Цей розділ документації Kubernetes містить сторінки, які
показують, як виконувати окремі завдання. Сторінка завдання показує, як виконати конкретну дію, зазвичай надаючи коротку послідовність кроків.
Встановлення інструментів Kubernetes на ваш компʼютер.
kubectl
Інструмент командного рядка Kubernetes, kubectl, дозволяє вам виконувати команди відносно кластерів Kubernetes. Ви можете використовувати kubectl для розгортання застосунків, огляду та управління ресурсами кластера,
а також перегляду логів. Для отримання додаткової інформації, включаючи повний перелік операцій kubectl, див. Документацію з посилань на kubectl.
kubectl можна встановити на різноманітних платформах Linux, macOS та Windows. Знайдіть свою вибрану операційну систему нижче.
Подібно до kind, minikube — це інструмент, який дозволяє вам запускати Kubernetes локально. minikube запускає одно- або багатовузловий локальний кластер Kubernetes на вашому персональному компʼютері (включаючи ПК з операційними системами Windows, macOS і Linux), так щоб ви могли випробувати Kubernetes або використовувати його для щоденної розробки.
Якщо ваша основна мета — встановлення інструменту, ви можете скористатися офіційним посібником Швидкий старт.
Ви можете використовувати інструмент kubeadm для створення та управління кластерами Kubernetes. Він виконує необхідні дії для запуску мінімально життєздатного та захищеного кластера за допомогою зручного інтерфейсу користувача.
1.1 - Встановлення та налаштування kubectl у Linux
Перш ніж ви розпочнете
Вам потрібно використовувати версію kubectl, яка має мінорну версію що відрізняється не більше ніж на одиницю від мінорної версії вашого кластера. Наприклад, клієнт v1.34 може співпрацювати з панелями управління v1.33, v1.34 та v1.35. Використання останньої сумісної версії kubectl допомагає уникнути непередбачуваних проблем.
Встановлення kubectl у Linux
Існують наступні методи встановлення kubectl у Linux:
Оновіть індекс пакунків apt та встановіть пакунки, необхідні для використання репозиторію apt Kubernetes:
sudo apt-get update
# apt-transport-https може бути макетним пакетом; якщо так, ви можете пропустити цей пакетsudo apt-get install -y apt-transport-https ca-certificates curl gnupg
Завантажте публічний ключ підпису для репозиторіїв пакунків Kubernetes. Той самий ключ підпису використовується для всіх репозиторіїв, тому ви можете проігнорувати версію в URL:
# Якщо тека `/etc/apt/keyrings` не існує, її слід створити перед запуском curl, прочитайте примітку нижче.# sudo mkdir -p -m 755 /etc/apt/keyringscurl -fsSL https://pkgs.k8s.io/core:/stable:/v1.34/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
sudo chmod 644 /etc/apt/keyrings/kubernetes-apt-keyring.gpg # дозволяє непривілейованим програмам APT читати цей ключ
Примітка:
У випусках старших за Debian 12 і Ubuntu 22.04 тека /etc/apt/keyrings не існує, її слід створити перед запуском команди curl.
Додайте відповідний репозиторій Kubernetes apt. Якщо ви хочете використовувати версію Kubernetes, відмінну від v1.34, замініть v1.34 на потрібну мінорну версію в команді нижче:
# Це перезапише будь-яку існуючу конфігурацію в /etc/apt/sources.list.d/kubernetes.listecho'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.34/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo chmod 644 /etc/apt/sources.list.d/kubernetes.list # допомагає правильно працювати з такими інструментами, як command-not-found
Примітка:
Щоб оновити kubectl до іншого мінорного видання, вам потрібно буде збільшити версію в /etc/apt/sources.list.d/kubernetes.list перед виконанням apt-get update та apt-get upgrade. Цю процедуру більш докладно описано в Зміні репозиторію пакунків Kubernetes.
Оновіть індекс пакунків apt, а потім встановіть kubectl:
Додайте репозиторій Kubernetes yum. Якщо ви хочете використовувати версію Kubernetes, відмінну від v1.34, замініть v1.34 на потрібну мінорну версію в команді нижче.
# Це перезапише будь-яку існуючу конфігурацію у /etc/yum.repos.d/kubernetes.repocat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.34/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.34/rpm/repodata/repomd.xml.key
EOF
Примітка:
Щоб оновити kubectl до іншого мінорного випуску, вам потрібно буде збільшити версію в /etc/yum.repos.d/kubernetes.repo перед виконанням yum update. Цю процедуру більш докладно описано в Зміні репозиторію пакунків Kubernetes.
Встановіть kubectl за допомогою yum:
sudo yum install -y kubectl
Додайте репозиторій Kubernetes zypper. Якщо ви хочете використовувати версію Kubernetes, відмінну від v1.34, замініть v1.34 на потрібну мінорну версію в команді нижче.
# Це перезапише будь-яку існуючу конфігурацію у /etc/zypp/repos.d/kubernetes.repocat <<EOF | sudo tee /etc/zypp/repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.34/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.34/rpm/repodata/repomd.xml.key
EOF
Примітка:
Щоб оновити kubectl до іншого мінорного випуску, вам потрібно буде збільшити версію в /etc/zypp/repos.d/kubernetes.repo перед виконанням zypper update. Цю процедуру більш докладно описано в
Зміні репозиторію пакунків Kubernetes.
Оновіть zypper і підтвердіть додавання нового репозиторію:
sudo zypper update
Коли зʼявиться таке повідомлення, натисніть 't' або 'a':
New repository or package signing key received:
Repository: Kubernetes
Key Fingerprint: 1111 2222 3333 4444 5555 6666 7777 8888 9999 AAAA
Key Name: isv:kubernetes OBS Project <isv:kubernetes@build.opensuse.org>
Key Algorithm: RSA 2048
Key Created: Thu 25 Aug 2022 01:21:11 PM -03
Key Expires: Sat 02 Nov 2024 01:21:11 PM -03 (expires in 85 days)
Rpm Name: gpg-pubkey-9a296436-6307a177
Note: Signing data enables the recipient to verify that no modifications occurred after the data
were signed. Accepting data with no, wrong or unknown signature can lead to a corrupted system
and in extreme cases even to a system compromise.
Note: A GPG pubkey is clearly identified by its fingerprint. Do not rely on the key's name. If
you are not sure whether the presented key is authentic, ask the repository provider or check
their web site. Many providers maintain a web page showing the fingerprints of the GPG keys they
are using.
Do you want to reject the key, trust temporarily, or trust always? [r/t/a/?] (r): a
Встановіть kubectl, використовуючи zypper:
sudo zypper install -y kubectl
Встановлення за допомогою іншого пакетного менеджера
Якщо ви користуєтеся Ubuntu або іншим дистрибутивом Linux, який підтримує менеджер пакунків snap, kubectl доступний як застосунок snap.
snap install kubectl --classic
kubectl version --client
Якщо ви користуєтеся Linux і використовуєте пакетний менеджер Homebrew, kubectl доступний для встановлення.
brew install kubectl
kubectl version --client
Перевірка конфігурації Verify
Щоб kubectl знайшов та отримав доступ до кластера Kubernetes, вам потрібен
файл kubeconfig, який створюється автоматично при створенні кластера за допомогою kube-up.sh або успішного розгортання кластера Minikube. Типово конфігурація kubectl знаходиться в ~/.kube/config.
Перевірте, що kubectl належним чином налаштований, отримавши стан кластера:
kubectl cluster-info
Якщо ви бачите у відповідь URL, kubectl налаштований на доступ до вашого кластера.
Якщо ви бачите повідомлення, подібне до наведеного нижче, kubectl не налаштований належним чином або не може приєднатися до кластера Kubernetes.
The connection to the server <server-name:port> was refused - did you specify the right host or port?
Наприклад, якщо ви плануєте запустити кластер Kubernetes на своєму ноутбуці (локально), вам спочатку потрібно встановити інструмент, такий як Minikube, а потім повторно виконати вказані вище команди.
Якщо kubectl cluster-info повертає у відповідь URL, але ви не можете отримати доступ до свого кластера, щоб перевірити, чи він налаштований належним чином, скористайтесь наступною командою:
kubectl cluster-info dump
Усунення несправностей повідомлення про помилку 'No Auth Provider Found'
У Kubernetes 1.26, kubectl видалив вбудовану автентифікацію для Kubernetes-кластерів керованих хмарними провайдерами. Ці провайдери випустили втулок для kubectl для надання хмарно-специфічної автентифікації. Для інструкцій див. документацію відповідного провайдера:
Сценарій автодоповнення kubectl для Bash може бути створений за допомогою команди kubectl completion bash. Підключення цього сценарію у вашій оболонці дозволить вам мати автодоповнення для kubectl.
Однак сценарій залежить від bash-completion, що означає, що спочатку вам потрібно встановити цей скрипт (ви можете перевірити, чи вже встановлено bash-completion, виконавши команду type _init_completion).
Встановлення bash-completion
bash-completion надається багатьма менеджерами пакунків (див. тут). Ви можете встановити його за допомогою apt-get install bash-completion або yum install bash-completion тощо.
Вищевказані команди створюють /usr/share/bash-completion/bash_completion, який є основним сценарієм bash-completion. Залежно від вашого менеджера пакунків, вам доведеться вручну додати цей файл у ваш ~/.bashrc файл.
Щоб дізнатися, перезавантажте вашу оболонку і виконайте type _init_completion. Якщо команда виконується успішно, значить, ви вже його встановили, інакше додайте наступне до вашого ~/.bashrc файлу:
source /usr/share/bash-completion/bash_completion
Перезавантажте вашу оболонку і перевірте, чи bash-completion правильно встановлено, ввівши type _init_completion.
Увімкнення автодоповнення kubectl
Bash
Тепер вам потрібно переконатися, що сценарій автодоповнення kubectl підключений у всіх ваших сеансах оболонки. Є два способи, якими це можна зробити:
Якщо у вас є аліас для kubectl, ви можете розширити автодоповнення оболонки, щоб воно працювало з ним:
echo'alias k=kubectl' >>~/.bashrc
echo'complete -o default -F __start_kubectl k' >>~/.bashrc
Примітка:
bash-completion підключає всі сценарії автодоповнення у /etc/bash_completion.d.
Обидва підходи еквівалентні. Після перезавантаження вашої оболонки автодоповнення kubectl повинно працювати. Щоб увімкнути автодоповнення bash у поточному сеансі оболонки, переініціалізуйте файл ~/.bashrc:
source ~/.bashrc
Примітка:
Автодоповнення для Fish вимагає kubectl версії 1.23 або пізніше.
Сценарій автозавершення kubectl для Fish може бути створений за допомогою команди kubectl completion fish. Підключення цього сценарію автозавершення у вашій оболонці вмикає автодоповнення для kubectl.
Щоб зробити це у всіх сеансах вашої оболонки, додайте наступний рядок до вашого файлу ~/.config/fish/config.fish:
kubectl completion fish | source
Після перезавантаження вашої оболонки, автодоповнення kubectl повинно працювати.
Сценарій автозавершення kubectl для Zsh може бути створений за допомогою команди kubectl completion zsh. Підключення цього сценарію автозавершення у вашій оболонці дозволяє ввімкнути автодоповнення для kubectl.
Щоб зробити це у всіх сеансах вашої оболонки, додайте наступне до вашого файлу ~/.zshrc:
source <(kubectl completion zsh)
Якщо у вас є аліас для kubectl, автодоповнення kubectl автоматично працюватиме з ним.
Після перезавантаження вашої оболонки автодоповнення kubectl повинно працювати.
Якщо ви отримуєте помилку типу 2: command not found: compdef, то додайте наступне до початку вашого файлу ~/.zshrc:
autoload -Uz compinit
compinit
Налаштування kuberc
Дивіться kuberc для отримання докладної інформації.
Встановлення втулка kubectl convert
Втулок для командного рядка Kubernetes kubectl, який дозволяє конвертувати маніфести між різними версіями API. Це може бути особливо корисно для міграції маніфестів до версій API, які все ще є актуальними, на новіші випуски Kubernetes. Для отримання додаткової інформації відвідайте перехід на актуальні API.
Завантажте останній випуск за допомогою наступної команди:
1.2 - Встановлення та налаштування kubectl у macOS
Перш ніж ви розпочнете
Вам потрібно використовувати версію kubectl, яка має мінорну версію що відрізняється не більше ніж на одиницю від мінорної версії вашого кластера. Наприклад, клієнт v1.34 може співпрацювати з панелями управління v1.33, v1.34 та v1.35. Використання останньої сумісної версії kubectl допомагає уникнути непередбачуваних проблем.
Встановлення kubectl у macOS
Існують наступні методи встановлення kubectl у macOS:
Переконайтеся, що /usr/local/bin є в вашій змінній середовища PATH.
Перевірте, що встановлена версія kubectl актуальна:
kubectl version --client
Або використовуйте це для детального перегляду версії:
kubectl version --client --output=yaml
Після встановлення та перевірки kubectl видаліть файл контрольної суми:
rm kubectl.sha256
Встановлення за допомогою Homebrew у macOS
Якщо ви користуєтеся macOS і пакетним менеджером Homebrew, ви можете встановити kubectl за допомогою Homebrew.
Виконайте команду встановлення:
brew install kubectl
або
brew install kubernetes-cli
Перевірте, що встановлена версія актуальна:
kubectl version --client
Встановлення за допомогою Macports у macOS
Якщо ви користуєтеся macOS і пакетним менеджером Macports, ви можете встановити kubectl за допомогою Macports.
Виконайте команду встановлення:
sudo port selfupdate
sudo port install kubectl
Перевірте, що встановлена версія актуальна:
kubectl version --client
Перевірка конфігурації kubectl
Щоб kubectl знайшов та отримав доступ до кластера Kubernetes, вам потрібен
файл kubeconfig, який створюється автоматично при створенні кластера за допомогою kube-up.sh або успішного розгортання кластера Minikube. Типово конфігурація kubectl знаходиться в ~/.kube/config.
Перевірте, що kubectl належним чином налаштований, отримавши стан кластера:
kubectl cluster-info
Якщо ви бачите у відповідь URL, kubectl налаштований на доступ до вашого кластера.
Якщо ви бачите повідомлення, подібне до наведеного нижче, kubectl не налаштований належним чином або не може приєднатися до кластера Kubernetes.
The connection to the server <server-name:port> was refused - did you specify the right host or port?
Наприклад, якщо ви плануєте запустити кластер Kubernetes на своєму ноутбуці (локально), вам спочатку потрібно встановити інструмент, такий як Minikube, а потім повторно виконати вказані вище команди.
Якщо kubectl cluster-info повертає у відповідь URL, але ви не можете отримати доступ до свого кластера, щоб перевірити, чи він налаштований належним чином, скористайтесь наступною командою:
kubectl cluster-info dump
Усунення несправностей повідомлення про помилку 'No Auth Provider Found'
У Kubernetes 1.26, kubectl видалив вбудовану автентифікацію для Kubernetes-кластерів керованих хмарними провайдерами. Ці провайдери випустили втулок для kubectl для надання хмарно-специфічної автентифікації. Для інструкцій див. документацію відповідного провайдера:
Сценарій автодоповнення для Bash kubectl можна згенерувати за допомогою команди kubectl completion bash. Підключення цього сценарію в вашій оболонці дозволяє використовувати автодоповнення для kubectl.
Проте, сценарій автодоповнення для kubectl залежить від bash-completion, який потрібно встановити заздалегідь.
Попередження:
Існують дві версії bash-completion: v1 і v2. V1 призначена для Bash 3.2 (яка є стандартною версією у macOS), а v2 — для Bash 4.1+. Сценарій автодоповнення для kubectl не працює коректно з bash-completion v1 та Bash 3.2. Для правильного використання автодоповнення для kubectl у macOS потрібно використовувати bash-completion v2 та Bash 4.1+. Таким чином, для коректного використання автодоповнення для kubectl у macOS вам необхідно встановити та використовувати Bash 4.1+ (інструкції). Наступні інструкції передбачають, що ви використовуєте Bash 4.1+ (тобто будь-яку версію Bash 4.1 чи новіше).
Оновлення Bash
Інструкції тут передбачають, що ви використовуєте Bash 4.1+. Ви можете перевірити версію свого Bash, виконавши:
echo$BASH_VERSION
Якщо вона є занадто старою, ви можете встановити/оновити її за допомогою Homebrew:
brew install bash
Перезавантажте вашу оболонку і перевірте, що використовується бажана версія:
echo$BASH_VERSION$SHELL
Зазвичай Homebrew встановлює його в /usr/local/bin/bash.
Встановлення bash-completion
Примітка:
Як вже зазначалося, ці інструкції передбачають використання Bash 4.1+, що означає, що ви будете встановлювати bash-completion v2 (на відміну від Bash 3.2 та bash-completion v1, у якому випадку автодоповнення для kubectl не буде працювати).
Ви можете перевірити, чи вже встановлена bash-completion v2, використавши команду type _init_completion. Якщо ні, ви можете встановити її за допомогою Homebrew:
brew install bash-completion@2
Як зазначено в виводі цієї команди, додайте наступне до вашого файлу ~/.bash_profile:
Перезавантажте вашу оболонку і перевірте, що bash-completion v2 встановлена коректно за допомогою type _init_completion.
Активація автодоповнення для kubectl
Тепер вам потрібно забезпечити, щоб сценарій автодоповнення для kubectl підключався в усіх ваших сеансах оболонки. Існують кілька способів досягнення цього:
Підключіть сценарій автодоповнення до вашого файлу ~/.bash_profile:
Якщо у вас є аліас для kubectl, ви можете розширити автодоповнення оболонки, щоб воно працювало з цим аліасом:
echo'alias k=kubectl' >>~/.bash_profile
echo'complete -o default -F __start_kubectl k' >>~/.bash_profile
Якщо ви встановили kubectl за допомогою Homebrew (як пояснено тут), то сценарій автодоповнення для kubectl вже повинен знаходитися у /usr/local/etc/bash_completion.d/kubectl. У цьому випадку вам нічого робити не потрібно.
Примітка:
Установка bash-completion v2 за допомогою Homebrew додає всі файли у теку BASH_COMPLETION_COMPAT_DIR, тому останні два методи працюють.
У будь-якому випадку, після перезавантаження оболонки, автодоповнення для kubectl повинно працювати.
Примітка:
Автодоповнення для Fish вимагає kubectl версії 1.23 або пізніше.
Сценарій автозавершення kubectl для Fish може бути створений за допомогою команди kubectl completion fish. Підключення цього сценарію автозавершення у вашій оболонці вмикає автодоповнення для kubectl.
Щоб зробити це у всіх сеансах вашої оболонки, додайте наступний рядок до вашого файлу ~/.config/fish/config.fish:
kubectl completion fish | source
Після перезавантаження вашої оболонки, автодоповнення kubectl повинно працювати.
Сценарій автозавершення kubectl для Zsh може бути створений за допомогою команди kubectl completion zsh. Підключення цього сценарію автозавершення у вашій оболонці дозволяє ввімкнути автодоповнення для kubectl.
Щоб зробити це у всіх сеансах вашої оболонки, додайте наступне до вашого файлу ~/.zshrc:
source <(kubectl completion zsh)
Якщо у вас є аліас для kubectl, автодоповнення kubectl автоматично працюватиме з ним.
Після перезавантаження вашої оболонки автодоповнення kubectl повинно працювати.
Якщо ви отримуєте помилку типу 2: command not found: compdef, то додайте наступне до початку вашого файлу ~/.zshrc:
autoload -Uz compinit
compinit
Налаштування kuberc
Дивіться kuberc для отримання докладної інформації.
Встановлення втулка kubectl convert
Втулок для командного рядка Kubernetes kubectl, який дозволяє конвертувати маніфести між різними версіями API. Це може бути особливо корисно для міграції маніфестів до версій API, які все ще є актуальними, на новіші випуски Kubernetes. Для отримання додаткової інформації відвідайте перехід на актуальні API.
1.3 - Встановлення та налаштування kubectl у Windows
Перш ніж ви розпочнете
Вам потрібно використовувати версію kubectl, яка має мінорну версію що відрізняється не більше ніж на одиницю від мінорної версії вашого кластера. Наприклад, клієнт v1.34 може співпрацювати з панелями управління v1.33, v1.34 та v1.35. Використання останньої сумісної версії kubectl допомагає уникнути непередбачуваних проблем.
Встановлення kubectl у Windows
Існують наступні методи встановлення kubectl у Windows:
Встановлення бінарника kubectl у Windows (за допомогою прямого завантаження або за допомогою curl)
У вас є два варіанти встановлення kubectl на вашому пристрої з Windows
Безпосереднє завантаження:
Завантажте останню версію 1.34 патчу безпосередньо для вашої архітектури, відвідавши сторінку випуску Kubernetes. Переконайтеся, що вибрано правильний двійковий файл для вашої архітектури (наприклад, amd64, arm64 тощо).
Використовуючи curl
Або, якщо у вас встановлено curl, використовуйте цю команду:
Додайте на початок чи в кінець змінної середовища PATH шлях до теки з kubectl.
Перевірте, що версія kubectl збігається з завантаженою:
kubectl version --client
Або використайте це для детального перегляду версії:
kubectl version --client --output=yaml
Примітка:
Docker Desktop for Windows додає свою власну версію kubectl до PATH. Якщо ви вже встановили Docker Desktop раніше, можливо, вам потрібно розмістити свій шлях в PATH перед тим, який додається інсталятором Docker Desktop, або видалити kubectl Docker Desktop.
Встановлення на Windows за допомогою Chocolatey, Scoop або winget
Для встановлення kubectl у Windows ви можете використовувати пакетний менеджер Chocolatey, командний інсталятор Scoop, або менеджер пакунків winget.
# Якщо ви використовуєте cmd.exe, виконайте: cd %USERPROFILE%cd ~
Створіть теку .kube:
mkdir .kube
Перейдіть до теки .kube, що ви щойно створили:
cd .kube
Налаштуйте kubectl для використання віддаленого кластера Kubernetes:
New-Item config -type file
Примітка:
Редагуйте файл конфігурації за допомогою текстового редактора на ваш вибір, наприклад, Notepad.
Перевірка конфігурації kubectl
Щоб kubectl знайшов та отримав доступ до кластера Kubernetes, вам потрібен
файл kubeconfig, який створюється автоматично при створенні кластера за допомогою kube-up.sh або успішного розгортання кластера Minikube. Типово конфігурація kubectl знаходиться в ~/.kube/config.
Перевірте, що kubectl належним чином налаштований, отримавши стан кластера:
kubectl cluster-info
Якщо ви бачите у відповідь URL, kubectl налаштований на доступ до вашого кластера.
Якщо ви бачите повідомлення, подібне до наведеного нижче, kubectl не налаштований належним чином або не може приєднатися до кластера Kubernetes.
The connection to the server <server-name:port> was refused - did you specify the right host or port?
Наприклад, якщо ви плануєте запустити кластер Kubernetes на своєму ноутбуці (локально), вам спочатку потрібно встановити інструмент, такий як Minikube, а потім повторно виконати вказані вище команди.
Якщо kubectl cluster-info повертає у відповідь URL, але ви не можете отримати доступ до свого кластера, щоб перевірити, чи він налаштований належним чином, скористайтесь наступною командою:
kubectl cluster-info dump
Усунення несправностей повідомлення про помилку 'No Auth Provider Found'
У Kubernetes 1.26, kubectl видалив вбудовану автентифікацію для Kubernetes-кластерів керованих хмарними провайдерами. Ці провайдери випустили втулок для kubectl для надання хмарно-специфічної автентифікації. Для інструкцій див. документацію відповідного провайдера:
Ця команда буде генерувати скрипт автодоповнення при кожному запуску PowerShell. Ви також можете додати згенерований скрипт безпосередньо до вашого файлу $PROFILE.
Щоб додати згенерований скрипт до вашого файлу $PROFILE, виконайте наступний рядок у вашому PowerShell:
kubectl completion powershell >> $PROFILE
Після перезавантаження вашої оболонки автодоповнення для kubectl має працювати.
Налаштування kuberc
Дивіться kuberc для отримання докладної інформації.
Встановлення втулка kubectl convert
Втулок для командного рядка Kubernetes kubectl, який дозволяє конвертувати маніфести між різними версіями API. Це може бути особливо корисно для міграції маніфестів до версій API, які все ще є актуальними, на новіші випуски Kubernetes. Для отримання додаткової інформації відвідайте перехід на актуальні API.
Щоб вказати IPv6 адресу для <control-plane-host>:<control-plane-port>, адресу IPv6 потрібно взяти у квадратні дужки, наприклад: [2001:db8::101]:2073.
Якщо у вас немає токена, ви можете отримати його, запустивши наступну команду на вузлі панелі управління:
# Запустіть це на вузлі панелі управлінняsudo kubeadm token list
Вивід буде приблизно таким:
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
8ewj1p.9r9hcjoqgajrj4gi 23h 2018-06-12T02:51:28Z authentication, The default bootstrap system:
signing token generated by bootstrappers:
'kubeadm init'. kubeadm:
default-node-token
Стандартно токени для приєднання вузлів мають термін дії 24 години. Якщо ви додаєте вузол до кластера після того, як поточний токен закінчився, ви можете створити новий токен, виконавши наступну команду на вузлі панелі управління:
# Запустіть це на вузлі панелі управлінняsudo kubeadm token create
Вивід буде приблизно таким:
5didvk.d09sbcov8ph2amjw
Щоб вивести команду kubeadm join і одночасно створити новий токен, можна використати:
sudo kubeadm token create --print-join-command
Якщо у вас немає значення --discovery-token-ca-cert-hash, ви можете отримати його, виконавши наступні команди на вузлі панелі управління:
# Запустіть це на вузлі панелі управлінняsudo cat /etc/kubernetes/pki/ca.crt | \
openssl x509 -pubkey | \
openssl rsa -pubin -outform der 2>/dev/null | \
openssl dgst -sha256 -hex | \
sed 's/^.* //'
Вивід команди kubeadm join має виглядати приблизно так:
[preflight] Running pre-flight checks
... (вивід процесу приєднання) ...
Node join complete:
* Запит на підписання сертифікату надіслано до панелі управління, отримано відповідь.
* Kubelet проінформований про нові деталі безпечного зʼєднання.
Запустіть 'kubectl get nodes' на панелі управління, щоб побачити приєднання цього вузла.
Через кілька секунд ви повинні побачити цей вузол у виводі команди kubectl get nodes. (наприклад, запустіть kubectl на вузлі панелі управління).
Примітка:
Оскільки вузли кластера зазвичай ініціалізуються послідовно, ймовірно, що всі Podʼи CoreDNS працюватимуть на першому вузлі панелі управління. Для забезпечення високої доступності перерозподіліть Podʼи CoreDNS за допомогою kubectl -n kube-system rollout restart deployment coredns після приєднання хоча б одного нового вузла.
Ця сторінка пояснює, як додати робочі вузли Windows до кластера kubeadm.
Перш ніж ви розпочнете
Запущений екземпляр Windows Server 2022 (або новіший) з адміністративним доступом.
Запущений кластер kubeadm, створений за допомогою kubeadm init та з дотриманням кроків з документа Створення кластера з kubeadm.
Додавання робочих вузлів Windows
Примітка:
Для полегшення додавання робочих вузлів Windows до кластера використовуються скрипти PowerShell з репозиторію https://sigs.k8s.io/sig-windows-tools.
Виконайте наступні кроки для кожної машини:
Відкрийте сесію PowerShell на машині.
Переконайтеся, що ви є адміністратором або привілейованим користувачем.
Потім виконайте наведені нижче кроки.
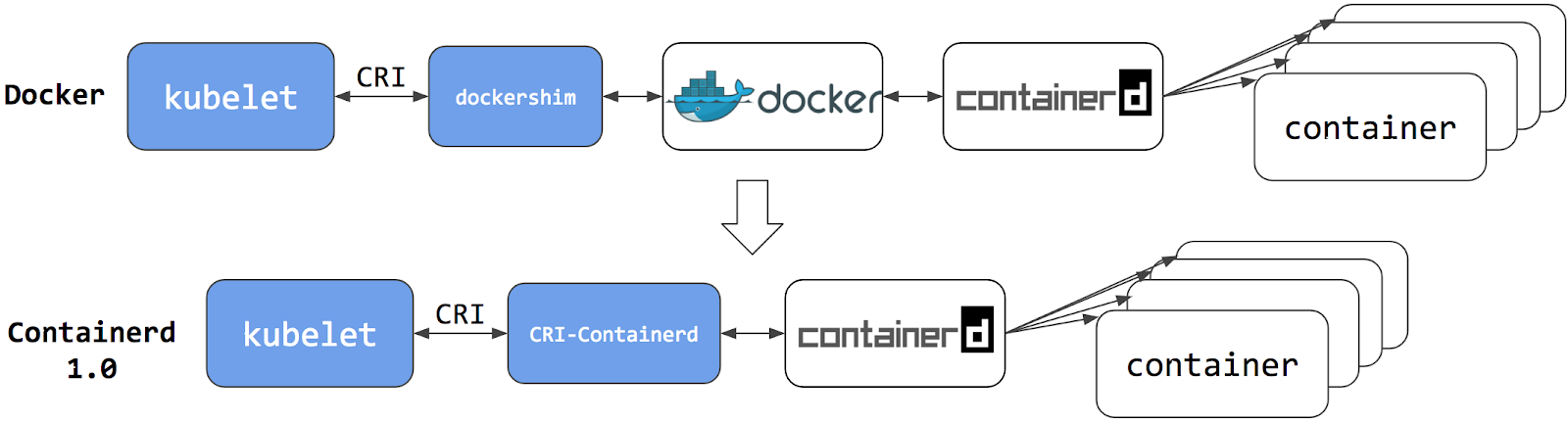
Встановлення containerd
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Щоб встановити containerd, спочатку виконайте наступну команду:
Потім виконайте наступну команду, але спочатку замініть CONTAINERD_VERSION на нещодавній реліз з репозиторію containerd. Версія не повинна містити префікс v. Наприклад, використовуйте 1.7.22 замість v1.7.22:
Налаштуйте будь-які інші параметри для Install-Containerd.ps1, такі як netAdapterName, за необхідності.
Встановіть skipHypervisorSupportCheck, якщо ваша машина не підтримує Hyper-V і не може розміщувати контейнери ізольовані Hyper-V.
Якщо ви змінюєте необовʼязкові параметри CNIBinPath та/або CNIConfigPath у Install-Containerd.ps1, вам потрібно буде налаштувати встановлений втулок CNI Windows з відповідними значеннями.
Встановлення kubeadm і kubelet
Виконайте наступні команди для установки kubeadm і kubelet:
Щоб вказати кортеж IPv6 для <control-plane-host>:<control-plane-port>, IPv6-адреса повинна бути взята у квадратні дужки, наприклад: [2001:db8::101]:2073.
Якщо у вас немає токена, ви можете отримати його, виконавши наступну команду на вузлі панелі управління:
# Виконайте це на вузлі панелі управлінняsudo kubeadm token list
Вивід буде подібний до цього:
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
8ewj1p.9r9hcjoqgajrj4gi 23h 2018-06-12T02:51:28Z authentication, The default bootstrap system:
signing token generated by bootstrappers:
'kubeadm init'. kubeadm:
default-node-token
Стандартно, токени приєднання вузлів діють 24 години. Якщо ви приєднуєте вузол до кластера після того, як токен закінчився, ви можете створити новий токен, виконавши наступну команду на вузлі панелі управління:
# Виконайте це на вузлі панелі управлінняsudo kubeadm token create
Вивід буде подібний до цього:
5didvk.d09sbcov8ph2amjw
Якщо ви не маєте значення --discovery-token-ca-cert-hash, ви можете отримати його, виконавши наступні команди на вузлі панелі управління:
Вивід команди kubeadm join має виглядати приблизно так:
[preflight] Running pre-flight checks
... (вивід журналу процесу приєднання) ...
Приєднання вузла завершено:
* Запит на підпис сертифіката надіслано до панелі управління та отримано відповідь.
* Kubelet поінформований про нові деталі захищеного з'єднання.
Запустіть 'kubectl get nodes' на панелі управління, щоб побачити цей вузол.
Через кілька секунд ви повинні помітити цей вузол у виводі kubectl get nodes. (наприклад, виконайте kubectl на вузлі панелі управління).
Налаштування мережі
Налаштування CNI в кластерах, що містять як Linux, так і вузли Windows, вимагає більше кроків, ніж просто запуск kubectl apply з файлом маніфесту. Крім того, втулок CNI, що працює на вузлах панелі управління, повинен бути підготовлений для підтримки втулка CNI, що працює на робочих вузлах Windows.
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Зараз лише кілька втулків CNI підтримують Windows. Нижче наведені інструкції для їх налаштування:
Ця сторінка пояснює, як оновити кластер Kubernetes, створений за допомогою kubeadm, з версії 1.33.x до версії 1.34.x і з версії 1.34.x до 1.34.y (де y > x). Пропуск МІНОРНИХ версій при оновленні не підтримується. Для отримання додаткових відомостей відвідайте Політику версій зміни.
Щоб переглянути інформацію про оновлення кластерів, створених за допомогою старіших версій kubeadm, зверніться до наступних сторінок:
Проєкт Kubernetes рекомендує оперативно оновлюватись до останніх випусків патчів, а також переконатися, що ви використовуєте підтримуваний мінорний випуск Kubernetes. Дотримання цих рекомендацій допоможе вам залишатись захищеними.
Процес оновлення загалом виглядає наступним чином:
Кластер повинен використовувати статичні вузли керування та контейнери etcd або зовнішній etcd.
Переконайтеся, що ви зробили резервне копіювання важливих компонентів, таких як стан на рівні застосунків, збережений у базі даних. kubeadm upgrade не торкнеться вашого робочого навантаження, лише компонентів, внутрішніх для Kubernetes, але резервне копіювання завжди є найкращою практикою.
Наведені нижче інструкції описують, коли потрібно вивести з експлуатації кожний вузол під час процесу оновлення. Якщо ви виконуєте оновлення для мінорного номера версії для будь-якого kubelet, ви обовʼязково спочатку повинні вивести вузол (або вузли) з експлуатації, які ви оновлюєте. У випадку вузлів панелі управління, на них можуть працювати контейнери CoreDNS або інші критичні робочі навантаження. Для отримання додаткової інформації дивіться Виведення вузлів з експлуатації.
Проєкт Kubernetes рекомендує щоб версії kubelet і kubeadm збігались. Замість цього ви можете використовувати версію kubelet, яка є старішою, ніж kubeadm, за умови, що вона знаходиться в межах підтримуваних версій. Для отримання додаткових відомостей, будь ласка, відвідайте Відхилення kubeadm від kubelet.
Всі контейнери перезавантажуються після оновлення, оскільки змінюється значення хешу специфікації контейнера.
Щоб перевірити, що служба kubelet успішно перезапустилась після оновлення kubelet, ви можете виконати systemctl status kubelet або переглянути логи служби за допомогою journalctl -xeu kubelet.
kubeadm upgrade підтримує параметр --config із типом API UpgradeConfiguration, який можна використовувати для налаштування процесу оновлення.
kubeadm upgrade не підтримує переналаштування наявного кластера. Замість цього виконайте кроки, описані в Переналаштування кластера kubeadm.
Що треба враховувати при оновленні etcd
Оскільки статичний Pod kube-apiserver працює постійно (навіть якщо ви вивели вузол з експлуатації), під час виконання оновлення kubeadm, яке включає оновлення etcd, запити до сервера зупиняться, поки новий статичний Pod etcd не перезапуститься. Як обхідний механізм, можна активно зупинити процес kube-apiserver на кілька секунд перед запуском команди kubeadm upgrade apply. Це дозволяє завершити запити, що вже відправлені, і закрити наявні зʼєднання, що знижує наслідки перерви роботи etcd. Це можна зробити на вузлах панелі управління таким чином:
killall -s SIGTERM kube-apiserver # виклик належного припинення роботи kube-apiserversleep 20# зачекайте трохи, щоб завершити запити, які вже були відправленіkubeadm upgrade ... # виконати команду оновлення kubeadm
Зміна репозиторію пакунків
Якщо ви використовуєте репозиторії пакунків, що керуються спільнотою (pkgs.k8s.io), вам потрібно увімкнути репозиторій пакунків для бажаної мінорної версії Kubernetes. Як це зробити можна дізнатись з документа Зміна репозиторію пакунків Kubernetes.
Примітка: Сховища застарілих пакунків (apt.kubernetes.io та yum.kubernetes.io) визнані
застарілими та заморожені станом на 13 вересня 2023.
Використання нових репозиторіїв пакунків, розміщених за адресою pkgs.k8s.io`,
настійно рекомендується і є обовʼязковим для встановлення версій Kubernetes, випущених після 13 вересня 2023 року.
Застарілі репозиторії та їхні вміст можуть бути видалені у будь-який момент у майбутньому і без попереднього повідомлення.
Нові репозиторії пакунків надають можливість завантаження версій Kubernetes, починаючи з v1.24.0.
Визначення версії, на яку потрібно оновитися
Знайдіть останнє патч-видання для Kubernetes 1.34 за допомогою менеджера пакунків ОС:
# Знайдіть останню версію 1.34 у списку.# Вона має виглядати як 1.34.x-*, де x — останній патч.sudo apt update
sudo apt-cache madison kubeadm
Для систем з DNF:
# Знайдіть останню версію 1.34 у списку.# Вона має виглядати як 1.34.x-*, де x — останній патч.sudo yum list --showduplicates kubeadm --disableexcludes=kubernetes
Для систем з DNF5:
# Знайдіть останню версію 1.34 у списку.# Вона має виглядати як 1.34.x-*, де x — останній патч.sudo yum list --showduplicates kubeadm --setopt=disable_excludes=kubernetes
Процедуру оновлення на вузлах панелі управління слід виконувати по одному вузлу за раз. Виберіть перший вузол панелі управління, який ви хочете оновити. Він повинен мати файл /etc/kubernetes/admin.conf.
# замініть x на останню версію патчаsudo apt-mark unhold kubeadm &&\
sudo apt-get update && sudo apt-get install -y kubeadm='1.34.x-*'&&\
sudo apt-mark hold kubeadm
Для систем з DNF:
# замініть x в 1.34.x-* на останню версію патчаsudo yum install -y kubeadm-'1.34.x-*' --disableexcludes=kubernetes
Для систем з DNF5:
# замініть x в 1.34.x-* на останню версію патчаsudo yum install -y kubeadm-'1.34.x-*' --setopt=disable_excludes=kubernetes
Перевірте, що завантаження працює і має очікувану версію:
kubeadm version
Перевірте план оновлення:
sudo kubeadm upgrade plan
Ця команда перевіряє можливість оновлення вашого кластера та отримує версії, на які ви можете оновитися. Також вона показує таблицю стану версій компонентів.
Примітка:
kubeadm upgrade також автоматично оновлює сертифікати, якими він керує на цьому вузлі. Щоб відмовитися від оновлення сертифікатів, можна використовувати прапорець --certificate-renewal=false. Для отримання додаткової інформації див. керівництво з керування сертифікатами.
Виберіть версію для оновлення та запустіть відповідну команду. Наприклад:
# замініть x на версію патча, яку ви вибрали для цього оновленняsudo kubeadm upgrade apply v1.34.x
Після завершення команди ви маєте побачити:
[upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.34.x". Enjoy!
[upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven't already done so.
Примітка:
Для версій, старіших, ніж v1.28, kubeadm типово використовував режим, який оновлює надбудови (включно з CoreDNS та kube-proxy) безпосередньо під час kubeadm upgrade apply, незалежно від того, чи є інші екземпляри вузлів панелі управління, які не були оновлені. Це може викликати проблеми сумісності. Починаючи з v1.28, kubeadm стандартно перевіряє, чи всі
екземпляри вузлів панелі управління були оновлені, перед початком оновлення надбудов. Ви повинні виконати оновлення екземплярів вузлів керування послідовно або принаймні забезпечити, що останнє оновлення екземпляра вузла панелі управління не розпочато, поки всі
інші екземпляри вузлів панелі управління не будуть повністю оновлені, і оновлення надбудов буде виконано після останнього оновлення екземпляра вузла керування.
Ваш постачальник мережевого інтерфейсу контейнера (CNI) може мати власні інструкції щодо оновлення. Перевірте надбудови для знаходження вашого постачальника CNI та перегляньте, чи потрібні додаткові кроки оновлення.
Цей крок не потрібен на додаткових вузлах панелі управління, якщо постачальник CNI працює як DaemonSet.
Для інших вузлів панелі управління
Те саме, що для першого вузла керування, але використовуйте:
sudo kubeadm upgrade node
замість:
sudo kubeadm upgrade apply
Також виклик kubeadm upgrade plan та оновлення постачальника мережевого інтерфейсу контейнера (CNI) вже не потрібні.
Виведення вузла з експлуатації
Готуємо вузол для обслуговування, відмітивши його як непридатний для планування та вивівши з нього робочі навантаження:
# замініть <node-to-drain> іменем вашого вузла, який ви хочете вивести з експлуатаціїkubectl drain <node-to-drain> --ignore-daemonsets
Відновіть роботу вузла, позначивши його як доступний для планування:
# замініть <node-to-uncordon> на імʼя вашого вузлаkubectl uncordon <node-to-uncordon>
Оновлення вузлів робочих навантажень
Процедуру оновлення на робочих вузлах слід виконувати один за одним або декільком вузлами одночасно, не посягаючи на мінімально необхідні можливості для виконання вашого навантаження.
Наступні сторінки показують, як оновити робочі вузли у Linux та Windows:
Після оновлення kubelet на всіх вузлах перевірте доступність всіх вузлів, виконавши наступну команду з будь-якого місця, де кubectl має доступу до кластера:
kubectl get nodes
У стовпці STATUS повинно бути вказано Ready для всіх ваших вузлів, а номер версії повинен бути оновлений.
Відновлення після несправності
Якщо kubeadm upgrade виявляється несправним і не відновлює роботу, наприклад через неочікуване вимкнення під час виконання, ви можете виконати kubeadm upgrade ще раз. Ця команда є ідемпотентною і, зрештою, переконується, що фактичний стан відповідає заданому вами стану.
Для відновлення з несправного стану ви також можете запустити sudo kubeadm upgrade apply --force без зміни версії, яку використовує ваш кластер.
Під час оновлення kubeadm записує наступні резервні теки у /etc/kubernetes/tmp:
kubeadm-backup-etcd-<дата>-<час>
kubeadm-backup-manifests-<дата>-<час>
kubeadm-backup-etcd містить резервну копію даних локального etcd для цього вузла панелі управління. У разі невдачі оновлення etcd і якщо автоматичне відновлення не працює, вміст цієї теки може бути відновлений вручну в /var/lib/etcd. У разі використання зовнішнього etcd ця тека резервного копіювання буде порожньою.
kubeadm-backup-manifests містить резервну копію файлів маніфестів статичних Podʼів для цього вузла панелі управління. У разі невдачі оновлення і якщо автоматичне відновлення не працює, вміст цієї теки може бути відновлений вручну в /etc/kubernetes/manifests. Якщо з будь-якої причини немає різниці між попереднім та файлом маніфесту після оновлення для певного компонента, резервна копія файлу для нього не буде записана.
Примітка:
Після оновлення кластера за допомогою kubeadm, тека резервних копій /etc/kubernetes/tmp залишиться, і ці резервні файли потрібно буде очистити вручну.
Як це працює
kubeadm upgrade apply робить наступне:
Перевіряє, що ваш кластер можна оновити:
Сервер API доступний
Всі вузли знаходяться у стані Ready
Панель управління працює належним чином
Застосовує політику різниці версій.
Переконується, що образи панелі управління доступні або доступні для отримання на машині.
Генерує заміни та/або використовує зміни підготовлені користувачем, якщо компонентні конфігурації вимагають оновлення версії.
Оновлює компоненти панелі управління або відкочується, якщо будь-який з них не може бути запущений.
Застосовує нові маніфести CoreDNS і kube-proxy і переконується, що створені всі необхідні правила RBAC.
Створює нові сертифікати та файли ключів API-сервера і робить резервні копії старих файлів, якщо вони мають закінчитися за 180 днів.
kubeadm upgrade node робить наступне на додаткових вузлах панелі управління:
Витягує ClusterConfiguration kubeadm з кластера.
Опційно робить резервні копії сертифіката kube-apiserver.
Оновлює маніфести статичних Podʼів для компонентів панелі управління.
Оновлює конфігурацію kubelet для цього вузла.
kubeadm upgrade node робить наступне на вузлах робочих навантажень:
Витягує ClusterConfiguration kubeadm з кластера.
Оновлює конфігурацію kubelet для цього вузла.
2.1.4 - Оновлення вузлів Linux
Ця сторінка пояснює, як оновити вузли робочих навантажень Linux, створені за допомогою kubeadm.
Перш ніж ви розпочнете
Вам потрібен доступ до оболонки на всіх вузлах, а також інструмент командного рядка kubectl повинен бути налаштований для спілкування з вашим кластером. Рекомендується виконувати цю інструкцію у кластері, який має принаймні два вузли, які не виконують функції вузлів панелі управління.
Якщо ви використовуєте репозиторії пакунків (pkgs.k8s.io), вам потрібно увімкнути репозиторій пакунків для потрібного мінорного релізу Kubernetes. Це пояснено в документі Зміна репозиторію пакунків Kubernetes.
Примітка: Сховища застарілих пакунків (apt.kubernetes.io та yum.kubernetes.io) визнані
застарілими та заморожені станом на 13 вересня 2023.
Використання нових репозиторіїв пакунків, розміщених за адресою pkgs.k8s.io`,
настійно рекомендується і є обовʼязковим для встановлення версій Kubernetes, випущених після 13 вересня 2023 року.
Застарілі репозиторії та їхні вміст можуть бути видалені у будь-який момент у майбутньому і без попереднього повідомлення.
Нові репозиторії пакунків надають можливість завантаження версій Kubernetes, починаючи з v1.24.0.
# замініть x у 1.34.x-* на останню версію патчаsudo apt-mark unhold kubeadm &&\
sudo apt-get update && sudo apt-get install -y kubeadm='1.34.x-*'&&\
sudo apt-mark hold kubeadm
Для систем з DNF:
# замініть x у 1.34.x-* на останню версію патчаsudo yum install -y kubeadm-'1.34.x-*' --disableexcludes=kubernetes
Для систем з DNF5:
# замініть x у 1.34.x-* на останню версію патчаsudo yum install -y kubeadm-'1.34.x-*' --setopt=disable_excludes=kubernetes
Виклик "kubeadm upgrade"
Для робочих вузлів це оновлює локальну конфігурацію kubelet:
sudo kubeadm upgrade node
Виведіть вузол з експлуатації
Підготуйте вузол до обслуговування, позначивши його як недоступний для планування та виселивши завдання:
# виконайте цю команду на вузлі панелі управління# замініть <node-to-drain> імʼям вузла, який ви виводите з експлуатаціїkubectl drain <node-to-drain> --ignore-daemonsets
Ця сторінка пояснює, як оновити вузол Windows, створений за допомогою kubeadm.
Перш ніж ви розпочнете
Вам потрібен доступ до оболонки на всіх вузлах, а також інструмент командного рядка kubectl повинен бути налаштований для спілкування з вашим кластером. Рекомендується виконувати цю інструкцію у кластері, який має принаймні два вузли, які не виконують функції вузлів панелі управління.
Версія вашого Kubernetes сервера має бути не старішою ніж 1.17.
Якщо ви запускаєте kube-proxy в контейнері HostProcess всередині Podʼа, а не як службу Windows, ви можете оновити kube-proxy, застосувавши нову версію ваших маніфестів kube-proxy.
Відновіть роботу вузла
З машини з доступом до API Kubernetes, поверніть вузол в роботу, позначивши його як придатний для планування:
Налаштування драйвера cgroup середовища виконання контейнерів
Сторінка Середовища виконання контейнерів пояснює, що для налаштувань на основі kubeadm рекомендується використовувати драйвер systemd замість типового драйвера cgroupfs kubelet, оскільки kubeadm керує kubelet як сервісом systemd.
На сторінці також наведено деталі щодо того, як налаштувати різні контейнерні середовища зі стандартним використанням драйвера systemd.
Налаштування драйвера cgroup для kubelet
kubeadm дозволяє передавати структуру KubeletConfiguration під час ініціалізації за допомогою kubeadm init. Ця структура KubeletConfiguration може включати поле cgroupDriver, яке контролює драйвер cgroup для kubelet.
Примітка:
Починаючи з v1.22, якщо користувач не встановить поле cgroupDriver у KubeletConfiguration, kubeadm стандартно задає його як systemd.
У Kubernetes v1.28 можна увімкнути автоматичне виявлення драйвера cgroup як експериментальну функцію. Див. Драйвер cgroup системи systemd для отримання детальнішої інформації.
Ось мінімальний приклад, який явним чином вказує значення поля cgroupDriver:
Такий файл конфігурації можна передати команді kubeadm:
kubeadm init --config kubeadm-config.yaml
Примітка:
Kubeadm використовує ту саму конфігурацію KubeletConfiguration для всіх вузлів у кластері. KubeletConfiguration зберігається в обʼєкті ConfigMap в просторі імен kube-system.
Виконання підкоманд init, join та upgrade призведе до запису kubeadm KubeletConfiguration у файл під /var/lib/kubelet/config.yaml і передачі його до kubelet локального вузла.
На кожному вузлі kubeadm виявляє сокет CRI та зберігає його деталі у файлі /var/lib/kubelet/instance-config.yaml. Коли виконуються підкоманди init, join або upgrade, kubeadm вносить зміни до значення containerRuntimeEndpoint з цієї конфігурації інстансу у /var/lib/kubelet/config.yaml.
Використання драйвера cgroupfs
Для використання cgroupfs і запобігання модифікації драйвера cgroup в KubeletConfiguration під час оновлення kubeadm в поточних налаштуваннях, вам потрібно явно вказати його значення. Це стосується випадку, коли ви не хочете, щоб майбутні версії kubeadm стандартно застосовували драйвер systemd.
Дивіться нижче розділ "Зміна ConfigMap у kubelet" для отримання деталей щодо явного вказання значення.
Якщо ви хочете налаштувати середовище виконання контейнерів на використання драйвера cgroupfs, вам слід звернутися до документації вашого середовища виконання контейнерів.
Міграція на використання драйвера systemd
Щоб змінити драйвер cgroup поточного кластера kubeadm з cgroupfs на systemd на місці, потрібно виконати подібну процедуру до оновлення kubelet. Це повинно включати обидва зазначені нижче кроки.
Примітка:
Також можливо замінити старі вузли в кластері новими, які використовують драйвер systemd. Для цього потрібно виконати лише перший крок нижче перед приєднанням нових вузлів та забезпечити те, що робочі навантаження можуть безпечно переміщатися на нові вузли перед видаленням старих вузлів.
Зміна ConfigMap у kubelet
Викличте kubectl edit cm kubelet-config -n kube-system.
Змініть наявне значення cgroupDriver або додайте нове поле, яке виглядає наступним чином:
cgroupDriver:systemd
Це поле повинно бути присутнє у розділі kubelet: в ConfigMap.
Оновлення драйвера cgroup на всіх вузлах
Для кожного вузла в кластері:
Відключіть вузол за допомогою kubectl drain <імʼя-вузла> --ignore-daemonsets
Зупиніть kubelet за допомогою systemctl stop kubelet
Зупиніть середовище виконання контейнерів
Змініть драйвер cgroup середовища виконання контейнерів на systemd
Встановіть cgroupDriver: systemd у /var/lib/kubelet/config.yaml
Запустіть середовище виконання контейнерів
Запустіть kubelet за допомогою systemctl start kubelet
Виконайте ці кроки на вузлах по одному, щоб забезпечити достатній час для розміщення робочих навантажень на різних вузлах.
Після завершення процесу переконайтеся, що всі вузли та робочі навантаження є справними.
2.1.7 - Управління сертифікатами з kubeadm
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.15 [stable]
Клієнтські сертифікати, що генеруються kubeadm, закінчуються через 1 рік. Ця сторінка пояснює, як управляти поновленням сертифікатів за допомогою kubeadm. Вона також охоплює інші завдання, повʼязані з управлінням сертифікатами kubeadm.
Проєкт Kubernetes рекомендує оперативно оновлюватись до останніх випусків патчів, а також переконатися, що ви використовуєте підтримуваний мінорний випуск Kubernetes. Дотримання цих рекомендацій допоможе вам залишатися в безпеці.
Ви маєте знати, як передати файл configuration командам kubeadm.
Цей посібник описує використання команди openssl (використовується для ручного підписання сертифікатів, якщо ви обираєте цей підхід), але ви можете використовувати інші інструменти, яким надаєте перевагу.
Деякі кроки тут використовують sudo для адміністративного доступу. Ви можете використовувати будь-який еквівалентний інструмент.
Використання власних сертифікатів
Типово, kubeadm генерує всі необхідні сертифікати для роботи кластера. Ви можете перевизначити цю поведінку, надавши власні сертифікати.
Для цього вам потрібно помістити їх у ту теку, яка вказується за допомогою прапорця --cert-dir або поля certificatesDir конфігурації кластера ClusterConfiguration kubeadm. Типово це /etc/kubernetes/pki.
Якщо певна пара сертифікатів і приватний ключ існують до запуску kubeadm init, kubeadm не перезаписує їх. Це означає, що ви можете, наприклад, скопіювати наявний ЦС (Центр сертифікації — Certificate authority) в /etc/kubernetes/pki/ca.crt та /etc/kubernetes/pki/ca.key, і kubeadm використовуватиме цей ЦС для підпису решти сертифікатів.
Вибір алгоритму шифрування
kubeadm дозволяє вибрати алгоритм шифрування, який використовується для створення відкритих і закритих ключів. Це можна зробити за допомогою поля encryptionAlgorithm у конфігурації kubeadm:
<ALGORITHM> може бути одним з: RSA-2048 (стандартно), RSA-3072, RSA-4096 або ECDSA-P256.
Вибір терміну дії сертифіката
kubeadm дозволяє вибирати період дії сертифікатів центрів сертифікації та листових сертифікатів. Це можна зробити за допомогою полів certificateValidityPeriod і caCertificateValidityPeriod
в конфігурації kubeadm:
apiVersion:kubeadm.k8s.io/v1beta4kind:ClusterConfigurationcertificateValidityPeriod: 8760h # Стандартно:365днів × 24 години = 1 рікcaCertificateValidityPeriod: 87600h # Стандартно:365днів × 24 години * 10 = 10 років
Значення полів відповідають прийнятому формату для значень Go's time.Duration, при цьому найдовшою одиницею виміру є h (години).
Режим зовнішнього ЦС
Також можливо надати лише файл ca.crt і не файл ca.key (це доступно лише для файлу кореневого ЦС, а не інших пар сертифікатів). Якщо всі інші сертифікати та файли kubeconfig на місці, kubeadm розпізнає цю умову та активує режим "Зовнішній ЦС". kubeadm буде продовжувати без ключа ЦС на диску.
Замість цього, запустіть контролер-менеджер самостійно з параметром --controllers=csrsigner та вкажіть на сертифікат та ключ ЦС.
Існують різні способи підготовки облікових даних компонента при використанні режиму зовнішнього ЦС.
Цей посібник описує використання команди openssl (використовується для ручного підписання сертифікатів, якщо ви обираєте цей підхід), але ви можете використовувати інші інструменти, яким надаєте перевагу.
Ручна підготовка облікових даних компонента
Сертифікати PKI та вимоги містять інформацію про те, як підготувати всі необхідні облікові дані для компонентів, які вимагаються kubeadm, вручну.
Підготовка облікових даних компонента шляхом підпису CSR, що генеруються kubeadm
kubeadm може генерувати файли CSR, які ви можете підписати вручну за допомогою інструментів, таких як openssl, та вашого зовнішнього ЦС. Ці файли CSR будуть включати всі вказівки для облікових даних, які вимагаються компонентами, розгорнутими kubeadm.
Автоматизована підготовка облікових даних компонента за допомогою фаз kubeadm
З іншого боку, можливо використовувати команди фаз kubeadm для автоматизації цього процесу.
Перейдіть на хост, який ви хочете підготувати як вузол панелі управління kubeadm з зовнішнім ЦС.
Скопіюйте зовнішні файли ЦС ca.crt та ca.key, які ви маєте, до /etc/kubernetes/pki на вузлі.
Підготуйте тимчасовий файл конфігурації kubeadm під назвою config.yaml, який можна використовувати з kubeadm init. Переконайтеся, що цей файл містить будь-яку відповідну інформацію на рівні кластера або хосту, яка може бути включена в сертифікати, таку як, ClusterConfiguration.controlPlaneEndpoint, ClusterConfiguration.certSANs та InitConfiguration.APIEndpoint.
На тому ж самому хості виконайте команди kubeadm init phase kubeconfig all --config config.yaml та kubeadm init phase certs all --config config.yaml. Це згенерує всі необхідні файли kubeconfig та сертифікати у теці /etc/kubernetes/ та її підтеці pki.
Перевірте згенеровані файли. Видаліть /etc/kubernetes/pki/ca.key, видаліть або перемістіть в безпечне місце файл /etc/kubernetes/super-admin.conf.
На вузлах, де буде викликано kubeadm join, також видаліть /etc/kubernetes/kubelet.conf. Цей файл потрібний лише на першому вузлі, де буде викликано kubeadm init.
Зауважте, що деякі файли, такі як pki/sa.*, pki/front-proxy-ca.* та pki/etc/ca.*, спільно використовуються між вузлами панелі управління, Ви можете згенерувати їх один раз та розподілити їх вручну на вузли, де буде викликано kubeadm join, або ви можете використовувати функціональність --upload-certskubeadm init та --certificate-keykubeadm join для автоматизації цього розподілу.
Після того, як облікові дані будуть підготовлені на всіх вузлах, викличте kubeadm init та kubeadm join для цих вузлів, щоб приєднати їх до кластера. kubeadm використовуватиме наявні файли kubeconfig та сертифікати у теці /etc/kubernetes/ та її підтеці pki.
Закінчення терміну дії сертифікатів та управління ними
Примітка:
kubeadm не може керувати сертифікатами, підписаними зовнішнім ЦС.
Ви можете використовувати підкоманду check-expiration, щоб перевірити термін дії сертифікатів:
kubeadm certs check-expiration
Вивід подібний до наступного:
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Dec 30, 2020 23:36 UTC 364d no
apiserver Dec 30, 2020 23:36 UTC 364d ca no
apiserver-etcd-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
apiserver-kubelet-client Dec 30, 2020 23:36 UTC 364d ca no
controller-manager.conf Dec 30, 2020 23:36 UTC 364d no
etcd-healthcheck-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-peer Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-server Dec 30, 2020 23:36 UTC 364d etcd-ca no
front-proxy-client Dec 30, 2020 23:36 UTC 364d front-proxy-ca no
scheduler.conf Dec 30, 2020 23:36 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Dec 28, 2029 23:36 UTC 9y no
etcd-ca Dec 28, 2029 23:36 UTC 9y no
front-proxy-ca Dec 28, 2029 23:36 UTC 9y no
Команда показує час закінчення та залишковий час для сертифікатів клієнта у теці /etc/kubernetes/pki та для сертифіката клієнта, вбудованого у файли kubeconfig, що використовуються kubeadm (admin.conf, controller-manager.conf та scheduler.conf).
Крім того, kubeadm повідомляє користувача, якщо керування сертифікатом відбувається ззовні; у цьому випадку користувачу слід самостійно забезпечити керування поновленням сертифікатів вручну/за допомогою інших інструментів.
На вузлах, створених за допомогою kubeadm init, до версії kubeadm 1.17, існує помилка, де вам потрібно вручну змінити зміст kubelet.conf. Після завершення kubeadm init ви повинні оновити kubelet.conf, щоб вказати на змінені сертифікати клієнта kubelet, замінивши client-certificate-data та client-key-data на:
kubeadm поновлює всі сертифікати під час оновлення панелі управління.
Ця функція призначена для вирішення найпростіших випадків використання; якщо у вас немає конкретних вимог до поновлення сертифікатів і ви регулярно виконуєте оновлення версії Kubernetes (частіше ніж 1 раз на рік між кожним оновленням), kubeadm буде піклуватися про те, щоб ваш кластер був завжди актуальним і досить безпечним.
Якщо у вас є складніші вимоги до поновлення сертифікатів, ви можете відмовитися від стандартної поведінки, передавши --certificate-renewal=false до kubeadm upgrade apply або до kubeadm upgrade node.
Ручне поновлення сертифікатів
Ви можете в будь-який момент вручну оновити свої сертифікати за допомогою команди kubeadm certs renew з відповідними параметрами командного рядка. Якщо ви використовуєте кластер з реплікованою панеллю управління, цю команду потрібно виконати на всіх вузлах панелі управління.
Ця команда виконує поновлення за допомогою сертифіката та ключа ЦС (або front-proxy-CA), збережених у /etc/kubernetes/pki.
kubeadm certs renew використовує поточні сертифікати як авторитетне джерело для атрибутів ( Common Name, Organization, subject alternative name) і не покладається на kubeadm-config ConfigMap. Незважаючи на це, проєкт Kubernetes рекомендує зберігати сертифікат, що обслуговується, та повʼязані з ним значення у цьому файлі ConfigMap синхронізовано, щоб уникнути будь-якого ризику плутанини.
Після виконання команди вам слід перезапустити Podʼи панелі управління. Це необхідно, оскільки
динамічне перезавантаження сертифікатів наразі не підтримується для всіх компонентів та сертифікатів. Статичні Podʼи керуються локальним kubelet і не API-сервером, тому kubectl не може бути використаний для їх видалення та перезапуску. Щоб перезапустити статичний Pod, ви можете тимчасово видалити файл його маніфеста з /etc/kubernetes/manifests/ і зачекати 20 секунд (див. значення fileCheckFrequency у KubeletConfiguration struct). kubelet завершить роботу Pod, якщо він більше не знаходиться в теці маніфестів. Потім ви можете повернути файл назад і після ще одного періоду fileCheckFrequency kubelet знову створить Pod, і поновлення сертифікатів для компонента буде завершено.
kubeadm certs renew може оновити будь-який конкретний сертифікат або, за допомогою підкоманди all, він може оновити всі з них, як показано нижче:
# Якщо ви використовуєте кластер з реплікованою панеллю управління, цю команду# потрібно виконати на всіх вузлах панеллі управління.kubeadm certs renew all
Кластери, побудовані за допомогою kubeadm, часто копіюють сертифікат admin.conf у $HOME/.kube/config, як вказано у Створення кластера за допомогою kubeadm. У такій системі, для оновлення вмісту $HOME/.kube/config після поновлення admin.conf, вам треба виконати наступні команди:
Поновлення сертифікатів за допомогою API сертифікатів Kubernetes
У цьому розділі надаються додаткові відомості про те, як виконати ручне поновлення сертифікатів за допомогою API сертифікатів Kubernetes.
Увага:
Це розширені теми для користувачів, які потребують інтеграції сертифікатної інфраструктури своєї організації в кластер, побудований за допомогою kubeadm. Якщо типово конфігурація kubeadm відповідає вашим потребам, вам слід дозволити kubeadm керувати сертифікатами.
Налаштування підписувача
Kubernetes Certificate Authority не працює зразу. Ви можете налаштувати зовнішнього підписувача, такого як cert-manager, або можете використовувати вбудованого підписувача.
У цьому розділі надаються додаткові відомості про те, як виконати ручне поновлення сертифікатів за допомогою зовнішнього ЦС.
Для кращої інтеграції з зовнішніми ЦС, kubeadm також може створювати запити на підпис сертифікатів (CSR). Запит на підпис сертифіката є запитом до ЦС на підписаний сертифікат для клієнта. За термінологією kubeadm, будь-який сертифікат, який зазвичай підписується ЦС на диску, може бути створений у вигляді CSR. Однак ЦС не може бути створено як CSR.
Поновлення за допомогою запитів на підпис сертифікатів (CSR)
Типово службовий сертифікат kubelet, розгорнутий за допомогою kubeadm, є самопідписним. Це означає, що зʼєднання зовнішніх служб, наприклад, сервера метрик з kubelet, не може бути захищено TLS.
Щоб налаштувати kubelet в новому кластері kubeadm для отримання належно підписаних службових сертифікатів, ви повинні передати наступну мінімальну конфігурацію до kubeadm init:
Якщо ви вже створили кластер, вам слід адаптувати його, виконавши наступне:
Знайдіть і відредагуйте ConfigMap kubelet-config в просторі імен kube-system. У ConfigMap ключ kubelet має документ KubeletConfiguration як своє значення. Відредагуйте документ KubeletConfiguration, щоб встановити serverTLSBootstrap: true.
На кожному вузлі додайте поле serverTLSBootstrap: true у /var/lib/kubelet/config.yaml і перезапустіть kubelet за допомогою systemctl restart kubelet.
Поле serverTLSBootstrap: true дозволить ініціювати завантаження службових сертифікатів kubelet, запитуючи їх з API certificates.k8s.io. Одне з відомих обмежень поля serverTLSBootstrap: true — CSRs (запити на підпис сертифікатів) для цих сертифікатів не можуть бути автоматично затверджені типовим підписувачем в kube-controller-manager — kubernetes.io/kubelet-serving. Це потребує дій користувача або стороннього контролера.
Ці CSRs можна переглянути за допомогою:
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-9wvgt 112s kubernetes.io/kubelet-serving system:node:worker-1 Pending
csr-lz97v 1m58s kubernetes.io/kubelet-serving system:node:control-plane-1 Pending
Щоб затвердити їх, ви можете виконати наступне:
kubectl certificate approve <CSR-name>
Типово ці службові сертифікати закінчуються через рік. Kubeadm встановлює поле rotateCertificates в true у KubeletConfiguration, що означає, що близько до закінчення буде створено новий набір CSRs для службових сертифікатів і їх слід затвердити, щоб завершити оновлення. Для отримання додаткової інформації дивіться Оновлення сертифікатів.
Якщо ви шукаєте рішення для автоматичного затвердження цих CSRs, рекомендується звернутися до свого постачальника хмарних послуг і дізнатись, чи він має підписувача CSR, який перевіряє ідентифікацію вузла за допомогою окремого механізму.
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Ви можете використовувати власні контролери сторонніх постачальників:
Такий контролер не є безпечним механізмом, якщо він перевіряє лише CommonName в CSR, але також перевіряє запитані IP-адреси та доменні імена. Це запобігло б зловмиснику, який має доступ до сертифіката клієнта kubelet, створювати CSRs, запитуючи службові сертифікати для будь-якої IP-адреси або доменного імені.
Генерація файлів kubeconfig для додаткових користувачів
Під час створення кластера, kubeadm init підписує сертифікат у super-admin.conf, щоб мати Subject: O = system:masters, CN = kubernetes-super-admin. system:masters є групою суперкористувачів, яка обходить рівень авторизації (наприклад, RBAC). Файл admin.conf також створюється за допомогою kubeadm на вузлах панелі управління і містить сертифікат з Subject: O = kubeadm:cluster-admins, CN = kubernetes-admin. kubeadm:cluster-admins це група, яка логічно належить до kubeadm. Якщо ваш кластер використовує RBAC (стандартний параметр kubeadm), група kubeadm:cluster-admins буде привʼязана до ClusterRole групи cluster-admin.
Попередження:
Уникайте спільного доступу до файлів super-admin.conf або admin.conf. Замість цього створіть найменш привілейований доступ навіть для людей, які працюють адміністраторами, і використовуйте цю найменш привілейовану альтернативу для будь-чого, крім аварійного (екстреного) доступу.
Замість цього, ви можете використовувати команду kubeadm kubeconfig user для генерації файлів kubeconfig для додаткових користувачів. Команда приймає змішаний набір параметрів командного рядка та опцій конфігурації kubeadm. Згенерований kubeconfig буде записаний до stdout і може бути перенаправлений у файл за допомогою kubeadm kubeconfig user ... > somefile.conf.
Приклад конфігураційного файлу, який можна використовувати з --config:
# example.yamlapiVersion:kubeadm.k8s.io/v1beta4kind:ClusterConfiguration# Буде використано як цільовий "кластер" у kubeconfigclusterName:"kubernetes"# Буде використано як "сервер" (IP або DNS-імʼя) цього кластера в kubeconfigcontrolPlaneEndpoint:"some-dns-address:6443"# Ключ і сертифікат ЦС кластера будуть завантажені з цієї локальної текиcertificatesDir:"/etc/kubernetes/pki"
Переконайтеся, що ці параметри відповідають бажаним параметрам цільового кластера. Щоб переглянути параметри поточного кластера, скористайтеся:
kubectl get cm kubeadm-config -n kube-system -o=jsonpath="{.data.ClusterConfiguration}"
Наступний приклад згенерує файл kubeconfig з обліковими даними, дійсними протягом 24 годин, для нового користувача johndoe, який належить до групи appdevs:
Наступний приклад згенерує файл kubeconfig з обліковими даними адміністратора, дійсними протягом 1 тижня:
kubeadm kubeconfig user --config example.yaml --client-name admin --validity-period 168h
Підписування запитів на підпис сертифікатів (CSR), згенерованих kubeadm
Ви можете створювати запити на підпис сертифікатів за допомогою kubeadm certs generate-csr. Виклик цієї команди згенерує пари файлів .csr / .key для звичайних сертифікатів. Для сертифікатів, вбудованих у файли kubeconfig, команда згенерує пару файлів .csr / .conf, де ключ вже вбудований у файл .conf.
Файл CSR містить всю необхідну інформацію для ЦС для підпису сертифіката. kubeadm використовує чітко визначену специфікацію для всіх своїх сертифікатів і CSR.
Типовою текою для сертифікатів є /etc/kubernetes/pki, тоді як типова тека для файлів kubeconfig є /etc/kubernetes. Ці стандартні значення можна змінити за допомогою прапорців --cert-dir та --kubeconfig-dir, відповідно.
Для передачі власних параметрів команді kubeadm certs generate-csr використовуйте прапорець --config, який приймає файл конфігурації kubeadm, так само як і команди, такі як kubeadm init. Будь-яка специфікація, така як додаткові SAN та власні IP-адреси, повинна зберігатися в тому ж файлі конфігурації та використовуватися для всіх відповідних команд kubeadm, передаючи його як --config.
Примітка:
У цьому керівництві буде використано стандартну теку Kubernetes /etc/kubernetes, що вимагає прав доступу суперкористувача. Якщо ви дотримуєтесь цього керівництва та використовуєте теки, в яки ви можете писати, (зазвичай, це означає виконання kubeadm з --cert-dir та --kubeconfig-dir), ви можете пропустити команду sudo.
Потім ви повинні скопіювати створені файли до теки /etc/kubernetes, щоб kubeadm init або kubeadm join могли їх знайти.
Підготовка файлів ЦС та сервісного облікового запису
На головному вузлі панелі управління, де буде виконано команду kubeadm init, виконайте наступні команди:
Це заповнить теки /etc/kubernetes/pki та /etc/kubernetes/pki/etcd усіма самопідписними файлами ЦС (сертифікати та ключі) та сервісним обліковим записом (публічні та приватні ключі), які необхідні kubeadm для вузла панелі управління.
Примітка:
Якщо ви використовуєте зовнішній ЦС, вам потрібно згенерувати ті ж самі файли окремо та вручну скопіювати їх на головний вузол панелі управління у /etc/kubernetes.
Після підписання всіх CSR ви можете видалити ключ кореневого ЦС (ca.key), як зазначено у розділі Режим зовнішнього ЦС.
Для другорядних вузлів панелі управління (kubeadm join --control-plane) нема потреби викликати вищезазначені команди. Залежно від того, як ви налаштували Високодоступний кластер, вам або потрібно вручну скопіювати ті ж самі файли з головного вузла панелі управління, або використати автоматизовану функціональність --upload-certs від kubeadm init.
Генерація CSR
Команда kubeadm certs generate-csr генерує CSR для всіх відомих сертифікатів, якими керує kubeadm. Після завершення команди вам потрібно вручну видалити файли .csr, .conf або .key, які вам не потрібні.
Врахування kubelet.conf
Цей розділ стосується як вузлів панелі управління, так і робочих вузлів.
Якщо ви видалили файл ca.key з вузлів панелі управління (Режим зовнішнього ЦС), активний kube-controller-manager у цьому кластері не зможе підписати клієнтські сертифікати kubelet. Якщо у вашій конфігурації не існує зовнішнього методу для підписання цих сертифікатів (наприклад, зовнішній підписувач), ви могли б вручну підписати kubelet.conf.csr, як пояснено в цьому посібнику.
Зверніть увагу, що це також означає, що автоматичне оновлення клієнтського сертифіката kubelet буде відключено. Таким чином, близько до закінчення терміну дії сертифіката, вам потрібно буде генерувати новий kubelet.conf.csr, підписувати сертифікат, вбудовувати його в kubelet.conf і перезапускати kubelet.
Якщо це не стосується вашої конфігурації, ви можете пропустити обробку kubelet.conf.csr на другорядних вузлах панелі управління та на робочих вузлах (всі вузли, що викликають kubeadm join ...). Це тому, що активний kube-controller-manager буде відповідальний за підписання нових клієнтських сертифікатів kubelet.
Примітка:
Ви повинні обробити файл kubelet.conf.csr на первинному вузлі панелі управління (хост, на якому ви спочатку запустили kubeadm init). Це повʼязано з тим, що kubeadm розглядає цей вузол як вузол, з якого завантажується кластер, і попередньо заповнений файл kubelet.conf потрібен.
Вузли панелі управління
Виконайте наступну команду на головному (kubeadm init) та вторинних (kubeadm join --control-plane) вузлах панелі управління, щоб згенерувати всі файли CSR:
sudo kubeadm certs generate-csr
Якщо має використовуватися зовнішній etcd, дотримуйтесь керівництва Зовнішній etcd з kubeadm, щоб зрозуміти, які файли CSR потрібні на вузлах kubeadm та etcd. Інші файли .csr та .key у теці /etc/kubernetes/pki/etcd можна видалити.
Виходячи з пояснення у розділі Врахування kubelet.conf, збережіть або видаліть файли kubelet.conf та kubelet.conf.csr.
та залиште лише файли kubelet.conf та kubelet.conf.csr. Альтернативно, повністю пропустіть кроки для робочих вузлів.
Підписання CSR для всіх сертифікатів
Примітка:
Якщо ви використовуєте зовнішній ЦС та вже маєте файли серійних номерів ЦС (.srl) для openssl, ви можете скопіювати такі файли на вузол kubeadm, де будуть оброблятися CSR. Файли .srl, які потрібно скопіювати, це: /etc/kubernetes/pki/ca.srl, /etc/kubernetes/pki/front-proxy-ca.srl та /etc/kubernetes/pki/etcd/ca.srl. Потім файли можна перемістити на новий вузол, де будуть оброблятися файли CSR.
Якщо файл .srl для ЦС відсутній на вузлі, скрипт нижче згенерує новий файл SRL з випадковим початковим серійним номером.
Щоб дізнатися більше про файли .srl, дивіться документацію openssl для прапорця --CAserial.
Повторіть цей крок для всіх вузлів, що мають файли CSR.
Запишіть наступний скрипт у теку /etc/kubernetes, перейдіть до цієї теки та виконайте скрипт. Скрипт згенерує сертифікати для всіх файлів CSR, які присутні в дереві /etc/kubernetes.
#!/bin/bash
# Встановіть термін дії сертифіката в дняхDAYS=365# Обробіть всі файли CSR, крім тих, що призначені для front-proxy і etcdfind ./ -name "*.csr" | grep -v "pki/etcd" | grep -v "front-proxy" | whileread -r FILE;
doecho"* Обробка ${FILE} ..."FILE=${FILE%.*}# Відкинути розширенняif[ -f "./pki/ca.srl"]; thenSERIAL_FLAG="-CAserial ./pki/ca.srl"elseSERIAL_FLAG="-CAcreateserial"fi openssl x509 -req -days "${DAYS}" -CA ./pki/ca.crt -CAkey ./pki/ca.key ${SERIAL_FLAG}\
-in "${FILE}.csr" -out "${FILE}.crt" sleep 2done# Обробіть всі CSR для etcdfind ./pki/etcd -name "*.csr" | whileread -r FILE;
doecho"* Обробка ${FILE} ..."FILE=${FILE%.*}# Відкинути розширенняif[ -f "./pki/etcd/ca.srl"]; thenSERIAL_FLAG=-CAserial ./pki/etcd/ca.srl
elseSERIAL_FLAG=-CAcreateserial
fi openssl x509 -req -days "${DAYS}" -CA ./pki/etcd/ca.crt -CAkey ./pki/etcd/ca.key ${SERIAL_FLAG}\
-in "${FILE}.csr" -out "${FILE}.crt"done# Обробіть CSR для front-proxyecho"* Обробка ./pki/front-proxy-client.csr ..."openssl x509 -req -days "${DAYS}" -CA ./pki/front-proxy-ca.crt -CAkey ./pki/front-proxy-ca.key -CAcreateserial \
-in ./pki/front-proxy-client.csr -out ./pki/front-proxy-client.crt
Вбудовування сертифікатів у файли kubeconfig
Повторіть цей крок для всіх вузлів, що мають файли CSR.
Запишіть наступний скрипт у теку /etc/kubernetes, перейдіть до цієї теки та виконайте скрипт. Скрипт візьме файли .crt, які були підписані для файлів kubeconfig з CSR на попередньому кроці, та вбудує їх у файли kubeconfig.
Виконайте цей крок на всіх вузлах, які мають файли CSR.
Запишіть наступний скрипт у теці /etc/kubernetes, перейдіть до цієї теки та виконайте скрипт.
#!/bin/bash
# Очищення файлів CSRrm -f ./*.csr ./pki/*.csr ./pki/etcd/*.csr # Очистка всіх файлів CSR# Очищення файлів CRT, які вже були вбудовані у файли kubeconfigrm -f ./*.crt
За бажанням, перемістіть файли .srl на наступний вузол, який буде оброблено.
За бажанням, якщо використовується зовнішній ЦС, видаліть файл /etc/kubernetes/pki/ca.key, як пояснено у розділі Вузол зовнішнього ЦС.
Ініціалізація вузла kubeadm
Як тільки файли CSR підписані і необхідні сертифікати розміщені на хостах, які ви хочете використовувати як вузли, ви можете використовувати команди kubeadm init та kubeadm join для створення Kubernetes кластера з цих вузлів. Під час init та join, kubeadm використовує існуючі сертифікати, ключі шифрування та файли kubeconfig, які він знаходить у дереві /etc/kubernetes у локальній файловій системі хоста.
2.1.8 - Переконфігурація кластера за допомогою kubeadm
kubeadm не підтримує автоматизованих способів переконфігурації компонентів, що були розгорнуті на керованих вузлах. Один зі способів автоматизації цього — використання власного оператора.
Для зміни конфігурації компонентів вам потрібно вручну редагувати повʼязані обʼєкти кластера та файли на диску.
Цей посібник показує правильну послідовність кроків, які потрібно виконати для досягнення переконфігурації кластера kubeadm.
Перш ніж ви розпочнете
Вам потрібен кластер, що був розгорнутий за допомогою kubeadm.
У вас мають бути адміністративні облікові дані (/etc/kubernetes/admin.conf) та мережеве зʼєднання з робочим kube-apiserver у кластері з хосту, на якому встановлено kubectl.
Мати текстовий редактор встановлений на всіх хостах.
Переконфігурація кластера
kubeadm записує набір параметрів конфігурації компонентів на рівні кластера у ConfigMaps та в інших обʼєктах. Ці обʼєкти потрібно редагувати вручну. Команда kubectl edit може бути використана для цього.
Команда kubectl edit відкриє текстовий редактор, в якому ви можете редагувати та зберегти обʼєкт безпосередньо.
Ви можете використовувати змінні середовища KUBECONFIG та KUBE_EDITOR для вказівки розташування файлу kubeconfig, який використовується kubectl, та обраного текстового редактора.
Після збереження будь-яких змін у цих обʼєктах кластера, компоненти, що працюють на вузлах, можуть не оновлюватись автоматично. У нижченаведених кроках вказано, як це зробити вручну.
Попередження:
Конфігурація компонентів у ConfigMaps зберігається як неструктуровані дані (рядки YAML). Це означає, що перевірка правильності не буде проводитися при оновленні вмісту ConfigMap. Вам потрібно бути обережними та слідувати документованому формату API для певної конфігурації компонента, а також уникати друкарських помилок та помилок у відступах в YAML.
Застосування змін у конфігурації кластера
Оновлення ClusterConfiguration
Під час створення кластера та його оновлення, kubeadm записує ClusterConfiguration у ConfigMap, з назвою kubeadm-config у просторі імен kube-system.
Щоб змінити певну опцію у ClusterConfiguration, ви можете редагувати ConfigMap за допомогою цієї команди:
kubectl edit cm -n kube-system kubeadm-config
Конфігурація знаходиться в ключі data.ClusterConfiguration.
Примітка:
ClusterConfiguration включає різноманітні параметри, які впливають на конфігурацію окремих компонентів, таких як kube-apiserver, kube-scheduler, kube-controller-manager, CoreDNS, etcd та kube-proxy. Зміни в конфігурації повинні бути віддзеркалені в компонентах вузла вручну.
Віддзеркалення змін ClusterConfiguration на вузлах панелі управління
kubeadm керує компонентами панелі управління як статичними маніфестами Pod, які розташовані в
теці /etc/kubernetes/manifests. Будь-які зміни у ClusterConfiguration в ключах apiServer, controllerManager, scheduler або etcd повинні віддзеркалюватись у відповідних файлах у теці маніфестів на вузлі панелі управління.
Такі зміни можуть включати:
extraArgs — потребує оновлення списку прапорців, які передаються контейнеру компонента
extraVolumes — потребує оновлення точок монтування для контейнера компонента
*SANs — потребує написання нових сертифікатів з Subject Alternative Names.
Перед продовженням цих змін переконайтеся, що ви зробили резервну копію теки /etc/kubernetes/.
Для написання нових сертифікатів ви можете використовувати:
Для написання нових файлів маніфестів у теці /etc/kubernetes/manifests ви можете використовувати:
# Для компонентів панелі управління Kuberneteskubeadm init phase control-plane <component-name> --config <config-file>
# Для локального etcdkubeadm init phase etcd local --config <config-file>
Зміст <config-file> повинен відповідати оновленням в ClusterConfiguration. Значення <component-name> повинно бути імʼям компонента панелі управління Kubernetes (apiserver, controller-manager або scheduler).
Примітка:
Оновлення файлу у /etc/kubernetes/manifests призведе до перезапуску статичного Podʼа для відповідного компонента. Спробуйте робити ці зміни один за одним на вузлі, щоб не переривати роботу кластера.
Застосування змін конфігурації kubelet
Оновлення KubeletConfiguration
Під час створення кластера та оновлення, kubeadm записує KubeletConfiguration у ConfigMap з назвою kubelet-config в просторі імен kube-system.
Ви можете редагувати цей ConfigMap за допомогою такої команди:
kubectl edit cm -n kube-system kubelet-config
Конфігурація розташована в ключі data.kubelet.
Віддзеркалення змін в kubelet
Щоб віддзеркалити зміни на вузлах kubeadm, вам потрібно виконати наступне:
Увійдіть на вузол kubeadm.
Виконайте команду kubeadm upgrade node phase kubelet-config, щоб завантажити свіжий вміст kubelet-config ConfigMap в локальний файл /var/lib/kubelet/config.yaml.
Відредагуйте файл /var/lib/kubelet/kubeadm-flags.env, щоб застосувати додаткову конфігурацію за допомогою прапорців.
Перезапустіть службу kubelet за допомогою systemctl restart kubelet.
Примітка:
Виконуйте ці зміни по одному вузлу за раз, щоб дозволити належне перепланування робочих навантажень.
Примітка:
Під час оновлення kubeadm, kubeadm завантажує KubeletConfiguration з ConfigMap kubelet-config і перезаписує вміст /var/lib/kubelet/config.yaml. Це означає, що локальна конфігурація вузла повинна бути застосована або за допомогою прапорців у /var/lib/kubelet/kubeadm-flags.env, або шляхом ручного оновлення вмісту /var/lib/kubelet/config.yaml після kubeadm upgrade, з подальшим перезапуском kubelet.
Застосування змін у конфігурації kube-proxy
Оновлення KubeProxyConfiguration
Під час створення кластера та оновлення, kubeadm записує KubeProxyConfiguration у ConfigMap в просторі імен kube-system з назвою kube-proxy.
Цей ConfigMap використовується DaemonSet kube-proxy в просторі імен kube-system.
Щоб змінити певну опцію в KubeProxyConfiguration, ви можете відредагувати ConfigMap за допомогою цієї команди:
kubectl edit cm -n kube-system kube-proxy
Конфігурація знаходиться в ключі data.config.conf.
Віддзеркалення змін у kube-proxy
Після оновлення ConfigMap kube-proxy, ви можете перезапустити всі Podʼи kube-proxy:
Видаліть Podʼи за допомогою:
kubectl delete po -n kube-system -l k8s-app=kube-proxy
Створюватимуться нові Podʼи, які використовують оновлений ConfigMap.
Примітка:
Оскільки kubeadm розгортає kube-proxy як DaemonSet, конфігурація, специфічна для вузла, не підтримується.
Застосування змін конфігурації CoreDNS
Оновлення розгортання CoreDNS та сервісу
kubeadm розгортає CoreDNS як Deployment з назвою coredns та Service з назвою kube-dns, обидва у просторі імен kube-system.
Для оновлення будь-яких налаштувань CoreDNS ви можете редагувати обʼєкти Deployment та Service:
kubeadm не дозволяє налаштування CoreDNS під час створення та оновлення кластера. Це означає, що якщо ви виконаєте kubeadm upgrade apply, ваші зміни в обʼєктах CoreDNS будуть втрачені та мають бути застосовані повторно.
Збереження переконфігурації
Під час виконання команди kubeadm upgrade на керованому вузлі kubeadm може перезаписати конфігурацію, яка була застосована після створення кластера (переконфігурація).
Збереження переконфігурації обʼєкту Node
kubeadm записує Labels, Taints, сокенти CRI та іншу інформацію в обʼєкті Node для конкретного вузла Kubernetes. Для зміни будь-якого змісту цього обʼєкта Node ви можете використовувати:
kubectl edit no <імʼя-вузла>
Під час виконання kubeadm upgrade вміст такого Node може бути перезаписаний. Якщо ви бажаєте зберегти свої зміни в обʼєкті Node після оновлення, ви можете підготувати команду патча для kubectl і застосувати її до обʼєкта Node:
kubectl patch no <імʼя-вузла> --patch-file <файл-патча>
Збереження переконфігурації компонента панелі управління
Основним джерелом конфігурації панелі управління є обʼєкт ClusterConfiguration, збережений у кластері. Для розширення конфігурації статичних маніфестів Podʼів можна використовувати патчі.
Ці файли патчів повинні залишатися як файли на вузлах панелі управління, щоб забезпечити можливість їх використання командою kubeadm upgrade ... --patches <directory>.
Якщо переконфігурування виконується для ClusterConfiguration і статичних маніфестів Podʼів на диску, то набір патчів для конкретного вузла повинен бути відповідно оновлений.
Збереження переконфігурації kubelet
Будь-які зміни в KubeletConfiguration, збережені у /var/lib/kubelet/config.yaml, будуть перезаписані під час виконання kubeadm upgrade, завантажуючи вміст конфігурації kubelet-config ConfigMap для всього кластера. Для збереження конфігурації kubelet для Node потрібно або вручну змінити файл /var/lib/kubelet/config.yaml після оновлення, або файл /var/lib/kubelet/kubeadm-flags.env може містити прапорці. Прапорці kubelet перевизначають відповідні параметри KubeletConfiguration, але слід зауважити, що деякі з прапорців є застарілими.
Після зміни /var/lib/kubelet/config.yaml або /var/lib/kubelet/kubeadm-flags.env потрібен перезапуск kubelet.
Ця сторінка пояснює, як увімкнути репозиторій пакунків для бажаного мінорного випуску Kubernetes під час оновлення кластера. Це потрібно лише для користувачів репозиторіїв пакунків, що підтримуються спільнотою та розміщені на pkgs.k8s.io. На відміну від застарілих репозиторіїв пакунків, репозиторії пакунків, що підтримуються спільнотою, структуровані таким чином, що для кожної мінорної версії Kubernetes є окремий репозиторій пакунків.
Примітка:
Цей посібник охоплює лише частину процесу оновлення Kubernetes. Для отримання додаткової інформації про оновлення кластерів Kubernetes див. посібник з оновлення.
Примітка:
Цей крок потрібно виконати лише під час оновлення кластера до іншого мінорного випуску. Якщо ви оновлюєтеся до іншого патч-релізу в межах тієї самої мінорної версії (наприклад, з v1.34.5 до v1.34.7), вам не потрібно дотримуватися цього посібника. Однак, якщо ви все ще використовуєте застарілі репозиторії пакунків, вам потрібно перейти на нові репозиторії пакунків, які підтримуються спільнотою, перед оновленням (див. наступний розділ для отримання деталей про те, як це зробити).
Перш ніж ви розпочнете
У цьому документі припускається, що ви вже використовуєте репозиторії пакунків, які підтримуються спільнотою (pkgs.k8s.io). Якщо це не так, наполегливо рекомендується перейти на репозиторії пакунків, які підтримуються спільнотою, як описано в офіційному оголошенні.
Примітка: Сховища застарілих пакунків (apt.kubernetes.io та yum.kubernetes.io) визнані
застарілими та заморожені станом на 13 вересня 2023.
Використання нових репозиторіїв пакунків, розміщених за адресою pkgs.k8s.io`,
настійно рекомендується і є обовʼязковим для встановлення версій Kubernetes, випущених після 13 вересня 2023 року.
Застарілі репозиторії та їхні вміст можуть бути видалені у будь-який момент у майбутньому і без попереднього повідомлення.
Нові репозиторії пакунків надають можливість завантаження версій Kubernetes, починаючи з v1.24.0.
Перевірка використання репозиторіїв пакунків Kubernetes
Якщо ви не впевнені, чи ви використовуєте репозиторії пакунків, які підтримуються спільнотою, чи застарілі репозиторії пакунків, виконайте наступні кроки для перевірки:
Виведіть вміст файлу, який визначає apt-репозиторій Kubernetes:
# У вашій системі цей файл конфігурації може мати іншу назвуpager /etc/apt/sources.list.d/kubernetes.list
Якщо ви бачите рядок, схожий на:
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.33/deb/ /
Ви використовуєте репозиторії пакунків Kubernetes, і цей посібник стосується вас. Інакше наполегливо рекомендується перейти на репозиторії пакунків Kubernetes, які підтримуються спільнотою, як описано в офіційному оголошенні.
Виведіть вміст файлу, який визначає yum-репозиторій Kubernetes:
# У вашій системі цей файл конфігурації може мати іншу назвуcat /etc/yum.repos.d/kubernetes.repo
Якщо ви бачите baseurl, схожий на baseurl в наведеному нижче виводі:
Ви використовуєте репозиторії пакунків Kubernetes, і цей посібник стосується вас.
Інакше наполегливо рекомендується перейти на репозиторії пакунків Kubernetes, які підтримуються спільнотою, як описано в офіційному оголошенні.
Виведіть вміст файлу, який визначає zypper-репозиторій Kubernetes:
# У вашій системі цей файл конфігурації може мати іншу назвуcat /etc/zypp/repos.d/kubernetes.repo
Якщо ви бачите baseurl, схожий на baseurl в наведеному нижче виводі:
Ви використовуєте репозиторії пакунків Kubernetes, і цей посібник стосується вас.
Інакше наполегливо рекомендується перейти на репозиторії пакунків Kubernetes, які підтримуються спільнотою, як описано в офіційному оголошенні.
Примітка:
URL, використаний для репозиторіїв пакунків Kubernetes, не обмежується pkgs.k8s.io, він також може бути одним із наступних:
pkgs.k8s.io
pkgs.kubernetes.io
packages.kubernetes.io
Перехід на інший репозиторій пакунків Kubernetes
Цей крок слід виконати при оновленні з одного мінорного випуску Kubernetes на інший для отримання доступу до пакунків бажаної мінорної версії Kubernetes.
Відкрийте файл, який визначає apt-репозиторій Kubernetes за допомогою текстового редактора на ваш вибір:
nano /etc/apt/sources.list.d/kubernetes.list
Ви повинні побачити один рядок з URL, що містить вашу поточну мінорну версію Kubernetes. Наприклад, якщо ви використовуєте v1.33, ви повинні побачити це:
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.33/deb/ /
Змініть версію в URL на наступний доступний мінорний випуск, наприклад:
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.34/deb/ /
Збережіть файл і вийдіть з текстового редактора. Продовжуйте дотримуватися відповідних інструкцій щодо оновлення.
Відкрийте файл, який визначає yum-репозиторій Kubernetes за допомогою текстового редактора на ваш вибір:
nano /etc/yum.repos.d/kubernetes.repo
Ви повинні побачити файл з двома URL, що містять вашу поточну мінорну версію Kubernetes. Наприклад, якщо ви використовуєте v1.33, ви повинні побачити це:
Ця сторінка допоможе вам налаштувати перевищення ємності вузла у вашому кластері Kubernetes. Перевищення ємності вузла — це стратегія, яка проактивно резервує частину обчислювальних ресурсів вашого кластера. Це резервування допомагає зменшити час, необхідний для планування нових podʼів під час подій масштабування, підвищуючи чутливість вашого кластера до раптових сплесків трафіку або навантаження.
Підтримуючи деяку невикористану ємність, ви забезпечуєте негайну доступність ресурсів при створенні нових podʼів, запобігаючи їх переходу в стан очікування під час масштабування кластера.
Перш ніж ви розпочнете
Вам потрібен кластер Kubernetes, і інструмент командного рядка kubectl має бути налаштований для звʼязку з вашим кластером.
У вашому кластері має бути налаштований з автомасштабувальник, який керує вузлами на основі попиту.
Створіть PriorityClass
Почніть з визначення PriorityClass для podʼів-заповнювачів. Спочатку створіть PriorityClass з негативним значенням пріоритету, який ви незабаром призначите podʼам-заповнювачам. Пізніше ви налаштуєте Deployment, яке використовує цей PriorityClass.
apiVersion:scheduling.k8s.io/v1kind:PriorityClassmetadata:name:placeholder# ці Podʼи передставляють ємність заповнювачаvalue:-1000globalDefault:falsedescription:"Відʼємний пріоритет для pod-заповнювачів, щоб увімкнути надлишкове розміщення."
Далі ви визначите Deployment, який використовує PriorityClass з негативним пріоритетом і запускає мінімальний контейнер. Коли ви додасте його до свого кластера, Kubernetes запустить ці podʼи-заповнювачі для резервування ємності. У разі нестачі ємності, панель управління вибере один з цих podʼів-заповнювачів як першого кандидата для випередження.
apiVersion:apps/v1kind:Deploymentmetadata:name:capacity-reservation# Ви маєте вирішити, в якому просторі імен розгортатиspec:replicas:1selector:matchLabels:app.kubernetes.io/name:capacity-placeholdertemplate:metadata:labels:app.kubernetes.io/name:capacity-placeholderannotations:kubernetes.io/description:"Capacity reservation"spec:priorityClassName:placeholderaffinity:# Спробуйте розмістити ці додаткові Podʼи на різних вузлах# якщо це можливоpodAntiAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight:100podAffinityTerm:labelSelector:matchLabels:app.kubernetes.io/name:capacity-placeholdertopologyKey:topology.kubernetes.io/hostnamecontainers:- name:pauseimage:registry.k8s.io/pause:3.6resources:requests:cpu:"50m"memory:"512Mi"limits:memory:"512Mi"
Оберіть простір імен для podʼів-заповнювачів
Виберіть, або створіть, {{ < glossary_tooltip text="простір імен" term_id="namespace" >}}, в якому ви будете запускати podʼи-заповнювачі.
Створіть Deployment-заповнювач
Створіть Deployment на основі цього маніфесту:
# Змініть `example` на простір імен, який ви вибралиkubectl --namespace example apply -f https://k8s.io/examples/deployments/deployment-with-capacity-reservation.yaml
Налаштуйте запити ресурсів для заповнювачів
Налаштуйте запити та обмеження ресурсів для podʼів-заповнювачів, щоб визначити кількість зарезервованих ресурсів, які ви хочете підтримувати. Це резервування забезпечує наявність певної кількості CPU та памʼяті для нових podʼів.
Щоб редагувати Deployment, змініть розділ resources у файлі маніфесту Deployment, щоб встановити відповідні запити та обмеження. Ви можете завантажити цей файл локально та відредагувати його за допомогою будь-якого текстового редактора.
Ви можете редагувати маніфест Deployment використовуючи kubectl:
kubectl edit deployment capacity-reservation
Наприклад, щоб зарезервувати 0.5 CPU та 1GiB памʼяті для 5 podʼів-заповнювачів, визначте запити та обмеження ресурсів для одного podʼа-заповнювача наступним чином:
Наприклад, з 5 репліками, кожна з яких резервує 0.1 CPU та 200MiB памʼяті:
Загальна зарезервована емність CPU: 5 × 0.1 = 0.5 (у специфікації podʼа ви напишете кількість 500m)
Загальна зарезервована памʼять: 5 × 200MiB = 1GiB (у специфікації podʼа ви напишете 1 Gi)
Щоб масштабувати Deployment, налаштуйте кількість реплік відповідно до розміру вашого кластера та очікуваного навантаження:
Вихідні дані повинні відображати оновлену кількість реплік:
NAME READY UP-TO-DATE AVAILABLE AGE
capacity-reservation 5/5 5 5 2m
Примітка:
Деякі автомасштабувальники, зокрема Karpenter, розглядають правила переважної спорідненості як жорсткі правила при розгляді масштабування вузлів. Якщо ви використовуєте Karpenter або інший автомасштабувальник вузлів, який використовує той самий евристичний підхід, кількість реплік, яку ви встановлюєте тут, також встановлює мінімальну кількість вузлів для вашого кластера.
Що далі
Дізнайтеся більше про PriorityClasses та як вони впливають на планування podʼів.
Дізнайтеся більше про автомасштабування вузлів, щоб динамічно налаштовувати розмір вашого кластера на основі навантаження.
Зрозумійте Випередження podʼів, ключовий механізм Kubernetes для обробки конфліктів ресурсів. Та ж сторінка охоплює поняття виселення, що менш актуально для підходу з podʼами-заповнювачами, але також є механізмом для Kubernetes для реагування на конфлікти ресурсів.
2.3 - Міграція з dockershim
Цей розділ містить інформацію, яку вам потрібно знати при міграції з dockershim на інші оточення виконання контейнерів.
Після оголошення про застарівання dockershim в Kubernetes 1.20, виникли питання, як це вплине на різні робочі навантаження та розгортання самого Kubernetes. Наш Dockershim Removal FAQ допоможе вам краще зрозуміти проблему.
Dockershim був видалений з Kubernetes з випуском v1.24. Якщо ви використовуєте Docker Engine через dockershim як своє оточення виконання контейнерів і хочете оновитись до v1.24, рекомендується або мігрувати на інше оточення виконання, або знайти альтернативний спосіб отримання підтримки Docker Engine. Ознайомтеся з розділом оточення виконання контейнерів, щоб дізнатися про ваші варіанти.
Версія Kubernetes з dockershim (1.23) вийшла з стану підтримки, а v1.24 скоро вийде зі стану підтримки. Переконайтеся, що повідомляєте про проблеми з міграцією, щоб проблеми могли бути вчасно виправлені, і ваш кластер був готовий до видалення dockershim. Після виходу v1.24 зі стану підтримки вам доведеться звертатися до вашого постачальника Kubernetes за підтримкою або оновлювати кілька версій одночасно, якщо є критичні проблеми, які впливають на ваш кластер.
Ваш кластер може мати більше одного типу вузлів, хоча це не є загальною конфігурацією.
Якщо ви знайшли дефект або іншу технічну проблему, повʼязану з відмовою від dockershim, ви можете повідомити про проблему проєкту Kubernetes.
2.3.1 - Заміна середовища виконання контейнерів на вузлі з Docker Engine на containerd
Це завдання визначає кроки, необхідні для оновлення вашого середовища виконання контейнерів на containerd з Docker. Воно буде корисним для операторів кластерів, які працюють з Kubernetes 1.23 або старішими версіями. Воно також охоплює приклад сценарію міграції з dockershim на containerd. З цієї сторінки можна вибрати альтернативні середовища виконання контейнерів.
Перш ніж ви розпочнете
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Встановіть пакунок containerd.io з офіційних репозиторіїв Docker. Інструкції щодо налаштування репозиторію Docker для вашого конкретного дистрибутиву Linux і встановлення пакунка containerd.io можна знайти у Починаючи з containerd.
Copy-Item -Path ".\bin\" -Destination "$Env:ProgramFiles\containerd" -Recurse -Force
cd $Env:ProgramFiles\containerd\
.\containerd.exe config default | Out-File config.toml -Encoding ascii
# Перегляньте конфігурацію. Залежно від налаштувань можливо, ви захочете внести корективи:# - образ sandbox_image (образ pause Kubernetes)# - розташування cni bin_dir та conf_dirGet-Content config.toml
# (Необовʼязково, але дуже рекомендується) Виключіть containerd зі сканування Windows DefenderAdd-MpPreference -ExclusionProcess "$Env:ProgramFiles\containerd\containerd.exe"
Налаштування kubelet для використання containerd як його середовища виконання контейнерів
Відредагуйте файл /var/lib/kubelet/kubeadm-flags.env та додайте середовище виконання контейнерів до прапорців; --container-runtime-endpoint=unix:///run/containerd/containerd.sock.
Використовуючи kubeadm, користувачі повинні знати, що інструмент kubeadm зберігає сокет CRI хоста в файлі /var/lib/kubelet/instance-config.yaml на кожному вузлі. Ви можете створити цей файл /var/lib/kubelet/instance-config.yaml на вузлі.
Файл /var/lib/kubelet/instance-config.yaml дозволяє налаштувати параметр containerRuntimeEndpoint.
Ви можете встановити значення цього параметра на шлях до вибраного вами сокета CRI (наприклад, unix:///run/containerd/containerd.sock).
Перезапустіть kubelet
systemctl start kubelet
Перевірте, що вузол справний
Запустіть kubectl get nodes -o wide, і containerd зʼявиться як середовище виконання для вузла, який ми щойно змінили.
Видаліть Docker Engine
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Попередні команди не видаляють образи, контейнери, томи або налаштовані файли конфігурації на вашому хості. Щоб їх видалити, слідуйте інструкціям Docker щодо Видалення Docker Engine.
Увага:
Інструкції Docker щодо видалення Docker Engine створюють ризик видалення containerd. Будьте обережні при виконанні команд.
Введення вузла в експлуатацію
kubectl uncordon <node-to-uncordon>
Замініть <node-to-uncordon> на імʼя вузла, який ви раніше вивели з експлуатації.
2.3.2 - Перевірте, яке середовище виконання контейнерів використовується на вузлі
На цій сторінці наведено кроки для визначення того, яке середовище виконання контейнерів використовують вузли у вашому кластері.
Залежно від того, як ви запускаєте свій кластер, середовище виконання контейнерів для вузлів може бути попередньо налаштованим або вам потрібно його налаштувати. Якщо ви використовуєте сервіс Kubernetes, що надається вам постачальником послуг, можуть існувати специфічні для нього способи перевірки того, яке середовище виконання контейнерів налаштоване для вузлів. Метод, описаний на цій сторінці, повинен працювати завжди, коли дозволяється виконання kubectl.
Визначте середовище виконання контейнерів, яке використовується на вузлі
Використовуйте kubectl, щоб отримати та показати інформацію про вузли:
kubectl get nodes -o wide
Вивід подібний до такого. Стовпець CONTAINER-RUNTIME виводить інформацію про середовище та його версію.
Для Docker Engine вивід схожий на цей:
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.16.15 docker://19.3.1
node-2 Ready v1.16.15 docker://19.3.1
node-3 Ready v1.16.15 docker://19.3.1
Якщо ваше середовище показується як Docker Engine, це все одно не означає, що вас точно торкнеться видалення dockershim у Kubernetes v1.24. Перевірте точку доступу середовища, щоб побачити, чи використовуєте ви dockershim. Якщо ви не використовуєте dockershim, вас це не стосується.
Для containerd вивід схожий на цей:
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.19.6 containerd://1.4.1
node-2 Ready v1.19.6 containerd://1.4.1
node-3 Ready v1.19.6 containerd://1.4.1
Дізнайтеся, яку точку доступу середовища виконання контейнерів ви використовуєте
Середовище виконання контейнерів спілкується з kubelet через Unix-сокет, використовуючи протокол CRI, який базується на фреймворку gRPC. Kubelet діє як клієнт, а середовище — як сервер. У деяких випадках може бути корисно знати, який сокет використовується на ваших вузлах. Наприклад, з видаленням dockershim у Kubernetes v1.24 і пізніше ви, можливо, захочете знати, чи використовуєте ви Docker Engine з dockershim.
Примітка:
Якщо ви зараз використовуєте Docker Engine на своїх вузлах з cri-dockerd, вас не торкнетеся видалення dockershim.
Ви можете перевірити, який сокет ви використовуєте, перевіривши конфігурацію kubelet на своїх вузлах.
Прочитайте початкові команди для процесу kubelet:
tr \\0' ' < /proc/"$(pgrep kubelet)"/cmdline
Якщо у вас немає tr або pgrep, перевірте командний рядок для процесу kubelet вручну.
У виведенні шукайте прапорець --container-runtime та прапорець --container-runtime-endpoint.
Якщо ваші вузли використовують Kubernetes v1.23 та старіший, і ці прапори відсутні або прапорець --container-runtime не є remote, ви використовуєте сокет dockershim з Docker Engine. Параметр командного рядка --container-runtime не доступний у Kubernetes v1.27 та пізніше.
Якщо прапорець --container-runtime-endpoint присутній, перевірте імʼя сокета, щоб дізнатися, яке середовище ви використовуєте. Наприклад, unix:///run/containerd/containerd.sock — це точка доступу containerd.
Якщо ви хочете змінити середовище виконання контейнерів на вузлі з Docker Engine на containerd, ви можете дізнатися більше інформації про міграцію з Docker Engine на containerd, або, якщо ви хочете продовжити використовувати Docker Engine у Kubernetes v1.24 та пізніше, мігруйте на сумісний з CRI адаптер, наприклад cri-dockerd.
2.3.3 - Виправлення помилок, повʼязаних з втулками CNI
Щоб уникнути помилок, повʼязаних з втулками CNI, переконайтеся, що ви використовуєте або оновлюєте середовище виконання контейнерів, яке було протестовано й працює коректно з вашою версією Kubernetes.
Про помилки "Incompatible CNI versions" та "Failed to destroy network for sandbox"
Проблеми з Service існують для налаштування та демонтажу мережі CNI для Pod в containerd v1.6.0-v1.6.3, коли втулки CNI не були оновлені та/або версія конфігурації CNI не вказана в файлах конфігурації CNI. Команда containerd повідомляє, що "ці проблеми вирішені в containerd v1.6.4."
З containerd v1.6.0-v1.6.3, якщо ви не оновите втулки CNI та/або не вкажете версію конфігурації CNI, ви можете стикнутися з наступними умовами помилок "Incompatible CNI versions" або "Failed to destroy network for sandbox".
Помилка "Incompatible CNI versions"
Якщо версія вашого втулка CNI не відповідає версії втулка в конфігурації, тому що версія конфігурації є новішою, ніж версія втулка, лог containerd, швидше за все, покаже повідомлення про помилку при запуску Pod подібне до:
Якщо версія втулка відсутня в конфігурації втулка CNI, Pod може запускатися. Однак припинення Podʼа призводить до помилки, подібної до:
ERROR[2022-04-26T00:43:24.518165483Z] StopPodSandbox for "b" failed
error="failed to destroy network for sandbox \"bbc85f891eaf060c5a879e27bba9b6b06450210161dfdecfbb2732959fb6500a\": invalid version \"\": the version is empty"
Ця помилка залишає Pod у стані "not-ready" з приєднаним простором імен мережі. Щоб відновити роботу після цієї проблеми, відредагуйте файл конфігурації CNI, щоб додати відсутню інформацію про версію. Наступна спроба зупинити Pod повинна бути успішною.
Оновлення ваших втулків CNI та файлів конфігурації CNI
Якщо ви використовуєте containerd v1.6.0-v1.6.3 та зіткнулися з помилками "Incompatible CNI versions" або "Failed to destroy network for sandbox", розгляньте можливість оновлення ваших втулків CNI та редагування файлів конфігурації CNI.
Після зупинки ваших служб середовища виконання контейнерів та kubelet виконайте наступні операції оновлення:
Якщо ви використовуєте втулки CNI, оновіть їх до останньої версії.
Якщо ви використовуєте не-CNI втулки, замініть їх втулками CNI. Використовуйте останню версію втулків.
Оновіть файл конфігурації втулка, щоб вказати або відповідати версії специфікації CNI, яку підтримує втулок, як показано у наступному розділі "Приклад файлу конфігурації containerd".
Для containerd переконайтеся, що ви встановили останню версію (v1.0.0 або пізніше) втулка CNI loopback.
Оновіть компоненти вузла (наприклад, kubelet) до Kubernetes v1.24.
Оновіть або встановіть найновішу версію середовища виконання контейнерів.
Поверніть вузол у ваш кластер, перезапустивши ваше середовище виконання контейнерів та kubelet. Увімкніть вузол (kubectl uncordon <імʼя_вузла>).
Приклад файлу конфігурації containerd
Наведений нижче приклад показує конфігурацію для середовища виконання контейнерів containerd версії v1.6.x, яке підтримує останню версію специфікації CNI (v1.0.0).
Будь ласка, перегляньте документацію від вашого постачальника втулків та мереж для подальших інструкцій з налаштування вашої системи.
У Kubernetes, середовище виконання контейнерів containerd додає типовий інтерфейс loopback, lo, до Podʼів. Середовище виконання контейнерів containerd налаштовує інтерфейс loopback через втулок CNI, loopback. Втулок loopback розповсюджується як частина пакунків релізу containerd, які мають позначення cni. containerd v1.6.0 та пізніше включає сумісний з CNI v1.0.0 втулок loopback, а також інші типові втулки CNI. Налаштування втулка loopback виконується внутрішньо за допомогою контейнерного середовища containerd і встановлюється для використання CNI v1.0.0. Це також означає, що версія втулка loopback повинна бути v1.0.0 або пізніше при запуску цієї новішої версії containerd.
Наступна команда bash генерує приклад конфігурації CNI. Тут значення 1.0.0 для версії конфігурації призначено для поля cniVersion для використання при запуску containerd втулком bridge CNI.
Оновіть діапазони IP-адрес у прикладі відповідно до вашого випадку використання та плану адресації мережі.
2.3.4 - Перевірка впливу видалення dockershim на ваш кластер
Компонент dockershim Kubernetes дозволяє використовувати Docker як середовище виконання контейнерів Kubernetes. Вбудований компонент dockershim Kubernetes був видалений у випуску v1.24.
Ця сторінка пояснює, як ваш кластер може використовувати Docker як середовище виконання контейнерів, надає деталі щодо ролі, яку відіграє dockershim при використанні, і показує кроки, які можна виконати, щоб перевірити, чи може видалення dockershim впливати на робочі навантаження.
Пошук залежностей вашого застосунку від Docker
Якщо ви використовуєте Docker для побудови контейнерів вашого застосунку, ви все ще можете запускати ці контейнери на будь-якому середовищі виконання контейнерів. Це використання Docker не вважається залежністю від Docker як середовища виконання контейнерів.
Коли використовується альтернативне середовище виконання контейнерів, виконання команд Docker може або не працювати, або призводити до неочікуваного виводу. Ось як ви можете зʼясувати, чи є у вас залежність від Docker:
Переконайтеся, що привілейовані Podʼи не виконують команди Docker (наприклад, docker ps), перезапускають службу Docker (команди типу systemctl restart docker.service) або змінюють файли Docker, такі як /etc/docker/daemon.json.
Перевірте наявність приватних реєстрів або налаштувань дзеркал образів у файлі конфігурації Docker (наприклад, /etc/docker/daemon.json). Зазвичай їх потрібно повторно налаштувати для іншого середовища виконання контейнерів.
Перевірте, що скрипти та застосунки, які працюють на вузлах поза вашою інфраструктурою Kubernetes, не виконують команди Docker. Це може бути:
SSH на вузли для усунення несправностей;
Сценарії запуску вузлів;
Встановлені безпосередньо на вузлах агенти безпеки та моніторингу.
Переконайтеся, що немає непрямих залежностей від поведінки dockershim. Це крайній випадок і ймовірно не вплине на ваш застосунок. Деякі інструменти можуть бути налаштовані реагувати на специфічну поведінку Docker, наприклад, видаляти сповіщення про певні метрики або шукати певне повідомлення у лозі як частину інструкцій щодо усунення несправностей. Якщо у вас налаштовано такі інструменти, перевірте поведінку на тестовому кластері перед міграцією.
Пояснення залежності від Docker
Середовище виконання контейнерів — це програмне забезпечення, яке може виконувати контейнери, які складаються з Podʼів Kubernetes. Kubernetes відповідає за оркестрування та планування Podʼів; на кожному вузлі kubelet використовує інтерфейс середовища виконання контейнерів як абстракцію, щоб ви могли використовувати будь-яке сумісне середовище виконання контейнерів.
У своїх перших випусках Kubernetes пропонував сумісність з одним середовищем виконання контейнерів — Docker. Пізніше, в історії проєкту Kubernetes, оператори кластерів хотіли б використовувати додаткові середовища виконання контейнерів. CRI було розроблено для того, щоб дозволити такий вид гнучкості — і kubelet почав підтримувати CRI. Однак, оскільки Docker існував до того, як була винайдена специфікація CRI, проєкт Kubernetes створив адаптер dockershim. Адаптер dockershim дозволяє kubelet взаємодіяти з Docker так, ніби Docker був середовищем виконання контейнерів, сумісним з CRI.
Перехід до Containerd як середовища виконання контейнерів прибирає посередника. Всі ті самі контейнери можуть бути запущені середовищем виконання контейнерів, такими як Containerd, як і раніше. Але тепер, оскільки контейнери розміщуються безпосередньо з середовищем виконання контейнерів, вони не є видимими для Docker. Отже, будь-який інструментарій Docker або стильний інтерфейс користувача, який ви могли використовувати раніше для перевірки цих контейнерів, більше не доступний.
Ви не можете отримати інформацію про контейнери за допомогою команд docker ps або docker inspect. Оскільки ви не можете отримувати перелік контейнерів, ви не можете отримати логи, зупинити контейнери або виконати щось всередині контейнера за допомогою docker exec.
Примітка:
Якщо ви запускаєте робочі навантаження через Kubernetes, найкращий спосіб зупинити контейнер — це через API Kubernetes, а не безпосередньо через середовище виконання контейнерів (ця порада стосується всіх розширень контейнерів, не тільки Docker).
Ви все ще можете отримувати образи або будувати їх за допомогою команди docker build. Але образи, побудовані або отримані Docker, не будуть видимі для середовища виконання контейнерів та Kubernetes. Їх потрібно буде розмістити у якомусь реєстрі, щоб їх можна було використовувати в Kubernetes.
Відомі проблеми
Деякі метрики файлової системи відсутні та формат метрик відрізняється
Точка доступу Kubelet /metrics/cadvisor надає метрики Prometheus, як описано в Метрики для системних компонентів Kubernetes. Якщо ви встановите збирач метрик, який залежить від цієї точки доступу, ви можете побачити такі проблеми:
Формат метрик на вузлі Docker - це k8s_<container-name>_<pod-name>_<namespace>_<pod-uid>_<restart-count>, але формат у іншому середовищі відрізняється. Наприклад, на вузлі containerd він має вигляд <container-id>.
Деякі метрики файлової системи відсутні, як описано нижче:
2.3.5 - Міграція агентів телеметрії та безпеки з dockershim
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Підтримка Kubernetes прямої інтеграції з Docker Engine є застарілою та була видалена. Більшість застосунків не мають прямої залежності від середовища виконання контейнерів. Однак, є ще багато агентів телеметрії та моніторингу, які мають залежність від Docker для збору метаданих, логів та метрик контейнерів. Цей документ збирає інформацію про те, як виявити ці залежності, а також посилання на те, як перенести ці агенти для використання загальних інструментів або альтернативних середовищ виконання.
Агенти телеметрії та безпеки
У кластері Kubernetes є кілька різних способів запуску агентів телеметрії чи безпеки. Деякі агенти мають пряму залежність від Docker Engine, коли вони працюють як DaemonSets або безпосередньо на вузлах.
Чому деякі агенти телеметрії взаємодіють з Docker Engine?
Історично Kubernetes був спеціально створений для роботи з Docker Engine. Kubernetes займався мережею та плануванням, покладаючись на Docker Engine для запуску та виконання контейнерів (у Podʼах) на вузлі. Деяка інформація, яка стосується телеметрії, наприклад, імʼя Podʼа, доступна лише з компонентів Kubernetes. Інші дані, такі як метрики контейнерів, не є обовʼязком середовища виконання контейнера. Ранні агенти телеметрії мали потребу у запиті середовища виконання контейнера та Kubernetes для передачі точної картини. З часом Kubernetes набув можливості підтримки кількох середовищ виконання контейнерів, і зараз підтримує будь-яке середовище виконання, яке сумісне з інтерфейсом середовища виконання контейнерів.
Деякі агенти телеметрії покладаються тільки на інструменти Docker Engine. Наприклад, агент може виконувати команду, таку як docker ps чи docker top для отримання переліку контейнерів та процесів або docker logs для отримання поточних логів. Якщо вузли у вашому проточному кластері використовують Docker Engine, і ви переходите на інше середовище виконання контейнерів, ці команди більше не працюватимуть.
Виявлення DaemonSets, що залежать від Docker Engine
Якщо Pod хоче викликати dockerd, що працює на вузлі, він повинен або:
змонтувати файлову систему, що містить привілейований сокет Docker, як том; або
безпосередньо змонтувати конкретний шлях привілейованого сокета Docker, також як том.
Наприклад: на образах COS Docker відкриває свій Unix сокет у /var/run/docker.sock. Це означає, що специфікація Pod буде містити монтування тому hostPath з /var/run/docker.sock.
Нижче наведено приклад сценарію оболонки для пошуку Podʼів, які мають монтування, які безпосередньо зіставляються з сокетом Docker. Цей сценарій виводить простір імен та імʼя Podʼа. Ви можете видалити grep '/var/run/docker.sock', щоб переглянути інші монтування.
Є альтернативні способи для Pod мати доступ до Docker на вузлі. Наприклад, батьківська тека /var/run може бути змонтована замість повного шляху (як у цьому прикладі). Представлений вище сценарій виявляє лише найпоширеніші використання.
Виявлення залежності від Docker агентів вузлів
Якщо вузли кластера налаштовані та встановлюють додаткові заходи безпеки та агенти телеметрії на вузлі, перевірте у вендора агента, чи має він будь-які залежності від Docker.
Вендори агентів телеметрії та безпеки
Цей розділ призначений для збирання інформації про різноманітних агентів телеметрії та безпеки, які можуть мати залежність від середовищ виконання контейнерів.
Ми зберігаємо робочу версію інструкцій щодо перенесення для різних вендорів агентів телеметрії та безпеки у документі Google. Будь ласка, звʼяжіться з вендором, щоб отримати актуальні інструкції щодо міграції з dockershim.
Як перенести: Міграція Falco з dockershim. Falco підтримує будь-яке середовище виконання, сумісне з CRI (стандартно використовується containerd); документація пояснює всі деталі. Pod, який має доступ до Docker, може мати назву, яка містить:
Перевірте документацію для Prisma Cloud, в розділі "Встановлення Prisma Cloud в кластер CRI (не Docker)". Pod, який має доступ до Docker, може мати назву, подібну до:
Смарт-агент SignalFx (застарілий) використовує кілька різних моніторів для Kubernetes, включаючи kubernetes-cluster, kubelet-stats/kubelet-metrics та docker-container-stats. Монітор kubelet-stats раніше був застарілим вендором на користь kubelet-metrics. Монітор docker-container-stats є одним з тих, що стосуються видалення dockershim. Не використовуйте монітор docker-container-stats з середовищами виконання контейнерів, відмінними від Docker Engine.
Як перейти з агента, залежного від dockershim:
Видаліть docker-container-stats зі списку налаштованих моніторів. Зверніть увагу, що залишення цього монітора увімкненим з не-dockershim середовищем виконання призведе до неправильних метрик при встановленні docker на вузлі та відсутності метрик, коли docker не встановлено.
При використанні автентифікації сертифіката клієнта ви можете генерувати сертифікати вручну за допомогою easyrsa, openssl або cfssl.
easyrsa
З easyrsa ви можете вручну генерувати сертифікати для вашого кластера.
Завантажте, розпакуйте та ініціалізуйте патчену версію easyrsa3.
curl -LO https://dl.k8s.io/easy-rsa/easy-rsa.tar.gz
tar xzf easy-rsa.tar.gz
cd easy-rsa-master/easyrsa3
./easyrsa init-pki
Згенеруйте новий центр сертифікації (CA). --batch встановлює автоматичний режим; --req-cn вказує загальну назву (CN, Common Name) для нового кореневого сертифіката CA.
Аргумент --subject-alt-name встановлює можливі IP-адреси та імена DNS, за якими буде доступний сервер API. MASTER_CLUSTER_IP зазвичай є першою IP-адресою з діапазону служб CIDR, який вказаний як аргумент --service-cluster-ip-range для сервера API та компонента керування контролером. Аргумент --days використовується для встановлення кількості днів чинності сертифіката. У прикладі нижче також припускається, що ви використовуєте cluster.local як типове імʼя домену DNS.
Створіть конфігураційний файл для генерування Certificate Signing Request (CSR).
Переконайтеся, що ви встановили власні значення для параметрів в кутових дужках, наприклад <MASTER_IP>, замінивши їх на власні значення перед збереженням файлу, наприклад з назвою csr.conf. Зауважте, що значення <MASTER_CLUSTER_IP> є IP-адресою API-сервера, як про це йдеться в попередньому розділі. Приклад конфігураційного файлу нижче використовує cluster.local як типове імʼя домену DNS.
Створіть конфігураційний файл JSON для генерації Certificate Signing Request (CSR), наприклад, ca-csr.json. Переконайтеся, що ви встановили власні значення для параметрів в кутових дужках.
Згенеруйте сертифікат CA (ca.pem) та ключ CA (ca-key.pem):
../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca
Створіть конфігураційний файл JSON для генерації ключів та сертифікатів для сервера API, наприклад, server-csr.json. Переконайтеся, що ви встановили власні значення для параметрів в кутових дужках. <MASTER_CLUSTER_IP> є IP-адресою кластера, як про це йдеться в попередньому розділі. В прикладі нижче також припускається, що ви використовуєте cluster.local як типове імʼя домену DNS.
Клієнтський вузол може не визнавати самопідписні сертифікати CA. Для оточення, що не є операційним, або для операційного оточення, що працює за корпоративним фаєрволом, ви можете розповсюджувати самопідписні сертифікати CA на всіх клієнтів та оновлювати перелік довірених сертифікатів.
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
API сертифікатів
Ви можете використовувати certificates.k8s.io API для надання сертифікатів x509 для використання для автентифікації, як про це йдеться на сторінці Керування TLS в кластері.
2.5 - Керування ресурсами памʼяті, CPU та API
2.5.1 - Налаштування типових запитів та обмежень памʼяті для простору імен
Визначте типове обмеження ресурсів памʼяті для простору імен, щоб кожний новий Контейнер у цьому просторі імен мав налаштоване обмеження ресурсів памʼяті.
Ця сторінка показує, як налаштувати типові запити та обмеження памʼяті для простору імен.
Кластер Kubernetes може бути розділений на простори імен. Якщо у вас є простір імен, в якому вже є типове обмеження памʼяті limit, і ви спробуєте створити Pod з контейнером, який не вказує своє власне обмеження памʼяті, то панель управління назначає типове обмеження памʼяті цьому контейнеру.
Kubernetes назначає типовий запит памʼяті за певних умов, які будуть пояснені пізніше в цій темі.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Тепер, якщо ви створите Pod у просторі імен default-mem-example, і будь-який контейнер у цьому Podʼі не вказує свої власні значення для запиту та обмеження памʼяті, то панель управління застосовує типові значення: запит памʼяті 256MiB та обмеження памʼяті 512MiB.
Ось приклад маніфесту для Pod, який має один контейнер. Контейнер не вказує запиту та обмеження памʼяті.
kubectl get pod memory-defaults-pod --namespace=default-mem-example
Вивід має показати, що контейнер Podʼа має обмеження на запит памʼяті 256MiB та обмеження памʼяті 512MiB. Ці значення були назначені через типові обмеження памʼяті, вказані в LimitRange.
kubectl get pod default-mem-demo-2 --output=yaml --namespace=default-mem-example
Вивід показує, що запит памʼяті контейнера встановлено таким чином, щоб відповідати його обмеженню памʼяті. Зверніть увагу, що контейнеру не було назначено типового значення запиту памʼяті 256Mi.
resources:limits:memory:1Girequests:memory:1Gi
Що якщо ви вказуєте запит контейнера, але не його обмеження?
Ось маніфест для Podʼа з одним контейнером. Контейнер вказує запит памʼяті, але не обмеження:
kubectl get pod default-mem-demo-3 --output=yaml --namespace=default-mem-example
Вивід показує, що запит памʼяті контейнера встановлено на значення, вказане в маніфесті контейнера. Контейнер обмежений використовувати не більше 512MiB памʼяті, що відповідає типовому обмеженню памʼяті для простору імен.
LimitRangeне перевіряє відповідність типових значень, які він застосовує. Це означає, що типове значення для обмеження, встановлене за допомогою LimitRange, може бути меншим за значення запиту, вказане для контейнера в специфікації, яку клієнт подає на сервер API. Якщо це станеться, остаточний Pod не буде можливим для розміщення. Дивіться Обмеження на ресурси лімітів та запитів для отримання додаткової інформації.
Мотивація для типових обмежень та запитів памʼяті
Якщо у вашому просторі імен налаштовано квоту ресурсів памʼяті, корисно мати типове значення для обмеження памʼяті. Ось три обмеження, які накладає квота ресурсів на простір імен:
Для кожного Podʼа, який працює у просторі імен, Pod та кожен з його контейнерів повинні мати обмеження памʼяті. (Якщо ви вказуєте обмеження памʼяті для кожного контейнера у Podʼі, Kubernetes може вивести типове обмеження памʼяті на рівні Podʼа, додавши обмеження для його контейнерів).
Обмеження памʼяті застосовує резервування ресурсів на вузлі, де запускається відповідний Pod. Загальна кількість памʼяті, зарезервована для всіх Podʼів у просторі імен, не повинна перевищувати вказаного обмеження.
Загальна кількість памʼяті, що фактично використовується всіма Podʼами у просторі імен, також не повинна перевищувати вказаного обмеження.
Коли ви додаєте обмеження (LimitRange):
Якщо будь-який Pod у цьому просторі імен, що містить контейнер, не вказує своє власне обмеження памʼяті, панель управління застосовує типове обмеження памʼяті для цього контейнера, і Podʼу може бути дозволено запуститися в просторі імен, який обмежено квотою ресурсів памʼяті.
2.5.2 - Налаштування типових запитів та обмежень CPU для простору імен
Визначте типове обмеження ресурсів CPU для простору імен так, щоб усі нові Podʼи у цьому просторі імен мали налаштоване обмеження ресурсів CPU.
Ця сторінка показує, як налаштувати типові запити та обмеження CPU для просторів імен.
Кластер Kubernetes може бути розділений на простори імен. Якщо ви створюєте Pod у просторі імен, який має типове обмеження CPU limit, і будь-який контейнер у цьому Podʼі не вказує
своє власне обмеження CPU, то панель управління назначає типове обмеження CPU цьому контейнеру.
Kubernetes назначає типовий запит CPU request, але лише за певних умов, які будуть пояснені пізніше на цій сторінці.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Тепер, якщо ви створюєте Pod у просторі імен default-cpu-example, і будь-який контейнер у цьому Podʼі не вказує свої власні значення для запиту та обмеження CPU, то панель управління застосовує типові значення: запит CPU 0.5 та типове обмеження CPU 1.
Ось маніфест для Podʼа з одним контейнером. Контейнер не вказує запит CPU та обмеження.
kubectl get pod default-cpu-demo --output=yaml --namespace=default-cpu-example
Вивід показує, що єдиний контейнер Podʼа має запит CPU 500m cpu (що ви можете читати як “500 millicpu”), і обмеження CPU 1 cpu. Це типові значення, вказані обмеженням.
kubectl get pod default-cpu-demo-2 --output=yaml --namespace=default-cpu-example
Вивід показує, що запит CPU контейнера встановлено таким чином, щоб відповідати його обмеженню CPU. Зверніть увагу, що контейнеру не було назначено типове значення запиту CPU 0.5 cpu:
resources:limits:cpu:"1"requests:cpu:"1"
Що якщо ви вказуєте запит контейнера, але не його обмеження?
Ось приклад маніфесту для Podʼа з одним контейнером. Контейнер вказує запит CPU, але не обмеження:
Перегляньте специфікацію Podʼа , який ви створили:
kubectl get pod default-cpu-demo-3 --output=yaml --namespace=default-cpu-example
Вивід показує, що запит CPU контейнера встановлено на значення, яке ви вказали при створенні Podʼа (іншими словами: воно відповідає маніфесту). Однак обмеження CPU цього ж контейнера встановлено на 1 cpu, що є типовим обмеженням CPU для цього простору імен.
resources:limits:cpu:"1"requests:cpu:750m
Мотивація для типових обмежень та запитів CPU
Якщо ваш простір імен має налаштовану квоту ресурсів CPU, корисно мати типове значення для обмеження CPU. Ось два обмеження, які накладає квота ресурсів CPU на простір імен:
Для кожного Podʼа, який працює в просторі імен, кожен з його контейнерів повинен мати обмеження CPU.
Обмеження CPU застосовує резервування ресурсів на вузлі, де запускається відповідний Pod. Загальна кількість CPU, яка зарезервована для використання всіма Podʼами в просторі імен, не повинна перевищувати вказане обмеження.
Коли ви додаєте LimitRange:
Якщо будь-який Pod у цьому просторі імен, що містить контейнер, не вказує своє власне обмеження CPU, панель управління застосовує типове обмеження CPU цьому контейнеру, і Pod може отримати дозвіл на запуск у просторі імен, який обмежено квотою ресурсів CPU.
2.5.3 - Налаштування мінімальних та максимальних обмежень памʼяті для простору імен
Визначте діапазон дійсних обмежень ресурсів памʼяті для простору імен, так щоб кожний новий Pod у цьому просторі імен знаходився в межах встановленого вами діапазону.
Ця сторінка показує, як встановити мінімальні та максимальні значення для памʼяті, яку використовують контейнери, що працюють у просторі імен. Мінімальні та максимальні значення памʼяті ви вказуєте у
LimitRange обʼєкті. Якщо Pod не відповідає обмеженням, накладеним LimitRange, його неможливо створити в просторі імен.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
kubectl get limitrange mem-min-max-demo-lr --namespace=constraints-mem-example --output=yaml
Вивід показує мінімальні та максимальні обмеження памʼяті як очікувалося. Але зверніть увагу, що, навіть якщо ви не вказали типові значення в конфігураційному файлі для LimitRange, вони були створені автоматично.
Тепер кожного разу, коли ви визначаєте Pod у просторі імен constraints-mem-example, Kubernetes
виконує такі кроки:
Якщо будь-який контейнер в цьому Podʼі не вказує свій власний запит памʼяті та обмеження, панель управління надає типовий запит та обмеження памʼяті цьому контейнеру.
Перевірте, що кожний контейнер у цьому Podʼі запитує принаймні 500 MiB памʼяті.
Перевірте, що кожний контейнер у цьому Podʼі запитує не більше 1024 MiB (1 GiB) памʼяті.
Ось маніфест для Podʼа з одним контейнером. У специфікації Podʼа, єдиний контейнер вказує запит памʼяті 600 MiB та обмеження памʼяті 800 MiB. Ці значення задовольняють мінімальні та максимальні обмеження памʼяті, накладені LimitRange.
Перевірте, що Pod працює і його контейнер є справним:
kubectl get pod constraints-mem-demo --namespace=constraints-mem-example
Перегляньте докладну інформацію про Pod:
kubectl get pod constraints-mem-demo --output=yaml --namespace=constraints-mem-example
Вивід показує, що контейнер у цьому Podʼі має запит памʼяті 600 MiB та обмеження памʼяті 800 MiB. Ці значення задовольняють обмеження, накладені LimitRange на цей простір імен:
Вивід показує, що Pod не було створено, оскільки він визначає контейнер, який запитує більше памʼяті, ніж дозволяється:
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-2.yaml":
pods "constraints-mem-demo-2" is forbidden: maximum memory usage per Container is 1Gi, but limit is 1536Mi.
Спроба створення Podʼа, який не відповідає мінімальному запиту памʼяті
Ось маніфест для Podʼа з одним контейнером. Цей контейнер вказує запит памʼяті 100 MiB та обмеження памʼяті 800 MiB.
Вивід показує, що Pod не було створено, оскільки він визначає контейнер який запитує менше памʼяті, ніж вимагається:
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-3.yaml":
pods "constraints-mem-demo-3" is forbidden: minimum memory usage per Container is 500Mi, but request is 100Mi.
Створення Podʼа, який не вказує жодного запиту памʼяті чи обмеження
Ось маніфест для Podʼа з одним контейнером. Контейнер не вказує запиту памʼяті, і він не вказує обмеження памʼяті.
kubectl get pod constraints-mem-demo-4 --namespace=constraints-mem-example --output=yaml
Вивід показує, що єдиний контейнер у цьому Podʼі має запит памʼяті 1 GiB та обмеження памʼяті 1 GiB. Як цей контейнер отримав ці значення?
resources:limits:memory:1Girequests:memory:1Gi
Тому що ваш Pod не визначає жодного запиту памʼяті та обмеження для цього контейнера, кластер
застосував типовий запит памʼяті та обмеження з LimitRange.
Це означає, що визначення цього Podʼа показує ці значення. Ви можете перевірити це за допомогою kubectl describe:
# Подивіться розділ "Requests:" виводуkubectl describe pod constraints-mem-demo-4 --namespace=constraints-mem-example
На цей момент ваш Pod може працювати або не працювати. Памʼятайте, що передумовою для цього завдання є те, що ваші вузли мають щонайменше 1 GiB памʼяті. Якщо кожен з ваших вузлів має лише 1 GiB памʼяті, тоді недостатньо виділеної памʼяті на будь-якому вузлі для обслуговування запиту памʼяті 1 GiB. Якщо ви використовуєте вузли з 2 GiB памʼяті, то, ймовірно, у вас достатньо місця для розміщення запиту 1 GiB.
Видаліть свій Pod:
kubectl delete pod constraints-mem-demo-4 --namespace=constraints-mem-example
Застосування мінімальних та максимальних обмежень памʼяті
Максимальні та мінімальні обмеження памʼяті, накладені на простір імен LimitRange, діють тільки під час створення або оновлення Podʼа. Якщо ви змінюєте LimitRange, це не впливає на Podʼи, що були створені раніше.
Причини для мінімальних та максимальних обмежень памʼяті
Як адміністратор кластера, вам може знадобитися накладати обмеження на кількість памʼяті, яку можуть використовувати Podʼи. Наприклад:
Кожен вузол у кластері має 2 GiB памʼяті. Ви не хочете приймати будь-який Pod, який запитує більше ніж 2 GiB памʼяті, оскільки жоден вузол у кластері не може підтримати запит.
Кластер використовується як виробництвом, так і розробкою вашими відділами. Ви хочете дозволити навантаженням в експлуатації використовувати до 8 GiB памʼяті, але ви хочете обмежити навантаження в розробці до 512 MiB. Ви створюєте окремі простори імен для експлуатації та розробки і застосовуєте обмеження памʼяті для кожного простору імен.
2.5.4 - Налаштування мінімальних та максимальних обмеженнь CPU для простору імен
Визначте діапазон допустимих обмежень ресурсів CPU для простору імен так, щоб кожен новий Pod у цьому просторі імен відповідав налаштованому діапазону.
Ця сторінка показує, як встановити мінімальні та максимальні значення ресурсів CPU, що використовуються контейнерами та Podʼами в просторі імен. Ви вказуєте мінімальні та максимальні значення CPU в обʼєкті LimitRange. Якщо Pod не відповідає обмеженням, накладеним LimitRange, його не можна створити у просторі імен.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Ви повинні мати доступ до створення просторів імен у своєму кластері.
Кожен вузол у вашому кластері повинен мати щонайменше 1,0 CPU, доступний для Podʼів. Див. значення CPU, щоб дізнатися, що означає в Kubernetes "1 CPU".
Створення простору імен
Створіть простір імен, щоб ресурси, які ви створюєте у цьому завданні, були відокремлені від інших частин вашого кластера.
kubectl get limitrange cpu-min-max-demo-lr --output=yaml --namespace=constraints-cpu-example
Вивід показує мінімальні та максимальні обмеження CPU, як очікувалося. Але зверніть увагу, що навіть якщо ви не вказали типових значень у конфігураційному файлі для LimitRange, вони були створені автоматично.
Тепер, кожного разу, коли ви створюєте Pod у просторі імен constraints-cpu-example (або який-небудь інший клієнт API Kubernetes створює еквівалентний Pod), Kubernetes виконує ці кроки:
Якщо який-небудь контейнер у цьому Podʼі не вказує свої власні CPU-запити та обмеження, панель управління призначає контейнеру типове значення для CPU-запиту та обмеження.
Перевірте, що кожен контейнер у цьому Podʼі вказує CPU-запит, який більший або дорівнює 200 мілі-CPU.
Перевірте, що кожен контейнер у цьому Podʼі вказує обмеження CPU, яке менше або дорівнює 800 мілі-CPU.
Примітка:
При створенні обʼєкта LimitRange можна вказати обмеження на використання великих сторінок або GPU. Однак, коли одночасно вказуються default та defaultRequest для цих ресурсів, два значення повинні бути однаковими.
Ось маніфест для Podʼа з одним контейнером. Маніфест контейнера вказує CPU-запит у розмірі 500 мілі-CPU та обмеження CPU у розмірі 800 мілі-CPU. Це задовольняє мінімальні та максимальні обмеження CPU, накладені LimitRange на цей простір імен.
Перевірте, що Pod працює, а його контейнер є справним:
kubectl get pod constraints-cpu-demo --namespace=constraints-cpu-example
Перегляньте детальну інформацію про Pod:
kubectl get pod constraints-cpu-demo --output=yaml --namespace=constraints-cpu-example
Вивід показує, що єдиний контейнер Podʼа має запит CPU у розмірі 500 мілі-CPU та обмеження CPU
800 мілі-CPU. Це задовольняє обмеження, накладеним LimitRange.
resources:limits:cpu:800mrequests:cpu:500m
Видаліть Pod
kubectl delete pod constraints-cpu-demo --namespace=constraints-cpu-example
Спроба створити Pod, який перевищує максимальне обмеження CPU
Ось маніфест для Podʼа з одним контейнером. Контейнер вказує запит CPU у розмірі 500 мілі-CPU та обмеження CPU у розмірі 1,5 CPU.
Вивід показує, що Pod не створено, оскільки визначений контейнер є неприйнятним. Цей контейнер є неприйнятним, оскільки він вказує обмеження CPU, яке занадто велике:
Error from server (Forbidden): error when creating "examples/admin/resource/cpu-constraints-pod-2.yaml":
pods "constraints-cpu-demo-2" is forbidden: maximum cpu usage per Container is 800m, but limit is 1500m.
Спроба створити Pod, який не відповідає мінімальному запиту CPU
Ось маніфест для Podʼа з одним контейнером. Контейнер вказує запит CPU у розмірі 100 мілі-CPU та обмеження CPU у розмірі 800 мілі-CPU.
Вивід показує, що Pod не створено, оскільки визначений контейнер є неприйнятним. Цей контейнер є неприйнятним, оскільки він вказує запит CPU, який нижче мінімального:
Error from server (Forbidden): error when creating "examples/admin/resource/cpu-constraints-pod-3.yaml":
pods "constraints-cpu-demo-3" is forbidden: minimum cpu usage per Container is 200m, but request is 100m.
Створення Podʼа, який не вказує жодного запиту або обмеження CPU
Ось маніфест для Podʼа з одним контейнером. Контейнер не вказує запит CPU і не вказує обмеження CPU.
kubectl get pod constraints-cpu-demo-4 --namespace=constraints-cpu-example --output=yaml
Вивід показує, що у Podʼі єдиний контейнер має запит CPU у розмірі 800 мілі-CPU та обмеження CPU у розмірі 800 мілі-CPU. Як цей контейнер отримав ці значення?
resources:limits:cpu:800mrequests:cpu:800m
Тому що цей контейнер не вказав свій власний запит CPU та обмеження, панель управління застосовує стандартні обмеження та запит CPU з LimitRange для цього простору імен.
На цьому етапі ваш Pod може бути запущеним або не запущеним. Згадайте, що передумовою для цієї задачі є те, що у ваших вузлах повинно бути щонайменше 1 CPU для використання. Якщо в кожному вузлі у вас є лише 1 CPU, то, можливо, немає достатньої кількості CPU на будь-якому вузлі для виконання запиту у розмірі 800 мілі-CPU. Якщо ви використовуєте вузли з 2 CPU, то, ймовірно, у вас достатньо CPU для виконання запиту у розмірі 800 мілі-CPU.
Видаліть ваш Pod:
kubectl delete pod constraints-cpu-demo-4 --namespace=constraints-cpu-example
Застосування мінімальних та максимальних обмежень CPU
Максимальні та мінімальні обмеження CPU, накладені на простір імен за допомогою LimitRange, застосовуються лише при створенні або оновленні Podʼа. Якщо ви зміните LimitRange, це не вплине на Podʼи, які були створені раніше.
Причини для мінімальних та максимальних обмежень CPU
Як адміністратор кластера, ви можете бажати накладати обмеження на ресурси CPU, які можуть використовувати Podʼи. Наприклад:
Кожен вузол у кластері має 2 CPU. Ви не хочете приймати жодного Podʼа, який запитує більше, ніж 2 CPU, оскільки жоден вузол у кластері не може підтримати цей запит.
Кластер використовується вашими відділами експлуатації та розробки. Ви хочете дозволити навантаженням в експлуатації споживати до 3 CPU, але ви хочете обмежити навантаження в розробці до 1 CPU. Ви створюєте окремі простори імен для експлуатації та розробки та застосовуєте обмеження CPU до кожного простору імен.
2.5.5 - Налаштування квот памʼяті та CPU для простору імен
Визначте загальні обмеження памʼяті та CPU для всіх Podʼів, які працюють у просторі імен.
На цій сторінці показано, як встановити квоти для загальної кількості памʼяті та CPU, які можуть бути використані всіма Podʼами, що працюють у просторі імен. Ви вказуєте квоти в обʼєкті ResourceQuota.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Перевірте, що Pod працює, і його (єдиний) контейнер є справним:
kubectl get pod quota-mem-cpu-demo --namespace=quota-mem-cpu-example
Знову перегляньте детальну інформацію про ResourceQuota:
kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example --output=yaml
У виводі вказано квоту разом з тим, скільки з квоти було використано. Ви можете побачити, що запити памʼяті та CPU для вашого Podʼа не перевищують квоту.
Якщо у вас є інструмент jq, ви також можете запитувати (використовуючи JSONPath) лише значення used, і друкувати ці значення з приємним форматуванням. Наприклад:
У маніфесті можна побачити, що Pod має запит памʼяті 700 MiB. Зверніть увагу, що сума використаного запиту памʼяті та цього нового запиту памʼяті перевищує квоту запиту памʼяті: 600 MiB + 700 MiB > 1 GiB.
Другий Pod не створюється. У виводі вказано, що створення другого Podʼа призведе до того, що загальний запит памʼяті перевищить квоту запиту памʼяті.
Error from server (Forbidden): error when creating "examples/admin/resource/quota-mem-cpu-pod-2.yaml":
pods "quota-mem-cpu-demo-2" is forbidden: exceeded quota: mem-cpu-demo,
requested: requests.memory=700Mi,used: requests.memory=600Mi, limited: requests.memory=1Gi
Обговорення
Як ви бачили у цьому завданні, ви можете використовувати ResourceQuota для обмеження загального запиту памʼяті для всіх Podʼів, що працюють у просторі імен. Ви також можете обмежити загальні суми для обмеження памʼяті, запиту CPU та обмеження CPU.
Замість керування загальним використанням ресурсів у просторі імен, ви, можливо, захочете обмежити окремі Podʼи або контейнери у цих Podʼах. Щоб досягти такого обмеження, використовуйте LimitRange.
2.5.6 - Налаштування квоти Podʼів для простору імен
Обмежте кількість Podʼів, які можна створити у просторі імен.
На цій сторінці показано, як встановити квоту на загальну кількість Podʼів, які можуть працювати в просторі імен. Ви вказуєте квоти в обʼєкті ResourceQuota.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
kubectl get deployment pod-quota-demo --namespace=quota-pod-example --output=yaml
У виводі показано, що навіть якщо Deployment вказує три репліки, було створено лише два Podʼи через раніше визначену вами квоту:
spec:...replicas:3...status:availableReplicas:2...lastUpdateTime:2021-04-02T20:57:05Zmessage: 'unable to create pods:pods "pod-quota-demo-1650323038-" is forbidden:exceeded quota: pod-demo, requested: pods=1, used: pods=2, limited:pods=2'
Вибір ресурсу
У цьому завданні ви визначили ResourceQuota, яке обмежує загальну кількість Podʼів, але ви також можете обмежити загальну кількість інших видів обʼєктів. Наприклад, ви можете вирішити обмежити кількість CronJobs, які можуть існувати в одному просторі імен.
2.6 - Встановлення постачальника мережевої політики
2.6.1 - Використання Antrea для NetworkPolicy
Ця сторінка показує, як встановити та використовувати втулок Antrea CNI в Kubernetes. Щоб дізнатися більше про проєкт Antrea, прочитайте Вступ до Antrea.
Для перевірки розгортання використовуйте наступну команду.
kubectl get pods --namespace=kube-system
Podʼи Calico починаються з calico. Перевірте, щоб кожен з них мав статус Running.
Створення локального кластера Calico з kubeadm
Щоб отримати локальний кластер Calico для одного хосту за пʼятнадцять хвилин за допомогою kubeadm, див. Швидкий старт Calico.
Що далі
Після того, як ваш кластер буде запущений, ви можете перейти до Оголошення мережевої політики, щоб спробувати в дії Kubernetes NetworkPolicy.
2.6.3 - Використання Cilium для NetworkPolicy
Ця сторінка показує, як використовувати Cilium для NetworkPolicy.
Щоб ознайомитися з основною інформацією про Cilium, прочитайте Вступ до Cilium.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Потім розпакуйте завантажений файл у вашу теку /usr/local/bin за допомогою наступної команди:
sudo tar xzvfC cilium-linux-amd64.tar.gz /usr/local/bin
rm cilium-linux-amd64.tar.gz
Після виконання вищевказаних команд, ви тепер можете встановити Cilium за допомогою наступної команди:
cilium install
Cilium автоматично визначить конфігурацію кластера та створить і встановить відповідні компоненти для успішної інсталяції. Компоненти включають:
Центр сертифікації (CA) у Secret cilium-ca та сертифікати для Hubble (шар спостереження Cilium).
Сервісні облікові записи.
Кластерні ролі.
ConfigMap.
Agent DaemonSet та Operator Deployment.
Після інсталяції ви можете переглянути загальний статус розгортання Cilium за допомогою команди cilium status. Дивіться очікуваний вивід команди statusтут.
Решта Початкового керівництва пояснює, як застосувати політики безпеки як L3/L4 (тобто IP-адреса + порт), так і L7 (наприклад, HTTP) за допомогою прикладної програми.
Розгортання Cilium для використання в операційному середовищі
Для докладних інструкцій з розгортання Cilium для операційного використання, дивіться: Керівництво з інсталяції Cilium Kubernetes. Ця документація включає докладні вимоги, інструкції та приклади файлів DaemonSet для продуктивного використання.
