Kubernetes добре налаштовується та розширюється. Тому випадки, коли вам потрібно робити форки та накладати патчі на Kubernetes, щоб змінити його поведінку, дуже рідкісні.
Цей розділ описує різні способи зміни поведінки вашого кластера Kubernetes. Він призначений для операторів, які хочуть зрозуміти, як адаптувати кластер до своїх потреб свого робочого оточення. Розробники, які є потенційними розробниками платформ чи учасники проєкту Kubernetes, також знайдуть цей розділ корисним як вступ до того, які точки та шаблони розширення існують, а також їх компроміси та обмеження.
Підходи до налаштувань можна взагалі розділити на конфігурацію, яка включає лише зміну аргументів командного рядка, локальних конфігураційних файлів або ресурсів API; та розширення, яке передбачає виконання додаткових програм, додаткових мережевих служб або обох. Цей документ в основному присвячений розширенням.
Конфігурація
Конфігураційні файли та аргументи командного рядка описані в розділі Довідник онлайн-документації, де кожен файл має свою сторінку:
Аргументи команд та файли конфігурації не завжди можуть бути змінені в службі Kubernetes, що надається постачальником, або дистрибутиві з керованою установкою. Коли їх можна змінювати, вони, як правило, змінюються лише оператором кластера. Крім того, вони можуть бути змінені в майбутніх версіях Kubernetes, і для їх налаштування може знадобитися перезапуск процесів. З цих причин їх слід використовувати лише тоді, коли немає інших варіантів.
Вбудовані API політики, такі як ResourceQuota, NetworkPolicy та доступ на основі ролей (RBAC), є вбудованими API Kubernetes, які надають можливості декларативного налаштування політик. API є доступними та в кластерах, які надаються провайдером, і в кластерах, якими ви керуєте самостійно. Вбудовані API політик використовують ті ж самі конвенції, що й інші ресурси Kubernetes, такі як Podʼи. Коли ви використовуєте стабільний API політик, ви отримуєте зиск від визначеної підтримки політик так само як й інші API Kubernetes. З цих причин використання API політик рекомендується на перевагу до конфігураційних файлів та аргументів командного рядка, де це можливо.
Розширення
Розширення — це компонент програмного забезпечення, який глибоко інтегрується з Kubernetes. Вони використовуються для додавання нових типів ресурсів та видів апаратного забезпечення.
Багато адміністраторів класів Kubernetes використовують кластери, що надаються провайдерами, чи встановленими з дистрибутивів. Ці кластери вже йдуть з розширеннями. В результаті, більшість користувачів Kubernetes не потребують встановлення розширень та дуже невелика частка потребує їх створення.
Шаблони розширень
Kubernetes спроєктовано так, щоб він був автоматизований шляхом створення клієнтських застосунків. Будь-яка програма, яка може писати та читати з API Kubernetes, може надавати корисні функції автоматизації. Ці функції можуть працювати як всередині кластера, так і ззовні. Слідуючи настановам з цього посібника, ви зможете створити надійні та високопродуктивні розширення. Автоматизація, як правило, працює з будь-яким кластером Kubernetes, незалежно від того, як він був встановлений.
Існує конкретний патерн написання клієнтських програм, які ефективно взаємодіють із Kubernetes, відомий як патерн контролера. Зазвичай контролери читають .spec обʼєкта, можливо виконують певні операції, а потім оновлюють .status обʼєкта.
Контролери є клієнтами API Kubernetes. Коли Kubernetes сам є клієнтом та звертається до віддаленого сервісу, виклики Kubernetes є вебхуками. Віддалений сервіс називається вебхук-бекендом. Так само як і стороні контролери, вебхуки додають ще одну точку вразливості.
Примітка:
Поза Kubernetes, термін «вебхук» зазвичай означає механізм асинхронного сповіщення, де вебхук звертається до сервісу з одностороннім сповіщенням до іншої системи чи компонента. В екосистемі Kubernetes, навіть асинхронний HTTP-запит часто описується як «вебхук».
В моделі вебхуків, Kubernetes надсилає мережеві запити до віддалених сервісів. Альтернативою є модель бінарних втулків, коли Kubernetes виконує бінарник (застосунок). Бінарні втулки використовуються в kublet (наприклад, втулок зберігання CSI та втулок мережі CNI), а також в kubeсtl (дивітьс розширення kubectl за допомогою втулків).
Точки розширення
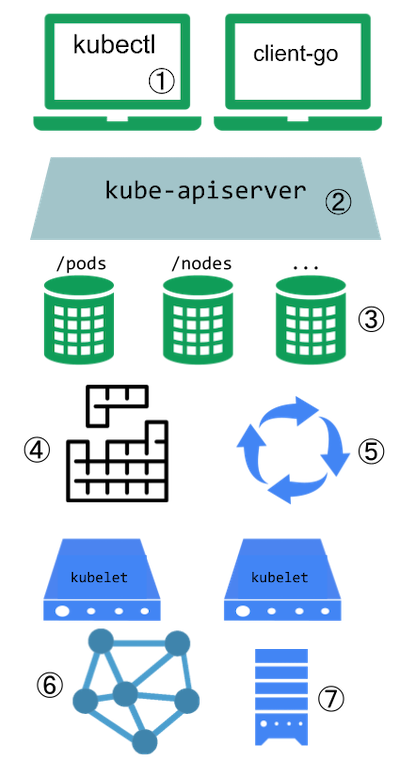
На цій діаграмі показано точки розширення в кластері Kubernetes та клієнти з доступом до них.
Точки розширення Kubernetes
Пояснення до діаграми
Користувачі часто взаємодіють з API Kubernetes через kubectl. Втулки підлаштовують поведінку клієнтів. Існують загальні розширення, які можна використовувати з будь-якими клієнтами, так само як і специфічні розширення для kubectl.
API сервер обробляє запити. Різні типи точок розширення на сервері API дозволяють автентифікувати запити або блокувати їх на основі їх вмісту, редагувати вміст та обробляти видалення. Про це в розділі розширення API доступу.
API сервер також обслуговує різні типи ресурсів. Вбудовані типи ресурсі, такі як Pod, визначені проєктом Kubernetes та не можуть бути змінені. Дивіться розширення API щоб дізнатися про можливості розширення API.
Планувальник вирішує на якому вузлі запустити кожний Pod. Існує кілька способів розширити планування, про це в розділі розширення планувальника.
Kublet виконує контейнери на вузлах, та допомагає Podʼами виглядати як віртуальні сервери з їх власними IP в мережі кластера. Мережеві втулки дозволяють реалізувати різні мережеві моделі.
Ви можете використовувати втулки пристроїв для використання спеціалізованих пристроїв або інших розташованих на вузлах ресурсів, та робити їх доступними для Podʼів у вашому кластері. Kublent містить підтримку для роботи з втулками пристроїв.
Kublet також монтує томи для Podʼів та їх контейнерів. Втулки зберігання дозволяють реалізувати різні моделі зберігання.
Вибір точки розширення
Якщо ви вагаєтесь звідки розпочати, ця діаграма може допомогти вам. Зауважте, що деякі рішення можуть включати кілька типів розширень.
Діаграма-посібник для вибору методу розширення.
Розширення клієнта
Втулки до kubectl дозволяють є окремими програмами, які можуть додавати чи замінувати поведінку певних команд. kubectl може інтегруватись з втулком облікових даних. Ці розширення впливають лише на локальне оточення користувача і не можуть додавати нові політики до кластера.
Зважте на додавання власних ресурсів у Kubernetes, якщо ви бажаєте визначити нові контролери, обʼєкти налаштування застосунків або інші декларативні API, та керувати ними використовуючи інструменти подібні до kubectl.
Ви можете використовувати шар агрегації API Kubernetes, щоб додати нові ресурси до API Kubernetes разом з додатковими службами, такими як метрики.
