Керування політиками топології на вузлі
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.27 [stable]Зростаюча кількість систем використовує комбінацію ЦП та апаратних прискорювачів для підтримки виконання, критичного з погляду затримок, та високопродуктивних паралельних обчислень. Ці системи включають робочі навантаження у таких галузях, як телекомунікації, наукові обчислення, машинне навчання, фінансові послуги та аналітика даних. Такі гібридні системи складають високопродуктивне середовище.
Для досягнення найкращої продуктивності потрібні оптимізації, що стосуються ізоляції ЦП, памʼяті та локальності пристроїв. Проте, в Kubernetes ці оптимізації обробляються роздільним набором компонентів.
Topology Manager — це компонент kubelet, який має на меті координацію набору компонентів, відповідальних за ці оптимізації.
Перш ніж ви розпочнете
Вам треба мати кластер Kubernetes, а також інструмент командного рядка kubectl має бути налаштований для роботи з вашим кластером. Рекомендується виконувати ці настанови у кластері, що має щонайменше два вузли, які не виконують роль вузлів управління. Якщо у вас немає кластера, ви можете створити його, за допомогою minikube або використовувати одну з цих пісочниць:
Версія вашого Kubernetes сервера має бути не старішою ніж v1.18.Для перевірки версії введіть kubectl version.
Як працює Topology Manager
До впровадження Topology Manager, CPU та Device Manager в Kubernetes приймають рішення про розподіл ресурсів незалежно одне від одного. Це може призводити до небажаних розподілів на системах з кількома сокетами, де застосунки, що чутливі до продуктивності/затримки, будуть страждати через ці небажані розподіли. Небажані в цьому випадку означає, наприклад, виділення ЦП та пристроїв з різних вузлів NUMA, що призводить до додаткової затримки.
Topology Manager — це компонент kubelet, який діє як джерело правди, щоб інші компоненти kubelet могли робити вибір щодо розподілу ресурсів з урахуванням топології.
Topology Manager надає інтерфейс для компонентів, званих Hint Providers, для надсилання та отримання інформації про топологію. У Topology Manager є набір політик рівня вузла, які пояснюються нижче.
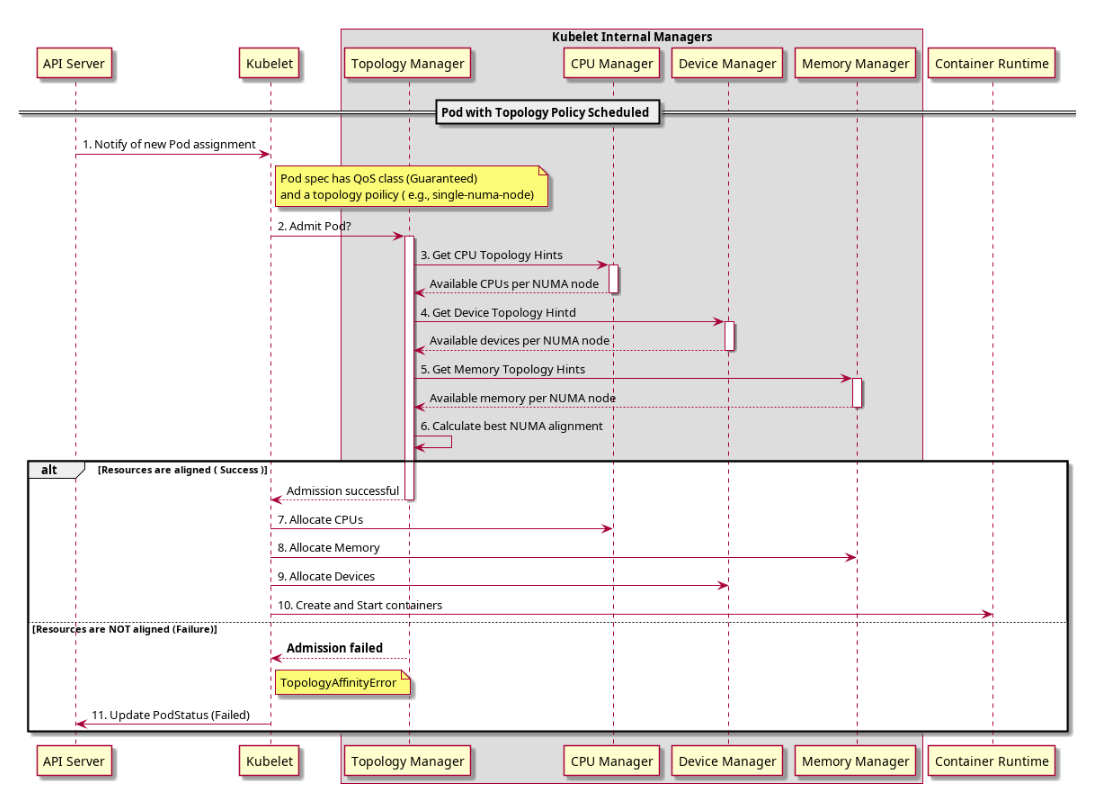
