Огляд адміністрування кластера призначений для всіх, хто створює або адмініструє кластер Kubernetes. Він передбачає певний рівень знайомства з основними концепціями.
Планування кластера
Ознайомтеся з посібниками в розділі Встановлення для прикладів планування, налаштування та конфігурації кластерів Kubernetes. Рішення, перераховані в цій статті, називаються distros.
Примітка:
Не всі distros активно підтримуються. Вибирайте distros, які були протестовані з останньою версією Kubernetes.
Перед вибором посібника врахуйте наступні моменти:
Чи хочете ви спробувати Kubernetes на своєму компʼютері, чи хочете побудувати кластер високої доступності з кількома вузлами? Вибирайте distros, які найкраще підходять для ваших потреб.
Чи будете ви використовувати кластер Kubernetes, розміщений на хостингу, такому як Google Kubernetes Engine, чи створюватимете свій власний кластер?
Чи буде ваш кластер на місці, чи в хмарі (IaaS)? Kubernetes напряму не підтримує гібридні кластери. Замість цього ви можете налаштувати кілька кластерів.
Якщо ви налаштовуєте Kubernetes на місці, розгляньте, яка модель мережі підходить найкраще.
Чи будете ви запускати Kubernetes на "bare metal" обладнанні чи на віртуальних машинах (VMs)?
Ви хочете мати робочий кластер, чи плануєте активний розвиток коду проєкту Kubernetes? Якщо останнє, вибирайте distros, які активно розвиваються. Деякі distros використовують лише бінарні релізи, але пропонують більшу різноманітність вибору.
Ознайомтеся з компонентами, необхідними для запуску кластера.
У кластері Kubernetes вузол може бути вимкнутий плановим відповідним способом або несподівано через такі причини, як відключення електропостачання або інші зовнішні обставини. Вимкнення вузла може призвести до відмови робочого навантаження, якщо вузол не буде виводитись з обслуговування перед вимкненням. Вимкнення вузла може бути відповідним або невідповідним (graceful or non-graceful).
Належне вимикання вузла
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.21 [beta] (стандартно увімкнено: true)
Kubelet намагається виявити вимикання системи вузла та завершує виконання Podʼів на вузлі.
Kubelet забезпечує виконання нормального процесу завершення роботи Podʼа під час вимикання вузла. Під час вимикання вузла kubelet не приймає нові Podʼи (навіть якщо ці Podʼи вже призначені вузлу).
Можливість належного вимикання вузла (graceful node shutdown) залежить від systemd, оскільки вона використовує блокування інгібіторів systemd для затримки вимкнення вузла на певний час.
Вимикання вузла керується функціональною можливістюGracefulNodeShutdown, що є типово увімкненим з версії 1.21.
Зауважте, що типово обидва налаштування конфігурації, описані нижче, shutdownGracePeriod та shutdownGracePeriodCriticalPods, встановлені на нуль, таким чином, не активуючи функціональність належного вимикання вузла. Для активації цієї функції, обидва налаштування конфігурації kubelet повинні бути належним чином налаштовані та встановлені на значення, відмінні від нуля.
Як тільки systemd виявляє або повідомляє про вимикання вузла, kubelet встановлює умову NotReady на вузлі з причиною "node is shutting down". Kube-scheduler дотримується цієї умови та не планує жодних Podʼів на цьому вузлі; очікується, що інші планувальники сторонніх постачальників дотримуватимуться такої ж логіки. Це означає, що нові Podʼи не будуть плануватися на цьому вузлі, і, отже, жоден із них не розпочне роботу.
Kubelet також відхиляє Podʼи під час фази PodAdmission, якщо виявлено поточне вимикання вузла, так що навіть Podʼи з toleration для node.kubernetes.io/not-ready:NoSchedule не почнуть виконання там.
Коли kubelet встановлює цю умову на своєму вузлі через API, kubelet також починає завершення будь-яких Podʼів, які виконуються локально.
Під час вимикання kubelet завершує Podʼи у два етапи:
Завершує роботу звичайних Podʼів, які виконуються на вузлі.
Функція належного вимикання вузла налаштовується двома параметрами конфігурації kubelet:
shutdownGracePeriod:
Визначає загальний час, протягом якого вузол повинен затримати вимикання. Це загальний термін допомагає завершити Podʼи як звичайні, так і критичні.
shutdownGracePeriodCriticalPods:
Визначає термін, який використовується для завершення критичних Podʼів під час вимикання вузла. Це значення повинно бути менше за shutdownGracePeriod.
Примітка:
Є випадки, коли вимкнення вузла було скасовано системою (або, можливо, вручну адміністратором). У будь-якому з цих випадків вузол повернеться до стану Ready. Однак Podʼи, які вже розпочали процес завершення, не будуть відновлені kubelet і їх потрібно буде перепланувати.
Наприклад, якщо shutdownGracePeriod=30s, а shutdownGracePeriodCriticalPods=10s, kubelet затримає вимикання вузла на 30 секунд. Під час вимикання перші 20 (30-10) секунд будуть зарезервовані для належного завершення звичайних Podʼів, а останні 10 секунд будуть зарезервовані для завершення критичних Podʼів.
Примітка:
Коли Podʼи були виселені під час належного вимикання вузла, вони позначаються як вимкнені. Виклик kubectl get pods показує стан виселених Podʼів як Terminated. І kubectl describe pod вказує, що Pod був виселений через вимикання вузла:
Reason: Terminated
Message: Pod was terminated in response to imminent node shutdown.
Належне вимикання вузла на основі пріоритету Podʼа
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.24 [beta] (стандартно увімкнено: true)
Щоб забезпечити більшу гнучкість під час належного вимикання вузла щодо порядку вимикання Podʼів, належне вимикання вузла враховує PriorityClass для Podʼів, за умови, що ви активували цю функцію у своєму кластері. Функція дозволяє адміністраторам кластера явно визначити порядок вимикання Podʼів під час належного вимикання вузла на основі priority classes.
Функція належного вимикання вузла, яка описана вище, вимикає Podʼи у дві фази: звичайні Podʼи, а потім критичні Podʼи. Якщо потрібна додаткова гнучкість для явного визначення порядку Podʼа під час вимикання в більш деталізований спосіб, можна використовувати належне (graceful) вимикання вузла на основі пріоритету Podʼа.
Коли вимикання вузла враховує пріоритет Podʼів, це дозволяє виконувати вимикання вузла у кілька етапів, кожен етап — це завершення роботи Podʼів певного класу пріоритету. Kubelet можна налаштувати з точним числом етапів та часом вимикання для кожного етапу.
Вищеописана таблиця означає, що будь-який Pod зі значенням priority >= 100000 отримає лише 10 секунд на вимкнення, будь-який Pod зі значенням >= 10000 і < 100000 отримає 180 секунд для вимкнення, будь-який Pod зі значенням >= 1000 і < 10000 отримає 120 секунд для вимкнення. Нарешті, всі інші Podʼи отримають 60 секунд для вимкнення.
Не обовʼязково вказувати значення, відповідні всім класам. Наприклад, можна використовувати ці налаштування:
Значення класу пріоритету Podʼа
Період вимкнення
100000
300 seconds
1000
120 seconds
0
60 seconds
У вищезазначеному випадку Podʼи з custom-class-b потраплять в ту ж саму групу, що й custom-class-c для вимкнення.
Якщо в певному діапазоні відсутні Podʼи, то kubelet не чекатиме на Podʼи у цьому діапазоні пріоритетів. Замість цього, kubelet безпосередньо перейде до наступного діапазону значень пріоритету.
Якщо ця функція увімкнена, а жодна конфігурація не надана, то дії з упорядкування не будуть виконані.
Використання цієї функції передбачає активацію функціональної можливостіGracefulNodeShutdownBasedOnPodPriority, та встановлення ShutdownGracePeriodByPodPriority в kubelet config до потрібної конфігурації, яка містить значення класу пріоритету Podʼа та відповідні періоди вимкнення.
Примітка:
Можливість враховування пріоритетів Podʼів під час належного вимикання вузла була введена як альфа-функція в Kubernetes v1.23. У Kubernetes 1.33 функція є бета-версією та є типово активованою.
Метрики graceful_shutdown_start_time_seconds та graceful_shutdown_end_time_seconds публікуються у підсистему kubelet для моніторингу вимкнень вузлів.
Обробка неналежних вимкнень вузлів
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.28 [stable] (стандартно увімкнено: true)
Дія вимкнення вузла може бути не виявленою Node Shutdown Manager вузла kubelet, чи то через те, що команда не активує механізм блокування інгібітора, який використовується kubelet, чи через помилку користувача, тобто ShutdownGracePeriod та ShutdownGracePeriodCriticalPods налаштовані неправильно. Будь ласка, зверніться до вищезазначеної секції Належне вимикання вузла для отримання докладнішої інформації.
Коли вузол вимикається, але це не виявляється Node Shutdown Manager вузла kubelet, Podʼи, які є частиною StatefulSet, залишаться в стані завершення на вимкненому вузлі та не зможуть перейти до нового робочого вузла. Це тому, що kubelet на вимкненому вузлі недоступний для видалення Podʼів, і StatefulSet не може створити новий Pod із такою ж назвою. Якщо є томи, які використовуються Podʼами, то VolumeAttachments не буде видалено з оригінального вимкненого вузла, і тому томи використовувані цими Podʼами не можуть бути приєднані до нового робочого вузла. В результаті застосунок, що виконується з StatefulSet, не може працювати належним чином. Якщо оригінальний вимкнений вузол вмикається, Podʼи будуть видалені kubelet, і нові Podʼи будуть створені на іншому робочому вузлі. Якщо оригінальний вимкнений вузол не повертається, ці Podʼи залишаться в стані завершення на вимкненому вузлі назавжди.
Для помʼякшення вищезазначеної ситуації користувач може вручну додати позначку (taint) node.kubernetes.io/out-of-service з ефектом NoExecute чи NoSchedule до вузла, вказавши, що він вийшов із ладу. Якщо вузол відзначений як такий, що вийшов з ладу з такою позначкою, Podʼи на вузлі будуть примусово видалені, якщо на них немає відповідних toleration, і операції відʼєднання томів для завершення Podʼів на вузлі відбудуться негайно. Це дозволяє Podʼам на вузлі, що вийшов з ладу, швидко відновитися на іншому вузлі.
Під час такого (non-graceful) вимикання робота Podʼів завершується у дві фази:
Насильно видаляються Podʼи, які не мають відповідних toleration out-of-service.
Негайно виконується операція відʼєднання томів для таких Podʼів.
Примітка:
Перш ніж додавати позначку node.kubernetes.io/out-of-service, слід перевірити, що вузол вже перебуває в стані припинення роботи чи вимикання (не в середині процесу перезапуску).
Користувач повинен вручну видалити позначку out-of-service після того, як Podʼи будуть переміщені на новий вузол, і користувач перевірив, що вимкнений вузол відновився, оскільки саме користувач додав позначку на початку.
Примусове відʼєднання сховища при перевищенні часу очікування
У будь-якій ситуації, де видалення Podʼа не вдалося протягом 6 хвилин, Kubernetes примусово відʼєднає томи, які розмонтувалися, якщо в цей момент вузол несправний. Будь-яке робоче навантаження, що все ще працює на вузлі та використовує том, який примусово відʼєднується, спричинить порушення специфікації CSI, яка стверджує, що ControllerUnpublishVolume "повинен бути викликаний після всіх викликів NodeUnstageVolume та NodeUnpublishVolume в томі, і вони успішно завершилися". В таких обставинах томи на такому вузлі можуть зіткнутися з пошкодженням даних.
Поведінка примусового відʼєднання сховища є необовʼязковою; користувачі можуть вибрати використання функції "Non-graceful node shutdown" замість цього.
Примусове відʼєднання сховища при перевищенні часу очікування можна вимкнути, встановивши поле конфігурації disable-force-detach-on-timeout в kube-controller-manager. Вимкнення функції примусового відʼєднання при перевищенні часу очікування означає, що у тому, який розміщено на вузлі, який несправний протягом понад 6 хвилин, не буде видалено його повʼязаний VolumeAttachment.
Після застосування цього налаштування, несправні Podʼи, які все ще приєднані до томів, повинні бути відновлені за допомогою процедури Обробки неналежних вимкнень вузлів, згаданої вище.
Відхилення від документованих вище кроків може призвести до пошкодження даних.
Належне припинення роботи вузла Windows
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.32 [alpha] (стандартно увімкнено: false)
Функція Windows graceful node shutdown залежить від того, чи працює kubelet як служба Windows, тоді він матиме зареєстрований service control handler для затримки події вимкнення на задану тривалість.
Керування вимкненням вузла Windows здійснюється за допомогою функціональної можливостіWindowsGracefulNodeShutdown, яку було представлено у 1.32 як альфа-версію.
Належне завершення роботи вузла у Windows не може бути скасовано.
Якщо kubelet не запущено як службу Windows, він не зможе встановити та відстежувати подію Preshutdown, вузол буде змушений пройти через процедуру Non-Graceful Node Shutdown, згадану вище.
У випадку, якщо у Windows увімкнено функцію належного завершення роботи вузла, але kubelet не запущено як службу Windows, kubelet продовжить роботу, а не завершить її. Однак, він буде реєструвати помилку, яка вказує на те, що його потрібно запустити як службу Windows.
Kubernetes може бути налаштовано на використання памʼяті підкачки на вузлі, що дозволяє ядру звільняти фізичну памʼять, підкачуючи сторінки до резервного сховища. Це корисно для багатьох випадків використання. Наприклад, вузли, на яких виконуються робочі навантаження, що можуть отримати вигоду від використання свопу, наприклад, ті, що займають багато памʼяті, але мають доступ лише до частини цієї памʼяті у будь-який момент часу. Це також допомагає запобігти завершенню роботи Podʼів під час стрибків тиску на памʼять, захищає вузли від системних стрибків памʼяті, які можуть порушити стабільність роботи, дозволяє гнучкіше керувати памʼяттю на вузлі та багато іншого.
Як її використовувати?
Передумови
На вузлі має бути увімкнено та налаштовано своп.
На вузлі має працювати операційна система Linux.
Вузол повинен використовувати cgroup v2. Kubernetes не підтримує підкачку на вузлах з cgroup v1.
Увімкнення підкачки для робочих навантажень Kubernetes
Щоб дозволити робочим навантаженням Kubernetes використовувати своп, ви повинні вимкнути стандартну поведінку kubelet, яка припиняє роботу при виявленні свопу, і вказати поведінку підкачки памʼяті як LimitedSwap:
Update kubelet configuration:
# цей фрагмент потрібно додати до конфігураційного файлу kubeletfailSwapOn:falsememorySwap:swapBehavior:LimitedSwap
Для параметра swapBehavior доступні наступні варіанти:
NoSwap (стандартно): Робочі навантаження Kubernetes не можуть використовувати своп. Однак, процеси поза межами Kubernetes, такі як системні демони (наприклад, сам kubelet!), можуть використовувати своп. Така поведінка корисна для захисту вузла від стрибків памʼяті на системному рівні, але вона не захищає самі робочі навантаження від таких стрибків.
LimitedSwap: Робочі навантаження Kubernetes можуть використовувати своп. Обсяг памʼяті підкачки, доступної для кожного з них, визначається автоматично. Для більш детальної інформації див. розділ нижче.
Якщо конфігурацію для memorySwap не вказано, стандартно kubelet буде поводитися так само, як і при налаштуванні NoSwap.
Зверніть увагу, що наступні Podʼи не матимуть доступу до свопу (див. більше інформації в розділі нижче):
Podʼи, які не класифікуються як Burstable QoS.
Podʼи високого пріоритету.
Контейнери з обмеженням памʼяті, яке дорівнює запиту памʼяті.
Примітка:
Kubernetes підтримує своп лише для вузлів Linux.
Як це працює?
Існує кілька можливих способів, якими можна уявити використання свопу на вузлі. Якщо kubelet вже працює на вузлі, його потрібно буде перезапустити після налаштування свопу, щоб він міг його виявити.
Коли kubelet запускається на вузлі, на якому налаштовано та доступно своп (з конфігурацією failSwapOn: false), kubelet буде:
Мати можливість запускатися на цьому вузлі з увімкненим свопом.
Направляти реалізацію Container Runtime Interface (CRI), часто звану контейнерним середовищем, щоб стандартно виділяти нульову памʼять свопу для робочих навантажень Kubernetes.
Конфігурація свопу на вузлі доступна для адміністратора кластера через memorySwap в KubeletConfiguration. Як адміністратор кластера, ви можете вказати поведінку вузла в присутності своп-памʼяті, встановивши memorySwap.swapBehavior.
Kubelet використовує API контейнерного середовища та направляє контейнерне середовище на застосування конкретної конфігурації (наприклад, у випадку cgroup v2, memory.swap.max) таким чином, щоб включити бажану конфігурацію свопу для контейнера. Для середовищ виконання, які використовують контрольні групи або cgroups, контейнерне середовище несе відповідальність за запис цих налаштувань у cgroup на рівні контейнера.
Спостережуваність для використання свопу
Статистика метрік рівня Node та контейнер
Kubelet тепер збирає статистику метрик на рівні вузлів і контейнерів, доступ до якої можна отримати за допомогою точок доступу HTTP Kubelet /metrics/resource (яка використовується в основному інструментами моніторингу, такими як Prometheus) і /stats/summary (яка використовується в основному автомасштабувальниками). Це дозволяє клієнтам, які можуть безпосередньо запитувати kubelet, відстежувати використання свопу та залишок памʼяті підкачки при використанні LimitedSwap. Крім того, до cadvisor було додано метрику machine_swap_bytes, яка показує загальний обсяг фізичної памʼяті підкачки на компʼютері. Докладні відомості наведено на цій сторінці.
Наприклад, підтримуються такі /metrics/resource:
node_swap_usage_bytes: Поточне використання свопу вузлом в байтах.
container_swap_usage_bytes: Поточна кількість використання свопу контейнером в байтах.
container_swap_limit_bytes: Поточна кількість ліміту свопу контейнера в байтах.
Використання kubectl top --show-swap
Запит метрик є цінним, але дещо громіздким, оскільки ці метрики призначені для використання програмним забезпеченням, а не людьми. Щоб споживати ці дані більш зручним способом, команда kubectl top була розширена для підтримки метрик свопу з використанням прапорця --show-swap.
Щоб отримати інформацію про використання свопу на вузлах, можна використовувати kubectl top nodes --show-swap:
Значення <unknown> вказує на те, що поле .status.nodeInfo.swap.capacity не встановлено для цього вузла. Це, ймовірно, означає, що на вузлі не передбачено свопу, або, що менш ймовірно, що kubelet не може визначити ємність свопу на вузлі.
Вивлення свопу за допомогою Node Feature Discovery (NFD)
Node Feature Discovery це надбудова Kubernetes для виявлення апаратних можливостей та конфігурації. Її можна використовувати для виявлення, які вузли мають своп.
Наприклад, щоб зʼясувати, які вузли мають своп, використовуйте наступну команду:
kubectl get nodes -o jsonpath='{range .items[?(@.metadata.labels.feature\.node\.kubernetes\.io/memory-swap)]}{.metadata.name}{"\t"}{.metadata.labels.feature\.node\.kubernetes\.io/memory-swap}{"\n"}{end}'
У цьому прикладі своп передбачено на вузлах k8s-worker1 та k8s-worker2, але не на k8s-worker3.
Ризики та застереження
Увага:
Наполегливо рекомендується шифрувати простір підкачки. Докладніші відомості наведено у розділі Томи з кешем.
Наявність у системі свопу знижує передбачуваність. Хоча своп може підвищити продуктивність за рахунок збільшення обсягу оперативної памʼяті, повернення даних назад у памʼять є важкою операцією, іноді повільнішою на багато порядків, що може призвести до неочікуваного зниження продуктивності. Крім того, своп змінює поведінку системи під тиском на памʼять. Увімкнення свопу збільшує ризик появи галасливих сусідів, коли Podʼи, які часто використовують свою оперативну памʼять, можуть спричинити спрацювання свопу в інших Podʼах. Крім того, оскільки у Kubernetes своп дозволяє збільшувати використання памʼяті для робочих навантажень, які неможливо передбачити, а також через непередбачувані конфігурації пакування, планувальник наразі не враховує використання памʼяті свопу. Це підвищує ризик появи галасливих сусідів.
Продуктивність вузла з увімкненою памʼяттю підкачки залежить від фізичного сховища. Коли використовується памʼять підкачки, продуктивність буде значно гіршою в середовищі з обмеженою кількістю операцій вводу/виводу в секунду (IOPS), наприклад, у хмарній віртуальній машині з гальмуванням вводу/виводу, порівняно з більш швидкими носіями даних, такими як твердотільні диски або NVMe. Оскільки своп може спричинити тиск на ввід-вивід, рекомендується надавати вищий пріоритет затримки вводу-виводу для критично важливих для системи демонів. Див. відповідний розділ у розділі рекомендовані практики нижче.
Томи з кешем
На вузлах Linux томи з кешем (такі як secret або emptyDir з medium: Memory) реалізуються за допомогою файлової системи tmpfs. Вміст таких томів повинен залишатися в памʼяті в будь-який час, отже, не повинен бути переміщений на диск. Щоб забезпечити збереження вмісту таких томів у памʼяті, використовується опція noswap для tmpfs.
Ядро Linux офіційно підтримує опцію noswap з версії 6.3 (докладніше можна знайти в Вимогах до версії ядра Linux). Однак різні дистрибутиви часто вирішують повернути цю опцію монтування до старіших версій Linux.
Щоб перевірити, чи підтримує вузол опцію noswap, kubelet виконає такі дії:
Якщо версія ядра перевищує 6.3, то буде вважатися, що опція noswap підтримується.
