У Kubernetes планування означає забезпечення відповідності Podʼів вузлам (Nodes), щоб kubelet міг їх запустити. Випередження — це процес припинення роботи Podʼів з низьким пріоритетом, щоб Podʼи з вищим пріоритетом могли розміщуватися на вузлах. Виселення — це процес проактивного припинення роботи одного або кількох Podʼів на вузлах.
Розлад в роботі Podʼа — це процес, за якого Podʼи на вузлах припиняють роботу добровільно, або примусово.
Добровільні розлади запускаються навмисно власниками застосунків або адміністраторами кластера. Примусові розлади є ненавмисними та можуть бути спричинені невідворотними проблемами, такими як вичерпання ресурсів вузлів, або випадковими видаленнями.
У Kubernetes планування означає забезпечення того, що Podʼи відповідно призначаються вузлам, щоб їх можна було запустити за допомогою Kubelet.
Огляд планування
Планувальник відстежує новостворені Podʼи, які не мають призначеного Вузла. Планувальник відповідає за знаходження найкращого Вузла для кожного виявленого Podʼа, на якому можна запустити цей Pod. Планувальник приймає рішення про розташування Podʼа, враховуючи принципи планування, описані нижче.
Якщо ви хочете зрозуміти, чому Podʼи розміщуються на певному Вузлі, або якщо ви плануєте реалізувати власний планувальник, ця сторінка допоможе вам дізнатися більше про планування.
kube-scheduler
kube-scheduler є стандартним планувальником для Kubernetes і працює як частина панелі управління. kube-scheduler розроблено так, що, якщо ви хочете і вам треба, ви можете написати власний компонент планування і використовувати його замість стандартного.
Kube-scheduler вибирає оптимальний вузол для запуску нових або ще не запланованих Podʼів. Оскільки контейнери в Podʼах, і самі Podʼи, можуть мати різні вимоги, планувальник фільтрує будь-які вузли, які не відповідають конкретним потребам планування Podʼа. Зазвичай через API можна вказати вузол для Podʼа при його створенні, але це робиться тільки у виняткових випадках.
У кластері Вузли, які відповідають вимогам планування для Podʼа, називаються feasible (придатними) вузлами. Якщо жоден з вузлів не підходить, Pod залишається незапланованим до тих пір, поки планувальник не зможе розмістити його.
Планувальник знаходить придатні Вузли для Podʼів, а потім виконує набір функцій для оцінки таких Вузлів і вибирає Вузол з найвищим рейтингом серед придатних для запуску Podʼа. Планувальник потім повідомляє сервер API про це рішення в процесі, який називається binding (привʼязкою).
Фактори, які потрібно враховувати при прийнятті рішень про планування, включають індивідуальні та загальні вимоги до ресурсів, обмеження апаратного та програмного забезпечення / політики, (анти)спорідненість (affinity), розташування даних, взаємовплив між робочими навантаженнями та інше.
Вибір вузла в kube-scheduler
kube-scheduler вибирає вузол для Podʼа в два етапи:
Фільтрація.
Оцінювання.
На етапі фільтрації визначається набір Вузлів, на яких можна розмістити Pod. Наприклад, фільтр PodFitsResources перевіряє, чи має Вузол-кандидат достатньо доступних ресурсів, щоб задовольнити конкретні вимоги до ресурсів Podʼа. Після цього етапу список вузлів містить придатні вузли; часто їх буде більше одного. Якщо список порожній, цей Pod не є (поки що) можливим для планування.
На етапі оцінювання планувальник ранжує вузли, що були обрані, щоб вибрати найбільш придатне розміщення для Podʼа. Планувальник надає кожному вузлу, який залишився після фільтрації, оцінку, базуючись на активних правилах оцінки.
На останньому етапі kube-scheduler призначає Pod вузлу з найвищим рейтингом. Якщо є більше одного вузла з однаковими рейтингами, kube-scheduler вибирає один з них випадковим чином.
Є два підтримуваних способи налаштування поведінки фільтрації та оцінювання планувальника:
Політики планування дозволяють налаштувати Предикати для фільтрації та Пріоритети для оцінювання.
Профілі планування дозволяють налаштувати Втулки, які реалізують різні етапи планування, включаючи: QueueSort, Filter, Score, Bind, Reserve, Permit та інші. Ви також можете налаштувати kube-scheduler для запуску різних профілів.
Ви можете обмежити Pod так, щоб він був обмежений для запуску на конкретних вузлах, або віддавав перевагу запуску на певних вузлах. Існують кілька способів як це зробити, а рекомендовані підходи використовують усі селектори міток для полегшення вибору. Зазвичай вам не потрібно встановлювати жодні обмеження такого роду; планувальник автоматично робить розумне розміщення (наприклад, розподіл Podʼів по вузлах так, щоб не розміщувати Podʼи на вузлі з недостатньою кількістю вільних ресурсів). Однак є деякі обставини, коли ви можете контролювати, на якому вузлі розгортається Pod, наприклад, щоб переконатися, що Pod потрапляє на вузол з прикріпленим до нього SSD, або спільно розміщувати Podʼи з двох різних служб, які багато спілкуються в одній зоні доступності.
Ви можете використовувати будь-який з наступних методів для вибору місця, де Kubernetes планує конкретні Podʼи:
Значення цих міток специфічне для хмарного середовища і не може бути надійним. Наприклад, значення kubernetes.io/hostname може бути таким самим, як імʼя вузла у деяких середовищах, і різним в інших середовищах.
Ізоляція/обмеження вузлів
Додавання міток до вузлів дозволяє вам позначати Podʼи для розміщення на конкретних вузлах або групах вузлів. Ви можете використовувати цю функціональність, щоб забезпечити, що певні Podʼи працюватимуть тільки на вузлах із певною ізоляцією, безпекою або регуляторними властивостями.
Якщо ви використовуєте мітки для ізоляції вузлів, обирайте ключі міток, які kubelet не може змінювати. Це заважає скомпрометованому вузлу встановлювати ці мітки на себе, щоб планувальник планував навантаження на скомпрометований вузол.
Втулок допуску NodeRestriction перешкоджає kubelet встановлювати або змінювати мітки з префіксом node-restriction.kubernetes.io/.
Щоб скористатися цим префіксом міток для ізоляції вузлів:
Переконайтеся, що ви використовуєте авторизатор вузлів і ввімкнули втулок допуску NodeRestriction.
Додайте мітки з префіксом node-restriction.kubernetes.io/ на ваші вузли, і використовуйте ці мітки у ваших селекторах вузлів. Наприклад, example.com.node-restriction.kubernetes.io/fips=true або example.com.node-restriction.kubernetes.io/pci-dss=true.
Вибір вузла з використанням nodeSelector
nodeSelector є найпростішим рекомендованим способом обмеження вибору вузла. Ви можете додати поле nodeSelector до специфікації вашого Podʼа і вказати мітки вузла, які має мати цільовий вузол. Kubernetes розміщує Pod лише на тих вузлах, які мають всі мітки, які ви вказали.
nodeSelector є найпростішим способом обмежити Podʼи вузлами з певними мітками. Спорідненість та антиспорідненість розширюють типи обмежень, які ви можете визначити. Деякі з переваг спорідненості та антиспорідненості включають:
Мова (анти)спорідненості є більш виразною. nodeSelector вибирає лише вузли з усіма вказаними мітками. (Анти)спорідненіcть дає вам більший контроль над логікою вибору.
Ви можете вказати, що правило є soft або preferred, таким чином, планувальник все ще розміщує Pod навіть якщо не може знайти відповідного вузла.
Ви можете обмежити Pod, використовуючи мітки на інших Podʼах, які працюють на вузлі (або іншій топологічній області), а не лише мітки вузла, що дозволяє визначати правила для того, які Podʼи можуть бути розташовані на одному вузлі.
Функція affinity складається з двох типів значень:
Спорідненість вузла працює подібно до поля nodeSelector, але є більш виразним і дозволяє вказувати мʼякі правила.
Між-Podʼова (анти)спорідненість дозволяє обмежувати Podʼи проти міток інших Podʼів.
Спорідненість вузла
Спорідненість вузла концептуально подібне до nodeSelector і дозволяє вам обмежувати, на яких вузлах може бути запланований ваш Pod на основі міток вузла. Існують два типи спорідненості вузла:
requiredDuringSchedulingIgnoredDuringExecution: Планувальник не може запланувати Pod, якщо правило не виконується. Це працює подібно до nodeSelector, але з більш виразним синтаксисом.
preferredDuringSchedulingIgnoredDuringExecution: Планувальник намагається знайти вузол, який відповідає правилу. Якщо відповідний вузол недоступний, планувальник все одно планує Pod.
Примітка:
У попередніх типах IgnoredDuringExecution означає, що якщо мітки вузла змінюються після того, як Kubernetes запланував Pod, Pod продовжує працювати.
Ви можете вказати спорідненість вузла, використовуючи поле .spec.affinity.nodeAffinity в специфікації вашого Podʼа.
Наприклад, розгляньте наступну специфікацію Podʼа:
Вузол повинен мати мітку з ключем topology.kubernetes.io/zone, а значення цієї мітки повинно бути або antarctica-east1, або antarctica-west1.
Вузол переважно має мати мітку з ключем another-node-label-key, а значення another-node-label-value.
Ви можете використовувати поле operator, щоб вказати логічний оператор, який Kubernetes буде використовувати при інтерпретації правил. Ви можете використовувати In, NotIn, Exists, DoesNotExist, Gt і Lt.
Прочитайте розділ Оператори, щоб дізнатися більше про те, як вони працюють.
NotIn та DoesNotExist дозволяють визначати поведінку антиспорідненості. Альтернативно, ви можете використовувати node taints для відштовхування Podʼів від конкретних вузлів.
Примітка:
Якщо ви вказуєте як nodeSelector, так і nodeAffinity, обидва вони повинні задовольнятися для того, щоб Pod був запланований на вузол.
Якщо ви вказуєте кілька умов в nodeSelectorTerms, повʼязаних з типами nodeAffinity, то Pod може бути запланований на вузол, якщо одна з вказаних умов може бути задоволеною (умови зʼєднуються логічним OR).
Якщо ви вказуєте кілька виразів в одному полі matchExpressions, повʼязаному з умовою в nodeSelectorTerms, то Pod може бути запланований на вузол лише в тому випадку, якщо всі вирази задовольняються (вирази зʼєднуються логічним AND).
Ви можете вказати weight (вагу) від 1 до 100 для кожного випадку спорідненості типу preferredDuringSchedulingIgnoredDuringExecution. Коли планувальник знаходить вузли, які відповідають усім іншим вимогам планування Podʼа, планувальник проходить по кожному правилу preferred, якому задовольняє вузол, і додає значення weight для цього виразу до суми.
Кінцева сума додається до загального балу інших функцій пріоритету для вузла. Вузли з найвищим загальним балом пріоритету отримують пріоритет у виборі планувальника при прийнятті рішення щодо планування Podʼа.
Наприклад, розгляньте наступну специфікацію Podʼа:
Якщо існують два можливих вузли, які відповідають правилу preferredDuringSchedulingIgnoredDuringExecution, один з міткою label-1:key-1, а інший з міткою label-2:key-2, планувальник бере до уваги weight кожного вузла і додає вагу до інших балів для цього вузла, і планує Pod на вузол з найвищим кінцевим балом.
Примітка:
Якщо ви хочете, щоб Kubernetes успішно запланував Podʼи в цьому прикладі, вам потрібно мати наявні вузли з міткою kubernetes.io/os=linux.
Спорідненість вузла для кожного профілю планування
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.20 [beta]
При налаштуванні кількох профілів планування ви можете повʼязати профіль зі спорідненістю вузла, що є корисним, якщо профіль застосовується лише до певного набору вузлів. Для цього додайте addedAffinity до поля args втулка NodeAffinity у конфігурації планувальника. Наприклад:
addedAffinity застосовується до всіх Podʼів, які встановлюють .spec.schedulerName в foo-scheduler, на додачу до NodeAffinity, вказаного в PodSpec. Тобто для збігу вузла з Podʼом потрібно задовольнити збіг між addedAffinity та .spec.NodeAffinity Podʼа.
Оскільки addedAffinity не є видимим для кінцевих користувачів, його поведінка може бути неочікуваною для них. Використовуйте мітки вузлів, які мають чіткий взаємозвʼязок з іменем профілю планування.
Примітка:
Контролер DaemonSet, який створює Podʼи для DaemonSet, не підтримує профілі планування. Коли контролер DaemonSet створює Podʼи, стандартний планувальник Kubernetes розміщує ці Podʼи та дотримується будь-яких правил nodeAffinity в контролері DaemonSet.
Між-podʼова спорідненість та антиспорідненість
Між-podʼова спорідненість та антиспорідненість дозволяють обмежити, на яких вузлах ваші Podʼи можуть бути заплановані на основі міток Podʼів, які вже працюють на цьому вузлі, а не міток вузлів.
Типи між-podʼової спорідненості та антиспорідненості
Між-podʼова спорідненість та антиспорідненість мають наступний вигляд: "цей Pod повинен (або, у випадку антиспорідненості, не повинен) працювати у X, якщо на цьому X вже працюють один або декілька Podʼів, які задовольняють правилу Y", де X є областю топології, такою як вузол, стійка, зона або регіон постачальника хмарних послуг, або щос подібне, а Y — це правило, яке Kubernetes намагається задовольнити.
Ви виражаєте ці правила (Y) як селектори міток з опційним повʼязаним списком просторів імен. Podʼи є обʼєктами з простором імен в Kubernetes, тому мітки Podʼів також неявно мають простори імен. Будь-які селектори міток для міток Podʼа повинні вказувати простори імен, в яких Kubernetes має переглядати ці мітки.
Ви виражаєте область топології (X), використовуючи topologyKey, який є ключем для мітки вузла, яку система використовує для позначення домену. Для прикладу дивіться у Відомі мітки, анотації та позначення.
Примітка:
Між-Podʼові спорідненість та антиспорідненість потребують значних обсягів обчислень, що може значно сповільнити планування великих кластерів. Ми не рекомендуємо їх використовувати в кластерах розміром більше декількох сотень вузлів.
Примітка:
Антиспорідненість Podʼа вимагає, щоб вузли систематично позначались, іншими словами, кожен вузол в кластері повинен мати відповідну мітку, яка відповідає topologyKey. Якщо деякі або всі вузли не мають вказаної мітки topologyKey, це може призвести до непередбачуваної поведінки.
Подібно до Node affinnity, існують два типи спорідненості та
антиспорідненості Podʼа:
requiredDuringSchedulingIgnoredDuringExecution
preferredDuringSchedulingIgnoredDuringExecution
Наприклад, ви можете використовувати спорідненість requiredDuringSchedulingIgnoredDuringExecution,
щоб повідомити планувальник про те, що потрібно розташувати Podʼи двох служб в тій самій зоні постачальника хмарних послуг, оскільки вони взаємодіють між собою дуже часто. Так само ви можете використовувати антиспорідненість
preferredDuringSchedulingIgnoredDuringExecution, щоб розподілити Podʼи служби по різних зонах постачальника хмарних послуг.
Для використання між-Podʼової спорідненості використовуйте поле affinity.podAffinity в специфікації Podʼа. Для між-Podʼової антиспорідненості використовуйте поле affinity. podAntiAffinity в специфікації Podʼа.
Поведінка планування
При плануванні нового Podʼа планувальник Kubernetes оцінює правила спорідненості/антиспорідненості Podʼа в контексті поточного стану кластера:
Жорсткі обмеження (фільтрація вузлів):
podAffinity.requiredDuringSchedulingIgnoredDuringExecution та podAntiAffinity.requiredDuringSchedulingIgnoredDuringExecution:
Планувальник гарантує, що новий Pod буде призначено вузлам, які задовольняють цим необхідним правилам спорідненості та антиспорідненості, на основі існуючих Podʼів.
Мʼякі обмеження (скоринг):
podAffinity.preferredDuringSchedulingIgnoredDuringExecution та podAntiAffinity.preferredDuringSchedulingIgnoredDuringExecution:
Планувальник оцінює вузли на основі того, наскільки добре вони відповідають цим бажаним правилам спорідненості та антиспорідненості, щоб оптимізувати розміщення Podʼів.
Ігноровані поля:
Наявні в Podʼах podAffinity.preferredDuringSchedulingIgnoredDuringExecution:
Ці кращі правила спорідненості не враховуються під час прийняття рішення щодо планування нових Podʼів.
Наявні в Podʼах podAntiAffinity.preferredDuringSchedulingIgnoredDuringExecution:
Аналогічно, при плануванні ігноруються бажані правила антиспорідненності наявних Podʼів.
Планування групи Podʼів з між-podʼовою спорідненістю
Якщо поточний Pod, який планується, є першим у серії, який має спорідненість один до одного, його можна планувати, якщо він проходить всі інші перевірки спорідненості. Це визначається тим, що не існує іншого Podʼа в кластері, який відповідає простору імен та селектору цього Podʼа, що Pod відповідає власним умовам і обраний вузол відповідає всім запитаним топологіям. Це забезпечує відсутність блокування навіть у випадку, якщо всі Podʼи мають вказану між-Podʼову спорідненість.
У цьому прикладі визначено одне правило спорідненості Podʼа та одне правило антиспорідненості Podʼа. Правило спорідненості Podʼа використовує "hard" requiredDuringSchedulingIgnoredDuringExecution, тоді як правило антиспорідненості використовує "soft" preferredDuringSchedulingIgnoredDuringExecution.
Правило спорідненості вказує, що планувальник може розмістити Pod лише на вузлі, який належить до певної зони, де інші Podʼи мають мітку security=S1. Наприклад, якщо у нас є кластер із призначеною зоною, скажімо, "Zone V", що складається з вузлів з міткою topology.kubernetes.io/zone=V, планувальник може призначити Pod на будь-який вузол у Zone V, якщо принаймні один Pod у Zone V вже має мітку security=S1. Зворотно, якщо в Zone V немає Podʼів з мітками security=S1, планувальник не призначить Pod з прикладц ні на один вузол в цій зоні.
Правило антиспорідненості вказує, що планувальник повинен уникати призначення Podʼа на вузол, якщо цей вузол належить до певної зони, де інші Podʼи мають мітку security=S2. Наприклад, якщо у нас є кластер із призначеною зоною, скажімо, "Zone R", що складається з вузлів з міткою topology.kubernetes.io/zone=R, планувальник повинен уникати призначення Podʼа на будь-який вузол у Zone R, якщо принаймні один Pod у Zone R вже має мітку security=S2. Зворотно, правило антиспорідненості не впливає на планування у Zone R, якщо немає Podʼів з мітками security=S2.
Щоб ближче ознайомитися з прикладами спорідненості та антиспорідненості Podʼів, зверніться до проєктної документації.
В полі operator для спорідненості та антиспорідненості Podʼа можна використовувати значення In, NotIn, Exists та DoesNotExist.
Для отримання додаткової інформації про те, як це працює, перегляньте Оператори.
У принципі, topologyKey може бути будь-яким допустимим ключем мітки з такими винятками з причин продуктивності та безпеки:
Для спорідненості та антиспорідненості Podʼа пусте поле topologyKey не дозволяється як для requiredDuringSchedulingIgnoredDuringExecution, так і для preferredDuringSchedulingIgnoredDuringExecution.
Для правил антиспорідненості Podʼа requiredDuringSchedulingIgnoredDuringExecution контролер допуску LimitPodHardAntiAffinityTopology обмежує topologyKey до kubernetes.io/hostname. Ви можете змінити або вимкнути контролер допуску, якщо хочете дозволити власні топології.