Поєднання нових API з автоматизаціями
Поєднання API власних ресурсів та циклів управління називається шаблонами контролерів. Якщо ваш контролер виконує функції оператора-людини, та розгортає інфраструктуру на основі бажаного стану, то, можливо, він також дотримується шаблону оператора. Шаблон Оператор використовується для управління конкретними застосунками; зазвичай це застосунки, які підтримують стан та вимагають уважного управління.
Ви також можете створювати власні API та цикли управління, які керують іншими ресурсами, такими як сховище, або визначають політики (наприклад, обмеження контролю доступу).
Зміна вбудованих ресурсів
Коли ви розширюєте API Kubernetes шляхом додавання власних ресурсів, ці ресурси завжди потрапляють до нової групи API. Ви не можете замінити чи змінити наявні групи API. Додавання API напряму не впливає на поведінку наявних API (таких як Podʼи), однак мають вплив на розширення API доступу.
Розширення API доступу
Коли запит потрапляє до API сервера Kubernetes, він спочатку автентифікується, потім авторизується, і потім він потрапляє до перевірки допуску (admission control) (по факту деякі запити є неавтентифікованими та отримують особливу обробку). Дивіться розділ про керування доступу до API Kubernetes для отримання деталей.
Кожен крок в процесі автентифікації/авторизації пропонує точки розширення.
Автентифікація
Автентифікація зіставляє заголовки або сертифікати усіх запитів з користувачами, які зробили запит.
Kubernetes має кілька вбудованих методів автентифікації. Крім того, він може знаходитись поза проксі-сервером автентифікації та може надсилати токени з заголовком Authorization до інших віддалених служб для перевірки (вебхуки автентифікації), якщо вбудовані методи не підходять.
Авторизація
Авторизація визначає, чи має користувач право читати, писати чи виконувати інші дії з ресурсами API. Це відбувається на рівні всього ресурсу, а не на рівні окремих обʼєктів.
Якщо вбудовані методи авторизації не підходять, Kubernetes може використовувати вебхуки авторизації, що дозволяють викликати власний код для визначення, чи має користувач право виконувати дію.
Динамічний контроль допуску
Після того, як запит пройшов та авторизацію, і якщо це операція запису, він також проходить через крок контролю допуску. На додачу до вбудованих кроків, є кілька розширень:
Вебхуки політик образів дозволяють визначити, які образи можуть бути запущені в контейнерах.
Для прийняття довільних рішень щодо допуску можуть використовуватись загальні вебхуки допуску. Деякі з вебхуків допуску змінюють дані вхідних запитів до того, як вони будуть опрацьовані Kubernetes.
Розширення інфраструктури
Втулки пристроїв
Втулки пристроїв дозволяють вузлам знаходити нові ресурси Node (на додачу до вбудованих, таких як ЦП та памʼять) за допомогою Втулків пристроїв.
Втулки зберігання
Втулок Container Storage Interface (CSI) надає спосіб розширювати Kubernetes шляхом підтримки нових типів сховищ. Томи можуть знаходитись в надійних зовнішніх системах зберігання, або впроваджувати ефемерні пристрої зберігання, або можуть надавити read-only інтерфейс до інформації використовуючи парадигму роботи з файловою системою.
Kubernetes має підтримку втулків FlexVolume, які вже визнані застаріилими у v1.23 (на користь CSI).
FlexVolume дозволяв користувачам монтувати типи томів які не підтримувались самим Kubernetes. Коли ви запускали Pod, що вимагав FlexVolume, kublet викликав відповідний FlexVolume драйвер, який виконував монтування томів. Архівована пропозиція з проєктування FlexVolume містить більше докладної інформації про те, як все мало відбуватись.
Ваш кластер Kubernetes потребує мережеві втулки для того, щоб мати робочу мережу для ваших Podʼів та підтримки аспектів мережевої моделі Kubernetes.
Мережеві втулки дозволяють Kubernetes працювати з різними мережевими топологіями та технологіями.
Втулки kublet image credential provider
СТАН ФУНКЦІОНАЛУ:Kubernetes 1.26 [stable]
Втулки kublet image credential provider дозволяють динамічно отримувати облікові дані для образів контейнерів з різних джерел. Облікові дані можуть бути використані для отримання образів контейнерів, які відповідають поточній конфігурації.
Втулки можуть спілкуватись з зовнішніми службами чи використовувати локальні файли для отримання облікових даних. В такому разу kublet не треба мати статичні облікові дані для кожного реєстру, і він може підтримувати різноманітні методи та протоколи автентифікації.
Планувальник є спеціальним типом контролера, який вирішує, на якому вузлі запустити який Pod. Стандартний планувальник можна повністю замінити, продовжуючи використовувати інші компоненти Kubernetes, або ж кілька планувальників можуть працювати разом.
Це значне завдання, і майже всі користувачі Kubernetes вважають, що їм не потрібно змінювати планувальник.
Ви можете контролювати активність втулків планувальника або асоціювати набори втулків з різними іменованими профілями планування. Ви також можете створювати свої власні втулки, які інтегруються з однією або кількома точками розширення kube-scheduler.
Зрештою, вбудований компонент kube-scheduler підтримує вебхуки, що дозволяє віддаленому HTTP-бекенду (розширенню планувальника) фільтрувати та/або пріоритизувати вузли, які kube-scheduler обирає для Podʼів.
Примітка:
Ви можете впливати лише на фільтрування вузлів та їх пріоритизацію за допомогою вебхуків розширювача планувальника; інші точки розширення через інтеграцію вебхука не доступні.
Цей розділ охоплює розширення вашого кластера, які не входять до складу Kubernetes. Ви можете використовувати ці розширення для розширення функціональності вузлів у вашому кластері або для створення основи для мережі, яка зʼєднує Podʼи.
Втулки Container Storage Interface (CSI) надають можливість розширити Kubernetes підтримкою нових типів томів. Томи можуть спиратись на надійні зовнішні сховища, або надавати тимчасові сховища, або можуть надавати доступ до інформації лише для читання використовуючи парадигму файлової системи.
Kubernetes також включає підтримку втулків FlexVolume, які є застарілими з моменту випуску Kubernetes v1.23 (використовуйте CSI замість них).
Втулки FlexVolume дозволяють користувачам монтувати типи томів, які не підтримуються нативно Kubernetes. При запуску Pod, який залежить від сховища FlexVolume, kubelet викликає бінарний втулок для монтування тому. В заархівованій пропозиції про дизайн FlexVolume є більше деталей щодо цього підходу.
Втулки пристроїв дозволяють вузлу виявляти нові можливості Node (на додаток до вбудованих ресурсів вузла, таких як cpu та memory) та надавати ці додаткові локальні можливості вузла для Podʼів, які їх запитують.
Втулки мережі дозволяють Kubernetes працювати з різними топологіями та технологіями мереж. Вашому кластеру Kubernetes потрібен втулок мережі для того, щоб мати працюючу мережу для Podʼів та підтримувати інші аспекти мережевої моделі Kubernetes.
Kubernetes (з версії 1.3 і до останньої версії 1.34 та можливо й потім) дозволяє використовувати мережевий інтерфейс контейнерів (CNI, Container Network Interface) для втулків мережі кластера. Вам потрібно використовувати втулок CNI, який сумісний з вашим кластером та відповідає вашим потребам. В екосистемі Kubernetes доступні різні втулки (як з відкритим, так і закритим кодом).
Вам потрібно використовувати втулок CNI, який сумісний з v0.4.0 або більш пізніми версіями специфікації CNI. Проєкт Kubernetes рекомендує використовувати втулок, який сумісний з v1.0.0 специфікації CNI (втулки можуть бути сумісними з кількома версіями специфікації).