В іншому випадку kubelet спробує змонтувати фейковий tmpfs з опцією noswap під час запуску. Якщо kubelet зазнає збою з помилкою, що вказує на невідому опцію, noswap буде вважатися не підтримуваною, отже, не буде використовуватися. У журналі kubelet буде виведено запис, щоб попередити користувача про те, що томи з кешем можуть бути переміщені на диск. Якщо kubelet успішно завершить цю операцію, фейковий tmpfs буде видалено, а опція noswap буде використовуватися.
Якщо опція noswap не підтримується, kubelet виведе запис попередження в журналі, а потім продовжить свою роботу.
Див. розділ вище з прикладом налаштування незашифрованого свопу. Однак обробка зашифрованого свопу не входить до сфери відповідальності kubelet; швидше, це загальна проблема конфігурації ОС і повинна бути вирішена на цьому рівні. Адміністратору належить забезпечити зашифрування свопу, щоб зменшити цей ризик.
Виселення
Налаштування порогів вивільнення памʼяті для вузлів з увімкненим свопом може бути складним завданням.
Якщо своп вимкнено, доцільно налаштувати пороги вивільнення памʼяті kubelet трохи нижче, ніж обсяг памʼяті на вузлі. Це повʼязано з тим, що ми хочемо, щоб Kubernetes починав виселяти Podʼи до того, як у вузла закінчиться памʼять і він викличе утиліту Out Of Memory (OOM), оскільки утиліта OOM не знає про Kubernetes, тому не враховує такі речі, як QoS, пріоритет podʼів або інші специфічні для Kubernetes фактори.
З увімкненим свопом ситуація складніша. У Linux параметр vm.min_free_kbytes визначає поріг памʼяті, після досягнення якого ядро починає агресивно вивільняти памʼять, що включає підкачку сторінок. Якщо пороги вивільнення памʼяті у kubelet встановлено таким чином, що воно відбувається до того, як ядро почне вивільняти памʼять, це може призвести до того, що робочі навантаження ніколи не зможуть вивільнити памʼять під час тиску на памʼять на вузлах. Однак, встановлення занадто високих порогів виселення може призвести до вичерпання памʼяті на вузлі та виклику функції OOM, що також не є ідеальним варіантом.
Щоб вирішити цю проблему, рекомендується встановлювати пороги виселення kubelet трохи нижчими за значення vm.min_free_kbytes. Таким чином, вузол може почати підкачку до того, як kubelet почне виселяти Podʼи, дозволяючи робочим навантаженням обмінюватися невикористаними даними і запобігаючи виселенню. З іншого боку, оскільки це значення трохи нижче, kubelet, швидше за все, почне виселяти Podʼи до того, як вузол вичерпає свої ресурси
cat /proc/sys/vm/min_free_kbytes
Невикористаний простір свопу
У режимі LimitedSwap обсяг памʼяті, доступної для Podʼа, визначається автоматично, виходячи з частки запитуваної памʼяті відносно загального обсягу памʼяті вузла (докладніше див. розділ нижче).
Така конструкція означає, що зазвичай для робочих навантажень Kubernetes залишатиметься певна частина памʼяті, яку буде обмежено. Наприклад, оскільки в даний час для podʼів з Guaranteed QoS заборонено використовувати своп, обсяг свопу, пропорційний запиту на памʼять, залишатиметься невикористаним для робочих навантажень Kubernetes.
Така поведінка несе в собі певний ризик у ситуації, коли багатьом podʼам не дозволено використовувати свопінг. З іншого боку, це ефективно зберігає деякий зарезервований системою обсяг памʼяті підкачки, який може бути використаний процесами поза межами Kubernetes, такими як системні демони і навіть сам kubelet.
Рекомендації щодо використання свопу в кластері Kubernetes
Вимкнення свопу для критично важливих системних демонів
Під час тестування та на основі відгуків користувачів було виявлено, що продуктивність критично важливих демонів і служб може знижуватися. Це означає, що системні демони, включаючи kubelet, можуть працювати повільніше, ніж зазвичай. Якщо це питання виникає, рекомендується налаштувати cgroup системного слайсу щоб запобігти свопінгу (тобто, встановити memory.swap.max=0).
Захист критично важливих демонів системи від затримок I/O
Своп може збільшити навантаження на I/O на вузлі. Коли тиск на памʼять змушує ядро швидко свопити сторінки, системні демони і служби, які покладаються на операції I/O, можуть зіштовхнутися зі зниженням продуктивності.
Щоб помʼякшити цю ситуацію, рекомендується для користувачів systemd пріоритизувати системний слайс з точки зору затримки I/O. Для користувачів, які не використовують systemd, рекомендується налаштувати окремий cgroup для системних демонів і процесів та пріоритизувати затримку I/O таким же чином. Це можна досягти, встановивши io.latency для системного слайсу, тим самим надаючи йому вищий пріоритет I/O. Дивіться документацію cgroup для отримання додаткової інформації.
Своп та вузли панелі управління
Проєкт Kubernetes рекомендує запускати вузли панелі управління без будь-якого налаштованого свопу. Панель управління в основному містить Podʼи з Guaranteed QoS, тому своп зазвичай можна вимкнути. Основна проблема полягає в тому, що свопінг критично важливих служб на панелі управління може негативно вплинути на продуктивність.
Використання виділеного диска для свопу
Проєкт Kubernetes рекомендує використовувати зашифрований своп, коли ви запускаєте вузли з увімкненим свопом. Якщо своп розташований на розділі або кореневій файловій системі, робочі навантаження можуть заважати системним процесам, які потребують запису на диск. Коли вони використовують один і той же диск, процеси можуть перевантажити своп, порушуючи I/O kubelet, контейнерного середовища та systemd, що вплине на інші робочі навантаження. Оскільки простір свопу розташований на диску, важливо забезпечити, щоб диск був достатньо швидким для запланованих випадків використання. Альтернативно, можна налаштувати пріоритети I/O між різними змонтованими областями одного пристрою зберігання.
Планування з урахуванням свопу
Kubernetes 1.33 не підтримує розподіл Podʼів між вузлами у спосіб, що враховує використання памʼяті підкачки. Планувальник зазвичай використовує запити на ресурси інфраструктури для керування розміщенням Podʼів, а Podʼи не запитують простір підкачки; вони лише запитують memory. Це означає, що планувальник не враховує памʼять підкачки при прийнятті рішень щодо планування. Хоча ми активно працюємо над цим, це ще не реалізовано.
Для того, щоб адміністратори могли гарантувати, що Podʼи не плануватимуться на вузлах з памʼяттю підкачки, якщо вони спеціально не призначені для її використання, адміністратори можуть позначити вузли з доступною памʼяттю підкачки, щоб захиститися від цієї проблеми. Таке позначення гарантує, що робочі навантаження, які допускають використання кешу, не перекидатимуться на вузли без кешу під навантаженням.
Вибір сховища для оптимальної продуктивності
Пристрій зберігання, призначений для простору підкачки, є критично важливим для підтримки чутливості системи під час високого використання памʼяті. Звичайні жорсткі диски (HDD) не підходять для цієї задачі, оскільки їх механічна природа вводить значну затримку, що призводить до серйозного зниження продуктивності та коливання системи. Для сучасних вимог до продуктивності, таким пристроєм, як твердотільний накопичувач (SSD), ймовірно, є відповідним вибором для свопу, оскільки його електронний доступ з низькою затримкою мінімізує сповільнення.
Детальна інформація про поведінку свопу
Як визначається ліміт свопу з LimitedSwap?
Конфігурація памʼяті підкачки, включаючи її обмеження, є значним викликом. Вона не тільки схильна до неправильного налаштування, але як властивість на рівні системи, будь-яке неправильне налаштування може потенційно скомпрометувати весь вузол, а не лише конкретне робоче навантаження. Щоб зменшити цей ризик і забезпечити справність вузла, ми реалізували своп з автоматичною конфігурацією обмежень.
За допомогою параметра LimitedSwap Podʼів, які не підпадають під класифікацію Burstable QoS (тобто BestEffort/Guaranteed QoS Pods), заборонено використовувати памʼять підкачки. QoS-поди BestEffort демонструють непередбачувані шаблони споживання памʼяті та не мають інформації про її використання, що ускладнює визначення безпечного розподілу памʼяті підкачки. І навпаки, QoS-поди Guaranteed зазвичай використовуються для застосунків, які покладаються на точний розподіл ресурсів, визначених робочим навантаженням, з негайним наданням памʼяті. Щоб підтримувати вищезгадані гарантії безпеки та працездатності вузла, цим Podʼам не дозволяється використовувати памʼять підкачки, коли діє LimitedSwap. Крім того, високопріоритетним podʼам заборонено використовувати памʼять підкачки, щоб гарантувати, що памʼять, яку вони споживають, завжди знаходиться на диску, а отже, завжди готова до використання.
Перш ніж детально описати обчислення ліміту памʼяті підкачки, необхідно визначити наступні терміни:
nodeTotalMemory: Загальний обсяг фізичної памʼяті, доступної на вузлі.
totalPodsSwapAvailable: Загальний обсяг памʼяті підкачки на вузлі, доступний для використання Podʼам (частина памʼяті підкачки може бути зарезервована для системного використання).
Іншими словами, обсяг памʼяті підкачки, яку може використовувати контейнер, пропорційний його запиту памʼяті, загальному обсягу фізичної памʼяті вузла та загальному обсягу памʼяті підкачки на вузлі, яка доступна для використання Podʼами.
Важливо зазначити, що для контейнерів у Podʼах з Burstable QoS можливо відмовитися від використання памʼяті підкачки, вказавши запити памʼяті, які дорівнюють лімітам памʼяті. Контейнери, налаштовані таким чином, не матимуть доступу до памʼяті підкачки.
Для отримання додаткової інформації, будь ласка, перегляньте оригінальний KEP, KEP-2400, та його дизайн.
3 - Автомасштабування Node
Автоматично надавайте та консолідуйте вузли у вашому кластері, щоб адаптуватися до попиту та оптимізувати витрати.
Для того, щоб запускати робочі навантаження у вашому кластері, вам потрібні Вузли. Вузли у вашому кластері можуть бути автомасштабовані - динамічно виділені, або консолідовані, щоб забезпечити необхідну потужність при оптимізації витрат. Автомасштабування виконується автомасштабувальниками Вузлів.
Виділення Вузлів
Якщо в кластері є Podʼи, які не можуть бути заплановані на існуючих вузлах, нові вузли можуть бути автоматично додані до кластера, щоб розмістити ці Podʼи. Це особливо корисно, якщо кількість Podʼів змінюється з часом, наприклад, в результаті поєднання горизонтального робочого навантаження з автомасштабуванням Вузлів.
Автомасштабувальники забезпечують роботу Вузлів, створюючи та видаляючи ресурси хмарного провайдера, що їх підтримують. Найчастіше ресурсами, які забезпечують роботу Вузлів, є віртуальні машини.
Основна мета резервування - зробити так, щоб всі Podʼи можна було розмістити. Ця мета не завжди досяжна через різні обмеження, включаючи досягнення налаштованих лімітів виділення ресурсів, несумісність конфігурації виділення ресурсів з певним набором вузлів або нестачу потужностей хмарного провайдера. Під час виділення ресурсів автомасштабувальник Вузлів часто намагається досягти додаткових цілей (наприклад, мінімізувати вартість виділених Вузлів або збалансувати кількість Вузлів між доменами відмов).
Конфігурація автомасштабування може також включати інші тригери виділення вузлів (наприклад, кількість вузлів, що падає нижче налаштованого мінімального ліміту).
Примітка:
Раніше виділення ресурсів було відоме як масштабування у Cluster Autoscaler.
Обмеження планування вузлів
Podʼи можуть виражати обмеження планування, щоб накласти обмеження на тип вузлів, на яких вони можуть бути заплановані. Автомасштабувальники Вузлів враховують ці обмеження, щоб гарантувати, що очікуючі Podʼи можуть бути заплановані на передбачені для них Вузли.
Найпоширенішим типом обмежень планування є запити на ресурси, визначені контейнерами Podʼа. Автомасштабувальники переконаються, що надані вузли мають достатньо ресурсів, щоб задовольнити ці запити. Однак, вони не враховують безпосередньо реальне використання ресурсів Podʼами після того, як вони почнуть працювати. Для того, щоб автоматично масштабувати вузли на основі фактичного використання ресурсів робочим навантаженням, ви можете поєднати горизонтальне автомасштабування робочого навантаження з автомасштабуванням Вузлів.
Обмеження Вузлів, що накладаються конфігурацією автомасштабувальника
Специфіка виділених Вузлів (наприклад, кількість ресурсів, наявність певної мітки) залежить від конфігурації автомасштабування. Автомасштабування може або вибирати їх із заздалегідь визначеного набору конфігурацій вузлів, або використовувати автоматичне виділення ресурсів.
Автоматичне виділення ресурсів
Автоматичне виділення вузлів - це режим виділення, в якому користувачеві не потрібно повністю налаштовувати характеристики вузлів, які можуть бути виділені. Замість цього автомасштабувальник динамічно вибирає конфігурацію Вузла на основі очікуючих Podʼів, на які він реагує, а також попередньо налаштованих обмежень (наприклад, мінімальна кількість ресурсів або потреба в певній мітці).
Консолідація Вузлів
Основним моментом при експлуатації кластера є забезпечення запуску всіх запланованих вузлів, при цьому вартість кластера має бути якомога нижчою. Щоб досягти цього, запити на ресурси від Podʼів повинні використовувати якомога більше ресурсів Вузлів. З цієї точки зору, загальне споживання Вузлів у кластері може бути використано як проксі для визначення того, наскільки економічно ефективним є кластер.
Примітка:
Правильне налаштування запитів на ресурси для ваших Podʼів так само важливе для загальної економічної ефективності кластера, як і оптимізація використання Вузлів. Поєднання автомасштабування Вузлів з вертикальним автомасштабуванням робочого навантаження може допомогти вам досягти цього.
Вузли у вашому кластері можуть бути автоматично консолідовані, щоб покращити загальне використання Вузлів, і, в свою чергу, економічну ефективність кластера. Консолідація відбувається шляхом видалення з кластера набору недовикористовуваних Вузлів. За бажанням, інший набір Вузлів може бути [виділенй] (#provisioning) для їх заміни.
Консолідація, як і резервування, при прийнятті рішень враховує лише запити на ресурси від Podʼів, а не реальне використання ресурсів.
Для цілей консолідації Вузол вважається порожнім, якщо на ньому запущено лише DaemonSet та статичні Podʼи. Видалення порожніх Вузлів під час консолідації простіше, ніж непорожніх, і автомасштабувальники часто мають оптимізацію, призначену спеціально для консолідації порожніх Вузлів.
Видалення непорожніх вузлів під час консолідації може призвести до збоїв у роботі, оскільки запущені на них Podʼи припиняють свою роботу, і, можливо, їх доведеться створювати заново (наприклад, за допомогою Deployment). Однак, всі такі відтворені Podʼи повинні мати можливість плануватися на існуючих вузлах кластера або на запасних Вузлах, наданих в рамках консолідації. Зазвичай жоден Pod не повинен перебувати у стані очікування в результаті консолідації.
Примітка:
Автомасштабувальники передбачають, як відтворений Pod, ймовірно, буде запланований після резервування або консолідації вузла, але вони не контролюють фактичне планування. Через це деякі Podʼи можуть перейти в стан очікування в результаті консолідації — якщо, наприклад, під час консолідації зʼявляється абсолютно новий Pod.
Конфігурація автомасштабування може також дозволяти запускати консолідацію за іншими умовами (наприклад, за часом, що минув з моменту створення Вузла), щоб оптимізувати різні властивості (наприклад, максимальну тривалість життя Вузлів у кластері).
Деталі того, як виконується консолідація, залежать від конфігурації конкретного автомасштабувальника.
Примітка:
Консолідація раніше була відома як зменшення масштабу у Cluster Autoscaler.
Автомасштабувальники
Функціональність, описану в попередніх розділах, забезпечують автоматичні масштабувальники Вузлів (Node autoscalers). На додаток до API Kubernetes, автомасштабувальники також повинні взаємодіяти з API хмарних провайдерів для виділення та консолідації Вузлів. Це означає, що вони повинні бути явно інтегровані з кожним підтримуваним хмарним провайдером. Продуктивність і набір функцій певного автомасштабувальника можуть відрізнятися в залежності від інтеграції з хмарним провайдером.
graph TD
na[Автомасштабувальник Вузлів]
k8s[Kubernetes]
cp[Хмарний провайдер]
k8s --> |get Pods/Nodes|na
na --> |drain Nodes|k8s
na --> |create/remove resources backing Nodes|cp
cp --> |get resources backing Nodes|na
classDef white_on_blue fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef blue_on_white fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class na blue_on_white;
class k8s,cp white_on_blue;
З точки зору користувача кластера, обидва автомасштабувальники повинні надавати схожий досвід автомасштабування Вузлів. Обидва надаватимуть нові вузли для незапланованих Podʼів, і обидва консолідуватимуть Вузли, які більше не використовуються оптимально.
Різні засоби автомасштабування можуть також надавати можливості, що виходять за рамки автомасштабування Вузлів, описані на цій сторінці, і ці додаткові можливості можуть відрізнятися між собою.
Consult the sections below, and the linked documentation for the individual autoscalers to decide which autoscaler fits your use case better.
Cluster Autoscaler
Cluster Autoscaler додає або видаляє Вузли до попередньо сконфігурованих груп Вузлів. Групи Вузлів зазвичай зіставляються з певною групою ресурсів хмарного провайдера (найчастіше з групою Віртуальних машин). Один екземпляр Cluster Autoscaler може одночасно керувати кількома групами Вузлів. Під час виділення ресурсів Cluster Autoscaler додає Вузли до тієї групи, яка найкраще відповідає запитам Podʼів, що знаходяться в очікуванні. Під час консолідації Cluster Autoscaler завжди вибирає конкретні Вузли для видалення, а не просто змінює розмір базової групи ресурсів хмарного провайдера.
Karpenter автоматично виділяє вузли на основі конфігурацій NodePool, наданих оператором кластера. Karpenter керує всіма аспектами життєвого циклу вузла, а не лише автоматичним масштабуванням. Це включає автоматичне оновлення вузлів, коли вони досягають певного терміну служби, і автоматичне оновлення Вузлів, коли випускаються нові образи робочих Вузлів. Він працює безпосередньо з індивідуальними ресурсами хмарного провайдера (найчастіше з окремими віртуальними машинами) і не покладається на групи ресурсів хмарного провайдера.
Основні відмінності між Cluster Autoscaler та Karpenter:
Cluster Autoscaler надає можливості, повʼязані лише з автомасштабуванням Вузлів. Karpenter має ширшу сферу застосування, а також надає функції, призначені для управління життєвим циклом Вузлів в цілому (наприклад, використання порушень для автоматичного відтворення Вузлів, коли вони досягають певного часу життя, або автоматичного оновлення до нових версій).
Cluster Autoscaler не підтримує автоматичне резервування, групи Вузлів, з яких він може надавати ресурси, мають бути попередньо налаштовані. Karpenter підтримує автоматичне резервування, тому користувачеві потрібно лише налаштувати набір обмежень для Вузлів, що резервуються, замість того, щоб повністю налаштовувати однорідні групи.
Cluster Autoscaler надає інтеграцію з хмарними провайдерами безпосередньо, що означає, що вони є частиною проєкту Kubernetes. Для Karpenter проєкт Kubernetes публікує Karpenter як бібліотеку, з якою провайдери хмарних обчислень можуть інтегруватися для створення автомасштабування вузлів.
Cluster Autoscaler забезпечує інтеграцію з багатьма хмарними провайдерами, в тому числі з невеликими і менш популярними провайдерами. Існує невелика кількість хмарних провайдерів, які інтегруються з Karpenter, зокрема AWS та Azure.
Поєднання робочого навантаження та автомасштабування Вузлів
Автомасштабування вузлів зазвичай працює у відповідь на появу Podʼів: воно створює нові Вузли для розміщення незапланованих Podʼів, а потім консолідує Вузли, коли в них відпадає потреба.
Горизонтальне автомасштабування робочого навантаження автоматично масштабує кількість реплік робочого навантаження для підтримки бажаного середнього використання ресурсів між репліками. Іншими словами, воно автоматично створює нові Podʼи у відповідь на навантаження програми, а потім видаляє Podʼи, як тільки навантаження зменшується.
Ви можете використовувати автомасштабування Вузлів разом з горизонтальним автомасштабуванням робочого навантаження для автоматичного масштабування Вузлів у вашому кластері на основі середнього реального використання ресурсів ваших Podʼів.
Якщо навантаження застосунку зростає, середнє використання його Podʼів також має зростати, що спонукає до автомасштабування робочого навантаження для створення нових Podʼів. Автомасштабування вузлів повинно забезпечити нові Вузли для розміщення нових Podʼів.
Як тільки навантаження застосунку зменшиться, автомасштабування робочого навантаження має видалити непотрібні Podʼи. Автомасштабування вузлів має, у свою чергу, консолідувати Вузли, які більше не потрібні.
При правильному налаштуванні цей шаблон гарантує, що ваш застосунок завжди матиме достатньо потужності Вузла, щоб впоратися зі сплесками навантаження, якщо це буде потрібно, але вам не доведеться платити за потужність, коли вона не потрібна.
При використанні автомасштабування Вузлів важливо правильно встановити запити на ресурси Podʼа. Якщо запити певного Podʼа занадто низькі, створення для нього нового Вузла може не допомогти йому запуститися. Якщо запити певного Podʼа занадто високі, це може некоректно запобігти консолідації його Вузла.
[Вертикальне автоматичне масштабування робочого навантаження] (/docs/concepts/workloads/autoscaling#scaling-workloads-vertically) автоматично коригує запити на ресурси ваших Podʼів на основі їхнього історичного використання ресурсів.