Крім labelSelector та topologyKey, ви можете опціонально вказати список просторів імен, з якими labelSelector повинен зіставлятися, використовуючи поле namespaces на тому ж рівні, що й labelSelector та topologyKey. Якщо відсутнє або порожнє, namespaces типово відноситься до простору імен Podʼа, де зʼявляється визначення спорідненості/антиспорідненості.
Селектор простору імен
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.24 [stable]
Ви також можете вибирати відповідні простори імен за допомогою namespaceSelector, який є запитом міток до набору просторів імен. Умова спорідненості застосовується до просторів імен, вибраних як namespaceSelector, так і полем namespaces. Зверніть увагу, що порожній namespaceSelector ({}) відповідає всім просторам імен, тоді як нульовий або порожній список namespaces і нульовий namespaceSelector відповідає простору імен Podʼа, де визначена правило.
matchLabelKeys
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [stable] (стандартно увімкнено: true)
Примітка:
Поле matchLabelKeys знаходиться на рівні бета-версії та є стандартно увімкненим в Kubernetes 1.33. Якщо ви бажаєте його вимкнути, вам потрібно зробити це явним чином за допомогою вимкнення функціональної можливостіMatchLabelKeysInPodAffinity.
У Kubernetes є опціональне поле matchLabelKeys для спорідненості або антиспорідненості Podʼа. Це поле вказує ключі для міток, які повинні відповідати міткам вхідного Podʼа під час задоволення спорідненості (антиспорідненості) Podʼа.
Ці ключі використовуються для отримання значень з міток Podʼа; ці ключ-значення міток поєднуються (використовуючи AND) з обмеженнями відповідно до поля labelSelector. Обʼєднане фільтрування вибирає набір наявниї Podʼів, які будуть враховуватися при розрахунку спорідненості (антиспорідненості) Podʼа.
Увага:
Не рекомендується використовувати matchLabelKeys з мітками, які можуть оновлюватися безпосередньо на podʼах. Навіть якщо ви редагуєте мітку podʼів, вказану у matchLabelKeys, безпосередньо, (тобто не через deployment), kube-apiserver не відобразить оновлення мітки у обʼєднаному `labelSelectorʼі.
Частим використанням є використання matchLabelKeys разом із pod-template-hash (встановленим у Podʼах, керованих як частина Deployment, де значення унікальне для кожного покоління). Використання pod-template-hash в matchLabelKeys дозволяє вам спрямовувати Podʼи, які належать тому ж поколінню, що й вхідний Pod, так щоб поступове оновлення не руйнувало споріденість.
apiVersion:apps/v1kind:Deploymentmetadata:name:application-server...spec:template:spec:affinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key:appoperator:Invalues:- databasetopologyKey:topology.kubernetes.io/zone# Тільки Podʼи з певного розгортання беруться до уваги при обчисленні спорідненості Podʼа.# Якщо ви оновите Deployment, підмінні Podʼи дотримуватимуться своїх власних правил спорідненості# (якщо вони визначені в новому шаблоні Podʼа).matchLabelKeys:- pod-template-hash
mismatchLabelKeys
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [stable] (стандартно увімкнено: true)
Примітка:
Поле mismatchLabelKeys знаходиться на рівні бета-версії та є стандартно увімкненим в Kubernetes 1.33. Якщо ви бажаєте його вимкнути, вам потрібно зробити це явним чином за допомогою вимкнення функціональної можливостіMatchLabelKeysInPodAffinity.
Kubernetes включає додаткове поле mismatchLabelKeys для спорідненості або антиспорідненості Podʼа. Це поле вказує ключі для міток, які не повинні мати збігу з мітками вхідного Podʼа, при задоволенні спорідненості чи антиспорідненості Podʼа.
Увага:
Не рекомендується використовувати mismatchLabelKeys з мітками, які можуть оновлюватися безпосередньо на podʼах. Навіть якщо ви відредагуєте мітку podʼів, вказану у mismatchLabelKeys, безпосередньо (тобто не через deployment), kube-apiserver не відобразить оновлення мітки на обʼєднаному `labelSelectorʼі.
Один з прикладів використання — це забезпечення того, що Podʼи будуть розміщені в топологічному домені (вузол, зона і т. д.), де розміщені лише Podʼи від того ж орендаря або команди. Іншими словами, ви хочете уникнути запуску Podʼів від двох різних орендарів в одному топологічному домені одночасно.
apiVersion:v1kind:Podmetadata:labels:# Припустимо, що всі відповідні Podʼи мають встановлену мітку "tenant"tenant:tenant-a...spec:affinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:# переконаємось, що Podʼи, повʼязані з цим орендарем, потрапляють у відповідний пул вузлів- matchLabelKeys:- tenanttopologyKey:node-poolpodAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:# переконаємось, що Podʼи, повʼязані з цим орендарем, не можуть розміщуватися на вузлах,# які використовуються для іншого орендаря- mismatchLabelKeys:- tenant# незалежно від значення мітки "tenant" для цього Podʼа, заборонити# розміщення на вузлах у будь-якому пулі, де працює будь-який Pod# від іншого орендаря.labelSelector:# Ми повинні мати labelSelector, який обирає лише Podʼи з міткою tenant,# інакше цей Pod матиме антиспорідненість до Podʼів з daemonsetʼів, наприклад,# які не повинні мати мітку tenant.matchExpressions:- key:tenantoperator:ExiststopologyKey:node-pool
Ще кілька практичних прикладів
Між-Podʼові спорідненість та антиспорідненість можуть бути навіть більш корисними, коли вони використовуються з колекціями вищого рівня, такими як ReplicaSets, StatefulSets, Deployments і т. д. Ці правила дозволяють налаштувати спільне розташування набору робочих навантажень у визначеній топології; наприклад, віддаючи перевагу розміщенню двох повʼязаних Podʼів на одному вузлі.
Наприклад: уявіть кластер з трьох вузлів. Ви використовуєте кластер для запуску вебзастосунку та також сервіс кешування в памʼяті (наприклад, Redis). Нехай для цього прикладу також буде фіксований максимальний рівень затримки між вебзастосунком та цим кешем, як це практично можливо. Ви можете використовувати між-Podʼові спорідненість та антиспорідненість, щоб спільні вебсервери з кешем, як це можна точніше, розташовувалися поруч.
У наступному прикладі Deployment для кешування Redis, репліки отримують мітку app=store. Правило podAntiAffinity повідомляє планувальникові уникати розміщення декількох реплік з міткою app=store на одному вузлі. Це створює кожен кеш на окремому вузлі.
У наступному прикладі Deployment для вебсерверів створює репліки з міткою app=web-store. Правило спорідненості Podʼа повідомляє планувальнику розмістити кожну репліку на вузлі, де є Pod з міткою app=store. Правило антиспорідненості Podʼа повідомляє планувальнику ніколи не розміщати декілька серверів app=web-store на одному вузлі.
Створення цих двох попередніх Deploymentʼів призводить до наступного структури кластера, де кожен вебсервер знаходиться поруч з кешем, на трьох окремих вузлах.
вузол-1
вузол-2
вузол-3
webserver-1
webserver-2
webserver-3
cache-1
cache-2
cache-3
Загальний ефект полягає в тому, що кожен екземпляр кешу ймовірно використовується одним клієнтом, який працює на тому ж самому вузлі. Цей підхід спрямований на мінімізацію як перекосу (нерівномірного навантаження), так і затримки.
У вас можуть бути інші причини використання антиспорідненості Podʼа. Дивіться посібник по ZooKeeper
для прикладу StatefulSet, налаштованого з антиспорідненостю для забезпечення високої
доступності, використовуючи ту ж саму техніку, що й цей приклад.
nodeName
nodeName є більш прямим способом вибору вузла, ніж спорідненісь або nodeSelector. nodeName — це поле в специфікації Pod. Якщо поле nodeName не порожнє, планувальник ігнорує Pod, і kubelet на названому вузлі намагається розмістити Pod на цьому вузлі. Використання nodeName переважає використання nodeSelector або правил спорідненості та антиспорідненості.
Деякі з обмежень використання nodeName для вибору вузлів:
Якщо зазначений вузол не існує, Pod не буде запущено, і у деяких випадках його може бути автоматично видалено.
Якщо зазначений вузол не має достатньо ресурсів для розміщення Podʼа, Pod зазнає збою, про що буде повідомлено, наприклад, OutOfmemory або OutOfcpu.
Назви вузлів у хмарних середовищах не завжди передбачувані або стабільні.
Попередження:
nodeName призначений для використання власними планувальниками або у більш складних випадках, де вам потрібно обійти будь-які налаштовані планувальники. Обхід планувальників може призвести до збійних Podʼів, якщо призначені вузли переповнені. Ви можете використовувати спорідненісь вузлів або поле nodeSelector, щоб призначити Pod до певного вузла без обходу планувальників.
Нижче наведено приклад специфікації Pod з використанням поля nodeName:
Вищевказаний Pod буде запущено лише на вузлі kube-01.
Обмеження розподілу топології Pod
Ви можете використовувати обмеження розподілу топології для керування тим, як Podʼи розподіляються по вашому кластеру серед недоступних доменів, таких як регіони, зони, вузли або будь-які інші топологічні домени, які ви визначаєте. Ви можете це зробити, щоб покращити продуктивність, очікувану доступність або
загальне використання.
Докладніше про роботу з обмеженнями розподілу топології Podʼів читайте тут.
Оператори
Наступні логічні оператори можна використовувати в полі operator для nodeAffinity та podAffinity, згаданих вище.
Оператор
Поведінка
In
Значення мітки присутнє у заданому наборі рядків
NotIn
Значення мітки не міститься у заданому наборі рядків
Exists
Мітка з цим ключем існує на обʼєкті
DoesNotExist
На обʼєкті не існує мітки з цим ключем
Наступні оператори можна використовувати лише з nodeAffinity.
Оператор
Поведінка
Gt
Значення поля буде розібране як ціле число, і це ціле число менше цілого числа, яке отримується при розборі значення мітки, названої цим селектором
Lt
Значення поля буде розібране як ціле число, і це ціле число більше цілого числа, яке отримується при розборі значення мітки, названої цим селектором
Примітка:
Оператори Gt та Lt не працюватимуть з нецілими значеннями. Якщо дане значення не вдається розібрати як ціле число, Pod не вдасться запланувати. Крім того, Gt та Lt не доступні для podAffinity.
Коли ви запускаєте Pod на вузлі, сам Pod потребує певної кількості системних ресурсів. Ці ресурси додаються до ресурсів, необхідних для запуску контейнерів всередині Pod. У Kubernetes Pod Overhead — це спосіб обліку ресурсів, які використовуються інфраструктурою Pod, понад запити та обмеження контейнерів.
У Kubernetes накладні витрати Pod встановлюються під час допуску з урахуванням перевищення, повʼязаного з RuntimeClass Pod.
Накладні витрати Pod вважаються додатковими до суми запитів ресурсів контейнера при плануванні Pod. Так само, kubelet включатиме накладні витрати Pod при визначенні розміру cgroup Podʼа і при виконанні ранжування виселення Podʼа.
Налаштування накладних витрат Pod
Вам потрібно переконатися, що використовується RuntimeClass, який визначає поле overhead.
Приклад використання
Для роботи з накладними витратами Podʼів вам потрібен RuntimeClass, який визначає поле overhead. Наприклад, ви можете використати таке визначення RuntimeClass з контейнерним середовищем віртуалізації (в цьому прикладі використовується Kata Containers поєднане з монітором віртуальної машини Firecracker), яке використовує приблизно 120MiB на Pod для віртуальної машини та гостьової ОС:
# Вам треба внести зміни в цей приклад, щоб назва відповідала вашому контейнерному середовищу# та ресурси overhead були додани до вашого кластера.apiVersion:node.k8s.io/v1kind:RuntimeClassmetadata:name:kata-fchandler:kata-fcoverhead:podFixed:memory:"120Mi"cpu:"250m"
Робочі навантаження, які створюються з використанням обробника RuntimeClass з іменем kata-fc, беруть участь в обчисленнях квот ресурсів, плануванні вузла, а також розмірі групи контейнерів Pod для памʼяті та CPU.
Розгляньте виконання поданого прикладу робочого навантаження, test-pod:
Якщо в визначенні Podʼа вказані лише limits, kubelet виведе requests з цих обмежень і встановить їх такими ж, як і визначені limits.
Під час обробки допуску (admission) контролер admission controller RuntimeClass оновлює PodSpec робочого навантаження, щоб включити overhead, що є в RuntimeClass. Якщо PodSpec вже має це поле визначеним, Pod буде відхилено. У поданому прикладі, оскільки вказано лише імʼя RuntimeClass, контролер обробки допуску змінює Pod, щоб включити overhead.
Після того, як контролер обробки допуску RuntimeClass вніс зміни, ви можете перевірити оновлене значення overhead Pod:
kubectl get pod test-pod -o jsonpath='{.spec.overhead}'
Вивід:
map[cpu:250m memory:120Mi]
Якщо визначено ResourceQuota, то обчислюється сума запитів контейнера, а також поля overhead.
Коли kube-scheduler вирішує, на якому вузлі слід запускати новий Pod, він бере до уваги overhead цього Pod, а також суму запитів контейнера для цього Pod. Для цього прикладу планувальник додає запити та overhead, а потім шукає вузол, на якому є 2,25 CPU та 320 MiB вільної памʼяті.
Після того, як Pod запланований на вузол, kubelet на цьому вузлі створює нову cgroup для Pod. Це саме той Pod, в межах якого контейнерне середовище створює контейнери.
Якщо для кожного контейнера визначено ліміт ресурсу (Guaranteed QoS або Burstable QoS з визначеними лімітами), то kubelet встановлює верхній ліміт для групи контейнерів Pod, повʼязаних з цим ресурсом (cpu.cfs_quota_us для CPU та memory.limit_in_bytes для памʼяті). Цей верхній ліміт базується на сумі лімітів контейнера плюс поле overhead, визначене в PodSpec.
Для CPU, якщо Pod має Guaranteed або Burstable QoS, то kubelet встановлює cpu.shares на основі суми запитів контейнера плюс поле overhead, визначене в PodSpec.
Подивіться приклад, перевірте запити контейнера для робочого навантаження:
kubectl get pod test-pod -o jsonpath='{.spec.containers[*].resources.limits}'
Загальні запити контейнера становлять 2000m CPU та 200MiB памʼяті:
Перевірте це у порівнянні з тим, що спостерігається вузлом:
kubectl describe node | grep test-pod -B2
Вивід показує запити для 2250m CPU та 320MiB памʼяті. Запити включають перевищення Pod:
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default test-pod 2250m (56%) 2250m (56%) 320Mi (1%) 320Mi (1%) 36m
Перевірка обмежень cgroup для Pod
Перевірте cgroup памʼяті для Pod на вузлі, де запускається робоче навантаження. У наступному прикладі використовується crictl на вузлі, який надає інтерфейс командного рядка для сумісних з CRI контейнерних середовищ. Це передбачається для демонстрації поведінки overhead Podʼа, і не очікується, що користувачі повинні безпосередньо перевіряти cgroups на вузлі.
Спочатку, на конкретному вузлі, визначте ідентифікатор Pod:
# Виконайте це на вузлі, де запущено PodPOD_ID="$(sudo crictl pods --name test-pod -q)"
З цього можна визначити шлях cgroup для Pod:
# Виконайте це на вузлі, де запущено Podsudo crictl inspectp -o=json $POD_ID | grep cgroupsPath
Результати шляху cgroup включають контейнер pause для Pod. Рівень cgroup на рівні Pod знаходиться на одну теку вище.
У цьому конкретному випадку, шлях cgroup для Pod — kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2. Перевірте налаштування рівня cgroup для памʼяті на рівні Pod:
# Виконайте це на вузлі, де запущено Pod.# Також, змініть назву cgroup, щоб відповідати призначеному вашому pod cgroup. cat /sys/fs/cgroup/memory/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/memory.limit_in_bytes
Це 320 МіБ, як і очікувалося:
335544320
Спостережуваність
Деякі метрики kube_pod_overhead_* доступні у kube-state-metrics для ідентифікації використання накладних витрат Pod та спостереження стабільності робочих навантажень, які працюють з визначеним overhead.
Podʼи вважалися готовими до планування відразу після створення. Планувальник Kubernetes виконує всі необхідні дії для знаходження вузлів для розміщення всіх Podʼів, що очікують. Однак на практиці деякі Podʼи можуть перебувати в стані "відсутні ресурси" ("miss-essential-resources") протягом тривалого періоду. Ці Podʼи фактично спричиняють зайве навантаження на планувальник (та інтегратори, по ходу далі, такі як Cluster AutoScaler), що є непотрібним.
Шляхом вказання/видалення поля .spec.schedulingGates для Podʼа ви можете контролювати, коли Pod готовий до розгляду для планування.
Налаштування schedulingGates Podʼа
Поле schedulingGates містить список рядків, і кожний рядок сприймається як критерій, який повинен бути задоволений перед тим, як Pod буде вважатися придатним для планування. Це поле можна ініціалізувати лише при створенні Podʼа (або клієнтом, або під час змін під час допуску). Після створення кожен schedulingGate можна видалити у довільному порядку, але додавання нового scheduling gate заборонено.
stateDiagram-v2
s1: Pod створено
s2: Планування Pod очікується
s3: Планування Pod готову
s4: Pod виконується
if: є порожні слоти планування?
[*] --> s1
s1 --> if
s2 --> if: обмеження планування зняте
if --> s2: ні
if --> s3: так
s3 --> s4
s4 --> [*]
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
class s1,s2,s3,s4,if k8s
Приклад використання
Щоб позначити Pod як не готовий до планування, ви можете створити його з одним або кількома шлюзами планування так:
Щоб повідомити планувальник, що цей Pod готовий до планування, ви можете повністю видалити його schedulingGates шляхом повторного застосування зміненого маніфесту:
Ви можете перевірити, чи очищено schedulingGates, виконавши:
kubectl get pod test-pod -o jsonpath='{.spec.schedulingGates}'
Очікується, що вивід буде порожнім. І ви можете перевірити його останній стан, запустивши:
kubectl get pod test-pod -o wide
Враховуючи те, що test-pod не запитує жодних ресурсів CPU/памʼяті, очікується, що стан цього Podʼа перейде з попереднього SchedulingGated в Running:
NAME READY STATUS RESTARTS AGE IP NODE
test-pod 1/1 Running 0 15s 10.0.0.4 node-2
Спостережуваність
Метрика scheduler_pending_pods має нову мітку "gated", щоб відрізняти, чи були спроби планувати Podʼа, але він був визначений як непридатний для планування, чи він явно позначений як не готовий для планування. Ви можете використовувати scheduler_pending_pods{queue="gated"} для перевірки результату метрики.
Змінні директиви планування Podʼа
Ви можете змінювати директиви планування Podʼа, коли вони мають шлюзи планування, з певними обмеженнями. Узагальнено, ви можете тільки робити директиви планування Podʼа жорсткішими. Іншими словами, оновлені директиви призведуть до можливості розміщення Podʼів тільки на підмножині вузлів, з якими вони раніше мали збіг. Конкретніше, правила для оновлення директив планування Podʼа такі:
Для .spec.nodeSelector дозволяються лише додавання. Якщо відсутнє, його можна встановити.
Для spec.affinity.nodeAffinity, якщо nil, тоді дозволяється встановлення будь-чого.