Topology manager отримує інформацію про топологію від Hint Providers у вигляді бітової маски, яка позначає доступні вузли NUMA та попередній показник виділення. Політики Topology Manager виконують набір операцій з наданими підказками та сходяться на підказці, визначеній політикою, щоб дати оптимальний результат, якщо небажана підказка зберігається, поле бажаної підказки буде встановлено у false. У поточних політиках найприйнятніше — це найвужча попередня маска. Обрана підказка зберігається як частина Topology Manager. Залежно від налаштованої політики, Pod може бути прийнятий або відхилений на вузлі на основі обраної підказки. Підказка потім зберігається в Topology Manager для використання Hint Providers під час прийняття рішень про розподіл ресурсів.
Потік можна побачити на наступній діаграмі.
Підтримка Windows
СТАН ФУНКЦІОНАЛУ:
Kubernetes v1.32 [alpha](стандартно вимкнено)Підтримку Topology Manager можна увімкнути у Windows за допомогою функціональної можливості WindowsCPUAndMemoryAffinity, і вона потребує підтримки під час виконання контейнера.
Scope та Policy в Topology Manager
Topology Manager наразі:
- узгоджує Podʼи усіх класів QoS.
- узгоджує запитані ресурси, які Hint Provider надає підказки топології.
Якщо ці умови виконані, Topology Manager узгоджує запитані ресурси.
Для того, щоб налаштувати, як це вирівнювання виконується, Topology Manager надає два відмінні параметри: scope та policy.
scope визначає гранулярність, на якій ви хочете, щоб виконувалось вирівнювання ресурсів, наприклад, на рівні pod або container. А policy визначає фактичну стратегію, яка використовується для виконання вирівнювання, наприклад, best-effort, restricted, single-numa-node і т.д. Деталі щодо різних scopes та policies, доступних на сьогодні, можна знайти нижче.
Примітка:
Щоб вирівняти ресурси ЦП з іншими запитаними ресурсами у специфікації Pod, потрібно включити CPU Manager та налаштувати відповідну політику CPU Manager на вузлі. Див. Управління політиками керування ЦП на вузлі.Примітка:
Щоб вирівняти памʼять (та великі сторінки) з іншими запитаними ресурсами у специфікації Pod, слід увімкнути Memory Manager та налаштувати відповідну політику Memory Manager на вузлі. Див. документацію Memory Manager.Scope в Topology Manager
Topology Manager може вирівнювати ресурси у кількох різних сферах:
container(стандартно)pod
Будь-яку з цих опцій можна вибрати під час запуску kubelet, налаштувавши параметр topologyManagerScope у файлі конфігурації kubelet.
Scope container
Scope container використовується стандартно. Ви також можете явно встановити параметр topologyManagerScope в container у файлі конфігурації kubelet.