Встановлення
Середовище виконання контейнерів (Container Runtime) у контексті мережі — це служба на вузлі, налаштована для надання сервісів CRI для kubelet. Зокрема, середовище виконання контейнерів повинно бути налаштоване для завантаження втулків CNI, необхідних для реалізації мережевої моделі Kubernetes.
Примітка:
До Kubernetes 1.24 втулками CNI також можна було керувати через kubelet за допомогою параметрів командного рядка cni-bin-dir та network-plugin. Ці параметри командного рядка були видалені в Kubernetes 1.24, і управління CNI більше не входить до сфери обовʼязків kubelet.
Для конкретної інформації про те, як середовище виконання контейнерів керує втулками CNI, дивіться документацію для цього середовища виконання контейнерів, наприклад:
Для конкретної інформації про те, як встановити та керувати втулком CNI, дивіться документацію для цього втулка або постачальника мережі.
Вимоги до мережевих втулків
Loopback CNI
Крім втулка CNI, встановленого на вузлах для реалізації мережевої моделі Kubernetes, Kubernetes також вимагає, щоб середовища виконання контейнерів надавали loopback інтерфейс lo, який використовується для кожної пісочниці (пісочниці Podʼів, пісочниці віртуальних машин тощо). Реалізацію інтерфейсу loopback можна виконати, використовуючи втулок loopback CNI або розробивши власний код для досягнення цього (дивіться цей приклад від CRI-O).
Підтримка hostPort
Втулок мережі CNI підтримує hostPort. Ви можете використовувати офіційний втулок portmap, який пропонується командою втулків CNI, або використовувати свій власний втулок з функціональністю portMapping.
Якщо ви хочете ввімкнути підтримку hostPort, вам потрібно вказати capability portMappings у вашому cni-conf-dir. Наприклад:
Втулок мережі CNI також підтримує формування вхідного та вихідного трафіку для Podʼів. Ви можете використовувати офіційний втулок bandwidth, що пропонується командою втулків CNI, або використовувати власний втулок з функціональністю контролю ширини смуги.
Якщо ви хочете ввімкнути підтримку формування трафіку, вам потрібно додати втулок bandwidth до вашого файлу конфігурації CNI (типово /etc/cni/net.d) та забезпечити наявність відповідного виконавчого файлу у вашій теці виконавчих файлів CNI (типово /opt/cni/bin).
Втулки пристроїв дозволяють налаштувати кластер із підтримкою пристроїв або ресурсів, які вимагають налаштування від постачальника, наприклад GPU, NIC, FPGA або енергонезалежної основної памʼяті.
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.26 [stable]
Kubernetes надає фреймворк втулків пристроїв, який ви можете використовувати для оголошення системних апаратних
ресурсів Kubelet.
Замість того, щоб вносити зміни в код самого Kubernetes, вендори можуть реалізувати втулки пристроїв, які ви розгортаєте або вручну, або як DaemonSet. Цільові пристрої включають GPU, мережеві інтерфейси високої продуктивності, FPGA, адаптери InfiniBand, та інші подібні обчислювальні ресурси, які можуть вимагати ініціалізації та налаштування від вендора.
Реєстрація втулка пристрою
kubelet надає службу Registration через gRPC:
service Registration {
rpc Register(RegisterRequest) returns (Empty) {}
}
Втулок пристрою може зареєструвати себе в kubelet через цю службу gRPC. Під час реєстрації втулок пристрою повинен надіслати:
Назву свого Unix сокету.
Версію API втулка пристрою, під яку він був зібраний.
ResourceName, яке він хоче оголошувати. Тут ResourceName повинно відповідати розширеній схемі найменування ресурсів у вигляді vendor-domain/resourcetype. (Наприклад, NVIDIA GPU рекламується як nvidia.com/gpu.)
Після успішної реєстрації втулок пристрою надсилає kubelet список пристроїв, якими він керує, і тоді kubelet стає відповідальним за оголошення цих ресурсів на сервері API як частини оновлення стану вузла. Наприклад, після того, як втулок пристрою зареєструє hardware-vendor.example/foo в kubelet і повідомить про наявність двох пристроїв на вузлі, статус вузла оновлюється для оголошення того, що на вузлі встановлено 2 пристрої "Foo" і вони доступні для використання.
Після цього користувачі можуть запитувати пристрої як частину специфікації Podʼа (див. container). Запит розширених ресурсів схожий на те, як ви керуєте запитами та лімітами для інших ресурсів, з такими відмінностями:
Розширені ресурси підтримуються лише як цілочисельні ресурси та не можуть бути перевищені.
Пристрої не можуть бути спільно використані між контейнерами.
Приклад
Припустимо, що в кластері Kubernetes працює втулок пристрою, який оголошує ресурс hardware-vendor.example/foo на певних вузлах. Ось приклад Podʼа, який використовує цей ресурс для запуску демонстраційного завдання:
---apiVersion:v1kind:Podmetadata:name:demo-podspec:containers:- name:demo-container-1image:registry.k8s.io/pause:3.8resources:limits:hardware-vendor.example/foo:2## Цей Pod потребує 2 пристроїв hardware-vendor.example/foo# і може бути розміщений тільки на Вузлі, який може задовольнити# цю потребу.## Якщо на Вузлі доступно більше 2 таких пристроїв, то# залишок буде доступний для використання іншими Podʼами.
Імплементація втулка пристрою
Загальний робочий процес втулка пристрою включає наступні кроки:
Ініціалізація. Під час цієї фази втулок пристрою виконує ініціалізацію та налаштування, специфічні для вендора, щоб забезпечити те, що пристрої перебувають в готовому стані.
Втулок запускає службу gRPC з Unix сокетом за шляхом хоста /var/lib/kubelet/device-plugins/, що реалізує наступні інтерфейси:
service DevicePlugin {
// GetDevicePluginOptions повертає параметри, що будуть передані до Менеджера пристроїв.
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// ListAndWatch повертає потік списку пристроїв
// Кожного разу, коли змінюється стан пристрою або пристрій зникає, ListAndWatch
// повертає новий список
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// Allocate викликається під час створення контейнера, щоб втулок
// пристрою міг виконати операції, специфічні для пристрою, та підказати kubelet
// кроки для доступу до пристрою в контейнері
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// GetPreferredAllocation повертає набір пріоритетних пристроїв для виділення
// зі списку доступних. Остаточне пріоритетне виділення не гарантується,
// це буде зроблене devicemanager. Це призначено лише для допомоги devicemanager у
// прийнятті більш обізнаних рішень про виділення, коли це можливо.
rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
// PreStartContainer викликається, якщо це вказано втулком пристрою під час фази реєстрації,
// перед кожним запуском контейнера. Втулок пристроїв може виконати певні операції
// такі як перезаватаження пристрою перед забезпеченням доступу до пристроїв в контейнері.
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}
Примітка:
Втулки не обовʼязково повинні надавати корисні реалізації для
GetPreferredAllocation() або PreStartContainer(). Прапорці, що вказують на доступність цих викликів, якщо такі є, повинні бути встановлені в повідомленні DevicePluginOptions, відправленому через виклик GetDevicePluginOptions(). kubelet завжди викликає GetDevicePluginOptions(), щоб побачити, які необовʼязкові функції доступні, перед тим як викликати будь-яку з них безпосередньо.
Втулок реєструється з kubelet через Unix сокет за шляхом хосту /var/lib/kubelet/device-plugins/kubelet.sock.
Примітка:
Послідовність робочого процесу є важливою. Втулок МАЄ почати обслуговування служби gRPC перед реєстрацією з kubelet для успішної реєстрації.
Після успішної реєстрації втулок працює в режимі обслуговування, під час якого він постійно відстежує стан пристроїв та повідомляє kubelet про будь-які зміни стану пристрою. Він також відповідальний за обслуговування запитів gRPC Allocate. Під час Allocate втулок пристрою може виконувати підготовку, специфічну для пристрою; наприклад, очищення GPU або ініціалізація QRNG. Якщо операції успішно виконуються, втулок повертає відповідь AllocateResponse, яка містить конфігурації контейнера для доступу до виділених пристроїв. Kubelet передає цю інформацію середовищу виконання контейнерів.