Якщо NodeSelectorTerms був пустим, дозволено встановлення. Якщо не пустий, тоді дозволяються лише додавання NodeSelectorRequirements до matchExpressions або fieldExpressions, а зміни наявних matchExpressions і fieldExpressions не будуть дозволені. Це через те, що терміни в .requiredDuringSchedulingIgnoredDuringExecution.NodeSelectorTerms, оцінюються через OR тоді як вирази в nodeSelectorTerms[].matchExpressions та nodeSelectorTerms[].fieldExpressions оцінюються через AND.
Для .preferredDuringSchedulingIgnoredDuringExecution всі оновлення дозволені. Це повʼязано з тим, що бажані умови не є авторитетними, і тому контролери політики не підтверджують ці умови.
Ви можете використовувати обмеження поширення топології для контролю того, як Podʼи розподіляються по вашому кластеру серед доменів відмов, таких як регіони, зони, вузли та інші користувацькі топологічні домени. Це може допомогти забезпечити високу доступність, а також ефективне використання ресурсів.
Ви можете встановлювати типові обмеження на рівні кластера або налаштовувати обмеження поширення топології для окремих навантажень.
Мотивація
Уявіть, що у вас є кластер, в якому до двадцяти вузлів, і ви хочете запустити навантаження, яке автоматично масштабує кількість реплік, які використовує. Тут може бути як два Podʼи, так і пʼятнадцять. Коли є лише два Podʼи, ви б хотіли, щоб обидва ці Podʼи не працювали на одному вузлі: ви ризикуєте, що відмова одного вузла призведе до зникнення доступу до вашого навантаження.
Крім цього основного використання, є деякі приклади використання, які дозволяють вашим навантаженням отримувати переваги високої доступності та використання кластера.
При масштабуванні та запуску більшої кількості Podʼів важливим стає інша проблема. Припустімо, що у вас є три вузли, на яких працюють по пʼять Podʼів кожен. У вузлах достатньо потужності для запуску такої кількості реплік; проте клієнти, які взаємодіють з цим навантаженням, розподілені по трьох різних центрах обробки даних (або зонах інфраструктури). Тепер ви менше хвилюєтеся про відмову одного вузла, але ви помічаєте, що затримка вища, ніж ви хотіли б, і ви платите за мережеві витрати, повʼязані з передачею мережевого трафіку між різними зонами.
Ви вирішуєте, що при нормальній роботі ви б хотіли, щоб у кожній інфраструктурній зоні була приблизно однакова кількість реплік, і ви хотіли б, щоб кластер самостійно відновлювався у разі виникнення проблеми.
Обмеження поширення топології Podʼів пропонують вам декларативний спосіб налаштування цього.
Поле topologySpreadConstraints
У API Pod є поле spec.topologySpreadConstraints. Використання цього поля виглядає так:
---apiVersion:v1kind:Podmetadata:name:example-podspec:# Налаштувати обмеження поширення топологіїtopologySpreadConstraints:- maxSkew:<ціле число>minDomains:<ціле число># необовʼязковоtopologyKey:<рядок>whenUnsatisfiable:<рядок>labelSelector:<обʼєкт>matchLabelKeys:<список># необовʼязково; бета з v1.27nodeAffinityPolicy:[Honor|Ignore]# необовязково; бета з v1.26nodeTaintsPolicy:[Honor|Ignore]# необовязково; бета з v1.26### інші поля Pod тут
Додаткову інформацію про це поле можна отримати, запустивши команду kubectl explain Pod.spec.topologySpreadConstraints або звернувшись до розділу планування довідки API для Pod.
Визначення обмежень поширення топології
Ви можете визначити один або кілька записів topologySpreadConstraints, щоб вказати kube-scheduler, як розмістити кожний вхідний Pod у відповідно до наявних Podʼів у всьому кластері. Ці поля включають:
maxSkew описує ступінь нерівномірного поширення Pod. Ви повинні вказати це поле, і число повинно бути більше нуля. Його семантика відрізняється залежно від значення whenUnsatisfiable:
якщо ви виберете whenUnsatisfiable: DoNotSchedule, тоді maxSkew визначає максимально допустиму різницю між кількістю відповідних Podʼів у цільовій топології та глобальним мінімумом (мінімальна кількість відповідних Podʼів у прийнятній області або нуль, якщо кількість прийнятних областей менше, ніж MinDomains). Наприклад, якщо у вас є 3 зони з 2, 2 та 1 відповідно відповідних Podʼів, MaxSkew встановлено на 1, тоді глобальний мінімум дорівнює 1.
якщо ви виберете whenUnsatisfiable: ScheduleAnyway, планувальник надає вищий пріоритет топологіям, які допомагають зменшити розрив.
minDomains вказує мінімальну кількість прийнятних областей. Це поле є необовʼязковим. Домен — це певний екземпляр топології. Прийнятний домен — це домен, чиї вузли відповідають селектору вузлів.
Примітка:
До Kubernetes v1.30 поле minDomains було доступним, якщо функціональну можливістьMinDomainsInPodTopologySpread було увімкнено (типово увімкнено починаючи з v1.28). В старіших кластерах Kubernetes воно може бути явно відключеним або поле може бути недоступним.
Значення minDomains повинно бути більше ніж 0, коли вказано. Ви можете вказати minDomains лише разом з whenUnsatisfiable: DoNotSchedule.
Коли кількість прийнятних доменів з відповідними ключами топології менше minDomains,
розподіл топології Pod розглядає глобальний мінімум як 0, а потім виконується розрахунок skew. Глобальний мінімум — це мінімальна кількість відповідних Podʼів у прийнятному домені, або нуль, якщо кількість прийнятних доменів менше, ніж minDomains.
Коли кількість прийнятних доменів з відповідними ключами топології дорівнює або більше
minDomains, це значення не впливає на планування.
Якщо ви не вказуєте minDomains, обмеження поводиться так, як якби minDomains дорівнював 1.
topologyKey — ключ міток вузла. Вузли, які мають мітку з цим ключем і ідентичними значеннями, вважаються присутніми в тій самій топології. Кожен екземпляр топології (іншими словами, пара <ключ, значення>) називається доменом. Планувальник спробує помістити вирівняну кількість Podʼів в кожен домен. Також ми визначаємо прийнятний домен як домен, вузли якої відповідають вимогам nodeAffinityPolicy та nodeTaintsPolicy.
whenUnsatisfiable вказує, як розвʼязувати проблему з Pod, якщо він не відповідає обмеженню поширення:
DoNotSchedule (типово) вказує планувальнику не планувати його.
ScheduleAnyway вказує планувальнику все одно його планувати, проте з пріоритетом вибору вузлів, що мінімізують розрив.
labelSelector використовується для знаходження відповідних Podʼів. Podʼи, які відповідають цьому селектору міток, враховуються для визначення кількості Podʼів у відповідному домені топології. Дивіться селектори міток для отримання додаткових відомостей.
matchLabelKeys — це список ключів міток Podʼа для вибору Podʼів, відносно яких буде розраховано поширення. Ключі використовуються для вибору значень з міток Podʼів, ці ключі-значення міток AND labelSelector вибирають групу наявних Podʼів, відносно яких буде розраховано поширення для вхідного Podʼа. Існування однакового ключа заборонене як у matchLabelKeys, так і в labelSelector. matchLabelKeys не може бути встановлено, коли labelSelector не встановлено. Ключі, яких не існує в мітках Podʼа, будуть проігноровані. Порожній або нульовий список означає, що збіг буде відповідати лише labelSelector.
З matchLabelKeys вам не потрібно оновлювати pod.spec між різними версіями. Контролер/оператор просто повинен встановити різні значення для того самого ключа мітки для різних версій. Планувальник автоматично припускає значення на основі matchLabelKeys. Наприклад, якщо ви налаштовуєте Deployment, ви можете використовувати мітку за ключем pod-template-hash, яка додається автоматично контролером Deployment, для розрізнення різних версій в одному Deployment.
Поле matchLabelKeys є полем на рівні бета-версії та включено стандартно у 1.27. Ви можете відключити його, вимкнувши функціональну можливістьMatchLabelKeysInPodTopologySpread.
nodeAffinityPolicy вказує, як ми будемо обробляти nodeAffinity/nodeSelector Pod, коли розраховуємо розрив поширення топології Podʼів. Опції:
Honor: до розрахунків включаються лише вузли, які відповідають nodeAffinity/nodeSelector.
Ignore: nodeAffinity/nodeSelector ігноруються. Включаються всі вузли.
Якщо це значення є null, поведінка еквівалентна політиці Honor.
Примітка:
Поле nodeAffinityPolicy було полем на рівні бета-версії з v1.26 та загальнодоступним з v 1.33. Воно є стандартно увімкеними і ви можете відключити його, вимкнувши функціональну можливістьNodeInclusionPolicyInPodTopologySpread.
nodeTaintsPolicy вказує, як ми будемо обробляти заплямованість вузлів при розрахунку
розриву поширення топології Podʼів. Опції:
Honor: включаються вузли без заплямованості, разом з заплямованими вузлами, для яких вхідний Pod має толерантність.
Ignore: заплямованість вузла ігноруються. Включаються всі вузли.
Якщо це значення є null, поведінка еквівалентна політиці Ignore.
Примітка:
Поле nodeAffinityPolicy було полем на рівні бета-версії з v1.26 та загальнодоступним з v 1.33. Воно є стандартно увімкеними і ви можете відключити його, вимкнувши функціональну можливістьNodeInclusionPolicyInPodTopologySpread.
Коли Pod визначає більше одного topologySpreadConstraint, ці обмеження комбінуються за допомогою операції AND: kube-scheduler шукає вузол для вхідного Podʼа, який задовольняє всі налаштовані обмеження.
Мітки вузлів
Обмеження поширення топології ґрунтуються на мітках вузлів для ідентифікації доменів топології, в яких знаходиться кожен вузол. Наприклад, вузол може мати такі мітки:
region:us-east-1zone:us-east-1a
Примітка:
У цьому прикладі не використовуються відомі ключі міток topology.kubernetes.io/zone та topology.kubernetes.io/region. Однак, рекомендується використовувати саме ці зареєстровані ключі міток, а не приватні (непідтверджені) ключі міток region та zone, які використовуються тут.
Не можна надійно припускати про наявність значення приватного ключа мітки в різних контекстах.
Припустимо, у вас є кластер з 4 вузлами з наступними мітками:
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready <none> 4m26s v1.16.0 node=node1,zone=zoneA
node2 Ready <none> 3m58s v1.16.0 node=node2,zone=zoneA
node3 Ready <none> 3m17s v1.16.0 node=node3,zone=zoneB
node4 Ready <none> 2m43s v1.16.0 node=node4,zone=zoneB
Тоді кластер логічно виглядає так:
graph TB
subgraph "zoneB"
n3(Node3)
n4(Node4)
end
subgraph "zoneA"
n1(Node1)
n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4 k8s;
class zoneA,zoneB cluster;
Узгодженість
Вам слід встановити однакові обмеження поширення топології Podʼів для всіх Podʼів у групі.
Зазвичай, якщо ви використовуєте контролер робочого навантаження, такий як Deployment, шаблон Podʼа забезпечує це за вас. Якщо ви комбінуєте різні обмеження поширення, то Kubernetes дотримується визначення API поля; однак, це більш ймовірно призведе до плутанини в поведінці, а усунення несправностей буде менш прямолінійним.
Вам потрібен механізм для забезпечення того, що всі вузли в домені топології (наприклад, регіон хмарного постачальника) мають однакові мітки. Щоб уникнути необхідності ручного маркування вузлів, більшість кластерів автоматично заповнюють відомі мітки, такі як kubernetes.io/hostname. Перевірте, чи підтримує ваш кластер це.
Приклад обмеження розподілу топології
Приклад: одне обмеження розподілу топології
Припустимо, у вас є кластер із чотирма вузлами, де 3 Podʼа з міткою foo: bar знаходяться на вузлах node1, node2 та node3 відповідно:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class zoneA,zoneB cluster;
Якщо ви хочете, щоб новий Pod рівномірно розподілявся з наявними Podʼами по зонах,
ви можете використовувати маніфест Podʼів, схожий на такий:
У цьому маніфесті topologyKey: zone означає, що рівномірне поширення буде застосовуватися лише до вузлів, які мають мітку zone: <будь-яке значення> (вузли, які не мають мітки zone, будуть пропущені). Поле whenUnsatisfiable: DoNotSchedule повідомляє планувальнику, що потрібно залишити новий Pod у стані очікування, якщо планувальник не може знайти спосіб задовольнити обмеження.
Якщо планувальник розмістить цей новий Pod у зоні A, розподіл Podʼів стане [3, 1]. Це означає, що фактичне відхилення складає 2 (розраховане як 3 - 1), що порушує maxSkew: 1. Щоб задовольнити умови обмеження та контекст для цього прикладу, новий Pod може бути розміщений лише на вузлі в зоні B.
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
або
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n3
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
Ви можете змінити специфікацію Podʼа, щоб вона відповідала різним вимогам:
Змініть maxSkew на більше значення, наприклад 2, щоб новий Pod також можна було розмістити в зоні A.
Змініть topologyKey на node, щоб рівномірно розподілити Podʼи по вузлах, а не зонам. У вищезазначеному прикладі, якщо maxSkew залишиться 1, новий Pod може бути розміщений лише на вузлі node4.
Змініть whenUnsatisfiable: DoNotSchedule на whenUnsatisfiable: ScheduleAnyway, щоб гарантувати, що новий Pod завжди можна розмістити (якщо інші API планування задовольняються). Однак перевага надається розміщенню в області топології, яка має менше відповідних Podʼів. (Памʼятайте, що ця перевага спільно нормалізується з іншими внутрішніми пріоритетами планування, такими як відношення використання ресурсів).
Приклад: декілька обмежень поширення топології
Цей приклад будується на попередньому. Припустимо, у вашому кластері з 4 вузлами є 3 Podʼа, позначених як foo: bar, що знаходяться на вузлі node1, node2 і node3 відповідно:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
Ви можете поєднати два обмеження поширення топології, щоб контролювати розподіл Podʼів як за вузлами, так і за зонами:
У цьому випадку для збігу з першим обмеженням новий Pod може бути розміщений лише на вузлах у зоні B; тоді як для відповідності другому обмеженню новий Pod може бути розміщений лише на вузлі node4. Планувальник розглядає лише варіанти, які задовольняють всі визначені обмеження, тому єдине допустиме розташування — це на вузлі node4.
Приклад: конфліктуючі обмеження розподілу топології
Кілька обмежень може призвести до конфліктів. Припустимо, у вас є кластер з 3 вузлами у 2 зонах:
graph BT
subgraph "zoneB"
p4(Pod) --> n3(Node3)
p5(Pod) --> n3
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n1
p3(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3,p4,p5 k8s;
class zoneA,zoneB cluster;
Якщо ви застосуєте two-constraints.yaml (файл маніфесту з попереднього прикладу) до цього кластера, ви побачите, що Pod mypod залишається у стані Pending. Це трапляється тому, що для задоволення першого обмеження Pod mypod може бути розміщений лише у зоні B; тоді як для відповідності другому обмеженню Pod mypod може бути розміщений лише на вузлі node2. Перетин двох обмежень повертає порожній набір, і планувальник не може розмістити Pod.
Щоб подолати цю ситуацію, ви можете або збільшити значення maxSkew, або змінити одне з обмежень, щоб використовувати whenUnsatisfiable: ScheduleAnyway. Залежно від обставин, ви також можете вирішити видалити наявний Pod вручну — наприклад, якщо ви розвʼязуєте проблему, чому розгортання виправлення помилки не виконується.
Взаємодія з селектором вузла та спорідненістю вузла
Планувальник пропустить вузли, що не відповідають, з обчислень нерівності, якщо у вхідного Podʼа визначено spec.nodeSelector або spec.affinity.nodeAffinity.
Приклад: обмеження поширення топології зі спорідненістю вузла
Припустимо, у вас є 5-вузловий кластер, розташований у зонах A до C:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
graph BT
subgraph "zoneC"
n5(Node5)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n5 k8s;
class zoneC cluster;
і ви знаєте, що зону C потрібно виключити. У цьому випадку ви можете скласти маніфест, як наведено нижче, щоб Pod mypod був розміщений у зоні B, а не у зоні C. Так само Kubernetes також враховує spec.nodeSelector.
Тут є кілька неявних домовленостей, на які варто звернути увагу:
Відповідними кандидатами можуть бути лише ті Podʼи, що мають той самий простір імен, що й вхідний Pod.
Планувальник розглядає лише ті вузли, у яких одночасно присутні всі topologySpreadConstraints[*].topologyKey. Вузли, у яких відсутній будь-який з цих topologyKey, обминаються. Це означає, що:
будь-які Podʼи, що розташовані на цих обхідних вузлах, не впливають на обчислення maxSkew — в прикладі вище, припустимо, що вузол node1 не має мітки "zone", тоді 2 Podʼи будуть проігноровані, тому вхідний Pod буде заплановано в зону A.
вхідний Pod не має шансів бути запланованим на такі вузли — у вищенаведеному прикладі, припустимо, що вузол node5 має невірно введену мітку zone-typo: zoneC (і не має жодної встановленої мітки zone). Після приєднання вузла node5 до кластера, він буде обходитися, і Podʼи для цього робочого навантаження не будуть плануватися туди.
Будьте уважні, якщо topologySpreadConstraints[*].labelSelector вхідного Podʼа не відповідає його власним міткам. У вищенаведеному прикладі, якщо ви видалите мітки вхідного Podʼа, він все ще може бути розміщений на вузлах у зоні B, оскільки обмеження все ще виконуються. Проте, після цього розміщення ступінь незбалансованості кластера залишається без змін — зона A все ще має 2 Podʼи з мітками foo: bar, а зона B має 1 Pod з міткою foo: bar. Якщо це не те, що ви очікуєте, оновіть topologySpreadConstraints[*].labelSelector робочого навантаження, щоб відповідати міткам в шаблоні Podʼа.
Типові обмеження на рівні кластера
Можливо встановити типові обмеження поширення топології для кластера. Типово обмеження поширення топології застосовуються до Podʼа лише в тому випадку, якщо:
Він не визначає жодних обмежень у своєму .spec.topologySpreadConstraints.
Він належить до Service, ReplicaSet, StatefulSet або ReplicationController.
Типові обмеження можна встановити як частину аргументів втулка PodTopologySpread в профілі планувальника. Обмеження вказуються з тими ж API вище, за винятком того, що labelSelector повинен бути пустим. Селектори обчислюються з Service, ReplicaSet, StatefulSet або ReplicationControllers, до яких належить Pod.
Приклад конфігурації може виглядати наступним чином:
Якщо ви не налаштовуєте жодних типових обмежень для поширення топології Podʼа на рівні кластера, то kube-scheduler діє так, ніби ви вказали наступні обмеження:
Також, типово відключений застарілий втулок SelectorSpread, який забезпечує еквівалентну поведінку.
Примітка:
Втулок PodTopologySpread не оцінює вузли, які не мають вказаних ключів топології в обмеженнях поширення. Це може призвести до іншої типової поведінки порівняно з застарілим втулком SelectorSpread, коли використовуються типові обмеження поширення топології.
Якщо ви не очікуєте, що ваші вузли матимуть обидві мітки kubernetes.io/hostname та topology.kubernetes.io/zone встановлені, визначте свої власні обмеження замість використання стандартних значень Kubernetes.