Розуміння компонентів Cilium
Розгортання кластера з Cilium додає Podʼи до простору імен kube-system. Щоб побачити цей список Podʼів, виконайте:
kubectl get pods --namespace=kube-system -l k8s-app=cilium
Ви побачите список Podʼів, подібний до цього:
NAME READY STATUS RESTARTS AGE
cilium-kkdhz 1/1 Running 0 3m23s
...
Pod cilium працює на кожному вузлі вашого кластера і забезпечує виконання мережевої політики для трафіку до/від Podʼів на цьому вузлі за допомогою Linux BPF.
Що далі
Після того, як ваш кластер буде запущений, ви можете перейти до Оголошення мережевої політики
для випробування Kubernetes NetworkPolicy з Cilium. Якщо у вас є запитання, звʼяжіться з нами за допомогою Каналу Cilium у Slack.
2.6.4 - Використання Kube-router для NetworkPolicy
Ця сторінка показує, як використовувати Kube-router для NetworkPolicy.
Перш ніж ви розпочнете
Вам потрібно мати запущений кластер Kubernetes. Якщо у вас ще немає кластера, ви можете створити його, використовуючи будь-які інсталятори кластерів, такі як Kops, Bootkube, Kubeadm тощо.
Встановлення надбудови Kube-router
Надбудова Kube-router містить контролер мережевих політик, який відстежує сервер API Kubernetes на предмет будь-яких оновлень NetworkPolicy та Podʼів і налаштовує правила iptables та ipsets для дозволу або блокування трафіку відповідно до політик. Будь ласка, слідуйте керівництву спробуйте Kube-router з інсталяторами кластерів для встановлення надбудови Kube-router.
Що далі
Після того, як ви встановили надбудову Kube-router, ви можете перейти до Оголошення мережевої політики для випробування Kubernetes NetworkPolicy.
2.6.5 - Використання Romana для NetworkPolicy
Ця сторінка показує, як використовувати Romana для NetworkPolicy.
Надбудова Weave Net для Kubernetes містить Контролер мережевих політик, який автоматично відстежує всі анотації мережевих політик у Kubernetes у всіх просторах імен і налаштовує правила iptables для дозволу або блокування трафіку відповідно до цих політик.
Тестування встановлення
Перевірте, що Weave працює коректно.
Введіть наступну команду:
kubectl get pods -n kube-system -o wide
Вивід буде схожим на це:
NAME READY STATUS RESTARTS AGE IP NODE
weave-net-1t1qg 2/2 Running 0 9d 192.168.2.10 worknode3
weave-net-231d7 2/2 Running 1 7d 10.2.0.17 worknodegpu
weave-net-7nmwt 2/2 Running 3 9d 192.168.2.131 masternode
weave-net-pmw8w 2/2 Running 0 9d 192.168.2.216 worknode2
На кожному вузлі є Pod Weave, і всі Podʼи Running та 2/2 READY. (2/2 означає, що кожен Pod має weave і weave-npc.)
Ця сторінка описує, як отримати доступ до кластера через API Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
При першому доступі до API Kubernetes використовуйте інструмент командного рядка Kubernetes, kubectl.
Для отримання доступу до кластера вам потрібно знати його розташування та мати облікові дані для входу. Зазвичай вони встановлюються автоматично, коли ви користуєтесь настановами зі сторінки Початок роботи, або ж ви вже маєте розгорнутий кластер з налаштованим доступом.
Перевірте місце знаходження та облікові дані, про які знає kubectl, за допомогою цієї команди:
kubectl config view
Багато прикладів містять введення в користування kubectl. Повну документацію ви можете знайти в довідці kubectl.
Прямий доступ до REST API
kubectl використовується для знаходження та автентифікації на сервері API. Якщо ви хочете дістатись REST API за допомогою інструментів на кшталт curl або wget, чи вебоглядача, існує кілька способів якими ви можете знайти та автентифікуватись на сервері API.
Запустіть kubectl у режимі проксі (рекомендовано). Цей метод рекомендується, оскільки він використовує збережене розташування сервера API та перевіряє відповідність сервера API за допомогою самопідписного сертифіката. За допомогою цього методу неможлива атака man-in-the-middle (MITM).
Крім того, ви можете вказати знаходження та облікові дані безпосередньо http-клієнту. Це працює з клієнтським кодом, який плутають проксі. Щоб захиститися від атак man in the middle, вам потрібно буде імпортувати кореневий сертифікат у свій вебоглядач.
Використання клієнтських бібліотек Go або Python забезпечує доступ до kubectl у режимі проксі.
Використання kubectl proxy
Наступна команда запускає kubectl у режимі, де він діє як зворотний проксі. Він виконує пошук сервера API та автентифікацію.
kubectl proxy --port=8080 &
Дивіться kubectl proxy для отримання додаткової інформації.
Потім ви можете дослідити API за допомогою curl, wget або вебоглядача, наприклад:
У вищенаведеному прикладі використовується прапорець --insecure. Це залишає систему вразливою до атак типу MITM (Man-In-The-Middle). Коли kubectl отримує доступ до кластера, він використовує збережений кореневий сертифікат та сертифікати клієнта для доступу до сервера. (Ці дані знаходяться у теці ~/.kube). Оскільки сертифікати кластера зазвичай самопідписні, може знадобитися спеціальна конфігурація, щоб ваш HTTP-клієнт використовував кореневий сертифікат.
На деяких кластерах сервер API може не вимагати автентифікації; він може обслуговувати локальний хост або бути захищений фаєрволом. Не існує стандарту для цього. Документ Керування доступом до API Kubernetes описує, як ви можете налаштувати це, як адміністратор кластера.
Програмний доступ до API
Kubernetes офіційно підтримує клієнтські бібліотеки для Go, Python, Java, dotnet, JavaScript та Haskell. Існують інші клієнтські бібліотеки, які надаються та підтримуються їхніми авторами, а не командою Kubernetes. Дивіться бібліотеки клієнтів для доступу до API з інших мов програмування та їхнього методу автентифікації.
Go-клієнт
Щоб отримати бібліотеку, виконайте наступну команду: go get k8s.io/client-go@kubernetes-<номер-версії-kubernetes>. Дивіться https://github.com/kubernetes/client-go/releases, щоб переглянути підтримувані версії.
Напишіть застосунок поверх клієнтів client-go.
Примітка:
client-go визначає власні обʼєкти API, тому у разі необхідності імпортуйте визначення API з client-go, а не з основного сховища. Наприклад, import "k8s.io/client-go/kubernetes" є правильним.
Go-клієнт може використовувати той самий файл kubeconfig,
як і kubectl CLI, для пошуку та автентифікації на сервері API. Дивіться цей приклад:
package main
import (
"context""fmt""k8s.io/apimachinery/pkg/apis/meta/v1""k8s.io/client-go/kubernetes""k8s.io/client-go/tools/clientcmd")
funcmain() {
// використовуємо поточний контекст з kubeconfig
// path-to-kubeconfig -- наприклад, /root/.kube/config
config, _ := clientcmd.BuildConfigFromFlags("", "<path-to-kubeconfig>")
// створює clientset
clientset, _ := kubernetes.NewForConfig(config)
// доступ API до списку Podʼів
pods, _ := clientset.CoreV1().Pods("").List(context.TODO(), v1.ListOptions{})
fmt.Printf("There are %d pods in the cluster\n", len(pods.Items))
}
Python-клієнт може використовувати той самий файл kubeconfig, як і kubectl CLI, для пошуку та автентифікації на сервері API. Дивіться цей приклад:
fromkubernetesimport client, config
config.load_kube_config()
v1=client.CoreV1Api()
print("Listing pods with their IPs:")
ret = v1.list_pod_for_all_namespaces(watch=False)
for i in ret.items:
print("%s\t%s\t%s"% (i.status.pod_ip, i.metadata.namespace, i.metadata.name))
Java-клієнт
Для встановлення Java-клієнта виконайте наступну команду:
# Зколнуйте код білліотеки javagit clone --recursive https://github.com/kubernetes-client/java
# Встановлення артефактів проєкту, POM й так даіл:cd java
mvn install
Java-клієнт може використовувати той самий файл kubeconfig, що і kubectl CLI, для пошуку та автентифікації на сервері API. Дивіться цей приклад:
packageio.kubernetes.client.examples;importio.kubernetes.client.ApiClient;importio.kubernetes.client.ApiException;importio.kubernetes.client.Configuration;importio.kubernetes.client.apis.CoreV1Api;importio.kubernetes.client.models.V1Pod;importio.kubernetes.client.models.V1PodList;importio.kubernetes.client.util.ClientBuilder;importio.kubernetes.client.util.KubeConfig;importjava.io.FileReader;importjava.io.IOException;/**
* Простий приклад використання Java API з застосунку поза кластером Kubernetes.
*
* Найпростіший спосіб запуску цього: mvn exec:java
* -Dexec.mainClass="io.kubernetes.client.examples.KubeConfigFileClientExample"
*
*/publicclassKubeConfigFileClientExample{publicstaticvoidmain(String[]args)throwsIOException,ApiException{// шлях до файлуу KubeConfigStringkubeConfigPath="~/.kube/config";// завантаження конфігурації ззовні кластера, kubeconfig із файлової системиApiClientclient=ClientBuilder.kubeconfig(KubeConfig.loadKubeConfig(newFileReader(kubeConfigPath))).build();// встановлення глобального api-client на того, що працює в межах кластера, як описано вищеConfiguration.setDefaultApiClient(client);// the CoreV1Api завантажує api-client з глобальної конфігурації.CoreV1Apiapi=newCoreV1Api();// виклик клієнта CoreV1ApiV1PodListlist=api.listPodForAllNamespaces(null,null,null,null,null,null,null,null,null);System.out.println("Listing all pods: ");for(V1Poditem:list.getItems()){System.out.println(item.getMetadata().getName());}}}
2.8 - Увімкнення або вимкнення функціональних можливостей
На цій сторінці показано, як увімкнути або вимкнути функціональні можливості для керування певними функціями Kubernetes у вашому кластері. Увімкнення функціональних можливостей дозволяє тестувати та використовувати функції Alpha або Beta до того, як вони стануть загальнодоступними.
Примітка:
Деякі стабільні (GA) можливості також можна вимкнути, зазвичай через один мінорний реліз після GA; однак у цьому випадку ваш кластер може не відповідати вимогам Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Знання про те, яку функцію ви хочете увімкнути (див. [Довідку про функціональні можливості] (/docs/reference/command-line-tools-reference/feature-gates/))
Примітка:
Загально доступні функції (GA) є завжди стандартно увімкненими. Зазвичай ви налаштовуєте можливості для функцій Alpha або Beta.
Альфа: стандартно вимкнена, може містити помилки. Використовуйте тільки в тестових кластерах.
Бета: зазвичай стандартно увімкнена, добре протестована.
GA: завжди стандартно увімкнена; іноді може бути вимкнена для одного випуску після GA.
Визначте, які компоненти вимагають використання функціональної можливості {#identify-which-components-need-the-feature gate}
Різні функціональні можливості впливають на різні компоненти Kubernetes:
Деякі функції вимагають увімкнення можливості на декількох компонентах (наприклад, API-сервері та менеджері контролерів)
Інші функції вимагають увімкнення можливості лише на одному компоненті (наприклад, лише kubelet)
У довідці про функціональні можливості зазвичай вказано, на які компоненти впливає кожна функція. Усі компоненти Kubernetes мають однакові визначення функціональних можливостей, тому всі функції відображаються у вікні довідки, але на поведінку кожного компонента впливають лише відповідні функції.
Конфігурація
Під час ініціалізації кластера
Створіть файл конфігурації, щоб увімкнути функціональні можливості для відповідних компонентів:
Для кластерів kubeadm конфігурацію функціональних можливостей можна налаштувати в декількох місцях, включаючи файли маніфесту, файли конфігурації та конфігурацію kubeadm.
Відредагуйте маніфести компонентів панелі управління в /etc/kubernetes/manifests/:
Для kube-apiserver, kube-controller-manager або kube-scheduler додайте прапорець до команди:
spec:containers:- command:- kube-apiserver- --feature-gates=FeatureName=true# ... інші прапорці
Збережіть файл. Pod автоматично перезапуститься.
Для kubelet, відредагуйте /var/lib/kubelet/config.yaml:
У кластерах kubeadm компоненти панелі управління (kube-apiserver, kube-controller-manager та kube-scheduler) зазвичай налаштовуються за допомогою прапорців командного рядка в їх маніфестах статичних подів, розташованих у /etc/kubernetes/manifests/. Хоча ці компоненти підтримують файли конфігурації за допомогою прапорця --config, kubeadm в основному використовує прапорці командного рядка.
Перевірка конфігурації функціональних можливостей
Після налаштування перевірте, чи функціональні можливості активні. Наступні методи застосовуються до кластерів kubeadm, де компоненти панелі управління працюють як статичні поди.
Перевірка маніфестів компонентів панелі управління
Перегляньте функціональні можливості, налаштовані в маніфесті статичного пода:
kubectl -n kube-system get pod kube-apiserver-<node-name> -o yaml | grep feature-gates
Або перевірте файл конфігурації безпосередньо на вузлі:
cat /var/lib/kubelet/config.yaml | grep -A 10 featureGates
Перевірка через точку доступу метрик
Статус функціональної можливості виводиться в метриках у стилі Prometheus компонентами Kubernetes
(доступно в Kubernetes 1.26+). Запитайте точку доступу метрик, щоб перевірити, які функціональні можливості
включені:
kubectl get --raw /metrics | grep kubernetes_feature_enabled
Щоб перевірити конкретну функціональну можливість:
kubectl get --raw /metrics | grep kubernetes_feature_enabled | grep FeatureName
Метрика показує 1 для увімкнених можливостей і 0 для вимкнених можливостей.
Примітка:
У кластерах kubeadm перевірте всі відповідні місця, де можуть бути налаштовані функціональні можливості, оскільки конфігурація розподілена між декількома файлами та місцями.
Розуміння вимог до конкретних компонентів
Деякі приклади функціональних можливостей, специфічних для компонентів:
Орієнтовані на API-сервер: такі функції, як StructuredAuthenticationConfiguration, в першу чергу впливають на kube-apiserver
Орієнтовані на Kubelet: такі функції, як GracefulNodeShutdown, в першу чергу впливають на kubelet
Кілька компонентів: деякі функції вимагають координації між компонентами
Увага:
Якщо для функції потрібно кілька компонентів, необхідно ввімкнути можливість на всіх відповідних компонентах. Увімкнення можливості лише на деяких компонентах може призвести до несподіваної поведінки або помилок.
Завжди спочатку тестуйте функціональні можливості на тестових середовищах. Функції Alpha можуть бути видалені без попередження.
Ця сторінка показує, як вказати розширені ресурси для вузла. Розширені ресурси дозволяють адміністраторам кластера оголошувати ресурси на рівні вузла, які інакше були б невідомі для Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Оголошення нового розширеного ресурсу на одному з ваших вузлів
Щоб оголосити новий розширений ресурс на вузлі, відправте HTTP PATCH запит до сервера API Kubernetes. Наприклад, припустимо, що один з ваших вузлів має чотири підключені dongle. Ось приклад запиту PATCH, який оголошує чотири ресурси dongle для вашого вузла.
Зверніть увагу, що Kubernetes не потрібно знати, що таке dongle або для чого він призначений. Попередній запит PATCH повідомляє Kubernetes, що ваш вузол має чотири речі, які ви називаєте dongle.
Запустіть проксі, щоб відправляти запити на сервер API Kubernetes:
kubectl proxy
У іншому вікні термінала відправте HTTP PATCH запит. Замініть <your-node-name> на імʼя вашого вузла:
У запиті ~1 — це кодування символу / у шляху патча. Значення шляху операцій в JSON-Patch трактується як JSON-вказівник. Докладніше дивіться
IETF RFC 6901, розділ 3.
Розширені ресурси схожі на памʼять та ресурси CPU. Наприклад, так само як на вузлі є певна кількість памʼяті та CPU для спільного використання всіма компонентами, що працюють на вузлі, він може мати певну кількість dongle для спільного використання всіма компонентами, що працюють на вузлі. І так само як розробники застосунків можуть створювати Podʼи, які вимагають певної кількості памʼяті та CPU, вони можуть створювати Podʼи, які вимагають певну кількість dongle.
Розширені ресурси є непрозорими для Kubernetes; Kubernetes не знає нічого про їх призначення. Kubernetes знає лише, що у вузла є їх певна кількість. Розширені ресурси мають оголошуватись у цілих числах. Наприклад, вузол може оголошувати чотири dongle, але не 4,5 dongle.
Приклад зберігання
Припустимо, що вузол має 800 ГіБ особливого типу дискового простору. Ви можете створити назву для спеціального сховища, скажімо, example.com/special-storage. Потім ви можете оголошувати його в частинах певного розміру, скажімо, 100 ГіБ. У цьому випадку, ваш вузол буде повідомляти, що в ньому є вісім ресурсів типу example.com/special-storage.
Capacity:...example.com/special-storage:8
Якщо ви хочете дозволити довільні запити на спеціальне зберігання, ви можете оголошувати спеціальне сховище частками розміром 1 байт. У цьому випадку ви оголошуєте 800Gi ресурсів типу example.com/special-storage.
Capacity:...example.com/special-storage:800Gi
Потім контейнер може запросити будь-яку кількість байтів спеціального сховища, до 800Gi.
Очищення
Ось запит PATCH, який видаляє оголошення dongle з вузла.
2.10 - Автоматичне масштабування служби DNS в кластері
Ця сторінка показує, як увімкнути та налаштувати автоматичне масштабування служби DNS у вашому кластері Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Перегляньте Deployment DNS у вашому кластері у просторі імен kube-system:
kubectl get deployment -l k8s-app=kube-dns --namespace=kube-system
Вивід схожий на такий:
NAME READY UP-TO-DATE AVAILABLE AGE
...
coredns 2/2 2 2 ...
...
Якщо ви не бачите Deployment для DNS-служб, ви також можете знайти його за імʼям:
kubectl get deployment --namespace=kube-system
і пошукайте Deployment з назвою coredns або kube-dns.
Ваша ціль масштабування:
Deployment/<імʼя вашого розгортання>
де <імʼя вашого розгортання> — це імʼя вашого Deployment DNS. Наприклад, якщо імʼя вашого Deployment для DNS — coredns, ваша ціль масштабування — Deployment/coredns.
Примітка:
CoreDNS — це стандартна служба DNS в Kubernetes. CoreDNS встановлює мітку k8s-app=kube-dns, щоб вона могла працювати в кластерах, які спочатку використовували kube-dns.
Увімкніть горизонтальне автоматичне масштабування DNS
У цьому розділі ви створюєте нове Deployment. Podʼи в Deployment працюють з контейнером на основі образу cluster-proportional-autoscaler-amd64.
Створіть файл з назвою dns-horizontal-autoscaler.yaml з таким вмістом:
kind:ServiceAccountapiVersion:v1metadata:name:kube-dns-autoscalernamespace:kube-system---kind:ClusterRoleapiVersion:rbac.authorization.k8s.io/v1metadata:name:system:kube-dns-autoscalerrules:- apiGroups:[""]resources:["nodes"]verbs:["list","watch"]- apiGroups:[""]resources:["replicationcontrollers/scale"]verbs:["get","update"]- apiGroups:["apps"]resources:["deployments/scale","replicasets/scale"]verbs:["get","update"]# Remove the configmaps rule once below issue is fixed:# kubernetes-incubator/cluster-proportional-autoscaler#16- apiGroups:[""]resources:["configmaps"]verbs:["get","create"]---kind:ClusterRoleBindingapiVersion:rbac.authorization.k8s.io/v1metadata:name:system:kube-dns-autoscalersubjects:- kind:ServiceAccountname:kube-dns-autoscalernamespace:kube-systemroleRef:kind:ClusterRolename:system:kube-dns-autoscalerapiGroup:rbac.authorization.k8s.io---apiVersion:apps/v1kind:Deploymentmetadata:name:kube-dns-autoscalernamespace:kube-systemlabels:k8s-app:kube-dns-autoscalerkubernetes.io/cluster-service:"true"spec:selector:matchLabels:k8s-app:kube-dns-autoscalertemplate:metadata:labels:k8s-app:kube-dns-autoscalerspec:priorityClassName:system-cluster-criticalsecurityContext:seccompProfile:type:RuntimeDefaultsupplementalGroups:[65534]fsGroup:65534nodeSelector:kubernetes.io/os:linuxcontainers:- name:autoscalerimage:registry.k8s.io/cpa/cluster-proportional-autoscaler:1.8.4resources:requests:cpu:"20m"memory:"10Mi"command:- /cluster-proportional-autoscaler- --namespace=kube-system- --configmap=kube-dns-autoscaler# Should keep target in sync with cluster/addons/dns/kube-dns.yaml.base- --target=<SCALE_TARGET># When cluster is using large nodes(with more cores), "coresPerReplica" should dominate.# If using small nodes, "nodesPerReplica" should dominate.- --default-params={"linear":{"coresPerReplica":256,"nodesPerReplica":16,"preventSinglePointFailure":true,"includeUnschedulableNodes":true}}- --logtostderr=true- --v=2tolerations:- key:"CriticalAddonsOnly"operator:"Exists"serviceAccountName:kube-dns-autoscaler
У файлі замініть <SCALE_TARGET> на вашу ціль масштабування.
Перейдіть в теку, яка містить ваш файл конфігурації, та введіть цю команду для створення Deployment:
kubectl apply -f dns-horizontal-autoscaler.yaml
Вивід успішної команди:
deployment.apps/kube-dns-autoscaler created
Тепер горизонтальне автоматичне масштабування DNS увімкнено.
Налаштування параметрів автоматичного масштабування DNS
Перевірте, що існує ConfigMap kube-dns-autoscaler:
Змініть поля відповідно до ваших потреб. Поле "min" вказує на мінімальну кількість резервних DNS. Фактична кількість резервних копій обчислюється за цією формулою:
Зверніть увагу, що значення як coresPerReplica, так і nodesPerReplica — це числа з комою.
Ідея полягає в тому, що, коли кластер використовує вузли з багатьма ядрами, coresPerReplica домінує. Коли кластер використовує вузли з меншою кількістю ядер, домінує nodesPerReplica.
Після видалення файлу маніфесту Addon Manager видалить розгортання kube-dns-autoscaler.
Розуміння того, як працює горизонтальне автоматичне масштабування DNS
Застосунок cluster-proportional-autoscaler розгортається окремо від служби DNS.
Pod автомасштабування працює клієнтом, який опитує сервер API Kubernetes для отримання кількості вузлів та ядер у кластері.
Обчислюється та застосовується бажана кількість резервних копій на основі поточних запланованих вузлів та ядер та заданих параметрів масштабування.
Параметри масштабування та точки даних надаються через ConfigMap Podʼа автомасштабування, і він оновлює свою таблицю параметрів щоразу під час періодичного опитування, щоб вона була актуальною з найновішими бажаними параметрами масштабування.
Зміни параметрів масштабування дозволені без перебудови або перезапуску Podʼа автомасштабування.
Автомасштабування надає інтерфейс контролера для підтримки двох шаблонів керування: linear та ladder.
2.11 - Зміна режиму доступу до PersistentVolume на ReadWriteOncePod
Ця сторінка показує, як змінити режим доступу наявного PersistentVolume на ReadWriteOncePod.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.22.
Для перевірки версії введіть kubectl version.
Примітка:
Режим доступу ReadWriteOncePod став стабільним у релізі Kubernetes v1.29. Якщо ви використовуєте версію Kubernetes старішу за v1.29, можливо, вам доведеться увімкнути feature gate. Перевірте документацію для вашої версії Kubernetes.
Примітка:
Режим доступу ReadWriteOncePod підтримується тільки для CSI томів. Щоб застосувати цей режим доступу до тому, вам потрібно оновити наступні CSI sidecars до цих версій або вище:
До версії Kubernetes v1.22 часто використовувався режим доступу ReadWriteOnce, щоб обмежити доступ до PersistentVolume для робочих навантажень, яким потрібен доступ одноосібного запису до сховища. Однак цей режим доступу мав обмеження: він обмежував доступ до тому одним вузлом, дозволяючи кільком Podʼам на одному вузлі одночасно читати та записувати в один і той же том. Це могло становити ризик для застосунків, які вимагають строгого доступу одноосібного запису для безпеки даних.
Якщо забезпечення доступу одноосібного запису є критичним для ваших робочих навантажень, розгляньте можливість міграції ваших томів на ReadWriteOncePod.
Міграція наявних PersistentVolumes
Якщо у вас є наявні PersistentVolumes, їх можна мігрувати на використання ReadWriteOncePod. Підтримується тільки міграція з ReadWriteOnce на ReadWriteOncePod.
У цьому прикладі вже є ReadWriteOnce "cat-pictures-pvc" PersistentVolumeClaim, який привʼязаний до "cat-pictures-pv" PersistentVolume, і "cat-pictures-writer" Deployment, який використовує цей PersistentVolumeClaim.
Примітка:
Якщо ваш втулок сховища підтримує Динамічне впровадження, "cat-pictures-pv" буде створено для вас, але його назва може відрізнятися. Щоб дізнатися назву вашого PersistentVolume, виконайте:
kubectl get pvc cat-pictures-pvc -o jsonpath='{.spec.volumeName}'
І ви можете переглянути PVC перед тим, як робити зміни. Перегляньте маніфест локально або виконайте kubectl get pvc <name-of-pvc> -o yaml. Вивід буде схожий на:
На першому етапі вам потрібно відредагувати spec.persistentVolumeReclaimPolicy вашого PersistentVolume і встановити його на Retain. Це забезпечить, що ваш PersistentVolume не буде видалений, коли ви видалите відповідний PersistentVolumeClaim:
Потім вам потрібно зупинити будь-які робочі навантаження, які використовують PersistentVolumeClaim, повʼязаний з PersistentVolume, який ви хочете мігрувати, а потім видалити PersistentVolumeClaim. Уникайте вносити будь-які інші зміни до PersistentVolumeClaim, такі як зміна розміру тому, поки міграція не буде завершена.
Якщо це зроблено, вам потрібно очистити spec.claimRef.uid вашого PersistentVolume, щоб забезпечити можливість звʼязування PersistentVolumeClaims з ним під час перестворення:
Режим доступу ReadWriteOncePod не може бути поєднаний з іншими режимами доступу. Переконайтеся, що ReadWriteOncePod — єдиний режим доступу до PersistentVolume при оновленні, в іншому випадку запит буде невдалим.
Після цього вам потрібно змінити ваш PersistentVolumeClaim, щоб встановити ReadWriteOncePod як єдиний режим доступу. Ви також повинні встановити spec.volumeName PersistentVolumeClaim на назву вашого PersistentVolume, щоб забезпечити його привʼязку саме до цього конкретного PersistentVolume.
Після цього ви можете перестворити ваш PersistentVolumeClaim та запустити ваші робочі навантаження:
# ВАЖЛИВО: Переконайтеся, що ви відредагували свій PVC в cat-pictures-pvc.yaml перед застосуванням. Вам потрібно:# - Встановити ReadWriteOncePod як єдиний режим доступу# - Встановити spec.volumeName на "cat-pictures-pv"kubectl apply -f cat-pictures-pvc.yaml
kubectl apply -f cat-pictures-writer-deployment.yaml
Нарешті, ви можете відредагувати spec.persistentVolumeReclaimPolicy вашого PersistentVolume і встановити його знову на Delete, якщо ви раніше змінювали його.
Ця сторінка показує, як змінити типовий StorageClass, який використовується для
створення томів для PersistentVolumeClaims, які не мають особливих вимог.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Залежно від методу встановлення, ваш кластер Kubernetes може бути розгорнутий з наявним StorageClass, який позначений як типовий. Цей типовий StorageClass потім використовується для динамічного створення сховищ для PersistentVolumeClaims, які не вимагають будь-якого конкретного класу сховища. Див. документацію по PersistentVolumeClaim для деталей.
Попередньо встановлений типовий StorageClass може не відповідати вашим очікуваним навантаженням; наприклад, він може створювати занадто дороге сховище. У цьому випадку ви можете змінити типовий StorageClass або повністю вимкнути його, щоб уникнути динамічного створення сховища.
Видалення типового StorageClass може бути недійсним, оскільки він може бути автоматично створений знову менеджером надбудов, що працює в вашому кластері. Будь ласка, перегляньте документацію для вашого встановлення для деталей про менеджера надбудов та способи вимкнення окремих надбудов.
Зміна типового StorageClass
Перегляньте StorageClasses у вашому кластері:
kubectl get storageclass
Вивід буде схожий на це:
NAME PROVISIONER AGE
standard (default) kubernetes.io/gce-pd 1d
gold kubernetes.io/gce-pd 1d
Типовий StorageClass позначений як (default).
Зніміть позначку default з типового StorageClass:
У типового StorageClass є анотація storageclass.kubernetes.io/is-default-class, встановлена на true. Будь-яке інше значення або відсутність анотації розглядається як false.
Щоб позначити StorageClass як не типовий, вам потрібно змінити його значення на false:
kubectl patch storageclass standard -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
де standard — це назва вашого вибраного StorageClass.
Позначте StorageClass як типовий:
Аналогічно попередньому кроку, вам потрібно додати/встановити анотацію
storageclass.kubernetes.io/is-default-class=true.
Зверніть увагу, що ви можете позначити декілька StorageClass як стандартні. Якщо позначено більше одного StorageClass як стандартного, PersistentVolumeClaim без явно визначеного storageClassName буде створено з використанням останнього створеного стандартного StorageClass. Коли PersistentVolumeClaim створено із зазначеним volumeName, він залишається у стані очікування, якщо storageClassName статичного тому не збігається з StorageClass у PersistentVolumeClaim.
Перевірте, що ваш вибраний StorageClass є default:
kubectl get storageclass
Вивід буде схожий на це:
NAME PROVISIONER AGE
standard kubernetes.io/gce-pd 1d
gold (default) kubernetes.io/gce-pd 1d
2.13 - Перехід від опитування до оновлення стану контейнера на основі подій CRI
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.26 [alpha](стандартно вимкнено)
Ця сторінка показує, як мігрувати вузли для використання оновлення стану контейнера на основі подій. Реалізація на основі подій зменшує використання ресурсів вузла kubeletʼом порівняно зі старим підходом, який ґрунтується на опитуванні. Ви можете знати цю функцію як evented Pod lifecycle event generator (PLEG). Це назва, яка використовується внутрішньо в проєкті Kubernetes для основних деталей реалізації.
Підхід на основі опитування відомий як generic PLEG.
Перш ніж ви розпочнете
Ви повинні запускати версію Kubernetes, яка надає цю функцію. Kubernetes v1.27 включає підтримку бета-версії оновлення стану контейнера на основі подій. Функція є бета-версією, але стандартно вимкнена, оскільки вона потребує підтримки від середовища виконання контейнерів.
Версія вашого Kubernetes сервера має бути не старішою ніж 1.26.
Для перевірки версії введіть kubectl version.
Якщо ви використовуєте іншу версію Kubernetes, перевірте документацію для цього релізу.
Використане контейнерне середовище повинно підтримувати події життєвого циклу контейнера. Kubelet автоматично повертається до старого механізму опитування generic PLEG, якщо контейнерне середовище не оголошує підтримку подій життєвого циклу контейнера, навіть якщо у вас увімкнено цей функціонал.
Навіщо переходити на Evented PLEG?
Generic PLEG викликає значне навантаження через часте опитування стану контейнерів.
Це навантаження загострюється паралельним опитуванням стану контейнерів kublet, що обмежує його масштабованість та призводить до проблем з поганим функціонуванням та надійністю.
Мета Evented PLEG — зменшити непотрібну роботу під час бездіяльності шляхом заміни періодичного опитування.
Перехід на Evented PLEG
Запустіть Kubelet з увімкненою функціональною можливістюEventedPLEG. Ви можете керувати feature gate kubelet редагуючи файл конфігурації kubelet і перезапустіть службу kubelet. Вам потрібно зробити це на кожному вузлі, де ви використовуєте цю функцію.
Якщо ви встановили --v у значення 4 і вище, ви можете побачити більше записів, що підтверджують, що kubelet використовує моніторинг стану контейнера на основі подій.
I0314 11:12:42.009542 1110177 evented.go:238] "Evented PLEG: Generated pod status from the received event" podUID=3b2c6172-b112-447a-ba96-94e7022912dc
I0314 11:12:44.623326 1110177 evented.go:238] "Evented PLEG: Generated pod status from the received event" podUID=b3fba5ea-a8c5-4b76-8f43-481e17e8ec40
I0314 11:12:44.714564 1110177 evented.go:238] "Evented PLEG: Generated pod status from the received event" podUID=b3fba5ea-a8c5-4b76-8f43-481e17e8ec40
2.14 - Зміна політики відновлення PersistentVolume
Ця сторінка показує, як змінити політику відновлення PersistentVolume в Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Навіщо змінювати політику відновлення PersistentVolume
У PersistentVolume можуть бути різні політики відновлення, включаючи "Retain", "Recycle" та "Delete". Для динамічно створених PersistentVolume типовою політикою відновлення є "Delete". Це означає, що динамічно створений том автоматично видаляється, коли користувач видаляє відповідний PersistentVolumeClaim. Ця автоматична поведінка може бути неприйнятною, якщо том містить важливі дані. У цьому випадку більш відповідною буде політика "Retain". З політикою "Retain", якщо користувач видаляє PersistentVolumeClaim, відповідний PersistentVolume не буде видалено. Замість цього він переміщується до фази Released, де всі його дані можуть бути вручну відновлені.
Зміна політики відновлення PersistentVolume
Виведіть список PersistentVolume в вашому кластері:
де <your-pv-name> — це імʼя вашого обраного PersistentVolume.
Примітка:
У Windows ви повинні двічі взяти в лапки будь-який шаблон JSONPath, що містить пробіли (не подвійні лапки як вказано вище для bash). Це своєю чергою означає, що ви повинні використовувати одинарні лапки або екрановані подвійні лапки навколо будь-яких літералів в шаблоні. Наприклад:
У попередньому виводі ви можете побачити, що том, привʼязаний до заявки default/claim3, має політику відновлення Retain. Він не буде автоматично видалений, коли користувач видаляє заявку default/claim3.
Оскільки хмарні провайдери розвиваються та випускають нові функції в іншому темпі порівняно з проєктом Kubernetes, абстрагування провайдеро-залежного коду у бінарний файл cloud-controller-manager дозволяє хмарним постачальникам розвиватися незалежно від основного коду Kubernetes.
cloud-controller-manager може бути повʼязаний з будь-яким хмарним провайдером, який відповідає вимогам cloudprovider.Interface. Для забезпечення зворотної сумісності, cloud-controller-manager, що постачається у складі основного проєкту Kubernetes, використовує ті ж хмарні бібліотеки, що і kube-controller-manager. Очікується, що хмарні постачальники, які вже підтримуються у ядрі Kubernetes, використовуватимуть вбудований cloud-controller-manager для передачі даних з ядра Kubernetes.
Адміністрування
Вимоги
Кожна хмара має свій власний набір вимог для запуску своєї інтеграції з власним провайдером, це не повинно суттєво відрізнятися від вимог до запуску kube-controller-manager. Загалом вам знадобиться:
автентифікація/авторизація в хмарі: вашій хмарі може знадобитися токен або правила IAM, щоб дозволити доступ до їхніх API
автентифікація/авторизація в Kubernetes: cloud-controller-manager може потребувати налаштування RBAC правила для звʼязку з apiserver Kubernetes
висока доступність: як і kube-controller-manager, вам може знадобитися налаштування високої доступності для cloud controller manager з використанням вибору лідера (стандартно увімкнено).
Робота cloud-controller-manager
Успішне виконання cloud-controller-manager вимагає деяких змін у конфігурації кластера.
kubelet, kube-apiserver та kube-controller-manager повинні бути налаштовані відповідно до використання користувачем зовнішнього CCM. Якщо користувач має зовнішній CCM (не внутрішні цикли управління хмарою в Kubernetes Controller Manager), то --cloud-provider=external повинен бути вказаний. В іншому випадку це не повинно бути вказано.
Майте на увазі, що налаштування кластера на використання контролера хмарного провайдера змінить поведінку вашого кластера:
Компоненти, що вказують --cloud-provider=external, додають спеціальний taint node.cloudprovider.kubernetes.io/uninitialized з ефектом NoSchedule під час ініціалізації. Це помічає вузол як такий, що потребує другої ініціалізації з зовнішнього контролера перед тим, як він зможе розпочати роботу. Зверніть увагу, що в разі недоступності cloud-controller-manager, нові вузли у кластері залишаться незапланованими. Taint важливий, оскільки планувальник може вимагати специфічної для хмари інформації про вузли, такої як їхній регіон чи тип (high cpu, gpu, high memory, spot instance тощо).
інформація про вузли в кластері більше не буде вибиратися з локальних метаданих, а замість цього всі виклики API для вибору інформації про вузли будуть проходити через cloud controller manager. Це може означати, що ви можете обмежити доступ до вашого API хмари на kubelet для кращої безпеки. Для великих кластерів вам може бути доцільно розглянути можливість обмеження швидкості викликів API cloud controller manager, оскільки він тепер відповідальний майже за всі виклики API вашої хмари зсередини кластера.
Контролер хмарного провайдера може надавати:
контролер Node — відповідає за оновлення вузлів Kubernetes з використанням API хмари та видалення вузлів Kubernetes, які були видалені у вашій хмарі.
контролер Service — відповідає за балансування навантаження у вашій хмарі для сервісів типу LoadBalancer.
контролер Route — відповідає за налаштування мережевих маршрутів у вашій хмарі
будь-які інші функції, які ви хочете реалізувати, якщо ви використовуєте провайдера не з ядра Kubernetes.
Для контролерів хмарних провайдерів, які не входять у ядро Kubernetes, ви можете знайти відповідні проєкти у репозиторіях, підтримуваних хмарними постачальниками або SIGs.
Для провайдерів, які вже є в ядрі Kubernetes, ви можете запускати вбудований контролер хмарного провайдера як DaemonSet у вашому кластері, використовуючи наступне як рекомендацію:
# Це приклад налаштування cloud-controller-manager як Daemonset у вашому кластері.# Він передбачає, що ваші мастери можуть запускати Podʼи та мають роль node-role.kubernetes.io/master.# Зверніть увагу, що цей Daemonset не працюватиме безпосередньо з коробки для вашого хмарного середовища, це# призначено як рекомендація.---apiVersion:v1kind:ServiceAccountmetadata:name:cloud-controller-managernamespace:kube-system---apiVersion:rbac.authorization.k8s.io/v1kind:ClusterRoleBindingmetadata:name:system:cloud-controller-managerroleRef:apiGroup:rbac.authorization.k8s.iokind:ClusterRolename:cluster-adminsubjects:- kind:ServiceAccountname:cloud-controller-managernamespace:kube-system---apiVersion:apps/v1kind:DaemonSetmetadata:labels:k8s-app:cloud-controller-managername:cloud-controller-managernamespace:kube-systemspec:selector:matchLabels:k8s-app:cloud-controller-managertemplate:metadata:labels:k8s-app:cloud-controller-managerspec:serviceAccountName:cloud-controller-managercontainers:- name:cloud-controller-manager# for in-tree providers we use registry.k8s.io/cloud-controller-manager# this can be replaced with any other image for out-of-tree providersimage:registry.k8s.io/cloud-controller-manager:v1.8.0command:- /usr/local/bin/cloud-controller-manager- --cloud-provider=[YOUR_CLOUD_PROVIDER] # Add your own cloud provider here!- --leader-elect=true- --use-service-account-credentials# these flags will vary for every cloud provider- --allocate-node-cidrs=true- --configure-cloud-routes=true- --cluster-cidr=172.17.0.0/16tolerations:# this is required so CCM can bootstrap itself- key:node.cloudprovider.kubernetes.io/uninitializedvalue:"true"effect:NoSchedule# these tolerations are to have the daemonset runnable on control plane nodes# remove them if your control plane nodes should not run pods- key:node-role.kubernetes.io/control-planeoperator:Existseffect:NoSchedule- key:node-role.kubernetes.io/masteroperator:Existseffect:NoSchedule# this is to restrict CCM to only run on master nodes# the node selector may vary depending on your cluster setupnodeSelector:node-role.kubernetes.io/master:""
Обмеження
Запуск контролера хмарного провайдера супроводжується кількома можливими обмеженнями. Хоча ці обмеження вирішуються у майбутніх релізах, важливо, щоб ви були обізнані з цими обмеженнями для операційних робочих навантажень.
Підтримка томів
Контролер хмарного провайдера не реалізує жодного з контролерів томів, що знаходяться в kube-controller-manager, оскільки інтеграція томів також потребує координації з kubelet. Під час розвитку CSI (інтерфейс контейнерного сховища) та додавання більш надійної підтримки втулків flex томів буде додано необхідну підтримку до контролера хмарного провайдера, щоб хмари могли повністю інтегруватися з томами. Дізнайтеся більше про зовнішні втулки томів CSI тут.
Масштабованість
Контролер хмарного провайдера запитує API вашого хмарного постачальника для отримання інформації про всі вузли. Для дуже великих кластерів розгляньте можливі вузькі місця, такі як вимоги до ресурсів та обмеження швидкості API.
Курча і яйце
Метою проєкту контролера хмарного провайдера є відділення розробки хмарних функцій від розробки проєкту ядра Kubernetes. На жаль, багато аспектів проєкту Kubernetes мають припущення, що функції хмарного провайдера тісно інтегровані у проєкт. Внаслідок цього, прийняття цієї нової архітектури може створити кілька ситуацій, коли робиться запит інформації від хмарного постачальника, але контролер хмарного провайдера може не мати можливості повернути цю інформацію без завершення початкового запиту.
Хорошим прикладом цього є функція TLS bootstrapping в Kubelet. TLS bootstrapping передбачає, що Kubelet має можливість запитати у хмарного провайдера (або локального сервісу метаданих) всі його типи адрес (приватні, публічні і т. д.), але контролер хмарного провайдера не може встановити типи адрес вузла без попередньої ініціалізації, що потребує, щоб kubelet мав TLS-сертифікати для звʼязку з apiserver.
Під час розвитку цієї ініціативи будуть внесені зміни для розвʼязання цих питань у майбутніх релізах.
2.16 - Налаштування постачальника облікових даних образів в kubelet
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.26 [stable]
Починаючи з Kubernetes v1.20, kubelet може динамічно отримувати облікові дані для реєстру образів контейнерів за допомогою використання втулків. Kubelet та втулок спілкуються через stdio (stdin, stdout та stderr), використовуючи версійні API Kubernetes. Ці втулки дозволяють kubelet запитувати облікові дані для реєстру контейнерів динамічно, на відміну від зберігання статичних облікових даних на диску. Наприклад, втулок може звертатися до локального сервера метаданих, щоб отримати облікові дані з обмеженим терміном дії для образу, який завантажується kubelet.
Ви можете бути зацікавлені у використанні цієї можливості, якщо будь-яке з нижче перерахованих тверджень є правдивим:
Потрібні виклики API до служби хмарного постачальника для отримання інформації для автентифікації реєстру.
Облікові дані мають короткий термін дії, і потрібно часто запитувати нові облікові дані.
Зберігання облікових даних реєстру на диску або в imagePullSecrets неприпустиме.
Цей посібник демонструє, як налаштувати механізм втулка постачальника облікових даних зображення kubelet.
Токен службового облікового запису для витягування образів
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.34 [beta](стандартно увімкнено)
Починаючи з Kubernetes v1.33, kubelet можна налаштувати так, щоб надсилати токен службового облікового запису, привʼязаного до того podʼу, для якого виконується отримання образу, до втулка постачальника облікових даних.
Це дозволить втулку обміняти токен на облікові дані для доступу до реєстру образів.
Щоб увімкнути цю можливість, в kubelet має бути увімкнено функціональну можливість KubeletServiceAccountTokenForCredentialProviders, а у файлі CredentialProviderConfig для втулка має бути задано поле tokenAttributes.
Поле tokenAttributes містить інформацію про токен службового облікового запису, який буде передано втулку, включаючи цільову аудиторію для токена і те, чи вимагає втулок, щоб pod мав службовий обліковий запис.
Використання облікових даних службового облікового запису може забезпечити наступні варіанти використання:
Уникнення необхідності використання ідентифікатора на основі kubelet/node для отримання образів з реєстру.
Дозволити робочим навантаженням отримувати образи на основі їхніх власних ідентифікаторів часу виконання без довготривалих/стійких секретів.
Перш ніж ви розпочнете
Вам потрібен кластер Kubernetes з вузлами, які підтримують втулки постачальника облікових даних kubelet. Ця підтримка доступна у Kubernetes 1.34; Kubernetes v1.24 та v1.25 мали це як бета-функцію, яка є типово увімкненою.
Якщо ви налаштовуєте втулок постачальника облікових даних, якому потрібен токен службового облікового запису, вам потрібен кластер Kubernetes з вузлами під керуванням Kubernetes v1.33 або новішої версії та ввімкненим на kubelet функціоналом KubeletServiceAccountTokenForCredentialProviders.
Робоча реалізація втулка постачальника облікових даних. Ви можете створити власний втулок або використовувати той що, наданий хмарним постачальником.
Версія вашого Kubernetes сервера має бути не старішою ніж v1.26.
Для перевірки версії введіть kubectl version.
Встановлення втулків на вузлах
Втулок постачальника облікових даних — це виконавчий бінарний файл, який kubelet буде використовувати. Переконайтеся, що бінарний файл втулка існує на кожному вузлі вашого кластера і зберігається в відомій теці. Ця тека буде потрібна пізніше при налаштуванні прапорців kubelet.
Налаштування Kubelet
Для використання цієї функції kubelet очікує встановлення двох прапорців:
--image-credential-provider-config — шлях до файлу конфігурації втулка постачальника облікових даних.
--image-credential-provider-bin-dir — шлях до теки, де знаходяться бінарні файли втулка постачальника облікових даних.
Налаштування постачальника облікових даних kubelet
Файл конфігурації, переданий в --image-credential-provider-config, зчитується kubelet для визначення, які виконавчі втулки слід викликати для яких образів контейнерів. Нижче наведено приклад файлу конфігурації, який ви, можливо, будете використовувати, якщо використовуєте втулок, оснований на ECR:
apiVersion:kubelet.config.k8s.io/v1kind:CredentialProviderConfig# providers — це список допоміжних втулків постачальників облікових даних, які будуть активовані# kubelet. Одному образу може відповідати декілька постачальників, в такому випадку облікові дані# від усіх постачальників будуть повернуті kubelet. Якщо для одного образу є кілька# постачальників, результати будуть обʼєднані. Якщо постачальники повертають ключі автентифікації,# що перекриваються, використовується значення від постачальника, який знаходиться раніше в цьому# списку.providers:# name — це обовʼязкове імʼя постачальника облікових даних. Воно повинно відповідати імені# виконавчого файлу постачальника, яке бачить kubelet. Виконавчий файл повинен знаходитися в# теці bin kubelet (встановлено за допомогою прапорця --image-credential-provider-bin-dir).- name:ecr-credential-provider# matchImages - обовʼязковий список рядків, які використовуються для порівняння з образами, щоб# визначити, чи потрібно викликати цього постачальника. Якщо один із рядків відповідає# запитаному образу від kubelet, втулок буде викликаний і отримає шанс надати облікові дані.# Очікується, що образи містять домен реєстру та URL-шлях.## Кожний запис в matchImages — це шаблон, який може необовʼязково містити порт та шлях.# Можна використовувати шаблони для домену, але не для порту або шляху. Шаблони підтримуються# як піддомени, наприклад, '*.k8s.io' або 'k8s.*.io', так і верхніх рівнів доменів, наприклад,# 'k8s.*'. Підтримується також частковий збіг піддоменів, наприклад, 'app*.k8s.io'. Кожен# шаблон може відповідати лише одному сегменту піддомену, тому `*.io` **не** відповідає# `*.k8s.io`.## Збіг існує між образами та matchImage, коли виконуються всі наведені нижче умови:# - Обидва мають однакову кількість частин домену і кожна частина має збіг.# - URL-шлях matchImages повинен бути префіксом URL-шляху цільового образу.# - Якщо matchImages містить порт, то порт також повинен мати збіг в образі.# Приклади значент matchImages:# - 123456789.dkr.ecr.us-east-1.amazonaws.com# - *.azurecr.io# - gcr.io# - *.*.registry.io# - registry.io:8080/pathmatchImages:- "*.dkr.ecr.*.amazonaws.com"- "*.dkr.ecr.*.amazonaws.com.cn"- "*.dkr.ecr-fips.*.amazonaws.com"- "*.dkr.ecr.us-iso-east-1.c2s.ic.gov"- "*.dkr.ecr.us-isob-east-1.sc2s.sgov.gov"# defaultCacheDuration — це типовий час, протягом якої втулок буде кешувати облікові дані у памʼяті,# якщо тривалість кешу не надана у відповіді втулку. Це поле є обовʼязковим.defaultCacheDuration:"12h"# Вхідна версія CredentialProviderRequest є обовʼязковою. Відповідь CredentialProviderResponse# ПОВИННА використовувати ту ж версію кодування, що й вхідна. Поточні підтримувані значення:# - credentialprovider.kubelet.k8s.io/v1apiVersion:credentialprovider.kubelet.k8s.io/v1# Аргументи, що перндаються команді під час її виконання.# +optional# args:# - --example-argument# Env визначає додаткові змінні середовища, які слід надати процесу. Ці# змінні обʼєднуються з оточенням хоста, а також змінними, які використовує client-go# для передачі аргументів до втулка.# +optionalenv:- name:AWS_PROFILEvalue:example_profile# tokenAttributes - конфігурація токену службового облікового запису, який буде передано втулку.# За допомогою цього поля постачальник облікових даних погоджується на використання токенів службових облікових записів для отримання образів.# якщо це поле встановлено без увімкненої функціональної можливості `KubeletServiceAccountTokenForCredentialProviders`, # kubelet не зможе запуститися з помилкою конфігурації.# +optionaltokenAttributes:# serviceAccountTokenAudience — це очікувана аудиторія для спроєцьованих токенів службових облікових запісів.# +requiredserviceAccountTokenAudience:"<audience for the token>"# cacheType вказує тип ключа кешу, що використовується для кешування облікових даних, повернених втулком# коли використовується токен службового облікового запису.# Найбільш консервативний варіант - встановити його на "Token", що означає, що kubelet буде кешувати# повернуті облікові дані на основі кожного токена. Це слід встановити, якщо термін дії повернутого облікового запису# обмежений терміном дії токена службового облікового запису.# Якщо логіка отримання облікових даних втулка залежить лише від службового облікового запису, а не від# заявок pod-specific, тоді втулок може встановити це значення на "ServiceAccount". У цьому випадку# kubelet буде кешувати повернуті облікові дані на основі кожного службового облікового запису. Використовуйте це, коли# повернуті облікові дані дійсні для всіх podʼів, які використовують той самий службовий обліковий запис.# +requiredcacheType:"<Token or ServiceAccount>"# requireServiceAccount вказує чи вимагає втулок, щоб pod мав службовий обліковий запис.# Якщов становлено true, kubelet буде викликати втулок тільки якщо pod має службовий обліковий запис.# Якщо встановлено false, kubelet буде викликати втулок навіть, тоді, коли pod не має службового облікового запису# та не вклбчатиме токен у CredentialProviderRequest. Це корисно для втулків,# які використовуються для отримання образів для podʼів без службових облікових записів (напр., статичні podʼи).# +requiredrequireServiceAccount:true# requiredServiceAccountAnnotationKeys є переліком ключів анотацій потрібних для втулків# та які мають бути присутні в службових облікових записах.# Ключі визначені в переліку будуть отримані з відповідного службового облікового запису та передані# до втулку як частина CredentialProviderRequest. Якщо будь-яких з ключів, з цього переліку# не знаходиться в службового обліковому записі, kubelet не викликатиме втулок та поверне помилку.# Це поле є опціональним та може бути пустим. Втулки можуть використовувати це поле для отримання додаткової інформації,# потрібної для отримання облікових даних або для дозволу робочому навантаженю використовувати токен службового облікового запису для отримання образів.# Якщо це не пусте значення, requireServiceAccount має бути рівним true.# Ключі визначені в цьому переліку мають бути унікальними та не перетинатись з ключами визначених в# переліку optionalServiceAccountAnnotationKeys.# +optionalrequiredServiceAccountAnnotationKeys:- "example.com/required-annotation-key-1"- "example.com/required-annotation-key-2"# optionalServiceAccountAnnotationKeys це перелік ключів анотації потрібні для втулку# та наявність яких в службового обліковому записі є опціональною.# Ключі визначені в цьому переліку будуть отримані з відповідного службового облікового запису та передані# втулку як частина CredentialProviderRequest. Перевірка наявності анотацій та їх значень покладається на втулок# Це поле є опціональним і може бути порожнім.# Втулки можуть використовувати це поле для отримання додаткової інформації для отримання облікових даних.# Ключі визначені в цьому переліку мають бути унікальними та не перетинатись з ключами з перелку# requiredServiceAccountAnnotationKeys.# +optionaloptionalServiceAccountAnnotationKeys:- "example.com/optional-annotation-key-1"- "example.com/optional-annotation-key-2"
Поле providers — це список увімкнених втулків, які використовує kubelet. Кожен запис має кілька обовʼязкових полів:
name: назва втулка, яка ПОВИННА відповідати назві виконавчого бінарного файлу, який існує в теці, вказаній у --image-credential-provider-bin-dir.
matchImages: список рядків, які використовуються для порівняння образів з метою визначення, чи слід викликати цього постачальника для конкретного образу контейнера. Докладніше про це нижче.
defaultCacheDuration: термін, протягом якого kubelet буде кешувати облікові дані в памʼяті, якщо втулок не надав термін кешування.
apiVersion: версія API, яку використовуватимуть kubelet і виконавчий втулок під час спілкування.
Кожен постачальник облікових даних також може мати додаткові аргументи та змінні середовища. Перегляньте реалізацію втулків, щоб визначити, який набір аргументів та змінних середовища потрібний для певного втулка.
Якщо ви використовуєте функціональну можливість KubeletServiceAccountTokenForCredentialProviders та налаштовуєте втулок для використання токена службового облікового запису через встановлення поля tokenAttributes, наступні поля є обовʼязковими:
serviceAccountTokenAudience: передбачувана аудиторія для спроєцьованого токена службового облікового запису . Це не може бути порожній рядок.
cacheType: тип ключа кешу, що використовується для кешування облікових даних, повернених втулком, коли використовується токен службового облікового запису. Найбільш консервативний варіант — встановити його в Token, що означає, що kubelet буде кешувати повернені облікові дані на основі кожного токена. Це слід встановити, якщо термін дії повернутого облікового запису обмежений терміном дії токена службового облікового запису. Якщо логіка отримання облікових даних втулка залежить лише від службового облікового запису, а не від специфічних для пода вимог, то втулок може встановити це в ServiceAccount. У цьому випадку kubelet буде кешувати повернені облікові дані на основі кожного службового облікового запису. Використовуйте це, коли повернений обліковий запис дійсний для всіх подів, які використовують один і той же службовий обліковий запис.
requireServiceAccount: чи потребує втулок, щоб pod мав службовий обліковий запис.
Якщо — true, kubelet викликатиме втулок коли pod має службовий обліковий запис.
Якщо — false, kubelet викликатиме втулок навіть тоді, коли pod не має службового облікового запису та не включатиме токен у CredentialProviderRequest.
Це є корисним для втулків, які використовуються для отримання образів для podʼів без службових облікових записів (напр., статичні podʼи).
Налаштування збігу образів
Поле matchImages для кожного постачальника облікових даних використовується kubelet для визначення того, чи слід викликати втулок для певного образу, що використовується в Podʼі. Кожний запис у matchImages — це шаблон образу, який може опціонально містити порт та шлях. Символи підстановки дозволяють використовувати шаблони для піддоменів, такі як *.k8s.io або k8s.*.io, а також для доменів верхнього рівня, такі як k8s.*. Збіг між імʼям образу та записом matchImage існує тоді, коли виконуються всі умови:
Обидва містять однакову кількість частин домену, і кожна частина має збіг.
Шлях URL matchImage повинен бути префіксом шляху URL цільового образу.
Якщо matchImages містить порт, то порт також повинен мати збіг в образі.
Ця сторінка показує, як налаштувати квоти для обʼєктів API, включаючи PersistentVolumeClaims та Services. Квота обмежує кількість обʼєктів певного типу, які можуть бути створені в просторі імен. Ви вказуєте квоти в обʼєкті ResourceQuota.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Перегляньте докладну інформацію про ResourceQuota:
kubectl get resourcequota object-quota-demo --namespace=quota-object-example --output=yaml
У виводі показано, що в просторі імен quota-object-example може бути максимум один PersistentVolumeClaim, максимум два Services типу LoadBalancer та жодного Services типу NodePort.
2.18 - Управління політиками керування ЦП на вузлі
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.26 [stable]
Kubernetes зберігає багато аспектів того, як Podʼи виконуються на вузлах, абстрагованими від користувача. Це зроблено навмисно. Проте деякі завдання вимагають більших гарантій з погляду часу реакції та/або продуктивності, щоб працювати задовільно. Kubelet надає методи для включення складніших політик розміщення завдань, зберігаючи абстракцію вільною від явних директив розміщення.
Для отримання детальної інформації про те, як у kubelet реалізовано управління ресурсами, зверніться до документації Node ResourceManagers.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.26.
Для перевірки версії введіть kubectl version.
Якщо ви використовуєте старішу версію Kubernetes, будь ласка, перегляньте документацію для версії, яку ви фактично використовуєте.
Налаштування політик керування CPU
Стандартно, kubelet використовує квоту CFS, щоб обмежувати ЦП для Podʼів. Коли вузол виконує багато Podʼів, залежних від ЦП, навантаження може переміщуватися на різні ядра ЦП залежно від того, чи обмежений Pod, і які ядра ЦП доступні на момент планування. Багато завдань не чутливі до цього переміщення і, отже, працюють нормально без будь-якого втручання.
Проте, в завданнях, де спорідненість кешу ЦП та затримка планування значно впливають на продуктивність робочого завдання, kubelet дозволяє використовувати альтернативні політики керування ЦП для визначення деяких вподобань розміщення на вузлі.
Підтримка Windows
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.32 [alpha](стандартно вимкнено)
Підтримку диспетчера процесорів можна увімкнути у Windows за допомогою WindowsCPUAndMemoryAffinity, і вона потребує підтримки під час виконання контейнера. Після увімкнення функціональної можливості виконайте наведені нижче кроки для налаштування політики диспетчера CPU.
Налаштування
Політика керування ЦП встановлюється прапорцем kubelet --cpu-manager-policy або полем cpuManagerPolicy в KubeletConfiguration. Підтримуються дві політики:
static: дозволяє контейнерам з певними характеристиками ресурсів отримувати збільшену спорідненість ЦП та ексклюзивність на вузлі.
Керування ЦП періодично записує оновлення ресурсів через CRI, щоб звести до мінімуму проблеми сумісності памʼяті та виправити їх. Частота зведення встановлюється за допомогою нового значення конфігурації Kubelet --cpu-manager-reconcile-period. Якщо вона не вказана, стандартно вона дорівнює тому ж часу, що й --node-status-update-frequency.
Поведінку статичної політики можна налаштувати за допомогою прапорця --cpu-manager-policy-options. Прапорець приймає список параметрів політики у вигляді ключ=значення. Якщо ви вимкнули функціональну можливістьCPUManagerPolicyOptions, то ви не зможете налаштувати параметри політик керування ЦП. У цьому випадку керування ЦП працюватиме лише зі своїми стандартними налаштуваннями.
Окрім верхнього рівня CPUManagerPolicyOptions, параметри політики розділені на дві групи: якість альфа (типово прихована) та якість бета (типово видима). Відмінно від стандарту Kubernetes, ці feature gate захищають групи параметрів, оскільки було б надто складно додати feature gate для кожного окремого параметра.
Зміна політики керування ЦП
Оскільки політику керування ЦП можна застосовувати лише коли kubelet створює нові Podʼи, просте змінення з "none" на "static" не застосується до наявних Podʼів. Тому, щоб правильно змінити політику керування ЦП на вузлі, виконайте наступні кроки:
Видаліть старий файл стану керування ЦП. Типовий шлях до цього файлу /var/lib/kubelet/cpu_manager_state. Це очищує стан, що зберігається CPUManager, щоб множини ЦП, налаштовані за новою політикою, не конфліктували з нею.
Відредагуйте конфігурацію kubelet, щоб змінити політику керування ЦП на потрібне значення.
Запустіть kubelet.
Повторіть цей процес для кожного вузла, який потребує зміни політики керування ЦП. Пропуск цього процесу призведе до постійної аварійної роботи kubelet з такою помилкою:
could not restore state from checkpoint: configured policy "static" differs from state checkpoint policy "none", please drain this node and delete the CPU manager checkpoint file "/var/lib/kubelet/cpu_manager_state" before restarting Kubelet
Примітка:
Якщо на вузлі змінюється набір доступних процесорів, то вузол необхідно спустошити та вручну перезавантажити CPU manager, видаливши
файл стану cpu_manager_state у кореневій теці kubelet.
Налаштування політики none
Ця політика не має додаткових елементів конфігурації.
Налаштування політики static
Ця політика керує спільним пулом ЦП, який на початку містить всі ЦП на вузлі. Кількість ексклюзивно виділених ЦП дорівнює загальній кількості ЦП на вузлі мінус будь-які резерви ЦП за допомогою параметрів kubelet --kube-reserved або --system-reserved. З версії 1.17 список резервувань ЦП може бути вказаний явно за допомогою параметру kubelet --reserved-cpus. Явний список ЦП, вказаний за допомогою --reserved-cpus, має пріоритет над резервуванням ЦП, вказаним за допомогою --kube-reserved та --system-reserved. ЦП, зарезервовані цими параметрами, беруться, у цілочисельній кількості, зі спільного пулу на основі фізичного ідентифікатора ядра. Цей спільний пул — це множина ЦП, на яких працюють контейнери в Podʼах з BestEffort та Burstable. Контейнери у Podʼах з гарантованою продуктивністю з цілими requests ЦП також працюють на ЦП у спільному пулі. Ексклюзивні ЦП призначаються лише контейнерам, які одночасно належать до Podʼа з гарантованою продуктивністю та мають цілочисельні requests ЦП.
Примітка:
Kubelet потребує, щоб було зарезервовано не менше одного ЦП за допомогою параметрів --kube-reserved і/або --system-reserved або --reserved-cpus, коли включена статична політика. Це тому, що нульове резервування ЦП дозволить спільному пулу стати порожнім.
Параметри політики static
Ви можете включати та виключати групи параметрів на основі їх рівня зрілості, використовуючи наступні feature gate:
CPUManagerPolicyBetaOptions — стандартно увімкнено. Вимкніть, щоб приховати параметри рівня бета.
CPUManagerPolicyAlphaOptions — стандартно вимкнено. Увімкніть, щоб показати параметри рівня альфа. Ви все ще повинні увімкнути кожен параметр за допомогою опції kubelet CPUManagerPolicyOptions.
Для політики static CPUManager існують наступні параметри:
full-pcpus-only (GA, типово видимий) (1.33 або вище)
distribute-cpus-across-numa (бета, типово видимий) (1.33 або вище)
align-by-socket (альфа, типово прихований) (1.25 або вище)
distribute-cpus-across-cores (альфа, типово прихований) (1.31 або вище)
strict-cpu-reservation (бета, типово видимий) (1.32 або вище)
prefer-align-cpus-by-uncorecache (бета, типово видимий) (1.34 або вище)
Параметр full-pcpus-only можна включити, додавши full-pcpus-only=true до параметрів політики CPUManager. Так само параметр distribute-cpus-across-numa можна включити, додавши distribute-cpus-across-numa=true до параметрів політики CPUManager. Якщо обидва встановлені, вони "адитивні" у тому сенсі, що ЦП будуть розподілені по вузлах NUMA в шматках повних фізичних ядер, а не окремих ядер. Параметр політики align-by-socket можна увімкнути, додавши align-by-socket=true до параметрів політики CPUManager. Він також адитивний до параметрів політики full-pcpus-only та distribute-cpus-across-numa.
Опцію distribute-cpus-across-cores можна увімкнути, додавши distribute-cpus-across-cores=true до параметрів політики CPUManager. Зараз її не можна використовувати разом з параметрами політики full-pcpus-only або distribute-cpus-across-numa.
Опцію strict-cpu-reservation можна увімкнути, додавши strict-cpu-reservation=true до параметрів політики CPUManager, після чого видалити файл /var/lib/kubelet/cpu_manager_state і перезапустити kubelet.
Параметр prefer-align-cpus-by-uncorecache можна увімкнути, додавши prefer-align-cpus-by-uncorecache до параметрів політики CPUManager. Якщо буде використано несумісні опції, kubelet не запуститься з помилкою, яку буде вказано у журналах.
Докладні відомості про поведінку окремих параметрів, які ви можете налаштувати, наведено у документації Node ResourceManagers.
2.19 - Керування політиками топології на вузлі
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.27 [stable]
Зростаюча кількість систем використовує комбінацію ЦП та апаратних прискорювачів для підтримки виконання, критичного з погляду затримок, та високопродуктивних паралельних обчислень. Ці системи включають робочі навантаження у таких галузях, як телекомунікації, наукові обчислення, машинне навчання, фінансові послуги та аналітика даних. Такі гібридні системи складають високопродуктивне середовище.
Для досягнення найкращої продуктивності потрібні оптимізації, що стосуються ізоляції ЦП, памʼяті та локальності пристроїв. Проте, в Kubernetes ці оптимізації обробляються роздільним набором компонентів.
Topology Manager — це компонент kubelet, який має на меті координацію набору компонентів, відповідальних за ці оптимізації.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.18.
Для перевірки версії введіть kubectl version.
Як працює Topology Manager
Перед введенням Topology Manager, CPU та Device Manager в Kubernetes приймають рішення про розподіл ресурсів незалежно одне від одного. Це може призводити до небажаних розподілів на системах з кількома сокетами, де застосунки, що чутливі до продуктивності/затримки, будуть страждати через ці небажані розподіли. Небажані в цьому випадку означає, наприклад, виділення ЦП та пристроїв з різних вузлів NUMA, що призводить до додаткової затримки.
Topology Manager — це компонент kubelet, який діє як джерело правди, щоб інші компоненти kubelet могли робити вибір щодо розподілу ресурсів з урахуванням топології.
Topology Manager надає інтерфейс для компонентів, званих Hint Providers, для надсилання та отримання інформації про топологію. У Topology Manager є набір політик рівня вузла, які пояснюються нижче.
Topology manager отримує інформацію про топологію від Hint Providers у вигляді бітової маски, яка позначає доступні вузли NUMA та попередній показник виділення. Політики Topology Manager виконують набір операцій з наданими підказками та сходяться на підказці, визначеній політикою, щоб дати оптимальний результат, якщо зберігається небажана підказка, бажане поле для підказки буде встановлено у false. У поточних політиках найприйнятніше — це найвужча попередня маска. Обрана підказка зберігається як частина Topology Manager. Залежно від налаштованої політики, Pod може бути прийнятий або відхилений на вузлі на основі обраної підказки. Підказка потім зберігається в Topology Manager для використання Hint Providers під час прийняття рішень про розподіл ресурсів.
Потік можна побачити на наступній діаграмі.
Підтримка Windows
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.32 [alpha](стандартно вимкнено)
Підтримку Topology Manager можна увімкнути у Windows за допомогою функціональної можливості WindowsCPUAndMemoryAffinity, і вона потребує підтримки під час виконання контейнера.
Scope та Policy в Topology Manager
Topology Manager наразі:
узгоджує Podʼи усіх класів QoS.
узгоджує запитані ресурси, які Hint Provider надає підказки топології.
Якщо ці умови виконані, Topology Manager узгоджує запитані ресурси.
Для того, щоб налаштувати, як це вирівнювання виконується, Topology Manager надає два відмінні параметри: scope та policy.
scope визначає гранулярність, на якій ви хочете, щоб виконувалось вирівнювання ресурсів, наприклад, на рівні pod або container. А policy визначає фактичну стратегію, яка використовується для виконання вирівнювання, наприклад, best-effort, restricted, single-numa-node і т.д. Деталі щодо різних scopes та policies, доступних на сьогодні, можна знайти нижче.
Примітка:
Щоб вирівняти ресурси ЦП з іншими запитаними ресурсами у специфікації Pod, потрібно включити CPU Manager та налаштувати відповідну політику CPU Manager на вузлі. Див. Управління політиками керування ЦП на вузлі.
Примітка:
Щоб вирівняти памʼять (та великі сторінки) з іншими запитаними ресурсами у специфікації Pod, слід увімкнути Memory Manager та налаштувати відповідну політику Memory Manager на вузлі. Див. документацію Memory Manager.
Scope в Topology Manager
Topology Manager може вирівнювати ресурси у кількох різних сферах:
container (стандартно)
pod
Будь-яку з цих опцій можна вибрати під час запуску kubelet, налаштувавши параметр topologyManagerScope у файлі конфігурації kubelet.
Scope container
Scope container використовується стандартно. Ви також можете явно встановити параметр topologyManagerScope в container у файлі конфігурації kubelet.
У цьому scope Topology Manager виконує кілька послідовних вирівнювань ресурсів, тобто для кожного контейнера (у Pod) окреме вирівнювання. Іншими словами, відсутнє поняття групування контейнерів у певний набір вузлів NUMA, для цього конкретного scope. Фактично Topology Manager виконує довільне вирівнювання окремих контейнерів на вузли NUMA.
Ідея групування контейнерів була затверджена та реалізована навмисно в наступному scope, наприклад, у scope pod.
Цей scope дозволяє групувати всі контейнери у Podʼі у спільний набір вузлів NUMA. Іншими словами, Topology Manager розглядає Pod як ціле та намагається виділити весь Pod (всі контейнери) на один вузол NUMA або спільний набір вузлів NUMA. Нижче наведено приклади вирівнювання, які виробляє Topology Manager у різні моменти:
всі контейнери можуть бути та виділені на один вузол NUMA;
всі контейнери можуть бути та виділені на спільний набір вузлів NUMA.
Загальна кількість певного ресурсу, запитаного для всього Podʼа, розраховується за формулою ефективні запити/обмеження, і, таким чином, це загальне значення дорівнює максимуму з:
сума всіх запитів контейнерів застосунку,
максимум запитів контейнерів ініціалізації,
для ресурсу.
Використання scope pod разом з політикою Topology Manager single-numa-node особливо цінне для робочих навантажень, які чутливі до затримок, або для високопродуктивних застосунків, які виконують міжпроцесну комунікацію (IPC). Поєднуючи обидва варіанти, ви можете помістити всі контейнери в Pod на один вузол NUMA; отже, можливість між-NUMA комунікації може бути усунена для цього Pod.
У випадку політики single-numa-node Pod приймається лише в тому разі, якщо серед можливих виділень є відповідний набір вузлів NUMA. Перегляньте приклад вище:
набір, що містить лише один вузол NUMA — це призводить до допуску Podʼа,
тоді як набір, що містить більше вузлів NUMA — це призводить до відхилення Podʼа (тому, що для задоволення виділення потрібен один вузол NUMA).
У підсумку, Topology Manager спочатку розраховує набір вузлів NUMA, а потім перевіряє його з політикою Topology Manager, яка призводить до відхилення або допуску Podʼа.
Політики Topology Manager
Topology Manager підтримує чотири політики виділення. Ви можете встановити політику за допомогою прапорця kubelet --topology-manager-policy. Існують чотири підтримувані політики:
none (стандартно)
best-effort
restricted
single-numa-node
Примітка:
Якщо Topology Manager налаштований зі scope Pod, контейнер, який розглядається політикою, відображає вимоги всього Podʼа, і тому кожний контейнер з Podʼа буде мати одне і те ж рішення про вирівнювання топології.
Політика none
Це стандартна політика і вона не виконує жодного вирівнювання топології.
Політика best-effort
Для кожного контейнера у Pod kubelet з політикою керування топологією best-effort викликає кожен Hint Provider, щоб дізнатися їхню доступність ресурсів. Використовуючи цю інформацію, Topology Manager зберігає привʼязку до найближчого вузла NUMA для цього контейнера. Якщо привʼязка не є бажаною, Topology Manager також зберігає це і допускає Pod до вузла не зважаючи на це.
Hint Providers можуть використовувати цю інформацію при прийнятті рішення про розподіл ресурсів.
Політика restricted
Для кожного контейнера у Pod kubelet з політикою керування топологією restricted викликає кожен Hint Provider, щоб дізнатися їхню доступність ресурсів. Використовуючи цю інформацію, Topology Manager зберігає привʼязку до вузла NUMA для цього контейнера. Якщо привʼязка не є бажаною, Topology Manager відхиляє Pod від вузла. Це призводить до того, що Pod переходить в стан Terminated з помилкою допуску Podʼа.
Якщо Pod перебуває в стані Terminated, планувальник Kubernetes не буде намагатися знову запланувати його. Рекомендується використовувати ReplicaSet або Deployment для того, щоб викликати повторне розгортання Podʼа. Зовнішній цикл керування також може бути реалізований для того, щоб викликати повторне розгортання Podʼів, які мають помилку Topology Affinity.
Якщо Pod прийнято, Hint Providers можуть використовувати цю інформацію при прийнятті рішення про розподіл ресурсів.
Політика single-numa-node
Для кожного контейнера у Pod kubelet з політикою керування топологією single-numa-node викликає кожен Hint Provider, щоб дізнатися їхню доступність ресурсів. Використовуючи цю інформацію, Topology Manager визначає, чи можлива привʼязка до одного вузла NUMA. Якщо можливо, Topology Manager зберігає це і Hint Providers можуть використовувати цю інформацію при прийнятті рішення про розподіл ресурсів. Якщо привʼязка не можлива, Topology Manager відхиляє Pod від вузла. Це призводить до того, що Pod перебуває в стані Terminated з помилкою прийняття Podʼа.
Якщо Pod перебуває в стані Terminated, планувальник Kubernetes не буде намагатися знову запланувати його. Рекомендується використовувати ReplicaSet або Deployment для того, щоб викликати повторне розгортання Podʼа. Зовнішній цикл керування також може бути реалізований для того, щоб викликати повторне розгортання Podʼів, які мають помилку Topology Affinity.
Параметри політики керування топологією
Підтримка параметрів політики керування топологією вимагає активації функціональної можливостіTopologyManagerPolicyOptions, щоб бути ввімкненими (типово увімкнено).
Ви можете увімкнути та вимкнути групи параметрів на основі їхнього рівня зрілості за допомогою наступних feature gate:
TopologyManagerPolicyBetaOptions типово увімкнено. Увімкніть, щоб показати параметри рівня бета.
TopologyManagerPolicyAlphaOptions типово вимкнено. Увімкніть, щоб показати параметри рівня альфа.
Ви все ще повинні активувати кожний параметр за допомогою опції kubelet TopologyManagerPolicyOptions.
prefer-closest-numa-nodes
Опція prefer-closest-numa-nodes є загально доступною з версії Kubernetes 1.32. У версії Kubernetes 1.34 ця політика стандартно доступна, якщо увімкнено функціональні можливостіTopologyManagerPolicyOptions та TopologyManagerPolicyBetaOptions.
Типово менеджер топології не враховує відстані між NUMA вузлами та не бере їх до уваги при прийнятті рішень про допуск Pod. Це обмеження проявляється в системах з кількома сокетами, а також у системах з одним сокетом і кількома NUMA вузлами, і може спричинити значне погіршення продуктивності у виконанні з критичною затримкою та високим пропуском даних, якщо менеджер топології вирішить розмістити ресурси на не сусідніх NUMA вузлах.
Якщо вказано параметр політики prefer-closest-numa-nodes, політики best-effort та restricted будуть віддавати перевагу наборам вузлів NUMA з коротшими відстанями між ними при прийнятті рішень про прийняття.
Стандартно (без цієї опції) менеджер топології розміщує ресурси або на одному NUMA вузлі, або, у випадку, коли потрібно більше одного NUMA вузла, використовує мінімальну кількість NUMA вузлів.
max-allowable-numa-nodes (бета)
Опція max-allowable-numa-nodes є бета-функцією з версії Kubernetes 1.31. У версії Kubernetes 1.34 ця політика стандартно доступна, якщо увімкнено функціональні можливостіTopologyManagerPolicyOptions та TopologyManagerPolicyBetaOptions.
Час на прийняття Podʼа повʼязаний з кількістю NUMA вузлів на фізичній машині. стандартно, Kubernetes не запускає kubelet з увімкненим менеджером топології на жодному (Kubernetes) вузлі, де виявлено більше ніж 8 NUMA вузлів.
Примітка:
Якщо ви виберете політику max-allowable-numa-nodes, вузли з більше ніж 8 NUMA вузлами можуть бути дозволені для роботи з увімкненим менеджером топології. Проєкт Kubernetes має обмежені дані про вплив використання менеджера топології на вузли (Kubernetes) з більше ніж 8 NUMA вузлами. Через відсутність даних, використання цієї політики з Kubernetes 1.34 не рекомендується і здійснюється на ваш власний ризик.
Ви можете увімкнути цю опцію, додавши max-allowable-numa-nodes=true до параметрів політики Topology Manager.
Встановлення значення max-allowable-numa-nodes не впливає безпосередньо на затримку допуску Pod, але привʼязка Pod до вузла (Kubernetes) з великою кількістю NUMA вузлів має вплив. Майбутні можливі поліпшення в Kubernetes можуть покращити продуктивність допуску Podʼів і зменшити високу затримку, яка виникає зі збільшенням кількості NUMA вузлів.
Взаємодія точок доступу Pod з політиками Topology Manager
Розгляньте контейнери у наступному маніфесті Podʼа:
spec:containers:- name:nginximage:nginx
Цей Pod працює в класі QoS BestEffort, оскільки не вказано жодних ресурсів requests або limits.
Цей Pod працює в класі QoS Burstable, оскільки запити менше, ніж ліміти.
Якщо вибрана політика відрізняється від none, Topology Manager враховуватиме ці специфікації Pod. Topology Manager буде консультувати Hint Provider для отримання підказок топології. У випадку static політики CPU Manager поверне типову підказку топології, оскільки ці Podʼи не мають явних запитів ресурсів CPU.
Цей Pod працює в класі QoS BestEffort, оскільки немає запитів CPU та памʼяті.
Topology Manager враховуватиме вищезазначені Podʼи. Topology Manager буде консультувати Hint Provider, які є CPU та Device Manager, для отримання підказок топології для Pod.
У випадку Guaranteed Pod із цілим запитом CPU, політика CPU Manager static поверне підказки топології, що стосуються виключно CPU, а Device Manager надішле підказки для запитаного пристрою.
У випадку Guaranteed Pod з спільним запитом CPU, політика CPU Manager static поверне типову підказку топології, оскільки немає виключного запиту CPU, а Device Manager надішле підказки для запитаних пристроїв.
У вищезазначених двох випадках Guaranteed Pod політика CPU Manager none поверне типову підказку топології.
У випадку BestEffort Pod, політика CPU Manager static поверне типову підказку топології, оскільки немає запиту CPU, а Device Manager надішле підказки для кожного запитаного пристрою.
На основі цієї інформації Topology Manager обчислить оптимальну підказку для Pod і збереже цю інформацію, яка буде використовуватися постачальниками підказок при призначенні ресурсів.
Відомі обмеження
Максимальна кількість вузлів NUMA, яку дозволяє Topology Manager, — 8. З більш ніж 8 вузлами NUMA відбудеться вибух стану при спробі перерахувати можливі спорідненості NUMA та генерувати їх підказки. Дивіться max-allowable-numa-nodes (бета) для отримання додаткової інформації.
Планувальник не знає топології, тому його можна запланувати на вузлі, а потім вивести з ладу на вузлі через Topology Manager.
2.20 - Налаштування служби DNS
На цій сторінці пояснюється, як налаштувати ваші DNS Pod та настроїти процес розвʼязання імен DNS у вашому кластері.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Ваш кластер повинен працювати з надбудовою CoreDNS.
Версія вашого Kubernetes сервера має бути не старішою ніж v1.12.
Для перевірки версії введіть kubectl version.
Вступ
DNS — це вбудована служба Kubernetes, яка автоматично запускається з допомогою менеджера надбудовcluster add-on.
Примітка:
Служба CoreDNS називається kube-dns у полі metadata.name. Метою є забезпечення більшої сумісності з навантаженнями, які покладалися на старе імʼя служби kube-dns для розвʼязання адрес в межах кластера. Використання служби з іменем kube-dns абстрагує деталі реалізації
за цим загальним імʼям DNS-провайдера.
Якщо ви працюєте з CoreDNS як з Deployment, його зазвичай викладають як Service Kubernetes зі статичною IP-адресою. Kubelet передає інформацію про резолвер DNS кожному контейнеру з прапорцем --cluster-dns=<ір-адреса-dns-служби>.
DNS-імена також потребують доменів. Ви налаштовуєте локальний домен в kubelet з прапорцем --cluster-domain=<типовий-локальний-домен>.
DNS-сервер підтримує прямий пошук (записи A та AAAA), пошук портів (записи SRV), зворотній пошук IP-адрес (записи PTR) та інші. Для отримання додаткової інформації дивіться DNS для Service та Pod.
Якщо для Pod dnsPolicy встановлено значення default, він успадковує конфігурацію розвʼязку імен від вузла, на якому працює Pod. Розвʼязок імен Pod повинен поводитися так само як і на вузлі. Проте див. Відомі проблеми.
Якщо вам це не потрібно, або якщо ви хочете іншу конфігурацію DNS для Podʼів, ви можете використовувати прапорець --resolv-conf kubelet. Встановіть цей прапорець у "" для того, щоб запобігти успадкуванню DNS від Podʼів. Встановіть його на дійсний шлях до файлу, щоб вказати файл, відмінний від /etc/resolv.conf для успадкування DNS.
CoreDNS
CoreDNS — це універсальний авторитетний DNS-сервер, який може служити як кластерний DNS, відповідаючи специфікаціям DNS.
Опції ConfigMap CoreDNS
CoreDNS — це DNS-сервер, який є модульним та розширюваним, з допомогою втулків, які додають нові можливості. Сервер CoreDNS може бути налаштований за допомогою збереження Corefile, який є файлом конфігурації CoreDNS. Як адміністратор кластера, ви можете змінювати ConfigMap для Corefile CoreDNS для зміни того, як поводитися служба виявлення служби DNS для цього кластера.
У Kubernetes CoreDNS встановлюється з наступною стандартною конфігурацією Corefile:
health: Справність CoreDNS повідомляється за адресою http://localhost:8080/health. У цьому розширеному синтаксисі lameduck зробить процес несправним, а потім зачекає 5 секунд, перш ніж процес буде вимкнено.
ready: HTTP-точка на порту 8181 поверне 200 ОК, коли всі втулки, які можуть сигналізувати готовність, зроблять це.
kubernetes: CoreDNS відповість на DNS-запити на основі IP-адрес Service та Pod. Ви можете знайти більше деталей про цей втулок на вебсайті CoreDNS.
ttl дозволяє встановити власний TTL для відповідей. Стандартно — 5 секунд. Мінімальний дозволений TTL — 0 секунд, а максимальний обмежений 3600 секундами. Встановлення TTL на 0 запобіжить кешуванню записів.
Опція pods insecure надається для сумісності з kube-dns.
Ви можете використовувати опцію pods verified, яка поверне запис A лише у випадку, якщо існує Pod в тому ж просторі імен зі потрібним IP.
Опцію pods disabled можна використовувати, якщо ви не використовуєте записи Podʼів.
prometheus: Метрики CoreDNS доступні за адресою http://localhost:9153/metrics у форматі Prometheus (також відомий як OpenMetrics).
forward: Будь-які запити, які не належать до домену Kubernetes кластера, будуть переслані на попередньо визначені резолвери (/etc/resolv.conf).
loop: Виявлення простих переспрямовуваннь та припинення процесу CoreDNS у випадку виявлення циклу.
reload: Дозволяє автоматичне перезавантаження зміненого Corefile. Після редагування конфігурації ConfigMap дайте дві хвилини для того, щоб ваші зміни набули чинності.
loadbalance: Це round-robin DNS-балансувальник, який випадковим чином змінює порядок записів A, AAAA та MX в відповіді.
Ви можете змінити типову поведінку CoreDNS, змінивши ConfigMap.
Конфігурація Stub-домену та віддаленого сервера імен за допомогою CoreDNS
CoreDNS має можливість налаштувати stub-домени та віддалені сервери імен за допомогою втулку forward.
Приклад
Якщо оператор кластера має сервер домену Consul за адресою "10.150.0.1", і всі імена Consul мають суфікс ".consul.local". Для його налаштування в CoreDNS адміністратор кластера створює наступний запис в ConfigMap CoreDNS.
Щоб явно пересилати всі не-кластерні DNS-пошуки через конкретний сервер імен за адресою 172.16.0.1, вказуйте forward на сервер імен замість /etc/resolv.conf.
forward . 172.16.0.1
Кінцевий ConfigMap разом з типовою конфігурацією Corefile виглядає так:
CoreDNS не підтримує FQDN для піддоменів та серверів імен (наприклад: "ns.foo.com"). Під час обробки всі імена серверів імен FQDN будуть виключені з конфігурації CoreDNS.
Ця сторінка надає вказівки щодо діагностування проблем DNS.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У цьому прикладі створюється Pod у просторі імен default. Розпізнавання DNS-імені для сервісів залежить від простору імен Podʼа. Для отримання додаткової інформації перегляньте DNS для Service and Pod.
Перевірте, що шлях пошуку та імʼя сервера налаштовані так, як показано нижче (зверніть увагу, що шлях пошуку може відрізнятися для різних постачальників хмарних послуг):
Використайте команду kubectl get pods, щоб перевірити, що Pod DNS працює.
kubectl get pods --namespace=kube-system -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
...
coredns-7b96bf9f76-5hsxb 1/1 Running 0 1h
coredns-7b96bf9f76-mvmmt 1/1 Running 0 1h
...
Примітка:
Значення для мітки k8s-app — kube-dns для розгортання як CoreDNS, так і kube-dns.
Якщо ви бачите, що жоден Pod CoreDNS не працює або що Pod несправний/завершено, надбудова DNS може не бути типово розгорнута у вашому поточному середовищі та вам доведеться розгорнути його вручну.
Перевірка помилок у Podʼі DNS
Використайте команду kubectl logs, щоб переглянути логи контейнерів DNS.
Перегляньте, чи є будь-які підозрілі або несподівані повідомлення у логах.
Чи працює служба DNS?
Перевірте, чи працює служба DNS за допомогою команди kubectl get service.
kubectl get svc --namespace=kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP 1h
...
Примітка:
Назва служби — kube-dns як для розгортання CoreDNS, так і для kube-dns.
Якщо ви створили Service або у випадку, якщо вона повинна типово створюватися, але вона не зʼявляється, див. налагодження Service для отримання додаткової інформації.
Чи відкриті точки доступу DNS?
Ви можете перевірити, чи викриті точки доступу DNS, використовуючи команду kubectl get endpointslice.
kubectl get endpointslice -l k8s.io/service-name=kube-dns --namespace=kube-system
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
kube-dns-zxoja IPv4 53 10.180.3.17,10.180.3.17 1h
Якщо ви не бачите точки доступу, дивіться розділ про точки доступу у документації налагодження Service.
Чи надходять/обробляються DNS-запити?
Ви можете перевірити, чи надходять запити до CoreDNS, додавши втулок log до конфігурації CoreDNS (тобто файлу Corefile). Файл CoreDNS Corefile зберігається у ConfigMap з назвою coredns. Щоб редагувати його, використовуйте команду:
kubectl -n kube-system edit configmap coredns
Потім додайте log у розділ Corefile, як показано у прикладі нижче:
Після збереження змін може знадобитися до хвилини або двох, щоб Kubernetes поширив ці зміни на Podʼи CoreDNS.
Далі зробіть кілька запитів і перегляньте логи, як показано у попередніх розділах цього документа. Якщо Podʼи CoreDNS отримують запити, ви повинні побачити їх в логах.
Деякі дистрибутиви Linux (наприклад, Ubuntu) стандартно використовують локальний резолвер DNS (systemd-resolved). Systemd-resolved переміщує та замінює /etc/resolv.conf на файл-заглушку, що може спричинити фатальний цикл переспрямовування при розпізнаванні імен на вихідних серверах. Це можна виправити вручну, використовуючи прапорець --resolv-conf kubelet, щоб вказати правильний resolv.conf (з systemd-resolved це /run/systemd/resolve/resolv.conf). kubeadm автоматично визначає systemd-resolved та налаштовує відповідні прапорці kubelet.
Установки Kubernetes не налаштовують файли resolv.conf вузлів для використання кластерного DNS стандартно, оскільки цей процес властивий для певного дистрибутиву. Це, можливо, має бути реалізовано надалі.
У Linux бібліотека libc (відома як glibc) має обмеження для записів nameserver DNS на 3 стандартно, і Kubernetes потрібно використовувати 1 запис nameserver. Це означає, що якщо локальна установка вже використовує 3 nameserver, деякі з цих записів будуть втрачені. Щоб обійти це обмеження, вузол може запускати dnsmasq, який надасть більше записів nameserver. Ви також можете використовувати прапорець --resolv-conf kubelet.
Якщо ви використовуєте Alpine версії 3.17 або раніше як базовий образ, DNS може працювати неправильно через проблему з дизайном Alpine. До версії musl 1.24 не включено резервне перемикання на TCP для stub-резолвера DNS, що означає, що будь-який виклик DNS понад 512 байтів завершиться невдачею. Будь ласка, оновіть свої образи до версії Alpine 3.18 або вище.
Цей документ допоможе вам розпочати використання API мережевої політики Kubernetes NetworkPolicy API, щоб оголосити політики мережі, які керують тим, як Podʼи спілкуються один з одним.
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.8.
Для перевірки версії введіть kubectl version.
Переконайтеся, що ви налаштували постачальника мережі з підтримкою політики мережі. Існує кілька постачальників мережі, які підтримують NetworkPolicy, включаючи:
Створення nginx deployment та надання доступу через Service
Щоб переглянути, як працює політика мережі Kubernetes, почніть зі створення Deployment nginx.
kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
Експонуйте Deployment через Service під назвою nginx.
kubectl expose deployment nginx --port=80
service/nginx exposed
Вищезазначені команди створюють Deployment з Podʼом nginx і експонують Deployment через Service під назвою nginx. Pod nginx та Deployment знаходяться в просторі імен default.
kubectl get svc,pod
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes 10.100.0.1 <none> 443/TCP 46m
service/nginx 10.100.0.16 <none> 80/TCP 33s
NAME READY STATUS RESTARTS AGE
pod/nginx-701339712-e0qfq 1/1 Running 0 35s
Перевірте роботу Service, звернувшись до неї з іншого Podʼа
Ви повинні мати можливість звернутися до нового Service nginx з інших Podʼів. Щоб отримати доступ до Service nginx з іншого Podʼа в просторі імен default, запустіть контейнер busybox:
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
У вашій оболонці запустіть наступну команду:
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
Обмеження доступу до Service nginx
Щоб обмежити доступ до Service nginx так, щоб запити до неї могли робити лише Podʼи з міткою access: true, створіть обʼєкт NetworkPolicy наступним чином:
Назва обʼєкта NetworkPolicy повинна бути дійсним піддоменом DNS.
Примітка:
NetworkPolicy включає podSelector, який вибирає групу Podʼів, до яких застосовується політика. Ви можете побачити, що ця політика вибирає Podʼи з міткою app=nginx. Мітка автоматично додавалася до Podʼа в Deployment nginx. Порожній podSelector вибирає всі Podʼи в просторі імен.
Назначте політику для Service
Використовуйте kubectl для створення NetworkPolicy з файлу nginx-policy.yaml вище:
networkpolicy.networking.k8s.io/access-nginx created
Перевірте доступ до Service, коли мітка доступу не визначена
Коли ви намагаєтеся отримати доступ до Service nginx з Podʼа без відповідних міток, запит завершується тайм-аутом:
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
У вашій оболонці виконайте команду:
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
wget: download timed out
Визначте мітку доступу і перевірте знову
Ви можете створити Pod із відповідними мітками, щоб переконатися, що запит дозволено:
kubectl run busybox --rm -ti --labels="access=true" --image=busybox -- /bin/sh
У вашій оболонці запустіть команду:
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
2.23 - Розробка Cloud Controller Manager
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.11 [beta]
Cloud Controller Manager (cloud-controller-manager) є компонент панелі управління Kubernetes, що інтегрує управління логікою певної хмари. Cloud controller manager дозволяє звʼязувати ваш кластер з API хмарного провайдера та відокремлює компоненти, що взаємодіють з хмарною платформою від компонентів, які взаємодіють тільки в кластері.
Відокремлюючи логіку сумісності між Kubernetes і базовою хмарною інфраструктурою, компонент cloud-controller-manager дає змогу хмарним провайдерам випускати функції з іншою швидкістю порівняно з основним проєктом Kubernetes.
Контекст
Оскільки постачальники хмар розвиваються та випускаються іншим темпом порівняно з проєктом Kubernetes, абстрагування специфічного для постачальників коду в окремий бінарний файл cloud-controller-manager дозволяє хмарним постачальникам еволюціонувати незалежно від основного коду Kubernetes.
Проєкт Kubernetes надає кістяк коду cloud-controller-manager з інтерфейсами Go, щоб дозволити вам (або вашому постачальнику хмар) додати свої власні реалізації. Це означає, що постачальник хмар може реалізувати cloud-controller-manager, імпортуючи пакунки з ядра Kubernetes; кожен постачальник хмар буде реєструвати свій власний код, викликаючи cloudprovider.RegisterCloudProvider, щоб оновити глобальну змінну доступних постачальників хмар.
Розробка
Зовнішня реалізація
Для створення зовнішнього cloud-controller-manager для вашої хмари:
Використовуйте main.go у cloud-controller-managerр з ядра Kubernetes як шаблон для свого main.go. Як зазначено вище, єдина відмінність полягатиме у пакунку хмари, який буде імпортуватися.
Багато постачальників хмар публікують свій код контролера як відкритий код. Якщо ви створюєте новий cloud-controller-manager з нуля, ви можете взяти наявний зовнішній cloud-controller-manager як вашу вихідну точку.
У коді Kubernetes
Для внутрішніх постачальників хмар ви можете запустити cloud-controller-managerу, що працює у внутрішньому коді, як DaemonSet у вашому кластері. Див. Адміністрування Cloud Controller Manager для отримання додаткової інформації.
2.24 - Увімкнення або вимкнення API Kubernetes
На цій сторінці показано, як увімкнути або вимкнути версію API зі вузла панелі управління вашого кластера.
Конкретні версії API можна увімкнути або вимкнути, передаючи --runtime-config=api/<version> як аргумент командного рядка до сервера API. Значення для цього аргументу є розділеним комами списком версій API. Пізніші значення перекривають попередні.
Аргумент командного рядка runtime-config також підтримує 2 спеціальні ключі:
api/all, що представляє всі відомі API.
api/legacy, що представляє лише застарілі API. Застарілі API — це будь-які API, які були явно визнані застарілими.
Наприклад, щоб вимкнути всі версії API, крім v1, передайте --runtime-config=api/all=false,api/v1=true до kube-apiserver.
Усі API в Kubernetes, які дозволяють записувати постійні дані ресурсів API, підтримують шифрування у спокої. Наприклад, ви можете увімкнути шифрування у спокої для Secret. Це шифрування у спокої є додатковим до будь-якого шифрування на рівні системи для кластера etcd або для файлових систем на вузлах, де ви запускаєте kube-apiserver.
На цій сторінці показано, як увімкнути та налаштувати шифрування даних API у спокої.
Примітка:
Це завдання охоплює шифрування даних ресурсів, збережених за допомогою Kubernetes API. Наприклад, ви можете шифрувати обʼєкти Secret, включаючи дані у формі ключ-значення.
Якщо ви хочете зашифрувати дані в файлових системах, які підключаються до контейнерів, вам замість цього потрібно або:
використовуйте інтеграцію зберігання, яка забезпечує шифровані томи
шифрувати дані всередині вашого власного застосунку
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Це завдання передбачає, що ви запускаєте сервер API Kubernetes як статичний Pod на кожному вузлі панелі управління.
Панель управління кластера обовʼязково має використовувати etcd версії 3.x (головна версія 3, будь-яка мінорна версія).
Для шифрування власного ресурсу ваш кластер повинен працювати на Kubernetes v1.26 або новіше.
Щоб використовувати символ підстановки для відповідності ресурсів, ваш кластер повинен працювати на Kubernetes v1.27 або новіше.
Для перевірки версії введіть kubectl version.
Визначте, чи вже увімкнено шифрування у спокої
Стандартно, сервер API зберігає текстові представлення ресурсів у etcd без шифрування у спокої.
Процес kube-apiserver приймає аргумент --encryption-provider-config, який вказує шлях до конфігураційного файлу. Зміст цього файлу, якщо ви його вказали, контролює спосіб шифрування даних API Kubernetes у etcd. Якщо ви запускаєте kube-apiserver без аргументу командного рядка --encryption-provider-config, то у вас немає увімкненого шифрування у спокої. Якщо ви запускаєте kube-apiserver з аргументом командного рядка --encryption-provider-config, і файл, на який він посилається, вказує на постачальника шифрування identity як першого постачальника шифрування у списку, то у вас немає увімкненого шифрування у спокої (типовий постачальник identity не надає захисту конфіденційності.)
Якщо ви запускаєте kube-apiserver з аргументом командного рядка --encryption-provider-config, і файл, на який він посилається, вказує на іншого постачальника, а не identity, як першого постачальника шифрування у списку, то ви вже маєте увімкнене шифрування у спокої. Однак ця перевірка не показує, чи вдалася попередня міграція до зашифрованого сховища. Якщо ви не впевнені, переконайтеся, що всі відповідні дані зашифровані.
Розуміння конфігурації шифрування у спокої
---## УВАГА: це приклад конфігурації.# Не використовуйте його для вашого кластера!#apiVersion:apiserver.config.k8s.io/v1kind:EncryptionConfigurationresources:- resources:- secrets- configmaps- pandas.awesome.bears.example# a custom resource APIproviders:# Ця конфігурація не забезпечує конфіденційність даних. Перший# налаштований постачальник вказує механізм "identity", який# зберігає ресурси як простий текст.#- identity:{}# простий текст, іншими словами, шифрування НЕМАЄ- aesgcm:keys:- name:key1secret:c2VjcmV0IGlzIHNlY3VyZQ==- name:key2secret:dGhpcyBpcyBwYXNzd29yZA==- aescbc:keys:- name:key1secret:c2VjcmV0IGlzIHNlY3VyZQ==- name:key2secret:dGhpcyBpcyBwYXNzd29yZA==- secretbox:keys:- name:key1secret:YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4eXoxMjM0NTY=- resources:- eventsproviders:- identity:{}# не шифрувати Events навіть якщо *.* вказаний нижче- resources:- '*.apps'# використання символу підстановки потребує Kubernetes 1.27 або пізнішеproviders:- aescbc:keys:- name:key2secret:c2VjcmV0IGlzIHNlY3VyZSwgb3IgaXMgaXQ/Cg==- resources:- '*.*'# використання символу підстановки потребує Kubernetes 1.27 або пізнішеproviders:- aescbc:keys:- name:key3secret:c2VjcmV0IGlzIHNlY3VyZSwgSSB0aGluaw==
Кожен елемент масиву resources — це окрема конфігурація і містить повну конфігурацію. Поле resources.resources — це масив імен ресурсів Kubernetes (resource або resource.group), які мають бути зашифровані, наприклад, Secrets, ConfigMaps або інші ресурси.
Якщо ви додаєте власні ресурси до EncryptionConfiguration, і версія кластера — 1.26 або новіша, то будь-які нові створені власні ресурси, зазначені в EncryptionConfiguration, будуть зашифровані. Будь-які власні ресурси, які існували в etcd до цієї версії та конфігурації, залишаться незашифрованими до тих пір, поки вони наступного разу не будуть записані у сховище. Така ж поведінка застосовується й до вбудованих ресурсів. Дивіться розділ Переконайтеся, що всі секрети зашифровані.
Масив providers — це упорядкований список можливих постачальників шифрування, які можна використовувати для перелічених вами API. Кожен постачальник підтримує кілька ключів — ключі перевіряються по черзі для розшифрування, і якщо постачальник є першим, перший ключ використовується для шифрування.
Для кожного елементу може бути вказано лише один тип постачальника (identity або aescbc може бути наданий, але не обидва в одному елементі). Перший постачальник у списку використовується для шифрування ресурсів, записаних у сховище. При читанні ресурсів зі сховища кожен постачальник, який відповідає збереженим даним, намагається по черзі розшифрувати дані. Якщо жоден постачальник не може прочитати збережені дані через несумісність формату або секретного ключа, повертається помилка, яка перешкоджає клієнтам отримати доступ до цього ресурсу.
EncryptionConfiguration підтримує використання символів підстановки для вказівки ресурсів, які мають бути зашифровані. Використовуйте '*.<group>', щоб зашифрувати всі ресурси у групі (наприклад, '*.apps' у вищезазначеному прикладі) або '*.*' для шифрування всіх ресурсів. '*.' може бути використаний для шифрування всіх ресурсів у групі ядра. '*.*' зашифрує всі ресурси, навіть власні ресурси, які додаються після запуску сервера API.
Примітка:
Використання символів підстановки, які перекриваються в тому ж списку ресурсів або між кількома елементами, не дозволяється, оскільки частина конфігурації буде неефективною. Порядок обробки та пріоритет списку resources визначаються порядком його вказання в конфігурації.
Якщо у вас є символ підстановки, який охоплює ресурси, і ви хочете відмовитися від шифрування у спокої певного типу ресурсу, ви можете досягати цього, додавши окремий елемент масиву resources з іменем ресурсу, який ви хочете виключити, за яким слідує елемент масиву providers, де ви вказуєте постачальника identity. Ви додаєте цей елемент до списку так, щоб він зʼявився раніше, ніж конфігурація, де ви вказуєте шифрування (постачальник, який не є identity).
Наприклад, якщо ввімкнено '*.*', і ви хочете відмовитися від шифрування для Events та ConfigMaps, додайте новий раніший елемент до resources, за яким слідує елемент масиву постачальників з identity як постачальник. Більш конкретний запис повинен зʼявитися перед записом з символом підстановки.
Новий елемент буде схожий на:
...- resources:- configmaps.# спеціально з ядра API групи,# через крапку в кінці- eventsproviders:- identity:{}# а потім інші записи в resources
Переконайтеся, що виключення перераховане до позначки символу підстановки '*.*' в масиві ресурсів, щоб надати йому пріоритет.
Для отримання більш детальної інформації про структуру EncryptionConfiguration, зверніться до API конфігурації шифрування.
Увага:
Якщо будь-який ресурс не може бути прочитаний через конфігурацію шифрування (через зміну ключів) та ви не можете відновити робочу конфігурацію, єдиним виходом буде видалити цей ключ безпосередньо з підтримуваного etcd.
Будь-які виклики до API Kubernetes, які намагаються прочитати цей ресурс, завершаться невдачею, поки він не буде видалений або надано дійсний ключ для розшифрування.
Доступні постачальники
Перш ніж налаштувати шифрування у спокої для даних у Kubernetes API вашого кластера, вам потрібно вибрати, які постачальники ви будете використовувати.
Наступна таблиця описує кожного доступного постачальника.
Постачальники для шифрування у спокої Kubernetes
Назва
Шифрування
Стійкість
Швидкість
Довжина ключа
identity
Відсутнє
Н/Д
Н/Д
Н/Д
Ресурси зберігаються як є без шифрування. Коли встановлено як перший постачальник, ресурс буде розшифрований при записі нових значень. Існуючі зашифровані ресурси автоматично не перезаписуються даними у відкритому тексті. Постачальник `identity` є типовим, якщо ви не вказали інше.
Не рекомендується через вразливість CBC до атаки padding oracle attacks. Вміст ключа доступний з хоста панелі управління.
aesgcm
AES-GCM з випадковим нонсом
Потрібно оновлювати через кожні 200,000 записів
Найшвидший
16, 24 або 32 байти
Не рекомендується для використання, крім як у випадку, коли реалізована автоматизована схема оновлення ключів. Вміст ключа доступний з хоста панелі управління.
kms v1 (застарілий з Kubernetes v1.28)
Використовує схему шифрування конвертів із DEK для кожного ресурсу.
Найміцніший
Повільний (порівняно з kms версією 2)
32 байти
Дані шифруються за допомогою ключів шифрування даних (DEK) з використанням AES-GCM;
DEK шифруються ключами шифрування ключів (KEKs) згідно з
конфігурацією в Службі управління ключами (KMS).
Просте оновлення ключа, з новим DEK, що генерується для кожного шифрування, та
оновлення KEK, контрольоване користувачем. Прочитайте, як налаштувати постачальника KMS V1.
kms v2
Використовує схему шифрування конвертів із DEK для кожного сервера API.
Найміцніший
Швидкий
32 байти
Дані шифруються за допомогою ключів шифрування даних (DEKs) з використанням AES-GCM; DEKs
шифруються ключами шифрування ключів (KEKs) згідно з конфігурацією
в Службі управління ключами (KMS).
Kubernetes генерує новий DEK для кожного шифрування з секретного насіння.
Насіння змінюється кожного разу, коли змінюється KEK. Добрий вибір, якщо використовується сторонній інструмент для управління ключами.
Доступний як стабільний з Kubernetes v1.29. Прочитайте, як налаштувати постачальника KMS V2.
secretbox
XSalsa20 і Poly1305
Найміцніший
Швидший
32 байти
Використовує відносно нові технології шифрування, які можуть не бути прийнятними в середовищах, які вимагають високого рівня перегляду. Вміст ключа доступний з хоста панелі управління.
Постачальник identity є типовим, якщо ви не вказали інше. Постачальник identity не шифрує збережені дані та не надає жодного додаткового захисту конфіденційності.
Зберігання ключів
Локальне зберігання ключів
Шифрування конфіденційних даних за допомогою локально керованих ключів захищає від компрометації etcd, але не забезпечує захисту від компрометації хосту. Оскільки ключі шифрування зберігаються на хості у файлі EncryptionConfiguration YAML, кваліфікований зловмисник може отримати доступ до цього файлу і витягнути ключі шифрування.
Зберігання ключів сервісом KMS
Постачальник KMS використовує шифрування конвертів: Kubernetes шифрує ресурси за допомогою ключа даних, а потім шифрує цей ключ даних за допомогою служби керування шифруванням. Kubernetes генерує унікальний ключ даних для кожного ресурсу. API-сервер зберігає зашифровану версію ключа даних в etcd поряд із шифротекстом; при читанні ресурсу API-сервер викликає служби керування шифруванням і надає як шифротекст, так і (зашифрований) ключ даних. У межах служби керування шифруванням, постачальник використовує ключ шифрування ключа, щоб розшифрувати ключ даних, розшифровує ключ даних і, нарешті, відновлює звичайний текст. Комунікація між панеллю управління та KMS вимагає захисту під час передачі, такого як TLS.
Використання шифрування конвертів створює залежність від ключа шифрування ключа, який не зберігається в Kubernetes. У випадку KMS зловмиснику, який намагається отримати несанкціонований доступ до значень у відкритому тексті, необхідно скомпрометувати etcd та стороннього постачальника KMS.
Захист для ключів шифрування
Вам слід прийняти належні заходи для захисту конфіденційної інформації, що дозволяє розшифрування, чи то це локальний ключ шифрування, чи то токен автентифікації, який дозволяє API-серверу викликати KMS.
Навіть коли ви покладаєтесь на постачальника для керування використанням та життєвим циклом основного ключа шифрування (або ключів), ви все одно відповідаєте за те, щоб контроль доступу та інші заходи безпеки для служби керування шифруванням були відповідними для ваших потреб у безпеці.
Зашифруйте ваші дані
Згенеруйте ключ шифрування
Наступні кроки передбачають, що ви не використовуєте KMS, тому кроки також передбачають, що вам потрібно згенерувати ключ шифрування. Якщо у вас вже є ключ шифрування, перейдіть до Написання файлу конфігурації шифрування.
Увага:
Зберігання сирого ключа шифрування у конфігурації шифрування забезпечує помірний рівень безпеки, порівняно з відсутністю шифрування.
Для додаткової секретності розгляньте використання постачальника kms, оскільки це ґрунтується на ключах, що зберігаються поза вашим кластером Kubernetes. Реалізації kms можуть працювати з модулями апаратного забезпечення для збереження ключів або з службами шифрування, які керуються вашим постачальником хмарних послуг.
Щоб дізнатися, як налаштувати шифрування в стані спокою з використанням KMS, див. Використання постачальника KMS для шифрування даних. Втулок постачальника KMS, який ви використовуєте, також може постачатися з додатковою конкретною документацією.
Розпочніть з генерації нового ключа шифрування, а потім закодуйте його за допомогою base64:
Згенеруйте випадковий ключ з 32 байтів і закодуйте його у форматі base64. Ви можете використовувати цю команду:
head -c 32 /dev/urandom | base64
Ви можете використовувати /dev/hwrng замість /dev/urandom, якщо ви хочете використовувати вбудований апаратний генератор ентропії вашого ПК. Не всі пристрої з Linux надають апаратний генератор випадкових чисел.
Згенеруйте випадковий ключ з 32 байтів і закодуйте його у форматі base64. Ви можете використовувати цю команду:
head -c 32 /dev/urandom | base64
Згенеруйте випадковий ключ з 32 байтів і закодуйте його у форматі base64. Ви можете використовувати цю команду:
# Не запускайте це в сесії, де ви встановили насіння генератора випадкових чисел.[Convert]::ToBase64String((1..32|%{[byte](Get-Random -Max 256)}))
Примітка:
Зберігайте ключ шифрування конфіденційно, включаючи його час генерації та, якщо можливо, після того, як ви більше активно його не використовуєте.
Реплікація ключа шифрування
Використовуючи безпечний механізм передачі файлів, зробіть копію цього ключа шифрування доступною кожному іншому вузлу керування.
Як мінімум використовуйте шифрування під час передачі даних — наприклад, захищену оболонку (SSH). Для більшої безпеки використовуйте асиметричне шифрування між вузлами або змініть підхід, який ви використовуєте, щоб ви покладалися на шифрування KMS.
Створіть файл конфігурації шифрування
Увага:
Файл конфігурації шифрування може містити ключі, які можуть розшифрувати вміст в etcd. Якщо файл конфігурації містить будь-який вміст ключа, вам слід належним чином обмежити дозволи на всіх ваших вузлах керування так, щоб лише користувач, який запускає kube-apiserver, міг читати цю конфігурацію.
Створіть новий файл конфігурації шифрування. Зміст повинен бути подібним до:
---apiVersion:apiserver.config.k8s.io/v1kind:EncryptionConfigurationresources:- resources:- secrets- configmaps- pandas.awesome.bears.exampleproviders:- aescbc:keys:- name:key1# Див. наступний текст для отримання додаткової інформації про секретне значенняsecret:<BASE 64 ENCODED SECRET>- identity:{}# цей резервний варіант дозволяє читати незашифровані секрети;# наприклад, під час початкової міграції
Вам потрібно буде приєднати новий файл конфігурації шифрування до статичного Podʼа kube-apiserver. Ось приклад того, як це зробити:
Збережіть новий файл конфігурації шифрування у /etc/kubernetes/enc/enc.yaml на вузлі панелі управління.
Відредагуйте маніфест для статичного Podʼа kube-apiserver: /etc/kubernetes/manifests/kube-apiserver.yaml, щоб він був подібний до:
---## Це фрагмент маніфеста для статичного Podʼа.# Перевірте, чи це правильно для вашого кластера та для вашого API-сервера.#apiVersion:v1kind:Podmetadata:annotations:kubeadm.kubernetes.io/kube-apiserver.advertise-address.endpoint:10.20.30.40:443creationTimestamp:nulllabels:app.kubernetes.io/component:kube-apiservertier:control-planename:kube-apiservernamespace:kube-systemspec:containers:- command:- kube-apiserver...- --encryption-provider-config=/etc/kubernetes/enc/enc.yaml # додайте цей рядокvolumeMounts:...- name:enc # додайте цей рядокmountPath:/etc/kubernetes/enc # додайте цей рядокreadOnly:true# додайте цей рядок...volumes:...- name:enc # додайте цей рядокhostPath:# додайте цей рядокpath:/etc/kubernetes/enc # додайте цей рядокtype:DirectoryOrCreate # додайте цей рядок...
Перезапустіть свій API-сервер.
Увага:
Ваш файл конфігурації містить ключі, які можуть розшифрувати вміст в etcd, тому вам слід належним чином обмежити дозволи на вузлах керування так, щоб лише користувач, який запускає kube-apiserver, міг читати його.
Тепер у вас є шифрування для одного вузла панелі управління. У типовому кластері Kubernetes є кілька вузлів керування, тому зробіть це на інших вузлах.
Переконфігуруйте інші вузли керування
Якщо у вашому кластері є кілька API-серверів, вам слід розгорнути зміни по черзі на кожному API-сервері.
Увага:
Для конфігурацій кластеру з двома або більше вузлами панелі управління, конфігурація шифруванняповинна бути ідентичною на кожному вузлі панелі управління.
Якщо існує різниця в конфігурації постачальника шифрування між вузлами панелі управління, ця різниця може означати, що kube-apiserver не може розшифрувати дані.
Коли ви плануєте оновлення конфігурації шифрування вашого кластера, сплануйте це так, щоб API-сервери у вашій панелі управління завжди могли розшифрувати збережені дані (навіть під час часткового впровадження змін).
Переконайтеся, що ви використовуєте однакову конфігурацію шифрування на кожному вузлі керування.
Перевірте, що нові дані записані зашифровано
Дані зашифровуються під час запису в etcd. Після перезапуску вашого kube-apiserver будь-який новий створений або оновлений Secret (або інші види ресурсів, налаштовані в EncryptionConfiguration), повинні бути зашифровані при зберіганні.
Щоб перевірити це, ви можете використовувати інтерфейс командного рядка etcdctl, щоб отримати вміст вашого секретного ключа.
Цей приклад показує, як це перевірити для шифрування Secret API.
Створіть новий Secret під назвою secret1 у просторі імен default:
Перевірте, що збережений Secret має префікс k8s:enc:aescbc:v1:, що вказує на те, що провайдер aescbc зашифрував результати. Переконайтеся, що імʼя ключа, вказане в etcd, відповідає імені ключа, вказаному в EncryptionConfiguration вище. У цьому прикладі ви бачите, що ключ шифрування під назвою key1 використовується в etcd і в EncryptionConfiguration.
Перевірте, що Secret правильно розшифровується під час отримання через API:
kubectl get secret secret1 -n default -o yaml
Вивід повинен містити mykey: bXlkYXRh, з вмістом mydata, закодованим за допомогою base64; прочитайте декодування Secret, щоб дізнатися, як повністю декодувати Secret.
Забезпечте шифрування всіх відповідних даних
Часто недостатньо лише переконатися, що нові обʼєкти зашифровані: ви також хочете, щоб шифрування застосовувалося до обʼєктів, які вже збережені.
У цьому прикладі ви налаштували свій кластер таким чином, що Secret зашифровані при записі. Виконання операції заміни для кожного Secret зашифрує цей вміст в спокої, де обʼєкти залишаються незмінними.
Ви можете виконати цю зміну для всіх Secret у вашому кластері:
# Виконайте це в якості адміністратора, який може читати і записувати всі Secretkubectl get secrets --all-namespaces -o json | kubectl replace -f -
Команда вище зчитує всі Secret, а потім оновлює їх з тими самими даними, щоб застосувати шифрування на стороні сервера.
Примітка:
Якщо виникає помилка через конфлікт запису, повторіть команду. Це безпечно виконати цю команду більше одного разу.
Для великих кластерів ви можете бажати розділити Secret за просторами імен або сценарію оновлення.
Запобігання отриманню відкритого тексту
Якщо ви хочете переконатися, що доступ до певного виду API здійснюється тільки за допомогою шифрування, ви можете позбавити API-сервер можливості читати дані, що підтримують це API, у вигляді простого тексту.
Попередження:
Ця зміна заважає API-серверу отримувати ресурси, які позначені як зашифровані в спокої, але насправді зберігаються у відкритому вигляді.
Коли ви налаштували шифрування у спокої для API (наприклад: вид API Secret, який представляє ресурси secrets в основній групі API), вам необхідно переконатися, що всі ці ресурси у цьому кластері дійсно зашифровані у спокої. Перевірте це, перш ніж продовжувати з наступними кроками.
Після того, як всі Secret у вашому кластері зашифровані, ви можете видалити identity частину конфігурації шифрування. Наприклад:
… а потім перезапустіть кожен API-сервер по черзі. Ця зміна запобігає API-серверу отримувати доступ до Secret у відкритому текстовому форматі, навіть випадково.
Ротація ключа розшифрування
Зміна ключа шифрування для Kubernetes без простою вимагає багатокрокової операції, особливо в умовах високодоступного розгортання, де працюють кілька процесів kube-apiserver.
Згенеруйте новий ключ і додайте його як другий запис ключа для поточного провайдера на всіх вузлах панелі управління.
Перезапустіть усі процеси kube-apiserver, щоб кожен сервер міг розшифрувати будь-які дані, які зашифровані новим ключем.
Зробіть безпечне резервне копіювання нового ключа шифрування. Якщо ви втратите всі копії цього ключа, вам доведеться видалити всі ресурси, які були зашифровані загубленим ключем, і робочі навантаження можуть не працювати як очікується протягом часу, коли шифровання у спокої зламане.
Зробіть новий ключ першим записом у масиві keys, щоб він використовувався для шифрування у спокої для нових записів.
Перезапустіть всі процеси kube-apiserver, щоб кожен хост панелі управління тепер шифрував за допомогою нового ключа.
Як привілейований користувач виконайте команду kubectl get secrets --all-namespaces -o json | kubectl replace -f -, щоб зашифрувати всі наявні секрети новим ключем.
Після того, як ви оновили всі наявні секрети, щоб вони використовували новий ключ, і зробили безпечне резервне копіювання нового ключа, видаліть старий ключ розшифрування з конфігурації.
Розшифрування всіх даних
У цьому прикладі показано, як зупинити шифрування API Secret у спокої. Якщо ви шифруєте інші види API, адаптуйте кроки відповідно.
Щоб вимкнути шифрування у спокої, розмістіть провайдера identity як перший запис у вашому файлі конфігурації шифрування:
---apiVersion:apiserver.config.k8s.io/v1kind:EncryptionConfigurationresources:- resources:- secrets# перерахуйте тут будь-які інші ресурси, які ви раніше# шифрували у спокоїproviders:- identity:{}# додайте цей рядок- aescbc:keys:- name:key1secret:<BASE 64 ENCODED SECRET># залиште це на місці# переконайтеся, що воно йде після "identity"
Потім виконайте таку команду, щоб примусити розшифрування всіх Secrets:
Після того, як ви замінили всі наявні зашифровані ресурси резервними даними, які не використовують шифрування, ви можете видалити налаштування шифрування з kube-apiserver.
Налаштування автоматичного перезавантаження
Ви можете налаштувати автоматичне перезавантаження конфігурації провайдера шифрування. Ця настройка визначає, чи має API server завантажувати файл, який ви вказали для --encryption-provider-config тільки один раз при запуску, або автоматично кожного разу, коли ви змінюєте цей файл. Увімкнення цієї опції дозволяє змінювати ключі для шифрування у спокої без перезапуску API server.
Щоб дозволити автоматичне перезавантаження, налаштуйте API server для запуску з параметром: --encryption-provider-config-automatic-reload=true. Коли ввімкнено, зміни файлів перевіряються кожну хвилину для спостереження за модифікаціями. Метрика apiserver_encryption_config_controller_automatic_reload_last_timestamp_seconds визначає час, коли нова конфігурація набирає чинності. Це дозволяє виконувати ротацію ключів шифрування без перезапуску API-сервера.
2.26 - Розшифровування конфіденційних даних, які вже зашифровані у спокої
Усі API в Kubernetes, що дозволяють записувати постійні дані ресурсів, підтримують шифрування у спокої. Наприклад, ви можете увімкнути шифрування у спокої для Secret. Це шифрування у спокої додається до будь-якого шифрування системного рівня для кластера etcd або файлових систем на вузлах, де запущений kube-apiserver.
Ця сторінка показує, як перейти від шифрування даних API у спокої, щоб дані API зберігалися у незашифрованому вигляді. Ви можете зробити це для покращення продуктивності; проте, якщо шифрування було раціональним рішенням для деяких даних, то його також варто залишити.
Примітка:
Це завдання охоплює шифрування даних ресурсів, збережених за допомогою Kubernetes API. Наприклад, ви можете шифрувати обʼєкти Secret, включно з даними ключ-значення, які вони містять.
Якщо вам потрібно керувати шифруванням даних у файлових системах, які монтувалися у контейнери, вам потрібно використовувати або:
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Це завдання передбачає, що Kubernetes API server працює як статичний Pod на кожному вузлі панелі управління.
Панель управління вашого кластера має використовувати etcd v3.x (основна версія 3, будь-яка мінорна версія).
Щоб зашифрувати власний ресурс, ваш кластер повинен працювати на Kubernetes v1.26 або новіше.
У вас повинні бути деякі дані API, які вже зашифровані.
Для перевірки версії введіть kubectl version.
Визначте, чи вже увімкнене шифрування у спокої
Стандартно API server використовує провайдера identity, який зберігає представлення ресурсів у текстовому вигляді. Стандартний провайдер identity не надає жодного захисту конфіденційності.
Процес kube-apiserver приймає аргумент --encryption-provider-config, який вказує шлях до файлу конфігурації. Вміст цього файлу, якщо ви вказали його, керує тим, як дані API Kubernetes шифруються в etcd. Якщо він не вказаний, у вас не увімкнене шифрування у спокої.
Якщо встановлено --encryption-provider-config, перевірте, які ресурси (наприклад, secrets) налаштовані для шифрування, і який провайдер використовується. Переконайтеся, що вподобаний провайдер для цього типу ресурсу не є identity; ви встановлюєте лише identity (без шифрування) як типовий, коли хочете вимкнути шифрування у спокої. Перевірте, чи перший провайдер, зазначений для ресурсу, щось інше, ніж identity, що означає, що будь-яка нова інформація, записана до ресурсів цього типу, буде зашифрована, як налаштовано. Якщо ви бачите, що identity — перший провайдер для якого-небудь ресурсу, це означає, що ці ресурси записуються в etcd без шифрування.
Розшифруйте всі дані
Цей приклад показує, як зупинити шифрування API Secret у спокої. Якщо ви шифруєте інші види API, адаптуйте кроки відповідно.
Визначте файл конфігурації шифрування
Спочатку знайдіть файли конфігурації API server. На кожному вузлі панелі управління маніфест статичного Pod для kube-apiserver вказує аргумент командного рядка --encryption-provider-config. Ймовірно, цей файл монтується у статичний Pod за допомогою томуhostPath. Після того, як ви знайдете том, ви можете знайти файл у файловій системі вузла і перевірити його.
Налаштуйте API server для розшифрування обʼєктів
Щоб вимкнути шифрування у спокої, розмістіть провайдера identity як перший запис у вашому файлі конфігурації шифрування.
Наприклад, якщо ваш наявний файл EncryptionConfiguration виглядає так:
---apiVersion:apiserver.config.k8s.io/v1kind:EncryptionConfigurationresources:- resources:- secretsproviders:- aescbc:keys:# Не використовуйте цей (недійсний) приклад ключа для шифрування- name:examplesecret:2KfZgdiq2K0g2YrYpyDYs9mF2LPZhQ==
то змініть його на:
---apiVersion:apiserver.config.k8s.io/v1kind:EncryptionConfigurationresources:- resources:- secretsproviders:- identity:{}# додайте цей рядок- aescbc:keys:- name:examplesecret:2KfZgdiq2K0g2YrYpyDYs9mF2LPZhQ==
і перезапустіть kube-apiserver Pod на цьому вузлі.
Переконфігуруйте інші вузли панелі управління
Якщо у вашому кластері є кілька серверів API, ви повинні по черзі впроваджувати зміни на кожен з серверів API.
Переконайтеся, що ви використовуєте однакову конфігурацію шифрування на кожному вузлі панелі управління.
Примусове розшифрування
Потім виконайте таку команду, щоб примусити розшифрування всіх Secrets:
# Якщо ви розшифровуєте інший тип обʼєкта, змініть "secrets" відповідно.kubectl get secrets --all-namespaces -o json | kubectl replace -f -
Після того, як ви замінили всі наявні зашифровані ресурси резервними даними, які не використовують шифрування, ви можете видалити налаштування шифрування з kube-apiserver.
Параметри командного рядка, які потрібно видалити:
--encryption-provider-config
--encryption-provider-config-automatic-reload
Знову перезапустіть kube-apiserver Pod, щоб застосувати нову конфігурацію.
Переконфігуруйте інші вузли панелі управління
Якщо у вашому кластері є кілька серверів API, ви знову повинні по черзі впроваджувати зміни на кожен з серверів API.
Переконайтеся, що ви використовуєте однакову конфігурацію шифрування на кожному вузлі панелі управління.
2.27 - Гарантоване планування для критичних Podʼів надбудов
Основні компоненти Kubernetes, такі як сервер API, планувальник і контролер-менеджер, працюють на вузлі панелі управління. Однак надбудови мають працювати на звичайному вузлі кластера. Деякі з цих надбудов є критичними для повноцінного функціонування кластера, наприклад, metrics-server, DNS та інтерфейс користувача. Кластер може перестати правильно працювати, якщо критичний Pod надбудови буде видалений (або вручну, або як побічний ефект іншої операції, такої як оновлення) і перейде в стан очікування (наприклад, коли кластер високо завантажений і інші очікувані Podʼи заплановані на місце, звільнене видаленим критичним Podʼом надбудови, або кількість доступних ресурсів на вузлі змінилася з якоїсь іншої причини).
Зверніть увагу, що позначення Podʼа як критичного не означає повного запобігання його видаленню; це лише запобігає тому, що Pod стає постійно недоступним. Статичний Pod, позначений як критичний, не може бути видалений. Однак, нестатичні Podʼи, позначені як критичні, завжди будуть переплановані.
Позначення Podʼа як критичного
Щоб позначити Pod як критичний, встановіть для цього Podʼа priorityClassName у system-cluster-critical або system-node-critical. system-node-critical має найвищий доступний пріоритет, вищий навіть, ніж system-cluster-critical.
2.28 - Керівництво користувача агента маскування IP
Ця сторінка показує, як налаштувати та ввімкнути ip-masq-agent.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
ip-masq-agent налаштовує правила iptables для приховування IP-адреси Podʼа за IP-адресою вузла кластера. Це зазвичай робиться, коли трафік надсилається до пунктів призначення за межами діапазону CIDR Podʼів кластера.
Основні терміни
NAT (Network Address Translation):
Це метод переназначення однієї IP-адреси на іншу шляхом модифікації інформації адреси відправника та/або одержувача у заголовку IP. Зазвичай виконується пристроєм, що здійснює маршрутизацію IP.
Маскування (Masquerading):
Форма NAT, яка зазвичай використовується для здійснення трансляції багатьох адрес в одну, де декілька початкових IP-адрес маскуються за однією адресою, яка зазвичай є адресою пристрою, що виконує маршрутизацію. У Kubernetes це IP-адреса вузла.
CIDR (Classless Inter-Domain Routing):
Заснований на маскуванні підмереж змінної довжини, дозволяє вказувати префікси довільної довжини. CIDR ввів новий метод представлення IP-адрес, тепер відомий як нотація CIDR, у якій адреса або маршрутизаційний префікс записується з суфіксом, що вказує кількість бітів префікса, наприклад 192.168.2.0/24.
Локальне посилання:
Локальна адреса посилання — це мережева адреса, яка є дійсною лише для комунікацій у межах сегмента мережі або домену розсилки, до якого підʼєднано хост. Локальні адреси для IPv4 визначені в блоку адрес 169.254.0.0/16 у нотації CIDR.
ip-masq-agent налаштовує правила iptables для обробки маскування IP-адрес вузлів/Podʼів при надсиланні трафіку до пунктів призначення за межами IP вузла кластера та діапазону IP кластера. Це по суті приховує IP-адреси Podʼів за IP-адресою вузла кластера. У деяких середовищах, трафік до "зовнішніх" адрес має походити з відомої адреси машини. Наприклад, у Google Cloud будь-який трафік до Інтернету має виходити з IP VM. Коли використовуються контейнери, як у Google Kubernetes Engine, IP Podʼа не буде мати виходу. Щоб уникнути цього, ми повинні приховати IP Podʼа за IP адресою VM — зазвичай відомою як "маскування". Типово агент налаштований так, що три приватні IP-діапазони, визначені RFC 1918, не вважаються діапазонами маскування CIDR. Ці діапазони — 10.0.0.0/8, 172.16.0.0/12 і 192.168.0.0/16. Агент також типово вважає локальне посилання (169.254.0.0/16) CIDR не-маскуванням. Агент налаштований на перезавантаження своєї конфігурації з розташування /etc/config/ip-masq-agent кожні 60 секунд, що також можна налаштувати.
Файл конфігурації агента повинен бути написаний у синтаксисі YAML або JSON і може містити три необовʼязкові ключі:
nonMasqueradeCIDRs: Список рядків у форматі CIDR, які визначають діапазони без маскування.
masqLinkLocal: Булеве значення (true/false), яке вказує, чи маскувати трафік до локального префіксу 169.254.0.0/16. Типово — false.
resyncInterval: Інтервал часу, через який агент намагається перезавантажити конфігурацію з диска. Наприклад: '30s', де 's' означає секунди, 'ms' — мілісекунди.
Трафік до діапазонів 10.0.0.0/8, 172.16.0.0/12 і 192.168.0.0/16 НЕ буде маскуватися. Будь-який інший трафік (вважається Інтернетом) буде маскуватися. Прикладом локального пункту призначення з Podʼа може бути IP-адреса його вузла, а також адреса іншого вузла або одна з IP-адрес у діапазоні IP кластера. Будь-який інший трафік буде стандартно маскуватися. Нижче наведено стандартний набір правил, які застосовує агент ip-masq:
iptables -t nat -L IP-MASQ-AGENT
target prot opt source destination
RETURN all -- anywhere 169.254.0.0/16 /* ip-masq-agent: клієнтський трафік в межах кластера не повинен піддаватися маскуванню */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 10.0.0.0/8 /* ip-masq-agent: клієнтський трафік в межах кластера не повинен піддаватися маскуванню */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 172.16.0.0/12 /* ip-masq-agent: клієнтський трафік в межах кластера не повинен піддаватися маскуванню */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 192.168.0.0/16 /* ip-masq-agent: клієнтський трафік в межах кластера не повинен піддаватися маскуванню */ ADDRTYPE match dst-type !LOCAL
MASQUERADE all -- anywhere anywhere /* ip-masq-agent: вихідний трафік повинен піддаватися маскуванню (ця відповідність повинна бути після відповідності клієнтським CIDR у межах кластера) */ ADDRTYPE match dst-type !LOCAL
Стандартно, в середовищі GCE/Google Kubernetes Engine, якщо ввімкнуто мережеву політику або ви використовуєте CIDR кластера не в діапазоні 10.0.0.0/8, агент ip-masq-agent буде запущений у вашому кластері. Якщо ви працюєте в іншому середовищі, ви можете додати DaemonSetip-masq-agent до свого кластера.
Створення агента маскування IP
Щоб створити агента маскування IP, виконайте наступну команду kubectl:
Додаткову інформацію можна знайти в документації агента маскування IP тут.
У більшості випадків стандартний набір правил має бути достатнім; однак, якщо це не так для вашого кластера, ви можете створити та застосувати ConfigMap, щоб налаштувати діапазони IP-адрес, що залучаються. Наприклад, щоб дозволити розгляд тільки діапазону 10.0.0.0/8 ip-masq-agent, ви можете створити наступний ConfigMap у файлі з назвою "config".
Примітка:
Важливо, що файл називається config, оскільки стандартно це буде використано як ключ для пошуку агентом ip-masq-agent:
nonMasqueradeCIDRs:- 10.0.0.0/8resyncInterval:60s
Виконайте наступну команду, щоб додати configmap до вашого кластера:
Це оновить файл, розташований у /etc/config/ip-masq-agent, який періодично перевіряється кожен resyncInterval та застосовується до вузла кластера. Після закінчення інтервалу синхронізації ви повинні побачити, що правила iptables відображають ваші зміни:
iptables -t nat -L IP-MASQ-AGENT
Chain IP-MASQ-AGENT (1 references)
target prot opt source destination
RETURN all -- anywhere 169.254.0.0/16 /* ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 10.0.0.0/8 /* ip-masq-agent: cluster-local
MASQUERADE all -- anywhere anywhere /* ip-masq-agent: outbound traffic should be subject to MASQUERADE (this match must come after cluster-local CIDR matches) */ ADDRTYPE match dst-type !LOCAL
Стандартно, діапазон локальних посилань (169.254.0.0/16) також обробляється агентом ip-masq, який налаштовує відповідні правила iptables. Щоб агент ip-masq ігнорував локальні посилання, ви можете встановити masqLinkLocal як true у ConfigMap.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Адміністратор кластера керує кластером від імені користувачів і хоче контролювати, скільки сховища може використати один простір імен, щоб контролювати витрати.
Адміністратор хоче обмежити:
Кількість заявок на постійні томи в просторі імен
Обсяг сховища, який може бути запитаний кожною заявкою
Загальний обсяг сховища, який може мати простір імен
LimitRange для обмеження запитів на сховище
Додавання LimitRange до простору імен забезпечує встановлення мінімального і максимального розміру запитів на сховище. Сховище запитується через PersistentVolumeClaim. Контролер допуску, який забезпечує дотримання лімітів, відхилить будь-яку PVC, яка перевищує або не досягає встановлених адміністратором значень.
У цьому прикладі, PVC, що запитує 10Gi сховища, буде відхилено, оскільки це перевищує максимум у 2Gi.
Мінімальні запити на сховище використовуються, коли провайдер сховища вимагає певних мінімумів. Наприклад, диски AWS EBS мають мінімальну вимогу у 1Gi.
ResourceQuota для обмеження кількості PVC та загальної місткості сховища
Адміністратори можуть обмежити кількість PVC в просторі імен, а також загальну місткість цих PVC. Нові PVC, які перевищують будь-яке максимальне значення, будуть відхилені.
У цьому прикладі, шоста PVC у просторі імен буде відхилена, оскільки вона перевищує максимальну кількість у 5. Альтернативно, максимальна квота у 5Gi при поєднанні з максимальним лімітом у 2Gi вище, не може мати 3 PVC, де кожна має по 2Gi. Це було б 6Gi, запитані для простору імен з лімітом у 5Gi.
Limit range може встановити максимальний поріг для запитів на сховище, тоді як квота на ресурси може ефективно обмежити обсяг сховища, використовуваного простором імен через кількість заявок та загальну місткість. Це дозволяє адміністратору кластера планувати бюджет на сховище кластера без ризику перевитрати будь-якого проєкту.
2.30 - Міграція реплікованої панелі управління на використання менеджера керування хмарою
Менеджер керування хмарою — компонент панелі управління Kubernetes, що інтегрує управління логікою певної хмари. Cloud controller manager дозволяє звʼязувати ваш кластер з API хмарного провайдера та відокремлює компоненти, що взаємодіють з хмарною платформою від компонентів, які взаємодіють тільки в кластері.
Відокремлюючи логіку сумісності між Kubernetes і базовою хмарною інфраструктурою, компонент cloud-controller-manager дає змогу хмарним провайдерам випускати функції з іншою швидкістю порівняно з основним проєктом Kubernetes.
Контекст
У рамках зусиль щодо виокремлення хмарного провайдера, всі контролери, специфічні для хмари, повинні бути виокремлені з kube-controller-manager. Усі поточні кластери, які використовують контролери хмари в kube-controller-manager, повинні перейти на запуск контролерів за допомогою специфічному для хмарного провайдера cloud-controller-manager.
Міграція лідера надає механізм, за допомогою якого високодоступні кластери можуть безпечно мігрувати у "хмароспецифічні" контролери між kube-controller-manager та cloud-controller-manager за допомогою загального замикання ресурсів між двома компонентами під час оновлення реплікованої панелі управління. Для панелі управління з одним вузлом або якщо недоступність менеджерів контролерів може бути терпимим під час оновлення, міграція лідера не потрібна, і цей посібник можна ігнорувати.
Міграція лідера може бути увімкнена, встановленням --enable-leader-migration у kube-controller-manager або cloud-controller-manager. Міграція лідера застосовується лише під час оновлення і може бути безпечно вимкнена або залишена увімкненою після завершення оновлення.
Цей посібник на крок за кроком показує вам процес оновлення вручну панелі управління з kube-controller-manager із вбудованим хмарним провайдером до запуску як kube-controller-manager, так і cloud-controller-manager. Якщо ви використовуєте інструмент для розгортання та управління кластером, будь ласка, зверніться до документації інструменту та хмарного провайдера для конкретних інструкцій щодо міграції.
Перш ніж ви розпочнете
Припускається, що панель управління працює на версії Kubernetes N і планується оновлення до версії N + 1. Хоча можливе мігрування в межах однієї версії, ідеально міграцію слід виконати як частину оновлення, щоб зміни конфігурації можна було узгодити з кожним випуском. Точні версії N та N + 1 залежать від кожного хмарного провайдера. Наприклад, якщо хмарний провайдер створює cloud-controller-manager для роботи з Kubernetes 1.24, то N може бути 1.23, а N + 1 може бути 1.24.
Вузли панелі управління повинні запускати kube-controller-manager з увімкненим вибором лідера, що є стандартною поведінкою. З версії N, вбудований хмарний провайдер має бути налаштований за допомогою прапорця --cloud-provider, а cloud-controller-manager ще не повинен бути розгорнутим.
Зовнішній хмарний провайдер повинен мати cloud-controller-manager зібраний з реалізацією міграції лідера. Якщо хмарний провайдер імпортує k8s.io/cloud-provider та k8s.io/controller-manager версії v0.21.0 або пізніше, міграція лідера буде доступною. Однак для версій до v0.22.0 міграція лідера є альфа-версією та потребує увімкнення ControllerManagerLeaderMigration в cloud-controller-manager.
Цей посібник передбачає, що kubelet кожного вузла панелі управління запускає kube-controller-manager та cloud-controller-manager як статичні контейнери, визначені їх маніфестами. Якщо компоненти працюють в іншому середовищі, будь ласка, відповідно скорегуйте дії.
Щодо авторизації цей посібник передбачає, що кластер використовує RBAC. Якщо інший режим авторизації надає дозволи на компоненти kube-controller-manager та cloud-controller-manager, будь ласка, надайте необхідний доступ таким чином, що відповідає режиму.
Надання доступу до Лізингу Міграції
Стандартні дозволи менеджера керування дозволяють доступ лише до їхнього основного Лізингу. Для того, щоб міграція працювала, потрібен доступ до іншого Лізингу.
Ви можете надати kube-controller-manager повний доступ до API лізингів, змінивши роль system::leader-locking-kube-controller-manager. Цей посібник передбачає, що назва лізингу для міграції — cloud-provider-extraction-migration.
Міграція лідера опціонально використовує файл конфігурації, що представляє стан призначення контролерів до менеджера. На цей момент, з вбудованим хмарним провайдером, kube-controller-manager запускає route, service, та cloud-node-lifecycle. Наведений нижче приклад конфігурації показує призначення.
Міграцію лідера можна увімкнути без конфігурації. Будь ласка, див. Станадартну конфігурацію для отримання деталей.
Альтернативно, оскільки контролери можуть працювати з менеджерами контролера, налаштування component на * для обох сторін робить файл конфігурації збалансованим між обома сторонами міграції.
# версія з підстановкоюkind:LeaderMigrationConfigurationapiVersion:controllermanager.config.k8s.io/v1leaderName:cloud-provider-extraction-migrationresourceLock:leasescontrollerLeaders:- name:routecomponent:*- name:servicecomponent:*- name:cloud-node-lifecyclecomponent:*
На кожному вузлі панелі управління збережіть вміст у /etc/leadermigration.conf, та оновіть маніфест kube-controller-manager, щоб файл був змонтований всередині контейнера за тим самим шляхом. Також, оновіть цей маніфест, щоб додати наступні аргументи:
--enable-leader-migration для увімкнення міграції лідера у менеджері керування
--leader-migration-config=/etc/leadermigration.conf для встановлення файлу конфігурації
Перезапустіть kube-controller-manager на кожному вузлі. Тепер, kube-controller-manager має увімкнену міграцію лідера і готовий до міграції.
Розгортання менеджера керування хмарою
У версії N + 1, бажаний стан призначення контролерів до менеджера може бути представлений новим файлом конфігурації, який показано нижче. Зверніть увагу, що поле component кожного controllerLeaders змінюється з kube-controller-manager на cloud-controller-manager. Альтернативно, використовуйте версію з підстановкою, згадану вище, яка має той самий ефект.
Під час створення вузлів панелі управління версії N + 1, вміст повинен бути розгорнутим в /etc/leadermigration.conf. Маніфест cloud-controller-manager повинен бути оновлений для монтування файлу конфігурації так само як і kube-controller-manager версії N. Також, додайте --enable-leader-migration та --leader-migration-config=/etc/leadermigration.conf до аргументів cloud-controller-manager.
Створіть новий вузол панелі управління версії N + 1 з оновленим маніфестом cloud-controller-manager, та з прапорцем --cloud-provider, встановленим на external для kube-controller-manager. kube-controller-manager версії N + 1 НЕ МУСИТЬ мати увімкненої міграції лідера, оскільки, зовнішній хмарний провайдер вже не запускає мігровані контролери, і, отже, він не бере участі в міграції.
Панель управління тепер містить вузли як версії N, так і N + 1. Вузли версії N запускають лише kube-controller-manager, а вузли версії N + 1 запускають як kube-controller-manager, так і cloud-controller-manager. Мігровані контролери, зазначені у конфігурації, працюють під менеджером управління хмарою версії N або cloud-controller-manager версії N + 1 залежно від того, який менеджер управління утримує лізинг міграції. Жоден контролер ніколи не працюватиме під обома менеджерами управління одночасно.
Поступово створіть новий вузол панелі управління версії N + 1 та вимкніть один вузол версії N до тих пір, поки панель управління не буде містити лише вузли версії N + 1. Якщо потрібно відкотитись з версії N + 1 на версію N, додайте вузли версії N з увімкненою міграцією лідера для kube-controller-manager назад до панелі управління, замінюючи один вузол версії N + 1 кожен раз, поки не залишаться лише вузли версії N.
(Необовʼязково) Вимкнення міграції лідера
Тепер, коли панель управління була оновлена для запуску як kube-controller-manager, так і cloud-controller-manager версії N + 1, міграція лідера завершила свою роботу і може бути безпечно вимкнена для збереження ресурсу лізингу. У майбутньому можна безпечно повторно увімкнути міграцію лідера для відкату.
Поступово у менеджері оновіть маніфест cloud-controller-manager, щоб скасувати встановлення як --enable-leader-migration, так і --leader-migration-config=, також видаліть підключення /etc/leadermigration.conf, а потім видаліть /etc/leadermigration.conf. Щоб повторно увімкнути міграцію лідера, створіть знову файл конфігурації та додайте його монтування та прапорці, які увімкнуть міграцію лідера назад до cloud-controller-manager.
Стандартна конфігурація
Починаючи з Kubernetes 1.22, Міграція лідера надає стандартну конфігурацію, яка підходить для стандартного призначення контролерів до менеджера. Стандартну конфігурацію можна увімкнути, встановивши --enable-leader-migration, але без --leader-migration-config=.
Для kube-controller-manager та cloud-controller-manager, якщо немає жодних прапорців, що увімкнуть будь-якого вбудованого хмарного провайдера або змінять володільця контролерів, можна використовувати стандартну конфігурацію, щоб уникнути ручного створення файлу конфігурації.
Спеціальний випадок: міграція контролера Node IPAM
Якщо ваш хмарний провайдер надає реалізацію контролера Node IPAM, вам слід перейти до реалізації в cloud-controller-manager. Вимкніть контролер Node IPAM в kube-controller-manager версії N + 1, додавши --controllers=*,-nodeipam до його прапорців. Потім додайте nodeipam до списку мігрованих контролерів.
# версія з підстановкою, з nodeipamkind:LeaderMigrationConfigurationapiVersion:controllermanager.config.k8s.io/v1leaderName:cloud-provider-extraction-migrationresourceLock:leasescontrollerLeaders:- name:routecomponent:*- name:servicecomponent:*- name:cloud-node-lifecyclecomponent:*- name:nodeipamcomponent:*
etcd — це сумісне та високодоступне сховище ключ-значення, яке використовується як сховище Kubernetes для резервування всіх даних кластера.
Якщо ваш кластер Kubernetes використовує etcd як сховище для резервування, переконайтеся, що у вас є план резервного копіювання даних.
Ви можете знайти докладну інформацію про etcd в офіційній документації.
Перш ніж ви розпочнете
Перш ніж слідувати інструкціям на цій сторінці щодо розгортання, керування, резервного копіювання або відновлення etcd, необхідно зрозуміти типові очікування при експлуатації кластера etcd. Зверніться до документації etcd для отримання додаткової інформації.
Основні деталі включають:
Мінімальні рекомендовані версії etcd для використання в операційній діяльності: 3.4.22+ і 3.5.6+.
etcd є розподіленою системою з визначенням лідера. Забезпечте, щоб лідер періодично надсилав своєчасні сигнали всім підлеглим для підтримки стабільності кластера.
Ви повинні запускати etcd як кластер з непарною кількістю членів.
Намагайтеся уникати виснаження ресурсів.
Продуктивність і стабільність кластера чутлива до наявності ресурсів мережі та введення/виведення даних на диск. Будь-яка нестача ресурсів може призвести до вичерпання тайм-ауту пульсу, що призводить до нестабільності кластера. Нестабільність etcd означає, що лідер не обраний. У таких обставинах кластер не може вносити зміни до свого поточного стану, що означає, що нові Podʼи не можуть бути заплановані.
Вимоги до ресурсів для etcd
Експлуатація etcd з обмеженими ресурсами підходить тільки для тестових цілей. Для розгортання в операційній діяльності потрібна розширена конфігурація обладнання. Перед розгортанням etcd в операційній діяльності дивіться довідник щодо вимог до ресурсів.
Підтримання стабільності кластерів etcd є критичним для стабільності кластерів Kubernetes. Тому запускайте кластери etcd на виділених машинах або в ізольованих середовищах для гарантованих вимог до ресурсів.
Інструменти
Залежно від конкретного завдання, яке ви виконуєте, вам знадобиться інструмент etcdctl або etcdutl (можливо, обидва).
Розуміння etcdctl і etcdutl
etcdctl і etcdutl — це інструменти командного рядка для взаємодії з кластерами etcd, але вони виконують різні завдання:
etcdctl — це основний клієнт командного рядка для взаємодії з etcd через мережу. Використовується для повсякденних операцій, таких як керування ключами та значеннями, адміністрування кластера, перевірка справності та багато іншого.
etcdutl — це утиліта адміністратора, призначена для роботи безпосередньо з файлами даних etcd, включаючи міграцію даних між версіями etcd, дефрагментацію бази даних, відновлення знімків і перевірку цілісності даних. Для мережевих операцій слід використовувати etcdctl.
Запустіть сервер API Kubernetes з прапорцем --etcd-servers=$PRIVATE_IP:2379.
Переконайтеся, що PRIVATE_IP встановлено на ваш IP-адрес клієнта etcd.
Багатовузловий кластер etcd
Для забезпечення надійності та високої доступності запускайте etcd як багатовузловий кластер для операційної діяльності та періодично робіть резервні копії. В операційній діяльності рекомендується використовувати кластер з пʼятьма членами. Для отримання додаткової інформації див. ЧаПи.
Оскільки ви використовуєте Kubernetes, у вас є можливість запускати etcd як контейнер всередині одного або декількох Podʼів. Інструмент kubeadm типово налаштовує etcd як статичні Podʼи, або ви можете розгорнути окремий кластер і вказати kubeadm використовувати цей кластер etcd як сховище для панелі управління.
Ви можете налаштувати кластер etcd або за допомогою статичної інформації про учасників, або за допомогою динамічного виявлення. Для отримання додаткової інформації про кластеризацію дивіться документацію з кластеризації etcd.