Ви можете використовувати автомасштабування Вузлів разом з вертикальним автомасштабуванням робочого навантаження, щоб регулювати запити на ресурси ваших Podʼів, зберігаючи при цьому можливості автомасштабування Вузлів у вашому кластері.
Увага:
При використанні автомасштабування Вузлів не рекомендується налаштовувати вертикальне автомасштабування робочого навантаження для DaemonSet Podʼів. Автомасштабування має передбачити, як виглядатимуть DaemonSet Podʼи на новому Вузлі, щоб спрогнозувати доступні ресурси Вузла. Вертикальне автомасштабування робочого навантаження може зробити ці прогнози ненадійними, що призведе до неправильних рішень щодо масштабування.
Супутні компоненти
У цьому розділі описано компоненти, що надають функціональність, повʼязану з автомасштабуванням Вузлів.
Descheduler
Планувальник descheduler — це компонент, що надає функціональність консолідації Вузлів на основі власних політик користувачів, а також інші можливості, повʼязані з оптимізацією Вузлів та Podʼів (наприклад, видалення Podʼів, що часто перезавантажуються).
Автомасштабування навантаження на основі розміру кластера
Щоб дізнатись, як генерувати сертифікати для вашого кластера, дивіться розділ Завдань — Сертифікати.
5 - Мережа в кластері
Мережі є центральною частиною Kubernetes, але часто важко зрозуміти, як саме вони мають працювати. Існують 4 відмінних мережевих проблеми, які потрібно вирішити:
Взаємодія контейнерів між собою: цю проблему вирішує використання Podʼів та взаємодія з localhost.
Взаємодія між Podʼами: це основна ціль даного документа.
Взаємодія між Podʼом та Service: ця проблема описана у Service.
Взаємодія Service із зовнішнім світом: це також описано в контексті Service.
Kubernetes — це система розподілу машин між застосунками. Зазвичай для розподілу машин потрібно переконатися, що два застосунки не намагаються використовувати одні й ті самі порти. Координацію портів між кількома розробниками дуже важко зробити в масштабі та наражає користувачів на проблеми на рівні кластера, що знаходяться поза їхнім контролем.
Динамічне призначення портів приносить багато ускладнень в систему — кожен застосунок має приймати порти як прапорці, серверам API потрібно знати, як вставляти динамічні номери портів у блоки конфігурації, сервісам потрібно знати, як знаходити один одного тощо. Замість цього Kubernetes обирає інший підхід.
Кластери Kubernetes потребують виділення IP-адрес, які не перекриваються, для Podʼів, Service та Вузлів, з діапазону доступних адрес, налаштованих у наступних компонентах:
Втулок мережі налаштований для призначення IP-адрес Podʼам.
Kube-apiserver налаштований для призначення IP-адрес Service.
Kubelet або cloud-controller-manager налаштовані для призначення IP-адрес Вузлам.
Типи мереж в кластері
Кластери Kubernetes, залежно від налаштованих типів IP адрес, можуть бути категоризовані на:
Лише IPv4: Втулок мережі, kube-apiserver та kubelet/cloud-controller-manager налаштовані для призначення лише IPv4-адрес.
Лише IPv6: Втулок мережі, kube-apiserver та kubelet/cloud-controller-manager налаштовані для призначення лише IPv6-адрес.
Втулок мережі налаштований для призначення IPv4 та IPv6-адрес.
Kube-apiserver налаштований для призначення IPv4 та IPv6-адрес.
Kubelet або cloud-controller-manager налаштовані для призначення IPv4 та IPv6-адрес.
Усі компоненти повинні узгоджуватися щодо налаштованої основного типу IP адрес.
Кластери Kubernetes враховують лише типи IP, які присутні в обʼєктах Podʼів, Service та Вузлів, незалежно від наявних IP-адрес представлених обʼєктів. Наприклад, сервер або Pod може мати кілька IP-адрес на своїх інтерфейсах, але для реалізації мережевої моделі Kubernetes та визначення типу кластера беруться до уваги лише IP-адреси в node.status.addresses або pod.status.ips.
Як реалізувати мережеву модель Kubernetes
Модель мережі реалізується середовищем виконання контейнерів на кожному вузлі. Найпоширеніші
середовища використовують Інтерфейс мережі контейнера (CNI) для керування своєю мережею та забезпечення безпеки. Існує багато різних CNI-втулків від різних вендорів. Деякі з них надають лише базові можливості додавання та видалення мережевих інтерфейсів, тоді як інші надають складніші рішення, такі як інтеграція з іншими системами оркестрування контейнерів, запуск кількох CNI-втулків, розширені функції IPAM та інше.
Див. цю сторінку
для неповного переліку мережевих надбудов, які підтримуються в Kubernetes.
Що далі
Ранній дизайн мережевої моделі та її обґрунтування докладно описані у документі дизайну мережі. Щодо майбутніх планів та деяких поточних зусиль, спрямованих на поліпшення мережевих функцій Kubernetes, будь ласка,
звертайтеся до SIG-Network KEPs.
6 - Архітектура логування
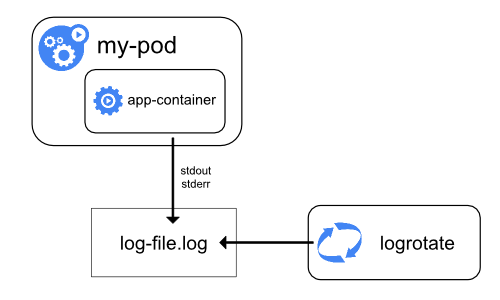
Логи застосунків можуть допомогти вам зрозуміти, що відбувається у нього всередині. Логи особливо корисні для виправлення проблем та моніторингу активності кластера. Більшість сучасних застосунків мають деякий механізм логування. Так само, рушії виконання контейнерів розроблені з підтримкою логування. Найпростіший і найбільш прийнятий метод логування для контейнеризованих застосунків — це запис у стандартні потоки виводу та помилок.
Однак, природня функціональність, яку надає рушій виконання контейнерів або середовище виконання, зазвичай недостатня для повного вирішення завдань логування.
Наприклад, вам може бути необхідно дістатись до логів вашого застосунку, якщо контейнер зазнає збою, Pod видаляється, або вузол припиняє роботу.
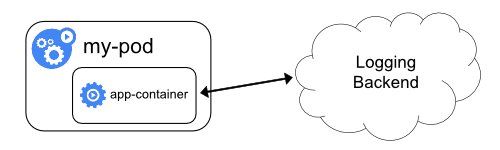
У кластері логи повинні мати окреме сховище та життєвий цикл незалежно від вузлів, Podʼів або контейнерів. Ця концепція називається логування на рівні кластера.
Архітектури логування на рівні кластера вимагають окремого бекенду для зберігання, аналізу, та отримання логів. Kubernetes не надає власного рішення для зберігання даних логів. Натомість існує багато рішень для логування, які інтегруються з Kubernetes. Наступні розділи описують, як обробляти та зберігати логи на вузлах.
Логи Podʼів та контейнерів
Kubernetes збирає логи з кожного контейнера в запущеному Podʼі.
Цей приклад використовує маніфест для Podʼу з контейнером, який записує текст у стандартний потік виводу, раз на секунду.
Для отримання логів використовуйте команду kubectl logs, як показано нижче:
kubectl logs counter
Вивід буде схожим на:
0: Fri Apr 1 11:42:23 UTC 2022
1: Fri Apr 1 11:42:24 UTC 2022
2: Fri Apr 1 11:42:25 UTC 2022
Ви можете використовувати kubectl logs --previous для отримання логів з попереднього запуску контейнера. Якщо ваш Pod має кілька контейнерів, вкажіть, логи якого контейнера ви хочете переглянути, додавши назву контейнера до команди з прапорцем -c, ось так:
kubectl logs counter -c count
Потоки логів контейнерів
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.32 [alpha] (стандартно увімкнено: false)
Як альфа-функція, kubelet може розділяти логи з двох стандартних потоків, що створюються контейнером: стандартний вивід та стандартна помилка. Щоб скористатися такою поведінкою, вам слід увімкнути функціональну можливістьPodLogsQuerySplitStreams. З її увімкненням Kubernetes 1.33 надає доступ до цих потоків логів безпосередньо за допомогою Pod API. Ви можете отримати конкретний потік, вказавши назву потоку (або Stdout, або Stderr) за допомогою рядка запиту stream. Ви повинні мати доступ до читання підресурсу log цього Pod.
Щоб продемонструвати цю можливість, ви можете створити Pod, який періодично записуватиме текст як до стандартного потоку виводу, так і до потоку помилок.
Система управління контейнерами обробляє та перенаправляє будь-який вивід, створений потоками stdout та stderr контейнеризованого застосунку. Різні системи управління контейнерами реалізують це по-різному; однак, інтеграція з kubelet стандартизована як формат логування CRI.
Стандартно, якщо контейнер перезапускається, kubelet зберігає один зупинений контейнер з його логами. Якщо Pod видаляється з вузла, всі відповідні контейнери також видаляються разом з їхніми логами.
Kubelet надає доступ до логів клієнтам через спеціальну функцію Kubernetes API. Зазвичай доступ до неї здійснюється за допомогою команди kubectl logs.
Ротація логів
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.21 [stable]
Kubelet відповідає за ротацію логів контейнерів та управління структурою тек логів. Kubelet передає цю інформацію до системи управління контейнерами (використовуючи CRI), а середовище виконання записує логи контейнерів у вказане місце.
Ви можете налаштувати два параметри конфігурації kubelet containerLogMaxSize (типово 10Mi) та containerLogMaxFiles (типово 5), використовуючи файл конфігурації kubelet. Ці параметри дозволяють вам налаштувати максимальний розмір для кожного файлу лога та максимальну кількість файлів, дозволених для кожного контейнера відповідно.
Для ефективної ротації логів у кластерах, де обсяг логів, згенерованих робочим навантаженням, великий, kubelet також надає механізм налаштування ротації логів з погляду кількості одночасних ротацій логів та інтервалу, з яким логи відстежуються та ротуються за потребою. Ви можете налаштувати два параметри конфігурації kubelet, containerLogMaxWorkers та containerLogMonitorInterval за допомогою файлу конфігурації kubelet.
Коли ви виконуєте kubectl logs як у прикладі базового логування, kubelet на вузлі обробляє запит і безпосередньо читає з файлу лога. Kubelet повертає вміст файлу лога.
Примітка:
Через kubectl logs доступний лише вміст останнього файлу лога.
Наприклад, якщо Pod пише 40 MiB логів і kubelet ротує логи після 10 MiB, виконання kubectl logs поверне максимум 10MiB даних.
Логи системних компонентів
Існують два типи системних компонентів: ті, які зазвичай працюють у контейнерах, та ті компоненти, які безпосередньо відповідають за запуск контейнерів. Наприклад:
Kubelet та система управління контейнерами не працюють у контейнерах. Kubelet виконує ваші контейнери (згруповані разом у Podʼи).
Планувальник Kubernetes, менеджер контролерів та сервер API працюють у Podʼах (зазвичай статичних Podʼах). Компонент etcd працює у планувальнику, і зазвичай також як статичний Pod. Якщо ваш кластер використовує kube-proxy, зазвичай ви запускаєте його як DaemonSet.
Знаходження логів
Спосіб, яким kubelet та система управління контейнерами записують логи, залежить від операційної системи, яку використовує вузол:
На вузлах Linux, які використовують systemd, типово kubelet та система управління контейнерами записують логи у журнал systemd. Ви можете використовувати journalctl для читання журналу systemd; наприклад: journalctl -u kubelet.
Якщо systemd відсутній, kubelet та система управління контейнерами записують логи у файли .log в директорії /var/log. Якщо ви хочете, щоб логи були записані в інше місце, ви можете опосередковано запустити kubelet через допоміжний інструмент, kube-log-runner, та використовувати цей інструмент для перенаправлення логів kubelet у вибрану вами теку.
Типово, kubelet спрямовує систему управління контейнерами на запис логів у теці всередині /var/log/pods.
Для отримання додаткової інформації про kube-log-runner, читайте Системні логи.
Типово kubelet записує логи у файли всередині теки C:\var\logs (⚠️ зверніть увагу, що це не C:\var\log).
Хоча C:\var\log є типовим місцем для цих логів Kubernetes, деякі інструменти розгортання кластера налаштовують вузли Windows так, щоб логи записувались у C:\var\log\kubelet.
Якщо ви хочете, щоб логи були записані в інше місце, ви можете опосередковано запустити kubelet через допоміжний інструмент, kube-log-runner, та використовувати цей інструмент для перенаправлення логів kubelet у вибрану вами директорію.
Проте, типово kubelet скеровує систему управління контейнерами на запис логів у теці всередині C:\var\log\pods.
Для отримання додаткової інформації про kube-log-runner, читайте Системні логи.
Для компонентів кластера Kubernetes, які працюють у Podʼах, логи записуються у файли всередині директорії /var/log, оминаючи типовий механізм логування (компоненти не записуються у журнал systemd). Ви можете використовувати механізми зберігання Kubernetes для відображення постійного зберігання у контейнері, який виконує компонент.
Kubelet дозволяє змінювати теку логів Podʼів зі стандартної /var/log/pods на власну. Це можна зробити за допомогою параметра podLogsDir у конфігураційному файлі kubelet.
Увага:
Важливо зазначити, що стандартне розташування /var/log/pods використовувалося протягом тривалого часу, і певні процеси можуть неявно використовувати цей шлях. Тому до зміни цього параметра слід підходити з обережністю і на власний ризик.
Ще одним застереженням є те, що kubelet підтримує розташування на тому ж диску, що і /var. В іншому випадку, якщо логи знаходяться в окремій від /var файловій системі, то kubelet не буде відстежувати використання цієї файлової системи, що може призвести до проблем, якщо вона заповниться.
Для отримання детальної інформації про etcd та його логи, перегляньте документацію etcd. Знову ж таки, ви можете використовувати механізми зберігання Kubernetes для відображення постійного зберігання у контейнері, який виконує компонент.
Примітка:
Якщо ви розгортаєте компоненти кластера Kubernetes (наприклад, планувальник) для запису у спільний том від батьківського вузла, вам потрібно враховувати та забезпечувати, що ці логи ротуються. Kubernetes не керує цією ротацією логів.
Ваша операційна система може автоматично здійснювати деяку ротацію логів — наприклад, якщо ви ділитеся текою /var/log у статичному Podʼі для компонента, обробка ротації логів на рівні вузла обробляє файл у цій теці так с так само як записаний будь-яким компонентом поза Kubernetes.
Деякі інструменти розгортання враховують цю ротацію логів та автоматизують її; інші залишають це на вашу відповідальність.
Архітектури логування на рівні кластера
Хоча Kubernetes не надає власного рішення для логування на рівні кластера, існують кілька загальних підходів, які ви можете розглянути. Ось деякі варіанти:
Використання агента логування на рівні вузла, який працює на кожному вузлі.
Додавання в Pod з застосунком в спеціального sidecaar-контейнера для логування.
Пряме надсилання логів безпосередньо до бекенду з застосунка.
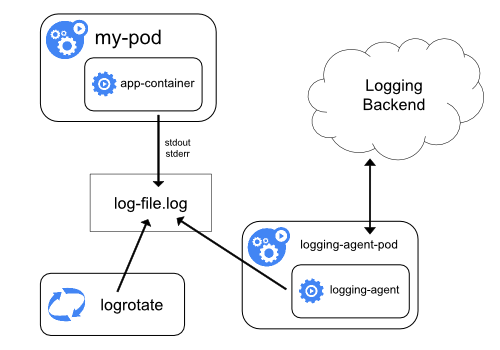
Використання агента логування на рівні вузла
Ви можете реалізувати логування на рівні кластера, включивши агента логування на рівні вузла на кожному вузлі. Агент логування — це спеціальний інструмент, який надає логи або надсилає їх до бекенду. Зазвичай агент логування є контейнером, який має доступ до теки з файлами логів з усіх контейнерів застосунків на цьому вузлі.
Оскільки агент логування повинен працювати на кожному вузлі, рекомендується запускати агента
як DaemonSet.
Логування на рівні вузла створює лише одного агента на вузол і не вимагає жодних змін в
застосунках, що працюють на вузлі.
Контейнери пишуть у stdout та stderr, але без узгодженого формату. Агент на рівні вузла збирає
ці логи та пересилає їх для агрегації.
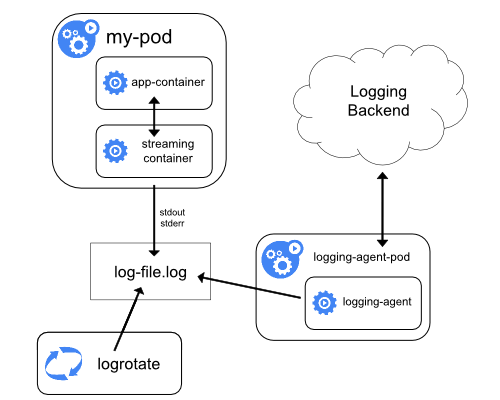
Використання sidecar контейнера з агентом логування
Ви можете використовувати sidecar контейнер у такий спосіб:
sidecar контейнер транслює логи застосунку у свій власний stdout.
sidecar контейнер запускає агента логування, який налаштований на збір логів з контейнера застосунку.
Sidecar контейнер для трансляції
Маючи свої sidecar контейнери які пишуть у власні stdout та stderr, ви можете скористатися kubelet та агентом логування, які вже працюють на кожному вузлі. Sidecar контейнери читають логи з файлу, сокета або журналу. Кожен sidecar контейнер виводить лог у свій власний потік stdout або stderr.
Цей підхід дозволяє вам розділити кілька потоків логів з різних частин вашого застосунку деякі з яких можуть не підтримувати запис у stdout або stderr. Логіка перенаправлення логів мінімальна, тому це не становить значного навантаження. Крім того, оскільки stdout та stderr обробляються kubelet, ви можете використовувати вбудовані інструменти, такі як kubectl logs.
Наприклад, Pod запускає один контейнер, і контейнер записує до двох різних файлів логів з використанням двох різних форматів. Ось маніфест для Podʼа:
apiVersion:v1kind:Podmetadata:name:counterspec:containers:- name:countimage:busybox:1.28args:- /bin/sh- -c- > i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
donevolumeMounts:- name:varlogmountPath:/var/logvolumes:- name:varlogemptyDir:{}
Не рекомендується записувати записи логів з різними форматами у той самий потік логу, навіть якщо вам вдалося перенаправити обидва компоненти до потоку stdout контейнера. Замість цього ви можете створити два додаткових sidecar контейнери. Кожен додатковий sidecar контейнер може перехоплювати певний файл логів зі спільного тома та перенаправляти логи до власного потоку stdout.
Ось маніфест для Podʼа, в якому є два sidecar контейнери:
Тепер, коли ви запускаєте цей Pod, ви можете отримати доступ до кожного потоку логів окремо, запустивши такі команди:
kubectl logs counter count-log-1
Результат буде подібним до:
0: Fri Apr 1 11:42:26 UTC 2022
1: Fri Apr 1 11:42:27 UTC 2022
2: Fri Apr 1 11:42:28 UTC 2022
...
kubectl logs counter count-log-2
Результат буде подібним до:
Fri Apr 1 11:42:29 UTC 2022 INFO 0
Fri Apr 1 11:42:30 UTC 2022 INFO 0
Fri Apr 1 11:42:31 UTC 2022 INFO 0
...
Якщо ви встановили агент на рівні вузла у свій кластер, цей агент автоматично перехоплює ці потоки логів без будь-якої додаткової конфігурації. Якщо вам цікаво, ви можете налаштувати агента для розбору рядків логів залежно від вихідного контейнера.
Навіть для Podʼів, які використовують низьке використання CPU та памʼяті (наприклад, декілька мілікорів (millicore) для CPU та кілька мегабайтів для памʼяті), запис логів до файлу та їх трансляція до stdout можуть подвоїти обсяг памʼяті, необхідний на вузлі. Якщо у вас є застосунок, який записує у єдиний файл, рекомендується встановити /dev/stdout як призначення, а не впроваджувати підхід з sidecar контейнером для трансляції.
Sidecar контейнери також можуть використовуватися для ротації файлів логів, ротація яких не може бути зроблена самим застосунком. Прикладом такого підходу є малий контейнер, який періодично запускає logrotate. Однак набагато простіше використовувати stdout та stderr безпосередньо і
залишити ротації та політику зберігання kubelet.
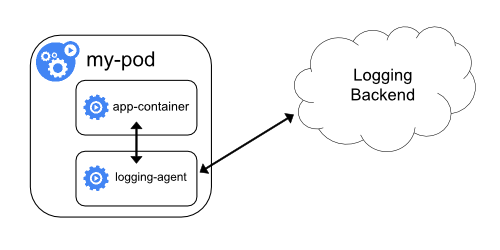
Sidecar контейнер з агентом логування
Якщо агент логування на рівні вузла не має достатньої гнучкості для вашої ситуації, ви можете створити sidecar контейнер з окремим агентом логування, який ви налаштували спеціально для роботи з вашим застосунком.
Примітка:
Використання агента логування у sidecar контейнері може призвести до значного використання ресурсів. Щобільше, ви не зможете отримати доступ до цих логів за допомогою kubectl logs, оскільки вони не керуються kubelet.
Ось два приклади маніфестів, які ви можете використати для впровадження sidecar контейнера з агентом логування. Перший маніфест містить ConfigMap, щоб налаштувати fluentd.
apiVersion:v1kind:ConfigMapmetadata:name:fluentd-configdata:fluentd.conf:| <source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Примітка:
У конфігураціях з прикладів ви можете замінити fluentd на будь-який агент логування, який читає з будь-якого джерела всередині контейнера застосунку.