Якщо ви не хочете використовувати типові обмеження поширення топології Podʼа для вашого кластера, ви можете відключити ці типові значення, встановивши defaultingType у List і залишивши порожніми defaultConstraints у конфігурації втулка PodTopologySpread:
У Kubernetes, між-Podʼова (анти)спорідненість контролює те, як Podʼи розміщуються відносно один одного — чи ущільнені, чи розріджені.
podAffinity
притягує Podʼи; ви можете намагатися упакувати будь-яку кількість Podʼів в кваліфікуючі топологічні домени.
podAntiAffinity
відштовхує Podʼи. Якщо ви встановите це у режим requiredDuringSchedulingIgnoredDuringExecution, тоді тільки один Pod може бути запланований в один топологічний домен; якщо ви виберете preferredDuringSchedulingIgnoredDuringExecution, то ви втратите можливість змусити виконання обмеження.
Для більш точного контролю ви можете вказати обмеження поширення топології для розподілу podʼів по різним топологічним доменам — для досягнення як високої доступності, так і економії коштів. Це також може допомогти в роботі з оновленнями без відмов та плавному
масштабуванні реплік.
Для отримання більш детальної інформації, див. розділ Motivation пропозиції щодо покращення про обмеження поширення топології Podʼів.
Відомі обмеження
Немає гарантії, що обмеження залишаться задоволеними при видаленні Podʼів. Наприклад, зменшення масштабування Deployment може призвести до нерівномірного розподілу Podʼів.
Ви можете використовувати інструменти, такі як Descheduler, для перебалансування розподілу Podʼів.
Podʼи, що відповідають заплямованим вузлам, враховуються. Див. Issue 80921.
Планувальник не має попереднього знання всіх зон або інших топологічних доменів, які має кластер. Вони визначаються на основі наявних вузлів у кластері. Це може призвести до проблем у автоматизованих кластерах, коли вузол (або група вузлів) масштабується до нуля вузлів, і ви очікуєте масштабування кластера, оскільки в цьому випадку ці топологічні домени не будуть враховуватися, поки в них є хоча б один вузол.
Ви можете обійти це, використовуючи інструменти автоматичного масштабування Вузлів, які враховують обмеження розподілу топології Podʼів та також знають загальний набір топологічних доменів.
Що далі
У статті блогу Introducing PodTopologySpread докладно пояснюється maxSkew, а також розглядаються деякі приклади використання.
Прочитайте розділ scheduling з довідки API для Pod.
6 - Заплямованість та Толерантність
Спорідненість вузла (node affinity) це властивість Podʼа, яка привертає Pod до набору вузлів (або як перевага, або як жорстка вимога). Заплямованість (taint) є протилежною властивістю — вона дозволяє вузлу відштовхувати набір Podʼів.
Толерантність застосовуються до Podʼів. Толерантність дозволяє планувальнику розміщувати Podʼи, що збігаються з відповідними позначками заплямованості. Толерантність дозволяє планування, але не гарантує його: планувальник також оцінює інші параметри в межах свого функціонала.
Заплямованість та толерантність працюють разом, щоб забезпечити те, щоб Podʼи не розміщувались на непридатних вузлах. Одна або декілька позначок заплямованості застосовуються до вузла; це дозволяє позначити, що вузол не повинен приймати жодних Podʼів, які не толерують цих позначок заплямованості.
Концепції
Ви додаєте позначку taint до вузла за допомогою kubectl taint. Наприклад,
kubectl taint nodes node1 key1=value1:NoSchedule
додає taint до вузла node1. Taint має ключ key1, значення value1 і ефект taint NoSchedule. Це означає, що жодний Pod не зможе розміститись на node1, якщо він не має відповідної толерантності.
Щоб видалити taint, доданий командою вище, можна виконати:
kubectl taint nodes node1 key1=value1:NoSchedule-
Ви вказуєте толерантність для Podʼа в PodSpec. Обидві наступні толерантності "відповідають" taint, створеному за допомогою команди kubectl taint вище, і, отже, Pod з будь-якою з толерантностей зможе розміститись на node1:
Основний планувальник Kubernetes бере до уваги taint та толерантності при виборі вузла для запуску певного Podʼа. Проте, якщо ви вручну вказуєте .spec.nodeName для Podʼа, ця дія оминає планувальник; Pod тоді привʼязується до вузла, на який ви його призначили, навіть якщо на цьому вузлі є taint типу NoSchedule, які ви обрали. Якщо це трапиться і на вузлі також встановлено taint типу NoExecute, kubelet видалятиме Pod, якщо не буде встановлено відповідну толерантність.
Ось приклад Podʼа, у якого визначено деякі толерантності:
Толерантність має "збіг" з taint, якщо ключі є однаковими та ефекти є однаковими також, і:
оператор — Exists (у цьому випадку не слід вказувати value), або
оператор — Equal, а значення повинні бути рівні.
Примітка:
Є два спеціальних випадки:
Якщо key порожній, то operator має бути Exists, що відповідає всім ключам і значенням. Зверніть увагу, що effect все одно має збігатися з ключем.
Порожній effect відповідає всім ефектам з ключем key1.
У вищенаведеному прикладі використовувався effectNoSchedule. Також можна використовувати effectPreferNoSchedule.
Дозволені значення для поля effect:
NoExecute
Це впливає на Podʼи, які вже запущені на вузлі наступним чином:
Podʼи, які не толерують taint, негайно виселяються
Podʼи, які толерують taint, не вказуючи tolerationSeconds в їхній специфікації толерантності, залишаються привʼязаними назавжди
Podʼи, які толерують taint з вказаним tolerationSeconds залишаються привʼязаними протягом зазначеного часу. Після закінчення цього часу контролер життєвого циклу вузла виводить Podʼи з вузла.
NoSchedule
На позначеному taint вузлі не буде розміщено нові Podʼи, якщо вони не мають відповідної толерантності. Podʼи, які вже працюють на вузлі, не виселяються.
PreferNoSchedule
PreferNoSchedule — це "preference" або "soft" варіант NoSchedule. Планувальник спробує уникнути розміщення Podʼа, який не толерує taint на вузлі, але це не гарантовано.
На один вузол можна накласти декілька taint і декілька толерантностей на один Pod. Спосіб, яким Kubernetes обробляє декілька taint і толерантностей, схожий на фільтр: починаючи з усіх taint вузла, потім ігнорує ті, для яких Pod має відповідну толерантність; залишаються невідфільтровані taint, які мають зазначені ефекти на Pod. Зокрема,
якщо є принаймні один невідфільтрований taint з ефектом NoSchedule, тоді Kubernetes не буде планувати Pod на цей вузол
якщо немає невідфільтрованих taint з ефектом NoSchedule, але є принаймні один невідфільтрований taint з ефектом PreferNoSchedule, тоді Kubernetes спробує не планувати Pod на цей вузол
якщо є принаймні один невідфільтрований taint з ефектом NoExecute, тоді Pod буде виселено з вузла (якщо він вже працює на вузлі), і він не буде плануватися на вузол (якщо він ще не працює на вузлі).
Наприклад, уявіть, що ви накладаєте taint на вузол таким чином
У цьому випадку Pod не зможе плануватися на вузол, оскільки відсутня толерантність, яка відповідає третьому taint. Але він зможе продовжувати працювати, якщо він вже працює на вузлі, коли до нього додається taint, оскільки третій taint — єдиний з трьох, який не толерується Podʼом.
Зазвичай, якщо до вузла додається taint з ефектом NoExecute, то будь-які Podʼи, які не толерують taint, будуть негайно виселені, а Podʼи, які толерують taint, ніколи не будуть виселені. Однак толерантність з ефектом NoExecute може вказати необовʼязкове поле tolerationSeconds, яке визначає, як довго Pod буде привʼязаний до вузла після додавання taint. Наприклад,
означає, що якщо цей Pod працює і до вузла додається відповідний taint, то Pod залишиться привʼязаним до вузла протягом 3600 секунд, а потім буде виселений. Якщо taint видаляється до цього часу, то Pod не буде виселений.
Приклади використання
Заплямованість та Толерантність є гнучким способом відвадити Podʼи від вузлів або виселення Podʼів, які не повинні працювати. Деякі з варіантів використання:
Призначені вузли: Якщо ви хочете призначити певний набір вузлів для виключного використання конкретним набором користувачів, ви можете додати taint на ці вузли (наприклад, kubectl taint nodes nodename dedicated=groupName:NoSchedule) і потім додати відповідну толерантність до їхніх Podʼів (це найкраще робити за допомогою власного контролера допуску). Podʼам з толерантностями буде дозволено використовувати позначені (призначені) вузли, а також будь-які інші вузли в кластері. Якщо ви хочете призначити вузли виключно для них та забезпечити, що вони використовують лише призначені вузли, то ви також повинні додатково додати мітку, аналогічну taint, до того ж набору вузлів (наприклад, dedicated=groupName), і контролер допуску повинен додатково додати спорідненість вузла, щоб вимагати, щоб Podʼи могли плануватися лише на вузли з міткою dedicated=groupName.
Вузли зі спеціальним обладнанням: У кластері, де невелика підмножина вузлів має спеціалізоване обладнання (наприклад, GPU), бажано утримувати Podʼи, які не потребують спеціалізованого обладнання, поза цими вузлами, щоб залишити місце для Podʼів, які дійсно потребують спеціалізованого обладнання. Це можна зробити, накладаючи taint на вузли зі спеціалізованим обладнанням (наприклад, kubectl taint nodes nodename special=true:NoSchedule або kubectl taint nodes nodename special=true:PreferNoSchedule) і додавання відповідної толерантності до Podʼів, які використовують спеціалізоване обладнання. Як і у випадку з призначеними вузлами, найпростіше застосовувати толерантності за допомогою власного контролера допуску. Наприклад, рекомендується використовувати Розширені ресурси
для представлення спеціального обладнання, позначайте вузли зі спеціальним обладнанням розширеним імʼям ресурсу і запускайте контролер допуску ExtendedResourceToleration. Тепер, оскільки вузли позначені, жоден Pod без толерантності не буде плануватися на них. Але коли ви надсилаєте Pod, який запитує розширений ресурс, контролер допуску ExtendedResourceToleration автоматично додасть правильну толерантність до Podʼа і цей Pod буде плануватися на вузли зі спеціальним обладнанням. Це забезпечить, що ці вузли зі спеціальним обладнанням призначені для Podʼів, які запитують таке обладнання, і вам не потрібно вручну додавати толерантності до ваших Podʼів.
Виселення на основі taint: Поведінка виселення, що налаштовується для кожного Podʼа, коли є проблеми з вузлом, яка описана в наступному розділі.
Виселення на основі taint
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.18 [stable]
Контролер вузла автоматично накладає taint на вузол, коли виконуються певні умови. Наступні taint є вбудованими:
node.kubernetes.io/not-ready: Вузол не готовий. Це відповідає тому, що стан NodeCondition "Ready" є "False".
node.kubernetes.io/unreachable: Вузол недоступний з контролера вузла. Це відповідає тому, що стан NodeCondition "Ready" є "Unknown".
node.kubernetes.io/memory-pressure: Вузол має проблеми з памʼяттю.
node.kubernetes.io/disk-pressure: Вузол має проблеми з диском.
node.kubernetes.io/pid-pressure: Вузол має проблеми з PID.
node.kubernetes.io/network-unavailable: Мережа вузла недоступна.
node.kubernetes.io/unschedulable: Вузол не піддається плануванню.
node.cloudprovider.kubernetes.io/uninitialized: Коли kubelet запускається з "зовнішнім" хмарним провайдером, цей taint накладається на вузол для позначення його як невикористовуваного. Після того як контролер з cloud-controller-manager ініціалізує цей вузол, kubelet видаляє цей taint.
У разі, якщо потрібно спорожнити вузол, контролер вузла або kubelet додає відповідні taint з ефектом NoExecute. Цей ефект типово додається для taint node.kubernetes.io/not-ready та node.kubernetes.io/unreachable. Якщо умова несправності повертається до нормального стану, kubelet або контролер вузла можуть видалити відповідні taint.
У деяких випадках, коли вузол недоступний, сервер API не може спілкуватися з kubelet на вузлі. Рішення про видалення Podʼів не може бути передане до kubelet до тих пір, поки звʼязок з сервером API не буде відновлено. Протягом цього часу Podʼи, які заплановані для видалення, можуть продовжувати працювати на розділеному вузлі.
Примітка:
Панель управління обмежує швидкість додавання нових taint на вузли. Це обмеження швидкості керує кількістю видалень, які спричиняються, коли одночасно недоступно багато вузлів (наприклад, якщо відбувається збій мережі).
Ви можете вказати tolerationSeconds для Podʼа, щоб визначити, як довго цей Pod залишається привʼязаним до несправного або вузла, ще не відповідає.
Наприклад, ви можете довго зберігати застосунок з великою кількістю локального стану, привʼязаного до вузла, у разі розділу мережі, сподіваючись, що розділ відновиться, і, таким чином, можна уникнути виселення Podʼа. Толерантність, яку ви встановили для цього Pod, може виглядати так:
Kubernetes автоматично додає толерантність для node.kubernetes.io/not-ready та node.kubernetes.io/unreachable з tolerationSeconds=300, якщо ви або контролер встановили ці толерантності явно.
Ці автоматично додані толерантності означають, що Podʼи залишаються привʼязаними до вузлів протягом 5 хвилин після виявлення однієї з цих проблем.
Podʼи DaemonSet створюються з толерантностями NoExecute для наступних taint без tolerationSeconds:
node.kubernetes.io/unreachable
node.kubernetes.io/not-ready
Це забезпечує, що Podʼи DaemonSet ніколи не будуть видалені через ці проблеми.
Позначення вузлів taint за умовами
Панель управління, використовуючи контролер вузла, автоматично створює taint з ефектом NoSchedule для умов вузла.
Планувальник перевіряє taint, а не умови вузла, коли він приймає рішення про планування. Це забезпечує те, що умови вузла не впливають безпосередньо на планування. Наприклад, якщо умова вузла DiskPressure активна, панель управління додає taint node.kubernetes.io/disk-pressure і не планує нові Podʼи на уражений вузол. Якщо умова вузла MemoryPressure активна, панель управління додає taint node.kubernetes.io/memory-pressure.
Ви можете ігнорувати умови вузла для новостворених Podʼів, додавши відповідні толерантності Podʼів. Панель управління також додає толерантність node.kubernetes.io/memory-pressure на Podʼи, які мають клас QoS інший, ніж BestEffort. Це тому, що Kubernetes вважає Podʼи у класах QoS Guaranteed або Burstable (навіть Podʼи без встановленого запиту на памʼять) здатними впоратися з тиском на памʼять, тоді як нові Podʼи BestEffort не плануються на уражений вузол.
Контролер DaemonSet автоматично додає наступні толерантності NoSchedule для всіх демонів, щоб запобігти порушенню роботи DaemonSet.
node.kubernetes.io/memory-pressure
node.kubernetes.io/disk-pressure
node.kubernetes.io/pid-pressure (1.14 або пізніше)
node.kubernetes.io/unschedulable (1.10 або пізніше)
node.kubernetes.io/network-unavailable (тільки для мережі хосту)
Додавання цих толерантностей забезпечує сумісність з попередніми версіями. Ви також можете додавати довільні толерантності до DaemonSets.
Позначення та толерування позначок taint пристроїв
Замість того, щоб позначати цілі вузли, адміністратори можуть також позначати окремі пристрої коли кластер використовує динамічний розподіл ресурсів для керування спеціальним обладнанням. Перевага полягає у тому, що позначення може бути спрямоване саме на те обладнання, яке є несправним або потребує обслуговування. Толерування також підтримуються і можуть бути вказані при запиті пристроїв. Як і позначки taint, вони застосовуються до всіх podʼів, які мають один і той самий виділений пристрій.
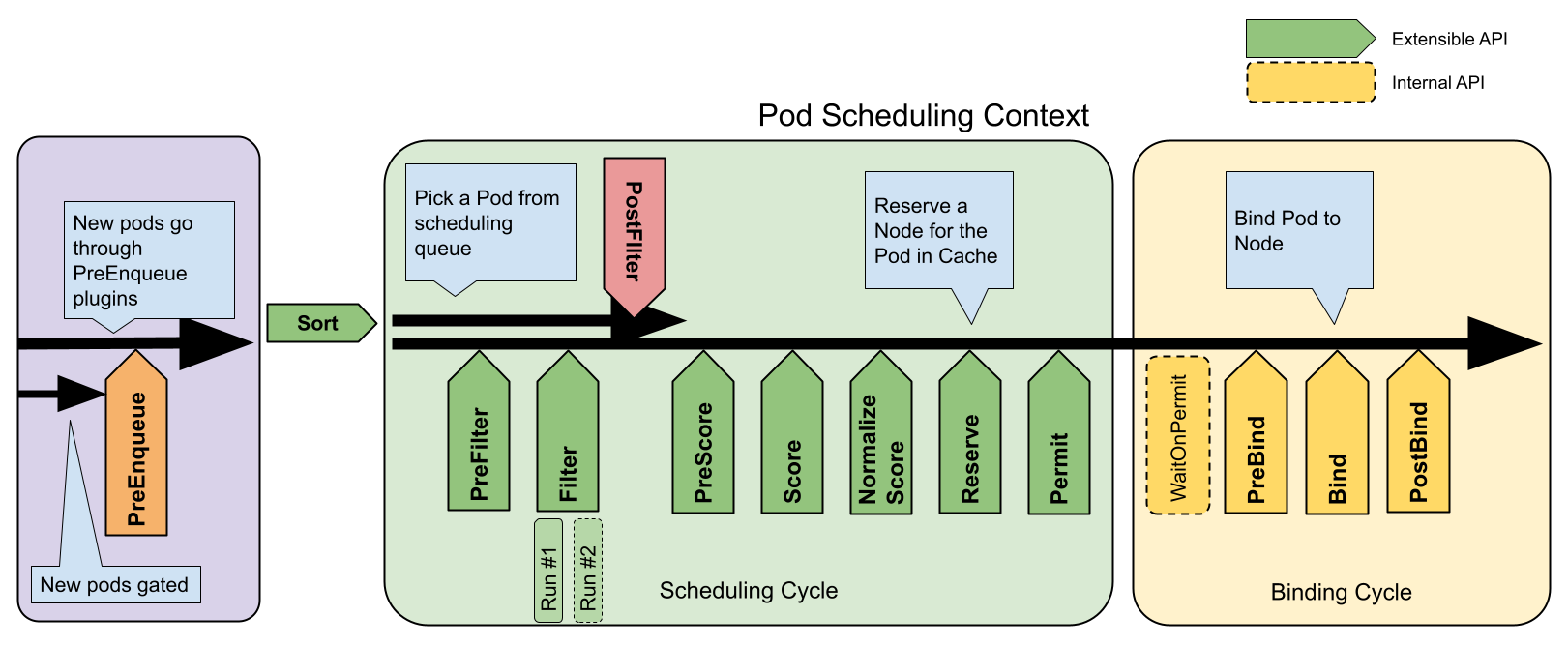
Фреймворк планування — це розширювана архітектура для планувальника Kubernetes. Вона складається з набору "втулків" API, які компілюються безпосередньо в планувальник. Ці API дозволяють реалізувати більшість функцій планування у вигляді втулків, зберігаючи при цьому основне ядро планування легким та зручним у використанні. Для отримання більш технічної інформації про дизайн цієї архітектури зверніться до пропозиції проєкту дизайну системи планування.
Робота фреймворку
Фреймворк планування визначає кілька точок розширення. Втулки планувальника реєструються для виклику в одній або кількох таких точках розширення. Деякі з цих втулків можуть змінювати рішення щодо планування, а деякі надають тільки інформаційний вміст.
Кожна спроба запланувати один Pod розділяється на два етапи: цикл планування та цикл привʼязки.
