass.storage.k8s.io/my-storageclass patched
确认 PersistentVolumeClaims 现在已被正确制备,并且已使用新的默认 StorageClass 进行了可追溯的更新。
kubectl get pvc输出类似于:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE pvc-1 Bound pvc-06a964ca-f997-4780-8627-b5c3bf5a87d8 1Gi RWO my-storageclass 87m
新指标
为了帮助你了解该特性是否按预期工作,我们还引入了一个新的 retroactive_storageclass_total
指标来显示 PV 控制器尝试更新 PersistentVolumeClaim 的次数,以及
retroactive_storageclass_errors_total 来显示这些尝试失败了多少次。
欢迎参与
我们始终欢迎新的贡献者,如果你想参与其中,欢迎加入 Kubernetes Storage Special Interest Group(存储特别兴趣小组) (SIG)。
如果你想分享反馈,可以在我们的公开 Slack 频道上反馈。
特别感谢所有提供精彩评论、分享宝贵见解并帮助实现此特性的贡献者们(按字母顺序排列):
- Deep Debroy (ddebroy)
- Divya Mohan (divya-mohan0209)
- Jan Šafránek (jsafrane)
- Joe Betz (jpbetz)
- Jordan Liggitt (liggitt)
- Michelle Au (msau42)
- Seokho Son (seokho-son)
- Shannon Kularathna (shannonxtreme)
- Tim Bannister (sftim)
- Tim Hockin (thockin)
- Wojciech Tyczynski (wojtek-t)
- Xing Yang (xing-yang)
Kubernetes v1.26:对跨名字空间存储数据源的 Alpha 支持
作者: Takafumi Takahashi (Hitachi Vantara)
译者: Michael Yao (DaoCloud)
上个月发布的 Kubernetes v1.26 引入了一个 Alpha 特性,允许你在源数据属于不同的名字空间时为
PersistentVolumeClaim 指定数据源。启用这个新特性后,你在新 PersistentVolumeClaim 的
dataSourceRef 字段中指定名字空间。一旦 Kubernetes 发现访问权限正常,新的 PersistentVolume
就可以从其他名字空间中指定的存储源填充其数据。在 Kubernetes v1.26 之前,如果集群已启用了
AnyVolumeDataSource 特性,你可能已经从相同的名字空间中的数据源制备新卷。
但这仅适用于同一名字空间中的数据源,因此用户无法基于一个名字空间中的数据源使用另一个名字空间中的声明来制备
PersistentVolume。为了解决这个问题,Kubernetes v1.26 在 PersistentVolumeClaim API 的
dataSourceRef 字段中添加了一个新的 Alpha namespace 字段。
工作原理
一旦 csi-provisioner 发现数据源是使用具有非空名字空间名称的 dataSourceRef 指定的,
它就会检查由 PersistentVolumeClaim 的 .spec.dataSourceRef.namespace
字段指定的名字空间内所授予的所有引用,以便确定可以访问数据源。
如果有 ReferenceGrant 允许访问,则 csi-provisioner 会基于数据源来制备卷。
试用
使用跨名字空间卷制备时以下事项是必需的:
- 为 kube-apiserver 和 kube-controller-manager 启用
AnyVolumeDataSource和CrossNamespaceVolumeDataSource特性门控 - 为特定的
VolumeSnapShot控制器安装 CRD - 安装 CSI Provisioner 控制器并启用
CrossNamespaceVolumeDataSource特性门控 - 安装 CSI 驱动程序
- 为 ReferenceGrants 安装 CRD
完整演练
要查看其工作方式,你可以安装样例并进行试用。 此样例使用 prod 名字空间中的 VolumeSnapshot 在 dev 名字空间中创建 PVC。 这是一个简单的例子。想要在真实世界中使用,你可能要用更复杂的方法。
这个例子的假设
- 部署你的 Kubernetes 集群时启用
AnyVolumeDataSource和CrossNamespaceVolumeDataSource特性门控 - 有两个名字空间:dev 和 prod
- CSI 驱动程序被部署
- 在 prod 名字空间中存在一个名为
new-snapshot-demo的 VolumeSnapshot - ReferenceGrant CRD(源于 Gateway API 项目)已被部署
为 CSI Provisioner 授予 ReferenceGrants 读取权限
仅当 CSI 驱动程序具有 CrossNamespaceVolumeDataSource 控制器功能时才需要访问 ReferenceGrants。
对于此示例,外部制备器对于 referencegrants(API 组 gateway.networking.k8s.io)需要
get、list 和 watch 权限。
- apiGroups: ["gateway.networking.k8s.io"]
resources: ["referencegrants"]
verbs: ["get", "list", "watch"]
为 CSI Provisioner 启用 CrossNamespaceVolumeDataSource 特性门控
将 --feature-gates=CrossNamespaceVolumeDataSource=true 添加到 csi-provisioner 命令行。
例如,使用此清单片段重新定义容器:
- args:
- -v=5
- --csi-address=/csi/csi.sock
- --feature-gates=Topology=true
- --feature-gates=CrossNamespaceVolumeDataSource=true
image: csi-provisioner:latest
imagePullPolicy: IfNotPresent
name: csi-provisioner
创建 ReferenceGrant
以下是 ReferenceGrant 示例的清单。
apiVersion: gateway.networking.k8s.io/v1beta1
kind: ReferenceGrant
metadata:
name: allow-prod-pvc
namespace: prod
spec:
from:
- group: ""
kind: PersistentVolumeClaim
namespace: dev
to:
- group: snapshot.storage.k8s.io
kind: VolumeSnapshot
name: new-snapshot-demo
通过使用跨名字空间数据源创建 PersistentVolumeClaim
Kubernetes 在 dev 上创建 PersistentVolumeClaim,CSI 驱动程序从 prod 上的快照填充在 dev 上使用的 PersistentVolume。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: example-pvc
namespace: dev
spec:
storageClassName: example
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
dataSourceRef:
apiGroup: snapshot.storage.k8s.io
kind: VolumeSnapshot
name: new-snapshot-demo
namespace: prod
volumeMode: Filesystem
怎样了解更多
增强提案 Provision volumes from cross-namespace snapshots 包含了此特性的历史和技术实现的大量细节。
若想参与,请加入 Kubernetes 存储特别兴趣小组 (SIG) 帮助我们增强此特性。SIG 内有许多好点子,我们很高兴能有更多!
致谢
制作出色的软件需要优秀的团队。 特别感谢以下人员对 CrossNamespaceVolumeDataSouce 特性的深刻见解、周密考量和宝贵贡献:
- Michelle Au (msau42)
- Xing Yang (xing-yang)
- Masaki Kimura (mkimuram)
- Tim Hockin (thockin)
- Ben Swartzlander (bswartz)
- Rob Scott (robscott)
- John Griffith (j-griffith)
- Michael Henriksen (mhenriks)
- Mustafa Elbehery (Elbehery)
很高兴与大家一起工作。
Kubernetes v1.26:Kubernetes 中流量工程的进步
作者:Andrew Sy Kim (Google)
译者:Wilson Wu (DaoCloud)
Kubernetes v1.26 在网络流量工程方面取得了重大进展, 两项功能(服务内部流量策略支持和 EndpointSlice 终止状况)升级为正式发布版本, 第三项功能(代理终止端点)升级为 Beta。这些增强功能的结合旨在解决人们目前所面临的流量工程短板,并在未来解锁新的功能。
滚动更新期间负载均衡器的流量丢失
在 Kubernetes v1.26 之前,将 externalTrafficPolicy 字段设置为 Local 时,
集群在滚动更新期间可能会遇到 Service 的负载均衡器流量丢失问题。
这里有很多活动部件作用其中,因此简述 Kubernetes 管理负载均衡器的机制可能对此有所帮助!
在 Kubernetes 中,你可以创建一个 type: LoadBalancer 的 Service,
并通过负载均衡器对外暴露应用。负载均衡器的实现因集群和平台而异,
但 Service 提供了表示负载均衡器的通用抽象,该抽象在所有 Kubernetes 环境中都是一致的。
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: my-app
ports:
- protocol: TCP
port: 80
targetPort: 9376
type: LoadBalancer
在底层,Kubernetes 为 Service 分配一个 NodePort,然后 kube-proxy 使用它来提供从 NodePort 到 Pod 的网络数据路径。然后,控制器将集群中的所有可用节点添加到负载均衡器的后端池中, 使用 Service 的指定 NodePort 作为后端目标端口。
图 1:Service 负载均衡器概览
通常,为 Service 设置 externalTrafficPolicy: Local 是有益的,
对于没有运行为该 Service 提供服务的健康 Pod 的节点而言,可以避免在这类节点之间的额外跳转。
使用 externalTrafficPolicy: Local 时,会分配一个额外的 NodePort 用于健康检查,
这样不包含健康 Pod 的节点就会被排除在负载均衡器的后端池之外。
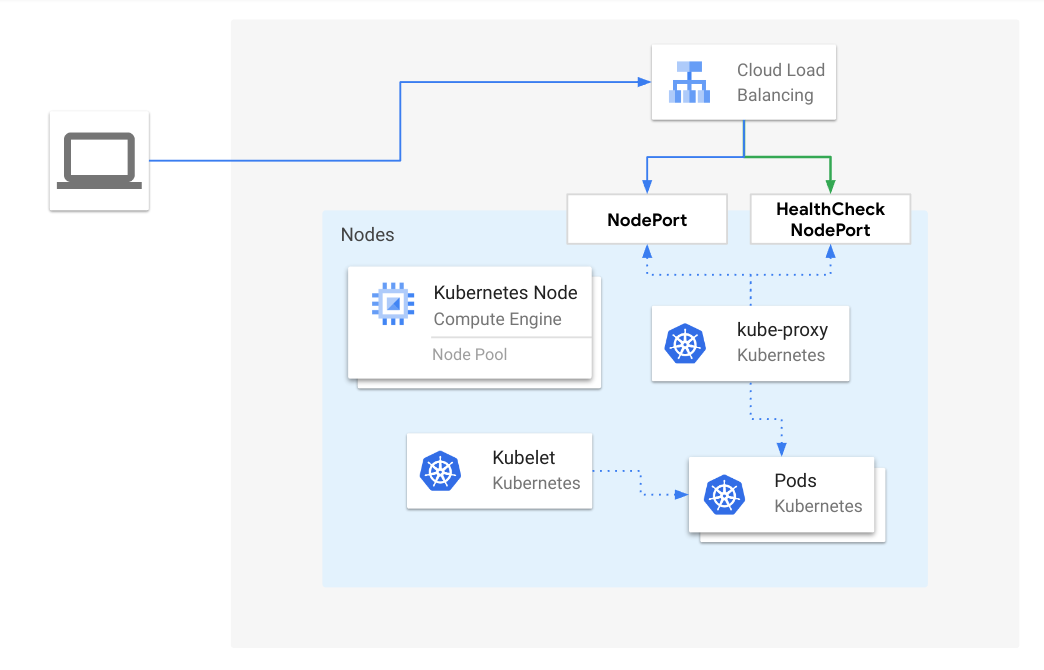
图 2:当 externalTrafficPolicy 为 Local 时,从负载均衡器到健康节点的流量情况
流量可能丢失的一种情况是,当节点失去了某个 Service 的所有 Pod,但外部负载均衡器尚未通过 NodePort 进行健康检查探测时。这种情况的发生概率很大程度上取决于负载均衡器上配置的健康检查时间间隔。 间隔越大,发生这种情况的可能性就越大,因为即使在 kube-proxy 删除了该服务的转发规则之后, 负载均衡器仍将继续向节点发送流量。当 Pod 在滚动更新期间开始终止时也会发生这种情况。 由于 Kubernetes 不会将正在终止的 Pod 视为“Ready”,因此当滚动更新期间任何给定节点上仅存在正在终止的 Pod 时,流量可能会丢失。
图 3:当 externalTrafficPolicy 为 Local 时,从负载均衡器到正在终止的端点的流量
从 Kubernetes v1.26 开始,kube-proxy 将默认启用 ProxyTerminatingEndpoints 功能,
该功能在流量将被丢弃时自动添加故障转移并将流量路由到正在终止的端点。更具体地说,
当存在滚动更新并且节点仅包含正在终止的 Pod 时,kube-proxy 会根据其就绪情况将流量路由到正在终止的 Pod 中。
此外,如果只有正在终止的 Pod 可用时,kube-proxy 将主动使 NodePort 的健康检查失败。
通过这种做法,kube-proxy 能够提醒外部负载均衡器新连接不应发送到该节点,并妥善处理现有连接的请求。
图 4:当 externalTrafficPolicy 为 Local 时,从负载均衡器到启用 ProxyTerminateEndpoints 的正在终止端点的流量
EndpointSlice 状况
为了支持 kube-proxy 中的这一新功能,EndpointSlice API 为端点引入了新状况:serving 和 terminating。
图 5:EndpointSlice 状况概述
serving 状况在语义上与 ready 相同,只是在 Pod 正在终止时它可以为 true 或 false,
而 ready 则由于兼容性原因对于正在终止的 Pod 始终为 false。
对于正在终止的 Pod(deletionTimestamp 不为空),terminating 状况为 true,否则为 false。
添加这两个状况使该 API 的使用者能够了解之前无法体现的 Pod 状态。 例如,我们现在可以同时跟踪“ready”和“not ready”的正在终止的 Pod。
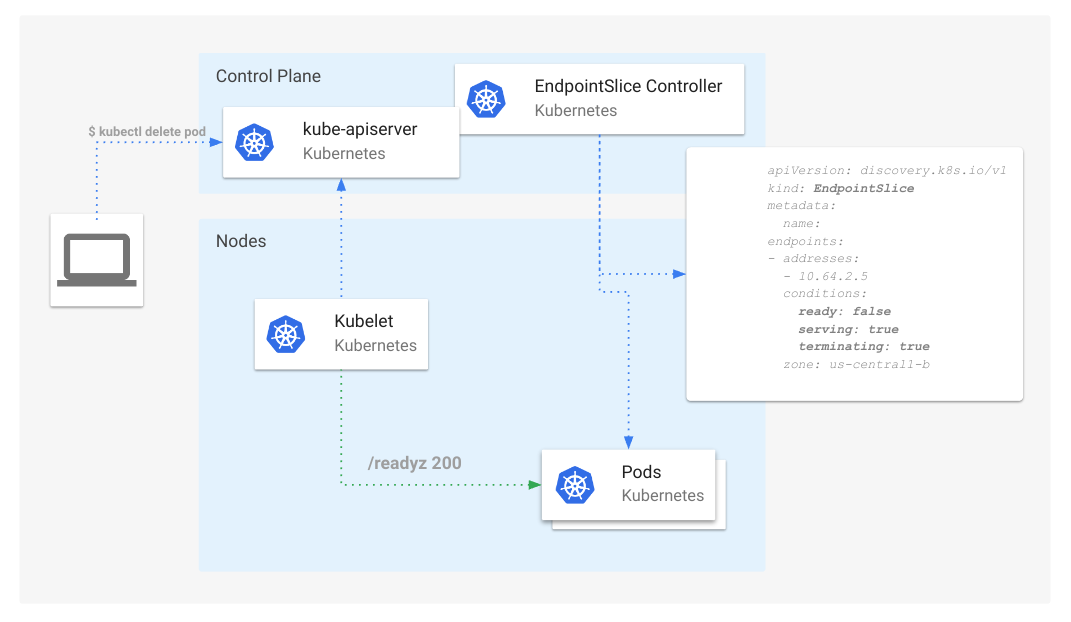
图 6:正在终止 Pod 的 EndpointSlice 状况
EndpointSlice API 的使用者(例如 Kube-proxy 和 Ingress Controller)现在可以使用这些状况来协调连接耗尽事件, 方法是继续转发现有连接的流量,但将新连接重新路由到其他非正在终止的端点。
优化内部节点本地流量
与 Service 可以设置 externalTrafficPolicy: Local 以避免外部来源流量的额外跃点类似,
Kubernetes 现在支持 internalTrafficPolicy: Local,以便对源自集群内部的流量启用相同的优化,
特别是对于使用 Service 集群 IP 的流量目标地址。该功能已在 Kubernetes v1.24 中升级为 Beta,并在 v1.26 中升级为正式发布版本。
Service 默认将 internalTrafficPolicy 字段设置为Cluster,使其流量随机分配到所有端点。
图 7:internalTrafficPolicy 为 Cluster 时的 Service 路由
当 internalTrafficPolicy 设置为 Local 时,仅当在相同节点存在本地可用端点时,kube-proxy 才会转发服务的内部流量。
图 8:internalTrafficPolicy 为 Local 时的服务路由
注意:
使用internalTrafficPoliy: Local 时,当没有可用的本地端点时,kube-proxy 将丢弃流量。欢迎参与
如果你对未来关于 Kubernetes 流量工程的讨论感兴趣,可以通过以下方式参与 SIG Network:
Kubernetes v1.26:CPUManager 正式发布
作者: Francesco Romani (Red Hat)
译者: Michael Yao (DaoCloud)
CPU 管理器是 kubelet 的一部分;kubelet 是 Kubernetes 的节点代理,能够让用户给容器分配独占 CPU。 CPU 管理器自从 Kubernetes v1.10 进阶至 Beta, 已证明了它本身的可靠性,能够充分胜任将独占 CPU 分配给容器,因此采用率稳步增长, 使其成为性能关键型和低延迟场景的基本组件。随着时间的推移,大多数变更均与错误修复或内部重构有关, 以下列出了几个值得关注、用户可见的变更:
- 支持显式保留 CPU: 之前已经可以请求为系统资源(包括 kubelet 本身)保留给定数量的 CPU,这些 CPU 将不会被用于独占 CPU 分配。 现在还可以显式选择保留哪些 CPU,而不是让 kubelet 自动拣选 CPU。
- 使用 kubelet 本地 PodResources API 向容器报告独占分配的 CPU,就像已为设备所做的一样。
- 优化系统资源的使用,消除不必要的 sysfs 变更。
CPU 管理器达到了“能胜任”的水平,因此在 Kubernetes v1.26 中,它进阶至正式发布(GA)状态。
CPU 管理器的自定义选项
CPU 管理器支持两种操作模式,使用其策略进行配置。
使用 none 策略,CPU 管理器将 CPU 分配给容器,除了 Pod 规约中设置的(可选)配额外,没有任何特定限制。
使用 static 策略,假设 Pod 属于 Guaranteed QoS 类,并且该 Pod 中的每个容器都请求一个整数核数的 vCPU,
则 CPU 管理器将独占分配 CPU。独占分配意味着(无论是来自同一个 Pod 还是来自不同的 Pod)其他容器都不会被调度到该 CPU 上。
这种简单的操作模型很好地服务了用户群体,但随着 CPU 管理器越来越成熟, 用户开始关注更复杂的使用场景以及如何更好地支持这些使用场景。
社区没有添加更多策略,而是意识到几乎所有新颖的用例都是 static CPU 管理器策略所赋予的一些行为变化。
因此,决定添加[调整静态策略行为的选项](https://github.com/Kubernetes/enhancements/tree/master/keps/sig-node/2625-cpumanager-policies-thread-placement #proposed-change)。
这些选项都达到了不同程度的成熟度,类似于其他的所有 Kubernetes 特性,
为了能够被接受,每个新选项在禁用时都能提供向后兼容的行为,并能在需要进行交互时记录彼此如何交互。
这使得 Kubernetes 项目能够将 CPU 管理器核心组件和核心 CPU 分配算法进阶至 GA,同时也开启了该领域新的实验时代。 在 Kubernetes v1.26 中,CPU 管理器支持三个不同的策略选项:
full-pcpus-only- 将 CPU 管理器核心分配算法限制为仅支持完整的物理核心,从而减少允许共享核心的硬件技术带来的嘈杂邻居问题。
distribute-cpus-across-numa- 驱动 CPU 管理器跨 NUMA 节点均匀分配 CPU,以应对需要多个 NUMA 节点来满足分配的情况。
align-by-socket- 更改 CPU 管理器将 CPU 分配给容器的方式:考虑 CPU 按插槽而不是 NUMA 节点边界对齐。
后续发展
在主要 CPU 管理器特性进阶后,每个现有的策略选项将遵循其进阶过程,独立于 CPU 管理器和其他选项。 添加新选项的空间虽然存在,但随着对更高灵活性的需求不断增长,CPU 管理器及其策略选项当前所提供的灵活性也有不足。
社区中正在讨论如何将 CPU 管理器和当前属于 kubelet 可执行文件的其他资源管理器拆分为可插拔的独立 kubelet 插件。 如果你对这项努力感兴趣,请加入 SIG Node 交流频道(Slack、邮件列表、每周会议)进行讨论。
进一步阅读
请查阅控制节点上的 CPU 管理策略任务页面以了解有关 CPU 管理器的更多信息及其如何适配其他节点级别资源管理器。
参与其中
此特性由 SIG Node 社区驱动。 请加入我们与社区建立联系,就上述特性和更多内容分享你的想法和反馈。我们期待你的回音!
Kubernetes 1.26:Pod 调度就绪态
作者: Wei Huang (Apple), Abdullah Gharaibeh (Google)
译者: XiaoYang Zhang (HuaWei)
Kubernetes 1.26 引入了一个新的 Pod 特性:调度门控。 在 Kubernetes 中,调度门控是通知调度器何时可以考虑 Pod 调度的关键。
它解决了什么问题?
当 Pod 被创建时,调度器会不断尝试寻找适合它的节点。这个无限循环一直持续到调度程序为 Pod 找到节点,或者 Pod 被删除。
长时间无法被调度的 Pod(例如,被某些外部事件阻塞的 Pod)会浪费调度周期。 一个调度周期可能需要约 20ms 或更长时间,这取决于 Pod 的调度约束的复杂度。 因此,大量浪费的被调度周期会严重影响调度器的性能。请参阅下面 “调度器” 框中的箭头。
调度门控有助于解决这个问题。它允许声明新创建的 Pod 尚未准备好进行调度。 当 Pod 上设置了调度门控时,调度程序会忽略该 Pod,从而避免不必要的调度尝试。 如果你在集群中安装了 Cluster Autoscaler,这些 Pod 也将被忽略。
清除门控是外部控制器的责任,外部控制器知道何时应考虑对 Pod 进行调度(例如,配额管理器)。
它是如何工作的?
总体而言,调度门控的工作方式与 Finalizer 非常相似。具有非空 spec.schedulingGates 字段的 Pod
的状态将显示为 SchedulingGated,并阻止被调度。请注意,添加多个门控是可以的,但它们都应该在创建 Pod
时添加(例如,你可以将它们作为规约的一部分或者通过变更性质的 Webhook)。
NAME READY STATUS RESTARTS AGE
test-pod 0/1 SchedulingGated 0 10s
要清除这些门控,你可以通过删除 Pod 的 schedulingGates 字段中的所有条目来更新 Pod。
不需要一次性移除所有门控,但是,只有当所有门控都移除后,调度器才会开始考虑对 Pod 进行调度。
在后台,调度门控以 PreEnqueue 调度器插件的方式实现,这是调度器框架的新扩展点,在每个调度周期开始时调用。
用例
此特性所支持的一个重要使用场景是动态配额管理。Kubernetes 支持资源配额, 但是 API Server 会在你尝试创建 Pod 时强制执行配额。例如,如果一个新的 Pod 超过了 CPU 配额,它就会被拒绝。 API Server 不会对 Pod 进行排队;因此,无论是谁创建了 Pod,都需要不断尝试重新创建它。 这意味着在资源可用和 Pod 实际运行之间会有延迟,或者意味着由于不断尝试,会增加 API Server 和 Scheduler 的负载。
调度门控允许外部配额管理器解决 ResourceQuota 的上述限制。具体来说,
管理员可以(使用变更性质的 Webhook)为集群中创建的所有 Pod 添加一个
example.com/quota-check 调度门控。当存在用于启动 Pod 的配额时,管理器将移除此门控
接下来
要使用此特性,必须在 API Server 和调度器中启用 PodScheduleingReadiness 特性门控。
非常欢迎你对其进行测试并告诉我们(SIG Scheduling)你的想法!
附加资源
- Kubernetes 文档中的 Pod 调度就绪态
- Kubernetes 增强提案
Kubernetes 1.26: 支持在挂载时将 Pod fsGroup 传递给 CSI 驱动程序
作者: Fabio Bertinatto (Red Hat), Hemant Kumar (Red Hat)
译者: Xin Li (DaoCloud)
将 fsGroup 委托给 CSI 驱动程序管理首先在 Kubernetes 1.22 中作为 Alpha 特性引入,
并在 Kubernetes 1.25 中进阶至 Beta 状态。
对于 Kubernetes 1.26,我们很高兴地宣布此特性已进阶至正式发布(GA)状态。
在此版本中,如果你在 Pod(Linux)
的安全上下文中指定一个 fsGroup,
则该 Pod 容器中的所有进程都是该附加组的一部分。
在以前的 Kubernetes 版本中,kubelet 总是根据 Pod 的
.spec.securityContext.fsGroupChangePolicy 字段中指定的策略,
将 fsGroup 属主关系和权限的更改应用于卷中的文件。
从 Kubernetes 1.26 开始,CSI 驱动程序可以选择在卷挂载期间应用 fsGroup 设置,
这使 kubelet 无需更改这些卷中文件和目录的权限。
它是如何工作的?
支持此功能的 CSI 驱动程序应通告其 VOLUME_MOUNT_GROUP 节点能力。
kubelet 识别此信息后,在 Pod 启动期间将 fsGroup 信息传递给 CSI 驱动程序。
这个过程是通过 NodeStageVolumeRequest
和 NodePublishVolumeRequest
CSI 调用完成的。
因此,CSI 驱动程序应使用挂载选项将 fsGroup 应用到卷中的文件上。
例如,Azure File CSIDriver
利用 gid 挂载选项将 fsGroup 信息映射到卷中的所有文件。
应该注意的是,在上面的示例中,kubelet 避免直接将权限更改应用于该卷文件中的文件和目录。
此外,有两个策略定义不再有效:CSIDriver 对象的 .spec.fsGroupPolicy 和
Pod 的 .spec.securityContext.fsGroupChangePolicy 都不再起作用。
有关此功能内部工作原理的更多详细信息,请查看 CSI
开发人员文档中的增强建议和
CSI 驱动程序 fsGroup 支持。
这一特性为何重要?
如果没有此功能,则无法在某些存储环境中将 fsGroup 信息应用于文件。
例如,Azure 文件不支持 POSIX 风格的文件所有权和权限概念,CSI 驱动程序只能在卷级别设置文件权限。
我该如何使用它?
此功能应该对用户基本透明。如果你维护应支持此功能的 CSI 驱动程序,
请阅读 CSI 驱动程序 fsGroup 支持
以获取有关如何在你的 CSI 驱动程序中支持此功能的更多信息。
不支持此功能的现有 CSI 驱动程序将继续照常工作:他们不会从 kubelet 收到任何
fsGroup 信息。除此之外,kubelet 将根据 CSIDriver 的
.spec.fsGroupPolicy 和相关 Pod 的 .spec.securityContext.fsGroupChangePolicy
中指定的策略,继续对这些卷中文件的属主关系和权限进行更改。
Kubernetes 1.26:设备管理器正式发布
作者: Swati Sehgal (Red Hat)
译者: Jin Li (UOS)
设备插件框架是在 Kubernetes v1.8 版本中引入的,它是一个与供应商无关的框架, 旨在实现对外部设备的发现、公布和分配,而无需修改核心 Kubernetes。 该功能在 v1.10 版本中升级为 Beta 版本。随着 Kubernetes v1.26 的最新发布, 设备管理器现已正式发布(GA)。
在 kubelet 中,设备管理器通过 Unix 套接字使用 gRPC 实现与设备插件的通信。
设备管理器和设备插件都充当 gRPC 服务器和客户端的角色,分别提供暴露的 gRPC 服务并进行连接。
设备插件提供 gRPC 服务,kubelet 连接该服务进行设备的发现、公布(作为扩展资源)和分配。
设备管理器连接到 kubelet 提供的 Registration gRPC 服务,以向 kubelet 注册自身。
请查阅文档中的示例, 了解一个 Pod 如何通过设备插件请求集群中暴露的设备。
以下是设备插件的一些示例实现:
自设备插件框架引入以来的重要进展
Kubelet APIs 移至 kubelet 暂存库
在 v1.17 版本中,面向外部的 deviceplugin API 包已从 k8s.io/kubernetes/pkg/kubelet/apis/
移动到了 k8s.io/kubelet/pkg/apis/。有关此变更背后的更多详细信息,
请参阅 Move external facing kubelet apis to staging
设备插件 API 更新
新增了额外的 gRPC 端点:
GetDevicePluginOptions用于设备插件向DeviceManager传递选项,以指示是否支持PreStartContainer、GetPreferredAllocation或其他将来的可选调用, 并可在向容器提供设备之前进行调用。
GetPreferredAllocation允许设备插件将优先分配信息传递给DeviceManager, 使其能够将此信息纳入其分配决策中。DeviceManager在 Pod 准入时向插件请求指定大小的优选设备分配,以便做出更明智的决策。 例如,在为容器分配设备时,指定设备间的约束条件以表明对最佳连接设备集合的偏好。
- 在注册阶段由设备插件指示时,
PreStartContainer会在每次容器启动之前被调用。 它允许设备插件在所请求的设备上执行特定的设备操作。 例如,在容器启动前对 FPGA 进行重新配置或重新编程。
引入这些更改的 PR 为:
- Invoke preStart RPC call before container start, if desired by plugin
- Add GetPreferredAllocation() call to the v1beta1 device plugin API
引入上述端点后,kubelet 中的设备管理器与设备管理器之间的交互如下所示:

设备插件框架概述
设备插件注册流程的语义变更
设备插件的代码经过重构,将 'plugin' 包独立于 devicemanager 包之外,
为引入 v1beta2 设备插件 API 做好了前期准备。
这将允许在 devicemanager 中添加支持,以便同时为多个设备插件 API 提供服务。
通过这次重构工作,现在设备插件必须在向 kubelet 注册之前开始提供其 gRPC 服务。 之前这两个操作是异步的,设备插件可以在启动其 gRPC 服务器之前注册自己,但现在不再允许。 更多细节请参考 PR #109016 和 Issue #112395。
动态资源分配
在 Kubernetes 1.26 中,受 Kubernetes 处理持久卷方式的启发, 引入了动态资源分配, 以满足那些具有更复杂资源需求的设备,例如:
- 将设备的初始化和分配与 Pod 生命周期解耦。
- 促进容器和 Pod 之间设备的动态共享。
- 支持自定义特定资源参数。
- 启用特定资源的设置和清理操作。
- 实现对网络附加资源的支持,不再局限于节点本地资源。
设备插件 API 目前已经稳定了吗?
不,设备插件 API 仍然不稳定;目前最新的可用设备插件 API 版本是 v1beta1。
社区计划引入 v1beta2 API,以便同时为多个插件 API 提供服务。
对每个 API 的调用都具有请求/响应类型,可以在不明确升级 API 的情况下添加对新 API 版本的支持。
除此之外,社区中存在一些提案,打算引入额外的端点 KEP-3162: Add Deallocate and PostStopContainer to Device Manager API。
Kubernetes 1.26: 节点非体面关闭进入 Beta 阶段
作者: Xing Yang (VMware), Ashutosh Kumar (VMware)
译者: Xin Li (DaoCloud)
Kubernetes v1.24 引入 了用于处理节点非体面关闭改进的 Alpha 质量实现。
什么是 Kubernetes 中的节点关闭
在 Kubernetes 集群中,节点可能会关闭。这可能在计划内发生,也可能意外发生。 你可能计划进行安全补丁或内核升级并需要重新启动节点,或者它可能由于 VM 实例抢占而关闭。 节点也可能由于硬件故障或软件问题而关闭。
要触发节点关闭,你可以在 shell 中运行 shutdown 或 poweroff 命令,或者按下按钮关闭机器电源。
下面分别介绍什么是节点体面关闭,什么是节点非体面关闭。
什么是节点体面关闭?
kubelet 对节点体面关闭 的处理在于允许 kubelet 检测节点关闭事件,正确终止该节点上的 Pod,并在实际关闭之前释放资源。 关键 Pod 在所有常规 Pod 终止后终止,以确保应用程序的基本功能可以尽可能长时间地继续工作。
什么是节点非体面关闭?
仅当 kubelet 的节点关闭管理器可以检测到即将到来的节点关闭操作时,节点关闭才可能是体面的。
但是,在某些情况下,kubelet 不能检测到节点关闭操作。
这可能是因为 shutdown 命令没有触发 Linux 上 kubelet 使用的 Inhibitor Locks
机制,或者是因为用户的失误导致。
例如,如果该节点的 shutdownGracePeriod 和 shutdownGracePeriodCriticalPods 详细信息配置不正确。
当一个节点关闭(或崩溃),并且 kubelet 节点关闭管理器没有检测到该关闭时,
就出现了非体面的节点关闭。节点非体面关闭对于有状态应用程序而言是一个问题。
如果节点以非正常方式关闭且节点上存在属于某 StatefulSet 的 Pod,
则该 Pod 将被无限期地阻滞在 Terminating 状态,并且控制平面无法在健康节点上为该 StatefulSet 创建替代 Pod。
你可以手动删除失败的 Pod,但这对于集群自愈来说并不是理想状态。
同样,作为 Deployment 的一部分创建的 ReplicaSet 中的 Pod 也将滞留在 Terminating 状态,
对于绑定到正在被关闭的节点上的其他 Pod,也将无限期地处于 Terminating 状态。
如果你设置了水平缩放限制,即使那些处于终止过程中的 Pod 也会被计入该限制,
因此如果你的工作负载已经达到最大缩放比例,则它可能难以自我修复。
(顺便说一句:如果非体面关闭的节点重新启动,kubelet 确实会删除旧的 Pod,并且控制平面可以进行替换。)
Beta 阶段带来的新功能
在 Kubernetes v1.26 中,非体面节点关闭特性是 Beta 版,默认被启用。
NodeOutOfServiceVolumeDetach 特性门控在
kube-controller-manager 中从可选启用变成默认启用。如果需要,
你仍然可以选择禁用此特性(也请提交一个 issue 来解释问题)。
在检测方面,kube-controller-manager 报告了两个新指标。
force_delete_pods_total:被强制删除的 Pod 数(在 Pod 垃圾收集控制器重启时重置)
force_delete_pod_errors_total:尝试强制删除 Pod 时遇到的错误数(也会在 Pod 垃圾收集控制器重启时重置)
它是如何工作的?
在节点关闭的情况下,如果正常关闭不起作用或节点由于硬件故障或操作系统损坏而处于不可恢复状态,
你可以在 Node 上手动添加 out-of-service 污点。
例如,污点可以是 node.kubernetes.io/out-of-service=nodeshutdown:NoExecute 或
node.kubernetes.io/out-of-service=nodeshutdown:NoSchedule。
如果 Pod 上没有与之匹配的容忍规则,则此污点会触发节点上的 Pod 被强制删除。
附加到关闭中的节点的持久卷将被分离,新的 Pod 将在不同的运行节点上成功创建。
kubectl taint nodes <node-name> node.kubernetes.io/out-of-service=nodeshutdown:NoExecute
注意:在应用 out-of-service 污点之前,你必须验证节点是否已经处于关闭或断电状态(而不是在重新启动中), 要么是因为用户有意关闭它,要么是由于硬件故障或操作系统问题等导致节点关闭。
与 out-of-service 节点有关联的所有工作负载的 Pod 都被移动到新的运行节点, 并且所关闭的节点已恢复之后,你应该删除受影响节点上的污点。
接下来
根据反馈和采用情况,Kubernetes 团队计划在 1.27 或 1.28 中将非体面节点关闭实现推向正式发布(GA)状态。
此功能需要用户手动向节点添加污点以触发工作负载的故障转移并在节点恢复后删除污点。
如果有一种编程方式可以确定节点确实关闭并且节点和存储之间没有 IO,
则集群操作员可以通过自动应用 out-of-service 污点来自动执行此过程。
在工作负载成功转移到另一个正在运行的节点并且曾关闭的节点已恢复后,集群操作员可以自动删除污点。
将来,我们计划寻找方法来自动检测来隔离已关闭或处于不可恢复状态的节点, 并将其工作负载故障转移到另一个节点。
如何学习更多?
要了解更多信息,请阅读 Kubernetes 文档中的非体面节点关闭。
如何参与
我们非常感谢所有帮助设计、实施和审查此功能的贡献者:
- Michelle Au (msau42)
- Derek Carr (derekwaynecarr)
- Danielle Endocrimes (endocrimes)
- Tim Hockin (thockin)
- Ashutosh Kumar (sonasingh46)
- Hemant Kumar (gnufied)
- Yuiko Mouri(YuikoTakada)
- Mrunal Patel (mrunalp)
- David Porter (bobbypage)
- Yassine Tijani (yastij)
- Jing Xu (jingxu97)
- Xing Yang (xing-yang)
一路上有很多人帮助审阅了设计和实现。我们要感谢为这项工作做出贡献的所有人,包括在过去几年中审查 KEP 和实现的大约 30 人。
此功能是 SIG Storage 和 SIG Node 之间的协作。对于那些有兴趣参与 Kubernetes 存储系统任何部分的设计和开发的人,请加入 Kubernetes 存储特别兴趣小组 (SIG)。 对于那些有兴趣参与支持 Pod 和主机资源之间受控交互的组件的设计和开发,请加入 Kubernetes Node SIG。
Kubernetes 1.26: 动态资源分配 Alpha API
作者: Patrick Ohly (Intel)、Kevin Klues (NVIDIA)
译者: 空桐
动态资源分配是一个用于请求资源的新 API。 它是对为通用资源所提供的持久卷 API 的泛化。它可以:
- 在不同的 pod 和容器中访问相同的资源实例,
- 将任意约束附加到资源请求以获取你正在寻找的确切资源,
- 通过用户提供的参数初始化资源。
第三方资源驱动程序负责解释这些参数,并在资源请求到来时跟踪和分配资源。
动态资源分配是一个 alpha 特性,只有在启用 DynamicResourceAllocation
特性门控
和 resource.k8s.io/v1alpha1 API 组 时才启用。
有关详细信息,参阅 --feature-gates 和 --runtime-config
kube-apiserver 参数。
kube-scheduler、kube-controller-manager 和 kubelet 也需要设置该特性门控。
kube-scheduler 的默认配置仅在启用特性门控时才启用 DynamicResources 插件。
自定义配置可能需要被修改才能启用它。
一旦启用动态资源分配,就可以安装资源驱动程序来管理某些类型的硬件。 Kubernetes 有一个用于端到端测试的测试驱动程序,但也可以手动运行。 逐步说明参见下文。
API
新的 resource.k8s.io/v1alpha1
API 组提供了四种新类型:
- ResourceClass
- 定义由哪个资源驱动程序处理哪种资源,并为其提供通用参数。 在安装资源驱动程序时,由集群管理员创建 ResourceClass。
- ResourceClaim
- 定义工作负载所需的特定资源实例。 由用户创建(手动管理生命周期,可以在不同的 Pod 之间共享), 或者由控制平面基于 ResourceClaimTemplate 为特定 Pod 创建 (自动管理生命周期,通常仅由一个 Pod 使用)。
- ResourceClaimTemplate
- 定义用于创建 ResourceClaim 的 spec 和一些元数据。 部署工作负载时由用户创建。
- PodScheduling
- 供控制平面和资源驱动程序内部使用, 在需要为 Pod 分配 ResourceClaim 时协调 Pod 调度。
ResourceClass 和 ResourceClaim 的参数存储在单独的对象中, 通常使用安装资源驱动程序时创建的 CRD 所定义的类型。
启用此 Alpha 特性后,Pod 的 spec 定义 Pod 运行所需的 ResourceClaim:
此信息放入新的 resourceClaims 字段。
该列表中的条目引用 ResourceClaim 或 ResourceClaimTemplate。
当引用 ResourceClaim 时,使用此 .spec 的所有 Pod
(例如 Deployment 或 StatefulSet 中的 Pod)共享相同的 ResourceClaim 实例。
引用 ResourceClaimTemplate 时,每个 Pod 都有自己的实例。
对于 Pod 中定义的容器,resources.claims 列表定义该容器可以访问的资源实例,
从而可以在同一 Pod 中的一个或多个容器之间共享资源。
例如,init 容器可以在应用程序使用资源之前设置资源。
下面是一个虚构的资源驱动程序的示例。 此 Pod 将创建两个 ResourceClaim 对象,每个容器都可以访问其中一个。
假设已安装名为 resource-driver.example.com 的资源驱动程序和以下资源类:
apiVersion: resource.k8s.io/v1alpha1
kind: ResourceClass
name: resource.example.com
driverName: resource-driver.example.com
这样,终端用户可以按如下方式分配两个类型为
resource.example.com 的特定资源:
---
apiVersion: cats.resource.example.com/v1
kind: ClaimParameters
name: large-black-cats
spec:
color: black
size: large
---
apiVersion: resource.k8s.io/v1alpha1
kind: ResourceClaimTemplate
metadata:
name: large-black-cats
spec:
spec:
resourceClassName: resource.example.com
parametersRef:
apiGroup: cats.resource.example.com
kind: ClaimParameters
name: large-black-cats
–--
apiVersion: v1
kind: Pod
metadata:
name: pod-with-cats
spec:
containers: # 两个示例容器;每个容器申领一个 cat 资源
- name: first-example
image: ubuntu:22.04
command: ["sleep", "9999"]
resources:
claims:
- name: cat-0
- name: second-example
image: ubuntu:22.04
command: ["sleep", "9999"]
resources:
claims:
- name: cat-1
resourceClaims:
- name: cat-0
source:
resourceClaimTemplateName: large-black-cats
- name: cat-1
source:
resourceClaimTemplateName: large-black-cats
调度
与原生资源(CPU、RAM)和扩展资源 (由设备插件管理,并由 kubelet 公布)不同,调度器不知道集群中有哪些动态资源, 也不知道如何将它们拆分以满足特定 ResourceClaim 的要求。 资源驱动程序负责这些任务。 资源驱动程序在为 ResourceClaim 保留资源后将其标记为已分配(Allocated)。 然后告诉调度器集群中可用的 ResourceClaim 的位置。
ResourceClaim 可以在创建时就进行分配(立即分配),不用考虑哪些 Pod 将使用该资源。 默认情况下采用延迟分配(等待第一个消费者), 直到依赖于 ResourceClaim 的 Pod 有资格调度时再进行分配。 这种两种分配选项的设计与 Kubernetes 处理 PersistentVolume 和 PersistentVolumeClaim 供应的存储类似。
在等待第一个消费者模式下,调度器检查 Pod 所需的所有 ResourceClaim。 如果 Pod 有 ResourceClaim,则调度器会创建一个 PodScheduling 对象(一种特殊对象,代表 Pod 请求调度详细信息)。 PodScheduling 的名称和命名空间与 Pod 相同,Pod 是它的所有者。 调度器使用 PodScheduling 通知负责这些 ResourceClaim 的资源驱动程序,告知它们调度器认为适合该 Pod 的节点。 资源驱动程序通过排除没有足够剩余资源的节点来响应调度器。
一旦调度器有了资源信息,它就会选择一个节点,并将该选择存储在 PodScheduling 对象中。 然后,资源驱动程序分配其 ResourceClaim,以便资源可用于选中的节点。 一旦完成资源分配,调度器尝试将 Pod 调度到合适的节点。这时候调度仍然可能失败; 例如,不同的 Pod 可能同时被调度到同一个节点。如果发生这种情况,已分配的 ResourceClaim 可能会被取消分配,从而让 Pod 可以被调度到不同的节点。
作为此过程的一部分,ResourceClaim 会为 Pod 保留。 目前,ResourceClaim 可以由单个 Pod 独占使用或不限数量的多个 Pod 使用。
除非 Pod 的所有资源都已分配和保留,否则 Pod 不会被调度到节点,这是一个重要特性。 这避免了 Pod 被调度到一个节点但无法在那里运行的情况, 这种情况很糟糕,因为被挂起 Pod 也会阻塞为其保留的其他资源,如 RAM 或 CPU。
限制
调度器插件必须参与调度那些使用 ResourceClaim 的 Pod。
通过设置 nodeName 字段绕过调度器会导致 kubelet 拒绝启动 Pod,
因为 ResourceClaim 没有被保留或甚至根本没有被分配。
未来可能去除此限制。
编写资源驱动程序
动态资源分配驱动程序通常由两个独立但相互协调的组件组成:
一个集中控制器和一个节点本地 kubelet 插件的 DaemonSet。
集中控制器与调度器协调所需的大部分工作都可以由样板代码处理。
只有针对插件所拥有的 ResourceClass 实际分配 ResourceClaim 时所需的业务逻辑才需要自定义。
因此,Kubernetes 提供了以下软件包,其中包括用于调用此样板代码的 API,
以及可以实现自定义业务逻辑的 Driver 接口:
同样,样板代码可用于向 kubelet 注册节点本地插件, 也可以启动 gRPC 服务器来实现 kubelet 插件 API。 对于用 Go 编写的驱动程序,推荐使用以下软件包:
驱动程序开发人员决定这两个组件如何通信。 KEP 详细介绍了使用 CRD 的方法。
在 SIG Node 中,我们还计划提供一个完整的示例驱动程序, 它可以当作其他驱动程序的模板。
运行测试驱动程序
下面的步骤直接使用 Kubernetes 源代码启一个本地单节点集群。 前提是,你的集群必须具有支持容器设备接口 (CDI)的容器运行时。 例如,你可以运行 CRI-O v1.23.2 或更高版本。containerd v1.7.0 发布后,我们期望你可以运行该版本或更高版本。 在下面的示例中,我们使用 CRI-O。
首先,克隆 Kubernetes 源代码。在其目录中,运行:
$ hack/install-etcd.sh
...
$ RUNTIME_CONFIG=resource.k8s.io/v1alpha1 \
FEATURE_GATES=DynamicResourceAllocation=true \
DNS_ADDON="coredns" \
CGROUP_DRIVER=systemd \
CONTAINER_RUNTIME_ENDPOINT=unix:///var/run/crio/crio.sock \
LOG_LEVEL=6 \
ENABLE_CSI_SNAPSHOTTER=false \
API_SECURE_PORT=6444 \
ALLOW_PRIVILEGED=1 \
PATH=$(pwd)/third_party/etcd:$PATH \
./hack/local-up-cluster.sh -O
...
要使用集群,你可以打开另一个终端/选项卡并运行:
export KUBECONFIG=/var/run/kubernetes/admin.kubeconfig
...
集群启动后,在另一个终端运行测试驱动程序控制器。
必须为以下所有命令设置 KUBECONFIG。
$ go run ./test/e2e/dra/test-driver --feature-gates ContextualLogging=true -v=5 controller
在另一个终端中,运行 kubelet 插件:
$ sudo mkdir -p /var/run/cdi && \
sudo chmod a+rwx /var/run/cdi /var/lib/kubelet/plugins_registry /var/lib/kubelet/plugins/
$ go run ./test/e2e/dra/test-driver --feature-gates ContextualLogging=true -v=6 kubelet-plugin
更改目录的权限,这样可以以普通用户身份运行和(使用 delve)调试 kubelet 插件,
这很方便,因为它使用已填充的 Go 缓存。
完成后,记得使用 sudo chmod go-w 还原权限。
或者,你也可以构建二进制文件并以 root 身份运行该二进制文件。
现在集群已准备好创建对象:
$ kubectl create -f test/e2e/dra/test-driver/deploy/example/resourceclass.yaml
resourceclass.resource.k8s.io/example created
$ kubectl create -f test/e2e/dra/test-driver/deploy/example/pod-inline.yaml
configmap/test-inline-claim-parameters created
resourceclaimtemplate.resource.k8s.io/test-inline-claim-template created
pod/test-inline-claim created
$ kubectl get resourceclaims
NAME RESOURCECLASSNAME ALLOCATIONMODE STATE AGE
test-inline-claim-resource example WaitForFirstConsumer allocated,reserved 8s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
test-inline-claim 0/2 Completed 0 21s
这个测试驱动程序没有做什么事情, 它只是将 ConfigMap 中定义的变量设为环境变量。 测试 pod 会转储环境变量,所以可以检查日志以验证是否正常:
$ kubectl logs test-inline-claim with-resource | grep user_a
user_a='b'
下一步
- 了解更多该设计的信息, 参阅动态资源分配 KEP。
- 阅读 Kubernetes 官方文档的动态资源分配。
- 你可以参与 SIG Node 和 CNCF 容器编排设备工作组。
- 你可以查看或评论动态资源分配的项目看板。
- 为了将该功能向 beta 版本推进,我们需要来自硬件供应商的反馈, 因此,有一个行动号召:尝试这个功能, 考虑它如何有助于解决你的用户遇到的问题,并编写资源驱动程序…
Kubernetes 1.26: 我们现在正在对二进制发布工件进行签名!
作者: Sascha Grunert
译者: XiaoYang Zhang (HUAWEI)
Kubernetes 特别兴趣小组 SIG Release 自豪地宣布,我们正在对所有发布工件进行数字签名,并且 Kubernetes 在这一方面现已达到 Beta。
签名工件为终端用户提供了验证下载资源完整性的机会。 它可以直接在客户端减轻中间人攻击,从而确保远程服务工件的可信度。 过去工作的总体目标是定义用于对所有 Kubernetes 相关工件进行签名的工具, 以及为相关项目(例如 kubernetes-sigs 中的项目)提供标准签名流程。
我们已经对所有官方发布的容器镜像进行了签名(从 Kubernetes v1.24 开始)。
在 v1.24 版本和 v1.25 版本中,镜像签名是 alpha 版本。
在 v1.26 版本中,我们将所有的 二进制工件 也加入到了签名过程中!
这意味着现在所有的客户端、服务器和源码压缩包、二进制工件、软件材料清单(SBOM)
以及构建源都将使用 cosign 进行签名!
从技术上讲,我们现在将额外的 *.sig(签名)和 *.cert(证书)文件与工件一起发布以用于验证其完整性。
要验证一个工件,例如 kubectl,你可以在下载二进制文件的同时下载签名和证书。
我使用 v1.26 的候选发布版本 rc.1 来演示,因为最终版本还没有发布:
curl -sSfL https://dl.k8s.io/release/v1.26.0-rc.1/bin/linux/amd64/kubectl -o kubectl
curl -sSfL https://dl.k8s.io/release/v1.26.0-rc.1/bin/linux/amd64/kubectl.sig -o kubectl.sig
curl -sSfL https://dl.k8s.io/release/v1.26.0-rc.1/bin/linux/amd64/kubectl.cert -o kubectl.cert
然后你可以使用 cosign 验证 kubectl:
COSIGN_EXPERIMENTAL=1 cosign verify-blob kubectl --signature kubectl.sig --certificate kubectl.cert
tlog entry verified with uuid: 5d54b39222e3fa9a21bcb0badd8aac939b4b0d1d9085b37f1f10b18a8cd24657 index: 8173886
Verified OK
可用 UUID 查询 rekor 透明日志:
rekor-cli get --uuid 5d54b39222e3fa9a21bcb0badd8aac939b4b0d1d9085b37f1f10b18a8cd24657
LogID: c0d23d6ad406973f9559f3ba2d1ca01f84147d8ffc5b8445c224f98b9591801d
Index: 8173886
IntegratedTime: 2022-11-30T18:59:07Z
UUID: 24296fb24b8ad77a5d54b39222e3fa9a21bcb0badd8aac939b4b0d1d9085b37f1f10b18a8cd24657
Body: {
"HashedRekordObj": {
"data": {
"hash": {
"algorithm": "sha256",
"value": "982dfe7eb5c27120de6262d30fa3e8029bc1da9e632ce70570e9c921d2851fc2"
}
},
"signature": {
"content": "MEQCIH0e1/0svxMoLzjeyhAaLFSHy5ZaYy0/2iQl2t3E0Pj4AiBsWmwjfLzrVyp9/v1sy70Q+FHE8miauOOVkAW2lTYVug==",
"publicKey": {
"content": "LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUN2akNDQWthZ0F3SUJBZ0lVRldab0pLSUlFWkp3LzdsRkFrSVE2SHBQdi93d0NnWUlLb1pJemowRUF3TXcKTnpFVk1CTUdBMVVFQ2hNTWMybG5jM1J2Y21VdVpHVjJNUjR3SEFZRFZRUURFeFZ6YVdkemRHOXlaUzFwYm5SbApjbTFsWkdsaGRHVXdIaGNOTWpJeE1UTXdNVGcxT1RBMldoY05Nakl4TVRNd01Ua3dPVEEyV2pBQU1Ga3dFd1lICktvWkl6ajBDQVFZSUtvWkl6ajBEQVFjRFFnQUVDT3h5OXBwTFZzcVFPdHJ6RFgveTRtTHZSeU1scW9sTzBrS0EKTlJDM3U3bjMreHorYkhvWVkvMUNNRHpJQjBhRTA3NkR4ZWVaSkhVaWFjUXU4a0dDNktPQ0FXVXdnZ0ZoTUE0RwpBMVVkRHdFQi93UUVBd0lIZ0RBVEJnTlZIU1VFRERBS0JnZ3JCZ0VGQlFjREF6QWRCZ05WSFE0RUZnUVV5SmwxCkNlLzIzNGJmREJZQ2NzbXkreG5qdnpjd0h3WURWUjBqQkJnd0ZvQVUzOVBwejFZa0VaYjVxTmpwS0ZXaXhpNFkKWkQ4d1FnWURWUjBSQVFIL0JEZ3dOb0UwYTNKbGJDMXpkR0ZuYVc1blFHczRjeTF5Wld4bGJtY3RjSEp2WkM1cApZVzB1WjNObGNuWnBZMlZoWTJOdmRXNTBMbU52YlRBcEJnb3JCZ0VFQVlPL01BRUJCQnRvZEhSd2N6b3ZMMkZqClkyOTFiblJ6TG1kdmIyZHNaUzVqYjIwd2dZb0dDaXNHQVFRQjFua0NCQUlFZkFSNkFIZ0FkZ0RkUFRCcXhzY1IKTW1NWkhoeVpaemNDb2twZXVONDhyZitIaW5LQUx5bnVqZ0FBQVlUSjZDdlJBQUFFQXdCSE1FVUNJRXI4T1NIUQp5a25jRFZpNEJySklXMFJHS0pqNkQyTXFGdkFMb0I5SmNycXlBaUVBNW4xZ283cmQ2U3ZVeXNxeldhMUdudGZKCllTQnVTZHF1akVySFlMQTUrZTR3Q2dZSUtvWkl6ajBFQXdNRFpnQXdZd0l2Tlhub3pyS0pWVWFESTFiNUlqa1oKUWJJbDhvcmlMQ1M4MFJhcUlBSlJhRHNCNTFUeU9iYTdWcGVYdThuTHNjVUNNREU4ZmpPZzBBc3ZzSXp2azNRUQo0c3RCTkQrdTRVV1UrcjhYY0VxS0YwNGJjTFQwWEcyOHZGQjRCT2x6R204K093PT0KLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo="
}
}
}
}
HashedRekordObj.signature.content 应与 kubectl.sig 的内容匹配,
HashedRekordObj.signature.publicKey.content 应与 kubectl.cert 的内容匹配。
也可以指定远程证书和签名的位置而不下载它们:
COSIGN_EXPERIMENTAL=1 cosign verify-blob kubectl \
--signature https://dl.k8s.io/release/v1.26.0-rc.1/bin/linux/amd64/kubectl.sig \
--certificate https://dl.k8s.io/release/v1.26.0-rc.1/bin/linux/amd64/kubectl.cert
tlog entry verified with uuid: 5d54b39222e3fa9a21bcb0badd8aac939b4b0d1d9085b37f1f10b18a8cd24657 index: 8173886
Verified OK
有关如何验证已签名的 Kubernetes 工件的官方文档中概述了所有提到的步骤以及如何验证容器镜像。 在下一个即将发布的 Kubernetes 版本中,我们将通过确保真正对所有 Kubernetes 工件进行签名来使之在全球更加成熟。 除此之外,我们正在考虑使用 Kubernetes 自有的基础设施来进行签名(根信任)和验证(透明日志)过程。
参与其中
如果你有兴趣为 SIG Release 做贡献,请考虑申请即将推出的 v1.27 影子计划(观看 k-dev 上的公告)或参加我们的周例会。
我们期待着在未来的 Kubernetes 版本中做出更多了不起的改变。例如,我们正在致力于
Kubernetes 发布过程中的 SLSA 3 级合规性或将 kubernetes/kubernetes 默认分支名称重命名为 main。
感谢你阅读这篇博文!我想借此机会向所有参与的 SIG Release 人员表示特别地感谢,感谢他们及时推出这一功能!
欢迎使用 SIG Release 邮件列表或 #sig-release Slack 频道与我们联系。
附加资源
Kubernetes 的取证容器检查点
作者: Adrian Reber (Red Hat)
取证容器检查点(Forensic container checkpointing)基于 CRIU(Checkpoint/Restore In Userspace ,用户空间的检查点/恢复), 并允许创建正在运行的容器的有状态副本,而容器不知道它正在被检查。容器的副本,可以在沙箱环境中被多次分析和恢复,而原始容器并不知道。 取证容器检查点是作为一个 alpha 特性在 Kubernetes v1.25 中引入的。
工作原理
在 CRIU 的帮助下,检查(checkpoint)和恢复容器成为可能。CRIU 集成在 runc、crun、CRI-O 和 containerd 中, 而在 Kubernetes 中实现的取证容器检查点使用这些现有的 CRIU 集成。
这一特性为何重要?
借助 CRIU 和相应的集成,可以获得磁盘上正在运行的容器的所有信息和状态,供以后进行取证分析。 取证分析对于在不阻止或影响可疑容器的情况下,对其进行检查可能很重要。如果容器确实受到攻击,攻击者可能会检测到检查容器的企图。 获取检查点并在沙箱环境中分析容器,提供了在原始容器和可能的攻击者不知道检查的情况下检查容器的可能性。
除了取证容器检查点用例,还可以在不丢失内部状态的情况下,将容器从一个节点迁移到另一个节点。 特别是对于初始化时间长的有状态容器,从检查点恢复,可能会节省重新启动后的时间,或者实现更快的启动时间。
如何使用容器检查点?
该功能在特性门控后面,因此在使用这个新功能之前, 请确保启用了 ContainerCheckpoint 特性门控。
运行时还必须支持容器检查点:
- containerd:相关支持目前正在讨论中。有关更多详细信息,请参见 containerd pull request #6965。
- CRI-O:v1.25 支持取证容器检查点。
CRI-O 的使用示例
要将取证容器检查点与 CRI-O 结合使用,需要使用命令行选项--enable-criu-support=true 启动运行时。 Kubernetes 方面,你需要在启用 ContainerCheckpoint 特性门控的情况下运行你的集群。 由于检查点功能是由 CRIU 提供的,因此也有必要安装 CRIU。 通常 runc 或 crun 依赖于 CRIU,因此它是自动安装的。
值得一提的是,在编写本文时,检查点功能被认为是 CRI-O 和 Kubernetes 中的一个 alpha 级特性,其安全影响仍在评估之中。
一旦容器和 pod 开始运行,就可以创建一个检查点。检查点目前只在 kubelet 级别暴露。 要检查一个容器,可以在运行该容器的节点上运行 curl,并触发一个检查点:
curl -X POST "https://localhost:10250/checkpoint/namespace/podId/container"
对于 default 命名空间中 counters Pod 中名为 counter 的容器,可通过以下方式访问 kubelet API 端点:
curl -X POST "https://localhost:10250/checkpoint/default/counters/counter"
为了完整起见,以下 curl 命令行选项对于让 curl 接受 kubelet 的自签名证书并授权使用
kubelet 检查点 API 是必要的:
--insecure --cert /var/run/kubernetes/client-admin.crt --key /var/run/kubernetes/client-admin.key
触发这个 kubelet API 将从 CRI-O 请求创建一个检查点,CRI-O 从你的低级运行时(例如 runc)请求一个检查点。
看到这个请求,runc 调用 criu 工具来执行实际的检查点操作。
检查点操作完成后,检查点应该位于
/var/lib/kubelet/checkpoints/checkpoint-<pod-name>_<namespace-name>-<container-name>-<timestamp>.tar
然后,你可以使用 tar 归档文件在其他地方恢复容器。
在 Kubernetes 外恢复检查点容器(使用 CRI-O)
使用检查点 tar 归档文件,可以在 Kubernetes 之外的 CRI-O 沙箱实例中恢复容器。 为了在恢复过程中获得更好的用户体验,建议你使用 CRI-O GitHub 的 main 分支中最新版本的 CRI-O。 如果你使用的是 CRI-O v1.25,你需要在启动容器之前手动创建 Kubernetes 会创建的某些目录。
在 Kubernetes 外恢复容器的第一步是使用 crictl 创建一个 pod 沙箱:
crictl runp pod-config.json
然后,你可以将之前的检查点容器恢复到新创建的 pod 沙箱中:
crictl create <POD_ID> container-config.json pod-config.json
你不需要在 container-config.json 的注册表中指定容器镜像,而是需要指定你之前创建的检查点归档文件的路径:
{
"metadata": {
"name": "counter"
},
"image":{
"image": "/var/lib/kubelet/checkpoints/<checkpoint-archive>.tar"
}
}
接下来,运行 crictl start <CONTAINER_ID>来启动该容器,然后应该会运行先前检查点容器的副本。
在 Kubernetes 中恢复检查点容器
要在 Kubernetes 中直接恢复之前的检查点容器,需要将检查点归档文件转换成可以推送到注册中心的镜像。
转换本地检查点存档的一种方法包括在 buildah 的帮助下执行以下步骤:
newcontainer=$(buildah from scratch)
buildah add $newcontainer /var/lib/kubelet/checkpoints/checkpoint-<pod-name>_<namespace-name>-<container-name>-<timestamp>.tar /
buildah config --annotation=io.kubernetes.cri-o.annotations.checkpoint.name=<container-name> $newcontainer
buildah commit $newcontainer checkpoint-image:latest
buildah rm $newcontainer
生成的镜像未经标准化,只能与 CRI-O 结合使用。请将此镜像格式视为 pre-alpha 格式。
社区正在讨论如何标准化这样的检查点镜像格式。
重要的是要记住,这种尚未标准化的镜像格式只有在 CRI-O 已经用--enable-criu-support=true 启动时才有效。
在 CRIU 支持下启动 CRI-O 的安全影响尚不清楚,因此应谨慎使用功能和镜像格式。
现在,你需要将该镜像推送到容器镜像注册中心。例如:
buildah push localhost/checkpoint-image:latest container-image-registry.example/user/checkpoint-image:latest
要恢复此检查点镜像(container-image-registry.example/user/checkpoint-image:latest), 该镜像需要在 Pod 的规约中列出。下面是一个清单示例:
apiVersion: v1
kind: Pod
metadata:
namePrefix: example-
spec:
containers:
- name: <container-name>
image: container-image-registry.example/user/checkpoint-image:latest
nodeName: <destination-node>
Kubernetes 将新的 Pod 调度到一个节点上。该节点上的 kubelet 指示容器运行时(本例中为 CRI-O)
基于指定为 registry/user/checkpoint-image:latest 的镜像创建并启动容器。
CRI-O 检测到 registry/user/checkpoint-image:latest 是对检查点数据的引用,而不是容器镜像。
然后,与创建和启动容器的通常步骤不同,CRI-O 获取检查点数据,并从指定的检查点恢复容器。
该 Pod 中的应用程序将继续运行,就像检查点未被获取一样;在该容器中, 应用程序的外观和行为,与正常启动且未从检查点恢复的任何其他容器相似。
通过这些步骤,可以用在不同节点上运行的新的等效 Pod,替换在一个节点上运行的 Pod,而不会丢失该 Pod中容器的状态。
如何参与?
你可以通过多种方式参与 SIG Node:
- Slack: #sig-node
- Mailing list
延伸阅读
有关如何分析容器检查点的详细信息,请参阅后续文章取证容器分析。
Kubernetes 1.26 中的移除、弃用和主要变更
作者 :Frederico Muñoz (SAS)
变化是 Kubernetes 生命周期不可分割的一部分:随着 Kubernetes 成长和日趋成熟, 为了此项目的健康发展,某些功能特性可能会被弃用、移除或替换为优化过的功能特性。 Kubernetes v1.26 也做了若干规划:根据 v1.26 发布流程中期获得的信息, 本文将列举并描述其中一些变更,这些变更目前仍在进行中,可能会引入更多变更。
Kubernetes API 移除和弃用流程
Kubernetes 项目对功能特性有一个文档完备的弃用策略。 该策略规定,只有当较新的、稳定的相同 API 可用时,原有的稳定 API 才可以被弃用, 每个稳定级别的 API 都有一个最短的生命周期。弃用的 API 指的是已标记为将在后续发行某个 Kubernetes 版本时移除的 API;移除之前该 API 将继续发挥作用(从弃用起至少一年时间), 但使用时会显示一条警告。被移除的 API 将在当前版本中不再可用,此时你必须迁移以使用替换的 API。
- 正式发布(GA)或稳定的 API 版本可能被标记为已弃用,但只有在 Kubernetes 大版本更新时才会被移除。
- 测试版(Beta)或预发布 API 版本在弃用后必须在后续 3 个版本中继续支持。
- Alpha 或实验性 API 版本可以在任何版本中被移除,不另行通知。
无论一个 API 是因为某功能特性从 Beta 进入稳定阶段而被移除,还是因为该 API 根本没有成功, 所有移除均遵从上述弃用策略。无论何时移除一个 API,文档中都会列出迁移选项。
有关移除 CRI v1alpha2 API 和 containerd 1.5 支持的说明
在 v1.24 中采用容器运行时接口 (CRI) 并[移除 dockershim] 之后,CRI 是 Kubernetes 与不同容器运行时交互所支持和记录的方式。 每个 kubelet 会协商使用哪个版本的 CRI 来配合该节点上的容器运行时。
Kubernetes 项目推荐使用 CRI v1 版本;在 Kubernetes v1.25 中,kubelet 也可以协商使用
CRI v1alpha2(在添加对稳定的 v1 接口的支持同时此项被弃用)。
Kubernetes v1.26 将不支持 CRI v1alpha2。如果容器运行时不支持 CRI v1,
则本次移除将导致 kubelet 不注册节点。
这意味着 Kubernetes 1.26 将不支持 containerd 1.5 小版本及更早的版本;如果你使用 containerd,
则需要升级到 containerd v1.6.0 或更高版本,然后才能将该节点升级到 Kubernetes v1.26。其他仅支持
v1alpha2 的容器运行时同样受到影响。如果此项移除影响到你,
你应该联系容器运行时供应商寻求建议或查阅他们的网站以获取有关如何继续使用的更多说明。
如果你既想从 v1.26 特性中获益又想保持使用较旧的容器运行时,你可以运行较旧的 kubelet。
kubelet 支持的版本偏差允许你运行
v1.25 的 kubelet,即使你将控制平面升级到了 Kubernetes 1.26 的某个次要版本,kubelet
仍然能兼容 v1alpha2 CRI。
除了容器运行时本身,还有像 stargz-snapshotter 这样的工具充当 kubelet 和容器运行时之间的代理,这些工具也可能会受到影响。
Kubernetes v1.26 中的弃用和移除
除了上述移除外,Kubernetes v1.26 还准备包含更多移除和弃用。
移除 v1beta1 流量控制 API 组
FlowSchema 和 PriorityLevelConfiguration 的 flowcontrol.apiserver.k8s.io/v1beta1 API
版本将不再在 v1.26 中提供。
用户应迁移清单和 API 客户端才能使用自 v1.23 起可用的 flowcontrol.apiserver.k8s.io/v1beta2 API 版本。
移除 v2beta2 HorizontalPodAutoscaler API
HorizontalPodAutoscaler 的 autoscaling/v2beta2 API
版本将不再在 v1.26 中提供。
用户应迁移清单和 API 客户端以使用自 v1.23 起可用的 autoscaling/v2 API 版本。
移除树内凭证管理代码
在即将发布的版本中,原来作为 Kubernetes 一部分的、特定于供应商的身份验证代码将从 client-go 和 kubectl
中移除。
现有机制为两个特定云供应商提供身份验证支持:Azure 和 Google Cloud。
作为替代方案,Kubernetes 在发布 v1.26
之前已提供了供应商中立的身份验证插件机制,
你现在就可以切换身份验证机制。如果你受到影响,你可以查阅有关如何继续使用
Azure 和
Google Cloud
的更多指导信息。
移除 kube-proxy userspace 模式
已弃用一年多的 userspace 代理模式不再受 Linux 或 Windows 支持,
并将在 v1.26 中被移除。Linux 用户应使用 iptables 或 ipvs,Windows 用户应使用 kernelspace:
现在使用 --mode userspace 会失败。
移除树内 OpenStack 云驱动
针对存储集成,Kubernetes 正在从使用树内代码转向使用容器存储接口 (CSI)。
作为这个转变的一部分,Kubernetes v1.26 将移除已弃用的 OpenStack 树内存储集成(cinder 卷类型)。
你应该迁移到外部云驱动或者位于 https://github.com/kubernetes/cloud-provider-openstack 的 CSI 驱动。
有关详细信息,请访问
Cinder in-tree to CSI driver migration。
移除 GlusterFS 树内驱动
树内 GlusterFS 驱动在 v1.25 中被弃用, 且从 Kubernetes v1.26 起将被移除。
弃用非包容性的 kubectl 标志
作为包容性命名倡议(Inclusive Naming Initiative)的实现工作的一部分,
--prune-whitelist 标志将被弃用,并替换为 --prune-allowlist。
强烈建议使用此标志的用户在未来某个版本中最终移除该标志之前进行必要的变更。
移除动态 kubelet 配置
动态 kubelet 配置 允许通过 Kubernetes API 推出新的 kubelet 配置, 甚至能在运作中集群上完成此操作。集群操作员可以通过指定包含 kubelet 应使用的配置数据的 ConfigMap 来重新配置节点上的 kubelet。动态 kubelet 配置已在 v1.24 中从 kubelet 中移除,并将在 v1.26 版本中从 API 服务器中移除。
弃用 kube-apiserver 命令行参数
--master-service-namespace 命令行参数对 kube-apiserver 没有任何效果,
并且已经被非正式地被弃用。
该命令行参数将在 v1.26 中正式标记为弃用,准备在未来某个版本中移除。
Kubernetes 项目预期不会因此项弃用和移除受到任何影响。
弃用 kubectl run 命令行参数
针对 kubectl run
子命令若干未使用的选项参数将被标记为弃用,这包括:
--cascade--filename--force--grace-period--kustomize--recursive--timeout--wait
这些参数已被忽略,因此预计不会产生任何影响:显式的弃用会设置一条警告消息并准备在未来的某个版本中移除这些参数。
移除与日志相关的原有命令行参数
Kubernetes v1.26 将移除一些与日志相关的命令行参数。 这些命令行参数之前已被弃用。有关详细信息, 请参阅弃用 Kubernetes 组件中的 klog 特定标志。
展望未来
Kubernetes 1.27 计划移除的 API 官方列表包括:
- 所有 Beta 版的 CSIStorageCapacity API;特别是
storage.k8s.io/v1beta1
了解更多
Kubernetes 发行说明中宣告了弃用信息。你可以在以下版本的发行说明中看到待弃用的公告:
我们将在 Kubernetes 1.26 的 CHANGELOG 中正式宣布该版本的弃用信息。
Kueue 介绍
作者: Abdullah Gharaibeh(谷歌),Aldo Culquicondor(谷歌)
无论是在本地还是在云端,集群都面临着资源使用、配额和成本管理方面的实际限制。 无论自动扩缩容能力如何,集群的容量都是有限的。 因此,用户需要一种简单的方法来公平有效地共享资源。
在本文中,我们介绍了 Kueue, 这是一个开源作业队列控制器,旨在将批处理作业作为一个单元进行管理。 Kueue 将 Pod 级编排留给 Kubernetes 现有的稳定组件。 Kueue 原生支持 Kubernetes Job API, 并提供用于集成其他定制 API 以进行批处理作业的钩子。
为什么是 Kueue?
作业队列是在本地和云环境中大规模运行批处理工作负载的关键功能。 作业队列的主要目标是管理对多个租户共享的有限资源池的访问。 作业排队决定了哪些作业应该等待,哪些可以立即启动,以及它们可以使用哪些资源。
一些最需要的作业队列要求包括:
- 用配额和预算来控制谁可以使用什么以及达到什么限制。 这不仅在具有静态资源(如本地)的集群中需要,而且在云环境中也需要控制稀缺资源的支出或用量。
- 租户之间公平共享资源。 为了最大限度地利用可用资源,应允许活动租户公平共享那些分配给非活动租户的未使用配额。
- 根据可用性,在不同资源类型之间灵活放置作业。 这在具有异构资源的云环境中很重要,例如不同的架构(GPU 或 CPU 模型)和不同的供应模式(即用与按需)。
- 支持可按需配置资源的自动扩缩容环境。
普通的 Kubernetes 不能满足上述要求。 在正常情况下,一旦创建了 Job,Job 控制器会立即创建 Pod,并且 kube-scheduler 会不断尝试将 Pod 分配给节点。 大规模使用时,这种情况可能会使控制平面死机。 目前也没有好的办法在 Job 层面控制哪些 Job 应该先获得哪些资源,也没有办法标明顺序或公平共享。 当前的 ResourceQuota 模型不太适合这些需求,因为配额是在资源创建时强制执行的,并且没有请求排队。 ResourceQuotas 的目的是提供一种内置的可靠性机制,其中包含管理员所需的策略,以防止集群发生故障转移。
在 Kubernetes 生态系统中,Job 调度有多种解决方案。但是,我们发现这些替代方案存在以下一个或多个问题:
- 它们取代了 Kubernetes 的现有稳定组件,例如 kube-scheduler 或 Job 控制器。 这不仅从操作的角度看是有问题的,而且重复的 Job API 也会导致生态系统的碎片化并降低可移植性。
- 它们没有集成自动扩缩容,或者
- 它们缺乏对资源灵活性的支持。
Kueue 的工作原理
借助 Kueue,我们决定采用不同的方法在 Kubernetes 上进行 Job 排队,该方法基于以下方面:
- 不复制已建立的 Kubernetes 组件提供的用于 Pod 调度、自动扩缩容和 Job 生命周期管理的现有功能。
- 将缺少的关键特性添加到现有组件中。例如,我们投资了 Job API 以涵盖更多用例,像 IndexedJob, 并修复了与 Pod 跟踪相关的长期存在的问题。 虽然离特性落地还有很长一段路,但我们相信这是可持续的长期解决方案。
- 确保与具有弹性和异构性的计算资源云环境兼容。
为了使这种方法可行,Kueue 需要旋钮来影响那些已建立组件的行为,以便它可以有效地管理何时何地启动一个 Job。 我们以两个特性的方式将这些旋钮添加到 Job API:
- Suspend 字段, 它允许在 Job 启动或停止时,Kueue 向 Job 控制器发出信号。
- 可变调度指令,
允许在启动 Job 之前更新 Job 的
.spec.template.spec.nodeSelector。 这样,Kueue 可以控制 Pod 放置,同时仍将 Pod 到节点的实际调度委托给 kube-scheduler。
请注意,任何自定义的 Job API 都可以由 Kueue 管理,只要该 API 提供上述两种能力。
资源模型
Kueue 定义了新的 API 来解决本文开头提到的需求。三个主要的 API 是:
- ResourceFlavor:一个集群范围的 API,用于定义可供消费的资源模板,如 GPU 模型。 ResourceFlavor 的核心是一组标签,这些标签反映了提供这些资源的节点上的标签。
- ClusterQueue: 一种集群范围的 API,通过为一个或多个 ResourceFlavor 设置配额来定义资源池。
- LocalQueue: 用于分组和管理单租户 Jobs 的命名空间 API。 在最简单的形式中,LocalQueue 是指向集群队列的指针,租户(建模为命名空间)可以使用它来启动他们的 Jobs。
有关更多详细信息,请查看 API 概念文档。 虽然这三个 API 看起来无法抗拒,但 Kueue 的大部分操作都以 ClusterQueue 为中心; ResourceFlavor 和 LocalQueue API 主要是组织包装器。
用例样例
想象一下在云上的 Kubernetes 集群上运行批处理工作负载的以下设置:
- 你在集群中安装了 cluster-autoscaler 以自动调整集群的大小。
- 有两种类型的自动缩放节点组,它们的供应策略不同:即用和按需。
分别对应标签:
instance-type=spot或者instance-type=ondemand。 此外,并非所有作业都可以容忍在即用节点上运行,节点可以用spot=true:NoSchedule污染。
- 为了在成本和资源可用性之间取得平衡,假设你希望 Jobs 使用最多 1000 个核心按需节点,最多 2000 个核心即用节点。
作为批处理系统的管理员,你定义了两个 ResourceFlavor,它们代表两种类型的节点:
---
apiVersion: kueue.x-k8s.io/v1alpha2
kind: ResourceFlavor
metadata:
name: ondemand
labels:
instance-type: ondemand
---
apiVersion: kueue.x-k8s.io/v1alpha2
kind: ResourceFlavor
metadata:
name: spot
labels:
instance-type: spot
taints:
- effect: NoSchedule
key: spot
value: "true"
然后通过创建 ClusterQueue 来定义配额,如下所示:
apiVersion: kueue.x-k8s.io/v1alpha2
kind: ClusterQueue
metadata:
name: research-pool
spec:
namespaceSelector: {}
resources:
- name: "cpu"
flavors:
- name: ondemand
quota:
min: 1000
- name: spot
quota:
min: 2000
注意 ClusterQueue 资源中的模板顺序很重要:Kueue 将尝试根据该顺序为 Job 分配可用配额,除非这些 Job 与特定模板有明确的关联。
对于每个命名空间,定义一个指向上述 ClusterQueue 的 LocalQueue:
apiVersion: kueue.x-k8s.io/v1alpha2
kind: LocalQueue
metadata:
name: training
namespace: team-ml
spec:
clusterQueue: research-pool
管理员创建一次上述配置。批处理用户可以通过在他们的命名空间中列出 LocalQueues 来找到他们被允许提交的队列。
该命令类似于:kubectl get -n my-namespace localqueues
要提交作业,需要创建一个 Job 并设置 kueue.x-k8s.io/queue-name 注解,如下所示:
apiVersion: batch/v1
kind: Job
metadata:
generateName: sample-job-
annotations:
kueue.x-k8s.io/queue-name: training
spec:
parallelism: 3
completions: 3
template:
spec:
tolerations:
- key: spot
operator: "Exists"
effect: "NoSchedule"
containers:
- name: example-batch-workload
image: registry.example/batch/calculate-pi:3.14
args: ["30s"]
resources:
requests:
cpu: 1
restartPolicy: Never
Kueue 在创建 Job 后立即进行干预以暂停 Job。 一旦 Job 位于 ClusterQueue 的头部,Kueue 就会通过检查 Job 请求的资源是否符合可用配额来评估它是否可以启动。
在上面的例子中,Job 容忍了 Spot 资源。如果之前承认的 Job 消耗了所有现有的按需配额, 但不是所有 Spot 配额,则 Kueue 承认使用 Spot 配额的 Job。Kueue 通过向 Job 对象发出单个更新来做到这一点:
- 更改
.spec.suspend标志位为 false - 将
instance-type: spot添加到 Job 的.spec.template.spec.nodeSelector中, 以便在 Job 控制器创建 Pod 时,这些 Pod 只能调度到 Spot 节点上。
最后,如果有可用的空节点与节点选择器条件匹配,那么 kube-scheduler 将直接调度 Pod。 如果不是,那么 kube-scheduler 将 pod 初始化标记为不可调度,这将触发 cluster-autoscaler 配置新节点。
未来工作以及参与方式
上面的示例提供了 Kueue 的一些功能简介,包括支持配额、资源灵活性以及与集群自动缩放器的集成。 Kueue 还支持公平共享、Job 优先级和不同的排队策略。 查看 Kueue 文档以了解这些特性以及如何使用 Kueue 的更多信息。
我们计划将许多特性添加到 Kueue 中,例如分层配额、预算和对动态大小 Job 的支持。 在不久的将来,我们将专注于增加对 Job 抢占的支持。
最新的 Kueue 版本在 Github 上可用; 如果你在 Kubernetes 上运行批处理工作负载(需要 v1.22 或更高版本),可以尝试一下。 这个项目还处于早期阶段,我们正在搜集大大小小各个方面的反馈,请不要犹豫,快来联系我们吧! 无论是修复或报告错误,还是帮助添加新特性或编写文档,我们欢迎一切形式的贡献者。 你可以通过我们的仓库、邮件列表或者 Slack 与我们联系。
最后是很重要的一点,感谢所有促使这个项目成为可能的贡献者们!
“Kubernetes 1.25:对使用用户名字空间运行 Pod 提供 Alpha 支持”
作者: Rodrigo Campos(Microsoft)、Giuseppe Scrivano(Red Hat)
Kubernetes v1.25 引入了对用户名字空间的支持。
这是在 Kubernetes 中运行安全工作负载的一项重大改进。 每个 Pod 只能访问系统上可用 UID 和 GID 的有限子集, 因此添加了一个新的安全层来保护 Pod 免受运行在同一系统上的其他 Pod 的影响。
它是如何工作的?
在 Linux 上运行的进程最多可以使用 4294967296 个不同的 UID 和 GID。
用户名字空间是 Linux 的一项特性,它允许将容器中的一组用户映射到主机中的不同用户, 从而限制进程可以实际使用的 ID。 此外,在新用户名字空间中授予的权能不适用于主机初始名字空间。
它为什么如此重要?
用户名字空间之所以重要,主要有两个原因:
提高安全性。因为它们限制了 Pod 可以使用的 ID, 因此每个 Pod 都可以在其自己的具有唯一 ID 的单独环境中运行。
以更安全的方式使用 root 身份运行工作负载。
在用户名字空间中,我们可以将 Pod 内的 root 用户映射到容器外的非零 ID, 容器将认为是 root 身份在运行,而从主机的角度来看,它们是常规的非特权 ID。
该进程可以保留通常仅限于特权 Pod 的功能,并以安全的方式执行这类操作, 因为在新用户名字空间中授予的功能不适用于主机初始名字空间。
如何启用用户名字空间
目前,对用户名字空间的支持是可选的,因此你必须在 Pod 规约部分将
hostUsers 设置为 false 以启用用户名字空间:
apiVersion: v1
kind: Pod
spec:
hostUsers: false
containers:
- name: nginx
image: docker.io/nginx
该特性目前还处于 Alpha 阶段,默认是禁用的,因此在使用此新特性之前,
请确保启用了 UserNamespacesStatelessPodsSupport 特性门控。
此外,运行时也必须支持用户名字空间:
Containerd:计划在 1.7 版本中提供支持。 进一步了解,请参阅 Containerd issue #7063。
CRI-O:v1.25 支持用户名字空间。
cri-dockerd 对用户名字空间的支持尚无计划。
我如何参与?
你可以通过多种方式联系 SIG Node:
Slack: #sig-node
你也可以直接联系我们:
GitHub / Slack: @rata @giuseppe
Kubernetes 1.25:应用滚动上线所用的两个特性进入稳定阶段
作者: Ravi Gudimetla (Apple)、Filip Křepinský (Red Hat)、Maciej Szulik (Red Hat)
这篇博客描述了两个特性,即用于 StatefulSet 的 minReadySeconds 以及用于 DaemonSet 的 maxSurge,
SIG Apps 很高兴宣布这两个特性在 Kubernetes 1.25 进入稳定阶段。
当 .spec.updateStrategy 字段设置为 RollingUpdate 时,
你可以设置 minReadySeconds, 通过让每个 Pod 等待一段预期时间来减缓 StatefulSet 的滚动上线。
当 .spec.updateStrategy 字段设置为 RollingUpdate 时,
maxSurge 允许 DaemonSet 工作负载在滚动上线期间在一个节点上运行同一 Pod 的多个实例。
这对于消费者而言有助于将 DaemonSet 的停机时间降到最低。
这两个特性也可用于 Deployment 和其他工作负载。此功能的提级有助于将这一功能在所有工作负载上对齐。
这两个特性能解决什么问题?
针对 StatefulSet 的 minReadySeconds
minReadySeconds 确保 StatefulSet 工作负载在给定的秒数内处于 Ready,
然后才会将该 Pod 报告为 Available。
处于 Ready 和 Available 状况的这种说法对工作负载相当重要。
例如 Prometheus 这些工作负载有多个 Alertmanager 实例,
只有 Alertmanager 的状态转换完成后才应该被视为 Available。
minReadySeconds 还有助于云驱动确定何时使用负载均衡器。
因为 Pod 应在给定的秒数内处于 Ready,所以这就提供了一段缓冲时间,
防止新 Pod 还没起来之前就在轮转过程中杀死了旧 Pod。
针对 DaemonSet 的 maxSurge
CNI、CSI 这类 Kubernetes 系统级别的组件通常以 DaemonSet 方式运行。如果这些 DaemonSet 在升级期间瞬间挂掉, 对应的组件可能会影响工作负载的可用性。此特性允许 DaemonSet Pod 临时增加数量,以此确保 DaemonSet 的停机时间为零。
请注意在 DaemonSet 中不允许同时使用 hostPort 和 maxSurge,
因为 DaemonSet Pod 被捆绑到了一个节点,所以两个活跃的 Pod 无法共享同一节点上的相同端口。
工作原理
针对 StatefulSet 的 minReadySeconds
StatefulSet 控制器监视 StatefulSet Pod 并统计特定的 Pod 已处于 Running 状态多长时间了,
如果这个值大于或等于 StatefulSet 的 .spec.minReadySeconds 字段中指定的时间,
StatefulSet 控制器将更新 StatefulSet 的状态中的 AvailableReplicas 字段。
针对 DaemonSet 的 maxSurge
DaemonSet 控制器根据 .spec.strategy.rollingUpdate.maxSurge 中给出的值创建额外 Pod
(超出 DaemonSet 规约所设定的预期数量)。
这些 Pod 将运行在旧 DaemonSet Pod 运行所在的同一节点上,直到这个旧 Pod 被杀死为止。
- 默认值为 0。
- 当
MaxUnavailable为 0 时此值不能为0。 - 此值可以指定为一个绝对的 Pod 个数或预期 Pod 总数的百分比(向上取整)。
我如何使用它?
针对 StatefulSet 的 minReadySeconds
执行以下命令为任意 StatefulSet 指定一个 minReadySeconds 值,
通过检验 AvailableReplicas 字段查看这些 Pod 是否可用:
kubectl get statefulset/<StatefulSet 名称> -o yaml
请注意 minReadySeconds 的默认值为 0。
针对 DaemonSet 的 maxSurge
为 .spec.updateStrategy.rollingUpdate.maxSurge 指定一个值并将
.spec.updateStrategy.rollingUpdate.maxUnavailable 设置为 0。
然后观察下一次滚动上线是不是更快,同时运行的 Pod 数量是不是更多。
kubectl rollout restart daemonset <name_of_the_daemonset>
kubectl get pods -w
我如何才能了解更多?
针对 StatefulSet 的 minReadySeconds
- 文档: https://k8s.io/zh-cn/docs/concepts/workloads/controllers/statefulset/#minimum-ready-seconds
- KEP: https://github.com/kubernetes/enhancements/issues/2599
- API 变更: https://github.com/kubernetes/kubernetes/pull/100842
针对 DaemonSet 的 maxSurge
- 文档: https://k8s.io/zh-cn/docs/tasks/manage-daemon/update-daemon-set/
- KEP: https://github.com/kubernetes/enhancements/issues/1591
- API 变更: https://github.com/kubernetes/kubernetes/pull/96375
我如何参与?
请通过 Slack #sig-apps 频道或通过 SIG Apps 邮件列表 kubernetes-sig-apps@googlegroups.com 联系我们。
Kubernetes 1.25:Pod 新增 PodHasNetwork 状况
作者: Deep Debroy (Apple)
Kubernetes 1.25 引入了对 kubelet 所管理的新的 Pod 状况 PodHasNetwork 的 Alpha 支持,
该状况位于 Pod 的 status 字段中 。对于工作节点,kubelet 将使用 PodHasNetwork 状况从容器运行时
(通常与 CNI 插件协作)创建 Pod 沙箱和网络配置的角度准确地了解 Pod 的初始化状态。
在 PodHasNetwork 状况的 status 设置为 "True" 后,kubelet 开始拉取容器镜像并启动独立的容器
(包括 Init 容器)。从集群基础设施的角度报告 Pod 初始化延迟的指标采集服务
(无需知道每个容器的镜像大小或有效负载等特征)就可以利用 PodHasNetwork
状况来准确生成服务水平指标(Service Level Indicator,SLI)。
某些管理底层 Pod 的 Operator 或控制器可以利用 PodHasNetwork 状况来优化 Pod 反复出现失败时要执行的操作。
这与现在为 Pod 所报告的 Intialized 状况有何不同?
根据 Pod 中是否存在 Init 容器,kubelet 会设置在 Pod 的 status 字段中报告的 Initialized 状况的状态。
如果 Pod 指定了 Init 容器,则 Pod 状态中的 Initialized 状况的 status 将不会设置为 "True",
直到该 Pod 的所有 Init 容器都成功为止。但是,用户配置的 Init 容器可能会出现错误(有效负载崩溃、无效镜像等),
并且 Pod 中配置的 Init 容器数量可能因工作负载不同而异。
因此,关于 Pod 初始化的集群范围基础设施 SLI 不能依赖于 Pod 的 Initialized 状况。
如果 Pod 未指定 Init 容器,则在 Pod 生命周期的早期,
Pod 状态中的 Initialized 状况的 status 会被设置为 "True"。
这一设置发生在 kubelet 开始创建 Pod 运行时沙箱及配置网络之前。
因此,即使容器运行时未能成功初始化 Pod 沙箱环境,没有 Init 容器的
Pod 也会将 Initialized 状况的 status 报告为 "True"。
相对于上述任何一种情况,PodHasNetwork 状况会在 Pod 运行时沙箱被初始化并配置了网络时能够提供更准确的数据,
这样 kubelet 可以继续在 Pod 中启动用户配置的容器(包括 Init 容器)。
特殊场景
如果一个 Pod 指定 hostNetwork 为 "True",
系统会根据 Pod 沙箱创建操作是否成功来决定要不要将 PodHasNetwork 状况设置为 "True",
设置此状况时会忽略 Pod 沙箱的网络配置状态。这是因为 Pod 的 hostNetwork 被设置为
"True" 时 CRI 实现通常会跳过所有 Pod 沙箱网络配置。
节点代理可以通过监视指定附加网络配置(例如 k8s.v1.cni.cncf.io/networks)的 Pod 注解变化,
来动态地为 Pod 重新配置网络接口。Pod 沙箱被 Kubelet 初始化(结合容器运行时)之后
Pod 网络配置的动态更新不反映在 PodHasNetwork 状况中。
试用 Pod 的 PodHasNetwork 状况
为了让 kubelet 在 Pod 的 status 字段中报告 PodHasNetwork 状况,需在 kubelet 上启用
PodHasNetworkCondition 特性门控。
对于已成功创建运行时沙箱并已配置网络的 Pod,在 status 设置为 "True" 后,
kubelet 将报告 PodHasNetwork 状况:
$ kubectl describe pod nginx1
Name: nginx1
Namespace: default
...
Conditions:
Type Status
PodHasNetwork True
Initialized True
Ready True
ContainersReady True
PodScheduled True
对于尚未创建运行时沙箱(也未配置网络)的 Pod,在 status 设置为 "False" 后,
kubelet 将报告 PodHasNetwork 状况:
$ kubectl describe pod nginx2
Name: nginx2
Namespace: default
...
Conditions:
Type Status
PodHasNetwork False
Initialized True
Ready False
ContainersReady False
PodScheduled True
下一步是什么?
Kubernetes 团队根据反馈和采用情况,计划在 1.26 或 1.27 中将 PodHasNetwork 状况的报告提升到 Beta 阶段。
我如何了解更多信息?
请查阅 PodHasNetwork 状况有关的文档,
以了解有关该状况的更多信息以及它与其他 Pod 状况的关系。
如何参与?
此特性由 SIG Node 社区驱动。请加入我们与社区建立联系,并就上述特性及其他问题分享你的想法和反馈。 我们期待你的回音!
致谢
我们要感谢以下人员围绕此特性对 KEP 和 PR 进行了极具洞察力和相当有助益的评审工作: Derek Carr (@derekwaynecarr)、Mrunal Patel (@mrunalp)、Dawn Chen (@dchen1107)、 Qiutong Song (@qiutongs)、Ruiwen Zhao (@ruiwen-zhao)、Tim Bannister (@sftim)、 Danielle Lancashire (@endocrimes) 和 Agam Dua (@agamdua)。
宣布自动刷新官方 Kubernetes CVE 订阅源
作者:Pushkar Joglekar (VMware)
Kubernetes 社区有一个长时间未解决的需求,即为最终用户提供一种编程方式来跟踪
Kubernetes 安全问题(也称为 “CVE”,这来自于跟踪不同产品和供应商的公共安全问题的数据库)。
随着 Kubernetes v1.25 的发布,我们很高兴地宣布以 alpha
特性的形式推出这样的订阅源。
在这篇博客中将介绍这项新服务的背景和范围。
动机
随着关注 Kubernetes 的人越来越多,与 Kubernetes 相关的 CVE 数量也在增加。 尽管大多数直接地、间接地或传递性地影响 Kubernetes 的 CVE 都被定期修复, 但 Kubernetes 的最终用户没有一个地方能够以编程方式来订阅或拉取固定的 CVE 数据。 目前的一些数据源要么已损坏,要么不完整。
范围
能做什么
创建一个定期自动刷新的、人和机器可读的官方 Kubernetes CVE 列表。
不能做什么
- 漏洞的分类和披露将继续由 SRC(Security Response Committee,安全响应委员会)完成。
- 不会列出在构建时依赖项和容器镜像中发现的 CVE。
- 只有 Kubernetes SRC 公布的官方 CVE 才会在订阅源中发布。
针对的受众
- 最终用户:使用 Kubernetes 部署他们的应用程序的个人或团队。
- 平台提供商:管理 Kubernetes 集群的个人或团队。
- 维护人员:通过各种特别兴趣小组和委员会在 Kubernetes 社区中创建和支持 Kubernetes 发布版本的个人或团队。
实现细节
发布了一个支持性的贡献者博客, 深入讲述这个 CVE 订阅源是如何实现的,如何确保该订阅源得到合理的保护以免被篡改, 如何在一个新的 CVE 被公布后自动更新这个订阅源。
下一步工作
为了完善此功能,SIG Security 正在收集使用此 Alpha 订阅源的最终用户的反馈。
因此,为了在未来的 Kubernetes 版本中改进订阅源,如果你有任何反馈,请通过添加评论至 问题追踪告诉我们, 或者在 #sig-security-tooling Kubernetes Slack 频道上告诉我们(从这里加入 Kubernetes Slack) 。
特别感谢 Neha Lohia (@nehalohia27) 和 Tim Bannister (@sftim), 感谢他们几个月来从“构思到实现”此特性的出色合作。
Kubernetes 的 iptables 链不是 API
作者: Dan Winship (Red Hat)
译者: Xin Li (DaoCloud)
一些 Kubernetes 组件(例如 kubelet 和 kube-proxy)在执行操作时,会创建特定的 iptables 链和规则。
这些链从未被计划使其成为任何 Kubernetes API/ABI 保证的一部分,
但一些外部组件仍然使用其中的一些链(特别是使用 KUBE-MARK-MASQ 将数据包标记为需要伪装)。
作为 v1.25 版本的一部分,SIG Network 明确声明: Kubernetes 创建的 iptables 链仅供 Kubernetes 内部使用(有一个例外), 第三方组件不应假定 Kubernetes 会创建任何特定的 iptables 链, 或者这些链将包含任何特定的规则(即使它们确实存在)。
然后,在未来的版本中,作为 KEP-3178 的一部分,我们将开始逐步淘汰 Kubernetes
本身不再需要的某些链。Kubernetes 自身之外且使用了 KUBE-MARK-MASQ、KUBE-MARK-DROP
或 Kubernetes 所生成的其它 iptables 链的组件应当开始迁移。
背景
除了各种为 Service 创建的 iptables 链之外,kube-proxy 还创建了某些通用 iptables 链,
用作服务代理的一部分。 过去,kubelet 还使用 iptables
来实现一些功能(例如为 Pod 设置 hostPort 映射),因此它也冗余地创建了一些重复的链。
然而,随着 1.24 版本 Kubernetes 中 [dockershim 的移除], kubelet 现在不再为某种目的使用任何 iptables 规则; 过去使用 iptables 来完成的事情现在总是由容器运行时或网络插件负责, 现在 kubelet 没有理由创建任何 iptables 规则。
同时,虽然 iptables 仍然是 Linux 上默认的 kube-proxy 后端,
但它不会永远是默认选项,因为相关的命令行工具和内核 API 基本上已被弃用,
并且不再得到改进。(RHEL 9 记录警告 如果你使用 iptables API,即使是通过 iptables-nft。)
尽管在 Kubernetes 1.25,iptables kube-proxy 仍然很流行, 并且 kubelet 继续创建它过去创建的 iptables 规则(尽管不再使用它们), 第三方软件不能假设核心 Kubernetes 组件将来会继续创建这些规则。
即将发生的变化
从现在开始的几个版本中,kubelet 将不再在 nat 表中创建以下 iptables 链:
KUBE-MARK-DROPKUBE-MARK-MASQKUBE-POSTROUTING
此外,filter 表中的 KUBE-FIREWALL 链将不再具有当前与
KUBE-MARK-DROP 关联的功能(并且它最终可能会完全消失)。
此更改将通过 IPTablesOwnershipCleanup 特性门控逐步实施。
你可以手动在 Kubernetes 1.25 中开启此特性进行测试。
目前的计划是将其在 Kubernetes 1.27 中默认启用,
尽管这可能会延迟到以后的版本。(不会在 Kubernetes 1.27 版本之前调整。)
如果你使用 Kubernetes 的 iptables 链怎么办
(尽管下面的讨论侧重于仍然基于 iptables 的短期修复, 但你可能也应该开始考虑最终迁移到 nftables 或其他 API。)
如果你使用 KUBE-MARK-MASQ 链...
如果你正在使用 KUBE-MARK-MASQ 链来伪装数据包,
你有两个选择:(1)重写你的规则以直接使用 -j MASQUERADE,
(2)创建你自己的替代链,完成“为伪装而设标记”的任务。
kube-proxy 使用 KUBE-MARK-MASQ 的原因是因为在很多情况下它需要在数据包上同时调用
-j DNAT 和 -j MASQUERADE,但不可能同时在 iptables 中调用这两种方法;
DNAT 必须从 PREROUTING(或 OUTPUT)链中调用(因为它可能会改变数据包将被路由到的位置)而
MASQUERADE 必须从 POSTROUTING 中调用(因为它伪装的源 IP 地址取决于最终的路由)。
理论上,kube-proxy 可以有一组规则来匹配 PREROUTING/OUTPUT
中的数据包并调用 -j DNAT,然后有第二组规则来匹配 POSTROUTING
中的相同数据包并调用 -j MASQUERADE。
但是,为了提高效率,kube-proxy 只匹配了一次,在 PREROUTING/OUTPUT 期间调用 -j DNAT,
然后调用 -j KUBE-MARK-MASQ 在内核数据包标记属性上设置一个比特,作为对自身的提醒。
然后,在 POSTROUTING 期间,通过一条规则来匹配所有先前标记的数据包,并对它们调用 -j MASQUERADE。
如果你有很多规则需要像 kube-proxy 一样对同一个数据包同时执行 DNAT 和伪装操作,
那么你可能需要类似的安排。但在许多情况下,使用 KUBE-MARK-MASQ 的组件之所以这样做,
只是因为它们复制了 kube-proxy 的行为,而不理解 kube-proxy 为何这样做。
许多这些组件可以很容易地重写为仅使用单独的 DNAT 和伪装规则。
(在没有发生 DNAT 的情况下,使用 KUBE-MARK-MASQ 的意义就更小了;
只需将你的规则从 PREROUTING 移至 POSTROUTING 并直接调用 -j MASQUERADE。)
如果你使用 KUBE-MARK-DROP...
KUBE-MARK-DROP 的基本原理与 KUBE-MARK-MASQ 类似:
kube-proxy 想要在 nat KUBE-SERVICES 链中做出丢包决定以及其他决定,
但你只能从 filter 表中调用 -j DROP。
通常,删除对 KUBE-MARK-DROP 的依赖的方法与删除对 KUBE-MARK-MASQ 的依赖的方法相同。
在 kube-proxy 的场景中,很容易将 nat 表中的 KUBE-MARK-DROP
的用法替换为直接调用 filter 表中的 DROP,因为 DNAT 规则和 DROP 规则之间没有复杂的交互关系,
因此 DROP 规则可以简单地从 nat 移动到 filter。
更复杂的场景中,可能需要在 nat 和 filter 表中“重新匹配”相同的数据包。
如果你使用 Kubelet 的 iptables 规则来确定 iptables-legacy 与 iptables-nft...
对于从容器内部操纵主机网络命名空间 iptables 规则的组件而言,需要一些方法来确定主机是使用旧的
iptables-legacy 二进制文件还是新的 iptables-nft 二进制文件(与不同的内核 API 交互)下。
iptables-wrappers 模块为此类组件提供了一种自动检测系统 iptables 模式的方法,
但在过去,它通过假设 kubelet 将在任何容器启动之前创建“一堆” iptables
规则来实现这一点,因此它可以通过查看哪种模式定义了更多规则来猜测主机文件系统中的
iptables 二进制文件正在使用哪种模式。
在未来的版本中,kubelet 将不再创建许多 iptables 规则, 因此基于计算存在的规则数量的启发式方法可能会失败。
然而,从 1.24 开始,kubelet 总是在它使用的任何 iptables 子系统的
mangle 表中创建一个名为 KUBE-IPTABLES-HINT 的链。
组件现在可以查找这个特定的链,以了解 kubelet(以及系统的其余部分)正在使用哪个 iptables 子系统。
(此外,从 Kubernetes 1.17 开始,kubelet 在 mangle 表中创建了一个名为 KUBE-KUBELET-CANARY 的链。
虽然这条链在未来可能会消失,但它仍然会在旧版本中存在,因此在任何最新版本的 Kubernetes 中,
至少会包含 KUBE-IPTABLES-HINT 或 KUBE-KUBELET-CANARY 两条链的其中一个。)
iptables-wrappers 包[已经被更新],以提供这个新的启发式逻辑,
所以如果你以前使用过它,你可以用它的更新版本重建你的容器镜像。
延伸阅读
KEP-3178 跟踪了清理 iptables 链所有权和弃用旧链的项目。
COSI 简介:使用 Kubernetes API 管理对象存储
作者: Sidhartha Mani (Minio, Inc)
本文介绍了容器对象存储接口 (COSI),它是在 Kubernetes 中制备和使用对象存储的一个标准。 它是 Kubernetes v1.25 中的一个 Alpha 功能。
文件和块存储通过 Container Storage Interface (CSI) 被视为 Kubernetes 生态系统中的一等公民。 使用 CSI 卷的工作负载可以享受跨供应商和跨 Kubernetes 集群的可移植性优势, 而无需更改应用程序清单。对象存储不存在等效标准。
近年来,对象存储作为文件系统和块设备的替代存储形式越来越受欢迎。 对象存储范式促进了计算和存储的分解,这是通过网络而不是本地提供数据来完成的。 分解的架构允许计算工作负载是无状态的,从而使它们更易于管理、扩展和自动化。
COSI
COSI 旨在标准化对象存储的使用,以提供以下好处:
- Kubernetes 原生 - 使用 Kubernetes API 来制备、配置和管理 Bucket
- 自助服务 - 明确划分管理和运营 (DevOps),为 DevOps 人员赋予自助服务能力
- 可移植性 - 通过跨 Kubernetes 集群和跨对象存储供应商的可移植性实现供应商中立性
跨供应商的可移植性只有在两家供应商都支持通用数据路径 API 时才有可能。 例如,可以从 AWS S3 移植到 Ceph,或从 AWS S3 移植到 MinIO 以及反向操作,因为它们都使用 S3 API。 但是无法从 AWS S3 和 Google Cloud 的 GCS 移植,反之亦然。
架构
COSI 由三个部分组成:
- COSI 控制器管理器
- COSI 边车
- COSI 驱动程序
COSI 控制器管理器充当处理 COSI API 对象更改的主控制器,它负责处理 Bucket 创建、更新、删除和访问管理的请求。 每个 Kubernetes 集群都需要一个控制器管理器实例。即使集群中使用了多个对象存储提供程序,也只需要一个。
COSI 边车充当 COSI API 请求和供应商特定 COSI 驱动程序之间的转换器。 该组件使用供应商驱动程序应满足的标准化 gRPC 协议。
COSI 驱动程序是供应商特定组件,它接收来自 sidecar 的请求并调用适当的供应商 API 以创建 Bucket、 管理其生命周期及对它们的访问。
接口
COSI 接口 以 Bucket 为中心,因为 Bucket 是对象存储的抽象单元。COSI 定义了三个旨在管理它们的 Kubernetes API
- Bucket
- BucketClass
- BucketClaim
此外,还定义了另外两个用于管理对 Bucket 的访问的 API:
- BucketAccess
- BucketAccessClass
简而言之,Bucket 和 BucketClaim 可以认为分别类似于 PersistentVolume 和 PersistentVolumeClaim。 BucketClass 在文件/块设备世界中对应的是 StorageClass。
由于对象存储始终通过网络进行身份验证,因此需要访问凭证才能访问 Bucket。 BucketAccess 和 BucketAccessClass 这两个 API 用于表示访问凭证和身份验证策略。 有关这些 API 的更多信息可以在官方 COSI 提案中找到 - https://github.com/kubernetes/enhancements/tree/master/keps/sig-storage/1979-object-storage-support
自助服务
除了提供 kubernetes-API 驱动的 Bucket 管理之外,COSI 还旨在使 DevOps 人员能够自行配置和管理 Bucket, 而无需管理员干预。这进一步使开发团队能够实现更快的周转时间和更快的上市时间。
COSI 通过在两个不同的利益相关者(即管理员(admin)和集群操作员)之间划分 Bucket 配置步骤来实现这一点。 管理员将负责就如何配置 Bucket 以及如何获取 Bucket 的访问权限设置广泛的策略和限制。 集群操作员可以在管理员设置的限制内自由创建和使用 Bucket。
例如,集群操作员可以使用管理策略将最大预置容量限制为 100GB,并且允许开发人员创建 Bucket 并将数据存储到该限制。 同样对于访问凭证,管理员将能够限制谁可以访问哪些 Bucket,并且开发人员将能够访问他们可用的所有 Bucket。
可移植性
COSI 的第三个目标是实现 Bucket 管理的供应商中立性。COSI 支持两种可移植性:
- 跨集群
- 跨提供商
跨集群可移植性允许在一个集群中配置的 Bucket 在另一个集群中可用。这仅在对象存储后端本身可以从两个集群访问时才有效。
跨提供商可移植性是指允许组织或团队无缝地从一个对象存储提供商迁移到另一个对象存储提供商, 而无需更改应用程序定义(PodTemplates、StatefulSets、Deployment 等)。这只有在源和目标提供者使用相同的数据时才有可能。
COSI 不处理数据迁移,因为它超出了其范围。如果提供者之间的移植也需要迁移数据,则需要采取其他措施来确保数据可用性。
接下来
令人惊叹的 sig-storage-cosi 社区一直在努力将 COSI 标准带入 Alpha 状态。 我们期待很多供应商加入编写 COSI 驱动程序并与 COSI 兼容!
我们希望为 COSI Bucket 添加更多身份验证机制,我们正在设计高级存储桶共享原语、多集群存储桶管理等等。 未来有很多伟大的想法和机会!
请继续关注接下来的内容,如果你有任何问题、意见或建议分解的架构允许计算工作负载是无状态
- 在 Kubernetes 上与我们讨论 Slack:#sig-storage-cosi
- 参加我们的 Zoom 会议,每周四太平洋时间 10:00
- 参与 bucket API 提案 PR 提出你的想法、建议等。
Kubernetes 1.25: cgroup v2 升级到 GA
作者: David Porter (Google), Mrunal Patel (Red Hat)
Kubernetes 1.25 将 cgroup v2 正式发布(GA), 让 kubelet 使用最新的容器资源管理能力。
什么是 cgroup?
有效的资源管理是 Kubernetes 的一个关键方面。 这涉及管理节点中的有限资源,例如 CPU、内存和存储。
cgroups 是一种可建立资源管理功能的 Linux 内核能力, 例如为正在运行的进程限制 CPU 使用率或设置内存限制。
当你使用 Kubernetes 中的资源管理能力时,例如配置 Pod 和容器的请求和限制, Kubernetes 会使用 cgroups 来强制执行你的资源请求和限制。
Linux 内核提供了两个版本的 cgroup:cgroup v1 和 cgroup v2。
什么是 cgroup v2?
cgroup v2 是 Linux cgroup API 的最新版本, 提供了一个具有增强的资源管理能力的统一控制系统。
自 2016 年以来,cgroup v2 一直在 Linux 内核中进行开发, 近年来在整个容器生态系统中已经成熟。在 Kubernetes 1.25 中, 对 cgroup v2 的支持已升级为正式发布。
默认情况下,许多最新版本的 Linux 发行版已切换到 cgroup v2, 因此 Kubernetes 继续在这些新更新的发行版上正常运行非常重要。
cgroup v2 对 cgroup v1 进行了多项改进,例如:
- API 中单个统一的层次结构设计
- 为容器提供更安全的子树委派能力
- 压力阻塞信息等新功能
- 增强的资源分配管理和跨多个资源的隔离
- 统一核算不同类型的内存分配(网络和内核内存等)
- 考虑非即时资源更改,例如页面缓存回写
一些 Kubernetes 特性专门使用 cgroup v2 来增强资源管理和隔离。 例如,MemoryQoS 特性提高了内存利用率并依赖 cgroup v2 功能来启用它。kubelet 中的新资源管理特性也将利用新的 cgroup v2 特性向前发展。
如何使用 cgroup v2?
许多 Linux 发行版默认切换到 cgroup v2; 你可能会在下次更新控制平面和节点的 Linux 版本时开始使用它!
推荐使用默认使用 cgroup v2 的 Linux 发行版。 一些使用 cgroup v2 的流行 Linux 发行版包括:
- Container-Optimized OS(从 M97 开始)
- Ubuntu(从 21.10 开始,推荐 22.04+)
- Debian GNU/Linux(从 Debian 11 Bullseye 开始)
- Fedora(从 31 开始)
- Arch Linux(从 2021 年 4 月开始)
- RHEL 和类似 RHEL 的发行版(从 9 开始)
要检查你的发行版是否默认使用 cgroup v2, 请参阅你的发行版文档或遵循识别 Linux 节点上的 cgroup 版本。
如果你使用的是托管 Kubernetes 产品,请咨询你的提供商以确定他们如何采用 cgroup v2, 以及你是否需要采取行动。
要将 cgroup v2 与 Kubernetes 一起使用,必须满足以下要求:
- 你的 Linux 发行版在内核版本 5.8 或更高版本上启用 cgroup v2
- 你的容器运行时支持 cgroup v2。例如:
- containerd v1.4 或更高版本
- cri-o v1.20 或更高版本
- kubelet 和容器运行时配置为使用 systemd cgroup 驱动程序
kubelet 和容器运行时使用 cgroup 驱动 来设置 cgroup 参数。使用 cgroup v2 时,强烈建议 kubelet 和你的容器运行时都使用 systemd cgroup 驱动程序, 以便系统上只有一个 cgroup 管理员。要配置 kubelet 和容器运行时以使用该驱动程序, 请参阅 systemd cgroup 驱动程序文档。
迁移到 cgroup v2
当你使用启用 cgroup v2 的 Linux 发行版运行 Kubernetes 时,只要你满足要求, kubelet 应该会自动适应而无需任何额外的配置。
在大多数情况下,除非你的用户直接访问 cgroup 文件系统, 否则当你切换到使用 cgroup v2 时,不会感知到用户体验有什么不同。
如果你在节点上或从容器内直接访问 cgroup 文件系统的应用程序, 你必须更新应用程序以使用 cgroup v2 API 而不是 cgroup v1 API。
你可能需要更新到 cgroup v2 的场景包括:
- 如果你运行依赖于 cgroup 文件系统的第三方监控和安全代理,请将代理更新到支持 cgroup v2 的版本。
- 如果你将 cAdvisor 作为独立的 DaemonSet 运行以监控 Pod 和容器, 请将其更新到 v0.43.0 或更高版本。
- 如果你使用 JDK 部署 Java 应用程序,首选使用完全支持 cgroup v2 的 JDK 11.0.16 及更高版本或 JDK 15 及更高版本。
进一步了解
- 阅读 Kubernetes cgroup v2 文档
- 阅读增强提案 KEP 2254
- 学习更多关于 Linux 手册页上的 cgroups 和 Linux 内核文档上的 cgroup v2
参与其中
随时欢迎你的反馈!SIG Node 定期开会,可在 Kubernetes Slack的
#sig-node 频道中获得,或使用 SIG 邮件列表。
cgroup v2 经历了漫长的旅程,是整个行业开源社区协作的一个很好的例子, 因为它需要跨堆栈的工作,从 Linux 内核到 systemd 到各种容器运行时,当然还有 Kubernetes。
致谢
我们要感谢 Giuseppe Scrivano 在 Kubernetes 中发起对 cgroup v2 的支持, 还要感谢 SIG Node 社区主席 Dawn Chen 和 Derek Carr 所作的审查和领导工作。
我们还要感谢 Docker、containerd 和 CRI-O 等容器运行时的维护者, 以及支持多种容器运行时的 cAdvisor 和 runc, libcontainer 等组件的维护者。 最后,如果没有 systemd 和上游 Linux 内核维护者的支持,这将是不可能的。
Kubernetes 1.25:CSI 内联存储卷正式发布
作者: Jonathan Dobson (Red Hat)
CSI 内联存储卷是在 Kubernetes 1.15 中作为 Alpha 功能推出的,并从 1.16 开始成为 Beta 版本。 我们很高兴地宣布,这项功能在 Kubernetes 1.25 版本中正式发布(GA)。
CSI 内联存储卷与其他类型的临时卷相似,如 configMap、downwardAPI 和 secret。
重要的区别是,存储是由 CSI 驱动提供的,它允许使用第三方供应商提供的临时存储。
卷被定义为 Pod 规约的一部分,并遵循 Pod 的生命周期,这意味着卷随着 Pod 的调度而创建,并随着 Pod 的销毁而销毁。
1.25 版本有什么新内容?
1.25 版本修复了几个与 CSI 内联存储卷相关的漏洞,
并且 CSIInlineVolume 特性门控
已正式发布,锁定为 True。
因为没有新的 API 变化,所以除了这些错误修复外,使用该功能 Beta 版本的用户应该不会注意到任何重大变化。
- #89290 - CSI inline volumes should support fsGroup
- #79980 - CSI volume reconstruction does not work for ephemeral volumes
何时使用此功能
CSI 内联存储卷是为简单的本地卷准备的,这种本地卷应该跟随 Pod 的生命周期。 它们对于使用 CSI 驱动为 Pod 提供 Secret、配置数据或其他特殊用途的存储可能很有用。
在以下情况下,CSI 驱动不适合内联使用:
- 卷需要持续的时间超过 Pod 的生命周期
- 卷快照、克隆或卷扩展是必需的
- CSI 驱动需要
volumeAttributes字段,此字段应该限制给管理员使用
如何使用此功能
为了使用这个功能,CSIDriver 规约必须明确将 Ephemeral 列举为 volumeLifecycleModes 的参数之一。
下面是一个来自 Secrets Store CSI Driver 的简单例子。
apiVersion: storage.k8s.io/v1
kind: CSIDriver
metadata:
name: secrets-store.csi.k8s.io
spec:
podInfoOnMount: true
attachRequired: false
volumeLifecycleModes:
- Ephemeral
所有 Pod 规约都可以引用该 CSI 驱动来创建一个内联卷,如下例所示。
kind: Pod
apiVersion: v1
metadata:
name: my-csi-app-inline
spec:
containers:
- name: my-frontend
image: busybox
volumeMounts:
- name: secrets-store-inline
mountPath: "/mnt/secrets-store"
readOnly: true
command: [ "sleep", "1000000" ]
volumes:
- name: secrets-store-inline
csi:
driver: secrets-store.csi.k8s.io
readOnly: true
volumeAttributes:
secretProviderClass: "my-provider"
如果驱动程序支持一些卷属性,你也可以将这些属性作为 Pod spec 的一部分。
csi:
driver: block.csi.vendor.example
volumeAttributes:
foo: bar
使用案例示例
支持 Ephemeral 卷生命周期模式的两个现有 CSI 驱动是 Secrets Store CSI 驱动和 Cert-Manager CSI 驱动。
Secrets Store CSI Driver 允许用户将 Secret 作为内联卷从外部挂载到一个 Pod 中。 当密钥存储在外部管理服务或 Vault 实例中时,这可能很有用。
Cert-Manager CSI Driver 与 cert-manager 协同工作, 无缝地请求和挂载证书密钥对到一个 Pod 中。这使得证书可以在应用 Pod 中自动更新。
安全考虑因素
应特别考虑哪些 CSI 驱动可作为内联卷使用。
volumeAttributes 通常通过 StorageClass 控制,并可能包含应限制给集群管理员的属性。
允许 CSI 驱动用于内联临时卷意味着任何有权限创建 Pod 的用户也可以通过 Pod 规约向驱动提供 volumeAttributes 字段。
集群管理员可以选择从 CSIDriver 规约中的 volumeLifecycleModes 中省略(或删除) Ephemeral,
以防止驱动被用作内联临时卷,或者使用准入 Webhook 来限制驱动的使用。
参考资料
关于此功能的更多信息,请参阅:
PodSecurityPolicy:历史背景
作者: Mahé Tardy (Quarkslab)
从 Kubernetes v1.25 开始,PodSecurityPolicy (PSP) 准入控制器已被移除。 在为 Kubernetes v1.21 发布的博文 PodSecurityPolicy 弃用:过去、现在和未来 中,已经宣布并详细说明了它的弃用情况。
本文旨在提供 PSP 诞生和演变的历史背景,解释为什么从未使该功能达到稳定状态,并说明为什么它被移除并被 Pod 安全准入控制取代。
PodSecurityPolicy 与其他专门的准入控制插件一样,作为内置的策略 API,对有关 Pod 安全设置的特定字段提供细粒度的权限。 它承认集群管理员和集群用户通常不是同一个人,并且以 Pod 形式或任何将创建 Pod 的资源的形式创建工作负载的权限不应该等同于“集群上的 root 账户”。 它还可以通过变更配置来应用更安全的默认值,并将底层 Linux 安全决策与部署过程分离来促进最佳实践。
PodSecurityPolicy 的诞生
PodSecurityPolicy 源自 OpenShift 的 SecurityContextConstraints (SCC), 它出现在 Red Hat OpenShift 容器平台的第一个版本中,甚至在 Kubernetes 1.0 之前。PSP 是 SCC 的精简版。
PodSecurityPolicy 的创建起源很难追踪,特别是因为它主要是在 Kubernetes 增强提案 (KEP) 流程之前添加的, 当时仍在使用设计提案(Design Proposal)。事实上,最终设计提案的存档仍然可以找到。 尽管如此,编号为 5 的 KEP 是在合并第一个拉取请求后创建的。
在添加创建 PSP 的第一段代码之前,两个主要的拉取请求被合并到 Kubernetes 中,
SecurityContext 子资源
定义了 Pod 容器上的新字段,以及 ServiceAccount
API 的第一次迭代。
Kubernetes 1.0 于 2015 年 7 月 10 日发布,除了 Alpha 阶段的 SecurityContextDeny 准入插件
(当时称为 scdeny)之外,
没有任何机制来限制安全上下文和工作负载的敏感选项。
SecurityContextDeny 插件
今天仍存在于 Kubernetes 中(作为 Alpha 特性),负责创建一个准入控制器,以防止在安全上下文中使用某些字段。
PodSecurityPolicy 的根源是早期关于安全策略的一个拉取请求, 它以 SCC(安全上下文约束)为基础,增加了新的 PSP 对象的设计方案。这是一个长达 9 个月的漫长讨论, 基于 OpenShift 的 SCC 反复讨论, 多次变动,并重命名为 PodSecurityPolicy,最终在 2016 年 2 月进入上游 Kubernetes。 现在 PSP 对象已经创建,下一步是添加一个可以执行这些政策的准入控制器。 第一步是添加不考虑用户或组 的准入控制。 2016 年 5 月,一个特定的使 PodSecurityPolicy 达到可用状态的问题被添加进来, 以跟踪进展,并在名为 PSP 准入的拉取请求中合并了准入控制器的第一个版本。 然后大约两个月后,发布了 Kubernetes 1.3。
下面是一个时间表,它以 1.0 和 1.3 版本作为参考点,回顾了 PodSecurityPolicy 及其准入控制器诞生的主要拉取请求。