Другий маніфест описує Pod, в якому є sidecar контейнер, що запускає fluentd. Pod монтує том, де fluentd може отримати свої дані конфігурації.
7 - Поради щодо динамічного розподілу ресурсів адміністратором кластера
На цій сторінці описано найкращі практики налаштування кластера Kubernetes із використанням динамічного розподілу ресурсів (DRA). Ці інструкції призначені для адміністраторів кластерів.
Окремі дозволи для API, повʼязаних з DRA
DRA координується через ряд різних API. Використовуйте інструменти авторизації (такі як RBAC або інше рішення), щоб контролювати доступ до правильних API залежно від ролі вашого користувача.
Загалом, доступ до DeviceClasses і ResourceSlices має бути обмеженим, тільки для адміністраторів і драйверів DRA. Операторам кластерів, які будуть розгортати Podʼи з запитами, знадобиться доступ до API ResourceClaim і ResourceClaimTemplate; обидва ці API обмежуються просторами імен.
Розгортання та обслуговування драйверів DRA
Драйвери DRA — це сторонні застосунки, які працюють на кожному вузлі кластера для взаємодії з апаратним забезпеченням цього вузла та власними компонентами DRA Kubernetes. Процедура встановлення залежить від обраного драйвера, але, ймовірно, він буде розгорнутий як DaemonSet на всіх або на вибраних вузлах (за допомогою селекторів вузлів або подібних механізмів) у кластері.
Використовуйте драйвери з безперебійним оновленням, якщо це можливо
Драйвери DRA реалізують інтерфейс пакунка kubeletplugin. Ваш драйвер може підтримувати безперебійні оновлення шляхом реалізації властивості цього інтерфейсу, яка дозволяє двом версіям одного і того ж драйвера DRA співіснувати протягом короткого часу. Ця функція доступна лише для версій kubelet 1.33 і вище і може не підтримуватися вашим драйвером для гетерогенних кластерів із підключеними вузлами, на яких працюють старіші версії Kubernetes, переконайтеся в цьому, ознайомившись з документацією вашого драйвера.
Якщо безперебійні оновлення доступні у вашій ситуації, розгляньте можливість їх використання, щоб мінімізувати затримки планування під час оновлення драйвера.
Якщо ви не можете використовувати безперебійні оновлення, під час простою драйвера для оновлень ви можете помітити, що:
Podʼи не можуть запускатися, якщо заявки, від яких вони залежать, не були підготовлені до використання.
Очищення після останнього Podʼа, який використовував заявку, затримується до тих пір, поки драйвер не стане знову доступним. Pod не позначається як завершений. Це запобігає повторному використанню ресурсів, які використовуються Podʼом, для інших Podʼів.
Запущені Podʼи продовжують працювати.
Переконайтеся, що драйвер DRA виставляє пробу життєздатності, і використовуйте її.
Ваш драйвер DRA, ймовірно, впроваджує gRPC-сокет для перевірки стану як частину порад щодо створення драйверів DRA. Найпростіший спосіб використати цей gRPC-сокет — налаштувати його як пробу життєздатності для DaemonSet, що розгортає ваш драйвер DRA. Документація вашого драйвера або інструменти розгортання можуть вже включати це, але якщо ви створюєте свою конфігурацію окремо або не запускаєте свій драйвер DRA як pod Kubernetes, переконайтеся, що ваші інструменти оркестрації перезапускають драйвер DRA при невдалих перевірках стану цього gRPC-сокета. Це мінімізує будь-які випадкові простої драйвера DRA і надасть йому більше можливостей для самовідновлення, зменшуючи затримки планування або час усунення несправностей.
Під час очищення вузла вимикайте драйвер якомога пізніше
Драйвер DRA відповідає за скасування підготовки будь-яких пристроїв, які були виділені Podʼам, і якщо драйвер DRA буде очищено до того, як Podʼи з заявками будуть видалені, він не зможе завершити своє очищення. Якщо ви реалізуєте власну логіку очищення для вузлів, переконайтеся, що немає виділених/зарезервованих ResourceClaim або ResourceClaimTemplates перед завершенням роботи самого драйвера DRA.
Відстежуйте та налаштовуйте компоненти для більшого навантаження, особливо у великомасштабних середовищах
Компонент панелі управління kube-scheduler та внутрішній контролер ResourceClaim, який координується компонентом kube-controller-manager виконують основну роботу під час планування Podʼів із заявками на основі метаданих, що зберігаються в API DRA. У порівнянні з Podʼами, що плануються без DRA, кількість викликів API-сервера, памʼяті та використання процесора, необхідних для цих компонентів, збільшується для Podʼів, що використовують заявки DRA. Крім того, локальні компоненти вузлів, такі як драйвер DRA та kubelet, використовують API DRA для розподілу запитів на апаратне забезпечення під час створення пісочниці Podʼа. Особливо в масштабних середовищах, де кластери мають багато вузлів та/або розгортають багато робочих навантажень, які інтенсивно використовують заявки на ресурси, визначені DRA, адміністратор кластера повинен налаштувати відповідні компоненти, щоб передбачити збільшення навантаження.
Наслідки неправильно налаштованих компонентів можуть мати прямий або каскадний вплив, викликаючи різні симптоми під час життєвого циклу Podʼа. Якщо параметри QPS та Burst компонента kube-scheduler занадто низькі, планувальник може швидко визначити підходящий вузол для Podʼа, але знадобиться більше часу, щоб привʼязати Pod до цього вузла. З DRA під час планування Podʼа параметри QPS та Burst у конфігурації client-go в kube-controller-manager є критичними.
Конкретні значення для налаштування вашого кластера залежать від різних факторів, таких як кількість вузлів/Podʼів, швидкість створення Podʼів, плинність, навіть у середовищах без DRA; див. README SIG Scalability про пороги масштабованості Kubernetes для отримання додаткової інформації. У масштабних тестах, проведених на кластері з увімкненим DRA з 100 вузлами, задіяними 720 довгоживучими Podʼами (90% насичення) та 80 Podʼами з плинністю (10% плинності, 10 разів), зі швидкістю створення завдань QPS 10, QPS kube-controller-manager можна було встановити на рівні 75, а Burst — 150, щоб досягти еквівалентних метрик для розгортань без DRA. На цьому нижньому рівні було помічено, що обмежувач швидкості на стороні клієнта спрацьовував достатньо, щоб захистити API-сервер від вибухового сплеску, але був достатньо високим, щоб не вплинути на SLO запуску Podʼів. Хоча це гарна відправна точка, ви можете отримати краще уявлення про те, як налаштувати різні компоненти, які найбільше впливають на продуктивність DRA для вашого розгортання, відстежуючи такі метрики. Для отримання додаткової інформації про всі стабільні метрики в Kubernetes див. Довідник з метрик Kubernetes.
Метрики kube-controller-manager
Наступні метрики детально аналізують внутрішній контролер ResourceClaim, який управляється компонентом kube-controller-manager.
Швидкість додавання до черги завдань: стежить за sum(rate(workqueue_adds_total{name="resource_claim"}[5m])), щоб оцінити, як швидко елементи додаються до контролера ResourceClaim.
Глибина черги завдань: стежить за sum(workqueue_depth{endpoint="kube-controller-manager",name="resource_claim"}), щоб виявити будь-які затримки в контролері ResourceClaim.
Тривалість виконання черги завдань: стежить за histogram_quantile(0.99,sum(rate(workqueue_work_duration_seconds_bucket{name="resource_claim"}[5m]))by(le)), щоб зрозуміти швидкість, з якою контролер ResourceClaim обробляє роботу.
Якщо ви спостерігаєте низьку швидкість додавання до черги завдань, високу глибину черги завдань та/або високу тривалість виконання черги завдань, це свідчить про те, що контролер не працює оптимально. Розгляньте можливість налаштування таких параметрів, як QPS, burst і конфігурації ЦП/памʼяті.
Якщо ви спостерігаєте високу швидкість додавання до черги завдань, високу глибину черги завдань, але розумну тривалість виконання черги завдань, це вказує на те, що контролер справляється з роботою, але паралелізм може бути недостатнім. Паралелізм закодований у контролері, тому як адміністратор кластера ви можете налаштувати це, зменшивши QPS створення Podʼів, щоб швидкість додавання до черги завдань ResourceClaim була більш керованою.
Метрики kube-scheduler
Наступні показники планувальника є показниками високого рівня, що агрегують продуктивність усіх запланованих Podʼів, а не тільки тих, що використовують DRA. Важливо зазначити, що на кінцеві показники впливає продуктивність kube-controller-manager при створенні ResourceClaims з ResourceClainTemplates у розгортаннях, які інтенсивно використовують ResourceClainTemplates.
Тривалість роботи планувальника від початку до кінця: відстежує histogram_quantile(0.99,sum(increase(scheduler_pod_scheduling_sli_duration_seconds_bucket[5m]))by(le)).
Коли Pod, привʼязаний до вузла, повинен задовольнити ResourceClaim, kubelet викликає методи NodePrepareResources та NodeUnprepareResources драйвера DRA. Ви можете спостерігати цю поведінку з точки зору kubelet за допомогою наступних метрик.
Драйвери DRA реалізують інтерфейс пакунка kubeletplugin, який відображає власні метрики для базових операцій gRPC NodePrepareResources та NodeUnprepareResources. Ви можете спостерігати цю поведінку з погляду внутрішнього kubeletplugin за допомогою наступних метрик.
Операція DRA kubeletplugin gRPC NodePrepareResources: спостерігає за histogram_quantile(0.99,sum(rate(dra_grpc_operations_duration_seconds_bucket{method_name=~".*NodePrepareResources"}[5m]))by(le)).
Операція DRA kubeletplugin gRPC NodeUnprepareResources: спостерігає за histogram_quantile(0.99,sum(rate(dra_grpc_operations_duration_seconds_bucket{method_name=~".*NodeUnprepareResources"}[5m]))by(le)).
8 - Рекомендації щодо використання вебхуків допуску
Рекомендації щодо проєктування та розгортання вебхуків допуску в Kubernetes.
Ця сторінка надає рекомендації та міркування щодо проєктування вебхуків допуску в Kubernetes. Ця інформація призначена для операторів кластерів, які запускають сервери вебхуків допуску або сторонні застосунки, що змінюють або перевіряють ваші API-запити.
Перед читанням цієї сторінки переконайтеся, що ви знайомі з наступними поняттями:
Контроль допуску відбувається, коли будь-який запит на створення, оновлення або видалення надсилається до API Kubernetes. Контролери допуску перехоплюють запити, які відповідають певним критеріям, які ви визначаєте. Ці запити потім надсилаються до модифікуючих вебхуків допуску або валідаційних вебхуків допуску. Ці вебхуки часто створюються для забезпечення наявності певних полів у специфікаціях обʼєктів або їх відповідності дозволеним значенням.
Вебхуки є потужним механізмом для розширення API Kubernetes. Погано спроєктовані вебхуки часто призводять до збоїв у роботі навантажень через те, наскільки великий контроль вебхуки мають над обʼєктами в кластері. Як і інші механізми розширення API, вебхуки складно тестувати в масштабі на сумісність з усіма вашими навантаженнями, іншими вебхуками, надбудовами та втулками.
Крім того, з кожним випуском Kubernetes додає або змінює API з новими функціями, підвищенням статусу функцій до бета або стабільного стану та застаріваннями. Навіть стабільні API Kubernetes можуть змінюватися. Наприклад, API Pod змінився у версії v1.29 для додавання функціоналу контейнерів Sidecar. Хоча рідко трапляється, що обʼєкт Kubernetes стає несправним через новий API Kubernetes, вебхуки, які працювали як очікувалося з попередніми версіями API, можуть не змогти узгодити більш нові зміни в цьому API. Це може призвести до неочікуваної поведінки після оновлення кластерів до новіших версій.
Ця сторінка описує загальні сценарії збоїв вебхуків і як їх уникнути шляхом обережного та вдумливого проєктування та реалізації ваших вебхуків.
Перевірте, чи ви використовуєте вебхуки допуску
Навіть якщо ви не запускаєте власні вебхуки допуску, деякі сторонні застосунки, які ви запускаєте у своїх кластерах, можуть використовувати модифікуючі або валідаційні вебхуки допуску.
Щоб перевірити, чи є у вашому кластері модифікуючий вебхук допуску, виконайте наступну команду:
kubectl get mutatingwebhookconfigurations
Вивід покаже будь-який контролер модифікуючого вебхуку допуску в кластері.
Щоб перевірити, чи є у вашому кластері валідаційний вебхук допуску, виконайте наступну команду:
kubectl get validatingwebhookconfigurations
Вивід покаже будь-який контролер валідаційного вебхуку допуску в кластері.
Вибір механізму контролю допуску
Kubernetes включає кілька варіантів контролю допуску та забезпечення політики. Знання, коли використовувати конкретний варіант, може допомогти вам покращити затримку та продуктивність, зменшити витрати на керування та уникнути проблем під час оновлення версій. Наступна таблиця описує механізми, які дозволяють змінювати або перевіряти ресурси під час допуску:
Керування модифікацією та валідацією допуску в Kubernetes
Перехоплюють API-запити перед допуском і перевіряють їх на відповідність виразам CEL.
Перевіряють критичні конфігурації перед допуском ресурсу.
Забезпечують дотримання логіки політик за допомогою виразів CEL.
Загалом, використовуйте вебхук контролю допуску, коли вам потрібен розширюваний спосіб задекларувати або налаштувати логіку. Використовуйте вбудований контроль допуску на основі CEL, коли вам потрібно задекларувати простішу логіку без накладних витрат на запуск сервера вебхуків. Проєкт Kubernetes рекомендує використовувати контроль допуску на основі CEL, коли це можливо.
Використовуйте вбудовану перевірку та встановлення стандартних значень для CustomResourceDefinitions
Якщо ви використовуєте CustomResourceDefinitions, не використовуйте вебхуки допуску для перевірки значень у специфікаціях CustomResource або для встановлення стандартних значень для полів. Kubernetes дозволяє вам визначати правила перевірки та стандартні значення полів під час створення CustomResourceDefinitions.
Цей розділ описує рекомендації щодо покращення продуктивності та зменшення затримки. У підсумку, вони такі:
Консолідуйте вебхуки та обмежте кількість API-викликів на кожен вебхук.
Використовуйте журнали аудиту для перевірки вебхуків, які повторюють одну й ту ж дію.
Використовуйте балансування навантаження для забезпечення доступності вебхука.
Встановіть невелике значення тайм-ауту для кожного вебхука.
Враховуйте потреби в доступності кластера під час проєктування вебхуків.
Проєктування вебхуків допуску для низької затримки
Модифікуючі вебхуки допуску викликаються послідовно. Залежно від налаштування вебхука, деякі вебхуки можуть викликатися кілька разів. Кожен виклик модифікуючого вебхуку додає затримку до процесу допуску. Це відрізняється від валідаційних вебхуків, які викликаються паралельно.
Під час проєктування ваших модифікуючих вебхуків враховуйте ваші вимоги до затримки та толерантність. Чим більше модитфікуючих вебхуків у вашому кластері, тим більша ймовірність збільшення затримки.
Розгляньте наступні рекомендації для зменшення затримки:
Консолідуйте вебхуки, які виконують подібні зміни на різних обʼєктах.
Зменшіть кількість API-викликів, зроблених у логіці сервера модифікуючих вебхуків.
Обмежте умови відповідності кожного модифікуючого вебхуку, щоб зменшити кількість вебхуків, які викликаються конкретним API-запитом.
Консолідуйте невеликі вебхуки в один сервер і конфігурацію для полегшення впорядкування та організації.
Враховуйте будь-які інші компоненти, які працюють у вашому кластері, які можуть конфліктувати зі змінами, які робить ваш вебхук. Наприклад, якщо ваш вебхук додає мітку, яку інший контролер видаляє, ваш вебхук викликатиметься знову. Це призводить до зациклювання.
Щоб виявити ці цикли, спробуйте наступне:
Оновіть політику аудиту вашого кластера для запису подій аудиту. Використовуйте наступні параметри:
level: RequestResponse
verbs: ["patch"]
omitStages: RequestReceived
Встановіть правило аудиту для створення подій для конкретних ресурсів, які ваш вебхук змінює.
Перевірте ваші події аудиту на предмет повторного виклику вебхуків з однаковим патчем, застосованим до одного й того ж обʼєкта, або на предмет оновлення та скасування поля обʼєкта кілька разів.
Встановіть невелике значення тайм-ауту
Вебхуки допуску повинні оцінюватися якомога швидше (зазвичай за мілісекунди), оскільки вони додають затримку до API-запиту. Використовуйте невелике значення тайм-ауту для вебхуків.
Використовуйте балансувальник навантаження для забезпечення доступності вебхука
Вебхуки допуску повинні використовувати якусь форму балансування навантаження для забезпечення високої доступності та продуктивності. Якщо вебхук працює всередині кластера, ви можете запустити кілька бекендів вебхука за Service типу ClusterIP.
Використовуйте модель розгортання з високою доступністю
Враховуйте вимоги до доступності вашого кластера під час проєктування вашого вебхуку. Наприклад, під час простою вузла або зональних збоїв, Kubernetes позначає Podʼи як NotReady, щоб дозволити балансувальникам навантаження перенаправляти трафік до доступних зон та вузлів. Ці оновлення Podʼів можуть викликати ваші модифікуючі вебхуки. Залежно від кількості задіяних Podʼів, сервер модифікуючого вебхука ризикує вийти за межі тайм-ауту або спричинити затримки в обробці Podʼа. В результаті, трафік не буде перенаправлений так швидко, як вам потрібно.
Враховуйте ситуації, подібні до наведеного прикладу, під час створення ваших вебхуків. Виключайте операції, які є результатом реакції Kubernetes на неминучі інциденти.
Фільтрація запитів
Цей розділ надає рекомендації щодо фільтрації запитів, які викликають конкретні вебхуки. У підсумку, вони такі:
Обмежте область дії вебхука, щоб уникати системних компонентів і запитів тільки для читання.
Обмежте вебхуки конкретними просторами імен.
Використовуйте умови відповідності для виконання тонкої фільтрації запитів.
Збіг має бути зі всіма версіям обʼєкта.
Обмежте область дії кожного вебхука
Вебхуки допуску викликаються тільки тоді, коли API-запит збігається з відповідною конфігурацією вебхука. Обмежте область дії кожного вебхука, щоб зменшити непотрібні виклики до сервера вебхука. Враховуйте наступні обмеження області дії:
Уникайте збігів зі всіма обʼєктами у просторі імен kube-system. Якщо ви запускаєте свої Podʼи у просторі імен kube-system, використовуйте objectSelector, щоб уникнути зміни критичного робочого навантаження.
Не змінюйте лізинг вузлів, які існують як обʼєкти Lease у системному просторі імен kube-node-lease. Зміна лізингу вузлів може призвести до невдалих оновлень вузлів. Застосовуйте контроль перевірки до обʼєктів Lease у цьому просторі імен тільки якщо ви впевнені, що контроль не завдасть вашому кластеру ризику.
Не змінюйте обʼєкти TokenReview або SubjectAccessReview. Це завжди запити тільки для читання. Зміна цих обʼєктів може порушити роботу вашого кластера.
Обмежте кожен вебхук конкретним простором імен за допомогою namespaceSelector.
Фільтруйте конкретні запити за допомогою умов збігу
Контролери допуску підтримують кілька полів, які ви можете використовувати для перевірки збігів з запитами, які відповідають певним критеріям. Наприклад, ви можете використовувати namespaceSelector для фільтрації запитів, які спрямовані на конкретний простір імен.
Для більш тонкої фільтрації запитів використовуйте поле matchConditions у вашій конфігурації вебхука. Це поле дозволяє вам створювати кілька виразів CEL, які повинні оцінюватися як true, щоб запит викликав ваш вебхук допуску. Використання matchConditions може значно зменшити кількість викликів до вашого сервера вебхука.
Стандартно, вебхуки допуску працюють на будь-яких версіях API, які впливають на вказаний ресурс. Поле matchPolicy у конфігурації вебхука контролює цю поведінку. Вкажіть значення Equivalent у полі matchPolicy або пропустіть поле, щоб дозволити вебхуку працювати на будь-якій версії API.
Цей розділ надає рекомендації щодо області дії змін та будь-яких особливих міркувань щодо полів обʼєктів. У підсумку, вони такі:
Патчіть тільки ті поля, які потрібно патчити.
Не перезаписуйте значення масивів.
Уникайте побічних ефектів у змінах, коли це можливо.
Уникайте самозмін.
Не приховуйте збої та перевіряйте кінцевий стан.
Плануйте майбутні оновлення полів у наступних версіях.
Запобігайте самовиклику вебхуків.
Не змінюйте незмінні обʼєкти.
Патчіть тільки необхідні поля
Сервери вебхуків допуску надсилають HTTP-відповіді, щоб вказати, що робити з конкретним API-запитом Kubernetes. Ця відповідь є обʼєктом AdmissionReview. Модифікуючий вебхук може додати конкретні поля для зміни перед дозволом допуску за допомогою поля patchType та поля patch у відповіді. Переконайтеся, що ви змінюєте тільки ті поля, які потребують змін.
Наприклад, розгляньте модифікуючий вебхук, який налаштований для забезпечення того, щоб Deployments web-server мали принаймні три репліки. Коли запит на створення обʼєкта Deployment відповідає вашій конфігурації вебхука, вебхук
повинен оновити тільки значення у полі spec.replicas.
Не перезаписуйте значення масивів
Поля у специфікаціях обʼєктів Kubernetes можуть містити масиви. Деякі масиви містять пари ключ:значення (наприклад, поле envVar у специфікації контейнера), тоді як інші масиви не мають ключів (наприклад, поле readinessGates у специфікації Pod). Порядок значень у полі масиву може бути важливим в деяких ситуаціях. Наприклад, порядок аргументів у полі args специфікації контейнера може впливати на контейнер.