AllocateResponse містить нуль або більше обʼєктів ContainerAllocateResponse. У цих обʼєктах втулок визначає зміни, які потрібно внести в опис контейнера для забезпечення
доступу до пристрою. Ці зміни включають:
Обробка повних імен пристроїв CDI Менеджером пристроїв потребує, щоб функціональну можливістьDevicePluginCDIDevices було увімкнено як для kubelet, так і для kube-apiserver. Це було додано як альфа-функція в Kubernetes v1.28 і було підняте до бета у v1.29 та GA у v1.31.
Обробка перезапусків kubelet
Очікується, що втулок пристрою виявлятиме перезапуски kubelet і повторно реєструватиметься з новим екземпляром kubelet. Новий екземпляр kubelet видаляє всі наявні Unix-сокети під /var/lib/kubelet/device-plugins, коли він стартує. Втулок пристрою може відстежувати вилучення своїх Unix-сокетів та повторно реєструватися після цієї події.
Втулок пристроїв та несправні пристрої
Існують випадки, коли пристрої виходять з ладу або вимикаються. Відповідальність втулку пристроїв у такому випадку полягає в тому, щоб повідомити kubelet про ситуацію за допомогою API ListAndWatchResponse.
Після того, як пристрій позначено як несправний, kubelet зменшить кількість виділених ресурсів для цього ресурсу на Вузлі, щоб відобразити, скільки пристроїв можна використовувати для планування нових Podʼів. Загальна величина кількості для ресурсу не змінюватиметься.
Podʼи, які були призначені несправним пристроям, залишаться призначеними до цього пристрою. Зазвичай код, що покладається на пристрій, почне виходити з ладу, і Pod може перейти у фазу Failed, якщо restartPolicy для Podʼа не був Always, або увійти в цикл збоїв в іншому випадку.
До Kubernetes v1.31, щоб дізнатися, чи повʼязаний Pod із несправним пристроєм, потрібно було використовувати PodResources API.
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.31 [alpha] (стандартно увімкнено: false)
Увімкнувши функціональну можливість ResourceHealthStatus, до кожного статусу контейнера в полі .status для кожного Pod буде додано поле allocatedResourcesStatus. Поле allocatedResourcesStatus надає інформацію про стан справності для кожного пристрою, призначеного контейнеру.
Для несправного Pod або коли ви підозрюєте несправність, ви можете використовувати цей статус, щоб зрозуміти, чи може поведінка Podʼа бути повʼязаною з несправністю пристрою. Наприклад, якщо прискорювач повідомляє про подію перегріву, поле allocatedResourcesStatus може відобразити цю інформацію.
Розгортання втулка пристрою
Ви можете розгорнути втулок пристрою як DaemonSet, як пакунок для операційної системи вузла або вручну.
Канонічна тека /var/lib/kubelet/device-plugins потребує привілейованого доступу, тому втулок пристрою повинен працювати у привілейованому контексті безпеки. Якщо ви розгортаєте втулок пристрою як DaemonSet, тека /var/lib/kubelet/device-plugins має бути змонтована як Том у PodSpec втулка.
Якщо ви обираєте підхід з використанням DaemonSet, ви можете розраховувати на Kubernetes щодо: розміщення Podʼа втулка пристрою на Вузлах, перезапуску Podʼа демона після відмови та автоматизації оновлень.
Сумісність API
Раніше схема керування версіями вимагала, щоб версія API втулка пристрою точно відповідала версії Kubelet. З моменту переходу цієї функції до бета-версії у версії 1.12 це більше не є жорсткою вимогою. API має версію і є стабільним з моменту випуску бета-версії цієї функції. Через це оновлення kubelet повинні бути безперебійними, але все ще можуть бути зміни в API до стабілізації, що робить оновлення не гарантовано непорушними.
Примітка:
Хоча компонент Kubernetes, Device Manager, є загальнодоступною функцією, API втулка пристроїв не є стабільним. Щоб отримати інформацію про API втулка пристрою та сумісність версій, прочитайте Версії API втулка пристрою.
Як проєкт, Kubernetes рекомендує розробникам втулка пристрою:
Слідкувати за змінами API втулка пристрою у майбутніх релізах.
Підтримувати кілька версій API втулка пристрою для забезпечення зворотної/майбутньої сумісності.
Для запуску втулка пристрою на вузлах, які потрібно оновити до випуску Kubernetes з новішою версією API втулка пристрою, оновіть ваші втулки пристроїв, щоб підтримувати обидві версії перед оновленням цих вузлів. Такий підхід забезпечить безперервну роботу виділення пристроїв під час оновлення.
Моніторинг ресурсів втулка пристрою
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.28 [stable]
Для моніторингу ресурсів, наданих втулками пристроїв, агенти моніторингу повинні мати змогу виявляти набір пристроїв, які використовуються на вузлі, та отримувати метадані, щоб описати, з яким контейнером повʼязаний показник метрики. Метрики Prometheus, експоновані агентами моніторингу пристроїв, повинні відповідати Рекомендаціям щодо інструментування Kubernetes, ідентифікуючи контейнери за допомогою міток prometheus pod, namespace та container.
Kubelet надає gRPC-сервіс для виявлення використовуваних пристроїв та надання метаданих для цих пристроїв:
// PodResourcesLister — це сервіс, який надається kubelet, який надає інформацію про
// ресурси вузла, використані контейнерами та Podʼами на вузлі
service PodResourcesLister {
rpc List(ListPodResourcesRequest) returns (ListPodResourcesResponse) {}
rpc GetAllocatableResources(AllocatableResourcesRequest) returns (AllocatableResourcesResponse) {}
rpc Get(GetPodResourcesRequest) returns (GetPodResourcesResponse) {}
}
Точка доступу gRPC List
Точка доступу List надає інформацію про ресурси запущених Podʼів, з деталями, такими як ідентифікатори виключно виділених ЦП, ідентифікатор пристрою так, як він був повідомлений втулками пристроїів, і ідентифікатор NUMA-вузла, де ці пристрої розміщені. Крім того, для машин, що базуються на NUMA, вона містить інформацію про памʼять та великі сторінки, призначені для контейнера.
Починаючи з Kubernetes v1.27, точка доступу List може надавати інформацію про ресурси запущених Podʼів, виділені в ResourceClaims за допомогою API DynamicResourceAllocation. Починаючи з Kubernetes v1.34, ця функціє є стандартно увімкненою. Щоб її вимкнути, kubelet повинен бути запущений з наступними прапорцями:
// ListPodResourcesResponse — це відповідь, повернута функцією List
message ListPodResourcesResponse {
repeated PodResources pod_resources = 1;
}
// PodResources містить інформацію про ресурси вузла, призначені для Podʼа
message PodResources {
string name = 1;
string namespace = 2;
repeated ContainerResources containers = 3;
}
// ContainerResources містить інформацію про ресурси, призначені для контейнера
message ContainerResources {
string name = 1;
repeated ContainerDevices devices = 2;
repeated int64 cpu_ids = 3;
repeated ContainerMemory memory = 4;
repeated DynamicResource dynamic_resources = 5;
}
// ContainerMemory містить інформацію про памʼять та великі сторінки, призначені для контейнера
message ContainerMemory {
string memory_type = 1;
uint64 size = 2;
TopologyInfo topology = 3;
}
// Topology описує апаратну топологію ресурсу
message TopologyInfo {
repeated NUMANode nodes = 1;
}
// NUMA представлення NUMA-вузла
message NUMANode {
int64 ID = 1;
}
// ContainerDevices містить інформацію про пристрої, призначені для контейнера
message ContainerDevices {
string resource_name = 1;
repeated string device_ids = 2;
TopologyInfo topology = 3;
}
// DynamicResource містить інформацію про пристрої, призначені для контейнера за допомогою Dynamic Resource Allocation
message DynamicResource {
string class_name = 1;
string claim_name = 2;
string claim_namespace = 3;
repeated ClaimResource claim_resources = 4;
}
// ClaimResource містить інформацію про ресурси у втулках
message ClaimResource {
repeated CDIDevice cdi_devices = 1 [(gogoproto.customname) = "CDIDevices"];
}
// CDIDevice визначає інформацію про пристрій CDI
message CDIDevice {
// Повністю кваліфіковане імʼя пристрою CDI
// наприклад: vendor.com/gpu=gpudevice1
// див. більше деталей в специфікації CDI:
// https://github.com/container-orchestrated-devices/container-device-interface/blob/main/SPEC.md
string name = 1;
}
Примітка:
cpu_ids у ContainerResources у точці доступу List відповідають виключно виділеним ЦП, призначеним для певного контейнера. Якщо мета — оцінити ЦП, які належать до загального пула, точку доступу List необхідно використовувати разом з точкою доступуGetAllocatableResources, як пояснено
нижче:
Викликайте GetAllocatableResources, щоб отримати список всіх доступних для виділення ЦП.