Цикл планування та цикл привʼязки
Цикл планування вибирає вузол для Podʼа, а цикл привʼязки застосовує це рішення до кластера. Разом цикл планування та цикл привʼязки називаються "контекстом планування".
Цикли планування виконуються послідовно, тоді як цикли привʼязки можуть виконуватися паралельно.
Цикл планування або привʼязки може бути перерваний, якщо виявлено, що Pod не може бути запланованим або якщо відбувається внутрішня помилка. Pod буде повернуто у чергу і спроба буде повторена.
Інтерфейси
Наступне зображення показує контекст планування Podʼа та інтерфейси, які надає фреймворк планування.
Один втулок може реалізовувати кілька інтерфейсів для виконання складніших завдань або завдань зі збереженням стану.
Деякі інтерфейси відповідають точкам розширення планувальника, які можна налаштувати через Конфігурацію Планувальника.
Точки розширення фреймворку планування
PreEnqueue
Ці втулки викликаються перед додаванням Podʼів до внутрішньої активної черги, де Podʼи відзначаються як готові до планування.
Тільки коли всі втулки PreEnqueue повертають Success, Pod допускається до внутрішньої активної черги. В іншому випадку він поміщається у відсортований список незапланованих Podʼів і не отримує умову Unschedulable.
Для отримання докладнішої інформації про те, як працюють внутрішні черги планувальника, прочитайте Черга планування в kube-scheduler.
EnqueueExtension
EnqueueExtension — це інтерфейс, де втулок може контролювати, чи потрібно повторно спробувати планування Podʼів, відхилені цим втулком, на основі змін у кластері. Втулки, які реалізують PreEnqueue, PreFilter, Filter, Reserve або Permit, повинні реалізувати цей інтерфейс.
QueueingHint
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.32 [beta]
QueueingHint — це функція зворотного виклику для вирішення того, чи можна повторно включити Pod до активної черги або черги відстрочки. Вона виконується кожного разу, коли в кластері відбувається певний вид події або зміна. Коли QueueingHint виявляє, що подія може зробити Pod запланованим, Pod поміщається в активну чергу або чергу відстрочки, щоб планувальник повторно спробував спланувати Pod.
Примітка:
У Kubernetes 1.33 ця функціональна можливість увімкнена стандартно, і ви можете вимкнути її за допомогою функціональної можливостіSchedulerQueueingHints.
QueueSort
Ці втулки використовуються для сортування Podʼів у черзі планування. Втулок сортування черги надає функцію Less(Pod1, Pod2). Одночасно може бути включений лише один втулок сортування черги.
PreFilter
Ці втулки використовуються для попередньої обробки інформації про Pod, або для перевірки певних умов, яким мають відповідати кластер або Pod. Якщо втулок PreFilter повертає помилку, цикл планування переривається.
Filter
Ці втулки використовуються для відфільтрування вузлів, на яких не можна запустити Pod. Для кожного вузла планувальник буде викликати втулки фільтрації в налаштованому порядку. Якщо будь-який втулок фільтра позначає вузол як неспроможний, для цього вузла не буде викликано інші втулки. Оцінка вузлів може відбуватися паралельно.
PostFilter
Ці втулки викликаються після фази фільтрації, але лише тоді, коли не було знайдено жодного можливого вузла для Podʼа. Втулки викликаються в налаштованому порядку. Якщо будь-який втулок postFilter позначає вузол як Schedulable, інші втулки не будуть викликані. Типовою реалізацією PostFilter є preemption, яка намагається зробити Pod запланованим, випереджаючи інші Pods.
PreScore
Ці втулки використовуються для виконання "попередньої оцінки", яка генерує загальний стан для використання втулками Score. Якщо втулок попередньої оцінки повертає помилку, цикл планування переривається.
Score
Ці втулки використовуються для ранжування вузлів, які пройшли фазу фільтрації. Планувальник викликає кожен втулок оцінювання для кожного вузла. Існує чіткий діапазон цілих чисел, який представляє мінімальні та максимальні оцінки. Після фази NormalizeScore, планувальник поєднує оцінки вузла з усіх втулків згідно з налаштованими коефіцієнтами втулків.
Оцінка сховища
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [alpha] (стандартно увімкнено: false)
У версії 1.32 для підтримки сховищ зі статичним резервуванням використовувався елемент VolumeCapacityPriority. Починаючи з версії 1.33, новий елемент StorageCapacityScoring замінює старий елемент VolumeCapacityPriority з додатковою підтримкою сховищ з динамічним резервуванням. Коли StorageCapacityScoring увімкнено, втулок VolumeBinding у kube-scheduler розширено, щоб оцінювати вузли на основі ємності сховища на кожному з них. Ця функція застосовується до томів CSI, які підтримують Обсяг сховища, включно з локальним сховищем, яке підтримується драйвером CSI.
NormalizeScore
Ці втулки використовуються для модифікації оцінок перед тим, як планувальник обчислить кінцеве ранжування Вузлів. Втулок, який реєструється для цієї точки розширення, буде викликаний з результатами Score від того ж втулка. Це робиться один раз для кожного втулка на один цикл планування.
Наприклад, припустимо, що втулок BlinkingLightScorer ранжує вузли на основі того, скільки лампочок, що блимають, в них є.
funcScoreNode(_ *v1.pod, n *v1.Node) (int, error) {
returngetBlinkingLightCount(n)
}
Однак максимальна кількість лампочок, що блимають, може бути невеликою порівняно з NodeScoreMax. Щоб виправити це, BlinkingLightScorer також повинен реєструватися для цієї точки розширення.
Якщо будь-який втулок NormalizeScore повертає помилку, цикл планування припиняється.
Примітка:
Втулки, які бажають виконати "pre-reserve", повинні використовувати точку розширення NormalizeScore.
Reserve
Втулок, який реалізує інтерфейс Reserve, має два методи, а саме Reserve та Unreserve, які підтримують дві інформаційні фази планування, які називаються Reserve та Unreserve, відповідно. Втулки, які підтримують стан виконання (так звані "статичні втулки"), повинні використовувати ці фази для повідомлення планувальнику про те, що ресурси на вузлі резервуються та скасовуються для вказаного Podʼа.
Фаза резервування (Reserve) відбувається перед тим, як планувальник фактично привʼязує Pod до призначеного вузла. Це робиться для запобігання виникненню умов перегонів (race condition) під час очікування на успішне привʼязування. Метод Reserve кожного втулка Reserve може бути успішним або невдалим; якщо один виклик методу Reserve не вдасться, наступні втулки не виконуються, і фаза резервування вважається невдалою. Якщо метод Reserve всіх втулків успішний, фаза резервування вважається успішною, виконується решта циклу планування та циклу привʼязки.
Фаза скасування резервування (Unreserve) спрацьовує, якщо фаза резервування або пізніша фаза виявиться невдалою. У такому випадку метод Unreserveвсіх втулків резервування буде виконано у порядку зворотному виклику методів Reserve. Ця фаза існує для очищення стану, повʼязаного з зарезервованим Podʼом.
Увага:
Реалізація методу Unreserve у втулках Reserve повинна бути ідемпотентною і не може зазнавати невдачі.
Permit
Втулки Permit викликаються в кінці циклу планування для кожного Podʼа, щоб запобігти або затримати привʼязку до вузла-кандидата. Втулок дозволу може робити одну з трьох речей:
approve Якщо всі втулки Permit схвалюють Pod, він відправляється для привʼязки.
deny Якщо будь-який втулок Permit відхиляє Pod, він повертається до черги планування. Це спричинить запуск фази Unreserve у втулках Reserve.
wait (із таймаутом) Якщо втулок Permit повертає "wait", тоді Pod залишається у внутрішньому списком "очікуючих" Podʼів, і цикл привʼязки цього Podʼа починається, але безпосередньо блокується, поки він не буде схвалений. Якщо виникає таймаут, wait стає deny і Pod повертається до черги планування, спричиняючи запуск фази Unreserve у втулках Reserve.
Примітка:
Хоча будь-який втулок може мати доступ до списку "очікуючих" Podʼів та схвалювати їх (див. FrameworkHandle), ми очікуємо, що лише втулки Permit схвалюватимуть привʼязку зарезервованих Podʼів, які перебувають у стані "wait". Після схвалення Podʼа він відправляється до фази PreBind.
PreBind
Ці втулки використовуються для виконання будь-яких необхідних операцій перед привʼязкою Podʼа. Наприклад, втулок PreBind може надавати мережевий том і монтувати його на цільовому вузлі перед тим, як дозволити Podʼа запускатися там.
Якщо будь-який втулок PreBind повертає помилку, Pod відхиляється і повертається до черги планування.
Bind
Ці втулки використовуються для привʼязки Podʼа до Вузла. Втулки Bind не будуть викликані, поки всі втулки PreBind не завершаться. Кожен втулок привʼязки викликається в налаштованому порядку. Втулок привʼязки може вибрати, чи обробляти вказаний Pod. Якщо втулок привʼязки обирає Pod для опрацювання, решта втулків привʼязки пропускаються.
PostBind
Це інформаційний інтерфейс. Втулки PostBind викликаються після успішної привʼязки Podʼа. Це завершення циклу привʼязки та може бути використано для очищення повʼязаних ресурсів.
API втулку
Існують два кроки в API втулку. По-перше, втулки повинні зареєструватися та отримати налаштування, а потім вони використовують інтерфейси точок розширення. Інтерфейси точок розширення мають наступну форму.
type Plugin interface {
Name() string}
type QueueSortPlugin interface {
Plugin
Less(*v1.pod, *v1.pod) bool}
type PreFilterPlugin interface {
Plugin
PreFilter(context.Context, *framework.CycleState, *v1.pod) error}
// ...
Налаштування втулків
Ви можете увімкнути або вимкнути втулки у конфігурації планувальника. Якщо ви використовуєте Kubernetes v1.18 або пізнішу версію, більшість втулків планування використовуються та є стандартно увімкненими.
Окрім стандартних втулків, ви також можете реалізувати власні втулки планування та налаштувати їх разом з стандартними втулками. Ви можете дізнатися більше на scheduler-plugins.
Якщо ви використовуєте Kubernetes v1.18 або пізнішу версію, ви можете налаштувати набір втулків як профіль планувальника, а потім визначити кілька профілів для різних видів робочих навантажень. Дізнайтеся більше за про декілька профілів.
8 - Динамічне виділення ресурсів
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.32 [beta] (стандартно увімкнено: false)
Динамічне виділення ресурсів — це API для запиту та спільного використання ресурсів між Podʼами та контейнерами всередині Podʼа. Це узагальнення API для постійних томів для загальних ресурсів. Зазвичай ці ресурси є пристроями, такими як GPU.
Драйвери сторонніх ресурсів відповідають за відстеження та підготовку ресурсів, а виділення ресурсів здійснюється Kubernetes за допомогою структурованих параметрів (введених у Kubernetes 1.30). Різні види ресурсів підтримують довільні параметри для визначення вимог та ініціалізації.
У версіях Kubernetes від 1.26 до 1.31 була реалізована (альфа) версія classic DRA, яка більше не підтримується. Ця документація для Kubernetes v1.33, пояснює поточний підхід до динамічного розподілу ресурсів у Kubernetes.
Перш ніж ви розпочнете
Kubernetes v1.33 включає підтримку API на рівні кластера для динамічного виділення ресурсів, але це потрібно включити явно. Ви також повинні встановити драйвер ресурсів для конкретних ресурсів, які мають бути керовані за допомогою цього API. Якщо ви не використовуєте Kubernetes v1.33, перевірте документацію для цієї версії Kubernetes.
API
Групи APIresource.k8s.io/v1beta1 та resource.k8s.io/v1beta2 надають наступні типи:
ResourceClaim
Визначає запит на доступ до ресурсів у кластері для використання робочими навантаженнями. Наприклад, якщо робоче навантаження потребує пристрою прискорювача з певними властивостями, саме так виражається цей запит. Розділ статусу відстежує, чи було виконано цей запит і які конкретні ресурси було виділено.
ResourceClaimTemplate
Визначає специфікацію та деякі метадані для створення ResourceClaims. Створюється користувачем під час розгортання робочого навантаження. Kubernetes автоматично створює та видаляє ResourceClaims для кожного Podʼа.
DeviceClass
Містить заздалегідь визначені критерії вибору для певних пристроїв та їх конфігурацію. DeviceClass створюється адміністратором кластера під час встановлення драйвера ресурсів. Кожен запит на виділення пристрою в ResourceClaim повинен посилатися на один конкретний DeviceClass.
ResourceSlice
Використовується драйверами DRA для публікації інформації про ресурси (в основному пристрої), які доступні у кластері.
DeviceTaintRule
Використовується адміністраторами або компонентами панелі управління для додавання позначок taint до пристроїв, описаних у ResourceSlices.
Всі параметри які використовуються для вибору пристроїв визначаються ResourceClaim та DeviceClass за вбудованими типами. Параметри конфігурації можна вбудувати тут. Який параметр є валідним визначається драйвером DRA, Kubernetes лише передає їх без їх інтерпретації.
PodSpeccore/v1 визначає ResourceClaims, які потрібні для Podʼа в полі resourceClaims. Записи в цьому списку посилаються або на ResourceClaim, або на ResourceClaimTemplate. При посиланні на ResourceClaim всі Podʼи, які використовують цей PodSpec (наприклад, всередині Deployment або StatefulSet), спільно використовують один екземпляр ResourceClaim. При посиланні на ResourceClaimTemplate, кожен Pod отримує свій власний екземпляр.
Список resources.claims для ресурсів контейнера визначає, чи отримує контейнер доступ до цих екземплярів ресурсів, що дозволяє спільне використання ресурсів між одним або кількома контейнерами.
Нижче наведено приклад для умовного драйвера ресурсів. Для цього Podʼа буде створено два обʼєкти ResourceClaim, і кожен контейнер отримає доступ до одного з них.
Планувальник відповідає за виділення ресурсів для ResourceClaim, коли Pod потребує їх. Він робить це, отримуючи повний список доступних ресурсів з обʼєктів ResourceSlice, відстежуючи, які з цих ресурсів вже були виділені наявним ResourceClaim, а потім вибираючи з тих ресурсів, що залишилися.
Єдиний тип підтримуваних ресурсів зараз — це пристрої. Пристрій має імʼя та кілька атрибутів та можливостей. Вибір пристроїв здійснюється за допомогою виразів CEL, які перевіряють ці атрибути та можливості. Крім того, набір вибраних пристроїв також може бути обмежений наборами, які відповідають певним обмеженням.
Обраний ресурс фіксується у статусі ResourceClaim разом з будь-якими вендор-специфічними налаштуваннями, тому коли Pod збирається запуститися на вузлі, драйвер ресурсу на вузлі має всю необхідну інформацію для підготовки ресурсу.
За допомогою структурованих параметрів планувальник може приймати рішення без спілкування з будь-якими драйверами ресурсів DRA. Він також може швидко планувати кілька Podʼів, зберігаючи інформацію про виділення ресурсів для ResourceClaim у памʼяті та записуючи цю інформацію в обʼєкти ResourceClaim у фоні, одночасно з привʼязкою Podʼа до вузла.
Моніторинг ресурсів
Kubelet надає службу gRPC для забезпечення виявлення динамічних ресурсів запущених Podʼів. Для отримання додаткової інформації про точки доступу gRPC дивіться звіт про виділення ресурсів.
Попередньо заплановані Podʼи
Коли ви, або інший клієнт API, створюєте Pod із вже встановленим spec.nodeName, планувальник пропускається. Якщо будь-який ResourceClaim, потрібний для цього Podʼа, ще не існує, не виділений або не зарезервований для Podʼа, то kubelet не зможе запустити Pod і періодично перевірятиме це, оскільки ці вимоги можуть бути задоволені пізніше.
Така ситуація також може виникнути, коли підтримка динамічного виділення ресурсів не була увімкнена в планувальнику на момент планування Podʼа (різниця версій, конфігурація, feature gate і т. д.). kube-controller-manager виявляє це і намагається зробити Pod працюючим, шляхом отримання потрібних ResourceClaims. Однак, це працює якщо вони були виділені планувальником для якогось іншого podʼа.
Краще уникати цього оминаючи планувальник, оскільки Pod, який призначений для вузла, блокує нормальні ресурси (ОЗП, ЦП), які потім не можуть бути використані для інших Podʼів, поки Pod є застряглим. Щоб запустити Pod на певному вузлі, при цьому проходячи через звичайний потік планування, створіть Pod із селектором вузла, який точно відповідає бажаному вузлу:
Можливо, ви також зможете змінити вхідний Pod під час допуску, щоб скасувати поле .spec.nodeName і використовувати селектор вузла замість цього.
Адміністративний доступ
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.32 [alpha] (стандартно увімкнено: false)
Ви можете позначити запит у ResourceClaim або ResourceClaimTemplate як такий, що має привілейовані можливості. Запит з правами адміністратора надає доступ до пристроїв, які використовуються, і
може увімкнути додаткові дозволи, якщо зробити пристрій доступним у
контейнері:
Якщо цю функцію вимкнено, поле adminAccess буде видалено автоматично при створенні такої вимоги до ресурсу.
Доступ адміністратора є привілейованим режимом і не повинен надаватися звичайним користувачам у багатокористувацьких кластерах. Починаючи з Kubernetes v1.33, лише користувачі, яким дозволено створювати обʼєкти ResourceClaim або ResourceClaimTemplate у просторах імен, позначених resource.k8s.io/admin-access: "true" (з урахуванням регістру) можуть використовувати поле adminAccess. Це гарантує, що користувачі, які не мають прав адміністратора, не зможуть зловживати цією можливістю.
Статус пристрою ResourceClaim
Драйвери можуть повідомляти дані про стан конкретного пристрою для кожного виділеного пристрою у вимозі на ресурс. Наприклад, IP-адреси, призначені пристрою мережевого інтерфейсу, можуть бути вказані у статусі ResourceClaim.
Драйвери встановлюють статус, точність інформації залежить від реалізації цих драйверів DRA. Тому стан пристрою, про який повідомляється, не завжди може відображати зміни стану пристрою в реальному часі.
Якщо цю функцію вимкнено, це поле автоматично очищується при збереженні ResourceClaim.
Статус пристрою в ResourceClaim підтримується, коли з драйвера DRA можна оновити наявний ResourceClaim, в якому встановлено поле status.devices.
Список пріоритетів
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [alpha] (стандартно увімкнено: false)
Ви можете надати пріоритетний список підзапитів для запитів у ResourceClaim. Потім планувальник вибере перший підзапит, який може бути розміщений. Це дозволяє користувачам вказати альтернативні пристрої, які можуть бути використані робочим навантаженням, якщо основний вибір недоступний.
У наведеному нижче прикладі шаблон ResourceClaimTemplate запросив пристрій чорного кольору і великого розміру. Якщо пристрій з цими атрибутами недоступний, він не може бути запланований. За допомогою функції пріоритетного списку можна вказати другу альтернативу, яка запитує два пристрої з білим кольором і маленьким розміром. Великий чорний пристрій буде призначено, якщо він доступний. Але якщо його немає, а два маленьких білих пристрої доступні, то pod все одно зможе працювати.
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [alpha] (стандартно увімкнено: false)
Пристрої, представлені в DRA, не обовʼязково мають бути одним пристроєм, підключеним до одного компʼютера, але також можуть бути логічними пристроями, що складаються з декількох пристроїв, підключених до декількох компʼютерів. Ці пристрої можуть споживати ресурси фізичних пристроїв, що перекриваються, а це означає, що при виділенні одного логічного пристрою інші пристрої будуть недоступні.