Враховуйте наступне під час зміни масивів:
По можливості використовуйте операцію JSONPatch add замість replace, щоб уникнути випадкового заміщення необхідного значення.
Ставтеся до масивів, які не використовують пари ключ:значення, як до множин.
Переконайтеся, що значення у полі, яке ви змінюєте, не повинні бути впорядковані певним чином.
Не перезаписуйте існуючі пари ключ:значення, якщо це тільки абсолютно необхідно.
Будьте обережні під час зміни полів міток. Випадкова зміна може призвести до порушення селекторів міток, що призведе до непередбачуваної поведінки.
Уникайте побічних ефектів
Переконайтеся, що ваші вебхуки працюють тільки з вмістом AdmissionReview, який надсилається їм, і не роблять змін поза межами. Ці додаткові зміни, звані побічними ефектами, можуть спричинити конфлікти під час допуску, якщо вони не узгоджені належним чином. Поле .webhooks[].sideEffects повинно бути встановлено в None, якщо вебхук не має побічних ефектів.
Якщо побічні ефекти необхідні під час оцінки допуску, вони повинні бути придушені під час обробки обʼєкта AdmissionReview з dryRun, встановлене у true, і поле .webhooks[].sideEffects повинно бути встановлено на NoneOnDryRun.
Вебхук, що працює всередині кластера, може спричинити взаємоблокування для свого власного розгортання, якщо він налаштований для перехоплення ресурсів, необхідних для запуску його власних Podʼів.
Наприклад, модифікуючий вебхук допуску налаштований для допуску запитів create Pod тільки якщо певна мітка встановлена у Pod (наприклад, env: prod). Сервер вебхука працює у Deployment, який не встановлює мітку env.
Коли вузол, який запускає Podʼи сервера вебхука, стає несправним, Deployment вебхука намагається перенаправити Podʼи на інший вузол. Однак, існуючий сервер вебхука відхиляє запити, оскільки мітка env не встановлена. В результаті, міграція не може відбутися.
Виключіть простір імен, де працює ваш вебхук, за допомогою namespaceSelector.
Уникайте циклічних залежностей
Цикли залежностей можуть виникати у таких сценаріях:
Два вебхуки перевіряють Podʼи один одного. Якщо обидва вебхуки стають недоступними одночасно, жоден з них не може запуститися.
Ваш вебхук перехоплює компоненти надбудови кластера, такі як мережеві втулки або втулки зберігання, від яких залежить ваш вебхук. Якщо обидва вебхук та залежна надбудова стають недоступними, жоден з компонентів не може функціонувати.
Щоб уникнути цих циклів залежностей, спробуйте наступне:
Запобігайте діям ваших вебхуків на залежні надбудови за допомогою objectSelector.
Не приховуйте збої та перевіряйте кінцевий стан
Модифікуючі вебхуки допуску підтримують поле конфігурації failurePolicy. Це поле вказує, чи повинен API-сервер допустити або відхилити запит у разі збою вебхука. Збої вебхука можуть статися через тайм-аути або помилки у логіці сервера.
Стандартно, вебхуки допуску встановлюють поле failurePolicy у Fail. API-сервер відхиляє запит, якщо вебхук зазнає збою. Однак, таке стандартне відхилення запитів може призвести до відхилення доцільних запитів під час простою вебхука.
Дозвольте вашим модифікуючим вебхукам "не приховувати збої", встановивши поле failurePolicy в Ignore. Використовуйте контролер перевірки для перевірки стану запитів, щоб забезпечити їх відповідність вашим політикам.
Цей підхід має наступні переваги:
Простій модифікуючих вебхуків не впливає на розгортання доцільних ресурсів.
Забезпечення дотримання політики відбувається під час контролю перевірки.
Модифікуючі вебхуки не заважають іншим контролерам в кластері.
Плануйте майбутні оновлення полів
Загалом, проєктуйте ваші вебхуки з урахуванням того, що API Kubernetes можуть змінитися в наступній версії. Не створюйте сервер, який приймає стабільність API як належне. Наприклад, випуск контейнерів sidecar у Kubernetes додав поле restartPolicy до API Pod.
Запобігайте самовиклику вашого вебхука
Модифікуючі вебхуки, які відповідають на широкий спектр API-запитів, можуть ненавмисно викликати самі себе. Наприклад, розгляньте вебхук, який відповідає на всі запити в кластері. Якщо ви налаштуєте вебхук для створення обʼєктів Event для кожної зміни, він буде відповідати на власні запити на створення обʼєктів Event.
Щоб уникнути цього, розгляньте можливість встановлення унікальної мітки у будь-яких ресурсах, які створює ваш вебхук. Перевіряте наявність цієї мітки в умовах збігу вашого вебхуку.
Не змінюйте незмінні обʼєкти
Деякі обʼєкти Kubernetes в API-сервері не можуть змінюватися. Наприклад, коли ви розгортаєте static Pod, kubelet на вузлі створює mirror Pod в API-сервері для відстеження статичного Podʼа. Однак, зміни у mirror Pod не поширюються на статичний Pod.
Не намагайтеся змінювати ці обʼєкти під час допуску. Усі mirror Podʼи мають анотацію kubernetes.io/config.mirror. Щоб виключити mirror Podʼи, зменшуючи ризик безпеки від ігнорування анотації, дозволяйте статичним Podʼам працювати тільки в конкретних просторах імен.
Порядок виклику модифікуючого вебхука та ідемпотентність
Цей розділ надає рекомендації щодо порядку виклику вебхука та проєктування ідемпотентних вебхуків. У підсумку, вони такі:
Не покладайтеся на конкретний порядок виконання.
Перевіряйте зміни перед допуском.
Перевіряйте, чи зміни не перезаписуються іншими контролерами.
Переконайтеся, що набір модифікуючих вебхуків є ідемпотентним, а не тільки окремі вебхуки.
Не покладайтеся на порядок виклику модифікуючих вебхуків
Модифікуючі вебхуки допуску не працюють у стабільному порядку. Різні фактори можуть змінити, коли конкретний вебхук викликається. Не покладайтеся на те, що ваш вебхук працює у конкретний момент у процесі допуску. Інші вебхуки все ще можуть змінити ваш змінений обʼєкт.
Наступні рекомендації можуть допомогти мінімізувати ризик непередбачуваних змін:
Використовуйте політику повторного виклику для спостереження за змінами обʼєкта іншими втулками та повторно викликайте вебхук за потреби. Для деталей дивіться Політику повторного виклику.
Переконайтеся, що модифікуючий вебхук у вашому кластері є ідемпотентними
Кожен модифікуючий вебхук допуску повинен бути ідемпотентним. Вебхук повинен бути здатним працювати на обʼєкті, який він вже змінив, без внесення додаткових змін, крім початкової зміни.
Крім того, усі модифікуючі вебхуки у вашому кластері повинні, як колекція, бути ідемпотентними. Після завершення фази зміни контролю допуску, кожен окремий модифікуючий вебхук повинен бути здатним працювати на обʼєкті без внесення додаткових змін до обʼєкта.
Залежно від вашого середовища, забезпечення ідемпотентності в масштабі може бути складним. Наступні рекомендації можуть допомогти:
Використовуйте контролери перевірки допуску для перевірки кінцевого стану критичних навантажень.
Тестуйте ваші розгортання у тестовому кластері, щоб перевірити, чи будь-які обʼєкти змінюються кілька разів одним і тим же вебхуком.
Переконайтеся, що область дії кожного модифікуючого вебхуку є конкретною та обмеженою.
Наступні приклади показують ідемпотентну логіку змін:
Для запиту create Pod встановіть поле
.spec.securityContext.runAsNonRoot Pod у true.
Для запиту create Pod, якщо поле .spec.containers[].resources.limits контейнера не встановлено, встановіть стандартні значення ресурсних обмежень.
Для запиту create Pod, додайте контейнер sidecar з імʼям foo-sidecar, якщо контейнер з імʼям foo-sidecar ще не існує.
У цих випадках вебхук може бути безпечно повторно викликаний або допустити обʼєкт, який вже має встановлені поля.
Наступні приклади показують неідемпотентну логіку змін:
Для запиту create Pod додайте контейнер sidecar з імʼям foo-sidecar, до якого додається поточний відбиток часу (наприклад, foo-sidecar-19700101-000000).
Повторний виклик вебхука може призвести до того, що той самий sidecar буде доданий кілька разів до Podʼа, кожного разу з іншим імʼям контейнера. Аналогічно, вебхук може додати дубльовані контейнери, якщо sidecar вже існує у podʼі користувача.
Для запиту create/update Pod відхиліть його, якщо Pod має встановлену мітку env, інакше додайте мітку env: prod до Pod.
Повторний виклик вебхука призведе до того, що вебхук не зможе обробити свій власний вивід.
Для запиту create Pod додайте контейнер sidecar з імʼям foo-sidecar без перевірки, чи існує контейнер foo-sidecar.
Повторний виклик webhook призведе до дублювання контейнерів у Pod, що робить запит недійсним і відхиленим API-сервером.
Тестування та перевірка змін
Цей розділ надає рекомендації щодо тестування ваших модифікуючих вебхуків та перевірки змінених обʼєктів. У підсумку, вони такі:
Тестуйте вебхуки в тестових середовищах.
Уникайте змін, які порушують перевірки.
Тестуйте оновлення мінорних версій на предмет регресій та конфліктів.
Перевіряйте змінені обʼєкти перед допуском.
Тестуйте вебхуки у тестових середовищах
Ретельне тестування повинно бути основною частиною вашого циклу випуску нових або оновлених вебхуків. Якщо можливо, тестуйте будь-які зміни до ваших кластерних вебхуків у тестовому середовищі, яке тісно нагадує ваші промислові кластери. Принаймні, розгляньте можливість використання інструменту, такого як minikube або kind, щоб створити невеликий тестовий кластер для змін вебхука.
Переконайтеся, що зміни не порушують перевірки
Ваші модифікуючі вебхуки не повинні порушувати жодні перевірки, які застосовуються до обʼєкта перед допуском. Наприклад, розгляньте модифікуючий вебхук, який встановлює стандартне значення для запиту CPU Podʼа. Якщо обмеження CPU цього Podʼа встановлено на нижче значення, ніж змінений запит, Pod не пройде допуск.
Тестуйте кожен модифікуючий вебхук на перевірки, які працюють у вашому кластері.
Тестуйте оновлення мінорних версій для забезпечення послідовної поведінки
Перед оновленням ваших промислових кластерів до нової мінорної версії, тестуйте ваші вебхуки та навантаження у тестовому середовищі. Порівняйте результати, щоб переконатися, що ваші вебхуки продовжують функціонувати як очікувалося після оновлення.
Крім того, використовуйте наступні ресурси, щоб бути в курсі змін API:
Модифікуючі вебхуки працюють до завершення перед тим, як будь-які валідаційні вебхуки починають працювати. Немає стабільного порядку, в якому зміни застосовуються до обʼєктів. В результаті, ваші зміни можуть бути перезаписані модифікуючим вебхуком, який працює пізніше.
Додайте контролер перевірки, такий як ValidatingAdmissionWebhook або ValidatingAdmissionPolicy, до вашого кластера, щоб переконатися, що ваші зміни залишаються. Наприклад, розгляньте модифікуючтй вебхук, який вставляє поле restartPolicy: Always до конкретних init-контейнерів, щоб зробити їх працюючими як sidecar-контейнери. Ви можете запустити валідаційний вебхук, щоб переконатися, що ці init-контейнери зберегли конфігурацію restartPolicy: Always після завершення всіх змін.
Цей розділ надає рекомендації щодо розгортання ваших модифікуючих вебхуків допуску. У підсумку, вони такі:
Поступово розгортайте конфігурацію вебхука та моніторте проблеми за просторами імен.
Обмежте доступ до редагування ресурсів конфігурації вебхука.
Обмежте доступ до простору імен, де працює сервер вебхука, якщо сервер знаходиться в кластері.
Встановлення та увімкнення модифікуючого вебхука
Коли ви готові розгорнути ваш модифікуючий вебхук у кластері, використовуйте наступний порядок дій:
Встановіть сервер вебхука та запустіть його.
Встановіть поле failurePolicy у маніфесті MutatingWebhookConfiguration в Ignore. Це дозволяє уникнути збоїв, спричинених неправильно налаштованими вебхуками.
Встановіть поле namespaceSelector у маніфесті MutatingWebhookConfiguration на тестовий простір імен.
Розгорніть MutatingWebhookConfiguration у вашому кластері.
Моніторте вебхук у тестовому просторі імен, щоб перевірити наявність будь-яких проблем, потім розгорніть вебхук в інших просторах імен. Якщо вебхук перехоплює API-запит, який він не повинен був перехоплювати, призупиніть розгортання та налаштуйте область дії конфігурації вебхука.
Обмежте доступ до редагування модифікуючих вебхуків
Модифікуючі вебхуки є потужними контролерами Kubernetes. Використовуйте RBAC або інший механізм авторизації для обмеження доступу до ваших конфігурацій вебхуків та серверів. Для RBAC переконайтеся, що наступний доступ доступний тільки довіреним субʼєктам:
Якщо сервер вашого модифікуючого вебхука працює у кластері, обмежте доступ до створення або зміни будь-яких ресурсів у цьому просторі імен.
Приклади якісних реалізацій
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Наступні проєкти є прикладами "якісних" реалізацій власних серверів вебхуків. Ви можете використовувати їх як відправну точку під час проєктування власних вебхуків. Не використовуйте ці приклади як є; використовуйте їх як відправну точку та проєктуйте ваші вебхуки для гарної роботи у вашому конкретному середовищі.
9 - Версія сумісності для компонентів панелі управління Kubernetes
Починаючи з версії 1.32, ми додали до компонентів панелі управління Kubernetes параметри сумісності версій та емуляції, що налаштовуються, щоб зробити оновлення безпечнішими, надаючи більше контролю та збільшуючи деталізацію кроків, доступних адміністраторам кластерів.
Емульована версія
Параметр емуляції задається прапорцем --emulated-version компонентів панелі управління. Він дозволяє компоненту емулювати поведінку (API, функції ...) більш ранньої версії Kubernetes.
При його використанні доступні можливості будуть відповідати емульованій версії:
Будь-які можливості, присутні в двійковій версії, які були додані після версії емуляції, будуть недоступні.
Будь-які можливості, вилучені після версії емуляції, будуть доступними.
Це дозволяє двійковій версії певного випуску Kubernetes емулювати поведінку попередньої версії з достатньою точністю, щоб можна було визначити сумісність з іншими компонентами системи у термінах емульованої версії.
Значення --emulated-version має бути <= binaryVersion. Діапазон підтримуваних емульованих версій див. у довідці до прапорця --emulated-version.
10 - Метрики для компонентів системи Kubernetes
Метрики системних компонентів можуть краще показати, що відбувається всередині. Метрики особливо корисні для побудови інформаційних панелей та сповіщень.
Компоненти Kubernetes видають метрики у форматі Prometheus. Цей формат являє собою структурований звичайний текст, призначений для зручного сприйняття як людьми, так і машинами.
Метрики в Kubernetes
У більшості випадків метрики доступні на точці доступу /metrics HTTP сервера. Для компонентів, які типово не показують цю точку, її можна активувати за допомогою прапорця --bind-address.
У промисловому середовищі ви, можливо, захочете налаштувати Prometheus Server або інший інструмент збору метрик для їх періодичного отримання і доступу у якомусь виді бази даних часових рядів.
Зверніть увагу, що kubelet також викладає метрики на /metrics/cadvisor, /metrics/resource та /metrics/probes. Ці метрики не мають того самого життєвого циклу.
Якщо ваш кластер використовує RBAC, для читання метрик потрібна авторизація через користувача, групу або ServiceAccount з ClusterRole, що дозволяє доступ до /metrics. Наприклад:
apiVersion:rbac.authorization.k8s.io/v1kind:ClusterRolemetadata:name:prometheusrules:- nonResourceURLs:- "/metrics"verbs:- get
Альфа метрики не мають гарантій щодо їх стабільності. Ці метрики можуть бути змінені або навіть вилучені в будь-який момент.
Стабільні метрики гарантують, що їх формат залишиться незмінним. Це означає що:
Стабільні метрики, які не мають позначки "DEPRECATED", не будуть змінені чи вилучені.
Тип стабільних метрик не буде змінений.
Метрики, які позначені як застарілі, заплановані для видалення, але все ще доступні для використання. Ці метрики мають анотацію щодо версії, у якій вони стали застарілими.
Наприклад:
Перед застарінням
# HELP some_counter this counts things
# TYPE some_counter counter
some_counter 0
Після застаріння
# HELP some_counter (Deprecated since 1.15.0) this counts things
# TYPE some_counter counter
some_counter 0
Приховані метрики більше не публікуються для збирання, але все ще доступні для використання. Щоб використовувати приховану метрику, будь ласка, звертайтесь до розділу Показ прихованих метрик.
Видалені метрики більше не публікуються і не можуть бути використані.
Показ прихованих метрик
Як описано вище, адміністратори можуть увімкнути приховані метрики через прапорець командного рядка для конкретного бінарного файлу. Це призначено для використання адміністраторами, якщо вони пропустили міграцію метрик, які стали застарілими в останньому релізі.
Прапорець show-hidden-metrics-for-version приймає версію, для якої ви хочете показати метрики, які стали застарілими у цьому релізі. Версія зазначається як x.y, де x — головна версія, y — мінорна версія. Версія патчу не потрібна, хоча метрика може бути застарілою в патч-релізі, причина в тому, що політика застарілих метрик працює з мінорними релізами.
Прапорець може приймати тільки попередню мінорну версію як своє значення. Усі метрики, які були приховані в попередній версії, будуть доступні, якщо адміністратори встановлять попередню версію на show-hidden-metrics-for-version. Занадто стара версія не дозволяється, оскільки це порушує політику застарілих метрик.
Візьміть метрику A як приклад, тут припускається, що A застаріла в 1.n. Згідно з політикою застарілих метрик, ми можемо зробити наступні висновки:
У випуску 1.n, метрика застаріла і може бути типово доступною.
У випуску 1.n+1, метрика є типово прихованою і може бути доступна через параметр командного рядка show-hidden-metrics-for-version=1.n.
У випуску 1.n+2, метрику слід видалити з кодової бази. Більше немає можливості її отримання.
Якщо ви оновлюєтеся з випуску 1.12 до 1.13, але все ще залежите від метрики A, яка застаріла в 1.12, ви повинні встановити приховані метрики через командний рядок: --show-hidden-metrics=1.12 і памʼятати про те, щоб видалити цю залежність від метрики до оновлення до 1.14.
Метрики компонентів
Метрики kube-controller-manager
Метрики менеджера контролера надають важливі відомості про продуктивність та стан контролера. Ці метрики включають загальні метрики часу виконання мови програмування Go, такі як кількість go_routine, а також специфічні для контролера метрики, такі як час виконання запитів до etcd або час виконання API Cloudprovider (AWS, GCE, OpenStack), які можна використовувати для оцінки стану кластера.
Починаючи з Kubernetes 1.7, доступні докладні метрики Cloudprovider для операцій зберігання для GCE, AWS, Vsphere та OpenStack. Ці метрики можуть бути використані для моніторингу стану операцій з постійними томами.
Планувальник надає опціональні метрики, які повідомляють про запитані ресурси та бажані обмеження всіх запущених Podʼів. Ці метрики можна використовувати для побудови панелей управління ресурсами, оцінки поточних або історичних обмежень планування, швидкого виявлення навантажень, які не можуть бути розміщені через відсутність ресурсів, і порівняння фактичного використання з запитом Podʼа.
kube-scheduler ідентифікує ресурсні запити та обмеження для кожного Podʼа; коли запит або обмеження не дорівнює нулю, kube-scheduler повідомляє про метричні часові ряди. Часові ряди мають мітки:
простір імен
імʼя Podʼа
вузол, на якому запущений Pod, або пустий рядок, якщо він ще не запущений
пріоритет
призначений планувальник для цього Podʼа
назва ресурсу (наприклад, cpu)
одиниця ресурсу, якщо відома (наприклад, core)
Як тільки Pod досягає завершення (має restartPolicyNever або OnFailure і перебуває в стані Succeeded або Failed, або був видалений і всі контейнери мають стан завершення), часова послідовність більше не повідомляється, оскільки тепер планувальник вільний для розміщення інших Podʼів для запуску. Дві метрики називаються kube_pod_resource_request та kube_pod_resource_limit.
Метрики доступні за адресою HTTP /metrics/resources. Вони та вимагають авторизації для точки доступу /metrics/resources, яка зазвичай надається за допомогою ClusterRole з дієсловом get для URL /metrics/resources, що не є ресурсом.
В Kubernetes 1.21 вам потрібно використовувати прапорець --show-hidden-metrics-for-version=1.20, щоб показати ці альфа-метрики.
Метрики kubelet Pressure Stall Information (PSI)
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [alpha]
У альфа-версії Kubernetes дозволяє налаштувати kubelet для збору даних про ядро Linux Інформація про зупинку тиску (PSI) про використання CPU, памʼяті та вводу-виводу. Інформація збирається на рівні вузлів, podʼів та контейнерів. Метрики виводяться у точці доступу /metrics/cadvisor з наступними назвами:
Ви можете явно вимкнути метрики за допомогою прапорця командного рядка --disabled-metrics. Це може бути бажано, наприклад, якщо метрика викликає проблеми з продуктивністю. Вхідні дані — це список вимкнених метрик (тобто --disabled-metrics=метрика1,метрика2).