Викликайте GetCpuIds на всі ContainerResources у системі.
Відніміть всі ЦП з викликів GetCpuIds з виклику GetAllocatableResources.
Точка доступу gRPC GetAllocatableResources
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.28 [stable]
Точка доступу GetAllocatableResources надає інформацію про ресурси, що спочатку доступні на робочому вузлі. Вона надає більше інформації, ніж kubelet експортує в APIServer.
Примітка:
GetAllocatableResources слід використовувати лише для оцінки виділених ресурсів на вузлі. Якщо мета - оцінити вільні/невикористані ресурси, її слід використовувати разом з точкою доступу List(). Результат, отриманий за допомогою GetAllocatableResources, залишиться таким самим, якщо ресурси, які експонуються для kubelet, не змінюються. Це відбувається рідко, але коли це відбувається (наприклад: hotplug/hotunplug, зміни стану пристроїв), очікується, що клієнт викличе точку доступу GetAllocatableResources.
Однак виклик точки доступу GetAllocatableResources не є достатнім у випадку оновлення ЦП та/або памʼяті, і для відображення правильної кількості та виділення ресурсів Kubelet повинен бути перезавантажений.
// AllocatableResourcesResponses містить інформацію про всі пристрої, відомі kubelet
message AllocatableResourcesResponse {
repeated ContainerDevices devices = 1;
repeated int64 cpu_ids = 2;
repeated ContainerMemory memory = 3;
}
ContainerDevices дійсно викладають інформацію про топологію, що вказує, до яких NUMA-клітин пристрій прикріплений. NUMA-клітини ідентифікуються за допомогою прихованого цілочисельного ідентифікатора, значення якого відповідає тому, що втулки пристроїв повідомляють коли вони реєструються у kubelet.
Сервіс gRPC обслуговується через unix-сокет за адресою /var/lib/kubelet/pod-resources/kubelet.sock. Агенти моніторингу для ресурсів втулків пристроїв можуть бути розгорнуті як демони, або як DaemonSet. Канонічна тека /var/lib/kubelet/pod-resources вимагає привілейованого доступу, тому агенти моніторингу повинні працювати у привілейованому контексті безпеки. Якщо агент моніторингу пристроїв працює як DaemonSet, /var/lib/kubelet/pod-resources має бути підключена як Том у PodSpec агента моніторингу пристроїв PodSpec.
Примітка:
При доступі до /var/lib/kubelet/pod-resources/kubelet.sock з DaemonSet або будь-якого іншого застосунку, розгорнутого як контейнер на вузлі, який монтує сокет як том, це є доброю практикою монтувати теку /var/lib/kubelet/pod-resources/ замість /var/lib/kubelet/pod-resources/kubelet.sock. Це забезпечить можливість перепідключення контейнера до цього сокету після перезавантаження kubelet.
Записи контейнера керуються за допомогою inode, що посилається на сокет або теку, залежно від того, що було змонтовано. Після перезапуску kubelet сокет видаляється і створюється новий сокет, тоді як тека залишається недоторканою. Таким чином, оригінальний inode для сокета стає непридатним для використання. inode для теки продовжить працювати.
Точка доступу gRPC Get
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.34 [beta]
Точка доступу Get надає інформацію про ресурси робочого Pod. Вона експонує інформацію, аналогічну тій, що описана в точці доступу List. Точка доступу Get вимагає PodName і PodNamespace робочого Pod.
// GetPodResourcesRequest містить інформацію про Pod
message GetPodResourcesRequest {
string pod_name = 1;
string pod_namespace = 2;
}
Для вимкнення цієї функції вам потрібно запустити ваші служби kubelet з такими прапорцями:
--feature-gates=KubeletPodResourcesGet=false
Точка доступу Get може надавати інформацію про Pod, повʼязану з динамічними ресурсами, виділеними за допомогою API динамічного виділення ресурсів. Починаючи з версії Kubernetes v1.34, ця функція є стандартно увімкненою. Щоб її вимкнути, kubelet повинен бути запущений з наступними прапорцями:
Менеджер Топології (Topology Manager) є компонентом Kubelet, який дозволяє координувати ресурси в манері, орієнтованій на топологію. Для цього API втулка пристрою (Device Plugin API) було розширено, щоб включити структуру TopologyInfo.
Втулки пристроїв, які хочуть використовувати Менеджер Топології, можуть надсилати заповнену структуру TopologyInfo як частину реєстрації пристрою, разом з ідентифікаторами пристроїв та станом справності пристрою. Менеджер пристроїв потім використовуватиме цю інформацію для консультації з Менеджером Топології та прийняття рішень щодо призначення ресурсів.
TopologyInfo підтримує встановлення поля nodes або у nil, або у список вузлів NUMA. Це дозволяє Втулку Пристрою оголошувати пристрій, який охоплює кілька вузлів NUMA.
Встановлення TopologyInfo в nil або надання порожнього списку вузлів NUMA для даного пристрою вказує на те, що Втулок Пристрою не має переваги щодо спорідненості NUMA для цього пристрою.
Приклад структури TopologyInfo, заповненої для пристрою Втулком Пристрою:
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Ось деякі приклади реалізації втулків пристроїв:
Akri дозволяє легко використовувати різнорідні пристрої вузла (такі як IP-камери та USB-пристрої).
HAMi для гетерогенного проміжного програмного забезпечення для віртуалізації обчислень ШІ (наприклад, NVIDIA, Cambricon, Hygon, Iluvatar, MThreads, Ascend, Metax)
The Втулок пристрою NVIDIA GPU, Офіційний втулок для пристроїв від NVIDIA, який експонує графічні процесори NVIDIA та відстежує стан графічних процесорів
Власні ресурси користувача є розширенням API Kubernetes. Kubernetes надає два способи додавання власних ресурсів до вашого кластера:
Механізм CustomResourceDefinition (CRD) дозволяє вам декларативно визначити новий власний API з API-групою, видом (kind) та схемою, які ви вказуєте. Панель управління Kubernetes обслуговує та обробляє зберіганням вашого власного ресурсу. CRD дозволяє створювати нові типи ресурсів для вашого кластера без написання та запуску власного API-сервера.
Шар агрегації розташований за основним API-сервером, який діє як проксі. Таке розташування називається агрегацією API (AA), яка дозволяє вам надавати спеціалізовані реалізації для ваших власних ресурсів, написавши та розгорнувши власний API-сервер. Основний API-сервер делегує запити до вашого API-сервера для власних API, які ви вказуєте, зробивши їх доступними для всіх своїх клієнтів.