У ResourceSlice API це представлено у вигляді списку іменованих наборів CounterSets, кожен з яких містить набір іменованих лічильників. Лічильники представляють ресурси, доступні на фізичному пристрої, які використовуються логічними пристроями, оголошеними через DRA.
Логічні пристрої можуть вказувати список ConsumesCounters. Кожен запис містить посилання на CounterSet і набір іменованих лічильників з кількістю, яку вони будуть споживати. Отже, щоб пристрій можна було призначити, набори лічильників, на які є посилання, повинні мати достатню кількість для лічильників, на які посилається пристрій.
Наведемо приклад двох пристроїв, кожен з яких споживає по 6 гігабайтів памʼяті зі спільного лічильника з 8 гігабайтами памʼяті. Таким чином, тільки один з пристроїв може бути виділений у будь-який момент часу. Планувальник обробляє це, і це прозоро для споживача, оскільки API ResourceClaim не зачіпається.
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [alpha] (стандартно увімкнено: false)
Позначки taint пристроїв подібні до позначок вузлів: позначка має рядок-ключ, рядок-значення та ефект. Ефект застосовується до ResourceClaim, який використовує познапчений пристрій, і до всіх Podʼів, що посилаються на цей ResourceClaim. Ефект “NoSchedule" запобігає плануванню цих Podʼів. Позначені пристрої ігноруються при спробі виділити ResourceClaim, тому що їх використання перешкоджає плануванню для Podʼів.
Ефект "NoExecute” означає "NoSchedule" і, крім того, спричиняє виселення всіх Podʼів, які вже були заплановані. Це виселення реалізовано у контролері виселення позначених пристроїв у kube-controller-manager шляхом видалення відповідних Podʼів.
ResourceClaims можуть толерантно ставитися до позначок. Якщо позначка толерується, її ефект не застосовується. Порожня толерантність відповідає всім позначкам. Толерантність може бути обмежена певними ефектами та/або відповідати певним парам ключ/значення. Толерантність може перевіряти існування певного ключа, незалежно від того, яке значення він має, або перевіряти конкретні значення ключа. Для отримання додаткової інформації про таке зіставлення див. концепції поначення вузлів.
Виселення може бути відкладено за допомогою толерантності до позначки протягом певного часу. Ця затримка починається з моменту додавання позначки на пристрій, що записується у полі taint.
Позначки застосовуються, як описано вище, також до ResourceClaims, що виділяють «всі» ("all") пристрої на вузлі. Всі пристрої не повинні бути позначені, або всі їхні позначки повинні бути толеровані. Виділення пристрою з доступом адміністратора (описано вище) також не є винятком. Адміністратор, який використовує цей режим, повинен явно толерантно ставитися до всіх позначок, щоб отримати доступ до позначених пристроїв.
Позначки можуть бути додані до пристроїв двома різними способами:
Позначки встановлені драйвером
Драйвер DRA може додавати позначки до інформації про пристрій, яку він публікує у ResourceSlices. Зверніться до документації драйвера DRA, щоб дізнатися, чи використовує він позначки і які їхні ключі та значення.
Позначки встановлені адміністратором
Адміністратор або компонент панелі управління може додавати позначуи на пристрої без необхідності вказувати драйверу DRA включати позначки до інформації про пристрій у ResourceSlices. Вони роблять це шляхом створення DeviceTaintRules. Кожне DeviceTaintRule додає одну позначку до пристроїв, які відповідають селектору пристрою. Без такого селектора жоден пристрій не буде позначений. Це ускладнює випадкове виселення всіх пристроїв за допомогою ResourceClaims, якщо помилково не вказати селектор.
Пристрої можна вибрати, вказавши імʼя класу DeviceClass, драйвера, пулу та/або пристрою. Клас пристроїв вибирає всі пристрої, які вибрані селекторами у цьому класі пристроїв. Маючи лише імʼя драйвера, адміністратор може позначити всі пристрої, що керуються цим драйвером, наприклад, під час виконання певного виду обслуговування цього драйвера у всьому кластері. Додавання назви пулу може обмежити позначення до одного вузла, якщо драйвер керує локальними пристроями вузла.
Нарешті, додаванням назви пристрою можна вибрати один конкретний пристрій. За бажанням, назву пристрою і назву пулу можна використовувати окремо. Наприклад, драйверам для локальних пристроїв рекомендується використовувати назву вузла як назву пулу. У такому разі позначення з таким іменем пулу автоматично призведе до позначення усіх пристроїв на вузлі.
Драйвери можуть використовувати стабільні назви на зразок «gpu-0», які приховують, який саме пристрій наразі призначено для цієї назви. Для підтримки позначення певного екземпляра обладнання у правилі DeviceTaintRule можна використовувати селектори CEL, які відповідатимуть унікальному атрибуту ідентифікатора виробника, якщо драйвер підтримує такий атрибут для свого обладнання.
Позначення застосовується доти, доки існує правило DeviceTaintRule. Його можна будь-коли змінити або вилучити. Ось один із прикладів DeviceTaintRule для вигаданого драйвера DRA:
apiVersion:resource.k8s.io/v1alpha3kind:DeviceTaintRulemetadata:name:examplespec:# Усе апаратне забезпечення для цього# конкретного драйвера зламано.# Виселити всі підсистеми і не планувати нові.deviceSelector:driver:dra.example.comtaint:key:dra.example.com/unhealthyvalue:Brokeneffect:NoExecute
Увімкнення динамічного виділення ресурсів
Динамічне виділення ресурсів є бета-функцією, яка стандартно вимкнена, та увімкнена коли увімкнуто функціональну можливістьDynamicResourceAllocation та групу APIresource.k8s.io/v1beta1 та resource.k8s.io/v1beta2. Для отримання деталей щодо цього дивіться параметри kube-apiserver--feature-gates та --runtime-config. Також варто увімкнути цю функцію в kube-scheduler, kube-controller-manager та kubelet.
Коли драйвер ресурсу повідомляє про стан пристроїв, то слід увімкнути функцію DRAResourceClaimDeviceStatus на додаток до DynamicResourceAllocation.
Швидка перевірка того, чи підтримує кластер Kubernetes цю функцію, полягає у виведенні обʼєктів DeviceClass за допомогою наступної команди:
kubectl get deviceclasses
Якщо ваш кластер підтримує динамічне виділення ресурсів, відповідь буде або список обʼєктів DeviceClass, або:
No resources found
Якщо це не підтримується, буде виведено помилку:
error: the server doesn't have a resource type "deviceclasses"
Типова конфігурація kube-scheduler вмикає втулок "DynamicResources" лише в разі увімкнення функціональної можливості та при використанні конфігурації API v1. Налаштування конфігурації може змінюватися, щоб включити його.
Крім увімкнення функції в кластері, також потрібно встановити драйвер ресурсів. Для отримання додаткової інформації звертайтеся до документації драйвера.
Увімкнення позначення та толерування позначок taint пристроїів
Позначення та толерування позначок taint пристроїв є альфа-функцією і вмикається лише тоді, коли увімкнено функціональну можливістьDRADeviceTaints у kube-apiserver, kube-controller-manager та kube-scheduler. Для використання DeviceTaintRules має бути увімкнена версія API resource.k8s.io/v1alpha3.
kube-scheduler — стандартний планувальник для Kubernetes. Він відповідає за розміщення Podʼів на вузлах кластера.
Вузли кластера, які відповідають вимогам планування Podʼа, називаються відповідними вузлами для Podʼа. Планувальник знаходить відповідні вузли для Podʼа, а потім виконує набір функцій для оцінки цих вузлів, вибираючи вузол з найвищим балом серед відповідних для запуску Podʼа. Планувальник потім повідомляє API-серверу про це рішення в процесі, що називається звʼязування.
На цій сторінці пояснюються оптимізації налаштування продуктивності, які є актуальними для великих кластерів Kubernetes.
У великих кластерах ви можете налаштувати роботу планувальника, збалансовуючи результати планування між часом відгуку (нові Podʼи розміщуються швидко) та точністю (планувальник рідко приймає погані рішення про розміщення).
Ви можете налаштувати це налаштування через параметр kube-scheduler percentageOfNodesToScore. Це налаштування KubeSchedulerConfiguration визначає поріг для планування вузлів у вашому кластері.
Налаштування порога
Опція percentageOfNodesToScore приймає цілі числові значення від 0 до 100. Значення 0 є спеціальним числом, яке позначає, що kube-scheduler повинен використовувати типовав вбудоване значення. Якщо ви встановлюєте percentageOfNodesToScore більше 100, kube-scheduler діє так, ніби ви встановили значення 100.
Щоб змінити значення, відредагуйте файл конфігурації kube-scheduler і перезапустіть планувальник. У багатьох випадках файл конфігурації можна знайти за шляхом /etc/kubernetes/config/kube-scheduler.yaml.
Після внесення цих змін ви можете виконати
kubectl get pods -n kube-system | grep kube-scheduler
щоб перевірити, що компонент kube-scheduler працює належним чином.
Поріг оцінки вузлів
Для поліпшення продуктивності планування kube-scheduler може припинити пошук відповідних вузлів, як тільки він знайде їх достатню кількість. У великих кластерах це заощаджує час порівняно з підходом, який би враховував кожен вузол.
Ви вказуєте поріг для того, яка кількість вузлів є достатньою, у відсотках від усіх вузлів у вашому кластері. Kube-scheduler перетворює це в ціле число вузлів. Під час планування, якщо kube-scheduler визначив достатню кількість відповідних вузлів, щоб перевищити налаштований відсоток, він припиняє пошук додаткових відповідних вузлів і переходить до фази оцінки.
Якщо ви не вказуєте поріг, Kubernetes розраховує значення за допомогою лінійної формули, яка дає 50% для кластера зі 100 вузлами та 10% для кластера з 5000 вузлів. Нижня межа для автоматичного значення — 5%.
Це означає, що kube-scheduler завжди оцінює принаймні 5% вашого кластера, незалежно від розміру кластера, якщо ви явно не встановили percentageOfNodesToScore менше ніж 5.
Якщо ви хочете, щоб планувальник оцінював всі вузли у вашому кластері, встановіть percentageOfNodesToScore на 100.
Приклад
Нижче наведено приклад конфігурації, яка встановлює percentageOfNodesToScore на 50%.
percentageOfNodesToScore повинен бути значенням від 1 до 100, а стандартне значення розраховується на основі розміру кластера. Також існує зашите мінімальне значення в 100 вузлів.
Примітка:
У кластерах з менш ніж 100 можливими вузлами планувальник все ще перевіряє всі вузли, тому що недостатньо можливих вузлів для того, щоб рано зупинити пошук планувальника.
У великому кластері, якщо ви встановите низьке значення для percentageOfNodesToScore, ваші зміни майже не матимуть ефекту, зі схожої причини.
Якщо у вашому кластері кілька сотень вузлів або менше, залиште цю опцію конфігурації у стандартному значенні. Ймовірно, внесення змін не суттєво покращить продуктивність планувальника.
Важливою деталлю, яку слід врахувати при встановленні цього значення, є те, що при меншій кількості вузлів у кластері, які перевіряються на придатність, деякі вузли не надсилаються для оцінки для вказаного Podʼа. В результаті вузол, який можливо міг би набрати більший бал для запуску вказаного Podʼа, може навіть не надійти до фази оцінки. Це призведе до менш ідеального розміщення Podʼа.
Вам слід уникати встановлення percentageOfNodesToScore дуже низьким, щоб kube-scheduler не часто приймав неправильні рішення щодо розміщення Podʼа. Уникайте встановлення відсотка нижче 10%, якщо продуктивність планувальника критична для вашого застосунку та оцінка вузлів не є важливою. Іншими словами, ви віддаєте перевагу запуску Podʼа на будь-якому вузлі, який буде придатним.
Як планувальник проходиться по вузлах
Цей розділ призначений для тих, хто бажає зрозуміти внутрішні деталі цієї функції.
Щоб всі вузли кластера мали рівні можливості бути враховані для запуску Podʼів, планувальник проходиться по вузлах по колу. Ви можете уявити, що вузли знаходяться у масиві. Планувальник починає з початку масиву вузлів і перевіряє придатність вузлів, поки не знайде достатню кількість відповідних вузлів, як вказано у percentageOfNodesToScore. Для наступного Podʼа планувальник продовжує з точки в масиві вузлів, де він зупинився при перевірці придатності вузлів для попереднього Podʼа.
Якщо вузли знаходяться в кількох зонах, планувальник проходиться по вузлах у різних зонах, щоб забезпечити, що враховуються вузли з різних зон. Наприклад, розгляньте шість вузлів у двох зонах:
Zone 1: Node 1, Node 2, Node 3, Node 4
Zone 2: Node 5, Node 6
Планувальник оцінює придатність вузлів у такому порядку:
Node 1, Node 5, Node 2, Node 6, Node 3, Node 4
Після переходу усіх вузлів він повертається до Вузла 1.
У scheduling-pluginNodeResourcesFit kube-scheduler є дві стратегії оцінювання, які підтримують пакування ресурсів: MostAllocated та RequestedToCapacityRatio.
Включення пакування ресурсів за допомогою стратегії MostAllocated
Стратегія MostAllocated оцінює вузли на основі використання ресурсів, віддаючи перевагу тим, у яких використання вище. Для кожного типу ресурсів ви можете встановити коефіцієнт, щоб змінити його вплив на оцінку вузла.
Щоб встановити стратегію MostAllocated для втулка NodeResourcesFit, використовуйте конфігурацію планувальника подібну до наступної:
Щоб дізнатися більше про інші параметри та їх стандартну конфігурацію, див. документацію API для NodeResourcesFitArgs.
Включення пакування ресурсів за допомогою стратегії RequestedToCapacityRatio
Стратегія RequestedToCapacityRatio дозволяє користувачам вказати ресурси разом з коефіцієнтами для кожного ресурсу для оцінювання вузлів на основі відношення запиту до потужності. Це дозволяє користувачам пакувати розширені ресурси, використовуючи відповідні параметри для покращення використання рідкісних ресурсів у великих кластерах. Вона віддає перевагу вузлам згідно з налаштованою функцією виділених ресурсів. Поведінку RequestedToCapacityRatio в функції оцінювання NodeResourcesFit можна керувати за допомогою поля scoringStrategy. У межах поля scoringStrategy ви можете налаштувати два параметри: requestedToCapacityRatio та resources. Параметр shape в requestedToCapacityRatio дозволяє користувачу налаштувати функцію як найменш чи найбільш затребувані на основі значень utilization та score. Параметр resources охоплює як name ресурсу, що оцінюється, так і weight для кожного ресурсу.
Нижче наведено приклад конфігурації, яка встановлює поведінку пакування ресурсів intel.com/foo та intel.com/bar за допомогою поля requestedToCapacityRatio.
Вищезазначені аргументи надають вузлу score 0, якщо utilization дорівнює 0%, та 10 для utilization 100%, що дозволяє пакування ресурсів. Щоб увімкнути найменш затребувані значення оцінки, значення оцінки має бути оберненим наступним чином.
Параметр weight є необовʼязковим та встановлений у 1, якщо він не вказаний. Також, він може бути встановлений у відʼємне значення.
Оцінка вузла для розподілу потужностей
Цей розділ призначений для тих, хто бажає зрозуміти внутрішні деталі цієї функціональності. Нижче наведено приклад того, як обчислюється оцінка вузла для заданого набору значень.
Podʼи можуть мати пріоритети. Пріоритети вказують на порівняну важливість одних Podʼів порівняно з іншими. Якщо Pod не може бути запланованим, планувальник намагається випередити (виселити) Pod з меншим пріоритетом, щоб зробити можливим планування Podʼів, які перебуваються в стані очікування.
Попередження:
У кластері, де не всі користувачі є довіреними, зловмисник може створити Podʼи з найвищими можливими пріоритетами, що призведе до виселення інших Podʼів або неможливості їх планування. Адміністратор може використовувати ResourceQuota, щоб запобігти користувачам створювати Podʼи з високими пріоритетами.
Створіть Podʼи з параметром priorityClassName, встановленим на один з доданих PriorityClasses. Звісно, вам не потрібно створювати Podʼи безпосередньо; зазвичай ви додаєте priorityClassName до шаблону Podʼа обʼєкта колекції, такого як Deployment.
Продовжуйте читати для отримання додаткової інформації про ці кроки.
PriorityClassє є обʼєктом, що не належить до простору імен, і визначає зіставлення імені класу пріоритету з цілим значенням пріоритету. Імʼя вказується в полі name метаданих обʼєкта PriorityClass. Значення вказується в обовʼязковому полі value. Чим вище значення, тим вищий пріоритет. Імʼя обʼєкта PriorityClass повинно бути дійсним піддоменом DNS, і воно не може мати префікс system-.
Обʼєкт PriorityClass може мати будь-яке 32-розрядне ціле значення, яке менше або дорівнює 1 мільярду. Це означає, що діапазон значень для обʼєкта PriorityClass становить від -2147483648 до 1000000000 включно. Більші числа зарезервовані для вбудованих PriorityClass, які представляють критичні системні Podʼів. Адміністратор кластера повинен створити один обʼєкт PriorityClass для кожного такого зіставлення.
PriorityClass також має два необовʼязкові поля: globalDefault та description. Поле globalDefault вказує, що значення цього класу пріоритету повинно використовуватися для Podʼів без priorityClassName. В системі може існувати лише один обʼєкт PriorityClass з globalDefault, встановленим в true. Якщо обʼєкт PriorityClass з globalDefault не встановлено, пріоритет Podʼів без priorityClassName буде рівний нулю.
Поле description є довільним рядком. Воно призначене для сповіщення користувачів кластера про те, коли вони повинні використовувати цей PriorityClass.
Примітки щодо PodPriority та наявних кластерів
Якщо ви оновлюєте наявний кластер без цієї функції, пріоритет ваших поточних Podʼів фактично дорівнює нулю.
Додавання PriorityClass з globalDefault, встановленим в true, не змінює пріоритети поточних Podʼів. Значення такого PriorityClass використовується тільки для Podʼів, створених після додавання PriorityClass.
Якщо ви видаляєте PriorityClass, поточні Podʼи, які використовують імʼя видаленого PriorityClass, залишаються незмінними, але ви не можете створювати більше Podʼів, які використовують імʼя видаленого PriorityClass.
Приклад PriorityClass
apiVersion:scheduling.k8s.io/v1kind:PriorityClassmetadata:name:high-priorityvalue:1000000globalDefault:falsedescription:"This priority class should be used for XYZ service pods only."
Невипереджаючий PriorityClass
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.24 [stable]
Podʼи з preemptionPolicy: Never будуть розміщені в черзі планування перед Podʼами з меншим пріоритетом, але вони не можуть випереджати інші Podʼи. Pod, який очікує на планування, залишиться в черзі планування, доки не буде достатньо вільних ресурсів, і його можна буде запланувати. Невипереджаючі Podʼи, подібно до інших Podʼів, підлягають відстроченню планування. Це означає, що якщо планувальник спробує запланувати ці Podʼи, і вони не можуть бути заплановані, спроби їх планування будуть здійснені з меншою частотою, що дозволяє іншим Podʼам з нижчим пріоритетом бути запланованими перед ними.
Невипереджаючі Podʼи все ще можуть бути випереджені іншими, Podʼами з високим пріоритетом. Типове значення preemptionPolicy — PreemptLowerPriority, що дозволяє Podʼам цього PriorityClass випереджати Podʼи з нижчим пріоритетом (бо це поточна типова поведінка). Якщо preemptionPolicy встановлено в Never, Podʼи в цьому PriorityClass будуть невипереджаючими.