Наприклад, розглянемо кластер etcd з пʼятьох членів, що працює з наступними URL-адресами клієнта: http://$IP1:2379, http://$IP2:2379, http://$IP3:2379, http://$IP4:2379 та http://$IP5:2379. Щоб запустити сервер API Kubernetes:
Запустіть сервери API Kubernetes з прапорцем
--etcd-servers=$IP1:2379,$IP2:2379,$IP3:2379,$IP4:2379,$IP5:2379.
Переконайтеся, що змінні IP<n> встановлені на ваші IP-адреси клієнтів.
Багатовузловий кластер etcd з балансувальником навантаження
Для запуску кластера etcd з балансувальником навантаження:
Налаштуйте кластер etcd.
Налаштуйте балансувальник навантаження перед кластером etcd. Наприклад, адреса балансувальника навантаження може бути $LB.
Запустіть сервери API Kubernetes з прапорцем --etcd-servers=$LB:2379.
Захист кластерів etcd
Доступ до etcd еквівалентний правам кореневого користувача в кластері, тому ідеально, щоб доступ до нього мав лише сервер API. З урахуванням чутливості даних рекомендується надавати дозвіл лише тим вузлам, які потребують доступу до кластерів etcd.
Для захисту etcd налаштуйте правила брандмауера або використовуйте засоби безпеки, надані etcd. Функції безпеки etcd залежать від інфраструктури відкритого ключа x509 (PKI). Для початку налаштуйте безпечні канали звʼязку, згенерувавши пару ключа та сертифікату. Наприклад, використовуйте пари ключів peer.key та peer.cert для захисту звʼязку між членами etcd та client.key та client.cert для захисту звʼязку між etcd та його клієнтами. Див. приклади скриптів, надані проєктом etcd, для генерації пар ключів та файлів ЦС для автентифікації клієнтів.
Захист комунікації
Для налаштування etcd з безпечною взаємодією між членами вкажіть прапорці --peer-key-file=peer.key та --peer-cert-file=peer.cert, та використовуйте протокол HTTPS у схемі URL.
Аналогічно, для налаштування etcd з безпечною взаємодією клієнтів вкажіть прапорці --key=k8sclient.key та --cert=k8sclient.cert, та використовуйте протокол HTTPS у схемі URL. Ось приклад команди клієнта, яка використовує безпечну комунікацію:
ETCDCTL_API=3 etcdctl --endpoints 10.2.0.9:2379 \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
member list
Обмеження доступу до кластерів etcd
Після налаштування безпечної комунікації обмежте доступ до кластера etcd лише для серверів API Kubernetes, використовуючи автентифікацію TLS.
Наприклад, розгляньте пари ключів k8sclient.key та k8sclient.cert, яким довіряє ЦС etcd.ca. Коли etcd налаштовано з параметром --client-cert-auth разом з TLS, він перевіряє сертифікати від клієнтів, використовуючи системні ЦС або ЦС, передані за допомогою прапорця --trusted-ca-file. Вказівка прапорців --client-cert-auth=true та --trusted-ca-file=etcd.ca обмежить доступ до клієнтів з сертифікатом k8sclient.cert.
Після коректного налаштування etcd до нього можуть отримувати доступ лише клієнти з дійсними сертифікатами. Щоб дати серверам API Kubernetes доступ, налаштуйте їх з прапорцями --etcd-certfile=k8sclient.cert, --etcd-keyfile=k8sclient.key та --etcd-cafile=ca.cert.
Примітка:
Автентифікація etcd не планується для Kubernetes.
Заміна несправного члена etcd
Кластер etcd досягає високої доступності, толеруючи невеликі відмови членів. Однак, для покращення загального стану кластера, замінюйте несправних членів негайно. Коли відмовляють декілька членів, замінюйте їх по одному. Заміна несправного члена включає два кроки: видалення несправного члена та додавання нового члена.
Хоча etcd зберігає унікальні ідентифікатори членів всередині, рекомендується використовувати унікальне імʼя для кожного члена, щоб уникнути фактора людської помилки. Наприклад, розгляньте кластер etcd з трьох членів. Нехай URL буде таким: member1=http://10.0.0.1, member2=http://10.0.0.2, і member3=http://10.0.0.3. Коли відмовляє member1, замініть його на member4=http://10.0.0.4.
Отримайте ідентифікатор несправного member1:
etcdctl --endpoints=http://10.0.0.2,http://10.0.0.3 member list
Якщо кожен сервер API Kubernetes налаштований на спілкування з усіма членами etcd, видаліть несправного члена з прапорця --etcd-servers, а потім перезапустіть кожен сервер API Kubernetes.
Якщо кожен сервер API Kubernetes спілкується з одним членом etcd, зупиніть сервер API Kubernetes, який спілкується з несправним etcd.
Зупиніть сервер etcd на несправному вузлі. Можливо, інші клієнти окрім сервера API Kubernetes створюють трафік до etcd, і бажано зупинити весь трафік, щоб запобігти записам до теки з даними.
Видаліть несправного члена:
etcdctl member remove 8211f1d0f64f3269
Показується наступне повідомлення:
Removed member 8211f1d0f64f3269 from cluster
Додайте нового члена:
etcdctl member add member4 --peer-urls=http://10.0.0.4:2380
Показується наступне повідомлення:
Member 2be1eb8f84b7f63e added to cluster ef37ad9dc622a7c4
Запустіть новододаного члена на машині з IP 10.0.0.4:
Якщо кожен сервер API Kubernetes налаштований на спілкування з усіма членами etcd, додайте новододаного члена до прапорця --etcd-servers, а потім перезапустіть кожен сервер API Kubernetes.
Якщо кожен сервер API Kubernetes спілкується з одним членом etcd, запустіть сервер API Kubernetes, який був зупинений на кроці 2. Потім налаштуйте клієнти сервера API Kubernetes знову маршрутизувати запити до сервера API Kubernetes, який був зупинений. Це часто можна зробити, налаштувавши балансувальник навантаження.
Усі обʼєкти Kubernetes зберігаються в etcd. Періодичне резервне копіювання даних кластера etcd важливо для відновлення кластерів Kubernetes у випадку катастрофи, такої як втрата всіх вузлів панелі управління. Файл знімка містить весь стан Kubernetes та критичну інформацію. Для збереження конфіденційних даних Kubernetes в безпеці зашифруйте файли знімків.
Резервне копіювання кластера etcd можна виконати двома способами: вбудованим засобами знімків etcd та знімком тому.
Вбудовані засоби знімків
etcd підтримує вбудовані засоби знімків. Знімок можна створити з активного члена за допомогою команди etcdctl snapshot save або скопіювавши файл member/snap/db з теки даних etcd, яка в цей момент не використовується процесом etcd. Створення знімка не вплине на продуктивність члена.
Нижче наведено приклад створення знімка простору ключів, який обслуговується за адресою $ENDPOINT, у файл snapshot.db:
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshot.db
Використання etcdctl snapshot status є застарілим починаючи з версії etcd v3.5.x і планується до вилучення у версії v3.6. Натомість рекомендується використовувати etcdutl.
Приклад нижче показує, як використовувати etcdctl для перевірки знімка:
exportETCDCTL_API=3etcdctl --write-out=table snapshot status snapshot.db
Це повинно згенерувати результат, подібний до наведеного нижче прикладу:
Якщо etcd працює за томом сховища, який підтримує резервне копіювання, наприклад, Amazon Elastic Block Store, зробіть резервну копію даних etcd, створивши знімок тому сховища.
Знімок за допомогою параметрів etcdctl
Ми також можемо створити знімок, використовуючи різноманітні параметри, надані etcdctl. Наприклад:
ETCDCTL_API=3 etcdctl -h
покаже різні параметри, доступні з etcdctl. Наприклад, ви можете створити знімок, вказавши точку доступу, сертифікати та ключ, як показано нижче:
де trusted-ca-file, cert-file та key-file можна отримати з опису модуля etcd.
Масштабування кластерів etcd
Масштабування кластерів etcd підвищує доступність шляхом зниження продуктивності. Масштабування не збільшує продуктивність або можливості кластера. Загальне правило — не масштабуйте кластери etcd. Не налаштовуйте жодних автоматичних груп масштабування для кластерів etcd. Наполегливо рекомендується завжди запускати статичний кластер etcd з 5-ти членів для операційних кластерів Kubernetes будь-якого офіційно підтримуваного масштабу.
Доречне масштабування — це оновлення кластера з трьох до пʼяти членів, коли потрібно більше надійності. Див. документацію з переконфігурації etcd для інформації про те, як додавати учасників у наявний кластер.
Відновлення кластера etcd
Увага:
Якщо будь-які API-сервери працюють у вашому кластері, ви не повинні намагатися відновлювати екземпляри etcd. Замість цього дотримуйтесь цих кроків для відновлення etcd:
зупиніть усі екземпляри API-сервера
відновіть стан у всіх екземплярах etcd
перезапустіть усі екземпляри API-сервера
Проєкт Kubernetes також рекомендує перезапускати компоненти Kubernetes (kube-scheduler, kube-controller-manager, kubelet), щоб гарантувати, що вони не покладаються на застарілі дані. На практиці відновлення займає деякий час. Під час відновлення критичні компоненти втратять блокування лідера і перезапустяться.
etcd підтримує відновлення зі знімків, які були створені з процесу etcd версії major.minor. Відновлення версії з іншої версії патча etcd також підтримується. Операція відновлення використовується для відновлення даних несправного кластера.
Перед початком операції відновлення повинен бути наявний файл знімка. Це може бути файл знімка з попередньої операції резервного копіювання або теки даних, що залишилась.
де <data-dir-location> — це тека, яка буде створена під час процесу відновлення.
Примітка:
Використання etcdctl для відновлення застаріло починаючи з версії etcd v3.5.x і планується до вилучення у версії v3.6. Натомість рекомендується використовувати etcdutl.
У наведеному нижче прикладі показано використання інструмента etcdctl для операції відновлення:
Якщо <data-dir-location> є тою самою текою, що й раніше, видаліть її та зупиніть процес etcd перед відновленням кластера. В іншому випадку, змініть конфігурацію etcd і перезапустіть процес etcd після відновлення, щоб він використовував нову теку даних: спочатку змініть /etc/kubernetes/manifests/etcd.yaml у volumes.hostPath.path для name: etcd-data на <data-dir-location>, потім виконайте kubectl -n kube-system delete pod <name-of-etcd-pod> або ystemctl restart kubelet.service (або обидві команди).
Якщо доступні URL-адреси відновленого кластера відрізняються від попереднього кластера, сервер API Kubernetes повинен бути відповідно переконфігурований. У цьому випадку перезапустіть сервери API Kubernetes з прапорцем --etcd-servers=$NEW_ETCD_CLUSTER замість прапорця --etcd-servers=$OLD_ETCD_CLUSTER. Замініть $NEW_ETCD_CLUSTER та $OLD_ETCD_CLUSTER на відповідні IP-адреси. Якщо перед кластером etcd використовується балансувальник навантаження, можливо, потрібно оновити балансувальник навантаження.
Якщо більшість членів etcd є остаточно несправними, кластер etcd вважається несправним. У цьому сценарії Kubernetes не може вносити зміни у свій поточний стан. Хоча заплановані Podʼи можуть продовжувати працювати, нові Podʼи не можуть бути заплановані. У таких випадках відновіть кластер etcd та, можливо, переконфігуруйте сервери API Kubernetes, щоб усунути проблему.
Оновлення кластерів etcd
Увага:
Перш ніж ви розпочнете оновлення, будь ласка, спочатку зробіть резервне копіювання свого кластера etcd.
🛇 Цей елемент посилається на сторонній проєкт або продукт, який не є частиною Kubernetes. Докладніше
Дефрагментація є дорогою операцією, тому її слід виконувати якомога рідше. З іншого боку, також необхідно переконатися, що жоден з учасників etcd не перевищить квоту зберігання. Проєкт Kubernetes рекомендує, що при виконанні дефрагментації ви використовували інструмент, такий як etcd-defrag.
Ви також можете запускати інструмент дефрагментації як Kubernetes CronJob, щоб переконатися, що дефрагментація відбувається регулярно. Дивіться etcd-defrag-cronjob.yaml для отримання деталей.
2.32 - Резервування обчислювальних ресурсів для системних служб
Вузли Kubernetes можуть бути заплановані на Capacity. Podʼи можуть використовувати типово всю доступну місткість на вузлі. Це проблема, оскільки на вузлах зазвичай працює досить багато системних служб, які забезпечують операційну систему та сам Kubernetes. Якщо не виділити ресурси для цих системних служб, Podʼи та системні служби конкурують за ресурси, що призводить до проблем з вичерпання ресурсів на вузлі.
kubelet надає можливість під назвою 'Node Allocatable', яка допомагає резервувати обчислювальні ресурси для системних служб. Kubernetes рекомендує адміністраторам кластера налаштовувати 'Node Allocatable' на основі щільності робочого навантаження на кожному вузлі.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
'Виділення' (Allocatable) на вузлі Kubernetes визначається як обсяг обчислювальних ресурсів, які доступні для Podʼів. Планувальник не надає перевищення обсягу 'Виділення'. Зараз підтримуються 'CPU', 'memory' та 'ephemeral-storage'.
Node Allocatable експонується як частина обʼєкта v1.Node в API та як частина kubectl describe node в CLI.
Ресурси можуть бути зарезервовані для двох категорій системних служб в kubelet.
Увімкнення QoS та cgroups на рівні Pod
Для належного застосування обмежень на вузлі виділення ресурсів вузлові вам потрібно увімкнути нову ієрархію cgroup за допомогою параметру налаштувань cgroupsPerQOS. Цей параметр є типово увімкненим. Коли він увімкнений, kubelet буде розташовувати всі Podʼи кінцевих користувачів в ієрархії cgroup, керованій kubelet.
Налаштування драйвера cgroup
kubelet підтримує маніпулювання ієрархією cgroup на хості за допомогою драйвера cgroup. Драйвер налаштовується за допомогою параметра cgroupDriver.
Підтримувані значення наступні:
cgroupfs — це типовий драйвер, який виконує пряме маніпулювання файловою системою cgroup на хості для управління пісочницями cgroup.
systemd — це альтернативний драйвер, який управляє пісочницями cgroup за допомогою тимчасових сегментів для ресурсів, які підтримуються цією системою ініціалізації.
Залежно від конфігурації відповідного контейнерного середовища, оператори можуть вибрати певний драйвер cgroup, щоб забезпечити належну роботу системи. Наприклад, якщо оператори використовують драйвер cgroup systemd, наданий контейнерним середовищем containerd, kubelet повинен бути налаштований на використання драйвера cgroup systemd.
Kube Reserved
KubeletConfiguration Setting: kubeReserved: {}. Example value {cpu: 100m, memory: 100Mi, ephemeral-storage: 1Gi, pid=1000}
kubeReserved призначено для захоплення резервування ресурсів для системних демонів Kubernetes, таких як kubelet, container runtime тощо. Він не призначений для резервування ресурсів для системних служб, які запускаються як Podʼи. kubeReserved зазвичай є функцією pod density на вузлах.
Крім cpu, memory та ephemeral-storage, можна вказати pid, щоб зарезервувати вказану кількість ідентифікаторів процесів для системних демонів Kubernetes.
Для необовʼязкового застосування kubeReserved до системних демонів Kubernetes вкажіть батьківську контрольну групу для демонів kube як значення параметра kubeReservedCgroup та додайте kube-reserved до enforceNodeAllocatable.
Рекомендується розміщувати системні демони Kubernetes під верхньою контрольною групою (runtime.slice на машинах з systemd, наприклад). Кожен системний демон повинен ідеально працювати у власній дочірній контрольній групі. Докладнішу інформацію про рекомендовану ієрархію контрольних груп дивіться у пропозиції дизайну.
Зверніть увагу, що Kubelet не створюєkubeReservedCgroup, якщо він не існує. Kubelet не запуститься, якщо вказано недійсну контрольну групу. З драйвером cgroup systemd вам слід дотримуватися певного шаблону для імені контрольної групи, яку ви визначаєте: імʼя повинно бути значенням, яке ви встановлюєте для kubeReservedCgroupp, з додаванням .slice.
System Reserved
KubeletConfiguration Setting: systemReserved: {}. Example value {cpu: 100m, memory: 100Mi, ephemeral-storage: 1Gi, pid=1000}
systemReserved призначено для захоплення резервування ресурсів для системних служб операційної системи, таких як sshd, udev і т. д. systemReserved повинно резервувати memory для kernel, оскільки памʼять kernel наразі не враховується для Podʼів у Kubernetes. Рекомендується також резервувати ресурси для сеансів входу користувача (user.slice у світі systemd).
Крім cpu, memory та ephemeral-storage, можна вказати pid, щоб зарезервувати вказану кількість ідентифікаторів процесів для системних служб операційної системи.
Для необовʼязкового застосування systemReserved до системних служб вкажіть батьківську контрольну групу для системних служб операційної системи як значення параметра systemReservedCgroup та додайте system-reserved до enforceNodeAllocatable.
Рекомендується розміщувати системні служби операційної системи під верхньою контрольною групою (system.slice на машинах з systemd, наприклад).
Зверніть увагу, що kubeletне створюєsystemReservedCgroup, якщо він не існує. kubelet відмовить у запуску, якщо вказано недійсну контрольну групу. З драйвером cgroup systemd вам слід дотримуватися певного шаблону для імені контрольної групи, яку ви визначаєте: імʼя повинно бути значенням, яке ви встановлюєте для systemReservedCgroup, з додаванням .slice.
reservedSystemCPUs призначено для визначення явного набору CPU для системних служб операційної системи та системних служб Kubernetes. reservedSystemCPUs призначений для систем, які не мають наміру визначати окремі верхні рівні контрольні групи для системних служб операційної системи та системних служб Kubernetes з урахуванням ресурсу cpuset. Якщо Kubelet не маєkubeReservedCgroup та systemReservedCgroup, явний набір cpuset, наданий reservedSystemCPUs, переважатиме над CPU, визначеними параметрами kubeReservedCgroup та systemReservedCgroup.
Ця опція спеціально розроблена для випадків використання в телекомунікаціях/NFV, де неконтрольовані переривання/таймери можуть впливати на продуктивність робочого навантаження. Ви можете використовувати цю опцію для визначення явного набору cpuset для системних/кластерних служб та переривань/таймерів, щоб решта процесорів у системі могли використовуватися виключно для робочих навантажень, з меншим впливом неконтрольованих переривань/таймерів. Щоб перенести системні служби, системні служби Kubernetes та переривання/таймери до явного набору cpuset, визначеного цією опцією, слід використовувати інші механізми поза Kubernetes. Наприклад: у CentOS це можна зробити за допомогою інструменту tuned.
Нестача памʼяті на рівні вузла призводить до System OOMs, що впливає на весь вузол та всі Podʼи, що працюють на ньому. Вузли можуть тимчасово вийти з ладу, поки памʼять не буде відновлена. Щоб уникнути (або зменшити ймовірність) System OOMs, kubelet надає управління ресурсами. Виселення підтримується тільки для memory та ephemeral-storage. Резервуючи певний обсяг памʼяті за допомогою параметра evictionHard, kubelet намагається виселити Podʼи, коли доступність памʼяті на вузлі впаде нижче зарезервованого значення. Гіпотетично, якщо системні служби не існують на вузлі, Podʼи не можуть використовувати більше, ніж capacity - eviction-hard. З цієї причини ресурси, зарезервовані для виселень, не доступні для Podʼів.
Планувальник розглядає 'Allocatable' як доступну capacity для Podʼів.
kubelet типово застосовує 'Allocatable' на всіх Podʼах. Застосування виконується шляхом видалення Podʼів, коли загальне використання у всіх Podʼах перевищує 'Allocatable'. Додаткові відомості про політику виселення можна знайти на сторінці Виселення внаслідок тиску на вузол. Це застосування контролюється, вказуючи значення pods для параметра enforceNodeAllocatable.
Необовʼязково, kubelet можна змусити застосовувати kubeReserved та systemReserved, вказавши значення kube-reserved та system-reserved у в одному і тому ж параметрі. Зверніть увагу, що для застосування kubeReserved або systemReserved, потрібно вказати kubeReservedCgroup або ystemReservedCgroup відповідно.
Загальні настанови
Очікується, що системні служби будуть оброблятися аналогічно гарантованим Podʼам. Системні служби можуть розширюватися в межах своїх обмежувальних контрольних груп, і цією поведінкою потрібно керувати як частиною розгортань Kubernetes. Наприклад, kubelet повинен мати свою власну контрольну групу і ділити ресурси kubeReserved з контейнерним середовищем. Однак Kubelet не може розширюватися і використовувати всі доступні ресурси вузла, якщо застосовується kubeReserved.
Будьте особливо обережні при застосуванні резервування systemReserved, оскільки це може призвести до нестачі ресурсів CPU для критичних системних служб, припинення роботи через нестачу памʼяті (OOM) або неможливості форка на вузлі. Рекомендація полягає в застосуванні systemReserved лише у випадку, якщо користувач детально проаналізував свої вузли, щоб надати точні оцінки та має впевненість у своїй здатності відновитися, якщо будь-який процес у цій групі буде примусово завершений через брак памʼяті.
Спочатку застосовуйте 'Allocatable' на Pod.
Як тільки буде встановлено достатньо моніторингу та попереджень для відстеження системних служб kube, спробуйте застосувати kubeReserved на основі використання евристик.
Якщо це абсолютно необхідно, з часом застосуйте systemReserved.
Вимоги до ресурсів системних служб kube можуть зростати з часом з введенням все більшої кількості функцій. З часом проєкт Kubernetes буде намагатися знизити використання системних служб вузла, але зараз це не пріоритет. Так що очікуйте зниження доступної місткості Allocatable у майбутніх версіях.
Приклад сценарію
Ось приклад для ілюстрації обчислення виділення ресурсів вузла:
Вузол має 32Гб памʼяті, 16 ЦП і 100Гб сховища
kubeReserved встановлено у {cpu: 1000m, memory: 2Gi, ephemeral-storage: 1Gi}
systemReserved встановлено у {cpu: 500m, memory: 1Gi, ephemeral-storage: 1Gi}
evictionHard встановлено у {memory.available: "<500Mi", nodefs.available: "<10%"}
У цьому сценарії "Allocatable" складатиме 14,5 ЦП, 28,5Гб памʼяті та 88Гб локального сховища. Планувальник забезпечує, що загальна памʼять запитів у всіх Podʼів на цьому вузлі не перевищує 28,5Гб, а сховище не перевищує 88Гб. Kubelet виселяє Podʼи, коли загальне використання памʼяті у всіх Podʼах перевищує 28,5Гб, або якщо загальне використання диска перевищує 88Гб. Якщо всі процеси на вузлі використовують як можна більше ЦП, Podʼи разом не можуть використовувати більше ніж 14,5 ЦП.
Якщо kubeReserved та/або systemReserved не застосовується, і системні служби перевищують своє резервування, kubelet виводить Podʼи, коли загальне використання памʼяті вузла вище 31,5Гб або storage перевищує 90Гб.
2.33 - Запуск компонентів вузла Kubernetes користувачем без прав root
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.22 [alpha]
У цьому документі описано, як запустити компоненти вузла Kubernetes, такі як kubelet, CRI, OCI та CNI, без прав root, використовуючи простір імен користувача.
Ця техніка також відома як rootless mode.
Примітка:
У цьому документі описано, як запустити компоненти вузла Kubernetes (і відповідно Podʼи), як не-root користувач.
Якщо ви шукаєте лише як запустити Pod як не-root користувача, див. SecurityContext.
Перш ніж ви розпочнете
Версія вашого Kubernetes сервера має бути не старішою ніж 1.22.
Запуск Kubernetes всередині непривілейованих контейнерів
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
sysbox
Sysbox — це відкрите програмне забезпечення для виконання контейнерів (подібне до "runc"), яке підтримує запуск робочих навантажень на рівні системи, таких як Docker та Kubernetes, всередині непривілейованих контейнерів, ізольованих за допомогою просторів користувачів Linux.
Sysbox підтримує запуск Kubernetes всередині непривілейованих контейнерів без потреби в Cgroup v2 і без використання KubeletInUserNamespace. Він досягає цього за допомогою розкриття спеціально створених файлових систем /proc та /sys всередині контейнера, а також кількох інших передових технік віртуалізації операційної системи.
Запуск Rootless Kubernetes безпосередньо на хості
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
K3s
K3s експериментально підтримує режим без root-прав.
Usernetes — це референсний дистрибутив Kubernetes, який може бути встановлений у теці $HOME без привілеїв root.
Usernetes підтримує як containerd, так і CRI-O як середовище виконання контейнерів CRI. Usernetes підтримує багатовузлові кластери з використанням Flannel (VXLAN).
Якщо ви намагаєтеся запустити Kubernetes в контейнері з простором користувача, такому як Rootless Docker/Podman або LXC/LXD, ви готові та можете перейти до наступного підрозділу.
Інакше вам доведеться створити простір користувача самостійно, викликавши unshare(2) з CLONE_NEWUSER.
Простір користувача також можна відокремити за допомогою інструментів командного рядка, таких як:
Після відокремлення простору користувача вам також доведеться відокремити інші простори імен, такі як простір імен монтування.
Вам не потрібно викликати chroot() або pivot_root() після відокремлення простору імен монтування, однак вам потрібно буде монтувати записувані файлові системи у кількох теках в просторі імен.
Принаймні, наступні теки повинні бути записуваними в просторі імен (не поза простором імен):
/etc
/run
/var/logs
/var/lib/kubelet
/var/lib/cni
/var/lib/containerd (для containerd)
/var/lib/containers (для CRI-O)
Створення делегованого дерева cgroup
Крім простору користувача, вам також потрібно мати записуване дерево cgroup з cgroup v2.
Примітка:
Підтримка Kubernetes для запуску компонентів вузла у просторах користувача передбачає використання cgroup v2. Cgroup v1 не підтримується.
Якщо ви намагаєтеся запустити Kubernetes у Rootless Docker/Podman або LXC/LXD на хості на основі systemd, у вас все готове.
У противному вам доведеться створити службу systemd з властивістю Delegate=yes, щоб делегувати дерево cgroup з правами на запис.
На вашому вузлі система systemd вже повинна бути налаштована на дозвіл делегування; для отримання докладнішої інформації дивіться cgroup v2 в документації Rootless
Containers.
Налаштування мережі
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Простір імен мережі компонентів вузла повинен мати не-loopback інтерфейс, який, наприклад, може бути налаштований з використанням slirp4netns, VPNKit, або lxc-user-nic(1).
Простори імен мережі Podʼів можна налаштувати за допомогою звичайних втулків CNI. Для мережі з багатьма вузлами відомо, що Flannel (VXLAN, 8472/UDP) працює.
Порти, такі як порт kubelet (10250/TCP) і порти служби NodePort, повинні бути викриті з простору імен мережі вузла на хост зовнішнім перенаправлювачем портів, таким як RootlessKit, slirp4netns, або socat(1).
Kubelet покладається на середовище виконання контейнерів. Ви повинні розгорнути середовище виконання контейнерів, таке як
containerd або CRI-O, і переконатися, що воно працює у просторі користувача до запуску kubelet.
Запуск CRI втулка containerd в просторі користувача підтримується з версії containerd 1.4.
Запуск containerd у просторі користувача вимагає наступних налаштувань.
version = 2[plugins."io.containerd.grpc.v1.cri"]
# Вимкнути AppArmor disable_apparmor = true# Ігнорувати помилку під час встановлення oom_score_adj restrict_oom_score_adj = true# Вимкнути контролер hugetlb cgroup v2 (тому що systemd не підтримує делегування контролера hugetlb) disable_hugetlb_controller = true[plugins."io.containerd.grpc.v1.cri".containerd]
# Можливий також використання non-fuse overlayfs для ядра >= 5.11, але потребує вимкненого SELinux snapshotter = "fuse-overlayfs"[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
# Ми використовуємо cgroupfs, який делегується системою systemd, тому ми не використовуємо драйвер SystemdCgroup# (якщо ви не запускаєте іншу систему systemd у просторі імен) SystemdCgroup = false
Типовий шлях конфігураційного файлу — /etc/containerd/config.toml. Шлях можна вказати з containerd -c /шлях/до/конфігураційного/файлу.toml.
Запуск CRI-O у просторі користувача підтримується з версії CRI-O 1.22.
CRI-O вимагає, щоб була встановлена змінна середовища _CRIO_ROOTLESS=1.
Також рекомендуються наступні налаштування:
[crio]
storage_driver = "overlay"# Можливий також використання non-fuse overlayfs для ядра >= 5.11, але потребує вимкненого SELinux storage_option = ["overlay.mount_program=/usr/local/bin/fuse-overlayfs"]
[crio.runtime]
# Ми використовуємо cgroupfs, який делегується системою systemd, тому ми не використовуємо драйвер "systemd"# (якщо ви не запускаєте іншу систему systemd у просторі імен) cgroup_manager = "cgroupfs"
Типовий шлях конфігураційного файлу — /etc/crio/crio.conf.
Шлях можна вказати з crio --config /шлях/до/конфігураційного/файлу/crio.conf.
Налаштування kubelet
Запуск kubelet у просторі користувача вимагає наступної конфігурації:
apiVersion:kubelet.config.k8s.io/v1beta1kind:KubeletConfigurationfeatureGates:KubeletInUserNamespace:true# Ми використовуємо cgroupfs, який делегується системою systemd, тому ми не використовуємо драйвер "systemd"# (якщо ви не запускаєте іншу систему systemd у просторі імен)cgroupDriver:"cgroupfs"
Коли увімкнено KubeletInUserNamespace, kubelet ігнорує помилки, які можуть виникнути під час встановлення наступних значень sysctl на вузлі.
vm.overcommit_memory
vm.panic_on_oom
kernel.panic
kernel.panic_on_oops
kernel.keys.root_maxkeys
kernel.keys.root_maxbytes.
У просторі користувача kubelet також ігнорує будь-яку помилку, яка виникає при спробі відкрити /dev/kmsg. Цей feature gate також дозволяє kube-proxy ігнорувати помилку під час встановлення RLIMIT_NOFILE.
KubeletInUserNamespace був введений у Kubernetes v1.22 зі статусом "alpha".
Запуск kubelet у просторі користувача без використання цього feature gate також можливий, шляхом монтування спеціально створеного файлової системи proc (як це робить Sysbox), але це не є офіційно підтримуваним.
Налаштування kube-proxy
Запуск kube-proxy у просторі користувача вимагає наступної конфігурації:
apiVersion:kubeproxy.config.k8s.io/v1alpha1kind:KubeProxyConfigurationmode:"iptables"# або "userspace"conntrack:# Пропустити встановлення значення sysctl "net.netfilter.nf_conntrack_max"maxPerCore:0# Пропустити встановлення "net.netfilter.nf_conntrack_tcp_timeout_established"tcpEstablishedTimeout:0s# Пропустити встановлення "net.netfilter.nf_conntrack_tcp_timeout_close"tcpCloseWaitTimeout:0s
Застереження
Більшість "нелокальних" драйверів томів, таких як nfs та iscsi, не працюють. Відомо, що працюють локальні томи, такі як local, hostPath, emptyDir, configMap, secret та downwardAPI.
Деякі втулки CNI можуть не працювати. Відомо, що працює Flannel (VXLAN).
Для отримання додаткової інформації з цього питання, див. сторінку Застереження та майбутня робота на веб-айті rootlesscontaine.rs.
Щоб забезпечити доступність ваших робочих навантажень під час технічного обслуговування, ви можете налаштувати PodDisruptionBudget.
Якщо доступність важлива для будь-яких застосунків, які запускаються або можуть запускатися на вузлах, які ви очищуєте, спочатку налаштуйте PodDisruptionBudget, а потім продовжуйте виконувати цей посібник.
Рекомендується встановити AlwaysAllowПолітика виселення несправного Podʼа для PodDisruptionBudgets, щоб підтримувати виселення погано працюючих застосунків під час очищення вузла. Стандартна поведінка полягає в очікуванні на те, щоб Podʼи застосунків стали справними, перш ніж можна буде продовжити очищення.
Використання kubectl drain для очищення вузла
Ви можете використовувати kubectl drain для безпечного виселення всіх ваших Podʼів з вузла перед тим, як ви будете виконувати обслуговування вузла (наприклад, оновлення ядра, обслуговування обладнання тощо). Безпечні виселення дозволяють контейнерам Podʼів належним чином завершувати роботу і дотримуватись PodDisruptionBudgets, які ви визначили.
Примітка:
Типово kubectl drain ігнорує певні системні Podʼи на вузлі, роботу яких не можна завершити примусово; докладніше див. документацію kubectl drain.
Коли kubectl drain успішно завершується, це означає, що всі Podʼи (крім тих, які виключені, як описано в попередньому абзаці) безпечно виселені (дотримуючись бажаного періоду належного завершення роботи та PodDisruptionBudget, який ви визначили). Тоді безпечно вимкніть вузол, вимкнувши його фізичний компʼютер або, якщо ви працюєте на хмарній платформі, видаливши його віртуальну машину.
Примітка:
Якщо нові Podʼи толерують taint node.kubernetes.io/unschedulable, то ці Podʼи можуть бути заплановані на вузол, який ви очистили. Уникайте толерування цього taint, крім як для DaemonSets.
Якщо ви або інший користувач API безпосередньо встановили поле nodeName для Podʼа (в обхід планувальника), то Pod буде привʼязаний до вказаного вузла і буде працювати там, навіть якщо ви його очистили та позначили як не придатний для планування.
Спочатку визначте імʼя вузла, який ви хочете очистити. Ви можете перелічити всі вузли у своєму кластері за допомогою
kubectl get nodes
Далі скажіть Kubernetes очистити вузол:
kubectl drain --ignore-daemonsets <імʼя вузла>
Якщо є Podʼи, керовані DaemonSet, вам потрібно вказати --ignore-daemonsets в kubectl, щоб успішно очистити вузол. Підкоманда kubectl drain сама по собі насправді не очищує вузол від його Podʼів DaemonSet: контролер DaemonSet (частина контролера управління) негайно замінює відсутні Podʼи новими еквівалентними Podʼами. Контролер DaemonSet також створює Podʼи, які ігнорують taint, що перешкоджають плануванню, що дозволяє новим Podʼам запуститися на вузлі, який ви очистили.
Після того, як процес завершиться (без помилки), ви можете безпечно вимкнути вузол (або еквівалентно, якщо ви працюєте на хмарній платформі, видалити віртуальну машину, на якій працює вузол). Якщо ви залишите вузол у кластері під час операції обслуговування, вам потрібно виконати
kubectl uncordon <імʼя вузла>
після того, як ви дасте цю команду Kubernetes, він може продовжити планування нових Podʼів на вузол.
Очищення кількох вузлів паралельно
Команду kubectl drain слід використовувати тільки для одного вузла за раз. Однак ви можете запускати кілька команд kubectl drain для різних вузлів паралельно, в різних терміналах або у фоні. Декілька команд очищення, які працюють паралельно, все одно дотримуються PodDisruptionBudget, який ви вказуєте.
Наприклад, якщо у вас є StatefulSet із трьома репліками та ви встановили PodDisruptionBudget для цього набору, вказуючи minAvailable: 2, kubectl drain видаляє тільки Pod з StatefulSet, якщо всі три репліки Pod є справними; якщо дати декілька команд паралельно, Kubernetes дотримується PodDisruptionBudget та забезпечує, що в будь-який момент часу лише один (обчислюється як replicas - minAvailable) Pod недоступний. Будь-які очищення, які призведуть до того, що кількість справних реплік падає нижче визначеного бюджету, блокуються.
API Eviction
Якщо ви не бажаєте використовувати kubectl drain (наприклад, для уникнення виклику зовнішньої команди або для отримання більш детального керування процесом виселення Podʼа), ви також можете програмно викликати виселення, використовуючи API Eviction.
У цьому документі розглядаються теми, повʼязані з захистом кластера від випадкового або зловмисного доступу та надаються загальні рекомендації безпеки.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Оскільки Kubernetes повністю заснований на API, контроль та обмеження, хто може мати доступ до кластера та які дії вони можуть виконувати, є першою лінією захисту.
Використання Transport Layer Security (TLS) для всього трафіку API
Kubernetes очікує, що всі комунікації API в кластері будуть типово зашифровані за допомогою TLS, і більшість методів встановлення дозволять створювати необхідні сертифікати та розподіляти їх між компонентами кластера. Зверніть увагу, що деякі компоненти та методи встановлення можуть дозволяти локальні порти через HTTP, і адміністраторам варто ознайомитися з налаштуваннями кожного компонента для ідентифікації потенційно незахищеного трафіку.
Автентифікація API
Виберіть механізм автентифікації для використання API-серверами, який відповідає загальним сценаріям доступу при встановленні кластера. Наприклад, невеликі, однокористувацькі кластери можуть бажати використовувати простий підхід з використанням сертифікатів або статичних токенів Bearer. Більші кластери можуть бажати інтегрувати наявний сервер OIDC або LDAP, який дозволяє розподіляти користувачів на групи.
Всі клієнти API повинні бути автентифіковані, навіть ті, що є частиною інфраструктури, такі як вузли, проксі, планувальник та втулки томів. Зазвичай ці клієнти є сервісними обліковими записами або використовують сертифікати клієнта x509, і вони створюються автоматично при запуску кластера або налаштовуються як частина встановлення кластера.
Після автентифікації кожен виклик API також повинен пройти перевірку авторизації. Kubernetes має вбудований компонент контролю доступу на основі ролей (Role-Based Access Control (RBAC)), який зіставляє користувача або групу набору дозволів, згрупованих за ролями. Ці дозволи поєднують дії (отримати, створити, видалити) з ресурсами (Podʼи, служби, вузли) і можуть бути обмежені простором імен або розгортанням кластера. Доступні набори стандартних ролей, які надають розумне розділення відповідальності залежно від дій, які може бажати виконати клієнт. Рекомендується використовувати авторизатори Node та RBAC разом з втулком входу NodeRestriction.
Так само як і з автентифікацією, для менших кластерів можуть бути відповідні прості та загальні ролі, але зі збільшенням кількості користувачів, які взаємодіють з кластером, може знадобитися розділити команди на окремі простори імен з більш обмеженими ролями.
При авторизації важливо розуміти, як оновлення одного обʼєкта може призвести до дій в інших місцях. Наприклад, користувач не зможе створити Podʼи безпосередньо, але дозволивши їм створювати Deployment, що створює Podʼи для них, дозволить їм створювати ці Podʼи опосередковано. Так само, видалення вузла з API призведе до припинення роботи Podʼів, запланованих на цей вузол, і їх повторного створення на інших вузлах. Стандартні ролі являють собою компроміс між гнучкістю та загальними випадками використання, але більш обмежені ролі повинні бути уважно переглянуті, щоб запобігти випадковому підвищенню привілеїв. Якщо стандартні ролі не відповідають вашим потребам, ви можете створити ролі, специфічні для вашого випадку використання.
Kubelet експонує HTTPS-точки доступу, які надають потужний контроль над вузлом та контейнерами. Типово Kubelet дозволяє неавтентифікований доступ до цього API.
Операційні кластери повинні увімкнути автентифікацію та авторизацію Kubelet.
Керування можливостями робочого навантаження або користувача під час виконання
Авторизація в Kubernetes має високий рівень, спрямований на грубі дії з ресурсами. Більш потужні елементи керування існують як політики для обмеження за випадком використання того, як ці обʼєкти діють на кластер, себе та інші ресурси.
Обмеження використання ресурсів у кластері
Квоти ресурсів обмежують кількість або потужність виділених ресурсів для простору імен. Це найчастіше використовується для обмеження обсягу процесора, памʼяті або постійного дискового простору, який може виділятися простору імен, але також може контролювати кількість Podʼів, Serviceʼів або томів, що існують у кожному просторі імен.
Діапазони обмежень обмежують максимальний або мінімальний розмір деяких з вищезазначених ресурсів, щоб уникнути можливості користувачів запитувати надмірно високі або низькі значення для часто зарезервованих ресурсів, таких як памʼять, або надавати типові значення, коли вони не вказані.
Керування привілеями, з якими працюють контейнери
В описі Podʼа міститься контекст безпеки, який дозволяє запитувати доступ до виконання від імені конкретного користувача Linux на вузлі (наприклад, root), доступ до виконання з підвищеними привілеями або доступ до мережі хосту та інші елементи керування, які інакше дозволили б йому працювати без обмежень на вузлі хосту.
Загалом, більшість робочих навантажень застосунків потребують обмеженого доступу до ресурсів хосту, щоб вони могли успішно працювати як процес root (uid 0) без доступу до інформації про хост. Однак, враховуючи привілеї, повʼязані з користувачем root, слід робити контейнери застосунків такими, що не вимагають прав root для виконання. Так само адміністратори, які бажають запобігти втечі клієнтських застосунків з їхніх контейнерів, повинні застосувати стандарт безпеки Pod Baseline або Restricted.
Запобігання завантаженню небажаних модулів ядра контейнерами
Ядро Linux автоматично завантажує модулі ядра з диска за потребою в певних обставинах, наприклад, коли пристрій приєднаний або файлова система змонтована. Особливо актуальним для Kubernetes є те, що навіть непривілейовані процеси можуть спричинити завантаження певних модулів, повʼязаних з мережевими протоколами, просто створюючи сокет відповідного типу. Це може дозволити зловмиснику використовувати дірку в безпеці ядра, щодо якої адміністратор має припущення, що вона не використовується.
Щоб запобігти автоматичному завантаженню конкретних модулів, ви можете деінсталювати їх з вузла або додати правила для їх блокування. У більшості дистрибутивів Linux ви можете це зробити, створивши файл, наприклад, /etc/modprobe.d/kubernetes-blacklist.conf, з таким вмістом:
# DCCP майже не потрібен, має кілька серйозних вразливостей
# і не знаходиться у доброму стані обслуговування.
blacklist dccp
# SCTP не використовується в більшості кластерів Kubernetes, і також мав
# вразливості в минулому.
blacklist sctp
Для більш загального блокування завантаження модулів можна використовувати Linux Security Module (наприклад, SELinux), щоб абсолютно відмовити контейнерам у дозволі module_request, запобігаючи ядру завантажувати модулі для контейнерів у будь-яких обставинах. (Podʼи все ще можуть використовувати модулі, які були завантажені вручну або модулі, які були завантажені ядром від імені якогось більш привілейованого процесу.)
Обмеження доступу до мережі
Мережеві політики для простору імен дозволяють авторам застосунків обмежувати, які Podʼи в інших просторах імен можуть отримувати доступ до Podʼів і портів у їхніх просторах імен. Багато з підтримуваних постачальників мережі Kubernetes зараз враховують мережеві політики.
Також можна використовувати квоти та діапазони обмежень, щоб контролювати, чи можуть користувачі запитувати порти вузла або послуги з балансування навантаження, що у багатьох кластерах може контролювати видимість застосунків цих користувачів поза межами кластера.
Додаткові захисти можуть бути доступні, які контролюють правила мережі на рівні втулка чи середовища, такі як брандмауери на рівні вузла, фізичне розділення вузлів кластера для запобігання звʼязку між ними або розширена політика мережевого зʼєднання.
Обмеження доступу до API метаданих хмари
Хмарні платформи (AWS, Azure, GCE і т. д.) часто надають доступ до служб метаданих локально на екземплярах обчислювальних потужностей. Типово ці API доступні Podʼам, що працюють на екземплярі, і можуть містити облікові дані хмари для цього вузла або дані про створення, такі як облікові дані kubelet. Ці облікові дані можуть бути використані для підвищення привілеїв всередині кластера або до інших хмарних служб за тим самим обліковим записом.
При запуску Kubernetes на хмарній платформі обмежуйте дозволи, надані обліковим записам екземплярів, використовуйте мережеві політики для обмеження доступу Podʼів до API метаданих та уникайте використання даних про створення для передачі секретів.
Як адміністратор, бета-втулок обробки доспуску PodNodeSelector може бути використаний для примусового призначення Podʼів у межах стандартного простору імен або для вимоги до вказання певного селектора вузла, і якщо кінцеві користувачі не можуть змінювати простори імен, це може суттєво обмежити розміщення всіх Podʼів в певному робочому навантаженні.
Захист компонентів кластера від компрометації
У цьому розділі описані деякі загальні шаблони для захисту кластерів від компрометації.
Обмеження доступу до etcd
Права на запис до бази даних etcd для API еквівалентні отриманню root-прав на весь кластер, а доступ на читання може бути використаний для ескалації досить швидко. Адміністратори повинні завжди використовувати надійні облікові дані від серверів API до сервера etcd, такі як взаємна автентифікація за допомогою сертифікатів TLS клієнта, і часто рекомендується ізолювати сервери etcd за допомогою брандмауера, до яких можуть отримувати доступ лише сервери API.
Увага:
Дозвіл іншим компонентам в межах кластера доступу до головного екземпляра etcd з правами на читання або запис повного простору ключів еквівалентний наданню прав адміністратора кластера. Рекомендується використовувати окремі екземпляри etcd для компонентів, які не є головними, або використовувати ACL etcd для обмеження доступу на читання та запис до підмножини простору ключів.
Увімкнення логування аудиту
Audit logger є бета-функцією, яка записує дії, виконані API, для подальшого аналізу в разі компрометації. Рекомендується увімкнути логування аудиту та архівувати файл аудиту на захищеному сервері.
Обмеження доступу до альфа- або бета-функцій
Альфа- і бета-функції Kubernetes знаходяться в активній розробці і можуть мати обмеження або помилки, які призводять до вразливостей безпеки. Завжди оцінюйте цінність, яку можуть надати альфа- або бета-функції, у порівнянні з можливим ризиком для вашої безпеки. У разі сумнівів вимикайте функції, які ви не використовуєте.
Часто змінюйте облікові дані інфраструктури
Чим коротший термін дії Secret або облікового запису, тим складніше для зловмисника використати цей обліковий запис. Встановлюйте короткі терміни дії на сертифікати та автоматизуйте їх ротацію. Використовуйте постачальника автентифікації, який може контролювати терміни дії виданих токенів та використовуйте короткі терміни дії, де це можливо. Якщо ви використовуєте токени службового облікового запису в зовнішніх інтеграціях, плануйте часту ротацію цих токенів. Наприклад, як тільки завершиться фаза запуску, токен запуску, використаний для налаштування вузлів, повинен бути відкликаний або його запис авторизації скасований.
Перегляд інтеграцій сторонніх розробників перед їх включенням
Багато сторонніх інтеграцій до Kubernetes можуть змінювати профіль безпеки вашого кластера. При включенні інтеграції завжди переглядайте дозволи, які запитує розширення, перед наданням доступу. Наприклад, багато інтеграцій з безпеки можуть запитувати доступ до перегляду всіх секретів у вашому кластері, що фактично робить цей компонент адміністратором кластера. У разі сумнівів обмежте інтеграцію на роботу в одному просторі імен, якщо це можливо.
Компоненти, які створюють Podʼи, також можуть мати неочікувану потужність, якщо вони можуть робити це всередині просторів імен, таких як простір імен kube-system, оскільки ці Podʼи можуть отримати доступ до секретів службових облікових записів або працювати з підвищеними привілеями, якщо цим службовим обліковим записам надано доступ до дозвольних PodSecurityPolicies.
Якщо ви використовуєте Pod Security admission та дозволяєте будь-якому компоненту створювати Podʼи в межах простору імен, що дозволяє привілейовані Podʼи, ці Podʼи можуть мати здатність втікати зі своїх контейнерів і використовувати цей розширений доступ для підвищення своїх привілеїв.
Ви не повинні дозволяти ненадійним компонентам створювати Podʼи в будь-якому системному просторі імен (те, що починається з kube-) або в будь-якому просторі імен, де цей доступ дозволяє можливість підвищення привілеїв.
Шифрування секретів у спокої
Загалом, база даних etcd буде містити будь-яку інформацію, доступну через API Kubernetes і може надати зловмиснику значний обсяг інформації про стан вашого кластера. Завжди шифруйте свої резервні копії за допомогою розглянутого рішення для резервного копіювання та шифрування, і розгляньте можливість використання повного шифрування диска, де це можливо.
Kubernetes підтримує необовʼязкове шифрування у спокої для інформації в API Kubernetes. Це дозволяє вам забезпечити те, що при збереженні Kubernetes даних для обʼєктів (наприклад, обʼєктів Secret або ConfigMap), сервер API записує зашифроване представлення обʼєкта. Це шифрування означає, що навіть у того, хто має доступ до даних резервних копій etcd, не має можливості переглянути вміст цих обʼєктів. У Kubernetes 1.34 ви також можете шифрувати власні ресурси; шифрування в спокої для розширених API, визначених у визначеннях CustomResourceDefinitions, було додано в Kubernetes як частина випуску v1.26.
Отримання сповіщень про оновлення безпеки та повідомлення про вразливості
Приєднуйтесь до групи kubernetes-announce, щоб отримувати електронні листи про оголошення з питань безпеки. Див. сторінку повідомлень про безпеку для отримання додаткової інформації щодо повідомлення про вразливості.
2.36 - Встановлення параметрів Kubelet через файл конфігурації
Перш ніж ви розпочнете
Деякі кроки на цій сторінці використовують інструмент jq. Якщо у вас немає jq, ви можете встановити його через отримання оновлень програм вашої операційної системи або завантажити з https://jqlang.github.io/jq/.
Деякі кроки також включають встановлення curl, який також можна встановити засобами встановлення програмного забезпечення вашої операційної системи.
Частину параметрів конфігурації kubelet можна встановити за допомогою конфігураційного файлу на диску, як альтернативу командним прапорцям.
Надання параметрів через файл конфігурації є рекомендованим підходом, оскільки це спрощує розгортання вузлів та управління конфігурацією.
Створіть файл конфігурації
Підмножина конфігурації kubelet, яку можна налаштувати через файл, визначається структурою KubeletConfiguration.
Файл конфігурації повинен бути у форматі JSON або YAML, який представляє параметри цієї структури. Переконайтеся, що у kubelet є права для читання файлу.
evictionHard: Kubelet буде виселяти Podʼи за однією з наступних умов:
Коли доступна памʼять вузла впаде нижче 100 МіБ.
Коли доступний простір основної файлової системи вузла менше 10%.
Коли доступний простір файлової системи образів менше 15%.
Коли більше ніж 95% inodes основної файлової системи вузла використано.
Примітка:
У прикладі, змінюючи лише один типовий параметр для evictionHard, типові значення інших параметрів не будуть успадковані та будуть встановлені в нуль. Щоб надати власні значення, вам слід надати всі порогові значення відповідно. Крім того, ви можете встановити MergeDefaultEvictionSettings в true у файлі конфігурації kubelet, якщо будь-який параметр буде змінено, то інші параметри успадкують стандартне значення замість 0.
imagefs — це опціональна файлова система, яку середовища виконання контейнерів використовують для зберігання образів контейнерів та записуваних шарів контейнерів.
Запуск процесу kubelet, налаштованого через файл конфігурації
Примітка:
Якщо ви використовуєте kubeadm для ініціалізації кластера, використовуйте kubelet-config під час створення вашого кластера за допомогою kubeadm init. Дивіться налаштування kubelet за допомогою kubeadm для деталей.
Запустіть kubelet з параметром --config, вказавши шлях до файлу конфігурації kubelet. Після цього kubelet завантажить свою конфігурацію з цього файлу.
Зверніть увагу, що параметри командного рядка, які стосуються того ж значення, що й файл конфігурації, перекриватимуть це значення. Це допомагає забезпечити зворотну сумісність з API командного рядка.
Також зверніть увагу, що відносні шляхи файлів у файлі конфігурації kubelet розглядаються відносно місця розташування файлу конфігурації kubelet, тоді як відносні шляхи в параметрах командного рядка розглядаються відносно поточної робочої теки kubelet.
Зауважте, що деякі типові значення відрізняються між параметрами командного рядка та файлом конфігурації kubelet. Якщо наданий параметр --config і значення не вказані через командний рядок, то застосовуються типові значення для версії KubeletConfiguration. У згаданому вище прикладі ця версія є kubelet.config.k8s.io/v1beta1.
Тека для файлів конфігурації kubelet
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.30 [beta]
Ви можете вказати теку конфігурації drop-in для kubelet. Стандартно kubelet не шукає файли конфігурації drop-in — ви повинні вказати шлях. Наприклад: --config-dir=/etc/kubernetes/kubelet.conf.d
Для Kubernetes v1.28 по v1.29 ви можете вказати лише --config-dir, якщо також встановите змінну середовища KUBELET_CONFIG_DROPIN_DIR_ALPHA для процесу kubelet (значення цієї змінної не має значення).
Примітка:
Суфікс дійсного файлу конфігурації drop-in для kubelet має бути .conf. Наприклад: 99-kubelet-address.conf
Kubelet обробляє файли у своїй теці конфігурації drop-in, сортуючи по повному імені файлу. Наприклад, 00-kubelet.conf обробляється першим, а потім перезаписується файлом з назвою 01-kubelet.conf.
Ці файли можуть містити часткові конфігурації, але не повинні бути не валідними та обовʼязково повинні включати метадані типу, зокрема apiVersion та kind. Перевірка виконується лише на кінцевій результівній структурі конфігурації, збереженій внутрішньо в kubelet. Це надає гнучкість в управлінні та злитті конфігурацій kubelet з різних джерел, запобігаючи небажаній конфігурації. Однак важливо зазначити, що поведінка варіюється залежно від типу даних поля конфігурації.
Різні типи даних у структурі конфігурації kubelet обʼєднуються по-різному. Дивіться посилання на довідку для отримання додаткової інформації.
Порядок обʼєднання конфігурації kubelet
При запуску kubelet обʼєднує конфігурацію з:
Feature gate, вказаних через командний рядок (найнижчий пріоритет).
Конфігурація kubelet.
Файли конфігурації drop-in, відповідно до порядку сортування.
Аргументи командного рядка, за винятком feature gate (найвищий пріоритет).
Примітка:
Механізм теки конфігурації drop-in для kubelet схожий, але відрізняється від того, як інструмент kubeadm дозволяє вам патчити конфігурацію. Інструмент kubeadm використовує конкретну стратегію застосування патчів для своєї конфігурації, тоді як єдина стратегія накладання патчів для файлів конфігурації drop-in kubelet це replace. Kubelet визначає порядок обʼєднання на основі сортування суфіксів алфавітно-цифровим чином, і замінює кожне поле, присутнє у файлі вищого пріоритету.
Перегляд конфігурації kubelet
Оскільки конфігурація тепер може бути розподілена у декілька файлів за допомогою цієї функції, якщо хтось хоче переглянути остаточну активовану конфігурацію, то вони можуть скористатися цими кроками для перегляду конфігурації kubelet:
Запустіть проксі-сервер за допомогою команди kubectl proxy у вашому терміналі.
kubectl proxy
Це дозволить отримати вивід подібний до:
Starting to serve on 127.0.0.1:8001
Відкрийте інше вікно термінала і скористайтесь curl, щоб отримати конфігурацію kubelet. Замініть <node-name> на фактичне імʼя вашого вузла:
curl -X GET http://127.0.0.1:8001/api/v1/nodes/<node-name>/proxy/configz | jq .
Дізнайтеся більше про обʼєднання конфігурації kubelet у довідці.
2.37 - Спільне використання кластера з просторами імен
Ця сторінка показує, як переглядати, працювати та видаляти простори імен. На сторінці також розказується, як використовувати простори імен Kubernetes для розділення вашого кластера.
Перелік поточних просторів імен у кластері можна отримати за допомогою команди:
kubectl get namespaces
NAME STATUS AGE
default Active 11d
kube-node-lease Active 11d
kube-public Active 11d
kube-system Active 11d
Kubernetes запускається з чотирма просторами імен:
default — стандартний простір імен для обʼєктів без іншого простору імен.
kube-node-lease — цей простір імен містить обʼєкти Lease, повʼязані з кожним вузлом. Лізинги вузлів дозволяють kubelet надсилати пульси, щоб панель управління було в змозі виявляти збої вузлів.
kube-public — цей простір імен створюється автоматично і доступний для читання всіма користувачами (включаючи неавтентифікованих). Цей простір імен зазвичай зарезервований для використання у межах кластера, у випадках коли деякі ресурси мають бути відкриті та доступні для загального огляду у всьому кластері. Публічний аспект цього простору імен є лише конвенцією, а не вимогою.
kube-system — простір імен для обʼєктів, створених системою Kubernetes.
Також ви можете отримати інформацію про певний простір імен за допомогою команди:
kubectl get namespaces <name>
Або отримати детальну інформацію за допомогою:
kubectl describe namespaces <name>
Name: default
Labels: <none>
Annotations: <none>
Status: Active
No resource quota.
Resource Limits
Type Resource Min Max Default
---- -------- --- --- -------
Container cpu - - 100m
Зверніть увагу, що ці деталі включають інформацію про квоти ресурсів (якщо вони є) та обмеження діапазону ресурсів.
Квота ресурсів відстежує загальне використання ресурсів у просторі імен та дозволяє операторам кластера встановлювати жорсткі ліміти використання ресурсів, які може споживати простір імен.
Обмеження діапазону визначає мінімальні/максимальні обмеження на кількість ресурсів, які може споживати одиниця у просторі імен.
Назва вашого простору імен повинна бути дійсною DNS-міткою.
Є необовʼязкове поле finalizers, яке дозволяє спостережувачам очищати ресурси кожного разу, коли простір імен видаляється. Майте на увазі, що якщо ви вказуєте неіснуючий finalizer, простір імен буде створений, але залишиться в стані Terminating, якщо користувач спробує його видалити.
Ця операція видалення є асинхронною, тому протягом певного часу ви будете бачити простір імен у стані Terminating.
Поділ кластера за допомогою просторів імен Kubernetes
Типово кластер Kubernetes створює простір імен default при його розгортанні, щоб утримувати стандартний набір Podʼів, Serviceʼів та Deploymentʼів, які використовуються в кластері.
Припускаючи, що у вас є новий кластер, ви можете перевірити наявні простори імен, виконавши наступне:
kubectl get namespaces
NAME STATUS AGE
default Active 13m
Створення нових просторів імен
У цьому завданні ми створимо два додаткових простори імен Kubernetes, щоб утримувати наш контент.
У випадку, коли організація використовує спільний кластер Kubernetes для розробки та операційної діяльності:
Команда розробників хотіла б мати простір у кластері, де вони можуть переглядати список Podʼів, Serviceʼів та Deploymentʼів, які вони використовують для створення та запуску свого застосунку. У цьому просторі ресурси Kubernetes зʼявляються та зникають, і обмеження на те, хто може або не може змінювати ресурси є слабкими для забезпечення гнучкої розробки.
Команда операторів хотіла б мати простір у кластері, де вони можуть використовувати строгі процедури на те, хто може або не може маніпулювати набором Podʼів, Serviceʼів та Deploymentʼів, що працюють в операційному середовищі.
Одним з можливих варіантів для цієї організації є розподіл кластера Kubernetes на два простори імен: development та production. Створімо два нових простори імен для нашої роботи.
Створіть простір імен development за допомогою kubectl:
Щоб переконатися, що все в порядку, виведемо список всіх просторів імен у нашому кластері.
kubectl get namespaces --show-labels
NAME STATUS AGE LABELS
default Active 32m <none>
development Active 29s name=development
production Active 23s name=production
Створення Podʼів в кожному просторі імен
Простір імен Kubernetes забезпечує область для Podʼів, Serviceʼів та Deploymentʼів у кластері. Користувачі, що взаємодіють з одним простором імен, не бачать вмісту іншого простору імен. Щоб продемонструвати це, створімо простий Deployment та Podʼи в просторі імен development.
Ми створили Deployment з 2 реплік, що запускає Pod з назвою snowflake з базовим контейнером, який обслуговує імʼя хосту.
kubectl get deployment -n=development
NAME READY UP-TO-DATE AVAILABLE AGE
snowflake 2/2 2 2 2m
kubectl get pods -l app=snowflake -n=development
NAME READY STATUS RESTARTS AGE
snowflake-3968820950-9dgr8 1/1 Running 0 2m
snowflake-3968820950-vgc4n 1/1 Running 0 2m
Це чудово, розробники можуть робити те, що вони хочуть, і їм не потрібно хвилюватися про те, як це вплине на контент у просторі імен production.
Перейдімо до простору імен production і покажемо, як ресурси в одному просторі імен приховані від іншого. Простір імен production повинен бути порожнім, і наступні команди не повинні повертати нічого.
kubectl get deployment -n=production
kubectl get pods -n=production
Операційна діяльність вимагає догляду за худобою, тому створімо кілька Podʼів для худоби.
NAME READY UP-TO-DATE AVAILABLE AGE
cattle 5/5 5 5 10s
kubectl get pods -l app=cattle -n=production
NAME READY STATUS RESTARTS AGE
cattle-2263376956-41xy6 1/1 Running 0 34s
cattle-2263376956-kw466 1/1 Running 0 34s
cattle-2263376956-n4v97 1/1 Running 0 34s
cattle-2263376956-p5p3i 1/1 Running 0 34s
cattle-2263376956-sxpth 1/1 Running 0 34s
На цьому етапі має бути зрозуміло, що ресурси, які користувачі створюють в одному просторі імен, приховані від іншого простору імен.
Поки політика підтримки в Kubernetes розвивається, ми розширимо цей сценарій, щоб показати, як можна надавати різні правила авторизації для кожного простору імен.
Розуміння мотивації використання просторів імен
Один кластер повинен задовольняти потреби кількох користувачів або груп користувачів (далі в цьому документі спільнота користувачів).
Простори імен Kubernetes допомагають різним проєктам, командам або клієнтам спільно використовувати кластер Kubernetes.
Механізму для прикріплення авторизації та політики до підрозділу кластера.
Використання кількох просторів імен не є обовʼязковим.
Кожна спільнота користувачів хоче мати можливість працювати в ізоляції від інших спільнот користувачів. У кожної спільноти користувачів свої:
ресурси (pods, services, replication controllers тощо)
політики (хто може або не може виконувати дії у своїй спільноті)
обмеження (цій спільноті дозволено стільки квоти тощо)
Оператор кластера може створити простір імен для кожної унікальної спільноти користувачів.
Простір імен забезпечує унікальну область для:
іменованих ресурсів (щоб уникнути базових конфліктів імен)
делегування прав управління довіреним користувачам
здатності обмежувати використання ресурсів спільнотою
Сценарії використання включають такі:
Як оператор кластера, я хочу підтримувати кілька спільнот користувачів на одному кластері.
Як оператор кластера, я хочу делегувати владу управління підрозділам кластера довіреним користувачам у цих спільнотах.
Як оператор кластера, я хочу обмежити кількість ресурсів, які кожна спільнота може споживати, щоб обмежити вплив на інші спільноти, що використовують кластер.
Як користувач кластера, я хочу взаємодіяти з ресурсами, які є важливими для моєї спільноти користувачів в ізоляції від того, що роблять інші спільноти користувачів на кластері.
Розуміння просторів імен та DNS
Коли ви створюєте Service, він створює відповідний DNS-запис. Цей запис має вигляд <імʼя-сервісу>.<імʼя-простору-імен>.svc.cluster.local, що означає, що якщо контейнер використовує <імʼя-сервісу>, воно буде розпізнано як сервіс, який знаходиться в межах простору імен. Це корисно для використання однакової конфігурації в кількох просторах імен, таких як Development, Staging та Production. Якщо ви хочете отримати доступ за межі просторів імен, вам потрібно використовувати повністю кваліфіковане доменне імʼя (FQDN).
Ця сторінка надає огляд кроків, які вам слід виконати для оновлення кластера Kubernetes.
Проєкт Kubernetes рекомендує оперативно оновлюватись до останніх випусків патчів, а також переконатися, що ви використовуєте підтримуваний мінорний випуск Kubernetes. Дотримання цих рекомендацій допоможе вам залишатися в безпеці.
Спосіб оновлення кластера залежить від того, як ви спочатку розгорнули його та від будь-яких наступних змін.
Відредагувати маніфести та інші ресурси на основі змін API, які супроводжують нову версію Kubernetes
Перш ніж ви розпочнете
Вам потрібно мати кластер. Ця сторінка присвячена оновленню з Kubernetes
1.33 до Kubernetes 1.34. Якщо ваш кластер зараз працює на Kubernetes 1.33, тоді, будь ласка, перевірте документацію для версії Kubernetes, на яку ви плануєте оновити.
Підходи до оновлення
kubeadm
Якщо ваш кластер був розгорнутий за допомогою інструменту kubeadm, дивіться Оновлення кластерів kubeadm для докладної інформації щодо оновлення кластера.
Для кожного вузла в вашому кластері, очистіть цей вузол, а потім або замініть його новим вузлом, який використовує 1.34 kubelet, або оновіть kubelet на цьому вузлі та відновіть його Service.
Увага:
Jxbotyyz вузлів перед оновленням kubelet забезпечує повторний вхід Podʼів та перезапуск контейнерів, що може бути необхідно для розвʼязання деяких проблем безпеки або інших важливих помилок.
Інші розгортання
Дивіться документацію для вашого інструменту розгортання кластера, щоб дізнатися рекомендовані кроки для підтримки.
Завдання після оновлення
Перемикання версії API зберігання кластера
Обʼєкти, які серіалізуються в etcd для внутрішнього представлення кластера ресурсів Kubernetes, записуються за допомогою певної версії API.
Коли підтримуване API змінюється, ці обʼєкти можуть потребувати перезаписування в новому API. Невиконання цього призведе до того, що ресурси не можна буде декодувати або використовувати за допомогою сервера API Kubernetes.
Для кожного ураженого обʼєкта, отримайте його, використовуючи останню підтримувану версію API, а потім записуйте його також, використовуючи останню підтримувану версію API.
Оновлення маніфестів
Оновлення до нової версії Kubernetes може надати нові API.
Ви можете використовувати команду kubectl convert для конвертації маніфестів між різними версіями API. Наприклад:
kubectl convert -f pod.yaml --output-version v1
Інструмент kubectl замінює вміст pod.yaml на маніфест, який встановлює kind на Pod (незмінно), але з оновленим apiVersion.
Втулки пристроїв
Якщо ваш кластер використовує втулки пристроїв і вузол потребує оновлення до випуску Kubernetes з новішою версією API втулка пристроїв, втулки пристроїв повинні бути оновлені для підтримки обох версій перед оновленням вузла, щоб гарантувати, що виділення пристроїв продовжує успішно завершуватися під час оновлення.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Вам також потрібно створити приклад Deployment, щоб експериментувати з різними типами каскадного видалення. Вам доведеться перестворити Deployment для кожного типу.
Перевірка власників у ваших Podʼах
Перевірте, що поле ownerReferences присутнє у ваших Podʼах:
Стандартно Kubernetes використовує фонове каскадне видалення для видалення залежностей обʼєкта. Ви можете переключитися на каскадне видалення на видноті за допомогою kubectl або за допомогою API Kubernetes, залежно від версії Kubernetes вашого кластера.
Для перевірки версії введіть kubectl version.
Ви можете видаляти обʼєкти за допомогою каскадного видалення, використовуючи kubectl або API Kubernetes.
Використовуйте або kubectl, або API Kubernetes для видалення Deployment, залежно від версії Kubernetes вашого кластера.
Для перевірки версії введіть kubectl version.
Ви можете видаляти обʼєкти за допомогою фонового каскадного видалення за допомогою kubectl
або API Kubernetes.
Kubernetes типово використовує фонове каскадне видалення, і робить це навіть якщо ви виконуєте наступні команди без прапорця --cascade або аргументу propagationPolicy.
Видалення власних обʼєктів та загублених залежностей
Типово, коли ви вказуєте Kubernetes видалити обʼєкт, controller також видаляє залежні обʼєкти. Ви можете загубити залежності використовуючи kubectl або API Kubernetes, залежно від версії Kubernetes вашого кластера.
2.40 - Використання постачальника KMS для шифрування даних
Ця сторінка показує, як налаштувати постачальника Служби керування ключами (KMS) та втулок для шифрування конфіденційних даних. У Kubernetes 1.34 існують дві версії шифрування даних за допомогою KMS у спокої. Якщо це можливо, вам слід використовувати KMS v2, оскільки KMS v1 застарів (починаючи з Kubernetes v1.28) та є типово вимкненим (починаючи з Kubernetes v1.29). KMS v2 пропонує значно кращі характеристики продуктивності, ніж KMS v1.
Увага:
Ця документація стосується загальновживаної реалізації KMS v2 (і застарілої реалізації версії 1). Якщо ви використовуєте будь-які компоненти панелі управління старші за Kubernetes v1.29, будь ласка, перевірте відповідну сторінку в документації для версії Kubernetes, яку використовує ваш кластер. Ранні версії Kubernetes мали різну поведінку, яка може бути важливою для інформаційної безпеки.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія Kubernetes, яка вам потрібна, залежить від того, яку версію API KMS ви вибрали. Kubernetes рекомендує використовувати KMS v2.
Якщо ви вибрали KMS API v1 для підтримки кластерів до версії v1.27 або якщо у вас є застарілий плагін KMS, який підтримує лише KMS v1, будь-яка підтримувана версія Kubernetes буде працювати. Цей API є застарілим починаючи з Kubernetes v1.28. Kubernetes не рекомендує використовувати цей API.
Для перевірки версії введіть kubectl version.
KMS v1
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.28 [deprecated]
Потрібна версія Kubernetes 1.10.0 або пізніше.
Починаючи з версії 1.29, реалізація v1 KMS типово вимкнена. Щоб увімкнути функцію, встановіть --feature-gates=KMSv1=true, щоб налаштувати постачальника KMS v1.
Ваш кластер повинен використовувати etcd v3 або пізніше.
KMS v2
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.29 [stable]
Ваш кластер повинен використовувати etcd v3 або пізніше.
Шифрування KMS та ключі для кожного обʼєкта
Постачальник шифрування KMS використовує схему шифрування конвертів для шифрування даних в etcd. Дані шифруються за допомогою ключа шифрування даних (data encryption key — DEK). DEK шифруються за допомогою ключа шифрування ключа (key encryption key — KEK), який зберігається та обслуговується на віддаленому KMS.
Якщо ви використовуєте (застарілу) реалізацію v1 KMS, для кожного шифрування генерується новий DEK.
З KMS v2 для кожного шифрування генерується новий DEK: API-сервер використовує функцію похідного ключа для генерації ключів шифрування даних з одноразовим використанням секретного початкового елемента (seed — насіння) у поєднанні з випадковими даними. Ротація насіння відбувається при кожній зміні KEK (див. розділ Розуміння key_id та Ротація ключів нижче для докладніших відомостей).
Постачальник KMS використовує gRPC для звʼязку з певним втулком KMS через сокет UNIX-домену. Втулок KMS, який реалізований як сервер gRPC та розгорнутий на тих самих вузлах що і панель управління Kubernetes, відповідає за всі комунікації з віддаленим KMS.
Налаштування постачальника KMS
Для налаштування постачальника KMS на API-сервері включіть постачальника типу kms у масиві providers у файлі конфігурації шифрування і встановіть наступні властивості:
KMS v1
apiVersion: Версія API для постачальника KMS. Залиште це значення порожнім або встановіть його на v1.
name: Показує назву втулка KMS. Не може бути змінено після встановлення.
endpoint: Адреса прослуховування сервера gRPC (втулка KMS). Точка доступу — це сокет UNIX-домену.
cachesize: Кількість ключів шифрування даних (DEK), які будуть збережені в кеші у відкритому вигляді. Коли ключі DEK збережені в кеші, вони можуть бути використані без додаткового звертання до KMS; тоді як ключі DEK, які не збережені в кеші, потребують звертання до KMS для розшифрування.
timeout: Скільки часу kube-apiserver має чекати на відповідь від втулка kms, перш ніж сповістити про помилку (типово — 3 секунди).
KMS v2
apiVersion: Версія API для постачальника KMS. Встановіть це на v2.
name:Показує назву втулка KMS. Не може бути змінено після встановлення.
endpoint: Адреса прослуховування сервера gRPC (втулка KMS). Точка доступу — це сокет UNIX-домену.
timeout: Скільки часу kube-apiserver має чекати на відповідь від втулка kms, перш ніж сповістити про помилку (типово — 3 секунди).
KMS v2 не підтримує властивість cachesize. Всі ключі шифрування даних (DEK) будуть збережені в кеші у відкритому вигляді, як тільки сервер розкриє їх за допомогою звертання до KMS. Після збереження в кеші, ключі DEK можуть бути використані для виконання розшифрування нескінченно довго без звертання до KMS.
Для реалізації втулка KMS ви можете розробити новий сервер gRPC втулка або увімкнути втулок KMS, який вже надається вашим постачальником хмарних послуг. Потім ви інтегруєте втулок з віддаленим KMS та розгортаєте його на панелі управління Kubernetes.
Увімкнення KMS, що підтримується вашим постачальником хмарних послуг
Зверніться до вашого постачальника хмарних послуг для отримання інструкцій щодо увімкнення втулка KMS, який він надає.
Розробка сервера gRPC втулка KMS
Ви можете розробити сервер gRPC втулка KMS, використовуючи файл шаблону, доступний для мови програмування Go. Для інших мов програмування ви можете використовувати файл proto для створення файлу шаблону, який ви можете використовувати для написання коду сервера gRPC.
KMS v1
Використовуючи Go: Використовуйте функції та структури даних у файлі шаблону: api.pb.go для написання коду сервера gRPC.
Використовуючи інших мов програмування: Використовуйте компілятор protoc з файлом proto: api.proto для генерації файлу шаблону для конкретної мови програмування.
KMS v2
Використовуючи Go: Надається високорівнева бібліотека для спрощення процесу. Низькорівневі реалізації можуть використовувати функції та структури даних у файлі шаблону: api.pb.go для написання коду сервера gRPC.
Використовуючи інших мов програмування: Використовуйте компілятор protoc з файлом proto: api.proto для генерації файлу шаблону для конкретної мови програмування.
Потім використовуйте функції та структури даних у файлі шаблону для написання коду сервера.
Примітки
KMS v1
Версія втулка kms: v1beta1
У відповідь на виклик процедури Version сумісний втулок KMS повинен повернути v1beta1 як VersionResponse.version.
Версія повідомлення: v1beta1
Усі повідомлення від постачальника KMS мають поле версії встановлене на v1beta1.
Протокол: UNIX доменний сокет (unix)
Втулок реалізований як сервер gRPC, який слухає UNIX доменний сокет. Розгортання втулка повинно створити файл у файловій системі для запуску зʼєднання gRPC unix domain socket. API-сервер (клієнт gRPC) налаштований на постачальника KMS (сервер gRPC) за допомогою точки доступу UNIX доменного сокета для звʼязку з ним. Може використовуватися абстрактний Linux сокет, точка доступу якого починається з /@, наприклад, unix:///@foo. Слід бути обережним при використанні цього типу сокета, оскільки вони не мають концепції ACL (на відміну від традиційних файлових сокетів). Однак вони підпадають під простір імен мережі Linux, тому будуть доступні лише контейнерам у тому ж самому Podʼі, якщо не використовується мережа хосту.
KMS v2
Версія втулка KMS: v2
У відповідь на віддалений виклик процедури Status сумісний втулок KMS повинен повернути свою версію сумісності KMS як StatusResponse.version. У цій відповіді на статус також повинен бути включений "ok" як StatusResponse.healthz і key_id (ідентифікатор KEK віддаленого KMS) як StatusResponse.key_id. Проєкт Kubernetes рекомендує зробити ваш втулок сумісним зі стабільним v2 API KMS. Kubernetes 1.34 також підтримує v2beta1 API для KMS; майбутні релізи Kubernetes, швидше за все, будуть продовжувати підтримувати цю бета-версію.
API-сервер надсилає віддалений виклик процедури Status приблизно кожну хвилину, коли все в справному стані, і кожні 10 секунд, коли втулок не справний. Втулки повинні пильнувати за оптимізацією цього виклику, оскільки він буде під постійним навантаженням.
Шифрування
Виклик процедури EncryptRequest надає текст для шифрування та UID для цілей логування. У відповіді повинен бути включений шифротекст, key_id для використаного KEK та, опціонально, будь-які метадані, які потрібні втулку KMS для допомоги в майбутніх викликах DecryptRequest (через поле annotations). Втулок повинен гарантувати, що будь-який різний текст призводить до різної відповіді (шифротекст, key_id, annotations).
Якщо втулок повертає непорожній масив annotations, всі ключі масиву повинні бути повністю кваліфікованими доменними іменами, такими як example.com. Приклад використання annotations — {"kms.example.io/remote-kms-auditid":"<audit ID використаний віддаленим KMS>"}
API-сервер не виконує виклик процедури EncryptRequest на високому рівні. Реалізації втулків повинні все ж старатися, щоб зберегти час очікування кожного запиту менше 100 мілісекунд.
Розшифрування
Виклик процедури DecryptRequest надає (ciphertext, key_id, annotations) з EncryptRequest та UID для цілей логування. Як і очікується, це протилежне виклику EncryptRequest. Втулки повинні перевірити, що key_id є тим, що вони розуміють — вони не повинні намагатися розшифрувати дані, якщо вони не впевнені, що вони були зашифровані ними раніше.
API-сервер може виконати тисячі викликів процедури DecryptRequest під час запуску для заповнення свого кешу перегляду. Таким чином, реалізації втулків повинні виконати ці виклики якнайшвидше, і повинні старатися зберегти час очікування кожного запиту менше 10 мілісекунд.
Розуміння key_id та Ротації ключа
key_id є публічним, незасекреченим імʼям віддаленого KEK KMS, який в цей момент використовується. Він може бути зареєстрований під час регулярної роботи API-сервера та, отже, не повинен містити ніяких приватних даних. Реалізації втулків повинні використовувати хеш, щоб уникнути витоку будь-яких даних. Метрики KMS v2 пильнують за хешуванням цього значення перед показом його через точку доступу /metrics.
API-сервер вважає, що key_id, отриманий з виклику процедури Status, є авторитетним. Отже, зміна цього значення сигналізує API-серверу, що віддалений KEK змінився, і дані, зашифровані старим KEK, повинні бути позначені як застарілі при виконанні операція запису без операції (як описано нижче). Якщо виклик процедури EncryptRequest повертає key_id, який відрізняється від Status, відповідь відкидається, і втулок вважається несправним. Таким чином, реалізації повинні гарантувати, що key_id, що повертається зі Status, буде таким самим, як той, що повертається з EncryptRequest. Крім того, втулки повинні забезпечити стабільність key_id і не допускати перемикання між значеннями (тобто під час ротації віддаленого KEK).
Втулки не повинні повторно використовувати key_id, навіть у ситуаціях, коли раніше використаний віддалений KEK був відновлений. Наприклад, якщо втулок використовував key_id=A, перемикнувся на key_id=B, а потім повернувся до key_id=A — замість того, щоб повідомити key_id=A, втулок повинен повідомити якесь похідне значення, таке як key_id=A_001 або використовувати нове значення, наприклад key_id=C.
Оскільки API-сервер опитує Status приблизно кожну хвилину, ротація key_id не є миттєвою. Крім того, API-сервер буде користуватися останнім дійсним станом протягом приблизно трьох хвилин. Таким чином, якщо користувач хоче здійснити пасивний підхід до міграції зберігання (тобто, чекаючи), він повинен запланувати міграцію на 3 + N + M хвилин після ротації віддаленого KEK (N — це час, необхідний для того, щоб втулок помітив зміну key_id, і M — бажаний буфер, щоб дозволити обробку змін конфігурації, рекомендується мінімальне значення M в пʼять хвилин). Зазначте, що для виконання ротації KEK перезапуск API-сервера не потрібен.
Увага:
Оскільки ви не контролюєте кількість записів, виконаних з DEK, проєкт Kubernetes рекомендує робити ротацію KEK принаймні кожні 90 днів.
Протокол: UNIX доменний сокет (unix)
Втулок реалізований як сервер gRPC, який слухає UNIX доменний сокет. Розгортання втулка повинно створити файл у файловій системі для запуску зʼєднання gRPC unix domain socket. API-сервер (клієнт gRPC) налаштований на постачальника KMS (сервер gRPC) за допомогою точки доступу UNIX доменного сокета для звʼязку з ним. Може використовуватися абстрактний Linux сокет, точка доступу якого починається з /@, наприклад, unix:///@foo. Слід бути обережним при використанні цього типу сокета, оскільки вони не мають концепції ACL (на відміну від традиційних файлових сокетів). Однак вони підпадають під простір імен мережі Linux, тому будуть доступні лише контейнерам у тому ж самому Podʼі, якщо не використовується мережа хосту.
Інтеграція втулка KMS з віддаленим KMS
Втулок KMS може спілкуватися з віддаленим KMS за допомогою будь-якого протоколу, який підтримується KMS. Усі дані конфігурації, включаючи облікові дані автентифікації, які використовує втулок KMS для спілкування з віддаленим KMS, зберігаються і керуються втулком KMS незалежно. Втулок KMS може кодувати шифротекст з додатковими метаданими, які можуть бути потрібні перед відправленням його в KMS для розшифрування (KMS v2 робить цей процес простішим, надаючи спеціальне поле annotations).
Розгортання втулка KMS
Переконайтеся, що втулок KMS працює на тих самих хостах, що і сервер(и) API Kubernetes.
Шифрування даних за допомогою постачальника KMS
Для шифрування даних виконайте наступні кроки:
Створіть новий файл EncryptionConfiguration, використовуючи відповідні властивості для постачальника kms, щоб шифрувати ресурси, такі як Secrets та ConfigMaps. Якщо ви хочете зашифрувати розширення API, яке визначено у визначенні CustomResourceDefinition, ваш кластер повинен працювати на Kubernetes v1.26 або новіше.
Встановіть прапорець --encryption-provider-config на kube-apiserver, щоб вказати місце розташування файлу конфігурації.
Аргумент --encryption-provider-config-automatic-reload типу boolean визначає, чи слід автоматично перезавантажувати файл, встановлений за допомогою --encryption-provider-config, у разі зміни вмісту на диску.
Встановлення --encryption-provider-config-automatic-reload в true обʼєднує всі перевірки стану в одну точку доступу перевірки стану. Індивідуальні перевірки стану доступні тільки тоді, коли використовуються постачальники KMS v1 і конфігурація шифрування не перезавантажується автоматично.
Наступна таблиця містить підсумки точок доступу перевірки стану для кожної версії KMS:
Конфігурації KMS
Без автоматичного перезавантаження
З автоматичним перезавантаженням
Тільки KMS v1
Індивідуальні перевірки
Одна перевірка
Тільки KMS v2
Одна перевірка
Одна перевірка
KMS v1 та KMS v2
Індивідуальні перевірки
Одна перевірка
Без KMS
Немає
Одна перевірка
Одна перевірка означає, що єдиною точкою доступу перевірки стану є /healthz/kms-providers.
Індивідуальні перевірки означає, що для кожного втулка KMS є асоційована точка доступу перевірки стану на основі його місця в конфігурації шифрування: /healthz/kms-provider-0, /healthz/kms-provider-1 тощо.
Ці шляхи точок доступу перевірки стану жорстко закодовані та генеруються/контролюються сервером. Індекси для індивідуальних перевірок відповідають порядку, у якому обробляється конфігурація шифрування KMS.
До виконання кроків, визначених у Забезпечення шифрування всіх секретів, список providers повинен закінчуватися постачальником identity: {}, щоб можна було читати незашифровані дані. Після шифрування всіх ресурсів постачальника identity слід видалити, щоб запобігти обробці незашифрованих даних сервером API.
Коли шифрування даних у стані спокою правильно налаштовано, ресурси шифруються під час запису. Після перезапуску вашого kube-apiserver, будь-які новостворені або оновлені Secret чи інші типи ресурсів, налаштовані в EncryptionConfiguration, мають бути зашифровані при зберіганні. Щоб перевірити, ви можете використовувати програму командного рядка etcdctl для отримання вмісту ваших секретних даних.
Створіть новий Secret з назвою secret1 в просторі імен default:
Використовуючи командний рядок etcdctl, прочитайте цей Secret з etcd:
ETCDCTL_API=3 etcdctl get /kubernetes.io/secrets/default/secret1 [...] | hexdump -C
де [...] містить додаткові аргументи для підключення до сервера etcd.
Переконайтеся, що збережений Secret починається з префікса k8s:enc:kms:v1: для KMS v1 або з префікса k8s:enc:kms:v2: для KMS v2, що вказує на те, що постачальник kms зашифрував результати даних.
Перевірте, що Secret правильно розшифровується при отриманні через API:
kubectl describe secret secret1 -n default
Secret повинен містити mykey: mydata.
Забезпечення шифрування всіх секретів
Коли шифрування даних у стані спокою правильно налаштовано, ресурси шифруються під час запису. Таким чином, ми можемо виконати оновлення без змін на місці, щоб переконатися, що дані зашифровані.
Наведена нижче команда читає всі Secret, а потім оновлює їх для застосування шифрування на сервері. У разі помилки через конфліктний запис, повторіть команду. Для більших кластерів вам може знадобитися поділити Secret за просторами імен або написати скрипт для оновлення.
Ця сторінка описує процес оновлення CoreDNS та як встановити CoreDNS замість kube-dns.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.9.
Для перевірки версії введіть kubectl version.
Про CoreDNS
CoreDNS — це гнучкий, розширюваний DNS-сервер, який може обслуговувати DNS кластера Kubernetes. Як і Kubernetes, проєкт CoreDNS є проєктом CNCF.
Ви можете використовувати CoreDNS замість kube-dns у своєму кластері, замінивши kube-dns у наявному розгортанні, або використовуючи інструменти, такі як kubeadm, які встановлюють і оновлюють кластер за вас.
Встановлення CoreDNS
Для ручного розгортання або заміни kube-dns, дивіться документацію на вебсайті CoreDNS.
Міграція на CoreDNS
Оновлення наявного кластера за допомогою kubeadm
У версії Kubernetes 1.21, kubeadm припинив підтримку kube-dns як застосунку DNS. Для kubeadm v1.34, єдиний підтримуваний DNS застосунок кластера —
це CoreDNS.
Ви можете перейти на CoreDNS, використовуючи kubeadm для оновлення кластера, який використовує kube-dns. У цьому випадку, kubeadm генерує конфігурацію CoreDNS ("Corefile") на основі ConfigMap kube-dns, зберігаючи конфігурації для stub доменів та сервера імен вище в ієрархії.
Оновлення CoreDNS
Ви можете перевірити версію CoreDNS, яку kubeadm встановлює для кожної версії Kubernetes на сторінці Версія CoreDNS у Kubernetes.
CoreDNS можна оновити вручну, якщо ви хочете тільки оновити CoreDNS або використовувати власний кастомізований образ. Є корисні рекомендації та посібник, доступні для забезпечення плавного оновлення. Переконайтеся, що поточна конфігурація CoreDNS ("Corefile") зберігається при
оновленні вашого кластера.
Якщо ви оновлюєте свій кластер за допомогою інструменту kubeadm, kubeadm може самостійно зберегти поточну конфігурацію CoreDNS.
Налаштування CoreDNS
Коли використання ресурсів є проблемою, може бути корисним налаштувати конфігурацію CoreDNS. Для детальнішої інформації перевірте документацію зі збільшення масштабу CoreDNS.
Що далі
Ви можете налаштувати CoreDNS для підтримки багатьох інших сценаріїв, ніж kube-dns, змінивши конфігурацію CoreDNS ("Corefile"). Для отримання додаткової інформації дивіться документацію для втулка kubernetes CoreDNS, або читайте Власні DNS записи для Kubernetes в блозі CoreDNS.
2.42 - Використання NodeLocal DNSCache в кластерах Kubernetes
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.18 [stable]
Ця сторінка надає огляд функції NodeLocal DNSCache в Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
NodeLocal DNSCache поліпшує продуктивність кластерного DNS, запускаючи агента кешування DNS на вузлах кластера як DaemonSet. За поточної архітектури, Podʼи в режимі DNS ClusterFirst звертаються до serviceIP kube-dns для DNS-запитів. Вони переводяться в точку доступу kube-dns/CoreDNS за допомогою прав iptables, доданих kube-proxy. За цією новою архітектурою Podʼи звертаються до агента кешування DNS, що працює на тому ж вузлі, тим самим уникнувши прав iptables DNAT та відстеження зʼєднань. Локальний агент кешування буде запитувати службу kube-dns про пропуски кешування для імен кластера (типовий суфікс "cluster.local").
Мотивація
За поточної архітектури DNS, є можливість того, що Podʼи з найвищим QPS DNS повинні звертатися до іншого вузла, якщо на цьому вузлі немає локального екземпляра kube-dns/CoreDNS. Наявність локального кешу допоможе покращити час відгуку в таких сценаріях.
Пропускаючи iptables DNAT та відстеження зʼєднань допоможе зменшити перегони з відстеженням зʼєднань та уникнути заповнення таблиці conntrack UDP DNS-записами.
Зʼєднання від локального агента кешування до служби kube-dns можуть бути підвищені до TCP. Записи conntrack для TCP будуть видалені при закритті зʼєднання, на відміну від записів UDP, які мусять перейти у режим очікування (типовоnf_conntrack_udp_timeout становить 30 секунд)
Перехід DNS-запитів з UDP до TCP зменшить хвостовий час відповіді, спричинений втратою пакетів UDP та зазвичай таймаутами DNS до 30 секунд (3 повтори + 10 секунд таймауту). Оскільки кеш NodeLocal прослуховує UDP DNS-запити, застосунки не потребують змін.
Метрики та видимість DNS-запитів на рівні вузла.
Відʼємне кешування можна повторно включити, тим самим зменшивши кількість запитів до служби kube-dns.
Діаграма архітектури
Це шлях, яким йдуть DNS-запити після ввімкнення NodeLocal DNSCache:
Потік NodeLocal DNSCache
Ця картинка показує, як NodeLocal DNSCache обробляє DNS-запити.
Конфігурація
Примітка:
Локальна IP-адреса прослуховування для NodeLocal DNSCache може бути будь-якою адресою, яка гарантовано не перетинається з будь-яким наявним IP у вашому кластері. Рекомендується використовувати адресу з місцевою областю, наприклад, з діапазону 'link-local' '169.254.0.0/16' для IPv4 або з діапазону 'Unique Local Address' у IPv6 'fd00::/8'.
Цю функцію можна ввімкнути за допомогою таких кроків:
Підготуйте маніфест, схожий на зразок nodelocaldns.yaml та збережіть його як nodelocaldns.yaml.
Якщо використовуєте IPv6, файл конфігурації CoreDNS потрібно закрити всі IPv6-адреси у квадратні дужки, якщо вони використовуються у форматі 'IP:Port'. Якщо ви використовуєте зразок маніфесту з попереднього пункту, це потребує зміни рядка конфігурації L70 таким чином: "health [__PILLAR__LOCAL__DNS__]:8080"
Підставте змінні в маніфест з правильними значеннями:
kubedns=`kubectl get svc kube-dns -n kube-system -o jsonpath={.spec.clusterIP}`domain=<cluster-domain>
localdns=<node-local-address>
<cluster-domain> типово "cluster.local". <node-local-address> — це локальна IP-адреса прослуховування, обрана для NodeLocal DNSCache.
Якщо kube-proxy працює в режимі IPTABLES:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/__PILLAR__DNS__SERVER__/$kubedns/g" nodelocaldns.yaml
__PILLAR__CLUSTER__DNS__ та __PILLAR__UPSTREAM__SERVERS__ будуть заповнені під час роботи підсистеми node-local-dns. У цьому режимі підсистеми node-local-dns прослуховують як IP-адресу служби kube-dns, так і <node-local-address>, тому Podʼи можуть шукати записи DNS, використовуючи будь-яку з цих IP-адрес.
Якщо kube-proxy працює в режимі IPVS:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/,__PILLAR__DNS__SERVER__//g; s/__PILLAR__CLUSTER__DNS__/$kubedns/g" nodelocaldns.yaml
У цьому режимі підсистеми node-local-dns прослуховують лише <node-local-address>. Інтерфейс node-local-dns не може привʼязати кластерну IP kube-dns, оскільки інтерфейс, що використовується для IPVS-балансування навантаження, вже використовує цю адресу. __PILLAR__UPSTREAM__SERVERS__ буде заповнено підсистемами node-local-dns.
Запустіть kubectl create -f nodelocaldns.yaml.
Якщо використовуєте kube-proxy в режимі IPVS, прапорець --cluster-dns для kubelet потрібно змінити на <node-local-address>, який прослуховує NodeLocal DNSCache. В іншому випадку не потрібно змінювати значення прапорця --cluster-dns, оскільки NodeLocal DNSCache прослуховує як IP-адресу служби kube-dns, так і <node-local-address>.
Після ввімкнення, Podʼи node-local-dns будуть працювати у просторі імен kube-system на кожному з вузлів кластера. Цей Pod працює з CoreDNS у режимі кешування, тому всі метрики CoreDNS, що надаються різними втулками, будуть доступні на рівні кожного вузла.
Цю функцію можна вимкнути, видаливши DaemonSet, використовуючи kubectl delete -f <manifest>. Також слід скасувати будь-які зміни, внесені до конфігурації kubelet.
Конфігурація StubDomains та Upstream серверів
StubDomains та upstream сервери, вказані в ConfigMap kube-dns в просторі імен kube-system автоматично використовуються підсистемами node-local-dns. Вміст ConfigMap повинен відповідати формату, показаному у прикладі. ConfigMap node-local-dns також можна змінити безпосередньо з конфігурацією stubDomain у форматі Corefile. Деякі хмарні постачальники можуть не дозволяти змінювати ConfigMap node-local-dns безпосередньо. У цьому випадку ConfigMap kube-dns можна оновити.
Налаштування обмежень памʼяті
Podʼи node-local-dns використовують памʼять для зберігання записів кешу та обробки запитів. Оскільки вони не стежать за обʼєктами Kubernetes, розмір кластера або кількість Service / EndpointSlice не впливає на використання памʼяті безпосередньо. Використання памʼяті впливає на шаблон DNS-запитів. З документації CoreDNS:
Типовий розмір кешу — 10000 записів, що використовує приблизно 30 МБ, коли повністю заповнений.
Це буде використання памʼяті для кожного блоку сервера (якщо кеш буде повністю заповнений). Використання памʼяті можна зменшити, вказавши менші розміри кешу.
Кількість одночасних запитів повʼязана з попитом памʼяті, оскільки кожен додатковий goroutine, використаний для обробки запиту, потребує певної кількості памʼяті. Ви можете встановити верхню межу за допомогою опції max_concurrent у втулку forward.
Якщо Pod node-local-dns намагається використовувати більше памʼяті, ніж доступно (через загальні системні ресурси або через налаштовані обмеження ресурсів), операційна система може вимкнути контейнер цього Podʼа. У разі цього, контейнер, якого вимкнено ("OOMKilled"), не очищає власні правила фільтрації пакетів, які він раніше додавав під час запуску. Контейнер node-local-dns повинен бути перезапущений (оскільки він керується як частина DaemonSet), але це призведе до короткої перерви у роботі DNS кожного разу, коли контейнер зазнає збою: правила фільтрації пакетів направляють DNS-запити до локального Podʼа, який не є справним.
Ви можете визначити прийнятне обмеження памʼяті, запустивши Podʼи node-local-dns без обмеження
та вимірявши максимальне використання. Ви також можете налаштувати та використовувати VerticalPodAutoscaler у recommender mode, а потім перевірити його рекомендації.
2.43 - Використання sysctl в кластері Kubernetes
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.21 [stable]
У цьому документі описано, як налаштовувати та використовувати параметри ядра в межах кластера Kubernetes, використовуючи інтерфейс sysctl.
Примітка:
Починаючи з версії Kubernetes 1.23, kubelet підтримує використання / або . як роздільники для назв sysctl. Починаючи з версії Kubernetes 1.25, налаштування Sysctls для контейнера підтримує встановлення sysctl зі слешами. Наприклад, ви можете представити ту саму назву sysctl як kernel.shm_rmid_forced, використовуючи крапку як роздільник, або як kernel/shm_rmid_forced, використовуючи слеш як роздільник. Для отримання додаткових відомостей щодо методу конвертації параметра sysctl див. сторінку sysctl.d(5) проєкту Linux man-pages.
Перш ніж ви розпочнете
Примітка:
sysctl — це інструмент командного рядка, специфічний для Linux, який використовується для налаштування різних параметрів ядра, і він недоступний в операційних системах, що не базуються на Linux.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для деяких кроків вам також потрібно мати змогу змінювати параметри командного рядка для kubelet, що працюють на вашому кластері.
Перелік всіх параметрів Sysctl
У Linux інтерфейс sysctl дозволяє адміністратору змінювати параметри ядра під час виконання. Параметри доступні через віртуальну файлову систему /proc/sys/. Параметри охоплюють різні підсистеми, такі як:
Щоб отримати список всіх параметрів, ви можете виконати команду:
sudo sysctl -a
Безпечні та Небезпечні Sysctl
Kubernetes класифікує sysctl як безпечні або небезпечні. Крім належного просторового розмежування, безпечний sysctl повинен бути належним чином ізольованим між Podʼами на тому ж вузлі. Це означає, що встановлення безпечного sysctl для одного Podʼа
не повинно мати жодного впливу на інші Podʼи на вузлі
не повинно дозволяти шкодити справності вузла
не повинно дозволяти отримувати CPU або ресурси памʼяті поза межами обмежень ресурсів Podʼа.
Наразі більшість просторово розмежованих (по просторах імен) sysctl не обовʼязково вважаються безпечними. До набору безпечних sysctl входять наступні параметри:
kernel.shm_rmid_forced;
net.ipv4.ip_local_port_range;
net.ipv4.tcp_syncookies;
net.ipv4.ping_group_range (починаючи з Kubernetes 1.18);
net.ipv4.ip_unprivileged_port_start (починаючи з Kubernetes 1.22);
net.ipv4.ip_local_reserved_ports (починаючи з Kubernetes 1.27, потрібне ядро 3.16+);
net.ipv4.tcp_keepalive_time (починаючи з Kubernetes 1.29, потрібне ядро 4.5+);
net.ipv4.tcp_fin_timeout (починаючи з Kubernetes 1.29, потрібне ядро 4.6+);
net.ipv4.tcp_keepalive_intvl (починаючи з Kubernetes 1.29, потрібне ядро 4.5+);
net.ipv4.tcp_keepalive_probes (починаючи з Kubernetes 1.29, потрібне ядро 4.5+).
Параметри sysctl net.* не дозволені з увімкненою мережею вузла.
Параметр sysctl net.ipv4.tcp_syncookies не має просторового розмежування в ядрах Linux версії 4.5 або нижче.
Цей список буде розширюватися у майбутніх версіях Kubernetes, коли kubelet буде підтримувати кращі механізми ізоляції.
Увімкнення небезпечних Sysctl
Всі безпечні sysctl є типово увімкненими.
Всі небезпечні sysctl типово вимкнені та повинні бути дозволені вручну адміністратором кластера на кожному вузлі окремо. Podʼи з вимкненими небезпечними sysctl будуть заплановані, але їх не вдасться запустити.
З врахуванням попередження вище, адміністратор кластера може дозволити певні небезпечні sysctl для дуже спеціальних ситуацій, таких як налаштування високопродуктивних або застосунків реального часу. Небезпечні sysctl вмикаються на основі вузла з прапорцем kubelet; наприклад:
Таким чином можна увімкнути лише просторово розмежовані sysctl.
Налаштування Sysctl для Podʼа
Численні sysctl просторово розмежовані в сучасних ядрах Linux. Це означає, що їх можна налаштовувати незалежно для кожного Pod на вузлі. Лише просторово розмежовані sysctl можна налаштовувати через securityContext Podʼа в межах Kubernetes.
Відомо, що наступні sysctl мають просторове розмежування. Цей список може змінитися в майбутніх версіях ядра Linux.
kernel.shm*
kernel.msg*
kernel.sem
fs.mqueue.*
Ті net.*, які можна налаштувати в просторі імен мережі контейнера. Однак є винятки (наприклад, net.netfilter.nf_conntrack_max та net.netfilter.nf_conntrack_expect_max можуть бути налаштовані в просторі імен мережі контейнера, але не мають просторового розмежування до Linux 5.12.2).
Sysctl без просторового розмежування називають вузловими sysctl. Якщо вам потрібно налаштувати їх, ви повинні вручну налаштувати їх в операційній системі кожного вузла або за допомогою DaemonSet з привілейованими контейнерами.
Використовуйте securityContext Podʼа для налаштування просторово розмежованих sysctl. securityContext застосовується до всіх контейнерів у тому ж Podʼі.
У цьому прикладі використовується securityContext Podʼа для встановлення безпечного sysctl kernel.shm_rmid_forced та двох небезпечних sysctl net.core.somaxconn та kernel.msgmax. В специфікації немає розрізнення між безпечними та небезпечними sysctl.
Попередження:
Змінюйте параметри sysctl лише після розуміння їхніх наслідків, щоб уникнути дестабілізації вашої операційної системи.
Через їхню природу бути небезпечними, використання небезпечних sysctl здійснюється на ваш власний ризик і може призвести до серйозних проблем, таких як неправильна поведінка контейнерів, нестача ресурсів або повний розлад вузла.
Хорошою практикою є вважати вузли з особливими налаштуваннями sysctl як позначені taint в межах кластера і планувати на них лише ті Podʼи, яким потрібні ці налаштування sysctl. Рекомендується використовувати функцію Заплямованість та Толерантність кластера Kubernetes, щоб реалізувати це.
Pod з небезпечними sysctl не вдасться запустити на будь-якому вузлі, на якому не були явно увімкнені ці два небезпечні sysctl. Як і з вузловими sysctl, рекомендується використовувати функцію Заплямованість та Толерантність або
заплямованість вузлів для планування цих Podʼів на відповідні вузли.
2.44 - Використання NUMA-орієнтованого менеджера памʼяті
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.32 [stable](стандартно увімкнено)
Менеджер памʼяті Kubernetes дозволяє функцію гарантованого виділення памʼяті (та великих сторінок) для Podʼів QoS класуGuaranteed.
Менеджер памʼяті використовує протокол генерації підказок для вибору найбільш відповідної спорідненості NUMA для точки доступу. Менеджер памʼяті передає ці підказки центральному менеджеру (Менеджеру топології). На основі як підказок, так і політики Менеджера топології, Pod відхиляється або допускається на вузол.
Крім того, Менеджер памʼяті забезпечує, що памʼять, яку запитує Pod, виділяється з мінімальної кількості NUMA-вузлів.
Менеджер памʼяті має відношення тільки до хостів на базі Linux.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.32.
Для перевірки версії введіть kubectl version.
Для вирівнювання ресурсів памʼяті з іншими запитаними ресурсами у специфікації Podʼа:
Менеджер CPU повинен бути увімкнений, і на вузлі повинна бути налаштована відповідна політика Менеджера CPU. Див. управління політиками керування CPU;
Менеджер топології повинен бути увімкнений, і на вузлі повинна бути налаштована відповідна політика Менеджера топології. Див. управління політиками керування топологією.
Починаючи з версії v1.22, Менеджер памʼяті типово увімкнено за допомогою функціональної можливостіMemoryManager.
Для версій до v1.22, kubelet повинен бути запущений з наступним прапорцем:
--feature-gates=MemoryManager=true
щоб увімкнути функцію Менеджера памʼяті.
Як працює Менеджер памʼяті?
Зараз Менеджер памʼяті пропонує виділення гарантованої памʼяті (та великих сторінок) для Podʼів у класі QoS Guaranteed. Щоб негайно ввести Менеджер памʼяті в роботу, слідкуйте вказівкам у розділі Налаштування Менеджера памʼяті, а потім підготуйте та розгорніть Pod Guaranteed, як показано в розділі Розміщення Podʼів класу QoS Guaranteed.
Менеджер памʼяті є постачальником підказок і надає підказки топології для Менеджера топології, який потім вирівнює запитані ресурси згідно з цими підказками топології. На Linux, він також застосовує cgroups (тобто cpuset.mems) для Podʼів. Повна схематична діаграма щодо процесу допуску та розгортання Podʼа показано у Memory Manager KEP: Design Overview та нижче:
Під час цього процесу Менеджер памʼяті оновлює свої внутрішні лічильники, що зберігаються в Node Map та Memory Maps, для управління гарантованим виділенням памʼяті.
Менеджер памʼяті оновлює Node Map під час запуску та виконання наступним чином.
Адміністратор повинен надати прапорець --reserved-memory при налаштуванні політики Static.
Робота
Посилання Memory Manager KEP: Memory Maps at runtime (with examples) ілюструє, як успішне розгортання Podʼа впливає на Node Map, і також повʼязано з тим, як потенційні випадки вичерпання памʼяті (OOM) далі обробляються Kubernetes або операційною системою.
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.32 [alpha](стандартно вимкнено)
Підтримку Windows можна увімкнути за допомогою функціональної можливості WindowsCPUAndMemoryAffinity і вона потребує підтримки під час виконання контейнера. У Windows підтримується лише політика BestEffort Policy.
Налаштування Менеджера памʼяті
Інші Менеджери повинні бути спочатку попередньо налаштовані. Далі, функцію Менеджера памʼяті слід увімкнути та запустити з політикою Static (розділ Політика Static). Опційно можна зарезервувати певну кількість памʼяті для системи або процесів kubelet, щоб збільшити стабільність вузла (розділ Прапорець зарезервованої памʼяті).
Політики
Менеджер памʼяті підтримує дві політики. Ви можете вибрати політику за допомогою прапорця kubelet--memory-manager-policy:
None (типово)
Static (тільки Linux)
BestEffort (тільки Windows)
Політика None
Це типова політика і вона не впливає на виділення памʼяті жодним чином. Вона працює так само як і коли Менеджер памʼяті взагалі відсутній.
Політика None повертає типову підказку топології. Ця спеціальна підказка позначає, що Hint Provider (в цьому випадку Менеджер памʼяті) не має переваги щодо спорідненості NUMA з будь-яким ресурсом.
Політика Static
У випадку Guaranteed Podʼа політика Менеджера памʼяті Static повертає підказки топології, що стосуються набору NUMA-вузлів, де памʼять може бути гарантованою, та резервує памʼять, оновлюючи внутрішній обʼєкт NodeMap.
У випадку Podʼа BestEffort або Burstable політика Менеджера памʼяті Static повертає назад типову підказку топології, оскільки немає запиту на гарантовану памʼять, і не резервує памʼять внутрішнього обʼєкта NodeMap.
Ця політика підтримується тільки в Linux.
Політика BestEffort
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.32 [alpha](стандартно вимкнено)
Ця політика підтримується лише у Windows.
У Windows призначення вузлів NUMA працює інакше, ніж у Linux. Не існує механізму, який би гарантував, що доступ до памʼяті надається лише з певного вузла NUMA. Замість цього планувальник Windows вибере найоптимальніший вузол NUMA на основі призначень процесора(ів). Можливо, Windows може використовувати інші вузли NUMA, якщо планувальник Windows вважатиме їх оптимальними.
Політика відстежує кількість доступної та запитуваної памʼяті за допомогою внутрішньої NodeMap. Менеджер памʼяті докладе максимум зусиль для забезпечення достатнього обсягу памʼяті навузлі NUMA перед тим, як призначити пам'ять. Це означає, що у більшості випадків розподіл памʼяті має відбуватися як очікується.
Прапорець зарезервованої памʼяті
Механізм виділення ресурсів вузла (Node Allocatable) зазвичай використовується адміністраторами вузлів для резервування системних ресурсів вузла K8S для kubelet або процесів операційної системи, щоб підвищити стабільність вузла. Для цього можна використовувати відповідний набір прапорців, щоб вказати загальну кількість зарезервованої памʼяті для вузла. Це попередньо налаштоване значення далі використовується для розрахунку реальної кількості "виділеної"
памʼяті вузла, доступної для Podʼів.
Планувальник Kubernetes використовує "виділену" памʼять для оптимізації процесу планування Podʼів. Для цього використовуються прапорці --kube-reserved, --system-reserved та --eviction-threshold. Сума їх значень враховує загальну кількість зарезервованої памʼяті.
Новий прапорець --reserved-memory було додано до Memory Manager, щоб дозволити цю загальну зарезервовану памʼять розділити (адміністратором вузла) і відповідно зарезервувати для багатьох вузлів NUMA.
Прапорець визначається як розділений комами список резервування памʼяті різних типів на NUMA-вузол. Резервації памʼяті по кількох NUMA-вузлах можна вказати, використовуючи крапку з комою як роздільник. Цей параметр корисний лише в контексті функції Менеджера памʼяті. Менеджер памʼяті не використовуватиме цю зарезервовану памʼять для виділення контейнерних робочих навантажень.
Наприклад, якщо у вас є NUMA-вузол "NUMA0" з доступною памʼяттю 10 ГБ, і було вказано --reserved-memory, щоб зарезервувати 1 ГБ памʼяті в "NUMA0", Менеджер памʼяті припускає, що для контейнерів доступно тільки 9 ГБ.
Ви можете не вказувати цей параметр, але слід памʼятати, що кількість зарезервованої памʼяті з усіх NUMA-вузлів повинна дорівнювати кількості памʼяті, вказаній за допомогою функції виділення ресурсів вузла. Якщо принаймні один параметр виділення вузла не дорівнює нулю, вам слід вказати --reserved-memory принаймні для одного NUMA-вузла. Фактично, порогове значення eviction-hard типово становить 100 Mi, отже, якщо використовується політика Static, --reserved-memory є обовʼязковим.
Також слід уникати наступних конфігурацій:
дублікатів, тобто того самого NUMA-вузла або типу памʼяті, але з іншим значенням;
встановлення нульового ліміту для будь-якого типу памʼяті;
ідентифікаторів NUMA-вузлів, які не існують в апаратному забезпеченні машини;
назв типів памʼяті відмінних від memory або hugepages-<size> (великі сторінки певного розміру <size> також повинні існувати).
При вказанні значень для прапорця --reserved-memory слід дотримуватися налаштування, яке ви вказали раніше за допомогою прапорців функції виділення вузла. Іншими словами, слід дотримуватися такого правила для кожного типу памʼяті:
Приклад командних аргументів kubelet, що стосуються конфігурації виділення вузла:
--kube-reserved=cpu=500m,memory=50Mi
--system-reserved=cpu=123m,memory=333Mi
--eviction-hard=memory.available<500Mi
Примітка:
Типове значення для жорсткого порога виселення становить 100MiB, а не нуль. Не забудьте збільшити кількість памʼяті, яку ви резервуєте, встановивши --reserved-memory на величину цього жорсткого порога виселення. В іншому випадку kubelet не запустить Менеджер памʼяті та покаже помилку.
Якщо вибрана політика відрізняється від None, Менеджер памʼяті ідентифікує Podʼи, які належать до класу обслуговування Guaranteed. Менеджер памʼяті надає конкретні підказки топології Менеджеру топології для кожного Podʼа з класом обслуговування Guaranteed. Для Podʼів, які належать до класу обслуговування відмінного від Guaranteed, Менеджер памʼяті надає Менеджеру топології типові підказки топології.
Наведені нижче уривки з маніфестів Podʼа призначають Pod до класу обслуговування Guaranteed.
Pod з цілим значенням CPU працює в класі обслуговування Guaranteed, коли requests дорівнюють limits:
Зверніть увагу, що для Podʼа потрібно вказати як запити CPU, так і памʼяті, щоб він належав до класу обслуговування Guaranteed.
Розвʼязання проблем
Для виявлення причин, чому Pod не вдалося розгорнути або він був відхилений на вузлі, можуть бути використані наступні засоби:
статус Podʼа — вказує на помилки топологічної спорідненості
системні логи — містять цінну інформацію для налагодження, наприклад, про згенеровані підказки
файл стану — вивід внутрішнього стану Менеджера памʼяті (включає Node Map та Memory Map)
починаючи з v1.22, можна використовувати API втулка ресурсів пристроїв, щоб отримати інформацію про памʼять, зарезервовану для контейнерів.
Статус Podʼа (TopologyAffinityError)
Ця помилка зазвичай виникає у наступних ситуаціях:
вузол не має достатньо ресурсів, щоб задовольнити запит Podʼа
запит Podʼа відхилено через обмеження певної політики Менеджера топології
Помилка показується у статусі Podʼа:
kubectl get pods
NAME READY STATUS RESTARTS AGE
guaranteed 0/1 TopologyAffinityError 0 113s
Використовуйте kubectl describe pod <id> або kubectl get events, щоб отримати докладне повідомлення про помилку:
Warning TopologyAffinityError 10m kubelet, dell8 Resources cannot be allocated with Topology locality
Системні логи
Шукайте системні логи для певного Podʼа.
У логах можна знайти набір підказок, які згенерував Менеджер памʼяті для Podʼа. Також у логах повинен бути присутній набір підказок, згенерований Менеджером CPU.
Менеджер топології обʼєднує ці підказки для обчислення єдиної найкращої підказки. Найкраща підказка також повинна бути присутня в логах.
Найкраща підказка вказує, куди виділити всі ресурси. Менеджер топології перевіряє цю підказку за своєю поточною політикою і, залежно від вердикту, або допускає Pod до вузла, або відхиляє його.
Також шукайте логи для випадків, повʼязаних з Менеджером памʼяті, наприклад, для отримання інформації про оновлення cgroups та cpuset.mems.
Аналіз стану менеджера памʼяті на вузлі
Спочатку розгляньмо розгорнутий зразок Guaranteed Podʼа, специфікація якого виглядає так:
З цього файлу стану можна дізнатись, що Pod був привʼязаний до обох NUMA вузлів, тобто:
"numaAffinity":[
0,
1],
Термін "привʼязаний" означає, що споживання памʼяті Podʼом обмежено (через конфігурацію cgroups) цими NUMA вузлами.
Це автоматично означає, що Менеджер памʼяті створив нову групу, яка обʼєднує ці два NUMA вузли, тобто вузли з індексами 0 та 1.
Зверніть увагу, що управління групами виконується досить складним способом, і подальші пояснення надані в Memory Manager KEP в цьому та цьому розділах.
Для аналізу ресурсів памʼяті, доступних у групі, потрібно додати відповідні записи з NUMA вузлів, які належать до групи.
Наприклад, загальна кількість вільної "звичайної" памʼяті в групі може бути обчислена шляхом додавання вільної памʼяті, доступної на кожному NUMA вузлі в групі, тобто в розділі "memory" NUMA вузла 0 ("free":0) та NUMA вузла 1 ("free":103739236352). Таким чином, загальна кількість вільної "звичайної" памʼяті в цій групі дорівнює 0 + 103739236352 байт.
Рядок "systemReserved":3221225472 вказує на те, що адміністратор цього вузла зарезервував 3221225472 байти (тобто 3Gi) для обслуговування процесів kubelet та системи на NUMA вузлі 0, використовуючи прапорець --reserved-memory.
API втулка ресурсів пристроїв
Kubelet надає службу gRPC PodResourceLister для включення виявлення ресурсів та повʼязаних метаданих. Використовуючи його точку доступу List gRPC, можна отримати інформацію про зарезервовану памʼять для кожного контейнера, яка міститься у protobuf повідомленні ContainerMemory. Цю інформацію можна отримати лише для Podʼів у класі якості обслуговування Guaranteed.
В процесі підготовки випуску Kubernetes підписує всі бінарні артефакти (tarballs, файли SPDX, окремі бінарні файли) за допомогою безключового підписування cosign. Щоб перевірити певний бінарний файл, отримайте його разом з підписом та сертифікатом:
URL=https://dl.k8s.io/release/v1.34.0/bin/linux/amd64
BINARY=kubectl
FILES=("$BINARY""$BINARY.sig""$BINARY.cert")for FILE in "${FILES[@]}"; do curl -sSfL --retry 3 --retry-delay 3"$URL/$FILE" -o "$FILE"done
Потім перевірте блоб, використовуючи cosign verify-blob:
Перевірка підписів образів за допомогою контролера допуску
Для образів, що не є частиною компонентів панелі управління (наприклад, образ conformance), підписи також можна перевірити під час розгортання за допомогою контролера допуску sigstore policy-controller.
Ось кілька корисних ресурсів для початку роботи з policy-controller:
Виконайте загальні завдання конфігурації для Pod і контейнерів.
3.1 - Виділення ресурсів памʼяті для контейнерів та Podʼів
Ця сторінка показує, як вказати запити та ліміти памʼяті для контейнерів. Контейнери гарантовано матимуть стільки памʼяті, скільки вказано у запиті, і не отримають більше, ніж вказано у ліміті.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Кожен вузол у вашому кластері повинен мати принаймні 300 МіБ памʼяті.
Деякі кроки на цій сторінці вимагають запуску служби metrics-server у вашому кластері. Якщо у вас запущено metrics-server,
ви можете пропустити ці кроки.
Якщо ви використовуєте Minikube, виконайте таку команду, щоб увімкнути metrics-server:
minikube addons enable metrics-server
Щоб перевірити, чи запущений metrics-server, або інший постачальник API ресурсів метрик (metrics.k8s.io), виконайте таку команду:
kubectl get apiservices
Якщо API ресурсів метрик доступне, у виводі буде міститися посилання на metrics.k8s.io.
NAME
v1beta1.metrics.k8s.io
Створення простору імен
Створіть простір імен, щоб ресурси, які ви створюєте у цьому завданні, були відокремлені від інших ресурсів у вашому кластері.
kubectl create namespace mem-example
Визначення запитів та лімітів памʼяті
Щоб вказати запит памʼяті для Контейнера, включіть поле resources:requests у маніфесті ресурсів Контейнера. Для вказівки ліміти памʼяті включіть resources:limits.
У цьому завданні ви створюєте Pod, який має один Контейнер. У Контейнера вказано запит памʼяті 100 МіБ і ліміти памʼяті 200 МіБ. Ось файл конфігурації для Podʼа:
Розділ args у файлі конфігурації надає аргументи для Контейнера при його запуску. Аргументи "--vm-bytes", "150M" вказують Контейнеру спробувати виділити 150 МіБ памʼяті.
Виконайте команду kubectl top, щоб отримати метрики для Podʼа:
kubectl top pod memory-demo --namespace=mem-example
Вивід показує, що Pod використовує приблизно 162,900,000 байт памʼяті, що становить близько 150 МіБ. Це більше, ніж запит Podʼа на 100 МіБ, але в межах ліміти Podʼа на 200 МіБ.
NAME CPU(cores) MEMORY(bytes)
memory-demo <something> 162856960
Видаліть свій Pod:
kubectl delete pod memory-demo --namespace=mem-example
Перевищення лімітів памʼяті Контейнера
Контейнер може перевищити свій запит на памʼять, якщо на вузлі є вільна памʼять. Але Контейнер не може використовувати памʼяті більше, ніж його ліміт памʼяті. Якщо Контейнер використовує більше памʼяті, ніж його ліміт, Контейнер стає кандидатом на зупинку роботи. Якщо Контейнер продовжує використовувати памʼять поза своїм лімітом, він зупиняється. Якщо Контейнер може бути перезапущений, kubelet перезапускає його, як із будь-яким іншим типом відмови під час роботи.
У цьому завданні ви створюєте Pod, який намагається виділити більше памʼяті, ніж його ліміт. Ось файл конфігурації для Podʼа, який має один Контейнер з запитом памʼяті 50 МіБ та лімітом памʼяті 100 МіБ:
Контейнер у цьому завданні може бути перезапущений, тому kubelet перезапускає його. Повторіть цю команду кілька разів, щоб переконатися, що Контейнер постійно знищується та перезапускається:
kubectl get pod memory-demo-2 --namespace=mem-example
Вивід показує, що Контейнер знищується, перезапускається, знищується знову, знову перезапускається і так далі:
kubectl get pod memory-demo-2 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-2 0/1 OOMKilled 1 37s
kubectl get pod memory-demo-2 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-2 1/1 Running 2 40s
Перегляньте детальну інформацію про історію Podʼа:
kubectʼ describe pod лімітомo-2 ʼ-namespace=mem-example
Вивід показує, що Контейнер починається і знову не вдається:
... Normal Created Created container with id 66a3a20aa7980e61be4922780bf9d24d1a1d8b7395c09861225b0eba1b1f8511
... Warning BackOff Back-off restarting failed container
Перегляньте детальну інформацію про вузли вашого кластера:
kubectl describe nodes
Вивід містить запис про знищення Контейнера через умову вичерпання памʼяті:
Warning OOMKilling Memory cgroup out of memory: Kill process 4481 (stress) score 1994 or sacrifice child
Видаліть свій Pod:
kubectl delete pod memory-demo-2 --namespace=mem-example
Визначення запиту памʼяті, що є завеликим для вашого вузла
Запити та ліміт памʼяті повʼязані з Контейнерами, але корисно думати про Pod як про елемент, що має запит та ліміт памʼяті. Запит памʼяті для Podʼа — це сума запитів памʼяті для всіх Контейнерів у Podʼі. Аналогічно, ліміт памʼяті для Podʼа — це сума лімітів всіх Контейнерів у Podʼі.
Планування Podʼа ґрунтується на запитах. Pod планується кзапуску на вузлі лише у разі, якщо вузол має достатньо вільної памʼяті, щоб задовольнити запит памʼяті Podʼа.
У цьому завданні ви створюєте Pod, у якого запит памʼяті настільки великий, що перевищує можливості будь-якого вузла у вашому кластері. Ось файл конфігурації для Podʼа, у якого один Контейнер з запитом на 1000 ГіБ памʼяті, що, ймовірно, перевищує можливості будь-якого вузла у вашому кластері.
kubectl get pod memory-demo-3 --namespace=mem-example
Вивід показує, що статус Podʼа — PENDING. Це означає, що Pod не заплановано для запуску на жодному вузлі, і він залишатиметься у стані PENDING безстроково:
kubectl get pod memory-demo-3 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-3 0/1 Pending 0 25s
Перегляньте детальну інформацію про Pod, включаючи події:
kubectl describe pod memory-demo-3 --namespace=mem-example
Вивід показує, що Контейнер не може бути запланований через нестачу памʼяті на вузлах:
Events:
... Reason Message
------ -------
... FailedScheduling No nodes are available that match all of the following predicates:: Insufficient memory (3).
Одиниці памʼяті
Ресурс памʼяті вимірюється у байтах. Ви можете виразити памʼять як ціле число або ціле число з одним із наступних суфіксів: E, P, T, G, M, K, Ei, Pi, Ti, Gi, Mi, Ki. Наприклад, наступні значення приблизно однакові:
128974848, 129e6, 129M, 123Mi
Видаліть свій Pod:
kubectl delete pod memory-demo-3 --namespace=mem-example
Якщо ви не вказуєте ліміт памʼяті
Якщо ви не вказуєте ліміт памʼяті для Контейнера, відбувається одне з наступного:
Контейнер не має верхньої межі на кількість використаної памʼяті. Контейнер може
використовувати всю доступну памʼять на вузлі, де він працює, що, своєю чергою, може спричинити активацію "OOM Killer". Крім того, в разі активації "OOM Kill" Контейнер без обмежень ресурсів матиме більше шансів на знищення.
Контейнер працює в просторі імен, який має стандартний ліміт памʼяті, і Контейнер автоматично отримує визначений стандартний ліміт. Адміністратори кластера можуть використовувати LimitRange для зазначення стандартного ліміту памʼяті.
Для чого вказувати запит та ліміт памʼяті
Налаштовуючи запити та ліміти памʼяті для Контейнерів, які працюють у вашому
кластері, ви можете ефективно використовувати ресурси памʼяті, доступні на вузлах вашого кластера. Знижуючи запит памʼяті для Podʼа, ви даєте Podʼу хороший шанс на планування. Маючи ліміти памʼяті, який перевищує запит памʼяті, ви досягаєте двох цілей:
Pod може мати періоди сплеску активності, коли він використовує доступну памʼять.
Обсяг памʼяті, який Pod може використовувати під час сплесків, обмежений до якогось розумного значення.
Очищення
Видаліть простір імен. Це видалить всі Podʼи, які ви створили для цього завдання:
kubectl delete namespace mem-example
Що далі
Для розробників застосунків #for-application-developers
3.2 - Виділення ресурсів CPU контейнерам та Podʼам
Ця сторінка показує, як вказати запит та ліміт CPU для контейнера. Контейнери не можуть використовувати більше CPU, ніж налаштований ліміт. При наявності вільного часу процесора контейнера гарантується виділення стільки CPU, скільки він запитує.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Кожен вузол у вашому кластері повинен мати принаймні 1 CPU.
Деякі кроки на цій сторінці вимагають запуску служби metrics-server у вашому кластері. Якщо у вас запущено metrics-server,
ви можете пропустити ці кроки.
Якщо ви використовуєте Minikube, виконайте таку команду, щоб увімкнути metrics-server:
minikube addons enable metrics-server
Щоб перевірити, чи запущений metrics-server, або інший постачальник API ресурсів метрик (metrics.k8s.io), виконайте таку команду:
kubectl get apiservices
Якщо API ресурсів метрик доступне, у виводі буде міститися посилання на metrics.k8s.io.
NAME
v1beta1.metrics.k8s.io
Створення простору імен
Створіть простір імен, щоб ресурси, які ви створюєте у цьому завданні, були відокремлені від інших ресурсів у вашому кластері.
kubectl create namespace cpu-example
Визначте запит ЦП та ліміт ЦП
Для вказання запиту ЦП для контейнера включіть поле resources:requests в маніфест ресурсів Контейнера. Щоб вказати ліміт ЦП, включіть resources:limits.
У цьому завданні ви створюєте Pod, у якого є один контейнер. Контейнер має запит на 0,5 CPU та ліміт 1 CPU. Ось файл конфігурації для Podʼа:
kubectl get pod cpu-demo --output=yaml --namespace=cpu-example
Вивід показує, що один контейнер у Podʼі має запит ЦП 500 міліCPU та ліміт ЦП 1 CPU.
resources:limits:cpu:"1"requests:cpu:500m
Використовуйте kubectl top, щоб отримати метрики для Podʼа:
kubectl top pod cpu-demo --namespace=cpu-example
У цьому прикладі виводу показано, що Pod використовує 974 міліCPU, що незначно менше, ніж ліміт 1 CPU, вказане в конфігурації Podʼа.
NAME CPU(cores) MEMORY(bytes)
cpu-demo 974m <something>
Нагадуємо, що, встановивши -cpu "2", ви налаштували контейнер на спробу використати 2 CPU, але контейнер може використовувати лише близько 1 CPU. Використання ЦП контейнером обмежується, оскільки контейнер намагається використовувати більше ресурсів ЦП, ніж його ліміт.
Примітка:
Інше можливе пояснення того, що використання ЦП менше 1.0, — це те, що на вузлі може не бути
достатньо ресурсів ЦП. Пригадайте, що передумовами для цієї вправи є наявність у вашому кластері принаймні 1 CPU для використання. Якщо ваш контейнер запускається на вузлі з лише 1 CPU, контейнер не може використовувати більше ніж 1 CPU, незалежно від ліміту ЦП, вказаного для контейнера.
Одиниці ЦП
Ресурс ЦП вимірюється в одиницях ЦП. Одна одиниця ЦП в Kubernetes еквівалентна:
1 AWS vCPU
1 GCP Core
1 Azure vCore
1 Hyperthread на процесорі Intel з гіперпотоками
Дозволені дробові значення. Контейнер, який запитує 0,5 ЦП, гарантовано отримує половину ЦП порівняно з контейнером, який запитує 1 ЦП. Ви можете використовувати суфікс m для позначення мілі. Наприклад, 100m ЦП, 100 міліЦП і 0,1 ЦП — це все одне й те саме. Точність, більша за 1m, не допускається.
ЦП завжди запитується як абсолютна кількість, ніколи як відносна кількість; 0.1 — це та сама кількість ЦП на одноядерному, двоядерному або 48-ядерному компʼютері.
Видаліть свій Pod:
kubectl delete pod cpu-demo --namespace=cpu-example
Визначте запит ЦП, який перевищує можливості ваших вузлів
Запити та ліміти ЦП повʼязані з контейнерами, але корисно вважати Pod таким, що має запит ЦП та ліміти. Запит ЦП для Podʼа — це сума запитів ЦП для всіх контейнерів у Podʼі. Так само, ліміти ЦП для Podʼа — це сума обмежень ЦП для всіх контейнерів у Podʼі.
Планування Podʼа базується на запитах. Pod буде запланований для запуску на вузлі тільки у випадку, якщо на вузлі є достатньо ресурсів ЦП для задоволення запиту ЦП Podʼа.
У цьому завданні ви створюєте Pod, який має запит ЦП такий великий, що він перевищує можливості будь-якого вузла у вашому кластері. Ось файл конфігурації для Podʼа, який має один контейнер. Контейнер запитує 100 ЦП, що ймовірно перевищить можливості будь-якого вузла у вашому кластері.
kubectl get pod cpu-demo-2 --namespace=cpu-example
Вивід показує, що статус Podʼа — Pending. Тобто Pod не був запланований для запуску на будь-якому вузлі, і він буде залишатися в стані Pending нескінченно:
NAME READY STATUS RESTARTS AGE
cpu-demo-2 0/1 Pending 0 7m
Перегляньте детальну інформацію про Pod, включаючи події:
kubectl describe pod cpu-demo-2 --namespace=cpu-example
Вивід показує, що контейнер не може бути запланований через недостатні ресурси ЦП на вузлах:
Events:
Reason Message
------ -------
FailedScheduling No nodes are available that match all of the following predicates:: Insufficient cpu (3).
Видаліть свій Pod:
kubectl delete pod cpu-demo-2 --namespace=cpu-example
Якщо ви не вказуєте ліміт ЦП
Якщо ви не вказуєте ліміт ЦП для контейнера, то застосовується одне з наступного:
Контейнер не має верхньої межі ресурсів ЦП, які він може використовувати. Контейнер
може використовувати всі доступні ресурси ЦП на вузлі, на якому він працює.
Контейнер працює в просторі імен, який має стандартний ліміт ЦП, і контейнеру автоматично призначається цей стандартний ліміт. Адміністратори кластера можуть використовувати LimitRange для зазначення стандартних значень лімітів ЦП.
Якщо ви вказуєте ліміт ЦП, але не вказуєте запит ЦП
Якщо ви вказуєте ліміт ЦП для контейнера, але не вказуєте запит ЦП, Kubernetes автоматично призначає запит ЦП, який збігається з лімітом. Аналогічно, якщо контейнер вказує свій власний ліміт памʼяті, але не вказує запит памʼяті, Kubernetes автоматично призначає запит памʼяті, який збігається з лімітом.
Для чого вказувати запит та ліміт ЦП
Налаштувавши запити та ліміти ЦП контейнерів, що працюють у вашому кластері, ви можете ефективно використовувати доступні ресурси ЦП на вузлах вашого кластера. Зберігаючи низький запит ЦП для Podʼа, ви забезпечуєте хороші шанси на його планування. Маючи ліміти ЦП, який перевищує запит ЦП, ви досягаєте двох речей:
Pod може мати періоди підвищеної активності, коли він використовує доступні ресурси ЦП.
Кількість ресурсів ЦП, які Pod може використовувати під час такої активності, обмежена розумною кількістю.
3.3 - Зміна розміру CPU та memory, призначених контейнерам
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [beta](стандартно увімкнено)
Ця сторінка пояснює як змінити запити та обмеження ресурсів CPU та памʼяті повʼязані з контейнером без перестворення Podʼу.
Зазвичай, зміна ресурсів Podʼа вимагає вилучення наявного Podʼа та створення його заміни, що виконується контролером робочого навантаження. Зміна розміру Podʼа на місці дозволяє змінювати виділені його контейнерам CPU/памʼять уникаючи потенційної перерви в роботі застосунку.
Ключові концепції:
Бажані ресурси: Поле spec.containers[*].resources контейнера представляє бажані ресурси і є змінюваним для значень CPU та memory.
Поточні ресурси: Поле status.containerStatuses[*].resources показує поточно налаштовані ресурси для запуску контейнера. Для контейнерів, що не були запущені воно показує ресурси виділені для наступного запуску контейнера.
Запуск зміни розміру: Ви можете запитати зміну розміру оновлюючи відповідні значення requests та limits в специфікації Podʼа. Це, як правило, робиться з використанням kubectl patch, kubectl apply або kubectl edit для Podʼа залучаючи субресурс resize. Коли бажаний ресурс не збігається з виділеними ресурсами, Kubelet намагатиметься змінити розмір контейнера.
Виділені ресурси (Advanced): Поле status.containerStatuses[*].allocatedResources відстежує значення ресурсів, що були підтверджені Kubelet, переважно використовується для внутрішньої логіки планування. Для більшості потреб моніторингу та валідації зосереджуйтесь на status.containerStatuses[*].resources.
Якщо у вузлі є podʼи з очікуваною або незавершеною зміною розміру (див Статус Pod Resize нижче), планувальник буде використовувати максимальні запити на бажані ресурси контейнера, запити виділення та запити поточних ресурсів зі статусу для прийняття рішення.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж 1.33.
Для перевірки версії введіть kubectl version.
Має бути увімкнено функціональну можливістьInPlacePodVerticalScaling для вашої панелі управління і для всіх вузлів вашого кластера.
Версія клієнта kubectl має бути принаймні v1.32 для використання прапорця --subresource=resize.
Статус Pod resize
Kubelet оновлює умови статусу Pod, щоб вказати стан запиту на зміну розміру:
type: PodResizePending: Kubelet не в змозі негайно виконати запит. Поле message надає пояснення чому.
reason: Infeasible: Запитана зміна розміру є неможливою на поточному вузлі (наприклад, запитано ресурсів більше ніж є на вузлі).
reason: Deferred: Запитана зміна ресурсу зараз є неможливою, але може стати можливою згодом (наприклад, інший pod буде вилучено). Kubelet спробує змінити розмір.
type: PodResizeInProgress: Kubelet прийняв зміну розміру та розподілив ресурси, але зміни все ще застосовуються. Зазвичай це швидко, але може зайняти більше часу залежно від типу ресурсу та поведінки під час виконання. Будь-які помилки під час активації повідомляються в полі message (разом з reason: Error).
Як kubelet повторно намагається змінити розмір Deferred
Якщо запитана зміна розміру є Deferred, kubelet періодично повторно намагатиметься змінити розмір, наприклад, коли інший pod буде видалено або масштабовано вниз. Якщо є кілька відкладених змін розміру, вони повторно намагаються відповідно до наступного пріоритету:
Podʼи з вищим пріоритетом (на основі PriorityClass) матимуть свої запити на зміну розміру повторно спробовані першими.
Якщо два podʼа мають однаковий пріоритет, зміна розміру гарантованих podʼів буде повторно спробована перед зміною розміру burstable podʼів.
Якщо все інше однакове, podʼи, які перебувають у стані Deferred довше, отримають пріоритет.
Зміна розміру з вищим пріоритетом, позначена як така, що очікує на виконання, не блокуватиме спроби зміни розміру, що залишаються в очікуванні; всі інші очікуючі зміни розміру все ще будуть повторно спробовані, навіть якщо зміна розміру з вищим пріоритетом знову буде відкладена.
Використання полів observedGeneration
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.34 [beta](стандартно увімкнено)
Поле верхнього рівня status.observedGeneration показує metadata.generation, що відповідає останній специфікації pod, яку визнала kubelet. Ви можете використовувати це, щоб визначити найостанніший запит на зміну розміру, який обробив kubelet.
У стані PodResizeInProgress поле conditions[].observedGeneration вказує на metadata.generation podSpec, коли була ініційована поточна зміна розміру.
У стані PodResizePending поле conditions[].observedGeneration вказує на metadata.generation podSpec, коли востаннє намагалися виділити ресурси для відкладеної зміни розміру.
Політики зміни розміру контейнерів
Ви можете вказати чи потрібно перезапускати контейнер під час зміни розміру за допомогою поля resizePolicy в специфікації контейнера. Це дозволяє докладний контроль за типами ресурсів (CPU чи memory).
NotRequired: (типово) застосовувати зміну ресурсів без перезапуску контейнера.
RestartContainer: перезапускати контейнер під час зміни ресурсів. Це часто необхідно для зміни memory оскільки багато застосунків та середовищ виконання не можуть підлаштовуватись до динамічної зміни виділення памʼяті.
Якщо resizePolicy[*].restartPolicy не вказано для ресурсу, типовим значенням буде NotRequired.
Примітка:
Якщо загальний параметр Podʼа restartPolicy має значення Never, тоді параметр resizePolicy кожного контейнера має бути NotRequired для всіх ресурсів. Ви не зможете налаштовувати зміну ресурсів, що вимагають перезапуску в таких Podʼах
Приклад сценарію:
Уявіть контейнер з налаштованими restartPolicy: NotRequired для CPU та restartPolicy: RestartContainer для memory.
Якщо тільки ресурс CPU буде змінено, розмір контейнера буде змінено на місці.
Якщо тільки ресурс memory буде змінено, контейнер буде перезапущено.
Якщо обидва ресурси CPU та memory будуть змінені одночасно, контейнер буде перезапущено (через правило перезапуску для ресурсу memory).
Обмеження
Для Kubernetes 1.34 зміна розміру ресурсів podʼа на місці має наступні обмеження:
Типи ресурсів: Тільки ресурси CPU та memory можуть змінювати розмір.
Зменшення memory: Якщо політика перезапуску зміни розміру памʼяті є NotRequired (або не вказана), kubelet зробить спробу запобігти oom-kills при зменшенні лімітів памʼяті, але не надає жодних гарантій. Перед зменшенням лімітів памʼяті контейнера, якщо використання памʼяті перевищує запитуваний ліміт, зміна розміру буде пропущена, а статус залишиться в стані "In Progress". Це вважається найкращим варіантом, оскільки все ще існує ризик виникнення ситуації, коли використання памʼяті може різко зрости одразу після виконання перевірки.
Клас QoS: Оригінальний клас Quality of Service (QoS) Podʼа (Guaranteed, Burstable або BestEffort) визначається під час створення і не може бути змінений під час зміни розміру. Зміна значень розміру ресурсів все ще має дотримуватись правил оригінальних класів QoS:
Guaranteed: Запити мають продовжувати дорівнювати лімітам як для CPU, так і для memory після зміни розміру.
Burstable: Запити та ліміти не можуть бути тотожними як для CPU, так і для memory одночасно (оскільки це призведе до їх зміни до Guaranteed).
BestEffort: Вимоги до ресурсів (requests чи limits) не можуть бути додані (оскільки це призведе до зміни до Burstable або Guaranteed).
Swap: Podʼи, що використовують swap-памʼять, не можуть змінювати розмір запитів памʼять якщо resizePolicy для memory не встановлено у RestartContainer.
Ці обмеження можуть бути послаблені в наступних версіях Kubernetes.
Приклад 1: Зміна розміру CPU без перезапуску
Спочатку, створіть Pod створений для зміни розміру CPU на місці та такий що вимагає перезапуску під час зміни memory.
apiVersion:v1kind:Podmetadata:name:resize-demospec:containers:- name:pauseimage:registry.k8s.io/pause:3.8resizePolicy:- resourceName:cpurestartPolicy:NotRequired# Це типове значення, вказане тут явно- resourceName:memoryrestartPolicy:RestartContainerresources:limits:memory:"200Mi"cpu:"700m"requests:memory:"200Mi"cpu:"700m"
Створіть Pod:
kubectl create -f pod-resize.yaml
Цей Pod запускається з класом Guaranteed QoS. Перевірте його початковий стан:
# Почекайте трохи доки pod запуститьсяkubectl get pod resize-demo --output=yaml
Погляньте на spec.containers[0].resources та status.containerStatuses[0].resources. Вони мають відповідати маніфесту (700m CPU, 200Mi memory). Зверніть увагу на status.containerStatuses[0].restartCount (має бути 0).
Тепер збільште запит та ліміт CPU до 800m. Використовуйте kubectl patch з аргументом командного рядка --subresource resize.
Для використання аргументу командного рядка --subresource resize у вас має бути версія клієнта kubectl не менша ніж v1.32.0.
Перевірте стан podʼа після накладання латки:
kubectl get pod resize-demo --output=yaml --namespace=qos-example
Ви мажте побачити:
spec.containers[0].resources тепер показує cpu: 800m.
status.containerStatuses[0].resources також показує cpu: 800m, що означає, що зміна розміру на вузлі відбулась.
status.containerStatuses[0].restartCount залишається 0, оскільки CPU resizePolicy було NotRequired.
Приклад 2: Зміна розміру memory без перезапуску
Тепер змінимо розмір memory в тому ж поді збільшивши її до 300Mi. Оскільки memory resizePolicy має значення RestartContainer, контейнер має перезапуститись.
Перевірте стан podʼа невдовзі після застосування латки:
kubectl get pod resize-demo --output=yaml
Ви маєте побачити:
spec.containers[0].resources показує memory: 300Mi.
status.containerStatuses[0].resources також показує memory: 300Mi.
status.containerStatuses[0].restartCount збільшився до 1 (або більше, якщо до цього вже відбувались перезапуски), що вказує на те, що контейнер було перезапущено після застосування зміни розміру memory.
Розвʼязання проблем: Неможливий запит на зміну розміру
Далі, спробуємо запитати якесь неможливе значення CPU, наприклад 1000 цілих ядер (записується як "1000", в той час, коли йдеться про міліядра це — "1000m"), що очевидно перевищує можливості вузла.
# Спроба застосувати латку з запитом явно більшої кількістю CPUkubectl patch pod resize-demo --subresource resize --patch \
'{"spec":{"containers":[{"name":"pause", "resources":{"requests":{"cpu":"1000"}, "limits":{"cpu":"1000"}}}]}}'
Запитайте інформацію Podʼа:
kubectl get pod resize-demo --output=yaml
Ви побачите зміни, що сповіщають про проблему:
Поле spec.containers[0].resources показує бажаний стан (cpu: "1000").
Стан з type: PodResizePending та reason: Infeasible було додано до Pod.
Поле message буде містити пояснення (Node didn't have enough capacity: cpu, requested: 800000, capacity: ...)
Найважливіше, status.containerStatuses[0].resources буде все ще показувати попередні значення (cpu: 800m, memory: 300Mi), тому що неможлива зміна розміру не була застосована Kubelet.
Поле restartCount не зміниться через невдалу спробу.
Щоб виправити це, вам потрібно застосувати латку до podʼа з прийнятними параметрами.
3.4 - Надання ресурсів CPU та памʼяті на рівні Podʼів
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.34 [beta](стандартно увімкнено)
Ця сторінка показує, як вказати ресурси CPU та памʼяті для Pod на рівні podʼів, додатково до специфікацій ресурсів на рівні контейнера. Вузол Kubernetes виділяє ресурси для podʼів на основі запитів ресурсів podʼом. Ці запити можуть бути визначені на рівні podʼа або індивідуально для контейнерів у podʼі. Коли присутні обидва, запити на рівні podʼа мають пріоритет.
Аналогічно, використання ресурсів podʼом обмежується лімітами, які також можуть бути встановлені на рівні podʼа або індивідуально для контейнерів у podʼі. Знову ж таки, ліміти на рівні podʼа мають пріоритет, коли присутні обидва. Це дозволяє гнучко керувати ресурсами, дозволяючи контролювати розподіл ресурсів як на рівні podʼа, так і на рівні контейнера.
Щоб вказати ресурси на рівні podʼа, необхідно увімкнути функціональну можливістьPodLevelResources.
Для ресурсів на рівні Podʼа:
Пріоритет: Коли вказані як ресурси на рівні podʼа, так і на рівні контейнера, ресурси на рівні podʼа мають пріоритет.
QoS: Ресурси на рівні podʼа мають пріоритет у впливі на клас QoS podʼа.
OOM Score: Розрахунок коригування OOM score враховує як ресурси на рівні podʼа, так і на рівні контейнера.
Сумісність: Ресурси на рівні pod розроблені для сумісності з наявними функціями.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж 1.34.
Для перевірки версії введіть kubectl version.
Функціональна можливістьPodLevelResources має бути увімкнена для вашої панелі управління та для всіх вузлів у вашому кластері.
Обмеження
Для Kubernetes 1.34, зміна розміру ресурсів на рівні podʼа має такі обмеження:
Типи ресурсів: Тільки ресурси CPU, памʼяті та hugepages можуть бути вказані на рівні podʼа.
Операційна система: Ресурси на рівні podʼа не підтримуються для Windows podʼів.
Менеджери ресурсів: Менеджери ресурсів Topology Manager, Memory Manager та CPU Manager не розташовують podʼи та контейнери на основі ресурсів на рівні podʼа, оскільки ці менеджери ресурсів наразі не підтримують ресурси на рівні podʼа.
In-Place Resize: Зміна розміру ресурсів на рівні podʼа не підтримується. Зміна лімітів або запитів ресурсів на рівні podʼа призводить до помилки field.Forbidden. Повідомлення про помилку чітко вказує: "pods with pod-level resources cannot be resized."
Створіть простір імен
Створіть простір імен, щоб ресурси, які ви створюєте в цій вправі, були ізольовані від решти вашого кластера.
kubectl create namespace pod-resources-example
Створіть pod із запитами та лімітами памʼяті на рівні podʼа
Щоб вказати запити памʼяті для pod на рівні podʼа, включіть поле resources.requests.memory у маніфест pod. Щоб вказати ліміт памʼяті, включіть resources.limits.memory.
У цій вправі ви створюєте pod, який має один контейнер. Pod має запит памʼяті 100 MiB і ліміт памʼяті 200 MiB. Ось конфігураційний файл для podʼа:
Розділ args у маніфесті надає аргументи для контейнера під час його запуску. Аргументи "--vm-bytes", "150M" вказують контейнеру спробувати виділити 150 MiB памʼаяті.
Запустіть kubectl top, щоб отримати метрики для pod:
kubectl top pod memory-demo --namespace=pod-resources-example
Вивід показує, що Pod використовує близько 162,900,000 байтів памʼяті, що становить близько 150 MiB. Це більше, ніж запит Pod у 100 MiB, але в межах ліміту Pod у 200 MiB.
NAME CPU(cores) MEMORY(bytes)
memory-demo <something> 162856960
Створіть pod із запитами та лімітами CPU на рівні podʼа
Щоб вказати запит CPU для Pod, включіть поле resources.requests.cpu у маніфест Pod. Щоб вказати ліміт CPU, включіть resources.limits.cpu.
У цій вправі ви створюєте Pod, який має один контейнер. Pod має запит 0.5 CPU і ліміт 1 CPU. Ось конфігураційний файл для Pod:
Розділ args конфігураційного файлу надає аргументи для контейнера під час його запуску. Аргумент -cpus "2" вказує контейнеру спробувати використовувати 2 CPU.
Використовуйте kubectl top, щоб отримати метрики для Pod:
kubectl top pod cpu-demo --namespace=pod-resources-example
Цей приклад виходу показує, що Pod використовує 974 milliCPU, що трохи менше ліміту 1 CPU, вказаного в конфігурації Pod.
NAME CPU(cores) MEMORY(bytes)
cpu-demo 974m <something>
Нагадаємо, що встановивши -cpu "2", ви налаштували контейнер на спробу використовувати 2 CPU, але контейнеру дозволено використовувати лише близько 1 CPU. Використання CPU контейнера обмежується, оскільки контейнер намагається використовувати більше ресурсів CPU, ніж ліміт CPU Pod.
Створіть pod із запитами та лімітами ресурсів як на рівні podʼа, так і на рівні контейнера
Щоб призначити ресурси CPU та памʼяті Pod, ви можете вказати їх як на рівні podʼа, так і на рівні контейнера. Включіть поле resources у специфікацію Podʼа, щоб визначити ресурси для всього Podʼа. Додатково включіть поле resources у специфікацію контейнера в маніфесті Podʼа, щоб встановити вимоги до ресурсів для конкретного контейнера.
У цій вправі ви створите Pod із двома контейнерами, щоб дослідити взаємодію специфікацій ресурсів на рівні podʼа і контейнера. Сам Pod матиме визначені запити та ліміти CPU, тоді як лише один із контейнерів матиме власні явні запити та ліміти ресурсів. Інший контейнер успадкує обмеження ресурсів від налаштувань на рівні podʼа. Ось конфігураційний файл для Podʼа:
kubectl get pod-resources-demo --namespace=pod-resources-example
Перегляньте детальну інформацію про Pod:
kubectl get pod memory-demo --output=yaml --namespace=pod-resources-example
Вивід показує, що один контейнер у Pod має запит памʼяті 50 MiB і запит CPU 0.5 ядер, з лімітом памʼяті 100 MiB і лімітом CPU 0.5 ядер. Сам Pod має запит памʼяті 100 MiB і запит CPU 1 ядро, і ліміт памʼяті 200 MiB і ліміт CPU 1 ядро.