У цьому scope Topology Manager виконує кілька послідовних вирівнювань ресурсів, тобто для кожного контейнера (у Pod) окреме вирівнювання. Іншими словами, відсутнє поняття групування контейнерів у певний набір вузлів NUMA, для цього конкретного scope. Фактично Topology Manager виконує довільне вирівнювання окремих контейнерів на вузли NUMA.
Ідея групування контейнерів була затверджена та реалізована навмисно в наступному scope, наприклад, у scope pod.
Scope pod
Для вибору scope pod, встановіть параметр topologyManagerScope у файлі конфігурації kubelet на pod.
Цей scope дозволяє групувати всі контейнери у Podʼі у спільний набір вузлів NUMA. Іншими словами, Topology Manager розглядає Pod як ціле та намагається виділити весь Pod (всі контейнери) на один вузол NUMA або спільний набір вузлів NUMA. Нижче наведено приклади вирівнювання, які виробляє Topology Manager у різні моменти:
- всі контейнери можуть бути та виділені на один вузол NUMA;
- всі контейнери можуть бути та виділені на спільний набір вузлів NUMA.
Загальна кількість певного ресурсу, запитаного для всього Podʼа, розраховується за формулою ефективні запити/обмеження, і, таким чином, це загальне значення дорівнює максимуму з:
- сума всіх запитів контейнерів застосунку,
- максимум запитів контейнерів ініціалізації,
для ресурсу.
Використання scope pod разом з політикою Topology Manager single-numa-node особливо цінне для робочих навантажень, які чутливі до затримок, або для високопродуктивних застосунків, які виконують міжпроцесну комунікацію (IPC). Поєднуючи обидва варіанти, ви можете помістити всі контейнери в Pod на один вузол NUMA; отже, можливість між-NUMA комунікації може бути усунена для цього Pod.
У випадку політики single-numa-node Pod приймається лише в тому разі, якщо серед можливих виділень є відповідний набір вузлів NUMA. Перегляньте приклад вище:
- набір, що містить лише один вузол NUMA — це призводить до допуску Podʼа,
- тоді як набір, що містить більше вузлів NUMA — це призводить до відхилення Podʼа (тому, що для задоволення виділення потрібен один вузол NUMA).
У підсумку, Topology Manager спочатку розраховує набір вузлів NUMA, а потім перевіряє його з політикою Topology Manager, яка призводить до відхилення або допуску Podʼа.
Політики Topology Manager
Topology Manager підтримує чотири політики виділення. Ви можете встановити політику за допомогою прапорця kubelet --topology-manager-policy. Існують чотири підтримувані політики:
none(стандартно)best-effortrestrictedsingle-numa-node
Примітка:
Якщо Topology Manager налаштований зі scope Pod, контейнер, який розглядається політикою, відображає вимоги всього Podʼа, і тому кожний контейнер з Podʼа буде мати одне і те ж рішення про вирівнювання топології.Політика none
Це стандартна політика і вона не виконує жодного вирівнювання топології.
Політика best-effort
Для кожного контейнера у Pod kubelet з політикою керування топологією best-effort викликає кожен Hint Provider, щоб дізнатися їхню доступність ресурсів. Використовуючи цю інформацію, Topology Manager зберігає привʼязку до найближчого вузла NUMA для цього контейнера. Якщо привʼязка не є бажаною, Topology Manager також зберігає це і допускає Pod до вузла не зважаючи на це.
Hint Providers можуть використовувати цю інформацію при прийнятті рішення про розподіл ресурсів.
Політика restricted
Для кожного контейнера у Pod kubelet з політикою керування топологією restricted викликає кожен Hint Provider, щоб дізнатися їхню доступність ресурсів. Використовуючи цю інформацію, Topology Manager зберігає привʼязку до вузла NUMA для цього контейнера. Якщо привʼязка не є бажаною, Topology Manager відхиляє Pod від вузла. Це призводить до того, що Pod переходить в стан Terminated з помилкою допуску Podʼа.