之后,PSP 准入控制器通过添加最初被搁置的内容进行了增强。 在 2016 年 11 月上旬合并鉴权机制, 允许管理员在集群中使用多个策略,为不同类型的用户授予不同级别的访问权限。 后来,2017 年 10 月合并的一个拉取请求 修复了 PodSecurityPolicies 在变更和字母顺序之间冲突的设计问题, 并继续构建我们所知道的 PSP 准入。之后,进行了许多改进和修复,以构建最近 Kubernetes 版本的 PodSecurityPolicy 功能。
Pod 安全准入的兴起
尽管 PodSecurityPolicy 试图解决的是一个关键问题,但它却包含一些重大缺陷:
- 有缺陷的鉴权模式 - 如果用户针对 PSP 具有执行 use 动作的权限,而此 PSP 准许该 Pod 或者该 Pod 的服务帐户对 PSP 执行 use 操作,则用户可以创建一个 Pod。
- 难以推广 - PSP 失败关闭。也就是说,在没有策略的情况下,所有 Pod 都会被拒绝。 这主要意味着默认情况下无法启用它,并且用户必须在启用该功能之前为所有工作负载添加 PSP, 因此没有提供审计模式来发现哪些 Pod 会不被新策略所允许。 这种采纳模式还导致测试覆盖率不足,并因跨特性不兼容而经常出现故障。 而且与 RBAC 不同的是,还不存在在项目中交付 PSP 清单的强大文化。
- 不一致的无边界 API - API 的发展有很多不一致的地方,特别是由于许多小众场景的请求: 如标签、调度、细粒度的卷控制等。它的可组合性很差,优先级模型较弱,会导致意外的变更优先级。 这使得 PSP 与其他第三方准入控制器的结合真的很困难。
- 需要安全知识 - 有效使用 PSP 仍然需要了解 Linux 的安全原语。 例如:MustRunAsNonRoot + AllowPrivilegeEscalation。
PodSecurityPolicy 的经验得出的结论是,大多数用户关心两个或三个策略,这导致了 Pod 安全标准的创建,它定义了三个策略:
- Privileged(特权的) - 策略不受限制。
- Baseline(基线的) - 策略限制很少,允许默认 Pod 配置。
- Restricted(受限的) - 安全最佳实践策略。
作为 PSP 的替代品,新的 Pod 安全准入是 Kubernetes v1.25 的树内稳定的准入插件,用于在命名空间级别强制执行这些标准。 无需深入的安全知识,就可以更轻松地实施基本的 Pod 安全性。 对于更复杂的用例,你可能需要一个可以轻松与 Pod 安全准入结合的第三方解决方案。
下一步是什么
有关 SIG Auth 流程的更多详细信息,包括 PodSecurityPolicy 删除和 Pod 安全准入的创建, 请参阅在 KubeCon NA 2021 的 SIG auth update at KubeCon NA 2019 和 PodSecurityPolicy Replacement: Past, Present, and Future 演示录像。
特别是在 PSP 移除方面,PodSecurityPolicy 弃用:过去、现在和未来博客文章仍然是准确的。
对于新的 Pod 安全许可,可以访问文档。 此外,博文 Kubernetes 1.23: Pod Security Graduers to Beta 以及 KubeCon EU 2022 演示文稿 the Hitchhicker’s Guide to Pod Security 提供了很好的实践教程来学习。
Kubernetes v1.25: Combiner
宣布 Kubernetes v1.25 的发版!
这个版本总共包括 40 项增强功能。 其中 15 项增强功能进入 Alpha,10 项进入 Beta,13 项进入 Stable。 我们也废弃/移除了两个功能。
版本主题和徽标
Kubernetes 1.25: Combiner

Kubernetes v1.25 的主题是 Combiner,即组合器。
Kubernetes 项目本身是由特别多单独的组件组成的,这些组件组合起来就形成了你今天看到的这个项目。 同时它也是由许多个人建立和维护的,这些人拥有不同的技能、经验、历史和兴趣, 他们不仅作为发布团队成员,而且作为许多 SIG 成员,常年通力合作支持项目和社区。
通过这次发版,我们希望向协作和开源的精神致敬, 这种精神使我们从分散在世界各地的独立开发者、作者和用户变成了能够改变世界的联合力量。 Kubernetes v1.25 包含了惊人的 40 项增强功能, 如果没有我们在一起工作时拥有的强大力量,这些增强功能都不会存在。
受我们的发布负责人的儿子 Albert Song 的启发,Kubernetes v1.25 是以你们每一个人命名的, 无论你们选择如何作为 Kubernetes 的联合力量贡献自己的独有力量。
新增内容(主要主题)
移除 PodSecurityPolicy;Pod Security Admission 成长为 Stable
PodSecurityPolicy 是在 1.21 版本中被弃用,到 1.25 版本被移除。 因为提升其可用性的变更会带来破坏性的变化,所以有必要将其删除,以支持一个更友好的替代品。 这个替代品就是 Pod Security Admission,它在这个版本里成长为 Stable。 如果你最近依赖于 PodSecurityPolicy,请参考 Pod Security Admission 迁移说明。
Ephemeral Containers 成长为 Stable
临时容器是在现有的 Pod 中存在有限时间的容器。
当你需要检查另一个容器,但因为该容器已经崩溃或其镜像缺乏调试工具不能使用 kubectl exec 时,它对故障排除特别有用。
临时容器在 Kubernetes v1.23 中成长为 Beta,并在这个版本中,该功能成长为 Stable。
对 cgroups v2 的支持进入 Stable 阶段
自 Linux 内核 cgroups v2 API 宣布稳定以来,已经有两年多的时间了。 随着一些发行版现在默认使用该 API,Kubernetes 必须支持它以继续在这些发行版上运行。 cgroups v2 比 cgroups v1 提供了一些改进,更多信息参见 cgroups v2 文档。 虽然 cgroups v1 将继续受到支持,但这一改进使我们能够为其最终的废弃和替代做好准备。
改善对 Windows 系统的支持
- 性能仪表板增加了对 Windows 系统的支持
- 单元测试增加了对 Windows 系统的支持
- 一致性测试增加了对 Windows 系统的支持
- 为 Windows Operational Readiness 创建了新的 GitHub 仓库
将容器注册服务从 k8s.gcr.io 迁移至 registry.k8s.io
将容器注册服务从 k8s.gcr.io 迁移至 registry.k8s.io 的 PR 已经被合并。 更多细节参考 wiki 页面, 同时公告已发送到 kubernetes 开发邮件列表。
SeccompDefault 升级为 Beta
SeccompDefault 升级为 Beta, 更多细节参考教程用 seccomp 限制一个容器的系统调用。
网络策略中 endPort 升级为 Stable
网络策略中的
endPort 已经迎来 GA 正式发布。
支持 endPort 字段的网络策略提供程序现在可使用该字段来指定端口范围,应用网络策略。
在之前的版本中,每个网络策略只能指向单一端口。
请注意,网络策略提供程序 必须支持 endPort 字段。
如果提供程序不支持 endPort,又在网络策略中指定了此字段,
则会创建出仅覆盖端口字段(单端口)的网络策略。
本地临时容器存储容量隔离升级为 Stable
本地临时存储容量隔离功能已经迎来 GA 正式发布版本。
该功能在 1.8 版中作为 alpha 版本引入,在 1.10 中升级为 beta,现在终于成为了稳定功能。
它提供了对 Pod 之间本地临时存储容量隔离的支持,如 EmptyDir,
因此,如果一个 Pod 对本地临时存储容量的消耗超过该限制,就可以通过驱逐 Pod 来硬性限制其对共享资源的消耗。
核心 CSI 迁移为稳定版
CSI 迁移是 SIG Storage 在之前多个版本中做出的持续努力。 目标是将树内数据卷插件转移到树外 CSI 驱动程序并最终移除树内数据卷插件。 此次核心 CSI 迁移已迎来 GA。 同样,GCE PD 和 AWS EBS 的 CSI 迁移也进入 GA 阶段。 vSphere 的 CSI 迁移仍为 beta(但也默认启用)。 Portworx 的 CSI 迁移同样处于 beta 阶段(但默认不启用)。
CSI 临时数据卷升级为稳定版
CSI 临时数据卷 功能允许在临时使用的情况下在 Pod 里直接指定 CSI 数据卷。 因此可以直接用它们在使用挂载卷的 Pod 内注入任意状态,如配置、秘密、身份、变量或类似信息。 这个功能最初是作为 alpha 功能在 1.15 版本中引入,现在已升级为 GA 通用版。 某些 CSI 驱动程序会使用此功能,例如存储密码的 CSI 驱动程序。
CRD 验证表达式语言升级为 Beta
CRD 验证表达式语言已升级为 beta 版本, 这使得声明如何使用通用表达式语言(CEL)验证自定义资源成为可能。 请参考验证规则指导。
服务器端未知字段验证升级为 Beta
ServerSideFieldValidation 特性门控已升级为 beta(默认开启)。
它允许在检测到未知字段时,有选择地触发 API 服务器上的模式验证机制。
因此这允许从 kubectl 中移除客户端验证的同时保持相同的核心功能,即对包含未知或无效字段的请求进行错误处理。
引入 KMS v2 API
引入 KMS v2 alpha1 API 以提升性能,实现轮替与可观察性改进。 此 API 使用 AES-GCM 替代了 AES-CBC,通过 DEK 实现静态数据(即 Kubernetes Secrets)加密。 过程中无需额外用户操作,而且仍然支持通过 AES-GCM 和 AES-CBC 进行读取。 更多信息参考使用 KMS provider 进行数据加密指南。
Kube-proxy 镜像当前基于无发行版镜像
在以前的版本中,kube-proxy 的容器镜像是以 Debian 作为基础镜像构建的。 从这个版本开始,其镜像现在使用 distroless 来构建。 这一改变将镜像的大小减少了近 50%,并将安装的软件包和文件的数量减少到只有 kube-proxy 工作所需的那些。
其他更新
稳定版升级
1.25 版本共包含 13 项升级至稳定版的增强功能:
- 临时容器
- 本地临时存储资源管理
- CSI 临时数据卷
- CSI 迁移 -- 核心
- kube-scheduler ComponentConfig 升级为 GA 通用版
- CSI 迁移 -- AWS
- CSI 迁移 -- GCE
- DaemonSets 支持 MaxSurge
- 网络策略端口范围
- cgroups v2
- Pod Security Admission
- Statefulsets 增加
minReadySeconds - 在 API 准入层级权威识别 Windows Pod
弃用和移除
1.25 版本废弃/移除两个功能。
发行版说明
Kubernetes 1.25 版本的完整信息可参考发行版说明。
获取
Kubernetes 1.25 版本可在 GitHub 下载获取。 开始使用 Kubernetes 请查看这些交互式教程或者使用 kind 把容器当作 “节点” 来运行本地 Kubernetes 集群。 你也可以使用 kubeadm 来简单的安装 1.25 版本。
发布团队
Kubernetes 的发展离不开其社区的支持、承诺和辛勤工作。 每个发布团队都是由专门的社区志愿者组成的,他们共同努力,建立了许多模块,这些模块结合起来,就构成了你所依赖的 Kubernetes。 从代码本身到文档和项目管理,这需要我们社区每一个人的专业技能。
重要用户
- Finleap Connect 在一个高度规范的环境中运作。 2019年,他们有五个月的时间在其集群的所有服务中实施交互 TLS(mTLS),以使其业务代码符合新的欧洲 PSD2 支付指令。
- PNC 试图开发一种方法,以确保新的代码能够自动满足安全标准和审计合规性要求--取代他们现有的 30 天的繁琐的人工流程。 使用 Knative,PNC 开发了内部工具来自动检查新代码和对修改现有代码。
- Nexxiot 公司需要高可用、安全、高性能以及低成本的 Kubernetes 集群。他们求助于 Cilium 作为 CNI 来锁定他们的集群,并通过可靠的 Day2 操作实现弹性网络。
- 因为创建网络安全策略的过程是一个复杂的多步骤过程, At-Bay 试图通过使用基于异步消息的通信模式/设施来改善运营。他们确定 Dapr 满足了其所需的要求清单,且远超预期。
生态系统更新
- 2022 北美 KubeCon + CloudNativeCon 将于 2022 年 10 月 24 - 28 日在密歇根州的底特律举行! 你可以在活动网站找到更多关于会议和注册的信息。
- KubeDay 系列活动将于 12 月 7 日在日本 KubeDay 拉开帷幕! 在活动网站上注册或提交提案。
- 在 2021 云原生调查中,CNCF 看见了创纪录的 Kubernetes 和容器应用。 请参考调查结果。
项目进度
CNCF K8s DevStats 项目汇集了大量关于 Kubernetes 和各种子项目研发进度相关性的有趣的数据点。 其中包括从个人贡献到参与贡献的公司数量的全面信息, 并证明了为发展 Kubernetes 生态系统所做努力的深度和广度。
在 1.25 版本的发布周期中, 该周期运行了 14 周 (May 23 to August 23), 我们看到来着 1065 家公司 以及 1620 位个人所做出的贡献。
即将举行的网络发布研讨会
加入 Kubernetes 1.25 版本发布团队的成员,将于 2022 年 9 月 22 日星期四上午 10 点至 11 点(太平洋时间)了解该版本的主要功能, 以及弃用和删除的内容,以帮助制定升级计划。 欲了解更多信息和注册,请访问活动页面。
参与其中
参与 Kubernetes 最简单的方法就是加入众多特殊兴趣小组(SIGs) 中你感兴趣的一个。 你有什么东西想要跟 Kubernetes 社区沟通吗? 来我们每周的社区会议分享你的想法,并参考一下渠道:
- 在 Kubernetes 贡献者网站了解更多关于为 Kubernetes 做贡献的信息。
- 在 Twitter @Kubernetesio 上关注我们,了解最新动态。
- 在 Discuss 上加入社区讨论。
- 在 Slack 上加入社区。
- 在 Server Fault 上发布问题(或者回答问题)。
- 分享你的 Kubernetes 故事
- 在博客上阅读更多关于 Kubernetes 的情况。
- 了解更多关于 Kubernetes 发布团队的信息。
聚焦 SIG Storage
作者:Frederico Muñoz (SAS)
自 Kubernetes 诞生之初,持久数据以及如何解决有状态应用程序的需求一直是一个重要的话题。 对无状态部署的支持是很自然的、从一开始就存在的,并引起了人们的关注,变得众所周知。 从早期开始,我们也致力于更好地支持有状态应用程序,每个版本都增加了可以在 Kubernetes 上运行的范围。
消息队列、数据库、集群文件系统:这些是具有不同存储要求的解决方案的一些示例, 如今这些解决方案越来越多地部署在 Kubernetes 中。 处理来自许多不同供应商的临时和持久存储(本地或远程、文件或块),同时考虑如何提供用户期望的所需弹性和数据一致性, 所有这些都在 SIG Storage 的整体负责范围之内。
在这次 SIG Storage 采访报道中,Frederico Muñoz (SAS 的云和架构负责人)与 VMware 技术负责人兼 SIG Storage 联合主席 Xing Yang,讨论了 SIG 的组织方式、当前的挑战是什么以及如何进行参与和贡献。
关于 SIG Storage
Frederico (FSM):你好,感谢你给我这个机会了解更多关于 SIG Storage 的情况。 你能否介绍一下你自己、你的角色以及你是如何参与 SIG Storage 的。
Xing Yang (XY):我是 VMware 的技术主管,从事云原生存储方面的工作。我也是 SIG Storage 的联合主席。 我从 2017 年底开始参与 K8s SIG Storage,开始为 VolumeSnapshot 项目做贡献。 那时,VolumeSnapshot 项目仍处于实验性的 pre-alpha 阶段。它需要贡献者。所以我自愿提供帮助。 然后我与其他社区成员合作,在 2018 年的 K8s 1.12 版本中将 VolumeSnapshot 带入 Alpha, 2019 年在 K8s 1.17 版本中带入 Beta,并最终在 2020 年在 1.20 版本中带入 GA。
FSM:仅仅阅读 SIG Storage 章程 就可以看出,SIG Storage 涵盖了很多领域,你能描述一下 SIG 的组织方式吗?
XY:在 SIG Storage 中,有两位联合主席和两位技术主管。来自 Google 的 Saad Ali 和我是联合主席。 来自 Google 的 Michelle Au 和来自 Red Hat 的 Jan Šafránek 是技术主管。
我们每两周召开一次会议,讨论我们正在为每个特定版本开发的功能,获取状态,确保每个功能都有开发人员和审阅人员在处理它, 并提醒人们发布截止日期等。有关 SIG 的更多信息,请查阅社区页面。 人们还可以将需要关注的 PR、需要讨论的设计提案和其他议题添加到会议议程文档中。 我们将在项目跟踪完成后对其进行审查。
我们还举行其他的定期会议,如 CSI 实施会议,Object Bucket API 设计会议,以及在需要时针对特定议题的一次性会议。 还有一个由 SIG Storage 和 SIG Apps 赞助的 K8s 数据保护工作组。 SIG Storage 拥有或共同拥有数据保护工作组正在讨论的功能特性。
存储和 Kubernetes
FSM:存储是很多模块的基础组件,尤其是 Kubernetes:你认为 Kubernetes 在存储管理方面的具体挑战是什么?
XY:在 Kubernetes 中,卷操作涉及多个组件。例如,创建一个使用 PVC 的 Pod 涉及多个组件。 有 Attach Detach Controller 和 external-attacher 负责将 PVC 连接到 Pod。 还有 Kubelet 可以将 PVC 挂载到 Pod 上。当然,CSI 驱动程序也参与其中。 在多个组件之间进行协调时,有时可能会出现竞争状况。
另一个挑战是关于核心与 Custom Resource Definitions(CRD), 这并不是特定于存储的。CRD 是一种扩展 Kubernetes 功能的好方法,同时又不会向 Kubernetes 核心本身添加太多代码。 然而,这也意味着运行 Kubernetes 集群时需要许多外部组件。
在 SIG Storage 方面,一个最好的例子是卷快照。卷快照 API 被定义为 CRD。 API 定义和控制器是 out-of-tree。有一个通用的快照控制器和一个快照验证 Webhook 应该部署在控制平面上,类似于 kube-controller-manager 的部署方式。 虽然 Volume Snapshot 是一个 CRD,但它是 SIG Storage 的核心特性。 建议 K8s 集群发行版部署卷快照 CRD、快照控制器和快照验证 Webhook,然而,大多数时候我们没有看到发行版部署它们。 因此,这对存储供应商来说就成了一个问题:现在部署这些非驱动程序特定的通用组件成为他们的责任。 如果客户需要使用多个存储系统,且部署多个 CSI 驱动,可能会导致冲突。
FSM:不仅要考虑单个存储系统的复杂性,还要考虑它们在 Kubernetes 中如何一起使用?
XY:是的,有许多不同的存储系统可以为 Kubernetes 中的容器提供存储。它们的工作方式不同。找到适合所有人的解决方案是具有挑战性的。
FSM:Kubernetes 中的存储还涉及与外部解决方案的交互,可能比 Kubernetes 的其他部分更多。 这种与供应商和外部供应商的互动是否具有挑战性?它是否以任何方式随着时间而演变?
XY:是的,这绝对是具有挑战性的。最初 Kubernetes 存储具有 in-tree 卷插件接口。 多家存储供应商实现了 in-tree 接口,并在 Kubernetes 核心代码库中拥有卷插件。这引起了很多问题。 如果卷插件中存在错误,它会影响整个 Kubernetes 代码库。所有卷插件必须与 Kubernetes 一起发布。 如果存储供应商需要修复其插件中的错误或希望与他们自己的产品版本保持一致,这是不灵活的。
FSM:这就是 CSI 加入的原因?
XY:没错,接下来就是容器存储接口(CSI)。 这是一个试图设计通用存储接口的行业标准,以便存储供应商可以编写一个插件并让它在一系列容器编排系统(CO)中工作。 现在 Kubernetes 是主要的 CO,但是在 CSI 刚开始的时候,除了 Kubernetes 之外,还有 Docker、Mesos、Cloud Foundry。 CSI 驱动程序是 out-of-tree 的,因此可以按照自己的节奏进行错误修复和发布。
与 in-tree 卷插件相比,CSI 绝对是一个很大的改进。CSI 的 Kubernetes 实现自 1.13 版本以来就达到 GA。 它已经发展了很长时间。SIG Storage 一直致力于将 in-tree 卷插件迁移到 out-of-tree 的 CSI 驱动,已经有几个版本了。
FSM:将驱动程序从 Kubernetes 主仓移到 CSI 中是一项重要的改进。
XY: CSI 接口是对 in-tree 卷插件接口的改进,但是仍然存在挑战。有很多存储系统。 目前在 CSI 驱动程序文档中列出了 100 多个 CSI 驱动程序。 这些存储系统也非常多样化。因此,很难设计一个适用于所有人的通用 API。 我们在 CSI 驱动层面引入了功能,但当同一驱动配置的卷具有不同的行为时,我们也会面临挑战。 前几天我们刚刚开会讨论每种卷 CSI 驱动程序功能。 当同一个驱动程序同时支持块卷和文件卷时,我们在区分某些 CSI 驱动程序功能时遇到了问题。 我们将召开后续会议来讨论这个问题。
持续的挑战
FSM:具体来说,对于 1.25 版本 们可以看到管道中有一些与存储相关的 KEPs。 你是否认为这个版本对 SIG 特别重要?
XY:我不会说一个版本比其他版本更重要。在任何给定的版本中,我们都在做一些非常重要的事情。
FSM:确实如此,但你是否想指出 1.25 版本的特定特性和亮点呢?
XY:好的。对于 1.25 版本,我想强调以下几点:
- CSI 迁移 是一项持续的工作,SIG Storage 已经工作了几个版本了。目标是将 in-tree 卷插件移动到 out-of-tree 的 CSI 驱动程序,并最终删除 in-tree 卷插件。在 1.25 版本中,有 7 个 KEP 与 CSI 迁移有关。 有一个核心 KEP 用于通用的 CSI 迁移功能。它的目标是在 1.25 版本中达到 GA。 GCE PD 和 AWS EBS 的 CSI 迁移以 GA 为目标。vSphere 的 CSI 迁移的目标是在默认情况下启用特性门控, 在 1.25 版本中达到 Beta。Ceph RBD 和 PortWorx 的目标是达到 Beta,默认关闭特性门控。 Ceph FS 的目标是达到 Alpha。
- 我要强调的第二个是 COSI,容器对象存储接口。 这是 SIG Storage 下的一个子项目。COSI 提出对象存储 Kubernetes API 来支持 Kubernetes 工作负载的对象存储操作的编排。 它还为对象存储提供商引入了 gRPC 接口,以编写驱动程序来配置存储桶。COSI 团队已经在这个项目上工作两年多了。 COSI 功能的目标是 1.25 版本中达到 Alpha。KEP 刚刚合入。COSI 团队正在根据更新后的 KEP 更新实现。
- 我要提到的另一个功能是 CSI 临时卷支持。 此功能允许在临时用例的 Pod 规约中直接指定 CSI 卷。它们可用于使用已安装的卷直接在 Pod 内注入任意状态, 例如配置、Secrets、身份、变量或类似信息。这最初是在 1.15 版本中作为一个 Alpha 功能引入的,现在它的目标是在 1.25 版本中达到 GA。
FSM:如果你必须单独列出一些内容,那么 SIG 正在研究的最紧迫的领域是什么?
XY:CSI 迁移绝对是 SIG 投入大量精力的领域之一,并且现在已经进行了多个版本。它还涉及来自多个云提供商和存储供应商的工作。
社区参与
FSM:Kubernetes 是一个社区驱动的项目。对任何希望参与 SIG Storage 工作的人有什么建议吗?他们应该从哪里开始?
XY:查看 SIG Storage 社区页面, 它有很多关于如何开始的信息。SIG 年度报告告诉你我们每年做了什么。 查看贡献指南。它有一些演示的链接,可以帮助你熟悉 Kubernetes 存储概念。
参加我们在星期四举行的双周会议。 了解 SIG 的运作方式以及我们为每个版本所做的工作。找到你感兴趣的项目并提供贡献。 正如我之前提到的,我通过参与 Volume Snapshot 项目开始了 SIG Storage。
FSM:你有什么要补充的结束语吗?
XY:SIG Storage 总是欢迎新的贡献者。 我们需要贡献者来帮助构建新功能、修复错误、进行代码审查、编写测试、监控测试网格的健康状况以及改进文档等。
FSM:非常感谢你抽出宝贵时间让我们深入了解 SIG Storage!
认识我们的贡献者 - 亚太地区(中国地区)
作者和受访者: Avinesh Tripathi、 Debabrata Panigrahi、 Jayesh Srivastava、 Priyanka Saggu、 Purneswar Prasad、 Vedant Kakde
大家好 👋
欢迎来到亚太地区的 “认识我们的贡献者” 博文系列第三期。
这篇博文介绍了四名来自中国的优秀贡献者,他们在上游 Kubernetes 项目中扮演了不同的领导角色和社区角色。
闲话少说,让我们直接进入正文。
Andy Zhang
Andy Zhang 目前就职于微软中国上海办事处,他主要关注 Kubernetes 存储驱动。 Andy 大约在 5 年前开始为 Kubernetes 做贡献。
他说由于自己为 Azure Kubernetes Service 团队工作,所以大部分时间都在为 Kubernetes 社区项目做贡献。 现在他是很多 Kubernetes 子项目的主要贡献者,例如 Kubernetes cloud-provider 仓库的代码。
他的开源贡献主要是出于自我激励。在过去的两年里,他通过 LFX Mentorship 计划指导了一些学生为 Kubernetes 做贡献, 其中一些学生凭借 Kubernetes 项目积累的专业知识和贡献经历而找到了工作。
Andy 是 Kubernetes 中国社区的活跃成员。 他补充说,Kubernetes 社区对如何成为 Member、Code Reviewer、Approver 有完善的指导说明, 后来他发现一些开源项目还处于非常早期的阶段,他积极地为这些项目做了贡献并成为了项目维护者。
Shiming Zhang
Shiming Zhang 是一名软件工程师,供职于中国上海道客网络科技。
他主要以 Reviewer 的身份参与 SIG Node。他的主要贡献集中在当下的 KEP 的漏洞修复和功能优化,这些工作全部围绕 SIG Node 展开。
他发起的一些主要 PR 有 fixing watchForLockfileContention memory leak、 fixing startupProbe behaviour、 adding Field status.hostIPs for Pod。
Paco Xu
Paco Xu 就职于上海的一家云原生公司:道客网络科技。 他与基础设施和开源团队合作,专注于基于 Kubernetes 的企业云原生平台。
他在 2017 年初开始使用 Kubernetes,他的第一个贡献是在 2018 年 3 月。 他的贡献始于自己发现的一个漏洞,但当时他的解决方案不是那么优雅,因此没有被接受。 然后他从一些 Good First Issue 开始做贡献,这在很大程度上帮助了他。 除此之外,在 2016 到 2017 年间,他还对 Docker 做出了一些小贡献。
目前,Paco 是 kubeadm(一个 SIG Cluster Lifecycle 产品)和 SIG Node 的 Reviewer。
Paco 说大家应该为自己使用的开源项目做贡献。 对他来说,开源项目就像一本要学习的书,通过与项目维护者们讨论可以获得启发。
在我看来,对我来说最好的方式是学习项目所有者如何处理项目。
Jintao Zhang
Jintao Zhang 目前受聘于 API7,他专注于 Ingress 和服务网格。
2017 年,他遇到了一个引发社区讨论的问题,并开始了对 Kubernetes 做贡献。 在为 Kubernetes 做贡献之前,Jintao 是 Docker 相关开源项目的长期贡献者。
目前 Jintao 是 ingress-nginx 项目的 Maintainer。
他建议关注开源公司的工作机会,这样你就可以找到一个可以让你全职贡献的机会。 对于新的贡献者们,Jintao 表示如果有人想为一个开源项目做重大贡献, 那么应该根据自己的兴趣选择项目,然后应该慷慨地投入时间。
如果你对我们下一步应该采访谁有任何想法/建议,请在 #sig-contribex 频道中告知我们。 我们很高兴有其他人帮助我们接触社区中更优秀的人。我们将不胜感激。
我们下期见。最后,祝大家都能快乐地为社区做贡献!👋
逐个 KEP 地增强 Kubernetes
作者: Ryler Hockenbury(Mastercard)
你是否知道 Kubernetes v1.24 有 46 个增强特性? 在为期 4 个月的发布周期内包含了大量新特性。 Kubernetes 发布团队协调发布的后勤工作,从修复测试问题到发布更新的文档。他们需要完成成吨的工作,但发布团队总是能按期交付。
发布团队由大约 30 人组成,分布在六个子团队:Bug Triage、CI Signal、Enhancements、Release Notes、Communications 和 Docs。 每个子团队负责管理发布的一个组件。这篇博文将重点介绍增强子团队的角色以及你如何能够参与其中。
增强子团队是什么?
好问题。我们稍后会讨论这个问题,但首先让我们谈谈 Kubernetes 中是如何管理功能特性的。
每个新特性都需要一个 Kubernetes 增强提案, 简称为 KEP。KEP 是一些小型结构化设计文档,提供了一种提出和协调新特性的方法。 KEP 作者描述其提案动机、设计理念(和替代方案)、风险和测试,然后社区成员会提供反馈以达成共识。
你可以通过 Kubernetes/enhancements 仓库的拉取请求(PR)工作流来提交和更新 KEP。 每个功能特性始于 Alpha 阶段,随着不断成熟,经由毕业流程进入 Beta 和 Stable 阶段。 这里有一个很酷的 KEP 例子,是关于 Windows Server 上的特权容器支持。 这个 KEP 在 Kubernetes v1.22 中作为 Alpha 引入,并在 v1.23 中进入 Beta 阶段。
现在回到上一个问题:增强子团队如何协调每个版本的 KEP 生命周期跟踪。 每个 KEP 都必须满足一组清晰具体的要求,才能被纳入一个发布版本中。 增强子团队负责验证每个 KEP 的要求并跟踪其状态。
在一个发行版本启动时,各个 Kubernetes 特别兴趣小组 (SIG) 会提交各自的增强特性以进入某版本发布。通常一个版本最初可能有 60 到 90 个增强特性。随后,许多增强特性会被过滤掉。 这是因为有些不完全符合 KEP 要求,而另一些还未完成代码的实现。最初选择加入的 KEP 中大约有 60% - 70% 将进入最终发布。
增强子团队做什么?
这是另一个很好的问题,切中了要点!增强特性的团队在每个版本中会涉及两个重要的里程碑:增强特性冻结和代码冻结。
增强特性冻结
增强特性冻结是一个 KEP 按序完成增强特性并纳入一个发布版本的最后期限。 这是一个质量门控,用于强制对齐与 KEP 维护和更新相关的事项。 最值得注意的要求是 (1) 生产就绪审查(PRR) 和 (2) 附带完整测试计划和毕业标准的 KEP 文件。
增强子团队通过在 Github 上对 KEP 问题发表评论与每位 KEP 作者进行沟通。 作为第一步,子团队成员将检查 KEP 状态并确认其是否符合要求。 KEP 在满足要求后被标记为已被跟踪(Tracked);否则,它会被认为有风险。 如果在增强特性冻结生效时 KEP 仍然存在风险,该 KEP 将被从发布版本中移除。
在发布周期的这个阶段,增强子团队通常是最繁忙的,因为他们要梳理大量的 KEP,可能需要反复审查每个 KEP 才能验证某个 KEP 是否满足要求。
代码冻结
代码冻结是从代码上实现所有增强特性的最后期限。 如果某增强特性的代码需要更改或更新,则必须在这个时间节点完成所有代码实现、代码审查和代码合并工作。 版本发布的最后三个工作专注于稳定代码库:修复测试问题,解决各种回归并准备文档。而在此之前,所有代码必须就位。
增强子团队将验证某增强特性相关的所有 PR 均已合并到 Kubernetes 代码库 (k/k)。 在此期间,子团队将联系 KEP 作者以了解哪些 PR 是 KEP 的一部分,检查这些 PR 是否已合并,然后更新 KEP 的状态。 如果在代码冻结的最后期限之前这些代码还未全部合并,该增强特性将从发布版本中移除。
我如何才能参与发布团队?
很高兴你提出这个问题。 最直接的方式就是申请成为一名发布团队影子。 影子角色是一个见习职位,旨在帮助个人在发布团队中担任领导职位做好准备。许多影子角色是非技术性的,且不需要事先对 Kubernetes 代码库做出贡献。
Kubernetes 每年发布 3 个版本,每个版本大约有 25 个影子,发布团队总是需要愿意做出贡献的人。 在每个发布周期之前,发布团队都会为影子计划打开申请渠道。当申请渠道上线时, 会公布在 Kubernetes 开发邮件清单中。 你可以订阅该列表中的通知(或定期查看!),以了解申请渠道何时开通。该公告通常会在 4 月中旬、7 月中旬和 12 月中旬发布, 或者在每个版本开始前大约一个月时发布。
我怎样才能找到更多信息?
如果你对所有 Kubernetes 发布子团队的详情感到好奇, 请查阅角色手册。 这些手册记录了每个子团队的后勤工作,包括每周对子团队活动的细分任务。这是更好地了解每个团队的绝佳参考。
你还可以查看与发布相关的 Kubernetes slack 频道,特别是 #release、#sig-release 和 #sig-arch。 这些频道围绕发布的许多方面进行了讨论和更新。
Kubernetes 1.25 的移除说明和主要变更
作者:Kat Cosgrove、Frederico Muñoz、Debabrata Panigrahi
随着 Kubernetes 成长和日趋成熟,为了此项目的健康发展,某些功能特性可能会被弃用、移除或替换为优化过的功能特性。 Kubernetes v1.25 包括几个主要变更和一个主要移除。
Kubernetes API 移除和弃用流程
Kubernetes 项目对功能特性有一个文档完备的弃用策略。 该策略规定,只有当较新的、稳定的相同 API 可用时,原有的稳定 API 才可能被弃用,每个稳定级别的 API 都有一个最短的生命周期。 弃用的 API 指的是已标记为将在后续发行某个 Kubernetes 版本时移除的 API; 移除之前该 API 将继续发挥作用(从弃用起至少一年时间),但使用时会显示一条警告。 移除的 API 将在当前版本中不再可用,此时你必须迁移以使用替换的 API。
- 正式发布(GA)或稳定的 API 版本可能被标记为已弃用,但只有在 Kubernetes 大版本更新时才会移除。
- 测试版(Beta)或预发布 API 版本在弃用后必须支持 3 个版本。
- Alpha 或实验性 API 版本可能会在任何版本中被移除,恕不另行通知。
无论一个 API 是因为某功能特性从 Beta 进入稳定阶段而被移除,还是因为该 API 根本没有成功, 所有移除均遵从上述弃用策略。无论何时移除一个 API,文档中都会列出迁移选项。
有关 PodSecurityPolicy 的说明
继 PodSecurityPolicy 在 v1.21 弃用后, Kubernetes v1.25 将移除 PodSecurityPolicy。PodSecurityPolicy 曾光荣地为我们服务, 但由于其复杂和经常令人困惑的使用方式,让大家觉得有必要进行修改,但很遗憾这种修改将会是破坏性的。 为此我们移除了 PodSecurityPolicy,取而代之的是 Pod Security Admission(即 PodSecurity 安全准入控制器), 后者在本次发行中也进入了稳定阶段。 如果你目前正依赖 PodSecurityPolicy,请遵循指示说明迁移到 PodSecurity 准入控制器。
Kubernetes v1.25 的主要变更
Kubernetes v1.25 除了移除 PodSecurityPolicy 之外,还将包括以下几个主要变更。
CSI Migration
将树内卷插件迁移到树外 CSI 驱动的努力还在继续,核心的 CSI Migration 特性在 v1.25 进入 GA 阶段。 对于全面移除树内卷插件而言,这是重要的一步。
存储驱动的弃用和移除
若干卷插件将被弃用或移除。
GlusterFS 将在 v1.25 中被弃用。 虽然为其构建了 CSI 驱动,但未曾得到维护。 社区曾讨论迁移到一个兼容 CSI 驱动的可能性, 但最终决定开始从树内驱动中弃用 GlusterFS 插件。 本次发行还会弃用 Portworx 树内卷插件。 Flocker、Quobyte 和 StorageOS 树内卷插件将被移除。
Flocker、 Quobyte 和 StorageOS 树内卷插件将作为 CSI Migration 的一部分在 v1.25 中移除。
对 vSphere 版本支持的变更
从 Kubernetes v1.25 开始,树内 vSphere 卷驱动将不支持任何早于 7.0u2 的 vSphere 版本。 查阅 v1.25 详细发行说明,了解如何处理这种状况的更多建议。
清理 IPTables 链的所有权
在 Linux 上,Kubernetes(通常)创建 iptables 链来确保这些网络数据包到达,
尽管这些链及其名称已成为内部实现的细节,但某些工具已依赖于此行为。
将仅支持内部 Kubernetes 使用场景。
从 v1.25 开始,Kubelet 将逐渐迁移为不在 nat 表中创建以下 iptables 链:
KUBE-MARK-DROPKUBE-MARK-MASQKUBE-POSTROUTING
此项变更将通过 IPTablesCleanup 特性门控分阶段完成。
尽管这不是正式的弃用,但某些最终用户已开始依赖 kube-proxy 特定的内部行为。
Kubernetes 项目总体上希望明确表示不支持依赖这些内部细节,并且未来的实现将更改它们在此处的行为。
展望未来
Kubernetes 1.26 计划移除的 API 的正式列表为:
- Beta 版 FlowSchema 和 PriorityLevelConfiguration API(flowcontrol.apiserver.k8s.io/v1beta1)
- Beta 版 HorizontalPodAutoscaler API(autoscaling/v2beta2)
了解更多
Kubernetes 发行说明公布了弃用信息。你可以在以下版本的发行说明中查看待弃用特性的公告:
- Kubernetes 1.21
- Kubernetes 1.22
- Kubernetes 1.23
- Kubernetes 1.24
- 我们将正式宣布 Kubernetes 1.25 的弃用信息,作为该版本 CHANGELOG 的一部分。
有关弃用和移除流程的信息,请查阅 Kubernetes 官方弃用策略文档。
聚光灯下的 SIG Docs
作者: Purneswar Prasad
简介
官方文档是所有开源项目的首选资料源。对于 Kubernetes,它是一个持续演进的特别兴趣小组 (SIG), 人们持续不断努力制作详实的项目资料,让新贡献者和用户更容易取用这些文档。 SIG Docs 在 kubernetes.io 上发布官方文档, 包括但不限于 Kubernetes 版本发布时附带的核心 API 文档、核心架构细节和 CLI 工具文档。
为了了解 SIG Docs 的工作及其在塑造社区未来方面的更多信息,我总结了自己与联合主席 Divya Mohan(下称 DM)、 Rey Lejano(下称 RL)和 Natali Vlatko(下称 NV)的谈话, 他们讲述了 SIG 的目标以及其他贡献者们如何从旁协助。
谈话汇总
你能告诉我们 SIG Docs 具体做什么吗?
SIG Docs 是 kubernetes.io 上针对 Kubernetes 项目文档的特别兴趣小组, 为 Kubernetes API、kubeadm 和 kubectl 制作参考指南,并维护官方网站的基础设施和数据分析。 他们的工作范围还包括文档发布、文档翻译、改进并向现有文档添加新功能特性、推送和审查官方 Kubernetes 博客的内容, 并在每个发布周期与发布团队合作以审查文档和博客。
Docs 下有 2 个子项目:博客和本地化。社区如何从中受益?你想强调的这些团队是否侧重于某些贡献?
博客:这个子项目侧重于介绍新的或毕业的 Kubernetes 增强特性、社区报告、SIG 更新或任何与 Kubernetes 社区相关的新闻,例如思潮引领、教程和项目更新,例如即将在 1.25 版本中移除 Dockershim 和 PodSecurityPolicy。 Tim Bannister 是 SIG Docs 技术负责人之一,他做得工作非常出色,是推动文档和博客贡献的主力人物。
本地化:通过这个子项目,Kubernetes 社区能够在用户和贡献者之间实现更大的包容性和多样性。 自几年前以来,这也帮助该项目获得了更多的贡献者,尤其是学生们。 主要亮点之一是即将到来的本地化版本:印地语和孟加拉语。印地语的本地化工作目前由印度的学生们牵头。
除此之外,还有另外两个子项目:reference-docs 和 website,后者采用 Hugo 构建,是 Kubernetes 拥有的一个重要阵地。
最近有很多关于 Kubernetes 生态系统以及业界对最新 1.24 版本中移除 Dockershim 的讨论。SIG Docs 如何帮助该项目确保最终用户们平滑变更?
与 Dockershim 移除有关的文档工作是一项艰巨的任务,需要修改现有文档并就弃用工作与各种利益相关方进行沟通。 这需要社区的努力,因此在 1.24 版本发布之前,SIG Docs 与 Docs and Comms 垂直行业、来自发布团队的发布负责人以及 CNCF 建立合作关系,帮助在全网宣传。设立了每周例会和 GitHub 项目委员会,以跟踪进度、审查问题和批准 PR, 并保持更新 Kubernetes 网站。这也有助于新的贡献者们了解这次弃用,因此如果出现任何 good-first-issue, 新的贡献者也可以参与进来。开通了专用的 Slack 频道用于交流会议更新、邀请反馈或就悬而未决的问题和 PR 寻求帮助。 每周例会在 1.24 发布后也持续了一个月,以审查并修复相关问题。 非常感谢 Celeste Horgan,与他的顺畅交流贯穿了这个弃用过程的前前后后。
为什么新老贡献者都应该考虑加入这个 SIG?
Kubernetes 是一个庞大的项目,起初可能会让很多人难以找到切入点。 任何开源项目的优劣总能从文档质量略窥一二,SIG Docs 的目标是建设一个欢迎新贡献者加入并对其有帮助的地方。 希望所有人可以轻松参与该项目的文档,并能从阅读中受益。他们还可以带来自己的新视角,以制作和改进文档。 从长远来看,如果他们坚持参与 SIG Docs,就可以拾阶而上晋升成为维护者。 这将有助于使 Kubernetes 这样的大型项目更易于解析和导航。
你如何帮助新的贡献者入门?加入有什么前提条件吗?
开始为 Docs 做贡献没有这样的前提条件。但肯定有一个很棒的对文档做贡献的指南,这个指南始终尽可能保持更新和贴合实际, 希望新手们多多阅读并将其放在趁手的地方。此外,社区 Slack 频道 #sig-docs 中有很多有用的便贴和书签。 kubernetes/website 仓库中带有 good-first-issue 标签的那些 GitHub 问题是创建你的第一个 PR 的好地方。 现在,SIG Docs 在每月的第一个星期二配合第一任 New Contributor Ambassador(新贡献者大使)角色 Arsh Sharma 召开月度 New Contributor Meet and Greet(新贡献者见面会)。 这有助于在 SIG 内为新的贡献者建立一个更容易参与的联络形式。
你是否有任何真正自豪的 SIG 相关成绩?
DM & RL :鉴于来自不同国家的贡献者们做出的所有出色工作, 过去几个月本地化子项目的正式推行对 SIG Docs 来说是一个巨大的胜利。 早些时候,本地化工作还没有任何流水线的流程,过去几个月的重点是通过起草一份 KEP 为本地化正式成为一个子项目提供一个框架, 这项工作计划在第三个季度结束时完成。
DM:另一个取得很大成功的领域是 New Contributor Ambassador(新贡献者大使)角色, 这个角色有助于为新贡献者参与项目提供更便捷的联系形式。
NV:对于每个发布周期,SIG Docs 都必须在短时间内评审突出介绍发布更新的发布文档和功能特性博客。 这对于文档和博客审阅者来说,始终需要付出巨大的努力。
你是否有一些关于 SIG Docs 未来令人兴奋的举措想让社区知道?
SIG Docs 现在期望设计一个路线图,建立稳定的人员流转机制以期推动对文档的改进, 简化社区参与 Issue 评判和已提交 PR 的评审工作。 为了建立一个这样由贡献者和 Reviewer 组成的群体,我们正在设立一项辅导计划帮助当前的贡献者们成为 Reviewer。 这绝对是一项值得关注的举措!
结束语
SIG Docs 在 KubeCon + CloudNativeCon North America 2021 期间举办了一次深度访谈,涵盖了他们很棒的 SIG 主题。 他们非常欢迎想要为 Kubernetes 项目做贡献的新人,对这些新人而言 SIG Docs 已成为加入 Kubernetes 的起跳板。 欢迎加入 SIG 会议, 了解最新的研究成果、来年的计划以及如何作为贡献者参与上游 Docs 团队!
Kubernetes Gateway API 进入 Beta 阶段
作者: Shane Utt (Kong)、Rob Scott (Google)、Nick Young (VMware)、Jeff Apple (HashiCorp)
译者: Michael Yao (DaoCloud)
我们很高兴地宣布 Gateway API 的 v0.5.0 版本发布。 我们最重要的几个 Gateway API 资源首次进入 Beta 阶段。 此外,我们正在启动一项新的倡议,探索如何将 Gateway API 用于网格,还引入了 URL 重写等新的实验性概念。 下文涵盖了这部分内容和更多说明。
什么是 Gateway API?
Gateway API 是以 Gateway 资源(代表底层网络网关/代理服务器)为中心的资源集合, Kubernetes 服务网络的健壮性得益于众多供应商实现、得到广泛行业支持且极具表达力、可扩展和面向角色的各个接口。
Gateway API 最初被认为是知名 Ingress API 的继任者,
Gateway API 的好处包括(但不限于)对许多常用网络协议的显式支持
(例如 HTTP、TLS、TCP 、UDP) 以及对传输层安全 (TLS) 的紧密集成支持。
特别是 Gateway 资源能够实现作为 Kubernetes API 来管理网络网关的生命周期。
如果你是对 Gateway API 的某些优势感兴趣的终端用户,我们邀请你加入并找到适合你的实现方式。 值此版本发布之时,对于流行的 API 网关和服务网格有十多种实现,还提供了操作指南便于快速开始探索。
入门
Gateway API 是一个类似 Ingress 的正式 Kubernetes API。Gateway API 代表了 Ingress 功能的一个父集,使得一些更高级的概念成为可能。 与 Ingress 类似,Kubernetes 中没有内置 Gateway API 的默认实现。 相反,有许多不同的实现可用,在提供一致且可移植体验的同时,还在底层技术方面提供了重要的选择。
查看 API 概念文档 并查阅一些指南以开始熟悉这些 API 及其工作方式。 当你准备好一个实用的应用程序时, 请打开实现页面并选择属于你可能已经熟悉的现有技术或集群提供商默认使用的技术(如果适用)的实现。 Gateway API 是一个基于 CRD 的 API,因此你将需要安装 CRD 到集群上才能使用该 API。
如果你对 Gateway API 做贡献特别有兴趣,我们非常欢迎你的加入! 你可以随时在仓库上提一个新的 issue,或加入讨论。 另请查阅社区页面以了解 Slack 频道和社区会议的链接。
发布亮点
进入 Beta 阶段
v0.5.0 版本特别具有历史意义,因为它标志着一些关键 API 成长至 Beta API 版本(v1beta1):
这一成就的标志是达到了以下几个进入标准:
- API 已广泛实现。
- 合规性测试基本覆盖了所有资源且可以让多种实现通过测试。
- 大多数 API 接口正被积极地使用。
- Kubernetes SIG Network API 评审团队已批准其进入 Beta 阶段。
有关 Gateway API 版本控制的更多信息,请参阅官方文档。 要查看未来版本的计划,请查看下一步。
发布渠道
此版本引入了 experimental 和 standard 发布渠道,
这样能够更好地保持平衡,在确保稳定性的同时,还能支持实验和迭代开发。
standard 发布渠道包括:
- 已进入 Beta 阶段的资源
- 已进入 standard 的字段(不再被视为 experimental)
experimental 发布渠道包括 standard 发布渠道的所有内容,另外还有:
alphaAPI 资源- 视为 experimental 且还未进入
standard渠道的字段
使用发布渠道能让内部实现快速流转的迭代开发,且能让外部实现者和最终用户标示功能稳定性。
本次发布新增了以下实验性的功能特性:
其他改进
有关 v0.5.0 版本中包括的完整变更清单,请参阅
v0.5.0 发布说明。
适用于服务网格的 Gateway API:GAMMA 倡议
某些服务网格项目已实现对 Gateway API 的支持。 服务网格接口 (Service Mesh Interface,SMI) API 和 Gateway API 之间的显著重叠 已激发了 SMI 社区讨论可能的集成方式。
我们很高兴地宣布,来自 Cilium Service Mesh、Consul、Istio、Kuma、Linkerd、NGINX Service Mesh 和 Open Service Mesh 等服务网格社区的代表汇聚一堂组成 GAMMA 倡议小组, 这是 Gateway API 子项目内一个专门的工作流,专注于网格管理所用的 Gateway API。
这个小组将交付增强提案, 包括对网格和网格相关用例适用的 Gateway API 规约的资源、添加和修改。
这项工作已从探索针对服务间流量使用 Gateway API 开始,并将继续增强身份验证和鉴权策略等领域。
下一步
随着我们不断完善用于生产用例的 API,以下是我们将为下一个 Gateway API 版本所做的一些重点工作:
- 针对 gRPC 流量路由的 GRPCRoute
- 路由代理
- 4 层 API 成熟度:TCPRoute、UDPRoute 和 TLSRoute 正进入 Beta 阶段
- GAMMA 倡议 - 针对服务网格的 Gateway API
如果你想参与此列表中的某些工作,或者你想倡导加入路线图的内容不在此列表中, 请通过 Kubernetes Slack 的 #sig-network-gateway-api 频道或我们每周的 社区电话会议加入我们。
2021 年度总结报告
作者: Paris Pittman(指导委员会)
去年,我们发布了第一期 2020 年度总结报告, 现在已经是时候发布第二期了!
这份总结反映了 2021 年已完成的工作以及 2022 下半年置于台面上的倡议。 请将这份总结转发给正参与上游活动、计划云原生战略和寻求帮助的那些组织和个人。 若要查阅特定社区小组的完整报告,请访问 kubernetes/community 仓库查找各小组的文件夹。例如: sig-api-machinery/annual-report-2021.md
你将看到这份总结报告本身涵盖的领域在增长。我们准备和制作这份报告大约用了 6 个月的时间。 作为一个随着长短期需求而快速发展的项目,这么长的制作周期对任何人来说可能帮助都不大, 报告的价值也有所缩水。我等苦思无良策,请诸君不吝赐教: https://github.com/kubernetes/steering/issues/242
参考: 年度报告文献
Kubernetes 1.24: StatefulSet 的最大不可用副本数
作者: Mayank Kumar (Salesforce)
译者: Xiaoyang Zhang(Huawei)
Kubernetes StatefulSet,
自 1.5 版本中引入并在 1.9 版本中变得稳定以来,已被广泛用于运行有状态应用。它提供固定的 Pod 身份标识、
每个 Pod 的持久存储以及 Pod 的有序部署、扩缩容和滚动更新功能。你可以将 StatefulSet
视为运行复杂有状态应用程序的原子构建块。随着 Kubernetes 的使用增多,需要 StatefulSet 的场景也越来越多。
当 StatefulSet 的 Pod 管理策略为 OrderedReady 时,其中许多场景需要比当前所支持的一次一个 Pod
的更新更快的滚动更新。
这里有些例子:
- 我使用 StatefulSet 来编排一个基于缓存的多实例应用程序,其中缓存的规格很大。 缓存冷启动,需要相当长的时间才能启动容器。所需要的初始启动任务有很多。在应用程序完全更新之前, 此 StatefulSet 上的 RollingUpdate 将花费大量时间。如果 StatefulSet 支持一次更新多个 Pod, 那么更新速度会快得多。
- 我的有状态应用程序由 leader 和 follower 或者一个 writer 和多个 reader 组成。 我有多个 reader 或 follower,并且我的应用程序可以容忍多个 Pod 同时出现故障。 我想一次更新这个应用程序的多个 Pod,特别是当我的应用程序实例数量很多时,这样我就能快速推出新的更新。 注意,我的应用程序仍然需要每个 Pod 具有唯一标识。
为了支持这样的场景,Kubernetes 1.24 提供了一个新的 alpha 特性。在使用新特性之前,必须启用
MaxUnavailableStatefulSet 特性标志。一旦启用,就可以指定一个名为 maxUnavailable 的新字段,
这是 StatefulSet spec 的一部分。例如:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
namespace: default
spec:
podManagementPolicy: OrderedReady # 你必须设为 OrderedReady
replicas: 5
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
# 镜像自发布以来已更改(以前使用的仓库为 "k8s.gcr.io")
- image: registry.k8s.io/nginx-slim:0.8
imagePullPolicy: IfNotPresent
name: nginx
updateStrategy:
rollingUpdate:
maxUnavailable: 2 # 这是 alpha 特性的字段,默认值是 1
partition: 0
type: RollingUpdate
如果你启用了新特性,但没有在 StatefulSet 中指定 maxUnavailable 的值,Kubernetes
会默认设置 maxUnavailable: 1。这与你不启用新特性时看到的行为是一致的。
我将基于该示例清单做场景演练,以演示此特性是如何工作的。我将部署一个有 5 个副本的 StatefulSet,
maxUnavailable 设置为 2 并将 partition 设置为 0。
我可以通过将镜像更改为 registry.k8s.io/nginx-slim:0.9 来触发滚动更新。一旦开始滚动更新,
就可以看到一次更新 2 个 Pod,因为 maxUnavailable 的当前值是 2。
下面的输出显示了一个时间段内的结果,但并不是完整过程。maxUnavailable 可以是绝对数值(例如 2)或所需 Pod
的百分比(例如 10%),绝对数是通过百分比计算结果进行四舍五入到最接近的整数得出的。
kubectl get pods --watch
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 85s
web-1 1/1 Running 0 2m6s
web-2 1/1 Running 0 106s
web-3 1/1 Running 0 2m47s
web-4 1/1 Running 0 2m27s
web-4 1/1 Terminating 0 5m43s ----> start terminating 4
web-3 1/1 Terminating 0 6m3s ----> start terminating 3
web-3 0/1 Terminating 0 6m7s
web-3 0/1 Pending 0 0s
web-3 0/1 Pending 0 0s
web-4 0/1 Terminating 0 5m48s
web-4 0/1 Terminating 0 5m48s
web-3 0/1 ContainerCreating 0 2s
web-3 1/1 Running 0 2s
web-4 0/1 Pending 0 0s
web-4 0/1 Pending 0 0s
web-4 0/1 ContainerCreating 0 0s
web-4 1/1 Running 0 1s
web-2 1/1 Terminating 0 5m46s ----> start terminating 2 (only after both 4 and 3 are running)
web-1 1/1 Terminating 0 6m6s ----> start terminating 1
web-2 0/1 Terminating 0 5m47s
web-1 0/1 Terminating 0 6m7s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 1s
web-1 1/1 Running 0 2s
web-2 0/1 Pending 0 0s
web-2 0/1 Pending 0 0s
web-2 0/1 ContainerCreating 0 0s
web-2 1/1 Running 0 1s
web-0 1/1 Terminating 0 6m6s ----> start terminating 0 (only after 2 and 1 are running)
web-0 0/1 Terminating 0 6m7s
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 1s
注意,滚动更新一开始,4 和 3(两个最高序号的 Pod)同时开始进入 Terminating 状态。
Pod 4 和 3 会按照自身节奏进行更新。一旦 Pod 4 和 3 更新完毕后,Pod 2 和 1 会同时进入
Terminating 状态。当 Pod 2 和 1 都准备完毕处于 Running 状态时,Pod 0 开始进入 Terminating 状态
在 Kubernetes 中,StatefulSet 更新 Pod 时遵循严格的顺序。在此示例中,更新从副本 4 开始,
然后是副本 3,然后是副本 2,以此类推,一次更新一个 Pod。当一次只更新一个 Pod 时,
副本 3 不可能在副本 4 之前准备好进入 Running 状态。当 maxUnavailable 值
大于 1 时(在示例场景中我设置 maxUnavailable 值为 2),副本 3 可能在副本 4 之前准备好并运行,
这是没问题的。如果你是开发人员并且设置 maxUnavailable 值大于 1,你应该知道可能出现这种情况,
并且如果有这种情况的话,你必须确保你的应用程序能够处理发生的此类顺序问题。当你设置 maxUnavailable
值大于 1 时,更新 Pod 的批次之间会保证顺序。该保证意味着在批次 0(副本 4 和 3)中的 Pod
准备好之前,更新批次 2(副本 2 和 1)中的 Pod 无法开始更新。
尽管 Kubernetes 将这些称为副本,但你的有状态应用程序可能不这样理解,StatefulSet 的每个 Pod 可能持有与其他 Pod 完全不同的数据。重要的是,StatefulSet 的更新是分批进行的, 你现在让批次大小大于 1(作为 alpha 特性)。
还要注意,上面的行为采用的 Pod 管理策略是 podManagementPolicy: OrderedReady。
如果你的 StatefulSet 的 Pod 管理策略是 podManagementPolicy: Parallel,
那么不仅是 maxUnavailable 数量的副本同时被终止,还会导致 maxUnavailable 数量的副本同时在
ContainerCreating 阶段。这就是所谓的突发(Bursting)。
因此,现在你可能有很多关于以下方面的问题:
- 当设置
podManagementPolicy:Parallel时,会产生什么行为? - 将
partition设置为非0值时会发生什么?
自己试试看可能会更好。这是一个 alpha 特性,Kubernetes 贡献者正在寻找有关此特性的反馈。 这是否有助于你实现有状态的场景?你是否发现了一个 bug,或者你认为实现的行为不直观易懂, 或者它可能会破坏应用程序或让他们感到吃惊?请登记一个 issue 告知我们。
进一步阅读和后续步骤
Kubernetes 1.24 中的上下文日志记录
作者: Patrick Ohly (Intel)
结构化日志工作组 在 Kubernetes 1.24 中为日志基础设施添加了新功能。这篇博文解释了开发者如何利用这些功能使日志输出更有用, 以及他们如何参与改进 Kubernetes。
结构化日志记录
结构化日志 记录的目标是用具有明确定义的语法的日志条目来取代 C 风格的格式化和由此产生的不透明的日志字符串,用于分别存储消息和参数,例如,作为一个 JSON 结构。
当使用传统的 klog 文本输出格式进行结构化日志调用时,字符串最初使用 \n 转义序列打印,除非嵌入到结构中。
对于结构体,日志条目仍然可以跨越多行,没有干净的方法将日志流拆分为单独的条目:
I1112 14:06:35.783529 328441 structured_logging.go:51] "using InfoS" longData={Name:long Data:Multiple
lines
with quite a bit
of text. internal:0}
I1112 14:06:35.783549 328441 structured_logging.go:52] "using InfoS with\nthe message across multiple lines" int=1 stringData="long: Multiple\nlines\nwith quite a bit\nof text." str="another value"
现在,< 和 > 标记以及缩进用于确保在行首的 klog 标头处拆分是可靠的,并且生成的输出是人类可读的:
I1126 10:31:50.378204 121736 structured_logging.go:59] "using InfoS" longData=<
{Name:long Data:Multiple
lines
with quite a bit
of text. internal:0}
>
I1126 10:31:50.378228 121736 structured_logging.go:60] "using InfoS with\nthe message across multiple lines" int=1 stringData=<
long: Multiple
lines
with quite a bit
of text.
> str="another value"
请注意,日志消息本身带有引号。它是一个用于标识日志条目的固定字符串,因此应避免使用换行符。
在 Kubernetes 1.24 之前,kube-scheduler 中的一些日志调用仍然使用 klog.Info 处理多行字符串,
以避免不可读的输出。现在所有日志调用都已更新以支持结构化日志记录。
上下文日志记录
上下文日志 基于 go-logr API。 关键的想法是,库被其调用者传递给一个记录器实例,并使用它来记录,而不是访问一个全局记录器。 二进制文件决定了日志的实现,而不是库。go-logr API 是围绕着结构化的日志记录而设计的,并支持将额外的信息附加到一个记录器上。
这使得以下用例成为可能:
调用者可以将附加信息附加到记录器:
WithName添加前缀WithValues添加键/值对
当将此扩展记录器传递给函数并且函数使用它而不是全局记录器时,附加信息随后将包含在所有日志条目中,而无需修改生成日志条目的代码。 这在高度并行的应用程序中很有用,在这些应用程序中,由于不同操作的输出会交错,因此很难识别某个操作的所有日志条目。
- 运行单元测试时,可以将日志输出与当前测试关联起来。当测试失败时,
go test只显示失败测试的日志输出。 默认情况下,该输出也可以更详细,因为它不会显示成功的测试。这些测试可以在不交错输出的情况下并行运行。
上下文日志记录的设计决策之一是允许将记录器作为值附加到 context.Context。
由于记录器封装了调用的预期记录的所有方面,它是上下文的部分,而不仅仅是使用它。
一个实际的优势是许多 API 已经有一个 ctx 参数,或者添加一个具有其他优势,例如能够摆脱函数内部的 context.TODO() 调用。
另一个决定是不破坏与 klog v2 的兼容性:
- 在已设置上下文日志记录的二进制文件中使用传统 klog 日志记录调用的库将通过二进制文件选择的日志记录后端工作和记录。 但是,这样的日志输出不会包含额外的信息,并且在单元测试中不能很好地工作,因此应该修改库以支持上下文日志记录。 结构化日志记录的迁移指南 已扩展为也涵盖上下文日志记录。
- 当一个库支持上下文日志并从其上下文中检索一个记录器时,它仍将在不初始化上下文日志的二进制文件中工作, 因为它将获得一个通过 klog 记录的记录器。
在 Kubernetes 1.24 中,上下文日志是一个新的 Alpha 特性,以 ContextualLogging 作为特性门控。
禁用时(默认),用于上下文日志记录的新 klog API 调用(见下文)变为无操作,以避免性能或功能回归。
尚未转换任何 Kubernetes 组件。 Kubernetes 存储库中的示例程序 演示了如何在一个二进制文件中启用上下文日志记录,以及输出如何取决于该二进制文件的参数:
$ cd $GOPATH/src/k8s.io/kubernetes/staging/src/k8s.io/component-base/logs/example/cmd/
$ go run . --help
...
--feature-gates mapStringBool A set of key=value pairs that describe feature gates for alpha/experimental features. Options are:
AllAlpha=true|false (ALPHA - default=false)
AllBeta=true|false (BETA - default=false)
ContextualLogging=true|false (ALPHA - default=false)
$ go run . --feature-gates ContextualLogging=true
...
I0404 18:00:02.916429 451895 logger.go:94] "example/myname: runtime" foo="bar" duration="1m0s"
I0404 18:00:02.916447 451895 logger.go:95] "example: another runtime" foo="bar" duration="1m0s"
example 前缀和 foo="bar" 是由记录 runtime 消息和 duration="1m0s" 值的函数的调用者添加的。
针对 klog 的示例代码包括一个单元测试示例 以及每个测试的输出。
klog 增强功能
上下文日志 API
以下调用管理记录器的查找:
FromContext
:来自 context 参数,回退到全局记录器
Background
:全局后备,无意支持上下文日志记录
TODO
:全局回退,但仅作为一个临时解决方案,直到该函数得到扩展能够通过其参数接受一个记录器
SetLoggerWithOptions
:更改后备记录器;当使用ContextualLogger(true) 调用时,
记录器已准备好被直接调用,在这种情况下,记录将无需执行通过 klog
为了支持 Kubernetes 中的特性门控机制,klog 对相应的 go-logr 调用进行了包装调用,并使用了一个全局布尔值来控制它们的行为:
在 Kubernetes 代码中使用这些函数是通过 linter 检查强制执行的。
上下文日志的 klog 默认是启用该功能,因为它在 klog 中被认为是稳定的。
只有在 Kubernetes 二进制文件中,该默认值才会被覆盖,并且(在某些二进制文件中)通过 --feature-gate 参数进行控制。
ktesting 记录器
新的 ktesting
包使用 klog 的文本输出格式通过 testing.T 实现日志记录。它有一个 single API call
用于检测测试用例和支持命令行标志。
klogr
klog/klogr 继续受支持,默认行为不变:
它使用其格式化结构化日志条目拥有自己的自定义格式并通过 klog 打印结果。
但是,不鼓励这种用法,因为这种格式既不是机器可读的(与 zapr 生成的真实 JSON 输出相比,Kubernetes 使用的 go-logr 实现)也不是人类友好的(与 klog 文本格式相比)。
相反,应该使用选择 klog 文本格式的 WithFormat(FormatKlog)
创建一个 klogr 实例。 一个更简单但结果相同的构造方法是新的 klog.NewKlogr。
这是 klog 在未配置任何其他内容时作为后备返回的记录器。
可重用输出测试
许多 go-logr 实现都有非常相似的单元测试,它们检查某些日志调用的结果。
如果开发人员不知道某些警告,例如调用时会出现恐慌的 String 函数,那么很可能缺少对此类警告的处理和单元测试。
klog.test 是一组可重用的测试用例,可应用于 go-logr 实现。
输出刷新
klog 用于在 init 期间无条件地启动一个 goroutine,它以硬编码的时间间隔刷新缓冲数据。
现在 goroutine 仅按需启动(即当写入具有缓冲的文件时)并且可以使用 StopFlushDaemon
和 StartFlushDaemon。
当 go-logr 实现缓冲数据时,可以通过使用 FlushLogger
选项注册记录器来将刷新该数据集成到 klog.Flush 中。
其他各种变化
有关所有其他增强功能的描述,请参见 发行说明。
日志检查
最初设计为结构化日志调用的 linter,[logcheck] 工具已得到增强,还支持上下文日志记录和传统的 klog 日志调用。
这些增强检查已经在 Kubernetes 中发现了错误,例如使用格式字符串和参数调用 klog.Info 而不是 klog.Infof。
它可以作为插件包含在 golangci-lint 调用中,这就是
Kubernetes 现在使用它的方式,或者单独调用。
我们正在 移动工具 到一个新的存储库中,因为它与 klog 没有真正的关系,并且应该正确跟踪和标记它的发布。
下一步
Structured Logging WG 一直在寻找新的贡献者。 从 C 风格的日志记录迁移现在将一步一步地针对结构化的上下文日志记录, 以减少整体代码流失和 PR 数量。 更改日志调用是对 Kubernetes 的良好贡献,也是了解各个不同领域代码的机会。
Kubernetes 1.24: 避免为 Services 分配 IP 地址时发生冲突
作者: Antonio Ojea (Red Hat)
在 Kubernetes 中,Services
是一种抽象,用来暴露运行在一组 Pod 上的应用。
Service 可以有一个集群范围的虚拟 IP 地址(使用 type: ClusterIP 的 Service)。
客户端可以使用该虚拟 IP 地址进行连接, Kubernetes 为对该 Service 的访问流量提供负载均衡,以访问不同的后端 Pod。
Service ClusterIP 是如何分配的?
Service ClusterIP 有如下分配方式:
动态
:集群的控制平面会自动从配置的 IP 范围内为 type:ClusterIP 的 Service 选择一个空闲 IP 地址。
静态 :你可以指定一个来自 Service 配置的 IP 范围内的 IP 地址。
在整个集群中,每个 Service 的 ClusterIP 必须是唯一的。
尝试创建一个已经被分配了 ClusterIP 的 Service 将会返回错误。
为什么需要预留 Service Cluster IP?
有时,你可能希望让 Service 运行在众所周知的 IP 地址上,以便集群中的其他组件和用户可以使用它们。
最好的例子是集群的 DNS Service。一些 Kubernetes 安装程序将 Service IP 范围中的第 10 个地址分配给 DNS Service。 假设你配置集群 Service IP 范围是 10.96.0.0/16,并且希望 DNS Service IP 为 10.96.0.10, 那么你必须创建一个如下所示的 Service:
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: CoreDNS
name: kube-dns
namespace: kube-system
spec:
clusterIP: 10.96.0.10
ports:
- name: dns
port: 53
protocol: UDP
targetPort: 53
- name: dns-tcp
port: 53
protocol: TCP
targetPort: 53
selector:
k8s-app: kube-dns
type: ClusterIP
但正如我之前解释的,IP 地址 10.96.0.10 没有被保留; 如果其他 Service 在动态分配之前创建或与动态分配并行创建,则它们有可能分配此 IP 地址, 因此,你将无法创建 DNS Service,因为它将因冲突错误而失败。
如何避免 Service ClusterIP 冲突?
在 Kubernetes 1.24 中,你可以启用一个新的特性门控 ServiceIPStaticSubrange。
启用此特性允许你为 Service 使用不同的 IP 分配策略,减少冲突的风险。
ClusterIP 范围将根据公式 min(max(16, cidrSize / 16), 256) 进行划分,
该公式可描述为 “在不小于 16 且不大于 256 之间有一个步进量(Graduated Step)”。
分配默认使用上半段地址,当上半段地址耗尽后,将使用下半段地址范围。 这将允许用户在下半段地址中使用静态分配从而降低冲突的风险。
举例:
Service IP CIDR 地址段: 10.96.0.0/24
地址段大小:28 - 2 = 254
地址段偏移:min(max(16, 256/16), 256) = min(16, 256) = 16
静态地址段起点:10.96.0.1
静态地址段终点:10.96.0.16
地址范围终点:10.96.0.254
Service IP CIDR 地址段: 10.96.0.0/20
地址段大小:212 - 2 = 4094
地址段偏移:min(max(16, 4096/16), 256) = min(256, 256) = 256
静态地址段起点:10.96.0.1
静态地址段终点:10.96.1.0
地址范围终点:10.96.15.254
Service IP CIDR 地址段: 10.96.0.0/16
地址段大小:216 - 2 = 65534
地址段偏移:min(max(16, 65536/16), 256) = min(4096, 256) = 256
静态地址段起点:10.96.0.1
静态地址段终点:10.96.1.0
地址范围终点:10.96.255.254
加入 SIG Network
当前 SIG-Network 在 GitHub 上的 KEPs 和 issues 表明了该 SIG 的重点领域。
SIG Network 会议是一个友好、热情的地方, 你可以与社区联系并分享你的想法。期待你的回音!
Kubernetes 1.24: 节点非体面关闭特性进入 Alpha 阶段
作者:Xing Yang 和 Yassine Tijani (VMware)
Kubernetes v1.24 引入了对节点非体面关闭 (Non-Graceful Node Shutdown)的 Alpha 支持。 此特性允许有状态工作负载在原节点关闭或处于不可恢复状态(如硬件故障或操作系统损坏)后,故障转移到不同的节点。
这与节点体面关闭有何不同
你可能听说过 Kubernetes 的节点体面关闭特性,
并且想知道节点非体面关闭特性与之有何不同。节点体面关闭允许 Kubernetes 检测节点何时完全关闭,并适当地处理这种情况。
只有当 kubelet 在实际关闭之前检测到节点关闭动作时,节点关闭才是“体面(graceful)”的。
但是,在某些情况下,kubelet 可能检测不到节点关闭操作。
这可能是因为 shutdown 命令没有触发 kubelet 所依赖的 systemd 抑制锁机制,
或者是因为配置错误(ShutdownGracePeriod 和 ShutdownGracePeriodCriticalPods 配置不正确)。
节点体面关闭依赖于特定 Linux 的支持。 kubelet 不监视 Windows 节点上即将关闭的情况(这可能在未来的 Kubernetes 版本中会有所改变)。
当一个节点被关闭但 kubelet 没有检测到时,该节点上的 Pod 也会非体面地关闭。 对于无状态应用程序,这通常不是问题(一旦集群检测到受影响的节点或 Pod 出现故障,ReplicaSet 就会添加一个新的 Pod)。 对于有状态的应用程序,情况要复杂得多。如果你使用一个 StatefulSet, 并且该 StatefulSet 中的一个 Pod 在某个节点上发生了不干净故障,则该受影响的 Pod 将被标记为终止(Terminating); StatefulSet 无法创建替换 Pod,因为该 Pod 仍存在于集群中。 因此,在 StatefulSet 上运行的应用程序可能会降级甚至离线。 如果已关闭的原节点再次出现,该节点上的 kubelet 会执行报到操作,删除现有的 Pod, 并且控制平面会在不同的运行节点上为该 StatefulSet 生成一个替换 Pod。 如果原节点出现故障并且没有恢复,这些有状态的 Pod 将处于终止状态且无限期地停留在该故障节点上。
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-0 1/1 Running 0 100m 10.244.2.4 k8s-node-876-1639279816 <none> <none>
web-1 1/1 Terminating 0 100m 10.244.1.3 k8s-node-433-1639279804 <none> <none>
尝试新的非体面关闭处理
要使用节点非体面关闭处理,你必须为 kube-controller-manager 组件启用
NodeOutOfServiceVolumeDetach 特性门控。
在节点关闭的情况下,你可以手动为该节点标记污点,标示其已停止服务。
在添加污点之前,你应该确保节点确实关闭了(不是在重启过程中)。
你可以在发生了节点关闭事件,且该事件没有被 kubelet 提前检测和处理的情况下,在节点关闭之后添加污点;
你可以使用该污点的另一种情况是当节点由于硬件故障或操作系统损坏而处于不可恢复状态时。
你可以为该污点设置的值是 node.kubernetes.io/out-of-service=nodeshutdown: "NoExecute" 或
node.kubernetes.io/out-of-service=nodeshutdown: "NoSchedule"。
如果你已经启用了前面提到的特性门控,在节点上设置 out-of-service 污点意味着节点上的 Pod 将被删除,
除非 Pod 上设置有与之匹配的容忍度。原来挂接到已关闭节点的持久卷(Persistent volume)将被解除挂接,
对于 StatefulSet,系统将在不同的运行节点上成功创建替换 Pod。
$ kubectl taint nodes <node-name> node.kubernetes.io/out-of-service=nodeshutdown:NoExecute
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-0 1/1 Running 0 150m 10.244.2.4 k8s-node-876-1639279816 <none> <none>
web-1 1/1 Running 0 10m 10.244.1.7 k8s-node-433-1639279804 <none> <none>
注意:在应用 out-of-service 污点之前,你必须确认节点是否已经处于关闭或断电状态(不是在重新启动过程中), 节点关闭的原因可能是用户有意将其关闭,也可能是节点由于硬件故障、操作系统问题等而关闭。
一旦关联到无法提供服务的节点的所有工作负载 Pod 都被移动到新的运行中的节点,并且关闭了的节点也已恢复, 你应该在节点恢复后删除受影响节点上的污点。如果你知道该节点不会恢复服务,则可以改为从集群中删除该节点。
下一步是什么?
根据反馈和采用情况,Kubernetes 团队计划在 1.25 或 1.26 版本中将节点非体面关闭实现推送到 Beta 阶段。
此功能需要用户手动向节点添加污点以触发工作负载故障转移,并要求用户在节点恢复后移除污点。 未来,我们计划寻找方法来自动检测和隔离已关闭的或已失败的节点,并自动将工作负载故障转移到另一个节点。
怎样才能了解更多?
查看节点非体面关闭相关文档。
如何参与?
此功能特性由来已久。Yassine Tijani(yastij)在两年多前启动了这个 KEP。 Xing Yang(xing-yang)继续推动这项工作。 SIG-Storage、SIG-Node 和 API 评审人员们进行了多次讨论,以确定设计细节。 Ashutosh Kumar(sonasingh46) 完成了大部分实现并在 Kubernetes 1.24 版本中将其引进到 Alpha 阶段。
我们要感谢以下人员的评审:Tim Hockin(thockin)对设计的指导; 来自 SIG-Storage 的 Jing Xu(jingxu97)、 Hemant Kumar(gnufied) 和 Michelle Au(msau42)的评论; 以及 Mrunal Patel(mrunalp)、 David Porter(bobbypage)、 Derek Carr(derekwaynecarr) 和 Danielle Endocrimes(endocrimes)来自 SIG-Node 方面的评论。
在此过程中,有很多人帮助审查了设计和实现。我们要感谢所有为此做出贡献的人, 包括在过去几年中审核 KEP 和实现的大约 30 人。
此特性是 SIG-Storage 和 SIG-Node 之间的协作。 对于那些有兴趣参与 Kubernetes Storage 系统任何部分的设计和开发的人, 请加入 Kubernetes 存储特别兴趣小组(SIG-Storage)。 对于那些有兴趣参与支持 Pod 和主机资源之间受控交互的组件的设计和开发的人, 请加入 Kubernetes Node SIG。
Kubernetes 1.24: 防止未经授权的卷模式转换
作者: Raunak Pradip Shah (Mirantis)
Kubernetes v1.24 引入了一个新的 alpha 级特性,可以防止未经授权的用户修改基于 Kubernetes
集群中已有的 VolumeSnapshot
创建的 PersistentVolumeClaim 的卷模式。
问题
卷模式确定卷是格式化为文件系统还是显示为原始块设备。
用户可以使用自 Kubernetes v1.20 以来就稳定的 VolumeSnapshot 功能,
基于 Kubernetes 集群中的已有的 VolumeSnapshot 创建一个 PersistentVolumeClaim (简称 PVC )。
PVC 规约包括一个 dataSource 字段,它可以指向一个已有的 VolumeSnapshot 实例。
查阅基于卷快照创建 PVC
获取更多详细信息。
当使用上述功能时,没有逻辑来验证快照所在的原始卷的模式是否与新创建的卷的模式匹配。
这引起了一个安全漏洞,允许恶意用户潜在地利用主机操作系统中的未知漏洞。
为了提高效率,许多流行的存储备份供应商在备份操作过程中转换卷模式, 这使得 Kubernetes 无法完全阻止该操作,并在区分受信任用户和恶意用户方面带来挑战。
防止未经授权的用户转换卷模式
在这种情况下,授权用户是指有权对 VolumeSnapshotContents(集群级资源)执行 Update
或 Patch 操作的用户。集群管理员只能向受信任的用户或应用程序(如备份供应商)提供这些权限。
如果在 snapshot-controller、snapshot-validation-webhook 和
external-provisioner 中启用了这个 alpha
特性,则基于 VolumeSnapshot 创建 PVC 时,将不允许未经授权的用户修改其卷模式。
如要转换卷模式,授权用户必须执行以下操作:
确定要用作给定命名空间中新创建 PVC 的数据源的
VolumeSnapshot。确定绑定到上面
VolumeSnapshot的VolumeSnapshotContent。kubectl get volumesnapshot -n <namespace>
- 给
VolumeSnapshotContent添加snapshot.storage.kubernetes.io/allowVolumeModeChange注解。
此注解可通过软件添加或由授权用户手动添加。
VolumeSnapshotContent注解必须类似于以下清单片段:kind: VolumeSnapshotContent metadata: annotations: - snapshot.storage.kubernetes.io/allowVolumeModeChange: "true" ...
注意:对于预先制备的 VolumeSnapshotContents,你必须采取额外的步骤设置 spec.sourceVolumeMode
字段为 Filesystem 或 Block,这取决于快照所在卷的模式。
如下为一个示例:
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
annotations:
- snapshot.storage.kubernetes.io/allowVolumeModeChange: "true"
name: new-snapshot-content-test
spec:
deletionPolicy: Delete
driver: hostpath.csi.k8s.io
source:
snapshotHandle: 7bdd0de3-aaeb-11e8-9aae-0242ac110002
sourceVolumeMode: Filesystem
volumeSnapshotRef:
name: new-snapshot-test
namespace: default
对于在备份或恢复操作期间需要转换卷模式的所有 VolumeSnapshotContents,重复步骤 1 到 3。
如果 VolumeSnapshotContent 对象上存在上面步骤 4 中显示的注解,Kubernetes 将不会阻止转换卷模式。
用户在尝试将注解添加到任何 VolumeSnapshotContent 之前,应该记住这一点。
接下来
启用此特性并让我们知道你的想法!
我们希望此功能不会中断现有工作流程,同时防止恶意用户利用集群中的安全漏洞。
若有任何问题,请在 #sig-storage slack 频道中创建一个会话, 或在 CSI 外部快照存储仓库中报告一个 issue。
Kubernetes 1.24: 卷填充器功能进入 Beta 阶段
作者: Ben Swartzlander (NetApp)
卷填充器功能现在已经经历两个发行版本并进入 Beta 阶段!
在 Kubernetes v1.24 中 AnyVolumeDataSource 特性门控默认被启用。
这意味着用户可以指定任何自定义资源作为 PVC 的数据源。
之前的一篇博客详细介绍了卷填充器功能的工作原理。 简而言之,集群管理员可以在集群中安装 CRD 和相关的填充器控制器, 任何可以创建 CR 实例的用户都可以利用填充器创建预填充卷。
出于不同的目的,可以一起安装多个填充器。存储 SIG 社区已经有了一些公开的实现,更多原型应该很快就会出现。
强烈建议集群管理人员在安装任何填充器之前安装 volume-data-source-validator 控制器和相关的
VolumePopulator CRD,以便用户可以获得有关无效 PVC 数据源的反馈。
新功能
构建填充器的 lib-volume-populator 库现在包含可帮助操作员监控和检测问题的指标。这个库现在是 beta 阶段,最新版本是 v1.0.1。
卷数据源校验器控制器也添加了指标支持,
处于 beta 阶段。VolumePopulator CRD 是 beta 阶段,最新版本是 v1.0.1。
尝试一下
要查看它是如何工作的,你可以安装 “hello” 示例填充器并尝试一下。
首先安装 volume-data-source-validator 控制器。
kubectl apply -f https://raw.githubusercontent.com/kubernetes-csi/volume-data-source-validator/v1.0.1/client/config/crd/populator.storage.k8s.io_volumepopulators.yaml
kubectl apply -f https://raw.githubusercontent.com/kubernetes-csi/volume-data-source-validator/v1.0.1/deploy/kubernetes/rbac-data-source-validator.yaml
kubectl apply -f https://raw.githubusercontent.com/kubernetes-csi/volume-data-source-validator/v1.0.1/deploy/kubernetes/setup-data-source-validator.yaml
接下来安装 hello 示例填充器。
kubectl apply -f https://raw.githubusercontent.com/kubernetes-csi/lib-volume-populator/v1.0.1/example/hello-populator/crd.yaml
kubectl apply -f https://raw.githubusercontent.com/kubernetes-csi/lib-volume-populator/87a47467b86052819e9ad13d15036d65b9a32fbb/example/hello-populator/deploy.yaml
你的集群现在有一个新的 CustomResourceDefinition,它提供了一个名为 Hello 的测试 API。
创建一个 Hello 自定义资源的实例,内容如下:
apiVersion: hello.example.com/v1alpha1
kind: Hello
metadata:
name: example-hello
spec:
fileName: example.txt
fileContents: Hello, world!
创建一个将该 CR 引用为其数据源的 PVC。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: example-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Mi
dataSourceRef:
apiGroup: hello.example.com
kind: Hello
name: example-hello
volumeMode: Filesystem
接下来,运行一个读取 PVC 中文件的 Job。
apiVersion: batch/v1
kind: Job
metadata:
name: example-job
spec:
template:
spec:
containers:
- name: example-container
image: busybox:latest
command:
- cat
- /mnt/example.txt
volumeMounts:
- name: vol
mountPath: /mnt
restartPolicy: Never
volumes:
- name: vol
persistentVolumeClaim:
claimName: example-pvc
等待 Job 完成(包括其所有依赖项)。
kubectl wait --for=condition=Complete job/example-job
最后检查 Job 中的日志。
kubectl logs job/example-job
输出应该是:
Hello, world!
请注意,该卷已包含一个文本文件,其中包含来自 CR 的字符串内容。这只是最简单的例子。 实际填充器可以将卷设置为包含任意内容。
如何编写自己的卷填充器
鼓励有兴趣编写新的填充器的开发人员使用 lib-volume-populator 库, 只提供一个小型控制器,以及一个能够连接到卷并向卷写入适当数据的 Pod 镜像。
单个填充器非常通用,它们可以与所有类型的 PVC 一起使用, 或者如果卷是来自同一供应商的特定 CSI 驱动程序供应的, 它们可以执行供应商特定的的操作以快速用数据填充卷,例如,通过通信直接使用该卷的存储。
我怎样才能了解更多?
增强提案, 卷填充器, 包含有关此功能的历史和技术实现的许多详细信息。
卷填充器与数据源, 在有关持久卷的文档主题中,解释了如何在集群中使用此功能。
请加入 Kubernetes 的存储 SIG,帮助我们增强这一功能。这里已经有很多好的主意了,我们很高兴能有更多!
Kubernetes 1.24:gRPC 容器探针功能进入 Beta 阶段
作者:Sergey Kanzhelev (Google)
译者:Xiaoyang Zhang(Huawei)
在 Kubernetes 1.24 中,gRPC 探针(probe)功能进入了 beta 阶段,默认情况下可用。 现在,你可以为 gRPC 应用程序配置启动、活跃和就绪探测,而无需公开任何 HTTP 端点, 也不需要可执行文件。Kubernetes 可以通过 gRPC 直接连接到你的工作负载并查询其状态。
一些历史
让管理你的工作负载的系统检查应用程序是否健康、启动是否正常,以及应用程序是否认为自己可以接收流量,是很有用的。 在添加 gRPC 探针支持之前,Kubernetes 已经允许你通过从容器镜像内部运行可执行文件、发出 HTTP 请求或检查 TCP 连接是否成功来检查健康状况。
对于大多数应用程序来说,这些检查就足够了。如果你的应用程序提供了用于运行状况(或准备就绪)检查的
gRPC 端点,则很容易重新调整 exec 探针的用途,将其用于 gRPC 运行状况检查。
在博文在 Kubernetes 上对 gRPC 服务器进行健康检查中,
Ahmet Alp Balkan 描述了如何做到这一点 —— 这种机制至今仍在工作。
2018 年 8 月 21 日所创建的一种常用工具可以启用此功能, 工具于 2018 年 9 月 19 日首次发布。
这种 gRPC 应用健康检查的方法非常受欢迎。使用 GitHub 上的基本搜索,发现了带有 grpc_health_probe
的 3,626 个 Dockerfile 文件和
6,621 个 yaml 文件(在撰写本文时)。
这很好地表明了该工具的受欢迎程度,以及对其本地支持的需求。
Kubernetes v1.23 引入了一个 alpha 质量的实现,原生支持使用 gRPC 查询工作负载状态。 因为这是一个 alpha 特性,所以在 1.23 版中默认是禁用的。
使用该功能
我们用与其他探针类似的方式构建了 gRPC 健康检查,相信如果你熟悉 Kubernetes 中的其他探针类型,
它会很容易使用。
与涉及 grpc_health_probe 可执行文件的解决办法相比,原生支持的健康探针有许多好处。
有了原生 gRPC 支持,你不需要在镜像中下载和携带 10MB 的额外可执行文件。
Exec 探针通常比 gRPC 调用慢,因为它们需要实例化一个新进程来运行可执行文件。
当 Pod 在最大资源下运行并且在实例化新进程时遇到困难时,它还使得对边界情况的检查变得不那么智能。
不过有一些限制。由于为探针配置客户端证书很难,因此不支持依赖客户端身份验证的服务。 内置探针也不检查服务器证书,并忽略相关问题。
内置检查也不能配置为忽略某些类型的错误(grpc_health_probe 针对不同的错误返回不同的退出代码),
并且不能“串接”以在单个探测中对多个服务运行健康检查。
但是所有这些限制对于 gRPC 来说都是相当标准的,并且有简单的解决方法。
自己试试
集群级设置
你现在可以尝试这个功能。要尝试原生 gRPC 探针,你可以自己启动一个启用了
GRPCContainerProbe 特性门控的 Kubernetes 集群,可用的工具有很多。
由于特性门控 GRPCContainerProbe 在 1.24 版本中是默认启用的,因此许多供应商支持此功能开箱即用。
因此,你可以在自己选择的平台上创建 1.24 版本集群。一些供应商允许在 1.23 版本集群上启用 alpha 特性。
例如,在编写本文时,你可以在 GKE 上运行测试集群来进行快速测试。 其他供应商可能也有类似的功能,尤其是当你在 Kubernetes 1.24 版本发布很久后才阅读这篇博客时。
在 GKE 上使用以下命令(注意,版本是 1.23,并且指定了 enable-kubernetes-alpha)。
gcloud container clusters create test-grpc \
--enable-kubernetes-alpha \
--no-enable-autorepair \
--no-enable-autoupgrade \
--release-channel=rapid \
--cluster-version=1.23
你还需要配置 kubectl 来访问集群:
gcloud container clusters get-credentials test-grpc
试用该功能
让我们创建 Pod 来测试 gRPC 探针是如何工作的。对于这个测试,我们将使用 agnhost 镜像。
这是一个 k8s 维护的镜像,可用于各种工作负载测试。例如,它有一个有用的
grpc-health-checking
模块,该模块暴露了两个端口:一个是提供健康检查服务的端口,另一个是对 make-serving 和
make-not-serving 命令做出反应的 http 端口。
下面是一个 Pod 定义示例。它启用 grpc-health-checking 模块,暴露 5000 和 8080 端口,并配置 gRPC 就绪探针:
---
apiVersion: v1
kind: Pod
metadata:
name: test-grpc
spec:
containers:
- name: agnhost
# 镜像自发布以来已更改(以前使用的仓库为 "k8s.gcr.io")
image: registry.k8s.io/e2e-test-images/agnhost:2.35
command: ["/agnhost", "grpc-health-checking"]
ports:
- containerPort: 5000
- containerPort: 8080
readinessProbe:
grpc:
port: 5000
如果清单文件名为 test.yaml,你可以用以下命令创建 Pod,并检查它的状态。如输出片段所示,Pod 将处于就绪状态。
kubectl apply -f test.yaml
kubectl describe test-grpc
输出将包含如下内容:
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
现在让我们将健康检查端点状态更改为 NOT_SERVING。为了调用 Pod 的 http 端口,让我们创建一个端口转发:
kubectl port-forward test-grpc 8080:8080
你可以用 curl 来调用这个命令。
curl http://localhost:8080/make-not-serving
几秒钟后,端口状态将切换到未就绪。
kubectl describe pod test-grpc
现在的输出将显示:
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
...
Warning Unhealthy 2s (x6 over 42s) kubelet Readiness probe failed: service unhealthy (responded with "NOT_SERVING")
一旦切换回来,Pod 将在大约一秒钟后恢复到就绪状态:
curl http://localhost:8080/make-serving
kubectl describe test-grpc
输出表明 Pod 恢复为 Ready:
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Kubernetes 上这种新的内置 gRPC 健康探测,使得通过 gRPC 实现健康检查比依赖使用额外的 exec
探测的旧方法更容易。请阅读官方
文档
了解更多信息并在该功能正式发布(GA)之前提供反馈。
总结
Kubernetes 是一个流行的工作负载编排平台,我们根据反馈和需求添加功能。 像 gRPC 探针支持这样的特性是一个小的改进,它将使许多应用程序开发人员的生活更容易,应用程序更有弹性。 在该功能 GA(正式发布)之前,现在就试试,并给出反馈。
Kubernetes 1.24 版本中存储容量跟踪特性进入 GA 阶段
作者: Patrick Ohly(Intel)
在 Kubernetes v1.24 版本中,存储容量跟踪已经成为一项正式发布的功能。
已经解决的问题
如上一篇关于此功能的博文中所详细介绍的, 存储容量跟踪允许 CSI 驱动程序发布有关剩余容量的信息。当 Pod 仍然有需要配置的卷时, kube-scheduler 使用该信息为 Pod 选择合适的节点。
如果没有这些信息,Pod 可能会被卡住,而不会被调度到合适节点,这是因为 kube-scheduler 只能盲目地选择节点。由于 CSI 驱动程序管理的下层存储系统没有足够的容量, kube-scheduler 常常会选择一个无法为其配置卷的节点。
因为 CSI 驱动程序发布的这些存储容量信息在被使用的时候可能已经不是最新的信息了, 所以最终选择的节点无法正常工作的情况仍然可能会发生。 卷配置通过通知调度程序需要在其他节点上重试来恢复。
升级到 GA 版本后重新进行的负载测试证实, 集群中部署了存储容量跟踪功能的 Pod 可以使用所有的存储,而没有部署此功能的 Pod 就会被卡住。
尚未解决的问题
如果尝试恢复一个制备失败的卷,存在一个已知的限制: 如果 Pod 使用两个卷并且只能制备其中一个,那么所有将来的调度决策都受到已经制备的卷的限制。 如果该卷是节点的本地卷,并且另一个卷无法被制备,则 Pod 会卡住。 此问题早在存储容量跟踪功能之前就存在,虽然苛刻的附加条件使这种情况不太可能发生, 但是无法完全避免,当然每个 Pod 仅使用一个卷的情况除外。
KEP 草案中提出了一个解决此问题的想法: 已制备但尚未被使用的卷不能包含任何有价值的数据,因此可以在其他地方释放并且再次被制备。 SIG Storage 正在寻找对此感兴趣并且愿意继续从事此工作的开发人员。
另一个没有解决的问题是 Cluster Autoscaler 对包含卷的 Pod 的支持。 对于具有存储容量跟踪功能的 CSI 驱动程序,我们开发了一个原型并在此 PR 中进行了讨论。 此原型旨在与任意 CSI 驱动程序协同工作,但这种灵活性使其难以配置并减慢了扩展操作: 因为自动扩展程序无法模拟卷制备操作,它一次只能将集群扩展一个节点,这是此方案的不足之处。
因此,这个 PR 没有被合入,需要另一种不同的方法,在自动缩放器和 CSI 驱动程序之间实现更紧密的耦合。 为此,需要更好地了解哪些本地存储 CSI 驱动程序与集群自动缩放结合使用。如果这会引出新的 KEP, 那么用户将不得不在实践中尝试实现,然后才能迁移到 beta 版本或 GA 版本中。 如果你对此主题感兴趣,请联系 SIG Storage。
致谢
非常感谢为此功能做出贡献或提供反馈的 SIG Scheduling、 SIG Autoscaling 和 SIG Storage 成员!
Kubernetes 1.24:卷扩充现在成为稳定功能
作者: Hemant Kumar (Red Hat)
卷扩充在 Kubernetes 1.8 作为 Alpha 功能引入, 在 Kubernetes 1.11 进入了 Beta 阶段。 在 Kubernetes 1.24 中,我们很高兴地宣布卷扩充正式发布(GA)。
此功能允许 Kubernetes 用户简单地编辑其 PersistentVolumeClaim 对象,
并在 PVC Spec 中指定新的大小,Kubernetes 将使用存储后端自动扩充卷,
同时也会扩充 Pod 使用的底层文件系统,使得无需任何停机时间成为可能。
如何使用卷扩充
通过编辑 PVC 的 spec 字段,指定不同的(和更大的)存储请求,
可以触发 PersistentVolume 的扩充。
例如,给定以下 PVC:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi # 在此处指定新的大小
你可以指定新的值来替代旧的 1Gi 大小来请求扩充下层 PersistentVolume。
一旦你更改了请求的大小,可以查看 PVC 的 status.conditions 字段,
确认卷大小的调整是否已完成。
当 Kubernetes 开始扩充卷时,它会给 PVC 添加 Resizing 状况。
一旦扩充结束,这个状况会被移除。通过监控与 PVC 关联的事件,
还可以获得更多关于扩充操作进度的信息:
kubectl describe pvc <pvc>
存储驱动支持
然而,并不是每种卷类型都默认支持扩充。
某些卷类型(如树内 hostpath 卷)不支持扩充。
对于 CSI 卷,
CSI 驱动必须在控制器或节点服务(如果合适,二者兼备)
中具有 EXPAND_VOLUME 能力。
请参阅 CSI 驱动的文档,了解其是否支持卷扩充。
有关支持卷扩充的树内(intree)卷类型, 请参阅卷扩充文档:扩充 PVC 申领。
通常,为了对可扩充的卷提供某种程度的控制,
只有在存储类将 allowVolumeExpansion 参数设置为 true 时,
动态供应的 PVC 才是可扩充的。
Kubernetes 集群管理员必须编辑相应的 StorageClass 对象,
并将 allowVolumeExpansion 字段设置为 true。例如:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: gp2-default
provisioner: kubernetes.io/aws-ebs
parameters:
secretNamespace: ""
secretName: ""
allowVolumeExpansion: true
在线扩充与离线扩充比较
默认情况下,Kubernetes 会在用户请求调整大小后立即尝试扩充卷。 如果一个或多个 Pod 正在使用该卷, Kubernetes 会尝试通过在线调整大小来扩充该卷; 因此,卷扩充通常不需要应用停机。 节点上的文件系统也可以在线扩充,因此不需要关闭任何正在使用 PVC 的 Pod。
如果要扩充的 PersistentVolume 未被使用,Kubernetes 会用离线方式调整卷大小 (而且,由于该卷未使用,所以也不会造成工作负载中断)。
但在某些情况下,如果底层存储驱动只能支持离线扩充, 则 PVC 用户必须先停止 Pod,才能让扩充成功。 请参阅存储提供商的文档,了解其支持哪种模式的卷扩充。
当卷扩充作为 Alpha 功能引入时, Kubernetes 仅支持在节点上进行离线的文件系统扩充, 因此需要用户重新启动 Pod,才能完成文件系统的大小调整。 今天,用户的行为已经被改变,无论底层 PersistentVolume 是在线还是离线, Kubernetes 都会尽最大努力满足任何调整大小的请求。 如果你的存储提供商支持在线扩充,则无需重启 Pod 即可完成卷扩充。
下一步
尽管卷扩充在最近的 v1.24 发行版中成为了稳定版本, 但 SIG Storage 团队仍然在努力让 Kubernetes 用户扩充其持久性存储变得更简单。 Kubernetes 1.23 引入了卷扩充失败后触发恢复机制的功能特性, 允许用户在大小调整失败后尝试自助修复。 更多详细信息,请参阅处理扩充卷过程中的失败。
Kubernetes 贡献者社区也在讨论有状态(StatefulSet)驱动的存储扩充的潜力。 这个提议的功能特性将允许用户通过直接编辑 StatefulSet 对象, 触发为 StatefulSet 提供存储的所有底层 PV 的扩充。 更多详细信息,请参阅通过 StatefulSet 支持卷扩充的改善提议。
Dockershim:历史背景
作者: Kat Cosgrove
自 Kubernetes v1.24 起,Dockershim 已被删除,这对项目来说是一个积极的举措。 然而,背景对于充分理解某事很重要,无论是社交还是软件开发,这值得更深入的审查。 除了 Kubernetes v1.24 中的 dockershim 移除之外, 我们在社区中看到了一些混乱(有时处于恐慌级别)和对这一决定的不满, 主要是由于缺乏有关此删除背景的了解。弃用并最终从 Kubernetes 中删除 dockershim 的决定并不是迅速或轻率地做出的。 尽管如此,它已经工作了很长时间,以至于今天的许多用户都比这个决定更新, 更不用提当初为何引入 dockershim 了。
那么 dockershim 是什么,为什么它会消失呢?
在 Kubernetes 的早期,我们只支持一个容器运行时,那个运行时就是 Docker Engine。 那时,并没有太多其他选择,而 Docker 是使用容器的主要工具,所以这不是一个有争议的选择。 最终,我们开始添加更多的容器运行时,比如 rkt 和 hypernetes,很明显 Kubernetes 用户希望选择最适合他们的运行时。因此,Kubernetes 需要一种方法来允许集群操作员灵活地使用他们选择的任何运行时。
容器运行时接口 (CRI) 已发布以支持这种灵活性。 CRI 的引入对项目和用户来说都很棒,但它确实引入了一个问题:Docker Engine 作为容器运行时的使用早于 CRI,并且 Docker Engine 不兼容 CRI。 为了解决这个问题,在 kubelet 组件中引入了一个小型软件 shim (dockershim),专门用于填补 Docker Engine 和 CRI 之间的空白, 允许集群操作员继续使用 Docker Engine 作为他们的容器运行时基本上不间断。
然而,这个小软件 shim 从来没有打算成为一个永久的解决方案。 多年来,它的存在给 kubelet 本身带来了许多不必要的复杂性。由于这个 shim,Docker 的一些集成实现不一致,导致维护人员的负担增加,并且维护特定于供应商的代码不符合我们的开源理念。 为了减少这种维护负担并朝着支持开放标准的更具协作性的社区迈进, 引入了 KEP-2221, 建议移除 dockershim。随着 Kubernetes v1.20 的发布,正式弃用。
我们没有很好地传达这一点,不幸的是,弃用公告在社区内引起了一些恐慌。关于这对 Docker作为一家公司意味着什么,Docker 构建的容器镜像是否仍然可以运行,以及 Docker Engine 究竟是什么导致了社交媒体上的一场大火,人们感到困惑。 这是我们的错;我们应该更清楚地传达当时发生的事情和原因。为了解决这个问题, 我们发布了一篇博客和相应的 FAQ 以减轻社区的恐惧并纠正对 Docker 是什么以及容器如何在 Kubernetes 中工作的一些误解。 由于社区的关注,Docker 和 Mirantis 共同决定继续以 cri-dockerd 的形式支持 dockershim 代码,允许你在需要时继续使用 Docker Engine 作为容器运行时。 对于想要尝试其他运行时(如 containerd 或 cri-o)的用户, 已编写迁移文档。
我们后来调查了社区发现还有很多用户有疑问和顾虑。 作为回应,Kubernetes 维护人员和 CNCF 承诺通过扩展文档和其他程序来解决这些问题。 事实上,这篇博文是这个计划的一部分。随着如此多的最终用户成功迁移到其他运行时,以及改进的文档, 我们相信每个人现在都为迁移铺平了道路。
Docker 不会消失,无论是作为一种工具还是作为一家公司。它是云原生社区的重要组成部分, 也是 Kubernetes 项目的历史。没有他们,我们就不会是现在的样子。也就是说,从 kubelet 中删除 dockershim 最终对社区、生态系统、项目和整个开源都有好处。 这是我们所有人齐心协力支持开放标准的机会,我们很高兴在 Docker 和社区的帮助下这样做。
Kubernetes 1.24: 观星者
我们很高兴地宣布 Kubernetes 1.24 的发布,这是 2022 年的第一个版本!
这个版本包括 46 个增强功能:14 个增强功能已经升级到稳定版,15 个增强功能正在进入 Beta 版, 13 个增强功能正在进入 Alpha 阶段。另外,有两个功能被废弃了,还有两个功能被删除了。
主要议题
从 kubelet 中删除 Dockershim
在 v1.20 版本中被废弃后,dockershim 组件已被从 Kubernetes v1.24 版本的 kubelet 中移除。 从 v1.24 开始,如果你依赖 Docker Engine 作为容器运行时, 则需要使用其他受支持的运行时之一 (如 containerd 或 CRI-O)或使用 CRI dockerd。 有关确保集群已准备好进行此删除的更多信息,请参阅本指南。
默认情况下关闭 Beta API
新的 beta API 默认不会在集群中启用。 默认情况下,现有 Beta API 和及其更新版本将继续被启用。
签署发布工件
发布工件使用 cosign 签名进行签名, 并且有验证图像签名的实验性支持。 发布工件的签名和验证是提高 Kubernetes 发布过程的软件供应链安全性 的一部分。
OpenAPI v3
Kubernetes 1.24 提供了以 OpenAPI v3 格式发布其 API 的 Beta 支持。
存储容量和卷扩展普遍可用
存储容量跟踪支持通过 CSIStorageCapacity 对象公开当前可用的存储容量, 并增强使用具有后期绑定的 CSI 卷的 Pod 的调度。
卷的扩展增加了对调整现有持久性卷大小的支持。
NonPreemptingPriority 到稳定
此功能为 PriorityClasses 添加了一个新选项,可以启用或禁用 Pod 抢占。
存储插件迁移
目前正在进行迁移树内存储插件的内部组件工作, 以便在保持原有 API 的同时调用 CSI 插件。Azure Disk 和 OpenStack Cinder 插件都已迁移。
gRPC 探针升级到 Beta
在 Kubernetes 1.24 中,gRPC 探测功能 已进入测试版,默认可用。现在,你可以在 Kubernetes 中为你的 gRPC 应用程序原生地配置启动、存活和就绪性探测, 而无需暴露 HTTP 端点或使用额外的可执行文件。
Kubelet 凭证提供者毕业至 Beta
kubelet 最初在 Kubernetes 1.20 中作为 Alpha 发布,现在它对镜像凭证提供者 的支持已升级到 Beta。这允许 kubelet 使用 exec 插件动态检索容器镜像仓库的凭据,而不是将凭据存储在节点的文件系统上。
Alpha 中的上下文日志记录
Kubernetes 1.24 引入了上下文日志 这使函数的调用者能够控制日志记录的所有方面(输出格式、详细程度、附加值和名称)。
避免 IP 分配给服务的冲突
Kubernetes 1.24 引入了一项新的选择加入功能, 允许你为服务的静态 IP 地址分配软保留范围。 通过手动启用此功能,集群将更喜欢从服务 IP 地址池中自动分配,从而降低冲突风险。
服务的 ClusterIP 可以按照以下两种方式分配:
- 动态,这意味着集群将自动在配置的服务 IP 范围内选择一个空闲 IP。
- 静态,这意味着用户将在配置的服务 IP 范围内设置一个 IP。
服务 ClusterIP 是唯一的;因此,尝试使用已分配的 ClusterIP 创建服务将返回错误。
从 Kubelet 中移除动态 Kubelet 配置
在 Kubernetes 1.22 中被弃用后,动态 Kubelet 配置已从 kubelet 中移除。 该功能将从 Kubernetes 1.26 的 API 服务器中移除。
CNI 版本相关的重大更改
在升级到 Kubernetes 1.24 之前,请确认你正在使用/升级到经过测试可以在此版本中正常工作的容器运行时。
例如,以下容器运行时正在为 Kubernetes 准备,或者已经准备好了。
- containerd v1.6.4 及更高版本,v1.5.11 及更高版本
- CRI-O 1.24 及更高版本
当 CNI 插件尚未升级和/或 CNI 配置版本未在 CNI 配置文件中声明时,在 containerd v1.6.0–v1.6.3 中存在 Pod CNI 网络设置和拆除的服务问题。containerd 团队报告说,“这些问题在 containerd v1.6.4 中得到解决。”
在 containerd v1.6.0-v1.6.3 版本中,如果你不升级 CNI 插件和/或声明 CNI 配置版本, 你可能会遇到以下 “Incompatible CNI versions” 或 “Failed to destroy network for sandbox” 的错误情况。
CSI 快照
此信息是在首次发布后添加的。
VolumeSnapshot v1beta1 CRD 已被移除。 Kubernetes 和容器存储接口 (CSI) 的卷快照和恢复功能,提供标准化的 API 设计 (CRD) 并添加了对 CSI 卷驱动程序的 PV 快照/恢复支持,在 v1.20 中升级至 GA。VolumeSnapshot v1beta1 在 v1.20 中被弃用,现在不受支持。 有关详细信息,请参阅 KEP-177: CSI 快照 和卷快照 GA 博客。
其他更新
毕业到稳定版
在此版本中,有 14 项增强功能升级为稳定版:
- 容器存储接口(CSI)卷扩展
- Pod 开销: 核算与 Pod 沙箱绑定的资源,但不包括特定的容器。
- 向 PriorityClass 添加非抢占选项
- 存储容量跟踪
- OpenStack Cinder In-Tree 到 CSI 驱动程序迁移
- Azure 磁盘树到 CSI 驱动程序迁移
- 高效的监视恢复: kube-apiserver 重新启动后,可以高效地恢复监视。
- Service Type=LoadBalancer 类字段:
引入新的服务注解
service.kubernetes.io/load-balancer-class, 允许在同一个集群中提供type: LoadBalancer服务的多个实现。 - 带索引的 Job:为带有固定完成计数的 Job 的 Pod 添加完成索引。
- 在 Job API 中增加 suspend 字段: 在 Job API 中增加一个 suspend 字段,允许协调者在创建作业时对 Pod 的创建进行更多控制。
- Pod 亲和性 NamespaceSelector:
为 Pod 亲和性/反亲和性规约添加一个
namespaceSelector字段。 - 控制器管理器的领导者迁移: kube-controller-manager 和 cloud-controller-manager 可以在 HA 控制平面中重新分配新的控制器到控制器管理器,而无需停机。
- CSR 期限: 用一种机制来扩展证书签名请求 API,允许客户为签发的证书请求一个特定的期限。
主要变更
此版本有两个主要变更:
发行说明
在我们的发行说明 中查看 Kubernetes 1.24 版本的完整详细信息。
可用性
Kubernetes 1.24 可在 GitHub 上下载。 要开始使用 Kubernetes,请查看这些交互式教程或在本地运行。 使用 kind,可以将容器作为 Kubernetes 集群的 “节点”。 你还可以使用 kubeadm 轻松安装 1.24。
发布团队
如果没有 Kubernetes 1.24 发布团队每个人做出的共同努力,这个版本是不可能实现的。 该团队齐心协力交付每个 Kubernetes 版本中的所有组件,包括代码、文档、发行说明等。
特别感谢我们的发布负责人 James Laverack 指导我们完成了一个成功的发布周期, 并感谢所有发布团队成员投入时间和精力为 Kubernetes 社区提供 v1.24 版本。
发布主题和徽标
Kubernetes 1.24: 观星者

