Архітектура логування
Логи застосунків можуть допомогти вам зрозуміти, що відбувається у нього всередині. Логи особливо корисні для виправлення проблем та моніторингу активності кластера. Більшість сучасних застосунків мають деякий механізм логування. Так само, рушії виконання контейнерів розроблені з підтримкою логування. Найпростіший і найбільш прийнятий метод логування для контейнеризованих застосунків — це запис у стандартні потоки виводу та помилок.
Однак, природня функціональність, яку надає рушій виконання контейнерів або середовище виконання, зазвичай недостатня для повного вирішення завдань логування.
Наприклад, вам може бути необхідно дістатись до логів вашого застосунку, якщо контейнер зазнає збою, Pod видаляється, або вузол припиняє роботу.
У кластері логи повинні мати окреме сховище та життєвий цикл незалежно від вузлів, Podʼів або контейнерів. Ця концепція називається логування на рівні кластера.
Архітектури логування на рівні кластера вимагають окремого бекенду для зберігання, аналізу, та отримання логів. Kubernetes не надає власного рішення для зберігання даних логів. Натомість існує багато рішень для логування, які інтегруються з Kubernetes. Наступні розділи описують, як обробляти та зберігати логи на вузлах.
Логи Podʼів та контейнерів
Kubernetes збирає логи з кожного контейнера в запущеному Podʼі.
Цей приклад використовує маніфест для Podʼу з контейнером, який записує текст у стандартний потік виводу, раз на секунду.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Для запуску цього Podʼа використовуйте наступну команду:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
Вивід буде таким:
pod/counter created
Для отримання логів використовуйте команду kubectl logs, як показано нижче:
kubectl logs counter
Вивід буде схожим на:
0: Fri Apr 1 11:42:23 UTC 2022
1: Fri Apr 1 11:42:24 UTC 2022
2: Fri Apr 1 11:42:25 UTC 2022
Ви можете використовувати kubectl logs --previous для отримання логів з попереднього запуску контейнера. Якщо ваш Pod має кілька контейнерів, вкажіть, логи якого контейнера ви хочете переглянути, додавши назву контейнера до команди з прапорцем -c, ось так:
kubectl logs counter -c count
Потоки логів контейнерів
Kubernetes v1.32 [alpha](стандартно вимкнено)Як альфа-функція, kubelet може розділяти логи з двох стандартних потоків, що створюються контейнером: стандартний вивід та стандартна помилка. Щоб скористатися такою поведінкою, вам слід увімкнути функціональну можливість PodLogsQuerySplitStreams. З її увімкненням Kubernetes 1.35 надає доступ до цих потоків логів безпосередньо за допомогою Pod API. Ви можете отримати конкретний потік, вказавши назву потоку (або Stdout, або Stderr) за допомогою рядка запиту stream. Ви повинні мати доступ до читання підресурсу log цього Pod.
Щоб продемонструвати цю можливість, ви можете створити Pod, який періодично записуватиме текст як до стандартного потоку виводу, так і до потоку помилок.
apiVersion: v1
kind: Pod
metadata:
name: counter-err
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; echo "$i: err" >&2 ; i=$((i+1)); sleep 1; done']
Для запуску цього podʼа скористайтесь наступною командою:
kubectl apply -f https://k8s.io/examples/debug/counter-pod-err.yaml
Щоб отримати лише потік логу stderr, ви можете виконати команду:
kubectl get --raw "/api/v1/namespaces/default/pods/counter-err/log?stream=Stderr"
Дивіться документацію kubectl logs для отримання додаткових деталей.
Як вузли обробляють логи контейнерів
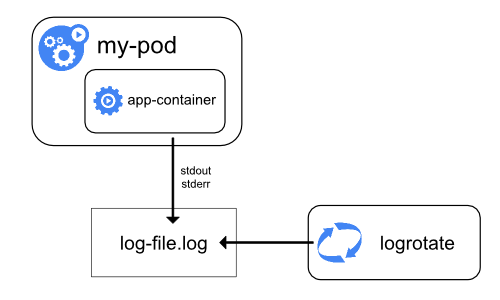
Система управління контейнерами обробляє та перенаправляє будь-який вивід, створений потоками stdout та stderr контейнеризованого застосунку. Різні системи управління контейнерами реалізують це по-різному; однак, інтеграція з kubelet стандартизована як формат логування CRI.
Стандартно, якщо контейнер перезапускається, kubelet зберігає один зупинений контейнер з його логами. Якщо Pod видаляється з вузла, всі відповідні контейнери також видаляються разом з їхніми логами.