Якщо Pod перебуває в стані Terminated, планувальник Kubernetes не буде намагатися знову запланувати його. Рекомендується використовувати ReplicaSet або Deployment для того, щоб викликати повторне розгортання Podʼа. Зовнішній цикл керування також може бути реалізований для того, щоб викликати повторне розгортання Podʼів, які мають помилку Topology Affinity.
Якщо Pod прийнято, Hint Providers можуть використовувати цю інформацію при прийнятті рішення про розподіл ресурсів.
Політика single-numa-node
Для кожного контейнера у Pod kubelet з політикою керування топологією single-numa-node викликає кожен Hint Provider, щоб дізнатися їхню доступність ресурсів. Використовуючи цю інформацію, Topology Manager визначає, чи можлива привʼязка до одного вузла NUMA. Якщо можливо, Topology Manager зберігає це і Hint Providers можуть використовувати цю інформацію при прийнятті рішення про розподіл ресурсів. Якщо привʼязка не можлива, Topology Manager відхиляє Pod від вузла. Це призводить до того, що Pod перебуває в стані Terminated з помилкою прийняття Podʼа.
Якщо Pod перебуває в стані Terminated, планувальник Kubernetes не буде намагатися знову запланувати його. Рекомендується використовувати ReplicaSet або Deployment для того, щоб викликати повторне розгортання Podʼа. Зовнішній цикл керування також може бути реалізований для того, щоб викликати повторне розгортання Podʼів, які мають помилку Topology Affinity.
Параметри політики керування топологією
Підтримка параметрів політики керування топологією вимагає активації функціональної можливості TopologyManagerPolicyOptions, щоб бути ввімкненими (типово увімкнено).
Ви можете увімкнути та вимкнути групи параметрів на основі їхнього рівня зрілості за допомогою наступних feature gate:
TopologyManagerPolicyBetaOptionsтипово увімкнено. Увімкніть, щоб показати параметри рівня бета.TopologyManagerPolicyAlphaOptionsтипово вимкнено. Увімкніть, щоб показати параметри рівня альфа.
Ви все ще повинні активувати кожний параметр за допомогою опції kubelet TopologyManagerPolicyOptions.
prefer-closest-numa-nodes
Опція prefer-closest-numa-nodes є загально доступною з версії Kubernetes 1.32. У версії Kubernetes 1.36 ця політика стандартно доступна, якщо увімкнено функціональні можливості TopologyManagerPolicyOptions та TopologyManagerPolicyBetaOptions.
Типово менеджер топології не враховує відстані між NUMA вузлами та не бере їх до уваги при прийнятті рішень про допуск Pod. Це обмеження проявляється в системах з кількома сокетами, а також у системах з одним сокетом і кількома NUMA вузлами, і може спричинити значне погіршення продуктивності у виконанні з критичною затримкою та високим пропуском даних, якщо менеджер топології вирішить розмістити ресурси на не сусідніх NUMA вузлах.
Якщо вказано параметр політики prefer-closest-numa-nodes, політики best-effort та restricted будуть віддавати перевагу наборам вузлів NUMA з коротшими відстанями між ними при прийнятті рішень про прийняття.
Стандартно (без цієї опції) менеджер топології розміщує ресурси або на одному NUMA вузлі, або, у випадку, коли потрібно більше одного NUMA вузла, використовує мінімальну кількість NUMA вузлів.
max-allowable-numa-nodes
Опція max-allowable-numa-nodes є загально доступною (GA) починаючи з версії Kubernetes 1.35. У версії Kubernetes 1.36 ця політика стандартно доступна, якщо увімкнено функціональні можливості TopologyManagerPolicyOptions.
Час на прийняття Podʼа повʼязаний з кількістю NUMA вузлів на фізичній машині. стандартно, Kubernetes не запускає kubelet з увімкненим менеджером топології на жодному (Kubernetes) вузлі, де виявлено більше ніж 8 NUMA вузлів.