Kubernetes 1.24 的主题是观星者(Stargazer)。
古代天文学家到建造 James Webb 太空望远镜的科学家,几代人都怀着敬畏和惊奇的心情仰望星空。 是这些星辰启发了我们,点燃了我们的想象力,引导我们在艰难的海上度过了漫长的夜晚。
通过此版本,我们向上凝视,当我们的社区聚集在一起时可能发生的事情。 Kubernetes 是全球数百名贡献者和数千名最终用户支持的成果, 是一款为数百万人服务的应用程序。每个人都是我们天空中的一颗星星,帮助我们规划路线。
发布标志由 Britnee Laverack 制作, 描绘了一架位于星空和昴星团的望远镜,在神话中通常被称为“七姐妹”。 数字 7 对于 Kubernetes 项目特别吉祥,是对我们最初的“项目七”名称的引用。
这个版本的 Kubernetes 为那些仰望夜空的人命名——为所有的观星者命名。 ✨
用户亮点
- 了解领先的零售电子商务公司 La Redoute 如何使用 Kubernetes 以及其他 CNCF 项目来转变和简化 其从开发到运营的软件交付生命周期。
- 为了确保对 API 调用的更改不会导致任何中断,Salt Security 完全在 Kubernetes 上构建了它的微服务, 它通过 gRPC 进行通信,而 Linkerd 确保消息是加密的。
- 为了从私有云迁移到公共云,Alllainz Direct 工程师在短短三个月内重新设计了其 CI/CD 管道, 同时设法将 200 个工作流压缩到 10-15 个。
- 看看英国金融科技公司 Bink 是如何用 Linkerd 更新其内部的 Kubernetes 分布,以建立一个云端的平台, 根据需要进行扩展,同时允许他们密切关注性能和稳定性。
- 利用Kubernetes,荷兰组织 Stichting Open Nederland 在短短一个半月内创建了一个测试门户网站,以帮助安全地重新开放荷兰的活动。 入门测试 (Testen voor Toegang) 平台利用 Kubernetes 的性能和可扩展性来帮助个人每天预订超过 400,000 个 COVID-19 测试预约。
- 与 SparkFabrik 合作并利用 Backstage,Santagostino 创建了开发人员平台 Samaritan 来集中服务和文档, 管理服务的整个生命周期,并简化 Santagostino 开发人员的工作。
生态系统更新
- KubeCon + CloudNativeCon Europe 2022 于 2022 年 5 月 16 日至 20 日在西班牙巴伦西亚举行! 你可以在活动网站上找到有关会议和注册的更多信息。
- 在 2021 年云原生调查 中,CNCF 看到了创纪录的 Kubernetes 和容器采用。参阅调查结果。
- Linux 基金会和云原生计算基金会 (CNCF) 宣布推出新的 云原生开发者训练营 为参与者提供设计、构建和部署云原生应用程序的知识和技能。查看公告以了解更多信息。
项目速度
The CNCF K8s DevStats 项目 汇总了许多与 Kubernetes 和各种子项目的速度相关的有趣数据点。这包括从个人贡献到做出贡献的公司数量的所有内容, 并且说明了为发展这个生态系统而付出的努力的深度和广度。
在运行 17 周 ( 1 月 10 日至 5 月 3 日)的 v1.24 发布周期中,我们看到 1029 家公司 和 1179 人 的贡献。
即将发布的网络研讨会
在太平洋时间 2022 年 5 月 24 日星期二上午 9:45 至上午 11 点加入 Kubernetes 1.24 发布团队的成员, 了解此版本的主要功能以及弃用和删除,以帮助规划升级。有关更多信息和注册, 请访问 CNCF 在线计划网站上的活动页面。
参与进来
参与 Kubernetes 的最简单方法是加入符合你兴趣的众多特别兴趣组(SIG)之一。 你有什么想向 Kubernetes 社区广播的内容吗? 在我们的每周的社区会议上分享你的声音,并通过以下渠道:
- 在 Kubernetes Contributors 网站上了解有关为 Kubernetes 做出贡献的更多信息
- 在 Twitter 上关注我们 @Kubernetesio 以获取最新更新
- 加入社区讨论 Discuss
- 加入 Slack 社区
- 在 Server Fault 上发布问题(或回答问题)。
- 分享你的 Kubernetes 故事
- 在博客上阅读有关 Kubernetes 正在发生的事情的更多信息
- 详细了解 Kubernetes 发布团队
Frontiers, fsGroups and frogs: Kubernetes 1.23 发布采访
作者: Craig Box (Google)
举办每周一次的来自 Google 的 Kubernetes 播客 的亮点之一是与每个新 Kubernetes 版本的发布经理交谈。发布团队不断刷新。许多人从小型文档修复开始,逐步晋升为影子角色,然后最终领导发布。
在我们为下周发布的 1.24 版本做准备时,按照长期以来的传统, 很高兴带大家回顾一下 1.23 的故事。该版本由 SUSE 的现场工程师 Rey Lejano 领导。 在 12 月我与 Rey 交谈过,当时他正在等待他的第一个孩子的出生。
请确保你订阅,无论你在哪里获得你的播客, 以便你听到我们所有来自云原生社区的故事,包括下周 1.24 的故事。
为清晰起见本稿件经过了简单的编辑和浓缩。
CRAIG BOX:我想从现在每个人最关心的问题开始。让我们谈谈非洲爪蛙!
REY LEJANO:[笑]哦,你是说 Xenopus lavis,非洲爪蛙的学名?
CRAIG BOX:当然。
REY LEJANO:知道的人不多,但我曾就读于戴維斯加利福尼亚大学的微生物学专业。 我在生物化学实验室做了大约四年的生物化学研究,并且我确实发表了一篇研究论文。 它实际上是在糖蛋白上,特别是一种叫做“皮质颗粒凝集素”的东西。我们使用青蛙,因为它们会产生大量的蛋,我们可以从中提取蛋白质。 这种蛋白质可以防止多精症。当精子进入卵子时,卵子会向细胞膜释放一种糖蛋白,即皮质颗粒凝集素,并阻止任何其他精子进入卵子。
CRAIG BOX:你是否能够从我们对青蛙进行的测试中汲取任何东西并将其推广到更高阶的哺乳动物?
REY LEJANO:是的。由于哺乳动物也有皮质颗粒凝集素,我们能够分析收敛和进化模式,不仅来自多种青蛙,还包括哺乳动物。
CRAIG BOX:现在,这里有几个不同的线索需要解开。当你年轻的时候,是什么引导你进入生物学领域,可以侧重介绍技术方面的内容吗?
REY LEJANO:我认为这主要来自家庭,因为我在医学领域确实有可以追溯到几代人的家族史。所以我觉得那是进入大学的自然路径。
CRAIG BOX:现在,你正在一个更抽象的技术领域工作。是什么让你离开了微生物学?
REY LEJANO:[笑]嗯,我一直对科技很感兴趣。我年轻的时候自学了一点编程,在高中之前,做了一些网络开发的东西。 只是在实验室里有点焦头烂额了,实际上是在地下室。我有一个很好的机会加入了一家专门从事 ITIL 的咨询公司。实际上,我从应用性能管理开始,进入监控,进入运营管理和 ITIL,也就是把你的 IT 资产管理和服务管理与商业服务结合起来。实际上,我在这方面做了很多年。
CRAIG BOX:这很有趣,当人们描述他们所经历的事情以及他们所从事的技术时,你几乎可以确定他们的年龄。 现在有很多人进入科技行业,但从未听说过 ITIL。他们不知道那是什么。它基本上和 SRE 类似,只是过程更加复杂。
REY LEJANO:是的,一点没错。它不是非常云原生的。[笑]
CRAIG BOX:一点也不。
REY LEJANO:在云原生环境中,你并没有真正听说过它。毫无疑问,如果有人专门从事过 ITIL 工作或之前曾与 ITIL 合作过,你肯定可以看出他们已经在该领域工作了一段时间。
CRAIG BOX:你提到你想离开地下室。这的确是程序员常待的地方。他们只是在新的地下室里给了你一点光吗?
REY LEJANO:[笑]他们确实给了我们更好的照明。有时也能获得一些维生素 D。
CRAIG BOX:总结一下你的过往职业经历:在过去的一年里,随着全球各地的发展变化,我认为如今微生物学技能可能比你在校时更受欢迎?
REY LEJANO:哦,当然。我肯定能看到进入这个领域的人数大增。此外,阅读当前世界正在发生的事情也会带回我过去所学的所有教育。
CRAIG BOX:你和当时的同学还在保持联系吗?
REY LEJANO:只是一些亲密的朋友,但不是在微生物学领域。
CRAIG BOX:我认为,这次的全球疫情可能让人们对科学、技术、工程和数学领域重新产生兴趣。 看看这对整个社会有什么影响,将是很有趣的。
REY LEJANO:是的。我认为那会很棒。
CRAIG BOX:你提到在一家咨询公司工作,从事 IT 管理、应用程序性能监控等工作。Kubernetes 是什么时候进入你的职业生涯的?
REY LEJANO:在我工作的公司,我的一位好朋友于 2015 年年中离职。他去了一家非常热衷于 Docker 的公司。 他教了我一点东西。我在 2015 年左右,也许是 2016 年,做了我的第一次 “docker run”。 然后,我们用于 ITIL 框架的一个应用程序在 2018 年左右被容器化了,也在 Kubernetes 中。 那个时候,它是有些问题的。那是我第一次接触 Kubernetes 和容器化应用程序。
然后我离开了那家公司,实际上我加入了我在 RX-M 的朋友,这是一家云原生咨询和培训公司。 他们专门从事 Docker 和 Kubernetes 的工作。我能够让我脚踏实地。我拿到了 CKD 和 CKA 证书。 他们在鼓励我们学习更多关于 Kubernetes 的知识和参与社区活动方面真的非常棒。
CRAIG BOX:然后,你将看到人们采用 Kubernetes 和容器化的整个生命周期,通过你自己的初始旅程,然后通过帮助客户。你如何描述这段旅程从早期到今天的变化?
REY LEJANO:我认为早期有很多问题,为什么我必须容器化?为什么我不能只使用虚拟机?
CRAIG BOX:这是你的简历上的一个条目。
REY LEJANO:[笑]是的。现在,我认为人们知道使用容器的价值,以及使用 Kubernetes 编排容器的价值。我不想说“赶上潮流”,但它已经成为编排容器的事实标准。
CRAIG BOX:这不是咨询公司需要走出去向客户推销他们应该做的事情。他们只是把它当作会发生的事情,并开始在这条路上走得更远一些,也许。
REY LEJANO:当然。
CRAIG BOX:在这样的咨询公司工作,你有多少时间致力于改善流程,也许是为多个客户,然后研究如何将这项工作推向上游,而不是每次只为单个客户做有偿工作?
REY LEJANO:那时,情况会有所不同。他们帮我介绍了自己,我也了解了很多关于云原生环境和 Kubernetes 本身的情况。 他们帮助我了解如何将云原生环境及其周围的工具一起使用。我在那家公司的老板,Randy,实际上他鼓励我们开始向上游做贡献, 并鼓励我加入发布团队。他只是说,这是个很好的机会。这对我在早期就开始做贡献有很大的帮助。
CRAIG BOX:发布团队是你参与上游 Kubernetes 贡献的方式吗?
REY LEJANO:实际上,没有。我的第一个贡献是 SIG Docs。我认识了 Taylor Dolezal——他是 1.19 的发布团队负责人,但他也参与了 SIG Docs。 我在 KubeCon 2019 遇到了他,在午餐时我坐在他的桌子旁。我记得 Paris Pittman 在万豪酒店主持了这次午餐会。 Taylor 说他参与了 SIG Docs。他鼓励我加入。我开始参加会议,开始做一些路过式的 PR。 这就是我们所说的 - 驱动式 - 小错字修复。然后做更多的事情,开始发送更好或更高质量的拉取请求,并审查 PR。
CRAIG BOX:你第一次正式担任发布团队的角色是什么时候?
REY LEJANO:那是在 12月的 1.18。 当时我的老板鼓励我去申请。我申请了,很幸运地被录取了,成为发布说明的影子。然后从那里开始,我在发布说明中呆了几个周期, 然后去了文档,自然而然地领导了文档,然后去了增强版,现在我是 1.23 的发行负责人。
CRAIG BOX:我不知道很多人都会考虑到一个好的发行说明需要什么。你说什么才是呢?
REY LEJANO:[笑]你必须告诉最终用户发生了什么变化,或者他们在发行说明中可能看到什么效果。 它不必是高度技术性的。它可以只是几行字,只是说有什么变化,如果他们也必须做任何事情,他们必须做什么。
CRAIG BOX:我不知道很多人会考虑一个好的发布说明的内容。你会说什么?
REY LEJANO:当我是这个周期的发布负责人时,我说过几次。你从发布团队得到的东西和你投入的东西一样多,或者说它直接与你投入的东西相一致。 我学到了很多东西。我在进入发布团队时就有这样的心态:向角色领导学习,也向其他影子学习。 这实际上是我的第一个角色负责人告诉我的一句话。我仍然铭记于心,那是在 1.18 中。那是 Eddie,在我们第一次见面时,我仍然牢记在心。
CRAIG BOX:当然,你是 1.23 的发布负责人。首先,祝贺发布。
REY LEJANO:非常感谢。
CRAIG BOX:这个版本的主题是最后战线。 请告诉我我们是如何确定主题和标志的故事。
REY LEJANO:最后战线代表了几件事。它不仅代表了此版本的下一个增强功能,而且 Kubernetes 本身也有《星际迷航》的参考历史。 Kubernetes 的原始代号是 Project Seven,指的是最初来自《星际迷航》中的 Seven of Nine。 在 Kubernetes 的 logo 中掌舵的七根辐条也是如此。当然,还有 Kubernetes 的前身 Borg。
最后战线继续星际迷航参考。这是星际迷航宇宙中两个标题的融合。一个是星际迷航 5:最后战线,还有星际迷航:下一代。
CRAIG BOX:你对《星际迷航 5》是一部奇数电影有什么看法,而且它们通常被称为比偶数电影票房少?
REY LEJANO:我不能说,因为我是一个科幻书呆子,我喜欢他们所有的人,尽管他们很糟糕。即使是《下一代》系列之后的电影,我仍然喜欢所有的电影,尽管我知道有些并不那么好。
CRAIG BOX:我记得星际迷航 5 是由 William Shatner 执导对吗?
REY LEJANO:是的,对的。
CRAIG BOX:我认为这说明了一切。
REY LEJANO:[笑]是的。
CRAIG BOX:现在,我明白了,主题来自于 SIG 发布章程?
REY LEJANO:是的。SIG 发布章程中有一句话,“确保有一个一致的社区成员小组来支持不同时期的发布过程。” 在发布团队中,我们每一个发布周期都有新的影子加入。有了这个,我们与这个社区一起成长。我们正在壮大发布团队的成员。 我们正在增加 SIG 版本。我们正在发展 Kubernetes 社区本身。对于很多人来说,这是他们第一次为开源做出贡献,所以我说这是他们新的开源前沿。
CRAIG BOX:而这个标志显然是受《星际迷航》的启发。让我感到惊讶的是,花了那么长时间才有人走这条路
REY LEJANO:我也很惊讶。我不得不重新学习 Adobe Illustrator 来创建标志。
CRAIG BOX:这是你自己的作品,是吗?
REY LEJANO:这是我自己的作品。
CRAIG BOX:非常好。
REY LEJANO:谢谢。有趣的是,相对于飞船,银河系实际上花了我最长的时间。我花了几天时间才把它弄正确。 我一直在对它进行微调,所以在真正发布时可能会有最后的改变。
CRAIG BOX:没有边界是真正的终结。
REY LEJANO:是的,非常正确。
CRAIG BOX:现在从发布的主题转到实质内容,也许,1.23 中有什么新内容?
REY LEJANO:我们有 47 项增强功能。我将运行大部分稳定的,甚至全部的,一些关键的 Beta 版,以及一些 1.23 版的 Alpha 增强。
其中一个关键的改进是双堆栈 IPv4/IPv6,它在 1.23 版本中采用了 GA。
一些背景信息:双堆栈在 1.15 中作为 Alpha 引入。你可能在 KubeCon 2019 上看到了一个主题演讲。 那时,双栈的工作方式是,你需要两个服务--你需要每个IP家族的服务。你需要一个用于 IPv4 的服务和一个用于 IPv6 的服务。 它在 1.20 版本中被重构了。在 1.21 版本中,它处于测试阶段;默认情况下,集群被启用为双堆栈。
然后在 1.23 版本中,我们确实删除了 IPv6 双栈功能标志。这不是强制性的使用双栈。它实际上仍然不是 "默认"的。 Pod,服务仍然默认为单栈。要使用双栈,有一些要求。节点必须可以在 IPv4 和 IPv6 网络接口上进行路由。 你需要一个支持双栈的 CNI 插件。Pod 本身必须被配置为双栈。而服务需要 ipFamilyPolicy 字段来指定喜欢双栈或要求双栈。
CRAIG BOX:这听起来暗示仍然需要 v4。你是否看到了一个我们实际上可以转移到仅有 v6 的集群的世界??
REY LEJANO:我认为在未来很多很多年里,我们都会谈论 IPv4 和 IPv6。我记得很久以前,他们一直在说 "这将全部是 IPv6",而那是几十年前的事了。
CRAIG BOX:我想我之前可能在节目中提到过,Vint Cerf 在伦敦参加了一个会议, 他当时做了一个公开演讲说,现在是v6的时代了。那是至少 10 年前的事了。现在还不是 v6 的时代,我的电脑桌面上还没有一天拥有 Linux。
REY LEJANO:[笑]在我看来,这是 1.23 版稳定的一大关键功能。
1.23 版的另一个亮点是 Pod 安全许可进入 Beta 版。 我知道这个功能将进入 Beta 版,但我强调这一点是因为有些人可能知道,PodSecurityPolicy 在 1.21 版本中被废弃,目标是在 1.25 版本中被移除。 Pod 安全接纳取代了 Pod 安全策略。它是一个准入控制器。它根据预定义的 Pod 安全标准集对 Pod 进行评估,以接纳或拒绝 Pod 的运行。
Pod 安全标准分为三个级别。特权,这是完全开放的。基线,已知的特权升级被最小化。或者 限制级,这是强化的。而且你可以将 Pod 安全标准设置为以三种模式运行, 即强制:拒绝任何违规的 Pod;审计:允许创建 Pod,但记录违规行为;或警告:它会向用户发送警告消息,并且允许该 Pod。
CRAIG BOX:你提到 PodSecurityPolicy 将在两个版本的时间内被弃用。我们是否对这些功能进行了排列,以便届时 Pod 安全接纳将成为 GA?
REY LEJANO:是的。当然可以。我稍后也会为另一个功能谈谈这个问题。还有另一个功能也进入了 GA。这是一个归入 GA 的 API, 因此 Beta 版的 API 现在被废弃了。我稍稍讲一下这个问题。
CRAIG BOX:好吧。让我们来谈谈名单上的下一个问题。
REY LEJANO:让我们继续讨论更稳定的增强功能。一种是 TTL 控制器。 它在作业完成后清理作业和 Pod。有一个 TTL 计时器在作业或 Pod 完成后开始计时。此 TTL 控制器监视所有作业, 并且需要设置 ttlSecondsAfterFinished。该控制器将查看 ttlSecondsAfterFinished,结合最后的过渡时间,如果它大于现在。 如果是,那么它将删除该作业和该作业的 Pod。
CRAIG BOX:粗略地说,它可以称为垃圾收集器吗?
REY LEJANO:是的。用于 Pod 和作业,或作业和 Pod 的垃圾收集器。
CRAIG BOX:如果 Kubernetes 真正成为一种编程语言,它当然必须实现垃圾收集器。
REY LEJANO:是的。还有另一个,也将在 Alpha 中出现。[笑]
CRAIG BOX:告诉我。
REY LEJANO: 那个是在 Alpha 中出现的。这实际上是我最喜欢的功能之一,今天我只想强调几个。 StafeulSet 的 PVC 将被清理。 当你删除那个 StatefulSet 时,它将自动删除由 StatefulSets 创建的 PVC。
CRAIG BOX:我们的稳定功能之旅的下一步是什么?
REY LEJANO:下一个是,跳过卷所有权更改进入稳定状态。 这是来自 SIG 存储。有的时候,当你运行一个有状态的应用程序时,就像许多数据库一样,它们对下面的权限位变化很敏感。 目前,当一个卷被绑定安装在容器内时,该卷的权限将递归更改。这可能需要很长时间。 -->
现在,有一个字段,即 fsGroupChangePolicy,它允许你作为用户告诉 Kubernetes 你希望如何更改该卷的权限和所有权。 你可以将其设置为总是、始终更改权限,或者只是在不匹配的情况下,只在顶层的权限所有权变化与预期不同的情况下进行。
CRAIG BOX:确实感觉很多这些增强功能都来自一个非常特殊的用例,有人说,“嘿,这对我来说不起作用,我已经研究了一个功能,它可以完全满足我需要的东西”
REY LEJANO:当然可以。人们为这些问题创建问题,然后创建 Kubernetes 增强提案,然后被列为发布目标。
CRAIG BOX:此版本中的另一个 GA 功能--临时卷。
REY LEJANO:我们一直能够将空目录用于临时卷,但现在我们实际上可以拥有[临时内联卷] (https://github.com/kubernetes/enhancements/issues/1698), 这意味着你可以使用标准 CSI 驱动程序并能够与它一起使用临时卷。
CRAIG BOX:而且,很长一段时间,CronJobs。
REY LEJANO:CronJobs 很有趣,因为它在 1.23 之前是稳定的。对于 1.23,它仍然被跟踪,但它只是清理了一些旧控制器。 使用 CronJobs,有一个 v2 控制器。1.23 中清理的只是旧的 v1 控制器。
CRAIG BOX:在这个版本中,是否有任何其他的重复或重大的清理工作值得注意?
REY LEJANO:是的。有几个你可能会在主要的主题中看到。其中一个有点棘手,围绕 FlexVolumes。这是 SIG 存储公司的努力之一。 他们正在努力将树内插件迁移到 CSI 驱动。这有点棘手,因为 FlexVolumes 实际上是在 2020 年 11 月被废弃的。我们 在 1.23 中正式宣布。
CRAIG BOX:在我看来,FlexVolumes 比 CSI 这个概念还要早。所以现在是时候摆脱它们了。
REY LEJANO:是的。还有另一个弃用,只是一些 klog 特定标志,但除此之外,1.23 中没有其他大的弃用。
CRAIG BOX:上一届 KubeCon 的流行语,在某种程度上也是过去 12 个月的主题,是安全的软件供应链。Kubernetes 在这一领域做了哪些改进工作?
REY LEJANO:对于 1.23 版本,Kubernetes 现在符合 SLSA 的 1 级标准,这意味着描述发布过程中分期和发布阶段的证明文件对于 SLSA 框架来说是令人满意的。
CRAIG BOX:需要做什么才能提升到更高的水平?
REY LEJANO:级别 1 意味着一些事情——构建是脚本化的;出处是可用的,这意味着工件是经过验证,并且已从一个阶段移交到下一个阶段; 并描述了工件是如何产生的。级别 2 意味着源是受版本控制的,也就是说,源是经过身份验证的,源是服务生成的,并且存在构建服务。SLSA 的合规性分为四个级别。
CRAIG BOX:看起来这些水平在很大程度上受到了建立这样一个大型安全项目的影响。例如,似乎不需要很多额外的工作来提升到可验证的出处。 可能只需要几行脚本即可满足其中许多要求。
REY LEJANO:当然。我觉得我们就快成功了;我们会看到 1.24 版本会出现什么。我确实想对 SIG 发布和发布工程部大加赞赏, 主要是 Adolfo García Veytia,他在 GitHub 和 Slack 上又名 Puerco。 他一直在推动这一进程。
CRAIG BOX:你提到了一些 API 正在及时升级以替换其已弃用的版本。告诉我有关新 HPA API 的信息。
REY LEJANO:horizontal pod autoscaler v2 API, 现已稳定,这意味着 v2beta2 API 已弃用。众所周知,v1 API 并未被弃用。不同之处在于 v2 添加了对用于 HPA 的多个和自定义指标的支持。
CRAIG BOX:现在还可以使用表达式语言验证我的 CRD。
REY LEJANO:是的。你可以使用 通用表达式语言,或 CEL 来验证你的 CRD,因此你不再需要使用 webhook。这也使 CRD 更加自包含和声明性,因为规则现在保存在 CRD 对象定义中。
CRAIG BOX:哪些新功能(可能是 Alpha 版或 Beta 版)引起了你的兴趣?
REY LEJANO:除了 Pod 安全策略,我真的很喜欢支持 kubectl 调试的临时容器。 它启动一个临时容器和一个正在运行的 Pod,共享这些 Pod 命名空间,你只需运行 kubectl debug 即可完成所有故障排除。
CRAIG BOX:使用 kubectl 处理事件的方式也发生了一些有趣的变化。
REY LEJANO:是的。kubectl events 总是有一些问题,比如事情没有排序。
kubectl 事件得到了改进,
所以现在你可以使用 --watch,它也可以使用 --watch 选项进行排序。那是新事物。
你实际上可以组合字段和自定义列。此外,你可以在时间线中列出最后 N 分钟的事件。你还可以使用其他标准对事件进行排序。
CRAIG BOX:你是 SUSE 的一名现场工程师。有什么事情是你所处理的个别客户所要注意的吗?
REY LEJANO:更多我期待帮助客户的东西。
CRAIG BOX:好吧。
REY LEJANO:我真的很喜欢 kubectl 事件。真的很喜欢用 StatefulSets 清理的 PVC。其中大部分是出于自私的原因,它将改进故障排除工作。[笑]
CRAIG BOX:我一直希望发布团队负责人对我说:“是的,我有自私的理由。我终于得到了我想要的东西。”
REY LEJANO:[大笑]
CRAIG BOX:也许我应该竞选发布团队的负责人,这样我就可以最终让 Init 容器一劳永逸地得到修复。
REY LEJANO:哦,Init 容器,我一直在寻找它。实际上,我已经制作了 GIF 动画,介绍了 Init 容器将如何与那个 Kubernetes 增强提案一起运行,但目前已经停止了。
CRAIG BOX:有一天。
REY LEJANO:总有一天。也许我不应该停下来。
CRAIG BOX:你提到的显然是你所关注的事情。是否有任何即将推出的东西,可能是 Alpha 功能,甚至可能只是你最近看到的建议,你个人真的很期待看到它们的发展方向?
REY LEJANO:是的。Oone 是一个非常有趣的问题,它影响了整个社区,所以这不仅仅是出于个人原因。 正如你可能已经知道的,Dockershim 已经被废弃了。而且我们确实发布了一篇博客,说它将在 1.24 中被删除。
CRAIG BOX:吓坏了一群人。
REY LEJANO:吓坏了一群人。从一项调查中,我们看到很多人仍在使用 Docker 和 Dockershim。 1.23 的增强功能之一是 kubelet CRI 进入 Beta 版。 这促进了 CRI API 的发展,而这是必需的。 这必须是 Beta 版才能在 1.24 中删除 Dockershim。
**CRAIG BOX:现在,在最后一次发布团队领导访谈中,我们与 Savitha Raghunathan 进行了交谈, 她谈到了作为她的继任者她会给你什么建议。她说要关注团队成员的心理健康。你是如何采纳这个建议的?
REY LEJANO:Savitha 的建议很好。我在每次发布团队会议上都记录了一些事情。 每次发布团队会议后,我都会停止录制,因为我们确实会录制所有会议并将其发布到 YouTube 上。 我向任何想要说任何未记录的内容的人开放发言,这不会出现在议程上。此外,我告诉人们不要在周末工作。 我曾经打破过这个规则,但除此之外,我告诉人们它可以等待。只要注意你的心理健康。
CRAIG BOX:刚刚宣布来自 Jetstack 的 James Laverack 将成为 1.24 的发布团队负责人。James 和我在 San Diego 的最后一届 KubeCon 上分享了一顿有趣的墨西哥晚餐。
REY LEJANO:哦,不错。我不知道你认识 James。
CRAIG BOX:英国科技界。我们是一个非常小的世界。你对 James 的建议是什么?
REY LEJANO:对于 1.24,我要告诉 James 的是在发布团队会议中使用教学时刻。当你第一次成为影子时,这是非常令人生畏的。 这非常困难,因为你不知道存储库。你不知道发布过程。周围的每个人似乎都知道发布过程,并且非常熟悉发布过程是什么。 但作为第一次出现的影子,你并不了解社区的所有白话。我只是建议使用教学时刻。在发布团队会议上花几分钟时间,让新影子更容易上手并熟悉发布过程。
CRAIG BOX:在你参与的这段时间里,这个过程是否有重大演变?或者你认为它正在有效地做它需要做的事情?
REY LEJANO:它总是在不断发展。我记得我第一次做发布说明时,1.18,我们说我们的目标是自动化和编程,这样我们就不再有发行说明团队了。 这改变了很多[笑]。尽管 Adolfo 和 James 在发布说明过程中取得了重大进展,但他们在 krel 中创建了一个子命令来生成发行说明。
但如今,他们所有的发行说明都更加丰富了。在自动化过程中,仍然没有达到。每个发布周期,都有一点不同的东西。 对于这个发布周期,我们有一个生产就绪审查截止日期。这是一个软期限。生产就绪审查是社区中几个人的审查。 实际上从 1.21 开始就需要它,它确保增强是可观察的、可扩展的、可支持的,并且在生产中运行是安全的,也可以被禁用或回滚。 在 1.23 中,我们有一个截止日期,要求在特定日期之前完成生产就绪审查。
CRAIG BOX:你如何发现每年发布三个版本,而不是四个版本?
REY LEJANO:从一年四个版本转为三个版本,在我看来是一种进步,因为我们支持最后三个版本, 现在我们实际上可以支持在一个日历年内的最后一个版本,而不是在 12 个月中只有 9 个月。
CRAIG BOX:日历上的下一个活动是下周一开始的 Kubernetes 贡献者庆典。我们可以从活动中期待什么?
REY LEJANO:这是我们第二次举办这个虚拟活动。这是一个虚拟的庆祝活动,以表彰整个社区和我们今年的所有成就,以及贡献者。 在这周的庆典中有许多活动。它从 12 月 13 日的那一周开始。
有像 Kubernetes 贡献者奖这样的活动,SIG 对社区和贡献者的辛勤工作进行表彰和奖励。 也有一个 DevOps 聚会游戏。还有一个云原生的烘烤活动。我强烈建议人们去 kubernetes.dev/celebration 了解更多。
CRAIG BOX: 究竟如何评判一个虚拟的烘焙比赛呢?
REY LEJANO:那我不知道。[笑]
CRAIG BOX:我尝了尝我的烤饼。我认为他们是最好的。我给他们打了 10 分(满分 10 分)。
REY LEJANO:是的。这是很难做到的。我不得不说,这道菜可能是什么,它与 Kubernetes 或开源或与 CNCF 的关系有多密切。 有几个评委。我知道 Josh Berkus 和 Rin Oliver 是主持烘焙比赛的几个评委。
CRAIG BOX:是的。我们与 Josh 谈到了他对厨房的热爱,因此他似乎非常适合这个角色。
REY LEJANO:他是。
CRAIG BOX:最后,你的妻子和你自己将在一月份迎来你们的第一个孩子。你是否为此进行过生产准备审查?
REY LEJANO:我认为我们没有通过审查。[笑]
CRAIG BOX:还有时间。
REY LEJANO:我们正在努力重构。我们将在 12 月进行一些重构,然后再次使用 --apply。
Rey Lejano 是 SUSE 的一名现场工程师,来自 Rancher Labs,并且是 Kubernetes 1.23 的发布团队负责人。 他现在也是 SIG Docs 的联合主席。他的儿子 Liam 现在 3 个半月大。
你可以在 Twitter 上的 @KubernetesPod 找到来自谷歌的 Kubernetes 播客, 你也可以订阅,这样你就不会错过任何一集。
在 Ingress-NGINX v1.2.0 中提高安全标准
作者: Ricardo Katz (VMware), James Strong (Chainguard)
Ingress 可能是 Kubernetes 最容易受攻击的组件之一。 Ingress 通常定义一个 HTTP 反向代理,暴露在互联网上,包含多个网站,并具有对 Kubernetes API 的一些特权访问(例如读取与 TLS 证书及其私钥相关的 Secret)。
虽然它是架构中的一个风险组件,但它仍然是正常公开服务的最流行方式。
Ingress-NGINX 一直是安全评估的重头戏,这类评估会发现我们有着很大的问题:
在将配置转换为 nginx.conf 文件之前,我们没有进行所有适当的清理,这可能会导致信息泄露风险。
虽然我们了解此风险以及解决此问题的真正需求,但这并不是一个容易的过程, 因此我们在当前(v1.2.0)版本中采取了另一种方法来减少(但不是消除!)这种风险。
了解 Ingress NGINX v1.2.0 和 chrooted NGINX 进程
主要挑战之一是 Ingress-NGINX 运行着 Web 代理服务器(NGINX),并与 Ingress 控制器一起运行
(后者是一个可以访问 Kubernetes API 并创建 nginx.conf 的组件)。
因此,NGINX 对控制器的文件系统(和 Kubernetes 服务帐户令牌,以及容器中的其他配置)具有相同的访问权限。
虽然拆分这些组件是我们的最终目标,但该项目需要快速响应;这让我们想到了使用 chroot()。
让我们看一下 Ingress-NGINX 容器在此更改之前的样子:
正如我们所见,用来提供 HTTP Proxy 的容器(不是 Pod,是容器!)也是是监视 Ingress 对象并将数据写入容器卷的容器。
现在,见识一下新架构:
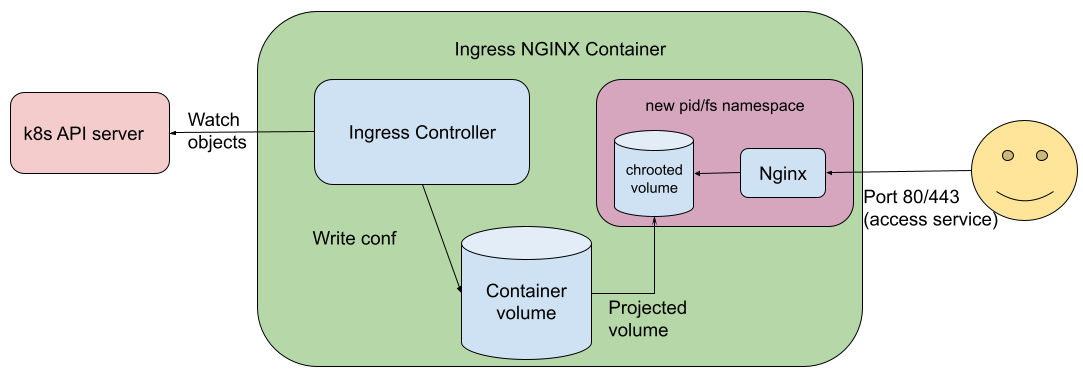
这一切意味着什么?一个基本的总结是:我们将 NGINX 服务隔离为控制器容器内的容器。
虽然这并不完全正确,但要了解这里所做的事情,最好了解 Linux 容器(以及内核命名空间等底层机制)是如何工作的。
你可以在 Kubernetes 词汇表中阅读有关 cgroup 的信息:cgroup,
并在 NGINX 项目文章什么是命名空间和 cgroup,以及它们如何工作?
中了解有关 cgroup 与命名空间交互的更多信息。(当你阅读时,请记住 Linux 内核命名空间与
Kubernetes 命名空间不同)。
跳过谈话,我需要什么才能使用这种新方法?
虽然这增加了安全性,但我们在这个版本中把这个功能作为一个选项,这样你就可以有时间在你的环境中做出正确的调整。 此新功能仅在 Ingress-NGINX 控制器的 v1.2.0 版本中可用。
要使用这个功能,在你的部署中有两个必要的改变:
- 将后缀 "-chroot" 添加到容器镜像名称中。例如:
gcr.io/k8s-staging-ingress-nginx/controller-chroot:v1.2.0 - 在你的 Ingress 控制器的 Pod 模板中,找到添加
NET_BIND_SERVICE权能的位置并添加SYS_CHROOT权能。 编辑清单后,你将看到如下代码段:
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
- SYS_CHROOT
如果你使用官方 Helm Chart 部署控制器,则在 values.yaml 中更改以下设置:
controller:
image:
chroot: true
Ingress 控制器通常部署在集群作用域(IngressClass API 是集群作用域的)。
如果你管理 Ingress-NGINX 控制器但你不是整个集群的操作员,
请在部署中启用它之前与集群管理员确认你是否可以使用 SYS_CHROOT 功能。
好吧,但这如何能提高我的 Ingress 控制器的安全性呢?
以下面的配置片段为例,想象一下,由于某种原因,它被添加到你的 nginx.conf 中:
location /randomthing/ {
alias /;
autoindex on;
}
如果你部署了这种配置,有人可以调用 http://website.example/randomthing 并获取对 Ingress 控制器的整个文件系统的一些列表(和访问权限)。
现在,你能在下面的列表中发现 chroot 处理过和未经 chroot 处理过的 Nginx 之间的区别吗?
不额外调用 chroot() | 额外调用 chroot() |
|---|---|
bin | bin |
dev | dev |
etc | etc |
home | |
lib | lib |
media | |
mnt | |
opt | opt |
proc | proc |
root | |
run | run |
sbin | |
srv | |
sys | |
tmp | tmp |
usr | usr |
var | var |
dbg | |
nginx-ingress-controller | |
wait-shutdown |
左侧的那个没有 chroot 处理。所以 NGINX 可以完全访问文件系统。右侧的那个经过 chroot 处理, 因此创建了一个新文件系统,其中只有使 NGINX 工作所需的文件。
此版本中的其他安全改进如何?
我们知道新的 chroot() 机制有助于解决部分风险,但仍然有人可以尝试注入命令来读取,例如 nginx.conf 文件并提取敏感信息。
所以,这个版本的另一个变化(可选择取消)是 深度探测(Deep Inspector)。 我们知道某些指令或正则表达式可能对 NGINX 造成危险,因此深度探测器会检查 Ingress 对象中的所有字段 (在其协调期间,并且还使用验证准入 webhook) 验证是否有任何字段包含这些危险指令。
Ingress 控制器已经通过注解做了这个工作,我们的目标是把现有的验证转移到深度探测中,作为未来版本的一部分。
你可以在 https://github.com/kubernetes/ingress-nginx/blob/main/internal/ingress/inspector/rules.go 中查看现有规则。
由于检查和匹配相关 Ingress 对象中的所有字符串的性质,此新功能可能会消耗更多 CPU。
你可以通过使用命令行参数 --deep-inspect=false 运行 Ingress 控制器来禁用它。
下一步是什么?
这不是我们的最终目标。我们的最终目标是拆分控制平面和数据平面进程。 事实上,这样做也将帮助我们实现 Gateway API 实现, 因为一旦它“知道”要提供什么,我们可能会有不同的控制器 数据平面(我们需要一些帮助!!)
Kubernetes 中的其他一些项目已经采用了这种方法(如 KPNG,
建议替换 kube-proxy),我们计划与他们保持一致,并为 Ingress-NGINX 获得相同的体验。
延伸阅读
如果你想了解如何在 Ingress NGINX 中完成 chrooting,请查看 https://github.com/kubernetes/ingress-nginx/pull/8337。 包含所有更改的版本 v1.2.0 可以在以下位置找到 https://github.com/kubernetes/ingress-nginx/releases/tag/controller-v1.2.0
Kubernetes 1.24 中的移除和弃用
作者:Mickey Boxell (Oracle)
随着 Kubernetes 的发展,一些特性和 API 会被定期重检和移除。 新特性可能会提供替代或改进的方法,来解决现有的问题,从而激励团队移除旧的方法。
我们希望确保你了解 Kubernetes 1.24 版本的变化。该版本将 弃用 一些(测试版/beta)API, 转而支持相同 API 的稳定版本。Kubernetes 1.24 版本的主要变化是移除 Dockershim。 这将在下面讨论,并将在发布时更深入地探讨。 要提前了解 Kubernetes 1.24 中的更改,请查看正在更新中的 CHANGELOG。
关于 Dockershim
可以肯定地说,随着 Kubernetes 1.24 的发布,最受关注的是移除 Dockershim。 Dockershim 在 1.20 版本中已被弃用。如 Kubernetes 1.20 变更日志中所述: "Docker support in the kubelet is now deprecated and will be removed in a future release. The kubelet uses a module called "dockershim" which implements CRI support for Docker and it has seen maintenance issues in the Kubernetes community." 随着即将发布的 Kubernetes 1.24,Dockershim 将最终被移除。
在文章别慌: Kubernetes 和 Docker 中, 作者简洁地记述了变化的影响,并鼓励用户保持冷静:
弃用 Docker 这个底层运行时,转而支持符合为 Kubernetes 创建的容器运行接口 Container Runtime Interface (CRI) 的运行时。 Docker 构建的镜像,将在你的集群的所有运行时中继续工作,一如既往。
已经有一些文档指南,提供了关于从 dockershim 迁移到与 Kubernetes 直接兼容的容器运行时的有用信息。 你可以在 Kubernetes 文档中的从 dockershim 迁移 页面上找到它们。
有关 Kubernetes 为何不再使用 dockershim 的更多信息, 请参见:Kubernetes 即将移除 Dockershim 和最新的弃用 Dockershim 的常见问题。
查看你的集群准备好使用 v1.24 版本了吗?一文, 了解如何确保你的集群在从 1.23 版本升级到 1.24 版本后继续工作。
Kubernetes API 移除和弃用流程
Kubernetes 包含大量随时间演变的组件。在某些情况下,这种演变会导致 API、标志或整个特性被移除。 为了防止用户面对重大变化,Kubernetes 贡献者采用了一项特性弃用策略。 此策略确保仅当同一 API 的较新稳定版本可用并且 API 具有以下稳定性级别所指示的最短生命周期时,才可能弃用稳定版本 API:
- 正式发布 (GA) 或稳定的 API 版本可能被标记为已弃用,但不得在 Kubernetes 的主版本中移除。
- 测试版(beta)或预发布 API 版本在弃用后必须支持 3 个版本。
- Alpha 或实验性 API 版本可能会在任何版本中被移除,恕不另行通知。
移除遵循相同的弃用政策,无论 API 是由于 测试版(beta)功能逐渐稳定还是因为该 API 未被证明是成功的而被移除。 Kubernetes 将继续确保在移除 API 时提供用来迁移的文档。
弃用的 API 是指那些已标记为在未来 Kubernetes 版本中移除的 API。 移除的 API 是指那些在被弃用后不再可用于当前受支持的 Kubernetes 版本的 API。 这些移除的 API 已被更新的、稳定的/普遍可用的 (GA) API 所取代。
Kubernetes 1.24 的 API 移除、弃用和其他更改
- 动态 kubelet 配置:
DynamicKubeletConfig用于启用 kubelet 的动态配置。Kubernetes 1.22 中弃用DynamicKubeletConfig标志。 在 1.24 版本中,此特性门控将从 kubelet 中移除。 更多详细信息,请参阅“移除动态 kubelet 配置” 的 KEP。
- 动态日志清洗:实验性的动态日志清洗功能已被弃用, 将在 1.24 版本中被移除。该功能引入了一个日志过滤器,可以应用于所有 Kubernetes 系统组件的日志, 以防止各种类型的敏感信息通过日志泄漏。有关更多信息和替代方法,请参阅 KEP-1753: Kubernetes 系统组件日志清洗。
- 从 kubelet 中移除 Dockershim:Docker 的容器运行时接口(CRI)(即 Dockershim)目前是 kubelet 代码中内置的容器运行时。它在 1.20 版本中已被弃用。 从 1.24 版本开始,kubelet 已经移除 dockershim。查看这篇博客, 了解你需要为 1.24 版本做些什么。
- Pod 调度的存储容量追踪:CSIStorageCapacity API 支持通过 CSIStorageCapacity 对象暴露当前可用的存储容量,并增强了使用带有延迟绑定的 CSI 卷的 Pod 的调度。 CSIStorageCapacity API 自 1.24 版本起提供稳定版本。升级到稳定版的 API 将弃用 v1beta1 CSIStorageCapacity API。 更多信息请参见 Pod 调度存储容量约束 KEP。
- kubeadm 控制面节点上不再存在
master标签。 对于新集群,控制平面节点将不再添加 'node-role.kubernetes.io/master' 标签, 只会添加 'node-role.kubernetes.io/control-plane' 标签。更多信息请参考 KEP-2067:重命名 kubeadm “master” 标签和污点。
- VolumeSnapshot v1beta1 CRD 在 1.24 版本中将被移除。 Kubernetes 和 Container Storage Interface (CSI) 的卷快照和恢复功能,在 1.20 版本中进入测试版。该功能提供标准化 API 设计 (CRD ) 并为 CSI 卷驱动程序添加了 PV 快照/恢复支持, VolumeSnapshot v1beta1 在 1.21 版本中已被弃用,现在不受支持。更多信息请参考 KEP-177:CSI 快照和 kubernetes-csi/external-snapshotter。
需要做什么
移除 Dockershim
如前所述,有一些关于从 dockershim 迁移的指南。 你可以从查明节点上所使用的容器运行时开始。 如果你的节点使用 dockershim,则还有其他可能的 Docker Engine 依赖项, 例如 Pod 或执行 Docker 命令的第三方工具或 Docker 配置文件中的私有镜像库。 你可以按照检查移除 Dockershim 是否对你有影响 的指南来查看可能的 Docker 引擎依赖项。在升级到 1.24 版本之前,你决定要么继续使用 Docker Engine 并 将 Docker Engine 节点从 dockershim 迁移到 cri-dockerd, 要么迁移到与 CRI 兼容的运行时。这是将节点上的容器运行时从 Docker Engine 更改为 containerd 的指南。
kubectl convert
kubectl 的 kubectl convert
插件有助于解决弃用 API 的迁移问题。该插件方便了不同 API 版本之间清单的转换,
例如,从弃用的 API 版本到非弃用的 API 版本。
关于 API 迁移过程的更多信息可以在已弃用 API 的迁移指南中找到。
按照安装 kubectl convert 插件
文档下载并安装 kubectl-convert 二进制文件。
展望未来
计划在今年晚些时候发布的 Kubernetes 1.25 和 1.26 版本,将停止提供一些 Kubernetes API 的 Beta 版本,这些 API 当前为稳定版。1.25 版本还将移除 PodSecurityPolicy, 它已在 Kubernetes 1.21 版本中被弃用,并且不会升级到稳定版。有关详细信息,请参阅 PodSecurityPolicy 弃用:过去、现在和未来。
Kubernetes 1.25 计划移除的 API 的官方列表是:
- Beta CronJob API (batch/v1beta1)
- Beta EndpointSlice API (discovery.k8s.io/v1beta1)
- Beta Event API (events.k8s.io/v1beta1)
- Beta HorizontalPodAutoscaler API (autoscaling/v2beta1)
- Beta PodDisruptionBudget API (policy/v1beta1)
- Beta PodSecurityPolicy API (policy/v1beta1)
- Beta RuntimeClass API (node.k8s.io/v1beta1)
Kubernetes 1.26 计划移除的 API 的官方列表是:
- Beta FlowSchema 和 PriorityLevelConfiguration API (flowcontrol.apiserver.k8s.io/v1beta1)
- Beta HorizontalPodAutoscaler API (autoscaling/v2beta2)
了解更多
Kubernetes 发行说明中宣告了弃用信息。你可以在以下版本的发行说明中看到待弃用的公告:
- Kubernetes 1.21
- Kubernetes 1.22
- Kubernetes 1.23
- 我们将正式宣布 Kubernetes 1.24 的弃用信息, 作为该版本 CHANGELOG 的一部分。
有关弃用和移除过程的信息,请查看 Kubernetes 官方弃用策略文档。
你的集群准备好使用 v1.24 版本了吗?
作者: Kat Cosgrove
早在 2020 年 12 月,Kubernetes 就宣布弃用 Dockershim。 在 Kubernetes 中,dockershim 是一个软件 shim, 它允许你将整个 Docker 引擎用作 Kubernetes 中的容器运行时。 在即将发布的 v1.24 版本中,我们将移除 Dockershim - 在宣布弃用之后到彻底移除这段时间内,我们至少预留了一年的时间继续支持此功能, 这符合相关的项目策略。 如果你是集群操作员,则该指南包含你在此版本中需要了解的实际情况。 另外还包括你需要做些什么来确保你的集群不会崩溃!
首先,这对你有影响吗?
如果你正在管理自己的集群或不确定此删除是否会影响到你, 请保持安全状态并检查你对 Docker Engine 是否有依赖。 请注意,使用 Docker Desktop 构建应用程序容器并不算是集群对 Docker 有依赖。 Docker 创建的容器镜像符合 Open Container Initiative (OCI) 规范, 而 OCI 是 Linux 基金会的一种治理架构,负责围绕容器格式和运行时定义行业标准。 这些镜像可以在 Kubernetes 支持的任何容器运行时上正常工作。
如果你使用的是云服务提供商管理的 Kubernetes 服务, 并且你确定没有更改过容器运行时,那么你可能不需要做任何事情。 Amazon EKS、Azure AKS 和 Google GKE 现在都默认使用 containerd, 但如果你的集群中有任何自定义的节点,你要确保它们不需要被更新。 要检查节点的运行时,请参考查明节点上所使用的容器运行时。
无论你是在管理自己的集群还是使用云服务提供商管理的 Kubernetes 服务, 你可能都需要迁移依赖 Docker Engine 的遥测或安全代理。
我对 Docker 有依赖。现在该怎么办?
如果你的 Kubernetes 集群对 Docker Engine 有依赖, 并且你打算升级到 Kubernetes v1.24 版本(出于安全和类似原因,你最终应该这样做), 你需要将容器运行时从 Docker Engine 更改为其他方式或使用 cri-dockerd。 由于 containerd 是一个已经毕业的 CNCF 项目, 并且是 Docker 本身的运行时,因此用它作为容器运行时的替代方式是一个安全的选择。 幸运的是,Kubernetes 项目已经以 containerd 为例, 提供了更改节点容器运行时的过程文档。 切换到其它支持的运行时的操作指令与此类似。
我想升级 Kubernetes,并且我需要保持与 Docker 作为运行时的兼容性。我有哪些选择?
别担心,你不会被冷落,也不必冒着安全风险继续使用旧版本的 Kubernetes。 Mirantis 和 Docker 已经联合发布并正在维护 dockershim 的替代品。 这种替代品称为 cri-dockerd。 如果你确实需要保持与 Docker 作为运行时的兼容性,请按照项目文档中的说明安装 cri-dockerd。
这样就可以了吗?
是的。只要你深入了解此版本所做的变更和你自己集群的详细信息, 并确保与你的开发团队进行清晰的沟通,它的不确定性就会降到最低。 你可能需要对集群、应用程序代码或脚本进行一些更改,但所有这些要求都已经有说明指导。 从使用 Docker Engine 作为运行时,切换到使用其他任何一种支持的容器运行时, 这意味着移除了中间层的组件,因为 dockershim 的作用是访问 Docker 本身使用的容器运行时。 从实际角度长远来看,这种移除对你和 Kubernetes 维护者都更有好处。
如果你仍有疑问,请先查看弃用 Dockershim 的常见问题。
认识我们的贡献者 - 亚太地区(澳大利亚-新西兰地区)
作者和采访者: Anubhav Vardhan、 Atharva Shinde、 Avinesh Tripathi、 Brad McCoy、 Debabrata Panigrahi、 Jayesh Srivastava、 Kunal Verma、 Pranshu Srivastava、 Priyanka Saggu、 Purneswar Prasad、 Vedant Kakde
大家好👋
欢迎来到亚太地区的”认识我们的贡献者”博文系列第二期。
这篇文章将介绍来自澳大利亚和新西兰地区的四位杰出贡献者, 他们在上游 Kubernetes 项目中承担着不同子项目的领导者和社区贡献者的角色。
闲话少说,让我们直接进入主题。
Caleb Woodbine
Caleb Woodbine 目前是 ii.nz 组织的成员。
他于 2018 年作为 Kubernetes Conformance 工作组的成员开始为 Kubernetes 项目做贡献。 他积极向上,他从一位来自新西兰的贡献者 Hippie Hacker 的早期指导中受益匪浅。
他在 SIG k8s-infra 和 k8s-conformance 工作组为 Kubernetes 项目做出了重大贡献。
Caleb 也是 CloudNative NZ 社区活动的联合组织者,该活动旨在扩大 Kubernetes 项目在整个新西兰的影响力,以鼓励科技教育和改善就业机会。
亚太地区需要更多的外联活动,教育工作者和大学必须学习 Kubernetes,因为他们非常缓慢, 而且已经落后了8年多。新西兰倾向于在海外付费,而不是教育当地人最新的云技术。
Dylan Graham
Dylan Graham 是来自澳大利亚 Adeliade 的云计算工程师。自 2018 年以来,他一直在为上游 Kubernetes 项目做出贡献。
他表示,成为如此大项目的一份子,最初压力是比较大的,但社区的友好和开放帮助他度过了难关。
开始在项目文档方面做贡献,现在主要致力于为亚太地区提供社区支持。
他相信,持续参加社区/项目会议,承担项目任务,并在需要时寻求社区指导,可以帮助有抱负的新开发人员成为有效的贡献者。
成为大社区的一份子感觉真的很特别。我遇到了一些了不起的人,甚至是在现实生活中疫情发生之前。
Hippie Hacker
Hippie 来自新西兰,曾在 CNCF.io 作为战略计划承包商工作 5 年多。他是 k8s-infra、 API 一致性测试、云提供商一致性提交以及上游 Kubernetes 和 CNCF 项目 apisnoop.cncf.io 域的积极贡献者。
他讲述了他们早期参与 Kubernetes 项目的情况,该项目始于大约 5 年前,当时他们的公司 ii.nz 演示了使用 PXE 从 Raspberry Pi 启动网络,并在集群中运行Gitlab,以便在服务器上安装 Kubernetes
他描述了自己的贡献经历:一开始,他试图独自完成所有艰巨的任务,但最终看到了团队协作贡献的好处, 分工合作减少了过度疲劳,这让人们能够凭借自己的动力继续前进。
他建议新的贡献者结对编程。
针对一个项目,多人关注和交叉交流往往比单独的评审、批准 PR 能产生更大的效果。
Nick Young
Nick Young 在 VMware 工作,是 CNCF 入口控制器 Contour 的技术负责人。 他从一开始就积极参与上游 Kubernetes 项目,最终成为 LTS 工作组的主席, 他提倡关注用户。他目前是 SIG Network Gateway API 子项目的维护者。
他的贡献之路是引人注目的,因为他很早就在 Kubernetes 项目的主要领域工作,这改变了他的轨迹。
他断言,一个新贡献者能做的最好的事情就是“开始贡献”。当然,如果与他的工作息息相关,那好极了; 然而,把非工作时间投入到贡献中去,从长远来看可以在工作上获得回报。 他认为,应该鼓励新的贡献者,特别是那些目前是 Kubernetes 用户的人,参与到更高层次的项目讨论中来。
只要积极主动,做出贡献,你就可以走很远。一旦你活跃了一段时间,你会发现你能够解答别人的问题, 这意味着会有人请教你或和你讨论,在你意识到这一点之前,你就已经是专家了。
如果你对我们接下来应该采访的人有任何意见/建议,请在 #sig-contribex 中告知我们。 非常感谢你的建议。我们很高兴有更多的人帮助我们接触到社区中更优秀的人。
我们下期再见。祝你有个愉快的贡献之旅!👋
更新:移除 Dockershim 的常见问题
本文是针对 2020 年末发布的弃用 Dockershim 的常见问题的博客更新。 本文包括 Kubernetes v1.24 版本的更新。
本文介绍了一些关于从 Kubernetes 中移除 dockershim 的常见问题。 该移除最初是作为 Kubernetes v1.20 版本的一部分宣布的。 Kubernetes 在 v1.24 版移除了 dockershim。
关于细节请参考博文 别慌: Kubernetes 和 Docker。
要确定移除 dockershim 是否会对你或你的组织的影响,可以查阅: 检查弃用 Dockershim 对你的影响 这篇文章。
在 Kubernetes 1.24 发布之前的几个月和几天里,Kubernetes 贡献者努力试图让这个过渡顺利进行。
- 一篇详细说明承诺和后续操作的博文。
- 检查是否存在迁移到其他 容器运行时 的主要障碍。
- 添加 从 dockershim 迁移的指南。
- 创建了一个有关 dockershim 移除和使用 CRI 兼容运行时的列表。 该列表包括一些已经提到的文档,还涵盖了选定的外部资源(包括供应商指南)。
为什么会从 Kubernetes 中移除 dockershim ?
Kubernetes 的早期版本仅适用于特定的容器运行时:Docker Engine。 后来,Kubernetes 增加了对使用其他容器运行时的支持。创建 CRI 标准是为了实现编排器(如 Kubernetes)和许多不同的容器运行时之间交互操作。 Docker Engine 没有实现(CRI)接口,因此 Kubernetes 项目创建了特殊代码来帮助过渡, 并使 dockershim 代码成为 Kubernetes 的一部分。
dockershim 代码一直是一个临时解决方案(因此得名:shim)。 你可以阅读 Kubernetes 移除 Dockershim 增强方案 以了解相关的社区讨论和计划。 事实上,维护 dockershim 已经成为 Kubernetes 维护者的沉重负担。
此外,在较新的 CRI 运行时中实现了与 dockershim 不兼容的功能,例如 cgroups v2 和用户命名空间。 从 Kubernetes 中移除 dockershim 允许在这些领域进行进一步的开发。
Docker 和容器一样吗?
Docker 普及了 Linux 容器模式,并在开发底层技术方面发挥了重要作用,但是 Linux 中的容器已经存在了很长时间,容器生态系统已经发展到比 Docker 广泛得多。 OCI 和 CRI 等标准帮助许多工具在我们的生态系统中发展壮大,其中一些替代了 Docker 的某些方面,而另一些则增强了现有功能。
我现有的容器镜像是否仍然有效?
是的,从 docker build 生成的镜像将适用于所有 CRI 实现,
现有的所有镜像仍将完全相同。
私有镜像呢?
当然可以,所有 CRI 运行时都支持在 Kubernetes 中使用的相同的 pull secrets 配置,无论是通过 PodSpec 还是 ServiceAccount。
在 Kubernetes 1.23 版本中还可以使用 Docker Engine 吗?
可以使用,在 1.20 版本中唯一的改动是,如果使用 Docker Engine, 在 kubelet 启动时会打印一个警告日志。 你将在 1.23 版本及以前版本看到此警告,dockershim 已在 Kubernetes 1.24 版本中移除 。
如果你运行的是 Kubernetes v1.24 或更高版本,请参阅 我仍然可以使用 Docker Engine 作为我的容器运行时吗? (如果你使用任何支持 dockershim 的版本,可以随时切换离开;从版本 v1.24 开始,因为 Kubernetes 不再包含 dockershim,你必须切换)。
我应该用哪个 CRI 实现?
这是一个复杂的问题,依赖于许多因素。 如果你正在使用 Docker Engine,迁移到 containerd 应该是一个相对容易地转换,并将获得更好的性能和更少的开销。 然而,我们鼓励你探索 CNCF landscape 提供的所有选项,做出更适合你的选择。
我还可以使用 Docker Engine 作为我的容器运行时吗?
首先,如果你在自己的电脑上使用 Docker 用来做开发或测试容器:它将与之前没有任何变化。 无论你为 Kubernetes 集群使用什么容器运行时,你都可以在本地使用 Docker。容器使这种交互成为可能。
Mirantis 和 Docker 已承诺
为 Docker Engine 维护一个替代适配器,
并在 dockershim 从 Kubernetes 移除后维护该适配器。
替代适配器名为 cri-dockerd。
你可以安装 cri-dockerd 并使用它将 kubelet 连接到 Docker Engine。
阅读将 Docker Engine 节点从 dockershim 迁移到 cri-dockerd
以了解更多信息。
现在是否有在生产系统中使用其他运行时的例子?
Kubernetes 所有项目在所有版本中出产的工件(Kubernetes 二进制文件)都经过了验证。
此外,kind 项目使用 containerd 已经有一段时间了,并且提高了其用例的稳定性。 Kind 和 containerd 每天都会被多次使用来验证对 Kubernetes 代码库的任何更改。 其他相关项目也遵循同样的模式,从而展示了其他容器运行时的稳定性和可用性。 例如,OpenShift 4.x 从 2019 年 6 月以来,就一直在生产环境中使用 CRI-O 运行时。
至于其他示例和参考资料,你可以查看 containerd 和 CRI-O 的使用者列表, 这两个容器运行时是云原生基金会(CNCF)下的项目。
人们总在谈论 OCI,它是什么?
OCI 是 Open Container Initiative 的缩写, 它标准化了容器工具和底层实现之间的大量接口。 它们维护了打包容器镜像(OCI image)和运行时(OCI runtime)的标准规范。 它们还以 runc 的形式维护了一个 runtime-spec 的真实实现, 这也是 containerd 和 CRI-O 依赖的默认运行时。 CRI 建立在这些底层规范之上,为管理容器提供端到端的标准。
当切换 CRI 实现时,应该注意什么?
虽然 Docker 和大多数 CRI(包括 containerd)之间的底层容器化代码是相同的, 但其周边部分却存在差异。迁移时要考虑如下常见事项:
- 日志配置
- 运行时的资源限制
- 调用 docker 或通过其控制套接字使用 Docker Engine 的节点配置脚本
- 需要
docker命令或 Docker Engine 控制套接字的kubectl插件 - 需要直接访问 Docker Engine 的 Kubernetes 工具(例如:已弃用的 'kube-imagepuller' 工具)
- 配置
registry-mirrors和不安全的镜像仓库等功能 - 保障 Docker Engine 可用、且运行在 Kubernetes 之外的脚本或守护进程(例如:监视或安全代理)
- GPU 或特殊硬件,以及它们如何与你的运行时和 Kubernetes 集成
如果你只是用了 Kubernetes 资源请求/限制或基于文件的日志收集 DaemonSet,它们将继续稳定工作, 但是如果你用了自定义了 dockerd 配置,则可能需要为新的容器运行时做一些适配工作。
另外还有一个需要关注的点,那就是当创建镜像时,系统维护或嵌入容器方面的任务将无法工作。
对于前者,可以用 crictl 工具作为临时替代方案
(参阅从 docker cli 到 crictl 的映射)。
对于后者,可以用新的容器创建选项,例如
img、
buildah、
kaniko 或
buildkit-cli-for-kubectl,
他们都不需要 Docker。
对于 containerd,你可查阅有关它的文档, 获取迁移时可用的配置选项。
有关如何在 Kubernetes 中使用 containerd 和 CRI-O 的说明, 请参阅 Kubernetes 相关文档。
我还有其他问题怎么办?
如果你使用了供应商支持的 Kubernetes 发行版,你可以咨询供应商他们产品的升级计划。 对于最终用户的问题,请把问题发到我们的最终用户社区的论坛。
你可以通过专用 GitHub 问题 讨论删除 dockershim 的决定。
你也可以看看这篇优秀的博客文章:等等,Docker 被 Kubernetes 弃用了? 对这些变化进行更深入的技术讨论。
是否有任何工具可以帮助我找到正在使用的 dockershim?
是的! Docker Socket 检测器 (DDS) 是一个 kubectl 插件,
你可以安装它用于检查你的集群。 DDS 可以检测运行中的 Kubernetes
工作负载是否将 Docker Engine 套接字 (docker.sock) 作为卷挂载。
在 DDS 项目的 README 中查找更多详细信息和使用方法。
我可以加入吗?
当然,只要你愿意,随时随地欢迎。🤗🤗🤗
SIG Node CI 子项目庆祝测试改进两周年
作者: Sergey Kanzhelev (Google), Elana Hashman (Red Hat)
保证 SIG 节点上游代码的可靠性是一项持续的工作,需要许多贡献者在幕后付出大量努力。 Kubernetes、基础操作系统、容器运行时和测试基础架构的频繁发布,导致了一个复杂的矩阵, 需要关注和稳定的投资来“保持灯火通明”。2020 年 5 月,Kubernetes Node 特殊兴趣小组 (“SIG Node”)为节点相关代码和测试组织了一个新的持续集成(CI)子项目。自成立以来,SIG Node CI 子项目每周举行一次会议,即使一整个小时通常也不足以完成对所有缺陷、测试相关的 PR 和问题的分类, 并讨论组内所有相关的正在进行的工作。
在过去两年中,我们修复了阻塞合并和阻塞发布的测试,由于减少了测试缺陷,缩短了合并 Kubernetes 贡献者的拉取请求的时间。通过我们的努力,任务通过率由开始时 42% 提高至稳定大于 90% 。我们已经解决了 144 个测试失败问题, 并在 kubernetes/kubernetes 中合并了 176 个拉取请求。 我们还帮助子项目参与者提升了 Kubernetes 贡献者的等级,新增了 3 名组织成员、6 名评审员和 2 名审批员。
Node CI 子项目是一个可入门的第一站,帮助新参与者开始使用 SIG Node。对于新贡献者来说, 解决影响较大的缺陷和测试修复的门槛很低,尽管贡献者要攀登整个贡献者阶梯还有很长的路要走: 为该团队培养了两个新的审批人花了一年多的时间。为 Kubernetes 节点及其测试基础设施提供动力的所有 不同组件的复杂性要求开发人员在很长一段时间内进行持续投资, 以深入了解整个系统,从宏观到微观。
虽然在我们的会议上有几个比较固定的贡献者;但是我们的评审员和审批员仍然很少。 我们的目标是继续增加贡献者,以确保工作的可持续分配,而不仅仅是少数关键批准者。
SIG 中的子项目如何形成、运行和工作并不总是显而易见的。每一个都是其背后的 SIG 所独有的, 并根据该小组打算支持的项目量身定制。作为一个欢迎了许多第一次 SIG Node 贡献者的团队, 我们想分享过去两年的一些细节和成就,帮助揭开我们内部工作的神秘面纱,并庆祝我们所有专注贡献者的辛勤工作!
时间线
2020 年 5 月 SIG Node CI 组于 2020 年 5 月 11 日成立,超过 30 名志愿者 注册,以改进 SIG Node CI 信号和整体可观测性。 Victor Pickard 专注于让 testgrid 可以运行 , 当时 Ning Liao 建议围绕这项工作组建一个小组,并提出 最初的小组章程文件 。 SIG Node 赞助成立以 Victor 作为子项目负责人的小组。Sergey Kanzhelev 不久后就加入 Victor,担任联合领导人。
在启动会议上,我们讨论了应该首先集中精力修复哪些测试,并讨论了阻塞合并和阻塞发布的测试, 其中许多测试由于基础设施问题或错误的测试代码而失败。
该子项目每周召开一小时的会议,讨论正在进行的工作会谈和分类。
2020 年 6 月 Morgan Bauer 、 Karan Goel 和 Jorge Alarcon Ochoa 因其贡献而被公认为 SIG Node CI 小组的评审员,为该子项目的早期阶段提供了重要帮助。 David Porter 和 Roy Yang 也加入了 SIG 检测失败的 GitHub 测试团队。
2020 年 8 月 所有的阻塞合并和阻塞发布的测试都通过了,伴有一些逻辑问题。 然而,只有 42% 的 SIG Node 测试作业是绿色的, 因为有许多逻辑错误和失败的测试。
2020 年 10 月 Amim Knabben 因对子项目的贡献成为 Kubernetes 组织成员。
2021 年 1 月 随着健全的预提交和关键定期工作的通过,子项目讨论了清理其余定期测试并确保其顺利通过的目标。
Elana Hashman 加入了这个子项目,在 Victor 离开后帮助领导该项目。
2021 年 2 月 Artyom Lukianov 因其对子项目的贡献成为 Kubernetes 组织成员。
2021 年 8 月 在 SIG Node 成功运行 bug scrub 以清理其累积的缺陷之后,会议的范围扩大到包括缺陷分类以提高整体可靠性, 在问题影响 CI 信号之前预测问题。
子项目负责人 Elana Hashman 和 Sergey Kanzhelev 都被认为是所有节点测试代码的审批人,由 SIG node 和 SIG Testing 支持。
2021 年 9 月 在 Francesco Romani 牵头的 1.22 版本系列测试取得重大进展后, 该子项目设定了一个目标,即在 1.23 发布日期之前让串行任务完全通过。
Mike Miranda 因其对子项目的贡献成为 Kubernetes 组织成员。
2021 年 11 月 在整个 2021 年, SIG Node 没有合并或发布的测试失败。 过去版本中的许多古怪测试都已从阻止发布的仪表板中删除,因为它们已被完全清理。
Danielle Lancashire 被公认为 SIG Node 子组测试代码的评审员。
最终节点系列测试已完全修复。系列测试由许多中断性和缓慢的测试组成,这些测试往往是碎片化的,很难排除故障。 到 1.23 版本冻结时,最后一次系列测试已修复,作业顺利通过。
1.23 版本在测试质量和 CI 信号方面得到了特别的关注。SIG Node CI 子项目很自豪能够为这样一个高质量的发布做出贡献, 部分原因是我们在识别和修复节点内外的碎片方面所做的努力。
2021 年 12 月 在 1.23 版本发布时,估计有 90% 的测试工作通过了测试(2020 年 8 月为 42%)。
Dockershim 代码已从 Kubernetes 中删除。这影响了 SIG Node 近一半的测试作业, SIG Node CI 子项目反应迅速,并重新确定了所有测试的目标。 SIG Node 是第一个完成 dockershim 外测试迁移的 SIG ,为其他受影响的 SIG 提供了示例。 绝大多数新工作在引入时都已通过,无需进一步修复。 从 Kubernetes 中将 dockershim 除名的工作 正在进行中。 随着我们发现 dockershim 对 dockershim 的依赖性越来越大,dockershim 的删除仍然存在一些问题, 但我们计划在 1.24 版本之前确保所有测试任务稳定。
统计数据
我们过去几个月的定期会议与会者和子项目参与者:
- Aditi Sharma
- Artyom Lukianov
- Arnaud Meukam
- Danielle Lancashire
- David Porter
- Davanum Srinivas
- Elana Hashman
- Francesco Romani
- Matthias Bertschy
- Mike Miranda
- Paco Xu
- Peter Hunt
- Ruiwen Zhao
- Ryan Phillips
- Sergey Kanzhelev
- Skyler Clark
- Swati Sehgal
- Wenjun Wu
kubernetes/test-infra 源代码存储库包含测试定义。该存储库中的节点 PR 数:
CI 委员会上的问题和 PRs 分类(包括子组范围之外的分类):
未来
只是“保持灯亮”是一项大胆的任务,我们致力于改善这种体验。 我们正在努力简化 SIG Node 的分类和审查流程。
具体来说,我们正在致力于更好的测试组织、命名和跟踪:
- https://github.com/kubernetes/enhancements/pull/3042
- https://github.com/kubernetes/test-infra/issues/24641
- Kubernetes SIG Node CI 测试网格跟踪器
我们还在改进测试的可调试性和去剥落方面不断取得进展。
如果你对此感兴趣,我们很乐意您能加入我们! 在调试测试失败中有很多东西需要学习,它将帮助你熟悉 SIG Node 维护的代码。
你可以在 SIG Node 页面上找到有关该组的信息。 我们在我们的维护者轨道会议上提供组更新,例如: KubeCon + CloudNativeCon Europe 2021 和 KubeCon + CloudNative North America 2021。 加入我们的使命,保持 kubelet 和其他 SIG Node 组件的可靠性,确保顺顺利利发布!
关注 SIG Multicluster
作者: Dewan Ahmed (Aiven) 和 Chris Short (AWS)
简介
SIG Multicluster 是专注于如何拓展 Kubernetes 的概念并将其用于集群边界之外的 SIG。 以往 Kubernetes 资源仅在 Kubernetes Resource Universe (KRU) 这个边界内进行交互,其中 KRU 不是一个实际的 Kubernetes 概念。 即使是现在,Kubernetes 集群对自身或其他集群并不真正了解。集群标识符的缺失就是一个例子。 随着多云和多集群部署日益普及,SIG Multicluster 所做的工作越来越受到关注。 在这篇博客中,来自 Google 的 Jeremy Olmsted-Thompson 和 来自 AWS 的 Chris Short 讨论了 SIG Multicluster 正在解决的一些有趣的问题和以及大家如何参与其中。 为简洁起见,下文将使用他们两位的首字母 JOT 和 CS。
谈话总结
CS:SIG Multicluster 存在多久了?SIG 在起步阶段情况如何?你参与这个 SIG 多长时间了?
JOT:我在 SIG Multicluster 工作了将近两年。我所知道的关于初创时期的情况都来自传说,但即使在早期,也一直是为了解决相同的问题。 早期工作的例子之一是 KubeFed。 我认为仍然有一些人在使用 KubeFed,但它只是一小部分。 那时,我认为人们在部署大量 Kubernetes 集群时,还没有达到我们拥有大量实际具体用例的地步。 像 KubeFed 和 Cluster Registry 这样的项目就是在那个时候开发的,当时的需求可以与这些项目相关联。 这些项目的动机是如何解决我们认为在开始扩展到多个集群时 会遇到的问题。 老实说,在某些方面,当时它试图做得太多了。
CS:KubeFed 与 SIG Multicluster 的现状有何不同?初创期 与 现在 有何不同?
JOT:嗯嗯,这就像总是要预防潜在问题而不是解决眼前具体的问题。我认为在 2019 年底, SIG Multicluster 工作有所放缓,我们通过最近最活跃的项目之一 SIG Multicluster services (MCS) 将其重新拾起。
现在我们向解决实际的具体问题开始转变。比如说。
我的工作负载分布在多个集群中,我需要它们相互通信。
好吧,这是非常直接的,我们也知道需要解决这个问题。 首先,让我们确保这些项目可以在一个通用的 API 上协同工作,这样你就可以获得与 Kubernetes 相同的可移植性。
目前有一些 MCS API 的实现,并且更多的实现正在开发中。但是,我们没有建立一个实现, 因为取决于你的部署方式不同,可能会有数百种实现。 只要你所需要的基本的多集群服务功能,它就可以在你想要的任何背景下工作,无论是 Submariner、GKE 还是服务网格。
我最喜欢的“过去与现在“的例子是集群 ID。几年前曾经有过定义集群 ID 的尝试。 针对这个概念,有很多非常好的想法。例如,我们如何使集群 ID 在多个集群中是唯一的。 我们如何使这个 ID 全球范围内唯一,以便它在各个通讯中发挥作用? 假设有团队被收购或合并 - 集群 ID 对于这些团队仍然是唯一的吗?
在 Multicluster 服务的相关工作中,我们发现需要一个实际的集群 ID,并且这一需求非常具体。 为了满足这一特定需求,我们不再考虑一个个 Kubernetes 集群,而是考虑 ClusterSets — 在某种范围内协同工作的集群分组。 与考虑所有时间点和所有空间位置上存在的集群相比,这一范畴要窄得多。 这一概念还让实现者具备了定义边界(ClusterSet)的灵活性,在该边界之外,该集群 ID 将不再是唯一的。
CS:你对 SIG Multicluster 的现状有何看法,你希望未来达到什么样的目标?
JOT:有一些项目正在起步,例如 Work API。 在未来,我认为围绕着如何跨集群部署应用的一些共同做法将会发展起来。
如果我的集群部署在不同的地区,那么最好的方式是什么?
答案几乎总是“视情况而定”。你为什么要这样做?是因为某种合规性使你关注位置吗?是性能问题吗?是可用性吗?
我认为,在我们有了集群 ID 之后,重新审视注册表模式可能是很自然的一步,也就是说, 你如何将这些集群真正关联在一起?也许你有一个分布式部署,你在世界各地的数据中心运行。 我想随着多集群特性的进一步开发,扩展该领域的 API 将变得很重要。 这实际上取决于社区开始使用这些工具做什么。
CS:在 Kubernetes 的早期,我们只有寥寥几个大型的 Kubernetes 集群,而现在我们面对的是大量的小型 Kubernetes 集群,就像我自己所在的开发环境中就使用了多个集群。 这种从几个大集群到许多小集群的转变对 SIG 有何影响?它是否加快了工作进度或在某种程度上使得问题变得更困难?
JOT:我认为它带来了很多需要解决的歧义。最初,你可能拥有一个 dev 集群、一个 staging 集群和一个 prod 集群。 当引入了多区域的考量时,我们开始在每个区域部署 dev/staging/prod 集群。 再后来,有时由于合规性或某些法规问题,集群确实需要更多的隔离。 因此,我们最终会有很多集群。我认为在你究竟应该有多少个集群上找到平衡是很重要的。Kubernetes 的强大之处在于能够部署由单个控制平面管理的大量事物。 因此,并不是每个被部署的工作负载都应该在自己的集群中。 但是,我认为同样很明显的是,我们不能将所有工作负载都放在一个集群中。
CS:你最喜欢 SIG 的哪些方面?
JOT:问题的复杂性、人的因素和领域的新颖性。我们还没有正确的答案,我们必须找到正确的答案。 一开始,我们甚至无法考虑多集群,因为无法跨集群连接服务。 现在我们开始着手解决这些问题,我认为这是一个非常有趣的地方,因为我预计 SIG 在未来几年会变得更加繁忙。 这是一个协作很密切的团体,我们绝对希望更多的人参与、加入我们,提出他们的问题和想法。
CS:你认为是什么让人们留在这个群体中?疫情对你有何影响?
JOT:我认为在疫情期间这个群体肯定会变得安静一些。但在大多数情况下,这是一个非常分散的小组, 因此无论你在会议室或者在家中参加我们的每周会议,都不会产生太大的影响。在疫情期间,很多人有时间专注于他们接下来的规模和增长。 我认为这就是让人们留在团队中的原因 - 我们有真正的问题需要解决,这些问题在这个领域是非常新颖的、有趣的。
结束语
CS:这就是我们今天的全部内容,感谢 Jeremy 的时间。
JOT:谢谢 Chris。我们的双周会议 欢迎所有人参加。我们希望尽可能多的人前来,并欢迎所有问题与想法。 这是一个新的领域,如果能让社区发展起来,那就太好了。
确保准入控制器的安全
作者: Rory McCune (Aqua Security)
准入控制和认证、授权都是 Kubernetes 安全性的关键部分。 Webhook 准入控制器被广泛用于以多种方式帮助提高 Kubernetes 集群的安全性, 包括限制工作负载权限和确保部署到集群的镜像满足组织安全要求。
然而,与添加到集群中的任何其他组件一样,安全风险也会随之出现。 一个安全风险示例是没有正确处理准入控制器的部署和管理。 为了帮助准入控制器用户和设计人员适当地管理这些风险, SIG Security 的安全文档小组 花费了一些时间来开发一个准入控制器威胁模型。 这种威胁模型着眼于由于不正确使用准入控制器而产生的可能的风险,可能允许绕过安全策略,甚至允许攻击者未经授权访问集群。
基于这个威胁模型,我们开发了一套安全最佳实践。 你应该采用这些实践来确保集群操作员可以获得准入控制器带来的安全优势,同时避免使用它们带来的任何风险。
准入控制器和安全的良好做法
基于这个威胁模型,围绕着如何确保准入控制器的安全性出现了几个主题。
安全的 webhook 配置
确保集群中的任何安全组件都配置良好是很重要的,在这里准入控制器也并不例外。 使用准入控制器时需要考虑几个安全最佳实践:
- 为所有 webhook 流量正确配置了 TLS。 API 服务器和准入控制器 webhook 之间的通信应该经过身份验证和加密,以确保处于网络中查看或修改此流量的攻击者无法查看或修改。 要实现此访问,API 服务器和 webhook 必须使用来自受信任的证书颁发机构的证书,以便它们可以验证相互的身份。
- 只允许经过身份验证的访问。 如果攻击者可以向准入控制器发送大量请求,他们可能会压垮服务导致其失败。 确保所有访问都需要强身份验证可以降低这种风险。
- 准入控制器关闭失败。 这是一种需要权衡的安全实践,集群操作员是否要对其进行配置取决于集群的威胁模型。 如果一个准入控制器关闭失败,当 API 服务器无法从它得到响应时,所有的部署都会失败。 这可以阻止攻击者通过禁用准入控制器绕过准入控制器,但可能会破坏集群的运行。 由于集群可以有多个 webhook,因此一种折中的方法是对关键控制允许故障关闭, 并允许不太关键的控制进行故障打开。
- 定期审查 webhook 配置。 配置错误可能导致安全问题,因此检查准入控制器 webhook 配置以确保设置正确非常重要。 这种审查可以由基础设施即代码扫描程序自动完成,也可以由管理员手动完成。
为准入控制保护集群配置
在大多数情况下,集群使用的准入控制器 webhook 将作为工作负载安装在集群中。 因此,确保正确配置了可能影响其操作的 Kubernetes 安全特性非常重要。
- 限制 RBAC 权限。 任何有权修改 webhook 对象的配置或准入控制器使用的工作负载的用户都可以破坏其运行。 因此,确保只有集群管理员拥有这些权限非常重要。
- 防止特权工作负载。 容器系统的一个现实是,如果工作负载被赋予某些特权, 则有可能逃逸到下层的集群节点并影响该节点上的其他容器。 如果准入控制器服务在它们所保护的集群上运行, 一定要确保对特权工作负载的所有请求都要经过仔细审查并尽可能地加以限制。
- 严格控制外部系统访问。 作为集群中的安全服务,准入控制器系统将有权访问敏感信息,如凭证。 为了降低此信息被发送到集群外的风险, 应使用网络策略 来限制准入控制器服务对外部网络的访问。
- 每个集群都有一个专用的 webhook。 虽然可能让准入控制器 webhook 服务于多个集群的, 但在使用该模型时存在对 webhook 服务的攻击会对共享它的地方产生更大影响的风险。 此外,在多个集群使用准入控制器的情况下,复杂性和访问要求也会增加,从而更难保护其安全。
准入控制器规则
对于用于 Kubernetes 安全的所有准入控制器而言,一个关键元素是它使用的规则库。 规则需要能够准确地满足其目标,避免假阳性和假阴性结果。
- 定期测试和审查规则。 需要测试准入控制器规则以确保其准确性。 还需要定期审查,因为 Kubernetes API 会随着每个新版本而改变, 并且需要在每个 Kubernetes 版本中评估规则,以了解使他们保持最新版本所需要做的任何改变。
认识我们的贡献者 - 亚太地区(印度地区)
作者和采访者: Anubhav Vardhan、 Atharva Shinde、 Avinesh Tripathi、 Debabrata Panigrahi、 Kunal Verma、 Pranshu Srivastava、 Pritish Samal、 Purneswar Prasad、 Vedant Kakde
编辑: Priyanka Saggu
大家好 👋
欢迎来到亚太地区的“认识我们的贡献者”博文系列第一期。
在这篇文章中,我们将向你介绍来自印度地区的五位优秀贡献者,他们一直在以各种方式积极地为上游 Kubernetes 项目做贡献,同时也是众多社区倡议的领导者和维护者。
💫 闲话少说,我们开始吧。
Arsh Sharma
Arsh 目前在 Okteto 公司中担任开发者体验工程师职务。作为一名新的贡献者,他意识到一对一的指导机会让他在开始上游项目中受益匪浅。
他目前是 Kubernetes 1.23 版本团队的 CI Signal 经理。他还致力于为 SIG Testing 和 SIG Docs 项目提供贡献,并且在 SIG Architecture 项目中负责 证书管理器 工具的开发工作。
对于新人来说,Arsh 帮助他们可持续地计划早期贡献。
我鼓励大家以可持续的方式为社区做贡献。 我的意思是,一个人很容易在早期的时候非常有热情,并且承担了很多超出个人实际能力的事情。 这通常会导致后期的倦怠。迭代地处理事情会让大家对社区的贡献变得可持续。
Kunal Kushwaha
Kunal Kushwaha 是 Kubernetes 营销委员会的核心成员。他同时也是 CNCF 学生计划 的创始人之一。他还在 1.22 版本周期中担任通信经理一职。
在他的第一年结束时,Kunal 开始为 fabric8io kubernetes-client 项目做贡献。然后,他被推选从事同一项目,此项目是 Google Summer of Code 的一部分。Kunal 在 Google Summer of Code、Google Code-in 等项目中指导过很多人。
作为一名开源爱好者,他坚信,社区的多元化参与是非常有益的,因为他引入了新的观念和观点,并尊重自己的伙伴。它曾参与过各种开源项目,他在这些社区中的参与对他作为开发者的发展有很大帮助。
我相信,如果你发现自己在一个了解不多的项目当中,那是件好事, 因为现在你可以一边贡献一边学习,社区也会帮助你。 它帮助我获得了很多技能,认识了来自世界各地的人,也帮助了他们。 你可以在这个过程中学习,自己不一定必须是专家。 请重视非代码贡献,因为作为初学者这是一项技能,你可以为组织带来新的视角。
Madhav Jivarajani
Madhav Jivarajani 在 VMware 上游 Kubernetes 稳定性团队工作。他于 2021 年 1 月开始为 Kubernetes 项目做贡献,此后在 SIG Architecture、SIG API Machinery 和 SIG ContribEx(贡献者经验)等项目的几个工作领域做出了重大贡献。
在这几个重要项目中,他最近致力于设计方案的存档工作, 重构 k8s-infra 存储库下的 "组"代码库, 使其具有可模拟性和可测试性,以及改进 GitHub k8s 机器人的功能。
除了在技术方面的贡献,Madhav 还监督许多旨在帮助新贡献者的项目。 他每两周组织一次的 “KEP 阅读俱乐部” 会议,帮助新人了解添加新功能、 摒弃旧功能以及对上游项目进行其他关键更改的过程。他还致力于开发 Katacoda 场景, 以帮助新的贡献者在为 k/k 做贡献的过程更加熟练。目前除了每周与社区成员会面外, 他还组织了几个新贡献者讲习班(NCW)。
一开始我对 Kubernetes 了解并不多。我加入社区是因为社区超级友好。 但让我留下来的不仅仅是人,还有项目本身。我在社区中不会感到不知所措, 这是因为我能够在感兴趣的和正在讨论的主题中获得尽可能多的背景和知识。 因此,我将继续深入探讨 Kubernetes 及其设计。 我是一个系统迷,kubernetes 对我来说绝对是一个金矿。
Rajas Kakodkar
Rajas Kakodkar 目前在 VMware 担任技术人员。自 2019 年以来,他一直多方面地从事上游 kubernetes 项目。
他现在是 Testing 特别兴趣小组的关键贡献者。他还活跃在 SIG Network 社区。最近,Rajas 为 NetworkPolicy++ 和 kpng 子项目做出了重大贡献。
他遇到的第一个挑战是,他所处的时区与上游项目的日常会议时间不同。不过,社区论坛上的异步交互逐渐解决了这个问题。
我喜欢为 kubernetes 做出贡献,不仅因为我可以从事尖端技术工作, 更重要的是,我可以和优秀的人一起工作,并帮助解决现实问题。
Rajula Vineet Reddy
Rajula Vineet Reddy,CERN 的初级工程师,是 SIG ContribEx 项目下营销委员会的成员。在 Kubernetes 1.22 和 1.23 版本周期中,他还担任 SIG Release 的版本经理。
在他的一位教授的帮助下,他开始将 kubernetes 项目作为大学项目的一部分。慢慢地,他花费了大量的时间阅读项目的文档、Slack 讨论、GitHub issues 和博客,这有助于他更好地掌握 kubernetes 项目,并激发了他对上游项目做贡献的兴趣。他的主要贡献之一是他在SIG ContribEx上游营销子项目中协助实现了自动化。
Rajas 说,参与项目会议和跟踪各种项目角色对于了解社区至关重要。
我发现社区非常有帮助,而且总是“你得到的回报和你贡献的一样多”。 你参与得越多,你就越会了解、学习和贡献新东西。
“挺身而出”的第一步是艰难的。但在那之后一切都会顺利的。勇敢地参与进来吧。
如果你对我们下一步应该采访谁有任何意见/建议,请在 #sig-contribex 中告知我们。我们很高兴有其他人帮助我们接触社区中更优秀的人。我们将不胜感激。
我们下期见。最后,祝大家都能快乐地为社区做贡献!👋
Kubernetes 即将移除 Dockershim:承诺和下一步
作者: Sergey Kanzhelev (Google), Jim Angel (Google), Davanum Srinivas (VMware), Shannon Kularathna (Google), Chris Short (AWS), Dawn Chen (Google)
Kubernetes 将在即将发布的 1.24 版本中移除 dockershim。我们很高兴能够通过支持开源容器运行时、支持更小的 kubelet 以及为使用 Kubernetes 的团队提高工程速度来重申我们的社区价值。 如果你使用 Docker Engine 作为 Kubernetes 集群的容器运行时, 请准备好在 1.24 中迁移!要检查你是否受到影响, 请参考检查移除 Dockershim 对你的影响。
为什么我们要离开 dockershim
Docker 是 Kubernetes 使用的第一个容器运行时。 这也是许多 Kubernetes 用户和爱好者如此熟悉 Docker 的原因之一。 对 Docker 的支持被硬编码到 Kubernetes 中——一个被项目称为 dockershim 的组件。
随着容器化成为行业标准,Kubernetes 项目增加了对其他运行时的支持。 最终实现了容器运行时接口(CRI),让系统组件(如 kubelet)以标准化的方式与容器运行时通信。 因此,dockershim 成为了 Kubernetes 项目中的一个异常现象。
对 Docker 和 dockershim 的依赖已经渗透到 CNCF 生态系统中的各种工具和项目中,这导致了代码脆弱。
通过删除 dockershim CRI,我们拥抱了 CNCF 的第一个价值: “快比慢好”。 请继续关注未来关于这个话题的交流!
弃用时间线
我们正式宣布于 2020 年 12 月弃用 dockershim。目标是在 2022 年 4 月, Kubernetes 1.24 中完全移除 dockershim。 此时间线与我们的弃用策略一致, 即规定已弃用的行为必须在其宣布弃用后至少运行 1 年。
包括 dockershim 的 Kubernetes 1.23 版本,在 Kubernetes 项目中将再支持一年。 对于托管 Kubernetes 的供应商,供应商支持可能会持续更长时间,但这取决于公司本身。 无论如何,我们相信所有集群操作都有时间进行迁移。如果你有更多关于 dockershim 移除的问题, 请参考弃用 Dockershim 的常见问题。
在这个你是否为 dockershim 的删除做好了准备的调查中, 我们询问你是否为 dockershim 的迁移做好了准备。我们收到了 600 多个回复。 感谢所有花时间填写调查问卷的人。
结果表明,在帮助你顺利迁移方面,我们还有很多工作要做。 存在其他容器运行时,并且已被广泛推广。但是,许多用户告诉我们他们仍然依赖 dockershim, 并且有时需要重新处理依赖项。其中一些依赖项超出控制范围。 根据收集到的反馈,我们采取了一些措施提供帮助。
我们的下一个步骤
根据提供的反馈:
- CNCF 和 1.24 版本团队致力于及时交付 1.24 版本的文档。这包括像本文这样的包含更多信息的博客文章, 更新现有的代码示例、教程和任务,并为集群操作人员生成迁移指南。
- 我们正在联系 CNCF 社区的其他成员,帮助他们为这一变化做好准备。
如果你是依赖 dockershim 的项目的一部分,或者如果你有兴趣帮助参与迁移工作,请加入我们! 无论是我们的迁移工具还是我们的文档,总是有更多贡献者的空间。 作为起步,请在 Kubernetes Slack 上的 #sig-node 频道打个招呼!
最终想法
作为一个项目,我们已经看到集群运营商在 2021 年之前越来越多地采用其他容器运行时。 我们相信迁移没有主要障碍。我们为改善迁移体验而采取的步骤将为你指明更清晰的道路。
我们知道,从 dockershim 迁移是你可能需要执行的另一项操作,以保证你的 Kubernetes 基础架构保持最新。 对于你们中的大多数人来说,这一步将是简单明了的。在某些情况下,你会遇到问题。 社区已经详细讨论了推迟 dockershim 删除是否会有所帮助。 例如,我们最近在 11 月 11 日的 SIG Node 讨论和 12 月 6 日 Kubernetes Steering 举行的委员会会议谈到了它。 我们已经在 2021 年推迟它一次, 因为其他运行时的采用率低于我们的预期,这也给了我们更多的时间来识别潜在的阻塞问题。
在这一点上,我们相信你(和 Kubernetes)从移除 dockershim 中获得的价值可以弥补你将要进行的迁移工作。 现在就开始计划以避免出现意外。在 Kubernetes 1.24 发布之前,我们将提供更多更新信息和指南。
Security Profiles Operator v0.4.0 中的新功能
作者: Jakub Hrozek, Juan Antonio Osorio, Paulo Gomes, Sascha Grunert
Security Profiles Operator (SPO) 是一种树外 Kubernetes 增强功能,用于更方便、更便捷地管理 seccomp、 SELinux 和 AppArmor 配置文件。 我们很高兴地宣布,我们最近发布了 v0.4.0 的 Operator,其中包含了大量的新功能、缺陷修复和可用性改进。
有哪些新特性
距离上次的 v0.3.0 的发布已经有一段时间了。在过去的半年里,我们增加了新的功能,对现有的功能进行了微调, 并且在过去的半年里,我们通过 290 个提交重新编写了文档。
亮点之一是我们现在能够使用 Operator 的日志增强组件
记录 seccomp 和 SELinux 的配置文件。
这使我们能够减少配置文件记录所需的依赖事项,使得仅剩的依赖变为在节点上运行
auditd 或 syslog(作为一种回退机制)。
通过使用 ProfileRecording CRD 及其对应的标签选择算符,
Operator 中的所有配置文件记录都以相同的方式工作。
日志增强组件本身也可用于获得有关节点上的 seccomp 和 SELinux 消息的有意义的洞察。
查看官方文档
了解更多信息。
与 seccomp 有关的改进
除了基于日志丰富器的记录之外,我们现在还使用 ebpf
作为记录 seccomp 配置文件的一种替代方法。可以通过将 enableBpfRecorder 设置为 true 来启用此可选功能。
启用之后会导致一个专用的容器被启动运行;该容器在每个节点上提供一个自定义 bpf 模块以收集容器的系统调用。
它甚至支持默认不公开 BPF 类型格式 (BTF)
的旧内核版本以及 amd64 和 arm64 架构。查看 我们的文档
以查看它的实际效果。顺便说一句,我们现在也将记录器主机的 seccomp 配置文件体系结构添加到记录的配置文件中。
我们还将 seccomp 配置文件 API 从 v1alpha1 升级到 v1beta1。
这符合我们随着时间的推移稳定 CRD API 的总体目标。
唯一改变的是 seccomp 配置文件类型 Architectures 现在指向 []Arch 而不是 []*Arch。
SELinux 增强功能
管理 SELinux 策略(相当于使用通常在单个服务器上调用的 semodule )不是由 SPO 本身完成的,
而是由另一个名为 selinuxd 的容器完成,以提供更好的隔离。此版本将所使用的 selinuxd
容器镜像从个人仓库迁移到位于我们团队的 quay.io 仓库下的镜像。
selinuxd 仓库也已移至GitHub 组织 containers。
请注意,selinuxd 动态链接到 libsemanage 并挂载节点上的 SELinux 目录, 这意味着 selinuxd 容器必须与集群节点运行相同的发行版。SPO 默认使用基于 CentOS-8 的容器, 但我们也构建基于 Fedora 的容器。如果你使用其他发行版并希望我们添加对它的支持, 请针对 selinuxd 提交 issue。
配置文件记录
此版本(0.4.0)增加了记录 SELinux 配置文件的支持。记录本身是通过 ProfileRecording 自定义资源的实例管理的,
如我们仓库中的示例
所示。从用户的角度来看,它的工作原理与记录 seccomp 配置文件几乎相同。
在后台,为了知道工作负载在做什么,SPO 安装了一个名为 selinuxrecording
的、限制宽松的策略,允许执行所有操作并将所有 AVC 记录到 audit.log 中。
这些 AVC 消息由日志增强组件抓取,当所记录的工作负载退出时,该策略被创建。
SELinuxProfile CRD 毕业
我们引入了 SelinuxProfile 对象的 v1alpha2 版本。
这个版本从对象中删除了原始的通用中间语言 (CIL),并添加了一种简单的策略语言来简化编写和解析体验。
此外,我们还引入了 RawSelinuxProfile 对象。该对象包含策略的包装和原始表示。
引入此对象是为了让人们能够尽快将他们现有的策略付诸实现。但是,策略的验证是在这里完成的。
AppArmor 支持
0.4.0 版本引入了对 AppArmor 的初始支持,允许用户通过使用新的 AppArmorProfile 在集群节点中 CRD 加载或卸载 AppArmor 配置文件。
要启用 AppArmor 支持,请使用 SPO 配置的 enableAppArmor 特性门控开关。 然后使用我们的 apparmor 示例 在集群中部署你第一个配置文件。
指标
Operator 现在能够公开在我们的新指标文档中详细描述的指标。
我们决定使用 kube-rbac-proxy 来保护指标检索过程,
同时我们提供了一个额外的 spo-metrics-client 集群角色(和绑定)以从集群内检索指标。
如果你使用 OpenShift,
那么我们提供了一个开箱即用的 ServiceMonitor
来访问指标。
可调试性和稳健性
除了所有这些新功能外,我们还决定在内部重组安全配置文件操作程序的部分内容,使其更易于调试和更稳健。
例如,我们现在维护了一个内部 gRPC API,以便在 Operator 内部跨不同功能组件进行通信。
我们还提高了日志增强组件的性能,现在它可以缓存结果,以便更快地检索日志数据。
Operator 可以通过将 verbosity 设置从 0 改为 1,启用更详细的日志模式(https://github.com/kubernetes-sigs/security-profiles-operator/blob/71b3915/installation-usage.md#set-logging-verbosity)。
我们还在启动时打印所使用的 libseccomp 和 libbpf 版本,
并通过 enableProfiling 选项
公开每个容器的 CPU 和内存性能分析端点。
Operator 守护程序内部的专用的存活态探测和启动探测现在能进一步改善 Operator 的生命周期管理。
总结
感谢你阅读这次更新。我们期待着 Operater 的未来改进,并希望得到你对最新版本的反馈。 欢迎通过 Kubernetes slack #security-profiles-operator 与我们联系,提出任何反馈或问题。
Kubernetes 1.23: StatefulSet PVC 自动删除 (alpha)
作者: Matthew Cary (谷歌)
Kubernetes v1.23 为 StatefulSets 引入了一个新的 alpha 级策略,用来控制由 StatefulSet 规约模板生成的 PersistentVolumeClaims (PVCs) 的生命周期, 用于当删除 StatefulSet 或减少 StatefulSet 中的 Pods 数量时 PVCs 应该被自动删除的场景。
它解决了什么问题?
StatefulSet 规约中可以包含 Pod 和 PVC 的模板。当副本先被创建时,如果 PVC 还不存在, Kubernetes 控制面会为该副本自动创建一个 PVC。在 Kubernetes 1.23 版本之前, 控制面不会删除 StatefulSet 创建的 PVCs——这依赖集群管理员或你需要部署一些额外的适用的自动化工具来处理。 管理 PVC 的常见模式是通过手动或使用 Helm 等工具,PVC 的具体生命周期由管理它的工具跟踪。 使用 StatefulSet 时必须自行确定 StatefulSet 创建哪些 PVC,以及它们的生命周期应该是什么。
在这个新特性之前,当一个 StatefulSet 管理的副本消失时,无论是因为 StatefulSet 减少了它的副本数, 还是因为它的 StatefulSet 被删除了,PVC 及其下层的卷仍然存在,需要手动删除。 当存储数据比较重要时,这样做是合理的,但在许多情况下,这些 PVC 中的持久化数据要么是临时的, 要么可以从另一个源端重建。在这些情况下,删除 StatefulSet 或减少副本后留下的 PVC 及其下层的卷是不必要的, 还会产生成本,需要手动清理。
新的 StatefulSet PVC 保留策略
如果你启用这个新 alpha 特性,StatefulSet 规约中就可以包含 PersistentVolumeClaim 的保留策略。
该策略用于控制是否以及何时删除基于 StatefulSet 的 volumeClaimTemplate 属性所创建的 PVCs。
保留策略的首次迭代包含两种可能删除 PVC 的情况。
第一种情况是 StatefulSet 资源被删除时(这意味着所有副本也被删除),这由 whenDeleted 策略控制的。
第二种情况是 StatefulSet 缩小时,即删除 StatefulSet 部分副本,这由 whenScaled 策略控制。
在这两种情况下,策略即可以是 Retain 不涉及相应 PVCs 的改变,也可以是 Delete 即删除对应的 PVCs。
删除是通过普通的对象删除完成的,
因此,的所有保留策略都会被遵照执行。
该策略形成包含四种情况的矩阵。我将逐一介绍,并为每一种情况给出一个例子。
whenDeleted和whenScaled都是Retain。 这与 StatefulSets 的现有行为一致, 即不删除 PVCs。 这也是默认的保留策略。它适用于 StatefulSet 卷上的数据是不可替代的且只能手动删除的情况。
whenDeleted是Delete但whenScaled是Retain。 在这种情况下, 只有当整个 StatefulSet 被删除时,PVCs 才会被删除。 如果减少 StatefulSet 副本,PVCs 不会删除,这意味着如果增加副本时,可以从前一个副本重新连接所有数据。 这可能用于临时的 StatefulSet,例如在 CI 实例或 ETL 管道中, StatefulSet 上的数据仅在 StatefulSet 生命周期内才需要,但在任务运行时数据不易重构。 任何保留状态对于所有先缩小后扩大的副本都是必需的。
whenDeleted和whenScaled都是Delete。 当其副本不再被需要时,PVCs 会立即被删除。 注意,这并不包括 Pod 被删除且有新版本被调度的情况,例如当节点被腾空而 Pod 需要迁移到别处时。 只有当副本不再被需要时,如按比例缩小或删除 StatefulSet 时,才会删除 PVC。 此策略适用于数据生命周期短于副本生命周期的情况。即数据很容易重构, 且删除未使用的 PVC 所节省的成本比快速增加副本更重要,或者当创建一个新的副本时, 来自以前副本的任何数据都不可用,必须重新构建。
whenDeleted是Retain但whenScaled是Delete。 这与前一种情况类似, 在增加副本时用保留的 PVCs 快速重构几乎没有什么益处。例如 Elasticsearch 集群就是使用的这种方式。 通常,你需要增大或缩小工作负载来满足业务诉求,同时确保最小数量的副本(例如:3)。 当减少副本时,数据将从已删除的副本迁移出去,保留这些 PVCs 没有任何用处。 但是,这对临时关闭整个 Elasticsearch 集群进行维护时是很有用的。 如果需要使 Elasticsearch 系统脱机,可以通过临时删除 StatefulSet 来实现, 然后通过重新创建 StatefulSet 来恢复 Elasticsearch 集群。 保存 Elasticsearch 数据的 PVCs 不会被删除,新的副本将自动使用它们。
查阅文档 获取更多详细信息。
下一步是什么?
启用该功能并尝试一下!在集群上启用 StatefulSetAutoDeletePVC 功能,然后使用新策略创建 StatefulSet。
测试一下,告诉我们你的体验!
我很好奇这个属主引用机制在实践中是否有效。例如,我们意识到 Kubernetes 中没有可以知道谁设置了引用的机制, 因此 StatefulSet 控制器可能会与设置自己的引用的自定义控制器发生冲突。 幸运的是,维护现有的保留行为不涉及任何新属主引用,因此默认行为是兼容的。
请用标签 sig/apps 标记你报告的任何问题,并将它们分配给 Matthew Cary
(在 GitHub上 @mattcary)。
尽情体验吧!
Kubernetes 1.23:树内存储向 CSI 卷迁移工作的进展更新
作者: Jiawei Wang(谷歌)
自 Kubernetes v1.14 引入容器存储接口(Container Storage Interface, CSI)的工作达到 alpha 阶段后,自 v1.17 起,Kubernetes 树内存储插件(in-tree storage plugin)向 CSI 的迁移基础设施已步入 beta 阶段。
自那时起,Kubernetes 存储特别兴趣组(special interest groups, SIG)及其他 Kubernetes 特别兴趣组就在努力确保这一功能的稳定性和兼容性,为正式发布做准备。 本文旨在介绍该功能的最新开发进展,以及 Kubernetes v1.17 到 v1.23 之间的变化。此外,我还将介绍每个存储插件的 CSI 迁移功能达到正式发布阶段的未来路线图。
快速回顾:CSI 迁移功能是什么?为什么要迁移?
容器存储接口旨在帮助 Kubernetes 取代其现有的树内存储驱动机制──特别是供应商的特定插件。自 v1.13 起,Kubernetes 对容器存储接口的支持工作已达到正式发布阶段。引入对 CSI 驱动的支持,将使得 Kubernetes 和存储后端技术之间的集成工作更易建立和维护。使用 CSI 驱动可以实现更好的可维护性(驱动作者可以决定自己的发布周期和支持生命周期)、减少出现漏洞的机会(得益于更少的树内代码,出现错误的风险会降低。另外,集群操作员可以只选择集群需要的存储驱动)。
随着更多的 CSI 驱动诞生并进入生产就绪阶段,Kubernetes 存储特别兴趣组希望所有 Kubernetes 用户都能从 CSI 模型中受益──然而,我们不应破坏与现有存储 API 类型的 API 兼容性。对此,我们给出的解决方案是 CSI 迁移:该功能实现将树内存储 API 翻译成等效的 CSI API,并把操作委托给一个替换的 CSI 驱动来完成。
CSI 迁移工作使存储后端现有的树内存储插件(如 kubernetes.io/gce-pd 或 kubernetes.io/aws-ebs)能够被相应的 CSI 驱动 所取代。如果 CSI 迁移功能正确发挥作用,Kubernetes 终端用户应该不会注意到有什么变化。现有的 StorageClass、PersistentVolume 和 PersistentVolumeClaim 对象应继续工作。当 Kubernetes 集群管理员更新集群以启用 CSI 迁移功能时,利用到 PVCs1(由树内存储插件支持)的现有工作负载将继续像以前一样运作──不过在幕后,Kubernetes 将所有存储管理操作(以前面向树内存储驱动的)交给 CSI 驱动控制。
举个例子。假设你是 kubernetes.io/gce-pd 用户,在启用 CSI 迁移功能后,你仍然可以使用 kubernetes.io/gce-pd 来配置新卷、挂载现有的 GCE-PD 卷或删除现有卷。所有现有的 API/接口 仍将正常工作──只不过,底层功能调用都将通向 GCE PD CSI 驱动,而不是 Kubernetes 的树内存储功能。
这使得 Kubernetes 终端用户可以顺利过渡。另外,对于存储插件的开发者,我们可以减少他们维护树内存储插件的负担,并最终将这些插件从 Kubernetes 核心的二进制中移除。
改进与更新
在 Kubernetes v1.17 及更早的工作基础上,此后的发布有了以下一系列改变:
新的特性门控(feature gate)
Kubernetes v1.21 弃用了 CSIMigration{provider}Complete 特性参数(feature flag),它们不再生效。取而代之的是名为 InTreePlugin{vendor}Unregister 的新特性参数,它们保留了 CSIMigration{provider}Complete 提供的所有功能。
CSIMigration{provider}Complete 是作为 CSI 迁移功能在所有节点上启用后的补充特性门控于之前引入的。这个参数可注销参数名称中 {provider} 部分所指定的树内存储插件。
当你启用该特性门控时,你的集群不再使用树内驱动代码,而是直接选择并使用相应的 CSI 驱动。同时,集群并不检查节点上 CSI 迁移功能是否启用,以及 CSI 驱动是否实际部署。
虽然这一特性门控是一个很好的帮手,但 Kubernetes 存储特别兴趣组(以及,我相信还有很多集群操作员)同样希望有一个特性门控可以让你即使在不启用 CSI 迁移功能时,也能禁用树内存储插件。例如,你可能希望在一个 GCE 集群上禁用 EBS 存储插件,因为 EBS 卷是其他供应商的云(AWS)所专有的。
为了使这成为可能,Kubernetes v1.21 引入了一个新的特性参数集合:InTreePlugin{vendor}Unregister。
InTreePlugin{vendor}Unregister 是一种特性门控,可以独立于 CSI 迁移功能来启用或禁用。当启用此种特性门控时,组件将不会把相应的树内存储插件注册到支持的列表中。如果集群操作员只启用了这种参数,终端用户将在使用该插件的 PVC1 处遇到错误,提示其找不到插件。如果集群操作员不想支持过时的树内存储 API,只支持 CSI,那么他们可能希望启用这种特性门控而不考虑 CSI 迁移功能。
可观察性
Kubernetes v1.21 引入了跟踪 CSI 迁移功能的指标。你可以使用这些指标来观察你的集群是如何使用存储服务的,以及对该存储的访问使用的是传统的树内驱动还是基于 CSI 的替代。
| 组件 | 指标 | 注释 |
|---|---|---|
| Kube-Controller-Manager | storage_operation_duration_seconds | 一个新的标签 migrated 被添加到指标中,以表明该存储操作是否由 CSI 迁移功能操作(字符串值为 true 表示启用,false 表示未启用)。 |
| Kubelet | csi_operations_seconds | 新的指标提供的标签包括 driver_name、method_name、grpc_status_code 和 migrated。这些标签的含义与 csi_sidecar_operations_seconds 相同。 |
| CSI Sidecars(provisioner, attacher, resizer) | csi_sidecar_operations_seconds | 一个新的标签 migrated 被添加到指标中,以表明该存储操作是否由 CSI 迁移功能操作(字符串值为 true 表示启用,false 表示未启用)。 |
错误修复和功能改进
籍由 beta 测试人员的帮助,我们修复了许多错误──如悬空附件、垃圾收集、拓扑标签错误等。
与 Kubernetes 云提供商特别兴趣组、集群生命周期特别兴趣组的合作
Kubernetes 存储特别兴趣组与云提供商特别兴趣组和集群生命周期特别兴趣组,正为了 CSI 迁移功能上线而密切合作。
如果你采用托管 Kubernetes 服务,请询问你的供应商是否有什么工作需要完成。在许多情况下,供应商将管理迁移,你不需要做额外的工作。
如果你使用的是 Kubernetes 的发行版,请查看其官方文档,了解对该功能的支持情况。对于已进入正式发布阶段的 CSI 迁移功能,Kubernetes 存储特别兴趣组正与Kubernetes 集群生命周期特别兴趣组合作,以便在这些功能于 Kubernetes 中可用时,使迁移机制也进入到周边工具(如 kubeadm)中。
时间计划及当前状态
各驱动的当前发布及目标发布如下表所示:
| 驱动 | Alpha | Beta(启用树内插件) | Beta(默认启用) | 正式发布 | 目标:移除“树内存储插件” |
|---|---|---|---|---|---|
| AWS EBS | 1.14 | 1.17 | 1.23 | 1.24 (Target) | 1.26 (Target) |
| GCE PD | 1.14 | 1.17 | 1.23 | 1.24 (Target) | 1.26 (Target) |
| OpenStack Cinder | 1.14 | 1.18 | 1.21 | 1.24 (Target) | 1.26 (Target) |
| Azure Disk | 1.15 | 1.19 | 1.23 | 1.24 (Target) | 1.26 (Target) |
| Azure File | 1.15 | 1.21 | 1.24 (Target) | 1.25 (Target) | 1.27 (Target) |
| vSphere | 1.18 | 1.19 | 1.24 (Target) | 1.25 (Target) | 1.27 (Target) |
| Ceph RBD | 1.23 | ||||
| Portworx | 1.23 |
以下存储驱动将不会支持 CSI 迁移功能。其中 ScaleIO 驱动已经被移除;其他驱动都被弃用,并将从 Kubernetes 核心中删除。
| 驱动 | 被弃用 | 代码移除 |
|---|---|---|
| ScaleIO | 1.16 | 1.22 |
| Flocker | 1.22 | 1.25 (Target) |
| Quobyte | 1.22 | 1.25 (Target) |
| StorageOS | 1.22 | 1.25 (Target) |
下一步的计划
随着更多的 CSI 驱动进入正式发布阶段,我们希望尽快将整个 CSI 迁移功能标记为正式发布状态。我们计划在 Kubernetes v1.26 和 v1.27 之前移除云提供商树内存储插件的代码。
作为用户,我应该做什么?
请注意,Kubernetes 存储系统的所有新功能(如卷快照)将只被添加到 CSI 接口。因此,如果你正在启动一个新的集群、首次创建有状态的应用程序,或者需要这些新功能,我们建议你在本地使用 CSI 驱动(而不是树内卷插件 API)。遵循最新的 CSI 驱动用户指南并使用新的 CSI API。
然而,如果您选择沿用现有集群或继续使用传统卷 API 的规约,CSI 迁移功能将确保我们通过新 CSI 驱动继续支持这些部署。但是,如果您想利用快照等新功能,则需要进行手动迁移,将现有的树内持久卷重新导入为 CSI 持久卷。
我如何参与其中?
Kubernetes Slack 频道 #csi-migration 以及任何一个标准的 SIG Storage 通信频道都是与 Kubernetes 存储特别兴趣组和迁移工作组团队联系的绝佳媒介。
该项目,和其他所有 Kubernetes 项目一样,是许多来自不同背景的贡献者共同努力的结果。我们非常感谢在过去几个季度里挺身而出帮助推动项目发展的贡献者们:
- Michelle Au (msau42)
- Jan Šafránek (jsafrane)
- Hemant Kumar (gnufied)
特别感谢以下人士对 CSI 迁移功能的精辟评论、全面考虑和宝贵贡献:
- Andy Zhang (andyzhangz)
- Divyen Patel (divyenpatel)
- Deep Debroy (ddebroy)
- Humble Devassy Chirammal (humblec)
- Jing Xu (jingxu97)
- Jordan Liggitt (liggitt)
- Matthew Cary (mattcary)
- Matthew Wong (wongma7)
- Neha Arora (nearora-msft)
- Oksana Naumov (trierra)
- Saad Ali (saad-ali)
- Tim Bannister (sftim)
- Xing Yang (xing-yang)
有兴趣参与 CSI 或 Kubernetes 存储系统任何部分的设计和开发的人,请加入 Kubernetes 存储特别兴趣组。我们正在迅速成长,并一直欢迎新的贡献者。
Kubernetes 1.23:IPv4/IPv6 双协议栈网络达到 GA
作者: Bridget Kromhout (微软)
“Kubernetes 何时支持 IPv6?” 自从 k8s v1.9 版本中首次添加对 IPv6 的 alpha 支持以来,这个问题的讨论越来越频繁。 虽然 Kubernetes 从 v1.18 版本开始就支持纯 IPv6 集群,但当时还无法支持 IPv4 迁移到 IPv6。 IPv4/IPv6 双协议栈网络 在 Kubernetes v1.23 版本中进入正式发布(GA)阶段。
让我们来看看双协议栈网络对你来说意味着什么?
更新 Service API
Services 在 1.20 版本之前是单协议栈的, 因此,使用两个 IP 协议族意味着需为每个 IP 协议族创建一个 Service。在 1.20 版本中对用户体验进行简化, 重新实现了 Service 以支持两个 IP 协议族,这意味着一个 Service 就可以处理 IPv4 和 IPv6 协议。 对于 Service 而言,任意的 IPv4 和 IPv6 协议组合都可以实现负载均衡。
Service API 现在有了支持双协议栈的新字段,取代了单一的 ipFamily 字段。
- 你可以通过将
ipFamilyPolicy字段设置为SingleStack、PreferDualStack或RequireDualStack来设置 IP 协议族。Service 可以在单协议栈和双协议栈之间进行转换(在某些限制内)。 - 设置
ipFamilies为指定的协议族列表,可用来设置使用协议族的顺序。 - 'clusterIPs' 的能力在涵盖了之前的 'clusterIP'的情况下,还允许设置多个 IP 地址。 所以不再需要运行重复的 Service,在两个 IP 协议族中各运行一个。你可以在两个 IP 协议族中分配集群 IP 地址。
请注意,Pods 也是双协议栈的。对于一个给定的 Pod,不可能在同一协议族中设置多个 IP 地址。
默认行为仍然是单协议栈
从 1.20 版本开始,重新实现的双协议栈服务处于 Alpha 阶段,无论集群是否配置了启用双协议栈的特性标志, Kubernetes 的底层网络都已经包括了双协议栈。
Kubernetes 1.23 删除了这个特性标志,说明该特性已经稳定。 如果你想要配置双协议栈网络,这一能力总是存在的。 你可以将集群网络设置为 IPv4 单协议栈 、IPv6 单协议栈或 IPV4/IPV6 双协议栈 。
虽然 Service 是根据你的配置设置的,但 Pod 默认是由 CNI 插件设置的。
如果你的 CNI 插件分配单协议栈 IP,那么就是单协议栈,除非 ipFamilyPolicy 设置为 PreferDualStack 或 RequireDualStack。
如果你的 CNI 插件分配双协议栈 IP,则 pod.status.PodIPs 默认为双协议栈。
尽管双协议栈是可用的,但并不强制你使用它。 在双协议栈服务配置 文档中的示例列出了可能出现的各种场景.
现在尝试双协议栈
虽然现在上游 Kubernetes 支持双协议栈网络 作为 GA 或稳定特性,但每个提供商对双协议栈 Kubernetes 的支持可能会有所不同。节点需要提供可路由的 IPv4/IPv6 网络接口。 Pod 需要是双协议栈的。网络插件 是用来为 Pod 分配 IP 地址的,所以集群需要支持双协议栈的网络插件。一些容器网络接口(CNI)插件支持双协议栈,例如 kubenet。
支持双协议栈的生态系统在不断壮大;你可以使用 kubeadm 创建双协议栈集群, 在本地尝试用 KIND 创建双协议栈集群, 还可以将双协议栈集群部署到云上(在查阅 CNI 或 kubenet 可用性的文档之后)
加入 Network SIG
SIG-Network 希望从双协议栈网络的社区体验中学习,以了解更多不断变化的需求和你的用例信息。 SIG-network 更新了来自 KubeCon 2021 北美大会的视频 总结了 SIG 最近的更新,包括双协议栈将在 1.23 版本中稳定。
当前 SIG-Network 在 GitHub 上的 KEPs 和 issues 说明了该 SIG 的重点领域。双协议栈 API 服务器 是一个考虑贡献的方向。
SIG-Network 会议 是一个友好、热情的场所,你可以与社区联系并分享你的想法。期待你的加入!
致谢
许多 Kubernetes 贡献者为双协议栈网络做出了贡献。感谢所有贡献了代码、经验报告、文档、代码审查以及其他工作的人。 Bridget Kromhout 在 Kubernetes的双协议栈网络 中详细介绍了这项社区工作。Tim Hockin 和 Khaled (Kal) Henidak 在 2019 年的 KubeCon 大会演讲 (Kubernetes 通往 IPv4/IPv6 双协议栈的漫漫长路) 和 Lachlan Evenson 在 2021 年演讲(我们来啦,Kubernetes 双协议栈网络) 中讨论了双协议栈的发展旅程,耗时 5 年和海量代码。
公布 2021 年指导委员会选举结果
作者:Kaslin Fields
2021 年指导委员会选举现已完成。 Kubernetes 指导委员会由 7 个席位组成,其中 4 个席位将在 2021 年进行选举。 新任委员会成员任期 2 年,所有成员均由 Kubernetes 社区选举产生。
这个社区机构非常重要,因为它监督整个 Kubernetes 项目的治理。 你可以在其章程中了解更多关于指导委员会的角色。
选举结果
祝贺当选的委员会成员,他们的两年任期即刻生效(按 GitHub handle 字母排序):
- Christoph Blecker(@cblecker), 红帽
- Stephen Augustus(@justaugustus), 思科
- Paris Pittman(@parispittman), 苹果
- Tim Pepper(@tpepper), VMware
他们加入永久成员:
- Davanum Srinivas(@dims), VMware
- Jordan Liggitt (@liggitt), 谷歌
- Bob Killen (@mrbobbytables), 谷歌
Paris Pittman 和 Christoph Blecker 将回到指导委员会。
非常感谢
感谢并祝贺完成本轮成功选举的选举官们:
- Alison Dowdney, (@alisondy)
- Noah Kantrowitz (@coderanger)
- Josh Berkus (@jberkus)
特别感谢 k8s-infra 联络员 Arnaud Meukam(@ameukam), 他在社区的基础设施上启动了我们的投票软件。
感谢荣誉退休的指导委员会成员。对你们之前对社区的贡献表示感谢:
- Derek Carr (@derekwaynecarr)
- Nikhita Raghunath (@nikhita)
感谢所有前来参加竞选的候选人。
参与指导委员会
与所有 Kubernetes 一样,这个管理机构对所有人开放。 你可以查看指导委员会的待办事项, 通过在他们的 repo 中提交一个 issue 或创建一个 PR 来参与讨论。 他们在每月的第一个星期一上午 9:30 举行公开会议, 并定期参加会见我们的贡献者活动。也可以通过他们的公共邮件列表 steering@kubernetes.io 联系他们。
你可以在 YouTube 播放列表 上观看之前的会议视频,了解指导委员会的会议讨论内容。
本文是由上游营销工作组撰写的。 如果你想撰写有关 Kubernetes 社区的故事,请了解更多关于我们的信息。
关注 SIG Node
Author: Dewan Ahmed, Red Hat
介绍
在 Kubernetes 中,一个 Node 是你集群中的某台机器。 SIG Node 负责这一非常重要的 Node 组件并支持各种子项目, 如 Kubelet, Container Runtime Interface (CRI) 以及其他支持 Pod 和主机资源间交互的子项目。 在这篇文章中,我们总结了和 Elana Hashman (EH) & Sergey Kanzhelev (SK) 的对话,是他们带领我们了解作为此 SIG 一份子的各个方面,并分享一些关于其他人如何参与的见解。
我们的对话总结
你能告诉我们一些关于 SIG Node 的工作吗?
SK:SIG Node 是一个垂直 SIG,负责支持 Pod 和主机资源之间受控互动的组件。我们管理被调度到节点上的 Pod 的生命周期。 这个 SIG 的重点是支持广泛的工作负载类型,包括具有硬件特性或性能敏感要求的工作负载。同时保持节点上 Pod 之间的隔离边界,以及 Pod 和主机的隔离边界。 这个 SIG 维护了相当多的组件,并有许多外部依赖(如容器运行时间或操作系统功能),这使得我们处理起来十分复杂。但我们战胜了这种复杂度,旨在不断提高节点的可靠性。
你能再解释一下 “SIG Node 是一种垂直 SIG” 的含义吗?
EH:有两种 SIG:横向和垂直。横向 SIG 关注 Kubernetes 中每个组件的特定功能:例如,SIG Security 考虑 Kubernetes 中每个组件的安全方面,或者 SIG Instrumentation 关注 Kubernetes 中每个组件的日志、度量、跟踪和事件。 这样的 SIG 并不太会拥有大量的代码。
相反,垂直 SIG 拥有一个单一的组件,并负责批准和合并该代码库的补丁。 SIG Node 拥有 "Node" 的垂直性,与 kubelet 和它的生命周期有关。这包括 kubelet 本身的代码,以及节点控制器、容器运行时接口和相关的子项目,比如节点问题检测器。
CI 子项目是如何开始的?这是专门针对 SIG Node 的吗?它对 SIG 有什么帮助?
SK:该子项目是在其中一个版本因关键测试的大量测试失败而受阻后开始跟进的。 这些测试并不是一下子就开始下降的,而是持续的缺乏关注导致了测试质量的缓慢下降。 SIG Node 一直将质量和可靠性放在首位,组建这个子项目是强调这一优先事项的一种方式。
作为 issue 和 PR 数量第三大的 SIG,你们 SIG 是如何兼顾这么多工作的?
EH:这归功于有组织性。当我在 2021 年 1 月增加对 SIG 的贡献时,我发现自己被大量的 PR 和 issue 淹没了,不知道该从哪里开始。 我们已经在 CI 子项目板上跟踪与测试有关的 issue 和 PR 请求,但这缺少了很多 bug 修复和功能工作。 因此,我开始为我们剩余的 PR 建立一个分流板,这使我能够根据状态和采取的行动对其进行分类,并为其他贡献者记录它的用途。 在过去的两个版本中,我们关闭或合并了超过 500 个 issue 和 PR。Kubernetes devstats 显示,我们的速度因此而大大提升。
6月,我们进行了第一次 bug 清除活动,以解决针对 SIG Node 的积压问题,确保它们被正确归类。 在这次 48 小时的全球活动中,我们关闭了 130 多个问题,但截至发稿时,我们仍有 333 个问题没有解决。
为什么新的和现有的贡献者应该考虑加入 Node 兴趣小组呢?
SK:作为 SIG Node 的贡献者会带给你有意义且有用的技能和认可度。 了解 Kubelet 的内部结构有助于构建更好的应用程序,调整和优化这些应用程序,并在 issue 排查上获得优势。 如果你是一个新手贡献者,SIG Node 为你提供了基础知识,这是理解其他 Kubernetes 组件的设计方式的关键。 现在的贡献者可能会受益于许多功能都需要 SIG Node 的这种或那种变化。所以成为 SIG Node 的贡献者有助于更快地建立其他 SIG 的功能。
SIG Node 维护着许多组件,其中许多组件都依赖于外部项目或操作系统功能。这使得入职过程相当冗长和苛刻。 但如果你愿意接受挑战,总有一个地方适合你,也有一群人支持你。
你是如何帮助新手贡献者开始工作的?
EH:在 SIG Node 的起步工作可能是令人生畏的,因为有太多的工作要做,我们的 SIG 会议非常大,而且很难找到一个开始的地方。
我总是鼓励新手贡献者在他们已经有一些投入的方向上更进一步。 在 SIG Node 中,这可能意味着自愿帮助修复一个只影响到你个人的 bug,或者按优先级去分流你关心的 bug。
为了尽快了解任何开源代码库,你可以采取两种策略:从深入探索一个特定的问题开始,然后根据需要扩展你的知识边缘,或者单纯地尽可能多的审查 issues 和变更请求,以了解更高层次的组件工作方式。 最终,如果你想成为一名 Node reviewer 或 approver,两件事是不可避免的。
Davanum Srinivas 和我各自举办了一次小组辅导,以帮助教导新手贡献者成为 Node reviewer 的技能,如果有兴趣,我们可以努力寻找一个导师来举办另一次会议。 我也鼓励新手贡献者参加我们的 Node CI 子项目会议:它的听众较少,而且我们不记录分流会议,所以它可以是一个比较温和的方式来开始 SIG 之旅。
有什么特别的技能者是你想招募的吗?对 SIG 可用性的贡献者可能会学到什么技能?
SK:SIG Node 在大相径庭的领域从事许多工作流。所有这些领域都是系统级的。 对于典型的代码贡献,你需要对建立和善用低级别的 API 以及编写高性能和可靠的组件有热情。 作为一个贡献者,你将学习如何调试和排除故障,剖析和监控这些组件,以及由这些组件运行的用户工作负载。 通常情况下,由于节点正在运行生产工作负载,所以对节点的访问是有限的,甚至是没有的。
另一种贡献方式是帮助记录 SIG Node 的功能。这种类型的贡献需要对功能有深刻的理解,并有能力用简单的术语解释它们。
最后,我们一直在寻找关于如何最好地运行你的工作负载的反馈。来解释一下它的具体情况,以及 SIG Node 组件中的哪些功能可能有助于更好地运行它。
你在哪些方面得到了积极的反馈,以及 SIG Node 的下一步计划是什么?
EH:在过去的一年里,SIG Node 采用了一些新的流程来帮助管理我们的功能开发和 Kubernetes 增强提议,其他 SIG 也向我们寻求在管理大型工作负载方面的灵感。 我希望这是一个我们可以继续领导并进一步迭代的领域。
现在,我们在新功能和废弃功能之间保持了很好的平衡。 废弃未使用或难以维护的功能有助于我们控制技术债务和维护负荷,例子包括 dockershim 和 DynamicKubeletConfiguration 的废弃。 新功能将在终端用户的集群中释放更多的功能,包括令人兴奋的功能,如支持 cgroups v2、交换内存、优雅的节点关闭和设备管理策略。
最后你有什么想法/资源要分享吗?
SK/EH:进入任何开源社区都需要时间和努力。一开始 SIG Node 可能会因为参与者的数量、工作量和项目范围而让你不知所措。但这是完全值得的。 请加入我们这个热情的社区! SIG Node GitHub Repo 包含许多有用的资源,包括 Slack、邮件列表和其他联系信息。
总结
SIG Node 举办了一场 KubeCon + CloudNativeCon Europe 2021 talk,对他们强大的 SIG 进行了介绍和深入探讨。 加入 SIG 的会议,了解最新的研究成果,未来一年的计划是什么,以及如何作为贡献者参与到上游的 Node 团队中!
更新 NGINX-Ingress 以使用稳定的 Ingress API
作者: James Strong, Ricardo Katz
对于所有 Kubernetes API,一旦它们被正式发布(GA),就有一个创建、维护和最终弃用它们的过程。 networking.k8s.io API 组也不例外。 即将发布的 Kubernetes 1.22 版本将移除几个与网络相关的已弃用 API:
- IngressClass 的
networking.k8s.io/v1beta1API 版本 - Ingress 的所有 Beta 版本:
extensions/v1beta1和networking.k8s.io/v1beta1
在 v1.22 Kubernetes 集群上,你能够通过稳定版本(v1)的 API 访问 Ingress 和 IngressClass 对象, 但无法通过其 Beta API 访问。
自 2017、 2019 以来一直讨论关于 Kubernetes 1.16 弃用 API 的更改, 最近的讨论是在 KEP-1453:Ingress API 毕业到 GA。
在社区会议中,网络特别兴趣小组决定继续支持带有 0.47.0 版本 Ingress-NGINX 的早于 1.22 版本的 Kubernetes。 在 Kubernetes 1.22 发布后,对 Ingress-NGINX 的支持将持续六个月。 团队会根据需要解决 Ingress-NGINX 的额外错误修复和 CVE 问题。
Ingress-NGINX 将拥有独立的分支和发布版本来支持这个模型,与 Kubernetes 项目流程相一致。 Ingress-NGINX 项目的未来版本将跟踪和支持最新版本的 Kubernetes。
| Kubernetes 版本 | Ingress-NGINX 版本 | 公告 |
|---|---|---|
| v1.22 | v1.0.0-alpha.2 | 新特性,以及错误修复。 |
| v1.21 | v0.47.x | 仅修复安全问题或系统崩溃的错误。没有宣布终止支持日期。 |
| v1.20 | v0.47.x | 仅修复安全问题或系统崩溃的错误。没有宣布终止支持日期。 |
| v1.19 | v0.47.x | 仅修复安全问题或系统崩溃的错误。仅在 Kubernetes v1.22.0 发布后的 6 个月内提供修复支持。 |
由于 Kubernetes 1.22 中的更新,v0.47.0 将无法与 Kubernetes 1.22 一起使用。
你需要做什么
团队目前正在升级 Ingress-NGINX 以支持向 v1 的迁移, 你可以在此处跟踪进度。 在对 Ingress v1 的支持完成之前, 我们不会对功能进行改进。
同时,团队会确保没有兼容性问题:
- 更新到最新的 Ingress-NGINX 版本, 目前是 v0.47.0。
- Kubernetes 1.22 发布后,请确保使用的是支持 Ingress 和 IngressClass 稳定 API 的最新版本的 Ingress-NGINX。
- 使用集群版本 >= 1.19 测试 Ingress-NGINX 版本 v1.0.0-alpha.2,并将任何问题报告给项目 GitHub 页面。
欢迎社区对此工作的反馈和支持。 Ingress-NGINX 子项目定期举行社区会议, 我们会讨论这个问题以及项目面临的其他问题。 有关子项目的更多信息,请参阅 SIG Network。
聚焦 SIG Usability
作者: Kunal Kushwaha、Civo
介绍
你是否有兴趣了解 SIG Usability 做什么? 你是否想知道如何参与?那你来对地方了。 SIG Usability 旨在让 Kubernetes 更易于触达新的伙伴,其主要活动是针对社区实施用户调研。 在本博客中,我们总结了与 Gaby Moreno 的对话, 他向我们介绍了成为 SIG 成员的各个方面,并分享了一些关于其他人如何参与的见解。
Gaby 是 SIG Usability 的联合负责人。 她在 IBM 担任产品设计师, 喜欢研究 Kubernetes、OpenShift、Terraform 和 Cloud Foundry 等开放式混合云技术的用户体验。
我们谈话的摘要
问:你能告诉我们一些关于 SIG Usability 的事情吗?
答:简单而言,启动 SIG Usability 的原因是那时 Kubernetes 没有专门的用户体验团队。 SIG Usability 的关注领域集中在为 Kubernetes 项目最终客户提供的易用性上。 主要活动是社区的用户调研,包括对 Kubernetes 用户宣讲。
所涉及的包括用户体验和可访问性等方面。 SIG 的目标是确保 Kubernetes 项目能够最大限度地被具有各类不同基础和能力的人使用, 例如引入文档的国际化并确保其开放性。
问:为什么新的和现有的贡献者应该考虑加入 SIG Usability?
答:新的贡献者可以在很多领域着手。例如:
- 用户研究项目可以让人们帮助了解最终用户体验的可用性,包括错误消息、端到端任务等。
- Kubernetes 社区组件的可访问性指南,包括:文档的国际化、色盲人群的颜色选择、 确保与屏幕阅读器技术的兼容性、核心 UI 组件的用户界面设计等等。
问:如何帮助新的贡献者入门?
答:新的贡献者们刚开始可以旁观参与其中一个用户访谈,浏览用户访谈记录,分析这些记录并设计调查过程。
SIG Usability 也对新的项目想法持开放态度。 如果你有想法,我们将尽我们所能支持它。 我们有定期的 SIG 会议,人们可以现场提问。 这些会议也会录制会议视频,方便那些可能无法参会的人。 与往常一样,你也可以在 Slack 上与我们联系。
问:调查包括什么?
答:简单来说,调查会收集人们如何使用 Kubernetes 的信息, 例如学习部署新系统的趋势、他们收到的错误消息和工作流程。
我们的目标之一是根据需要对反馈进行标准化。 最终目标是分析那些需求没有得到满足的重要用户故事的调查反馈。
问:招募贡献者时你希望他们具备什么特别的技能吗?SIG Usability 的贡献者可能要学习哪些技能?
答:虽然为 SIG Usability 做贡献没有任何先决条件, 但用户研究、定性研究的经验或之前如何进行访谈的经验将是很好的加分项。 定量研究,如调查设计和筛选,也很有帮助,也是我们希望贡献者学习的东西。
问:您在哪些方面获得了积极的反馈,以及 SIG Usability 接下来会发生什么?
答:我们一直有新成员加入并经常参加月度会议,并表现出对成为贡献者和帮助社区的兴趣。 我们也有很多人通过 Slack 与我们联系,表达他们对 SIG 的兴趣。
目前,我们正专注于完成我们演讲中提到的调研, 也是我们今年的项目。我们总是很高兴有新的贡献者加入我们。
问:在结束之前,你还有什么想法/资源要分享吗?
答:我们喜欢结识新的贡献者并帮助他们研究不同的 Kubernetes 项目领域。 我们将与其他 SIG 合作,以促进与最终用户的互动,开展调研,并帮助他们将可访问的设计实践整合到他们的开发实践中。
这里有一些资源供你入门:
总结
SIG Usability 举办了一个关于调研 Kubernetes 用户体验的 KubeCon 演讲。 演讲的重点是用户调研项目的更新,了解谁在使用 Kubernetes、他们试图实现什么、项目如何满足他们的需求、以及我们需要改进项目和客户体验的地方。 欢迎加入 SIG 的更新,了解最新的调研成果、来年的计划以及如何作为贡献者参与上游可用性团队!
卷健康监控的 Alpha 更新
作者: Xing Yang (VMware)
最初在 1.19 中引入的 CSI 卷健康监控功能在 1.21 版本中进行了大规模更新。
为什么要向 Kubernetes 添加卷健康监控?
如果没有卷健康监控,在 PVC 被 Pod 配置和使用后,Kubernetes 将不知道存储系统的底层卷的状态。 在 Kubernetes 中配置卷后,底层存储系统可能会发生很多事情。 例如,卷可能在 Kubernetes 之外被意外删除、卷所在的磁盘可能发生故障、容量不足、磁盘可能被降级而影响其性能等等。 即使卷被挂载到 Pod 上并被应用程序使用,以后也可能会出现诸如读/写 I/O 错误、文件系统损坏、在 Kubernetes 之外被意外卸载卷等问题。 当发生这样的事情时,调试和检测根本原因是非常困难的。
卷健康监控对 Kubernetes 用户非常有益。 它可以与 CSI 驱动程序通信以检索到底层存储系统检测到的错误。 用户可以收到报告上来的 PVC 事件继而采取行动。 例如,如果卷容量不足,他们可以请求卷扩展以获得更多空间。
什么是卷健康监控?
CSI 卷健康监控允许 CSI 驱动程序检测来自底层存储系统的异常卷状况,并将其作为 PVC 或 Pod 上的事件报送。
监控卷和使用卷健康信息报送事件的 Kubernetes 组件包括:
- Kubelet 除了收集现有的卷统计信息外,还将观察该节点上 PVC 的卷健康状况。 如果 PVC 的健康状况异常,则会在使用 PVC 的 Pod 对象上报送事件。 如果多个 Pod 使用相同的 PVC,则将在使用该 PVC 的所有 Pod 上报送事件。
- 一个外部卷健康监视控制器监视 PVC 的卷健康并报告 PVC 上的事件。
请注意,在 Kubernetes 1.19 版本中首次引入此功能时,节点侧卷健康监控逻辑是一个外部代理。
在 Kubernetes 1.21 中,节点侧卷健康监控逻辑从外部代理移至 Kubelet,以避免 CSI 函数重复调用。
随着 1.21 中的这一变化,为 Kubelet 中的卷健康监控逻辑引入了一个新的 alpha 特性门 CSIVolumeHealth。
目前,卷健康监控功能仅供参考,因为它只报送 PVC 或 Pod 上的异常卷健康事件。 用户将需要检查这些事件并手动修复问题。 此功能可作为 Kubernetes 未来以编程方式检测和解决卷健康问题的基石。
如何在 Kubernetes 集群上使用卷健康?
要使用卷健康功能,首先确保你使用的 CSI 驱动程序支持此功能。 请参阅此 CSI 驱动程序文档以了解哪些 CSI 驱动程序支持此功能。
要从节点侧启用卷健康监控,需要启用 alpha 特性门 CSIVolumeHealth。
如果 CSI 驱动程序支持控制器端的卷健康监控功能,则有关异常卷条件的事件将记录在 PVC 上。
如果 CSI 驱动程序支持控制器端的卷健康监控功能,
当部署外部健康监控控制器时 enable-node-watcher 标志设置为 true,用户还可以获得有关节点故障的事件。
当检测到节点故障事件时,会在 PVC 上报送一个事件,指示使用该 PVC 的 Pod 在故障节点上。
如果 CSI 驱动程序支持节点端的卷健康监控功能,则有关异常卷条件的事件将使用 PVC 记录在 Pod 上。
作为存储供应商,如何向 CSI 驱动程序添加对卷健康的支持?
卷健康监控包括两个部分:
- 外部卷健康监控控制器从控制器端监控卷健康。
- Kubelet 从节点端监控卷的健康状况。
有关详细信息,请参阅 CSI 规约 和 Kubernetes-CSI 驱动开发者指南。
CSI 主机路径驱动程序中有一个卷健康的示例实现。
控制器端卷健康监控
要了解如何部署外部卷健康监控控制器, 请参阅 CSI 文档中的 CSI external-health-monitor-controller。
如果检测到异常卷条件,
外部健康监视器控制器调用 ListVolumes 或者 ControllerGetVolume CSI RPC 并报送 VolumeConditionAbnormal 事件以及 PVC 上的消息。
只有具有 LIST_VOLUMES 和 VOLUME_CONDITION 控制器能力、
或者具有 GET_VOLUME 和 VOLUME_CONDITION 能力的 CSI 驱动程序才支持外部控制器中的卷健康监控。
要从控制器端实现卷健康功能,CSI 驱动程序必须添加对新控制器功能的支持。
如果 CSI 驱动程序支持 LIST_VOLUMES 和 VOLUME_CONDITION 控制器功能,它必须实现控制器 RPC ListVolumes 并在响应中报送卷状况。
如果 CSI 驱动程序支持 GET_VOLUME 和 VOLUME_CONDITION 控制器功能,它必须实现控制器 PRC ControllerGetVolume 并在响应中报送卷状况。
如果 CSI 驱动程序支持 LIST_VOLUMES、GET_VOLUME 和 VOLUME_CONDITION 控制器功能,则外部健康监视控制器将仅调用 ListVolumes CSI RPC。
节点侧卷健康监控
如果检测到异常的卷条件,
Kubelet 会调用 NodeGetVolumeStats CSI RPC 并报送 VolumeConditionAbnormal 事件以及 Pod 上的信息。
只有具有 VOLUME_CONDITION 节点功能的 CSI 驱动程序才支持 Kubelet 中的卷健康监控。
要从节点端实现卷健康功能,CSI 驱动程序必须添加对新节点功能的支持。
如果 CSI 驱动程序支持 VOLUME_CONDITION 节点能力,它必须在节点 RPC NodeGetVoumeStats 中报送卷状况。
下一步是什么?
根据反馈和采纳情况,Kubernetes 团队计划在 1.22 或 1.23 中将 CSI 卷健康实施推向 beta。
我们还在探索如何在 Kubernetes 中使用卷健康信息进行编程检测和自动协调。
如何了解更多?
要了解卷健康监控的设计细节,请阅读卷健康监控增强提案。
卷健康检测控制器源代码位于: https://github.com/kubernetes-csi/external-health-monitor。
容器存储接口文档中还有关于卷健康检查的更多详细信息。
如何参与?
Kubernetes Slack 频道 #csi 和任何标准 SIG Storage 通信频道都是联系 SIG Storage 和 CSI 团队的绝佳媒介。
我们非常感谢在 1.21 中帮助发布此功能的贡献者。 我们要感谢 Yuquan Ren (NickrenREN) 在外部健康监控仓库中实现了初始卷健康监控控制器和代理, 感谢 Ran Xu (fengzixu) 在 1.21 中将卷健康监控逻辑从外部代理转移到 Kubelet, 我们特别感谢以下人员的深刻评论: David Ashpole (dashpole)、 Michelle Au (msau42)、 David Eads (deads2k)、 Elana Hashman (ehashman)、 Seth Jennings (sjenning) 和 Jiawei Wang (Jiawei0227)
那些有兴趣参与 CSI 或 Kubernetes 存储系统任何部分的设计和开发的人, 请加入 Kubernetes Storage 特殊兴趣小组(SIG)。 我们正在迅速发展,并且欢迎新的贡献者。
弃用 PodSecurityPolicy:过去、现在、未来
作者:Tabitha Sable(Kubernetes SIG Security)
更新:随着 Kubernetes v1.25 的发布,PodSecurityPolicy 已被删除。
你可以在 Kubernetes 1.25 发布说明 中阅读有关删除 PodSecurityPolicy 的更多信息。
PodSecurityPolicy (PSP) 在 Kubernetes 1.21 中被弃用。 PSP 日后会被移除,但目前不会改变任何其他内容。在移除之前,PSP 将继续在后续多个版本中完全正常运行。 与此同时,我们正在开发 PSP 的替代品,希望可以更轻松、更可持续地覆盖关键用例。
什么是 PSP?为什么需要 PSP?为什么要弃用,未来又将如何发展? 这对你有什么影响?当我们准备告别 PSP,这些关键问题浮现在脑海中, 所以让我们一起来讨论吧。本文首先概述 Kubernetes 如何移除一些特性。
Kubernetes 中的弃用是什么意思?
每当 Kubernetes 决定弃用某项特性时,我们会遵循弃用策略。 首先将该特性标记为已弃用,然后经过足够长的时间后,最终将其移除。
Kubernetes 1.21 启动了 PodSecurityPolicy 的弃用流程。与弃用任何其他功能一样, PodSecurityPolicy 将继续在后续几个版本中完全正常运行。目前的计划是在 1.25 版本中将其移除。
在彻底移除之前,PSP 仍然是 PSP。至少在未来一年时间内,最新的 Kubernetes 版本仍将继续支持 PSP。大约两年之后,PSP 才会在所有受支持的 Kubernetes 版本中彻底消失。
什么是 PodSecurityPolicy?
PodSecurityPolicy 是一个内置的准入控制器, 允许集群管理员控制 Pod 规约中涉及安全的敏感内容。
首先,在集群中创建一个或多个 PodSecurityPolicy 资源来定义 Pod 必须满足的要求。 然后,创建 RBAC 规则来决定为特定的 Pod 应用哪个 PodSecurityPolicy。 如果 Pod 满足其 PSP 的要求,则照常被允许进入集群。 在某些情况下,PSP 还可以修改 Pod 字段,有效地为这些字段创建新的默认值。 如果 Pod 不符合 PSP 要求,则被拒绝进入集群,并且无法运行。
关于 PodSecurityPolicy,还需要了解:它与 PodSecurityContext 不同。
作为 Pod 规约的一部分,PodSecurityContext(及其每个容器对应的 SecurityContext)
是一组字段的集合,这些字段为 Pod 指定了与安全相关的许多设置。
安全上下文指示 kubelet 和容器运行时究竟应该如何运行 Pod。
相反,PodSecurityPolicy 仅约束可能在安全上下文中设置的值(或设置默认值)。
弃用 PSP 不会以任何方式影响 PodSecurityContext。
以前为什么需要 PodSecurityPolicy?
在 Kubernetes 中,我们定义了 Deployment、StatefulSet 和 Service 等资源。 这些资源代表软件应用程序的构建块。Kubernetes 集群中的各种控制器根据这些资源做出反应, 创建更多的 Kubernetes 资源或配置一些软件或硬件来实现我们的目标。
在大多数 Kubernetes 集群中,由 RBAC(基于角色的访问控制)规则
控制对这些资源的访问。 list、get、create、edit 和 delete 是 RBAC 关心的 API 操作类型,
但 RBAC 不考虑其所控制的资源中加入了哪些设置。例如,
Pod 几乎可以是任何东西,例如简单的网络服务器,或者是特权命令提示(提供对底层服务器节点和所有数据的完全访问权限)。
这对 RBAC 来说都是一样的:Pod 就是 Pod 而已。
要控制集群中定义的资源允许哪些类型的设置,除了 RBAC 之外,还需要准入控制。 从 Kubernetes 1.3 开始,内置 PodSecurityPolicy 一直被作为 Pod 安全相关字段的准入控制机制。 使用 PodSecurityPolicy,可以防止“创建 Pod”这个能力自动变成“每个集群节点上的 root 用户”, 并且无需部署额外的外部准入控制器。
现在为什么 PodSecurityPolicy 要消失?
自从首次引入 PodSecurityPolicy 以来,我们已经意识到 PSP 存在一些严重的可用性问题, 只有做出断裂式的改变才能解决。
实践证明,PSP 应用于 Pod 的方式让几乎所有尝试使用它们的人都感到困惑。 很容易意外授予比预期更广泛的权限,并且难以查看某种特定情况下应用了哪些 PSP。 “更改 Pod 默认值”功能很方便,但仅支持某些 Pod 设置,而且无法明确知道它们何时会或不会应用于的 Pod。 如果没有“试运行”或审计模式,将 PSP 安全地改造并应用到现有集群是不切实际的,并且永远都不可能默认启用 PSP。
有关这些问题和其他 PSP 困难的更多信息,请查看 KubeCon NA 2019 的 SIG Auth 维护者频道会议记录:
如今,你不再局限于部署 PSP 或编写自己的自定义准入控制器。 有几个外部准入控制器可用,它们结合了从 PSP 中吸取的经验教训以提供更好的用户体验。 K-Rail、 Kyverno、 OPA/Gatekeeper 都家喻户晓,各有粉丝。
尽管现在还有其他不错的选择,但我们认为,提供一个内置的准入控制器供用户选择,仍然是有价值的事情。 考虑到这一点,以及受 PSP 经验的启发,我们转向下一步。
下一步是什么?
Kubernetes SIG Security、SIG Auth 和其他社区成员几个月来一直在倾力合作,确保接下来的方案能令人惊叹。 我们拟定了 Kubernetes 增强提案(KEP 2579) 以及一个新功能的原型,目前称之为“PSP 替代策略”。 我们的目标是在 Kubernetes 1.22 中发布 Alpha 版本。
PSP 替代策略始于,我们认识到已经有一个强大的外部准入控制器生态系统可用, 所以,PSP 的替代品不需要满足所有人的所有需求。与外部 Webhook 相比, 部署和采用的简单性是内置准入控制器的关键优势。我们专注于如何最好地利用这一优势。
PSP 替代策略旨在尽可能简单,同时提供足够的灵活性以支撑大规模生产场景。 它具有柔性上线能力,以便于将其改装到现有集群,并且新的策略是可配置的,可以设置为默认启用。 PSP 替代策略可以被部分或全部禁用,以便在高级使用场景中与外部准入控制器共存。
这对你意味着什么?
这一切对你意味着什么取决于你当前的 PSP 情况。如果已经在使用 PSP,那么你有足够的时间来计划下一步行动。 请查看 PSP 替代策略 KEP 并考虑它是否适合你的使用场景。
如果你已经在通过众多 PSP 和复杂的绑定规则深度利用 PSP 的灵活性,你可能会发现 PSP 替代策略的简单性有太多限制。 此时,建议你在接下来的一年中评估一下生态系统中的其他准入控制器选择。有些资源可以让这种过渡更容易, 比如 Gatekeeper Policy Library。
如果只是使用 PSP 的基础功能,只用几个策略并直接绑定到每个命名空间中的服务帐户, 你可能会发现 PSP 替代策略非常适合你的需求。 对比 Kubernetes Pod 安全标准 评估你的 PSP, 了解可以在哪些情形下使用限制策略、基线策略和特权策略。 欢迎关注或为 KEP 和后续发展做出贡献,并在可用时试用 PSP 替代策略的 Alpha 版本。
如果刚刚开始 PSP 之旅,你可以通过保持简单来节省时间和精力。
你可以使用 Pod 安全标准的 PSP 来获得和目前 PSP 替代策略相似的功能。
如果你将基线策略或限制策略绑定到 system:serviceaccounts 组来设置集群默认值,
然后使用 ServiceAccount 绑定
在某些命名空间下根据需要制定更宽松的策略,就可以避免许多 PSP 陷阱并轻松迁移到 PSP 替代策略。
如果你的需求比这复杂得多,那么建议将精力花在采用比上面提到的功能更全的某个外部准入控制器。
我们致力于使 Kubernetes 成为我们可以做到的最好的容器编排工具, 有时这意味着我们需要删除长期存在的功能,以便为更好的特性腾出空间。 发生这种情况时,Kubernetes 弃用策略可确保你有足够的时间来计划下一步行动。 对于 PodSecurityPolicy,有几个选项可以满足一系列需求和用例。 现在就开始为 PSP 的最终移除提前制定计划,请考虑为它的替换做出贡献!
致谢: 研发优秀的软件需要优秀的团队。感谢为 PSP 替代工作做出贡献的所有人, 尤其是(按字母顺序)Tim Allclair、Ian Coldwater 和 Jordan Liggitt。 和你们共事非常愉快。
一个编排高可用应用的 Kubernetes 自定义调度器
作者: Chris Seto (Cockroach Labs)
只要你愿意遵守规则,那么在 Kubernetes 上的部署和探索可以是相当愉快的。更多时候,事情会 "顺利进行"。 然而,如果一个人对与必须保持存活的鳄鱼一起旅行或者是对必须保持可用的数据库进行扩展有兴趣, 情况可能会变得更复杂一点。 相较于这个问题,建立自己的飞机或数据库甚至还可能更容易一些。撇开与鳄鱼的旅行不谈,扩展一个高可用的有状态系统也不是一件小事。
任何系统的扩展都有两个主要组成部分。
- 增加或删除系统将运行的基础架构,以及
- 确保系统知道如何处理自身额外实例的添加和删除。
大多数无状态系统,例如网络服务器,在创建时不需要意识到对等实例。而有状态的系统,包括像 CockroachDB 这样的数据库, 必须与它们的对等实例协调,并对数据进行 shuffle。运气好的话,CockroachDB 可以处理数据的再分布和复制。 棘手的部分是在确保数据和实例分布在许多故障域(可用性区域)的操作过程中能够容忍故障的发生。
Kubernetes 的职责之一是将 "资源"(如磁盘或容器)放入集群中,并满足其请求的约束。 例如。"我必须在可用性区域 A"(见在多个区域运行), 或者 "我不能被放置到与某个 Pod 相同的节点上" (见亲和与反亲和)。
作为对这些约束的补充,Kubernetes 提供了 StatefulSets, 为 Pod 提供身份,以及 "跟随" 这些指定 Pod 的持久化存储。 在 StatefulSet 中,身份是由 Pod 名称末尾一个呈增序的整数处理的。 值得注意的是,这个整数必须始终是连续的:在一个 StatefulSet 中, 如果 Pod 1 和 3 存在,那么 Pod 2 也必须存在。
在架构上,CockroachCloud 将 CockroachDB 的每个区域作为 StatefulSet 部署在自己的 Kubernetes 集群中 -- 参见 Orchestrate CockroachDB in a Single Kubernetes Cluster。 在这篇文章中,我将着眼于一个单独的区域,一个 StatefulSet 和一个至少分布有三个可用区的 Kubernetes 集群。
一个三节点的 CockroachCloud 集群如下所示:
在向集群增加额外的资源时,我们也会将它们分布在各个区域。 为了获得最快的用户体验,我们同时添加所有 Kubernetes 节点,然后扩大 StatefulSet 的规模。
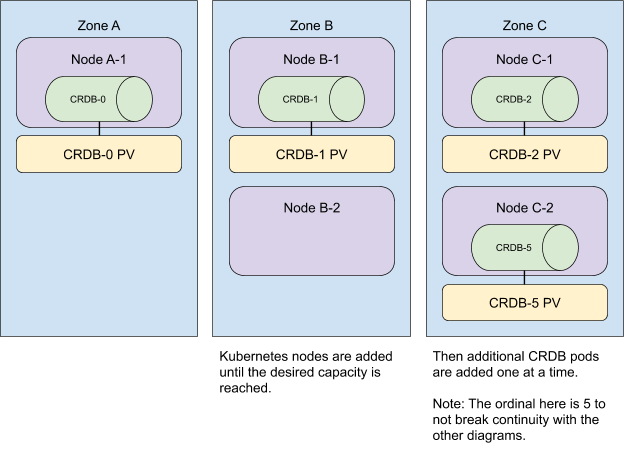
请注意,无论 Pod 被分配到 Kubernetes 节点的顺序如何,都会满足反亲和性。 在这个例子中,Pod 0、1、2 分别被分配到 A、B、C 区,但 Pod 3 和 4 以不同的顺序被分配到 B 和 A 区。 反亲和性仍然得到满足,因为 Pod 仍然被放置在不同的区域。
要从集群中移除资源,我们以相反的顺序执行这些操作。
我们首先缩小 StatefulSet 的规模,然后从集群中移除任何缺少 CockroachDB Pod 的节点。
现在,请记住,规模为 n 的 StatefulSet 中的 Pods 一定具有 [0,n) 范围内的 id。
当把一个 StatefulSet 规模缩减了 m 时,Kubernetes 会移除 m 个 Pod,从最高的序号开始,向最低的序号移动,
与它们被添加的顺序相反。
考虑一下下面的集群拓扑结构。
当从这个集群中移除 5 号到 3 号 Pod 时,这个 StatefulSet 仍然横跨三个可用区。
然而,Kubernetes 的调度器并不像我们一开始预期的那样 保证 上面的分布。
我们对以下内容的综合认识是导致这种误解的原因。
- Kubernetes 自动跨区分配 Pod 的能力
- 一个有 n 个副本的 StatefulSet,当 Pod 被部署时,它们会按照
{0...n-1}的顺序依次创建。 更多细节见 StatefulSet。
考虑以下拓扑结构:
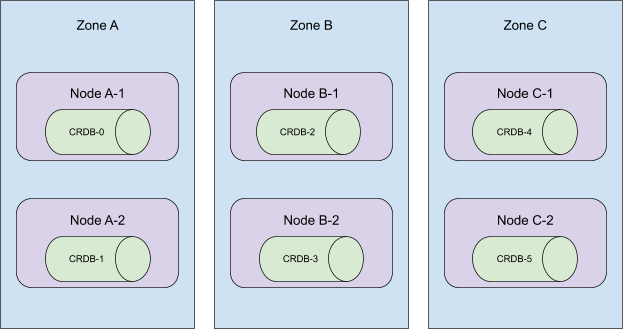
这些 Pod 是按顺序创建的,它们分布在集群里所有可用区。当序号 5 到 3 的 Pod 被终止时, 这个集群将从 C 区消失!
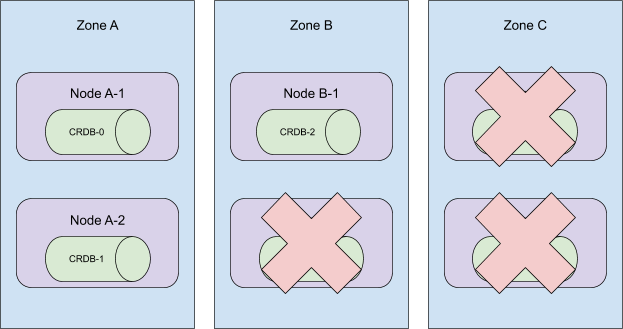
更糟糕的是,在这个时候,我们的自动化机制将删除节点 A-2,B-2,和 C-2。 并让 CRDB-1 处于未调度状态,因为持久性卷只在其创建时所处的区域内可用。
为了纠正后一个问题,我们现在采用了一种“狩猎和啄食”的方法来从集群中移除机器。 与其盲目地从集群中移除 Kubernetes 节点,不如只移除没有 CockroachDB Pod 的节点。 更为艰巨的任务是管理 Kubernetes 的调度器。
一场头脑风暴后我们有了 3 个选择。
1. 升级到 kubernetes 1.18 并利用 Pod 拓扑分布约束
虽然这似乎是一个完美的解决方案,但在写这篇文章的时候,Kubernetes 1.18 在公有云中两个最常见的 托管 Kubernetes 服务( EKS 和 GKE )上是不可用的。 此外,Pod 拓扑分布约束在 1.18 中仍是测试版功能, 这意味着即使在 v1.18 可用时,它也不能保证在托管集群中可用。 整个努力让人联想到在 Internet Explorer 8 还存在的时候访问 caniuse.com。
2. 在每个区部署一个 StatefulSet。
与跨所有可用区部署一个 StatefulSet 相比,在每个区部署一个带有节点亲和性的 StatefulSet 可以实现手动控制分区拓扑结构。 我们的团队过去曾考虑过这个选项,我们也倾向此选项。 但最终,我们决定放弃这个方案,因为这需要对我们的代码库进行大规模的修改,而且在现有的客户集群上进行迁移也是一个同样大的工程。
3. 编写一个自定义的 Kubernetes 调度器
感谢 Kelsey Hightower 的例子和
Banzai Cloud 的博文,我们决定投入进去,编写自己的自定义 Kubernetes 调度器。
一旦我们的概念验证被部署和运行,我们很快就发现,Kubernetes 的调度器也负责将持久化卷映射到它所调度的 Pod 上。
kubectl get events
的输出让我们相信有另一个系统在发挥作用。
在我们寻找负责存储声明映射的组件的过程中,我们发现了
kube-scheduler 插件系统。
我们的下一个 POC 是一个"过滤器"插件,它通过 Pod 的序号来确定适当的可用区域,并且工作得非常完美。
我们的自定义调度器插件是开源的,并在我们所有的 CockroachCloud 集群中运行。 对 StatefulSet Pod 的调度方式有掌控力,让我们有信心扩大规模。 一旦 GKE 和 EKS 中的 Pod 拓扑分布约束可用,我们可能会考虑让我们的插件退役,但其维护的开销出乎意料地低。 更好的是:该插件的实现与我们的业务逻辑是横向的。部署它,或取消它,就像改变 StatefulSet 定义中的 "schedulerName" 字段一样简单。
Chris Seto 是 Cockroach 实验室的一名软件工程师,负责 CockroachCloud CockroachDB 的 Kubernetes 自动化。
Kubernetes 1.20:CSI 驱动程序中的 Pod 身份假扮和短时卷
作者: Shihang Zhang(谷歌)
通常,当 CSI 驱动程序挂载 诸如 Secret 和证书之类的凭据时,它必须通过存储提供者的身份认证才能访问这些凭据。 然而,对这些凭据的访问是根据 Pod 的身份而不是 CSI 驱动程序的身份来控制的。 因此,CSI 驱动程序需要某种方法来取得 Pod 的服务帐户令牌。
当前,有两种不是那么理想的方法来实现这一目的,要么通过授予 CSI 驱动程序使用 TokenRequest API 的权限,要么直接从主机文件系统中读取令牌。
两者都存在以下缺点:
- 违反最少特权原则
- 每个 CSI 驱动程序都需要重新实现获取 Pod 的服务帐户令牌的逻辑
第二种方式问题更多,因为:
- 令牌的受众默认为 kube-apiserver
- 该令牌不能保证可用(例如,
AutomountServiceAccountToken=false) - 该方法不适用于以与 Pod 不同的(非 root 用户)用户身份运行的 CSI 驱动程序。请参见 服务帐户令牌的文件许可权部分
- 该令牌可能是旧的 Kubernetes 服务帐户令牌,如果
BoundServiceAccountTokenVolume=false,该令牌不会过期。
Kubernetes 1.20 引入了一个内测功能 CSIServiceAccountToken 以改善安全状况。这项新功能允许 CSI 驱动程序接收 Pod 的绑定服务帐户令牌。
此功能还提供了一个重新发布卷的能力,以便可以刷新短时卷。
Pod 身份假扮
使用 GCP APIs
使用 Workload Identity,Kubernetes 服务帐户可以在访问 Google Cloud API 时验证为 Google 服务帐户。
如果 CSI 驱动程序要代表其为挂载卷的 Pod 访问 GCP API,则可以使用 Pod 的服务帐户令牌来
交换 GCP 令牌。启用功能 CSIServiceAccountToken 后,
可通过 NodePublishVolume RPC 调用中的卷上下文来访问 Pod 的服务帐户令牌。例如:通过 Secret 存储 CSI 驱动
访问 Google Secret Manager。
使用Vault
如果用户将 Kubernetes 作为身份验证方法配置,
则 Vault 使用 TokenReview API 来验证 Kubernetes 服务帐户令牌。
对于使用 Vault 作为资源提供者的 CSI 驱动程序,它们需要将 Pod 的服务帐户提供给 Vault。
例如,Secret 存储 CSI 驱动和
证书管理器 CSI 驱动。
短时卷
为了使诸如证书之类的短时卷保持有效,CSI 驱动程序可以在其 CSIDriver 对象中指定 RequiresRepublish=true,
以使 kubelet 定期针对已挂载的卷调用 NodePublishVolume。
这些重新发布操作使 CSI 驱动程序可以确保卷内容是最新的。
下一步
此功能是 Alpha 版,预计将在 1.21 版中移至 Beta 版。 请参阅以下 KEP 和 CSI 文档中的更多内容:
随时欢迎您提供反馈!
- SIG-Auth 定期开会,可以通过 Slack 和邮件列表加入
- SIG-Storage 定期开会,可以通过 Slack 和邮件列表加入
Kubernetes 1.20: 最新版本
我们很高兴地宣布 Kubernetes 1.20 的发布,这是我们 2020 年的第三个也是最后一个版本!此版本包含 42 项增强功能:11 项增强功能已升级到稳定版,15 项增强功能正在进入测试版,16 项增强功能正在进入 Alpha 版。
1.20 发布周期在上一个延长的发布周期之后恢复到 11 周的正常节奏。这是一段时间以来功能最密集的版本之一:Kubernetes 创新周期仍呈上升趋势。此版本具有更多的 Alpha 而非稳定的增强功能,表明云原生生态系统仍有许多需要探索的地方。
主题
Volume 快照操作变得稳定
此功能提供了触发卷快照操作的标准方法,并允许用户以可移植的方式在任何 Kubernetes 环境和支持的存储提供程序上合并快照操作。
此外,这些 Kubernetes 快照原语充当基本构建块,解锁为 Kubernetes 开发高级企业级存储管理功能的能力,包括应用程序或集群级备份解决方案。
请注意,快照支持要求 Kubernetes 分销商捆绑 Snapshot 控制器、Snapshot CRD 和验证 webhook。还必须在集群上部署支持快照功能的 CSI 驱动程序。
Kubectl Debug 功能升级到 Beta
kubectl alpha debug 功能在 1.20 中升级到测试版,成为 kubectl debug. 该功能直接从 kubectl 提供对常见调试工作流的支持。此版本的 kubectl 支持的故障排除场景包括:
- 通过创建使用不同容器映像或命令的 pod 副本,对在启动时崩溃的工作负载进行故障排除。
- 通过在 pod 的新副本或使用临时容器中添加带有调试工具的新容器来对 distroless 容器进行故障排除。(临时容器是默认未启用的 alpha 功能。)
- 通过创建在主机命名空间中运行并可以访问主机文件系统的容器来对节点进行故障排除。
请注意,作为新的内置命令,kubectl debug 优先于任何名为 “debug” 的 kubectl 插件。你必须重命名受影响的插件。
kubectl alpha debug 现在不推荐使用,并将在后续版本中删除。更新你的脚本以使用 kubectl debug。 有关更多信息 kubectl debug,请参阅[调试正在运行的 Pod]((https://kubernetes.io/zh-cn/docs/tasks/debug/debug-application/debug-running-pod/)。
测试版:API 优先级和公平性 {#beta-api-priority-and-fairness)
Kubernetes 1.20 由 1.18 引入,现在默认启用 API 优先级和公平性 (APF)。这允许 kube-apiserver 按优先级对传入请求进行分类。
Alpha 更新:IPV4/IPV6
基于用户和社区反馈,重新实现了 IPv4/IPv6 双栈以支持双栈服务。 这允许将 IPv4 和 IPv6 服务集群 IP 地址分配给单个服务,还允许服务从单 IP 堆栈转换为双 IP 堆栈,反之亦然。
GA:进程 PID 稳定性限制
进程 ID (pid) 是 Linux 主机上的基本资源。达到任务限制而不达到任何其他资源限制并导致主机不稳定是很可能发生的。
管理员需要机制来确保用户 pod 不会导致 pid 耗尽,从而阻止主机守护程序(运行时、kubelet 等)运行。此外,重要的是要确保 pod 之间的 pid 受到限制,以确保它们对节点上的其他工作负载的影响有限。
默认启用一年后,SIG Node 在 SupportNodePidsLimit(节点到 Pod PID 隔离)和 SupportPodPidsLimit(限制每个 Pod 的 PID 的能力)上都将 PID 限制升级为 GA。
Alpha:节点体面地关闭
用户和集群管理员希望 Pod 遵守预期的 Pod 生命周期,包括 Pod 终止。目前,当一个节点关闭时,Pod 不会遵循预期的 Pod 终止生命周期,也不会正常终止,这可能会导致某些工作负载出现问题。
该 GracefulNodeShutdown 功能现在处于 Alpha 阶段。GracefulNodeShutdown 使 kubelet 知道节点系统关闭,从而在系统关闭期间正常终止 pod。
主要变化
Dockershim 弃用
Dockershim,Docker 的容器运行时接口 (CRI) shim 已被弃用。不推荐使用对 Docker 的支持,并将在未来版本中删除。由于 Docker 映像遵循开放容器计划 (OCI) 映像规范,因此 Docker 生成的映像将继续在具有所有 CRI 兼容运行时的集群中工作。 Kubernetes 社区写了一篇关于弃用的详细博客文章,并为其提供了一个专门的常见问题解答页面。
Exec 探测超时处理
一个关于 exec 探测超时的长期错误可能会影响现有的 pod 定义,已得到修复。在此修复之前,exec 探测器不考虑 timeoutSeconds 字段。相反,探测将无限期运行,甚至超过其配置的截止日期,直到返回结果。
通过此更改,如果未指定值,将应用默认值 1 second,并且如果探测时间超过一秒,现有 pod 定义可能不再足够。
新引入的 ExecProbeTimeout 特性门控所提供的修复使集群操作员能够恢复到以前的行为,但这种行为将在后续版本中锁定并删除。为了恢复到以前的行为,集群运营商应该将此特性门控设置为 false。
有关更多详细信息,请查看有关配置探针的更新文档。
其他更新
稳定版
- RuntimeClass
- 内置 API 类型默认值
- 添加了对 Pod 层面启动探针和活跃性探针的扼制
- 在 Windows 上支持 CRI-ContainerD
- SCTP 对 Services 的支持
- 将 AppProtocol 添加到 Services 和 Endpoints 上
值得注意的功能更新
发行说明
你可以在发行说明中查看 1.20 发行版的完整详细信息。
可用的发布
Kubernetes 1.20 可在 GitHub 上下载。有一些很棒的资源可以帮助你开始使用 Kubernetes。你可以在 Kubernetes 主站点上查看一些交互式教程,或者使用 kind 的 Docker 容器在你的机器上运行本地集群。如果你想尝试从头开始构建集群,请查看 Kelsey Hightower 的 Kubernetes the Hard Way 教程。
发布团队
这个版本是由一群非常敬业的人促成的,他们在世界上发生的许多事情的时段作为一个团队走到了一起。 非常感谢发布负责人 Jeremy Rickard 以及发布团队中的其他所有人,感谢他们相互支持,并努力为社区发布 1.20 版本。
发布 Logo