Оскільки вказані запити та ліміти на рівні podʼа, гарантії запитів для обох контейнерів у podʼі будуть рівні 1 ядру CPU та 100Mi памʼяті. Крім того, обидва контейнери разом не зможуть використовувати більше ресурсів, ніж вказано в лімітах на рівні podʼа, забезпечуючи, що вони не можуть перевищити загальну суму 200 MiB памʼяті та 1 ядро CPU.
3.5 - Налаштування GMSA для Windows Podʼів та контейнерів
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.18 [stable]
Ця сторінка показує, як налаштувати Group Managed Service Accounts (GMSA) для Podʼів та контейнерів, які будуть запущені на вузлах Windows. Group Managed Service Accounts це специфічний тип облікового запису Active Directory, який забезпечує автоматичне управління паролями, спрощене управління іменами служб (SPN) та можливість делегування управління іншим адміністраторам на кількох серверах.
У Kubernetes специфікації облікових даних GMSA налаштовуються на рівні кластера Kubernetes як Custom Resources. Windows Podʼи, також як і окремі контейнери в Podʼі, можуть бути налаштовані для використання GMSA для доменних функцій (наприклад, автентифікація Kerberos) при взаємодії з іншими службами Windows.
Перш ніж ви розпочнете
Вам необхідно мати кластер Kubernetes і інструмент командного рядка kubectl, налаштований для керування з вашим кластером. Очікується, що в кластері будуть вузли Windows. Цей розділ охоплює набір початкових кроків, необхідних один раз для кожного кластера:
Встановлення CRD для GMSACredentialSpec
CustomResourceDefinition(CRD) для ресурсів специфікації облікових даних GMSA потрібно налаштувати на кластері, щоб визначити тип настроюваного ресурсу GMSACredentialSpec. Завантажте GMSA CRD YAML і збережіть як gmsa-crd.yaml. Далі встановіть CRD за допомогою kubectl apply -f gmsa-crd.yaml.
Встановлення вебхуків для перевірки користувачів GMSA
Два вебхуки потрібно налаштувати на кластері Kubernetes для заповнення та перевірки посилань на специфікації облікових даних GMSA на рівні Podʼа або контейнера:
Модифікаційний вебхук, який розширює посилання на GMSAs (за іменем зі специфікації Podʼа) до повної специфікації облікових даних у форматі JSON у специфікації Podʼа.
Валідаційний вебхук забезпечує, що всі посилання на GMSAs уповноважені для використання службовим обліковим записом Podʼа.
Встановлення зазначених вище вебхуків та повʼязаних обʼєктів вимагає наступних кроків:
Створіть пару ключів сертифікатів (яка буде використовуватися для забезпечення звʼязку контейнера вебхука з кластером)
Встановіть Secret із вищезазначеним сертифікатом.
Створіть Deployment для основної логіки вебхука.
Створіть конфігурації валідаційного та модифікаційного вебхуків, посилаючись на Deployment.
Скрипт можна використовувати для розгортання та налаштування вебхуків GMSA та повʼязаних з ними обʼєктів, зазначених вище. Скрипт можна запускати з опцією --dry-run=server, щоб ви могли переглянути зміни, які будуть внесені в ваш кластер.
YAML шаблон, що використовується скриптом, також може бути використаний для ручного розгортання вебхуків та повʼязаних обʼєктів (з відповідними замінами параметрів)
Налаштування GMSA та вузлів Windows в Active Directory
Перш ніж Podʼи в Kubernetes можуть бути налаштовані на використання GMSA, необхідно провести налаштування бажаних GMSA в Active Directory, як описано в документації Windows GMSA. Вузли робочих станцій Windows (які є частиною кластера Kubernetes) повинні бути налаштовані в Active Directory для доступу до секретних облікових даних, що повʼязані з бажаним GMSA, як описано в документації Windows GMSA.
Створення ресурсів GMSA Credential Spec
Після встановлення CRD GMSACredentialSpec (як описано раніше), можна налаштувати власні ресурси, що містять специфікації облікових даних GMSA. Специфікація облікових даних GMSA не містить конфіденційні або секретні дані. Це інформація, яку контейнерне середовище може використовувати для опису бажаної GMSA контейнера для Windows. Специфікації облікових даних GMSA можуть бути створені у форматі YAML за допомогою утиліти сценарію PowerShell.
Ось кроки для створення YAML-файлу специфікації облікових даних GMSA вручну у форматі JSON і подальше його конвертування:
Створіть специфікацію облікових даних у форматі JSON за допомогою команди New-CredentialSpec. Щоб створити специфікацію облікових даних GMSA з іменем WebApp1, викличте New-CredentialSpec -Name WebApp1 -AccountName WebApp1 -Domain $(Get-ADDomain -Current LocalComputer).
Використайте команду Get-CredentialSpec, щоб показати шлях до файлу JSON.
Конвертуйте файл credspec з формату JSON у YAML та застосуйте необхідні заголовкові поля apiVersion, kind, metadata та credspec, щоб зробити його специфікацією GMSACredentialSpec, яку можна налаштувати в Kubernetes.
Наступна конфігурація YAML описує специфікацію облікових даних GMSA з іменем gmsa-WebApp1:
apiVersion:windows.k8s.io/v1kind:GMSACredentialSpecmetadata:name:gmsa-WebApp1 # Це довільне імʼя, але воно буде використовуватися як посиланняcredspec:ActiveDirectoryConfig:GroupManagedServiceAccounts:- Name:WebApp1 # Імʼя користувача облікового запису GMSAScope:CONTOSO # Імʼя домену NETBIOS- Name:WebApp1 # Імʼя користувача облікового запису GMSAScope:contoso.com# Імʼя домену DNSCmsPlugins:- ActiveDirectoryDomainJoinConfig:DnsName:contoso.com # Імʼя домену DNSDnsTreeName:contoso.com# Корінь імені домену DNSGuid:244818ae-87ac-4fcd-92ec-e79e5252348a # GUID для DomainMachineAccountName:WebApp1# Імʼя користувача облікового запису GMSANetBiosName:CONTOSO # Імʼя домену NETBIOSSid:S-1-5-21-2126449477-2524075714-3094792973# SID для Domain
Вищезазначений ресурс специфікації облікових даних може бути збережений як gmsa-Webapp1-credspec.yaml і застосований до кластера за допомогою: kubectl apply -f gmsa-Webapp1-credspec.yaml.
Налаштування ролі кластера для включення RBAC у конкретні специфікації облікових даних GMSA
Для кожного ресурсу специфікації облікових даних GMSA потрібно визначити роль в кластері. Це авторизує дію use ("використовувати") на конкретному ресурсі GMSA певним субʼєктом, який, як правило, є службовим обліковим записом. Наведений нижче приклад показує роль в кластері, яка авторизує використання специфікації облікових даних gmsa-WebApp1 зверху. Збережіть файл як gmsa-webapp1-role.yaml і застосуйте його за допомогою kubectl apply -f gmsa-webapp1-role.yaml.
# Створення ролі для читання credspecapiVersion:rbac.authorization.k8s.io/v1kind:ClusterRolemetadata:name:webapp1-rolerules:- apiGroups:["windows.k8s.io"]resources:["gmsacredentialspecs"]verbs:["use"]resourceNames:["gmsa-WebApp1"]
Призначення ролі службовому обліковому запису для використання конкретних специфікацій облікових даних GMSA
Службовий обліковий запис (з якими будуть налаштовані Podʼи) повинен бути привʼязаний до ролі в кластері, створеної вище. Це авторизує службовий обліковий запис використовувати бажаний ресурс специфікації облікових даних GMSA. Нижче показано, як стандартний службовий обліковий запис привʼязується до ролі в кластера webapp1-role для використання ресурсу специфікації облікових даних gmsa-WebApp1, створеного вище.
Налаштування посилання на специфікацію облікових даних GMSA в специфікації Pod
Поле securityContext.windowsOptions.gmsaCredentialSpecName у специфікації Pod використовується для вказівки посилань на бажані ресурси специфікації облікових даних GMSA в специфікаціях Pod. Це налаштовує всі контейнери в специфікації Pod на використання вказаного GMSA. Нижче наведено приклад специфікації Pod з анотацією, заповненою для посилання на gmsa-WebApp1:
Індивідуальні контейнери в специфікації Pod також можуть вказати бажану специфікацію облікових даних GMSA, використовуючи поле securityContext.windowsOptions.gmsaCredentialSpecName на рівні окремого контейнера. Наприклад:
Під час застосування специфікацій Pod з заповненими полями GMSA (як описано вище) в кластері відбувається наступна послідовність подій:
Модифікаційний вебхук розвʼязує та розширює всі посилання на ресурси специфікації облікових даних GMSA до вмісту специфікації облікових даних GMSA.
Валідаційний вебхук переконується, що службовий обліковий запис, повʼязаний з Pod, авторизований для дії use на вказаній специфікації облікових даних GMSA.
Контейнерне середовище налаштовує кожен контейнер Windows із вказаною специфікацією облікових даних GMSA, щоб контейнер міг прийняти елемент GMSA в Active Directory та отримати доступ до служб в домені, використовуючи цей елемент.
Автентифікація на мережевих ресурсах за допомогою імені хосту або повного доменного імені
Якщо ви маєте проблеми з підключенням до SMB-ресурсів з Podʼів за допомогою імені хосту або повного доменного імені, але можете отримати доступ до ресурсів за їх адресою IPv4, переконайтеся, що встановлений наступний ключ реєстру на вузлах Windows.
Після цього потрібно перестворити Podʼи, щоб вони врахували зміни в поведінці. Додаткову інформацію про те, як використовується цей ключ реєстру, можна знайти тут.
Усунення несправностей
Якщо у вас виникають труднощі з налаштуванням роботи GMSA в вашому середовищі, існують кілька кроків усунення несправностей, які ви можете виконати.
Спочатку переконайтеся, що credspec був переданий до Podʼа. Для цього вам потрібно виконати команду exec в одному з ваших Podʼів і перевірити вивід команди nltest.exe /parentdomain.
У наступному прикладі Pod не отримав credspec правильно:
Результат команди nltest.exe /parentdomain показує наступну помилку:
Getting parent domain failed: Status = 1722 0x6ba RPC_S_SERVER_UNAVAILABLE
Якщо ваш Pod отримав credspec правильно, наступним кроком буде перевірка звʼязку з доменом. Спочатку, зсередини вашого Podʼа, виконайте nslookup, щоб знайти корінь вашого домену.
Це дозволить нам визначити 3 речі:
Pod може досягти контролера домену (DC).
Контролер домену (DC) може досягти Podʼа.
DNS працює правильно.
Якщо тест DNS та комунікації успішний, наступним буде перевірка, чи Pod встановив захищений канал звʼязку з доменом. Для цього, знову ж таки, виконайте команду exec в вашому Podʼі та запустіть команду nltest.exe /query.
nltest.exe /query
Результат буде наступним:
I_NetLogonControl failed: Статус = 1722 0x6ba RPC_S_SERVER_UNAVAILABLE
Це говорить нам те, що з якоїсь причини Pod не зміг увійти в домен, використовуючи обліковий запис, вказаний у credspec. Ви можете спробувати полагодити захищений канал за допомогою наступного:
nltest /sc_reset:domain.example
Якщо команда успішна, ви побачите подібний вивід:
Flags: 30 HAS_IP HAS_TIMESERV
Trusted DC Name \\dc10.domain.example
Trusted DC Connection Status Status = 0 0x0 NERR_Success
The command completed successfully
Якщо дії вище виправили помилку, ви можете автоматизувати цей крок, додавши наступний виклик у час життєвого циклу до специфікації вашого Podʼа. Якщо це не виправило помилку, вам потрібно перевірити ваш credspec ще раз та підтвердити, що він правильний та повний.
Якщо ви додасте розділ lifecycle до специфікації вашого Podʼа, Pod виконає вказані команди для перезапуску служби netlogon до того, як команда nltest.exe /query вийде без помилок.
3.6 - Призначення пристроїв Podʼам та контейнерам
Призначення інфраструктурних ресурсів для ваших робочих навантажень Kubernetes.
3.6.1 - Налаштування DRA у кластері
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.34 [stable](стандартно увімкнено)
На цій сторінці показано, як налаштувати динамічне виділення ресурсів (DRA) у кластері Kubernetes шляхом активації груп API та налаштування класів пристроїв. Ці інструкції призначені для адміністраторів кластерів.
Про DRA
Функція Kubernetes, яка дозволяє вам запитувати ресурси та ділитися ними з іншими Podʼами. Ці ресурси часто приєднуються до пристроїів, наприклад, до апаратних прискорювачів.
З DRA драйвери пристроїв і адміністратори кластерів визначають класи пристроїв, які доступні для заявки в робочих навантаженнях. Kubernetes виділяє відповідні пристрої для конкретних заявок і розміщує відповідні Podʼи на вузлах, які можуть отримати доступ до виділених пристроїв.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Підключіть пристрої до вашого кластера безпосередньо або опосередковано. Щоб уникнути можливих проблем із драйверами, дочекайтеся налаштування функції DRA для вашого кластера перед встановленням драйверів.
Опціонально: увімкніть застарілі групи API DRA
DRA перейшов на стабільну версію в Kubernetes 1.34 і є стандартно увімкненим. Деякі старі драйвери або робочі навантаження DRA можуть все ще потребувати API v1beta1 з Kubernetes 1.30 або v1beta2 з Kubernetes 1.32. Тільки якщо потрібна підтримка цих версій, увімкніть наступні API groups:
Щоб перевірити правильність налаштування кластера, спробуйте вивести список DeviceClasses:
kubectl get deviceclasses
Якщо конфігурація компонентів була правильною, ви побачите подібний результат:
No resources found
Якщо DRA налаштовано неправильно, результат буде схожий на:
error: the server doesn't have a resource type "deviceclasses"
Спробуйте наступні кроки для усунення несправностей:
Переконфігуруйте та перезапустіть компонент kube-apiserver.
Якщо повне поле .spec.resourceClaims видаляється з Podʼів, або якщо Podʼи плануються без урахування ResourceClaims, перевірте, чи не вимкнено функціональну можливістьDynamicResourceAllocation для kube-apiserver, kube-controller-manager, kube-scheduler або kubelet.
Встановіть драйвери пристроїв
Після активації DRA для вашого кластера ви можете встановити драйвери для підключених пристроїв. Інструкції шукайте у документації виробника пристрою або проєкту, що підтримує драйвери. Встановлені драйвери мають бути сумісні з DRA.
Щоб перевірити роботу встановлених драйверів, виведіть список ResourceSlices у кластері:
kubectl get resourceslices
Вивід буде схожий на:
NAME NODE DRIVER POOL AGE
cluster-1-device-pool-1-driver.example.com-lqx8x cluster-1-node-1 driver.example.com cluster-1-device-pool-1-r1gc 7s
cluster-1-device-pool-2-driver.example.com-29t7b cluster-1-node-2 driver.example.com cluster-1-device-pool-2-446z 8s
Спробуйте наступні кроки для усунення несправностей:
Перевірте стан драйвера DRA та шукайте повідомлення про помилки щодо публікації ResourceSlices у виводі його журналу. Постачальник драйвера може надати додаткові інструкції щодо встановлення та усунення несправностей.
Створіть DeviceClasses
Ви можете визначити категорії пристроїв, які оператори ваших застосунків можуть використовувати у робочих навантаженнях, створюючи DeviceClasses. Деякі постачальники драйверів також можуть рекомендувати створити DeviceClasses під час встановлення драйверів.
ResourceSlices, які публікує ваш драйвер, містять інформацію про пристрої, якими керує драйвер, такі як ємність, метадані та атрибути. Ви можете використовувати Загальна мова виразів для фільтрації властивостей у DeviceClasses, що спрощує пошук пристроїв для операторів навантажень.
Щоб знайти властивості пристрою, які можна вибирати у DeviceClasses за допомогою виразів CEL, отримайте специфікацію ResourceSlice:
kubectl get resourceslice <resourceslice-name> -o yaml
Вивід буде схожий на:
apiVersion:resource.k8s.io/v1kind:ResourceSlice# lines omitted for clarityspec:devices:- attributes:type:string:gpucapacity:memory:value:64Giname:gpu-0- attributes:type:string:gpucapacity:memory:value:64Giname:gpu-1driver:driver.example.comnodeName:cluster-1-node-1# lines omitted for clarity
Ви також можете переглянути документацію постачальника драйверів для доступних властивостей і значень.
Ознайомтеся з прикладом маніфесту DeviceClass, який вибирає будь-який пристрій, керований драйвером driver.example.com:
3.6.2 - Призначення пристроїв робочим навантаженням за допомогою DRA
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.34 [stable](стандартно увімкнено)
На цій сторінці показано, як призначати пристрої для ваших Podʼів за допомогою динамічного розподілу ресурсів (DRA). Ці інструкції призначені для операторів робочих навантажень. Перед прочитанням цієї сторінки ознайомтеся з принципами роботи DRA та термінами, такими як ResourceClaims і ResourceClaimTemplates. Докладніше дивіться у розділі Динамічний розподіл ресурсів (DRA).
Про призначення пристроїв з DRA
Як оператор робочих навантажень, ви можете запитувати пристрої для своїх навантажень, створюючи ResourceClaims або ResourceClaimTemplates. Під час розгортання навантаження Kubernetes і драйвери пристроїв знаходять доступні пристрої, призначають їх вашим Podʼам і розміщують Podʼи на вузлах, які мають доступ до цих пристроїв.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Переконайтеся, що адміністратор вашого кластера налаштував DRA, підключив пристрої та встановив драйвери. Докладніше дивіться у розділі Налаштування DRA у кластері.
Визначення пристроїв для подання заявок на них
Адміністратор вашого кластера або драйвери пристроїв створюють DeviceClasses, які визначають категорії пристроїв. Ви можете отримувати пристрої, використовуючи Загальна мова виразів для фільтрації за конкретними властивостями пристроїв.
Отримайте список DeviceClasses у кластері:
kubectl get deviceclasses
Вивід буде схожим на наступний:
NAME AGE
driver.example.com 16m
Якщо ви отримали помилку доступу, можливо, у вас немає прав для перегляду DeviceClasses. Зверніться до адміністратора кластера або постачальника драйверів щодо доступних властивостей пристроїв.
Запитування ресурсів
Ви можете запитувати ресурси з DeviceClass за допомогою ResourceClaims. Щоб створити ResourceClaim, виконайте одну з наступних дій:
Створіть ResourceClaim вручну, якщо ви хочете, щоб декілька Podʼів мали спільний доступ до одних і тих самих пристроїв, або якщо ви хочете, щоб claim існував довше, ніж Pod.
Використовуйте ResourceClaimTemplate, щоб Kubernetes генерував і керував ResourceClaims для кожного Podʼа. Створіть ResourceClaimTemplate, якщо ви хочете, щоб кожен Pod мав доступ до окремих пристроїв із подібними конфігураціями. Наприклад, це може знадобитися для одночасного доступу до пристроїв у Pod для Job, який використовує паралельне виконання.
Якщо ви безпосередньо посилаєтеся на конкретний ResourceClaim у Pod, цей ResourceClaim вже має існувати у кластері. Якщо зазначений ResourceClaim не існує, Pod залишатиметься у стані очікування, доки ResourceClaim не буде створено. Ви можете посилатися на автоматично створений ResourceClaim у Podʼі, але це не рекомендується, оскільки такі ResourceClaim прив'язані до часу життя Pod, який їх створив.
Щоб створити робоче навантаження, яке отримує ресурси, виберіть одну з наступних опцій:
Запит пристроїв у робочих навантаженнях за допомогою DRA
Щоб запросити пристрій, вкажіть ResourceClaim або ResourceClaimTemplate у полі resourceClaims специфікації Podʼа. Потім запросіть конкретний claim за назвою у полі resources.claims контейнера цього Podʼа. Ви можете вказати декілька записів у полі resourceClaims та використовувати конкретні claims у різних контейнерах.
Коли робоче навантаження не запускається, як очікувалося, перевірте обʼєкти на кожному рівні з kubectl describe, щоб дізнатися, чи є якісь поля статусу або події, які можуть пояснити, чому робоче навантаження не запускається.
Коли створення Pod не вдається з must specify one of: resourceClaimName, resourceClaimTemplateName, перевірте, що всі записи в pod.spec.resourceClaims мають точно одне з цих полів. Якщо так, то можливо, що в кластері встановлено модифікуючий веб-хук Podʼа, який був створений для API Kubernetes < 1.32. Попросіть адміністратора кластера перевірити це.
Очищення
Щоб видалити обʼєкти Kubernetes, створені у цьому завданні, виконайте наступні кроки:
3.7 - Налаштування RunAsUserName для Podʼів та контейнерів Windows
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.18 [stable]
Ця сторінка показує, як використовувати параметр runAsUserName для Podʼів та контейнерів, які будуть запущені на вузлах Windows. Це приблизно еквівалент параметра runAsUser, який використовується для Linux, і дозволяє виконувати програми в контейнері від імені іншого імені користувача, ніж типово.
Перш ніж ви розпочнете
Вам потрібно мати кластер Kubernetes, а також інструмент командного рядка kubectl повинен бути налаштований для взаємодії з вашим кластером. Очікується, що в кластері будуть використовуватися вузли Windows, де будуть запускатися Podʼи з контейнерами, що виконують робочі навантаження у Windows.
Встановлення імені користувача для Podʼа
Щоб вказати імʼя користувача, з яким потрібно виконати процеси контейнера Podʼа, включіть поле securityContext (PodSecurityContext) в специфікацію Podʼа, а всередині нього — поле windowsOptions (WindowsSecurityContextOptions), що містить поле runAsUserName.
Опції безпеки Windows, які ви вказуєте для Podʼа, застосовуються до всіх контейнерів та контейнерів ініціалізації у Podʼі.
Ось конфігураційний файл для Podʼа Windows зі встановленим полем runAsUserName:
Перевірте, що оболонка працює від імені відповідного користувача:
echo $env:USERNAME
Вивід повинен бути:
ContainerUser
Встановлення імені користувача для контейнера
Щоб вказати імʼя користувача, з яким потрібно виконати процеси контейнера, включіть поле securityContext (SecurityContext) у маніфесті контейнера, а всередині нього — поле windowsOptions (WindowsSecurityContextOptions), що містить поле runAsUserName.
Опції безпеки Windows, які ви вказуєте для контейнера, застосовуються тільки до цього окремого контейнера, і вони перевизначають налаштування, зроблені на рівні Podʼа.
Ось конфігураційний файл для Podʼа, який має один Контейнер, а поле runAsUserName встановлене на рівні Podʼа та на рівні Контейнера:
Перевірте, що оболонка працює від імені відповідного користувача (того, який встановлений на рівні контейнера):
echo $env:USERNAME
Вивід повинен бути:
ContainerAdministrator
Обмеження імен користувачів Windows
Для використання цієї функції значення, встановлене у полі runAsUserName, повинно бути дійсним імʼям користувача. Воно повинно мати наступний формат: DOMAIN\USER, де DOMAIN\ є необовʼязковим. Імена користувачів Windows регістронезалежні. Крім того, існують деякі обмеження стосовно DOMAIN та USER:
Поле runAsUserName не може бути порожнім і не може містити керуючі символи (ASCII значення: 0x00-0x1F, 0x7F)
DOMAIN може бути або NetBios-імʼям, або DNS-імʼям, кожне з власними обмеженнями:
NetBios імена: максимум 15 символів, не можуть починатися з . (крапка), і не можуть містити наступні символи: \ / : * ? " < > |
DNS-імена: максимум 255 символів, містять тільки буквено-цифрові символи, крапки та дефіси, і не можуть починатися або закінчуватися . (крапка) або - (дефіс).
USER може мати не більше 20 символів, не може містити тільки крапки або пробіли, і не може містити наступні символи: " / \ [ ] : ; | = , + * ? < > @.
Приклади припустимих значень для поля runAsUserName: ContainerAdministrator, ContainerUser, NT AUTHORITY\NETWORK SERVICE, NT AUTHORITY\LOCAL SERVICE.
Для отримання додаткової інформації про ці обмеження, перевірте тут та тут.
Windows HostProcess контейнери дозволяють вам запускати контейнеризовані робочі навантаження на хості Windows. Ці контейнери працюють як звичайні процеси, але мають доступ до мережевого простору імен хосту, сховища та пристроїв, коли надані відповідні права користувача. Контейнери HostProcess можуть бути використані для розгортання мережевих втулків, сховищ конфігурацій, пристроїв, kube-proxy та інших компонентів на вузлах Windows без потреби у власних проксі або безпосереднього встановлення служб хосту.
Адміністративні завдання, такі як встановлення патчів безпеки, збір подій логів тощо, можна виконувати без потреби входу операторів кластера на кожен вузол Windows. Контейнери HostProcess можуть працювати як будь-який користувач, що доступний на хості або в домені машини хосту, що дозволяє адміністраторам обмежити доступ до ресурсів через дозволи користувача. Хоча і не підтримуються ізоляція файлової системи або процесу, при запуску контейнера на хості створюється новий том, щоб надати йому чисте та обʼєднане робоче середовище. Контейнери HostProcess також можуть бути побудовані на базі наявних образів базової системи Windows і не успадковують ті ж вимоги сумісності як контейнери Windows server, що означає, що версія базового образу не повинна відповідати версії хосту. Однак рекомендується використовувати ту ж версію базового образу, що й ваші робочі навантаження контейнерів Windows Server, щоб уникнути зайвого використання місця на вузлі. Контейнери HostProcess також підтримують монтування томів всередині тома контейнера.
Коли варто використовувати контейнери Windows HostProcess?
Коли потрібно виконати завдання, які потребують мережевого простору імен хосту. Контейнери HostProcess мають доступ до мережевих інтерфейсів хосту та IP-адрес.
Вам потрібен доступ до ресурсів на хості, таких як файлова система, події логів тощо.
Встановлення конкретних драйверів пристроїв або служб Windows.
Обʼєднання адміністративних завдань та політик безпеки. Це зменшує ступінь привілеїв, які потрібні вузлам Windows.
Перш ніж ви розпочнете
Цей посібник стосується конкретно Kubernetes v1.34. Якщо ви використовуєте іншу версію Kubernetes, перевірте документацію для цієї версії Kubernetes.
У Kubernetes 1.34 контейнери HostProcess є типово увімкненими. kubelet буде спілкуватися з containerd безпосередньо, передаючи прапорець hostprocess через CRI. Ви можете використовувати останню версію containerd (v1.6+) для запуску контейнерів HostProcess. Як встановити containerd.
Обмеження
Ці обмеження стосуються Kubernetes v1.34:
Контейнери HostProcess вимагають середовища виконання контейнерів containerd 1.6 або вище, рекомендується використовувати containerd 1.7.
Podʼи HostProcess можуть містити лише контейнери HostProcess. Це поточне обмеження ОС Windows; непривілейовані контейнери Windows не можуть спільно використовувати vNIC з простором імен IP хосту.
Контейнери HostProcess запускаються як процес на хості та не мають жодного рівня ізоляції, окрім обмежень ресурсів, накладених на обліковий запис користувача HostProcess. Ізоляція ні файлової системи, ні ізоляції Hyper-V не підтримуються для контейнерів HostProcess.
Монтування томів підтримуються і монтуватимуться як томом контейнера. Див. Монтування томів
Стандартно для контейнерів HostProcess доступний обмежений набір облікових записів користувачів хосту. Див. Вибір облікового запису користувача.
Обмеження ресурсів (диск, памʼять, кількість процесорів) підтримуються так само як і процеси на хості.
Як іменовані канали, так і сокети Unix-домену не підтримуються і замість цього слід отримувати доступ до них через їх шлях на хості (наприклад, \\.\pipe\*)
Вимоги до конфігурації HostProcess Pod
Для активації Windows HostProcess Pod необхідно встановити відповідні конфігурації у конфігурації безпеки Podʼа. З усіх політик, визначених у Стандартах безпеки Pod, HostProcess Podʼи заборонені за базовою та обмеженою політиками. Тому рекомендується, щоб HostProcess Podʼи працювали відповідно до привілейованого профілю.
Під час роботи з привілейованою політикою, ось конфігурації, які потрібно встановити для активації створення HostProcess Pod:
Оскільки контейнери HostProcess мають привілейований доступ до хоста, поле runAsNonRoot не може бути встановлене в true.
Дозволені значення
Undefined/Nil
false
Приклад маніфесту (частково)
spec:securityContext:windowsOptions:hostProcess:truerunAsUserName:"NT AUTHORITY\\Local service"hostNetwork:truecontainers:- name:testimage:image1:latestcommand:- ping- -t- 127.0.0.1nodeSelector:"kubernetes.io/os": windows
Монтування томів
Контейнери HostProcess підтримують можливість монтування томів у просторі томів контейнера. Поведінка монтування томів відрізняється залежно від версії контейнерного середовища containerd, яке використовується на вузлі.
Containerd v1.6
Застосунки, що працюють усередині контейнера, можуть отримувати доступ до підключених томів безпосередньо за допомогою відносних або абсолютних шляхів. Під час створення контейнера встановлюється змінна середовища $CONTAINER_SANDBOX_MOUNT_POINT, яка містить абсолютний шлях хосту до тому контейнера. Відносні шляхи базуються на конфігурації .spec.containers.volumeMounts.mountPath.
Для доступу до токенів службового облікового запису (наприклад) у контейнері підтримуються такі структури шляхів:
Застосунки, які працюють усередині контейнера, можуть отримувати доступ до підключених томів безпосередньо через вказаний mountPath тому (аналогічно Linux і не-HostProcess контейнерам Windows).
Для забезпечення зворотної сумісності зі старими версіями, доступ до томів також може бути здійснений через використання тих самих відносних шляхів, які були налаштовані у containerd v1.6.
Наприклад, для доступу до токенів службового облікового запису усередині контейнера ви можете використовувати один із таких шляхів:
Обмеження ресурсів (диск, памʼять, кількість CPU) застосовуються до задачі і є загальними для всієї задачі. Наприклад, при обмеженні в 10 МБ памʼяті, памʼять, виділена для будь-якого обʼєкта задачі HostProcess, буде обмежена 10 МБ. Це така ж поведінка, як і в інших типах контейнерів Windows. Ці обмеження вказуються так само як і зараз для будь-якого середовища виконання контейнерів або оркестрування, яке використовується. Єдина відмінність полягає у розрахунку використання дискових ресурсів для відстеження ресурсів через відмінності у способі
ініціалізації контейнерів HostProcess.
Вибір облікового запису користувача
Системні облікові записи
Типово контейнери HostProcess підтримують можливість запуску з одного з трьох підтримуваних облікових записів служб Windows:
Вам слід вибрати відповідний обліковий запис служби Windows для кожного контейнера HostProcess, спираючись на обмеження ступеня привілеїв, щоб уникнути випадкових (або навіть зловмисних) пошкоджень хосту. Обліковий запис служби LocalSystem має найвищий рівень привілеїв серед трьох і повинен використовуватися лише у разі абсолютної необхідності. Де це можливо, використовуйте обліковий запис служби LocalService, оскільки він має найнижчий рівень привілеїв серед цих трьох варіантів.
Локальні облікові записи
Якщо налаштовано, контейнери HostProcess також можуть запускатися як локальні облікові записи користувачів, що дозволяє операторам вузлів надавати деталізований доступ до робочих навантажень.
Для запуску контейнерів HostProcess як локального користувача, спершу на вузлі має бути створена локальна група користувачів, і імʼя цієї локальної групи користувачів повинно бути вказане у полі runAsUserName у Deployment. Перед ініціалізацією контейнера HostProcess має бути створено новий ефемерний локальний обліковий запис користувача та приєднано його до вказаної групи користувачів, з якої запускається контейнер. Це надає кілька переваг, включаючи уникнення необхідності управління паролями для локальних облікових записів користувачів. Початковий контейнер HostProcess, що працює як службовий обліковий запис, може бути використаний для підготовки груп користувачів для подальших контейнерів HostProcess.
Примітка:
Запуск контейнерів HostProcess як локальних облікових записів користувачів вимагає containerd v1.7+
Приклад:
Створіть локальну групу користувачів на вузлі (це може бути зроблено в іншому контейнері HostProcess).
net localgroup hpc-localgroup /add
Надайте доступ до потрібних ресурсів на вузлі локальній групі користувачів. Це можна зробити за допомогою інструментів, таких як icacls.
Встановіть runAsUserName на імʼя локальної групи користувачів для Podʼа або окремих контейнерів.
Контейнери HostProcess не запускаються, помилка failed to create user process token: failed to logon user: Access is denied.: unknown.
Переконайтеся, що containerd працює як службовий обліковий запис LocalSystem або LocalService. Облікові записи користувачів (навіть адміністраторські облікові записи) не мають дозволів на створення токенів входу для будь-яких підтримуваних облікових записів користувачів.
3.9 - Налаштування якості обслуговування для Podʼів
Ця сторінка показує, як налаштувати Podʼи так, щоб їм були призначені певні класи якості обслуговування (QoS). Kubernetes використовує класи QoS для прийняття рішень про видалення Podʼів, коли використання ресурсів вузла збільшується.
Коли Kubernetes створює Pod, він призначає один з таких класів QoS для Podʼа:
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Також вам потрібно мати можливість створювати та видаляти простори імен.
Створення простору імен
Створіть простір імен, щоб ресурси, які ви створюєте у цьому завданні, були ізольовані від решти вашого кластера.
kubectl create namespace qos-example
Створення Podʼа, якому призначено клас QoS Guaranteed
Щоб Podʼа був наданий клас QoS Guaranteed:
Кожний контейнер у Pod повинен мати ліміт памʼяті та запит памʼяті.
Для кожного контейнера у Pod ліміт памʼяті повинен дорівнювати запиту памʼяті.
Кожний контейнер у Pod повинен мати ліміт CPU та запит CPU.
Для кожного контейнера у Pod ліміт CPU повинен дорівнювати запиту CPU.
Ці обмеження так само застосовуються до контейнерів ініціалізації і до контейнерів застосунків. Ефемерні контейнери не можуть визначати ресурси, тому ці обмеження не застосовуються до них.
Нижче подано маніфест для Podʼа з одним контейнером. Контейнер має ліміт памʼяті та запит памʼяті, обидва дорівнюють 200 MiB. Контейнер має ліміт CPU та запит CPU, обидва дорівнюють 700 міліCPU:
kubectl get pod qos-demo --namespace=qos-example --output=yaml
Вивід показує, що Kubernetes призначив Podʼу клас QoS Guaranteed. Також вивід підтверджує, що у контейнера Podʼа є запит памʼяті, який відповідає його ліміту памʼяті, і є запит CPU, який відповідає його ліміту CPU.
Якщо контейнер вказує свій власний ліміт памʼяті, але не вказує запит памʼяті, Kubernetes автоматично призначає запит памʼяті, який відповідає ліміту. Так само, якщо контейнер вказує свій власний ліміт CPU, але не вказує запит CPU, Kubernetes автоматично призначає запит CPU, який відповідає ліміту.
Очищення
Видаліть свій Pod:
kubectl delete pod qos-demo --namespace=qos-example
Створення Podʼа, якому призначено клас QoS Burstable
Podʼу надається клас QoS Burstable, якщо:
Pod не відповідає критеріям для класу QoS Guaranteed.
Принаймні один контейнер у Podʼі має запит або ліміт памʼяті або CPU.
Нижче подано маніфест для Podʼа з одним контейнером. Контейнер має ліміт памʼяті 200 MiB
та запит памʼяті 100 MiB.
kubectl delete pod qos-demo-3 --namespace=qos-example
Створення Podʼа з двома контейнерами
Нижче подано маніфест для Podʼа з двома контейнерами. Один контейнер вказує запит памʼяті 200 MiB. Інший контейнер не вказує жодних запитів або лімітів.
Зверніть увагу, що цей Pod відповідає критеріям класу QoS Burstable. Тобто, він не відповідає критеріям для класу QoS Guaranteed, і один з його контейнерів має запит памʼяті.
Ця сторінка показує, як призначити розширені ресурси контейнеру.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Щоб запитати розширений ресурс, включіть поле resources:requests у ваш маніфест контейнера. Розширені ресурси повністю кваліфікуються будь-яким доменом поза *.kubernetes.io/. Дійсні імена розширених ресурсів мають форму example.com/foo, де example.com замінено на домен вашої організації, а foo — це описове імʼя ресурсу.
Нижче подано конфігураційний файл для Podʼа з одним контейнером:
Текст виводу показує, що Pod не може бути запланованим, оскільки немає вузла, на якому було б доступно 2 донгли:
Conditions:
Type Status
PodScheduled False
...
Events:
...
... Warning FailedScheduling pod (extended-resource-demo-2) failed to fit in any node
fit failure summary on nodes : Insufficient example.com/dongle (1)
Перегляньте статус Podʼа:
kubectl get pod extended-resource-demo-2
Текст виводу показує, що Pod було створено, але не заплановано для виконання на вузлі. Він має статус Pending:
NAME READY STATUS RESTARTS AGEextended-resource-demo-2 0/1 Pending 0 6m
Очищення
Видаліть Podʼи, які ви створили для цього завдання:
kubectl delete pod extended-resource-demo
kubectl delete pod extended-resource-demo-2
3.11 - Налаштування Podʼа для використання тому для зберігання
Ця сторінка показує, як налаштувати Pod для використання тому для зберігання.
Файлова система контейнера існує лише поки існує сам контейнер. Отже, коли контейнер завершує роботу та перезавантажується, зміни в файловій системі втрачаються. Для більш стійкого зберігання, яке не залежить від контейнера, ви можете використовувати том. Це особливо важливо для застосунків, що зберігають стан, таких як бази даних і сховища ключ-значення (наприклад, Redis).
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У цьому завданні ви створюєте Pod, який запускає один контейнер. У цьому Podʼі є том типу emptyDir, який існує протягом усього життєвого циклу Podʼа, навіть якщо контейнер завершиться та перезапуститься. Ось конфігураційний файл для Podʼа:
Крім локального сховища на диску, яке надає emptyDir, Kubernetes підтримує багато різних рішень для мережевого сховища, включаючи PD на GCE та EBS на EC2, які бажані для критичних даних та будуть обробляти деталі, такі як монтування та розмонтування пристроїв на вузлах. Дивіться Volumes для отримання додаткової інформації.
3.12 - Налаштування Podʼа для використання PersistentVolume для зберігання
Ця сторінка показує, як налаштувати Pod для використання PersistentVolumeClaim для зберігання. Ось короткий опис процесу:
Ви, як адміністратор кластера, створюєте PersistentVolume на основі фізичного сховища. Ви не повʼязуєте том з жодним Podʼом.
Ви, як розробник / користувач кластера, створюєте PersistentVolumeClaim, який автоматично привʼязується до відповідного PersistentVolume.
Ви створюєте Pod, який використовує вищезгаданий PersistentVolumeClaim для зберігання.
Перш ніж ви розпочнете
Вам потрібно мати кластер Kubernetes, який має лише один вузол, і kubectl повинен бути налаштований на спілкування з вашим кластером. Якщо у вас ще немає кластера з одним вузлом, ви можете створити його, використовуючи Minikube.
Відкрийте оболонку на єдиному вузлі вашого кластера. Спосіб відкриття оболонки залежить від того, як ви налаштували ваш кластер. Наприклад, якщо ви використовуєте Minikube, ви можете відкрити оболонку до вашого вузла, введенням minikube ssh.
У вашій оболонці на цьому вузлі створіть теку /mnt/data:
# Це передбачає, що ваш вузол використовує "sudo" для запуску команд# як суперкористувачsudo mkdir /mnt/data
У теці /mnt/data створіть файл index.html:
# Це також передбачає, що ваш вузол використовує "sudo" для запуску команд# як суперкористувачsudo sh -c "echo 'Hello from Kubernetes storage' > /mnt/data/index.html"
Примітка:
Якщо ваш вузол використовує інструмент для доступу суперкористувача, відмінний від sudo, ви зазвичай можете зробити це, якщо заміните sudo на імʼя іншого інструмента.
Перевірте, що файл index.html існує:
cat /mnt/data/index.html
Виведення повинно бути:
Hello from Kubernetes storage
Тепер ви можете закрити оболонку вашого вузла.
Створення PersistentVolume
У цьому завданні ви створюєте hostPath PersistentVolume. Kubernetes підтримує hostPath для розробки та тестування на одновузловому кластері. PersistentVolume типу hostPath використовує файл або теку на вузлі для емуляції мережевого сховища.
В операційному кластері ви не використовували б hostPath. Замість цього адміністратор кластера створив би мережевий ресурс, такий як постійний диск Google Compute Engine, розділ NFS або том Amazon Elastic Block Store. Адміністратори кластера також можуть використовувати StorageClasses для динамічного налаштування.
Ось файл конфігурації для PersistentVolume типу hostPath:
Файл конфігурації вказує, що том знаходиться в /mnt/data на вузлі кластера. Конфігурація також вказує розмір 10 гібібайт та режим доступу ReadWriteOnce, що означає, що том може бути підключений як для читання-запису лише одним вузлом. Визначається імʼя StorageClassmanual для PersistentVolume, яке буде використовуватися для привʼязки запитів PersistentVolumeClaim до цього PersistentVolume.
Примітка:
У цьому прикладі використовується режим доступу ReadWriteOnce для спрощення. Для
операційного застосування проєкт Kubernetes рекомендує використовувати режим доступу ReadWriteOncePod.
Вивід показує, що PersistentVolume має STATUSAvailable. Це означає, що він ще не був привʼязаний до PersistentVolumeClaim.
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
task-pv-volume 10Gi RWO Retain Available manual 4s
Створення PersistentVolumeClaim
Наступним кроком є створення PersistentVolumeClaim. Podʼи використовують PersistentVolumeClaim для запиту фізичного сховища. У цій вправі ви створюєте PersistentVolumeClaim, який запитує том не менше трьох гібібайт, який може забезпечити доступ до читання-запису не більше одного вузла за раз.
Після створення PersistentVolumeClaim панель управління Kubernetes шукає PersistentVolume, який відповідає вимогам заявки. Якщо панель управління знаходить відповідний PersistentVolume з тим самим StorageClass, вона привʼязує заявку до тому.
Знову подивіться на PersistentVolume:
kubectl get pv task-pv-volume
Тепер вивід показує STATUS як Bound.
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
task-pv-volume 10Gi RWO Retain Bound default/task-pv-claim manual 2m
Подивіться на PersistentVolumeClaim:
kubectl get pvc task-pv-claim
Вивід показує, що PersistentVolumeClaim привʼязаний до вашого PersistentVolume,
task-pv-volume.
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
task-pv-claim Bound task-pv-volume 10Gi RWO manual 30s
Створення Podʼа
Наступним кроком є створення Podʼа, який використовує ваш PersistentVolumeClaim як том.
Відкрийте оболонку для контейнера, що працює у вашому Podʼі:
kubectl exec -it task-pv-pod -- /bin/bash
У вашій оболонці перевірте, що nginx обслуговує файл index.html з тому hostPath:
# Обовʼязково запустіть ці 3 команди всередині кореневої оболонки, яка є результатом# виконання "kubectl exec" на попередньому кроціapt update
apt install curl
curl http://localhost/
Вивід показує текст, який ви записали у файл index.html у томі hostPath:
Hello from Kubernetes storage
Якщо ви бачите це повідомлення, ви успішно налаштували Pod для використання зберігання з PersistentVolumeClaim.
Очищення
Видаліть Pod:
kubectl delete pod task-pv-pod
Монтування одного і того ж PersistentVolume у двох місцях
Ви зрозуміли, як створити PersistentVolume і PersistentVolumeClaim, а також як змонтувати том в одне місце в контейнері. Розгляньмо, як можна змонтувати один і той самий PersistentVolume у двох різних місцях контейнера. Нижче наведено приклад:
Відкрийте оболонку на одному з вузлів кластера. Спосіб відкриття оболонки залежить від того, як ви налаштували кластер. Наприклад, якщо ви використовуєте Minikube, ви можете відкрити оболонку на вашому вузлі, скориставшись командою minikube ssh.
Створіть теку /mnt/data/html:
# Це припускає, що ваш вузол використовує "sudo" для запуску команд# від імені суперкористувачаsudo mkdir /mnt/data/html
Перемістіть index.html в теку:
# Перемістіть index.html з поточного розташування до теки htmlsudo mv /mnt/data/index.html html
Тут ми створимо pod, який використовує наявні persistentVolume і persistentVolumeClaim. Однак, він монтує до контейнера лише певний файл nginx.conf і теку html.
Отримайте доступ до оболонки контейнера у вашому Podʼі:
kubectl exec -it test -- /bin/bash
У вашій оболонці переконайтеся, що nginx обслуговує файл index.html з тому hostPath:
# Переконайтеся, що ці 3 команди виконано в оболонці root, з якої запущено# "kubectl exec" у попередньому кроціapt update
apt install curl
curl http://localhost/
На виході буде показано текст, який ви записали до файлу index.html у томі hostPath:
Hello from Kubernetes storage
У вашій оболонці також переконайтеся, що nginx обслуговує файл nginx.conf з тома hostPath:
# Переконайтеся, що ці команди виконано в оболонці root, з якої запущено# "kubectl exec" у попередньому кроціcat /etc/nginx/nginx.conf | grep keepalive_timeout
На виході буде показано змінений текст, який ви записали до файлу nginx.conf на томі hostPath:
keepalive_timeout 60;
Якщо ви бачите ці повідомлення, це означає, що ви успішно налаштували Pod на використання певного файлу і теки у сховищі з PersistentVolumeClaim.
Якщо у вас ще не відкрито оболонку до вузла у вашому кластері, відкрийте нову оболонку так само як ви робили це раніше.
У оболонці на вашому вузлі видаліть файл і теку, які ви створили:
# Це передбачає, що ваш Вузол використовує "sudo" для виконання команд# з правами суперкористувачаsudo rm /mnt/data/html/index.html
sudo rm /mnt/data/nginx.conf
sudo rmdir /mnt/data
Тепер ви можете закрити оболонку доступу до вашого вузла.
Контроль доступу
Зберігання даних із використанням ідентифікатора групи (GID) дозволяє запис лише для Podʼів, які використовують той самий GID. Невідповідність або відсутність GID призводить до помилок доступу. Щоб зменшити необхідність координації з користувачами, адміністратор може анотувати PersistentVolume з GID. Після цього GID автоматично додається до будь-якого Podʼа, який використовує цей PersistentVolume.
Коли Pod використовує PersistentVolume з анотацією GID, анотований GID застосовується до всіх контейнерів у Podʼі так само як GID, зазначені у контексті безпеки Podʼа. Кожен GID, незалежно від того, чи походить він з анотації PersistentVolume або специфікації Podʼа, застосовується до першого процесу, запущеного в кожному контейнері.
Примітка:
Коли Pod використовує PersistentVolume, GID, асоційовані з PersistentVolume, не відображаються на самому ресурсі Podʼа.
3.13 - Налаштування Pod для використання projected тому для зберігання
Ця сторінка показує, як використовувати projected том, щоб змонтувати декілька наявних джерел томів у одну теку. Наразі можна проєктувати томи типів secret, configMap, downwardAPI, та serviceAccountToken.
Примітка:
serviceAccountToken не є типом тому.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У цьому завданні ви створите Secrets із локальних файлів для імені користувача та пароля. Потім ви створите Pod, який запускає один контейнер, використовуючи projected том для монтування секретів у спільну теку.
3.14 - Налаштування контексту безпеки для Podʼа або контейнера
Контекст безпеки визначає параметри привілеїв та контролю доступу для Podʼа або контейнера. Налаштування контексту безпеки включають, але не обмежуються:
allowPrivilegeEscalation: Контролює, чи може процес отримувати більше привілеїв, ніж його батьківський процес. Ця логічна величина безпосередньо контролює, чи встановлюється прапорець no_new_privs для процесу контейнера. allowPrivilegeEscalation завжди true, коли контейнер:
запущений з привілеями, або
має CAP_SYS_ADMIN
readOnlyRootFilesystem: Підключає кореневу файлову систему контейнера тільки для читання.
Вищевказані пункти не є повним набором налаштувань контексту безпеки,докладну інформацію див. у SecurityContext для повного переліку.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Щоб вказати параметри безпеки для Podʼа, включіть поле securityContext в специфікацію Pod. Поле securityContext є обʼєктом PodSecurityContext. Параметри безпеки, які ви вказуєте для Pod, застосовуються до всіх контейнерів в Podʼі. Ось файл конфігурації для Podʼа з securityContext та томом emptyDir:
У файлі конфігурації поле runAsUser вказує, що для будь-яких контейнерів в Podʼі, всі процеси виконуються з ідентифікатором користувача 1000. Поле runAsGroup вказує основний ідентифікатор групи 3000 для усіх процесів у контейнерах Pod. Якщо це поле відсутнє, основний ідентифікатор групи контейнерів буде root(0). Будь-які створені файли також належатимуть користувачу 1000 та групі 3000 при вказанні runAsGroup. Оскільки вказано поле fsGroup, всі процеси контейнера також належать до додаткової групи ідентифікатора 2000. Власником тому /data/demo та всіх створених файлів у цьому томі буде груповий ідентифікатор 2000. Додатково, коли вказане поле supplementalGroups, всі процеси контейнера також є частиною вказаних груп. Якщо це поле пропущене, це означає, що воно порожнє.
Виведений результат показує, що процеси виконуються від імені користувача 1000, що є значенням runAsUser:
PID USER TIME COMMAND
1 1000 0:00 sleep 1h
6 1000 0:00 sh
...
У вашій оболонці перейдіть до /data, та виведіть список тек:
cd /data
ls -l
Виведений результат показує, що тека /data/demo має ідентифікатор групи 2000, що є значенням fsGroup.
drwxrwsrwx 2 root 2000 4096 Jun 6 20:08 demo
У вашій оболонці перейдіть до /data/demo, та створіть файл:
cd demo
echo hello > testfile
Виведіть список файлів у теці /data/demo:
ls -l
Виведений результат показує, що testfile має ідентифікатор групи 2000, що є значенням fsGroup.
-rw-r--r-- 1 1000 2000 6 Jun 6 20:08 testfile
Виконайте наступну команду:
id
Результат буде схожий на цей:
uid=1000 gid=3000 groups=2000,3000,4000
З результату видно, що gid дорівнює 3000, що є таким самим, як поле runAsGroup. Якби поле runAsGroup було пропущено, gid залишився б 0 (root), і процес зміг би взаємодіяти з файлами, які належать групі root(0) та групам, які мають необхідні права групи для групи root (0). Ви також можете побачити, що groups містить ідентифікатори груп, які вказані в fsGroup і supplementalGroups, поряд з gid.
Вийдіть з оболонки:
exit
Неявні членства груп, визначені в /etc/group в контейнерному образі
Стандартно Kubernetes обʼєднує інформацію про групи з Podʼа з інформацією, визначеною в /etc/group в контейнерному образі.
Цей контекст безпеки Podʼа містить runAsUser, runAsGroup та supplementalGroups. Проте ви можете побачити, що фактичні додаткові групи, що прикріплені до процесу контейнера, включатимуть ідентифікатори груп, які походять з /etc/group всередині контейнерного образу.
Ви можете побачити, що groups включає ідентифікатор групи 50000. Це тому, що користувач (uid=1000), який визначений в образі, належить до групи (gid=50000), яка визначена в /etc/group всередині контейнерного образу.
Неявно обʼєднані додаткові групи можуть викликати проблеми з безпекою, особливо при доступі до томів (див. kubernetes/kubernetes#112879 для деталей). Щоб уникнути цього, перегляньте розділ нижче.
Налаштування SupplementalGroups для Podʼа
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [beta](стандартно увімкнено)
Цю функцію можна увімкнути, встановивши функціональну можливістьSupplementalGroupsPolicy для kubelet та kube-apiserver, а також налаштувавши поле .spec.securityContext.supplementalGroupsPolicy для Podʼа.
Поле supplementalGroupsPolicy визначає політику для розрахунку додаткових груп для процесів контейнера в Podʼі. Для цього поля є два дійсних
значення:
Merge: Членство в групах, визначене в /etc/group для основного користувача контейнера, буде обʼєднано. Це є стандартною політикою, якщо не зазначено інше.
Strict: Тільки ідентифікатори груп у полях fsGroup, supplementalGroups або runAsGroup прикріплюються як додаткові групи для процесів контейнера. Це означає, що жодне членство в групах з /etc/group для основного користувача контейнера не буде обʼєднано.
Коли функція увімкнена, вона також надає ідентичність процесу, прикріплену до першого процесу контейнера в полі .status.containerStatuses[].user.linux. Це буде корисно для виявлення, чи прикріплені неявні ідентифікатори груп.
Цей маніфест Podʼа визначає supplementalGroupsPolicy=Strict. Ви можете побачити, що жодне членство в групах, визначене в /etc/group, не обʼєднується в додаткові групи для процесів контейнера.
Зверніть увагу, що значення в полі status.containerStatuses[].user.linux є першою прикріпленою ідентичністю процесу до першого процесу контейнера в контейнері. Якщо контейнер має достатні привілеї для здійснення системних викликів, повʼязаних з ідентичністю процесу (наприклад, setuid(2), setgid(2) або setgroups(2) та ін.), процес контейнера може змінити свою ідентичність. Отже, реальна ідентичність процесу буде динамічною.
Реалізації
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Відомо, що наступні середовища виконання контейнерів підтримують контроль додаткових груп з тонкою настройкою.
В цьому альфа-випуску (з v1.31 до v1.32), коли pod з SupplementalGroupsPolicy=Strict призначений до вузла, який НЕ підтримцє цю фцнкцію (напр. .status.features.supplementalGroupsPolicy=false), політика додаткових груп podʼа повернеться до політики Mergeмовчки.
Однак, починаючи з бета-версії (v1.33), для суворішого забезпечення дотримання політики, таке створення podʼів буде відхилено kubelet, оскільки вузол не може забезпечити дотримання зазначеної політики. Коли ваш pod буде відхилено, ви побачите попередження reason=SupplementalGroupsPolicyNotSupported, як показано нижче:
apiVersion:v1kind:Event...type:Warningreason:SupplementalGroupsPolicyNotSupportedmessage:"SupplementalGroupsPolicy=Strict is not supported in this node"involvedObject:apiVersion:v1kind:Pod...
Налаштування політики зміни дозволів та прав власності тому для Pod
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.23 [stable]
Типово Kubernetes рекурсивно змінює права власності та дозволи для вмісту кожного тому так, щоб вони відповідали значенню fsGroup, вказаному в securityContext Podʼа при підключенні цього тому. Для великих томів перевірка та зміна власності та дозволів може займати багато часу, сповільнюючи запуск Podʼів. Ви можете використовувати поле fsGroupChangePolicy в securityContext для контролю способу, яким Kubernetes перевіряє та керує власністю та дозволами для тому.
fsGroupChangePolicy — fsGroupChangePolicy визначає поведінку зміни власності та дозволів тому перед тим, як він буде використаний в Pod. Це поле застосовується лише до типів томів, які підтримують контроль власності та дозволів за допомогою fsGroup. Це поле має два можливі значення:
OnRootMismatch: Змінювати дозволи та права власності тільки у випадку, якщо дозволи та права кореневої теки не відповідають очікуваним дозволам тому. Це може допомогти скоротити час зміни власності та дозволів тому.
Always: Завжди змінювати дозволи та права власності тому під час підключення.
Делегування зміни прав власності та дозволів тому до драйвера CSI
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.26 [stable]
Якщо ви розгортаєте драйвер Container Storage Interface (CSI), який підтримує VOLUME_MOUNT_GROUPNodeServiceCapability, процес встановлення права власності та дозволів файлу на основі fsGroup, вказаного в securityContext, буде виконуватися драйвером CSI, а не Kubernetes. У цьому випадку, оскільки Kubernetes не виконує жодної зміни права власності та дозволів, fsGroupChangePolicy не набуває чинності, і згідно з вказаним CSI, очікується, що драйвер монтує том з наданим fsGroup, що призводить до отримання тому, який є доступними для читаання/запису для fsGroup.
Встановлення контексту безпеки для контейнера
Для вказання параметрів безпеки для контейнера, включіть поле securityContext в маніфест контейнера. Поле securityContext є обʼєктом SecurityContext. Параметри безпеки, які ви вказуєте для контейнера, застосовуються тільки до окремого контейнера, і вони перевизначають налаштування, зроблені на рівні Podʼа, коли є перетин. Налаштування контейнера не впливають на томи Podʼів.
Ось файл конфігурації для Podʼа з одним контейнером. Як Pod, так і контейнер мають поле securityContext:
Виведений результат показує, що процеси виконуються від імені користувача 2000. Це значення
runAsUser, вказане для контейнера. Воно перевизначає значення 1000, вказане для Pod.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
2000 1 0.0 0.0 4336 764 ? Ss 20:36 0:00 /bin/sh -c node server.js
2000 8 0.1 0.5 772124 22604 ? Sl 20:36 0:00 node server.js
...
Вийдіть з оболонки:
exit
Встановлення можливостей для контейнера
За допомогою можливостей Linux, ви можете надати певні привілеї процесу, не надаючи всі привілеї користувачеві з правами root. Щоб додати або видалити можливості Linux для контейнера, включіть поле capabilities в розділ securityContext маніфесту контейнера.
Спочатку подивімося, що відбувається, коли ви не включаєте поле capabilities. Ось файл конфігурації, який не додає або не видаляє жодних можливостей контейнера:
У bitmap можливостей першого контейнера біти 12 і 25 не встановлені. У другому контейнері, біти 12 і 25 встановлені. Біт 12 — це CAP_NET_ADMIN, а біт 25 — це CAP_SYS_TIME. Дивіться capability.h для визначень констант можливостей.
Примітка:
Константи можливостей Linux мають форму CAP_XXX. Але коли ви перелічуєте можливості у маніфесті вашого контейнера, вам необхідно пропустити частину CAP_ константи. Наприклад, для додавання CAP_SYS_TIME, включіть SYS_TIME у ваш список можливостей.
Встановлення профілю Seccomp для контейнера
Щоб встановити профіль Seccomp для контейнера, включіть поле seccompProfile в розділ securityContext вашого маніфесту Pod або контейнера. Поле seccompProfile є обʼєктом SeccompProfile, який складається з type та localhostProfile. Допустимі варіанти для type включають RuntimeDefault, Unconfined та Localhost. localhostProfile повинен бути встановлений лише якщо type: Localhost. Він вказує шлях до попередньо налаштованого профілю на вузлі, повʼязаного з розташуванням налаштованого профілю Seccomp kubelet (налаштованого за допомогою прапорця --root-dir).
Ось приклад, який встановлює профіль Seccomp до стандартного профілю контейнера вузла:
Щоб налаштувати профіль AppArmor для контейнера, включіть поле appArmorProfile в секцію securityContext вашого контейнера. Поле appArmorProfile є обʼєктом AppArmorProfile, що складається з type та localhostProfile. Дійсні опції для type включають RuntimeDefault (стандартно), Unconfined і Localhost. localhostProfile слід встановлювати тільки якщо type є Localhost. Це вказує на назву попередньо налаштованого профілю на вузлі. Профіль повинен бути завантажений на всіх вузлах, які підходять для Podʼа, оскільки ви не знаєте, де буде розгорнуто Pod. Підходи до налаштування власних профілів обговорюються в Налаштування вузлів з профілями.
Примітка: Якщо containers[*].securityContext.appArmorProfile.type явно встановлено на RuntimeDefault, то Pod не буде допущено, якщо AppArmor не включено на вузлі. Однак, якщо containers[*].securityContext.appArmorProfile.type не зазначено, то стандартне значення (що також є RuntimeDefault) буде застосовано тільки якщо вузол має увімкнений AppArmor. Якщо вузол має вимкнений AppArmor, Pod буде допущено, але контейнер не буде обмежено профілем RuntimeDefault.
Ось приклад, який встановлює профіль AppArmor на стандартний профіль контейнерного середовища вузла:
Щоб призначити мітки SELinux контейнеру, включіть поле seLinuxOptions в розділ securityContext вашого маніфесту Podʼа або контейнера. Поле seLinuxOptions є обʼєктом SELinuxOptions. Ось приклад, який застосовує рівень SELinux:
Для призначення міток SELinux модуль безпеки SELinux повинен бути завантажений в операційну систему хосту. На робочих вузлах Windows та Linux без підтримки SELinux це поле та будь-які описані нижче функціональні можливості SELinux не мають жодного впливу.
Ефективне переозначення обʼєктів SELinux в томах
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.28 [beta](стандартно увімкнено)
Примітка:
У Kubernetes v1.27 було введено обмежену ранню форму такої поведінки, яка була застосовна тільки до томів (та PersistentVolumeClaims), які використовують режим доступу ReadWriteOncePod.
Kubernetes v1.33 пропонує функціональні можливостіSELinuxChangePolicy та SELinuxMount в стані бета, щоб розширити це поліпшення продуктивності на інші види PersistentVolumeClaims, як пояснено докладніше нижче. Зважаючи на стан бета, SELinuxMount станадртно вимкнено.
З вимкненною функціональною можливістю SELinuxMount (стандартно в Kubernetes 1.33 та попередніх виписках), контейнерне середовище стандартно рекурсивно призначає мітку SELinux для всіх файлів на всіх томах Pod. Щоб прискорити цей процес, Kubernetes може миттєво змінити мітку SELinux тому за допомогою параметра монтування -o context=<мітка>.
Щоб скористатися цим прискоренням, мають бути виконані всі ці умови:
Pod повинен використовувати PersistentVolumeClaim з відповідними accessModes та функціональною можливстю:
Або том має accessModes: ["ReadWriteOncePod"], і властивість включення SELinuxMountReadWriteOncePod увімкнена.
Або том може використовувати будь-які інші режими доступу та SELinuxMountReadWriteOncePod, SELinuxChangePolicy та SELinuxMount повинні бути увімкнені, а Pod мати spec.securityContext.seLinuxChangePolicy або nil (стандартно), або MountOption.
Pod (або всі його контейнери, які використовують PersistentVolumeClaim) повинні мати встановлені параметри seLinuxOptions.
Відповідний PersistentVolume повинен бути або:
Том, який використовує старі типи томів iscsi, rbd або fc.
Або том, який використовує драйвер CSI CSI. Драйвер CSI повинен оголосити, що він підтримує монтування з -o context, встановивши spec.seLinuxMount: true у його екземплярі CSIDriver.
Коли будь-яка з цих умов не задовольняється, переозначення SELinux відбувається іншим шляхом: контейнерне середовище рекурсивно змінює мітку SELinux для всіх inodes (файлів і тек) у томі. Якщо вказати явно, це стосується ефемерних томів Kubernetes, таких як secret, configMap та projected, а також усіх томів, екземпляр CSIDriver яких явно не оголошує монтування за допомогою -o context.
Коли використовується це прискорення, всі Podʼи, які одночасно використовують той самий відповідний том на одному вузлі, повинні мати однакову мітку SELinux. Pod з іншою міткою SELinux не запуститься та буде у стані ContainerCreating, доки всі Podʼи з іншими мітками SELinux, що використовують цей том, не будуть видалені.
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [beta](стандартно увімкнено)
Для Podʼів, які хочуть відмовитися від зміни міток за допомогою параметрів монтування, вони можуть встановити spec.securityContext.seLinuxChangePolicy у значення Recursive. Це потрібно у випадку, коли декілька podʼів використовують один том на одному вузлі, але вони працюють з різними мітками SELinux, що дозволяє одночасний доступ до тома. Наприклад, привілейований pod працює з міткою spc_t, а непривілейований pod працює зі стандартною міткою container_file_t. За відсутності значення spec.securityContext.seLinuxChangePolicy (або зі стандартним значенням MountOption) на вузлі може працювати лише один з таких podʼів, інший отримує ContainerCreating з помилкою conflicting SELinux labels of volume <назва тома>: <мітка виконуваного тома> і <мітка тома, який не може запуститися>.
SELinuxWarningController
Щоб полегшити ідентифікацію Podʼів, на які вплинула зміна міток томів SELinux, у kube-controller-manager було додано новий контролер, який називається SELinuxWarningController. Стандартно він вимкнений і може бути увімкнений або встановленням --controllers=*,selinux-warning-controllerпрапорець командного рядка, або за допомогою параметра genericControllerManagerConfiguration.controllersполе у KubeControllerManagerConfiguration. Цей контролер потребує увімкнення функціональної можливості SELinuxChangePolicy.
Якщо її увімкнено, контролер відстежує запущені Podʼи і виявляє, що два Podʼи використовують один і той самий том з різними мітками SELinux:
Він надсилає подію обом Podʼам. kubectl describe pod <назва podʼа> показує, що SELinuxLabel "<мітка на podʼі>" конфліктує з podʼом <назва іншого podʼа>, який використовує той самий том, що і цей pod з SELinuxLabel "<мітка іншого podʼа>". Якщо обидва podʼи розміщено на одному вузлі, лише один з них може отримати доступ до тома.
Підніміть метрику selinux_warning_controller_selinux_volume_conflict. Метрика містить назви томів + простори імен у якості міток для легкої ідентифікації постраждалих томів.
Адміністратор кластера може використовувати цю інформацію, щоб визначити, на які саме Podʼи впливає зміна планування, і проактивно виключити їх з оптимізації (наприклад, встановити spec.securityContext.seLinuxChangePolicy: Recursive).
Попередження:
Ми наполегливо рекомендуємо кластерам, що використовують SELinux, увімкнути цей контролер і переконатися, що метрика selinux_warning_controller_selinux_volume_conflict не повідомляє про жодні конфлікти, перш ніж увімкнути функціональну можливість SELinuxMount або оновити його до версії, де SELinuxMount стандартно увімкнено.
Функціональні можливості
Наступні функціональні можливості керують поведінкою перепризначення томів SELinux:
SELinuxMountReadWriteOncePod: вмикає оптимізацію для томів з accessModes: ["ReadWriteOncePod"]. Це дуже безпечна можливість, оскільки не може статися так, що два пристрої можуть використовувати один том з таким режимом доступу. Стандартно її увімкнено з v1.28.
SELinuxChangePolicy: вмикає поле spec.securityContext.seLinuxChangePolicy у Pod і повʼязаний з ним SELinuxWarningController у kube-controller-manager. Ця функція може бути використана перед увімкненням SELinuxMount для перевірки Podʼів, запущених на кластері, і для проактивного виключення Podʼів з оптимізації. Ця функція вимагає увімкнення SELinuxMountReadWriteOncePod. Це бета-версія і є стандартно увімкненою у версії 1.33.
SELinuxMount вмикає оптимізацію для всіх допустимих томів. Оскільки це може порушити роботу наявних робочих навантажень, ми рекомендуємо спочатку увімкнути SELinuxChangePolicy + SELinuxWarningController, щоб перевірити вплив змін. Ця функціональна можливість вимагає увімкнення SELinuxMountReadWriteOncePod і SELinuxChangePolicy. Це бета-версія, однак вона стандартно вимкнена у 1.33.
Управління доступом до файлової системи /proc
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [beta](стандартно увімкнено)
Для середовищ виконання, які слідують специфікації виконання OCI, контейнери типово запускаються у режимі, де є кілька шляхів, які промасковані та доступні тільки для читання. Результатом цього є те, що в межах простору імен монтування контейнера присутні ці шляхи, і вони можуть працювати подібно до того, якби контейнер був ізольованим хостом, але процес контейнера не може записувати до них. Список промаскованих і доступних тільки для читання шляхів такий:
Промасковані шляхи:
/proc/asound
/proc/acpi
/proc/kcore
/proc/keys
/proc/latency_stats
/proc/timer_list
/proc/timer_stats
/proc/sched_debug
/proc/scsi
/sys/firmware
/sys/devices/virtual/powercap
Шляхи доступні тільки для читання:
/proc/bus
/proc/fs
/proc/irq
/proc/sys
/proc/sysrq-trigger
Для деяких Podʼів вам може знадобитися обійти стандартний шлях маскування. Найбільш поширений контекст, коли це потрібно, — це спроба запуску контейнерів у межах контейнера Kubernetes (у межах Podʼа).
Поле procMount в securityContext дозволяє користувачеві запитати, щоб /proc контейнера був Unmasked, або міг бути підмонтований для читання-запису контейнерним процесом. Це також стосується /sys/firmware, який не знаходиться в /proc.
...securityContext:procMount:Unmasked
Примітка:
Встановлення procMount в Unmasked потребує, щоб значення spec.hostUsers в специфікації Pod було false. Іншими словами: контейнер, який бажає мати Unmasked /proc або Unmasked /sys, також повинен бути у просторі імен користувача. У версіях Kubernetes v1.12 по v1.29 це вимога не дотримувалася.
Обговорення
Контекст безпеки для Pod застосовується до Контейнерів Pod і також до Томів Pod при необхідності. Зокрема, fsGroup та seLinuxOptions застосовуються до Томів наступним чином:
fsGroup: Томи, які підтримують управління власністю, модифікуються так, щоб бути власністю та доступними для запису за GID, вказаним у fsGroup. Докладніше див. Документ із проєктування управління власністю томів.
seLinuxOptions: Томи, які підтримують мітку SELinux, переозначаються так, щоб бути доступними за міткою, вказаною у seLinuxOptions. Зазвичай вам потрібно лише встановити розділ level. Це встановлює мітку Multi-Category Security (MCS), яку отримують всі Контейнери у Pod, а також Томи.
Попередження:
Після вказання мітки MCS для Pod всі Pod з такою міткою можуть отримати доступ до Тома. Якщо вам потрібен захист між Podʼами, вам слід призначити унікальну мітку MCS для кожного Pod.
Очищення
Видаліть Pod:
kubectl delete pod security-context-demo
kubectl delete pod security-context-demo-2
kubectl delete pod security-context-demo-3
kubectl delete pod security-context-demo-4
Для отримання додаткової інформації про механізми безпеки в Linux дивіться Огляд функцій безпеки ядра Linux (Примітка: деяка інформація може бути застарілою)
3.15 - Налаштування службових облікових записів для Podʼів
Kubernetes пропонує два відмінні способи автентифікації для клієнтів, які працюють у межах вашого кластера або мають взаємозвʼязок з панеллю управління вашого кластера для автентифікації в API-сервері.
Службовий обліковий запис надає ідентичність процесам, які працюють у Podʼі, і відповідає обʼєкту ServiceAccount. Коли ви автентифікуєтеся в API-сервері, ви ідентифікуєте себе як певного користувача. Kubernetes визнає поняття користувача, але сам Kubernetes не має API User.
Це завдання стосується Службових облікових записів, які існують в API Kubernetes. Керівництво показує вам деякі способи налаштування Службових облікових записів для Podʼів.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Використання стандартного службового облікового запису для доступу до API-сервера
Коли Podʼи звертаються до API-сервера, вони автентифікуються як певний Службовий обліковий запис (наприклад, default). В кожному просторі імен завжди є принаймні один Службовий обліковий запис.
У кожному просторі імен Kubernetes завжди міститься принаймні один Службовий обліковий запис: стандартний службовий обліковий запис для цього простору імен, з назвою default. Якщо ви не вказуєте Службовий обліковий запис при створенні Podʼа, Kubernetes автоматично призначає Службовий обліковий запис з назвою default у цьому просторі імен.
Ви можете отримати деталі для Podʼа, який ви створили. Наприклад:
kubectl get pods/<імʼя_пода> -o yaml
У виводі ви побачите поле spec.serviceAccountName. Kubernetes автоматично встановлює це значення, якщо ви не вказали його при створенні Podʼа.
Застосунок, який працює усередині Podʼа, може отримати доступ до API Kubernetes, використовуючи автоматично змонтовані облікові дані службового облікового запису. Для отримання додаткової інформації див. доступ до кластера.
Коли Pod автентифікується як Службовий обліковий запис, його рівень доступу залежить від втулка авторизації та політики, які використовуються.
Облікові дані API автоматично відкликаються, коли Pod видаляється, навіть якщо є завершувачі. Зокрема, облікові дані API відкликаються через 60 секунд після встановленого на Pod значення .metadata.deletionTimestamp (час видалення зазвичай дорівнює часу, коли запит на видалення був прийнятий плюс період належного завершення роботи Pod).
Відмова від автоматичного монтування облікових даних API
Якщо ви не бажаєте, щоб kubelet автоматично монтував облікові дані API ServiceAccount, ви можете відмовитися від такої стандартної поведінки. Ви можете відмовитися від автоматичного монтування облікових даних API у /var/run/secrets/kubernetes.io/serviceaccount/token для службового облікового запису, встановивши значення automountServiceAccountToken: false у ServiceAccount:
Якщо як ServiceAccount, так і .spec Podʼа вказують значення для automountServiceAccountToken, специфікація Podʼа має перевагу.
Використання більше ніж одного ServiceAccount
У кожному просторі імен є принаймні один ServiceAccount: типовий ServiceAccount, який називається default. Ви можете переглянути всі ресурси ServiceAccount у вашому поточному просторі імен за допомогою:
kubectl get serviceaccounts
Вихідні дані схожі на наступні:
NAME SECRETS AGE
default 1 1d
Ви можете створити додаткові обʼєкти ServiceAccount таким чином:
Щоб використовувати не-стандартний обліковий запис, встановіть поле spec.serviceAccountName Podʼа на імʼя ServiceAccount, який ви хочете використовувати.
Ви можете встановити лише поле serviceAccountName при створенні Podʼа або в шаблоні для нового Podʼа. Ви не можете оновлювати поле .spec.serviceAccountName Podʼа, який вже існує.
Примітка:
Поле .spec.serviceAccount є застарілою альтернативою для .spec.serviceAccountName. Якщо ви хочете видалити поля з ресурсу робочого навантаження, встановіть обидва поля явно пустими у шаблоні Pod.
Очищення
Якщо ви спробували створити ServiceAccount build-robot з прикладу вище, ви можете видалити його виконавши:
kubectl delete serviceaccount/build-robot
Вручну створіть API-токен для ServiceAccount
Припустимо, у вас вже є службовий обліковий запис з назвою "build-robot", як зазначено вище.
Ви можете отримати тимчасовий API-токен для цього ServiceAccount за допомогою kubectl:
kubectl create token build-robot
Вихідні дані з цієї команди — це токен, який ви можете використовувати для автентифікації цього ServiceAccount. Ви можете запросити певний час дії токена, використовуючи аргумент командного рядка --duration для kubectl create token (фактичний час дії виданого токену може бути коротшим або навіть довшим).
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [stable](стандартно увімкнено)
Використовуючи kubectl v1.31 або новішу версію, можна створити токен службового облікового запису, який буде безпосередньо привʼязано до вузла:
Токен буде чинний до закінчення його терміну дії або до видалення відповідного вузла чи службового облікового запису.
Примітка:
У версіях Kubernetes до v1.22 автоматично створювалися довгострокові облікові дані для доступу до API Kubernetes. Цей старий механізм базувався на створенні Secret токенів, які потім можна було монтувати в запущені контейнери. У більш пізніх версіях, включаючи Kubernetes v1.34, облікові дані API отримуються безпосередньо за допомогою TokenRequest API, і вони монтуються в контейнери за допомогою projected тому. Токени, отримані за допомогою цього методу, мають обмежений термін дії та автоматично анулюються, коли контейнер, у який вони монтувалися, видаляється.
Ви все ще можете вручну створити Secret токен службового облікового запису; наприклад, якщо вам потрібен токен, який ніколи не закінчується. Однак рекомендується використовувати TokenRequest для отримання токена для доступу до API.
Вручну створіть довговічний API-токен для ServiceAccount
Якщо ви бажаєте отримати API-токен для службового облікового запису, ви створюєте новий Secret з особливою анотацією kubernetes.io/service-account.name.
ви побачите, що тепер Secret містить API-токен для ServiceAccount "build-robot".
Через анотацію, яку ви встановили, панель управління автоматично генерує токен для цього службового облікового запису і зберігає їх у відповідному Secret. Крім того, панель управління також очищає токени для видалених службових облікових записів.
При здійсненні перегляду вмісту Secret kubernetes.io/service-account-token уважно відносьтеся, щоб не відображати його будь-де, де його може побачити сторонній спостерігач.
При видаленні ServiceAccount, який має відповідний Secret, панель управління Kubernetes автоматично очищає довговічний токен з цього Secret.
Примітка:
Якщо ви переглянете ServiceAccount використовуючи:
kubectl get serviceaccount build-robot -o yaml
Ви не побачите Secret build-robot-secret у полях API-обʼєктів службового облікового запису .secrets, оскільки це поле заповнюється лише автоматично згенерованими Secret.
За допомогою вашого редактора видаліть рядок з ключем resourceVersion, додайте рядки для imagePullSecrets: та збережіть це. Залиште значення uid таким же, як ви його знайшли.
Після внесення змін, відредагований ServiceAccount виглядатиме схоже на це:
Перевірте, що imagePullSecrets встановлені для нових Podʼів
Тепер, коли створюється новий Pod у поточному просторі імен і використовується типовий ServiceAccount, у новому Podʼі автоматично встановлюється поле spec.imagePullSecrets:
kubectl run nginx --image=<імʼя реєстру>/nginx --restart=Never
kubectl get pod nginx -o=jsonpath='{.spec.imagePullSecrets[0].name}{"\n"}'
Вивід:
myregistrykey
Проєцювання токенів ServiceAccount
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.20 [stable]
Примітка:
Для включення та використання проєкції запиту токена вам необхідно вказати кожен з наступних аргументів командного рядка для kube-apiserver:
--service-account-issuer
визначає ідентифікатор емітента токена службового облікового запису. Ви можете вказати аргумент --service-account-issuer аргумент кілька разів, це може бути корисно, щоб увімкнути зміну емітента без переривання роботи. Коли цей прапорець вказано кілька разів, перший використовується для генерації токенів та всі використовуються для визначення прийнятних емітентів. Вам потрібно використовувати Kubernetes v1.22 або пізніше, щоб мати можливість вказати --service-account-issuer кілька разів.
--service-account-key-file
вказує шлях до файлу, який містить PEM-кодований X.509 приватний або публічний ключі (RSA або ECDSA), які використовуються для перевірки токенів ServiceAccount. Вказаний файл може містити кілька ключів, а прапорець може бути вказаний кілька разів з різними файлами. Якщо вказано кілька разів, токени, підписані будь-яким із вказаних ключів, вважаються сервером Kubernetes API дійсними.
--service-account-signing-key-file
вказує шлях до файлу, який містить поточний приватний ключ емітента токенів службового облікового запису. Емітент підписує видані ID токени з цим приватним ключем.
--api-audiences (може бути опущено)
визначає аудиторії для токенів ServiceAccount. Автентифікатор токенів службових облікових записів перевіряє, що токени, використані в API, привʼязані принаймні до однієї з цих аудиторій. Якщо api-audiences вказано кілька разів, токени для будь-якої з вказаних аудиторій вважаються сервером Kubernetes API дійсними. Якщо ви вказали аргумент командного рядка --service-account-issuer, але не встановили --api-audiences, панель управління типово має одноелементний список аудиторій, що містить лише URL емітента.
Kubelet також може проєцювати токен ServiceAccount в Pod. Ви можете вказати бажані властивості токена, такі як аудиторія та тривалість дії. Ці властивості не конфігуруються для типового токена ServiceAccount. Токен також стане недійсним щодо API, коли будь-який з Podʼів або ServiceAccount буде видалено.
Ви можете налаштувати цю поведінку для spec Podʼа за допомогою типу projected тому, що називається ServiceAccountToken.
Токен з цього projected тому — JSON Web Token (JWT). JSON-вміст цього токена слідує чітко визначеній схемі — приклад вмісту для токена, повʼязаного з Pod:
{"aud": [# відповідає запитаним аудиторіям або стандартним аудиторіям API-сервера, якщо явно не запитано"https://kubernetes.default.svc"],"exp": 1731613413,"iat": 1700077413,"iss": "https://kubernetes.default.svc",# відповідає першому значенню, переданому прапорцю --service-account-issuer"jti": "ea28ed49-2e11-4280-9ec5-bc3d1d84661a","kubernetes.io": {"namespace": "kube-system","node": {"name": "127.0.0.1","uid": "58456cb0-dd00-45ed-b797-5578fdceaced"},"pod": {"name": "coredns-69cbfb9798-jv9gn","uid": "778a530c-b3f4-47c0-9cd5-ab018fb64f33"},"serviceaccount": {"name": "coredns","uid": "a087d5a0-e1dd-43ec-93ac-f13d89cd13af"},"warnafter": 1700081020},"nbf": 1700077413,"sub": "system:serviceaccount:kube-system:coredns"}
Запуск Podʼа з використанням проєцювання токену службового облікового запису
Щоб надати Podʼу токен з аудиторією vault та терміном дії дві години, ви можете визначити маніфест Podʼа, схожий на цей:
Kubelet буде: запитувати та зберігати токен від імені Podʼа; робити токен доступним для Podʼа за налаштованим шляхом до файлу; і оновлювати токен поблизу його закінчення. Kubelet активно запитує ротацію для токена, якщо він старший, ніж 80% від загального часу життя (TTL), або якщо токен старший, ніж 24 години.
Застосунок відповідає за перезавантаження токена при його ротації. Зазвичай для застосунку достатньо завантажувати токен за розкладом (наприклад: один раз кожні 5 хвилин), без відстеження фактичного часу закінчення.
Виявлення емітента службового облікового запису
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.21 [stable]
Якщо ви увімкнули проєцювання токенів для ServiceAccounts у вашому кластері, то ви також можете скористатися функцією виявлення. Kubernetes надає спосіб клієнтам обʼєднуватись як постачальник ідентифікаційних даних, щоб одна або кілька зовнішніх систем могли діяти як сторона, що їм довіряє.
Примітка:
URL емітента повинен відповідати Специфікації виявлення OIDC. На практиці це означає, що він повинен використовувати схему https, і має обслуговувати конфігурацію постачальника OpenID за адресою {емітент-облікового-запису}/.well-known/openid-configuration.
Якщо URL не відповідає, точки доступу виявлення емітента ServiceAccount не зареєстровані або недоступні.
Якщо увімкнено, Kubernetes API-сервер публікує документ конфігурації постачальника OpenID через HTTP. Документ конфігурації публікується за адресою /.well-known/openid-configuration. Документ конфігурації OpenID постачальника іноді називається документом виявлення. Kubernetes API-сервер також публікує повʼязаний набір ключів JSON Web (JWKS), також через HTTP, за адресою /openid/v1/jwks.
Примітка:
Відповіді, що обслуговуються за адресами /.well-known/openid-configuration та /openid/v1/jwks, призначені для сумісності з OIDC, але не є строго сумісними з OIDC. Ці документи містять лише параметри, необхідні для виконання перевірки токенів службових облікових записів Kubernetes.
Кластери, які використовують RBAC, включають типову роль кластера з назвою system:service-account-issuer-discovery. Типовий ClusterRoleBinding надає цю роль групі system:serviceaccounts, до якої неявно належать всі ServiceAccounts. Це дозволяє Podʼам, які працюють у кластері, отримувати доступ до документа виявлення службового облікового запису через їх змонтований токен службового облікового запису. Адміністратори також можуть вибрати привʼязку ролі до system:authenticated або system:unauthenticated залежно від їх вимог до безпеки та зовнішніх систем, з якими вони мають намір обʼєднуватись.
Відповідь JWKS містить публічні ключі, які може використовувати залежна сторона для перевірки токенів службових облікових записів Kubernetes. Залежні сторони спочатку запитують конфігурацію постачальника OpenID, а потім використовують поле jwks_uri у відповіді, щоб знайти JWKS.
У багатьох випадках API-сервери Kubernetes не доступні через глобальну мережу, але публічні точки доступу, які обслуговують кешовані відповіді від API-сервера, можуть бути доступні для користувачів або постачальників послуг. У таких випадках можливо перевизначити jwks_uri в конфігурації постачальника OpenID, щоб вона вказувала на глобальну точку доступу, а не на адресу API-сервера, передаючи прапорець --service-account-jwks-uri до API-сервера. Як і URL емітента, URI JWKS повинен використовувати схему https.
але також майте на увазі, що використання Secret для автентифікації як службового облікового запису є застарілим. Рекомендований альтернативний метод — проєціювання токенів службового облікового запису.
Ця сторінка показує, як створити Pod, що використовує Secret для отримання образу з приватного реєстру або сховища контейнерних образів. Існує багато приватних реєстрів, які використовуються. У цьому завданні використовується Docker Hub як приклад реєстру.
🛇 Цей елемент посилається на сторонній проєкт або продукт, який не є частиною Kubernetes. Докладніше
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для виконання цієї вправи вам потрібно мати інструмент командного рядка docker, а також ідентифікатор Docker, та пароль до якого ви знаєте.
Якщо ви використовуєте інший приватний контейнерний реєстр, вам потрібен інструмент командного рядка для цього реєстру та будь-яка інформація для входу в реєстр.
Увійдіть до Docker Hub
На вашому компʼютері вам необхідно автентифікуватися в реєстрі, щоб отримати приватний образ.
Використовуйте інструмент docker, щоб увійти до Docker Hub. Докладніше про це дивіться у розділі log in на сторінці Docker ID accounts.
docker login
Коли буде запитано, введіть свій ідентифікатор Docker, а потім обрані вами облікові дані (токен доступу чи пароль до вашого Docker ID).
Якщо ви використовуєте сховище облікових даних Docker, ви не побачите цей запис auth, а замість нього буде запис credsStore з назвою сховища як значення. У цьому випадку ви можете створити Secret безпосередньо. Дивіться Створення Secret, за допомогою вводу облікових даних в командному рядку.
Створення Secret на основі наявних облікових даних
Кластер Kubernetes використовує Secret типу kubernetes.io/dockerconfigjson для автентифікації в контейнерному реєстрі для отримання приватного образу.
Якщо ви вже виконали команду docker login, ви можете скопіювати ці облікові дані в Kubernetes:
Якщо вам потрібно більше контролю (наприклад, встановити простір імен чи мітку для нового Secret), то ви можете налаштувати Secret перед збереженням його. Переконайтеся, що:
встановлено назву елемента даних як .dockerconfigjson
файл конфігурації Docker закодовано у base64, а потім вставлено цей рядок без розривів як значення для поля data[".dockerconfigjson"]
встановлено type як kubernetes.io/dockerconfigjson
Якщо ви отримали повідомлення про помилку error: no objects passed to create, це може означати, що закодований у base64 рядок є недійсним. Якщо ви отримали повідомлення про помилку, подібне до Secret "myregistrykey" is invalid: data[.dockerconfigjson]: invalid value ..., це означає, що закодований у base64 рядок у даних успішно декодувався, але не може бути розпізнаний як файл .docker/config.json.
Створення Secret, за допомогою вводу облікових даних в командному рядку
<your-registry-server> — це повна доменна назва вашого приватного реєстру Docker.
Використовуйте https://index.docker.io/v1/ для DockerHub.
<your-name> — це ваше імʼя користувача Docker.
<your-pword> — це ваш пароль Docker.
<your-email> — це ваша електронна адреса Docker.
Ви успішно встановили ваші облікові дані Docker у кластері як Secret під назвою regcred.
Примітка:
Ввід секретів у командному рядку може зберігатися в історії вашої оболонки в незахищеному вигляді, і ці секрети також можуть бути видимими для інших користувачів на вашому компʼютері протягом часу, коли виконується kubectl.
Перегляд Secret regcred
Щоб зрозуміти вміст Secret regcred, який ви створили, спочатку перегляньте Secret у форматі YAML:
Для отримання образу з приватного реєстру Kubernetes потрібні облікові дані. Поле imagePullSecrets у файлі конфігурації вказує, що Kubernetes повинен отримати облікові дані з Secret з назвою regcred.
Створіть Pod, який використовує ваш Secret, і перевірте, що Pod працює:
kubectl apply -f my-private-reg-pod.yaml
kubectl get pod private-reg
Примітка:
Щоб використовувати Secret для отримання образів для Pod (або Deployment, або іншого обʼєкта, який має шаблон Pod, який ви використовуєте), вам потрібно переконатися, що відповідний Secret існує в правильному просторі імен. Простір імен для використання — той самий, де ви визначили Pod.
Також, якщо запуск Podʼа не вдається і ви отримуєте статус ImagePullBackOff, перегляньте події Pod:
kubectl describe pod private-reg
Якщо ви побачите подію з причиною, встановленою на FailedToRetrieveImagePullSecret, Kubernetes не може знайти Secret із назвою (regcred, у цьому прикладі).
Переконайтеся, що вказаний вами Secret існує і що його назва вірно вказана.
Events:
... Reason ... Message
------ -------
... FailedToRetrieveImagePullSecret ... Unable to retrieve some image pull secrets (<regcred>); attempting to pull the image may not succeed.
Використання образів з кількох реєстрів
Pod може складатись з кількох контейнерів, образи для яких можуть бути з різних реєстрів. Ви можете використовувати кілька imagePullSecrets з одним Podʼом, і кожен може містити кілька облікових даних.
Для витягування образів з реєстрів буде спробувано кожний обліковий запис, який відповідає реєстру. Якщо жоден обліковий запис не відповідає реєстру, витягування образу буде відбуватись без авторизації або з використанням конфігурації, специфічної для виконавчого середовища.
Kubelet використовує проби життєздатності для визначення моменту перезапуску контейнера. Наприклад, проби життєздатності можуть виявити проблеми, коли застосунок працює, але не може досягти результату. Перезапуск контейнера в такому стані може допомогти зробити застосунок більш доступним, попри помилки.
Загальний шаблон для проб життєздатності — використовує ту саму недорогу HTTP-точку доступу, що й для проб готовності, але з більшим значенням failureThreshold. Це гарантує, що Pod може спостерігатись як не готовий впродовж певного часу перед тим, як примусово завершити його роботу.
Kubelet використовує проби готовності для визначення моменту, коли контейнер готовий приймати трафік. Одним з використань цього сигналу є контроль за тим, які Podʼи використовуються як бекенди для Service. Pod вважається готовим, коли його станReady є true. Коли Pod не готовий, його видаляють з балансувальників навантаження Serviceʼів. Стан Ready у Pod є false, коли стан Ready у його Node не є true, коли один з readinessGates Pod є хибним, або коли принаймні один з його контейнерів не готовий.
Kubelet використовує проби запуску для визначення моменту запуску застосунку контейнера. Якщо така проба налаштована, проби життєздатності та готовності не починають працювати, поки вона не успішна, щоб переконатися, що ці проби не перешкоджають запуску застосунку. Це може бути використано для впровадження перевірки життєздатності для повільних контейнерів, що дозволяє уникати їхнього вимкнення kubelet перед тим, як вони будуть готові до роботи.
Увага:
Проби життєздатності можуть бути потужним засобом відновлення після відмов застосунків, але їх слід використовувати обережно. Проби життєздатності повинні бути налаштовані ретельно, щоб вони дійсно вказували на незворотню відмову застосунку, наприклад, на застрягання.
Примітка:
Неправильна реалізація проб життєздатності може призвести до каскадних відмов. Це призводить до перезапуску контейнера при великому навантаженні; невдалих запитів клієнтів через зменшення масштабованості вашого застосунку; та збільшеного навантаження на інші Podʼи через невдалі Podʼи. Розумійте різницю між пробами готовності та життєздатності та коли застосовувати їх для вашого застосунку.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Багато застосунків, що працюють протягом тривалого часу, зрештою переходять у непрацездатний стан і не можуть відновитися, крім як знову бути перезапущеними. Kubernetes надає проби життєздатності для виявлення та виправлення таких ситуацій.
У цьому завданні ви створите Pod, який запускає контейнер на основі образу registry.k8s.io/busybox:1.27.2. Ось файл конфігурації для Podʼа:
У файлі конфігурації можна побачити, що у Podʼа є один Container. Поле periodSeconds вказує, що kubelet повинен виконувати пробу життєздатності кожні 5 секунд. Поле initialDelaySeconds повідомляє kubelet, що він повинен зачекати 5 секунд перед виконанням першої проби. Для виконання проби kubelet виконує команду cat /tmp/healthy у цільовому контейнері. Якщо команда успішно виконується, вона повертає 0, і kubelet вважає контейнер живим і справним. Якщо команда повертає ненульове значення, kubelet примусово зупиняє контейнер і перезапускає його.
Під час запуску контейнера виконується ця команда:
Протягом перших 30 секунд життя контейнера існує файл /tmp/healthy. Таким чином, протягом перших 30 секунд команда cat /tmp/healthy повертає код успіху. Після 30 секунд cat /tmp/healthy повертає код невдачі.
Виведений текст показує, що жодна проба життєздатності ще не зазнав невдачі:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 11s default-scheduler Successfully assigned default/liveness-exec to node01
Normal Pulling 9s kubelet, node01 Pulling image "registry.k8s.io/busybox:1.27.2"
Normal Pulled 7s kubelet, node01 Successfully pulled image "registry.k8s.io/busybox:1.27.2"
Normal Created 7s kubelet, node01 Created container liveness
Normal Started 7s kubelet, node01 Started container liveness
Після 35 секунд знову перегляньте події Podʼа:
kubectl describe pod liveness-exec
У нижній частині виводу є повідомлення про те, що проби життєздатності зазнали невдачі, і непрацездатні контейнери були примусово зупинені та перезапущені.
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 57s default-scheduler Successfully assigned default/liveness-exec to node01
Normal Pulling 55s kubelet, node01 Pulling image "registry.k8s.io/busybox:1.27.2"
Normal Pulled 53s kubelet, node01 Successfully pulled image "registry.k8s.io/busybox:1.27.2"
Normal Created 53s kubelet, node01 Created container liveness
Normal Started 53s kubelet, node01 Started container liveness
Warning Unhealthy 10s (x3 over 20s) kubelet, node01 Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Normal Killing 10s kubelet, node01 Container liveness failed liveness probe, will be restarted
Почекайте ще 30 секунд та перевірте, що контейнер був перезапущений:
kubectl get pod liveness-exec
Виведений текст показує, що RESTARTS було збільшено. Зауважте, що лічильник RESTARTS збільшується, як тільки непрацездатний контейнер знову переходить у стан виконання:
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m
Визначення HTTP-запиту життєздатності
Ще один вид проб життєздатності використовує HTTP GET-запит. Ось файл конфігурації для Podʼа, який запускає контейнер на основі образу registry.k8s.io/e2e-test-images/agnhost.
У файлі конфігурації можна побачити, що у Podʼа є один контейнер. Поле periodSeconds вказує, що kubelet повинен виконувати пробу життєздатності кожні 3 секунди. Поле initialDelaySeconds повідомляє kubelet, що він повинен зачекати 3 секунди перед виконанням першої проби. Для виконання проби kubelet надсилає HTTP GET-запит на сервер, який працює в контейнері та слухає порт 8080. Якщо обробник для шляху /healthz сервера повертає код успіху, kubelet вважає контейнер живим і справним. Якщо обробник повертає код невдачі, ubelet примусово зупиняє контейнер і перезапускає його.
Будь-який код, більший або рівний 200 і менший за 400, вказує на успіх. Будь-який інший код вказує на невдачу.
Ви можете переглянути вихідний код сервера в server.go.
Протягом перших 10 секунд, коли контейнер живий, обробник /healthz повертає статус 200. Після цього обробник повертає статус 500.
Kubelet починає виконувати перевірку стану справності через 3 секунди після запуску контейнера. Таким чином, перші кілька перевірок стану справності будуть успішними. Але після 10 секунд перевірки стану справності будуть невдалими, і kubelet зупинить та перезапустить контейнер.
Щоб спробувати перевірку стану справності через HTTP, створіть Pod:
Через 10 секунд перегляньте події Podʼа, щоб перевірити, що проби життєздатності зазнали невдачі, і контейнер був перезапущений:
kubectl describe pod liveness-http
У випусках після v1.13 налаштування локального HTTP-проксі не впливають на пробу життєздатності через HTTP.
Визначення проби життєздатності через TCP-сокет
Третій тип проби життєздатності використовує TCP сокет. З цією конфігурацією kubelet спробує відкрити зʼєднання з вашим контейнером на вказаному порту. Якщо він може встановити зʼєднання, контейнер вважається справним, якщо ні — це вважається невдачею.
Як можна побачити, конфігурація для перевірки TCP досить схожа на перевірку через HTTP. У цьому прикладі використовуються як проби готовності, так і життєздатності. Kubelet надішле першу пробу життєздатності через 15 секунд після запуску контейнера. Ця проба спробує підʼєднатися до контейнера goproxy на порту 8080. Якщо проба на життєздатність не спрацює, контейнер буде перезапущено. Kubelet продовжить виконувати цю перевірку кожні 10 секунд.
Крім проби життєздатності, ця конфігурація включає пробу готовності. Kubelet запустить першу пробу готовності через 15 секунд після запуску контейнера. Аналогічно проби життєздатності, це спроба підʼєднатися до контейнера goproxy на порту 8080. Якщо проба пройде успішно, Pod буде позначений як готовий і отримає трафік від сервісів. Якщо перевірка готовності не вдасться, то Pod буде позначений як не готовий і не отримає трафік від жодного з сервісів.
Щоб спробувати перевірку життєздатності через TCP, створіть Pod:
Через 15 секунд перегляньте події Podʼа, щоб перевірити, що проби життєздатності:
kubectl describe pod goproxy
Визначення проби життєздатності через gRPC
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.27 [stable]
Якщо ваш застосунок реалізує Протокол gRPC перевірки стану справності, цей приклад показує, як налаштувати Kubernetes для його використання для перевірок життєздатності застосунку. Так само ви можете налаштувати проби готовності та запуску.
Для використання проби gRPC має бути налаштований port. Якщо ви хочете розрізняти проби різних типів та проби для різних функцій, ви можете використовувати поле service. Ви можете встановити service у значення liveness та вказати вашій точці доступу gRPC перевірки стану справності відповідати на цей запит інакше, ніж коли ви встановлюєте service у значення readiness. Це дозволяє використовувати ту саму точку доступу для різних видів перевірки стану справності контейнера замість прослуховування двох різних портів. Якщо ви хочете вказати свою власну назву сервісу та також вказати тип проби, Kubernetes рекомендує використовувати імʼя, яке складається з цих двох частин. Наприклад: myservice-liveness (використовуючи - як роздільник).
Примітка:
На відміну від проб HTTP або TCP, ви не можете вказати порт перевірки стану справності за іменем, але не можете налаштувати власне імʼя для хосту.
Проблеми конфігурації (наприклад: неправильний порт чи Service, нереалізований протокол перевірки стану справності) вважаються невдачею проби, подібно до проб через HTTP та TCP.
Щоб спробувати перевірку життєздатності через gRPC, створіть Pod за допомогою наступної команди.
У наведеному нижче прикладі, Pod etcd налаштований для використання проби життєздатності через gRPC.
Через 15 секунд перегляньте події Podʼа, щоб перевірити, що перевірка життєздатності не зазнала невдачі:
kubectl describe pod etcd-with-grpc
При використанні проби через gRPC, є кілька технічних деталей, на які варто звернути увагу:
Проби запускаються для IP-адреси Podʼа або його імені хосту. Обовʼязково налаштуйте вашу кінцеву точку gRPC для прослуховування IP-адреси Podʼа.
Проби не підтримують жодних параметрів автентифікації (наприклад, -tls).
Немає кодів помилок для вбудованих проб. Усі помилки вважаються невдачами проби.
Якщо ExecProbeTimeout feature gate встановлено у false, grpc-health-probe не дотримується налаштування timeoutSeconds (яке стандартно становить 1 с), тоді як вбудована проба зазнає невдачі через тайм-аут.
Використання іменованого порту
Ви можете використовувати іменований port для проб HTTP та TCP. Проби gRPC не підтримують іменовані порти.
Захист контейнерів, що повільно запускаються за допомогою проб запуску
Іноді вам доводиться мати справу з застосунками, які вимагають додаткового часу запуску при їх першій ініціалізації. У таких випадках може бути складно налаштувати параметри проби життєздатності без компромісів щодо швидкої відповіді на затримки, які мотивували використання такої проби. Рішення полягає в тому, щоб налаштувати пробу запуску з тою самою командою, перевіркою через HTTP або TCP, з failureThreshold * periodSeconds, достатньо довгим, щоб покрити найгірший випадок щодо часу запуску.
Завдяки пробі запуску застосунок матиме максимум 5 хвилин (30 * 10 = 300 с), щоб завершити свій запуск. Як тільки проба запуску вдалася один раз, проба життєздатності бере роль на себе, щоб забезпечити швидку відповідь на затримки роботи контейнера. Якщо проба запуску ніколи не вдається, контейнер буде зупинений після 300 с і підпадатиме під restartPolicy Podʼа.
Визначення проб готовності
Іноді застосунки тимчасово не можуть обслуговувати трафік. Наприклад, застосунок може потребувати завантаження великих даних або конфігураційних файлів під час запуску, або залежати від зовнішніх служб після запуску. У таких випадках ви не хочете примусово припиняти роботу застосунку, але ви також не хочете надсилати йому запити. Kubernetes надає проби готовності для виявлення та помʼякшення таких ситуацій. Pod з контейнерами, які повідомляють, що вони не готові, не отримують трафіку через Service Kubernetes.
Примітка:
Проби готовності працюють у контейнері протягом його всього життєвого циклу.
Увага:
Проби готовності та життєздатності не залежать одна від одної для успішного виконання. Якщо ви хочете зачекати перед виконанням проби готовності, вам слід використовувати initialDelaySeconds або startupProbe.
Проби готовності налаштовуються аналогічно пробам життєздатності. Єдина відмінність полягає в тому, що ви використовуєте поле readinessProbe замість поля livenessProbe.
Конфігурація для проб готовності через HTTP та TCP також залишається ідентичною конфігурації пробам життєздатності.
Проби готовності та життєздатності можуть використовуватися паралельно для того самого контейнера. Використання обох може забезпечити, що трафік не досягне контейнера, який не готовий до нього, та що контейнери будуть перезапускатися у разі виникнення несправностей.
Налаштування проб
Проби мають кілька полів, які можна використовувати для більш точного керування поведінкою перевірок запуску, життєздатності та готовності:
initialDelaySeconds: Кількість секунд після запуску контейнера, перш ніж будуть ініційовані перевірки запуску, життєздатності або готовності. Якщо визначено перевірку запуску, затримки перевірки життєздатності та готовності не починаються, поки перевірка запуску не буде успішною. У деяких старих версіях Kubernetes initialDelaySeconds може ігноруватися, якщо periodSeconds було встановлено на значення, вище за initialDelaySeconds. Однак у поточних версіях initialDelaySeconds завжди враховується, і перевірка не розпочнеться до закінчення цієї початкової затримки. Стандартно — 0 секунд. Мінімальне значення — 0.
periodSeconds: Як часто (у секундах) виконувати пробу. Стандартно — 10 секунд. Мінімальне значення — 1. Поки контейнер не має статусу Ready, ReadinessProbe може бути виконаний у час, відмінний від налаштованого інтервалу periodSeconds. Це робиться для того, щоб пришвидшити готовність Podʼа.
timeoutSeconds: Кількість секунд, після яких проба завершиться по тайм-ауту. Стандартно — 1 секунда. Мінімальне значення — 1.
successThreshold: Мінімальна послідовна кількість успіхів для того, щоб проба вважалася успішною після невдачі. Стандартно — 1. Має бути 1 для проб життєздатності та запуску. Мінімальне значення — 1.
failureThreshold: Після того, як проба не вдається failureThreshold разів поспіль, Kubernetes вважає, що загальна перевірка невдала: контейнер не готовий/справний. У випадку проби запуску або життєздатності, якщо принаймні failureThreshold проб зазнали невдачі, Kubernetes розглядає контейнер як несправний та виконує перезапуск для цього конкретного контейнера. Kubelet дотримується налаштування terminationGracePeriodSeconds для цього контейнера. Для невдалих проб готовності kubelet продовжує запускати контейнер, який не пройшов перевірку, і також продовжує запускати додаткові проби; через те, що перевірка не пройшла, kubelet встановлює умову Ready для Podʼа у значення false.
terminationGracePeriodSeconds: налаштуйте період-допуск для kubelet, щоб чекати між тригером вимкнення невдалих контейнерів та примусовим зупиненням контейнера середовищем виконання. Стандартно — значення успадковується від рівня Podʼа для terminationGracePeriodSeconds (якщо не вказано, то 30 секунд), а мінімальне значення — 1. Див. terminationGracePeriodSeconds на рівні проби для більш детальної інформації.
Увага:
Неправильна реалізація проб готовності може призвести до зростання кількості процесів в контейнері та вичерпання ресурсів, якщо це не буде виправлено.
HTTP проби
HTTP проби мають додаткові поля, які можна встановити в httpGet:
host: Імʼя хосту для підключення, стандартно — IP-адреса Podʼа. Ймовірно, ви захочете встановити "Host" в httpHeaders замість цього.
scheme: Схема для підключення до хосту (HTTP або HTTPS). Стандартно — "HTTP".
path: Шлях до доступу на HTTP сервері. Стандартно — "/".
httpHeaders: Власні заголовки, що встановлюються у запиті. HTTP дозволяє повторювані заголовки.
port: Імʼя або номер порту для доступу до контейнера. Номер повинен бути в діапазоні від 1 до 65535.
Для HTTP проби kubelet надсилає HTTP-запит на вказаний порт та шлях, щоб виконати перевірку. Kubelet надсилає пробу до IP-адреси Podʼа, якщо адреса не перевизначена необовʼязковим полем host у httpGet. Якщо поле scheme встановлено на HTTPS, kubelet надсилає запит HTTPS, пропускаючи перевірку сертифіката. У більшості сценаріїв ви не хочете встановлювати поле host. Ось один сценарій, коли ви його встановлюєте. Припустимо, що контейнер слухає на 127.0.0.1, а поле hostNetwork Podʼа встановлене на true. Тоді host у httpGet повинен бути встановлений на 127.0.0.1. Якщо ваш Pod спирається на віртуальні хости, що, ймовірно, є більш поширеним випадком, ви не повинні використовувати host, але краще встановити заголовок Host в httpHeaders.
Для HTTP проби kubelet надсилає два заголовки запиту, крім обовʼязкового заголовка Host:
User-Agent: Стандартне значення — kube-probe/1.34, де 1.34 — версія kubelet.
Accept: Стандартне значення — */*.
Ви можете перевизначити стандартне значення цих двох заголовків, визначивши httpHeaders для проби. Наприклад:
Коли kubelet перевіряє Pod за допомогою HTTP, він виконує переадресацію тільки в тому випадку, якщо переадресація відбувається на той самий хост. Якщо kubelet отримує 11 або більше переадресувань під час перевірки, проба вважається успішною і створюється відповідна подія:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 29m default-scheduler Successfully assigned default/httpbin-7b8bc9cb85-bjzwn to daocloud
Normal Pulling 29m kubelet Pulling image "docker.io/kennethreitz/httpbin"
Normal Pulled 24m kubelet Successfully pulled image "docker.io/kennethreitz/httpbin" in 5m12.402735213s
Normal Created 24m kubelet Created container httpbin
Normal Started 24m kubelet Started container httpbin
Warning ProbeWarning 4m11s (x1197 over 24m) kubelet Readiness probe warning: Probe terminated redirects
Якщо kubelet отримує переадресацію, де імʼя хосту відрізняється від запиту, результат проби вважається успішним, і kubelet створює подію для повідомлення про збій переадресації.
Увага:
Під час обробки проби httpGet kubelet припиняє читати тіло відповіді після 10 Кбайт. Успішність проби визначається виключно кодом статусу відповіді, який міститься в заголовках відповіді.
Якщо ви перевіряєте точку доступу, яка повертає тіло відповіді розміром більше 10 Кбайт, kubelet все одно позначить перевірку як успішну на основі коду статусу, але закриє зʼєднання після досягнення межі в 10 Кбайт. Це раптове закриття може спричинити появу в журналах вашого застосунку помилок connection reset by peer або broken pipe, які може бути важко відрізнити від справжніх проблем із мережею.
Для надійних проб httpGet наполегливо рекомендується використовувати спеціальні точки доступу для перевірки працездатності, які повертають мінімальний обсяг тіла відповіді. Якщо ви мусите використовувати наявну точку доступу з великим обсягом даних, розгляньте можливість використання проби exec для виконання запиту HEAD.
TCP проби
Для TCP-проби kubelet встановлює зʼєднання проби на вузлі, а не в Podʼі, що означає, що ви не можете використовувати імʼя сервісу в параметрі host, оскільки kubelet не може його розпізнати.
terminationGracePeriodSeconds на рівні проб
СТАН ФУНКЦІОНАЛУ:Kubernetes 1.25 [stable]
У версіях 1.25 і вище користувачі можуть вказувати terminationGracePeriodSeconds на рівні проби в рамках специфікації проби. Коли одночасно встановлені terminationGracePeriodSeconds на рівні Podʼа і на рівні проби, kubelet використовуватиме значення на рівні проби.
При встановленні terminationGracePeriodSeconds слід звернути увагу на наступне:
Kubelet завжди враховує поле terminationGracePeriodSeconds на рівні проби, якщо
воно присутнє в Podʼі.
Якщо у вас є поточні Podʼи, де поле terminationGracePeriodSeconds встановлене і ви більше не бажаєте використовувати індивідуальні терміни відповідного завершення роботи для проб, вам слід видалити ці Podʼи.
Наприклад:
spec:terminationGracePeriodSeconds:3600# на рівні Podʼаcontainers:- name:testimage:...ports:- name:liveness-portcontainerPort:8080livenessProbe:httpGet:path:/healthzport:liveness-portfailureThreshold:1periodSeconds:60# Перевизначити `terminationGracePeriodSeconds` на рівні Podʼа #terminationGracePeriodSeconds:60
terminationGracePeriodSeconds на рівні проби не може бути встановлене для проб готовності. Воно буде відхилене API-сервером.
Ця сторінка показує, як призначити Pod Kubernetes на певний вузол в кластері Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Виведіть список вузлів у вашому кластері разом з їхніми мітками:
kubectl get nodes --show-labels
Вивід буде схожий на такий:
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
Виберіть один з ваших вузлів і додайте до нього мітку:
kubectl label nodes <your-node-name> disktype=ssd
де <your-node-name> — це імʼя вашого обраного вузла.
Перевірте, що ваш обраний вузол має мітку disktype=ssd:
kubectl get nodes --show-labels
Вивід буде схожий на такий:
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,disktype=ssd,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
У попередньому виводі можна побачити, що вузол worker0 має мітку disktype=ssd.
Створіть Pod, який буде призначений на ваш обраний вузол
Цей файл конфігурації Podʼа описує Pod, який має селектор вузла disktype: ssd. Це означає, що Pod буде призначений на вузол, який має мітку disktype=ssd.
3.19 - Призначення Podʼів на вузли за допомогою спорідненості вузла
На цій сторінці показано, як призначити Pod Kubernetes на певний вузол за допомогою спорідненості вузла в кластері Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.10.
Для перевірки версії введіть kubectl version.
Додайте мітку до вузла
Виведіть список вузлів у вашому кластері разом з їхніми мітками:
kubectl get nodes --show-labels
Вивід буде схожий на такий:
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
Виберіть один з ваших вузлів і додайте до нього мітку:
kubectl label nodes <your-node-name> disktype=ssd
де <your-node-name> — це імʼя вашого обраного вузла.
Перевірте, що ваш обраний вузол має мітку disktype=ssd:
kubectl get nodes --show-labels
Вивід буде схожий на такий:
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,disktype=ssd,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
У попередньому виводі можна побачити, що вузол worker0 має мітку disktype=ssd.
Розмістіть Pod, використовуючи потрібну спорідненість вузла
Цей маніфест описує Pod, який має спорідненість вузла requiredDuringSchedulingIgnoredDuringExecution, disktype: ssd. Це означає, що Pod буде розміщений лише на вузлі, який має мітку disktype=ssd.
Перевірте, що Pod працює на вашому обраному вузлі:
kubectl get pods --output=wide
Вивід буде схожий на такий:
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
Розмістіть Pod, використовуючи бажану спорідненість вузла
Цей маніфест описує Pod, який має бажану спорідненість вузла preferredDuringSchedulingIgnoredDuringExecution, disktype: ssd. Це означає, що Pod надасть перевагу вузлу, який має мітку disktype=ssd.
На цій сторінці показано, як використовувати Init Container для ініціалізації Podʼа перед запуском контейнера застосунку.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У цьому завданні ви створите Pod, який має один контейнер застосунку та один Init Container. Контейнер ініціалізації виконується до завершення перед тим, як розпочне виконання контейнер застосунку.
apiVersion:v1kind:Podmetadata:name:init-demospec:containers:- name:nginximage:nginxports:- containerPort:80volumeMounts:- name:workdirmountPath:/usr/share/nginx/html# Цей контейр виконуєть під час ініціалізації podʼуinitContainers:- name:installimage:busybox:1.28command:- wget- "-O"- "/work-dir/index.html"- http://info.cern.chvolumeMounts:- name:workdirmountPath:"/work-dir"dnsPolicy:Defaultvolumes:- name:workdiremptyDir:{}
У файлі конфігурації ви бачите, що в Podʼі є Том, який обидва контейнери (ініціалізації та застосунку) спільно використовують.
Контейнер ініціалізації монтує спільний Том у /work-dir, а контейнер застосунку монтує спільний Том у /usr/share/nginx/html. Контейнер ініціалізації виконує наступну команду, а потім завершується:
wget -O /work-dir/index.html http://info.cern.ch
Зверніть увагу, що контейнер ініціалізації записує файл index.html в кореневу теку сервера nginx.
Вивід показує, що nginx обслуговує вебсторінку, яку записав контейнер ініціалізації:
<html><head></head><body><header>
<title>http://info.cern.ch</title>
</header>
<h1>http://info.cern.ch - home of the first website</h1>
...
<li><ahref="http://info.cern.ch/hypertext/WWW/TheProject.html">Browse the first website</a></li>
...
Ця сторінка показує, як прикріплювати обробники до подій життєвого циклу контейнера. Kubernetes підтримує події postStart та preStop. Kubernetes надсилає подію postStart безпосередньо після того, як контейнер стартує, і він надсилає подію preStop безпосередньо перед завершенням роботи контейнера. Контейнер може вказати один обробник для кожної події.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
apiVersion:v1kind:Podmetadata:name:lifecycle-demospec:containers:- name:lifecycle-demo-containerimage:nginxlifecycle:postStart:exec:command:["/bin/sh","-c","echo Hello from the postStart handler > /usr/share/message"]preStop:exec:command:["/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done"]
У файлі конфігурації ви бачите, що команда postStart записує файл message в теку /usr/share контейнера. Команда preStop відповідним чином вимикає nginx. Це корисно, якщо контейнер перериває роботу через помилку.
Отримайте доступ до оболонки контейнера, який працює в Podʼі:
kubectl exec -it lifecycle-demo -- /bin/bash
У своїй оболонці перевірте, що обробник postStart створив файл message:
root@lifecycle-demo:/# cat /usr/share/message
Вивід показує текст, записаний обробником postStart:
Hello from the postStart handler
Обговорення
Kubernetes надсилає подію postStart безпосередньо після створення контейнера. Проте, немає гарантії, що обробник postStart буде викликаний перед тим, як буде викликано точку входу контейнера. Обробник postStart працює асинхронно відносно коду контейнера, але керування Kubernetes блокується до завершення обробника postStart. Статус контейнера не встановлюється як RUNNING до завершення обробника postStart.
Kubernetes надсилає подію preStop безпосередньо перед завершенням роботи контейнера. Керування Kubernetes контейнером блокується до завершення обробника preStop, якщо тайм-аут оновлення Podʼа не закінчився. Докладніше див. Життєвий цикл Podʼа.
Примітка:
Kubernetes надсилає подію preStop лише тоді, коли Pod або контейнер у Podʼі завершується. Це означає, що обробник preStop не викликається, коли Pod завершує роботу. Про це обмеження дізнайтеся більше в розділі Контейнерні обробники.
Дивіться terminationGracePeriodSeconds в Spec Podʼа
3.22 - Налаштування Podʼів для використання ConfigMap
Велика кількість застосунків покладаються на налаштування, які використовуються під час їх ініціалізації та виконання. В більшості випадків ці налаштування можна визначити за допомогою конфігураційних параметрів. Kubernetes надає можливість додавати конфігураційні параметри до Podʼів за допомогою обʼєктів ConfigMap.
Концепція ConfigMap дозволяє виокремити конфігураційні параметри з образу контейнера, що робить застосунок більш переносним. Наприклад, ви можете завантажити та використовувати один й той самий образ контейнера для використання контейнера для потреб локальної розробки, тестування системи, або в операційному середовищі.
Ця сторінка надає ряд прикладів, які демонструють як створювати ConfigMap та налаштувати Podʼи для використання даних, що містяться в ConfigMap.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У вас має бути встановлено wget. Якщо ви використовуєте інший інструмент, такий як curl, замініть команди wget на відповідні команди для вашого інструменту.
Створення ConfigMap
Ви можете скористатись або kubectl create configmap або генератором ConfigMap в kustomization.yaml для створення ConfigMap.
Створення ConfigMap за допомогою kubectl create configmap
Скористайтесь командою kubectl create configmap, щоб створити ConfigMap з тек, файлів, або літералів:
kubectl create configmap <map-name> <data-source>
де, <map-name> — це імʼя ConfigMap, а <data-source> — це тека, файл чи літерал з даними, які ви хочете включити в ConfigMap. Імʼя обʼєкта ConfigMap повинно бути вірним імʼям субдомену DNS.
Коли ви створюєте ConfigMap на основі файлу, ключ в <data-source> визначається імʼям файлу, а значення — вмістом файлу.
Ви можете використовувати kubectl create configmap, щоб створити ConfigMap з кількох файлів у тій самій теці. Коли ви створюєте ConfigMap на основі теки, kubectl ідентифікує файли, імʼя яких є допустимим ключем у теці, та пакує кожен з цих файлів у новий ConfigMap. Всі записи теки, окрім звичайних файлів, ігноруються (наприклад: підтеки, символьні посилання, пристрої, канали тощо).
Примітка:
Імʼя кожного файлу, яке використовується для створення ConfigMap, має складатися лише з прийнятних символів, а саме: літери (A до Z та a до z), цифри (0 до 9), '-', '_', або '.'. Якщо ви використовуєте kubectl create configmap з текою, де імʼя будь-якого файлу містить неприйнятний символ, команда kubectl може завершитись з помилкою.
Команда kubectl не виводить повідомлення про помилку, коли зустрічає недопустиме імʼя файлу.
Створіть локальну теку:
mkdir -p configure-pod-container/configmap/
Тепер завантажте приклад конфігурації та створіть ConfigMap:
Вказана вище команда упаковує кожен файл, у цьому випадку game.properties та ui.properties у теці configure-pod-container/configmap/ у ConfigMap game-config. Ви можете показати деталі ConfigMap за допомогою наступної команди:
Використовуйте опцію --from-env-file для створення ConfigMap з env-файлу, наприклад:
# Env-файли містять список змінних оточення.# На ці синтаксичні правила слід звертати увагу:# Кожен рядок у env-файлі повинен бути у форматі VAR=VAL.# Рядки, які починаються з # (тобто коментарі), ігноруються.# Порожні рядки ігноруються.# Особливого врахування лапок немає (тобто вони будуть частиною значення у ConfigMap).# Завантажте приклад файлів у теку `configure-pod-container/configmap/`wget https://kubernetes.io/examples/configmap/game-env-file.properties -O configure-pod-container/configmap/game-env-file.properties
wget https://kubernetes.io/examples/configmap/ui-env-file.properties -O configure-pod-container/configmap/ui-env-file.properties
# Env-файл `game-env-file.properties` виглядає такcat configure-pod-container/configmap/game-env-file.properties
enemies=aliens
lives=3allowed="true"# Цей коментар та порожній рядок вище ігноруються
Починаючи з Kubernetes v1.23, kubectl підтримує аргумент --from-env-file, який може бути вказаний кілька разів для створення ConfigMap із кількох джерел даних.
Ви можете визначити ключ, відмінний від імені файлу, який буде використаний у розділі data вашого ConfigMap під час використання аргументу --from-file:
де <my-key-name> — це ключ, який ви хочете використовувати в ConfigMap, а <path-to-file> — це місцезнаходження файлу джерела даних, яке ключ має представляти.
Ви також можете створити ConfigMap за допомогою генераторів, а потім застосувати його для створення обʼєкта на API сервері кластера. Ви повинні вказати генератори у файлі kustomization.yaml в межах теки.
Генерація ConfigMaps з файлів
Наприклад, для створення ConfigMap з файлів configure-pod-container/configmap/game.properties:
Зверніть увагу, що до згенерованої назви ConfigMap додано суфікс хешування вмісту. Це забезпечує генерацію нового ConfigMap кожного разу, коли вміст змінюється.
Визначення ключа для використання при генерації ConfigMap з файлу
Ви можете визначити ключ, відмінний від імені файлу, для використання у генераторі ConfigMap. Наприклад, для генерації ConfigMap з файлів configure-pod-container/configmap/game.properties з ключем game-special-key:
Застосуйте теки kustomization для створення обʼєкта ConfigMap.
kubectl apply -k .
configmap/game-config-5-m67dt67794 created
Генерація ConfigMap з літералів
У цьому прикладі показано, як створити ConfigMap з двох пар ключ/значення: special.type=charm та special.how=very, використовуючи Kustomize та kubectl. Для досягнення цього, ви можете вказати генератор ConfigMap. Створіть (або замініть) kustomization.yaml, щоб мати наступний вміст:
---# Вміст kustomization.yaml для створення ConfigMap з літералівconfigMapGenerator:- name:special-config-2literals:- special.how=very- special.type=charm
Застосуйте теку kustomization для створення обʼєкта ConfigMap:
kubectl apply -k .
configmap/special-config-2-c92b5mmcf2 created
Проміжна очистка
Перед продовженням, очистіть деякі з ConfigMaps, які ви створили:
apiVersion:v1kind:Podmetadata:name:dapi-test-podspec:containers:- name:test-containerimage:registry.k8s.io/busybox:1.27.2command:["/bin/sh","-c","env"]env:# Визначення змінної середовища- name:SPECIAL_LEVEL_KEYvalueFrom:configMapKeyRef:# ConfigMap, що містить значення, яке потрібно присвоїти SPECIAL_LEVEL_KEYname:special-config# Вказує ключ, повʼязаний зі значеннямkey:special.howrestartPolicy:Never
Тепер виведення Pod містить змінні середовища SPECIAL_LEVEL=very та
SPECIAL_TYPE=charm.
Як тільки ви готові перейти далі, видаліть цей Pod:
kubectl delete pod dapi-test-pod --now
Використання змінних середовища, визначених у ConfigMap, у командах Pod
Ви можете використовувати змінні середовища, визначені у ConfigMap, у розділі command та args контейнера за допомогою синтаксису підстановки Kubernetes $(VAR_NAME).
Цей Pod видає наступний вивід від контейнера test-container:
kubectl logs dapi-test-pod
very charm
Як тільки ви готові перейти далі, видаліть цей Pod:
kubectl delete pod dapi-test-pod --now
Додавання даних ConfigMap до тому
Як пояснено у розділі Створення ConfigMap з файлів, коли ви створюєте ConfigMap, використовуючи --from-file, імʼя файлу стає ключем, збереженим у розділі data ConfigMap. Вміст файлу стає значенням ключа.
Приклади в цьому розділі відносяться до ConfigMap з іменем special-config:
Додайте імʼя ConfigMap у розділ volumes специфікації Pod. Це додасть дані ConfigMap до теки, вказаної як volumeMounts.mountPath (у цьому випадку, /etc/config). Розділ command перераховує файли теки з іменами, що відповідають ключам у ConfigMap.
apiVersion:v1kind:Podmetadata:name:dapi-test-podspec:containers:- name:test-containerimage:registry.k8s.io/busybox:1.27.2command:["/bin/sh","-c","ls /etc/config/"]volumeMounts:- name:config-volumemountPath:/etc/configvolumes:- name:config-volumeconfigMap:# Надає назву ConfigMap, що містить файли, які ви бажаєте# додати до контейнераname:special-configrestartPolicy:Never
Коли Pod працює, команда ls /etc/config/ виводить наступне:
SPECIAL_LEVEL
SPECIAL_TYPE
Текстові дані показуються у вигляді файлів з використанням кодування символів UTF-8. Щоб використовувати інше кодування символів, скористайтеся binaryData (див. обʼєкт ConfigMap для докладніших відомостей).
Примітка:
Якщо в теці /etc/config образу контейнера є будь-які файли, то змонтований том робить ці файли образу недоступними.
Якщо ви готові перейти до наступного кроку, видаліть цей Pod:
kubectl delete pod dapi-test-pod --now
Додавання конфігурації ConfigMap до певного шляху у томі
Використовуйте поле path, щоб вказати бажаний шлях до файлів для конкретних елементів ConfigMap. У цьому випадку елемент SPECIAL_LEVEL буде змонтовано у томі config-volume за адресою /etc/config/keys.
Коли pod запущено, команда cat /etc/config/keys видасть наведений нижче вивід:
very
Увага:
Як і раніше, усі попередні файли у теці /etc/config/ буде видалено.
Видаліть цей Pod:
kubectl delete pod dapi-test-pod --now
Спроєцюйте ключі на конкретні шляхи та встановлюйте права доступу до файлів
Ви можете спроєцювати ключі на конкретні шляхи. Зверніться до відповідного розділу в Посібнику Secret для ознайомлення з синтаксисом. Ви можете встановлювати права доступу POSIX для ключів. Зверніться до відповідного розділу в Посібнику Secret ознайомлення з синтаксисом.
Необовʼязкові посилання
Посилання на ConfigMap може бути позначене як необовʼязкове. Якщо ConfigMap не існує, змонтований том буде порожнім. Якщо ConfigMap існує, але посилання на ключ не існує, шлях буде відсутній під точкою монтування. Дивіться Опціональні ConfigMaps для отримання додаткових відомостей.
Змонтовані ConfigMap оновлюються автоматично
Коли змонтований ConfigMap оновлюється, спроєцьований вміст врешті-решт оновлюється також. Це стосується випадку, коли ConfigMap, на який посилатися необовʼязково, зʼявляється після того, як Pod вже почав працювати.
Kubelet перевіряє, чи змонтований ConfigMap є актуальним під час кожної періодичної синхронізації. Однак він використовує свій локальний кеш на основі TTL для отримання поточного значення ConfigMap. В результаті загальна затримка від моменту оновлення ConfigMap до моменту, коли нові ключі проєцюються у Pod може бути таким, як період синхронізації kubelet (стандартно — 1 хвилина) + TTL кешу ConfigMaps (стандартно — 1 хвилина) в kubelet. Ви можете викликати негайне оновлення, оновивши одну з анотацій Podʼа.
Примітка:
Контейнери, які використовують ConfigMap як том subPath не отримуватимуть оновлення ConfigMap.
Розуміння ConfigMap та Podʼів
Ресурс ConfigMap API зберігає конфігураційні дані у вигляді пар ключ-значення. Дані можуть бути використані в Podʼах або надавати конфігураційні дані для системних компонентів, таких як контролери. ConfigMap схожий на Secret, але надає засоби для роботи з рядками, що не містять конфіденційної інформації. Користувачі та системні компоненти можуть зберігати конфігураційні дані в ConfigMap.
Примітка:
ConfigMaps повинні посилатися на файли властивостей, а не заміняти їх. Подумайте про ConfigMap як щось подібне до теки /etc в Linux та її вмісту. Наприклад, якщо ви створюєте Том Kubernetes з ConfigMap, кожен елемент даних у ConfigMap представлений окремим файлом у томі.
Поле data у ConfigMap містить дані конфігурації. Як показано у прикладі нижче, це може бути простим (наприклад, окремі властивості, визначені за допомогою --from-literal) або складним (наприклад, файли конфігурації або JSON-фрагменти, визначені за допомогою --from-file).
apiVersion:v1kind:ConfigMapmetadata:creationTimestamp:2016-02-18T19:14:38Zname:example-confignamespace:defaultdata:# приклад простої властивості, визначеної за допомогою --from-literalexample.property.1:helloexample.property.2:world# приклад складної властивості, визначеної за допомогою --from-fileexample.property.file:|- property.1=value-1
property.2=value-2
property.3=value-3
Коли kubectl створює ConfigMap з вхідних даних, які не є ASCII або UTF-8, цей інструмент поміщає їх у поле binaryData ConfigMap, а не в data. Як текстові, так і бінарні дані можуть бути поєднані в одному ConfigMap.
Якщо ви хочете переглянути ключі binaryData (і їх значення) в ConfigMap, ви можете виконати kubectl get configmap -o jsonpath='{.binaryData}' <імʼя>.
Podʼи можуть завантажувати дані з ConfigMap, що використовують як data, так і binaryData.
Опціональні ConfigMaps
Ви можете позначити посилання на ConfigMap як опціональне в специфікації Pod. Якщо ConfigMap не існує, конфігурація, для якої вона надає дані в Pod (наприклад: змінна середовища, змонтований том), буде пустою. Якщо ConfigMap існує, але посилання на ключ не існує, дані також будуть пустими.
Наприклад, наступна специфікація Pod позначає змінну середовища з ConfigMap як опціональну:
apiVersion:v1kind:Podmetadata:name:dapi-test-podspec:containers:- name:test-containerimage:gcr.io/google_containers/busyboxcommand:["/bin/sh","-c","env"]env:- name:SPECIAL_LEVEL_KEYvalueFrom:configMapKeyRef:name:a-configkey:akeyoptional:true# позначає змінну як опціональнуrestartPolicy:Never
Якщо ви запустите цей Pod, і ConfigMap з імʼям a-config не існує, вивід буде пустим. Якщо ви запустите цей Pod, і ConfigMap з імʼям a-config існує, але в цьому ConfigMap немає ключа з імʼям akey, вивід також буде пустим. Якщо ж ви задасте значення для akey в ConfigMap a-config, цей Pod надрукує це значення і потім завершить роботу.
Ви також можете позначити томи та файли, надані ConfigMap, як опціональні. Kubernetes завжди створює шляхи для монтування томів, навіть якщо зазначений ConfigMap або ключ не існують. Наприклад, наступна специфікація Pod позначає том, який посилається на ConfigMap, як опціональний:
apiVersion:v1kind:Podmetadata:name:dapi-test-podspec:containers:- name:test-containerimage:gcr.io/google_containers/busyboxcommand:["/bin/sh","-c","ls /etc/config"]volumeMounts:- name:config-volumemountPath:/etc/configvolumes:- name:config-volumeconfigMap:name:no-configoptional:true# позначає ConfigMap як опціональнийrestartPolicy:Never
Обмеження
Ви повинні створити обʼєкт ConfigMap до того, як ви посилатиметесь на нього в специфікації Pod. Альтернативно, позначте посилання на ConfigMap як optional в специфікації Pod (див. Опціональні ConfigMaps). Якщо ви посилаєтесь на ConfigMap, який не існує, і ви не позначите посилання як optional, Podʼи не запуститься. Аналогічно, посилання на ключі, які не існують в ConfigMap, також перешкоджатимуть запуску Podʼа, якщо ви не позначите посилання на ключі як optional.
Якщо ви використовуєте envFrom для визначення змінних середовища з ConfigMaps, ключі, які вважаються недійсними, будуть пропущені. Podʼу буде дозволено запускатися, але недійсні імена будуть записані в лог подій (InvalidVariableNames). Повідомлення логу містить кожен пропущений ключ. Наприклад:
kubectl get events
Вивід буде схожий на цей:
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON SOURCE MESSAGE
0s 0s 1 dapi-test-pod Pod Warning InvalidEnvironmentVariableNames {kubelet, 127.0.0.1} Keys [1badkey, 2alsobad] from the EnvFrom configMap default/myconfig were skipped since they are considered invalid environment variable names.
ConfigMaps знаходяться в конкретному Namespace. Podʼи можуть посилатися лише на ConfigMaps, які знаходяться в тому ж контексті, що і сам Pod.
Ви не можете використовувати ConfigMaps для статичних Podʼів, оскільки kubelet їх не підтримує.
Очищення
Вилучить ConfigMaps та Pod, які ви створили, використовуючи наступні команди:
kubectl delete configmaps/game-config configmaps/game-config-2 configmaps/game-config-3 \
configmaps/game-config-env-file
kubectl delete pod dapi-test-pod --now
# Можливо, ви вже видалили наступний набірkubectl delete configmaps/special-config configmaps/env-config
kubectl delete configmap -l 'game-config in (config-4,config-5)'
Видаліть файл kustomization.yaml, який ви створили для генерації ConfigMap:
rm kustomization.yaml
Якщо ви створили ntre configure-pod-container і вже не потребуєте її, вам слід також її видалити або перемістити в кошик або місце для видалених файлів.
3.23 - Поділ простору імен процесів між контейнерами у Podʼі
На цій сторінці показано, як налаштувати поділ простору імен процесів для Podʼа. Коли поділ простору імен процесів увімкнено, процеси в контейнері стають видимими для всіх інших контейнерів у тому ж Podʼі.
Ви можете використовувати цю функцію для налаштування контейнерів, що взаємодіють один з одним, таких як контейнер sidecar обробника логу, або для дослідження образів контейнера, які не містять інструментів для налагодження, наприклад, оболонки.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Приєднайтеся до контейнера shell та запустіть команду ps:
kubectl exec -it nginx -c shell -- /bin/sh
Якщо ви не бачите символу командного рядка, спробуйте натиснути клавішу Enter. У оболонці контейнера:
# виконайте це всередині контейнера "shell"ps ax
Вивід схожий на такий:
PID USER TIME COMMAND
1 root 0:00 /pause
8 root 0:00 nginx: master process nginx -g daemon off;
14 101 0:00 nginx: worker process
15 root 0:00 sh
21 root 0:00 ps ax
Ви можете відправляти сигнали процесам в інших контейнерах. Наприклад, відправте SIGHUP до nginx, щоб перезапустити робочий процес. Для цього потрібна можливість SYS_PTRACE.
# виконайте це всередині контейнера "shell"kill -HUP 8# змініть "8" на відповідний PID лідера процесу nginx, якщо потрібноps ax
Вивід схожий на такий:
PID USER TIME COMMAND
1 root 0:00 /pause
8 root 0:00 nginx: master process nginx -g daemon off;
15 root 0:00 sh
22 101 0:00 nginx: worker process
23 root 0:00 ps ax
Навіть можливо отримати доступ до файлової системи іншого контейнера, використовуючи посилання /proc/$pid/root.
# виконайте це всередині контейнера "shell"# змініть "8" на PID процесу Nginx, якщо потрібноhead /proc/8/root/etc/nginx/nginx.conf
Podʼи ділять багато ресурсів, тому логічно, що вони також будуть ділитися простором імен процесів. Деякі контейнери можуть очікувати ізоляції від інших, тому важливо розуміти відмінності:
Процес контейнера вже не має PID 1. Деякі контейнери відмовляються запускатися без PID 1 (наприклад, контейнери, що використовують systemd) або виконують команди типу kill -HUP 1 для відправлення сигналу процесу контейнера. У Podʼах зі спільним простором імен процесів kill -HUP 1 відправить сигнал пісочниці Podʼа (/pause у вищезазначеному прикладі).
Процеси видимі іншим контейнерам у Podʼі. Це включає всю інформацію, доступну у /proc, таку як паролі, що були передані як аргументи або змінні середовища. Ці дані захищені лише звичайними правами Unix.
Файлові системи контейнерів видимі іншим контейнерам у Podʼі через посилання /proc/$pid/root. Це полегшує налагодження, але також означає, що секрети файлової системи захищені лише правами файлової системи.
3.24 - Використання простору імен користувача з Podʼом
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [beta](стандартно увімкнено)
Ця сторінка показує, як налаштувати простір імен користувача для Podʼів. Це дозволяє ізолювати користувача, що працює всередині контейнера, від того, який працює на хості.
Процес, що працює як root у контейнері, може працювати як інший (не root) користувач на хості; іншими словами, процес має повні привілеї для операцій всередині простору імен користувача, але не має привілеїв для операцій за межами простору імен.
Ви можете використовувати цю функцію, щоб зменшити шкоду, яку скомпрометований контейнер може завдати хосту або іншим Podʼам на тому ж вузлі. Є кілька уразливостей безпеки, оцінених як ВИСОКІ або КРИТИЧНІ, які не були використовні при активному використанні просторів імен користувача. Очікується, що простори імен користувача захистять від деяких майбутніх уразливостей також.
Без використання просторів імен користувача контейнер, що працює як root, у випадку втечі з контейнера має привілеї root на вузлі. І якщо деякі можливості були надані контейнеру, то ці можливості також дійсні на хості. Цього не відбувається, коли використовуються простори імен користувача.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Feature gate для увімкнення просторів імен користувача раніше називався UserNamespacesStatelessPodsSupport, коли підтримувалися лише Podʼи без збереження стану. Тільки Kubernetes v1.25 по v1.27 визнають UserNamespacesStatelessPodsSupport.
Кластер, який ви використовуєте, обовʼязково повинен містити принаймні один вузол, який відповідає вимогам щодо використання просторів імен користувача з Podʼами.
Якщо у вас є суміш вузлів і лише деякі з них надають підтримку просторів імен користувача для
Podʼів, вам також потрібно забезпечити те, що Podʼи з просторами імен користувача будуть
заплановані на відповідні вузли.
Запуск Podʼа, що використовує простір імен користувача
Простір імен користувача для Podʼа вимкається, встановленням поля hostUsers в .spec
на false. Наприклад:
Приєднайтеся до Podʼа і виконайте readlink /proc/self/ns/user:
kubectl exec -ti userns -- bash
Виконайте цю команду:
readlink /proc/self/ns/user
Вивід схожий на:
user:[4026531837]
Також виконайте:
cat /proc/self/uid_map
Вивід схожий на:
083361792065536
Потім відкрийте оболонку на хості та виконайте ті ж самі команди.
Команда readlink показує простір імен користувача, в якому працює процес. Він повинен бути різним, коли ви виконуєте його на хості і всередині контейнера.
Останнє число у файлі uid_map всередині контейнера повинно бути 65536, на хості це число повинно бути більшим.
Якщо ви запускаєте kubelet всередині простору імен користувача, вам потрібно порівняти вивід команди в Pod з виводом, отриманим на хості:
readlink /proc/$pid/ns/user
замінивши $pid на PID kubelet.
3.25 - Використання тому Image в Pod
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [beta](стандартно вимкнено)
Ця сторінка демонструє, як налаштувати Pod для використання томів image. Це дозволяє монтувати вміст з OCI реєстрів всередині контейнерів.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Том image для Podʼа активується шляхом налаштування поля volumes.[*].image у .spec на дійсне посилання та використання його в volumeMounts контейнера. Наприклад:
Статичні Podʼи керуються безпосередньо демоном kubelet на конкретному вузлі, без спостереження за ними з боку API сервера. На відміну від Podʼів, які керуються панеллю управління (наприклад, Deployment), kubelet спостерігає за кожним статичним Podʼом (і перезапускає його у разі невдачі).
Статичні Podʼи завжди привʼязані до одного Kubelet на конкретному вузлі.
Kubelet автоматично намагається створити дзеркальний Pod на сервері Kubernetes API для кожного статичного Podʼа. Це означає, що Podʼи, які запущені на вузлі, є видимими на сервері API, але не можуть бути керовані звідти. Назви Podʼів будуть мати суфікс з іменем хосту вузла відділеним дефісом.
Примітка:
Якщо ви використовуєте кластеризований Kubernetes і використовуєте статичні Podʼи для запуску Podʼа на кожному вузлі, вам, ймовірно, слід використовувати DaemonSet замість цього.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
На цій сторінці передбачається, що ви використовуєте CRI-O для запуску Podʼів, а також що ваші вузли працюють під управлінням операційної системи Fedora. Інструкції для інших дистрибутивів або встановлень Kubernetes можуть відрізнятися.
Маніфести — це стандартні визначення Podʼів у форматі JSON або YAML в певній теці. Використовуйте поле staticPodPath: <тека> у конфігураційному файлі kubelet, який періодично сканує теку і створює/видаляє статичні Podʼи, коли у цій теці зʼявляються/зникають файли YAML/JSON. Зверніть увагу, що kubelet ігнорує файли, що починаються з крапки при скануванні вказаної теки.
Наприклад, так можна запустити простий вебсервер як статичний Pod:
Виберіть вузол, на якому ви хочете запустити статичний Pod. У цьому прикладі це my-node1.
ssh my-node1
Виберіть теку, наприклад /etc/kubernetes/manifests, і помістіть туди визначення Podʼа вебсервера, наприклад, /etc/kubernetes/manifests/static-web.yaml:
# Виконайте цю команду на вузлі, де працює kubeletmkdir -p /etc/kubernetes/manifests/
cat <<EOF >/etc/kubernetes/manifests/static-web.yaml
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
EOF
Альтернативний і застарілий метод полягає в налаштуванні kubelet на тому вузлі, щоб він шукав маніфести статичного Podʼа локально, використовуючи аргумент командного рядка. Щоб використовувати застарілий підхід, запустіть kubelet з аргументом --pod-manifest-path=/etc/kubernetes/manifests/.
Перезапустіть kubelet. У Fedora ви виконаєте:
# Виконайте цю команду на вузлі, де працює kubeletsystemctl restart kubelet
Маніфест Podʼа, розміщений на вебсервері
Kubelet періодично завантажує файл, вказаний аргументом --manifest-url=<URL>,
і розглядає його як файл JSON/YAML, який містить визначення Podʼів.
Подібно до того, як працюють маніфести, розміщені в файловій системі, kubelet
перевіряє маніфест за розкладом. Якщо відбулися зміни в списку статичних
Podʼів, kubelet застосовує їх.
Щоб скористатися цим підходом:
Створіть YAML-файл і збережіть його на веб-сервері, щоб ви могли передати URL цього файлу kubelet.
Налаштуйте kubelet на обраному вузлі для використання цього веб-маніфесту,
запустивши його з аргументом --manifest-url=<URL-маніфесту>.
У Fedora відредагуйте /etc/kubernetes/kubelet, щоб додати цей рядок:
# Виконайте цю команду на вузлі, де працює kubeletsystemctl restart kubelet
Спостереження за поведінкою статичного Podʼа
Після запуску kubelet автоматично запускає всі визначені статичні Podʼи. Оскільки ви визначили статичний Pod і перезапустили kubelet, новий статичний Pod вже має бути запущений.
Ви можете переглянути запущені контейнери (включно зі статичними Podʼами), виконавши (на вузлі):
# Виконайте цю команду на вузлі, де працює kubeletcrictl ps
Вивід може бути наступним:
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
129fd7d382018 docker.io/library/nginx@sha256:... 11 minutes ago Running web 0 34533c6729106
Примітка:
crictl виводить URI образу та контрольну суму SHA-256. NAME буде виглядати більш подібним до: docker.io/library/nginx@sha256:0d17b565c37bcbd895e9d92315a05c1c3c9a29f762b011a10c54a66cd53c9b31.
Ви можете побачити дзеркальний Pod на сервері API:
kubectl get pods
NAME READY STATUS RESTARTS AGE
static-web-my-node1 1/1 Running 0 2m
Примітка:
Переконайтеся, що kubelet має дозвіл на створення дзеркального Podʼа на сервері API. якщо — ні, запит на створення буде відхилено сервером API.
Мітки зі статичного Podʼа передаються в дзеркальний Pod. Ви можете використовувати ці мітки як зазвичай через селектори, і т.д.
Якщо ви спробуєте використовувати kubectl для видалення дзеркального Podʼа з сервера API, kubelet не видаляє статичний Pod:
kubectl delete pod static-web-my-node1
pod "static-web-my-node1" deleted
Ви побачите, що Pod все ще працює:
kubectl get pods
NAME READY STATUS RESTARTS AGE
static-web-my-node1 1/1 Running 0 4s
Поверніться на вузол, де працює kubelet, і спробуйте вручну зупинити контейнер. Ви побачите, що після певного часу kubelet помітить це та автоматично перезапустить Pod:
# Виконайте ці команди на вузлі, де працює kubeletcrictl stop 129fd7d382018 # замініть на ID вашого контейнераsleep 20crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
89db4553e1eeb docker.io/library/nginx@sha256:... 19 seconds ago Running web 1 34533c6729106
Після того як ви визначите потрібний контейнер, ви можете отримати журнал для цього контейнера за допомогою crictl:
# Виконайте ці команди на вузлі, де працює контейнерcrictl logs <container_id>
Запущений kubelet періодично сканує налаштовану теку (/etc/kubernetes/manifests у нашому прикладі) на предмет змін та додає/видаляє Podʼи при появі/зникненні файлів в цій теці.
# Це передбачає, що ви використовуєте файлову конфігурацію статичних Podʼів# Виконайте ці команди на вузлі, де працює контейнер#mv /etc/kubernetes/manifests/static-web.yaml /tmp
sleep 20crictl ps
# Ви бачите, що ніякий контейнер nginx не працюєmv /tmp/static-web.yaml /etc/kubernetes/manifests/
sleep 20crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
f427638871c35 docker.io/library/nginx@sha256:... 19 seconds ago Running web 1 34533c6729106
3.27 - Конвертація файлу Docker Compose в ресурси Kubernetes
Що таке Kompose? Це інструмент конвертації для всього, що стосується композиції (зокрема Docker Compose) в ресурси систем оркестрування (Kubernetes або OpenShift).
Додаткову інформацію можна знайти на вебсайті Kompose за адресою https://kompose.io.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Щоб конвертувати файл docker-compose.yml у файли, які можна використовувати з kubectl, запустіть kompose convert, а потім kubectl apply -f <output file>.
kompose convert
Вивід подібний до:
INFO Kubernetes file "redis-leader-service.yaml" created
INFO Kubernetes file "redis-replica-service.yaml" created
INFO Kubernetes file "web-tcp-service.yaml" created
INFO Kubernetes file "redis-leader-deployment.yaml" created
INFO Kubernetes file "redis-replica-deployment.yaml" created
INFO Kubernetes file "web-deployment.yaml" created
deployment.apps/redis-leader created
deployment.apps/redis-replica created
deployment.apps/web created
service/redis-leader created
service/redis-replica created
service/web-tcp created
Ваші розгортання, що працюють в Kubernetes.
Доступ до вашого застосунку.
Якщо ви вже використовуєте minikube для вашого процесу розробки:
minikube service web-tcp
В іншому випадку, подивімось, яку IP використовує ваш Service!
Kompose підтримує двох провайдерів: OpenShift і Kubernetes. Ви можете вибрати відповідного постачальника, використовуючи глобальну опцію --provider. Якщо постачальник не вказаний, буде встановлено Kubernetes.
kompose convert
Kompose підтримує конвертацію файлів Docker Compose версій V1, V2 і V3 в обʼєкти Kubernetes та OpenShift.
Приклад kompose convert для Kubernetes
kompose --file docker-voting.yml convert
WARN Unsupported key networks - ignoring
WARN Unsupported key build - ignoring
INFO Kubernetes file "worker-svc.yaml" created
INFO Kubernetes file "db-svc.yaml" created
INFO Kubernetes file "redis-svc.yaml" created
INFO Kubernetes file "result-svc.yaml" created
INFO Kubernetes file "vote-svc.yaml" created
INFO Kubernetes file "redis-deployment.yaml" created
INFO Kubernetes file "result-deployment.yaml" created
INFO Kubernetes file "vote-deployment.yaml" created
INFO Kubernetes file "worker-deployment.yaml" created
INFO Kubernetes file "db-deployment.yaml" created
INFO Kubernetes file "frontend-service.yaml" created
INFO Kubernetes file "mlbparks-service.yaml" created
INFO Kubernetes file "mongodb-service.yaml" created
INFO Kubernetes file "redis-master-service.yaml" created
INFO Kubernetes file "redis-slave-service.yaml" created
INFO Kubernetes file "frontend-deployment.yaml" created
INFO Kubernetes file "mlbparks-deployment.yaml" created
INFO Kubernetes file "mongodb-deployment.yaml" created
INFO Kubernetes file "mongodb-claim0-persistentvolumeclaim.yaml" created
INFO Kubernetes file "redis-master-deployment.yaml" created
INFO Kubernetes file "redis-slave-deployment.yaml" created
WARN [worker] Service cannot be created because of missing port.
INFO OpenShift file "vote-service.yaml" created
INFO OpenShift file "db-service.yaml" created
INFO OpenShift file "redis-service.yaml" created
INFO OpenShift file "result-service.yaml" created
INFO OpenShift file "vote-deploymentconfig.yaml" created
INFO OpenShift file "vote-imagestream.yaml" created
INFO OpenShift file "worker-deploymentconfig.yaml" created
INFO OpenShift file "worker-imagestream.yaml" created
INFO OpenShift file "db-deploymentconfig.yaml" created
INFO OpenShift file "db-imagestream.yaml" created
INFO OpenShift file "redis-deploymentconfig.yaml" created
INFO OpenShift file "redis-imagestream.yaml" created
INFO OpenShift file "result-deploymentconfig.yaml" created
INFO OpenShift file "result-imagestream.yaml" created
Також підтримує створення buildconfig для директиви build в сервісі. Стандартно використовується віддалений репозиторій для поточної гілки git як джерело репозиторію, та поточну гілку як гілку джерела для збірки. Ви можете вказати інше джерело репозиторію та гілку джерела, використовуючи опції --build-repo та --build-branch відповідно.