Kubelet надає доступ до логів клієнтам через спеціальну функцію Kubernetes API. Зазвичай доступ до неї здійснюється за допомогою команди kubectl logs.
Ротація логів
Kubernetes v1.21 [stable]Kubelet відповідає за ротацію логів контейнерів та управління структурою тек логів. Kubelet передає цю інформацію до системи управління контейнерами (використовуючи CRI), а середовище виконання записує логи контейнерів у вказане місце.
Ви можете налаштувати два параметри конфігурації kubelet containerLogMaxSize (типово 10Mi) та containerLogMaxFiles (типово 5), використовуючи файл конфігурації kubelet. Ці параметри дозволяють вам налаштувати максимальний розмір для кожного файлу лога та максимальну кількість файлів, дозволених для кожного контейнера відповідно.
Для ефективної ротації логів у кластерах, де обсяг логів, згенерованих робочим навантаженням, великий, kubelet також надає механізм налаштування ротації логів з погляду кількості одночасних ротацій логів та інтервалу, з яким логи відстежуються та ротуються за потребою. Ви можете налаштувати два параметри конфігурації kubelet, containerLogMaxWorkers та containerLogMonitorInterval за допомогою файлу конфігурації kubelet.
Коли ви виконуєте kubectl logs як у прикладі базового логування, kubelet на вузлі обробляє запит і безпосередньо читає з файлу лога. Kubelet повертає вміст файлу лога.
Примітка:
Через kubectl logs доступний лише вміст останнього файлу лога.
Наприклад, якщо Pod пише 40 MiB логів і kubelet ротує логи після 10 MiB, виконання kubectl logs поверне максимум 10MiB даних.
Логи системних компонентів
Існують два типи системних компонентів: ті, які зазвичай працюють у контейнерах, та ті компоненти, які безпосередньо відповідають за запуск контейнерів. Наприклад:
- Kubelet та система управління контейнерами не працюють у контейнерах. Kubelet виконує ваші контейнери (згруповані разом у Podʼи).
- Планувальник Kubernetes, менеджер контролерів та сервер API працюють у Podʼах (зазвичай статичних Podʼах). Компонент etcd працює у планувальнику, і зазвичай також як статичний Pod. Якщо ваш кластер використовує kube-proxy, зазвичай ви запускаєте його як
DaemonSet.
Знаходження логів
Спосіб, яким kubelet та система управління контейнерами записують логи, залежить від операційної системи, яку використовує вузол:
На вузлах Linux, які використовують systemd, типово kubelet та система управління контейнерами записують логи у журнал systemd. Ви можете використовувати journalctl для читання журналу systemd; наприклад: journalctl -u kubelet.
Якщо systemd відсутній, kubelet та система управління контейнерами записують логи у файли .log в директорії /var/log. Якщо ви хочете, щоб логи були записані в інше місце, ви можете опосередковано запустити kubelet через допоміжний інструмент, kube-log-runner, та використовувати цей інструмент для перенаправлення логів kubelet у вибрану вами теку.
Типово, kubelet спрямовує систему управління контейнерами на запис логів у теці всередині /var/log/pods.
Для отримання додаткової інформації про kube-log-runner, читайте Системні логи.
Типово kubelet записує логи у файли всередині теки C:\var\logs (⚠️ зверніть увагу, що це не C:\var\log).
Хоча C:\var\log є типовим місцем для цих логів Kubernetes, деякі інструменти розгортання кластера налаштовують вузли Windows так, щоб логи записувались у C:\var\log\kubelet.
Якщо ви хочете, щоб логи були записані в інше місце, ви можете опосередковано запустити kubelet через допоміжний інструмент, kube-log-runner, та використовувати цей інструмент для перенаправлення логів kubelet у вибрану вами директорію.
Проте, типово kubelet скеровує систему управління контейнерами на запис логів у теці всередині C:\var\log\pods.
Для отримання додаткової інформації про kube-log-runner, читайте Системні логи.
Для компонентів кластера Kubernetes, які працюють у Podʼах, логи записуються у файли всередині директорії /var/log, оминаючи типовий механізм логування (компоненти не записуються у журнал systemd). Ви можете використовувати механізми зберігання Kubernetes для відображення постійного зберігання у контейнері, який виконує компонент.
Kubelet дозволяє змінювати теку логів Podʼів зі стандартної /var/log/pods на власну. Це можна зробити за допомогою параметра podLogsDir у конфігураційному файлі kubelet.
Увага:
Важливо зазначити, що стандартне розташування /var/log/pods використовувалося протягом тривалого часу, і певні процеси можуть неявно використовувати цей шлях. Тому до зміни цього параметра слід підходити з обережністю і на власний ризик.