Примітка:
Якщо ви виберете політикуmax-allowable-numa-nodes, вузли з більше ніж 8 NUMA вузлами можуть бути дозволені для роботи з увімкненим менеджером топології. Проєкт Kubernetes має обмежені дані про вплив використання менеджера топології на вузли (Kubernetes) з більше ніж 8 NUMA вузлами. Через відсутність даних, використання цієї політики з Kubernetes 1.36 не рекомендується і здійснюється на ваш власний ризик.Ви можете увімкнути цю опцію, додавши max-allowable-numa-nodes=<integer> до параметрів політики Topology Manager, де значення integer повинно бути більше 8. Стандартно встановлено 8, що зберігає існуюче обмеження.
Встановлення значення max-allowable-numa-nodes не впливає безпосередньо на затримку допуску Pod, але привʼязка Pod до вузла (Kubernetes) з великою кількістю NUMA вузлів має вплив. Майбутні можливі поліпшення в Kubernetes можуть покращити продуктивність допуску Podʼів і зменшити високу затримку, яка виникає зі збільшенням кількості NUMA вузлів.
Взаємодія точок доступу Pod з політиками Topology Manager
Розгляньте контейнери у наступному маніфесті Podʼа:
spec:
containers:
- name: nginx
image: nginx
Цей Pod працює в класі QoS BestEffort, оскільки не вказано жодних ресурсів requests або limits.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
Цей Pod працює в класі QoS Burstable, оскільки запити менше, ніж ліміти.
Якщо вибрана політика відрізняється від none, Topology Manager враховуватиме ці специфікації Pod. Topology Manager буде консультувати Hint Provider для отримання підказок топології. У випадку static політики CPU Manager поверне типову підказку топології, оскільки ці Podʼи не мають явних запитів ресурсів CPU.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
Цей Pod із цілим запитом CPU працює в класі QoS Guaranteed, оскільки requests дорівнює limits.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
Цей Pod з спільним запитом CPU працює в класі QoS Guaranteed, оскільки requests дорівнює limits.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
example.com/deviceA: "1"
example.com/deviceB: "1"
requests:
example.com/deviceA: "1"
example.com/deviceB: "1"
Цей Pod працює в класі QoS BestEffort, оскільки немає запитів CPU та памʼяті.
Topology Manager враховуватиме вищезазначені Podʼи. Topology Manager буде консультувати Hint Provider, які є CPU та Device Manager, для отримання підказок топології для Pod.
У випадку Guaranteed Pod із цілим запитом CPU, політика CPU Manager static поверне підказки топології, що стосуються виключно CPU, а Device Manager надішле підказки для запитаного пристрою.
У випадку Guaranteed Pod з спільним запитом CPU, політика CPU Manager static поверне типову підказку топології, оскільки немає виключного запиту CPU, а Device Manager надішле підказки для запитаних пристроїв.
У вищезазначених двох випадках Guaranteed Pod політика CPU Manager none поверне типову підказку топології.
У випадку BestEffort Pod, політика CPU Manager static поверне типову підказку топології, оскільки немає запиту CPU, а Device Manager надішле підказки для кожного запитаного пристрою.
На основі цієї інформації Topology Manager обчислить оптимальну підказку для Pod і збереже цю інформацію, яка буде використовуватися постачальниками підказок при призначенні ресурсів.
Відомі обмеження
Максимальна кількість вузлів NUMA, яку дозволяє Topology Manager, — 8. З більш ніж 8 вузлами NUMA відбудеться вибух стану при спробі перерахувати можливі спорідненості NUMA та генерувати їх підказки. Дивіться
max-allowable-numa-nodes(бета) для отримання додаткової інформації.Планувальник не знає топології, тому його можна запланувати на вузлі, а потім вивести з ладу на вузлі через Topology Manager.
Що далі
- Прочитайте про Менеджери ресурсів на рівні Podʼа.