WARN [foo] Service cannot be created because of missing port.
INFO OpenShift Buildconfig using git@github.com:rtnpro/kompose.git::master as source.
INFO OpenShift file "foo-deploymentconfig.yaml" created
INFO OpenShift file "foo-imagestream.yaml" created
INFO OpenShift file "foo-buildconfig.yaml" created
Примітка:
Якщо ви вручну публікуєте артефакти OpenShift за допомогою oc create -f, вам потрібно забезпечити, щоб ви публікували артефакт imagestream перед артефактом buildconfig, щоб уникнути цієї проблеми OpenShift: https://github.com/openshift/origin/issues/4518.
Альтернативні конвертації
Типово kompose перетворює файли у форматі yaml на обʼєкти Kubernetes Deployments та Services. У вас є альтернативна опція для генерації json за допомогою -j. Також, ви можете альтернативно згенерувати обʼєкти Replication Controllers, Daemon Sets, або Helm чарти.
kompose convert -j
INFO Kubernetes file "redis-svc.json" created
INFO Kubernetes file "web-svc.json" created
INFO Kubernetes file "redis-deployment.json" created
INFO Kubernetes file "web-deployment.json" created
Файли *-deployment.json містять обʼєкти Deployment.
kompose convert --replication-controller
INFO Kubernetes file "redis-svc.yaml" created
INFO Kubernetes file "web-svc.yaml" created
INFO Kubernetes file "redis-replicationcontroller.yaml" created
INFO Kubernetes file "web-replicationcontroller.yaml" created
Файли *-replicationcontroller.yaml містять обʼєкти Replication Controller. Якщо ви хочете вказати кількість реплік (стандартно 1), використовуйте прапорець --replicas: kompose convert --replication-controller --replicas 3.
kompose convert --daemon-set
INFO Kubernetes file "redis-svc.yaml" created
INFO Kubernetes file "web-svc.yaml" created
INFO Kubernetes file "redis-daemonset.yaml" created
INFO Kubernetes file "web-daemonset.yaml" created
Файли *-daemonset.yaml містять обʼєкти DaemonSet.
Якщо ви хочете згенерувати чарт для використання з Helm, виконайте:
kompose convert -c
INFO Kubernetes file "web-svc.yaml" created
INFO Kubernetes file "redis-svc.yaml" created
INFO Kubernetes file "web-deployment.yaml" created
INFO Kubernetes file "redis-deployment.yaml" created
chart created in "./docker-compose/"
kompose.service.expose визначає, чи потрібно сервісу бути доступним ззовні кластера чи ні. Якщо значення встановлено на "true", постачальник автоматично встановлює точку доступу, і для будь-якого іншого значення, значення встановлюється як імʼя хосту. Якщо в сервісі визначено кілька портів, вибирається перший.
Для постачальника Kubernetes створюється ресурс Ingress, припускається, що контролер Ingress вже налаштований.
Мітка kompose.service.type повинна бути визначена лише з ports, інакше kompose завершиться невдачею.
Перезапуск
Якщо ви хочете створити звичайні Podʼи без контролерів, ви можете використовувати конструкцію restart у docker-compose, щоб визначити це. Дивіться таблицю нижче, щоб побачити, що відбувається при значенні restart.
docker-composerestart
створений обʼєкт
restartPolicy Podʼа
""
обʼєкт контролера
Always
always
обʼєкт контролера
Always
on-failure
Капсула
OnFailure
no
Капсула
Never
Примітка:
Обʼєкт контролера може бути deployment або replicationcontroller.
Наприклад, сервіс pival стане Podʼом нижче. Цей контейнер обчислює значення pi.
Якщо в Docker Compose файлі вказано том для сервісу, стратегія Deployment (Kubernetes) або DeploymentConfig (OpenShift) змінюється на "Recreate" замість "RollingUpdate" (типово). Це робиться для того, щоб уникнути одночасного доступу кількох екземплярів сервісу до тому.
Якщо в Docker Compose файлі імʼя сервісу містить _ (наприклад, web_service), то воно буде замінено на -, і імʼя сервісу буде перейменовано відповідно (наприклад, web-service). Kompose робить це, оскільки "Kubernetes" не дозволяє _ в імені обʼєкта.
Зверніть увагу, що зміна назви сервісу може зіпсувати деякі файли docker-compose.
Версії Docker Compose
Kompose підтримує версії Docker Compose: 1, 2 та 3. Ми маємо обмежену підтримку версій 2.1 та 3.2 через їх експериментальний характер.
Повний список сумісності між усіма трьома версіями перераховано у нашому документі з конвертації, включаючи список всіх несумісних ключів Docker Compose.
3.28 - Забезпечення стандартів безпеки Podʼів шляхом конфігурування вбудованого контролера допуску
Kubernetes надає вбудований контролер допуску, щоб забезпечити дотримання стандартів безпеки Podʼів. Ви можете налаштувати цей контролер допуску, щоб встановити глобальні стандартні значення та винятки.
Перш ніж ви розпочнете
Після альфа-релізу в Kubernetes v1.22, Pod Security Admission став стандартно доступним в Kubernetes v1.23, у вигляді бета. Починаючи з версії 1.25, Pod Security Admissio доступний загалом.
Для перевірки версії введіть kubectl version.
Якщо у вас не запущено Kubernetes 1.34, ви можете перемикнутися на перегляд цієї сторінки в документації для версії Kubernetes, яку ви використовуєте.
Налаштування контролера допуску
Примітка:
Конфігурація pod-security.admission.config.k8s.io/v1 потребує v1.25+. Для v1.23 та v1.24, використовуйте v1beta1. Для v1.22, використовуйте v1alpha1.
apiVersion:apiserver.config.k8s.io/v1kind:AdmissionConfigurationplugins:- name:PodSecurityconfiguration:apiVersion:pod-security.admission.config.k8s.io/v1# див. примітку про сумісністьkind:PodSecurityConfiguration# Стандартні значення, які застосовуються, коли мітка режиму не встановлена.## Значення мітки рівня повинні бути одним з:# - "privileged" (станадртно)# - "baseline"# - "restricted"## Значення мітки версії повинні бути одним з:# - "latest" (станадртно)# - конкретна версія, наприклад "v1.34"defaults:enforce:"privileged"enforce-version:"latest"audit:"privileged"audit-version:"latest"warn:"privileged"warn-version:"latest"exemptions:# Масив імен користувачів для виключення.usernames:[]# Масив імен класів виконання для виключення.runtimeClasses:[]# Масив просторів імен для виключення.namespaces:[]
Примітка:
Вищезазначений маніфест потрібно вказати через --admission-control-config-file для kube-apiserver.
3.29 - Забезпечення стандартів безпеки Podʼів за допомогою міток простору імен
Pod Security Admission був доступний в Kubernetes v1.23, у вигляді бета. Починаючи з версії 1.25, Pod Security Admission доступний загалом.
Для перевірки версії введіть kubectl version.
Вимога стандарту безпеки Pod baseline за допомогою міток простору імен
Цей маніфест визначає Простір імен my-baseline-namespace, який:
Блокує будь-які Podʼи, які не відповідають вимогам політики baseline.
Генерує попередження для користувача та додає анотацію аудиту до будь-якого створеного Podʼа, який не відповідає вимогам політики restricted.
Фіксує версії політик baseline та restricted на v1.34.
apiVersion:v1kind:Namespacemetadata:name:my-baseline-namespacelabels:pod-security.kubernetes.io/enforce:baselinepod-security.kubernetes.io/enforce-version:v1.34# Ми встановлюємо ці рівні за нашим _бажаним_ `enforce` рівнем.pod-security.kubernetes.io/audit:restrictedpod-security.kubernetes.io/audit-version:v1.34pod-security.kubernetes.io/warn:restrictedpod-security.kubernetes.io/warn-version:v1.34
Додавання міток до наявних просторів імен за допомогою kubectl label
Примітка:
Коли мітка політики enforce (або версії) додається або змінюється, втулок допуску буде тестувати кожен Pod в просторі імен на відповідність новій політиці. Порушення повертаються користувачу у вигляді попереджень.
Корисно застосувати прапорець --dry-run при початковому оцінюванні змін профілю безпеки для просторів імен. Перевірки стандарту безпеки Pod все ще будуть виконуватися в режимі dry run, що дозволяє отримати інформацію про те, як нова політика буде обробляти наявні Podʼи, без фактичного оновлення політики.
Якщо ви тільки починаєте зі Pod Security Standards, відповідний перший крок — налаштувати всі простори імен з анотаціями аудиту для строгого рівня, такого як baseline:
Зверніть увагу, що це не встановлює рівень примусового виконання, щоб можна було відрізняти простори імен, для яких не було явно встановлено рівень примусового виконання. Ви можете перелічити простори імен без явно встановленого рівня примусового виконання за допомогою цієї команди:
kubectl get namespaces --selector='!pod-security.kubernetes.io/enforce'
Застосування до конкретного простору імен
Ви також можете оновити конкретний простір імен. Ця команда додає політику enforce=restricted до простору імен my-existing-namespace, закріплюючи версію обмеженої політики на v1.34.
3.30 - Міграція з PodSecurityPolicy до вбудованого контролера допуску PodSecurity
Ця сторінка описує процес міграції з PodSecurityPolicy до вбудованого контролера допуску PodSecurity. Це можна зробити ефективно за допомогою комбінації запуску dry-run та режимів audit та warn, хоча це стає складнішим, якщо використовуються мутуючі PSP.
Перш ніж ви розпочнете
Версія вашого Kubernetes сервера має бути не старішою ніж v1.22.
Для перевірки версії введіть kubectl version.
Якщо ви використовуєте відмінну від 1.34 версію Kubernetes, вам можливо захочеться перейти до перегляду цієї сторінки у документації для версії Kubernetes, яку ви фактично використовуєте.
Ця сторінка передбачає, що ви вже знайомі з основними концепціями Pod Security Admission.
Загальний підхід
Існує кілька стратегій для міграції з PodSecurityPolicy до Pod Security Admission. Наведені нижче кроки — це один з можливих шляхів міграції, з метою мінімізації ризиків виробничої перерви та пробілів у безпеці.
Вирішіть, чи Pod Security Admission відповідає вашому випадку використання.
Перегляньте дозволи простору імен.
Спростіть та стандартизуйте PodSecurityPolicies.
Оновіть простори імен
Визначте відповідний рівень безпеки Podʼа.
Перевірте рівень безпеки Podʼів.
Застосуйте рівень безпеки Podʼів.
Оминіть PodSecurityPolicy.
Перегляньте процеси створення просторів імен.
Вимкніть PodSecurityPolicy.
0. Вирішіть, чи Pod Security Admission підходить для вас
Pod Security Admission був розроблений для задоволення найбільш поширених потреб у безпеці з коробки, а також для забезпечення стандартного набору рівнів безпеки у всіх кластерах. Однак він менш гнучкий, ніж PodSecurityPolicy. Зокрема, наступні функції підтримуються за допомогою PodSecurityPolicy, але не за допомогою Pod Security Admission:
Встановлення типових обмежень безпеки — Pod Security Admission є немутуючим контролером допуску, що означає, що він не буде змінювати Podʼи перед їх перевіркою. Якщо ви покладалися на цей аспект PodSecurityPolicy, вам доведеться або модифікувати ваші робочі навантаження, щоб вони відповідали обмеженням безпеки Podʼів, або використовувати Мутуючий вебхук допуску для внесення цих змін. Дивіться Спрощення та стандартизація PodSecurityPolicies нижче для детальнішої інформації.
Докладний контроль над визначенням політики — Pod Security Admission підтримує тільки 3 стандартні рівні. Якщо вам потрібно більше контролю над конкретними обмеженнями, вам доведеться використовувати Вебхук допуску з перевіркою для виконання цих політик.
Деталізація політики на рівні підпросторів імен — PodSecurityPolicy дозволяє вам призначати різні політики різним службовим обліковим записам або користувачам, навіть в межах одного простору імен. Цей підхід має багато підводних каменів і не рекомендується, але якщо вам все одно потрібна ця функція, вам потрібно буде використовувати сторонній вебхук. Виняток становить випадок, коли вам потрібно повністю виключити певних користувачів або RuntimeClasses, у цьому випадку Pod Security Admission все ж надає деякі статичні конфігурації для виключень.
Навіть якщо Pod Security Admission не відповідає всім вашим потребам, він був розроблений для доповнення інших механізмів контролю політики, і може бути корисним допоміжним засобом, який працює нарівно з іншими вебхуками допуску.
1. Перегляньте дозволи простору імен
Pod Security Admission керується мітками в просторах імен. Це означає, що будь-хто, хто може оновлювати (або накладати патчі, або створювати) простір імен, також може змінювати рівень безпеки Podʼів для цього простору імен, що може бути використано для обходу більш обмеженої політики. Перш ніж продовжувати, переконайтеся, що ці дозволи на простір імен мають лише довірені, привілейовані користувачі. Не рекомендується надавати ці могутні дозволи користувачам, які не повинні мати підвищені привілеї, але якщо вам доведеться це зробити, вам потрібно буде використовувати вебхук допуску, щоб накласти додаткові обмеження на встановлення міток безпеки Podʼів на обʼєкти Namespace.
2. Спрощення та стандартизація PodSecurityPolicies
На цьому етапі зменште кількість мутуючих PodSecurityPolicies і видаліть параметри, що виходять за межі Pod Security Standards. Зміни, рекомендовані тут, слід внести в офлайн-копію оригіналу PodSecurityPolicy, який ви змінюєте. Клонована PSP повинна мати іншу назву, яка в алфавітному порядку стоїть перед оригінальною (наприклад, додайте 0 до її назви). Не створюйте нові політики в Kubernetes зараз — це буде розглянуто в розділі Впровадження оновлених політик нижче.
2.а. Видалення явно мутуючих полів
Якщо PodSecurityPolicy змінює Podʼи, то ви можете опинитись з Podʼами, які не відповідають вимогам рівня безпеки Podʼів, коли ви нарешті вимкнете PodSecurityPolicy. Щоб уникнути цього, вам слід усунути всі мутації PSP перед переходом. На жаль, PSP чітко не розділяє мутуючі та валідуючі поля, тому цей перехід не є простим.
.spec.defaultAddCapabilities — хоча це технічно мутуюче і валідуюче поле, його слід обʼєднати з .spec.allowedCapabilities, яке виконує ту саму валідацію без мутації.
Увага:
Видалення цих полів може призвести до відсутності необхідних конфігурацій у робочих навантаженнях і спричинити проблеми. Дивіться Впровадження оновлених політик нижче, щоб отримати поради про те, як безпечно впроваджувати ці зміни.
2.б. Вилучення параметрів, що не підпадають під Pod Security Standards
Існують кілька полів в PodSecurityPolicy, які не входять до складу Pod Security Standards. Якщо вам потрібно забезпечити ці опції, вам доведеться доповнити Pod Security Admission за допомогою вебхуків допуску, що не входить в рамки цього посібника.
Спочатку ви можете видалити явно валідуючі поля, які не охоплюються Pod Security Standards. Ці поля (також перераховані в довіднику Перенесення PodSecurityPolicies у Pod Security Standards з поміткою "no opinion") включають:
.spec.allowedHostPaths
.spec.allowedFlexVolumes
.spec.allowedCSIDrivers
.spec.forbiddenSysctls
.spec.runtimeClass
Ви також можете видалити наступні поля, які стосуються управління групами POSIX / UNIX.
Увага:
Якщо хоча б одне з них використовує стратегію MustRunAs, вони можуть бути мутуючими! Вилучення цих полів може призвести до того, що робочі навантаження не встановлюватимуть необхідні групи та спричинити проблеми. Дивіться Впровадження оновлених політик нижче, щоб отримати поради щодо безпечного впровадження цих змін.
.spec.runAsGroup
.spec.supplementalGroups
.spec.fsGroup
Залишені мутуючі поля потрібні для належної підтримки Pod Security Standards і будуть оброблені в окремому порядку:
.spec.requiredDropCapabilities — Потрібно видалити ALL щоб зробити профіль Restricted.
.spec.seLinux — (Тільки мутуюче з правилом MustRunAs) потрібно для забезпечення вимог SELinux для профілів Baseline & Restricted.
.spec.runAsUser — (Не мутує з правилом RunAsAny) потрібно для забезпечення RunAsNonRoot для профілю Restricted.
.spec.allowPrivilegeEscalation — (Тільки мутується, якщо встановлено false) потрібно для профілю Restricted.
2.в. Впровадження оновлених PSP
Далі ви можете впровадити оновлені політики у ваш кластер. Вам слід діяти обережно, оскільки видалення мутуючих опцій може призвести до того, що робочі навантаження пропустять необхідну конфігурацію.
Для кожної оновленої PodSecurityPolicy:
Визначте, які Podʼи працюють під оригінальною PSP. Це можна зробити за допомогою анотації kubernetes.io/psp. Наприклад, використовуючи kubectl:
PSP_NAME="original"# Встановіть назву PSP, яку ви перевіряєтеkubectl get pods --all-namespaces -o jsonpath="{range .items[?(@.metadata.annotations.kubernetes\.io\/psp=='$PSP_NAME')]}{.metadata.namespace} {.metadata.name}{'\n'}{end}"
Порівняйте ці робочі навантаження з оригінальною специфікацією Podаʼа, щоб визначити, чи змінила PodSecurityPolicy Pod. Для Podʼів, створених за ресурсами робочого навантаження, ви можете порівняти Pod з PodTemplate в ресурсі контролера. Якщо будь-які зміни виявлені, оригінальний Pod або PodTemplate слід оновити з необхідною конфігурацією. Поля для перегляду:
.metadata.annotations['container.apparmor.security.beta.kubernetes.io/*'] (замініть * на назву кожного контейнера)
.spec.runtimeClassName
.spec.securityContext.fsGroup
.spec.securityContext.seccompProfile
.spec.securityContext.seLinuxOptions
.spec.securityContext.supplementalGroups
У контейнерів, під .spec.containers[*] та .spec.initContainers[*]:
.securityContext.allowPrivilegeEscalation
.securityContext.capabilities.add
.securityContext.capabilities.drop
.securityContext.readOnlyRootFilesystem
.securityContext.runAsGroup
.securityContext.runAsNonRoot
.securityContext.runAsUser
.securityContext.seccompProfile
.securityContext.seLinuxOptions
Створіть нові PodSecurityPolicies. Якщо будь-які Roles або ClusterRoles надають use на всі PSP, це може призвести до використання нових PSP замість їх мутуючих аналогів.
Оновіть вашу авторизацію, щоб дозволити доступ до нових PSP. У RBAC це означає оновлення будь-яких Roles або ClusterRoles, які надають дозвіл use на оригінальну PSP, щоб також надати його оновленому PSP.
Перевірте: після деякого часу повторно виконайте команду з кроку 1, щоб переглянути, чи використовуються будь-які Podʼи за оригінальними PSP. Зверніть увагу, що Podʼи повинні бути перестворені після того, як нові політики будуть впроваджені, перш ніж їх можна буде повністю перевірити.
(опціонально) Після того, як ви перевірили, що оригінальні PSP більше не використовуються, ви можете їх видалити.
3. Оновлення просторів імен
Наступні кроки потрібно виконати для кожного простору імен у кластері. Команди, на які посилаються в цих кроках, використовують змінну $NAMESPACE для посилання на простір імен, який оновлюється.
Існує кілька способів вибору рівня безпеки Podʼа для вашого простору імен:
За вимогами безпеки для простору імен — Якщо ви знайомі з очікуваним рівнем доступу для простору імен, ви можете вибрати відповідний рівень, базуючись на цих вимогах, подібно до підходу, який можна застосувати в новому кластері.
За поточними PodSecurityPolicies — Використовуючи довідник Перенесення PodSecurityPolicies у Pod Security Standards, ви можете віднести кожен PSP до рівня стандарту безпеки Podʼа. Якщо ваші PSP не базуються на Pod Security Standards, вам може знадобитися вирішити, обирати рівень, який є принаймні таким же дозвільним, як PSP, або рівень, який є принаймні таким же обмежувальним. Які PSP використовуються для Podʼів у даному просторі імен, ви можете побачити за допомогою цієї команди:
За поточними Podʼами — Використовуючи стратегії з розділу Перевірка рівня безпеки Podʼа, ви можете перевірити рівні Baseline і Restricted, щоб побачити, чи є вони достатньо дозвільними для наявних робочих навантажень, і вибрати найменш привілейований валідний рівень.
Увага:
Опції 2 і 3 вище базуються на поточних Podʼах і можуть не враховувати робочі навантаження, які в цей момент не запущені, такі як CronJobs, робочі навантаження з масштабуванням до нуля або інші робочі навантаження, які ще не були розгорнуті.
3.б. Перевірка рівня безпеки Podʼа
Після того як ви обрали рівень безпеки Podʼа для простору імен (або якщо ви пробуєте кілька), добре було б спершу його протестувати (цей крок можна пропустити, якщо використовується рівень Privileged). Безпека Podʼа включає кілька інструментів для тестування та безпечного впровадження профілів.
Спочатку ви можете виконати пробний запуск політики, який оцінить Podʼи, що вже працюють у просторі імен, відносно застосованої політики, не впроваджуючи нову політику в дію:
# $LEVEL - рівень для пробного запуску, або "baseline", або "restricted".kubectl label --dry-run=server --overwrite ns $NAMESPACE pod-security.kubernetes.io/enforce=$LEVEL
Ця команда поверне попередження для будь-яких наявних Podʼів, які не відповідають запропонованому рівню.
Другий варіант краще підходить для виявлення робочих навантажень, які в цей момент не запущені: режим аудиту. Коли запущено в режимі аудиту (на відміну від примусового впровадження), Podʼи, які порушують рівень політики, реєструються у логах аудиту, які можна переглянути пізніше після деякого часу, але вони не заборонені. Режим попередження працює подібно, але надсилає попередження користувачу негайно. Ви можете встановити рівень аудиту для простору імен за допомогою цієї команди:
Якщо будь-який з цих підходів призведе до несподіваних порушень, вам потрібно буде або оновити робочі навантаження, що їх спричиняють, щоб відповідати вимогам політики, або послабити рівень безпеки простору імен Pod.
3.в. Впровадження рівня безпеки Podʼа
Коли ви переконаєтеся, що обраний рівень може бути безпечно впроваджений для простору імен, ви можете оновити простір імен, щоб впровадити бажаний рівень:
Наостанок, ви можете ефективно оминути PodSecurityPolicy на рівні простору імен, привʼязавши повністю
привілейовану PSP
до всіх службових облікових записів у просторі імен.
# Наступні команди, які виконуються на рівні кластера, потрібні лише один раз.kubectl apply -f privileged-psp.yaml
kubectl create clusterrole privileged-psp --verb use --resource podsecuritypolicies.policy --resource-name privileged
# Вимкнення на рівні простору іменkubectl create -n $NAMESPACE rolebinding disable-psp --clusterrole privileged-psp --group system:serviceaccounts:$NAMESPACE
Оскільки привілейована PSP не є мутуючою, а контролер прийняття рішення PSP завжди віддає перевагу немутуючим PSP, це гарантує, що Podʼи в цьому просторі імен більше не змінюються або не обмежуються PodSecurityPolicy.
Перевага вимкнення PodSecurityPolicy на рівні простору імен полягає в тому, що у разі виникнення проблеми ви можете легко скасувати зміну, видаливши RoleBinding. Просто переконайтеся, що попередньо наявні PodSecurityPolicy все ще застосовуються!
# Скасування вимкнення PodSecurityPolicy.kubectl delete -n $NAMESPACE rolebinding disable-psp
4. Перегляд процесів створення просторів імен
Тепер, коли поточні простори імен оновлено для забезпечення прийняття рішень щодо Pod Security Admission, вам слід переконатися, що ваші процеси та/або політики для створення нових просторів імен оновлено, щоб гарантувати застосування відповідного профілю безпеки Pod для нових просторів імен.
Ви також можете статично налаштувати контролер Pod Security Admission для встановлення типового рівня впровадження, аудиту та/або попередження для просторів імен без міток. Див. Налаштування контролера допуску для отримання додаткової інформації.
5. Вимкнення PodSecurityPolicy
Нарешті, ви готові вимкнути PodSecurityPolicy. Для цього вам потрібно змінити конфігурацію допуску сервера API: Як я можу вимкнути контролер допуску?.
Щоб перевірити, що контролер допуску PodSecurityPolicy більше не активний, ви можете вручну запустити тест, видаючи себе за користувача без доступу до будь-яких PodSecurityPolicies (див. приклад PodSecurityPolicy), або перевірити логи сервера API. При запуску сервер API виводить рядки логу, що перераховують завантажені втулки контролера допуску:
I0218 00:59:44.903329 13 plugins.go:158] Loaded 16 mutating admission controller(s) successfully in the following order: NamespaceLifecycle,LimitRanger,ServiceAccount,NodeRestriction,TaintNodesByCondition,Priority,DefaultTolerationSeconds,ExtendedResourceToleration,PersistentVolumeLabel,DefaultStorageClass,StorageObjectInUseProtection,RuntimeClass,DefaultIngressClass,MutatingAdmissionWebhook.
I0218 00:59:44.903350 13 plugins.go:161] Loaded 14 validating admission controller(s) successfully in the following order: LimitRanger,ServiceAccount,PodSecurity,Priority,PersistentVolumeClaimResize,RuntimeClass,CertificateApproval,CertificateSigning,CertificateSubjectRestriction,DenyServiceExternalIPs,ValidatingAdmissionWebhook,ResourceQuota.
Ви маєте побачити PodSecurity (у списку контролерів допуску для перевірки валідності), і жоден зі списків не повинен містити PodSecurityPolicy.
Після того, як ви впевнені, що контролер допуску PSP вимкнуто (і після достатнього часу, щоб бути впевненим, що вам не потрібно буде відкочувати зміни), ви вільні видалити ваші PodSecurityPolicies та будь-які повʼязані Roles, ClusterRoles, RoleBindings та ClusterRoleBindings (просто переконайтеся, що вони не надають будь-яких інших неповʼязаних дозволів).
4 - Моніторинг, логування та налагодження
Налаштуйте моніторинг та логування для розвʼязання проблем кластера або налагодження контейнеризованих застосунків.
Іноді трапляються неприємності. Цей посібник допоможе вам зібрати необхідну інформацію та вирішити проблеми. Він складається з чотирьох розділів:
Налагодження вашого застосунку — корисно для користувачів, які розгортають код у Kubernetes та цікавляться причиною його непрацездатності.
Налагодження вашого кластера — корисно для адміністраторів кластерів та людей, чиї кластери Kubernetes не перебувають у найкращому стані.
Логи в Kubernetes — Корисно для адміністраторів кластерів, які хочуть налаштувати та керувати логами у Kubernetes.
Моніторинг в Kubernetes — Корисно для адміністраторів кластерів, які хочуть увімкнути моніторинг у кластері Kubernetes.
Вам також слід перевірити відомі проблеми для випуску, який ви використовуєте.
Отримання допомоги
Якщо вашу проблему не вдається вирішити жодною з інструкцій вище, існує ряд способів, як отримати допомогу від спільноти Kubernetes.
Питання
Документація на цьому сайті структурована таким чином, щоб надавати відповіді на широкий спектр питань. Концепції пояснюють архітектуру Kubernetes та роботу кожного компонента, в той час, як Налаштування надає практичні інструкції для початку роботи. Завдання показують, як виконати широке коло завдань, а Посібники — це більш комплексні огляди сценаріїв реального життя, специфічних для галузей або розробки з початку до кінця. Розділ Довідник надає детальну документацію з API Kubernetes та інтерфейсів командного рядка (CLI), таких як kubectl.
Допоможіть! Моє питання не розглянуто! Мені потрібна допомога зараз!
Stack Exchange, Stack Overflow або Server Fault
Якщо у вас є питання, повʼязане з розробкою програмного забезпечення для вашого контейнеризованого застосунку, ви можете задати його на Stack Overflow.
Якщо у вас є питання про Kubernetes, повʼязані з управлінням кластером або конфігурацією, ви можете задати їх на Server Fault.
Також існують кілька більш конкретних сайтів мережі Stack Exchange, які можуть бути відповідним місцем для питань про Kubernetes в таких областях, як DevOps, Software Engineering або InfoSec.
Хтось зі спільноти може вже ставив схоже питання або може допомогти з вашою проблемою.
Команда Kubernetes також слідкуватиме за постами з теґом Kubernetes. Якщо немає наявних питань, які можуть допомогти, будь ласка, переконайтеся, що ваше питання відповідає правилам Stack Overflow, Server Fault або сайту мережі Stack Exchange, на якому ви його ставите, і ознайомтеся з інструкцією як поставити нове питання, перед тим як задавати нове!
Slack
Багато людей зі спільноти Kubernetes збираються у Kubernetes Slack в каналі #kubernetes-users. Slack вимагає реєстрації; ви можете запросити запрошення, і реєстрація відкрита для всіх). Запрошуємо приходити та ставити будь-які питання. Після реєстрації ви отримайте доступ до організації Kubernetes у Slack у вебоглядачі або в застосунку Slack.
Після реєстрації переглядайте список каналів для різних тем. Наприклад, люди, які тільки вчаться Kubernetes, також можуть приєднатися до каналу #kubernetes-novice. Як ще один приклад, розробникам корисно приєднатися до каналу #kubernetes-contributors.
Також існують багато каналів, специфічних для країн / мов. Запрошуємо приєднатися до цих каналів для локалізованої підтримки та інформації:
Якщо у вас є ознаки помилки або ви хочете подати запит на новий функціонал, будь ласка, скористайтесь тікетами GitHub.
Перед тим як створити тікет, будь ласка, перегляньте наявні проблеми, щоб переконатися, чи є вже вирішення для вашої проблеми.
Якщо ви подаєте звіт про помилку, будь ласка, включіть детальні відомості про те, як відтворити проблему, таку як:
Версія Kubernetes: kubectl version
Хмарний провайдер, дистрибутив ОС, конфігурація мережі та версія оточення виконання контейнерів
Кроки для відтворення проблеми
4.1 - Логи в Kubernetes
Архітектура журналювання та системні логи.
Ця сторінка надає ресурси, які описують журналювання в Kubernetes. Ви можете дізнатися, як збирати, отримувати доступ і аналізувати логи за допомогою вбудованих інструментів і популярних стеків журналювання:
Ця сторінка надає ресурси, які описують моніторинг в Kubernetes. Ви можете дізнатися, як збирати системні метрики та трасування для компонентів системи Kubernetes:
Виправлення загальних проблем з контейнеризованими застосунками.
Цей розділ містить набір ресурсів для виправлення проблем з контейнеризованими застосунками. Він охоплює такі речі, як загальні проблеми з ресурсами Kubernetes (наприклад, Pods, Services або StatefulSets), поради щодо розуміння повідомлень про припинення роботи контейнера та способи налагодження запущених контейнерів.
4.3.1 - Налагодження Podʼів
Цей посібник допоможе користувачам налагодити програми, які розгорнуті у Kubernetes та які поводяться некоректно. Це не настанова для людей, які хочуть налагоджувати свій кластер. Для цього вам слід ознайомитися з цим посібником.
Діагностика проблеми
Перший крок у розвʼязанні проблем — перевірка. Що сталося? Проблема у ваших Podʼах, Контролері Реплікацій чи Service?
Перший крок у налагоджені Podʼа — це його перевірка. Перевірте поточний стан Podʼа та останні події за допомогою наступної команди:
kubectl describe pods ${POD_NAME}
Огляньте стан контейнерів у Podʼі. Чи всі вони Running (працюють)? Чи були нещодавні перезапуски?
Продовжуйте налагодження, виходячи зі стану Podʼів.
Мій Pod залишається в стані Pending
Якщо Pod застряг у стані Pending, це означає, що його не можна запланувати на вузол. Зазвичай це відбувається через недостатні ресурси одного типу чи іншого, які заважають плануванню. Подивіться на вивід команди kubectl describe ... вище. Там мають бути повідомлення від планувальника про причини, чому він не може запланувати ваш Pod. Причини включають:
У вас недостатньо ресурсів: Можливо, ви вичерпали запас CPU або памʼяті у вашому кластері, у цьому випадку вам потрібно видалити Podʼи, налаштувати запити на ресурси, або додати нові вузли до вашого кластера. Дивіться документ про обчислювальні ресурси для отримання додаткової інформації.
Ви використовуєте hostPort: Коли ви привʼязуєте Pod до hostPort, існує обмежена кількість місць, де можна запланувати цей Pod. У більшості випадків, hostPort не є необхідним, спробуйте використати обʼєкт Service для відкриття доступу вашому Podʼу. Якщо вам все ж потрібен hostPort, то ви можете запланувати лише стільки Podʼів, скільки у вас вузлів у кластері Kubernetes.
Мій Pod залишається у стані Waiting
Якщо Pod застряг у стані Waiting, то він був запланований на робочий вузол, але не може працювати на цій машині. Знову ж таки, вивід команди kubectl describe ... має бути інформативним. Найпоширенішою причиною Podʼів у стані Waiting є неможливість завантаження образу. Тут є три речі, які потрібно перевірити:
Переконайтеся, що ви правильно вказали імʼя образу.
Чи ви завантажили образ у реєстр?
Спробуйте вручну завантажити образ, щоб перевірити, чи можна його завантажити. Наприклад, якщо ви використовуєте Docker на вашому ПК, виконайте docker pull <image>.
Мій Pod залишається у стані Terminating
Якщо Pod застряг у стані Terminating (завершення), це означає, що було видано наказ про видалення Podʼа, але панель управління не може видалити обʼєкт Pod.
Це зазвичай відбувається, якщо у Podʼа є завершувач та встановлений вубхук допуску у кластері, який перешкоджає панелі управління видалити завершувач.
Щоб виявити цей сценарій, перевірте, чи у вашому кластері є вебхуки ValidatingWebhookConfiguration або MutatingWebhookConfiguration, які спрямовані на операції UPDATE для ресурсів pods.
Якщо вебхук надається стороннім постачальником:
Переконайтеся, що ви використовуєте останню версію.
Вимкніть вебхук для операцій UPDATE.
Повідомте про проблему відповідного постачальника.
Якщо ви є автором вебхуку:
Для мутуючого вебхуку переконайтеся, що він ніколи не змінює незмінні поля під час операцій UPDATE. Наприклад, зміни контейнерів зазвичай не дозволяються.
Для перевірки вебхуку переконайтеся, що ваші політики валідації застосовуються лише до нових змін. Іншими словами, ви повинні дозволяти Podʼам з наявними порушеннями пройти валідацію. Це дозволяє Podʼам, які були створені до встановлення вебхуку валідації, продовжувати працювати.
Мій Pod виходить з ладу або несправний іншим чином
Мій Pod працює, але не робить те, що я йому сказав робити
Якщо ваш Pod не поводиться так, як ви очікували, це може бути повʼязано з помилкою у вашому описі Podʼа (наприклад, файл mypod.yaml на вашому локальному компʼютері), і цю помилку було мовчки проігноровано під час створення Podʼа. Часто розділ опису Podʼа вкладено неправильно, або імʼя ключа набрано неправильно, і тому ключ ігнорується. Наприклад, якщо ви помилилися в написанні command як commnd, тоді Pod буде створено, але не використовуватиме командний рядок, який ви планували.
Перша річ, яку варто зробити, — видалити свій Pod і спробувати створити його знову з опцією --validate. Наприклад, виконайте kubectl apply --validate -f mypod.yaml. Якщо ви помилилися в написанні command як commnd, то отримаєте помилку на кшталт цієї:
I0805 10:43:25.129850 46757 schema.go:126] unknown field: commnd
I0805 10:43:25.129973 46757 schema.go:129] this may be a false alarm, see https://github.com/kubernetes/kubernetes/issues/6842
pods/mypod
Наступне, що варто перевірити, — чи збігається Pod на апісервері з Podʼом, який ви збиралися створити (наприклад, у файлі YAML на вашому локальному компʼютері). Наприклад, виконайте kubectl get pods/mypod -o yaml > mypod-on-apiserver.yaml а потім вручну порівняйте оригінальний опис Podʼа, mypod.yaml, з тим, який ви отримали з апісервера, mypod-on-apiserver.yaml. Зазвичай деякі рядки в версії "апісервера" відсутні в оригінальній версії. Це очікувано. Однак, якщо є рядки в оригінальному описі, яких немає в версії апісервера, то це може свідчити про проблему з вашими специфікаціями Podʼа.
Налагодження Контролерів Реплікацій
Контролери реплікацій досить прості. Вони можуть або створювати Podʼи, або не можуть. Якщо вони не можуть створювати Podʼи, будь ласка, зверніться до інструкцій вище, щоб налагодити ваші Podʼи.
Ви також можете використовувати kubectl describe rc ${CONTROLLER_NAME} для вивчення подій, що стосуються контролера реплікацій.
Налагодження Serviceʼів
Serviceʼи забезпечують балансування навантаження між набором Podʼів. Є кілька загальних проблем, які можуть призвести до неправильної роботи Serviceʼів. Наступні інструкції допоможуть дослідити проблеми з Serviceʼами.
Спочатку перевірте, що для Service є точки доступу. Для кожного обʼєкта Service апісервер робить доступними один чи більше ресурсів EndpointSlice.
Ви можете переглянути ці ресурси за допомогою:
kubectl get endpointslices -l kubernetes.io/service-name=${SERVICE_NAME}
Переконайтеся, що точки доступу в EndpointSlices відповідають кількості Podʼів, які ви очікуєте бачити в складі вашого Service. Наприклад, якщо ваш Service для контейнера nginx має 3 репліки, ви очікуєте побачити три різних IP-адреси у зразах точок доступу Serviceʼу.
Мій Service відсутні точки доступу
Якщо вам не вистачає точок доступу, спробуйте передивитись перелік Podʼів за допомогою міток, які використовує Service. Уявіть, що у вас є Service, де є такі мітки:
...spec:- selector:name:nginxtype:frontend
Ви можете використовувати:
kubectl get pods --selector=name=nginx,type=frontend
щоб отримати перелік Podʼів, які відповідають цьому селектору. Перевірте, чи список відповідає Podʼам, які ви очікуєте бачити у вашому Service. Перевірте, чи containerPort Podʼа відповідає targetPort Serviceʼа.
Якщо жоден із вищезазначених методів не розвʼязує вашу проблему, слідкуйте інструкціям у документі про налагодження Serviceʼу щоб переконатися, що ваш Service працює, має Endpoints, і ваші Podʼи фактично обслуговуються; DNS працює, встановлені правила iptables, і kube-proxy поводиться відповідно.
Досить часто виникає проблема в нових інсталяціях Kubernetes, коли Service не працює належним чином. Ви запустили свої Podʼи за допомогою Deployment (або іншого контролера робочих навантажень) і створили Service, але не отримуєте відповіді при спробі отримати до нього доступ. Цей документ, сподіваємось, допоможе вам зрозуміти, що йде не так.
Виконання команд у Podʼі
Для багатьох кроків ви захочете побачити, що бачить Pod, який працює в кластері. Найпростіший спосіб зробити це — запустити інтерактивний Pod busybox:
kubectl run -it --rm --restart=Never busybox --image=gcr.io/google-containers/busybox sh
Примітка:
Якщо ви не бачите командний рядок, спробуйте натиснути enter.
Якщо у вас вже є Pod, який ви хочете використовувати для цього, ви можете виконати команду у ньому за допомогою:
Для цілей цього огляду запустімо кілька Podʼів. Оскільки ви, швидше за все, налагоджуєте власний Service, ви можете використати свої власні дані, або ви можете слідувати разом із нами та отримати інші дані.
За допомогою kubectl create deployment в значення мітки "app" автоматично встановлюється імʼя Deployment.
Ви можете підтвердити, що ваші Podʼи працюють:
kubectl get pods -l app=hostnames
NAME READY STATUS RESTARTS AGE
hostnames-632524106-bbpiw 1/1 Running 0 2m
hostnames-632524106-ly40y 1/1 Running 0 2m
hostnames-632524106-tlaok 1/1 Running 0 2m
Ви також можете підтвердити, що ваші Podʼи обслуговуються. Ви можете отримати список IP-адрес Podʼів та протестувати їх безпосередньо.
kubectl get pods -l app=hostnames \
-o go-template='{{range .items}}{{.status.podIP}}{{"\n"}}{{end}}'
10.244.0.5
10.244.0.6
10.244.0.7
Приклад контейнера, використаного для цього огляду, обслуговує своє власне імʼя хосту через HTTP на порті 9376, але якщо ви налагоджуєте свій власний застосунок, вам потрібно буде використовувати номер порту, на якому слухають ваші Podʼи.
З середини Podʼа:
for ep in 10.244.0.5:9376 10.244.0.6:9376 10.244.0.7:9376; do wget -qO- $epdone
Якщо ви не отримуєте очікувані відповіді на цьому етапі, ваші Pod\и можуть бути несправними або можуть не прослуховувати порт, який ви вважаєте. Можливо, kubectl logs буде корисним для перегляду того, що відбувається, або, можливо, вам потрібно буде виконати kubectl exec безпосередньо у вашому Podʼі та робити налагодження звідти.
Якщо все пройшло згідно з планом до цього моменту, ви можете почати розслідування того, чому ваш Service не працює.
Чи Service існує?
Уважний читач може зауважити, що ви фактично ще не створили Service — це навмисно. Це крок, який іноді забувають, і це перше, що треба перевірити.
Що станеться, якщо ви спробуєте отримати доступ до Service, що не існує? Якщо у вас є інший Pod, який використовує цей Service за іменем, ви отримаєте щось на зразок:
wget -O- hostnames
Resolving hostnames (hostnames)... failed: Name or service not known.
wget: unable to resolve host address 'hostnames'
Перше, що треба перевірити — це чи насправді існує цей Service:
kubectl get svc hostnames
No resources found.
Error from server (NotFound): services "hostnames" not found
Створімо Service. Як і раніше, це для цього огляду — ви можете використовувати свої власні дані Service тут.
Щоб підкреслити повний спектр налаштувань, Service, який ви створили тут, використовує інший номер порту, ніж Podʼи. Для багатьох реальних Serviceʼів ці значення можуть бути однаковими.
Чи впливають будь-які правила Network Policy Ingress на цільові Podʼи?
Якщо ви розгорнули будь-які правила Network Policy Ingress, які можуть вплинути на вхідний трафік до hostnames-* Pod, їх потрібно переглянути.
Будь ласка, зверніться до Мережевих політик для отримання додаткових відомостей.
Чи працює Service за DNS-іменем?
Один із найпоширеніших способів, яким клієнти використовують Service, — це через DNS-імʼя.
Якщо це не вдається, можливо, ваш Pod і Service знаходяться в різних Namespace, спробуйте використати імʼя з Namespace (знову ж таки, зсередини Podʼа):
Якщо це працює, вам потрібно налаштувати свій застосунок на використання імені, яке входить у Namespace, або запустіть ваш застосунок та Service в тому ж Namespace. Якщо це все ще не працює, спробуйте повне імʼя:
Зверніть увагу на суфікс тут: "default.svc.cluster.local". "default" — це Namespace, в якому ви працюєте. "svc" позначає, що це Service. "cluster.local" — це ваш домен кластера, який МОЖЕ відрізнятися у вашому власному кластері.
Ви також можете спробувати це з вузла в кластері:
Примітка:
10.0.0.10 - це IP-адреса Service DNS кластера, ваша може бути іншою.
Якщо ви можете зробити пошук повного імені, але не відноснлшл, вам потрібно перевірити, чи правильний ваш файл /etc/resolv.conf в Podʼі. Зсередини Podʼа:
Рядок nameserver повинен вказувати на Service DNS вашого кластера. Це передається в kubelet з прапорцем --cluster-dns.
Рядок search повинен включати відповідний суфікс, щоб ви змогли знайти імʼя Serviceʼу. У цьому випадку він шукає Serviceʼи в локальному Namespace ("default.svc.cluster.local"), Serviceʼи у всіх Namespace ("svc.cluster.local"), і наостанок для імен в кластері ("cluster.local"). Залежно від вашого власного налаштування, у вас можуть бути додаткові записи після цього (до 6 загалом). Суфікс кластера передається в kubelet з прапорцем --cluster-domain. У цьому документі передбачається, що суфікс кластера — "cluster.local". У ваших власних кластерах це може бути налаштовано по-іншому, у такому випадку вам слід змінити це в усіх попередніх командах.
Чи працює будь-який Service за допомогою DNS-імені?
Якщо вищезазначене все ще не працює, DNS-запити не працюють для вашого Service. Ви можете зробити крок назад і побачити, що ще не працює. Service майстра Kubernetes повинен завжди працювати. Зсередини Podʼа:
Якщо це не вдається, будь ласка, перегляньте розділ kube-proxy цього документа, або навіть поверніться до початку цього документа і почніть знову, але замість налагодження вашого власного Service, спробуйте Service DNS.
Чи працює Service за IP?
Припускаючи, що ви підтвердили, що DNS працює, наступне, що варто перевірити, — це чи ваш Service працює за його IP-адресою. З Podʼа в вашому кластері, зверніться до IP-адреси Service (з вищезазначеного виводу kubectl get).
for i in $(seq 1 3); do wget -qO- 10.0.1.175:80
done
Якщо ваш Service працює, ви повинні отримати правильні відповіді. Якщо ні, існує кілька можливих причин, через які це може не працювати. Дивіться далі.
Чи правильно визначений Service?
Це може звучати дивно, але ви справді повинні подеколи перевірити, що ваш Service вірний і відповідає порту вашого Podʼа. Перегляньте свій Service і перевірте його:
Чи вказано порт Serviceʼу, який ви намагаєтеся отримати доступ в spec.ports[]?
Чи правильний targetPort для ваших Podʼів (деякі Podʼи використовують інший порт, ніж Service)?
Якщо ви мали на увазі використання числового порту, це число (9376) чи рядок "9376"?
Якщо ви мали на увазі використання порту за іменем, чи ваші Podʼи використовують порт з тим самим імʼям?
Чи правильний протокол порту для ваших Podʼів?
Чи має Service будь-які EndpointSlices?
Якщо ви дійшли до цього пункту, ви підтвердили, що ваш Service правильно визначений і його можна знайти через DNS. Тепер перевірмо, що Podʼи, які ви запустили, фактично вибираються Serviceʼом.
Раніше ви бачили, що Podʼи працюють. Ви можете перевірити це ще раз:
kubectl get pods -l app=hostnames
NAME READY STATUS RESTARTS AGE
hostnames-632524106-bbpiw 1/1 Running 0 1h
hostnames-632524106-ly40y 1/1 Running 0 1h
hostnames-632524106-tlaok 1/1 Running 0 1h
Аргумент -l app=hostnames — це селектор міток, налаштований у Service.
Стовпець "AGE" вказує, що ці Podʼи працюють добре і не мали збоїв.
Стовпець "RESTARTS" вказує, що ці Podʼи не часто мають збої або не перезавантажуються. Часті перезапуски можуть призвести до періодичних проблем зі зʼєднанням. Якщо кількість перезапусків висока, прочитайте більше про те, як налагоджувати Podʼи.
У межах системи Kubernetes є цикл керування, який оцінює селектор кожного Service і зберігає результати до одного чи більше обʼєктів EndpointSlice.
kubectl get endpointslices -l k8s.io/service-name=hostnames
NAME ADDRESSTYPE PORTS ENDPOINTS
hostnames-ytpni IPv4 9376 10.244.0.5,10.244.0.6,10.244.0.7
Це підтверджує, що контролер EndpointSlice знайшов правильні Podʼи для вашого Service. Якщо стовпець ENDPOINTS має значення <none>, вам слід перевірити, що поле spec.selector вашого Service дійсно вибирає значення metadata.labels у ваших Podʼах. Частою помилкою є наявність хибодруку або іншої помилки, наприклад, Service вибирає app=hostnames, але Deployment вказує run=hostnames, як у версіях до 1.18, де команда kubectl run також могла бути використана для створення Deployment.
Чи працюють Podʼи?
На цьому етапі ви знаєте, що ваш Service існує і вибрав ваші Podʼи. На початку цього кроку ви перевірили самі Podʼи. Давайте ще раз перевіримо, що Podʼи дійсно працюють — ви можете оминути механізм Service і звернутися безпосередньо до Podʼів, які вказані в Endpoints вище.
Примітка:
Ці команди використовують порт Podʼа (9376), а не порт Service (80).
З середини Podʼа:
for ep in 10.244.0.5:9376 10.244.0.6:9376 10.244.0.7:9376; do wget -qO- $epdone
Ви очікуєте, що кожний Pod в списку endpoints поверне свій власний hostname. Якщо це не те, що відбувається (або будь-яка інша правильна поведінка для ваших власних Podʼів), вам слід дослідити, що відбувається там.
Чи працює kube-proxy?
Якщо ви дісталися до цього моменту, ваш Service працює, має EndpointSlices, і ваші Podʼи фактично обслуговують запити. На цьому етапі увесь механізм проксі Service під підозрою. Підтвердьмо це крок за кроком.
Стандартна реалізація Service, і та, яка використовується в більшості кластерів, — це kube-proxy. Це програма, яка працює на кожному вузлі і конфігурує один з невеликого набору механізмів для надання абстракції Service. Якщо ваш кластер не використовує kube-proxy, наступні розділи не застосовуються, і вам доведеться дослідити будь-яку реалізацію Service, яку ви використовуєте.
Чи запущено kube-proxy?
Підтвердіть, що kube-proxy працює на ваших Вузлах. Запустіть команду безпосередньо на Вузлі, і ви повинні побачити щось на зразок такого:
Далі переконайтесь, що він не має явних проблем, таких як неможливість звʼязатися з майстром. Для цього вам доведеться переглянути логи. Доступ до логів залежить від вашої ОС Вузла. На деяких ОС це файл, наприклад /var/log/kube-proxy.log, тоді як на інших ОС використовується journalctl для доступу до логів. Ви повинні побачити щось на зразок:
I1027 22:14:53.995134 5063 server.go:200] Running in resource-only container "/kube-proxy"
I1027 22:14:53.998163 5063 server.go:247] Using iptables Proxier.
I1027 22:14:54.038140 5063 proxier.go:352] Setting endpoints for "kube-system/kube-dns:dns-tcp" to [10.244.1.3:53]
I1027 22:14:54.038164 5063 proxier.go:352] Setting endpoints for "kube-system/kube-dns:dns" to [10.244.1.3:53]
I1027 22:14:54.038209 5063 proxier.go:352] Setting endpoints for "default/kubernetes:https" to [10.240.0.2:443]
I1027 22:14:54.038238 5063 proxier.go:429] Not syncing iptables until Services and Endpoints have been received from master
I1027 22:14:54.040048 5063 proxier.go:294] Adding new service "default/kubernetes:https" at 10.0.0.1:443/TCP
I1027 22:14:54.040154 5063 proxier.go:294] Adding new service "kube-system/kube-dns:dns" at 10.0.0.10:53/UDP
I1027 22:14:54.040223 5063 proxier.go:294] Adding new service "kube-system/kube-dns:dns-tcp" at 10.0.0.10:53/TCP
Якщо ви бачите повідомлення про помилки щодо неможливості звʼязатися з майстром, вам слід перевірити конфігурацію і кроки інсталяції вашого Вузла.
Kube-proxy може працювати в одному з декількох режимів. У вищенаведеному журналі рядок Using iptables Proxier вказує на те, що kube-proxy працює в режимі "iptables". Ще один поширений режим — "ipvs".
Режим iptables
У режимі "iptables" ви повинні побачити щось на зразок наступного на Вузлі:
iptables-save | grep hostnames
-A KUBE-SEP-57KPRZ3JQVENLNBR -s 10.244.3.6/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-57KPRZ3JQVENLNBR -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.3.6:9376
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -s 10.244.1.7/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.1.7:9376
-A KUBE-SEP-X3P2623AGDH6CDF3 -s 10.244.2.3/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-X3P2623AGDH6CDF3 -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.2.3:9376
-A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames: cluster IP" -m tcp --dport 80 -j KUBE-SVC-NWV5X2332I4OT4T3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2IHDGP2BOBGZ
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-X3P2623AGDH6CDF3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -j KUBE-SEP-57KPRZ3JQVENLNBR
Для кожного порту кожного Service повинно бути 1 правило у KUBE-SERVICES і один ланцюжок KUBE-SVC-<хеш>. Для кожного endpoint Podʼа повинна бути невелика кількість правил у цьому KUBE-SVC-<хеш> і один ланцюжок KUBE-SEP-<хеш> з невеликою кількістю правил. Точні правила будуть варіюватися залежно від вашої конфігурації (включаючи порти вузлів та балансувальники навантаження).
Режим IPVS
У режимі "ipvs" ви повинні побачити щось на зразок наступного на Вузлі:
Для кожного порту кожного Service, плюс будь-які NodePorts, зовнішні IP-адреси та IP-адреси балансувальника навантаження, kube-proxy створить віртуальний сервер. Для кожного endpoint Podʼа він створить відповідні реальні сервери. У цьому прикладі служба hostnames(10.0.1.175:80) має 3 endpoint (10.244.0.5:9376, 10.244.0.6:9376, 10.244.0.7:9376).
Чи kube-proxy керує трафіком?
Якщо ви бачите один із вищезазначених випадків, спробуйте ще раз отримати доступ до вашого Service за допомогою IP з одного з ваших Вузлів:
curl 10.0.1.175:80
hostnames-632524106-bbpiw
Якщо це все ще не вдається, перегляньте логи kube-proxy на наявність конкретних рядків, подібних до:
Setting endpoints for default/hostnames:default to [10.244.0.5:9376 10.244.0.6:9376 10.244.0.7:9376]
Якщо ви не бачите цього, спробуйте перезапустити kube-proxy з прапорцем -v, встановленим на 4, і потім знову перегляньте логи.
Крайній випадок: Pod не може звернутися до себе за допомогою IP-адреси Service
Це може здатися малоймовірним, але це може трапитися і має працювати.
Це може статися, коли мережа не належним чином налаштована для "зачісування" трафіку, зазвичай коли kube-proxy працює в режимі iptables, а Podʼи підключені за допомогою мережі bridge. Kubelet надає прапорецьhairpin-mode, який дозволяє точкам доступу Service балансувати навантаження поверненням до себе, якщо вони намагаються отримати доступ до своєї власної VIP-адреси Service. Прапорець hairpin-mode має бути встановлено на значення hairpin-veth або promiscuous-bridge.
Загальні кроки для розвʼязання цього випадку мають бути такими:
Підтвердіть, що hairpin-mode встановлено у значення hairpin-veth або promiscuous-bridge. Можливий вигляд нижченаведеного. У наступному прикладі hairpin-mode встановлено на promiscuous-bridge.
Підтвердіть поточний hairpin-mode. Для цього вам потрібно переглянути логи kubelet. Доступ до логів залежить від вашої операційної системи. На деяких ОС це файл, наприклад /var/log/kubelet.log, тоді як на інших ОС використовується journalctl для доступу до логів. Зверніть увагу, що поточний режим hairpin може не відповідати прапорцю --hairpin-mode через сумісність. Перевірте, чи є будь-які рядки в лозі з ключовим словом hairpin в kubelet.log. Повинні бути рядки в лозі, які показують поточний режим hairpin, схожі на наступне:
I0629 00:51:43.648698 3252 kubelet.go:380] Hairpin mode set to "promiscuous-bridge"
Якщо поточний режим hairpin — hairpin-veth, переконайтеся, що Kubelet має дозвіл на роботу в /sys на вузлі. Якщо все працює належним чином, ви побачите щось на зразок:
for intf in /sys/devices/virtual/net/cbr0/brif/*; do cat $intf/hairpin_mode; done
1
1
1
1
Якщо поточний режим hairpin — promiscuous-bridge, переконайтеся, що Kubelet має дозвіл на маніпулювання bridge в Linux на вузлі. Якщо bridge cbr0 використовується і налаштований належним чином, ви побачите:
ifconfig cbr0 |grep PROMISC
UP BROADCAST RUNNING PROMISC MULTICAST MTU:1460 Metric:1
Зверніться за допомогою, якщо жоден з вищезазначених методів не працює.
Пошук допомоги
Якщо ви дійшли до цього моменту, відбувається щось дуже дивне. Ваш Service працює, має EndpointSlices, і ваші Podʼи насправді обслуговують запити. DNS працює, і kube-proxy схоже не діє неправильно. Проте ваш Service не працює. Будь ласка, дайте нам знати, що відбувається, щоб ми могли допомогти вам розслідувати цю проблему!
Ця задача показує, як усувати несправності у StatefulSet.
Перш ніж ви розпочнете
Вам потрібен кластер Kubernetes, та інструмент командного рядка kubectl повинен бути налаштований на звʼязок з вашим кластером.
Ви повинні мати запущений StatefulSet, який ви хочете дослідити.
Усунення несправностей у StatefulSet
Для того, щоб переглянути всі Podʼи, які належать до StatefulSet і мають мітку app.kubernetes.io/name=MyApp на них, ви можете використовувати наступне:
kubectl get pods -l app.kubernetes.io/name=MyApp
Якщо ви помітили, що будь-які Podʼи вказані у стані Unknown або Terminating протягом тривалого періоду часу, зверніться до завдання Видалення Podʼів StatefulSet за інструкціями щодо дії з ними. Ви можете усувати несправності окремих Podʼів у StatefulSet, використовуючи Посібник з усунення несправностей Podʼів.
Ця сторінка показує, як записувати та читати повідомлення про припинення роботи контейнера.
Повідомлення про припинення роботи надають можливість контейнерам записувати інформацію про фатальні події у місце, звідки її можна легко витягти та показувати за допомогою інструментів, таких як інформаційні панелі та програмне забезпечення моніторингу. У більшості випадків інформацію, яку ви вводите у повідомлення про припинення роботи, також слід записати в логи Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У файлі YAML у полях command та args ви можете побачити, що контейнер перебуває в стані очікування (спить) протягом 10 секунд, а потім записує "Sleep expired" у файл /dev/termination-log. Після того, як контейнер записує повідомлення "Sleep expired", він завершує роботу.
Покажіть інформацію про Pod:
kubectl get pod termination-demo
Повторіть попередню команду, доки Pod більше не буде запущений.
Використовуйте шаблон Go для фільтрування виводу так, щоб він містив лише повідомлення про припинення роботи контейнера:
kubectl get pod termination-demo -o go-template="{{range .status.containerStatuses}}{{.lastState.terminated.message}}{{end}}"
Якщо у вас працює багатоконтейнерний Pod, ви можете використовувати шаблон Go, щоб включити імʼя контейнера. Таким чином, ви можете визначити, який з контейнерів несправний:
kubectl get pod multi-container-pod -o go-template='{{range .status.containerStatuses}}{{printf "%s:\n%s\n\n" .name .lastState.terminated.message}}{{end}}'
Налаштування повідомлення про припинення роботи
Kubernetes отримує повідомлення про припинення роботи з файлу повідомлення, вказаного в полі terminationMessagePath контейнера, яке має стандартне значення /dev/termination-log. Налаштувавши це поле, ви можете сказати Kubernetes використовувати інший файл. Kubernetes використовує вміст зазначеного файлу для заповнення повідомлення про стан контейнера як у випадку успіху, так і невдачі.
Повідомлення про припинення має бути коротким остаточним статусом, таким як повідомлення про помилку твердження. Kubelet обрізає повідомлення, які довше 4096 байтів.
Загальна довжина повідомлення по всіх контейнерах обмежена 12KiB і рівномірно розподілена між всіма контейнерами. Наприклад, якщо є 12 контейнерів (initContainers або containers), кожен має 1024 байти доступного простору для повідомлень про припинення роботи.
Стандартний шлях для повідомлення про припинення роботи — /dev/termination-log. Ви не можете встановити шлях повідомлення про припинення роботи після запуску Podʼа.
У наступному прикладі контейнер записує повідомлення про завершення в /tmp/my-log для отримання Kubernetes:
Крім того, користувачі можуть налаштувати поле terminationMessagePolicy контейнера для подальшої настройки. Типово це поле встановлене на "File", що означає, що повідомлення про припинення роботи отримуються лише з файлу повідомлення про припинення роботи. Встановивши terminationMessagePolicy на "FallbackToLogsOnError", ви можете вказати Kubernetes використовувати останній фрагмент виводу контейнера, якщо файл повідомлення про припинення роботи порожній, і контейнер завершився з помилкою. Вивід логу обмежується 2048 байтами або 80 рядками, якщо вибірка менша.
Що далі
Перегляньте поле terminationMessagePath в Контейнері.
Ця сторінка показує, як розвʼязувати проблеми, повʼязані з запуском контейнерів ініціалізації. Приклади команд нижче вказують на Pod як <pod-name> та на контейнери ініціалізації як <init-container-1> та <init-container-2>.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Ви також можете отримувати доступ до статусів контейнерів ініціалізації програмно, читаючи поле status.initContainerStatuses у Pod Spec:
kubectl get pod <pod-name> --template '{{.status.initContainerStatuses}}'
Ця команда поверне ту саму інформацію, що й вище, відформатовану за допомогою Go template.
Отримання логів з контейнерів ініціалізації
Вкажіть імʼя контейнера ініціалізації разом з імʼям Podʼа, щоб отримати його логи.
kubectl logs <pod-name> -c <init-container-2>
Контейнери ініціалізації, що виконують скрипт оболонки, друкують команди в міру їх виконання. Наприклад, це можна зробити в Bash, запустивши set -x на початку скрипта.
Розуміння статусів Podʼа
Статус Podʼа, що починається з Init:, узагальнює стан виконання контейнерів ініціалізації. У таблиці нижче наведено деякі приклади значень статусу, які ви можете бачити під час налагодження контейнерів ініціалізації.
Статус
Значення
Init:N/M
Pod має M контейнерів ініціалізації, і N вже завершено.
Init:Error
Контейнер ініціалізації не вдалося виконати.
Init:CrashLoopBackOff
Контейнер ініціалізації неперервно виходить з ладу.
Pending
Pod ще не розпочав виконувати контейнер ініціалізації.
PodInitializing або Running
Pod вже завершив виконання контейнерів ініціалізації.
4.3.6 - Налагодження запущених Podʼів
Ця сторінка пояснює, як налагоджувати Podʼи, що запущені (або зазнають збою) на вузлі.
Перш ніж ви розпочнете
Ваш Pod вже повинен бути запланований та запущений. Якщо ваш Pod ще не запущений, почніть з Налагодження Podʼів.
Для деяких з розширених кроків налагодження вам потрібно знати, на якому вузлі запущений Pod, і мати доступ до оболонки для виконання команд на цьому вузлі. Вам не потрібен такий доступ для виконання стандартних кроків налагодження, що використовують kubectl.
Використання kubectl describe pod для отримання деталей про Podʼи
Для цього прикладу ми використовуватимемо Deployment для створення двох Podʼів, схожих на попередній приклад.
Перевірте статус Podʼа за допомогою наступної команди:
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-67d4bdd6f5-cx2nz 1/1 Running 0 13s
nginx-deployment-67d4bdd6f5-w6kd7 1/1 Running 0 13s
Ми можемо отримати більше інформації про кожен з цих Podʼів, використовуючи kubectl describe pod. Наприклад:
kubectl describe pod nginx-deployment-67d4bdd6f5-w6kd7
Name: nginx-deployment-67d4bdd6f5-w6kd7
Namespace: default
Priority: 0
Node: kube-worker-1/192.168.0.113
Start Time: Thu, 17 Feb 2022 16:51:01 -0500
Labels: app=nginx
pod-template-hash=67d4bdd6f5
Annotations: <none>
Status: Running
IP: 10.88.0.3
IPs:
IP: 10.88.0.3
IP: 2001:db8::1
Controlled By: ReplicaSet/nginx-deployment-67d4bdd6f5
Containers:
nginx:
Container ID: containerd://5403af59a2b46ee5a23fb0ae4b1e077f7ca5c5fb7af16e1ab21c00e0e616462a
Image: nginx
Image ID: docker.io/library/nginx@sha256:2834dc507516af02784808c5f48b7cbe38b8ed5d0f4837f16e78d00deb7e7767
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Thu, 17 Feb 2022 16:51:05 -0500
Ready: True
Restart Count: 0
Limits:
cpu: 500m
memory: 128Mi
Requests:
cpu: 500m
memory: 128Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-bgsgp (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-bgsgp:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Guaranteed
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 34s default-scheduler Successfully assigned default/nginx-deployment-67d4bdd6f5-w6kd7 to kube-worker-1
Normal Pulling 31s kubelet Pulling image "nginx"
Normal Pulled 30s kubelet Successfully pulled image "nginx" in 1.146417389s
Normal Created 30s kubelet Created container nginx
Normal Started 30s kubelet Started container nginx
Тут ви можете побачити інформацію про конфігурацію контейнерів та Podʼа (мітки, вимоги до ресурсів і т. д.), а також інформацію про статус контейнерів та Podʼа (стан, готовність, кількість перезапусків, події й т.д.).
Стан контейнера може бути Waiting (очікування), Running (виконання) або Terminated (завершено). Залежно від стану, буде надано додаткову інформацію — наприклад, ви можете побачити, коли контейнер був запущений, якщо він перебуває в стані Running.
Ready показує, чи пройшов контейнер останню пробу готовності. (У цьому випадку контейнер не має налаштованої проби готовності; вважається, що контейнер готовий, якщо проба готовності не налаштована.)
Restart Count показує, скільки разів контейнер був перезапущений; ця інформація може бути корисною для виявлення циклів аварійного перезапуску в контейнерах, які налаштовані на перезапуск Always (завжди).
Наразі єдина умова, повʼязана з Podʼом, — це бінарна умова Ready, яка вказує, що Pod може обслуговувати запити та повинен бути доданий до пулів балансування навантаження всіх відповідних Serviceʼів.
Нарешті, ви бачите логи недавніх подій, що стосуються вашого Podʼа. "From" вказує на компонент, який реєструє подію. "Reason" та "Message" розповідають вам, що сталося.
Приклад: налагодження Podʼів у стані Pending
Одна з поширених ситуацій, яку ви можете виявити за допомогою подій, — це коли ви створили Pod, який не може бути розміщений на жодному вузлі. Наприклад, Pod може вимагати більше ресурсів, ніж вільно на будь-якому вузлі, або він може вказати селектор міток, який не відповідає жодному вузлу. Скажімо, ми створили Deployment з 5 репліками (замість 2) і вимагаємо 600 міліядер замість 500, на чотирьох вузловому кластері, де кожна (віртуальна) машина має 1 ЦП. У цьому випадку один з Podʼів не зможе бути запланованим. (Зауважте, що через надбудови кластера, такі як fluentd, skydns тощо, які працюють на кожному вузлі, якби ми запросили 1000 міліядер, то жоден з Podʼів не міг би бути запланованим.)
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-1006230814-6winp 1/1 Running 0 7m
nginx-deployment-1006230814-fmgu3 1/1 Running 0 7m
nginx-deployment-1370807587-6ekbw 1/1 Running 0 1m
nginx-deployment-1370807587-fg172 0/1 Pending 0 1m
nginx-deployment-1370807587-fz9sd 0/1 Pending 0 1m
Щоб дізнатися, чому Pod nginx-deployment-1370807587-fz9sd не працює, ми можемо використовувати kubectl describe pod у Podʼі у стані Pending та переглянути його події:
kubectl describe pod nginx-deployment-1370807587-fz9sd
Name: nginx-deployment-1370807587-fz9sd
Namespace: default
Node: /
Labels: app=nginx,pod-template-hash=1370807587
Status: Pending
IP:
Controllers: ReplicaSet/nginx-deployment-1370807587
Containers:
nginx:
Image: nginx
Port: 80/TCP
QoS Tier:
memory: Guaranteed
cpu: Guaranteed
Limits:
cpu: 1
memory: 128Mi
Requests:
cpu: 1
memory: 128Mi
Environment Variables:
Volumes:
default-token-4bcbi:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4bcbi
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 48s 7 {default-scheduler } Warning FailedScheduling pod (nginx-deployment-1370807587-fz9sd) failed to fit in any node
fit failure on node (kubernetes-node-6ta5): Node didn't have enough resource: CPU, requested: 1000, used: 1420, capacity: 2000
fit failure on node (kubernetes-node-wul5): Node didn't have enough resource: CPU, requested: 1000, used: 1100, capacity: 2000
Тут ви можете побачити подію, створену планувальником, яка говорить, що Pod не вдалося запланувати з причиною FailedScheduling (і, можливо, інші). Повідомлення говорить нам, що на будь-якому з вузлів не було достатньо ресурсів для Podʼа.
Для виправлення цієї ситуації ви можете використовувати kubectl scale, щоб оновити ваш Deployment та вказати чотири або менше реплік. (Або ви можете залишити один Pod у стані Pending, що нешкідливо.)
Події, такі як ті, які ви бачили в кінці kubectl describe pod, зберігаються в etcd та надають високорівневу інформацію про те, що відбувається в кластері. Щоб переглянути всі події, ви можете використовувати
kubectl get events
але вам потрібно памʼятати, що події належать до простору імен. Це означає, що якщо вас цікавлять події для обʼєкта з простором імен (наприклад, що сталося з Podʼами в просторі імен my-namespace), вам потрібно явно вказати простір імен для команди:
kubectl get events --namespace=my-namespace
Щоб побачити події з усіх просторів імен, ви можете використовувати аргумент --all-namespaces.
Крім команди kubectl describe pod, інший спосіб отримати додаткову інформацію про Pod (поза тим, що надає kubectl get pod) — це передати прапорець формату виводу -o yaml команді kubectl get pod. Це надасть вам, у форматі YAML, ще більше інформації, ніж kubectl describe pod — фактично всю інформацію, яку система має про Pod. Тут ви побачите такі речі, як анотації (це метадані ключ-значення без обмежень міток, які використовуються внутрішньо компонентами системи Kubernetes), політику перезапуску, порти та томи.
kubectl get pod nginx-deployment-1006230814-6winp -o yaml
Налагодження за допомогою виконання команд у контейнері
Якщо образ контейнера містить утиліти для налагодження, як це трапляється в образах, побудованих на основі базових образів операційних систем Linux і Windows, ви можете виконати команди всередині конкретного контейнера за допомогою kubectl exec:
Ефемерні контейнери корисні для інтерактивного усунення несправностей, коли kubectl exec недостатній через аварію контейнера або те, що образ контейнера не містить утиліт для налагодження, наприклад, в образах distroless.
Приклад налагодження за допомогою ефемерних контейнерів
Ви можете використовувати команду kubectl debug, щоб додати ефемерні контейнери до запущеного Podʼа. Спочатку створіть Pod для прикладу:
kubectl run ephemeral-demo --image=registry.k8s.io/pause:3.1 --restart=Never
У цьому розділі приклади використовують образ контейнера pause, оскільки він не містить утиліт для налагодження, але цей метод працює з будь-якими образом контейнера.
Якщо ви спробуєте використати kubectl exec для створення оболонки, ви побачите помилку, оскільки в цьому образі контейнера немає оболонки.
kubectl exec -it ephemeral-demo -- sh
OCI runtime exec failed: exec failed: container_linux.go:346: starting container process caused "exec: \"sh\": executable file not found in $PATH": unknown
Замість цього ви можете додати контейнер для налагодження за допомогою kubectl debug. Якщо ви вказуєте аргумент -i/--interactive, kubectl автоматично приєднується до консолі ефемерного контейнера.
Defaulting debug container name to debugger-8xzrl.
If you don't see a command prompt, try pressing enter.
/ #
Ця команда додає новий контейнер busybox і приєднується до нього. Параметр --target спрямовує простір імен процесу до іншого контейнера. Це необхідно тут, оскільки kubectl run не ввімкнув процес спільного використання простору імен у Pod, який він створює.
Примітка:
Параметр --target повинен підтримуватись середовищем виконання контейнерів. Якщо не підтримується, то ефемерний контейнер не може бути запущений, або він може бути запущений з ізольованим простором імен процесу, так що команда ps не відображатиме процеси в інших контейнерах.
Ви можете переглянути стан нового ефемерного контейнера, використовуючи kubectl describe:
Використовуйте kubectl delete, щоб видалити Pod, коли ви закінчите:
kubectl delete pod ephemeral-demo
Налагодження за допомогою копії Podʼа
Іноді параметри конфігурації Podʼа ускладнюють усунення несправностей у певних ситуаціях. Наприклад, ви не можете виконувати kubectl exec, щоб усунути несправності у вашому контейнері, якщо ваш образ контейнера не містить оболонки або якщо ваш застосунок аварійно завершується при запуску. У цих ситуаціях ви можете використовувати kubectl debug, щоб створити копію Podʼа зі зміненими значеннями конфігурації для полегшення налагодження.
Копіювання Podʼа з додаванням нового контейнера
Додавання нового контейнера може бути корисним, коли ваш застосунок працює, але не так, як ви очікували, і ви хочете додати додаткові засоби усунення несправностей до Podʼа.
Наприклад, можливо, образ контейнера вашого застосунку збудований на основі busybox, але вам потрібні засоби для налагодження, які не включені в busybox. Ви можете симулювати цей сценарій за допомогою kubectl run:
kubectl run myapp --image=busybox:1.28 --restart=Never -- sleep 1d
Виконайте цю команду, щоб створити копію myapp з назвою myapp-debug, яка додає новий контейнер Ubuntu для налагодження:
Defaulting debug container name to debugger-w7xmf.
If you don't see a command prompt, try pressing enter.
root@myapp-debug:/#
Примітка:
kubectl debug автоматично генерує назву контейнера, якщо ви не вибрали одну за допомогою прапорця --container.
Прапорець -i стандартно призводить до приєднання kubectl debug до нового контейнера. Ви можете запобігти цьому, вказавши --attach=false. Якщо ваша сесія розірвана, ви можете повторно приєднатися за допомогою kubectl attach.
Ви можете використовувати kubectl debug, щоб створити копію цього Podʼа з командою зміненою на інтерактивну оболонку:
kubectl debug myapp -it --copy-to=myapp-debug --container=myapp -- sh
If you don't see a command prompt, try pressing enter.
/ #
Тепер у вас є інтерактивна оболонка, яку ви можете використовувати для виконання завдань, таких як перевірка шляхів файлової системи або виконання команди контейнера вручну.
Примітка:
Щоб змінити команду для конкретного контейнера, вам потрібно вказати його назву за допомогою --container, інакше kubectl debug створить новий контейнер для виконання вказаної вами команди.
Прапорець -i призводить до того, що kubectl debug автоматично приєднується до контейнера. Ви можете це запобігти, вказавши --attach=false. Якщо ваша сесія розірвана, ви можете повторно приєднатися за допомогою kubectl attach.
Не забудьте прибрати Pod для налагодження, коли ви закінчите:
kubectl delete pod myapp myapp-debug
Копіювання Podʼа з заміною образів контейнерів
Іноді вам може знадобитися змінити образ Podʼа, який поводитися неналежним чином, зі звичайного образу, що використовується в операційній діяльності, на образ, що містить збірку для налагодження або додаткові утиліти.
Наприклад, створіть Pod за допомогою kubectl run:
kubectl run myapp --image=busybox:1.28 --restart=Never -- sleep 1d
Тепер використовуйте kubectl debug, щоб створити копію та змінити його образ контейнера на ubuntu:
Синтаксис --set-image використовує ту ж синтаксис container_name=image, що й kubectl set image. *=ubuntu означає зміну образу всіх контейнерів на ubuntu.
Не забудьте прибрати Pod для налагодження, коли ви закінчите:
kubectl delete pod myapp myapp-debug
Налагодження через оболонку на вузлі
Якщо жоден з цих підходів не працює, ви можете знайти вузол, на якому працює Pod, і створити Pod, який буде виконуватися на цьому вузлі. Щоб створити інтерактивну оболонку на вузлі за допомогою kubectl debug, виконайте:
kubectl debug node/mynode -it --image=ubuntu
Creating debugging pod node-debugger-mynode-pdx84 with container debugger on node mynode.
If you don't see a command prompt, try pressing enter.
root@ek8s:/#
При створенні сесії налагодження на вузлі майте на увазі, що:
kubectl debug автоматично генерує назву нового Podʼа на основі назви вузла.
Коренева файлова система вузла буде змонтована в /host.
Контейнер працює у просторах імен IPC, мережі та PID вузла, хоча Pod не є привілейованим, тому читання деякої інформації про процеси може не вдатися, і chroot /host може не спрацювати.
Якщо вам потрібен привілейований Pod, створіть його вручну або використовуйте прапорець --profile=sysadmin
Не забудьте прибрати Pod для налагодження, коли ви закінчите з ним:
kubectl delete pod node-debugger-mynode-pdx84
Налагодження Pod або Node під час застосування профілю
Коли ви використовуєте kubectl debug для налагодження вузла за допомогою Podʼа налагодження, Pod за ефемерним контейнером або скопійованого Pod, ви можете застосувати до них профіль. Застосовуючи профіль, ви можете встановити конкретні властивості, такі як securityContext, що дозволяє адаптуватися до різних сценаріїв. Наразі використовується два типи профілів: static та custom.
Застосування профілю static
Профіль static є набором наперед визначених властивостей які ви можете застосовувати за допомогою прапорця --profile. Доступні наступні профілі:
Профіль
Опис
legacy
Набір властивостей для зворотної сумісності з поведінкою 1.22
general
Розумний набір загальних властивостей для кожного завдання налагодження
Набір властивостей, включаючи привілеї адміністратора мережі
sysadmin
Набір властивостей, включаючи привілеї системного адміністратора (root)
Примітка:
Якщо ви не вкажете --profile, стандартно використовується профіль legacy, але його планується найближчим часом визнати застарілим. Тому рекомендується використовувати інші профілі, такі як general.
Припустимо, що ви створюєте Pod і налагоджуєте його. Спочатку створіть Pod з назвою myapp, наприклад:
kubectl run myapp --image=busybox:1.28 --restart=Never -- sleep 1d
Потім, перевірте Pod за допомогою ефемерного контейнера. Якщо ефемерному контейнеру потрібно мати привілеї, ви можете використовувати профіль sysadmin:
Targeting container "myapp". If you don't see processes from this container it may be because the container runtime doesn't support this feature.
Defaulting debug container name to debugger-6kg4x.
If you don't see a command prompt, try pressing enter.
/ #
Перевірте можливості процесу ефемерного контейнера, виконавши наступну команду всередині контейнера:
Це означає, що процес контейнера наділений усіма можливостями як привілейований контейнер завдяки застосуванню профілю sysadmin. Дивіться більше деталей про можливості.
Ви також можете перевірити, що ефемерний контейнер був створений як привілейований контейнер:
kubectl get pod myapp -o jsonpath='{.spec.ephemeralContainers[0].securityContext}'
{"privileged":true}
Очистіть Pod, коли ви закінчите з ним:
kubectl delete pod myapp
Застосування профілю custom
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.32 [stable]
Ви можете визначити часткову специфікацію контейнера для налагодження як профіль custom у форматі JSON або YAML, та застосувати її з прапорцем --custom.
Примітка:
Профіль custom підтримує лише зміну специфікації контейнера, однак зміни полів name, image, command, lifecycle та volumeDevices не дозволяються. Також не підтримується зміна специфікації Podʼа.
Створіть Pod з назвою myapp, наприклад:
kubectl run myapp --image=busybox:1.28 --restart=Never -- sleep 1d
Створіть профіль custom у форматі JSON або YAML. Тут ми створимо файл сustom-profile.yaml з наступним вмістом:
kubectl get pod myapp -o jsonpath='{.spec.ephemeralContainers[0].securityContext}'
{"capabilities":{"add":["NET_ADMIN","SYS_TIME"]}}
Закінчивши роботу, очистіть Pod:
kubectl delete pod myapp
4.3.7 - Отримання доступу до оболонки запущеного контейнера
Ця сторінка показує, як використовувати kubectl exec для отримання доступу до оболонки запущеного контейнера.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Подвійне тире (--) відокремлює аргументи, які ви хочете передати команді, від аргументів kubectl.
У своїй оболонці виведіть список кореневої теки:
# Виконайте це всередині контейнераls /
У своїй оболонці експериментуйте з іншими командами. Ось деякі приклади:
# Ви можете виконати ці приклади команд всередині контейнераls /
cat /proc/mounts
cat /proc/1/maps
apt-get update
apt-get install -y tcpdump
tcpdump
apt-get install -y lsof
lsof
apt-get install -y procps
ps aux
ps aux | grep nginx
Редагування головної сторінки nginx
Знову перегляньте файл конфігурації вашого Podʼа. Pod має том emptyDir, і контейнер монтує цей том в /usr/share/nginx/html.
У своїй оболонці створіть файл index.html у теці /usr/share/nginx/html:
# Виконайте це всередині контейнераecho'Hello shell demo' > /usr/share/nginx/html/index.html
У своїй оболонці надішліть GET-запит до сервера nginx:
# Виконайте це в оболонці всередині вашого контейнераapt-get update
apt-get install curl
curl http://localhost/
Результат покаже текст, який ви написали в файл index.html:
Hello shell demo
Коли ви закінчите з вашою оболонкою, введіть exit.
exit# Щоб вийти з оболонки в контейнері
Виконання окремих команд в контейнері
У звичайному вікні команд виведіть змінні оточення в запущеному контейнері:
kubectl exec shell-demo -- env
Експериментуйте з виконанням інших команд. Ось деякі приклади:
kubectl exec shell-demo -- ps aux
kubectl exec shell-demo -- ls /
kubectl exec shell-demo -- cat /proc/1/mounts
Відкриття оболонки, коли в Podʼі є більше одного контейнера
Якщо в Podʼі є більше одного контейнера, використовуйте --container або -c для зазначення контейнера в команді kubectl exec. Наприклад, припустимо, у вас є Pod на ім’я my-pod, і в Podʼі є два контейнери з іменами main-app та helper-app. Наступна команда відкриє оболонку до контейнера main-app.
Виправлення загальних проблем з кластером Kubernetes.
Цей документ присвячений усуненню несправностей в кластері; ми передбачаємо, що ви вже виключили свій застосунок з переліку причин проблеми, з якою ви стикаєтеся. Дивіться посібник Налагодження застосунку для порад з перевірки застосунків. Ви також можете звернутися до загального документа з усунення несправностей для отримання додаткової інформації.
Іноді при налагодженні може бути корисно переглянути стан вузла, наприклад, через те, що ви помітили дивну поведінку Podʼа, який працює на вузлі, або щоб дізнатися, чому Pod не може розміститися на вузлі. Так само як і з Podʼами, ви можете використовувати kubectl describe node та kubectl get node -o yaml, щоб отримати детальну інформацію про вузли. Наприклад, ось що ви побачите, якщо вузол вимкнено (відключено від мережі, або kubelet припинив роботу і не може перезапуститися і т. д.). Зверніть увагу на події, які показують, що вузол не готовий, і також зверніть увагу, що Podʼи більше не працюють (їх буде виселено після пʼяти хвилин стану NotReady).
kubectl get nodes
NAME STATUS ROLES AGE VERSION
kube-worker-1 NotReady <none> 1h v1.23.3
kubernetes-node-bols Ready <none> 1h v1.23.3
kubernetes-node-st6x Ready <none> 1h v1.23.3
kubernetes-node-unaj Ready <none> 1h v1.23.3
kubectl describe node kube-worker-1
Name: kube-worker-1
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=kube-worker-1
kubernetes.io/os=linux
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Thu, 17 Feb 2022 16:46:30 -0500
Taints: node.kubernetes.io/unreachable:NoExecute
node.kubernetes.io/unreachable:NoSchedule
Unschedulable: false
Lease:
HolderIdentity: kube-worker-1
AcquireTime: <unset>
RenewTime: Thu, 17 Feb 2022 17:13:09 -0500
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Thu, 17 Feb 2022 17:09:13 -0500 Thu, 17 Feb 2022 17:09:13 -0500 WeaveIsUp Weave pod has set this
MemoryPressure Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
DiskPressure Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
PIDPressure Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
Ready Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
Addresses:
InternalIP: 192.168.0.113
Hostname: kube-worker-1
Capacity:
cpu: 2
ephemeral-storage: 15372232Ki
hugepages-2Mi: 0
memory: 2025188Ki
pods: 110
Allocatable:
cpu: 2
ephemeral-storage: 14167048988
hugepages-2Mi: 0
memory: 1922788Ki
pods: 110
System Info:
Machine ID: 9384e2927f544209b5d7b67474bbf92b
System UUID: aa829ca9-73d7-064d-9019-df07404ad448
Boot ID: 5a295a03-aaca-4340-af20-1327fa5dab5c
Kernel Version: 5.13.0-28-generic
OS Image: Ubuntu 21.10
Operating System: linux
Architecture: amd64
Container Runtime Version: containerd://1.5.9
Kubelet Version: v1.23.3
Kube-Proxy Version: v1.23.3
Non-terminated Pods: (4 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default nginx-deployment-67d4bdd6f5-cx2nz 500m (25%) 500m (25%) 128Mi (6%) 128Mi (6%) 23m
default nginx-deployment-67d4bdd6f5-w6kd7 500m (25%) 500m (25%) 128Mi (6%) 128Mi (6%) 23m
kube-system kube-proxy-dnxbz 0 (0%) 0 (0%) 0 (0%) 0 (0%) 28m
kube-system weave-net-gjxxp 100m (5%) 0 (0%) 200Mi (10%) 0 (0%) 28m
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1100m (55%) 1 (50%)
memory 456Mi (24%) 256Mi (13%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
...
kubectl get node kube-worker-1 -o yaml
apiVersion:v1kind:Nodemetadata:annotations:node.alpha.kubernetes.io/ttl:"0"volumes.kubernetes.io/controller-managed-attach-detach:"true"creationTimestamp:"2022-02-17T21:46:30Z"labels:beta.kubernetes.io/arch:amd64beta.kubernetes.io/os:linuxkubernetes.io/arch:amd64kubernetes.io/hostname:kube-worker-1kubernetes.io/os:linuxname:kube-worker-1resourceVersion:"4026"uid:98efe7cb-2978-4a0b-842a-1a7bf12c05f8spec:{}status:addresses:- address:192.168.0.113type:InternalIP- address:kube-worker-1type:Hostnameallocatable:cpu:"2"ephemeral-storage:"14167048988"hugepages-2Mi:"0"memory:1922788Kipods:"110"capacity:cpu:"2"ephemeral-storage:15372232Kihugepages-2Mi:"0"memory:2025188Kipods:"110"conditions:- lastHeartbeatTime:"2022-02-17T22:20:32Z"lastTransitionTime:"2022-02-17T22:20:32Z"message:Weave pod has set thisreason:WeaveIsUpstatus:"False"type:NetworkUnavailable- lastHeartbeatTime:"2022-02-17T22:20:15Z"lastTransitionTime:"2022-02-17T22:13:25Z"message:kubelet has sufficient memory availablereason:KubeletHasSufficientMemorystatus:"False"type:MemoryPressure- lastHeartbeatTime:"2022-02-17T22:20:15Z"lastTransitionTime:"2022-02-17T22:13:25Z"message:kubelet has no disk pressurereason:KubeletHasNoDiskPressurestatus:"False"type:DiskPressure- lastHeartbeatTime:"2022-02-17T22:20:15Z"lastTransitionTime:"2022-02-17T22:13:25Z"message:kubelet has sufficient PID availablereason:KubeletHasSufficientPIDstatus:"False"type:PIDPressure- lastHeartbeatTime:"2022-02-17T22:20:15Z"lastTransitionTime:"2022-02-17T22:15:15Z"message:kubelet is posting ready status. AppArmor enabledreason:KubeletReadystatus:"True"type:ReadydaemonEndpoints:kubeletEndpoint:Port:10250nodeInfo:architecture:amd64bootID:22333234-7a6b-44d4-9ce1-67e31dc7e369containerRuntimeVersion:containerd://1.5.9kernelVersion:5.13.0-28-generickubeProxyVersion:v1.23.3kubeletVersion:v1.23.3machineID:9384e2927f544209b5d7b67474bbf92boperatingSystem:linuxosImage:Ubuntu 21.10systemUUID:aa829ca9-73d7-064d-9019-df07404ad448
Аналіз логів
Тепер для докладнішого вивчення кластера потрібно увійти на відповідні машини. Ось розташування відповідних файлів журналу. На системах, що використовують systemd, може знадобитися використання journalctl замість перегляду файлів журналу.
Вузли панелі управління
/var/log/kube-apiserver.log — Сервер API, відповідальний за обслуговування API
/var/log/kube-scheduler.log — Планувальник, відповідальний за прийняття рішень щодо планування
/var/log/kube-controller-manager.log — Компонент, який виконує більшість вбудованих контролерів Kubernetes, за винятком планування (за це відповідає планувальник kube-scheduler).
Робочі вузли
/var/log/kubelet.log — логи kubelet, відповідального за запуск контейнерів на вузлі
/var/log/kube-proxy.log — логи kube-proxy, відповідального за направлення трафіку на Service endpoints.
Режими відмови кластера
Це неповний перелік того, що може піти не так, та як виправити вашу конфігурацію кластера для помʼякшення проблем.
Причини відмов
Вимкнення віртуальних машин(и)
Розділ мережі в межах кластера чи між кластером та користувачами
Крах програмного забезпечення Kubernetes
Втрата даних або недоступність постійного сховища (наприклад, GCE PD або томів AWS EBS)
Помилка оператора, наприклад, неправильно налаштоване програмне забезпечення Kubernetes або застосунку
Конкретні сценарії
Вимкнення віртуальної машини або аварійне вимикання apiserver
Результати
не можна зупинити, оновити чи запустити нові Podʼи, Services, контролер реплікацій
наявні Podʼи та Services мають продовжувати нормальну роботу, якщо вони не залежать від API Kubernetes
Втрата даних, на яких ґрунтується API сервер
Результати
компонент kube-apiserver не може успішно стартувати та стати спроможним обслуговувати запити
kubelet не зможе досягти його, але продовжить виконувати ті самі Podʼи та забезпечувати той самий сервіс проксі
необхідне ручне відновлення або відновлення стану apiserver перед його перезапуском
Припинення роботи служб підтримки (контролер вузлів, менеджер контролера реплікацій, планувальник і т. д.) або їх крах
наразі вони розміщені разом з apiserver, і їхня недоступність має схожі наслідки, що й в apiserver
у майбутньому ці служби також будуть репліковані та не можуть бути розміщені в одному місці
вони не мають власного постійного стану
Вимкнення окремого вузла (віртуальна машина або фізична машина)
Результати
Podʼи на цьому вузлі перестають працювати
Розрив мережі
Результати
розділ A вважає, що вузли в розділі B вимкнені; розділ B вважає, що apiserver вимкнений.
(Якщо майстер-вузол опиниться в розділі A.)
Збій програмного забезпечення kubelet
Результати
аварійно вимкнений kubelet не може стартувати нові Podʼи на вузлі
kubelet може видаляти Podʼи або ні
вузол позначений як неспроможний
контролери реплікацій стартують нові Podʼи в іншому місці
Помилка оператора кластера
Результати
втрата Podʼів, Services і т. ін.
втрата сховища даних для apiserver
користувачі не можуть читати API
і т.д.
Помʼякшення
Дія: Використовуйте функцію автоматичного перезапуску віртуальних машин IaaS для віртуальних машин IaaS
Помʼякшує: Вимкнення віртуальної машини або аварійне вимикання apiserver
Помʼякшує: Вимкнення служб підтримки або їх краху
Дія: Використовуйте надійне сховище IaaS (наприклад, GCE PD або том AWS EBS) для віртуальних машин з apiserver+etcd
Помʼякшує: Втрата даних, на яких ґрунтується API сервер
Ця документація присвячена дослідженню та діагностиці повʼязаних проблем kubectl. Якщо ви зіткнулися з проблемами доступу до kubectl або зʼєднанням з вашим кластером, цей документ окреслює різні загальні сценарії та потенційні рішення, які допоможуть виявити та усунути ймовірну причину.
Переконайтеся, що ви правильно встановили та налаштували kubectl на вашому локальному компʼютері. Перевірте версію kubectl, щоб впевнитися, що вона актуальна та сумісна з вашим кластером.
Якщо замість Server Version ви бачите Unable to connect to the server: dial tcp <server-ip>:8443: i/o timeout, вам потрібно дослідити проблеми зʼєднання kubectl з вашим кластером.
kubectl вимагає файл kubeconfig для зʼєднання з Kubernetes кластером. Файл kubeconfig зазвичай знаходиться в теці ~/.kube/config. Переконайтеся, що у вас є валідний файл kubeconfig. Якщо у вас немає файлу kubeconfig, ви можете отримати його у вашого адміністратора Kubernetes, або ви можете скопіювати його з теки /etc/kubernetes/admin.conf вашої панелі управління Kubernetes. Якщо ви розгортали ваш Kubernetes кластер на хмарній платформі та втратили ваш файл kubeconfig, ви можете згенерувати його знову за допомогою інструментів вашого хмарного провайдера. Дивіться документацію хмарного провайдера щодо генерації файлу kubeconfig.
Перевірте, чи правильно налаштовано змінну середовища $KUBECONFIG. Ви можете встановити змінну середовища $KUBECONFIG або використовувати параметр --kubeconfig з kubectl, щоб вказати теку файлу kubeconfig.
Перевірка VPN зʼєднання
Якщо ви використовуєте Віртуальну Приватну Мережу (VPN) для доступу до вашого Kubernetes кластеру, переконайтеся, що ваше VPN зʼєднання активне і стабільне. Іноді, перебої у зʼєднанні VPN можуть призвести до проблем зі зʼєднанням з кластером. Підʼєднайтеся до VPN знову і спробуйте отримати доступ до кластера знову.
Автентифікація та авторизація
Якщо ви використовуєте автентифікацію на базі токенів і kubectl повертає помилку щодо автентифікаційного токена або адреси сервера автентифікації, перевірте, що токен автентифікації Kubernetes та адреса сервера автентифікації налаштовані правильно.
Якщо kubectl повертає помилку щодо авторизації, переконайтеся, що ви використовуєте дійсні дані користувача. Та маєте дозвіл на доступ до ресурсу, який ви запросили.
Перевірка контекстів
Kubernetes підтримує роботу з кількома кластерами та контекстами. Переконайтеся, що ви використовуєте правильний контекст для взаємодії з вашим кластером.
Перелік доступних контекстів:
kubectl config get-contexts
Перемикання на відповідний контекст:
kubectl config use-context <context-name>
API сервер та балансувальник навантаження
kube-apiserver є центральним компонентом кластера Kubernetes. Якщо сервер API або балансувальник навантаження, який працює перед вашими серверами API, не доступний або не реагує, ви не зможете взаємодіяти з кластером.
Перевірте, чи доступний хост сервера API, використовуючи команду ping. Перевірте мережеве зʼєднання кластера та файервол. Якщо ви використовуєте хмарного провайдера для розгортання кластера, перевірте стан проб справності вашого хмарного провайдера для сервера API кластера.
Перевірте стан балансувальника навантаження (якщо використовується), щоб переконатися, що він справний і передає трафік на сервер API.
Проблеми з TLS
Потрібні додаткові інструменти — base64 та openssl версії 3.0 або вище.
Сервер API Kubernetes типово обслуговує лише HTTPS запити. У цьому випадку можуть виникнути проблеми з TLS з різних причин, таких як закінчення строку дії сертифіката або дійсність ланцюга довіри.
Ви можете знайти TLS сертифікат у файлі kubeconfig, який знаходиться у теці ~/.kube/config. Атрибут certificate-authority містить сертифікат ЦА, а атрибут client-certificate містить клієнтський сертифікат.
Деякі допоміжні інструменти kubectl забезпечують легкий доступ до кластерів Kubernetes. Якщо ви використовували такі інструменти та стикаєтеся з проблемами зʼєднання, переконайтеся, що необхідні налаштування все ще присутні.
Перевірте конфігурацію kubectl для отримання інформації про автентифікацію:
kubectl config view
Якщо раніше ви використовували допоміжний інструмент (наприклад, kubectl-oidc-login), переконайтеся, що він все ще встановлений і правильно налаштований.
4.4.2 - Конвеєер метрик ресурсів
Для Kubernetes Metrics API пропонує базовий набір метрик для підтримки автоматичного масштабування та подібних випадків використання. Це API робить доступною інформацію про використання ресурсів для вузла та Podʼа, включаючи метрики для CPU та памʼяті. Якщо ви розгортаєте Metrics API у своєму кластері, клієнти API Kubernetes можуть запитувати цю інформацію, і ви можете використовувати механізми контролю доступу Kubernetes для управління дозволами на це.
HorizontalPodAutoscaler (HPA) та VerticalPodAutoscaler (VPA) використовують дані з API метрик для налаштування реплік робочого навантаження та ресурсів для задоволення вимог користувачів.
Ви також можете переглядати метрики ресурсів, використовуючи команду kubectl top.
Примітка:
Metrics API та конвеєр метрик, який він дозволяє, надають лише мінімальний набір метрик CPU та памʼяті для автоматичного масштабування за допомогою HPA та / або VPA. Якщо ви хочете надати повніший набір метрик, ви можете доповнити простіший Metrics API, розгорнувши другий
конвеєр метрик який використовує Custom Metrics API.
flowchart RL
subgraph cluster[Кластер]
direction RL
S[
]
A[Сервер- метрик]
subgraph B[Вузли]
direction TB
D[cAdvisor] --> C[kubelet]
E[Середовище виконання контейнерів] --> D
E1[Середовище виконання контейнерів] --> D
P[Дані Podʼа] -.- C
end
L[API-сервер]
W[HPA]
C ---->|метрики ресурсів на рівні вузла| A -->|Metrics API| L --> W
end
L ---> K[kubectl top]
classDef box fill:#fff,stroke:#000,stroke-width:1px,color:#000;
class W,B,P,K,cluster,D,E,E1 box
classDef spacewhite fill:#ffffff,stroke:#fff,stroke-width:0px,color:#000
class S spacewhite
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:1px,color:#fff;
class A,L,C k8s
Схема 1. Конвеєр метрик ресурсів
Компоненти архітектури, справа наліво на схемі, включають наступне:
cAdvisor: Демон для збору, агрегування та викладання метрик контейнера, включених в Kubelet.
kubelet: Агент вузла для управління ресурсами контейнера. Метрики ресурсів доступні за допомогою точок доступу API kubelet /metrics/resource та /stats.
метрики ресурсів на рівні вузла: API, наданий kubelet для виявлення та отримання підсумкових статистичних даних на рівні вузла, доступних через точку доступу /metrics/resource.
сервер метрик: Компонент надбудови кластера, який збирає та агрегує метрики ресурсів, витягнуті з кожного kubelet. Сервер API надає API метрик для використання HPA, VPA та команди kubectl top. Сервер метрик є посиланням на реалізацію Metrics API.
Metrics API: API Kubernetes, що підтримує доступ до CPU та памʼяті, використаних для автоматичного масштабування робочого навантаження. Щоб це працювало у вашому кластері, вам потрібен сервер розширення API, який надає API метрик.
Примітка:
cAdvisor підтримує читання метрик з cgroups, що працює з типовими середовищами виконання контейнерів на Linux. Якщо ви використовуєте середовище виконання контейнерів, яке використовує інший механізм ізоляції ресурсів, наприклад, віртуалізацію, то це середовище виконання контейнерів повинно підтримувати метрики контейнера CRI для того, щоб метрики були доступні kubelet.
Metrics API
СТАН ФУНКЦІОНАЛУ:Kubernetes 1.8 [beta]
Metrics-server реалізує Metrics API. Це API дозволяє отримувати доступ до використання CPU та памʼяті для вузлів та Podʼів у вашому кластері. Його основна роль — надавати метрики використання ресурсів компонентам автомасштабування K8s.
Ось приклад запиту до Metrics API для вузла minikube, обробленого через jq для зручного перегляду:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes/minikube" | jq '.'
Ось приклад запиту до Metrics API для Podʼа kube-scheduler-minikube, що міститься в просторі імен kube-system, оброблений через jq для зручного перегляду:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/namespaces/kube-system/pods/kube-scheduler-minikube" | jq '.'
Ви повинні розгорнути metrics-server або альтернативний адаптер, який надає Metrics API, щоб мати змогу отримувати до нього доступ.
Вимірювання використання ресурсів
ЦП
Відомості про CPU показуються як середнє значення використання ядра, виміряне в одиницях процесорного часу. Один CPU, у Kubernetes, еквівалентний 1 віртуальному процесору/ядру для хмарних постачальників, і 1 гіперпотоку на процесорах Intel для bare-metal конфігурацій.
Це значення обчислюється шляхом взяття швидкості над кумулятивним лічильником CPU, який надається ядром (як для Linux, так і для Windows ядер). Вікно часу, яке використовується для обчислення CPU, показано у полі window в Metrics API.
Щоб дізнатися більше про те, як Kubernetes розподіляє та вимірює ресурси CPU, див. значення CPU.
Памʼять
Відомості про памʼять показуються як обсяг робочого набору, виміряний в байтах, в момент збору метрики.
У ідеальному світі "робочий набір" — це обсяг памʼяті, що використовується, який не може бути звільнений під час тиску на памʼять. Однак розрахунок робочого набору варіюється залежно від операційної системи хосту і, як правило, інтенсивно використовує евристики для оцінки.
Модель Kubernetes для робочого набору контейнера передбачає, що робочий набір контейнера, що розглядається, підраховується відносно анонімної памʼяті, повʼязаної з цим контейнером. Зазвичай метрика робочого набору також включає деяку кешовану (файлоподібну) памʼять, оскільки операційна система хосту не завжди може повторно використовувати сторінки.
Щоб дізнатися більше про те, як Kubernetes розподіляє та вимірює ресурси памʼяті, див. значення памʼяті.
Metrics Server
Metrics-server витягує метрики ресурсів з kubeletʼів і надає їх в API-серверу Kubernetes через Metrics API для використання HPA та VPA. Ви також можете переглядати ці метрики за допомогою команди kubectl top.
Metrics-server використовує API Kubernetes для відстеження вузлів та Podʼів у вашому кластері. Metrics-server запитує кожний вузол через HTTP, щоб отримати метрики. Metrics-server також створює внутрішнє представлення метаданих про Pod та зберігає кеш стану справності Podʼа. Ця кешована інформація про стан справності Podʼів доступна через розширення API, яке надає metrics-server.
Наприклад, при запиті HPA metrics-server повинен визначити, які Podʼи відповідають селекторам міток у Deployment.
Metrics-server викликає API kubelet для збору метрик з кожного вузла. Залежно від версії metrics-server використовується:
Точка доступу ресурсів метрик /metrics/resource у версії v0.6.0+ або
Точка доступу Summary API /stats/summary у старших версіях
Щоб дізнатися про те, як kubelet надає метрики вузла, і як ви можете отримати до них доступ через API Kubernetes, прочитайте Дані метрик вузлів.
4.4.3 - Інструменти для моніторингу ресурсів
Щоб масштабувати застосунок і надавати надійні послуги, вам потрібно розуміти, як застосунок працює при його розгортанні. Ви можете аналізувати продуктивність застосунку в кластері Kubernetes, перевіряючи контейнери, Podʼи, Serviceʼи та загальні характеристики кластера. Kubernetes надає докладну інформацію про використання ресурсів застосункам на кожному з цих рівнів. Ця інформація дозволяє оцінити продуктивність вашого застосунку та визначити місця, де можна видалити перешкоди, щоб покращити загальну продуктивність.
У Kubernetes моніторинг застосунків не залежить від єдиного рішення для моніторингу. На нових кластерах ви можете використовувати конвеєри метрик ресурсів або повні метрики, щоб збирати статистику для моніторингу.
Конвеєр метрик ресурсів
Конвеєр метрик ресурсів надає обмежений набір метрик, повʼязаних з компонентами кластера, такими як контролер Горизонтального автомасштабування Podʼів та утилітою kubectl top. Ці метрики збираються легким, тимчасовим, розташованим в памʼяті metrics-server та експонується через API metrics.k8s.io.
Metrics-server виявляє всі вузли в кластері та запитує kubelet кожного вузла для визначення використання центрального процесора та памʼяті. Kubelet виступає як міст між майстром Kubernetes та вузлами, керуючи Podʼами та контейнерами, що працюють на машині. Kubelet перетворює кожний Pod у його складові контейнери та отримує статистику використання кожного контейнера через інтерфейс середовища виконання контейнерів. Якщо ви використовуєте середовище виконання контейнерів, яке використовує Linux cgroups та простори імен для роботи контейнерів, і середовище виконання контейнерів не публікує статистику використання, тоді kubelet може отримувати ці статистичні дані безпосередньо (використовуючи код з cAdvisor). Незалежно від того, як надходять ці статистичні дані, kubelet після цього використовує агреговану статистику використання ресурсів Podʼів через metrics-server Resource Metrics API. Цей API надається за адресою /metrics/resource/v1beta1 на автентифікованих та портах kublet, доступних тільки для читання.
Конвеєр повних метрик
Конвеєр повних метрик дає вам доступ до більш розширених метрик. Kubernetes може відповідати на ці метрики, автоматично масштабуючи або адаптуючи кластер на основі його поточного стану за допомогою механізмів, таких як Горизонтальне автомасштабування Podʼів. Конвеєр моніторингу витягує метрики з kubelet та експонує їх в Kubernetes через адаптер, реалізуючи API custom.metrics.k8s.io або external.metrics.k8s.io.
Якщо ви переглянете CNCF Landscape, ви побачите ряд проєктів моніторингу, які можуть працювати з Kubernetes, витягуючи дані метрик та використовуючи їх, щоб допомоги вам спостерігати за вашим кластером. Вам слід вибрати інструмент або інструменти, які відповідають вашим потребам. Ландшафт CNCF для спостереження та аналізу включає комбінацію вільного програмного забезпечення, платного програмного забезпечення-як-сервісу та інших комерційних продуктів.
При проєктуванні та реалізації конвеєра повних метрик ви можете зробити ці моніторингові дані доступні зворотньо у Kubernetes. Наприклад, HorizontalPodAutoscaler може використовувати оброблені метрики для розрахунку кількості Podʼів, які потрібно запустити як складову вашого навантаження.
Інтеграція конвеєра повних у вашу реалізацію Kubernetes знаходиться поза межами документації Kubernetes через дуже широкий спектр можливих рішень.
Вибір моніторингової платформи значно залежить від ваших потреб, бюджету та технічних ресурсів. Kubernetes не надає жодних переваг щодо конкретних конвеєрів метрик; існує багато варіантів. Ваша система моніторингу повинна бути здатна обробляти стандарт передачі метрик OpenMetrics і має бути обрана так, щоб найкраще вписуватися в вашу загальну концепцію та розгортання інфраструктури.
Що далі
Дізнайтеся про додаткові інструменти для налагодження, включаючи:
Node Problem Detector — це служба для моніторингу та звітування про стан вузла. Ви можете запустити Node Problem Detector як DaemonSet або окремий демон. Node Problem Detector збирає інформацію про проблеми вузла з різних демонів і повідомляє їх на сервер API як стан вузла або як події.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Node Problem Detector використовує формат логу ядра для повідомлення про проблеми ядра.
Щоб дізнатися, як розширити формат логу ядра, див. Додавання підтримки для іншого формату логу.
Увімкнення Node Problem Detector
Деякі хмарні постачальники увімкнуть Node Problem Detector як надбудову. Ви також можете увімкнути Node Problem Detector за допомогою kubectl або створити Addon DaemonSet.
Використання kubectl для увімкнення Node Problem Detector
kubectl надає найбільш гнучке керування Node Problem Detector. Ви можете перезаписати типову конфігурацію, щоб вона відповідала вашому середовищу або виявляла спеціалізовані проблеми вузла. Наприклад:
Створіть конфігурацію Node Problem Detector, аналогічну node-problem-detector.yaml:
Використання Podʼа надбудови для увімкнення Node Problem Detector
Якщо ви використовуєте власне рішення для ініціалізації кластера та не потребуєте перезапису типової конфігурації, ви можете скористатися Podʼом надбудови, щоб автоматизувати розгортання.
Створіть node-problem-detector.yaml та збережіть конфігурацію в теці Podʼа надбудови /etc/kubernetes/addons/node-problem-detector на вузлі панелі управління.
Перезапис конфігурації
Типова конфігурація вбудована під час збирання Docker-образу Node Problem Detector.
Однак ви можете використовувати ConfigMap для перезапису конфігурації:
apiVersion:apps/v1kind:DaemonSetmetadata:name:node-problem-detector-v0.1namespace:kube-systemlabels:k8s-app:node-problem-detectorversion:v0.1kubernetes.io/cluster-service:"true"spec:selector:matchLabels:k8s-app:node-problem-detector version:v0.1kubernetes.io/cluster-service:"true"template:metadata:labels:k8s-app:node-problem-detectorversion:v0.1kubernetes.io/cluster-service:"true"spec:hostNetwork:truecontainers:- name:node-problem-detectorimage:registry.k8s.io/node-problem-detector:v0.1securityContext:privileged:trueresources:limits:cpu:"200m"memory:"100Mi"requests:cpu:"20m"memory:"20Mi"volumeMounts:- name:logmountPath:/logreadOnly:true- name:config# Overwrite the config/ directory with ConfigMap volumemountPath:/configreadOnly:truevolumes:- name:loghostPath:path:/var/log/- name:config# Define ConfigMap volumeconfigMap:name:node-problem-detector-config
Перестворіть Node Problem Detector з новим файлом конфігурації:
# Якщо у вас вже працює Node Problem Detector, видаліть перед перствореннямkubectl delete -f https://k8s.io/examples/debug/node-problem-detector.yaml
kubectl apply -f https://k8s.io/examples/debug/node-problem-detector-configmap.yaml
Примітка:
Цей підхід застосовується тільки до Node Problem Detector, запущеного за допомогою kubectl.
Перезапис конфігурації не підтримується, якщо Node Problem Detector працює як надбудова кластера. Менеджер надбудов не підтримує ConfigMap.
Демони проблем
Демон проблем — це піддемон Node Problem Detector. Він моніторить певні види проблем вузла та повідомляє про них Node Problem Detector. Існує кілька типів підтримуваних демонів проблем.
Тип демона SystemLogMonitor моніторить системні логи та повідомляє про проблеми та метрики згідно з попередньо визначеними правилами. Ви можете настроїти конфігурації для різних джерел логів таких як filelog, kmsg, kernel, abrt, та systemd.
Тип демона SystemStatsMonitor збирає різноманітні статистичні дані системи, повʼязані зі справністю, як метрики. Ви можете настроїти його поведінку, оновивши його файл конфігурації.
Тип демона CustomPluginMonitor викликає та перевіряє різні проблеми вузла, запускаючи сценарії, визначені користувачем. Ви можете використовувати різні власні втулки для моніторингу різних проблем і настроювати поведінку демона, оновивши файл конфігурації.
Тип демона HealthChecker перевіряє стан kubelet та контейнерного середовища на вузлі.
Додавання підтримки для іншого формату логів
Монітор системного логу наразі підтримує файлові логи, journald та kmsg. Додаткові джерела можна додати, реалізувавши новий спостерігач за логами.
Додавання власних втулків моніторингу
Ви можете розширити Node Problem Detector для виконання будь-яких сценаріїв моніторингу, написаних будь-якою мовою програмування, розробивши власний втулок. Сценарії моніторингу повинні відповідати протоколу втулка щодо коду виходу та стандартного виводу. Для отримання додаткової інформації див. пропозицію інтерфейсу втулка.
Експортер
Експортер повідомляє про проблеми та/або метрики вузлів до певних бекендів. Підтримуються наступні експортери:
Експортер Kubernetes: цей експортер повідомляє про проблеми вузлів на сервер API Kubernetes. Тимчасові проблеми повідомляються як Події, а постійні проблеми — як Стан вузла.
Експортер Prometheus: цей експортер локально повідомляє про проблеми вузлів та метрики у форматі Prometheus (або OpenMetrics). Ви можете вказати IP-адресу та порт для експортера, використовуючи аргументи командного рядка.
Експортер Stackdriver: цей експортер повідомляє про проблеми вузлів та метрики в службу моніторингу Stackdriver. Поведінку експорту можна налаштувати, використовуючи файл конфігурації.
Рекомендації та обмеження
Рекомендується запускати Node Problem Detector в вашому кластері для моніторингу стану вузлів. При запуску Node Problem Detector можна очікувати додаткове навантаження ресурсів на кожному вузлі. Зазвичай це прийнятно, оскільки:
Лог ядра росте відносно повільно.
Для Node Problem Detector встановлено обмеження ресурсів.
4.4.5 - Налагодження вузлів Kubernetes за допомогою crictl
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.11 [stable]
crictl — це інтерфейс командного рядка для сумісних з CRI контейнерних середовищ. Ви можете використовувати його для огляду та налагодження контейнерних середовищ та застосунків на вузлі Kubernetes. crictl та його вихідний код розміщені у репозиторії cri-tools.
Перш ніж ви розпочнете
Для роботи crictl потрібна операційна система Linux з CRI середовищем.
Встановлення crictl
Ви можете завантажити архів crictl зі сторінки релізів у репозиторії cri-tools release page, для різних архітектур. Завантажте версію, яка відповідає вашій версії Kubernetes. Розпакуйте її та перемістіть у розташування у вашому системному шляху, наприклад, /usr/local/bin/.
Використання
Команда crictl має кілька підкоманд та прапорців для використання. Використовуйте crictl help або crictl <підкоманда> help для отримання більш детальної інформації.
Ви можете встановити точку доступу для crictl, виконавши одну з наступних дій:
Встановіть прапорці --runtime-endpoint та --image-endpoint.
Встановіть змінні середовища CONTAINER_RUNTIME_ENDPOINT та IMAGE_SERVICE_ENDPOINT.
Встановіть точку доступу в файлі конфігурації /etc/crictl.yaml. Щоб вказати інший файл, використовуйте прапорець --config=ШЛЯХ_ДО_ФАЙЛУ під час запуску crictl.
Примітка:
Якщо ви не встановите точку доступу, crictl спробує приєднатися до списку відомих точок доступу, що може вплинути на продуктивність.
Ви також можете вказати значення тайм-ауту при підключенні до сервера та увімкнути або вимкнути налагодження, вказавши значення timeout або debug в файлі конфігурації або використовуючи прапорці командного рядка --timeout та --debug.
Щоб переглянути або змінити поточну конфігурацію, перегляньте або відредагуйте вміст /etc/crictl.yaml. Наприклад, конфігурація при використанні виконавчого середовища containerd буде схожа на цю:
Нижче наведено деякі приклади команд crictl та їх вивід.
Отримання переліку Podʼів
Вивести перелік усіх Podʼів:
crictl pods
Вихідний результат схожий на такий:
POD ID CREATED STATE NAME NAMESPACE ATTEMPT
926f1b5a1d33a About a minute ago Ready sh-84d7dcf559-4r2gq default 0
4dccb216c4adb About a minute ago Ready nginx-65899c769f-wv2gp default 0
a86316e96fa89 17 hours ago Ready kube-proxy-gblk4 kube-system 0
919630b8f81f1 17 hours ago Ready nvidia-device-plugin-zgbbv kube-system 0
Список Podʼів за назвою:
crictl pods --name nginx-65899c769f-wv2gp
Вихідний результат схожий на такий:
POD ID CREATED STATE NAME NAMESPACE ATTEMPT
4dccb216c4adb 2 minutes ago Ready nginx-65899c769f-wv2gp default 0
Список Podʼів за мітками:
crictl pods --label run=nginx
Вихідний результат схожий на такий:
POD ID CREATED STATE NAME NAMESPACE ATTEMPT
4dccb216c4adb 2 minutes ago Ready nginx-65899c769f-wv2gp default 0
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
1f73f2d81bf98 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 7 хвилин тому Running sh 1
9c5951df22c78 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 8 хвилин тому Exited sh 0
87d3992f84f74 nginx@sha256:d0a8828cccb73397acb0073bf34f4d7d8aa315263f1e7806bf8c55d8ac139d5f 8 хвилин тому Running nginx 0
1941fb4da154f k8s-gcrio.azureedge.net/hyperkube-amd64@sha256:00d814b1f7763f4ab5be80c58e98140dfc69df107f253d7fdd714b30a714260a 18 годин тому Running kube-proxy 0
Вивести працюючі контейнери:
crictl ps
Вихідний результат схожий на такий:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
1f73f2d81bf98 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 6 хвилин тому Running sh 1
87d3992f84f74 nginx@sha256:d0a8828cccb73397acb0073bf34f4d7d8aa315263f1e7806bf8c55d8ac139d5f 7 хвилин тому Running nginx 0
1941fb4da154f k8s-gcrio.azureedge.net/hyperkube-amd64@sha256:00d814b1f7763f4ab5be80c58e98140dfc69df107f253d7fdd714b30a714260a 17 годин тому Running kube-proxy 0
Аудит Kubernetes забезпечує безпеку шляхом створення хронологічного набору записів, які документують послідовність дій у кластері. Кластер аудитує дії, що генеруються користувачами, застосунками, які використовують API Kubernetes, а також самою панеллю управління.
Аудит дозволяє адміністраторам кластера відповісти на такі питання:
що сталося?
коли це сталося?
хто це ініціював?
на чому це сталося?
де це було помічено?
звідки це було ініційовано?
куди це направлялося?
Записи аудиту починають свій життєвий цикл всередині компонента kube-apiserver. Кожен запит на кожному етапі його виконання генерує подію аудиту, яка потім передається до попередньої обробки відповідно до певної політики та записується в бекенд. Політика визначає, що буде записано, а бекенд зберігає записи. Поточні реалізації бекендів включають файли логів та вебхуки.
Кожний запит може бути записаний з асоційованим stage. Визначені етапи:
RequestReceived — Етап для подій, що генеруються, як тільки обробник аудиту отримує запит, і до того, як він передає його вниз по ланцюжку обробників.
ResponseStarted — Після надсилання заголовків відповіді, але перед відправленням тіла відповіді. Цей етап генерується лише для тривалих запитів (наприклад, watch).
ResponseComplete — Тіло відповіді завершено і більше байтів не буде відправлено.
Panic — Події, що генеруються при виникненні паніки.
Функція логування аудиту збільшує витрати памʼяті сервера API, оскільки для кожного запиту зберігається певний контекст, необхідний для аудитування. Витрати памʼяті залежать від конфігурації логування аудиту.
Політика аудиту
Політика аудиту визначає правила того, які події повинні бути записані та які дані вони повинні містити. Структура обʼєкта політики аудиту визначена в групі API audit.k8s.io. Коли подія обробляється, її порівнюють зі списком прав по черзі. Перший збіг прав встановлює рівень аудиту події. Визначені рівні аудиту:
None — не записувати події, які відповідають цьому правилу.
Metadata — реєструвати події з метаданими (користувач, часова відмітка, ресурс, дія тощо), але не тіло запиту чи відповіді.
Request — реєструвати події з метаданими та тілом запиту, але не з тілом відповіді. Це не застосовується до запитів на ресурси.
RequestResponse — реєструвати події з метаданими запиту, тілом запиту та тілом відповіді. Це не застосовується до запитів на ресурси.
Ви можете передати файл з політикою до kube-apiserver, використовуючи прапорець --audit-policy-file. Якщо прапорець пропущено, жодні події не записуються. Зверніть увагу, що поле rulesобовʼязково повинно бути вказано у файлі політики аудиту. Політика з нульовою кількістю (0) прав вважається неприпустимою.
apiVersion:audit.k8s.io/v1# Це обовʼязково.kind:Policy# Не генерувати події аудиту для всіх запитів на етапі RequestReceived.omitStages:- "RequestReceived"rules:# Логувати зміни у вузлах на рівні RequestResponse- level:RequestResponseresources:- group:""# Ресурс "pods" не відповідає запитам на будь-який підресурс вузлів,# що відповідає політиці RBAC.resources:["pods"]# Логувати "pods/log", "pods/status" на рівні Metadata- level:Metadataresources:- group:""resources:["pods/log","pods/status"]# Не логувати запити на configmap під назвою "controller-leader"- level:Noneresources:- group:""resources:["configmaps"]resourceNames:["controller-leader"]# Не логувати watch-запити "system:kube-proxy" на endpoints або services- level:Noneusers:["system:kube-proxy"]verbs:["watch"]resources:- group:""# Основна група APIresources:["endpoints","services"]# Не логувати автентифіковані запити до певних URL-шляхів, що не є ресурсами.- level:NoneuserGroups:["system:authenticated"]nonResourceURLs:- "/api*"# Зіставлення з шаблоном.- "/version"# Логувати тіло запиту на зміни configmap у kube-system.- level:Requestresources:- group:""# Основна група APIresources:["configmaps"]# Це правило застосовується тільки до ресурсів в просторі імен "kube-system".# Порожній рядок "" можна використовувати для вибору ресурсів без простору імен.namespaces:["kube-system"]# Логувати зміни configmap і secret у всіх інших просторах імен на рівні Metadata.- level:Metadataresources:- group:""# Основна група APIresources:["secrets","configmaps"]# Логувати всі інші ресурси в основній і розширюваній групах на рівні Request.- level:Requestresources:- group:""# Основна група API- group:"extensions"# Версія групи НЕ повинна включатися.# Загальне правило для логування всіх інших запитів на рівні Metadata.- level:Metadata# Довгострокові запити, такі як watches, які підпадають під це правило,# не генерують подію аудиту на етапі RequestReceived.omitStages:- "RequestReceived"
Ви можете використовувати мінімальну політику аудиту для логування всіх запитів на рівні Metadata:
# Записати всі запити на рівні Metadata.apiVersion:audit.k8s.io/v1kind:Policyrules:- level:Metadata
Якщо ви створюєте власний профіль аудиту, ви можете скористатися профілем аудиту для Google Container-Optimized OS як вихідною точкою. Ви можете перевірити сценарій configure-helper.sh, який генерує файл політики аудиту. Більшість файлу політики аудиту можна побачити, дивлячись безпосередньо на цей сценарій.
Події аудиту зберігаються в зовнішньому сховищі за допомогою бекендів аудиту. Стандартно kube-apiserver надає два бекенди:
Файловий бекенд, який записує події у файлову систему.
Бекенд Webhook, який відправляє події на зовнішній HTTP API.
У всіх випадках події аудиту слідують структурі, визначеній API Kubernetes в групі API audit.k8s.io.
Примітка:
У випадку патчів тіло запиту є масивом JSON з операціями патча, а не обʼєктом JSON з відповідним обʼєктом API Kubernetes. Наприклад, наступне тіло запиту є допустимим запитом на накладання патча до /apis/batch/v1/namespaces/some-namespace/jobs/some-job-name:
Бекенд логів записує події аудиту у файл у форматі JSONlines. Ви можете налаштувати бекенд логів за допомогою наступних прапорців kube-apiserver:
--audit-log-path вказує шлях до файлу логу, який бекенд логів використовує для запису подій аудиту. Відсутність цього прапорця вимикає бекенд логів; - означає стандартний вивід
--audit-log-maxage визначає максимальну кількість днів для зберігання старих файлів логів аудиту
--audit-log-maxbackup визначає максимальну кількість файлів логів аудиту для зберігання
--audit-log-maxsize визначає максимальний розмір в мегабайтах файлу логів аудиту до його ротації
Якщо панель управління вашого кластера працює з kube-apiserver як з Pod, не забудьте змонтувати hostPath до місця розташування файлу політики та файлу логів, щоб записи аудиту були збережені. Наприклад:
Бекенд аудиту webhook надсилає події аудиту до віддаленого веб-API, яке вважається формою Kubernetes API, включаючи засоби автентифікації. Ви можете налаштувати бекенд webhook за допомогою наступних прапорців kube-apiserver:
--audit-webhook-config-file вказує шлях до файлу з конфігурацією webhook. Конфігурація webhook фактично є спеціалізованим kubeconfig.
--audit-webhook-initial-backoff вказує час очікування після першого невдалого запиту перед повторною спробою. Наступні запити повторюються з експоненційною затримкою.
Файл конфігурації webhook використовує формат kubeconfig для вказування віддаленої адреси служби та облікових даних, які використовуються для підключення до неї.
Пакетна обробка подій
Обидва типи бекенд систем, як log, так і webhook, підтримують пакетну обробку. Нижче наведено перелік доступних прапорців для кожного бекенду. Стандартно пакетна обробка увімкнена для webhook і вимкнена для log.
--audit-webhook-mode визначає стратегію буферизації. Одна з наступних:
batch — буферизувати події та асинхронно обробляти їх пакетами. Це стандартне значення для webhook.
blocking — блокувати відповіді сервера API на обробці кожної окремої події.
blocking-strict — те саме, що й blocking, але коли відбувається збій під час логування аудиту на етапі RequestReceived, весь запит до kube-apiserver зазнає збою.
Наступні прапорці використовуються тільки в режимі batch:
--audit-webhook-batch-buffer-size визначає кількість подій для буферизації перед пакетною обробкою. Якщо швидкість надходження подій переповнює буфер, події відкидаються. Стандартне значення — 10000.
--audit-webhook-batch-max-size визначає максимальну кількість подій в одному пакеті. Стандартне значення — 400.
--audit-webhook-batch-max-wait визначає максимальний час очікування перед безумовною буферизацією подій у черзі.
--audit-webhook-batch-throttle-enable визначає, чи увімкнено тротлінг пакетів. Стандартно тротлінг увімкнено.
--audit-webhook-batch-throttle-qps визначає максимальну середню кількість пакетів, що генеруються за секунду. Стандартне значення — 10.
--audit-webhook-batch-throttle-burst визначає максимальну кількість пакетів, які генеруються в той же момент, якщо дозволений QPS раніше не використовувався повністю. Стандартне значення — 10.
--audit-log-mode визначає стратегію буферизації. Одна з наступних:
batch — буферизувати події та асинхронно обробляти їх пакетами. Пакетна обробка не рекомендується для бекенду log.
blocking — блокувати відповіді сервера API при обробці кожної окремої події. Це стандартний режим для бекенду log.
blocking-strict — те ж саме, що і блокування, але при збої під час логування аудиту на етапі RequestReceived, весь запит до kube-apiserver зазнає невдачі.
Наступні прапорці використовуються тільки в режимі batch (стандартно для бекенду log пакетна обробка вимкнена, і коли пакетну обробку вимкнено, всі прапорці, повʼязані з пакетною обробкою, ігноруються):
--audit-log-batch-buffer-size визначає кількість подій для буферизації перед пакетною обробкою. Якщо кількість подій, що надходять, переповнює буфер, події буде відкинуто.
--audit-log-batch-max-size визначає максимальну кількість подій в одному пакеті.
--audit-log-batch-max-wait визначає максимальний час очікування перед безумовною обробкою подій у черзі.
--audit-log-batch-throttle-enable визначає, чи увімкнено тротлінг пакетної обробки.
--audit-log-batch-throttle-qps визначає максимальну середню кількість пакетів, що генеруються за секунду.
--audit-log-batch-throttle-burst визначає максимальну кількість пакетів, згенерованих за один момент часу, якщо раніше було недовикористано дозволений QPS.
Налаштування параметрів
Параметри повинні бути встановлені з урахуванням навантаження на API-сервер.
Наприклад, якщо kube-apiserver отримує 100 запитів кожну секунду, і кожен запит проходить аудит лише на етапах ResponseStarted та ResponseComplete, вам слід розрахувати приблизно 200 подій аудиту, які генеруються кожну секунду. Припускаючи, що в пакеті може бути до 100 подій, вам слід встановити рівень обмеження принаймні у 2 запити на секунду. Припускаючи, що система може потребувати до 5 секунд для запису подій, вам слід встановити розмір буфера для зберігання подій протягом до 5 секунд; це означає: 10 пакетів або 1000 подій.
Проте в більшості випадків стандартні значення параметрів повинні бути достатніми, і вам не потрібно хвилюватися про їх ручне встановлення. Ви можете переглянути наступні метрики Prometheus, які експонує kube-apiserver, а також логи, щоб контролювати стан підсистеми аудиту.
Метрика apiserver_audit_event_total містить загальну кількість експортованих подій аудиту.
Метрика apiserver_audit_error_total містить загальну кількість подій, які були втрачені через помилку під час експортування.
Обмеження розміру запису в лозі
Обидва бекенди і логів, і webhook підтримують обмеження розміру подій, які записуються. Наприклад, ось список прапорців, доступних для бекенду логів:
audit-log-truncate-enabled визначає, чи ввімкнене обрізання подій та пакетів.
audit-log-truncate-max-batch-size максимальний розмір у байтах пакета, який надсилається до бекенду.
audit-log-truncate-max-event-size максимальний розмір у байтах аудитивної події, яка надсилається до бекенду.
Типово обрізання вимкнено як у webhook, так і у log. Адміністратор кластера повинен встановити audit-log-truncate-enabled або audit-webhook-truncate-enabled, щоб увімкнути цю функцію.
Дізнайтеся більше про типи ресурсів Event та Policy з Довідки налаштування аудиту.
4.4.7 - Налагодження вузлів Kubernetes за допомогою kubectl
Ця сторінка показує, як налагоджувати вузол на кластері Kubernetes за допомогою команди kubectl debug.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж 1.2.
Для перевірки версії введіть kubectl version.
Вам потрібно мати дозвіл на створення Podʼів та призначення їх новим Вузлам. Також вам потрібно мати дозвіл на створення Podʼів, які мають доступ до файлових систем з хосту.
Налагодження вузла за допомогою kubectl debug node
Використовуйте команду kubectl debug node, щоб розмістити Pod на Вузлі, який ви хочете налагодити. Ця команда корисна в сценаріях, коли ви не можете отримати доступ до свого Вузла за допомогою зʼєднання SSH. Після створення Podʼа, відкривається інтерактивний інтерфейс оболонки на Вузлі. Щоб створити інтерактивну оболонку на Вузлі з назвою “mynode”, виконайте:
kubectl debug node/mynode -it --image=ubuntu
Creating debugging pod node-debugger-mynode-pdx84 with container debugger on node mynode.
If you don't see a command prompt, try pressing enter.
root@mynode:/#
Команда налагоджування допомагає збирати інформацію та розвʼязувати проблеми. Команди, які ви можете використовувати, включають ip, ifconfig, nc, ping, ps тощо. Ви також можете встановити інші інструменти, такі як mtr, tcpdump та curl, з відповідного менеджера пакунків.
Примітка:
Команди для налагодження можуть відрізнятися залежно від образу, який використовує Pod налагодження, і ці команди можуть потребувати встановлення.
Pod налагодження може отримувати доступ до кореневої файлової системи Вузла, підключеної за адресою /host в Podʼі. Якщо ви використовуєте kubelet у просторі імен файлової системи, Pod налагодження бачить корінь для цього простору імен, а не всього Вузла. Для типового вузла Linux ви можете переглянути наступні шляхи для пошуку відповідних логів:
/host/var/log/kubelet.log
Логи kubelet, який відповідає за запуск контейнерів на вузлі.
/host/var/log/kube-proxy.log
Логи kube-proxy, який відповідає за направлення трафіку на точки доступу Service.
/host/var/log/containerd.log
Логи процесу containerd, який працює на вузлі.
/host/var/log/syslog
Показує загальні повідомлення та інформацію щодо системи.
/host/var/log/kern.log
Показує логи ядра.
При створенні сеансу налагодження на Вузлі майте на увазі, що:
kubectl debug автоматично генерує імʼя нового контейнера на основі імені вузла.
Коренева файлова система Вузла буде змонтована за адресою /host.
Хоча контейнер працює у просторі імен IPC, мережі та PID хосту, Pod не є привілейованим. Це означає, що читання деякої інформації про процес може бути неможливим, оскільки доступ до цієї інформації мають тільки суперкористувачі. Наприклад, chroot /host буде невдалим. Якщо вам потрібен привілейований контейнер, створіть його вручну або використовуйте прапорець --profile=sysadmin.
Коли ви закінчите використання Podʼа налагодження, видаліть його:
kubectl get pods
NAME READY STATUS RESTARTS AGE
node-debugger-mynode-pdx84 0/1 Completed 0 8m1s
# Змініть імʼя контейнера відповідноkubectl delete pod node-debugger-mynode-pdx84 --now
pod "node-debugger-mynode-pdx84" deleted
Примітка:
Команда kubectl debug node не працюватиме, якщо Вузол відключений (відʼєднаний від мережі, або kubelet вимкнено і він не перезапускається тощо). Перевірте налагодження вимкненого/недоступного вузла в цьому випадку.
4.4.8 - Розробка та налагодження сервісів локально за допомогою telepresence
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Зазвичай застосунки Kubernetes складаються з кількох окремих сервісів, кожен з яких працює у своєму власному контейнері. Розробка та налагодження цих сервісів на віддаленому кластері Kubernetes може бути незручною, оскільки ви змушені отримати оболонку в робочому контейнері для запуску інструментів налагодження.
telepresence — це інструмент, який полегшує процес розробки та налагодження сервісів локально, прокидаючи проксі для сервісу на віддаленому кластері Kubernetes. Використання telepresence дозволяє використовувати власні інструменти, такі як налагоджувач та IDE, для локального сервісу та забезпечує повний доступ до ConfigMap, Secret та Service, що працюють на віддаленому кластері.
У цьому документі описано використання telepresence для розробки та налагодження сервісів локально, які працюють на віддаленому кластері.
Підʼєднання вашого локального компʼютера до віддаленого кластера Kubernetes
Після встановлення telepresence запустіть telepresence connect, щоб запустити його Демона та підʼєднати ваш робочий компʼютер до кластера.
$ telepresence connect
Launching Telepresence Daemon
...
Connected to context default (https://<cluster public IP>)
Ви можете використовувати команду curl для отримання доступу до сервісів за синтаксисом Kubernetes, наприклад, curl -ik https://kubernetes.default.
Розробка або налагодження наявного сервісу
При розробці застосунку у Kubernetes ви зазвичай програмуєте або налагоджувати один сервіс. Цей сервіс може потребувати доступу до інших сервісів для тестування та налагодження. Один із варіантів — використання конвеєра постійного розгортання (continuous
deployment pipeline), але навіть найшвидший конвеєр розгортання додає затримку в цикл програмування або налагодження.
Використовуйте команду telepresence intercept $SERVICE_NAME --port $LOCAL_PORT:$REMOTE_PORT для створення "перехоплення" для перенаправлення трафіку віддаленого сервісу.
Де:
$SERVICE_NAME — це назва вашого локального сервісу
$LOCAL_PORT — це порт, на якому працює ваш сервіс на вашому локальному робочому місці
$REMOTE_PORT — це порт, на який ваш сервіс слухає в кластері
Виконавши цю команду, Telepresence каже перенаправляти віддалений трафік на ваш локальний сервіс замість сервісу в віддаленому кластері Kubernetes. Вносьте зміни до вихідного коду вашого сервісу локально, зберігайте та переглядайте відповідні зміни, коли ви отримуєте доступ до вашого віддаленого застосунку, ефект буде відразу. Ви також можете запустити ваш локальний сервіс, використовуючи налагоджувач або будь-який інший локальний інструмент розробки.
Як працює Telepresence?
Telepresence встановлює агента перенаправлення трафіку поряд із контейнером вашого наявного застосунку, який працює в віддаленому кластері. Він перехоплює всі запити на трафік, що надходять до Podʼа, і замість того, щоб пересилати це до застосунку у віддаленому кластері, він маршрутизує весь трафік (коли ви створюєте глобальне перехоплення або підмножину трафіку (коли ви створюєте персональне перехоплення) до вашого локального середовища розробки.
Що далі
Якщо вас цікавить практичний посібник, перегляньте ось цей посібник, в якому покроково описано розробку програми Guestbook локально на Google Kubernetes Engine.
Мої Podʼи застрягли на "Container Creating" або постійно перезавантажуються.
Переконайтеся, що ваш образ pause відповідає версії вашої операційної системи Windows. Див. Контейнер pause для перегляду останнього/рекомендованого образу pause та/або отримання додаткової інформації.
Примітка:
Якщо ви використовуєте containerd як оточення для виконання контейнерів, образ pause вказується в полі plugins.plugins.cri.sandbox_image файлу конфігурації config.toml.
Мої Podʼи показують статус як ErrImgPull або ImagePullBackOff.
Переконайтеся, що ваш Pod планується на сумісний вузол Windows.
Додаткову інформацію про те, як вказати сумісний вузол для вашого Podʼа, можна знайти в
цьому посібнику.
Розвʼязання проблем мережі
Мої Podʼи Windows не мають підключення до мережі.
Якщо ви використовуєте віртуальні машини, переконайтеся, що MAC spoofing увімкнено на всіх адаптерах мережі віртуальних машин.
Мої Podʼи Windows не можуть пінгувати зовнішні ресурси.
Podʼи Windows не мають правил для вихідного трафіку, програмованих для протоколу ICMP. Однак, підтримується TCP/UDP. При спробі продемонструвати підключення до ресурсів за межами кластера, замініть ping <IP> відповідними командами curl <IP>.
Якщо у вас все ще виникають проблеми, ймовірно, ваша мережева конфігурація в
cni.conf потребує додаткової уваги. Ви завжди можете редагувати цей статичний файл. Оновлення конфігурації буде застосовано до будь-яких нових ресурсів Kubernetes.
Одним із вимог мережі Kubernetes (див. Модель Kubernetes) є внутрішнє звʼязування кластера без NAT всередині. Щоб відповідати цій вимозі, існує ExceptionList для всього трафіку, де ви не хочете, щоб відбувалось використання NAT назовні. Однак, це також означає, що вам потрібно виключити зовнішню IP-адресу, яку ви намагаєтесь запитати з ExceptionList. Тільки тоді трафік, який походить з вашого Podʼа Windows, буде коректно SNAT'ed для отримання відповіді зі світу. З цього погляду ваш ExceptionList у cni.conf повинен виглядати так:
"ExceptionList": [
"10.244.0.0/16", # Підмережа кластера
"10.96.0.0/12", # Підмережа служби
"10.127.130.0/24" # Управління (хост) підмережа
]
Мій вузол Windows не може отримати доступ до служб типу NodePort.
Доступ до локального NodePort з самого вузла не вдається. Це відоме обмеження. Доступ до NodePort працює з інших вузлів або зовнішніх клієнтів.
vNICs та HNS точки доступу контейнерів видаляються.
Цю проблему може викликати відмова в передачі параметра hostname-override до kube-proxy. Щоб вирішити це, користувачі повинні передавати імʼя хосту kube-proxy наступним чином:
Мій вузол Windows не може отримати доступ до моїх Service за допомогою IP-адреси Service
Це відоме обмеження стека мережі на Windows. Однак, Podʼи Windows можуть отримувати доступ до IP-адреси Service.
Під час запуску kubelet не знайдено мережевого адаптера.
Для правильної роботи мережі Windows потрібен віртуальний адаптер. Якщо наступні команди не повертають результатів (в оболонці адміністратора), створення віртуальної мережі, необхідна передумова для роботи kubelet, не вдалося:
Get-HnsNetwork | ? Name -ieq"cbr0"Get-NetAdapter | ? Name -Like"vEthernet (Ethernet*"
Часто варто змінити параметр InterfaceName у скрипті start.ps1, в разі, якщо мережевий адаптер хосту не є "Ethernet". В іншому випадку зверніться до виводу скрипту start-kubelet.ps1, щоб побачити, чи є помилки під час створення віртуальної мережі.
DNS-перетворення не працює належним чином.
Перевірте обмеження DNS для Windows у цьому розділі.
kubectl port-forward видає помилку "unable to do port forwarding: wincat not found"
Це було реалізовано в Kubernetes 1.15, включивши wincat.exe в інфраструктурний контейнер pause mcr.microsoft.com/oss/kubernetes/pause:3.6. Будьте впевнені, що використовуєте підтримувану версію Kubernetes. Якщо ви хочете побудувати власний контейнер інфраструктури pause, обовʼязково додайте wincat.
Моє встановлення Kubernetes падає, тому що мій вузол сервера Windows знаходиться за проксі
Якщо ви перебуваєте за проксі, наступні змінні середовища PowerShell повинні бути визначені:
З Flannel мої вузли мають проблеми після повторного приєднання до кластера.
Кожного разу, коли раніше видалений вузол повторно приєднується до кластера, flannelD намагається призначити нову підмережу Podʼа вузлу. Користувачі повинні видалити старі файли конфігурації підмережі Podʼа за наступними шляхами:
Flanneld застрягає в "Waiting for the Network to be created"
Є численні звіти про цю проблему; ймовірно, це проблема з часом встановлення управлінської IP-адреси мережі flannel. Обхідним рішенням є перезапуск start.ps1 або перезапуск його вручну так:
Мої Podʼи Windows не можуть запуститися через відсутність /run/flannel/subnet.env.
Це вказує на те, що Flannel не запустився правильно. Ви можете спробувати перезапустити flanneld.exe або вручну скопіювати файли з /run/flannel/subnet.env на майстрі Kubernetes в C:\run\flannel\subnet.env на робочий вузол Windows та змінити рядок FLANNEL_SUBNET на інший номер. Наприклад, якщо підмережа вузла 10.244.4.1/24 бажана:
Якщо ці кроки не розвʼязують вашої проблеми, ви можете отримати допомогу у запуску контейнерів Windows на вузлах Windows у Kubernetes у наступних ресурсах:
Декларативні та імперативні парадигми взаємодії з API Kubernetes.
5.1 - Декларативне керування обʼєктами Kubernetes з використанням конфігураційних файлів
Обʼєкти Kubernetes можна створювати, оновлювати та видаляти, зберігаючи декілька файлів конфігурації обʼєктів у теці та використовувати kubectl apply для рекурсивного створення та оновлення цих обʼєктів за потреби. Цей метод зберігає записи, зроблені у поточних обʼєктах, без злиття змін до файлів конфігурації обʼєкта. За допомогою kubectl diff також можна переглянути зміни, які буде внесено командою apply.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Декларативна конфігурація обʼєктів потребує чіткого розуміння визначень та конфігурації обʼєктів Kubernetes. Прочитайте наступні документи, якщо ви ще цього не зробили:
Нижче подано визначення термінів, використаних у цьому документі:
файл конфігурації обʼєкта / файл конфігурації: Файл, який визначає конфігурацію для обʼєкта Kubernetes. Ця тема показує, як передавати файли конфігурації до kubectl apply. Файли конфігурації зазвичай зберігаються у системі контролю версій, такі як Git.
поточна конфігурація обʼєкта / поточна конфігурація: Поточні значення конфігурації обʼєкта, які використовуються кластером Kubernetes. Їх зберігають у сховищі кластера Kubernetes, зазвичай etcd.
декларативний записувач конфігурації / декларативний письменник: Особа або компонент програмного забезпечення, який вносить оновлення до поточного обʼєкта. Поточні записувачі, на які посилається ця тема, вносять зміни до файлів конфігурації обʼєктів та запускають kubectl apply для запису змін.
Як створити обʼєкти
Використовуйте kubectl apply, щоб створити всі обʼєкти, за винятком тих, що вже існують, які визначені у конфігураційних файлах у вказаній теці:
kubectl apply -f <тека>
Це встановлює анотацію kubectl.kubernetes.io/last-applied-configuration: '{...}' для кожного обʼєкта. Анотація містить вміст файлу конфігурації обʼєкта, який був використаний для створення обʼєкта.
Примітка:
Додайте прапорець -R, щоб рекурсивно обробляти теки.
Оскільки diff виконує запит на стороні сервера для застосування в режимі без внесення змін, для його роботи потрібно дозволити дії PATCH, CREATE та UPDATE. Детальніше див. Авторизація запуску dry-run.
Виведіть поточну конфігурацію за допомогою kubectl get:
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
Вивід показує, що анотація kubectl.kubernetes.io/last-applied-configuration була записана до поточної конфігурації та відповідає конфігураційному файлу:
kind:Deploymentmetadata:annotations:# ...# Це json-представлення simple_deployment.yaml# Воно було створено за допомогою kubectl apply під час створення обʼєктаkubectl.kubernetes.io/last-applied-configuration:| {"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.14.2","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}# ...spec:# ...minReadySeconds:5selector:matchLabels:# ...app:nginxtemplate:metadata:# ...labels:app:nginxspec:containers:- image:nginx:1.14.2# ...name:nginxports:- containerPort:80# ...# ...# ...# ...
Як оновити обʼєкти
Ви також можете використовувати kubectl apply, щоб оновити всі обʼєкти, визначені у теці, навіть якщо ці обʼєкти вже існують. Цей підхід виконує наступне:
Встановлює поля, що зʼявляються у файлі конфігурації, у поточній конфігурації.
Очищає поля, які були видалені з файлу конфігурації, у поточній конфігурації.
kubectl diff -f <тека>
kubectl apply -f <тека>
Примітка:
Додайте прапорець -R, щоб рекурсивно обробляти теки.
З метою ілюстрації, попередня команда посилається на один конфігураційний файл замість теки.
Виведіть поточну конфігурацію за допомогою kubectl get:
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
Вивід показує, що анотація kubectl.kubernetes.io/last-applied-configuration була записана до поточної конфігурації та відповідає конфігураційному файлу:
kind:Deploymentmetadata:annotations:# ...# Це json-представлення simple_deployment.yaml# Воно було створено за допомогою kubectl apply під час створення обʼєктаkubectl.kubernetes.io/last-applied-configuration:| {"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.14.2","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}# ...spec:# ...minReadySeconds:5selector:matchLabels:# ...app:nginxtemplate:metadata:# ...labels:app:nginxspec:containers:- image:nginx:1.14.2# ...name:nginxports:- containerPort:80# ...# ...# ...# ...
Напряму оновіть поле replicas у поточній конфігурації за допомогою kubectl scale. Для цього не використовується kubectl apply:
Виведіть поточну конфігурацію за допомогою kubectl get:
kubectl get deployment nginx-deployment -o yaml
Вивід показує, що поле replicas встановлено на 2, і анотація last-applied-configuration
не містить поле replicas:
apiVersion:apps/v1kind:Deploymentmetadata:annotations:# ...# Зверніть увагу, що анотація не містить replicas# тому що воно не було оновлено через applykubectl.kubernetes.io/last-applied-configuration:| {"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.14.2","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}# ...spec:replicas:2# Встановлено за допомогою `kubectl scale`. Ігнорується `kubectl apply`.# ...minReadySeconds:5selector:matchLabels:# ...app:nginxtemplate:metadata:# ...labels:app:nginxspec:containers:- image:nginx:1.14.2# Встановлено за допомогою `kubectl apply`# ...name:nginxports:- containerPort:80# ...# ...# ...
Оновіть конфігураційний файл simple_deployment.yaml, щоб змінити образ з nginx:1.14.2 на nginx:1.16.1 та видалити поле minReadySeconds:
Виведіть поточну конфігурацію за допомогою kubectl get:
kubectl get -f https://k8s.io/examples/application/update_deployment.yaml -o yaml
Вивід показує наступні зміни в поточній конфігурації:
Поле replicas зберігає значення 2, встановлене за допомогою kubectl scale. Це можливо через його відсутність у конфігураційному файлі.
Поле image було оновлено на nginx:1.16.1 з nginx:1.14.2.
Анотація last-applied-configuration була оновлена новим образом.
Поле minReadySeconds було очищено.
Анотація last-applied-configuration більше не містить поле minReadySeconds.
apiVersion:apps/v1kind:Deploymentmetadata:annotations:# ...# Анотація містить оновлений образ nginx 1.16.1,# але не містить оновлення копій на 2kubectl.kubernetes.io/last-applied-configuration:| {"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.16.1","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}# ...spec:replicas:2# Встановлено за допомогою `kubectl scale`. Ігнорується `kubectl apply`.# minReadySeconds очищено за допомогою `kubectl apply`# ...selector:matchLabels:# ...app:nginxtemplate:metadata:# ...labels:app:nginxspec:containers:- image:nginx:1.16.1# Встановлено за допомогою `kubectl apply`# ...name:nginxports:- containerPort:80# ...# ...# ...
Попередження:
Змішування kubectl apply з імперативними командами конфігурації обʼєктів create та replace не підтримується. Це через те, що create та replace не зберігають анотацію kubectl.kubernetes.io/last-applied-configuration, яку використовує kubectl apply для обробки оновлень.
Як видалити обʼєкти
Існують два підходи до видалення обʼєктів, керованих за допомогою kubectl apply.