Ще одним застереженням є те, що kubelet підтримує розташування на тому ж диску, що і /var. В іншому випадку, якщо логи знаходяться в окремій від /var файловій системі, то kubelet не буде відстежувати використання цієї файлової системи, що може призвести до проблем, якщо вона заповниться.
Для отримання детальної інформації про etcd та його логи, перегляньте документацію etcd. Знову ж таки, ви можете використовувати механізми зберігання Kubernetes для відображення постійного зберігання у контейнері, який виконує компонент.
Примітка:
Якщо ви розгортаєте компоненти кластера Kubernetes (наприклад, планувальник) для запису у спільний том від батьківського вузла, вам потрібно враховувати та забезпечувати, що ці логи ротуються. Kubernetes не керує цією ротацією логів.
Ваша операційна система може автоматично здійснювати деяку ротацію логів — наприклад, якщо ви ділитеся текою /var/log у статичному Podʼі для компонента, обробка ротації логів на рівні вузла обробляє файл у цій теці так с так само як записаний будь-яким компонентом поза Kubernetes.
Деякі інструменти розгортання враховують цю ротацію логів та автоматизують її; інші залишають це на вашу відповідальність.
Архітектури логування на рівні кластера
Хоча Kubernetes не надає власного рішення для логування на рівні кластера, існують кілька загальних підходів, які ви можете розглянути. Ось деякі варіанти:
- Використання агента логування на рівні вузла, який працює на кожному вузлі.
- Додавання в Pod з застосунком в спеціального sidecaar-контейнера для логування.
- Пряме надсилання логів безпосередньо до бекенду з застосунка.
Використання агента логування на рівні вузла
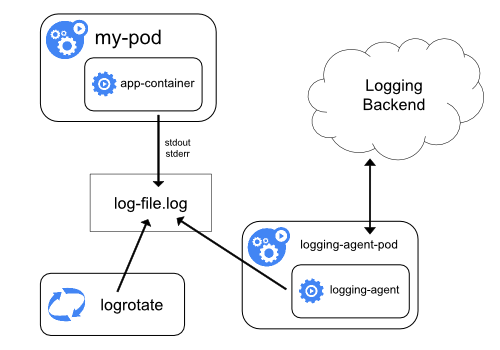
Ви можете реалізувати логування на рівні кластера, включивши агента логування на рівні вузла на кожному вузлі. Агент логування — це спеціальний інструмент, який надає логи або надсилає їх до бекенду. Зазвичай агент логування є контейнером, який має доступ до теки з файлами логів з усіх контейнерів застосунків на цьому вузлі.
Оскільки агент логування повинен працювати на кожному вузлі, рекомендується запускати агента
як DaemonSet.
Логування на рівні вузла створює лише одного агента на вузол і не вимагає жодних змін в застосунках, що працюють на вузлі.
Контейнери пишуть у stdout та stderr, але без узгодженого формату. Агент на рівні вузла збирає ці логи та пересилає їх для агрегації.
Використання sidecar контейнера з агентом логування
Ви можете використовувати sidecar контейнер у такий спосіб:
- sidecar контейнер транслює логи застосунку у свій власний
stdout. - sidecar контейнер запускає агента логування, який налаштований на збір логів з контейнера застосунку.
Sidecar контейнер для трансляції
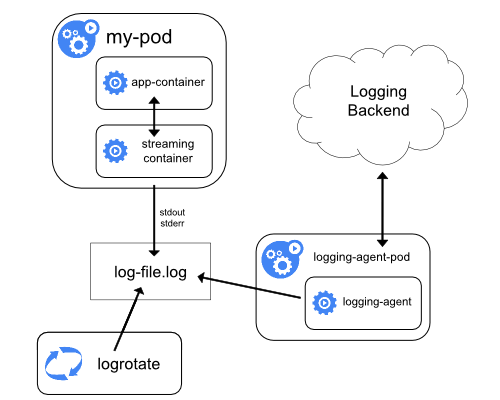
Маючи свої sidecar контейнери які пишуть у власні stdout та stderr, ви можете скористатися kubelet та агентом логування, які вже працюють на кожному вузлі. Sidecar контейнери читають логи з файлу, сокета або журналу. Кожен sidecar контейнер виводить лог у свій власний потік stdout або stderr.
Цей підхід дозволяє вам розділити кілька потоків логів з різних частин вашого застосунку деякі з яких можуть не підтримувати запис у stdout або stderr. Логіка перенаправлення логів мінімальна, тому це не становить значного навантаження. Крім того, оскільки stdout та stderr обробляються kubelet, ви можете використовувати вбудовані інструменти, такі як kubectl logs.