2.1 - Власні Ресурси
Власні ресурси є розширеннями API Kubernetes. Ця сторінка обговорює, коли додавати власний ресурс до вашого кластера Kubernetes та коли використовувати як самостійний сервіс. Вона описує два методи додавання власних ресурсів і як вибрати між ними.
Власні ресурси
Ресурс — це точка доступу в API Kubernetes, яка зберігає колекцію обʼєктів API певного виду; наприклад, вбудований ресурс pods містить колекцію обʼєктів Pod.
Власний ресурс — це розширення API Kubernetes, яке не обовʼязково доступне в типовій установці Kubernetes. Він представляє собою налаштування конкретного встановлення Kubernetes. Однак багато основних функцій Kubernetes тепер побудовані з використанням власних ресурсів, що робить Kubernetes більш модульним.
Власні ресурси можуть зʼявлятися та зникають в працюючому кластері через динамічну реєстрацію, і адміністратори кластера можуть оновлювати власні ресурси незалежно від самого кластера. Як тільки власний ресурс встановлено, користувачі можуть створювати та отримувати доступ до його обʼєктів за допомогою kubectl, так само як для вбудованих ресурсів, таких як Pod.
Власні контролери
Самі по собі власні ресурси дозволяють зберігати та отримувати структуровані дані. Коли ви поєднуєте власний ресурс з власним контролером, власні ресурси надають справжній декларативний API.
Декларативний API Kubernetes забезпечує розділення обовʼязків. Ви оголошуєте бажаний стан вашого ресурсу. Контролер Kubernetes підтримує поточний стан обʼєктів Kubernetes відповідно до вашого оголошеного бажаного стану. Це відрізняється від імперативного API, де ви вказуєте серверу, що робити.
Ви можете розгортати та оновлювати власний контролер на робочому кластері, незалежно від життєвого циклу кластера. Власні контролери можуть працювати з будь-яким видом ресурсів, але вони особливо ефективні, коли поєднуються з власними ресурсами. Шаблон Оператора поєднує власні ресурси та власні контролери. Ви можете використовувати власні контролери для включення доменного знання для конкретних застосунків у розширення API Kubernetes.
Чи слід додавати власний ресурс до мого кластера Kubernetes?
Ваш API складається з відносно невеликої кількості відносно невеликих обʼєктів (ресурсів).
Обʼєкти визначають конфігурацію застосунків або інфраструктури.
Обʼєкти оновлюються відносно рідко.
Люди часто мають читати та записувати обʼєкти.
Основні операції з обʼєктами — це CRUD (створення, читання, оновлення та видалення).
Транзакції між обʼєктами не потрібні: API представляє бажаний стан, а не точний стан.
Імперативні API не є декларативними. Ознаки того, що ваш API може не бути декларативним, включають:
Клієнт каже "зробіть це", і потім отримує синхронну відповідь, коли це виконано.
Клієнт каже "зробіть це", а потім отримує ідентифікатор операції назад і повинен перевірити окремий обʼєкт операції, щоб визначити завершення запиту.
Ви говорите про виклики віддалених процедур (RPC).
Пряме зберігання великої кількості даних; наприклад, > кілька кБ на обʼєкт, або > 1000 обʼєктів.
Потрібен високий доступ до пропускної здатності (десятки запитів на секунду тривалий час).
Збереження даних кінцевого користувача (наприклад, зображень, PII тощо) або інших великих обсягів даних, оброблених застосунками.
Природні операції з обʼєктами не є CRUD-подібними.
API не легко моделюється як обʼєкти.
Ви вибрали представлення очікуючих операцій за допомогою ідентифікатора операції або обʼєкта операції.
Чи слід використовувати ConfigMap або власний ресурс?
Використовуйте ConfigMap, якщо застосовується будь-який з наступних пунктів:
Існує вже відомий, добре задокументований формат файлу конфігурації, такий як mysql.cnf або pom.xml.
Ви хочете помістити всю конфігурацію в один ключ ConfigMap.
Основне використання файлу конфігурації — для програми, що працює у Pod у вашому кластері, для використання файлу для самоналаштування.
Споживачі файлу вважають за краще отримувати його через файл у Pod або змінну оточення у Pod, а не через Kubernetes API.
Ви хочете виконувати послідовне оновлення за допомогою Deployment тощо, коли файл оновлюється.
Примітка:
Використовуйте Secret для конфіденційних даних, який є схожим на ConfigMap, але безпечнішим.
Використовуйте власний ресурс (CRD або Aggregated API), якщо застосовується більшість з наступних пунктів:
Ви хочете використовувати бібліотеки та CLI Kubernetes для створення та оновлення нового ресурсу.
Ви хочете отримати підтримку на вищому рівні від kubectl; наприклад, kubectl get my-object object-name.
Ви хочете побудувати нову автоматизацію, яка стежить за оновленнями нового обʼєкта, а потім виконує CRUD інших обʼєктів, або навпаки.
Ви хочете написати автоматизацію, яка обробляє оновлення обʼєкта.
Ви хочете використовувати конвенції Kubernetes API, такі як .spec, .status, та .metadata.
Ви хочете, щоб обʼєкт був абстракцією над колекцією контрольованих ресурсів або узагальненням інших ресурсів.
Додавання власних ресурсів
Kubernetes надає два способи додавання власних ресурсів до вашого кластера:
CRD (Custom Resource Definition) є простим і може бути створений без будь-якого програмування.
API Aggregation потребує програмування, але надає більший контроль над поведінкою API, такою як зберігання даних та конвертація між версіями API.
Kubernetes надає ці два варіанти, щоб задовольнити потреби різних користувачів, щоб ні зручність використання, ні гнучкість не зазнавали утисків.
Агреговані API є підлеглими API-серверами, які розташовані позаду основного API-сервера, який діє як проксі. Ця організація називається API Aggregation(AA). Для користувачів API Kubernetes виглядає розширеним.
CRD дозволяють користувачам створювати нові типи ресурсів без додавання іншого API-сервера. Вам не потрібно розуміти API Aggregation, щоб використовувати CRD.
Незалежно від того, як вони встановлені, нові ресурси називаються Custom Resources, щоб відрізняти їх від вбудованих ресурсів Kubernetes (наприклад, Pod).
Примітка:
Уникайте використання Custom Resource як сховища даних для застосунків, користувачів або моніторингу: архітектурні рішення, які зберігають дані застосунків в API Kubernetes, зазвичай представляють занадто тісно повʼязану конструкцію.
З архітектурного погляду хмарні архітектура застосунків надає перевагу вільному звʼязуванню між компонентами. Якщо частина вашого завдання вимагає сервісу підтримки для його рутинної роботи, запускайте цей сервіс як компонент або використовуйте його як зовнішній сервіс. Таким чином, ваше робоче навантаження не залежить від API Kubernetes для його нормальної роботи.
CustomResourceDefinitions
API-ресурс CustomResourceDefinition дозволяє вам визначати власні ресурси. Визначення обʼєкта CRD створює новий власний ресурс з імʼям і схемою, яку ви вказуєте. API Kubernetes обслуговує та обробляє зберігання вашого власного ресурсу. Назва самого обʼєкта CRD повинна бути дійсною назвою піддомену DNS, утвореною від визначеної назви ресурсу та його API групи; для детальнішої інформації дивіться як створити CRD. Крім того, назва обʼєкта, чий тип/ресурс визначається CRD, також повинна бути дійсною назвою піддомену DNS.
Це звільняє вас від написання власного API-сервера для обробки власного ресурсу, але загальна природа реалізації означає, що у вас менше гнучкості, ніж з агрегацією сервера API.
Для прикладу того, як зареєструвати новий власний ресурс, для роботи з екземплярами вашого нового типу ресурсу та використовувати контролер для обробки подій, дивіться приклад власного контролера.