Забезпечення послідовності метрик
Метрики з нескінченними розмірами можуть викликати проблеми з памʼяттю в компонентах, які їх інструментують. Щоб обмежити використання ресурсів, ви можете використовувати опцію командного рядка --allow-metric-labels, щоб динамічно налаштувати список дозволених значень міток для метрики.
На стадії альфа, цей прапорець може приймати лише серію зіставлень як список дозволених міток метрики. Кожне зіставлення має формат <metric_name>,<label_name>=<allowed_labels>, де <allowed_labels> — це розділені комами допустимі назви міток.
Крім того, що це можна вказати з командного рядка, теж саме можна зробити за допомогою конфігураційного файлу. Ви можете вказати шлях до цього файлу конфігурації, використовуючи аргумент командного рядка --allow-metric-labels-manifest для компонента. Ось приклад вмісту цього конфігураційного файлу:
Додатково, метрика cardinality_enforcement_unexpected_categorizations_total записує кількість неочікуваних категоризацій під час вказання послідовності, тобто кожного разу, коли значення мітки зустрічається, що не дозволяється з урахуванням обмежень списку дозволених значень.
kube-state-metrics — це агент-надбудова для генерації та надання метрик на рівні кластера.
Стан обʼєктів Kubernetes у Kubernetes API може бути поданий у вигляді метрик. Агент-надбудова kube-state-metrics може підключатися до сервера Kubernetes API та надавати доступ до точки доступу з метриками, що генеруються зі стану окремих обʼєктів у кластері. Він надає різні дані про стан обʼєктів, такі як мітки та анотації, час запуску та завершення, статус або фазу, в яких обʼєкт знаходиться зараз. Наприклад, контейнери, що працюють у Podʼах, створюють метрику kube_pod_container_info. Вона включає імʼя контейнера, імʼя Podʼа, до якого він належить, простір імен, в якому працює Pod, імʼя образу контейнера, ідентифікатор образу, імʼя образу з опису контейнера, ідентифікатор працюючого контейнера та ідентифікатор Podʼа як мітки.
🛇 Цей елемент посилається на сторонній проєкт або продукт, який не є частиною Kubernetes. Докладніше
Зовнішній компонент, який може зчитувати точку доступу kube-state-metrics (наприклад, за допомогою Prometheus), можна використовувати для активації наступних варіантів використання.
Приклад: використання метрик з kube-state-metrics для запиту стану кластера
Серії метрик, що генеруються kube-state-metrics, допомагають отримати додаткові уявлення про кластер, оскільки їх можна використовувати для запитів.
Якщо ви використовуєте Prometheus або інструмент, який використовує ту саму мову запитів, наступний запит PromQL поверне кількість Podʼів, які не готові:
count(kube_pod_status_ready{condition="false"}) by (namespace, pod)
Приклад: сповіщення на основі kube-state-metrics
Метрики, що генеруються з kube-state-metrics, також дозволяють сповіщати про проблеми в кластері.
Якщо ви використовуєте Prometheus або схожий інструмент, який використовує ту саму мову правил сповіщень, наступне сповіщення буде активовано, якщо є Podʼи, які перебувають у стані Terminating протягом понад 5 хвилин:
groups:- name:Pod staterules:- alert:PodsBlockedInTerminatingStateexpr:count(kube_pod_deletion_timestamp) by (namespace, pod) * count(kube_pod_status_reason{reason="NodeLost"} == 0) by (namespace, pod) > 0for:5mlabels:severity:pageannotations:summary:Pod {{$labels.namespace}}/{{$labels.pod}} blocked in Terminating state.
12 - Системні логи
Логи компонентів системи фіксують події, які відбуваються в кластері, що може бути дуже корисним для налагодження. Ви можете налаштувати рівень деталізації логів, щоб бачити більше або менше деталей. Логи можуть бути настільки грубими, що вони показують лише помилки у компоненті, або настільки дрібними, що вони показують крок за кроком слідування за подіями (наприклад, логи доступу HTTP, зміни стану події, дії контролера або рішення планувальника).
Попередження:
На відміну від описаних тут прапорців командного рядка, вивід логу сам по собі не підпадає під гарантії стійкості API Kubernetes: окремі записи логу та їх форматування можуть змінюватися від одного релізу до наступного!
Klog
klog — це бібліотека реєстрації подій для системних компонентів Kubernetes. klog генерує повідомлення логу для системних компонентів Kubernetes.
Kubernetes знаходиться в процесі спрощення реєстрації подій у своїх компонентах. Наступні прапорці командного рядка klog є застарілими починаючи з Kubernetes v1.23 і будуть видалені у Kubernetes v1.26:
--add-dir-header
--alsologtostderr
--log-backtrace-at
--log-dir
--log-file
--log-file-max-size
--logtostderr
--one-output
--skip-headers
--skip-log-headers
--stderrthreshold
Вивід буде завжди записуватися у stderr, незалежно від формату виводу. Очікується, що перенаправлення виводу буде оброблено компонентом, який викликає компонент Kubernetes. Це може бути оболонка POSIX або інструмент, такий як systemd.
У деяких випадках, наприклад, у контейнері distroless або службі Windows, ці параметри недоступні. У цьому випадку можна використовувати бінарний файл kube-log-runner як обгортку навколо компонента Kubernetes для перенаправлення виводу. Вже скомпільований бінарний файл включено в декілька базових образів Kubernetes під його традиційною назвою /go-runner та як kube-log-runner в архівах випусків сервера та вузла.
Ця таблиця показує відповідність викликів kube-log-runner перенаправленню оболонки:
Рядок повідомлення може містити перенесення рядків:
I1025 00:15:15.525108 1 example.go:79] This is a message
which has a line break.
Структуроване ведення логів
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.23 [beta]
Попередження:
Перехід до структурованого формату ведення логів є поточним процесом. Не всі повідомлення логів мають структурований формат у цій версії. Під час обробки логів вам також доведеться працювати з неструктурованими повідомленнями логів.
Форматування логів та серіалізація значень можуть змінюватися.
Структуроване ведення логів вводить єдину структуру в повідомлення логів, що дозволяє програмно отримувати інформацію. Ви можете зберігати та обробляти структуровані логи з меншими зусиллями та витратами. Код, який генерує повідомлення логів, визначає, чи використовує він традиційний неструктурований вивід klog, чи структуроване ведення логів.
Формат структурованих повідомлень логів є типово текстовим, у форматі, який зберігає сумісність з традиційним klog:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
Рядки беруться в лапки. Інші значення форматуються за допомогою %+v, що може призводити до того, що повідомлення логів продовжуватимуться на наступному рядку залежно від даних.
I1025 00:15:15.525108 1 example.go:116] "Example" data="This is text with a line break\nand \"quotation marks\"." someInt=1 someFloat=0.1 someStruct={StringField: First line,
second line.}
Контекстне ведення логів
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.30 [beta]
Контекстне ведення логів базується на структурованому веденні логів. Це переважно стосується того, як розробники використовують системні виклики ведення логів: код, побудований на цьому концепті, є більш гнучким і підтримує додаткові варіанти використання, як описано в KEP щодо контекстного ведення логів.
Якщо розробники використовують додаткові функції, такі як WithValues або WithName, у своїх компонентах, то записи в журнал міститимуть додаткову інформацію, яка передається у функції своїм абонентам.
Для Kubernetes Kubernetes 1.33, це керується через функціональну можливістьContextualLogging, що є типово увімкненою. Інфраструктура для цього була додана в 1.24 без модифікації компонентів. Команда component-base/logs/example показує, як використовувати нові виклики ведення логів та як компонент поводиться, якщо він підтримує контекстне ведення логів.
$cd$GOPATH/src/k8s.io/kubernetes/staging/src/k8s.io/component-base/logs/example/cmd/
$ go run . --help
...
--feature-gates mapStringBool Набір пар ключ=значення, які описують feature gate для експериментальних функцій. Опції:
AllAlpha=true|false (ALPHA - стандартно=false)
AllBeta=true|false (BETA - стандартно=false)
ContextualLogging=true|false (BETA - default=true)
$ go run . --feature-gates ContextualLogging=true...
I0222 15:13:31.645988 197901 example.go:54] "runtime" logger="example.myname" foo="bar" duration="1m0s"
I0222 15:13:31.646007 197901 example.go:55] "another runtime" logger="example" foo="bar" duration="1h0m0s" duration="1m0s"
Ключ logger та foo="bar" були додані абонентом функції, яка записує повідомлення runtime та значення duration="1m0s", без необхідності модифікувати цю функцію.
Коли контекстне ведення логів вимкнене, функції WithValues та WithName нічого не роблять, а виклики ведення логів пройшли через глобальний реєстратор klog. Отже, ця додаткова інформація більше не виводиться в журнал:
$ go run . --feature-gates ContextualLogging=false...
I0222 15:14:40.497333 198174 example.go:54] "runtime" duration="1m0s"
I0222 15:14:40.497346 198174 example.go:55] "another runtime" duration="1h0m0s" duration="1m0s"
Формат логу у форматі JSON
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.19 [alpha]
Попередження:
Вивід у форматі JSON не підтримує багато стандартних прапорців klog. Для списку непідтримуваних прапорців klog дивіться Посібник командного рядка.
Не всі логи гарантовано будуть записані у форматі JSON (наприклад, під час запуску процесу). Якщо ви плануєте розбирати логи, переконайтеся, що можете обробити також рядки логу, які не є JSON.
Назви полів та серіалізація JSON можуть змінюватися.
Прапорець --logging-format=json змінює формат логу з власного формату klog на формат JSON. Приклад формату логу у форматі JSON (форматований для зручності):
Прапорець -v керує рівнем деталізації логу. Збільшення значення збільшує кількість зареєстрованих подій. Зменшення значення зменшує кількість зареєстрованих подій. Збільшення рівнів деталізації записує все менш важливі події. На рівні деталізації 0 журнал реєструє лише критичні події.
Розташування логів
Існують два типи системних компонентів: ті, які працюють у контейнері, та ті, які не працюють у контейнері. Наприклад:
Планувальник Kubernetes та kube-proxy працюють у контейнері.
На машинах з systemd, kubelet та середовище виконання контейнерів записують логи в journald. В іншому випадку вони записуються в файли .log в теці /var/log. Системні компоненти всередині контейнерів завжди записуються в файли .log у теці /var/log, обходячи типовий механізм ведення логу. Аналогічно логам контейнерів, вам слід регулярно виконувати ротацію логів системних компонентів у теці /var/log. У кластерах Kubernetes, створених сценарієм kube-up.sh, ротація логів налаштована за допомогою інструменту logrotate. Інструмент logrotate виконує ротацію логів щоденно або якщо розмір логу перевищує 100 МБ.
Отримання логів
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.30 [beta] (стандартно увімкнено: false)
Для допомоги у розвʼязанні проблем на вузлах Kubernetes версії v1.27 введено функцію, яка дозволяє переглядати логи служб, що працюють на вузлі. Щоб скористатися цією функцією, переконайтеся, що для цього вузла увімкнути функціональну можливістьNodeLogQuery, а також що параметри конфігурації kubelet enableSystemLogHandler та enableSystemLogQuery обидва встановлені в значення true. На Linux ми припускаємо, що логи служб доступні через journald. На Windows ми припускаємо, що логи служб доступні в постачальнику логів застосунків. В обох операційних системах логи також доступні за допомогою читання файлів у теці /var/log/.
Якщо у вас є дозвіл на взаємодію з обʼєктами Node, ви можете спробувати цю функцію на всіх ваших вузлах або лише на їх підмножині. Ось приклад отримання логу служби kubelet з вузла:
# Отримати логи kubelet з вузла під назвою node-1.examplekubectl get --raw "/api/v1/nodes/node-1.example/proxy/logs/?query=kubelet"
Ви також можете отримувати файли, за умови, що файли знаходяться в теці, для якої kubelet дозволяє читання логів. Наприклад, ви можете отримати лог з /var/log/ на вузлі Linux:
kubectl get --raw "/api/v1/nodes/<назва-вузла>/proxy/logs/?query=/<назва-файлу-логу>"
Kubelet використовує евристику для отримання логів. Це допомагає, якщо ви не знаєте, чи даний системний сервіс записує логи до стандартного реєстратора операційної системи, такого як journald, чи до файлу логу у /var/log/. Спочатку евристика перевіряє стандартний реєстратор, а якщо його немає, вона намагається отримати перші логи з /var/log/<імʼя-служби> або /var/log/<назва-служби>.log або /var/log/<назва-служби>/<назва-служби>.log.
Повний перелік параметрів, які можна використовувати:
Опція
Опис
boot
показує повідомлення про завантаження з певного завантаження системи
pattern
фільтрує записи логу за заданим регулярним виразом, сумісним з Perl
query
вказує службу(и) або файли, з яких слід повернути логи (обовʼязково)
sinceTime
час відображення логу, починаючи з RFC3339 (включно)
untilTime
час до якого показувати логи, за RFC3339 (включно)
tailLines
вказує, скільки рядків з кінця логу отримати; типово отримується весь журнал
Приклад складнішого запиту:
# Отримати логи kubelet з вузла під назвою node-1.example, у яких є слово "error"kubectl get --raw "/api/v1/nodes/node-1.example/proxy/logs/?query=kubelet&pattern=error"
Трейси системних компонентів реєструють затримку та звʼязки між операціями у кластері.
Компоненти Kubernetes відправляють трейси за допомогою Протоколу OpenTelemetry з експортером gRPC і можуть бути зібрані та направлені до різних систем відслідковування за допомогою OpenTelemetry Collector.
Збір трейсів
Компоненти Kubernetes мають вбудовані експортери gRPC для OTLP для експорту трейсів, або через OpenTelemetry Collector, або без нього.
Для повного посібника зі збору трейсів та використання колектора див. Початок роботи з OpenTelemetry Collector. Однак є кілька речей, на які варто звернути увагу, що є специфічними для компонентів Kubernetes.
Типово компоненти Kubernetes експортують трейси за допомогою експортера grpc для OTLP на
порт IANA OpenTelemetry, 4317. Наприклад, якщо колектор працює як sidecar контейнер для компонента Kubernetes, наступна конфігурація приймача збере відрізки (spans) та відправить їх у стандартний вивід:
receivers:otlp:protocols:grpc:exporters:# Замініть цей експортер на експортер для вашої системиexporters:debug:verbosity:detailedservice:pipelines:traces:receivers:[otlp]exporters:[debug]
Для безпосереднього надсилання трейсів до бекенду без використання колектора, вкажіть поле endpoint у конфігурації Kubernetes з адресою бекенду. Цей метод усуває потребу в колекторі та спрощує загальну структуру.
Для конфігурації заголовків backend trace, включаючи дані автентифікації, можна використовувати змінні середовища з OTEL_EXPORTER_OTLP_HEADERS, див. Конфігурація Експортера OTLP.
Додатково, для конфігурації атрибутів ресурсів trace, таких як назва кластера Kubernetes, простір імен, імʼя Pod і т. д., також можна використовувати змінні середовища з OTEL_RESOURCE_ATTRIBUTES, див. Ресурс Kubernetes OTLP.
Трейси компонентів
Трейси kube-apiserver
Kube-apiserver генерує відрізки для вхідних HTTP-запитів та для вихідних запитів до веб-хуків, etcd та повторних запитів. Він передає W3C Trace Context з вихідними запитами, але не використовує контекст трейса, доданий до вхідних запитів, оскільки kube-apiserver часто є загальнодоступною точкою доступу.
Увімкнення трейсів в kube-apiserver
Щоб увімкнути трейси, надайте kube-apiserver файл конфігурації тресів з --tracing-config-file=<шлях-до-конфігу>. Це приклад конфігурації, яка записує відрізки для 1 з 10000 запитів та використовує типову точку доступу OpenTelemetry:
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.27 [beta] (стандартно увімкнено: true)
Інтерфейс CRI kubelet та автентифіковані http-сервери інструментовані для генерації відрізків трейсів. Як і apiserver, адресу та частоту зразків можна налаштувати. Контекст трейсів також налаштований. Рішення про зразок батьківського відрізка завжди береться до уваги. Частота зразків трейсів, надана в конфігурації, застосовуватиметься до відрізків без батьків. Ввімкнено без налаштованої точки доступу, типова адреса приймача OpenTelemetry Collector — "localhost:4317".
Увімкнення трейсів в kubelet
Щоб увімкнути трейси, застосуйте конфігурацію. Це приклад шматка конфігурації kubelet, що записує відрізки для 1 з 10000 запитів та використовує типову точку доступу OpenTelemetry:
Якщо samplingRatePerMillion встановлено на мільйон (1000000), то кожен відрізок буде відправлений до експортера.
Kubelet у Kubernetes v1.33 збирає відрізки зі збирання сміття, процесів синхронізації Podʼів, а також кожного методу gRPC. Kubelet передає контекст трейсів із запитами gRPC, щоб контейнерні середовища з інструментованими трейсами, такі як CRI-O та containerd, могли асоціювати їх експортовані відрізки з контекстом трейсів від kubelet. Отримані трейси будуть мати посилання батько-дитина між відрізками kubelet та контейнерним середовищем, надаючи корисний контекст при налагодженні вузла.
Зверніть увагу, що експортування відрізків завжди супроводжується невеликим перевантаженням мережі та CPU, залежно від загальної конфігурації системи. Якщо в кластері, в якому увімкнено трейси, виникає будь-яка проблема, така як ця, то помʼякшіть проблему шляхом зменшення samplingRatePerMillion або повністю вимкніть трейси, видаливши конфігурацію.
Стабільність
Інструментування трейсів все ще перебуває в активній розробці та може змінюватися різними способами. Це стосується назв відрізків, приєднаних атрибутів, інструментованих точок доступу та інших. До того часу, поки ця функція не стане стабільною, не надається жодних гарантій зворотної сумісності для інструментів трейсів.
існування та реалізація різниться від кластера до кластера (наприклад, nginx)
розташований між всіма клієнтами та одним або кількома apiservers
діє як балансувальник навантаження, якщо є кілька apiservers.
Хмарні балансувальники навантаження на зовнішньому Service:
надаються деякими хмарними провайдерами (наприклад, AWS ELB, Google Cloud Load Balancer)
створюються автоматично, коли у Service Kubernetes тип — LoadBalancer
зазвичай підтримують лише UDP/TCP
підтримка SCTP залежить від реалізації балансувальника навантаження хмарного провайдера
реалізація відрізняється від провайдера хмарних послуг.
Зазвичай користувачі Kubernetes не повинні турбуватися про щось, крім перших двох типів. Зазвичай адміністратор кластера забезпечує правильне налаштування останніх типів.
Запит на перенаправлення
Проксі замінили можливості перенаправлення. Перенаправлення були визнані застарілими.
15 - API Priority та Fairness
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.29 [stable]
Контроль поведінки сервера API Kubernetes у ситуації перевантаження є основним завданням для адміністраторів кластера. У kube-apiserver є деякі елементи керування (тобто прапорці командного рядка --max-requests-inflight та --max-mutating-requests-inflight), щоб обмежити обсяг невиконаної роботи, яка буде прийнята, запобігаючи перевантаженню потоку вхідних запитів та потенційному збою сервера API, але цих прапорців недостатньо для забезпечення проходження найважливіших запитів у період високого навантаження.
Елементи API Priority та Fairness (APF) є альтернативою, яка покращує зазначені обмеження щодо максимального числа невиконаних завдань. APF класифікує та ізолює запити більш деталізованим способом. Вони також вводять обмеження на черги, щоб ніякі запити не були відхилені в разі дуже коротких вибухів. Запити надсилаються з черг за допомогою техніки справедливих черг, так що, наприклад, контролер, який погано поводиться не має вичерпати інші ресурси (навіть на тому ж рівні пріоритету).
Ця функція розроблена для співпраці зі стандартними контролерами, які використовують інформатори та реагують на невдачі запитів API з експоненційним збільшенням часу очікування, та іншими клієнтами, які також працюють таким чином.
Увага:
Деякі запити, класифіковані як "тривалі", такі як виконання віддалених команд або отримання останніх записів з логів, не є предметом фільтрації API Priority та Fairness. Це також стосується прапорця командного рядка --max-requests-inflight без увімкненої функціональності API Priority та Fairness. API Priority та Fairness застосовується до watch запитів. Коли функціональність API Priority та Fairness вимкнена, watch запити не підлягають обмеженню --max-requests-inflight.
Увімкнення/вимкнення API Priority та Fairness
API Priority та Fairness контролюється прапорцем командного рядка та є типово увімкненим. Див. Опції для загального пояснення доступних опцій командного рядка kube-apiserver та того, як їх увімкнути та вимкнути. Назва параметра командного рядка для APF — "--enable-priority-and-fairness". Ця функція також включає API Group, яка має: (a) стабільну версію v1, введена у версії 1.29, і типово увімкнена, (b) версію v1beta3, типово увімкнена та застаріла у версії v1.29. Ви можете вимкнути бета-версію групи API v1beta3, додавши наступні параметри командного рядка до запуску kube-apiserver:
kube-apiserver \
--runtime-config=flowcontrol.apiserver.k8s.io/v1beta3=false\
# …і інші прапорці, як завжди
Параметр командного рядка --enable-priority-and-fairness=false вимкне API Priority та Fairness.
Рекурсивні сценарії сервера
API Priority and Fairness повинні використовуватися обережно в рекурсивних сценаріях сервера. Це сценарії, в яких сервер A, обробляючи запит, надсилає допоміжний запит на сервер B. Можливо, сервер B може навіть зробити подальший допоміжний виклик назад до сервера A. У ситуаціях, коли контроль Пріоритету і Справедливості застосовується як до оригінального запиту, так і до деяких допоміжних, незалежно від глибини рекурсії, існує небезпека пріоритетних інверсій та/або взаємоблокувань.