Наприклад, Pod запускає один контейнер, і контейнер записує до двох різних файлів логів з використанням двох різних форматів. Ось маніфест для Podʼа:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Не рекомендується записувати записи логів з різними форматами у той самий потік логу, навіть якщо вам вдалося перенаправити обидва компоненти до потоку stdout контейнера. Замість цього ви можете створити два додаткових sidecar контейнери. Кожен додатковий sidecar контейнер може перехоплювати певний файл логів зі спільного тома та перенаправляти логи до власного потоку stdout.
Ось маніфест для Podʼа, в якому є два sidecar контейнери:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Тепер, коли ви запускаєте цей Pod, ви можете отримати доступ до кожного потоку логів окремо, запустивши такі команди:
kubectl logs counter count-log-1
Результат буде подібним до:
0: Fri Apr 1 11:42:26 UTC 2022
1: Fri Apr 1 11:42:27 UTC 2022
2: Fri Apr 1 11:42:28 UTC 2022
...
kubectl logs counter count-log-2
Результат буде подібним до:
Fri Apr 1 11:42:29 UTC 2022 INFO 0
Fri Apr 1 11:42:30 UTC 2022 INFO 0
Fri Apr 1 11:42:31 UTC 2022 INFO 0
...
Якщо ви встановили агент на рівні вузла у свій кластер, цей агент автоматично перехоплює ці потоки логів без будь-якої додаткової конфігурації. Якщо вам цікаво, ви можете налаштувати агента для розбору рядків логів залежно від вихідного контейнера.
Навіть для Podʼів, які використовують низьке використання CPU та памʼяті (наприклад, декілька мілікорів (millicore) для CPU та кілька мегабайтів для памʼяті), запис логів до файлу та їх трансляція до stdout можуть подвоїти обсяг памʼяті, необхідний на вузлі. Якщо у вас є застосунок, який записує у єдиний файл, рекомендується встановити /dev/stdout як призначення, а не впроваджувати підхід з sidecar контейнером для трансляції.
Sidecar контейнери також можуть використовуватися для ротації файлів логів, ротація яких не може бути зроблена самим застосунком. Прикладом такого підходу є малий контейнер, який періодично запускає logrotate. Однак набагато простіше використовувати stdout та stderr безпосередньо і
залишити ротації та політику зберігання kubelet.
Sidecar контейнер з агентом логування
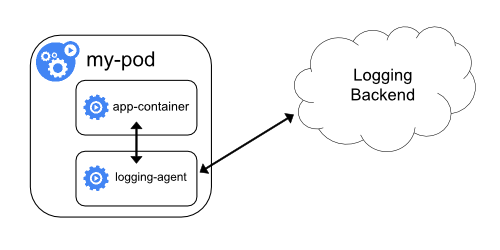
Якщо агент логування на рівні вузла не має достатньої гнучкості для вашої ситуації, ви можете створити sidecar контейнер з окремим агентом логування, який ви налаштували спеціально для роботи з вашим застосунком.
Примітка:
Використання агента логування у sidecar контейнері може призвести до значного використання ресурсів. Щобільше, ви не зможете отримати доступ до цих логів за допомогоюkubectl logs, оскільки вони не керуються kubelet.Ось два приклади маніфестів, які ви можете використати для впровадження sidecar контейнера з агентом логування. Перший маніфест містить ConfigMap, щоб налаштувати fluentd.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Примітка:
У конфігураціях з прикладів ви можете замінити fluentd на будь-який агент логування, який читає з будь-якого джерела всередині контейнера застосунку.Другий маніфест описує Pod, в якому є sidecar контейнер, що запускає fluentd. Pod монтує том, де fluentd може отримати свої дані конфігурації.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
Викладення логів безпосередньо з застосунку
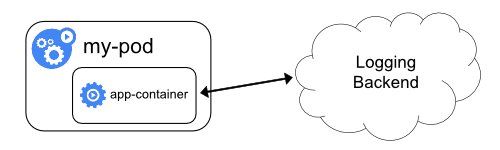
Кластерне логування, яке викладає або надсилає логи безпосередньо з кожного застосунку, виходить за межі цілей Kubernetes.
Що далі
- Дізнайтеся про системні журнали Kubernetes
- Дізнайтеся про Trace для компонентів системи Kubernetes
- Дізнайтеся, як налаштувати повідомлення про припинення роботи яке Kubernetes записує, коли Pod зазнає збою.