Рекомендований: kubectl delete -f <filename>
Ручне видалення обʼєктів за допомогою імперативної команди є рекомендованим підходом, оскільки він більш явно вказує на те, що видаляється, і менш ймовірно призводить до випадкового видалення чогось:
Як альтернативу kubectl delete, ви можете використовувати kubectl apply для ідентифікації обʼєктів, які мають бути видалені після видалення їх маніфестів з теки у локальній файловій системі.
У Kubernetes 1.34, доступні два режими очищення в kubectl apply:
Очищення на основі allowlist: Цей режим існує з моменту kubectl v1.5, але все ще знаходиться на етапі альфа-тестування через проблеми з використанням, коректністю і продуктивністю його дизайну. Режим на основі ApplySet призначений для заміни його.
Очищення на основі ApplySet: apply set — це обʼєкт на стороні сервера (типово, Secret), який kubectl може використовувати для точного та ефективного відстеження членства в наборі під час операцій apply. Цей режим був введений у альфа-версії в kubectl v1.27 як заміна очищенню на основі allowlist.
Будьте обережні при використанні --prune з kubectl apply в режимі allow list. Те, які обʼєкти очищаються, залежить від значень прапорців --prune-allowlist, --selector та --namespace, і ґрунтується на динамічному виявленні обʼєктів, що підпадають під область застосування. Особливо, якщо значення прапорців змінюються між викликами, це може призвести до неочікуваного видалення або збереження обʼєктів.
Щоб використовувати очищення на основі allowlist, додайте наступні прапорці до свого виклику kubectl apply:
--prune: Видалити попередньо застосовані обʼєкти, які не є у наборі, що передані поточному виклику.
--prune-allowlist: Список груп-версій-типів (GVK, group-version-kind), які розглядаються для очищення. Цей прапорець є необовʼязковим, але наполегливо рекомендується, оскільки його стандартне значення є частковим списком обʼєктів з просторами імен та областями застосування, що може призвести до несподіваних результатів.
--selector/-l: Використовуйте селектор міток для обмеження набору обʼєктів, обраних для очищення. Цей прапорець є необовʼязковим, але наполегливо рекомендується.
--all: використовуйте замість --selector/-l, щоб явно вибрати всі попередньо застосовані обʼєкти відповідних типів, які знаходяться у списку дозволених.
Очищення на основі allowlist запитує API-сервер щодо всіх обʼєктів затверджених GVK, які відповідають заданим міткам (якщо є), і намагається зіставити конфігурації активних обʼєктів, отриманих в результаті, з файлами маніфестів обʼєктів. Якщо обʼєкт відповідає запиту і він не має маніфесту в теці, і має анотацію kubectl.kubernetes.io/last-applied-configuration, він видаляється.
Очищення з використанням --prune повинне бути виконане тільки для кореневої теки, що містить маніфести обʼєктів. Виконання для підтек може призвести до неочікуваного видалення обʼєктів, які раніше були застосовані, мають задані мітки (якщо є) і не зʼявляються у підтеці.
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.27 [alpha]
Увага:
kubectl apply --prune --applyset знаходиться на етапі альфа-тестування, і в майбутніх випусках можуть бути внесені зміни, що несумісні з попередніми версіями.
Для використання очищення на основі ApplySet встановіть змінну середовища KUBECTL_APPLYSET=true, і додайте наступні прапорці до свого виклику kubectl apply:
--prune: Видалити попередньо застосовані обʼєкти, які не є у наборі, що передані поточному виклику.
--applyset: Назва обʼєкта, який kubectl може використовувати для точного та ефективного відстеження членства в наборі під час операцій apply.
Типово тип батьківського обʼєкта ApplySet, що використовується, — Secret. Однак також можуть бути використані ConfigMaps у форматі: --applyset=configmaps/<name>. При використанні Secret або ConfigMap, kubectl створить обʼєкт, якщо він ще не існує.
Також можливе використання власних ресурсів як батьківських обʼєктів ApplySet. Для цього позначте міткою Custom Resource Definition (CRD), що визначає ресурс, який ви хочете використовувати з наступним: applyset.kubernetes.io/is-parent-type: true. Потім створіть обʼєкт, який ви хочете використовувати як батьківський обʼєкт ApplySet (kubectl цього не робить автоматично для Custom Resource). Нарешті, посилайтеся на цей обʼєкт у прапорці applyset таким чином: --applyset=<resource>.<group>/<name> (наприклад, widgets.custom.example.com/widget-name).
Під час очищення на основі ApplySet kubectl додає мітку applyset.kubernetes.io/part-of=<parentID> до кожного обʼєкта в наборі, перш ніж вони будуть надіслані на сервер. З метою продуктивності він також збирає список типів ресурсів і просторів імен, які включаються у набір, і додає ці дані в анотації поточного батьківського обʼєкта. В кінеці операції apply, він запитує API-сервер щодо обʼєктів цих типів в цих просторах імен (або в областях кластера, якщо це доречно), які належать до набору, визначеного міткою applyset.kubernetes.io/part-of=<parentID>.
Застереження та обмеження:
Кожен обʼєкт може бути членом не більше одного набору.
Прапорець --namespace є обовʼязковим при використанні будь-якого обʼєкта з простором імен, включаючи типово Secret. Це означає, що ApplySets, які охоплюють кілька просторів імен, повинні використовувати кластерний обʼєкт з кореневою текою.
Щоб безпечно використовувати очищення на основі ApplySet з декількома теками, використовуйте унікальне імʼя ApplySet для кожного.
Як переглянути обʼєкт
Ви можете використовувати kubectl get з -o yaml, щоб переглянути конфігурацію поточного обʼєкта:
kubectl get -f <filename|url> -o yaml
Як apply обчислює різницю та обʼєднує зміни
Увага:
Патч (накладання латок) — це операція оновлення, яка обмежена конкретними полями обʼєкта замість всього обʼєкта. Це дозволяє оновлювати лише певний набір полів обʼєкта без читання всього обʼєкта.
Коли kubectl apply оновлює поточну конфігурацію обʼєкта, він робить це, надсилаючи запит на патч до API-сервера. Патч визначає оновлення для конкретних полів конфігурації живого обʼєкта. Команда kubectl apply обчислює цей запит на патч за допомогою файлу конфігурації, поточної конфігурації та анотації last-applied-configuration, збереженої в поточній конфігурації.
Обчислення злиття патчів
Команда kubectl apply записує вміст файлу конфігурації до анотації kubectl.kubernetes.io/last-applied-configuration. Вона використовується для ідентифікації полів, які були видалені з файлу конфігурації та які потрібно видалити з поточної конфігурації. Ось кроки, які використовуються для обчислення того, які поля потрібно видалити або встановити:
Обчислити поля для видалення. Це поля, які присутні в last-applied-configuration та відсутні в файлі конфігурації.
Обчислити поля для додавання або встановлення. Це поля, які присутні в файлі конфігурації, значення яких не відповідають поточній конфігурації.
Ось приклад. Припустимо, що це файл конфігурації для обʼєкта типу Deployment:
Також, припустимо, що це поточна конфігурація для того самого обʼєкта типу Deployment:
apiVersion:apps/v1kind:Deploymentmetadata:annotations:# ...# Зауважте, що анотація не містить поля replicas,# оскільки воно не було оновлено через applykubectl.kubernetes.io/last-applied-configuration:| {"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.14.2","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}# ...spec:replicas:2# вказано через scale# ...minReadySeconds:5selector:matchLabels:# ...app:nginxtemplate:metadata:# ...labels:app:nginxspec:containers:- image:nginx:1.14.2# ...name:nginxports:- containerPort:80# ...
Ось обчислення злиття, які виконає kubectl apply:
Обчислення полів для видалення, отримуючи значення з last-applied-configuration і порівнюючи їх зі значеннями у файлі конфігурації. Очищення полів, які явно встановлені на null у локальному файлі конфігурації обʼєкта, незалежно від того, чи вони зʼявляються в анотації last-applied-configuration. У цьому прикладі minReadySeconds зʼявляється в анотації last-applied-configuration, але не зʼявляється у файлі конфігурації. Дія: Прибрати minReadySeconds з поточної конфігурації.
Обчислення полів для встановлення, отримуючи значення з файлу конфігурації та порівнюючи їх зі значеннями у поточній конфігурації. У цьому прикладі значення image у файлі конфігурації не відповідає значенню у поточній конфігурації. Дія: Встановити значення image у поточній конфігурації.
Встановити анотацію last-applied-configuration, щоб вона відповідала значенню файлу конфігурації.
Обʼєднати результати з 1, 2, 3 у єдиний запит на патч до API-сервера.
Ось поточна конфігурація, яка є результатом злиття:
apiVersion:apps/v1kind:Deploymentmetadata:annotations:# ...# Анотація містить оновлений образ nginx 1.16.1,# але не містить оновлення реплік до 2kubectl.kubernetes.io/last-applied-configuration:| {"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.16.1","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}# ...spec:selector:matchLabels:# ...app:nginxreplicas:2# Встановлено за допомогою `kubectl scale`. Ігнорується `kubectl apply`.# minReadySeconds очищено за допомогою `kubectl apply`# ...template:metadata:# ...labels:app:nginxspec:containers:- image:nginx:1.16.1# Встановлено за допомогою `kubectl apply`# ...name:nginxports:- containerPort:80# ...# ...# ...# ...
Як зливаються поля різних типів
Як певне поле в конфігураційному файлі зливається з поточною конфігурацією залежить від типу поля. Існують кілька типів полів:
primitive: Поле типу рядок, ціле число або логічне значення. Наприклад, image та replicas є полями примітивів. Дія: Замінити.
map, також відомий як object: Поле типу map або комплексний тип, який містить підполя. Наприклад, labels, annotations, spec та metadata — це всі map. Дія: Злити елементи або підполя.
list: Поле, яке містить список елементів, які можуть бути або типами primitive, або map. Наприклад, containers, ports та args є списками. Дія: Варіюється.
Коли kubectl apply оновлює map або list, він зазвичай не замінює все поле цілком, а замість цього оновлює окремі піделементи. Наприклад, при злитті spec в Deployment, весь spec не
замінюється. Замість цього порівнюються та зливаються підполя spec, такі як replicas.
Злиття змін для полів типу primitive
Поля primitive замінюються або очищаються.
Примітка:
- використовується для "not applicable", оскільки значення не використовується.
Поле в конфігураційному файлі обʼєкта
Поле в поточній конфігурації обʼєкта
Поле в останній застосованій конфігурації
Дія
Так
Так
-
Встановити поточне значення з конфігураційного файлу.
Так
Ні
-
Встановити поточне значення з локального конфігураційного файлу.
Ні
-
Так
Очистити з поточної конфігурації.
Ні
-
Ні
Нічого не робити. Зберегти значення поточного обʼєкта.
Злиття змін у полях типу map
Поля, які є map, зливаються шляхом порівняння кожного з підполів або елементів map:
Примітка:
- використовується для "not applicable", оскільки значення не використовується.
Ключ в конфігураційному файлі обʼєкта
Ключ у поточній конфігурації обʼєкта
Поле в останній застосованій конфігурації
Дія
Так
Так
-
Порівняти значення підполів.
Так
Ні
-
Встановити поточне значення з локального конфігураційного файлу.
Ні
-
Так
Видалити з поточної конфігурації.
Ні
-
Ні
Нічого не робити. Зберігти значення поточного обʼєкта.
Злиття змін для полів типу list
Злиття змін у list використовує одну з трьох стратегій:
Заміна list, якщо всі його елементи є primitive.
Злиття окремих елементів у списку комплексних елементів.
Злиття list елементів primitive.
Вибір стратегії залежить від конкретного поля.
Заміна list, якщо всі його елементи є primitive
Такий список трактується так само як і поле primitive. Замініть або видаліть
весь список. Це зберігає порядок.
Приклад: Використовуйте kubectl apply, щоб оновити поле args контейнера в Podʼі. Це встановлює значення args в поточній конфігурації на значення у файлі конфігурації. Будь-які елементи args, які раніше були додані до поточної конфігурації, втрачаються. Порядок елементів args, визначених у файлі конфігурації, зберігається у поточній конфігурації.
# Значення last-applied-configurationargs:["a","b"]# Значення файлу конфігураціїargs:["a","c"]# Поточна конфігураціяargs:["a","b","d"]# Результат після злиттяargs:["a","c"]
Пояснення: Злиття використовує значення файлу конфігурації як нове значення списку.
Злиття окремих елементів списку комлексних елементів:
Трактуйте список як map, а конкретне поле кожного елемента як ключ. Додавайте, видаляйте або оновлюйте окремі елементи. Це не зберігає порядок.
Ця стратегія злиття використовує спеціальний теґ на кожному полі, який називається patchMergeKey. patchMergeKey визначено для кожного поля в коді Kubernetes: types.go При злитті списку map, поле, вказане як patchMergeKey для певного елемента, використовується як ключ map для цього елемента.
Приклад: Використайте kubectl apply, щоб оновити поле containers у PodSpec. Це злиття списку, ніби він був map, де кожен елемент має ключ name.
# Значення last-applied-configurationcontainers:- name:nginximage:nginx:1.16- name: nginx-helper-a # ключ:nginx-helper-a; буде видалено у результатіimage:helper:1.3- name: nginx-helper-b # ключ:nginx-helper-b; буде збереженоimage:helper:1.3# Значення файлу конфігураціїcontainers:- name:nginximage:nginx:1.16- name:nginx-helper-bimage:helper:1.3- name: nginx-helper-c # ключ:nginx-helper-c; буде додано у результатіimage:helper:1.3# Поточна конфігураціяcontainers:- name:nginximage:nginx:1.16- name:nginx-helper-aimage:helper:1.3- name:nginx-helper-bimage:helper:1.3args:["run"]# Поле буде збережено- name: nginx-helper-d # ключ:nginx-helper-d; буде збереженоimage:helper:1.3# Результат після злиттяcontainers:- name:nginximage:nginx:1.16# Елемент nginx-helper-a був видалений- name:nginx-helper-bimage:helper:1.3args:["run"]# Поле було збережено- name:nginx-helper-c# Елемент був доданийimage:helper:1.3- name:nginx-helper-d# Елемент був ігнорованийimage:helper:1.3
Пояснення:
Контейнер з імʼям "nginx-helper-a" був видалений, оскільки жодного контейнера з іменем "nginx-helper-a" не знайдено у файлі конфігурації.
Контейнер з імʼям "nginx-helper-b" зберіг зміни у args в поточній конфігурації. kubectl apply зміг ідентифікувати, що "nginx-helper-b" у поточній конфігурації був тим самим "nginx-helper-b", що й у файлі конфігурації, навіть якщо їхні поля мали різні значення (немає args у файлі конфігурації). Це тому, що значення поля patchMergeKey (name) було ідентичним у обох.
Контейнер з імʼям "nginx-helper-c" був доданий, оскільки жодного контейнера з таким імʼям не було у поточній конфігурації, але один з таким імʼям був у файлі конфігурації.
Контейнер з імʼям "nginx-helper-d" був збережений, оскільки жодного елемента з таким імʼям не було в last-applied-configuration.
Злиття списку елементів типу primitive
Зараз, починаючи з Kubernetes 1.5, злиття списків елементів типу primitive не підтримується.
Примітка:
Яка зі стратегій вище вибирається для певного поля контролюється теґом patchStrategy у types.go. Якщо для поля типу списку не вказано patchStrategy, тоді список замінюється.
Стандартні значення полів
Сервер API встановлює в певні поля станадартні значення у поточній конфігурації, якщо вони не вказані при створенні обʼєкта.
Ось файл конфігурації для обʼєкта Deployment. У файлі не вказано strategy:
Виведіть поточну конфігурацію, використовуючи kubectl get:
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
Вивід показує, що сервер API встановив в деякі поля стандартні значення у поточній конфігурації. Ці поля не були вказані в файлі конфігурації.
apiVersion:apps/v1kind:Deployment# ...spec:selector:matchLabels:app:nginxminReadySeconds:5replicas:1# станадратне значення додане apiserverstrategy:rollingUpdate:# станадратне значення додане apiserver - походить з strategy.typemaxSurge:1maxUnavailable:1type:RollingUpdate# станадратне значення додане apiservertemplate:metadata:creationTimestamp:nulllabels:app:nginxspec:containers:- image:nginx:1.14.2imagePullPolicy:IfNotPresent# станадратне значення додане apiservername:nginxports:- containerPort:80protocol:TCP# станадратне значення додане apiserverresources:{}# станадратне значення додане apiserverterminationMessagePath:/dev/termination-log# станадратне значення додане apiserverdnsPolicy:ClusterFirst# станадратне значення додане apiserverrestartPolicy:Always# станадратне значення додане apiserversecurityContext:{}# станадратне значення додане apiserverterminationGracePeriodSeconds:30# станадратне значення додане apiserver# ...
У запиті на патч, поля, які мають станаддартні значення, не перезаписуються, якщо вони явно не очищені як частина запиту на патч. Це може призвести до неочікуваної поведінки для полів, які мають стнадартні значення на основі значень інших полів. Після зміни інших полів значення, які мають стандартні значення з них, не будуть оновлені, якщо їх не явно очищено.
З цієї причини рекомендується, щоб певні поля, стандартні значення яких встановлює сервер, були явно визначені в файлі конфігурації обʼєкта, навіть якщо бажані значення відповідають станадартним значенням сервера. Це полегшить розпізнавання суперечливих значень, які не будуть перезаписані сервером на станадартні значення.
Приклад:
# last-applied-configurationspec:template:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.14.2ports:- containerPort:80# конфігураційний файлspec:strategy:type:Recreate# оновленне значенняtemplate:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.14.2ports:- containerPort:80# поточна конфігураціяspec:strategy:type:RollingUpdate# встановлене типове значенняrollingUpdate:# встановлене типове значення отримане з typemaxSurge :1maxUnavailable:1template:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.14.2ports:- containerPort:80# результат після злиття - ПОМИЛКА!spec:strategy:type: Recreate # оновленне значення:несумісне з rollingUpdaterollingUpdate: # встановлене типове значення:несумісне з "type: Recreate"maxSurge :1maxUnavailable:1template:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.14.2ports:- containerPort:80
Пояснення:
Користувач створює Deployment без визначення strategy.type.
Сервер встановлює станадартне значення для strategy.type на RollingUpdate тв стандартне значення для strategy.rollingUpdate.
Користувач змінює strategy.type на Recreate. Значення strategy.rollingUpdate залишаються стандартними значеннями, хоча сервер очікує, що вони будуть очищені. Якщо значення strategy.rollingUpdate були визначені спочатку в файлі конфігурації, було б більш зрозуміло, що їх потрібно було б видалити.
Оновлення не вдається через те, що strategy.rollingUpdate не очищено. Поле strategy.rollingupdate не може бути визначено з strategy.typeRecreate.
Рекомендація: Ці поля слід явно визначити в файлі конфігурації обʼєкта:
Селектори та мітки PodTemplate для робочих навантажень, таких як Deployment, StatefulSet, Job, DaemonSet, ReplicaSet та ReplicationController.
Стратегія розгортання Deployment.
Як очистити стандартні поля встановлені сервером або поля, встановлені іншими записувачами
Поля, які не зʼявляються у файлі конфігурації, можна очистити, встановивши їх значення в null, а потім застосувати файл конфігурації. Для полів, стандартні значення яких встановлено сервером, це спричинить перезапис цих значень.
Як змінити власника поля між файлом конфігурації та прямими імперативними записувачами
Ці методи — єдиний вірний спосіб змінювати окреме поле обʼєкта:
Використовуйте kubectl apply.
Пишіть безпосередньо в поточну конфігурацію без змін файлу конфігурації: наприклад, використовуйте kubectl scale.
Зміна власника з прямого імперативного записувача на файл конфігурації
Додайте поле до файлу конфігурації. Для цього поля припиніть прямі оновлення поточної конфігурації, які не проходять через kubectl apply.
Зміна власника з файлу конфігурації на безпосереднього імперативного записувача
Починаючи з Kubernetes 1.5, зміна власника поля з файлу конфігурації на імперативного запусувача вимагає виконання наступних кроків:
Видаліть поле з файлу конфігурації.
Видаліть поле з анотації kubectl.kubernetes.io/last-applied-configuration на поточному обʼєкті.
Зміна методів управління
Обʼєктами Kubernetes слід керувати за допомогою лише одного методу одночасно. Перехід з одного методу на інший можливий, але це вимагає ручної обробки.
Примітка:
Використання імперативного видалення з декларативним управлінням є прийнятним.
Міграція з управління імперативними командами до декларативної конфігурації обʼєктів
Міграція з управління імперативними командами до декларативної конфігурації обʼєктів включає кілька ручних кроків:
Експортуйте поточний обʼєкт у локальний файл конфігурації:
kubectl get <kind>/<name> -o yaml > <kind>_<name>.yaml
Видаліть вручну поле status з файлу конфігурації.
Примітка:
Цей крок є необовʼязковим, оскільки kubectl apply не оновлює поле статусу, навіть якщо воно присутнє у файлі конфігурації.
Встановіть анотацію kubectl.kubernetes.io/last-applied-configuration на обʼєкті:
Змініть процеси так, щоб використовували kubectl apply виключно для керування обʼєктом.
Визначення селекторів контролера та міток PodTemplate
Попередження:
Рекомендується утриматися від оновлення селекторів на контролерах.
Рекомендований підхід — це визначення єдиного, незмінного підпису PodTemplate, який використовується тільки селектором контролера без іншого семантичного значення.
Починаючи з версії 1.14, kubectl також підтримує керування обʼєктами Kubernetes за допомогою файлу кастомізації. Для перегляду ресурсів, знайдених у теці, що містить файл кастомізації, виконайте наступну команду:
kubectl kustomize <kustomization_directory>
Щоб застосувати ці ресурси, запустіть kubectl apply з прапорцем --kustomize або -k:
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Kustomize — це інструмент для налаштування конфігурацій Kubernetes. Він має наступні функції для керування файлами конфігурації застосунків:
генерація ресурсів з інших джерел
встановлення наскрізних полів для ресурсів
складання та налаштування колекцій ресурсів
Генерування ресурсів
ConfigMaps та Secrets зберігають конфігураційні або конфіденційні дані, які використовуються іншими обʼєктами Kubernetes, наприклад, Podʼами. Джерело істини для ConfigMaps або Secrets є зазвичай зовнішнім до кластера, наприклад як файл .properties або файл ключів SSH. Kustomize має secretGenerator та configMapGenerator, які створюють Secret та ConfigMap з файлів або літералів.
configMapGenerator
Щоб створити ConfigMap з файлу, додайте запис до списку files в configMapGenerator. Ось приклад створення ConfigMap з елементом даних з файлу .properties:
Щоб створити ConfigMap з файлу оточення (env), додайте запис до списку envs в configMapGenerator. Ось приклад створення ConfigMap з елементом даних з файлу .env:
Кожна змінна у файлі .env стає окремим ключем в ConfigMap, який ви генеруєте. Це відрізняється від попереднього прикладу, в якому вбудовується файл з назвою application.properties (та всі його записи) як значення для одного ключа.
ConfigMaps також можна створювати з літеральних пар ключ-значення. Щоб створити ConfigMap з літеральною парою ключ-значення, додайте запис до списку literals в configMapGenerator. Ось приклад створення ConfigMap з елементом даних з пари ключ-значення:
Щоб використовувати згенерований ConfigMap у Deployment, посилайтеся на нього за іменем configMapGenerator. Kustomize автоматично замінить це імʼя згенерованим.
Ось приклад Deployment, що використовує згенерований ConfigMap:
Ви можете створювати Secrets з файлів або літеральних пар ключ-значення. Щоб створити Secret з файлу, додайте запис до списку files в secretGenerator. Ось приклад створення Secret з елементом даних з файлу:
Щоб створити Secret з літеральною парою ключ-значення, додайте запис до списку literals в secretGenerator. Ось приклад створення Secret з елементом даних з пари ключ-значення:
Згенеровані ConfigMaps та Secrets мають суфікс хешу вмісту, що додається. Це забезпечує створення нового ConfigMap або Secret при зміні вмісту. Щоб вимкнути поведінку додавання суфікса, можна використовувати generatorOptions. Крім того, також можливо вказати загальні опції для згенерованих ConfigMaps та Secrets.
Часто в проєкті складають набір ресурсів та керують ними всередині одного файлу чи теки. Kustomize пропонує компонування ресурсів з різних файлів та застосування патчів чи інших налаштувань до них.
Компонування
Kustomize підтримує компонування різних ресурсів. Поле resources у файлі kustomization.yaml визначає список ресурсів, які слід включити в конфігурацію. Встановіть шлях до файлу конфігурації ресурсу у списку resources. Ось приклад додавання до конфігурації застосунку NGINX, що складається з Deployment та Service:
Ресурси з kubectl kustomize ./ містять обʼєкти як Deployment, так і Service.
Кастомізація
Патчі можуть бути використані для застосування різних кастомізацій до ресурсів. Kustomize підтримує різні механізми патчів через StrategicMerge та Json6902 за допомогою поля patches. patches може бути файлом або вбудованим рядком, спрямованим на один або декілька ресурсів.
Поле patches містить список застосованих патчів у порядку їхнього зазначення. Патч вибирає ресурси за group, version, kind, name, namespace, labelSelector і annotationSelector.
Рекомендується створювати невеликі патчі, які виконують одну задачу. Наприклад, створіть один патч для збільшення номера репліки розгортання, а інший — для встановлення ліміту памʼяті. Цільовий ресурс буде знайдено за допомогою полів group, version, kind і name з файлу патчу.
Не всі ресурси чи поля підтримують патчі strategicMerge. Для підтримки зміни довільних полів у довільних Ресурсах, Kustomize пропонує застосування JSON патчів через patchesJson6902. Щоб знайти правильний Ресурс для патча Json6902, обовʼязково потрібно вказати поле target у файлі kustomization.yaml.
Наприклад, збільшити кількість реплік обʼєкта Deployment можна також за допомогою патчу Json6902. Цільовий ресурс знаходиться за допомогою group, version, kind та name з поля target.
Крім патчів, Kustomize також пропонує налаштування контейнерних образів або введення значень полів з інших обʼєктів в контейнери без створення патчів. Наприклад, ви можете змінити використаний образ усередині контейнерів, вказавши новий образ у полі images у kustomization.yaml.
Іноді застосунок, що працює у Podʼі, може потребувати використання значень конфігурації з інших обʼєктів. Наприклад, Pod з обʼєкту Deployment повинен читати відповідне імʼя Service з Env або як аргумент команди. Оскільки імʼя Service може змінюватися через namePrefix або nameSuffix, додавання імені Service у командний аргумент не рекомендується. Для цього використовується Kustomize, що вводить імʼя Service в контейнери через replacements.
У Kustomize існують концепції base та overlay. Base — це тека з файлом kustomization.yaml, яка містить набір ресурсів та повʼязані налаштування. Base може бути як локальною текою, так і текою з віддаленого репозиторію, якщо присутній файл kustomization.yaml. Overlay — це тека з файлом kustomization.yaml, яка посилається на інші теки з налаштуваннями як на свої base компоненти. Base не знає про overlay і може використовуватися в кількох overlay.
Файл kustomization.yaml у теці overlay може посилатися на декілька bases, обʼєднуючи всі ресурси, визначені у цих базах, в єдину конфігурацію. Крім того, він може застосовувати кастомізації поверх цих ресурсів, щоб задовольнити певні вимоги.
Цю базу можна використовувати в кількох overlay. Ви можете додавати різний namePrefix або інші загальні поля у різних overlay. Ось два overlay, які використовують один і той же base.
Як застосувати/переглядати/видаляти обʼєкти використовуючи Kustomize
Використовуйте --kustomize або -k у командах kubectl, щоб визначити Ресурси, які керуються kustomization.yaml. Зверніть увагу, що -k повинен посилатися на теку з налаштуваннями kustomization, наприклад,
5.3 - Керування обʼєктами Kubernetes за допомогою імперативних команд
Обʼєкти Kubernetes можна швидко створювати, оновлювати та видаляти безпосередньо за допомогою імперативних команд, вбудованих в інструмент командного рядка kubectl. Цей документ пояснює, як організовано ці команди та як їх використовувати для керування поточними обʼєктами.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Інструмент kubectl підтримує команди, що базуються на дії, для створення деяких найпоширеніших типів обʼєктів. Команди названі так, щоб їх можна було впізнати користувачам, що не знайомі з типами обʼєктів Kubernetes.
run: Створює новий Pod для запуску контейнера.
expose: Створює новий обʼєкт Service для балансування трафіку між Pod.
autoscale: Створює новий обʼєкт Autoscaler для автоматичного горизонтального масштабування контролера, наприклад, Deployment.
Інструмент kubectl також підтримує команди створення, що базуються на типі обʼєкта. Ці команди підтримують більше типів обʼєктів і більш явно вказують на їх наміри, але вимагають, щоб користувачі знали типи обʼєктів, які вони мають намір створити.
create <типобʼєкта> [<підтип>] <імʼяекземпляра>
Деякі типи обʼєктів мають підтипи, які можна вказати в команді create. Наприклад, обʼєкт Service має кілька підтипів, включаючи ClusterIP, LoadBalancer та NodePort. Ось приклад створення Service з підтипом NodePort:
kubectl create service nodeport <myservicename>
У попередньому прикладі команда create service nodeport викликається як підкоманда команди create service.
Ви можете використовувати прапорець -h, щоб знайти аргументи та прапорці, які підтримуються підкомандою:
kubectl create service nodeport -h
Як оновлювати обʼєкти
Команда kubectl підтримує команди, що базуються на дії, для деяких загальних операцій оновлення. Ці команди названі так, щоб користувачі, які не знайомі з обʼєктами Kubernetes, могли виконувати оновлення, не знаючи конкретних полів, які потрібно встановити:
scale: Горизонтально масштабувати контролер для додавання або видалення Podʼів шляхом оновлення кількості реплік контролера.
annotate: Додати або видалити анотацію з обʼєкта.
label: Додати або видалити мітку з обʼєкта.
Команда kubectl також підтримує команди оновлення, що базуються на аспекті обʼєкта. Встановлення цього аспекту може встановлювати різні поля для різних типів обʼєктів:
set<поле>: Встановити аспект обʼєкта.
Примітка:
У версії Kubernetes 1.5 не кожна команда, що базується на дії, має повʼязану команду, що базується на аспекті.
Інструмент kubectl підтримує ці додаткові способи оновлення поточного обʼєкта безпосередньо, однак вони вимагають кращого розуміння схеми обʼєктів Kubernetes.
edit: Безпосередньо редагувати сирі конфігурації поточного обʼєкта, відкриваючи його конфігурацію в редакторі.
patch: Безпосередньо модифікувати конкретні поля поточного обʼєкта, використовуючи рядок патча. Докладніше про рядки патча див. розділ патча в Конвенціях API.
Як видаляти обʼєкти
Ви можете використовувати команду delete, щоб видалити обʼєкт з кластера:
delete <тип>/<імʼя>
Примітка:
Ви можете використовувати kubectl delete як для імперативних команд, так і для імперативного конфігурування обʼєкта. Різниця полягає в аргументах, переданих команді. Щоб використовувати kubectl delete як імперативну команду, передайте обʼєкт для видалення як аргумент. Ось приклад, який передає обʼєкт Deployment з іменем nginx:
kubectl delete deployment/nginx
Як переглянути обʼєкт
Існують кілька команд для виведення інформації про обʼєкт:
get: Виводить базову інформацію про відповідні обʼєкти. Використовуйте get -h, щоб побачити список опцій.
describe: Виводить агреговану детальну інформацію про відповідні обʼєкти.
logs: Виводить stdout та stderr для контейнера, що працює в Pod.
Використання команд set для модифікації обʼєктів перед створенням
Є деякі поля обʼєктів, для яких не існує прапорця, який можна використовувати в команді create. У деяких з цих випадків ви можете використовувати комбінацію set та create, щоб вказати значення для поля перед створенням обʼєкта. Це робиться за допомогою перенаправлення виводу команди create на команду set, а потім назад на команду create. Ось приклад:
Команда kubectl create service -o yaml --dry-run=client створює конфігурацію для Service, але виводить її на stdout у форматі YAML замість надсилання до сервера API Kubernetes.
Команда kubectl set selector --local -f - -o yaml читає конфігурацію з stdin і записує оновлену конфігурацію на stdout у форматі YAML.
Команда kubectl create -f - створює обʼєкт, використовуючи надану конфігурацію через stdin.
Використання --edit для модифікації обʼєктів перед створенням
Можна використовувати kubectl create --edit, щоб зробити довільні зміни обʼєкта перед його створенням. Ось приклад:
5.4 - Імперативне керування обʼєктами Kubernetes за допомогою файлів конфігурації
Обʼєкти Kubernetes можна створювати, оновлювати та видаляти за допомогою інструменту командного рядка kubectl разом із файлом конфігурації обʼєкта, написаним у форматі YAML або JSON. У цьому документі пояснюється, як визначати та керувати обʼєктами за допомогою файлів конфігурації.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Ви можете використовувати kubectl create -f для створення обʼєкта з файлу конфігурації. Дивіться Довідник API Kubernetes для отримання деталей.
kubectl create -f <filename|url>
Як оновити обʼєкти
Попередження:
Оновлення обʼєктів за допомогою команди replace призводить до видалення всіх частин специфікації, які не вказані в файлі конфігурації. Це не слід використовувати з обʼєктами, чиї специфікації частково керуються кластером, наприклад, Service типу LoadBalancer, де поле externalIPs керується незалежно від файлу конфігурації. Поля, які керуються незалежно, повинні бути скопійовані в файл конфігурації, щоб уникнути їх втрати під час виконання replace.
Ви можете використовувати kubectl replace -f для оновлення поточного обʼєкта згідно з файлом конфігурації.
kubectl replace -f <filename|url>
Як видалити обʼєкти
Ви можете використовувати kubectl delete -f для видалення обʼєкта, який описаний у файлі конфігурації.
kubectl delete -f <filename|url>
Попередження:
Якщо файл конфігурації вказує поле generateName в секції metadata замість поля name, ви не можете видалити обʼєкт, використовуючи kubectl delete -f <filename|url>. Вам доведеться використовувати інші прапорці для видалення обʼєкта. Наприклад:
Ви можете використовувати kubectl get -f, щоб переглянути інформацію про обʼєкт, що описаний у файлі конфігурації.
kubectl get -f <filename|url> -o yaml
Прапорець -o yaml вказує, що повна конфігурація обʼєкта виводиться. Використовуйте kubectl get -h, щоб побачити список опцій.
Обмеження
Команди create, replace та delete працюють добре, коли кожна конфігурація обʼєкта повністю визначена і записана у своєму файлі конфігурації. Однак, коли поточний обʼєкт оновлюється, і оновлення не обʼєднуються в його файл конфігурації, оновлення будуть втрачені після наступного виконання replace. Це може статися, якщо контролер, такий як HorizontalPodAutoscaler, вносить оновлення безпосередньо до поточного обʼєкта. Ось приклад:
Ви створюєте обʼєкт з файлу конфігурації.
Інше джерело оновлює обʼєкт, змінюючи якесь поле.
Ви замінюєте обʼєкт з файлу конфігурації. Зміни, внесені іншим джерелом на кроці 2, втрачені.
Якщо вам потрібна підтримка кількох записувачів для одного обʼєкта, ви можете використовувати kubectl apply для керування обʼєктом.
Створення та редагування обʼєкта за URL без зберігання конфігурації
Припустимо, що у вас є URL файлу конфігурації обʼєкта. Ви можете використовувати kubectl create --edit для внесення змін до конфігурації перед створенням обʼєкта. Це особливо корисно для підручників та завдань, які вказують на файл конфігурації, який може бути змінений читачем.
kubectl create -f <url> --edit
Міграція від імперативних команд до імперативного конфігурування обʼєктів
Міграція від імперативних команд до імперативної конфігурації обʼєктів включає декілька кроків, які потрібно виконати вручну.
Експортуйте поточний обʼєкт у локальний файл конфігурації обʼєкта:
kubectl get <kind>/<name> -o yaml > <kind>_<name>.yaml
Ручне видалення поля стану з файлу конфігурації обʼєкта.
Для подальшого керування обʼєктом виключно використовуйте replace.
kubectl replace -f <kind>_<name>.yaml
Визначення селекторів контролерів та міток PodTemplate
Попередження:
Оновлення селекторів на контролерах наполегливо не рекомендується.
Рекомендований підхід — визначити одну незмінну мітку PodTemplate, яка використовується тільки селектором контролера без іншого семантичного значення.
5.5 - Оновлення обʼєктів API на місці за допомогою kubectl patch
Використовуйте kubectl patch для оновлення обʼєктів Kubernetes API на місці. Виконайте стратегічний патч злиття або патч злиття JSON.
Це завдання показує, як використовувати kubectl patch для оновлення обʼєкта API на місці. Вправи в цьому завданні демонструють стратегічний патч злиття та патч злиття JSON.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Вивід показує, що Deployment має два Podʼи. 1/1 вказує на те, що кожен Pod має один контейнер:
NAME READY STATUS RESTARTS AGE
patch-demo-28633765-670qr 1/1 Running 0 23s
patch-demo-28633765-j5qs3 1/1 Running 0 23s
Зробіть позначку про імена працюючих Podʼів. Пізніше ви побачите, що ці Podʼи будуть завершені та замінені новими.
На цей момент кожен Pod має один контейнер, який запускає образ nginx. Тепер, здавалося б, вам потрібно, щоб кожен Pod мав два контейнери: один, який запускає nginx, і один, який запускає redis.
Створіть файл з іменем patch-file.yaml, який має такий вміст:
Перегляньте Podʼи, повʼязані з вашим Deployment після накладання патчу:
kubectl get pods
Вивід показує, що працюючі Podʼи мають різні імена Podʼів, у порівнняні з тими що працювали раніше. Deployment припинив роботу старих Podʼів та створив два нові Podʼи, які відповідають оновленій специфікації Deployment. 2/2 вказує на те, що кожен Pod має два контейнера:
NAME READY STATUS RESTARTS AGE
patch-demo-1081991389-2wrn5 2/2 Running 0 1m
patch-demo-1081991389-jmg7b 2/2 Running 0 1m
Придивіться уважніше до одного з Podʼів patch-demo:
kubectl get pod <your-pod-name> --output yaml
Вивід показує, що Pod має два контейнери: один, який запускає nginx, і один, який запускає redis:
containers:- image:redis...- image:nginx...
Примітки щодо стратегічного патчу злиття
Патч, який ви виконали у попередній вправі, називається стратегічним патчем злиття. Зверніть увагу, що патч не замінив список containers. Замість цього він додав новий контейнер до списку. Іншими словами, список у патчі був обʼєднаний з поточним списком. Це не завжди трапляється, коли ви використовуєте стратегічний патч злиття для списку. У деяких випадках список замінюється, а не обʼєднується.
За допомогою стратегічних патчів злиття список або замінюється, або обʼєднується залежно від його стратегії патча. Стратегія патча вказується значенням ключа patchStrategy у мітці поля в вихідному коді Kubernetes. Наприклад, поле Containers структури PodSpec має patchStrategy рівне merge:
"io.k8s.api.core.v1.PodSpec": {...,"containers": {"description": "List of containers belonging to the pod. ...."},"x-kubernetes-patch-merge-key": "name","x-kubernetes-patch-strategy": "merge"}
Зверніть увагу, що список tolerations в PodSpec був замінений, а не обʼєднаний. Це тому, що поле Tolerations структури PodSpec не має ключа patchStrategy у своїй мітці поля. Тому стратегія патча, що використовується стандартно, дорівнює replace.
type PodSpec struct {
... Tolerations []Toleration `json:"tolerations,omitempty" protobuf:"bytes,22,opt,name=tolerations"`...}
Використання патчу злиття JSON для оновлення Deployment
Стратегічне патч злиття відрізняється від JSON merge patch. З JSON merge patch, якщо вам потрібно оновити список, вам потрібно вказати цілий новий список. І новий список повністю замінює поточний список.
Команда kubectl patch має параметр type, який ви можете встановити на одне з цих значень:
Список containers, який ви вказали у патчі, має лише один контейнер. Вивід показує, що ваш список з одним контейнером замінив наявний список containers.
У виводі ви можете побачити, що наявні Podʼи були завершені, а нові Podʼи — створені. 1/1 вказує на те, що кожен новий Pod працює лише з одним контейнером.
NAME READY STATUS RESTARTS AGE
patch-demo-1307768864-69308 1/1 Running 0 1m
patch-demo-1307768864-c86dc 1/1 Running 0 1m
Використання стратегічного патча злиття для оновлення Deployment з використанням стратегії retainKeys
Ось файл конфігурації для Deployment, що використовує стратегію RollingUpdate:
У виводі ви побачите, що неможливо встановити type як Recreate, коли значення визначено для spec.strategy.rollingUpdate:
The Deployment "retainkeys-demo" is invalid: spec.strategy.rollingUpdate: Forbidden: may not be specified when strategy `type` is 'Recreate'
Способом видалити значення для spec.strategy.rollingUpdate під час оновлення значення для type є використання стратегії retainKeys для стратегічного злиття.
Створіть ще один файл з іменем patch-file-retainkeys.yaml з таким вмістом:
spec:strategy:$retainKeys:- typetype:Recreate
З цим патчем ми вказуємо, що ми хочемо зберегти лише ключ type обʼєкта strategy. Таким чином, під час операції патча значення rollingUpdate буде видалено.
Знову застосуйте патч до вашого Deployment з цим новим патчем:
kubectl get deployment retainkeys-demo --output yaml
У виводі показано, що обʼєкт стратегії в Deployment більше не містить ключа rollingUpdate:
spec:strategy:type:Recreatetemplate:
Примітки щодо стратегічного патчу злиття з використанням стратегії retainKeys
Патч, який ви виконали в попередній вправі, називається стратегічним патчем злиття з використанням стратегії retainKeys. Цей метод вводить нову директиву $retainKeys, яка має наступні стратегії:
Вона містить список рядків.
Усі поля, які потрібно зберегти, повинні бути присутні в списку $retainKeys.
Поля, які присутні, будуть обʼєднані з поточним обʼєктом.
Всі відсутні поля будуть очищені під час застосування патча.
Усі поля у списку $retainKeys повинні бути надмножиною або такими ж, як і поля, що присутні в патчі.
Стратегія retainKeys не працює для всіх обʼєктів. Вона працює лише тоді, коли значення ключа patchStrategy у мітці поля в вихідному коді Kubernetes містить retainKeys. Наприклад, поле Strategy структури DeploymentSpec має patchStrategy рівне retainKeys:
"io.k8s.api.apps.v1.DeploymentSpec": {...,"strategy": {"$ref": "#/definitions/io.k8s.api.apps.v1.DeploymentStrategy","description": "The deployment strategy to use to replace existing pods with new ones.","x-kubernetes-patch-strategy": "retainKeys"},....}
Оновлення кількості реплік обʼєкта за допомогою kubectl patch з --subresource
Прапорець --subresource=[імʼя-субресурсу] використовується з командами kubectl, такими як get, patch, edit, apply і replace, для отримання та оновлення субресурсів status, scale та resize cубресурсів вказаних вами ресурсів. Ви можете вказати субресурс для будь-якого ресурсу API Kubernetes (вбудованих та CR), які мають субресурси status, scale або resize.
Наприклад, Deployment має субресурси status та scale, тож ви можете використовувати kubectl для отримання та зміни субресрусу status Deploymentʼа.
apiVersion:apps/v1kind:Deploymentmetadata:name:nginx-deploymentspec:selector:matchLabels:app:nginxreplicas:2# вказує Deployment запустити 2 Podʼи, що відповідають шаблонуtemplate:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.14.2ports:- containerPort:80
Якщо ви запускаєте kubectl patch і вказуєте прапорець --subresource для ресурсу, який не підтримує цей конкретний субресурс, сервер API повертає помилку 404 Not Found.
Підсумки
У цій вправі ви використали kubectl patch, щоб змінити поточну конфігурацію обʼєкта Deployment. Ви не змінювали файл конфігурації, який ви спочатку використовували для створення обʼєкта Deployment. Інші команди для оновлення обʼєктів API включають kubectl annotate, kubectl edit, kubectl replace, kubectl scale, та kubectl apply.
Примітка:
Стратегічний патч злиття не підтримується для власних ресурсів.
5.6 - Міграція обʼєктів Kubernetes за допомогою міграції версій сховища
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.30 [alpha](стандартно вимкнено)
Kubernetes покладається на активне переписування даних API, щоб підтримувати деякі дії обслуговування, повʼязані зі збереженням у спокої. Два видатні приклади цього — це версійна схема збережених ресурсів (тобто зміна перевіреної схеми збереження від v1 до v2 для певного ресурсу) та шифрування у спокої (тобто перезапис старих даних на основі зміни у способі шифрування даних).
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.30.
Для перевірки версії введіть kubectl version.
Переконайтеся, що у вашому кластері увімкнено функціональні можливостіStorageVersionMigrator та InformerResourceVersion. Для внесення цих змін вам знадобиться доступ адміністратора панелі управління.
Увімкніть REST API для міграції версій сховища, встановивши параметр конфігурації storagemigration.k8s.io/v1alpha1 на true для API-сервера. Для отримання додаткової інформації про те, як це зробити, прочитайте увімкнення або вимкнення API Kubernetes.
Перешифрування Secret Kubernetes за допомогою міграції версій сховища
Для початку, налаштуйте постачальника KMS для шифрування даних у спокої в etcd, використовуючи наступну конфігурацію шифрування.
Переконайтеся, що автоматичне перезавантаження конфігурації шифрування встановлено на значення true, встановивши --encryption-provider-config-automatic-reload.
Перевірте
збережений Secret тепер починається з k8s:enc:aescbc:v1:key2.
Оновлення бажаної схеми зберігання CRD
Розгляньте сценарій, де створено CustomResourceDefinition (CRD), щоб обслуговувати власні ресурси (CR), і встановлено як бажана схема сховища. Коли настане час ввести v2 CRD, його можна додати для обслуговування лише з вебхуком. Це дозволяє плавний перехід, де користувачі можуть створювати CR за допомогою схеми v1 або v2, з вкбхуком, що виконує необхідну конвертацію схеми між ними. Перш ніж встановити v2 як бажану версію схеми сховища, важливо переконатися, що всі наявні CR, збережені як v1, мігрували на v2. Ця міграція може бути досягнута через Storage Version Migration для міграції всіх CR від v1 до v2.
Створіть маніфест для CRD з назвою test-crd.yaml, наступного змісту:
apiVersion:apiextensions.k8s.io/v1kind:CustomResourceDefinitionmetadata:name:selfierequests.stable.example.comspec:group:stable.example.comnames:plural:SelfieRequestssingular:SelfieRequestkind:SelfieRequestlistKind:SelfieRequestListscope:Namespacedversions:- name:v1served:truestorage:trueschema:openAPIV3Schema:type:objectproperties:hostPort:type:stringconversion:strategy:Webhookwebhook:clientConfig:url:"https://127.0.0.1:9443/crdconvert"caBundle:<Інформація про CA Bundle>conversionReviewVersions:- v1- v2
Створіть CRD за допомогою kubectl:
kubectl apply -f test-crd.yaml
Створіть маніфест для прикладу testcrd. Назва маніфесту — cr1.yaml, з наступним змістом:
Перевірте, що CR записано і збережено як v1, отримавши обʼєкт з etcd.
ETCDCTL_API=3 etcdctl get /kubernetes.io/stable.example.com/testcrds/default/cr1 [...] | hexdump -C
де [...] містить додаткові аргументи для підключення до сервера etcd.
Оновіть CRD test-crd.yaml, щоб додати версію v2 для обслуговування і сховища, а також v1 як обслуговування тільки, наступним чином:
apiVersion:apiextensions.k8s.io/v1kind:CustomResourceDefinitionmetadata:name:selfierequests.stable.example.comspec:group:stable.example.comnames:plural:SelfieRequestssingular:SelfieRequestkind:SelfieRequestlistKind:SelfieRequestListscope:Namespacedversions:- name:v2served:truestorage:trueschema:openAPIV3Schema:type:objectproperties:host:type:stringport:type:string- name:v1served:truestorage:falseschema:openAPIV3Schema:type:objectproperties:hostPort:type:stringconversion:strategy:Webhookwebhook:clientConfig:url:"https://127.0.0.1:9443/crdconvert"caBundle:<Інформація про CA Bundle>conversionReviewVersions:- v1- v2
Оновіть CRD за допомогою kubectl:
kubectl apply -f test-crd.yaml
Створіть файл ресурсу CR з назвою cr2.yaml наступного змісту:
Створіть обʼєкт за допомогою kubectl наступним чином:
kubectl apply -f migrate-crd.yaml
Спостерігайте за міграцією Secretʼів, використовуючи статус. Успішна міграція повинна мати умову Succeeded, встановлену на "True" у полі статусу. Отримайте ресурс міграції наступним чином:
kubectl get storageversionmigration.storagemigration.k8s.io/crdsvm -o yaml
Перевірте, що раніше створений cr1 тепер записано і збережено як v2, отримавши обʼєкт з etcd.
ETCDCTL_API=3 etcdctl get /kubernetes.io/stable.example.com/testcrds/default/cr1 [...] | hexdump -C
де [...] містить додаткові аргументи для підключення до сервера etcd.
6 - Керування Secret
Керування конфіденційними налаштуваннями за допомогою Secret.
6.1 - Керування Secret за допомогою kubectl
Створення обʼєктів Secret за допомогою інструменту командного рядка kubectl.
На цій сторінці ви дізнаєтесь, як створювати, редагувати, керувати та видаляти Secret Kubernetes за допомогою інструменту командного рядка kubectl.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Обʼєкт Secret зберігає конфіденційні дані, такі як облікові дані, які використовуються потоками для доступу до служб. Наприклад, вам може знадобитися Secret для зберігання імені користувача та пароля, необхідних для доступу до бази даних.
Ви можете створити Secret, передаючи необроблену інформацію у команді, або зберігаючи облікові дані у файлах, які ви передаєте в команді. Наступні команди створюють Secret, який зберігає імʼя користувача admin та пароль S!B\*d$zDsb=.
Вам потрібно використовувати одинарні лапки '', щоб екранувати спеціальні символи, такі як $, \, *, =, і ! у вашому рядку. Якщо ви цього не зробите, ваша оболонка буде інтерпретувати ці символи відповідним чином.
Примітка:
Поле stringData для Secret не працює добре з apply на боці сервера.
Прапорець -n гарантує, що згенеровані файли не матимуть додаткового символу нового рядка в кінці тексту. Це важливо, оскільки коли kubectl зчитує файл і кодує вміст у рядок base64, додатковий символ нового рядка також буде закодований. Вам не потрібно екранувати спеціальні символи у рядках, які ви включаєте в файл.
Команди kubectl get та kubectl describe стандартно уникають показу вмісту Secret. Це зроблено для захисту Secret від випадкового розкриття або збереження в журналі термінала.
Розкодування Secret
Перегляньте вміст створеного вами Secret:
kubectl get secret db-user-pass -o jsonpath='{.data}'
Це приклад для цілей документації. На практиці цей метод може спричинити збереження команди з закодованими даними в історії вашої оболонки. Будь-хто, хто має доступ до вашого компʼютера, може знайти цю команду та розкодувати Secret. Кращий підхід — поєднувати команди перегляду та розкодування.
kubectl get secret db-user-pass -o jsonpath='{.data.password}' | base64 --decode
Редагування Secret
Ви можете редагувати наявний обʼєкт Secret, якщо він не є незмінним. Щоб редагувати Secret, виконайте наступну команду:
kubectl edit secrets <secret-name>
Це відкриває ваш стандартний редактор і дозволяє оновити значення Secret, закодовані в base64, у полі data, як у наступному прикладі:
# Будь ласка, відредагуйте обʼєкт нижче. Рядки, що починаються з '#', будуть ігноруватися,# і порожній файл припинить редагування. Якщо виникне помилка під час збереження цього файлу, він буде# знову відкритий з відповідними збоями.#apiVersion:v1data:password:UyFCXCpkJHpEc2I9username:YWRtaW4=kind:Secretmetadata:creationTimestamp:"2022-06-28T17:44:13Z"name:db-user-passnamespace:defaultresourceVersion:"12708504"uid:91becd59-78fa-4c85-823f-6d44436242actype:Opaque
6.2 - Керування Secret за допомогою конфігураційного файлу
Створення обʼєктів Secret за допомогою конфігураційного файлу ресурсів.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Ви можете спочатку визначити обʼєкт Secret у форматі JSON або YAML у маніфесті, а потім створити цей обʼєкт. Ресурс Secret містить два словники: data та stringData. Поле data використовується для зберігання довільних даних, закодованих за допомогою base64. Поле stringData надається для зручності, і воно дозволяє вам надавати ті самі дані у вигляді незакодованих рядків. Ключі data та stringData повинні складатися з буквено-цифрових символів, -, _ або ..
Наведений нижче приклад зберігає два рядки у Secret, використовуючи поле data.
Серіалізовані значення JSON та YAML даних Secret кодуються як рядки base64. Переходи на новий рядок не дійсні у цих рядках та повинні бути вилучені. При використанні утиліти base64 у Darwin/macOS користувачі повинні уникати використання опції -b для розбиття довгих рядків. Навпаки, користувачам Linux слід додавати опцію -w 0 до команд base64 або конвеєру base64 | tr -d '\n', якщо опція -w недоступна.
Вказання незакодованих даних під час створення Secret
Для певних сценаріїв можливо вам захочеться використовувати поле stringData. Це поле дозволяє вам розміщувати незакодований рядок безпосередньо у Secret, і цей рядок буде закодований за вас при створенні або оновленні Secret.
Практичний приклад цього може бути там, де ви розгортаєте застосунок, що використовує Secret для зберігання файлу конфігурації, і ви хочете заповнити частини цього файлу конфігурації під час процесу розгортання.
Наприклад, якщо ваш застосунок використовує такий файл конфігурації:
Щоб редагувати дані у Secret, створеному за допомогою маніфесту, змініть поле data або stringData у вашому маніфесті та застосуйте файл у вашому кластері. Ви можете редагувати наявний обʼєкт Secret, за винятком випадку, коли він є незмінним.
Наприклад, якщо ви хочете змінити пароль з попереднього прикладу на birdsarentreal, виконайте наступне:
Kubernetes оновлює наявний обʼєкт Secret. Докладно, інструмент kubectl помічає, що є обʼєкт Secret з тим самим імʼям. kubectl отримує поточний обʼєкт, планує зміни в ньому і надсилає змінений обʼєкт Secret до панелі управління кластера.
Створення обʼєктів Secret за допомогою файлу kustomization.yaml.
kubectl підтримує використання інструменту керування обʼєктами Kustomize для керування Secret та ConfigMap. Ви можете створити генератор ресурсів за допомогою Kustomize, який створює Secret, який ви можете застосувати до сервера API за допомогою kubectl.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Ви можете створити Secret, визначивши secretGenerator у файлі kustomization.yaml, який посилається на інші наявні файли, файли .env або літеральні значення. Наприклад, наведені нижче інструкції створюють файл конфігурації kustomization для імені користувача admin та пароля 1f2d1e2e67df.
Примітка:
Поле stringData для Secret погано працює із застосуванням на стороні сервера.
Ви також можете визначити secretGenerator у файлі kustomization.yaml, надаючи файли .env. Наприклад, наступний файл kustomization.yaml використовує дані з файлу .env.secret:
У всіх випадках вам не потрібно кодувати значення base64. Імʼя YAML файлу має бути kustomization.yaml або kustomization.yml.
Застосування файлу kustomization
Для створення Secret застосуйте теку, який містить файл kustomization:
kubectl apply -k <directory-path>
Вивід буде подібний до:
secret/database-creds-5hdh7hhgfk created
Коли Secret генерується, імʼя Secret створюється шляхом хешування даних Secret і додавання до нього значення хешу. Це забезпечує, що при зміні даних генерується новий Secret.
Щоб перевірити, що Secret був створений та розкодувати дані Secret,
kubectl get -k <directory-path> -o jsonpath='{.data}'
У вашому файлі kustomization.yaml змініть дані, наприклад, password.
Застосуйте теку, який містить файл kustomization:
kubectl apply -k <directory-path>
Вивід буде подібний до:
secret/db-user-pass-6f24b56cc8 created
Змінений Secret створюється як новий обʼєкт Secret, а не оновлюється наявний обʼєкт Secret. Можливо, вам знадобиться оновити посилання на Secret у ваших контейнерах.
Визначення конфігурації та інших даних для Podʼів, на яких працює ваше навантаження.
7.1 - Визначення команд та аргументів для контейнера
Ця сторінка показує, як визначати команди та аргументи при запуску контейнера
в Pod.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Визначення команди та аргументів при створенні Podʼа
При створенні Podʼа ви можете визначити команду та аргументи для контейнерів, які працюють в Podʼі. Щоб визначити команду, включіть поле command у файл конфігурації. Щоб визначити аргументи для команди, включіть поле args у файл конфігурації. Команду та аргументи, які
ви визначаєте, не можна змінити після створення Podʼа.
Команда та аргументи, які ви визначаєте у файлі конфігурації, перевизначають станадртну команду та аргументи, надані образом контейнера. Якщо ви визначаєте аргументи, але не визначаєте команду, використовується стандартна команда з вашими новими аргументами.
Примітка:
Поле command відповідає ENTRYPOINT, а поле args відповідає CMD у деяких реалізаціях середовища виконання контейнерів.
У цьому завданні ви створюєте Pod, який запускає один контейнер. Файл конфігурації для Podʼа визначає команду та два аргументи:
Вивід показує, що контейнер, який працював у Podʼі command-demo, завершився.
Щоб побачити вивід команди, яка запустилася в контейнері, перегляньте логи з Podʼа:
kubectl logs command-demo
Вивід показує значення змінних середовища HOSTNAME та KUBERNETES_PORT:
command-demo
tcp://10.3.240.1:443
Використання змінних середовища для визначення аргументів
У попередньому прикладі ви визначили аргументи безпосередньо, надавши їх. Як альтернативу наданню рядків безпосередньо, ви можете визначати аргументи, використовуючи змінні середовища:
Це означає, що ви можете визначити аргумент для Podʼа, використовуючи будь-які з технік доступних для визначення змінних середовища, включаючи ConfigMap та Secret.
Примітка:
Змінна середовища зʼявляється у дужках, "$(VAR)". Це необхідно для того, щоб змінна була розгорнута у полі command або args.
Виконання команди в оболонці
У деяких випадках вам потрібно, щоб ваша команда запускалася в оболонці. Наприклад, ваша
команда може складатися з кількох команд, обʼєднаних в конвеєр, або це може бути сценарій оболонки. Щоб запустити вашу команду в оболонці, оберніть її так:
command: ["/bin/sh"]args: ["-c", "while true; do echo hello; sleep 10;done"]
Ця сторінка показує, як визначати залежні змінні середовища для контейнера у Podʼі Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Визначення змінної залежної від середовища для контейнера
При створенні Podʼа ви можете встановлювати залежні змінні середовища для контейнерів, які працюють в Podʼі. Для встановлення залежних змінних середовища ви можете використовувати $(VAR_NAME) у valueenv у файлі конфігурації.
У цьому завданні ви створюєте Pod, який запускає один контейнер. Файл конфігурації для Podʼа визначає залежну змінну середовища з визначеним загальним використанням. Ось маніфест конфігурації для Podʼа:
Як показано вище, ви визначили правильне посилання на залежність SERVICE_ADDRESS, неправильне посилання на залежність UNCHANGED_REFERENCE і пропустили залежні посилання на залежність ESCAPED_REFERENCE.
Коли змінна середовища вже визначена при посиланні, посилання може бути правильно розгорнуте, як у випадку з SERVICE_ADDRESS.
Зверніть увагу, що порядок має значення у списку env. Змінна середовища не вважається "визначеною", якщо вона вказана далі в списку. Тому UNCHANGED_REFERENCE не вдається розгорнути $(PROTOCOL) у прикладі вище.
Коли змінна середовища невизначена або містить лише деякі змінні, невизначена змінна середовища трактується як звичайний рядок, як у випадку з UNCHANGED_REFERENCE. Зверніть увагу, що неправильно опрацьовані змінні середовища, як правило, не блокують запуск контейнера.
Синтаксис $(VAR_NAME) може бути екранований подвійним $, тобто: $$(VAR_NAME). Екрановані посилання ніколи не розгортаються, незалежно від того, чи визначена посилана змінна, чи ні. Це можна побачити у випадку з ESCAPED_REFERENCE вище.
7.3 - Визначення змінних середовища для контейнера
Ця сторінка показує, як визначити змінні середовища для контейнера у Kubernetes Pod.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
При створенні Pod ви можете задати змінні середовища для контейнерів, які запускаються в Pod. Щоб задати змінні середовища, включіть поле env або envFrom у файлі конфігурації.
Поля env та envFrom мають різний ефект.
env
дозволяє вам задати змінні середовища для контейнера, вказуючи значення безпосередньо для кожної змінної, яку ви називаєте.
envFrom
дозволяє вам задати змінні середовища для контейнера, посилаючись на ConfigMap або Secret. Коли ви використовуєте envFrom, всі пари ключ-значення у зазначеному ConfigMap або Secret встановлюються як змінні середовища для контейнера. Ви також можете вказати спільний префіксовий рядок.
У цьому завданні ви створюєте Pod, який запускає один контейнер. Конфігураційний файл для Pod визначає змінну середовища з імʼям DEMO_GREETING та значенням "Привіт із середовища". Ось маніфест конфігурації для Pod:
apiVersion:v1kind:Podmetadata:name:envar-demolabels:purpose:demonstrate-envarsspec:containers:- name:envar-demo-containerimage:gcr.io/google-samples/hello-app:2.0env:- name:DEMO_GREETINGvalue:"Hello from the environment"- name:DEMO_FAREWELLvalue:"Such a sweet sorrow"
NAME READY STATUS RESTARTS AGE
envar-demo 1/1 Running 0 9s
Перегляньте змінні середовища контейнера Pod:
kubectl exec envar-demo -- printenv
Вивід буде подібний до такого:
NODE_VERSION=4.4.2
EXAMPLE_SERVICE_PORT_8080_TCP_ADDR=10.3.245.237
HOSTNAME=envar-demo
...
DEMO_GREETING=Привіт із середовища
DEMO_FAREWELL=Такий солодкий прощальний слова
Примітка:
Змінні середовища, встановлені за допомогою полів env або envFrom, перевизначають будь-які змінні середовища, вказані в образі контейнера.
Примітка:
Змінні середовища можуть посилатися одна на одну, проте важливий порядок. Змінні, які використовують інші, визначені в тому ж контексті, повинні йти пізніше у списку. Також уникайте циклічних посилань.
Використання змінних середовища у вашій конфігурації
Змінні середовища, які ви визначаєте у конфігурації Pod у .spec.containers[*].env[*], можна використовувати в інших частинах конфігурації, наприклад, у командах та аргументах, які ви задаєте для контейнерів Pod. У наступній конфігурації прикладу, змінні середовища GREETING, HONORIFIC та NAME встановлені на Warm greetings to, The Most Honorable та Kubernetes відповідно. Змінна середовища MESSAGE комбінує набір усіх цих змінних середовища, а потім використовує їх як аргумент командного рядка, переданий контейнеру env-print-demo.
7.4 - Визначення значень змінних середовища за допомогою контейнера ініціалізації
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.34 [alpha](стандартно вимкнено)
Ця сторінка показує, як налаштувати змінні середовища для контейнерів у Pod за допомогою файлу.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
В маніфесті ви можете побачити, що initContainer монтує том emptyDir і записує змінні середовища у файл всередині нього, а звичайні контейнери посилаються на нього як на файл, так і на ключ змінної середовища через поле fileKeyRef, не потребуючи монтування тому. Коли поле optional встановлено в false, вказаний key у fileKeyRef повинен існувати у файлі змінних середовища.
Том буде змонтовано лише в контейнер, який записує у файл
(initContainer), тоді як контейнер-споживач, який споживає змінну середовища, не матиме змонтованого тому.
Під час ініціалізації контейнера kubelet отримує змінні середовища
з вказаних файлів у томі emptyDir і надає їх контейнеру.
Примітка:
Всі типи контейнерів (initContainers, звичайні контейнери, sidecars контейнери та епhemeral контейнери) підтримують завантаження змінних середовища з файлів.
Хоча ці змінні середовища можуть зберігати конфіденційну інформацію, томи emptyDir не забезпечують тих самих механізмів захисту, що й спеціалізовані об'єкти Secret. Тому вважається, що відкриття конфіденційних змінних середовища для контейнерів за допомогою цієї функції не є кращою практикою з точки зору безпеки.
Вивід показує значення вибраних змінних середовища:
DB_ADDRESS=address
Синтаксис файлів env
Формат файлів env Kubernetes походить з файлів .env.
У середовищі оболонки файли .env зазвичай завантажуються за допомогою команди source .env.
Для Kubernetes визначений формат файлів env дотримується більш суворих правил синтаксису:
Порожні рядки: Порожні рядки ігноруються.
Початкові пробіли: Початкові пробіли у всіх рядках ігноруються.
Оголошення змінних: Змінні повинні бути оголошені у форматі VAR=VAL. Пробіли навколо = та пробіли в кінці ігноруються.
VAR=VAL → VAL
Коментарі: Рядки, що починаються з #, вважаються коментарями і ігноруються.
# comment
VAR=VAL → VAL
VAR=VAL # not a comment → VAL # not a comment
Продовження рядка: Зворотний слеш (\) в кінці рядка оголошення змінної вказує на те, що значення продовжується на наступному рядку. Рядки об'єднуються з одним пробілом.
7.5 - Використання змінних середовища для передачі контейнерам інформації про Pod
Ця сторінка показує, як Pod може використовувати змінні середовища для передачі інформації про себе контейнерам, які працюють в Pod, використовуючи downward API. Ви можете використовувати змінні середовища для експозиції полів Pod, полів контейнера або обох.
У Kubernetes є два способи експозиції полів Pod та контейнера для запущеного контейнера:
Разом ці два способи експозиції полів Pod та контейнера називаються downward API.
Оскільки Service є основним засобом взаємодії між контейнеризованими застосунками, якими керує Kubernetes, корисно мати можливість виявляти їх під час виконання.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У цьому маніфесті ви бачите пʼять змінних середовища. Поле env є масивом визначень змінних середовища. Перший елемент у масиві вказує, що змінна середовища MY_NODE_NAME отримує своє значення з поля spec.nodeName Pod. Аналогічно, інші змінні середовища отримують свої назви з полів Pod.
Примітка:
Поля в цьому прикладі є полями Pod. Вони не є полями контейнера в Pod.
Щоб побачити, чому ці значення є в лозі, подивіться на поля command та args у файлі конфігурації. При запуску контейнера він записує значення пʼяти змінних середовища у stdout. Він повторює це кожні десять секунд.
Далі, отримайте оболонку в контейнер, який працює в вашому Pod:
kubectl exec -it dapi-envars-fieldref -- sh
У вашій оболонці перегляньте змінні середовища:
# Виконайте це в оболонці всередині контейнераprintenv
Вивід показує, що деякі змінні середовища мають призначені значення
полів Pod:
Використання полів контейнера як значень для змінних середовища
У попередньому завданні ви використовували інформацію з полів рівня Pod як значення для змінних середовища. У наступному завданні ви плануєте передати поля, які є частиною визначення Pod, але взяті з конкретного контейнера замість всього Pod загалом.
Ось маніфест для іншого Pod, який знову має лише один контейнер:
У цьому маніфесті ви бачите чотири змінні середовища. Поле env є масивом визначень змінних середовища. Перший елемент у масиві вказує, що змінна середовища MY_CPU_REQUEST отримує своє значення з поля requests.cpu контейнера з іменем test-container. Аналогічно, інші змінні середовища отримують свої значення з полів, що є специфічними для цього контейнера.
7.6 - Передача інформації про Pod контейнерам через файли
Ця сторінка показує, як Pod може використовувати volumeDownwardAPI, щоб передати інформацію про себе контейнерам, які працюють в Pod. volumeDownwardAPI може викривати поля Pod та контейнера.
У Kubernetes є два способи експозиції полів Pod та контейнера для запущеного контейнера:
Разом ці два способи експозиції полів Pod та контейнера називаються downward API.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У маніфесті ви бачите, що у Pod є volumeDownwardAPI, і контейнер монтує том за шляхом /etc/podinfo.
Подивіться на масив items під downwardAPI. Кожен елемент масиву визначає volumeDownwardAPI. Перший елемент вказує, що значення поля metadata.labels Pod має бути збережене в файлі з назвою labels. Другий елемент вказує, що значення поля annotations Pod має бути збережене в файлі з назвою annotations.
Примітка:
Поля в цьому прикладі є полями Pod. Вони не є полями контейнера в Pod.
У виводі ви побачите, що файли labels та annotations знаходяться в тимчасовій підтеці: у цьому прикладі, ..2982_06_02_21_47_53.299460680. У теці /etc/podinfo, ..data є символічним посиланням на тимчасову підтеку. Також у теці /etc/podinfo, labels та annotations є символічними посиланнями.
drwxr-xr-x ... Feb 6 21:47 ..2982_06_02_21_47_53.299460680
lrwxrwxrwx ... Feb 6 21:47 ..data -> ..2982_06_02_21_47_53.299460680
lrwxrwxrwx ... Feb 6 21:47 annotations -> ..data/annotations
lrwxrwxrwx ... Feb 6 21:47 labels -> ..data/labels
/etc/..2982_06_02_21_47_53.299460680:
total 8
-rw-r--r-- ... Feb 6 21:47 annotations
-rw-r--r-- ... Feb 6 21:47 labels
Використання символічних посилань дозволяє динамічне атомарне оновлення метаданих; оновлення записуються у новий тимчасову теку, а символічне посилання ..data оновлюється атомарно за допомогою rename(2).
Примітка:
Контейнер, який використовує Downward API як том з subPath монтуванням, не отримає оновлень від Downward API.
Вийдіть з оболонки:
/# exit
Зберігання полів контейнера
У попередньому завданні ви зробили поля Pod доступними за допомогою Downward API. У наступній вправі ви передаєте поля, які є частиною визначення Pod, але беруться з конкретного контейнера скоріше, ніж з Pod загалом. Ось маніфест для Pod, що має лише один контейнер:
У маніфесті ви бачите, що у Pod є volumeDownwardAPI, і що контейнер у цьому Pod монтує том за шляхом /etc/podinfo.
Подивіться на масив items під downwardAPI. Кожен елемент масиву визначає файл у томі downward API.
Перший елемент вказує, що в контейнері з назвою client-container, значення поля limits.cpu у форматі, вказаному як 1m, має бути опубліковане як файл з назвою cpu_limit. Поле divisor є необовʼязковим і має стандартне значення 1. Дільник 1 означає ядра для ресурсів cpu, або байти для ресурсів memory.
Отримайте доступ до оболонки в контейнері, який працює в вашому Pod:
kubectl exec -it kubernetes-downwardapi-volume-example-2 -- sh
У вашій оболонці перегляньте файл cpu_limit:
# Виконайте це в оболонці всередині контейнераcat /etc/podinfo/cpu_limit
Ви можете використовувати подібні команди, щоб переглянути файли cpu_request, mem_limit та mem_request.
Проєцювання ключів на конкретні шляхи та дозволи на файли
Ви можете проєціювати ключі на конкретні шляхи та конкретні дозволи на файл на основі файлу. Для отримання додаткової інформації дивіться Secret.
Що далі
Прочитайте spec API-визначення для Pod. Специфікація включає визначення Контейнера (частина Pod).
Прочитайте список доступних полів, які ви можете викрити за допомогою downward API.
Дізнайтеся про томи в легасі довідці API:
Перегляньте Volume API-визначення, яке визначає загальний том у Pod для доступу контейнерів.
Перегляньте DownwardAPIVolumeSource API-визначення, яке визначає том, який містить інформацію Downward API.
Перегляньте DownwardAPIVolumeFile API-визначення, яке містить посилання на обʼєкт або поля ресурсу для заповнення файлу у томі Downward API.
Перегляньте ResourceFieldSelector API-визначення, яке вказує ресурси контейнера та їх формат виведення.
7.7 - Розповсюдження облікових даних з використанням Secret
Ця сторінка показує, як безпечно передати чутливі дані, такі як паролі та ключі шифрування, у Podʼи.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Припустимо, ви хочете мати дві частини секретних даних: імʼя користувача my-app та пароль 39528$vdg7Jb. Спочатку використайте інструмент кодування base64, щоб перетворити ваше імʼя користувача та пароль на base64. Ось приклад використання загальнодоступної програми base64:
apiVersion:v1kind:Podmetadata:name:secret-test-podspec:containers:- name:test-containerimage:nginxvolumeMounts:# ім'я повинно відповідати імені тома нижче- name:secret-volumemountPath:/etc/secret-volumereadOnly:true# Дані секрету доступні контейнерам у Podʼі через том.volumes:- name:secret-volumesecret:secretName:test-secret
NAME READY STATUS RESTARTS AGE
secret-test-pod 1/1 Running 0 42m
Отримайте доступ до оболонки в контейнері, що працює у вашому Podʼі:
kubectl exec -i -t secret-test-pod -- /bin/bash
Секретні дані доступні контейнеру через Том, змонтований у /etc/secret-volume.
У вашій оболонці перегляньте файли у теці /etc/secret-volume:
# Виконайте це в оболонці всередині контейнераls /etc/secret-volume
Вивід показує два файли, один для кожної частини секретних даних:
password username
У вашій оболонці gthtukzymnt вміст файлів username та password:
# Виконайте це в оболонці всередині контейнераecho"$( cat /etc/secret-volume/username )"echo"$( cat /etc/secret-volume/password )"
Вивід — ваше імʼя користувача та пароль:
my-app
39528$vdg7Jb
Змініть ваш образ або командний рядок так, щоб програма шукала файли у теці mountPath. Кожен ключ у масиві data Secretʼу стає імʼям файлу у цій теці.
Спроєцюйте ключі Secret на конкретні шляхи файлів
Ви також можете контролювати шляхи в томі, куди проєцюються ключі Secret. Використовуйте поле .spec.volumes[].secret.items, щоб змінити шлях для кожного ключа:
При розгортанні цього Podʼа відбувається наступне:
Ключ username з mysecret доступний контейнеру за шляхом /etc/foo/my-group/my-username замість /etc/foo/username.
Ключ password з цього Secret не проєцюється.
Якщо ви отримуєте перелік ключів явно за допомогою .spec.volumes[].secret.items, розгляньте наступне:
Проєцюються тільки ключі, вказані у items.
Щоб використовувати всі ключі з Secret, всі вони повинні бути перераховані у полі items.
Усі перераховані ключі повинні існувати у відповідному Secret. Інакше Том не створюється.
Встановіть POSIX-права доступу до ключів Secret
Ви можете встановити POSIX права доступу до файлів для окремого ключа Secret. Якщо ви не вказали жодних дозволів, стандартно використовується 0644. Ви також можете встановити стандартно режим файлу POSIX для всього тому Secret, і ви можете перевизначити його за потреби для кожного ключа.
Наприклад, ви можете вказати режим стандартно так:
Секрет Secret у /etc/foo; всі файли, створені томом секрету, мають дозволи 0400.
Примітка:
Якщо ви визначаєте Pod або шаблон Podʼа за допомогою JSON, зверніть увагу, що специфікація JSON не підтримує вісімкові літерали для чисел, оскільки JSON розглядає 0400 як десяткове значення 400. У JSON використовуйте десяткові значення для defaultMode. Якщо ви пишете YAML, ви можете написати defaultMode в вісімковій системі числення.
Визначте змінні середовища контейнера, використовуючи дані з Secret
Ви можете використовувати дані у Secret як змінні середовища у ваших контейнерах.
Якщо контейнер вже використовує Secret у змінній середовища, оновлення Secret не буде видно контейнеру, якщо він не буде перезапущений. Існують сторонні рішення для виклику перезавантажень, коли змінюються Secret.
Визначення змінної середовища контейнера з даними з одного Secret
Визначте змінну середовища як пару ключ-значення в Secret:
Приклад: Надавання операційних/тестових облікових даних Podʼам за допомогою Secret
У цьому прикладі показано Pod, який використовує Secret, що містить облікові дані операційного середовища, і ще один Pod, який використовує Secret з обліковими даними тестового середовища.
Створіть Secret для облікових даних операційного середовища:
Спеціальні символи, такі як $, \, *, =, та !, будуть інтерпретовані вашою оболонкою і вимагатимуть екранування.
У більшості оболонок найпростіший спосіб екранування пароля полягає в обрамленні його одинарними лапками ('). Наприклад, якщо ваш фактичний пароль — S!B\*d$zDsb=, ви повинні виконати команду наступним чином:
Запуск та керування застосунками зі збереженням стану так і без збереження стану"
8.1 - Запуск застосунку без збереження стану за допомогою Deployment
Ця сторінка показує, як запустити застосунок за допомогою обʼєкта Deployment в Kubernetes.
Цілі
Створити розгортання nginx.
Використання kubectl для виведення інформації про розгортання.
Оновити розгортання.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.9.
Для перевірки версії введіть kubectl version.
Створення та дослідження розгортання nginx
Ви можете запустити застосунок, створивши обʼєкт Kubernetes Deployment, і ви можете описати Deployment у файлі YAML. Наприклад, цей файл YAML описує Deployment, який використовує образ Docker nginx:1.14.2:
apiVersion:apps/v1kind:Deploymentmetadata:name:nginx-deploymentspec:selector:matchLabels:app:nginxreplicas:2# вказує Deployment запустити 2 Podʼи, що відповідають шаблонуtemplate:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.14.2ports:- containerPort:80
apiVersion:apps/v1kind:Deploymentmetadata:name:nginx-deploymentspec:selector:matchLabels:app:nginxreplicas:2template:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.16.1# Оновлення версії nginx з 1.14.2 до 1.16.1ports:- containerPort:80
Спостерігайте, як розгортання створює Podʼи з новими іменами і видаляє старі Podʼи:
kubectl get pods -l app=nginx
Масштабування застосунку шляхом збільшення кількості реплік
Ви можете збільшити кількість Podʼів у вашому Deployment, застосувавши новий YAML файл. Цей файл YAML встановлює replicas на 4, що вказує, що Deployment повиннен мати чотири Podʼи:
apiVersion:apps/v1kind:Deploymentmetadata:name:nginx-deploymentspec:selector:matchLabels:app:nginxreplicas:4# Update the replicas from 2 to 4template:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.16.1ports:- containerPort:80
NAME READY STATUS RESTARTS AGE
nginx-deployment-148880595-4zdqq 1/1 Running 0 25s
nginx-deployment-148880595-6zgi1 1/1 Running 0 25s
nginx-deployment-148880595-fxcez 1/1 Running 0 2m
nginx-deployment-148880595-rwovn 1/1 Running 0 2m
Видалення Deployment
Видаліть Deployment за іменем:
kubectl delete deployment nginx-deployment
ReplicationControllers — Старий спосіб
Перевагою створення реплікованих застосунків є використання Deployment, який своєю чергою використовує ReplicaSet. До того, як в Kubernetes були додані Deployment та ReplicaSet, репліковані застосунки конфігурувалися за допомогою ReplicationController.
8.2 - Запуск одноекземплярного застосунку зі збереженням стану
На цій сторінці показано, як запустити одноекземплярний застосунок зі збереженням стану (Stateful) в Kubernetes, використовуючи PersistentVolume та Deployment. Застосунок — MySQL.
Цілі
Створити PersistentVolume, посилаючись на диск у вашому середовищі.
Створити Deployment MySQL.
Використання MySQL для інших Podʼів в кластері за відомим DNS-імʼям.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Ви можете запустити stateful застосунок, створивши Deployment Kubernetes та підʼєднавши його до наявного PersistentVolume за допомогою PersistentVolumeClaim. Наприклад, цей файл YAML описує Deployment, що запускає MySQL та посилається на PersistentVolumeClaim. Файл визначає монтування тому для /var/lib/mysql, а потім створює PersistentVolumeClaim, який шукає том 20G. Ця заявка виконується будь-яким наявним томом, який відповідає вимогам, або за допомогою динамічного провізора.
Примітка: пароль визначений в файлі конфігурації yaml, і це не є безпечним. Див. Kubernetes Secrets для безпечнішого рішення.
Попередній YAML-файл створює Service, який дозволяє іншим Podʼам в кластері отримувати доступ до бази даних. Опція Service clusterIP: None дозволяє імені DNS Serviceʼа безпосередньо посилатись на IP-адресу Podʼа. Це оптимально, коли у вас є лише один Pod за Service і ви не маєте наміру збільшувати кількість Podʼів.
Запустіть клієнта MySQL, щоб підʼєднатися до сервера:
kubectl run -it --rm --image=mysql:9 --restart=Never mysql-client -- mysql -h mysql -ppassword
Ця команда створює новий Pod у кластері, що виконує клієнта MySQL та підʼєднується до сервера через Service. Якщо підʼєднання вдалося, ви знаєте, що ваша stateful база даних MySQL працює.
Waiting for pod default/mysql-client-274442439-zyp6i to be running, status is Pending, pod ready: false
If you don't see a command prompt, try pressing enter.
mysql>
Оновлення
Образ або будь-яку іншу частину Deployment можна оновити як зазвичай за допомогою команди kubectl apply. Ось деякі заходи обережності, які специфічні для застосунків зі збереженням стану:
Не масштабуйте застосунок. Цей варіант призначений лише для застосунків з одним екземпляром. Основний PersistentVolume можна примонтувати лише до одного Podʼа. Для кластеризованих застосунків зі збереженням стану див. документацію StatefulSet.
Використовуйте strategy:type: Recreate в файлі конфігурації YAML Deployment. Це вказує Kubernetes не використовувати постійні (rolling) оновлення. Такі оновлення не працюватимуть, оскільки ви не можете мати більше одного Podʼа, що працює одночасно. Стратегія Recreate зупинить перший Pod перед створенням нового з оновленою конфігурацією.
Якщо ви вручну вказували PersistentVolume, вам також потрібно вручну видалити його, а також звільнити основний ресурс. Якщо ви використовували динамічного провізора, він автоматично видаляє PersistentVolume, коли бачить, що ви видалили PersistentVolumeClaim. Деякі динамічні провізори (наприклад, ті, що стосуються EBS та PD) також звільняють основний ресурс після видалення PersistentVolume.
8.3 - Запуск реплікованого застосунку зі збереженням стану
Ця сторінка показує, як запустити реплікований застосунок зі збереженням стану (StatefulSet). Цей застосунок — реплікована база даних MySQL. У топології цього прикладу є один головний сервер і кілька реплік, що використовують асинхронну реплікацію на основі рядків.
Примітка:
Ця конфігурація не для операційної експлуатації. Налаштування MySQL залишаються на небезпечних стандартних значеннях, щоб зосередитися на загальних патернах запуску застосунків зі збереженням стану в Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
apiVersion:v1kind:ConfigMapmetadata:name:mysqllabels:app:mysqlapp.kubernetes.io/name:mysqldata:primary.cnf:| # Застосовує цю конфігурацію до primary.
[mysqld]
log-binreplica.cnf:| # Застосовує цю конфігурацію до реплік.
[mysqld]
super-read-only
Цей ConfigMap надає перевизначення для my.cnf, що дозволяє вам незалежно керувати конфігурацією на головному сервері MySQL та його репліках. У цьому випадку ви хочете, щоб головний сервер міг обслуговувати логи реплікацій реплік, а репліки відхиляли будь-які записи, які надходять не через реплікацію.
Немає нічого особливого у самому ConfigMap, що зумовлює застосування різних частин до різних Podʼів. Кожен Pod вирішує, яку частину дивитися при ініціалізації, на основі інформації, що надає контролер StatefulSet.
Створення Service
Створіть Service із наступного файлу конфігурації YAML:
# Service headless для стабільних записів DNS членів StatefulSet.apiVersion:v1kind:Servicemetadata:name:mysqllabels:app:mysqlapp.kubernetes.io/name:mysqlspec:ports:- name:mysqlport:3306clusterIP:Noneselector:app:mysql---# Service клієнт для підʼєднання до екземпляру MySQL для читання.# Для запису ви повинні підключитися до основного: mysql-0.mysql.apiVersion:v1kind:Servicemetadata:name:mysql-readlabels:app:mysqlapp.kubernetes.io/name:mysqlreadonly:"true"spec:ports:- name:mysqlport:3306selector:app:mysql
Service headless надає місце для DNS-записів, які контролери StatefulSet створюють для кожного Podʼа, що є частиною набору. Оскільки headless Service називається mysql, Podʼи доступні за допомогою зіставлення <pod-name>.mysql з будь-якого іншого Podʼа в тому ж Kubernetes кластері та просторі імен.
Клієнтський Service, з назвою mysql-read, є звичайним Service з власним кластерним IP, який розподіляє підключення між всіма Podʼами MySQL, які повідомляють про готовність. Набір потенційних точок доступу включає головний сервер MySQL та всі репліки.
Зверніть увагу, що лише запити на читання можуть використовувати балансувальник Service. Оскільки існує лише один головний сервер MySQL, клієнти повинні підключатися безпосередньо до головного Podʼа MySQL (через його DNS-запис у головному Service) для виконання записів.
Створення StatefulSet
Наостанок, створіть StatefulSet із наступного файлу конфігурації YAML:
Ви можете спостерігати за процесом запуску, виконавши:
kubectl get pods -l app=mysql --watch
Через деякий час ви повинні побачити, що всі 3 Podʼи стануть Running:
NAME READY STATUS RESTARTS AGE
mysql-0 2/2 Running 0 2m
mysql-1 2/2 Running 0 1m
mysql-2 2/2 Running 0 1m
Натисніть Ctrl+C, щоб скасувати перегляд.
Примітка:
Якщо ви не бачите жодних змін, переконайтеся, що у вас увімкнений динамічний PersistentVolume провізор, як зазначено у передумовах.
Цей маніфест використовує різноманітні техніки для керування Podʼами як частиною StatefulSet. У наступному розділі підкреслено деякі з цих технік, щоб пояснити, що відбувається під час створення Podʼів StatefulSet.
Розуміння ініціалізації Podʼа зі збереженням стану
Контролер StatefulSet запускає Podʼи по одному, в порядку їх індексів. Він чекає, доки кожен Pod не повідомить про готовність, перш ніж запустити наступний.
Крім того, контролер призначає кожному Podʼу унікальне, стабільне імʼя у формі <statefulset-name>-<ordinal-index>, в результаті отримуємо Podʼи з іменами mysql-0, mysql-1 та mysql-2.
Шаблон Podʼа у вищенаведеному маніфесті StatefulSet використовує ці властивості, щоб здійснити впорядкований запуск реплікації MySQL.
Створення конфігурації
Перед запуском будь-яких контейнерів у специфікації Podʼа, спочатку Pod запускає будь-які
контейнери ініціалізації у визначеному порядку.
Перший контейнер ініціалізації, init-mysql, генерує спеціальні конфігураційні файли MySQL на основі порядкового індексу.
Скрипт визначає свій власний порядковий індекс, витягуючи його з кінця імені Podʼа, яке повертається командою hostname. Потім він зберігає порядковий індекс (з числовим зміщенням для уникнення зарезервованих значень) у файлі з назвою server-id.cnf в теці conf.d MySQL. Це перетворює унікальний, стабільний ідентифікатор, наданий StatefulSet, у домен ідентифікаторів серверів MySQL, які вимагають таких же властивостей.
Скрипт у контейнері init-mysql також застосовує або primary.cnf, або replica.cnf з ConfigMap, копіюючи вміст у conf.d. Оскільки у топології цього прикладу є лише один головний сервер MySQL та будь-яка кількість реплік, скрипт призначає порядковий індекс 0 головному серверу, а всі інші — репліками. Разом з гарантією контролера StatefulSet щодо порядку розгортання, це забезпечує готовність головного сервера MySQL перед створенням реплік, щоб вони могли почати реплікацію.
Клонування наявних даних
Загалом, коли новий Pod приєднується до набору як репліка, він повинен припускати, що головний сервер MySQL може вже містити дані. Також він повинен припускати, що логи реплікації можуть не бути повністю отримані з самого початку. Ці консервативні припущення є ключем до можливості запуску робочого StatefulSet масштабуватися вгору та вниз з часом, а не залишатися фіксованим на своєму початковому розмірі.
Другий контейнер ініціалізації, з назвою clone-mysql, виконує операцію клонування на реплікаційному Podʼі першого разу, коли він запускається на порожньому PersistentVolume. Це означає, що він копіює всі наявні дані з іншого працюючого Podʼа, таким чином, його локальний стан є достатньо консистентним для початку реплікації з головного сервера.
MySQL сам по собі не надає механізму для цього, тому приклад використовує популярний відкритий інструмент — Percona XtraBackup. Під час клонування MySQL сервер може мати знижену продуктивність. Щоб мінімізувати вплив на головний сервер MySQL, скрипт вказує кожному Podʼу отримувати дані з Podʼа, чий порядковий індекс на одиницю менший. Це працює через те, що контролер StatefulSet завжди гарантує, що Pod N є готовим перед запуском Podʼа N+1.
Початок реплікації
Після успішного завершення контейнерів ініціалізації запускаються звичайні контейнери. Podʼи MySQL складаються з контейнера mysql, в якому працює фактичний сервер mysqld, та контейнера xtrabackup, який діє як sidecar.
Sidecar xtrabackup переглядає клоновані файли даних і визначає, чи необхідно ініціалізувати реплікацію MySQL на репліці. У цьому випадку він чекає, доки mysqld буде готовий, а потім виконує команди CHANGE MASTER TO та START SLAVE з параметрами реплікації, отриманими з клонованих файлів XtraBackup.
Після того як репліка починає реплікацію, вона запамʼятовує свій головний сервер MySQL і автоматично підʼєднується, якщо сервер перезавантажується або зʼєднання втрачається. Також, оскільки репліки шукають головний сервер за його стабільним DNS-імʼям (mysql-0.mysql), вони автоматично знаходять головний сервер навіть якщо він отримує новий IP Podʼа через перепланування.
Нарешті, після початку реплікації, контейнер xtrabackup слухає зʼєднання з інших Podʼів, які запитують клон даних. Цей сервер залишається активним нескінченно довго в разі, якщо StatefulSet масштабується вгору, або якщо наступний Pod втрачає свій PersistentVolumeClaim і потрібно повторно виконати клонування.
Надсилання клієнтського трафіку
Ви можете надіслати тестові запити до головного сервера MySQL (хост mysql-0.mysql) запустивши тимчасовий контейнер з образом mysql:5.7 і використовуючи бінарний файл клієнта mysql.
kubectl run mysql-client --image=mysql:5.7 -i --rm --restart=Never --\
mysql -h mysql-0.mysql <<EOF
CREATE DATABASE test;
CREATE TABLE test.messages (message VARCHAR(250));
INSERT INTO test.messages VALUES ('hello');
EOF
Використовуйте хост mysql-read, щоб надіслати тестові запити до будь-якого сервера, який повідомляє про готовність:
kubectl run mysql-client --image=mysql:5.7 -i -t --rm --restart=Never --\
mysql -h mysql-read -e "SELECT * FROM test.messages"
Ви повинні отримати вивід схожий на цей:
Waiting for pod default/mysql-client to be running, status is Pending, pod ready: false
+---------+
| message |
+---------+
| hello |
+---------+
pod "mysql-client" deleted
Щоб продемонструвати, що Service mysql-read розподіляє підключення між
серверами, ви можете запустити SELECT @@server_id у циклі:
kubectl run mysql-client-loop --image=mysql:5.7 -i -t --rm --restart=Never --\
bash -ic "while sleep 1; do mysql -h mysql-read -e 'SELECT @@server_id,NOW()'; done"
Ви повинні бачити, що @@server_id змінюється випадковим чином, оскільки може бути вибрана інша точка доступу при кожній спробі підключення:
Ви можете натиснути Ctrl+C, коли захочете зупинити цикл, але цікаво тримати його запущеним в іншому вікні, щоб бачити ефект від наступних кроків.
Симуляція відмови Podʼа та Вузла
Щоб продемонструвати підвищену доступність читання з пулу реплік замість одного сервера, залиште цикл SELECT @@server_id, запущений вище, активним, тоді як ви змушуєте Pod вийти зі стану Ready.
Збій проби готовності
Проба готовності для контейнера mysql виконує команду mysql -h 127.0.0.1 -e 'SELECT 1', щоб переконатися, що сервер запущений і може виконувати запити.
Одним зі способів змусити цю пробу готовності збоїти — це пошкодити цю команду:
kubectl exec mysql-2 -c mysql -- mv /usr/bin/mysql /usr/bin/mysql.off
Ця дія втручається у файлову систему контейнера Podʼа mysql-2 і перейменовує команду mysql, щоб проба готовності не могла її знайти. Через кілька секунд Pod повинен повідомити про один зі своїх контейнерів як неготовий, що можна перевірити за допомогою:
kubectl get pod mysql-2
Перевірте значення 1/2 у стовпці READY:
NAME READY STATUS RESTARTS AGE
mysql-2 1/2 Running 0 3m
На цьому етапі ви повинні бачити продовження роботи вашого циклу SELECT @@server_id, хоча він більше не повідомляє про 102. Нагадаємо, що скрипт init-mysql визначив server-id як 100 + $ordinal, тож ідентифікатор сервера 102 відповідає Поду mysql-2.
Тепер відновіть Pod і він повинен знову зʼявитися у виводі циклу через кілька секунд:
kubectl exec mysql-2 -c mysql -- mv /usr/bin/mysql.off /usr/bin/mysql
Видалення Podʼів
Контролер StatefulSet також створює Podʼи знову, якщо вони видалені, подібно до того, як це робить ReplicaSet для Podʼів без збереження стану.
kubectl delete pod mysql-2
Контролер StatefulSet помічає, що Podʼа mysql-2 більше не існує, і створює новий з тією ж назвою та повʼязаний з тим самим PersistentVolumeClaim. Ви повинні побачити, що ідентифікатор сервера 102 зникне з виводу циклу протягом певного часу і потім повернеться самостійно.
Виведення вузла з експлуатації
Якщо у вашому кластері Kubernetes є кілька вузлів, ви можете симулювати відмову вузла(наприклад, під час оновлення вузлів) за допомогою команди drain.
Спочатку визначте, на якому вузлі знаходиться один із Podʼів MySQL:
kubectl get pod mysql-2 -o wide
Назва вузла повинна зʼявитися у останньому стовпчику:
NAME READY STATUS RESTARTS AGE IP NODE
mysql-2 2/2 Running 0 15m 10.244.5.27 kubernetes-node-9l2t
Потім виведіть вузол з експлуатації, виконавши наступну команду, яка забороняє новим Podʼам запускатися на цьому вузлі та видаляє будь-які існуючі Podʼи. Замість <node-name> підставте назву вузла, яку ви знайшли на попередньому кроці.
Увага:
Виведення вузла з експлуатації може вплинути на інші завдання та застосунки, що працюють на тому ж вузлі. Виконуйте наступний крок тільки на тестовому кластері.
# Дивіться вище поради щодо впливу на інші завданняkubectl drain <node-name> --force --delete-emptydir-data --ignore-daemonsets
Тепер ви можете спостерігати, як Pod переплановується на іншому вузлі:
І знову, ви повинні побачити, що ідентифікатор сервера 102 зник з виводу циклу SELECT @@server_id протягом певного часу, а потім повернувся.
Тепер знову дозвольте вузлу приймати навантаження:
kubectl uncordon <node-name>
Масштабування кількості реплік
Коли ви використовуєте реплікацію MySQL, ви можете збільшувати кількість запитів на читання, додаючи репліки. Для StatefulSet це можна зробити однією командою:
kubectl scale statefulset mysql --replicas=5
Спостерігайте, як нові Podʼи запускаються, виконавши:
kubectl get pods -l app=mysql --watch
Коли вони будуть готові, ви побачите, що ідентифікатори серверів 103 та 104 починають зʼявлятися у виводі циклу SELECT @@server_id.
Ви також можете перевірити, що ці нові сервери мають дані, які ви додали до них до того, як вони існували:
kubectl run mysql-client --image=mysql:5.7 -i -t --rm --restart=Never --\
mysql -h mysql-3.mysql -e "SELECT * FROM test.messages"
Waiting for pod default/mysql-client to be running, status is Pending, pod ready: false
+---------+
| message |
+---------+
| hello |
+---------+
pod "mysql-client" deleted
Зменшити кількість реплік також можна однією командою:
kubectl scale statefulset mysql --replicas=3
Примітка:
Хоча збільшення створює нові PersistentVolumeClaims автоматично, зменшення автоматично не видаляє ці PVC.
Це дає вам можливість залишити ці ініціалізовані PVC для швидшого збільшення, або вилучити дані перед їх видаленням.
Ви можете перевірити це, виконавши:
kubectl get pvc -l app=mysql
Це покаже, що всі 5 PVC все ще існують, попри те, що StatefulSet був зменшений до 3:
Припинить цикл SELECT @@server_id, натиснувши Ctrl+C в його терміналі або виконавши наступне з іншого терміналу:
kubectl delete pod mysql-client-loop --now
Видаліть StatefulSet. Це також розпочне завершення Podʼів.
kubectl delete statefulset mysql
Перевірте, що Podʼи зникають. Вони можуть зайняти деякий час для завершення роботи.
kubectl get pods -l app=mysql
Ви будете знати, що Podʼи завершилися, коли вищезазначена команда поверне:
No resources found.
Видаліть ConfigMap, Services та PersistentVolumeClaims.
kubectl delete configmap,service,pvc -l app=mysql
Якщо ви вручну створювали PersistentVolumes, вам також потрібно вручну видалити їх, а також звільнити відповідні ресурси. Якщо ви використовували динамічний провізор, він автоматично видаляє PersistentVolumes, коли бачить, що ви видалили PersistentVolumeClaims. Деякі динамічні провізори (такі як ті, що стосуються EBS та PD) також звільняють відповідні ресурси при видаленні PersistentVolumes.
Подивіться в сховищі Helm чартів інші приклади застосунків зі збереженням стану.
8.4 - Масштабування StatefulSet
Це завдання показує, як масштабувати StatefulSet. Масштабування StatefulSet означає збільшення або зменшення кількості реплік.
Перш ніж ви розпочнете
StatefulSets доступні тільки в версії Kubernetes 1.5 або пізніше. Щоб перевірити вашу версію Kubernetes, виконайте kubectl version.
Не всі застосунки зі збереженням стану гарно масштабуються. Якщо ви не впевнені, чи масштабувати ваші StatefulSets, див. Концепції StatefulSet або Посібник StatefulSet для отримання додаткової інформації.
Ви повинні виконувати масштабування лише тоді, коли ви впевнені, що ваш кластер застосунку зі збереженням стану є повністю справним.
Масштабування StatefulSets
Використання kubectl для масштабування StatefulSets
Спочатку знайдіть StatefulSet, який ви хочете масштабувати.
Виконання оновлень на місці для вашого StatefulSets
Альтернативно, ви можете виконати оновлення на місці для ваших StatefulSets.
Якщо ваш StatefulSet спочатку був створений за допомогою kubectl apply, оновіть .spec.replicas маніфестів StatefulSet, а потім виконайте kubectl apply:
kubectl apply -f <stateful-set-file-updated>
Інакше, відредагуйте це поле за допомогою kubectl edit:
Ви не можете зменшити масштаб StatefulSet, коли будь-який з Stateful Podʼів, яким він керує, є нездоровим. Масштабування відбувається лише після того, як ці Stateful Podʼи стають запущеними та готовими.
Якщо spec.replicas > 1, Kubernetes не може визначити причину несправності Podʼа. Це може бути наслідком постійного збою або тимчасового збою. Тимчасовий збій може бути викликаний перезапуском, необхідним для оновлення або обслуговування.
Якщо Pod несправний через постійний збій, масштабування без виправлення дефекту може призвести до стану, коли кількість членів StatefulSet опускається нижче певної мінімальної кількості реплік, необхідних для правильної роботи це може призвести до недоступності вашого StatefulSet.
Якщо Pod несправний через тимчасовий збій і Pod може стати доступним знову, тимчасова помилка може перешкоджати вашій операції масштабування вгору або вниз. Деякі розподілені бази даних мають проблеми, коли вузли приєднуються та відключаються одночасно. Краще розуміти операції масштабування на рівні застосунків у таких випадках і виконувати масштабування лише тоді, коли ви впевнені, що ваш кластер застосунку зі збереженням стану є цілком справним.
Це завдання передбачає, що у вас є застосунок, який працює на вашому кластері та представлений StatefulSet.
Видалення StatefulSet
Ви можете видалити StatefulSet так само як і інші ресурси в Kubernetes: використовуйте команду kubectl delete та вкажіть StatefulSet або файлом, або імʼям.
kubectl delete -f <file.yaml>
kubectl delete statefulsets <statefulset-name>
Після видалення StatefulSet може знадобитися окремо видалити повʼязаний headless service.
kubectl delete service <імʼя-сервісу>
Під час видалення StatefulSet через kubectl, StatefulSet масштабується до 0. Всі Podʼи, які є частиною цього робочого навантаження, також видаляються. Якщо ви хочете видалити лише StatefulSet і не Podʼи, використовуйте --cascade=orphan. Наприклад:
kubectl delete -f <файл.yaml> --cascade=orphan
Передачею --cascade=orphan до kubectl delete Podʼи, що керуються StatefulSet залишаються після того, як обʼєкт StatefulSet сам по собі буде видалений. Якщо Podʼи мають мітку app.kubernetes.io/name=MyApp, ви можете видалити їх наступним чином:
Видалення Podʼів у StatefulSet не призведе до видалення повʼязаних томів. Це зроблено для того, щоб ви мали можливість скопіювати дані з тому перед його видаленням. Видалення PVC після завершення роботи Podʼів може спричинити видалення зазначених постійних томів залежно від класу сховища та політики повторного використання. Ніколи не припускайте можливість доступу до тому
після видалення заявки.
Примітка:
Будьте обережні при видаленні PVC, оскільки це може призвести до втрати даних.
Повне видалення StatefulSet
Щоб видалити все у StatefulSet, включаючи повʼязані Podʼи, ви можете виконати серію команд, схожих на наступні:
У вище наведеному прикладі Podʼи мають мітку app.kubernetes.io/name=MyApp; підставте вашу власну мітку за потреби.
Примусове видалення Podʼів StatefulSet
Якщо ви помітите, що деякі Podʼи у вашому StatefulSet застрягли у стані 'Terminating' або 'Unknown' протягом тривалого періоду часу, вам може знадобитися втрутитися вручну, щоб примусово видалити Podʼи з apiserverʼа. Це потенційно небезпечне завдання. Див.
Примусове видалення Podʼів StatefulSet для отримання детальної інформації.
Ця сторінка показує, як видаляти Podʼи, які є частиною StatefulSet, та пояснює важливі моменти, які слід враховувати під час цього.
Перш ніж ви розпочнете
Це досить високорівневе завдання і може порушити деякі властивості, притаманні StatefulSet.
Перед продовженням ознайомтеся з розглянутими нижче моментами.
Міркування про StatefulSet
При нормальному функціонуванні StatefulSet ніколи немає потреби у примусовому видаленні Podʼів StatefulSet. Контролер StatefulSet відповідає за створення, масштабування та видалення членів StatefulSet. Він намагається забезпечити, щоб зазначена кількість Podʼів від ordinal 0 до N-1 були справними та готовими. StatefulSet забезпечує те, що в будь-який момент часу в кластері працює не більше одного Podʼа з заданою ідентичністю. Це називається семантикою як максимум один, яку забезпечує StatefulSet.
Примусове видалення слід виконувати з обережністю, оскільки воно може порушити семантику "як максимум один", притаманну StatefulSet. StatefulSet можуть використовуватися для запуску розподілених і кластерних застосунків, які потребують стабільної мережевої ідентичності та стабільного сховища. Ці застосунки часто мають конфігурацію, яка ґрунтується на ансамблі фіксованої кількості членів з фіксованими ідентичностями. Наявність декількох членів із тією самою ідентичністю може бути руйнівною і може призвести до втрати даних (наприклад, у випадку "розщеплення мозку" в системах на основі кворуму).
Видалення Podʼів
Ви можете виконати коректне видалення Podʼа за допомогою наступної команди:
kubectl delete pods <pod>
Щоб таке видалення призвело до коректного завершення, необхідно вказати pod.Spec.TerminationGracePeriodSeconds більше 0. Практика встановлення pod.Spec.TerminationGracePeriodSeconds на 0 секунд є небезпечною та категорично не рекомендується для Podʼів StatefulSet. Коректне видалення є безпечним і забезпечить, що Pod коректно завершить роботу перед тим, як kubelet видалить імʼя з apiserver.
Pod не видаляється автоматично, коли вузол недоступний. Podʼи, які працюють на недоступному вузлі, потрапляють у стан 'Terminating' або 'Unknown' після тайм-ауту. Podʼи також можуть потрапляти в ці стани, коли користувач спробує коректне видалення Podʼа на недоступному вузлі. Єдині способи, якими Pod у такому стані може бути видалено з apiserver, наступні:
kubelet на недоступному Вузлі починає відповідати, припиняє роботу Pod та видаляє запис з apiserver.
Примусове видалення Podʼа користувачем.
Рекомендована практика — використовувати перший або другий підхід. Якщо вузол підтверджено є несправним (наприклад, постійно відключений від мережі, вимкнений тощо), то видаліть обʼєкт Node. Якщо вузол страждає від розділення мережі, то спробуйте вирішити це або зачекайте на його вирішення. Коли розділення мережі виправляється, kubelet завершить видалення Podʼа та звільнить його імʼя в apiserver.
Зазвичай система завершує видалення, як тільки Pod більше не працює на Вузлі, або Вузол видаляється адміністратором. Ви можете перевизначити це за допомогою примусового видалення Podʼа.
Примусове видалення
Примусові видалення не чекають підтвердження від kubelet про те, що Pod було завершено. Незалежно від того, чи успішно примусове завершення Podʼа припиняє його роботу чи ні, воно негайно звільняє імʼя з apiserverʼа. Це дозволить контролеру StatefulSet створити новий Pod з тією самою ідентичністю; це може призвести до дублювання все ще працюючого Podʼа, і якщо цей Pod все ще може спілкуватися з іншими членами StatefulSet, це порушить семантику "як максимум один", яку StatefulSet має гарантувати.
Коли ви примусово видаляєте Pod StatefulSet, ви стверджуєте, що цей Pod більше ніколи не буде знову взаємодіяти з іншими Podʼами StatefulSet, і його імʼя може бути безпечно звільнено для створення заміни.
Якщо ви хочете примусово видалити Pod за допомогою kubectl версії >= 1.5, виконайте наступне:
У Kubernetes HorizontalPodAutoscaler автоматично оновлює ресурс навантаження (наприклад, Deployment або StatefulSet), з метою автоматичного масштабування робочого навантаження у відповідь на попит.
Горизонтальне масштабування означає, що реакція на збільшення навантаження полягає у розгортанні додаткових Podʼів. Це відрізняється від вертикального масштабування, що для Kubernetes означає призначення додаткових ресурсів (наприклад, памʼяті або CPU) для уже запущених Podʼів робочого навантаження.
Якщо навантаження зменшується, а кількість Podʼів перевищує налаштований мінімум, HorizontalPodAutoscaler інструктує ресурс навантаження (Deployment, StatefulSet або інший схожий ресурс) масштабуватися вниз.
Горизонтальне автоматичне масштабування Podʼів не застосовується до обʼєктів, які не можна масштабувати (наприклад, DaemonSet).
HorizontalPodAutoscaler реалізований як ресурс API Kubernetes та контролер. Ресурс визначає поведінку контролера. Контролер горизонтального автоматичного масштабування Podʼів, який працює в панелі управління Kubernetes, періодично коригує бажану шкалу своєї цілі (наприклад, Deployment), щоб відповідати спостережуваним метрикам, таким як середнє використання CPU, середня використання памʼяті або будь-яка інша метрика, яку ви вказуєте.
Ось приклад використання горизонтального автоматичного масштабування Podʼів.
Як працює HorizontalPodAutoscaler?
graph BT
hpa[HorizontalPodAutoscaler] --> scale[Scale]
subgraph rc[RC / Deployment]
scale
end
scale -.-> pod1[Pod 1]
scale -.-> pod2[Pod 2]
scale -.-> pod3[Pod N]
classDef hpa fill:#D5A6BD,stroke:#1E1E1D,stroke-width:1px,color:#1E1E1D;
classDef rc fill:#F9CB9C,stroke:#1E1E1D,stroke-width:1px,color:#1E1E1D;
classDef scale fill:#B6D7A8,stroke:#1E1E1D,stroke-width:1px,color:#1E1E1D;
classDef pod fill:#9FC5E8,stroke:#1E1E1D,stroke-width:1px,color:#1E1E1D;
class hpa hpa;
class rc rc;
class scale scale;
class pod1,pod2,pod3 pod
Схема 1. HorizontalPodAutoscaler керує масштабуванням Deployment та його ReplicaSet
У Kubernetes горизонтальне автоматичне масштабування Podʼів реалізовано як цикл керування, що працює інтервально (це не постійний процес). Інтервал встановлюється параметром --horizontal-pod-autoscaler-sync-period для kube-controller-manager (а стандартне значення — 15 секунд).
Один раз протягом кожного періоду менеджер контролера запитує використання ресурсів відповідно до метрик, вказаних у визначенні кожного HorizontalPodAutoscaler. Менеджер контролера знаходить цільовий ресурс, визначений за допомогою scaleTargetRef, потім вибирає Podʼи на основі міток .spec.selector цільового ресурсу та отримує метрики зі специфічних метрик ресурсів API (для метрик ресурсів на кожен Pod) або API власних метрик (для всіх інших метрик).
Для метрик ресурсів на кожен Pod (наприклад, CPU) контролер отримує метрики з API метрик ресурсів для кожного Pod, на який впливає HorizontalPodAutoscaler. Потім, якщо встановлено значення цільового використання, контролер обчислює значення використання як відсоток еквівалентного ресурсного запиту на контейнери в кожному Pod. Якщо встановлено сирцеве цільове значення, використовуються сирі (необроблені) значення метрик. Потім контролер бере середнє значення використання або сире значення (залежно від типу вказаної цілі) для всіх цільових Podʼів і створює співвідношення, яке використовується для масштабування кількості бажаних реплік.
Зверніть увагу, що якщо деякі контейнери Podʼів не мають відповідного ресурсного запиту, використання CPU для Pod не буде визначене, і автоматичний масштабувальник не буде виконувати жодних дій для цієї метрики. Дивіться розділ подробиці алгоритму нижче для отримання додаткової інформації про те, як працює алгоритм автомасштабування.
Для власних метрик на кожен Pod контролер працює аналогічно метрикам ресурсів на кожен Pod, за винятком того, що він працює з сирцевими значеннями, а не значеннями використання.
Для метрик обʼєктів та зовнішніх метрик витягується одна метрика, яка описує обʼєкт. Цю метрику порівнюють з цільовим значенням, щоб отримати співвідношення, як вище. У версії API autoscaling/v2 це значення можна за необхідності розділити на кількість Podʼів до порівняння.
Звичайне використання HorizontalPodAutoscaler — налаштувати його на витягування метрик з агрегованих API (metrics.k8s.io, custom.metrics.k8s.io або external.metrics.k8s.io). API metrics.k8s.io зазвичай надається Metrics Server, який потрібно запустити окремо. Для отримання додаткової інформації про метрики ресурсів див. Metrics Server.
Підтримка API метрик пояснює гарантії стабільності та статус підтримки цих різних API.
Контролер HorizontalPodAutoscaler має доступ до відповідних ресурсів робочого навантаження, які підтримують масштабування (такі як Deployment та StatefulSet). Ці ресурси мають субресурс з назвою scale, інтерфейс, який дозволяє динамічно встановлювати кількість реплік і переглядати поточний стан кожного з них. Для загальної інформації про субресурси в API Kubernetes див. Поняття API Kubernetes.
Алгоритм
По простому, контролер HorizontalPodAutoscaler працює зі співвідношенням між бажаним значенням метрики та поточним значенням метрики:
Наприклад, якщо поточне значення метрики — 200м, а бажане значення — 100м, кількість реплік буде подвоєна, оскільки \( { 200.0 \div 100.0 } = 2.0 \). Якщо поточне значення замість цього — 50м, кількість реплік буде зменшена вдвічі, оскільки \( { 50.0 \div 100.0 } = 0.5 \). Панель управління пропускає будь-яку дію масштабування, якщо співвідношення достатньо близьке до 1,0 (в межах налаштовуваних допусків, типово 0.1).
Якщо вказано targetAverageValue або targetAverageUtilization, поточне значення метрики обчислюється шляхом визначення середнього значення вказаної метрики для всіх Podʼів у цільовому масштабі HorizontalPodAutoscaler.
Перед перевіркою допустимості та визначенням кінцевих значень панель управління також розглядає, чи є відсутні будь-які метрики, і скільки Podʼів є Ready. Всі Podʼи зі встановленим відбитками часу видалення (обʼєкти з відбитками часу видалення перебувають у процесі завершення роботи/видалення) ігноруються, а всі збійні Podʼи не враховуються.
Якщо конкретний Pod не маж метрики, його відкладено на потім; Podʼи з відсутніми метриками будуть використані для коригування кінцевої кількості масштабування.
При масштабуванні за CPU, якщо будь-який pod ще не став готовим (він все ще ініціалізується, або можливо, несправний) або остання точка метрики для Pod була до того, як він став готовим, цей Pod також відкладено.
Через технічні обмеження, контролер HorizontalPodAutoscaler не може точно визначити перший раз, коли Pod стає готовим при визначенні, чи відкласти певні метрики CPU. Замість цього вважається, що Pod "ще не готовий", якщо він ще не готовий і перейшов у готовий стан протягом короткого, налаштованого вікна часу з моменту початку. Це значення налаштоване за допомогою параметра командного рядка --horizontal-pod-autoscaler-initial-readiness-delay, і типово воно складає 30 секунд. Як тільки Pod став готовим, будь-який перехід в готовий стан вважається першим, якщо це сталося протягом довшого, налаштованого часу від початку. Це значення налаштоване за допомогою параметра командного рядка --horizontal-pod-autoscaler-cpu-initialization-period, і його стандартне значення — 5 хвилин.
Базове співвідношення масштабу \( currentMetricValue \over desiredMetricValue \) потім обчислюється залишковими Podʼами, які не були відкладені або відкинуті вище.
Якщо були відсутні метрики, панель управління перераховує середнє значення більш консервативно, припускаючи, що ці Podʼи споживають 100% бажаного значення у випадку масштабування вниз і 0% у випадку масштабування вгору. Це зменшує величину можливого масштабу.
Крім того, якщо присутні будь-які ще не готові Podʼи, і робоче навантаження мало б масштабуватися вгору без врахування відсутніх метрик або ще не готових Podʼів, контролер консервативно припускає, що ще не готові Podʼи споживають 0% бажаної метрики, зменшуючи величини масштабу.
Після врахування ще не готових Podʼів та відсутніх метрик контролер повторно обчислює відношення використання. Якщо нове співвідношення змінює напрямок масштабування або знаходиться в межах допустимості, контролер не вживає жодних дій щодо масштабування. У інших випадках нове співвідношення використовується для прийняття будь-яких змін кількості Podʼів.
Зверніть увагу, що початкове значення для середнього використання повертається через статус HorizontalPodAutoscaler, без врахування ще не готових Podʼів або відсутніх метрик, навіть коли використовується нове відношення використання.
Якщо в HorizontalPodAutoscaler вказано кілька метрик, цей розрахунок виконується для кожної метрики, а потім обирається найбільше з бажаних кількостей реплік. Якщо будь-яка з цих метрик не може бути переведена у бажану кількість реплік (наприклад, через помилку отримання метрик з API метрик) і запропоновано масштабування вниз за метриками, які можна витягнути, масштабування пропускається. Це означає, що HPA все ще може масштабуватися вгору, якщо одна або декілька метрик дають значення desiredReplicas, більше, ніж поточне значення.
Нарешті, прямо перед тим, як HPA масштабує ціль, рекомендація масштабування записується. Контролер розглядає всі рекомендації в налаштованому вікні та обирає найвищу рекомендацію в межах цього вікна. Це значення можна налаштувати за допомогою параметра командного рядка --horizontal-pod-autoscaler-downscale-stabilization, який стандартно складає 5 хвилин. Це означає, що зменшення масштабу відбуватиметься поступово, згладжуючи вплив метрик, що швидко змінюються.
Готовіність Podʼа та метрики автомасштабування
Контролер HorizontalPodAutoscaler (HPA) містить два параметри командного рядка, які впливають на те, як збираються показники CPU з Podʼів під час запуску:
Цей параметр визначає часовий проміжок після запуску Podʼа, протягом якого використання CPU ігнорується, крім випадків, коли це необхідно:
- Pod перебуває у стані Readyта
- Зразок метрики було взято повністю протягом періоду, коли він перебував у стані Ready.
Цей параметр командного рядка допомагає виключити високе споживання CPU Podʼів, що ініціалізуються (напр., Java-застосунки, що перебувають у своїй підготовчій фазі) з рішень HPA щодо масштабування.
Цей параметр командного рядка визначає короткі періоди затримки після запуску Podʼа, протягом якого контролер HPA розглядає Podʼи, що перебувають у стані Ready, як такі, що все ще ініціалізуються, навіть якщо вони раніше ненадовго перейшли у стан Ready.
Він призначений для цього щоб:
- Уникнути включення Podʼів, які швидко коливаються між Ready та Unready під час запуску.
- Забезпечити стабільність початкового сигналу готовності до того, як HPA вважатиме їх метрики дійсними.
Ви можете встановити ці параметри командного рядка тільки для всього кластера.
Ключова поведінка для готовності Podʼа
Якщо Pod перебуває в стані Ready і залишається в цьому стані, він може бути зарахований як такий, що надає метрики навіть протягом затримки.
Якщо Pod швидко перемикається між станом Ready та Unready, метрики ігноруються, поки він не стане стабільно Ready.
Поради стосовно готовності Podʼа
Налаштуйте startupProbe, який не проходить, поки високе використання CPU не мине, або
Переконайтеся, що ваш readinessProbe повідомляє про Ready тільки після того, як пік використання CPU спаде, використовуючи initialDelaySeconds.
А в ідеалі також встановіть --horizontal-pod-autoscaler-cpu-initialization-period, щоб покрити тривалість запуску.
Обʼєкт API
HorizontalPodAutoscaler є типом API в групі API Kubernetes autoscaling. Поточна стабільна версія знаходиться в версії API autoscaling/v2, яка включає підтримку масштабування за памʼяттю та власними метриками. Нові поля, введені в autoscaling/v2, зберігаються як анотації при роботі з autoscaling/v1.
При створенні обʼєкта API HorizontalPodAutoscaler переконайтеся, що вказане імʼя є дійсним піддоменом DNS. Більше деталей про обʼєкт API можна знайти на сторінці Обʼєкт HorizontalPodAutoscaler.
Стабільність масштабування робочого навантаження
При керуванні масштабом групи реплік за допомогою HorizontalPodAutoscaler можливі часті коливання кількості реплік через динамічний характер оцінюваних метрик. Це іноді називають коливанням, або flapping. Це схоже на концепцію гістерезису в кібернетиці.
Масштабування під час поступового оновлення
Kubernetes дозволяє виконувати поступове оновлення для Deployment. У цьому випадку Deployment керує підлеглими ReplicaSets за вас. Коли ви налаштовуєте автомасштабування для Deployment, ви звʼязуєте HorizontalPodAutoscaler з одним Deployment. HorizontalPodAutoscaler керує полем replicas Deployment. Контролер розгортання відповідає за встановлення replicas підлеглих ReplicaSets так, щоб вони складали відповідну кількість під час розгортання, а також після його завершення.
Якщо ви виконуєте поступове оновлення StatefulSet, у якого є автомасштабована кількість реплік, StatefulSet безпосередньо керує своїм набором Podʼів (немає проміжного ресурсу, аналогічного ReplicaSet).
Підтримка метрик ресурсів
Будь-який обʼєкт HPA може бути масштабований на основі використання ресурсів у Podʼах цільового масштабування. При визначенні специфікації Podʼа повинні бути вказані запити ресурсів, такі як cpu та memory. Це використовується для визначення використання ресурсів і використовується контролером HPA для масштабування цілі вгору або вниз. Щоб використовувати масштабування на основі використання ресурсів, вкажіть джерело метрики так:
З цією метрикою контролер HPA буде підтримувати середнє використання ресурсів у Podʼах цільового масштабування на рівні 60%. Використання — це співвідношення між поточним використанням ресурсу та запитаними ресурсами Podʼа. Дивіться Алгоритм для отримання додаткової інформації про те, як обчислюється та усереднюється використання.
Примітка:
Оскільки використання ресурсів всіх контейнерів сумується, загальне використання Podʼа може не точно відображати використання ресурсів окремих контейнерів. Це може призвести до ситуацій, коли один контейнер може працювати з високим використанням, а HPA не буде масштабувати його, оскільки загальне використання Podʼа все ще знаходиться в припустимих межах.
Метрики ресурсів контейнера
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.30 [stable](стандартно увімкнено)
API HorizontalPodAutoscaler також підтримує джерело метрик контейнера, де HPA може відстежувати використання ресурсів окремих контейнерів у наборі Podʼів, щоб масштабувати цільовий ресурс. Це дозволяє налаштовувати пороги масштабування для контейнерів, які мають найбільше значення в конкретному Pod. Наприклад, якщо у вас є вебзастосунок і контейнер допоміжного сервісу (sidecar), який надає логування, ви можете масштабувати на основі використання ресурсів вебзастосунка, ігноруючи контейнер допоміжного сервісу (sidecar) та його використання ресурсів.
Якщо ви переглянете цільовий ресурс, щоб мати нову специфікацію Pod з іншим набором контейнерів, ви повинні відредагувати специфікацію HPA, якщо цей ново доданий контейнер також має бути використаний для масштабування. Якщо вказаний контейнер у джерелі метрики відсутній або присутній лише в підмножині Podʼів, то ці Podʼи ігноруються, і рекомендація перераховується. Дивіться Алгоритм для отримання додаткової інформації про обчислення. Щоб використовувати ресурси контейнера для автомасштабування, визначте джерело метрики таким чином:
У вищенаведеному прикладі контролер HPA масштабує ціль так, що середнє використання cpu у контейнері application у всіх подах становить 60%.
Примітка:
Якщо ви зміните імʼя контейнера, який відстежує HorizontalPodAutoscaler, ви можете зробити цю зміну у певному порядку, щоб забезпечити доступність та ефективність масштабування під час застосування змін. Перед тим, як ви оновите ресурс, який визначає контейнер (наприклад, Deployment), вам слід оновити повʼязаний HPA, щоб відстежувати як нові, так і старі імена контейнерів. Таким чином, HPA може розраховувати рекомендацію масштабування протягом усього процесу оновлення.
Після того, як ви розгорнули зміну імені контейнера на ресурсі навантаження, закінчіть, видаливши старе імʼя контейнера з характеристик HPA.
Масштабування на основі власних метрик
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.23 [stable]
(версія API autoscaling/v2beta2 раніше надавала цю можливість як бета-функцію)
За умови використання версії API autoscaling/v2 ви можете налаштувати HorizontalPodAutoscaler на масштабування на основі власної метрики (яка не є вбудованою в Kubernetes або будь-який компонент Kubernetes). Потім контролер HorizontalPodAutoscaler запитує ці власні метрики з Kubernetes API.
(версія API autoscaling/v2beta2 раніше надавала цю можливість як бета-функцію)
За умови використання версії API autoscaling/v2 ви можете вказати декілька метрик для HorizontalPodAutoscaler для масштабування на їх основі. Потім контролер HorizontalPodAutoscaler оцінює кожну метрику і пропонує новий масштаб на основі цієї метрики. HorizontalPodAutoscaler бере максимальний масштаб, рекомендований для кожної метрики, і встановлює робоче навантаження на такий розмір (за умови, що це не більше загального максимуму, який ви налаштували).
Підтримка API метрик
Стандартно контролер HorizontalPodAutoscaler отримує метрики з низки API. Для того щоб мати доступ до цих API, адміністратори кластера повинні забезпечити:
Для метрик ресурсі це metrics.k8s.ioAPI, яке зазвичай надає metrics-server. Це може бути запущено як надбудова кластера.
Для власних метрик це custom.metrics.k8s.ioAPI. Його надають сервери API "адаптера", які надають постачальники рішень метрик. Перевірте у своєї системи метрик, чи доступний адаптер метрик Kubernetes.
Для зовнішніх метрик це external.metrics.k8s.ioAPI. Він може бути наданий адаптерами власних метрик, які наведено вище.
(версія API autoscaling/v2beta2 раніше надавала цю можливість як бета-функцію)
Якщо ви використовуєте API HorizontalPodAutoscaler v2, ви можете використовувати поле behavior (див. довідку API) для налаштування окремих поведінок масштабування вгору та вниз. Ви вказуєте ці поведінки, встановлюючи scaleUp та/або scaleDown
у полі behavior.
Політики масштабування також дозволяють контролювати швидкість зміни реплік під час масштабування. Також можна використани два параметри для запобігання коливанню: ви можете вказати вікно стабілізації для чіткіщого підрахунку кількості реплік та допуск для ігнорування незначних коливань метрик нижче вказаного порогового значення.
Політики масштабування
Одну або декілька політик масштабування можна вказати у розділі behavior специфікації. Коли вказано кілька політик, політика, яка дозволяє найбільше змін, є політикою, яка типово вибирається. Наступний приклад показує цю поведінку під час зменшення масштабу:
periodSeconds вказує на проміжок часу в минулому, протягом якого політика має бути істинною. Максимальне значення, яке можна встановити для periodSeconds, — 1800 (пів години). Перша політика (Pods) дозволяє зменшення максимум до 4 репліки протягом однієї хвилини. Друга політика (Percent) дозволяє зменшити максимум 10% поточних реплік протягом однієї хвилини.
Оскільки стандартно вибирається політика, яка дозволяє найбільше змін, друга політика буде використовуватися лише тоді, коли кількість реплік буде більше ніж 40. З 40 або менше реплік, буде застосована перша політика. Наприклад, якщо є 80 реплік, і ціль — зменшити масштаб до 10 реплік тоді під час першого кроку буде скорочено 8 реплік. На наступній ітерації, коли кількість реплік становить 72, 10% від реплік — 7,2, але число заокруглюється вгору до 8. На кожному кроці контролера автомасштабування перераховується кількість реплік, які мають бути змінені, на основі кількості поточних реплік. Коли кількість реплік падає нижче 40, застосовується перша політика (Pods) і зменшується по 4 репліки за раз.
Вибір політики можна змінити, вказавши поле selectPolicy для напрямку масштабування. Встановлення значення Min вибере політику, яка дозволяє найменшу зміну кількості реплік. Встановлення значення Disabled повністю вимикає масштабування в даному напрямку.
Вікно стабілізації
Вікно стабілізації використовується для обмеження перепадів кількості реплік, коли метрики, які використовуються для масштабування, постійно коливаються. Алгоритм автоматичного масштабування використовує це вікно, щоб виявити попередній бажаний стан та уникнути непотрібних змін у масштабі навантаження.
Наприклад, у наступному виразі фрагменту коду вказано вікно стабілізації для scaleDown.
behavior:scaleDown:stabilizationWindowSeconds:300
Коли метрики показують, що потрібно зменшити ціль, алгоритм дивиться на раніше розраховані бажані стани і використовує найвище значення з вказаного інтервалу. У вищезазначеному прикладі всі попередні бажані стани за останні 5 хвилин будуть враховані.
Це наближається до ковзного максимуму і уникає ситуації, коли алгоритм масштабування часто видаляє Podʼи лише для того, щоб викликати повторне створення еквівалентного Podʼа за мить.
Допуск
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [alpha](стандартно вимкнено)
Поле tolerance налаштовує порогове значення для мінливості метрики, запобігаючи масштабуванню нижче вказанного значення.
Цей допуск визначається як величина відхилення навколо бажаного значення метрики, нижче якої масштабування не відбуватиметься. Наприклад, розглянемо HorizontalPodAutoscaler, налаштований з цільовим споживанням памʼяті 100 МБ та допуском масштабування 5%:
behavior:scaleUp:tolerance:0.05# 5% допукс для масштабування
За такої конфігурації алгоритм HPA розглядатиме масштабування лише в тому випадку, якщо споживання памʼяті перевищує 105 МБ (тобто на 5% вище цільового значення).
Якщо це поле не встановлено, HPA застосовуватиме стандартний допуск кластера — 10%. Це стандартне значення може бути оновлено як для масштабування вгору так і вниз використовуючи kube-controller-manager з аргументом командного рядка --horizontal-pod-autoscaler-tolerance. (Ви не можете використовувати API Kubernetes для налашування цього стандартного значення.)
Стандартна поведінка
Для використання власного масштабування не всі поля повинні бути вказані. Можна вказати лише значення, які потрібно налаштувати. Ці власні значення злиті зі стандартними значеннями. Стандартні значення відповідають існуючій поведінці в алгоритмі HPA.
Для зменшення масштабу вікно стабілізації становить 300 секунд (або значення параметра командного рядка --horizontal-pod-autoscaler-downscale-stabilization, якщо воно вказане). Є лише одна політика для зменшення масштабу, яка дозволяє видалити 100% поточно запущених реплік, що означає, що ціль масштабування може бути зменшена до мінімально допустимих реплік. Для збільшення масштабу вікно стабілізації відсутнє. Коли метрики показують, що ціль повинна бути збільшена, ціль збільшується негайно. Є 2 політики, за якими кожні 15 секунд можна додати не більше 4 Podʼів або 100% поточно запущених реплік до тих пір, поки HPA не досягне стабільного стану.
Приклад: зміна вікна стабілізації для зменшення масштабу
Щоб вказати власне значення вікна стабілізації для зменшення масштабу тривалістю в 1 хвилину, в HPA буде додано наступну поведінку:
behavior:scaleDown:stabilizationWindowSeconds:60
Приклад: обмеження коєфіцієнту зменшення масштабу
Щоб обмежити коєфіцієнт, з яким Podʼи видаляються HPA, до 10% за хвилину, до HPA додається наступна поведінка:
Щоб переконатися, що за хвилину видаляється не більше 5 Podʼів, можна додати другу політику зменшення масштабу з фіксованим розміром 5 та встановити selectPolicy на значення Min. Встановлення selectPolicy на Min означає, що автомасштабувальник вибирає політику, яка впливає на найменшу кількість Podʼів:
Значення selectPolicyDisabled вимикає масштабування вказаного напрямку. Щоб запобігти зменшенню масштабу, буде використана наступна політика:
behavior:scaleDown:selectPolicy:Disabled
Підтримка HorizontalPodAutoscaler в kubectl
HorizontalPodAutoscaler, як і кожний ресурс API, підтримується стандартним чином у kubectl. Ви можете створити новий автомасштабувальник за допомогою команди kubectl create. Ви можете переглянути список автомасштабувальників за допомогою kubectl get hpa або отримати детальний опис за допомогою kubectl describe hpa. Нарешті, ви можете видалити автомасштабувальник за допомогою kubectl delete hpa.
Крім того, є спеціальна команда kubectl autoscale для створення обʼєкта HorizontalPodAutoscaler. Наприклад, виконання kubectl autoscale rs foo --min=2 --max=5 --cpu-percent=80 створить автомасштабувальник для ReplicaSet foo, з цільовим використанням процесора, встановленим на 80% і кількістю реплік від 2 до 5.
Неявне деактивування режиму підтримки
Ви можете неявно деактивувати HPA для цільового обʼєкта без необхідності змінювати конфігурацію HPA самостійно. Якщо бажана кількість реплік цільового обʼєкта встановлена на 0, а мінімальна кількість реплік HPA більше 0, HPA припиняє коригування цільового обʼєкта (і встановлює умову ScalingActive на собі в false) до тих пір, поки ви не активуєте його вручну, змінивши бажану кількість реплік цільового обʼєкта або мінімальну кількість реплік HPA.
Перехід Deployment та StatefulSet на горизонтальне масштабування
При увімкненні HPA рекомендується видалити значення spec.replicas з Deployment та/або StatefulSet в їхніх маніфестах. Якщо цього не зроблено, будь-яка зміна в цьому обʼєкті, наприклад за допомогою kubectl apply -f deployment.yaml, буде інструкцією Kubernetes масштабувати поточну кількість Podʼів до значення ключа spec.replicas. Це може бути небажаним і призводити до проблем, коли HPA активно працює.
Майте на увазі, що видалення spec.replicas може спричинити одноразове зниження кількості Podʼів, оскільки стандартне значення цього ключа — 1 (див. Репліки Deployment). Після оновлення всі Podʼи, крім одного, розпочнуть процедури їхнього завершення. Після цього будь-яке подальше розгортання застосунку буде працювати як звичайно і буде дотримуватися конфігурації плавного оновлення за бажанням. Ви можете уникнути цього зниження, обравши один із двох наступних методів в залежності від того, як ви модифікуєте свої розгортання:
У редакторі видаліть spec.replicas. Після збереження та виходу з редактора, kubectl застосовує оновлення. На цьому етапі не відбувається змін кількості Podʼів.
Тепер ви можете видалити spec.replicas з маніфеста. Якщо ви використовуєте систему управління вихідним кодом, також зафіксуйте ваші зміни або виконайте будь-які інші кроки для перегляду вихідного коду, які відповідають вашому способу відстеження оновлень.
Відтепер ви можете запускати kubectl apply -f deployment.yaml
Якщо ви налаштовуєте автомасштабування у вашому кластері, вам також може бути корисно розглянути використання автомасштабування вузлів для забезпечення того, що ви запускаєте правильну кількість вузлів.
Для отримання додаткової інформації про HorizontalPodAutoscaler:
Прочитайте приклад для автоматичного горизонтального масштабування Podʼів.
Якщо ви бажаєте написати власний адаптер для власних метрик, перегляньте початковий код, щоб почати.
Ознайомтесь з Довідкою API для HorizontalPodAutoscaler.
8.8 - Покрокове керівництво HorizontalPodAutoscaler
HorizontalPodAutoscaler (HPA)
автоматично оновлює ресурс робочого навантаження (наприклад, Deployment або StatefulSet), з метою автоматичного масштабування робочого навантаження, щоб відповідати попиту.
Горизонтальне масштабування означає, що відповідь на збільшене навантаження полягає в розгортанні додаткових Podʼів. Це відрізняється від вертикального масштабування, що для Kubernetes означає призначення додаткових ресурсів (наприклад: памʼять або CPU) для Podʼів, які вже працюють для робочого навантаження.
Якщо навантаження зменшується, а кількість Podʼів перевищує налаштований мінімум, HorizontalPodAutoscaler інструктує ресурс робочого навантаження (Deployment, StatefulSet
або інший схожий ресурс) зменшити масштаб.
Цей документ детально розглядає приклад увімкнення HorizontalPodAutoscaler для автоматичного управління масштабуванням для прикладу вебзастосунку. Це приклад навантаження — Apache httpd, що виконує деякий код PHP.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж 1.23.
Для перевірки версії введіть kubectl version.
Якщо ви використовуєте старі версії Kubernetes, зверніться до документації для цієї версії (див. доступні версії документації).
Для виконання рекомендацій цього посібника, вам також потрібно використовувати кластер, в якому розгорнутий і налаштований Metrics Server. Сервер метрик Kubernetes збирає метрики ресурсів з kubelets у вашому кластері та використовує ці метрики через Kubernetes API, використовуючи APIService, щоб додати нові види ресурсів, які представляють метричні показники.
Якщо ви використовуєте Minikube, виконайте наступну команду для ввімкнення metrics-server:
minikube addons enable metrics-server
Запустіть та надайте доступ до сервера php-apache
Для демонстрації HorizontalPodAutoscaler ви спочатку запустите Deployment, який запускає контейнер за допомогою образу hpa-example, та експонуєте його як Service за допомогою наступного маніфесту:
deployment.apps/php-apache створено
service/php-apache створено
Створіть HorizontalPodAutoscaler
Тепер, коли сервер працює, створіть автомасштабувальник за допомогою kubectl. Підкоманда kubectl autoscale, частина kubectl, допоможе зробити це.
За мить ви виконаєте команду, яка створить HorizontalPodAutoscaler, що підтримує від 1 до 10 реплік контрольованих Podʼів за допомогою Deployment php-apache, який ви створили на першому етапі цих інструкцій.
Грубо кажучи, контролер контролер HPA збільшує або зменшує кількість реплік (шляхом оновлення Deployment) для підтримки середнього використання процесора на рівні 50% по всіх Podʼах. Deployment потім оновлює ReplicaSet — це частина всіх Deployment у Kubernetes — і потім ReplicaSet додає або видаляє Podʼи на основі змін у його .spec.
Оскільки кожен Pod запитує 200 мілі-ядер за допомогою kubectl run, це означає середнє використання процесора 100 мілі-ядер. Див. Деталі алгоритму для отримання додаткової інформації щодо алгоритму.
Ви можете перевірити поточний стан нового HorizontalPodAutoscaler, виконавши:
# Ви можете використовувати "hpa" або "horizontalpodautoscaler"; обидва імені працюють добре.kubectl get hpa
Вивід схожий на:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 18s
(якщо ви бачите інші HorizontalPodAutoscalers з різними іменами, це означає, що вони вже існували, і це зазвичай не проблема).
Зверніть увагу, що поточне використання ЦП становить 0%, оскільки немає клієнтів, що відправляють запити на сервер (стовпець «TARGET» показує середнє значення по всіх Podʼах, що контролюються відповідним розгортанням).
Збільшення навантаження
Далі перегляньте, як автомасштабувальник реагує на збільшене навантаження. Для цього ви запустите інший Pod, який буде виступати в ролі клієнта. Контейнер всередині Podʼа клієнта працює у нескінченному циклі, надсилаючи запити до служби php-apache.
# Виконайте це в окремому терміналі,# щоб навантаження продовжувалося, і ви могли продовжити роботу з рештою кроківkubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
Тепер виконайте:
# натисніть Ctrl+C, щоб припинити перегляд, коли будете готовіkubectl get hpa php-apache --watch
Протягом хвилини ви повинні побачити вище навантаження процесора; наприклад:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 305% / 50% 1 10 1 3m
а потім більше реплік. Наприклад:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 305% / 50% 1 10 7 3m
Тут споживання ЦП збільшилося до 305% від запиту. В результаті Deployment був змінений до 7 реплік:
kubectl get deployment php-apache
Ви повинні побачити, що кількість реплік відповідає цифрі з HorizontalPodAutoscaler
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 7/7 7 7 19m
Примітка:
Може знадобитися кілька хвилин, щоб стабілізувалася кількість реплік. Оскільки обсяг навантаження не контролюється, може статися так, що кінцева кількість реплік буде відрізнятися від цього прикладу.
Зупиніть генерування навантаження
Для завершення прикладу припиніть надсилання навантаження.
У терміналі, де ви створили Pod, який працює з образом busybox, зупиніть генерування навантаження, натиснувши <Ctrl> + C.
Потім перевірте результат (через хвилину чи так):
# натисніть Ctrl+C, щоб припинити перегляд, коли будете готовіkubectl get hpa php-apache --watch
Вивід схожий на:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 11m
і Deployment також показує, що він зменшився:
kubectl get deployment php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 1/1 1 1 27m
Як тільки використання CPU знизилося до 0, HPA автоматично зменшив кількість реплік до 1.
Автоматичне масштабування реплік може зайняти кілька хвилин.
Автомасштабування за допомогою кількох метрик та власних метрик
Ви можете вводити додаткові метрики для використання при автомасштабуванні Deployment php-apache, використовуючи версію API autoscaling/v2.
Спочатку отримайте YAML вашого HorizontalPodAutoscaler у формі autoscaling/v2:
kubectl get hpa php-apache -o yaml > /tmp/hpa-v2.yaml
Відкрийте файл /tmp/hpa-v2.yaml у редакторі, і ви побачите YAML, що виглядає наступним чином:
Зверніть увагу, що поле targetCPUUtilizationPercentage було замінено масивом під назвою metrics. Метрика використання ЦП є ресурсною метрикою, оскільки вона представлена як відсоток ресурсу, вказаного в контейнерах Podʼа. Зверніть увагу, що ви можете вказати інші ресурсні метрики крім ЦП. Стандартно, єдиним іншим підтримуваним типом ресурсної метрики є memory. Ці ресурси не змінюють назви з кластера на кластер і завжди повинні бути доступними, поки API metrics.k8s.io доступне.
Ви також можете вказати ресурсні метрики у вигляді безпосередніх значень, а не як відсотки від запитаного значення, використовуючи target.typeAverageValue замість Utilization, і встановлюючи відповідне поле target.averageValue замість target.averageUtilization.
Є ще два інші типи метрик, які обидва вважаються власними метриками: метрики Podʼів і метрики обʼєктів. Ці метрики можуть мати назви, які специфічні для кластера, і вимагають більш розширеної настройки моніторингу кластера.
Перший з цих альтернативних типів метрик — це метрики Podʼів. Ці метрики описують Podʼи і вони усереднюються разом по Podʼах і порівнюються з цільовим значенням для визначення кількості реплік. Вони працюють так само як ресурсні метрики, за винятком того, що вони тільки підтримують тип targetAverageValue.
Метрики Podʼів вказуються за допомогою блоку метрики, подібного до цього:
Другий альтернативний тип метрики — це метрики обʼєктів. Ці метрики описують інший обʼєкт в тому ж просторі імен, замість опису Podʼів. Метрики не обовʼязково отримуються з обʼєкта; вони лише описують його. Метрики обʼєктів підтримують типи target як Value і AverageValue. З Value ціль порівнюється безпосередньо з метрикою отриманою з API. З AverageValue значення, повернене з API власних метрик, ділиться на кількість Podʼів перед порівнянням з цільовим значенням. Ось приклад YAML представлення метрики requests-per-second.
Якщо ви надаєте кілька таких блоків метрик, HorizontalPodAutoscaler буде розглядати кожну метрику по черзі. HorizontalPodAutoscaler розраховуватиме запропоновані кількості реплік для кожної метрики, а потім вибере той, який має найбільшу кількість реплік.
Наприклад, якщо ваша система моніторингу збирає метрики про мережевий трафік, ви можете оновити визначення вище за допомогою kubectl edit так, щоб воно виглядало наступним чином:
Тоді ваш HorizontalPodAutoscaler намагатиметься забезпечити, щоб кожен Pod витрачав приблизно 50% від своєї запитаної CPU, обслуговував 1000 пакетів за секунду та всі Podʼи за головним маршрутом Ingress обслуговували в загальному 10000 запитів за секунду.
Автомасштабування за більш конкретними метриками
Багато систем метрик дозволяють описувати метрики або за назвою, або за набором додаткових описів, які називаються мітками (labels). Для всіх типів метрик, крім ресурсних (Podʼів, обʼєктів і зовнішніх, описаних нижче), ви можете вказати додатковий селектор міток, який передається вашій системі метрик. Наприклад, якщо ви збираєте метрику http_requests з міткою verb, ви можете вказати наступний блок метрики, щоб масштабувати тільки на запити GET:
Цей селектор використовує такий же синтаксис, як і повні селектори міток Kubernetes. Система моніторингу визначає, як зведені кілька серій в одне значення, якщо імʼя та селектор відповідають кільком серіям. Селектор є додатковим, і не може вибирати метрики, що описують обʼєкти, які не є цільовим обʼєктом (цільові Podʼи у випадку типу Pods, та описаний обʼєкт у випадку типу Object).
Автомасштабування за метриками, що не стосуються обʼєктів Kubernetes
Застосунки, які працюють на Kubernetes, можуть потребувати автоматичного масштабування на основі метрик, які не мають очевидного стосунку до будь-якого обʼєкта в кластері Kubernetes, наприклад, метрики, що описують хостову службу з жодною прямою кореляцією з просторами імен Kubernetes. У Kubernetes 1.10 і пізніших версіях ви можете вирішити цей випадок використовуючи зовнішні метрики.
Для використання зовнішніх метрик потрібно знання вашої системи моніторингу; налаштування аналогічно необхідному при використанні власних метрик. Зовнішні метрики дозволяють автоматично масштабувати ваш кластер на основі будь-якої метрики, доступної в вашій системі моніторингу. Надайте блок metric з name та selector, як вище, і використовуйте тип метрики External замість Object. Якщо кілька часових рядів відповідають metricSelector, то сума їх значень використовується HorizontalPodAutoscaler. Зовнішні метрики підтримують як типи цілей Value, так і AverageValue, які працюють точно так само, як коли ви використовуєте тип Object.
Наприклад, якщо ваш додаток обробляє завдання з хостової служби черги, ви можете додати наступний розділ до вашого маніфесту HorizontalPodAutoscaler, щоб вказати, що вам потрібен один робочий процес на кожні 30 невиконаних завдань.
Коли це можливо, краще використовувати типи цілей власних метрик замість зовнішніх метрик, оскільки для адміністраторів кластера легше захистити API власних метрик. Зовнішнє API метрик потенційно дозволяє доступ до будь-якої метрики, тому адміністратори кластера повинні бути обережні при його використанні.
Додаток: Умови стану горизонтального автомасштабування Podʼів
При використанні форми autoscaling/v2 HorizontalPodAutoscaler ви зможете бачити умови стану, встановлені Kubernetes на HorizontalPodAutoscaler. Ці умови стану вказують, чи може або не може HorizontalPodAutoscaler масштабуватися, а також чи є в цей час будь-які обмеження.
Умови зʼявляються у полі status.conditions. Щоб побачити умови, які впливають на HorizontalPodAutoscaler, ми можемо використати kubectl describe hpa:
kubectl describe hpa cm-test
Name: cm-test
Namespace: prom
Labels: <none>
Annotations: <none>
CreationTimestamp: Fri, 16 Jun 2017 18:09:22 +0000
Reference: ReplicationController/cm-test
Metrics: ( current / target )
"http_requests" on pods: 66m / 500m
Min replicas: 1
Max replicas: 4
ReplicationController pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale the last scale time was sufficiently old as to warrant a new scale
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_requests
ScalingLimited False DesiredWithinRange the desired replica count is within the acceptable range
Events:
Для цього HorizontalPodAutoscaler ви можете побачити кілька умов у справному стані. Перше, AbleToScale, вказує, чи може або не може HPA отримувати та оновлювати масштаби, а також чи будь-які умови затримки повʼязані з масштабуванням. Друге, ScalingActive, вказує, чи увімкнений HPA (тобто кількість реплік цілі не дорівнює нулю) та чи може розраховувати потрібні масштаби. Якщо це False, це, як правило, вказує на проблеми з отриманням метрик. Нарешті, остання умова, ScalingLimited, вказує на те, що потрібний масштаб був обмежений максимальним або мінімальним значенням HorizontalPodAutoscaler. Це свідчить про те, що ви можливо захочете збільшити або зменшити мінімальну або максимальну кількість реплік на вашому HorizontalPodAutoscaler.
Кількості
Усі метрики в HorizontalPodAutoscaler та API метрик вказуються за спеціальною цільною числовою нотацією, відомою в Kubernetes як кількість. Наприклад, кількість 10500m буде записана як 10.5 у десятковій нотації. API метрик повертатимуть цілі числа без суфікса, якщо це можливо, і зазвичай повертають кількості в міліодиницях у протилежному випадку. Це означає, що ви можете бачити зміну вашого значення метрики між 1 і 1500m, або між 1 і 1.5, коли воно записане в десятковій нотації.
Інші можливі сценарії
Створення автомасштабування декларативно
Замість використання команди kubectl autoscale для створення HorizontalPodAutoscaler імперативно, ми можемо використати наступний маніфест, щоб створити його декларативно:
horizontalpodautoscaler.autoscaling/php-apache created
8.9 - Вказання бюджету розладів для вашого застосунку
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.21 [stable]
На цій сторінці показано, як обмежити кількість одночасних розладів, які очікує ваш застосунок, що дозволяє підвищити доступність і дозволяє адміністратору кластера управляти вузлами кластера.
Перш ніж ви розпочнете
Версія вашого Kubernetes сервера має бути не старішою ніж v1.21.
Для перевірки версії введіть kubectl version.
Ви є власником застосунку, який працює в кластері Kubernetes і вимагає високої доступності.
Ви повинні підтвердити з власником кластера або постачальником послуг, що вони дотримуються Бюджетів розладів Podʼів.
Захист застосунку за допомогою PodDisruptionBudget
Визначте, який застосунок ви хочете захистити за допомогою PodDisruptionBudget (PDB).