Прикладом використання є робочі навантаження для роботи з дослідження даних. Користувач може надіслати завдання, якому він хоче дати пріоритет перед іншими робочими навантаженнями, але не бажає скасувати поточне робоче навантаження, випереджаючи запущені Podʼи. Завдання з високим пріоритетом із preemptionPolicy: Never буде заплановано перед іншими Podʼами в черзі, як тільки будуть наявні вільні ресурси кластера.
Приклад невипереджаючого PriorityClass
apiVersion:scheduling.k8s.io/v1kind:PriorityClassmetadata:name:high-priority-nonpreemptingvalue:1000000preemptionPolicy:NeverglobalDefault:falsedescription:"This priority class will not cause other pods to be preempted."
Пріоритет Podʼа
Після того, як у вас є один або кілька PriorityClasses, ви можете створювати Podʼи, які вказують одне з імен цих PriorityClass у їх специфікаціях. Контролер допуску пріоритетів використовує поле priorityClassName і заповнює ціле значення пріоритету. Якщо клас пріоритету не знайдено, Pod відхиляється.
Наведений нижче YAML — це приклад конфігурації Podʼа, який використовує PriorityClass, створений у попередньому прикладі. Контролер допуску пріоритетів перевіряє специфікацію та розраховує пріоритет Podʼа як 1000000.
Коли пріоритет Podʼа увімкнено, планувальник впорядковує Podʼи, що перебувають в очікуванні за їх пріоритетом, і такий Pod розташовується попереду інших очікуючих Podʼів з меншим пріоритетом в черзі планування. В результаті Pod з вищим пріоритетом може бути запланований швидше, ніж Podʼи з нижчим пріоритетом, якщо відповідні вимоги до планування виконуються. Якщо такий Pod не може бути запланований, планувальник продовжить спроби запланувати інші Podʼи з меншим пріоритетом.
Випередження
Коли Podʼи створюються, вони потрапляють у чергу та очікують на планування. Планувальник вибирає Pod з черги та намагається запланувати його на вузлі. Якщо не знайдено жодного вузла, який задовольняє всі вказані вимоги Podʼа, для очікуючого Podʼа спрацьовує логіка випередження в черзі. Назвімо очікуючий Pod P. Логіка випередження спробує знайти вузол, де видалення одного або декількох Podʼів з нижчим пріоритетом, ніж P, дозволить запланувати P на цьому вузлі. Якщо такий вузол знайдено, один або декілька Podʼів з нижчим пріоритетом будуть виселені з вузла. Після того, як Podʼи підуть, P може бути запланований на вузлі.
Інформація, доступна користувачеві
Коли Pod P випереджає один або кілька Podʼів на вузлі N, поле nominatedNodeName статусу Podʼа P встановлюється на імʼя вузла N. Це поле допомагає планувальнику відстежувати ресурси, зарезервовані для Podʼа P, і також надає користувачам інформацію про випередження в їх кластерах.
Зверніть увагу, що Pod P не обовʼязково планується на "назначений вузол". Планувальник завжди спочатку спробує "назначений вузол", перед тим як перевіряти будь-які інші вузли. Після того, як Podʼи жертви випереджуються, вони отримують свій період належної зупинки. Якщо під час очікування на завершення роботи Podʼів жертв зʼявляється інший вузол, планувальник може використати інший вузол для планування Podʼа P. В результаті поля nominatedNodeName та nodeName специфікації Podʼа не завжди збігаються. Крім того, якщо планувальник випереджає Podʼи на вузлі N, а потім прибуває Pod вищого пріоритету, ніж Pod P, планувальник може надати вузол N новому Podʼу вищого пріоритету. У такому випадку планувальник очищає nominatedNodeName Podʼа P. Цим самим планувальник робить Pod P придатним для випередження Podʼів на іншому вузлі.
Обмеження випередження
Відповідне завершення роботи жертв випередження
Коли Podʼи випереджаються, жертви отримують свій період належного завершення роботи. У них є стільки часу, скільки вказано в цьому періоді, для завершення своєї роботи та виходу. Якщо вони цього не роблять, їх робота завершується примусово. Цей період належного завершення створює проміжок часу між моментом, коли планувальник випереджає Podʼи, і моментом, коли Pod (P), який перебуває в очікування, може бути запланований на вузол (N). Тим часом планувальник продовжує планувати інші Podʼи, що чекають. Поки жертви завершують роботу самі або примусово, планувальник намагається запланувати Podʼи з черги очікування. Тому, зазвичай є проміжок часу між моментом, коли планувальник випереджає жертв, і моментом, коли Pod P стає запланований. Щоб зменшити цей проміжок, можна встановити період належного завершення для Podʼів з низьким пріоритетом на нуль або мале число.
PodDisruptionBudget підтримується, але не гарантується
PodDisruptionBudget (PDB) дозволяє власникам застосунків обмежувати кількість Podʼів реплікованого застосунку, які одночасно вимикаються через добровільні розлади. Kubernetes підтримує PDB при випередженні Podʼів, але гарантоване дотримання PDB не забезпечується. Планувальник намагається знайти жертв, PDB яких не порушується в результаті випередження, але якщо жодної такої жертви не знайдено, випередження все одно відбудеться, і Podʼи з низьким пріоритетом будуть видалені, попри порушення їх PDB.
Між-Podʼова спорідненість для Podʼів з низьким пріоритетом
Вузол розглядається для випередження тільки тоді, коли відповідь на це питання ствердна: "Якщо всі Podʼи з меншим пріоритетом, ніж очікуваний Pod, будуть видалені з вузла, чи може очікуваний Pod бути запланованим на вузлі?"
Примітка:
Випередження не обовʼязково видаляє всі Podʼи з меншим пріоритетом. Якщо очікуваний Pod може бути запланований, видаливши менше, ніж всі Podʼи з меншим пріоритетом, то видаляється лише частина Podʼів з меншим пріоритетом. З усім тим, відповідь на попереднє питання повинна бути ствердною. Якщо відповідь негативна, то вузол не розглядається для випередження.
Якщо очікуваний Pod має між-Podʼову спорідненість з одним або декількома Podʼами з низьким пріоритетом на вузлі, правило між-Podʼової спорідненості не може бути виконане у відсутності цих Podʼів з низьким пріоритетом. У цьому випадку планувальник не випереджає жодних Podʼів на вузлі. Замість цього він шукає інший вузол. Планувальник може знайти відповідний вузол або може і не знайти. Немає гарантії, що очікуваний Pod може бути запланований.
Рекомендованим рішенням для цієї проблеми є створення між-Podʼової спорідненості лише для Podʼів з рівним або вищим пріоритетом.
Міжвузлове випередження
Припустимо, що вузол N розглядається для випередження, щоб запланувати очікуваний Pod P на N. Pod P може стати можливим на вузлі N лише у випадку випередження Podʼа на іншому вузлі. Ось приклад:
Pod P розглядається для вузла N.
Pod Q запущений на іншому вузлі в тій же зоні, що й вузол N.
Pod P має антиспорідненість по всій зоні з Podʼом Q (з topologyKey: topology.kubernetes.io/zone).
Інших випадків антиспорідненості між Podʼом P та іншими Podʼами в зоні немає.
Щоб запланувати Pod P на вузлі N, Pod Q може бути випереджений, але планувальник не виконує міжвузлове випередження. Отже, Pod P буде вважатися незапланованим на вузлі N.
Якщо Pod Q буде видалено зі свого вузла, порушення антиспорідненості Podʼа буде усунено, і Pod P, можливо, можна буде запланувати на вузлі N.
Ми можемо розглянути додавання міжвузлового випередження в майбутніх версіях, якщо буде достатньо попиту і якщо ми знайдемо алгоритм з прийнятною продуктивністю.
Розвʼязання проблем
Пріоритет та випередження Podʼа можуть мати небажані побічні ефекти. Ось кілька прикладів потенційних проблем і способів їх вирішення.
Podʼи випереджаються безпідставно
Випередження видаляє наявні Podʼи з кластера в умовах недостатнього ресурсу для звільнення місця для високопріоритетних очікуваних Podsʼів. Якщо ви помилково встановили високі пріоритети для певних Podʼів, ці Podʼи можуть призвести до випередження в кластері. Пріоритет Podʼа вказується, встановленням поля priorityClassName в специфікації Podʼа. Потім ціле значення пріоритету розраховується і заповнюється у поле prioritypodSpec.
Щоб розвʼязати цю проблему, ви можете змінити priorityClassName для цих Podʼів, щоб використовувати класи з меншим пріоритетом, або залишити це поле порожнім. Порожній priorityClassName типово вважається нулем.
Коли Pod випереджається, для такого Podʼа будуть записані події. Випередження повинно відбуватися лише тоді, коли в кластері недостатньо ресурсів для Podʼа. У таких випадках випередження відбувається лише тоді, коли пріоритет очікуваного Podʼа (випереджаючого) вище, ніж у Podʼів жертв. Випередження не повинно відбуватися, коли немає очікуваного Podʼа, або коли очікувані Podʼи мають рівні або нижчі пріоритети, ніж у жертв. Якщо випередження відбувається в таких сценаріях, будь ласка, сповістіть про це для розвʼязання проблеми.
Podʼи випереджаються, але кандидат не планується
Коли Podʼи випереджаються, вони отримують запитаний період належного завершення, який типово становить 30 секунд. Якщо використовувані Podʼи не завершуються протягом цього періоду, вони завершуються примусово. Після того, як всі жертви зникають, Pod кандидат, може бути запланований.
Поки Pod кандидат, чекає, поки жертви зникнуть, може бути створений Pod з вищим пріоритетом, який підходить на той самий вузол. У цьому випадку планувальник запланує Pod з вищим пріоритетом замість кандидата.
Це очікувана поведінка: Pod з вищим пріоритетом повинен зайняти місце Podʼа з нижчим пріоритетом.
Podʼи з вищим пріоритетом припиняють роботу перед Podʼами з нижчим пріоритетом
Планувальник намагається знайти вузли, на яких можна запустити очікуваний Pod. Якщо вузол не знайдено, планувальник намагається видалити Podʼи з меншим пріоритетом з довільного вузла, щоб звільнити місце для очікуваного Podʼа. Якщо вузол з Podʼами низького пріоритету не може бути використаний для запуску очікуваного Podʼа, планувальник може вибрати інший вузол з Podʼами вищого пріоритету (порівняно з Podʼами на іншому вузлі) для випередження. Жертви все ще повинні мати нижчий пріоритет, ніж Pod кандидат.
Коли є доступні кілька вузлів для випередження, планувальник намагається вибрати вузол з набором Podʼів з найнижчим пріоритетом. Однак якщо такі Podʼи мають PodDisruptionBudget, який буде порушений, якщо вони будуть випереджені, то планувальник може вибрати інший вузол з Podʼами вищого пріоритету.
Коли є кілька вузлів для випередження і жоден з вищезазначених сценаріїв не застосовується, планувальник вибирає вузол з найнижчим пріоритетом.
Взаємодія між пріоритетом Podʼа та якістю обслуговування
Пріоритет Podʼа та клас QoS є двома протилежними функціями з невеликою кількістю взаємодій та без типових обмежень щодо встановлення пріоритету Podʼа на основі його класів QoS. Логіка випередження планувальника не враховує QoS при виборі цілей випередження. Випередження враховує пріоритет Podʼа і намагається вибрати набір цілей з найнижчим пріоритетом. Podʼи вищого пріоритету розглядаються для випередження лише тоді, коли видалення Podʼів з найнижчим пріоритетом не є достатнім для того, щоб дозволити планувальнику розмістити Pod кандидат, або якщо Podʼи з найнижчим пріоритетом захищені PodDisruptionBudget.
kubelet використовує пріоритет для визначення порядку Podʼів для виселення через тиск на вузол. Ви можете використовувати клас QoS для оцінки порядку, в якому ймовірно будуть виселятись Podʼи. kubelet ранжує Podʼи для виселення на основі наступних факторів:
Чи використання, якому недостатньо ресурсів, перевищує запити
Пріоритет Podʼа
Обсяг використання ресурсів в порівнянні із запитами
Виселення kubeletʼом через тиск на вузол не виселяє Podʼи, коли їх використання не перевищує їх запити. Якщо Pod з нижчим пріоритетом не перевищує свої запити, він не буде виселений. Інший Pod з вищим пріоритетом, який перевищує свої запити, може бути виселений.
Виселення через тиск на вузол — це процес, при якому kubelet активно завершує роботу Podʼів для звільнення ресурсів на вузлах.
Примітка:
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.31 [beta] (стандартно увімкнено: true)
Функція split image filesystem, яка забезпечує підтримку файлової системи containerfs, додає кілька нових сигналів виселення, порогів та метрик. Щоб використовувати containerfs, у випуску Kubernetes v1.33 потрібно увімкнути функціональну можливістьKubeletSeparateDiskGC. Наразі підтримка файлової системи containerfs доступна лише в CRI-O (версія 1.29 або вище).
The kubelet моніторить ресурси, такі як памʼять, простір на диску та i-nodeʼи файлової системи на вузлах вашого кластера. Коли один або декілька з цих ресурсів досягають певних рівнів використання, kubelet може проактивно припинити роботу одного або кількох Podʼів на вузлі, щоб відновити ресурси та запобігти голодуванню.
Під час виселення внаслідок тиску на вузол, kubelet встановлює фазу для вибраних Podʼів в значення Failed та завершує роботу Podʼа.
kubelet не дотримується вашого налаштованого PodDisruptionBudget або параметру terminationGracePeriodSeconds Podʼа. Якщо ви використовуєте порогові значення мʼякого виселення, kubelet дотримується вашого налаштованого eviction-max-pod-grace-period. Якщо ви використовуєте порогові значення жорсткого виселення, kubelet використовує граничний період 0s (негайне завершення) для завершення роботи Podʼа.
Самовідновлення
kubelet намагається відновлювати ресурси на рівні вузла перед тим, як він завершує роботу Podʼів кінцевих користувачів. Наприклад, він видаляє не використані образи контейнерів, коли дискових ресурсів недостатньо.
Якщо Podʼи управляються обʼєктом workload (таким як StatefulSet або Deployment), який заміщує несправні Podʼи, панель управління (kube-controller-manager) створює нові Podʼи на місці виселених Podʼів.
Самовідновлення статичних Podʼів
Якщо ви запускаєте статичний Pod на вузлі, який перебуває під тиском нестачі ресурсів, kubelet може виселити цей статичний Pod. Потім kubelet намагається створити заміну, оскільки статичні Podʼи завжди представляють намір запустити Pod на цьому вузлі.
Kubelet враховує пріоритет статичного Podʼа при створенні заміни. Якщо маніфест статичного Podʼа вказує низький пріоритет, і в межах панелі управління кластера визначені Podʼи з вищим пріоритетом, і вузол перебуває під тиском нестачі ресурсів, то kubelet може не мати можливості звільнити місце для цього статичного Podʼа. Kubelet продовжує намагатися запустити всі статичні Podʼи навіть тоді, коли на вузлі є тиск на ресурси.
Сигнали та пороги виселення
Kubelet використовує різні параметри для прийняття рішень щодо виселення, такі як:
Сигнали виселення
Пороги виселення
Інтервали моніторингу
Сигнали виселення
Сигнали виселення — це поточний стан певного ресурсу в конкретний момент часу. Kubelet використовує сигнали виселення для прийняття рішень про виселення, порівнюючи їх з порогами виселення, які є мінімальною кількістю ресурсу, яка повинна бути доступна на вузлі.
У цій таблиці стовпець Опис показує, як kubelet отримує значення сигналу. Кожен сигнал підтримує відсоткове або літеральне значення. Kubelet обчислює відсоткове значення відносно загальної потужності, повʼязаної з сигналом.
Сигнали памʼяті
На вузлах Linux, значення для memory.available походить з cgroupfs замість таких інструментів, як free -m. Це важливо, оскільки free -m не працює у контейнері, і якщо користувачі використовують можливість виділення ресурсів для вузла, рішення про відсутність ресурсів
приймаються локально для Podʼа кінцевого користувача, який є частиною ієрархії cgroup, а також кореневого вузла. Цей скрипт або скрипт cgroupv2 відтворює той самий набір кроків, які kubelet виконує для обчислення memory.available. Kubelet виключає зі свого обчислення inactive_file (кількість байтів памʼяті, що резервується файлами, у списку неактивних LRU) на основі припущення, що памʼять можна вилучити під час натиску.
На Windows-вузлах значення memory.available отримується з глобального рівня комітів памʼяті вузла (запитується через системний виклик GetPerformanceInfo()) шляхом віднімання глобального значення CommitTotal від CommitLimit вузла. Зверніть увагу, що значення CommitLimit може змінюватися, якщо змінюється розмір файлу підкачки вузла!
Сигнали файлової системи
Kubelet розпізнає три конкретні ідентифікатори файлової системи, які можна використовувати зі сигналами виселення (<identifier>.inodesFree або <identifier>.available):
nodefs: Основна файлова система вузла, використовується для локальних дискових томів, томів emptyDir, які не підтримуються памʼяттю, зберігання логів, ефемерного зберігання та іншого. Наприклад, nodefs містить /var/lib/kubelet.
imagefs: Опціональна файлова система, яку середовище виконання контейнерів може використовувати для зберігання образів контейнерів (що є тільки для читання) і записуваних шарів контейнерів.
containerfs: Опціональна файлова система, яку середовище виконання контейнерів може використовувати для зберігання записуваних шарів. Подібно до основної файлової системи (див. nodefs), вона використовується для зберігання локальних дискових томів, томів emptyDir, які не підтримуються памʼяттю, зберігання логів і ефемерного зберігання, за винятком образів контейнерів. Коли використовується containerfs, файлова система imagefs може бути розділена так, щоб зберігати лише образи (шари тільки для читання) і більше нічого.
Таким чином, kubelet зазвичай підтримує три варіанти файлових систем для контейнерів:
Все зберігається на єдиній файловій системі nodefs, також відомій як "rootfs" або просто "root", і немає окремої файлової системи для образів.
Зберігання контейнерів (див. nodefs) на окремому диску, а imagefs (записувані та лише для читання шари) відокремлені від кореневої файлової системи. Це часто називають "split disk" (або "separate disk") файловою системою.
Файлова система контейнерів containerfs (така ж, як nodefs, плюс записувані шари) знаходиться на root, а образи контейнерів (шари лише для читання) зберігаються на окремій imagefs. Це часто називають "split image" файловою системою.
Kubelet спробує автоматично виявити ці файлові системи з їхньою поточною конфігурацією безпосередньо з підсистеми контейнерів і ігноруватиме інші локальні файлові системи вузла.
Kubelet не підтримує інші файлові системи контейнерів або конфігурації зберігання і наразі не підтримує кілька файлових систем для образів і контейнерів.
Застарілі функції збору сміття kubelet
Деякі функції сміттєзбірника kubelet застаріли на користь процесу виселення:
Наявний Прапорець
Обґрунтування
--maximum-dead-containers
застаріло, коли старі журнали зберігаються поза контекстом контейнера
--maximum-dead-containers-per-container
застаріло, коли старі журнали зберігаються поза контекстом контейнера
--minimum-container-ttl-duration
застаріло, коли старі журнали зберігаються поза контекстом контейнера
Пороги виселення
Ви можете вказати спеціальні пороги виселення для kubelet, які він буде використовувати під час прийняття рішень про виселення. Ви можете налаштувати мʼякі та жорсткі пороги виселення.