Агрегація сервера API
Зазвичай кожен ресурс в API Kubernetes вимагає коду, який обробляє REST-запити та керує постійним зберіганням обʼєктів. Основний сервер API Kubernetes обробляє вбудовані ресурси, такі як Pod та Service, а також узагальнено може керувати власними ресурсами через CRD.
Шар агрегації дозволяє вам надати спеціалізовані реалізації для ваших власних ресурсів, написавши та розгорнувши власний сервер API. Основний сервер API делегує запити до вашого сервера API для власних ресурсів, які ви обробляєте, роблячи їх доступними для всіх його клієнтів.
Вибір методу для додавання власних ресурсів
CRD простіші у використанні. Агреговані API більш гнучкі. Виберіть метод, який найкраще відповідає вашим потребам.
Зазвичай CRD підходять, якщо:
У вас багато полів.
Ви використовуєте ресурс у своїй компанії або як частину невеликого відкритого проєкту (на відміну від комерційного продукту).
Порівняння простоти використання
Створення CRD простіше, ніж Aggregated APIs.
CRD
Aggregated API
Не потребує програмування. Користувачі можуть вибрати будь-яку мову для контролера CRD.
Вимагає програмування та створення бінарного файлу та образу.
Немає додаткової служби для запуску; CRD обробляються сервером API.
Додаткова служба для створення, яка може зазнати невдачі.
Немає підтримки після створення CRD. Будь-які виправлення помилок виконуються як частина звичайних оновлень майстра Kubernetes.
Може вимагати періодичного отримування виправлення помилок від постачальника та перебудови та оновлення сервера Aggregated API.
Не потрібно керувати декількома версіями вашого API; наприклад, коли ви контролюєте клієнта для цього ресурсу, ви можете оновлювати його синхронно з API.
Потрібно керувати декількома версіями вашого API; наприклад, коли розробляєте розширення для спільного використання.
Розширені функції та гнучкість
Агреговані API пропонують більше розширених можливостей API та налаштування інших функцій; наприклад, рівень зберігання.
Функція
Опис
CRD
Aggregated API
Валідація
Допомагає користувачам уникати помилок та дозволяє вам самостійно розвивати ваше API незалежно від ваших клієнтів. Ці функції найбільш корисні, коли є багато клієнтів, які не можуть всі одночасно оновлюватися.
Так. Більшість валідацій можуть бути вказані у CRD за допомогою валідації OpenAPI v3.0. Можливість CRDValidationRatcheting дозволяє ігнорувати валідації, вказані за допомогою OpenAPI, якщо збійна частина ресурсу не була змінена. Будь-яка інша валідація підтримується за допомогою Вебхука валідації.
Так, довільні перевірки валідації
Стандартне значення
Див. вище
Так, або через валідацію OpenAPI v3.0 за допомогою ключового слова default (GA в 1.17), або через Вебхук мутації (хоча це не буде виконано при зчитуванні з etcd для старих обʼєктів).
Так
Мультиверсіонність
Дозволяє обслуговувати той самий обʼєкт через дві версії API. Може допомогти спростити зміни API, такі як перейменування полів. Менш важливо, якщо ви контролюєте версії вашого клієнта.
Якщо вам потрібне сховище з іншим режимом продуктивності (наприклад, база даних часових рядів замість сховища ключ-значення) або ізоляція для безпеки (наприклад, шифрування конфіденційної інформації тощо).
Немає
Так
Власна бізнес-логіка
Виконуйте довільні перевірки або дії при створенні, читанні, оновленні або видаленні обʼєкта
Дозволяє деталізований контроль доступу, де користувач записує розділ spec, а контролер записує розділ status. Дозволяє інкрементувати Generation обʼєкту при мутації даних власного ресурсу (вимагає окремих розділів spec та status у ресурсі).
Додавання операцій крім CRUD, таких як "logs" або "exec".
Немає
Так
strategic-merge-patch
Нові точки доступу підтримують PATCH з Content-Type: application/strategic-merge-patch+json. Корисно для оновлення обʼєктів, які можуть бути змінені як локально, так і сервером. Докладніше див. "Оновлення обʼєктів API на місці за допомогою kubectl patch"
Немає
Так
Protocol Buffers
Новий ресурс підтримує клієнтів, які хочуть використовувати Protocol Buffers
Немає
Так
Схема OpenAPI
Чи є схема OpenAPI (swagger) для типів, які можуть бути динамічно завантажені з сервера? Чи захищений користувач від помилок у написанні назв полів, забезпечуючи, що лише дозволені поля встановлені? Чи використовуються типи (іншими словами, не розміщуйте int в string полі?)
Чи накладає цей механізм розширення будь-які обмеження на назви обʼєктів, тип/ресурс яких визначено таким чином?
Так, назва такого обʼєкта повинна бути дійсною назвою піддомену DNS.
Ні
Загальні функції
При створенні власного ресурсу, будь-то через CRD або AA, ви отримуєте багато функцій для вашого API порівняно з його втіленням поза платформою Kubernetes:
Функція
Опис
CRUD
Нові точки доступу підтримують CRUD базові операції через HTTP та kubectl
Watch
Нові точки доступу підтримують операції Watch Kubernetes через HTTP
Discovery
Клієнти, такі як kubectl та інтерфейс, автоматично пропонують операції list, display та edit для полів у ваших ресурсах
json-patch
Нові точки доступу підтримують PATCH з Content-Type: application/json-patch+json
merge-patch
Нові точки доступу підтримують PATCH з Content-Type: application/merge-patch+json
HTTPS
Нові точки доступу використовують HTTPS
Вбудована автентифікація
Доступ до розширення використовує ядро сервера API (рівень агрегації) для автентифікації
Вбудована авторизація
Доступ до розширення може використовувати авторизацію, яка використовується ядром сервера API; наприклад, RBAC.
Finalizers
Блокування видалення ресурсів розширення до тих пір, поки не відбудеться зовнішнє очищення.
Admission Webhooks
Встановлення стандартних значень та валідація ресурсів розширення під час будь-якої операції створення/оновлення/видалення.
Відображення в інтерфейсі/CLI
Kubectl, інтерфейс можуть відображати ресурси розширення.
Не встановлено чи Порожньо
Клієнти можуть розрізняти невстановлені поля від полів з нульовим значенням.
Генерація бібліотек клієнтів
Kubernetes надає загальні бібліотеки клієнтів, а також інструменти для генерації бібліотек клієнтів для конкретних типів даних.
Мітки та анотації
Загальні метадані між обʼєктами, для яких інструменти знають, як їх редагувати для основних та власних ресурсів.
Підготовка до встановлення власного ресурсу
Перш ніж додавати власний ресурс до вашого кластера, слід врахувати кілька моментів.
Код від сторонніх розробників та нові точки відмов
Створення CRD не автоматично додає будь-які нові точки відмов (наприклад, за допомогою запуску коду сторонніх розробників на вашому сервері API), проте пакети (наприклад, Charts) або інші збірники для встановлення часто включають CRD, а також Deployment з кодом сторонніх розробників, який реалізує бізнес-логіку для нового власного ресурсу.
Встановлення агрегованого сервера API завжди передбачає запуск нового Deployment.
Зберігання
Власні ресурси споживають місце зберігання так само як і ConfigMaps. Створення занадто великих власних ресурсів може перевантажити простір зберігання сервера API.
Агреговані сервери API можуть використовувати те саме зберігання, що і головний сервер API, в такому разі застосовуються ті самі попередження.
Автентифікація, авторизація та аудит
CRD завжди використовують ту саму автентифікацію, авторизацію та ведення аудиту, що й вбудовані ресурси вашого сервера API.