Прикладом рекурсії є випадок, коли kube-apiserver робить виклик admission webhook на сервер B, і під час обробки цього виклику сервер B робить подальший допоміжний запит назад до kube-apiserver. Інший приклад рекурсії — коли обʼєкт APIService спрямовує kube-apiserver делегувати запити щодо певної групи API на власний зовнішній сервер B користувача (це один з аспектів, які називаються "агрегацією").
Коли відомо, що оригінальний запит належить до певного рівня пріоритету, і допоміжні контрольовані запити класифікуються на вищі рівні пріоритету, це може бути одним з можливих рішень. Коли оригінальні запити можуть належати до будь-якого рівня пріоритету, допоміжні контрольовані запити повинні бути звільнені від обмежень Priority and Fairness. Один із способів це зробити — за допомогою обʼєктів, які налаштовують класифікацію та обробку, обговорених нижче. Інший спосіб — повністю відключити Priority and Fairness на сервері B, використовуючи техніки, обговорені вище. Третій спосіб, який найпростіше використовувати, коли сервер B не є kube-apiserver, це побудувати сервер B з відключеним у коді Priority and Fairness.
Концепції
API Priority та Fairness включає кілька різних функцій. Вхідні запити класифікуються за атрибутами запиту за допомогою FlowSchemas, і призначаються пріоритетним рівням. Пріоритетні рівні додають ступінь ізоляції, підтримуючи окремі обмеження паралелізму, так що запити, які призначені для різних пріоритетних рівнів, не можуть позбавляти ресурсів один одного. У межах пріоритетного рівня алгоритм справедливого чергування не дозволяє запитам з різних потоків позбавляти ресурсів один одного, і дозволяє чергувати запити, щоб запобігти відмовам від запитів у випадках, коли середнє навантаження прийнятно низьке.
Рівні пріоритету
Без увімкненої функції APF загальний паралелізм в API-сервері обмежується прапорцями --max-requests-inflight та --max-mutating-requests-inflight у kube-apiserver. З увімкненою функцією APF ліміти паралелізму, визначені цими прапорцями, сумуються, а потім сума розподіляється серед налаштованого набору рівнів пріоритету. Кожен вхідний запит призначається одному з рівнів пріоритету, і кожен рівень пріоритету буде обробляти лише стільки одночасних запитів, скільки дозволяє його конкретний ліміт.
Наприклад, у типовій конфігурації існують окремі рівні пріоритету для запитів на вибір лідера, запитів від вбудованих контролерів і запитів від Podʼів. Це означає, що Podʼи, які поводяться погано і завалюють API-сервер запитами, не можуть перешкодити вибору лідера або виконанню дій вбудованими контролерами.
Межі паралелізму рівнів пріоритету періодично коригуються, що дозволяє недостатньо використовуваним рівням пріоритету тимчасово надавати паралелізм сильно використовуваних рівнів. Ці обмеження базуються на номінальних обмеженнях та межах того, скільки паралелізму може позичити рівень пріоритету та скільки він може позичити, всі отримані з обʼєктів конфігурації, згаданих нижче.
Місця, зайняті за запитом
Наведений вище опис управління паралелізмом є базовою поведінкою. Запити мають різну тривалість, але враховуються однаково в будь-який момент при порівнянні з лімітом паралелізму на рівні пріоритету. У базовій поведінці кожен запит займає одну одиницю паралелізму. Слово "місце" (seat) використовується для позначення однієї одиниці паралелізму, під впливом від того, як кожен пасажир у поїзді або літаку займає одне з фіксованих місць.
Але деякі запити займають більше, ніж одне місце. Деякі з них — це запити list, які сервер оцінює, що повертають велику кількість обʼєктів. Вони виявилися надзвичайно важкою ношею для сервера. З цієї причини сервер оцінює кількість обʼєктів, які будуть повернуті, і вважає, що запит займає кількість місць, пропорційну цій оцінці.
Коригування часу виконання для запитів watch
API Priority та Fairness керує запитами watch, але це передбачає ще кілька відступів від базової поведінки. Перше стосується того, як довго запит watch вважається таким, що займає своє місце. Залежно від параметрів запиту, відповідь на запит на watch може або не може розпочинатися зі сповіщень create для всіх відповідних попередніх обʼєктів. API Priority та Fairness вважає, що запит watch завершено зі своїм місцем, як тільки цей початковий вибух сповіщень, якщо такі є, закінчився.
Нормальні сповіщення надсилаються у паралельному сплеску на всі потрібні потоки відповіді на watch, коли сервер отримує сповіщення про створення/оновлення/видалення обʼєкта. Для врахування цієї роботи API Priority та Fairness вважає, що кожен записний запит витрачає додатковий час, займаючи місця після завершення фактичного запису. Сервер оцінює кількість сповіщень, які будуть надіслані, і коригує кількість місць та час зайнятості місця для записного запиту, щоб врахувати цю додаткову роботу.
Черги
Навіть на рівні пріоритету може бути велика кількість різних джерел трафіку. У ситуації перевантаження важливо запобігти тому, щоб один потік вичерпував ресурси інших (зокрема, у відносно поширеному випадку, коли один помилковий клієнт переповнює kube-apiserver запитами, цей помилковий клієнт в ідеалі взагалі не мав би помітного впливу на інших клієнтів). Це обробляється за допомогою алгоритму справедливої черги для обробки запитів, яким присвоєно однаковий рівень пріоритету. Кожен запит присвоюється потоку, ідентифікованому за назвою відповідної FlowSchema плюс розрізнювач потоку - який є або запитуючим користувачем, або простором імен цільового ресурсу, або нічим - і система намагається надати приблизно однакову вагу запитам у різних потоках одного і того ж рівня пріоритету. Щоб забезпечити чітку обробку різних екземплярів, контролери, які мають багато екземплярів, повинні автентифікуватися за допомогою різних імен користувачів
Це забезпечується за допомогою алгоритму справедливих черг обробки запитів, які призначені для того ж рівня пріоритету. Кожен запит призначається для потоку, ідентифікованого імʼям відповідного FlowSchema плюс розрізнювач потоку — яким є або користувач-абонент, або простір імен цільового ресурсу, або нічого — і система намагається надати приблизно рівну вагу запитам в різних потоках того ж рівня пріоритету.
Після класифікації запиту у потік, API Priority та Fairness може призначити запит до черги. Це призначення використовує техніку, відому як shuffle sharding, яка досить ефективно використовує черги для ізоляції потоків низької інтенсивності від потоків високої інтенсивності.
Деталі алгоритму черг налаштовуються для кожного рівня пріоритету і дозволяють адміністраторам збалансувати використання памʼяті, справедливість (властивість того, що незалежні потоки всі рухатимуться вперед, коли загальний трафік перевищує потужність), толерантність до бурхливого трафіку та доданий час очікування, що виникає через черги.
Ексклюзивні запити
Деякі запити вважаються достатньо важливими, щоб не підлягати жодним обмеженням, які накладає ця функція. Ці винятки запобігають тому, щоб неправильно налаштована конфігурація керування потоком повністю вимкнула API-сервер.
Ресурси
API керування потоком включає два види ресурсів. Конфігурації рівня пріоритету визначають доступні рівні пріоритету, частку доступного бюджету паралелізму, яку кожен може обробити, та дозволяють налаштовувати поведінку черги. FlowSchemas використовуються для класифікації окремих вхідних запитів, відповідність кожного з PriorityLevelConfiguration.
PriorityLevelConfiguration
PriorityLevelConfiguration представляє один рівень пріоритету. Кожен PriorityLevelConfiguration має незалежні обмеження на кількість невиконаних запитів та обмеження на кількість запитів у черзі.
Номінальне обмеження паралелізму для PriorityLevelConfiguration не визначається в абсолютній кількості місць, а в "номінальних частках паралелізму". Загальне обмеження паралелізму для API-сервера розподіляється серед наявних конфігурацій рівня пріоритету пропорційно цим часткам, щоб кожен рівень отримав своє номінальне обмеження у вигляді місць. Це дозволяє адміністратору кластера збільшувати або зменшувати загальний обсяг трафіку до сервера, перезапускаючи kube-apiserver з іншим значенням для --max-requests-inflight (або --max-mutating-requests-inflight), і всі PriorityLevelConfiguration побачать, що їх максимально допустимий паралелізм збільшиться (або зменшиться) на ту саму частку.
Увага:
У версіях до v1beta3 відповідне поле PriorityLevelConfiguration має назву "assured concurrency shares" замість "nominal concurrency shares". Також у версії Kubernetes 1.25 та раніше не проводилося періодичних налаштувань: номінальні/забезпечені обмеження застосовувалися завжди без коригування.
Межі того, скільки паралелізму може надати рівень пріоритету та скільки він може позичити, виражені в PriorityLevelConfiguration у відсотках від номінального обмеження рівня. Ці значення перетворюються на абсолютні числа місць, множачи їх на номінальне обмеження / 100.0 та округлюючи. Динамічно кориговане обмеження паралелізму рівня пріоритету обмежене нижньою межею його номінального обмеження мінус кількість місць, які він може позичити, та верхньою межею його номінального обмеження плюс місця, які він може позичити. Під час кожного налаштування динамічні межі визначаються кожним рівнем пріоритету, відновлюючи будь-які позичені місця, на які востаннє зʼявлявся попит, та спільно відповідаючи на попит за місцями на рівнях пріоритету в межах вищезазначених меж.
Увага:
При увімкненні функції Priority та Fairness загальне обмеження паралелізму для сервера встановлюється як сума --max-requests-inflight та --max-mutating-requests-inflight. Більше не робиться різниці між змінними та незмінними запитами; якщо ви хочете обробляти їх окремо для певного ресурсу, створіть окремі FlowSchemas, які відповідають відповідним діям.
Коли обсяг вхідних запитів, які призначені для одного PriorityLevelConfiguration, перевищує його дозволений рівень паралелізму, поле type його специфікації визначає, що відбудеться з додатковими запитами. Тип Reject означає, що зайвий трафік буде негайно відхилено з помилкою HTTP 429 (Too Many Requests). Тип Queue означає, що запити, які перевищують поріг, будуть ставитися у чергу, із використанням технік випадкового розміщення та справедливої черги для збалансування прогресу між потоками запитів.
Конфігурація черги дозволяє налаштувати алгоритм справедливої черги для рівня пріоритету. Деталі алгоритму можна знайти у пропозиції про вдосконалення, ось скорочено:
Збільшення queues зменшує швидкість зіткнень між різними потоками, коштом збільшення використання памʼяті. Значення 1 тут фактично вимикає логіку справедливої черги, але все ще дозволяє ставити запити в чергу.
Збільшення queueLengthLimit дозволяє підтримувати більші потоки трафіку без відкидання будь-яких запитів, коштом збільшення затримки та використання памʼяті.
Зміна handSize дозволяє вам налаштувати ймовірність зіткнень між різними потоками та загальний паралелізм, доступний для одного потоку в ситуації перевантаження.
Примітка:
Більше значення handSize дає менше ймовірності, що два окремі потоки зіткнуться (і, отже, один зможе відібрати ресурси в іншого), але більше ймовірності того, що невелика кількість потоків може домінувати в apiserver. Більше значення handSize також потенційно збільшує кількість затримок, які може спричинити один потік з високим трафіком. Максимальна кількість запитів, які можна поставити в чергу від одного потоку, становить handSize * queueLengthLimit.
Нижче наведена таблиця з цікавою колекцією конфігурацій випадкового розміщення, що показує для кожної ймовірність те, що певна миша (потік низької інтенсивності) буде розчавлена слонами (потоками високої інтенсивності) для ілюстративної колекції числа слонів. Див.
https://play.golang.org/p/Gi0PLgVHiUg, який обчислює цю таблицю.
Приклади конфігурацій випадкового розміщення
HandSize
Черги
1 слон
4 слони
16 слонів
12
32
4.428838398950118e-09
0.11431348830099144
0.9935089607656024
10
32
1.550093439632541e-08
0.0626479840223545
0.9753101519027554
10
64
6.601827268370426e-12
0.00045571320990370776
0.49999929150089345
9
64
3.6310049976037345e-11
0.00045501212304112273
0.4282314876454858
8
64
2.25929199850899e-10
0.0004886697053040446
0.35935114681123076
8
128
6.994461389026097e-13
3.4055790161620863e-06
0.02746173137155063
7
128
1.0579122850901972e-11
6.960839379258192e-06
0.02406157386340147
7
256
7.597695465552631e-14
6.728547142019406e-08
0.0006709661542533682
6
256
2.7134626662687968e-12
2.9516464018476436e-07
0.0008895654642000348
6
512
4.116062922897309e-14
4.982983350480894e-09
2.26025764343413e-05
6
1024
6.337324016514285e-16
8.09060164312957e-11
4.517408062903668e-07
FlowSchema
FlowSchema — це визначення, яке відповідає деяким вхідним запитам і призначає їх певному рівню пріоритету. Кожний вхідний запит перевіряється на відповідність FlowSchemas, починаючи з тих, що мають найменше числове значення matchingPrecedence, і працюючи вгору. Перший збіг перемагає.
Увага:
Лише перший збіг FlowSchema для даного запиту має значення. Якщо для одного вхідного запиту відповідає декілька FlowSchema, він буде призначений відповідно до того, що має найвищий matchingPrecedence. Якщо кілька FlowSchema з рівним matchingPrecedence відповідають тому ж запиту, переможе та, яка має лексикографічно менший name, але краще не покладатися на це, а замість цього переконатися, що жодні дві FlowSchema не мають одного й того ж matchingPrecedence.
FlowSchema відповідає даному запиту, якщо принаймні одне з rules має збіг. Правило має збіг, якщо принаймні один з його subjectsта принаймні один з його resourceRules або nonResourceRules (залежно від того, чи є вхідний запит для ресурсу, чи нересурсного URL) відповідає запиту.
Для поля name в підсумках та полів verbs, apiGroups, resources, namespaces та nonResourceURLs правил ресурсів та нересурсних правил можна вказати маску *, щоб відповідати всім значенням для вказаного поля, яке фактично видаляє його з використання.
Тип distinguisherMethod.type FlowSchema визначає, як запити, які відповідають цій схемі, будуть розділені на потоки. Це може бути ByUser, коли один користувач має можливість позбавити інших користувачів можливості використовувати ресурси; ByNamespace, коли запити до ресурсів в одному просторі імен не можуть позбавити запити до ресурсів в інших просторах імен можливості використовувати їх; або порожнє значення (або distinguisherMethod може бути пропущений повністю), коли всі запити, які відповідають цій FlowSchema, будуть вважатися частиною одного потоку. Правильний вибір для даної FlowSchema залежить від ресурсу та вашого конкретного середовища.
Стандартні
Кожен kube-apiserver підтримує два різновиди обʼєктів API Priority та Fairnes: обовʼязкові та рекомендовані.
Обовʼязкові обʼєкти конфігурації
Чотири обовʼязкові обʼєкти конфігурації відображають фіксовану вбудовану поведінку обмежень безпеки. Це поведінка, яку сервери мають до того, як ці обʼєкти почнуть існувати, і коли ці обʼєкти існують, їх специфікації відображають цю поведінку. Чотири обовʼязкові обʼєкти є такими:
Обовʼязковий пріоритетний рівень exempt використовується для запитів, які взагалі не підлягають контролю потоку: вони завжди будуть надсилатися негайно. Обовʼязкова FlowSchema exempt класифікує всі запити з групи system:masters у цей рівень пріоритету. Ви можете визначити інші FlowSchemas, які направляють інші запити на цей рівень пріоритету, якщо це доцільно.
Обовʼязковий пріоритетний рівень catch-all використовується в поєднанні з обовʼязковою FlowSchema catch-all, щоб переконатися, що кожен запит отримує якийсь вид класифікації. Зазвичай ви не повинні покладатися на цю універсальну catch-all конфігурацію і повинні створити свою власну FlowSchema та PriorityLevelConfiguration для обробки всіх запитів. Оскільки очікується, що він не буде використовуватися нормально, обовʼязковий рівень пріоритету catch-all має дуже невелику частку паралелізму і не ставить запити в чергу.
Рекомендовані обʼєкти конфігурації
Рекомендовані FlowSchema та PriorityLevelConfigurations складають обґрунтовану типову конфігурацію. Ви можете змінювати їх або створювати додаткові обʼєкти конфігурації за необхідності. Якщо ваш кластер може зазнати високого навантаження, то варто розглянути, яка конфігурація працюватиме краще.
Рекомендована конфігурація групує запити в шість рівнів пріоритету:
Рівень пріоритету node-high призначений для оновлень стану вузлів.
Рівень пріоритету system призначений для запитів, які не стосуються стану справності, з групи system:nodes, тобто Kubelets, які повинні мати можливість звʼязатися з сервером API, щоб завдання могли плануватися на них.
Рівень пріоритету leader-election призначений для запитів на вибір лідера від вбудованих контролерів (зокрема, запити на endpoints, configmaps або leases, що надходять від користувачів та облікових записів служб з групи system:kube-controller-manager або system:kube-scheduler в просторі імен kube-system). Ці запити важливо ізолювати від іншого трафіку, оскільки невдачі у виборі лідера призводять до збоїв їх контролерів і перезапуску, що в свою чергу призводить до більших витрат трафіку, оскільки нові контролери синхронізують свої сповіщувачі.
Рівень пріоритету workload-high призначений для інших запитів від вбудованих контролерів.
Рівень пріоритету workload-low призначений для запитів від будь-якого іншого облікового запису служби, що зазвичай включає всі запити від контролерів, що працюють в капсулах.
Рівень пріоритету global-default обробляє весь інший трафік, наприклад, інтерактивні команди kubectl, запущені непривілейованими користувачами.
Рекомендовані FlowSchema служать для направлення запитів на вищезазначені рівні пріоритету, і тут вони не перераховані.
Підтримка обовʼязкових та рекомендованих обʼєктів конфігурації
Кожен kube-apiserver незалежно підтримує обовʼязкові та рекомендовані обʼєкти конфігурації, використовуючи початкову та періодичну поведінку. Отже, в ситуації з сумішшю серверів різних версій може відбуватися турбулентність, поки різні сервери мають різні погляди на відповідний вміст цих обʼєктів.
Кожен kube-apiserver робить початковий обхід обовʼязкових та рекомендованих обʼєктів конфігурації, а після цього здійснює періодичну обробку (один раз на хвилину) цих обʼєктів.
Для обовʼязкових обʼєктів конфігурації підтримка полягає в тому, щоб забезпечити наявність обʼєкта та, якщо він існує, мати правильну специфікацію. Сервер відмовляється дозволити створення або оновлення зі специфікацією, яка не узгоджується з поведінкою огородження сервера.
Підтримка рекомендованих обʼєктів конфігурації призначена для того, щоб дозволити перевизначення їх специфікації. Видалення, з іншого боку, не враховується: підтримка відновить обʼєкт. Якщо вам не потрібен рекомендований обʼєкт конфігурації, то вам потрібно залишити його, але встановити його специфікацію так, щоб мінімально впливати на систему. Підтримка рекомендованих обʼєктів також призначена для підтримки автоматичної міграції при виході нової версії kube-apiserver, хоча, можливо, з турбулентністю при змішаній популяції серверів.
Підтримка рекомендованого обʼєкта конфігурації включає його створення, зі специфікацією, яку пропонує сервер, якщо обʼєкт не існує. З іншого боку, якщо обʼєкт вже існує, поведінка підтримка залежить від того, чи контролюють обʼєкт kube-apiservers чи користувачі. У першому випадку сервер забезпечує, що специфікація обʼєкта відповідає тому, що пропонує сервер; у другому випадку специфікація залишається без змін.
Питання про те, хто контролює обʼєкт, вирішується спочатку шляхом пошуку анотації з ключем apf.kubernetes.io/autoupdate-spec. Якщо така анотація є і її значення true, то обʼєкт контролюється kube-apiservers. Якщо така анотація існує і її значення false, то обʼєкт контролюють користувачі. Якщо жодна з цих умов не виконується, тоді перевіряється metadata.generation обʼєкта. Якщо вона дорівнює 1, то обʼєкт контролюють kube-apiservers. В іншому випадку обʼєкт контролюють користувачі. Ці правила були введені у версії 1.22, і врахування ними metadata.generation призначена для міграції з більш простої попередньої поведінки. Користувачі, які хочуть контролювати рекомендований обʼєкт конфігурації, повинні встановити анотацію apf.kubernetes.io/autoupdate-spec в false.
Підтримка обовʼязкового або рекомендованого обʼєкта конфігурації також включає забезпечення наявності анотації apf.kubernetes.io/autoupdate-spec, яка точно відображає те, чи контролюють kube-apiservers обʼєкт.
Підтримка також включає видалення обʼєктів, які не є обовʼязковими або рекомендованими, анотованих як apf.kubernetes.io/autoupdate-spec=true.
Звільнення від паралелізму перевірки справності
Запропонована конфігурація не надає спеціального поводження запитам на перевірку стану здоровʼя на kube-apiservers від їхніх локальних kubelets, які зазвичай використовують захищений порт, але не надають жодних облікових даних. Запити цього типу вказаної конфігурації призначаються до FlowSchema global-default і відповідного пріоритетного рівня global-default, де інші запити можуть їх перенавантажувати.
Якщо ви додасте наступний додатковий FlowSchema, це звільнить ці запити від обмежень.
Увага:
Ці зміни, також дозволяють будь-якому, навіть зловмисникам надсилати запити перевірки стану справності, які відповідають цьій FlowSchema, у будь-якому обсязі. Якщо у вас є фільтр вебтрафіку або подібний зовнішній механізм безпеки для захисту сервера API вашого кластера від загального зовнішнього трафіку, ви можете налаштувати правила для блокування будь-яких запитів на перевірку стану справності, які походять ззовні вашого кластера.