raddest: adjective, Slang. excellent; wonderful; cool:
Kubernetes 1.20 版本是迄今为止最激动人心的版本。
2020 年对我们中的许多人来说都是充满挑战的一年,但 Kubernetes 贡献者在此版本中提供了创纪录的增强功能。这是一项了不起的成就,因此发布负责人希望以一点轻松的方式结束这一年,并向 Kubernetes 1.14 - Caturnetes 和一只名叫 Humphrey 的 “rad” 猫致敬。
Humphrey是发布负责人的猫,有一个永久的 blep. 在 1990 年代,Rad 是美国非常普遍的俚语,激光背景也是如此。Humphrey 在 1990 年代风格的学校照片中感觉像是结束这一年的有趣方式。希望 Humphrey 和它的 blep 在 2020 年底给你带来一点快乐!
发布标志由 Henry Hsu - @robotdancebattle 创建。
用户亮点
- Apple 正在世界各地的数据中心运行数千个节点的 Kubernetes 集群。观看 Alena Prokarchyk 的 KubeCon NA 主题演讲,了解有关他们的云原生之旅的更多信息。
项目速度
CNCF K8S DevStats 项目聚集了许多有关Kubernetes和各分项目的速度有趣的数据点。这包括从个人贡献到做出贡献的公司数量的所有内容,并且清楚地说明了为发展这个生态系统所做的努力的深度和广度。
在持续 11 周(9 月 25 日至 12 月 9 日)的 v1.20 发布周期中,我们看到了来自 26 个国家/地区 的 967 家公司 和 1335 名个人(其中 44 人首次为 Kubernetes 做出贡献)的贡献。
生态系统更新
- KubeCon North America 三周前刚刚结束,这是第二个虚拟的此类活动!现在所有演讲都可以点播,供任何需要赶上的人使用!
- 6 月,Kubernetes 社区成立了一个新的工作组,作为对美国各地发生的 Black Lives Matter 抗议活动的直接回应。WG Naming 的目标是尽可能彻底地删除 Kubernetes 项目中有害和不清楚的语言,并以可移植到其他 CNCF 项目的方式进行。在 KubeCon 2020 North America 上就这项重要工作及其如何进行进行了精彩的介绍性演讲,这项工作的初步影响实际上可以在 v1.20 版本中看到。
- 此前于今年夏天宣布,在 Kubecon NA 期间发布了经认证的 Kubernetes 安全专家 (CKS) 认证 ,以便立即安排!遵循 CKA 和 CKAD 的模型,CKS 是一项基于性能的考试,侧重于以安全为主题的能力和领域。该考试面向当前的 CKA 持有者,尤其是那些想要完善其在保护云工作负载方面的基础知识的人(这是我们所有人,对吧?)。
活动更新
KubeCon + CloudNativeCon Europe 2021 将于 2021 年 5 月 4 日至 7 日举行!注册将于 1 月 11 日开放。你可以在此处找到有关会议的更多信息。 请记住,CFP 将于太平洋标准时间 12 月 13 日星期日晚上 11:59 关闭!
即将发布的网络研讨会
请继续关注今年 1 月即将举行的发布网络研讨会。
参与其中
如果你有兴趣为 Kubernetes 社区做出贡献,那么特别兴趣小组 (SIG) 是一个很好的起点。其中许多可能符合你的兴趣!如果你有什么想与社区分享的内容,你可以参加每周的社区会议,或使用以下任一渠道:
- 在新的 Kubernetes Contributor 网站上了解更多关于为Kubernetes 做出贡献的信息
- 在 Twitter @Kubernetesio 上关注我们以获取最新更新
- 加入关于讨论的社区讨论
- 加入 Slack 社区
- 分享你的 Kubernetes 故事
- 在博客上阅读更多关于 Kubernetes 发生的事情
- 了解有关 Kubernetes 发布团队的更多信息
别慌: Kubernetes 和 Docker
作者: Jorge Castro, Duffie Cooley, Kat Cosgrove, Justin Garrison, Noah Kantrowitz, Bob Killen, Rey Lejano, Dan “POP” Papandrea, Jeffrey Sica, Davanum “Dims” Srinivas
更新:Kubernetes 通过 dockershim 对 Docker 的支持现已移除。
有关更多信息,请阅读移除 FAQ。
你还可以通过专门的 GitHub issue 讨论弃用。
Kubernetes 从版本 v1.20 之后,弃用 Docker 这个容器运行时。
不必慌张,这件事并没有听起来那么吓人。
弃用 Docker 这个底层运行时,转而支持符合为 Kubernetes 创建的容器运行接口 Container Runtime Interface (CRI) 的运行时。 Docker 构建的镜像,将在你的集群的所有运行时中继续工作,一如既往。
如果你是 Kubernetes 的终端用户,这对你不会有太大影响。
这事并不意味着 Docker 已死、也不意味着你不能或不该继续把 Docker 用作开发工具。
Docker 仍然是构建容器的利器,使用命令 docker build 构建的镜像在 Kubernetes 集群中仍然可以运行。
如果你正在使用 GKE、EKS、或 AKS 这类托管 Kubernetes 服务, 你需要在 Kubernetes 后续版本移除对 Docker 支持之前, 确认工作节点使用了被支持的容器运行时。 如果你的节点被定制过,你可能需要根据你自己的环境和运行时需求更新它们。 请与你的服务供应商协作,确保做出适当的升级测试和计划。
如果你正在运营你自己的集群,那还应该做些工作,以避免集群中断。
在 v1.20 版中,你仅会得到一个 Docker 的弃用警告。
当对 Docker 运行时的支持在 Kubernetes 某个后续发行版(目前的计划是 2021 年晚些时候的 1.22 版)中被移除时,
你需要切换到 containerd 或 CRI-O 等兼容的容器运行时。
只要确保你选择的运行时支持你当前使用的 Docker 守护进程配置(例如 logging)。
那为什么会有这样的困惑,为什么每个人要害怕呢?
我们在这里讨论的是两套不同的环境,这就是造成困惑的根源。 在你的 Kubernetes 集群中,有一个叫做容器运行时的东西,它负责拉取并运行容器镜像。 Docker 对于运行时来说是一个流行的选择(其他常见的选择包括 containerd 和 CRI-O), 但 Docker 并非设计用来嵌入到 Kubernetes,这就是问题所在。
你看,我们称之为 “Docker” 的物件实际上并不是一个物件——它是一个完整的技术堆栈, 它其中一个叫做 “containerd” 的部件本身,才是一个高级容器运行时。 Docker 既酷炫又实用,因为它提供了很多用户体验增强功能,而这简化了我们做开发工作时的操作, Kubernetes 用不到这些增强的用户体验,毕竟它并非人类。
因为这个用户友好的抽象层,Kubernetes 集群不得不引入一个叫做 Dockershim 的工具来访问它真正需要的 containerd。 这不是一件好事,因为这引入了额外的运维工作量,而且还可能出错。 实际上正在发生的事情就是:Dockershim 将在不早于 v1.23 版中从 kubelet 中被移除,也就取消对 Docker 容器运行时的支持。 你心里可能会想,如果 containerd 已经包含在 Docker 堆栈中,为什么 Kubernetes 需要 Dockershim。
Docker 不兼容 CRI, 容器运行时接口。 如果支持,我们就不需要这个 shim 了,也就没问题了。 但这也不是世界末日,你也不需要恐慌——你唯一要做的就是把你的容器运行时从 Docker 切换到其他受支持的容器运行时。
要注意一点:如果你依赖底层的 Docker 套接字(/var/run/docker.sock),作为你集群中工作流的一部分,
切换到不同的运行时会导致你无法使用它。
这种模式经常被称之为嵌套 Docker(Docker in Docker)。
对于这种特殊的场景,有很多选项,比如:
kaniko、
img、和
buildah。
那么,这一改变对开发人员意味着什么?我们还要写 Dockerfile 吗?还能用 Docker 构建镜像吗?
此次改变带来了一个不同的环境,这不同于我们常用的 Docker 交互方式。 你在开发环境中用的 Docker 和你 Kubernetes 集群中的 Docker 运行时无关。 我们知道这听起来让人困惑。 对于开发人员,Docker 从所有角度来看仍然有用,就跟这次改变之前一样。 Docker 构建的镜像并不是 Docker 特有的镜像——它是一个 OCI(开放容器标准)镜像。 任一 OCI 兼容的镜像,不管它是用什么工具构建的,在 Kubernetes 的角度来看都是一样的。 containerd 和 CRI-O 两者都知道怎么拉取并运行这些镜像。 这就是我们制定容器标准的原因。
所以,改变已经发生。 它确实带来了一些问题,但这不是一个灾难,总的说来,这还是一件好事。 根据你操作 Kubernetes 的方式的不同,这可能对你不构成任何问题,或者也只是意味着一点点的工作量。 从一个长远的角度看,它使得事情更简单。 如果你还在困惑,也没问题——这里还有很多事情; Kubernetes 有很多变化中的功能,没有人是100%的专家。 我们鼓励你提出任何问题,无论水平高低、问题难易。 我们的目标是确保所有人都能在即将到来的改变中获得足够的了解。 我们希望这已经回答了你的大部分问题,并缓解了一些焦虑!❤️
还在寻求更多答案吗?请参考我们附带的 移除 Dockershim 的常见问题 (2022年2月更新)。
弃用 Dockershim 的常见问题
更新:本文有较新版本。
本文回顾了自 Kubernetes v1.20 版宣布弃用 Dockershim 以来所引发的一些常见问题。 关于 Kubernetes kubelets 从容器运行时的角度弃用 Docker 的细节以及这些细节背后的含义,请参考博文 别慌: Kubernetes 和 Docker。
此外,你可以阅读检查 Dockershim 移除是否影响你以检查它是否会影响你。
为什么弃用 dockershim
维护 dockershim 已经成为 Kubernetes 维护者肩头一个沉重的负担。 创建 CRI 标准就是为了减轻这个负担,同时也可以增加不同容器运行时之间平滑的互操作性。 但反观 Docker 却至今也没有实现 CRI,所以麻烦就来了。
Dockershim 向来都是一个临时解决方案(因此得名:shim)。 你可以进一步阅读 移除 Dockershim 这一 Kubernetes 增强方案 以了解相关的社区讨论和计划。
此外,与 dockershim 不兼容的一些特性,例如:控制组(cgoups)v2 和用户名字空间(user namespace),已经在新的 CRI 运行时中被实现。 移除对 dockershim 的支持将加速这些领域的发展。
在 Kubernetes 1.20 版本中,我还可以用 Docker 吗?
当然可以,在 1.20 版本中仅有的改变就是:如果使用 Docker 运行时,启动 kubelet 的过程中将打印一条警告日志。
什么时候移除 dockershim
考虑到此改变带来的影响,我们使用了一个加长的废弃时间表。 在 Kubernetes 1.22 版之前,它不会被彻底移除;换句话说,dockershim 被移除的最早版本会是 2021 年底发布的 1.23 版。 更新:dockershim 计划在 Kubernetes 1.24 版被移除, 请参阅移除 Dockershim 这一 Kubernetes 增强方案。 我们将与供应商以及其他生态团队紧密合作,确保顺利过渡,并将依据事态的发展评估后续事项。
从 Kubernetes 中移除后我还能使用 dockershim 吗?
更新:Mirantis 和 Docker 已承诺在 dockershim 从 Kubernetes 中删除后对其进行维护。
我现有的 Docker 镜像还能正常工作吗?
当然可以,docker build 创建的镜像适用于任何 CRI 实现。
所有你的现有镜像将和往常一样工作。
私有镜像呢?
当然可以。所有 CRI 运行时均支持 Kubernetes 中相同的拉取(pull)Secret 配置, 不管是通过 PodSpec 还是通过 ServiceAccount 均可。
Docker 和容器是一回事吗?
虽然 Linux 的容器技术已经存在了很久, 但 Docker 普及了 Linux 容器这种技术模式,并在开发底层技术方面发挥了重要作用。 容器的生态相比于单纯的 Docker,已经进化到了一个更宽广的领域。 像 OCI 和 CRI 这类标准帮助许多工具在我们的生态中成长和繁荣, 其中一些工具替代了 Docker 的某些部分,另一些增强了现有功能。
现在是否有在生产系统中使用其他运行时的例子?
Kubernetes 所有项目在所有版本中出产的工件(Kubernetes 二进制文件)都经过了验证。
此外,kind 项目使用 containerd 已经有年头了, 并且在这个场景中,稳定性还明显得到提升。 Kind 和 containerd 每天都会做多次协调,以验证对 Kubernetes 代码库的所有更改。 其他相关项目也遵循同样的模式,从而展示了其他容器运行时的稳定性和可用性。 例如,OpenShift 4.x 从 2019 年 6 月以来,就一直在生产环境中使用 CRI-O 运行时。
至于其他示例和参考资料,你可以查看 containerd 和 CRI-O 的使用者列表, 这两个容器运行时是云原生基金会(CNCF)下的项目。
人们总在谈论 OCI,那是什么?
OCI 代表开放容器标准, 它标准化了容器工具和底层实现(technologies)之间的大量接口。 他们维护了打包容器镜像(OCI image-spec)和运行容器(OCI runtime-spec)的标准规范。 他们还以 runc 的形式维护了一个 runtime-spec 的真实实现, 这也是 containerd 和 CRI-O 依赖的默认运行时。 CRI 建立在这些底层规范之上,为管理容器提供端到端的标准。
我应该用哪个 CRI 实现?
这是一个复杂的问题,依赖于许多因素。 在 Docker 工作良好的情况下,迁移到 containerd 是一个相对容易的转换,并将获得更好的性能和更少的开销。 然而,我们建议你先探索 CNCF 全景图 提供的所有选项,以做出更适合你的环境的选择。
当切换 CRI 底层实现时,我应该注意什么?
Docker 和大多数 CRI(包括 containerd)的底层容器化代码是相同的,但其周边部分却存在一些不同。 迁移时一些常见的关注点是:
- 日志配置
- 运行时的资源限制
- 直接访问 docker 命令或通过控制套接字调用 Docker 的节点供应脚本
- 需要访问 docker 命令或控制套接字的 kubectl 插件
- 需要直接访问 Docker 的 Kubernetes 工具(例如:kube-imagepuller)
- 配置像
registry-mirrors和不安全的镜像仓库等功能 - 需要 Docker 保持可用、且运行在 Kubernetes 之外的,其他支持脚本或守护进程(例如:监视或安全代理)
- GPU 或特殊硬件,以及它们如何与你的运行时和 Kubernetes 集成
如果你只是用了 Kubernetes 资源请求/限制或基于文件的日志收集 DaemonSet,它们将继续稳定工作, 但是如果你用了自定义了 dockerd 配置,则可能需要为新容器运行时做一些适配工作。
另外还有一个需要关注的点,那就是当创建镜像时,系统维护或嵌入容器方面的任务将无法工作。
对于前者,可以用 crictl 工具作为临时替代方案
(参见从 docker 命令映射到 crictl);
对于后者,可以用新的容器创建选项,比如
cr、
img、
buildah、
kaniko、或
buildkit-cli-for-kubectl,
他们均不需要访问 Docker。
对于 containerd,你可以从它们的 文档 开始,看看在迁移过程中有哪些配置选项可用。
对于如何协同 Kubernetes 使用 containerd 和 CRI-O 的说明,参见 Kubernetes 文档中这部分: 容器运行时。
我还有问题怎么办?
如果你使用了一个有供应商支持的 Kubernetes 发行版,你可以咨询供应商他们产品的升级计划。 对于最终用户的问题,请把问题发到我们的最终用户社区的论坛。
你也可以看看这篇优秀的博文: 等等,Docker 刚刚被 Kubernetes 废掉了? 一个对此变化更深入的技术讨论。
我可以加入吗?
只要你愿意,随时随地欢迎加入!
为开发指南做贡献
当大多数人想到为一个开源项目做贡献时,我猜想他们可能想到的是贡献代码修改、新功能和错误修复。作为一个软件工程师和一个长期的开源用户和贡献者,这也正是我的想法。 虽然我已经在不同的工作流中写了不少文档,但规模庞大的 Kubernetes 社区是一种新型 "客户"。我只是不知道当 Google 要求我和 Lion's Way 的同胞们对 Kubernetes 开发指南进行必要更新时会发生什么。
本文最初出现在 Kubernetes Contributor Community blog。
与社区合作的乐趣
作为专业的写手,我们习惯了受雇于他人去书写非常具体的项目。我们专注于技术服务,产品营销,技术培训以及文档编制,范围从相对宽松的营销邮件到针对 IT 和开发人员的深层技术白皮书。 在这种专业服务下,每一个可交付的项目往往都有可衡量的投资回报。我知道在从事开源文档工作时不会出现这个指标,但我不确定它将如何改变我与项目的关系。
我们的写作和传统客户之间的关系有一个主要的特点,就是我们在一个公司里面总是有一两个主要的对接人。他们负责审查我们的文稿,并确保文稿内容符合公司的声明且对标于他们正在寻找的受众。 这随之而来的压力--正好解释了为什么我很高兴我的写作伙伴、鹰眼审稿人同时也是嗜血编辑的 Joel 处理了大部分的客户联系。
在与 Kubernetes 社区合作时,所有与客户接触的压力都消失了,这让我感到惊讶和高兴。
"我必须得多仔细?如果我搞砸了怎么办?如果我让开发商生气了怎么办?如果我树敌了怎么办?"。 当我第一次加入 Kubernetes Slack 上的 "#sig-contribex " 频道并宣布我将编写 开发指南 时,这些问题都在我脑海中奔腾,让我感觉如履薄冰。
"Kubernetes 编码准则已经生效,让我们共同勉励。" — Jorge Castro, SIG ContribEx co-chair
事实上我的担心是多虑的。很快,我就感觉到自己是被欢迎的。我倾向于认为这不仅仅是因为我正在从事一项急需的任务,而是因为 Kubernetes 社区充满了友好、热情的人们。 在每周的 SIG ContribEx 会议上,我们关于开发指南进展情况的报告会被立即纳入其中。此外,会议的领导会一直强调 Kubernetes 编码准则,我们应该像 Bill 和 Ted 一样,相互进步。
这并不意味着这一切都很简单
开发指南需要一次全面检查。当我们拿到它的时候,它已经捆绑了大量的信息和很多新开发者需要经历的步骤,但随着时间的推移和被忽视,它变得相当陈旧。 文档的确需要全局观,而不仅仅是点与点的修复。结果,最终我向这个项目提交了一个巨大的 pull 请求。社区仓库:新增 267 行,删除 88 行。
pull 请求的周期需要一定数量的 Kubernetes 组织成员审查和批准更改后才能合并。这是一个很好的做法,因为它使文档和代码都保持在相当不错的状态, 但要哄骗合适的人花时间来做这样一个赫赫有名的审查是很难的。 因此,那次大规模的 PR 从我第一次提交到最后合并,用了 26 天。 但最终,它是成功的.
由于 Kubernetes 是一个发展相当迅速的项目,而且开发人员通常对编写文档并不十分感兴趣,所以我也遇到了一个问题,那就是有时候, 描述 Kubernetes 子系统工作原理的秘密珍宝被深埋在 天才工程师的迷宫式思维 中,而不是用单纯的英文写在 Markdown 文件中。 当我要更新端到端(e2e)测试的入门文档时,就一头撞上了这个问题。
这段旅程将我带出了编写文档的领域,进入到一些未完成软件的全新用户角色。最终我花了很多心思与新的 kubetest2`框架 的开发者之一合作, 记录了最新 e2e 测试的启动和运行过程。 你可以通过查看我的 已完成的 pull request 来自己判断结果。
没有人是老板,每个人都给出反馈。
但当我暗自期待混乱的时候,为 Kubernetes 开发指南做贡献以及与神奇的 Kubernetes 社区互动的过程却非常顺利。 没有争执,我也没有树敌。每个人都非常友好和热情。这是令人愉快的。
对于一个开源项目,没人是老板。Kubernetes 项目,一个近乎巨大的项目,被分割成许多不同的特殊兴趣小组(SIG)、工作组和社区。 每个小组都有自己的定期会议、职责分配和主席推选。我的工作与 SIG ContribEx(负责监督并寻求改善贡献者体验)和 SIG Testing(负责测试)的工作有交集。 事实证明,这两个 SIG 都很容易合作,他们渴望贡献,而且都是非常友好和热情的人。
在 Kubernetes 这样一个活跃的、有生命力的项目中,文档仍然需要与代码库一起进行维护、修订和测试。 开发指南将继续对 Kubernetes 代码库的新贡献者起到至关重要的作用,正如我们的努力所显示的那样,该指南必须与 Kubernetes 项目的发展保持同步。
Joel 和我非常喜欢与 Kubernetes 社区互动并为开发指南做出贡献。我真的很期待,不仅能继续做出更多贡献,还能继续与过去几个月在这个庞大的开源社区中结识的新朋友进行合作。
结构化日志介绍
作者: Marek Siarkowicz(谷歌),Nathan Beach(谷歌)
日志是可观察性的一个重要方面,也是调试的重要工具。 但是Kubernetes日志传统上是非结构化的字符串,因此很难进行自动解析,以及任何可靠的后续处理、分析或查询。
在Kubernetes 1.19中,我们添加结构化日志的支持,该日志本身支持(键,值)对和对象引用。 我们还更新了许多日志记录调用,以便现在将典型部署中超过99%的日志记录量迁移为结构化格式。
为了保持向后兼容性,结构化日志仍将作为字符串输出,其中该字符串包含这些“键” =“值”对的表示。 从1.19的Alpha版本开始,日志也可以使用--logging-format = json标志以JSON格式输出。
使用结构化日志
我们在klog库中添加了两个新方法:InfoS和ErrorS。 例如,InfoS的此调用:
klog.InfoS("Pod status updated", "pod", klog.KObj(pod), "status", status)
将得到下面的日志输出:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
或者, 如果 --logging-format=json 模式被设置, 将会产生如下结果:
{
"ts": 1580306777.04728,
"msg": "Pod status updated",
"pod": {
"name": "coredns",
"namespace": "kube-system"
},
"status": "ready"
}
这意味着下游日志记录工具可以轻松地获取结构化日志数据,而无需使用正则表达式来解析非结构化字符串。这也使处理日志更容易,查询日志更健壮,并且分析日志更快。
使用结构化日志,所有对Kubernetes对象的引用都以相同的方式进行结构化,因此您可以过滤输出并且仅引用特定Pod的日志条目。您还可以发现指示调度程序如何调度Pod,如何创建Pod,监测Pod的运行状况以及Pod生命周期中的所有其他更改的日志。
假设您正在调试Pod的问题。使用结构化日志,您可以只过滤查看感兴趣的Pod的日志条目,而无需扫描可能成千上万条日志行以找到相关的日志行。
结构化日志不仅在手动调试问题时更有用,而且还启用了更丰富的功能,例如日志的自动模式识别或日志和所跟踪数据的更紧密关联性(分析)。
最后,结构化日志可以帮助降低日志的存储成本,因为大多数存储系统比非结构化字符串更有效地压缩结构化键值数据。
参与其中
虽然在典型部署中,我们已按日志量更新了99%以上的日志条目,但仍有数千个日志需要更新。 选择一个您要改进的文件或目录,然后迁移现有的日志调用以使用结构化日志。这是对Kubernetes做出第一笔贡献的好方法!
警告: 有用的预警
作者: Jordan Liggitt (Google)
作为 Kubernetes 维护者,我们一直在寻找在保持兼容性的同时提高可用性的方法。 在开发功能、分类 Bug、和回答支持问题的过程中,我们积累了有助于 Kubernetes 用户了解的信息。 过去,共享这些信息仅限于发布说明、公告电子邮件、文档和博客文章等带外方法。 除非有人知道需要寻找这些信息并成功找到它们,否则他们不会从中受益。
在 Kubernetes v1.19 中,我们添加了一个功能,允许 Kubernetes API
服务器向 API 客户端发送警告。
警告信息使用标准 Warning 响应头发送,
因此它不会以任何方式更改状态代码或响应体。
这一设计使得服务能够发送任何 API 客户端都可以轻松读取的警告,同时保持与以前的客户端版本兼容。
警告在 kubectl v1.19+ 的 stderr 输出中和 k8s.io/client-go v0.19.0+ 客户端库的日志中出现。
k8s.io/client-go 行为可以在进程或客户端层面重载。
弃用警告
我们第一次使用此新功能是针对已弃用的 API 调用发送警告。
Kubernetes 是一个大型、快速发展的项目。 跟上每个版本的变更可能是令人生畏的, 即使对于全职从事该项目的人来说也是如此。一种重要的变更是 API 弃用。 随着 Kubernetes 中的 API 升级到 GA 版本,预发布的 API 版本会被弃用并最终被删除。
即使有延长的弃用期, 并且在发布说明中也包含了弃用信息, 他们仍然很难被追踪。在弃用期内,预发布 API 仍然有效, 允许多个版本过渡到稳定的 API 版本。 然而,我们发现用户往往甚至没有意识到他们依赖于已弃用的 API 版本, 直到升级到不再提供相应服务的新版本。
从 v1.19 开始,系统每当收到针对已弃用的 REST API 的请求时,都会返回警告以及 API 响应。 此警告包括有关 API 将不再可用的版本以及替换 API 版本的详细信息。
因为警告源自服务器端,并在客户端层级被拦截,所以它适用于所有 kubectl 命令,
包括像 kubectl apply 这样的高级命令,以及像 kubectl get --raw 这样的低级命令:

这有助于受弃用影响的人们知道他们所请求的API已被弃用, 他们有多长时间来解决这个问题,以及他们应该使用什么 API。 这在用户应用不是由他们创建的清单文件时特别有用, 所以他们有时间联系作者要一个更新的版本。
我们还意识到使用已弃用的 API 的人通常不是负责升级集群的人, 因此,我们添加了两个面向管理员的工具来帮助跟踪已弃用的 API 的使用情况并确定何时升级安全。
度量指标
从 Kubernetes v1.19 开始,当向已弃用的 REST API 端点发出请求时,
在 kube-apiserver 进程中,apiserver_requested_deprecated_apis 度量指标会被设置为 1。
该指标具有 API group、version、resource 和 subresource 的标签,
和一个 removed_release 标签,表明不再提供 API 的 Kubernetes 版本。
下面是一个使用 kubectl 的查询示例,prom2json
和 jq 用来确定当前 API
服务器实例上收到了哪些对已弃用的 API 请求:
kubectl get --raw /metrics | prom2json | jq '
.[] | select(.name=="apiserver_requested_deprecated_apis").metrics[].labels
'
输出:
{
"group": "extensions",
"removed_release": "1.22",
"resource": "ingresses",
"subresource": "",
"version": "v1beta1"
}
{
"group": "rbac.authorization.k8s.io",
"removed_release": "1.22",
"resource": "clusterroles",
"subresource": "",
"version": "v1beta1"
}
输出展示在此服务器上请求了已弃用的 extensions/v1beta1 Ingress 和 rbac.authorization.k8s.io/v1beta1
ClusterRole API,这两个 API 都将在 v1.22 中被删除。
我们可以将该信息与 apiserver_request_total 指标结合起来,以获取有关这些 API 请求的更多详细信息:
kubectl get --raw /metrics | prom2json | jq '
# set $deprecated to a list of deprecated APIs
[
.[] |
select(.name=="apiserver_requested_deprecated_apis").metrics[].labels |
{group,version,resource}
] as $deprecated
|
# select apiserver_request_total metrics which are deprecated
.[] | select(.name=="apiserver_request_total").metrics[] |
select(.labels | {group,version,resource} as $key | $deprecated | index($key))
'
输出:
{
"labels": {
"code": "0",
"component": "apiserver",
"contentType": "application/vnd.kubernetes.protobuf;stream=watch",
"dry_run": "",
"group": "extensions",
"resource": "ingresses",
"scope": "cluster",
"subresource": "",
"verb": "WATCH",
"version": "v1beta1"
},
"value": "21"
}
{
"labels": {
"code": "200",
"component": "apiserver",
"contentType": "application/vnd.kubernetes.protobuf",
"dry_run": "",
"group": "extensions",
"resource": "ingresses",
"scope": "cluster",
"subresource": "",
"verb": "LIST",
"version": "v1beta1"
},
"value": "1"
}
{
"labels": {
"code": "200",
"component": "apiserver",
"contentType": "application/json",
"dry_run": "",
"group": "rbac.authorization.k8s.io",
"resource": "clusterroles",
"scope": "cluster",
"subresource": "",
"verb": "LIST",
"version": "v1beta1"
},
"value": "1"
}
上面的输出展示,对这些 API 发出的都只是读请求,并且大多数请求都用来监测已弃用的 Ingress API。
你还可以通过以下 Prometheus 查询获取这一信息, 该查询返回关于已弃用的、将在 v1.22 中删除的 API 请求的信息:
apiserver_requested_deprecated_apis{removed_release="1.22"} * on(group,version,resource,subresource)
group_right() apiserver_request_total
审计注解
度量指标是检查是否正在使用已弃用的 API 以及使用率如何的快速方法,
但它们没有包含足够的信息来识别特定的客户端或 API 对象。
从 Kubernetes v1.19 开始,
对已弃用的 API 的请求进行审计时,审计事件中会包括
审计注解 "k8s.io/deprecated":"true"。
管理员可以使用这些审计事件来识别需要更新的特定客户端或对象。
自定义资源定义
除了 API 服务器对已弃用的 API 使用发出警告的能力外,从 v1.19 开始,CustomResourceDefinition 可以指示它定义的资源的特定版本已被弃用。 当对自定义资源的已弃用的版本发出 API 请求时,将返回一条警告消息,与内置 API 的行为相匹配。
CustomResourceDefinition 的作者还可以根据需要自定义每个版本的警告。 这允许他们在需要时提供指向迁移指南的信息或其他信息。
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
name: crontabs.example.com
spec:
versions:
- name: v1alpha1
# 这表示 v1alpha1 版本的自定义资源已经废弃了。
# 对此版本的 API 请求会在服务器响应中收到警告。
deprecated: true
# 这会把返回给发出 v1alpha1 API 请求的客户端的默认警告覆盖。
deprecationWarning: "example.com/v1alpha1 CronTab is deprecated; use example.com/v1 CronTab (see http://example.com/v1alpha1-v1)"
...
- name: v1beta1
# 这表示 v1beta1 版本的自定义资源已经废弃了。
# 对此版本的 API 请求会在服务器响应中收到警告。
# 此版本返回默认警告消息。
deprecated: true
...
- name: v1
...
准入 Webhook
准入 Webhook是将自定义策略或验证与 Kubernetes 集成的主要方式。 从 v1.19 开始,Admission Webhook 可以返回警告消息, 传递给发送请求的 API 客户端。警告可以与允许或拒绝的响应一起返回。
例如,允许请求但警告已知某个配置无法正常运行时,准入 Webhook 可以发送以下响应:
{
"apiVersion": "admission.k8s.io/v1",
"kind": "AdmissionReview",
"response": {
"uid": "<value from request.uid>",
"allowed": true,
"warnings": [
".spec.memory: requests >1GB do not work on Fridays"
]
}
}
如果你在实现一个返回警告消息的 Webhook,这里有一些提示:
- 不要在消息中包含 “Warning:” 前缀(由客户端在输出时添加)
- 使用警告消息来正确描述能被发出 API 请求的客户端纠正或了解的问题
- 保持简洁;如果可能,将警告限制为 120 个字符以内
准入 Webhook 可以通过多种方式使用这个新功能,我期待看到大家想出来的方法。 这里有一些想法可以帮助你入门:
- 添加 “complain” 模式的 Webhook 实现,它们返回警告而不是拒绝, 允许在开始执行之前尝试策略以验证它是否按预期工作
- “lint” 或 “vet” 风格的 Webhook,检查对象并在未遵循最佳实践时显示警告
自定义客户端处理方式
使用 k8s.io/client-go 库发出 API 请求的应用程序可以定制如何处理从服务器返回的警告。
默认情况下,收到的警告会以日志形式输出到 stderr,
但在进程层面或[客户端层面]
(https://godoc.org/k8s.io/client-go/rest#Config)均可定制这一行为。
这个例子展示了如何让你的应用程序表现得像 kubectl,
在进程层面重载整个消息处理逻辑以删除重复的警告,
并在支持的情况下使用彩色输出突出显示消息:
import (
"os"
"k8s.io/client-go/rest"
"k8s.io/kubectl/pkg/util/term"
...
)
func main() {
rest.SetDefaultWarningHandler(
rest.NewWarningWriter(os.Stderr, rest.WarningWriterOptions{
// only print a given warning the first time we receive it
Deduplicate: true,
// highlight the output with color when the output supports it
Color: term.AllowsColorOutput(os.Stderr),
},
),
)
...
下一个示例展示如何构建一个忽略警告的客户端。 这对于那些操作所有资源类型(使用发现 API 在运行时动态发现) 的元数据并且不会从已弃用的特定资源的警告中受益的客户端很有用。 对于需要使用特定 API 的客户端,不建议抑制弃用警告。
import (
"k8s.io/client-go/rest"
"k8s.io/client-go/kubernetes"
)
func getClientWithoutWarnings(config *rest.Config) (kubernetes.Interface, error) {
// copy to avoid mutating the passed-in config
config = rest.CopyConfig(config)
// set the warning handler for this client to ignore warnings
config.WarningHandler = rest.NoWarnings{}
// construct and return the client
return kubernetes.NewForConfig(config)
}
Kubectl 强制模式
如果你想确保及时注意到弃用问题并立即着手解决它们,
kubectl 在 v1.19 中添加了 --warnings-as-errors 选项。使用此选项调用时,
kubectl 将从服务器收到的所有警告视为错误,并以非零码退出:

这可以在 CI 作业中用于将清单文件应用到当前服务器, 其中要求通过零退出码才能使 CI 作业成功。
未来的可能性
现在我们有了一种在上下文中向用户传达有用信息的方法, 我们已经在考虑使用其他方法来改善人们使用 Kubernetes 的体验。 我们接下来要研究的几个领域是关于已知有问题的值的警告。 出于兼容性原因,我们不能直接拒绝,而应就使用已弃用的字段或字段值 (例如使用 beta os/arch 节点标签的选择器, 在 v1.14 中已弃用) 给出警告。 我很高兴看到这方面的进展,继续让 Kubernetes 更容易使用。
Docsy 带来更好的 Docs UX
作者: Zach Corleissen,Cloud Native Computing Foundation
编者注:Zach 是 Kubernetes 文档特别兴趣小组(SIG Docs)的主席之一。
我很高兴地宣布 Kubernetes 网站现在采用了 Docsy Hugo 主题。
Docsy 主题改进了网站的组织结构和导航性能,并开辟了改进 API 参考的途径。 在 4 年多的时间里,尽管对用户体验方面的改进不多,但 Docsy 针对技术内容实现了一些最佳实践。 该主题使 Kubernetes 网站更易于阅读,并使各个页面更易于导航。 它大大改进了网站所需的外在形象。
例如:添加用于在页面上导航主题的右侧栏。无需再向上滚动导航!
该主题为网站的未来改进开辟了道路。
我最兴奋的 Docsy 功能是主题的 swaggerui shortcode,
它为从 OpenAPI 规范生成 API 引用提供了本地支持。
CNCF 正在与 Google Season of Docs(GSoD)合作,希望在今年第四季度实现更好的 API 参考。
我们很有希望被选中,我们期待着谷歌在 8 月 16 日公布的项目清单。
自从我 2017 年第一次开始使用 SIG Docs 以来,更好的 API 参考一直是我的个人目标。
看到这个目标触手可及,真是令人兴奋。
作为 SIG Docs 的技术负责人之一,Karen Bradshaw 做了很多繁重的工作来解决广泛的网站兼容性问题, 包括在 2018 年我们从 Jekyll 迁移到 Hugo 时修复的最后一个遗留问题。 我们的其他技术负责人,Tim Bannister 和 Taylor Dolezal 提出过很多意见。
还要感谢 Björn-Erik Pedersen,他提供了关于如何在 0.60.0 版本之后进行 Hugo 升级的宝贵建议。
CNCF 与不列颠哥伦比亚省维多利亚市的 Gearbox 签约,将主题应用于该网站。 感谢 Aidan、Troy 和团队其他成员的所有工作!
Kubernetes 1.18: Fit & Finish
我们很高兴宣布 Kubernetes 1.18 版本的交付,这是我们 2020 年的第一版!Kubernetes 1.18 包含 38 个增强功能:15 项增强功能已转为稳定版,11 项增强功能处于 beta 阶段,12 项增强功能处于 alpha 阶段。
Kubernetes 1.18 是一个近乎 “完美” 的版本。为了改善 beta 和稳定的特性,已进行了大量工作, 以确保用户获得更好的体验。我们在增强现有功能的同时也增加了令人兴奋的新特性,这些有望进一步增强用户体验。
对 alpha、beta 和稳定版进行几乎同等程度的增强是一项伟大的成就。它展现了社区在提高 Kubernetes 的可靠性以及继续扩展其现有功能方面所做的巨大努力。
主要内容
Kubernetes 拓扑管理器(Topology Manager)进入 Beta 阶段 - 对齐!
Kubernetes 在 1.18 版中的 Beta 阶段功能拓扑管理器特性启用 CPU 和设备(例如 SR-IOV VF)的 NUMA 对齐,这将使你的工作负载在针对低延迟而优化的环境中运行。 在引入拓扑管理器之前,CPU 和设备管理器将做出彼此独立的资源分配决策。 这可能会导致在多处理器系统上非预期的资源分配结果,从而导致对延迟敏感的应用程序的性能下降。
Serverside Apply 推出 Beta 2
Serverside Apply 在1.16 中进入 Beta 阶段,但现在在 1.18 中进入了第二个 Beta 阶段。 这个新版本将跟踪和管理所有新 Kubernetes 对象的字段更改,从而使你知道什么更改了资源以及何时发生了更改。
使用 IngressClass 扩展 Ingress 并用 IngressClass 替换已弃用的注释
在 Kubernetes 1.18 中,Ingress 有两个重要的补充:一个新的 pathType 字段和一个新的
IngressClass 资源。pathType 字段允许指定路径的匹配方式。除了默认的
ImplementationSpecific 类型外,还有新的 Exact 和 Prefix 路径类型。
IngressClass 资源用于描述 Kubernetes 集群中 Ingress 的类型。Ingress 对象可以通过在
Ingress 资源类型上使用新的 ingressClassName 字段来指定与它们关联的类。
这个新的资源和字段替换了不再建议使用的 kubernetes.io/ingress.class 注解。
SIG-CLI 引入了 kubectl alpha debug
SIG-CLI 一直在争论着调试工具的必要性。随着临时容器的发展,
我们如何使用基于 kubectl exec 的工具来支持开发人员的必要性变得越来越明显。
kubectl alpha debug 命令的增加,
(由于是 alpha 阶段,非常欢迎你反馈意见),使开发人员可以轻松地在集群中调试 Pod。
我们认为这个功能的价值非常高。此命令允许创建一个临时容器,该容器在要尝试检查的
Pod 旁边运行,并且还附加到控制台以进行交互式故障排除。
为 Kubernetes 引入 Windows CSI 支持(Alpha)
用于 Windows 的 CSI 代理的 Alpha 版本随 Kubernetes 1.18 一起发布。CSI 代理通过允许 Windows 中的容器执行特权存储操作来启用 Windows 上的 CSI 驱动程序。
其它更新
毕业转为稳定版
- 基于污点的逐出操作
kubectl diff- CSI 块存储支持
- API 服务器 dry run
- 在 CSI 调用中传递 Pod 信息
- 支持树外 vSphere 云驱动
- 对 Windows 负载支持 GMSA
- 对不可挂载的CSI卷跳过挂载
- PVC 克隆
- 移动 kubectl 包代码到 staging
- Windows 的 RunAsUserName
- 服务和端点的 AppProtocol
- 扩展 Hugepage 特性
- client-go signature refactor to standardize options and context handling
- Node-local DNS cache
主要变化
- EndpointSlice API
- Moving kubectl package code to staging
- CertificateSigningRequest API
- Extending Hugepage Feature
- client-go 的调用规范重构来标准化选项和管理上下文
发布说明
在我们的发布文档中查看 Kubernetes 1.18 发行版的完整详细信息。
下载安装
Kubernetes 1.18 可以在 GitHub 上下载。要开始使用 Kubernetes,请查看这些交互教程或通过 kind 使用 Docker 容器运行本地 kubernetes 集群。你还可以使用 kubeadm 轻松安装 1.18。
发布团队
通过数百位贡献了技术和非技术内容的个人的努力,使本次发行成为可能。 特别感谢由 Searchable AI 的网站可靠性工程师 Jorge Alarcon Ochoa 领导的发布团队。 34 位发布团队成员协调了发布的各个方面,从文档到测试、验证和功能完整性。
随着 Kubernetes 社区的发展壮大,我们的发布过程很好地展示了开源软件开发中的协作。 Kubernetes 继续快速获取新用户。这种增长创造了一个积极的反馈回路, 其中有更多的贡献者提交了代码,从而创建了更加活跃的生态系统。迄今为止,Kubernetes 已有 40,000 独立贡献者和一个超过 3000 人的活跃社区。
发布 logo
![]()
为什么是 LHC
LHC 是世界上最大,功能最强大的粒子加速器。它是由来自世界各地成千上万科学家合作的结果, 所有这些合作都是为了促进科学的发展。以类似的方式,Kubernetes 已经成为一个聚集了来自数百个组织的数千名贡献者–所有人都朝着在各个方面改善云计算的相同目标努力的项目! 发布名称 “A Bit Quarky” 的意思是提醒我们,非常规的想法可以带来巨大的变化,对开放性保持开放态度将有助于我们进行创新。
关于设计者
Maru Lango 是目前居住在墨西哥城的设计师。她的专长是产品设计,她还喜欢使用 CSS + JS 进行品牌、插图和视觉实验,为技术和设计社区的多样性做贡献。你可能会在大多数社交媒体上以 @marulango 的身份找到她,或查看她的网站: https://marulango.com
高光用户
- 爱立信正在使用 Kubernetes 和其他云原生技术来交付高标准的 5G 网络, 这可以在 CI/CD 上节省多达 90% 的支出。
- Zendesk 正在使用 Kubernetes 运行其现有应用程序的约 70%。 它还正在使所构建的所有新应用都可以在 Kubernetes 上运行,从而节省时间、提高灵活性并加快其应用程序开发的速度。
- LifeMiles 因迁移到 Kubernetes 而降低了 50% 的基础设施开支。 Kubernetes 还使他们可以将其可用资源容量增加一倍。
生态系统更新
- CNCF 发布了年度调查的结果, 表明 Kubernetes 在生产中的使用正在飞速增长。调查发现,有 78% 的受访者在生产中使用 Kubernetes,而去年这一比例为 58%。
- CNCF 举办的 “Kubernetes 入门” 课程有超过 100,000 人注册。
项目速度
CNCF 继续完善 DevStats。这是一个雄心勃勃的项目,旨在对项目中的无数贡献数据进行可视化展示。 K8s DevStats 展示了主要公司贡献者的贡献细目, 以及一系列令人印象深刻的预定义的报告,涉及从贡献者个人的各方面到 PR 生命周期的各个方面。
在过去的一个季度中,641 家不同的公司和超过 6,409 个个人为 Kubernetes 作出贡献。 查看 DevStats 以了解有关 Kubernetes 项目和社区发展速度的信息。
活动信息
Kubecon + CloudNativeCon EU 2020 已经推迟 - 有关最新信息, 请查看新型肺炎发布页面。
即将到来的发布的线上会议
在 2020 年 4 月 23 日,和 Kubernetes 1.18 版本团队一起了解此版本的主要功能, 包括 kubectl debug、拓扑管理器、Ingress 毕业为 V1 版本以及 client-go。 在此处注册: https://www.cncf.io/webinars/kubernetes-1-18/ 。
如何参与
参与 Kubernetes 的最简单方法是加入众多与你的兴趣相关的特别兴趣小组(SIGs)之一。 你有什么想向 Kubernetes 社区发布的内容吗?参与我们的每周社区会议, 并通过以下渠道分享你的声音。感谢你一直以来的反馈和支持。
- 在 Twitter 上关注我们 @Kubernetesio,了解最新动态
- 在 Discuss 上参与社区讨论
- 加入 Slack 上的社区
- 在 Stack Overflow 提问(或回答)
- 分享你的 Kubernetes 故事
- 通过 blog 了解更多关于 Kubernetes 的新鲜事
- 了解更多关于 Kubernetes 发布团队的信息
基于 MIPS 架构的 Kubernetes 方案
作者: 石光银,尹东超,展望,江燕,蔡卫卫,高传集,孙思清(浪潮)
背景
MIPS (Microprocessor without Interlocked Pipelined Stages) 是一种采取精简指令集(RISC)的处理器架构 (ISA),出现于 1981 年,由 MIPS 科技公司开发。如今 MIPS 架构被广泛应用于许多电子产品上。
Kubernetes 官方目前支持众多 CPU 架构诸如 x86, arm/arm64, ppc64le, s390x 等。然而目前还不支持 MIPS 架构,始终是一个遗憾。随着云原生技术的广泛应用,MIPS 架构下的用户始终对 Kubernetes on MIPS 有着迫切的需求。
成果
多年来,为了丰富开源社区的生态,我们一直致力于在 MIPS 架构下适配 Kubernetes。随着 MIPS CPU 的不断迭代优化和性能的提升,我们在 mips64el 平台上取得了一些突破性的进展。
多年来,我们一直积极投入 Kubernetes 社区,在 Kubernetes 技术应用和优化方面具备了丰富的经验。最近,我们在研发过程中尝试将 Kubernetes 适配到 MIPS 架构平台,并取得了阶段性成果。成功完成了 Kubernetes 以及相关组件的迁移适配,不仅搭建出稳定高可用的 MIPS 集群,同时完成了 Kubernetes v1.16.2 版本的一致性测试。
图一 Kubernetes on MIPS
K8S-MIPS 组件构建
几乎所有的 Kubernetes 相关的云原生组件都没有提供 MIPS 版本的安装包或镜像,在 MIPS 平台上部署 Kubernetes 的前提是自行编译构建出全部所需组件。这些组件主要包括:
- golang
- docker-ce
- hyperkube
- pause
- etcd
- calico
- coredns
- metrics-server
得益于 Golang 优秀的设计以及对于 MIPS 平台的良好支持,极大地简化了上述云原生组件的编译过程。首先,我们在 mips64el 平台编译出了最新稳定的 golang, 然后通过源码构建的方式编译完成了上述大部分组件。
在编译过程中,我们不可避免地遇到了很多平台兼容性的问题,比如关于 golang 系统调用 (syscall) 的兼容性问题, syscall.Stat_t 32 位 与 64 位类型转换,EpollEvent 修正位缺失等等。
构建 K8S-MIPS 组件主要使用了交叉编译技术。构建过程包括集成 QEMU 工具来实现 MIPS CPU 指令的转换。同时修改 Kubernetes 和 E2E 镜像的构建脚本,构建了 Hyperkube 和 MIPS 架构的 E2E 测试镜像。
成功构建出以上组件后,我们使用工具完成 Kubernetes 集群的搭建,比如 kubespray、kubeadm 等。
| 名称 | 版本 | MIPS 镜像仓库 |
|---|---|---|
| MIPS 版本 golang | 1.12.5 | - |
| MIPS 版本 docker-ce | 18.09.8 | - |
| MIPS 版本 CKE 构建 metrics-server | 0.3.2 | registry.inspurcloud.cn/library/cke/kubernetes/metrics-server-mips64el:v0.3.2 |
| MIPS 版本 CKE 构建 etcd | 3.2.26 | registry.inspurcloud.cn/library/cke/etcd/etcd-mips64el:v3.2.26 |
| MIPS 版本 CKE 构建 pause | 3.1 | registry.inspurcloud.cn/library/cke/kubernetes/pause-mips64el:3.1 |
| MIPS 版本 CKE 构建 hyperkube | 1.14.3 | registry.inspurcloud.cn/library/cke/kubernetes/hyperkube-mips64el:v1.14.3 |
| MIPS 版本 CKE 构建 coredns | 1.6.5 | registry.inspurcloud.cn/library/cke/kubernetes/coredns-mips64el:v1.6.5 |
| MIPS 版本 CKE 构建 calico | 3.8.0 | registry.inspurcloud.cn/library/cke/calico/cni-mips64el:v3.8.0 registry.inspurcloud.cn/library/cke/calico/ctl-mips64el:v3.8.0 registry.inspurcloud.cn/library/cke/calico/node-mips64el:v3.8.0 registry.inspurcloud.cn/library/cke/calico/kube-controllers-mips64el:v3.8.0 |
注: CKE 是浪潮推出的一款基于 Kubernetes 的容器云服务引擎
图二 K8S-MIPS 集群组件

图三 CPU 架构
图四 集群节点信息
运行 K8S 一致性测试
验证 K8S-MIP 集群稳定性和可用性最简单直接的方式是运行 Kubernetes 的 一致性测试。
一致性测试是一个独立的容器,用于启动 Kubernetes 端到端的一致性测试。
当执行一致性测试时,测试程序会启动许多 Pod 进行各种端到端的行为测试,这些 Pod 使用的镜像源码大部分来自于 kubernetes/test/images 目录下,构建的镜像位于 gcr.io/kubernetes-e2e-test-images/。由于镜像仓库中目前并不存在 MIPS 架构的镜像,我们要想运行 E2E 测试,必须首先构建出测试所需的全部镜像。
构建测试所需镜像
第一步是找到测试所需的所有镜像。我们可以执行 sonobuoy images-p e2e 命令来列出所有镜像,或者我们可以在 /test/utils/image/manifest.go 中找到这些镜像。尽管 Kubernetes 官方提供了完整的 Makefile 和 shell 脚本,为构建测试映像提供了命令,但是仍然有许多与体系结构相关的问题未能解决,比如基础映像和依赖包的不兼容问题。因此,我们无法通过直接执行这些构建命令来制作 mips64el 架构镜像。
多数测试镜像都是使用 golang 编写,然后编译出二进制文件,并基于相应的 Dockerfile 制作出镜像。这些镜像对我们来说可以轻松地制作出来。但是需要注意一点:测试镜像默认使用的基础镜像大多是 alpine, 目前 Alpine 官方并不支持 mips64el 架构,我们暂时未能自己制作出 mips64el 版本的 alpine 础镜像,只能将基础镜像替换为我们目前已有的 mips64el 基础镜像,比如 debian-stretch,fedora, ubuntu 等。替换基础镜像的同时也需要替换安装依赖包的命令,甚至依赖包的版本等。
有些测试所需镜像的源码并不在 kubernetes/test/images 下,比如 gcr.io/google-samples/gb-frontend:v6 等,没有明确的文档说明这类镜像来自于何方,最终还是在 github.com/GoogleCloudPlatform/kubernetes-engine-samples 这个仓库找到了原始的镜像源代码。但是很快我们遇到了新的问题,为了制作这些镜像,还要制作它依赖的基础镜像,甚至基础镜像的基础镜像,比如 php:5-apache、redis、perl 等等。
经过漫长庞杂的的镜像重制工作,我们完成了总计约 40 个镜像的制作 ,包括测试镜像以及直接和间接依赖的基础镜像。
最终我们将所有镜像在集群内准备妥当,并确保测试用例内所有 Pod 的镜像拉取策略设置为 imagePullPolicy: ifNotPresent。
这是我们构建出的部分镜像列表:
docker.io/library/busybox:1.29docker.io/library/nginx:1.14-alpinedocker.io/library/nginx:1.15-alpinedocker.io/library/perl:5.26docker.io/library/httpd:2.4.38-alpinedocker.io/library/redis:5.0.5-alpinegcr.io/google-containers/conformance:v1.16.2gcr.io/google-containers/hyperkube:v1.16.2gcr.io/google-samples/gb-frontend:v6gcr.io/kubernetes-e2e-test-images/agnhost:2.6gcr.io/kubernetes-e2e-test-images/apparmor-loader:1.0gcr.io/kubernetes-e2e-test-images/dnsutils:1.1gcr.io/kubernetes-e2e-test-images/echoserver:2.2gcr.io/kubernetes-e2e-test-images/ipc-utils:1.0gcr.io/kubernetes-e2e-test-images/jessie-dnsutils:1.0gcr.io/kubernetes-e2e-test-images/kitten:1.0gcr.io/kubernetes-e2e-test-images/metadata-concealment:1.2gcr.io/kubernetes-e2e-test-images/mounttest-user:1.0gcr.io/kubernetes-e2e-test-images/mounttest:1.0gcr.io/kubernetes-e2e-test-images/nautilus:1.0gcr.io/kubernetes-e2e-test-images/nonewprivs:1.0gcr.io/kubernetes-e2e-test-images/nonroot:1.0gcr.io/kubernetes-e2e-test-images/resource-consumer-controller:1.0gcr.io/kubernetes-e2e-test-images/resource-consumer:1.5gcr.io/kubernetes-e2e-test-images/sample-apiserver:1.10gcr.io/kubernetes-e2e-test-images/test-webserver:1.0gcr.io/kubernetes-e2e-test-images/volume/gluster:1.0gcr.io/kubernetes-e2e-test-images/volume/iscsi:2.0gcr.io/kubernetes-e2e-test-images/volume/nfs:1.0gcr.io/kubernetes-e2e-test-images/volume/rbd:1.0.1registry.k8s.io/etcd:3.3.15(镜像自发布以来已更改(以前使用的仓库为 "k8s.gcr.io"))registry.k8s.io/pause:3.1(镜像自发布以来已更改(以前使用的仓库为 "k8s.gcr.io"))
最终我们执行一致性测试并且得到了测试报告,包括 e2e.log,显示我们通过了全部的测试用例。此外,我们将测试结果以 pull request 的形式提交给了 k8s-conformance 。
图五 一致性测试结果的 PR
后续计划
我们手动构建了 K8S-MIPS 组件以及执行了 E2E 测试,验证了 Kubernetes on MIPS 的可行性,极大的增强了我们对于推进 Kubernetes 支持 MIPS 架构的信心。
后续,我们将积极地向社区贡献我们的工作经验以及成果,提交 PR 以及 Patch For MIPS 等, 希望能够有更多的来自社区的力量加入进来,共同推进 Kubernetes for MIPS 的进程。
后续开源贡献计划:
- 贡献构建 E2E 测试镜像代码
- 贡献构建 MIPS 版本 hyperkube 代码
- 贡献构建 MIPS 版本 kubeadm 等集群部署工具
Kubernetes 1.17:稳定
我们高兴的宣布Kubernetes 1.17版本的交付,它是我们2019年的第四个也是最后一个发布版本。Kubernetes v1.17包含22个增强功能:有14个增强已经逐步稳定(stable),4个增强功能已经进入公开测试版(beta),4个增强功能刚刚进入内部测试版(alpha)。
主要的主题
云服务提供商标签基本可用
作为公开测试版特性添加到 v1.2 ,v1.17 中可以看到云提供商标签达到基本可用。
卷快照进入公开测试版
在 v1.17 中,Kubernetes卷快照特性是公开测试版。这个特性是在 v1.12 中以内部测试版引入的,第二个有重大变化的内部测试版是 v1.13 。
容器存储接口迁移公开测试版
在 v1.17 中,Kubernetes树内存储插件到容器存储接口(CSI)的迁移基础架构是公开测试版。容器存储接口迁移最初是在Kubernetes v1.14 中以内部测试版引入的。
云服务提供商标签基本可用
当节点和卷被创建,会基于基础云提供商的Kubernetes集群打上一系列标准标签。节点会获得一个实例类型标签。节点和卷都会得到两个描述资源在云提供商拓扑的位置标签,通常是以区域和地区的方式组织。
Kubernetes组件使用标准标签来支持一些特性。例如,调度者会保证pods和它们所声明的卷放置在相同的区域;当调度部署的pods时,调度器会优先将它们分布在不同的区域。你还可以在自己的pods标准中利用标签来配置,如节点亲和性,之类的事。标准标签使得你写的pod规范在不同的云提供商之间是可移植的。
在这个版本中,标签已经达到基本可用。Kubernetes组件都已经更新,可以填充基本可用和公开测试版标签,并对两者做出反应。然而,如果你的pod规范或自定义的控制器正在使用公开测试版标签,如节点亲和性,我们建议你可以将它们迁移到新的基本可用标签中。你可以从如下地方找到新标签的文档:
卷快照进入公开测试版
在 v1.17 中,Kubernetes卷快照是是公开测试版。最初是在 v1.12 中以内部测试版引入的,第二个有重大变化的内部测试版是 v1.13 。这篇文章总结它在公开版本中的变化。
卷快照是什么?
许多的存储系统(如谷歌云持久化磁盘,亚马逊弹性块存储和许多的内部存储系统)支持为持久卷创建快照。快照代表卷在一个时间点的复制。它可用于配置新卷(使用快照数据提前填充)或恢复卷到一个之前的状态(用快照表示)。
为什么给Kubernetes加入卷快照?
Kubernetes卷插件系统已经提供了功能强大的抽象用于自动配置、附加和挂载块文件系统。
支持所有这些特性是Kubernetes负载可移植的目标:Kubernetes旨在分布式系统应用和底层集群之间创建一个抽象层,使得应用可以不感知其运行集群的具体信息并且部署也不需特定集群的知识。
Kubernetes存储特别兴趣组(SIG)将快照操作确定为对很多有状态负载的关键功能。如数据库管理员希望在操作数据库前保存数据库卷快照。
在Kubernetes接口中提供一种标准的方式触发快照操作,Kubernetes用户可以处理这种用户场景,而不必使用Kubernetes API(并手动执行存储系统的具体操作)。
取而代之的是,Kubernetes用户现在被授权以与集群无关的方式将快照操作放进他们的工具和策略中,并且确信它将对任意的Kubernetes集群有效,而与底层存储无关。
此外,Kubernetes 快照原语作为基础构建能力解锁了为Kubernetes开发高级、企业级、存储管理特性的能力:包括应用或集群级别的备份方案。
你可以阅读更多关于发布容器存储接口卷快照公开测试版
容器存储接口迁移公测版
为什么我们迁移内建树插件到容器存储接口?
在容器存储接口之前,Kubernetes提供功能强大的卷插件系统。这些卷插件是树内的意味着它们的代码是核心Kubernetes代码的一部分并附带在核心Kubernetes二进制中。然而,为Kubernetes添加插件支持新卷是非常有挑战的。希望在Kubernetes上为自己存储系统添加支持(或修复现有卷插件的bug)的供应商被迫与Kubernetes发行进程对齐。此外,第三方存储代码在核心Kubernetes二进制中会造成可靠性和安全问题,并且这些代码对于Kubernetes的维护者来说是难以(一些场景是不可能)测试和维护的。在Kubernetes上采用容器存储接口可以解决大部分问题。
随着更多容器存储接口驱动变成生产环境可用,我们希望所有的Kubernetes用户从容器存储接口模型中获益。然而,我们不希望强制用户以破坏现有基本可用的存储接口的方式去改变负载和配置。道路很明确,我们将不得不用CSI替换树内插件接口。什么是容器存储接口迁移?
在容器存储接口迁移上所做的努力使得替换现有的树内存储插件,如kubernetes.io/gce-pd或kubernetes.io/aws-ebs,为相应的容器存储接口驱动成为可能。如果容器存储接口迁移正常工作,Kubernetes终端用户不会注意到任何差别。迁移过后,Kubernetes用户可以继续使用现有接口来依赖树内存储插件的功能。
当Kubernetes集群管理者更新集群使得CSI迁移可用,现有的有状态部署和工作负载照常工作;然而,在幕后Kubernetes将存储管理操作交给了(以前是交给树内驱动)CSI驱动。
Kubernetes组非常努力地保证存储接口的稳定性和平滑升级体验的承诺。这需要细致的考虑现有特性和行为来确保后向兼容和接口稳定性。你可以想像成在加速行驶的直线上给赛车换轮胎。
你可以在这篇博客中阅读更多关于容器存储接口迁移成为公开测试版.
其它更新
稳定💯
- 按条件污染节点
- 可配置的Pod进程共享命名空间
- 采用kube-scheduler调度DaemonSet Pods
- 动态卷最大值
- Kubernetes容器存储接口支持拓扑
- 在SubPath挂载提供环境变量扩展
- 为Custom Resources提供默认值
- 从频繁的Kublet心跳到租约接口
- 拆分Kubernetes测试Tarball
- 添加Watch书签支持
- 行为驱动一致性测试
- 服务负载均衡终结保护
- 避免每一个Watcher独立序列化相同的对象
主要变化
其它显著特性
可用性
Kubernetes 1.17 可以在GitHub下载。开始使用Kubernetes,看看这些交互教学。你可以非常容易使用kubeadm安装1.17。
发布团队
正是因为有上千人参与技术或非技术内容的贡献才使这个版本成为可能。特别感谢由Guinevere Saenger领导的发布团队。发布团队的35名成员在发布版本的多方面进行了协调,从文档到测试,校验和特性的完善。
随着Kubernetes社区的成长,我们的发布流程是在开源软件协作方面惊人的示例。Kubernetes快速并持续获得新用户。这一成长产生了良性的反馈循环,更多的贡献者贡献代码创造了更加活跃的生态。Kubernetes已经有超过39000位贡献者和一个超过66000人的活跃社区。
网络研讨会
2020年1月7号,加入Kubernetes 1.17发布团队,学习关于这次发布的主要特性。这里注册。
参与其中
最简单的参与Kubernetes的方式是加入其中一个与你兴趣相同的特别兴趣组(SIGs)。有什么想要广播到Kubernetes社区吗?通过如下的频道,在每周的社区会议分享你的声音。感谢你的贡献和支持。
- 在Twitter上关注我们@Kubernetesio获取最新的更新
- 在Discuss参与社区的讨论
- 在Slack加入社区
- 在Stack Overflow发布问题(或回答问题)
- 分享你的Kubernetes故事
使用 Java 开发一个 Kubernetes controller
作者: Min Kim (蚂蚁金服), Tony Ado (蚂蚁金服)
Kubernetes Java SDK 官方项目最近发布了他们的最新工作,为 Java Kubernetes 开发人员提供一个便捷的 Kubernetes 控制器-构建器 SDK,它有助于轻松开发高级工作负载或系统。
综述
Java 无疑是世界上最流行的编程语言之一,但由于社区中缺少库资源,一段时间以来,那些非 Golang 开发人员很难构建他们定制的 controller/operator。在 Golang 的世界里,已经有一些很好的 controller 框架了,例如,controller runtime,operator SDK。这些现有的 Golang 框架依赖于 Kubernetes Golang SDK 提供的各种实用工具,这些工具经过多年证明是稳定的。受进一步集成到 Kubernetes 平台的需求驱动,我们不仅将 Golang SDK 中的许多基本工具移植到 kubernetes Java SDK 中,包括 informers、work-queues、leader-elections 等,也开发了一个控制器构建 SDK,它可以将所有东西连接到一个可运行的控制器中,而不会产生任何问题。
背景
为什么要使用 Java 实现 kubernetes 工具?选择 Java 的原因可能是:
集成遗留的企业级 Java 系统:许多公司的遗留系统或框架都是用 Java 编写的,用以支持稳定性。我们不能轻易把所有东西搬到 Golang。
更多开源社区的资源:Java 是成熟的,并且在过去几十年中累计了丰富的开源库,尽管 Golang 对于开发人员来说越来越具有吸引力,越来越流行。此外,现在开发人员能够在 SQL 存储上开发他们的聚合-apiserver,而 Java 在 SQL 上有更好的支持。
如何去使用
以 maven 项目为例,将以下依赖项添加到您的依赖中:
<dependency>
<groupId>io.kubernetes</groupId>
<artifactId>client-java-extended</artifactId>
<version>6.0.1</version>
</dependency>
然后我们可以使用提供的生成器库来编写自己的控制器。例如,下面是一个简单的控制,它打印出关于监视通知的节点信息, 在此处 查看完整的例子:
...
Reconciler reconciler = new Reconciler() {
@Override
public Result reconcile(Request request) {
V1Node node = nodeLister.get(request.getName());
System.out.println("triggered reconciling " + node.getMetadata().getName());
return new Result(false);
}
};
Controller controller =
ControllerBuilder.defaultBuilder(informerFactory)
.watch(
(workQueue) -> ControllerBuilder.controllerWatchBuilder(V1Node.class, workQueue).build())
.withReconciler(nodeReconciler) // required, set the actual reconciler
.withName("node-printing-controller") // optional, set name for controller for logging, thread-tracing
.withWorkerCount(4) // optional, set worker thread count
.withReadyFunc( nodeInformer::hasSynced) // optional, only starts controller when the cache has synced up
.build();
如果您留意,新的 Java 控制器框架很多地方借鉴于 controller-runtime 的设计,它成功地将控制器内部的复杂组件封装到几个干净的接口中。在 Java 泛型的帮助下,我们甚至更进一步,以更好的方式简化了封装。
我们可以将多个控制器封装到一个 controller-manager 或 leader-electing controller 中,这有助于在 HA 设置中进行部署。
未来计划
Kubernetes Java SDK 项目背后的社区将专注于为希望编写云原生 Java 应用程序来扩展 Kubernetes 的开发人员提供更有用的实用程序。如果您对更详细的信息感兴趣,请查看我们的仓库 kubernetes-client/java。请通过问题或 Slack 与我们分享您的反馈。
使用 Microk8s 在 Linux 上本地运行 Kubernetes
作者: Ihor Dvoretskyi,开发支持者,云原生计算基金会;Carmine Rimi
本文是关于 Linux 上的本地部署选项系列的第二篇,涵盖了 MicroK8s。Microk8s 是本地部署 Kubernetes 集群的 'click-and-run' 方案,最初由 Ubuntu 的发布者 Canonical 开发。
虽然 Minikube 通常为 Kubernetes 集群创建一个本地虚拟机(VM),但是 MicroK8s 不需要 VM。它使用snap 包,这是一种应用程序打包和隔离技术。
这种差异有其优点和缺点。在这里,我们将讨论一些有趣的区别,并且基于 VM 的方法和非 VM 方法的好处。第一个因素是跨平台的移植性。虽然 Minikube VM 可以跨操作系统移植——它不仅支持 Linux,还支持 Windows、macOS、甚至 FreeBSD,但 Microk8s 需要 Linux,而且只在那些支持 snaps 的发行版上。支持大多数流行的 Linux 发行版。
另一个考虑到的因素是资源消耗。虽然 VM 设备为您提供了更好的可移植性,但它确实意味着您将消耗更多资源来运行 VM,这主要是因为 VM 提供了一个完整的操作系统,并且运行在管理程序之上。当 VM 处于休眠时你将消耗更多的磁盘空间。当它运行时,你将会消耗更多的 RAM 和 CPU。因为 Microk8s 不需要创建虚拟机,你将会有更多的资源去运行你的工作负载和其他设备。考虑到所占用的空间更小,MicroK8s 是物联网设备的理想选择-你甚至可以在 Paspberry Pi 和设备上使用它!
最后,项目似乎遵循了不同的发布节奏和策略。Microk8s 和 snaps 通常提供渠道允许你使用测试版和发布 KUbernetes 新版本的候选版本,同样也提供先前稳定版本。Microk8s 通常几乎立刻发布 Kubernetes 上游的稳定版本。
但是等等,还有更多!Minikube 和 Microk8s 都是作为单节点集群启动的。本质上来说,它们允许你用单个工作节点创建 Kubernetes 集群。这种情况即将改变 - MicroK8s 早期的 alpha 版本包括集群。有了这个能力,你可以创建正如你希望多的工作节点的 KUbernetes 集群。对于创建集群来说,这是一个没有主见的选项 - 开发者在节点之间创建网络连接和集成了其他所需要的基础设施,比如一个外部的负载均衡。总的来说,MicroK8s 提供了一种快速简易的方法,使得少量的计算机和虚拟机变成一个多节点的 Kubernetes 集群。以后我们将撰写更多这种体系结构的文章。
免责声明
这不是 MicroK8s 官方介绍文档。你可以在它的官方网页查询运行和使用 MicroK8s 的详情信息,其中覆盖了不同的用例,操作系统,环境等。相反,这篇文章的意图是提供在 Linux 上运行 MicroK8s 清晰易懂的指南。
前提条件
一个支持 snaps 的 Linux 发行版是被需要的。这篇指南,我们将会用支持 snaps 且即开即用的 Ubuntu 18.04 LTS。如果你对运行在 Windows 或者 Mac 上的 MicroK8s 感兴趣,你应该检查多通道,安装一个快速的 Ubuntu VM,作为在你的系统上运行虚拟机 Ubuntu 的官方方式。
MicroK8s 安装
简洁的 MicroK8s 安装:
sudo snap install microk8s --classic
使用 microk8s
使用 MicrosK8s 就像和安装它一样便捷。MicroK8s 本身包括一个 kubectl 库,该库可以通过执行 microk8s.kubectl 命令去访问。例如:
microk8s.kubectl get nodes
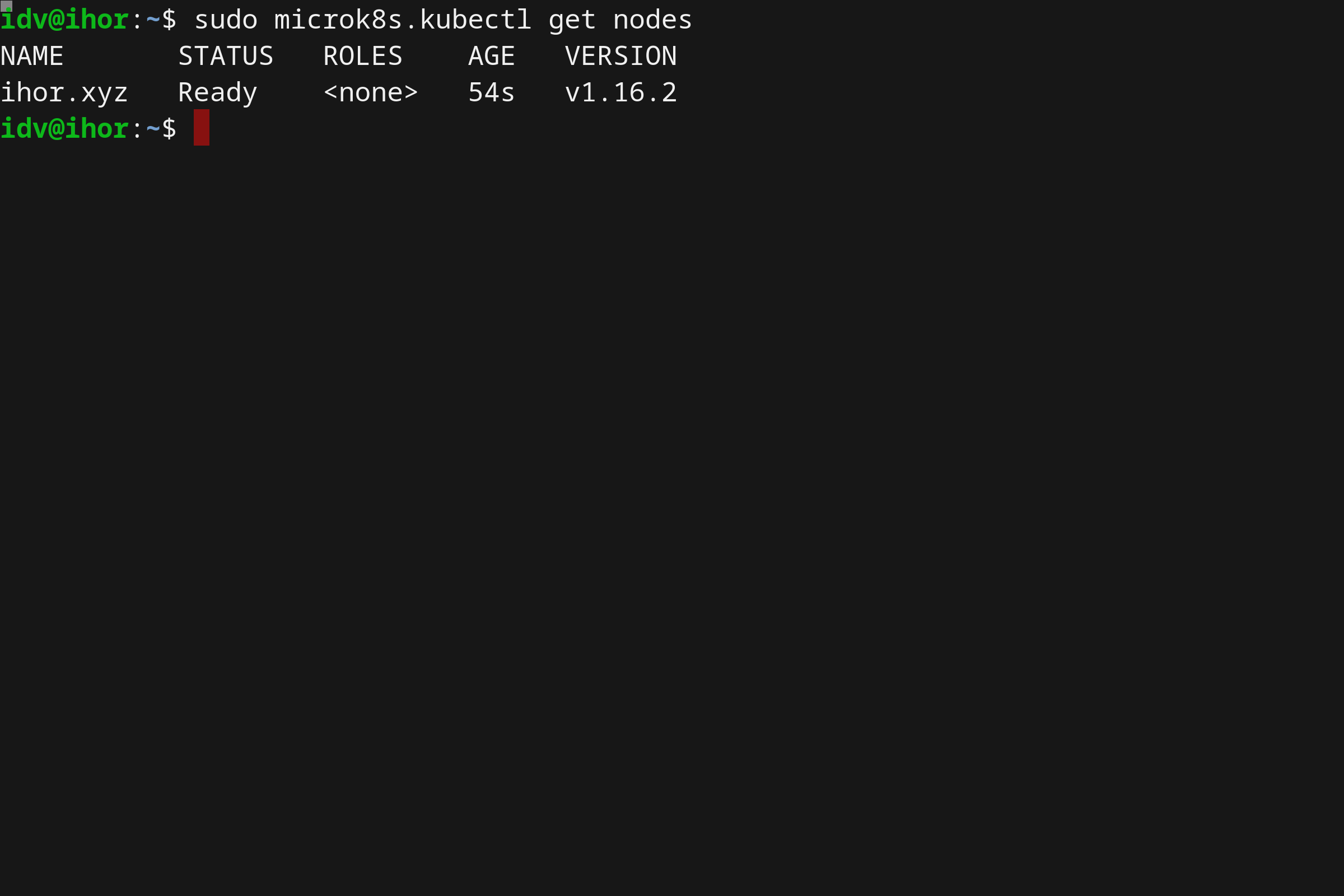
当使用前缀 microk8s.kubectl 时,允许在没有影响的情况下并行地安装另一个系统级的 kubectl,你可以便捷地使用 snap alias 命令摆脱它:
sudo snap alias microk8s.kubectl kubectl
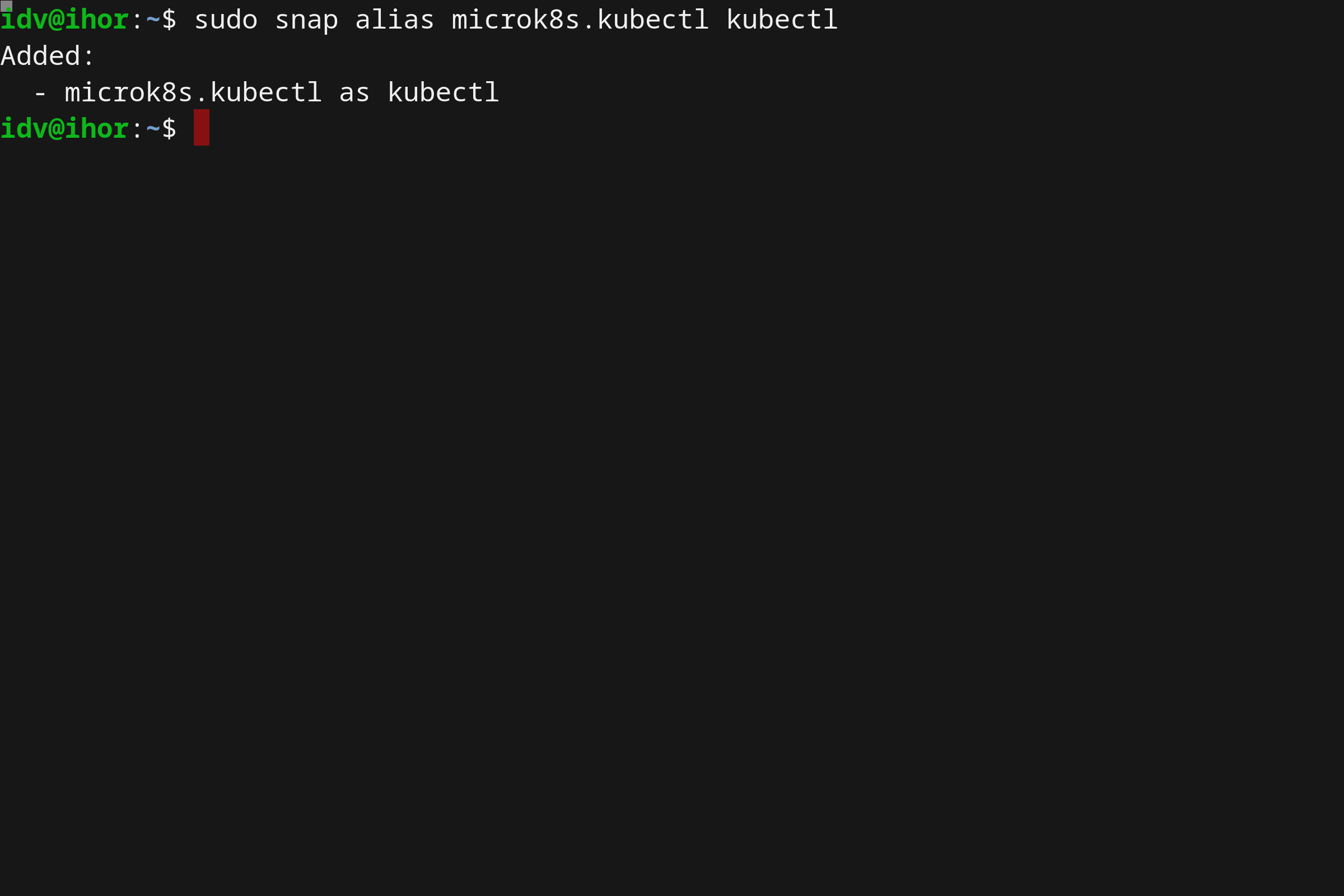
这将允许你以后便捷地使用 kubectl,你可以用 snap unalias命令恢复这个改变。
kubectl get nodes
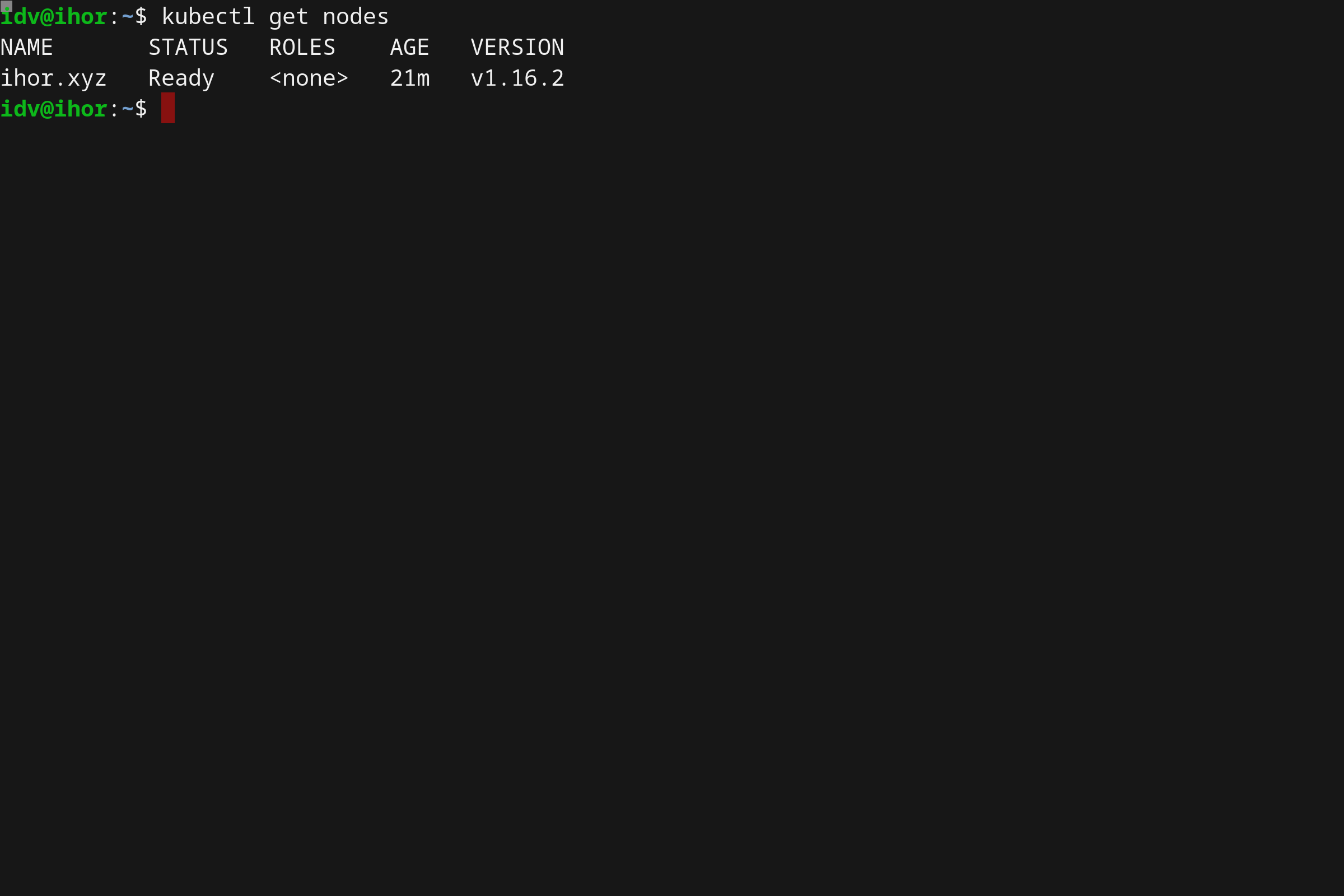
MicroK8s 插件
使用 MicroK8s 其中最大的好处之一事实上是也支持各种各样的插件和扩展。更重要的是它们是开箱即用的,用户仅仅需要启动它们。通过运行 microk8s.status 命令检查出扩展的完整列表。
sudo microk8s.status
截至到写这篇文章为止,MicroK8s 已支持以下插件:
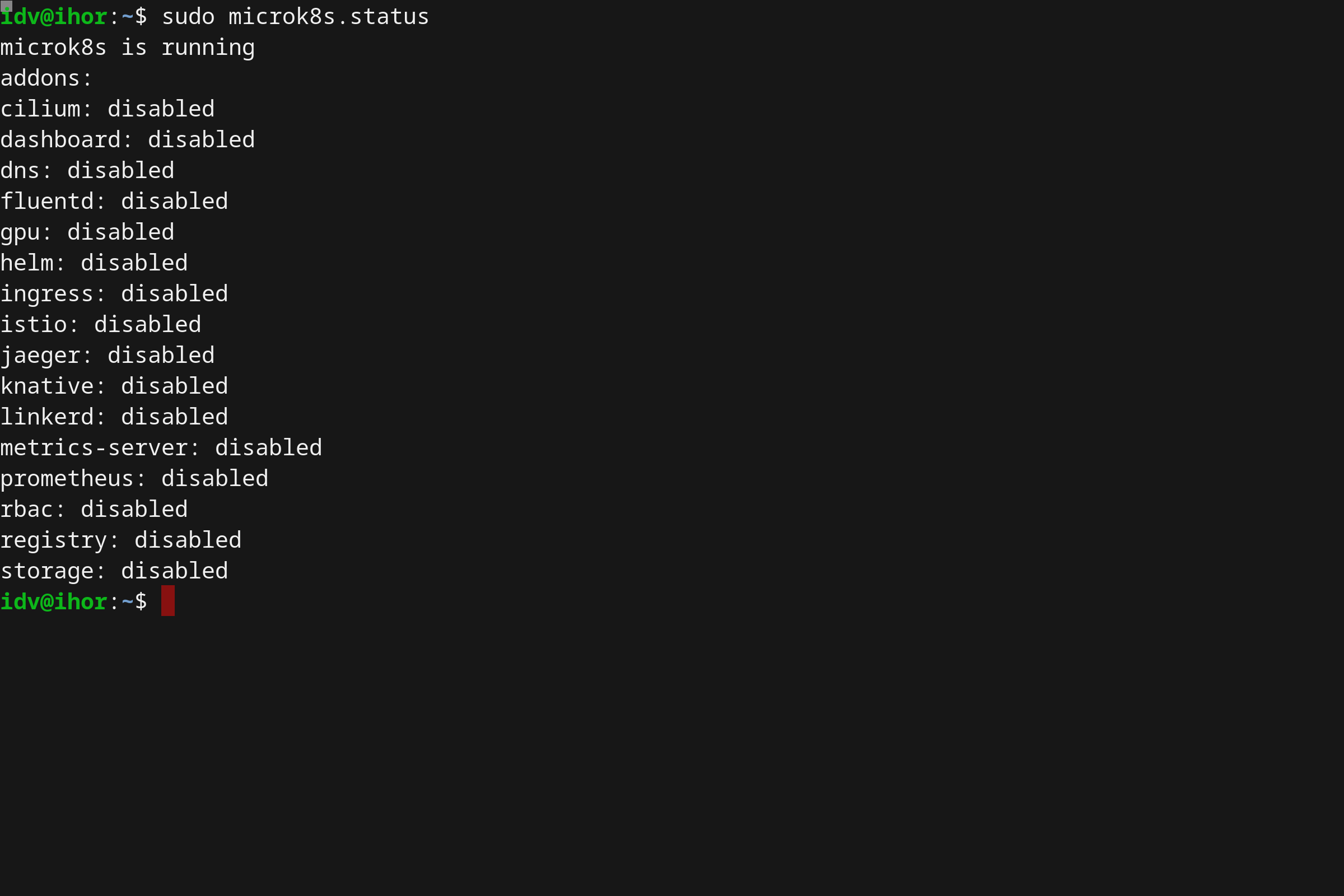
社区创建和贡献了越来越多的插件,经常检查他们是十分有帮助的。
发布渠道
sudo snap info microk8s
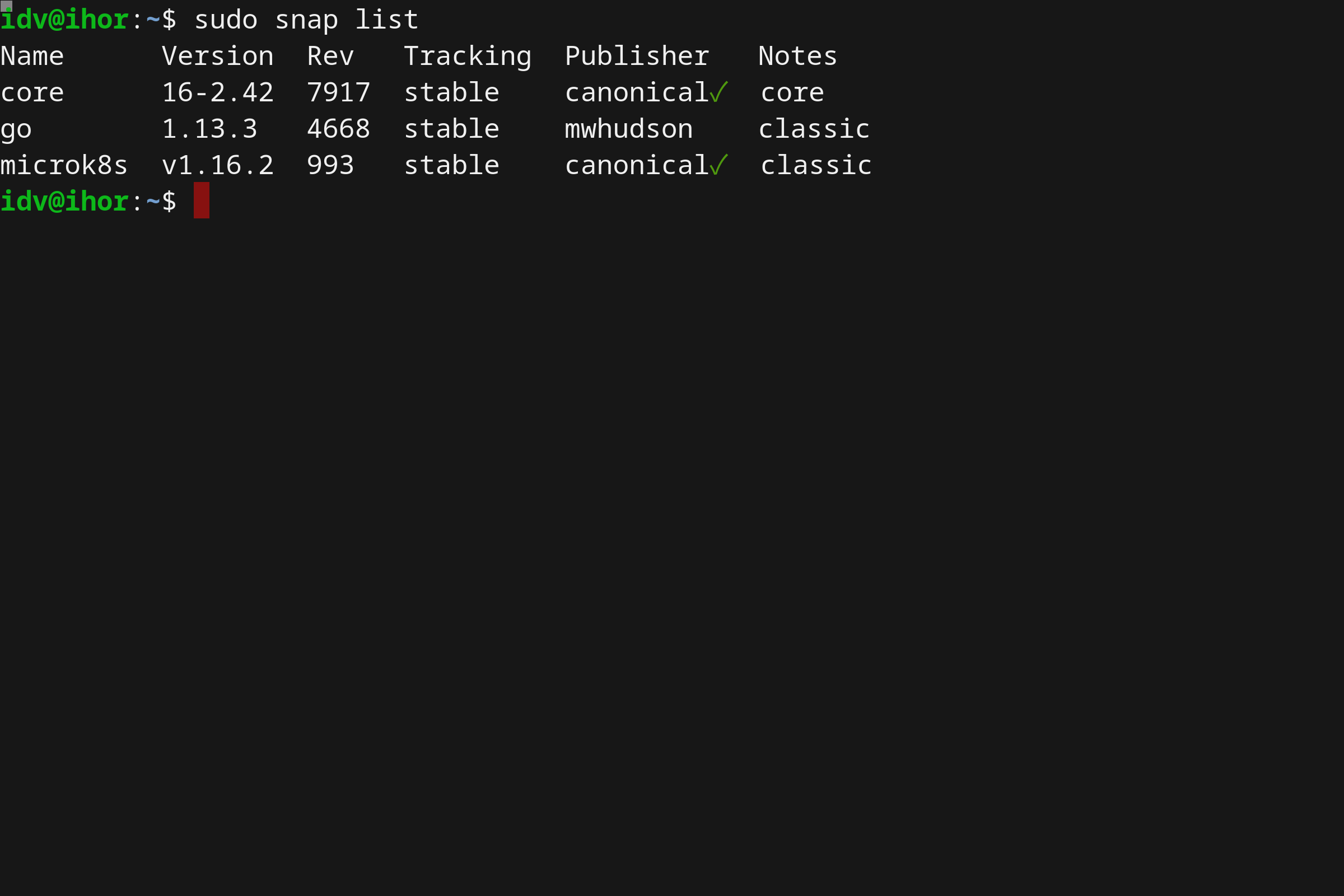
安装简单的应用
在这篇指南中我将会用 NGINX 作为一个示例应用程序(官方 Docker Hub 镜像)。
kubectl create deployment nginx --image=nginx
为了检查安装,让我们运行以下命令:
kubectl get deployments
kubectl get pods
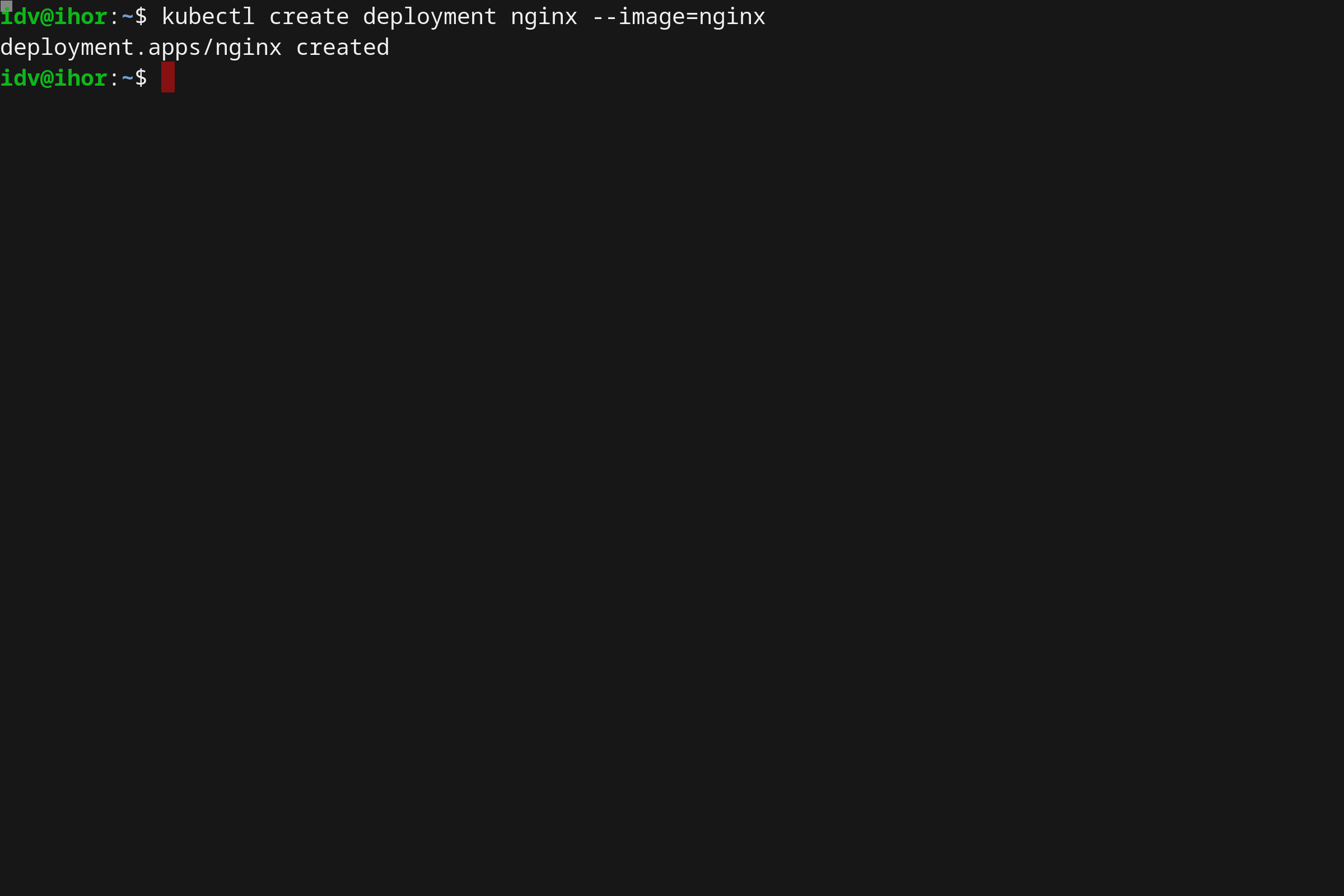
我们也可以检索出 Kubernetes 集群中所有可用对象的完整输出。
kubectl get all --all-namespaces
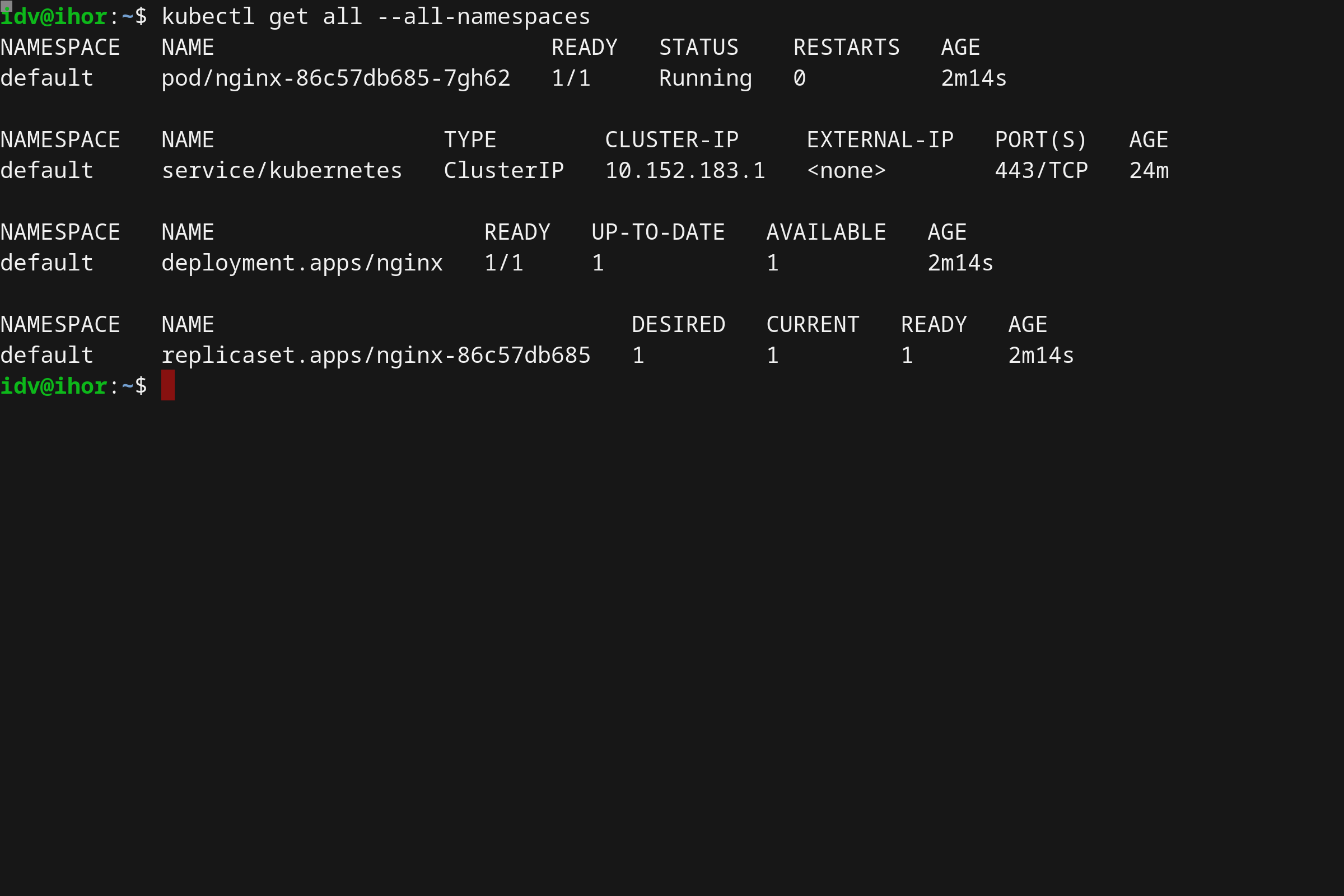
卸载 MircroK8s
卸载您的 microk8s 集群与卸载 Snap 同样便捷。
sudo snap remove microk8s
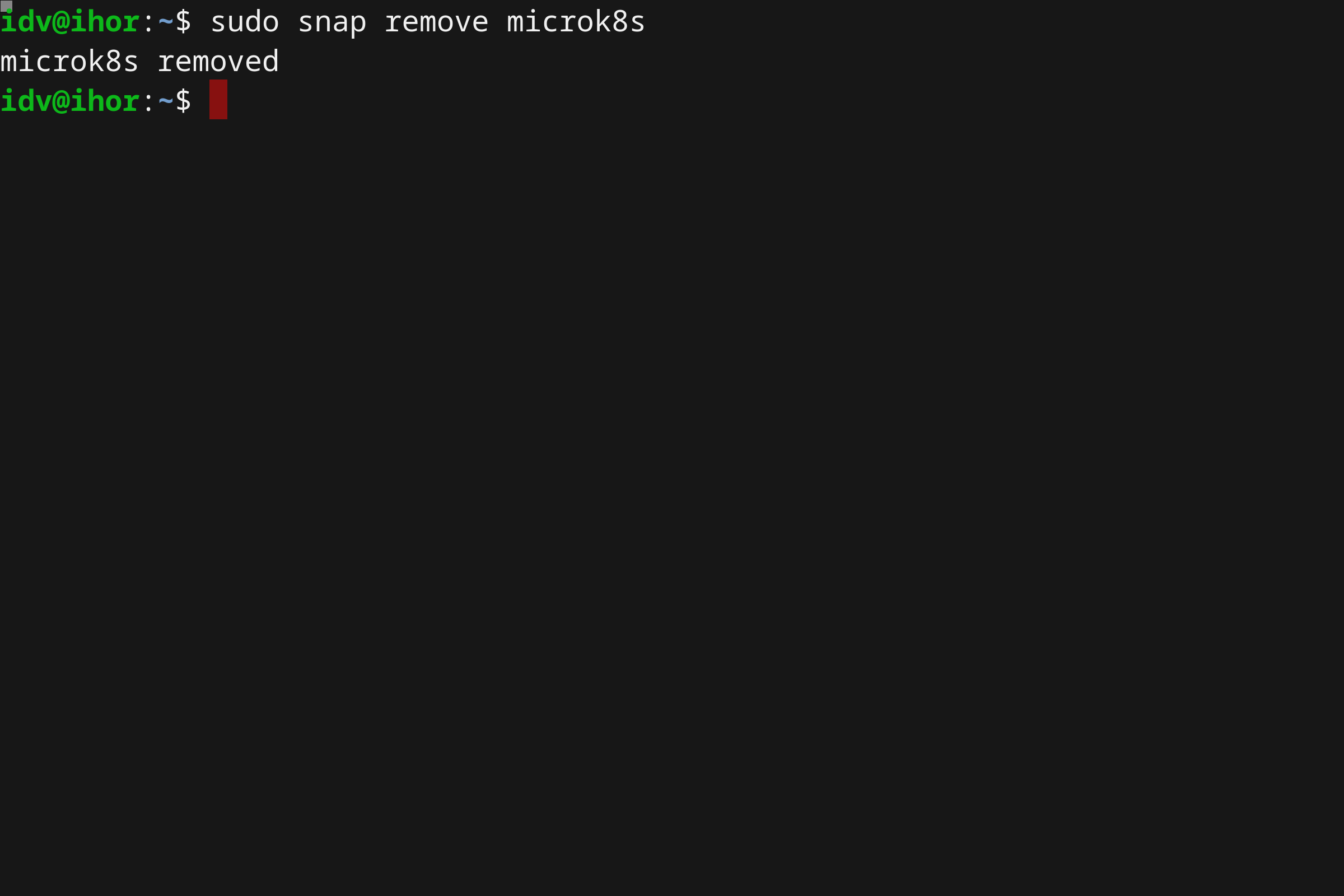
截屏视频