Пороги виселення мають формат [eviction-signal][operator][quantity], де:
operator — це оператор відношення, який ви хочете використати, наприклад, < (менше ніж).
quantity — це кількість порогу виселення, наприклад, 1Gi. Значення quantity повинно відповідати представленню кількості, яке використовується в Kubernetes. Ви можете використовувати як літеральні значення, так і відсотки (%).
Наприклад, якщо вузол має загальний обсяг памʼяті 10ГіБ і ви хочете спровокувати виселення, якщо доступна памʼять знизиться до менше ніж 1ГіБ, ви можете визначити поріг виселення як memory.available<10% або memory.available<1Gi (використовувати обидва варіанти одночасно не можна).
Мʼякі пороги виселення
Мʼякий поріг виселення поєднує в собі поріг виселення з обовʼязковим пільговим періодом, вказаним адміністратором. Kubelet не виселяє Podʼи до закінчення пільгового періоду. Kubelet повертає помилку при запуску, якщо ви не вказали пільговий період.
Ви можете вказати як пільговий період для мʼякого порогу виселення, так і максимально дозволений пільговий період для завершення Podʼів, який kubelet використовуватиме під час виселення. Якщо ви вказали максимально дозволений пільговий період і мʼякий поріг виселення досягнутий, kubelet використовує менший із двох пільгових періодів. Якщо ви не вказали максимально дозволений пільговий період, kubelet негайно завершує роботу виселених Podʼів без очікування належного завершення їх роботи.
Ви можете використовувати наступні прапорці для налаштування мʼяких порогів виселення:
eviction-soft: Набір порогів виселення, наприклад, memory.available<1.5Gi, які можуть спровокувати виселення Podʼів, якщо вони утримуються протягом вказаного пільгового періоду.
eviction-soft-grace-period: Набір пільгових періодів для виселення, наприклад, memory.available=1m30s, які визначають, як довго мʼякий поріг виселення повинен утримуватися, перш ніж буде спровоковане виселення Podʼа.
eviction-max-pod-grace-period: Максимально дозволений пільговий період (у секундах) для використання при завершенні Podʼів у відповідь на досягнення мʼякого порогу виселення.
Жорсткі пороги виселення
Жорсткий поріг виселення не має пільгового періоду. Коли досягнуто жорсткого порогу виселення, kubelet негайно завершує роботу Podʼів без очікування належного завершення їх роботи, щоб повернути ресурси, яких бракує.
Ви можете використовувати прапорець eviction-hard для налаштування набору жорстких порогів виселення, наприклад memory.available<1Gi.
Kubelet має наступні стандартні жорсткі пороги виселення:
memory.available<100Mi (для вузлів Linux)
memory.available<50Mi (для вузлів Windows)
nodefs.available<10%
imagefs.available<15%
nodefs.inodesFree<5% (для вузлів Linux)
imagefs.inodesFree<5% (для вузлів Linux)
Ці стандартні значення жорстких порогів виселення будуть встановлені лише у випадку, якщо жоден з параметрів не змінено. Якщо ви зміните значення будь-якого параметра, то значення інших параметрів не будуть успадковані як стандартні та будуть встановлені в нуль. Щоб надати власні значення, ви повинні вказати всі пороги відповідно. Ви також можете встановити значення параметру kubelet config MergeDefaultEvictionSettings рівним true у файлі конфігурації kubelet. Якщо встановити значення true і змінити будь-який параметр, то інші параметри успадкують їх стандартні значення, а не 0.
Порогові стандартні значення для containerfs.available і containerfs.inodesFree (для Linux-вузлів) будуть встановлені наступним чином:
Якщо для всього використовується одна файлова система, то порогові значення для containerfs встановлюються такими ж, як і для nodefs.
Якщо налаштовані окремі файлові системи для образів і контейнерів, то порогові значення для containerfs встановлюються такими ж, як і для imagefs.
Наразі налаштування власниї порогових значень, повʼязаних із containerfs, не підтримується, і буде видано попередження, якщо спробувати це зробити; будь-які надані власні значення будуть ігноровані.
Інтервал моніторингу виселення
Kubelet оцінює пороги виселення, виходячи з налаштованого інтервалу прибирання (housekeeping-interval), який типово становить 10с.
Стани вузла
Kubelet повідомляє про стан вузла, показуючи, що вузол перебуває під тиском через досягнення порогу жорсткого або мʼякого виселення, незалежно від налаштованих пільгових періодів для належного завершення роботи.
Kubelet зіставляє сигнали виселення зі станами вузла наступним чином:
Умова вузла
Сигнал виселення
Опис
MemoryPressure
memory.available
Доступна памʼять на вузлі досягла порогового значення для виселення
DiskPressure
nodefs.available, nodefs.inodesFree, imagefs.available, imagefs.inodesFree, containerfs.available, або containerfs.inodesFree
Доступний диск і вільні іноди на кореневій файловій системі вузла, файловій системі образів або файловій системі контейнерів досягли порогового значення для виселення
PIDPressure
pid.available
Доступні ідентифікатори процесів на (Linux) вузлі зменшилися нижче порогового значення для виселення
Панель управління також зіставляє ці стани вузла у вигляді taint.
Kubelet оновлює стани вузла відповідно до налаштованої частоти оновлення стану вузла (--node-status-update-frequency), яка за типово становить 10с.
Коливання стану вузла
У деяких випадках вузли коливаються вище та нижче мʼяких порогів виселення без затримки на визначених пільгових періодах. Це призводить до того, що звітний стан вузла постійно перемикається між true та false, що призводить до поганих рішень щодо виселення.
Для захисту від коливань можна використовувати прапорець eviction-pressure-transition-period, який контролює, як довго kubelet повинен чекати перед переходом стану вузла в інший стан. Період переходу має стандартне значення 5 хв.
Повторне використання ресурсів на рівні вузла
Kubelet намагається повторно використовувати ресурси на рівні вузла перед виселенням контейнерів кінцевих користувачів.
Коли вузол повідомляє про умову DiskPressure, kubelet відновлює ресурси на рівні вузла на основі файлових систем на вузлі.
Без imagefs або containerfs
Якщо на вузлі є лише файлова система nodefs, яка відповідає пороговим значенням для виселення, kubelet звільняє диск у наступному порядку:
Виконує збір сміття для померлих Podʼів і контейнерів.
Видаляє непотрібні образи.
З використанням imagefs
Якщо на вузлі є окрема файлова система imagefs, яку використовують інструменти управління контейнерами, то kubelet робить наступне:
Якщо файлова система nodefs відповідає пороговим значенням для виселення, то kubelet видаляє мертві Podʼи та мертві контейнери.
Якщо файлова система imagefs відповідає пороговим значенням для виселення, то kubelet видаляє всі невикористані образи.
З imagefs та containerfs
Якщо на вузлі налаштовані окремі файлові системи containerfs разом із файловою системою imagefs, яку використовують середовища виконання контейнерів, то kubelet намагатиметься відновити ресурси наступним чином:
Якщо файлова система containerfs досягає порогових значень для виселення, kubelet виконує збір сміття метрвих Podʼів і контейнерів.
Якщо файлова система imagefs досягає порогових значень для виселення, kubelet видаляє всі непотрібні образи.
Вибір Podʼів для виселення kubelet
Якщо спроби kubelet відновити ресурси на рівні вузла не знижують сигнал виселення нижче порогового значення, kubelet починає виселяти Podʼи кінцевих користувачів.
Kubelet використовує наступні параметри для визначення порядку виселення Podʼів:
Чи перевищує використання ресурсів Podʼа їх запити
Використання ресурсів Podʼа в порівнянні з запитами
В результаті kubelet ранжує та виселяє Podʼи в наступному порядку:
Podʼи BestEffort або Burstable, де використання перевищує запити. Ці Podʼи виселяються на основі їх пріоритету, а потім на те, наскільки їхнє використання перевищує запит.
Podʼи Guaranteed та Burstable, де використання менше за запити, виселяються останніми, на основі їх пріоритету.
Примітка:
Kubelet не використовує клас QoS Podʼа для визначення порядку виселення. Ви можете використовувати клас QoS для оцінки найбільш ймовірного порядку виселення Podʼа при відновленні ресурсів, таких як памʼять. Класифікація QoS не застосовується до запитів EphemeralStorage, тому вищезазначений сценарій не буде застосовуватися, якщо вузол, наприклад, перебуває під DiskPressure.
Podʼи Guaranteed гарантовані лише тоді, коли для всіх контейнерів вказано запити та обмеження, і вони є однаковими. Ці Podʼи ніколи не будуть виселятися через споживання ресурсів іншим Podʼом. Якщо системний демон (наприклад, kubelet та journald) споживає більше ресурсів, ніж було зарезервовано за допомогою розподілів system-reserved або kube-reserved, і на вузлі залишилися лише Guaranteed або Burstable Podʼи, які використовують менше ресурсів, ніж запити, то kubelet повинен вибрати Pod для виселення для збереження стабільності вузла та обмеження впливу нестачі ресурсів на інші Podʼи. У цьому випадку він вибере Podʼи з найнижчим пріоритетом першими.
Якщо ви використовуєте статичний Pod і хочете уникнути його виселення під час нестачі речурсів, встановіть поле priority для цього Podʼа безпосередньо. Статичні Podʼи не підтримують поле priorityClassName.
Коли kubelet виселяє Podʼи у відповідь на вичерпання inode або ідентифікаторів процесів, він використовує відносний пріоритет Podʼів для визначення порядку виселення, оскільки для inode та PID не існує запитів.
Kubelet сортує Podʼи по-різному залежно від того, чи є на вузлі відведений файловий ресурс imagefs чи containerfs:
Без imagefs або containerfs (nodefs і imagefs використовують одну і ту ж файлову систему)
Якщо nodefs ініціює виселення, kubelet сортує Podʼи на основі їх загального використання диска (локальні томи + логи та записуваний шар усіх контейнерів).
З imagefs (nodefs і imagefs — окремі файлові системи)
Якщо nodefs ініціює виселення, kubelet сортує Podʼи на основі використання nodefs (локальні томи + логи всіх контейнерів).
Якщо imagefs ініціює виселення, kubelet сортує Podʼи на основі використання записуваного шару всіх контейнерів.
З imagefs та containerfs (imagefs та containerfs розділені)
Якщо containerfs ініціює виселення, kubelet сортує Podʼи на основі використання containerfs (локальні томи + логи та записуваний шар усіх контейнерів).
Якщо imagefs ініціює виселення, kubelet сортує Podʼи на основі ранжування storage of images, яке відображає використання диска для даного образу.
Мінімальна кількість ресурсів для відновлення після виселення
Примітка:
У Kubernetes v1.33, ви не можете встановити власне значення для метрики containerfs.available. Конфігурація для цієї конкретної метрики буде встановлена автоматично, щоб відображати значення, задані для nodefs або imagefs, залежно від конфігурації.
У деяких випадках виселення підтримує лише невелику кількість виділеного ресурсу. Це може призвести до того, що kubelet постійно стикається з пороговими значеннями для виселення та виконує кілька виселень.
Ви можете використовувати прапорець --eviction-minimum-reclaim або файл конфігурації kubelet для налаштування мінімальної кількості відновлення для кожного ресурсу. Коли kubelet помічає нестачу ресурсу, він продовжує відновлення цього ресурсу до тих пір, поки не відновить кількість, яку ви вказали.
Наприклад, наступна конфігурація встановлює мінімальні кількості відновлення:
У цьому прикладі, якщо сигнал nodefs.available досягає порога виселення, kubelet відновлює ресурс до тих пір, поки сигнал не досягне порога в 1 ГіБ, а потім продовжує відновлення мінімальної кількості 500 МіБ до тих пір, поки доступне значення nodefs збереження не досягне 1,5 ГіБ.
Аналогічно, kubelet намагається відновити ресурс imagefs до тих пір, поки значення imagefs.available не досягне 102 ГіБ, що представляє 102 ГіБ доступного сховища для образів контейнерів. Якщо кількість сховища, яку може відновити kubelet, менше за 2 ГіБ, kubelet нічого не відновлює.
Стандартно eviction-minimum-reclaim є 0 для всіх ресурсів.
Поведінка в разі вичерпання памʼяті на вузлі
Якщо вузол зазнає події out of memory (OOM) до того, як kubelet зможе відновити памʼять, вузол залежить від реагування oom_killer.
Kubelet встановлює значення oom_score_adj для кожного контейнера на основі QoS для Podʼа.
Kubelet також встановлює значення oom_score_adj рівне -997 для будь-яких контейнерів у Podʼах, які мають пріоритет system-node-critical.
Якщо kubelet не може відновити памʼять до того, як вузол зазнає OOM, oom_killer обчислює оцінку oom_score на основі відсотка памʼяті, яку він використовує на вузлі, а потім додає oom_score_adj, щоб отримати ефективну оцінку oom_score для кожного контейнера. Потім він примусово завершує роботу контейнера з найвищим показником.
Це означає, що спочатку припиняється робота контейнерів у Podʼах низького QoS, які споживають велику кількість памʼяті в порівнянні з їх запитами на планування.
На відміну від виселення Podʼа, якщо роботу контейнера було припинено через вичерпання памʼяті, kubelet може перезапустити його відповідно до його restartPolicy.
Поради
У наступних розділах описано найкращі практики конфігурації виселення.
Ресурси, доступні для планування, та політики виселення
При конфігурації kubelet з політикою виселення слід переконатися, що планувальник не буде розміщувати Podʼи, які спричинять виселення через те, що вони безпосередньо викликають тиск на памʼять.
Розгляньте такий сценарій:
Обсяг памʼяті вузла: 10 ГіБ
Оператор бажає зарезервувати 10% обсягу памʼяті для системних служб (ядро, kubelet, тощо)
Оператор бажає виселяти Podʼи при використанні памʼяті на рівні 95%, щоб зменшити випадки виснаження системи.
У цій конфігурації прапорець --system-reserved резервує 1,5 ГіБ памʼяті для системи, що становить 10% від загальної памʼяті + кількість порогу виселення.
Вузол може досягти порогу виселення, якщо Pod використовує більше, ніж його запит, або якщо система використовує більше 1 ГіБ памʼяті, що знижує значення memory.available нижче 500 МіБ і спричиняє спрацювання порогу.
DaemonSets та виселення через тиск на вузол
Пріоритет Podʼа — це основний фактор при прийнятті рішень про виселення. Якщо вам не потрібно, щоб kubelet виселяв Podʼи, які належать до DaemonSet, встановіть цим Podʼам достатньо високий пріоритет, вказавши відповідний priorityClassName в специфікації Podʼа. Ви також можете використовувати менший пріоритет або типове значення, щоб дозволити запускати Podʼи з цього DaemonSet тільки тоді, коли є достаньо ресурсів.
Відомі проблеми
У наступних розділах описані відомі проблеми, повʼязані з обробкою вичерпання ресурсів.
kubelet може не сприймати тиск на памʼять одразу
Стандартно, kubelet опитує cAdvisor, щоб регулярно збирати статистику використання памʼяті. Якщо використання памʼяті збільшується протягом цього інтервалу швидко, kubelet може не помітити MemoryPressure настільки швидко, і буде викликаний OOM killer.
Ви можете використовувати прапорець --kernel-memcg-notification, щоб увімкнути API сповіщення memcg в kubelet і отримувати повідомлення негайно, коли перетинається поріг.
Якщо ви не намагаєтеся досягти екстремального використання, але не перескочити розумний рівень перевикористання, розумним обходом для цієї проблеми є використання прапорців --kube-reserved та --system-reserved для виділення памʼяті для системи.
active_file памʼять не вважається доступною памʼяттю
В Linux ядро відстежує кількість байтів файлової памʼяті в активному списку останніх використаних (LRU) як статистику active_file. Kubelet розглядає області памʼяті active_file як непіддаються вилученню. Для робочих навантажень, що інтенсивно використовують локальне сховище з блоковою підтримкою, включаючи ефемерне локальне сховище, кеші ядра файлів та блоків означає, що багато недавно доступних сторінок кеша, ймовірно, будуть враховані як active_file. Якщо достатньо цих буферів блоків ядра перебувають на активному списку LRU, kubelet може сприйняти це як високе використання ресурсів та позначити вузол як такий, що страждає від тиску на памʼять — спровокувавши виселення Podʼів.
Ви можете обійти цю проблему, встановивши для контейнерів, які ймовірно виконують інтенсивну діяльність з операцій введення/виведення, однакове обмеження памʼяті та запит памєяті. Вам потрібно оцінити або виміряти оптимальне значення обмеження памʼяті для цього контейнера.
Виселення, ініційоване API — процес, під час якого використовується Eviction API для створення обʼєкта Eviction, який викликає належне завершення роботи Podʼа.
Ви можете ініціювати виселення, викликавши Eviction API безпосередньо або програмно,
використовуючи клієнт API-сервера, наприклад, команду kubectl drain. Це створює обʼєкт Eviction, що призводить до завершення роботи Podʼа через API-сервер.
Використання API для створення обʼєкта Eviction для Podʼа схоже на виконання контрольованої політикою операції DELETE на Podʼі.
Виклик Eviction API
Ви можете використовувати клієнт кластера Kubernetes, щоб отримати доступ до API Kubernetes та створити обʼєкт Eviction. Для цього ви надсилаєте POST-запит на виконання операції, схожий на наступний приклад:
Коли ви запитуєте виселення за допомогою API, сервер API виконує перевірки допуску
і відповідає одним із таких способів:
200 ОК: виселення дозволено, субресурс Eviction створюється, і Pod видаляється, подібно до надсилання DELETE-запиту на URL Podʼа.
429 Забагато запитів: виселення на цей момент не дозволено через налаштований PodDisruptionBudget. Можливо, ви зможете спробувати виселення пізніше. Ви також можете отримати цю відповідь через обмеження швидкості API.
500 Внутрішня помилка сервера: виселення не дозволено через помилкову конфігурацію, наприклад, якщо декілька PodDisruptionBudget посилаються на той самий Pod.
Якщо Pod, який ви хочете виселити, не є частиною робочого навантаження, яке має PodDisruptionBudget, сервер API завжди повертає 200 OK та дозволяє виселення.
Якщо сервер API дозволяє виселення, Pod видаляється наступним чином:
Ресурс Pod в сервері API оновлюється з часовою міткою видалення, після чого сервер API вважає ресурс Pod таким, що завершив роботу. Ресурс Pod також позначений для відповідного звершення роботи.
Kubelet на вузлі, на якому запущений локальний Pod, помічає, що ресурс Pod позначений для припинення та починає видаляти локальний Pod.
Під час припинення роботи Podʼа kubelet видаляє Pod з обʼєктів EndpointSlice. В результаті контролери більше не вважають Pod за дійсний обʼєкт.
Після закінчення періоду належного завершення роботи для Podʼа kubelet примусово вимикає локальний Pod.
kubelet повідомляє сервер API про видалення ресурсу Pod.
Сервер API видаляє ресурс Pod.
Виправлення застряглих виселень
У деяких випадках ваші застосунки можуть потрапити в непрацездатний стан, де Eviction API буде повертати лише відповіді 429 або 500, поки ви не втрутитеся. Це може відбуватися, наприклад, якщо ReplicaSet створює Podʼи для вашого застосунку, але нові Podʼи не переходять в стан Ready. Ви також можете помітити це поведінку у випадках, коли останній виселений Pod мав довгий період належного завершення роботи при примусовому завершенні роботи.
Якщо ви помічаєте застряглі виселення, спробуйте одне з таких рішень:
Скасуйте або призупиніть автоматизовану операцію, що викликає проблему. Дослідіть застряглий застосунок, перш ніж перезапустити операцію.
Почекайте трохи, а потім безпосередньо видаліть Pod з панелі управління вашого кластера замість використання API виселення.