Подумайте про те, як ваш застосунок реагує на розлади.
Створіть визначення PDB у вигляді файлу YAML.
Створіть обʼєкт PDB з файлу YAML.
Визначення застосунку для захисту
Найбільш поширене використання полягає в захисті застосунку, який визначено одним із вбудованих контролерів Kubernetes:
Deployment (Розгортання)
ReplicationController (Контролер Реплікації)
ReplicaSet (Набір Реплік)
StatefulSet (Набір зі збереженням стану)
У цьому випадку обовʼязково відзначте .spec.selector контролера; той самий селектор використовується в .spec.selector PDBs.
Починаючи з версії 1.15, PDB підтримують власні контролери, де включено субресурс масштабування.
Також можна використовувати PDB зі сторонніми Podʼами, які не контролюються одним із вищевказаних контролерів, або з довільними групами Podʼів, але є деякі обмеження, описані у Довільні робочі навантаження та довільні селектори.
Подумайте про реакцію вашого застосунку на розлади
Вирішіть, скільки екземплярів може бути вимкнено одночасно на короткий період часу через добровільні розлади.
Фронтенди без збереження стану:
Застереження: не зменшуйте потужність обслуговування більш ніж на 10%.
Рішення: використовуйте PDB з minAvailable 90%, наприклад.
Одноекземплярний застосунок зі збереженням стану:
Застереження: не закривайте цей застосунок без спілкування зі мною.
Можливе рішення 1: Не використовуйте PDB і толеруйте випадковий простій.
Можливе рішення 2: Встановіть PDB з maxUnavailable=0. Маючи розуміння (поза Kubernetes), що оператор кластера повинен звʼязатися з вами перед закриттям. Коли оператор кластера звертається до вас, готуйтеся до простою, а потім видаліть PDB, щоб показати готовність до розладу. Після цього створіть новий.
Багатоекземплярний застосунок зі збереженням стану, такий як Consul, ZooKeeper або etcd:
Застереження: не зменшуйте кількість екземплярів нижче кворуму, в іншому випадку записи будуть невдалі.
Можливе рішення 1: встановіть maxUnavailable на рівень 1 (працює з різними масштабами застосунку).
Можливе рішення 2: встановіть minAvailable рівним розміру кворуму (наприклад, 3 при масштабуванні 5). (Дозволяє більше розладів одночасно).
Пакетне завдання (Job) з перезапуском:
Застереження: завдання повинно завершитися у разі добровільного розладу.
Можливе рішення: Не створюйте PDB. Контролер завдань створить Pod на заміну.
Логіка округлення при вказанні відсотків
Значення для minAvailable або maxUnavailable можуть бути виражені як цілі числа або як відсотки.
Коли ви вказуєте ціле число, воно представляє кількість Podʼів. Наприклад, якщо ви встановите minAvailable на 10, то завжди повинно бути доступно 10 Podʼів, навіть під час розладу.
Коли ви вказуєте відсоток, встановивши значення як рядкове представлення відсотка (наприклад, "50%"), воно представляє відсоток від загальної кількості Podʼів. Наприклад, якщо ви встановите minAvailable на "50%", то принаймні 50% Podʼів залишаться доступними під час розладу.
Коли ви вказуєте значення як відсоток, це може не відповідати точній кількості Podʼів. Наприклад, якщо у вас є 7 Podʼів і ви встановите minAvailable на "50%", то не зразу очевидно, чи має це означати, що повинно бути доступно 3 або 4 Podʼи. Kubernetes округлює до найближчого цілого числа, тому в цьому випадку повинно бути доступно 4 Podʼи. Коли ви вказуєте значення maxUnavailable як відсоток, Kubernetes округлює кількість Podʼів, які можуть мати розлади. Таким чином, розлад може перевищувати ваш визначений відсоток maxUnavailable. Ви можете ознайомитися з кодом, який керує такою поведінкою.
Вказання PodDisruptionBudget
PodDisruptionBudget має три поля:
Селектор міток .spec.selector, щоб вказати набір Podʼів, до яких він застосовується. Це поле обовʼязкове.
.spec.minAvailable — це опис кількості Podʼів з цього набору, які повинні залишитися доступними після виселення, навіть у відсутності виселеного Podʼа. minAvailable може бути абсолютним числом або відсотком.
.spec.maxUnavailable (доступний у Kubernetes 1.7 та вище) — це опис кількості Podʼів з цього набору, які можуть бути недоступними після виселення. Це також може бути абсолютним числом або відсотком.
Примітка:
Поведінка для порожнього селектора відрізняється між policy/v1beta1 та policy/v1 API для PodDisruptionBudgets. Для policy/v1beta1 порожній селектор відповідає нулю Podʼів, тоді як для policy/v1 порожній селектор відповідає кожному Podʼа у просторі імен.
Ви можете вказати лише один із maxUnavailable або minAvailable в одному PodDisruptionBudget. maxUnavailable може бути використаний лише для контролю виселення Podʼів, які всі мають той самий повʼязаний контролер, який керує ними. У наведених нижче прикладах, "бажані репліки" — це scale контролера, що керує Podʼами, які вибрані PodDisruptionBudget.
Приклад 1: З minAvailable 5, виселення дозволяються, поки залишаються 5 або більше справних Podʼів серед тих, які вибрані селектором PodDisruptionBudget.
Приклад 2: З minAvailable 30%, виселення дозволяються, якщо принаймні 30% від кількості бажаних реплік є справними.
Приклад 3: З maxUnavailable 5, виселення дозволяються, поки є не більше 5 несправних реплік серед загальної кількості бажаних реплік.
Приклад 4: З maxUnavailable 30%, виселення дозволяються, якщо кількість несправних реплік не перевищує 30% від загальної кількості бажаних реплік, округленої до найближчого цілого числа. Якщо загальна кількість бажаних реплік — лише одна, ця єдина репліка все ще допускається до виселення, що призводить до ефективної недоступності на 100%.
У типовому використанні один бюджет використовуватиметься для збірки Podʼів, керованих контролером — наприклад, Podʼів у одному ReplicaSet або StatefulSet.
Примітка:
Бюджет розладів фактично не гарантує, що вказана кількість/відсоток Podʼів завжди буде активними. Наприклад, вузол, на якому розміщено Pod зі збірки, може вийти з ладу, коли збірка досягне мінімального розміру, вказаного в бюджеті, що призведе до зменшення кількості доступних Podʼів зі збірки нижче вказаного розміру. Бюджет може захищати лише від добровільних виселень, а не від всіх причин недоступності.
Якщо ви встановите maxUnavailable на 0% або 0, або ви встановите minAvailable на 100% або рівну кількості реплік, ви вимагаєте нульових добровільних виселень. Коли ви встановлюєте нульові добровільні виселення для робочого навантаження, такого як ReplicaSet, тоді ви не зможете успішно вивести з експлуатації вузол, на якому працює один з цих Podʼів. Якщо ви намагаєтеся вивести з експлуатації вузол, де працює невиселяємий Pod, відключення ніколи не завершиться. Це допускається згідно з семантикою PodDisruptionBudget.
Ви можете знайти приклади визначення бюджетів розладів Podʼів нижче. Вони відповідають Podʼам з міткою app: zookeeper.
Наприклад, якщо вищезгаданий обʼєкт zk-pdb вибирає Podʼи з StatefulSet розміром 3, обидві специфікації мають точно таке ж значення. Рекомендується використання maxUnavailable, оскільки він автоматично реагує на зміни кількості реплік відповідного контролера.
Створення обʼєкта PodDisruptionBudget
Для створення або оновлення обʼєкта PDB використовуйте наступну команду kubectl:
kubectl apply -f mypdb.yaml
Перевірка статусу обʼєкта PodDisruptionBudget
Щоб перевірити статус обʼєкта PDB, скористайтеся наступною командою kubectl.
Якщо в вашому просторі імен відсутні Podʼи, що відповідають мітці app: zookeeper, ви побачите щось подібне:
kubectl get poddisruptionbudgets
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
zk-pdb 2 N/A 0 7s
Якщо є Podʼи, які відповідають умовам (скажімо, 3), то ви побачите щось на кшталт:
kubectl get poddisruptionbudgets
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
zk-pdb 2 N/A 1 7s
Ненульове значення для ALLOWED DISRUPTIONS означає, що контролер розладів Podʼів бачив Podʼи, порахував відповідні Podʼи і оновив статус PDB.
Ви можете отримати більше інформації про статус PDB за допомогою цієї команди:
Поточна реалізація вважає Podʼи справними, якщо вони мають елемент .status.conditions з type="Ready" і status="True". Ці Podʼи відстежуються через поле .status.currentHealthy в статусі PDB.
Політика виселення несправних Podʼів
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.31 [stable](стандартно увімкнено)
PodDisruptionBudget, який охороняє застосунок, забезпечує, що кількість Podʼів зі статусом .status.currentHealthy не опуститься нижче, ніж кількість, вказана у .status.desiredHealthy, не дозволяючи виселення справних Podʼів. Використовуючи .spec.unhealthyPodEvictionPolicy, ви також можете визначити критерії, коли несправні Podʼи повинні розглядатися для виселення. Стандартна поведінка, коли політика не вказана, відповідає політиці IfHealthyBudget.
Політики:
IfHealthyBudget
Запущені Podʼи (.status.phase="Running"), але ще не справні, можуть бути виселені тільки якщо охоронюваний застосунок не перебуває в розладі (.status.currentHealthy щонайменше дорівнює .status.desiredHealthy).
Ця політика забезпечує, що запущені Podʼи застосунку, що перебуває в стані розлажу, мають кращі шанси стати справними. Це має негативні наслідки для виведення вузлів з експлуатації, які можуть бути заблоковані неправильно працюючими застосунками, які охороняються PDB. Зокрема, застосунки з Podʼами у стані CrashLoopBackOff (через помилку або неправильну конфігурацію), або Podʼи, яким просто не вдається повідомити стан Ready.
AlwaysAllow
Запущені Podʼи (.status.phase="Running"), але ще не справні вважаються такими що перебувають в стані розладу та можуть бути виселені незалежно від того, чи виконуються критерії в PDB.
Це означає, що майбутні запущені Podʼи застосунку, що перебуває в стані розладу, можуть не мати можливості стати справними. Використовуючи цю політику, менеджери кластера можуть легко вивести з експлуатації неправильно працюючі застосунки, які охороняються PDB. Зокрема, застосунки з Podʼами у стані CrashLoopBackOff (через помилку або неправильну конфігурацію), або Podʼи, яким просто не вдається повідомити стан Ready.
Примітка:
Podʼи у фазах Pending, Succeeded або Failed завжди вважаються кандидатами на виселення.
Довільні робочі навантаження та селектори
Ви можете пропустити цей розділ, якщо ви використовуєте PDB лише з вбудованими ресурсами навантаження (Deployment, ReplicaSet, StatefulSet та ReplicationController) або з власними ресурсами, які реалізують субресурсscale, і де селектор PDB точно відповідає селектору власного ресурсу Podʼа.
Ви можете використовувати PDB з підпроцесами, керованими іншим ресурсом, "оператором" або чистими подами, але з такими обмеженнями:
можна використовувати лише .spec.minAvailable, а не .spec.maxUnavailable.
можна використовувати лише ціле значення з .spec.minAvailable, а не відсоток.
Неможливо використовувати інші конфігурації доступності, оскільки Kubernetes не може вивести загальну кількість Podʼів без підтримуваного власного ресурсу.
Ви можете використовувати селектор, який вибирає підмножину або надмножину Podʼів, що належать ресурсу навантаження. Eviction API не дозволить виселення будь-якого Podʼа, покритого кількома PDB, тому більшість користувачів захочуть уникати перетинаючих селекторів. Одним розумним використанням перетинаючих PDB є перехід Podʼів з одного PDB до іншого.
8.10 - Отримання доступу до API Kubernetes з Pod
Цей посібник демонструє, як отримати доступ до API Kubernetes з середини Pod.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
При доступі до API з середини Pod, пошук та автентифікація до сервера API відрізняються трохи від зовнішнього клієнта.
Найпростіший спосіб використовувати API Kubernetes з Pod — використовувати одну з офіційних клієнтських бібліотек. Ці бібліотеки можуть автоматично визначати сервер API та автентифікувати.
Використання офіційних клієнтських бібліотек
З середини Pod рекомендовані способи підключення до API Kubernetes:
Для клієнта Go використовуйте офіційну бібліотеку клієнтів Go. Функція rest.InClusterConfig() автоматично обробляє визначення хосту API та автентифікацію. Див. приклад тут.
Для клієнта Python використовуйте офіційну бібліотеку клієнтів Python. Функція config.load_incluster_config() автоматично обробляє визначення хоста API та автентифікацію. Див. приклад тут.
У кожному випадку облікові дані облікового службово запису Pod використовуються для забезпечення безпечного звʼязку з сервером API.
Прямий доступ до REST API
Під час роботи в Pod ваш контейнер може створити HTTPS URL для сервера API Kubernetes, отримавши змінні середовища KUBERNETES_SERVICE_HOST та KUBERNETES_SERVICE_PORT_HTTPS. Внутрішня адреса сервера API також публікується для Service з іменем kubernetes в просторі імен default, щоб Pod можна було використовувати kubernetes.default.svc як DNS-імʼя для локального сервера API.
Примітка:
Kubernetes не гарантує, що сервер API має дійсний сертифікат для імені хосту kubernetes.default.svc; однак очікується, що панель управління представить дійсний сертифікат для імені хоста або IP-адреси, яку представляє $KUBERNETES_SERVICE_HOST.
Рекомендований спосіб автентифікації на сервері API — за допомогою службового облікового запису. Стандартно, Pod повʼязаний з службовим обліковим записом, і обліковий запис (токен) для цього службового облікового запису розміщується в дереві файлової системи кожного контейнера в цьому Pod, у /var/run/secrets/kubernetes.io/serviceaccount/token.
Якщо доступно, пакет сертифікатів розміщується в дереві файлової системи кожного контейнера за адресою /var/run/secrets/kubernetes.io/serviceaccount/ca.crt, і його слід використовувати для перевірки сертифіката сервера API.
Нарешті, простір імен default для операцій з просторовими іменами API розміщується в файлі у /var/run/secrets/kubernetes.io/serviceaccount/namespace в кожному контейнері.
Використання kubectl proxy
Якщо ви хочете запитувати API без офіційної клієнтської бібліотеки, ви можете запустити kubectl proxy як команду нового контейнера sidecar в Pod. Таким чином, kubectl proxy буде автентифікуватися до API та викладати його на інтерфейс localhost Pod, щоб інші контейнери в Pod могли використовувати його безпосередньо.
Без використання проксі
Можливо уникнути використання kubectl proxy, передаючи токен автентифікації прямо на сервер API. Внутрішній сертифікат забезпечує зʼєднання.
# Вказати імʼя хоста внутрішнього API-сервераAPISERVER=https://kubernetes.default.svc
# Шлях до токена ServiceAccountSERVICEACCOUNT=/var/run/secrets/kubernetes.io/serviceaccount
# Прочитати простір імен цього PodNAMESPACE=$(cat ${SERVICEACCOUNT}/namespace)# Прочитати токен облікового службового записуTOKEN=$(cat ${SERVICEACCOUNT}/token)# Звертатися до внутрішнього центру сертифікації (CA)CACERT=${SERVICEACCOUNT}/ca.crt
# Досліджувати API за допомогою TOKENcurl --cacert ${CACERT} --header "Authorization: Bearer ${TOKEN}" -X GET ${APISERVER}/api
9.1 - Виконання автоматизованих завдань за допомогою CronJob
Ця сторінка показує, як виконувати автоматизовані завдання за допомогою обʼєкта Kubernetes CronJob.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Після створення CronJob отримайте його статус за допомогою цієї команди:
kubectl get cronjob hello
Вивід буде подібний до цього:
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 <none> 10s
Як видно з результатів команди, CronJob ще не планував або не запускав жодних завдань. Спостерігайте (watch) за створенням завдання протягом хвилини:
kubectl get jobs --watch
Вивід буде подібний до цього:
NAME COMPLETIONS DURATION AGE
hello-4111706356 0/1 0s
hello-4111706356 0/1 0s 0s
hello-4111706356 1/1 5s 5s
Тепер ви бачите одне запущене завдання, заплановане cron job "hello". Ви можете припинити спостереження за завданням і переглянути cron job ще раз, щоб побачити, що він запланував завдання:
kubectl get cronjob hello
Вивід буде подібний до цього:
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 50s 75s
Ви повинні побачити, що cron job hello успішно запланував завдання в час, вказаний у LAST SCHEDULE. Наразі немає активних завдань, що означає, що завдання завершилось або зазнало невдачі.
Тепер знайдіть Podʼи, які створило останнє заплановане завдання, та перегляньте стандартний вивід одного з них.
Примітка:
Назва завдання відрізняється від назви Pod.
# Замініть "hello-4111706356" на назву завдання у вашій системіpods=$(kubectl get pods --selector=job-name=hello-4111706356 --output=jsonpath={.items[*].metadata.name})
Покажіть лог Pod:
kubectl logs $pods
Вивід буде подібний до цього:
Fri Feb 22 11:02:09 UTC 2019
Hello from the Kubernetes cluster
Видалення CronJob
Коли вам більше не потрібно cron job, видаліть його за допомогою kubectl delete cronjob <cronjob name>:
kubectl delete cronjob hello
Видалення cron job призводить до видалення всіх створених ним завдань і Podʼів і припинення створення додаткових завдань. Докладніше про видалення завдань читайте в збиранні сміття.
9.2 - Груба паралельна обробка за допомогою черги роботи
У цьому прикладі ви запустите Job Kubernetes з кількома паралельними робочими процесами.
У цьому прикладі, при створенні кожного Pod, він бере одиницю роботи з черги завдань, завершує її, видаляє її з черги та завершує роботу.
Ось огляд кроків у цьому прикладі:
Запустіть службу черги повідомлень. У цьому прикладі ви використовуєте RabbitMQ, але ви можете використовувати іншу. На практиці ви налаштовували б службу черги повідомлень один раз і використовували б її для багатьох робочих завдань.
Створіть чергу та заповніть її повідомленнями. Кожне повідомлення являє собою одне завдання для виконання. У цьому прикладі повідомлення — це ціле число, на якому ми будемо виконувати тривалі обчислення.
Запустіть Job, що працює над завданнями з черги. Job створює декілька Podʼів. Кожен Pod бере одне завдання з черги повідомлень, обробляє його та завершує роботу.
Перш ніж ви розпочнете
Ви вже маєте бути знайомі з основним, не-паралельним використанням Job.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Вам знадобиться реєстр образів контейнерів, куди ви можете завантажувати образи для запуску у своєму кластері.
Цей приклад завдання також передбачає, що у вас вже встановлений Docker локально.
Запуск служби черги повідомлень
У цьому прикладі використовується RabbitMQ, проте ви можете адаптувати приклад для використання іншої служби повідомлень типу AMQP.
На практиці ви можете налаштувати службу черги повідомлень один раз у кластері та використовувати її для багатьох завдань, а також для служб з тривалим виконанням.
Запустіть RabbitMQ таким чином:
# Створіть Service для використання StatefulSetkubectl create -f https://kubernetes.io/examples/application/job/rabbitmq/rabbitmq-service.yaml
Тепер ми можемо спробувати доступ до черги повідомлень. Ми створимо тимчасовий інтерактивний Pod, встановимо деякі інструменти на ньому, і спробуємо працювати з чергами.
Waiting for pod default/temp-loe07 to be running, status is Pending, pod ready: false
... [ previous line repeats several times .. hit return when it stops ] ...
Зверніть увагу, що ваше імʼя Pod та запрошення командного рядка будуть відрізнятися.
Далі встановіть amqp-tools, щоб працювати з чергами повідомлень. Наступні команди показують, що вам потрібно запустити в середовищі інтерактивної оболонки у цьому Pod:
Якщо надбудова kube-dns не налаштована правильно, попередній крок може не працювати для вас. Ви також можете знайти IP-адресу для цього Service у змінній середовища:
# виконайте цю перевірку всередині Podenv | grep RABBITMQ_SERVICE | grep HOST
RABBITMQ_SERVICE_SERVICE_HOST=10.0.147.152
(IP-адреса буде відрізнятися)
Далі перевірте, що ви можете створити чергу, і публікувати та отримувати повідомлення.
# Виконайте ці команди всередині Pod# У наступному рядку rabbitmq-service - це імʼя хоста, за яким можна звертатися до rabbitmq-service.# 5672 - це стандартний порт для rabbitmq.exportBROKER_URL=amqp://guest:guest@rabbitmq-service:5672
# Якщо ви не могли отримати доступ до "rabbitmq-service" на попередньому кроці,# використовуйте цю команду натомість:BROKER_URL=amqp://guest:guest@$RABBITMQ_SERVICE_SERVICE_HOST:5672
# Тепер створіть чергу:/usr/bin/amqp-declare-queue --url=$BROKER_URL -q foo -d
foo
Опублікуйте одне повідомлення в черзі:
/usr/bin/amqp-publish --url=$BROKER_URL -r foo -p -b Hello
# І отримайте його назад./usr/bin/amqp-consume --url=$BROKER_URL -q foo -c 1 cat &&echo 1>&2
Hello
У останній команді інструмент amqp-consume взяв одне повідомлення (-c 1) з черги, і передав це повідомлення на стандартний ввід довільної команди. У цьому випадку програма cat виводить символи, зчитані зі стандартного вводу, а echo додає символ нового рядка, щоб приклад був читабельним.
Заповнення черги завданнями
Тепер заповніть чергу деякими симульованими завданнями. У цьому прикладі завдання — це рядки, які потрібно надрукувати.
На практиці вміст повідомлень може бути таким:
назви файлів, які потрібно обробити
додаткові прапорці для програми
діапазони ключів у таблиці бази даних
параметри конфігурації для симуляції
номери кадрів сцени для рендерингу
Якщо є великі дані, які потрібно лише для читання всіма Podʼами Job, зазвичай це розміщують на спільній файловій системі, наприклад NFS, і монтується це на всі Podʼи тільки для читання, або напишіть програму в Pod так, щоб вона могла нативно читати дані з кластерної файлової системи (наприклад: HDFS).
У цьому прикладі ви створите чергу та заповните її, використовуючи інструменти командного рядка AMQP. На практиці ви можете написати програму для заповнення черги, використовуючи бібліотеку клієнтів AMQP.
# Виконайте це на вашому компʼютері, а не в Pod/usr/bin/amqp-declare-queue --url=$BROKER_URL -q job1 -d
job1
Додайте елементи до черги:
for f in apple banana cherry date fig grape lemon melon
do /usr/bin/amqp-publish --url=$BROKER_URL -r job1 -p -b $fdone
Ви додали 8 повідомлень у чергу.
Створення образу контейнера
Тепер ви готові створити образ, який ви будете запускати як Job.
Job буде використовувати утиліту amqp-consume для читання повідомлення з черги та виконання реальної роботи. Ось дуже простий приклад програми:
#!/usr/bin/env python# Просто виводить стандартний вивід і очікує протягом 10 секунд.importsysimporttimeprint("Processing "+ sys.stdin.readlines()[0])
time.sleep(10)
Дайте скрипту дозвіл на виконання:
chmod +x worker.py
Тепер створіть образ. Створіть тимчасову теку, перейдіть в неї, завантажте Dockerfile, і worker.py. У будь-якому випадку, створіть образ за допомогою цієї команди:
docker build -t job-wq-1 .
Для Docker Hub позначте ваш образ застосунка вашим імʼям користувача і завантажте його на Hub за допомогою таких команд. Замініть <username> на ваше імʼя користувача Hub.
docker tag job-wq-1 <username>/job-wq-1
docker push <username>/job-wq-1
Якщо ви використовуєте альтернативний реєстр образів контейнерів, позначте образ і завантажте його туди замість цього.
Визначення Job
Ось маніфест для Job. Вам потрібно зробити копію маніфеста Job (назвіть його ./job.yaml), і змініть імʼя образу контейнера, щоб відповідало імені, яке ви використовували.
У цьому прикладі кожен Pod працює над одним елементом з черги, а потім виходить. Таким чином, кількість завершень завдання відповідає кількості виконаних робочих елементів. Тому у прикладі маніфесту .spec.completions встановлено на 8.
Запуск Job
Тепер запустіть завдання:
# це передбачає, що ви вже завантажили та відредагували маніфестkubectl apply -f ./job.yaml
Ви можете зачекати, доки завдання успішно виконається, використовуючи тайм-аут:
# Перевірка для умови що імена нечутливі до регіструkubectl wait --for=condition=complete --timeout=300s job/job-wq-1
Далі перевірте стан завдання:
kubectl describe jobs/job-wq-1
Name: job-wq-1
Namespace: default
Selector: controller-uid=41d75705-92df-11e7-b85e-fa163ee3c11f
Labels: controller-uid=41d75705-92df-11e7-b85e-fa163ee3c11f
job-name=job-wq-1
Annotations: <none>
Parallelism: 2
Completions: 8
Start Time: Wed, 06 Sep 2022 16:42:02 +0000
Pods Statuses: 0 Running / 8 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=41d75705-92df-11e7-b85e-fa163ee3c11f
job-name=job-wq-1
Containers:
c:
Image: container-registry.example/causal-jigsaw-637/job-wq-1
Port:
Environment:
BROKER_URL: amqp://guest:guest@rabbitmq-service:5672
QUEUE: job1
Mounts: <none>
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
───────── ──────── ───── ──── ───────────── ────── ────── ───────
27s 27s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-hcobb
27s 27s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-weytj
27s 27s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-qaam5
27s 27s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-b67sr
26s 26s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-xe5hj
15s 15s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-w2zqe
14s 14s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-d6ppa
14s 14s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-p17e0
Усі Podʼи для цього завдання успішно виконалися! У вас вийшло.
Альтернативи
Цей підхід має перевагу у тому, що вам не потрібно змінювати вашу "робочу" програму, щоб вона була обізнана, що є черга роботи. Ви можете включити незмінену робочу програму у свій контейнерний образ.
Використання цього підходу передбачає запуск сервісу черги повідомлень. Якщо запуск сервісу черги є не зручним, ви можете розглянути один з інших шаблонів завдань.
Цей підхід створює Pod для кожного робочого елемента. Якщо ваші робочі елементи займають лише декілька секунд, створення Podʼа для кожного робочого елемента може додати багато накладних витрат. Розгляньте інший дизайн, наприклад, у прикладі тонкої паралельної черги робочих елементів, що виконує кілька робочих елементів на кожному Pod.
У цьому прикладі ви використовували утиліту amqp-consume для читання повідомлення з черги та запуску реальної програми. Це має перевагу у тому, що вам не потрібно модифікувати свою програму, щоб вона була обізнана про існування черги. У прикладі тонкої паралельної черги робочих елементів показано, як спілкуватися з чергою робочих елементів за допомогою клієнтської бібліотеки.
Обмеження
Якщо кількість завершень встановлена меншою, ніж кількість елементів у черзі, то не всі елементи будуть оброблені.
Якщо кількість завершень встановлена більшою, ніж кількість елементів у черзі, то завдання не буде здаватися завершеним, навіть якщо всі елементи у черзі були оброблені. Воно буде запускати додаткові Podʼи, які будуть блокуватися, чекаючи на повідомлення. Вам потрібно буде створити свій власний механізм для виявлення наявності роботи для виконання і вимірювати розмір черги, встановлюючи кількість завершень відповідно.
Існують малоймовірні перегони для цього патерну. Якщо контейнер був завершений між часом, коли повідомлення було підтверджено командою amqp-consume, і часом, коли контейнер вийшов з успішним завершенням, або якщо вузол зазнає збою, перш ніж kubelet зможе розмістити успіх Podʼа назад до сервера API, то завдання не буде здаватися завершеним, навіть якщо всі елементи
у черзі були оброблені.
9.3 - Тонка паралельна обробка за допомогою черги роботи
In цьому прикладі ви запустите Job Kubernetes, яке виконує декілька паралельних завдань як робочі процеси, кожен з яких працює як окремий Pod.
У цьому прикладі, при створенні кожного Podʼа, він бере одиницю роботи з черги завдань, обробляє її та повторює цей процес до досягнення кінця черги.
Ось загальний огляд кроків у цьому прикладі:
Запустіть службу зберігання, щоб зберігати чергу завдань. У цьому прикладі ви використаєте Redis для зберігання робочих елементів. У попередньому прикладі, ви використали RabbitMQ. У цьому прикладі ви будете використовувати Redis та власну бібліотеку клієнтів черг завдань; це тому, що AMQP не надає зручний спосіб клієнтам виявити, коли скінчиться черга робочих елементів з обмеженою довжиною. На практиці ви налаштуєте сховище, таке як Redis, один раз і повторно використовуватимете його для черг робочих завдань багатьох завдань та іншого.
Створіть чергу та заповніть її повідомленнями. Кожне повідомлення представляє одне завдання, яке потрібно виконати. У цьому прикладі повідомленням є ціле число, над яким ми виконаємо тривалі обчислення.
Запустіть завдання, яке працює над завданнями з черги. Завдання запускає декілька Podʼів. Кожний Pod бере одне завдання з черги повідомлень, обробляє його та повторює цей процес до досягнення кінця черги.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Вам знадобиться реєстр контейнерних образів, де ви можете завантажувати образи для запуску у вашому кластері. У прикладі використовується Docker Hub, але ви можете адаптувати його до іншого реєстру контейнерних образів.
Цей приклад передбачає, що у вас встановлено Docker локально. Ви будете використовувати Docker для створення контейнерних образів.
Ви маєти бути знайомі з базовим, не-паралельним використанням Job.
Запуск Redis
У цьому прикладі, для спрощення, ви запустите один екземпляр Redis. Дивіться Приклад Redis для прикладу розгортання Redis масштабовано та надійно.
Ви також можете завантажити наступні файли безпосередньо:
Примітка: якщо у вас неправильно налаштовано Kube DNS, вам може знадобитися змінити перший крок вищезазначеного блоку на redis-cli -h $REDIS_SERVICE_HOST.
Створення образу контейнера
Тепер ви готові створити образ, який буде обробляти завдання в цій черзі.
Ви будете використовувати робочу програму на Python з клієнтом Redis для читання повідомлень з черги повідомлень.
Надається проста бібліотека клієнтів черги роботи Redis, яка називається rediswq.py (Завантажити).
Програма "робітник" в кожному Pod Job використовує бібліотеку клієнтів черги роботи, щоб отримати роботу. Ось вона:
#!/usr/bin/env pythonimporttimeimportrediswqhost="redis"# Якщо у вас немає працюючого Kube-DNS, розкоментуйте наступні два рядки.# import os# host = os.getenv("REDIS_SERVICE_HOST")q = rediswq.RedisWQ(name="job2", host=host)
print("Worker with sessionID: "+ q.sessionID())
print("Initial queue state: empty="+str(q.empty()))
whilenot q.empty():
item = q.lease(lease_secs=10, block=True, timeout=2)
if item isnotNone:
itemstr = item.decode("utf-8")
print("Working on "+ itemstr)
time.sleep(10) # Put your actual work here instead of sleep. q.complete(item)
else:
print("Waiting for work")
print("Queue empty, exiting")
Ви також можете завантажити файли worker.py, rediswq.py та Dockerfile, а потім побудувати контейнерний образ. Ось приклад використання Docker для побудови образу:
docker build -t job-wq-2 .
Збереження образу в реєстрі
Для Docker Hub, позначте свій образ програми імʼям користувача та завантажте його до Hub за допомогою наступних команд. Замість <username> вкажіть своє імʼя користувача Hub.
docker tag job-wq-2 <username>/job-wq-2
docker push <username>/job-wq-2
Не забудьте відредагувати маніфест, змінивши gcr.io/myproject на свій власний шлях.
У цьому прикладі кожний Pod працює з кількома елементами черги, а потім виходить, коли елементи закінчуються. Оскільки самі робочі процеси виявляють порожнечу робочої черги, а контролер завдань не володіє інформацією про робочу чергу, він покладається на робочі процеси, щоб сигналізувати, коли вони закінчили роботу. Робочі процеси сигналізують, що черга порожня, вийшовши з успіхом. Таким чином, як тільки будь-який робочий процес виходить з успіхом, контролер знає, що робота виконана, і що Podʼи скоро вийдуть. Тому вам потрібно залишити лічильник завершення завдання невизначеним. Контролер завдань зачекає, доки інші Podʼи завершаться також.
Запуск завдання
Отже, зараз запустіть завдання:
# передбачається, що ви вже завантажили та відредагували маніфестkubectl apply -f ./job.yaml
Тепер зачекайте трохи, а потім перевірте стан завдання:
Ви можете зачекати, поки завдання завершиться успішно, з тайм-аутом:
# Перевірка умови назви нечутлива до регіструkubectl wait --for=condition=complete --timeout=300s job/job-wq-2
kubectl logs pods/job-wq-2-7r7b2
Worker with sessionID: bbd72d0a-9e5c-4dd6-abf6-416cc267991f
Initial queue state: empty=False
Working on banana
Working on date
Working on lemon
Як бачите, один з Podʼів для цього завдання працював над кількома робочими одиницями.
Альтернативи
Якщо запуск служби черги або модифікація ваших контейнерів для використання робочої черги є незручними, ви можете розглянути один з інших шаблонів завдань.
Якщо у вас є постійний потік фонової обробки, яку потрібно виконувати, то розгляньте запуск ваших фонових робітників за допомогою ReplicaSet, і розгляньте використання бібліотеки фонової обробки, такої як https://github.com/resque/resque.
9.4 - Індексоване завдання (Job) для паралельної обробки з фіксованим призначенням роботи
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.24 [stable]
У цьому прикладі ви запустите Job Kubernetes, яке використовує кілька паралельних робочих процесів. Кожен робочий процес — це різний контейнер, що працює у власному Podʼі. Podʼи мають індексний номер, який автоматично встановлює панель управління, що дозволяє кожному Podʼу визначити, над якою частиною загального завдання працювати.
Індекс Podʼа доступний в анотаціїbatch.kubernetes.io/job-completion-index у вигляді рядка, який представляє його десяткове значення. Щоб контейнеризований процес завдання отримав цей індекс, можна опублікувати значення анотації за допомогою механізму downward API. Для зручності панель управління автоматично встановлює downward API для експонування індексу в змінну середовища JOB_COMPLETION_INDEX.
Нижче наведено огляд кроків у цьому прикладі:
Визначте маніфест завдання з використанням індексованого завершення. Downward API дозволяє передавати індекс Podʼа як змінну середовища або файл до контейнера.
Запустіть Indexed завдання на основі цього маніфесту.
Перш ніж ви розпочнете
Ви маєти бути знайомі з базовим, не-паралельним використанням Job.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.21.
Для перевірки версії введіть kubectl version.
Оберіть підхід
Щоб отримати доступ до робочого елемента з програми робочого процесу, у вас є кілька варіантів:
Прочитайте змінну середовища JOB_COMPLETION_INDEX. Job контролер автоматично повʼязує цю змінну з анотацією, що містить індекс завершення.
Прочитайте файл, який містить індекс завершення.
Припускаючи, що ви не можете змінити програму, ви можете обгорнути її сценарієм, який читає індекс за допомогою будь-якого з методів вище і перетворює його в щось, що програма може використовувати як вхід.
У цьому прикладі уявіть, що ви вибрали третій варіант, і ви хочете запустити rev утиліту. Ця програма приймає файл як аргумент і виводить зміст у зворотньому порядку.
rev data.txt
Ви будете використовувати інструмент rev з контейнерного образу busybox.
Оскільки це лише приклад, кожен Pod робить лише невеликий шматок роботи (реверсування короткого рядка). У реальному навантаженні ви, наприклад, можете створити Job, що представляє задачу рендерингу 60 секунд відео на основі даних про сцену. Кожен робочий елемент в завданні відеорендерингу буде створювати певний кадр цього відеокліпу. Індексоване завершення означатиме, що кожен Pod у Job знає, який кадр рендерити та опублікувати, рахуючи кадри від початку кліпу.
Визначте Indexed Job
Ось приклад маніфесту Job, який використовує режим завершення Indexed:
У вищенаведеному прикладі ви використовуєте вбудовану змінну середовища JOB_COMPLETION_INDEX, яку встановлює контролер завдань для всіх контейнерів. Контейнер ініціалізації відображає індекс на статичне значення та записує його в файл, який спільно використовується з контейнером, що виконує робочий процес через том emptyDir. Додатково ви можете визначити свою власну змінну середовища через downward API для публікації індексу в контейнерах. Ви також можете вибрати завантаження списку значень з ConfigMap як змінної середовища або файлу.
# Це використовує перший підхід (покладаючись на $JOB_COMPLETION_INDEX)kubectl apply -f https://kubernetes.io/examples/application/job/indexed-job.yaml
При створенні цього Завдання панель управління створює серію Podʼів, по одному для кожного вказаного індексу. Значення .spec.parallelism визначає, скільки може працювати одночасно, в той час, як .spec.completions визначає, скільки Podʼів створює Job в цілому.
Оскільки .spec.parallelism менше, ніж .spec.completions, панель управління чекає, поки деякі з перших Podʼів завершаться, перш ніж запустити ще.
Ви можете зачекати, поки Завдання завершиться успішно, з тайм-аутом:
# Перевірка умови назви нечутлива до регіструkubectl wait --for=condition=complete --timeout=300s job/indexed-job
Тепер опишіть Завдання та переконайтеся, що воно виконалося успішно.
kubectl describe jobs/indexed-job
Вивід схожий на:
Name: indexed-job
Namespace: default
Selector: controller-uid=bf865e04-0b67-483b-9a90-74cfc4c3e756
Labels: controller-uid=bf865e04-0b67-483b-9a90-74cfc4c3e756
job-name=indexed-job
Annotations: <none>
Parallelism: 3
Completions: 5
Start Time: Thu, 11 Mar 2021 15:47:34 +0000
Pods Statuses: 2 Running / 3 Succeeded / 0 Failed
Completed Indexes: 0-2
Pod Template:
Labels: controller-uid=bf865e04-0b67-483b-9a90-74cfc4c3e756
job-name=indexed-job
Init Containers:
input:
Image: docker.io/library/bash
Port: <none>
Host Port: <none>
Command:
bash
-c
items=(foo bar baz qux xyz)
echo ${items[$JOB_COMPLETION_INDEX]} > /input/data.txt
Environment: <none>
Mounts:
/input from input (rw)
Containers:
worker:
Image: docker.io/library/busybox
Port: <none>
Host Port: <none>
Command:
rev
/input/data.txt
Environment: <none>
Mounts:
/input from input (rw)
Volumes:
input:
Type: EmptyDir (тимчасова тека, яка поділяє життя Podʼа)
Medium:
SizeLimit: <unset>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 4s job-controller Created pod: indexed-job-njkjj
Normal SuccessfulCreate 4s job-controller Created pod: indexed-job-9kd4h
Normal SuccessfulCreate 4s job-controller Created pod: indexed-job-qjwsz
Normal SuccessfulCreate 1s job-controller Created pod: indexed-job-fdhq5
Normal SuccessfulCreate 1s job-controller Created pod: indexed-job-ncslj
У цьому прикладі ви запускаєте Job з власними значеннями для кожного індексу. Ви можете оглянути вивід одного з Podʼів:
kubectl logs indexed-job-fdhq5 # Змініть це, щоб відповідати імені Podʼа з цього Завдання ```
Вивід схожий на:
xuq
9.5 - Завдання (Job) з комунікацією Pod-Pod
У цьому прикладі ви запустите Job в Indexed completion mode, налаштований таким чином, щоб Podʼи, створені Job, могли комунікувати один з одним, використовуючи назви хостів Podʼів, а не IP-адреси Podʼів.
Podʼи в межах Job можуть потребувати комунікації між собою. Робоче навантаження користувача, що виконується в кожному Podʼі, може звертатися до сервера API Kubernetes для отримання IP-адрес інших Podʼів, але набагато простіше покладатися на вбудований DNS-резолвер Kubernetes.
Job в Indexed completion mode автоматично встановлюють назви хостів Podʼів у форматі
${jobName}-${completionIndex}. Ви можете використовувати цей формат для детермінованого створення назв хостів Podʼів та забезпечення комунікації між Podʼами без необхідності створювати клієнтське з’єднання з панеллю управління Kubernetes для отримання назв хостів/IP-адрес Podʼів через API-запити.
Ця конфігурація корисна для випадків, коли необхідна мережева взаємодія Podʼів, але ви не хочете залежати від мережевого з’єднання з сервером API Kubernetes.
Перш ніж ви розпочнете
Ви повинні вже бути знайомі з основами використання Job.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.21.
Для перевірки версії введіть kubectl version.
Примітка:
Якщо ви використовуєте minikube або подібний інструмент, можливо, вам потрібно буде вжити
додаткових заходів, щоб переконатись, що ви використовуєте DNS.
Запуск роботи з комунікацією між Podʼами
Щоб увімкнути комунікацію між Podʼами з використанням назв хостів Podʼів у Job, ви повинні зробити наступне:
Налаштуйте headless Service
з дійсним селектором міток для Podʼів, створених вашим Job. Headless Service має бути в тому ж просторі імен, що й Job. Один із простих способів зробити це — використати селектор job-name: <your-job-name>, оскільки мітка job-name буде додана Kubernetes автоматично. Ця конфігурація активує систему DNS для створення записів назв хостів Podʼів, що виконують ваш обʼєкт Job.
Налаштуйте headless Service як піддомен для Podʼів Job, включивши наступне значення у ваш шаблон специфікації Job: з дійсним селектором міток для podʼів, створених вашим Job. Headless Service повинен знаходитися в тому ж просторі імен, що і Job. Один з простих способів зробити це — використовувати job-name: <ваша-назва-job>, оскільки Kubernetes автоматично додасть мітку job-name. Ця конфігурація змусить систему DNS створити записи з іменами вузлів, на яких виконується ваше завдання.
Налаштуйте service headless як сервіс субдомену для завдань, включивши наступне значення у специфікацію template Job:
subdomain:<headless-svc-name>
Приклад
Нижче наведено робочий приклад Job з увімкненою комунікацією між Podʼами через назви хостів Podʼів. Job завершується лише після того, як усі Podʼи успішно пінгують один одного за допомогою назв хостів.
Примітка:
У Bash-скрипті, що виконується на кожному Podʼі у прикладі нижче, назви хостів Podʼів можуть мати префікс простору імен, якщо Pod повинен бути доступний ззовні простору імен.
apiVersion:v1kind:Servicemetadata:name:headless-svcspec:clusterIP:None# clusterIP має бути None для створення headless serviceselector:job-name:example-job# має відповідати імені Job---apiVersion:batch/v1kind:Jobmetadata:name:example-jobspec:completions:3parallelism:3completionMode:Indexedtemplate:spec:subdomain:headless-svc# має відповідати імені ServicerestartPolicy:Nevercontainers:- name:example-workloadimage:bash:latestcommand:- bash- -c- | for i in 0 1 2
do
gotStatus="-1"
wantStatus="0"
while [ $gotStatus -ne $wantStatus ]
do
ping -c 1 example-job-${i}.headless-svc > /dev/null 2>&1
gotStatus=$?
if [ $gotStatus -ne $wantStatus ]; then
echo "Failed to ping pod example-job-${i}.headless-svc, retrying in 1 second..."
sleep 1
fi
done
echo "Successfully pinged pod: example-job-${i}.headless-svc"
done
Після застосування наведеного вище прикладу, Podʼи зможуть звертатись один до одного в мережі, використовуючи: <pod-hostname>.<headless-service-name>. Ви повинні побачити вихідні дані, подібні до наступних:
kubectl logs example-job-0-qws42
Failed to ping pod example-job-0.headless-svc, retrying in 1 second...
Successfully pinged pod: example-job-0.headless-svc
Successfully pinged pod: example-job-1.headless-svc
Successfully pinged pod: example-job-2.headless-svc
Примітка:
Майте на увазі, що формат імені <pod-hostname>.<headless-service-name>, використаний у цьому прикладі, не працюватиме з політикою DNS, встановленою на None або Default. Ви можете дізнатися більше про політику DNS для Podʼів.
9.6 - Паралельна обробка з розширенням
Це завдання демонструє запуск кількох Jobs на основі загального шаблону. Ви можете використовувати цей підхід для обробки пакетних завдань паралельно.
У цьому прикладі є лише три елементи: apple, banana та cherry. Приклади Job обробляють кожен елемент, виводячи рядок, а потім очікуючи дії користувача.
Вам слід бути знайомим з базовим, не-паралельним використанням Job.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
# Використайте curl для завантаження job-tmpl.yamlcurl -L -s -O https://k8s.io/examples/application/job/job-tmpl.yaml
Завантажений вами файл ще не є валідним маніфестом Kubernetes. Замість цього цей шаблон є YAML-представленням об’єкта Job з деякими заповнювачами, які потрібно замінити перед використанням. Синтаксис $ITEM не має значення для Kubernetes.
Створення маніфестів з шаблону
Наступний код використовує sed для заміни $ITEM на значення змінної з циклу, зберігаючи результат в тимчасову теку jobs:
# Розмноження шаблону на кілька файлів, по одному для коженого процесуmkdir -p ./jobs
for item in apple banana cherry
do cat job-tmpl.yaml | sed "s/\$ITEM/$i/g" > ./jobs/job-$i.yaml
done
На виході ви маєте отримати три файли:
job-apple.yaml
job-banana.yaml
job-cherry.yaml
Створення Завдань (Job) з маніфестів
Далі, створіть всі три Job, використовуючи файли, які ви створили:
kubectl apply -f ./jobs
Вивід буде подібний до цього:
job.batch/process-item-apple created
job.batch/process-item-banana created
job.batch/process-item-cherry created
Тепер ви можете перевірити стан Job:
kubectl get jobs -l jobgroup=jobexample
Вивід буде подібний до цього:
NAME COMPLETIONS DURATION AGE
process-item-apple 1/1 14s 22s
process-item-banana 1/1 12s 21s
process-item-cherry 1/1 12s 20s
Використання опції -l для kubectl вибирає лише Job, які є частиною цієї групи Job (в системі можуть бути інші не Завдання (Job)).
Ви також можете перевірити стан Podʼів, використовуючи той самий селектор міток:
kubectl get pods -l jobgroup=jobexample
Вивід буде подібний до цього:
NAME READY STATUS RESTARTS AGE
process-item-apple-kixwv 0/1 Completed 0 4m
process-item-banana-wrsf7 0/1 Completed 0 4m
process-item-cherry-dnfu9 0/1 Completed 0 4m
Ви можете використати цю одну команду для перевірки виводу всіх Job одночасно:
kubectl logs -f -l jobgroup=jobexample
Вивід має бути таким:
Processing item apple
Processing item banana
Processing item cherry
Очищення
# Видаліть створені Job# Ваш кластер автомтично видаляє пов’язані з Job Podkubectl delete jobs -l jobgroup=jobexample
Використання розширених параметрів шаблонів
В першому прикладі, кожен екземпляр шаблону мав один параметр, цей параметр тако використовувався в назві Job. Однак, назви обмежені набором символів, які можна використовувати.
Ось трохи складніший шаблон Jinja, для створення маніфестів та обʼєктів на їх основі, з кількома параметрами для кожного Завдання (Job).
В першій частині завдання скористайтесь однорядковим скриптом Python для перетворення шаблонів в набір маніфестів.
Спочатку скопіюйте та вставте наступний шаблон обʼєкта Job у файл з назвою job.yaml.jinja2:
{% set params = [{ "name": "apple", "url": "http://dbpedia.org/resource/Apple", },
{ "name": "banana", "url": "http://dbpedia.org/resource/Banana", },
{ "name": "cherry", "url": "http://dbpedia.org/resource/Cherry" }]
%}
{% for p in params %}
{% set name = p["name"] %}
{% set url = p["url"] %}
---
apiVersion: batch/v1
kind: Job
metadata:
name: jobexample-{{ name }}
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: jobexample
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: busybox:1.28
command: ["sh", "-c", "echo Processing URL {{ url }} && sleep 5"]
restartPolicy: Never
{% endfor %}
Наведений шаблон визначає два параметри для кожного обʼєкта Job за допомогою списку словників Python (рядки 1-4). Цикл for генерує один маніфест Job для кожного набору параметрів (інші рядки).
Цей приклад використовує можливості YAML. Один файл YAML може містити кілька документів (у цьому випадку маніфестів Kubernetes), розділених рядком ---.
Ви можете передати вивід безпосередньо до kubectl, щоб створити Jobs.
Далі використовуйте цю однорядковий скрипт Python для розширення шаблону:
Використання Jobs у реальних робочих навантаженнях
У реальному випадку використання кожен Job виконує деяку суттєву обчислювальну задачу, наприклад, рендеринг кадру фільму або обробку діапазону рядків у базі даних. Якщо ви рендерите відео, ви будете встановлювати $ITEM на номер кадру. Якщо ви обробляєте рядки з таблиці бази даних, ви будете встановлювати $ITEM для представлення діапазону рядків бази даних, які потрібно обробити.
У завданні ви виконували команду для збирання виводу з Podʼів, отримуючи їхні логи. У реальному випадку використання кожен Pod для Job записує свій вивід у надійне сховище перед завершенням. Ви можете використовувати PersistentVolume для кожного Job або зовнішню службу зберігання даних. Наприклад, якщо ви рендерите кадри для відео, використовуйте HTTP PUT щоб включити дані обробленого кадру до URL, використовуючи різні URL для кожного кадру.
Мітки на Job та Podʼах
Після створення Job, Kubernetes автоматично додає додаткові мітки, які вирізняють Podʼи одного Job від Podʼів іншого Job.
У цьому прикладі кожен Job та його шаблон Pod мають мітку: jobgroup=jobexample.
Сам Kubernetes не звертає уваги на мітки з іменем jobgroup. Встановлення мітки для всіх Job, які ви створюєте за шаблоном, робить зручним керування всіма цими Jobs одночасно. У першому прикладі ви використовували шаблон для створення кількох Job. Шаблон гарантує, що кожен Pod також отримує ту саму мітку, тому ви можете перевірити всі Podʼи для цих шаблонних Job за допомогою однієї команди.
Примітка:
Ключ мітки jobgroup не є особливим чи зарезервованим. Ви можете обрати свою власну схему міток. Існують рекомендовані мітки, які ви можете використовувати, якщо бажаєте.
Альтернативи
Якщо ви плануєте створити велику кількість обʼєктів Job, ви можете виявити, що:
Навіть використовуючи мітки, керування такою кількістю Job є громіздким.
Якщо ви створюєте багато Job одночасно, ви можете створити високе навантаження на панель управління Kubernetes. Крім того, сервер API Kubernetes може обмежити швидкість запитів, тимчасово відхиляючи ваші запити зі статусом 429.
Ви обмежені квотою ресурсів на Job: сервер API постійно відхиляє деякі ваші запити, коли ви створюєте велику кількість роботи за один раз.
Існують інші шаблони роботи з Job, які ви можете використовувати для обробки значного обсягу роботи без створення великої кількості обʼєктів Job.
Ви також можете розглянути можливість написання власного контролера, щоб автоматично керувати обʼєктами Job.
9.7 - Обробка повторюваних і неповторюваних помилок Pod за допомогою політики збоїв Pod
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.31 [stable](стандартно увімкнено)
Цей документ показує, як використовувати політику збоїв Pod, у поєднанні з типовою політикою відмови Podʼа, для покращення контролю над обробкою збоїв на рівні контейнера або Pod у Job.
Визначення політики збоїв Pod може допомогти вам:
краще використовувати обчислювальні ресурси, уникаючи непотрібних повторних запусків Podʼів.
Ви повинні вже бути знайомі з основним використанням Job.
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Використання політики збоїв Pod для уникнення непотрібних повторних запусків Podʼів
В наступному прикладі ви можете навчитися використовувати політику збоїв Pod, щоб уникати непотрібних перезапусків Pod, коли збій Pod вказує на неповторювану помилку програмного забезпечення.
Через приблизно 30 секунд весь Job повинен завершитися. Перевірте статус Job, виконавши команду:
kubectl get jobs -l job-name=job-pod-failure-policy-failjob -o yaml
У статусі Job відображаються такі умови:
Умова FailureTarget: має поле reason, встановлене в PodFailurePolicy, і поле message з додатковою інформацією про завершення, наприклад, Container main for pod default/job-pod-failure-policy-failjob-8ckj8 failed with exit code 42 matching FailJob rule at index 0. Контролер Job додає цю умову, як тільки Job вважається невдалим. Для отримання деталей дивіться Завершення Job Podʼів.
Умова Failed: те ж саме значення для reason і message, що й в умови FailureTarget. Контролер Job додає цю умову після того, як усі Podʼи Job завершено.
Для порівняння, якщо політика збоїв Pod була вимкнена, це б зайняло 6 спроб повторного запуску Pod, на що треба щонайменше 2 хвилини.
Використання політики збоїв Pod для ігнорування розладів Pod
На наступному прикладі ви можете навчитися використовувати політику збоїв Pod, щоб ігнорувати розлади Pod, які збільшують лічильник повторних спроб Pod до межі .spec.backoffLimit.
Увага:
Час має значення для цього прикладу, тому вам слід прочитати про кроки перед їх виконанням. Щоб викликати розлад Podʼа, важливо запустити очищення вузла, поки Pod працює на ньому (протягом 90 секунд після розміщення Pod).
Зверніть увагу, що Pod залишається у фазі Pending, оскільки йому не вдається завантажити неправильно налаштований образ. Це, в принципі, може бути тимчасовою проблемою, і образ може бути завантажений. Однак у цьому випадку образу не існує, тому ми вказуємо на цей факт за допомогою власної умови.
Додайте власну умову. Спочатку підготуйте патч, виконавши команду:
Видаліть Pod для переходу його до фази Failed, виконавши команду:
kubectl delete pods/$podName
Перевірте статус Job, виконавши:
kubectl get jobs -l job-name=job-pod-failure-policy-config-issue -o yaml
У статусі Job перегляньте умову Failed з полем reason, рівним PodFailurePolicy. Додатково, поле message містить більш детальну інформацію про завершення завдання, таку як: Pod default/job-pod-failure-policy-config-issue-k6pvp має умову ConfigIssue, яка відповідає правилу FailJob за індексом 0.
Примітка:
В операційному середовищі кроки 3 та 4 повинні бути автоматизовані контролером, наданим користувачем.
Використання політики збоїв Pod для уникнення непотрібних повторних запусків Pod на основі індексів
Щоб уникнути непотрібних перезапусків Podʼів для кожного індексу, ви можете використовувати функції Політики збоїв Podʼа та Ліміт відстрочки для кожного індексу. У цьому розділі сторінки показано, як використовувати ці функції разом.
apiVersion:batch/v1kind:Jobmetadata:name:job-backoff-limit-per-index-failindexspec:completions:4parallelism:2completionMode:IndexedbackoffLimitPerIndex:1template:spec:restartPolicy:Nevercontainers:- name:mainimage:docker.io/library/python:3command:# Скрипт:# - завершує роботу Podʼа з індексом 0 з кодом виходу 1, що призводить до однієї повторної спроби;# - завершує роботу Podʼа з індексом 1 з кодом виходу 42, що призводить до# призводить до невдачі індексу без повторної спроби.# - завершує роботу Podʼа з будь-яким іншим індексом.- python3- -c- | import os, sys
index = int(os.environ.get("JOB_COMPLETION_INDEX"))
if index == 0:
sys.exit(1)
elif index == 1:
sys.exit(42)
else:
sys.exit(0)backoffLimit:6podFailurePolicy:rules:- action:FailIndexonExitCodes:containerName:mainoperator:Invalues:[42]
Приблизно через 15 секунд перевірте стан Podʼів для Job. Ви можете зробити це, виконавши команду:
kubectl get pods -l job-name=job-backoff-limit-per-index-failindex -o yaml
Ви побачите результат, подібний до цього:
NAME READY STATUS RESTARTS AGE
job-backoff-limit-per-index-failindex-0-4g4cm 0/1 Error 0 4s
job-backoff-limit-per-index-failindex-0-fkdzq 0/1 Error 0 15s
job-backoff-limit-per-index-failindex-1-2bgdj 0/1 Error 0 15s
job-backoff-limit-per-index-failindex-2-vs6lt 0/1 Completed 0 11s
job-backoff-limit-per-index-failindex-3-s7s47 0/1 Completed 0 6s
Зверніть увагу, що вивід показує наступне:
Два Podʼа мають індекс 0 через обмеження backoff, дозволене для однієї спроби індексування.
Тільки один Pod має індекс 1, оскільки код виходу невдалого Podʼа збігався з політикою збою podʼа з дією FailIndex.
Перевірте стан Job виконавши:
kubectl get jobs -l job-name=job-backoff-limit-per-index-failindex -o yaml
У статусі Job побачите, що поле failedIndexes показує "0,1", оскільки обидва індекси зазнали невдачі. Оскільки індекс 1 не було повторено, кількість збійних Podʼів, зазначена в полі статусу "failed", дорівнює 3.
Ви можете покладатись виключно на політику відмови Pod backoff, вказавши поле .spec.backoffLimit завдання. Однак у багатьох ситуаціях важко знайти баланс між встановленням низького значення для .spec.backoffLimit для уникнення непотрібних повторних спроб виконання Podʼів, але достатньо великого, щоб забезпечити, що Job не буде припинено через втручання у роботу Podʼів.
10 - Доступ до застосунків у кластері
Налаштування балансування навантаження, перенаправлення портів або налаштування фаєрволу або DNS-конфігурацій для доступу до застосунків у кластері.
10.1 - Розгортання та доступ до Інфопанелі Kubernetes
Розгорніть вебінтерфейс (Kubernetes Dashboard) та отримайте до нього доступ.
Інфопанель Kubernetes — це вебінтерфейс для кластерів Kubernetes. Ви можете використовувати Інфопанель для розгортання контейнерізованих застосунків в кластері Kubernetes, керувати ресурсами кластера, відстежувати та виправляти проблеми в роботі застосунків. Ви можете використовувати Інфопанель для перегляду роботи застосунків у вашому кластері, створення або зміни ресурсів Kubernetes (таких як Deployment, Job, DaemonSet та інші). Наприклад, ви можете масштабувати Deployment, ініціювати поступове оновлення, перезапустити Pod чи розгорнути новий застосунок за допомоги помічника з розгортання.
Інфопанель також надає інформацію про стан ресурсів Kubernetes у вашому кластері та про помилки, що можуть виникати.
Розгортання Dashboard UI
Примітка:
Наразі Kubernetes Dashboard підтримує лише встановлення на основі Helm, оскільки це швидше і дає нам кращий контроль над усіма залежностями, необхідними для роботи Dashboard.
Стандартно Інфопанель не встановлена в кластері Kubernetes. Щоб розгорнути Інфопанель, ви повинні виконати наступну команду:
Для захисту даних вашого кластера, Dashboard типово розгортається з мінімальною конфігурацією RBAC. Наразі Dashboard підтримує лише вхід за допомогою токену на предʼявника (Bearer Token). Для створення токена для цього демо ви можете скористатися нашим посібником зі створення користувача.
Попередження:
Користувач, створений у підручнику, матиме адміністративні привілеї та призначений лише для освітніх цілей.
Проксі з командного рядка
Ви можете увімкнути доступ до Dashboard за допомогою інструменту командного рядка kubectl, виконавши наступну команду:
Інтерфейс можна лише відкрити з машини, на якій виконується команда. Дивіться kubectl port-forward --help для отримання додаткових опцій.
Примітка:
Метод автентифікації kubeconfig не підтримує зовнішніх постачальників ідентифікації або автентифікацію на основі сертифікатів X.509.
Вітальна сторінка
Коли ви отримуєте доступ до Інфопанелі в порожньому кластері, ви побачите вітальну сторінку. Ця сторінка містить посилання на цей документ, а також кнопку для розгортання вашого першого застосунку. Крім того, ви можете побачити, які системні застосунки запускаються стандартно у просторі іменkube-system вашого кластера, наприклад, сама Інфопанель.
Розгортання контейнеризованих застосунків
Dashboard дозволяє створювати та розгортати контейнеризований застосунок як Deployment та необов’язковий Service за допомогою простого майстра. Ви можете або вручну вказати деталі застосунку, або завантажити YAML або JSON файл маніфесту, що містить конфігурацію застосунку.
Натисніть кнопку CREATE у верхньому правому куті будь-якої сторінки, щоб розпочати.
Встановлення параметрів застосунку
Майстер розгортання очікує, що ви надасте наступну інформацію:
Назва застосунку (обов’язково): Назва вашого застосунку. Мітка з цією назвою буде додана до Deployment та Service (якщо є), які будуть розгорнуті.
Назва застосунку повинна бути унікальною в межах вибраного простору імен Kubernetes. Вона повинна починатися з малої літери та закінчуватися малою літерою або цифрою, і містити лише малі літери, цифри та дефіси (-). Обмеження на довжину становить 24 символи. Початкові та кінцеві пробіли ігноруються.
Образ контейнера (обов’язково):
URL публічного Docker образу контейнера у будь-якому реєстрі, або приватного образу (зазвичай розміщеного в Google Container Registry або Docker Hub). Специфікація образу контейнера повинна закінчуватися двокрапкою.
Кількість Podʼів (обов’язково): Кількість Podʼів, з використанням яких ви хочете розгорнути свій застосунок. Значення повинно бути позитивним цілим числом.
Буде створено Deployment, щоб підтримувати потрібну кількість Podʼів у вашому кластері.
Service (необов’язково): Для деяких частин вашого застосунку (наприклад, фронтендів) ви можете захотіти експонувати Service на зовнішню, можливо, публічну IP-адресу за межами вашого кластера (зовнішній Service).
Примітка:
Для зовнішніх Service, можливо, вам доведеться відкрити один або кілька портів для цього.
Інші Service, які видно тільки всередині кластера, називаються внутрішніми Service.
Незалежно від типу Service, якщо ви вирішите створити Service і ваш контейнер слухає на порту (вхідному), вам потрібно вказати два порти. Service буде створено, шляхом зіставлення порту (вхідного) на цільовий порт, який бачить контейнер. Цей Service буде переспрямовувати трафік на ваші розгорнуті Podʼи. Підтримувані протоколи — TCP та UDP. Внутрішнє DNS-імʼя для цього Service буде значенням, яке ви вказали як назву застосунку вище.
Якщо необхідно, ви можете розгорнути розділ Advanced options, де можна вказати більше налаштувань:
Опис: Текст, який ви введете тут, буде додано як анотацію до Deployment та відображатиметься в деталях застосунку.
Мітки: Стандартні мітки, що використовуються для вашого застосунку, — це назва застосунку та версія. Ви можете вказати додаткові мітки, які будуть застосовані до Deployment, Service (якщо є) та Podʼів, такі як release, environment, tier, partition та release track.
Простір імен: Kubernetes підтримує кілька віртуальних кластерів, що працюють поверх одного фізичного кластера. Ці віртуальні кластери називаються просторами імен. Вони дозволяють розділити ресурси на логічно названі групи.
Dashboard пропонує всі доступні простори імен у розгортаючомуся списку та дозволяє створити новий простір імен. Назва простору імен може містити максимум 63 алфавітно-цифрових символи та дефіси (-), але не може містити великі літери. Назви просторів імен не повинні складатися лише з цифр. Якщо назва встановлена як число, наприклад 10, Pod буде розміщений у просторі імен default.
У разі успішного створення простору імен він обирається стандартним. Якщо створення не вдається, вибирається перший простір імен.
Secret завантаження образу: У випадку, якщо вказаний Docker образ контейнера є приватним, він може вимагати облікові дані Secret завантаження.
Dashboard пропонує всі доступні Secret у розгортаючомуся списку та дозволяє створити новий. Назва Secret повинна відповідати синтаксису доменного імені DNS, наприклад new.image-pull.secret. Вміст Secret повинен бути закодований у base64 і вказаний у файлі .dockercfg. Назва Secret може складатися максимум з 253 символів.
У разі успішного створення Secret завантаження образу він обирається стандартним. Якщо створення не вдається, жоден Secret не застосовується.
Вимога до процесора (ядра) та Вимога до памʼяті (MiB): Ви можете вказати мінімальні обмеження ресурсів для контейнера. Стандартно Podʼи працюють без обмежень на процесор і памʼять.
Команда запуску та Аргументи команди запуску: Стандартно ваші контейнери виконують вказану Docker образом контейнера команду запуску. Ви можете використовувати опції команд і аргументів для перевизначення стандартної команди.
Запуск у привілейованому режимі: Це налаштування визначає, чи є процеси в привілейованих контейнерах еквівалентними процесам, що виконуються з правами root на хості. Привілейовані контейнери можуть використовувати можливості, такі як маніпулювання мережею та доступ до пристроїв.
Змінні середовища: Kubernetes експонує Service через змінні середовища. Ви можете складати змінні середовища або передавати аргументи до ваших команд, використовуючи значення змінних середовища. Вони можуть використовуватися в застосунках для пошуку Service. Значення можуть посилатися на інші змінні за допомогою синтаксису $(VAR_NAME).
Завантаження YAML або JSON файлу
Kubernetes підтримує декларативну конфігурацію. У цьому стилі всі конфігурації зберігаються в маніфестах (конфігураційних файлах YAML або JSON). Маніфести використовують схеми ресурсів API Kubernetes.
Як альтернатива вказанню деталей застосунку в майстрі розгортання, ви можете визначити ваш застосунок в одному або декількох маніфестах та завантажити файли за допомогою Dashboard.
Використання Dashboard
Наступні розділи описують вигляди інтерфейсу користувача Dashboard Kubernetes; що вони забезпечують і як їх можна використовувати.
Навігація
Коли у кластері визначено обʼєкти Kubernetes, Dashboard показує їх у початковому вигляді. Типово показуються лише обʼєкти з простору імен default, це можна змінити за допомогою селектора простору імен, розташованого в меню навігації.
Dashboard показує більшість типів обʼєктів Kubernetes та групує їх у кілька категорій меню.
Огляд адміністратора
Для адміністраторів кластерів та просторів імен Dashboard перелічує вузли (Nodes), простори імен (Namespaces) та постійні томи (PersistentVolumes) і має детальні елементи для них. Список вузлів містить метрики використання ЦП та памʼяті, агреговані по всіх вузлах. Детальний вигляд показує метрики для вузла, його специфікацію, стан, виділені ресурси, події та Podʼи, що працюють на вузлі.
Навантаження
Показує всі застосунки, що працюють у вибраному просторі імен. Елемент перераховує застосунки за типом навантаження (наприклад: Deployments, ReplicaSets, StatefulSets). Кожен тип навантаження можна переглядати окремо. Списки узагальнюють корисну інформацію про навантаження,
таку як кількість готових Podʼів для ReplicaSet або поточне використання памʼяті для Pod.
Детальні панелі для навантажень показують інформацію про стан та специфікацію і показують звʼязки між обʼєктами. Наприклад, Podʼи, які контролює ReplicaSet, або нові ReplicaSets та HorizontalPodAutoscalers для Deployments.
Services
Показує ресурси Kubernetes, які дозволяють експонувати Service для зовнішнього світу та
виявляти їх всередині кластеру. З цієї причини, панелі Service та Ingress показують Podʼи, на які вони спрямовані, внутрішні точки доступу для мережевих зʼєднань в кластері та зовнішні точки доступу для зовнішніх користувачів.
Сховище
Панель сховища показує ресурси PersistentVolumeClaim, які використовуються застосунками для зберігання даних.
ConfigMaps та Secrets
Показує всі ресурси Kubernetes, які використовуються для поточної конфігурації застосунків, що працюють у кластерах. Панель дозволяє редагувати та керувати обʼєктами конфігурації та показує Secret, які є типово прихованими.
Переглядач логів
Списки Podʼів та детальні сторінки мають посилання на переглядача логів, вбудованого у Dashboard. Переглядач дозволяє переглядати логи з контейнерів, що належать окремому Podʼу.
В цій темі обговорюється кілька способів взаємодії з кластерами.
Перший доступ з kubectl
При першому доступі до Kubernetes API ми пропонуємо використовувати Kubernetes CLI, kubectl.
Щоб отримати доступ до кластера, вам потрібно знати розташування кластера та мати облікові дані для доступу до нього. Зазвичай це налаштовується автоматично, коли ви проходите Посібник Початок роботи, або хтось інший налаштував кластер і надав вам облікові дані та його розташування.
Перевірте розташування та облікові дані, про які знає kubectl, за допомогою цієї команди:
kubectl config view
Багато з прикладів надають введення до використання
kubectl, а повна документація знаходиться у довіднику kubectl.
Прямий доступ до REST API
Kubectl опрацьовує розташування та автентифікацію до apiserver. Якщо ви хочете безпосередньо звертатися до REST API за допомогою http-клієнта, такого як curl або wget, або вебоглядача, існує кілька способів знайти розташування та автентифікуватись:
Запустіть kubectl в режимі проксі.
Рекомендований підхід.
Використовує збережене розташування apiserver.
Перевіряє особу apiserver за допомогою самопідписного сертифікату. Немає можливості MITM.
Виконує автентифікацію на apiserver.
У майбутньому може здійснювати інтелектуальне балансування навантаження та відмовостійкість на стороні клієнта.
Надайте розташування та облікові дані безпосередньо http-клієнту.
Альтернативний підхід.
Працює з деякими типами клієнтського коду, які не працюють з проксі.
Потрібно імпортувати кореневий сертифікат у ваш оглядач для захисту від MITM.
Використання kubectl proxy
Наступна команда запускає kubectl в режимі, де він діє як зворотний проксі. Вона обробляє розташування apiserver та автентифікацію. Запустіть її так:
kubectl proxy --port=8080
Дивіться опис kubectl proxy для отримання додаткової інформації.
Після цього ви можете досліджувати API за допомогою curl, wget або оглядача, замінюючи localhost на [::1] для IPv6, ось так:
Вищенаведені приклади використовують прапорець --insecure. Це залишає їх вразливими до атак MITM. Коли kubectl отримує доступ до кластера, він використовує збережений кореневий сертифікат та клієнтські сертифікати для доступу до сервера. (Вони встановлюються в теку ~/.kube). Оскільки сертифікати кластера зазвичай самопідписні, це може вимагати спеціальної конфігурації, щоб змусити вашого http-клієнта використовувати кореневий сертифікат.
У деяких кластерах apiserver не вимагає автентифікації; він може працювати на localhost або бути захищеним файрволом. Для цього немає стандарту. Контроль доступу до API описує, як адміністратор кластера може це налаштувати.
Програмний доступ до API
Kubernetes офіційно підтримує клієнтські бібліотеки для Go та Python.
Клієнт Go
Щоб отримати бібліотеку, виконайте наступну команду: go get k8s.io/client-go@kubernetes-<kubernetes-version-number>, дивіться INSTALL.md для детальних інструкцій з встановлення. Дивіться https://github.com/kubernetes/client-go щоб дізнатися, які версії підтримуються.
Напишіть додаток на основі клієнтів client-go. Зверніть увагу, що client-go визначає свої власні API обʼєкти, тому, якщо необхідно, будь ласка, імпортуйте визначення API з client-go, а не з основного репозиторію, наприклад, import "k8s.io/client-go/kubernetes" є правильним.
Go клієнт може використовувати той же файл kubeconfig, що й CLI kubectl для знаходження та автентифікації до apiserver. Дивіться цей приклад.
Якщо застосунок розгорнуто як Pod у кластері, будь ласка, зверніться до наступного розділу.
Клієнт Python може використовувати той же файл kubeconfig, що й CLI kubectl для знаходження та автентифікації до apiserver. Дивіться цей приклад.
Інші мови
Існують клієнтські бібліотеки для доступу до API з інших мов. Дивіться документацію для інших бібліотек щодо того, як вони автентифікуються.
Доступ до API з Pod
При доступі до API з Pod, розташування та автентифікація на API сервері дещо відрізняються.
Будь ласка, перевірте Доступ до API з Pod для отримання додаткової інформації.
Доступ до сервісів, що працюють на кластері
Попередній розділ описує, як підʼєднатися до API сервера Kubernetes. Для інформації про підключення до інших сервісів, що працюють на кластері Kubernetes, дивіться Доступ до сервісів кластера.
Запит перенаправлення
Можливості перенаправлення були визнані застарілими та видалені. Будь ласка, використовуйте проксі (дивіться нижче) замість цього.
Так багато проксі
Існує кілька різних проксі, які ви можете зустріти при використанні Kubernetes:
Проксі/Балансувальник навантаження перед apiserver(ами):
існування та реалізація варіюється від кластера до кластера (наприклад, nginx)
знаходиться між усіма клієнтами та одним або декількома apiserver
діє як балансувальник навантаження, якщо є кілька apiserver.
Хмарні балансувальники навантаження на зовнішніх сервісах:
надаються деякими постачальниками хмарних послуг (наприклад, AWS ELB, Google Cloud Load Balancer)
створюються автоматично, коли сервіс Kubernetes має тип LoadBalancer
використовують лише UDP/TCP
реалізація варіюється серед постачальників хмарних послуг.
Користувачі Kubernetes зазвичай не повинні турбуватися про будь-що, крім перших двох типів. Адміністратор кластера зазвичай забезпечить правильне налаштування останніх типів.
10.3 - Налаштування доступу до декількох кластерів
Ця сторінка показує, як налаштувати доступ до декількох кластерів за допомогою конфігураційних файлів. Після того, як ваші кластери, користувачі та контексти визначені в одному або декількох конфігураційних файлах, ви можете швидко перемикатися між кластерами, використовуючи команду kubectl config use-context.
Примітка:
Файл, що використовується для налаштування доступу до кластера, іноді називається kubeconfig файлом. Це загальний спосіб посилання на файли конфігурації. Це не означає, що існує файл з назвою kubeconfig.
Попередження:
Використовуйте kubeconfig файли тільки з надійних джерел. Використання спеціально створеного kubeconfig файлу може призвести до виконання шкідливого коду або витоку файлів. Якщо вам необхідно використовувати ненадійний kubeconfig файл, уважно перевірте його перед використанням, так само як ви б перевіряли shell скрипт.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Щоб перевірити, чи встановлений kubectl, виконайте команду kubectl version --client. Версія kubectl повинна бути в межах однієї мінорної версії API сервера вашого кластера.
Визначення кластерів, користувачів і контекстів
Припустимо, у вас є два кластери: один для розробки, а інший для тестування. У кластері development ваші фронтенд розробники працюють в просторі імен frontend, а розробники, які опікуються зберіганням даних працюють в просторі імен storage. У кластері test розробники працюють в стандартному просторі імен default або створюють додаткові простори імен за потреби. Доступ до кластера розробки вимагає автентифікації за сертифікатом. Доступ до тестового кластера вимагає автентифікації за іменем користувача та паролем.
Створіть теку з назвою config-exercise. У вашій теці config-exercise створіть файл з назвою config-demo з наступним вмістом:
Конфігураційний файл описує кластери, користувачів і контексти. Ваш файл config-demo має структуру для опису двох кластерів, двох користувачів і трьох контекстів.
Перейдіть до теки config-exercise. Виконайте ці команди, щоб додати деталі кластера до вашого конфігураційного файлу:
kubectl config --kubeconfig=config-demo set-cluster development --server=https://1.2.3.4 --certificate-authority=fake-ca-file
kubectl config --kubeconfig=config-demo set-cluster test --server=https://5.6.7.8 --insecure-skip-tls-verify
Додайте відомості про користувачів до вашого конфігураційного файлу:
Увага:
Зберігання паролів у конфігурації клієнта Kubernetes ризиковано. Краще використовувати втулок для автентифікації та зберігати паролі окремо. Дивіться: client-go втулки автентифікації
Відкрийте ваш файл config-demo, щоб побачити додані деталі. Як альтернативу відкриттю файлу config-demo, можна використовувати команду config view.
kubectl config --kubeconfig=config-demo view
Вивід показує два кластери, двох користувачів і три контексти:
apiVersion:v1clusters:- cluster:certificate-authority:fake-ca-fileserver:https://1.2.3.4name:development- cluster:insecure-skip-tls-verify:trueserver:https://5.6.7.8name:testcontexts:- context:cluster:developmentnamespace:frontenduser:developername:dev-frontend- context:cluster:developmentnamespace:storageuser:developername:dev-storage- context:cluster:testnamespace:defaultuser:experimentername:exp-testcurrent-context:""kind:Configpreferences:{}users:- name:developeruser:client-certificate:fake-cert-fileclient-key:fake-key-file- name:experimenteruser:# Примітка до документації (цей коментар НЕ є частиною виводу команди).# Зберігання паролів у конфігурації клієнта Kubernetes є ризикованим.# Кращою альтернативою буде використання втулка облікових даних# і зберігати облікові дані окремо.# Див. https://kubernetes.io/docs/reference/access-authn-authz/authentication/client-go-credential-pluginspassword:some-passwordusername:exp
Файли fake-ca-file, fake-cert-file та fake-key-file вище є заповнювачами для шляхів до сертифікатів. Вам потрібно замінити їх на реальні шляхи до сертифікатів у вашому середовищі.
Іноді ви можете захотіти використовувати дані у форматі Base64 замість окремих файлів сертифікатів; у такому випадку вам потрібно додати суфікс -data до ключів, наприклад, certificate-authority-data, client-certificate-data, client-key-data.
Кожен контекст є трійкою (кластер, користувач, простір імен). Наприклад, контекст dev-frontend означає: "Використовувати облікові дані користувача developer для доступу до простору імен frontend у кластері development".
Тепер, коли ви введете команду kubectl, дія буде застосовуватися до кластера і простору імен, вказаних у контексті dev-frontend. І команда буде використовувати облікові дані користувача, вказаного у контексті dev-frontend.
Щоб побачити лише інформацію про конфігурацію, повʼязану з поточним контекстом, використовуйте прапорець --minify.
Тепер будь-яка команда kubectl, яку ви введете, буде застосовуватися до стандартного простору імен default кластера test. І команда буде використовувати облікові дані користувача, вказаного у контексті exp-test.
Перегляньте конфігурацію, повʼязану з новим поточним контекстом exp-test.
Вищезазначений конфігураційний файл визначає новий контекст з назвою dev-ramp-up.
Встановіть змінну середовища KUBECONFIG
Перевірте, чи є у вас змінна середовища з назвою KUBECONFIG. Якщо так, збережіть поточне значення вашої змінної середовища KUBECONFIG, щоб ви могли відновити її пізніше. Наприклад:
Linux
exportKUBECONFIG_SAVED="$KUBECONFIG"
Windows PowerShell
$Env:KUBECONFIG_SAVED=$ENV:KUBECONFIG
Змінна середовища KUBECONFIG є списком шляхів до конфігураційних файлів. Список розділяється двокрапкою для Linux і Mac та крапкою з комою для Windows. Якщо у вас є змінна середовища KUBECONFIG, ознайомтеся з конфігураційними файлами у списку.
Тимчасово додайте два шляхи до вашої змінної середовища KUBECONFIG. Наприклад:
У вашій теці config-exercise виконайте цю команду:
kubectl config view
Вивід показує обʼєднану інформацію з усіх файлів, зазначених у вашій змінній середовища KUBECONFIG. Зокрема, зверніть увагу, що обʼєднана інформація містить контекст dev-ramp-up з файлу config-demo-2 і три контексти з файлу config-demo:
Якщо у вас вже є кластер і ви можете використовувати kubectl для взаємодії з кластером, то, ймовірно, у вас є файл з назвою config у теці $HOME/.kube.
Перейдіть до теки $HOME/.kube і перегляньте, які файли там знаходяться. Зазвичай, там є файл з назвою config. Також можуть бути інші конфігураційні файли у цій теці. Ознайомтеся зі змістом цих файлів.
Додайте $HOME/.kube/config до вашої змінної середовища KUBECONFIG
Якщо у вас є файл $HOME/.kube/config і він ще не зазначений у вашій змінній середовища KUBECONFIG, додайте його до вашої змінної середовища KUBECONFIG зараз. Наприклад:
Перегляньте інформацію про конфігурацію, обʼєднану з усіх файлів, які зараз зазначені у вашій змінній середовища KUBECONFIG. У вашій теці config-exercise введіть:
kubectl config view
Очищення
Поверніть вашу змінну середовища KUBECONFIG до її оригінального значення. Наприклад:
Linux
exportKUBECONFIG="$KUBECONFIG_SAVED"
Windows PowerShell
$Env:KUBECONFIG=$ENV:KUBECONFIG_SAVED
Перевірте субʼєкт, представлений kubeconfig
Не завжди очевидно, які атрибути (імʼя користувача, групи) ви отримаєте після автентифікації в кластері. Це може бути ще складніше, якщо ви керуєте більше ніж одним кластером одночасно.
Існує підкоманда kubectl для перевірки атрибутів субʼєкта, таких як імʼя користувача, для вашого вибраного контексту клієнта Kubernetes: kubectl auth whoami.
10.4 - Використання перенаправлення портів для доступу до застосунків у кластері
Ця сторінка показує, як використовувати kubectl port-forward для підключення до сервера MongoDB, який працює у кластері Kubernetes. Такий тип підключення може бути корисним для налагодження бази даних.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Вивід успішної команди підтверджує, що Service був створений:
service/mongo created
Перевірте створений Service:
kubectl get service mongo
Вивід показує створений Service:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mongo ClusterIP 10.96.41.183 <none> 27017/TCP 11s
Переконайтеся, що сервер MongoDB працює у Pod та слухає на порту 27017:
# Замініть mongo-75f59d57f4-4nd6q на імʼя Podkubectl get pod mongo-75f59d57f4-4nd6q --template='{{(index (index .spec.containers 0).ports 0).containerPort}}{{"\n"}}'
Вивід показує порт для MongoDB у цьому Pod:
27017
27017 є офіційним TCP портом для MongoDB.
Перенаправлення локального порту на порт Pod
kubectl port-forward дозволяє використовувати імʼя ресурсу, такого як імʼя Podʼа, для вибору відповідного Podʼа для перенаправлення портів.
# Замініть mongo-75f59d57f4-4nd6q на імʼя Podkubectl port-forward mongo-75f59d57f4-4nd6q 28015:27017
Будь-яка з наведених вище команд працює. Вивід схожий на це:
Forwarding from 127.0.0.1:28015 -> 27017
Forwarding from [::1]:28015 -> 27017
Примітка:
kubectl port-forward не повертає інформацію. Щоб продовжити вправи, вам потрібно буде відкрити інший термінал.
Запустіть інтерфейс командного рядка MongoDB:
mongosh --port 28015
На командному рядку MongoDB введіть команду ping:
db.runCommand( { ping: 1 } )
Успішний запит ping повертає:
{ ok: 1 }
Дозвольте kubectl вибрати локальний порт
Якщо вам не потрібен конкретний локальний порт, ви можете дозволити kubectl вибрати та призначити локальний порт і таким чином позбавити себе від необхідності керувати конфліктами локальних портів, з дещо простішим синтаксисом:
kubectl port-forward deployment/mongo :27017
Інструмент kubectl знаходить номер локального порту, який не використовується (уникаючи низьких номерів портів, оскільки вони можуть використовуватися іншими застосунками). Вивід схожий на:
Forwarding from 127.0.0.1:63753 -> 27017
Forwarding from [::1]:63753 -> 27017
Обговорення
Підключення до локального порту 28015 пересилаються на порт 27017 Podʼа, який запускає сервер MongoDB. З цим підключенням ви можете використовувати свій локальний робочий компʼютер для налагодження бази даних, яка працює у Pod.
Примітка:
kubectl port-forward реалізовано тільки для TCP портів. Підтримка UDP протоколу відстежується у issue 47862.
10.5 - Використання Service для доступу до застосунку у кластері
Ця сторінка показує, як створити обʼєкт Service в Kubernetes, який зовнішні клієнти можуть використовувати для доступу до застосунку, що працює у кластері. Service забезпечує балансування навантаження для застосунку, який має два запущені екземпляри.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Занотуйте значення NodePort для Service. Наприклад, у попередньому виводі значення NodePort становить 31496.
Перегляньте Podʼи, що запускають застосунок Hello World:
kubectl get pods --selector="run=load-balancer-example" --output=wide
Вивід буде схожий на цей:
NAME READY STATUS ... IP NODE
hello-world-2895499144-bsbk5 1/1 Running ... 10.200.1.4 worker1
hello-world-2895499144-m1pwt 1/1 Running ... 10.200.2.5 worker2
Отримайте публічну IP-адресу одного з ваших вузлів, що запускає Pod Hello World. Як ви отримаєте цю адресу залежить від того, як ви налаштували свій кластер. Наприклад, якщо ви використовуєте Minikube, ви можете побачити адресу вузла, виконавши команду kubectl cluster-info. Якщо ви використовуєте trptvgkzhb Google Compute Engine, ви можете використати команду gcloud compute instances list для перегляду публічних адрес ваших вузлів.
На обраному вами вузлі створіть правило брандмауера, яке дозволяє TCP-трафік на вашому порту вузла. Наприклад, якщо ваш Service має значення NodePort 31568, створіть правило брандмауера, яке дозволяє TCP-трафік на порт 31568. Різні постачальники хмарних послуг пропонують різні способи налаштування правил брандмауера.
Використовуйте адресу вузла та порт вузла для доступу до застосунку Hello World:
curl http://<public-node-ip>:<node-port>
де <public-node-ip> — це публічна IP-адреса вашого вузла, а <node-port> — це значення NodePort для вашого Service. Відповідь на успішний запит буде повідомленням з привітанням:
10.6 - Зʼєднання фронтенду з бекендом за допомогою Service
Це завдання показує, як створити мікросервіси frontend та backend. Мікросервіс бекенд є сервісом для привітання. Фронтенд експонує backend за допомогою nginx та обʼєкта Kubernetes Service.
Цілі
Створити та запустити зразок мікросервісу бекенд hello за допомогою обʼєкта Deployment.
Використовувати обʼєкт Service для надсилання трафіку до кількох реплік мікросервісу бекенд.
Створити та запустити мікросервіс фронтенд nginx, також використовуючи обʼєкт Deployment.
Налаштувати мікросервіс фронтенд для надсилання трафіку до мікросервісу бекенд.
Використовувати обʼєкт Service типу LoadBalancer для експонування мікросервісу фронтенд назовні кластера.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Name: backend
Namespace: default
CreationTimestamp: Mon, 24 Oct 2016 14:21:02 -0700
Labels: app=hello
tier=backend
track=stable
Annotations: deployment.kubernetes.io/revision=1
Selector: app=hello,tier=backend,track=stable
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 1 max unavailable, 1 max surge
Pod Template:
Labels: app=hello
tier=backend
track=stable
Containers:
hello:
Image: "gcr.io/google-samples/hello-go-gke:1.0"
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: hello-3621623197 (3/3 replicas created)
Events:
...
Створення обʼєкта Service hello
Ключовим елементом для надсилання запитів з фронтенду до бекенду є бекенд Service. Service створює постійну IP-адресу та запис DNS, так що мікросервіс бекенд завжди може бути доступним. Service використовує селектори, щоб знайти Podʼи, до яких треба спрямувати трафік.
Спочатку ознайомтеся з конфігураційним файлом Service:
На цьому етапі у вас є Deployment backend, що виконує три репліки вашого hello застосунку, та Service, який може маршрутизувати трафік до них. Проте цей Service не є доступним та не може бути доступний за межами кластера.
Створення frontend
Тепер, коли ваш бекенд запущено, ви можете створити frontend, який буде доступним за межами кластера та підключатиметься до backend, проксуючи запити до нього.
Фронтенд надсилає запити до Podʼів backend, використовуючи DNS-імʼя, надане Serviceʼу бекенд. DNS-імʼя — це hello, яке є значенням поля name у конфігураційному файлі examples/service/access/backend-service.yaml.
Podʼи у Deployment фронтенд запускають образ nginx, налаштований для проксіювання запитів до Service бекенда hello. Ось конфігураційний файл nginx:
# The identifier Backend is internal to nginx, and used to name this specific upstream
upstream Backend {
# hello is the internal DNS name used by the backend Service inside Kubernetes
server hello;
}
server {
listen 80;
location / {
# The following statement will proxy traffic to the upstream named Backend
proxy_pass http://Backend;
}
}
Подібно до бекенду, фронтенд має Deployment та Service. Важливою відмінністю між Serviceʼами бекендаа та фронтенда є те, що конфігурація для Service фронтенда має type: LoadBalancer, що означає, що Service використовує балансувальник навантаження, який надається вашим хмарним провайдером, і буде доступним за межами кластеру.
10.7 - Створення зовнішнього балансувальника навантаження
Ця сторінка показує, як створити зовнішній балансувальник навантаження.
Під час створення Service ви маєте можливість автоматично створити балансувальник навантаження в хмарі. Він забезпечує доступну назовні IP-адресу, яка надсилає трафік на відповідний порт ваших вузлів кластера, за умови, що ваш кластер працює в підтримуваному середовищі та налаштований з відповідним пакетом постачальника хмарного балансувальника навантаження.
Ви також можете використовувати Ingress замість Service. Для отримання додаткової інформації ознайомтеся з документацією Ingress.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
IP-адреса балансувальника навантаження вказана поруч з LoadBalancer Ingress.
Примітка:
Якщо ви запускаєте свій сервіс на Minikube, ви можете знайти призначену IP-адресу та порт за допомогою:
minikube service example-service --url
Збереження вихідної IP-адреси клієнта
Типово, вихідна IP-адреса, яку бачить цільовий контейнер, не є оригінальною вихідною IP-адресою клієнта. Щоб увімкнути збереження IP-адреси клієнта, можна налаштувати наступні поля в .spec Service:
.spec.externalTrafficPolicy — вказує, чи бажає цей Service маршрутизувати зовнішній трафік до вузлів локально або по всьому кластеру. Є два доступні варіанти: Cluster (стандартно) і Local. Cluster приховує вихідну IP-адресу клієнта та може спричинити другий перехід на інший вузол, але має гарне загальне розподілення навантаження. Local зберігає вихідну IP-адресу клієнта та уникає другого переходу для сервісів типу LoadBalancer та NodePort, але є ризик потенційно нерівномірного розподілення трафіку.
.spec.healthCheckNodePort — вказує порт для перевірки стану вузлів (числовий номер порту) для Service. Якщо ви не вкажете healthCheckNodePort, контролер Service виділить порт з діапазону NodePort вашого кластера. Ви можете налаштувати цей діапазон, встановивши параметр командного рядка API-сервера --service-node-port-range. Service використовуватиме значення healthCheckNodePort, якщо ви його вкажете, за умови, що type Service встановлено як LoadBalancer і externalTrafficPolicy встановлено як Local.
Встановлення externalTrafficPolicy на Local у маніфесті Service активує цю функцію. Наприклад:
Застереження та обмеження при збереженні вихідних IP-адрес
Сервіси балансування навантаження деяких хмарних провайдерів не дозволяють налаштувати різну вагу для кожної цілі.
Коли кожна ціль має однакову вагу для надсилання трафіку на вузли, зовнішній трафік нерівномірно розподіляється між різними Podʼами. Зовнішній балансувальник навантаження не знає кількість Podʼів на кожному вузлі, які використовуються як ціль.
Якщо NumServicePods << NumNodes або NumServicePods >> NumNodes, спостерігається майже рівномірний розподіл, навіть без коефіцієнтів.
Внутрішній трафік між Podʼами повинен поводитися подібно до Service типу ClusterIP, з рівною ймовірністю для всіх Podʼів.
Балансувальники для збору сміття
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.17 [stable]
У звичайному випадку, відповідні ресурси балансувальника навантаження у хмарного провайдера повинні бути видалені незабаром після видалення Service типу LoadBalancer. Але відомо, що є різні крайні випадки, коли хмарні ресурси залишаються після видалення асоційованого Service. Для запобігання цьому було введено захист за допомогою завершувачів для Service LoadBalancers. Використовуючи завершувачі, ресурс Service ніколи не буде видалено, поки відповідні ресурси балансувальника навантаження також не будуть видалені.
Зокрема, якщо Service має type LoadBalancer, контролер Service додасть завершувач з назвою service.kubernetes.io/load-balancer-cleanup. Завершувач буде видалений тільки після видалення ресурсу балансувальника навантаження. Це запобігає залишенню ресурсів балансувальника навантаження навіть у крайніх випадках, таких як падіння контролера сервісу.
Постачальники зовнішніх балансувальників навантаження
Важливо зазначити, що шлях даних для цієї функціональності забезпечується зовнішнім для кластера Kubernetes балансувальником навантаження.
Коли type Service встановлено як LoadBalancer, Kubernetes забезпечує функціональність, еквівалентну type ClusterIP для Podʼів у кластері, і розширює її, програмуючи (зовнішній для Kubernetes) балансувальник навантаження з записами для вузлів, що є місцем розташування відповідних Podʼів Kubernetes. Панель управління Kubernetes автоматизує створення зовнішнього балансувальника навантаження, перевірки стану (якщо необхідно), і правила фільтрації пакетів (якщо необхідно). Після того як хмарний провайдер виділить IP-адресу для балансувальника навантаження, панель управління знаходить цю зовнішню IP-адресу та вносить її в обʼєкт Service.
10.8 - Отримання переліку всіх образів контейнерів, що працюють у кластері
Ця сторінка показує, як використовувати kubectl для отримання переліку всіх образів контейнерів для Podʼів, що працюють у кластері.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У цьому завданні ви використовуватимете kubectl для отримання всіх Podʼів, що працюють у кластері, і форматування виводу для отримання списку контейнерів для кожного з них.
Перелік всіх образів контейнерів у всіх просторах імен
Отримайте всі Podʼи у всіх просторах імен за допомогою kubectl get pods --all-namespaces.
Форматуйте вивід для включення лише списку імен образів контейнерів, використовуючи -o jsonpath={.items[*].spec['initContainers', 'containers'][*].image}. Це рекурсивно розбирає поле image з отриманого JSON.
Ознайомтеся з довідником по jsonpath для додаткової інформації про використання jsonpath.
Форматуйте вивід за допомогою стандартних інструментів: tr, sort, uniq.
Використовуйте tr для заміни пробілів на нові рядки.
Використовуйте sort для сортування результатів.
Використовуйте uniq для агрегування кількості образів.
['initContainers', 'containers'][*]: для кожного контейнера.
.image: отримати образ.
Примітка:
При отриманні одного Podʼа за іменем, наприклад, kubectl get pod nginx, частину шляху .items[*] слід опустити, оскільки повертається один Pod, а не список елементів.
Отримання переліку образів контейнерів в розрізі Podʼів
Форматування може бути додатково налаштоване за допомогою операції range для ітерації по елементах індивідуально.
Отримання переліку образів контейнерів за мітками Podʼів
Щоб опрацьовувати лише Podʼи, які відповідають конкретній мітці, використовуйте прапорець -l. Наступне відповідає збігам лише для Podʼів з мітками, що відповідають app=nginx.
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" -l app=nginx
Отримання переліку образів контейнерів в розрізі просторів імен Podʼів
Щоб опрацьовувати лише Podʼи в конкретному просторі імен, використовуйте прапорець namespace. Наступне відповідає збігам лише для Podʼів у просторі імен kube-system.
kubectl get pods --namespace kube-system -o jsonpath="{.items[*].spec.containers[*].image}"
Отримання переліку образів контейнерів з використанням go-template замість jsonpath
Як альтернативу jsonpath, Kubectl підтримує використання go-templates для форматування виходу:
kubectl get pods --all-namespaces -o go-template --template="{{range .items}}{{range .spec.containers}}{{.image}} {{end}}{{end}}"
10.9 - Спілкування між контейнерами в одному Podʼі за допомогою спільного тому
Ця сторінка показує, як використовувати Том для спілкування між двома контейнерами, що працюють в одному Podʼі. Також дивіться, як дозволити процесам спілкуватися між контейнерами через спільний простір процесів.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У цьому завданні ви створите Pod, який запускає два контейнери. Ці два контейнери спільно використовують Том, який вони можуть використовувати для спілкування. Ось конфігураційний файл для Podʼа:
apiVersion:v1kind:Podmetadata:name:two-containersspec:restartPolicy:Nevervolumes:- name:shared-dataemptyDir:{}containers:- name:nginx-containerimage:nginxvolumeMounts:- name:shared-datamountPath:/usr/share/nginx/html- name:debian-containerimage:debianvolumeMounts:- name:shared-datamountPath:/pod-datacommand:["/bin/sh"]args:["-c","echo Hello from the debian container > /pod-data/index.html"]
У конфігураційному файлі видно, що Pod має Том з назвою shared-data.
Перший контейнер, зазначений у конфігураційному файлі, запускає сервер nginx. Шлях монтування для спільного тому — /usr/share/nginx/html. Другий контейнер базується на образі debian і має шлях монтування /pod-data. Другий контейнер виконує наступну команду і потім завершується.
echo Hello from the debian container > /pod-data/index.html
Зверніть увагу, що другий контейнер записує файл index.html в кореневу теку сервера nginx.
USER PID ... STAT START TIME COMMAND
root 1 ... Ss 21:12 0:00 nginx: master process nginx -g daemon off;
Згадайте, що контейнер debian створив файл index.html в кореневій теці nginx. Використовуйте curl, щоб надіслати GET запит на сервер nginx:
root@two-containers:/# curl localhost
Вихідні дані показують, що nginx обслуговує вебсторінку, написану контейнером debian:
Hello from the debian container
Обговорення
Основна причина, через яку Podʼи можуть мати кілька контейнерів, полягає у підтримці допоміжних застосунків, що допомагають основному застосунку. Типові приклади допоміжних застосунків включають інструменти для завантаження, надсилання даних та проксі. Допоміжні та основні застосунки часто потребують спілкування між собою. Зазвичай це робиться через спільну файлову систему, як показано в цій вправі, або через інтерфейс локальної мережі, localhost. Прикладом цього шаблону є вебсервер разом із допоміжним застосунком, яка перевіряє репозиторій Git на наявність нових оновлень.
Том у цьому завданні надає спосіб спілкування контейнерів під час життя Pod. Якщо Pod видалено та створено знову, всі дані, збережені в спільному томі, будуть втрачені.
Kubernetes пропонує надбудову DNS для кластера, яку типово увімкнено у більшості підтримуваних середовищ. У Kubernetes версії 1.11 і пізніших версіях рекомендовано використовувати CoreDNS, який стандартно встановлюється з kubeadm.
Для отримання додаткової інформації про налаштування CoreDNS для кластера Kubernetes дивіться Налаштування DNS-сервісу.
Докладнішу інформацію про налаштування CoreDNS для кластера Kubernetes див. у розділі Налаштування служби DNS.
10.11 - Доступ до Service, що працюють в кластерах
Ця сторінка показує, як підʼєднатись до Serviceʼів, що працюють у кластері Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У Kubernetes Вузли,
Podʼи та Serviceʼи мають власні IP-адреси. У багатьох випадках IP-адреси вузлів, Podʼів та деякі IP-адреси Service у кластері не можуть бути маршрутизовані, тому вони не будуть досяжними з машини за межами кластера, такої як ваш настільний компʼютер.
Способи приєднання
Ви маєте кілька варіантів приєднання до вузлів, Podʼів та Serviceʼів ззовні кластера:
Доступ до Servicʼів через публічні IP-адреси.
Використовуйте Service з типом NodePort або LoadBalancer, щоб зробити Service доступним ззовні кластера. Дивіться документацію Service та kubectl expose.
Залежно від середовища вашого кластера, це може тільки відкрити Service для вашої корпоративної мережі, або ж зробити його доступним в інтернеті. Подумайте, чи є Service безпечним для відкриття. Чи має він власну автентифікацію?
Розміщуйте Podʼи за Serviceʼами. Щоб отримати доступ до одного конкретного Pod з набору реплік, наприклад, для налагодження, додайте унікальну мітку до Podʼа і створіть новий Service, який обирає цю мітку.
У більшості випадків розробнику застосунків не потрібно безпосередньо звертатися до вузлів за їх IP-адресами.
Доступ до Serviceʼів, вузлів або Podʼів за допомогою проксі-дієслова (Proxy Verb).
Виконує автентифікацію та авторизацію на api-сервері перед доступом до віддаленого Service. Використовуйте це, якщо Service недостатньо безпечні для відкриття в інтернеті, або для доступу до портів на IP-адресі вузла, або для налагодження.
Проксі можуть викликати проблеми для деяких вебзастосунків.
Запустіть Pod та отримайте доступ до shell у ньому за допомогою kubectl exec. Підʼєднуйтесь до інших вузлів, Podʼів та Serviceʼів з цього shell.
Деякі кластери можуть дозволити вам підʼєднатись по SSH до вузла в кластері. Звідти ви можете отримати доступ до Serviceʼів кластера. Це нестандартний метод і працюватиме на одних кластерах, але на інших — ні. Оглядачі та інші інструменти можуть бути встановлені або не встановлені. DNS кластера може не працювати.
Виявлення вбудованих Service
Зазвичай у кластері є кілька Serviceʼів, які запускаються у просторі імен kube-system. Отримайте їх список
за допомогою команди kubectl cluster-info:
kubectl cluster-info
Вихідні дані подібні до цього:
Kubernetes master is running at https://192.0.2.1
elasticsearch-logging is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy
kibana-logging is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/kibana-logging/proxy
kube-dns is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/kube-dns/proxy
grafana is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
heapster is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/monitoring-heapster/proxy
Це показує URL з проксі-дієсловом для доступу до кожного Service. Наприклад, у цьому кластері ввімкнено кластерне логування (з використанням Elasticsearch), до якого можна звернутися за адресою https://192.0.2.1/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/ за умови наявності відповідних облікових даних або через проксі kubectl за адресою: http://localhost:8080/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/.
Як згадувалося вище, ви використовуєте команду kubectl cluster-info, щоб отримати URL проксі для Service. Щоб створити URL-адреси проксі, що включають точки доступу Service, суфікси та параметри, додайте до URL проксі Serviceʼу:
http://kubernetes_master_address/api/v1/namespaces/namespace_name/services/[https:]service_name[:port_name]/proxy
Якщо ви не задали імʼя для вашого порту, вам не потрібно вказувати port_name в URL. Ви також можете використовувати номер порту замість port_name для іменованих та неіменованих портів.
Стандартно апі-сервер проксює до вашого Serviceʼу за допомогою HTTP. Щоб використовувати HTTPS, додайте префікс до імені Serviceʼу https:: http://<kubernetes_master_address>/api/v1/namespaces/<namespace_name>/services/<service_name>/proxy.
Підтримувані формати для сегмента <service_name> URL-адреси:
<service_name> — проксює до стандартного порту або до неіменованого порту за допомогою http
<service_name>:<port_name> — проксює до вказаного імені порту або номера порту за допомогою http
https:<service_name>: — проксює до стандартного порту або до неіменованого порту за допомогою https (зверніть увагу на кінцеву двокрапку)
https:<service_name>:<port_name> — проксює до вказаного імені порту або номера порту за допомогою https
Приклади
Для доступу до точки доступу сервісу Elasticsearch _search?q=user:kimchy, використовуйте:
Використання вебоглядачів для доступу до Serviceʼів, що працюють у кластері
Ви можете вставити URL-адресу проксі api-сервера у адресний рядок оглядача. Однак:
Вебоглядачі зазвичай не можуть передавати токени, тому вам може доведеться використовувати базову автентифікацію (пароль). Api-сервер можна налаштувати для роботи з базовою автентифікацією, але ваш кластер може бути не налаштований для цього.
Деякі вебзастосунки можуть не працювати, особливо ті, що використовують клієнтський javascript для створення URL-адрес, не знаючи про префікс шляху проксі.
11 - Розширення Kubernetes
Розуміння розширених способів адаптації кластера Kubernetes до потреб вашого робочого середовища.
11.1 - Використання власних ресурсів
11.1.1 - Розширення API Kubernetes за допомогою CustomResourceDefinitions
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж 1.16.
Для перевірки версії введіть kubectl version.
Якщо ви використовуєте старішу версію Kubernetes, яка все ще підтримується, використовуйте документацію для цієї версії, щоб отримати поради, які є відповідними для вашого кластера.
Створення CustomResourceDefinition
При створенні нового CustomResourceDefinition (CRD) сервер API Kubernetes створює новий RESTful ресурсний шлях для кожної версії, яку ви вказуєте. Власний ресурс, створений з обʼєкта CRD, може бути або просторово обмеженим за іменем, або обмеженим на рівні кластера, як вказано в полі spec.scope CRD. Як і з наявними вбудованими обʼєктами, видалення простору імен видаляє всі власні обʼєкти в цьому просторі імен. CustomResourceDefinition самі за собою не мають простору імен і доступні для всіх просторів імен.
Наприклад, якщо ви збережете наступне визначення CustomResourceDefinition у resourcedefinition.yaml:
apiVersion:apiextensions.k8s.io/v1kind:CustomResourceDefinitionmetadata:# назва повинна відповідати полям специфікації нижче, і мати формат: <plural>.<group>name:crontabs.stable.example.comspec:# назва групи, яка буде використана для REST API: /apis/<group>/<version>group:stable.example.com# список версій, підтримуваних цим визначенням власних ресурсівversions:- name:v1# Кожну версію можна ввімкнути/вимкнути за допомогою прапорця Served.served:true# Одна і лише одна версія повинна бути позначена як версія зберігання.storage:trueschema:openAPIV3Schema:type:objectproperties:spec:type:objectproperties:cronSpec:type:stringimage:type:stringreplicas:type:integer# або просторово обмежений за іменем, або на рівні кластераscope:Namespacednames:# назва множини, яка буде використана в URL: /apis/<group>/<version>/<plural>plural:crontabs# назва однини, яка буде використана як псевдонім у CLI та для показуsingular:crontab# вид - зазвичай це тип у форматі CamelCased однини. Ваші маніфести ресурсів використовують це.kind:CronTab# короткі назви дозволяють мати збіг для скорочених рядків з вашим ресурсом у CLIshortNames:- ct
та створите його:
kubectl apply -f resourcedefinition.yaml
Тоді буде створено новий просторово обмежений RESTful API шлях за адресою:
Цю URL-адресу шляху можна буде використовувати для створення та управління власними обʼєктами. kind цих обʼєктів буде CronTab зі специфікації обʼєкта CustomResourceDefinition, який ви створили вище.
Може знадобитися кілька секунд, щоб створити точку доступу. Ви можете спостерігати, що умова Established вашого CustomResourceDefinition стає true або спостерігати інформацію про відкриття сервера API для вашого ресурсу, щоб він зʼявився.
Створення власних обʼєктів
Після створення обʼєкта CustomResourceDefinition ви можете створювати власні обʼєкти. Власні обʼєкти можуть містити власні поля. Ці поля можуть містити довільний JSON. У наступному прикладі поля cronSpec та image встановлені у власний обʼєкт типу CronTab. Тип CronTab походить зі специфікації обʼєкта CustomResourceDefinition, який ви створили вище.
Якщо ви збережете наступний YAML у my-crontab.yaml:
Потім ви можете управляти вашими обʼєктами CronTab за допомогою kubectl. Наприклад:
kubectl get crontab
Повинен вивести список, подібний до такого:
NAME AGE
my-new-cron-object 6s
Назви ресурсів нечутливі до регістру при використанні kubectl, і ви можете використовувати як однину, так і множину, визначені в CRD, а також будь-які короткі назви.
Ви також можете переглянути дані YAML:
kubectl get ct -o yaml
Ви повинні побачити, що він містить власні поля cronSpec та image з YAML, який ви використовували для його створення:
Коли ви видаляєте CustomResourceDefinition, сервер деінсталює RESTful API шлях та видаляє всі власні обʼєкти, збережені в ньому.
kubectl delete -f resourcedefinition.yaml
kubectl get crontabs
Error from server (NotFound): Unable to list {"stable.example.com" "v1" "crontabs"}: the server could not
find the requested resource (get crontabs.stable.example.com)
Якщо ви пізніше створите те саме CustomResourceDefinition, воно буде порожнім з початку.
Визначення структурної схеми
CustomResources зберігають структуровані дані у власних полях (разом з вбудованими полями apiVersion, kind та metadata, які сервер API перевіряє неявно). З валідацією OpenAPI v3.0 можна вказати схему, яка перевіряється під час створення та оновлення. Подивіться нижче для деталей та обмежень такої схеми.
З apiextensions.k8s.io/v1 визначення структурної схеми є обовʼязковим для визначення власних ресурсів. У бета-версії CustomResourceDefinition структурна схема була необовʼязковою.
Структурна схема — це схема валідації OpenAPI v3.0, яка:
вказує непорожній тип (за допомогою type в OpenAPI) для кореня, для кожного вказаного поля вузла обʼєкта (за допомогою properties або additionalProperties в OpenAPI) та для кожного елемента вузла масиву (за допомогою items в OpenAPI), за винятком:
вузла з x-kubernetes-int-or-string: true
вузла з x-kubernetes-preserve-unknown-fields: true
для кожного поля в обʼєкті та кожного елемента в масиві, які вказані всередині будь-якого з allOf, anyOf, oneOf або not, схема також вказує поле/елемент поза цими логічними виразами (порівняйте приклад 1 та 2).
не встановлює description, type, default, additionalProperties, nullable всередині allOf, anyOf, oneOf або not, за винятком двох шаблонів для x-kubernetes-int-or-string: true (див. нижче).
якщо вказано metadata, то дозволяються обмеження тільки на metadata.name та metadata.generateName.
properties:foo:pattern:"abc"metadata:type:objectproperties:name:type:stringpattern:"^a"finalizers:type:arrayitems:type:stringpattern:"my-finalizer"anyOf:- properties:bar:type:integerminimum:42required:["bar"]description:"foo bar object"
не є структурною схемою через наступні порушення:
тип у корені відсутній (правило 1).
тип foo відсутній (правило 1).
bar всередині anyOf не вказаний зовні (правило 2).
тип bar в anyOf (правило 3).
опис встановлено в anyOf (правило 3).
metadata.finalizers можуть бути не обмежені (правило 4).
Натомість наступна відповідна схема є структурною:
type:objectdescription:"foo bar object"properties:foo:type:stringpattern:"abc"bar:type:integermetadata:type:objectproperties:name:type:stringpattern:"^a"anyOf:- properties:bar:minimum:42required:["bar"]
Порушення правил структурної схеми повідомляються в умові NonStructural у CustomResourceDefinition.
Обрізка полів
CustomResourceDefinitions зберігають перевірені дані ресурсів у сховищі постійного зберігання кластера, etcd.Так само як і з вбудованими ресурсами Kubernetes, такими як ConfigMap, якщо ви вказуєте поле, яке сервер API не впізнає, невідоме поле обрізається (видаляється) перед зберіганням.
CRD, перетворені з apiextensions.k8s.io/v1beta1 на apiextensions.k8s.io/v1, можуть бути позбавлені структурних схем, і spec.preserveUnknownFields може бути встановлено в true.
Для застарілих обʼєктів власного визначення ресурсів, створених як apiextensions.k8s.io/v1beta1 з spec.preserveUnknownFields встановленим в true, також вірно наступне:
Обрізка не ввімкнена.
Ви можете зберігати довільні дані.
Для сумісності з apiextensions.k8s.io/v1 оновіть визначення своїх власних
ресурсів:
Використовуйте структурну схему OpenAPI.
Встановіть spec.preserveUnknownFields в false.
Якщо ви збережете наступний YAML у my-crontab.yaml:
Зверніть увагу, що поле someRandomField було обрізано.
У цьому прикладі вимкнено перевірку на клієнтському боці, щоб показати поведінку сервера API, додавши параметр командного рядка --validate=false. Оскільки схеми валідації OpenAPI також публікуються для клієнтів, kubectl також перевіряє невідомі поля та відхиляє ці обʼєкти задовго до їх надсилання на сервер API.
Контроль обрізки полів
Типово усі невизначені поля власного ресурсу, у всіх версіях, обрізаються. Однак можна відмовитися від цього для певних піддерев полів, додавши x-kubernetes-preserve-unknown-fields: true у структурну схему валідації OpenAPI v3.
Також ці вузли частково виключаються з правила 3 у тому сенсі, що дозволяються наступні два шаблони (саме ці, без варіацій в порядку або додаткових полів):
Оскільки поруч вказано x-kubernetes-preserve-unknown-fields: true, нічого не обрізається. Використання x-kubernetes-preserve-unknown-fields: true є опціональним.
З x-kubernetes-embedded-resource: true поля apiVersion, kind і metadata неявно задаються та перевіряються на валідність.
Обслуговування декількох версій CRD
Дивіться версіювання визначення власних ресурсів для отримання додаткової інформації про обслуговування декількох версій вашого CustomResourceDefinition і міграцію ваших обʼєктів з однієї версії на іншу.
Розширені теми
Завершувачі
Завершувачі дозволяють контролерам реалізовувати асинхронні гаки перед видаленням. Власні обʼєкти підтримують завершувачі, аналогічні вбудованим обʼєктам.
Ви можете додати завершувач до власного обʼєкта ось так:
Ідентифікатори власних завершувачів складаються з імені домену, косої риски та назви завершувача. Будь-який контролер може додати завершувач до списку завершувачів будь-якого обʼєкта.
Перший запит на видалення обʼєкта з завершувачами встановлює значення для поля metadata.deletionTimestamp, але не видаляє його. Після встановлення цього значення можна лише видаляти записи у списку finalizers. Поки залишаються будь-які завершувачі, неможливо примусово видалити обʼєкт.
Коли поле metadata.deletionTimestamp встановлене, контролери, які стежать за обʼєктом, виконують будь-які завершувачі, які вони обробляють, і видаляють завершувач зі списку після завершення. Відповідальність за видалення свого завершувача зі списку лежить на кожному контролері.
Значення поля metadata.deletionGracePeriodSeconds контролює інтервал між оновленнями опитування.
Після того, як список завершувачів стане порожнім, тобто всі завершувачі будуть виконані, ресурс буде видалено Kubernetes.
Валідація
Власні ресурси перевіряються за допомогою схем OpenAPI v3.0, за допомогою x-kubernetes-validations, коли функція Правил валідації ввімкнена, і ви можете додати додаткову валідацію за допомогою вебхуків допуску.
Крім того, до схеми застосовуються такі обмеження:
Ці поля не можна встановлювати:
definitions,
dependencies,
deprecated,
discriminator,
id,
patternProperties,
readOnly,
writeOnly,
xml,
$ref.
Поле uniqueItems не можна встановлювати в true.
Поле additionalProperties не можна встановлювати в false.
Поле additionalProperties є взаємозаперечним із properties.
Зверніться до розділу структурних схем для інших обмежень та функцій CustomResourceDefinition.
Схема визначається у CustomResourceDefinition. У наведеному нижче прикладі CustomResourceDefinition застосовує такі перевірки до власного обʼєкта:
spec.cronSpec повинен бути рядком і відповідати формі, описаній регулярним виразом.
spec.replicas повинен бути цілим числом і мати мінімальне значення 1 та максимальне значення 10.
Збережіть CustomResourceDefinition у файл resourcedefinition.yaml:
apiVersion:apiextensions.k8s.io/v1kind:CustomResourceDefinitionmetadata:name:crontabs.stable.example.comspec:group:stable.example.comversions:- name:v1served:truestorage:trueschema:# openAPIV3Schema - це схема для перевірки власних обʼєктів.openAPIV3Schema:type:objectproperties:spec:type:objectproperties:cronSpec:type:stringpattern:'^(\d+|\*)(/\д+)?(\s+(\d+|\*)(/\д+)?){4}$'image:type:stringreplicas:type:integerminimum:1maximum:10scope:Namespacednames:plural:crontabssingular:crontabkind:CronTabshortNames:- ct
і створіть його:
kubectl apply -f resourcedefinition.yaml
Запит на створення власного обʼєкта типу CronTab буде відхилено, якщо поля містять недійсні значення. У наведеному нижче прикладі власний обʼєкт містить поля з недійсними значеннями:
spec.cronSpec не відповідає регулярному виразу.
spec.replicas більше 10.
Якщо ви збережете наступний YAML у файл my-crontab.yaml:
The CronTab "my-new-cron-object" is invalid: []: Invalid value: map[string]interface {}{"apiVersion":"stable.example.com/v1", "kind":"CronTab", "metadata":map[string]interface {}{"name":"my-new-cron-object", "namespace":"default", "deletionTimestamp":interface {}(nil), "deletionGracePeriodSeconds":(*int64)(nil), "creationTimestamp":"2017-09-05T05:20:07Z", "uid":"e14d79e7-91f9-11e7-a598-f0761cb232d1", "clusterName":""}, "spec":map[string]interface {}{"cronSpec":"* * * *", "image":"my-awesome-cron-image", "replicas":15}}:
validation failure list:
spec.cronSpec in body should match '^(\d+|\*)(/\д+)?(\с+(\д+|\*)(/\д+)?){4}$'
spec.replicas in body should be less than or equal to 10
Якщо поля містять дійсні значення, запит на створення обʼєкта буде прийнято.
kubectl apply -f my-crontab.yaml
crontab "my-new-cron-object" created
Проковзування валідації
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [stable](стандартно увімкнено)
Якщо ви використовуєте версію Kubernetes старше v1.30, вам потрібно явно ввімкнути функціональну можливістьCRDValidationRatcheting, щоб використовувати цю поведінку, яка потім застосовується до всіх CustomResourceDefinitions у вашому кластері.
За умови увімкнення функціональної можливості, Kubernetes реалізує проковзування валідації для CustomResourceDefinitions. API сервер готовий прийняти оновлення ресурсів, які є недійсними після оновлення, за умови, що кожна частина ресурсу, яка не пройшла валідацію, не була змінена операцією оновлення. Іншими словами, будь-яка недійсна частина ресурсу, яка залишається недійсною, вже повинна була бути неправильною. Ви не можете використовувати цей механізм для оновлення дійсного ресурсу, щоб він став недійсним.
Ця функція дозволяє авторам CRD впевнено додавати нові перевірки до схеми OpenAPIV3 за певних умов. Користувачі можуть безпечно оновлюватися до нової схеми без зміни версії обʼєкта або порушення робочих процесів.
Хоча більшість перевірок, розміщених у схемі OpenAPIV3 CRD, підтримують обмеження, є кілька винятків. Наступні перевірки схеми OpenAPIV3 не підтримуються обмеженнями у реалізації в Kubernetes 1.34 і якщо порушені, продовжуватимуть видавати помилку як зазвичай:
Квантори
allOf
oneOf
anyOf
not
будь-які перевірки в нащадках одного з цих полів
x-kubernetes-validations Для Kubernetes 1.28, правила валідації CRD ігноруються обмеженнями. Починаючи з Alpha 2 у Kubernetes 1.29, x-kubernetes-validations обмежуються лише, якщо вони не посилаються на oldSelf.
Перехідні правила ніколи не обмежуються: лише помилки, які виникають через правила, які не використовують oldSelf, автоматично обмежуються, якщо їх значення не змінені.
Щоб написати власну логіку обмеження для виразів CEL, перегляньте optionalOldSelf.
x-kubernetes-list-type Помилки, що виникають через зміну типу списку у підсхемі, не будуть
обмежені. Наприклад, додавання set до списку з дублікатів завжди призведе до помилки.
x-kubernetes-list-map-keys Помилки, що виникають через зміну ключів карти у схемі списку, не будуть обмежені.
required Помилки, що виникають через зміну списку обовʼязкових полів, не будуть обмежені.
properties Додавання/видалення/модифікація імен властивостей не обмежуються, але зміни до перевірок у схемах та підсхемах властивостей можуть бути обмежені, якщо імʼя властивості залишається незмінним.
additionalProperties Видалення раніше вказаної валідації additionalProperties не буде
обмежено.
metadata Помилки, що виникають через вбудовану валідацію обʼєкта metadata у Kubernetes, не будуть обмежені (наприклад, імʼя обʼєкта або символи у значенні мітки). Якщо ви вказуєте свої власні додаткові правила для метаданих власного ресурсу, ця додаткова валідація буде обмежена.
Правила валідації
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.29 [stable]
Правила валідації використовують Common Expression Language (CEL) для валідації значень власних ресурсів. Правила валідації включаються в схеми CustomResourceDefinition за допомогою розширення x-kubernetes-validations.
Правило обмежується місцем знаходження розширення x-kubernetes-validations у схемі. Змінна self у виразі CEL привʼязана до значення, що перевіряється.
Всі правила валідації обмежені поточним обʼєктом: ніякі міжобʼєктні або stateful правила валідації не підтримуються.
Наприклад:
# ...openAPIV3Schema:type:objectproperties:spec:type:objectx-kubernetes-validations:- rule:"self.minReplicas <= self.replicas"message:"replicas should be greater than or equal to minReplicas."- rule:"self.replicas <= self.maxReplicas"message:"replicas should be smaller than or equal to maxReplicas."properties:# ...minReplicas:type:integerreplicas:type:integermaxReplicas:type:integerrequired:- minReplicas- replicas- maxReplicas
відхилить запит на створення цього власного ресурсу:
The CronTab "my-new-cron-object" is invalid:
* spec: Invalid value: map[string]interface {}{"maxReplicas":10, "minReplicas":0, "replicas":20}: replicas should be smaller than or equal to maxReplicas.
x-kubernetes-validations може містити декілька правил. rule під x-kubernetes-validations представляє вираз, який буде оцінюватися CEL. message представляє повідомлення, що показується при невдачі валідації. Якщо повідомлення не встановлено, відповідь буде такою:
The CronTab "my-new-cron-object" is invalid:
* spec: Invalid value: map[string]interface {}{"maxReplicas":10, "minReplicas":0, "replicas":20}: failed rule: self.replicas <= self.maxReplicas
Примітка:
Ви можете швидко перевірити вирази CEL на CEL Playground.
Правила валідації компілюються при створенні/оновленні CRD. Запит на створення/оновлення CRD буде відхилено, якщо компіляція правил валідації зазнає невдачі. Процес компіляції включає перевірку типів.
Помилки компіляції:
no_matching_overload: ця функція не має перевантаження для типів аргументів.
Наприклад, правило self == true для поля типу integer призведе до помилки:
Invalid value: apiextensions.ValidationRule{Rule:"self == true", Message:""}: compilation failed: ERROR: \<input>:1:6: found no matching overload for '_==_' applied to '(int, bool)'
no_such_field: не містить бажаного поля.
Наприклад, правило self.nonExistingField > 0 для неіснуючого поля поверне наступну помилку:
Якщо правило обмежене коренем ресурсу, воно може вибирати поля з будь-яких полів, оголошених у схемі OpenAPIv3 CRD, а також apiVersion, kind, metadata.name та metadata.generateName. Це включає вибір полів як у spec, так і в status в одному виразі:
Якщо Rule обмежене обʼєктом з властивостями, доступні властивості обʼєкта можна вибирати за допомогою self.field, а наявність поля можна перевірити за допомогою has(self.field). Поля зі значенням null трактуються як відсутні поля у виразах CEL.
Якщо Rule обмежене обʼєктом з додатковими властивостями (тобто map), значення map доступні через self[mapKey], наявність map можна перевірити за допомогою mapKey in self, а всі записи з map доступні за допомогою макросів і функцій CEL, таких як self.all(...).
apiVersion, kind, metadata.name та metadata.generateName завжди доступні з кореня обʼєкта та з будь-яких обʼєктів з анотацією x-kubernetes-embedded-resource. Інші властивості метаданих недоступні.
Невідомі дані, збережені у власниї ресурсах за допомогою x-kubernetes-preserve-unknown-fields, не доступні у виразах CEL. Це включає:
Невідомі значення полів, які зберігаються у схемах обʼєктів з x-kubernetes-preserve-unknown-fields.
Властивості обʼєктів, де схема властивостей має "unknown type". "Unknown type" визначається рекурсивно як:
Схема без типу і з встановленим x-kubernetes-preserve-unknown-fields
Масив, де схема елементів має "unknown type"
Обʼєкт, де схема additionalProperties має "unknown type"
Доступні лише назви властивостей форми [a-zA-Z_.-/][a-zA-Z0-9_.-/]*. Доступні назви властивостей екрануються за наступними правилами при доступі у виразі:
Примітка: зарезервоване ключове слово CEL повинно точно збігатися з назвою властивості, щоб бути екранованим (наприклад, int у слові sprint не буде екрановано).
Приклади екранування:
назва властивості
правило з екранованою назвою властивості
namespace
self.__namespace__ > 0
x-prop
self.x__dash__prop > 0
redact__d
self.redact__underscores__d > 0
string
self.startsWith('kube')
Рівність масивів з x-kubernetes-list-type типу set або map ігнорує порядок елементів, тобто [1, 2] == [2, 1]. Конкатенація масивів з x-kubernetes-list-type використовує семантику
типу списку:
set: X + Y виконує обʼєднання, де зберігаються позиції елементів у X, а непересічні елементи у Y додаються, зберігаючи їх частковий порядок.
map: X + Y виконує злиття, де зберігаються позиції всіх ключів у X, але значення перезаписуються значеннями у Y, коли ключі X та Y перетинаються. Елементи у Y з непересічними ключами додаються, зберігаючи їх частковий порядок.
Ось відповідність типів між OpenAPIv3 та CEL:
Тип OpenAPIv3
Тип CEL
'object' з Properties
object / "message type"
'object' з AdditionalProperties
map
'object' з x-kubernetes-embedded-type
object / "message type", 'apiVersion', 'kind', 'metadata.name' та 'metadata.generateName' неявно включені у схему
'object' з x-kubernetes-preserve-unknown-fields
object / "message type", невідомі поля НЕ доступні у виразі CEL
x-kubernetes-int-or-string
динамічний обʼєкт, який може бути або int, або string, type(value) можна використовувати для перевірки типу
'array
list
'array' з x-kubernetes-list-type=map
list з порівнянням на основі map та гарантіями унікальності ключів
'array' з x-kubernetes-list-type=set
list з порівнянням на основі множини та гарантіями унікальності елементів
Поле messageExpression, аналогічно до поля message, визначає рядок, яким буде повідомлено про негативний результат правила валідації. Однак messageExpression дозволяє використовувати вираз CEL для побудови повідомлення, що дозволяє вставляти більш описову інформацію в повідомлення про невдачу валідації. messageExpression має оцінюватися як рядок і може використовувати ті ж змінні, що і поле rule. Наприклад:
x-kubernetes-validations:- rule:"self.x <= self.maxLimit"messageExpression:'"x перевищує максимальний ліміт " + string(self.maxLimit)'
Майте на увазі, що конкатенація рядків CEL (оператор +) автоматично не призводить до перетворення в рядок. Якщо у вас є скаляр, який не є рядком, використовуйте функцію string(<значення>) для перетворення скаляра в рядок, як показано в прикладі вище.
messageExpression повинен оцінюватися як рядок, і це перевіряється при створенні CRD. Зауважте, що можна встановити як message, так і messageExpression для одного правила, і якщо обидва присутні, буде використовуватися messageExpression. Однак, якщо messageExpression оцінюється як помилка, буде використовуватися рядок, визначений у message, і помилка messageExpression буде зафіксована. Це повернення до попереднього стану також відбудеться, якщо вираз CEL, визначений у messageExpression, генерує порожній рядок або рядок, що містить розриви рядків.
Якщо одна з вищезазначених умов виконується і message не було встановлено, то буде використовуватися стандартне повідомлення про негативний результат валідації.
messageExpression є виразом CEL, тому обмеження, зазначені в розділі Використання ресурсів функціями валідації, застосовуються. Якщо оцінка зупиняється через обмеження ресурсів під час виконання messageExpression, жодні подальші правила валідації не будуть виконуватися.
Встановлення messageExpression є необовʼязковим.
Поле message
Якщо ви хочете встановити статичне повідомлення, ви можете передати message замість messageExpression. Значення message використовується як непрозорий рядок помилки, якщо перевірка не пройшла успішно.
Встановлення message є необовʼязковим.
Поле reason
Ви можете додати машинно-читаєму причину негативного результату перевірки в межах validation, щоб повертати її, коли запит не відповідає цьому правилу перевірки.
Код стану HTTP, повернутий абоненту, буде відповідати причині першої невдачі перевірки. Наразі підтримуються такі причини: "FieldValueInvalid", "FieldValueForbidden", "FieldValueRequired", "FieldValueDuplicate". Якщо причини не встановлені або невідомі, типово використовується "FieldValueInvalid".
Встановлення reason є необовʼязковим.
Поле fieldPath
Ви можете вказати шлях поля, який повертається, коли перевірка завершується негативним результатом.
У вищенаведеному прикладі перевіряється значення поля x, яке повинно бути менше значення maxLimit. Якщо не вказано fieldPath, коли результат перевірки негативний , fieldPath буде типово відповідати місцю розташування self. З вказаним fieldPath повернена помилка буде мати fieldPath, який належним чином посилатиметься на місце поля x.
Значення fieldPath повинно бути відносним шляхом JSON, що обмежений місцем цього розширення x-kubernetes-validations у схемі. Крім того, воно повинно посилатися на існуюче поле в межах схеми. Наприклад, коли перевірка перевіряє, чи є певний атрибут foo у map testMap, ви можете встановити fieldPath на ".testMap.foo" або .testMap['foo']'. Якщо для перевірки потрібно перевірити унікальні атрибути у двох списках, fieldPath можна встановити для будь-якого зі списків. Наприклад, його можна встановити на .testList1 або .testList2. Наразі підтримується дочірня операція для посилання на існуюче поле. Для отримання додаткової інформації див. Підтримка JSONPath у Kubernetes. Поле fieldPath не підтримує індексування масивів числовими значеннями.
Встановлення fieldPath є необовʼязковим.
Поле optionalOldSelf
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [stable](стандартно увімкнено)
Якщо у вашому кластері не включено проковзування перевірки CRD, API визначення власного ресурсу не містить цього поля, і спроба встановити його може призвести
до помилки.
Поле optionalOldSelf є булевим полем, яке змінює поведінку Правил переходу, описаних нижче. Зазвичай правило переходу не оцінюється, якщо oldSelf не може бути визначено: під час створення обʼєкта або коли нове значення вводиться під час оновлення.
Якщо optionalOldSelf встановлено в true, тоді правила переходу завжди будуть оцінюватися, і тип oldSelf буде змінено на тип CEL Optional.
optionalOldSelf корисно в тих випадках, коли автори схеми хочуть мати більше інструментів керування ніж надається за стандартно на основі рівності, щоб ввести нові, зазвичай строгіші обмеження на нові значення, зазвичай більш жорсткі для нових значень, але все ще дозволяючи те, що старі значення можуть бути пропущені з використанням старих правил.
Проковзування правила. Якщо значення має значення «foo», воно повинно залишатися foo. Але якщо воно існувало до того, як було введено обмеження «foo», воно може використовувати будь-яке значення
Правило, яке містить вираз з посиланням на ідентифікатор oldSelf, неявно вважається правилом переходу. Правила переходу дозволяють авторам схеми запобігати певним переходам між двома в іншому випадку допустимими станами. Наприклад:
type:stringenum:["low","medium","high"]x-kubernetes-validations:- rule:"!(self == 'high' && oldSelf == 'low') && !(self == 'low' && oldSelf == 'high')"message:не можна переходити безпосередньо між 'low' та 'high'
На відміну від інших правил, правила переходу застосовуються тільки до операцій, що відповідають наступним критеріям:
Операція оновлює існуючий обʼєкт. Правила переходу ніколи не застосовуються до операцій створення.
Існують як старе, так і нове значення. Залишається можливим перевірити, чи було додано або вилучено значення, розмістивши правило переходу на батьківському вузлі. Правила переходу ніколи не застосовуються до створення власних ресурсів. Якщо вони розміщені в необовʼязковому полі, правило переходу не буде застосовуватися до операцій оновлення, які встановлюють або прибирають поле.
Шлях до вузла схеми, який перевіряється правилом переходу, повинен розподілятися на вузол, який може порівнюватися між старим обʼєктом і новим обʼєктом. Наприклад, елементи списку та їх нащадки (spec.foo[10].bar) не обовʼязково будуть кореліювати між існуючим обʼєктом та пізнішим оновленням того ж обʼєкта.
Помилки будуть генеруватися при записі CRD, якщо вузол схеми містить правило переходу, яке ніколи не може бути застосоване, наприклад "oldSelf не може бути використано на некорельованій частині схеми у межах path".
Правила переходу дозволені тільки для корелятивних частин схеми. Частина схеми є корелятивною, якщо всі батьківські схеми масиву мають тип x-kubernetes-list-type=map; будь-які батьківські схеми масиву типу set чи atomic роблять неможливим однозначне корелювання між self та oldSelf.
Нижче наведено кілька прикладів правил переходу:
Приклади правил переходу
Використання
Правило
Незмінність
self.foo == oldSelf.foo
Запобігання модифікації/видаленню після присвоєння
Якщо попереднє значення було X, нове значення може бути лише A або B, не Y або Z
oldSelf != 'X' || self in ['A', 'B']
Монотонні (незменшувані) лічільники
self >= oldSelf
Використання ресурсів функціями перевірки
Коли ви створюєте або оновлюєте CustomResourceDefinition, що використовує правила перевірки, API сервер перевіряє можливий вплив виконання цих правил перевірки. Якщо правило оцінюється як надмірно витратне у виконанні, API сервер відхиляє операцію створення або оновлення та повертає повідомлення про помилку. Подібна система використовується під час виконання, яка спостерігає за діями інтерпретатора. Якщо інтерпретатор виконує занадто багато інструкцій, виконання правила буде припинено, і виникне помилка. Кожен CustomResourceDefinition також має певний ліміт ресурсів для завершення виконання всіх своїх правил перевірки. Якщо сумарна оцінка всіх правил перевищує цей ліміт під час створення, то також виникне помилка перевірки.
Ймовірність виникнення проблем з ресурсним бюджетом перевірки низька, якщо ви лише зазначаєте правила, які завжди займають однакову кількість часу незалежно від розміру вхідних даних. Наприклад, правило, яке стверджує, що self.foo == 1, само по собі не має ризику відхилення через ресурсний бюджет перевірки. Але якщо foo є рядком і ви визначаєте правило перевірки self.foo.contains("someString"), то це правило займає довше часу на виконання в залежності від довжини foo. Інший приклад: якщо foo є масивом, і ви вказали правило перевірки self.foo.all(x, x > 5). Система оцінки завжди припускає найгірший сценарій, якщо не вказано ліміт на довжину foo, і це буде стосуватися будь-якого обʼєкта, який можна ітерувати (списки, мапи тощо).
Через це, вважається найкращою практикою встановлювати ліміт через maxItems, maxProperties і maxLength для будь-якого обʼєкта, який обробляється в правилі перевірки, щоб уникнути помилок перевірки під час оцінки витрат. Наприклад, якщо є наступна схема з одним правилом:
то API сервер відхилить це правило через бюджет перевірки з помилкою:
spec.validation.openAPIV3Schema.properties[spec].properties[foo].x-kubernetes-validations[0].rule: Forbidden:
CEL rule exceeded budget by more than 100x (try simplifying the rule, or adding maxItems, maxProperties, and
maxLength where arrays, maps, and strings are used)
Відхилення відбувається тому, що self.all передбачає виклик contains() для кожного рядка у foo, що в свою чергу перевіряє, чи містить даний рядок 'a string'. Без обмежень, це дуже витратне правило.
Якщо ви не вказуєте жодного ліміту перевірки, оцінена вартість цього правила перевищить ліміт вартості для одного правила. Але якщо додати обмеження в потрібні місця, правило буде дозволено:
Система оцінки витрат враховує кількість разів, коли правило буде виконане, крім оціненої вартості самого правила. Наприклад, наступне правило матиме таку ж оцінену вартість, як і попередній приклад (незважаючи на те, що правило тепер визначено для окремих елементів масиву):
Якщо у списку всередині іншого списку є правило перевірки, яке використовує self.all, це значно дорожче, ніж правило для не вкладеного списку. Правило, яке було б дозволено для не вкладеного списку, може потребувати нижчих обмежень для обох вкладених списків, щоб бути дозволеним. Наприклад, навіть без встановлення обмежень, наступне правило дозволено:
openAPIV3Schema:type:objectproperties:foo:type:arrayitems:type:integerx-kubernetes-validations:- rule:"self.all(x, x == 5)"
Але те саме правило для наступної схеми (з доданим вкладеним масивом) викликає помилку перевірки:
openAPIV3Schema:type:objectproperties:foo:type:arrayitems:type:arrayitems:type:integerx-kubernetes-validations:- rule:"self.all(x, x == 5)"
Це тому, що кожен елемент foo сам є масивом, і кожен підмасив викликає self.all. Уникайте вкладених списків і map, якщо це можливо, де використовуються правила перевірки.
Встановлення станадартних значень
Примітка:
Щоб використовувати встановлення стандартних значень, ваш CustomResourceDefinition повинен використовувати версію API apiextensions.k8s.io/v1.
apiVersion:apiextensions.k8s.io/v1kind:CustomResourceDefinitionmetadata:name:crontabs.stable.example.comspec:group:stable.example.comversions:- name:v1served:truestorage:trueschema:# openAPIV3Schema це схема для перевірки власних обʼєктів.openAPIV3Schema:type:objectproperties:spec:type:objectproperties:cronSpec:type:stringpattern:'^(\d+|\*)(/\d+)?(\s+(\d+|\*)(/\д+)?){4}$'default:"5 0 * * *"image:type:stringreplicas:type:integerminimum:1maximum:10default:1scope:Namespacednames:plural:crontabssingular:crontabkind:CronTabshortNames:- ct
Таким чином, і cronSpec, і replicas будуть мати стандартні значення:
Встановлення стандартних значень відбувається на обʼєкті
в запиті до API сервера з використанням стандартних значень версії запиту,
під час читання з etcd з використанням стандартних значень версії зберігання,
після втулків для мутаційного допуску з невипадковими змінами з використанням стандартних значень версії веб-хука допуску.
Стандартне значення, застосовані під час читання даних з etcd, автоматично не записуються назад у etcd. Потрібен запит на оновлення через API для збереження цих стандартних значень у etcd.
Стандартні значення для невкладених полів мають бути обрізані (за винятком стандартних значень полів metadata) та відповідати схемі перевірки. Наприклад, у наведеному вище прикладі, стандартне значення {"replicas": "foo", "badger": 1} для поля spec буде недійсним, оскільки badger є невідомим полем, а replicas не є рядком.
Стандартні значення полів metadata вузлів x-kubernetes-embedded-resources: true (або частин типових значень з metadata) не будуть обрізані під час створення CustomResourceDefinition, але будуть обрізані під час оброки запитів.
Стандартні значення та nullable
Значення null для полів, які або не вказують прапорець nullable, або задають його значення як false, будуть видалені до того, як буде застосовано стандартне значення. Якщо стандартне значення присутнє, воно буде застосоване. Коли nullable дорівнює true, значення null будуть збережені і не будуть змінені на стандартні значення.
створення обʼєкта зі значеннями null для foo, bar і baz:
spec:foo:nullbar:nullbaz:null
призведе до
spec:foo:"default"bar:null
де foo буде обрізане та встановлене стандартне значення, оскільки поле є ненульовим, bar залишиться зі значенням null через nullable: true, а baz буде видалено, оскільки поле є ненульовим і не має стандартного значення.
Публікація схеми валідації в OpenAPI
Схеми валідації OpenAPI v3 CustomResourceDefinition, які є структурованими та дозволяють обрізку, публікуються як OpenAPI v3 та OpenAPI v2 з сервера API Kubernetes. Рекомендується використовувати документ OpenAPI v3, оскільки він є представленням схеми валідації OpenAPI v3 для CustomResourceDefinition без втрат, тоді як OpenAPI v2 представляє перетворення з втратами.
Kubectl використовує опубліковану схему для виконання клієнтської валідації (kubectl create та kubectl apply), пояснення схеми (kubectl explain) для власних ресурсів. Опублікована схема також може бути використана для інших цілей, таких як генерація клієнтів або документації.
Сумісність з OpenAPI V2
Для сумісності з OpenAPI V2, схема валідації OpenAPI v3 виконує перетворення з втратамиу схему OpenAPI v2. Схема зʼявляється в полях definitions та paths у специфікації OpenAPI v2.
Під час перетворення застосовуються наступні зміни для збереження зворотної сумісності з kubectl версії 1.13. Ці зміни запобігають занадто строгій роботі kubectl та відхиленню дійсних схем OpenAPI, які він не розуміє. Перетворення не змінює схему валідації, визначену в CRD, і тому не впливає на валідацію на сервері API.
Наступні поля видаляються, оскільки вони не підтримуються OpenAPI v2:
Поля allOf, anyOf, oneOf та not видаляються
Якщо встановлено nullable: true, ми видаляємо type, nullable, items та properties, оскільки OpenAPI v2 не може відобразити nullable. Це необхідно для того, щоб kubectl не відхиляв правильні обʼєкти.
Додаткові колонки виводу
Інструмент kubectl покладається на форматування виводу на стороні сервера. Сервер API вашого кластера вирішує, які колонки показуються командою kubectl get. Ви можете налаштувати ці колонки для CustomResourceDefinition. Наступний приклад додає колонки Spec, Replicas та Age.
Збережіть CustomResourceDefinition у файл resourcedefinition.yaml:
apiVersion:apiextensions.k8s.io/v1kind:CustomResourceDefinitionmetadata:name:crontabs.stable.example.comspec:group:stable.example.comscope:Namespacednames:plural:crontabssingular:crontabkind:CronTabshortNames:- ctversions:- name:v1served:truestorage:trueschema:openAPIV3Schema:type:objectproperties:spec:type:objectproperties:cronSpec:type:stringimage:type:stringreplicas:type:integeradditionalPrinterColumns:- name:Spectype:stringdescription:The cron spec defining the interval a CronJob is runjsonPath:.spec.cronSpec- name:Replicastype:integerdescription:The number of jobs launched by the CronJobjsonPath:.spec.replicas- name:Agetype:datejsonPath:.metadata.creationTimestamp
Створіть CustomResourceDefinition:
kubectl apply -f resourcedefinition.yaml
Створіть екземпляр, використовуючи my-crontab.yaml з попереднього розділу.
Викличте вивід на стороні сервера:
kubectl get crontab my-new-cron-object
Зверніть увагу на колонки NAME, SPEC, REPLICAS та AGE у виводі:
NAME SPEC REPLICAS AGE
my-new-cron-object * * * * * 1 7s
Примітка:
Колонка NAME є неявною і не потребує визначення в CustomResourceDefinition.
Пріоритет
Кожна колонка включає поле priority. Наразі пріоритет розрізняє стовпці, що показуються у стандартному вигляді або в розгорнутому (за допомогою прапорця -o wide).
Колонки з пріоритетом 0 показані у стандартному вигляді.
Колонки з пріоритетом більшим за 0 показані тільки у широкому (wide) вигляді.
date — виводиться диференційовано як час, що минув від цієї мітки.
Якщо значення всередині CustomResource не відповідає типу, зазначеному для колонки, значення буде пропущено. Використовуйте валідацію CustomResource, щоб переконатися, що типи значень правильні.
Формат
Поле format колонки може бути одним з наступних:
int32
int64
float
double
byte
date
date-time
password
Поле format колонки контролює стиль, який використовується при виводі значення за допомогою kubectl.
Селектори полів
Селектори полів дозволяють клієнтам вибирати власні ресурси на основі значення одного або декількох полів ресурсу.
Усі власні ресурси підтримують вибір полів metadata.name та metadata.namespace.
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.32 [stable](стандартно увімкнено)
Поле spec.versions[*].selectableFields у CustomResourceDefinition може бути використане для оголошення, які інші поля у власному ресурсі можуть бути використані у селекторах полів з функціональною можливісюьCustomResourceFieldSelectors (Ця функція є стандартно увімкненою з Kubernetes v1.31). Ось приклад, який додає поля .spec.color та .spec.size як доступні для вибору.
Збережіть CustomResourceDefinition у файл shirt-resource-definition.yaml:
NAME COLOR SIZE
example1 blue S
example2 blue M
example3 green M
Отримайте сорочки синього кольору (отримайте сорочки у яких color має значення blue):
kubectl get shirts.stable.example.com --field-selector spec.color=blue
Повинен зʼявитися такий вивід:
NAME COLOR SIZE
example1 blue S
example2 blue M
Отримайте лише ресурси з кольором green та розміром M:
kubectl get shirts.stable.example.com --field-selector spec.color=green,spec.size=M
Повинен зʼявитися такий вивід:
NAME COLOR SIZE
example2 blue M
Субресурси
Власні ресурси підтримують субресурси /status та /scale.
Субресурси status та scale можна опціонально увімкнути, визначивши їх у CustomResourceDefinition.
Субресурс Status
Коли субресурс статусу увімкнено, субресурс /status для власного ресурсу буде доступним.
Стани status та spec представлені відповідно за допомогою JSONPath .status та .spec всередині власного ресурсу.
Запити PUT до субресурсу /status приймають обʼєкт власного ресурсу і ігнорують зміни до будь-чого, крім стану status.
Запити PUT до субресурсу /status лише перевіряють стан status власного ресурсу.
Запити PUT/POST/PATCH до власного ресурсу ігнорують зміни до стану status.
Значення .metadata.generation збільшується для всіх змін, за винятком змін у .metadata або .status.
У корені схеми валідації OpenAPI CRD дозволяються тільки такі конструкції:
description
example
exclusiveMaximum
exclusiveMinimum
externalDocs
format
items
maximum
maxItems
maxLength
minimum
minItems
minLength
multipleOf
pattern
properties
required
title
type
uniqueItems
Субресурс Scale
Коли субресурс масштабу увімкнено, субресурс /scale для власного ресурсу буде доступним.
Обʼєкт autoscaling/v1.Scale надсилається як навантаження для /scale.
Для увімкнення субресурсу масштабу наступні поля визначаються в CustomResourceDefinition.
specReplicasPath визначає JSONPath всередині власного ресурсу, що відповідає scale.spec.replicas.
Це обовʼязкове значення.
Дозволяються тільки JSONPath під .spec і з позначенням через крапку.
Якщо у власному ресурсі немає значення під specReplicasPath, субресурс /scale поверне помилку при GET запиті.
statusReplicasPath визначає JSONPath всередині власного ресурсу, що відповідає scale.status.replicas.
Це обовʼязкове значення.
Дозволяються тільки JSONPath під .status і з позначенням через крапку.
Якщо у власному ресурсі немає значення під statusReplicasPath, значення репліки статусу у субресурсі /scale стандартно дорівнюватиме 0.
labelSelectorPath визначає JSONPath всередині власного ресурсу, що відповідає
Scale.Status.Selector.
Це необовʼязкове значення.
Воно повинно бути встановлено для роботи з HPA та VPA.
Дозволяються тільки JSONPath під .status або .spec і з позначенням через крапку.
Якщо у власному ресурсі немає значення під labelSelectorPath, значення селектора статусу у субресурсі /scale стандартно буде порожнім рядком.
Поле, на яке вказує цей JSONPath, повинно бути рядковим полем (не комплексним селектором), що містить серіалізований селектор міток у вигляді рядка.
У наступному прикладі увімкнено обидва субресурси: статусу та масштабу.
Збережіть CustomResourceDefinition у файл resourcedefinition.yaml:
apiVersion:apiextensions.k8s.io/v1kind:CustomResourceDefinitionmetadata:name:crontabs.stable.example.comspec:group:stable.example.comversions:- name:v1served:truestorage:trueschema:openAPIV3Schema:type:objectproperties:spec:type:objectproperties:cronSpec:type:stringimage:type:stringreplicas:type:integerstatus:type:objectproperties:replicas:type:integerlabelSelector:type:string# subresources описує субресурси для власних ресурсів.subresources:# status увімкнення субресурсу статусу.status:{}# scale увімкнення субресурсу масштабу.scale:# specReplicasPath визначає JSONPath всередині власного ресурсу, що відповідає Scale.Spec.Replicas.specReplicasPath:.spec.replicas# statusReplicasPath визначає JSONPath всередині власного ресурсу, що відповідає Scale.Status.Replicas.statusReplicasPath:.status.replicas# labelSelectorPath визначає JSONPath всередині власного ресурсу, що відповідає Scale.Status.Selector.labelSelectorPath:.status.labelSelectorscope:Namespacednames:plural:crontabssingular:crontabkind:CronTabshortNames:- ct
І створіть його:
kubectl apply -f resourcedefinition.yaml
Після створення обʼєкта CustomResourceDefinition, ви можете створювати власні обʼєкти.
Якщо ви збережете наступний YAML у файл my-crontab.yaml:
Власний ресурс можна масштабувати за допомогою команди kubectl scale. Наприклад, наступна команда встановлює .spec.replicas власного ресурсу, створеного вище, до 5:
Ви можете використовувати PodDisruptionBudget, щоб захистити власні ресурси, які мають увімкнений субресурс масштабу.