У версіях Kubernetes перед v1.20 мітки flow_schema та priority_level мали нестабільні назви flowSchema та priorityLevel, відповідно. Якщо ви використовуєте версії Kubernetes v1.19 та раніше, вам слід звертатися до документації для вашої версії.
Після увімкнення функції API Priority та Fairness, kube-apiserver експортує додаткові метрики. Моніторинг цих метрик може допомогти вам визначити, чи правильно ваша конфігурація обробляє важливий трафік, або знайти проблемні робочі навантаження, які можуть шкодити справності системи.
Рівень зрілості BETA
apiserver_flowcontrol_rejected_requests_total — це вектор лічильника (накопичувальний з моменту запуску сервера) запитів, які були відхилені, розбитий за мітками flow_schema (показує той, який підходить до запиту), priority_level (показує той, до якого був призначений запит) і reason. Мітка reason буде мати одне з наступних значень:
queue-full, що вказує на те, що занадто багато запитів вже було в черзі.
concurrency-limit, що вказує на те, що конфігурація PriorityLevelConfiguration налаштована відхиляти замість того, щоб ставити в чергу зайві запити.
time-out, що вказує на те, що запит все ще перебував в черзі, коли його обмеження часу в черзі закінчилося.
cancelled, що вказує на те, що запит не закріплений і викинутий з черги.
apiserver_flowcontrol_dispatched_requests_total — це вектор лічильника (накопичувальний з моменту запуску сервера) запитів, які почали виконуватися, розбитий за flow_schema та priority_level.
apiserver_flowcontrol_current_inqueue_requests — це вектор мітки миттєвого числа запитів, які знаходяться в черзі (не виконуються), розбитий за priority_level та flow_schema.
apiserver_flowcontrol_current_executing_requests — це вектор мітки миттєвого числа виконуваних (не очікуючих в черзі) запитів, розбитий за priority_level та flow_schema.
apiserver_flowcontrol_current_executing_seats — це вектор мітки миттєвого числа зайнятих місць, розбитий за priority_level та flow_schema.
apiserver_flowcontrol_request_wait_duration_seconds — це вектор гістограми того, скільки часу запити провели в черзі, розбитий за мітками flow_schema, priority_level та execute. Мітка execute вказує, чи почалося виконання запиту.
Примітка:
Оскільки кожна FlowSchema завжди призначає запити для одного PriorityLevelConfiguration, ви можете додати гістограми для всіх FlowSchemas для одного рівня пріоритету, щоб отримати ефективну гістограму для запитів, призначених для цього рівня пріоритету.
apiserver_flowcontrol_nominal_limit_seats — це вектор вектор, що містить номінальну межу паралелізму кожного рівня пріоритету, обчислювану з загального ліміту паралелізму сервера API та налаштованих номінальних спільних ресурсів паралелізму рівня пріоритету.
Рівень зрілості ALPHA
apiserver_current_inqueue_requests — це вектор вимірювання останніх найвиших значень кількості запитів, обʼєднаних міткою request_kind, значення якої можуть бути mutating або readOnly. Ці величини описують найбільше значення спостереження в односекундному вікні процесів, що недавно завершилися. Ці дані доповнюють старий графік apiserver_current_inflight_requests, що містить високу точку кількості запитів в останньому вікні, які активно обслуговуються.
apiserver_current_inqueue_seats — це вектор мітки миттєвого підсумку запитів, які будуть займати найбільшу кількість місць, згрупованих за мітками з назвами flow_schema та priority_level.
apiserver_flowcontrol_read_vs_write_current_requests — це гістограма спостережень, зроблених в кінці кожної наносекунди, кількості запитів, розбита за мітками phase (приймає значення waiting та executing) та request_kind (приймає значення mutating та readOnly). Кожне спостереження є коефіцентом, від 0 до 1, кількості запитів, поділеним на відповідний ліміт кількості запитів (обмеження обсягу черги для очікування та обмеження паралелізму для виконання).
apiserver_flowcontrol_request_concurrency_in_use — це вектор мітки миттєвого числа зайнятих місць, розбитий за priority_level та flow_schema.
apiserver_flowcontrol_priority_level_request_utilization — це гістограма спостережень, зроблених в кінці кожної наносекунди, кількості запитів, розбита за мітками phase (яка приймає значення waiting та executing) та priority_level. Кожне спостереження є відношенням, від 0 до 1, кількості запитів поділеної на відповідний ліміт кількості запитів (обмеження обсягу черги для очікування та обмеження паралелізму для виконання).
apiserver_flowcontrol_priority_level_seat_utilization — це гістограма спостережень, зроблених в кінці кожної наносекунди, використання обмеження пріоритету паралелізму, розбита за priority_level. Це використання є часткою (кількість зайнятих місць) / (обмеження паралелізму). Цей показник враховує всі етапи виконання (як нормальні, так і додаткові затримки в кінці запису для відповідного сповіщення про роботу) всіх запитів, крім WATCH; для них він враховує лише початковий етап, що доставляє сповіщення про попередні обʼєкти. Кожна гістограма в векторі також має мітку phase: executing (для фази очікування не існує обмеження на кількість місць).
apiserver_flowcontrol_request_queue_length_after_enqueue — це гістограма вектора довжини черги для черг, розбита за priority_level та flow_schema, як вибірка за запитом у черзі. Кожен запит, який потрапив в чергу, вносить один зразок в свою гістограму, що вказує довжину черги негайно після додавання запиту. Зверніть увагу, що це дає інші показники, ніж неупереджене опитування.
Примітка:
Сплеск у значенні гістограми тут означає, що ймовірно, один потік (тобто запити від одного користувача або для одного простору імен, в залежності від конфігурації) затоплює сервер API та піддається обмеженню. На відміну, якщо гістограма одного рівня пріоритету показує, що всі черги для цього рівня пріоритету довші, ніж ті для інших рівнів пріоритету, може бути доцільно збільшити частки паралелізму цієї конфігурації пріоритету.
apiserver_flowcontrol_request_concurrency_limit такий же, як apiserver_flowcontrol_nominal_limit_seats. До введення пралелізму запозичення між рівнями пріоритету, це завжди дорівнювало apiserver_flowcontrol_current_limit_seats (який не існував як окремий метричний показник).
apiserver_flowcontrol_lower_limit_seats — це вектор мітки миттєвої нижньої межі динамічного обмеження паралелізму для кожного рівня пріоритету.
apiserver_flowcontrol_upper_limit_seats — це вектор мітки миттєвої верхньої межі динамічного обмеження паралелізму для кожного рівня пріоритету.
apiserver_flowcontrol_demand_seats — це гістограма вектора підрахунку спостережень, в кінці кожної наносекунди, відношення кожного рівня пріоритету до (вимоги місць) / (номінального обмеження паралелізму). Вимога місць на рівні пріоритету — це сума, як віконаних запитів, так і тих, які перебувають у початковій фазі виконання, максимум кількості зайнятих місць у початкових та кінцевих фазах виконання запиту.
apiserver_flowcontrol_demand_seats_high_watermark — це вектор мітки миттєвого максимального запиту на місця, що спостерігався протягом останнього періоду адаптації до позичання паралелізму для кожного рівня пріоритету.
apiserver_flowcontrol_demand_seats_average - це вектор мітки миттєвого часового середнього значення вимог місць для кожного рівня пріоритету, що спостерігався протягом останнього періоду адаптації до позичання паралелізму.
apiserver_flowcontrol_demand_seats_stdev - це вектор мітки миттєвого стандартного відхилення популяції вимог місць для кожного рівня пріоритету, що спостерігався протягом останнього періоду адаптації до позичання паралелізму.
apiserver_flowcontrol_demand_seats_smoothed - це вектор мітки миттєвого вирівняного значення вимог місць для кожного рівня пріоритету, визначений на останній період адаптації.
apiserver_flowcontrol_target_seats - це вектор мітки миттєвого усередненого значення вимог місць для кожного рівня пріоритету, яке виходить в алокації позичання.
apiserver_flowcontrol_seat_fair_frac - це мітка миттєвого значення частки справедливого розподілу, визначеного при останній адаптації позичання.
apiserver_flowcontrol_current_limit_seats - це вектор мітки миттєвого динамічного обмеження паралелізму для кожного рівня пріоритету, яке було виведено в останню корекцію.
apiserver_flowcontrol_request_execution_seconds - це гістограма, яка показує, скільки часу займає виконання запитів, розбита за flow_schema та priority_level.
apiserver_flowcontrol_watch_count_samples - це гістограма вектора кількості активних WATCH-запитів, що стосуються певного запису, розбита за flow_schema та priority_level.
apiserver_flowcontrol_work_estimated_seats - це гістограма вектора кількості оцінених місць (максимум початкової та кінцевої стадії виконання) для запитів, розбита за flow_schema та priority_level.
apiserver_flowcontrol_request_dispatch_no_accommodation_total - це лічильник вектора кількості подій, які в принципі могли призвести до відправки запиту, але не зробили цього через відсутність доступного паралелізму, розбитий за flow_schema та priority_level.
apiserver_flowcontrol_epoch_advance_total - це лічильник вектора кількості спроб зрушити вимірювач прогресу рівня пріоритету назад, щоб уникнути переповнення числових значень, згрупований за priority_level та success.
Поради щодо використання API Priority та Fairness
Коли певний рівень пріоритету перевищує свій дозволений паралелізм, запити можуть зазнавати збільшеного часу очікування або бути відкинуті з HTTP 429 (Забагато запитів) помилкою. Щоб запобігти цим побічним ефектам APF, ви можете змінити ваше навантаження або налаштувати ваші налаштування APF, щоб забезпечити достатню кількість місць для обслуговування ваших запитів.
Щоб виявити, чи відкидаються запити через APF, перевірте наступні метрики:
apiserver_flowcontrol_rejected_requests_total — загальна кількість відкинутих запитів за FlowSchema та PriorityLevelConfiguration.
apiserver_flowcontrol_current_inqueue_requests — поточна кількість запитів в черзі за FlowSchema та PriorityLevelConfiguration.
apiserver_flowcontrol_request_wait_duration_seconds — затримка, додана до запитів, що очікують у черзі.
apiserver_flowcontrol_priority_level_seat_utilization — використання місць на рівні пріоритету за PriorityLevelConfiguration.
Зміни в навантаженні
Щоб запобігти встановленню запитів у чергу та збільшенню затримки або їх відкиданню через APF, ви можете оптимізувати ваші запити шляхом:
Зменшення швидкості виконання запитів. Менша кількість запитів протягом фіксованого періоду призведе до меншої потреби у місцях в будь-який момент часу.
Уникання видачі великої кількості дороговартісних запитів одночасно. Запити можна оптимізувати, щоб вони використовували менше місць або мали меншу затримку, щоб ці запити утримували ці місця протягом коротшого часу. Запити списку можуть займати більше 1 місця в залежності від кількості обʼєктів, отриманих під час запиту. Обмеження кількості обʼєктів, отриманих у запиті списку, наприклад, за допомогою розбиття на сторінки (pagination), буде використовувати менше загальних місць протягом коротшого періоду. Крім того, заміна запитів списку запитами перегляду потребуватиме менше загальних часток паралелізму, оскільки запити перегляду займають лише 1 місце під час свого початкового потоку повідомлень. Якщо використовується потоковий перегляд списків у версіях 1.27 і пізніше, запити перегляду займатимуть таку ж кількість місць, як і запит списку під час його початкового потоку повідомлень, оскільки всі стани колекції мають бути передані по потоку. Зауважте, що в обох випадках запит на перегляд не буде утримувати жодних місць після цієї початкової фази.
Памʼятайте, що встановлення запитів у чергу або їх відкидання через APF можуть бути викликані як збільшенням кількості запитів, так і збільшенням затримки для існуючих запитів. Наприклад, якщо запити, які зазвичай виконуються за 1 секунду, починають виконуватися за 60 секунд, це може призвести до того, що APF почне відкидати запити, оскільки вони займають місця протягом тривалого часу через це збільшення затримки. Якщо APF починає відкидати запити на різних рівнях пріоритету без значного змінення навантаження, можливо, існує проблема з продуктивністю контролера, а не з навантаженням або налаштуваннями APF.
Налаштування Priority та fairness
Ви також можете змінити типові обʼєкти FlowSchema та PriorityLevelConfiguration або створити нові обʼєкти цих типів, щоб краще врахувати ваше навантаження.
Налаштування APF можна змінити для:
Надання більшої кількості місць для запитів високого пріоритету.
Ізоляція необовʼязкових або дорогих запитів, які можуть забрати рівень паралелізму, якщо він буде спільно використовуватися з іншими потоками.
Надання більшої кількості місць для запитів високого пріоритету
У разі можливості кількість місць, доступних для всіх рівнів пріоритету для конкретного kube-apiserver, можна збільшити, збільшивши значення прапорців max-requests-inflight та max-mutating-requests-inflight. Іншим варіантом є горизонтальне масштабування кількості екземплярів kube-apiserver, що збільшить загальну одночасність на рівень пріоритету по всьому кластеру за умови належного балансування навантаження запитів.
Ви можете створити новий FlowSchema, який посилається на PriorityLevelConfiguration з більшим рівнем паралелізму. Ця нова PriorityLevelConfiguration може бути існуючим рівнем або новим рівнем зі своїм набором номінальних поширень паралелізму. Наприклад, новий FlowSchema може бути введений для зміни PriorityLevelConfiguration для ваших запитів з global-default на workload-low з метою збільшення кількості місць, доступних для ваших користувачів. Створення нової PriorityLevelConfiguration зменшить кількість місць, призначених для існуючих рівнів. Нагадаємо, що редагування типових FlowSchema або PriorityLevelConfiguration потребує встановлення анотації apf.kubernetes.io/autoupdate-spec в значення false.
Ви також можете збільшити значення NominalConcurrencyShares для PriorityLevelConfiguration, що обслуговує ваші запити високого пріоритету. Як альтернативу, для версій 1.26 та пізніших, ви можете збільшити значення LendablePercent для конкуруючих рівнів пріоритету, щоб даний рівень пріоритету мав вищий пул місць, які він може позичати.
Ізоляція неважливих запитів, для попередження виснаження інших потоків
Для ізоляції запитів можна створити FlowSchema, чий субʼєкт збігається з користувачеві, що робить ці запити, або створити FlowSchema, яка відповідає самому запиту (відповідає resourceRules). Далі цю FlowSchema можна зіставити з PriorityLevelConfiguration з низьким пулом місць.
Наприклад, припустимо, що запити на перегляд подій з Podʼів, що працюють в стандартному просторі імен, використовують по 10 місць кожен і виконуються протягом 1 хвилини. Щоб запобігти впливу цих дорогих запитів на інші запити від інших Podʼів, які використовують поточну FlowSchema для сервісних облікових записів, можна застосувати таку FlowSchema для ізоляції цих викликів списків від інших запитів.
Приклад обʼєкта FlowSchema для ізоляції запитів на перегляд подій:
FlowSchema захоплює всі виклики списків подій, виконані типовим сервісним обліковим записом у стандартному просторі імен. Пріоритет відповідності 8000 менший за значення 9000, що використовується поточною FlowSchema для сервісних облікових записів, тому ці виклики списків подій будуть відповідати list-events-default-service-account, а не service-accounts.
Використовується конфігурація пріоритету catch-all для ізоляції цих запитів. Пріоритетний рівень catch-all має дуже малий пул місць і не ставить запитів в чергу.
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Надбудови розширюють функціональність Kubernetes.
Ця сторінка містить список доступних надбудов та посилання на відповідні інструкції з встановлення. Список не намагається бути вичерпним.
Мережа та політика мережі
ACI надає інтегровану мережу контейнерів та мережеву безпеку з Cisco ACI.
Antrea працює на рівні 3/4, щоб надати мережеві та служби безпеки для Kubernetes, використовуючи Open vSwitch як мережеву панель даних. Antrea є проєктом CNCF на рівні Sandbox.
Calico є постачальником мережі та мережевої політики. Calico підтримує гнучкий набір мережевих опцій, щоб ви могли вибрати найефективнішу опцію для вашої ситуації, включаючи мережі з та без оверлею, з або без BGP. Calico використовує однаковий рушій для забезпечення мережевої політики для хостів, Podʼів та (якщо використовуєте Istio та Envoy) застосунків на рівні шару сервісної мережі.
Canal обʼєднує Flannel та Calico, надаючи мережу та мережеву політику.
Cilium: це рішення для мережі, спостереження та забезпечення безпеки з eBPF-орієнтованою панеллю даних. Cilium надає просту мережу Layer 3 з можливістю охоплення декількох кластерів в режимі маршрутизації або режимі налагодження/інкапсуляції та може застосовувати політики мережі на рівнях L3-L7 з використанням моделі безпеки на основі ідентифікації, що відʼєднана від мережевого адресування. Cilium може діяти як заміна для kube-proxy; він також пропонує додаткові функції спостереження та безпеки.
CNI-Genie: Дозволяє Kubernetes безперешкодно підключатися до вибору втулків CNI, таких як Calico, Canal, Flannel або Weave.
Contiv: надає налаштовану мережу (L3 з використанням BGP, оверлей за допомогою vxlan, класичний L2 та Cisco-SDN/ACI) для різних варіантів використання та повнофункціональний фреймворк політик. Проєкт Contiv є проєктом з повністю відкритими сирцями. Встановлювач надає як варіанти установки, як з, так і без, kubeadm.
Contrail: оснований на Tungsten Fabric, це відкритою платформою мережевої віртуалізації та управління політикою для кількох хмар. Contrail і Tungsten Fabric інтегровані з системами оркестрування, такими як Kubernetes, OpenShift, OpenStack і Mesos, і надають режими ізоляції для віртуальних машин, контейнерів/Podʼів та обробки робочих навантажень на bare metal.
Flannel: постачальник мережі на основі оверлеїв, який можна використовувати з Kubernetes.
Gateway API: відкритий проєкт, керований SIG Network, який надає виразний, розширюваний та рольовий API для моделювання сервісних мереж.
Knitter є втулком для підтримки кількох мережевих інтерфейсів в Podʼі Kubernetes.
Multus: мультивтулок для підтримки кількох мереж у Kubernetes для підтримки всіх втулків CNI (наприклад, Calico, Cilium, Contiv, Flannel), а також навантаження SRIOV, DPDK, OVS-DPDK та VPP у Kubernetes.
OVN-Kubernetes: постачальник мережі для Kubernetes на основі OVN (Open Virtual Network), віртуальної мережевої реалізації, яка вийшла з проєкту Open vSwitch (OVS). OVN-Kubernetes забезпечує реалізацію мережі на основі оверлеїв для Kubernetes, включаючи реалізацію балансування навантаження на основі OVS та політики мережі.
Nodus: втулок контролера CNI на основі OVN для надання хмарних послуг на основі послуг хмарної обробки (SFC).
NSX-T Container Plug-in (NCP): забезпечує інтеграцію між VMware NSX-T та оркестраторами контейнерів, такими як Kubernetes, а також інтеграцію між NSX-T та контейнерними платформами CaaS/PaaS, такими як Pivotal Container Service (PKS) та OpenShift.
Nuage: платформа SDN, яка забезпечує мережеву політику між кластерами Kubernetes Pods та некластерними середовищами з можливістю моніторингу видимості та безпеки.
Romana: рішення мережі рівня Layer 3 для мережевих мереж Podʼів, яке також підтримує NetworkPolicy API.
Spiderpool: рішення мережі основи та RDMA для Kubernetes. Spiderpool підтримується на bare metal, віртуальних машинах та публічних хмарних середовищах.
Terway: це набір втулків CNI, заснований на мережевих продуктах VPC та ECS від AlibabaCloud. Він забезпечує нативну мережу VPC та мережеві політики в середовищах AlibabaCloud.
Weave Net: надає мережу та політику мережі, буде продовжувати працювати з обох боків розділу мережі та не потребує зовнішньої бази даних.
Виявлення служб
CoreDNS — це гнучкий, розширюваний DNS-сервер, який може бути встановлений як DNS в кластері для Podʼів.
Візуалізація та управління
Dashboard — це вебінтерфейс для управління Kubernetes.
Інфраструктура
KubeVirt — це додатковий інструмент для запуску віртуальних машин на Kubernetes. Зазвичай використовується на кластерах на bare metal.
Існують ще кілька інших надбудов, які документуються в застарілій теці cluster/addons.
Добре підтримувані мають бути вказані тут. Приймаються запити на включення!
17 - Координовані вибори лідера
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [beta] (стандартно увімкнено: false)
Kubernetes 1.33 включає бета-функцію, яка дозволяє компонентам панелі управління детерміновано обирати лідера через координовані вибори лідера. Це корисно для задоволення обмежень щодо несумісності версій Kubernetes під час оновлення кластера. Наразі єдина вбудована стратегія вибору — це OldestEmulationVersion, що надає перевагу лідеру з найнижчою версією емуляції, за яким йде бінарна версія, а потім позначка часу створення.
Увімкнення координованих виборів лідера
Переконайтеся, що функціональну можливістьCoordinatedLeaderElection увімкнено під час запуску API Server та що група API coordination.k8s.io/v1beta1 увімкнена також.
Це можна зробити, встановивши прапорці --feature-gates="CoordinatedLeaderElection=true" та --runtime-config="coordination.k8s.io/v1beta1=true".
Конфігурація компонентів
За умови, що ви увімкнули функціональну можливість CoordinatedLeaderElectionта увімкнули групу API coordination.k8s.io/v1beta1, сумісні компоненти панелі управління автоматично використовують LeaseCandidate та Lease API для вибору лідера за потреби.
Для Kubernetes 1.33 два компоненти панелі управління (kube-controller-manager і kube-scheduler) автоматично використовують координовані вибори лідера, коли функціональну можливість та група API увімкнені.