Якщо ви використовуєте RBAC для авторизації, більшість ролей RBAC не надають доступ до нових ресурсів (окрім ролі cluster-admin або будь-якої ролі, створеної з шаблонами). Вам потрібно явно надати доступ до нових ресурсів. CRD та агреговані сервери API часто постачаються з новими визначеннями ролей для типів, які вони додають.
Агреговані сервери API можуть або не можуть використовувати ту саму автентифікацію, авторизацію та ведення аудиту, що й основний сервер API.
Доступ до власного ресурсу
Бібліотеки клієнтів Kubernetes можна використовувати для доступу до власних ресурсів. Не всі бібліотеки клієнтів підтримують власні ресурси. Go та Python бібліотеки клієнтів це роблять.
Після додавання власного ресурсу ви можете отримати до нього доступ за допомогою:
kubectl
Динамічного клієнта Kubernetes.
REST-клієнта, який ви напишете.
Клієнта, згенерованого за допомогою інструментів генерації клієнта Kubernetes (генерація є складним завданням, але деякі проєкти можуть постачати клієнтів разом з CRD або AA).
Селектори полів власних ресурсів
Селектори полів дозволяють клієнтам вибирати власні ресурси за значенням полів одного чи більше ресурсів.
Всі власні ресурси підтримують селектори полів metadata.name та metadata.namespace.
Поля власних ресурсів, які підтримуються селекторами
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.32 [stable] (стандартно увімкнено: true)
Поле spec.versions[*].selectableFields в CustomResourceDefinition може бути використане для вказівки, які інші поля в власному ресурсі можуть бути використані в полях селекторів.
Наступний приклад додає поля .spec.color та .spec.size, як поля які можна вибирати.
Шар агрегації дозволяє розширювати можливості Kubernetes за допомогою додаткових API, поза тим, що пропонується ядром основних API Kubernetes. Додаткові API можуть бути як готові рішення, такі як сервер метрик, так і API, які ви розробляєте самостійно.
Шар агрегації працює в процесі разом з kube-apiserver. До того, як розширений ресурс буде зареєстровано, шар агрегації не виконуватиме жодних дій. Для реєстрації API ви додаєте обʼєкт APIService, який "запитує" URL-шлях у Kubernetes API. На цьому етапі шар агрегації буде передавати будь-що, що надійде на цей API-шлях (наприклад, /apis/myextension.mycompany.io/v1/…), зареєстрованому APIService.
Найпоширеніший спосіб реалізації APIService — це запуск розширеного API-сервера в Podʼах, які працюють у вашому кластері. Якщо ви використовуєте розширений API-сервер для управління ресурсами у своєму кластері, розширений API-сервер (також пишеться як "extension-apiserver") зазвичай сполучається з одним або кількома контролерами. Бібліотека apiserver-builder надає кістяк як для розширених API-серверів, так і для відповідних контролерів.
Затримки відповіді
Розширені API-сервери повинні мати малі затримки мережевого звʼязку до та від kube-apiserver. Запити на виявлення повинні долати шлях до та від kube-apiserver до пʼяти секунд або менше.
Якщо ваш розширений API-сервер не може досягти цієї вимоги щодо затримки, розгляньте внесення змін, які дозволять вам відповідати їй.
Дізнайтеся про Концепції декларативної валідації, внутрішній механізм визначення правил валідації, який в майбутньому допоможе підтримувати валідацію для розробки серверів API розширень.
Оператори — це розширення програмного забезпечення для Kubernetes, які використовують власні ресурси для управління застосунками та їх компонентами. Оператори дотримуються принципів Kubernetes, зокрема control loop.
Мотивація
Шаблон operator спрямований на досягнення ключової мети людини-оператора, яка керує сервісом або набором сервісів. Люди-оператори, які відповідають за конкретні застосунки та сервіси, мають глибокі знання про те, як система повинна себе вести, як її розгорнути та як реагувати у разі проблем.
Люди, які запускають робочі навантаження в Kubernetes, часто хочуть використовувати автоматизацію для виконання повторюваних завдань. Шаблон operator показує, як ви можете написати код для автоматизації завдання, яке виходить за межі того, що надає сам Kubernetes.
Оператори в Kubernetes
Kubernetes створений для автоматизації. З коробки ви отримуєте багато вбудованої автоматизації від ядра Kubernetes. Ви можете використовувати Kubernetes для автоматизації розгортання та запуску робочих навантажень, та ви можете автоматизувати те, як це робить Kubernetes.
Концепція шаблону operator Kubernetes дозволяє розширити поведінку кластера без зміни коду самого Kubernetes, звʼязавши контролери з одним або кількома власними ресурсами. Оператори є клієнтами API Kubernetes, які діють як контролери для власного ресурсу.
Приклад оператора
Деякі завдання, які можна автоматизувати за допомогою оператора, включають:
розгортання застосунку за запитом
створення та відновлення резервних копій стану цього застосунку
керування оновленнями коду застосунку разом з повʼязаними змінами, такими як схеми баз даних або додаткові налаштування
публікація Serviceʼів для застосунків, які не підтримують Kubernetes API, для їх виявлення
емуляція відмови в усьому або частині кластера для перевірки його стійкості
обрання лідера для розподіленого застосунку без внутрішнього процесу такого вибору.
Яким може бути оператор у більш детальному вигляді? Ось приклад:
Власний ресурс з назвою SampleDB, який можна налаштувати в кластері.
Deployment, який запускає Pod, що містить частину контролера оператора.
Образ контейнера з кодом оператора.
Код контролера, який надсилає запити до панелі управління, щоб дізнатися, яким чином налаштовано ресурси SampleDB.
Ядром оператора є код, який говорить API серверу, які дії потрібно виконати, щоб поточний стан ресурсу SampleDB відповідав бажаному стану ресурсів.
Якщо ви додаєте новий ресурс SampleDB, оператор створює PersistentVolumeClaim для забезпечення місця для надійного зберігання даних, StatefulSet — для запуску SampleDB, та завдання (Job) для ініціалізації бази даних.
Якщо ви видаляєте ресурс SampleDB, оператор зробить зліпок з усіх даних, потім переконається, що ресурси StatefulSet та Volume також видалені.
Оператор також керує процесом створення резервних копій бази даних. Для кожного ресурсу SampleDB оператор визначає, коли потрібно створити Pod, який підʼєднається до бази даних, та зробить резервну копію. Ці Podʼи можуть використовувати ConfigMap чи Secret, що містять облікові дані для підʼєднання до бази даних.
Оскільки оператор призначений для надання високого рівня автоматизації для керування ресурсами, тож для цього може використовуватись додатковий код. Наприклад, код, що визначає, чи база даних працює на старій версії, та якщо так, то створює Job для оновлення бази даних.
Розгортання операторів
Найпоширеніший спосіб розгортання операторів — це додавання CustomResourceDefinition (CRD) та контролера для них до вашого кластера. Контролери мають зазвичай запускатись за межами панелі управління кластера, так само як ви запускаєте будь-який інший контейнеризований застосунок. Наприклад, ви можете запустити ваш контролер як Deployment.
Використання операторів
Після того, як ви розгорнете оператора, ви будете використовувати його, додаючи, змінюючи або видаляючи тип ресурсу, який використовує оператор. Наслідуючи наведений вище приклад, ви б налаштували розгортання для самого оператора, а потім:
kubectl get SampleDB # пошук налаштованої бази данихkubectl edit SampleDB/example-database # ручна заміна деяких параметрів
…і все! Оператор візьме на себе роботу застосування змін, а такою як і підтримання сервісу у відповідному стані.
Створення власних операторів
Якщо в екосистемі немає оператора, який реалізує потрібну вам поведінку, ви можете створити власний.
Ви також можете створити оператор (тобто, Контролер) використовуючи мову або рушій виконання, який працює як клієнт API Kubernetes.
Нижче наведено кілька бібліотек та інструментів, які ви можете використовувати для написання власного хмарного оператора.
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.