Kubernetes 文档最终用户调研
Author: Aimee Ukasick and SIG Docs
9月,SIG Docs 进行了第一次关于 Kubernetes 文档的用户调研。我们要感谢 CNCF 的 Kim McMahon 帮助我们创建调查并获取结果。
主要收获
受访者希望能在概念、任务和参考部分得到更多示例代码、更详细的内容和更多图表。
74% 的受访者希望教程部分包含高级内容。
69.70% 的受访者认为 Kubernetes 文档是他们首要寻找关于 Kubernetes 资料的地方。
调查方法和受访者
我们用英语进行了调查。由于时间限制,调查的有效期只有 4 天。 我们在 Kubernetes 邮件列表、Kubernetes Slack 频道、Twitter、Kube Weekly 上发布了我们的调查问卷。 这份调查有 23 个问题, 受访者平均用 4 分钟完成这个调查。
关于受访者的简要情况
- 48.48% 是经验丰富的 Kubernetes 用户,26.26% 是专家,25.25% 是初学者
- 57.58% 的人同时使用 Kubernetes 作为管理员和开发人员
- 64.65% 的人使用 Kubernetes 文档超过 12 个月
- 95.96% 的人阅读英文文档
问题和回答要点
人们为什么访问 Kubernetes 文档
大多数受访者表示,他们访问文档是为了了解概念。
这与我们在 Google Analytics 上看到的略有不同:在今年浏览量最多的10个页面中,第一是在参考部分的 kubectl 的备忘单,其次是概念部分的页面。
对文档的满意程度
我们要求受访者从概念、任务、参考和教程部分记录他们对细节的满意度:
- 概念:47.96% 中等满意
- 任务:50.54% 中等满意
- 参考:40.86% 非常满意
- 教程:47.25% 中等满意
SIG Docs 如何改进文档的各个部分
我们询问如何改进每个部分,为受访者提供可选答案以及文本输入框。绝大多数人想要更多 示例代码、更详细的内容、更多图表和更高级的教程:
- 就个人而言,希望看到更多的类比,以帮助进一步理解。
- 如果代码的相应部分也能解释一下就好了
- 通过扩展概念把它们融合在一起 - 它们现在宛如在一桶水内朝各个方向游动的一条条鳗鱼。
- 更多的图表,更多的示例代码
受访者使用“其他”文本框记录引发阻碍的区域:
- 使概念保持最新和准确
- 保持任务主题的最新性和准确性。亲身试验。
- 彻底检查示例。很多时候显示的命令输出不是实际情况。
- 我从来都不知道如何导航或解释参考部分
- 使教程保持最新,或将其删除
SIG Docs 如何全面改进文档
我们询问受访者如何从整体上改进 Kubernetes 文档。一些人抓住这次机会告诉我们我们正在做一个很棒的 工作:
- 对我而言,这是我见过的文档最好的开源项目。
- 继续努力!
- 我觉得文档很好。
- 你们做得真好。真的。
其它受访者提供关于内容的反馈:
- ...但既然我们谈论的是文档,多多益善。更多的高级配置示例对我来说将是最好的选择。比如每个配置主题的用例页面,
从初学者到高级示例场景。像这样的东西真的是令人惊叹......
- 更深入的例子和用例将是很好的。我经常感觉 Kubernetes 文档只是触及了一个主题的表面,这可能对新用户很好,
但是它没有让更有经验的用户获取多少关于如何实现某些东西的“官方”指导。
- 资源节(特别是 secrets)希望有更多类似于产品的示例或指向类似产品的示例的链接
- 如果能像很多其它技术项目那样有非常清晰的“快速启动” 逐步教学完成搭建就更好了。现有的快速入门内容屈指可数,
也没有统一的指南。结果是信息泛滥。
少数受访者提供的技术建议:
- 使用 ReactJS 或者 Angular component 使表的列可排序和可筛选。
- 对于大多数人来说,我认为用 Hugo - 一个静态站点生成系统 - 创建文档是不合适的。有更好的系统来记录大型软件项目。
具体来说,我希望看到 k8s 切换到 Sphinx 来获取文档。Sphinx 有一个很好的内置搜索。如果你了解 markdown,学习起来也很容易。
Sphinx 被其他项目广泛采用(例如,在 readthedocs.io、linux kernel、docs.python.org 等等)。
总体而言,受访者提供了建设性的批评,其关注点是高级用例以及更深入的示例、指南和演练。
哪里可以看到更多
调查结果摘要、图表和原始数据可在 kubernetes/community sig-docs
survey
目录下。
圣迭戈贡献者峰会日程公布!
作者: Josh Berkus (Red Hat), Paris Pittman (Google), Jonas Rosland (VMware)
除了新贡献者研讨会之外,贡献者峰会还安排了许多精彩的会议,这些会议分布在当前五个贡献者内容的会议室中。由于这是一个上游贡献者峰会,并且我们不经常见面,所以作为一个全球分布的团队,这些会议大多是讨论或动手实践,而不仅仅是演示。我们希望大家互相学习,并于他们的开源代码队友玩的开心。
像去年一样,非组织会议将重新开始,会议将在周一上午进行选择。对于最新的热门话题和贡献者想要进行的特定讨论,这是理想的选择。在过去的几年中,我们涵盖了不稳定的测试,集群生命周期,KEP(Kubernetes增强建议),指导,安全性等等。

尽管在每个时间间隙日程安排都包含困难的决定,但我们选择了以下几点,让您体验一下您将在峰会上听到、看到和参与的内容:
- 预见: SIG组织将分享他们对于明年和以后Kubernetes开发发展方向的认识。
- 安全: Tim Allclair和CJ Cullen将介绍Kubernetes安全的当前情况。在另一个安全性演讲中,Vallery Lancey将主持有关使我们的平台默认情况下安全的讨论。
- Prow: 有兴趣与Prow合作并为Test-Infra做贡献,但不确定从哪里开始? Rob Keilty将帮助您在笔记本电脑上运行Prow测试环境
- Git: GitHub的员工将与Christoph Blecker合作,为Kubernetes贡献者分享实用的Git技巧。
- 审阅: 蒂姆·霍金(Tim Hockin)将分享成为一名出色的代码审阅者的秘密,而乔丹·利吉特(Jordan Liggitt)将进行实时API审阅,以便您可以进行一次或至少了解一次审阅。
- 终端用户: 应Cheryl Hung邀请,来自CNCF合作伙伴生态的数个终端用户,将回答贡献者的问题,以加强我们的反馈循环。
- 文档: 与往常一样,SIG Docs将举办一个为时三个小时的文档撰写研讨会。
我们还将向在2019年杰出的贡献者颁发奖项,周一星期一结束时将有一个巨大的见面会,供新的贡献者找到他们的SIG(以及现有的贡献者询问他们的PR)。
希望能够在峰会上见到您,并且确保您已经提前注册!
2019 指导委员会选举结果
作者:Bob Killen (University of Michigan), Jorge Castro (VMware), Brian Grant (Google), and Ihor Dvoretskyi (CNCF)
2019 指导委员会选举 是 Kubernetes 项目的重要里程碑。最初的自助委员会正逐步退休,现在该委员会已缩减到最后分配的 7 个席位。指导委员会的所有成员现在都由 Kubernetes 社区选举产生。
接下来的选举将选出 3 到 4 名委员,任期两年。
选举结果
Kubernetes 指导委员会选举现已完成,以下候选人提前获得立即开始的两年任期 (按 GitHub handle 的字母顺序排列) :
- Christoph Blecker (@cblecker), Red Hat
- Derek Carr (@derekwaynecarr), Red Hat
- Nikhita Raghunath (@nikhita), Loodse
- Paris Pittman (@parispittman), Google
他们加入了 Aaron Crickenberger (@spiffxp), Google;Davanum Srinivas (@dims),VMware; and Timothy St. Clair (@timothysc), VMware,使得委员会更圆满。Aaron、Davanum 和 Timothy 占据的这些席位将会在明年的这个时候进行选举。
诚挚的感谢!
- 感谢最初的引导委员会创立了最初项目的管理并监督了多年的过渡期:
- Joe Beda (@jbeda), VMware
- Brendan Burns (@brendandburns), Microsoft
- Clayton Coleman (@smarterclayton), Red Hat
- Brian Grant (@bgrant0607), Google
- Tim Hockin (@thockin), Google
- Sarah Novotny (@sarahnovotny), Microsoft
- Brandon Philips (@philips), Red Hat
- 同样感谢其他的已退休指导委员会成员。社区对你们先前的服务表示赞赏:
- Quinton Hoole (@quinton-hoole), Huawei
- Michelle Noorali (@michelleN), Microsoft
- Phillip Wittrock (@pwittrock), Google
- 感谢参选的候选人。 愿在每次选举中,我们都能拥有一群像您一样推动社区向前发展的人。
- 感谢所有投票的377位选民。
- 最后,感谢康奈尔大学举办的 CIVS!
参与指导委员会
你可以跟进指导委员会的 代办事项,通过提出问题或者向 仓库 提交一个 pr 。他们每两周一次,在 UTC 时间周三晚上 8 点 会面,并定期与我们的贡献者见面。也可以通过他们的公共邮件列表 steering@kubernetes.io 联系他们。
指导委员会会议:
San Diego 贡献者峰会开放注册!
作者: Paris Pittman (Google), Jeffrey Sica (Red Hat), Jonas Rosland (VMware)
2019 San Diego 贡献者峰会活动页面 在创纪录的时间内,新贡献者研讨会 活动已满员!
11月17日,星期日
晚间贡献者庆典:
QuartYard†
地址: 1301 Market Street, San Diego, CA 92101
时间: 下午6:00 - 下午9:00
11月18日,星期一
全天贡献者峰会:
Marriott Marquis San Diego Marina
地址: 333 W Harbor Dr, San Diego, CA 92101
时间: 上午9:00 - 下午5:00
虽然 Kubernetes 项目只有五年的历史,但是在 KubeCon + CloudNativeCon 之前,今年11月在圣迭戈时我们举办的第九届贡献者峰会了。快速增长的原因是在我们之前所做的北美活动中增加了欧洲和亚洲贡献者峰会。我们将继续在全球举办贡献者峰会,因为重要的是,我们的贡献者要以各种形式的多样性地成长。
Kubernetes 拥有一个庞大的分布式远程贡献团队,由来自世界各地的 个人和组织 组成。贡献者峰会每年为社区提供三次聚会的机会,围绕社区主题开展工作,并有互相了解的时间。即将举行的 San Diego 峰会预计将吸引 450 多名与会者,并将包含多个方向,适合所有人。重点将围绕贡献者的增长和可持续性。我们将在这里停留,为举行未来峰会做准备;我们希望这次活动为个人和项目提供价值。我们已经从峰会与会者的反馈中得知,完成工作、学习和与人们面对面交流是当务之急。通过限制参加人数并在更多地方提供贡献者聚会,将有助于我们实现这些目标。
这次峰会是独一无二的,因为我们在贡献者体验活动团队的坚持自我方面已采取了重大举措。从发行团队的手册中摘录,我们添加了其他核心团队和跟随学习角色,使其成为天然的辅导关系(包括监督和实施)。预计跟随学习者将在 2020 年的三项活动中扮演另一个角色,核心团队成员将带头完成。为这个团队做准备,我们开源了 技术手册,指南,最佳做法,并开放了 会议 和 项目委员会。我们的团队组成了 Kubernetes 项目的许多部分,并确保所有声音都得到体现。
您是否已经在 KubeCon + CloudNativeCon 上,但无法参与会议? 在 KubeCon + CloudNativeCon 期间查看 SIG入门和深潜课程 参与问答,并听取每个特殊兴趣小组(SIG)的最新消息。活动结束后,我们还将记录所有贡献者峰会的课题,在讨论中做笔记,并与您分享。
我们希望能在 San Diego 的 Kubernetes 贡献者峰会上与大家见面,确保您直接进入并点击 立即注册! 此活动将关闭 - 特此提醒。 :笑脸:
查看往期博客有关 围绕我们的活动构建角色 和 巴塞罗那峰会故事。
†=QuartYard 有一个巨大的舞台!想要在您的贡献者同行面前做点什么?加入我们吧! community@kubernetes.io
机器可以完成这项工作,一个关于 kubernetes 测试、CI 和自动化贡献者体验的故事
作者:Aaron Crickenberger(谷歌)和 Benjamin Elder(谷歌)
”大型项目有很多不那么令人兴奋,但却很辛苦的工作。比起辛苦工作,我们更重视把时间花在自动化重复性工作上,如果这项工作无法实现自动化,我们的文化就是承认并奖励所有类型的贡献。然而,英雄主义是不可持续的。“ - Kubernetes Community Values
像许多开源项目一样,Kubernetes 托管在 GitHub 上。 如果项目位于在开发人员已经工作的地方,使用的开发人员已经知道的工具和流程,那么参与的障碍将是最低的。 因此,该项目完全接受了这项服务:它是我们工作流程,问题跟踪,文档,博客平台,团队结构等的基础。
这个策略奏效了。 它运作良好,以至于该项目迅速超越了其贡献者的人类能力。 接下来是一次令人难以置信的自动化和创新之旅。 我们不仅需要在飞行途中重建我们的飞机而不会崩溃,我们需要将其转换为火箭飞船并发射到轨道。 我们需要机器来完成这项工作。
工作
最初,我们关注的事实是,我们需要支持复杂的分布式系统(如 Kubernetes)所要求的大量测试。 真实世界中的故障场景必须通过端到端(e2e)测试来执行,确保正确的功能。 不幸的是,e2e 测试容易受到薄片(随机故障)的影响,并且需要花费一个小时到一天才能完成。
进一步的经验揭示了机器可以为我们工作的其他领域:
- Pull Request 工作流程
- 贡献者是否签署了我们的 CLA?
- Pull Request 通过测试吗?
- Pull Request 可以合并吗?
- 合并提交是否通过了测试?
- 鉴别分类
- 谁应该审查 Pull Request?
- 是否有足够的信息将问题发送给合适的人?
- 问题是否依旧存在?
- 项目健康
- 项目中发生了什么?
- 我们应该注意什么?
当我们开发自动化来改善我们的情况时,我们遵循了以下几个指导原则:
- 遵循适用于 Kubernetes 的推送/拉取控制循环模式
- 首选无状态松散耦合服务
- 更倾向于授权整个社区权利,而不是赋予少数核心贡献者权力
- 做好自己的事,而不要重新造轮子
了解 Prow
这促使我们创建 Prow 作为我们自动化的核心组件。 Prow有点像 If This, Then That 用于 GitHub 事件, 内置 commands, plugins, 和实用程序。 我们在 Kubernetes 之上建立了 Prow,让我们不必担心资源管理和日程安排,并确保更愉快的运营体验。
Prow 让我们做以下事情:
- 允许我们的社区通过评论诸如“/priority critical-urgent”,“/assign mary”或“/close”之类的命令对 issues/Pull Requests 进行分类
- 根据用户更改的代码数量或创建的文件自动标记 Pull Requests
- 标出长时间保持不活动状态 issues/Pull Requests
- 自动合并符合我们PR工作流程要求的 Pull Requests
- 运行定义为Knative Builds的 Kubernetes Pods或 Jenkins jobs的 CI 作业
- 实施组织范围和重构 GitHub 仓库策略,如Knative Builds和GitHub labels
Prow最初由构建 Google Kubernetes Engine 的工程效率团队开发,并由 Kubernetes SIG Testing 的多个成员积极贡献。 Prow 已被其他几个开源项目采用,包括 Istio,JetStack,Knative 和 OpenShift。 Getting started with Prow需要一个 Kubernetes 集群和 kubectl apply starter.yaml(在 Kubernetes 集群上运行 pod)。
一旦我们安装了 Prow,我们就开始遇到其他的问题,因此需要额外的工具以支持 Kubernetes 所需的规模测试,包括:
- Boskos: 管理池中的作业资源(例如 GCP 项目),检查它们是否有工作并自动清理它们 (with monitoring)
- ghProxy: 优化用于 GitHub API 的反向代理 HTTP 缓存,以确保我们的令牌使用不会达到 API 限制 (with monitoring)
- Greenhouse: 允许我们使用远程 bazel 缓存为 Pull requests 提供更快的构建和测试结果 (with monitoring)
- Splice: 允许我们批量测试和合并 Pull requests,确保我们的合并速度不仅限于我们的测试速度
- Tide: 允许我们合并通过 GitHub 查询选择的 Pull requests,而不是在队列中排序,允许显着更高合并速度与拼接一起
## 关注项目健康状况
随着工作流自动化的实施,我们将注意力转向了项目健康。我们选择使用 Google Cloud Storage (GCS)作为所有测试数据的真实来源,允许我们依赖已建立的基础设施,并允许社区贡献结果。然后,我们构建了各种工具来帮助个人和整个项目理解这些数据,包括:
- Gubernator: 显示给定 Pull Request 的结果和测试历史
- Kettle: 将数据从 GCS 传输到可公开访问的 bigquery 数据集
- PR dashboard: 一个工作流程识别仪表板,允许参与者了解哪些 Pull Request 需要注意以及为什么
- Triage: 识别所有作业和测试中发生的常见故障
- Testgrid: 显示所有运行中给定作业的测试结果,汇总各组作业的测试结果
我们与云计算本地计算基金会(CNCF)联系,开发 DevStats,以便从我们的 GitHub 活动中收集见解,例如:
- Which prow commands are people most actively using
- PR reviews by contributor over time
- Time spent in each phase of our PR workflow
Into the Beyond
今天,Kubernetes 项目跨越了5个组织125个仓库。有31个特殊利益集团和10个工作组在项目内协调发展。在过去的一年里,该项目有 来自13800多名独立开发人员的参与。
在任何给定的工作日,我们的 Prow 实例运行超过10,000个 CI 工作; 从2017年3月到2018年3月,它有430万个工作岗位。 这些工作中的大多数涉及建立整个 Kubernetes 集群,并使用真实场景来实施它。 它们使我们能够确保所有受支持的 Kubernetes 版本跨云提供商,容器引擎和网络插件工作。 他们确保最新版本的 Kubernetes 能够启用各种可选功能,安全升级,满足性能要求,并跨架构工作。
今天来自CNCF的公告 - 注意到 Google Cloud 有开始将 Kubernetes 项目的云资源的所有权和管理权转让给 CNCF 社区贡献者,我们很高兴能够开始另一个旅程。 允许项目基础设施由贡献者社区拥有和运营,遵循对项目其余部分有效的相同开放治理模型。 听起来令人兴奋。 请来 kubernetes.slack.com 上的 #sig-testing on kubernetes.slack.com 与我们联系。
想了解更多? 快来看看这些资源:
OPA Gatekeeper:Kubernetes 的策略和管理
作者: Rita Zhang (Microsoft), Max Smythe (Google), Craig Hooper (Commonwealth Bank AU), Tim Hinrichs (Styra), Lachie Evenson (Microsoft), Torin Sandall (Styra)
可以从项目 Open Policy Agent Gatekeeper 中获得帮助,在 Kubernetes 环境下实施策略并加强治理。在本文中,我们将逐步介绍该项目的目标,历史和当前状态。
以下是 Kubecon EU 2019 会议的录音,帮助我们更好地开展与 Gatekeeper 合作:
出发点
如果您所在的组织一直在使用 Kubernetes,您可能一直在寻找如何控制终端用户在集群上的行为,以及如何确保集群符合公司政策。这些策略可能需要满足管理和法律要求,或者符合最佳执行方法和组织惯例。使用 Kubernetes,如何在不牺牲开发敏捷性和运营独立性的前提下确保合规性?
例如,您可以执行以下策略:
- 所有镜像必须来自获得批准的存储库
- 所有入口主机名必须是全局唯一的
- 所有 Pod 必须有资源限制
- 所有命名空间都必须具有列出联系的标签
在接收请求被持久化为 Kubernetes 中的对象之前,Kubernetes 允许通过 admission controller webhooks 将策略决策与 API 服务器分离,从而拦截这些请求。Gatekeeper 创建的目的是使用户能够通过配置(而不是代码)自定义控制许可,并使用户了解集群的状态,而不仅仅是针对评估状态的单个对象,在这些对象准许加入的时候。Gatekeeper 是 Kubernetes 的一个可定制的许可 webhook ,它由 Open Policy Agent (OPA) 强制执行, OPA 是 Cloud Native 环境下的策略引擎,由 CNCF 主办。
发展
在深入了解 Gatekeeper 的当前情况之前,让我们看一下 Gatekeeper 项目是如何发展的。
- Gatekeeper v1.0 - 使用 OPA 作为带有 kube-mgmt sidecar 的许可控制器,用来强制执行基于 configmap 的策略。这种方法实现了验证和转换许可控制。贡献方:Styra
- Gatekeeper v2.0 - 使用 Kubernetes 策略控制器作为许可控制器,OPA 和 kube-mgmt sidecar 实施基于 configmap 的策略。这种方法实现了验证和转换准入控制和审核功能。贡献方:Microsoft
- Gatekeeper v3.0 - 准入控制器与 OPA Constraint Framework 集成在一起,用来实施基于 CRD 的策略,并可以可靠地共享已完成声明配置的策略。使用 kubebuilder 进行构建,实现了验证以及最终转换(待完成)为许可控制和审核功能。这样就可以为 Rego 策略创建策略模板,将策略创建为 CRD 并存储审核结果到策略 CRD 上。该项目是 Google,Microsoft,Red Hat 和 Styra 合作完成的。
Gatekeeper v3.0 的功能
现在我们详细看一下 Gatekeeper 当前的状态,以及如何利用所有最新的功能。假设一个组织希望确保集群中的所有对象都有 department 信息,这些信息是对象标签的一部分。如何利用 Gatekeeper 完成这项需求?
验证许可控制
在集群中所有 Gatekeeper 组件都 安装 完成之后,只要集群中的资源进行创建、更新或删除,API 服务器将触发 Gatekeeper 准入 webhook 来处理准入请求。
在验证过程中,Gatekeeper 充当 API 服务器和 OPA 之间的桥梁。API 服务器将强制实施 OPA 执行的所有策略。
策略与 Constraint
结合 OPA Constraint Framework,Constraint 是一个声明,表示作者希望系统满足给定的一系列要求。Constraint 都使用 Rego 编写,Rego 是声明性查询语言,OPA 用 Rego 来枚举违背系统预期状态的数据实例。所有 Constraint 都遵循逻辑 AND。假使有一个 Constraint 不满足,那么整个请求都将被拒绝。
在定义 Constraint 之前,您需要创建一个 Constraint Template,允许大家声明新的 Constraint。每个模板都描述了强制执行 Constraint 的 Rego 逻辑和 Constraint 的模式,其中包括 CRD 的模式和传递到 enforces 中的参数,就像函数的参数一样。
例如,以下是一个 Constraint 模板 CRD,它的请求是在任意对象上显示某些标签。
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:
name: k8srequiredlabels
spec:
crd:
spec:
names:
kind: K8sRequiredLabels
listKind: K8sRequiredLabelsList
plural: k8srequiredlabels
singular: k8srequiredlabels
validation:
# Schema for the `parameters` field
openAPIV3Schema:
properties:
labels:
type: array
items: string
targets:
- target: admission.k8s.gatekeeper.sh
rego: |
package k8srequiredlabels
deny[{"msg": msg, "details": {"missing_labels": missing}}] {
provided := {label | input.review.object.metadata.labels[label]}
required := {label | label := input.parameters.labels[_]}
missing := required - provided
count(missing) > 0
msg := sprintf("you must provide labels: %v", [missing])
}
在集群中部署了 Constraint 模板后,管理员现在可以创建由 Constraint 模板定义的单个 Constraint CRD。例如,这里以下是一个 Constraint CRD,要求标签 hr 出现在所有命名空间上。
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredLabels
metadata:
name: ns-must-have-hr
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Namespace"]
parameters:
labels: ["hr"]
类似地,可以从同一个 Constraint 模板轻松地创建另一个 Constraint CRD,该 Constraint CRD 要求所有命名空间上都有 finance 标签。
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredLabels
metadata:
name: ns-must-have-finance
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Namespace"]
parameters:
labels: ["finance"]
如您所见,使用 Constraint framework,我们可以通过 Constraint 模板可靠地共享 rego,使用匹配字段定义执行范围,并为 Constraint 提供用户定义的参数,从而为每个 Constraint 创建自定义行为。
审核
根据集群中强制执行的 Constraint,审核功能可定期评估复制的资源,并检测先前存在的错误配置。Gatekeeper 将审核结果存储为 violations,在相关 Constraint 的 status 字段中列出。
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredLabels
metadata:
name: ns-must-have-hr
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Namespace"]
parameters:
labels: ["hr"]
status:
auditTimestamp: "2019-08-06T01:46:13Z"
byPod:
- enforced: true
id: gatekeeper-controller-manager-0
violations:
- enforcementAction: deny
kind: Namespace
message: 'you must provide labels: {"hr"}'
name: default
- enforcementAction: deny
kind: Namespace
message: 'you must provide labels: {"hr"}'
name: gatekeeper-system
- enforcementAction: deny
kind: Namespace
message: 'you must provide labels: {"hr"}'
name: kube-public
- enforcementAction: deny
kind: Namespace
message: 'you must provide labels: {"hr"}'
name: kube-system
数据复制
审核要求将 Kubernetes 复制到 OPA 中,然后才能根据强制的 Constraint 对其进行评估。数据复制同样也需要 Constraint,这些 Constraint 需要访问集群中除评估对象之外的对象。例如,一个 Constraint 要强制确定入口主机名的唯一性,就必须有权访问集群中的所有其他入口。
对 Kubernetes 数据进行复制,请使用复制到 OPA 中的资源创建 sync config 资源。例如,下面的配置将所有命名空间和 Pod 资源复制到 OPA。
apiVersion: config.gatekeeper.sh/v1alpha1
kind: Config
metadata:
name: config
namespace: "gatekeeper-system"
spec:
sync:
syncOnly:
- group: ""
version: "v1"
kind: "Namespace"
- group: ""
version: "v1"
kind: "Pod"
未来计划
Gatekeeper 项目背后的社区将专注于提供转换许可控制,可以用来支持转换方案(例如:在创建新资源时使用 department 信息自动注释对象),支持外部数据以将集群外部环境加入到许可决策中,支持试运行以便在执行策略之前了解策略对集群中现有资源的影响,还有更多的审核功能。
如果您有兴趣了解更多有关该项目的信息,请查看 Gatekeeper 存储库。如果您有兴趣帮助确定 Gatekeeper 的方向,请加入 #kubernetes-policy OPA Slack 频道,并加入我们的 周会 一同讨论开发、任务、用例等。
欢迎参加在上海举行的贡献者峰会
Author: Josh Berkus (Red Hat)

连续第二年,我们将在 KubeCon China 之前举行一天的 贡献者峰会。 不管您是否已经是一名 Kubernetes 贡献者,还是想要加入社区队伍,贡献一份力量,都请考虑注册参加这次活动。 这次峰会将于六月 24 号,在上海世博中心(和 KubeCon 的举办地点相同)举行, 一天的活动将包含“现有贡献者活动”,以及“新贡献者工作坊”和“文档小组活动”。
现有贡献者活动
去年的贡献者节之后,我们的团队收到了很多反馈意见,很多亚洲和大洋洲的贡献者也想要针对当前贡献者的峰会内容。 有鉴于此,我们在今年的安排中加入了当前贡献者的主题。
尽管我们还没有一个完整的时间安排,下面是当前贡献者主题所会包含的话题:
- 如何撰写 Kubernetes 改进议案 (KEP)
- 代码库研习
- 本地构建以及测试调试
- 不写代码的贡献机会
- SIG-Azure 面对面交流
- SIG-Scheduling 面对面交流
- 其他兴趣小组的面对面机会
整个计划安排将会在完全确定之后,整理放在社区页面上。
如果您的 SIG 想要在 Kubecon Shanghai 上进行面对面的交流,请联系 Josh Berkus。
新贡献者工作坊
参与过去年新贡献者工作坊(NCW)的学生觉得这项活动非常的有价值, 这项活动也帮助、引导了很多亚洲和大洋洲的开发者更多地参与到 Kubernetes 社区之中。
“这次活动可以让人一次快速熟悉社区。”其中的一位参与者提到。
如果您之前从没有参与过 Kubernetes 的贡献,或者只是做过一次或两次贡献,都请考虑注册参加新贡献者工作坊。
“熟悉了从 CLA 到 PR 的整个流程,也认识结交了很多贡献者。”另一位开发者提到。
文档小组活动
文档小组的新老贡献者都会聚首一天,讨论如何提升文档质量,以及将文档翻译成更多的语言。 如果您对翻译文档,将这些知识和信息翻译成中文和其他语言感兴趣的话,请在这里注册,报名参加文档小组活动。
参与之前
不论您参与的是哪一项活动,所有人都需要在到达贡献者峰会前签署 Kubernetes CLA。 您也同时需要考虑带一个合适的笔记本电脑,帮助文档写作或是编程开发。
壮大我们的贡献者研讨会
作者: Guinevere Saenger (GitHub) 和 Paris Pittman (Google)(谷歌)
tl;dr - 与我们一起了解贡献者社区,并获得你的第一份 PR ! 我们在[巴塞罗那][欧洲]有空位(登记 在5月15号周三结束,所以抓住这次机会!)并且在[上海][中国]有即将到来的峰会。
巴塞罗那的活动将是我们迄今为止最大的一次,登记的参与者比以往任何时候都多!
你是否曾经想为 Kubernetes 做贡献,但不知道从哪里开始?你有没有曾经看过我们社区的许多代码库并认为需要改进的地方?我们为你准备了一个工作室!
KubeCon + CloudNativeCon 巴塞罗那的研讨会新贡献者研讨会将是第四个这样的研讨会,我们真的很期待!
这个研讨会去年在哥本哈根的 KubeConEU 启动,到目前为止,我们已经把它带到了上海和西雅图,现在是巴塞罗那,以及一些非 KubeConEU 的地方。
我们根据以往课程的反馈,不断更新和改进研讨会的内容。
这一次,我们将根据参与者对开源和 Kubernetes 的经验和适应程度来进行划分。
作为101课程的一部分,我们将为完全不熟悉开源和 Kubernetes 的人提供开发人员设置和项目工作流支持,并希望为每个参与者开展他们自己的第一期工作。
在201课程中,我们将为那些在开源方面有更多经验但可能不熟悉我们社区开发工具的人进行代码库演练和本地开发和测试演示。
对于这两门课程,你将有机会亲自动手并体会到其中的乐趣。因为不是每个贡献者都使用代码,也不是每项贡献都是技术性的,所以我们将在研讨会开始时学习如何构建和组织项目,以及如何进行找到合适的人,以及遇到困难时在哪里寻求帮助。
辅导机会
我们还将回归 SIG Meet-and-Greet,在这里新入门的菜鸟贡献者将有机会与当值的贡献者交流,这也许会让他们找到他们梦想的 SIG,了解他们可以帮助哪些激动人心的领域,获得导师,结交朋友。
PS - 5月23日星期四,在 KubeCon+CloudNativeCon 会议期间会有两次导师会议。[在这里注册][导师]。在西雅图活动期间,60% 的与会者会向贡献者提问。
曾经与会者的故事 - Vallery Lancy,Lyft 的工程师
在一系列采访中,我们与一些过去的参与者进行了交谈,这些采访将在今年全年公布。
在我们的前两个片段中,我们会提到 Vallery Lancy,Lyft 公司的工程师,也是我们最近西雅图版研讨会的75名与会者之一。她在社区里闲逛了一段时间,想看看能不能投身到某个领域当中。
在这里观看 Vallery 讲述她的经历:
Vallery 和那些对研讨会感兴趣的人或者参加巴塞罗那会议的人说了些什么?
想变得和 Vallery 还有数百名参与之前的新贡献者研讨会的与会者一样的话:在巴塞罗那(或者上海-或者圣地亚哥!)加入我们!你会有一个与众不同的体验,而不再是死读我们的文档!
Have the opportunity to meet with the experts and go step by step into your journey with your peers around you. We’re looking forward to seeing you there! Register here --> 你将有机会与专家见面,并与周围的同龄人一步步走上属于你的道路。我们期待着在那里与你见面! 在这里注册
如何参与 Kubernetes 文档的本地化工作
作者: Zach Corleissen(Linux 基金会)
去年我们对 Kubernetes 网站进行了优化,加入了多语言内容的支持。贡献者们踊跃响应,加入了多种新的本地化内容:截至 2019 年 4 月,Kubernetes 文档有了 9 个不同语言的未完成版本,其中有 6 个是 2019 年加入的。在每个 Kubernetes 文档页面的上方,读者都可以看到一个语言选择器,其中列出了所有可用语言。
不论是完成度最高的中文版 v1.12,还是最新加入的葡萄牙文版 v1.14,各语言的本地化内容还未完成,这是一个进行中的项目。如果读者有兴趣对现有本地化工作提供支持,请继续阅读。
什么是本地化
翻译是以词表意的问题。而本地化在此基础之上,还包含了过程和设计方面的工作。
本地化和翻译很像,但是包含更多内容。除了进行翻译之外,本地化还要为编写和发布过程的框架进行优化。例如,Kubernetes.io 多数的站点浏览功能(按钮文字)都保存在单独的文件之中。所以启动新本地化的过程中,需要包含加入对特定文件中字符串进行翻译的工作。
本地化很重要,能够有效的降低 Kubernetes 的采纳和支持门槛。如果能用母语阅读 Kubernetes 文档,就能更轻松的开始使用 Kubernetes,并对其发展作出贡献。
如何启动本地化工作
不同语言的本地化工作都是单独的功能——和其它 Kubernetes 功能一致,贡献者们在一个 SIG 中进行本地化工作,分享出来进行评审,并加入项目。
贡献者们在团队中进行内容的本地化工作。因为自己不能批准自己的 PR,所以一个本地化团队至少应该有两个人——例如意大利文的本地化团队有两个人。这个团队规模可能很大:中文团队有几十个成员。
每个团队都有自己的工作流。有些团队手工完成所有的内容翻译;有些会使用带有翻译插件的编译器,并使用评审机来提供正确性的保障。SIG Docs 专注于输出的标准;这就给了本地化团队采用适合自己工作情况的工作流。这样一来,团队可以根据最佳实践进行协作,并以 Kubernetes 的社区精神进行分享。
为本地化工作添砖加瓦
如果你有兴趣为 Kubernetes 文档加入新语种的本地化内容,Kubernetes contribution guide 中包含了这方面的相关内容。
已经启动的的本地化工作同样需要支持。如果有兴趣为现存项目做出贡献,可以加入本地化团队的 Slack 频道,去做个自我介绍。各团队的成员会帮助你开始工作。
下一步?
最新的印地文本地化工作正在启动。为什么不加入你的语言?
身为 SIG Docs 的主席,我甚至希望本地化工作跳出文档范畴,直接为 Kubernetes 组件提供本地化支持。有什么组件是你希望支持不同语言的么?可以提交一个 Kubernetes Enhancement Proposal 来促成这一进步。
使用 Kubernetes 设备插件和 RuntimeClass 在 Ingress 控制器中实现硬件加速 SSL/TLS 终止
作者: Mikko Ylinen (Intel)
译者: pegasas
摘要
Kubernetes Ingress 是在集群服务与集群外部世界建立连接的一种方法。为了正确地将流量路由到服务后端,集群需要一个 Ingress 控制器。Ingress 控制器负责根据 Ingress API 对象的信息设置目标到正确的后端。实际流量通过代理服务器路由, 代理服务器负责诸如负载均衡和 SSL/TLS (稍后的“SSL”指 SSL 或 TLS)终止等任务。由于涉及加密操作,SSL 终止是一个 CPU 密集型操作。为了从 CPU 中分载一些 CPU 密集型工作,基于 OpenSSL 的代理服务器可以利用 OpenSSL Engine API 和专用加密硬件的优势。 这将为其他事情释放 CPU 周期,并提高代理服务器的总体吞吐量。
在这篇博客文章中,我们将展示使用最近创建的 Kubernetes 构建块(设备插件框架和 RuntimeClass)为运行 Ingress 控制器代理的容器提供硬件加速加密是多么容易。最后,给出了一个参考设置使用基于 HAproxy 的 Ingress 控制器 加速使用 Intel® QuickAssist 技术卡。
关于代理、OpenSSL 引擎和加密硬件
代理服务器在 Kubernetes Ingress 控制器功能中起着至关重要的作用。它将流量代理到每个 Ingress 对象路由的后端。 在高流量负载下,性能变得至关重要,特别是当代理涉及到诸如 SSL 加密之类的 CPU 密集型操作时。
OpenSSL 项目为实现 SSL 协议提供了广泛采用的库。Kubernetes Ingress 控制器使用的常用代理服务器中,Nginx 和 HAproxy 使用 OpenSSL。 CNCF 毕业项目 Envoy 使用 BoringSSL,但是 Envoy 社区似乎也有兴趣使用 OpenSSL 作为替代。
OpenSSL SSL 协议库依赖于实现加密功能的 libcrypto。很长一段时间以来(在 0.9.6 版本中首次引入), OpenSSL 提供了一个引擎概念, 允许将这些加密操作卸载到专用的加密加速硬件。后来,一个特殊的动态引擎使加密硬件的特定部分能够在一个独立的可加载模块中实现, 该模块可以在 OpenSSL 代码库之外开发并单独分发。从应用程序的角度来看,这也是理想的,因为他们不需要知道如何使用硬件的细节, 并且当硬件可用时,可以加载/使用特定于硬件的模块。
如前所述,由于 SSL 操作中的硬件加速处理,基于硬件的加密可以极大地提高云应用程序的性能, 并且可以提供密钥/随机数生成等其他加密服务。云可以使用动态引擎轻松地提供硬件,并且存在几种可加载模块实现, 例如 CloudHSM 、 IBMCA 或 QAT Engine 。
对于云部署,理想的场景是将这些模块作为容器工作负载的一部分交付。工作负载将在提供模块需要访问的底层硬件的节点上调度。 另一方面,不管加密加速硬件是否可用,工作负载都应该以相同的方式运行,并且不需要修改代码。OpenSSL 动态引擎支持这一点。 下面图 1 以一个典型的 Ingress 控制器容器为例说明了这两个场景。红色的框表示启用了加密硬件引擎的容器与“标准”容器之间的区别。 值得指出的是,所显示的配置更改并不一定需要容器的另一个版本,因为配置可以被管理,例如使用 ConfigMap。
图 1. Ingress 控制器容器
硬件资源和隔离
为了能够部署具有硬件依赖关系的工作负载,Kubernetes 提供了优秀的扩展和可配置机制。 让我们进一步研究 Kubernetes 设备插件框架(beta 1.14) 和 RuntimeClass(beta 1.14), 并了解如何利用它们向工作负载暴露加密硬件。
在 Kubernetes 1.8 中首次引入的设备插件框架为硬件供应商提供了一种向 Kubelets 注册和分配节点硬件资源的方法。 插件实现了特定于硬件的初始化逻辑和资源管理。Pod 可以在其 PodSpec 中请求硬件资源, 进而保证 Pod 被调度到能够提供这些资源的节点上。
容器的设备资源分配非常重要。对于处理安全性的应用程序,硬件级别隔离是至关重要的。 基于 PCIe 的加密加速设备功能 可以受益于 IO 硬件虚拟化,通过 I/O 内存管理单元(IOMMU),提供隔离:IOMMU 将设备分组,为工作负载提供隔离的资源 (假设加密卡不与其他设备共享 IOMMU 组)。如果PCIe设备支持单根 I/O 虚拟化(SR-IOV)规范,则可以进一步增加隔离资源的数量。 SR-IOV 允许将 PCIe 设备将 物理功能项(Physical Functions,PF) 设备进一步拆分为 虚拟功能项(Virtual Functions, VF),并且每个设备都属于自己的 IOMMU 组。 要将这些借助 IOMMU 完成隔离的设备功能项暴露给用户空间和容器,主机内核应该将它们绑定到特定的设备驱动程序。 在 Linux 中,这个驱动程序是 vfio-pci, 它通过字符设备将设备提供给用户空间。内核 vfio-pci 驱动程序使用一种称为 PCI 透传(PCI Passthrough) 的机制, 为用户空间应用程序提供了对 PCIe 设备与功能项的直接的、IOMMU 支持的访问。 用户空间框架,如数据平面开发工具包(Data Plane Development Kit,DPDK)可以利用该接口。 此外,虚拟机(VM)管理程序可以向 VM 提供这些用户空间设备节点,并将它们作为 PCI 设备暴露给寄宿内核。 在寄宿内核的支持下,VM 将接近于直接访问底层主机设备的本机性能。
为了向 Kubernetes 发布这些设备资源,我们可以使用一个简单的 Kubernetes 设备插件来运行初始化(绑定),
调用 kubelet 的 Registration gRPC 服务,并实现 kubelet 调用的 DevicePlugin gRPC 服务,
例如,在 Pod 创建时 Allocate 资源。
设备分配和Pod部署
此时,你可能会问容器可以使用 VFIO 设备节点做什么?我们首先快速查看 Kubernetes RuntimeClass 之后,答案会出现。
创建 Kubernetes RuntimeClass 是为了对集群中可用的各种运行时提供更好的控制和可配置性 (前面的一篇博客文章详细介绍了它的需求、状态和路线图)。 本质上,RuntimeClass 为集群用户提供了更好的工具来选择和使用最适合 Pod 用例的运行时。
OCI 兼容的 Kata Containers 运行时为工作负载提供了一个硬件虚拟化隔离层。
除了工作负载隔离之外,Kata Containers VM 还有一个额外的好处,即 VFIO 设备,由设备插件 Allocate 而来,
可以作为硬件隔离设备传递给容器。惟一的要求是,Kata Containers 内核启用了暴露设备的驱动程序。
这就是为容器工作负载启用硬件加速加密所需要的全部。总结:
- 集群需要在提供硬件的节点上运行一个设备插件
- 设备插件使用 VFIO 驱动程序向用户空间暴露硬件
- Pod 在 PodSpec 中请求设备资源并指定 Kata Containers 作为 RuntimeClass
- 容器中具有硬件适配库和 OpenSSL 引擎模块
图2显示了使用前面演示的容器的总体设置。
图 2. Deployment 概述
参考设置
最后,我们描述构建图 2 中描述的可以工作的设置所需的构建块和步骤。具体设置使用了 Intel® QuickAssist 技术(QAT) PCIe 设备。 在 Ingress 控制器中启用硬件加速 SSL 终止。应该注意的是,用例并不局限于 Ingress 控制器, 任何基于 OpenSSL 的工作负载都可以加速。
集群配置:
- Kubernetes 1.14(
RuntimeClass和DevicePlugin特性门控已启用(两者在 1.14 中都是true) - 配置了 RuntimeClass 就绪运行时和 Kata Containers
主机配置:
- Intel® QAT 驱动程序发行版,内核驱动程序同时安装在主机内核和 Kata Containers 内核(或在 rootfs 上作为可加载模块)
- 已部署 QAT 设备插件 DaemonSet
Ingress 控制器配置和部署:
- 一个修改后的 HAproxy-ingress Ingress 控制器的容器
- QAT HW HAL 用户空间库(Intel® QAT SW 发行版的一部分)
- 内置 OpenSSL QAT 引擎
- 使用 Haproxy-ingress ConfigMap 启用 QAT 引擎
ssl-engine=”qat”ssl-mode-async=true
- Haproxy-ingress Deployment
.yaml- 请求
qat.intel.com: n资源 - 请求
runtimeClassName: kata-containers(名称值取决于集群配置)
- 请求
- (容器中配置了可用的 OpenSSL 引擎的 QAT 设备配置文件)
一旦构建块可用,就可以按照 TLS 终止示例
步骤测试硬件加速 SSL/TLS。
为了验证硬件的使用,你可以检查主机上的 /sys/kernel/debug/*/fw_counters 文件,
它们会由 Intel® QAT 固件更新。
使用 HAproxy-ingress 和 HAproxy,是因为可以使用 ssl-engine <name> [algo ALGOs]
配置标志直接配置 HAproxy 来使用 OpenSSL 引擎,
而无需修改全局 OpenSSL 配置文件。此外,HAproxy 可以使用异步调用(使用ssl-mode-async)卸载已配置的算法,以进一步提高性能。
呼吁
在这篇博客文章中,我们展示了 Kubernetes 设备插件和 RuntimeClass 如何为 Pod 中的应用程序提供隔离的硬件访问,以便将加密操作卸载给硬件加速器。 硬件加速器可以用来加速加密操作,并将 CPU 周期节省给其他任务。我们演示了使用 HAproxy 的设置, 它已经支持 OpenSSL 中的异步加密卸载。
我们团队的下一步是对 Envoy 重复相同的步骤(使用一个基于 OpenSSL 的 TLS 传输套接字作为扩展构建)。 此外,我们正在努力增强 Envoy 功能,使其能够将 BoringSSL 异步私钥操作卸载到加密加速硬件。 感谢你的反馈和帮助!
当将加密处理卸载到专用加速器时,你的加密应用程序可以为其他任务节省多少 CPU 周期?
Kubernetes 1.14 稳定性改进中的进程ID限制
作者: Derek Carr
你是否见过有人拿走了比属于他们那一份更多的饼干? 一个人走过来,抓起半打新鲜烤制的大块巧克力饼干然后匆匆离去,就像饼干怪兽大喊 “Om nom nom nom”。
在一些罕见的工作负载中,Kubernetes 集群内部也发生了类似的情况。每个 Pod 和 Node 都有有限数量的可能的进程 ID(PID),供所有应用程序共享。尽管很少有进程或 Pod 能够进入并获取所有 PID,但由于这种行为,一些用户会遇到资源匮乏的情况。 因此,在 Kubernetes 1.14 中,我们引入了一项增强功能,以降低单个 Pod 垄断所有可用 PID 的风险。
你能预留一些 PIDs 吗?
在这里,我们谈论的是某些容器的贪婪性。 在理想情况之外,失控进程有时会发生,特别是在测试集群中。 因此,在这些集群中会发生一些混乱的非生产环境准备就绪的事情。
在这种情况下,可能会在节点内部发生类似于 fork 炸弹耗尽 PID 的攻击。随着资源的缓慢腐蚀,被一些不断产生子进程的僵尸般的进程所接管,其他正常的工作负载会因为这些像气球般不断膨胀的浪费的处理能力而开始受到冲击。这可能导致同一 Pod 上的其他进程缺少所需的 PID。这也可能导致有趣的副作用,因为节点可能会发生故障,并且该Pod的副本将安排到新的机器上,至此,该过程将在整个集群中重复进行。
解决问题
因此,在 Kubernetes 1.14 中,我们添加了一个特性,允许通过配置 kubelet,限制给定 Pod 可以消耗的 PID 数量。如果该机器支持 32768 个 PIDs 和 100 个 Pod,则可以为每个 Pod 提供 300 个 PIDs 的预算,以防止 PIDs 完全耗尽。如果管理员想要像 CPU 或内存那样过度使用 PIDs,那么他们也可以配置超额使用,但是这样会有一些额外风险。不管怎样,没有一个Pod能搞坏整个机器。这通常会防止简单的分叉函数炸弹接管你的集群。
此更改允许管理员保护一个 Pod 不受另一个 Pod 的影响,但不能确保计算机上的所有 Pod 都能保护节点和节点代理本身不受影响。因此,我们在这个版本中以 Alpha 的形式引入了这个一个特性,它提供了 PIDs 在节点代理( kubelet、runtime 等)与 Pod 上的最终用户工作负载的分离。管理员可以预定特定数量的 pid(类似于今天如何预定 CPU 或内存),并确保它们不会被该计算机上的 pod 消耗。一旦从 Alpha 进入到 Beta,然后在将来的 Kubernetes 版本中稳定下来,我们就可以使用这个特性防止 Linux 资源耗尽。
开始使用 Kubernetes 1.14。
##参与其中
如果您对此特性有反馈或有兴趣参与其设计与开发,请加入[节点特别兴趣小组](https://github.com/kubernetes/community/tree/master/sig Node)。
###关于作者: Derek Carr 是 Red Hat 高级首席软件工程师。他也是 Kubernetes 的贡献者和 Kubernetes 社区指导委员会的成员。
Raw Block Volume 支持进入 Beta
作者: Ben Swartzlander (NetApp), Saad Ali (Google)
Kubernetes v1.13 中对原生数据块卷(Raw Block Volume)的支持进入 Beta 阶段。此功能允许将持久卷作为块设备而不是作为已挂载的文件系统暴露在容器内部。
什么是块设备?
块设备允许对固定大小的块中的数据进行随机访问。硬盘驱动器、SSD 和 CD-ROM 驱动器都是块设备的例子。
通常,持久性性存储是在通过在块设备(例如磁盘或 SSD)之上构造文件系统(例如 ext4)的分层方式实现的。这样应用程序就可以读写文件而不是操作数据块进。操作系统负责使用指定的文件系统将文件读写转换为对底层设备的数据块读写。
值得注意的是,整个磁盘都是块设备,磁盘分区也是如此,存储区域网络(SAN)设备中的 LUN 也是一样的。
为什么要将 raw block volume 添加到 kubernetes?
有些特殊的应用程序需要直接访问块设备,原因例如,文件系统层会引入不必要的开销。最常见的情况是数据库,通常会直接在底层存储上组织数据。原生的块设备(Raw Block Devices)还通常由能自己实现某种存储服务的软件(软件定义的存储系统)使用。
从程序员的角度来看,块设备是一个非常大的字节数组,具有某种最小读写粒度,通常为 512 个字节,大部分情况为 4K 或更大。
随着在 Kubernetes 中运行数据库软件和存储基础架构软件变得越来越普遍,在 Kubernetes 中支持原生块设备的需求变得越来越重要。
哪些卷插件支持 raw block?
在发布此博客时,以下 in-tree 卷类型支持原生块设备:
- AWS EBS
- Azure Disk
- Cinder
- Fibre Channel
- GCE PD
- iSCSI
- Local volumes
- RBD (Ceph)
- Vsphere
Out-of-tree CSI 卷驱动程序 可能也支持原生数据块卷。Kubernetes CSI 对原生数据块卷的支持目前为 alpha 阶段。参考 这篇 文档。
Kubernetes raw block volume 的 API
原生数据块卷与普通存储卷有很多共同点。两者都通过创建与 PersistentVolume 对象绑定的 PersistentVolumeClaim 对象发起请求,并通过将它们加入到 PodSpec 的 volumes 数组中来连接到 Kubernetes 中的 Pod。
但是有两个重要的区别。首先,要请求原生数据块设备的 PersistentVolumeClaim 必须在 PersistentVolumeClaimSpec 中设置 volumeMode = "Block"。volumeMode 为空时与传统设置方式中的指定 volumeMode = "Filesystem" 是一样的。PersistentVolumes 在其 PersistentVolumeSpec 中也有一个 volumeMode 字段,"Block" 类型的 PVC 只能绑定到 "Block" 类型的 PV 上,而"Filesystem" 类型的 PVC 只能绑定到 "Filesystem" PV 上。
其次,在 Pod 中使用原生数据块卷时,必须在 PodSpec 的 Container 部分指定一个 VolumeDevice,而不是 VolumeMount。VolumeDevices 具备 devicePaths 而不是 mountPaths,在容器中,应用程序将看到位于该路径的设备,而不是挂载了的文件系统。
应用程序打开、读取和写入容器内的设备节点,就像它们在非容器化或虚拟环境中与系统上的任何块设备交互一样。
创建一个新的原生块设备 PVC
首先,请确保与您选择的存储类关联的驱动支持原生块设备。然后创建 PVC。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteMany
volumeMode: Block
storageClassName: my-sc
resources:
requests:
storage: 1Gi
使用原生块 PVC
在 Pod 定义中使用 PVC 时,需要选择块设备的设备路径,而不是文件系统的安装路径。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: busybox
command:
- sleep
- “3600”
volumeDevices:
- devicePath: /dev/block
name: my-volume
imagePullPolicy: IfNotPresent
volumes:
- name: my-volume
persistentVolumeClaim:
claimName: my-pvc
作为存储供应商,我如何在 CSI 插件中添加对原生块设备的支持?
CSI 插件的原生块支持仍然是 alpha 版本,但是现在可以改进了。CSI 规范 详细说明了如何处理具有 BlockVolume 能力而不是 MountVolume 能力的卷的请求。CSI 插件可以支持两种类型的卷,也可以支持其中一种或另一种。更多详细信息,请查看 这个文档。
问题/陷阱
由于块设备实质上还是设备,因此可以从容器内部对其进行底层操作,而文件系统的卷则无法执行这些操作。例如,实际上是块设备的 SCSI 磁盘支持使用 Linux ioctl 向设备发送 SCSI 命令。
默认情况下,Linux 不允许容器将 SCSI 命令从容器内部发送到磁盘。为此,必须向容器安全层级认证 SYS_RAWIO 功能实现这种行为。请参阅 这篇 文档。
另外,尽管 Kubernetes 保证可以将块设备交付到容器中,但不能保证它实际上是 SCSI 磁盘或任何其他类型的磁盘。用户必须确保所需的磁盘类型与 Pod 一起使用,或只部署可以处理各种块设备类型的应用程序。
如何学习更多?
在此处查看有关 snapshot 功能的其他文档:Raw Block Volume 支持
如何参与进来?
加入 Kubernetes 存储 SIG 和 CSI 社区,帮助我们添加更多出色的功能并改进现有功能,就像 raw block 存储一样!
https://github.com/kubernetes/community/tree/master/sig-storage https://github.com/container-storage-interface/community/blob/master/README.md
特别感谢所有为 Kubernetes 增加 block volume 支持的贡献者,包括:
- Ben Swartzlander (https://github.com/bswartz)
- Brad Childs (https://github.com/childsb)
- Erin Boyd (https://github.com/erinboyd)
- Masaki Kimura (https://github.com/mkimuram)
- Matthew Wong (https://github.com/wongma7)
- Michelle Au (https://github.com/msau42)
- Mitsuhiro Tanino (https://github.com/mtanino)
- Saad Ali (https://github.com/saad-ali)
新贡献者工作坊上海站
作者: Josh Berkus (红帽), Yang Li (The Plant), Puja Abbassi (Giant Swarm), XiangPeng Zhao (中兴通讯)

KubeCon 上海站新贡献者峰会与会者,摄影:Jerry Zhang
最近,在中国的首次 KubeCon 上,我们完成了在中国的首次新贡献者峰会。看到所有中国和亚洲的开发者(以及来自世界各地的一些人)有兴趣成为贡献者,这令人非常兴奋。在长达一天的课程中,他们了解了如何、为什么以及在何处为 Kubernetes 作出贡献,创建了 PR,参加了贡献者圆桌讨论,并签署了他们的 CLA。
这是我们的第二届新贡献者工作坊(NCW),它由前一次贡献者体验 SIG 成员创建和领导的哥本哈根研讨会延伸而来。根据受众情况,本次活动采用了中英文两种语言,充分利用了 CNCF 赞助的一流的同声传译服务。同样,NCW 团队由社区成员组成,既有说英语的,也有说汉语的:Yang Li、XiangPeng Zhao、Puja Abbassi、Noah Abrahams、Tim Pepper、Zach Corleissen、Sen Lu 和 Josh Berkus。除了演讲和帮助学员外,团队的双语成员还将所有幻灯片翻译成了中文。共有五十一名学员参加。

Noah Abrahams 讲解 Kubernetes 沟通渠道。摄影:Jerry Zhang
NCW 让参与者完成了为 Kubernetes 作出贡献的各个阶段,从决定在哪里作出贡献开始,接着介绍了 SIG 系统和我们的代码仓库结构。我们还有来自文档和测试基础设施领域的「客座讲者」,他们负责讲解有关的贡献。最后,我们在创建 issue、提交并批准 PR 的实践练习后,结束了工作坊。
这些实践练习使用一个名为贡献者游乐场的代码仓库,由贡献者体验 SIG 创建,让新贡献者尝试在一个 Kubernetes 仓库中执行各种操作。它修改了 Prow 和 Tide 自动化,使用与真实代码仓库类似的 Owners 文件。这可以让学员了解为我们的仓库做出贡献的有关机制,同时又不妨碍正常的开发流程。

Yang Li 讲到如何让你的 PR 通过评审。摄影:Josh Berkus
「防火长城」和语言障碍都使得在中国为 Kubernetes 作出贡献变得困难。而且,中国的开源商业模式并不成熟,员工在开源项目上工作的时间有限。
中国工程师渴望参与 Kubernetes 的研发,但他们中的许多人不知道从何处开始,因为 Kubernetes 是一个如此庞大的项目。通过本次工作坊,我们希望帮助那些想要参与贡献的人,不论他们希望修复他们遇到的一些错误、改进或本地化文档,或者他们需要在工作中用到 Kubernetes。我们很高兴看到越来越多的中国贡献者在过去几年里加入社区,我们也希望将来可以看到更多。
「我已经参与了 Kubernetes 社区大约三年」,XiangPeng Zhao 说,「在社区,我注意到越来越多的中国开发者表现出对 Kubernetes 贡献的兴趣。但是,开始为这样一个项目做贡献并不容易。我尽力帮助那些我在社区遇到的人,但是,我认为可能仍有一些新的贡献者离开社区,因为他们在遇到麻烦时不知道从哪里获得帮助。幸运的是,社区在 KubeCon 哥本哈根站发起了 NCW,并在 KubeCon 上海站举办了第二届。我很高兴受到 Josh Berkus 的邀请,帮助组织这个工作坊。在工作坊期间,我当面见到了社区里的朋友,在练习中指导了与会者,等等。所有这些对我来说都是难忘的经历。作为有着多年贡献者经验的我,也学习到了很多。我希望几年前我开始为 Kubernetes 做贡献时参加过这样的工作坊」。

贡献者圆桌讨论。摄影:Jerry Zhang
工作坊以现有贡献者圆桌讨论结束,嘉宾包括 Lucas Käldström、Janet Kuo、Da Ma、Pengfei Ni、Zefeng Wang 和 Chao Xu。这场圆桌讨论旨在让新的和现有的贡献者了解一些最活跃的贡献者和维护者的幕后日常工作,不论他们来自中国还是世界各地。嘉宾们讨论了从哪里开始贡献者的旅程,以及如何与评审者和维护者进行互动。他们进一步探讨了在中国参与贡献的主要问题,并向与会者预告了在 Kubernetes 的未来版本中可以期待的令人兴奋的功能。
工作坊结束后,XiangPeng Zhao 和一些与会者就他们的经历在微信和 Twitter 上进行了交谈。他们很高兴参加了 NCW,并就改进工作坊提出了一些建议。一位名叫 Mohammad 的与会者说:「我在工作坊上玩得很开心,学习了参与 k8s 贡献的整个过程。」另一位与会者 Jie Jia 说:「工作坊非常精彩。它系统地解释了如何为 Kubernetes 做出贡献。即使参与者之前对此一无所知,他(她)也可以理解这个过程。对于那些已经是贡献者的人,他们也可以学习到新东西。此外,我还可以在工作坊上结识来自国内外的新朋友。真是棒极了!」
贡献者体验 SIG 将继续在未来的 KubeCon 上举办新贡献者工作坊,包括西雅图站、巴塞罗那站,然后在 2019 年六月回到上海。如果你今年未能参加,请在未来的 KubeCon 上注册。并且,如果你遇到工作坊的与会者,请务必欢迎他们加入社区。
链接:
- 中文版幻灯片:PDF
- 英文版幻灯片:PDF 或 带有演讲者笔记的 Google Docs
- 贡献者游乐场
Kubernetes 文档更新,国际版
作者:Zach Corleissen (Linux 基金会)
作为文档特别兴趣小组(SIG Docs)的联合主席,我很高兴能与大家分享 Kubernetes 文档在本地化(l10n)方面所拥有的一个完全成熟的工作流。
丰富的缩写
L10n 是 localization 的缩写。
I18n 是 internationalization 的缩写。
I18n 定义了做什么 能让 l10n 更容易。而 L10n 更全面,相比翻译( t9n )具备更完善的流程。
为什么本地化很重要
SIG Docs 的目标是让 Kubernetes 更容易为尽可能多的人使用。
一年前,我们研究了是否有可能由一个独立翻译 Kubernetes 文档的中国团队来主持文档输出。经过多次交谈(包括 OpenStack l10n 的专家),多次转变,以及重新致力于更轻松的本地化,我们意识到,开源文档就像开源软件一样,是在可能的边缘不断进行实践。
整合工作流程、语言标签和团队级所有权可能看起来像是十分简单的改进,但是这些功能使 l10n 可以扩展到规模越来越大的 l10n 团队。随着 SIG Docs 不断改进,我们已经在单一工作流程中偿还了大量技术债务并简化了 l10n。这对未来和现在都很有益。
整合的工作流程
现在,本地化已整合到 kubernetes/website 存储库。我们已经配置了 Kubernetes CI/CD 系统,Prow 来处理自动语言标签分配以及团队级 PR 审查和批准。
语言标签
Prow 根据文件路径自动添加语言标签。感谢 SIG Docs 贡献者 June Yi,他让人们还可以在 pull request(PR)注释中手动分配语言标签。例如,当为 issue 或 PR 留下下述注释时,将为之分配标签 language/ko(Korean)。
/language ko
这些存储库标签允许审阅者按语言过滤 PR 和 issue。例如,您现在可以过滤 kubernetes/website 面板中具有中文内容的 PR。
团队审核
L10n 团队现在可以审查和批准他们自己的 PR。例如,英语的审核和批准权限在位于用于显示英语内容的顶级子文件夹中的 OWNERS 文件中指定。
将 OWNERS 文件添加到子目录可以让本地化团队审查和批准更改,而无需由可能并不擅长该门语言的审阅者进行批准。
下一步是什么
我们期待着上海的 doc sprint 能作为中国 l10n 团队的资源。
我们很高兴继续支持正在取得良好进展的日本和韩国 l10n 队伍。
如果您有兴趣将 Kubernetes 本地化为您自己的语言或地区,请查看我们的本地化 Kubernetes 文档指南,并联系 SIG Docs 主席团获取支持。
加入SIG Docs
如果您对 Kubernetes 文档感兴趣,请参加 SIG Docs 每周会议,或在 Kubernetes Slack 加入 #sig-docs。
Kubernetes 2018 年北美贡献者峰会
作者:
Bob Killen(密歇根大学) Sahdev Zala(IBM), Ihor Dvoretskyi(CNCF)
2018 年北美 Kubernetes 贡献者峰会将在西雅图 KubeCon + CloudNativeCon 会议之前举办,这将是迄今为止规模最大的一次盛会。
这是一个将新老贡献者聚集在一起,面对面交流和分享的活动;并为现有的贡献者提供一个机会,帮助塑造社区发展的未来。它为新的社区成员提供了一个学习、探索和实践贡献工作流程的良好空间。
与之前的贡献者峰会不同,本次活动为期两天,有一个更为轻松的行程安排,一般贡献者将于 12 月 9 日(周日)下午 5 点至 8 点在距离会议中心仅几步远的 Garage Lounge and Gaming Hall 举办峰会。在那里,贡献者也可以进行台球、保龄球等娱乐活动,而且还有各种食品和饮料。
接下来的一天,也就是 10 号星期一,有三个独立的会议你可以选择参与:
新贡献者研讨会:
为期半天的研讨会旨在让新贡献者加入社区,并营造一个良好的 Kubernetes 社区工作环境。 请在开会期间保持在场,该讨论会不允许随意进出。
当前贡献者追踪:
保留给那些积极参与项目开发的贡献者;目前的贡献者追踪包括讲座、研讨会、聚会、Unconferences 会议、指导委员会会议等等! 请留意 GitHub 中的时间表,因为内容经常更新。
Docs 冲刺:
SIG-Docs 将在活动日期临近的时候列出一个需要处理的问题和挑战列表。
注册:
要注册贡献者峰会,请参阅 Git Hub 上的活动详情注册部分。请注意报名正在审核中。 如果您选择了 “当前贡献者追踪”,而您却不是一个活跃的贡献者,您将被要求参加新贡献者研讨会,或者被要求进入候补名单。 成千上万的贡献者只有 300 个位置,我们需要确保正确的人被安排席位。
如果您有任何问题或疑虑,请随时通过 community@kubernetes.io 联系贡献者峰会组织团队。
期待在那里看到每个人!
2018 年督导委员会选举结果
作者: Jorge Castro (Heptio), Ihor Dvoretskyi (CNCF), Paris Pittman (Google)
结果
Kubernetes 督导委员会选举现已完成,以下候选人获得了立即开始的两年任期:
- Aaron Crickenberger, Google, @spiffxp
- Davanum Srinivas, Huawei, @dims
- Tim St. Clair, Heptio, @timothysc
十分感谢!
- 督导委员会荣誉退休成员 Quinton Hoole,表扬他在过去一年为社区所作的贡献。我们期待着
- 参加竞选的候选人。愿我们永远拥有一群强大的人,他们希望在每一次选举中都能像你们一样推动社区向前发展。
- 共计 307 名选民参与投票。
- 本次选举由康奈尔大学主办 CIVS!
加入督导委员会
你可以关注督导委员会的任务清单,并通过向他们的代码仓库提交 issue 或 PR 的方式来参与。他们也会在UTC 时间每周三晚 8 点举行会议,并定期与我们的贡献者见面。
督导委员会会议:
与我们的贡献者会面:
Kubernetes 中的拓扑感知数据卷供应
作者: Michelle Au(谷歌)
通过提供拓扑感知动态卷供应功能,具有持久卷的多区域集群体验在 Kubernetes 1.12 中得到了改进。此功能使得 Kubernetes 在动态供应卷时能做出明智的决策,方法是从调度器获得为 Pod 提供数据卷的最佳位置。在多区域集群环境,这意味着数据卷能够在满足你的 Pod 运行需要的合适的区域被供应,从而允许你跨故障域轻松部署和扩展有状态工作负载,从而提供高可用性和容错能力。
以前的挑战
在此功能被提供之前,在多区域集群中使用区域化的持久磁盘(例如 AWS ElasticBlockStore、 Azure Disk、GCE PersistentDisk)运行有状态工作负载存在许多挑战。动态供应独立于 Pod 调度处理,这意味着只要你创建了一个 PersistentVolumeClaim(PVC),一个卷就会被供应。 这也意味着供应者不知道哪些 Pod 正在使用该卷,也不清楚任何可能影响调度的 Pod 约束。
这导致了不可调度的 Pod,因为在以下区域中配置了卷:
- 没有足够的 CPU 或内存资源来运行 Pod
- 与节点选择器、Pod 亲和或反亲和策略冲突
- 由于污点(taint)不能运行 Pod
另一个常见问题是,使用多个持久卷的非有状态 Pod 可能会在不同的区域中配置每个卷,从而导致一个不可调度的 Pod。
次优的解决方法包括节点超配,或在正确的区域中手动创建卷,但这会造成难以动态部署和扩展有状态工作负载的问题。
拓扑感知动态供应功能解决了上述所有问题。
支持的卷类型
在 1.12 中,以下驱动程序支持拓扑感知动态供应:
- AWS EBS
- Azure Disk
- GCE PD(包括 Regional PD)
- CSI(alpha) - 目前只有 GCE PD CSI 驱动实现了拓扑支持
设计原则
虽然最初支持的插件集都是基于区域的,但我们设计此功能时遵循 Kubernetes 跨环境可移植性的原则。 拓扑规范是通用的,并使用类似于基于标签的规范,如 Pod nodeSelectors 和 nodeAffinity。 该机制允许你定义自己的拓扑边界,例如内部部署集群中的机架,而无需修改调度程序以了解这些自定义拓扑。
此外,拓扑信息是从 Pod 规范中抽象出来的,因此 Pod 不需要了解底层存储系统的拓扑特征。 这意味着你可以在多个集群、环境和存储系统中使用相同的 Pod 规范。
入门
要启用此功能,你需要做的就是创建一个将 volumeBindingMode 设置为 WaitForFirstConsumer 的 StorageClass:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: topology-aware-standard
provisioner: kubernetes.io/gce-pd
volumeBindingMode: WaitForFirstConsumer
parameters:
type: pd-standard
这个新设置表明卷配置器不立即创建卷,而是等待使用关联的 PVC 的 Pod 通过调度运行。
请注意,不再需要指定以前的 StorageClass zone 和 zones 参数,因为现在在哪个区域中配置卷由 Pod 策略决定。
接下来,使用此 StorageClass 创建一个 Pod 和 PVC。 此过程与之前相同,但在 PVC 中指定了不同的 StorageClass。 以下是一个假设示例,通过指定许多 Pod 约束和调度策略来演示新功能特性:
- 一个 Pod 多个 PVC
- 跨子区域的节点亲和
- 同一区域 Pod 反亲和
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- us-central1-a
- us-central1-f
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: failure-domain.beta.kubernetes.io/zone
containers:
- name: nginx
image: gcr.io/google_containers/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
- name: logs
mountPath: /logs
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: topology-aware-standard
resources:
requests:
storage: 10Gi
- metadata:
name: logs
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: topology-aware-standard
resources:
requests:
storage: 1Gi
之后,你可以看到根据 Pod 设置的策略在区域中配置卷:
$ kubectl get pv -o=jsonpath='{range .items[*]}{.spec.claimRef.name}{"\t"}{.metadata.labels.failure\-domain\.beta\.kubernetes\.io/zone}{"\n"}{end}'
www-web-0 us-central1-f
logs-web-0 us-central1-f
www-web-1 us-central1-a
logs-web-1 us-central1-a
我怎样才能了解更多?
有关拓扑感知动态供应功能的官方文档可在此处获取: https://kubernetes.io/docs/concepts/storage/storage-classes/#volume-binding-mode
有关 CSI 驱动程序的文档,请访问: https://kubernetes-csi.github.io/docs/
下一步是什么?
我们正积极致力于改进此功能以支持:
- 更多卷类型,包括本地卷的动态供应
- 动态容量可附加计数和每个节点的容量限制
我如何参与?
如果你对此功能有反馈意见或有兴趣参与设计和开发,请加入 Kubernetes 存储特别兴趣小组(SIG)。 我们正在快速成长,并始终欢迎新的贡献者。
特别感谢帮助推出此功能的所有贡献者,包括 Cheng Xing (verult)、 Chuqiang Li (lichuqiang)、David Zhu (davidz627)、 Deep Debroy (ddebroy)、Jan Šafránek (jsafrane)、 Jordan Liggitt (liggitt)、Michelle Au (msau42)、 Pengfei Ni (feiskyer)、Saad Ali (saad-ali)、 Tim Hockin (thockin),以及 Yecheng Fu (cofyc)。
Kubernetes v1.12: RuntimeClass 简介
作者: Tim Allclair (Google)
Kubernetes 最初是为了支持在 Linux 主机上运行本机应用程序的 Docker 容器而创建的。 从 Kubernetes 1.3 中的 rkt 开始,更多的运行时间开始涌现, 这导致了容器运行时接口(Container Runtime Interface)(CRI)的开发。 从那时起,备用运行时集合越来越大: 为了加强工作负载隔离,Kata Containers 和 gVisor 等项目被发起, 并且 Kubernetes 对 Windows 的支持正在稳步发展。
由于存在诸多针对不同用例的运行时,集群对混合运行时的需求变得明晰起来。 但是,所有这些不同的容器运行方式都带来了一系列新问题要处理:
- 用户如何知道哪些运行时可用,并为其工作负荷选择运行时?
- 我们如何确保将 Pod 被调度到支持所需运行时的节点上?
- 哪些运行时支持哪些功能,以及我们如何向用户显示不兼容性?
- 我们如何考虑运行时的各种资源开销?
RuntimeClass 旨在解决这些问题。
Kubernetes 1.12 中的 RuntimeClass
最近,RuntimeClass 在 Kubernetes 1.12 中作为 alpha 功能引入。 最初的实现侧重于提供运行时选择 API,并为解决其他未解决的问题铺平道路。
RuntimeClass 资源代表 Kubernetes 集群中支持的容器运行时。 集群制备组件安装、配置和定义支持 RuntimeClass 的具体运行时。 在 RuntimeClassSpec 的当前形式中,只有一个字段,即 RuntimeHandler。 RuntimeHandler 由在节点上运行的 CRI 实现解释,并映射到实际的运行时配置。 同时,PodSpec 被扩展添加了一个新字段 RuntimeClassName,命名应该用于运行 Pod 的 RuntimeClass。
为什么 RuntimeClass 是 Pod 级别的概念? Kubernetes 资源模型期望 Pod 中的容器之间可以共享某些资源。 如果 Pod 由具有不同资源模型的不同容器组成,支持必要水平的资源共享变得非常具有挑战性。 例如,要跨 VM 边界支持本地回路(localhost)接口非常困难,但这是 Pod 中两个容器之间通信的通用模型。
下一步是什么?
RuntimeClass 资源是将运行时属性显示到控制平面的重要基础。 例如,要对具有支持不同运行时间的异构节点的集群实施调度程序支持,我们可以在 RuntimeClass 定义中添加 NodeAffinity 条件。 另一个需要解决的领域是管理可变资源需求以运行不同运行时的 Pod。 Pod Overhead 提案是一项较早的尝试,与 RuntimeClass 设计非常吻合,并且可能会进一步推广。
人们还提出了许多其他 RuntimeClass 扩展,随着功能的不断发展和成熟,我们会重新讨论这些提议。 正在考虑的其他扩展包括:
- 提供运行时支持的可选功能,并更好地查看由不兼容功能导致的错误。
- 自动运行时或功能发现,支持无需手动配置的调度决策。
- 标准化或一致的 RuntimeClass 名称,用于定义一组具有相同名称的 RuntimeClass 的集群应支持的属性。
- 动态注册附加的运行时,因此用户可以在不停机的情况下在现有集群上安装新的运行时。
- 根据 Pod 的要求“匹配” RuntimeClass。 例如,指定运行时属性并使系统与适当的 RuntimeClass 匹配,而不是通过名称显式分配 RuntimeClass。
至少要到 2019 年,RuntimeClass 才会得到积极的开发,我们很高兴看到从 Kubernetes 1.12 中的 RuntimeClass alpha 开始,此功能得以形成。
学到更多
- 试试吧!作为 Alpha 功能,还有一些其他设置步骤可以使用 RuntimeClass。 有关如何使其运行,请参考 RuntimeClass 文档。
- 查看 RuntimeClass Kubernetes 增强建议以获取更多细节设计细节。
- 沙盒隔离级别决策记录了最初使 RuntimeClass 成为 Pod 级别选项的思考过程。
- 加入讨论,并通过 SIG-Node 社区帮助塑造 RuntimeClass 的未来。
KubeDirector:在 Kubernetes 上运行复杂状态应用程序的简单方法
作者:Thomas Phelan(BlueData)
KubeDirector 是一个开源项目,旨在简化在 Kubernetes 上运行复杂的有状态扩展应用程序集群。KubeDirector 使用自定义资源定义(CRD) 框架构建,并利用了本地 Kubernetes API 扩展和设计哲学。这支持与 Kubernetes 用户/资源 管理以及现有客户端和工具的透明集成。
我们最近介绍了 KubeDirector 项目,作为我们称为 BlueK8s 的更广泛的 Kubernetes 开源项目的一部分。我很高兴地宣布 KubeDirector 的 pre-alpha 代码现在已经可用。在这篇博客文章中,我将展示它是如何工作的。
KubeDirector 提供以下功能:
- 无需修改代码即可在 Kubernetes 上运行非云原生有状态应用程序。换句话说,不需要分解这些现有的应用程序来适应微服务设计模式。
- 本机支持保存特定于应用程序的配置和状态。
- 与应用程序无关的部署模式,最大限度地减少将新的有状态应用程序装载到 Kubernetes 的时间。
KubeDirector 使熟悉数据密集型分布式应用程序(如 Hadoop、Spark、Cassandra、TensorFlow、Caffe2 等)的数据科学家能够在 Kubernetes 上运行这些应用程序 -- 只需极少的学习曲线,无需编写 GO 代码。由 KubeDirector 控制的应用程序由一些基本元数据和相关的配置工件包定义。应用程序元数据称为 KubeDirectorApp 资源。
要了解 KubeDirector 的组件,请使用类似于以下的命令在 GitHub 上克隆存储库:
git clone http://<userid>@github.com/bluek8s/kubedirector.
Spark 2.2.1 应用程序的 KubeDirectorApp 定义位于文件 kubedirector/deploy/example_catalog/cr-app-spark221e2.json 中。
~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json
{
"apiVersion": "kubedirector.bluedata.io/v1alpha1",
"kind": "KubeDirectorApp",
"metadata": {
"name" : "spark221e2"
},
"spec" : {
"systemctlMounts": true,
"config": {
"node_services": [
{
"service_ids": [
"ssh",
"spark",
"spark_master",
"spark_worker"
],
…
应用程序集群的配置称为 KubeDirectorCluster 资源。示例 Spark 2.2.1 集群的 KubeDirectorCluster 定义位于文件
kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml 中。
~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml
apiVersion: "kubedirector.bluedata.io/v1alpha1"
kind: "KubeDirectorCluster"
metadata:
name: "spark221e2"
spec:
app: spark221e2
roles:
- name: controller
replicas: 1
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: worker
replicas: 2
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: jupyter
…
使用 KubeDirector 在 Kubernetes 上运行 Spark
使用 KubeDirector,可以轻松在 Kubernetes 上运行 Spark 集群。
首先,使用命令 kubectl version 验证 Kubernetes(版本 1.9 或更高)是否正在运行
~> kubectl version
Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
使用以下命令部署 KubeDirector 服务和示例 KubeDirectorApp 资源定义:
cd kubedirector
make deploy
这些将启动 KubeDirector pod:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-qd9hb 1/1 Running 0 1m
kubectl get KubeDirectorApp 列出中已安装的 KubeDirector 应用程序
~> kubectl get KubeDirectorApp
NAME AGE
cassandra311 30m
spark211up 30m
spark221e2 30m
现在,您可以使用示例 KubeDirectorCluster 文件和 kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yaml 命令
启动 Spark 2.2.1 集群。验证 Spark 集群已经启动:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-djdwl 1/1 Running 0 19m
spark221e2-controller-zbg4d-0 1/1 Running 0 23m
spark221e2-jupyter-2km7q-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-1 1/1 Running 0 23m
现在运行的服务包括 Spark 服务:
~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20s
将浏览器指向端口 31533 连接到 Spark 主节点 UI:
就是这样! 事实上,在上面的例子中,我们还部署了一个 Jupyter notebook 和 Spark 集群。
要启动另一个应用程序(例如 Cassandra),只需指定另一个 KubeDirectorApp 文件:
kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yaml
查看正在运行的 Cassandra 集群:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
cassandra311-seed-v24r6-0 1/1 Running 0 1m
cassandra311-seed-v24r6-1 1/1 Running 0 1m
cassandra311-worker-rqrhl-0 1/1 Running 0 1m
cassandra311-worker-rqrhl-1 1/1 Running 0 1m
kubedirector-58cf59869-djdwl 1/1 Running 0 1d
spark221e2-controller-tq8d6-0 1/1 Running 0 22m
spark221e2-jupyter-6989v-0 1/1 Running 0 22m
spark221e2-worker-d9892-0 1/1 Running 0 22m
spark221e2-worker-d9892-1 1/1 Running 0 22m
现在,您有一个 Spark 集群(带有 Jupyter notebook )和一个运行在 Kubernetes 上的 Cassandra 集群。
使用 kubectl get service 查看服务集。
~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m
svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m
svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m
svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m
svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24m
参与其中
KubeDirector 是一个完全开放源码的 Apache v2 授权项目 – 在我们称为 BlueK8s 的更广泛的计划中,它是多个开放源码项目中的第一个。 KubeDirector 的 pre-alpha 代码刚刚发布,我们希望您加入到不断增长的开发人员、贡献者和使用者社区。 在 Twitter 上关注 @BlueK8s,并通过以下渠道参与:
在 Kubernetes 上对 gRPC 服务器进行健康检查
作者: Ahmet Alp Balkan (Google)
更新(2021 年 12 月): “Kubernetes 从 v1.23 开始具有内置 gRPC 健康探测。 了解更多信息,请参阅配置存活探针、就绪探针和启动探针。 本文最初是为有关实现相同任务的外部工具所写。”
gRPC 将成为本地云微服务间进行通信的通用语言。如果您现在将 gRPC 应用程序部署到 Kubernetes,您可能会想要了解配置健康检查的最佳方法。在本文中,我们将介绍 grpc-health-probe,这是 Kubernetes 原生的健康检查 gRPC 应用程序的方法。
如果您不熟悉,Kubernetes的 健康检查(存活探针和就绪探针)可以使您的应用程序在睡眠时保持可用状态。当检测到没有回应的 Pod 时,会将其标记为不健康,并使这些 Pod 重新启动或重新安排。
Kubernetes 原本 不支持 gRPC 健康检查。gRPC 的开发人员在 Kubernetes 中部署时可以采用以下三种方法:
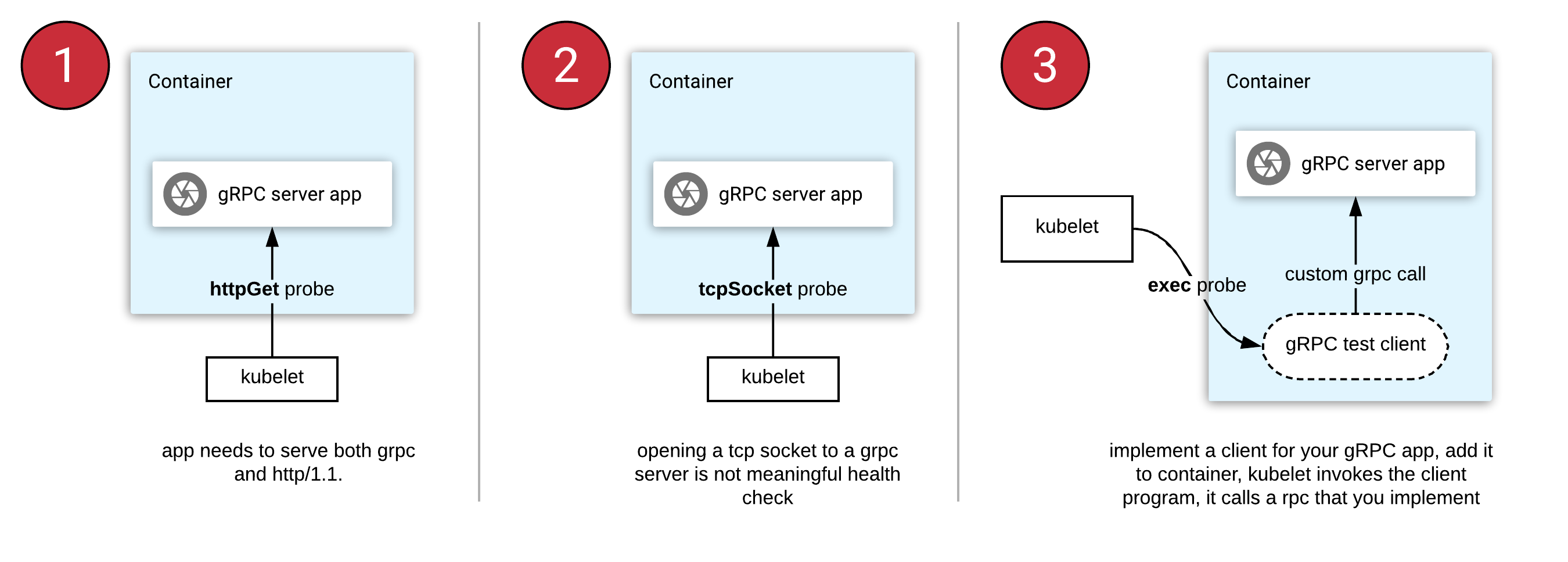
- httpGet prob: 不能与 gRPC 一起使用。您需要重构您的应用程序,必须同时支持 gRPC 和 HTTP/1.1 协议(在不同的端口号上)。
- tcpSocket probe: 打开 gRPC 服务器的 Socket 是没有意义的,因为它无法读取响应主体。
- exec probe: 将定期调用容器生态系统中的程序。对于 gRPC,这意味着您要自己实现健康 RPC,然后使用容器编写并交付客户端工具。
我们可以做得更好吗?这是肯定的。
介绍 “grpc-health-probe”
为了使上述 "exec probe" 方法标准化,我们需要:
- 可以在任何 gRPC 服务器中轻松实现的 标准 健康检查 "协议" 。
- 一种 标准 健康检查 "工具" ,可以轻松查询健康协议。
幸运的是,gRPC 具有 标准的健康检查协议。可以用任何语言轻松调用它。几乎所有实现 gRPC 的语言都附带了生成的代码和用于设置健康状态的实用程序。
如果您在 gRPC 应用程序中 实现 此健康检查协议,那么可以使用标准或通用工具调用 Check() 方法来确定服务器状态。
接下来您需要的是 "标准工具" grpc-health-probe。