Категорії
Категорії — це список групованих ресурсів, до яких належить власний ресурс (наприклад, all). Ви можете використовувати kubectl get <category-name>, щоб вивести список ресурсів, що належать до категорії.
Наступний приклад додає all у список категорій у CustomResourceDefinition та ілюструє, як вивести власний ресурс за допомогою kubectl get all.
Збережіть наступний CustomResourceDefinition у файл resourcedefinition.yaml:
apiVersion:apiextensions.k8s.io/v1kind:CustomResourceDefinitionmetadata:name:crontabs.stable.example.comspec:group:stable.example.comversions:- name:v1served:truestorage:trueschema:openAPIV3Schema:type:objectproperties:spec:type:objectproperties:cronSpec:type:stringimage:type:stringreplicas:type:integerscope:Namespacednames:plural:crontabssingular:crontabkind:CronTabshortNames:- ct# categories - це список групованих ресурсів, до яких належить власний ресурс.categories:- all
і створіть його:
kubectl apply -f resourcedefinition.yaml
Після створення обʼєкта CustomResourceDefinition, ви можете створювати власні обʼєкти.
Обслуговуйте кілька версій CustomResourceDefinition.
11.1.2 - Версії у CustomResourceDefinitions
Ця сторінка пояснює, як додати інформацію про версії до CustomResourceDefinitions, щоб вказати рівень стабільності ваших CustomResourceDefinitions або перейти на нову версію з конвертацією між представленнями API. Також описується, як оновити обʼєкт з однієї версії до іншої.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.16.
Для перевірки версії введіть kubectl version.
Огляд
API CustomResourceDefinition надає робочий процес для впровадження та оновлення нових версій CustomResourceDefinition.
Коли створюється CustomResourceDefinition, перша версія встановлюється в списку spec.versions CustomResourceDefinition на відповідний рівень стабільності та номер версії. Наприклад, v1beta1 буде вказувати, що перша версія ще не стабільна. Всі обʼєкти власних ресурсів спочатку будуть зберігатися в цій версії.
Після створення CustomResourceDefinition, клієнти можуть почати використовувати API v1beta1.
Пізніше може знадобитися додати нову версію, наприклад v1.
Додавання нової версії:
Виберіть стратегію конвертації. Оскільки обʼєкти власних ресурсів повинні мати можливість обслуговуватися в обох версіях, це означає, що вони іноді будуть обслуговуватися у версії, відмінній від тієї, в якій зберігаються. Для цього іноді потрібно конвертувати обʼєкти власних ресурсів між версією, в якій вони зберігаються, та версією, в якій вони обслуговуються. Якщо конвертація передбачає зміни схеми та вимагає власної логіки, слід використовувати конвертаційний webhook. Якщо змін схеми немає, можна використовувати стратегію конвертації None, і при обслуговуванні різних версій буде змінено лише поле apiVersion.
Якщо використовуються конвертаційні webhook'и, створіть і розгорніть конвертаційний webhook. Див. Конвертація через webhook для отримання більш детальної інформації.
Оновіть CustomResourceDefinition, включивши нову версію в список spec.versions з served:true. Також встановіть поле spec.conversion на вибрану стратегію конвертації. Якщо використовується конвертаційний webhook, налаштуйте поле spec.conversion.webhookClientConfig для виклику webhook.
Після додавання нової версії клієнти можуть поступово перейти на нову версію. Цілком безпечно для деяких клієнтів використовувати стару версію, тоді як інші використовують нову версію.
Клієнти можуть безпечно використовувати як стару, так і нову версію до, під час і після оновлення обʼєктів до нової збереженої версії.
Видалення старої версії:
Переконайтеся, що всі клієнти повністю перейшли на нову версію. Логи kube-apiserver можна переглянути для виявлення клієнтів, які все ще використовують стару версію.
Встановіть served на false для старої версії в списку spec.versions. Якщо якісь клієнти все ще несподівано використовують стару версію, вони можуть почати повідомляти про помилки при спробі доступу до обʼєктів власних ресурсів у старій версії. У такому випадку поверніться до використання served:true на старій версії, мігруйте залишкових клієнтів на нову версію та повторіть цей крок.
Перевірте, що storage встановлено на true для нової версії в списку spec.versions в CustomResourceDefinition.
Перевірте, що стара версія більше не згадується в status.storedVersions CustomResourceDefinition.
Видаліть стару версію зі списку spec.versions CustomResourceDefinition.
Припиніть підтримку конвертації для старої версії в конвертаційних webhook'ах.
Зазначення кількох версій
Поле versions в CustomResourceDefinition API може бути використане для підтримки кількох версій розроблених вами власних ресурсів. Версії можуть мати різні схеми, а конвертаційні webhook'и можуть конвертувати власні ресурси між версіями. Конвертації через webhook повинні дотримуватися конвенцій Kubernetes API в тих випадках, де це застосовується. Зокрема, дивіться документацію по змінах API для набору корисних порад та рекомендацій.
Примітка:
У apiextensions.k8s.io/v1beta1 було поле version замість versions. Поле version є застарілим і необовʼязковим, але якщо воно не пусте, воно повинно відповідати першому елементу у полі versions.
У цьому прикладі показано CustomResourceDefinition з двома версіями. У першому прикладі припускається, що всі версії мають однакову схему без конвертації між ними. У YAML-файлах наведено коментарі, які надають додатковий контекст.
apiVersion:apiextensions.k8s.io/v1kind:CustomResourceDefinitionmetadata:# назва повинна відповідати полям spec нижче, і бути у формі: <plural>.<group>name:crontabs.example.comspec:# імʼя групи, яке буде використовуватися для REST API: /apis/<group>/<version>group:example.com# список версій, підтримуваних цим CustomResourceDefinitionversions:- name:v1beta1# Кожна версія може бути увімкнена/вимкнена прапорцем Served.served:true# Лише одна версія повинна бути позначена як версія зберігання.storage:true# Схема обовʼязковаschema:openAPIV3Schema:type:objectproperties:host:type:stringport:type:string- name:v1served:truestorage:falseschema:openAPIV3Schema:type:objectproperties:host:type:stringport:type:string# Секція конвертації була введена в Kubernetes 1.13+ зі стандартним значенням# конвертації None (стратегії встановленя субполів None).conversion:# Конвертація None передбачає ту ж саму схему для всіх версій, і лише встановлює apiVersion# поле власних ресрів у відповідне значенняstrategy:None# або Namespaced або Clusterscope:Namespacednames:# plural, назва ресрусу в що використовується в URL: /apis/<group>/<version>/<plural>plural:crontabs# singular, назва ресурсу в що буде використовуватись як аліас в CLI та у виводіsingular:crontab# kind, зазвичай тип в однині в CamelCase. Ваші маніфести будуть використовувати це.kind:CronTab# shortNames, дозволяють коротше звертатися до ресурсу в CLIshortNames:- ct
# Застаріло у версії v1.16 на користь apiextensions.k8s.io/v1apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinitionmetadata:# імʼя має збігатися з полями spec нижче і бути у формі: <plural>.<group>name:crontabs.example.comspec:# імʼя групи для використання в REST API: /apis/<group>/<version>group:example.com# список версій, які підтримуються цим CustomResourceDefinitionversions:- name:v1beta1# Кожна версія може бути увімкненна/вимкнена за допомогою прапорця Served.served:true# Лише одна версія повинна бути позначена як версія зберігання.storage:true- name:v1served:truestorage:falsevalidation:openAPIV3Schema:type:objectproperties:host:type:stringport:type:string# Розділ конвертації введений у Kubernetes 1.13+ зі стандартним значенням конвертації# None (підполе strategy встановлено на None).conversion:# None конфертація передбачає однакову схему для всіх версій і лише встановлює поле apiVersion# власних ресурсів у правильне значенняstrategy:None# або Namespaced, або Clusterscope:Namespacednames:# plural, назва ресрусу в що використовується в URL: /apis/<group>/<version>/<plural>plural:crontabs# singular, назва ресурсу в що буде використовуватись як аліас в CLI та у виводіsingular:crontab# kind, зазвичай тип в однині в PascalCased. Ваші маніфести будуть використовувати це.kind:CronTab# shortNames, дозволяють коротше звертатися до ресурсу в CLIshortNames:- ct
Ви можете зберегти CustomResourceDefinition у YAML-файлі, а потім використати kubectl apply, щоб створити його.
kubectl apply -f my-versioned-crontab.yaml
Після створення API-сервер починає обслуговувати кожну включену версію за HTTP REST-точкою доступу. У наведеному вище прикладі, версії API доступні за адресами /apis/example.com/v1beta1 та /apis/example.com/v1.
Пріоритет версії
Незалежно від порядку, в якому версії визначені в CustomResourceDefinition, версія з найвищим пріоритетом використовується kubectl як стандартна версія для доступу до обʼєктів. Пріоритет визначається шляхом аналізу поля name для визначення номера версії, стабільності (GA, Beta або Alpha) та послідовності в межах цього рівня стабільності.
Алгоритм, який використовується для сортування версій, розроблений для сортування версій таким же чином, як проєкт Kubernetes сортує версії Kubernetes. Версії починаються з v, за яким слідує число, опціональне позначення beta або alpha, та опціональна додаткова числова інформація про версію. В загальному вигляді рядок версії може виглядати як v2 або v2beta1. Версії сортуються за таким алгоритмом:
Записи, що відповідають шаблонам версій Kubernetes, сортуються перед тими, що не відповідають шаблонам.
Для записів, що відповідають шаблонам версій Kubernetes, числові частини рядка версії сортуються від більшого до меншого.
Якщо після першої числової частини йдуть рядки beta або alpha, вони сортуються в такому порядку після еквівалентного рядка без суфікса beta або alpha (який вважається GA версією).
Якщо після beta або alpha йде ще одне число, ці числа також сортуються від більшого до меншого.
Рядки, що не відповідають зазначеному формату, сортуються за алфавітом, і числові частини не мають спеціального порядку. Зауважте, що в наведеному нижче прикладі foo1 сортується вище за foo10. Це відрізняється від сортування числових частин записів, що відповідають шаблонам версій Kubernetes.
Це може бути зрозуміло, якщо подивитися на наступний відсортований список версій:
Для прикладу у розділі Зазначення кількох версій, порядок сортування версій — v1, за яким слідує v1beta1. Це змушує команду kubectl використовувати v1 як стандартну версію, якщо у наданому обʼєкті не вказано версію.
Застарівання версій
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.19 [stable]
Починаючи з версії v1.19, CustomResourceDefinition може вказувати, що певна версія ресурсу, який він визначає, є застарілою. Коли API-запити до застарілої версії цього ресурсу здійснюються, у відповідь API повертається попереджувальне повідомлення в заголовку. Попереджувальне повідомлення для кожної застарілої версії ресурсу можна налаштувати за бажанням.
Налаштоване попереджувальне повідомлення повинно вказувати застарілу API-групу, версію та тип (kind), і, якщо це можливо, вказувати, яку API-групу, версію та тип слід використовувати замість цього.
apiVersion:apiextensions.k8s.io/v1kind:CustomResourceDefinitionname:crontabs.example.comspec:group:example.comnames:plural:crontabssingular:crontabkind:CronTabscope:Namespacedversions:- name:v1alpha1served:truestorage:false# Це вказує, що версія v1alpha1 власного ресурсу є застарілою.# API-запити до цієї версії отримують попереджувальний заголовок у відповіді сервера.deprecated:true# Це перевизначає стандартне попереджувальне повідомлення, яке повертається клієнтам API, що здійснюють запити до v1alpha1.deprecationWarning:"example.com/v1alpha1 CronTab застарілий; див. http://example.com/v1alpha1-v1 для інструкцій щодо переходу на example.com/v1 CronTab"schema:...- name:v1beta1served:true# Це вказує, що версія v1beta1 власного ресурсу є застарілою.# API-запити до цієї версії отримують попереджувальний заголовок у відповіді сервера.# Стандартне попереджувальне повідомлення повертається для цієї версії.deprecated:trueschema:...- name:v1served:truestorage:trueschema:...
# Застаріло у v1.16 на користь apiextensions.k8s.io/v1apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinitionmetadata:name:crontabs.example.comspec:group:example.comnames:plural:crontabssingular:crontabkind:CronTabscope:Namespacedvalidation:...versions:- name:v1alpha1served:truestorage:false# Це вказує, що версія v1alpha1 власного ресурсу є застарілою.# API-запити до цієї версії отримують попереджувальний заголовок у відповіді сервера.deprecated:true# Це перевизначає стандартне попереджувальне повідомлення, яке повертається клієнтам API, що здійснюють запити до v1alpha1.deprecationWarning:"example.com/v1alpha1 CronTab застарілий; див. http://example.com/v1alpha1-v1 для інструкцій щодо переходу на example.com/v1 CronTab"- name:v1beta1served:true# Це вказує, що версія v1beta1 власного ресурсу є застарілою.# API-запити до цієї версії отримують попереджувальний заголовок у відповіді сервера.# Стандартне попереджувальне повідомлення повертається для цієї версії.deprecated:true- name:v1served:truestorage:true
Видалення версії
Стара версія API не може бути видалена з маніфесту CustomResourceDefinition, доки наявні збережені дані не будуть мігровані до новішої версії API для всіх кластерів, які обслуговували стару версію власного ресурсу, та поки стара версія не буде видалена зі списку status.storedVersions у CustomResourceDefinition.
apiVersion:apiextensions.k8s.io/v1kind:CustomResourceDefinitionname:crontabs.example.comspec:group:example.comnames:plural:crontabssingular:crontabkind:CronTabscope:Namespacedversions:- name:v1beta1# Це вказує, що версія v1beta1 власного ресурсу більше не обслуговується.# API-запити до цієї версії отримують помилку "не знайдено" у відповіді сервера.served:falseschema:...- name:v1served:true# Нова версія, що обслуговується повинна бути встановлена як версія зберіганняstorage:trueschema:...
Конвертація за допомогою вебхука
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.16 [stable]
Примітка:
Конвертація за допомогою вебхука доступна як бета-версія з версії 1.15, і як альфа-версія з Kubernetes 1.13. Функція CustomResourceWebhookConversion повинна бути увімкнена, що автоматично відбувається для багатьох кластерів з бета-функціями. Будь ласка, зверніться до документації функціональні можливості для отримання додаткової інформації.
Наведений вище приклад має None-конвертацію між версіями, яка лише встановлює поле apiVersion під час конвертації та не змінює решту обʼєкта. API-сервер також підтримує конвертації за допомогою вебхука, які викликають зовнішній сервіс у випадку, коли потрібна конвертація. Наприклад, коли:
власний ресурс запитується у версії, яка відрізняється від збереженої версії.
створюється спостереження (Watch) в одній версії, але змінений обʼєкт зберігається в іншій версії.
запит на PUT для власного ресурсу здійснюється в іншій версії, ніж версія зберігання.
Щоб охопити всі ці випадки та оптимізувати конвертацію за допомогою API-сервера, запити на конвертацію можуть містити кілька обʼєктів з метою мінімізації зовнішніх викликів. Вебхук повинен виконувати ці конвертації незалежно.
Написання сервера для конвертації за допомогою вебхука
Будь ласка, зверніться до реалізації сервера вебхука для конвертації власних ресурсів, який проходить перевірку в e2e тесті Kubernetes. Вебхук обробляє запити ConversionReview, що надсилаються API-серверами, і надсилає назад результати конвертації, загорнуті в ConversionResponse. Зверніть увагу, що запит містить список власних ресурсів, які потрібно конвертувати незалежно, не змінюючи порядок обʼєктів. Приклад сервера організований таким чином, щоб його можна було повторно використовувати для інших конвертацій. Більшість загального коду знаходиться у файлі фреймворку, залишаючи лише одну функцію для реалізації різних конвертацій.
Примітка:
Приклад сервера вебхука для конвертації залишає поле ClientAuthпорожнім, що стандартно встановлюється в NoClientCert. Це означає, що сервер вебхука не автентифікує особу клієнтів, ймовірно API-серверів. Якщо вам потрібен взаємний TLS або інші способи автентифікації клієнтів, дивіться, як автентифікувати API-сервери.
Допустимі зміни
Вебхук для конвертації не повинен змінювати нічого в полі metadata обʼєкта, окрім labels та annotations. Спроби змінити name, UID та namespace відхиляються і призводять до помилки запиту, що спричинив конвертацію. Усі інші зміни ігноруються.
Розгортання сервера вебхука для конвертації
Документація для розгортання вебхука для конвертації аналогічна документації для прикладу сервісу вебхука для допуску. Наступні секції передбачають, що сервер вебхука для конвертації розгорнутий як сервіс з іменем example-conversion-webhook-server у просторі імен default та обслуговує трафік за шляхом /crdconvert.
Примітка:
Коли сервер вебхука розгорнуто в кластер Kubernetes як сервіс, він має бути доступний через сервіс на порту 443 (сам сервер може використовувати довільний порт, але обʼєкт сервісу повинен зіставити його з портом 443). Комунікація між API-сервером і сервісом вебхука може не вдатися, якщо використовується інший порт для сервісу.
Налаштування CustomResourceDefinition для використання вебхуків конвертації
Приклад None конвертації можна розширити для використання вебхука конвертації, змінивши розділ conversion в розділі spec:
apiVersion:apiextensions.k8s.io/v1kind:CustomResourceDefinitionmetadata:# імʼя повинно відповідати полям spec нижче, і мати форму: <plural>.<group>name:crontabs.example.comspec:# назва групи, яку використовувати для REST API: /apis/<group>/<version>group:example.com# список версій, які підтримуються цим CustomResourceDefinitionversions:- name:v1beta1# Кожну версію можна увімкнути/вимкнути за допомогою прапорця Served.served:true# Одна і тільки одна версія повинна бути позначена як версія для зберігання.storage:true# Кожна версія може визначити свою власну схему, коли немає визначеної схеми верхнього рівня.schema:openAPIV3Schema:type:objectproperties:hostPort:type:string- name:v1served:truestorage:falseschema:openAPIV3Schema:type:objectproperties:host:type:stringport:type:stringconversion:# стратегія Webhook інструктує сервер API викликати зовнішній вебхук для будь-якої конвертації між власними ресурсами.strategy:Webhook# вебхук необхідний, коли стратегія - `Webhook`, і він налаштовує точку доступу вебхука для виклику сервером API.webhook:# conversionReviewVersions вказує, які версії ConversionReview розуміються/надається перевага вебхуком.# Перша версія у списку, яку розуміє сервер API, надсилається до вебхуку.# Вебхук повинен відповісти обʼєктом ConversionReview в тій самій версії, що й отримана.conversionReviewVersions:["v1","v1beta1"]clientConfig:service:namespace:defaultname:example-conversion-webhook-serverpath:/crdconvertcaBundle:"Ci0tLS0tQk...<base64-encoded PEM bundle>...tLS0K"# або Namespaced, або Clusterscope:Namespacednames:# plural, назва ресурсу в що використовується в URL: /apis/<group>/<version>/<plural>plural:crontabs# singular, назва ресурсу в що буде використовуватись як аліас в CLI та у виводіsingular:crontab# kind, зазвичай тип в однині в CamelCased. Ваші маніфести будуть використовувати це.kind:CronTab# shortNames, дозволяють коротше звертатися до ресурсу в CLIshortNames:- ct
# Застаріло у v1.16 на користь apiextensions.k8s.io/v1apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinitionmetadata:# імʼя повинно відповідати полям spec нижче, і мати форму: <plural>.<group>name:crontabs.example.comspec:# назва групи, яку використовувати для REST API: /apis/<group>/<version>group:example.com# обрізає поля обʼєктів, які не вказані у схемах OpenAPI нижче.preserveUnknownFields:false# список версій, які підтримуються цим CustomResourceDefinitionversions:- name:v1beta1# Кожну версію можна включити/вимкнути за допомогою прапорця Served.served:true# Одна і тільки одна версія повинна бути позначена як версія зберігання.storage:true# Кожна версія може визначити свою власну схему, коли немає визначеної схеми верхнього рівня.schema:openAPIV3Schema:type:objectproperties:hostPort:type:string- name:v1served:truestorage:falseschema:openAPIV3Schema:type:objectproperties:host:type:stringport:type:stringconversion:# стратегія Webhook інструктує сервер API викликати зовнішній вебхук для будь-якої конвертації між власними ресурсами.strategy:Webhook# webhookClientConfig необхідний, коли стратегія - `Webhook`, і він налаштовує точку доступу вебхука для виклику сервером API.webhookClientConfig:service:namespace:defaultname:example-conversion-webhook-serverpath:/crdconvertcaBundle:"Ci0tLS0tQk...<base64-encoded PEM bundle>...tLS0K"# або Namespaced, або Clusterscope:Namespacednames:# plural, назва ресурсу в що використовується в URL: /apis/<group>/<version>/<plural>plural:crontabs# singular, назва ресурсу в що буде використовуватись як аліас в CLI та у виводіsingular:crontab# kind, зазвичай тип в однині в CamelCased. Ваші маніфести будуть використовувати це.kind:CronTab# shortNames, дозволяють коротше звертатися до ресурсу в CLIshortNames:- ct
Ви можете зберегти опис CustomResourceDefinition у файлі YAML, а потім використовувати
kubectl apply, щоб застосувати його.
Переконайтеся, що сервіс конвертації працює, перш ніж застосовувати нові зміни.
Звʼязок з вебхуком
Після того, як сервер API визначив, що запит потрібно надіслати до вебхуку конвертації, йому потрібно знати, як звʼязатися з вебхуком. Це вказується в розділі webhookClientConfig конфігурації вебхука.
Вебхуки конвертації можуть бути викликані або через URL, або через посилання на сервіс, і можуть додатково містити власний пакет CA для перевірки TLS-зʼєднання.
URL
url вказує знаходження вебхука, у стандартній формі URL (scheme://host:port/path).
host не повинен посилатися на сервіс, що працює в кластері; використовуйте посилання на сервіс, вказавши замість цього поле service. Хост може бути вирішений через зовнішній DNS в деяких apiserver-ах (тобто kube-apiserver не може виконувати внутрішній DNS, оскільки це було б порушенням рівня). host також може бути IP-адресою.
Зверніть увагу, що використання localhost або 127.0.0.1 як host є ризикованим, якщо ви не приділяєте велику увагу тому, щоб запустити цей вебхук на всіх хостах, на яких працює apiserver, який може потребувати звернень до цього вебхука. Такі установки, швидше за все, не будуть переносними або не можуть бути легко запущені в новому кластері.
Схема повинна бути "https"; URL повинен починатися з "https://".
Спроба використання автентифікації користувача або базової автентифікації (наприклад, "user:password@") заборонена. Фрагменти ("#...") та параметри запиту ("?...") також не дозволені.
Ось приклад вебхука конвертації, налаштованого на виклик URL (і очікується, що сертифікат TLS буде перевірений за допомогою коренів довіри системи, тому не вказується caBundle):
# Застаріло у v1.16 на користь apiextensions.k8s.io/v1apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinition...spec:...conversion:strategy:WebhookwebhookClientConfig:url:"https://my-webhook.example.com:9443/my-webhook-path"...
Посилання на сервіс
Розділ service всередині webhookClientConfig є посиланням на сервіс для вебхука конвертації. Якщо вебхук працює всередині кластера, то ви повинні використовувати service замість url. Простір імен та імʼя сервісу є обовʼязковими. Порт є необовʼязковим і типово дорівнює 443. Шлях є необовʼязковим і типово дорівнює "/".
Ось приклад вебхука, який налаштований на виклик сервісу на порту "1234" з шляхом "/my-path", і для перевірки TLS-зʼєднання на ServerName my-service-name.my-service-namespace.svc з використанням власного пакету CA.
# Застаріло у v1.16 на користь apiextensions.k8s.io/v1apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinition...spec:...conversion:strategy:WebhookwebhookClientConfig:service:namespace:my-service-namespacename:my-service-namepath:/my-pathport:1234caBundle:"Ci0tLS0tQk...<base64-encoded PEM bundle>...tLS0K"...
Запити та відповіді вебхуків
Запит
Вебхуки надсилають POST-запит з Content-Type: application/json, з обʼєктом API ConversionReview з API-групи apiextensions.k8s.io, який серіалізується в JSON як тіло запиту.
Вебхуки можуть вказати, які версії обʼєктів ConversionReview вони приймають, за допомогою поля conversionReviewVersions у своїй CustomResourceDefinition:
Поле conversionReviewVersions є обовʼязковим при створенні custom resource definitions apiextensions.k8s.io/v1. Вебхуки повинні підтримувати принаймні одну версію ConversionReview, яку розуміє поточний та попередній API сервер.
# Застаріло у v1.16 на користь apiextensions.k8s.io/v1apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinition...spec:...conversion:strategy:WebhookconversionReviewVersions:["v1","v1beta1"]...
Якщо conversionReviewVersions не вказано, стандартно при створенні custom resource definitions apiextensions.k8s.io/v1beta1 використовується v1beta1.
API сервери надсилають першу версію ConversionReview у списку conversionReviewVersions, яку вони підтримують. Якщо жодна з версій у списку не підтримується API сервером, створення custom resource definition не буде дозволено. Якщо API сервер зустрічає конфігурацію вебхука конвертації, яка була створена раніше і не підтримує жодної з версій ConversionReview, які сервер може надіслати, спроби виклику вебхука завершаться невдачею.
Цей приклад показує дані, що містяться в обʼєкті ConversionReview для запиту на конверсію обʼєктів CronTab до example.com/v1:
{"apiVersion": "apiextensions.k8s.io/v1","kind": "ConversionReview","request": {# Випадковий uid, який унікально ідентифікує цей виклик конвертації"uid": "705ab4f5-6393-11e8-b7cc-42010a800002",# API група та версія, до якої повинні бути конвертовані обʼєкти"desiredAPIVersion": "example.com/v1",# Список обʼєктів для конвертації.# Може містити один або більше обʼєктів, у одній або більше версіях."objects": [{"kind": "CronTab","apiVersion": "example.com/v1beta1","metadata": {"creationTimestamp": "2019-09-04T14:03:02Z","name": "local-crontab","namespace": "default","resourceVersion": "143","uid": "3415a7fc-162b-4300-b5da-fd6083580d66"},"hostPort": "localhost:1234"},{"kind": "CronTab","apiVersion": "example.com/v1beta1","metadata": {"creationTimestamp": "2019-09-03T13:02:01Z","name": "remote-crontab","resourceVersion": "12893","uid": "359a83ec-b575-460d-b553-d859cedde8a0"},"hostPort": "example.com:2345"}]}}
{# Застаріло у v1.16 на користь apiextensions.k8s.io/v1"apiVersion": "apiextensions.k8s.io/v1beta1","kind": "ConversionReview","request": {# Випадковий uid, який унікально ідентифікує цей виклик конвертації"uid": "705ab4f5-6393-11e8-b7cc-42010a800002",# API група та версія, до якої повинні бути конвертовані обʼєкти"desiredAPIVersion": "example.com/v1",# Список обʼєктів для конвертації.# Може містити один або більше обʼєктів, у одній або більше версіях."objects": [{"kind": "CronTab","apiVersion": "example.com/v1beta1","metadata": {"creationTimestamp": "2019-09-04T14:03:02Z","name": "local-crontab","namespace": "default","resourceVersion": "143","uid": "3415a7fc-162b-4300-b5da-fd6083580d66"},"hostPort": "localhost:1234"},{"kind": "CronTab","apiVersion": "example.com/v1beta1","metadata": {"creationTimestamp": "2019-09-03T13:02:01Z","name": "remote-crontab","resourceVersion": "12893","uid": "359a83ec-b575-460d-b553-d859cedde8a0"},"hostPort": "example.com:2345"}]}}
Відповідь
Вебхуки відповідають зі статусом HTTP 200, Content-Type: application/json та тілом, що містить обʼєкт ConversionReview (у тій самій версії, у якій вони були надіслані), з заповненим розділом response, серіалізованим у JSON.
Якщо конвертація успішна, вебхук має повернути розділ response, що містить наступні поля:
uid, скопійований з request.uid, надісланого до вебхука
result, встановлений на {"status":"Success"}
convertedObjects, що містить всі обʼєкти з request.objects, конвертовані до request.desiredAPIVersion
Приклад мінімально успішної відповіді від вебхука:
{"apiVersion": "apiextensions.k8s.io/v1","kind": "ConversionReview","response": {# має збігатись з <request.uid>"uid": "705ab4f5-6393-11e8-b7cc-42010a800002","result": {"status": "Success"},# Обʼєкти мають відповідати порядку request.objects та мати apiVersion, встановлений у <request.desiredAPIVersion>.# поля kind, metadata.uid, metadata.name та metadata.namespace не повинні змінюватися вебхуком.# поля metadata.labels та metadata.annotations можуть бути змінені вебхуком.# всі інші зміни полів metadata, зроблені вебхуком, ігноруються."convertedObjects": [{"kind": "CronTab","apiVersion": "example.com/v1","metadata": {"creationTimestamp": "2019-09-04T14:03:02Z","name": "local-crontab","namespace": "default","resourceVersion": "143","uid": "3415a7fc-162b-4300-б5da-fd6083580d66"},"host": "localhost","port": "1234"},{"kind": "CronTab","apiVersion": "example.com/v1","metadata": {"creationTimestamp": "2019-09-03T13:02:01Z","name": "remote-crontab","resourceVersion": "12893","uid": "359a83ec-b575-460d-б553-d859cedde8a0"},"host": "example.com","port": "2345"}]}}
{# Застаріло у версії v1.16 на користь apiextensions.k8s.io/v1"apiVersion": "apiextensions.k8s.io/v1beta1","kind": "ConversionReview","response": {# має відповідати <request.uid>"uid": "705ab4f5-6393-11e8-б7cc-42010a800002","result": {"status": "Failed"},# Обʼєкти мають відповідати порядку request.objects та мати apiVersion, встановлений у <request.desiredAPIVersion>.# поля kind, metadata.uid, metadata.name та metadata.namespace не повинні змінюватися вебхуком.# поля metadata.labels та metadata.annotations можуть бути змінені вебхуком.# всі інші зміни полів metadata, зроблені вебхуком, ігноруються."convertedObjects": [{"kind": "CronTab","apiVersion": "example.com/v1","metadata": {"creationTimestamp": "2019-09-04T14:03:02Z","name": "local-crontab","namespace": "default","resourceVersion": "143","uid": "3415a7fc-162b-4300-б5da-fd6083580d66"},"host": "localhost","port": "1234"},{"kind": "CronTab","apiVersion": "example.com/v1","metadata": {"creationTimestamp": "2019-09-03T13:02:01Z","name": "remote-crontab","resourceVersion": "12893","uid": "359a83ec-б575-460d-б553-d859cedde8a0"},"host": "example.com","port": "2345"}]}}
Якщо конвертація не вдалася, вебхук має повернути розділ response, що містить наступні поля:
uid, скопійований з request.uid, надісланого до вебхуку
result, встановлений на {"status":"Failed"}
Попередження:
Невдала конвертація може порушити доступ для читання та запису до власних ресурсів, включаючи можливість оновлення або видалення ресурсів. Збоїв у конвертації слід уникати за будь-якої можливості, і не слід використовувати їх для забезпечення дотримання обмежень на валідацію (використовуйте схеми валідації або admission webhook).
Приклад відповіді від вебхуку, що вказує на невдачу запиту конвертації, з додатковим повідомленням:
{"apiVersion": "apiextensions.k8s.io/v1","kind": "ConversionReview","response": {"uid": "<значення з request.uid>","result": {"status": "Failed","message": "hostPort не вдалося розділити на окремі host та port"}}}
{# Застаріло у версії v1.16 на користь apiextensions.k8s.io/v1"apiVersion": "apiextensions.k8s.io/v1beta1","kind": "ConversionReview","response": {"uid": "<значення з request.uid>","result": {"status": "Failed","message": "hostPort не вдалося розділити на окремі host та port"}}}
Запис, читання та оновлення обʼєктів CustomResourceDefinition з версіями
Коли обʼєкт записується, він зберігається у версії, визначеній як версія зберігання на момент запису. Якщо версія зберігання змінюється, наявні обʼєкти ніколи не конвертуються автоматично. Проте новостворені або оновлені обʼєкти записуються у новій версії зберігання. Можливо, що обʼєкт було записано у версії, яка більше не обслуговується.
Коли ви зчитуєте обʼєкт, ви вказуєте версію як частину шляху. Ви можете запитати обʼєкт у будь-якій версії, яка наразі обслуговується. Якщо ви вказуєте версію, яка відрізняється від версії, у якій зберігається обʼєкт, Kubernetes повертає вам обʼєкт у запитуваній версії, але збережений обʼєкт не змінюється на диску.
Що відбувається з обʼєктом, який повертається під час обслуговування запиту на читання, залежить від того, що вказано у spec.conversion CRD:
Якщо вказано стандартне значення стратегії None, єдині зміни обʼєкта — це зміна рядка apiVersion і, можливо, обрізання невідомих полів (залежно від конфігурації). Зазначимо, що це навряд чи призведе до хороших результатів, якщо схеми відрізняються між версіями зберігання та запитуваною версією. Зокрема, не слід використовувати цю стратегію, якщо ті самі дані представлені у різних полях між версіями.
Якщо ви оновлюєте існуючий обʼєкт, він перезаписується у версії, яка наразі є версією зберігання. Це єдиний спосіб, за допомогою якого обʼєкти можуть змінюватися з однієї версії на іншу.
Щоб проілюструвати це, розглянемо наступну гіпотетичну послідовність подій:
Версія зберігання — v1beta1. Ви створюєте обʼєкт. Він зберігається у версії v1beta1.
Ви додаєте версію v1 до вашого CustomResourceDefinition і призначаєте її версією зберігання. Схеми для v1 та v1beta1 є ідентичними, що зазвичай має місце під час підвищення API до стабільного стану в екосистемі Kubernetes.
Ви читаєте свій обʼєкт у версії v1beta1, потім читаєте обʼєкт знову у версії v1. Обидва отримані обʼєкти є ідентичними, за винятком поля apiVersion.
Ви створюєте новий обʼєкт. Він зберігається у версії v1. Тепер у вас є два обʼєкти: один у версії v1beta1, інший у версії v1.
Ви оновлюєте перший обʼєкт. Тепер він зберігається у версії v1, оскільки це поточна версія зберігання.
Попередні версії зберігання
API сервер записує кожну версію, яка коли-небудь була позначена як версія зберігання у полі статусу storedVersions. Обʼєкти можуть бути збережені у будь-якій версії, яка коли-небудь була визначена як версія зберігання. Ніякі обʼєкти не можуть існувати у зберіганні у версії, яка ніколи не була версією зберігання.
Оновлення існуючих обʼєктів до нової версії зберігання
При застаріванні версій та припиненні підтримки виберіть процедуру оновлення зберігання.
Видаліть стару версію з поля status.storedVersions CustomResourceDefinition.
Варіант 2: Ручне оновлення наявних обʼєктів до нової версії зберігання
Наведено приклад процедури оновлення з v1beta1 до v1.
Встановіть v1 як версію зберігання у файлі CustomResourceDefinition та застосуйте це за допомогою kubectl. Тепер storedVersions містить v1beta1, v1.
Напишіть процедуру оновлення для отримання всіх наявних обʼєктів і запишіть їх з тим самим вмістом. Це змушує бекенд записувати обʼєкти у поточній версії зберігання, якою є v1.
Видаліть v1beta1 з поля status.storedVersions CustomResourceDefinition.
Примітка:
Ось приклад того, як накладати патч на субресурс status обʼєкта CRD за допомогою kubectl:
Налаштування шару агрегації дозволяє розширити apiserver Kubernetes додатковими API, які не є частиною основних API Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Існує кілька вимог щодо налаштування для роботи шару агрегації у вашому середовищі, щоб підтримувати взаємну автентифікацію TLS між проксі-сервером та apiserverʼом розширення. Kubernetes та kube-apiserver мають декілька ЦС (центрів сертифікації), тому переконайтеся, що проксі підписаний ЦС шару агрегації, а не іншим ЦС, таким як загальний ЦС Kubernetes.
Увага:
Повторне використання одного ЦС для різних типів клієнтів може негативно вплинути на здатність кластера функціонувати. Для отримання додаткової інформації див. Повторне використання ЦС та конфлікти.
Потоки автентифікації
На відміну від Custom Resource Definitions (CRDs), API агрегації включає ще один сервер, ваш apiserver розширення, крім стандартного apiserver Kubernetes. Kubernetes apiserver повинен взаємодіяти з вашим apiserver розширення, а ваш apiserver розширення повинен взаємодіяти з Kubernetes apiserver. Щоб ця взаємодія була захищеною, Kubernetes apiserver використовує x509 сертифікати для автентифікації себе перед apiserver розширення.
У цьому розділі описано, як працюють потоки автентифікації та авторизації та як їх налаштувати.
Основний потік виглядає наступним чином:
Kubernetes apiserver: автентифікація користувача, що запитує, та авторизація його прав на запитаний API шлях.
Kubernetes apiserver: проксіювання запиту до apiserverʼа розширення.
apiserver розширення: автентифікація запиту від Kubernetes apiserver.
apiserver розширення: авторизація запиту від початкового користувача.
apiserver розширення: виконання.
У решті цього розділу описуються ці кроки детально.
Потік можна побачити на наступній діаграмі.
Джерело для вищезазначених потоків можна знайти у вихідному коді цього документа.
Автентифікація та авторизація Kubernetes Apiserver
Запит до API шляху, який обслуговується apiserver розширення, починається так само, як і всі API запити: з комунікації з Kubernetes apiserver. Цей шлях вже був зареєстрований з Kubernetes apiserver apiserver розширення.
Користувач взаємодіє з Kubernetes apiserver, запитуючи доступ до шляху. Kubernetes apiserver використовує стандартну автентифікацію та авторизацію, налаштовану в Kubernetes apiserver, для автентифікації користувача та авторизації доступу до конкретного шляху.
Для загального огляду автентифікації в кластері Kubernetes див. "Автентифікація в кластері". Для загального огляду авторизації доступу до ресурсів кластера Kubernetes див. "Огляд авторизації".
Все до цього моменту було стандартними запитами API Kubernetes, автентифікацією та авторизацією.
Kubernetes apiserver тепер готовий відправити запит до apiserverʼа розширення.
Проксіювання запиту Kubernetes Apiserver
Kubernetes apiserver тепер відправить або проксує запит до apiserverʼа розширення, який зареєстрований для обробки цього запиту. Для цього потрібно знати кілька речей:
Як Kubernetes apiserver повинен автентифікуватися у apiserver розширення, інформуючи його, що запит, який надходить мережею, надходить від дійсного Kubernetes apiserver?
Як Kubernetes apiserver повинен інформувати apiserver розширення про імʼя користувача та групу, з якими оригінальний запит був автентифікований?
Щоб забезпечити ці два аспекти, ви повинні налаштувати Kubernetes apiserver, використовуючи кілька прапорців.
Автентифікація клієнта Kubernetes Apiserver
Kubernetes apiserver підключається до apiserverʼа розширення через TLS, автентифікується за допомогою клієнтського сертифіката. Ви повинні надати наступне для Kubernetes apiserver при запуску, використовуючи вказані параметри:
файл приватного ключа через --proxy-client-key-file
підписаний файл клієнтського сертифіката через --proxy-client-cert-file
сертифікат CA, який підписав файл клієнтського сертифіката через --requestheader-client-ca-file
дійсні значення загального імені (CN) в підписаному клієнтському сертифікаті через --requestheader-allowed-names
Kubernetes apiserver використовуватиме файли, вказані --proxy-client-*-file, щоб автентифікуватися у apiserver розширення. Щоб запит був вважався дійсним відповідно до стандартів apiserverʼа розширення, мають виконуватися наступні умови:
Підключення має бути виконане за допомогою клієнтського сертифіката, який підписаний CA, сертифікат якого знаходиться в --requestheader-client-ca-file.
Підключення має бути виконане за допомогою клієнтського сертифіката, CN якого знаходиться в одному з тих, що перелічені в --requestheader-allowed-names.
Примітка:
Ви можете встановити цей параметр як порожній рядок: --requestheader-allowed-names="". Це позначатиме для apiserverʼа розширення, що будь-яке CN прийнятне.
Після запуску з цими параметрами Kubernetes apiserver:
Використовуватиме їх для автентифікації у apiserver розширення.
Створить ConfigMap у просторі імен kube-system з назвою extension-apiserver-authentication, в який він помістить сертифікат CA та дозволені CN. Ці дані можна отримати apiserverʼа розширенняs для перевірки запитів.
Зверніть увагу, що той самий клієнтський сертифікат використовується Kubernetes apiserver для автентифікації для усіх apiserverʼів розширень. Він не створює окремий клієнтський сертифікат для кожного apiserverʼа розширення, а лише один, щоб автентифікуватися як Kubernetes apiserver. Цей самий сертифікат використовується для всіх запитів apiserverʼа розширення.
Імʼя користувача та група оригінального запиту
Коли Kubernetes apiserver проксіює запит до apiserverʼа розширення, він повідомляє apiserver розширення імʼя користувача та групу, з якими успішно був автентифікований початковий запит. Він надає це у http заголовках свого проксі-запиту. Ви повинні повідомити Kubernetes apiserver назви заголовків, які слід використовувати.
заголовок, в якому зберігати імʼя користувача через --requestheader-username-headers
заголовок, в якому зберігати групу через --requestheader-group-headers
префікс для всіх додаткових заголовків через --requestheader-extra-headers-prefix
Ці назви заголовків також поміщаються в ConfigMap extension-apiserver-authentication, так що їх можна отримати та використати apiserverʼа розширенняs.
Apiserver розширення автентифікує запит
apiserver розширення, отримавши проксі-запит від Kubernetes apiserver, повинен перевірити, що запит дійсно надійшов від дійсного автентифікуючого проксі, роль якого виконує Kubernetes apiserver. apiserver розширення перевіряє його за допомогою:
Отримання наступного з ConfigMap в kube-system, як описано вище:
Сертифікат CA клієнта
Список дозволених імен (CN)
Назви заголовків для імені користувача, групи та додаткової інформації
Перевірте, що TLS-зʼєднання було автентифіковано за допомогою сертифіката клієнта, який:
Був підписаний CA, чий сертифікат відповідає отриманому сертифікату CA.
Має CN у списку дозволених CN, якщо список не порожній, в іншому випадку дозволяються всі CN.
Витягу імені користувача та групи з відповідних заголовків.
Якщо вище зазначене пройшло, тоді запит є дійсним проксійним запитом від законного проксі автентифікації, у цьому випадку — apiserver Kubernetes.
Зверніть увагу, що відповідальність за надання вищезазначеного лежить на реалізації apiserverʼа розширення. Більшість роблять це стандартно, використовуючи пакет k8s.io/apiserver/. Інші можуть надати опції для зміни цього за допомогою параметрів командного рядка.
Для того, щоб мати дозвіл на отримання конфігураційного файлу, apiserver розширення потребує відповідної ролі. Існує стандартна роль з назвою extension-apiserver-authentication-reader в просторі імен kube-system, яка може бути призначена.
Apiserver розширення авторизує запит
Тепер apiserver розширення може перевірити, що користувач/група, отримані з заголовків, мають дозвіл на виконання даного запиту. Він робить це, надсилаючи стандартний запит SubjectAccessReview до apiserver Kubernetes.
Для того, щоб apiserver розширення мав право на надсилання запиту SubjectAccessReview до apiserver Kubernetes, йому потрібні відповідні дозволи. Kubernetes включає стандартну ClusterRole з назвою system:auth-delegator, яка має необхідні дозволи. Її можна надати службовому обліковому запису apiserverʼа розширенняа.
Виконання Apiserver розширення
Якщо перевірка SubjectAccessReview пройде успішно, apiserver розширення виконує запит.
Увімкнення прапорців Apiserver Kubernetes
Увімкніть агрегаційний шар за допомогою наступних прапорців kube-apiserver. Вони можуть вже бути налаштовані вашим постачальником.
--requestheader-client-ca-file=<шлях до сертифікату CA агрегатора>
--requestheader-allowed-names=front-proxy-client
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--proxy-client-cert-file=<шлях до сертифікату проксі-клієнта агрегатора>
--proxy-client-key-file=<шлях до ключа проксі-клієнта агрегатора>
Повторне використання та конфлікти сертифікатів CA
У Kubernetes apiserver є два параметри CA клієнта:
--client-ca-file
--requestheader-client-ca-file
Кожен з цих параметрів працює незалежно і може конфліктувати один з одним, якщо їх не використовувати належним чином.
--client-ca-file: Коли запит надходить на Kubernetes apiserver, якщо цей параметр увімкнено, Kubernetes apiserver перевіряє сертифікат запиту. Якщо він підписаний одним з сертифікатів CA в файлі, на який вказує --client-ca-file, то запит вважається законним, а користувач — значенням загального імені CN=, а група — організацією O=. Див. документацію з автентифікації TLS.
--requestheader-client-ca-file: Коли запит надходить на Kubernetes apiserver, якщо цей параметр увімкнено, Kubernetes apiserver перевіряє сертифікат запиту. Якщо він підписаний одним із сертифікатів CA у файлі, на який вказує --requestheader-client-ca-file, то запит вважається потенційно законним. Потім Kubernetes apiserver перевіряє, чи є загальне імʼя CN= одним з імен у списку, наданому параметром --requestheader-allowed-names. Якщо імʼя дозволене, запит схвалюється; якщо ні, запит відхиляється.
Якщо обидва параметри --client-ca-file та --requestheader-client-ca-file надані, то спочатку запит перевіряє CA --requestheader-client-ca-file, а потім --client-ca-file. Зазвичай для кожного з цих параметрів використовуються різні сертифікати CA, або кореневі CA, або проміжні CA; звичайні клієнтські запити відповідають --client-ca-file, тоді як агрегаційні запити відповідають --requestheader-client-ca-file. Однак, якщо обидва використовують той самий CA, то звичайні клієнтські запити, які зазвичай пройшли б через --client-ca-file, не пройдуть, оскільки CA буде відповідати CA в --requestheader-client-ca-file, але загальне імʼя CN=не буде відповідати одному з припустимих загальних імен в --requestheader-allowed-names. Це може призвести до того, що kublete та інші компоненти панелі управління, так само як і інші клієнти, не зможуть автентифікуватись на Kubernetes apiserver.
З цієї причини використовуйте різні сертифікати CA для опції --client-ca-file, щоб авторизувати компоненти панелі управління та кінцевих користувачів, і опції --requestheader-client-ca-file, щоб авторизувати запити apiserverʼа агрегації.
Попередження:
Не використовуйте знову CA, який використовується в іншому контексті, якщо ви не розумієте ризики та механізми захисту використання CA.
Якщо ви не запускаєте kube-proxy на хості, на якому працює API-сервер, вам потрібно впевнитися, що система ввімкнена з наступним прапорцем kube-apiserver:
--enable-aggregator-routing=true
Реєстрація обʼєктів APIService
Ви можете динамічно налаштувати, які клієнтські запити будуть проксійовані до apiserverʼа розширення. Нижче наведено приклад реєстрації:
apiVersion:apiregistration.k8s.io/v1kind:APIServicemetadata:name:<імʼя обʼєкта реєстрації>spec:group:<назва групи API, яку обслуговує цей apiserver розширення>version:<версія API, яку обслуговує цей apiserver розширення>groupPriorityMinimum:<пріоритет цього APIService для цієї групи, див. документацію API>versionPriority:<пріоритет упорядкування цієї версії у межах групи, див. документацію API>service:namespace:<простір імен сервісу apiserverʼа розширення>name:<імʼя сервісу apiserverʼа розширення>caBundle:<pem-кодований ca-сертифікат, який підписує сертифікат сервера, який використовується вебзапитом>
Після того, як Kubernetes apiserver вирішив, що запит потрібно надіслати до apiserverʼа розширення, він повинен знати, як з ним звʼязатися.
Блок service — це посилання на сервіс для apiserverʼа розширення. Простір імен та імʼя сервісу обовʼязкові. Порт є необовʼязковим і типово дорівнює 443.
Ось приклад apiserverʼа розширення, який налаштований для виклику на порті "1234" та перевірки зʼєднання TLS проти ServerName my-service-name.my-service-namespace.svc, використовуючи власний пакет CA.
Налаштування API сервера розширення для роботи з шаром агрегації дозволяє розширювати apiserver Kubernetes додатковими API, які не є частиною основних API Kubernetes.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Налаштування API сервера розширення для роботи з шаром агрегації
Наступні кроки описують налаштування apiserverʼа розширення на високому рівні. Ці кроки застосовуються незалежно від того, чи використовуєте ви YAML конфігурації, чи API. Робиться спроба конкретно визначити будь-які відмінності між цими двома підходами. Для конкретного прикладу їх реалізації за допомогою YAML конфігурацій, ви можете ознайомитися з sample-apiserver у репозиторії Kubernetes.
Альтернативно, ви можете використовувати наявне стороннє рішення, таке як apiserver-builder, яке має згенерувати кістяк та автоматизувати всі наступні кроки для вас.
Переконайтеся, що APIService API увімкнено (перевірте --runtime-config). Воно має бути типово увімкнене, якщо воно не було свідомо вимкнено у вашому кластері.
Можливо, вам потрібно створити правило RBAC, яке дозволяє додавати обʼєкти APIService, або попросити адміністратора вашого кластера створити його. (Оскільки розширення API впливають на весь кластер, не рекомендується проводити тестування/розробку/налагодження розширення API у робочому кластері.)
Створіть простір імен Kubernetes, у якому ви хочете запустити свій api-сервер розширення.
Отримайте сертифікат CA, який буде використовуватися для підпису сертифіката сервера, що використовує api-сервер розширення для HTTPS.
Створіть серверний сертифікат/ключ для api-сервера, який буде використовуватися для HTTPS. Цей сертифікат повинен бути підписаний вище згаданим CA. Він також повинен мати CN у вигляді імені Kube DNS. Це імʼя формується на основі сервісу Kubernetes і має вигляд <service name>.<service name namespace>.svc.
Створіть Secret Kubernetes з серверним сертифікатом/ключем у вашому просторі імен.
Створіть Deployment Kubernetes для api-сервера розширення і переконайтеся, що ви завантажуєте Secret як том. Він повинен містити посилання на робочий образ вашого api-сервера розширення. Deployment також повинен бути у вашому просторі імен.
Переконайтеся, що ваш api-сервер розширення завантажує ці сертифікати з того тому і що вони використовуються в процесі рукостискання (handshake) HTTPS.
Створіть службовий обліковий запис (service account) Kubernetes у вашому просторі імен.
Створіть кластерну роль Kubernetes для операцій, які ви хочете дозволити над вашими ресурсами.
Створіть привʼязку кластерної ролі до службового облікового запису (service account) у вашому просторі імен до створеної кластерної ролі.
Створіть привʼязку кластерної ролі до службового облікового запису (service account) у вашому просторі імен до кластерної ролі system:auth-delegator для делегування рішень щодо автентифікації на основному API серверу Kubernetes.
Створіть привʼязку службового облікового запису (service account) у вашому просторі імен до ролі extension-apiserver-authentication-reader. Це дозволяє вашому api-серверу розширення отримувати доступ до ConfigMap extension-apiserver-authentication.
Створіть apiservice Kubernetes. CA сертифікат повинен бути закодований в base64, не містити позбавлений нових рядків і використаний як spec.caBundle в apiservice. Він не повинен бути привʼязаний до простору імен. Якщо ви використовуєте kube-aggregator API, передайте лише PEM-кодований CA bundle, оскільки кодування в base64 виконується за вас.
Використовуйте kubectl для отримання вашого ресурсу. Під час запуску kubectl повинен повернути "No resources found.". Це повідомлення вказує на те, що все спрацювало, але наразі у вас немає створених обʼєктів цього типу ресурсу.
Kubernetes постачається зі стандартним планувальником. Якщо стандартний планувальник не підходить для ваших потреб, ви можете реалізувати власний. До того, ви можете одночасно запускати кілька планувальників поряд зі стандартним планувальником і вказувати Kubernetes, який планувальник використовувати для кожного з ваших Podʼів. Тепер навчимося запускати кілька планувальників в Kubernetes на прикладі.
Детальний опис того, як реалізувати планувальник, виходить за рамки цього документа. Будь ласка, зверніться до реалізації kube-scheduler в pkg/scheduler в теці вихідних кодів Kubernetes для канонічного прикладу.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Упакуйте ваш планувальник у контейнерний образ. Для цілей цього прикладу ви можете використовувати стандартний планувальник (kube-scheduler) як ваш другий планувальник. Клонуйте вихідний код Kubernetes з GitHub і зберіть планувальник з сирців.
git clone https://github.com/kubernetes/kubernetes.git
cd kubernetes
make
Створіть контейнерний образ, що містить виконавчий файл kube-scheduler. Ось Dockerfile для створення образу:
FROM busyboxADD ./_output/local/bin/linux/amd64/kube-scheduler /usr/local/bin/kube-scheduler
Збережіть файл як Dockerfile, зберіть образ і завантажте його до реєстру. У цьому прикладі образ завантажується до Google Container Registry (GCR). Для отримання додаткової інформації, будь ласка, прочитайте документацію GCR. Як альтернативу ви також можете використовувати docker hub. Для отримання додаткової інформації зверніться до документації docker hub.
docker build -t gcr.io/my-gcp-project/my-kube-scheduler:1.0 . # Назва образу та репозиторіюgcloud docker -- push gcr.io/my-gcp-project/my-kube-scheduler:1.0 # тут є лише прикладом
Визначення розгортання Kubernetes для планувальника
Тепер, коли ви маєте ваш планувальник у контейнерному образі, створіть конфігурацію Podʼа для нього і запустіть його у вашому кластері Kubernetes. Але замість того, щоб створювати Pod безпосередньо в кластері, ви можете використовувати Deployment для цього прикладу. Deployment керує Replica Set, який, своєю чергою, керує Podʼами, забезпечуючи стійкість планувальника до збоїв. Ось конфігурація розгортання. Збережіть її як my-scheduler.yaml:
У наведеному вище маніфесті ви використовуєте KubeSchedulerConfiguration для налаштування поведінки вашої реалізації планувальника. Ця конфігурація була передана kube-scheduler під час ініціалізації за допомогою параметра --config. Конфігураційний файл зберігається у ConfigMap my-scheduler-config. Pod Deployment my-scheduler монтує ConfigMap my-scheduler-config як том.
У вищезгаданій конфігурації планувальника ваша реалізація планувальника представлена за допомогою KubeSchedulerProfile.
Примітка:
Щоб визначити, чи відповідає планувальник за планування конкретного Podʼа, поле spec.schedulerName в PodTemplate або Pod маніфесті повинно збігатися з полем schedulerName профілю KubeSchedulerProfile. Усі планувальники, що працюють у кластері, повинні мати унікальні імена.
Також зверніть увагу, що ви створюєте окремий службовий обліковий запис my-scheduler і привʼязуєте до нього кластерну роль system:kube-scheduler, щоб він міг отримати ті ж привілеї, що й kube-scheduler.
Щоб запустити ваш планувальник у кластері Kubernetes, створіть Deployment вказаний у конфігурації вище у кластері Kubernetes:
kubectl create -f my-scheduler.yaml
Переконайтеся, що Pod планувальника працює:
kubectl get pods --namespace=kube-system
NAME READY STATUS RESTARTS AGE
....
my-scheduler-lnf4s-4744f 1/1 Running 0 2m
...
У цьому списку ви повинні побачити Pod "Running" my-scheduler, на додачу до стандартного планувальника kube-scheduler.
Увімкнення обрання лідера
Щоб запустити кілька планувальників з увімкненим обранням лідера, ви повинні зробити наступне:
Оновіть наступні поля для KubeSchedulerConfiguration у ConfigMap my-scheduler-config у вашому YAML файлі:
leaderElection.leaderElect до true
leaderElection.resourceNamespace до <lock-object-namespace>
leaderElection.resourceName до <lock-object-name>
Примітка:
Панель управління створює обʼєкти блокування для вас, але простір імен вже повинен існувати. Ви можете використовувати простір імен kube-system.
Якщо у вашому кластері увімкнено RBAC, ви повинні оновити кластерну роль system:kube-scheduler. Додайте імʼя вашого планувальника до імен ресурсів у правилі, яке застосовується до ресурсів endpoints та leases, як у наступному прикладі:
Тепер, коли ваш другий планувальник працює, створіть кілька Podʼів і вкажіть, щоб вони
планувалися або стандартним планувальником, або тим, який ви розгорнули. Щоб запланувати Pod за допомогою конкретного планувальника, вкажіть імʼя планувальника у специфікації Podʼа. Розгляньмо три приклади.
Специфікація Podʼа без вказаного імені планувальника
Планувальник вказується шляхом надання його імені як значення для spec.schedulerName. У цьому випадку ми надаємо імʼя стандартного планувальника, яке є default-scheduler.
Збережіть цей файл як pod2.yaml і надішліть його до кластера Kubernetes.
У цьому випадку ми вказуємо, що цей Pod має бути запланований за допомогою планувальника, який ми розгорнули — my-scheduler. Зверніть увагу, що значення spec.schedulerName повинно відповідати імені, яке було надано планувальнику в полі schedulerName профілю KubeSchedulerProfile.
Збережіть цей файл як pod3.yaml і надішліть його до кластера Kubernetes.
kubectl create -f pod3.yaml
Переконайтеся, що всі три Podʼи працюють.
kubectl get pods
Перевірка, що Podʼи були заплановані за допомогою бажаних планувальників
Для спрощення роботи з цими прикладами ми не перевірили, що Podʼи дійсно були заплановані за допомогою бажаних планувальників. Ми можемо перевірити це, змінивши порядок подання конфігурацій Podʼів і розгортання вище. Якщо ми передамо всі конфігурації Podʼів до кластера Kubernetes перед передачею конфігурації розгортання планувальника, ми побачимо, що Pod annotation-second-scheduler залишається в стані "Pending" назавжди, тоді як інші два Podʼи заплановані. Після надсилання конфігурації розгортання планувальника і запуску нашого нового планувальника, Pod annotation-second-scheduler також запланується.
Як альтернативу, ви можете переглянути записи "Scheduled" у лозі подій, щоб перевірити, що Podʼи були заплановані бажаними планувальниками.
kubectl get events
Ви також можете використовувати власну конфігурацію планувальника або власний контейнерний образ для основного планувальника кластера, змінивши його статичний маніфест Podʼа на відповідних вузлах панелі управління.
11.5 - Використання HTTP-проксі для доступу до Kubernetes API
Ця сторінка показує, як використовувати HTTP-проксі для доступу до Kubernetes API.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
11.6 - Використання SOCKS5-проксі для доступу до Kubernetes API
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.24 [stable]
Ця сторінка показує, як використовувати SOCKS5-проксі для доступу до API віддаленого кластера Kubernetes. Це корисно, коли кластер, до якого ви хочете отримати доступ, не відкриває свій API безпосередньо в інтернет.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.24.
Для перевірки версії введіть kubectl version.
Вам потрібне програмне забезпечення для SSH-клієнта (інструмент ssh) і сервіс SSH, що працює на віддаленому сервері. Ви повинні мати можливість увійти до сервісу SSH на віддаленому сервері.
Контекст завдання
Примітка:
У цьому прикладі трафік тунелюється за допомогою SSH, де SSH-клієнт і сервер виступають як SOCKS-проксі. Ви можете також використовувати будь-які інші види SOCKS5 проксі.
На схемі 1 представлено, що ви збираєтесь досягти в цьому завданні.
У вас є компʼютер-клієнт, який називається локальним у подальших кроках, з якого ви будете створювати запити для спілкування з Kubernetes API.
Сервер Kubernetes/API розміщений на віддаленому сервері.
Ви будете використовувати програмне забезпечення SSH-клієнта і сервера для створення безпечного SOCKS5-тунелю між локальним і віддаленим сервером. HTTPS-трафік між клієнтом і Kubernetes API буде проходити через SOCKS5-тунель, який сам тунелюється через SSH.
graph LR;
subgraph local[Локальний клієнтський компʼютер]
client([клієнт])-. локальний трафік .-> local_ssh[Локальний SSH SOCKS5 проксі];
end
local_ssh[SSH SOCKS5 проксі]-- SSH-тунель -->sshd
subgraph remote[Віддалений сервер]
sshd[SSH сервер]-- локальний трафік -->service1;
end
client([клієнт])-. проксійований HTTPS-трафік проходить через проксі .->service1[Kubernetes API];
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class ingress,service1,service2,pod1,pod2,pod3,pod4 k8s;
class client plain;
class cluster cluster;
Схема 1. Компоненти уроку про SOCKS5
Використання ssh для створення SOCKS5-проксі
Наступна команда запускає SOCKS5-проксі між вашим клієнтським компʼютером і віддаленим SOCKS-сервером:
# SSH-тунель продовжує працювати у фоновому режимі після виконання цієї командиssh -D 1080 -q -N username@kubernetes-remote-server.example
SOCKS5-проксі дозволяє вам підключатися до сервера API вашого кластера на основі наступної конфігурації:
-D 1080: відкриває SOCKS-проксі на локальному порту :1080.
-q: тихий режим. Приглушує більшість попереджень і діагностичних повідомлень.
-N: не виконувати віддалені команди. Корисно для простого пересилання портів.
username@kubernetes-remote-server.example: віддалений SSH-сервер, за яким працює кластер Kubernetes (наприклад, bastion host).
Конфігурація клієнта
Щоб отримати доступ до сервера Kubernetes API через проксі, вам потрібно вказати kubectl надсилати запити через створений раніше SOCKS проксі. Зробіть це або налаштуванням відповідної змінної середовища, або через атрибут proxy-url у файлі kubeconfig. Використання змінної середовища:
exportHTTPS_PROXY=socks5://localhost:1080
Щоб завжди використовувати це налаштування в конкретному контексті kubectl, вкажіть атрибут proxy-url у відповідному записі cluster у файлі ~/.kube/config. Наприклад:
apiVersion:v1clusters:- cluster:certificate-authority-data:LRMEMMW2# скорочено для читабельностіserver:https://<API_SERVER_IP_ADDRESS>:6443 # сервер "Kubernetes API", тобто IP-адреса kubernetes-remote-server.exampleproxy-url:socks5://localhost:1080 # "SSH SOCKS5 проксі" на діаграмі вищеname:defaultcontexts:- context:cluster:defaultuser:defaultname:defaultcurrent-context:defaultkind:Configpreferences:{}users:- name:defaultuser:client-certificate-data:LS0tLS1CR==# скорочено для читабельностіclient-key-data:LS0tLS1CRUdJT= # скорочено для читабельності
Після створення тунелю через команду ssh, зазначену вище, і визначення змінної середовища або атрибуту proxy-url, ви можете взаємодіяти з вашим кластером через цей проксі. Наприклад:
kubectl get pods
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-85cb69466-klwq8 1/1 Running 0 5m46s
Примітка:
До версії kubectl 1.24 більшість команд kubectl працювали з використанням socks-проксі, за винятком kubectl exec.
kubectl підтримує як змінні середовища HTTPS_PROXY, так і https_proxy. Вони використовуються іншими програмами, які підтримують SOCKS, такими як curl. Тому в деяких випадках краще визначити змінну середовища в командному рядку:
HTTPS_PROXY=socks5://localhost:1080 kubectl get pods
При використанні proxy-url проксі використовується лише для відповідного контексту kubectl, тоді як змінна середовища вплине на всі контексти.
Імʼя хосту сервера k8s API можна додатково захистити від витоку DNS, використовуючи протокольну назву socks5h замість більш відомого протоколу socks5, показаного вище. У цьому випадку kubectl попросить проксі-сервер (наприклад, ssh bastion) виконати розвʼязання доменного імені сервера k8s API замість його розвʼязання у системі, яка запускає kubectl. Зауважте також, що з socks5h URL сервера k8s API, як-от https://localhost:6443/api, не стосується вашого локального клієнтського компʼютера. Натомість він стосується localhost, відомого на проксі-сервері (наприклад, ssh bastion).
Очищення
Зупиніть процес пересилання портів ssh, натиснувши CTRL+C у терміналі, де він працює.
Введіть unset https_proxy у терміналі, щоб припинити пересилання HTTP-трафіку через проксі.
Служба Konnectivity надає проксі на рівні TCP для комунікації між панеллю управління та кластером.
Перш ніж ви розпочнете
Вам потрібно мати кластер Kubernetes, а також інструмент командного рядка kubectl повинен бути налаштований на звʼязок з вашим кластером. Рекомендується виконувати цей посібник на кластері з щонайменше двома вузлами, які не є хостами панелі управління. Якщо у вас ще немає кластера, ви можете створити його за допомогою minikube.
Налаштування служби Konnectivity
Для виконання наступних кроків потрібна конфігурація egress, наприклад:
apiVersion:apiserver.k8s.io/v1beta1kind:EgressSelectorConfigurationegressSelections:# Оскільки ми хочемо контролювати вихідний трафік з кластеру, ми використовуємо# "cluster" як назву. Інші підтримувані значення: "etcd" та "controlplane".- name:clusterconnection:# Це керує протоколом між API-сервером та сервером Konnectivity.# Підтримувані значення: "GRPC" та "HTTPConnect". Між двома режимами# немає відмінностей для кінцевого користувача. Вам потрібно встановити# сервер Konnectivity в тому ж режимі.proxyProtocol:GRPCtransport:# Це керує транспортом, який використовує API-сервер для спілкування з# сервером Konnectivity. Якщо сервер Konnectivity розташований на тому ж# компʼютері, рекомендується використовувати UDS. Вам потрібно налаштувати# сервер Konnectivity на прослуховування того самого UDS-сокету.# Інший підтримуваний транспорт - "tcp". Вам потрібно налаштувати TLS-конфігурацію# для захисту TCP-транспорту.uds:udsName:/etc/kubernetes/konnectivity-server/konnectivity-server.socket
Вам потрібно налаштувати API-сервер для використання служби Konnectivity та направлення мережевого трафіку на вузли кластера:
Згенеруйте або отримайте сертифікат та kubeconfig для konnectivity-server. Наприклад, ви можете використовувати інструмент командного рядка OpenSSL для створення сертифіката X.509, використовуючи сертифікат CA кластера /etc/kubernetes/pki/ca.crt з хосту панелі управління.
Розгорніть сервер Konnectivity на ваших вузлах панелі управління. Наданий маніфест konnectivity-server.yaml передбачає, що компоненти Kubernetes розгорнуті як статичний Pod у вашому кластері. Якщо ні, ви можете розгорнути сервер Konnectivity як DaemonSet.
apiVersion:v1kind:Podmetadata:name:konnectivity-servernamespace:kube-systemspec:priorityClassName:system-cluster-criticalhostNetwork:truecontainers:- name:konnectivity-server-containerimage:registry.k8s.io/kas-network-proxy/proxy-server:v0.0.37command:["/proxy-server"]args:["--logtostderr=true",# Це повинно збігатися зі значенням, встановленим у egressSelectorConfiguration."--uds-name=/etc/kubernetes/konnectivity-server/konnectivity-server.socket","--delete-existing-uds-file",# Наступні два рядки передбачають, що сервер Konnectivity# розгорнуто на тому ж компʼютері, що й apiserver, і сертифікати та# ключ API-сервера знаходяться за вказаною шляхом."--cluster-cert=/etc/kubernetes/pki/apiserver.crt","--cluster-key=/etc/kubernetes/pki/apiserver.key",# Це повинно збігатися зі значенням, встановленим у egressSelectorConfiguration."--mode=grpc","--server-port=0","--agent-port=8132","--admin-port=8133","--health-port=8134","--agent-namespace=kube-system","--agent-service-account=konnectivity-agent","--kubeconfig=/etc/kubernetes/konnectivity-server.conf","--authentication-audience=system:konnectivity-server"]livenessProbe:httpGet:scheme:HTTPhost:127.0.0.1port:8134path:/healthzinitialDelaySeconds:30timeoutSeconds:60ports:- name:agentportcontainerPort:8132hostPort:8132- name:adminportcontainerPort:8133hostPort:8133- name:healthportcontainerPort:8134hostPort:8134volumeMounts:- name:k8s-certsmountPath:/etc/kubernetes/pkireadOnly:true- name:kubeconfigmountPath:/etc/kubernetes/konnectivity-server.confreadOnly:true- name:konnectivity-udsmountPath:/etc/kubernetes/konnectivity-serverreadOnly:falsevolumes:- name:k8s-certshostPath:path:/etc/kubernetes/pki- name:kubeconfighostPath:path:/etc/kubernetes/konnectivity-server.conftype:FileOrCreate- name:konnectivity-udshostPath:path:/etc/kubernetes/konnectivity-servertype:DirectoryOrCreate
Потім розгорніть агентів Konnectivity у вашому кластері:
apiVersion:apps/v1# Instead of this, you can deploy agents as Deployments. It is not necessary to have an agent on each node.kind:DaemonSetmetadata:labels:addonmanager.kubernetes.io/mode:Reconcilek8s-app:konnectivity-agentnamespace:kube-systemname:konnectivity-agentspec:selector:matchLabels:k8s-app:konnectivity-agenttemplate:metadata:labels:k8s-app:konnectivity-agentspec:priorityClassName:system-cluster-criticaltolerations:- key:"CriticalAddonsOnly"operator:"Exists"containers:- image:us.gcr.io/k8s-artifacts-prod/kas-network-proxy/proxy-agent:v0.0.37name:konnectivity-agentcommand:["/proxy-agent"]args:["--logtostderr=true","--ca-cert=/var/run/secrets/kubernetes.io/serviceaccount/ca.crt",# Оскільки сервер konnectivity працює з hostNetwork=true,# це є IP-адреса машини-майстра."--proxy-server-host=35.225.206.7","--proxy-server-port=8132","--admin-server-port=8133","--health-server-port=8134","--service-account-token-path=/var/run/secrets/tokens/konnectivity-agent-token"]volumeMounts:- mountPath:/var/run/secrets/tokensname:konnectivity-agent-tokenlivenessProbe:httpGet:port:8134path:/healthzinitialDelaySeconds:15timeoutSeconds:15serviceAccountName:konnectivity-agentvolumes:- name:konnectivity-agent-tokenprojected:sources:- serviceAccountToken:path:konnectivity-agent-tokenaudience:system:konnectivity-server
Нарешті, якщо RBAC включено у вашому кластері, створіть відповідні правила RBAC:
Дізнайтесь, як захистити трафік у вашому кластері за допомогою TLS (Transport Layer Security).
12.1 - Випуск сертифіката для клієнта Kubernetes API за допомогою CertificateSigningRequest
Kubernetes дозволяє використовувати інфраструктуру відкритих ключів (PKI) для автентифікації у кластері в якості клієнта.
Для того, щоб звичайний користувач міг автентифікуватися і викликати API, потрібно виконати кілька кроків. По-перше, цей користувач повинен мати сертифікат X.509, виданий органом, якому довіряє ваш кластер Kubernetes. Потім клієнт повинен предʼявити цей сертифікат API Kubernetes.
Ви використовуєте запит CertificateSigningRequest як частину цього процесу, і ви або інша довірена особа маєте схвалити запит.
Ви створите приватний ключ, а потім отримаєте виданий сертифікат і, нарешті, налаштуєте цей приватний ключ для клієнта.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Вам знадобляться утиліти kubectl, openssl та base64.
Ця сторінка передбачає, що ви використовуєте Kubernetes контроль доступу на основі ролей (RBAC). Якщо ви використовуєте альтернативні або додаткові механізми безпеки для авторизації, вам також потрібно врахувати їх.
Створення приватного ключа
На цьому кроці ви створюєте приватний ключ. Ви повинні тримати його в таємниці; будь-хто, хто його має, може видавати себе за користувача.
Це не те саме, що API CertificateSigningRequest з подібною назвою; файл, який ви генеруєте тут, входить до CertificateSigningRequest.
Важливо встановити атрибути CN та O для CSR. CN — це імʼя користувача, а O — група, до якої цей користувач буде належати. Ви можете ознайомитися з RBAC для отримання інформації про стандартні групи.
# Змініть загальне ім’я "myuser" на фактичне ім’я користувача, яке ви хочете використовуватиopenssl req -new -key myuser.key -out myuser.csr -subj "/CN=myuser"
Створіть CertificateSigningRequest Kubernetes
Закодуйте документ CSR, використовуючи цю команду:
cat myuser.csr | base64 | tr -d "\n"
Створіть CertificateSigningRequest та надішліть його до кластера Kubernetes через kubectl. Нижче наведено уривок коду оболонки, який ви можете використати для генерації CertificateSigningRequest.
cat <<EOF | kubectl apply -f -
apiVersion: certificates.k8s.io/v1
kind: CertificateSigningRequest
metadata:
name: myuser # example
spec:
# Це закодований CSR. Змініть його на вміст myuser.csr у кодуванні base64
request: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURSBSRVFVRVNULS0tLS0KTUlJQ1ZqQ0NBVDRDQVFBd0VURVBNQTBHQTFVRUF3d0dZVzVuWld4aE1JSUJJakFOQmdrcWhraUc5dzBCQVFFRgpBQU9DQVE4QU1JSUJDZ0tDQVFFQTByczhJTHRHdTYxakx2dHhWTTJSVlRWMDNHWlJTWWw0dWluVWo4RElaWjBOCnR2MUZtRVFSd3VoaUZsOFEzcWl0Qm0wMUFSMkNJVXBGd2ZzSjZ4MXF3ckJzVkhZbGlBNVhwRVpZM3ExcGswSDQKM3Z3aGJlK1o2MVNrVHF5SVBYUUwrTWM5T1Nsbm0xb0R2N0NtSkZNMUlMRVI3QTVGZnZKOEdFRjJ6dHBoaUlFMwpub1dtdHNZb3JuT2wzc2lHQ2ZGZzR4Zmd4eW8ybmlneFNVekl1bXNnVm9PM2ttT0x1RVF6cXpkakJ3TFJXbWlECklmMXBMWnoyalVnald4UkhCM1gyWnVVV1d1T09PZnpXM01LaE8ybHEvZi9DdS8wYk83c0x0MCt3U2ZMSU91TFcKcW90blZtRmxMMytqTy82WDNDKzBERHk5aUtwbXJjVDBnWGZLemE1dHJRSURBUUFCb0FBd0RRWUpLb1pJaHZjTgpBUUVMQlFBRGdnRUJBR05WdmVIOGR4ZzNvK21VeVRkbmFjVmQ1N24zSkExdnZEU1JWREkyQTZ1eXN3ZFp1L1BVCkkwZXpZWFV0RVNnSk1IRmQycVVNMjNuNVJsSXJ3R0xuUXFISUh5VStWWHhsdnZsRnpNOVpEWllSTmU3QlJvYXgKQVlEdUI5STZXT3FYbkFvczFqRmxNUG5NbFpqdU5kSGxpT1BjTU1oNndLaTZzZFhpVStHYTJ2RUVLY01jSVUyRgpvU2djUWdMYTk0aEpacGk3ZnNMdm1OQUxoT045UHdNMGM1dVJVejV4T0dGMUtCbWRSeEgvbUNOS2JKYjFRQm1HCkkwYitEUEdaTktXTU0xMzhIQXdoV0tkNjVoVHdYOWl4V3ZHMkh4TG1WQzg0L1BHT0tWQW9FNkpsYWFHdTlQVmkKdjlOSjVaZlZrcXdCd0hKbzZXdk9xVlA3SVFjZmg3d0drWm89Ci0tLS0tRU5EIENFUlRJRklDQVRFIFJFUVVFU1QtLS0tLQo=
signerName: kubernetes.io/kube-apiserver-client
expirationSeconds: 86400 # one day
usages:
- client auth
EOF
Деякі моменти, на які слід звернути увагу:
usages має бути client auth (від імені клієнта)
expirationSeconds можна зробити довшим (наприклад, 864000 для десяти днів) або коротшим (наприклад, 3600 для однієї години). Ви не можете подати запит тривалістю менше ніж 10 хвилин.
request — це закодоване в base64 значення вмісту файлу CSR.
Схваліть CertificateSigningRequest
Використовуйте kubectl, щоб знайти CSR, який ви створили, і вручну схвалити його.
Отримайте список CSR:
kubectl get csr
Схваліть CSR:
kubectl certificate approve myuser
Отримайте сертифікат
Отримайте сертифікат із CSR, щоб перевірити, чи виглядає він правильно.
kubectl get csr/myuser -o yaml
Значення сертифікату знаходиться в Base64-кодованому форматі в розділі .status.certificate.
Експортуйте виданий сертифікат з CertificateSigningRequest.
kubectl get csr myuser -o jsonpath='{.status.certificate}'| base64 -d > myuser.crt
Налаштуйте сертифікат у kubeconfig
Наступним кроком буде додавання цього користувача до файлу kubeconfig.
Ви повинні побачити вивід, який підтверджує, що ви є «myuser».
Створіть Role та RoleBinding
Примітка:
Якщо ви не використовуєте Kubernetes RBAC, пропустіть цей крок і внесіть відповідні зміни до механізму авторизації який використовується у вашому кластері.
Після створення сертифіката настав час визначити Role і RoleBinding для цього користувача для доступу до ресурсів кластера Kubernetes.
Це приклад команди для створення Role для цього нового користувача:
kubectl create role developer --verb=create --verb=get --verb=list --verb=update --verb=delete --resource=pods
Це приклад команди для створення RoleBinding для цього нового користувача:
12.2 - Налаштування ротації сертифікатів для Kubelet
Ця сторінка показує, як увімкнути та налаштувати ротацію сертифікатів для kubelet.
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.19 [stable]
Перш ніж ви розпочнете
Потрібна версія Kubernetes 1.8.0 або пізніша
Огляд
Kubelet використовує сертифікати для автентифікації в Kubernetes API. Типово ці сертифікати створюються з терміном дії один рік, щоб їх не потрібно було оновлювати занадто часто.
Kubernetes містить ротацію сертифікатів kubelet, яка автоматично генерує новий ключ і запитує новий сертифікат від Kubernetes API, коли поточний сертифікат наближається до закінчення терміну дії. Коли новий сертифікат стає доступним, він буде використовуватись для автентифікації зʼєднань з Kubernetes API.
Увімкнення ротації клієнтських сертифікатів
Процес kubelet приймає аргумент --rotate-certificates, який контролює, чи буде kubelet автоматично запитувати новий сертифікат, коли наближається термін дії поточного сертифіката.
Процес kube-controller-manager приймає аргумент --cluster-signing-duration (--experimental-cluster-signing-duration до версії 1.19), який контролює, на який термін будуть випускатись сертифікати.
Розуміння налаштувань ротації сертифікатів
Коли kubelet запускається, якщо він налаштований для початкового завантаження (використовуючи прапорець --bootstrap-kubeconfig), він використовуватиме свій початковий сертифікат для підключення до Kubernetes API та надсилатиме запит на підписання сертифіката. Ви можете переглянути статус запитів на підписання сертифікатів за допомогою:
kubectl get csr
Спочатку запит на підписання сертифіката від kubelet на вузлі матиме статус Pending. Якщо запит на підписання сертифіката відповідає певним критеріям, він буде автоматично схвалений менеджером контролерів, після чого він матиме статус Approved. Далі, менеджер контролерів підпише сертифікат, виданий на термін, вказаний параметром --cluster-signing-duration, і підписаний сертифікат буде прикріплений до запиту на підписання сертифіката.
Kubelet отримає підписаний сертифікат від Kubernetes API та запише його на диск у місці, вказаному параметром --cert-dir. Потім kubelet використовуватиме новий сертифікат для приєднання до Kubernetes API.
Коли наближається закінчення терміну дії підписаного сертифіката, kubelet автоматично надішле новий запит на підписання сертифіката, використовуючи Kubernetes API. Це може статись у будь-який момент між 30% та 10% залишкового часу дії сертифіката. Знову ж таки, менеджер контролерів автоматично схвалить запит на сертифікат і прикріпить підписаний сертифікат до запиту на підписання сертифіката. Kubelet отримає новий підписаний сертифікат від Kubernetes API та запише його на диск. Потім він оновить зʼєднання з Kubernetes API, щоб приєднатись за допомогою нового сертифіката.
12.3 - Ручна ротація сертифікатів центру сертифікації (CA)
Ця сторінка показує, як робити вручну ротацію сертифікатів центру сертифікації (CA).
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Для отримання додаткової інформації про автентифікацію в Kubernetes, див.
Автентифікація.
Для отримання додаткової інформації про найкращі практики для сертифікатів CA, див. Один кореневий CA.
Ручна ротація сертифікатів CA
Увага:
Обовʼязково створіть резервну копію вашої теки сертифікатів разом із конфігураційними файлами та будь-якими іншими необхідними файлами.
Цей підхід передбачає роботу панелі управління Kubernetes у конфігурації HA з декількома серверами API. Передбачається також коректне завершення роботи сервера API, щоб клієнти могли чисто відʼєднатися від одного сервера API та приєднатися до іншого.
Конфігурації з одним сервером API потрапляють в стан недоступності під час перезавантаження сервера API.
Розподіліть нові сертифікати CA та приватні ключі (наприклад: ca.crt, ca.key, front-proxy-ca.crt і front-proxy-ca.key) на всі вузли вашої панелі управління у теці сертифікатів Kubernetes.
Оновіть прапорець --root-ca-file для kube-controller-manager, щоб включити як старий, так і новий CA, після чого перезавантажте kube-controller-manager.
Будь-який ServiceAccount, створений після цього, отримає Secretʼи, що містять як старий, так і новий CA.
Примітка:
Файли, зазначені у прапорцях kube-controller-manager --client-ca-file та --cluster-signing-cert-file, не можуть бути наборами CA. Якщо ці прапорці та --root-ca-file вказують на один і той же файл ca.crt, який зараз є набором (включає як старий, так і новий CA), ви зіткнетеся з помилкою. Щоб обійти цю проблему, ви можете скопіювати новий CA до окремого файлу та змусити прапорці --client-ca-file та --cluster-signing-cert-file вказувати на копію. Коли ca.crt більше не буде набором, ви можете повернути проблемні прапорці, щоб вказувати на ca.crt, та видалити копію.
Issue 1350 для kubeadm відстежує помилку з тим, що kube-controller-manager не може прийняти набір CA.
Зачекайте, поки менеджер контролерів оновить ca.crt у Secretʼах облікових записів сервісів, щоб включити як старі, так і нові сертифікати CA.
Якщо будь-які Podʼи були запущені до того, як новий CA буде використаний серверами API, нові Podʼи отримають це оновлення та будуть довіряти як старим, так і новим CA.
Перезавантажте всі Podʼи, що використовують внутрішні конфігурації (наприклад: kube-proxy, CoreDNS тощо), щоб вони могли використовувати оновлені дані сертифікату центру сертифікації із Secretʼів, що повʼязані з ServiceAccounts.
Переконайтеся, що CoreDNS, kube-proxy та інші Podʼи, що використовують внутрішні конфігурації, працюють належним чином.
Додайте як старий, так і новий CA до файлу, зазначеного у прапорці --client-ca-file та --kubelet-certificate-authority в конфігурації kube-apiserver.
Додайте як старий, так і новий CA до файлу, зазначеного у прапорці --client-ca-file в конфігурації kube-scheduler.
Оновіть сертифікати для облікових записів користувачів, замінивши вміст client-certificate-data та client-key-data.
Крім того, оновіть розділ certificate-authority-data у kubeconfig файлах, відповідно до закодованих у Base64 даних старого та нового центру сертифікації.
Оновіть прапорець --root-ca-file для Cloud Controller Manager, щоб включити як старий, так і новий CA, після чого перезавантажте cloud-controller-manager.
Примітка:
Якщо ваш кластер не має cloud-controller-manager, ви можете пропустити цей крок.
Виконайте наступні кроки поступово.
Перезавантажте будь-які інші агреговані сервери API або обробники вебхуків, щоб довіряти новим сертифікатам CA.
Перезавантажте kubelet, оновивши файл, зазначений у clientCAFile в конфігурації kubelet, та certificate-authority-data у kubelet.conf, щоб використовувати як старий, так і новий CA на всіх вузлах.
Якщо ваш kubelet не використовує ротацію клієнтських сертифікатів, оновіть client-certificate-data та client-key-data у kubelet.conf на всіх вузлах разом із файлом клієнтського сертифіката kubelet, зазвичай розташованим у /var/lib/kubelet/pki.
Перезавантажте сервери API із сертифікатами (apiserver.crt, apiserver-kubelet-client.crt та front-proxy-client.crt), підписаними новим CA. Ви можете використовувати наявні приватні ключі або нові приватні ключі. Якщо ви змінили приватні ключі, то також оновіть їх у теці сертифікатів Kubernetes.
Оскільки Podʼи у вашому кластері довіряють як старим, так і новим CA, буде короткочасне відключення, після чого клієнти Kubernetes у Podʼах переприєднаються до нового сервера API. Новий сервер API використовує сертифікат, підписаний новим CA.
Перезавантажте kube-scheduler, щоб використовувати та
довіряти новим CA.
Переконайтеся, що логи компонентів панелі управління не містять помилок TLS.
Примітка:
Для генерації сертифікатів та приватних ключів для вашого кластера за допомогою `openssl`, див. [Сертифікати (`openssl`)](/docs/tasks/administer-cluster/certificates/#openssl). Ви також можете використовувати [`cfssl`](/docs/tasks/administer-cluster/certificates/#cfssl).
Анотуйте будь-які DaemonSets та Deployments, щоб викликати заміну Podʼів у більш безпечний спосіб.
for namespace in $(kubectl get namespace -o jsonpath='{.items[*].metadata.name}'); dofor name in $(kubectl get deployments -n $namespace -o jsonpath='{.items[*].metadata.name}'); do kubectl patch deployment -n ${namespace}${name} -p '{"spec":{"template":{"metadata":{"annotations":{"ca-rotation": "1"}}}}}';
donefor name in $(kubectl get daemonset -n $namespace -o jsonpath='{.items[*].metadata.name}'); do kubectl patch daemonset -n ${namespace}${name} -p '{"spec":{"template":{"metadata":{"annotations":{"ca-rotation": "1"}}}}}';
donedone
Примітка:
Щоб обмежити кількість одночасних порушень, з якими стикається ваш застосунок, див. [налаштування бюджетів порушень Podʼів](/docs/tasks/run-application/configure-pdb/).
Залежно від того, як ви використовуєте StatefulSets, вам також може знадобитися виконати подібну поступову заміну.
Якщо ваш кластер використовує токени для початкового завантаження для приєднання вузлів, оновіть ConfigMap cluster-info в просторі імен kube-public з новим CA.
Перевірте логи компонентів панелі управління, а також kubelet та kube-proxy. Переконайтеся, що ці компоненти не повідомляють про помилки TLS; див. перегляд журналів для отримання додаткових деталей.
Перевірте логи будь-яких агрегованих серверів API та Podʼів, що використовують внутрішню конфігурацію.
Після успішної перевірки функціональності кластера:
Оновіть всі токени службових облікових записів, щоб включити лише новий сертифікат CA.
Всі Podʼи, що використовують внутрішній kubeconfig, згодом потрібно буде перезапустити, щоб отримати новий Secret, щоб жоден Pod не залежав від старого CA кластера.
Перезавантажте компоненти панелі управління, видаливши старий CA з kubeconfig файлів та файлів, зазначених у прапорцях --client-ca-file та --root-ca-file.
На кожному вузлі перезавантажте kubelet, видаливши старий CA з файлу, зазначеного у прапорі clientCAFile, та з файлу kubeconfig для kubelet. Ви повинні виконати це як поступове оновлення.
Якщо ваш кластер дозволяє вам внести цю зміну, ви також можете здійснити це шляхом заміни вузлів, а не їх переконфігурування.
12.4 - Управління TLS сертифікатами в кластері
Kubernetes надає API certificates.k8s.io, який дозволяє вам отримувати TLS сертифікати, підписані Центром Сертифікації (CA), який ви контролюєте. Ці CA та сертифікати можуть використовуватися вашими робочими навантаженнями для встановлення довіри.
API certificates.k8s.io використовує протокол, подібний до чернетки ACME.
Примітка:
Сертифікати, створені за допомогою API certificates.k8s.io, підписуються
спеціальним CA. Можливо налаштувати ваш кластер так, щоб використовувати кореневий кластерний CA для цієї мети, але не слід на це покладатися. Не припускайте, що ці сертифікати будуть перевірятися кореневим кластерним CA.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Деякі кроки на цій сторінці використовують інструмент jq. Якщо у вас його немає, ви можете встановити його через джерела програмного забезпечення вашої операційної системи або завантажити з https://jqlang.github.io/jq/.
Довіра до TLS в кластері
Довіра до власного CA з боку застосунків, що працюють як Podʼи, зазвичай вимагає додаткової конфігурації. Вам потрібно додати пакет сертифікатів CA до списку сертифікатів CA, яким довіряє TLS клієнт або сервер. Наприклад, ви можете зробити це за допомогою налаштування TLS в Golang, проаналізувавши ланцюжок сертифікатів і додавши проаналізовані сертифікати до поля RootCAs в структурі tls.Config.
Примітка:
Навіть якщо власний сертифікат CA може бути включений у файлову систему (в ConfigMap kube-root-ca.crt), не слід використовувати цей центр сертифікації для будь-якої мети, окрім перевірки внутрішніх точок доступу Kubernetes. Прикладом внутрішньої точки доступу Kubernetes є
Service з іменем kubernetes в просторі імен default. Якщо ви хочете використовувати власний центр сертифікації для ваших робочих навантажень, слід створити цей CA окремо та розповсюдити його сертифікат CA за допомогою ConfigMap, до якого ваші Podʼи мають доступ для читання.
Запит сертифіката
Наступний розділ демонструє, як створити TLS сертифікат для Kubernetes сервісу, до якого звертаються через DNS.
Примітка:
Цей підручник використовує CFSSL: інструментарій PKI та TLS від Cloudflare натисніть тут, щоб дізнатися більше.
Створення запиту на підписання сертифіката
Згенеруйте приватний ключ і запит на підписання сертифіката (або CSR), виконавши наступну команду:
Де 192.0.2.24 — це кластерний IP Serviceʼу, my-svc.my-namespace.svc.cluster.local — це DNS-імʼя Serviceʼу, 10.0.34.2 —це IP Podʼа, а my-pod.my-namespace.pod.cluster.local — це DNS-імʼя Podʼа. Ви повинні побачити вивід подібний до:
Ця команда генерує два файли; server.csr, що містить PEM закодований PKCS#10 запит на сертифікат, і server-key.pem, що містить PEM закодований ключ до сертифіката, який ще потрібно створити.
Створення обʼєкта CertificateSigningRequest для надсилання до Kubernetes API
Згенеруйте маніфест CSR (у форматі YAML) і надішліть його на сервер API. Ви можете зробити це, виконавши наступну команду:
Зверніть увагу, що файл server.csr, створений на кроці 1, кодується base64 та зберігається в полі .spec.request. Ви також запитуєте сертифікат з використанням ключів "digital signature", "key encipherment" і "server auth", підписаний підписувачем example.com/serving. Повинен бути запитаний конкретний signerName. Перегляньте документацію для підтримуваних імен підписувачів для отримання додаткової інформації.
CSR тепер має бути видимий з API у стані Pending. Ви можете побачити це, виконавши:
kubectl describe csr my-svc.my-namespace
Name: my-svc.my-namespace
Labels: <none>
Annotations: <none>
CreationTimestamp: Tue, 01 Feb 2022 11:49:15 -0500
Requesting User: yourname@example.com
Signer: example.com/serving
Status: Pending
Subject:
Common Name: my-pod.my-namespace.pod.cluster.local
Serial Number:
Subject Alternative Names:
DNS Names: my-pod.my-namespace.pod.cluster.local
my-svc.my-namespace.svc.cluster.local
IP Addresses: 192.0.2.24
10.0.34.2
Events: <none>
Отримання схвалення CertificateSigningRequest
Схвалення запиту на підписання сертифіката виконується або автоматичною процедурою схвалення, або одноразово адміністратором кластера. Якщо у вас є дозвіл на схвалення запиту на сертифікат, ви можете зробити це вручну за допомогою kubectl; наприклад:
NAME AGE SIGNERNAME REQUEST
OR REQUESTEDDURATION CONDITION
my-svc.my-namespace 10m example.com/serving yourname@example.com <none> Approved
Це означає, що запит на сертифікат був схвалений і чекає на
підписання запрошеним підписувачем.
Підписання CertificateSigningRequest
Далі ви зіграєте роль підписувача сертифікатів, видасте сертифікат і завантажите його в API.
Підписувач зазвичай спостерігає за API CertificateSigningRequest для обʼєктів з його signerName, перевіряє, що вони були схвалені, підписує сертифікати для цих запитів, і оновлює статус обʼєкта API з виданим сертифікатом.
Створення Центру Сертифікації
Вам потрібен центр сертифікації, щоб забезпечити цифровий підпис нового сертифікату.
Спочатку створіть підписний сертифікат, виконавши наступне:
cat <<EOF | cfssl gencert -initca - | cfssljson -bare ca
{
"CN": "My Example Signer",
"key": {
"algo": "rsa",
"size": 2048
}
}
EOF
Ви повинні побачити вивід подібний до:
2022/02/01 11:50:39 [INFO] generating a new CA key and certificate from CSR
2022/02/01 11:50:39 [INFO] generate received request
2022/02/01 11:50:39 [INFO] received CSR
2022/02/01 11:50:39 [INFO] generating key: rsa-2048
2022/02/01 11:50:39 [INFO] encoded CSR
2022/02/01 11:50:39 [INFO] signed certificate with serial number 263983151013686720899716354349605500797834580472
Це створює файл ключа центру сертифікації (ca-key.pem) і сертифікат (ca.pem).
Це використовує інструмент jq для заповнення вмісту, закодованого base64, в поле .status.certificate. Якщо у вас немає jq, ви також можете зберегти вивід JSON у файл, вручну заповнити це поле і завантажити отриманий файл.
Після схвалення CSR і завантаження підписаного сертифіката, виконайте:
kubectl get csr
Вивід буде подібним до:
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
my-svc.my-namespace 20m example.com/serving yourname@example.com <none> Approved,Issued
Завантаження сертифіката та його використання
Тепер, як запитувач, ви можете завантажити виданий сертифікат і зберегти його у файл server.crt, виконавши наступне:
Тепер ви можете заповнити server.crt і server-key.pem у Секрет, який ви можете пізніше монтувати в Pod (наприклад, для використання з вебсервером,
який обслуговує HTTPS).
kubectl create secret tls server --cert server.crt --key server-key.pem
secret/server created
Нарешті, ви можете заповнити ca.pem у ConfigMap і використовувати його як кореневий довірчий сертифікат для перевірки серверного сертифіката:
Адміністратор Kubernetes (з відповідними дозволами) може вручну схвалювати
(або відхиляти) CertificateSigningRequests за допомогою команд kubectl certificate approve та kubectl certificate deny. Однак, якщо ви плануєте активно використовувати цей API, варто розглянути можливість написання автоматизованого контролера сертифікатів.
Увага:
Можливість схвалювати CSR вирішує, хто кому довіряє у вашому середовищі. Це повноваження не слід надавати широко або легковажно.
Слід переконатися, що ви впевнено розумієте як вимоги щодо перевірки, так і наслідки видачі конкретного сертифіката перед тим, як надати дозвіл на approve.
Чи це буде машина або людина, яка використовує kubectl, роль схвалювача полягає у перевірці, що CSR відповідає двом вимогам:
Субʼєкт CSR контролює приватний ключ, який використовується для підписання CSR. Це зменшує ризик того, що є третя сторона, яка видає себе за авторизованого субʼєкта. У вищезазначеному прикладі цей крок передбачає перевірку того, що Pod контролює приватний ключ, який використовується для створення CSR.
Субʼєкт CSR має право діяти в запитуваному контексті. Це зменшує ризик появи небажаного субʼєкта, який приєднується до кластера. У вищезазначеному прикладі цей крок передбачає перевірку того, що Pod має дозвіл на участь у запитуваному сервісі.
Якщо і тільки якщо ці дві вимоги виконані, схвалювач повинен схвалити CSR інакше він повинен відхилити CSR.
Для отримання додаткової інформації про схвалення сертифікатів та контроль доступу, прочитайте сторінку довідника Запити на підписання сертифікатів.
Налаштування вашого кластера для виконання накладання підписів
Ця сторінка припускає, що підписувач налаштований для обслуговування API сертифікатів. Менеджер контролерів Kubernetes надає стандартну реалізацію підписувача. Щоб увімкнути його, передайте параметри --cluster-signing-cert-file та --cluster-signing-key-file до менеджера контролерів з шляхами до пари ключів вашого центру сертифікації.
13 - Керування фоновими процесами кластера
Виконуйте загальні завдання для керування DaemonSet, такі як виконання поступового оновлення.
13.1 - Створення базового DaemonSet
Ця сторінка демонструє, як створити базовий DaemonSet, який запускає Pod на кожному вузлі в кластері Kubernetes. Вона охоплює простий випадок монтування файлу з хоста, запису його вмісту за допомогою контейнера ініціалізації та використання контейнера паузи.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Кластер Kubernetes з принаймні двома вузлами (один вузол панелі управління та один робочий вузол), щоб продемонструвати поведінку DaemonSets.
Визначення DaemonSet
У цьому завданні створюється базовий DaemonSet, який забезпечує, що копія Pod запланована на кожному вузлі. Pod буде використовувати контейнер ініціалізації для читання та запису вмісту /etc/machine-id з хосту, у той час, як основний контейнер буде контейнером pause, який підтримує роботу Pod.
Цей простий приклад DaemonSet вводить ключові компоненти, такі як контейнери ініціалізації та томи шляху хосту, які можна розширити для складніших випадків використання. Для отримання додаткової інформації зверніться до DaemonSet.
Ця сторінка показує, як виконати поетапне оновлення (rolling update) DaemonSet.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
OnDelete: Зі стратегією оновлення OnDelete, після оновлення шаблону DaemonSet нові Podʼи DaemonSet будуть створюватися лише після вручну видалених старих Podʼів DaemonSet. Це та ж поведінка, що й у версії Kubernetes 1.5 або раніше.
RollingUpdate: Це стандартна стратегія оновлення. Зі стратегією оновлення RollingUpdate, після оновлення шаблону DaemonSet старі Podʼи DaemonSet будуть видалені, і нові Podʼи DaemonSet будуть створені автоматично, у контрольованому режимі. Під час усього процесу оновлення на кожному вузлі працюватиме максимум один Pod DaemonSet.
Виконання поетапного оновлення
Щоб увімкнути функцію поетапного оновлення DaemonSet, необхідно встановити
.spec.updateStrategy.type на RollingUpdate.
apiVersion:apps/v1kind:DaemonSetmetadata:name:fluentd-elasticsearchnamespace:kube-systemlabels:k8s-app:fluentd-loggingspec:selector:matchLabels:name:fluentd-elasticsearchupdateStrategy:type:RollingUpdaterollingUpdate:maxUnavailable:1template:metadata:labels:name:fluentd-elasticsearchspec:tolerations:# ці tolerations дозволяють запускати DaemonSet на вузлах панелі управління# видаліть їх, якщо ваші вузли панелі управління не повинні запускати Podʼи- key:node-role.kubernetes.io/control-planeoperator:Existseffect:NoSchedule- key:node-role.kubernetes.io/masteroperator:Existseffect:NoSchedulecontainers:- name:fluentd-elasticsearchimage:quay.io/fluentd_elasticsearch/fluentd:v5.0.1volumeMounts:- name:varlogmountPath:/var/log- name:varlibdockercontainersmountPath:/var/lib/docker/containersreadOnly:trueterminationGracePeriodSeconds:30volumes:- name:varloghostPath:path:/var/log- name:varlibdockercontainershostPath:path:/var/lib/docker/containers
Після перевірки стратегії оновлення в маніфесті DaemonSet, створіть DaemonSet:
Якщо вивід не RollingUpdate, поверніться назад і змініть обʼєкт DaemonSet або його маніфест відповідно.
Оновлення шаблону DaemonSet
Будь-які оновлення до .spec.templateRollingUpdate DaemonSet викличуть поетапне оновлення. Оновімо DaemonSet, застосувавши новий YAML файл. Це можна зробити за допомогою кількох різних команд kubectl.
apiVersion:apps/v1kind:DaemonSetmetadata:name:fluentd-elasticsearchnamespace:kube-systemlabels:k8s-app:fluentd-loggingspec:selector:matchLabels:name:fluentd-elasticsearchupdateStrategy:type:RollingUpdaterollingUpdate:maxUnavailable:1template:metadata:labels:name:fluentd-elasticsearchspec:tolerations:# ці tolerations дозволяють запускати DaemonSet на вузлах панелі управління# видаліть їх, якщо ваші вузли панелі управління не повинні запускати Podʼи- key:node-role.kubernetes.io/control-planeoperator:Existseffect:NoSchedule- key:node-role.kubernetes.io/masteroperator:Existseffect:NoSchedulecontainers:- name:fluentd-elasticsearchimage:quay.io/fluentd_elasticsearch/fluentd:v5.0.1resources:limits:memory:200Mirequests:cpu:100mmemory:200MivolumeMounts:- name:varlogmountPath:/var/log- name:varlibdockercontainersmountPath:/var/lib/docker/containersreadOnly:trueterminationGracePeriodSeconds:30volumes:- name:varloghostPath:path:/var/log- name:varlibdockercontainershostPath:path:/var/lib/docker/containers
Декларативні команди
Якщо ви оновлюєте DaemonSets за допомогою конфігураційних файлів, використовуйте kubectl apply:
Якщо вам потрібно оновити лише образ контейнера у шаблоні DaemonSet, тобто
.spec.template.spec.containers[*].image, використовуйте kubectl set image:
kubectl set image ds/fluentd-elasticsearch fluentd-elasticsearch=quay.io/fluentd_elasticsearch/fluentd:v2.6.0 -n kube-system
Спостереження за станом поетапного оновлення
Нарешті, спостерігайте за станом останнього поетапного оновлення DaemonSet:
kubectl rollout status ds/fluentd-elasticsearch -n kube-system
Коли оновлення завершиться, вивід буде подібний до цього:
daemonset "fluentd-elasticsearch" successfully rolled out
Усунення несправностей
Поетапне оновлення DaemonSet застрягло
Іноді поетапне оновлення DaemonSet може застрягнути. Ось деякі можливі причини:
Деякі вузли вичерпали ресурси
Оновлення застрягло, оскільки нові Podʼи DaemonSet не можуть бути заплановані на принаймні один вузол. Це можливо, коли вузол вичерпує ресурси.
Коли це трапляється, знайдіть вузли, на яких не заплановані Podʼи DaemonSet, порівнявши вихід kubectl get nodes з виходом:
kubectl get pods -l name=fluentd-elasticsearch -o wide -n kube-system
Після того, як ви знайдете ці вузли, видаліть деякі не-DaemonSet Podʼи з вузла, щоб звільнити місце для нових Podʼіів DaemonSet.
Примітка:
Це викличе переривання обслуговування, коли видалені Podʼи не контролюються жодними контролерами або Podʼи не реплікуються. Це також не враховує PodDisruptionBudget.
Неправильне оновлення
Якщо недавнє оновлення шаблону DaemonSet є неправильним, наприклад, контейнер зациклюється або образ контейнера не існує (часто через помилку у назві), поетапне оновлення DaemonSet не просуватиметься.
Щоб виправити це, оновіть шаблон DaemonSet ще раз. Нове оновлення не буде блокуватися попередніми несправними оновленнями.
Невідповідність годинників
Якщо у DaemonSet задано значення .spec.minReadySeconds, невідповідність годинників між мастером та вузлами зробить DaemonSet нездатним визначити правильний прогрес оновлення.
Ця сторінка показує, як виконати відкат на DaemonSet.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Причина зміни копіюється з анотації DaemonSet kubernetes.io/change-cause до його ревізій під час створення. Ви можете вказати --record=true в kubectl, щоб записати команду, виконану в анотації причини зміни.
Щоб переглянути деталі конкретної ревізії:
kubectl rollout history daemonset <daemonset-name> --revision=1
Крок 2: Поверніться до конкретної ревізії DaemonSet
# Вкажіть номер ревізії, отриманий на кроці 1, у --to-revisionkubectl rollout undo daemonset <daemonset-name> --to-revision=<revision>
Якщо команда успішна, вона поверне:
daemonset "<daemonset-name>" rolled back
Примітка:
Якщо прапорець --to-revision не вказано, kubectl обирає найновішу ревізію.
Крок 3: Спостерігайте за процесом відкату DaemonSet
kubectl rollout undo daemonset вказує серверу почати відкочування
DaemonSet. Реальний відкат виконується асинхронно всередині панелі управління кластера.
Щоб спостерігати за процесом відкату:
kubectl rollout status ds/<daemonset-name>
Коли відкочування завершиться, вивід буде подібним до цього:
daemonset "<daemonset-name>" successfully rolled out
Розуміння ревізій DaemonSet
У попередньому кроці kubectl rollout history ви отримали список ревізій DaemonSet. Кожна ревізія зберігається в ресурсі під назвою ControllerRevision.
Щоб побачити, що зберігається в кожній ревізії, знайдіть сирцеві ресурси ревізії DaemonSet:
kubectl get controllerrevision -l <daemonset-selector-key>=<daemonset-selector-value>
Це поверне список ControllerRevisions:
NAME CONTROLLER REVISION AGE
<daemonset-name>-<revision-hash> DaemonSet/<daemonset-name> 1 1h
<daemonset-name>-<revision-hash> DaemonSet/<daemonset-name> 2 1h
Кожен ControllerRevision зберігає анотації та шаблон ревізії DaemonSet.
kubectl rollout undo бере конкретний ControllerRevision і замінює шаблон DaemonSet на шаблон, збережений у ControllerRevision. kubectl rollout undo еквівалентний оновленню шаблону DaemonSet до попередньої ревізії за допомогою інших команд, таких як kubectl edit або kubectl apply.
Примітка:
Ревізії DaemonSet завжди рухаються вперед. Тобто, після завершення відкату номер ревізії (поле .revision) ControllerRevision, до якого було виконано відкат, збільшиться. Наприклад, якщо у вас є ревізії 1 і 2 в системі, і ви повертаєтеся з ревізії 2 до ревізії 1, ControllerRevision з .revision: 1 стане .revision: 3.
Ця сторінка демонструє, як можна запускати Podʼи лише на деяких вузлах як частину DaemonSet
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Уявімо, що ви хочете запустити DaemonSet, але вам потрібно запускати ці Pod демонів
лише на вузлах, які мають локальне SSD-сховище. Наприклад, Pod може надавати кеш-сервіс для вузла, і кеш корисний тільки тоді, коли доступне локальне сховище з низькою затримкою.
Створіть DaemonSet з маніфесту, використовуючи kubectl create або kubectl apply.
Додамо мітку ще одному вузлу ssd=true.
kubectl label nodes example-node-3 ssd=true
Додавання мітки вузлу автоматично запускає панель управління (конкретно, контролер DaemonSet), щоб запустити новий Pod для демона на цьому вузлі.
kubectl get pods -o wide
Вивід буде схожим на:
NAME READY STATUS RESTARTS AGE IP NODE
<daemonset-name><some-hash-01> 1/1 Running 0 13s ..... example-node-1
<daemonset-name><some-hash-02> 1/1 Running 0 13s ..... example-node-2
<daemonset-name><some-hash-03> 1/1 Running 0 5s ..... example-node-3
14 - Мережа
Дізнайтесь, як налаштувати мережу для вашого кластера Kubernetes.
14.1 - Додавання записів до файлу /etc/hosts у Pod за допомогою HostAliases
Додавання записів до файлу /etc/hosts у Pod надає можливість перевизначення розподілу імен на рівні Pod, коли DNS та інші параметри не застосовуються. Ви можете додавати ці власні записи за допомогою поля HostAliases у PodSpec.
Проєкт Kubernetes рекомендує змінювати конфігурацію DNS за допомогою поля hostAliases (частина файлу .spec для Podʼа), а не за допомогою контейнера init або інших засобів для редагування безпосередньо /etc/hosts. Зміни, внесені в інший спосіб, можуть бути перезаписані kubelet під час створення або перезапуску Pod.
Типовий вміст файлу hosts
Запустіть Pod з Nginx, який має призначену IP-адресу Podʼа:
kubectl run nginx --image nginx
pod/nginx created
Перевірте IP-адресу Podʼа:
kubectl get pods --output=wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
Типово файл hosts містить тільки шаблони IPv4 та IPv6, такі як localhost та власне імʼя хосту.
Додавання додаткових записів за допомогою hostAliases
Крім стандартних шаблонів, ви можете додати додаткові записи до файлу hosts. Наприклад: щоб перевести foo.local, bar.local в 127.0.0.1 та foo.remote, bar.remote в 10.1.2.3, ви можете налаштувати HostAliases для Pod в підполі .spec.hostAliases:
kubelet керує файлом hosts для кожного контейнера Podʼа, щоб запобігти модифікації файлу контейнерним середовищем після того, як контейнери вже були запущені. Історично Kubernetes завжди використовував Docker Engine як своє контейнерне середовище, і Docker Engine модифікував файл /etc/hosts після запуску кожного контейнера.
Поточна версія Kubernetes може використовувати різні контейнерні середовища; проте, kubelet керує файлом hosts у кожному контейнері, щоб результат був таким, як очікувалося, незалежно від використаного контейнерного середовища.
Увага:
Уникайте внесення ручних змін до файлу hosts всередині контейнера.
Якщо ви вносите ручні зміни до файлу hosts, ці зміни будуть втрачені при виході з контейнера.
14.2 - Розширення діапазонів IP Service
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [stable](стандартно увімкнено)
У цьому документі описано, як розширити наявний діапазон IP-адрес, призначених Serviceʼу в кластері.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.29.
Для перевірки версії введіть kubectl version.
Примітка:
Хоча ви можете використовувати цю функцію в більш ранніх версіях, вона доступна лише в GA і офіційно підтримується починаючи з версії 1.33.
Розширені діапазони Service IP
Кластери Kubernetes з kube-apiservers, у яких увімкнено функціональну можливістьMultiCIDRServiceAllocator та API група networking.k8s.io/v1, створюватимуть обʼєкт ServiceCIDR, який має відоме імʼя kubernetes, та визначатимуть діапазон IP-адрес, заснований на значенні аргументу командного рядка --service-cluster-ip-range для kube-apiserver.
kubectl get servicecidr
NAME CIDRS AGE
kubernetes 10.96.0.0/28 17d
Відомий сервіс kubernetes, який використовується для відкриття точки доступу kube-apiserver для Podʼів, обчислює першу IP-адресу зі стандартного діапазону ServiceCIDR та використовує цю IP-адресу як свою кластерну IP-адресу.
kubectl get service kubernetes
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 17d
Стандартний Service у цьому випадку використовує ClusterIP 10.96.0.1, що має відповідний обʼєкт IPAddress.
kubectl get ipaddress 10.96.0.1
NAME PARENTREF
10.96.0.1 services/default/kubernetes
ServiceCIDRs захищені за допомогою завершувачів, щоб уникнути залишання Service ClusterIPs сиріт; завершувач видаляється лише в разі, якщо існує інша підмережа, яка містить наявні IP-адреси або немає IP-адрес, що належать до підмережі.
Розширення кількості доступних IP для Service
Існують випадки, коли користувачам потрібно збільшити кількість доступних адрес для Serviceʼів; раніше, збільшення діапазону Service було руйнівною операцією, яка також може призвести до втрати даних. З цією новою функцією користувачам потрібно лише додати новий ServiceCIDR, щоб збільшити кількість доступних адрес.
Додавання нового ServiceCIDR
У кластері з діапазоном 10.96.0.0/28 для Serviceʼів доступно лише 2^(32-28) - 2 = 14 IP-адрес. Service kubernetes.default завжди створюється; для цього прикладу у вас залишається лише 13 можливих Serviceʼів.
for i in $(seq 1 13); do kubectl create service clusterip "test-$i" --tcp 80 -o json | jq -r .spec.clusterIP; done
10.96.0.11
10.96.0.5
10.96.0.12
10.96.0.13
10.96.0.14
10.96.0.2
10.96.0.3
10.96.0.4
10.96.0.6
10.96.0.7
10.96.0.8
10.96.0.9
error: failed to create ClusterIP service: Internal error occurred: failed to allocate a serviceIP: range is full
Ви можете збільшити кількість IP-адрес, доступних для Serviceʼів, створивши новий ServiceCIDR, який розширює або додає нові діапазони IP-адрес.
це дозволить вам створювати нові Service з ClusterIP, які будуть вибрані з цього нового діапазону.
for i in $(seq 13 16); do kubectl create service clusterip "test-$i" --tcp 80 -o json | jq -r .spec.clusterIP; done
10.96.0.48
10.96.0.200
10.96.0.121
10.96.0.144
Видалення ServiceCIDR
Ви не можете видалити ServiceCIDR, якщо існують IP-адреси, які залежать від ServiceCIDR.
kubectl delete servicecidr newcidr1
servicecidr.networking.k8s.io "newcidr1" deleted
Kubernetes використовує завершувач на ServiceCIDR для відстеження цього залежного відношення.
kubectl get servicecidr newcidr1 -o yaml
apiVersion:networking.k8s.io/v1kind:ServiceCIDRmetadata:creationTimestamp:"2023-10-12T15:11:07Z"deletionGracePeriodSeconds:0deletionTimestamp:"2023-10-12T15:12:45Z"finalizers:- networking.k8s.io/service-cidr-finalizername:newcidr1resourceVersion:"1133"uid:5ffd8afe-c78f-4e60-ae76-cec448a8af40spec:cidrs:- 10.96.0.0/24status:conditions:- lastTransitionTime:"2023-10-12T15:12:45Z"message:There are still IPAddresses referencing the ServiceCIDR, please removethem or create a new ServiceCIDRreason:OrphanIPAddressstatus:"False"type:Ready
Видаляючи Serviceʼи, що містять IP-адреси, які блокують видалення ServiceCIDR
for i in $(seq 13 16); do kubectl delete service "test-$i" ; done
service "test-13" deleted
service "test-14" deleted
service "test-15" deleted
service "test-16" deleted
панель управління помічає видалення. Панель управління потім видаляє свій завершувач, так що ServiceCIDR, який був у черзі на видалення, фактично буде видалено.
kubectl get servicecidr newcidr1
Error from server (NotFound): servicecidrs.networking.k8s.io "newcidr1" not found
Політики Kubernetes Service CIDR
Адміністратори кластера можуть застосовувати політики для керування створенням і зміною ресурсів ServiceCIDR у кластері. Це дозволяє централізовано керувати діапазонами IP-адрес, які використовуються для Services, і допомагає запобігти ненавмисним або конфліктним конфігураціям. Kubernetes надає такі механізми, як Validating Admission Policies (Перевірка політик допуску) для забезпечення дотримання цих правил.
Запобігання несанкціонованому створенню/оновленню ServiceCIDR з використанням політики перевірки допуску
Бувають ситуації, коли адміністратори кластера хочуть обмежити діапазони, які можна дозволити, або повністю заборонити будь-які зміни в діапазонах IP-адрес Service кластера.
Примітка:
Стандартний ServiceCIDR "kubernetes" створюється kube-apiserver для забезпечення узгодженості у кластері і є необхідним для роботи кластера, тому він завжди має бути дозволений. Ви можете переконатися, що ваша ValidatingAdmissionPolicy не обмежує стандартно ServiceCIDR, додавши цей пункт:
Обмеження діапазонів Service CIDR конкретними діапазонами
Нижче наведено приклад політики ValidatingAdmissionPolicy, яка дозволяє створювати ServiceCIDR, тільки якщо вони є піддіапазонами заданих allowed діапазонів. (Таким чином, у прикладі політики буде дозволено створення ServiceCIDR з cidrs: ['10.96.1.0/24'] або cidrs: ['2001:db8:0:0:ffff::/80', '10.96.0.0/20'] але не дозволить ServiceCIDR з cidrs: ['172.20.0.0/16'].) Ви можете скопіювати цю політику і змінити значення allowed на відповідне для вашого кластера.
apiVersion:admissionregistration.k8s.io/v1kind:ValidatingAdmissionPolicymetadata:name:"servicecidrs.default"spec:failurePolicy:FailmatchConstraints:resourceRules:- apiGroups:["networking.k8s.io"]apiVersions:["v1"]operations:["CREATE","UPDATE"]resources:["servicecidrs"]matchConditions:- name:'exclude-default-servicecidr'expression:"object.metadata.name != 'kubernetes'"variables:- name:allowedexpression:"['10.96.0.0/16','2001:db8::/64']"validations:- expression:"object.spec.cidrs.all(newCIDR, variables.allowed.exists(allowedCIDR, cidr(allowedCIDR).containsCIDR(newCIDR)))"# Для всіх CIDR (newCIDR), перерахованих в spec.cidrs переданого обʼєкту ServiceCIDR# перевірити, чи існує хоча б один CIDR (allowedCIDR) у списку `allowed`.# списку VAP такий, що allowedCIDR повністю містить newCIDR.---apiVersion:admissionregistration.k8s.io/v1kind:ValidatingAdmissionPolicyBindingmetadata:name:"servicecidrs-binding"spec:policyName:"servicecidrs.default"validationActions:[Deny,Audit]
Зверніться до документації CEL, щоб дізнатися більше про CEL, якщо ви хочете написати власний валідаційний expression.
Обмеження будь-якого використання API ServiceCIDR
Наступний приклад демонструє, як використовувати ValidatingAdmissionPolicy та її привʼязку для обмеження створення будь-яких нових діапазонів Service CIDR, окрім стандартного ServiceCIDR "kubernetes":
14.3 - Перевірка наявності підтримки подвійного стеку IPv4/IPv6
Цей документ розповідає, як перевірити підтримку dual-stack IPv4/IPv6 в увімкнених кластерах Kubernetes.
Перш ніж ви розпочнете
Підтримка постачальника для мереж з підтримкою подвійного стека (постачальник хмарних послуг або інший постачальник повинен забезпечити вузлам Kubernetes мережеві інтерфейси з маршрутними IPv4/IPv6)
Версія вашого Kubernetes сервера має бути не старішою ніж v1.23.
Для перевірки версії введіть kubectl version.
Примітка:
Хоча ви можете перевірити це за допомогою попередньої версії, функція доступна та офіційно підтримується лише починаючи з v1.23.
Перевірка адресації
Перевірка адресування вузлів
Кожен вузол з подвійним стеком має мати виділені один блок IPv4 та один блок IPv6. Перевірте, що діапазони адрес IPv4/IPv6 для Pod налаштовані за допомогою наступної команди. Замініть імʼя вузла з прикладу на наявний вузол з подвійним стеком у вашому кластері. У цьому прикладі імʼя вузла — k8s-linuxpool1-34450317-0:
kubectl get nodes k8s-linuxpool1-34450317-0 -o go-template --template='{{range .spec.podCIDRs}}{{printf "%s\n" .}}{{end}}'
10.244.1.0/24
2001:db8::/64
Має бути виділено один блок IPv4 та один блок IPv6.
Перевірте, що на вузлі виявлено інтерфейс IPv4 та IPv6. Замініть імʼя вузла на дійсний вузол з кластера. У цьому прикладі імʼя вузла - k8s-linuxpool1-34450317-0:
Перевірте, що у Pod є призначена адреса IPv4 та IPv6. Замініть імʼя Pod на наявний Pod у вашому кластері. У цьому прикладі імʼя Pod - pod01:
kubectl get pods pod01 -o go-template --template='{{range .status.podIPs}}{{printf "%s\n" .ip}}{{end}}'
10.244.1.4
2001:db8::4
Ви також можете перевірити IP-адреси Pod за допомогою Downward API через поле .status.podIPs. Наступний уривок показує, як ви можете використовувати IP-адреси Pod через змінну середовища з назвою MY_POD_IPS всередині контейнера.
Наступна команда виводить значення змінної середовища MY_POD_IPS всередині контейнера. Значення — це кома, що розділяє список, який відповідає IPv4 та IPv6 адресам Pod.
kubectl exec -it pod01 -- set | grep MY_POD_IPS
MY_POD_IPS=10.244.1.4,2001:db8::4
IP-адреси Pod також будуть записані в /etc/hosts всередині контейнера. Наступна команда виконує cat на /etc/hosts в Podʼі з подвійним стеком. З виводу ви можете перевірити як IPv4, так і IPv6 IP-адресу для Pod.
Створіть наступний Service, який не визначає явно .spec.ipFamilyPolicy. Kubernetes призначить кластерний IP для Service з першого налаштованого service-cluster-ip-range і встановить .spec.ipFamilyPolicy на SingleStack.
Використовуйте kubectl, щоб переглянути YAML для Service.
kubectl get svc my-service -o yaml
У Service .spec.ipFamilyPolicy встановлено на SingleStack, а .spec.clusterIP встановлено на IPv4-адрес з першого налаштованого діапазону, встановленого за допомогою прапорця --service-cluster-ip-range на kube-controller-manager.
Створіть наступний Service, який явно визначає IPv6 як перший елемент масиву в .spec.ipFamilies. Kubernetes призначить кластерний IP для Service з діапазону IPv6, налаштованого в service-cluster-ip-range, і встановить .spec.ipFamilyPolicy на SingleStack.
Використовуйте kubectl, щоб переглянути YAML для Service.
kubectl get svc my-service -o yaml
У Service .spec.ipFamilyPolicy встановлено на SingleStack, а .spec.clusterIP встановлено на IPv6-адрес з діапазону IPv6, налаштованого за допомогою прапорця --service-cluster-ip-range у kube-controller-manager.
Створіть наступний Service, який явно визначає PreferDualStack в .spec.ipFamilyPolicy. Kubernetes призначить як IPv4, так і IPv6 адреси кластера (оскільки в цьому кластері ввімкнено подвійний стек) і вибере .spec.ClusterIP зі списку .spec.ClusterIPs на основі сімʼї адрес, що вказана в першому елементі масиву .spec.ipFamilies.
Команда kubectl get svc покаже лише основну IP-адресу в полі CLUSTER-IP.
kubectl get svc -l app.kubernetes.io/name=MyApp
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-service ClusterIP 10.0.216.242 <none> 80/TCP 5s
Перевірте, що Service отримує кластерні IP з діапазонів IPv4 та IPv6, використовуючи kubectl describe. Потім ви можете перевірити доступ до Service за допомогою IP та портів.
Створення Service з подвійним стеком для балансування навантаження
Якщо постачальник хмарних послуг підтримує надання зовнішніх балансувальників навантаження з підтримкою IPv6, створіть наступний Service з PreferDualStack в .spec.ipFamilyPolicy, IPv6 як перший елемент масиву .spec.ipFamilies, а також встановіть поле type на LoadBalancer.
Перевірте, що Service отримує CLUSTER-IP адресу з блоку адрес IPv6 разом із EXTERNAL-IP. Потім ви можете перевірити доступ до Service за допомогою IP та портів.
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-service LoadBalancer 2001:db8:fd00::7ebc 2603:1030:805::5 80:30790/TCP 35s
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.33 [stable](стандартно увімкнено)
У цьому документі описано, як переналаштувати стандартний діапазон IP-адрес Service, призначених кластеру.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
У цьому документі пояснюється, як керувати діапазоном IP-адрес Service у кластері Kubernetes, який також впливає на підтримувані кластером сімейства IP-адрес для Service.
Сімейства IP-адрес, доступні для Service ClusterIP-адрес, визначаються прапорцем --service-cluster-ip-range у kube-apiserver. Для кращого розуміння розподілу IP-адрес Сервісів зверніться до документації Відстеження розподілу IP-адрес Сервісів.
Починаючи з Kubernetes 1.33, сімейства IP-адрес Service, налаштовані для кластера, відображаються обʼєктом ServiceCIDR з іменем kubernetes. Обʼєкт ServiceCIDR kubernetes створюється першим екземпляром kube-apiserver, який запускається, на основі налаштованого прапорця --service-cluster-ip-range. Для забезпечення узгодженої поведінки кластера всі екземпляри kube-apiserver мають бути налаштовані з однаковими значеннями --service-cluster-ip-range, які мають відповідати стандартному обʼєкту ServiceCIDR kubernetes.
Категорії реконфігурації Kubernetes ServiceCIDR
Ми можемо класифікувати реконфігурацію ServiceCIDR за наступними сценаріями:
Розширення наявних ServiceCIDR: Це можна зробити динамічно, додавши нові обʼєкти ServiceCIDR без необхідності переконфігурації kube-apiserver. Будь ласка, зверніться до відповідної документації щодо Розширення діапазонів IP-адрес Service.
Перетворення з одного стека на два зі збереженням первинного ServiceCIDR: Це передбачає введення другого сімейства IP-адрес (IPv6 у кластер, що використовує лише IPv4, або IPv4 у кластер, що використовує лише IPv6), при цьому первинне сімейство IP-адрес залишається первинним. Це вимагає оновлення конфігурації kube-apiserver і відповідної модифікації різних компонентів кластера, які повинні працювати з цим додатковим сімейством IP. Ці компоненти включають, але не обмежуються ними, kube-proxy, CNI або мережевий втулок, реалізації сервісних мереж та DNS-сервіси.
Перетворення з подвійного на одинарний зі збереженням первинного ServiceCIDR: Це передбачає видалення вторинного сімейства IP з двостекового кластера, повернення до єдиного сімейства IP зі збереженням початкового первинного сімейства IP. На додачу до реконфігурації компонентів відповідно до нового сімейства IP, вам може знадобитися звернутися до Services, які були явно налаштовані на використання видаленого сімейства IP.
Усе, що призводить до зміни первинного ServiceCIDR: Повна заміна стандартного ServiceCIDR є складною операцією. Якщо новий ServiceCIDR не перетинається з наявним, це вимагатиме перенумерації всіх наявних Services і зміни Service kubernetes.default. Випадок, коли змінюється первинне сімейство IP-адрес, є ще складнішим і може вимагати зміни декількох компонентів кластера (kubelet, мережеві втулки тощо), щоб вони відповідали новому первинному сімейству IP-адрес.
Ручні операції для заміни стандартного ServiceCIDR
Переналаштування стандартного ServiceCIDR потребує ручних дій з боку оператора кластера, адміністратора або програмного забезпечення, що керує життєвим циклом кластера. Зазвичай вони включають в себе наступні дії:
Оновлення конфігурації kube-apiserver: Змініть прапорець --service-cluster-ip-range новим діапазоном (діапазонами) IP-адрес.
Переналаштування мережевих компонентів: Це дуже важливий крок, і конкретна процедура залежить від різних мережевих компонентів, що використовуються. Вона може включати оновлення конфігураційних файлів, перезапуск агентів або оновлення компонентів для керування новими ServiceCIDR і бажаною конфігурацією сімейства IP-адрес для Podʼів. Типовими компонентами можуть бути реалізація Сервісів Kubernetes, таких як kube-proxy, і налаштований мережевий втулок, а також потенційно інші мережеві компоненти, такі як контролери сервісних мереж і DNS-сервери, щоб переконатися, що вони можуть коректно обробляти трафік і виконувати виявлення сервісів з новою конфігурацією сімейства IP-адрес.
Керування наявними Сервісами: Сервіси з IP-адресами зі старого CIDR мають бути адресовані, якщо вони не входять до нових налаштованих діапазонів. Варіанти включають відновлення (що призводить до простою і нових призначень IP-адрес) або потенційно складніші стратегії реконфігурації.
Повторне створення внутрішніх сервісів Kubernetes: Сервіс kubernetes.default необхідно видалити та створити заново, щоб отримати IP-адресу з нового ServiceCIDR, якщо первинне сімейство IP-адрес змінено або замінено на іншу мережу.
Ілюстративні кроки реконфігурації
Наступні кроки описують контрольовану реконфігурацію, зосереджену на повній заміні стандартного ServiceCIDR і перестворенні Service kubernetes.default:
Запустіть kube-apiserver з початковим --service-cluster-ip-range.
Створіть початкові Сервіси, які отримують IP з цього діапазону.
Створіть новий ServiceCIDR як тимчасову ціль для реконфігурації.
Позначте стандартний ServiceCIDR kubernetes для видалення (він залишиться в очікуванні через наявні IP-адреси та завершувачі). Це запобігає новим розподілам зі старого діапазону.
Повторно створіть наявні Сервіси. Тепер їм мають бути виділені IP-адреси з нового, тимчасового ServiceCIDR.
Перезапустіть kube-apiserver з налаштованими новими ServiceCIDR і вимкніть старий екземпляр.
Видаліть сервіс kubernetes.default. Новий kube-apiserver відтворить його у новому ServiceCIDR.
Дізнайтеся, як розширити kubectl за допомогою втулків.
Цей посібник демонструє, як встановлювати та створювати розширення для kubectl. Вважаючи основні команди kubectl основними будівельними блоками для взаємодії з кластером Kubernetes, адміністратор кластера може розглядати втулки як засіб використання цих будівельних блоків для створення складнішої поведінки. Втулки розширюють kubectl новими підкомандами, що дозволяє використовувати нові та власні функції, які не входять до основного дистрибутиву kubectl.
Перш ніж ви розпочнете
Вам потрібно мати встановлений працюючий бінарний файл kubectl.
Встановлення втулків для kubectl
Втулок — це автономний виконуваний файл, назва якого починається з kubectl-. Для встановлення втулка перемістіть його виконуваний файл до будь-якої теки, що знаходиться в вашому PATH.
Ви також можете знайти та встановити втулки для kubectl, наявні у відкритому доступі, за допомогою Krew. Krew — це менеджер втулків, підтримуваний спільнотою Kubernetes SIG CLI.
Увага:
Втулки для kubectl, доступні через індекс втулків Krew, не перевіряються на безпеку. Ви повинні встановлювати та запускати втулки на власний розсуд, оскільки це довільні програми, що виконуються на вашому компʼютері.
Пошук втулків
kubectl надає команду kubectl plugin list, яка оглядає ваш PATH для відповідних виконуваних файлів втулків. Виконання цієї команди призводить до огляду всіх файлів у вашому PATH. Будь-які файли, які є виконуваними та починаються з kubectl-, зʼявляться в порядку їх розташування в вашому PATH у виводі цієї команди. Для будь-яких файлів, що починаються з kubectl- та не є виконуваними, буде додано попередження. Також буде додане попередження для будь-яких вірних файлів втулків, назви яких перекриваються.
Ви можете використовувати Krew, щоб шукати та встановлювати втулки для kubectl з індексу втулків, який підтримується спільнотою.
Створення втулків
kubectl дозволяє втулкам додавати власні команди у вигляді kubectl create something шляхом створення виконуваного файлу з іменем kubectl-create-something та розміщення його в вашому PATH.
Обмеження
Зараз неможливо створити втулки, які перезаписують чинні команди kubectl або розширюють команди відмінні від create. Наприклад, створення втулка kubectl-version призведе до того, що цей втулок ніколи не буде виконаний, оскільки наявна команда kubectl version завжди матиме пріоритет. За цим обмеженням також не можна використовувати втулки для додавання нових підкоманд до наявних команд kubectl. Наприклад, додавання підкоманди kubectl attach vm, назвавши свій втулок kubectl-attach-vm, призведе до його ігнорування.
kubectl plugin list виводить попередження для будь-яких вірних втулків, які намагаються це зробити.
Написання втулків для kubectl
Ви можете написати втулок будь-якою мовою програмування або скриптом, який дозволяє вам створювати команди для командного рядка.
Для втулків не потрібно жодної установки чи попереднього завантаження. Виконувані файли втулків успадковують середовище від бінарного файлу kubectl. Втулок визначає, який шлях команди він бажає реалізувати на основі свого імені. Наприклад, втулок з іменем kubectl-foo надає команду kubectl foo. Вам потрібно встановити виконуваний файл втулка десь у вашому PATH.
Приклад втулка
#!/bin/bash
# optional argument handlingif[["$1"=="version"]]thenecho"1.0.0"exit0fi# optional argument handlingif[["$1"=="config"]]thenecho"$KUBECONFIG"exit0fiecho"I am a plugin named kubectl-foo"
Користування втулком {#using-a-plugin
Для використання втулка зробіть його виконуваним:
sudo chmod +x ./kubectl-foo
та помістіть його в теку, яка знаходиться в вашому PATH:
sudo mv ./kubectl-foo /usr/local/bin
Тепер ви можете викликати втулок, використовуючи kubectl foo:
kubectl foo
I am a plugin named kubectl-foo
Всі аргументи та прапорці, передаються втулку як-вони-є для виконання:
kubectl foo version
1.0.0
Всі змінні оточення також передається у вигляді як-вони-є:
Крім того, перший аргумент, який передається втуку, завжди буде повним шляхом до місця, де його було викликано ($0 буде дорівнювати /usr/local/bin/kubectl-foo в прикладі вище).
Іменування втулків
Як видно в прикладі вище, втулок визначає шлях команди, яку він буде реалізовувати, на основі свого імені файлу. Кожна підкоманда в шляху, для якої використовується втулок, розділена дефісом (-). Наприклад, втулок, який бажає запускатись, коли користувач викликає команду kubectl foo bar baz, матиме імʼя файлу kubectl-foo-bar-baz.
Обробка прапорців та аргументів
Примітка:
Механізм втулків не створює жодних специфічних для втулків значень або змінних середовища для процесу втулка.
Раніше існувавший механізм втулків kubectl надавав змінні середовища, такі як KUBECTL_PLUGINS_CURRENT_NAMESPACE; таке вже не відбувається.
Втулки kubectl повинні розбирати та перевіряти всі передані їм аргументи. Див. використання пакета command line runtime для отримання відомостей про бібліотеку Go, призначену на авторів втулків.
Нижче наведено кілька додаткових випадків, коли користувачі викликають ваш втулок, надаючи додаткові прапорці та аргументи. Розберемо це на прикладі втулка kubectl-foo-bar-baz з вищезазначеного сценарію.
Якщо ви виконуєте kubectl foo bar baz arg1 --flag=value arg2, механізм втулків kubectl спочатку намагатиметься знайти втулок з найдовшим можливим імʼям, що в цьому випадку буде kubectl-foo-bar-baz-arg1. Не знайшовши цього втулка, kubectl тоді розглядає останнє значення, розділене дефісами, як аргумент (тут arg1) та намагається знайти наступне найдовше можливе імʼя, kubectl-foo-bar-baz. Знайшовши втулок з таким імʼям, kubectl викликає цей втулок, передаючи всі аргументи та прапорці після імені втулка як аргументи для процесу втулка.
Приклад:
# створимо втулокecho -e '#!/bin/bash\n\necho "My first command-line argument was $1"' > kubectl-foo-bar-baz
sudo chmod +x ./kubectl-foo-bar-baz
# "iвстановимо" ваш втулок перемістивши його у теку з $PATHsudo mv ./kubectl-foo-bar-baz /usr/local/bin
# перевіримо, що kubectl розпізнав ваш втулокkubectl plugin list
The following kubectl-compatible plugins are available:
/usr/local/bin/kubectl-foo-bar-baz
# перевірте, що виклик вашого втулка через команду "kubectl" працює# навіть тоді, коли користувач передає додаткові аргументи та прапорці# до виконуваного користувачем виконуваного файлу вашого втулка.kubectl foo bar baz arg1 --meaningless-flag=true
My first command-line argument was arg1
Як бачите, ваш втулок було знайдено на основі команди kubectl, вказаної користувачем, і всі додаткові аргументи та прапорці були передані як є до виконуваного файлу втулка після того, як його було знайдено.
Назви з дефісами та підкреслюваннями
Хоча механізм втулків kubectl використовує дефіси (-) у іменах файлів втулків для розділення послідовності підкоманд, оброблених втулком, все ж можна створити втулок з іменем, що містить дефіс в його виклику з командного рядка, використовуючи підкреслення (_) у його імені файлу.
Приклад:
# створимо втулок, що містить підкреслення в назві файлуecho -e '#!/bin/bash\n\necho "I am a plugin with a dash in my name"' > ./kubectl-foo_bar
sudo chmod +x ./kubectl-foo_bar
# перемістимо втулок у теку з $PATHsudo mv ./kubectl-foo_bar /usr/local/bin
# тепер ви можете викликати ваш втулок через kubectl:kubectl foo-bar
I am a plugin with a dash in my name
Зауважте, що додавання підкреслення в імʼя файлу втулка не заважає створенню команд, таких як kubectl foo_bar. Команду з прикладу вище можна викликати як з дефісом (-), так і з підкресленням (_):
# Ви можете викликати вашу власну команду з дефісомkubectl foo-bar
I am a plugin with a dash in my name
# Ви ткаож можете викликати свою власну команду з підкресленнямиkubectl foo_bar
I am a plugin with a dash in my name
Конфлікти імен та затьмарення
Можливе існування кількох втулків з однаковою назвою файлу в різних розташуваннях у вашому PATH. Наприклад, при наступному значенні PATH: PATH=/usr/local/bin/plugins:/usr/local/bin/moreplugins, копія втулка kubectl-foo може існувати в /usr/local/bin/plugins та /usr/local/bin/moreplugins, так що результат виклику команди kubectl plugin list буде наступним:
PATH=/usr/local/bin/plugins:/usr/local/bin/moreplugins kubectl plugin list
The following kubectl-compatible plugins are available:
/usr/local/bin/plugins/kubectl-foo
/usr/local/bin/moreplugins/kubectl-foo
- warning: /usr/local/bin/moreplugins/kubectl-foo is overshadowed by a similarly named plugin: /usr/local/bin/plugins/kubectl-foo
error: one plugin warning was found
У вказаному вище сценарії попередження під /usr/local/bin/moreplugins/kubectl-foo говорить вам, що цей втулок ніколи не буде виконано. Замість цього виконується файл, який зʼявляється першим у вашому PATH, /usr/local/bin/plugins/kubectl-foo, завдяки механізму втулків kubectl.
Спосіб розвʼязання цієї проблеми — переконатися, що розташування втулка, яким ви хочете скористатися з kubectl, завжди стоїть на першому місці в вашому PATH. Наприклад, якщо ви хочете завжди використовувати /usr/local/bin/moreplugins/kubectl-foo в будь-який раз, коли викликається команда kubectl foo, змініть значення вашого PATH на /usr/local/bin/moreplugins:/usr/local/bin/plugins.
Виклик найдовшого імені виконуваного файлу
Є ще один вид перекриття, який може виникнути з іменами втулків. Допустимо, є два втулки у шляху користувача: kubectl-foo-bar та kubectl-foo-bar-baz. Механізм втулків kubectl завжди вибиратиме найдовше можливе імʼя втулка для заданої команди користувача. Нижче наведено деякі приклади, які докладніше пояснюють це:
# для заданої команди `kubectl` завжди буде вибиратися втулок з найдовшим можливим іменем файлаkubectl foo bar baz
Plugin kubectl-foo-bar-baz is executed
kubectl foo bar
Plugin kubectl-foo-bar is executed
kubectl foo bar baz buz
Plugin kubectl-foo-bar-baz is executed, with "buz" as its first argument
kubectl foo bar buz
Plugin kubectl-foo-bar is executed, with "buz" as its first argument
Цей вибір дизайну гарантує, що підкоманди втулків можуть бути реалізовані у кількох файлах, якщо це необхідно, і що ці підкоманди можуть бути вкладені під "батьківською" командою втулка:
Ви можете скористатися вищезазначеною командою kubectl plugin list, щоб переконатися, що ваш втулок можна викликати за допомогою kubectl, та перевірити, чи немає попереджень, які перешкоджають його виклику як команди kubectl.
kubectl plugin list
The following kubectl-compatible plugins are available:
test/fixtures/pkg/kubectl/plugins/kubectl-foo
/usr/local/bin/kubectl-foo
- warning: /usr/local/bin/kubectl-foo is overshadowed by a similarly named plugin: test/fixtures/pkg/kubectl/plugins/kubectl-foo
plugins/kubectl-invalid
- warning: plugins/kubectl-invalid identified as a kubectl plugin, but it is not executable
error: 2 plugin warnings were found
Використання пакунка виконання командного рядка
Якщо ви пишете втулку для kubectl і використовуєте Go, ви можете скористатися cli-runtime бібліотеками.
Ці бібліотеки надають помічників для парсингу або оновлення файлу kubeconfig користувача, для виконання запитів REST до API-сервера або звʼязування прапорців повʼязаних з конфігурацією та друком.
Перегляньте Sample CLI Plugin для прикладу використання інструментів, які надаються у репозиторії CLI Runtime.
Розповсюдження втулків для kubectl
Якщо ви розробили втулок для того, щоб інші користувачі могли його використовувати, вам слід розглянути, як ви його пакуєте, розповсюджуєте і надаєте оновлення для користувачів.
Krew
Krew пропонує крос-платформний спосіб пакування та розповсюдження ваших втулків. Таким чином, ви використовуєте єдиний формат пакування для всіх цільових платформ (Linux, Windows, macOS і т.д.) і надаєте оновлення користувачам. Krew також підтримує індекс втулків, щоб інші люди могли знайти ваш втулок та встановлювати його.
Нативне / платформозалежне керування пакетами
З іншого боку, ви можете використовувати традиційні системи керування пакунками, такі як apt або yum в Linux, Chocolatey в Windows і Homebrew в macOS. Будь-який менеджер пакунків підійде, якщо він може розмістити нові виконувані файли в теці PATH користувача. Як автор втулка, якщо ви обираєте цей варіант, вам також слід покласти на себе тягар оновлення пакунка для розповсюдження ваших втулків для kubectl для кожного релізу на кожній платформі.
Сирці
Ви можете публікувати сирці, наприклад, як Git-репозиторій. Якщо ви обираєте цей варіант, той, хто хоче використовувати цей втулок, повинен витягти код, налаштувати середовище збірки (якщо він потребує компіляції) та використовувати втулок. Якщо ви також надаєте доступні скомпільовані пакунки або використовуєте Krew, це спростить процес встановлення.
Що далі
Перегляньте репозиторій Sample CLI Plugin для детального прикладу втулка, написаного на Go.
У разі будь-яких питань, не соромтеся звертатися до команди SIG CLI.
Дізнайтеся більше про Krew, менеджер пакунків для втулків kubectl.
16 - Керування HugePages
Налаштування та керування великими сторінками як запланованим ресурсом в кластері.
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.14 [stable](стандартно увімкнено)
Kubernetes підтримує виділення та використання заздалегідь розміщених великих сторінок (huge pages) застосунками в Podʼі. Ця сторінка описує, як користувачі можуть використовувати великі сторінки.
Вузол може резервувати великі сторінки різних розмірів, наприклад, наступний рядок у файлі /etc/default/grub резервує 2*1 ГБ памʼяті для сторінок розміром 1 ГБ і 512*2 МБ для сторінок розміром 2 МБ:
Для динамічно виділених сторінок (після завантаження), Kubelet потрібно перезапустити, щоб нові обсяги були показані.
API
Великі сторінки можна використовувати за допомогою вимог до ресурсів на рівні контейнера з використанням імені ресурсу hugepages-<size>, де <size> — це найбільш компактне двійкове позначення з використанням цілочисельних значень, які підтримуються на певному вузлі. Наприклад, якщо вузол підтримує розміри сторінок 2048KiB та 1048576KiB, він буде показувати розміри hugepages-2Mi та hugepages-1Gi. На відміну від CPU або памʼяті, великі сторінки не підтримують перевищення. Зверніть увагу, що при запиті ресурсів великих сторінок також потрібно вказувати ресурси памʼяті або CPU.
Pod може мати різні розміри великих сторінок в одній специфікації Podʼа. У цьому випадку для всіх точок монтування томів вона повинна використовувати нотацію medium: HugePages-<hugepagesize>.
Запити великих сторінок повинні дорівнювати лімітам. Це є стандартним, якщо ліміти вказані, а запити — ні.
Великі сторінки ізольовані на рівні контейнера, тому кожен контейнер має власний ліміт, як вказано у специфікації контейнера.
Томи EmptyDir, що підтримуються великими сторінками, не можуть споживати більше памʼяті великих сторінок, ніж запитується для Podʼа.
Застосунки, які використовують великі сторінки за допомогою shmget() з SHM_HUGETLB, повинні працювати з допоміжною групою, яка відповідає за proc/sys/vm/hugetlb_shm_group.
Використанням великих сторінок у просторі імен можливо керувати за допомогою ResourceQuota, подібно іншим обчислювальним ресурсам, таким як cpu або memory, використовуючи токен hugepages-<size>.
17 - Планування GPU
Налаштування та планування GPU для використання як ресурсу вузлів у кластері.
СТАН ФУНКЦІОНАЛУ:Kubernetes v1.26 [stable]
Kubernetes має стабільну підтримку для управління графічними обчислювальними пристроями (GPU) від AMD та NVIDIA на різних вузлах вашого кластера, використовуючи втулки пристроїв.
На цій сторінці описано, як користувачі можуть використовувати GPU і наведені деякі обмеження в реалізації.
Використання втулків пристроїв
Kubernetes використовує втулки пристроїв, щоб дозволити Podʼам отримувати доступ до спеціалізованих апаратних можливостей, таких як GPU.
Примітка: Цей розділ містить посилання на проєкти сторонніх розробників, які надають функціонал, необхідний для Kubernetes. Автори проєкту Kubernetes не несуть відповідальності за ці проєкти. Проєкти вказано в алфавітному порядку. Щоб додати проєкт до цього списку, ознайомтеся з посібником з контенту перед надсиланням змін. Докладніше.
Як адміністратору, вам потрібно встановити драйвери GPU від відповідного виробника обладнання на вузлах і запустити відповідний втулок пристрою від виробника GPU. Ось кілька посилань на інструкції від виробників:
Після встановлення втулка ваш кластер використовує власний ресурс планування, такий як amd.com/gpu або nvidia.com/gpu.
Ви можете використовувати ці GPU у ваших контейнерах, запитуючи власний ресурс GPU,, так само як ви запитуєте cpu чи memory.
Однак є обмеження у специфікації вимог до ресурсів для власних пристроїв.
GPU повинні бути вказані тільки в розділі limits, що означає:
Ви можете вказати limits для GPU без вказівки requests, оскільки Kubernetes за стандартно використовує ліміт як значення запиту.
Ви можете вказати GPU як в limits, так і в requests, але ці два значення повинні бути рівними.
Ви не можете вказати requests для GPU без вказівки limits.
Ось приклад маніфесту для Podʼі, який запитує GPU:
apiVersion:v1kind:Podmetadata:name:example-vector-addspec:restartPolicy:OnFailurecontainers:- name:example-vector-addimage:"registry.example/example-vector-add:v42"resources:limits:gpu-vendor.example/example-gpu:1# запит на 1 GPU
Керуйте кластерами з різними типами GPU
Якщо в різних вузлах вашого кластера є різні типи GPU, то ви можете використовувати мітки вузлів і селектори вузлів для планування Podʼів на відповідних вузлах.
Наприклад:
# Позначте свої вузли з типом прискорювача, яким вони володіють.kubectl label nodes node1 accelerator=example-gpu-x100
kubectl label nodes node2 accelerator=other-gpu-k915
Ця мітка ключа accelerator лише приклад; ви можете використовувати інший ключ мітки, якщо це зручніше.
Автоматичне позначення вузлів
Як адміністратор, ви можете автоматично виявляти та мітити всі ваши вузли з підтримкою GPU, розгорнувши Виявлення функцій вузлів Kubernetes (NFD). NFD виявляє апаратні функції, які доступні на кожному вузлі в кластері Kubernetes. Зазвичай NFD налаштовується таким чином, щоб оголошувати ці функції як мітки вузла, але NFD також може додавати розширені ресурси, анотації та заплямування вузла (node taints). NFD сумісний з усіма підтримуваними версіями Kubernetes. Типово NFD створює мітки функцій для виявлених функцій. Адміністратори можуть використовувати NFD, щоб також мітити вузли конкретними функціями, щоб на них можна було планувати лише Podʼи, які запитують ці функції.
Вам також потрібен втулок для NFD, який додає відповідні мітки до ваших вузлів; це можуть бути загальні мітки або вони можуть бути вендор-специфічними. Ваш вендор GPU може надати втулок від третіх сторін для NFD; перевірте їх документацію для отримання додаткової інформації.
apiVersion:v1kind:Podmetadata:name:example-vector-addspec:# Виможете використовувати Kubernetes node affinity для планування цього Podʼа на вузол# який надає kind типу GPU, який потрібе його контейнеру для роботиaffinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key:"gpu.gpu-vendor.example/installed-memory"operator:Gt# (greater than)values:["40535"]- key:"feature.node.kubernetes.io/pci-10.present"# NFD Feature labelvalues:["true"]# (optional) only schedule on nodes with PCI device 10restartPolicy:OnFailurecontainers:- name:example-vector-addimage:"registry.example/example-vector-add:v42"resources:limits:gpu-vendor.example/example-gpu:1# запит 1 GPU