使用此工具,您可以在所有 gRPC 应用程序中使用相同的健康检查配置。这种方法有以下要求:
- 用您喜欢的语言找到 gRPC 的 "健康" 模块并开始使用它(例如 Go 库)。
- 将二进制文件 grpc_health_probe 送到容器中。
- 配置 Kubernetes 的 "exec" 检查模块来调用容器中的 "grpc_health_probe" 工具。
在这种情况下,执行 "grpc_health_probe" 将通过 localhost 调用您的 gRPC 服务器,因为它们位于同一个容器中。
下一步工作
grpc-health-probe 项目仍处于初期阶段,需要您的反馈。它支持多种功能,例如与 TLS 服务器通信和配置延时连接/RPC。
如果您最近要在 Kubernetes 上运行 gRPC 服务器,请尝试使用 gRPC Health Protocol,并在您的 Deployment 中尝试 grpc-health-probe,然后 进行反馈。
更多内容
使用 CSI 和 Kubernetes 实现卷的动态扩容
作者:Orain Xiong(联合创始人, WoquTech)
Kubernetes 本身有一个非常强大的存储子系统,涵盖了相当广泛的用例。而当我们计划使用 Kubernetes 构建产品级关系型数据库平台时,我们面临一个巨大的挑战:提供存储。本文介绍了如何扩展最新的 Container Storage Interface 0.2.0 和与 Kubernetes 集成,并演示了卷动态扩容的基本方面。
介绍
当我们专注于客户时,尤其是在金融领域,采用容器编排技术的情况大大增加。
他们期待着能用开源解决方案重新设计已经存在的整体应用程序,这些应用程序已经在虚拟化基础架构或裸机上运行了几年。
考虑到可扩展性和技术成熟程度,Kubernetes 和 Docker 排在我们选择列表的首位。但是将整体应用程序迁移到类似于 Kubernetes 之类的分布式容器编排平台上很具有挑战性,其中关系数据库对于迁移来说至关重要。
关于关系数据库,我们应该注意存储。Kubernetes 本身内部有一个非常强大的存储子系统。它非常有用,涵盖了相当广泛的用例。当我们计划在生产环境中使用 Kubernetes 运行关系型数据库时,我们面临一个巨大挑战:提供存储。目前,仍有一些基本功能尚未实现。特别是,卷的动态扩容。这听起来很无聊,但在除创建,删除,安装和卸载之类的操作外,它是非常必要的。
目前,扩展卷仅适用于这些存储供应商:
- gcePersistentDisk
- awsElasticBlockStore
- OpenStack Cinder
- glusterfs
- rbd
为了启用此功能,我们应该将特性开关 ExpandPersistentVolumes 设置为 true 并打开 PersistentVolumeClaimResize 准入插件。 一旦启用了 PersistentVolumeClaimResize,则其对应的 allowVolumeExpansion 字段设置为 true 的存储类将允许调整大小。
不幸的是,即使基础存储提供者具有此功能,也无法通过容器存储接口(CSI)和 Kubernetes 动态扩展卷。
本文将给出 CSI 的简化视图,然后逐步介绍如何在现有 CSI 和 Kubernetes 上引入新的扩展卷功能。最后,本文将演示如何动态扩展卷容量。
容器存储接口(CSI)
为了更好地了解我们将要做什么,我们首先需要知道什么是容器存储接口。当前,Kubernetes 中已经存在的存储子系统仍然存在一些问题。 存储驱动程序代码在 Kubernetes 核心存储库中维护,这很难测试。 但是除此之外,Kubernetes 还需要授予存储供应商许可,以将代码签入 Kubernetes 核心存储库。 理想情况下,这些应在外部实施。
CSI 旨在定义行业标准,该标准将使支持 CSI 的存储提供商能够在支持 CSI 的容器编排系统中使用。
该图描述了一种与 CSI 集成的高级 Kubernetes 原型:
- 引入了三个新的外部组件以解耦 Kubernetes 和存储提供程序逻辑
- 蓝色箭头表示针对 API 服务器进行调用的常规方法
- 红色箭头显示 gRPC 以针对 Volume Driver 进行调用
更多详细信息,请访问: https://github.com/container-storage-interface/spec/blob/master/spec.md
扩展 CSI 和 Kubernetes
为了实现在 Kubernetes 上扩展卷的功能,我们应该扩展几个组件,包括 CSI 规范,“in-tree” 卷插件,external-provisioner 和 external-attacher。
扩展CSI规范
最新的 CSI 0.2.0 仍未定义扩展卷的功能。应该引入新的3个 RPC,包括 RequiresFSResize, ControllerResizeVolume 和 NodeResizeVolume。
service Controller {
rpc CreateVolume (CreateVolumeRequest)
returns (CreateVolumeResponse) {}
……
rpc RequiresFSResize (RequiresFSResizeRequest)
returns (RequiresFSResizeResponse) {}
rpc ControllerResizeVolume (ControllerResizeVolumeRequest)
returns (ControllerResizeVolumeResponse) {}
}
service Node {
rpc NodeStageVolume (NodeStageVolumeRequest)
returns (NodeStageVolumeResponse) {}
……
rpc NodeResizeVolume (NodeResizeVolumeRequest)
returns (NodeResizeVolumeResponse) {}
}
扩展 “In-Tree” 卷插件
除了扩展的 CSI 规范之外,Kubernetes 中的 csiPlugin 接口还应该实现 expandablePlugin。csiPlugin 接口将扩展代表 ExpanderController 的 PersistentVolumeClaim。
type ExpandableVolumePlugin interface {
VolumePlugin
ExpandVolumeDevice(spec Spec, newSize resource.Quantity, oldSize resource.Quantity) (resource.Quantity, error)
RequiresFSResize() bool
}
实现卷驱动程序
最后,为了抽象化实现的复杂性,我们应该将单独的存储提供程序管理逻辑硬编码为以下功能,这些功能在 CSI 规范中已明确定义:
- CreateVolume
- DeleteVolume
- ControllerPublishVolume
- ControllerUnpublishVolume
- ValidateVolumeCapabilities
- ListVolumes
- GetCapacity
- ControllerGetCapabilities
- RequiresFSResize
- ControllerResizeVolume
展示
让我们以具体的用户案例来演示此功能。
- 为 CSI 存储供应商创建存储类
allowVolumeExpansion: true
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-qcfs
parameters:
csiProvisionerSecretName: orain-test
csiProvisionerSecretNamespace: default
provisioner: csi-qcfsplugin
reclaimPolicy: Delete
volumeBindingMode: Immediate
在 Kubernetes 集群上部署包括存储供应商
csi-qcfsplugin在内的 CSI 卷驱动创建 PVC
qcfs-pvc,它将由存储类csi-qcfs动态配置
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: qcfs-pvc
namespace: default
....
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 300Gi
storageClassName: csi-qcfs
- 创建 MySQL 5.7 实例以使用 PVC
qcfs-pvc - 为了反映完全相同的生产级别方案,实际上有两种不同类型的工作负载,包括: * 批量插入使 MySQL 消耗更多的文件系统容量 * 浪涌查询请求
- 通过编辑 pvc
qcfs-pvc配置动态扩展卷容量
Prometheus 和 Grafana 的集成使我们可以可视化相应的关键指标。
我们注意到中间的读数显示在批量插入期间 MySQL 数据文件的大小缓慢增加。 同时,底部读数显示文件系统在大约20分钟内扩展了两次,从 300 GiB 扩展到 400 GiB,然后扩展到 500 GiB。 同时,上半部分显示,扩展卷的整个过程立即完成,几乎不会影响 MySQL QPS。
结论
不管运行什么基础结构应用程序,数据库始终是关键资源。拥有更高级的存储子系统以完全支持数据库需求至关重要。这将有助于推动云原生技术的更广泛采用。
使用 Kubernetes 调整 PersistentVolume 的大小
作者: Hemant Kumar (Red Hat)
编者注:这篇博客是深度文章系列的一部分,这个系列介绍了 Kubernetes 1.11 中的新增特性
在 Kubernetes v1.11 中,持久化卷扩展功能升级为 Beta。
该功能允许用户通过编辑 PersistentVolumeClaim(PVC)对象,轻松调整已存在数据卷的大小。
用户不再需要手动与存储后端交互,或者删除再重建 PV 和 PVC 对象来增加卷的大小。缩减持久化卷暂不支持。
卷扩展是在 v1.8 版本中作为 Alpha 功能引入的,
在 v1.11 之前的版本都需要开启特性门控 ExpandPersistentVolumes 以及准入控制器 PersistentVolumeClaimResize(防止扩展底层存储供应商不支持调整大小的 PVC)。
在 Kubernetes v1.11+ 中,特性门控和准入控制器都是默认启用的。
虽然该功能默认是启用的,但集群管理员必须选择允许用户调整数据卷的大小。
Kubernetes v1.11 为以下树内卷插件提供了卷扩展支持:
AWS-EBS、GCE-PD、Azure Disk、Azure File、Glusterfs、Cinder、Portworx 和 Ceph RBD。
一旦管理员确定底层供应商支持卷扩展,
就可以通过在 StorageClass 对象中设置 allowVolumeExpansion 字段为 true,让用户可以使用该功能。
只有由这个 StorageClass 创建的 PVC 才能触发卷扩展。
~> cat standard.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
parameters:
type: pd-standard
provisioner: kubernetes.io/gce-pd
allowVolumeExpansion: true
reclaimPolicy: Delete
从这个 StorageClass 创建的任何 PVC 都可以被编辑(如下图所示)以请求更多的空间。
Kubernetes 会将存储字段的变化解释为对更多空间的请求,并触发卷大小的自动调整。

文件系统扩展
如 GCE-PD、AWS-EBS、Azure Disk、Cinder 和 Ceph RBD 这类的块存储卷类型, 通常需要在扩展卷的额外空间被 Pod 使用之前进行文件系统扩展。 Kubernetes 会在引用数据卷的 Pod 重新启动时自动处理这个问题。
网络附加文件系统(如 Glusterfs 和 Azure File)可以被扩展,而不需要重新启动引用的 Pod, 因为这些系统不需要特殊的文件系统扩展。
文件系统扩展必须通过终止使用该卷的 Pod 来触发。更具体地说:
- 编辑 PVC 以请求更多的空间。
- 一旦底层卷被存储提供商扩展后, PersistentVolume 对象将反映更新的大小,PVC 会有
FileSystemResizePending状态。
你可以通过运行 kubectl get pvc <pvc_name> -o yaml 来验证这一点。
~> kubectl get pvc myclaim -o yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
namespace: default
uid: 02d4aa83-83cd-11e8-909d-42010af00004
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 14Gi
storageClassName: standard
volumeName: pvc-xxx
status:
capacity:
storage: 9G
conditions:
- lastProbeTime: null
lastTransitionTime: 2018-07-11T14:51:10Z
message: Waiting for user to (re-)start a pod to finish file system resize of
volume on node.
status: "True"
type: FileSystemResizePending
phase: Bound
- 一旦 PVC 具有
FileSystemResizePending状态 ,就可以重启使用该 PVC 的 Pod 以完成节点上的文件系统大小调整。 重新启动可以通过删除并重新创建 Pod,或者通过 Deployment 缩容后再扩容来实现。 - 一旦文件系统的大小调整完成,PVC 将自动更新以展现新的大小。
在扩展文件系统时遇到的任何错误都应作为 Pod 的事件而存在。
在线文件系统扩展
Kubernetes v1.11 里还引入了一个名为在线文件系统扩展的 Alpha 功能。
该功能可以让一个正在被 Pod 使用的卷进行文件系统扩展。
因为这个功能是 Alpha 阶段,所以它需要启用特性门控 ExpandInUsePersistentVolumes。
树内卷插件 GCE-PD、AWS-EBS、Cinder 和 Ceph RBD 都支持该功能。
当这个功能被启用时,引用调整后的卷的 Pod 不需要被重新启动。
相反,在使用中文件系统将作为卷扩展的一部分自动调整大小。
文件系统的扩展是在一个 Pod 引用调整后的卷时才发生的,所以如果没有引用卷的 Pod 在运行,文件系统的扩展就不会发生。
更多信息
在这里查看有关这一特性的其他文档: https://kubernetes.io/zh-cn/docs/concepts/storage/persistent-volumes/
动态 Kubelet 配置
作者: Michael Taufen (Google)
编者注:在 1.22 版本弃用后,该功能已在 1.24 版本中删除。
编者注:这篇文章是一系列深度文章 的一部分,这个系列介绍了 Kubernetes 1.11 中的新增功能
为什么要进行动态 Kubelet 配置?
Kubernetes 提供了以 API 为中心的工具,可显着改善用于管理应用程序和基础架构的工作流程。 但是,在大多数的 Kubernetes 安装中,kubelet 在每个主机上作为本机进程运行,因此 未被标准 Kubernetes API 覆盖。
过去,这意味着集群管理员和服务提供商无法依靠 Kubernetes API 在活动集群中重新配置 Kubelets。 实际上,这要求操作员要 SSH 登录到计算机以执行手动重新配置,要么使用第三方配置管理自动化工具, 或创建已经安装了所需配置的新 VM,然后将工作迁移到新计算机上。 这些方法是特定于环境的,并且可能很耗时费力。
动态 Kubelet 配置使集群管理员和服务提供商能够通过 Kubernetes API 在活动集群中重新配置 Kubelet。
什么是动态 Kubelet 配置?
Kubernetes v1.10 使得可以通过 Beta 版本的配置文件 API 配置 kubelet。 Kubernetes 已经提供了用于在 API 服务器中存储任意文件数据的 ConfigMap 抽象。
动态 Kubelet 配置扩展了 Node 对象,以便 Node 可以引用包含相同类型配置文件的 ConfigMap。 当节点更新为引用新的 ConfigMap 时,关联的 Kubelet 将尝试使用新的配置。
它是如何工作的?
动态 Kubelet 配置提供以下核心功能:
- Kubelet 尝试使用动态分配的配置。
- Kubelet 将其配置已检查点的形式保存到本地磁盘,无需 API 服务器访问即可重新启动。
- Kubelet 在 Node 状态中报告已指定的、活跃的和最近已知良好的配置源。
- 当动态分配了无效的配置时,Kubelet 会自动退回到最后一次正确的配置,并在 Node 状态中报告错误。
要使用动态 Kubelet 配置功能,集群管理员或服务提供商将首先发布包含所需配置的 ConfigMap, 然后设置每个 Node.Spec.ConfigSource.ConfigMap 引用以指向新的 ConfigMap。 运营商可以以他们喜欢的速率更新这些参考,从而使他们能够执行新配置的受控部署。
每个 Kubelet 都会监视其关联的 Node 对象的更改。 更新 Node.Spec.ConfigSource.ConfigMap 引用后, Kubelet 将通过将其包含的文件通过检查点机制写入本地磁盘保存新的 ConfigMap。 然后,Kubelet 将退出,而操作系统级进程管理器将重新启动它。 请注意,如果未设置 Node.Spec.ConfigSource.ConfigMap 引用, 则 Kubelet 将使用其正在运行的计算机本地的一组标志和配置文件。
重新启动后,Kubelet 将尝试使用来自新检查点的配置。 如果新配置通过了 Kubelet 的内部验证,则 Kubelet 将更新 Node.Status.Config 用以反映它正在使用新配置。 如果新配置无效,则 Kubelet 将退回到其最后一个正确的配置,并在 Node.Status.Config 中报告错误。
请注意,默认的最后一次正确配置是 Kubelet 命令行标志与 Kubelet 的本地配置文件的组合。 与配置文件重叠的命令行标志始终优先于本地配置文件和动态配置,以实现向后兼容。
有关单个节点的配置更新的高级概述,请参见下图:
我如何了解更多?
请参阅/docs/tasks/administer-cluster/reconfigure-kubelet/上的官方教程, 其中包含有关用户工作流,某配置如何成为“最新的正确的”配置,Kubelet 如何对配置执行“检查点”操作等, 更多详细信息,以及可能的故障模式。
用于 Kubernetes 集群 DNS 的 CoreDNS GA 正式发布
作者:John Belamaric (Infoblox)
**编者注:这篇文章是 系列深度文章 中的一篇,介绍了 Kubernetes 1.11 新增的功能
介绍
在 Kubernetes 1.11 中,CoreDNS 已经达到基于 DNS 服务发现的 General Availability (GA),可以替代 kube-dns 插件。这意味着 CoreDNS 会作为即将发布的安装工具的选项之一上线。实际上,从 Kubernetes 1.11 开始,kubeadm 团队选择将它设为默认选项。
很久以来, kube-dns 集群插件一直是 Kubernetes 的一部分,用来实现基于 DNS 的服务发现。 通常,此插件运行平稳,但对于实现的可靠性、灵活性和安全性仍存在一些疑虑。
CoreDNS 是通用的、权威的 DNS 服务器,提供与 Kubernetes 向后兼容但可扩展的集成。它解决了 kube-dns 遇到的问题,并提供了许多独特的功能,可以解决各种用例。
在本文中,您将了解 kube-dns 和 CoreDNS 的实现有何差异,以及 CoreDNS 提供的一些非常有用的扩展。
实现差异
在 kube-dns 中,一个 Pod 中使用多个 容器:kubedns、dnsmasq、和 sidecar。kubedns 容器监视 Kubernetes API 并根据 Kubernetes DNS 规范 提供 DNS 记录,dnsmasq 提供缓存和存根域支持,sidecar 提供指标和健康检查。
随着时间的推移,此设置会导致一些问题。一方面,以往 dnsmasq 中的安全漏洞需要通过发布 Kubernetes 的安全补丁来解决。但是,由于 dnsmasq 处理存根域,而 kubedns 处理外部服务,因此您不能在外部服务中使用存根域,导致这个功能具有局限性(请参阅 dns#131)。
在 CoreDNS 中,所有这些功能都是在一个容器中完成的,该容器运行用 Go 编写的进程。所启用的不同插件可复制(并增强)在 kube-dns 中存在的功能。
配置 CoreDNS
在 kube-dns 中,您可以 修改 ConfigMap 来更改服务发现的行为。用户可以添加诸如为存根域提供服务、修改上游名称服务器以及启用联盟之类的功能。
在 CoreDNS 中,您可以类似地修改 CoreDNS Corefile 的 ConfigMap,以更改服务发现的工作方式。这种 Corefile 配置提供了比 kube-dns 中更多的选项,因为它是 CoreDNS 用于配置所有功能的主要配置文件,即使与 Kubernetes 不相关的功能也可以操作。
使用 kubeadm 将 kube-dns 升级到 CoreDNS 时,现有的 ConfigMap 将被用来为您生成自定义的 Corefile,包括存根域、联盟和上游名称服务器的所有配置。更多详细信息,请参见
使用 CoreDNS 进行服务发现。
错误修复和增强
在 CoreDNS 中解决了 kube-dn 的多个未解决问题,无论是默认配置还是某些自定义配置。
dns#55 - kube-dns 的自定义 DNS 条目 可以使用 kubernetes 插件 中的 "fallthrough" 机制,使用 rewrite 插件,或者分区使用不同的插件,例如 file 插件。
dns#116 - 对具有相同主机名的、提供无头服务服务的 Pod 仅设置了一个 A 记录。无需任何其他配置即可解决此问题。
dns#131 - externalName 未使用 stubDomains 设置。无需任何其他配置即可解决此问题。
dns#167 - 允许 skyDNS 为 A/AAAA 记录提供轮换。可以使用 负载均衡插件 配置等效功能。
dns#190 - kube-dns 无法以非 root 用户身份运行。今天,通过使用 non-default 镜像解决了此问题,但是在将来的版本中,它将成为默认的 CoreDNS 行为。
dns#232 - 在 dns srv 记录中修复 pod hostname 为 podname 是通过下面提到的 "endpoint_pod_names" 功能进行支持的增强功能。
指标
CoreDNS 默认配置的功能性行为与 kube-dns 相同。但是,你需要了解的差别之一是二者发布的指标是不同的。在 kube-dns 中,您将分别获得 dnsmasq 和 kubedns(skydns)的度量值。在 CoreDNS 中,存在一组完全不同的指标,因为它们在同一个进程中。您可以在 CoreDNS Prometheus 插件 页面上找到有关这些指标的更多详细信息。
一些特殊功能
标准的 CoreDNS Kubernetes 配置旨在与以前的 kube-dns 在行为上向后兼容。但是,通过进行一些配置更改,CoreDNS 允许您修改 DNS 服务发现在集群中的工作方式。这些功能中的许多功能仍要符合 Kubernetes DNS规范;它们在增强了功能的同时保持向后兼容。由于 CoreDNS 并非 仅 用于 Kubernetes,而是通用的 DNS 服务器,因此您可以做很多超出该规范的事情。
Pod 验证模式
在 kube-dns 中,Pod 名称记录是 "伪造的"。也就是说,任何 "a-b-c-d.namespace.pod.cluster.local" 查询都将返回 IP 地址 "a.b.c.d"。在某些情况下,这可能会削弱 TLS 提供的身份确认。因此,CoreDNS 提供了一种 "Pod 验证" 的模式,该模式仅在指定名称空间中存在具有该 IP 地址的 Pod 时才返回 IP 地址。
基于 Pod 名称的端点名称
在 kube-dns 中,使用无头服务时,可以使用 SRV 请求获取该服务的所有端点的列表:
dnstools# host -t srv headless
headless.default.svc.cluster.local has SRV record 10 33 0 6234396237313665.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 10 33 0 6662363165353239.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 10 33 0 6338633437303230.headless.default.svc.cluster.local.
dnstools#
但是,端点 DNS 名称(出于实际目的)是随机的。在 CoreDNS 中,默认情况下,您所获得的端点 DNS 名称是基于端点 IP 地址生成的:
dnstools# host -t srv headless
headless.default.svc.cluster.local has SRV record 0 25 443 172-17-0-14.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 172-17-0-18.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 172-17-0-4.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 172-17-0-9.headless.default.svc.cluster.local.
对于某些应用程序,你会希望在这里使用 Pod 名称,而不是 Pod IP 地址(例如,参见 kubernetes#47992 和 coredns#1190)。要在 CoreDNS 中启用此功能,请在 Corefile 中指定 "endpoint_pod_names" 选项,结果如下:
dnstools# host -t srv headless
headless.default.svc.cluster.local has SRV record 0 25 443 headless-65bb4c479f-qv84p.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 headless-65bb4c479f-zc8lx.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 headless-65bb4c479f-q7lf2.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 headless-65bb4c479f-566rt.headless.default.svc.cluster.local.
自动路径
CoreDNS 还具有一项特殊功能,可以改善 DNS 中外部名称请求的延迟。在 Kubernetes 中,Pod 的 DNS 搜索路径指定了一长串后缀。这一特点使得你可以针对集群中服务使用短名称 - 例如,上面的 "headless",而不是 "headless.default.svc.cluster.local"。但是,当请求一个外部名称(例如 "infoblox.com")时,客户端会进行几个无效的 DNS 查询,每次都需要从客户端到 kube-dns 往返(实际上是到 dnsmasq,然后到 kubedns),因为 禁用了负缓存)
- infoblox.com.default.svc.cluster.local -> NXDOMAIN
- infoblox.com.svc.cluster.local -> NXDOMAIN
- infoblox.com.cluster.local -> NXDOMAIN
- infoblox.com.your-internal-domain.com -> NXDOMAIN
- infoblox.com -> 返回有效记录
在 CoreDNS 中,可以启用 autopath 的可选功能,该功能使搜索路径在 服务器端 遍历。也就是说,CoreDNS 将基于源 IP 地址判断客户端 Pod 所在的命名空间,并且遍历此搜索列表,直到获得有效答案为止。由于其中的前三个是在 CoreDNS 本身内部解决的,因此它消除了客户端和服务器之间所有的来回通信,从而减少了延迟。
其他一些特定于 Kubernetes 的功能
在 CoreDNS 中,您可以使用标准 DNS 区域传输来导出整个 DNS 记录集。这对于调试服务以及将集群区导入其他 DNS 服务器很有用。
您还可以按名称空间或标签选择器进行过滤。这样,您可以运行特定的 CoreDNS 实例,该实例仅服务与过滤器匹配的记录,从而通过 DNS 公开受限的服务集。
可扩展性
除了上述功能之外,CoreDNS 还可轻松扩展,构建包含您独有的功能的自定义版本的 CoreDNS。例如,这一能力已被用于扩展 CoreDNS 来使用 unbound 插件 进行递归解析、使用 pdsql 插件 直接从数据库提供记录,以及使用 redisc 插件 与多个 CoreDNS 实例共享一个公共的 2 级缓存。
已添加的还有许多其他有趣的扩展,您可以在 CoreDNS 站点的 外部插件 页面上找到这些扩展。Kubernetes 和 Istio 用户真正感兴趣的是 kubernetai 插件,它允许单个 CoreDNS 实例连接到多个 Kubernetes 集群并在所有集群中提供服务发现 。
下一步工作
CoreDNS 是一个独立的项目,许多与 Kubernetes 不直接相关的功能正在开发中。但是,其中许多功能将在 Kubernetes 中具有对应的应用。例如,与策略引擎完成集成后,当请求无头服务时,CoreDNS 能够智能地选择返回哪个端点。这可用于将流量分流到本地 Pod 或响应更快的 Pod。更多的其他功能正在开发中,当然作为一个开源项目,我们欢迎您提出建议并贡献自己的功能特性!
上述特征和差异是几个示例。CoreDNS 还可以做更多的事情。您可以在 CoreDNS 博客 上找到更多信息。
参与 CoreDNS
CoreDNS 是一个 CNCF 孵化项目。
我们在 Slack(和 GitHub)上最活跃:
- Slack: #coredns on https://slack.cncf.io
- GitHub: https://github.com/coredns/coredns
更多资源请浏览:
- Website: https://coredns.io
- Blog: https://blog.coredns.io
- Twitter: @corednsio
- Mailing list/group: coredns-discuss@googlegroups.com
基于 IPVS 的集群内部负载均衡
作者: Jun Du(华为), Haibin Xie(华为), Wei Liang(华为)
注意: 这篇文章出自 系列深度文章 介绍 Kubernetes 1.11 的新特性
介绍
根据 Kubernetes 1.11 发布的博客文章, 我们宣布基于 IPVS 的集群内部服务负载均衡已达到一般可用性。 在这篇博客中,我们将带您深入了解该功能。
什么是 IPVS ?
IPVS (IP Virtual Server)是在 Netfilter 上层构建的,并作为 Linux 内核的一部分,实现传输层负载均衡。
IPVS 集成在 LVS(Linux Virtual Server,Linux 虚拟服务器)中,它在主机上运行,并在物理服务器集群前作为负载均衡器。IPVS 可以将基于 TCP 和 UDP 服务的请求定向到真实服务器,并使真实服务器的服务在单个IP地址上显示为虚拟服务。 因此,IPVS 自然支持 Kubernetes 服务。
为什么为 Kubernetes 选择 IPVS ?
随着 Kubernetes 的使用增长,其资源的可扩展性变得越来越重要。特别是,服务的可扩展性对于运行大型工作负载的开发人员/公司采用 Kubernetes 至关重要。
Kube-proxy 是服务路由的构建块,它依赖于经过强化攻击的 iptables 来实现支持核心的服务类型,如 ClusterIP 和 NodePort。 但是,iptables 难以扩展到成千上万的服务,因为它纯粹是为防火墙而设计的,并且基于内核规则列表。
尽管 Kubernetes 在版本v1.6中已经支持5000个节点,但使用 iptables 的 kube-proxy 实际上是将集群扩展到5000个节点的瓶颈。 一个例子是,在5000节点集群中使用 NodePort 服务,如果我们有2000个服务并且每个服务有10个 pod,这将在每个工作节点上至少产生20000个 iptable 记录,这可能使内核非常繁忙。
另一方面,使用基于 IPVS 的集群内服务负载均衡可以为这种情况提供很多帮助。 IPVS 专门用于负载均衡,并使用更高效的数据结构(哈希表),允许几乎无限的规模扩张。
基于 IPVS 的 Kube-proxy
参数更改
参数: --proxy-mode 除了现有的用户空间和 iptables 模式,IPVS 模式通过--proxy-mode = ipvs 进行配置。 它隐式使用 IPVS NAT 模式进行服务端口映射。
参数: --ipvs-scheduler
添加了一个新的 kube-proxy 参数来指定 IPVS 负载均衡算法,参数为 --ipvs-scheduler。 如果未配置,则默认为 round-robin 算法(rr)。
- rr: round-robin
- lc: least connection
- dh: destination hashing
- sh: source hashing
- sed: shortest expected delay
- nq: never queue
将来,我们可以实现特定于服务的调度程序(可能通过注释),该调度程序具有更高的优先级并覆盖该值。
参数: --cleanup-ipvs 类似于 --cleanup-iptables 参数,如果为 true,则清除在 IPVS 模式下创建的 IPVS 配置和 IPTables 规则。
参数: --ipvs-sync-period 刷新 IPVS 规则的最大间隔时间(例如'5s','1m')。 必须大于0。
参数: --ipvs-min-sync-period 刷新 IPVS 规则的最小间隔时间间隔(例如'5s','1m')。 必须大于0。
参数: --ipvs-exclude-cidrs 清除 IPVS 规则时 IPVS 代理不应触及的 CIDR 的逗号分隔列表,因为 IPVS 代理无法区分 kube-proxy 创建的 IPVS 规则和用户原始规则 IPVS 规则。 如果您在环境中使用 IPVS proxier 和您自己的 IPVS 规则,则应指定此参数,否则将清除原始规则。
设计注意事项
IPVS 服务网络拓扑
创建 ClusterIP 类型服务时,IPVS proxier 将执行以下三项操作:
- 确保节点中存在虚拟接口,默认为 kube-ipvs0
- 将服务 IP 地址绑定到虚拟接口
- 分别为每个服务 IP 地址创建 IPVS 虚拟服务器
这是一个例子:
# kubectl describe svc nginx-service
Name: nginx-service
...
Type: ClusterIP
IP: 10.102.128.4
Port: http 3080/TCP
Endpoints: 10.244.0.235:8080,10.244.1.237:8080
Session Affinity: None
# ip addr
...
73: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 1a:ce:f5:5f:c1:4d brd ff:ff:ff:ff:ff:ff
inet 10.102.128.4/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:3080 rr
-> 10.244.0.235:8080 Masq 1 0 0
-> 10.244.1.237:8080 Masq 1 0 0
请注意,Kubernetes 服务和 IPVS 虚拟服务器之间的关系是“1:N”。 例如,考虑具有多个 IP 地址的 Kubernetes 服务。 外部 IP 类型服务有两个 IP 地址 - 集群IP和外部 IP。 然后,IPVS 代理将创建2个 IPVS 虚拟服务器 - 一个用于集群 IP,另一个用于外部 IP。 Kubernetes 的 endpoint(每个IP +端口对)与 IPVS 虚拟服务器之间的关系是“1:1”。
删除 Kubernetes 服务将触发删除相应的 IPVS 虚拟服务器,IPVS 物理服务器及其绑定到虚拟接口的 IP 地址。
端口映射
IPVS 中有三种代理模式:NAT(masq),IPIP 和 DR。 只有 NAT 模式支持端口映射。 Kube-proxy 利用 NAT 模式进行端口映射。 以下示例显示 IPVS 服务端口3080到Pod端口8080的映射。
TCP 10.102.128.4:3080 rr
-> 10.244.0.235:8080 Masq 1 0 0
-> 10.244.1.237:8080 Masq 1 0
会话关系
IPVS 支持客户端 IP 会话关联(持久连接)。 当服务指定会话关系时,IPVS 代理将在 IPVS 虚拟服务器中设置超时值(默认为180分钟= 10800秒)。 例如:
# kubectl describe svc nginx-service
Name: nginx-service
...
IP: 10.102.128.4
Port: http 3080/TCP
Session Affinity: ClientIP
# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:3080 rr persistent 10800
IPVS 代理中的 Iptables 和 Ipset
IPVS 用于负载均衡,它无法处理 kube-proxy 中的其他问题,例如 包过滤,数据包欺骗,SNAT 等
IPVS proxier 在上述场景中利用 iptables。 具体来说,ipvs proxier 将在以下4种情况下依赖于 iptables:
- kube-proxy 以 --masquerade-all = true 开头
- 在 kube-proxy 启动中指定集群 CIDR
- 支持 Loadbalancer 类型服务
- 支持 NodePort 类型的服务
但是,我们不想创建太多的 iptables 规则。 所以我们采用 ipset 来减少 iptables 规则。 以下是 IPVS proxier 维护的 ipset 集表:
设置名称 成员 用法 KUBE-CLUSTER-IP 所有服务 IP + 端口 masquerade-all=true 或 clusterCIDR 指定的情况下进行伪装 KUBE-LOOP-BACK 所有服务 IP +端口+ IP 解决数据包欺骗问题 KUBE-EXTERNAL-IP 服务外部 IP +端口 将数据包伪装成外部 IP KUBE-LOAD-BALANCER 负载均衡器入口 IP +端口 将数据包伪装成 Load Balancer 类型的服务 KUBE-LOAD-BALANCER-LOCAL 负载均衡器入口 IP +端口 以及 externalTrafficPolicy=local 接受数据包到 Load Balancer externalTrafficPolicy=local KUBE-LOAD-BALANCER-FW 负载均衡器入口 IP +端口 以及 loadBalancerSourceRanges 使用指定的 loadBalancerSourceRanges 丢弃 Load Balancer类型Service的数据包 KUBE-LOAD-BALANCER-SOURCE-CIDR 负载均衡器入口 IP +端口 + 源 CIDR 接受 Load Balancer 类型 Service 的数据包,并指定loadBalancerSourceRanges KUBE-NODE-PORT-TCP NodePort 类型服务 TCP 将数据包伪装成 NodePort(TCP) KUBE-NODE-PORT-LOCAL-TCP NodePort 类型服务 TCP 端口,带有 externalTrafficPolicy=local 接受数据包到 NodePort 服务 使用 externalTrafficPolicy=local KUBE-NODE-PORT-UDP NodePort 类型服务 UDP 端口 将数据包伪装成 NodePort(UDP) KUBE-NODE-PORT-LOCAL-UDP NodePort 类型服务 UDP 端口 使用 externalTrafficPolicy=local 接受数据包到NodePort服务 使用 externalTrafficPolicy=local
通常,对于 IPVS proxier,无论我们有多少 Service/ Pod,iptables 规则的数量都是静态的。
在 IPVS 模式下运行 kube-proxy
目前,本地脚本,GCE 脚本和 kubeadm 支持通过导出环境变量(KUBE_PROXY_MODE=ipvs)或指定标志(--proxy-mode=ipvs)来切换 IPVS 代理模式。 在运行IPVS 代理之前,请确保已安装 IPVS 所需的内核模块。
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack_ipv4
最后,对于 Kubernetes v1.10,“SupportIPVSProxyMode” 默认设置为 “true”。 对于 Kubernetes v1.11 ,该选项已完全删除。 但是,您需要在v1.10之前为Kubernetes 明确启用 --feature-gates = SupportIPVSProxyMode = true。
参与其中
参与 Kubernetes 的最简单方法是加入众多特别兴趣小组 (SIG)中与您的兴趣一致的小组。 你有什么想要向 Kubernetes 社区广播的吗? 在我们的每周社区会议或通过以下渠道分享您的声音。
感谢您的持续反馈和支持。 在Stack Overflow上发布问题(或回答问题)
加入K8sPort的倡导者社区门户网站
在 Twitter 上关注我们 @Kubernetesio获取最新更新
在Slack上与社区聊天
分享您的 Kubernetes 故事
Airflow 在 Kubernetes 中的使用(第一部分):一种不同的操作器
作者: Daniel Imberman (Bloomberg LP)
介绍
作为 Bloomberg 持续致力于开发 Kubernetes 生态系统的一部分, 我们很高兴能够宣布 Kubernetes Airflow Operator 的发布; Apache Airflow的一种机制,一种流行的工作流程编排框架, 使用 Kubernetes API 可以在本机启动任意的 Kubernetes Pod。
什么是 Airflow?
Apache Airflow 是“配置即代码”的 DevOps 理念的一种实现。 Airflow 允许用户使用简单的 Python 对象 DAG(有向无环图)启动多步骤流水线。 你可以在易于阅读的 UI 中定义依赖关系,以编程方式构建复杂的工作流,并监视调度的作业。
为什么在 Kubernetes 上使用 Airflow?
自成立以来,Airflow 的最大优势在于其灵活性。 Airflow 提供广泛的服务集成,包括Spark和HBase,以及各种云提供商的服务。 Airflow 还通过其插件框架提供轻松的可扩展性。 但是,该项目的一个限制是 Airflow 用户仅限于执行时 Airflow 站点上存在的框架和客户端。 单个组织可以拥有各种 Airflow 工作流程,范围从数据科学流到应用程序部署。 用例中的这种差异会在依赖关系管理中产生问题,因为两个团队可能会在其工作流程使用截然不同的库。
为了解决这个问题,我们使 Kubernetes 允许用户启动任意 Kubernetes Pod 和配置。 Airflow 用户现在可以在其运行时环境,资源和机密上拥有全部权限,基本上将 Airflow 转变为“你想要的任何工作”工作流程协调器。
Kubernetes Operator
在进一步讨论之前,我们应该澄清 Airflow 中的 Operator 是一个任务定义。 当用户创建 DAG 时,他们将使用像 “SparkSubmitOperator” 或 “PythonOperator” 这样的 Operator 分别提交/监视 Spark 作业或 Python 函数。 Airflow 附带了 Apache Spark,BigQuery,Hive 和 EMR 等框架的内置运算符。 它还提供了一个插件入口点,允许DevOps工程师开发自己的连接器。
Airflow 用户一直在寻找更易于管理部署和 ETL 流的方法。 在增加监控的同时,任何解耦流程的机会都可以减少未来的停机等问题。 以下是 Airflow Kubernetes Operator 提供的好处:
- 提高部署灵活性: Airflow 的插件 API一直为希望在其 DAG 中测试新功能的工程师提供了重要的福利。 不利的一面是,每当开发人员想要创建一个新的 Operator 时,他们就必须开发一个全新的插件。 现在,任何可以在 Docker 容器中运行的任务都可以通过完全相同的运算符访问,而无需维护额外的 Airflow 代码。
- 配置和依赖的灵活性:
对于在静态 Airflow 工作程序中运行的 Operator,依赖关系管理可能变得非常困难。 如果开发人员想要运行一个需要 SciPy 的任务和另一个需要 NumPy 的任务, 开发人员必须维护所有 Airflow 节点中的依赖关系或将任务卸载到其他计算机(如果外部计算机以未跟踪的方式更改,则可能导致错误)。 自定义 Docker 镜像允许用户确保任务环境,配置和依赖关系完全是幂等的。
- 使用kubernetes Secret以增加安全性: 处理敏感数据是任何开发工程师的核心职责。Airflow 用户总有机会在严格条款的基础上隔离任何API密钥,数据库密码和登录凭据。 使用 Kubernetes 运算符,用户可以利用 Kubernetes Vault 技术存储所有敏感数据。 这意味着 Airflow 工作人员将永远无法访问此信息,并且可以容易地请求仅使用他们需要的密码信息构建 Pod。
架构
Kubernetes Operator 使用 Kubernetes Python客户端生成由 APIServer 处理的请求(1)。 然后,Kubernetes将使用你定义的需求启动你的 Pod(2)。 镜像文件中将加载环境变量,Secret 和依赖项,执行单个命令。 一旦启动作业,Operator 只需要监视跟踪日志的状况(3)。 用户可以选择将日志本地收集到调度程序或当前位于其 Kubernetes 集群中的任何分布式日志记录服务。
使用 Kubernetes Operator
一个基本的例子
以下 DAG 可能是我们可以编写的最简单的示例,以显示 Kubernetes Operator 的工作原理。 这个 DAG 在 Kubernetes 上创建了两个 Pod:一个带有 Python 的 Linux 发行版和一个没有它的基本 Ubuntu 发行版。 Python Pod 将正确运行 Python 请求,而没有 Python 的那个将向用户报告失败。 如果 Operator 正常工作,则应该完成 “passing-task” Pod,而“ falling-task” Pod 则向 Airflow 网络服务器返回失败。
from airflow import DAG
from datetime import datetime, timedelta
from airflow.contrib.operators.kubernetes_pod_operator import KubernetesPodOperator
from airflow.operators.dummy_operator import DummyOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime.utcnow(),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
dag = DAG(
'kubernetes_sample', default_args=default_args, schedule_interval=timedelta(minutes=10))
start = DummyOperator(task_id='run_this_first', dag=dag)
passing = KubernetesPodOperator(namespace='default',
image="Python:3.6",
cmds=["Python","-c"],
arguments=["print('hello world')"],
labels={"foo": "bar"},
name="passing-test",
task_id="passing-task",
get_logs=True,
dag=dag
)
failing = KubernetesPodOperator(namespace='default',
image="ubuntu:1604",
cmds=["Python","-c"],
arguments=["print('hello world')"],
labels={"foo": "bar"},
name="fail",
task_id="failing-task",
get_logs=True,
dag=dag
)
passing.set_upstream(start)
failing.set_upstream(start)
但这与我的工作流程有什么关系?
虽然这个例子只使用基本映像,但 Docker 的神奇之处在于,这个相同的 DAG 可以用于你想要的任何图像/命令配对。 以下是推荐的 CI/CD 管道,用于在 Airflow DAG 上运行生产就绪代码。
1:github 中的 PR
使用Travis或Jenkins运行单元和集成测试,请你的朋友PR你的代码,并合并到主分支以触发自动CI构建。
2:CI/CD 构建 Jenkins - > Docker 镜像
在 Jenkins 构建中生成 Docker 镜像和更新版本。
3:Airflow 启动任务
最后,更新你的 DAG 以反映新版本,你应该准备好了!
production_task = KubernetesPodOperator(namespace='default',
# image="my-production-job:release-1.0.1", <-- old release
image="my-production-job:release-1.0.2",
cmds=["Python","-c"],
arguments=["print('hello world')"],
name="fail",
task_id="failing-task",
get_logs=True,
dag=dag
)
启动测试部署
由于 Kubernetes Operator 尚未发布,我们尚未发布官方 helm 图表或 Operator(但两者目前都在进行中)。 但是,我们在下面列出了基本部署的说明,并且正在积极寻找测试人员来尝试这一新功能。 要试用此系统,请按以下步骤操作:
步骤1:将 kubeconfig 设置为指向 kubernetes 集群
步骤2:克隆 Airflow 仓库:
运行 git clone https://github.com/apache/incubator-airflow.git 来克隆官方 Airflow 仓库。
步骤3:运行
为了运行这个基本 Deployment,我们正在选择我们目前用于 Kubernetes Executor 的集成测试脚本(将在本系列的下一篇文章中对此进行解释)。 要启动此部署,请运行以下三个命令:
sed -ie "s/KubernetesExecutor/LocalExecutor/g" scripts/ci/kubernetes/kube/configmaps.yaml
./scripts/ci/kubernetes/Docker/build.sh
./scripts/ci/kubernetes/kube/deploy.sh
在我们继续之前,让我们讨论这些命令正在做什么:
sed -ie "s/KubernetesExecutor/LocalExecutor/g" scripts/ci/kubernetes/kube/configmaps.yaml
Kubernetes Executor 是另一种 Airflow 功能,允许动态分配任务已解决幂等 Pod 的问题。 我们将其切换到 LocalExecutor 的原因只是一次引入一个功能。 如果你想尝试 Kubernetes Executor,欢迎你跳过此步骤,但我们将在以后的文章中详细介绍。
./scripts/ci/kubernetes/Docker/build.sh
此脚本将对Airflow主分支代码进行打包,以根据Airflow的发行文件构建Docker容器
./scripts/ci/kubernetes/kube/deploy.sh
最后,我们在你的集群上创建完整的Airflow部署。这包括 Airflow 配置,postgres 后端,web 服务器和调度程序以及之间的所有必要服务。 需要注意的一点是,提供的角色绑定是集群管理员,因此如果你没有该集群的权限级别,可以在 scripts/ci/kubernetes/kube/airflow.yaml 中进行修改。
步骤4:登录你的网络服务器
现在你的 Airflow 实例正在运行,让我们来看看 UI! 用户界面位于 Airflow Pod的 8080 端口,因此只需运行即可:
WEB=$(kubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}' | grep "airflow" | head -1)
kubectl port-forward $WEB 8080:8080
现在,Airflow UI 将存在于 http://localhost:8080上。
要登录,只需输入airflow/airflow,你就可以完全访问 Airflow Web UI。
步骤5:上传测试文档
要修改/添加自己的 DAG,可以使用 kubectl cp 将本地文件上传到 Airflow 调度程序的 DAG 文件夹中。
然后,Airflow 将读取新的 DAG 并自动将其上传到其系统。以下命令将任何本地文件上载到正确的目录中:
kubectl cp <local file> <namespace>/<pod>:/root/airflow/dags -c scheduler
步骤6:使用它!
那么我什么时候可以使用它?
虽然此功能仍处于早期阶段,但我们希望在未来几个月内发布该功能以进行广泛发布。
参与其中
此功能只是将 Apache Airflow 集成到 Kubernetes 中的多项主要工作的开始。 Kubernetes Operator 已合并到 Airflow 的 1.10 发布分支(实验模式中的执行模块), 以及完整的 k8s 本地调度程序称为 Kubernetes Executor(即将发布文章)。 这些功能仍处于早期采用者/贡献者可能对这些功能的未来产生巨大影响的阶段。
对于有兴趣加入这些工作的人,我建议按照以下步骤:
- 加入 airflow-dev 邮件列表 dev@airflow.apache.org。
- 在 Apache Airflow JIRA中提出问题
- 周三上午 10点 太平洋标准时间加入我们的 SIG-BigData 会议。
- 在 kubernetes.slack.com 上的 #sig-big-data 找到我们。
特别感谢 Apache Airflow 和 Kubernetes 社区,特别是 Grant Nicholas,Ben Goldberg,Anirudh Ramanathan,Fokko Dreisprong 和 Bolke de Bruin, 感谢你对这些功能的巨大帮助以及我们未来的努力。
Kubernetes 的动态 Ingress
Kubernetes 可以轻松部署由许多微服务组成的应用程序,但这种架构的关键挑战之一是动态地将流量路由到这些服务中的每一个。 一种方法是使用 Ambassador, 一个基于 Envoy Proxy 构建的 Kubernetes 原生开源 API 网关。 Ambassador 专为动态环境而设计,这类环境中的服务可能被频繁添加或删除。
Ambassador 使用 Kubernetes 注解进行配置。 注解用于配置从给定 Kubernetes 服务到特定 URL 的具体映射关系。 每个映射中可以包括多个注解,用于配置路由。 注解的例子有速率限制、协议、跨源请求共享(CORS)、流量影射和路由规则等。
一个简单的 Ambassador 示例
Ambassador 通常作为 Kubernetes Deployment 来安装,也可以作为 Helm Chart 使用。 配置 Ambassador 时,请使用 Ambassador 注解创建 Kubernetes 服务。 下面是一个例子,用来配置 Ambassador,将针对 /httpbin/ 的请求路由到公共的 httpbin.org 服务:
apiVersion: v1
kind: Service
metadata:
name: httpbin
annotations:
getambassador.io/config: |
---
apiVersion: ambassador/v0
kind: Mapping
name: httpbin_mapping
prefix: /httpbin/
service: httpbin.org:80
host_rewrite: httpbin.org
spec:
type: ClusterIP
ports:
- port: 80
例子中创建了一个 Mapping 对象,其 prefix 设置为 /httpbin/,service 名称为 httpbin.org。 其中的 host_rewrite 注解指定 HTTP 的 host 头部字段应设置为 httpbin.org。
Kubeflow
Kubeflow 提供了一种简单的方法,用于在 Kubernetes 上轻松部署机器学习基础设施。 Kubeflow 团队需要一个代理,为 Kubeflow 中所使用的各种服务提供集中化的认证和路由能力;Kubeflow 中许多服务本质上都是生命期很短的。
服务配置
有了 Ambassador,Kubeflow 可以使用分布式模型进行配置。 Ambassador 不使用集中的配置文件,而是允许每个服务通过 Kubernetes 注解在 Ambassador 中配置其路由。 下面是一个简化的配置示例:
---
apiVersion: ambassador/v0
kind: Mapping
name: tfserving-mapping-test-post
prefix: /models/test/
rewrite: /model/test/:predict
method: POST
service: test.kubeflow:8000
示例中,“test” 服务使用 Ambassador 注解来为服务动态配置路由。 所配置的路由仅在 HTTP 方法是 POST 时触发;注解中同时还给出了一条重写规则。
Kubeflow 和 Ambassador
通过 Ambassador,Kubeflow 可以使用 Kubernetes 注解轻松管理路由。
Kubeflow 配置同一个 Ingress 对象,将流量定向到 Ambassador,然后根据需要创建具有 Ambassador 注解的服务,以将流量定向到特定后端。
例如,在部署 TensorFlow 服务时,Kubeflow 会创建 Kubernetes 服务并为其添加注解,
以便用户能够在 https://<ingress主机>/models/<模型名称>/ 处访问到模型本身。
Kubeflow 还可以使用 Envoy Proxy 来进行实际的 L7 路由。
通过 Ambassador,Kubeflow 能够更充分地利用 URL 重写和基于方法的路由等额外的路由配置能力。
如果您对在 Kubeflow 中使用 Ambassador 感兴趣,标准的 Kubeflow 安装会自动安装和配置 Ambassador。
如果您有兴趣将 Ambassador 用作 API 网关或 Kubernetes 的 Ingress 解决方案, 请参阅 Ambassador 入门指南。
Kubernetes 这四年
作者:Joe Beda(Heptio 首席技术官兼创始人)
2014 年 6 月 6 日,我检查了 Kubernetes 公共代码库的第一次 commit 。许多人会认为这是故事开始的地方。这难道不是一切开始的地方吗?但这的确不能把整个过程说清楚。

第一次 commit 涉及的人员众多,自那以后 Kubernetes 的成功归功于更大的开发者阵容。
Kubernetes 建立在过去十年曾经在 Google 的 Borg 集群管理系统中验证过的思路之上。而 Borg 本身也是 Google 和其他公司早期努力的结果。
具体而言,Kubernetes 最初是从 Brendan Burns 的一些原型开始,结合我和 Craig McLuckie 正在进行的工作,以更好地将 Google 内部实践与 Google Cloud 的经验相结合。 Brendan,Craig 和我真的希望人们使用它,所以我们建议将这个原型构建为一个开源项目,将 Borg 的最佳创意带给大家。
在我们所有人同意后,就开始着手构建这个系统了。我们采用了 Brendan 的原型(Java 语言),用 Go 语言重写了它,并且以上述核心思想去构建该系统。到这个时候,团队已经成长为包括 Ville Aikas,Tim Hockin,Brian Grant,Dawn Chen 和 Daniel Smith。一旦我们有了一些工作需求,有人必须承担一些脱敏的工作,以便为公开发布做好准备。这个角色最终由我承担。当时,我不知道这件事情的重要性,我创建了一个新的仓库,把代码搬过来,然后进行了检查。所以在我第一次提交 public commit 之前,就有工作已经启动了。
那时 Kubernetes 的版本只是现在版本的简单雏形。核心概念已经有了,但非常原始。例如,Pods 被称为 Tasks,这在我们推广前一天就被替换。2014年6月10日 Eric Brewe 在第一届 DockerCon 上的演讲中正式发布了 Kubernetes。你可以在此处观看该视频:
但是,无论多么原始,这小小的一步足以激起一个开始强大而且变得更强大的社区的兴趣。在过去的四年里,Kubernetes 已经超出了我们所有人的期望。我们对 Kubernetes 社区的所有人员表示感谢。该项目所取得的成功不仅基于代码和技术,还基于一群出色的人聚集在一起所做的有意义的事情。Sarah Novotny 策划的一套 Kubernetes 价值观是以上最好的表现形式。
让我们一起期待下一个 4 年!🎉🎉🎉
向 Discuss Kubernetes 问好
作者: Jorge Castro (Heptio)
就一个超过 35,000 人的全球性社区而言,参与其中时沟通是非常关键的。 跟踪 Kubernetes 社区中的所有内容可能是一项艰巨的任务。 一方面,我们有官方资源,如 Stack Overflow,GitHub 和邮件列表,另一方面,我们有更多瞬时性的资源,如 Slack,你可以加入进去、与某人聊天然后各走各路。
Slack 非常适合随意和及时的对话,并与其他社区成员保持联系,但未来很难轻易引用通信。此外,在35,000名参与者中提问并得到回答很难。邮件列表在有问题尝试联系特定人群并且想要跟踪大家的回应时非常有用,但是对于大量人员来说可能是麻烦的。 Stack Overflow 和 GitHub 非常适合在涉及代码的项目或问题上进行协作,并且如果在将来要进行搜索也很有用,但某些主题如“你最喜欢的 CI/CD 工具是什么”或“Kubectl提示和技巧“在那里是没有意义的。
虽然我们目前的各种沟通渠道对他们自己来说都很有价值,但我们发现电子邮件和实时聊天之间仍然存在差距。在网络的其他部分,许多其他开源项目,如 Docker、Mozilla、Swift、Ghost 和 Chef,已经成功地在Discourse之上构建社区,一个开放的讨论平台。那么,如果我们可以使用这个工具将我们的讨论结合在一个平台下,使用开放的API,或许也不会让我们的大部分信息消失在网络中呢?只有一种方法可以找到:欢迎来到discuss.kubernetes.io
马上,我们有用户可以浏览的类别。检查和发布这些类别允许用户参与他们可能感兴趣的事情,而无需订阅列表。精细的通知控件允许用户只订阅他们想要的类别或标签,并允许通过电子邮件回复主题。
生态系统合作伙伴和开发人员现在有一个地方可以宣布项目,他们正在为用户工作,而不会想知道它是否会在官方列表中脱离主题。我们可以让这个地方不仅仅是关于核心 Kubernetes,而是关于我们社区正在建设的数百个精彩工具。
这个新的社区论坛为人们提供了一个可以讨论 Kubernetes 的地方,也是开发人员在 Kubernetes 周围发布事件的声音板,同时可以搜索并且更容易被更广泛的用户访问。
在 Kubernetes 上开发
作者: Michael Hausenblas (Red Hat), Ilya Dmitrichenko (Weaveworks)
您将如何开发一个 Kubernetes 应用?也就是说,您如何编写并测试一个要在 Kubernetes 上运行的应用程序?本文将重点介绍在独自开发或者团队协作中,您可能希望了解到的为了成功编写 Kubernetes 应用程序而需面临的挑战,工具和方法。
我们假定您是一位开发人员,有您钟爱的编程语言,编辑器/IDE(集成开发环境),以及可用的测试框架。在针对 Kubernetes 开发应用时,最重要的目标是减少对当前工作流程的影响,改变越少越好,尽量做到最小。举个例子,如果您是 Node.js 开发人员,习惯于那种热重载的环境 - 也就是说您在编辑器里一做保存,正在运行的程序就会自动更新 - 那么跟容器、容器镜像或者镜像仓库打交道,又或是跟 Kubernetes 部署、triggers 以及更多头疼东西打交道,不仅会让人难以招架也真的会让开发过程完全失去乐趣。
在下文中,我们将首先讨论 Kubernetes 总体开发环境,然后回顾常用工具,最后进行三个示例性工具的实践演练。这些工具允许针对 Kubernetes 进行本地应用程序的开发和迭代。
您的集群运行在哪里?
作为开发人员,您既需要考虑所针对开发的 Kubernetes 集群运行在哪里,也需要思考开发环境如何配置。概念上,有四种开发模式:
许多工具支持纯 offline 开发,包括 Minikube、Docker(Mac 版/Windows 版)、Minishift 以及下文中我们将详细讨论的几种。有时,比如说在一个微服务系统中,已经有若干微服务在运行,proxied 模式(通过转发把数据流传进传出集群)就非常合适,Telepresence 就是此类工具的一个实例。live 模式,本质上是您基于一个远程集群进行构建和部署。最后,纯 online 模式意味着您的开发环境和运行集群都是远程的,典型的例子是 Eclipse Che 或者 Cloud 9。现在让我们仔细看看离线开发的基础:在本地运行 Kubernetes。
Minikube 在更加喜欢于本地 VM 上运行 Kubernetes 的开发人员中,非常受欢迎。不久前,Docker 的 Mac 版和 Windows 版,都试验性地开始自带 Kubernetes(需要下载 “edge” 安装包)。在两者之间,以下原因也许会促使您选择 Minikube 而不是 Docker 桌面版:
- 您已经安装了 Minikube 并且它运行良好
- 您想等到 Docker 出稳定版本
- 您是 Linux 桌面用户
- 您是 Windows 用户,但是没有配有 Hyper-V 的 Windows 10 Pro
运行一个本地集群,开发人员可以离线工作,不用支付云服务。云服务收费一般不会太高,并且免费的等级也有,但是一些开发人员不喜欢为了使用云服务而必须得到经理的批准,也不愿意支付意想不到的费用,比如说忘了下线而集群在周末也在运转。
有些开发人员却更喜欢远程的 Kubernetes 集群,这样他们通常可以获得更大的计算能力和存储容量,也简化了协同工作流程。您可以更容易的拉上一个同事来帮您调试,或者在团队内共享一个应用的使用。再者,对某些开发人员来说,尽可能的让开发环境类似生产环境至关重要,尤其是您依赖外部厂商的云服务时,如:专有数据库、云对象存储、消息队列、外商的负载均衡器或者邮件投递系统。
总之,无论您选择本地或者远程集群,理由都足够多。这很大程度上取决于您所处的阶段:从早期的原型设计/单人开发到后期面对一批稳定微服务的集成。
既然您已经了解到运行环境的基本选项,那么我们就接着讨论如何迭代式的开发并部署您的应用。
常用工具
我们现在回顾既可以允许您可以在 Kubernetes 上开发应用程序又尽可能最小地改变您现有的工作流程的一些工具。我们致力于提供一份不偏不倚的描述,也会提及使用某个工具将会意味着什么。
请注意这很棘手,因为即使在成熟定型的技术中做选择,比如说在 JSON、YAML、XML、REST、gRPC 或者 SOAP 之间做选择,很大程度也取决于您的背景、喜好以及公司环境。在 Kubernetes 生态系统内比较各种工具就更加困难,因为技术发展太快,几乎每周都有新工具面市;举个例子,仅在准备这篇博客的期间,Gitkube 和 Watchpod 相继出品。为了进一步覆盖到这些新的,以及一些相关的已推出的工具,例如 Weave Flux 和 OpenShift 的 S2I,我们计划再写一篇跟进的博客。
Draft
Draft 旨在帮助您将任何应用程序部署到 Kubernetes。它能够检测到您的应用所使用的编程语言,并且生成一份 Dockerfile 和 Helm 图表。然后它替您启动构建并且依照 Helm 图表把所生产的镜像部署到目标集群。它也可以让您很容易地设置到 localhost 的端口映射。
这意味着:
- 用户可以任意地自定义 Helm 图表和 Dockerfile 模版,或者甚至创建一个 custom pack(使用 Dockerfile、Helm 图表以及其他)以备后用
- 要想理解一个应用应该怎么构建并不容易,在某些情况下,用户也许需要修改 Draft 生成的 Dockerfile 和 Heml 图表
- 如果使用 Draft version 0.12.01 或者更老版本,每一次用户想要测试一个改动,他们需要等 Draft 把代码拷贝到集群,运行构建,推送镜像并且发布更新后的图表;这些步骤可能进行得很快,但是每一次用户的改动都会产生一个镜像(无论是否提交到 git )
- 在 Draft 0.12.0版本,构建是本地进行的
- 用户不能选择 Helm 以外的工具进行部署
- 它可以监控本地的改动并且触发部署,但是这个功能默认是关闭的
- 它允许开发人员使用本地或者远程的 Kubernetes 集群
- 如何部署到生产环境取决于用户, Draft 的作者推荐了他们的另一个项目 - Brigade
- 可以代替 Skaffold, 并且可以和 Squash 一起使用
更多信息:
【1】:此处疑为 0.11.0,因为 0.12.0 已经支持本地构建,见下一条
Skaffold
Skaffold 让 CI 集成具有可移植性的,它允许用户采用不同的构建系统,镜像仓库和部署工具。它不同于 Draft,同时也具有一定的可比性。它具有生成系统清单的基本能力,但那不是一个重要功能。Skaffold 易于扩展,允许用户在构建和部署应用的每一步选取相应的工具。
这意味着:
- 模块化设计
- 不依赖于 CI,用户不需要 Docker 或者 Kubernetes 插件
- 没有 CI 也可以工作,也就是说,可以在开发人员的电脑上工作
- 它可以监控本地的改动并且触发部署
- 它允许开发人员使用本地或者远程的 Kubernetes 集群
- 它可以用于部署生产环境,用户可以精确配置,也可以为每一套目标环境提供不同的生产线
- 可以代替 Draft,并且和其他工具一起使用
更多信息:
Squash
Squash 包含一个与 Kubernetes 全面集成的调试服务器,以及一个 IDE 插件。它允许您插入断点和所有的调试操作,就像您所习惯的使用 IDE 调试一个程序一般。它允许您将调试器应用到 Kubernetes 集群中运行的 pod 上,从而让您可以使用 IDE 调试 Kubernetes 集群。
这意味着:
- 不依赖您选择的其它工具
- 需要一组特权 DaemonSet
- 可以和流行 IDE 集成
- 支持 Go、Python、Node.js、Java 和 gdb
- 用户必须确保容器中的应用程序使编译时使用了调试符号
- 可与此处描述的任何其他工具结合使用
- 它可以与本地或远程 Kubernetes 集群一起使用
更多信息:
Telepresence
Telepresence 使用双向代理将开发人员工作站上运行的容器与远程 Kubernetes 集群连接起来,并模拟集群内环境以及提供对配置映射和机密的访问。它消除了将应用部署到集群的需要,并利用本地容器抽象出网络和文件系统接口,以使其看起来应用好像就在集群中运行,从而改进容器应用程序开发的迭代时间。
这意味着:
- 它不依赖于其它您选取的工具
- 可以同 Squash 一起使用,但是 Squash 必须用于调试集群中的 pods,而传统/本地调试器需要用于调试通过 Telepresence 连接到集群的本地容器
- Telepresence 会产生一些网络延迟
- 它通过辅助进程提供连接 - sshuttle,基于SSH的一个工具
- 还提供了使用 LD_PRELOAD/DYLD_INSERT_LIBRARIES 的更具侵入性的依赖注入模式
- 它最常用于远程 Kubernetes 集群,但也可以与本地集群一起使用
更多信息:
- Telepresence: fast, realistic local development for Kubernetes microservices
- Getting Started Guide
- How It Works
Ksync
Ksync 在本地计算机和运行在 Kubernetes 中的容器之间同步应用程序代码(和配置),类似于 oc rsync 在 OpenShift 中的角色。它旨在通过消除构建和部署步骤来缩短应用程序开发的迭代时间。
这意味着:
- 它绕过容器图像构建和修订控制
- 使用编译语言的用户必须在 pod(TBC)内运行构建
- 双向同步 - 远程文件会复制到本地目录
- 每次更新远程文件系统时都会重启容器
- 无安全功能 - 仅限开发
- 使用 Syncthing,一个用于点对点同步的 Go 语言库
- 需要一个在集群中运行的特权 DaemonSet
- Node 必须使用带有 overlayfs2 的 Docker - 在写作本文时,尚不支持其他 CRI 实现
更多信息:
- Getting Started Guide
- How It Works
- Katacoda scenario to try out ksync in your browser
- Syncthing Specification
实践演练
我们接下来用于练习使用工具的应用是一个简单的股市模拟器,包含两个微服务:
stock-gen(股市数据生成器)微服务是用 Go 编写的,随机生成股票数据并通过 HTTP 端点/ stockdata公开- 第二个微服务,
stock-con(股市数据消费者)是一个 Node.js 应用程序,它使用来自stock-gen的股票数据流,并通过 HTTP 端点/average/$SYMBOL提供股价移动平均线,也提供一个健康检查端点/healthz。
总体上,此应用的默认配置如下图所示:
在下文中,我们将选取以上讨论的代表性工具进行实践演练:ksync,具有本地构建的 Minikube 以及 Skaffold。对于每个工具,我们执行以下操作:
- 设置相应的工具,包括部署准备和
stock-con微服务数据的本地读取 - 执行代码更新,即更改
stock-con微服务的/healthz端点的源代码并观察网页刷新
请注意,我们一直使用 Minikube 的本地 Kubernetes 集群,但是您也可以使用 ksync 和 Skaffold 的远程集群跟随练习。
实践演练:ksync
作为准备,安装 ksync,然后执行以下步骤配置开发环境:
$ mkdir -p $(pwd)/ksync
$ kubectl create namespace dok
$ ksync init -n dok
完成基本设置后,我们可以告诉 ksync 的本地客户端监控 Kubernetes 的某个命名空间,然后我们创建一个规范来定义我们想要同步的文件夹(本地的 $(pwd)/ksync 和容器中的 / app )。请注意,目标 pod 是用 selector 参数指定:
$ ksync watch -n dok
$ ksync create -n dok --selector=app=stock-con $(pwd)/ksync /app
$ ksync get -n dok
现在我们部署股价数据生成器和股价数据消费者微服务:
$ kubectl -n=dok apply \
-f https://raw.githubusercontent.com/kubernauts/dok-example-us/master/stock-gen/app.yaml
$ kubectl -n=dok apply \
-f https://raw.githubusercontent.com/kubernauts/dok-example-us/master/stock-con/app.yaml
一旦两个部署建好并且 pod 开始运行,我们转发 stock-con 服务以供本地读取(另开一个终端窗口):
$ kubectl get -n dok po --selector=app=stock-con \
-o=custom-columns=:metadata.name --no-headers | \
xargs -IPOD kubectl -n dok port-forward POD 9898:9898
这样,通过定期查询 healthz 端点,我们就应该能够从本地机器上读取 stock-con 服务,查询命令如下(在一个单独的终端窗口):
$ watch curl localhost:9898/healthz
现在,改动 ksync/stock-con 目录中的代码,例如改动 service.js 中定义的 /healthz 端点代码,在其 JSON 形式的响应中新添一个字段并观察 pod 如何更新以及 curl localhost:9898/healthz 命令的输出发生何种变化。总的来说,您最后应该看到类似的内容:
实践演练:带本地构建的 Minikube
对于以下内容,您需要启动并运行 Minikube,我们将利用 Minikube 自带的 Docker daemon 在本地构建镜像。作为准备,请执行以下操作
$ git clone https://github.com/kubernauts/dok-example-us.git && cd dok-example-us
$ eval $(minikube docker-env)
$ kubectl create namespace dok
现在我们部署股价数据生成器和股价数据消费者微服务:
$ kubectl -n=dok apply -f stock-gen/app.yaml
$ kubectl -n=dok apply -f stock-con/app.yaml
一旦两个部署建好并且 pod 开始运行,我们转发 stock-con 服务以供本地读取(另开一个终端窗口)并检查 healthz 端点的响应:
$ kubectl get -n dok po --selector=app=stock-con \
-o=custom-columns=:metadata.name --no-headers | \
xargs -IPOD kubectl -n dok port-forward POD 9898:9898 &
$ watch curl localhost:9898/healthz
现在,改一下 ksync/stock-con 目录中的代码,例如修改 service.js 中定义的 /healthz 端点代码,在其 JSON 形式的响应中添加一个字段。在您更新完代码后,最后一步是构建新的容器镜像并启动新部署,如下所示:
$ docker build -t stock-con:dev -f Dockerfile .
$ kubectl -n dok set image deployment/stock-con *=stock-con:dev
总的来说,您最后应该看到类似的内容:
实践演练:Skaffold
要进行此演练,首先需要安装 Skaffold。完成后,您可以执行以下步骤来配置开发环境:
$ git clone https://github.com/kubernauts/dok-example-us.git && cd dok-example-us
$ kubectl create namespace dok
现在我们部署股价数据生成器(但是暂不部署股价数据消费者,此服务将使用 Skaffold 完成):
$ kubectl -n=dok apply -f stock-gen/app.yaml
请注意,最初我们在执行 skaffold dev 时发生身份验证错误,为避免此错误需要安装问题322 中所述的修复。本质上,需要将 〜/.docker/config.json 的内容改为:
{
"auths": {}
}
接下来,我们需要略微改动 stock-con/app.yaml,这样 Skaffold 才能正常使用此文件:
在 stock-con 部署和服务中添加一个 namespace 字段,其值为 dok
将容器规范的 image 字段更改为 quay.io/mhausenblas/stock-con,因为 Skaffold 可以即时管理容器镜像标签。
最终的 stock-con 的 app.yaml 文件看起来如下:
apiVersion: apps/v1beta1
kind: Deployment
metadata:
labels:
app: stock-con
name: stock-con
namespace: dok
spec:
replicas: 1
template:
metadata:
labels:
app: stock-con
spec:
containers:
- name: stock-con
image: quay.io/mhausenblas/stock-con
env:
- name: DOK_STOCKGEN_HOSTNAME
value: stock-gen
- name: DOK_STOCKGEN_PORT
value: "9999"
ports:
- containerPort: 9898
protocol: TCP
livenessProbe:
initialDelaySeconds: 2
periodSeconds: 5
httpGet:
path: /healthz
port: 9898
readinessProbe:
initialDelaySeconds: 2
periodSeconds: 5
httpGet:
path: /healthz
port: 9898
---
apiVersion: v1
kind: Service
metadata:
labels:
app: stock-con
name: stock-con
namespace: dok
spec:
type: ClusterIP
ports:
- name: http
port: 80
protocol: TCP
targetPort: 9898
selector:
app: stock-con
我们能够开始开发之前的最后一步是配置 Skaffold。因此,在 stock-con/ 目录中创建文件 skaffold.yaml,其中包含以下内容:
apiVersion: skaffold/v1alpha2
kind: Config
build:
artifacts:
- imageName: quay.io/mhausenblas/stock-con
workspace: .
docker: {}
local: {}
deploy:
kubectl:
manifests:
- app.yaml
现在我们准备好开始开发了。为此,在 stock-con/ 目录中执行以下命令:
$ skaffold dev
上面的命令将触发 stock-con 图像的构建和部署。一旦 stock-con 部署的 pod 开始运行,我们再次转发 stock-con 服务以供本地读取(在单独的终端窗口中)并检查 healthz 端点的响应:
$ kubectl get -n dok po --selector=app=stock-con \
-o=custom-columns=:metadata.name --no-headers | \
xargs -IPOD kubectl -n dok port-forward POD 9898:9898 &
$ watch curl localhost:9898/healthz
现在,如果您修改一下 stock-con 目录中的代码,例如 service.js 中定义的 /healthz 端点代码,在其 JSON 形式的响应中添加一个字段,您应该看到 Skaffold 可以检测到代码改动并创建新图像以及部署它。您的屏幕看起来应该类似这样:
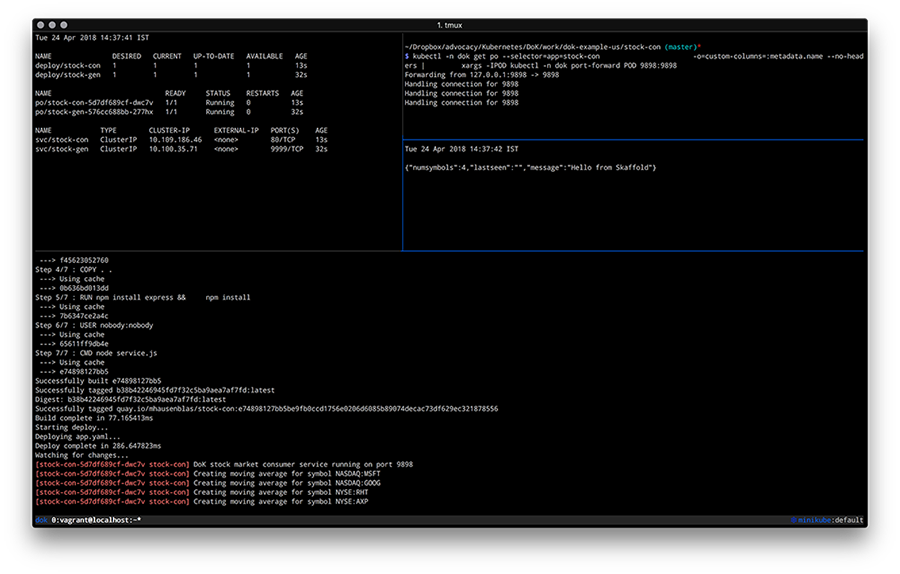
至此,您应该对不同的工具如何帮您在 Kubernetes 上开发应用程序有了一定的概念,如果您有兴趣了解有关工具和/或方法的更多信息,请查看以下资源:
- Blog post by Shahidh K Muhammed on Draft vs Gitkube vs Helm vs Ksonnet vs Metaparticle vs Skaffold (03/2018)
- Blog post by Gergely Nemeth on Using Kubernetes for Local Development, with a focus on Skaffold (03/2018)
- Blog post by Richard Li on Locally developing Kubernetes services (without waiting for a deploy), with a focus on Telepresence
- Blog post by Abhishek Tiwari on Local Development Environment for Kubernetes using Minikube (09/2017)
- Blog post by Aymen El Amri on Using Kubernetes for Local Development — Minikube (08/2017)
- Blog post by Alexis Richardson on GitOps - Operations by Pull Request (08/2017)
- Slide deck GitOps: Drive operations through git, with a focus on Gitkube by Tirumarai Selvan (03/2018)
- Slide deck Developing apps on Kubernetes, a talk Michael Hausenblas gave at a CNCF Paris meetup (04/2018)
- YouTube videos:
- Raw responses to the Kubernetes Application Survey 2018 by SIG Apps
有了这些,我们这篇关于如何在 Kubernetes 上开发应用程序的博客就可以收尾了,希望您有所收获,如果您有反馈和/或想要指出您认为有用的工具,请通过 Twitter 告诉我们:Ilya 和 Michael
Kubernetes 社区 - 2017 年开源排行榜榜首
对于 Kubernetes 来说,2017 年是丰收的一年,GitHub的最新 Octoverse 报告 说明了该项目获得了多少关注。
Kubernetes 是 用于运行应用程序容器的开源平台,它提供了一个统一的界面,使开发人员和操作团队能够自动执行部署、管理和扩展几乎任何基础架构上的各种应用程序。
Kubernetes 所做的,是通过利用广泛的专业知识和行业经验来解决这些共同的挑战,可以帮助工程师专注于在堆栈的顶部构建自己的产品,而不是不必要地进行重复工作,比如现在已经存在的 “云原生” 工具包的标准部分。
但是,通过临时的集体组织来实现这些收益是它独有的挑战,这使得支持开源,社区驱动的工作变得越来越困难。
继续阅读以了解 Kubernetes 社区如何解决这些挑战,从而在 GitHub 的 2017 Octoverse 报告中位居榜首。
GitHub 上讨论最多的
2017 年讨论最多的两个仓库都是基于 Kubernetes 的:
!讨论最多
在 GitHub 的所有开源存储库中,没有比 kubernetes/kubernetes 收到更多的评论。 OpenShift, CNCF 认证的 Kubernetes 发行版 排名第二。
利用充足时间进行公开讨论来获取社区反馈和审查,有助于建立共享的基础架构并为云原生计算建立新标准。
GitHub 上审阅最多的
成功扩展开放源代码工作的通信通常会带来更好的协调和更高质量的功能交付。Kubernetes 项目的 Special Interest Group(SIG) 结构已使其成为 GitHub 审阅第二多的项目:
!审阅最多
使用 SIG 对社区参与机制进行细分和标准化有助于从资格更高的社区成员中获得更频繁的审阅。
如果得到有效管理,活跃的社区讨论不仅表明代码库存在很大的争议,也可能表明项目包含大量未满足的需求。
扩展项目处理问题和社区互动的能力有助于扩大交流。同时,大型社区具有更多不同的用例和更多的支持问题需要管理。Kubernetes SIG 组织结构 帮助应对大规模复杂通信的挑战。
SIG 会议为不同学科的用户、维护者和专家提供了重点合作的机会,以共同协作来支持社区的工作。这些在组织上的投资有助于创建一个环境,在这样的环境中,可以更轻松地将架构讨论和规划的优先级排到提交速度前面,并使项目能够维持这种规模。
加入我们!
您可能已经在 Kubernetes 上成功使用管理和扩展的解决方案。例如,托管 Kubernetes 上游源代码的 GitHub.com 现在也可以在 Kubernetes 上运行 !
请查看 Kubernetes 贡献者指南 ,以获取有关如何开始作为贡献者的更多信息。
您也可以参加 每周 Kubernetes 的社区会议 并考虑 加入一个或两个 SIG。
“基于容器的应用程序设计原理”
如今,可以将几乎所有应用程序放入容器中并运行它。 但是,创建云原生应用程序(由 Kubernetes 等云原生平台自动有效地编排的容器化应用程序)需要付出额外的努力。 云原生应用程序会预期失败; 它们可以可靠的运行和扩展,即使基础架构出现故障。 为了提供这样的功能,像 Kubernetes 这样的云原生平台对应用程序施加了一系列约定和约束。 这些合同确保运行的应用程序符合某些约束条件,并允许平台自动执行应用程序管理。
我总结了容器化应用要成为彻底的云原生应用所要遵从的七个原则。
| ----- |
| 
| 容器设计原则 |
这七个原则涵盖了构建时间和运行时问题。
建立时间
- 单独关注点: 每个容器都解决了一个单独的关注点,并做到了。
- 自包含: 容器仅依赖于Linux内核的存在。 构建容器时会添加其他库。
- 镜像不可变性: 容器化应用程序是不可变的,并且一旦构建,就不会在不同环境之间发生变化。
运行时
- 高度可观察性: 每个容器都必须实现所有必要的API,以帮助平台以最佳方式观察和管理应用程序。
- 生命周期一致性: 容器必须具有读取来自平台的事件并通过对这些事件做出反应来进行一致性的方式。
- 进程可丢弃: 容器化的应用程序必须尽可能短暂,并随时可以被另一个容器实例替换。
- 运行时可约束 每个容器必须声明其资源需求,并根据所标明的需求限制其资源使用。 构建时间原则可确保容器具有正确的颗粒度,一致性和适当的结构。 运行时原则规定了必须执行哪些功能才能使容器化的应用程序具有云原生功能。 遵循这些原则有助于确保您的应用程序适合Kubernetes中的自动化。
白皮书可以免费下载:
要了解有关为Kubernetes设计云原生应用程序的更多信息,请翻阅我的Kubernetes 模式这本书。
— Bilgin Ibryam,首席架构师,Red Hat
推特:
博客: http://www.ofbizian.com
领英:
Bilgin Ibryam(@bibryam)是 Red Hat 的首席架构师,ASF 的开源提交者,博客,作者和发言人。 他是骆驼设计模式和 Kubernetes 模式书籍的作者。 在日常工作中,Bilgin 乐于指导,培训和领导团队,以使他们在分布式系统,微服务,容器和云原生应用程序方面取得成功。
Kubernetes 1.9 对 Windows Server 容器提供 Beta 版本支持
随着 Kubernetes v1.9 的发布,我们确保所有人在任何地方都能正常运行 Kubernetes 的使命前进了一大步。我们的 Beta 版本对 Windows Server 的支持进行了升级,并且在 Kubernetes 和 Windows 平台上都提供了持续的功能改进。为了在 Kubernetes 上运行许多特定于 Windows 的应用程序和工作负载,SIG-Windows 自2016年3月以来一直在努力,大大扩展了 Kubernetes 的实现场景和企业适用范围。
各种规模的企业都在 .NET 和基于 Windows 的应用程序上进行了大量投资。如今许多企业产品组合都包含 .NET 和 Windows,Gartner 声称 80% 的企业应用都在 Windows 上运行。根据 StackOverflow Insights,40% 的专业开发人员使用 .NET 编程语言(包括 .NET Core)。
但为什么这些信息都很重要?这意味着企业既有传统的,也有新生的云(microservice)应用程序,利用了大量的编程框架。业界正在大力推动将现有/遗留应用程序现代化到容器中,使用类似于“提升和转移”的方法。同时,也能灵活地向其他 Windows 或 Linux 容器引入新功能。容器正在成为打包、部署和管理现有程序和微服务应用程序的业界标准。IT 组织正在寻找一种更简单且一致的方法来跨 Linux 和 Windows 环境进行协调和管理容器。Kubernetes v1.9 现在对 Windows Server 容器提供了 Beta 版本支持,使之成为策划任何类型容器的明确选择。
特点
Kubernetes 中对 Windows Server 容器的 Alpha 支持是非常有用的,尤其是对于概念项目和可视化 Kubernetes 中 Windows 支持的路线图。然而,Alpha 版本有明显的缺点,并且缺少许多特性,特别是在网络方面。SIG Windows、Microsoft、Cloudbase Solutions、Apprenda 和其他社区成员联合创建了一个全面的 Beta 版本,使 Kubernetes 用户能够开始评估和使用 Windows。
Kubernetes 对 Windows 服务器容器的一些关键功能改进包括:
- 改进了对 Pod 的支持!Pod 中多个 Windows Server 容器现在可以使用 Windows Server 中的网络隔离专区共享网络命名空间。此功能中 Pod 的概念相当于基于 Linux 的容器
- 可通过每个 Pod 使用单个网络端点来降低网络复杂性
- 可以使用 Virtual Filtering Platform(VFP)的 Hyper-v Switch Extension(类似于 Linux iptables)达到基于内核的负载平衡
- 具备 Container Runtime Interface(CRI)的 Pod 和 Node 级别的统计信息。可以使用从 Pod 和节点收集的性能指标配置 Windows Server 容器的 Horizontal Pod Autoscaling
- 支持 kubeadm 命令将 Windows Server 的 Node 添加到 Kubernetes 环境。Kubeadm 简化了 Kubernetes 集群的配置,通过对 Windows Server 的支持,您可以在您的基础配置中使用单一的工具部署 Kubernetes
- 支持 ConfigMaps, Secrets, 和 Volumes。这些是非常关键的特性,您可以将容器的配置从实施体系中分离出来,并且在大部分情况下是安全的
然而,kubernetes 1.9 windows 支持的最大亮点是网络增强。随着 Windows 服务器 1709 的发布,微软在操作系统和 Windows Host Networking Service(HNS)中启用了关键的网络功能,这为创造大量与 Kubernetes 中的 Windows 服务器容器一起工作的 CNI 插件铺平了道路。Kubernetes 1.9 支持的第三层路由和网络覆盖插件如下所示:
- 上游 L3 路由 - 上游 ToR 中配置的 IP 路由
- Host-Gateway - 在每个主机上配置的 IP 路由
- 具有 Overlay 的 Open vSwitch(OVS)和 Open Virtual Network(OVN) - 支持 STT 和 Geneve 的 tunneling 类型 您可以阅读更多有关 配置、设置和运行时功能 的信息,以便在 Kubernetes 中为您的网络堆栈做出明智的选择。
如果您需要继续在 Linux 中运行 Kubernetes Control Plane 和 Master Components,现在也可以将 Windows Server 作为 Kubernetes 中的一个节点引入。对一个社区来说,这是一个巨大的里程碑和成就。现在,我们将会在 Kubernetes 中看到 .NET,.NET Core,ASP.NET,IIS,Windows 服务,Windows 可执行文件以及更多基于 Windows 的应用程序。
接下来还会有什么
这个 Beta 版本进行了大量工作,但是社区意识到在将 Windows 支持作为生产工作负载发布为 GA(General Availability)之前,我们需要更多领域的投资。2018年前两个季度的重点关注领域包括:
- 继续在网络领域取得更多进展。其他 CNI 插件正在开发中,并且即将完成
- Overlay - win-Overlay(vxlan 或 IP-in-IP 使用 Flannel 封装)
- Win-l2bridge(host-gateway)
- 使用云网络的 OVN - 不再依赖 Overlay
- 在 ovn-Kubernetes 中支持 Kubernetes 网络策略
- 支持 Hyper-V Isolation
- 支持有状态应用程序的 StatefulSet 功能
- 生成适用于任何基础架构以及跨多公共云提供商(例如 Microsoft Azure,Google Cloud 和 Amazon AWS)的安装工具和文档
- SIG-Windows 的 Continuous Integration/Continuous Delivery(CI/CD)基础结构
- 可伸缩性和性能测试 尽管我们尚未承诺正式版的具体时间线,但估计 SIG-Windows 将于2018年上半年正式发布。
加入我们
随着我们在 Kubernetes 的普遍可用性方向不断取得进展,我们欢迎您参与进来,贡献代码、提供反馈,将 Windows 服务器容器部署到 Kubernetes 集群,或者干脆加入我们的社区。
- 如果你想要开始在 Kubernetes 中部署 Windows Server 容器,请阅读我们的开始导览 /docs/getting-started-guides/windows/
- 我们每隔一个星期二在美国东部标准时间(EST)的12:30在 https://zoom.us/my/sigwindows 开会。所有会议内容都记录在 Youtube 并附上了参考材料 https://www.youtube.com/playlist?list=PL69nYSiGNLP2OH9InCcNkWNu2bl-gmIU4
- 通过 Slack 联系我们 https://kubernetes.slack.com/messages/sig-windows
- 在 Github 上找到我们 https://github.com/kubernetes/community/tree/master/sig-windows
谢谢大家,
Michael Michael (@michmike77)
SIG-Windows 领导人
Apprenda 产品管理高级总监
Kubernetes 中自动缩放
Kubernetes 允许开发人员根据当前的流量和负载自动调整集群大小和 pod 副本的数量。这些调整减少了未使用节点的数量,节省了资金和资源。 在这次演讲中,谷歌的 Marcin Wielgus 将带领您了解 Kubernetes 中 pod 和 node 自动调焦的当前状态:它是如何工作的,以及如何使用它,包括在生产应用程序中部署的最佳实践。
喜欢这个演讲吗? 12 月 6 日至 8 日,在 Austin 参加 KubeCon 关于扩展和自动化您的 Kubernetes 集群的更令人兴奋的会议。现在注册。
一定要查看由 Ron Lipke, Gannet/USA Today Network, 平台即服务高级开发人员,在公共云中自动化和测试产品就绪的 Kubernetes 集群。
Kubernetes 1.8 的五天
Kubernetes 1.8 已经推出,数百名贡献者在这个最新版本中推出了成千上万的提交。
社区已经有超过 66,000 个提交在主仓库,并在主仓库之外继续快速增长,这标志着该项目日益成熟和稳定。仅 v1.7.0 到 v1.8.0,社区就记录了所有仓库的超过 120,000 次提交和 17839 次提交。
在拥有 1400 多名贡献者,并且不断发展壮大的社区的帮助下,我们合并了 3000 多个 PR,并发布了 5000 多个提交,最后的 Kubernetes 1.8 在安全和工作负载方面添加了很多的更新。 这一切都表明稳定性的提高,这是我们整个项目关注成熟流程、形式化架构和加强 Kubernetes 的治理模型的结果。
虽然有很多改进,但我们在下面列出的这一系列深度文章中突出了一些关键特性。跟随并了解存储,安全等方面的新功能和改进功能。
第一天: Kubernetes 1.8 的五天 第二天: kubeadm v1.8 为 Kubernetes 集群引入了简单的升级 第三天: Kubernetes v1.8 回顾:提升一个 Kubernetes 需要一个 Village 第四天: 使用 RBAC,一般在 Kubernetes v1.8 中提供 第五天: 在 Kubernetes 执行网络策略
链接
- 在 Stack Overflow 上发布问题(或回答问题)
- 加入 K8sPort 布道师的社区门户网站
- 在 Twitter @Kubernetesio 关注我们以获取最新更新
- 与 Slack 上的社区联系
- 参与 GitHub 上的 Kubernetes 项目
Kubernetes 社区指导委员会选举结果
自 2015 年 OSCON 发布 Kubernetes 1.0 以来,大家一直在共同努力,在 Kubernetes 社区中共同分享领导力和责任。
在 Brandon Philips、Brendan Burns、Brian Grant、Clayton Coleman、Joe Beda、Sarah Novotny 和 Tim Hockin 组成的自举治理委员会的工作下 - 代表 5 家不同公司的长期领导者,他们对 Kubernetes 生态系统进行了大量的人才投资和努力 - 编写了初始的指导委员会章程,并发起了一次社区选举,以选举 Kubernetes 指导委员会成员。
引用章程 -
_指导委员会的最初职责是实例化 Kubernetes 治理的正式过程。除定义初始治理过程外,指导委员会还坚信提供一种方法来迭代指导委员会定义的方法很重要。我们不相信我们会在第一次或以后把这些做好,也不会一口气完成治理开发工作。指导委员会的作用是成为一个积极响应的机构,可以根据需要进行重构和改造,以适应不断变化的项目和社区。
这是将我们隐式治理结构明确化的最大一步。Kubernetes 的愿景一直是成为一个包容而广泛的社区,用我们的软件带给用户容器的便利性。指导委员会将是一个强有力的引领声音,指导该项目取得成功。
Kubernetes 社区很高兴地宣布 2017 年指导委员会选举的结果。 请祝贺 Aaron Crickenberger、Derek Carr、Michelle Noorali、Phillip Wittrock、Quinton Hoole 和 Timothy St. Clair,他们将成为新成立的 Kubernetes 指导委员会的自举治理委员会成员。Derek、Michelle 和 Phillip 将任职 2 年。Aaron、Quinton、和 Timothy 将任职 1 年。
该小组将定期开会,以阐明和简化项目的结构和运行。早期的工作将包括选举 CNCF 理事会的代表,发展项目流程,完善和记录项目的愿景和范围,以及授权和委派更多主题社区团体。
请参阅完整的指导委员会待办事项列表以获取更多详细信息。
使用 Kubernetes Pet Sets 和 Datera Elastic Data Fabric 的 FlexVolume 扩展有状态的应用程序
编者注:今天的邀请帖子来自 Datera 公司的软件架构师 Shailesh Mittal 和高级产品总监 Ashok Rajagopalan,介绍在 Datera Elastic Data Fabric 上用 Kubernetes 配置状态应用程序。
简介
用户从无状态工作负载转移到运行有状态应用程序,Kubernetes 中的持久卷是基础。虽然 Kubernetes 早已支持有状态的应用程序,比如 MySQL、Kafka、Cassandra 和 Couchbase,但是 Pet Sets 的引入明显改善了情况。特别是,Pet Sets 具有持续扩展和关联的能力,在配置和启动的顺序过程中,可以自动缩放“Pets”(需要连续处理和持久放置的应用程序)。
Datera 是用于云部署的弹性块存储,可以通过 FlexVolume 框架与 Kubernetes 无缝集成。基于容器的基本原则,Datera 允许应用程序的资源配置与底层物理基础架构分离,为有状态的应用程序提供简洁的协议(也就是说,不依赖底层物理基础结构及其相关内容)、声明式格式和最后移植的能力。
Kubernetes 可以通过 yaml 配置来灵活定义底层应用程序基础架构,而 Datera 可以将该配置传递给存储基础结构以提供持久性。通过 Datera AppTemplates 声明,在 Kubernetes 环境中,有状态的应用程序可以自动扩展。
部署永久性存储
永久性存储是通过 Kubernetes 的子系统 PersistentVolume 定义的。PersistentVolumes 是卷插件,它定义的卷的生命周期和使用它的 Pod 相互独立。PersistentVolumes 由 NFS、iSCSI 或云提供商的特定存储系统实现。Datera 开发了用于 PersistentVolumes 的卷插件,可以在 Datera Data Fabric 上为 Kubernetes 的 Pod 配置 iSCSI 块存储。
Datera 卷插件从 minion nodes 上的 kubelet 调用,并通过 REST API 回传到 Datera Data Fabric。以下是带有 Datera 插件的 PersistentVolume 的部署示例:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-datera-0
spec:
capacity:
storage: 100Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
flexVolume:
driver: "datera/iscsi"
fsType: "xfs"
options:
volumeID: "kube-pv-datera-0"
size: “100"
replica: "3"
backstoreServer: "[tlx170.tlx.daterainc.com](http://tlx170.tlx.daterainc.com/):7717”
为 Pod 申请 PersistentVolume,要按照以下清单在 Datera Data Fabric 中配置 100 GB 的 PersistentVolume。
[root@tlx241 /]# kubectl get pv
NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv-datera-0 100Gi RWO Available 8s
pv-datera-1 100Gi RWO Available 2s
pv-datera-2 100Gi RWO Available 7s
pv-datera-3 100Gi RWO Available 4s
配置
Datera PersistenceVolume 插件安装在所有 minion node 上。minion node 的声明是绑定到之前设置的永久性存储上的,当 Pod 进入具备有效声明的 minion node 上时,Datera 插件会转发请求,从而在 Datera Data Fabric 上创建卷。根据配置请求,PersistentVolume 清单中所有指定的选项都将发送到插件。
在 Datera Data Fabric 中配置的卷会作为 iSCSI 块设备呈现给 minion node,并且 kubelet 将该设备安装到容器(在 Pod 中)进行访问。

使用永久性存储
Kubernetes PersistentVolumes 与具备 PersistentVolume Claims 的 Pod 一起使用。定义声明后,会被绑定到与声明规范匹配的 PersistentVolume 上。上面提到的定义 PersistentVolume 的典型声明如下所示:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pv-claim-test-petset-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
定义这个声明并将其绑定到 PersistentVolume 时,资源与 Pod 规范可以一起使用:
[root@tlx241 /]# kubectl get pv
NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv-datera-0 100Gi RWO Bound default/pv-claim-test-petset-0 6m
pv-datera-1 100Gi RWO Bound default/pv-claim-test-petset-1 6m
pv-datera-2 100Gi RWO Available 7s
pv-datera-3 100Gi RWO Available 4s
[root@tlx241 /]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
pv-claim-test-petset-0 Bound pv-datera-0 0 3m
pv-claim-test-petset-1 Bound pv-datera-1 0 3m
Pod 可以使用 PersistentVolume 声明,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: kube-pv-demo
spec:
containers:
- name: data-pv-demo
image: nginx
volumeMounts:
- name: test-kube-pv1
mountPath: /data
ports:
- containerPort: 80
volumes:
- name: test-kube-pv1
persistentVolumeClaim:
claimName: pv-claim-test-petset-0
程序的结果是 Pod 将 PersistentVolume Claim 作为卷。依次将请求发送到 Datera 卷插件,然后在 Datera Data Fabric 中配置存储。
[root@tlx241 /]# kubectl describe pods kube-pv-demo
Name: kube-pv-demo
Namespace: default
Node: tlx243/172.19.1.243
Start Time: Sun, 14 Aug 2016 19:17:31 -0700
Labels: \<none\>
Status: Running
IP: 10.40.0.3
Controllers: \<none\>
Containers:
data-pv-demo:
Container ID: [docker://ae2a50c25e03143d0dd721cafdcc6543fac85a301531110e938a8e0433f74447](about:blank)
Image: nginx
Image ID: [docker://sha256:0d409d33b27e47423b049f7f863faa08655a8c901749c2b25b93ca67d01a470d](about:blank)
Port: 80/TCP
State: Running
Started: Sun, 14 Aug 2016 19:17:34 -0700
Ready: True
Restart Count: 0
Environment Variables: \<none\>
Conditions:
Type Status
Initialized True
Ready True
PodScheduled True
Volumes:
test-kube-pv1:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: pv-claim-test-petset-0
ReadOnly: false
default-token-q3eva:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-q3eva
QoS Tier: BestEffort
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
43s 43s 1 {default-scheduler } Normal Scheduled Successfully assigned kube-pv-demo to tlx243
42s 42s 1 {kubelet tlx243} spec.containers{data-pv-demo} Normal Pulling pulling image "nginx"
40s 40s 1 {kubelet tlx243} spec.containers{data-pv-demo} Normal Pulled Successfully pulled image "nginx"
40s 40s 1 {kubelet tlx243} spec.containers{data-pv-demo} Normal Created Created container with docker id ae2a50c25e03
40s 40s 1 {kubelet tlx243} spec.containers{data-pv-demo} Normal Started Started container with docker id ae2a50c25e03
永久卷在 minion node(在本例中为 tlx243)中显示为 iSCSI 设备:
[root@tlx243 ~]# lsscsi
[0:2:0:0] disk SMC SMC2208 3.24 /dev/sda
[11:0:0:0] disk DATERA IBLOCK 4.0 /dev/sdb
[root@tlx243 datera~iscsi]# mount ``` grep sdb
/dev/sdb on /var/lib/kubelet/pods/6b99bd2a-628e-11e6-8463-0cc47ab41442/volumes/datera~iscsi/pv-datera-0 type xfs (rw,relatime,attr2,inode64,noquota)
在 Pod 中运行的容器按照清单中将设备安装在 /data 上:
[root@tlx241 /]# kubectl exec kube-pv-demo -c data-pv-demo -it bash
root@kube-pv-demo:/# mount ``` grep data
/dev/sdb on /data type xfs (rw,relatime,attr2,inode64,noquota)
使用 Pet Sets
通常,Pod 被视为无状态单元,因此,如果其中之一状态异常或被取代,Kubernetes 会将其丢弃。相反,PetSet 是一组有状态的 Pod,具有更强的身份概念。PetSet 可以将标识分配给应用程序的各个实例,这些应用程序没有与底层物理结构连接,PetSet 可以消除这种依赖性。
每个 PetSet 需要{0..n-1}个 Pet。每个 Pet 都有一个确定的名字、PetSetName-Ordinal 和唯一的身份。每个 Pet 最多有一个 Pod,每个 PetSet 最多包含一个给定身份的 Pet。要确保每个 PetSet 在任何特定时间运行时,具有唯一标识的“pet”的数量都是确定的。Pet 的身份标识包括以下几点:
- 一个稳定的主机名,可以在 DNS 中使用
- 一个序号索引
- 稳定的存储:链接到序号和主机名
使用 PersistentVolume Claim 定义 PetSet 的典型例子如下所示:
# A headless service to create DNS records
apiVersion: v1
kind: Service
metadata:
name: test-service
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1alpha1
kind: PetSet
metadata:
name: test-petset
spec:
serviceName: "test-service"
replicas: 2
template:
metadata:
labels:
app: nginx
annotations:
[pod.alpha.kubernetes.io/initialized:](http://pod.alpha.kubernetes.io/initialized:) "true"
spec:
terminationGracePeriodSeconds: 0
containers:
- name: nginx
image: [gcr.io/google\_containers/nginx-slim:0.8](http://gcr.io/google_containers/nginx-slim:0.8)
ports:
- containerPort: 80
name: web
volumeMounts:
- name: pv-claim
mountPath: /data
volumeClaimTemplates:
- metadata:
name: pv-claim
annotations:
[volume.alpha.kubernetes.io/storage-class:](http://volume.alpha.kubernetes.io/storage-class:) anything
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 100Gi
我们提供以下 PersistentVolume Claim:
[root@tlx241 /]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
pv-claim-test-petset-0 Bound pv-datera-0 0 41m
pv-claim-test-petset-1 Bound pv-datera-1 0 41m
pv-claim-test-petset-2 Bound pv-datera-2 0 5s
pv-claim-test-petset-3 Bound pv-datera-3 0 2s
配置 PetSet 时,将实例化两个 Pod:
[root@tlx241 /]# kubectl get pods
NAMESPACE NAME READY STATUS RESTARTS AGE
default test-petset-0 1/1 Running 0 7s
default test-petset-1 1/1 Running 0 3s
以下是一个 PetSet:test-petset 实例化之前的样子:
[root@tlx241 /]# kubectl describe petset test-petset
Name: test-petset
Namespace: default
Image(s): [gcr.io/google\_containers/nginx-slim:0.8](http://gcr.io/google_containers/nginx-slim:0.8)
Selector: app=nginx
Labels: app=nginx
Replicas: 2 current / 2 desired
Annotations: \<none\>
CreationTimestamp: Sun, 14 Aug 2016 19:46:30 -0700
Pods Status: 2 Running / 0 Waiting / 0 Succeeded / 0 Failed
No volumes.
No events.
一旦实例化 PetSet(例如下面的 test-petset),随着副本数(从 PetSet 的初始 Pod 数量算起)的增加,实例化的 Pod 将变得更多,并且更多的 PersistentVolume Claim 会绑定到新的 Pod 上:
[root@tlx241 /]# kubectl patch petset test-petset -p'{"spec":{"replicas":"3"}}'
"test-petset” patched
[root@tlx241 /]# kubectl describe petset test-petset
Name: test-petset
Namespace: default
Image(s): [gcr.io/google\_containers/nginx-slim:0.8](http://gcr.io/google_containers/nginx-slim:0.8)
Selector: app=nginx
Labels: app=nginx
Replicas: 3 current / 3 desired
Annotations: \<none\>
CreationTimestamp: Sun, 14 Aug 2016 19:46:30 -0700
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
No volumes.
No events.
[root@tlx241 /]# kubectl get pods
NAME READY STATUS RESTARTS AGE
test-petset-0 1/1 Running 0 29m
test-petset-1 1/1 Running 0 28m
test-petset-2 1/1 Running 0 9s
现在,应用修补程序后,PetSet 正在运行3个 Pod。
当上述 PetSet 定义修补完成,会产生另一个副本,PetSet 将在系统中引入另一个 pod。反之,这会导致在 Datera Data Fabric 上配置更多的卷。因此,在 PetSet 进行扩展时,要配置动态卷并将其附加到 Pod 上。
为了平衡持久性和一致性的概念,如果 Pod 从一个 Minion 转移到另一个,卷确实会附加(安装)到新的 minion node 上,并与旧的 Minion 分离(卸载),从而实现对数据的持久访问。
结论
本文展示了具备 Pet Sets 的 Kubernetes 协调有状态和无状态工作负载。当 Kubernetes 社区致力于扩展 FlexVolume 框架的功能时,我们很高兴这个解决方案使 Kubernetes 能够在数据中心广泛运行。
加入我们并作出贡献:Kubernetes Storage SIG.
- 下载 Kubernetes
- 参与 Kubernetes 项目 GitHub
- 发布问题(或者回答问题) Stack Overflow
- 联系社区 k8s Slack
- 在 Twitter 上关注我们 @Kubernetesio for latest updates
SIG Apps: 为 Kubernetes 构建应用并在 Kubernetes 中进行运维
编者注:这篇文章由 Kubernetes SIG-Apps 团队撰写,分享他们如何关注在 Kubernetes 中运行应用的开发者和 devops 经验。
Kubernetes 是容器化应用程序的出色管理者。因此,众多 公司 已经 开始 在 Kubernetes 中运行应用程序。
Kubernetes 特殊兴趣小组 (SIGs) 自 1.0 版本开始就一直致力于支持开发者和运营商社区。围绕网络、存储、扩展和其他运营领域组织的人员。
随着 Kubernetes 的兴起,对工具、最佳实践以及围绕构建和运营云原生应用程序的讨论的需求也随之增加。为了满足这一需求, Kubernetes SIG Apps 应运而生。
SIG Apps 为公司和个人提供以下支持:
- 查看和分享正在构建的、为应用操作人员赋能的工具的演示
- 了解和讨论应用运营人员的需求
- 组织各方努力改善体验
自从 SIG Apps 成立以来,我们已经进行了项目演示,例如 KubeFuse、 KPM,和 StackSmith。 我们还对那些负责 Kubernetes 中应用运维的人进行了调查。
从调查结果中,我们学到了很多东西,包括:
- 81% 的受访者希望采用某种形式的自动扩缩
- 为了存储秘密信息,47% 的受访者使用内置 Secret。目前这些资料并未实现静态加密。 (如果你需要关于加密的帮助,请参见问题。)
- 响应最多的问题与第三方工具和调试有关
- 对于管理应用程序的第三方工具,没有明确的赢家。有各种各样的做法
- 总体上对缺乏有用文件有较多抱怨。(请在此处帮助提交文档。)
- 数据量很大。很多回答是可选的,所以我们很惊讶所有候选人的所有问题中有 935 个都被填写了。 如果你想亲自查看数据,可以在线查看。
就应用运维而言,仍然有很多东西需要解决和共享。如果你对运行应用程序有看法或者有改善体验的工具, 或者只是想潜伏并了解状况,请加入我们。
--Matt Farina ,Hewlett Packard Enterprise 首席工程师
Kubernetes 生日快乐。哦,这是你要去的地方!
编者按,今天的嘉宾帖子来自一位独立的 kubernetes 撰稿人 Justin Santa Barbara,分享了他对项目从一开始到未来发展的思考。
亲爱的 K8s,
很难相信你是唯一的一个 - 成长这么快的。在你一岁生日的时候,我想我可以写一个小纸条,告诉你为什么我在你出生的时候那么兴奋,为什么我觉得很幸运能成为抚养你长大的一员,为什么我渴望看到你继续成长!
--Justin
你从一个优秀的基础 - 良好的声明性功能开始,它是围绕一个具有良好定义的模式和机制的坚实的 API 构建的,这样我们就可以向前发展了。果然,在你的第一年里,你增长得如此之快:autoscaling、HTTP load-balancing support (Ingress)、support for persistent workloads including clustered databases (PetSets)。你已经和更多的云交了朋友(欢迎 azure 和 openstack 加入家庭),甚至开始跨越区域和集群(Federation)。这些只是一些最明显的变化 - 在你的大脑里发生了太多的变化!
我觉得你一直保持开放的态度真是太好了 - 你好像把所有的东西都写在 github 上 - 不管是好是坏。我想我们在这方面都学到了很多,比如让工程师做缩放声明的风险,然后在没有完全相同的精确性和严谨性框架的情况下,将这些声明与索赔进行权衡。但我很自豪你选择了不降低你的标准,而是上升到挑战,只是跑得更快 - 这可能不是最现实的办法,但这是唯一的方式能移动山!
然而,不知何故,你已经设法避免了许多其他开源软件陷入的共同死胡同,特别是当那些项目越来越大,开发人员最终要做的比直接使用它更多的时候。你是怎么做到的?有一个很可能是虚构的故事,讲的是 IBM 的一名员工犯了一个巨大的错误,被传唤去见大老板,希望被解雇,却被告知“我们刚刚花了几百万美元培训你。我们为什么要解雇你?“。尽管谷歌对你进行了大量的投资(包括 redhat 和其他公司),但我有时想知道,我们正在避免的错误是否更有价值。有一个非常开放的开发过程,但也有一个“oracle”,它有时会通过告诉我们两年后如果我们做一个特定的设计决策会发生什么来纠正错误。这是你应该听的父母!
所以,尽管你只有一岁,你真的有一个旧灵魂。我只是很多人抚养你中的一员,但对我来说,能够与那些建立了这些令人难以置信的系统并拥有所有这些领域知识的人一起工作是一次极好的学习经历。然而,因为我们是白手起家(而不是采用现有的 Borg 代码),我们处于同一水平,仍然可以就如何培养你进行真正的讨论。好吧,至少和我们的水平一样接近,但值得称赞的是,他们都太好了,从来没提过!
如果我选择两个聪明人做出的明智决定:
- 标签和选择器给我们声明性的“pointers”,所以我们可以说“为什么”我们想要东西,而不是直接列出东西。这是如何扩展到[伟大高度]的秘密(https://kubernetes.io/blog/2016/07/thousand-instances-of-cassandra-using-kubernetes-pet-set);不是命名每一步,而是说“像第一步一样多走一千步”。
- 控制器是状态同步器:我们指定目标,您的控制器将不遗余力地工作,使系统达到该状态。它们工作在强类型 API 基础上,并且贯穿整个代码,因此 Kubernetes 比一个大的程序多一百个小程序。仅仅从技术上扩展到数千个节点是不够的;这个项目还必须扩展到数千个开发人员和特性;控制器帮助我们达到目的。
等等我们就走!我们将取代那些控制器,建立更多,API 基金会让我们构建任何我们可以用这种方式表达的东西 - 大多数东西只是标签或注释远离!但你的思想不会由语言来定义:有了第三方资源,你可以表达任何你选择的东西。现在我们可以不用在 Kubernetes 建造Kubernetes 了,创造出与其他任何东西一样感觉是 Kubernetes 的一部分的东西。最近添加的许多功能,如ingress、DNS integration、autoscaling and network policies ,都已经完成或可以通过这种方式完成。最终,在这些事情发生之前很难想象你会是怎样的一个人,但是明天的标准功能可以从今天开始,没有任何障碍或看门人,甚至对一个听众来说也是这样。
所以我期待着看到越来越多的增长发生在离 Kubernetes 核心越来越远的地方。我们必须通过这些阶段来工作;从需要在 kubernetes 内核中发生的事情开始——比如用部署替换复制控制器。现在我们开始构建不需要核心更改的东西。但我们仍然在讨论基础设施和应用程序。接下来真正有趣的是:当我们开始构建依赖于 kubernetes api 的应用程序时。我们一直有使用 kubernetes api 进行自组装的 cassandra 示例,但我们还没有真正开始更广泛地探讨这个问题。正如 S3 APIs 改变了我们构建记忆事物的方式一样,我认为 k8s APIs 也将改变我们构建思考事物的方式。
所以我很期待你的二岁生日:我可以试着预测你那时的样子,但我知道你会超越我所能想象的最大胆的东西。哦,这是你要去的地方!
-- Justin Santa Barbara, 独立的 Kubernetes 贡献者
将端到端的 Kubernetes 测试引入 Azure (第二部分)
作者标注:今天的邀请帖子是 Travis Newhouse 的 系列 中的第二部分,他是 AppFormix 的首席架构师,这篇文章介绍了他们对 Kubernetes 的贡献。
历史上,Kubernetes 测试一直由谷歌托管,在 谷歌计算引擎 (GCE) 和 谷歌容器引擎 (GKE) 上运行端到端测试。实际上,提交队列的选通检查是在这些测试平台上执行测试的子集。联合测试旨在通过使组织托管各种平台的测试作业并贡献测试结果,从而让 Kubernetes 项目受益来扩大测试范围。谷歌和 SIG-Testing 的 Kubernetes 测试小组成员已经创建了一个 Kubernetes 测试历史记录仪表板,可以发布所有联合测试作业(包括谷歌托管的作业)的全部结果。
在此博客文章中,我们介绍了扩展 Azure 的端到端测试工作,并展示了如何为 Kubernetes 项目贡献联合测试。
Azure 的端到端集成测试
成功实现 在 Azure 上自动部署 Kubernetes 的 “development distro” 脚本 之后,我们的下一个目标是运行端到端集成测试,并与 Kubernetes 社区共享结果。
通过在私有 Jenkins 服务器中定义夜间工作,我们自动化了在 Azure 上执行 Kubernetes 端到端测试的工作流程。图2显示了使用 kube-up.sh 在运行于 Azure 的 Ubuntu 虚拟机上部署 Kubernetes,然后执行端到端测试的工作流程。测试完成后,该作业将测试结果和日志上传到 Google Cloud Storage 目录中,其格式可以由 生成测试历史记录仪表板的脚本 进行处理。我们的 Jenkins 作业使用 hack/jenkins/e2e-runner.sh 和 hack/jenkins/upload-to-gcs.sh 脚本生成正确格式的结果。
| 
如何进行端到端测试
在创建 Azure 端到端测试工作的整个过程中,我们与 SIG-Testing 的成员进行了合作,找到了一种将结果发布到 Kubernetes 社区的方法。合作的结果是以文档和简化的流程从联合测试工作中贡献结果。贡献端到端测试结果的过程可以归纳为4个步骤。
- 创建一个 Google Cloud Storage 空间用来发布结果。
- 定义一个自动化作业来运行端到端测试,通过设置一些环境变量,使用 hack/jenkins/e2e-runner.sh 部署 Kubernetes 二进制文件并执行测试。
- 使用 hack/jenkins/upload-to-gcs.sh 上传结果。
- 通过提交对 kubernetes/test-infra 中的几个文件进行修改的请求,将结果合并到测试历史记录仪表板中。
联合测试文档更详细地描述了这些步骤。运行端到端测试并上传结果的脚本简化了贡献新联合测试作业的工作量。设置自动化测试作业的具体步骤以及在其中部署 Kubernetes 的合适环境将留给读者进行选择。对于使用 Jenkins 的组织,用于 GCE 和 GKE 测试的 jenkins-job-builder 配置可能会提供有用的示例。
回顾
Azure 上的端到端测试已经运行了几周。在此期间,我们在 Kubernetes 中发现了两个问题。Weixu Zhuang 立即发布了修补程序并已合并到 Kubernetes master 分支中。
当我们想用 Ubuntu VM 在 Azure 上用 SaltStack 打开 Kubernetes 集群时,发生了第一个问题。一个提交 (07d7cfd3) 修改了 OpenVPN 证书生成脚本,使用了一个仅由集群或者ubuntu中的脚本初始化的变量。证书生成脚本对参数是否存在进行严格检查会导致其他使用该脚本的平台失败(例如,为支持 Azure 而进行的更改)。我们提交了一个解决问题的请求 ,通过使用默认值初始化变量让证书生成脚本在所有平台类型上都更加健壮,。
第二个 清理未使用导入的请求 在 Daemonset 单元测试文件中。import 语句打破了 golang 1.4 的单元测试。我们的夜间 Jenkins 工作帮助我们找到错误并且迅速完成修复。
结论与未来工作
在 Azure 上为 Kubernetes 添加了夜间端到端测试工作,这有助于定义为 Kubernetes 项目贡献联合测试的过程。在工作过程中,当 Azure 测试工作发现兼容性问题时,我们还发现了将测试覆盖范围扩展到更多平台的直接好处。
我们要感谢 Aaron Crickenberger, Erick Fejta, Joe Finney 和 Ryan Hutchinson 的帮助,将我们的 Azure 端到端测试结果纳入了 Kubernetes 测试历史。如果您想参与测试来创建稳定的、高质量的 Kubernetes 版本,请加入我们的 Kubernetes Testing SIG (sig-testing)。
--Travis Newhouse, AppFormix 首席架构师
Dashboard - Kubernetes 的全功能 Web 界面
编者按:这篇文章是一系列深入的文章 中关于Kubernetes 1.3的新内容的一部分 Kubernetes Dashboard是一个旨在为 Kubernetes 世界带来通用监控和操作 Web 界面的项目。三个月前,我们发布第一个面向生产的版本,从那时起 dashboard 已经做了大量的改进。在一个 UI 中,您可以在不离开浏览器的情况下,与 Kubernetes 集群执行大多数可能的交互。这篇博客文章分解了最新版本中引入的新功能,并概述了未来的路线图。
全功能的 Dashboard
由于社区和项目成员的大量贡献,我们能够为Kubernetes 1.3发行版提供许多新功能。我们一直在认真听取用户的反馈(参见摘要信息图表),并解决了最高优先级的请求和难点。 -->
Dashboard UI 现在处理所有工作负载资源。这意味着无论您运行什么工作负载类型,它都在 web 界面中可见,并且您可以对其进行操作更改。例如,可以使用Pet Sets修改有状态的 mysql 安装,使用部署对 web 服务器进行滚动更新,或使用守护程序安装集群监视。

除了查看资源外,还可以创建、编辑、更新和删除资源。这个特性支持许多用例。例如,您可以杀死一个失败的 pod,对部署进行滚动更新,或者只组织资源。您还可以导出和导入云应用程序的 yaml 配置文件,并将它们存储在版本控制系统中。

这个版本包括一个用于管理和操作用例的集群节点的 beta 视图。UI 列出集群中的所有节点,以便进行总体分析和快速筛选有问题的节点。details 视图显示有关该节点的所有信息以及指向在其上运行的 pod 的链接。

我们随发行版提供的还有许多小范围的新功能,即:支持命名空间资源、国际化、性能改进和许多错误修复(请参阅发行说明中的更多内容)。所有这些改进都会带来更好、更简单的产品用户体验。
Future Work
该团队对跨越多个用例的未来有着雄心勃勃的计划。我们还对所有功能请求开放,您可以在我们的问题跟踪程序上发布这些请求。
以下是我们接下来几个月的重点领域:
- Handle more Kubernetes resources - 显示集群用户可能与之交互的所有资源。一旦完成,dashboard 就可以完全替代cli。
- Monitoring and troubleshooting - 将资源使用统计信息/图表添加到 Dashboard 中显示的对象。这个重点领域将允许对云应用程序进行可操作的调试和故障排除。
- Security, auth and logging in - 使仪表板可从集群外部的网络访问,并使用自定义身份验证系统。
联系我们
我们很乐意与您交谈并听取您的反馈!
- 请在[SIG-UI邮件列表](https://groups.google.com/forum/向我们发送电子邮件!论坛/kubernetes sig ui)
- 在 kubernetes slack 上与我们聊天。#SIG-UI channel
- 参加我们的会议:东部时间下午4点。请参阅SIG-UI日历了解详细信息。
Citrix + Kubernetes = 全垒打
编者按:今天的客座文章来自 Citrix Systems 的产品管理总监 Mikko Disini,他分享了他们在 Kubernetes 集成上的合作经验。 _
技术合作就像体育运动。如果你能像一个团队一样合作,你就能在最后关头取得胜利。这就是我们对谷歌云平台团队的经验。
最近,我们与 Google 云平台(GCP)联系,代表 Citrix 客户以及更广泛的企业市场,希望就工作负载的迁移进行协作。此迁移需要将 [NetScaler Docker 负载均衡器]https://www.citrix.com/blogs/2016/06/20/the-best-docker-load-balancer-at-dockercon-in-seattle-this-week/) CPX 包含到 Kubernetes 节点中,并解决将流量引入 CPX 代理的任何问题。
为什么是 NetScaler 和 Kubernetes
- Citrix 的客户希望他们开始使用 Kubernetes 部署他们的容器和微服务体系结构时,能够像当初迁移到云计算时一样,享有 NetScaler 所提供的第 4 层到第 7 层能力
- Kubernetes 提供了一套经过验证的基础设施,可用来运行容器和虚拟机,并自动交付工作负载;
- NetScaler CPX 提供第 4 层到第 7 层的服务,并为日志和分析平台 NetScaler 管理和分析系统 提供高效的度量数据。
我希望我们所有与技术合作伙伴一起工作的经验都能像与 GCP 一起工作一样好。我们有一个列表,包含支持我们的用例所需要解决的问题。我们能够快速协作形成解决方案。为了解决这些问题,GCP 团队提供了深入的技术支持,与 Citrix 合作,从而使得 NetScaler CPX 能够在每台主机上作为客户端代理启动运行。
接下来,需要在 GCP 入口负载均衡器的数据路径中插入 NetScaler CPX,使 NetScaler CPX 能够将流量分散到前端 web 服务器。NetScaler 团队进行了修改,以便 NetScaler CPX 监听 API 服务器事件,并配置自己来创建 VIP、IP 表规则和服务器规则,以便跨前端应用程序接收流量和负载均衡。谷歌云平台团队提供反馈和帮助,验证为克服技术障碍所做的修改。完成了!
NetScaler CPX 用例在 Kubernetes 1.3 中提供支持。Citrix 的客户和更广泛的企业市场将有机会基于 Kubernetes 享用 NetScaler 服务,从而降低将工作负载转移到云平台的阻力。
您可以在此处了解有关 NetScaler CPX 的更多信息。
_ -- Mikko Disini,Citrix Systems NetScaler 产品管理总监
容器中运行有状态的应用!? Kubernetes 1.3 说 “是!”
编者注: 今天的来宾帖子来自 Diamanti 产品副总裁 Mark Balch,他将分享有关他们对 Kubernetes 所做的贡献的更多信息。
祝贺 Kubernetes 社区发布了另一个有价值的版本。 专注于有状态应用程序和联邦集群是我对 1.3 如此兴奋的两个原因。 Kubernetes 对有状态应用程序(例如 Cassandra、Kafka 和 MongoDB)的支持至关重要。 重要服务依赖于数据库、键值存储、消息队列等。 此外,随着应用程序的发展为全球数百万用户提供服务,仅依靠一个数据中心或容器集群将无法正常工作。 联邦集群允许用户跨多个集群和数据中心部署应用程序,以实现规模和弹性。
您可能之前听过我说过,容器是下一个出色的应用程序平台。 Diamanti 正在加速在生产中使用有状态应用程序的容器-在这方面,性能和易于部署非常重要。
应用程序不仅仅需要牛
除了诸如Web服务器之类的无状态容器(因为它们是可互换的,因此被称为“牛”)之外,用户越来越多地使用容器来部署有状态工作负载,以从“一次构建,随处运行”中受益并提高裸机效率/利用率。 这些“宠物”(之所以称为“宠物”,是因为每个宠物都需要特殊的处理)带来了新的要求,包括更长的生命周期,配置依赖项,有状态故障转移以及性能敏感性。 容器编排必须满足这些需求,才能成功部署和扩展应用程序。
输入 Pet Set,这是 Kubernetes 1.3 中的新对象,用于改进对状态应用程序的支持。 Pet Set 在每个数据库副本的启动阶段进行排序(例如),以确保有序的主/从配置。 Pet Set 还利用普遍存在的 DNS SRV 记录简化了服务发现,DNS SRV 记录是一种广为人知且长期了解的机制。
Diamanti 对 Kubernetes 的 FlexVolume 贡献 通过为持久卷提供低延迟存储并保证性能来实现有状态工作负载,包括从容器到媒体的强制服务质量。
联邦主义者
为应用可用性作规划的用户必须应对故障迁移问题并在整个地理区域内扩展。 跨集群联邦服务允许容器化的应用程序轻松跨多个集群进行部署。 联邦服务解决了诸如管理多个容器集群以及协调跨联邦集群的服务部署和发现之类的挑战。
像严格的集中式模型一样,联邦身份验证提供了通用的应用程序部署界面。 但是,由于每个集群都具有自治权,因此联邦会增加了在网络中断和其他事件期间在本地管理集群的灵活性。 跨集群联邦服务还可以提供跨容器集群应用一致的服务命名和采用,简化 DNS 解析。
很容易想象在将来的版本中具有跨集群联邦服务的强大多集群用例。 一个示例是根据治理,安全性和性能要求调度容器。 Diamanti 的调度程序扩展是在考虑了这一概念的基础上开发的。 我们的第一个实现使 Kubernetes 调度程序意识到每个集群节点本地的网络和存储资源。 将来,类似的概念可以应用于跨集群联邦服务的更广泛的放置控件。
参与其中
随着对有状态应用的兴趣日益浓厚,人们已经开始进一步增强 Kubernetes 存储的工作。 存储特别兴趣小组正在讨论支持本地存储资源的提案。 Diamanti 期待将 FlexVolume 扩展到包括更丰富的 API,这些 API 可以启用本地存储和存储服务,包括数据保护,复制和缩减。 我们还正在研究有关通过 Kubernetes 跨集群联邦服务改善应用程序放置,迁移和跨容器集群故障转移的建议。
加入对话并做出贡献! 这里是一些入门的地方:
-- Diamanti 产品副总裁 Mark Balch。 Twitter @markbalch
CoreOS Fest 2016: CoreOS 和 Kubernetes 在柏林(和旧金山)社区见面会
CoreOS Fest 2016 将汇集容器和开源分布式系统社区,其中包括 Kubernetes 领域的许多思想领袖。 这是第二次年度 CoreOS 社区会议,于5月9日至10日在柏林首次举行。 CoreOS 相信 Kubernetes 是提供 GIFEE(适用于所有人的 Google 的基础架构)服务的合适的容器编排组件。
在今年的 CoreOS Fest 上,有专门针对 Kubernetes 的报道,您将听到有关 Kubernetes 性能和可伸缩性,持续交付以及 Kubernetes,rktnetes,stackanetes 等各种主题的信息。 此外,这里将有各种各样的讲座,涵盖从入门讲习班到深入探讨容器和相关软件的方方面面。
不要错过柏林会议上的精彩演讲:
- 深入了解 Kubernetes 的性能和可扩展性 由 Google 的高级软件工程师 Filip Grzadkowski 演讲
- 在 Kubernetes 云中启动一个复杂的应用程序 由 immmr Gmbh(德国电信研发部门开发的服务)的运营和基础架构负责人Thomas Fricke 和 Jannis Rake-Revelant 演讲
- 我有 Kubernetes,现在呢? 由 Engine Yard 的 CTO 和 Deis 的创建者 Gabriel Monroy 演讲
- 当 rkt 与 Kubernetes 碰面时 :一个故障排除的故事 由 Sysdig 的软件工程师 Luca Marturana 演讲
- 使用 Kubernetes 部署电信应用程序 由华为技术有限公司高级工程师 Victor Hu 演讲
- 连续交付,Kubernetes 和您 由 Wercker首席执行官兼创始人 Micha Hernandez van Leuffen 演讲
- #GIFEE,更多容器,更多问题 由 CoreOS 构造负责人 Ed Rooth 演讲
- 带有 dex 的 Kubernetes 访问控制 由 CoreOS 的软件工程师 Eric Chiang 演讲
如果您无法到达柏林,Kubernetes 还是** CoreOS Fest 旧金山 ** 卫星事件 的焦点,这是一个专门针对 CoreOS 和 Kubernetes 的一日活动。 实际上, Google 的高级工程师, Kubernetes 的创建者之一 Tim Hockin 将以专门介绍 Kubernetes 更新的主题演讲拉开序幕。
专门针对 Kubernetes 的旧金山会议包括:
- Tim Hockin的主题演讲,Google 高级工程师
- 当 rkt 与 Kubernetes 相遇时:Sysdig 首席执行官 Loris Degioanni 的故障排除故事
- rktnetes: CoreOS的软件工程师Derek Gonyeo提供了容器运行时和 Kubernetes 的新功能
- 神奇的安全性蔓延:CoreOS 和 Kubernetes 上的安全,弹性微服务,浮力技术总监 Oliver Gould
** SF 的 Kubernetes 研讨会**:Kubernetes 入门, Google 开发人员计划工程师 Carter Morgan 和 Bill Prin 于5月10日(星期二)上午9:00至1:00 pm在 Google 旧金山办公室(Spear 街345号第7层)举办会议,之后将提供午餐。 席位有限,请 此处免费提供 RSVP 。
获取门票 :
- CoreOS Fest - 柏林, 位于 柏林会议中心 (酒店选项)
- 卫星事件在 旧金山, 在 111 米娜美术馆
要了解更多信息,请访问: coreos.com/fest/ 和 Twitter @CoreOSFest #CoreOSFest
-- Sarah Novotny, Kubernetes 社区管理者
SIG-ClusterOps: 提升 Kubernetes 集群的可操作性和互操作性
编者注: 本周我们将推出 Kubernetes 特殊兴趣小组;今天的帖子由 SIG-ClusterOps 团队负责,其任务是促进 Kubernetes 集群的可操作性和互操作性 -- 倾听,帮助和升级。
我们认为 Kubernetes 是大规模运行应用程序的绝佳方法! 不幸的是,存在一个引导问题:我们需要良好的方法来围绕 Kubernetes 构建安全可靠的扩展环境。 虽然平台管理的某些部分利用了平台(很酷!),这有一些基本的操作主题需要解决,还有一些问题(例如升级和一致性)需要回答。
输入 Cluster Ops SIG – 在平台下工作以保持其运行的社区成员。
我们对 Cluster Ops 的目标是首先成为一个人对人的社区,其次才是意见、文档、测试和脚本的来源。 这意味着我们将花费大量时间和精力来简单地比较有关工作内容的注释并讨论实际操作。 这些互动为我们提供了形成意见的数据。 这也意味着我们可以利用实际经验来为项目提供信息。
我们旨在成为对该项目进行运营审查和反馈的论坛。 为了使 Kubernetes 取得成功,运营商需要通过每周参与并收集调查数据在项目中拥有重要的声音。 我们并不是想对操作发表意见,但我们确实想创建一个协调的资源来收集项目的运营反馈。 作为一个公认的团体,操作员更容易获得影响力。
现实世界中的可交付成果如何?
我们也有切实成果的计划。 我们已经在努力实现具体的交付成果,例如参考架构,工具目录,社区部署说明和一致性测试。 Cluster Ops 希望成为运营资源的交换所。 我们将根据实际经验和经过战斗测试的部署来进行此操作。
联系我们。
集群运营可能会很辛苦–别一个人做。 我们在这里倾听,在我们可以帮助的时候提供帮助,而在我们不能帮助的时候向上一级反映。 在以下位置加入对话:
- 在 Cluster Ops Slack 频道 与我们聊天
- 通过 Cluster Ops SIG 电子邮件列表 给我们发送电子邮件
SIG Cluster Ops 每周四在太平洋标准时间下午 13:00 开会,您可以通过 视频环聊 加入我们并查看最新的 会议记录 了解所涉及的议程和主题。
-- RackN 首席执行官 Rob Hirschfeld
“SIG-Networking:1.3 版本引入 Kubernetes 网络策略 API”
编者注:本周我们将推出 Kubernetes 特殊兴趣小组、 Network-SIG 小组今天的帖子描述了 1.3 版中的网络策略 API-安全,隔离和多租户策略。
自去年下半年以来,Kubernetes SIG-Networking 一直在定期开会,致力于将网络策略引入 Kubernetes,我们开始看到这个努力的结果。
许多用户面临的一个问题是,Kubernetes 的开放访问网络策略不适用于需要对访问容器或服务的流量进行更精确控制的应用程序。 如今,这种应用可能是多层应用,其中仅允许来自某个相邻层的流量。 但是,随着新的云原生应用不断通过组合微服务构建出来,对服务间流动的数据进行控制的能力变得更加重要。
在大多数 IaaS 环境(公共和私有)中,通过允许 VM 加入“安全组(Security Group)”来提供这种控制, 其中“安全组”成员的流量由网络策略或访问控制列表( ACL )定义,并由网络数据包过滤器实施。
SIG-Networking 开始这项工作时的第一步是辩识需要特定网络隔离以增强安全性的 特定用例场景。 确保所定义的 API 适用于这些简单和常见的用例非常重要,因为它们为在 Kubernetes 内 实现更复杂的网络策略以支持多租户奠定了基础。
基于这些场景,团队考虑了几种可能的方法,并定义了一个最小的 策略规范 。 基本思想是,如果按命名空间启用了隔离,则特定流量类型被允许时会选择特定的 Pod。
快速支持此实验性 API 的最简单方法是对 API 服务器的 ThirdPartyResource 扩展,今天在 Kubernetes 1.2 中就可以实现。
如果您不熟悉它的工作方式,则可以通过定义 ThirdPartyResources 来扩展 Kubernetes API ,ThirdPartyResources 在指定的 URL 上创建一个新的 API 端点。
third-party-res-def.yaml
kind: ThirdPartyResource
apiVersion: extensions/v1beta1
metadata:
name: network-policy.net.alpha.kubernetes.io
description: "Network policy specification"
versions:
- name: v1alpha1
$kubectl create -f third-party-res-def.yaml
这将创建一个 API 端点(每个名称空间一个):
/net.alpha.kubernetes.io/v1alpha1/namespace/default/networkpolicys/
第三方网络控制器现在可以在这些端点上进行侦听,并在创建,修改或删除资源时根据需要做出反应。 注意:在即将发布的 Kubernetes 1.3 版本中-当网络政策 API 以 beta 形式发布时-无需创建如上所示的 ThirdPartyResource API 端点。
默认情况下,网络隔离处于关闭状态,以便所有Pod都能正常通信。 但是,重要的是要知道,启用网络隔离后,所有命名空间中所有容器的所有流量都会被阻止,这意味着启用隔离将改变容器的行为
通过在名称空间上定义 network-isolation 注解来启用网络隔离,如下所示:
net.alpha.kubernetes.io/network-isolation: [on | off]
启用网络隔离后,必须应用显式网络策略才能启用 Pod 通信。
可以将策略规范应用于命名空间,以定义策略的详细信息,如下所示:
POST /apis/net.alpha.kubernetes.io/v1alpha1/namespaces/tenant-a/networkpolicys/
{
"kind": "NetworkPolicy",
"metadata": {
"name": "pol1"
},
"spec": {
"allowIncoming": {
"from": [
{ "pods": { "segment": "frontend" } }
],
"toPorts": [
{ "port": 80, "protocol": "TCP" }
]
},
"podSelector": { "segment": "backend" }
}
}
在此示例中,‘ tenant-a ’名称空间将按照指示应用策略‘ pol1 ’。 具体而言,带有segment标签 ‘ 后端 ’ 的容器将允许接收来自带有“segment**标签‘ frontend ’的容器的端口80上的TCP流量。
现今,Romana, OpenShift, OpenContrail 和 Calico 支持应用于名称空间和容器的网络策略。 思科和 VMware 也在努力实施。 Romana 和 Calico 最近都在 KubeCon 上使用 Kubernetes 1.2 演示了这些功能。 你可以在此处观看他们的演讲:Romana (slides), Calico (slides)。
它是如何工作的?
每个解决方案都有其自己的特定实现细节。 今天,他们依靠某种形式的主机执行机制,但是将来的实现也可以构建为在虚拟机管理程序上,甚至直接由网络本身应用策略构建。
外部策略控制软件(具体情况因实现而异)将监视新 API 终结点是否正在创建容器和/或正在应用新策略。 当发生需要配置策略的事件时,侦听器将识别出更改,并且控制器将通过配置接口并应用策略来做出响应。 下图显示了 API 侦听器和策略控制器,它通过主机代理在本地应用网络策略来响应更新。 主机上的网络接口由主机上的 CNI 插件配置(未显示)。

如果您由于网络隔离和/或安全性问题而一直拒绝使用 Kubernetes 开发应用程序,那么这些新的网络策略将为您提供所需的控制功能大有帮助。 无需等到 Kubernetes 1.3,因为网络策略现在作为实验性 API 可用,已启用 ThirdPartyResource。
如果您对 Kubernetes 和网络感兴趣,有几种参与方式-请通过以下方式加入我们:
- 我们的 Kubernetes Networking Special Interest Group 电子邮件列表
网络“特殊兴趣小组”,每两周一次,在太平洋时间下午 3 点(15:00)在SIG-Networking 环聊开会。
--Pani Networks 联合创始人 Chris Marino
在 Rancher 中添加对 Kuernetes 的支持
今天的来宾帖子由 Rancher Labs(用于管理容器的开源软件平台)的首席架构师 Darren Shepherd 撰写。
在过去的一年中,我们看到希望在其软件开发和IT组织中利用容器的公司数量激增。 为了实现这一目标,组织一直在研究如何构建集中式的容器管理功能,该功能将使用户可以轻松访问容器,同时集中管理IT组织的可见性和控制力。 2014年,我们启动了开源 Rancher 项目,通过构建容器管理平台来解决此问题。
最近,我们发布了 Rancher v1.0。 在此最新版本中,用于管理容器的开源软件平台 Rancher 现在在创建环境时支持 Kubernetes 作为容器编排框架。 现在,使用 Rancher 启动 Kubernetes 环境是完全自动化的,只需 5 至 10 分钟即可交付运行正常的集群。
我们创建 Rancher 的目的是为组织提供完整的容器管理平台。 作为其中的一部分,我们始终支持使用 Docker API 和 Docker Compose 在本地部署 Docker 环境。 自成立以来, Kubernetes 的运营成熟度给我们留下了深刻的印象,而在此版本中,我们使得其可以在同一管理平台上部署各种容器编排和调度框架。
添加 Kubernetes 使用户可以访问增长最快的平台之一,用于在生产中部署和管理容器。 我们将在 Rancher 中提供一流的 Kubernetes 支持,并将继续支持本机 Docker 部署。
将 Kubernetes 带到 Rancher

{kind=link}
{kind=link}
{kind=link}
{kind=link}
我们的平台已经可以扩展为各种不同的包装格式,因此我们对拥抱 Kubernetes 感到乐观。 没错,作为开发人员,与 Kubernetes 项目一起工作是一次很棒的经历。 该项目的设计使这一操作变得异常简单,并且我们能够利用插件和扩展来构建 Kubernetes 发行版,从而利用我们的基础架构和应用程序服务。 例如,我们能够将 Rancher 的软件定义的网络,存储管理,负载平衡,DNS 和基础结构管理功能直接插入 Kubernetes,而无需更改代码库。
更好的是,我们已经能够围绕 Kubernetes 核心功能添加许多服务。 例如,我们在 Kubernetes 上实现了常用的 应用程序目录 。 过去,我们曾使用 Docker Compose 定义应用程序模板,但是在此版本中,我们现在支持 Kubernetes 服务、副本控制器和和 Pod 来部署应用程序。 使用目录,用户可以连接到 git 仓库并自动部署和升级作为 Kubernetes 服务部署的应用。 然后,用户只需单击一下按钮,即可配置和部署复杂的多节点企业应用程序。 升级也是完全自动化的,并集中向用户推出。
回馈
与 Kubernetes 一样,Rancher 是一个开源软件项目,任何人均可免费使用,并且不受任何限制地分发给社区。 您可以在 GitHub 上找到 Rancher 的所有源代码,即将发布的版本和问题。 我们很高兴加入 Kubernetes 社区,并期待与所有其他贡献者合作。 在Rancher here 中查看有关 Kubernetes 新支持的演示。
-- Rancher Labs 首席架构师 Darren Shepherd
KubeCon EU 2016:伦敦 Kubernetes 社区
KubeCon EU 2016 是首届欧洲 Kubernetes 社区会议,紧随 2015 年 11 月召开的北美会议。KubeCon 致力于为 Kubernetes 爱好者、产品用户和周围的生态系统提供教育和社区参与。
快来加入我们在伦敦,与 Kubernetes 社区的数百人一起出去,体验各种深入的技术专家讲座和用例。
不要错过这些优质的演讲:
“Kubernetes 硬件黑客:通过旋钮、推杆和滑块探索 Kubernetes API” 演讲者 Ian Lewis 和 Brian Dorsey,谷歌开发布道师* http://sched.co/6Bl3
“rktnetes: 容器运行时和 Kubernetes 的新功能” 演讲者 Jonathan Boulle, CoreOS 的主程 -* http://sched.co/6BY7
“Kubernetes 文档:贡献、修复问题、收集奖金” 作者:John Mulhausen,首席技术作家,谷歌 -* http://sched.co/6BUP
“OpenStack 在 Kubernetes 的世界中扮演什么角色?” 作者:Thierry carez, OpenStack 基金会工程总监 -* http://sched.co/6BYC
“容器调度的实用指南” 作者:Mandy Waite,开发者倡导者,谷歌 -* http://sched.co/6BZa
“《纽约时报》编辑部正在制作 Kubernetes” Eric Lewis,《纽约时报》网站开发人员 -* http://sched.co/67f2
“使用 NGINX 为 Kubernetes 创建一个高级负载均衡解决方案” 作者:Andrew Hutchings, NGINX 技术产品经理 -* http://sched.co/6Bc9
在这里获取您的 KubeCon EU 门票。
会场地址:CodeNode * 英国伦敦南广场 10 号
酒店住宿:酒店
网站:[kubecon.io] (https://www.kubecon.io/)
推特:[@KubeConio] (https://twitter.com/kubeconio)
谷歌是 KubeCon EU 2016 的钻石赞助商。下个月 3 月 10 - 11 号来伦敦,参观 13 号展位,了解 Kubernetes,Google Container Engine(GKE),Google Cloud Platform 的所有信息!
_KubeCon 是由 KubeAcademy、LLC 组织的,这是一个由社区驱动的开发者团体,专注于开发人员的教育和 kubernetes 的推广 -* Sarah Novotny, 谷歌的 Kubernetes 社区经理
Kubernetes 社区会议记录 - 20160218
2月18号 - kmachine 演示、SIG clusterops 成立、新的 k8s.io 网站预览、1.2 版本更新和 1.3 版本计划
Kubernetes 贡献社区会议大多在星期四的 10:00 召开,通过视频会议讨论项目现有情况。这里是最近一次会议的笔记。
- 记录员: Rob Hirschfeld
- 示例 (10 min): kmachine [Sebastien Goasguen]
- 开始 :01 视频介绍
- 为 Kubernetes 创建 Docker tools 的镜像 (例如 machine,compose 等等)
- kmachine ( 它是 Docker Machine的一个分叉, 因此两者有相同的 endpoints)
- 演示案例 (10 min): 开始时间 :15
- SIG 汇报启动会
- 周五进行 Cluster Ops 启动会 (doc). [Rob Hirschfeld]
- 时区讨论 [:22]
- 当前时区不适合亚洲。
- 考虑轮转时间 - 每一个月一次
- 大约 5 或者 6 PT
- Rob 建议把例会时间上调一些
- k8s.io 网站 概述 [John Mulhausen] [:27]
- 使用 github 进行文档操作。你可以通过网站进行 fork 操作并且做一个 pull request 请求
- Google 将会提供一个 "doc bounty","doc bounty" 是一个让你得到 GCP 积分来为你的文档使用的地方
- 使用 Jekyll 创建网站 (例如 the ToC)
- 100% 使用 GitHub 页面原则; 没有脚本或者插件外挂, 仅仅只有 fork/clone,edit,和 push 操作
- 希望能在 Kubecon EU 启动
- 主页唯一概述地址: http://kub.unitedcreations.xyz
- 1.2 版本观看 [T.J. Goltermann] [:38]
- 1.3 版本更新计划 [T.J. Goltermann]
- GSoC 分享会 -- 截止日期 2月19号 [Sarah Novotny]
- 3月10号 会议? [Sarah Novotny]
想要加入 Kubernetes 社区的人,考虑加入 [Slack channel] 3频道, 在 GitHub 上看看Kubernetes project, 或者加入Kubernetes-dev Google group。
如果你对此真的充满激情,你可以做完上述所有事情并加入我们的下一次社区对话 - 在2016年2月25日。
请将您自己或您想了解的主题添加到agenda,加入this group组即可获得日历邀请。
"https://youtu.be/L5BgX2VJhlY?list=PL69nYSiGNLP1pkHsbPjzAewvMgGUpkCnJ"
_-- Kubernetes 社区 _
Kubernetes 社区会议记录 - 20160204
2 月 4 日 - rkt 演示(祝贺 1.0 版本,CoreOS!),eBay 将 k8s 放在 Openstack 上并认为 Openstack 在 k8s,SIG 和片状测试激增方面取得了进展。
Kubernetes 贡献社区在每周四 10:00 PT 开会,通过视频会议讨论项目状态。以下是最近一次会议的笔记。
- 书记员:Rob Hirschfeld
- 演示视频(20 分钟):CoreOS rkt + Kubernetes [Shaya Potter]
- 期待在未来几个月内看到与rkt和k8s的整合(“rkt-netes”)。 还没有集成到 v1.2 版本中。
- Shaya 做了一个演示(8分钟的会议视频参考)
- rkt 的 CLI 显示了旋转容器
- [注意:音频在点数上是乱码]
- 关于 k8s&rkt 整合的讨论
- 下周 rkt 社区同步: https://groups.google.com/forum/#!topic/rkt-dev/FlwZVIEJGbY
- Dawn Chen:
- 将 rkt 与 kubernetes 集成的其余问题:1)cadivsor 2) DNS 3)与日志记录相关的错误
- 但是需要在 e2e 测试套件上做更多的工作
- 用例(10分钟):在 OpenStack 上的 eBay k8s 和 k8s 上的 OpenStack [Ashwin Raveendran]
- eBay 目前正在 OpenStack 上运行 Kubernetes
- eBay 的目标是管理带有 k8s 的 OpenStack 控制平面。目标是实现升级。
- OpenStack Kolla 为控制平面创建容器。使用 Ansible+Docker 来管理容器。
- 致力于 k8s 控制计划管理 - Saltstack 被证明是他们想运营的规模的管理挑战。寻找 k8s 控制平面的自动化管理。
- SIG 报告
- 测试更新 [Jeff, Joe, 和 Erick]
- 努力使有助于 K8s 的工作流程更容易理解
- pull/19714有 bot 流程图来帮助用户理解
- 需要一种一致的方法来运行测试 w/hacking 配置脚本(你现在必须伪造一个 Jenkins 进程)
- 想要创建必要的基础设施,使测试设置不那么薄弱
- 想要将测试开始(单次或完整)与 Jenkins分离
- 目标是指出你有一个可以指向任何集群的脚本
- 演示包括 Google 内部视图 - 努力尝试获取外部视图。
- 希望能够收集测试运行结果
- Bob Wise 不赞同在 v1.3 版本进行测试方面的基础设施建设。
- 关于测试实践的长期讨论…
- 我们希望在多个平台上进行测试的共识。
- 为测试报告提供一个全面转储会很有帮助
- 可以使用"phone-home"收集异常
- 努力使有助于 K8s 的工作流程更容易理解
- 1.2发布观察
- CoC [Sarah]
- GSoC [Sarah]
要参与 Kubernetes 社区,请考虑加入我们的 Slack 频道,查看 GitHub 上的 Kubernetes 项目,或加入 Kubernetes-dev Google 小组。 如果你真的很兴奋,你可以完成上述所有工作并加入我们的下一次社区对话 - 2016 年 2 月 11 日。 请将你自己或你想要了解的主题添加到议程并通过加入此组来获取日历邀请。
"https://youtu.be/IScpP8Cj0hw?list=PL69nYSiGNLP1pkHsbPjzAewvMgGUpkCnJ"
容器世界现状,2016 年 1 月
新年伊始,我们进行了一项调查,以评估容器世界的现状。 我们已经准备好发送 2 月版但在此之前,让我们从 119 条回复中看一下 1 月的数据(感谢您的参与!)。
关于这些数字的注释: 首先,您可能会注意到,这些数字加起来并不是 100%,在大多数情况下,选择不是唯一的,因此给出的百分比是选择特定选择的所有受访者的百分比。 其次,虽然我们尝试覆盖广泛的云社区,但调查最初是通过 Twitter 发送给@brendandburns,@kelseyhightower,@sarahnovotny,@juliaferraioli,@thagomizer_rb,因此受众覆盖可能并不完美。 我们正在努力扩大样本数量(我是否提到过2月份的调查?点击立即参加)。
言归正传,来谈谈数据:
首先,很多人正在使用容器!目前有 71% 的人正在使用容器,而其中有 24% 的人正在考虑尽快使用它们。 显然,这表明样本集有些偏颇。 在更广泛的社区中,容器使用的数量有所不同,但绝对低于 71%。 因此,对这些数字的其余部分要持怀疑态度。
那么人们在使用容器做什么呢? 超过 80% 的受访者使用容器进行开发,但只有 50% 的人在生产环境下使用容器。 但是他们有计划很快投入到生产环境之中,78% 的容器用户表示了意愿。
你们在哪里部署容器? 你的笔记本电脑显然是赢家,53% 的人使用笔记本电脑。 接下来是 44% 的人在自己的 VM 上运行(Vagrant?OpenStack?我们将在2月的调查中尝试深入研究),然后是 33% 的人在物理基础架构上运行,而 31% 的人在公共云 VM 上运行。
如何部署容器? 你们当中有 54% 的人使用 Kubernetes,虽然看起来有点受样本集的偏见(请参阅上面的注释),但真是令人惊讶,但有 45% 的人在使用 shell 脚本。 是因为 Kubernetes 存储库中正在运行大量(且很好)的 Bash 脚本吗? 继续下去,我们可以看到真相…… 数据显示,25% 使用 CAPS (Chef/Ansible/Puppet/Salt)系统,约 13% 使用 Docker Swarm、Mesos 或其他系统。
最后,我们让人们自由回答使用容器的挑战。 这儿有一些进行了分组和复制的最有趣的答案:
开发复杂性
- “孤立的开发环境/工作流程可能是零散的,调试容器时可以轻松访问日志等工具,但有时却不太直观,需要大量知识来掌握整个基础架构堆栈和部署/ 更新 kubernetes,到底层网络等。”
- “迁移开发者的工作流程。 那些不熟悉容器、卷等的人只是想工作。”
安全
- “网络安全”
- “Secrets”
不成熟
- “缺乏全面的非专有标准(例如,非 Docker),例如 runC / OCI”
- “仍处于早期阶段,只有很少的工具和许多缺少的功能。”
- “糟糕的 CI 支持,很多工具仍然处于非常早期的阶段。”
- "我们以前从未那样做过。"
复杂性
- “网络支持, 为 kubernetes 在裸机上为每个 Pod 提供 IP”
- “集群化还是太难了”
- “设置 Mesos 和 Kubernetes 太复杂了!!”
数据
- “卷缺乏灵活性(与 VM,物理硬件等相同的问题)”
- “坚持不懈”
- “存储”
- “永久数据”
下载完整的调查结果 链接 (CSV 文件)。
_Up-- Brendan Burns,Google 软件工程师
Kubernetes 社区会议记录 - 20160114
1 月 14 日 - RackN 演示、测试问题和 KubeCon EU CFP。
记录者:Joe Beda
演示:在 Metal,AWS 和其他平台上使用 Digital Rebar 自动化部署,来自 RackN 的 Rob Hirschfeld 和 Greg Althaus。
Greg Althaus。首席技术官。Digital Rebar 是产品。裸机置备工具。
检测硬件,启动硬件,配置 RAID、操作系统并部署工作负载。
处理 Kubernetes 的工作负载。
看到始于云,然后又回到裸机的趋势。
新的提供商模型可以在云和裸机上使用预配置系统。
UI, REST API, CLI
演示:数据包--裸机即服务
4个正在运行的节点归为一个“部署”
每个节点选择的功能性角色/操作。
分解的 kubernetes 带入可以订购和同步的单元。依赖关系树--诸如在启动 k8s master 之前等待 etcd 启动的事情。
在封面下使用 Ansible。
演示带来了另外5个节点--数据包将构建这些节点
从 ansible 中提取基本参数。诸如网络配置,DNS 设置等内容。
角色层次结构引入了其他组件--使节点成为主节点会带来一系列其他必要的角色。
通过简单的配置文件将所有这些组合到命令行工具中。
转发:扩展到多个云以进行测试部署。还希望在裸机和云之间创建拆分/复制。
问:秘密?
答:使用 Ansible。构建自己的证书,然后分发它们。想要将它们抽象出来并将其推入上游。问:您是否支持使用 PXE 引导从真正的裸机启动?
答:是的--将发现裸机系统并安装操作系统,安装 ssh 密钥,建立网络等。
[来自 SIG-scalability]问:转到 golang 1.5 的状态如何?
答:在 HEAD,我们是1.5,但也会支持1.4。有一些跟稳定性相关的问题,但看起来现在情况稳定了。还希望使用1.5供应商实验。不再使用 godep。但只有在基线为1.5之前,才能这样做。
Sarah:现在我们正在工作的事情之一就是提供做这些事的小奖品。云积分,T恤,扑克筹码,小马。
[来自可伸缩性兴趣小组]问:清理基于 jenkins 的提交队列的状态如何?社区可以做些什么来帮助您?
答:最近几天一直很艰难。每个方面都应该有相关的问题。在这些问题上有一个片状标签。仍在进行联盟测试。现在有更多测试资源。随着新人们的进步,事情有希望进展的更快。这对让很多人在他们的环境中进行端到端测试非常有用。
Erick Fjeta 是新的测试负责人
Brendan很乐意帮助分享有关 Jenkins 设置的详细信息,但这不是必须的。
联盟可以使用 Jenkins API,但不需要 Jenkins 本身。
Joe 嘲笑以 Jenkins 的方式运行 e2e 测试是一件棘手的事实。布伦丹说,它应该易于运行。乔再看一眼。
符合性测试? etune 做到了,但他不在。 -重新访问20150121
* 3月10日至11日在伦敦举行。地点将于本周宣布。请发送讲话!CFP 截止日期为2月5日。
令人兴奋。看起来是700-800人。比SF版本大(560 人)。
提前购买门票--早起的鸟儿价格将很快结束,价格将上涨到100英镑。
为演讲者提供住宿吗?
三星 Bob 的提问:我们可以针对以下问题获得更多警告/计划吗:
答:Sarah -- 我不太早就听说过这些东西,但会尝试整理一下清单。努力使 kubernetes.io 上的事件页面更易于使用。
答:JJ -- 我们将确保我们早日为下届美国会议提供更多信息。
规模测试[RackN 的 Rob Hirschfeld] -- 如果您想帮助进行规模测试,我们将非常乐意为您提供帮助。
Bob 邀请 Rob 加入规模特别兴趣小组。
还有一个大型的裸机集群,通过 CNCF(来自 Intel)也很有用。尚无确切日期。
笔记/视频将发布在 k8s 博客上。(未录制20150114的视频。失败。)
要加入 Kubernetes 社区,请考虑加入我们的Slack 频道,看看GitHub上的Kubernetes 项目,或加入Kubernetes-dev Google 论坛。如果您真的对此感到兴奋,则可以完成上述所有操作,并加入我们的下一次社区对话-2016年1月27日。请将您自己或您想了解的话题添加到议程中,并获得一个加入此群组进行日历邀请。
为什么 Kubernetes 不用 libnetwork
在 1.0 版本发布之前,Kubernetes 已经有了一个非常基础的网络插件形式-大约在引入 Docker’s libnetwork 和 Container Network Model (CNM) 的时候。与 libnetwork 不同,Kubernetes 插件系统仍然保留它的 'alpha' 名称。现在 Docker 的网络插件支持已经发布并得到支持,我们发现一个明显的问题是 Kubernetes 尚未采用它。毕竟,供应商几乎肯定会为 Docker 编写插件-我们最好还是用相同的驱动程序,对吧?
在进一步说明之前,重要的是记住 Kubernetes 是一个支持多种容器运行时的系统, Docker 只是其中之一。配置网络只是每一个运行时的一个方面,所以当人们问起“ Kubernetes 会支持CNM吗?”,他们真正的意思是“ Kubernetes 会支持 Docker 运行时的 CNM 驱动吗?”如果我们能够跨运行时实现通用的网络支持会很棒,但这不是一个明确的目标。
实际上, Kubernetes 还没有为 Docker 运行时采用 CNM/libnetwork 。事实上,我们一直在研究 CoreOS 提出的替代 Container Network Interface (CNI) 模型以及 App Container (appc) 规范的一部分。为什么我们要这么做?有很多技术和非技术的原因。
首先,Docker 的网络驱动程序设计中存在一些基本假设,这些假设会给我们带来问题。
Docker 有一个“本地”和“全局”驱动程序的概念。本地驱动程序(例如 "bridge" )以机器为中心,不进行任何跨节点协调。全局驱动程序(例如 "overlay" )依赖于 libkv (一个键值存储抽象库)来协调跨机器。这个键值存储是另一个插件接口,并且是非常低级的(键和值,没有其他含义)。 要在 Kubernetes 集群中运行类似 Docker's overlay 驱动程序,我们要么需要集群管理员来运行 consul, etcd 或 zookeeper 的整个不同实例 (see multi-host networking) 否则我们必须提供我们自己的 libkv 实现,那被 Kubernetes 支持。
后者听起来很有吸引力,并且我们尝试实现它,但 libkv 接口是非常低级的,并且架构在内部定义为 Docker 。我们必须直接暴露我们的底层键值存储,或者提供键值语义(在我们的结构化API之上,它本身是在键值系统上实现的)。对于性能,可伸缩性和安全性原因,这些都不是很有吸引力。最终结果是,当使用 Docker 网络的目标是简化事情时,整个系统将显得更加复杂。
对于愿意并且能够运行必需的基础架构以满足 Docker 全局驱动程序并自己配置 Docker 的用户, Docker 网络应该“正常工作。” Kubernetes 不会妨碍这样的设置,无论项目的方向如何,该选项都应该可用。但是对于默认安装,实际的结论是这对用户来说是一个不应有的负担,因此我们不能使用 Docker 的全局驱动程序(包括 "overlay" ),这消除了使用 Docker 插件的很多价值。
Docker 的网络模型做出了许多对 Kubernetes 无效的假设。在 docker 1.8 和 1.9 版本中,它包含一个从根本上有缺陷的“发现”实现,导致容器中的 /etc/hosts 文件损坏 (docker #17190) - 并且这不容易被关闭。在 1.10 版本中,Docker 计划 捆绑一个新的DNS服务器,目前还不清楚是否可以关闭它。容器级命名不是 Kubernetes 的正确抽象 - 我们已经有了自己的服务命名,发现和绑定概念,并且我们已经有了自己的 DNS 模式和服务器(基于完善的 SkyDNS )。捆绑的解决方案不足以满足我们的需求,但不能禁用。
与本地/全局拆分正交, Docker 具有进程内和进程外( "remote" )插件。我们调查了是否可以绕过 libnetwork (从而跳过上面的问题)并直接驱动 Docker remote 插件。不幸的是,这意味着我们无法使用任何 Docker 进程中的插件,特别是 "bridge" 和 "overlay",这再次消除了 libnetwork 的大部分功能。
另一方面, CNI 在哲学上与 Kubernetes 更加一致。它比 CNM 简单得多,不需要守护进程,并且至少有合理的跨平台( CoreOS 的 rkt 容器运行时支持它)。跨平台意味着有机会启用跨运行时(例如 Docker , Rocket , Hyper )运行相同的网络配置。 它遵循 UNIX 的理念,即做好一件事。
此外,包装 CNI 插件并生成更加个性化的 CNI 插件是微不足道的 - 它可以通过简单的 shell 脚本完成。 CNM 在这方面要复杂得多。这使得 CNI 对于快速开发和迭代是有吸引力的选择。早期的原型已经证明,可以将 kubelet 中几乎 100% 的当前硬编码网络逻辑弹出到插件中。
我们调查了为 Docker 编写 "bridge" CNM驱动程序 并运行 CNI 驱动程序。事实证明这非常复杂。首先, CNM 和 CNI 模型非常不同,因此没有一种“方法”协调一致。 我们仍然有上面讨论的全球与本地和键值问题。假设这个驱动程序会声明自己是本地的,我们必须从 Kubernetes 获取有关逻辑网络的信息。
不幸的是, Docker 驱动程序很难映射到像 Kubernetes 这样的其他控制平面。具体来说,驱动程序不会被告知连接容器的网络名称 - 只是 Docker 内部分配的 ID 。这使得驱动程序很难映射回另一个系统中存在的任何网络概念。
这个问题和其他问题已由网络供应商提出给 Docker 开发人员,并且通常关闭为“按预期工作”,(libnetwork #139, libnetwork #486, libnetwork #514, libnetwork #865, docker #18864),即使它们使非 Docker 第三方系统更难以与之集成。在整个调查过程中, Docker 明确表示他们对偏离当前路线或委托控制的想法不太欢迎。这对我们来说非常令人担忧,因为 Kubernetes 补充了 Docker 并增加了很多功能,但它存在于 Docker 之外。
出于所有这些原因,我们选择投资 CNI 作为 Kubernetes 插件模型。这会有一些不幸的副作用。它们中的大多数都相对较小(例如, docker inspect 不会显示 IP 地址),特别是由 docker run 启动的容器可能无法与 Kubernetes 启动的容器通信,如果网络集成商想要与 Kubernetes 完全集成,则必须提供 CNI 驱动程序。但另一方面, Kubernetes 将变得更简单,更灵活,早期引入的许多丑陋的(例如配置 Docker 使用我们的网桥)将会消失。
当我们沿着这条道路前进时,我们会保持开放,以便更好地整合和简化。如果您对我们如何做到这一点有所想法,我们真的希望听到它们 - 在 slack 或者 network SIG mailing-list 找到我们。
Tim Hockin, Software Engineer, Google
Kubernetes 和 Docker 简单的 leader election
概述
Kubernetes 简化了集群上运行的服务的部署和操作管理。但是,它也简化了这些服务的发展。在本文中,我们将看到如何使用 Kubernetes 在分布式应用程序中轻松地执行 leader election。分布式应用程序通常为了可靠性和可伸缩性而复制服务的任务,但通常需要指定其中一个副本作为负责所有副本之间协调的负责人。
通常在 leader election 中,会确定一组成为领导者的候选人。这些候选人都竞相宣布自己为领袖。其中一位候选人获胜并成为领袖。一旦选举获胜,领导者就会不断地“信号”以表示他们作为领导者的地位,其他候选人也会定期地做出新的尝试来成为领导者。这样可以确保在当前领导因某种原因失败时,快速确定新领导。
实现 leader election 通常需要部署 ZooKeeper、etcd 或 Consul 等软件并将其用于协商一致,或者也可以自己实现协商一致算法。我们将在下面看到,Kubernetes 使在应用程序中使用 leader election 的过程大大简化。
####在 Kubernetes 实施领导人选举
Leader election 的首要条件是确定候选人的人选。Kubernetes 已经使用 Endpoints 来表示组成服务的一组复制 pod,因此我们将重用这个相同的对象。(旁白:您可能认为我们会使用 ReplicationControllers,但它们是绑定到特定的二进制文件,而且通常您希望只有一个领导者,即使您正在执行滚动更新)
要执行 leader election,我们使用所有 Kubernetes api 对象的两个属性:
- ResourceVersions - 每个 API 对象都有一个惟一的 ResourceVersion,您可以使用这些版本对 Kubernetes 对象执行比较和交换
- Annotations - 每个 API 对象都可以用客户端使用的任意键/值对进行注释。
给定这些原语,使用 master election 的代码相对简单,您可以在这里找到here。我们自己来做吧。
$ kubectl run leader-elector --image=gcr.io/google_containers/leader-elector:0.4 --replicas=3 -- --election=example
这将创建一个包含3个副本的 leader election 集合:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
leader-elector-inmr1 1/1 Running 0 13s
leader-elector-qkq00 1/1 Running 0 13s
leader-elector-sgwcq 1/1 Running 0 13s
要查看哪个pod被选为领导,您可以访问其中一个 pod 的日志,用您自己的一个 pod 的名称替换
${pod_name}, (e.g. leader-elector-inmr1 from the above)
$ kubectl logs -f ${name}
leader is (leader-pod-name)
…或者,可以直接检查 endpoints 对象:
_'example' 是上面 kubectl run … 命令_中候选集的名称
$ kubectl get endpoints example -o yaml
现在,要验证 leader election 是否实际有效,请在另一个终端运行:
$ kubectl delete pods (leader-pod-name)
这将删除现有领导。由于 pod 集由 replication controller 管理,因此新的 pod 将替换已删除的pod,确保复制集的大小仍为3。通过 leader election,这三个pod中的一个被选为新的领导者,您应该会看到领导者故障转移到另一个pod。因为 Kubernetes 的吊舱在终止前有一个 grace period,这可能需要30-40秒。
Leader-election container 提供了一个简单的 web 服务器,可以服务于任何地址(e.g. http://localhost:4040)。您可以通过删除现有的 leader election 组并创建一个新的 leader elector 组来测试这一点,在该组中,您还可以向 leader elector 映像传递--http=(host):(port) 规范。这将导致集合中的每个成员通过 webhook 提供有关领导者的信息。
# delete the old leader elector group
$ kubectl delete rc leader-elector
# create the new group, note the --http=localhost:4040 flag
$ kubectl run leader-elector --image=gcr.io/google_containers/leader-elector:0.4 --replicas=3 -- --election=example --http=0.0.0.0:4040
# create a proxy to your Kubernetes api server
$ kubectl proxy
然后您可以访问:
http://localhost:8001/api/v1/proxy/namespaces/default/pods/(leader-pod-name):4040/
你会看到:
{"name":"(name-of-leader-here)"}
有副手的 leader election
好吧,那太好了,你可以通过 HTTP 进行leader election 并找到 leader,但是你如何从自己的应用程序中使用它呢?这就是 sidecar 的由来。Kubernetes 中,Pods 由一个或多个容器组成。通常情况下,这意味着您将 sidecar containers 添加到主应用程序中以组成 pod。(关于这个主题的更详细的处理,请参阅我之前的博客文章)。 Leader-election container 可以作为一个 sidecar,您可以从自己的应用程序中使用。Pod 中任何对当前 master 感兴趣的容器都可以简单地访问http://localhost:4040,它们将返回一个包含当前 master 名称的简单 json 对象。由于 pod中 的所有容器共享相同的网络命名空间,因此不需要服务发现!
例如,这里有一个简单的 Node.js 应用程序,它连接到 leader election sidecar 并打印出它当前是否是 master。默认情况下,leader election sidecar 将其标识符设置为 hostname。
var http = require('http');
// This will hold info about the current master
var master = {};
// The web handler for our nodejs application
var handleRequest = function(request, response) {
response.writeHead(200);
response.end("Master is " + master.name);
};
// A callback that is used for our outgoing client requests to the sidecar
var cb = function(response) {
var data = '';
response.on('data', function(piece) { data = data + piece; });
response.on('end', function() { master = JSON.parse(data); });
};
// Make an async request to the sidecar at http://localhost:4040
var updateMaster = function() {
var req = http.get({host: 'localhost', path: '/', port: 4040}, cb);
req.on('error', function(e) { console.log('problem with request: ' + e.message); });
req.end();
};
/ / Set up regular updates
updateMaster();
setInterval(updateMaster, 5000);
// set up the web server
var www = http.createServer(handleRequest);
www.listen(8080);
当然,您可以从任何支持 HTTP 和 JSON 的语言中使用这个 sidecar。
结论
希望我已经向您展示了使用 Kubernetes 为您的分布式应用程序构建 leader election 是多么容易。在以后的部分中,我们将向您展示 Kubernetes 如何使构建分布式系统变得更加容易。同时,转到Google Container Engine或kubernetes.io开始使用Kubernetes。
使用 Puppet 管理 Kubernetes Pod、Service 和 Replication Controller
今天的嘉宾帖子是由 IT 自动化领域的领导者 Puppet Labs 的高级软件工程师 Gareth Rushgrove 撰写的。Gareth告诉我们一个新的 Puppet 模块,它帮助管理 Kubernetes 中的资源。
熟悉[Puppet]的人(https://github.com/puppetlabs/puppet)可能使用它来管理主机上的文件、包和用户。但是Puppet首先是一个配置管理工具,配置管理是一个比管理主机级资源更广泛的规程。配置管理的一个很好的定义是它旨在解决四个相关的问题:标识、控制、状态核算和验证审计。这些问题存在于任何复杂系统的操作中,并且有了新的Puppet Kubernetes module,我们开始研究如何为 Kubernetes 解决这些问题。
Puppet Kubernetes 模块
Puppet kubernetes 模块目前假设您已经有一个 kubernetes 集群 [启动并运行]](http://kubernetes.io/gettingstarted/)。它的重点是管理 Kubernetes中的资源,如 Pods、Replication Controllers 和 Services,而不是(现在)管理底层的 kubelet 或 etcd services。下面是描述 Puppet’s DSL 中一个 Pod 的简短代码片段。
kubernetes_pod { 'sample-pod':
ensure => present,
metadata => {
namespace => 'default',
},
spec => {
containers => [{
name => 'container-name',
image => 'nginx',
}]
},
}
如果您熟悉 YAML 文件格式,您可能会立即识别该结构。 该接口故意采取相同的格式以帮助在不同格式之间进行转换 — 事实上,为此提供支持的代码是从Kubernetes API Swagger自动生成的。 运行上面的代码,假设我们将其保存为 pod.pp,就像下面这样简单:
puppet apply pod.pp
身份验证使用标准的 kubectl 配置文件。您可以在模块的自述文件中找到完整的README。
Kubernetes 有很多资源,来自 Pods、 Services、 Replication Controllers 和 Service Accounts。您可以在Puppet 中的 kubernetes 留言簿示例文章中看到管理这些资源的模块示例。这演示了如何将规范的 hello-world 示例转换为使用 Puppet代码。
然而,使用 Puppet 的一个主要优点是,您可以创建自己的更高级别和更特定于业务的接口,以连接 kubernetes 管理的应用程序。例如,对于留言簿,可以创建如下内容:
guestbook { 'myguestbook':
redis_slave_replicas => 2,
frontend_replicas => 3,
redis_master_image => 'redis',
redis_slave_image => 'gcr.io/google_samples/gb-redisslave:v1',
frontend_image => 'gcr.io/google_samples/gb-frontend:v3',
}
您可以在Puppet博客文章在 Puppet 中为 Kubernetes 构建自己的抽象中阅读更多关于使用 Puppet 定义的类型的信息,并看到更多的代码示例。
结论
使用 Puppet 而不仅仅是使用标准的 YAML 文件和 kubectl 的优点是:
- 能够创建自己的抽象,以减少重复和设计更高级别的用户界面,如上面的留言簿示例。
- 使用 Puppet 的开发工具验证代码和编写单元测试。
- 与 Puppet Server 等其他工具配合,以确保代码中的模型与集群的状态匹配,并与 PuppetDB 配合工作,以存储报告和跟踪更改。
- 能够针对 Kubernetes API 重复运行相同的代码,以检测任何更改或修正配置。
值得注意的是,大多数大型组织都将拥有非常异构的环境,运行各种各样的软件和操作系统。拥有统一这些离散系统的单一工具链可以使采用 Kubernetes 等新技术变得更加容易。
可以肯定地说,Kubernetes提供了一组优秀的组件来构建云原生系统。使用 Puppet,您可以解决在生产中运行任何复杂系统所带来的一些操作和配置管理问题。告诉我们如果您试用了该模块,您会有什么想法,以及您希望在将来看到哪些支持。
Gareth Rushgrove,Puppet Labs 高级软件工程师
Kubernetes 1.1 性能升级,工具改进和社区不断壮大
自从 Kubernetes 1.0 在七月发布以来,我们已经看到大量公司采用建立分布式系统来管理其容器集群。 我们也对帮助 Kubernetes 社区变得更好,迅速发展的人感到钦佩。 我们已经看到诸如 CoreOS 的 Tectonic 和 RedHat Atomic Host 之类的商业产品应运而生,用以提供 Kubernetes 的部署和支持。 一个不断发展的生态系统增加了 Kubernetes 的支持,包括 Sysdig 和 Project Calico 等工具供应商。
在数百名贡献者的帮助下,我们自豪地宣布 Kubernetes 1.1 的可用性,它提供了主要的性能升级、改进的工具和新特性,使应用程序更容易构建和部署。
我们想强调的一些工作包括:
- 实质性的性能提升 :从第一天开始,我们就设计了 Kubernetes 来处理 Google 规模的工作负载,而我们的客户已经按照自己的进度进行了调整。 在 Kubernetes 1.1 中,我们进行了进一步的投资,以确保您可以在超大规模环境中运行; 本周晚些时候,我们将分享运行数千个节点集群,并针对单个集群运行超过一百万个 QPS 的示例。
- 网络吞吐量显着提高 : 运行 Google 规模的工作负载也需要 Google 规模的网络。 在 Kubernetes 1.1 中,我们提供了使用本机IP表的选项,可将尾部延迟减少80%,几乎完全消除了CPU开销,并提高了可靠性和系统架构,从而确保Kubernetes可以很好地处理未来的大规模吞吐量。
- 水平 Pod 自动缩放 (测试版):许多工作负载可能会经历尖峰的使用期,从而给用户带来不均匀的体验。 Kubernetes 现在支持水平 Pod 自动缩放,这意味着您的 Pod 可以根据 CPU 使用率进行缩放。 阅读有关水平 Pod 自动缩放的更多信息。
- HTTP 负载均衡器 (测试版):Kubernetes 现在具有基于数据包自省功能来路由 HTTP 流量的内置功能。 这意味着您可以让 ‘http://foo.com/bar’ 使用一项服务,而 ‘http://foo.com/meep’ 使用一项完全独立的服务。 阅读有关Ingress对象的更多信息。
- Job 对象 (测试版):我们也经常需要集成的批处理 Job ,例如处理一批图像以创建缩略图,或者将特别大的数据文件分解成很多块。 Job 对象引入了一个新的 API 对象,该对象运行工作负载, 如果失败,则重新启动它,并继续尝试直到成功完成。 阅读有关Job 对象的更多信息。
- 新功能可缩短开发人员的测试周期 :我们将继续致力于快速便捷地为 Kubernetes 开发应用程序。 加快开发人员工作流程的两项新功能包括以交互方式运行容器的功能,以及改进的架构验证功能,可在部署配置文件之前让您知道配置文件是否存在任何问题。
- 滚动更新改进 : DevOps 运动的核心是能够发布新更新,而不会影响正在运行的服务。 滚动更新现在可确保在继续更新之前,已更新的 Pod 状况良好。
- 还有很多。有关更新的完整列表,请参见1.1. 发布在GitHub上的笔记
今天,我们也很荣幸地庆祝首届Kubernetes会议KubeCon,约有400个社区成员以及数十个供应商参加支持 Kubernetes 项目的会议。
我们想强调几个使 Kubernetes 变得更好的众多合作伙伴中的几位:
“我们押注我们的主要产品 Tectonic-它能使任何公司都能在任何地方部署、管理和保护其容器-在 Kubernetes 上使用,因为我们认为这是数据中心的未来。 Kubernetes 1.1 的发布是另一个重要的里程碑,它将使分布式系统和容器得到更广泛的采用,并使我们走上一条必将导致新一代产品和服务的道路。” – CoreOS 首席执行官Alex Polvi
“Univa 的客户正在寻找可扩展的企业级解决方案,以简化企业中容器和非容器工作负载的管理。 我们选择Kubernetes作为我们新的 Navops 套件的基础,它将帮助 IT 和 DevOps 将容器化工作负载快速集成到他们的生产系统中,并将这些工作负载扩展到云服务中。” – Univa 首席执行官 Gary Tyreman
“我们看到通过 Kubernetes 大规模运行容器的巨大客户需求是推动 Redapt 专业服务业务增长的关键因素。 作为值得信赖的顾问,在我们的工具带中有像 Kubernetes 这样的工具能够帮助我们的客户实现他们的目标,这是非常棒的。“ – Redapt SR 云解决方案副总裁 Paul Welch
如上所述,我们希望得到您的帮助:
- 在 GitHub上参与 Kubernetes 项目;
- 通过 Slack 与社区联系;
- 关注我们的 Twitter @Kubernetesio 获取最新信息;
- 在 Stackoverflow 上发布问题(或回答问题)
- 开始运行,部署和使用 Kubernetes 指南;
但是,最重要的是,请让我们知道您是如何使用 Kubernetes 改变您的业务的,以及我们如何可以帮助您更快地做到这一点。谢谢您的支持!
- David Aronchick, Kubernetes 和谷歌容器引擎的高级产品经理
Kubernetes 社区每周环聊笔记——2015 年 7 月 31 日
每周,Kubernetes 贡献社区都会通过Google 环聊虚拟开会。我们希望任何有兴趣的人都知道本论坛讨论的内容。
这是今天会议的笔记:
私有镜像仓库演示 - Muhammed
将 docker-registry 作为 RC/Pod/Service 运行
在每个节点上运行代理
以 localhost:5000 访问
讨论:
我们应该在可能的情况下通过 GCS 或 S3 支持它吗?
在每个节点上运行由 $object_store 支持的真实镜像仓库
DNS 代替 localhost?
分解 docker 镜像字符串?
更像 DNS 策略吗?
运行大型集群 - Joe
三星渴望看到大规模 O(1000)
- 从 AWS 开始
RH 也有兴趣 - 需要测试计划
计划下周:讨论工作组
如果您有兴趣加入有关集群可扩展性的对话,请发送邮件至[joe@0xBEDA.com][4]
资源 API 提案 - Clayton
新东西需要更多资源信息
关于资源 API 的提案 - 向 apiserver 询问有关pod的信息
发送反馈至:#11951
关于快照,时间序列和聚合的讨论
容器化 kubelet - Clayton
打开 pull
Docker挂载传播 - RH 带有补丁
有关整个系统引导程序的大问题
- 双:引导docker /系统docker
Kube-in-docker非常好,但可能并不关键
做些小事以取得进步
对 docker 施加压力
Web UI(preilly)
Web UI 放在哪里?
确定将其拆分出去
将其用作容器镜像
作为 kube 发布过程的一部分构建映像
vendor回来了吗?也许吧,也许不是。
DNS将被拆分吗?
- 可能更紧密地集成在一起,而不是
其他潜在的衍生产品:
apiserver
clients
宣布首个Kubernetes企业培训课程
在谷歌,我们依赖 Linux 容器应用程序去运行我们的核心基础架构。所有服务,从搜索引擎到Gmail服务,都运行在容器中。事实上,我们非常喜欢容器,甚至我们的谷歌云计算引擎虚拟机也运行在容器上!由于容器对于我们的业务至关重要,我们已经与社区合作开发许多基本的容器技术(从 cgroups 到 Docker 的 LibContainer),甚至决定去构建谷歌的下一代开源容器调度技术,Kubernetes。
在 Kubernetes 项目进行一年后,在 OSCON 上发布 V1 版本的前夕,我们很高兴的宣布Kubernetes 的主要贡献者 Mesosphere 组织了有史以来第一次正规的以企业为中心的 Kubernetes 培训会议。首届会议将于 6 月 20 日在波特兰的 OSCON 举办,由来自 Mesosphere 的 Zed Shaw 和 Michael Hausenblas 演讲。Pre-registration 对于优先注册者是免费的,但名额有限,立刻行动吧!
这个为期一天的课程将包涵使用 Kubernetes 构建和部署容器化应用程序的基础知识。它将通过完整的流程引导与参会者创建一个 Kubernetes 的应用程序体系结构,创建和配置 Docker 镜像,并把它们部署到 Kubernetes 集群上。用户还将了解在我们的谷歌容器引擎和 Mesosphere 的数据中心操作系统上部署 Kubernetes 应用程序和服务的基础知识。
即将推出的 Kubernetes bootcamp 将是学习如何应用 Kubernetes 解决长期部署和应用程序管理问题的一个好途径。相对于我们所预期的,来自于广泛社区的众多培训项目而言,这只是其中一个。
幻灯片:Kubernetes 集群管理,爱丁堡大学演讲
2015年6月5日星期五,我在爱丁堡大学给普通听众做了一个演讲,题目是使用 Kubernetes 进行集群管理。这次演讲包括一个带有 Kibana 前端 UI 的音乐存储系统的例子,以及一个基于 Elasticsearch 的后端,该后端有助于生成具体的概念,如 pods、复制控制器和服务。
OpenStack 上的 Kubernetes

今天,OpenStack 基金会通过在其社区应用程序目录中包含 Kubernetes,使您更容易在 OpenStack 云上部署和管理 Docker 容器集群。 今天在温哥华 OpenStack 峰会上的主题演讲中,OpenStack 基金会的首席运营官:Mark Collier 和 Mirantis 产品线经理 Craig Peters 通过利用 OpenStack 云中已经存在的计算、存储、网络和标识系统,在几秒钟内启动了 Kubernetes 集群,展示了社区应用程序目录的工作流。
目录中的条目不仅包括启动 Kubernetes 集群的功能,还包括部署在 Kubernetes 管理的 Docker 容器中的一系列应用程序。这些应用包括:
Apache web 服务器
Nginx web 服务器
Crate - Docker的分布式数据库
GlassFish - Java EE 7 应用服务器
Tomcat - 一个开源的 web 服务器和 servlet 容器
InfluxDB - 一个开源的、分布式的、时间序列数据库
Grafana - InfluxDB 的度量仪表板
Jenkins - 一个可扩展的开放源码持续集成服务器
MariaDB 数据库
MySql 数据库
Redis - 键-值缓存和存储
PostgreSQL 数据库
MongoDB NoSQL 数据库
Zend 服务器 - 完整的 PHP 应用程序平台
此列表将会增长,并在此处进行策划。您可以检查(并参与)YAML 文件,该文件告诉 Murano 如何根据此处定义来安装和启动 ...apps/blob/master/Docker/Kubernetes/KubernetesCluster/package/Classes/KubernetesCluster.yaml)安装和启动 Kubernetes 集群。
Kubernetes 开源项目继续受到社区的欢迎,并且势头越来越好,GitHub 上有超过 11000 个提交和 7648 颗星。从 Red Hat 和 Intel 到 CoreOS 和 Box.net,它已经代表了从企业 IT 到前沿创业企业的一系列客户。我们鼓励您尝试一下,给我们您的反馈,并参与到我们不断增长的社区中来。
- Martin Buhr, Kubernetes 开源项目产品经理
Kubernetes 社区每周聚会笔记- 2015年5月1日
每个星期,Kubernetes 贡献者社区几乎都会在谷歌 Hangouts 上聚会。我们希望任何对此感兴趣的人都能了解这个论坛的讨论内容。
简单的滚动更新 - Brendan
滚动更新 = RCs和Pods很好的例子。
...pause… (Brendan 需要 Kelsey 的演示恢复技巧)
滚动更新具有恢复功能:取消更新并重新启动,更新从停止的地方继续。
新控制器获取旧控制器的名称,因此外观是纯粹的更新。
还可以在 update 中命名版本(最后不会重命名)。
Rocket 演示 - CoreOS 的伙计们
Rocket 和 docker 之间的主要区别: Rocket 是无守护进程和以 pod 为中心。。
Rocket 具有原生的 AppContainer 格式,但也支持 docker 镜像格式。
可以在同一个 pod 中运行 AppContainer 和 docker 容器。
变更接近于合并。
演示 service accounts 和 secrets 被添加到 pod - Jordan
问题:很难获得与API通信的令牌。
新的API对象:"ServiceAccount"
ServiceAccount 是命名空间,控制器确保命名空间中至少存在一个个默认 service account。
键入 "ServiceAccountToken",控制器确保至少有一个默认令牌。
演示
* 可以使用 ServiceAccountToken 创建新的 service account。控制器将为它创建令牌。可以创建一个带有 service account 的 pod, pod 将在 /var/run/secrets/kubernetes.io/…
Kubelet 在容器中运行 - Paul
- Kubelet 成功地运行了带有 secret 的 pod。
通过 RKT 对 Kubernetes 的 AppC 支持
我们最近接受了对 Kubernetes 项目的拉取请求,以增加对 Kubernetes 社区的应用程序支持。 AppC 是由 CoreOS 发起的新的开放容器规范,并通过 CoreOS rkt 容器运行时受到支持。
对于Kubernetes项目和更广泛的容器社区而言,这是重要的一步。 它为容器语言增加了灵活性和选择余地,并为Kubernetes开发人员带来了令人信服的新安全性和性能功能。
与智能编排技术(例如 Kubernetes 和/或 Apache Mesos)配合使用时,基于容器的运行时(例如 Docker 或 rkt)对开发人员构建和运行其应用程序的方式是一种合法干扰。 尽管支持技术还处于新生阶段,但它们确实为组装,部署,更新,调试和扩展解决方案提供了一些非常强大的新方法。 我相信,世界还没有意识到容器的全部潜力,未来几年将特别令人兴奋! 考虑到这一点,有几个具有不同属性和不同目的的项目才有意义。能够根据给定应用程序的特定需求将不同的部分(无论是容器运行时还是编排工具)插入在一起也是有意义的。
Docker 在使容器技术民主化并使外界可以访问它们方面做得非常出色,我们希望 Kubernetes 能够无限期地支持 Docker。CoreOS 还开始与 rkt 进行有趣的工作,以创建一个优雅,干净,简单和开放的平台,该平台提供了一些非常有趣的属性。 这看起来蓄势待发,可以为容器提供安全,高性能的操作环境。 Kubernetes 团队已经与 CoreOS 的 appc 团队合作了一段时间,在许多方面,他们都将 Kubernetes 作为简单的可插入运行时组件来构建 rkt。
真正的好处是,借助 Kubernetes,您现在可以根据工作负载的需求选择最适合您的容器运行时,无需替换集群环境即可更改运行时,甚至可以将在同一集群中在不同容器中运行的应用程序的不同部分混合在一起。 其他选择无济于事,但最终使最终开发人员受益。
-- Craig McLuckie Google 产品经理和 Kubernetes 联合创始人
Kubernetes 社区每周聚会笔记- 2015年4月24日
每个星期,Kubernetes 贡献者社区几乎都会在谷歌 Hangouts 上聚会。我们希望任何对此感兴趣的人都能了解这个论坛的讨论内容。
日程安排:
- Flocker 和 Kubernetes 集成演示
笔记:
- flocker 和 kubernetes 集成演示
Flocker Q/A
迁移后文件是否仍存在于node1上?
Brendan: 有没有计划把它做成一本书?我们不需要 powerstrip?
Luke: 需要找出感兴趣的来决定我们是否想让它成为 kube 中的一个一流的持久性磁盘提供商。
Brendan: 删除对 powerstrip 的需求会使其易于使用。完全去做。
Tim: 将它添加到 kubernetes 应该不超过45分钟:)
* Derek: 持久卷和请求相比呢?
* Luke: 除了基于 ZFS 的新后端之外,差别不大。使工作负载真正可移植。
* Tim: 与基于网络的卷非常不同。有趣的是,它是唯一允许升级媒体的产品。
* Brendan: 请求,它如何查找重复请求?Cassandra 希望在底层复制数据。向上和向下扩缩是有效的。根据负载动态地创建存储。它的步骤不仅仅是快照——通过编程使用预分配创建副本。
* Tim: 帮助自动配置。
* Brian: flocker 是否需要其他组件?
* Kai: Flocker 控制服务与主服务器位于同一位置。(dia 在博客上)。Powerstrip + Powerstrip Flocker。对在 etcd 中持久化状态非常有趣。它保存关于每个卷的元数据。
* Brendan: 在未来,flocker 可以是一个插件,我们将负责持久性。发布 v1.0。
* Brian: 有兴趣为 flocker 等服务添加通用插件。
* Luke: 当扩展到单个节点上的许多容器时,Zfs 会变得非常有价值。
* Alex: flocker 服务可以作为 pod 运行吗?
* Kai: 是的,唯一的要求是 flocker 控制服务应该能够与 zfs 代理对话。需要在主机上安装 zfs 代理,并且需要访问 zfs 二进制文件。
* Brendan: 从理论上讲,所有 zfs 位都可以与设备一起放入容器中。
* Luke: 是的,仍然在处理跨容器安装问题。
* Tim: pmorie 正在通过它使 kubelet 在容器中工作。可能重复使用。
* Kai: Cinder 支持即将到来。几天之后。
- Bob: 向 GKE 推送 kube 的过程是怎样的?需要更多的可见度。
Borg: Kubernetes 的前身
十多年来,谷歌一直在生产中运行容器化工作负载。 无论是像网络前端和有状态服务器之类的工作,像 Bigtable 和 Spanner一样的基础架构系统,或是像 MapReduce 和 Millwheel一样的批处理框架, Google 的几乎一切都是以容器的方式运行的。今天,我们揭开了 Borg 的面纱,Google 传闻已久的面向容器的内部集群管理系统,并在学术计算机系统会议 Eurosys 上发布了详细信息。你可以在 此处 找到论文。
Kubernetes 直接继承自 Borg。 在 Google 的很多从事 Kubernetes 的开发人员以前都是 Borg 项目的开发人员。 我们在 Kubernetes 中结合了 Borg 的最佳创意,并试图解决用户多年来在 Borg 中发现的一些痛点。
Kubernetes 中的以下四个功能特性源于我们从 Borg 获得的经验:
- Pods。 Pod 是 Kubernetes 中调度的单位。 它是一个或多个容器在其中运行的资源封装。 保证属于同一 Pod 的容器可以一起调度到同一台计算机上,并且可以通过本地卷共享状态。
Borg 有一个类似的抽象,称为 alloc(“资源分配”的缩写)。 Borg 中 alloc 的常见用法包括运行 Web 服务器,该服务器生成日志,一起部署一个轻量级日志收集进程, 该进程将日志发送到集群文件系统(和 fluentd 或 logstash 没什么不同 ); 运行 Web 服务器,该 Web 服务器从磁盘目录提供数据, 该磁盘目录由从集群文件系统读取数据并为 Web 服务器准备/暂存的进程填充(与内容管理系统没什么不同); 并与存储分片一起运行用户定义的处理功能。
Pod 不仅支持这些用例,而且还提供类似于在单个 VM 中运行多个进程的环境 -- Kubernetes 用户可以在 Pod 中部署多个位于同一地点的协作过程,而不必放弃一个应用程序一个容器的部署模型。
- 服务。 尽管 Borg 的主要角色是管理任务和计算机的生命周期,但是在 Borg 上运行的应用程序还可以从许多其它集群服务中受益,包括命名和负载均衡。 Kubernetes 使用服务抽象支持命名和负载均衡:带名字的服务,会映射到由标签选择器定义的一组动态 Pod 集(请参阅下一节)。 集群中的任何容器都可以使用服务名称链接到服务。
在幕后,Kubernetes 会自动在与标签选择器匹配到 Pod 之间对与服务的连接进行负载均衡,并跟踪 Pod 在哪里运行,由于故障,它们会随着时间的推移而重新安排。
- 标签。 Borg 中的容器通常是一组相同或几乎相同的容器中的一个副本,该容器对应于 Internet 服务的一层(例如 Google Maps 的前端)或批处理作业的工人(例如 MapReduce)。 该集合称为 Job ,每个副本称为任务。 尽管 Job 是一个非常有用的抽象,但它可能是有限的。 例如,用户经常希望将其整个服务(由许多 Job 组成)作为一个实体进行管理,或者统一管理其服务的几个相关实例,例如单独的 Canary 和稳定的发行版。 另一方面,用户经常希望推理和控制 Job 中的任务子集 --最常见的示例是在滚动更新期间,此时作业的不同子集需要具有不同的配置。
通过使用标签组织 Pod ,Kubernetes 比 Borg 支持更灵活的集合,标签是用户附加到 Pod(实际上是系统中的任何对象)的任意键/值对。 用户可以通过在其 Pod 上使用 “job:<jobname>” 标签来创建与 Borg Jobs 等效的分组,但是他们还可以使用其他标签来标记服务名称,服务实例(生产,登台,测试)以及一般而言,其 pod 的任何子集。 标签查询(称为“标签选择器”)用于选择操作应用于哪一组 Pod 。 结合起来,标签和复制控制器 允许非常灵活的更新语义,以及跨等效项的操作 Borg Jobs。
- 每个 Pod 一个 IP。在 Borg 中,计算机上的所有任务都使用该主机的 IP 地址,从而共享主机的端口空间。 虽然这意味着 Borg 可以使用普通网络,但是它给基础结构和应用程序开发人员带来了许多负担:Borg 必须将端口作为资源进行调度;任务必须预先声明它们需要多少个端口,并将要使用的端口作为启动参数;Borglet(节点代理)必须强制端口隔离;命名和 RPC 系统必须处理端口以及 IP 地址。
多亏了软件定义的覆盖网络,例如 flannel 或内置于公有云网络的出现,Kubernetes 能够为每个 Pod 提供服务并为其提供自己的 IP 地址。 这消除了管理端口的基础架构的复杂性,并允许开发人员选择他们想要的任何端口,而不需要其软件适应基础架构选择的端口。 后一点对于使现成的易于运行 Kubernetes 上的开源应用程序至关重要 -- 可以将 Pod 视为 VMs 或物理主机,可以访问整个端口空间,他们可能与其他 Pod 共享同一台物理计算机,这一事实已被忽略。
随着基于容器的微服务架构的日益普及,Google 从内部运行此类系统所汲取的经验教训已引起外部 DevOps 社区越来越多的兴趣。 通过揭示集群管理器 Borg 的一些内部工作原理,并将下一代集群管理器构建为一个开源项目(Kubernetes)和一个公开可用的托管服务(Google Container Engine),我们希望这些课程可以使 Google 之外的广大社区受益,并推动容器调度和集群管理方面的最新技术发展。
Kubernetes 社区每周聚会笔记- 2015年4月17日
每个星期,Kubernetes 贡献者社区几乎都会在谷歌 Hangouts 上聚会。我们希望任何对此感兴趣的人都能了解这个论坛的讨论内容。
议程
- Mesos 集成
- 高可用性(HA)
- 向 e2e 添加性能和分析详细信息以跟踪回归
- 客户端版本化
笔记
Mesos 集成
Mesos 集成提案:
没有阻塞集成的因素。
文档需要更新。
HA
提案今天应该会提交。
Etcd 集群。
apiserver 负载均衡。
控制器管理器和其他主组件的冷备用。
向 e2e 添加性能和分析详细信息以跟踪回归
希望红色为性能回归
需要公共数据库才能发布数据
- 查看
Justin 致力于多平台 e2e 仪表盘
客户端版本化
*
* 客户端库当前使用内部 API 对象。
* 尽管没有人反映频繁修改 `types.go` 有多痛苦,但我们很为此担心。
* 结构化类型在客户端中很有用。版本化的结构就可以了。
* 如果从 json/yaml (kubectl) 开始,则不应转换为结构化类型。使用 swagger。
Security context
* 管理员可以限制谁可以运行特权容器或需要特定的 unix uid
* kubelet 将能够从 apiserver 获取证书
* 政策提案将于下周左右出台
讨论用户的上游,等等进入Kubernetes,至少是可选的
1.0 路线图
重点是性能,稳定性,集群升级
TJ 一直在对roadmap.md进行一些编辑,但尚未发布PR
Kubernetes UI
依赖关系分解为第三方
@lavalamp 是评论家
[*[3:27 PM]: 2015-04-17T15:27:00-07:00
Kubernetes Release: 0.15.0
Release 说明:
- 启用 1beta3 API 并将其设置为默认 API 版本 (#6098)
- 增加了多端口服务(#6182)
- 添加了一个控制器框架 (#5270, #5473)
- Kubelet 现在监听一个安全的 HTTPS 端口 (#6380)
- 使 kubectl 错误更加友好 (#6338)
- apiserver 现在支持客户端 cert 身份验证 (#6190)
- apiserver 现在限制了它处理的并发请求的数量 (#6207)
- 添加速度限制删除 pod (#6355)
- 将平衡资源分配算法作为优先级函数实现在调度程序包中 (#6150)
- 从主服务器启用日志收集功能 (#6396)
- 添加了一个 api 端口来从 Pod 中提取日志 (#6497)
- 为调度程序添加了延迟指标 (#6368)
- 为 REST 客户端添加了延迟指标 (#6409)
- etcd 现在在 master 上的一个 pod 中运行 (#6221)
- nginx 现在在 master上的容器中运行 (#6334)
- 开始为主组件构建 Docker 镜像 (#6326)
- 更新了 GCE 程序以使用 gcloud 0.9.54 (#6270)
- 更新了 AWS 程序来修复区域与区域语义 (#6011)
- 记录镜像 GC 失败时的事件 (#6091)
- 为 kubernetes 客户端添加 QPS 限制器 (#6203)
- 减少运行 make release 所需的时间 (#6196)
- 新卷的支持
- 更新到 heapster 版本到 v0.10.0 (#6331)
- 更新到 etcd 2.0.9 (#6544)
- 更新到 Kibana 到 v1.2 (#6426)
- 漏洞修复
要下载,请访问 https://github.com/GoogleCloudPlatform/kubernetes/releases/tag/v0.15.0
每周 Kubernetes 社区例会笔记 - 2015 年 4 月 3 日
Kubernetes: 每周 Kubernetes 社区聚会笔记
每周,Kubernetes 贡献社区几乎都会通过 Google Hangouts 开会。 我们希望任何有兴趣的人都知道本论坛讨论的内容。
议程:
- Quinton - 集群联邦
- Satnam - 性能基准测试更新
会议记录:
- Quinton - 集群联邦
- 在旧金山见面会后,想法浮出水面
- 请阅读、评论
- 不是 1.0,而是将文档放在一起以显示路线图
- 可以在 Kubernetes 之外构建
- 用于控制多个集群中事物的 API ,包括一些逻辑
Auth(n)(z)
调度策略
……
- 集群联邦的不同原因
区域(非)可用性:对区域故障的弹性
混合云:有些在云中,有些在本地。 由于各种原因
避免锁定云提供商。 由于各种原因
"Cloudbursting" - 自动溢出到云中
- 困难的问题
位置亲和性。Pod 需要多近?
工作负载的耦合
绝对位置(例如,欧盟数据需要在欧盟内)
跨集群服务发现
- 服务/DNS 如何跨集群工作
跨集群工作负载迁移
- 如何在跨集群中逐块移动应用程序?
跨集群调度
如何充分了解集群以知道在哪里进行调度
可能使用成本函数以最小的复杂性得出亲和性
还可以使用成本来确定调度位置(使用不足的集群比过度使用的集群便宜)
- 隐含要求
跨集群集成不应创建跨集群故障模式
- 在 Ubernetes 死亡的灾难情况下可以独立使用。
统一可见性
- 希望有统一的监控,报警,日志,内省,用户体验等。
统一的配额和身份管理
- 希望将用户数据库和 auth(n)/(z) 放在一个位置
- 需要注意的是,导致软件故障的大多数原因不是基础架构
拙劣的软件升级
拙劣的配置升级
拙劣的密钥分发
过载
失败的外部依赖
- 讨论:
”ubernetes“ 的边界确定
- 可能在可用区,但也可能在机架,或地区
重要的是不要鸽子洞并防止其他用户
- Satnam - 浸泡测试
- 想要测量长时间运行的事务,以确保集群在一段时间内是稳定的。性能不会降低,不会发生内存泄漏等。
- github.com/GoogleCloudPlatform/kubernetes/test/soak/…
- 单个二进制文件,在每个节点上放置许多 Pod,并查询每个 Pod 以确保其正在运行。
- Pod 的创建速度越来越快(即使在过去一周内),也可以使事情进展得更快。
- Pod 运行起来后,我们通过代理点击 Pod。决定使用代理是有意的,因此我们测试了 kubernetes apiserver。
- 代码已经签入。
- 将 Pod 固定在每个节点上,练习每个 Pod,确保你得到每个节点的响应。
- 单个二进制文件,永远运行。
- Brian - v1beta3 默认启用, v1beta1 和 v1beta2 不支持,在6月关闭。仍应与升级现有集群等一起使用。
Kubernetes 社区每周聚会笔记 - 2015 年 3 月 27 日
每个星期,Kubernetes 贡献者社区几乎都会在谷歌 Hangouts 上聚会。我们希望任何对此感兴趣的人都能了解这个论坛的讨论内容。
日程安排:
- Andy - 演示远程执行和端口转发
- Quinton - 联邦集群 - 延迟
- Clayton - 围绕 Kubernetes 的 UI 代码共享和协作
从会议指出:
1. Andy 从 RedHat:
- 演示远程执行
* kubectl exec -p $POD -- $CMD
* 作为代理与主机建立连接,找出 pod 所在的节点,代理与 kubelet 的连接,这一点很有趣。通过 nsenter。
* 使用 SPDY 通过 HTTP 进行多路复用流式传输
* 还有互动模式:
* 假设第一个容器,可以使用 -c $CONTAINER 一个特定的。
* 如果在容器中预先安装了 gdb,则可以交互地将其附加到正在运行的进程中
* backtrace、symbol tbles、print 等。 使用gdb可以做的大多数事情。
* 也可以用精心制作的参数在上面运行 rsync 或者在容器内设置 sshd。
* 一些聊天反馈:
- Andy 还演示了端口转发
- nnsenter 与 docker exec
* 想要在主机的控制下注入二进制文件,类似于预启动钩子
* socat、nsenter,任何预启动钩子需要的
- 如果能在博客上发表这方面的文章就太好了
- wheezy 中的 nginx 版本太旧,无法支持所需的主代理功能
2. Clayton: 我们的社区组织在哪里,例如 kubernetes UI 组件?
- google-containers-ui IRC 频道,邮件列表。
- Tim: google-containers 前缀是历史的,应该只做 "kubernetes-ui"
- 也希望将设计资源投入使用,并且 bower 期望自己的仓库。
- 通用协议
3. Brian Grant:
- 测试 v1beta3,准备进入。
- Paul 致力于改变命令行的内容。
- 下周初至中旬,尝试默认启用v1beta3 ?
- 对于任何其他更改,请发出文件并抄送 thockin。
4. 一般认为30分钟比60分钟好
- 不应该为了填满时间而人为地延长。
Kubernetes 采集视频
如果你错过了上个月在旧金山举行的 Kubernetes 大会,不要害怕!以下是在 YouTube 上组织成播放列表的晚间演示文稿中的视频。

欢迎来到 Kubernetes 博客!
欢迎来到新的 Kubernetes 博客。关注此博客,了解 Kubernetes 开源项目。我们计划时不时的发布发布说明,操作方法文章,活动,甚至一些非常有趣的话题。
如果您正在使用 Kubernetes 或为该项目做出贡献并想要发帖子,请告诉我。
首先,以下是 Kubernetes 最近在其他网站上发布的文章摘要:
- 使用 Vitess 和 Kubernetes 在云中扩展 MySQL
- 虚拟机上的容器集群
- 想知道的关于 kubernetes 的一切,却又不敢问
- 什么构成容器集群?
- 将 OpenStack 和 Kubernetes 与 Murano 集成
- 容器介绍,Kubernetes 以及现代云计算的发展轨迹
- 什么是 Kubernetes 以及如何使用它?
- OpenShift V3,Docker 和 Kubernetes 策略
- Kubernetes 简介
快乐的云计算!
- Kit Merker - Google 云平台产品经理